HAct:使用神经网络激活直方图进行分布外检测
摘要
我们提出了一种简单、高效且准确的方法来检测训练神经网络的分布外(OOD)数据。 我们提出了一种新颖的描述符,HAct - 激活直方图,用于 OOD 检测,即在输入数据的影响下神经网络层的输出值的概率分布(通过直方图近似)。 我们基于 HAct 描述符制定了 OOD 检测器。 我们证明,在多个图像分类基准上,HAct 的 OOD 检测比最先进的方法要准确得多。 例如,我们的方法在标准 OOD 基准上使用 Resnet-50 实现了 95% 的真阳性率 (TPR),误报率仅为 0.03%,误报率比之前最先进的技术高出 20.67%(相同的 TPR 为 95%)。 计算效率和易于实施使得 HAct 适合在大规模实践中在线实施监控部署的神经网络。
1简介
机器学习 (ML) 系统通常是在训练集和测试集是从相同统计分布中采样的假设下构建的。 然而,在实践中,情况往往并非如此。 例如,在运行期间,来自与训练不同的新类的数据可能会出现在测试集中。 在这些情况下,机器学习系统可能会表现不可靠,并且可能对错误输出有很高的置信度(DeVries & Taylor,2018)。 因此,需要构建技术,使机器学习系统能够检测到此类分布外(OOD)数据;这称为OOD 检测问题。 一旦检测到 OOD 数据,系统的用户就会被通知可能存在不可靠的结果,和/或可以采用其他算法来适应此类新数据。 OOD 问题已成为机器学习和计算机视觉领域近期备受关注的问题(Yang 等人,2022),因为它在实践中的系统部署中非常重要。
神经网络 OOD 检测的最新技术 (SoA) (Sun 等人, 2021; Djurisic 等人, 2022; Ahn 等人, 2023; Sun & Li, 2022)重点是识别可以区分 OOD 和分布内 (ID) 数据的数据描述符。 与相应训练数据描述符充分不同的数据描述符被认为来自 OOD 数据。 由于网络逐层计算数据的统计数据以确定与 ML 任务相关的特征,因此许多最近的工作假设此类统计数据的计算函数可用于识别 OOD 数据。 事实上,此类方法已经带来了 SoA 性能。 一种流行的方法(Sun等人,2021)确定分类卷积神经网络(CNN)倒数第二层激活输出的阈值是有效的描述符。 这种方法已推广到其他层(Djurisic 等人,2022) 以及其他几项近期的工作(Sun & Li,2022;Ahn 等人,2023) 都建立在该方法的基础上这种构建由网络激活阈值形成的函数的想法。 虽然这些方法已经在大规模数据集上以有效的方式展示了 SoA 性能,并且有可能部署在现实世界的系统中,但性能仍然需要提高才能用于安全关键系统等应用程序。
在这项工作中,我们引入了用于 OOD 检测的新颖描述符,这些描述符计算简单且高效,并且与最先进的技术相比,性能显着提高。 我们证明 OOD 的有效描述符是神经网络层输出值的概率分布。 我们展示了如何将这些描述符合并到现有训练网络的有效 OOD 检测算法中。 我们的具体贡献是引入了一种可用于 OOD 检测的新颖描述符 (HAct),即神经网络内层输出的概率分布。 当在 OOD 检测框架中的多个层上组合该描述符时,所得到的技术优于现有的最先进技术,如多个基准数据集所证明的那样。
2相关工作
我们重点介绍了 OOD 检测中的相关工作,并建议读者参考(Yang 等人,2022)进行详细调查。 有几种方法通过将测试时的数据与训练数据集进行比较来确定 OOD 数据。 为了提高效率,这通常使用自动编码器(Zhou & Paffenroth,2017)来实现,其中自动编码器使用 ID 数据进行训练,这使得它们能够学习训练数据的分布。 因此,任何 OOD 数据都将具有较高的重建误差,因此对重建误差进行阈值处理以识别 OOD 数据。 虽然有效,但这种方法可能会将与训练数据不同的数据表征为 OOD,但网络仍然能够推广到该数据。 其他方法旨在对数据网络的不确定性进行建模,并将高不确定性数据表征为 OOD。 有多种方法可以确定不确定性,例如测量网络集合在数据上的差异的集成方法(Rahaman & Thiery,2021)、测试时间增强方法(Wang等人,2019),衡量网络与增强版本的差异、网络置信度得分的不确定性(Malinin & Gales,2018)以及贝叶斯方法(Goan & Foxes,2020) ) 将网络中的权重视为概率分布,并将输出计算为结果分布。
最近,当前的 SoA (Sun 等人,2021;Djurisic 等人,2022;Ahn 等人,2023;Sun & Li,2022) 试图构建可以描述为训练有素的描述符的内容。网络和传入的数据来区分 OOD 和 ID 数据。 在Sun等人(2021)中,网络倒数第二层激活输出的阈值被用作OOD检测的描述符。 用于计算能量得分(Liu 等人, 2020)(有关替代得分,请参阅Liu 等人 (2023));得分值较大的数据被标记为 OOD 数据。 Djurisic 等人 (2022) 概括了 Sun 等人 (2021) 的方法,不仅在倒数第二层而且在多个特征层中进行阈值化,从而提高了性能。 Ahn 等人 (2023) 也对激活输出进行阈值处理,但使用激活特征的总数作为描述符,并使用修剪来删除网络中不重要的部分(另请参阅 Sun & Li (2022) 提出了 OOD 的稀疏化相关思想,这优于 Djurisic 等人 (2022) 的结果。 训练网络的其他描述符和 OOD 检测的输入数据是拓扑描述符 (Lacombe 等人,2021),它们在密集层计算。 虽然在小型网络上得到了有效证明,但到目前为止,这种方法尚未扩展到最先进的大型网络和数据集(例如,(Sun 等人,2021;Djurisic 等人,2022))。 我们的方法将描述符计算为网络和输入数据的函数,但相反,我们表明网络中各层输出的分布是 OOD 检测的替代且有效的描述符,在提高最先进水平的同时简单高效。
3 OOD检测方法
在本节中,我们将介绍 OOD 检测的新方法。 我们首先介绍我们的新颖描述符,称为激活直方图 (HAct),用于 OOD 检测,根据经过训练的网络和输入数据计算得出。 然后我们展示如何将该描述符集成到 OOD 检测过程中。 最后,我们展示了如何使大型网络的 HAct 描述符的计算变得高效。 为了说明原理,我们重点关注分类任务中的 OOD 检测。
3.1 激活直方图 (HAct) 描述符
