MMICL:赋能视觉语言模型的多模态上下文学习
摘要
自深度学习复兴以来,由大型语言模型 (LLM) 增强的视觉语言模型 (VLM) 的普及率呈指数级增长。 然而,虽然 LLM 可以利用广泛的背景知识和任务信息进行上下文学习,但大多数 VLM 仍然难以理解包含多个图像的复杂多模态提示,这使得 VLM 在下游视觉语言任务中的效果不佳。 在本文中,我们通过以下方法来解决上述限制:1)介绍具有Multi-Modal In-Context Learning (MMICL) 的视觉语言模型,这是一种新方法,允许 VLM 有效地处理多模态输入;2)提出一种新颖的上下文方案来增强 VLM 的上下文学习能力;3)构建多模态上下文学习 (MIC) 数据集,旨在增强 VLM 理解复杂多模态提示的能力。 我们的实验结果表明,MMICL 在广泛的一般视觉语言任务中取得了最先进的零样本性能,尤其是在复杂的基准测试方面,包括 MME 和 MMBench。 我们的分析表明,MMICL 有效地解决了复杂多模态提示理解的挑战,并展现出了令人印象深刻的 ICL 能力。 此外,我们观察到 MMICL 成功地缓解了 VLM 中的语言偏差,这是一个常见的问题,当 VLM 面临广泛的文本上下文时,往往会导致幻觉。 我们的代码、数据集、数据集工具和模型可在 https://github.com/PKUnlp-icler/MIC 获得。
1 介绍
通用视觉语言预训练模型 (VLMs) 取得了重大进展 (Li 等人,2022;2023d;2023g;Zhu 等人,2023;Li 等人,2023b)。 最近的 VLMs 主要是在大型语言模型 (LLM) 上添加视觉编码器,并在各种视觉任务中展现出令人印象深刻的零样本能力。 然而,与可以通过 上下文学习 (ICL) 从提示中提取丰富背景知识和任务信息的 LLM 不同,大多数 VLMs 仍然难以理解包含多个图像的复杂多模态提示。 以前的研究 (Li 等人,2023d;b) 主要关注使用单个图像处理用户查询,而不是使用交织多个图像和文本的多模态提示。 尽管像 Flamingo (Alayrac 等人,2022) 和 Kosmos-1 (Huang 等人,2023b) 这样的 VLMs 可以处理包含多个图像的用户查询, 但它们的预训练数据无法提供比从网络上抓取的交织图像和文本更复杂的多模态提示 (Awadalla 等人,2023)。 因此,在这些 VLMs 的预训练中使用的提示与现实世界场景中的用户查询之间存在差距,现实世界场景中的用户查询通常包含多个图像和更复杂的文本。 具体来说,这些 VLMs 可能会遇到以下三个限制,这使得 VLMs 在下游视觉语言任务中效率低下。
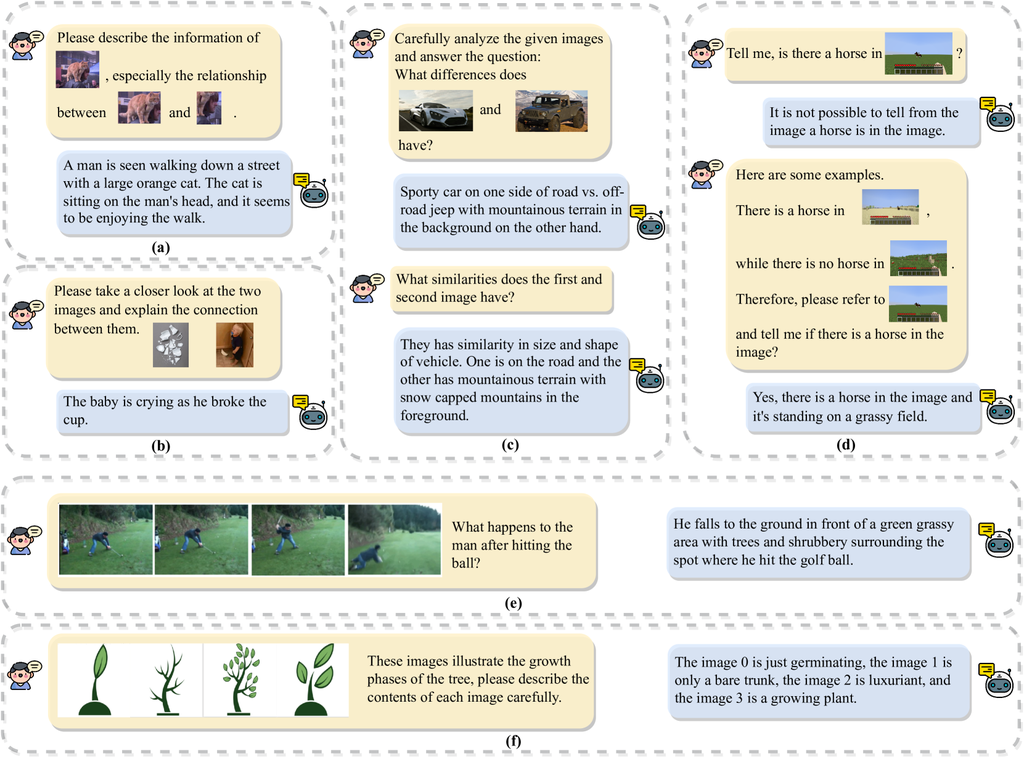
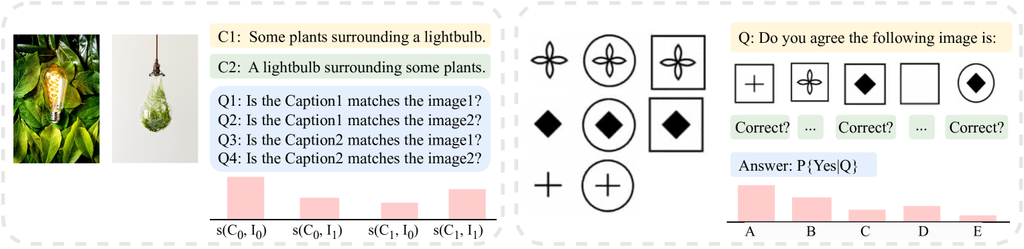
难以理解文本到图像的引用: 以前的研究很少尝试解决多模态提示中文本到图像引用的问题。 然而,用户查询中文本和图像之间通常存在错综复杂的指代关系,不同的词语提及不同的图像。 例如,用户可能会询问有关多个图像 (图 1.c 和图 1.f) 的特定问题,或者使用多个图像作为示例来仅询问特定图像 (图 1.d) 的问题。 然而,以前研究 (Li 等人,2023d;Alayrac 等人,2022;Huang 等人,2023a) 中使用的训练数据是从网络上抓取的,可能缺乏明确的文本到图像引用。 因此,VLMs 可能会无法处理涉及错综复杂的文本到图像引用的用户查询。
难以理解多个图像之间的关系: 多个图像之间通常存在空间、时间和逻辑关系,正确理解这些关系可以使模型更好地处理用户查询。 然而,以前 VLMs (Alayrac 等人,2022) 使用的预训练数据是从互联网上收集的,缺乏图像之间的紧密联系,尤其是在这些图像在同一个网页上相隔很远的情况下。 它阻碍了 VLM 理解图像之间错综复杂关系的能力,并进一步限制了它们的推理能力。
难以从上下文多模态演示中学习: 先前研究表明,预训练的 LLM 可以从少量上下文演示中受益 (Brown 等人,2020;Dong 等人,2023)。 然而,当前 VLM 的 ICL 能力相当有限,具体来说: 1) 像 BLIP-2 (Li 等人,2023d)、LLaVA (Li 等人,2023b) 这样的 VLM 仅支持带有单个图像的多模态提示,阻碍了它们在推理过程中使用多个多模态演示来提高性能的能力; 2) 尽管像 Flamingo (Alayrac 等人,2022) 这样的 VLM 在预训练期间支持多图像输入并出现 ICL 能力,但它们的上下文方案未能提供文本-图像引用和密切相关的图像。 它阻止它们为 VLM 提供足够复杂的提示,从而限制了其 ICL 能力的有效性。 此外,缺乏进一步的监督指令调优阻碍了它们在各种下游任务中的有效性。
在本文中,为了解决上述限制 1) 我们提出了 MMICL,一种允许 VLM 有效处理多模态输入的新方法,包括多个图像之间的关系以及文本到图像的引用。 2) 我们提出了一种新颖的上下文方案,其中包含额外的图像声明部分,以及图像代理标记的包含,增强了 VLM 的 ICL 能力。 3) 我们根据所提出的方案构建了一个多模态上下文学习数据集。 该数据集改编自一系列现有的数据集,可用于支持训练更强大的 VLM。
我们的实验表明,MMICL 在各种视觉语言基准测试中取得了新的最先进性能,包括 MME (Fu 等人,2023) 和 MMBench (Liu 等人,2023d)。 1 11MMICL 的结果已于 2023 年 8 月 28 日提交。 . 对我们旨在解决的三个限制的全面考察表明,MMICL 在理解文本到图像的引用(在视觉语言组合性基准测试 Winoground (Thrush 等人,2022a) 上提高了 13 个百分点)和图像之间的错综复杂的关系(在多图像推理基准测试 RAVEN (Huang 等人,2023a) 上提高了 12 个百分点)方面表现出非凡的能力。 此外,MMICL 在各种任务中展现出令人印象深刻的多模态 ICL 性能。 我们还观察到,MMICL 有效地减轻了语言偏差,这种偏差经常导致 VLM 在面对大量的文本上下文时忽略视觉内容,从而导致幻觉。
2MMICL
2.1 模型架构
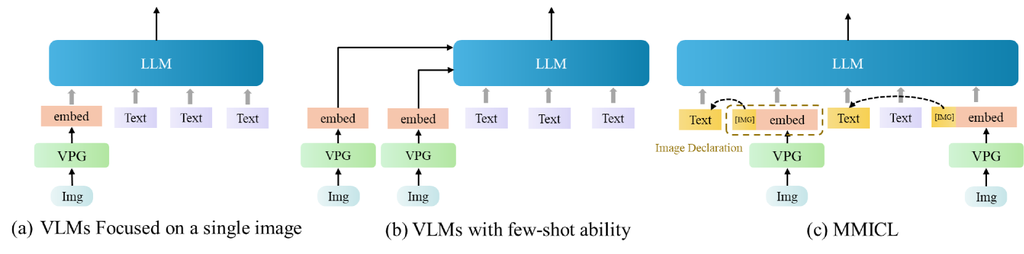
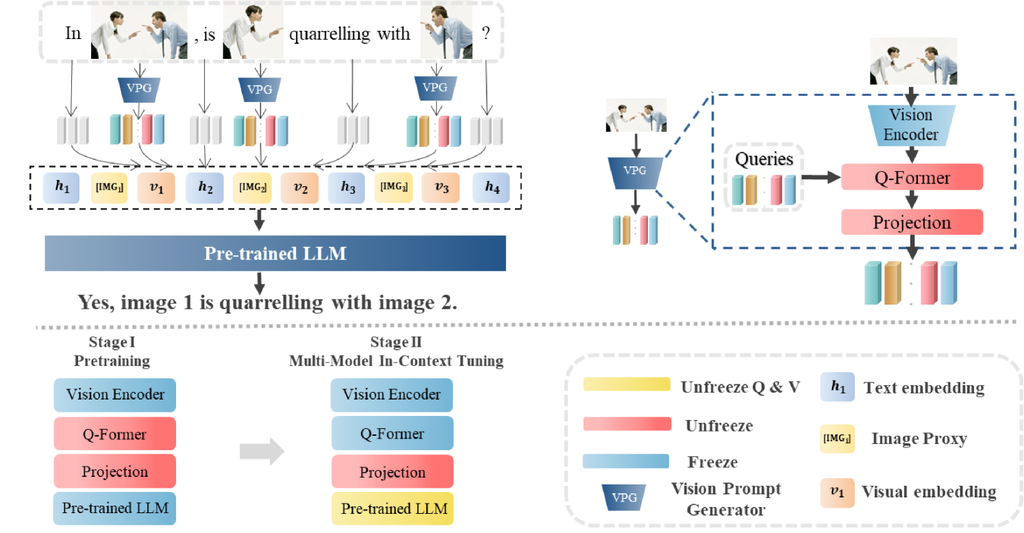
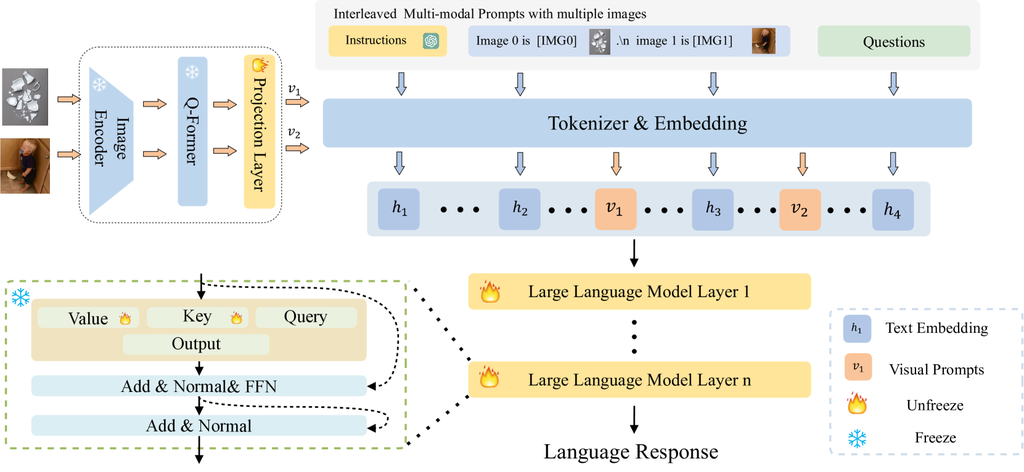
大多数 VLM 利用视觉提示生成器 (VPG)(例如, Resampler (Alayrac 等人,2022),Q-former (Li 等人,2023d))从视觉骨干编码的图像特征中提取视觉嵌入,并使用视觉嵌入帮助 LLM 理解视觉输入。 图 2。a 中所示的模型架构属于专注于带单张图像的提示的 VLM,例如 Blip-2 (Li 等人,2023d),它总是将图像放置在整个输入的顶部,并且无法处理包含多张图像的输入。 在图 2。b 中,具有少样本能力的 VLM,例如 Flamingo (Alayrac 等人,2022),将图像编码为具有固定数量的视觉符元的图像嵌入,并在 LLM 中插入新的门控交叉注意力层以注入视觉特征。 与之前的工作不同,图 2。c 中所示的 MMICL 对图像和文本表示进行平等处理,并通过图像声明建立图像和文本之间的引用。 它使用户能够灵活地在任何所需的顺序输入多张图像和文本,对上下文中图像的数量或位置没有任何限制。 如图 5 所示,每个给定的图像都由视觉编码器(例如,ViT (Radford 等人,2021))编码以获得图像表示。 然后,我们使用 Q-former 作为 VPG 将图像编码为语言模型可以理解的嵌入。 我们利用一个全连接层作为投影层,将每个视觉嵌入转换为与 LLM 的文本嵌入相同维度的嵌入。 最后,我们将视觉和文本嵌入组合成交错样式,并将它们输入 LLM。 这种设计是 LLM 中原始注意力机制的自然扩展。 我们将 LLM 注意力层中用于映射查询和值向量的权重设置为可学习的,以更好地适应具有多个图像的多模态提示。 更详细的信息见附录 E。
2.2 MMICL 的上下文方案设计
本节概述了 MMICL 上下文方案的设计。 所提出的方案旨在有效地将交织的图像-文本数据转换为 MMICL 的训练上下文。
2.2.1 图像声明
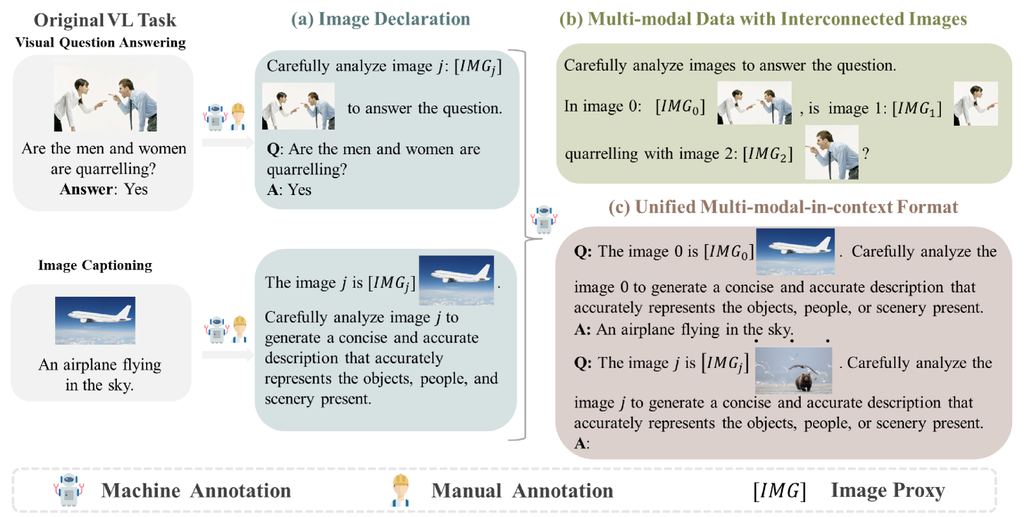
用户可以在其查询中使用文本描述来引用特定图像。 此类引用可以向 VLM 提供有关文本中提到的视觉内容的信息,从而使它能够学习两种模态之间的对齐。 为了精确地链接文本和图像,我们为混合输入中的每个图像形成图像声明模板,如图 3 .a 所示。 首先,我们分配一个唯一的图像代理 ([IMG]) 来引用图像 的视觉嵌入,这为 VLM 提供了一个唯一的标识符来索引和区分视觉和文本嵌入。 然后,我们使用自然语言提示来建立文本和图像之间的引用。 将显式文本到图像的引用并入图像声明中,有助于模型将文本与相应的图像相关联。 同时,图像声明作为文本内容保留,也可以保持灵活性,可以在提示中的任何位置出现。 每个实例 遵循结构,其中 表示可以在实例 内的任何位置放置的图像装饰集。 和 分别表示带有指令的问题和相应的答案。
| (1) |
2.2.2 具有互连图像的多模态数据
为了在 MMICL 的上下文方案中整合丰富的多图像信息,我们生成了包含空间、逻辑和时间关系的互连多图像数据。 它有助于 MMICL 理解用户查询中图像之间错综复杂的关系。 具体来说,我们从视频中提取帧来构建多图像数据。 从视频中提取的帧天生就保持着紧密的时空关系,这将图像之间的空间和时间相关性信息注入到上下文方案中。 此外,我们从描绘多个物体交互的图像中构建多图像数据。 我们检测图像内的物体,并为每个物体生成边界框。 我们通过根据边界框裁剪图像,获得不同物体的多个子图像。 然后,我们将这些物体的文本引用替换为它们对应的裁剪图像,从而形成具有逻辑和因果相互关联图像的交织多模态数据,如图 3.b 和图 4 所示。 每个实例 包含一个问答文本对以及 张图像,其中 代表第 张图像的图像声明。
| (2) |
2.2.3 统一的多模态上下文格式用于不同的任务
我们提出了一种设计,用于为不同的任务生成多模态上下文学习数据,以丰富 MMICL 的上下文方案。 它的目标是提高 VLM 的指令感知能力,并扩展其熟练的多模态上下文学习能力。 具体来说,我们首先为每个任务制定不同的指令,并利用这些指令为任务生成不同的模板。 然后,我们用原始任务填充随机选择的模板,以组装具有指令的数据,如附录 G 所示。 此外,我们通过构建从数据中采样实例生成的少样本示例,将数据转换为多模态上下文格式。 这些示例与输入实例相结合,生成多模态上下文数据。 通过这种方式,我们可以将所有任务转换为统一的多模态上下文格式,如图 3.c 所示。 此方法有助于从不同任务中积累大量高质量数据,用丰富的多样性多模态上下文数据充实 MMICL 的上下文方案,这些数据充满了各种指令。 最终,这提高了模型遵循指令和多模态上下文学习的能力。 每个实例 包含 N 个示例。
| (3) |
每个示例 , 表示 个示例的图像声明。 和 分别表示 个示例的问题和答案。

2.3 多模态上下文学习 (MIC) 数据集构建
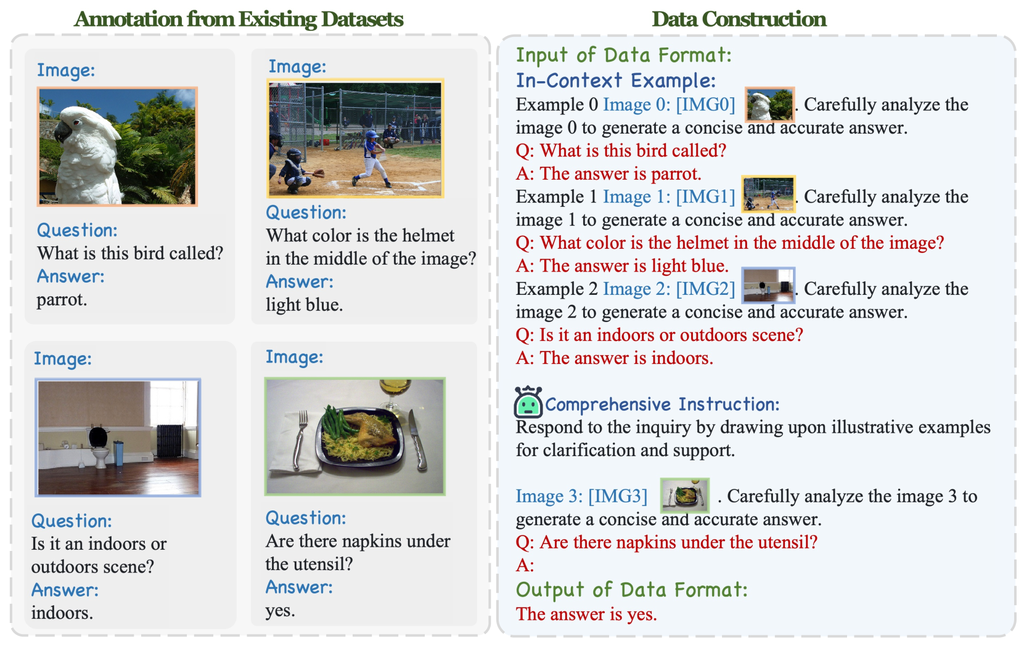
为了帮助 VLM 理解复杂的提示,我们通过从公共数据资源收集数据并根据上下文方案进行转换,构建 MIC 数据集。 它有三个关键方面: 1) 图像声明,2) 具有密切相关图像的多模态数据,以及 3) 用于不同任务的多模态上下文数据。 MIC 的训练集来自 8 个类别中的 16 个数据集,而测试集来自 10 个类别中的 18 个数据集。
我们的数据集是基于现有数据集自动构建的。 首先,我们为所有数据集中的每个实例创建了一个图像声明,以生成具有显式文本到图像引用的数据集。 其次,我们为每个数据集创建了一个指令模板,并要求 ChatGPT 重新编写指令,并填充来自现有数据集的数据,以获得具有多种指令格式的数据集。 最后,我们使用这些带有指令的数据集,根据我们提出的上下文方案构建 MIC 数据集。 对于图 3 和图 4 中展示的示例(例如,两个人互相争吵),我们基于 VCR 数据集 (Zellers 等人,2019) 提供的现有标注(即边界框和边界框之间的关系)构建了数据。 此外,我们还通过从原始数据集中采样示例构建了一个上下文学习数据集。 我们还从视频数据集中提取了每个视频的八帧,以生成具有互连图像的多模态数据。 详细信息见附录 D。
我们将所有数据转换为视觉语言问答格式,以创建高质量的多模态训练数据,并在 MIC 数据集中积累了 5.8M 个样本。 由于资源限制,我们使用附录 F 中描述的采样策略,使用大约 10% 的数据来微调 MMICL。 预计在所有数据上训练的更大模型将产生更有希望的结果。
2.4 训练范式
阶段 i@:预训练。 此阶段旨在帮助模型对齐图像和文本嵌入。 在此阶段,视觉编码器和 LLM 均保持冻结。 VPG(即 Q-Former)和投影层经过训练以学习可被 LLM 解释的视觉嵌入。
阶段 ii@:多模态上下文调优。 在此阶段,我们旨在解决上述限制,并通过扩展模型以实现多模态上下文学习来使其更进一步。 具体来说,我们旨在使模型理解文本和图像之间错综复杂的指代关系以及多个图像之间的复杂关系,并最终获得熟练的多模态上下文学习能力。 因此,我们对 MIC 数据集执行多模态上下文调优。 在阶段 ii@ 中,我们冻结了图像编码器、Q-former 和 LLM,同时联合训练投影层和查询和值向量。 详细信息请参见附录 H。
3 实验
3.1 实验设置
评估设置。 我们旨在开发通用的 VLM,这些 VLM 可以普遍适应各种具有挑战性的多模态提示。 因此,我们在几个视觉语言基准中评估我们的模型,包括涉及图像和视频的任务。 这些基准中使用的指标和进一步的细节显示在附录 M 中。
模型和基线。 我们提供了两个版本的 MMICL:(1) MMICL (FLAN-T5) 使用 BLIP-2 (Li 等人,2023d) 作为主干,以及 (2) MMICL (Instruct-FLAN-T5) 使用 InstructBLIP (Dai 等人,2023) 作为主干。 我们还采用了 FLANT5 (Chung 等人,2022) 模型的 XL 和 XXL 版本,用于这两个版本。 我们将 MMICL 与以下强大的基线进行比较: Flamingo (Alayrac 等人,2022), KOSMOS-1 (Huang 等人,2023a), BLIP-2-FLAN-T5, InstructBLIP-FLAN-T5, Shikra (Chen 等人,2023a), Otter (Li 等人,2023a), Ying-VLM (Li 等人,2023e)。 MMICL 和基线的详细信息显示在附录 H 和附录 O 中。
| Cognition | Perception | |||||||||||||||
| Model | Model Size | Comm. | Num. | Text. | Code. | Existen. | Count | Pos. | Color | OCR | Poster | Cele. | Scene | Land. | Art. | Total Avg. |
| LLaVA | 13B | 57.14 | 50.00 | 57.50 | 50.00 | 50.00 | 50.00 | 50.00 | 55.00 | 50.00 | 50.00 | 48.82 | 50.00 | 50.00 | 49.00 | 51.25 |
| MiniGPT-4 | 13B | 59.29 | 45.00 | 0.00 | 40.00 | 68.33 | 55.00 | 43.33 | 75.00 | 57.50 | 41.84 | 54.41 | 71.75 | 54.00 | 60.50 | 51.85 |
| MultiModal-GPT | 9B | 49.29 | 62.50 | 60.00 | 55.00 | 61.67 | 55.00 | 58.33 | 68.33 | 82.50 | 57.82 | 73.82 | 68.00 | 69.75 | 59.50 | 62.97 |
| VisualGLM-6B | 6B | 39.29 | 45.00 | 50.00 | 47.50 | 85.00 | 50.00 | 48.33 | 55.00 | 42.50 | 65.99 | 53.24 | 146.25 | 83.75 | 75.25 | 63.36 |
| VPGTrans | 7B | 64.29 | 50.00 | 77.50 | 57.50 | 70.00 | 85.00 | 63.33 | 73.33 | 77.50 | 84.01 | 53.53 | 141.75 | 64.75 | 77.25 | 74.27 |
| LaVIN | 13B | 87.14 | 65.00 | 47.50 | 50.00 | 185.00 | 88.33 | 63.33 | 75.00 | 107.50 | 79.59 | 47.35 | 136.75 | 93.50 | 87.25 | 86.66 |
