检索遇到长上下文大语言模型
摘要
扩展大语言模型的上下文窗口最近很流行,而通过检索增强大语言模型的解决方案已经存在多年。 自然的问题是: i)检索增强与长上下文窗口,哪一个更适合下游任务? ii) 是否可以将这两种方法结合起来以获得两全其美的效果? 在这项工作中,我们通过使用两个最先进的预训练大语言模型(即专有的 43B GPT 和 Llama2-70B)研究这两种解决方案来回答这些问题。 也许令人惊讶的是,我们发现在生成时使用简单的检索增强的具有 4K 上下文窗口的大语言模型可以在长上下文任务上通过位置插值实现与具有 16K 上下文窗口的微调大语言模型相当的性能,同时计算量少得多。 更重要的是,我们证明检索可以显着提高大语言模型的性能,无论其扩展上下文窗口大小如何。 我们最好的模型,具有 32K 上下文窗口的检索增强 Llama2-70B,在九个长上下文任务(包括问答、基于查询的摘要和上下文中)的平均得分方面优于 GPT-3.5-turbo-16k 和 Davinci003 少样本学习任务。 它的性能还远远优于其非检索 Llama2-70B-32k 基线,同时生成速度更快。 我们的研究为从业者提供了关于大语言模型的检索增强与长上下文扩展的选择的一般见解。
1简介
长上下文大语言模型(大语言模型)最近在生产(例如,Anthropic,2023;OpenAI,2023b)、研究界(例如,Chen 等人)中受到了广泛关注,2023;Liu 等人,2023;Tworkowski 等人,2023),以及开源社区(例如 Kaiokendev,2023)。 尽管近似注意力方法已经研究了多年(例如,Tay等人,2022a)(由于自注意力机制在序列长度上的二次时间和记忆复杂性),具有精确注意力的长上下文大语言模型的最新进展主要是由具有更多内存和内存高效的精确注意力的更快GPU的发展驱动的(Dao等人,2022;Dao ,2023)。
处理长上下文的替代且长期存在的解决方案是检索。 具体来说,大语言模型仅读取从独立检索器检索到的相关上下文(例如,Karpukhin 等人,2020;Wang 等人,2022;Lin 等人,2023),这更容易扩展 111密集嵌入检索器可以使用快速相似性搜索库(Johnson等人,2019)轻松地从数十亿个标记中检索上下文。 在选择相关上下文方面,其运行速度比大语言模型快几个数量级。 从概念上讲,仅检索增强解码器的大语言模型可以被视为在其长上下文窗口上应用稀疏注意力,其中稀疏模式不是预定义为 Child 等人 (2019) 而是由下式确定:独立的检索器。 换句话说,未检索到的上下文被视为不相关,并且注意力权重为零。
鉴于人们对长上下文大语言模型研究的兴趣激增,以及推理时需要更多的计算 222例如,32k上下文长度的GPT-4的价格是8k上下文模型的两倍。,对于实践者来说,仍然不清楚扩展大语言模型的上下文窗口是否比具有信息查询的下游任务的检索增强提供更高的准确性。 此外,如果我们能够结合两种方法的优势并实现更高的准确度,那将是令人信服的。 在这项工作中,我们试图通过全面的研究来回答上述问题。
具体来说,我们做出以下贡献:
-
1.
我们使用两个最先进的大语言模型(专有的 43B 预训练 GPT 和 Llama2-70B (Touvron 等人,2023b) 对 9 个下游长上下文任务(包括单个和多文档问答 (QA)、基于查询的摘要以及上下文少样本学习任务。
-
2.
我们证明检索增强显着提高了 4K 上下文大语言模型的性能。 也许令人惊讶的是,我们发现这个简单的检索增强基线可以与 16K 长上下文大语言模型相媲美,即使用 GPT-43B 时的平均得分为 29.32 vs. 29.45,使用 Llama2-70B 时的平均得分为 36.02 vs. 36.78,同时使用大量更少的计算。
-
3.
此外,我们证明长上下文大语言模型(即 16K 或 32K)的性能仍然可以通过检索来提高,特别是对于较大的 Llama2-70B。 因此,我们最好的模型检索增强了 Llama2-70B-32k-ret 的 32K 上下文窗口(平均)。 得分 43.6),优于 GPT-3.5-turbo-16k(平均分) 得分 42.8) 和 Davinci-003 的平均得分。 它还大大优于其非检索 Llama2-70B-32k 基线(平均)。 得分 40.9),而生成速度可以快得多(例如,NarrativeQA 上快 4)。
2相关工作
在本节中,我们讨论长上下文大语言模型、高效注意力方法和检索增强语言模型的相关工作。
2.1 并行工作
当我们准备这篇手稿时,我们注意到并行的工作(Bai等人,2023)(arXived于2023年8月28日)也研究了检索对长上下文大语言模型的影响,包括黑-盒模型 GPT-3.5-Turbo-16k (OpenAI, 2022)、白盒模型 Llama2-7B-chat-4k (Touvron 等人, 2023b) 和 ChatGLM2 -6B-32k (曾等人,2022)。 与我们的发现不同,他们发现检索仅对具有 4K 上下文窗口的 Llama2-7B-chat-4k 有帮助,但对长上下文模型(即 GPT-3.5-Turbo-16k 和 ChatGLM2-6B-32k)没有帮助。 我们假设主要原因是:i)使用黑盒 API 进行对照实验具有挑战性,ii)他们的研究中使用的白盒大语言模型是相对较小,因此它们通过检索合并上下文的零样本能力有限。 我们的结论是从更大的大语言模型中得出的。 特别是,我们最好的长上下文模型 Llama2-70B-32k 的性能与 Davinci003 和 GPT-3.5-turbo-16k 一样好,同时它仍然可以通过检索进一步增强(参见表 3)。
2.2长上下文大语言模型
在过去的几年里,由于具有更多内存和内存效率的精确注意力的更快 GPU,预训练具有长上下文窗口的大型语言模型(大语言模型)成为可行的解决方案(例如,Dao 等人,2022). 例如,预训练大语言模型的上下文窗口从 GPT-2 (Radford 等人, 2019) 的 1024 增加到 GPT-3 (Brown 等人, 2020)的 2048 、Llama 2 的 4096(Touvron 等人,2023b),到 GPT-4 的 8192(OpenAI,2023a)。 然而,进一步扩展预训练中的上下文窗口可能具有挑战性,因为 i) 预训练大语言模型从头开始使用长上下文(例如,>16K tokens)由于二次时间而非常昂贵和精确注意力的记忆复杂性,以及 ii) 预训练语料库中的大多数文档(例如 Common Crawl)都相对较短。
最近,研究人员开始通过持续训练或微调来扩展大语言模型的上下文窗口(例如,Kaiokendev, 2023; Nijkamp 等人, 2023; Chen 等人, 2023; Tworkowski 等人, 2023; Mohtashami &贾吉,2023)。 Tworkowski 等人 (2023) 通过微调 3B 和 7B OpenLLaMA 检查点以及 8K 上下文长度上的对比训练,引入了 LongLLaMA。 地标注意力(Mohtashami & Jaggi,2023)通过引入“地标标记”来表示上下文块并微调注意力以使用地标标记来将 LLaMA 7B 的上下文长度从 4K 扩展到 32K选择相关块。 Chen 等人 (2023) 和 Kaiokendev (2023) 引入了位置插值来扩展基于 RoPE 的 的上下文窗口大小(Su等人, 2021) 预训练的大语言模型。 特别是,Chen 等人 (2023) 在 LLaMA 7B 到 65B (Touvron 等人, 2023a) 上展示了有希望的结果,只需最少的微调工作(1000 步以内)。 ALiBi (Press 等人, 2021) 通过删除位置嵌入来推断上下文窗口长度,同时简单地使用与距离成正比的线性惩罚来偏置关键查询注意力分数,因此不需要微调用于上下文窗口外推。 Ratner 等人 (2023) 将长上下文分块到多个子窗口中,并在这些窗口中重复使用位置嵌入,因此可以处理更长的上下文,而无需任何进一步的微调。 在这项工作中,我们应用位置插值方法将专有的43B预训练大语言模型和Llama2-70B (Touvron等人,2023b)的4K上下文窗口扩展到16K和 32K,因为它们都在预训练处使用旋转位置嵌入。 在评估方面,我们重点关注指令调优后的下游任务性能(例如,Shaham 等人,2023;Bai 等人,2023)(Wei 等人,2021) 。