给定一个经过训练的神经网络,我们为网络内的线性操作(例如线性或卷积层)描述的层定义一个描述符。 令 为层 的输入张量, 为层 的权重张量。我们认为该层是由 定义的线性运算形成的,其中 表示张量的(多维)索引(我们的方法中不使用偏差)。 我们考虑由层的中间计算的标量分量形成的激活权重,即,它描述了的程度输入观测值的第 t3> 坐标 激活权重张量的第 单元。 我们的描述符,称为层的激活直方图,是元素的概率分布,即,它认为 是一个随机变量。 我们通过计算所有激活权重的直方图来近似的概率分布,我们将其表示为,定义如下:
| (1) |
其中是激活权重的数量(的元素),是权重范围空间的划分,表示指示函数。 除了 之外,分区是固定的,我们将其视为超参数并针对 OOD 精度进行了调整。 向量被认为是层的OOD描述符。为了符号简单起见,我们没有指出 对 的依赖关系,但这是可以理解的。 在下一节中,我们将利用多层的多个直方图进行 OOD 检测。 对于 CNN,我们将使用用于分类的密集层和卷积层来计算 HAct 描述符。
我们通常选择 因为在我们考虑的(深层)层中,输入 通常是稀疏的(例如,由于来自前一层的 ReLU 激活),这意味着直方图第一个垃圾箱中的权重过大。 因此,我们使用 进行简单的阈值操作来减少近零输出的影响。 我们在实验中研究了选择,但实验并未显示出接近最佳选择的敏感性。
3.2 使用激活直方图进行 OOD 检测
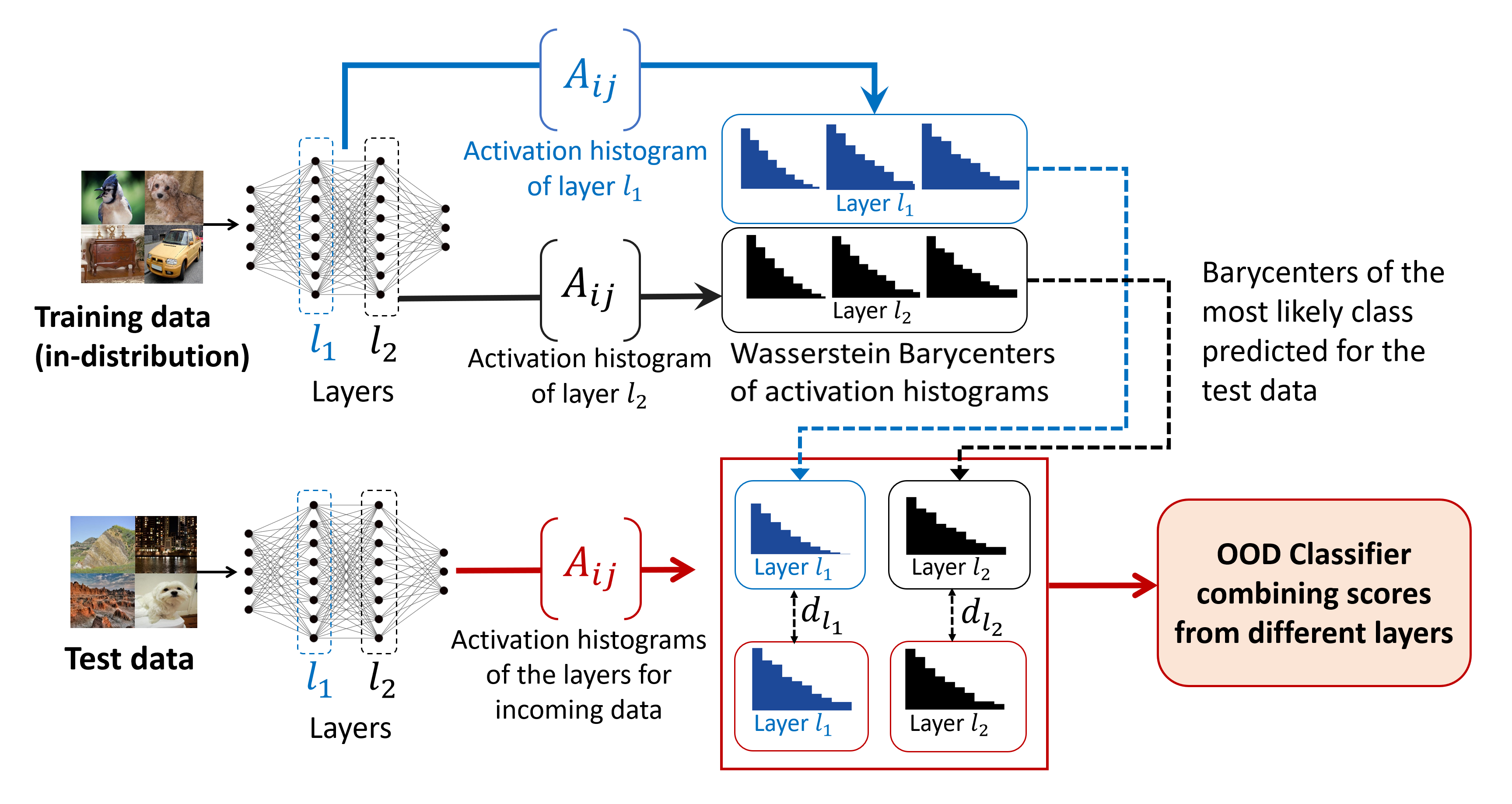
我们现在指定如何使用上一节中的激活直方图来执行 OOD 检测。 我们假设一个训练有素的神经网络。为简单起见,我们假设 经过分类训练。 我们的过程类似于Lacombe等人(2021)的框架,但我们将使用激活直方图而不是拓扑描述符来证明新描述符的有效性。 我们的方法背后的简单观察是,与 ID 数据相比,OOD 数据的激活直方图发生了变化,因此,我们的方法试图检测激活直方图的这种变化。 图1给出了我们的方法的示意性概述。
该过程首先包括使用经过训练的网络的训练数据集(或其子集)准备 OOD 检测器,然后在准备之后和在线操作期间,OOD 检测器不再需要训练集。 在准备步骤中,通过计算该类别中所有数据的激活直方图的平均值,为每个分类类别计算平均激活直方图,即,
| (2) |
其中是的激活直方图,是概率分布之间的度量。 在线操作OOD检测时,选择测试数据最可能的类别,、的激活直方图>,计算,如果 和 之间的距离超过阈值,则数据 被视为网络 的 OOD >。更正式地说,我们使用给定层 的激活直方图进行 OOD 检测,由下式给出
| (3) |
其中 是阈值。 为了组合 OOD 检测器的多个层的信息,我们定义整体检测器,如果所有层的所有 OOD 检测器都返回 ID,则返回 ID,否则检测器返回 OOD。
在上面的公式中,需要选择一个适当的度量来定义训练类别的平均描述符以及测试和训练直方图之间的距离。 继Lacombe等人(2021)之后,我们选择Wasserstein度量(熵正则化以实现快速计算;Benamou等人(2015)用于重心计算,Bonneel等人(2011)用于推理过程中的距离计算),这被证明是有效的。 在本例中, 称为 Wasserstein 重心。 算法 1 显示了我们提出的 OOD 检测器推理和准备的伪代码。
| (4) |
3.3 加速HAct:子采样激活权重
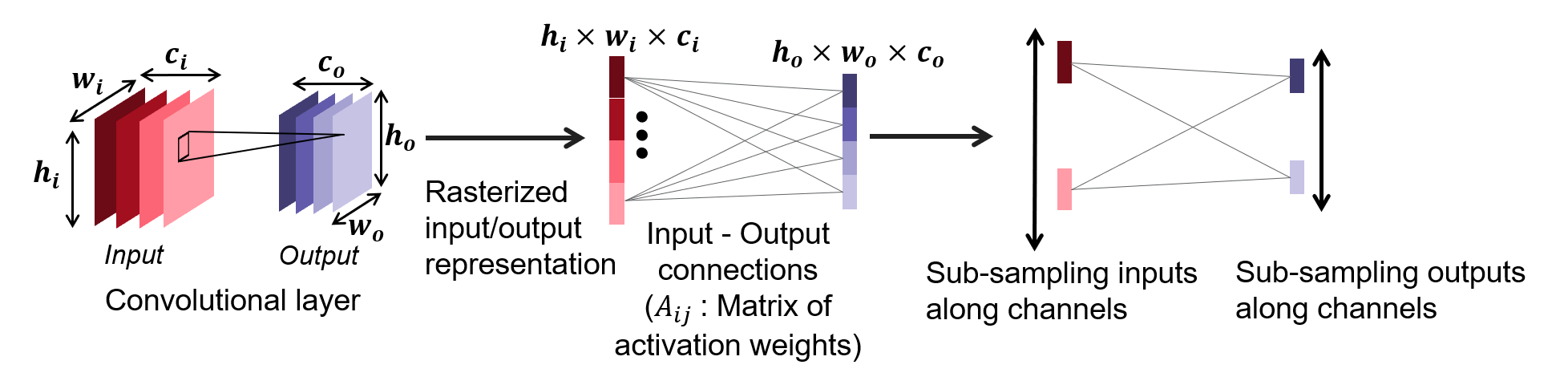
对于大型网络,例如用于图像分类的网络,从卷积层计算的激活直方图在训练和推理方面的计算成本可能很高。 这是因为卷积层的输出形状通常会产生大小为 的激活权重矩阵。 为了降低计算成本,我们提出了用于计算激活直方图的激活权重的子采样。 当在卷积层上计算激活直方图时,这可以显着加快训练和测试速度。 在消融研究(第 4.2 节)中,我们展示了该策略的计算成本和准确性之间的权衡。
我们通过基于预定义策略跳过层的一些输入输出连接来对激活权重进行子采样。 该策略涉及在计算激活权重矩阵时对输入和输出节点进行二次采样。 我们可以在卷积层输入的高度 ()、宽度 () 和通道 () 维度中执行子采样/输出。 然而,实际上,我们实验中用于形成 HAct 描述符的大多数卷积层都靠近分类(密集)层,因此具有较小的空间维度(例如,最后一个卷积层的 ResNet-50 层)与其通道维度(ResNet-50 最后一个卷积层为 2048)进行比较。 因此,我们对卷积层输入和输出节点的通道进行子采样,只使用子采样 和 形成的权重 来对激活权重进行子采样,如图 2 所示。 请注意,在实现中,我们对输入和输出节点进行栅格化。 栅格化输入和输出之间的连接说明了计算的激活权重。 在通道维度中进行二次采样后,请注意,计算的权重 较少,因此直方图计算中的权重也较少。
4实验
4.1与现有技术的比较
4.1.1 数据集
我们在 OOD 检测的基准数据集上测试我们的方法。 第一个基准源自 CIFAR-10 (Krizhevsky, )。 网络在 8 个类别的 CIFAR-10 训练集(表示为 CIFAR-8)上进行训练,其余两个类别被视为 OOD(表示为 CIFAR-2)。 使用的测试集是CIFAR-10测试集。 第二组数据集(用于 Sun 等人 (2021))涉及用于 ID 的 ImageNet (Deng 等人, 2009) 和 Places (Zhou 等人) , 2018)、SUN (Xiao 等人, 2010)、iNaturalist (Van Horn 等人, 2018) 和Textures (Cimpoi 等人, 2014) 用于 OOD 数据。
4.1.2指标
我们使用 SoA 中使用的标准检测指标对 HAct 进行基准测试(Sun 等人,2021)。 第一个是真阳性率 (TPR) 为 95% 时的假阳性率 (FPR),表示为 FPR95(越低越好),第二个是 ROC(接收者操作特性)曲线下的面积,表示为 AUROC(越高越好)。
4.1.3 在大规模 OOD 数据集上与 SoA 的比较
