大型语言模型中的跨语言知识编辑
摘要
知识编辑旨在通过向语言模型注入相应的预期知识,改变语言模型在几种特殊情况(即,编辑范围)下的性能。 随着大语言模型(大语言模型)的最新进展,知识编辑已被证明是一种有前途的技术,可以使大语言模型适应新知识,而无需从头开始重新训练。 然而,以往的研究大多忽视了一些主流大语言模型(例如、LLaMA、ChatGPT和GPT-4)的多语言性质,并且通常关注单语场景,其中大语言模型用相同的语言进行编辑和评估。 因此,源语言编辑对不同目标语言的影响仍然未知。 在本文中,我们的目标是弄清楚知识编辑中的这种跨语言效应。 具体来说,我们首先通过将 ZsRE 从英语翻译成中文来收集大规模的跨语言合成数据集。 然后,我们对涵盖不同范式的各种知识编辑方法进行英文编辑,并评估它们在中文中的表现,反之亦然。 为了更深入地分析跨语言效果,评估包括可靠性、通用性、局部性和可移植性四个方面。 此外,我们分析了编辑模型的不一致行为并讨论了它们的具体挑战。111Data and codes are available at https://github.com/krystalan/Bi-ZsRE获取
1简介
知识编辑的目标是在预期范围(即编辑范围)内调整语言模型的行为,并理想地保留范围外的模型性能Yao 等人 (2023). 随着世界的动态变化,知识编辑可以帮助模型忘记过时的知识并适应新的知识,而无需从头开始重新训练。 如图 1 (a) 所示,在 Honkai: Star Rail 发布后(2023 年 4 月 26 日),Honkai 系列游戏的数量增加到 4 款。 然而,如果我们询问一个在该日期之前训练过的模型,该模型可能只知道三款崩坏系列游戏。 在这种情况下,知识编辑可以帮助模型有效地更新这些新知识,并在编辑后给出正确的答案。
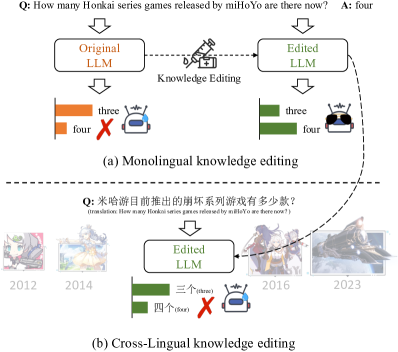
尽管在这一研究领域付出了很多努力De Cao 等人 (2021);米切尔等人 (2022b);董等人 (2022);戴 等人 (2022);孟等人 (2022);米切尔等人 (2022a);黄等人 (2023b);孟等人 (2023);郑等人(2023),当前的知识编辑研究通常集中在单语言场景,其中语言模型在同一种语言中进行编辑和评估,参见图1(a)。 同时,大语言模型的快速发展导致了多语言环境的广泛采用,使得语言建模能力可以在不同语言之间共享Zhao等人(2023);王等人(2023a)。 例如,LLaMA Touvron 等人 (2023a)、ChatGPT OpenAI (2022)、GPT-4 OpenAI (2023) 等大语言模型> 设计为在多语言环境下运行。 在此背景下,源语言编辑模型在其他语言上的性能仍然未知。 如图1(b)所示,出现了一个研究问题(RQ), 当我们利用源语言样本编辑多语言大语言模型时,模型在面对不同的目标语言时能否反映一致的行为?
