Roulette:用于深度学习分类任务的语义隐私保护设备边缘协作推理框架
摘要
深度学习分类器在人工智能时代至关重要。 基于设备边缘的协同推理已被广泛采用作为促进其在物联网和5G/6G网络中应用的有效框架。 然而,它在非独立同分布下会出现精度下降的问题。 数据分发和隐私披露。 对于精度下降,直接使用迁移学习和分割学习成本很高,并且隐私问题仍然存在。 对于隐私泄露,基于密码学的方法会导致巨大的开销。 其他轻量级方法假设真实情况不敏感并且可以暴露。 但对于许多应用程序来说,基本事实是用户的关键隐私敏感信息。 在本文中,我们提出了一个 Roulette 框架,这是一种面向任务的深度学习分类器的语义隐私保护协作推理框架。 除了输入数据之外,我们还将数据的基本事实视为私人信息。 我们开发了一种新颖的分割学习范例,其中后端 DNN 被冻结,而前端 DNN 被重新训练为特征提取器和加密器。 此外,我们提供了差异隐私保证并分析了地面实况推理攻击的难度。 为了验证所提出的轮盘赌,我们使用现实数据集进行了广泛的性能评估,这表明轮盘赌可以有效防御各种攻击,同时实现良好的模型准确性。 在非独立同分布的情况下 在非常严重的情况下,Roulette 将推理准确率平均比基准提高了 21%,同时使歧视攻击的准确率几乎相当于随机猜测。
索引术语:
隐私保护、深度学习分类器、协同推理、边缘计算1 简介
1.1 背景和动机
过去十年,深度学习(DL)和深度神经网络(DNN)如火如荼地进行。 深度学习分类器作为其最重要的分支之一,在计算机视觉、自然语言处理、机器人等领域表现出色[1, 2]。 近年来,在5G/6G等先进通信技术的推动下,人工智能物联网(AIoT)应用不断涌现,许多设备(如摄像头、机器人、车辆等)对实时深度学习分类服务有强烈需求[3]。
然而,设备资源有限阻碍了AIoT的广泛推广。 具体来说,深度学习模型的尺寸变得越来越大,计算量也越来越大,但终端设备通常受到资源限制,并且在其上执行的任务通常对延迟敏感(远程医疗、自动驾驶等),这需要大量的计算资源。计算资源[4]。 使资源受限设备上的实时 DNN 推理成为可能的一种有前途的方法是利用边缘计算原理的基于设备边缘的协作推理(协同推理)[5]。 为了进行协同推理,预训练的 DNN 被分为两部分:前端部分和后端部分。 设备在本地执行前端部分,然后将相应的中间表示卸载到附近的边缘服务器,边缘服务器通过 5G/6G 网络支持的高质量无线访问执行后端部分。 协同推理被广泛认为是分布式 DNN 任务处理系统的关键构建模块,并从执行速度加速和成本优化的角度进行了深入研究[6,7,8]。 然而,文献中仍然有两个关键问题尚不清楚。
一方面,当设备的本地数据和预训练DNN的原始数据集不是独立同分布(非独立同分布),并且训练样本数量有限时,模型精度会显着下降[9]。 一种直接的方法是服务器预先为每个分布准备一个模型。 此外,解决非独立同分布问题的两种更明智的方法是迁移学习[10, 11]和分割学习[12]。 然而,所有这些方法通常都需要一个独特的定制 DNN 模型或多个模型111A single user’s data may span multiple distributions, and different users may share the same distribution,这会带来较高的存储和计算成本以及较低的可扩展性。 因此,服务器预先为每个分布准备好模型,迁移学习和分割学习不能在不进行适配的情况下直接应用于资源受限的AIoT应用中。
另一方面,共同推理很容易受到隐私攻击,这可能导致重大信息泄露。 特别是,从设备卸载到边缘服务器的DNN中间表示实际上包含来自设备的数据的大量特征信息。 边缘服务器或者任何恶意攻击者截获中间表示后,在收到中间表示后,可以发起模型反转攻击(即实例恢复攻击)来重建原始数据[13,14,15]。 此外,还可以发起成员推理攻击[16, 17]来推断实例是否在训练数据集中。 事实上,许多国家和地区都制定了隐私保护相关法律,例如欧盟的《通用数据保护条例》(GDPR)。 因此,非常需要基于设备边缘的协同推理服务来解决关键的隐私问题。
传统基于密码学的隐私保护解决方案,如同态加密(HE)[18]、安全多方计算(SMC)[19]、可信执行环境( TEE)[20]等,可以保证充分的隐私保护,但这些方案要么引入严重的计算延迟,要么需要特殊设备支持[21,22,23,24]. 因此,将它们应用到AIoT的许多应用场景中是昂贵且不切实际的。 此外,这些解决方案是任务无关的并且不知道这些位传达的含义或它们将如何使用。
为了防止或限制隐私泄露,最近有一些解决方案利用了轻量级隐私保护 DNN 推理。 他们大多数假设与DNN推理任务相关的主要信息被视为可以暴露的非敏感内容,但除此之外的额外信息被认为是私密的。 因此,这些工作的目标是在保留主要信息的同时最大限度地减少额外信息。 例如,给定人脸数据集和在该数据集上训练的性别分类器,这些工作将性别信息视为非敏感内容,而将额外信息(例如发型)视为私人信息。 为了实现这一目标,人们提出了不同类型的方法,例如动态噪声注入[25, 26]、对抗训练[27,28,29]。 这些解决方案是task-oblivious,即分类器的任务输出根本不受保护。 然而,这些输出预测本身通常是设备本地数据和下游任务处理的私人信息,这可能会带来严重的隐私泄露风险。 从深度学习分类任务的角度来看,我们将其称为语义隐私保护问题,因为对于许多应用场景,深度学习分类器的输入上下文可以是图像、视频或文本,其输出是代表关键语义的分类标签。含义(例如图像识别和物体检测)或相关语义设置下的动作/响应(例如基于视觉的无人机导航控制)。
受上述两个关键问题的推动,本文旨在回答以下关键问题: 我们能否设计一个面向任务的隐私保护协同推理框架,为深度学习分类器提供语义隐私并达到可接受的模型精度?
1.2 框架草图
在本文中,我们提出轮盘赌222我们将所提出的框架命名为轮盘赌,因为我们随机打破了原始数据标签对应关系并在操作过程中注入噪声,并且不确定性原理类似于轮盘赌游戏,其中数字随机分布在圆圈周围,人工旋转是“嘈杂的”。,一种用于深度学习分类器的语义隐私保护协同推理框架。 具体来说,为了处理非独立同分布问题,我们以传统的分割学习为基础,并使用设备的本地数据集重新训练前端 DNN 参数。 通过这种方式,我们获得了一个特定于设备的前端DNN模型来防御由于非独立同分布而导致的精度下降,而不是使用预先训练的前端模型。 至于隐私问题,在本文中,除了输入数据之外,我们还将分类任务中设备上数据的真实情况视为我们应该保护的敏感语义隐私。 为此,与传统的分割学习将整个模型作为一个整体进行训练不同,我们将边缘服务器上的后端模型固定为确定性函数。 然后我们 训练前端 DNN 部分,使其能够将具有基本事实 的输入映射到可以通过确定性函数分类的中间表示,即边缘服务器的后端部分,如下所示除了 之外的另一个基本事实。 换句话说,前端模型被训练为不仅是特征提取器,而且是加密器。 为此,我们在训练之前用随机生成的映射替换原始数据标签对应关系,并在训练期间使用新的映射来计算分类损失(即交叉熵[30])。 同时,为了强制不同映射的中间表示的分布保持一致且不可区分,我们在损失函数中引入了一种新的距离最小化项,以最小化原始中间输出和新中间输出之间的差异。 此外,我们还利用差分隐私机制,为中间结果添加随机噪声。
这种分离学习在安全性方面的主要优势在于,它可以保护有关设备的特定模型架构和参数的信息免受边缘服务器和其他对手的攻击,这使得服务器很难推断出任何信息,从而保护了隐私,但原始的分割学习并没有提供任何隐私理论保证。 相反,在本文中,我们提供差异隐私保证,并在给定中间表示和局部模型参数的情况下证明地面实况推理攻击的难度。 值得注意的是,训练阶段是离线训练,前端部分的训练可以在设备所有者的私人服务器上进行,而不是直接在设备上进行,以加快进程。 在在线推理阶段,设备执行前端部分以生成加密的中间表示(而不是实际的中间表示)并将其卸载到边缘服务器。
为了更形象地说明我们的框架,我们给出一个推理阶段操作的例子,如图1所示。 考虑具有“狗”和“猫”类的多类分类任务。 假设一个数据实例具有真实标签“cat”。 将实例传递到重新训练的前端模型中以生成中间表示。 然后,服务器从中间表示中获取推理结果“狗”而不是“猫”,并将“狗”发送回设备。 然后设备查找预定义的映射表以获得真正的结果“猫”。