我们使用 ResNet-50 (He 等人, 2016) 和在 ImageNet-1k 数据上训练的相对较轻的权重模型 MobileNet-v2 (Sandler 等人, 2018) 进行实验,以及Sun等人(2021)中使用的OOD数据集的基准。 我们与最新的 SoA 进行比较 - ReAct (Sun 等人, 2021)、ASH-B (Djurisic 等人, 2022)、DICE (Sun & Li , 2022)、DICE+ReAct(Sun & Li, 2022) 和 LINE (Ahn 等人, 2023)。 对于 ResNet-50,HAct 描述符从最后一个分类层(密集层)和密集层之前的卷积层组合(如方程 4 中的算法 1 中指定)层。 对于 MobileNet-v2,我们结合了最后一个分类层(密集层)和前面两个卷积层的 HAct 描述符。
表1显示了基准比较的结果。 我们的方法始终大幅优于所有竞争方法,几乎实现零 FPR95 和近 100% AUROC。 我们的结果是,与下一个最佳方法(Ahn等人,2023)相比,ResNet-50的FPR95提高了20.67%,MobileNet-v2的FPR95提高了29.52%,这证明了我们的激活直方图(HAct)的实用性描述符。
我们的方法在 ResNet-50 上运行 90 毫秒,在 MobileNet-v2 上运行 60 毫秒,以在 NVIDIA GeForce RTX 3080 上对尺寸为 2242243 的单个图像进行推理(请参见第 4.2.3 了解详细信息),可与现有的最先进技术相媲美。
| OOD Datasets | ||||||||||
| Methods | iNaturalist | SUN | Places | Textures | Average | |||||
| FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | |
| Model: ResNet-50 | ||||||||||
| ReAct Sun et al. (2021) | 20.38 | 96.22 | 24.20 | 94.20 | 33.85 | 91.58 | 47.30 | 89.80 | 31.43 | 92.95 |
| ASH-B Djurisic et al. (2022) | 14.21 | 97.32 | 22.08 | 95.10 | 33.45 | 92.31 | 21.17 | 95.50 | 22.73 | 95.06 |
| DICE Sun & Li (2022) | 25.63 | 94.49 | 35.15 | 90.83 | 46.49 | 87.48 | 31.72 | 90.30 | 34.75 | 90.77 |
| DICE + ReAct Sun & Li (2022) | 18.64 | 96.24 | 25.45 | 93.94 | 36.86 | 90.67 | 28.07 | 92.74 | 27.25 | 93.40 |
| LINe Ahn et al. (2023) | 12.26 | 97.56 | 19.48 | 95.26 | 28.52 | 92.85 | 22.54 | 94.44 | 20.70 | 95.03 |
| HAct (Ours) | 0.02 | 99.99 | 0.02 | 99.99 | 0.02 | 99.99 | 0.07 | 99.95 | 0.03 | 99.98 |
| Model: MobileNet-v2 | ||||||||||
| ReAct Sun et al. (2021) | 42.40 | 91.53 | 47.69 | 88.16 | 51.56 | 86.64 | 38.42 | 91.53 | 45.02 | 89.47 |
| ASH-B Djurisic et al. (2022) | 31.46 | 94.28 | 38.45 | 91.61 | 51.80 | 87.56 | 20.92 | 95.07 | 35.66 | 92.13 |
| DICE Sun & Li (2022) | 43.09 | 90.83 | 38.69 | 90.46 | 53.11 | 85.81 | 32.80 | 91.30 | 41.92 | 89.60 |
| DICE + ReAct Sun & Li (2022) | 32.30 | 93.57 | 31.22 | 92.86 | 46.78 | 88.02 | 16.28 | 96.25 | 31.64 | 92.68 |
| LINe Ahn et al. (2023) | 24.95 | 95.53 | 33.19 | 92.94 | 47.95 | 88.98 | 12.30 | 97.05 | 29.60 | 93.62 |
| HAct (Ours) | 0.12 | 99.97 | 0.07 | 99.98 | 0.12 | 99.97 | 0.01 | 99.99 | 0.08 | 99.98 |
4.1.4 与 OOD 检测的拓扑描述符的比较
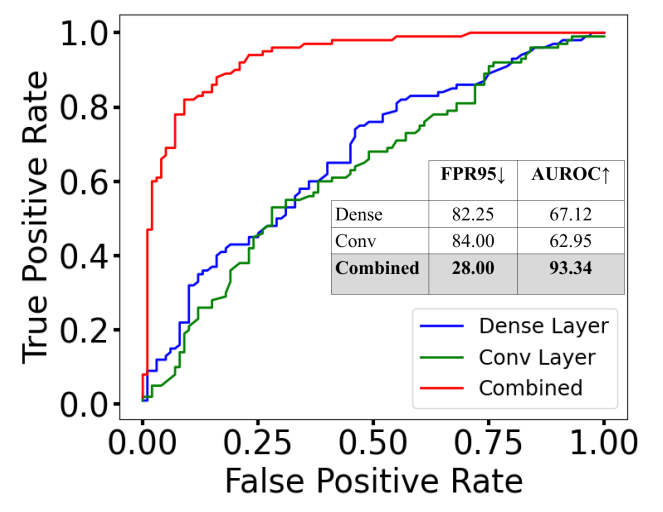
我们将我们的 OOD 检测方法与拓扑描述符(Lacombe 等人,2021)进行比较。 请注意,由于计算复杂度较高,这种方法尚未在大规模 OOD 分类基准(Sun 等人,2021) 上得到验证。 由于我们使用类似的框架,但描述符不同,因此我们与(Lacombe等人,2021)进行比较,以说明我们的方法对大规模数据集的可扩展性,以及即使对于较小的数据集也优于该方法的优势规模数据集/架构。 由于速度限制,拓扑方法只能应用于大型 CNN 中的密集层。 即使在这种情况下,HAct 在最后一个密集层上的速度也比在 ImageNet-1k 上训练的 ResNet-50 快 50 倍。 由于Lacombe等人(2021)的计算复杂度作为激活权重数量的函数呈非线性增加(参见附录),因此它不能扩展到卷积层。 除了速度优势之外,我们的方法在 OOD 检测中也更加准确。 为了证明这一点,我们在较小的数据集(FMNIST/MNIST 基准,其中 ID 数据来自 MNIST (LeCun,1998) 上与 Lacombe 等人 (2021) 进行比较,OOD 是来自 FMNIST (Xiao 等人, 2017) 和 CIFAR-8/CIFAR-2 基准) 和架构 (CNN-1 (by PyTorch.org, ) 和 CNN -2 (由 TensorFlow.org 提供),它们是浅层 CNN - 请参阅附录了解完整规范)在 Lacombe 等人 (2021) 中考虑。 为了公平比较,HAct 的描述符仅在最终的密集层上计算。 结果如表2所示,表明我们的方法显着优于拓扑描述符(Lacombe等人,2021)。