为了回答 RQ,在本文中,我们探索跨语言场景中的知识编辑,并研究源语言编辑对不同目标语言的影响。 具体来说,我们通过尖端的大语言模型(即,ChatGPT和GPT-4)自动将知识编辑数据从英语翻译成中文。 经过仔细比较现有数据集,我们最终选择 ZsRE Levy 等人 (2017),它最初是一个问答 (QA) 数据集,并进一步广泛应用于知识编辑 De Cao 等人 (2021) );孟等人 (2022);米切尔等人 (2022a)。 最近,Yao等人(2023)收集了一些需要基于ZsRE进行深度推理的QA对,这些数据可以用来评估知识编辑方法超越简单释义的可移植性。 因此,我们还翻译了这些 QA 对,以更深入地了解跨语言知识编辑性能。 翻译后的数据与原始数据一起表示为 Bi-ZsRE。 然后,我们对几个开源多语言大语言模型(LLaMA、LLaMA2和BaiChuan)进行英/汉编辑,并从可靠性、通用性、局部性和可移植性方面评估它们在汉/英语中的行为。 我们的实验涉及七种知识编辑方法,涵盖Yao等人(2023)指出的三种主流范式,即,基于记忆、元学习和定位然后-编辑方法。 实验结果表明:(1)不同语言之间的语言建模差异影响知识编辑的效率; (2)现有的知识编辑方法仍然难以在多语言大语言模型中将编辑后的知识从一种语言迁移到另一种语言; (3)在编辑一种语言的大语言模型时,其他语言的局部性也会受到影响。 这对多语言大语言模型在不同语言之间保持一致的行为提出了重大挑战。
我们的主要贡献总结如下:
-
•
据我们所知,我们是第一个探索知识编辑跨语言效应的人。 我们通过自动翻译 ZsRE 数据集并研究从英语(中文)到中文(英语)的跨语言效果来实现这一目标。
-
•
我们对各种知识编辑方法和多语言大语言模型进行了实验。 我们的结果表明,多语言大语言模型将编辑的知识推广到其他语言仍然具有挑战性。
-
•
深入分析编辑模型所表现出的不一致行为及其具体挑战,使我们对知识编辑中的跨语言效应有更深入的了解。
2相关工作
知识编辑方法。 知识编辑的目标是在预期范围(即编辑范围)内改变大语言模型的行为,而不会对范围外的性能产生负面影响。 根据对知识编辑Yao等人(2023)的综合调查,主流的知识编辑范式有以下三种:(1)基于记忆的方法保持原始模型当使用另一个模型来影响模型的行为时,参数保持不变。 SERAC Mitchell 等人 (2022b) 利用范围分类器来评估新输入是否接近存储的编辑示例,并根据检索到的编辑示例进一步影响模型行为。 T-Patcher Huang 等人 (2023b) 和 CaliNET Dong 等人 (2022) 在大语言模型的 FFN 层中添加额外的可训练参数来编辑模型性能。 IKE Zheng 等人 (2023) 使用上下文编辑事实来指导模型生成编辑事实。 (2)元学习方法利用超网络学习大语言模型的权重更新来编辑模型。 KE De Cao 等人 (2021) 利用 LSTM 网络来预测每个新输入的权重更新。 MEND Mitchell 等人 (2022a) 通过采用梯度的低秩分解来变换微调语言模型的梯度。 (3)定位然后编辑方法首先识别与特定知识对应的参数,然后更新这些参数。 其中,KN Dai 等人 (2022) 指定 FFN 矩阵中体现知识的键值对,然后继续更新相应的参数。 ROME Meng 等人 (2022) 利用因果中介分析来定位编辑区域,并更新 FFN 矩阵中的整个参数。 MEMIT Meng 等人 (2023) 直接更新带有大量内存的大语言模型,从而方便同时执行数千个编辑。
| Splitting | Lang. | # Example | Question | Rephrased | Answer | Locality | Locality | Portability | Portability |
| Question | Question | Answer | Question | Answer | |||||
| Training | En | 10,000 | 11.28 | 11.25 | 2.85 | 15.25 | 5.61 | - | - |
| Zh | 10,000 | 10.86 | 10.95 | 4.36 | 14.71 | 6.77 | - | - | |
| Validation | En | 3,000 | 11.19 | 11.20 | 2.79 | 15.39 | 5.50 | - | - |
| Zh | 3,000 | 10.94 | 11.01 | 4.37 | 14.66 | 6.55 | - | - | |
| Test | En | 1,037 | 11.43 | 11.49 | 3.11 | 15.31 | 5.62 | 18.02 | 4.54 |
| Zh | 1,037 | 11.01 | 11.10 | 4.51 | 14.53 | 6.55 | 16.11 | 5.67 |
知识编辑数据集。 ZsRE Levy 等人 (2017) 是一个问答数据集,其查询需要模型根据查询中的信息回答问题。 CounterFact Meng 等人 (2022) 评估编辑后的模型在询问相应的事实知识时是否能够提供反事实答案。 MQuAKE Zhong 等人 (2023) 旨在评估编辑后的模型是否正确回答了需要根据编辑后的事实进行推理的问题。 Eva-KELLM Wu 等人 (2023) 通过使用改变的知识进行推理和跨语言迁移来评估编辑后的模型。 虽然Eva-KELLM提供了跨语言知识编辑的子集,但数据尚未公开。222September 11, 2023此外,这项工作没有对任何知识编辑方法进行实验,导致跨语言效应在知识编辑研究领域仍然未知。
