CDDM:无线语义通信的信道去噪扩散模型
摘要
扩散模型(DM)可以逐渐学习去除噪声,近年来在人工智能生成内容(AIGC)中得到了广泛的应用。 DM消除噪声的特性让我们想知道DM是否可以应用于无线通信以帮助接收器减轻信道噪声。 为了解决这个问题,我们在本文中提出了用于无线信道语义通信的信道去噪扩散模型(CDDM)。 CDDM可以作为信道均衡之后的新的物理层模块来应用,以学习信道输入信号的分布,然后利用所学习的知识来去除信道噪声。 我们根据专门为适应信道模型而设计的前向扩散过程推导了CDDM的相应训练和采样算法,并从理论上证明了训练有素的CDDM可以在小采样步长下有效降低接收信号的条件熵。 此外,我们将 CDDM 应用于基于联合源通道编码(JSCC)的图像传输语义通信系统。 大量的实验结果表明,CDDM可以在最小均方误差(MMSE)均衡器之后进一步降低均方误差(MSE),并且CDDM和JSCC联合系统取得了比JSCC系统和低密度奇偶校验的传统JPEG2000更好的性能。校验(LDPC)码方法。
索引术语:
扩散模型、无线图像传输、语义通信、联合源信道编码。我简介
扩散模型 (DM)[2,3,4] 最近在人工智能生成内容 (AIGC)[5] 方面取得了前所未有的成功,包括多模态图像生成和编辑[6, 7],文本和视频生成[8, 9]。 DM 是一类受非平衡热力学启发的潜变量模型。 他们通过变分下界直接对似然函数的得分函数进行建模,从而获得先进的生成性能。 与之前的生成模型相比,例如变分自动编码器(VAE)[10]、生成对抗网络(GAN)[11]和归一化流(NF)[12],DM可以学习细粒度的分布知识,使其能够生成细节丰富的内容。 此外,扩散模型能够生成更加多样化的图像,并且已被证明能够抵抗模式崩溃。 隐式分类器的出现赋予扩散模型灵活可控性、提高效率并保证条件生成任务中的忠实生成。
更具体地说,DM在前向扩散过程中逐渐将高斯噪声添加到可用的训练数据中,直到数据变成纯噪声。 然后,在反向采样过程中,它学习从噪声中恢复数据,如图1所示。 一般来说,给定数据分布,前向扩散过程通过采样高斯向量来生成的第个样本如下
| (1) |
其中 和 是超参数。
在无线通信中,众所周知,接收信号 是发送信号 的噪声和失真版本,例如,对于加性高斯白噪声,我们有以下公式: AWGN)通道
| (2) |
其中 是高斯白噪声。
有趣的是,与(1)和(2)相比,我们可以发现DM和无线通信系统的设计过程是相似的。 DM 逐步学习有效消除噪声,从而生成与原始分布非常相似的数据,而无线通信系统中的接收器旨在从接收到的信号中恢复发送的信号。 清楚地, DM可以应用到无线通信系统中帮助接收器去除噪声吗?
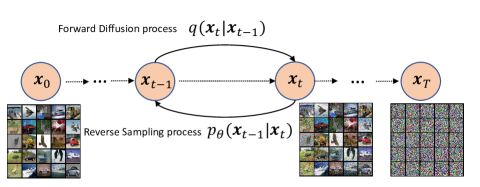
受此启发,在本文中,我们设计了用于无线通信系统中语义通信的信道去噪扩散模型(CDDM)。 所提出的 CDDM 以接收信号和信道估计结果为条件,以消除信道噪声。 与仅生成符合原始数据分布的数据的传统生成模型相比,CDDM直接生成与传输信号非常相似的数据,从而提高了通信系统的性能。 通过采用基于接收信号的显式条件概率模型的精心设计的前向扩散和反向采样过程,CDDM 可以适应不同的信道条件,例如具有不同信噪比 (SNR) 的 AWGN 信道和瑞利衰落信道。 为了利用接收到的信号,我们从接收到的信号而不是纯噪声开始反向采样过程,大大减少了反向采样步骤的数量,从而加速了该过程。
与 AIGC 对 DM 的广泛研究相比,迄今为止,关于无线通信中 DM 的工作还很少。 在[13]中,DM被用来生成端到端通信系统的无线信道,实现了与信道感知情况几乎相同的性能。 在[14]中,提出了采用自适应扩散过程的DM来解码代数分组码。 此外,[15]应用DM作为语义解码器,在原始图像的传输语义片段标签上生成图像条件,实现了优异的并集平均交集(mIoU)和学习感知图像块相似度( LPIPS)性能。
另一方面,语义通信[16, 17]已成为一种新的范式,促进信息和通信技术与人工智能(AI)的无缝集成,被认为是一种非常有前途的技术。第六代 (6G) 无线网络解决方案[18]。 语义通信强调的是有价值的语义信息的传输而不是比特,从而保证了传输效率和可靠性的提高。 语义通信背后的一个基本概念是桥接香农理论[19]的源和通道组件,从而提高端到端传输的整体性能。 关注信源和信道编码处理集成设计的范式被称为联合信源信道编码(JSCC),它是编码理论和信息论中的经典学科[20,21,22]。 然而,传统的 JSCC 技术主要植根于复杂且明确的概率模型,严重依赖专家手动设计,这在处理复杂源时常常面临挑战。 此外,这些 JSCC 技术忽视了语义方面,缺乏针对特定任务或人类视觉感知的优化。