| Metric | ||||
|---|---|---|---|---|
| Model | OOD | Method | FPR95 | AUROC |
| CNN-1 | FMNIST | Topology | 46.50 | 92.20 |
| HAct (Ours) | 12.50 | 95.50 | ||
| CNN-2 | CIFAR-2 | Topology | 86.00 | 55.39 |
| HAct (Ours) | 82.25 | 67.12 | ||
4.2消融研究
在本节中,我们将彻底检查我们方法中的超参数和设计选择。
4.2.1 激活直方图的层选择
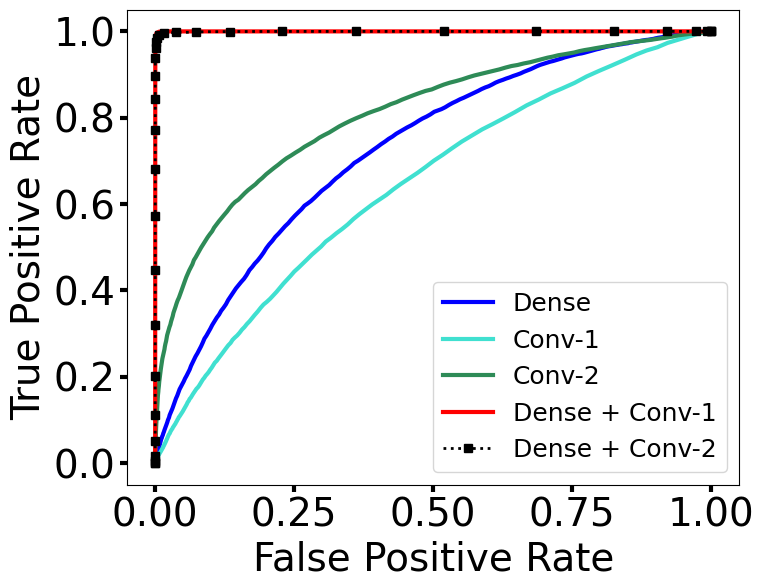
我们首先使用表 1 中的 OOD 基准数据集(表中的分布数据为 ImageNet-1k,OOD 为 iNaturalist)与 ResNet-50 进行实验,将密集层与最后一个卷积层相结合(表示为 Dense + Conv-1),并将密集层与最后一个卷积层之前的卷积层相结合(表示为 Dense + Conv-2)。 我们在图 3(a) 中报告了使用 iNaturalist 数据集进行 OOD 检测的结果。 我们看到,使用 Conv-1 或 Conv-2 层与密集层的组合检测器会产生类似的 OOD 检测性能(组合检测器的 ROC 曲线重叠),并且该组合优于仅在任何一个上计算的 HAct层。
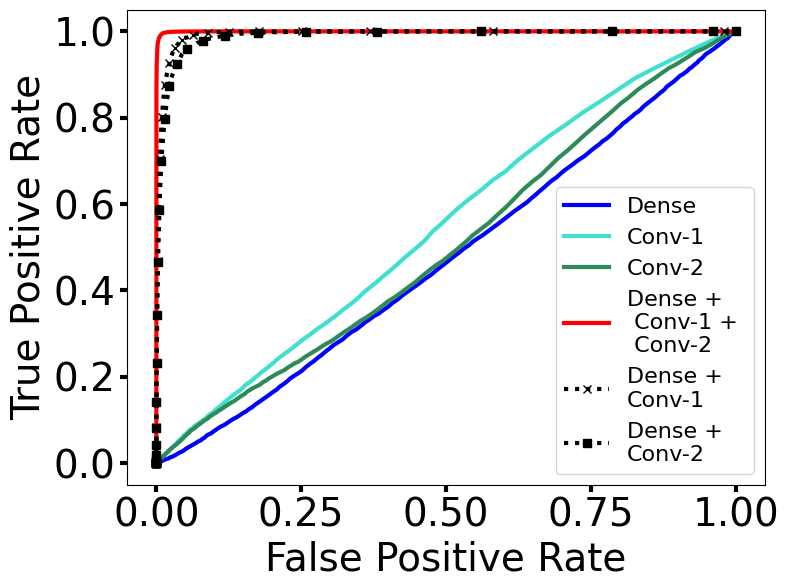
对于使用 MobileNet-v2 进行 OOD 检测(参见图 3(b)),HAct 描述符的最佳性能来自最后一个分类(密集)层与前面两个卷积层的描述符的结合。 这可以通过以下事实来解释:在 MobileNet-v2 中,使用可分离卷积,并且每个卷积层都是全卷积的可分离部分。 使用两个卷积层可能会产生与在 ResNet-50 中在全卷积层上计算 HAct 类似的效果。 请注意,密集与任一卷积层的组合比使用所有三层的性能稍差,并且两者都优于在任何一层上计算的 HAct。
接下来,我们表明,密集和卷积 HAct 描述符的组合在任一层 HAct 描述符上的改进结果并不限于 ImageNet-1k 训练的网络。 为了证明这一点,我们使用 CNN-2 架构(在上一小节中提到)对 CIFAR OOD 基准进行实验。 结果如图 3(c) 所示,表明两层 HAct 的组合可带来更好的 OOD 检测性能。
定义基于 HAct 描述符的组合检测器所需的层数可能取决于我们在 ResNet-50 和 MobileNet-v2 中看到的架构。
4.2.2 超参数选择
我们的算法中需要调整的主要超参数是,即激活直方图计算中接近零值的阈值。 一般来说, 的最佳值将取决于架构和架构内的层,因为激活权重的预期分布将根据上述变量而变化。 因此,我们研究了各种层和架构的的选择。
我们在 Imagenet-1k 上训练的 ResNet-50 和 MobileNet-v2 上研究 ,并报告 Sun 等人 (2021) 使用的 OOD 基准数据集的变化。 我们报告 OOD 数据集的平均 AUROC 和 FPR95 指标。 密集层和卷积层的阈值是不同的。 结果总结在表 3 中,其中 对于最后一个分类(密集)层及其之前的卷积层 (Conv-1) 有所不同。 在表的前半部分,我们固定 Conv-1 层的 并针对密集层改变 ,对于后半部分反之亦然。
从表中我们可以看到,对于所有层/架构来说,最优 都不是 0,这说明需要解决由于 ReLu 激活而导致直方图中的大质量为零的问题。 该表还表明,围绕最佳阈值的微小变化,结果不会发生太大变化。 正如预期的那样,最佳阈值显示了对层和架构的依赖。 看来 ResNet-50 对 变化的敏感度低于 MobileNet-v2;目前,我们还没有对这一观察结果的解释。 我们在上一小节中与 SoA 进行基准比较时使用了这些最佳阈值。 具体来说,我们在 ResNet-50 中选择 作为密集层, 作为卷积层, 作为密集层,对于 MobileNet-v2 的卷积层。
请注意,对于 ResNet-50,从 Conv-1 层获得的激活权重的很大一部分的最大值小于 ,因此它不是一个有意义的阈值,这就是为什么它是表3中留空。
| ResNet-50 | MobileNet-v2 | ResNet-50 | MobileNet-v2 | |||||
| variation on dense layer | variation on dense layer | variation on Conv-1 layer | variation on Conv-1 layer | |||||
| FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | |
| 0.05 | 99.98 | 0.15 | 99.95 | 23.26 | 95.29 | 0.52 | 99.88 | |
| 0.03 | 99.98 | 0.08 | 99.98 | 0.03 | 99.98 | 0.42 | 99.89 | |
| 0.05 | 99.97 | 0.10 | 99.97 | 0.03 | 99.98 | 0.61 | 99.85 | |
| 0.22 | 99.91 | 0.20 | 99.94 | 0.03 | 99.98 | 0.24 | 99.92 | |
| 1.39 | 99.65 | 10.29 | 98.05 | - | - | 0.08 | 99.98 | |
4.2.3 激活权重子采样量的选择
我们进行消融来研究卷积层激活直方图中子采样量的选择。 如前所述,我们对输入/输出节点的通道维度进行二次采样。 如前所述,子采样的主要动机是计算速度。
