语言代理树搜索将语言模型中的推理、执行和规划统一起来
摘要
虽然语言模型 (LM) 在一系列决策任务中显示出潜力,但它们对简单执行过程的依赖限制了它们作为自主代理的广泛部署。 在本文中,我们介绍了语言代理树搜索(LATS)——第一个通用框架,它协同 LM 在推理、行动和规划方面的能力。 通过利用 LM 的上下文学习能力,我们将蒙特卡罗树搜索集成到 LATS 中,使 LM 成为代理,以及 LM 驱动的价值函数和自我反思,以实现熟练的探索和增强的决策。 我们方法的一个关键特征是纳入外部反馈环境,它提供了一种更加深思熟虑和适应性更强的问题解决机制,超越了现有技术的限制。 我们跨不同领域(包括编程、交互式问答 (QA)、网络导航和数学)的实验评估验证了 LATS 在决策方面的有效性和通用性,同时保持了竞争力或提高了推理性能。 值得注意的是,LATS 使用 GPT-4 在 HumanEval 上进行编程时实现了最先进的 pass@1 准确率 (92.7%),并展示了与基于梯度的 Web 导航微调相当的无梯度性能(平均分 75.9)在带有 GPT-3.5 的网上商店上。 代码可以在 https://github.com/lapisrocks/LanguageAgentTreeSearch 找到。
1简介
能够在各种环境中进行推理和决策的通用自主代理(Wooldridge 和 Jennings,1995)一直是人工智能领域的关注点。 虽然传统上这是在强化学习中进行研究的,但最近语言模型 (LM) (Brown 等人,2020;Chowdhery 等人,2023;Touvron 等人,2023;OpenAI,2023) 的兴起强大的推理能力和普遍的适应性提供了另一种范式。 LM 不仅在标准自然语言处理 (NLP) 任务中表现出色,例如摘要(Nallapati 等人,2016)和语言推理(Bowman 等人,2015),而且它们还适应了日益多样化的任务,这些任务通常需要先进的常识推理或定量技能(Cobbe等人,2021;Saparov和He,2023)。 此外,LM能够在涉及知识和推理的复杂环境中执行,例如网络导航(Yao 等人, 2022; Deng 等人, 2023)、工具使用(Schick等人,2023),以及开放式游戏(范等人,2022)。
通过利用来自外部环境的反馈或观察来增强 LM 的提示技术,推理和行动能力得到了进一步的提高,如 ReAct (Yao 等人, 2023b) 和其他工作 (Gao 等)人,2023;Shinn 等人,2023)。 这样就不需要完全依赖 LM 的基本能力,通过外部工具或语义反馈来增强它们。 尽管有这些优势,但这些方法是反射性的,缺乏人类解决问题时深思熟虑的决策特征(Sloman,1996;Evans,2010)。 特别是,他们未能考虑多种推理路径或提前计划。 最近的搜索引导LM工作(Xie等人,2023;Yao等人,2023a;Hao等人,2023)通过搜索多个推理链来解决这个问题。 在实现规划的同时,此类方法是孤立运行的,缺乏能够改进推理的外部反馈。