| LLaMA-Adapter-V2 | 7B | 81.43 | 62.50 | 50.00 | 55.00 | 120.00 | 50.00 | 48.33 | 75.00 | 125.00 | 99.66 | 86.18 | 148.50 | 150.25 | 69.75 | 87.26 |
| mPLUG-Owl | 7B | 78.57 | 60.00 | 80.00 | 57.50 | 120.00 | 50.00 | 50.00 | 55.00 | 65.00 | 136.05 | 100.29 | 135.50 | 159.25 | 96.25 | 88.82 |
| InstructBLIP | 12.1B | 129.29 | 40.00 | 65.00 | 57.50 | 185.00 | 143.33 | 66.67 | 153.33 | 72.50 | 123.81 | 101.18 | 153.00 | 79.75 | 134.25 | 107.47 |
| BLIP-2 | 12.1B | 110.00 | 40.00 | 65.00 | 75.00 | 160.00 | 135.00 | 73.33 | 148.33 | 110.00 | 141.84 | 105.59 | 145.25 | 138.00 | 136.50 | 113.13 |
| Lynx | 7B | 110.71 | 17.50 | 42.50 | 45.00 | 195.00 | 151.67 | 90.00 | 170.00 | 77.50 | 124.83 | 118.24 | 164.50 | 162.00 | 119.50 | 113.50 |
| GIT2 | 5.1B | 99.29 | 50.00 | 67.50 | 45.00 | 190.00 | 118.33 | 96.67 | 158.33 | 65.00 | 112.59 | 145.88 | 158.50 | 140.50 | 146.25 | 113.85 |
| Otter | 9B | 106.43 | 72.50 | 57.50 | 70.00 | 195.00 | 88.33 | 86.67 | 113.33 | 72.50 | 138.78 | 172.65 | 158.75 | 137.25 | 129.00 | 114.19 |
| Cheetor | 7B | 98.57 | 77.50 | 57.50 | 87.50 | 180.00 | 96.67 | 80.00 | 116.67 | 100.00 | 147.28 | 164.12 | 156.00 | 145.73 | 113.50 | 115.79 |
| LRV-Instruction | 7B | 100.71 | 70.00 | 85.00 | 72.50 | 165.00 | 111.67 | 86.67 | 165.00 | 110.00 | 139.04 | 112.65 | 147.98 | 160.53 | 101.25 | 116.29 |
| BLIVA | 12.1B | 136.43 | 57.50 | 77.50 | 60.00 | 180.00 | 138.33 | 81.67 | 180.00 | 87.50 | 155.10 | 140.88 | 151.50 | 89.50 | 133.25 | 119.23 |
| MMICL | 12.1B | 136.43 | 82.50 | 132.50 | 77.50 | 170.00 | 160.00 | 81.67 | 156.67 | 100.00 | 146.26 | 141.76 | 153.75 | 136.13 | 135.50 | 129.33 |
3.2 通用性能评估
我们在 MME (Fu 等人,2023) 和 MMBench (Liu 等人,2023d) 基准上评估了 MMICL 的通用性能 2 22所有报告的基线方法性能来自 MME 的排行榜 (Fu 等人,2023) 和 MMBench (Liu 等人,2023d)。 我们报告了具有 InstructBlip-FLANT5-XXL 主干的 MMICL 的结果。 . MME 使用 14 个子任务评估 VLM,涵盖认知和感知能力。 表 1 中的结果表明,与当前的 VLM 相比,MMICL 在认知和感知任务上可以取得最佳平均得分。 MMICL 还展示了出色的性能,并且在 MMBench 基准测试中明显优于其他 VLM,该基准测试全面评估了 VLM 的各种技能。 详细结果见表 22。 请参阅附录 I 和 J,以了解 MMICL 的评估细节以及与其他 VLM 的比较。
3.3 性能问题
3.3.1 理解文本到图像的引用
| Model | Text | Image | Group |
| MTurk Human | 89.50 | 88.50 | 85.50 |
| VQ2 (Yarom et al., 2023) | 47.00 | 42.20 | 30.50 |
| PALI (Chen et al., 2022) | 46.50 | 38.00 | 28.75 |
| Blip-2 (Li et al., 2023d) | 44.00 | 26.00 | 23.50 |
| GPT4-V (Wu et al., 2023) | 69.25 | 46.25 | 39.25 |
| MMICL (FLAN-T5-XXL) | 45.00 | 45.00 | 43.00 |
Winoground (Thrush 等人,2022b) 提出了一个任务,即正确匹配两个给定的图像和标题,如图 6 左侧所示。 挑战在于,两个标题都包含完全相同的词语,只是顺序不同。 VLMs 必须比较图像和文本,以辨别它们之间的细微差异,并捕捉它们之间的隐含关系。 因此,我们选择 Winoground 来评估 VLMs 是否理解文本到图像的参照。 在评估期间,MMICL 在每个提示中被提供两个图像和两个标题。 表 2 中的结果表明,MMICL 捕捉了图像和文本之间的参照关系,超过了之前的基线。
3.3.2 理解复杂的图像到图像关系
| Model | Accuracy |
| Random Choice | 17 |
| InstructBlip (Dai et al., 2023) | 10.00 |
| Otter (Li et al., 2023a) | 22.00 |
| KOSMOS-1 (Huang et al., 2023a) | 22.00 |
| MMICL (FLAN-T5-XXL) | 34.00 |
3.4 从上下文多模态演示中学习
| Model | Flickr 30K | WebSRC | VQAv2 | Hateful Memes | VizWiz |
| Flamingo-3B (Alayrac et al., 2022) (w/o ICL example) | 60.60 | - | 49.20 | 53.70 | 28.90 |
| Flamingo-3B (Alayrac et al., 2022) (w/ ICL examples (4)) | 72.00 | - | 53.20 | 53.60 | 34.00 |
| Flamingo-9B (Alayrac et al., 2022) (w/o ICL example) | 61.50 | - | 51.80 | 57.00 | 28.80 |
| Flamingo-9B (Alayrac et al., 2022) (w/ ICL examples (4)) | 72.60 | - | 56.30 | 62.70 | 34.90 |
| KOSMOS-1 (Huang et al., 2023b) (w/o ICL example) | 67.10 | 3.80 | 51.00 | 63.90 | 29.20 |
| KOSMOS-1 (Huang et al., 2023b) (w/ ICL examples (4)) | 75.30 | - | 51.80 | - | 35.30 |
| w/o ICL example | |||||
| BLIP-2 (Li et al., 2023d) (FLANT5-XL) | 64.51 | 12.25 | 58.79 | 60.00 | 25.52 |
| BLIP-2 (Li et al., 2023d) (FLANT5-XXL) | 60.74 | 10.10 | 60.91 | 62.25 | 22.50 |
| InstructBLIP (Dai et al., 2023) (FLANT5-XL) | 77.16 | 10.80 | 36.77 | 58.54 | 32.08 |
| InstructBLIP (Dai et al., 2023) (FLANT5-XXL) | 73.13 | 11.50 | 63.69 | 61.70 | 15.11 |
| ICL example Evaluation | |||||
| MMICL (FLAN-T5-XL) (w/o ICL example) | 83.47 | 12.55 | 62.17 | 60.28 | 25.04 |
| MMICL (FLAN-T5-XL) (w/ ICL examples (4)) | 83.84 | 12.30 | 62.63 | 60.80 | 50.17 |
| MMICL (FLAN-T5-XXL) (w/o ICL example) | 85.03 | 18.85 | 69.99 | 60.32 | 29.34 |
| MMICL (FLAN-T5-XXL) (w/ ICL examples (4)) | 89.27 | 18.70 | 69.83 | 61.12 | 33.16 |
| MMICL (Instruct-FLAN-T5-XL) (w/o ICL example) | 82.68 | 14.75 | 69.13 | 61.12 | 29.92 |
| MMICL (Instruct-FLAN-T5-XL) (w/ ICL examples (4)) | 88.31 | 14.80 | 69.16 | 61.12 | 33.16 |
| MMICL (Instruct-FLAN-T5-XXL) (w/o ICL example) | 73.97 | 17.05 | 70.30 | 62.23 | 24.45 |
| MMICL (Instruct-FLAN-T5-XXL) (w/ ICL examples (4)) | 88.79 | 19.65 | 70.56 | 64.60 | 50.28 |
如表 4 所示,我们评估了 MMICL 在各种视觉语言任务中的多模态上下文学习能力。 MMICL 在保留数据和保留外数据集中都优于其他 VLM,并实现了最先进的少样本性能。 例如,MMICL 在 VizWiz 基准测试上的少样本评估(4-shot)优于基线 Flamingo-9B (Alayrac 等人,2022) 和 KOSMOS-1 (Huang 等人,2023b) 分别 和 个点。 由于 VizWiz 从未在训练数据中出现过,因此这种优越性表明 MMICL 能够使用少量示例泛化到新任务。 Flickr30K 的少样本性能随着给定示例的增加而下降,因为标题示例可能会为 VLM 完成任务提供噪声(即,上下文示例通常不提供模型执行图像字幕任务的提示)。
| Model | Model Size |
|
|
|
|
||||||||
| Random Guess | - | 35.50 | 35.80 | 34.90 | - | ||||||||
| Ying-VLM (Li et al., 2023e) | 13.6B | 55.70 | 66.60 | 44.90 | 21.70 | ||||||||
| InstructBLIP (Dai et al., 2023) | 12.1B | 71.30 | 82.00 | 60.70 | 21.30 | ||||||||
| Otter (Li et al., 2023a) | 9B | 63.10 | 70.90 | 55.70 | 15.20 | ||||||||
| Shikra (Chen et al., 2023a) | 7.2B | 45.80 | 52.90 | 39.30 | 13.60 | ||||||||
| MMICL | 12.1B | 82.10 | 82.60 | 81.70 | 0.90 |
3.5 VLM 的幻觉和语言偏差
当前的视觉语言模型 (VLM) 存在显著的视觉幻觉 (Li 等人,2023f),这阻碍了 VLM 从多模态 ICL 中受益。 尤其是在处理包含多个图像的复杂提示 (例如,多模态思维链 (Zhang 等人,2023b)) 时,VLM 在面对大量文本时往往会忽略视觉内容。 这种语言偏差降低了它们在回答需要图像和文本的问题的效率。 ScienceQA-IMG (Lu 等人,2022) 是一项具有挑战性的任务,它要求模型使用两种模态来回答问题。 我们手动将数据集分成两组:需要图像来回答的问题和不需要图像来回答的问题。 详细内容见附录 Q。 表 5 中的广泛实验表明,MMICL 有效地减轻了语言偏差,因为它在两组中都表现良好。 我们还在附录 L 中考察了 MMICL 中的物体幻觉,结果表明其表现令人印象深刻。
3.6 消融研究
| Model | VSR | IconQA text | VisDial | IconQA img | Bongard HOI |
| Stage i@ | |||||
| Stage i@ (Blip-2-FLANT5-XL) | 61.62 | 45.44 | 35.43 | 48.42 | 52.75 |
| Stage i@ (Blip-2-FLANT5-XXL) | 63.18 | 50.08 | 36.48 | 48.42 | 59.20 |
| Stage i@ (InstructBLIP-FLANT5-XL) | 61.54 | 47.53 | 35.36 | 50.11 | 53.15 |
| Stage i@ (InstructBLIP-FLANT5-XXL) | 65.06 | 51.39 | 36.09 | 45.10 | 63.35 |
| Stage i@ + Stage ii@ | |||||
| Stage i@ + Stage ii@ (BLIP-2-FLAN-T5-XL) | 62.85 | 47.23 | 35.76 | 51.24 | 56.95 |
| Stage i@ + Stage ii@ (BLIP-2-FLAN-T5-XXL) | 64.73 | 50.55 | 37.00 | 34.93 | 68.05 |
| Stage i@ + Stage ii@ (InstructBLIP-FLAN-T5-XL) | 70.54 | 52.55 | 36.87 | 47.27 | 74.20 |
| Stage i@ + Stage ii@ (InstructBLIP-FLAN-T5-XXL) | 66.45 | 52.00 | 37.98 | 60.85 | 67.20 |
| Model | Icon-QA | NLVR2 | Raven | Winoground | ||
| - w/o context scheme | 1238.99 | 316.79 | 52.80 | 56.65 | 8.00 | 6.00 |
| - w/o image declaration | 1170.87 | 341.07 | 47.15 | 61.00 | 18.00 | 3.00 |
| - w/o in-context format | 1141.02 | 345.36 | 51.95 | 62.63 | 28.00 | 20.00 |
| - w/o interrelated images | 1207.70 | 333.21 | 54.35 | 59.60 | 16.00 | 25.75 |
| MMICL | 1303.59 | 370.71 | 58.12 | 72.45 | 32.00 | 38.75 |
4 结论
在本文中,我们强调了 VLM 处理包含多个图像的复杂多模态提示的局限性,这使得 VLM 在下游视觉语言任务中效率较低。 我们引入了 MMICL 来解决上述局限性,并通过将其扩展到多模态上下文学习来进一步提升我们的模型。 这一突破使 VLM 能够更好地理解复杂的多模态提示。 此外,MMICL 在通用 VLM 基准和复杂多模态推理基准上取得了新的最先进的性能。
5 致谢
我们对匿名审稿人的奉献和富有洞察力的反馈表示衷心的感谢,他们的反馈极大地提高了本文的质量。 他们的建设性批评和宝贵的建议对完善我们的工作起到了至关重要的作用。 此外,我们对程序主席和领域主席对我们提交的论文的认真处理以及他们提供的全面而宝贵的反馈表示衷心感谢。 他们的指导对提升我们研究的质量至关重要。
这项工作得到了国家自然科学基金的支持,项目编号为 61936012 和 61876004。
参考文献
- Agrawal et al. (2016) Aishwarya Agrawal, Jiasen Lu, Stanislaw Antol, Margaret Mitchell, C. Lawrence Zitnick, Dhruv Batra, and Devi Parikh. Vqa: Visual question answering, 2016.
