1567 研究部 Chenglong Wang、John Thompson 和 Bongshin Lee 就职于 Microsoft Research。 电子邮件:{ Chenglong.wang, johnthompson, bongshin}@microsoft.com。
数据制定者:人工智能驱动的概念驱动可视化创作
摘要
使用大多数现代可视化工具,作者需要将数据转换为整齐的格式以创建他们想要的可视化效果。 由于这需要编程或单独的数据处理工具的经验,因此数据转换仍然是可视化创作中的障碍。 为了应对这一挑战,我们提出了一种新的可视化范例,即概念绑定,它利用人工智能代理将高级可视化意图和低级数据转换步骤分开。 我们在 Data Formulator(一种交互式可视化创作工具)中实现了这种范例。 使用 Data Formulator,作者首先定义他们计划使用自然语言或示例进行可视化的数据概念,然后将它们绑定到视觉通道。 然后,Data Formulator 调度其 AI 代理自动转换输入数据以呈现这些概念并生成所需的可视化效果。 当呈现 AI 代理的结果(转换后的表格和输出可视化)时,Data Formulator 会提供反馈以帮助作者检查和理解它们。 一项有 10 名参与者参与的用户研究表明,参与者可以学习和使用 Data Formulator 创建涉及具有挑战性的数据转换的可视化效果,并提出有趣的未来研究方向。
关键词:
人工智能、可视化创作、数据转换、示例编程、自然语言、大语言模型介绍
大多数现代可视化创作工具(例如 Charticulator [ren2019charticulator]、Data Illustrator [liu2018data]、Lyra [satyanarayan2014lyra])和库(例如, ggplot2 [wickham2009ggplot2]、Vega-Lite [satyanarayan2017vegalite])期望整洁的数据[wickham2014tidy-data],其中要可视化的每个变量都是列,每个观察值都是一行。 当输入数据采用整齐格式时,作者只需将数据列绑定到视觉通道(例如,日期轴,温度-轴,图中的城市 颜色。 1 )。 否则,他们需要准备数据,即使原始数据是干净的并且包含所需的所有信息[bartram2021untidy]。 作者通常依赖数据转换库(例如 tidyverse [wickham2019tidyverse]、pandas [the_pandas_development_team_2023_7741580])或单独的交互式工具(例如 Wrangler [kandel2011wrangler]) 将数据转换为适当的格式。 然而,作者需要编程经验或工具专业知识来转换数据,并且他们必须承受可视化和数据转换步骤之间切换的开销。 数据转换的挑战仍然是可视化创作的障碍。
