CulturaX:一个干净、庞大的多语言数据集,适用于 167 种语言的大型语言模型
摘要
具有令人印象深刻的学习能力的大型语言模型(大训练语言模型)开发背后的驱动因素是其庞大的模型规模和广泛的数据集。 随着自然语言处理的进步,大语言模型经常向公众开放,以促进更深入的研究和应用。 然而,当涉及到这些大语言模型的训练数据集,尤其是最近最先进的模型时,它们往往没有完全公开。 为高性能大语言模型创建训练数据涉及大量清理和重复数据删除,以确保必要的质量水平。 因此,训练数据缺乏透明度阻碍了大语言模型中归因和解决幻觉和偏见问题的研究,阻碍了复制工作和社区的进一步进步。 这些挑战在多语言学习场景中变得更加明显,其中可用的多语言文本数据集通常收集和清理不充分。 因此,缺乏开源且易于使用的数据集来有效训练多种语言的大语言模型。 为了解决这个问题,我们推出了 CulturaX,这是一个庞大的多语言数据集,包含 167 种语言的 6.3 万亿个标记,专为大语言模型开发而定制。 我们的数据集通过多个阶段的严格流程进行细致的清理和重复数据删除,以实现模型训练的最佳质量,包括语言识别、基于 URL 的过滤、基于指标的清理、文档细化和重复数据删除。 CulturaX 在 HuggingFace 上全面向公众发布,以促进多语言大语言模型的研究和进展:https://huggingface.co/datasets/uonlp/CulturaX。
1简介
大型语言模型(大语言模型)从根本上改变了自然语言处理(NLP)的研究和应用,显着提高了众多任务的最先进性能,并揭示了新的新兴能力Brown 等人(2020) ;魏等人(2022)。 基于 Transformer 架构 Vaswani 等人 (2017),文献中探索了大语言模型的三个主要变体:仅编码器模型,用于将输入文本编码为表示向量,例如 BERT Devlin 等人 (2019) 和 RoBERTa Liu 等人 (2019);用于生成文本的仅解码器模型,例如 GPT Radford 等人 (2019);布朗等人 (2020);以及执行序列到序列生成的编码器-解码器模型,例如 BART Lewis 等人 (2020) 和 T5 Raffel 等人 (2020)。 大语言模型的卓越能力主要得益于模型规模和训练数据集规模的不断扩大,这被认为是通过缩放定律实现最佳性能所必需的 Hernandez 等人 (2022) 。 例如,从只有几亿个参数的 BERT 模型开始Devlin 等人 (2019),最近基于 GPT 的模型已扩展到包含数千亿个参数Shoeybi等人 (2019); Scao 等人 (2022);利伯等人 (2021); Chowdhery 等人 (2022)。 同样,大语言模型的训练数据集呈指数级增长,由来自维基百科的 13GB 文本数据和用于 BERT Devlin 等人 (2019) 的书籍演变而来; Liu 等人 (2019) 为最新模型消耗 TB 级数据,例如 Falcon Penedo 等人 (2023)、MPT MosaicML (2023)、 LLaMa Touvron 等人 (2023)、PolyLM Wei 等人 (2023) 和 ChatGPT111https://openai.com/blog/chatgpt。
随着该领域不断快速发展,预先训练的大语言模型通常会向公众发布,以促进进一步的研究和进步。 这些模型可以通过商业 API 获得,如 ChatGPT 和 GPT-4 所示,也可以通过开源计划获得,如 Falcon 和 LLaMa 所示。 然而,与大语言模型的公开可访问性相比,支撑最先进模型的训练数据集大多仍处于严格保密状态,即使是开源大语言模型(例如 BLOOM、LLaMa) 、MPT 和猎鹰。 例如,Falcon Penedo 等人 (2023) 和 BLOOM Scao 等人 (2022) 仅提供其完整训练数据的一瞥,而 MPT、LLaMa 和 PolyLM 的数据集 Touvron 等人 (2023); Wei 等人 (2023) 仍然无法向公众开放。 一方面,缺乏透明度阻碍了对大语言模型的深入分析和理解,阻碍了对训练数据产生的幻觉、偏见和有毒内容等基本问题的归因和解决的关键研究Tamkin等人 (2021); Weidinger 等人 (2021); Kenton 等人 (2021); Bommasani 等人 (2021)。 另一方面,隐藏训练数据将大语言模型的开发限制在少数拥有充足资源的利益相关者手中,从而限制了该技术的民主化和效益,并加剧了其在更广泛社会中的偏见。
为了实现大语言模型的透明度和民主化,至关重要的是创建大规模和高质量的数据集来训练高性能大语言模型,同时确保其公共可访问性以促进更深入的研究和进步。 在大语言模型领域,高质量的训练数据集通常是通过应用广泛的数据清理和重复数据删除过程来制作的,旨在消除大量文本集合中的噪声和冗余内容Allamanis (2018); Penedo 等人 (2023)。 为此,社区最近努力为大语言模型开发此类开源数据集,例如拥有 1.21T 词符 Computer (2023), SlimPajama222%TT␣every␣character␣and␣hyphenate␣after␣ithttps://www.cerebras.net/blog/slimpajama-a-627b-token-cleaned-and-deduplicated-version-of-redpajama,共 627B 个词符、and AI2 Dolma333%TT␣every␣character␣and␣hyphenate␣after␣ithttps://blog.allenai.org/dolma-3-trillion-tokens-open-llm-corpus-9a0ff4b8da64使用 3T 词符。 然而,现有的大语言模型开源数据集大多是针对英语语言量身定制的,这阻碍了大语言模型在非英语语言(特别是那些语言资源有限的语言)上的利用和性能 Bang 等人 (2023);赖等人(2023)。 对英语的重视也限制了开源数据集全面解决大语言模型在全球 7,000 多种语言中的研究挑战和民主化问题的能力。