先前的许多研究调查了基于深度学习的 JSCC 语义通信技术[23,24,25,26,27,28]。 大多数研究集中于为不同的数据模式设计特定的框架,并且与传统的无线传输方案相比取得了更好的性能。 针对无线图像传输,[24]提出了一种基于注意力机制的新型JSCC方法,可以自动适应各种信道条件。 在[26]中,提出了一种熵模型来实现基于深度学习的语义通信JSCC架构的自适应速率控制。 [27]中,将swin Transformer [29]集成到深层JSCC框架中,以提高无线图像传输的性能。 [28]开发了联合编码调制方法,实现了端到端的图像传输数字语义通信系统,在低信噪比下优于基于模拟的JSCC系统。 总体而言,基于深度学习的 JSCC 表现出了超越经典的基于分离的 JPEG2000 源编码和先进的低密度奇偶校验 (LDPC) 通道编码的出色性能,特别是对于小尺寸图像和人类视觉感知评估矩阵(例如多图像)尺度结构相似性指数测度(MSSSIM)[30]。
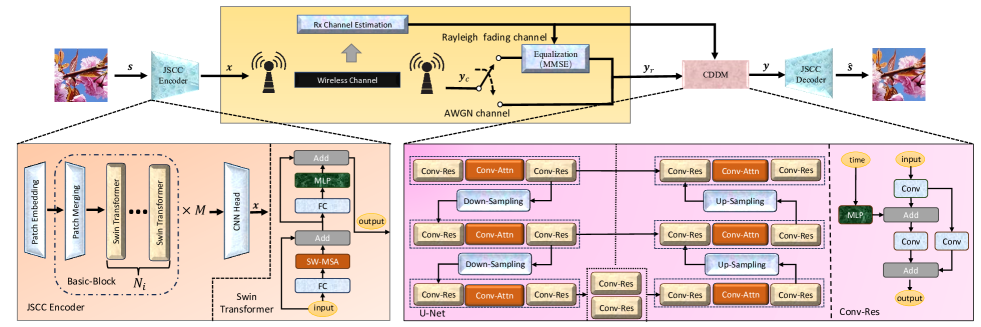
尽管潜力巨大,但之前的研究主要集中在开发更复杂的模型架构,以提高整体性能的能力。 信道失真是通过直接的端到端优化来处理的。 在这种情况下,JSCC 模型仅通过利用接收到的信号样本来学习编码和解码策略,以对抗信道干扰。 为了更有效地减轻信道干扰,我们将CDDM与基于JSCC的语义通信系统集成用于无线图像传输,其中CDDM之后的信号被馈送到JSCC解码器以恢复图像。 如前所述,我们的 CDDM 专门开发用于通过基于接收信号的显式概率消除信道噪声来减轻信道失真,从而提高基于 JSCC 的语义通信系统的性能。
本文的贡献可总结如下。
-
•
我们基于无线通信中的U-Net框架设计了一个CDDM模块,该模块位于瑞利信道(或AWGN信道)上的信道均衡(或没有信道均衡)之后。 CDDM模块学习通道输入信号的分布来预测通道噪声并将其消除。 该模型通过专门为适应信道模型而设计的前向扩散过程进行训练,不需要了解当前的信道状态。 训练结束后,CDDM对均衡后的接收信号采用相应的采样算法进行处理,成功消除了信道噪声。
-
•
根据信道数学模型和均衡算法,推导了均衡后接收信号的显式条件概率,指导我们设计相应的前向扩散过程来匹配条件分布。 所提出的 CDDM 的训练是通过最大化对数最大似然函数的变分下界来完成的,该函数通过在前向扩散过程中引入一系列潜在变量来放松。 此外,我们将变分下界分解为与潜在变量相关的多个分量,并使用重新参数化和重新加权技术分别优化这些分量来导出最终损失函数。 通过利用贝叶斯条件后验概率,我们获得了一种成功有效地减轻信道噪声的采样算法。
-
•
我们推导了逆采样算法降低接收信号的条件熵的充分条件。 通过蒙特卡罗实验,我们发现条件熵上限的降低幅度因不同采样步长而不同,为选择最大采样步长提供了见解。
-
•
我们将CDDM应用于基于JSCC技术的无线图像传输语义通信系统,称为CDDM和JSCC联合系统。 CDDM后发射信号与接收信号之间的均方误差(MSE)实验证明,与没有CDDM的系统相比,有CDDM的系统对于瑞利衰落信道和AWGN信道都有更小的MSE性能,这表明提出的方法CDDM可以通过学习有效降低信道噪声的影响。 最后,在不同数据集上的大量实验结果表明,在 AWGN 和瑞利衰落信道下,CDDM 和 JSCC 联合系统在峰值信噪比 (PSNR) 方面均优于 JSCC 系统和带有 LDPC 编解码器的传统 JPEG2000 系统和 MSSSIM。 我们还评估了其对信道估计误差的固有鲁棒性及其对各种信噪比的适应性。
本文的其余部分安排如下。 第二节介绍了系统模型。 第三节介绍了拟议的 CDDM 的详细信息。 第四节介绍了用于语义通信的联合 CDDM 和 JSCC 系统。 最后,第五节给出了广泛的实验结果,第六节得出了结论。
二系统模型
在本节中,我们将描述在通道均衡后采用所提出的 CDDM 的系统,如图 2 所示。 CDDM使用适合无线信道的专门噪声调度表进行训练,使其能够通过采样算法有效消除信道噪声。
令 为实值符号。 这里,是通道使用次数。 是可以通过无线信道传输的复值符号,的第个传输符号可以表示为,对于
因此,接收信号的第个接收符号为
| (3) |
其中 是独立同分布 (i.i.d.) 瑞利衰落增益,具有功率约束,并且是i.i.d。 AWGN 样本。
然后, 通过均衡处理为 ,随后归一化重塑模块输出实向量 。 我们认为接收端可以通过信道估计获得信道状态,在本文中,我们采用最小均方误差(MMSE)作为均衡器。 因此,我们可以利用已知的和导出的条件分布,并用公式来指导CDDM的前向扩散和反向采样过程。
Proposition 1。
对于MMSE,已知和的在瑞利衰落信道下的条件分布为
| (4) |
其中 、 和
| (5) |
证明。
根据定义,和是对角矩阵,其中第和第()对角元素是
| (6) |
MMSE 的第输出可以表示为
| (7) |
基于(II),我们有