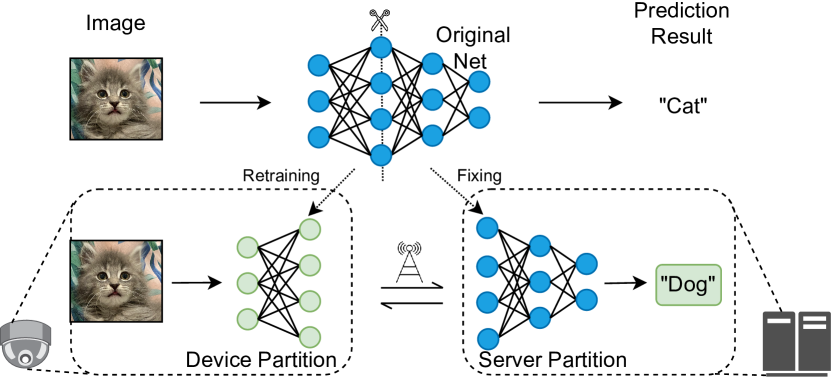
1.3 主要贡献
本文的主要贡献如下:
-
•
我们针对基于设备边缘的深度学习分类任务提出了一种新颖的语义隐私保护轮盘协同推理框架,该框架具有显着的优势。 首先,与非独立同分布下的朴素共同推理相比,该框架实现了更高的准确性。 其次,该框架允许针对本地数据异构性进行针对特定设备的前端模型重新训练,并且也有利于实际部署,使得边缘服务器可以仅托管通用后端模型来服务多个异构设备。
-
•
我们提出了一种双重隐私保护方法。 首先,我们将前端模型训练为不仅是特征提取器,而且是加密器,以向服务器隐藏真实情况并证明地面事实推理攻击的难度。 其次,我们提出了一种基于差分隐私的干扰本地数据转换的隐私保护机制,并分析了相应的隐私保障。
-
•
我们使用真实的数据集进行彻底的性能评估。 我们观察到,所提出的轮盘赌框架对隐私攻击的防御能力非常出色,例如,它可以有效地阻止模型反转和影子模型攻击,并且差分隐私预算相对较小。 同时,Roulette在非独立同分布的数据分布下也能取得良好的模型精度。
2 技术知识
2.1 分离学习与协同推理
DNN: DNN是由几种不同类型的层组成的参数化函数,包括卷积层、池化层、全连接层等。 每层有多个神经元,神经元从前层获取加权张量并为下一层生成激活。 要应用 DNN,需要一个训练集 ,并通过反向传播和随机梯度下降对 进行迭代训练,得到与 和 之间的反射相匹配的最优参数 ,即 和 、
| (1) |
其中是损失函数,衡量的输出与真实值之间的偏差程度。 反向传播过程计算对于中每个参数的偏导数,然后取批次的平均值,即,其中 是批量大小。 的更新规则为:
| (2) |
其中 是学习率。 训练后,给定,DNN可以产生推理结果。 关于DNN更详细的介绍,请参考[1,2,31]。
分割学习: 分割学习通过将 DNN 模型划分为设备和边缘服务器之间的两个连续块来实现分布式学习。 由于其效率和简单性,它引起了特别的兴趣[32]。 在分割学习中,设备拥有模型的第一个分区,而边缘服务器维护剩余的神经网络。 设备模型的架构和超参数由阶段前的设备决定。 特别是,他们就深度学习模型的合适划分达成一致,并将必要的信息发送到边缘服务器。 边缘服务器没有决策权,会忽略设备[33]上部署的第一个分区。 在分割学习中,训练是通过垂直分布的反向传播来执行的。 设备模型参数的升级基于边缘服务器发送的偏导数,如图2所示。 在监督损失函数的情况下,分割学习要求设备与边缘服务器共享标签。 为了防止标签泄漏,还可以在设备侧进行损失计算。 边缘服务器将的输出(logits)发送给设备,设备计算损失并上传到边缘服务器。
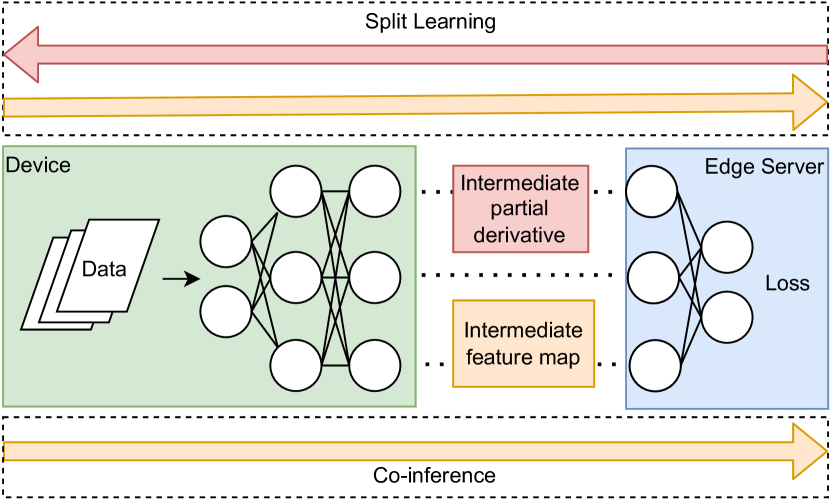
协同推理:作为快速边缘推理的重要解决方案,协同推理已得到广泛研究。 基本思想是将 DNN 划分为多个分区,每个部分分配给不同的参与者。 在协同推理中,预训练的 DNN 被划分为 个分区 并交付给 不同的参与者。 给定输入,推理结果为。 不失一般性,本文仅研究的情况。 分割学习与协同推理的关系如图2所示。
在隐私保护协同推理的文献中,有些坚持假设整个模型已经给定,隐私增强不能修改主要任务的预训练DNN的结构和固定参数,这被称为推理-as -a-service (INFaas) [34, 35, 36, 25, 26]。 相反,其他人则重新设计满足的全新形式的模型进行共同推理以保护的隐私,例如MixCon [37]、DataMix [38]、复杂值网络 [39]。 在我们的框架中,我们采用半半策略,即边缘服务器使用固定的预训练模型,而设备重新训练新模型,而不是使用原始的预训练模型。 我们的情况符合INFaas的模式,但在设备上重新训练分区,充分发挥可扩展性。
2.2 差异隐私
差分隐私是为隐私保护数据分析而定义的数学框架,旨在为敏感数据提供隐私保证,被视为严格隐私的标准概念[40]。 -差分隐私的正式定义如下。
Definition 2.1。
(-差异隐私)。 给定两个相邻的输入 和 ,它们只有一项不同,如果 ,其中 是 的任意输出集,则随机算法 满足 差分隐私。
这里,参数是权衡算法输出的效用和隐私的隐私预算。 越小,表示隐私保护越强。 根据这个定义,差分隐私算法可以提供关于一组数据项的聚合表示,而不会泄漏任何数据项的信息。
为了实现差分隐私,常用的技术是将拉普拉斯噪声注入确定性函数的输出:
| (3) |
其中是的全局敏感度,它被定义为两个相邻输入的函数结果之间的最大距离。 并且,是从拉普拉斯分布中采样的随机变量,尺度为。
差分隐私具有不受后处理影响的极好特性[41],这意味着任何后处理算法都不会导致额外的隐私泄露。
2.3 非独立同分布共同推理问题
共同推理的重大挑战之一是非独立同分布。 本地数据和原始训练数据之间的差异,这会降低模型的准确性。 文献中存在两种非独立同分布问题,标签倾斜和属性分布倾斜[9]。 标签倾斜意味着标签分布与原始训练数据集不同。 第二种是属性分布倾斜。 属性分布偏差是指具有相同标签的数据样本的属性不同。 例如,标准的 MNIST [42] 和 SVHN [43] 数据集都是标记为 0-9 的“数字”,但 MNIST 中的数据样本清晰简单,样本SVHN 中伴随着更多的干扰、噪声和旋转。 在本文中,我们将通过网络的本地再训练部分来应对这一挑战。
2.4 威胁模型
在我们的模型中,有两方:设备和边缘服务器。 为了实现分割学习和协同推理,设备必须上传通过部署在其上的 DNN 生成的中间表示以及学习任务的损失值。 在我们的设置中,服务器是一个诚实但好奇的对手。 我们假设服务器不会操纵和劫持设备 DNN 模型的学习过程[32]。 然而,对手会拦截中间表示并执行任何攻击,例如实例恢复攻击 [13, 14]、成员推理攻击 [16, 17] 和属性推理攻击[44]。
3 轮盘框架
我们首先对轮盘赌进行高级概述,然后在 3.1 节中介绍其组件和技术设计。 Roulette是一种端到端的非侵入式解决方案,由两个互不相交的阶段组成:离线分割学习和在线协同推理,如图3所示。 训练阶段由三个主要部分组成:前向传播、损失计算和反向传播,这将在3.2节、3.3节和3.4 我们在3.5节中介绍了在线协同推理阶段。
3.1 轮盘概述
首先,我们介绍一下该框架的一些必要的符号。 令 类分类任务的标签(基本事实)范围为 。 考虑预训练的 类分类 DNN 模型 ,其中 是扁平输入大小, 是参数完全确定函数的模型。 值得注意的是,类分类DNN 的实际输出是一个维one-hot向量,即,但为了方便起见,我们使用标量指示器来表示。 边缘服务器与设备协商将划分为、、并部署在边缘服务器上,其中 是中间表示的展平维度。 值得注意的是,设备分区的参数是训练和更新的,而边缘服务器分区始终保持不变。 由于分区完成后不会发生变化,为简单起见,将记为,记为 以及本文的其余部分。 设备重新设计了一个模型,其输入大小为,输出大小与的输入大小相同,其中表示可训练参数。 我们将表示为第轮训练的参数。 值得注意的是,用户只需选择合适的分割点并确保上传向量的维度有效(与的输入维度相同)即可。 的结构完全可以根据自己设备的容量自行决定,用户也可以使用轻量级的AutoML [45]工具自动生成本地结构。 我们将双射函数表示为加密密钥,将其反函数表示为解密密钥。
回想一下本地数据是非独立同分布的挑战。 使用用于预训练原始端部模型的数据集,这是用户的异构性质之一。 此外,每个用户的设备的容量是不同的,即不同的内存、CPU/GPU频率和电池状态。 轮盘允许每个用户选择分区点并设计自己的设备特定个性化本地模型(前面部分)结构。 具体地,每个用户可以结合本地设备的容量和数据集的容量来自定义。 然后,用户进行多轮微调来更新前端模型的参数。 最终,用户将获得个性化的特定于设备的本地模型。
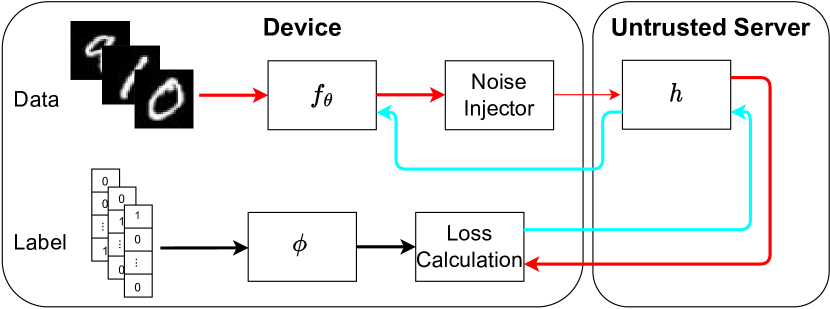
然后,我们在图 3 中说明了一批数据的工作流程的高级概述。 在训练阶段,设备从本地训练数据集中随机采样一批数据,并通过和噪声注入器生成差分私有中间表示。 接下来,将嘈杂的中间表示上传到不受信任的边缘服务器。 秒。 3.2将介绍详细的差分隐私变换。 然后,服务器将中间表示馈送到预训练的 DNN 后端,获取 logits 输出,并将 logits 发送到设备。 上述前向传播过程如图3(a)中红色箭头所示。 然后,每个设备根据自己的加密密钥对采样数据对应的标签进行加密,并计算损失函数。 详细的加密生成和损失函数设计在第 2 节中进行了解释。 3.3。 然后,设备将损失值发送到服务器,服务器将错误反向传播到。 最后,设备将参数更新为。 反向传播数据流在3(a)中用亮蓝色箭头标记。 在线推理阶段如3(b)所示。 推理过程与训练阶段的前向传播类似,只是在推理结束时,每个设备通过解密密钥对结果进行解密。