还有其他研究表明检索增强和长上下文大语言模型之间的相互作用。 Liu 等人 (2023) 对现有大语言模型产品的长上下文能力进行黑盒评估,包括 ChatGPT 3.5 (OpenAI, 2022)、GPT-4 (OpenAI,2023a),Claude (Anthropic,2023),在检索增强设置中,并识别这些模型中的“迷失在中间”现象。
2.3 高效的注意力方法
在之前的研究中,引入了许多近似注意力方法(Tay等人,2022a)来处理自注意力的二次复杂度,这成为长上下文的计算瓶颈。 它们可以分为以下几类:i)具有预定义稀疏模式的稀疏注意力机制(例如,Child等人,2019;Parmar等人,2018;Ho等人,2019;Beltagy等人, 2020; Zaheer 等人, 2020; Zhu 等人, 2021), ii) 基于递归的方法(Dai 等人, 2019; Bulatov 等人, 2022 ), iii) 低阶投影注意力 (例如,Wang 等人,2020;Xiong 等人,2021;Tay 等人,2021;Zhu 等人,2021) , iv) 基于记忆的机制(例如,Rae 等人,2020;Liu 等人,2018),v)基于相似性和聚类的方法(例如,Kitaev 等人,2020;Tay 等人,2020;Roy 等人,2021)。 这些近似方法引入了归纳偏差(例如,预定义的稀疏性),可以很好地适合特定领域,但可能会降低一般大语言模型训练中的模型质量。
最近,引入了 FlashAttention (Dao 等人,2022;Dao,2023),通过考虑 GPU 内存级别之间的读写来加速精确的注意力计算。 FlashAttention 对于处理较长的序列特别有用。
2.4 检索增强语言模型
多年来,检索已被集成到语言模型中,以提高复杂性(Borgeaud 等人,2022;Wang 等人,2023)、事实准确性(Nakano 等人,2021),下游任务准确率(Guu 等人, 2020; Izacard & Grave, 2021; Izacard 等人, 2022; Lewis 等人, 2020)和情境学习能力(Huang 等人, 2023)。 结合独立的检索器(Karpukhin 等人,2020;Wang 等人,2022;Lin 等人,2023),检索增强大语言模型非常适合处理长文档和中的问答。开放域。 在之前的研究中,语言模型通过推理检索(Khandelwal等人,2019;Yogatama等人,2021)、微调(Izacard等人,2022;Lewis等人)来增强。 ,2020;Guu 等人,2020)和预训练(Borgeaud 等人,2022;Izacard 等人,2022;Wang 等人,2023)。 还有一些方法尝试将大语言模型和检索器集成在单个模型中并构建端到端解决方案(例如,Jiang等人,2022;Shi等人,2023)。 然而,除了最近的一些作品(例如,Shi等人,2023)之外,大多数先前的作品主要研究具有大约100亿个参数的大语言模型的检索增强。
在这项工作中,我们专注于在数万亿个 Token 上训练的具有 43B 和 70B 参数的仅解码器大语言模型,因为如此规模的大语言模型表现出强大的零样本能力,可以在指令调整后合并上下文(Wei等人,2021;2022)。
3实验设置
在本节中,我们将介绍实验设置的详细信息。
3.1 大型语言模型
我们重点比较通过检索或大语言模型自身的自注意力机制整合长上下文信息以进行生成性问答或摘要任务的零样本能力。 (Kaiokendev, 2023; Nijkamp et al., 2023; Tworkowski et al、2023;Mohtashami & Jaggi, 2023),我们通过探索指令微调后大于 40B 的模型规模来收集见解,因为先前的研究表明,当仅解码器的大语言模型具有约 50B 参数时,指令微调才会变得有效(Wei 等人,2021;2022)。
具体来说,我们试验了两种预训练的 GPT 模型:专有的 Nemo GPT-43B 和 Llama2-70B。 GPT-43B是一个430亿个参数的模型,使用1.1T tokens进行训练,其中70%是英语语料库,另外30%是多语言和代码数据。 对于英语预训练语料库,GPT-43B 使用 Common Crawl web archive (WARC)、Wikipedia、Reddit、Books、Gutenberg、ArXiv、StackExchange、PubMed 等。 它包含 48 层,隐藏维度为 8,192。 它使用 4,096 的序列长度和 RoPE 嵌入(Su等人,2021)进行训练。 另一个 Llama2-70B 是一个公开的 70B GPT 模型,使用大约 90% 的英语数据在 2T Token 上进行训练。 它包含 80 层,隐藏维度为 8,192。 它还具有 4,096 的上下文窗口大小,并使用 RoPE 嵌入进行训练。
3.2 数据集和指标
在这项研究中,我们包括七个数据集,从单文档 QA、多文档 QA 到基于查询的总结,以进行零样本评估。 具体来说,我们包括来自 Scroll 基准验证集的四个数据集(Shaham 等人,2022)。
-
•
QMSum (QM) (Zhong 等人, 2021) 是一个基于查询的摘要数据集,由来自学术、工业等多个领域的会议记录及其相应的摘要组成产品。 在这个任务中,给出了会议对话记录,并提出了一个总结对话某个主题的问题,例如“他们之间达成了什么协议”。 答案一般包含几句话。
-
•
Qasper (QASP) (Dasigi 等人, 2021) 是从语义学者开放研究语料库 (S2ORC) 过滤出来的 NLP 论文问答数据集 (Lo 等人,2020)。 Qasper 包含抽象问题、提取问题、是/否问题以及无法回答的问题。 在此任务中,提供一个脚本和一个信息搜索问题,例如“它们与哪些多语言方法进行比较?”。 模型需要通过对给定上下文的推理来给出简短的答案。
-
•
NarrativeQA (NQA) (Kočiský 等人, 2018) 是古腾堡计划中整本书的既定问答数据集333https://www.gutenberg.org/ 以及网站列表中的电影脚本。 在这个任务中,给定的段落是从书本上抄录下来的,通常很吵。 需要一个模型通过对长而嘈杂的文本进行推理来生成简短的短语。
-
•
QuALITY (QLTY) (Pang 等人, 2022) 是一个问答数据集,涵盖从多个资源收集的故事和文章,例如古腾堡计划和开放美国国家语料库444https://anc.org/。 与所有其他任务不同,这是一个多选择数据集,需要一个模型从四个给定选项中选择一个。