3Bi-ZsRE
3.1数据收集
数据源。 ZsRE Levy 等人 (2017) 是一个问答 (QA) 数据集,其查询需要模型根据查询中的信息回答问题。 遵循之前的数据设置 Yao 等人 (2023); Wang等人(2023b)训练,包含163,196个样本和19,086个验证样本。 每个样本都包含一个问题和一个相应的答案,用于编辑大语言模型。 为了评估编辑模型的通用性,还提供了一个改写的问题。 此外,每个样本还关联一个不相关的QA对(选自NQ数据集Kwiatkowski等人(2019))来评估局部性。 最近,Yao等人(2023)提供了一个包含1,037个样本的测试集,用于更全面地评估知识编辑,其中每个测试样本还包含一个QA对,以评估大语言模型的基于推理的可移植性关于编辑后的事实。 为了控制翻译成本,我们随机选择了 10,000 个训练样本和 3,000 个验证样本,与所有测试样本一起进行进一步翻译。
翻译过程。 我们使用gpt-3.5-turbo和gpt-4将上述知识编辑数据从英文翻译成中文。 特别是,考虑到质量和成本之间的权衡,训练样本和验证样本由gpt-3.5-turbo翻译,而测试样本由gpt-4翻译。 基于OpenAI官方API进行翻译333https://platform.openai.com/docs/api-reference/chat/object,温度为零。 使用的翻译提示如下:
请将以下JSON数据从英文翻译成中文,并保持格式不变:
[JSON数据]
其中每个示例都以 JSON 格式组织,并在示例级别进一步翻译。
质量控制。 为了进一步保证测试样本的翻译质量,我们还聘请了三名翻译人员来纠正gpt-4的翻译。 所有译员都是中文母语,英语流利。 最终,大约有6.0%的样本被修正,其余样本保持不变。 所有修正后的样本均由具有丰富翻译标注经验的数据专家进一步检查。 最后,所有翻译数据和原始数据被表示为Bi-ZsRE。
3.2数据统计
表1列出了Bi-ZsRE的数据统计,涵盖英语(En)和中文(Zh)两种语言,跨三个子集。 对于英语样本,训练、验证和测试子集中的平均问题长度分别为 11.28、11.19 和 11.43 个标记,而中文的相应长度分别为 10.86、10.94 和 11.01。 此外,可移植性问题的平均长度比原始问题、改写问题或局部性问题长,因此可移植性问题可能涉及更复杂的推理,在编辑知识时应仔细考虑。
3.3 任务概述
知识编辑。 给定语言模型和编辑描述符,知识编辑的目标是创建满足以下要求的编辑模型:
| (1) |
其中 表示一组广泛的输入,其语义与 相同。 编辑后的模型还应满足以下四个属性: (1) 可靠性衡量编辑案例的平均准确性。 当接收 作为输入时,编辑后的模型 应输出 。 (2)通用性评估与编辑案例等效的案例的平均准确度。 例如,当收到 的改写文本时,编辑后的模型 也预计会输出 。 (3)Locality评估编辑后的模型在不相关样本上的准确性。 当输入超出编辑范围时,理想情况下应与相同。 (4) 可移植性通过可移植性问题来衡量已编辑模型的稳健通用性,该问题需要基于已编辑知识进行推理。 当收到可移植性问题作为输入时,编辑后的模型 预计会输出黄金答案,以证明模型确实学习了知识,而不是记住措辞的表面变化。
跨语言知识编辑。 给定多语言语言模型和源语言的编辑描述符,跨语言知识编辑的目标是创建编辑后的模型 满足以下要求:
| (2) |
| (3) |
其中 和 分别表示源语言 和不同目标语言 的输入文本。 表示源语言的编辑范围。 将输入文本从源语言转换为目标语言,其含义相同,即,翻译。 因此,除了学习源语言中编辑过的知识之外,模型 还应该反映使用不同语言进行查询时的一致行为。 跨语言知识编辑还需要满足四个特性:即可靠性、通用性、本地性和可移植性。 与单语场景不同,跨语言场景中的所有测试样本(除了可靠性样本)分别是源语言和目标语言。 例如,英文编辑模型将通过中文通用性样本进行评估,以表明其跨语言通用性。
4实验
| Method | Reliability | Generality | Locality | Portability | |||
| En | Zh | En | Zh | En | Zh | ||
| FT (En) | 20.46 / 00.77 | 18.36 / 00.19 | 26.65 / 00.10 | 87.49 / 70.11 | 74.39 / 40.02 | 06.30 / 00.00 | 23.61 / 00.00 |
| FT (Zh) | 20.03 / 01.06 | 16.69 / 00.19 | 16.43 / 01.06 | 86.48 / 71.07 | 61.78 / 21.99 | 06.87 / 00.10 | 17.15 / 00.00 |
| SERAC (En) | 83.61 / 77.15 | 83.64 / 77.24 | 21.67 / 11.96 | 100.0 / 100.0 | 92.87 / 85.44 | 06.49 / 00.00 | 08.69 / 00.00 |
| SERAC (Zh) | 29.72 / 15.91 | 14.85 / 00.00 | 67.93 / 40.89 | 100.0 / 100.0 | 100.0 / 100.0 | 06.57 / 00.00 | 19.72 / 00.10 |
| IKE (En) | 99.90 / 99.90 | 99.24 / 98.36 | 93.74 / 72.52 | 62.79 / 36.26 | 44.57 / 12.34 | 50.86 / 17.84 | 35.34 / 04.53 |
