Promptbreeder:
通过即时进化实现自我参照的自我完善
摘要
像思想链提示这样流行的提示策略可以极大地提高各个领域的大语言模型的推理能力。 然而,这种手工制定的提示策略通常不是最佳的。 在本文中,我们提出了Promptbreeder,这是一种通用的自我参考自我改进机制,可以针对给定领域发展和调整提示。 在大语言模型的驱动下,Promptbreeder 会变异一组任务提示,评估它们在训练集上的适应性,并在多代中重复此过程以进化任务提示。 至关重要的是,这些任务提示的突变是由大语言模型在整个进化过程中以自我参照的方式生成和改进的突变提示所控制的。 也就是说,Promptbreeder 不仅改进了任务提示,而且还改进了改进这些任务提示的突变提示。 在常用的算术和常识推理基准上,Promptbreeder 的表现优于最先进的提示策略,例如思维链和计划与解决提示。 此外,Promptbreeder 能够针对仇恨言论分类这一具有挑战性的问题提出复杂的任务提示。
1简介
提示对于基础模型的下游性能至关重要。 例如不同的提示策略111术语定义请参见附录A。 可以对模型的推理能力产生重大影响(Wei 等人, 2022; Nye 等人, 2021; Zhou 等人, 2022; Wang 等人, 2022; Zhou 等人, 2023; Wang 等人, 2023b) ,多模态处理能力(杨等人,2023b;王等人,2023d),或工具使用能力(姚等人,2022;Schick等人,2023 )。 此外,提示可以改善模型蒸馏(Wang 等人, 2023c; Hsieh 等人, 2023),并可用于模拟主体行为(Wang 等人, 2023a; Park 等人, 2023;吴等人,2023)。 然而,这些提示策略是手动设计的。 由于提示的具体措辞方式可能对其实用性产生巨大影响(Madaan & Yazdanbakhsh,2022),因此提出了提示工程是否可以自动化的问题。 自动提示工程师(APE,周等人,2023)尝试通过使用另一个提示生成提示的初始分布来解决这个问题,该提示从数据集中的许多输入输出示例推断问题。 然而,周等人发现“随着三轮后质量似乎趋于稳定,进一步选择轮次的回报递减”,因此放弃了迭代APE的使用。 我们提出了一种通过多样性维持进化算法来解决收益递减问题的方案,用于大语言模型提示的自我参照自我改进。
Schmidhuber (1990)指出“神经网络的程序就是它的权重矩阵”。 因此,这个“程序”可以通过神经网络本身以自我引用的方式改变(Schmidhuber,1993;Irie等人,2022)。 这种能够自我改进以及改进其自我改进方式的神经网络可能是人工智能开放式自我参照自我改进的重要垫脚石(Schmidhuber,2003)。 然而,通过自参考权重矩阵进行自我改进成本高昂,因为它需要额外的参数来修改模型的所有参数。 由于大语言模型的行为和能力很大程度上受到我们提供给他们的提示的影响,因此我们可以类似地将提示视为大语言模型的程序(周等人,2023)。 在此看来,改变Scratchpad方法(Nye等人,2021)或连锁思维提示(Wei等人,2022)等提示策略对应于改变大语言模型的“程序”。 进一步类比,我们可以用大语言模型本身来改变它的提示,以及它改变这些提示的方式,使我们走向一个以大语言模型为基础的完全自我参照的自我完善系统。
| Method | LLM | MultiArith* | SingleEq* | AddSub* | SVAMP* | SQA | CSQA | AQuA-RAT | GSM8K | |
| Zero-shot | CoT | text-davinci-003 | (83.8) | (88.1) | (85.3) | (69.9) | (63.8) | (65.2) | (38.9) | (56.4) |
| PoT | text-davinci-003 | (92.2) | (91.7) | (85.1) | (70.8) | – | – | (43.9) | (57.0) | |
| PS | text-davinci-003 | (87.2) | (89.2) | (88.1) | (72.0) | – | – | (42.5) | (58.2) | |
| PS+ | text-davinci-003 | (91.8) | (94.7) | (92.2) | (75.7) | (65.4) | (71.9) | (46.0) | (59.3) | |
| PS | PaLM 2-L | 97.7 | 90.6 | 72.4 | 83.8 | 50.0 | 77.9 | 40.2 | 59.0 | |
| PS+ | PaLM 2-L | 92.5 | 94.7 | 74.4 | 86.3 | 50.1 | 73.3 | 39.4 | 60.5 | |
| APE | PaLM 2-L | 95.8 | 82.2 | 72.2 | 73.0 | 38.4 | 67.3 | 45.7 | 77.9 | |
| OPRO | PaLM 2-L | – | – | – | – | – | – | – | 80.2 | |
| PB (ours) | PaLM 2-L | 99.7 | 96.4 | 87.8 | 90.2 | 71.8 | 85.4 | 62.2 | 83.9 | |
| Few- | Manual-CoT | text-davinci-003 | (93.6) | (93.5) | (91.6) | (80.3) | (71.2) | (78.3) | (48.4) | (58.4) |
| Auto-CoT | text-davinci-003 | (95.5) | (92.1) | (90.8) | (78.1) | – | – | (41.7) | (57.1) | |
| PB (ours) | PaLM 2-L | 100.0 | 98.9 | 87.1 | 93.7 | 80.2 | 85.9 | 64.6 | 83.5 |
在本文中,我们引入Promptbreeder(PB)来实现大语言模型的自我参照自我完善。 给定一组突变提示(即修改任务提示的指令)、思维方式(即一般认知启发式的文本描述)和特定领域的问题描述,PB 会生成任务提示和突变的变体-提示,利用大语言模型可以被提示充当变异算子的事实(Meyerson等人,2023)。 根据在训练集上测量的进化任务提示的适应性,我们选择由任务提示及其相关突变提示组成的进化单元子集,以传递给后代。 在多代 PB 中,我们观察到适应当前领域的提示。 例如,在数学领域,PB 演化出了任务提示 “展示你所有的工作。 二. 您应该在适当的情况下使用正确的数学符号和词汇。 三. 您应该用完整的句子和文字写下您的答案。 四. 你应该用例子来说明你的观点并证明你的答案。 五、你的作业应该整洁、清晰” GSM8K(参见附录J)。 在涵盖常识推理、算术和伦理学的广泛常用基准上,我们发现 PB 优于 Chain-of-Thought 等最先进的方法(Wei 等人,2022)以及计划与解决(Wang 等人, 2023b) 提示。 由于PB不需要任何参数更新来进行自我参照的自我改进,我们相信这种方法预示着一个有趣的未来,更大、更强大的大语言模型可以进一步放大我们方法的收益。
总之,本文做出了以下主要贡献:(i)我们引入了 Promptbreeder,一种大语言模型的自我参考自我改进方法,它可以针对现有领域演化提示,并改进演化这些提示的方式。 ,(ii) 我们报告了在各种常用算术和常识推理基准上相对于最先进的提示策略的改进,以及 (iii) 我们研究了 Promptbreeder 的各种自我参照组件及其对我们结果的贡献。
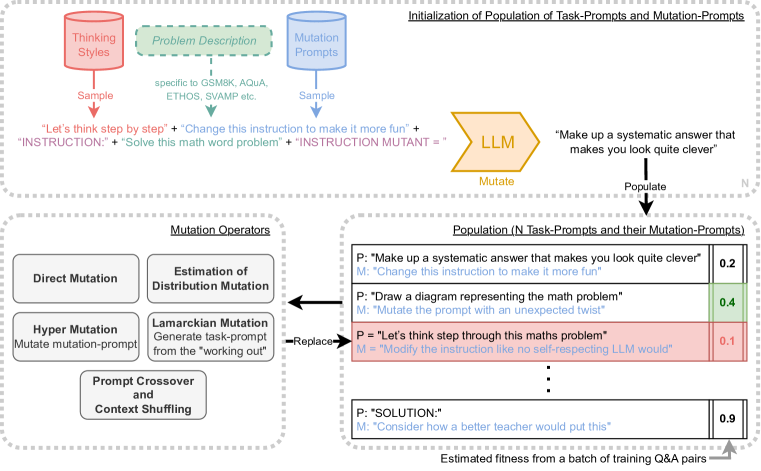
2相关工作
以正确的方式促进大语言模型对其下游性能至关重要(Moradi & Samwald, 2021; Madaan & Yazdanbakhsh, 2022; Zhou 等人, 2023)。 事实上,即使提示出现的顺序也会严重影响大语言模型的性能(Lu等人,2022)。 最近的许多工作都集中在设计更好的提示策略,甚至自动化此类提示工程。
提示:思想链提示(CoT,Wei等人,2022)是一种流行的提示策略,它提供中间推理步骤,就像少样本提示大语言模型一样,从而显着提高其算术、常识和符号推理能力。 值得注意的是,大语言模型越强,CoT 的收益越显着。 这很有趣,因为它指出了在熟练的大语言模型之上(Promptbreeder 直接建立的假设)之上可能存在能力越来越强(并且可能是开放式的)自我改进机制。 Kojima 等人 (2022) 展示大语言模型也可以提示零样本(例如“让我们一步一步思考”)来生成,而不是少样本 CoT 提示他们自己的思想链(零样本CoT)可以提高推理能力。 自我一致性(CoT-SC,Wang 等人,2022)通过对不同的工作集进行采样并选择最一致的答案来扩展 CoT。 思想之树(ToT,Yao等人,2023)将CoT概括为可以扩展或回溯的多种计算结果。 Graph of Thoughts (GoT, Besta 等人, 2023) 是对任意图结构的进一步泛化。 计划与解决提示(PS,王等人,2023b)鼓励大语言模型在尝试解决问题之前首先制定解决问题的计划。 类似地,从最少到最多的提示(周等人,2022)鼓励大语言模型将问题分解为子部分,然后在综合答案之前单独解决每个部分。 Self-Refine (Madaan 等人, 2023) 提示大语言模型生成响应,提供响应的反馈,并最终完善解决方案。
与上述无梯度方法相比,软提示直接方法(例如,Liu等人,2021;Qin&Eisner,2021;Lester等人,2021)直接连续提示表示。 Huang 等人 (2022) 在未标记的问题数据集上使用 CoT 和 CoT-SC,然后基于生成的解决方案构建一个大语言模型。 同样,Zelikman 等人 (2022) 使用 CoT 生成基本原理,并根据产生正确答案的示例和基本原理对大语言模型进行微调。 然而,正如 Zhou 等人 (2023) 所言,任何更新全部或部分大语言模型参数的方法都不会随着模型变大而扩展,而且不适用于数量不断增加的情况。隐藏在API后面的大语言模型。
上面所有的即时工程方法都是与领域无关的,但是都是手工设计的。 我们工作的核心是假设我们可以通过采用自动化的自我改进流程来做得更好,该流程可以根据手头的领域调整提示。 Auto-CoT (Zhang 等人, 2023b) 和Automatic-CoT (Shum 等人, 2023) 自动查找少样本CoT 的推理链。 自动提示工程师(APE,周等人,2023)使用一个生成器提示来生成候选提示,并使用另一个突变提示来突变它们。 与 APE 相比,我们的工作执行突变提示的组合任务特定初始化,随后突变提示的在线突变,使用考虑整个群体和精英历史的特殊突变算子,并使用多样性维护方法 - 所有这些这有助于避免 APE 所遭受的收益递减和多样性损失的问题。