为了应对数据转换挑战,我们利用人工智能代理探索了一种完全不同的可视化创作方法。 我们将高级可视化意图“可视化内容”与低级数据转换步骤“如何格式化数据以可视化”分开,并将后者自动化减轻数据转换负担。 具体来说,我们支持可视化创作所需的两种关键类型的数据转换(及其组合):
- •
- •
在本文中,我们介绍了 Data Formulator,这是一种交互式可视化创作工具,它体现了一种新范式:概念绑定。 为了使用 Data Formulator 创建可视化,作者通过将数据概念绑定到视觉通道来提供可视化意图。 在加载数据表时,现有数据列被提供为已知数据概念。 当所需的数据概念无法用于创作给定图表时,作者可以创建概念:使用自然语言提示(用于推导)或通过提供示例(用于重塑)。 Data Formulator 以不同的方式处理这两种情况,具有不同的输入和反馈风格,我们在 Section 1 中提供了如何处理它们的详细描述>。 一旦获得必要的数据概念,作者就可以选择图表类型(例如散点图、直方图)并将数据概念映射到所需的视觉通道。 如果需要,Data Formulator 会调度后端 AI 代理来推断必要的数据转换,以根据输入数据实例化这些新概念并创建候选可视化。 由于作者的高级规范可能不明确,并且 Data Formulator 可能会生成多个候选者,因此 Data Formulator 提供反馈来解释和比较结果。 通过这些反馈,作者可以检查、消除歧义并完善建议的可视化。 之后,他们可以重用或创建其他数据概念来继续其可视化创作过程。
我们还报告了一项由 10 名参与者进行的图表复制研究,旨在收集有关采用 AI 代理的新概念绑定方法的反馈,并评估 Data Formulator 的可用性。 经过一小时的教程和练习后,大多数参与者可以通过创建数据概念(包括推导和重塑转换)来创建所需的图表。 最后,我们讨论了从 Data Formulator 的设计和评估中吸取的经验教训,以及未来的重要研究方向。
1 说明性场景
1.1 编程经验
我们首先说明经验丰富的数据科学家 Eunice 如何使用 Python 中的 pandas 和 Altair 库进行编程来创建所需的可视化效果。
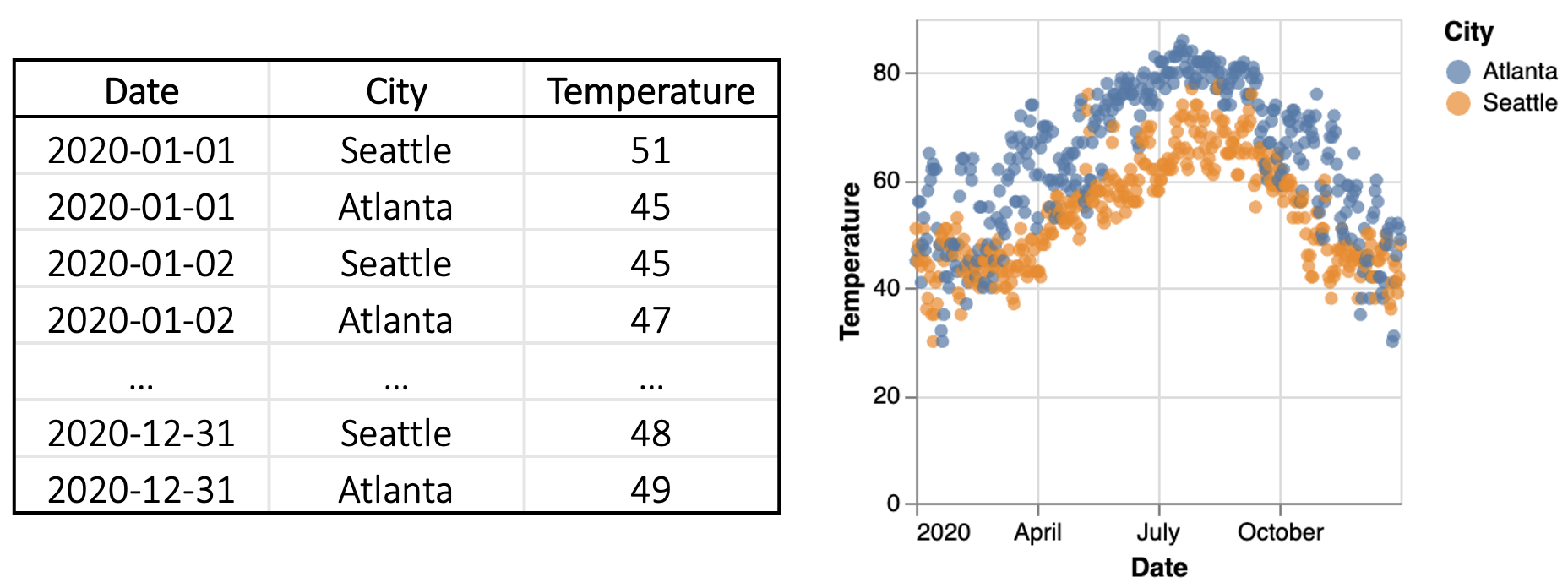
每日温度趋势。 Eunice 从图1中的散点图开始。 因为 df 是整齐的格式,有 Date、City 和 Temperature 可用,Eunice 不需要数据转换,编写一个简单的 Altair 程序来创建绘图:
⬇ alt.Chart(df).mark_circle().encode(x=’Date’, y=’Temperature’, color=’City’)
该程序调用 Altair 库 (alt),选择输入数据集 df 和散点图函数 mark_circle,并将列映射到 和颜色通道。 它在 Fig. 1 中呈现所需的散点图。