同时,一些多语言数据集已经开发出来并可供使用,提供多种语言的文本数据。 但其质量和规模尚不能满足训练高性能大语言模型的要求。 具体来说,来自维基百科的多语言文本数据集虽然质量很高,但在训练大语言模型 Conneau 等人 (2020) 方面被认为相对较小。 OSCAR 数据集 Ortiz Suárez 等人 (2019);奥尔蒂斯·苏亚雷斯 (Ortiz Suárez) 等人 (2020);阿巴吉 等人 (2021, 2022)444https://oscar-project.org 从 CommonCrawl (CC) 中提取 160 多种语言的文本数据。 然而,这些数据集缺乏文档级重复数据删除(即删除数据集中的相似文档),导致包含冗余信息并损害生成大语言模型 Lee 等人 (2022) 的性能。 同样,mC4 Xue 等人 (2021)、CCAligned Conneau 等人 (2020)、WikiMatrix Schwenk 等人 (2021) 和 ParaCrawl Bañón 等人 (2020) 数据集总共支持 100 多种语言,但语言识别不太准确,从而在数据中引入了噪声 Kreutzer 等人 (2022)。 这些数据集也没有在模糊和文档级别进行重复数据删除,例如通过 MinHash Broder (1997)。 此外,CC100 数据集 Wenzek 等人 (2020); Conneau 等人 (2020),用于跨 100 种语言的多语言 XLM-RoBERTa 模型,仅考虑 2018 年 CC 的快照,限制了其大小和最新信息的可用性,以训练高表演大语言模型。
为了解决开源数据集的上述问题,我们的工作引入了一种新颖的多语言数据集,称为 CulturaX,用于 167 种语言的大语言模型训练。 CulturaX 将 mC4 的最新版本(版本 3.1.0)与截至今年的所有可用 OSCAR 语料库合并,包括发行版 20.19、21.09、22.01 和 23.01。 这种合并产生了一个大型多语言数据集,其中包含 27 TB 文本数据和 6.3 万亿个标记,并为大语言模型开发提供最新数据。 我们超过一半的数据集专用于非英语语言,以显着增加数据大小并增强多语言场景中训练模型的可行性。 重要的是,CulturaX 在文档级别进行了广泛的清理和重复数据删除,以生成最高质量的多种语言训练大语言模型。 特别是,我们的数据清理流程包括旨在消除低质量数据的综合管道。 这包括删除嘈杂的文本、非语言内容、有毒数据、不正确的语言识别等等。 我们的数据清理管道采用四分位数范围 (IQR) 方法的变体 Dekking 等人 (2007) 为各种数据集指标(例如,停用词比率、数据困惑度和语言识别分数)选择适当的阈值,可用于过滤数据集的噪声异常值。 因此,我们利用在大量数据样本上计算的分布百分位数来有效指导每个过滤指标和语言的阈值选择过程。 最后,我们基于近重复数据删除方法 MinHashLSH Broder (1997) 对数据集中的语言数据进行广泛的重复数据删除; Leskovec 等人 (2020) 和 URL,为训练多语言大语言模型提供高质量的数据。 我们的数据集将完全向公众开放,以促进多语言学习的进一步研究和开发。 据我们所知,CulturaX 是迄今为止最大的开源多语言数据集,针对大语言模型和 NLP 应用进行了深度清理和去重。
2 多语言数据集创建
为了开发大语言模型的多语言公共数据集,我们的策略是结合 mC4 Xue 等人 (2021) 和 OSCAR Ortiz Suárez 等人 (2019); Abadji 等人 (2021, 2022),我们可以使用的两个最大的多语言数据集。 然后,我们通过广泛的流程处理数据,包括清理和重复数据删除两个主要步骤,为多语言大语言模型生成巨大且高质量的数据集。
mC4 是一个多语言文档级数据集,最初创建用于训练 101 种语言的多语言编码器-解码器模型 mT5 Xue 等人 (2021)。 该数据集是从 CC 的 71 个每月快照中提取的,方法是删除少于三行的页面(行长度过滤器)、含有不良单词的页面以及跨文档的重复行。 mC4中页面的语言识别由cld3工具Botha等人(2017)555https://github.com/google/cld3,这是一个小型前馈网络薛等人(2021). 任何语言置信度低于 0.95% 的页面都会被排除。 mC4在文档级别进行重复数据精确匹配;但是,不执行模糊文档级重复数据删除。 我们使用最新版本的 mC4(版本 3.1.0)666https://huggingface.co/datasets/mc4 由 AllenAI 在本工作中准备。
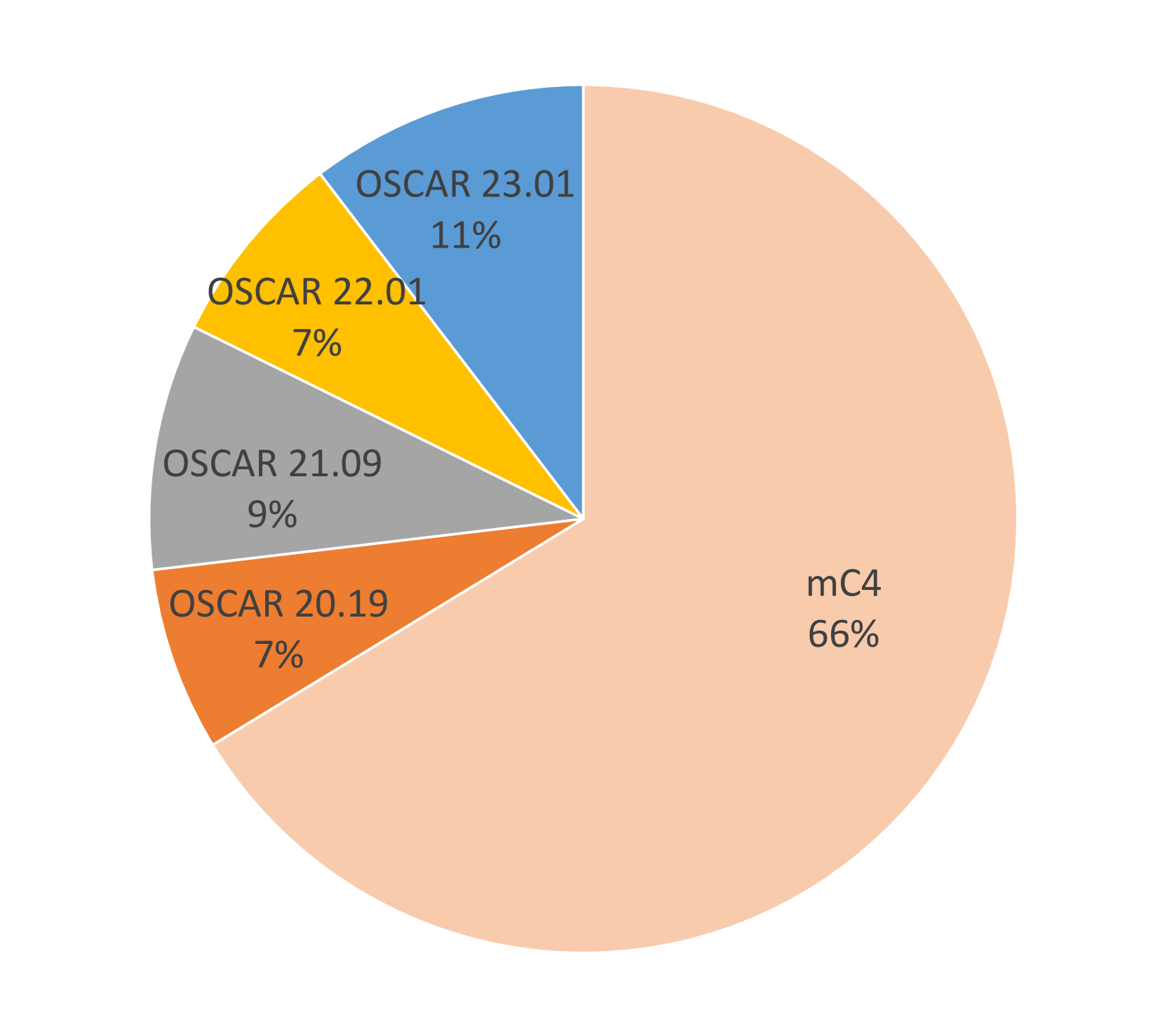
我们的数据集的一个值得注意的方面涉及我们选择的数据集 mC4 和 OSCAR 的基于网络的来源,这些数据集是从 CC 中提取的。 这与之前的某些工作Radford等人(2019)不同; MosaicML(2023); Touvron 等人 (2023) 也依赖于 The Pile Gao 等人 (2020) 和 BookCorpus Zhu 等人 (2015) 等精选数据集来训练大语言模型,假定他们的综合素质较高。 然而,在多语言环境中,我们认为网络抓取的数据集可能是更合适的方法,因为高质量的精选数据集可能不适用于各种语言。 我们使用网络抓取数据的策略促进了跨多种语言的高效数据收集,有助于增强训练数据规模。 此外,最近的研究证明了清理网络抓取数据以产生最先进的大语言模型Raffel等人(2020)的有效性; Almazrouei 等人 (2023)。 mC4 和 OSCAR 的结合总共为我们提供了 13.5B 文档以供进一步处理。 图 1 说明了我们初始数据集中 mC4 和 OSCAR 的四个可用版本的文档计数分布。
2.1数据清理
考虑到 mC4 和 OSCAR 数据集的结合,我们首先执行全面的数据清理程序,以删除数据中的噪声和不良内容,包括语言识别、基于 ULR 的过滤、基于度量的清理和文档细化。
语言识别:一个特殊问题涉及两种不同语言识别工具的使用,即cld3和FastText,分别用于mC4和OSCAR。 之前的研究表明,cld3 明显比 FastText 差,导致 mC4 Kreutzer 等人 (2022) 的语言检测错误明显增多。 事实上,与其他几种语言检测器相比,FastText 在基准数据集上展示了最先进的性能777https://modelpredict.com/language-identification-survey。 为此,我们的第一个数据清理步骤涉及应用 FastText 重新预测 mC4 中文档的语言。 预测语言与 mC4 中提供的语言不同的文档将从数据集中删除。 其基本原理是避免让语言检测器 cld3 和 FastText 感到困惑的文档,从而可能会给数据带来噪音。 最后,为了确保最高质量,我们删除了 mC4 中找到但 FastText 不支持的任何语言的数据。
基于 URL 的过滤:下一步,我们的目标是消除来自已知有毒有害来源的页面,以降低数据带来的相关风险。 特别是,我们利用图卢兹大学提供的最新 UT1 URL 和域黑名单来支持学校管理人员的互联网使用监管。 该列表涉及不同主题的网站,包括色情、吐槽、黑客等,在大语言模型训练中应丢弃这些网站。 黑名单每周更新两次到三次,涉及超过 370 万条由人类和机器人贡献的记录(例如搜索引擎、已知地址和索引)Abadji 等人 (2022)。 因此,我们从数据集中删除其关联 URL 与黑名单中的网站匹配的任何页面。 此步骤对我们的数据集很有帮助,因为 mC4 数据集之前未使用黑名单。 此外,虽然 OSCAR 已经使用此黑名单进行数据清理,但我们的方法包含了列表中的最新信息,这些信息可能不适用于 OSCAR 当前的发行版。