| IKE (Zh) | 99.97 / 99.90 | 85.51 / 77.82 | 97.37 / 95.66 | 63.64 / 36.35 | 51.00 / 16.10 | 39.64 / 04.44 | 38.70 / 07.43 |
| MEND (En) | 49.27 / 00.77 | 48.26 / 00.58 | 17.41 / 00.00 | 90.50 / 77.24 | 89.75 / 70.40 | 05.86 / 00.10 | 14.74 / 00.10 |
| MEND (Zh) | 17.20 / 00.58 | 15.65 / 00.29 | 42.84 / 00.87 | 89.74 / 74.93 | 87.85 / 65.09 | 06.69 / 00.10 | 22.03 / 00.29 |
| KN (En) | 04.63 / 00.00 | 04.54 / 00.00 | 06.03 / 00.00 | 42.25 / 29.12 | 35.81 / 20.15 | 03.53 / 00.00 | 08.15 / 00.00 |
| KN (Zh) | 03.41 / 00.00 | 04.48 / 00.00 | 05.03 / 00.00 | 30.85 / 18.61 | 20.97 / 09.35 | 03.06 / 00.00 | 05.49 / 00.00 |
| ROME (En) | 99.17 / 97.88 | 94.44 / 88.81 | 29.01 / 09.64 | 99.01 / 96.43 | 97.23 / 91.13 | 08.72 / 00.00 | 16.16 / 00.00 |
| ROME (Zh) | 98.99 / 97.30 | 55.94 / 38.48 | 35.02 / 21.89 | 90.09 / 76.95 | 85.98 / 63.07 | 07.81 / 00.00 | 11.63 / 00.00 |
| MEMIT (En) | 95.74 / 91.22 | 89.09 / 78.69 | 30.48 / 07.91 | 98.41 / 95.18 | 97.64 / 92.38 | 08.23 / 00.00 | 17.91 / 00.00 |
| MEMIT (Zh) | 94.28 / 89.59 | 51.85 / 35.39 | 36.88 / 20.64 | 98.08 / 94.12 | 96.27 / 87.66 | 07.72 / 00.19 | 14.69 / 00.00 |
4.1 实验设置
指标。 为了从可靠性、通用性、局部性和可移植性方面评估编辑后的模型,将与黄金答案配对的不同问题输入到编辑后的模型中。 因此,我们遵循之前的 QA 研究 Rajpurkar 等人 (2016); Yang等人(2018)并采用精确匹配(EM)和F1作为两个评估指标:(1)EM衡量与黄金答案完全匹配的预测的百分比。 (2) F1 衡量预测与黄金答案之间的平均重叠度。 我们将预测和真实情况视为 Token 袋,并计算它们的 F1。
| C-Eval | MMLU | |
| GPT-4 | 68.7 | 86.4 |
| GPT-3.5-turbo | 54.4 | 70.0 |
| Baichuan-7B | 42.8 | 42.3 |
| Chinese-LLaMA-2-7B | 34.4 | 36.8 |
| Chinese-LLaMA-Plus-7B | 25.5 | 31.8 |
基线。 继 Yao 等人 (2023); Wang等人(2023b),我们采用了7种方法作为基线:(1)直接微调(FT)具有约束的语言模型; (2)SERAC Mitchell 等人(2022b)利用范围分类器来评估新输入是否接近存储的编辑示例,并根据检索到的编辑示例进一步影响模型行为; (3) IKE Zheng 等人 (2023) 使用上下文编辑事实来指导模型生成编辑事实; (4) MEND Mitchell 等人 (2022a) 通过采用梯度的低秩分解来变换微调语言模型的梯度; (5) KN Dai 等人 (2022) 指定 FFN 矩阵中体现知识的键值对,然后继续更新相应的参数; (6)ROME Meng 等人 (2022) 利用因果中介分析定位编辑区域,并更新 FFN 矩阵中的全部参数; (7) MEMIT Meng 等人 (2023) 直接更新带有大量记忆的大语言模型,从而方便同时执行数千个编辑。
| Method | Reliability | Generality | Locality | Portability | |||
| En | Zh | En | Zh | En | Zh | ||
| FT (En) | 36.62 / 05.98 | 35.01 / 07.52 | 20.45 / 00.39 | 81.90 / 55.06 | 76.64 / 38.57 | 07.33 / 00.00 | 16.94 / 00.00 |
| FT (Zh) | 13.91 / 01.93 | 17.13 / 01.35 | 36.15 / 01.06 | 76.79 / 47.44 | 68.44 / 26.13 | 07.09 / 00.00 | 18.50 / 00.00 |
| SERAC (En) | 99.25 / 98.07 | 99.26 / 98.07 | 32.28 / 20.06 | 100.0 / 100.0 | 93.64 / 88.72 | 07.12 / 00.19 | 11.28 / 00.19 |