| (8) |
通过重采样技巧,的实部和虚部的条件分布为
| (9) |
| (10) |
因此,我们可以将 重写为
| (11) |
分布为。
因此,我们有
| (12) |
∎
类似地,我们对 AWGN 信道有以下命题。
Proposition 2。
在AWGN信道下,已知的的条件分布为
| (13) |
其中和在AWGN信道下都变成了。
命题1和命题2证明均衡和归一化整形后的信道噪声可以使用重新采样。 另外,噪声系数矩阵与的模形式有关。 因此,可以表示为
| (14) |
因此,所提出的 CDDM 经过训练以获得 ,这是对 的估计。 这里,是CDDM的所有参数。 通过使用和,提出了一种采样算法来获得,目的是恢复,这将在下一节。
III 通道去噪扩散模型
CDDM前向扩散和反向采样过程的整体结构如图3所示。 在本节中,我们首先描述所提出的 CDDM 的训练算法和采样算法。 然后,我们推导出反向采样算法减少接收信号的条件熵的充分条件。
III-A CDDM的训练算法
对于所提出的 CDDM 的前向过程,原始源 是
| (15) |
令 为超参数。 与(1)类似,对于所有,我们定义
| (16) |
然后可以将其重新参数化为
| (17) |
这样分布 是
| (18) |
这表明,通过定义前向扩散过程,我们逐渐生成一个信号,其分布与通过真实通道和均衡器的信号的分布相同。 这样CDDM就可以在而不是上进行训练。 由步骤定义为(16),这样在采样过程中,CDDM的预测分布可以分解为 小步,每个步都是 对应 。
CDDM的目标是通过学习的分布并消除通道噪声来恢复。 因此,CDDM的训练是通过优化负对数似然上的变分界来进行的。 的变分界由 和 组成,由下式给出
| (20) |
其中 指示选择超参数 。在本文中,我们选择
| (21) |
与[3]中的过程类似,可以使用Rao-Blackwellized方法以封闭形式计算。 采用重新参数化和重新加权的方法可以简化的优化对象,如下所示
| (22) |
其中 是 CDDM 的输出。 此外,(22)可以通过忽略噪声系数矩阵来重新加权,如下所示
| (23) |
最后,为了优化所有的(23),所提出的CDDM的损失函数表示如下
| (24) |
总之,所提出的 CDDM 具有估计噪声的能力,因为它能够在训练过程中学习用其参数化分布 来近似真实的后验分布 。 分布近似可以推导出噪声估计,如(24)所示。 算法1总结了所提出的CDDM的训练过程。
Input:
Training set , hyper-parameter and .
Output:
The trained CDDM.
III-B CDDM的采样算法
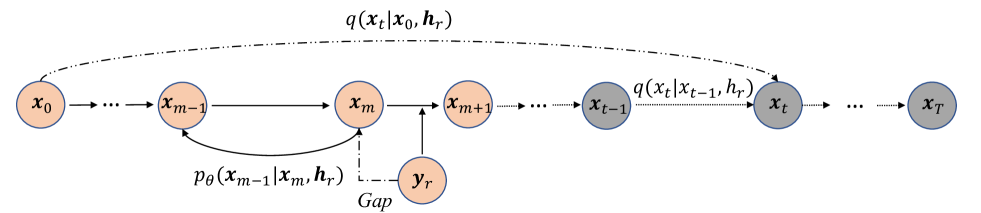
为了减少采样过程的时间消耗并准确地恢复传输信号,(III-A)意味着根据(21)选择并且设置 是一种很有前途的方法。 利用接收到的信号,只需要执行步。 对于每个时间步 ,训练有素的 CDDM 会输出 ,它试图在不知道 的情况下从 预测 。 需要采样算法来对进行采样。 该过程执行次,最终可以计算出。
我们首先根据的知识定义采样过程如下
| (25) |
应用贝叶斯规则,分布可以表示为高斯分布
| (26) |
Input:
,,hyperparameter
Output:
其中 是通过重写 (17) 获得的,如下所示
| (27) |
但是,只有可用于采样。 是通过将 替换为 的估计过程得出的,如下所示
| (28) |
因此,采样过程被替换为
| (29) |
在不知道的情况下,的样本是
| (30) |
III-C 条件熵分析
为了解释 CDDM 的去噪能力,我们比较了 和 之间的条件熵,其中 被视为接收信号,因为 (19)表明可以属于与接收信号相同的条件分布。
对于所有 , 被获取为 (17)。 根据(18),我们可以得到的第个元素的条件熵为,。 这里,是一个常数。 被采样为 (III-B)。 但是, 在 中是未知的。 我们可以用 (17) 重新参数 (III-B) 并获得
| (32) |
其中 和 。 因此 是相对于 具有未知分布的随机变量。
现在,我们引入两个假设来进行下面的分析。
Assumption 1。
元素损失函数上存在常量界限 :
| (33) |
这个合理且必要的假设源自网络已充分优化的事实,即损失函数,可以写成逐元素形式为(33)。
Assumption 2。
网络输出的数学期望为0,即
| (34) |
下面将通过蒙特卡洛来验证这一假设。 因此,我们有以下定理。
Theorem 1。
基于上述两个假设,对于所有和,充分条件为
| (35) |
是
| (36) |
证明:
根据假设1,我们可以推导出两个随机变量和的互相关系数如下
| (37) |
然后我们有
| (38) |
令 为 的上限。 根据最大熵原理,我们有
| (40) |