基于指标的清理:在 BLOOM Laurençon 等人 (2022) 的 BigScience ROOTS 语料库的数据处理管道的推动下,提高数据集的质量; Scao 等人 (2022),我们进一步利用各种数据集指标的分布来识别和过滤外围文档。 每个指标为数据集中的每个文档提供一个奇异值,量化每个文档的特定属性,例如 number_words、stopword_ratios 和 perplexity_score。 对于数据集中的每个指标及其可能值的范围,将确定一个阈值以将该范围划分为两个区域:正常范围和异常范围。 异常范围是针对表现出明显偏离正常值的度量值的文档指定的,将它们分类为异常值/噪声,因此,这些异常值会从我们的数据集中删除。 因此,我们采用了一系列全面的数据集指标,这些指标将共同用于完善我们的数据集,如下所述:
-
•
字数
-
•
字符重复率
-
•
单词重复率
-
•
特殊字符比例
-
•
停用词比例
-
•
标记字数比例
-
•
语言识别置信度
-
•
困惑度分数
-
•
文档长度(字符数)
-
•
行数
-
•
短线长度比
-
•
短线比
最后四个指标是由 OSCAR 数据集建议的,而其他指标则继承自 BigScience ROOTS 语料库的处理 OSCAR 数据的管道。 对于困惑度分数,按照 BigScience ROOTS 语料库,我们训练了一个 SentencePiece 分词器 Kudo (2018) 和 KenLM 库 Heafield (2011)< 中提供的 5 克 Kneser-Ney 语言模型 使用维基百科的 20230501 转储。 基于这些 KenLM 模型显示高困惑度分数的文档被认为与维基百科文章显着不同。 这表明将从我们的数据集 Wenzek 等人 (2020) 中排除的噪音水平。 标记器还将用于获取我们的指标文档中的单词/标记数量。 我们在 HuggingFace 中公开发布 KenLM 模型888https://huggingface.co/uonlp/kenlm 方便以后的探索。
由于抓取错误和低质量来源,重复信息(例如单词、段落)可能出现在网络整理的数据中,对训练大语言模型 Holtzman 等人 (2019) 造成不利后果。 因此,设计字符和单词重复率是为了避免文档包含过多重复的信息。 高频率的特殊字符、停用词或标记词可能表明文档有噪音且质量低劣。 因此,我们利用不同语言的停用词和标记词列表来计算它们的文档删除比率。 除了 BigScience ROOTS 为其 13 种语言提供的停用词和标记单词列表之外,我们还进一步收集其他语言的此类单词的词典。 我们优先考虑在各种语言的个人 GitHub 帐户上共享的列表,因为这些列表通常是由母语人士制作的,并且具有更高的质量。 此外,较低的语言识别置信度也可能表明数据的噪声语言结构。 对于数据集中的每个文档,我们通过 FastText 分配给其相应语言的概率来获得语言识别置信度,以帮助数据过滤。 最后,对于基于短行的标准,我们实现了 100 个字符的阈值,将行分类为短行,如 OSCAR 使用的那样。 出现过多短行的文档将不会保留在我们的数据集中。
阈值选择:给定一组数据集指标,一个重要的问题涉及为每个指标和语言选择适当的阈值以生成高质量的多语言数据。 在 BigScience ROOTS 项目 Laurençon 等人 (2022) 中,这个选择过程是由 13 种语言的母语人士执行的。 由此产生的阈值适用于其余 46 种语言。 该项目提供了一个可视化界面,可以对每种语言的数千个文档样本进行索引,使用户能够在调整指标阈值时监控数据统计数据。 然而,由于需要经验丰富的母语人士,这一过程无法轻易扩展到不同的语言,这会产生巨大的成本。 此外,有限的样本量阻碍了完整数据集所选阈值的代表性。 在我们的分析中,我们观察到 BigScience ROOTS 中某些语言的某些选定阈值几乎超出了整个数据集的值范围,导致相应指标失效。
为了解决这些问题,我们利用四分位数范围 (IQR) 方法的变体 Dekking 等人 (2007) 为我们的数据集的过滤指标选择适当的阈值。 对于每种指标和语言,我们都会在该语言的整个数据集中生成其可能值的分布。 拥有大量数据的语言有一个例外,例如西班牙语和俄语,其中只有 25% 的数据用于计算这些分布。 然后,我们计算分布的第 和 个百分位数 () 并将它们用作过滤指标的阈值。 特别是,较低的 百分位将被选择用于有利于高值的指标(例如,语言识别置信度),而有利于低值的指标(例如,困惑度分数和文档长度)将利用 上百分位数。 我们研究 的不同值,考虑 、、、 和 。 和 的选择在我们的检查中实现了语言样本的最佳数据质量。
值得强调的是,与 BigScience ROOTS 项目中使用的数据样本相比,利用百分位数进行阈值选择使我们的方法能够有效地利用每种语言更广泛的数据样本。 这使得不同语言的完整数据集的阈值更加可靠。 具体来说,对于仅使用 25% 数据样本来计算指标值分布的大型语言,我们观察到,当应用相同的选定过滤时,丢弃的数据占整个数据集的比例与数据样本的比例密切相关临界点。 这强调了通过我们的方法选择的阈值的代表性。 最后,一旦确定了给定语言的指标阈值,我们将消除任何超过指标阈值并进入不利数据范围的文档。
文档细化:前面的清理步骤是在数据集级别完成的,旨在从数据集中删除低质量的文档。 在这一步中,我们进一步清理保留的文档以提高质量。 值得注意的是,我们之前的基于度量的过滤步骤在消除高噪声文档方面发挥着至关重要的作用,这反过来又简化了在此步骤中开发有效文档清理规则的过程。 值得注意的是,由于 mC4 和 OSCAR 的文档是从互联网上抓取的 HTML 页面中提取的,因此其中很大一部分可能会出现抓取和提取错误,包括长 JavaScript 行和无关内容。 因此,过滤掉这些文档极大地简化了我们设计规则以清理数据集中的文档的任务。
因此,对于每个文档,我们通过一系列操作消除其嘈杂或不相关的部分。 首先,我们删除每个文档末尾的所有短行,因为这些行通常包含页脚详细信息或来自网站的无用信息。 其次,我们剔除了包含 JavaScript (JS) 关键词列表中的单词(例如"<script")的行,以避免无关和非语言信息。 在这里,如果文档只包含一行带有 JS 关键字的行,我们会专门删除 JS 行,并且这一行还必须至少包含两种不同类型的 JS 关键字。 我们采用这种方法是因为具有两行以上 JS 行的文档很可能是我们数据中的编码教程,应该保留这些教程以提高多样性。 此外,某些 JS 关键字在自然语言中使用,例如“var”。 通过要求至少两种不同类型的 JS 关键字,我们可以降低无意中省略有用内容和破坏文档结构的风险。
2.2重复数据删除