为了克服这些挑战,我们提出了语言代理树搜索(LATS)——一个使用语言模型进行决策和推理的统一框架。 如图1所示,LATS 通过将ReAct (Yao等人,2023b)扩展为搜索可能的推理和行动步骤的组合空间。 这项工作并非易事——使搜索算法适应语言代理,并从非交互式任务转变为交互式任务,需要对节点、提示和搜索算法进行实质性的新颖设计。 特别是,节点和提示必须有效地存储和检索外部反馈,搜索算法会将这些信息合并到有用的启发式中以进行值分配。 事实上,我们的实证评估,如第 2 节中的 HotPotQA (Yang 等人,2018) 所示。 5.1,揭示了现有方法的简单组合是不够的,甚至无法超越内部推理性能,尽管可以从环境中获取真实答案。
我们支持 LATS 的关键见解是采用蒙特卡罗树搜索 (MCTS),其灵感来自于基于模型的强化学习(Silver 等人,2017 年) 和 观察到许多 LM 任务允许恢复到早期步骤,即语言代理,将预先训练的 LM 重新用作具有 LM 驱动的价值函数和自我反思的代理,以进行更聪明的探索。 利用现代 LM 的一般功能和上下文学习能力,我们使用语言作为每个组件之间的接口,使 LATS 能够使规划适应环境条件而无需额外的训练。 据我们所知,LATS 是第一个框架,它结合了推理、行动和规划来增强 LM 性能。 值得注意的是,LATS 在 HotPotQA (Yang 等人,2018) 上的性能比 ReAct (Yao 等人,2023b) 提高了一倍,并将平均得分提高了 在 WebShop (Yao 等人, 2022) 上使用 GPT-3.5。 当与 GPT-4 一起使用时,LATS 在 HumanEval (Chen 等人,2021) 上实现了 Pass@1 率,创下了最先进的水平。
我们的贡献如下:1)我们引入了 LATS,这是一个基于蒙特卡罗树搜索的框架,可以从采样的动作中构建最佳轨迹,与反射性提示方法相比,能够更灵活、更具适应性地解决问题。 2)我们提出了一种新颖的价值函数,它指导搜索过程并结合自我完善和自我一致性等成功的启发式方法。 3)通过整合外部反馈和自我反思,LATS增强了模型的敏感性,使智能体能够从经验中学习,超越了基于推理的搜索方法。 通过跨不同领域(包括编程、交互式问答 (QA)、网络导航和数学)的实验,我们展示了 LATS 在增强自主推理和决策方面的多功能性。
2相关工作
| Approach | Reasoning | Acting | Planning | Self- | External |
| Reflection | Memory | ||||
| CoT (Wei et al., 2022) | ✓ | ||||
| ReAct (Yao et al., 2023b) | ✓ | ✓ | |||
| ToT (Yao et al., 2023a) | ✓ | ✓ | ✓ | ✓ | |
| RAP (Hao et al., 2023) | ✓ | ✓ | ✓ | ||
| Self-Refine (Madaan et al., 2023) | ✓ | ✓ | |||
| Beam Search (Xie et al., 2023) | ✓ | ✓ | |||
| Reflexion (Shinn et al., 2023) | ✓ | ✓ | ✓ | ✓ | |
| LATS (Ours) | ✓ | ✓ | ✓ | ✓ | ✓ |