3.2 前向传播
图3(a)中的红色箭头代表前向传播的数据流,前向传播是通过设备与边缘服务器之间的交互完成的,这将在接下来介绍。
具有设备分区的数据转换器。 为了提取训练(输入,输出)对来学习设备分区的参数,一批训练数据应该被输入到。 受之前结论的启发,dropout是一种相对有效的防御模型反转攻击的方法[14],并且dropout越早,防御效果越好[46],我们屏蔽具有均匀随机生成的无效矩阵的输入数据。然后,得到无效数据,其中指的是两个矩阵的逐元素相乘,中零的个数占总数是预期无效率。
噪声注入器。 一些作品(例如,[25, 44])表明特定属性或数据集中的实例是否可以在给定一些背景知识的情况下从中间表示推断出来。 为了减轻推理攻击,通过采用差分隐私的强概念,我们在将中间表示发送到服务器之前设计了一个 DP 保证的噪声注入器。 噪声注入器将噪声张量逐元素添加到中间表示中。 提供-差分隐私的一种直观尝试是将遵循尺度的拉普拉斯分布的噪声添加到输出中,如下所示(3),其中 是隐私预算参数。 然而,估计 DNN 的全局灵敏度很困难,我们使用裁剪过程(即 来限制 的值。 表示时保留,时缩小为。 那么,全局敏感度可以估计为。 绑定阈值 与输入无关,因此不会泄漏任何敏感信息。 边界可以设置为关于一批训练示例[46]的无穷范数的中位数。 此外,[29]表明拉普拉斯机制可以以分裂学习的方式应用于任何局部层。 尽管在最后一个本地层之前的层中添加噪声可能会导致精度较差,但通过此操作可以使差分隐私预算更加严格。 我们的框架允许重新训练,这可以减轻准确性消除的情况。 因此,我们也考虑到这种概括。 我们用表示。 和分别指添加噪声之前和之后的层。 算法1概述了设备端的整个差分隐私数据转换。 正式的定量差异隐私预算将在第 2 节中给出。 F。
在我们的框架中,机制输出的维度相对要小得多(在第三次转换时)。 LeNet [47] 的分割点,为 400),比向梯度注入噪声的方法(LeNet 约为 60000)高,因此高斯机制的强度 [41]<差分隐私DNN中广泛应用的/t1>训练[40]无法体现。 此外,具体的网络结构、批量大小和划分点决定了机制输出的维度。 在不失一般性的情况下,为了简单起见,我们在本文中采用拉普拉斯机制,但高斯机制也可以很容易地扩展。
带有服务器分区的 Logits 生成器。 为了能够完成学习过程,需要一批 logits(神经网络最后一个分类层(通常是 softmax)之前的层的输出)与标签配对。 为了生成逻辑,将噪声中间表示馈送到云分区,即
| (4) |
然后,边缘服务器将logits发送到设备进行损失计算。
3.3 损失函数计算
在本小节中,我们将详细介绍加密密钥如何生成以及如何影响函数设计。
3.3.1 加解密密钥生成
加解密密钥的生成在训练开始前完成,并且在每个设备的训练过程中不会发生变化。 回想一下,我们的前端模型 不仅应该是特征提取器,而且应该是加密器。 特征提取器功能可以通过基于正常分类误差反向传播的逐步参数更新来实现。 为了实现加密器功能,我们希望打破原始的数据标签对应关系并应用随机生成的新对应关系。 换句话说,我们需要随机生成一个混乱。 具体来说,给定基本事实集,我们表示由所有排列(即从集合到自身的双射函数)形成的组,而无需重复并且没有 的固定点 () 作为 。 然后,我们的目标是从 中随机选择一个排列,即 ,作为新的数据标签对应关系。 起到加密密钥的作用,其反函数是解密密钥。 为了更清楚地说明映射,我们以柯西的两行表示法[48]为例。 的特定 可以写为
| (5) |
这意味着 满足 ,以及 等。
此外,在实践中先形成,然后从中均匀采样是不切实际的,因为 (下界由循环排列的数量决定)。 一种简单的方法是首先使用标准的洗牌算法,然后将位置不变的元素与附近的元素交换。 然而,使结果符合均匀分布并非易事。 感谢 C. Martínez 等人 (2008) 提出了一种生成随机混乱的优雅算法[49]。 我们采用优雅的算法作为我们的加密密钥生成器。 KeyGen 算法表示为算法 2,其中
| (6) |
这是给定 的确切混乱数。 从生成随机数的数量来看,该算法的平均成本为。 然后,我们将使用生成的映射(密钥)来加密本地标签。 加密确保了具有数据集分布背景知识但没有确切模型参数的影子模型攻击者的搜索空间(例如)的复杂性。
3.3.2 损失函数及方法
我们的损失函数涉及两项。 第一项是计算分类误差。 我们没有直接获取 和相应的标签 ,而是首先通过加密密钥 加密 ,即:
| (7) |
其中 是批量大小, 是与数据 对应的真实标签。
此外,为了使不同 下的中间表示更加难以区分,我们需要添加一项来最小化 和 之间的距离,即
| (8) |
其中 应该是距离测量函数。 然而,由于中间表示空间通常是高维的,并且决策边界是非线性的,因此很难找到合适的显式距离函数。 我们注意到我们关注的距离实际上取决于分类决策边界。 因此,非常适合应用生成对抗网络(GAN)[50]来隐式最小化距离。 为此,我们引入了一个由 参数化的附加 DNN 来模拟判别器,该判别器区分中间表示是否由原始网络生成。 那么,可以写成,
| (9) |
其中 是中间表示类型指示符,即
| (10) |
因此,最终的损失函数和-优化问题可以写为:
| (11) |
算法3概述了轮盘赌的混合训练方法。 在执行算法3之前,设备首先在没有任务目标的情况下通常预训练判别器,以获得区分中间表示类型的最佳性能。 然后,在每个训练批次中,设备首先通过最大化 来更新 。 然后,将通过最小化来更新。
3.4 反向传播
的更新可以在本地完成,但将涉及的错误反向传播到。 我们注意到,关于分割学习的文献很少阐明反向传播在分割学习模式下到底如何工作,因此我们首先对其进行详细说明。 假设DNN 共有层,划分点为层,即和. 我们将任何层的可训练参数表示为,。前馈神经网络中每个卷积层或全连接层的前向传播操作网络可以形式化为:
| (12) |
其中指的是第层的输入特征图,是输入向量的仿射变换(包括卷积层和全连接层) 。 是非线性层,包括激活函数、池化等,或者恒等函数(在非线性层之前分割)。 那么第层参数对损失函数的偏导数(梯度)可以计算为:
| (13) |
可以看出设备本地拥有和。 从服务器更新第 层和第 层之前的参数的唯一必要条件是 ,它独立于 . 这也是设备可以自由设计自己的结构的基础。 发送到服务器,服务器可以通过将错误反向传播到溢出层。 因此,反向传播可以总结如下:
使用服务器分区的反向传播。 损失计算完成后,将损失值发送到边缘服务器进行反向传播。 然后,边缘服务器反向传播梯度,设备下载中间偏导数。
使用设备分区进行反向传播和参数更新。 设备收到后,根据(2)和(13)更新的参数。
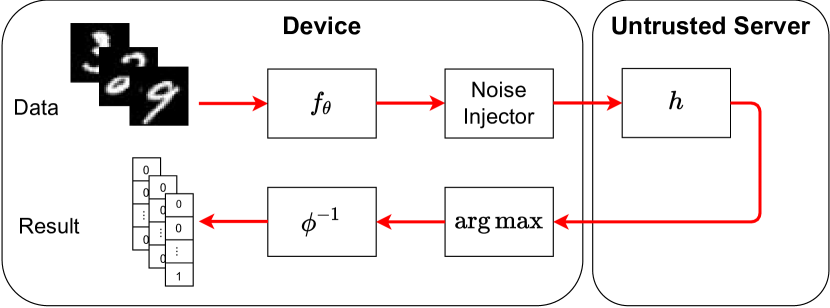
3.5 在线协同推理
分割学习后,Roulette 准备进行协同推理,如图3(b)所示。 设备对一批经过验证的数据进行采样并将其输入,然后执行算法1以生成差分私有中间表示并将其卸载到边缘服务器。 边缘服务器计算后端 DNN 并将 logits 发送回设备。 最后设备解密并根据下式得到真实的预测结果
| (14) |
需要强调的是,设备的前端模型训练可以离线完成。 用户可以拥抱比在线推理资源相对更丰富的设备。 此外,离线训练意味着训练过程对延迟不敏感。 例如,在训练阶段,用户可以在私有服务器上执行本地训练过程(与远程服务器交互)。 相反,对于部署(推理阶段),经过训练的本地模型必须部署在资源受限的现实设备(例如相机、无人机)上以用于实际应用。 这种情况下,离线训练的实时性要求要低于在线推理阶段。
4 安全分析
我们的隐私保护有两种方式:差异隐私和利用地面事实推理攻击。
4.1 差异隐私
我们将从拉普拉斯分布中采样的随机噪声添加到有界输出中,并丢弃输入图像的一定比例的元素以干扰数据作为差分隐私机制。 差分隐私转换的一个重要问题是确定代表所设计机制提供的严格隐私保证的隐私预算。 我们正式证明以下结果。
Theorem 4.1.