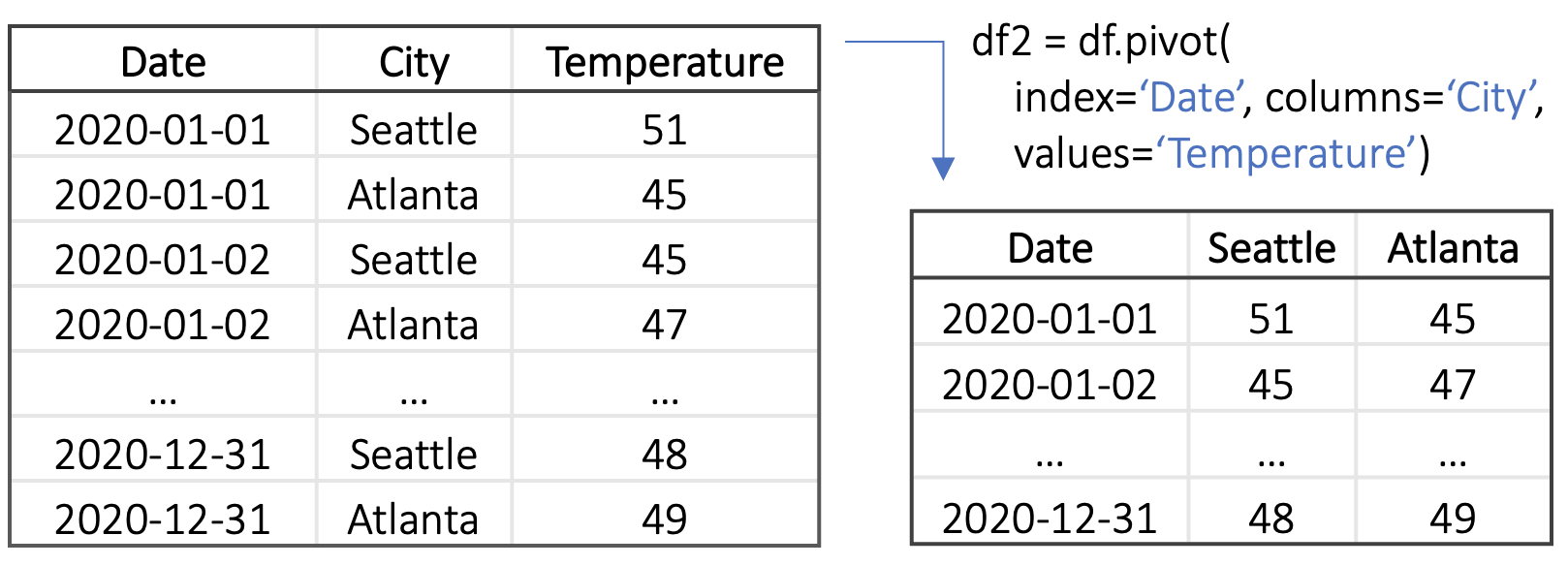
西雅图 vs 亚特兰大 气温。 为了更直接地比较两个城市的气温,Eunice 希望创建一个不同的散点图(图 2- )通过将西雅图和亚特兰大温度映射到轴。 但是,西雅图 和亚特兰大 温度无法作为 df 中的列提供。 因此,她需要转换 df 来显示它们。 由于df采用“长”格式,两个城市的温度都存储在一列Temperature中,因此她需要将表格转换为“宽”格式。 Eunice 切换到数据转换步骤,并使用 pandas 库中的 pivot 函数来重塑 df(图 3 )。 此程序将 Seattle 和 Atlanta 填充为 City 列中的新列名称,并移动其相应的 Temperature 值按日期添加到这些新列。 通过 df2,Eunice 创建了所需的可视化效果,将 Seattle 和 Atlanta 映射到散点图的 轴以下程序:
⬇ alt.Chart(df2).mark_circle().encode(x=’Seattle’, y=’Atlanta’)
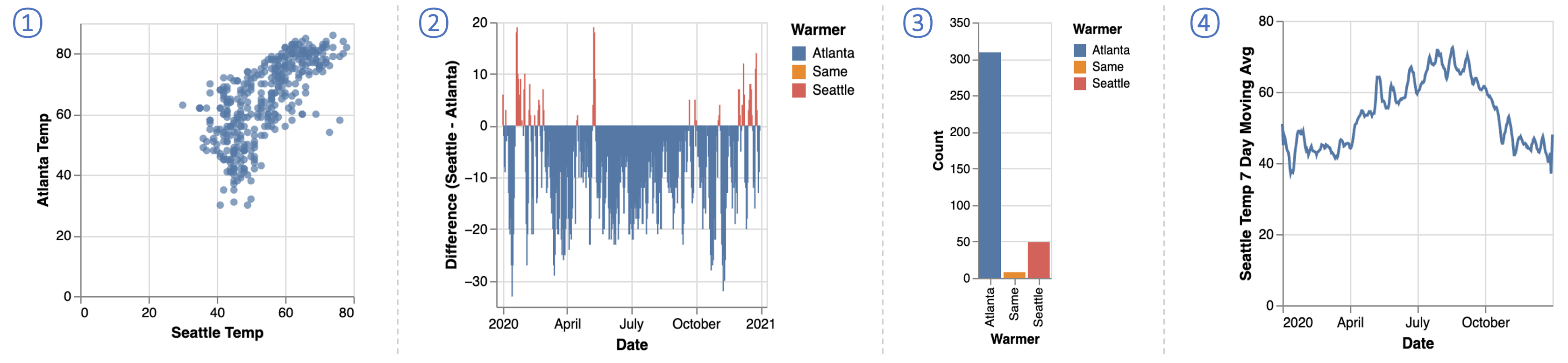
温差。 Eunice 希望创建两个可视化效果来显示亚特兰大与西雅图相比温暖了多少:一个条形图,用于可视化每日温差(图 2 - )和显示每个城市变暖天数的直方图(图 2- )。 同样,由于必要的字段 Difference 和 Warmer 不在 df2 中,因此 Eunice 需要转换数据。 这次,她编写了一个程序来执行按列计算,该程序用两个新列 Warmer 和 Difference 扩展了 df2 (图 4)。 然后,Eunice 通过将 Date 和 Difference 映射到 轴来创建每日温差图表,并通过映射 Warmer 来创建直方图到 轴,聚合函数 count() 到 轴来计算条目数。
⬇ # extend df2 with new columns ’Difference’ and ’Warmer’ df2[’Difference’] = df2[’Seattle’] - df2[’Atlanta’] df2[’Warmer’] = df2[’Difference’].apply( lambda x: ’Seattle’ if x > 0 else (’Atlanta’ if x < 0 else ’Same’)) \par# create the bar chart alt.Chart(df2).mark_bar().encode(x=’Date’, y=’Difference’, color=’Warmer’) # create the histogram alt.Chart(df2).mark_bar().encode(x=’Warmer’, y=’count()’, color=’Warmer’)