在这里,我们有。 因此,很容易得到不等式的必要性和充分性条件如下
| (41) |
将必要性和充分性条件代入(III-C),可以得到理论上的充分性条件。 ∎
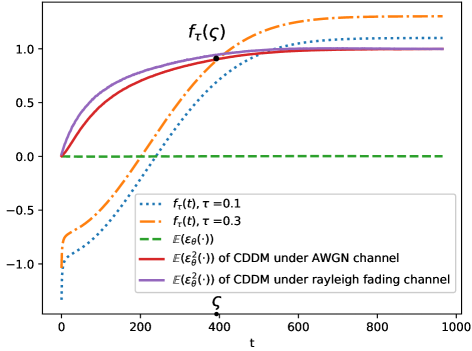
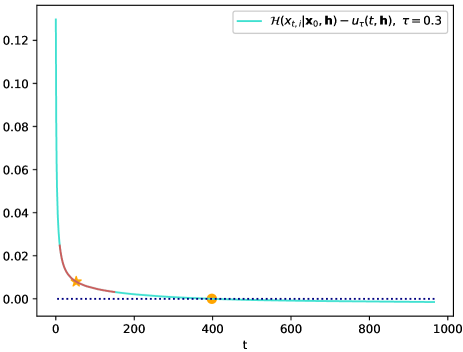
在图4中,虚线表示的蒙特卡罗结果趋近于零,这证明假设2在所提出的模型中成立。 它还表明存在限制。 如果,则条件(41)成立。 这表明应限制采样步骤的数量以实现性能改进。 图5显示了处的值与采样步骤的关系。可以看出,曲线最初表现出急剧下降,随后迅速趋于平稳。 综合考虑两个图,在信道噪声功率过高的情况下,不能利用(21)来确定CDDM的采样步长,因为它会超过阈值。 此外,即使采样步长低于,当梯度落在平坦区域内时,梯度也会变得非常小。 这可能导致条件熵保持停滞状态,从而导致性能没有提高。 另一方面,如果采样步长太小,则可能无法充分消除信道噪声。 根据以上分析,我们建议设置最大采样步长,如图5红线所示。 相应地,(21)修改为
| (42) |
IV CDDM和JSCC联合进行语义通信
在本节中,所提出的 CDDM 应用于基于 JSCC 的语义通信系统,用于无线图像传输。
IV-A 系统结构
IV-B 训练算法
CDDM和JSCC联合系统的整个训练算法由三个阶段组成。 在第一阶段,除了CDDM模块之外,JSCC编码器和解码器通过图2所示的通道进行联合训练,以最小化距离。 因此,该阶段的损失函数由下式给出
| (43) |
其中和分别封装了JSCC编码器和解码器的所有参数。
在第二阶段,固定JSCC编码器的参数,使得CDDM可以通过算法1学习的分布。 训练过程不受信道噪声功率的影响,因为算法1有一个特殊的前向扩散过程,并且该过程是专门为了模拟信道噪声的分布而设计的。 受益于这一点,CDDM 专为处理各种信道条件而设计,并且只需要一个训练过程。
在第三阶段,JSCC解码器与经过训练的JSCC编码器和CDDM联合重新训练,以最小化。 整个联合CDDM和JSCC系统是通过真实通道执行的,而仅更新解码器的参数。 损失函数推导为
| (44) |
训练算法总结在算法3中。
Input:
Training set , hyper-parameter , , and the channel estimation results and .
Output:
The well-trained joint CDDM and JSCC system.
IV-C 模型结构
CDDM中JSCC编码器和U-Net结构的原理图如图2所示。 在 JSCC 编码器中,初始模块是补丁嵌入,负责将源图像划分为不重叠的补丁。 随后,使用基本块从源图像中提取语义特征。 第个基本块由补丁合并模块和 Swim Transformers组成,其中。 通过基本块寻址后,特征的高度和宽度减半,而通道尺寸增加到。 最后,采用卷积头(Conv Head)层来计算特征作为传输信号。 JSCC解码器的结构与JSCC编码器的结构相同,不同之处在于JSCC编码器中的下采样模块被替换为上采样模块。
CDDM的模型结构主要基于卷积改进的U-Net架构[31]。 最初,经过一个卷积层,然后作为U-Net的输入。 随后,U-Net的输出被另一个卷积层进一步处理,生成最终输出。 U-Net 由各种组件组成,包括卷积残差 (Conv-Res) 块[32]、卷积注意力 (Conv-Attn) 块、下采样块和上采样块。 下采样块是执行下采样并保持相同数量的输入和输出通道的卷积层。 上采样块由一个插值层和一个卷积层组成。 Conv-Attn 是经典 Transformer [33] 中常用的注意块,但其显着区别是使用卷积层来替代全连接(FC)层。 Conv-Res的结构如图2所示。 与经典残差块相比,Conv-Res 块用卷积层替代 FC 层。 此外,在残差路径中加入了一个额外的卷积层来调整数据维度并增强模型的能力。 采样步骤 由 MLP 寻址并嵌入 Conv-Res 块的中间。 这些块的多个实例按顺序连接,包含两个额外的剩余路径,最终形成 U-Net 架构。
V 实验结果
在本节中,我们详细描述了实验设置,并提供了大量的实验结果,全面证明了我们提出的 CDDM 系统的有效性。 此外,我们还评估了其对信道估计误差的天然鲁棒性及其对不同 SNR 的适应性。
V-A 实验设置
数据集:为了获得全面且普遍适用的结果,我们在两个图像数据集上训练和评估所提出的联合 CDDM 和 JSCC 系统。 CIFAR10 [34]数据集用于尺寸为的低分辨率图像,包括50000张用于训练的彩色图像和10000张用于测试的图像。 高分辨率图像来自DIV2K数据集[35],其中包括800张用于训练的图像和100张用于测试的图像。 这些图像是从广泛的现实世界场景中收集的,并且具有统一的 2K 分辨率。 在训练过程中,高分辨率图像被随机裁剪成大小为的块。