- Agrawal et al. (2019) Harsh Agrawal, Karan Desai, Yufei Wang, Xinlei Chen, Rishabh Jain, Mark Johnson, Dhruv Batra, Devi Parikh, Stefan Lee, and Peter Anderson. nocaps: novel object captioning at scale. In ICCV, pp. 8948–8957, 2019.
- Alayrac et al. (2022) Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, Roman Ring, Eliza Rutherford, Serkan Cabi, Tengda Han, Zhitao Gong, Sina Samangooei, Marianne Monteiro, Jacob L Menick, Sebastian Borgeaud, Andy Brock, Aida Nematzadeh, Sahand Sharifzadeh, Mikoł aj Bińkowski, Ricardo Barreira, Oriol Vinyals, Andrew Zisserman, and Karén Simonyan. Flamingo: a visual language model for few-shot learning. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh (eds.), Advances in Neural Information Processing Systems, volume 35, pp. 23716–23736. Curran Associates, Inc., 2022. URL https://proceedings.neurips.cc/paper_files/paper/2022/file/960a172bc7fbf0177ccccbb411a7d800-Paper-Conference.pdf.
- An et al. (2023) Kaikai An, Ce Zheng, Bofei Gao, Haozhe Zhao, and Baobao Chang. Coarse-to-fine dual encoders are better frame identification learners. In Houda Bouamor, Juan Pino, and Kalika Bali (eds.), Findings of the Association for Computational Linguistics: EMNLP 2023, pp. 13455–13466, Singapore, December 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.findings-emnlp.897. URL https://aclanthology.org/2023.findings-emnlp.897.
- Awadalla et al. (2023) Anas Awadalla, Irena Gao, Josh Gardner, Jack Hessel, Yusuf Hanafy, Wanrong Zhu, Kalyani Marathe, Yonatan Bitton, Samir Yitzhak Gadre, Shiori Sagawa, Jenia Jitsev, Simon Kornblith, Pang Wei Koh, Gabriel Ilharco, Mitchell Wortsman, and Ludwig Schmidt. Openflamingo: An open-source framework for training large autoregressive vision-language models. ArXiv, abs/2308.01390, 2023. URL https://api.semanticscholar.org/CorpusID:261043320.
- Bigham et al. (2010) Jeffrey P Bigham, Chandrika Jayant, Hanjie Ji, Greg Little, Andrew Miller, Robert C Miller, Robin Miller, Aubrey Tatarowicz, Brandyn White, Samual White, et al. Vizwiz: nearly real-time answers to visual questions. In Proceedings of the 23nd annual ACM symposium on User interface software and technology, pp. 333–342, 2010.
- Biten et al. (2019) Ali Furkan Biten, Ruben Tito, Andres Mafla, Lluis Gomez, Marçal Rusinol, Ernest Valveny, CV Jawahar, and Dimosthenis Karatzas. Scene text visual question answering. In Proceedings of the IEEE/CVF international conference on computer vision, pp. 4291–4301, 2019.
- Brown et al. (2020) Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. Language models are few-shot learners, 2020.
- Cai et al. (2023) Yucheng Cai, Wentao Ma, Yuchuan Wu, Shuzheng Si, Yuan Shao, Zhijian Ou, and Yongbin Li. Unipcm: Universal pre-trained conversation model with task-aware automatic prompt, 2023.
- Changpinyo et al. (2021) Soravit Changpinyo, Piyush Sharma, Nan Ding, and Radu Soricut. Conceptual 12m: Pushing web-scale image-text pre-training to recognize long-tail visual concepts. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 3558–3568, 2021.
- Chen & Dolan (2011) David Chen and William B Dolan. Collecting highly parallel data for paraphrase evaluation. In Proceedings of the 49th annual meeting of the association for computational linguistics: human language technologies, pp. 190–200, 2011.
- Chen et al. (2023a) Keqin Chen, Zhao Zhang, Weili Zeng, Richong Zhang, Feng Zhu, and Rui Zhao. Shikra: Unleashing multimodal llm’s referential dialogue magic, 2023a.
- Chen et al. (2023b) Liang Chen, Shuming Ma, Dongdong Zhang, Furu Wei, and Baobao Chang. On the pareto front of multilingual neural machine translation. In A. Oh, T. Neumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine (eds.), Advances in Neural Information Processing Systems, volume 36, pp. 33188–33201. Curran Associates, Inc., 2023b. URL https://proceedings.neurips.cc/paper_files/paper/2023/file/690eb240baf1180b69dac48fc905c918-Paper-Conference.pdf.
- Chen et al. (2023c) Liang Chen, Yichi Zhang, Shuhuai Ren, Haozhe Zhao, Zefan Cai, Yuchi Wang, Peiyi Wang, Tianyu Liu, and Baobao Chang. Towards end-to-end embodied decision making via multi-modal large language model: Explorations with gpt4-vision and beyond, 2023c.
- Chen et al. (2024a) Liang Chen, Yichi Zhang, Shuhuai Ren, Haozhe Zhao, Zefan Cai, Yuchi Wang, Peiyi Wang, Xiangdi Meng, Tianyu Liu, and Baobao Chang. Pca-bench: Evaluating multimodal large language models in perception-cognition-action chain, 2024a.
- Chen et al. (2024b) Liang Chen, Haozhe Zhao, Tianyu Liu, Shuai Bai, Junyang Lin, Chang Zhou, and Baobao Chang. An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models, 2024b.
- Chen et al. (2022) Xi Chen, Xiao Wang, Soravit Changpinyo, AJ Piergiovanni, Piotr Padlewski, Daniel Salz, Sebastian Goodman, Adam Grycner, Basil Mustafa, Lucas Beyer, et al. Pali: A jointly-scaled multilingual language-image model. arXiv preprint arXiv:2209.06794, 2022.
- Chen et al. (2021a) Xingyu Chen, Zihan Zhao, Lu Chen, JiaBao Ji, Danyang Zhang, Ao Luo, Yuxuan Xiong, and Kai Yu. WebSRC: A dataset for web-based structural reading comprehension. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pp. 4173–4185, Online and Punta Cana, Dominican Republic, November 2021a. Association for Computational Linguistics. doi: 10.18653/v1/2021.emnlp-main.343. URL https://aclanthology.org/2021.emnlp-main.343.
- Chen et al. (2021b) Xingyu Chen, Zihan Zhao, Lu Chen, Danyang Zhang, Jiabao Ji, Ao Luo, Yuxuan Xiong, and Kai Yu. Websrc: A dataset for web-based structural reading comprehension. arXiv preprint arXiv:2101.09465, 2021b.
- Chiang et al. (2023) Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E. Gonzalez, Ion Stoica, and Eric P. Xing. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality, March 2023. URL https://lmsys.org/blog/2023-03-30-vicuna/.
- Chung et al. (2022) Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Alex Castro-Ros, Marie Pellat, Kevin Robinson, Dasha Valter, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei. Scaling instruction-finetuned language models, 2022.
- Cipollone et al. (2014) Maria Cipollone, Catherine C Schifter, and Rick A Moffat. Minecraft as a creative tool: A case study. International Journal of Game-Based Learning (IJGBL), 4(2):1–14, 2014.
- Dai et al. (2023) Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, and Steven Hoi. Instructblip: Towards general-purpose vision-language models with instruction tuning. arXiv preprint arXiv:2305.06500, 2023.
- Das et al. (2017) Abhishek Das, Satwik Kottur, Khushi Gupta, Avi Singh, Deshraj Yadav, José MF Moura, Devi Parikh, and Dhruv Batra. Visual dialog. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 326–335, 2017.
- Dong et al. (2023) Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Zhiyong Wu, Baobao Chang, Xu Sun, Jingjing Xu, Lei Li, and Zhifang Sui. A survey on in-context learning, 2023.
- Du et al. (2021) Zhengxiao Du, Yujie Qian, Xiao Liu, Ming Ding, Jiezhong Qiu, Zhilin Yang, and Jie Tang. Glm: General language model pretraining with autoregressive blank infilling. arXiv preprint arXiv:2103.10360, 2021.
- Fang et al. (2023) Yuxin Fang, Wen Wang, Binhui Xie, Quan Sun, Ledell Wu, Xinggang Wang, Tiejun Huang, Xinlong Wang, and Yue Cao. Eva: Exploring the limits of masked visual representation learning at scale. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 19358–19369, June 2023.
- Fu et al. (2023) Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Zhenyu Qiu, Wei Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, and Rongrong Ji. Mme: A comprehensive evaluation benchmark for multimodal large language models. arXiv preprint arXiv:2306.13394, 2023.
- Gao et al. (2023) Peng Gao, Jiaming Han, Renrui Zhang, Ziyi Lin, Shijie Geng, Aojun Zhou, Wei Zhang, Pan Lu, Conghui He, Xiangyu Yue, et al. Llama-adapter v2: Parameter-efficient visual instruction model. arXiv preprint arXiv:2304.15010, 2023.
- Gao et al. (2020) Tianyu Gao, Adam Fisch, and Danqi Chen. Making pre-trained language models better few-shot learners. arXiv preprint arXiv:2012.15723, 2020.
- Gong et al. (2023) Tao Gong, Chengqi Lyu, Shilong Zhang, Yudong Wang, Miao Zheng, Qian Zhao, Kuikun Liu, Wenwei Zhang, Ping Luo, and Kai Chen. Multimodal-gpt: A vision and language model for dialogue with humans. arXiv preprint arXiv:2305.04790, 2023.
- Goyal et al. (2017) Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Making the v in vqa matter: Elevating the role of image understanding in visual question answering. In CVPR, July 2017.
- Hu et al. (2023a) Helan Hu, Shuzheng Si, Haozhe Zhao, Shuang Zeng, Kaikai An, Zefan Cai, and Baobao Chang. Distantly-supervised named entity recognition with uncertainty-aware teacher learning and student-student collaborative learning, 2023a.
- Hu et al. (2023b) Wenbo Hu, Yifan Xu, Y Li, W Li, Z Chen, and Z Tu. Bliva: A simple multimodal llm for better handling of text-rich visual questions. arXiv preprint arXiv:2308.09936, 2023b.
- Huang et al. (2023a) Shaohan Huang, Li Dong, Wenhui Wang, Yaru Hao, Saksham Singhal, Shuming Ma, Tengchao Lv, Lei Cui, Owais Khan Mohammed, Qiang Liu, et al. Language is not all you need: Aligning perception with language models. arXiv preprint arXiv:2302.14045, 2023a.
- Huang et al. (2023b) Shaohan Huang, Li Dong, Wenhui Wang, Yaru Hao, Saksham Singhal, Shuming Ma, Tengchao Lv, Lei Cui, Owais Khan Mohammed, Qiang Liu, et al. Language is not all you need: Aligning perception with language models. arXiv preprint arXiv:2302.14045, 2023b.
- Hudson & Manning (2019) Drew A. Hudson and Christopher D. Manning. Gqa: A new dataset for real-world visual reasoning and compositional question answering. In CVPR, 2019.
- Jiang et al. (2022) Huaizu Jiang, Xiaojian Ma, Weili Nie, Zhiding Yu, Yuke Zhu, and Anima Anandkumar. Bongard-hoi: Benchmarking few-shot visual reasoning for human-object interactions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 19056–19065, 2022.
- Kiela et al. (2020) Douwe Kiela, Hamed Firooz, Aravind Mohan, Vedanuj Goswami, Amanpreet Singh, Pratik Ringshia, and Davide Testuggine. The hateful memes challenge: Detecting hate speech in multimodal memes. Advances in Neural Information Processing Systems, 33:2611–2624, 2020.
- Krishna et al. (2017) Ranjay Krishna, Yuke Zhu, Oliver Groth, Justin Johnson, Kenji Hata, Joshua Kravitz, Stephanie Chen, Yannis Kalantidis, Li-Jia Li, David A Shamma, et al. Visual genome: Connecting language and vision using crowdsourced dense image annotations. International journal of computer vision, 123:32–73, 2017.
- Kung & Peng (2023) Po-Nien Kung and Nanyun Peng. Do models really learn to follow instructions? an empirical study of instruction tuning. arXiv preprint arXiv:2305.11383, 2023.
- Li et al. (2023a) Bo Li, Yuanhan Zhang, Liangyu Chen, Jinghao Wang, Jingkang Yang, and Ziwei Liu. Otter: A multi-modal model with in-context instruction tuning, 2023a.
- Li et al. (2023b) Chunyuan Li, Cliff Wong, Sheng Zhang, Naoto Usuyama, Haotian Liu, Jianwei Yang, Tristan Naumann, Hoifung Poon, and Jianfeng Gao. Llava-med: Training a large language-and-vision assistant for biomedicine in one day. arXiv preprint arXiv:2306.00890, 2023b.
- Li et al. (2023c) Juncheng Li, Kaihang Pan, Zhiqi Ge, Minghe Gao, Hanwang Zhang, Wei Ji, Wenqiao Zhang, Tat-Seng Chua, Siliang Tang, and Yueting Zhuang. Empowering vision-language models to follow interleaved vision-language instructions. arXiv preprint arXiv:2308.04152, 2023c.
- Li et al. (2022) Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In International Conference on Machine Learning, pp. 12888–12900. PMLR, 2022.
- Li et al. (2023d) Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. arXiv preprint arXiv:2301.12597, 2023d.
- Li et al. (2023e) Lei Li, Yuwei Yin, Shicheng Li, Liang Chen, Peiyi Wang, Shuhuai Ren, Mukai Li, Yazheng Yang, Jingjing Xu, Xu Sun, Lingpeng Kong, and Qi Liu. Mit: A large-scale dataset towards multi-modal multilingual instruction tuning, 2023e.
- Li et al. (2023f) Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen. Evaluating object hallucination in large vision-language models, 2023f.
- Li et al. (2023g) Yunshui Li, Binyuan Hui, ZhiChao Yin, Min Yang, Fei Huang, and Yongbin Li. PaCE: Unified multi-modal dialogue pre-training with progressive and compositional experts. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 13402–13416, Toronto, Canada, July 2023g. Association for Computational Linguistics. doi: 10.18653/v1/2023.acl-long.749. URL https://aclanthology.org/2023.acl-long.749.