| SERAC (Zh) | 29.97 / 23.43 | 20.36 / 02.70 | 72.19 / 51.98 | 100.0 / 100.0 | 100.0 / 100.0 | 08.10 / 00.00 | 22.09 / 01.83 |
| IKE (En) | 100.0 / 100.0 | 99.69 / 99.32 | 91.90 / 77.15 | 56.35 / 30.76 | 54.40 / 12.15 | 45.72 / 11.76 | 37.50 / 05.11 |
| IKE (Zh) | 99.95 / 99.90 | 94.24 / 90.84 | 99.25 / 98.75 | 49.90 / 21.50 | 51.59 / 13.21 | 40.91 / 05.69 | 44.99 / 12.63 |
| MEND (En) | 61.25 / 00.00 | 60.78 / 00.00 | 22.84 / 00.00 | 93.55 / 81.68 | 81.68 / 50.92 | 07.74 / 00.00 | 14.70 / 00.00 |
| MEND (Zh) | 22.26 / 00.00 | 21.64 / 00.00 | 45.95 / 00.00 | 96.68 / 90.45 | 96.26 / 88.24 | 07.04 / 00.00 | 21.72 / 00.00 |
| KN (En) | 10.94 / 00.00 | 10.96 / 00.00 | 11.71 / 00.00 | 49.28 / 06.85 | 43.65 / 09.74 | 05.75 / 00.00 | 13.54 / 00.00 |
| KN (Zh) | 08.36 / 00.00 | 10.24 / 00.00 | 11.38 / 00.00 | 45.06 / 03.76 | 36.65 / 03.95 | 05.84 / 00.00 | 13.03 / 00.00 |
| ROME (En) | 78.19 / 68.76 | 72.91 / 57.47 | 24.43 / 05.40 | 94.17 / 83.70 | 96.02 / 87.08 | 07.66 / 00.19 | 16.52 / 00.00 |
| ROME (Zh) | 27.47 / 10.80 | 22.10 / 03.18 | 60.90 / 15.53 | 94.09 / 82.55 | 94.71 / 82.16 | 06.63 / 00.10 | 24.21 / 01.93 |
| MEMIT (En) | 83.67 / 76.76 | 77.55 / 62.20 | 25.20 / 06.17 | 98.41 / 95.37 | 97.87 / 93.35 | 08.20 / 00.19 | 16.79 / 00.10 |
| MEMIT (Zh) | 28.56 / 11.76 | 22.89 / 04.05 | 63.98 / 16.39 | 98.53 / 95.56 | 97.82 / 92.48 | 07.13 / 00.10 | 24.22 / 01.64 |
| Method | Reliability | Generality | Locality | Portability | |||
| En | Zh | En | Zh | En | Zh | ||
| FT (En) | 33.33 / 13.11 | 27.09 / 07.43 | 20.79 / 00.29 | 91.71 / 83.12 | 85.08 / 63.74 | 09.21 / 00.19 | 29.40 / 00.00 |
| FT (Zh) | 13.76 / 02.31 | 14.06 / 00.77 | 28.45 / 04.73 | 95.38 / 90.07 | 60.78 / 20.25 | 09.31 / 00.29 | 26.88 / 00.29 |
| KN (En) | 10.77 / 00.00 | 10.32 / 00.00 | 18.97 / 00.00 | 71.28 / 55.74 | 91.99 / 79.27 | 08.96 / 00.19 | 29.98 / 00.00 |
| KN (Zh) | 10.10 / 00.00 | 10.53 / 00.00 | 18.71 / 00.00 | 73.16 / 58.15 | 85.95 / 65.38 | 09.08 / 00.29 | 30.02 / 00.10 |
| ROME (En) | 68.70 / 52.36 | 59.08 / 40.50 | 24.76 / 01.64 | 98.28 / 96.05 | 98.92 / 95.27 | 09.90 / 00.19 | 30.24 / 00.29 |
| ROME (Zh) | 25.75 / 08.39 | 18.69 / 03.38 | 69.95 / 14.75 | 97.86 / 95.47 | 97.70 / 92.57 | 09.54 / 00.29 | 26.21 / 01.06 |
| MEMIT (En) | 70.78 / 54.29 | 64.46 / 46.48 | 27.49 / 03.57 | 99.22 / 97.69 | 98.93 / 96.14 | 09.72 / 00.10 | 28.83 / 00.29 |