比较方案:我们对所提出的联合 CDDM 和 JSCC 系统与其他两个系统进行了比较分析:没有 CDDM 的 JSCC 系统和经典的手工制作的基于分离的源和信道编码系统。 更具体地说,JSCC 系统在 CDDM 和 JSCC 联合系统内共享相同的结构和训练配置。 值得强调的是,如果信道信噪比发生变化,两个系统都会进行重新训练,以优化其在特定信噪比条件下的性能。 对于经典系统,我们采用JPEG2000编解码器进行压缩,使用LDPC[36]编解码器进行通道编码,标记为“JPEG2000+LDPC”。 在这里,我们考虑块长度为 64800 位的 DVB-T2 LDPC 码,用于适应信道条件的不同编码率和正交幅度调制 (QAM)。
评估指标:我们使用 PSNR 和 MSSSIM 来评估所有三种方案的性能。 PSNR 是一种广泛使用的像素级度量,用于测量重建图像和参考图像之间的误差可见性。 PSNR 值越高,图像质量损失越小。 在这种情况下,我们在优化网络时采用MSE来计算。 MSSSIM是一种专门关注图像的结构相似性和内容的感知度量,与人类视觉系统(HVS)的评估结果更加一致。 多尺度设计使其能够在不同分辨率的图像上展示一致的性能。 MSSSIM的取值范围为0到1,值越高表示与参考图像的相似度越高。 同样在这种情况下,我们在优化网络时采用1-MSSSIM来计算。 在测试性能时,我们将MSSSIM转换为dB的形式,以便更直观的观察和比较。 公式为。

训练细节:对于CDDM训练和采样算法,我们配置参数并将设置为从初始值 到最终值。 我们为 CIFAR10 数据集设置 ,为 DIV2K 数据集设置 。 在优化 CDDM 期间,我们采用 Adma 优化器 [37] 并实现初始学习率为 0.0001 的余弦预热学习率计划 [38]。 就JSCC结构而言,基本块和补丁的数量根据数据集而变化。 对于CIFAR10数据集,Basicblocks的数量(表示为)设置为,Swin Transformer数量和通道尺寸 。 另一方面,对于包含高分辨率图像的 DIV2K 数据集, 设置为 ,Swin Transformer 编号 和通道尺寸 . 我们采用学习率为 0.0001 的 Adam 优化器来优化 JSCC [27]。
V-B MSE 性能和可视化结果
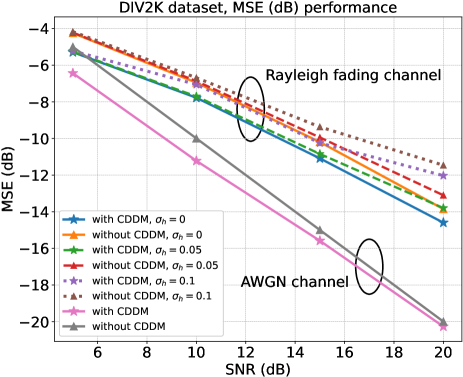
图6说明了CDDM在不同SNR状态下的MSE性能。 结果基于 DIV2K 数据集,并经过训练以最大化 PSNR 的 JSCC,并且信道带宽比 (CBR) 设置为 。 在使用CDDM的情况下,我们计算和之间的MSE,而在不使用CDDM的情况下,我们计算和之间的MSE。 。 如图2所示,和分别是CDDM的输入和输出。 图6中的实线表明,在AWGN和瑞利衰落信道下,在所有SNR范围内,具有CDDM的系统比没有CDDM的系统表现得更好。 例如,对于 AWGN 信道,所提出的 CDDM 在 SNR= dB 时将 MSE 降低 dB。 同时可以看出,随着SNR的降低,MSE中CDDM的增益增加。 这表明随着 SNR 的降低,即信道噪声的增加,所提出的 CDDM 更容易去除更多的噪声,例如AWGN 信道的 SNR= dB 时的 dB 增益。 而且,需要注意的是,在瑞利衰落信道下,MMSE理论上已经最小化了MSE,但是CDDM可以在MMSE之后进一步降低MSE。 这样做的原因是CDDM可以学习的分布,并利用这些学习到的知识来消除噪声,从而进一步降低MSE。
此外,为了对我们的模型进行更全面的评估,我们评估了所提出的 CDDM 在存在信道估计误差的瑞利衰落信道下的鲁棒性。 接收器获得 的噪声估计,表示为 ,其公式为 ,其中 。 在图6中,虚线对应于的较低估计误差,虚线表示的较高估计误差。 据观察,在下,联合CDDM和JSCC系统在所有SNR范围内保持相对于完美信道估计的增益。 然而,随着增加到,增益趋于减小。 这种降低在 SNR 为 和 dB 时尤其显着。
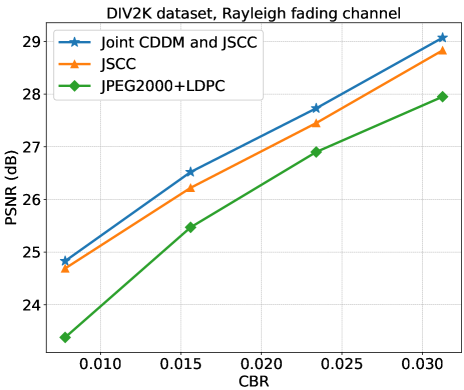
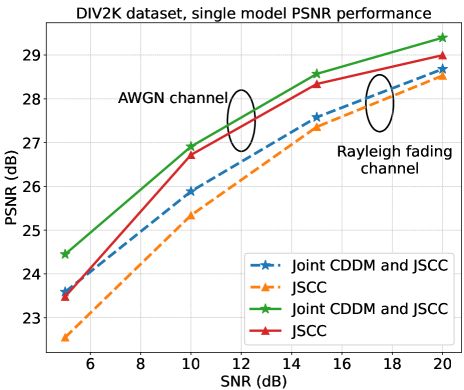
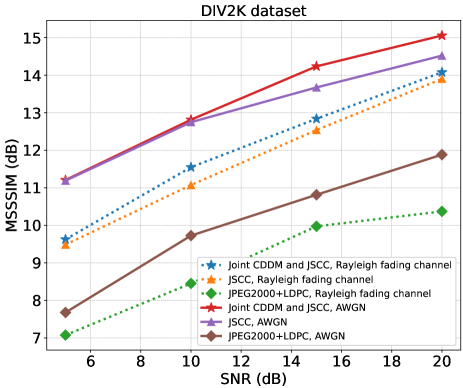
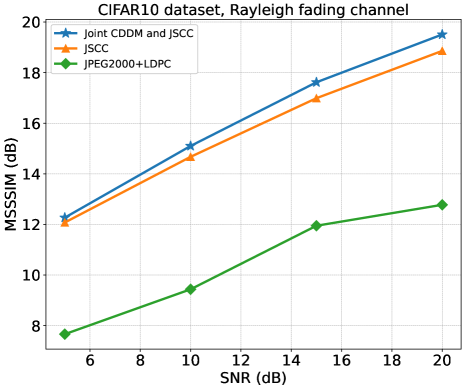
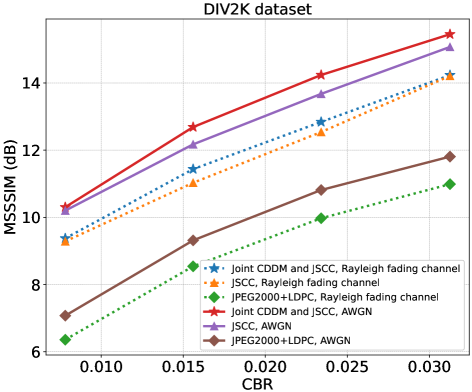
图7可视化了三个系统生成的重建。 结果是在瑞利衰落信道下获得的,具有完美的信道估计和 dB 的 SNR。 可以清楚地观察到,尽管 CBR 稍低,但两种基于 JSCC 的系统在视觉质量方面均优于 JPEG2000+LDPC。 然而,与相应的原始图像相比,从 JSCC 系统获得的重建图像表现出明显的色差。 例如,第一图像呈现出倾向于浅黄色色调,而第二和第三图像倾向于倾向于青色色调。 相反,我们的联合 CDDM 和 JSCC 系统同时表现出卓越的色彩一致性和更好的视觉质量。