用于推理的 LM。 对于语言模型,推理涉及将复杂的输入分解为连续的中间步骤,以得出最终答案(Cobbe 等人,2021),通过思想链(CoT)提示(Wei 等人, 2022)及其变体(Wei等人,2022;Kojima等人,2022;Wang等人,2022)。 然而,这些在单步中自回归创建链的方法,由于复合误差,随着步数的增加,常常会出现误差传播(Guo 等人, 2018; Chen 等人, 2023b) 。 各种进步旨在缓解这个问题;一些方法,例如自洽(Wang等人,2022),对采样链采用多数投票,而其他方法则侧重于多步分解,例如从最低到最高提示 (周等人,2022)。 最近,CoT 通过搜索算法(Yao 等人,2023a;Hao 等人,2023;Besta 等人,2023) 进行了改进,可以更有效地采样轨迹。 思想树 (ToT) 提示(Yao 等人, 2023a) 使用由 LM 生成的启发式引导的 DFS 或基于 BFS 的(深度/广度优先)搜索,同时通过规划进行推理( RAP) (Hao 等人, 2023) 使用 MCTS 并通过 LM 模拟推出。 然而,它们仅依赖于LM内部知识,无法适应有用的外部反馈。
LM 的表演。 LM 强大的推理和常识能力已进一步适应决策或执行任务,作为交互式环境中的政策模型。 在机器人领域,LM 已被用作控制策略的高级控制器(Ahn 等人,2022;Huang 等人,2022;Driess 等人,2023)。 类似的工作 (Baker 等人, 2022; Wang 等人, 2023) 也将 LM 代理应用于复杂的多模态游戏,例如 Minecraft (Guss 等人, 2019; Fan 等人, 2022) 。 LM 在基于文本的环境中特别有用(Liu 等人,2018;Shridhar 等人,2020;Liu 等人,2024),其中基于行为的提示技术,例如 ReAct (Yao等人,2023b) 已经取得了成功。 与 CoT 类似,ReAct 因其简单性而受到限制,无法有效适应环境条件。 人们提出了许多扩展来解决这个问题,包括自我改进(Madaan等人,2023)和反射(Shinn等人,2023),它们使用自我改进增强推理和决策能力,以及包含正反馈和负反馈的 AdaPlanner (Sun 等人, 2023)。 然而,这些方法侧重于完善个体轨迹,而不考虑每一步的替代选择。 此外,最近的工作(Huang等人,2024)表明LM无法自我纠正其内部推理,因此使用外部反馈至关重要。 或者,对于纯粹的决策环境,通过提供对外部工具(例如 API、搜索引擎、计算器和其他模型)的访问,LM 的推理和实践能力得到了增强(Schick 等人,2023;Shen 等人,2023;苏里斯等人,2023)。 我们在表中总结了之前的工作。 1.
基于树的搜索。 基于树的搜索在搜索过程中探索结果的多个分支,广泛应用于许多规划算法(Swiechowski 等人,2021;LaValle,1998)和强化学习(RL)( Hafner 等人,2019;Du 等人,2023;Wu 等人,2023) 算法具有良好的探索-利用权衡。 请注意,虽然基于树的搜索需要一个可以从任意状态扩展的环境模型 (Vodopivec 等人, 2017),但通常需要在 RL 中进行额外训练 (Hafner 等人, 2023),对于大多数 LM 任务不存在这样的问题。 