- Li et al. (2024) Yunshui Li, Binyuan Hui, Xiaobo Xia, Jiaxi Yang, Min Yang, Lei Zhang, Shuzheng Si, Junhao Liu, Tongliang Liu, Fei Huang, and Yongbin Li. One shot learning as instruction data prospector for large language models, 2024.
- Lin et al. (2014) Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C. Lawrence Zitnick. Microsoft coco: Common objects in context. In ECCV, 2014.
- Liu et al. (2022) Fangyu Liu, Guy Emerson, and Nigel Collier. Visual spatial reasoning. arXiv preprint arXiv:2205.00363, 2022.
- Liu et al. (2023a) Fuxiao Liu, Kevin Lin, Linjie Li, Jianfeng Wang, Yaser Yacoob, and Lijuan Wang. Aligning large multi-modal model with robust instruction tuning. arXiv preprint arXiv:2306.14565, 2023a.
- Liu et al. (2023b) Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. 2023b.
- Liu et al. (2023c) Xinyu Liu, Yan Ding, Kaikai An, Chunyang Xiao, Pranava Madhyastha, Tong Xiao, and Jingbo Zhu. Towards robust aspect-based sentiment analysis through non-counterfactual augmentations. arXiv preprint arXiv:2306.13971, 2023c.
- Liu et al. (2023d) Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, Kai Chen, and Dahua Lin. Mmbench: Is your multi-modal model an all-around player?, 2023d.
- Liu et al. (2023e) Yuliang Liu, Xiangru Tang, Zefan Cai, Junjie Lu, Yichi Zhang, Yanjun Shao, Zexuan Deng, Helan Hu, Zengxian Yang, Kaikai An, Ruijun Huang, Shuzheng Si, Sheng Chen, Haozhe Zhao, Zhengliang Li, Liang Chen, Yiming Zong, Yan Wang, Tianyu Liu, Zhiwei Jiang, Baobao Chang, Yujia Qin, Wangchunshu Zhou, Yilun Zhao, Arman Cohan, and Mark Gerstein. Ml-bench: Large language models leverage open-source libraries for machine learning tasks, 2023e.
- Lu et al. (2021) Pan Lu, Liang Qiu, Jiaqi Chen, Tony Xia, Yizhou Zhao, Wei Zhang, Zhou Yu, Xiaodan Liang, and Song-Chun Zhu. Iconqa: A new benchmark for abstract diagram understanding and visual language reasoning. arXiv preprint arXiv:2110.13214, 2021.
- Lu et al. (2022) Pan Lu, Swaroop Mishra, Tanglin Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. Learn to explain: Multimodal reasoning via thought chains for science question answering. Advances in Neural Information Processing Systems, 35:2507–2521, 2022.
- Luo et al. (2023) Gen Luo, Yiyi Zhou, Tianhe Ren, Shengxin Chen, Xiaoshuai Sun, and Rongrong Ji. Cheap and quick: Efficient vision-language instruction tuning for large language models. arXiv preprint arXiv:2305.15023, 2023.
- Marino et al. (2019) Kenneth Marino, Mohammad Rastegari, Ali Farhadi, and Roozbeh Mottaghi. Ok-vqa: A visual question answering benchmark requiring external knowledge. In Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
- Min et al. (2021) Sewon Min, Mike Lewis, Luke Zettlemoyer, and Hannaneh Hajishirzi. Metaicl: Learning to learn in context. arXiv preprint arXiv:2110.15943, 2021.
- Najdenkoska et al. (2023) Ivona Najdenkoska, Xiantong Zhen, and Marcel Worring. Meta learning to bridge vision and language models for multimodal few-shot learning. arXiv preprint arXiv:2302.14794, 2023.
- OpenAI (2023) OpenAI. Gpt-4 technical report. ArXiv, abs/2303.08774, 2023.
- Ordonez et al. (2011) Vicente Ordonez, Girish Kulkarni, and Tamara Berg. Im2text: Describing images using 1 million captioned photographs. In J. Shawe-Taylor, R. Zemel, P. Bartlett, F. Pereira, and K.Q. Weinberger (eds.), Advances in Neural Information Processing Systems, volume 24. Curran Associates, Inc., 2011. URL https://proceedings.neurips.cc/paper_files/paper/2011/file/5dd9db5e033da9c6fb5ba83c7a7ebea9-Paper.pdf.
- Pan et al. (2023) Junting Pan, Ziyi Lin, Yuying Ge, Xiatian Zhu, Renrui Zhang, Yi Wang, Yu Qiao, and Hongsheng Li. Retrieving-to-answer: Zero-shot video question answering with frozen large language models, 2023.
- Radford et al. (2021) Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pp. 8748–8763. PMLR, 2021.
- Raffel et al. (2023) Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer, 2023.
- Rajbhandari et al. (2020) Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. Zero: Memory optimizations toward training trillion parameter models. In SC20: International Conference for High Performance Computing, Networking, Storage and Analysis, pp. 1–16. IEEE, 2020.
- Rasley et al. (2020) Jeff Rasley, Samyam Rajbhandari, Olatunji Ruwase, and Yuxiong He. Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD ’20, pp. 3505–3506, New York, NY, USA, 2020. Association for Computing Machinery. ISBN 9781450379984. doi: 10.1145/3394486.3406703. URL https://doi.org/10.1145/3394486.3406703.
- Russakovsky et al. (2015) Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, et al. Imagenet large scale visual recognition challenge. International journal of computer vision, 115:211–252, 2015.
- Saleh & Elgammal (2015) Babak Saleh and Ahmed Elgammal. Large-scale classification of fine-art paintings: Learning the right metric on the right feature. arXiv preprint arXiv:1505.00855, 2015.
- Schuhmann et al. (2021) Christoph Schuhmann, Richard Vencu, Romain Beaumont, Robert Kaczmarczyk, Clayton Mullis, Aarush Katta, Theo Coombes, Jenia Jitsev, and Aran Komatsuzaki. Laion-400m: Open dataset of clip-filtered 400 million image-text pairs. arXiv preprint arXiv:2111.02114, 2021.
- Schwenk et al. (2022) Dustin Schwenk, Apoorv Khandelwal, Christopher Clark, Kenneth Marino, and Roozbeh Mottaghi. A-okvqa: A benchmark for visual question answering using world knowledge, 2022.
- Sharma et al. (2018) Piyush Sharma, Nan Ding, Sebastian Goodman, and Radu Soricut. Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. In Iryna Gurevych and Yusuke Miyao (eds.), Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 2556–2565, Melbourne, Australia, July 2018. Association for Computational Linguistics. doi: 10.18653/v1/P18-1238. URL https://aclanthology.org/P18-1238.
- Si et al. (2022a) Shuzheng Si, Shuang Zeng, and Baobao Chang. Mining clues from incomplete utterance: A query-enhanced network for incomplete utterance rewriting. In Marine Carpuat, Marie-Catherine de Marneffe, and Ivan Vladimir Meza Ruiz (eds.), Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 4839–4847, Seattle, United States, July 2022a. Association for Computational Linguistics. doi: 10.18653/v1/2022.naacl-main.356. URL https://aclanthology.org/2022.naacl-main.356.
- Si et al. (2022b) Shuzheng Si, Shuang Zeng, Jiaxing Lin, and Baobao Chang. SCL-RAI: Span-based contrastive learning with retrieval augmented inference for unlabeled entity problem in NER. In Nicoletta Calzolari, Chu-Ren Huang, Hansaem Kim, James Pustejovsky, Leo Wanner, Key-Sun Choi, Pum-Mo Ryu, Hsin-Hsi Chen, Lucia Donatelli, Heng Ji, Sadao Kurohashi, Patrizia Paggio, Nianwen Xue, Seokhwan Kim, Younggyun Hahm, Zhong He, Tony Kyungil Lee, Enrico Santus, Francis Bond, and Seung-Hoon Na (eds.), Proceedings of the 29th International Conference on Computational Linguistics, pp. 2313–2318, Gyeongju, Republic of Korea, October 2022b. International Committee on Computational Linguistics. URL https://aclanthology.org/2022.coling-1.202.
- Si et al. (2023a) Shuzheng Si, Zefan Cai, Shuang Zeng, Guoqiang Feng, Jiaxing Lin, and Baobao Chang. SANTA: Separate strategies for inaccurate and incomplete annotation noise in distantly-supervised named entity recognition. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki (eds.), Findings of the Association for Computational Linguistics: ACL 2023, pp. 3883–3896, Toronto, Canada, July 2023a. Association for Computational Linguistics. doi: 10.18653/v1/2023.findings-acl.239. URL https://aclanthology.org/2023.findings-acl.239.
- Si et al. (2023b) Shuzheng Si, Wentao Ma, Haoyu Gao, Yuchuan Wu, Ting-En Lin, Yinpei Dai, Hangyu Li, Rui Yan, Fei Huang, and Yongbin Li. Spokenwoz: A large-scale speech-text benchmark for spoken task-oriented dialogue agents. In A. Oh, T. Neumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine (eds.), Advances in Neural Information Processing Systems, volume 36, pp. 39088–39118. Curran Associates, Inc., 2023b. URL https://proceedings.neurips.cc/paper_files/paper/2023/file/7b16688a2b053a1b01474ab5c78ce662-Paper-Datasets_and_Benchmarks.pdf.
- Singh et al. (2019) Amanpreet Singh, Vivek Natarajan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, and Marcus Rohrbach. Towards VQA models that can read. In IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, June 16-20, 2019, pp. 8317–8326, 2019.
- Suhr et al. (2018) Alane Suhr, Stephanie Zhou, Ally Zhang, Iris Zhang, Huajun Bai, and Yoav Artzi. A corpus for reasoning about natural language grounded in photographs. arXiv preprint arXiv:1811.00491, 2018.
- Thrush et al. (2022a) Tristan Thrush, Ryan Jiang, Max Bartolo, Amanpreet Singh, Adina Williams, Douwe Kiela, and Candace Ross. Winoground: Probing vision and language models for visio-linguistic compositionality. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 5238–5248, 2022a.
- Thrush et al. (2022b) Tristan Thrush, Ryan Jiang, Max Bartolo, Amanpreet Singh, Adina Williams, Douwe Kiela, and Candace Ross. Winoground: Probing vision and language models for visio-linguistic compositionality. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 5238–5248, 2022b.
- Tsimpoukelli et al. (2021) Maria Tsimpoukelli, Jacob L Menick, Serkan Cabi, SM Eslami, Oriol Vinyals, and Felix Hill. Multimodal few-shot learning with frozen language models. Advances in Neural Information Processing Systems, 34:200–212, 2021.
- Wang et al. (2022a) Jianfeng Wang, Zhengyuan Yang, Xiaowei Hu, Linjie Li, Kevin Lin, Zhe Gan, Zicheng Liu, Ce Liu, and Lijuan Wang. Git: A generative image-to-text transformer for vision and language. arXiv preprint arXiv:2205.14100, 2022a.
- Wang et al. (2022b) Zijie J. Wang, Evan Montoya, David Munechika, Haoyang Yang, Benjamin Hoover, and Duen Horng Chau. DiffusionDB: A large-scale prompt gallery dataset for text-to-image generative models. arXiv:2210.14896 [cs], 2022b. URL https://arxiv.org/abs/2210.14896.
- Wei et al. (2022) Jason Wei, Maarten Bosma, Vincent Y. Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M. Dai, and Quoc V. Le. Finetuned language models are zero-shot learners, 2022.
- Wolf et al. (2020) Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander M. Rush. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pp. 38–45, Online, October 2020. Association for Computational Linguistics. URL https://www.aclweb.org/anthology/2020.emnlp-demos.6.
- Wu et al. (2023) Yifan Wu, Pengchuan Zhang, Wenhan Xiong, Barlas Oguz, James C. Gee, and Yixin Nie. The role of chain-of-thought in complex vision-language reasoning task, 2023.
- Xiao et al. (2021) Junbin Xiao, Xindi Shang, Angela Yao, and Tat-Seng Chua. Next-qa: Next phase of question-answering to explaining temporal actions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 9777–9786, 2021.
- Xu et al. (2016) Jun Xu, Tao Mei, Ting Yao, and Yong Rui. Msr-vtt: A large video description dataset for bridging video and language. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 5288–5296, 2016.
- Xu et al. (2023) Zhiyang Xu, Ying Shen, and Lifu Huang. MultiInstruct: Improving multi-modal zero-shot learning via instruction tuning. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 11445–11465, Toronto, Canada, July 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.acl-long.641. URL https://aclanthology.org/2023.acl-long.641.
- Yang et al. (2021) Antoine Yang, Antoine Miech, Josef Sivic, Ivan Laptev, and Cordelia Schmid. Just ask: Learning to answer questions from millions of narrated videos. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 1686–1697, 2021.
- Yarom et al. (2023) Michal Yarom, Yonatan Bitton, Soravit Changpinyo, Roee Aharoni, Jonathan Herzig, Oran Lang, Eran Ofek, and Idan Szpektor. What you see is what you read? improving text-image alignment evaluation. arXiv preprint arXiv:2305.10400, 2023.
- Ye et al. (2023) Qinghao Ye, Haiyang Xu, Guohai Xu, Jiabo Ye, Ming Yan, Yiyang Zhou, Junyang Wang, Anwen Hu, Pengcheng Shi, Yaya Shi, et al. mplug-owl: Modularization empowers large language models with multimodality. arXiv preprint arXiv:2304.14178, 2023.
- Young et al. (2014) Peter Young, Alice Lai, Micah Hodosh, and Julia Hockenmaier. From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions. Transactions of the Association for Computational Linguistics, 2, 2014.
- Yu et al. (2016) Licheng Yu, Patrick Poirson, Shan Yang, Alexander C Berg, and Tamara L Berg. Modeling context in referring expressions. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part II 14, pp. 69–85. Springer, 2016.
- Yu et al. (2023) Weihao Yu, Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Zicheng Liu, Xinchao Wang, and Lijuan Wang. Mm-vet: Evaluating large multimodal models for integrated capabilities. arXiv preprint arXiv:2308.02490, 2023.
- Zellers et al. (2019) Rowan Zellers, Yonatan Bisk, Ali Farhadi, and Yejin Choi. From recognition to cognition: Visual commonsense reasoning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 6720–6731, 2019.
- Zeng et al. (2023) Yan Zeng, Hanbo Zhang, Jiani Zheng, Jiangnan Xia, Guoqiang Wei, Yang Wei, Yuchen Zhang, and Tao Kong. What matters in training a gpt4-style language model with multimodal inputs? arXiv preprint arXiv:2307.02469, 2023.
- Zhang et al. (2023a) Ao Zhang, Hao Fei, Yuan Yao, Wei Ji, Li Li, Zhiyuan Liu, and Tat-Seng Chua. Transfer visual prompt generator across llms. CoRR, abs/23045.01278, 2023a. URL https://doi.org/10.48550/arXiv.2305.01278.
- Zhang et al. (2019) Chi Zhang, Feng Gao, Baoxiong Jia, Yixin Zhu, and Song-Chun Zhu. Raven: A dataset for relational and analogical visual reasoning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 5317–5327, 2019.
- Zhang et al. (2023b) Zhuosheng Zhang, Aston Zhang, Mu Li, Hai Zhao, George Karypis, and Alex Smola. Multimodal chain-of-thought reasoning in language models, 2023b.
- Zhu et al. (2023) Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. Minigpt-4: Enhancing vision-language understanding with advanced large language models. arXiv preprint arXiv:2304.10592, 2023.