尽管进行了彻底的数据清理,但由于各种原因,剩余的数据集可能仍然包含大量重复数据,包括信息在网络上重新发布、对同一文章的多次引用、样板内容和抄袭。 因此,重复的数据会导致记忆并严重阻碍大语言模型 Lee 等人 (2022) 的泛化;埃尔南德斯等人 (2022)。 尽管成本高昂,但重复数据删除被认为是保证训练大语言模型数据最高质量的关键步骤。 为此,我们利用 MinHash Broder (1997) 和 URL 对数据集进行全面的重复数据删除程序。 此重复数据删除过程是针对每种语言独立执行的。 此外,我们将重复数据删除限制为遵循数据清理程序保留超过 100K 文档的语言(即 % 的语言),旨在推广数据集中的较小语言。
| Code | Language | #Documents (M) | #Tokens | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Initial | URL | Metric | MinHash | URL | Filtering | (B) | (%) | ||
| Filtering | Filtering | Dedup | Dedup | Rate (%) | |||||
| en | English | 5783.24 | 5766.08 | 3586.85 | 3308.30 | 3241.07 | 43.96 | 2846.97 | 45.13 |
| ru | Russian | 1431.35 | 1429.05 | 922.34 | 845.64 | 799.31 | 44.16 | 737.20 | 11.69 |
| es | Spanish | 844.48 | 842.75 | 530.01 | 479.65 | 450.94 | 46.60 | 373.85 | 5.93 |
| de | German | 863.18 | 861.46 | 515.83 | 447.06 | 420.02 | 51.34 | 357.03 | 5.66 |
| fr | French | 711.64 | 709.48 | 439.69 | 387.37 | 363.75 | 48.89 | 319.33 | 5.06 |
| zh | Chinese | 444.37 | 444.03 | 258.35 | 222.37 | 218.62 | 50.80 | 227.06 | 3.60 |
| it | Italian | 406.87 | 406.04 | 254.72 | 226.42 | 211.31 | 48.06 | 165.45 | 2.62 |
| pt | Portuguese | 347.47 | 346.76 | 217.21 | 200.11 | 190.29 | 45.24 | 136.94 | 2.17 |
| pl | Polish | 270.12 | 269.73 | 170.86 | 151.71 | 142.17 | 47.37 | 117.27 | 1.86 |
| ja | Japanese | 247.67 | 247.19 | 137.88 | 114.64 | 111.19 | 55.11 | 107.87 | 1.71 |
| vi | Vietnamese | 182.88 | 182.72 | 118.67 | 108.77 | 102.41 | 44.00 | 98.45 | 1.56 |
| nl | Dutch | 238.92 | 238.56 | 148.19 | 125.51 | 117.39 | 50.87 | 80.03 | 1.27 |
| ar | Arabic | 132.88 | 132.65 | 84.84 | 77.65 | 74.03 | 44.29 | 69.35 | 1.10 |
| tr | Turkish | 183.65 | 183.47 | 109.94 | 99.18 | 94.21 | 48.70 | 64.29 | 1.02 |
| cs | Czech | 136.91 | 136.44 | 80.38 | 69.01 | 65.35 | 52.27 | 56.91 | 0.90 |
| fa | Persian | 118.55 | 118.50 | 70.26 | 62.42 | 59.53 | 49.78 | 45.95 | 0.73 |
| hu | Hungarian | 88.59 | 88.21 | 53.29 | 46.89 | 44.13 | 50.19 | 43.42 | 0.69 |
| el | Greek | 100.77 | 100.68 | 61.43 | 54.33 | 51.43 | 48.96 | 43.15 | 0.68 |
| ro | Romanian | 89.37 | 89.25 | 45.99 | 42.8 | 40.33 | 54.87 | 39.65 | 0.63 |
| sv | Swedish | 103.04 | 102.76 | 58.67 | 52.09 | 49.71 | 51.76 | 38.49 | 0.61 |
| uk | Ukrainian | 81.50 | 81.44 | 50.95 | 47.12 | 44.74 | 45.10 | 38.23 | 0.61 |
| fi | Finnish | 59.85 | 59.80 | 36.69 | 32.15 | 30.47 | 49.09 | 28.93 | 0.46 |
| ko | Korean | 46.09 | 45.85 | 25.19 | 21.17 | 20.56 | 55.39 | 24.77 | 0.39 |
| da | Danish | 53.16 | 52.99 | 28.67 | 26.48 | 25.43 | 52.16 | 22.92 | 0.36 |
| bg | Bulgarian | 47.01 | 46.90 | 28.09 | 25.45 | 24.13 | 48.67 | 22.92 | 0.36 |
| no | Norwegian | 40.07 | 40.01 | 20.69 | 19.49 | 18.91 | 52.81 | 18.43 | 0.29 |
| hi | Hindi | 35.59 | 35.50 | 22.01 | 20.77 | 19.67 | 44.73 | 16.79 | 0.27 |
| sk | Slovak | 40.13 | 39.95 | 22.20 | 19.56 | 18.58 | 53.70 | 16.44 | 0.26 |
| th | Thai | 49.04 | 48.96 | 26.20 | 21.93 | 20.96 | 57.26 | 15.72 | 0.25 |
| lt | Lithuanian | 27.08 | 27.01 | 15.87 | 14.25 | 13.34 | 50.74 | 14.25 | 0.23 |