V-C 峰值信噪比性能
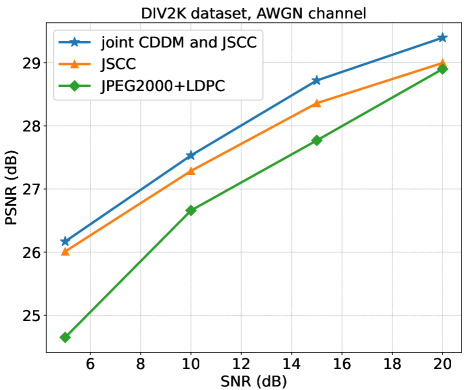
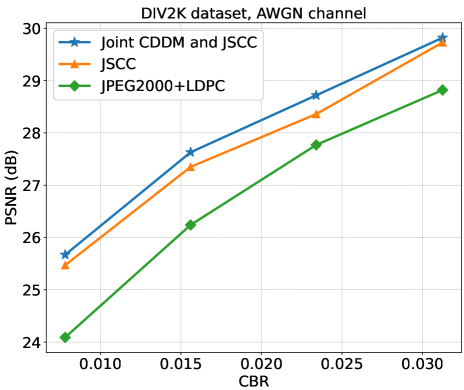
图8说明了 DIV2K 数据集的 PSNR 性能与 AWGN 信道下的 SNR 的关系。 CBR 配置为。 与 JSCC 系统相比,我们的联合 CDDM 和 JSCC 系统在 到 dB 的 SNR 范围内表现出卓越的性能。 此外,与JPEG2000+LDPC系统相比,联合CDDM和JSCC系统取得了明显更好的性能。 具体来说,在 dB的SNR下,JPEG2000+LDPC系统的性能与JSCC系统的性能相当,但与我们联合的CDDM相比仍然表现出 dB劣势和JSCC系统。
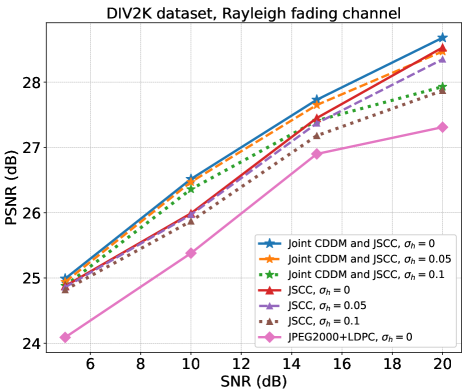
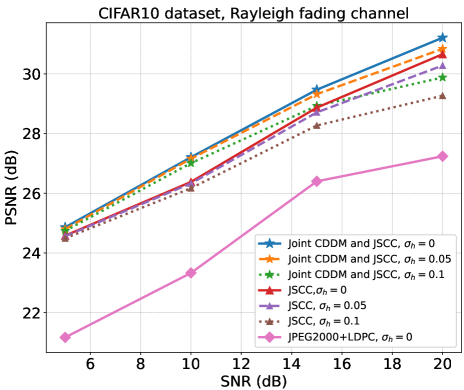
图9和10说明了瑞利衰落信道下DIV2K和CIFAR10数据集的PSNR性能。 DIV2K 的 CBR 为 ,CIFAR10 的 CBR 为 。 实线、虚线和虚线分别表示为、和。 可以看出,CDDM 和 JSCC 联合系统在两个数据集和所有 SNR 上始终优于 JSCC 系统,即在 SNR 下,CIFAR10 数据集的 dB 和 DIV2K 数据集的 dB = dB 具有完美的信道估计。 同时,值得注意的是,DIV2K 数据集的 PSNR 性能增益在 时随着 SNR 的增加而趋于下降,这与 MSE 性能增益的下降是一致的。 两个数据集下的实验结果均在 的信道估计误差水平下进行,突显了我们的系统在面临高信道估计误差和高 SNR 条件时缺乏自然鲁棒性。 这一发现强调需要设计一个专门的框架来减轻信道估计误差的影响并增强未来系统的鲁棒性。
图11和12分别显示了在AWGN和瑞利衰落信道下不同CBR中DIV2K数据集的PSNR性能。 SNR 设置为 dB。 很明显,我们的联合 CDDM 和 JSCC 系统在各种 CBR 上保持了复杂的高分辨率 DIV2K 数据集的有效性,尽管性能增益随着 CBR 的增加而降低。 这种现象可以归因于当 CBR 增加时,传输信号的维数增加,从而导致学习分布的复杂性显着增加。 然而,为了保持实验的公平性,CDDM的结构和深度对于不同的CBR保持不变,从而阻碍了模型有效学习复杂分布的能力,导致性能增益下降。
图13说明了 DIV2K 数据集在 AWGN 和瑞利衰落信道上的 PSNR 性能与 SNR 的关系。 在此实验中,联合 CDDM 和 JSCC 系统以及 JSCC 系统均以 dB 的固定 SNR 进行训练,并在不同的 SNR 值上进行评估。 很明显,我们的联合 CDDM 和 JSCC 系统始终优于 JSCC 系统。 更重要的是,随着瑞利衰落信道中信噪比的降低,性能增益变得更加明显。 我们将这种现象归因于我们的 CDDM 使用算法 1 进行训练,该算法涵盖了广泛的 SNR。 因此,当SNR变化时,我们的CDDM仍然通过调整采样步长有效地降低噪声,从而提高性能。 相比之下,JSCC 系统的性能随着 SNR 的降低而迅速恶化。 这一观察结果验证了我们的联合 CDDM 和 JSCC 系统对不同 SNR 的适应性。
V-D MSSSIM性能
图14显示了 DIV2K 数据集在 AWGN 信道和瑞利衰落信道上的 MSSSIM 性能与 SNR 的关系。 实线表示AWGN信道下的性能,虚线表示瑞利衰落信道下的性能。 结果表明,在 AWGN 信道下,我们的 CDDM 和 JSCC 联合系统在 SNR 为 dB 和 dB(即 )时实现了 MSSSIM 性能显着改善。 > dB,SNR= dB。 在较低的信噪比下,我们仍然可以实现性能的增强,尽管幅度相当小。 在瑞利衰落信道下,我们在所有 SNR 上都取得了显着的改进。 图15展示了CIFAR10数据集在瑞利衰落信道上的MSSSIM性能。 可以看出,CDDM 和 JSCC 联合系统在所有 SNR 上均优于 JSCC 系统和 JPEG2000+LDPC 系统。
图16分别展示了在 AWGN 信道和瑞利衰落信道下 DIV2K 的 MSSSIM 性能与 CBR 的比较。 结果表明,我们的联合 CDDM 和 JSCC 系统在所有检查条件下均优于 JSCC 系统。 与 PSNR 性能类似,当 CBR 较大时,由于相同的原因,增益幅度会减小。 此外,所有使用 MSSSIM 性能进行的实验结果都显示出一致的现象,即 JPEG2000+LDPC 系统的 MSSSIM 性能在所有实验配置中都非常差,与基于 JSCC 的系统相比表现出巨大的差异。 这些现象证明,在考虑HVS时,JSCC系统比JPEG2000+LDPC系统表现出显着优势。 此外,在这种情况下,我们的联合 CDDM 和 JSCC 系统仍然可以提高性能。