定理4.1的证明见附录A。 我们所说的隐私保证是关于重新训练(分割学习)和协同推理的,它是元素级事件级差分隐私[41]。 差分隐私机制是消除单个元素在输出上的移位来隐藏信息的有力保证。 给定适当的隐私预算,它可以保护数据免受成员推理攻击[16, 17]。
4.2 地面实况推理攻击的难度
尽管差异隐私提供了严格的保证,但关于避免整体统计隐私侵犯的说法并不明确[51]。 我们的真实隐私就属于这种侵犯行为。 因此,除了差分隐私之外,我们还需要更仔细地分析真实隐私。 接下来,我们将分析当服务器具有不同水平的背景知识时的真实隐私。
无参数且无数据集分布。 首先,推理结果的隐私性可以从局部参数的保密性和分割学习的数据集得到。 之前的几篇关于分割学习的作品也做出了这样的表述[12]。 据我们所知,当边缘服务器既不知道设备的本地参数也不知道数据集分布时,就不会出现成功的攻击。
有参数但没有数据集分布。 此外,我们研究了知道本地模型参数但不知道本地数据集分布的更强攻击者。 这样的攻击者可以执行地面实况推理攻击。 我们给出以下定义:
Definition 4.1。
给定前端模型和中间表示,我们说攻击者拥有完美的地面实况推理函数,
| (16) |
当且仅当 时,其中 是与输入数据对应的真实标签。
粗略地说,定义4.1意味着给定,如果服务器能够找到与接收到的完全匹配的输入模式,那么服务器能够找出基本事实。 这个定义对于现实中的攻击者来说过于严格。 可以想象,即使攻击者根据找到了可以与几乎匹配的近似输入模式,也可以将链接到地面真相。 因此,我们给出定义4.1的宽松版本,如下:
Definition 4.2。
给定前端模型 和中间表示 ,我们说攻击者有一个 近似的真实推理函数 那
| (17) |
当且仅当 时,其中 是与输入数据对应的真实标签。
定义4.2中,因子仅用于归一化,并非必需。 根据定义,我们证明了攻击者找到 近似的地面实况推理函数的难度。 该定理正式表述如下。
Theorem 4.2.
存在一个常数,除非RP=NP,否则很难为攻击者找到一个近似的地面实况推理函数。
没有参数但有数据集分布。 如果服务器知道本地数据集的分布但不知道,则可以遍历所有可能的来训练相应的前端模型或提取一些特征。 然而,当稍微大一点时,搜索空间就会非常大,因为。 因此,当分类系统输出的数量很大时,服务器很难推断出真实情况。 当很小时,我们在第2节中通过实验研究了服务器和设备之间分布差异的影响。 5。
带参数和带数据集分布。 在这种情况下,服务器可以通过将从数据集分布中采样的输入与模型输出进行匹配来轻松找出真实情况。 但实际上,服务器很难满足背景知识。 特别是,设备没有动机向服务器公开其模型参数。
最后,人们可能会质疑我们是否在没有隐私保护措施的情况下直接上传损失值。 我们澄清关于分类任务的真实隐私是什么。 与目标跟踪、对象分割等标签包含大量原始数据真实内容的任务不同,分类任务的标签是序列号或one-hot向量,如果没有具体的对应数据,这些标签是没有意义的。 因此,我们的方法旨在保护原始数据标签对应关系而不是标签本身。 这也是为什么我们强调它是真实事实而不是标签。 例如,对于一个有“狗”和“猫”的分类系统,设置“狗”对应标签“0”,“猫”对应标签“1”,或者反之,都没有关系。
| Dataset | MNIST | CIFAR10 | EMNIST | CIFAR100 |
|---|---|---|---|---|
| Target Model | LeNet-5 | 6 conv + 2 fc | ResNet18 | ResNet50 |
| Split Point | 3nd cnov | 4th conv | 4th ResBlock | 6th ResBlock |
5 实验评估

| Dataset | Method | Accuracy | MSE | SSIM |
|---|---|---|---|---|
| Baseline | 99.05% | 0.7062 | 0.2742 | |
| Noise-adding | 9.34% | 0.7175 | 0.0670 | |
| MNIST | Dropout | 72.19% | 0.7751 | 0.0267 |
| Pure local | 96.71% | |||
| Ours | 94.32% | 0.8942 | 0.0113 | |
| Baseline | 80.40% | 0.7532 | 0.4295 | |
| CIFAR10 | Noise-adding | 11.32% | 0.7625 | 0.1336 |
| Dropout | 37.25% | 0.8243 | 0.1132 | |
| Pure local | 32.17% | |||
| Ours | 71.46% | 0.9455 | 0.1025 | |
| Baseline | 89.19% | 0.7045 | 0.2644 | |
| EMNIST | Noise-adding | 14.35% | 0.7412 | 0.0217 |
| Dropout | 47.22% | 0.7956 | 0.0379 | |
| Pure local | 31.19% | |||
| Ours | 82.84% | 0.9546 | 0.0113 | |
| Baseline | 65.41% | 0.7245 | 0.4187 | |
| CIFAR100 | Noise-adding | 9.46% | 0.7741 | 0.1787 |
| Dropout | 26.56% | 0.8345 | 0.1154 | |
| Pure local | 6.21% | |||
| Ours | 57.46% | 0.9287 | 0.1125 |
5.1 实验设置
我们在四个标准 DNN 基准数据集上评估所提出的框架:MNIST [42]、CIFAR-10 [53]、EMNIST [54]、和 CIFAR-100 [55]。 MNIST 用于手写数字识别,CIFAR-10 用于对象分类。 EMNIST 是 MNIST 的扩展,包含 47 类手写数字和字母。 CIFAR-100 是 CIFAR-10 的扩展,包含 100 个对象类别。 此外,SVHN [43] 用于验证当私有数据集与原始网络训练数据集具有不同域时对抗影子模型攻击的有效性,即我们假设服务器在 MNIST 上训练模型用户持有 SVHN 数据集。 SVHN 数据集是真实世界的数据集,取自 Google 街景门牌号图像,其风格与 MNIST 类似。 我们在 MNIST 数据集上采用 LeNet [47],在 CIFAR-10 数据集上采用具有 6 个卷积层和 2 个全连接层的 CNN。 此外,我们分别针对 EMNIST 和 CIFAR100 应用更深的模型 ResNet18 和 ResNet50 [56]。 值得注意的是,一个用户只拥有标准数据集总数的1/10或接近1/10,我们稍后会介绍每个实验的具体设置。 Roulette 主要关注隐私和准确性问题,因此我们运行基于 CPU/GPU 的数值仿真,而不是通过硬件实现部署在现实网络环境中。 部署在现实系统上的协同推理的运行时性能在许多现有工作中得到了广泛的探索和优化,例如[6, 7]。 为了提高实时性能,Roulette 可以直接应用这些方法。 此外,我们将所有卷积层作为分区点进行遍历,以显示第 5.4 节中中间结果的重新训练精度、局部模型计算(FLOPs)和张量大小,这可以作为部署的参考。 在我们的设置中,分区后,虽然放置在设备中的部分可以根据设备的容量和通信成本优化和更改网络结构,但我们首先采用[25]中建议的分区点并为了简单起见保留设备分区的本地模型结构。 然后我们将评估分割点和局部模型结构的影响。 目标模型和所有攻击均使用 Pytorch 1.8.1 实现。 我们在配备 1 个 NVIDIA Tesla A100 40G MIG 1g.5gb(最小的 MIG 计算实例)和 2 个 Intel(R) Xeon(R) Gold 6240 CPU @ 2.60GHz(总共 36 个核心/72 个)的服务器上运行实验。线程)。

5.2 隐私保护的有效性
5.2.1 模型反转攻击
我们评估了所提出的框架针对模型反转攻击的保护能力。 [13]中提出了模型反转攻击,即实例恢复攻击。 给定一个表示 ,攻击者尝试通过解决以下问题来找到原始输入 :
| (18) |
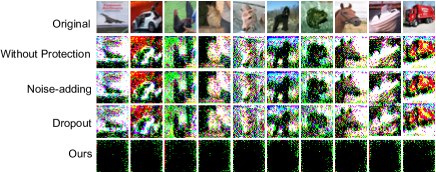
其中是衡量和相似度的损失函数,(18)可以通过迭代梯度求解血统。 请注意,在分析模型反转攻击时,我们假设设备和边缘服务器拥有的数据集是一致的,因为攻击者在此设置中最强[13]。 我们通过模型反演攻击定性和定量地评估反演的质量。 在图4中,我们从视觉角度展示了针对 MNIST 和 CIFAR10 数据集的一些示例测试图像的模型反转攻击防护。 我们展示了原始图像和通过对中间表示进行攻击而得到的重建图像。 具体来说,第一行图像为原始图像。 第二行和第三行中的图像分别是具有纯噪声添加 [57] 和 dropout [14] 防御的恢复图像。 第四行是从受提议框架保护的中间表示中恢复的图像。 所提出的框架添加了与噪声添加方法相同尺度的拉普拉斯噪声,即 MNIST 和 EMNIST 的 ,以及 CIFAR10 和 CIFAR100 的 ,并且我们修复了 首先。 MNIST 的退出比例为 ,CIFAR10 的退出比例为 。 从图4中可以看出,使用添加噪声和丢弃方法恢复的图像仍然可以在视觉上识别,但是在我们提出的框架下很难从图像中获得任何有用的信息。
此外,我们通过报告 (18) 恢复的 100 对图像与其原始样本之间的平均相似度来定量测量反演性能。 我们用来衡量恢复图像与原始图像之间相似性的指标是均方误差(MSE)和结构相似性指数指标(SSIM)[58]。 MSE 和 SSIM 值越大,表明两幅图像之间的相似性越低或越高。 我们在表II中总结了可接受的相似性(几乎视觉上无法区分)下的定量结果。 可以看出,在可接受的相似度下,噪声和dropout方法的消除精度偏大。 此外,我们的框架集成了噪声添加和丢失,但实现了更高的准确性和更低的相似性。 该结果表明轮盘赌相对于朴素的噪声添加和丢失方法的优越性。 由于个性化的再训练,甚至集成了噪声添加和丢弃以保护隐私,轮盘赌实现了更高的准确性。 此外,轮盘赌改变了标签映射关系,这使得攻击者很难从中间表示中推断出信息。 此外,我们以纯本地方式考虑训练和推理,本地模型的参数数量与前端模型几乎相同。 事实证明,轮盘赌比纯本地方法获得了更好的模型精度。