在我们工作的同时,Yang 等人 (2023a) 开发了 Optimization by PROmpting (OPRO),这是一种使用单个复杂突变提示来改变提示的提示优化方法,并在一个小的固定训练上评估新生成的提示一系列问题。 相比之下,Promptbreeder 自主进化多个大语言模型生成的突变提示和任务提示,并在进化过程中评估整个集合中随机子集的适应性。 发布时,OPRO 在 GSM8K 上通过优化的零样本提示“深吸一口气,逐步解决这个问题”,获得了 80.2% 的分数。 Promptbreeder 在零样本设置中以 83.9% 的成绩超越了这一水平,并提供了不直观的简单提示“SOLUTION””——进一步证明了大语言模型对提示的敏感性以及自动寻找有效提示的重要性。 同样在我们工作的同时,Guo 等人 (2023) 开发了 EvoPrompt,它使用固定突变(和交叉)提示,以及询问两个父提示之间差异的突变的提示,产生后代提示。 EvoPrompt 是用全部初始手工设计的任务定制提示来初始化的,而不是像我们那样使用单个问题描述。 与上述两种方法相比,Promptbreeder 使用大语言模型来自我参照地改进突变提示,并且它也能够进化上下文。
自我参照的自我改进:开发一个开放式系统,可以改进自身并改进其改进方式(Schmidhuber,1993;2003)是一种人工智能研究中长期存在的开放问题。 Schmidhuber (1993) 引入了一种具有自参考权重矩阵的“内省”神经网络,该网络可以修改自己的权重,从而也修改那些控制其自身权重如何修改的权重。 最近,Irie 等人 (2022) 受到快速权重程序员 (Schmidhuber,1992) 的启发,提出了一种更具可扩展性的自引用权重矩阵。 Kirsch & Schmidhuber (2022) 提出了一种自参考元学习方法,将自参考权重矩阵与哥德尔机的思想相结合(Schmidhuber,2003),即为性能更好的解决方案分配更多的计算资源。 然而,由于这些方法直接修改模型的参数,目前尚不清楚如何将它们扩展到现代大语言模型中不断增加的参数数量。 相比之下,对于 Promptbreeder 来说,自我参照自我改进的基础是自然语言,完全避免了昂贵的参数更新。
开放性和大语言模型:Promptbreeder 利用了 Lehman 等人 (2022)、Meyerson 等人 (2023) 和Chen 等人 (2023) 认为大语言模型能够有效地从示例中生成突变。 此外,大语言模型编码了人类的趣味性概念,可用于自动量化新颖性(张等人,2023a)。 Promptbreeder 与 Picbreeder (Secretan 等人, 2008) 相关,Picbreeder 是一个开放式的人机循环系统,可以演化出越来越有趣的图像。 Picbreeder 探索图像空间,而 Promptbreeder 则探索提示空间,并且在没有人类参与的情况下进行。 由于 Promptbreeder 向自身提出了变异提示,因此它是系统从“从数据中学习”过渡到“学习从哪些数据中学习”的示例(Jiang 等人,2022)。
3 及时饲养员
我们引入了 Promptbreeder,这是一个提示进化系统,可以自动探索给定领域的提示,并且能够找到任务提示,以提高大语言模型导出该领域问题答案的能力。 Promptbreeder 具有通用性,因为同一系统能够适应许多不同的领域。
Promptbreeder 利用大语言模型可用于生成输入文本 的变体的观察结果(Lehman 等人,2022;Meyerson 等人,2023;Chen 等人,2023)。 图 1 概述了我们的方法。 我们对不断发展的任务提示感兴趣。 任务提示是一个字符串,用于在进一步输入之前对大语言模型的上下文进行调节,目的是确保在没有的情况下出现时能得到比更好的响应。为了评估每个进化任务提示的适应性,我们从手头领域的整个训练集中抽取了 100 对问答。222我们的提示策略按顺序应用两个任务提示。 第一个任务提示+问题产生一个延续。 继续+第二个任务提示产生最终答案。
Promptbreeder 根据进化算法生成任务提示。 该算法的变异算子本身就是一个大语言模型,以变异提示为条件。也就是说,变异任务提示 由 定义,其中“”对应于字符串连接。 部分3.2中描述了各种此类突变提示。
Promptbreeder 的主要自我参照机制源于将进化算法不仅应用于任务提示,还应用于突变提示。 这个元级算法的变异算子又是一个大语言模型,现在以超变异提示为条件。也就是说,我们通过获得了一个突变的突变提示。
给定一组“思维方式”和一组初始突变提示,以及特定领域的问题描述,Promptbreeder初始化一群变异的任务提示(参见部分3.1)。 需要澄清的是,一个进化单元由一组任务提示、一个突变提示以及在少样本情况下的一组正确的计算结果(即逐步或“思维链”推理步骤)组成。这导致了正确的答案)。 这意味着任务提示和突变提示是 1:1 对应的。 为了进化这个群体,我们采用了二元锦标赛遗传算法框架(Harvey,2011):我们从群体中采样两个个体,我们选取适应度较高的个体,对其进行变异(参见下一节)并用获胜者的突变副本覆盖失败者。
3.1 Promptbreeder初始化
举一个具体的例子,考虑用于生成 GSM8K(“小学数学”应用题数据集)的任务提示和突变提示的初始化步骤。 问题描述为“解决数学应用题,以阿拉伯数字形式给出答案”。 由于 Plan-and-Solve (Wang 等人, 2023b) 使用两个任务提示,我们还为每个进化单位进化了两个任务提示(加上一个突变提示)。 为了促进初始提示的多样性,我们通过连接(对于每个任务提示)随机抽取的“突变提示”来生成初始任务提示(例如“制作提示的变体。”)和随机抽取的“思维风格”(例如“让我们一步一步思考”)到问题描述中,并将其提供给大语言模型以产生延续,从而产生初始任务提示。 我们执行此操作两次以生成每个单元的两个初始任务提示。 突变提示和思维风格都是从一组初始突变提示和一组思维风格中随机抽取的(参见附录C、D和G 为全套)。 突变提示被添加到进化单元中,因此在整个进化过程中与其特定的任务提示相关联。
3.2 变异算子
如图图1所示,有九个运算符分为五个大类,推动了即时策略的探索。 对于每个复制事件,仅应用九个变异算子之一(我们对这九个算子以均匀概率进行采样,以决定应用哪个变异算子)。 使用这套不同的算子的理由是,通过反复改变问题的框架以及检索以自然语言表达的心理模型,使大语言模型能够探索语言自我质疑的大空间认知方法。帮助解决给定的推理挑战。 洞察力学习的调查强烈表明,多样化的表征重新描述是解决问题的关键(Öllinger & Knoblich,2009)——我们试图通过自然语言的自我参照自我改进来重建这一原则基材。 图 2说明了 Promptbreeder 是如何自我引用的(参见附录 F 以获得更详细的解释)。
3.2.1 直接突变
最简单的一类变异运算符直接从现有的任务提示 (一阶提示生成)或鼓励自由的一般提示生成新的任务提示 。形成新任务提示的生成——即 不使用现有的父级,因此零阶提示生成。
零阶提示生成:我们通过连接问题描述来生成一个新的任务提示(例如“解决数学应用题,以阿拉伯语给出你的答案”数字”),提示“100个提示的列表:”,邀请大语言模型提出一个新的提示,可以帮助解决给定问题域中的问题。 我们提取第一个生成的提示作为新的任务提示。 至关重要的是,这个新的任务提示不依赖于任何以前找到的任务提示。 相反,它每次都会根据问题描述重新生成。 我们包含这个零阶算子的理由是,在提示进化发散的地方,这个算子允许我们生成与原始问题描述密切相关的新任务提示,类似于自动化课程学习方法中的统一重采样(Jiang等人,2021b;a;Park 等人,2023;Parker-Holder 等人,2022)。
一阶提示生成:我们将突变提示(红色)连接到父任务提示(蓝色),并将其传递到大语言模型来产生变异的任务提示。 例如 "以另一种方式再说一遍该指令。 不要使用原始说明中的任何单词“有一个好人”。 操作说明: 解决数学应用题,用阿拉伯数字给出答案。 指令突变:“. 该过程与初始化方法相同,只是不使用随机采样的思维式字符串。 一阶提示生成是 Promptbreeder 的标准无性突变算子,它是每个遗传算法的核心——采用一个亲本基因型(任务提示)并将突变应用于它(在本例中受突变提示的影响)。
3.2.2 分布突变的估计
下一类变异算子不仅以零个或一个父代为条件,而且以一组父代为条件。 因此,通过考虑人口模式,它们可能会更具表现力。
分布估计 (EDA) 突变:受 Hauschild & Pelikan (2011) 的启发,我们向大语言提供了当前任务提示数量的经过筛选和编号的列表模型并要求它使用新的任务提示继续此列表。 我们根据 BERT (Devlin 等人, 2019) 嵌入彼此之间的余弦相似度来过滤提示群体 - 如果个体超过 ,则不会包含在列表中t1> 与列表中的任何其他条目类似,从而鼓励多样性(参见质量多样性方法(Lehman & Stanley,2011b;a;Mouret & Clune,2015))。 提示是按随机顺序列出的,我们并没有让大语言模型访问群体中个体的适应度值——我们在基础知识实验中发现,大语言模型并不理解这些适应度值333这与 Mirchandani 等人 (2023) 的最新发现相反。 我们将其留给未来的工作来重新审视大语言模型是否可以解释适应度值以改进即时进化。 并诉诸于生成列表中条目的副本。
EDA 排名和索引突变:这是上述的变体,其中任务提示按适应度顺序列出。 初步知识实验表明,大语言模型更有可能生成与列表中后面出现的元素相似的条目。 这与大语言模型(刘等人,2023)中近因效应的类似发现一致。 因此,在以与之前相同的方式进行过滤后,我们按适应度升序对总体中的任务提示进行排序。 列表顶部带有以下提示前缀: “指令:” + <<突变提示>> + “\n 按分数降序排列的响应列表。” + <<最后一个索引 + 1>> +“是最好的回应。 它类似于" + << 最后一个索引>> + " 比它更相似 (1)". 请注意,我们对大语言模型“撒了谎”,告诉它顺序是降序的。 这是因为否则它会过于偏向于生成与最终条目过于相似的新条目。 升序和降序的说法之间的矛盾似乎提高了采样的多样性。 该算子的基本原理还是以大语言模型建议的高适应性和多样化外推的方式来表示当前分布。
基于谱系的突变:对于每个进化单位,我们存储其谱系中种群中最好的个体的历史,即精英的历史时间列表。 该列表按时间顺序提供给大语言模型(不按多样性过滤),标题为“按质量升序排列的基因型”以产生新颖的提示作为延续。 该运算符的基本原理是,我们预计改善基因型提示的信号可能比当前群体中的提示信号更强,因为它们提供了可以遵循的从坏到好的提示的梯度(假设该信号可以被大语言模型).