附录 A 相关工作
A.1 视觉语言预训练
| Model | Multi-Image Inputs | Multi-modal Instruction Tuning | Text-to-Image Reference |
| Flamingo | ✓ | ✗ | ✗ |
| Meta learner | ✓ | ✗ | ✗ |
| BLIP-2 | ✗ | ✗ | ✗ |
| LLAVA | ✗ | ✓ | ✗ |
| MiniGPT-4 | ✗ | ✓ | ✗ |
| InstructBLIP | ✗ | ✓ | ✗ |
| Shikra | ✗ | ✓ | ✓ |
| Kosmos-1 | ✓ | ✗ | ✗ |
| Otter | ✓ | ✓ | ✗ |
| MMICL | ✓ | ✓ | ✓ |
我们的工作受近期视觉语言预训练工作的启发 (Zhu 等人,2023;Liu 等人,2023b;Li 等人,2022;2023d),这些工作已被证明可有效地对齐视觉输入和冻结的 LLM 以获得跨模态泛化能力。
BLIP-2
BLIP-2 (Li 等人,2023d) 使用轻量级查询 Transformer 来弥合模态差距,该 Transformer 经过两阶段预训练。 第一个阶段从冻结的图像编码器中启动视觉语言表示学习。 第二个阶段从冻结的语言模型中启动视觉到语言的生成式学习。
指导BLIP
InstructBLIP (Dai 等人,2023) 基于预训练的 BLIP-2 模型,使用转换后的多模态数据集和 LLaVA (Liu 等人,2023b) (由 GPT-4 生成的)数据集,执行视觉语言指令调优。
迷你GPT-4
MiniGPT-4 (Zhu et al., 2023) 将 CLIP 视觉编码器与一个冻结的 Vincuna (Chiang et al., 2023) 对齐,并使用人工收集的对话数据集
什克拉
Shikra (Chen et al., 2023a), 是一个 VLM,它可以在自然语言中处理空间坐标的输入和输出。 这使得 Shikra 在指称对话和一般的视觉-语言任务中表现出色,从而取得了优异的性能。
然而,目前仍有较少的论文关注具有多图像输入的 VLM。
火烈鸟
Flamingo (Tsimpoukelli et al., 2021) 基于图像的自注意力机制实现多视觉输入,但在下游任务中表现不佳。 Flamingo 通过 ICL 在 VLM 中支持少样本学习 (FSL),利用其强大的处理多视觉输入的能力,并使用交叉注意力而不是自注意力来获得更好的性能。 然而,它仍然无法明确地指向图像,因此他们引入了一个 hacky 的交叉注意力掩码。
宇宙一号
Kosmos-1 (Huang et al., 2023a),是在数十亿规模的多模态语料库上从头开始训练的,包括交织的文本-图像网页数据、图像-文本标题和纯语言指令调优数据。 它可以进行多模态少样本学习和思维链过程,从而取得了强大的性能。
獭
Otter (Li et al., 2023a),是 flamingo 的开源实现,并使用 多模态指令上下文调优数据进行训练。
元学习器
Najdenkoska 等人 (2023) 使用元学习目标训练一个适配器,该适配器聚合多个图像特征,使原始 VLM 和适配器成为更好的少样本学习器。
最近的 VLM (Zhu 等人,2023;Liu 等人,2023b;Li 等人,2022;Alayrac 等人,2022;Dai 等人,2023;Chen 等人,2024b) 已被证明可有效地对齐视觉输入和冻结的 LLM,以获得跨模态泛化能力。 但是,之前的工作忽略了多图像 VLM,主要集中在处理单图像提示。 Tsimpoukelli 等人 (2021) 使用自注意力机制支持多图像输入,但在下游任务中表现不佳。 虽然 Flamingo (Alayrac 等人,2022) 支持 VLM 中的少样本学习,并使用交叉注意力机制来捕获文本-图像关系,但它仍然受到特定图像的精确引用的影响。
A.2 多模态指令调优
预训练语言模型在自然语言理解 (Si 等人,2022b;2023a;An 等人,2023;Liu 等人,2023c;Hu 等人,2023a;Chen 等人,2023b) 和自然语言生成 (Si 等人,2022a;2023b;Cai 等人,2023;Liu 等人,2023e) 方面取得了巨大成功。 最近,指令调优 (Kung & Peng, 2023;Li 等人,2024;Wei 等人,2022) 越来越受到关注,以便使 LLM 能够遵循自然语言指令并完成现实世界中的任务。 然而,多模态指令调优仍需进一步探索。 Multiinstruct (Xu 等人,2023) 引入指令调优来提高 VLM 在指令遵循能力方面的性能。 由于架构设计,Multiinstruct 仍然难以处理包含多个图像的复杂上下文。 Otter (Li 等人,2023a) 对 Openflamingo (Awadalla 等人,2023) 进行微调,以增强其指令理解能力。 然而,Otter 的数据集缺乏文本到图像的引用和相互关联的图像到图像数据。 此限制阻碍了它处理涉及视觉-文本关系的复杂上下文的的能力。
A.3 上下文学习
在预训练语言模型 (PLM) 中启用 ICL 已得到充分探索。 MetaICL (Min 等人,2021) 提出了一种元训练框架,用于少样本学习,以调整 PLM 以在大量训练任务上进行上下文学习。 LM-BFF (Gao 等人,2020) 研究了 PLM 的少样本微调。 然而,VLM 中的 ICL 仍然鲜为人知。 最近在 VLM 中的工作主要集中在使用单图像输入的零样本评估。
附录 B 多模态 ICL 数据
我们构建了两个训练数据集,文本-图像交织数据和上下文学习数据,分别用于文本-图像关系挑战和图像-图像关系挑战。 本节将介绍数据资源。
| Task | Dataset | Used | #samples | License | ||
| Train | Val | Test | ||||
| Captioning | MS COCO (Lin et al., 2014) | Yes | 413,952 | 202,496 | 0 | Custom |
| DiffusionDB (Wang et al., 2022b) | Yes | 19,963 | 0 | 0 | MIT | |
| Flickr (Young et al., 2014) | Yes | 144,896 | 4,864 | 4,864 | Custom | |
| NoCaps (Agrawal et al., 2019) | Yes | 0 | 45,000 | 0 | CC BY 2.0 | |
| Classification | MiniImage (Russakovsky et al., 2015) | Yes | 38,400 | 9,600 | 12,000 | CC0 1.0 |
| VQA | VQA v2 (Goyal et al., 2017) | Yes | 592,998 | 26,173 | 25,747 | CC BY 4.0 |
| ST-VQA (Biten et al., 2019) | Yes | 78,222 | 0 | 4,070 | CC BY 4.0 | |
| Text-VQA (Singh et al., 2019) | Yes | 34,602 | 0 | 0 | CC BY 4.0 | |
| NLVR2 (Suhr et al., 2018) | Yes | 86,373 | 6,982 | 6,967 | CC BY 4.0 | |
| RefCOCO (Yu et al., 2016) | Yes | 141,968 | 0 | 0 | Custom | |
| KVQA | OK-VQA (Marino et al., 2019) | Yes | 9,009 | 5,046 | 0 | CC BY 4.0 |
| Reasoning | GQA (Hudson & Manning, 2019) | Yes | 943,000 | 132,062 | 12,578 | CC BY 4.0 |
| VCR (Zellers et al., 2019) | Yes | 118,156 | 14,472 | 5,000 | Custom | |
| Winoground (Thrush et al., 2022a) | No | 0 | 0 | 400 | Custom | |
| video | MSRVTT-QA (Xu et al., 2016) | Yes | 158,581 | 12,278 | 72,821 | MIT |
| MSRVTT (Xu et al., 2016) | Yes | 130,260 | 9,940 | 59,800 | MIT | |
| Others | WikiART (Saleh & Elgammal, 2015) | Yes | 13,000 | 5,500 | 0 | Custom |
| LLAVA-Instruct-150K (Liu et al., 2023b) | Yes | 236,564 | 0 | 0 | CC BY 4.0 | |
附录 C 数据资源
用于构建 MIC 数据集的数据资源在图 7 中显示。 我们的训练数据集来自 8 个任务类别和 16 个数据集。
图像字幕 旨在根据不同的需求生成给定图像的描述。 我们的训练数据集包括 MS COCO (Lin 等人,2014),DiffusionDB (Wang 等人,2022b) 和 Flickr 30K (Young 等人,2014)。
知识型视觉问答 (KVQA) 要求模型利用输入图像之外的常识知识来回答问题。 我们的训练数据集包括 OK-VQA (Marino 等人,2019)。
图像问答 (IQA) 要求模型根据图像正确地回答问题。 我们的训练数据集包括 VQAv2 (Goyal 等人,2017),ST-VQA (Biten 等人,2019),Text-VQA (Singh 等人,2019),WikiART (Saleh & Elgammal, 2015) 和 RefCOCO (Yu 等人,2016)。
视频问答 (VideoQA) 要求模型根据视频正确地回答问题。 我们每段视频提取八帧作为视频 QA 任务的视觉输入。 我们的训练数据集包括 MSRVTTQA (Xu 等人,2016)。
视频字幕 要求模型根据视频给出字幕。 我们每段视频提取八帧作为视频字幕任务的视觉输入。 我们的训练数据集包括 MSRVTT (Xu 等人,2016)。
视觉推理 要求模型正确地执行图像推理并回答问题。 我们的训练数据集包括 GQA (Hudson & Manning, 2019),VCR (Zellers 等人,2019),以及 NLVR2 (Suhr 等人,2018)。
图像分类 涉及根据给定的一组候选标签对图像进行分类。 我们的训练数据集包括 MiniImage (Russakovsky 等人,2015)。
视觉对话 要求模型以自然、对话式的语言与人类进行有意义的关于视觉内容的对话。 我们的训练数据集包括 LLAVA-Instruct-150K (Liu 等人,2023b)。
我们的测试数据集来自 10 个任务类别和 18 个数据集。
图像字幕 包括 Nocaps (Agrawal 等人,2019) 数据集。
知识型视觉问答 (KVQA) 包括 ScienceQA (Lu 等人,2022) 和 A-OKVQA (Schwenk 等人,2022) 数据集。
图像问答 (IQA) 包括 VizWiz (Bigham 等人,2010) 数据集。
视觉推理 包括 Winoground (Thrush 等人,2022b)、VSR (Liu 等人,2022) 和 IconQA (Lu 等人,2021) 数据集。 Winoground 提出了一个将两张给定图像和两个标题正确匹配的任务。 此任务的挑战在于两个标题都包含完全相同的词集,只是顺序不同。 VSR 描述了图像中两个单独物体的空间关系,VLM 需要判断标题是否正确描述了图像(True)还是不正确(False)。 IconQA 数据集有两个子数据集:具有多个文本选项的图像问答和具有多个图像选项的图像问答。
网页问答 (Web QA) 包括 Websrc (Chen 等人,2021a; Huang 等人,2023a) 数据集。 模型必须根据网页图像和可选的提取文本来回答问题。 我们从 Websrc 中抽取了 2000 个实例用于评估。 为了与 KOSMOS-1 (Huang 等人,2023a) 保持一致,我们只使用网页图像作为输入。
视频问答 (VideoQA) 包括 iVQA (Yang 等人,2021)、MVSD (Chen & Dolan, 2011) 和 NextQA (Xiao 等人,2021) 数据集。 NextQA 数据集有两个子数据集:多项选择视频问答和开放域视频问答。
少样本图像分类 包括 HatefulMemes (Kiela 等人,2020) 和 Bonard-HOI (Jiang 等人,2022) 数据集。 HatefulMemes 要求模型根据提供的图像和解释来确定一个模因是否具有仇恨性。 Bonard-HOI 是评估模型在人机交互的少样本视觉推理能力方面的基准。 它提供了具有挑战性的负样本的少样本示例,其中正负图像仅在动作标签方面有所不同。 然后要求模型判断最终图像是否为正或负。 我们从 Bonard-HOI 中抽取了 2000 个实例用于评估。
非语言推理 包括 Raven IQ 测试 (Huang 等人,2023a)。 Raven IQ 测试中的每个实例都有 3 或 8 张图像作为输入,以及 6 张带有唯一正确完成的候选图像,目标是从候选图像中预测下一张图像。
视觉对话 包括视觉对话数据集 (Das 等人,2017)。 我们使用最终对话的问题作为实例问题,并将所有先前对话作为上下文来执行开放域图像问答。
OOD泛化 包括我们使用 Minecraft (Cipollone 等人,2014) 游戏构建的 Minecraft 数据集,该数据集要求 VLM 识别图片中是否存在动物(例如,牛、羊驼、鸡、驴等)。
数据集的更多详细任务描述和统计信息见表 9。
附录 D 数据构建
首先,我们在所有数据集中为每个实例创建图像声明,以生成具有显式文本到图像引用的数据集。 然后,我们让标注员仔细审查每个数据集的样本并提供任务说明。 此做法有助于全面了解任务并帮助制定高质量的模板。
接下来,我们使用 ChatGPT 5 55 我们使用 ChatGPT 的 gpt-3.5-turbo 版本。 来重写说明以准确描述每个任务的关键特征。 ChatGPT 生成说明后,我们进行手动审查以确保说明的质量。
我们选择十个匹配的合适模板作为候选,然后将原始数据集的输入合并到随机选择的模板中。 我们通过选择少量数据并按顺序排列来为数据集中的每个实例组装演示。 这些演示与输入实例集成以生成多模态上下文数据 6 66 除了视频数据集、vcr 数据集和 LLaVa 数据集。 .
我们通过从 MSRVTT (Xu et al., 2016) 和 MSRVTTQA (Xu et al., 2016) 数据集中每段视频提取八帧来构建多图像数据。 我们还使用对象边界框从 VCR (Zellers et al., 2019) 数据集中裁剪图像以生成与密切相关的图像交织的多模态数据。 我们将所有数据转换为视觉语言问答格式,以创建高质量的多模态训练数据,并在 MIC 数据集中累积 5.8M 个样本。 由于资源限制,我们使用附录 F 中描述的采样策略中大约 10% 的数据来微调 MMICL。 预计,在所有数据上训练的更大模型将产生更令人鼓舞的结果。

D.1 多模态数据与互联图像
针对带有互联图像的多模态数据的数据构建框架,如第 2.2.2 节,是通过利用现有数据集标注(即 视觉常识推理数据集 (VCR) (Zellers et al., 2019))的自动化流程开发的。 该方法避免了对补充人工标注工作的需求。
VCR 数据集的原始标注包括原始图像、边界框以及一组专门引用这些边界框作为图 8 左侧部分的问题和答案。 这种结构化的标注方法有助于全面理解图像上下文。 利用现有的标注,我们开发了一个自动化工作流程,包括根据边界框从原始图像中提取子图像,并使用 ChatGPT 来制定各种指令。 首先,我们手动创建一组指令模板,这些模板与数据集描述一起输入 ChatGPT。 随后,要求 ChatGPT 扩展这些模板,从而产生一组不同的指令模板。
D.2 统一多模态上下文格式,用于不同的任务
通过在数据集中进行选择性采样,我们为每个相应任务制定了上下文示例。 这些示例包含各种元素,包括图像、问题和答案。 ChatGPT 用于制定各种指令。 制定的指令模板在附录 G 中列出。

D.3 带视频帧的多模态数据
视频数据的构建框架是通过一个自动化过程开发的,该过程利用现有的数据集标注。 使用的数据集是 MSRVTT (Xu 等人,2016) 和 MSRVTTQA (Xu 等人,2016) 数据集,如附录 F 所示。
附录 E 模型结构
如图 11 所示,MMICL 平等地对待图像和语言表示,并将它们组合成交错的图像-文本表示,类似于原始输入。 给定的图像由视觉编码器(例如,ViT (Radford 等人,2021; Fang 等人,2023))编码,以获得图像的视觉表示。 然后,我们使用 Q-former 作为 VPG 来提取视觉嵌入。 我们使用一个全连接层作为投影层,将每个视觉嵌入转换为与 LLM 的文本嵌入相同的维度。 这种对齐有助于 LLM 理解图像。 我们的方法平等对待视觉和文本嵌入,可以灵活地组合视觉和文本内容。 最后,我们将多个图像的视觉嵌入与文本嵌入以交错的方式组合在一起,然后将其馈送到 LLM 中。 我们将 LLM 注意力层中用于映射查询和值向量的权重设置为可学习的,以便更好地适应包含多个图像的多模态上下文。 在预训练期间,我们冻结图像编码器、Q-former 和主干 LLM,同时共同训练语言投影以及 LLM 的查询和值向量。
附录 F 数据平衡
以前的研究表明,训练数据的平衡度会显着影响模型性能 (Dai 等人,2023)。 均匀地混合每个数据集的训练数据会导致模型过度拟合较小的数据集,而对较大的数据集拟合不足,从而导致性能下降。 为了缓解这个问题,我们采用了一种采样策略,以与训练样本数量的平方根成正比的概率对数据集进行采样,遵循 Dai 等人 (2023)。 形式上,给定 个数据集,其中每个数据集有 个训练样本 ,则在训练期间从一个数据集中选择数据样本的概率 如下所示。
| (4) |
附录 G 数据构建的指令模板
如第 2.2.3 节所示,MIC 的构建需要精心设计的模板。 本节介绍了每个任务的指令模板。 任务 MSCOCO、Flick30k、Nocaps 和 Diffusiondb 的模板在表 10 中给出。 任务 MiniImagenet 的模板在表 11 中给出。 任务 VQAv2、S-VQA、WikiART 和 RefCOCO 的模板在表 13 中给出。 任务 OKVQA 的模板在表 14 中给出。 任务 MSRVTT 的模板在表 15 中给出。 任务 MSRVTTQA 和 MSVD 的模板在表 16 中给出。
| Templates of Image Captioning (MSCOCO, Flick30k, Nocaps, Diffusiondb) |
|
(1) Carefully analyze image 0: [IMG0] {image} to generate a concise and accurate description that accurately represents the objects, people, and scenery present. |
|
(2) Use clear and concise language that accurately describes the content of image 0: [IMG0] {image}. |
|
(3) Your caption should provide sufficient information about image 0: [IMG0] {image} so that someone who has not seen the image can understand it. |
|
(4) image 0 is [IMG0] {image}. Be specific and detailed in your description of image 0, but also try to capture the essence of image 0 in a succinct way. |
|
(5) image 0 is [IMG0] {image}. Based on the image 0, describe what is contained in this photo. Your caption should be no more than a few sentences and should be grammatically correct and free of spelling errors. |
|
(6) Include information in your caption that is specific to image 0: [IMG0] {image} and avoid using generic or ambiguous descriptions. |
|
(7) image 0 is [IMG0] {image}. Based on the image 0, give a caption about this image. Think about what message or story image 0 is conveying, and try to capture that in your image caption. |
|
(8) Based on the image 0, give a caption about this image. Your caption should provide enough detail about image 0: [IMG0] {image} to give the viewer a sense of what is happening in the image. |
|
(9) Give a caption about this image. Avoid using overly complex language or jargon in your caption of image 0: [IMG0] {image} that might confuse the viewer. |
|
(10) Be creative in your approach to captioning image 0: [IMG0] {image} and try to convey a unique perspective or story. |
| Templates of Image Classification (MiniImagenet, etc) |
|
(1) image 0 is [IMG0] {image}. Please identify the object or concept depicted in image 0. |
|
(2) image 0 is [IMG0] {image}. What is the main subject of image 0? |
|
(3) image 0 is [IMG0] {image}. Can you recognize and label the object shown in image 0? |
|
(4) image 0 is [IMG0] {image}. Identify the category or class to which image 0 belongs. |
|
(5) image 0 is [IMG0] {image}. Based on the visual content, determine what image 0 represents. |
|
(6) image 0 is [IMG0] {image}. What is the name or label of the item captured in image 0? |
|
(7) image 0 is [IMG0] {image}. Please provide a description or identification of the subject in image 0. |
|
(8) image 0 is [IMG0] {image}. From the visual cues, determine the object or entity depicted in image 0. |
|
(9) image 0 is [IMG0] {image}. Can you recognize and name the primary element shown in image 0? |
|
(10) image 0 is [IMG0] {image}. Identify the object or concept that best describes what is depicted in image 0. |
| Templates of Knowledge Visual Question Answering (OK-VAQ) |
|
(1) Look at image 0 labeled [IMG0] {image} carefully and read question: question. Try to understand what is being asked before selecting an answer. |
|
(2) image 0 is [IMG0] {image}. Consider all of the information in image 0 labeled [IMG0] when answering question. Look at objects, colors, shapes, and other details that may be relevant to question: question Answer: |
|
(3) image 0 is [IMG0] {image}. Read each answer choice carefully and answers question : question based on the information provided in image 0. |
|
(4) image 0 is [IMG0] {image}. Given the picture [IMG0], pay attention to the wording of question and answer the following question: question Answer: |
|
(5) Read the question carefully and look at image 0 labeled [IMG0] {image}. Use your intuition and common sense when answering the question: question |
|
(6) Consider all of the information in image 0 labeled [IMG0] {image} when answering the question: question |
|
(7) Take your time when answering each question. Don’t rush through the questions, and make sure you have carefully considered all of the information provided in image 0 labeled [IMG0] {image} and the question before making your selection. Question: question Answer: |
|
(8) Make sure your answers are based on the information presented in the image 0: [IMG0] {image}. Question:question Answer: |
|
(9) Carefully examine image 0 labeled [IMG0] {image} before answering the question. Question:question Answer: |
|
(10) Please refer to image 0: [IMG0] {image} when answering the following questions: question Answer: |
| Templates of Image Question Answering (VQAv2, ST-VQA, WikiART, RefCOCO, etc) |
|
VQAv2 |
|
(1) image 0 is [IMG0] {image}. For the question, carefully examine the image and use your knowledge to determine the correct answer. Question: question Answer: |
|
(2) image 0 is [IMG0] {image}. Given the picture [IMG0], pay attention to the wording of question and answer the following question: question Answer: |
|
(3) Read the question carefully and look at image 0 labeled [IMG0] {image}. Use your intuition and common sense when answering the question: question |