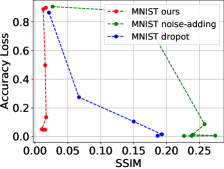
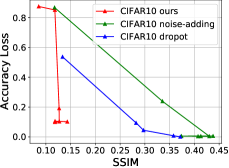
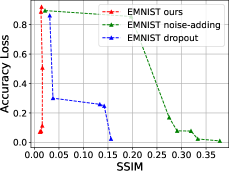
然后,我们绘制了不同添加噪声规模下的框架、噪声添加和 dropout 方法之间的比较,以准确率损失为纵轴,以相似度指数为横轴 ()和dropout比例(),如图5所示。 可以看出,不进行再训练的纯加噪和纯dropout方法在追求较小的模型精度损失时会付出巨大的隐私牺牲代价,但所提出的框架对于防御模型反转攻击的噪声尺度不敏感。
定性和定量结果都表明,在考虑到精度损失不太大的情况下,所提出的框架对模型反演攻击具有良好的防御能力。
5.2.2 梯度反转攻击
然后,我们尝试对联邦学习执行基于 SOTA 梯度的重建攻击,即 Roulette 上的 GradInversion [59]。 具体来说,我们使用前面相同的模型和分区策略,对特征图的梯度发起攻击。 我们假设一个非常强大的攻击者模型,它可以访问本地模型的确切模型初始参数。 另外,我们设置batch size为1,第一轮发起攻击,即最强攻击者设置[60]。 即使在这种强威胁模型下,轮盘赌也能很好地防御梯度反转攻击。 两个恢复的例子如图6所示。

事实上,针对联邦学习的共享参数(梯度)的攻击不能合理地预期会对 Roulette 产生影响。 回想一下,轮盘赌将网络分为两部分,即本地部分(前端)和预训练的远程部分(后端)。 在训练和推理过程中,用户与服务器交互的是中间表示(特征图)、特征图的梯度和损失值。 Roulette不需要上传任何本地部分参数到服务器。 此外,预训练的远程部分是使用公共数据集进行训练的,并且作为确定性函数始终保持不变,这意味着远程部分参数不携带有关本地数据的任何信息。 对于特征图,我们进行了重建攻击(模型恢复攻击),并在第 5.2 节-图 4 中展示了 Roulette 很好地防御了该攻击。 与特征图相比,特征图的梯度经过更多的非线性计算,并且丢失了更多关于本地数据的信息。 非线性计算越多,非线性计算越多,反演攻击的难度就越大[13]。 轮盘赌还添加噪声并重建数据标签对应关系,使得重建攻击更难有效。
5.2.3 影子模型攻击
在本小节中,我们评估针对真实隐私的更直接的攻击。 针对地面真实隐私,我们提出影子模型攻击,即训练替代模型来模仿真实模型,然后基于影子模型进行攻击,例如反转攻击或属性推断攻击。 具体来说,攻击者训练一组可能的模型,对应于个可能的标签映射,然后基于梯度下降,通过求解来训练判别网络 :
| (19) |
其中是交叉熵损失。 然后,分配来判断设备正在使用哪种映射。 上一节我们已经分析过,当较大时,影子模型攻击是不可追踪的。 本节给出最坏情况的实证分析。 我们评估了所提出的系统针对三类分类系统的影子模型攻击的性能,使其对于攻击者来说是一个二元分类问题。 我们没有重新设计新的分类系统,而是重新标记原始的10类数据集,以保持相同的特征提取能力[25]。 具体来说,对于 MNIST,我们将数据重新标记为“”、“”和“”。 对于 CIFAR10,我们将数据重新标记为“哺乳动物”(猫、狗、马、鹿)、“非哺乳动物”(鸟、青蛙)和“车辆”(飞机、汽车、轮船、卡车)。
我们从理论上证明,当类别数量略有变化时,攻击者很难(指数难度)发起歧视攻击。 本小节是近乎最坏情况的分析,例如攻击者在不知情的情况下的三类分类问题(我们将 MNIST 和 CIFAR-10 重新标记为数字范围分类问题和哺乳动物/非哺乳动物/车辆分类问题)模型参数但具有数据分布。 此外,我们设置了一个非常强的攻击者,如果它弄清楚用户是否使用了特定的密钥,就可以认为攻击成功。 然后,我们改变分布差异(非独立同分布) 度)在用户和服务器的数据集之间进行评估,以评估攻击性能。 在没有额外开销的情况下彻底保护隐私是很困难的,因此本小节中的实验旨在探索 Roulette 可以提供的防御能力的边缘。
根据[9],有两个主要的非独立同分布问题,例如标签偏差和属性分布偏差。 第一个意味着服务器和用户之间的标签分配不同。 第二个表示在同一标签下,i.i.d. 数据集与每个样本共享相似的风格,而非独立同分布数据集则不然,并且可能会引入更多的干扰、噪声和旋转。 因此,在本小节中,我们考虑三种不同的局部数据分布,它们与原始训练数据集、非独立同分布标签数据集和属于不同域的数据集(非独立同分布特征数据集)几乎相同。 我们定义来表征非独立同分布标签数据中数据异质性的程度。 将设备和边缘服务器视为两个代理。 我们将标签为 的样本统一随机分配给索引最后一位为 的两个智能体。 对于分配给代理的每个样本,我们以 的概率将该样本分配给具有相同概率的随机代理,并以 的概率将该样本分配给边缘服务器;较大的 会导致更大的数据异质性。 这两个数据集是 i.i.d. 当且仅当。
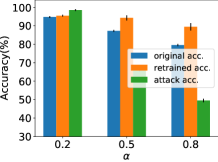
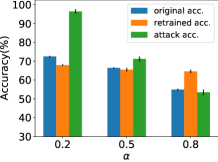
首先,我们为 MNIST 设置 ,为 CIFAR10 设置 ,并改变 ()。 评价结果如图7所示。 原始准确率是指未经重新训练的本地数据集的测试准确率,新准确率是基于本地数据重新训练本地分区的测试准确率,攻击准确率定义为:
| (20) |
其中是中影子模型对应的真实映射的索引,是异或运算,是测试数据集大小。 从图7可以看出,当本地数据分布与原始数据集不同时,我们提出的框架不仅可以保护隐私,还可以提高推理精度。 同时,非独立同分布程度越高,所提出的框架的隐私保护效果越好。 当时,攻击成功的概率几乎等于随机猜测。 另一方面,如果两个代理数据集之间的非独立同分布程度较低,则所提出的方法存在地面实况隐私泄露的高风险。 请注意,对于攻击精度,随机猜测值为 0.5,对于原始精度和保留精度,随机猜测值接近 0.33。
此外,当本地数据集的域与原始训练数据集不同时,我们评估了所提出框架的性能。 具体来说,原始数据集是 MNIST,我们在 SVHN 上重新训练本地分区。 为了模拟设备有限的数据量,我们将重新训练数据集设置为以整个 SVHN 的 1/10 均匀采样。 MNIST和SVHN数据样本的直观对比如图8所示。 可以看出,MNIST和SVHN的特征分布不同,但两个数据集都是数字。 实验中将SVHN中的原始RGB图像转换为灰度图像。 平均原始准确率、重新训练准确率和攻击准确率分别为0.4428、0.7683和0.4922,这意味着当域差异较大时,模型准确率消除严重,并且通过所提出的框架,隐私性和模型准确率都得到了提高。



5.3 差分隐私参数的影响
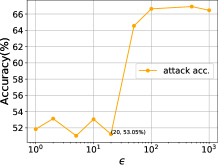
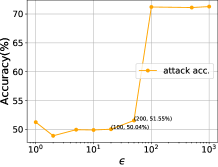
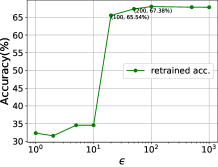
我们首先分析差分隐私预算参数的影响。 本节仍然以上一节的三类分类系统为研究对象。 我们修复 并将 从 1 更改为 1000,以评估影子模型攻击精度和重新训练精度。 如图9所示,对于MNIST来说,拉普拉斯机制下的DNN对于本质上没有任何效用。 然而,当时,精度迅速接近无噪声精度。 对于CIFAR10,阈值约为100。 然后可以看出,对于MNIST,当时,再训练精度达到0.8829,而攻击精度仅为0.5123。 对于CIFAR10,当时,再训练精度达到0.6554、0.6738,而攻击精度仅为0.5004、0.5155。 这表明所提出的框架具有噪声尺度的最佳点,选择可以防御攻击的同时保持模型效用。 我们还注意到,当 大于阈值时,即使攻击准确率变大且稳定,但该值仍然相对较小(仅比随机猜测高 10%+)。 然而,一般情况下,较高的()值仍然可能提供无意义的差分隐私[51],这意味着原始的拉普拉斯机制不适合直接使用但我们有定理4.1来减少该值。
然后,我们根据定理4.1分析总差分隐私预算,该预算由两个隐私相关参数控制,即和。 在这里,我们将 MNIST 的 值固定为 0.1,将 CIFAR10 固定为 0.05,并通过将 1 更改为 1000 来更改隐私预算 。 我们将噪声添加层设置在第一个转换之后。 层。 图10(a)表明,所提出的框架可以在广泛的隐私预算下保持较高的准确度。 结果还表明无效操作起着重要作用。 与 相比, 显然很小。 这些结果表明,所提出的框架适用于不同的隐私要求。 当隐私预算紧张时,可以防御成员推理攻击[61]。
结果还表明,即使在隐私预算更紧张的情况下,与相同超参数但无需重新训练的情况下使用噪声添加和丢弃的方法相比,它也可以有效提高性能,如图10(b)。 很明显,接近原始噪声添加的原始精度的阈值预算大于所提出的方法。 这种改善是本地再培训带来的。
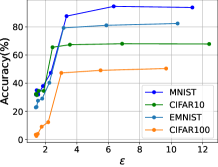
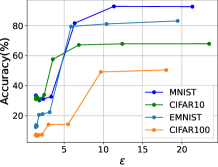
5.4 局部模型结构和划分点的影响
所提出的框架允许改变设备上的本地模型结构,这可以避免当划分点位于早期层且模型容量不足而消除推理精度时出现早期划分的问题。 然而,使用更大的结构的代价是资源有限的本地设备需要承担更多的计算,从而导致更多的计算延迟。 因此,在本小节中,我们将探讨如何选择划分点并根据经验设计局部网络结构。 为此,我们遍历模型的潜在划分点并增加局部模型的层数以观察推理精度。 不同本地模型和中间张量大小的计算负载如表IV(d)所示,分别是本地计算延迟和与边缘服务器通信延迟的指标。 注意,为了保持局部模型的输出形状不变,实验中我们添加的层的卷积核大小为,padding为1。