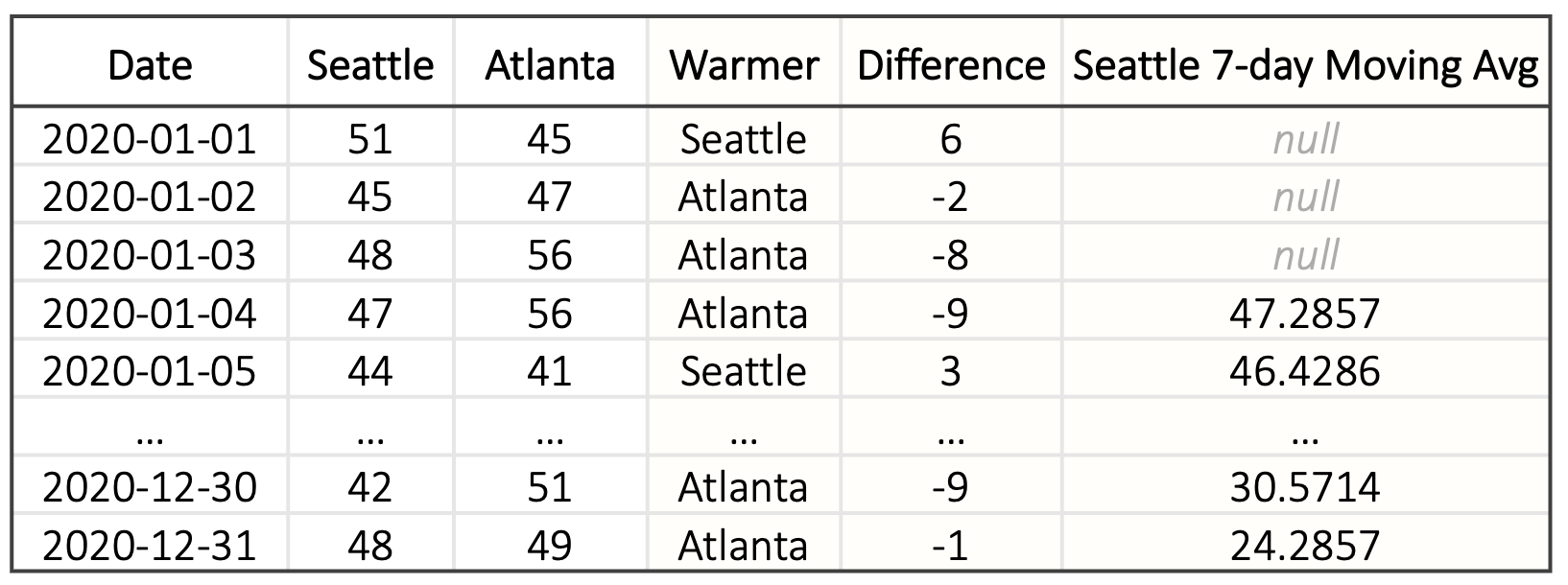
西雅图气温的 7 天移动平均值。 最后,尤尼斯希望在报告中包含西雅图气温趋势的折线图。 由于每日气温波动,她决定根据 7 天移动平均气温创建一个平滑的折线图。 Eunice 需要一个分析函数来计算移动平均值。 由于输入数据按 Date 排序,Eunice 选择 pandas 的 rolling 函数:她设置 window=7 和 center=True ,以便通过滑动窗口计算每个日期从天到天的移动平均值。此转换将新列 Seattle 7-day Moving Avg 添加到 df2(图0> 41>;由于数据不足,前 3 天为空),Eunice 将 Date2> 和新列映射到折线图以创建所需的可视化效果(图4> 25>3>- )。
⬇ df2[’Seattle 7-day Moving Avg’] = df2[’Seattle’].rolling(window=7, center=True) alt.Chart(df2).mark_line().encode(x=’Date’, y=’Seattle 7-day Moving Avg’)
备注。 在所有情况下,Eunice 都可以使用简单的 Altair 程序通过将数据列映射到视觉通道来指定可视化。 然而,数据转换步骤使可视化过程充满挑战。 Eunice 需要根据输入数据和所需的可视化选择正确的转换类型(例如,在 Fig. 1 中创建散点图df2 需要取消透视)。 此外,Eunice 还需要了解 pandas 的相关知识,以便为每项任务选择正确的函数和参数(例如,如果 Eunice 想要计算 df 中每个城市的移动平均值,则 rolling 将不适合)。 Eunice 的编程经验和数据分析专业知识使她能够成功完成所有任务。 但经验不足的数据科学家 Megan 发现这个过程具有挑战性。 Megan 决定使用 Data Formulator 来减少数据转换开销。
1.2 数据公式设计经验
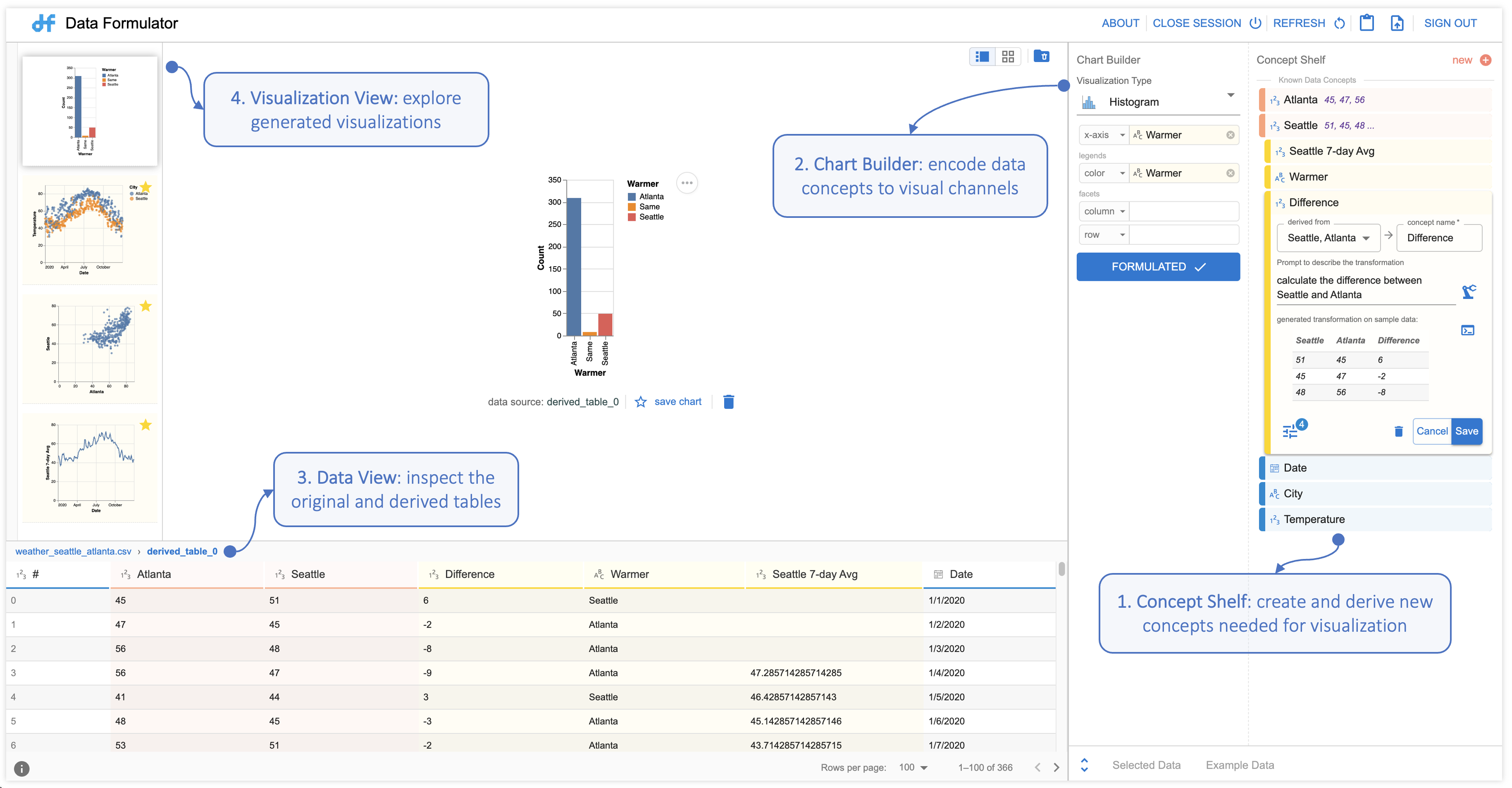
Data Formulator(图 5)具有与 Tableau 或 Power BI 等“货架配置”式可视化工具类似的界面。 但与这些仅支持从输入数据列到视觉通道的映射的工具不同,Data Formulator 使作者能够创建和派生新的数据概念,并将其映射到视觉通道以创建可视化效果,无需手动数据转换。
每日温度趋势。 一旦 Megan 加载输入数据 (Fig. 1),Data Formulator 就会填充现有数据列 (Date, 城市和温度)作为概念架中已知的数据概念。 由于所有三个数据概念均已可用,因此无需进行数据转换。 Megan 选择可视化类型“散点图”,并通过拖放交互将这些数据概念映射到图表生成器中的 和颜色通道。 然后,Data Formulator 生成所需的散点图。