这是因为我们可以通过将输入设置为上下文以及来自 LM 的许多任务的相应先前输出来方便地恢复到任何状态。 因此,我们在基于树的框架上进行操作,并使用 MCTS (Swiechowski 等人, 2021) 来充分释放 LM 的潜力。 此外,我们通过利用语言模型的上下文学习(Brown等人,2020)能力,避免了在语言描述上训练价值函数的成本。 并发工作(Liu等人,2023)还探索了将搜索算法与LM代理相结合,但使用了现成的搜索算法,这对于LM来说可能不是最佳的。 最后,根据Yao 等人(2023a)和Hao 等人(2023),我们注意到我们使用了规划和搜索算法 在本文中可互换使用。
3 预赛
3.1问题设置与提示
我们首先定义了我们的问题,并概述了几种利用语言模型进行推理或决策的成熟方法。 在LM推理或决策中,我们得到一个自然语言的输入和一个由参数化的预训练语言模型;我们的目标是生成与答案(推理)或完成任务(决策)相对应的最终输出。 和 都是语言序列,它们由一系列标记(自然语言的基本元素,通常是单词),表示为 和 ,其中 和 是长度。 LM 以自回归方式解码文本,即在没有其他输入的情况下,LM 生成序列 的概率由 给出。 通常,为了提高推理能力,提示会与输入一起提供,这些提示是具体的说明或少量样本输入输出示例。 我们表示输入 通过 LM 将输入 转换为输出 的通用过程:。
思维链(CoT)提示 (Wei等人,2022年)适用于从到的直接映射错综复杂的场景,例如当来自数学查询或挑战性问题时。 它取决于创建想法 ,作为和之间的垫脚石;每个思想都是一个语言序列。 要使用 CoT 提示,思想将按 顺序提取,最终输出为 。
思想树(ToT)提示 (姚等人,2023a)通过探索思想的多种推理路径来扩展 CoT 提示。 它将问题构建为树上的搜索,其中每个节点 表示部分解决方案状态,包括原始输入 和思维序列 。 想法是通过提案或CoT抽样产生的。 深度优先 (DFS) 或广度优先 (BFS) 搜索等搜索算法用于系统地探索树,并以基于每个状态的 LM 评估 的启发法为指导。
ReAct (Yao 等人, 2023b) 将语言模型扩展到任务,其中从 到 的映射通过或增强需要与外部环境(例如游戏或 API)进行交互。 该技术构建了一个动作空间 ,将允许的动作 添加到来自 CoT 的推理轨迹 中。 来自环境的观察用于改进推理和行动。 为了解决 ReAct 的问题,每次观察后,都会从 依次生成操作,如 ,最终输出为 。 在本文中,与 ReAct 和 Reflexion 等其他 LM 代理方法(Shinn 等人,2023) 一致,我们专注于决策任务在迭代之间恢复是可行的 。
虽然前面描述的提示技术提高了 LM 在推理任务上的性能,但由于以下几个缺点,它们在涉及多方面决策的困难任务上表现不佳:1)灵活性:基础提示设计(CoT 或 ReAct)自回归采样来自 LM,忽略来自特定状态的潜在替代延续。 2)敏感性:基于推理的方法(CoT、RAP (Hao 等人, 2023) 或 ToT)仅依赖于 LM 的内部表示,无法考虑外部观察。 这种依赖性在设置性能上限时存在事实幻觉和错误传播的风险。 3)适应性:当前的规划策略(RAP或ToT)使用简单的搜索算法(例如BFS)或无法利用环境反馈来改进规划。 此外,代理是静态的,无法重用以前的经验或从试验和错误中学习。 虽然 RAP 也采用 MCTS,但它仅限于 LM 可以成为世界模型并准确预测状态的任务。 这些缺点限制了 LM 被部署为一般问题解决代理的能力,并形成了 LATS 的动机。