我们在表 III 中使用近似阈值来描绘可接受的范围。 对于 LeNet,我们将 FLOPs 小于 40k、精度大于 0.9、张量大小小于 500 视为可接受的值。 对于 CIFAR10,我们将 FLOPs 小于 100k、精度大于 0.6、张量大小小于 20k 视为可接受的值。 对于 EMNIST,我们将 FLOPs 小于 3M、精度大于 0.9、张量大小小于 10k 视为可接受的值。 对于 CIFAR100,我们将 FLOPs 小于 1.5M、精度大于 0.45、张量大小小于 10k 视为可接受的值。 请注意,近似阈值是根据经验选择的。 具体选择可以参考[6]中的方法。 建议使用与所有三个值均呈灰色显示的行对应的分割点。 可以看出,当划分点太早时,中间表示的尺寸往往很大,添加新层对于精度提升来说效率很低。 一般来说,选择更深的分割点和修改更少的结构比相反更有效。 在实践中,我们可以选择一个足够深但又与托管设备的计算能力相匹配的合适的分区点。
| Partition Point | FLOPs (k) | Accuracy | Tensor Size |
|---|---|---|---|
| 12.70 | 0.4723 | ||
| 1conv | 35.41 | 0.7328 | 1176 |
| 543.62 | 0.9578 | ||
| 2conv | 37.65 | 0.9425 | 400 |
| 3conv | 42.48 | 0.9622 | 120 |
| Partition Point | FLOPs (k) | Accuracy | Tensor size |
| 1.9 | 0.2548 | ||
| 1 conv | 39.78 | 0.4753 | 65536 |
| 77.66 | 0.5547 | ||
| 115.54 | 0.5722 | ||
| 39.85 | 0.4986 | ||
| 2 conv | 49.32 | 0.6423 | 16384 |
| 3 conv | 58.79 | 0.7016 | 32768 |
| 4 conv | 96.63 | 0.7261 | 8192 |
| 5 conv | 106.09 | 0.7584 | 8192 |
| 6 conv | 115.54 | 0.7982 | 2048 |
| Partition point | FLOPs (k) | Accuracy | Tensor size |
|---|---|---|---|
| 2 ResBlock | 149.82 | 0.6345 | 65536 |
| 4 ResBlock | 675.39 | 0.8284 | 32768 |
| 6 ResBlock | 2775.10 | 0.8842 | 16384 |
| 8 ResBlock | 11168.83 | 0.8991 | 8192 |
| Partition point | FLOPs(k) | Accuracy | Tensor size |
|---|---|---|---|
| ResBlock1 | 84.54 | 0.0456 | 16384 |
| ResBlock2 | 154.94 | 0.0873 | 16384 |
| ResBlock3 | 225.34 | 0.1963 | 16384 |
| ResBlock4 | 604.74 | 0.4599 | 8192 |
| ResBlock5 | 884.80 | 0.4631 | 8192 |
| ResBlock6 | 1164.86 | 0.5746 | 8192 |
| ResBlock7 | 1444.93 | 0.5846 | 8192 |
| ResBlock8 | 2957.376 | 0.6213 | 4096 |
| ResBlock10 | 5191.744 | 0.6344 | 4096 |
| ResBlock12 | 7426.112 | 0.6347 | 4096 |
| ResBlock13 | 8543.296 | 0.6412 | 4096 |
| ResBlock12 | 14582.848 | 0.6408 | 2048 |
6 相关作品
在本节中,我们回顾了协同推理领域的相关工作以及相关的隐私保护解决方案。 这些隐私保护解决方案可分为三大类:噪声注入、基于编码的解决方案和密码解决方案,每个类别将在以下小节中进行回顾。
6.1 协同推理
作为快速边缘推理的突出解决方案,协作推理(co-inference)已被广泛研究。 基本思想是将 DNN 划分为多个分区,每个部分分配给不同的参与者。 分区系统旨在根据[7, 8]中的计算、通信和能量约束选择最佳分区点。 最近,为了协调异构设备集群之间的工作负载,CoEdge [62] 自适应地对输入图像进行分区,以适应不同的计算能力和动态网络条件。 此外,自学神经外科医生[6]应用在线学习来预测不确定的远程时间。 这些工作努力提高实时性,但何等人[14]指出协同推理可能导致隐私泄露,并建议该领域的研究人员更加关注隐私问题而不是只考虑实时性能[13, 14]。 然后,分析隐私泄漏与DNN深度之间的关系,提出一种同时考虑实时性和隐私性的Lyapunov优化框架来选择划分点[63]。 然而,它仅测量与主要任务相关的信息在不同分区点的衰减,而没有任何隐私增强。
6.2 语义沟通
语义和任务导向的沟通是沟通研究界的热门话题。 语义或面向任务的通信的核心思想是通过考虑发送端发送信息的“含义”来构建下一代通信系统,而不是考虑每个比特相等的[64, 65]。 在最近的工作中,分裂学习和协同推理被广泛应用于语义通信系统。 J. Shao等人设计了一种面向任务的通信系统,其中部署在设备上的DNN扮演着特征提取器和联合源通道编码编码器的角色[66]。 Z. Weng等人提出了语音语义通信系统[67]。 在[67]中,发送器和接收器由语义和信道编码器(解码器)组成。 编码器和解码器都是DNN的形式,训练过程遵循分割学习模式。 然而,在这些作品中,他们并没有考虑到隐私问题。 有关语义和面向任务的通信的更多详细信息,我们建议读者参阅调查[64]和[65]。
6.3 噪声注入
基于噪声的隐私保护在数据收集和模型训练中被广泛研究,但只有少数涉及推理。 噪声注入的一个明显缺点是它总是在隐私和实用性之间强加一种深奥的权衡。 为了在实用性和隐私之间找到更好的平衡,Mireshghallah 等人提出了 Shredder [25],这是一种设备边缘协同推理系统,其中添加到 IR 的噪声是从学习到的噪声分布中提取的,而不是从学习到的噪声分布中提取的。随机噪声。 此外,基于差分隐私(DP),Cloak[26]将云端预训练的网络视为确定性函数,设计了满足Local的拉普拉斯机制-DP向原始数据添加噪声以进行进一步推理。 然而,初级掩模的推理结果直接暴露给云端或边缘服务器。
6.4 保护隐私的联邦学习
联邦学习 (FL) 已成为一种很有前途的方法,可以在分散数据源上实现协作机器学习,同时保护数据隐私[68]。 FL 利用分散式架构,其中多个设备或节点共同训练共享模型,而不共享其原始本地数据。 近年来,一些工作利用了一些特征,甚至可以从多方交互过程中的梯度和模型参数中恢复原始本地数据[69, 70]。 隐私保护联邦学习(PPFL)专注于增强 FL 框架内的隐私保证。 它在训练过程中采用各种技术来保护敏感数据的机密性[71, 72]。 具有子模型设计的 FL 可能是轮盘赌的替代方案,例如 [73, 74]。 然而,它没有提供严格的隐私和安全分析。 此外,一些子模型设计不能直接部署在一般分类问题上。 例如,[73]中提出的系统只能应用于非常特殊的场景,其中每个客户端的推荐系统模型可以自然解耦。
6.5 基于编码的解决方案
基于编码的解决方案分别为设备和服务器训练本地编码器和远程解码器。 这些解决方案可以分为隐私保护的潜在表示学习和实例编码。 研究最广泛的隐私保护潜在表示学习是对抗性训练,其中给定隐私属性标签,他们在防御者和对手之间执行最小-最大游戏来学习隐私保护表示[75,27,28]. 此外,Li等人提出了TIPRDC[76],一个任务无关的框架,其中编码器可以在不知道隐私属性标签的情况下生成隐私保护表示。 MixCon [37]研究模型反演攻击与表示可分离性之间的关系,并开发一致性损失来调整表示的可分离性,以平衡数据效用和反演攻击的难度。 这些方法无法保护主要任务的信息。 复值网络[39]不仅使用对抗性训练,还将实数转换为复数来隐藏私人信息,从而大大降低了攻击者的成功率。 然而,所有这些方法,包括 TIPRDC 和复值网络,在考虑隐私问题时都没有考虑效率。 实例编码,DataMix [38] 和 InstaHide [77],对原始数据集中的多个实例进行编码以生成新数据集,并使用它来训练一个新模型,该模型几乎具有与在原始数据集上训练的原始模型具有相同的准确性,这似乎是“免费的午餐”,但最近的研究[78]表明,“没有免费的午餐”,实例编码可以以低成本被击败。
6.6 加密解决方案
基于密码学的推理主要包括三种方法:同态加密(HE)[18]、安全多方计算(SMC)[19]和可信执行环境(TEE) ) [20]。 HE 允许对加密数据进行计算。 现有一些致力于应用 HE 和 SMC 进行隐私保护推理的工作,但它们都存在严重的计算延迟,并且需要特殊的额外硬件。 即使是最先进的 HE,DELPHI [22] 也将推理速度降低了 318 [26],这在AIoT场景中是不可接受的。 基于 TEE 的方法也存在类似的缺点,它需要服务器升级硬件作为安全飞地(例如,[20, 79]),并且已被证明容易受到旁道攻击。
7 结论
在本文中,我们提出了 Roulette,一种用于深度学习分类器的语义隐私保护框架。 与传统的协同推理不同,我们基于分裂学习重新训练本地网络,使得远程网络无法获得正确的推理结果,从而保护语义隐私并提高模型准确性。 此外,为了实现差异隐私,允许本地设备在将 DNN 中间表示上传到边缘服务器之前对输入数据进行无效化并添加噪声。 我们给出隐私保证并分析地面实况推理攻击的难度。 我们广泛评估了所提出的框架,测试其防御各种主要攻击的性能。 实验结果表明,所提出的框架能够有效保护语义隐私,同时获得良好的模型精度。 这项工作的局限性在于,我们没有为不同背景知识的攻击者构建统一的理论分析框架,这将在未来的工作中考虑。
附录A定理证明4.1
在证明定理4.1之前,我们首先证明以下两个定理。
Theorem A.1.
给定输入 和确定性函数 、、,随机机制 为 -差分私有。
证明。
Theorem A.2.