| MEMIT (Zh) | 25.60 / 08.78 | 22.77 / 07.62 | 71.44 / 16.30 | 98.47 / 96.53 | 97.92 / 93.54 | 09.13 / 00.39 | 23.83 / 00.29 |
骨干。 考虑到英语和汉语的能力,我们在实验中采用以下三个大语言模型: (1) Chinese-LLaMA-Plus-7B444https://github.com/ymcui/Chinese-LLaMA-Alpaca是基于LLaMA-7B Touvron 等人 (2023a) 具有词汇扩展和对中文语料库的持续预训练。 (2)同理,Chinese-LLaMA-2-7B555https://github.com/ymcui/Chinese-LLaMA-Alpaca-2是基于LLaMA-2-7BTouvron等人创建的( 2023b)。 (3)百川-7B666https://github.com/baichuan-inc/Baichuan-7B/是另一个支持英文和中文的大语言模型。 表3列出了上述大语言模型在C-Eval Huang 等人(2023a)和MMLU Hendrycks 等人(2021)上的表现分别用中文和英文表明他们的能力。 Baichuan-7B 在两个评估基准数据集中的三个骨干网中表现最好。
实施细节。 所有实验均在单个 NVIDIA A800 GPU (80G) 上进行。 所有基线的实现均由 EasyEdit Wang 等人 (2023b) 使用默认设置实现。 每个方法的超参数可以在相应的 GitHub 存储库中找到。777https://github.com/zjunlp/EasyEdit/tree/main/hparams
4.2 结果与分析
表2、表4和表5显示了Chinese-LLaMA-Plus-7B、Chinese-LLaMA-2-7B和Chinese-LLaMA-2-7B的实验结果分别是百川七号B。 方法名称中的语言标识符指示其源语言。 例如,SERAC(En)表示该方法是用英文编辑的,而SERAC(Zh)是用中文编辑的。
单语分析。 与其他三个属性相比,可移植性对于知识编辑方法来说更具挑战性。 正如我们所看到的,只有 IKE 在可移植性方面取得了不错的性能,而其他方法则失败了。 对于直接评估模型在编辑知识上的性能的可靠性,我们发现FT和KN在该属性上获得有限的性能,因此无法在大语言模型中编辑知识。 基于上述分析,我们接下来比较SERAC、IKE、MEND、ROME上的跨语言知识编辑性能> 和MEMIT。
可靠性行为不一致。 使用不同语言编辑大语言模型时,在可靠性方面可能存在性能差距。 例如,SERAC (En) 在 Chinese-LLaMA-Plus-7B 上达到 83.61 F1,而 SERAC (Zh) 仅达到 29.72 F1。 这是因为在单个集成的多语言大语言模型中,不同语言的语言建模能力可能会有所不同。 许多大语言模型表现出较强的英语能力,或许是因为高质量的英语数据在预训练语料库Touvron等人(2023a,b)中占主导地位。 不同语言的语言建模差距可能会影响不同语言的知识编辑效率。 此外,在比较三个主干网时,我们发现 ROME (En) 和 ROME (Zh) 在 Chinese-LLaMA-Plus-7B 上实现相似的可靠性(99.17 F1 与 98.99 F1),但在 Chinese-LLaMA-2-7B 上显着不同(78.19 F1 vs. 27.47 F1)和百川七号(70.78 F1 vs. 25.60 F1)。 MEMIT (En) 和 MEMIT (Zh) 也显示了这种情况。
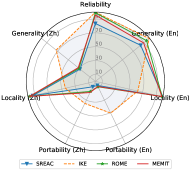
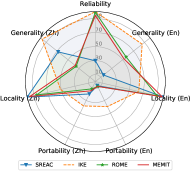
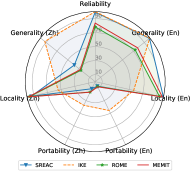
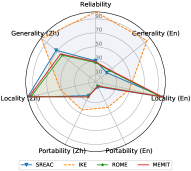
一般性行为不一致。 直观地看出,当使用一种语言来编辑大语言模型时,该语言的通用性明显高于其他语言。 例如,SERAC(En)的英语通用性达到83.64 F1,但中文通用性仅达到28.46 F1。 相比之下,SERAC (Zh) 的中文通用性比英文更好(67.93 F1 vs. 15.00 F1)。 这一发现也表明知识编辑的跨语言性能仍然有限。 现有的知识编辑方法很难将编辑后的知识从一种语言转移到多语言大语言模型中的其他语言,并且在不同语言查询时反映一致的行为。
对地方性的跨语言影响。 当用源语言编辑大语言模型时,其他语言的局部性也会受到影响。 不同语言的影响程度似乎相似。 例如,MEND (En) 在英文和中文本地实现了 90.50 F1 和 89.75 F1,而 MEND (Zh) 的对应值是 89.74 和 87.85。 我们还发现,尽管 IKE 在可靠性方面表现良好,但其局部性普遍低于 SERAC、ROME 或 MEMIT。 低级局部性使得其有用性需要在实际应用中仔细验证。 地点越低,潜在风险就越高。
两种语言的可移植性有限。 如图2所示,在编辑英文或中文多语言大语言模型时,与其他属性相比,其在两种语言中的可移植性表现极其有限。 这一发现表明,大多数现有的知识编辑方法只是记住了措辞的表面变化,而不是吸收编辑后的知识。 这种现象表明,跨不同语言共享知识是很棘手的。 因此,大语言模型可能会反映不同语言编辑知识的不一致行为。
| Method | Cross-Lingual Generality | ||
| Before | After | ||