3.2蒙特卡罗树搜索(MCTS)
蒙特卡罗树搜索(MCTS)是一种启发式搜索算法,在许多决策环境中被证明是成功的,例如 Atari (Ye 等人,2021) 和 Go (Silver 等人, 2016)。 MCTS 构建一棵决策树,其中树中的每个节点都是一个状态,边是一个动作。 MCTS 运行 集;对于每个情节,它从根(即初始状态)开始,迭代地执行两个步骤来扩展树:1)扩展,其中探索多个子状态通过采样 操作来确定当前父状态 ,以及 2) 选择,其中具有最高 UCT 的子状态(置信上限应用于Trees) (Kocsis 和 Szepesvári,2006) 值被选择用于下一次迭代的扩展。 子状态的UCT计算如下:
| (1) |
其中, 是节点 的访问次数, 是来自 子树的值函数(预期回报), 是探索权重, 是 的父节点。当到达一个情节的终点时,会进行反向传播:返回值用于用公式更新路径上的每一个,其中是旧值函数。 通常,MCTS 的主要缺点是它需要一个环境模型来撤消先前的步骤并形成搜索树,这可能是一个强有力的假设。 然而,对于许多 LM 任务来说,这个限制并不存在,因为我们可以通过简单地复制粘贴历史文本输入来方便地重置到任何步骤。 这种特殊的性质是我们工作的主要动力。
4统一推理、行动和计划
4.1LM代理
根据基础提示框架设计,LATS 支持顺序推理或决策任务。 在时间步,代理从环境接收观察,并按照某些策略采取操作。 我们使用 初始化代理,以利用 LM 的有用语言表示作为基本决策者。 我们遵循ReAct实例化,其中动作空间由允许的动作空间和推理痕迹的语言空间组成。 行动直接影响环境并导致观察,而思想则通过组织信息、规划未来行动或注入内部知识来正式决策。 操作空间的确切实例化取决于特定的环境 - 对于决策任务,操作可能由网站上的命令组成,而对于推理任务,操作空间可能仅限于一些外部工具或 API。 在没有反馈的环境中,例如推理任务,我们使用 CoT 作为基本提示框架。
我们不是贪婪地解码一个轨迹或解决方案,而是使用当前状态从 中采样 动作。 这是基于这样的直觉:对于复杂的决策任务,可能存在一系列正确的潜在轨迹或推理路径(Evans,2010)。 在每个步骤中对不同的候选集进行采样可以减轻 LM 文本生成的随机性,并能够在决策和推理空间中进行更大的探索。 我们将 包装在我们提出的搜索算法中,以故意从采样的动作中构建最佳轨迹。
4.2LATS
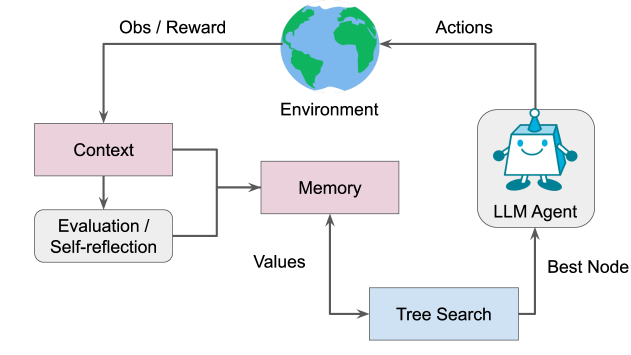
LATS 的主要组成部分是一种搜索算法,通过规划来控制问题解决过程。 为了找到最有希望的轨迹并系统地平衡探索与利用,我们采用了 MCTS 的变体,将决策制定为树搜索,其中每个节点 表示包含原始输入 、动作序列和观察序列,其中是文本序列中的词符。
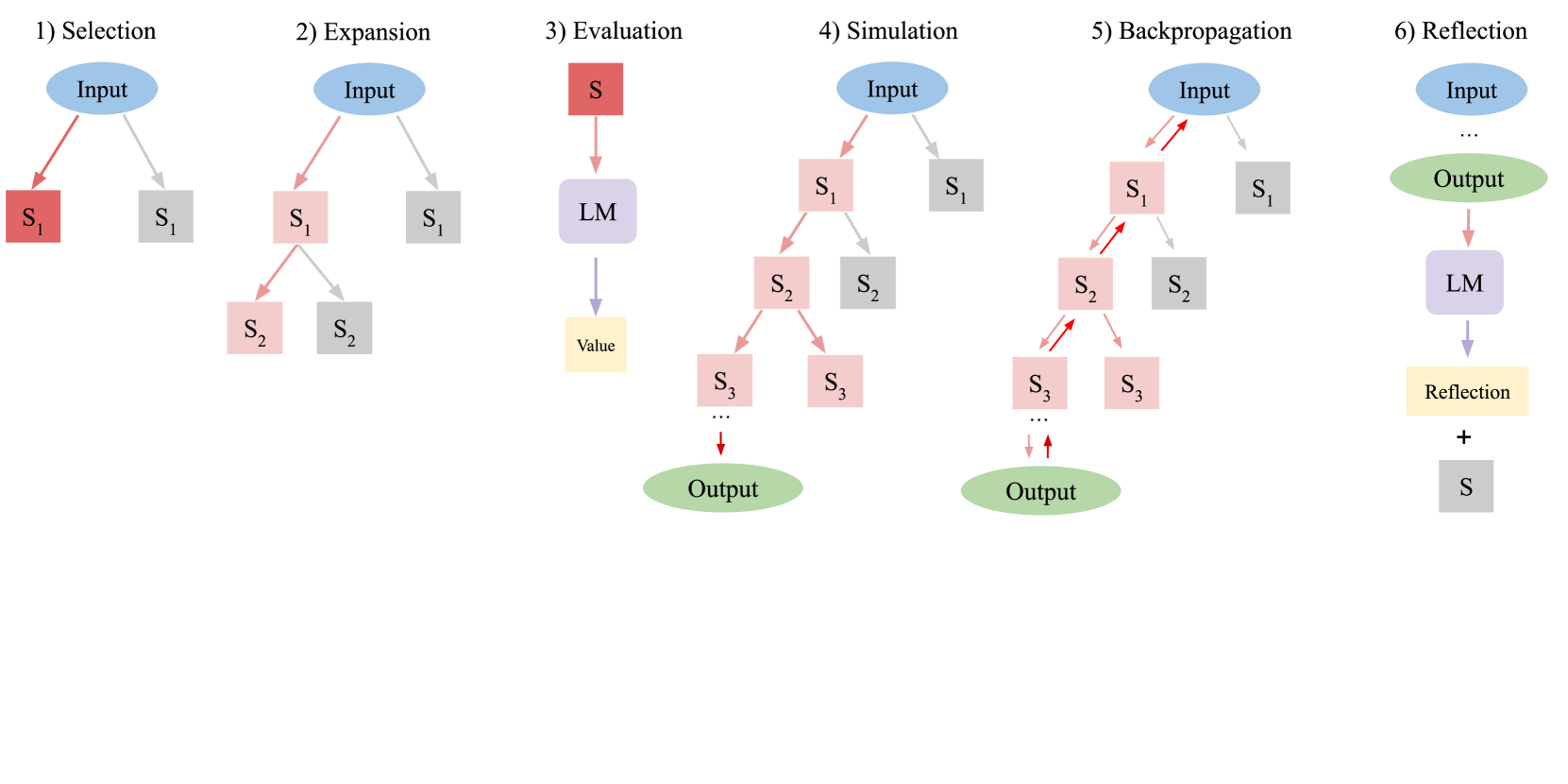