给定输入 和具有无效率 的任意无效矩阵 ,如果 是 -差分隐私机制,那么是一个-差分隐私机制,其中
| (22) |
证明。
然后,我们证明定理4.1。
附录B定理证明4.2
我们提供了近似结果的硬度来寻找地面实况推理函数。 特别是,我们证明除非RP=NP,否则攻击者不存在多项式时间可以在定义4.2。 证明的主体取决于[37]。 形式上,考虑逆问题
| (30) |
其中 是接收到的隐藏层表示,在不失一般性的情况下,我们将输入标准化为 。 是设备的网络,我们考虑具有 ReLU 激活函数的两个神经网络,具体来说,
| (31) |
其中是ReLU函数,是线性变换参数。 如果攻击者可以大致恢复输入数据,那么它就可以发起成功的地面实况推理攻击。
首先,我们给出必要的定义和有用的相关结果。
Definition B.1.
(3SAT 问题)。 给定一个合取范式 CNF 公式中的 n 个变量和 m 个子句,每个子句的大小最多为 3,目标是确定是否存在对 n 个布尔变量的赋值来满足 CNF 公式。
Definition B.2.
(MAX3SAT)。 给定 n 个变量和 m 个子句,一个合取范式 CNF 公式,每个子句的大小最多为 3,目标是找到满足最大子句数的赋值。
我们使用 MAXE3SAT(Q) 来表示 MAX3SAT 的受限特殊情况,其中每个变量最多出现在 Q 子句中,然后我们有,
Theorem B.1.
([80])。 除非 RP=NP,否则 MAXE3SAT(B) 没有多项式时间 (7/8 + 5) 近似算法。
现在,我们准备正式证明定理4.2。
证明。
给定一个带有 变量和 子句的 3SAT 实例 ,其中每个变量最多出现在 Q 个子句中,我们构造一个两层神经网络和输出表示满足以下条件:
-
•
完整性。 如果 是可指定的,则存在 使得
-
•
健全性。 对于任何,例如,我们可以恢复对的赋值,它至少满足子句
我们设置和。 对于任何 ,我们使用 表示第 子句,并使用 表示 个神经元,即 ,其中 是 的第 行。 对于任何 ,我们使用 来表示第 个变量。
我们使用输入 来表示变量,并使用第一层中的第一个 神经元来表示 子句。 通过采取
| (32) |
和 对于任何 ,并将 视为 为 false,将 视为 是真的。 如果子句满足,则可以验证 ;如果子句不满足,则可以验证 。 我们只需将第二层中的值复制为。 对于其他神经元,我们为输出层中的每个 制作 副本。 这可以通过采取
| (33) | ||||
并设置
| (34) | |||
对于任何,。 最后,我们将目标输出设置为
| (35) |
我们需要证明我们对神经网络 和目标输出 所做的两个声明。 对于第一个声明,假设 可满足,并且 是赋值。 然后,正如之前所讨论的,如果 为假并且 为 为真,我们可以简单地取 。 人们可以检查。
对于第二个声明,假设我们得到 这样
| (36) |
我们从 是二进制的简单情况开始,即 。同样,如果 则将 设为 true,如果 则将 设为 false。 可以检查不满足的子句的数量最多为
| (37) | ||||
第三步从开始,最后一步从开始。
接下来,我们转向一般情况 。我们根据符号将 舍入为 -1 或 +1。 将 定义为
| (38) |
我们将证明 引发的赋值满足 条款。 足以证明
| (39) |
因为这意味着不满足的子句的数量受以下限制
| (40) | ||||
最后一步是从 开始的。 此外,我们定义和。 然后我们有
| (41) | ||||
第三步是从 开始,对于 以及 和 给定 。 第四步是从开始的。 第五步遵循 ReLU 的 1-Lipschitz 连续性。 第六步是每个变量最多出现在 子句中。 第二个主张就此结束。 ∎
参考
- [1] V. Sze, Y. Chen, T. Yang, and J. S. Emer, “Efficient processing of deep neural networks: A tutorial and survey,” Proc. IEEE, vol. 105, no. 12, pp. 2295–2329, 2017.
- [2] M. I. Jordan and T. M. Mitchell, “Machine learning: Trends, perspectives, and prospects,” Science, vol. 349, no. 6245, pp. 255–260, 2015.
- [3] J. Zhang and D. Tao, “Empowering things with intelligence: A survey of the progress, challenges, and opportunities in artificial intelligence of things,” IEEE Internet of Things Journal, 2020.
- [4] E. Li, L. Zeng, Z. Zhou, and X. Chen, “Edge ai: On-demand accelerating deep neural network inference via edge computing,” IEEE Transactions on Wireless Communications, vol. 19, no. 1, pp. 447–457, 2019.
- [5] J. Shao and J. Zhang, “Bottlenet++: An end-to-end approach for feature compression in device-edge co-inference systems,” in Proc. IEEE ICC Workshops, 2020, pp. 1–6.
- [6] L. Zhang, L. Chen, and J. Xu, “Autodidactic neurosurgeon: Collaborative deep inference for mobile edge intelligence via online learning,” CoRR, vol. abs/2102.02638, 2021.
- [7] S. Laskaridis, S. I. Venieris, M. Almeida, I. Leontiadis, and N. D. Lane, “SPINNs: synergistic progressive inference of neural networks over device and cloud,” in Proc. ACM Mobicom, 2020, pp. 1–15.
- [8] E. Li, Z. Zhou, and X. Chen, “Edge intelligence: On-demand deep learning model co-inference with device-edge synergy,” in Proc. ACM Sigcomm Workshops, 2018, pp. 31–36.
- [9] H. Zhu, J. Xu, S. Liu, and Y. Jin, “Federated learning on non-iid data: A survey,” Neurocomputing, vol. 465, pp. 371–390, 2021.
- [10] S. J. Pan and Q. Yang, “A survey on transfer learning,” IEEE Transactions on knowledge and data engineering, vol. 22, no. 10, pp. 1345–1359, 2009.
- [11] L. Torrey and J. Shavlik, “Transfer learning,” in Handbook of research on machine learning applications and trends: algorithms, methods, and techniques. IGI global, 2010, pp. 242–264.
- [12] Y. Gao, M. Kim, S. Abuadbba, Y. Kim, C. Thapa, K. Kim, S. A. Camtep, H. Kim, and S. Nepal, “End-to-end evaluation of federated learning and split learning for internet of things,” in Proc. IEEE SRDS, 2020, pp. 91–100.
- [13] Z. He, T. Zhang, and R. B. Lee, “Model inversion attacks against collaborative inference,” in Proc. ACM ACSAC, 2019, pp. 148–162.
- [14] ——, “Attacking and protecting data privacy in edge-cloud collaborative inference systems,” IEEE Internet Things Journal, vol. 8, no. 12, pp. 9706–9716, 2021.
- [15] Q. Li, J. Ren, Y. Zhou, and Y. Zhang, “Privacy-preserving DNN model authorization against model theft and feature leakage,” in IEEE ICC, 2022, pp. 5633–5638.
- [16] L. Melis, C. Song, E. De Cristofaro, and V. Shmatikov, “Exploiting unintended feature leakage in collaborative learning,” in Proc. IEEE S & P, 2019, pp. 691–706.
- [17] R. Shokri, M. Stronati, C. Song, and V. Shmatikov, “Membership inference attacks against machine learning models,” in Proc. IEEE S & P, 2017, pp. 3–18.
- [18] M. Naehrig, K. Lauter, and V. Vaikuntanathan, “Can homomorphic encryption be practical?” in Proc. ACM Workshop on Cloud Computing Security, 2011, pp. 113–124.
- [19] C. Zhao, S. Zhao, M. Zhao, Z. Chen, C.-Z. Gao, H. Li, and Y.-a. Tan, “Secure multi-party computation: Theory, practice and applications,” Information Sciences, vol. 476, pp. 357–372, 2019.
- [20] K. G. Narra, Z. Lin, Y. Wang, K. Balasubramaniam, and M. Annavaram, “Privacy-preserving inference in machine learning services using trusted execution environments,” CoRR, vol. abs/1912.03485, 2019.
- [21] Z. Ghodsi, A. K. Veldanda, B. Reagen, and S. Garg, “CryptoNAS: Private inference on a relu budget,” in Proc. NeurIPS, 2020.
- [22] P. Mishra, R. Lehmkuhl, A. Srinivasan, W. Zheng, and R. A. Popa, “Delphi: A cryptographic inference service for neural networks,” in Proc. USENIX Security, 2020, pp. 2505–2522.
- [23] I. Jarin and B. Eshete, “PRICURE: Privacy-preserving collaborative inference in a multi-party setting,” arXiv preprint arXiv:2102.09751, 2021.
- [24] Q. Li, J. Ren, X. Pan, Y. Zhou, and Y. Zhang, “ENIGMA: Low-latency and privacy-preserving edge inference on heterogeneous neural network accelerators,” in Proc. IEEE ICDCS, 2022, pp. 458–469.
- [25] F. Mireshghallah, M. Taram, P. Ramrakhyani, A. Jalali, D. M. Tullsen, and H. Esmaeilzadeh, “Shredder: Learning noise distributions to protect inference privacy,” in Proc. ACM ASPLOS. ACM, 2020, pp. 3–18.
- [26] F. Mireshghallah, M. Taram, A. Jalali, A. T. Elthakeb, D. Tullsen, and H. Esmaeilzadeh, “A principled approach to learning stochastic representations for privacy in deep neural inference,” arXiv preprint arXiv:2003.12154, 2020.
- [27] S. Liu, J. Du, A. Shrivastava, and L. Zhong, “Privacy adversarial network: representation learning for mobile data privacy,” Proc. ACM IMWUT, vol. 3, no. 4, pp. 1–18, 2019.
- [28] S. J. Oh, M. Fritz, and B. Schiele, “Adversarial image perturbation for privacy protection a game theory perspective,” in Proc. IEEE ICCV, 2017, pp. 1491–1500.
- [29] A. Li, Y. Duan, H. Yang, Y. Chen, and J. Yang, “TIPRDC: task-independent privacy-respecting data crowdsourcing framework for deep learning with anonymized intermediate representations,” in Proc. ACM SIGKDD, 2020, pp. 824–832.
- [30] S. Mannor, D. Peleg, and R. Rubinstein, “The cross entropy method for classification,” in Proc. ICML, 2005, pp. 561–568.
