Owl ![[Uncaptioned image]](owl.png) :IT 运营的大型语言模型
:IT 运营的大型语言模型
摘要
随着IT运营的快速发展,高效管理和分析大量数据对于实际应用变得越来越重要。 自然语言处理(NLP)技术在命名实体识别、机器翻译和对话系统等各种任务中表现出了卓越的能力。 最近,大型语言模型(大语言模型)在各种 NLP 下游任务上取得了显着的改进。 然而,目前缺乏专门用于IT运营的大语言模型。 在本文中,我们介绍了 Owl,这是一种在我们收集的 Owl-Instruct 数据集上训练的大型语言模型,其中包含广泛的 IT 相关信息,其中提出了混合适配器策略来改进跨不同领域或任务的参数高效调整。 此外,我们还在我们建立的 Owl-Bench 和开放的 IT 相关基准上评估了 Owl 的性能。 Owl 在 IT 任务上展示了卓越的性能结果,其性能明显优于现有模型。 此外,我们希望我们的工作结果能够提供更多见解,以专门的大语言模型彻底改变IT运营技术。
1简介
Large Language Models (大语言模型) Chowdhery 等人 (2022b); Touvron 等人 (2023a, b) 已成为自然语言处理 (NLP) 和人工智能 (AI) 领域的强大工具。 2020年GPT-3Brown等人(2020a)的发布,展示了训练大型自回归大语言模型的优势。 GPT-3 拥有 1750 亿个参数,在阅读理解、问答、代码生成等多项大语言模型任务中超越了之前的模型。 其他模型也取得了类似的结果。 此外,有证据表明,较大的模型表现出突发行为,并拥有较小模型所不具备的能力。 例如,他们可以从几个例子中学习任务,这种现象被称为“少样本提示”。 此功能扩展了支持任务的范围,并有助于用户自动执行新语言任务。 然而,大多数研究工作都是针对构建涵盖广泛学科的通用大语言模型(大语言模型),某些在特定领域数据上训练的模型在其特定领域(例如科学和技术)中表现出了卓越的性能。药品。 这些发现强调了特定领域模型进一步进步的必要性。
在IT运维领域杜等人(2017);刘等人 (2023);郭等人(2023a),自然语言处理(NLP)技术的重要性正在稳步上升。 本文承担的关键任务是描述 IT 运营领域内的一组具体任务,涵盖信息安全、系统架构和其他任务等领域。 然而,IT 运营的复杂性和特定术语带来了巨大的挑战,包括传统 NLP 模型不易解读的一组独特的术语、流程和上下文细微差别。 因此,越来越明显的是,迫切需要开发和部署专门针对此类专业领域内 IT 操作的紧急情况而定制的语言模型。 为此目的而定制的经过微调的大型语言模型有望成为在这些高度专业化的领域内解决 IT 运营复杂性的宝贵资产。 这种专门的大语言模型将极大地提高这些利基领域内 IT 相关任务和通信的效率、准确性和理解力,最终将推动 IT 运营管理领域的发展。
在本文中,我们介绍了 Owl,这是一个大型语言模型,在我们收集的具有广泛 IT 相关知识的数据集上进行训练,其中我们的数据集名为 as,包含 9 个常见领域,包括信息安全、应用程序运维、系统架构、软件架构、中间件运维、网络运维、操作系统运维、基础设施运维等领域。 此外,我们还探讨了自指令 Xu 等人 (2023b) 的使用; Wang 等人 (2023a) 策略使大语言模型能够从一组人工注释的数据样本中准确生成大量、高质量和多样化的指令数据,其中引入 Owl-Instruct 数据集来训练我们的 猫头鹰。 此外,我们引入了 Owl-Bench 数据集来评估不同大语言模型在 IT 相关任务上的性能。 此外,为了提高不同任务之间指令调优的性能,我们进一步提出了适配器混合策略以促进监督微调。
我们论文的贡献如下:
-
•
Owl-指导数据集构建。 我们首先收集并标记 3000 个种子样本,然后提示 ChatGPT 生成不同的指令。 为了涵盖实际场景,我们策划了涉及单回合和多回合场景的指令。
-
•
Owl-Bench 基准构建。 我们建立了运维领域大语言模型能力衡量大模型测试基准,该基准由9个运维相关领域组成,分层展示了该领域大语言模型能力的多样性。
-
•
训练策略。 我们提出了一种混合适配器策略来提高指令调整性能。
-
•
令人印象深刻的表现。 我们在多个基准数据集(包括 Owl-Bench 和开放 IT 相关基准)上评估了 Owl 与其他大语言模型的性能。 Owl 在 IT 任务上展示了卓越的性能结果,其性能显着优于现有模型,并在 Owl-Bench 上保持有效的泛化能力。
2 Owl-指导数据集构建

大语言模型训练中使用的数据质量是影响语言模型最终性能的关键决定因素Zhou 等人(2023)。 事实上,它甚至可能超越模型架构和训练方法的重要性。 最近的研究论文和技术报告强调了在训练大规模模型时数据的多样性和质量的重要性。 因此,我们必须策划一个高品质的教学数据集,我们将其称为 Owl-Instruct 数据集,专为运营和维护 (O&M) 领域量身定制。
构建Owl-Instruct的概述如图1所示。 表 1 中提供了该数据集的统计分析,图 2 中描述了关键字的直观表示。 此次数据集构建和分析工作旨在增强大语言模型训练数据的丰富性和卓越性,从而提高其在运维领域的效率。
| Dataset | Number of seed data | Number of total dialogues | Average number of turns | Average length of dialogues (Token level) |
| Single-turn | 2000 | 9118 | 1 | 335 |
| Multi-turn | 1000 | 8740 | 2.9 | 918 |

2.1 种子数据收集
在项目的初始阶段,我们聘请运营和维护领域的主题专家精心设计输入和输出序列以及全面的说明。 这些涵盖了广泛的共同领域和任务。 具体来说,我们的数据集包含来自运维 (O&M) 中九个常见领域的数据:信息安全、应用程序、系统架构、软件架构、中间件、网络、操作系统、基础设施和数据库。
每个领域都封装了大量的任务,包括但不限于基于知识的问答、部署、监控、故障诊断、性能优化、日志分析、脚本编写、备份和恢复等。 我们为每项任务精心设计了不同的指令提示,从而促进了我们的大型语言模型的监督微调过程。
结果,我们积累了一个包含 2,000 个单轮和 1,000 个多轮种子数据实例的语料库。 这些作为数据增强的基础,进一步扩大了我们数据集的规模和多样性。
2.2 数据集扩充
单轮数据集构建
在我们的努力中,我们构建了一个专门针对运营和维护领域定制的全面的单轮对话数据集,拥有令人印象深刻的 9,118 个精心策划的数据条目。 从自我指导方法 Wang 等人 (2023a) 中汲取灵感,我们采取了额外的步骤来进一步丰富我们的数据集。 这种丰富涉及从种子数据生成补充样本,这是由我们的领域专家精心标记的语料库。 我们对数据质量的承诺延伸到将 ChatGPT Jiao 等人 (2023) 视为参考和监督者,以确保我们数据集的卓越性。 这种细致的数据集构建和增强方法强调了我们致力于促进操作和维护对话系统领域的卓越性能和稳健性。
多轮数据集构建
根据Baize Xu 等人(2023b)中阐述的方法,我们在运维领域内的多轮对话数据集的生成过程包含以下四个不同的阶段:
-
•
种子数据收集:这个初始阶段涉及对原始种子数据的精心管理,这些数据是由运维领域知名的领域专家精心注释的。
-
•
主题生成:基于上一步获取的种子数据,我们利用 GPT-3.5 API Jiao 等人 (2023) 生成大量主题。 这个过程经过精心设计,以确保生成的内容牢固地扎根于操作和维护领域,同时保持理想的主题多样性水平。
-
•
多轮对话生成:在这个关键阶段,我们采用了白泽多轮对话生成方法Xu等人(2023b)。 利用前一阶段形成的主题,该方法巧妙地制作了与操作和维护领域本质上相关的多轮对话数据。
-
•
手动和 GPT4 筛选:为了进一步提高生成数据的质量,我们利用了 GPT-4 OpenAI (2023b) 的功能。 除了自动筛选之外,我们的数据集还经过严格的手动检查和交叉验证。 这个细致的过程确保每个数据输入都经过至少三个人的仔细审查。 不符合高质量标准的参赛作品将被立即删除。 因此,我们的综合多回合数据集总共包含 8,740 个对话条目,平均每个对话大约有 3 个回合。
2.3数据质量
为了保持严格的数据质量标准,我们采用了双管齐下的方法,将 GPT-4 OpenAI (2023b) 评分与细致的手动验证相结合。 这种双重验证过程确保了我们生成的数据的完整性和可靠性,同时提高了其整体质量。 当利用 GPT-4 进行评分时,我们精心设计了适合我们数据集的特定提示。 这些提示经过精心设计,使 GPT-4 能够根据预定义的质量标准对生成的数据进行评估和评级。 这种自动评分机制使我们能够快速识别并过滤掉任何低质量的数据实例。 此外,它还是标记数据集中潜在问题和需要改进的领域的宝贵工具。 同时,我们的数据集经过严格的手动验证。 专家评审团队对每个数据条目进行深入评估。 此手动检查过程需要对内容、连贯性以及对特定领域知识的遵守情况进行彻底检查。 不符合我们严格质量标准的条目会被仔细标记,然后从数据集中删除。 自动评分和手动验证的结合不仅确保了低质量数据的消除,而且有助于数据质量的整体提高。 我们为 GPT-4 使用的提示是专门为引发富有洞察力的评估而定制的,如下所示:
3 Owl-Bench 基准构建
概述:
由于缺乏专门用于评估运维 (O&M) 背景下大型语言模型性能的基准,我们有效评估和比较该领域模型的能力存在严重差距。 为了解决这一缺陷,我们开始开发 Owl-Bench,这是一个广泛的双语基准,由两个不同的部分组成:由 317 个条目组成的 Q&A(问题-答案)部分,以及包含表中 1,000 个问题的多项选择部分2。 运维领域具有广阔性和多学科性,学术著作众多当等人(2019); Rijal 等人 (2022); Gau 和 Pishdad-Bozorgi (2019) 对各个方面进行了深思熟虑的总结。 根据从这些作品中收集到的见解,我们精心策划了 Owl-Bench 中包含的子领域。 我们考虑了包含该领域的众多现实世界工业场景,确保我们的基准展现出全面的多样性。 我们的数据收集过程涉及从九个不同的子领域获取测试数据,即信息安全、应用程序、系统架构、软件架构、中间件、网络、操作系统、基础设施和数据库。 这些数据以精心设计的问答对和多项选择题的形式呈现。 必须强调的是,Owl-Bench 中纳入的数据与 Owl-Instruct 中的数据显着不同。 前者直接源自现实场景的考试题,没有通过 GPT 进行任何修改或扩展。 在表 3 中,我们展示了 Owl-Bench 跨越这九个领域的多项选择题的说明性示例,让您一睹基准测试中所包含的丰富多样性。
3.1数据收集