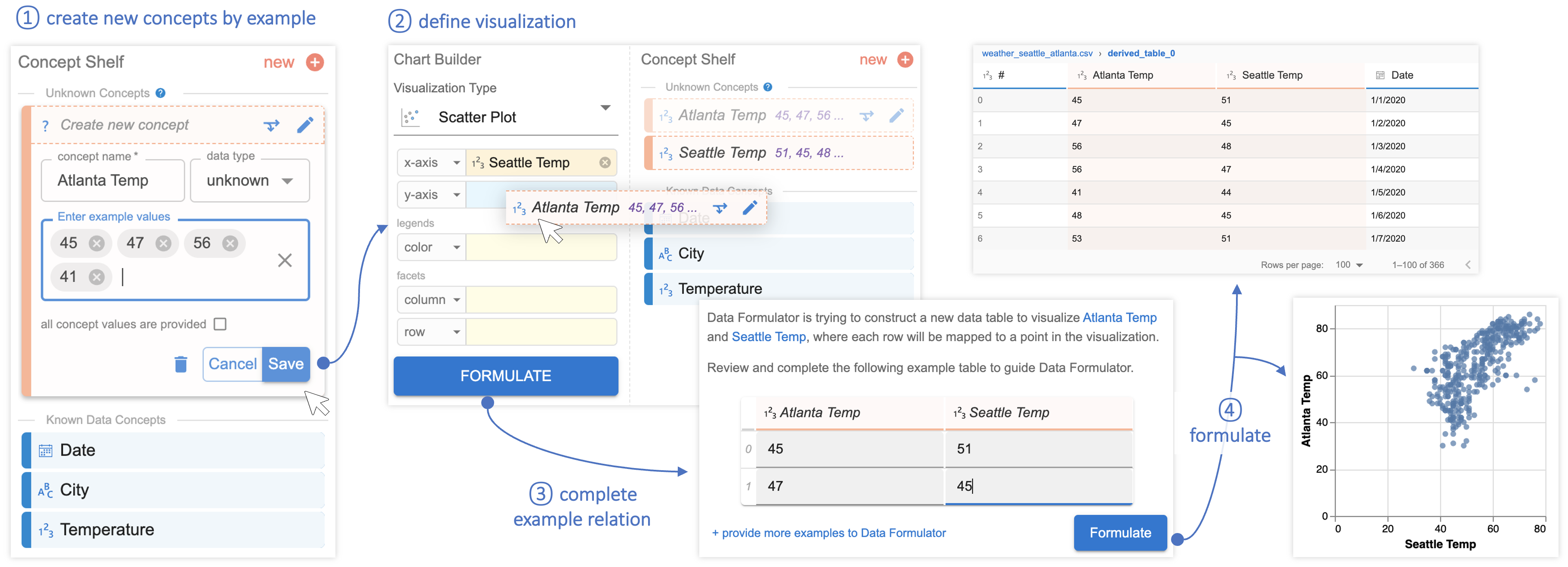
西雅图 vs 亚特兰大 气温。 创建第二个散点图(图 4- ),Megan 需要将 西雅图 和 亚特兰大 温度映射到散点图的 轴。 由于西雅图和亚特兰大温度尚未作为概念提供,Megan 首先创建一个新的数据概念亚特兰大温度 (图 6- ):她点击 新的 概念架中的按钮,打开一个概念卡,要求她命名新概念并提供一些示例值; Megan 从输入数据中提供了四个亚特兰大温度(45、47、56、41)作为示例并保存。 同样,梅根创造了另一个新概念Seattle Temp。 由于 Data Formulator 目前对他们的了解仅限于其名称和示例值,因此这两个概念目前都被列为未知概念。 (稍后提供更多信息后将解决这些问题。)
选择这些新概念和散点图后,Megan 将新数据概念 西雅图温度 和 亚特兰大温度 映射到 轴 (图 6- ),然后单击“公式”按钮,让 Data Formulator 公式化数据并实例化图表。 根据可视化规范,Data Formulator 意识到这两个未知概念彼此相关,但尚不确定它们与输入数据的关系。 因此,Data Formulator 会提示 Megan 填写示例表格:示例表格中的每一行都将是所需散点图中的数据点。 Megan 需要从输入数据中提供至少两个数据点,以指导 Data Formulator 如何生成此转换(图 6- )。 在这里,Megan 从表 Fig. 1 中提供了亚特兰大和西雅图 01/01/2020 和 01/02/2020 的气温。 当 Megan 提交示例时,Data Formulator 会推断出一个程序,该程序可以转换输入数据以生成一个新表,其中包含字段 Atlanta Temp 和 Seattle Temp,该表包含由梅根。 数据公式生成新表并呈现所需的散点图(图 6- )。 Megan 检查派生表和可视化并接受它们是正确的。
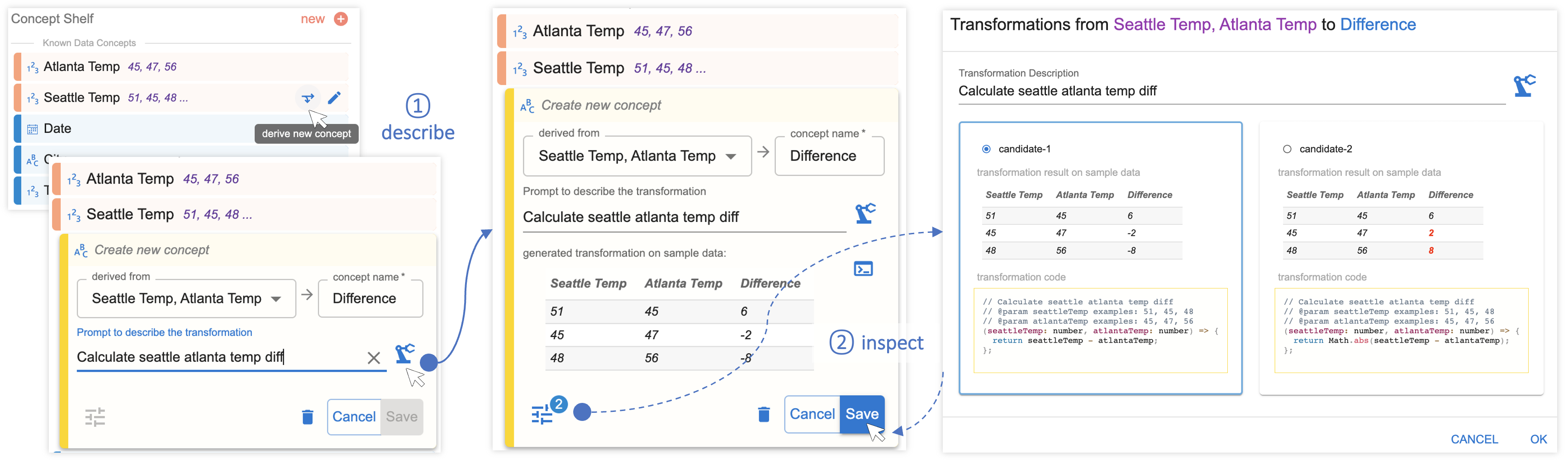
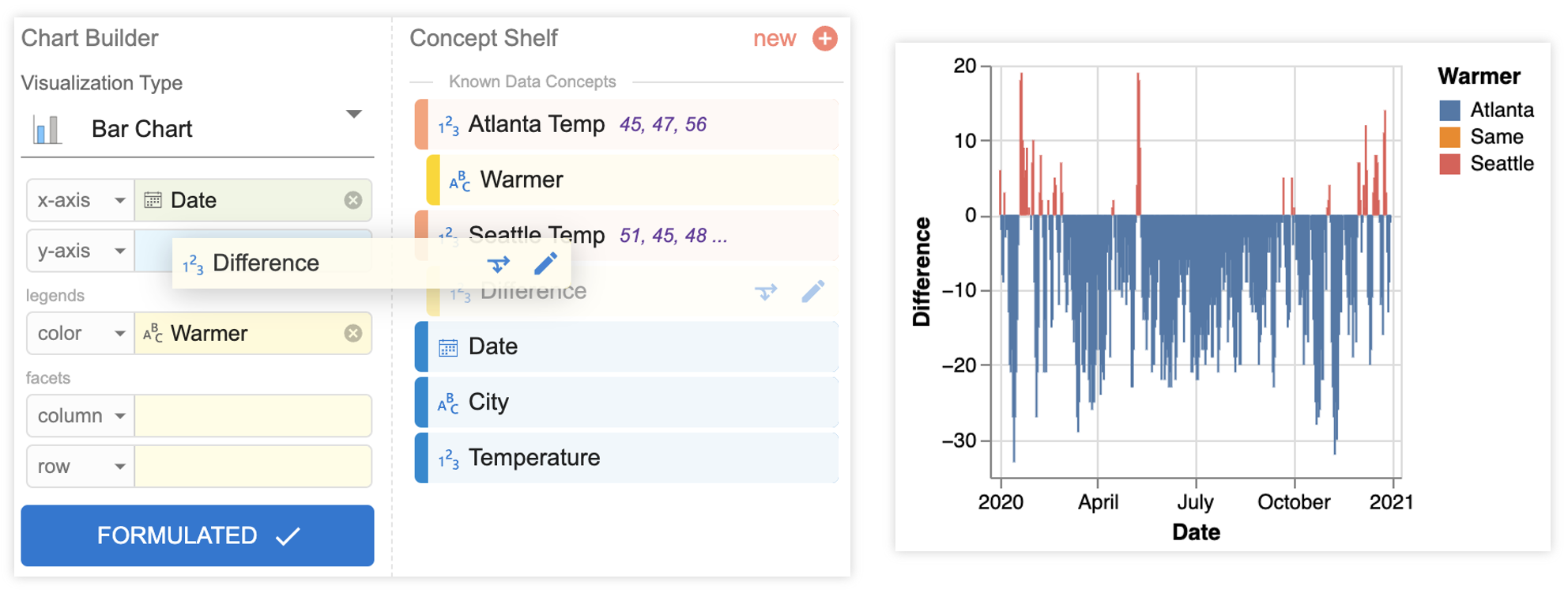
温差。 为了创建条形图和直方图来可视化两个城市之间的温差,Megan 需要两个新概念:Difference 和 Warmer。 这次,Megan 注意到这两个概念都可以基于按列映射从现有字段派生,因此她使用了 Data Formulator 的“派生”功能(图 7)。 Megan 首先单击现有概念 Seattle Temp 上的“导出新概念”选项,这将打开一个概念卡,让她使用自然语言描述她想要的转换。 