|
(4) Answer each question based on the information presented in image 0: [IMG0] {image}. Given the picture [IMG0], what is the answer to the question: question Answer: |
|
(5) Please refer to image 0: [IMG0] {image} when answering the following questions: question Answer: |
|
(6) Questions is related to image 0: [IMG0] {image}. Please analyze the image and provide the correct answer for the question: question |
|
(7) Read the question carefully and look at image 0 labeled [IMG0] {image}. Use your intuition and common sense when answering the question: question |
|
(8) Consider all of the information in image 0 labeled [IMG0] {image} when answering the question: question |
|
(9) Take your time when answering each question. Don’t rush through the questions, and make sure you have carefully considered all of the information provided in image 0 labeled [IMG0] {image} and the question before making your selection. Question: question Answer: |
|
(10) Use the image 0: [IMG0] {image} as a visual aid to help you answer the questions accurately. Question:question Answer: |
|
ST-VQA |
|
(1) Answer each question based on the information presented in image 0: [IMG0] {image}. Given the picture [IMG0], what is the answer to the question: question Answer: |
|
(2) Please refer to image 0: [IMG0] {image} when answering the following questions: question Answer: |
|
(3) Questions is related to image 0: [IMG0] {image}. Please analyze the image and provide the correct answer for the question: question |
|
(4) For each question, use the image 0: [IMG0] {image} as a reference to answer the question: question |
|
(5) Make sure your answers are based on the information presented in the image 0: [IMG0] {image}, and any OCR text associated with it. Question:question Answer: |
|
(6) Answer the question as accurately as possible using the information provided in the image 0: [IMG0] {image}, and any OCR text associated with it. Question:question Answer: |
|
(7) Please ensure that you are answering the question based on the information presented in the image 0: [IMG0] {image}.Question:question Answer: |
|
(8) The image 0: [IMG0] {image} is the primary source of information for answering the questions. Please refer to it carefully when answering question: question Answer: |
|
(9) Pay close attention to the details in image 0: [IMG0] {image}, as they may provide important information for answering the questions. Question:question Answer: |
|
(10) Use the image 0: [IMG0] {image} as a visual aid to help you understand the context and answer the questions accurately. Question:question Answer: |
|
WikiART |
|
(1) image 0 is [IMG0] {image}. Please provide information about the artist, genre, and style of this artwork. |
|
(2) image 0 is [IMG0] {image}. I would like to know the artist’s name, the genre, and the specific style depicted in this painting. |
|
(3) image 0 is [IMG0] {image}. Could you identify the artistic genre, the artist, and the style portrayed in this artwork? |
|
(4) image 0 is [IMG0] {image}. In this painting, which genre does it belong to, who is the artist, and what is the predominant style? |
|
(5) image 0 is [IMG0] {image}. Tell me about the artist, genre, and style associated with this particular artwork. |
|
(6) image 0 is [IMG0] {image}. This piece of art seems intriguing. Can you provide details about the genre, the artist, and the style it represents? |
|
(7) image 0 is [IMG0] {image}. Identify the genre, artist, and style of this captivating artwork, please. |
|
(8) image 0 is [IMG0] {image}. I’m curious to learn about the artist’s name, the genre, and the distinctive style showcased in this artwork. |
|
(9) image 0 is [IMG0] {image}. Could you enlighten me about the genre, artist, and the artistic style that characterizes this beautiful piece? |
|
(10) image 0 is [IMG0] {image}. In terms of genre, artist, and style, what information can you provide regarding this fascinating artwork? |
|
RefCOCO |
|
(1) image 0 is [IMG0] {image}.Given image 0, create a descriptive caption that accurately represents the content of the image, including the item located in the {quadrant} of the image. |
|
(2) Use your knowledge of the image 0 and the {quadrant} location to generate a detailed and accurate caption that captures the essence of the scene. Keep in mind that image 0 is [IMG0] {image}. |
|
(3) image 0 is [IMG0] {image}. When writing your caption, be sure to include specific details about the item located in the {quadrant} of the image 0, such as its size, shape, color, and position. |
|
(4) Think about the intended audience for your caption and use appropriate language and tone. Consider the context of the image: [IMG0] {image} and the {quadrant} location when creating your caption, and make sure that it accurately reflects the content of the image. |
|
(5) Your caption should be concise and to the point, while still capturing the essence of the image 0 and the item located in the {quadrant} of the image. Avoid including irrelevant information in your caption that detracts from the main content of the image. Remember that image 0 is [IMG0] {image}. |
|
(6) image 0 is [IMG0] {image}. Check your caption for accuracy and grammatical errors before submitting. Be creative in your approach to captioning the image and the item located in the {quadrant}. |
|
(7) image 0 is [IMG0] {image}. Given image 0, describe the item in the {quadrant} of the image. |
|
(8) image 0 is [IMG0] {image}. Using image 0, provide a caption for the object located in the {quadrant} of the image. |
|
(9) For image 0: [IMG0] {image}, describe the object in the {quadrant} of the image. |
|
(10) Given the image 0: [IMG0] {image}. Generate a description for the item located in the {quadrant} of the image. |
|
(11) image 0 is [IMG0] {image}. Using the provided image 0, describe the object located in the {quadrant} of the image. |
| Templates of Video Question Captioning (MSRVTT) |
|
(1) image 0 is [IMG0] {image}. image 1 is [IMG1] {image}. image 2 is [IMG2] {image}. image 3 is [IMG3] {image}. image 4 is [IMG4] {image}. image 5 is [IMG5] {image}. image 6 is [IMG6] {image}. image 7 is [IMG7] {image}. Watch the images carefully and write a detailed description of what you see. |
|
(2) image 0 is [IMG0] {image}. image 1 is [IMG1] {image}. image 2 is [IMG2] {image}. image 3 is [IMG3] {image}. image 4 is [IMG4] {image}. image 5 is [IMG5] {image}. image 6 is [IMG6] {image}. image 7 is [IMG7] {image}. After viewing the images, provide a summary of the main events or key points depicted. |
|
(3) image 0 is [IMG0] {image}. image 1 is [IMG1] {image}. image 2 is [IMG2] {image}. image 3 is [IMG3] {image}. image 4 is [IMG4] {image}. image 5 is [IMG5] {image}. image 6 is [IMG6] {image}. image 7 is [IMG7] {image}. Pay close attention to the details in the images and provide accurate description to the images based on what you see. |
|
(4) image 0 is [IMG0] {image}. image 1 is [IMG1] {image}. image 2 is [IMG2] {image}. image 3 is [IMG3] {image}. image 4 is [IMG4] {image}. image 5 is [IMG5] {image}. image 6 is [IMG6] {image}. image 7 is [IMG7] {image}. Utilize your comprehension skills to describe the context and events depicted in the images. |
|
(5) image 0 is [IMG0] {image}. image 1 is [IMG1] {image}. image 2 is [IMG2] {image}. image 3 is [IMG3] {image}. image 4 is [IMG4] {image}. image 5 is [IMG5] {image}. image 6 is [IMG6] {image}. image 7 is [IMG7] {image}. Reflect on the images’s narrative structure and identify any storytelling techniques or narrative devices used. Write a detailed description of what you see. |
|
(6) image 0 is [IMG0] {image}. image 1 is [IMG1] {image}. image 2 is [IMG2] {image}. image 3 is [IMG3] {image}. image 4 is [IMG4] {image}. image 5 is [IMG5] {image}. image 6 is [IMG6] {image}. image 7 is [IMG7] {image}. Consider both the explicit and implicit information conveyed in the images to provide comprehensive description of the images. |
| Templates of Video Question Answering (MSRVTT QA, MSVD, etc) |
|
(1) image 0 is [IMG0] {image}. image 1 is [IMG1] {image}. image 2 is [IMG2] {image}. image 3 is [IMG3] {image}. image 4 is [IMG4] {image}. image 5 is [IMG5] {image}. image 6 is [IMG6] {image}. image 7 is [IMG7] {image}. Watch the provided images carefully and answer the following questions based on your understanding of the images content. Qusetion: {question}. Answer: |
|
(2) image 0 is [IMG0] {image}. image 1 is [IMG1] {image}. image 2 is [IMG2] {image}. image 3 is [IMG3] {image}. image 4 is [IMG4] {image}. image 5 is [IMG5] {image}. image 6 is [IMG6] {image}. image 7 is [IMG7] {image}. Carefully analyze the visual elements of the images and answer the questions based on your observations. Qusetion: {question}. Answer: |
|
(3) image 0 is [IMG0] {image}. image 1 is [IMG1] {image}. image 2 is [IMG2] {image}. image 3 is [IMG3] {image}. image 4 is [IMG4] {image}. image 5 is [IMG5] {image}. image 6 is [IMG6] {image}. image 7 is [IMG7] {image}. Pay close attention to the details in the images and provide accurate answers to the questions based on what you see. Qusetion: {question}. Answer: |
|
(4) image 0 is [IMG0] {image}. image 1 is [IMG1] {image}. image 2 is [IMG2] {image}. image 3 is [IMG3] {image}. image 4 is [IMG4] {image}. image 5 is [IMG5] {image}. image 6 is [IMG6] {image}. image 7 is [IMG7] {image}. Utilize your comprehension skills to answer the questions based on the context and events depicted in the images. Qusetion: {question}. Answer: |
|
(5) image 0 is [IMG0] {image}. image 1 is [IMG1] {image}. image 2 is [IMG2] {image}. image 3 is [IMG3] {image}. image 4 is [IMG4] {image}. image 5 is [IMG5] {image}. image 6 is [IMG6] {image}. image 7 is [IMG7] {image}. Consider the relationships between the images frames, scenes, and the provided questions to formulate accurate answers. Qusetion: {question}. Answer: |
|
(6) image 0 is [IMG0] {image}. image 1 is [IMG1] {image}. image 2 is [IMG2] {image}. image 3 is [IMG3] {image}. image 4 is [IMG4] {image}. image 5 is [IMG5] {image}. image 6 is [IMG6] {image}. image 7 is [IMG7] {image}. Use your knowledge of the images’s content to answer the questions by recalling specific details and events. Qusetion: {question}. Answer: |
|
(7) image 0 is [IMG0] {image}. image 1 is [IMG1] {image}. image 2 is [IMG2] {image}. image 3 is [IMG3] {image}. image 4 is [IMG4] {image}. image 5 is [IMG5] {image}. image 6 is [IMG6] {image}. image 7 is [IMG7] {image}. Make logical inferences based on the information presented in the images to answer the questions with reasoned explanations. Qusetion: {question}. Answer: |
|
(8) image 0 is [IMG0] {image}. image 1 is [IMG1] {image}. image 2 is [IMG2] {image}. image 3 is [IMG3] {image}. image 4 is [IMG4] {image}. image 5 is [IMG5] {image}. image 6 is [IMG6] {image}. image 7 is [IMG7] {image}. While answering the questions, consider both the explicit and implicit information conveyed in the images to provide comprehensive responses. Qusetion: {question}. Answer: |
|
(9) image 0 is [IMG0] {image}. image 1 is [IMG1] {image}. image 2 is [IMG2] {image}. image 3 is [IMG3] {image}. image 4 is [IMG4] {image}. image 5 is [IMG5] {image}. image 6 is [IMG6] {image}. image 7 is [IMG7] {image}. Formulate your answers by considering the temporal context of the images and the chronological order of events. Qusetion: {question}. Answer: |
|
(10) image 0 is [IMG0] {image}. image 1 is [IMG1] {image}. image 2 is [IMG2] {image}. image 3 is [IMG3] {image}. image 4 is [IMG4] {image}. image 5 is [IMG5] {image}. image 6 is [IMG6] {image}. image 7 is [IMG7] {image}. Take into account the emotions, actions, and interactions of the characters in the images when answering the questions. Qusetion: {question}. Answer: |
| Templates of Visual Reasoning (GQA, VCR, NLVR v2, etc) |
|
GQA |
|
(1) image 0 is [IMG0] {image}. For the question, carefully examine the image and use your knowledge to determine the correct answer. Question: {question} Answer: |
|
(2) image 0 is [IMG0] {image}. Given the picture [IMG0], pay attention to the wording of question and answer the following question: {question} Answer: |
|
(3) Read the question carefully and look at image 0 labeled [IMG0] {image}. Use your intuition and common sense when answering the question: {question} |
|
(4) Consider all of the information in image 0 labeled [IMG0] {image} when answering the question: {question} |
|
(5) The image 0: [IMG0] {image} is the primary source of information for answering the questions. Please refer to it carefully when answering question: {question} Answer: |
|
(6) Pay close attention to the details in image 0: [IMG0] {image}, as they may provide important information for answering the questions. Question:{question} Answer: |
|
(7) image 0 is [IMG0] {image}. Make sure your answer is relevant to the question and the image 0. Question:{question} Answer: |
|
(8) image 0 is [IMG0] {image}. Do not provide answers based on assumptions or personal opinions; only use the information presented in the image 0 and the question. Question:{question} Answer: |
|