我们的主要数据源包括可在互联网上免费访问的模拟考试。 这些练习考试通常用于磨练有抱负的专业人士的技能,是运营和维护领域中现实问题和场景的宝贵存储库。 此外,为了进一步丰富我们基准的质量和真实性,我们与运营和维护专家进行了合作。 经过这些专家仔细审查的大约 200 个问题已无缝集成到 Owl-Bench 中。 这种协作努力不仅增强了基准的可信度,而且还为其注入了特定领域的专业知识。 值得强调的是我们对开放和知识共享的承诺。 Owl-Bench 中的所有问题都将是开源的,这证明了我们致力于在研究社区内营造协作和透明的环境。 该举措旨在促进更广泛地获取高质量数据,以促进运营和维护相关的研究和创新。
3.2数据处理
收集的数据有多种格式,主要是 PDF 或 Microsoft Word 文档,还有少量网页。 PDF 文档最初使用 OCR 工具Li 等人 (2023) 处理为文本。 一些难以处理的情况会被手工解析成结构化格式,类似于Hendrycks等人(2021);泰勒等人 (2022)。
| Middleware | Information security | Infrastructure | Application | Operating system | Database | System architecture | Network | Software architecture | |
| Q&A | |||||||||
| Number of questions | 30 | 26 | 41 | 36 | 39 | 38 | 25 | 40 | 42 |
| Average length of dialogues (Token level) | 301 | 275 | 287 | 311 | 297 | 342 | 286 | 308 | 298 |
| multiple-choice | |||||||||
| Number of questions | 136 | 108 | 110 | 102 | 118 | 119 | 87 | 122 | 98 |
| Average length of dialogues (Token level) | 212 | 287 | 264 | 343 | 247 | 310 | 255 | 294 | 301 |
| Domain | Infrastructure operation and maintenance |
| Suppose you are an operation and maintenance engineer of a large network company, and you need to write a Bash script to regularly monitor and record the CPU and memory usage of the server. Which of the following commands can be used in a Bash script to gather this information? (A) ifconfig (B) Use automated VM-based recovery strategies (C) Use a multi-region or multi-AZ deployment (D) Perform regular physical maintenance on the server | |
| Domain | Middleware operation and maintenance |
| In the disaster recovery and backup solution of web applications based on cloud technology, which of the following methods can effectively reduce the single point of failure rate of the system and make the program show high availability? (A) Back up all data and applications in only a single region (B) Use automated VM-based recovery strategies (C) Use a multi-region or multi-AZ deployment (D) Perform regular physical maintenance on the server | |
| Domain | Application business operation and maintenance |
| You are operating a large-scale e-commerce website, which will face huge traffic pressure during special festivals such as ”Black Friday” or ”Double Eleven”. Which of the following is a strategy you might use to cope with this stress? (A) All website updates and maintenance operations are suspended during the festive period. (B) Increase the number of servers ahead of time to handle expected traffic growth. (C) Partition the database to enhance query efficiency and concurrent processing capabilities. (D) Limit the number of purchases per user during the holiday season. | |
| Domain | System architecture operation and maintenance |
| When designing and implementing a high-availability, scalable cluster system, which of the following is not an implementation solution that needs to be considered? (A) Data storage: adopt a distributed storage solution to store data in multiple nodes, such as using NoSQL database or distributed file system and other technologies. (B) Load balancing: use hardware load balancer or software load balancer to realize the distribution of requests to ensure the load balance of each node. (C) Fault tolerance: through technologies such as backup, redundancy, and failover, it is guaranteed that the system can still maintain availability in the event of node failure or network failure. (D) Data compression: By compressing system data, storage space requirements are reduced and storage efficiency is improved. | |
| Domain | Database operation and maintenance |
| In a system disaster recovery scenario, which of the following options is not primarily used to reduce data loss? (A) Using the master-backup architecture, that is, all the data and configuration of the master server are copied to the backup server in real time. (B) Regularly back up critical data and configuration files, with full backups available daily and incremental backups hourly. (C) For database servers, use database replication techniques, such as master-slave replication or multi-master replication, to replicate data to backup servers in real time. (D) Establish an automated disaster recovery process, including steps such as system recovery, data recovery, and configuration recovery. | |
| Domain | Network operation and maintenance |
| A DNS server architecture includes components such as master-slave DNS servers, DNS cache servers, and domain name resolution routers. Which of these components is mainly responsible for distributing DNS query traffic of users to different DNS servers, so as to improve the reliability and scalability of the network? (A) primary DNS server (B) from DNS server (C) DNS cache server (D) domain name resolution router | |
| Domain | Software architecture operation and maintenance |