我们从 LongBench (Bai 等人, 2023) 中获取另外三个数据集。
-
•
HotpotQA (HQA) (Yang 等人, 2018) 是一个基于维基百科的问答数据集。 与上述单一热门数据集不同,HQA 是一个多跳数据集,需要阅读多个支持文档来进行回答和推理,并且问题多样且不受任何预先存在的知识库的限制。
-
•
MuSiQue (MSQ) (Trivedi 等人, 2022) 是另一个多跳问答数据集。 与 HQA 相比,MSQ 需要通过减少潜在的推理捷径、最大限度地减少训练测试泄漏以及包含更困难的干扰上下文来进行连接推理。 因此,MSQ 是比 HQA 更困难的任务,而且更不易作弊。
-
•
MultiFieldQA-en (MFQA) (Bai 等人, 2023) 是手动策划的,以更好地测试模型跨不同领域的长上下文理解能力。 来自多个来源的证据,包括法律文件、政府报告、百科全书和学术论文,在文件中相当随机地放置,以避免文件开头或结尾可能出现的偏见。
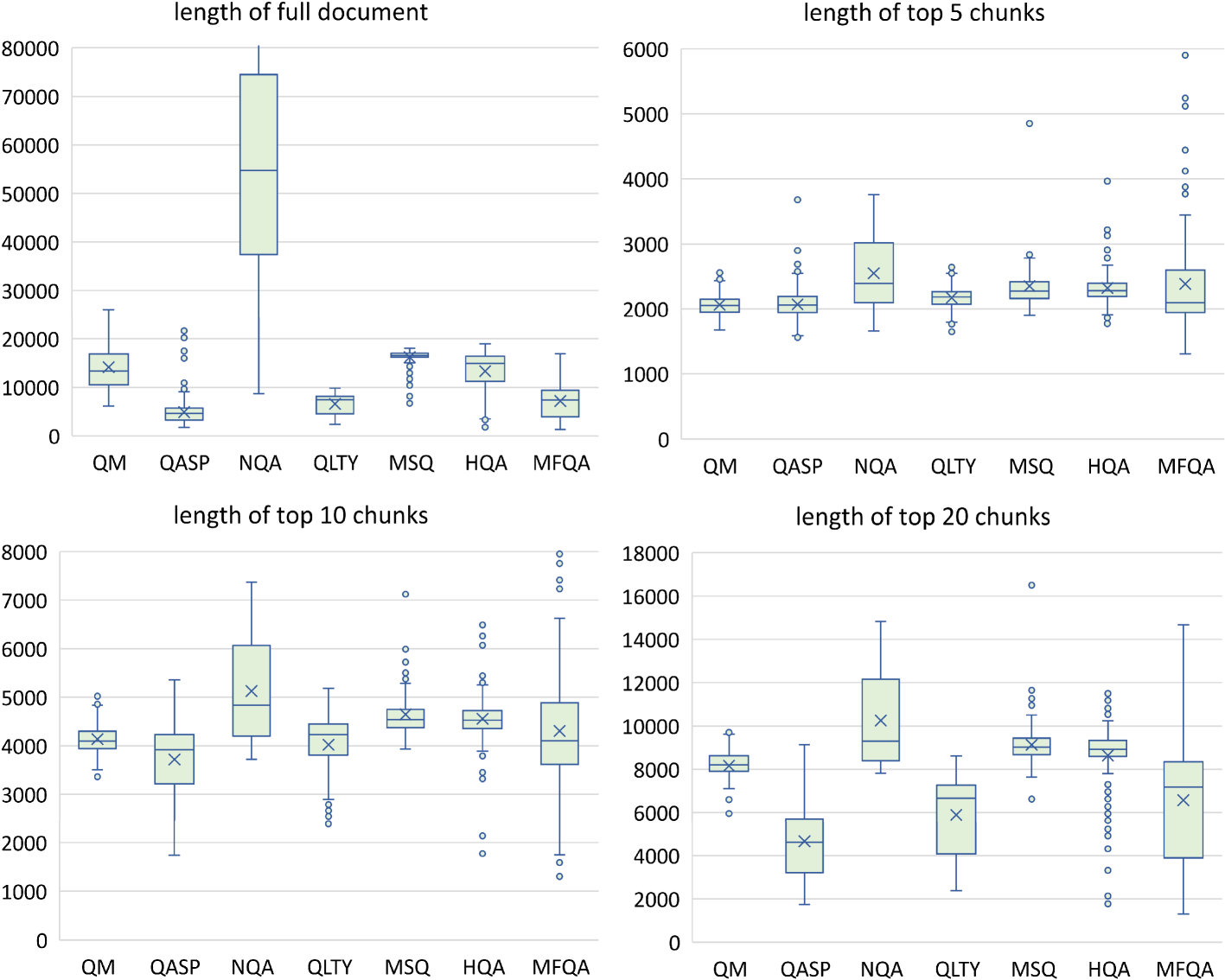
数据集的完整详细信息可以在表1中找到。 我们可以看到,我们的评估数据集的平均文档长度范围很广,从 4.9k (QASP) 到 84k (NQA)。 因此,对于没有检索的基线模型,我们相应地截断文档以适应输入序列长度。
| QM | QASP | NQA | QLTY | MSQ | HQA | MFQA | |
|---|---|---|---|---|---|---|---|
| # of samples | 200 | 1,726 | 2,000 | 2,000 | 200 | 200 | 150 |
| avg doc length | 14,140 | 4,912 | 84,770 | 6,592 | 16,198 | 13,319 | 7,185 |
| avg top-5 chunks | 2,066 | 2,071 | 2,549 | 2,172 | 2,352 | 2,322 | 2,385 |
| avg top-10 chunks | 4,137 | 3,716 | 5,125 | 4,018 | 4,644 | 4,554 | 4,305 |
| avg top-20 chunks | 8,160 | 4,658 | 10,251 | 5,890 | 9,133 | 8,635 | 6,570 |
根据官方指标,我们报告 QM 的 ROUGE 分数的几何平均值(即 ROUGE-1/2/L)(Lin,2004)、QLTY 的精确匹配 (EM) 分数,以及其余五个数据集 QASP、NQA、MSQ、HQA 和 MFQA 的 F1 分数。
3.3 上下文窗口扩展
我们使用位置插值方法 (Chen 等人, 2023) 来扩展上下文窗口长度,因为它对于 RoPE 嵌入来说简单且有效。 我们将 GPT-43B 的 4K 上下文窗口扩展到 16K。 对于 Llama2,我们将 Llama2-7B 的 4K 上下文窗口扩展至 32k,将 Llama2-70B 的上下文窗口扩展至 16K 和 32K。 我们遵循 Chen 等人 (2023) 并在 Pile 数据集 (Gao 等人, 2021) 上对大语言模型进行微调,批量大小为 128,恒定学习率为 5e -6 适应位置嵌入。
3.4检索
对于检索器,我们尝试了三种检索器:1) Dragon (Lin 等人, 2023) 因为它在监督和零上都取得了最先进的结果样本信息检索基准(Thakur等人,2021)。 Dragon 是一个双编码器模型,由查询编码器和上下文编码器组成。 2)广泛使用的Contriever模型(Izacard等人,2021)。 遵循 MoCo 技术(He 等人,2020),Contriever 使用简单的对比学习框架来预训练信息检索模型。 它在没有监督的情况下进行了训练,并在 BEIR 基准上与 BM25 for R@100 取得了有竞争力的结果(Thakur 等人,2021),以及 3)OpenAI 嵌入555https://platform.openai.com/docs/guides/embeddings。 对于OpenAI嵌入模型,我们使用OpenAI推荐的最新“text-embedding-ada-002”。 对于一个序列,它最多接受 8,191 个输入标记,输出向量为 1,536 维。 然后计算问题和上下文列表之间的余弦相似度以进行检索排名。
3.5 配置参数
为了将预训练的大语言模型训练为遵循指令进行问答或文本摘要,我们还进行了指令调整。 我们首先构建了一个混合指令调优数据集,其中包含来自 Soda 数据集 (Kim 等人, 2022)、ELI5 数据集 (Fan 等人, 2019) 的 102K 训练样本, FLAN 数据集 (Wei 等人, 2021)、Open Assistant 数据集 (Köpf 等人, 2023)、Dolly (Conover 等人, 2023)以及专有的对话数据集,以使所有基础模型适应遵循指令。 模板方面,我们采用“系统:{系统}\n\n用户:{问题}\n\n助理:{答案}”的格式来支持多轮对话训练。 由于所有任务都包含推理时推理所需的上下文信息,因此我们在对话之前添加上下文,即“系统:{系统}\n\n{上下文}\n\n用户:{问题}\n\n助理: {回答}”。
我们通过仅在 {Answer} 部分上进行损失来微调大语言模型,批量大小为 128,学习率为 5e-6,步长为 1000。 对于本文的其余部分,结果均使用基于基础 GPT-43B、Llama2-7B 和 Llama2-70B 之上的指令调整聊天模型来报告。
| Model | Seq len. | Avg. | QM | QASP | NQA | QLTY | MSQ | HQA | MFQA |
| GPT-43B | 4k | 26.44 | 15.56 | 23.66 | 15.64 | 49.35 | 11.08 | 28.91 | 40.90 |
| + ret | 4k | 29.32 | 16.60 | 23.45 | 19.81 | 51.55 | 14.95 | 34.26 | 44.63 |
| GPT-43B | 16k | 29.45 | 16.09 | 25.75 | 16.94 | 50.05 | 14.74 | 37.48 | 45.08 |
| + ret | 16k | 29.65 | 15.69 | 23.82 | 21.11 | 47.90 | 15.52 | 36.14 | 47.39 |
| Llama2-70B | 4k | 31.61 | 16.34 | 27.70 | 19.07 | 63.55 | 15.40 | 34.64 | 44.55 |
| + ret | 4k | 36.02 | 17.41 | 28.74 | 23.41 | 70.15 | 21.39 | 42.06 | 48.96 |
| Llama2-70B | 16k | 36.78 | 16.72 | 30.92 | 22.32 | 76.10 | 18.78 | 43.97 | 48.63 |
| + ret | 16k | 37.23 | 18.70 | 29.54 | 23.12 | 70.90 | 23.28 | 44.81 | 50.24 |
| Llama2-70B | 32k | 37.36 | 15.37 | 31.88 | 23.59 | 73.80 | 19.07 | 49.49 | 48.35 |