- [31] I. Goodfellow, Y. Bengio, and A. Courville, Deep learning. MIT press, 2016.
- [32] D. Pasquini, G. Ateniese, and M. Bernaschi, “Unleashing the tiger: Inference attacks on split learning,” in Proc. ACM CCS, 2021, pp. 2113–2129.
- [33] M. Langer, Z. He, W. Rahayu, and Y. Xue, “Distributed training of deep learning models: A taxonomic perspective,” IEEE Transactions on Parallel and Distributed Systems, vol. 31, no. 12, pp. 2802–2818, 2020.
- [34] J. Soifer, J. Li, M. Li, J. Zhu, Y. Li, Y. He, E. Zheng, A. Oltean, M. Mosyak, C. Barnes et al., “Deep learning inference service at microsoft,” in Proc. USENIX OpML, 2019, pp. 15–17.
- [35] H. J. La, M. K. Kim, and S. D. Kim, “A personal healthcare system with inference-as-a-service,” in Proc. IEEE SCC, 2015, pp. 249–255.
- [36] M. Samragh, H. Hosseini, A. Triastcyn, K. Azarian, J. Soriaga, and F. Koushanfar, “Unsupervised information obfuscation for split inference of neural networks,” arXiv preprint arXiv:2104.11413, 2021.
- [37] X. Li, Y. Huang, B. Peng, Z. Song, and K. Li, “MixCon: Adjusting the separability of data representations for harder data recovery,” CoRR, vol. abs/2010.11463, 2020.
- [38] Z. Liu, Z. Wu, C. Gan, L. Zhu, and S. Han, “Datamix: Efficient privacy-preserving edge-cloud inference,” in Proc. ECCV, ser. Lecture Notes in Computer Science, vol. 12356. Springer, 2020, pp. 578–595.
- [39] L. Xiang, H. Zhang, H. Ma, Y. Zhang, J. Ren, and Q. Zhang, “Interpretable complex-valued neural networks for privacy protection,” in Proc. ICLR, 2019.
- [40] M. Abadi, A. Chu, I. Goodfellow, H. B. McMahan, I. Mironov, K. Talwar, and L. Zhang, “Deep learning with differential privacy,” in Proc. ACM CCS, 2016, pp. 308–318.
- [41] C. Dwork, A. Roth et al., “The algorithmic foundations of differential privacy,” Foundations and Trends in Theoretical Computer Science, vol. 9, no. 3-4, pp. 211–407, 2014.
- [42] Y. LeCun, C. Cortes, and C. J. Burges, “MNIST handwritten digit database,” ATT Labs [Online]. Available: http://yann. lecun. com/exdb/mnist, 2010.
- [43] Y. Netzer, T. Wang, A. Coates, A. Bissacco, B. Wu, and A. Y. Ng, “The street view house numbers (SVHN) dataset,” Tech. Report, 2011.
- [44] K. Ganju, Q. Wang, W. Yang, C. A. Gunter, and N. Borisov, “Property inference attacks on fully connected neural networks using permutation invariant representations,” in Proc. ACM CCS, 2018, pp. 619–633.
- [45] C. Wang, Q. Wu, M. Weimer, and E. Zhu, “FLAML: A fast and lightweight automl library,” Proc. MLSys, vol. 3, pp. 434–447, 2021.
- [46] J. Wang, J. Zhang, W. Bao, X. Zhu, B. Cao, and P. S. Yu, “Not just privacy: Improving performance of private deep learning in mobile cloud,” in Proc. ACM KDD, 2018, pp. 2407–2416.
- [47] Y. LeCun et al., “LeNet-5, convolutional neural networks,” URL: http://yann. lecun. com/exdb/lenet, vol. 20, no. 5, p. 14, 2015.
- [48] H. Wussing, The genesis of the abstract group concept: a contribution to the history of the origin of abstract group theory. Courier Corporation, 2007.
- [49] C. Martínez, A. Panholzer, and H. Prodinger, “Generating random derangements,” in Proc. SIAM ANALCO, 2008, pp. 234–240.
- [50] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative adversarial networks,” Communications of the ACM, vol. 63, no. 11, pp. 139–144, 2020.
- [51] D. Desfontaines, “Is differential privacy the right fit for your problem?” https://desfontain.es/privacy/litmus-test-differential-privacy.html, 07 2022, ted is writing things (personal blog).
- [52] Q. Lei, A. Jalal, I. S. Dhillon, and A. G. Dimakis, “Inverting deep generative models, one layer at a time,” Advances in neural information processing systems, vol. 32, 2019.
- [53] A. Krizhevsky and G. Hinton, “Learning multiple layers of features from tiny images,” Citeseer, 2009.
- [54] G. Cohen, S. Afshar, J. Tapson, and A. van Schaik, “EMNIST: an extension of MNIST to handwritten letters,” arXiv preprint arXiv:1702.05373, 2017.
- [55] A. Torralba, R. Fergus, and Y. Weiss, “80 million tiny images: A large dataset for non-parametric object and scene recognition,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 30, no. 11, pp. 1958–1970, 2008.
- [56] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778.
- [57] J. Ryu, Y. Zheng, Y. Gao, S. Abuadbba, J. Kim, D. Won, S. Nepal, H. Kim, and C. Wang, “Can differential privacy practically protect collaborative deep learning inference for the internet of things?” CoRR, vol. abs/2104.03813, 2021.
- [58] Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli, “Image quality assessment: from error visibility to structural similarity,” IEEE Transactions on Image Processing, vol. 13, no. 4, pp. 600–612, 2004.
- [59] H. Yin, A. Mallya, A. Vahdat, J. M. Alvarez, J. Kautz, and P. Molchanov, “See through gradients: Image batch recovery via gradinversion,” in Proc. IEEE/CVF CVPR, 2021, pp. 16 337–16 346.
- [60] F. Wang, E. Hugh, and B. Li, “More than enough is too much: Adaptive defenses against gradient leakage in production federated learning,” 2023.
- [61] X. Li, Y. Chen, C. Wang, and C. Shen, “When deep learning meets differential privacy: Privacy, security, and more,” IEEE Network, vol. 35, no. 6, pp. 148–155, 2021.
- [62] L. Zeng, X. Chen, Z. Zhou, L. Yang, and J. Zhang, “Coedge: Cooperative dnn inference with adaptive workload partitioning over heterogeneous edge devices,” IEEE/ACM Transactions on Networking, vol. 29, no. 2, pp. 595–608, 2020.
- [63] C. Shi, L. Chen, C. Shen, L. Song, and J. Xu, “Privacy-aware edge computing based on adaptive DNN partitioning,” in Proc. IEEE GLOBECOM, 2019, pp. 1–6.
- [64] X. Luo, H.-H. Chen, and Q. Guo, “Semantic communications: Overview, open issues, and future research directions,” IEEE Wireless Communications, vol. 29, no. 1, pp. 210–219, 2022.
- [65] E. C. Strinati and S. Barbarossa, “6G networks: Beyond shannon towards semantic and goal-oriented communications,” Computer Networks, vol. 190, p. 107930, 2021.
- [66] J. Shao, Y. Mao, and J. Zhang, “Learning task-oriented communication for edge inference: An information bottleneck approach,” IEEE Journal on Selected Areas in Communications, vol. 40, no. 1, pp. 197–211, 2022.
- [67] Z. Weng and Z. Qin, “Semantic communication systems for speech transmission,” IEEE Journal on Selected Areas in Communications, vol. 39, no. 8, pp. 2434–2444, 2021.
- [68] Q. Yang, Y. Liu, T. Chen, and Y. Tong, “Federated machine learning: Concept and applications,” ACM Transactions on Intelligent Systems and Technology (TIST), vol. 10, no. 2, pp. 1–19, 2019.
- [69] Z. Li, J. Zhang, L. Liu, and J. Liu, “Auditing privacy defenses in federated learning via generative gradient leakage,” in Proc. IEEE/CVF CVPR, 2022, pp. 10 132–10 142.
- [70] L. Zhu, Z. Liu, and S. Han, “Deep leakage from gradients,” vol. 32, 2019.
- [71] R. Xu, N. Baracaldo, Y. Zhou, A. Anwar, and H. Ludwig, “Hybridalpha: An efficient approach for privacy-preserving federated learning,” in Proc. AISEC, 2019, pp. 13–23.
- [72] C. Zhang, S. Li, J. Xia, W. Wang, F. Yan, and Y. Liu, “Batchcrypt: Efficient homomorphic encryption for cross-silo federated learning,” in Proc. USENIX ATC, 2020.
- [73] C. Niu, F. Wu, S. Tang, L. Hua, R. Jia, C. Lv, Z. Wu, and G. Chen, “Billion-scale federated learning on mobile clients: A submodel design with tunable privacy,” in ACM Proc. MobiCom, 2020, pp. 1–14.
- [74] A. Li, J. Sun, P. Li, Y. Pu, H. Li, and Y. Chen, “Hermes: an efficient federated learning framework for heterogeneous mobile clients,” in ACM Proc. MobiCom, 2021, pp. 420–437.
- [75] S. A. Osia, A. Taheri, A. S. Shamsabadi, K. Katevas, H. Haddadi, and H. R. Rabiee, “Deep private-feature extraction,” IEEE Transactions on Knowledge and Data Engineering, vol. 32, no. 1, pp. 54–66, 2018.
- [76] Ú. Erlingsson, V. Pihur, and A. Korolova, “Rappor: Randomized aggregatable privacy-preserving ordinal response,” in Proc. ACM CCS, 2014, pp. 1054–1067.
- [77] Y. Huang, Z. Song, K. Li, and S. Arora, “Instahide: Instance-hiding schemes for private distributed learning,” in Proc. ICML, 2020, pp. 4507–4518.
- [78] N. Carlini, S. Deng, S. Garg, S. Jha, S. Mahloujifar, M. Mahmoody, A. Thakurta, and F. Tramèr, “Is private learning possible with instance encoding?” Proc. IEEE S & P, 2019.
- [79] Y. Tian, L. Njilla, J. Yuan, and S. Yu, “Low-latency privacy-preserving outsourcing of deep neural network inference,” IEEE Internet Things Journal, vol. 8, no. 5, pp. 3300–3309, 2021.
- [80] L. Trevisan, “Non-approximability results for optimization problems on bounded degree instances,” in Proc. ACM STOC, 2001, pp. 453–461.