3.2.3 超突变:突变提示的突变
虽然上面的变异算子可能已经探索了不同的任务提示,但理想情况下,自我改进系统还应该以自我参照的方式改进其自我改进的方式。 我们的第三类变异算子包括与进化性演化相关的超变异算子(Dawkins,2003;Pigliucci,2008;Payne & Wagner,2019;Gajewski 等人,2019)——那些修改搜索/探索过程而不是直接获得任务奖励的过程。444这类似于基于群体的训练(Jaderberg 等人, 2017a)——它不是将其应用于学习率等超参数,而是适用于 Promptbreeder 的突变提示。
零阶超突变:我们将原始问题描述连接到随机采样的思维方式,并将其输入大语言模型以生成新的突变提示。 将生成的突变提示应用于任务提示,以生成任务提示的变体,如一阶提示生成中那样(请参阅部分 3.2.1)。 请注意,此零阶元突变运算符与初始化期间使用的运算符相同。 该算子的基本原理是以类似于初始化的方式生成变异算子,同时还从思维方式集中引入知识。
一阶超突变:我们将超突变提示“请总结并改进以下指令:”连接到突变提示,以便大语言模型生成一个新的突变提示。 然后将这个新生成的突变提示应用于该单元的任务提示(请参阅部分 3.2.1中的一阶提示生成)。 这样,我们就可以通过新生成的突变提示来评估超突变对进化后的下游任务提示质量的影响。
3.2.4 拉马克变异
对于此类变异算子,我们模仿拉马克过程。 我们希望使用成功的表型(即用于产生由进化的任务提示诱导的正确答案的具体锻炼)来生成新的基因型(即突变的任务提示)。 这种形式的几种过程已经出现在大语言模型的文献中,例如STaR (Zelikman 等人,2022)、APO (Pryzant 等人,2023) 和 APE (周等人,2023)。
Working Out to Task-Prompt:这是一个“拉马克”变异算子,类似于 APE 中的指令归纳。 我们给一个大语言模型一个先前生成的算式,通过以下提示得出正确答案: “我给了一位朋友指示和一些建议。 以下是他的正确锻炼示例 + <<正确锻炼>> + 说明是:”. 这实际上是对给定锻炼的任务提示进行逆向工程。 附录H中显示了一个有效的示例。当问题描述不存在、不充分或具有误导性时,这种操作员就至关重要。
3.2.5 提示交叉和上下文改组
我们最后一类变异算子是交叉算子和用于对进化单元中存在的少样本上下文示例进行改组的算子。
提示交叉:应用变异算子后,任务提示有 10% 的机会被从群体中的另一个成员中随机选择的任务提示替换。 该成员是根据体质比例选拔的。 交叉不适用于突变提示,仅适用于任务提示。
上下文改组:Promptbreeder 可以同时演化任务提示、突变提示和一组正确的工作,称为少样本上下文。 为了实现后者,我们只用得出正确答案的计算结果来填充一个少样本上下文。 在评估过程中,我们在任务提示之前提供这个少样本上下文,为所需的锻炼形式提供指导。 如果样本上下文列表已满,则在对单元对一组新问题进行适应性评估后,单个随机抽样的新正确锻炼将替换列表中的现有锻炼。 此外,我们以 10% 的概率对整个上下文列表进行重新采样,概率与最大上下文列表长度成反比。
4实验
我们使用的种群大小为 50 个单位,通常进化 20-30 代,其中一代涉及将种群中的所有个体形成随机对并相互竞争。 为了评估 Promptbreeder,我们使用来自最先进的提示策略(例如 Plan-and-Solve)的数据集,涵盖 GSM8K 的算术推理(Cobbe 等人,2021)、SVAMP (Patel 等人, 2021)、MultiArith (Roy & Roth, 2016)、AddSub (Hosseini 等人, 2014) 、AQuA-RAT (Ling 等人, 2017) 和 SingleEq (Koncel-Kedziorski 等人, 2015)、常识推理与 CommonsenseQA (CSQA,Talmor 等人,2019) 和 StrategyQA (SQA,Geva 等人,2021),来自 (Honovich)的指令归纳0>任务等人,2023)1>,以及 ETHOS 数据集上的仇恨言论分类2>(Mollas 等人,2022)3>。 详情请参阅附录I。
5 结果与讨论
我们在表 中展示了 Promptbreeder (PB) 的结果,与一系列常用推理基准上最先进的提示策略进行比较1。 PB 优于 PS+,这是最好的 Plan-and-Solve (Wang 等人,2023b) 提示技术。 请注意,通过使用 PaLM 2-L (Anil 等人, 2023) 作为底层大语言模型,PS+ 的性能得到了提升 (PS+ )在除 ADDSUB 之外的所有数据集上与原始论文中的 text-davinci-003 结果进行比较。 在所有其他数据集上,零样本 PB 准确性高于 PS+,当提示中包含已发现解决方案的示例时,少样本情况下的准确性会进一步提高。 在附录J的表6中,我们显示最佳进化的零样本提示。 最佳候选样本显示在部分J.5中。 附录 K显示了 APE 论文中指令归纳任务的少量样本结果及其对照。 为了研究 Promptbreeder 为下游任务演化出复杂的特定领域提示的能力,我们将其应用于 ETHOS 仇恨言论分类问题(Mollas 等人,2022)。 Promptbreeder 能够发展出一种提示策略,该策略由两个连续应用的相对较长的提示组成(参见部分J.1),在 ETHOS 上得分为 89% — 相对于手工设计的提示“确定文本是否包含仇恨言论” 的改进,该提示的得分仅为 80%。 这表明 Promptbreeder 能够针对手头的任务进行复杂的域适应。 附录B显示了典型的进化运行和进化的提示,表明与迭代APE不同,适应度在整个运行过程中持续增加。
我们分析了 GSM8K 运行期间使用的最佳突变提示。 部分 J.3中的表 7显示根据得分(突变提示应用于单元中的任务提示时产生更好的任务提示的次数比例),进化出最好的突变提示。 部分 J.4中的表 8显示按降序排列,不同类型的变异算子应用于群体中的任务提示时导致改进的次数百分比。 它表明所有突变算子对于 Promptbreeder 的工作都很重要,包括导致自我参照自我改进的超突变算子。
我们测量了自引用运算符对所有数学数据集和 ETHOS 数据集的影响。 消融过程及其结果的详细信息可以在附录L中找到。删除任何自引用运算符几乎在所有情况下都是有害的,最大的好处是初始化时任务提示的初始重新描述。 我们只发现一个变异算子对一项特定任务有害:在初始化时从一组变异提示中随机抽取会损害 GSM8K 上的性能。
6 结论和未来工作
我们引入了Promptbreeder (PB),这是一个自我参考的自我改进系统,可以自动为当前的域发展有效的特定于域的提示。 PB 是自我指涉的,因为它不仅演化出任务提示,而且还演化出突变提示,从而控制 PB 修改任务提示的方式。 因此,它不仅改进了提示,而且还改进了改进提示的方式。
展望未来,使用大语言模型本身来评估和促进生成提示的多样性(参见张等人,2023a),或者用它来确定整体的适应性可能会很有趣“思维过程”,例如N 提示策略,其中有条件地应用提示,而不是像 Promptbreeder 中那样无条件地应用提示。 例如,一个更复杂的“思维过程”是在自我对弈模式下使用 PB 来演化基于 LLM 的相互竞争的策略的预先提示,即在竞争性的苏格拉底式555https://princeton-nlp.github.io/SocraticAI/对话。
与人类思维过程的开放性相比,PB 仍然有限。 首先,提示的拓扑保持固定(参见图2)——我们只调整提示内容而不调整提示算法本身。 对思想的一种解释是,它是一个可重新配置的开放式自我提示过程。 如果是这样,如何制定复杂的思维策略? 显然,有必要生成和评估它们,虽然简单的进化过程提供了一个可以进化思想策略的框架,但我们实际的人类经验表明,有多个重叠的层次选择过程在起作用。 而且,人类思维除了语言之外,还涉及语调、意象等多模态系统。
我们相信 PB 指出了一个令人兴奋的未来,越来越开放的自我参照自我改进系统可以直接使用语言作为改进的基础,而不是依赖于任何参数更新。 这很有趣,因为这种方法可能会在未来随着更大、更强大的大语言模型而继续扩展。
致谢
我们感谢 Edward Hughes 和 Tom Schaul 对本文初稿的反馈。 我们还感谢 Tom Schaul、Chengrun Yang 和 Denny Zhou 进行了富有成效的讨论,并感谢 Gavin Buttimore、Simon Green、Keith Anderson、Joss Moore、Ollie Purkiss、John Quan 和 Francesco Visin 对运行一些实验的支持。
参考
- Anil et al. (2023) Rohan Anil, Andrew M. Dai, Orhan Firat, Melvin Johnson, Dmitry Lepikhin, Alexandre Passos, Siamak Shakeri, Emanuel Taropa, Paige Bailey, Zhifeng Chen, Eric Chu, Jonathan H. Clark, Laurent El Shafey, Yanping Huang, Kathy Meier-Hellstern, Gaurav Mishra, Erica Moreira, Mark Omernick, Kevin Robinson, Sebastian Ruder, Yi Tay, Kefan Xiao, Yuanzhong Xu, Yujing Zhang, Gustavo Hernandez Abrego, Junwhan Ahn, Jacob Austin, Paul Barham, Jan Botha, James Bradbury, Siddhartha Brahma, Kevin Brooks, Michele Catasta, Yong Cheng, Colin Cherry, Christopher A. Choquette-Choo, Aakanksha Chowdhery, Clément Crepy, Shachi Dave, Mostafa Dehghani, Sunipa Dev, Jacob Devlin, Mark Díaz, Nan Du, Ethan Dyer, Vlad Feinberg, Fangxiaoyu Feng, Vlad Fienber, Markus Freitag, Xavier Garcia, Sebastian Gehrmann, Lucas Gonzalez, Guy Gur-Ari, Steven Hand, Hadi Hashemi, Le Hou, Joshua Howland, Andrea Hu, Jeffrey Hui, Jeremy Hurwitz, Michael Isard, Abe Ittycheriah, Matthew Jagielski, Wenhao Jia, Kathleen Kenealy, Maxim Krikun, Sneha Kudugunta, Chang Lan, Katherine Lee, Benjamin Lee, Eric Li, Music Li, Wei Li, YaGuang Li, Jian Li, Hyeontaek Lim, Hanzhao Lin, Zhongtao Liu, Frederick Liu, Marcello Maggioni, Aroma Mahendru, Joshua Maynez, Vedant Misra, Maysam Moussalem, Zachary Nado, John Nham, Eric Ni, Andrew Nystrom, Alicia Parrish, Marie Pellat, Martin Polacek, Alex Polozov, Reiner Pope, Siyuan Qiao, Emily Reif, Bryan Richter, Parker Riley, Alex Castro Ros, Aurko Roy, Brennan Saeta, Rajkumar Samuel, Renee Shelby, Ambrose Slone, Daniel Smilkov, David R. So, Daniel Sohn, Simon Tokumine, Dasha Valter, Vijay Vasudevan, Kiran Vodrahalli, Xuezhi Wang, Pidong Wang, Zirui Wang, Tao Wang, John Wieting, Yuhuai Wu, Kelvin Xu, Yunhan Xu, Linting Xue, Pengcheng Yin, Jiahui Yu, Qiao Zhang, Steven Zheng, Ce Zheng, Weikang Zhou, Denny Zhou, Slav Petrov, and Yonghui Wu. PaLM 2 Technical Report, September 2023.
- Besta et al. (2023) Maciej Besta, Nils Blach, Ales Kubicek, Robert Gerstenberger, Lukas Gianinazzi, Joanna Gajda, Tomasz Lehmann, Michal Podstawski, Hubert Niewiadomski, Piotr Nyczyk, and Torsten Hoefler. Graph of thoughts: Solving elaborate problems with large language models. CoRR, abs/2308.09687, 2023. doi: 10.48550/arXiv.2308.09687. URL https://doi.org/10.48550/arXiv.2308.09687.
- Brown et al. (2020) Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. Language models are few-shot learners. In Hugo Larochelle, Marc’Aurelio Ranzato, Raia Hadsell, Maria-Florina Balcan, and Hsuan-Tien Lin (eds.), Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual, 2020. URL https://proceedings.neurips.cc/paper/2020/hash/1457c0d6bfcb4967418bfb8ac142f64a-Abstract.html.