| + ret | 32k | 39.60 | 18.34 | 31.27 | 24.53 | 69.55 | 26.72 | 53.89 | 52.91 |
| Llama2-7B | 4k | 22.65 | 14.25 | 22.07 | 14.38 | 40.90 | 8.66 | 23.13 | 35.20 |
| + ret | 4k | 26.04 | 16.45 | 22.97 | 18.18 | 43.25 | 14.68 | 26.62 | 40.10 |
| Llama2-7B | 32k | 28.20 | 16.09 | 23.66 | 19.07 | 44.50 | 15.74 | 31.63 | 46.71 |
| + ret | 32k | 27.63 | 17.11 | 23.25 | 19.12 | 43.70 | 15.67 | 29.55 | 45.03 |
4结果
在本节中,我们报告结果并提供详细分析。
4.1 主要结果
在表2中,我们使用 GPT-43B 和 Llama2-70B 比较了上下文长度从 4K 到长达 32K 的不同模型变体。 首先,我们发现不检索 4k 序列长度的基线模型对于 GPT-43B 和 Llama2-70B 来说效果最差。 这是因为所有七个任务的最小平均序列长度超过 4096,基础模型的上下文窗口以及因此有价值的文本被随机截断。 因此,检索对于 4K 大语言模型特别有帮助,例如 Llama2-70B-4K 从 31.61 提高到 35.73,而 GPT-43B-4K 从 26.44 提高到 29.32。 其次,我们观察到 HotpotQA (HQA) 特别青睐长序列模型,当序列长度从 4k 增加到 16k 时,Llama2-70B 的得分从 34.64 提高到 43.97,GPT-43B 的得分从 28.91 提高到 37.48。 这是因为 Hotpot QA 是一个多跳数据集,其中的问题并不难回答,但所有中间跳都是获得正确答案所必需的。 因此,长上下文有利于增加合并所有中间跳跃的召回率。
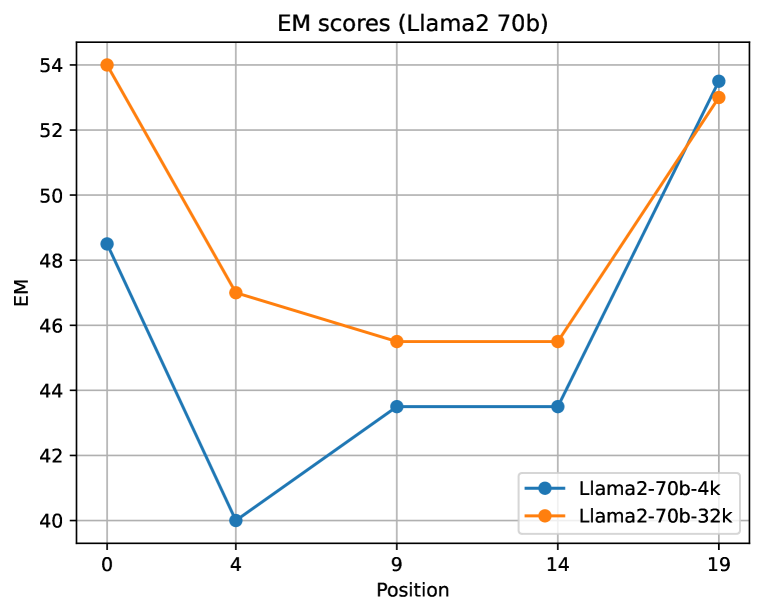
非常有趣的是,检索增强的长上下文大语言模型(例如16K和32K)可以获得比检索增强的4K上下文大语言模型更好的结果,即使它们提供相同的前5个证据块。 我们假设这个有趣的观察与“迷失在中间”现象(刘等人,2023)有关,其中大语言模型具有这样的“U形”性能曲线。 具体来说,大语言模型更擅长利用出现在其输入上下文窗口的开头或结尾的相关信息。 为了进一步验证假设,我们按照Liu等人(2023)对Llama2-70B-4k和Llama2-70B-32k进行了“迷失在中间”研究。 如图1所示,我们确认这种现象也存在于具有不同上下文长度的Llama2-70B中。 特别是,Llama2-70B-4k 和 Llama2-70B-32k 的曲线比较表明,长上下文模型对于合并前 5 个检索到的上下文具有更好的准确性。
| Model | Avg-7 | Avg-4* | QM* | QASP* | NQA* | QLTY* | MSQ | HQA | MFQA |
|---|---|---|---|---|---|---|---|---|---|
| Davinci003 (175B) | 39.2 | 40.8* | 16.9* | 52.7* | 24.6* | 69.0* | 22.1 | 41.2 | 47.8 |
| GPT-3.5-turbo (4k) | 38.4 | 39.2* | 15.6* | 49.3* | 25.1* | 66.6* | 21.2 | 40.9 | 49.2 |
| +ret | 24.4 | 49.5 | 49.5 | ||||||
| GPT-3.5-turbo-16k | 42.8 | 42.4 | 17.6 | 50.5 | 28.8 | 72.6 | 26.9 | 51.6 | 52.3 |
| +ret | 30.4 | 46.6 | 52.8 | ||||||
| Llama2-70B-32k | 40.9 | 42.4 | 15.6 | 45.9 | 28.4 | 79.6 | 19.1 | 49.5 | 48.4 |
| Llama2-70B-32k-ret | 43.6 | 43.0 | 18.5 | 46.3 | 31.5 | 75.6 | 26.7 | 53.9 | 52.9 |
请注意,我们与 LongBench 工作 (Bai 等人,2023) 得出的结论有很大不同:“检索为长上下文能力较弱的模型带来了改进,但性能仍然不佳落后于具有较强长上下文理解能力的模型”。 在这里,我们证明检索可以显着提高 GPT-43B 和 Llama2-70B 的性能,无论它们的上下文窗口大小如何。 例如,我们最好的检索增强 Llama2-70B-32k-ret 的性能优于其基线(无检索),即 39.60 与 37.36。 我们认为造成这种不同结论的主要原因是Bai等人(2023)使用了更小的大语言模型,参数为6B和7B,其零样本能力通常相对较差,无法整合检索到的分块上下文。 为了进一步验证假设,我们还在表5中报告了使用 Llama2-7B 的结果。 其实可以得出与Bai等人(2023)类似的结论。 我们认为根本原因是: i) 对于 Llama2-7B-chat-4k,其较短的上下文长度是长上下文任务的瓶颈。 因此,检索增强很大程度上改善了结果。 ii) 对于 Llama2-7B-chat-32 和 ChatGLM2-6B-32k,上下文长度瓶颈已基本消除。 然而,由于尺寸较小,他们的检索增强模型合并检索到的上下文块的零样本能力有限。 因此,检索对于 Llama2-7B-32k 和 ChatGLM2-6B-32k 都没有帮助,这与我们案例中的 Llama2-70B-32k 等大型大语言模型不同。
相比之下,像Llama2-70B这样的更大的指令调整大语言模型具有更强的零样本能力来整合检索到的证据。 当人们比较 GPT-43B 和 Llama2-70B 之间的检索增强增益时,这一观察结果变得更加清晰,其中 Llama2-70B 在通过检索合并上下文方面享有更大的好处。
4.2与 OpenAI 模型比较
为了进一步了解我们的最佳模型(即通过检索增强 Llama2-70B-32k)有多好,我们还将其与这七个数据集上的 GPT-3.5-turbo(4k)、GPT-3.5-turbo-16k 和 Davinci-003 进行比较。666对于 QMSum (QM)、Qasper (QASP)、NarrativeQA (NQA)、QuALITY (QLTY),我们使用了 ZeroSCROLLS 排行榜中的测试集,因为组织者已在那里准备了 GPT-3.5-turbo (4k) 和 Davinci-003 的分数。 我们发现 Llama2-70B-32k-ret 在 7 个数据集的平均准确率方面取得了比 GPT-3.5-turbo-16k 更好的结果,而在 4 个任务的平均准确率方面优于 Davinci-003(带 175B 参数)。 这表明具有检索功能的 Llama2-70B-32k 是这些长上下文任务的强大模型,我们的结论是建立在最先进的结果之上的。