进行的实验一致证明了我们联合 CDDM 和 JSCC 系统的有效性,在各种条件下都超越了 JSCC 系统和 JPEG2000+LDPC 系统的性能。 这些条件包括不同的 SNR、不同的 CBR、不同的评估指标、不同的通道类型和不同的图像分辨率。
六结论
在本文中,我们提出了信道去噪扩散模型来消除瑞利衰落信道和AWGN信道下的信道噪声。 CDDM 使用适合无线信道的专门噪声调度进行训练,这允许在反向采样过程中通过合适的采样算法有效消除信道噪声。 此外,我们推导了 CDDM 可以减少接收信号的条件熵的充分条件,并通过蒙特卡罗实验证明,训练有素的模型满足较小采样步骤的条件。 然后将CDDM应用到基于JSCC的语义通信系统中。 在CIFAR10和DIV2K数据集上的大量实验结果表明,在AWGN和瑞利衰落信道下,联合CDDM和JSCC系统在MSE、PSNR和MSSSIM方面比没有CDDM的JSCC系统表现得更好。
参考
- [1] T. Wu, Z. Chen, D. He, L. Qian, Y. Xu, M. Tao, and W. Zhang, “Cddm: Channel denoising diffusion models for wireless communications,” accepted by IEEE GLOBECOM 2023, pp. 1–5, 2023.
- [2] J. Sohl-Dickstein, E. Weiss, N. Maheswaranathan, and S. Ganguli, “Deep unsupervised learning using non-equilibrium thermodynamics,” in Proc. Int. Conf. Mach. Learn., pp. 2256–2265, 2015.
- [3] J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” in Proc. Adv. Neural Inf. Process. Syst., vol. 33, pp. 6840–6851, 2020.
- [4] J. Song, C. Meng, and S. Ermon, “Denoising diffusion implicit models,” in Proc. International Conference on Learning Representations, 2021.
- [5] L. Yang, Z. Zhang, and S. Hong, “Diffusion models: A comprehensive survey of methods and applications,” ArXiv, vol. abs/2209.00796, 2022.
- [6] M. Chenlin, H. Yutong, and S. Yang, “SDEdit: Guided image synthesis and editing with stochastic differential equations,” in Proc. International Conference on Learning Representations, 2022.
- [7] J. Choi, S. Kim, Y. Jeong, Y. Gwon, and S. Yoon, “ILVR: Conditioning Method for Denoising Diffusion Probabilistic Models,” in Proc. IEEE/CVF ICCV, pp. 14 347–14 356, 2021.
- [8] L. Zheng, J. Yuan, L. Yu, and L. Kong, “A reparameterized discrete diffusion model for text generation,” https://arxiv.org/abs/2302.05737, 2023.
- [9] S. Yu, K. Sohn, S. Kim, and J. Shin, “Video probabilistic diffusion models in projected latent space,” in Proc. IEEE/CVF CVPR 2023, pp. 18 456–18 466.
- [10] D. Kingma and M. Welling, “Auto-encoding variational bayes,” in Proc.ICLR 2014, 2014.