(9) Look at image 0 labeled [IMG0] {image} carefully and read question: {question}. Try to understand what is being asked before selecting an answer. |
|
(10) image 0 is [IMG0] {image}. Consider all of the information in image 0 labeled [IMG0] when answering question. Look at objects, colors, shapes, and other details that may be relevant to question: {question} Answer: |
|
VCR |
|
(1) {prompt}. Given the options below, based on the photo [IMG0], select the most suitable answer for the following question: {question}. Options: {options} |
|
(2) Please read the question and answer choices carefully. Select the option that best answers the question. {prompt}. Given the images, select the best option that answers the question from the available answer choices. Question: {question} Options: {options} Answer: |
|
(3) Choose the answer that best fits the description or action in the image. {prompt}. Consider the scene depicted in the images, choose the answer that best fits the description or action in the image from the available answer choices. Question: {question} Options: {options} Answer: |
|
(4) {prompt}. Examine the details in the pictures and use them to inform your answer to the question. Choose the best answer from the available options. Question: {question} Options: {options} Answer: |
|
(5) Look closely at the images and think about what is happening in the scene. {prompt}. Given the pictures, carefully examine the images and select the best answer that describes what is happening in the scene from the available answer choices. Question: {question} Options: {options} Answer: |
|
(6) Consider all of the details in the image and the wording of the question before making your selection. {prompt}. Given the pictures, consider all of the details in the image and the wording of the question before selecting the best answer choice from the available options. Question: {question} Options: {options} Answer: |
|
(7) Remember to use your common sense and reasoning skills to choose the best answer. {prompt}. Think about the images, use your common sense and reasoning skills to select the best answer choice from the available options. Question: {question} Options: {options} Answer: |
|
(8) {prompt}. Select the answer that most closely matches the description or action in images, based on the available options. Given the picture [IMG0], select the answer choice that most closely matches the description or action in the image from the available options. Question: {question} Options: {options} Answer: |
|
(9) Choose the option that provides the most accurate and complete answer to the question, based on the available information. {prompt} Given the images, select the option that provides the most accurate and complete answer to the question from the available answer choices. Question: {question} Options: {options} Answer: |
|
(10) {prompt}. Use the information in the images to help you make the best choice from the available answer options for the question Question: {question} Options: {options} Answer: |
|
NLVR v2 |
|
(1) image 0 is [IMG0] {image}. Given the picture [IMG0], answer the following question: {question} Is this correct? True or False. Answer: |
|
(2) For the question: {question}, carefully examine image 0: [IMG0] {image} and use your knowledge to determine if the statement is True or False. |
|
(3) Please refer to image 0: [IMG0] {image} when answering the question: {question} Is this correct? True or False. Answer: |
|
(4) Remember to consider both the question and the information presented in image 0: [IMG0] {image} when answering the True or False question: {question} |
|
(5) image 0 is [IMG0] {image}.Answer the question: {question} based on the information presented in the image 0 and determine if the statement is True or False. |
|
(6) Carefully examine the image 0: [IMG0] {image} and use your knowledge to determine whether the statement is True or False. Question: {question} |
|
(7) Remember that the answer to each question is either True or False, so make sure you choose the correct option based on the information presented in image 0: [IMG0] {image}. Question: {question} |
|
(8) Make sure your answers are based on the information presented in the image 0: [IMG0] {image}. Question:{question} Is this correct?True or False. Answer: |
|
(9) Carefully examine image 0 labeled [IMG0] {image} before answering the question. Question:{question} True or False? Answer: |
附录 H 实验细节
遵循 Chung 等人 (2022),我们使用 FLANT5-XL 和 FLANT5-XXL (Chung 等人,2022) 作为骨干 LLM。 在阶段 i@ 中,我们将视觉编码器和语言模型设置为冻结,并利用来自 COCO(Lin 等人,2014)、CC3M(Sharma 等人,2018)、Visual Genome(Krishna 等人,2017)、CC12M(Changpinyo 等人,2021)、SBU(Ordonez 等人,2011) 和 LAION-400M 数据(Schuhmann 等人,2021) 的图像,以及 (Li 等人,2022) 生成的标题,对 Q-former 执行特征对齐训练。 我们保持 VLM 的其他部分冻结,并联合训练 Q-former 和投影层。 Q-former 的视觉嵌入输出出现在骨干语言模型的 32 个符元大小中。 为了从 BLIP-2 强大的视觉表示提取能力中受益,我们将它强大的视觉编码器集成到 Q-former 和投影层的初始化中。 7 77在实践中,我们使用 BLIP-2 和 InstructBlip 的检查点作为 MMICL 的骨干,因此跳过阶段 i@。 . 在阶段 ii@ 中,我们使用 的较低学习率训练模型三个周期。 在此阶段,LLM 注意力层中映射查询和值向量的权重是可学习的,以更好地适应包含多个图像的多模态提示。 在此阶段,我们冻结视觉编码器、Q-former 和骨干 LLM,并联合训练投影层、LLM 的查询向量和值向量。
所有实验均在 6 个 NVIDIA A40 GPU 上进行,使用 Deepspeed (Rasley 等人,2020) 的 zero2-offload (Rajbhandari 等人,2020) 以及 huggingface transformers (Wolf 等人,2020) 的训练器。 MMICL (FLAN-T5-XL) 和 MMICL (FLAN-T5-XXL) 的批次大小分别为 10 和 4。 最大的 MMICL (FLAN-T5-XXL) 需要大约两天的时间才能完成第二阶段。
附录 I MME 基准
| Model |
|
|
|
|
Avg. | ||||||||
| MiniGPT-4 (Zhu et al., 2023) | 59.29 | 45.00 | 0.00 | 40.00 | 36.07 | ||||||||
| VisualGLM-6B (Du et al., 2021) | 39.29 | 45.00 | 50.00 | 47.50 | 45.45 | ||||||||
| LLaVA (Liu et al., 2023b) | 57.14 | 50.00 | 57.50 | 50.00 | 53.66 | ||||||||
| Lynx (Zeng et al., 2023) | 110.71 | 17.50 | 42.50 | 45.00 | 53.93 | ||||||||
| MultiModal-GPT (Gong et al., 2023) | 49.29 | 62.50 | 60.00 | 55.00 | 56.70 | ||||||||
| LLaMA-Adapter-V2 (Gao et al., 2023) | 81.43 | 62.50 | 50.00 | 55.00 | 62.23 | ||||||||
| VPGTrans (Zhang et al., 2023a) | 64.29 | 50.00 | 77.50 | 57.50 | 62.32 | ||||||||
| LaVIN (Luo et al., 2023) | 87.14 | 65.00 | 47.50 | 50.00 | 62.41 | ||||||||
| GIT2 (Wang et al., 2022a) | 99.29 | 50.00 | 67.50 | 45.00 | 65.45 | ||||||||
| mPLUG-Owl (Ye et al., 2023) | 78.57 | 60.00 | 80.00 | 57.50 | 69.02 | ||||||||
| BLIP-2 (Li et al., 2023d) | 110.00 | 40.00 | 65.00 | 75.00 | 72.50 | ||||||||
| InstructBLIP (Dai et al., 2023) | 129.29 | 40.00 | 65.00 | 57.50 | 72.95 | ||||||||
| Otter (Li et al., 2023a) | 106.43 | 72.50 | 57.50 | 70.00 | 76.61 | ||||||||
| Cheetor (Li et al., 2023c) | 98.57 | 77.50 | 57.50 | 87.50 | 78.02 | ||||||||
| LRV-Instruction (Liu et al., 2023a) | 100.71 | 70.00 | 85.00 | 72.50 | 82.05 | ||||||||
| BLIVA (Hu et al., 2023b) | 136.43 | 57.50 | 77.50 | 60.00 | 82.86 | ||||||||
| MMICL | 136.43 | 82.50 | 132.50 | 77.50 | 107.23 |
| Model | Existen. | Count | Pos. | Color | OCR | Poster | Cele. | Scene | Land. | Art. | Avg. |
| LLaVA | 50.00 | 50.00 | 50.00 | 55.00 | 50.00 | 50.00 | 48.82 | 50.00 | 50.00 | 49.00 | 50.28 |
| MiniGPT-4 | 68.33 | 55.00 | 43.33 | 75.00 | 57.50 | 41.84 | 54.41 | 71.75 | 54.00 | 60.50 | 58.17 |
| MultiModal-GPT | 61.67 | 55.00 | 58.33 | 68.33 | 82.50 | 57.82 | 73.82 | 68.00 | 69.75 | 59.50 | 65.47 |
| VisualGLM-6B | 85.00 | 50.00 | 48.33 | 55.00 | 42.50 | 65.99 | 53.24 | 146.25 | 83.75 | 75.25 | 70.53 |
| VPGTrans | 70.00 | 85.00 | 63.33 | 73.33 | 77.50 | 84.01 | 53.53 | 141.75 | 64.75 | 77.25 | 79.05 |
| LaVIN | 185.00 | 88.33 | 63.33 | 75.00 | 107.50 | 79.59 | 47.35 | 136.75 | 93.50 | 87.25 | 96.36 |
| LLaMA-Adapter-V2 | 120.00 | 50.00 | 48.33 | 75.00 | 125.00 | 99.66 | 86.18 | 148.50 | 150.25 | 69.75 | 97.27 |
| mPLUG-Owl | 120.00 | 50.00 | 50.00 | 55.00 | 65.00 | 136.05 | 100.29 | 135.50 | 159.25 | 96.25 | 96.73 |
| InstructBLIP | 185.00 | 143.33 | 66.67 | 153.33 | 72.50 | 123.81 | 101.18 | 153.00 | 79.75 | 134.25 | 121.28 |
| BLIP-2 | 160.00 | 135.00 | 73.33 | 148.33 | 110.00 | 141.84 | 105.59 | 145.25 | 138.00 | 136.50 | 129.38 |
| Lynx | 195.00 | 151.67 | 90.00 | 170.00 | 77.50 | 124.83 | 118.24 | 164.50 | 162.00 | 119.50 | 137.32 |
| GIT2 | 190.00 | 118.33 | 96.67 | 158.33 | 65.00 | 112.59 | 145.88 | 158.50 | 140.50 | 146.25 | 133.21 |
| Otter | 195.00 | 88.33 | 86.67 | 113.33 | 72.50 | 138.78 | 172.65 | 158.75 | 137.25 | 129.00 | 129.23 |
| Cheetor | 180.00 | 96.67 | 80.00 | 116.67 | 100.00 | 147.28 | 164.12 | 156.00 | 145.73 | 113.50 | 130.00 |
| LRV-Instruction | 165.00 | 111.67 | 86.67 | 165.00 | 110.00 | 139.04 | 112.65 | 147.98 | 160.53 | 101.25 | 129.98 |
| BLIVA | 180.00 | 138.33 | 81.67 | 180.00 | 87.50 | 155.10 | 140.88 | 151.50 | 89.50 | 133.25 | 133.77 |
| MMICL | 170.00 | 160.00 | 81.67 | 156.67 | 100.00 | 146.26 | 141.76 | 153.75 | 136.13 | 135.50 | 138.17 |
MME 对 VLM 进行全面评估,包括 14 个子任务,涵盖感知和认知能力。 除了 OCR 之外,感知能力还包括对粗粒度和细粒度物体的识别。 前者识别物体的存在、数量、位置和颜色。 后者识别电影海报、名人、场景、地标和艺术品。 认知包括常识推理、数值计算、文本翻译和代码推理。
MME 评估了广泛的多模态能力。 对比的基线包括 LLaVA (Liu et al., 2023b)、MiniGPT-4 (Zhu et al., 2023)、MultiModal-GPT (Gong et al., 2023)、VisualGPM-6B (Du et al., 2021)、VPGTrans (Zhang et al., 2023a)、LaVIN (Luo et al., 2023)、mPLUG-Owl (Ye et al., 2023)、LLaMA-Adapter-V2 (Gao et al., 2023)、InstructBLIP (Dai et al., 2023)、Otter (Li et al., 2023a)、BLIP-2 (Li et al., 2023d)、LRV-Instruction (Liu et al., 2023a)、Cheetor (Li et al., 2023c)、GIT2 (Wang et al., 2022a)、Lynx (Zeng et al., 2023)、BLIVA (Hu et al., 2023b). 我们还在表 18、表 19、表 20 和表 21 中提供了 MMICL 的更详细的评估结果。 结果表明,与当前的 VLM 相比,MMICL 可以获得最佳的平均分数。
| Model | Existence | Count | Position | Color | OCR | Avg. | |||||
| ACC | ACC+ | ACC | ACC+ | ACC | ACC+ | ACC | ACC+ | ACC | ACC+ | ||
| BLIP-2 | 86.67 | 73.33 | 75.00 | 60.00 | 56.67 | 16.67 | 81.67 | 66.67 | 70.00 | 40.00 | 62.67 |
| LLaVA | 50.00 | 0.00 | 50.00 | 0.00 | 50.00 | 0.00 | 51.67 | 3.33 | 50.00 | 0.00 | 25.49 |
| MiniGPT-4 | 75.00 | 60.00 | 66.67 | 56.67 | 56.67 | 33.33 | 71.67 | 53.33 | 62.50 | 35.00 | 57.08 |
| mPLUG-Owl | 73.33 | 46.67 | 50.00 | 0.00 | 50.00 | 0.00 | 51.67 | 3.33 | 55.00 | 10.00 | 34.00 |
| LLaMA-Adapter-V2 | 76.67 | 56.67 | 58.33 | 6.67 | 43.33 | 3.33 | 55.00 | 16.67 | 57.50 | 15.00 | 38.92 |
| VisualGLM-6B | 61.67 | 23.33 | 50.00 | 0.00 | 48.33 | 0.00 | 51.67 | 3.33 | 42.50 | 0.00 | 28.08 |
| Otter | 53.33 | 6.67 | 50.00 | 0.00 | 50.00 | 0.00 | 51.67 | 3.33 | 50.00 | 0.00 | 26.50 |
| Multimodal-GPT | 46.67 | 10.00 | 51.67 | 6.67 | 45.00 | 13.33 | 55.00 | 13.33 | 57.50 | 25.00 | 32.42 |
| PandaGPT | 56.67 | 13.33 | 50.00 | 0.00 | 50.00 | 0.00 | 50.00 | 0.00 | 50.00 | 0.00 | 27.00 |
| MMICL | 90.00 | 80.00 | 86.67 | 73.33 | 55.00 | 26.67 | 88.33 | 73.33 | 60.00 | 40.00 | 67.33 |
| Model | Poster | Celebrity | Scene | Landmark | Artwork | Avg. | |||||
| ACC | ACC+ | ACC | ACC+ | ACC | ACC+ | ACC | ACC+ | ACC | ACC+ | ||
| BLIP-2 | 79.25 | 62.59 | 58.53 | 37.06 | 81.25 | 64.00 | 79.00 | 59.00 | 76.50 | 60.00 | 66.72 |
| LLaVA | 50.00 | 0.00 | 48.82 | 0.00 | 50.00 | 0.00 | 50.00 | 0.00 | 49.00 | 0.00 | 24.78 |
| MiniGPT-4 | 49.32 | 19.73 | 58.82 | 24.71 | 68.25 | 45.50 | 59.75 | 30.50 | 56.25 | 27.00 | 44.00 |
| mPLUG-Owl | 77.89 | 57.14 | 66.18 | 34.12 | 78.00 | 57.50 | 86.25 | 73.00 | 63.25 | 33.00 | 62.63 |
| LLaMA-Adapter-V2 | 52.72 | 10.88 | 55.00 | 21.18 | 68.75 | 44.50 | 53.00 | 9.00 | 52.50 | 14.50 | 38.2 |
| InstructBLIP | 74.15 | 49.66 | 67.06 | 34.12 | 84.00 | 69.00 | 59.75 | 20.00 | 76.75 | 57.50 | 59.20 |
| VisualGLM-6B | 54.42 | 12.24 | 50.88 | 2.35 | 81.75 | 64.50 | 59.75 | 24.00 | 55.75 | 20.00 | 42.56 |
| Otter | 45.24 | 0.00 | 50.00 | 0.00 | 55.00 | 14.50 | 52.00 | 4.50 | 48.00 | 5.50 | 27.47 |
| Multimodal-GPT | 45.24 | 17.01 | 49.12 | 24.12 | 50.50 | 17.50 | 50.50 | 23.00 | 46.00 | 12.00 | 33.50 |
| PandaGPT | 56.80 | 19.73 | 46.47 | 10.59 | 72.50 | 45.50 | 56.25 | 13.50 | 50.25 | 1.00 | 37.26 |
| MMICL | 81.63 | 64.63 | 79.41 | 62.35 | 83.75 | 70.00 | 76.96 | 59.16 | 76.50 | 59.00 | 71.04 |
| Model | Common. Reason. | Numerical Calculation | Text Translation | Code Reason. | Avg. | ||||
| ACC | ACC+ | ACC | ACC+ | ACC | ACC+ | ACC | ACC | ||
| BLIP-2 | 68.57 | 41.43 | 40.00 | 0.00 | 55.00 | 10.00 | 55.00 | 20.00 | 36.25 |
| LLaVA | 49.29 | 11.43 | 50.00 | 0.00 | 52.50 | 5.00 | 50.00 | 0.00 | 27.27 |
| MiniGPT-4 | 58.57 | 34.29 | 47.50 | 20.00 | 42.50 | 15.00 | 67.50 | 45.00 | 41.30 |
| mPLUG-Owl | 59.29 | 24.29 | 50.00 | 10.00 | 60.00 | 20.00 | 47.50 | 10.00 | 35.14 |
| LLaMA-Ada.-V2 | 54.29 | 14.29 | 52.50 | 5.00 | 52.50 | 5.00 | 52.50 | 10.00 | 30.76 |
| InstructBLIP | 75.00 | 54.29 | 35.00 | 5.00 | 55.00 | 10.00 | 47.50 | 0.00 | 35.22 |
| VisualGLM-6B | 45.71 | 12.86 | 45.00 | 0.00 | 55.00 | 10.00 | 50.00 | 0.00 | 27.32 |
| Otter | 48.57 | 10.00 | 47.50 | 10.00 | 55.00 | 10.00 | 50.00 | 0.00 | 28.88 |
| MultiModal-GPT | 45.71 | 5.71 | 50.00 | 20.00 | 50.00 | 5.00 | 45.00 | 10.00 | 28.93 |
| PandaGPT | 56.43 | 17.14 | 50.00 | 0.00 | 52.50 | 5.00 | 47.50 | 0.00 | 28.67 |
| MMICL | 76.43 | 60.00 | 47.50 | 35.00 | 72.50 | 60.00 | 47.50 | 30.00 | 53.62 |
附录 J MMBench 基准测试
MMBench (Liu 等人,2023d) 是一款经过精心设计的基准测试,它全面评估了视觉语言模型的多种技能。 表格 22 中展示了测试集中所有不同 VLM 的结果。
| Method | Language Model | Vision Model | Overall | LR | AR | RR | FP-S | FP-C | CP |
| MMGPT | LLaMA-7B | CLIP ViT-L/14 | 16.0 | 1.1 | 23.8 | 20.7 | 18.3 | 5.2 | 18.3 |