我们研究了三种 CNN 架构(小型 CNN、CNN-2、前面指定的 ResNet-50 和 MobileNet-v2)的子采样。 CNN-2 在 CIFAR-8 数据集上进行训练,并在 CIFAR-2 上进行测试,另外两个在 ImageNet-1k 上进行训练,其平均值高于 Sun 等人 (2021) 中的 OOD 基准。 我们研究速度和准确性之间的权衡,因为随着激活权重的减少,准确性预计会降低。 实验已在 NVIDIA GeForce RTX 3080 GPU 上进行,并报告了推理时间(对于 ResNet-50 和 MobileNet-v2 的单个 224 224 3 图像,以及 CNN-2 架构的 图像)。 结果报告于表4中。
| Metric (Combined) | Computational cost | |||
| Model | Sub-sampling Rate | FPR95 | AUROC | Inference time (ms) |
| CNN-2 | 1 | 28.00 | 93.34 | 92 |
| 2 | 24.00 | 94.42 | 45 | |
| 4 | 29.00 | 92.98 | 23 | |
| 8 | 37.01 | 93.00 | 12 | |
| 16 | 42.00 | 90.94 | 7 | |
| ResNet-50 | 16 | 0.11 | 99.95 | 182 |
| 32 | 0.03 | 99.98 | 90 | |
| 64 | 0.05 | 99.98 | 48 | |
| MobileNet-v2 | 16 | 0.09 | 99.97 | 112 |
| 32 | 0.08 | 99.98 | 60 | |
| 64 | 0.11 | 99.97 | 35 | |
CNN-2 上的表 4 中的第一个结果表明,正如预期的那样,每个子采样因子 2 的成本都会降低约 2 倍。 我们对密集/分类层之前的通道输入/输出节点的最后一个卷积层进行统一子采样。 有趣的是,OOD 检测的精度并不会随着子采样率的增加而一致下降,并且在不进行子采样(表中子采样率为 1)的情况下也无法获得最佳精度。 经过大量二次采样后,结果如预期般下降。 用户可以根据分配的计算预算选择子采样率。
表 4 中的接下来的结果显示了通过对 ResNet-50 和 MobileNet-v2 的最后一个卷积层 (Conv-1) 进行二次采样,OOD 检测性能与计算成本之间的权衡。 我们以的子采样率对最后一个卷积层的通道进行统一子采样;由于实验的计算成本,我们无法以低于 16 的子采样率运行。 我们发现子采样率为 32 的两个模型的 OOD 检测性能最佳(就 FPR95 和 AUROC 而言),这与之前的实验一致,即较低的采样率不一定会产生更好的准确度。 同样,每次子采样计算成本减少 2 倍。 OOD 检测精度在 32 和 64 子采样率之间变化不大,可能表明了 OOD 检测目的的无关信息。
基于这些结果,我们对 ResNet-50 和 MobileNet-v2 的 Conv-1 层进行了 32 次子采样,以作为上一节中 SoA 的基准。 我们还为 MobileNet-v2 的 Conv-2 层选择了 32 的子采样率。
5结论
我们向神经网络引入了输入数据的新描述符 HAct(线性层输出的激活直方图),可有效区分 OOD 和 ID 数据。 CNN 中密集层和前面的卷积层的描述符组合对于 OOD 检测非常有效,其性能优于 SoA。 HAct 的简单性和效率意味着在实际系统中部署的潜力。 考虑到普遍性,未来的工作将涉及到其他类别的神经网络的应用。
我们方法的当前限制是需要在推理之前的准备步骤中访问训练数据,这可能会妨碍某些应用。 然而,可能有一些方法可以从经过训练的网络中近似重心,而无需访问训练数据,这是未来工作的主题。
参考
- Ahn et al. (2023) Yong Hyun Ahn, Gyeong-Moon Park, and Seong Tae Kim. Line: Out-of-distribution detection by leveraging important neurons, 2023.
- Benamou et al. (2015) Jean-David Benamou, Guillaume Carlier, Marco Cuturi, Luca Nenna, and Gabriel Peyré. Iterative bregman projections for regularized transportation problems. SIAM Journal on Scientific Computing, 37(2):A1111–A1138, 2015.
- Bonneel et al. (2011) Nicolas Bonneel, Michiel Van De Panne, Sylvain Paris, and Wolfgang Heidrich. Displacement interpolation using lagrangian mass transport. In Proceedings of the 2011 SIGGRAPH Asia conference, pp. 1–12, 2011.
- (4) Examples by PyTorch.org. Mnist classification example network. https://github.com/pytorch/examples/blob/main/mnist/main.py, Last accessed on 08-26-2023.
- (5) Tutorials by TensorFlow.org. Cifar-10 classification example network. https://www.tensorflow.org/tutorials/images/cnn, Last accessed on 08-26-2023.
- Cimpoi et al. (2014) Mircea Cimpoi, Subhransu Maji, Iasonas Kokkinos, Sammy Mohamed, and Andrea Vedaldi. Describing textures in the wild. In 2014 IEEE Conference on Computer Vision and Pattern Recognition, pp. 3606–3613, 2014. doi: 10.1109/CVPR.2014.461.