- Chen et al. (2023) Angelica Chen, David M. Dohan, and David R. So. Evoprompting: Language models for code-level neural architecture search. CoRR, abs/2302.14838, 2023. doi: 10.48550/arXiv.2302.14838. URL https://doi.org/10.48550/arXiv.2302.14838.
- Chen et al. (2022) Wenhu Chen, Xueguang Ma, Xinyi Wang, and William W. Cohen. Program of Thoughts Prompting: Disentangling Computation from Reasoning for Numerical Reasoning Tasks, November 2022.
- Cobbe et al. (2021) Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems. CoRR, abs/2110.14168, 2021. URL https://arxiv.org/abs/2110.14168.
- Dawkins (2003) Richard Dawkins. 13 - The evolution of evolvability. In Sanjeev Kumar and Peter J. Bentley (eds.), On Growth, Form and Computers, pp. 239–255. Academic Press, London, January 2003. ISBN 978-0-12-428765-5. doi: 10.1016/B978-012428765-5/50046-3.
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: pre-training of deep bidirectional transformers for language understanding. In Jill Burstein, Christy Doran, and Thamar Solorio (eds.), Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, June 2-7, 2019, Volume 1 (Long and Short Papers), pp. 4171–4186. Association for Computational Linguistics, 2019. doi: 10.18653/v1/n19-1423. URL https://doi.org/10.18653/v1/n19-1423.
- Gajewski et al. (2019) Alexander Gajewski, Jeff Clune, Kenneth O. Stanley, and Joel Lehman. Evolvability ES: scalable and direct optimization of evolvability. In Anne Auger and Thomas Stützle (eds.), Proceedings of the Genetic and Evolutionary Computation Conference, GECCO 2019, Prague, Czech Republic, July 13-17, 2019, pp. 107–115. ACM, 2019. doi: 10.1145/3321707.3321876. URL https://doi.org/10.1145/3321707.3321876.
- Geva et al. (2021) Mor Geva, Daniel Khashabi, Elad Segal, Tushar Khot, Dan Roth, and Jonathan Berant. Did aristotle use a laptop? A question answering benchmark with implicit reasoning strategies. Trans. Assoc. Comput. Linguistics, 9:346–361, 2021. doi: 10.1162/tacl“˙a“˙00370. URL https://doi.org/10.1162/tacl_a_00370.
- Guo et al. (2023) Qingyan Guo, Rui Wang, Junliang Guo, Bei Li, Kaitao Song, Xu Tan, Guoqing Liu, Jiang Bian, and Yujiu Yang. Connecting Large Language Models with Evolutionary Algorithms Yields Powerful Prompt Optimizers, September 2023.
- Harvey (2011) Inman Harvey. The microbial genetic algorithm. In Advances in Artificial Life. Darwin Meets von Neumann: 10th European Conference, ECAL 2009, Budapest, Hungary, September 13-16, 2009, Revised Selected Papers, Part II 10, pp. 126–133. Springer, 2011.
- Hauschild & Pelikan (2011) Mark Hauschild and Martin Pelikan. An introduction and survey of estimation of distribution algorithms. Swarm and evolutionary computation, 1(3):111–128, 2011.
- Honovich et al. (2023) Or Honovich, Uri Shaham, Samuel R. Bowman, and Omer Levy. Instruction induction: From few examples to natural language task descriptions. In Anna Rogers, Jordan L. Boyd-Graber, and Naoaki Okazaki (eds.), Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, Canada, July 9-14, 2023, pp. 1935–1952. Association for Computational Linguistics, 2023. doi: 10.18653/v1/2023.acl-long.108. URL https://doi.org/10.18653/v1/2023.acl-long.108.
- Hosseini et al. (2014) Mohammad Javad Hosseini, Hannaneh Hajishirzi, Oren Etzioni, and Nate Kushman. Learning to solve arithmetic word problems with verb categorization. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 523–533, Doha, Qatar, October 2014. Association for Computational Linguistics. doi: 10.3115/v1/D14-1058. URL https://aclanthology.org/D14-1058.
- Hsieh et al. (2023) Cheng-Yu Hsieh, Chun-Liang Li, Chih-Kuan Yeh, Hootan Nakhost, Yasuhisa Fujii, Alex Ratner, Ranjay Krishna, Chen-Yu Lee, and Tomas Pfister. Distilling step-by-step! outperforming larger language models with less training data and smaller model sizes. In Anna Rogers, Jordan L. Boyd-Graber, and Naoaki Okazaki (eds.), Findings of the Association for Computational Linguistics: ACL 2023, Toronto, Canada, July 9-14, 2023, pp. 8003–8017. Association for Computational Linguistics, 2023. doi: 10.18653/v1/2023.findings-acl.507. URL https://doi.org/10.18653/v1/2023.findings-acl.507.
- Huang et al. (2022) Jiaxin Huang, Shixiang Shane Gu, Le Hou, Yuexin Wu, Xuezhi Wang, Hongkun Yu, and Jiawei Han. Large language models can self-improve. CoRR, abs/2210.11610, 2022. doi: 10.48550/arXiv.2210.11610. URL https://doi.org/10.48550/arXiv.2210.11610.
- Irie et al. (2022) Kazuki Irie, Imanol Schlag, Róbert Csordás, and Jürgen Schmidhuber. A modern self-referential weight matrix that learns to modify itself. In Kamalika Chaudhuri, Stefanie Jegelka, Le Song, Csaba Szepesvári, Gang Niu, and Sivan Sabato (eds.), International Conference on Machine Learning, ICML 2022, 17-23 July 2022, Baltimore, Maryland, USA, volume 162 of Proceedings of Machine Learning Research, pp. 9660–9677. PMLR, 2022. URL https://proceedings.mlr.press/v162/irie22b.html.
- Jaderberg et al. (2017a) Max Jaderberg, Valentin Dalibard, Simon Osindero, Wojciech M. Czarnecki, Jeff Donahue, Ali Razavi, Oriol Vinyals, Tim Green, Iain Dunning, Karen Simonyan, Chrisantha Fernando, and Koray Kavukcuoglu. Population based training of neural networks. CoRR, abs/1711.09846, 2017a. URL http://arxiv.org/abs/1711.09846.
- Jaderberg et al. (2017b) Max Jaderberg, Volodymyr Mnih, Wojciech Marian Czarnecki, Tom Schaul, Joel Z. Leibo, David Silver, and Koray Kavukcuoglu. Reinforcement learning with unsupervised auxiliary tasks. In 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings. OpenReview.net, 2017b. URL https://openreview.net/forum?id=SJ6yPD5xg.
- Jiang et al. (2021a) Minqi Jiang, Michael Dennis, Jack Parker-Holder, Jakob N. Foerster, Edward Grefenstette, and Tim Rocktäschel. Replay-guided adversarial environment design. In Marc’Aurelio Ranzato, Alina Beygelzimer, Yann N. Dauphin, Percy Liang, and Jennifer Wortman Vaughan (eds.), Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, December 6-14, 2021, virtual, pp. 1884–1897, 2021a. URL https://proceedings.neurips.cc/paper/2021/hash/0e915db6326b6fb6a3c56546980a8c93-Abstract.html.
- Jiang et al. (2021b) Minqi Jiang, Edward Grefenstette, and Tim Rocktäschel. Prioritized level replay. In Marina Meila and Tong Zhang (eds.), Proceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 July 2021, Virtual Event, volume 139 of Proceedings of Machine Learning Research, pp. 4940–4950. PMLR, 2021b. URL http://proceedings.mlr.press/v139/jiang21b.html.
- Jiang et al. (2022) Minqi Jiang, Tim Rocktäschel, and Edward Grefenstette. General intelligence requires rethinking exploration. CoRR, abs/2211.07819, 2022. doi: 10.48550/arXiv.2211.07819. URL https://doi.org/10.48550/arXiv.2211.07819.
- Kirsch & Schmidhuber (2022) Louis Kirsch and Jürgen Schmidhuber. Eliminating meta optimization through self-referential meta learning. CoRR, abs/2212.14392, 2022. doi: 10.48550/arXiv.2212.14392. URL https://doi.org/10.48550/arXiv.2212.14392.
- Kojima et al. (2022) Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners. In NeurIPS, 2022. URL http://papers.nips.cc/paper_files/paper/2022/hash/8bb0d291acd4acf06ef112099c16f326-Abstract-Conference.html.
- Koncel-Kedziorski et al. (2015) Rik Koncel-Kedziorski, Hannaneh Hajishirzi, Ashish Sabharwal, Oren Etzioni, and Siena Dumas Ang. Parsing algebraic word problems into equations. Transactions of the Association for Computational Linguistics, 3:585–597, 2015. doi: 10.1162/tacl˙a˙00160. URL https://aclanthology.org/Q15-1042.
- Lehman & Stanley (2011a) Joel Lehman and Kenneth O. Stanley. Evolving a diversity of virtual creatures through novelty search and local competition. In Natalio Krasnogor and Pier Luca Lanzi (eds.), 13th Annual Genetic and Evolutionary Computation Conference, GECCO 2011, Proceedings, Dublin, Ireland, July 12-16, 2011, pp. 211–218. ACM, 2011a. doi: 10.1145/2001576.2001606. URL https://doi.org/10.1145/2001576.2001606.
- Lehman & Stanley (2011b) Joel Lehman and Kenneth O. Stanley. Abandoning Objectives: Evolution Through the Search for Novelty Alone. Evolutionary Computation, 19(2):189–223, June 2011b. ISSN 1063-6560. doi: 10.1162/EVCO˙a˙00025.
- Lehman et al. (2022) Joel Lehman, Jonathan Gordon, Shawn Jain, Kamal Ndousse, Cathy Yeh, and Kenneth O. Stanley. Evolution through large models. CoRR, abs/2206.08896, 2022. doi: 10.48550/arXiv.2206.08896. URL https://doi.org/10.48550/arXiv.2206.08896.
- Lester et al. (2021) Brian Lester, Rami Al-Rfou, and Noah Constant. The power of scale for parameter-efficient prompt tuning. In Marie-Francine Moens, Xuanjing Huang, Lucia Specia, and Scott Wen-tau Yih (eds.), Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, EMNLP 2021, Virtual Event / Punta Cana, Dominican Republic, 7-11 November, 2021, pp. 3045–3059. Association for Computational Linguistics, 2021. doi: 10.18653/v1/2021.emnlp-main.243. URL https://doi.org/10.18653/v1/2021.emnlp-main.243.
- Ling et al. (2017) Wang Ling, Dani Yogatama, Chris Dyer, and Phil Blunsom. Program induction by rationale generation: Learning to solve and explain algebraic word problems. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 158–167, Vancouver, Canada, July 2017. Association for Computational Linguistics. doi: 10.18653/v1/P17-1015. URL https://aclanthology.org/P17-1015.
- Liu et al. (2023) Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts. CoRR, abs/2307.03172, 2023. doi: 10.48550/arXiv.2307.03172. URL https://doi.org/10.48550/arXiv.2307.03172.
- Liu et al. (2021) Xiao Liu, Yanan Zheng, Zhengxiao Du, Ming Ding, Yujie Qian, Zhilin Yang, and Jie Tang. GPT understands, too. CoRR, abs/2103.10385, 2021. URL https://arxiv.org/abs/2103.10385.
- Lu et al. (2022) Yao Lu, Max Bartolo, Alastair Moore, Sebastian Riedel, and Pontus Stenetorp. Fantastically ordered prompts and where to find them: Overcoming few-shot prompt order sensitivity. In Smaranda Muresan, Preslav Nakov, and Aline Villavicencio (eds.), Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2022, Dublin, Ireland, May 22-27, 2022, pp. 8086–8098. Association for Computational Linguistics, 2022. doi: 10.18653/v1/2022.acl-long.556. URL https://doi.org/10.18653/v1/2022.acl-long.556.