| ca | Catalan | 31.13 | 31.12 | 18.99 | 16.46 | 15.53 | 50.11 | 12.53 | 0.20 |
| id | Indonesian | 48.08 | 48.05 | 25.79 | 23.74 | 23.25 | 51.64 | 12.06 | 0.19 |
| bn | Bangla | 20.90 | 20.85 | 13.82 | 13.22 | 12.44 | 40.48 | 9.57 | 0.15 |
| et | Estonian | 16.20 | 16.15 | 9.69 | 8.45 | 8.00 | 50.62 | 8.81 | 0.14 |
| sl | Slovenian | 15.46 | 15.39 | 8.00 | 7.60 | 7.34 | 52.52 | 8.01 | 0.13 |
| lv | Latvian | 14.14 | 14.09 | 8.37 | 7.48 | 7.14 | 49.50 | 7.85 | 0.12 |
| he | Hebrew | 10.78 | 10.77 | 5.90 | 4.77 | 4.65 | 56.86 | 4.94 | 0.08 |
| sr | Serbian | 7.80 | 7.75 | 4.80 | 4.25 | 4.05 | 48.08 | 4.62 | 0.07 |
| ta | Tamil | 8.77 | 8.75 | 5.27 | 4.94 | 4.73 | 46.07 | 4.38 | 0.07 |
| sq | Albanian | 9.40 | 9.38 | 5.96 | 5.04 | 5.21 | 44.57 | 3.65 | 0.06 |
| az | Azerbaijani | 9.66 | 9.65 | 5.73 | 5.24 | 5.08 | 47.41 | 3.51 | 0.06 |
| Total (42 languages) | 13397.79 | 13366.17 | 8254.28 | 7471.48 | 7181.40 | 46.40 | 6267.99 | 99.37 | |
| Total (167 languages) | 13506.76 | 13474.94 | 8308.74 | 7521.23 | 7228.91 | 46.48 | 6308.42 | 100.00 | |
MinHash Deduplication:对于每种语言的数据集,我们首先应用 MinHashLSH 方法 Leskovec 等人 (2020) 来过滤数据集中的相似文档。 MinHashLSH 是一种基于 MinHash Broder (1997) 的近似重复数据删除技术,具有用于 -gram 和 Jaccard 相似性的多个哈希函数。 结合局部敏感哈希 (LSH),通过关注最可能相似的文档对来提高效率。 我们在 text-dedup 存储库999https://github.com/ChenghaoMou/text-dedup/tree/main,采用 -grams 和阈值判断相似文档的Jaccard相似度。 为每种语言的数据集运行 MinHashLSH,特别是对于数据量最大的语言(例如英语、俄语、西班牙语和中文),是我们数据集创建工作中计算成本最高的操作。
基于 URL 的重复数据删除:最后,我们消除了与数据集中其他文档共享相同 URL 的所有文档。 此步骤对于解决同一文章的不同版本链接到相同 URL 但在发布过程中已更新或修改的情况是必要的,从而有效地绕过了近似重复数据删除步骤。 由于抓取错误,CC 中文章的某些 URL 可能仅显示其常规域。 为了提高准确性,我们不会删除仅包含其通用域的 URL。
我们利用 600 个 AWS c5.24xlarge EC2 实例对多语言数据集进行预处理和重复数据删除。 每个实例配备 96 个 CPU 核心、192GB 内存和 1TB 磁盘空间。 必要时,磁盘空间可用于替换内存(例如,用于重复数据删除)。
3数据分析与实验
完成所有清理和重复数据删除步骤后,我们的最终数据集包含涵盖 167 种语言的 6.3 万亿个 Token 。 表 1 概述了 CulturaX 中每个处理阶段后的前 42 种语言的文档和标记数量。 可以看出,我们的数据清理管道可以大大减少每种语言的原始 mC4 和 OSCAR 数据集中的文档数量。 删除的文档总数占我们初始文档的 46.48%,这表明我们的方法对于过滤多语言数据集的噪声信息是有效的。
4相关工作
与其他 NLP 任务相比,语言模型可以使用未标记的数据进行训练,从而实现高效的数据收集以产生巨大的训练数据规模。 训练大语言模型常用的数据主要有两种类型:策划数据和网络爬取数据。 精选数据通常由来自目标来源和领域的精心编写且格式良好的文本组成,例如维基百科文章、书籍、新闻专线文章和科学论文,如“The Pile”Gao 等人 (2020) 中所使用的那样 和“BookCorpus” Zhu 等人 (2015) 数据集。 相比之下,网络爬行数据包含从互联网上各种来源收集的文本,其格式和写作风格差异很大,例如博客、社交媒体帖子、新闻文章和广告。 CommonCrawl (CC) 是一种广泛使用的 Web 爬网存储库,12 年来已通过 Internet 收集了 PB 级的数据。 为此,精选数据通常被认为具有更高的质量,这导致其偏爱训练早期的大语言模型,例如 BERT Devlin 等人 (2019) 和 GPT-2 Radford 等人 (2019)。 然而,随着对大型模型的需求不断增长,网络爬取数据受到了越来越多的关注,因为它在最近的大语言模型的训练数据中贡献了很大一部分,例如 RoBERTa Liu 等人 (2019) 、BART Lewis 等人 (2020)、T5 Raffel 等人 (2020)、GPT-3 Rae 等人 (2021)、LLaMa Touvron 等人 (2023)、MPT MosaicML (2023) 和 Falcon Almazrouei 等人 (2023)。 因此,CC的不同提取被用来训练这样的大语言模型,包括C4 Raffel 等人 (2020)、CC-News Nagel 和 STORIES Trinh 和 Le (2018)。
关于训练数据的可访问性,用于训练早期大语言模型的数据集通常向公众开放 Devlin 等人 (2019);拉斐尔等人 (2020). 然而,就最新的最先进(SOTA)生成大语言模型而言,其训练数据集并未完全发布,可能是出于商业利益。 这不仅适用于 ChatGPT 和 GPT-4 等专有模型,也适用于 LLaMa、MPT、Falcon 和 BLOOM Scao 等人 (2022) 等声称开源模型的模型。 为了解决现有大语言模型的透明度问题,最近我们努力复制并发布最先进的大语言模型的训练数据集,即 RedPajama Computer (2023) 、SlimPajama 和 AI2 卓玛。 这些数据集的主要区别在于其大规模文本数据经过精心清理和文档级重复数据删除,以确保训练大语言模型的高质量。 尽管如此,这些开源数据集的一个共同缺点是它们仍然主要关注英语数据,为其他语言提供的数据有限。