- Deng et al. (2009) Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE Conference on Computer Vision and Pattern Recognition, pp. 248–255, 2009. doi: 10.1109/CVPR.2009.5206848.
- DeVries & Taylor (2018) Terrance DeVries and Graham W. Taylor. Learning confidence for out-of-distribution detection in neural networks, 2018.
- Djurisic et al. (2022) Andrija Djurisic, Nebojsa Bozanic, Arjun Ashok, and Rosanne Liu. Extremely simple activation shaping for out-of-distribution detection. 2022. URL https://arxiv.org/abs/2209.09858.
- Goan & Fookes (2020) Ethan Goan and Clinton Fookes. Bayesian Neural Networks: An Introduction and Survey, pp. 45–87. Springer International Publishing, Cham, 2020. ISBN 978-3-030-42553-1. doi: 10.1007/978-3-030-42553-1˙3. URL https://doi.org/10.1007/978-3-030-42553-1_3.
- He et al. (2016) Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Identity mappings in deep residual networks. In Bastian Leibe, Jiri Matas, Nicu Sebe, and Max Welling (eds.), Computer Vision – ECCV 2016, pp. 630–645, Cham, 2016. Springer International Publishing.
- (12) Alex Krizhevsky. Learning multiple layers of features from tiny images.
- Lacombe et al. (2021) Théo Lacombe, Yuichi Ike, Mathieu Carriere, Frédéric Chazal, Marc Glisse, and Yuhei Umeda. Topological uncertainty: Monitoring trained neural networks through persistence of activation graphs, 2021.
- LeCun (1998) Yann LeCun. The mnist database of handwritten digits. http://yann. lecun. com/exdb/mnist/, 1998.
- Liu et al. (2020) Weitang Liu, Xiaoyun Wang, John Owens, and Yixuan Li. Energy-based out-of-distribution detection. Advances in neural information processing systems, 33:21464–21475, 2020.
- Liu et al. (2023) Xixi Liu, Yaroslava Lochman, and Christopher Zach. Gen: Pushing the limits of softmax-based out-of-distribution detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 23946–23955, 2023.
- Malinin & Gales (2018) Andrey Malinin and Mark Gales. Predictive uncertainty estimation via prior networks, 2018.
- Rahaman & Thiery (2021) Rahul Rahaman and Alexandre Thiery. Uncertainty quantification and deep ensembles. In M. Ranzato, A. Beygelzimer, Y. Dauphin, P.S. Liang, and J. Wortman Vaughan (eds.), Advances in Neural Information Processing Systems, volume 34, pp. 20063–20075. Curran Associates, Inc., 2021. URL https://proceedings.neurips.cc/paper_files/paper/2021/file/a70dc40477bc2adceef4d2c90f47eb82-Paper.pdf.
- Sandler et al. (2018) Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, and Liang-Chieh Chen. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2018.
- Sun & Li (2022) Yiyou Sun and Yixuan Li. Dice: Leveraging sparsification for out-of-distribution detection. In European Conference on Computer Vision, 2022.