| The software development process includes sub-processes such as requirements analysis, general design, detailed design, coding, testing, and maintenance. The overall structure design of the software is completed in the ( ) sub-process. (A) demand analysis (B) outline design (C) detailed design (D) Write code | |
| Domain | Operating system operation and maintenance |
| Which command can be used to check the file system under Linux? (A) ls (B) dd (C) grep (D) fsck | |
| Domain | Information security operation and maintenance |
| From the following logs, what conclusions can be drawn? [2022-01-01 10:00:00] INFO: User login successful, username: admin [2022-01-01 10:05:00] WARNING: Memory usage exceeded threshold, performing memory cleanup [2022-01-01 10 :10:00] ERROR: File system corruption, performing repair [2022-01-01 10:15:00] DEBUG: Network connection problem detected, investigating (A) The system has a memory leak (B) Login failed for user admin (C) The file system was repaired successfully (D) The system is processing a network connection problem | |
4 标记化
由于LLaMA Touvron 等人(2023a)旨在支持拉丁语或西里尔语系的自然语言,因此与IT运营数据的兼容性并不理想(LLaMA的词汇表仅包含32K单词)。 对IT操作数据进行分词时,往往会将一个IT操作术语拆分成多个部分(日志数据的一个术语需要2-3个token组合),这会大大降低编解码的效率。 为了与自然语言和日志数据兼容,我们使用额外的数据扩展词汇表。 具体来说,我们在 Owl-Instruct 数据集上训练一个分词器模型,然后通过组合词汇表将 LLama 分词器与 LLaMA 原生分词器合并为耦合分词器模型。 因此,我们获得词汇量为 48,553 的合并分词器。 为了使 LLaMA 模型适应新的分词器,我们将词嵌入和语言模型头的大小从形状 调整为 ,其中 表示原始词汇大小, 是新的词汇量。 新行附加到原始嵌入矩阵的末尾,确保原始词汇表中标记的嵌入不受影响。
5型号
5.1 旋转嵌入
基于 Transformer 的语言模型使用自注意力机制来考虑各个 token 的位置信息,这有利于位于不同位置的 token 之间的知识交换。 多头注意力可以描述为:
| (1) | ||||
其中是softmax函数,是注意力头的特征串联。 输入表示与学习到的矩阵一起投影到 中。
为了考虑相对位置信息,我们需要一个函数 ,它对单词嵌入 及其相对位置 作为输入变量进行操作。 目标是确保查询 和键 的内积仅以其相对形式编码位置信息。 为了将位置信息与自注意力相结合,我们将位置信息分别注入查询和键中。 我们将这两项的内积设置为一个函数,明确地取决于它们的相对距离:
| (2) |
其中 是具有预定义参数的旋转矩阵,用于将相对位置信息合并到注意力机制中。
考虑到IT操作的长上下文输入,受到嵌入位置的最大位置的限制。 我们采用最近的工作 NBCE Su (2023) 来解决长上下文输入。 假设是要生成的目标句子,被给予与原始句子分离的一组相对独立的上下文,我们需要生成目标句子基于独立序列。 最终的预测描述为:
| (3) | ||||
其中,我们用权重 将基于不同上下文的预测对数似然结果 合在一起,然后用权重 减去无上下文预测结果 。无上下文预测结果 是为了让模型更倾向于结合上下文,而不是纯粹根据自己的知识来回答。 对于大于最大长度的原始输入句子,我们将它们分成多个段并将它们输入到模型中计算其对应的对数似然,最终获得对数似然原始输入句子。
5.2 适配器混合
参数高效调优 Houlsby 等人 (2019);朱 等人 (2021);胡等人 (2022);杨等人 (2022);他等人 (2022); Wang等人(2023b, 2022)是大语言模型中一种简单但有效的技术,它通过对固定的预训练模型引入特定于任务的修改来实现高效灵活的迁移。 对于跨语言迁移,我们针对不同领域和任务使用了多种适配器,其中一组 LoRA 适配器与预训练模型相比是轻量级的。 具有低秩下投影矩阵和上投影矩阵的适配器可以直接插入到预先训练的嵌入、注意力和前馈网络中。 给定 标记的源语句 和一组 适配器,我们使用适配器混合来学习特定于任务和特定于域的不同输入的表示:
| (4) | ||||
其中是从语言表示中选出的LoRA专家。 表示 LoRA 适配器模块, 表示适配器池。 的计算公式为:
| (5) | ||||
其中 由低阶分解 () 表示。 矩阵 和 由随机高斯分布和零初始化。 是缩放因子, 是内部尺寸。 表示来自
在方程5中,所有专家只需要微调少量特定于语言的参数,而不是预训练模型的所有参数。 因此,我们可以同时为不同语言训练多个专家,它们都共享相同的冻结预训练参数。 我们使用选定子集中的多个适配器来最大限度地跨语言知识转移:
| (6) | ||||
其中是选择函数,我们计算所有LoRA适配器的选择概率,并选择服从概率分布的顶级LoRA专家。 是来自语言表示的标量(我们使用每层特殊词符[CLS]的隐藏状态)。 和用于合并不同的专家。
我们使用学习矩阵 将语言 的语言表示 投影到 LoRA 专家分布中,其中 是隐藏大小是专家的数量。 LoRA专家的权重计算公式为:
| (7) | ||||
其中。 对于预训练模型的所有模块,我们利用混合适配器策略通过激活顶级专家来学习不同输入句子的语言敏感表示。
5.3 监督微调
给定多个任务,我们构建多任务语料库,其中每个数据集包含一系列三元组(和是指令的输入和输出样本。 我们的训练目标是优化模型,它能够通过建模来生成目标句子。 将指令句子和输入句子连接为一个整体并输入模型来预测目标句子。
大规模指令性能
为了进一步扩大多任务训练语料库的规模,我们采用自指令Wang等人(2023a)来增加数据的多样性和复杂性。 将人工编写的种子指令作为上下文示例(从初始指令池中随机采样 任务指令),生成新指令,然后将其合并到指令池中。 人工编写和模型生成的指令用作少样本生成的上下文演示,其中仅将基于 ROUGE-L 分数的不同模型生成的指令放入指令池中。 该过程重复多次,直到不再生成新的合法指令。 根据任务描述及其指令,我们利用大型语言模型来扩展每条指令的训练数据,输出样本输入,然后产生答案。 为了过滤掉低质量的数据,我们通过将样本 输入到大型语言模型中来对模型生成的样本进行评分,并由三位人类专家修复或丢弃非法样本,其中评分提示显示在2.3 节。 经过启发式过滤处理(重复的、过长或过短的实例将被剔除),一条新的、通过专家检查的高分指令将被添加到指令池中并获得。 我们可以获得模型生成的训练语料。 将原始训练语料库和模型生成语料库合并为一个整体,进行多任务训练。
多任务训练
给定监督指令语料库和模型生成语料库,监督指令调优的训练目标可以描述为:
| (8) | ||||
其中 是示例输入, 是来自原始训练语料库和模型生成的训练语料库的指令 的示例输出。
6评估
我们评估了 Owl 在 Owl-Bench 和一般下游任务上的性能,其中 Owl-Bench 帮助我们测试了我们的假设,即在高质量数据上进行训练将在运维问题上产生更好的结果区域。 一般任务调查我们模型的性能是否可以与之前发布的结果直接比较。 对于一般下游任务,我们从多个现有基准中提取结果并将结果分为以下类别:日志解析和日志异常检测任务。 为了公平地比较模型,我们避免对提示和其他技术进行任何调整,这些调整可能会改善某些(但不是全部)模型的结果。 因此,对于下游任务的测试,每个任务都使用cue模板进行测试,即不对底层模型进行任何参数修改。 向模型提供的少量示例取决于任务,我们在相应的部分中介绍这些详细信息。
6.1实验设置
对于指令调整,学习率为 ,权重衰减为 0.1,批量大小为 16。 序列长度为。 我们使用 Adam 作为优化算法,其中包含 、 和 。 训练纪元为 3。 LoRA Hu 等人 (2022) 的排名和 alpha 分别为 8 和 32。 LoRA的dropout为0.05。 我们训练 LoRA 5 轮。
6.2 Owl-Bench 评估
在本节中,我们将在我们的基准(Owl-Bench)上比较大多数大型语言模型(大语言模型)的结果。 实验结果主要由两部分组成:选择题结果和问答测试。 选择题主要考察模型对目标领域常识的学习能力,问答题主要考察模型对运维问题的综合处理和逻辑能力。 我们选择比较的模型与 Owl 大小相似,并且是开源的,可以重现结果:ChatGLM2-6b Du 等人 (2022)、ChaGLM-6b Du 等人 (2022) )、LLaMA2-13b Touvron 等人 (2023b)、Qwen-7b ††https://github.com/QwenLM/Qwen-7B 和 InternLM-7b 团队 (2023)。 此外,我们还将我们的模型与 ChatGPT Jiao 等人 (2023) 进行比较。
6.2.1 问答测试结果
评价方式
关注近期作品Huang 等人 (2023); Xu等人(2023b),评估方式有两种:单分模式和成对评分模式。 对于单分模式,我们首先选择要测试的模型,让模型根据给定的问题直接给出答案。 然后,我们选择评分模型(GPT4 OpenAI (2023b)),让评分模型根据问题内容给出从1到10的分数。 评分值越高表示反应越好。 显示了评分模型的输入提示的示例:
对于pairwise-score模式,受著作Zheng等人(2023)的启发,我们首先选择两个模型进行评估,让模型根据给定的问题给出答案。 然后,让评分模型根据问题内容、两个评估模型的答案以及参考答案来判断评估模型中哪个模型更好。 较好的模型计为一场胜利,较差的模型计为一场损失,如果模型的回答水平相似,则它们都计为平局。 评分模型的输入提示示例如下所示:
问答表现
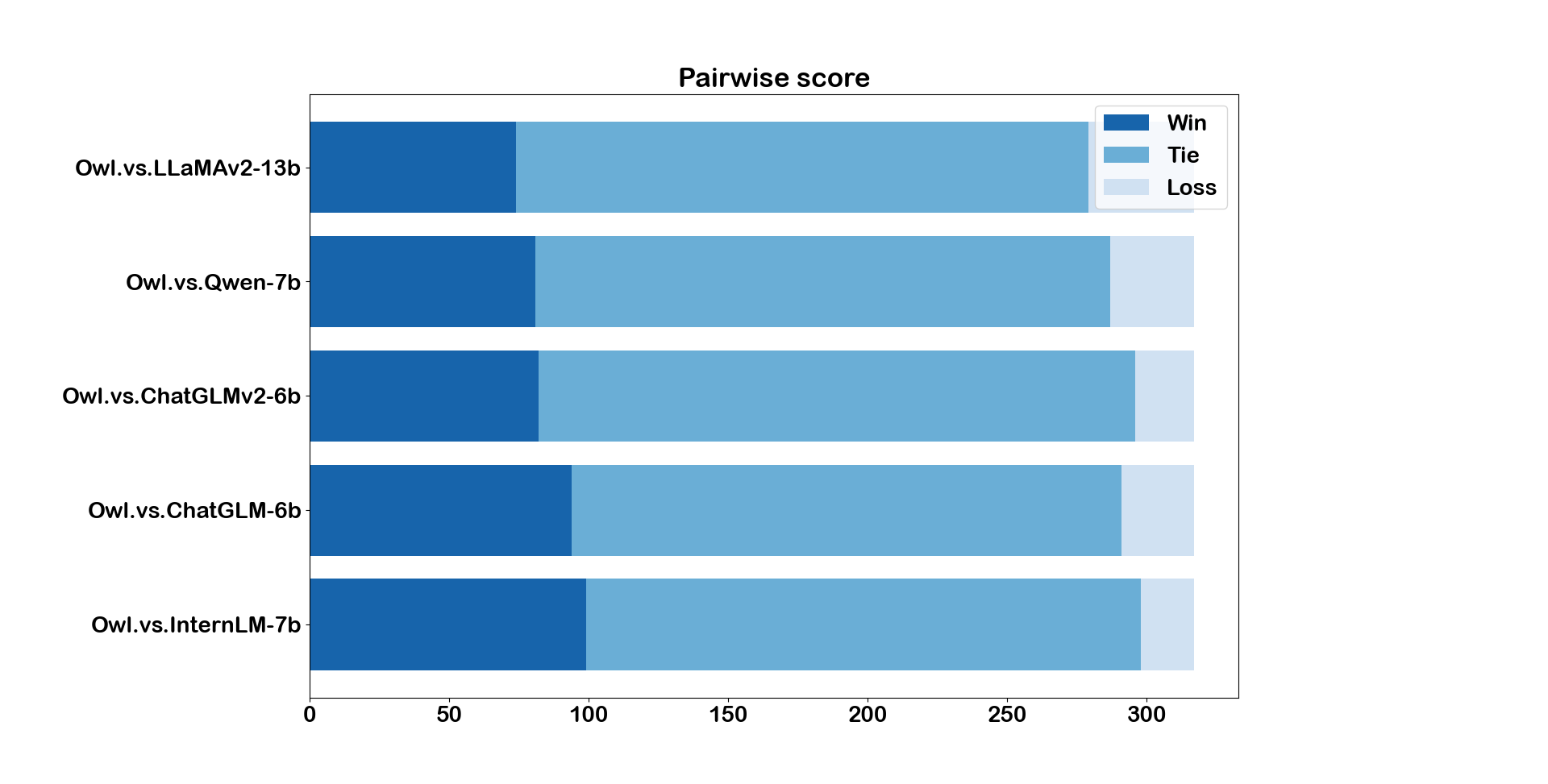
在表4中,我们展示了问答测试的平均得分,其中Owl得分最高,总体模型表现良好,得分差异较小。 至于成对得分,从图3中我们可以看到,Owl也以最好的性能击败了其余模型,但抽签次数偏多,这意味着在大多数情况下,两者都会生成令 GPT4 满意的答案。
| LLaMA2-13b | ChatGLM-6b | ChatGLM2-6b | Qwen-7b | InternLM-7b | Owl-13b | |
| Average score | 8.57 | 8.12 | 8.27 | 8.41 | 8.19 | 8.86 |
6.2.2 多项选择题的结果
评价方式
对于多项选择题,我们的方法涉及直接模型响应生成,允许模型从提供的选项(A、B、C、D)中选择单个答案。 这种方式不仅简化了评估过程,而且还提供了评估模型理解和决策能力的标准化格式。 每个问题都提供一组选择,模型的任务是做出最符合其对问题上下文和语义的理解的单一选择。 这种评估方法广泛应用于教育和评估环境中,以衡量模型在多种可能性中选择正确答案的准确性和熟练程度。 它提供了一种直接有效的方法来评估模型在多项选择问题设置中的性能,从而促进清晰简洁的评估过程。
多项选择 表现
图4和图5结果显示,ChatGPT Jiao 等人 (2023) 在这 9 个域中平均分最高,Owl 也仅比 ChatGPT 低一点点,但优于其他模型。 另外,Owl在系统架构领域比ChatGPT取得了更高的成绩。


6.3 长上下文输入评估
| Model | Sequence Length | |||
| 1024 | 2048 | 4096 | 8192 | |
| Owl-13b | 4.34 | 22.79 | 106.33 | 314.49 |
| Owl-13b + NBCE Su (2023) | 4.34 | 6.18 | 7.35 | 8.24 |
我们基于 NBCE (Su, 2023) 纳入了对免训练长上下文推理的支持。 具体来说,NBCE 采用基本贝叶斯原理来扩展大语言模型(大语言模型)的上下文处理能力。 值得注意的是,这种扩展与模型无关,不需要微调,并且提供线性效率增益。 为了证实这种方法的有效性,我们从 Owl-Bench 数据集中随机选择问答对,并将问题连接起来以创建不同长度的输入序列。 结果如表 5 所示,根据困惑度 (PPL) 进行评估。 这些发现明确强调了 NBCE 的有效性。 此外,当不使用 NBCE 时,PPL 随着输入长度的增加而按比例增加。
6.4 混合适配器的效果
在表6中,我们进行了消融实验来比较使用和不使用Mixture-of-Adapter(MoA)策略的多项选择的结果,实验表明我们的MoA是有效的,并且我们也将其与时尚LoRA Hu等人(2022),更好地展示了我们模型的效率。 具体来说,当使用不带 MoA 的指令调优时,模型的整体性能略有下降,而当使用 LoRA 微调时,最终性能接近不带 MoA 的结果。
| Method | Middleware | Information security | Infrastructure | Application | Operating system | Database | System architecture | Network | Software architecture | Mean |
| Zero-shot Testing Performance | ||||||||||
| Owl w/o MoA | 0.70 | 0.72 | 0.74 | 0.73 | 0.69 | 0.75 | 0.85 | 0.73 | 0.70 | 0.73 |
| Owl w/ LoRA | 0.69 | 0.70 | 0.72 | 0.70 | 0.65 | 0.71 | 0.82 | 0.71 | 0.72 | 0.71 |
| Owl w/ MoA | 0.75 | 0.76 | 0.77 | 0.75 | 0.72 | 0.77 | 0.86 | 0.72 | 0.72 | 0.76 |
6.5下游基准评估
6.5.1 日志解析
任务描述
日志解析代表了日志分析领域的一个经典挑战。 尽管现有方法在日志分析方面取得了显着的进步,特别是与深度学习技术结合使用时,但在实际场景中部署时它们遇到了巨大的挑战。 首先,当遇到训练样本稀缺且大量以前未见过的日志的情况时,当前方法的有效性会明显下降——这种情况在工业界经常遇到,通常被称为“在线情况”。在最极端的情况下,完全没有域内日志需要开发有效的零样本日志分析方法。
其次,日志分析技术的实用实施因其有限的可解释性而受到阻碍。 传统方法提供的预测没有附带解释。 缺乏理由使得人类分析师很难相信分析结果并根据分析结果采取行动。 相反,分析的可解释输出不仅有助于识别错误警报,而且还简化了追踪问题根本原因并随后采取适当纠正措施的任务。
数据集和基线
我们在广泛认可的LogHub基准He等人(2020)上进行了实验,该基准作为评估日志解析性能的标准。 为了评估 Owl 在零样本条件下的日志解析性能,我们采用了 LogPrompt Liu 等人 (2023) 中概述的实验设置。 我们选择了 11 种基线方法进行比较,包括 LKE Fu 等人 (2009)、LogSig Tang 等人 (2011)、Spell Du and Li (2016) 、IPLoM Makanju 等人 (2009)、Drain He 等人 (2017)、FT-tree Zhang 等人 (2017)、MoLFI Messaoudi 等人 (2018)、Logstamp Tao 等人 (2022)、LogPPT Le 和 Zhang (2023) 和 LogPrompt 刘等人(2023)。
我们的评估采用与 LogPrompt 相同的指标,其中包括 RandIndex Rand (1971);涛等人 (2022);张等人 (2017);孟等人(2020)和精细级F1-score。 RandIndex 是一种粗粒度的准确性指标,强调具有相同模板的日志的精确聚类。 相比之下,精细级 F1 分数要求准确识别日志中的可变成分。
为了遵守 LogPrompt 中规定的零样本范式,我们遵循以下方法:对于每个数据集,大多数基线都在最初 10% 的日志上进行训练,然后在剩余的 90% 上进行评估。 具体来说,LogPPT仅在前0.05%的日志上进行训练,而LogPrompt和Owl则直接在其余90%的日志上进行测试。 我们利用的提示:
结果与分析
| Methods | T.R.a | HDFS | Hadoop | Zookeeper | BGL | HPC | Linux | Proxifier | Android | Avg. | |||||||||
| RIb | F1 | RI | F1 | RI | F1 | RI | F1 | RI | F1 | RI | F1 | RI | F1 | RI | F1 | RI | F1 | ||
| IPLoM Makanju et al. (2009) | 0.914 | 0.389 | 0.636 | 0.068 | 0.787 | 0.225 | 0.858 | 0.391 | 0.228 | 0.002 | 0.695 | 0.225 | 0.822 | 0.500 | 0.918 | 0.419 | 0.733 | 0.277 | |
| LKE Fu et al. (2009) | 0.861 | 0.424 | 0.150 | 0.198 | 0.787 | 0.225 | 0.848 | 0.379 | 0.119 | 0.381 | 0.825 | 0.388 | 0.379 | 0.309 | 0.045 | 0.000 | 0.502 | 0.288 | |
| LogSig Tang et al. (2011) | 0.872 | 0.344 | 0.651 | 0.050 | 0.787 | 0.225 | 0.806 | 0.333 | 0.119 | 0.002 | 0.715 | 0.146 | 0.559 | 0.339 | 0.732 | 0.116 | 0.655 | 0.194 | |
| FT-tree Zhang et al. (2017) | 0.908 | 0.385 | 0.668 | 0.046 | 0.773 | 0.186 | 0.275 | 0.497 | 0.119 | 0.002 | 0.709 | 0.211 | 0.722 | 0.420 | 0.918 | 0.581 | 0.636 | 0.291 | |
| Spell Du and Li (2016) | 0.871 | 0.000 | 0.721 | 0.058 | 0.102 | 0.045 | 0.503 | 0.536 | 0.882 | 0.000 | 0.706 | 0.091 | 0.621 | 0.000 | 0.822 | 0.245 | 0.654 | 0.122 | |
| Drain He et al. (2017) | 0.914 | 0.389 | 0.647 | 0.068 | 0.787 | 0.225 | 0.822 | 0.397 | 0.119 | 0.002 | 0.695 | 0.225 | 0.822 | 0.500 | 0.916 | 0.413 | 0.716 | 0.277 | |
| MoLFI Messaoudi et al. (2018) | 0.871 | 0.000 | 0.699 | 0.095 | 0.899 | 0.000 | 0.792 | 0.333 | 0.881 | 0.000 | 0.410 | 0.026 | 0.621 | 0.000 | 0.173 | 0.208 | 0.668 | 0.083 | |
| LogParse Meng et al. (2020) | 0.907 | 0.632 | 0.349 | 0.502 | 0.982 | 0.348 | 0.992 | 0.665 | 0.194 | 0.330 | 0.825 | 0.588 | 0.490 | 0.334 | 0.288 | 0.233 | 0.628 | 0.454 | |
| LogStamp Tao et al. (2022) | 10% | 0.954 | 0.523 | 0.927 | 0.594 | 0.992 | 0.275 | 0.984 | 0.818 | 0.949 | 0.434 | 0.760 | 0.658 | 0.811 | 0.438 | 0.974 | 0.899 | 0.919 | 0.580 |