Megan 选择 Seattle Temp 和 Atlanta Temp 作为“衍生自”概念,为新概念提供名称 Difference,并使用自然语言,“计算西雅图亚特兰大温差。”然后,Megan 单击生成按钮,Data Formulator 会调度其后端 AI 代理来生成代码。 Data Formulator 返回两个候选代码并在概念卡中显示第一个代码。 Megan 打开对话框来检查两个候选选项,并了解到,由于她的描述没有明确指定她是否想要差异或其绝对值,因此数据公式工具将两个选项返回为候选选项。 在检查了示例表和 Data Formulator 提供的转换代码后,Megan 确认了第一个候选并保存了概念差异。 同样,Megan 根据西雅图温度和亚特兰大温度创建了一个概念,更温暖,描述为“检查哪个城市更温暖,亚特兰大、西雅图、或相同。” Data Formulator 在上一个任务的派生表之上应用数据转换,并在数据视图中显示扩展表(图 5) 。 由于这两个概念现在都可以使用,Megan 将它们映射到图表生成器以创建所需的可视化效果(图 8)。
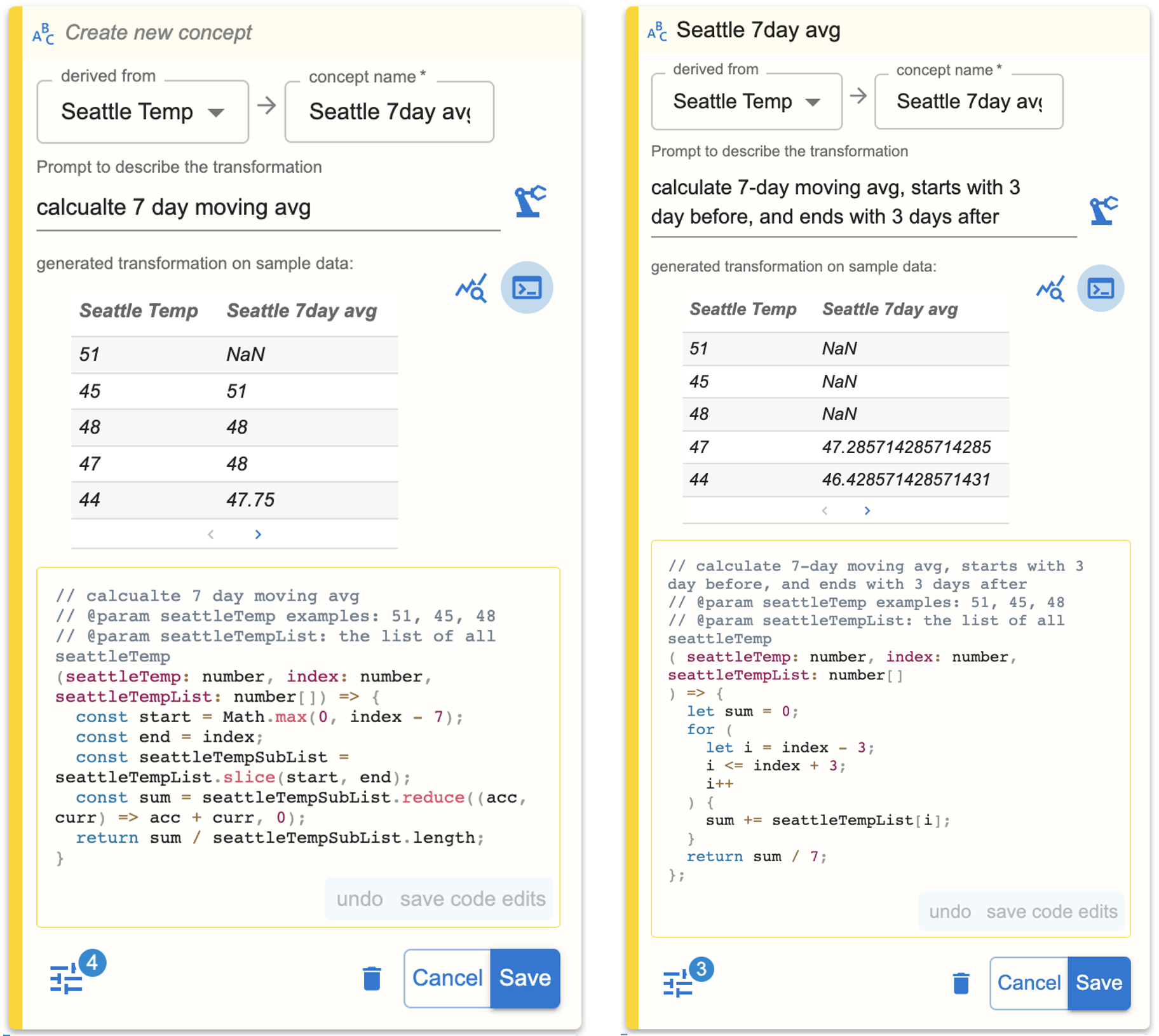
西雅图气温的 7 天移动平均值。 最后,Megan 需要创建一个包含 7 天移动平均温度的折线图。 由于可以从 Seattle Temp 列导出移动平均值,Megan 再次选择使用导出函数。 Megan 首先简要描述“计算 7 天移动平均值”,然后调用 Data Formulator 来生成所需的转换。 经过检查,Megan 发现生成的 Transformer 虽然很接近,但与她的意图并不完全一致:7 天移动平均数从 开始,每天 到 ,而不是 到 (图 9)。 基于这一观察,Megan 将描述更改为“计算 7 天移动平均值,从 3 天前开始,到 3 天后结束”并重新运行 Data Formulator。 这次,Data Formulator 生成正确的转换并在图5中呈现扩展数据表。 然后 Megan 将日期和西雅图 7 天移动平均值映射到折线图的轴。
备注。 在 Data Formulator 的帮助下,Megan 无需手动转换数据即可创建可视化效果。 相反,梅根指定了她想要可视化的数据概念:
-
•
使用示例构建新概念(当新概念分布在多个列中或多个概念存储在同一列中时,例如,Seattle Temp 和 Atlanta Temp 都存储在温度列);和
-
•
使用自然语言推导新概念(当新概念可以使用按列运算符从现有概念计算出来时,例如,差异与西雅图温度和亚特兰大温度)。