我们还报告了 GPT3.5-turbo 在 MSQ、HQA 和 MFQA 上的检索增强结果。 对于 GPT3.5-turbo-4k,检索显着提高了性能(平均从 37.08 提高到 41.15)。 对于 GPT3.5-turbo-16k,检索平均得分 (43.27) 和非检索得分 (43.60) 彼此接近,均低于我们的 Llam2-70B-32k-ret 结果 (44.51)。 请注意,GPT3.5-turbo-16k 是一个黑盒 API,我们不知道它是如何实现的、模型大小以及任何预处理步骤。
| Seq len | Setting | Avg. | QM | QASP | NQA | QLTY | MSQ | HQA | MFQA |
|---|---|---|---|---|---|---|---|---|---|
| 4k | baseline (w/o ret) | 31.61 | 16.34 | 27.70 | 19.07 | 63.55 | 15.40 | 34.64 | 44.55 |
| Dragon | 35.73 | 18.14 | 29.20 | 23.39 | 70.30 | 20.09 | 41.54 | 47.45 | |
| Contriever | 36.02 | 17.41 | 28.74 | 23.41 | 70.15 | 21.39 | 42.06 | 48.96 | |
| OpenAI-embedding | 35.79 | 17.76 | 28.85 | 23.57 | 70.70 | 19.92 | 41.76 | 47.99 | |
| 32k | baseline (w/o ret) | 37.36 | 15.37 | 31.88 | 23.59 | 73.80 | 19.07 | 49.49 | 48.35 |
| Dragon | 39.60 | 18.34 | 31.27 | 24.53 | 69.55 | 26.72 | 53.89 | 52.91 | |
| Contriever | 38.85 | 17.60 | 31.56 | 23.88 | 69.00 | 26.61 | 49.65 | 53.66 | |
| OpenAI-embedding | 39.34 | 18.24 | 32.07 | 24.36 | 69.45 | 24.90 | 51.64 | 54.75 |
| Seq len | Setting | Avg. | QM | QASP | NQA | QLTY | MSQ | HQA | MFQA |
|---|---|---|---|---|---|---|---|---|---|
| 4k | base | 31.61 | 16.34 | 27.70 | 19.07 | 63.55 | 15.40 | 34.64 | 44.55 |
| top-5 | 35.73 | 18.14 | 29.20 | 23.39 | 70.30 | 20.09 | 41.54 | 47.45 | |
| top-10 | 34.62 | 16.54 | 28.67 | 24.38 | 68.70 | 19.00 | 42.18 | 42.84 | |
| top-20 | 34.61 | 16.52 | 28.67 | 24.38 | 68.70 | 19.00 | 42.18 | 42.84 | |
| 16k | base | 36.78 | 16.72 | 30.92 | 22.32 | 76.10 | 18.78 | 43.97 | 48.63 |
| top-5 | 37.23 | 18.70 | 29.54 | 23.12 | 70.90 | 23.28 | 44.81 | 50.24 | |
| top-10 | 38.31 | 18.41 | 30.20 | 25.53 | 73.60 | 22.78 | 47.72 | 49.91 | |
| top-20 | 36.61 | 17.26 | 29.60 | 25.81 | 72.30 | 22.69 | 41.36 | 47.23 | |
| 32k | base | 37.36 | 15.37 | 31.88 | 23.59 | 73.80 | 19.07 | 49.49 | 48.35 |
| top-5 | 39.60 | 18.34 | 31.27 | 24.53 | 69.55 | 26.72 | 53.89 | 52.91 | |
| top-10 | 38.98 | 17.71 | 30.34 | 25.94 | 70.45 | 22.80 | 55.73 | 49.88 | |
| top-20 | 38.38 | 16.36 | 30.42 | 24.42 | 69.60 | 24.51 | 54.67 | 48.65 |
4.3 不同猎犬的消融
为了研究不同检索器对 Llama2-70B 的影响,我们比较了 Llama2-70B-4k 和 Llama2-70B-32k 上的 Dragon、Contriever 和 OpenAI 嵌入。 表4中的结果证实了我们的发现,即检索可以提高短上下文和长上下文大语言模型的性能,在不同的检索器中是一致的。
4.4 增加检索块的数量
4.5少样本任务的检索
| Model | Trec | SAMSum |
|---|---|---|
| GPT-3.5-turbo-16k | 68 | 41.7 |
| Llama2-70B | 73 | 46.5 |
| Llama2-70B-ret | 76 | 47.3 |
除了上述基于查询的摘要任务和问答任务的零样本任务之外,我们还使用来自 LongBench 的两个附加数据集(Trec 和 SAMSum)进一步研究了少样本任务的长上下文模型的好处。 我们将每个数据集中的问题作为查询,并使用它来搜索给定的少样本示例中提供的相关问答对。 表 6 显示我们的最佳模型 Llama2-70B-32k-ret 的性能大幅优于其非检索 Llama2-70B-32k 基线以及 GPT-3.5-turbo-16k。 它再次证实了将检索与长上下文模型结合使用的好处。
5结论
在这项工作中,我们在对各种长上下文 QA 和基于查询的摘要任务进行指令调整后,使用最先进的大语言模型系统地研究检索增强与长上下文扩展。 经过研究,我们有以下有趣的发现: i) 检索极大地提高了 4K 短上下文大语言模型和 16K/32K 长上下文大语言模型的性能。 ii) 具有简单检索增强的4K上下文大语言模型可以与16K长上下文大语言模型相媲美,同时推理效率更高。 iii) 经过上下文窗口扩展和检索增强后,最佳模型 Llama2-70B-32k-ret 在一组下游任务的平均得分方面优于 GPT-3.5-turbo-16k 和 Davinci003提供信息丰富的查询。 我们的研究揭示了将检索和长上下文技术结合起来以构建更好的大语言模型的有前途的方向。
6 未来方向
这项工作可以扩展许多潜在的研究方向。 一个方向是为现有的预训练大型语言模型开发先进的方法(例如记忆或分层注意力)。 Llama2-70B,它本身就很重要。 此外,对于大型 70B 参数模型,进一步将上下文窗口扩展到 64k 甚至更长将是一项非常有趣的研究,尽管预训练更长的序列需要更多的计算。 最后,如何减轻“迷失在中间”现象是一个开放的研究课题,继续预训练 UL2 损失 (Tay 等人, 2022b) 可能是一个潜在的解决方案。
参考
- Anthropic (2023) Anthropic. Introducing 100k context windows. https://www.anthropic.com/index/100k-context-windows, 2023.