| LogPPT Le and Zhang (2023) | 0.05% | 0.960 | 0.838 | 0.987 | 0.526 | 0.988 | 0.795 | 0.859 | 0.982 | 0.238 | 0.287 | 0.831 | 0.423 | 0.804 | 0.638 | 0.782 | 0.313 | 0.806 | 0.600 |
| LogPrompt(ChatGPT) Liu et al. (2023) | 0% | 0.890 | 0.927 | 0.879 | 0.862 | 0.948 | 0.934 | 0.964 | 0.943 | 0.934 | 0.796 | 0.758 | 0.860 | 0.567 | 0.998 | 0.978 | 0.725 | 0.865 | 0.881 |
| Owl | 0% | 0.916 | 0.933 | 0.925 | 0.898 | 0.966 | 0.955 | 0.941 | 0.932 | 0.946 | 0.812 | 0.737 | 0.849 | 0.704 | 0.968 | 0.959 | 0.804 | 0.886 | 0.894 |
| a T.R. denotes training ratio, the ratio of logs utilized for training. | |||||||||||||||||||
| b RI stands for RandIndex. F1 stands for fine-level F1-score. | |||||||||||||||||||
日志解析任务的结果如表7所示。 值得注意的是,尽管缺乏训练数据,Owl 在 RandIndex 和最佳 F1 分数上取得了可比的表现。 在 RandIndex 比较的背景下,与 LogStamp(一种在域内日志上进行广泛训练的模型)相比,Owl 仅表现出边际性能下降。 在精细级别的 F1 比较领域,Owl 显着优于其他基线,显示出准确识别以前未见过的日志中的变量的非凡能力。 值得注意的是,值得一提的是,logPrompt 的基础模型是 ChatGPT Ouyang 等人 (2022a)。 与相同基本设置下的 ChatGPT 相比,Owl 在此任务中表现出色,凸显了我们的大型模型在运维 (O&M) 领域强大的泛化能力。
6.5.2 日志异常检测
任务描述
日志异常检测是自动化日志分析的重要组成部分,用于实时系统问题检测。 随着大规模IT系统的快速扩张,众多企业对高质量云服务的需求不断升级。 正如 Breier 和 Branišová (2015) 的著作中所阐述的那样,异常检测在审查日志数据中的特性方面具有极其重要的意义。 这些日志提供了对实时发生的系统事件以及大规模服务范围内的用户意图的复杂洞察,正如研究 Zhang 等人 (2015) 中所述。 仅从本地角度查明异常日志的努力充满了潜在的错误。 此外,由于IT服务的增长,日志数据量迅速增长,使得传统方法变得不可行。 因此,人们提出了大量的深度学习技术来解决日志异常检测挑战Du等人(2017);张等人 (2019);郭等人(2022a,2023a)。
数据集和基线
对于异常检测任务,我们在 LogHub He 等人 (2020) 上进行实验。 我们将 Owl 与四种现有方法进行比较:DeepLog Du 等人 (2017)、LogAnomaly Meng 等人 (2019)、LogRobust Zhang 等人 (2019) t2> 和 LogPrompt Liu 等人 (2023)。 基本实验设置与LogPrompt一致,以确保零样本场景,我们使用每个数据集中的前4000条日志消息来训练基线。 然后在剩余日志上测试 LogPrompt 和经过训练的基线。 评估指标为F1-score,其中代表成功识别异常会话(、、 我们为 ChatGPT 和 Owl 使用的提示:
对于异常检测,我们的实验是利用 LogHub 数据集 He 等人 (2020) 进行的。 我们将 Owl 与四种现有方法进行比较:DeepLog Du 等人 (2017)、LogAnomaly Meng 等人 (2019)、LogRobust Zhang 等人 ( 2019),以及 LogPrompt Liu 等人 (2023)。 为了保持实验设置的一致性,我们遵循 LogPrompt 中概述的基本设置,以促进零样本场景。 具体来说,我们将每个数据集中的初始 4000 条训练日志消息用于基线模型。 随后,使用剩余的日志对基线模型进行测试。
采用的评估指标是 F1 分数,其中 表示成功检测到异常会话(同样对于 、 和 )。 ChatGPT 和我们的 Owl 使用的提示如下:
结果与分析
| Methods | BGL | Spirit | ||||||
| T.N.a | P | R | F | T.N. | P | R | F | |
| DeepLog Du et al. (2017) | 4000 | 0.156 | 0.939 | 0.268 | 4000 | 0.249 | 0.289 | 0.267 |
| LogAnomaly Meng et al. (2019) | 4000 | 0.016 | 0.056 | 0.025 | 4000 | 0.231 | 0.141 | 0.175 |
| LogRobust Zhang et al. (2019) | 4000 | 0.095 | 0.425 | 0.156 | 4000 | 0.109 | 0.135 | 0.120 |
| LogPrompt(ChatGPT) Liu et al. (2023) | 0 | 0.249 | 0.834 | 0.384 | 0 | 0.290 | 0.999 | 0.450 |
| Owl | 0 | 0.301 | 0.866 | 0.446 | 0 | 0.354 | 0.972 | 0.518 |
| a T.N. denotes the number of logs utilized for training. | ||||||||
| P denotes Precision. R denotes Recall. F1 denotes F1-score. | ||||||||
异常检测任务的结果如表8所示。 值得注意的是,Owl 在这两个数据集中都优于现有方法,尽管后者是在数千条日志上进行训练的。 与 ChatGPT (LogPrompt) 相比,Owl 在两个数据集的 F1 分数方面平均提高了 6.5%。 然而,即使具有强大的大型语言模型功能,零样本场景中异常检测的绝对性能仍然有限,这突显了在存在严重有限的历史域内日志的情况下进行异常检测所面临的巨大挑战。
7相关作品
语言模型。
语言是一种独特的人类技能,在一生中不断发展,并从幼儿期开始发展Bai 等人 (2023);郭 等人 (2023b, 2022b);刘等人(2022)。 如果没有先进的人工智能 (AI) 算法的帮助,机器缺乏自然理解和使用人类语言的固有能力。 基于自监督学习训练目标和大规模数据的语言建模已被广泛用于获取上下文表示。 预训练大型 Transformer 编码器/解码器 Vaswani 等人 (2017); Chi 等人 (2020); Yang等人(2023b)为各种下游自然语言处理任务带来了显着的改进。 此外,预训练 Transformer 解码器 Brown 等人 (2020b) 有利于无条件文本生成。 通过增加模型或数据大小来扩大预训练语言模型 (PLM),可以在各种任务中带来巨大的性能提升,同时遵循已知的扩展原则。 为了探索这一点,大量研究通过训练越来越大的 PLM Chowdhery 等人 (2022a) 来突破界限; Anil 等人 (2023); Touvron 等人 (2023a, b);徐等人 (2023a); Ghosal等人(2023),比如1750亿参数的GPT-3和5400亿参数PaLM。 大语言模型的标度律 Kaplan 等人 (2020); Aghajanyan 等人 (2023) 可以指导大语言模型的训练。
尽管主要关注扩展模型大小,同时保留相似的架构和预训练任务,但与较小的 PLM 相比,这些扩展的 PLM 表现出不同的行为 Brown 等人 (2020b); OpenAI (2023a)。 这些广泛的模型展示了不可预见的能力,通常被称为“新兴能力”,这使他们能够在复杂的任务中表现出色。 大语言模型应用的一个典型例子是ChatGPT,它改编了GPT系列的大语言模型来进行对话,展示了与人类非凡的对话能力。 在大量数据集上进行微调的大语言模型显示出有希望的结果 Chung 等人 (2022);王等人 (2023a);罗等人 (2023); Wei 等人 (2022); Chen等人(2022),其中用于指令调优的提示可以由人类或大语言模型自己创建,后续指令可用于细化生成。 一种方法 Wei 等人 (2022); Chen 等人 (2022) 与指令调整相关的是思维链提示,即在给出复杂问题时提示模型解释其推理,以增加其最终答案正确的可能性。 RLHF Ouyang 等人 (2022b) 已成为微调大型语言模型的强大策略,可显着提高其性能。 在我们的工作中,我们收集 Owl-Instruct 进行训练并评估建议的 Owl。
专门的大型语言模型。
训练专用解码器大语言模型的价值在许多领域得到广泛应用,例如金融大语言模型 Wu 等人 (2023); Yang 等人 (2023a),代码大语言模型 Rozière 等人 (2023); Luo 等人 (2023)、Layer 大语言模型 Cui 等人 (2023);阮(2023)。 常见的策略包括训练专门的模型,以继续使用新的特定领域数据来预训练现有模型。 在IT运营领域,自然语言处理(NLP)技术发挥着至关重要的作用Zhang等人(2017); Messaoudi 等人 (2018); Fu等人(2009);杜和李(2016);他等人 (2017);张等人(2019),例如日志分析和解析。 IT运维大语言模型可以处理基础设施运维、中间件运维、软件架构运维等多个领域的问答任务。
8结论
在本文中,我们提出了 Owl,一种用于 IT 操作的大型语言模型。 首先,我们基于自指导策略收集Owl-Instruct数据集,其中包含各种与IT相关的任务,以提高大语言模型对IT操作的泛化能力。 然后,为了评估现有大语言模型在IT运维方面的性能,我们还引入了包含9个运维领域的Owl-Bench评估基准数据集。 此外,我们还引入了混合适配器策略来进一步增强指令调优性能。 此外,我们的 Owl-Bench 上的大量实验结果证明了我们的 Owl 对于 IT 运营的有效性。
参考