我们的主要技术贡献是使 MCTS 适应语言代理。 LATS 将 重新用作代理、状态评估器和反馈生成器,利用现代 LM 的有用语言表示来促进规划。 标准 MCTS 和 RAP (Hao 等人, 2023) 依靠内部动力学模型来促进模拟,而 LATS 使用环境交互,不需要世界模型。 如图2所示,LATS由一系列操作组成 - 选择、扩展、评估、模拟、反向传播和反射 - 连续执行直到任务成功采样 轨迹后已完成或达到计算限制。 LATS 的完整伪代码可以在第 2 节中找到。附录中的A。
选择。 在第一个操作中,算法识别当前树中最适合后续扩展的段。 从根节点(表示为初始状态)开始,在每个树级别选择子节点,直到到达叶节点。 为了平衡探索和利用,我们使用 UCT 算法,如式(1)所示。 1。
扩展。 选择节点后,第二个操作通过从 中采样 操作来扩展树,如上一节所述。 环境接收每个动作并返回相应的反馈作为观察。 这会导致 个新子节点添加到树中。 该树存储在外部长期记忆结构中。
评估。 第三个操作为每个新的子节点分配一个标量值以进行选择和反向传播。 该值有效地量化了代理在任务完成方面的进度,作为引导搜索算法走向树中最有希望的区域的启发式方法。 由于 LATS 不涉及训练,因此我们基于两个组成部分为此设置提出了一种新颖的价值函数:(1)自我生成 LM 分数和(2)自我一致性 分数。
受 ToT 的启发,我们通过提示其推理给定状态,将 重新调整为值函数。 为了获得标量值,我们指示 以指示轨迹正确性的分数结束其推理跟踪。 我们与ToT的主要区别在于,我们在获得环境反馈后获得这个价值,改善价值分配。 这也使得能够扩展到更具挑战性的环境,因为如果没有外部反馈,LM 很难改进其响应(Huang 等人,2024)。 此外,为了进一步改进价值分配,我们引入了一种基于自我一致性的额外启发式(Wang等人,2022),其中在同一状态下多次采样的动作往往更准确。 由此得出整体价值函数:
| (2) |
其中 是超参数。 值得注意的是,我们的方法比编程启发式方法(Campbell 等人,2002)提供了更高的灵活性,并且比学习启发式方法(Silver 等人,2017)提供了更高的效率。
模拟。 第四个操作扩展当前选定的节点,直到达到最终状态。 在每个深度级别,我们使用相同的操作对节点进行采样和评估,但优先考虑最高值的节点。 达到最终状态可以提供有关轨迹正确性的客观反馈。 如果任务成功完成,则 LATS 终止搜索。 如果解决方案部分成功或不成功,那么我们将执行如下所述的两个附加操作。 轨迹的成功取决于特定环境的设计,例如在网络导航环境中完成购买。
反向传播。 此操作根据轨迹的结果更新树的值。 对于从搜索树的根(初始状态)到叶子(最终状态)的轨迹中的每个节点,其值被更新以反映 和 模拟的结果,其中 是奖励。 这些更新后的值用于 UCT 公式(Eq. 1)中以指导下一个节点的选择。
反思。 除了环境反馈之外,我们还利用自我反思来进一步细化决策过程(Shinn 等人,2023;Madaan 等人,2023)。 当遇到不成功的终端节点时,会被提示轨迹和最终奖励,以提供口头自我反思,总结推理或行动过程中的错误,并提出更好的替代方案。 我们将失败的轨迹和相应的反射存储在内存中。 在随后的迭代中,它们被集成为代理和价值函数的附加上下文,并通过上下文学习来完善两者。 这赋予了比标量值更有用的语义梯度信号,使代理能够从试验和错误中学习,而无需花费昂贵的优化(例如强化学习)的成本。