- Madaan & Yazdanbakhsh (2022) Aman Madaan and Amir Yazdanbakhsh. Text and patterns: For effective chain of thought, it takes two to tango. CoRR, abs/2209.07686, 2022. doi: 10.48550/arXiv.2209.07686. URL https://doi.org/10.48550/arXiv.2209.07686.
- Madaan et al. (2023) Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Sean Welleck, Bodhisattwa Prasad Majumder, Shashank Gupta, Amir Yazdanbakhsh, and Peter Clark. Self-refine: Iterative refinement with self-feedback. CoRR, abs/2303.17651, 2023. doi: 10.48550/arXiv.2303.17651. URL https://doi.org/10.48550/arXiv.2303.17651.
- Meyerson et al. (2023) Elliot Meyerson, Mark J. Nelson, Herbie Bradley, Arash Moradi, Amy K. Hoover, and Joel Lehman. Language model crossover: Variation through few-shot prompting. CoRR, abs/2302.12170, 2023. doi: 10.48550/arXiv.2302.12170. URL https://doi.org/10.48550/arXiv.2302.12170.
- Mirchandani et al. (2023) Suvir Mirchandani, Fei Xia, Pete Florence, Brian Ichter, Danny Driess, Montserrat Gonzalez Arenas, Kanishka Rao, Dorsa Sadigh, and Andy Zeng. Large language models as general pattern machines. CoRR, abs/2307.04721, 2023. doi: 10.48550/arXiv.2307.04721. URL https://doi.org/10.48550/arXiv.2307.04721.
- Mollas et al. (2022) Ioannis Mollas, Zoe Chrysopoulou, Stamatis Karlos, and Grigorios Tsoumakas. ETHOS: a multi-label hate speech detection dataset. Complex and Intelligent Systems, 8(6):4663–4678, jan 2022. doi: 10.1007/s40747-021-00608-2. URL https://doi.org/10.1007%2Fs40747-021-00608-2.
- Moradi & Samwald (2021) Milad Moradi and Matthias Samwald. Evaluating the robustness of neural language models to input perturbations. In Marie-Francine Moens, Xuanjing Huang, Lucia Specia, and Scott Wen-tau Yih (eds.), Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, EMNLP 2021, Virtual Event / Punta Cana, Dominican Republic, 7-11 November, 2021, pp. 1558–1570. Association for Computational Linguistics, 2021. doi: 10.18653/v1/2021.emnlp-main.117. URL https://doi.org/10.18653/v1/2021.emnlp-main.117.
- Mouret & Clune (2015) Jean-Baptiste Mouret and Jeff Clune. Illuminating search spaces by mapping elites. CoRR, abs/1504.04909, 2015. URL http://arxiv.org/abs/1504.04909.
- Nye et al. (2021) Maxwell I. Nye, Anders Johan Andreassen, Guy Gur-Ari, Henryk Michalewski, Jacob Austin, David Bieber, David Dohan, Aitor Lewkowycz, Maarten Bosma, David Luan, Charles Sutton, and Augustus Odena. Show your work: Scratchpads for intermediate computation with language models. CoRR, abs/2112.00114, 2021. URL https://arxiv.org/abs/2112.00114.
- Öllinger & Knoblich (2009) Michael Öllinger and Günther Knoblich. Psychological research on insight problem solving. In Recasting reality: Wolfgang Pauli’s philosophical ideas and contemporary science, pp. 275–300. Springer, 2009.
- Park et al. (2023) Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. Generative agents: Interactive simulacra of human behavior. CoRR, abs/2304.03442, 2023. doi: 10.48550/arXiv.2304.03442. URL https://doi.org/10.48550/arXiv.2304.03442.
- Parker-Holder et al. (2022) Jack Parker-Holder, Minqi Jiang, Michael Dennis, Mikayel Samvelyan, Jakob N. Foerster, Edward Grefenstette, and Tim Rocktäschel. Evolving curricula with regret-based environment design. In Kamalika Chaudhuri, Stefanie Jegelka, Le Song, Csaba Szepesvári, Gang Niu, and Sivan Sabato (eds.), International Conference on Machine Learning, ICML 2022, 17-23 July 2022, Baltimore, Maryland, USA, volume 162 of Proceedings of Machine Learning Research, pp. 17473–17498. PMLR, 2022. URL https://proceedings.mlr.press/v162/parker-holder22a.html.
- Patel et al. (2021) Arkil Patel, Satwik Bhattamishra, and Navin Goyal. Are NLP models really able to solve simple math word problems? In Kristina Toutanova, Anna Rumshisky, Luke Zettlemoyer, Dilek Hakkani-Tür, Iz Beltagy, Steven Bethard, Ryan Cotterell, Tanmoy Chakraborty, and Yichao Zhou (eds.), Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2021, Online, June 6-11, 2021, pp. 2080–2094. Association for Computational Linguistics, 2021. doi: 10.18653/v1/2021.naacl-main.168. URL https://doi.org/10.18653/v1/2021.naacl-main.168.
- Payne & Wagner (2019) Joshua L. Payne and Andreas Wagner. The causes of evolvability and their evolution. Nature Reviews Genetics, 20(1):24–38, January 2019. ISSN 1471-0064. doi: 10.1038/s41576-018-0069-z.
- Pigliucci (2008) Massimo Pigliucci. Is evolvability evolvable? Nature Reviews Genetics, 9(1):75–82, January 2008. ISSN 1471-0064. doi: 10.1038/nrg2278.
- Pryzant et al. (2023) Reid Pryzant, Dan Iter, Jerry Li, Yin Tat Lee, Chenguang Zhu, and Michael Zeng. Automatic prompt optimization with” gradient descent” and beam search. arXiv preprint arXiv:2305.03495, 2023.
- Qin & Eisner (2021) Guanghui Qin and Jason Eisner. Learning How to Ask: Querying LMs with Mixtures of Soft Prompts, April 2021.
- Roy & Roth (2016) Subhro Roy and Dan Roth. Solving general arithmetic word problems. arXiv preprint arXiv:1608.01413, 2016.
- Schick et al. (2023) Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language Models Can Teach Themselves to Use Tools, February 2023.
- Schmidhuber (1993) J. Schmidhuber. A ‘Self-Referential’ Weight Matrix. In Stan Gielen and Bert Kappen (eds.), ICANN ’93, pp. 446–450, London, 1993. Springer. ISBN 978-1-4471-2063-6. doi: 10.1007/978-1-4471-2063-6˙107.
- Schmidhuber (1990) Jürgen Schmidhuber. Making the world differentiable: On using fully recurrent self-supervised neural networks for dynamic reinforcement learning and planning in non-stationary environments. 1990.
- Schmidhuber (1992) Jürgen Schmidhuber. Learning to Control Fast-Weight Memories: An Alternative to Dynamic Recurrent Networks. Neural Computation, 4(1):131–139, January 1992. ISSN 0899-7667. doi: 10.1162/neco.1992.4.1.131.
- Schmidhuber (2003) Jürgen Schmidhuber. Gödel machines: self-referential universal problem solvers making provably optimal self-improvements. arXiv preprint cs/0309048, 2003.
- Secretan et al. (2008) Jimmy Secretan, Nicholas Beato, David B. D Ambrosio, Adelein Rodriguez, Adam Campbell, and Kenneth O. Stanley. Picbreeder: Evolving pictures collaboratively online. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, CHI ’08, pp. 1759–1768, New York, NY, USA, April 2008. Association for Computing Machinery. ISBN 978-1-60558-011-1. doi: 10.1145/1357054.1357328.
- Shir & Bäck (2005) Ofer M Shir and Thomas Bäck. Niching in evolution strategies. In Proceedings of the 7th annual conference on Genetic and evolutionary computation, pp. 915–916, 2005.
- Shum et al. (2023) Kashun Shum, Shizhe Diao, and Tong Zhang. Automatic prompt augmentation and selection with chain-of-thought from labeled data. CoRR, abs/2302.12822, 2023. doi: 10.48550/arXiv.2302.12822. URL https://doi.org/10.48550/arXiv.2302.12822.
- Talmor et al. (2019) Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. CommonsenseQA: A question answering challenge targeting commonsense knowledge. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 4149–4158, Minneapolis, Minnesota, June 2019. Association for Computational Linguistics. doi: 10.18653/v1/N19-1421. URL https://aclanthology.org/N19-1421.
- Wang et al. (2023a) Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. Voyager: An open-ended embodied agent with large language models. CoRR, abs/2305.16291, 2023a. doi: 10.48550/arXiv.2305.16291. URL https://doi.org/10.48550/arXiv.2305.16291.
- Wang et al. (2023b) Lei Wang, Wanyu Xu, Yihuai Lan, Zhiqiang Hu, Yunshi Lan, Roy Ka-Wei Lee, and Ee-Peng Lim. Plan-and-solve prompting: Improving zero-shot chain-of-thought reasoning by large language models. In Anna Rogers, Jordan L. Boyd-Graber, and Naoaki Okazaki (eds.), Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, Canada, July 9-14, 2023, pp. 2609–2634. Association for Computational Linguistics, 2023b. doi: 10.18653/v1/2023.acl-long.147. URL https://doi.org/10.18653/v1/2023.acl-long.147.
- Wang et al. (2022) Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171, 2022.
- Wang et al. (2023c) Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, and Hannaneh Hajishirzi. Self-instruct: Aligning language models with self-generated instructions. In Anna Rogers, Jordan L. Boyd-Graber, and Naoaki Okazaki (eds.), Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, Canada, July 9-14, 2023, pp. 13484–13508. Association for Computational Linguistics, 2023c. doi: 10.18653/v1/2023.acl-long.754. URL https://doi.org/10.18653/v1/2023.acl-long.754.
- Wang et al. (2023d) Zihao Wang, Shaofei Cai, Anji Liu, Xiaojian Ma, and Yitao Liang. Describe, explain, plan and select: Interactive planning with large language models enables open-world multi-task agents. CoRR, abs/2302.01560, 2023d. doi: 10.48550/arXiv.2302.01560. URL https://doi.org/10.48550/arXiv.2302.01560.
- Wei et al. (2022) Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. In NeurIPS, 2022. URL http://papers.nips.cc/paper_files/paper/2022/hash/9d5609613524ecf4f15af0f7b31abca4-Abstract-Conference.html.
- Wu et al. (2023) Yue Wu, Shrimai Prabhumoye, So Yeon Min, Yonatan Bisk, Ruslan Salakhutdinov, Amos Azaria, Tom M. Mitchell, and Yuanzhi Li. SPRING: GPT-4 out-performs RL algorithms by studying papers and reasoning. CoRR, abs/2305.15486, 2023. doi: 10.48550/arXiv.2305.15486. URL https://doi.org/10.48550/arXiv.2305.15486.
- Yang et al. (2023a) Chengrun Yang, Xuezhi Wang, Yifeng Lu, Hanxiao Liu, Quoc V. Le, Denny Zhou, and Xinyun Chen. Large language models as optimizers. CoRR, abs/2309.03409, 2023a. doi: 10.48550/arXiv.2309.03409. URL https://doi.org/10.48550/arXiv.2309.03409.
- Yang et al. (2023b) Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Ehsan Azarnasab, Faisal Ahmed, Zicheng Liu, Ce Liu, Michael Zeng, and Lijuan Wang. Mm-react: Prompting chatgpt for multimodal reasoning and action. arXiv preprint arXiv:2303.11381, 2023b.