- Aghajanyan et al. (2023) Armen Aghajanyan, Lili Yu, Alexis Conneau, Wei-Ning Hsu, Karen Hambardzumyan, Susan Zhang, Stephen Roller, Naman Goyal, Omer Levy, and Luke Zettlemoyer. Scaling laws for generative mixed-modal language models. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett, editors, International Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA, volume 202 of Proceedings of Machine Learning Research, pages 265–279. PMLR, 2023. URL https://proceedings.mlr.press/v202/aghajanyan23a.html.
- Anil et al. (2023) Rohan Anil, Andrew M. Dai, Orhan Firat, Melvin Johnson, Dmitry Lepikhin, Alexandre Passos, Siamak Shakeri, Emanuel Taropa, Paige Bailey, Zhifeng Chen, Eric Chu, Jonathan H. Clark, Laurent El Shafey, Yanping Huang, Kathy Meier-Hellstern, Gaurav Mishra, Erica Moreira, Mark Omernick, Kevin Robinson, Sebastian Ruder, Yi Tay, Kefan Xiao, Yuanzhong Xu, Yujing Zhang, Gustavo Hernández Ábrego, Junwhan Ahn, Jacob Austin, Paul Barham, Jan A. Botha, James Bradbury, Siddhartha Brahma, Kevin Brooks, Michele Catasta, Yong Cheng, Colin Cherry, Christopher A. Choquette-Choo, Aakanksha Chowdhery, Clément Crepy, Shachi Dave, Mostafa Dehghani, Sunipa Dev, Jacob Devlin, Mark Díaz, Nan Du, Ethan Dyer, Vladimir Feinberg, Fangxiaoyu Feng, Vlad Fienber, Markus Freitag, Xavier Garcia, Sebastian Gehrmann, Lucas Gonzalez, and et al. Palm 2 technical report. CoRR, abs/2305.10403, 2023. doi: 10.48550/arXiv.2305.10403. URL https://doi.org/10.48550/arXiv.2305.10403.
- Bai et al. (2023) Jiaqi Bai, Hongcheng Guo, Jiaheng Liu, Jian Yang, Xinnian Liang, Zhao Yan, and Zhoujun Li. Griprank: Bridging the gap between retrieval and generation via the generative knowledge improved passage ranking. arXiv preprint arXiv:2305.18144, 2023.
- Breier and Branišová (2015) Jakub Breier and Jana Branišová. Anomaly detection from log files using data mining techniques. In Information Science and Applications, pages 449–457. Springer, 2015.
- Brown et al. (2020a) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020a.
- Brown et al. (2020b) Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. Language models are few-shot learners. CoRR, abs/2005.14165, 2020b. URL https://arxiv.org/abs/2005.14165.
- Chen et al. (2022) Wenhu Chen, Xueguang Ma, Xinyi Wang, and William W. Cohen. Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks. CoRR, abs/2211.12588, 2022. doi: 10.48550/arXiv.2211.12588. URL https://doi.org/10.48550/arXiv.2211.12588.
- Chi et al. (2020) Zewen Chi, Li Dong, Furu Wei, Wenhui Wang, Xian-Ling Mao, and Heyan Huang. Cross-lingual natural language generation via pre-training. In The Thirty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2020, The Thirty-Second Innovative Applications of Artificial Intelligence Conference, IAAI 2020, The Tenth AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2020, New York, NY, USA, February 7-12, 2020, pages 7570–7577. AAAI Press, 2020. doi: 10.1609/aaai.v34i05.6256. URL https://doi.org/10.1609/aaai.v34i05.6256.
- Chowdhery et al. (2022a) Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, Parker Schuh, Kensen Shi, Sasha Tsvyashchenko, Joshua Maynez, Abhishek Rao, Parker Barnes, Yi Tay, Noam Shazeer, Vinodkumar Prabhakaran, Emily Reif, Nan Du, Ben Hutchinson, Reiner Pope, James Bradbury, Jacob Austin, Michael Isard, Guy Gur-Ari, Pengcheng Yin, Toju Duke, Anselm Levskaya, Sanjay Ghemawat, Sunipa Dev, Henryk Michalewski, Xavier Garcia, Vedant Misra, Kevin Robinson, Liam Fedus, Denny Zhou, Daphne Ippolito, David Luan, Hyeontaek Lim, Barret Zoph, Alexander Spiridonov, Ryan Sepassi, David Dohan, Shivani Agrawal, Mark Omernick, Andrew M. Dai, Thanumalayan Sankaranarayana Pillai, Marie Pellat, Aitor Lewkowycz, Erica Moreira, Rewon Child, Oleksandr Polozov, Katherine Lee, Zongwei Zhou, Xuezhi Wang, Brennan Saeta, Mark Diaz, Orhan Firat, Michele Catasta, Jason Wei, Kathy Meier-Hellstern, Douglas Eck, Jeff Dean, Slav Petrov, and Noah Fiedel. Palm: Scaling language modeling with pathways. CoRR, abs/2204.02311, 2022a. doi: 10.48550/arXiv.2204.02311. URL https://doi.org/10.48550/arXiv.2204.02311.
- Chowdhery et al. (2022b) Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. Palm: Scaling language modeling with pathways. arXiv preprint arXiv:2204.02311, 2022b.
- Chung et al. (2022) Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Y. Zhao, Yanping Huang, Andrew M. Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei. Scaling instruction-finetuned language models. CoRR, abs/2210.11416, 2022. doi: 10.48550/arXiv.2210.11416. URL https://doi.org/10.48550/arXiv.2210.11416.
- Cui et al. (2023) Jiaxi Cui, Zongjian Li, Yang Yan, Bohua Chen, and Li Yuan. Chatlaw: Open-source legal large language model with integrated external knowledge bases. CoRR, abs/2306.16092, 2023. doi: 10.48550/arXiv.2306.16092. URL https://doi.org/10.48550/arXiv.2306.16092.