讨论。 从概念上讲,LATS 作为 LM 代理进行推理和决策的通用框架具有几个显着的优势。 (1) 通用性:LATS 通过定义思想和行动的共享空间来支持推理和决策任务。 (2) 深思熟虑:利用 LATS 中的 MCTS 和 LM 价值函数,确保有原则的搜索,选择具有高价值的选项,同时探索有前途的替代方案。 (3) 适应性:通过 LATS 中的观察和自我反思纳入外部反馈,可以在解决问题时实现更大的适应性。 (4)灵活性:LATS可以通过修改状态设计和树维度来适应不同的场景、环境和资源规定。 (5) 模块化:基本 LM 代理、反射生成器和值函数可以独立更改并适应各个 LM 属性。
| Prompt Method | HotpotQA (EM) |
|---|---|
| Base LM | 0.32 |
| CoT (Wei et al., 2022) | 0.34 |
| CoT - SC (Wang et al., 2022) | 0.38 |
| ToT (Yao et al., 2023a) | 0.55 |
| RAP (Hao et al., 2023) | 0.60 |
| RAP () | 0.60 |
| LATS (CoT) | 0.62 |
5实验
为了证明 LATS 的普遍适用性,我们在需要推理和行动的各种领域评估了我们的方法:编程 (Chen 等人, 2021; Austin 等人, 2022)、HotPotQA (杨等人,2018)、网店(姚等人,2022)、24人游戏(姚等人,2023a)。
5.1HotPotQA
| Prompt Method | HotpotQA (EM) |
|---|---|
| ReAct (Yao et al., 2023b) | 0.32 |
| ReAct (best of ) | 0.38 |
| Reflexion (Shinn et al., 2023) | 0.51 |
| ToT (ReAct) | 0.39 |
| RAP (ReAct) | 0.54 |
| LATS (ReAct) | 0.63 |
| LATS () | 0.58 |
| LATS () | 0.65 |
| LATS (CoT + ReAct) | 0.71 |
对于可以同时使用基于推理和基于行为的策略来完成的任务,我们考虑 HotPotQA (Yang 等人,2018),这是一种多跳问答基准,需要检索超过两个或多个更多维基百科段落。 对于动作空间,除了 LM 思想之外,我们还遵循 Yao 等人 (2023b) 的设置,它为代理提供 API 调用来搜索和检索信息。 这些 API 调用的输出和自生成的反射形成了观察空间。 请注意,与之前的工作(Yao等人,2023b;Shinn等人,2023)一致,我们为HotPotQA使用了预言机设置,其中环境在收到答案后提供有关答案正确性的反馈。 这使得我们能够在反馈质量较高的情况下对我们的方法和基线进行公平比较,从而使我们能够将评估重点放在智能体吸收外部反馈的情况上。 我们为每种方法使用 100 个问题的子集和三个样本示例。 对于 ToT,我们使用 DFS 作为基本搜索算法。 对于所有涉及采样的方法(包括 LATS),我们对 轨迹进行采样。 更多详细信息请参见附录二。 D。