- Bai et al. (2023) Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, et al. Longbench: A bilingual, multitask benchmark for long context understanding. arXiv preprint arXiv:2308.14508, 2023.
- Beltagy et al. (2020) Iz Beltagy, Matthew E Peters, and Arman Cohan. Longformer: The long-document transformer. arXiv preprint arXiv:2004.05150, 2020.
- Borgeaud et al. (2022) Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Rutherford, Katie Millican, George Bm Van Den Driessche, Jean-Baptiste Lespiau, Bogdan Damoc, Aidan Clark, et al. Improving language models by retrieving from trillions of tokens. In ICML, 2022.
- Brown et al. (2020) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. NeurIPS, 2020.
- Bulatov et al. (2022) Aydar Bulatov, Yury Kuratov, and Mikhail Burtsev. Recurrent memory transformer. NeurIPS, 2022.
- Chen et al. (2023) Shouyuan Chen, Sherman Wong, Liangjian Chen, and Yuandong Tian. Extending context window of large language models via positional interpolation. arXiv preprint arXiv:2306.15595, 2023.
- Child et al. (2019) Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever. Generating long sequences with sparse transformers. arXiv preprint arXiv:1904.10509, 2019.
- Conover et al. (2023) Mike Conover, Matt Hayes, Ankit Mathur, Jianwei Xie, Jun Wan, Sam Shah, Ali Ghodsi, Patrick Wendell, Matei Zaharia, and Reynold Xin. Free dolly: Introducing the world’s first truly open instruction-tuned llm, 2023. URL https://www.databricks.com/blog/2023/04/12/dolly-first-open-commercially-viable-instruction-tuned-llm.
- Dai et al. (2019) Zihang Dai, Zhilin Yang, Yiming Yang, Jaime Carbonell, Quoc V Le, and Ruslan Salakhutdinov. Transformer-XL: Attentive language models beyond a fixed-length context. In ACL, 2019.
- Dao (2023) Tri Dao. Flashattention-2: Faster attention with better parallelism and work partitioning. arXiv preprint arXiv:2307.08691, 2023.
- Dao et al. (2022) Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory-efficient exact attention with io-awareness. NeurIPS, 2022.
- Dasigi et al. (2021) Pradeep Dasigi, Kyle Lo, Iz Beltagy, Arman Cohan, Noah A. Smith, and Matt Gardner. A dataset of information-seeking questions and answers anchored in research papers. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 4599–4610, Online, June 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.naacl-main.365. URL https://aclanthology.org/2021.naacl-main.365.
- Fan et al. (2019) Angela Fan, Yacine Jernite, Ethan Perez, David Grangier, Jason Weston, and Michael Auli. Eli5: Long form question answering. arXiv preprint arXiv:1907.09190, 2019.
- Gao et al. (2021) Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, Shawn Presser, and Connor Leahy. The pile: An 800gb dataset of diverse text for language modeling. CoRR, abs/2101.00027, 2021. URL https://arxiv.org/abs/2101.00027.
- Guu et al. (2020) Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Mingwei Chang. REALM: Retrieval augmented language model pre-training. In ICML, 2020.
- He et al. (2020) Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2020.
- Ho et al. (2019) Jonathan Ho, Nal Kalchbrenner, Dirk Weissenborn, and Tim Salimans. Axial attention in multidimensional transformers. arXiv preprint arXiv:1912.12180, 2019.
- Huang et al. (2023) Jie Huang, Wei Ping, Peng Xu, Mohammad Shoeybi, Kevin Chen-Chuan Chang, and Bryan Catanzaro. Raven: In-context learning with retrieval augmented encoder-decoder language models. arXiv preprint arXiv:2308.07922, 2023.
- Izacard & Grave (2021) Gautier Izacard and Édouard Grave. Leveraging passage retrieval with generative models for open domain question answering. In EACL, 2021.
- Izacard et al. (2021) Gautier Izacard, Mathilde Caron, Lucas Hosseini, Sebastian Riedel, Piotr Bojanowski, Armand Joulin, and Edouard Grave. Unsupervised dense information retrieval with contrastive learning, 2021. URL https://arxiv.org/abs/2112.09118.
- Izacard et al. (2022) Gautier Izacard, Patrick Lewis, Maria Lomeli, Lucas Hosseini, Fabio Petroni, Timo Schick, Jane Dwivedi-Yu, Armand Joulin, Sebastian Riedel, and Edouard Grave. Few-shot learning with retrieval augmented language models. arXiv preprint arXiv:2208.03299, 2022.
- Jiang et al. (2022) Zhengbao Jiang, Luyu Gao, Jun Araki, Haibo Ding, Zhiruo Wang, Jamie Callan, and Graham Neubig. Retrieval as attention: End-to-end learning of retrieval and reading within a single transformer. In EMNLP, 2022.
- Johnson et al. (2019) Jeff Johnson, Matthijs Douze, and Hervé Jégou. Billion-scale similarity search with GPUs. IEEE Transactions on Big Data, 7(3):535–547, 2019.
- Kaiokendev (2023) Kaiokendev. Things I’m learning while training SuperHOT. https://kaiokendev.github.io/til#extending-context-to-8k, 2023.
- Karpukhin et al. (2020) Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. In EMNLP, 2020.
- Khandelwal et al. (2019) Urvashi Khandelwal, Omer Levy, Dan Jurafsky, Luke Zettlemoyer, and Mike Lewis. Generalization through memorization: Nearest neighbor language models. arXiv preprint arXiv:1911.00172, 2019.