- Dang et al. (2019) Yingnong Dang, Qingwei Lin, and Peng Huang. Aiops: real-world challenges and research innovations. In 2019 IEEE/ACM 41st International Conference on Software Engineering: Companion Proceedings (ICSE-Companion), pages 4–5. IEEE, 2019.
- Du and Li (2016) Min Du and Feifei Li. Spell: Streaming parsing of system event logs. In 2016 IEEE 16th International Conference on Data Mining (ICDM), pages 859–864. IEEE, 2016.
- Du et al. (2017) Min Du, Feifei Li, Guineng Zheng, and Vivek Srikumar. Deeplog: Anomaly detection and diagnosis from system logs through deep learning. In Proceedings of the 2017 ACM SIGSAC conference on computer and communications security, pages 1285–1298, 2017.
- Du et al. (2022) Zhengxiao Du, Yujie Qian, Xiao Liu, Ming Ding, Jiezhong Qiu, Zhilin Yang, and Jie Tang. Glm: General language model pretraining with autoregressive blank infilling. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 320–335, 2022.
- Fu et al. (2009) Qiang Fu, Jian-Guang Lou, Yi Wang, and Jiang Li. Execution anomaly detection in distributed systems through unstructured log analysis. In 2009 ninth IEEE international conference on data mining, pages 149–158, 2009.
- Gao and Pishdad-Bozorgi (2019) Xinghua Gao and Pardis Pishdad-Bozorgi. Bim-enabled facilities operation and maintenance: A review. Advanced engineering informatics, 39:227–247, 2019.
- Ghosal et al. (2023) Deepanway Ghosal, Yew Ken Chia, Navonil Majumder, and Soujanya Poria. Flacuna: Unleashing the problem solving power of vicuna using FLAN fine-tuning. CoRR, abs/2307.02053, 2023. doi: 10.48550/arXiv.2307.02053. URL https://doi.org/10.48550/arXiv.2307.02053.
- Guo et al. (2022a) Hongcheng Guo, Xingyu Lin, Jian Yang, Yi Zhuang, Jiaqi Bai, Tieqiao Zheng, Bo Zhang, and Zhoujun Li. Translog: A unified transformer-based framework for log anomaly detection. CoRR, abs/2201.00016, 2022a.
- Guo et al. (2022b) Hongcheng Guo, Jiaheng Liu, Haoyang Huang, Jian Yang, Zhoujun Li, Dongdong Zhang, and Zheng Cui. Lvp-m3: Language-aware visual prompt for multilingual multimodal machine translation. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 2862–2872, 2022b.
- Guo et al. (2023a) Hongcheng Guo, Yuhui Guo, Jian Yang, Jiaheng Liu, Zhoujun Li, Tieqiao Zheng, Liangfan Zheng, Weichao Hou, and Bo Zhang. Loglg: Weakly supervised log anomaly detection via log-event graph construction. In DASFAA 2023, volume 13946, pages 490–501. Springer, 2023a.
- Guo et al. (2023b) Jinyang Guo, Jiaheng Liu, Zining Wang, Yuqing Ma, Ruihao Gong, Ke Xu, and Xianglong Liu. Adaptive contrastive knowledge distillation for BERT compression. In Findings of the Association for Computational Linguistics: ACL 2023, pages 8941–8953, Toronto, Canada, July 2023b. Association for Computational Linguistics.
- He et al. (2022) Junxian He, Chunting Zhou, Xuezhe Ma, Taylor Berg-Kirkpatrick, and Graham Neubig. Towards a unified view of parameter-efficient transfer learning. In The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net, 2022. URL https://openreview.net/forum?id=0RDcd5Axok.
- He et al. (2017) Pinjia He, Jieming Zhu, Zibin Zheng, and Michael R Lyu. Drain: An online log parsing approach with fixed depth tree. In 2017 IEEE international conference on web services (ICWS), pages 33–40. IEEE, 2017.
- He et al. (2020) Shilin He, Jieming Zhu, Pinjia He, and Michael R Lyu. Loghub: a large collection of system log datasets towards automated log analytics. arXiv preprint arXiv:2008.06448, 2020.
- Hendrycks et al. (2021) Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset. In Joaquin Vanschoren and Sai-Kit Yeung, editors, Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks 1, NeurIPS Datasets and Benchmarks 2021, December 2021, virtual, 2021.
- Houlsby et al. (2019) Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin de Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. Parameter-efficient transfer learning for NLP. In Kamalika Chaudhuri and Ruslan Salakhutdinov, editors, Proceedings of the 36th International Conference on Machine Learning, ICML 2019, 9-15 June 2019, Long Beach, California, USA, volume 97 of Proceedings of Machine Learning Research, pages 2790–2799. PMLR, 2019. URL http://proceedings.mlr.press/v97/houlsby19a.html.
- Hu et al. (2022) Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. In The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net, 2022. URL https://openreview.net/forum?id=nZeVKeeFYf9.
- Huang et al. (2023) Yuzhen Huang, Yuzhuo Bai, Zhihao Zhu, Junlei Zhang, Jinghan Zhang, Tangjun Su, Junteng Liu, Chuancheng Lv, Yikai Zhang, Jiayi Lei, Yao Fu, Maosong Sun, and Junxian He. C-eval: A multi-level multi-discipline chinese evaluation suite for foundation models. CoRR, abs/2305.08322, 2023.
- Jiao et al. (2023) Wenxiang Jiao, Wenxuan Wang, Jen-tse Huang, Xing Wang, and Zhaopeng Tu. Is chatgpt a good translator? a preliminary study. arXiv preprint arXiv:2301.08745, 2023.
- Kaplan et al. (2020) Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models. CoRR, abs/2001.08361, 2020. URL https://arxiv.org/abs/2001.08361.
- Le and Zhang (2023) Van-Hoang Le and Hongyu Zhang. Log parsing with prompt-based few-shot learning. In 2023 IEEE/ACM International Conference on Software Engineering (ICSE). IEEE, 2023.
- Li et al. (2023) Minghao Li, Tengchao Lv, Jingye Chen, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, and Furu Wei. Trocr: Transformer-based optical character recognition with pre-trained models. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 13094–13102, 2023.
- Liu et al. (2022) Jiaheng Liu, Tan Yu, Hanyu Peng, Mingming Sun, and Ping Li. Cross-lingual cross-modal consolidation for effective multilingual video corpus moment retrieval. In Findings of the Association for Computational Linguistics: NAACL 2022, pages 1854–1862, Seattle, United States, July 2022. Association for Computational Linguistics.
- Liu et al. (2023) Yilun Liu, Shimin Tao, Weibin Meng, Jingyu Wang, Wenbing Ma, Yanqing Zhao, Yuhang Chen, Hao Yang, Yanfei Jiang, and Xun Chen. Logprompt: Prompt engineering towards zero-shot and interpretable log analysis. CoRR, abs/2308.07610, 2023.
- Luo et al. (2023) Ziyang Luo, Can Xu, Pu Zhao, Qingfeng Sun, Xiubo Geng, Wenxiang Hu, Chongyang Tao, Jing Ma, Qingwei Lin, and Daxin Jiang. Wizardcoder: Empowering code large language models with evol-instruct. CoRR, abs/2306.08568, 2023. doi: 10.48550/arXiv.2306.08568. URL https://doi.org/10.48550/arXiv.2306.08568.
- Makanju et al. (2009) Adetokunbo AO Makanju, A Nur Zincir-Heywood, and Evangelos E Milios. Clustering event logs using iterative partitioning. In Proceedings of the 15th ACM SIGKDD international conference on Knowledge discovery and data mining, pages 1255–1264, 2009.
- Meng et al. (2019) Weibin Meng, Ying Liu, Yichen Zhu, et al. Loganomaly: Unsupervised detection of sequential and quantitative anomalies in unstructured logs. In IJCAI, volume 19, pages 4739–4745, 2019.
- Meng et al. (2020) Weibin Meng, Ying Liu, Federico Zaiter, et al. Logparse: Making log parsing adaptive through word classification. In 2020 29th International Conference on Computer Communications and Networks (ICCCN), pages 1–9, 2020.
- Messaoudi et al. (2018) Salma Messaoudi, Annibale Panichella, Domenico Bianculli, Lionel Briand, and Raimondas Sasnauskas. A search-based approach for accurate identification of log message formats. In 2018 IEEE/ACM 26th International Conference on Program Comprehension (ICPC), pages 167–16710. IEEE, 2018.
- Nguyen (2023) Ha-Thanh Nguyen. A brief report on lawgpt 1.0: A virtual legal assistant based on GPT-3. CoRR, abs/2302.05729, 2023. doi: 10.48550/arXiv.2302.05729. URL https://doi.org/10.48550/arXiv.2302.05729.
- OpenAI (2023a) OpenAI. GPT-4 technical report. CoRR, abs/2303.08774, 2023a. doi: 10.48550/arXiv.2303.08774. URL https://doi.org/10.48550/arXiv.2303.08774.
- OpenAI (2023b) OpenAI. Gpt-4 technical report, 2023b.
- Ouyang et al. (2022a) Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730–27744, 2022a.