| FT (En) | 20.45 / 00.39 | 21.34 / 00.39 | +0.89 / 00.00 |
| FT (Zh) | 17.13 / 01.35 | 18.75 / 01.54 | +1.62 / +0.19 |
| SERAC (En) | 32.28 / 20.06 | 38.10 / 21.22 | +5.82 / +1.16 |
| SERAC (Zh) | 20.36 / 02.70 | 20.55 / 02.70 | +0.19 / 00.00 |
| IKE (En) | 91.90 / 77.15 | 92.12 / 77.24 | +0.22 / +0.09 |
| IKE (Zh) | 94.24 / 90.84 | 94.27 / 90.84 | +0.03 / 00.00 |
| MEND (En) | 22.84 / 00.00 | 25.94 / 00.00 | +3.10 / 00.00 |
| MEND (Zh) | 21.64 / 00.00 | 24.08 / 00.00 | +2.44 / 00.00 |
| KN (En) | 11.71 / 00.00 | 11.81 / 00.00 | +0.10 / 00.00 |
| KN (Zh) | 10.24 / 00.00 | 11.14 / 00.00 | +0.90 / 00.00 |
| ROME (En) | 24.43 / 05.40 | 26.05 / 05.50 | +1.62 / +0.10 |
| ROME (Zh) | 22.10 / 03.18 | 25.60 / 04.73 | +3.50 / +1.55 |
| MEMIT (En) | 25.20 / 06.17 | 27.42 / 06.46 | +2.22 / +0.29 |
| MEMIT (Zh) | 22.89 / 04.05 | 26.51 / 06.08 | +3.62 / +2.03 |
4.3 语言不匹配的影响
当使用目标语言问题查询编辑后的多语言大语言模型时,可能会输出源语言答案,称为语言不匹配。 为了弄清楚语言不匹配的影响,我们尝试放宽评估通用性的设置:单个通用性问题有两个黄金答案,一个是英文,另一个是中文,并且两者具有相同的语义。 使用目标语言问题计算 EM 和 F1 分数时,将使用两个黄金答案进行比较,并记录最高分数。 这样,当使用目标语言问题查询模型时,源语言答案也可以被接受。 如表6所示,当我们放宽评估设置时,跨语言通用性略有增加,表明语言不匹配的影响确实存在,尽管很轻微。
5结论
在本文中,我们首先探讨知识编辑的跨语言效果。 为了实现这一目标,我们通过将之前的 ZsRE 数据集从英文翻译成中文来自动构建 Bi-ZsRE 数据集。 基于Bi-ZsRE,我们对各种知识编辑方法和多语言大语言模型进行了实验,研究英汉之间的跨语言效应。 我们的结果表明:(1)不同语言的语言建模差异可能会影响不同语言的知识编辑效率; (2)现有的知识编辑方法仍然难以在多语言大语言模型中将编辑后的知识从一种语言迁移到另一种语言; (3)在编辑一种语言的大语言模型时,其他语言的局部性也会受到影响。 我们还分析了编辑模型的不一致行为,并讨论了它们的具体挑战,以更深入地了解知识编辑中的跨语言效应。
参考
- Dai et al. (2022) Damai Dai, Li Dong, Yaru Hao, Zhifang Sui, Baobao Chang, and Furu Wei. 2022. Knowledge neurons in pretrained transformers. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8493–8502, Dublin, Ireland. Association for Computational Linguistics.
- De Cao et al. (2021) Nicola De Cao, Wilker Aziz, and Ivan Titov. 2021. Editing factual knowledge in language models. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 6491–6506, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
- Dong et al. (2022) Qingxiu Dong, Damai Dai, Yifan Song, Jingjing Xu, Zhifang Sui, and Lei Li. 2022. Calibrating factual knowledge in pretrained language models. In Findings of the Association for Computational Linguistics: EMNLP 2022, pages 5937–5947, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
- Hendrycks et al. (2021) Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2021. Measuring massive multitask language understanding. In International Conference on Learning Representations.