- Kim et al. (2022) Hyunwoo Kim, Jack Hessel, Liwei Jiang, Ximing Lu, Youngjae Yu, Pei Zhou, Ronan Le Bras, Malihe Alikhani, Gunhee Kim, Maarten Sap, et al. Soda: Million-scale dialogue distillation with social commonsense contextualization. arXiv preprint arXiv:2212.10465, 2022.
- Kitaev et al. (2020) Nikita Kitaev, Łukasz Kaiser, and Anselm Levskaya. Reformer: The efficient transformer. In ICLR, 2020.
- Köpf et al. (2023) Andreas Köpf, Yannic Kilcher, Dimitri von Rütte, Sotiris Anagnostidis, Zhi-Rui Tam, Keith Stevens, Abdullah Barhoum, Nguyen Minh Duc, Oliver Stanley, Richárd Nagyfi, et al. Openassistant conversations–democratizing large language model alignment. arXiv preprint arXiv:2304.07327, 2023.
- Kočiský et al. (2018) Tomáš Kočiský, Jonathan Schwarz, Phil Blunsom, Chris Dyer, Karl Moritz Hermann, Gábor Melis, and Edward Grefenstette. The NarrativeQA Reading Comprehension Challenge. Transactions of the Association for Computational Linguistics, 6:317–328, 05 2018. ISSN 2307-387X. doi: 10.1162/tacl_a_00023. URL https://doi.org/10.1162/tacl_a_00023.
- Lewis et al. (2020) Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. NeurIPS, 2020.
- Lin (2004) Chin-Yew Lin. ROUGE: A package for automatic evaluation of summaries. In Text Summarization Branches Out, pp. 74–81, Barcelona, Spain, July 2004. Association for Computational Linguistics. URL https://aclanthology.org/W04-1013.
- Lin et al. (2023) Sheng-Chieh Lin, Akari Asai, Minghan Li, Barlas Oguz, Jimmy Lin, Yashar Mehdad, Wen-tau Yih, and Xilun Chen. How to train your dragon: Diverse augmentation towards generalizable dense retrieval. arXiv preprint arXiv:2302.07452, 2023.
- Liu et al. (2023) Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts. arXiv preprint arXiv:2307.03172, 2023.
- Liu et al. (2018) Peter J Liu, Mohammad Saleh, Etienne Pot, Ben Goodrich, Ryan Sepassi, Lukasz Kaiser, and Noam Shazeer. Generating wikipedia by summarizing long sequences. In ICLR, 2018.
- Lo et al. (2020) Kyle Lo, Lucy Lu Wang, Mark Neumann, Rodney Kinney, and Daniel Weld. S2ORC: The semantic scholar open research corpus. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pp. 4969–4983, Online, July 2020. Association for Computational Linguistics. doi: 10.18653/v1/2020.acl-main.447. URL https://aclanthology.org/2020.acl-main.447.
- Mohtashami & Jaggi (2023) Amirkeivan Mohtashami and Martin Jaggi. Landmark attention: Random-access infinite context length for transformers. arXiv preprint arXiv:2305.16300, 2023.
- Nakano et al. (2021) Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, et al. WebGPT: Browser-assisted question-answering with human feedback. arXiv preprint arXiv:2112.09332, 2021.
- Nijkamp et al. (2023) Erik Nijkamp, Hiroaki Hayashi, Tian Xie, Congying Xia, Bo Pang, Congying Xia, and et al. Long sequence modeling with XGen: A 7b LLM trained on 8k input sequence length. https://blog.salesforceairesearch.com/xgen/, 2023.
- OpenAI (2022) OpenAI. Introducing chatgpt. https://openai.com/blog/chatgpt, 2022.
- OpenAI (2023a) OpenAI. Gpt-4. https://openai.com/research/gpt-4, 2023a.
- OpenAI (2023b) OpenAI. Function calling and other API updates (longer context). https://openai.com/blog/function-calling-and-other-api-updates, 2023b.
- Pang et al. (2022) Richard Yuanzhe Pang, Alicia Parrish, Nitish Joshi, Nikita Nangia, Jason Phang, Angelica Chen, Vishakh Padmakumar, Johnny Ma, Jana Thompson, He He, and Samuel Bowman. QuALITY: Question answering with long input texts, yes! In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 5336–5358, Seattle, United States, July 2022. Association for Computational Linguistics. doi: 10.18653/v1/2022.naacl-main.391. URL https://aclanthology.org/2022.naacl-main.391.
- Parmar et al. (2018) Niki Parmar, Ashish Vaswani, Jakob Uszkoreit, Lukasz Kaiser, Noam Shazeer, Alexander Ku, and Dustin Tran. Image transformer. In ICML, pp. 4055–4064, 2018.
- Press et al. (2021) Ofir Press, Noah A Smith, and Mike Lewis. Train short, test long: Attention with linear biases enables input length extrapolation. In ICLR, 2021.
- Radford et al. (2019) Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners. 2019.
- Rae et al. (2020) Jack W Rae, Anna Potapenko, Siddhant M Jayakumar, and Timothy P Lillicrap. Compressive Transformers for long-range sequence modelling. In ICLR, 2020.
- Ratner et al. (2023) Nir Ratner, Yoav Levine, Yonatan Belinkov, Ori Ram, Inbal Magar, Omri Abend, Ehud Karpas, Amnon Shashua, Kevin Leyton-Brown, and Yoav Shoham. Parallel context windows for large language models. In ACL, 2023.
- Roy et al. (2021) Aurko Roy, Mohammad Saffar, Ashish Vaswani, and David Grangier. Efficient content-based sparse attention with routing transformers. Transactions of the Association for Computational Linguistics, 2021.
- Shaham et al. (2022) Uri Shaham, Elad Segal, Maor Ivgi, Avia Efrat, Ori Yoran, Adi Haviv, Ankit Gupta, Wenhan Xiong, Mor Geva, Jonathan Berant, and Omer Levy. SCROLLS: Standardized CompaRison over long language sequences. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pp. 12007–12021, Abu Dhabi, United Arab Emirates, December 2022. Association for Computational Linguistics. URL https://aclanthology.org/2022.emnlp-main.823.
- Shaham et al. (2023) Uri Shaham, Maor Ivgi, Avia Efrat, Jonathan Berant, and Omer Levy. Zeroscrolls: A zero-shot benchmark for long text understanding. arXiv preprint arXiv:2305.14196, 2023.
- Shi et al. (2023) Weijia Shi, Sewon Min, Michihiro Yasunaga, Minjoon Seo, Rich James, Mike Lewis, Luke Zettlemoyer, and Wen-tau Yih. RePlug: Retrieval-augmented black-box language models. arXiv preprint arXiv:2301.12652, 2023.
- Su et al. (2021) Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:2104.09864, 2021.
- Tay et al. (2020) Yi Tay, Dara Bahri, Liu Yang, Donald Metzler, and Da-Cheng Juan. Sparse sinkhorn attention. In ICML, 2020.
- Tay et al. (2021) Yi Tay, Dara Bahri, Donald Metzler, Da-Cheng Juan, Zhe Zhao, and Che Zheng. Synthesizer: Rethinking self-attention for transformer models. In ICML, 2021.
- Tay et al. (2022a) Yi Tay, Mostafa Dehghani, Dara Bahri, and Donald Metzler. Efficient transformers: A survey. ACM Computing Surveys, 2022a.
- Tay et al. (2022b) Yi Tay, Mostafa Dehghani, Vinh Q Tran, Xavier Garcia, Jason Wei, Xuezhi Wang, Hyung Won Chung, Dara Bahri, Tal Schuster, Steven Zheng, et al. Ul2: Unifying language learning paradigms. In The Eleventh International Conference on Learning Representations, 2022b.