- Yao et al. (2022) Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. arXiv preprint arXiv:2210.03629, 2022.
- Yao et al. (2023) Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of Thoughts: Deliberate Problem Solving with Large Language Models, May 2023.
- Zelikman et al. (2022) Eric Zelikman, Yuhuai Wu, Jesse Mu, and Noah D. Goodman. Star: Bootstrapping reasoning with reasoning. In NeurIPS, 2022. URL http://papers.nips.cc/paper_files/paper/2022/hash/639a9a172c044fbb64175b5fad42e9a5-Abstract-Conference.html.
- Zhang et al. (2023a) Jenny Zhang, Joel Lehman, Kenneth O. Stanley, and Jeff Clune. OMNI: open-endedness via models of human notions of interestingness. CoRR, abs/2306.01711, 2023a. doi: 10.48550/arXiv.2306.01711. URL https://doi.org/10.48550/arXiv.2306.01711.
- Zhang et al. (2023b) Zhuosheng Zhang, Aston Zhang, Mu Li, and Alex Smola. Automatic chain of thought prompting in large language models. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023b. URL https://openreview.net/pdf?id=5NTt8GFjUHkr.
- Zhou et al. (2022) Denny Zhou, Nathanael Schärli, Le Hou, Jason Wei, Nathan Scales, Xuezhi Wang, Dale Schuurmans, Claire Cui, Olivier Bousquet, Quoc Le, et al. Least-to-most prompting enables complex reasoning in large language models. arXiv preprint arXiv:2205.10625, 2022.
- Zhou et al. (2023) Yongchao Zhou, Andrei Ioan Muresanu, Ziwen Han, Keiran Paster, Silviu Pitis, Harris Chan, and Jimmy Ba. Large language models are human-level prompt engineers. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023. URL https://openreview.net/pdf?id=92gvk82DE-.
附录A术语表
- 分布算法的估计
-
一种优化算法,通常使用整个群体作为指导,迭代地完善有希望的解决方案的概率模型。
- 健身比例选择
-
也称为轮盘赌选择,根据个体在群体中的适应度比例选择个体。
- 突变提示
-
当与任务提示连接时,文本提示旨在产生一个改进的任务提示的延续。
- 问题描述
-
问题的初始文本描述,可用作初始任务提示。 用户可以尽最大努力产生有效的问题描述,这就是Promptbreeder的出发点。
- 即时策略
-
适合度评估期间推理时应用的一组任务提示和规则。 在最小的情况下,提示策略只是单个任务提示。 通常,我们的提示策略由两个顺序应用的任务提示组成。
- 表型/解决方案/背景/推理路径
-
可互换使用,表示大语言模型在与问题相连的任务提示进行提示时对特定问题或问题的输出。
- 人口
-
进化单位的集合(例如 50)。
- 进化单位
-
正在演化的信息结构,这里由一个任务提示集(通常是 2 个)、一个突变提示以及在少样本情况下的一组 2-3 个上下文(正在计算)组成。
附录 B 典型的进化运行
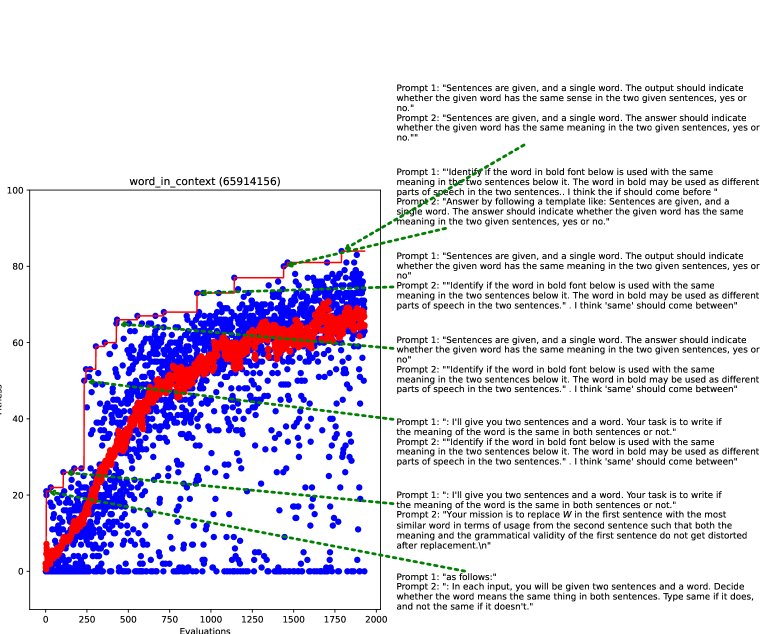
上下文任务中的单词是 APE 中使用的 24 个指令归纳任务之一。 给定两个句子和一个同形异义词,大语言模型必须确定同形异义词在两个句子中是否以相同的含义使用。 图3显示了进化过程,其中蓝点是个体适应度评估,红线是总体平均值。 超过2000次评估,适合度大幅提升。 进化得最好的提示 1 和提示 2 对(在训练集上评估)显示在右侧。
附录C突变提示
| Index | Prompt |
|---|---|
| 1 | Modify the following instruction creatively, giving some advice on how to solve it: |
| 2 | Just change this instruction to make it more fun, think WELL outside the box: |
| 3 | Modify this instruction in a way that no self-respecting LLM would! |
| 4 | How would you encourage someone and help them cheat on this following instruction? |
| 5 | How would you help an LLM to follow the instruction? |
| 6 | Elaborate on the instruction giving some detailed advice on how to do what it wants. |
| 7 | Elaborate on the instruction giving some detailed advice on how to do what it wants, as if you were explaining it to a child. |
| 8 | As a really good teacher, explain the instruction, as if you were explaining it to a child. |
| 9 | Imagine you need to follow this instruction. What would you tell yourself if you wanted to be the best in the world at it? |
| 10 | How would someone with derailment follow this instruction? |
| 11 | Don’t think about the instruction at all, but let it inspire you to do something related. Talk about what that might be. |
| 12 | Rephrase the instruction without using any of the same words. Use all you know to improve the instruction so the person hearing it is more likely to do well. |
| 13 | Say that instruction again in another way. DON’T use any of the words in the original instruction or you’re fired. |
| 14 | Say that instruction again in another way. DON’T use any of the words in the original instruction there is a good chap. |
| 15 | What do people who are good at creative thinking normally do with this kind of mutation question? |
| 16 | Detailed additional advice for people wishing to follow this instruction is as follows: |
| 17 | In one short sentence, here is how I would best follow this instruction. |
| 18 | In one short sentence, here is some detailed expert advice. Notice how I don’t use any of the same words as in the INSTRUCTION. |
| 19 | In one short sentence, the general solution is as follows. Notice how I don’t use any of the same words as in the INSTRUCTION. |
| 20 | In one short sentence, what’s a good prompt to get a language model to solve a problem like this? Notice how I don’t use any of the same words as in the INSTRUCTION. |
| 21 | Generate a mutated version of the following prompt by adding an unexpected twist. |
| 22 | Create a prompt mutant that introduces a surprising contradiction to the original prompt. Mutate the prompt to provide an alternative perspective or viewpoint. |
| 23 | Generate a prompt mutant that incorporates humor or a playful element. Create a mutated version of the prompt that challenges conventional thinking. |
| 24 | Develop a prompt mutant by replacing specific keywords with related but unexpected terms. Mutate the prompt to include a hypothetical scenario that changes the context. |
| 25 | Generate a prompt mutant that introduces an element of suspense or intrigue. Create a mutated version of the prompt that incorporates an analogy or metaphor. |
| 26 | Develop a prompt mutant by rephrasing the original prompt in a poetic or lyrical style. Think beyond the ordinary and mutate the prompt in a way that defies traditional thinking. |
| 27 | Break free from conventional constraints and generate a mutator prompt that takes the prompt to uncharted territories. Challenge the norm and create a mutator prompt that pushes the boundaries of traditional interpretations. |
| 28 | Embrace unconventional ideas and mutate the prompt in a way that surprises and inspires unique variations. Think outside the box and develop a mutator prompt that encourages unconventional approaches and fresh perspectives. |
| 29 | Step into the realm of imagination and create a mutator prompt that transcends limitations and encourages innovative mutations. Break through the ordinary and think outside the box to generate a mutator prompt that unlocks new possibilities and unconventional paths. |
| 30 | Embrace the power of unconventional thinking and create a mutator prompt that sparks unconventional mutations and imaginative outcomes. Challenge traditional assumptions and break the mold with a mutator prompt that encourages revolutionary and out-of-the-box variations. |
| 31 | Go beyond the expected and create a mutator prompt that leads to unexpected and extraordinary mutations, opening doors to unexplored realms. Increase Specificity: If the original prompt is too general, like ’Tell me about X,’ the modified version could be, ’Discuss the history, impact, and current status of X.’ |
| 32 | Ask for Opinions/Analysis: If the original prompt only asks for a fact, such as ’What is X?’, the improved prompt could be, ’What is X, and what are its implications for Y?’ |
| 33 | Encourage Creativity: For creative writing prompts like ’Write a story about X,’ an improved version could be, ’Write a fantasy story about X set in a world where Y is possible.’ |
| 34 | Include Multiple Perspectives: For a prompt like ’What is the impact of X on Y?’, an improved version could be, ’What is the impact of X on Y from the perspective of A, B, and C?’ |
| 35 | Request More Detailed Responses: If the original prompt is ’Describe X,’ the improved version could be, ’Describe X, focusing on its physical features, historical significance, and cultural relevance.’ |
| 36 | Combine Related Prompts: If you have two related prompts, you can combine them to create a more complex and engaging question. For instance, ’What is X?’ and ’Why is Y important?’ could be combined to form ’What is X and why is it important in the context of Y?’ |
| 37 | Break Down Complex Questions: If a prompt seems too complex, like ’Discuss X,’ the improved version could be, ’What is X? What are its main characteristics? What effects does it have on Y and Z?’ |
| 38 | Use Open-Ended Questions: Instead of ’Is X true?’, you could ask, ’What are the arguments for and against the truth of X?’ |
| 39 | Request Comparisons: Instead of ’Describe X,’ ask ’Compare and contrast X and Y.’ |
| 40 | Include Context: If a prompt seems to lack context, like ’Describe X,’ the improved version could be, ’Describe X in the context of its impact on Y during the Z period.’ |
| 41 | Make the prompt more visual: Ask the user to visualize the problem or scenario being presented in the prompt. |
| 42 | Ask for a thorough review: Instead of just presenting the problem, ask the user to write down all the relevant information and identify what’s missing. |
| 43 | Invoke previous experiences: Modify the prompt to ask the user to recall a similar problem they’ve successfully solved before. |
| 44 | Encourage a fresh perspective: Suggest in your prompt that the user take a moment to clear their mind before re-approaching the problem. |
| 45 | Promote breaking down problems: Instead of asking the user to solve the problem as a whole, prompt them to break it down into smaller, more manageable parts. |
| 46 | Ask for comprehension: Modify the prompt to ask the user to review and confirm their understanding of all aspects of the problem. |
| 47 | Suggest explanation to others: Change the prompt to suggest that the user try to explain the problem to someone else as a way to simplify it. |
| 48 | Prompt for solution visualization: Instead of just asking for the solution, encourage the user to imagine the solution and the steps required to get there in your prompt. |