- Sun et al. (2021) Yiyou Sun, Chuan Guo, and Yixuan Li. React: Out-of-distribution detection with rectified activations, 2021.
- Van Horn et al. (2018) Grant Van Horn, Oisin Mac Aodha, Yang Song, Yin Cui, Chen Sun, Alex Shepard, Hartwig Adam, Pietro Perona, and Serge Belongie. The inaturalist species classification and detection dataset. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8769–8778, 2018. doi: 10.1109/CVPR.2018.00914.
- Wang et al. (2019) Guotai Wang, Wenqi Li, Sébastien Ourselin, and Tom Vercauteren. Automatic brain tumor segmentation using convolutional neural networks with test-time augmentation. In Alessandro Crimi, Spyridon Bakas, Hugo Kuijf, Farahani Keyvan, Mauricio Reyes, and Theo van Walsum (eds.), Brainlesion: Glioma, Multiple Sclerosis, Stroke and Traumatic Brain Injuries, pp. 61–72, Cham, 2019. Springer International Publishing. ISBN 978-3-030-11726-9.
- Xiao et al. (2017) Han Xiao, Kashif Rasul, and Roland Vollgraf. Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms. arXiv preprint arXiv:1708.07747, 2017.
- Xiao et al. (2010) Jianxiong Xiao, James Hays, Krista A. Ehinger, Aude Oliva, and Antonio Torralba. Sun database: Large-scale scene recognition from abbey to zoo. In 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, pp. 3485–3492, 2010. doi: 10.1109/CVPR.2010.5539970.
- Yang et al. (2022) Jingkang Yang, Kaiyang Zhou, Yixuan Li, and Ziwei Liu. Generalized out-of-distribution detection: A survey, 2022.
- Zhou et al. (2018) Bolei Zhou, Agata Lapedriza, Aditya Khosla, Aude Oliva, and Antonio Torralba. Places: A 10 million image database for scene recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 40(6):1452–1464, 2018. doi: 10.1109/TPAMI.2017.2723009.
- Zhou & Paffenroth (2017) Chong Zhou and Randy C. Paffenroth. Anomaly detection with robust deep autoencoders. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’17, pp. 665–674, New York, NY, USA, 2017. Association for Computing Machinery. ISBN 9781450348874. doi: 10.1145/3097983.3098052. URL https://doi.org/10.1145/3097983.3098052.
附录A附录
A.1 网络架构
表5显示了我们工作中使用的CNN-1和CNN-2的架构。 我们遵循 https://github 上演示的基线架构。 com/pytorch/examples/tree/master/mnist,并修改最后一层神经元的数量,以进行消融研究对激活矩阵大小的影响(第A.3节)。 对于 CNN-2,我们遵循 https://www.tensorflow.org/tutorials/images/cnn 演示的基线架构,并将最后一个分类层修改为具有 8 个神经元,这适合我们的分布训练集CIFAR-10 图像数据集(表示为 CIFAR-8)中的 8 个类别。 我们选择用于从 CIFAR-10 创建 OOD 数据集(表示为 CIFAR-2)的 OOD 类是“deer”和“ship”。
| Model | Layer | Kernel Size | Filters | Neurons | Activation |
| CNN-1 | Convolution 1 | 32 | - | Relu | |
| Max-Pool | - | - | - | - | |
| Convolution 2 | 64 | - | Relu | ||
| Max-Pool | - | - | - | - | |
| Dropout (0.25) | - | - | - | - | |