然后,梅根将数据概念拖放到图表的可视通道中。 在此过程中,对于派生概念,Data Formulator 显示生成的候选代码和示例表,以帮助 Megan 检查和选择转换;对于通过示例创建的概念,Data Formulator 会提示 Megan 通过完成示例表来详细说明它们的关系。 然后,Data Formulator 转换数据并生成所需的可视化效果。 Data Formulator 将指定数据转换的任务转变为检查生成数据的任务,从而减少了 Megan 的可视化开销。 由于 Data Formulator 的交互模型以数据概念为中心,Megan 不需要直接使用表级运算符,例如 pivot、map/reduce 和 partitioning,这很难掌握。
2 数据公式设计
在本节中,我们将描述我们的设计原则,解释 Data Formulator 的交互模型,以及 Data Formulator 如何根据作者的输入导出数据概念并制定可视化效果。
2.1设计原则
Data Formulator 引入了数据概念,这是作者指定其目标可视化所需的列的抽象。 为了消除作者在绘图前手动转换数据表的负担,我们根据以下指导设计原则设计了 Data Formulator。
将设计概念视为一流的对象。 数据概念的概念是表列的概括:它是对当前表和未来转换表中的列的引用。 它们有两个好处。 首先,概念级转换比表级运算符更容易描述和理解。 表级转换需要高级运算符(如 pivot 和 unpivot)或高阶函数(如 map 和 window) ,而概念级运算符是基本元素(例如算术)或列表(例如百分位数)上的一阶函数。 这使得作者更容易与 AI 代理进行通信并验证结果。 其次,我们可以在人们已经熟悉的现有设计之上构建交互体验:数据概念类似于现有货架配置工具常用的数据列。
利用多种交互方法的优势。 Data Formulator 采用自然语言交互(用于导出概念)和示例编程方法(用于构建自定义概念)。 自然语言描述具有将高级意图转化为可执行代码的卓越能力,并且大型语言模型(大语言模型)可以推理自然概念(例如,学术成绩为 A、B、C、D 和 F;月份为一月至十二月)。 然而,如果作者不理解诸如旋转之类的概念,则可能很难提供正确的描述,并且自然语言描述可能不精确且含糊不清。 相比之下,虽然程序合成器无法推理自然概念,但它们的歧义性较小,并且作者更容易通过演示输出关系来传达重塑操作。 通过结合针对不同转换类型(派生与重塑)的多种方法和反馈,Data Formulator 充分利用了这两种方法,减少了规范障碍并提高了 AI 代理生成正确且可解释代码的可能性。
确保正确的数据转换并促进信任。 虽然大语言模型和程序综合器可以自动生成代码以消除作者的手动数据转换负担,但它们可能会错误地概括作者的规范。 因此,作者对结果的查看和验证至关重要。 我们的设计采用机制来确保作者进行此类检查:(1)显示多个候选者供作者审查(如果有),(2)显示代码(过程)和示例输出值(结果)以帮助作者理解(3) 允许作者编辑生成的转换代码以更正或完善它。