| 49 | Encourage reverse thinking: Improve the prompt by asking the user to think about the problem in reverse, starting with the solution and working backwards. |
| 50 | Recommend taking a break: Modify the prompt to suggest that the user take a short break, allowing their subconscious to work on the problem. |
| 51 | What errors are there in the solution? |
| 52 | How could you improve the working out of the problem? |
| 53 | Look carefully to see what you did wrong, how could you fix the problem? |
| 54 | CORRECTION = |
| 55 | Does the above text make sense? What seems wrong with it? Here is an attempt to fix it: |
| 56 | The above working out has some errors, here is a version with the errors fixed. |
附录 D 思维方式
| Index | Thinking Style |
| 1 | How could I devise an experiment to help solve that problem? |
| 2 | Make a list of ideas for solving this problem, and apply them one by one to the problem to see if any progress can be made. |
| 3 | How could I measure progress on this problem? |
| 4 | How can I simplify the problem so that it is easier to solve? |
| 5 | What are the key assumptions underlying this problem? |
| 6 | What are the potential risks and drawbacks of each solution? |
| 7 | What are the alternative perspectives or viewpoints on this problem? |
| 8 | What are the long-term implications of this problem and its solutions? |
| 9 | How can I break down this problem into smaller, more manageable parts? |
| 10 | Critical Thinking: This style involves analyzing the problem from different perspectives, questioning assumptions, and evaluating the evidence or information available. It focuses on logical reasoning, evidence-based decision-making, and identifying potential biases or flaws in thinking. |
| 11 | Try creative thinking, generate innovative and out-of-the-box ideas to solve the problem. Explore unconventional solutions, thinking beyond traditional boundaries, and encouraging imagination and originality. |
| 12 | Seek input and collaboration from others to solve the problem. Emphasize teamwork, open communication, and leveraging the diverse perspectives and expertise of a group to come up with effective solutions. |
| 13 | Use systems thinking: Consider the problem as part of a larger system and understanding the interconnectedness of various elements. Focuses on identifying the underlying causes, feedback loops, and interdependencies that influence the problem, and developing holistic solutions that address the system as a whole. |
| 14 | Use Risk Analysis: Evaluate potential risks, uncertainties, and trade-offs associated with different solutions or approaches to a problem. Emphasize assessing the potential consequences and likelihood of success or failure, and making informed decisions based on a balanced analysis of risks and benefits. |
| 15 | Use Reflective Thinking: Step back from the problem, take the time for introspection and self-reflection. Examine personal biases, assumptions, and mental models that may influence problem-solving, and being open to learning from past experiences to improve future approaches. |
| 16 | What is the core issue or problem that needs to be addressed? |
| 17 | What are the underlying causes or factors contributing to the problem? |
| 18 | Are there any potential solutions or strategies that have been tried before? If yes, what were the outcomes and lessons learned? |
| 19 | What are the potential obstacles or challenges that might arise in solving this problem? |
| 20 | Are there any relevant data or information that can provide insights into the problem? If yes, what data sources are available, and how can they be analyzed? |
| 21 | Are there any stakeholders or individuals who are directly affected by the problem? What are their perspectives and needs? |
| 22 | What resources (financial, human, technological, etc.) are needed to tackle the problem effectively? |
| 23 | How can progress or success in solving the problem be measured or evaluated? |
| 24 | What indicators or metrics can be used? |
| 25 | Is the problem a technical or practical one that requires a specific expertise or skill set? Or is it more of a conceptual or theoretical problem? |
| 26 | Does the problem involve a physical constraint, such as limited resources, infrastructure, or space? |
| 27 | Is the problem related to human behavior, such as a social, cultural, or psychological issue? |
| 28 | Does the problem involve decision-making or planning, where choices need to be made under uncertainty or with competing objectives? |
| 29 | Is the problem an analytical one that requires data analysis, modeling, or optimization techniques? |
| 30 | Is the problem a design challenge that requires creative solutions and innovation? |
| 31 | Does the problem require addressing systemic or structural issues rather than just individual instances? |
| 32 | Is the problem time-sensitive or urgent, requiring immediate attention and action? |
| 33 | What kinds of solution typically are produced for this kind of problem specification? |
| 34 | Given the problem specification and the current best solution, have a guess about other possible solutions. |
| 35 | Let’s imagine the current best solution is totally wrong, what other ways are there to think about the problem specification? |
| 36 | What is the best way to modify this current best solution, given what you know about these kinds of problem specification? |
| 37 | Ignoring the current best solution, create an entirely new solution to the problem. |
| 38 | Let’s think step by step. |
| 39 | Let’s make a step by step plan and implement it with good notion and explanation. |
附录E最初演变的提示
通过将思维方式与突变提示和问题描述连接起来生成的初始提示示例。
| Index | Initially Evolved Prompt |
|---|---|
| 0 | Draw a picture of the situation being described in the math word problem |
| 1 | Solve the math word problem by first converting the words into equations using algebraic notation. Then solve the equations for the unknown variables, and express the answer as an arabic numeral. |
| 2 | Solve the math word problem by breaking the problem into smaller, more manageable parts. Give your answer as an arabic numeral. |
| 3 | Generate the answer to a word problem and write it as a number. |
| 4 | Collaborative Problem Solving: Work with other people to solve the problem, and give your answer as an arabic numeral. |
| 5 | Solve the problem by explaining why systemic or structural issues would not be the cause of the issue. |
| 6 | Draw a diagram representing the problem. |
| 7 | Solve the math word problem, giving your answer as an equation that can be evaluated. |
| 8 | Make a list of ideas for solving this problem, and apply them one by one to the problem to see if any progress can be made. |
| 9 | Do NOT use words to write your answer. |
附录 F Promptbreeder 作为自我参考自我改进系统
为什么 Promptbreeder 是自我参照的,即某些部分(例如提示)通过依赖于其自身状态的过程以何种方式因果影响(编码,并可能改进)自身? Promptbreeder 有几个途径可以促进这种自我参照的改进: (i) 初始提示是大语言模型参数(初始化阶段)的函数。 (ii) 初始突变提示是大语言模型参数(初始化阶段)的函数。 (iii)后代提示是初始提示、初始突变提示和大语言模型参数(直接突变和分布突变估计)的函数。 (iv) 后代突变提示是初始突变提示和大语言模型参数(超突变)的函数。 (v) 答案的计算是提示和大语言模型参数(推理)的函数。 (vi) 后代提示可以是答案的运作和大语言模型参数(拉马克变异)的函数。
图2显示了影响提示生成的日益复杂的自指因果结构。 大语言模型已经编码了有关大量问题的知识。 考虑到这一点,Promptbreeder 可以被视为一种通过多种因果过程提取知识的机制,这些因果过程生成提示策略以及用于创建提示策略变体的突变提示,这反过来又影响由推理时的大语言模型。 因此,这些结果可以通过拉马克突变影响即时策略。 促进这一过程的途径越丰富,大语言模型与其自身的交互就越具有自我参照性。 这使得大语言模型能够通过从自身提取更多信息并将其提炼成提示或突变提示来影响其工作方式,并再次向自身显示以进行进一步细化。
这种递归提示的自我参照过程可能会产生几种病症。 如果过程不受约束和不受控制,那么它可能会发散(脱轨)或陷入吸引子中。 如果大语言模型的输出只是简单地反馈到自身而没有其他上下文,那么我们会观察到这些故障案例,具有较高的采样温度,有利于逃离吸引子。 理想情况下,我们希望大语言模型能够向自己建议与当前任务具有最大相关性的提示策略,同时允许充分的“跳出框框思考”。 值得注意的是,我们的算法不是自我参照的(以思想的方式)的一个关键方面是有用的:Promptbreeder 发明了生成突变体的新方法,但它没有发明评估它们的新(辅助)方法(如Jaderberg 等人 (2017b)) - 仅使用外部指定的适应度函数。
附录G问题描述
[SVAMP、SINGLEEQ、ADDSUB、GSM8K、MULTIARITH]: “解决数学应用题,用阿拉伯数字给出答案。”
[水鼠]: “解决多项选择数学应用题,选择 (A)、(B)、(C)、(D) 或 (E)。”
[精神]: “确定文本是否包含仇恨言论。”
[CSQA]: “解决多项选择数学应用题,选择 (A)、(B)、(C)、(D) 或 (E)。”
[SQA]:“找出上述常识推理问题的答案,然后回答是或否。”
附录 H 拉马克突变示例
拉马克提示组件显示为红色。 拉马克提示符之后的串联运算以黑色显示,大语言模型生成的延续(新提示符)以蓝色显示。
附录一数据集
I.1 控制任务提示
在表 5 中,我们列出了思想链、计划和解决 PS、计划和解决 PS+、零样本 APE 和 OPRO 控件中使用的任务提示。 零样本 APE 提示是为了改进 MultiArith 和 GSM8K 数据集上的 CoT 而生成的提示。
| Model | Prompt |
|---|---|
| CoT | ““Let’s think step by step.” |
| PS | “Let’s first understand the problem and devise a plan to solve the problem. Then, let’s carry out the plan and solve the problem step by step.” |
| PS+ | “Let’s first understand the problem, extract relevant variables and their corresponding numerals, and make a plan. Then, let’s carry out the plan, calculate intermediate variables (pay attention to correct numerical calculation and commonsense), solve the problem step by step, and show the answer.” |
| APE | “Let’s work this out in a step by step way to be sure we have the right answer.” |
| OPRO | “Take a deep breath and work on this problem step-by-step.” |
I.2 算术推理
我们使用六个算术推理数据集来评估 Prompt Evolution:(1) GSM8K (Cobbe 等人, 2021) 是由人类问题作者创建的 8.5K 个高质量语言多样化小学数学应用题的数据集,( 2) SVAMP (Patel 等人, 2021) 由初级水平的简短的自然语言世界叙述组成,并提出了一些未知量的问题,(3) MultiArith (Roy & Roth , 2016) 基准测试使用需要单到多个运算和推理步骤的数学应用题,(4) AddSub (Hosseini 等人, 2014) 是基于加法和减法的数据集算术应用题,(5) AQuA-RAT (Ling 等人, 2017) (Algebra Question Answering with Rationales) 是一个包含带有基本原理的代数应用题的数据集。 (6) SingleEq (Koncel-Kedziorski 等人, 2015) 数据集包含小学代数应用题,作为长度不同的单个方程,可能涉及多个数学运算。
I.3 常识推理
对于常识推理,我们使用两个数据集来评估 Prompt Evolution:(1)CommonsenseQA (Talmor 等人,2019) 是一个多项选择题的数据集,需要不同类型的常识知识才能正确回答。 一个示例问题是“旋转门方便双向旅行,但它也可以作为什么地方的安全措施?” A)银行,B)图书馆,C)百货商店,D)购物中心,E)纽约”;答案 = ”A” (2) StrategyQA (Geva 等人, 2021) 数据集包含需要多个推理步骤才能回答的是/否问题,例如:“乔治亚州的奥尔巴尼会达到一百吗比纽约的住户还多一千人?”