- Thakur et al. (2021) Nandan Thakur, Nils Reimers, Andreas Rücklé, Abhishek Srivastava, and Iryna Gurevych. Beir: A heterogenous benchmark for zero-shot evaluation of information retrieval models. In NeurIPS, 2021.
- Touvron et al. (2023a) Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023a.
- Touvron et al. (2023b) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023b.
- Trivedi et al. (2022) Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. MuSiQue: Multihop questions via single-hop question composition. Transactions of the Association for Computational Linguistics, 10:539–554, 2022. doi: 10.1162/tacl_a_00475. URL https://aclanthology.org/2022.tacl-1.31.
- Tworkowski et al. (2023) Szymon Tworkowski, Konrad Staniszewski, Mikołaj Pacek, Yuhuai Wu, Henryk Michalewski, and Piotr Miłoś. Focused transformer: Contrastive training for context scaling. arXiv preprint arXiv:2307.03170, 2023.
- Wang et al. (2023) Boxin Wang, Wei Ping, Peng Xu, Lawrence McAfee, Zihan Liu, Mohammad Shoeybi, Yi Dong, Oleksii Kuchaiev, Bo Li, Chaowei Xiao, et al. Shall we pretrain autoregressive language models with retrieval? a comprehensive study. arXiv preprint arXiv:2304.06762, 2023.
- Wang et al. (2022) Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Majumder, and Furu Wei. Text embeddings by weakly-supervised contrastive pre-training. arXiv preprint arXiv:2212.03533, 2022.
- Wang et al. (2020) Sinong Wang, Belinda Li, Madian Khabsa, Han Fang, and Hao Ma. Linformer: Self-attention with linear complexity. arXiv preprint arXiv:2006.04768, 2020.
- Wei et al. (2021) Jason Wei, Maarten Bosma, Vincent Y Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M Dai, and Quoc V Le. Finetuned language models are zero-shot learners. arXiv preprint arXiv:2109.01652, 2021.
- Wei et al. (2022) Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, et al. Emergent abilities of large language models. arXiv preprint arXiv:2206.07682, 2022.
- Xiong et al. (2021) Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, and Vikas Singh. Nyströmformer: A nyström-based algorithm for approximating self-attention. AAAI, 2021.
- Yang et al. (2018) Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. HotpotQA: A dataset for diverse, explainable multi-hop question answering. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pp. 2369–2380, Brussels, Belgium, October-November 2018. Association for Computational Linguistics. doi: 10.18653/v1/D18-1259. URL https://aclanthology.org/D18-1259.
- Yogatama et al. (2021) Dani Yogatama, Cyprien de Masson d’Autume, and Lingpeng Kong. Adaptive semiparametric language models. Transactions of the Association for Computational Linguistics, 9:362–373, 2021.
- Zaheer et al. (2020) Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, et al. Big Bird: Transformers for longer sequences. In NeurIPS, 2020.
- Zeng et al. (2022) Aohan Zeng, Xiao Liu, Zhengxiao Du, Zihan Wang, Hanyu Lai, Ming Ding, Zhuoyi Yang, Yifan Xu, Wendi Zheng, Xiao Xia, et al. Glm-130b: An open bilingual pre-trained model. arXiv preprint arXiv:2210.02414, 2022.
- Zhong et al. (2021) Ming Zhong, Da Yin, Tao Yu, Ahmad Zaidi, Mutethia Mutuma, Rahul Jha, Ahmed Hassan Awadallah, Asli Celikyilmaz, Yang Liu, Xipeng Qiu, and Dragomir Radev. QMSum: A new benchmark for query-based multi-domain meeting summarization. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 5905–5921, Online, June 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.naacl-main.472. URL https://aclanthology.org/2021.naacl-main.472.
- Zhu et al. (2021) Chen Zhu, Wei Ping, Chaowei Xiao, Mohammad Shoeybi, Tom Goldstein, Anima Anandkumar, and Bryan Catanzaro. Long-short transformer: Efficient transformers for language and vision. NeurIPS, 2021.
我们在下面展示了一个示例,其中较小的模型 Llama2-7B 无法合并相关上下文,而具有检索功能的较大模型可以成功预测正确答案。
附录A附录
| Chunk 1 |
On September 18, 2015, the deluxe edition of the album was released containing live and instrumental tracks from the standard edition album, in addition to the single "Light" featuring Little Dragon. Critical reception … Angelspit has toured with Angel Theory, Ayria, Ikon, KMFDM, Tankt and The Crüxshadows, and have also shared the stage with bands such as The Sisters of Mercy, Nitzer Ebb, Skinny Puppy and Front Line Assembly. They performed with Lords of Acid during a 22-date U.S. tour in March 2011 and toured the United States with Blood on the Dance Floor in October 2011. History Karl Learmont (ZooG) and Amelia Tan (Destroyx) met on an online zine forum. They shared an interest in zines and started the distro Vox Populis in 2002. |
|---|---|
| Chunk 2 |
They then started making zines for themselves which became the lyrical inspiration for releases to follow. Angelspit was formed in 2003, and the duo then self-released their debut EP, Nurse Grenade on 3 October 2004. … A video for the remix of "Sleep Now" was released on 2 October 2010. They released their third remix album, Carbon Beauty on 8 March 2011. This new remix album contains 3 new tracks as well as 10 remixes of tracks from the Hideous and Perfect album. A video for "Toxic Girl" was released on 13 April 2011, and a video for "Like It? |
| Chunk 3 |
Passage 1: Blood on the Dance Floor (band) Blood on the Dance Floor was an American electronic music group from Orlando, Florida, formed in 2006. The group’s longest standing lineup, from 2009 to 2016, consisted of Jesus David Torres also known as Dahvie Vanity (born 1984) and Jayy Von Monroe (born 1991). … The CD was self-released in October 2008. Only 300 copies were made.Vanity and Ecstasy recorded the singles "Siq With a Q" and "Suicide Club" as a duo in 2008, and released three extended plays over the first half of 2009, I Scream I Scream, OMFG Sneak Peak, and Extended Play. |
| Chunk 4 |
title: , source: Lick It!" was released on 27 July 2011. On 15 April 2011, Angelspit announced the addition of three new members: guitarist Valerie Gentile (Black Tape for a Blue Girl, The Crüxshadows), drummer Chris Kling (Hanzel und Gretyl, Mortiis) and videojammer The Liar. The new line-up of Angelspit released their fourth studio album, Hello My Name Is on 11 October 2011. Matt James replaced Chris Kling in early 2012, and former Crüxshadows guitarist George Bikos filled in for Valerie Gentile on the band’s 2012 tour… |
| Chunk 5 |
Vanity denied these allegations in a video.In April 2017, Vanity announced that there would be a new member, and that Blood on the Dance Floor would be returning on May 5 of that year without Jayy Von Monroe. … On January 1, 2021, Vanity released a new version of Blood on the Dance Floor’s "Bewitched" as "Bewitched Reimagined" featuring singer Sammy Beare. As of 2016, Jayy Von Monroe has continued to work as a drag monster under the name "The Dahli" and Vanity has continued to release music and merchandise by himself under both "The Most Vivid Nightmares" and "Dark Arts Official". |
| Question: |
Angelspit toured the United States with an American electronic music duo from Orlando, Florida, that formed in what year? |
| LLaMA2-7b-32k |
Angelspit toured the United States with Blood on the Dance Floor in October 2011. |
| LLaMA2-7b-32k-ret |
Angelspit toured the United States with Blood on the Dance Floor in October 2011. |
| LLaMA2-70b-32k |
2011 |
| LLaMA2-70b-32k-ret |
2006 |
| Ground truth |
2006 |