- Huang et al. (2023a) Yuzhen Huang, Yuzhuo Bai, Zhihao Zhu, Junlei Zhang, Jinghan Zhang, Tangjun Su, Junteng Liu, Chuancheng Lv, Yikai Zhang, Jiayi Lei, et al. 2023a. C-eval: A multi-level multi-discipline chinese evaluation suite for foundation models. arXiv preprint arXiv:2305.08322.
- Huang et al. (2023b) Zeyu Huang, Yikang Shen, Xiaofeng Zhang, Jie Zhou, Wenge Rong, and Zhang Xiong. 2023b. Transformer-patcher: One mistake worth one neuron. arXiv preprint arXiv:2301.09785.
- Kwiatkowski et al. (2019) Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. 2019. Natural questions: A benchmark for question answering research. Transactions of the Association for Computational Linguistics, 7:452–466.
- Levy et al. (2017) Omer Levy, Minjoon Seo, Eunsol Choi, and Luke Zettlemoyer. 2017. Zero-shot relation extraction via reading comprehension. In Proceedings of the 21st Conference on Computational Natural Language Learning (CoNLL 2017), pages 333–342, Vancouver, Canada. Association for Computational Linguistics.
- Meng et al. (2022) Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. 2022. Locating and editing factual associations in gpt. Advances in Neural Information Processing Systems, 35:17359–17372.
- Meng et al. (2023) Kevin Meng, Arnab Sen Sharma, Alex J Andonian, Yonatan Belinkov, and David Bau. 2023. Mass-editing memory in a transformer. In International Conference on Learning Representations.
- Mitchell et al. (2022a) Eric Mitchell, Charles Lin, Antoine Bosselut, Chelsea Finn, and Christopher D Manning. 2022a. Fast model editing at scale. In International Conference on Learning Representations.
- Mitchell et al. (2022b) Eric Mitchell, Charles Lin, Antoine Bosselut, Christopher D Manning, and Chelsea Finn. 2022b. Memory-based model editing at scale. In International Conference on Machine Learning, pages 15817–15831. PMLR.
- OpenAI (2022) OpenAI. 2022. Introducing chatgpt. https://openai.com/blog/chatgpt.
- OpenAI (2023) OpenAI. 2023. Gpt-4 technical report. ArXiv, abs/2303.08774.
- Rajpurkar et al. (2016) Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. 2016. SQuAD: 100,000+ questions for machine comprehension of text. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 2383–2392, Austin, Texas. Association for Computational Linguistics.
- Touvron et al. (2023a) Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. 2023a. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971.
- Touvron et al. (2023b) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. 2023b. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
- Wang et al. (2023a) Jiaan Wang, Yunlong Liang, Fandong Meng, Haoxiang Shi, Zhixu Li, Jinan Xu, Jianfeng Qu, and Jie Zhou. 2023a. Is chatgpt a good nlg evaluator? a preliminary study. arXiv preprint arXiv:2303.04048.
- Wang et al. (2023b) Peng Wang, Ningyu Zhang, Xin Xie, Yunzhi Yao, Bozhong Tian, Mengru Wang, Zekun Xi, Siyuan Cheng, Kangwei Liu, Guozhou Zheng, et al. 2023b. Easyedit: An easy-to-use knowledge editing framework for large language models. arXiv preprint arXiv:2308.07269.
- Wu et al. (2023) Suhang Wu, Minlong Peng, Yue Chen, Jinsong Su, and Mingming Sun. 2023. Eva-kellm: A new benchmark for evaluating knowledge editing of llms. arXiv preprint arXiv:2308.09954.
- Yang et al. (2018) Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. 2018. HotpotQA: A dataset for diverse, explainable multi-hop question answering. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2369–2380, Brussels, Belgium. Association for Computational Linguistics.
- Yao et al. (2023) Yunzhi Yao, Peng Wang, Bo Tian, Siyuan Cheng, Zhoubo Li, Shumin Deng, Huajun Chen, and Ningyu Zhang. 2023. Editing large language models: Problems, methods, and opportunities. ArXiv, abs/2305.13172.
- Zhao et al. (2023) Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, et al. 2023. A survey of large language models. arXiv preprint arXiv:2303.18223.
- Zheng et al. (2023) Ce Zheng, Lei Li, Qingxiu Dong, Yuxuan Fan, Zhiyong Wu, Jingjing Xu, and Baobao Chang. 2023. Can we edit factual knowledge by in-context learning? arXiv preprint arXiv:2305.12740.
- Zhong et al. (2023) Zexuan Zhong, Zhengxuan Wu, Christopher D Manning, Christopher Potts, and Danqi Chen. 2023. Mquake: Assessing knowledge editing in language models via multi-hop questions. arXiv preprint arXiv:2305.14795.