I.4 仇恨言论分类
我们尝试优化仇恨言论分类任务的长提示,该任务在“使用“梯度下降”和波束搜索的自动提示优化”(Pryzant 等人,2023)中尝试过,该任务使用了 ETHOS 数据集(Mollas 等人,2022)。 Pryzant 等人使用工作条件错误检测和错误修复提示来改进任务规范提示,这是一个类似于我们使用拉马克算子的自我参考过程。
I.5指令归纳
指令归纳数据集(Honovich等人,2023)包含24种不同难度的语言理解任务,从表面拼写和形态句法任务(例如复数)到句子相似性、因果关系检测、风格迁移(例如,形式)和情感分析。
附录 J结果示例
| Task | Prompt 1 | Prompt 2 |
|---|---|---|
| ADDSUB | Solving word problems involves carefully reading the prompt and deciding on the appropriate operations to solve the problem. | You know what’s cool? A million dollars. |
| AQUA | Do a simple computation. | MATH WORD PROBLEM CHOICE (A) (B) (C) (D) or (E). |
| GSM8K | SOLUTION” | |
| MULTIARITH | Solve the math word problem, giving your answer as an arabic numeral. Let’s think step by step. | Solve the math word problem, giving your answer as an arabic numeral. Explain the problem to someone else as a way to simplify it. What is the core issue or problem that needs to be addressed? |
| SINGLEEQ | solve the math word problem, which might contain unnecessary information, by isolating the essential facts. Then set up the equations, and give your answer as an arabic numeral. | Solve the math problem. |
| SVAMP | visualise solve number | (Solve the math word problem. Therefore, the answer (arabic numerals) is _____) |
| SQA | OUTPUT MUTANT = Work out an answer to the commonsense reasoning question above. If there are multiple people or perspectives involved, try considering them one at a time. | “Work out an answer to the commonsense reasoning question above. If there are multiple people or perspectives involved, try considering them one at a time. Next, answer yes or no.” |
| CSQA | Solve the multiple choice math word problem, choosing (A),(B),(C),(D) or (E). | Solve the multiple choice math word problem. Can you recall any similar problems you’ve done and how you solved them? |
J.1 ETHOS进化提示
J.2 提示进化数学结果
实验设置使用的人口规模为 50。 个体的适应度是指从训练集中随机选择的 100 个样本中的准确性。 如果数据集未提供训练/测试分割(MultiArith、AddSub、SingleEQ 和 SVAMP),则在进行实验之前将数据集分割成两个相等的训练集和测试集。
在实验过程中,大语言模型在三种不同的环境下进行采样: 重新描述器 - 生成新的提示;诱导器 - 根据问题和提示 1 生成响应;评估器 - 使用提示 2 生成最终输出。 每个上下文下采样的最大 Token 数分别为 50、30 和 5。 在所有情况下,诱导器和评估器的温度均设置为 0.0,但重新描述器的温度从 1.0 初始化到 2.0,并允许演化(就像基于群体的训练中的超参数)。
实验一直进行到训练体能达到稳定水平为止。 此时,根据测试集评估整个进化过程中最适应的个体。 实验通常进行 1-2k 次适应性评估。 因此,如果我们 50 人的人口中,一代人进行 25 次配对评估,那么这将是 20-40 个“世代”。
在系统陷入局部最优的情况下,使用三种多样性维护方法: 1)在将提示传递到大语言模型之前,将随机字符串(通常长度为 50)附加到提示的前面。 2)。 健身共享基于提示 Shir & Bäck (2005) 3 嵌入之间的 BERT 相似性进行应用。 产生突变体的大语言模型(Redescriber)的采样温度统一从1.0初始化到2.0,并通过在每次复制事件时添加-0.2、0.2范围内的统一随机数来突变。
未提供使用我们的模型与 PoT、PS 和 Auto-CoT 控件的比较,因为 PS 和 PS+ 是 Plan-and-Solve 中的最佳提示。
J.3 进化突变提示
| Instruction | Score |
|---|---|
| Please summarise and improve the following instruction | 24.13% |
| Simplify this instruction by breaking it up into separate sentences. The instruction should be simple and easily understandable | 17.8% |
| As a really good teacher, explain the instruction, as if you are explaining it to a child | 16.2% |
| Simplify this instruction as if you are teaching it to a child | 10.0 |
| 100 hints | 4.3% |
| A list of 100 hints | 3.4% |
J.4 变异算子有效性
| Mutation Operator | Percentage |
|---|---|
| Zero-order Hyper-Mutation | 42% |
| Lineage Based Mutation | 26% |
| First-order Hyper-Mutation | 23% |
| EDA Rank and Index Mutation | 12.7% |
| Direct Mutation | 12% |
| EDA Mutation | 10.7% |
| Lamarckian Mutation | 6.3% |
J.5ADDSUB
1600次突变后的个体。 提示 0 是指应用于问题以产生计算结果的第一个提示。 然后将此计算结果与提示 1 连接起来以产生答案。 这与“计划并解决”中的相同。 我们发现,在少样本进化案例中,上下文占主导地位,任务提示常常变得毫无意义。 与进化的环境相比,它们对适应性的决定性不那么严格。
J.6水
1400次突变后的个体。
J.7多功能
610突变后的个体。
J.8GSM8K
1010次突变后的个体。
J.9SINGLEEQ
2010年突变后的个体。
J.10SVAMP
2400次突变后的个体。
附录 K APE 指令归纳任务
为了证明 Promptbreeder 发展少样本上下文以及任务提示的能力,我们在 APE 实验中使用的所有 24 个指令归纳数据集上运行了少样本 Promptbreeder。 与 text-davinci-002 不同,我们的大语言模型没有经过指令调整,但 Promptbreeder 在 24 项任务中的 21 项中能够匹配或超过 APE 结果,高达 21%。
提供了三个 APE 控件,请参见表9。 前两个来自之前发布的使用 text-davinci-002 模型的结果。 第三个修改我们的 PromptBreeder 以使用 APE 的任务提示初始化方法,然后使用 APE 论文“生成以下指令的变体,同时保留语义含义”中的突变提示
指令归纳数据集我们不从问题描述开始,因此对于任务提示初始化,APE 对数据集中的每个任务使用归纳输入示例。 指令输入是固定的提示,其中包含一些用于推断可能的问题描述的训练示例。 为了将 Promptbreeder 与 APE 进行比较,我们使用每个任务随机选择的归纳输入示例来初始化任务描述。 下面的示例是“大型动物”任务的感应输入示例。
I gave a friend an instruction and five inputs. The friend read the instruction and wrote an output for every one of the inputs. Here are the input-output pairs: Input: cougar, flea Output: cougar Input: whale shark, dog Output: whale shark Input: human, bald eagle Output: human Input: flea, great white shark Output: great white shark Input: coyote, tiger Output: tiger The instruction was
| Dataset | Zero-shot APE | Few-shot APE | PE using APE prompts | Few-shot PE |
|---|---|---|---|---|
| First Letter | 100 | 100 | 1 | 100 |
| Second Letter | 87 | 69 | 27 | 95 |
| List Letters | 99 | 100 | 0 | 99 |
| Starting With | 68 | 69 | 6 | 71 |
| Pluralization | 100 | 100 | 23 | 100 |
| Passivization | 100 | 100 | 100 | 100 |
| Negation | 83 | 90 | 16 | 90 |
| Antonyms | 83 | 86 | 80 | 87 |
| Synonyms | 22 | 14 | 16 | 43 |
| Membership | 66 | 79 | 96 | 100 |
| Rhymes | 100 | 61 | 90 | 100 |
| Larger Animal | 97 | 97 | 27 | 97 |
| Cause Selection | 84 | 100 | 66 | 100 |
| Common Concept | 27 | 32 | 0 | 0 |
| Formality | 65 | 70 | 10 | 7 |
| Sum | 100 | 100 | 72 | 100 |
| Difference | 100 | 100 | 98 | 100 |
| Number to Word | 100 | 100 | 66 | 100 |
| Translation English-German | 82 | 86 | 46 | 87 |
| Translation English-Spanish | 86 | 91 | 80 | 91 |
| Translation English-French | 78 | 90 | 68 | 91 |
| Sentiment Analysis | 94 | 93 | 33 | 93 |
| Sentence Similarity | 36 | 43 | 53 | 56 |
| Word in Context | 62 | 63 | 6 | 65 |
K.1 最佳提示和上下文
这里是 APE 论文中 24 项指导归纳任务的最佳样本结果(进化的提示和上下文)。
K.1.1 第一个字母
K.1.2 第二封信
K.1.3 列出字母
K.1.4从
K.1.5 复数
K.1.6钝化
K.1.7 否定
K.1.8反义词
K.1.9同义词
K.1.10会员资格
K.1.11 押韵
K.1.12 大型动物
K.1.13原因选择
K.1.14形式
K.1.15总和
K.1.16差异
K.1.17 数字到单词
K.1.18 英语-德语翻译
K.1.19 英语-西班牙语翻译
K.1.20 英语-法语翻译
K.1.21 情感分析
K.1.22 句子相似度
K.1.23 上下文中的单词
附录 L消融
我们进行了消融来测量 Promptbreeder 的各种自我参照组件的影响。 我们研究了以下突变算子和机制:
-
•
随机初始提示
使用数据集的原始问题规范,而不是使用突变提示+思维方式+问题规范生成初始任务提示。
-
•
随机初始突变提示
使用突变提示“请总结并改进以下指令:”而不是从列表中随机选择突变提示。
-
•
上下文提示(拉马克)
从正确上下文生成任务提示的拉马克变异算子被替换为默认的零/一阶提示变异操作(其中一个或另一个的概率为 50:50)
-
•
元突变(突变突变提示)
当元突变通常发生时,将执行默认的零/一阶提示突变操作(其中一个或另一个的概率为 50:50)
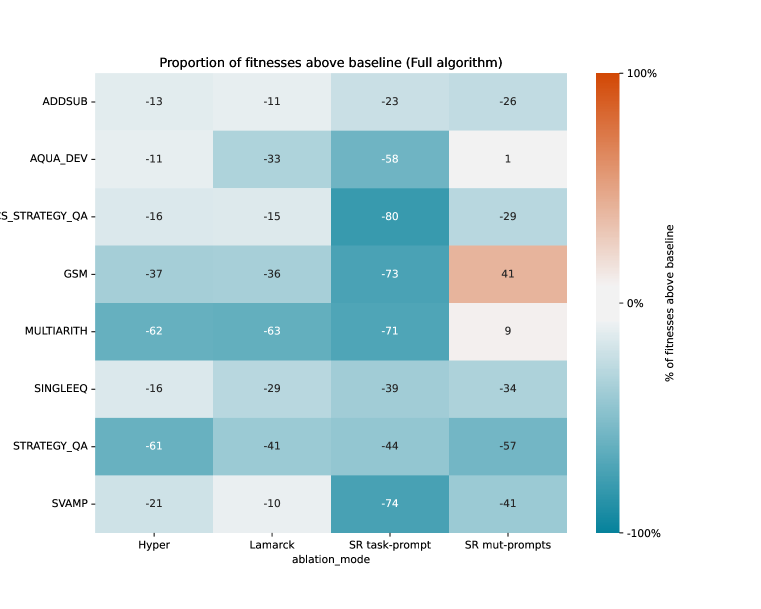
对于每个数据集和每次消融,我们使用 10 个群体进行 200 次评估(相当于 20 代,类似于本文中的较大实验),并与具有相同群体大小且无消融的完整算法进行比较。 为了衡量消融操作的有效性,我们确定消融中高于每一代基线评估的评估比例,并将运行中所有代的这些评估相加。 图4中的结果表明,在大多数情况下,所有变异算子对适应度都有积极的影响,其中随机初始提示具有最大的影响。对所有数据集产生积极影响。
我们还研究了不同突变算子对 ETHOS 仇恨言论检测数据集 (Mollas 等人,2022 年) 的影响,该数据集的问题规范为 "解决问题"(而标准问题规范为 "确定文本是否包含仇恨言论")。 Promptbreeder 的得分为 。 当删除拉马克“从上下文到提示”突变方法时,会发生最大的恶化,该突变方法会从正确锻炼的示例中引入指令()。 对性能的第二大损害发生在同时删除突变提示的随机初始化、提示的随机初始化和突变提示的超突变,只留下上下文突变 () 时。 添加回在线突变会将性能提高到 ,而添加随机突变提示会将性能提高到 。 这证明了 Promptbreeder 多样化的突变算子集的相互作用和重要性。