- Ouyang et al. (2022b) Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F. Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedback. In NeurIPS, 2022b. URL http://papers.nips.cc/paper_files/paper/2022/hash/b1efde53be364a73914f58805a001731-Abstract-Conference.html.
- Rand (1971) William M Rand. Objective criteria for the evaluation of clustering methods. Journal of the American Statistical association, 66(336):846–850, 1971.
- Rijal et al. (2022) Laxmi Rijal, Ricardo Colomo-Palacios, and Mary Sánchez-Gordón. Aiops: A multivocal literature review. Artificial Intelligence for Cloud and Edge Computing, pages 31–50, 2022.
- Rozière et al. (2023) Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton-Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usunier, Thomas Scialom, and Gabriel Synnaeve. Code llama: Open foundation models for code. CoRR, abs/2308.12950, 2023. doi: 10.48550/arXiv.2308.12950. URL https://doi.org/10.48550/arXiv.2308.12950.
- Su (2023) Jianlin Su. Naive bayes-based context extension. https://github.com/bojone/NBCE, 2023.
- Tang et al. (2011) Liang Tang, Tao Li, and Chang-Shing Perng. Logsig: Generating system events from raw textual logs. In Proceedings of the 20th ACM international conference on Information and knowledge management, pages 785–794, 2011.
- Tao et al. (2022) Shimin Tao, Weibin Meng, Yimeng Cheng, Yichen Zhu, Ying Liu, Chunning Du, Tao Han, Yongpeng Zhao, Xiangguang Wang, and Hao Yang. Logstamp: Automatic online log parsing based on sequence labelling. ACM SIGMETRICS Performance Evaluation Review, 49(4):93–98, 2022.
- Taylor et al. (2022) Ross Taylor, Marcin Kardas, Guillem Cucurull, Thomas Scialom, Anthony Hartshorn, Elvis Saravia, Andrew Poulton, Viktor Kerkez, and Robert Stojnic. Galactica: A large language model for science. CoRR, abs/2211.09085, 2022.
- Team (2023) InternLM Team. Internlm: A multilingual language model with progressively enhanced capabilities. https://github.com/InternLM/InternLM, 2023.
- Touvron et al. (2023a) Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurélien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. Llama: Open and efficient foundation language models. CoRR, abs/2302.13971, 2023a.
- Touvron et al. (2023b) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton-Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez, Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushkar Mishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing Ellen Tan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurélien Rodriguez, Robert Stojnic, Sergey Edunov, and Thomas Scialom. Llama 2: Open foundation and fine-tuned chat models. CoRR, abs/2307.09288, 2023b. doi: 10.48550/arXiv.2307.09288. URL https://doi.org/10.48550/arXiv.2307.09288.
- Vaswani et al. (2017) Ashish Vaswani, Noam M. Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. NIPS, 2017.
- Wang et al. (2022) Yaqing Wang, Sahaj Agarwal, Subhabrata Mukherjee, Xiaodong Liu, Jing Gao, Ahmed Hassan Awadallah, and Jianfeng Gao. Adamix: Mixture-of-adaptations for parameter-efficient model tuning. In Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang, editors, Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, EMNLP 2022, Abu Dhabi, United Arab Emirates, December 7-11, 2022, pages 5744–5760. Association for Computational Linguistics, 2022. URL https://aclanthology.org/2022.emnlp-main.388.
- Wang et al. (2023a) Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, and Hannaneh Hajishirzi. Self-instruct: Aligning language models with self-generated instructions. In Anna Rogers, Jordan L. Boyd-Graber, and Naoaki Okazaki, editors, Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, Canada, July 9-14, 2023, pages 13484–13508. Association for Computational Linguistics, 2023a. URL https://aclanthology.org/2023.acl-long.754.
- Wang et al. (2023b) Zixiang Wang, Linzheng Chai, Jian Yang, Jiaqi Bai, Yuwei Yin, Jiaheng Liu, Hongcheng Guo, Tongliang Li, Liqun Yang, Hebboul Zine El Abidine, and Zhoujun Li. Mt4crossoie: Multi-stage tuning for cross-lingual open information extraction. CoRR, abs/2308.06552, 2023b. doi: 10.48550/arXiv.2308.06552. URL https://doi.org/10.48550/arXiv.2308.06552.
- Wei et al. (2022) Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. In NeurIPS, 2022. URL http://papers.nips.cc/paper_files/paper/2022/hash/9d5609613524ecf4f15af0f7b31abca4-Abstract-Conference.html.
- Wu et al. (2023) Shijie Wu, Ozan Irsoy, Steven Lu, Vadim Dabravolski, Mark Dredze, Sebastian Gehrmann, Prabhanjan Kambadur, David S. Rosenberg, and Gideon Mann. Bloomberggpt: A large language model for finance. CoRR, abs/2303.17564, 2023. doi: 10.48550/arXiv.2303.17564. URL https://doi.org/10.48550/arXiv.2303.17564.
- Xu et al. (2023a) Can Xu, Qingfeng Sun, Kai Zheng, Xiubo Geng, Pu Zhao, Jiazhan Feng, Chongyang Tao, and Daxin Jiang. Wizardlm: Empowering large language models to follow complex instructions. CoRR, abs/2304.12244, 2023a. doi: 10.48550/arXiv.2304.12244. URL https://doi.org/10.48550/arXiv.2304.12244.
- Xu et al. (2023b) Canwen Xu, Daya Guo, Nan Duan, and Julian McAuley. Baize: An open-source chat model with parameter-efficient tuning on self-chat data. arXiv preprint arXiv:2304.01196, 2023b.
- Yang et al. (2023a) Hongyang Yang, Xiao-Yang Liu, and Christina Dan Wang. Fingpt: Open-source financial large language models. CoRR, abs/2306.06031, 2023a. doi: 10.48550/arXiv.2306.06031. URL https://doi.org/10.48550/arXiv.2306.06031.
- Yang et al. (2022) Jian Yang, Yuwei Yin, Shuming Ma, Dongdong Zhang, Zhoujun Li, and Furu Wei. High-resource language-specific training for multilingual neural machine translation. In Luc De Raedt, editor, Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence, IJCAI 2022, Vienna, Austria, 23-29 July 2022, pages 4461–4467. ijcai.org, 2022. doi: 10.24963/ijcai.2022/619. URL https://doi.org/10.24963/ijcai.2022/619.
- Yang et al. (2023b) Jian Yang, Shuming Ma, Li Dong, Shaohan Huang, Haoyang Huang, Yuwei Yin, Dongdong Zhang, Liqun Yang, Furu Wei, and Zhoujun Li. Ganlm: Encoder-decoder pre-training with an auxiliary discriminator. In Anna Rogers, Jordan L. Boyd-Graber, and Naoaki Okazaki, editors, Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, Canada, July 9-14, 2023, pages 9394–9412. Association for Computational Linguistics, 2023b. doi: 10.18653/v1/2023.acl-long.522. URL https://doi.org/10.18653/v1/2023.acl-long.522.
- Zhang et al. (2015) Shenglin Zhang, Ying Liu, Dan Pei, Yu Chen, Xianping Qu, Shimin Tao, and Zhi Zang. Rapidand robust impact assessment of software changes in large internet-based services. In ENET 2015, 2015.
- Zhang et al. (2017) Shenglin Zhang, Weibin Meng, et al. Syslog processing for switch failure diagnosis and prediction in datacenter networks. In IEEE/ACM 25th International Symposium on Quality of Service (IWQoS’17), pages 1–10, 2017.
- Zhang et al. (2019) Xu Zhang, Yong Xu, Qingwei Lin, Bo Qiao, Hongyu Zhang, Yingnong Dang, Chunyu Xie, Xinsheng Yang, Qian Cheng, Ze Li, et al. Robust log-based anomaly detection on unstable log data. In Proceedings of the 2019 27th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, pages 807–817, 2019.
- Zheng et al. (2023) Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena. CoRR, abs/2306.05685, 2023.
- Zhou et al. (2023) Chunting Zhou, Pengfei Liu, Puxin Xu, Srini Iyer, Jiao Sun, Yuning Mao, Xuezhe Ma, Avia Efrat, Ping Yu, Lili Yu, Susan Zhang, Gargi Ghosh, Mike Lewis, Luke Zettlemoyer, and Omer Levy. LIMA: less is more for alignment. CoRR, abs/2305.11206, 2023.
- Zhu et al. (2021) Yaoming Zhu, Jiangtao Feng, Chengqi Zhao, Mingxuan Wang, and Lei Li. Counter-interference adapter for multilingual machine translation. In Marie-Francine Moens, Xuanjing Huang, Lucia Specia, and Scott Wen-tau Yih, editors, Findings of the Association for Computational Linguistics: EMNLP 2021, Virtual Event / Punta Cana, Dominican Republic, 16-20 November, 2021, pages 2812–2823. Association for Computational Linguistics, 2021. doi: 10.18653/v1/2021.findings-emnlp.240. URL https://doi.org/10.18653/v1/2021.findings-emnlp.240.