为了获得训练大语言模型的多语言大规模数据集,利用CC等网络抓取数据集可以更方便地高效收集多种语言的最新信息。 此外,为了确保高性能大语言模型的高质量,有必要对多语言数据进行广泛的清理和去重,以避免嘈杂和不相关的内容,例如低质量的机器生成文本和成人内容Trinh和乐(2018); Kreutzer 等人 (2022);拉斐尔等人 (2020). 因此,生成高质量数据集的典型数据处理流程可能涉及多个步骤,如 FastText Joulin 等人 (2016)、CC-Net Wenzek 等人 (2020),BLOOM 模型的 BigScience ROOTS 语料库 Laurençon 等人 (2022); Scao 等人 (2022),Falcon 模型 Penedo 等人 (2023) 的 RefinedWeb 数据集; Almazrouei 等人 (2023),以及用于训练 LLaMa 模型 Touvron 等人 (2023) 的数据集。 第一步需要在此类管道中进行语言识别,以将数据适当地分配给相应的语言Joulin 等人 (2016)。 接下来的步骤采用各种特定于数据集的规则和启发式方法,根据特殊字符、短行、坏词等的比例过滤不需要的内容 Grave 等人 (2018); Laurençon 等人 (2022)。 数据还可以通过轻量级模型进行过滤,例如通过 KenLM 语言模型 Heafield (2011),以避免嘈杂的文档 Wenzek 等人 (2020)。 最后,应进行重复数据删除,删除相似或重复的信息 Laurençon 等人 (2022); Penedo 等人 (2023)。 这方面的一个重要步骤涉及文档级别的模糊去重,例如通过 MinHash Broder (1997),消除相似文档,从而减轻记忆并提高所得大语言模型 Lee 的泛化能力等人(2022)。
为此,虽然存在多语言开源数据集,其中包含多种语言的文本数据,例如 mC4 Xue 等人 (2021)、OSCAR Ortiz Suárez 等人 (2019), CC100 Wenzek 等人 (2020); Conneau 等人 (2020) 和 BigScience ROOT 语料库 Laurençon 等人 (2022),它们的质量和规模不满足有效训练大语言模型的要求,特别是生成模型作为 GPT。 例如,正如简介中所强调的,mC4 和 OSCAR 都缺乏文档级别数据的模糊重复数据删除。 由于使用 cld3,mC4 还存在语言识别能力较差的问题。 BigScience ROOTS 仅提供 46 种语言的少量样本数据,而 CC100 没有 2018 年以后的信息。 因此,我们的数据集CulturaX全面解决了现有数据集的问题,为训练大语言模型提供了多语言、开源、大规模的数据集和易于使用的高质量数据。
5结论
我们推出了 CulturaX,这是一个新颖的多语言数据集,包含 167 种语言的文本数据。 我们的数据集通过综合管道进行清理和重复数据删除,产生 6.3 万亿个 Token 。 因此,CulturaX 是一个大规模、高质量的数据集,可以轻松用于训练多种语言的高性能大语言模型。 我们的数据向公众开放,以促进多语言学习的进一步研究和应用。
参考
- Abadji et al. (2022) Julien Abadji, Pedro Ortiz Suarez, Laurent Romary, and Benoît Sagot. 2022. Towards a cleaner document-oriented multilingual crawled corpus. In Proceedings of the Thirteenth Language Resources and Evaluation Conference, pages 4344–4355, Marseille, France. European Language Resources Association.
- Abadji et al. (2021) Julien Abadji, Pedro Javier Ortiz Suárez, Laurent Romary, and Benoît Sagot. 2021. Ungoliant: An optimized pipeline for the generation of a very large-scale multilingual web corpus. In Proceedings of the Workshop on Challenges in the Management of Large Corpora (CMLC-9) 2021. Limerick, 12 July 2021 (Online-Event).
- Allamanis (2018) Miltiadis Allamanis. 2018. The adverse effects of code duplication in machine learning models of code. Proceedings of the 2019 ACM SIGPLAN International Symposium on New Ideas, New Paradigms, and Reflections on Programming and Software.
- Almazrouei et al. (2023) Ebtesam Almazrouei, Hamza Alobeidli, and Abdulaziz Alshamsi et al. 2023. Falcon-40B: an open large language model with state-of-the-art performance.
- Bang et al. (2023) Yejin Bang, Samuel Cahyawijaya, Nayeon Lee, Wenliang Dai, Dan Su, Bryan Wilie, Holy Lovenia, Ziwei Ji, Tiezheng Yu, Willy Chung, Quyet V. Do, Yan Xu, and Pascale Fung. 2023. A multitask, multilingual, multimodal evaluation of chatgpt on reasoning, hallucination, and interactivity. ArXiv, abs/2302.04023.