- [11] I. J. Goodfellow, J. Pouget-Abadie, and M. Mirza, “Generative adversarial nets,” in Proc. the 27th International Conference on Neural Information Processing Systems, pp. 2672–2680, 2014.
- [12] D. J. Rezende and S. Mohamed, “Variational inference with normalizing flows,” in Proce. the 32nd International Conference on International Conference on Machine Learning, pp. 1530–1538, 2015.
- [13] M. Kim, R. Fritschek, and R. F. Schaefer, “Learning end-to-end channel coding with diffusion models,” in Proc. WSA & SCC 2023, 2023, pp. 1–6.
- [14] Y. Choukroun and L. Wolf, “Denoising diffusion error correction codes,” in Proc. the Eleventh International Conference on Learning Representations, 2023.
- [15] D. C. Eleonora Grassucci, Sergio Barbarossa, “Generative semantic communication: Diffusion models beyond bit recovery,” ArXiv, vol. abs/2306.04321, 2023.
- [16] Q. Lan, D. Wen, and Z. Zhang, “What is semantic communication? a view on conveying meaning in the era of machine intelligence,” Journal of Communications and Information Networks, vol. 6, no. 4, pp. 336–371, 2021.
- [17] J. Choi and J. Park, “Semantic communication as a signaling game with correlated knowledge bases,” in Proc. IEEE VTC 2022-Fall, pp. 1–5, 2022.
- [18] W. Yang, H. Du, Z. Q. Liew, W. Y. B. Lim, Z. Xiong, D. Niyato, X. Chi, X. S. Shen, and C. Miao, “Semantic communications for future internet: Fundamentals, applications, and challenges,” IEEE Communications Surveys & Tutorials, pp. 1–1, 2022.
- [19] C. E. Shannon, “A mathematical theory of communication,” The Bell System Technical Journal, vol. 27, no. 3, pp. 379–423, 1948.
- [20] M. Fresia, F. Peréz-Cruz, H. V. Poor, and S. Verdú, “Joint source and channel coding,” IEEE Signal Processing Magazine, vol. 27, no. 6, pp. 104–113, 2010.
- [21] A. Guyader, E. Fabre, C. Guillemot, and M. Robert, “Joint source-channel turbo decoding of entropy-coded sources,” IEEE Journal on Selected Areas in Communications, vol. 19, no. 9, pp. 1680–1696, 2001.
- [22] C. Chen, L. Wang, and F. C. M. Lau, “Joint optimization of protograph ldpc code pair for joint source and channel coding,” IEEE Transactions on Communications, vol. 66, no. 8, pp. 3255–3267, 2018.
- [23] E. Bourtsoulatze, D. Burth Kurka, and D. Gündüz, “Deep joint source-channel coding for wireless image transmission,” IEEE Transactions on Cognitive Communications and Networking, vol. 5, no. 3, pp. 567–579, 2019.
- [24] J. Xu, B. Ai, W. Chen, A. Yang, P. Sun, and M. Rodrigues, “Wireless image transmission using deep source channel coding with attention modules,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 32, no. 4, pp. 2315–2328, 2022.
- [25] J. Xu, T.-Y. Tung, B. Ai, W. Chen, Y. Sun, and D. Gunduz, “Deep Joint Source-Channel Coding for Semantic Communications,” https://arxiv.org/abs/2211.08747, 2022.
- [26] J. Dai, S. Wang, K. Tan, Z. Si, X. Qin, K. Niu, and P. Zhang, “Nonlinear transform source-channel coding for semantic communications,” IEEE Journal on Selected Areas in Communications, vol. 40, no. 8, pp. 2300–2316, 2022.
- [27] K. P. Yang, S. Wang, J. Dai, K. Tan, K. Niu, and P. Zhang, “WITT: A Wireless Image Transmission Transformer for Semantic Communications,” in IEEE ICASSP, pp. 1–5, 2023.
- [28] Y. Bo, Y. Duan, S. Shao, and M. Tao, “Learning based joint coding-modulation for digital semantic communication systems,” in Proc. International Conference on Wireless Communications and Signal Processing (WCSP), pp. 1–6, 2022.
- [29] Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, S. Lin, and B. Guo, “Swin Transformer: Hierarchical Vision Transformer using Shifted Windows,” in Proc. IEEE/CVF ICCV, pp. 9992–10 002, 2021.
- [30] Z. Wang, E. Simoncelli, and A. Bovik, “Multiscale structural similarity for image quality assessment,” in Proc. The Thrity-Seventh Asilomar Conference on Signals, Systems & Computers, 2003, vol. 2, pp. 1398–1402 Vol.2, 2003.
- [31] O. Ronneberger and B. T. Fuscger P, “U-net: Convolutional networks for biomedical image segmentation,” Medical Image Computing and Computer-Assisted Intervention-MICCAI 2015, pp. 234–241, 2015.
- [32] S. Zagoruyko and N. Komodakis, “Wide residual networks,” in Proce. the British Machine Vision Conference, 2016.
- [33] A. Vaswani, N. Shazeer, and N. Parmar, “Attention is all you need,” in Proc. the 31st International Conference on Neural Information Processing Systems, pp. 6000–6010, 2017.
- [34] A. Krizhevsky, “Learning multiple layers of features from tiny images,” Master’s thesis, University of Tront, 2009.
- [35] R. Timofte, E. Agustsson, and L. Van Gool, “Ntire 2017 challenge on single image super-resolution: Methods and results,” in Proc. IEEE/CVF CVPR Workshops, July 2017.
- [36] “Frame stucture channel coding and modulation for the second generation digital terrestrial television broadcasting system (DVB-T2),” DVB Document A122, 2008.
- [37] K. Diederik P and B. Jimmy, “Adam: A method for stochastic optimization,” in Proc. International Conference on Learning Representations, 2015.
- [38] I. Loshchilov and F. Hutter, “Sgdr: Stochastic gradient descent with warm restarts,” in Proc. International Conference on Learning Representations, 2016.