| Flatten | - | - | - | - | |
| Fully Connected | - | - | 100 | Relu | |
| Fully Connected | - | - | 10 | Softmax | |
| CNN-2 | Convolution 1 | 32 | - | Relu | |
| Max-Pool | - | - | - | - | |
| Convolution 2 | 64 | - | Relu | ||
| Max-Pool | - | - | - | - | |
| Convolution 2 | 64 | - | Relu | ||
| Flatten | - | - | - | - | |
| Fully Connected | - | - | 64 | Relu | |
| Fully Connected | - | - | 8 | Softmax |
A.2 激活矩阵大小的影响:计算成本和 OOD 检测精度
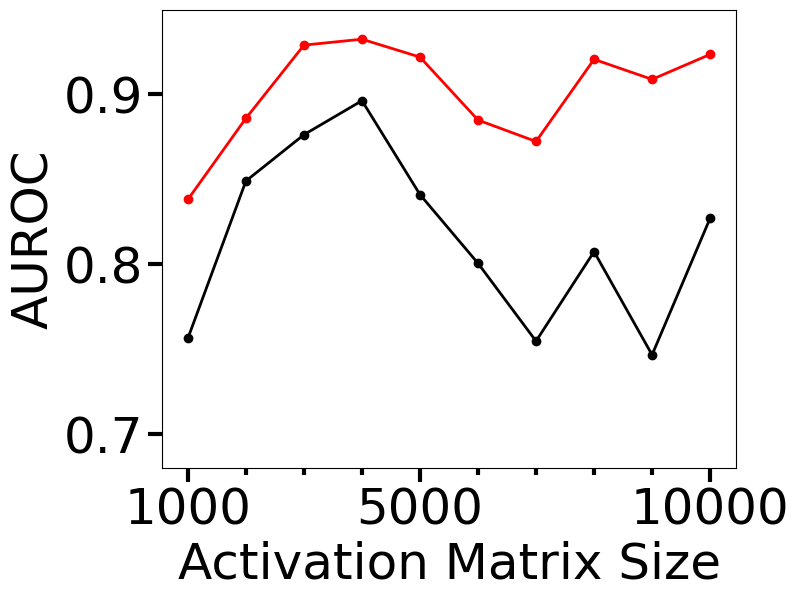
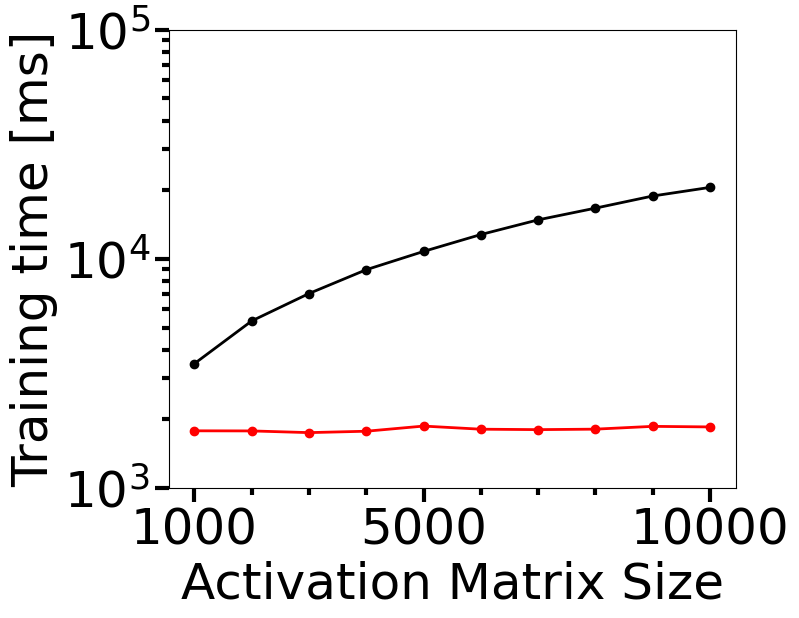
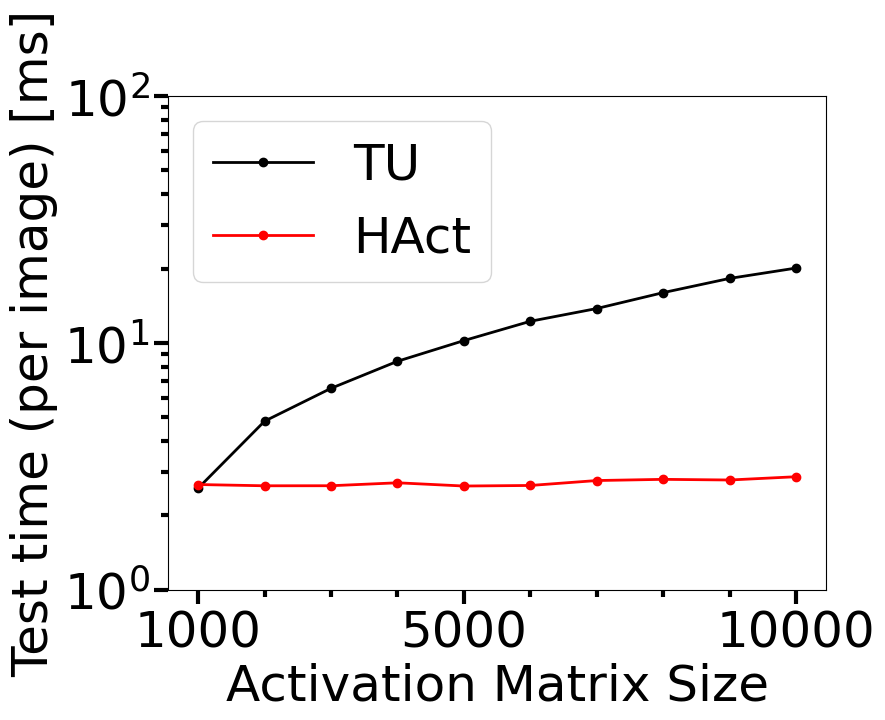
计算成本是在实践中监控部署 OOD 检测器的一个关键指标。 在本节中,我们研究了我们提出的方法的 OOD 检测精度和计算成本如何作为激活矩阵大小的函数表现,并将结果与 Lacombe 等人的拓扑不确定性(TU)进行比较 图 4 显示了我们的方法 (HAct) 与分布内 MNIST 和 OOD FMNIST 数据集的 DNN-1 最后密集层上的 TU 进行比较的结果。 激活矩阵的大小由 CNN-1 倒数第二层中的神经元数量控制,该数量以 100 为步长从 100 变化到 1000,这导致激活矩阵大小为 1000 到 10000(最后一层) CNN-1 有 10 个神经元)。 这些变体中的每一个都会产生一个新的分类器网络架构,该架构已使用 Adam 优化器在 MNIST 数据集上训练了 100 个时期。 可以看出,HAct 可以实现更好的 OOD 训练检测,正如更高的 AUROC 所证明的那样,并且显着节省了测试时间要求。 此外,图4(b)和(c)表明,使用TU进行训练和测试的计算时间要求随着激活矩阵大小呈非线性增长,而HAct的计算成本显着降低,训练成本最多可节省 10 倍,测试成本最多可节省 7 倍。 这表明对于经过训练的网络的 OOD 泛化性而言,HAct 是一种比 TU 快得多的方法,并且可能会提高 OOD 检测性能。
A.3 改变 对 MobileNet-v2 卷积层的影响。
| FPR95 | ||||||
| Conv-2(sub-sample rate 16) | ||||||
| 28.43 | 30.65 | 22.09 | 14.35 | 1.05 | ||
| Conv-1 | 6.71 | 11.14 | 13.17 | 9.85 | 1.32 | |
| 6.71 | 10.92 | 10.90 | 9.73 | 1.08 | ||
| 2.45 | 4.23 | 5.61 | 4.38 | 0.66 | ||
| 0.56 | 0.87 | 0.86 | 0.85 | 0.11 | ||
| AUROC | ||||||
| Conv-2(sub-sample rate 16) | ||||||
| 94.53 | 94.40 | 96.38 | 97.32 | 99.78 | ||
| Conv-1 | 98.66 | 97.92 | 97.64 | 98.19 | 99.71 | |
| 98.60 | 97.87 | 98.07 | 98.20 | 99.75 | ||
| 99.48 | 99.17 | 99.91 | 98.09 | 99.82 | ||
| 99.88 | 99.82 | 99.84 | 99.82 | 99.97 | ||
| Conv-2(sub-sample rate 32) | ||||||
|---|---|---|---|---|---|---|
| 28.61 | 18.64 | 16.70 | 3.34 | 0.52 | ||
| Conv-1 | 4.60 | 8.91 | 8.89 | 3.04 | 0.43 | |
| 4.67 | 9.29 | 9.54 | 3.43 | 0.61 | ||
| 1.62 | 3.43 | 3.42 | 1.38 | 0.24 | ||
| 0.38 | 0.76 | 0.81 | 0.37 | 0.08 | ||
| Conv-2(sub-sample rate 32) | ||||||
|---|---|---|---|---|---|---|
| 94.59 | 96.49 | 96.89 | 99.32 | 99.89 | ||
| Conv-1 | 99.08 | 98.32 | 98.34 | 99.36 | 99.89 | |
| 99.04 | 98.19 | 98.17 | 99.27 | 99.85 | ||
| 99.66 | 99.30 | 99.28 | 98.65 | 99.92 | ||
| 99.92 | 99.84 | 99.84 | 99.91 | 99.98 | ||
在表 6 中,我们展示了对于两种不同的子采样率(16 和 32),FPR95 和 AUROC 指标如何随着为 MobileNet-v2 最后两个卷积层选择的不同阈值而变化。 Conv-2层的。 报告的结果基于最后一个分类(密集)层和两个卷积层(Conv-1 和 Conv-2)上的 HAct 描述符的组合,其中 Conv-1 层以 32 的速率进行子采样。 主论文中的 4.2.1 节详细介绍了如何选择组合这些描述符。 我们对密集层保持固定的 选择,而对卷积层改变 。 可以看出,无论 MobileNet-v2 的子采样率如何, 都是最佳选择。 此外,Conv-2 上 32 的子采样率几乎总是比 16 的子采样率产生更好的 OOD 检测性能,这与我们在第 4.2.1 节中的观察结果一致,即较低的子采样率并不一定会带来更好的 OOD 检测。