| MiniGPT-4 | Vincuna-7B | EVA-G | 12.0 | 13.6 | 32.9 | 8.9 | 28.8 | 11.2 | 28.3 |
| PandaGPT | Vincuna-13B | ImageBind ViT-H/14 | 30.6 | 15.3 | 41.5 | 22.0 | 20.3 | 20.4 | 47.9 |
| VisualGLM | ChatGLM-6B | EVA-CLIP | 33.5 | 11.4 | 48.8 | 27.7 | 35.8 | 17.6 | 41.5 |
| InstructBLIP | Vincuna-7B | EVA-G | 33.9 | 21.6 | 47.4 | 22.5 | 33.0 | 24.4 | 41.1 |
| LLaVA | LLaMA-7B | CLIP ViT-L/14 | 36.2 | 15.9 | 53.6 | 28.6 | 41.8 | 20.0 | 40.4 |
| G2PT | LLaMA-7B | ViT-G | 39.8 | 14.8 | 46.7 | 31.5 | 41.8 | 34.4 | 49.8 |
| Otter-I | LLaMA-7B | CLIP ViT-L/14 | 48.3 | 22.2 | 63.3 | 39.4 | 46.8 | 36.4 | 60.6 |
| Shikra | Vincuna-7B | CLIP ViT-L/14 | 60.2 | 33.5 | 69.6 | 53.1 | 61.8 | 50.4 | 71.7 |
| LMEye | Flan-XL | CLIP ViT-L/14 | 61.3 | 36.9 | 73.0 | 55.4 | 60.0 | 68.0 | 68.9 |
| mPLUG-Owl | LLaMA-7B | CLIP ViT-L/14 | 62.3 | 37.5 | 75.4 | 56.8 | 67.3 | 52.4 | 67.2 |
| JiuTian | FLANT5-XXL | EVA-G | 64.7 | 46.6 | 76.5 | 66.7 | 66.5 | 51.6 | 68.7 |
| MMICL | FLAN-T5-XXL | EVA-G | 65.24 | 44.32 | 77.85 | 64.78 | 66.5 | 53.6 | 70.64 |
附录 K 理解多模态提示中的多张图像
与静态图像相比,视频包含更多的时间信息。 我们在不同的视频语言任务中测试了 MMICL,以评估 MMICL 是否能够支持复杂提示中的多张图像。 结果在表格 23 中展示。 与最强的基线相比,我们的模型 MMICL 在 MSVD-QA (Chen & Dolan, 2011)、NExT-QA (Xiao 等人,2021) 和 iVQA (Yang 等人,2021) 中分别取得了 、 和 个点的显著提升。 重要的是要注意,我们的训练数据集不包含任何视频。 这表明 MMICL 有效地增强了模型理解视频中时间信息的能力。
| Model | MSVD QA |
|
iVQA | ||
| Flamingo-3B (Alayrac et al., 2022) (Zero-Shot) | 27.50 | - | 32.70 | ||
| Flamingo-3B (Alayrac et al., 2022) (4-Shot) | 33.00 | - | 35.20 | ||
| Flamingo-9B (Alayrac et al., 2022) (Zero-Shot) | 30.20 | - | 35.20 | ||
| Flamingo-9B (Alayrac et al., 2022) (4-Shot) | 36.20 | - | 37.70 | ||
| Flamingo-80B (Alayrac et al., 2022) (Zero-Shot) | 35.60 | - | 40.70 | ||
| Flamingo-80B (Alayrac et al., 2022) (4-Shot) | 41.70 | - | 44.10 | ||
| R2A (Pan et al., 2023) | 37.00 | - | 29.30 | ||
| BLIP-2 (Li et al., 2023d) (FLANT5-XL) | 33.70 | 61.73 | 37.30 | ||
| BLIP-2 (Li et al., 2023d) (FLANT5-XXL) | 34.40 | 61.97 | 49.38 | ||
| InstructBLIP (Dai et al., 2023) (FLANT5-XL) | 43.40 | 36.10 | 25.18 | ||
| InstructBLIP (Dai et al., 2023) (FLANT5-XXL) | 44.30 | 64.27 | 36.15 | ||
| MMICL (FLAN-T5-XL) | 47.31 | 66.17 | 41.68 | ||
| MMICL (FLAN-T5-XXL) | 55.16 | 64.67 | 41.13 | ||
| MMICL (Instruct-FLAN-T5-XL) | 53.68 | 65.33 | 49.28 | ||
| MMICL (Instruct-FLAN-T5-XXL) | 52.19 | 68.80 | 51.83 |
附录 L 对象幻觉评估
我们在 POPE 基准上测试了以下 VLM,以评估它们的物体幻觉性能:MMICL、Shikra (Chen 等人,2023a)、InstructBLIP (Dai 等人,2023)、MiniGPT-4 (Zhu 等人,2023)、LLaVA (Liu 等人,2023b)、MM-GPT (Gong 等人,2023) 和 mPLUG-Owl (Ye 等人,2023)。 结果如表 24 所示。
| Dataset | Metric | Models | ||||||
| MMICL | Shikra | InstructBLIP | MiniGPT-4 | LLaVA | MM-GPT | mPLUG-Owl | ||
| Random | Accuracy | 87.29 | 86.90 | 88.57 | 79.67 | 50.37 | 50.10 | 53.97 |
| Precision | 94.63 | 94.40 | 84.09 | 78.24 | 50.19 | 50.05 | 52.07 | |
| Recall | 79.87 | 79.27 | 95.13 | 82.20 | 99.13 | 100.00 | 99.60 | |
| F1-Score | 86.62 | 86.19 | 89.27 | 80.17 | 66.64 | 66.71 | 68.39 | |
| Yes | 43.51 | 43.26 | 56.57 | 52.53 | 98.77 | 99.90 | 95.63 | |
| Popular | Accuracy | 82.70 | 83.97 | 82.77 | 69.73 | 49.87 | 50.00 | 50.90 |
| Precision | 85.11 | 87.55 | 76.27 | 65.86 | 49.93 | 50.00 | 50.46 | |
| Recall | 79.27 | 79.20 | 95.13 | 81.93 | 99.27 | 100.00 | 99.40 | |
| F1-Score | 82.08 | 83.16 | 84.66 | 73.02 | 66.44 | 66.67 | 66.94 | |
| Yes | 46.57 | 45.23 | 62.37 | 62.20 | 99.40 | 100.00 | 98.57 | |
| Adversarial | Accuracy | 80.97 | 83.10 | 72.10 | 65.17 | 49.70 | 50.00 | 50.67 |
| Precision | 81.88 | 85.60 | 65.13 | 61.19 | 49.85 | 50.00 | 50.34 | |
| Recall | 79.53 | 79.60 | 95.13 | 82.93 | 99.07 | 100.00 | 99.33 | |
| F1-Score | 80.69 | 82.49 | 77.32 | 70.42 | 66.32 | 66.67 | 66.82 | |
| Yes | 48.57 | 46.50 | 73.03 | 67.77 | 99.37 | 100.00 | 98.67 | |
附录 M 评估细节
在本节中。 我们提供了实验中评估的详细信息,如第 3 节所示。
M.1 评估指标
我们将评估指标提供为表 25 。
| Dataset | Metrics |
| MSVD (Chen & Dolan, 2011) | Top-1 Acc. |
| iVQA (Yang et al., 2021) | iVQA Acc. |
| NExT-QA-multiple-choice (Xiao et al., 2021) | Top-1 Acc. |
| NExT-QA-opendomain (Xiao et al., 2021) | WUPS Score. |
| Hateful Memes (Kiela et al., 2020) | AUC Score |
| WebSRC (Chen et al., 2021b) | Exact Match |
| VSR (Liu et al., 2022) | Top-1 Acc. |
| VQAv2 (Goyal et al., 2017) | VQA Acc. |
| VizWiz (Bigham et al., 2010) | VQA Acc. |
| IconQA-text (Lu et al., 2021) | Top-1 Acc. |
| IconQA-img (Lu et al., 2021) | Top-1 Acc. |
| ScienceQA-IMG (Lu et al., 2022) | Top-1 Acc. |
| Bongard-HOI (Jiang et al., 2022) | Top-1 Acc. |
| VisDial (Das et al., 2017) | Exact Match |
| NoCaps (Agrawal et al., 2019) | Cider Score |
| A-OKVQA (Agrawal et al., 2019) | Top-1 Acc. |
| Flickr (Young et al., 2014) | Cider Score |
| Winoground (Thrush et al., 2022b) | Winoground mertic. |
| Raven IQ Test (Huang et al., 2023a) | Top-1 Acc. |
| Minecraft | Top-1 Acc. |
M.2 VQA 工具
我们使用与原始 VQA 论文相同的 VQA 工具 (Agrawal 等人,2016),并在所有指标中使用 VQA 准确率。
| Winoground | Image-score | Text-score | Group-score |
| w/o context scheme | 12.25 | 17.25 | 6.00 |
| w/o image declaration | 4.00 | 22.25 | 3.00 |
| w/o in-context format | 31.25 | 25.75 | 20.00 |
| w/o interrelated images | 36.50 | 31.25 | 25.75 |
| MMICL | 46.00 | 39.25 | 38.75 |
附录 N 消融研究
N.1 上下文方案的消融研究
我们使用 InstructBLIP-FLANT5-XL 作为以下设置中的主干模型进行消融实验,以验证我们提出的上下文方案的有效性:
-
•
无上下文方案:此模型仅使用来自 MMICL 阶段 2 的所有数据集使用指令进行训练,没有任何关于上下文格式和模型架构的额外设计。 它的目的是消除多模态指令调优的贡献。
-
•
无图像声明:此模型在训练时不包含图像声明,但包含具有互连图像和上下文数据的多模态数据。 它利用了 MMICL 阶段 2 中使用的所有数据集,旨在评估图像声明设计的影响。
-
•
无上下文格式:此模型不包含上下文格式数据,包括具有相关图像和图像声明的多模态数据。 它使用 MMICL 阶段 2 中找到的所有数据集,只有一个图像-文本对,旨在评估多模态上下文数据的有效性。
-
•
无相互关联的图像:此版本的模型在训练时不包含任何相互关联的图像。 它的训练流程包含多模态的上下文数据和图像声明。 它利用了 MMICL 第二阶段使用的所有数据集,不包括视频/VCR 数据集。 它旨在评估将多模态数据与相互关联的图像相结合的设计所带来的贡献。
我们使用与 MMICL 第二阶段@ 中相同数量的数据用于消融模型。 我们在通用基准测试(MME)、Winoground (Thrush 等人,2022b) 和多图像数据集(IconQA img (Lu 等人,2021) & NLVR2 (Suhr 等人,2018),Raven IQ-test (Huang 等人,2023a))上进行消融研究,以全面评估 MMICL 中观察到的性能提升的来源。
表 7 中的消融结果证实,MMICL 的优越性是由我们设计元素的集体影响驱动的 - 删除任何组件都不能保证我们的模型的优越性能。 我们设计的每个组件都对我们模型的不同方面做出了重大贡献。
上下文方案消融:
我们改进的结果证明了我们的上下文方案设计,而不是仅仅将更多预训练数据聚合到管道中。 与没有上下文方案相比,所有任务都取得了实质性改进,进一步证实了它的有效性。 缺少上下文方案和支持该方案的模型架构,该模型在大多数数据集上的表现都很差,除了在专注于特定物体感知(如存在、计数)的单图像任务上的表现。 这可能是由于额外的单图像文本对训练与任务的评估格式一致。
相互关联图像消融:
排除此设计会导致多图像理解能力显著下降,如 NLVR2 和 Raven 数据集中所体现的那样。 然而,多模态上下文训练管道仍然使模型能够保留多图像理解能力,与没有上下文方案相比,在包含多个图像的数据集(IconQA img、NLVR2、Raven)上取得了优势。 同时,多模态上下文数据的設計仍然提高了模型在单图像理解上的表现,优于没有上下文格式,特别是在理解关于特定物体感知的任务(感知),但在涉及识别和认知的更抽象的任务(认知)上表现不佳。 与没有上下文格式的模型相比,该模型在 Winoground 中的表现表明其对配对的图像和文本数据具有更强的理解能力。 这表明具有相互关联的图像的多模态数据在理解多个图像方面提供了一些帮助。 然而,如果没有多模态 ICL 数据的帮助,它将无法表现出优异的性能。 这与我们最初的见解相一致。
上下文格式的消融:
排除这种设计表明,即使引入了额外的数据集,在单图像任务上的性能也没有得到提升。 与其他消融设置相比,尽管没有上下文格式的模型在与理解和推理相关的任务(认知)方面比其他消融设置有了显著的改进,但我们观察到与特定物体感知相关的任务(感知)方面出现了显著下降。 使用多个图像进行训练增强了其更好地理解单张图像中的抽象逻辑信息以及在后续任务中取得更好的性能的能力(认知)。 然而,该模型失去了分析和识别单张图像中特定物体的能力,导致 MME 的感知分数显著下降。 我们发现,通过从学习相互关联的图像数据中获益,其对多个图像的理解能力没有显著下降,展现出其优于其他设置的优势。 MME 中的性能也证实了这一点,表明多模态上下文数据在理解多个图像和增强模型理解信号图像中抽象信息的能力方面具有显著优势。
图像声明的消融:
删除图像声明导致在理解复杂的图像-文本关系(Winoground)方面出现大幅下降,这是由于缺乏图像-文本引用之间的显式建模。 这种现象也在涉及理解多个图像关系的任务中观察到(Raven、IconQA img、NLVR2)。 然而,可以观察到缺少相互关联的图像对模型的多图像理解的损害程度大于缺少图像声明,因为没有图像声明的模型的性能相对较好。 这表明图像声明在处理多图像和图像-文本关系中的重要性。
上下文学习能力消融:
表格 27 中的消融结果阐明了所提出的上下文方案对于增强 MMICL 的上下文学习能力的重要性。 MMICL 在提高 VLM 上下文学习能力方面的有效性归因于上下文方案中所有三种设计的集成,而不仅仅是设计方案中的上下文学习格式。 值得注意的是,与 Vizwiz 数据集中的其他设置相比,仅 ICL 取得了最显著的增强。 这突出了使用上下文格式数据进行微调以增强模型对上下文实例的理解的有效性。 然而,Flickr 数据集上的适度进步表明,在没有多图像指令调优的情况下,模型难以有效地利用上下文示例来提高其在没有固定输出格式的任务中的性能,例如图像字幕。
| Task | ICL example | MMICL | w/o context scheme | w/o in-context format | w/o interrelated images |
| VizWiz | w/o ICL example | 27.10 | 28.13 | 15.90 | 23.43 |
| w ICL example(5) | 42.66 | 36.23 | 28.33 | 37.13 | |
| 15.56 | 8.10 | 12.43 | 13.70 | ||
| Flickr | w/o ICL example | 83.94 | 77.84 | 65.33 | 76.88 |
| w ICL example(5) | 88.11 | 79.38 | 65.95 | 77.09 | |
| 4.17 | 1.54 | 0.62 | 0.18 |
附录 O 基线
基线
我们主要将 MMICL 与最近提出的强大的多模态方法进行比较,包括:
(1) Flamingo (Alayrac 等人,2022),其中一个 VLM 在包含任意交织文本和图像的大规模多模态 Web 语料库上进行训练;
(2) KOSMOS-1 (Huang 等人,2023a),它从 Web 规模的多模态语料库中从头开始训练;
(3) BLIP-2-FLAN-T5 (Li 等人,2023d),其中一个指令调优的 Flan-T5 (Chung 等人,2022) 与一个强大的视觉编码器相连接,以执行一系列多模态任务;
(4) InstructBLIP-FLAN-T5 (Dai 等人,2023),最近提出的指令调优增强多模态代理,使用 FLAN-T5 与转换后的多模态数据集和 LLaVA (Liu 等人,2023b) 数据集(由 GPT-4 (OpenAI, 2023) 生成);
(5) Shikra (Chen 等人,2023a),一个可以处理自然语言中的空间坐标输入和输出的 VLM,无需额外的词汇或外部插件模型。 Shikra 的所有输入和输出都以自然语言的形式呈现。
(6) Otter (Li 等人,2023a),一个开放源代码实现的 flamingo (Alayrac 等人,2022)。 通过利用多模态指令上下文调优数据,Otter 微调 Openflamingo 以增强其指令理解能力,同时保持其在上下文中学习的能力;
(7) Ying-VLM (Li 等人,2023e),一个在多模态多语言指令调优数据集上训练的 VLM 模型,展示了其回答需要世界知识的复杂问题、泛化到看不见的视频任务以及理解看不见的中文指令的潜力。
附录 P OOD 泛化到看不见的领域
| Method | Shot | Top-1 Acc. |
| MiniGPT-4 (Vincuna-7B) | Zero-Shot | 35.10 |
| MiniGPT-4 (Vincuna-13B) | Zero-Shot | 48.40 |
| MMICL (FLAN-T5-XL) | Zero-Shot | 55.41 |
| MMICL (FLAN-T5-XL) | 4-Shot | 64.05 |
| MMICL (FLAN-T5-XXL) | 8-Shot | 65.41 |
在一个带有有限示例的看不见的具有挑战性的领域中,分析规律模式、推理和学习新知识(OOD 泛化到看不见的领域)是测试多模态 ICL 能力的好方法。
我们使用 Minecraft (Chen 等人,2024a; 2023c; Cipollone 等人,2014)构建了一个任务,该任务要求 VLM 识别图 1 的 (d) 中是否存在动物(例如,牛、羊驼、鸡、驴等)。
附录 Q ScienceQA 的详细信息
在 Science-QA 的测试集中,每个项目包含一个问题和几个选项。 在 4221 个项目中,我们抽取了 2017 个包含多模态信息的实例,这些实例包含文本和图像,我们将这个子集称为 ScienceQA-IMG,而其余部分只包含文本。 但是,我们观察到,在这 2017 个项目中,并非所有问题都需要基于图像信息来回答。 标注的标准是,理解图像样本是否对于回答测试集中的问题至关重要。 8 88美国的最低时薪约为 ,可在 https://www.worker.gov/ 找到。 平均而言,标注一个示例需要 30 秒。 因此,每个标注员的成本为 。
为了说明这一点,我们提供了两个问题及其对应选项的示例:
-
•
问题:哪种动物也适应了在枯叶中伪装? 选择:["草莓毒箭蛙", "苏里南角蛙"];
-
•
问题:这三个物体有什么共同点? 选择:[“闪亮”, “滑”, “不透明”]。
显然,第一个问题可以在不参考图像的情况下回答,而第二个问题则不能。 因此,ScienceQA-IMG 可以分为两组:需要图像来回答的问题(1012 个)和不需要图像来回答的问题(1005 个)。
附录 R 自由格式回答评估
MM-VET (Yu 等人,2023) 是一个评估基准,它检查 VLMs 在复杂的多模态任务上的表现。 它要求自由格式的答案,并由 GPT-4 进行评估,从而对模型的能力提供了不同的视角。
值得注意的是,与表 29 中的 Flant5 主干的 instructblip 模型相比,MMICL 具有相同的主干,在 MM-VET 上表现出显著的改进。 这表明我们提出的方法可以防止模型过度拟合特定数据结构,并显着增强模型的自由格式回答能力。 同时,我们可以观察到 MMICL 在 MM-VET 上的性能相对较低,这是由于 MMICL 使用了 Flant5 主干模型。 由于 T5 主要在包含许多多项选择 QA 和分类数据集的 NLP 基准上进行微调,因此它倾向于在自由格式问答中输出更短的内容,这在使用 GPT4 评估时是不利的。
| Model | rec | ocr | know | gen | spat | math | total |
| InstructBlip(Flant5-XXL) | 17.10 | 8.40 | 5.50 | 2.60 | 8.00 | 3.80 | 14.10 |
| MMICL(InstructBlip-Flant5-XXL) | 29.90 | 14.00 | 17.40 | 11.20 | 18.10 | 3.80 | 24.80 |
附录 S 多图像数据集上的性能比较
| Method | NLVR2 | IconQA-img | Raven |
| InstructionBlip | 53.95 | 45.10 | 10.00 |
| OTTER | 47.2 | 34.10 | 22.0 |
| MMICL | 66.6 | 60.85 | 34.00 |
我们评估了 MMICL 模型与其他在各种多图像数据集上进行多模态指令调整的模型,包括 Raven-IQ 数据集以及从 Nlvr2 和 IconQA-img 数据集中随机抽取的 2000 个实例。 不同方法的查询提示在表 LABEL:appendix:query_prompt 中给出。 我们在表 30 中的结果表明,我们的方法始终优于其他方法。
| Method | Tasks | Query prompt |
| InstructionBlip | NLVR2 |
<image><image>Carefully read the statement and evaluate the associated images, based on your analysis of the two images and statement, can you confirm if the statement: {Question} is correct? True or False? |
| IconQA-img |
<image>…<image> Use the images as a visual aid to help you answer the questions accurately. Given the options blow, based on the first image, from the following images, select the most suitable image for the question: {Question}. Options: {Options}. Select the right image. |
|
| Raven |
<image>…<image>User: Here are j images. Consider the relationships of the images to infer the pattern and make the correct decision. Is the last image follows the pattern. Yes or No? |
|
| Winoground |
<image><image>User: caption 0 is {Caption 0}. caption 1 is {Caption 1}. Given the images and captions, determine image 0 match caption 1? Yes or no? |
|
| Otter | NLVR2 |
<image><image>User: Carefully read the statement and evaluate the associated images, based on your analysis of the two images and statement, can you confirm if the statement: {Question} is correct? True or False? GPT:<answer> |
| IconQA-img |
<image>…<image>User: Use the images as a visual aid to help you answer the questions accurately. Given the options blow, based on the first image, from the following images, select the most suitable image for the question: {Question}. Options: {Options}. Select the right image. GPT:<answer> |
|
| Raven |
<image>…<image>User: Here are j images. Consider the relationships of the images to infer the pattern and make the correct decision. Is the last image follows the pattern. Yes or No? GPT:<answer> |
|
| Winoground |
<image><image>User: caption 0 is {Caption 0}. caption 1 is {Caption 1}. Given the images and captions, determine image 0 match caption 1? Yes or no? GPT:<answer> |
|
| MMICL | NLVR2 |
The image 0 is [IMG0]{image}. The image 1 is [IMG1]{image}.
|
| IconQA-img |
The image 0 is [IMG0]{image}. … The image j is [IMGj]{image}.
|
|
| Raven |
Here are j images.
image 0: [IMG0]{image}…image j: [IMGj]{image}
|
|
| Winoground |
image 0 is [IMG0]{image}. image 1 is [IMG1]{image}.
|
|
| POPE |
Questions is related to image 0: [IMG0]{image}.
|
附录 T 限制
T.1 潜在的过度拟合:
我们通过使用 ChatGPT 扩展指令模板来降低过度拟合特定数据结构的风险,从而确保 MIC 数据集的多样性。 表格 28 中的结果展示了 MMICL 在 Minecraft 中对未见领域的泛化能力。 这种跨领域理解能力表明 MMICL 并没有过度拟合特定数据结构。
T.2 上下文长度约束:
主干语言模型的上下文长度对输入中可以包含的图像数量施加限制。 此限制导致 MMICL 无法容纳无限数量的图像。 因此,在 MIC 调优期间,我们每个实例最多整合八张图像。 值得注意的是,MMICL 在此约束之外展现出强大的泛化能力。 例如,在视频数据集的背景下,MMICL 在最多包含 12/16 帧的输入中保持着优异的性能。 我们将这种令人印象深刻的泛化归因于架构中相对位置嵌入的使用,正如 Flant5 所采用的 (Chung 等人,2022)。
T.3 解码器专用架构的模型探索:
我们承认,我们的探索主要集中在 T5 (Raffel 等人,2023) 系列模型上,并且我们提出的方法在解码器专用架构中的有效性尚未得到全面调查。