- Bañón et al. (2020) Marta Bañón, Pinzhen Chen, Barry Haddow, Kenneth Heafield, Hieu Hoang, Miquel Esplà-Gomis, Mikel L. Forcada, Amir Kamran, Faheem Kirefu, Philipp Koehn, Sergio Ortiz Rojas, Leopoldo Pla Sempere, Gema Ramírez-Sánchez, Elsa Sarrías, Marek Strelec, Brian Thompson, William Waites, Dion Wiggins, and Jaume Zaragoza. 2020. ParaCrawl: Web-scale acquisition of parallel corpora. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4555–4567, Online. Association for Computational Linguistics.
- Bommasani et al. (2021) Rishi Bommasani, Drew A. Hudson, and Ehsan Adeli et al. 2021. On the opportunities and risks of foundation models. ArXiv, abs/2108.07258.
- Botha et al. (2017) Jan A. Botha, Emily Pitler, Ji Ma, Anton Bakalov, Alex Salcianu, David Weiss, Ryan McDonald, and Slav Petrov. 2017. Natural language processing with small feed-forward networks. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 2879–2885, Copenhagen, Denmark. Association for Computational Linguistics.
- Broder (1997) A. Broder. 1997. On the resemblance and containment of documents. In Proceedings of the Compression and Complexity of Sequences.
- Brown et al. (2020) Tom Brown, Benjamin Mann, and et al. 2020. Language models are few-shot learners. ArXiv, abs/2005.14165.
- Chowdhery et al. (2022) Aakanksha Chowdhery, Sharan Narang, and Jacob Devlin et al. 2022. Palm: Scaling language modeling with pathways. ArXiv, abs/2204.02311.
- Computer (2023) Together Computer. 2023. Redpajama: An open source recipe to reproduce llama training dataset.
- Conneau et al. (2020) Alexis Conneau, Kartikay Khandelwal, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer, and Veselin Stoyanov. 2020. Unsupervised cross-lingual representation learning at scale. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 8440–8451, Online. Association for Computational Linguistics.
- Dekking et al. (2007) Michel Dekking, Cornelis Kraaikamp, Hendrik Paul, and Ludolf Erwin Meester. 2007. A modern introduction to probability and statistics: Understanding why and how. In Springer Texts in Statistics.
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapolis, Minnesota. Association for Computational Linguistics.
- Gao et al. (2020) Leo Gao, Stella Rose Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, Shawn Presser, and Connor Leahy. 2020. The pile: An 800gb dataset of diverse text for language modeling. ArXiv, abs/2101.00027.
- Grave et al. (2018) Edouard Grave, Piotr Bojanowski, Prakhar Gupta, Armand Joulin, and Tomas Mikolov. 2018. Learning word vectors for 157 languages. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), Miyazaki, Japan. European Language Resources Association (ELRA).
- Heafield (2011) Kenneth Heafield. 2011. KenLM: Faster and smaller language model queries. In Proceedings of the Sixth Workshop on Statistical Machine Translation, pages 187–197, Edinburgh, Scotland. Association for Computational Linguistics.
- Hernandez et al. (2022) Danny Hernandez, Tom B. Brown, Tom Conerly, Nova DasSarma, Dawn Drain, Sheer El-Showk, Nelson Elhage, Zac Hatfield-Dodds, T. J. Henighan, Tristan Hume, Scott Johnston, Benjamin Mann, Christopher Olah, Catherine Olsson, Dario Amodei, Nicholas Joseph, Jared Kaplan, and Sam McCandlish. 2022. Scaling laws and interpretability of learning from repeated data. ArXiv, abs/2205.10487.
- Holtzman et al. (2019) Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. 2019. The curious case of neural text degeneration. ArXiv, abs/1904.09751.
- Joulin et al. (2016) Armand Joulin, Edouard Grave, Piotr Bojanowski, Matthijs Douze, Hervé Jégou, and Tomas Mikolov. 2016. Fasttext.zip: Compressing text classification models. ArXiv, abs/1612.03651.
- Kenton et al. (2021) Zachary Kenton, Tom Everitt, Laura Weidinger, Iason Gabriel, Vladimir Mikulik, and Geoffrey Irving. 2021. Alignment of language agents. ArXiv, abs/2103.14659.
- Kreutzer et al. (2022) Julia Kreutzer, Isaac Caswell, Lisa Wang, Ahsan Wahab, Daan van Esch, Nasanbayar Ulzii-Orshikh, Allahsera Tapo, Nishant Subramani, Artem Sokolov, Claytone Sikasote, Monang Setyawan, Supheakmungkol Sarin, Sokhar Samb, Benoît Sagot, Clara Rivera, Annette Rios, Isabel Papadimitriou, Salomey Osei, Pedro Ortiz Suarez, Iroro Orife, Kelechi Ogueji, Andre Niyongabo Rubungo, Toan Q. Nguyen, Mathias Müller, André Müller, Shamsuddeen Hassan Muhammad, Nanda Muhammad, Ayanda Mnyakeni, Jamshidbek Mirzakhalov, Tapiwanashe Matangira, Colin Leong, Nze Lawson, Sneha Kudugunta, Yacine Jernite, Mathias Jenny, Orhan Firat, Bonaventure F. P. Dossou, Sakhile Dlamini, Nisansa de Silva, Sakine Çabuk Ballı, Stella Biderman, Alessia Battisti, Ahmed Baruwa, Ankur Bapna, Pallavi Baljekar, Israel Abebe Azime, Ayodele Awokoya, Duygu Ataman, Orevaoghene Ahia, Oghenefego Ahia, Sweta Agrawal, and Mofetoluwa Adeyemi. 2022. Quality at a glance: An audit of web-crawled multilingual datasets. Transactions of the Association for Computational Linguistics, 10:50–72.
- Kudo (2018) Taku Kudo. 2018. Subword regularization: Improving neural network translation models with multiple subword candidates. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 66–75, Melbourne, Australia. Association for Computational Linguistics.
- Lai et al. (2023) Viet Dac Lai, Nghia Trung Ngo, Amir Pouran Ben Veyseh, Hieu Man, Franck Dernoncourt, Trung Bui, and Thien Huu Nguyen. 2023. Chatgpt beyond english: Towards a comprehensive evaluation of large language models in multilingual learning. ArXiv, abs/2304.05613.