提高系统的表现力。 Data Formulator 的表现力是由转换函数和可视化语言的组合定义的。 Data Formulator 的可视化规范建立在 Vega-Lite 规范之上。 虽然 Data Formulator 的 UI 不提供分层标记选项,但作者可以导入分层可视化的自定义 Vega-Lite 规范来实现相同的设计。 对于数据转换,Data Formulator 支持 tidyverse 中的重塑选项,如 Section 1 中所述,并且它支持按列推导和分析计算可以由大语言模型生成。 请注意,虽然我们的转换语言不包含聚合,但作者可以通过在所需轴上设置聚合选项来实现相同的可视化(例如,将 Month 映射到 轴和 avg(Seattle Temp) 到 轴以创建平均温度的条形图)。 然而,根据当前的设计,作者无法在不重新导入聚合数据的情况下导出或重塑首先需要聚合的数据。
2.2交互模型
图 10显示了Data Formulator的高级交互模型。 Data Formulator 首先将输入表中的数据列加载为原始(已知)概念(例如,图 5中的 日期、城市和 温度概念)。 如果需要,作者可以通过两种方式(Section 2.3)使用概念架创建新的数据概念: (1) 导出概念通过使用自然语言与 AI 代理交互来从现有概念中提取出来,或者 (2) 通过提供示例值来构建自定义概念。 如果新概念源自已知概念,Data Formulator 会立即扩展当前数据表并将其注册为已知概念。
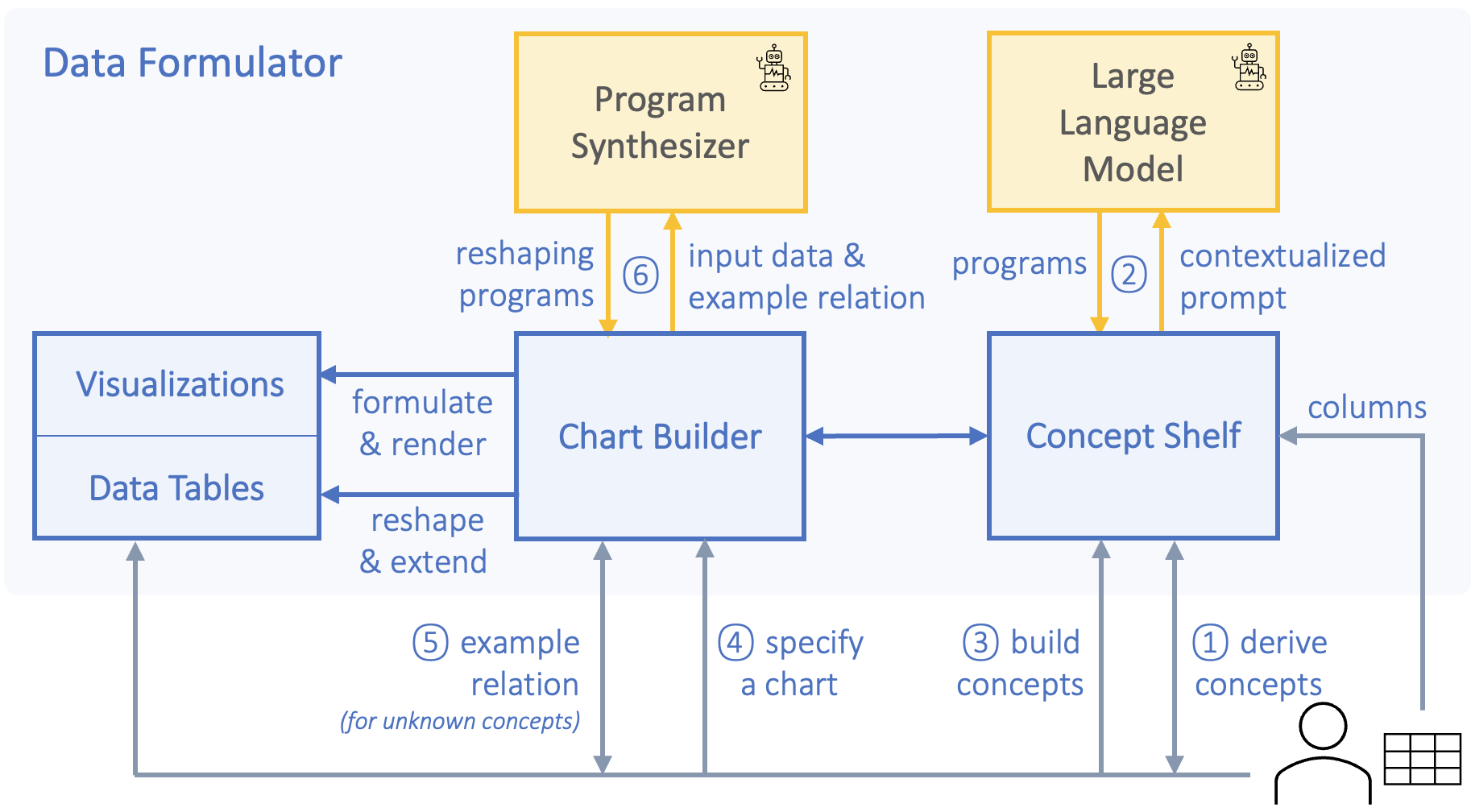
已知必要的数据概念后,作者使用图表生成器将数据概念映射到图表的可视通道。 如果使用未知的自定义概念来指定可视化,Data Formulator 会要求作者提供编码概念之间的示例关系,以使用示例编程方法转换输入表。 应用必要的数据公式后,Data Formulator 会生成 Vega-Lite 规范并呈现可视化效果。
2.3 创建新的数据概念
作者可以通过与 Data Formulator 的 AI 代理交互,从一个或多个数据概念中推导出一个概念(图 10- )。 除了概念名称之外,作者还提供了衍生新概念的源概念列表以及转换的自然语言描述(图 7- )。 然后,Data Formulator 会生成上下文提示,将描述建立在源概念的上下文中。 该提示将作者的描述和所有源概念的输入参数的描述(以及从其域中采样的示例值)结合起来作为注释,并将其与函数前缀连接起来,以指示 AI 代理完成 Typescript 函数(而不是生成非代码文本或不受控制的代码片段)。 Data Formulator 为每个查询准备了两种类型的提示,涵盖简单推导(示例 1)和分析计算(示例 2),因为它事先并不知道是否需要分析计算。
示例1: “计算西雅图亚特兰大温度差异”的提示,其中包含源概念 西雅图温度 和 亚特兰大温度(图 7)。