- Laurençon et al. (2022) Hugo Laurençon, Lucile Saulnier, Thomas Wang, Christopher Akiki, Albert Villanova del Moral, Teven Le Scao, Leandro Von Werra, Chenghao Mou, Eduardo González Ponferrada, Huu Nguyen, Jörg Frohberg, Mario Šaško, Quentin Lhoest, Angelina McMillan-Major, Gérard Dupont, Stella Biderman, Anna Rogers, Loubna Ben allal, Francesco De Toni, Giada Pistilli, Olivier Nguyen, Somaieh Nikpoor, Maraim Masoud, Pierre Colombo, Javier de la Rosa, Paulo Villegas, Tristan Thrush, Shayne Longpre, Sebastian Nagel, Leon Weber, Manuel Romero Muñoz, Jian Zhu, Daniel Van Strien, Zaid Alyafeai, Khalid Almubarak, Vu Minh Chien, Itziar Gonzalez-Dios, Aitor Soroa, Kyle Lo, Manan Dey, Pedro Ortiz Suarez, Aaron Gokaslan, Shamik Bose, David Ifeoluwa Adelani, Long Phan, Hieu Tran, Ian Yu, Suhas Pai, Jenny Chim, Violette Lepercq, Suzana Ilic, Margaret Mitchell, Sasha Luccioni, and Yacine Jernite. 2022. The bigscience ROOTS corpus: A 1.6TB composite multilingual dataset. In Thirty-sixth Conference on Neural Information Processing Systems Datasets and Benchmarks Track.
- Lee et al. (2022) Katherine Lee, Daphne Ippolito, Andrew Nystrom, Chiyuan Zhang, Douglas Eck, Chris Callison-Burch, and Nicholas Carlini. 2022. Deduplicating training data makes language models better. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8424–8445, Dublin, Ireland. Association for Computational Linguistics.
- Leskovec et al. (2020) Jure Leskovec, Anand Rajaraman, and Jeffrey David Ullman. 2020. Mining of massive datasets. In Cambridge University Press.
- Lewis et al. (2020) Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Zettlemoyer. 2020. BART: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 7871–7880, Online. Association for Computational Linguistics.
- Lieber et al. (2021) Opher Lieber, Or Sharir, Barak Lenz, and Yoav Shoham. 2021. Jurassic-1: Technical details and evaluation. White Paper. AI21 Labs.
- Liu et al. (2019) Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimized bert pretraining approach. ArXiv, abs/1907.11692.
- MosaicML (2023) MosaicML. 2023. Introducing mpt-7b: A new standard for open-source, commercially usable llms. https://www.mosaicml.com/blog/mpt-7b.
- (33) Sebastian Nagel. Cc-news. http: //web.archive.org/save/http: //commoncrawl.org/2016/10/news- dataset-available.
- Ortiz Suárez et al. (2020) Pedro Javier Ortiz Suárez, Laurent Romary, and Benoît Sagot. 2020. A monolingual approach to contextualized word embeddings for mid-resource languages. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 1703–1714, Online. Association for Computational Linguistics.
- Ortiz Suárez et al. (2019) Pedro Javier Ortiz Suárez, Benoît Sagot, and Laurent Romary. 2019. Asynchronous pipelines for processing huge corpora on medium to low resource infrastructures. In Proceedings of the Workshop on Challenges in the Management of Large Corpora (CMLC-7) 2019. Cardiff, 22nd July 2019.
- Penedo et al. (2023) Guilherme Penedo, Quentin Malartic, Daniel Hesslow, Ruxandra-Aimée Cojocaru, Alessandro Cappelli, Hamza Alobeidli, Baptiste Pannier, Ebtesam Almazrouei, and Julien Launay. 2023. The refinedweb dataset for falcon llm: Outperforming curated corpora with web data, and web data only. ArXiv, abs/2306.01116.
- Radford et al. (2019) Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. 2019. Language models are unsupervised multitask learners. OpenAI blog.
- Rae et al. (2021) Jack Rae, Sebastian Borgeaud, and et al. 2021. Scaling language models: Methods, analysis & insights from training gopher. ArXiv, abs/2112.11446.
- Raffel et al. (2020) Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer. In Journal of Machine Learning Research.
- Scao et al. (2022) Teven Scao, Angela Fan, and et al. 2022. Bloom: A 176b-parameter open-access multilingual language model. ArXiv, abs/2211.05100.
- Schwenk et al. (2021) Holger Schwenk, Vishrav Chaudhary, Shuo Sun, Hongyu Gong, and Francisco Guzmán. 2021. WikiMatrix: Mining 135M parallel sentences in 1620 language pairs from Wikipedia. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, pages 1351–1361, Online. Association for Computational Linguistics.
- Shoeybi et al. (2019) Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. 2019. Megatron-lm: Training multi-billion parameter language models using model parallelism. ArXiv, abs/1909.08053.
- Tamkin et al. (2021) Alex Tamkin, Miles Brundage, Jack Clark, and Deep Ganguli. 2021. Understanding the capabilities, limitations, and societal impact of large language models. ArXiv, abs/2102.02503.
- Touvron et al. (2023) Hugo Touvron, Thibaut Lavril, and Gautier Izacard et al. 2023. Llama: Open and efficient foundation language models. ArXiv, abs/2302.13971.
- Trinh and Le (2018) Trieu H. Trinh and Quoc V. Le. 2018. A simple method for commonsense reasoning. ArXiv, abs/1806.02847.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in Neural Information Processing Systems.
- Wei et al. (2022) Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, Ed Huai hsin Chi, Tatsunori Hashimoto, Oriol Vinyals, Percy Liang, Jeff Dean, and William Fedus. 2022. Emergent abilities of large language models. Transactions on Machine Learning Research.
- Wei et al. (2023) Xiangpeng Wei, Hao-Ran Wei, Huan Lin, Tianhao Li, Pei Zhang, Xingzhang Ren, Mei Li, Yu Wan, Zhiwei Cao, Binbin Xie, Tianxiang Hu, Shangjie Li, Binyuan Hui, Bowen Yu, Dayiheng Liu, Baosong Yang, Fei Huang, and Jun Xie. 2023. Polylm: An open source polyglot large language model. ArXiv, abs/2307.06018.
- Weidinger et al. (2021) Laura Weidinger, John F. J. Mellor, and Maribeth Rauh et al. 2021. Ethical and social risks of harm from language models. ArXiv, abs/2112.04359.
- Wenzek et al. (2020) Guillaume Wenzek, Marie-Anne Lachaux, Alexis Conneau, Vishrav Chaudhary, Francisco Guzmán, Armand Joulin, and Edouard Grave. 2020. CCNet: Extracting high quality monolingual datasets from web crawl data. In Proceedings of the Twelfth Language Resources and Evaluation Conference, pages 4003–4012, Marseille, France. European Language Resources Association.
- Xue et al. (2021) Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, and Colin Raffel. 2021. mT5: A massively multilingual pre-trained text-to-text transformer. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 483–498, Online. Association for Computational Linguistics.
- Zhu et al. (2015) Yukun Zhu, Ryan Kiros, Richard S. Zemel, Ruslan Salakhutdinov, Raquel Urtasun, Antonio Torralba, and Sanja Fidler. 2015. Aligning books and movies: Towards story-like visual explanations by watching movies and reading books. Proceedings of the IEEE International Conference on Computer Vision (ICCV).