我们通过从上下文中删除动作和观察来评估内部推理策略,对应于 CoT (Wei 等人, 2022) 及其变体 CoT-SC (Wang 等人, 2022)、ToT (姚等人,2023a)和 RAP (郝等人,2023)。 这些方法仅依赖于智能体现有的知识来回答问题。 我们进一步考虑基于行为的方法 ReAct、Reflexion 和 LATS,它们通过交互式 API 环境增强代理,并主要评估其信息检索能力。 我们还设计了搜索算法与 LM 代理的简单集成,通过 ReAct 提示扩展 ToT 和 RAP,以处理外部观察。 此外,虽然 LATS 是为外部反馈可以增强推理的场景而设计的,但我们还实现了一个以 CoT 作为基本提示框架的纯推理版本。 此外,我们在 LATS 中结合了内部和外部推理,首先使用基于 CoT 的提示进行提示,然后在失败时切换到基于 ReAct 的提示。 这更接近人类处理此任务的方式,仅在答案未知时才使用工具检索附加信息。
结果。 我们在选项卡中观察到。 2 和选项卡。 3 内部推理和外部检索策略在 HotPotQA 上都表现良好。 由于其大规模的训练语料库,现代语言模型已经对事实知识进行了编码,并且通常可以直接正确回答问题。 虽然 CoT 可以稍微提高需要推理的问题的表现,但使用搜索方法 ToT 和 RAP 可以观察到更大的收益(表 1)。 2,第 4、5 行),可以采样和探索更多输出。 我们在基于行动的方法中观察到类似的结果。 即使在采样相同数量的轨迹时,LATS 也通过原则性搜索扩展更多节点,从而超越了 ReAct。 这在修改 (每次迭代期间扩展的节点数)时得到了证明。 增加 可以持续提高性能,但计算和推理成本更高。 LATS 在内部推理方面也优于 RAP,但在 HotPotQA 的决策设置上比推理设置具有更高的性能。 与 LATS 相反,ToT 和 RAP 的 ReAct 版本(表 1)。 3,第 4、5 行)比 HotPotQA 的仅推理设置表现更差,这表明基于表演的设置更具挑战性,并且适应决策场景的搜索算法并非易事。 在 LATS 中结合内部和外部推理可以获得最高的性能,这表明外部反馈在增强推理方面的重要性,即使在基础 LM 已经可以执行的任务中也是如此。
5.2编程
| Prompt Method | Model | Pass@1 |
| CoT (Wei et al., 2022) | GPT-3.5 | 46.9 |
| ReAct (Yao et al., 2023b) | GPT-3.5 | 56.9 |
| Reflexion (Shinn et al., 2023) | GPT-3.5 | 68.1 |
| ToT (Yao et al., 2023a) | GPT-3.5 | 54.4 |
| RAP (Hao et al., 2023) | GPT-3.5 | 63.1 |
| LATS (ReAct) | GPT-3.5 | 83.8 |
| Base LM | GPT-4 | 80.1 |
| Reflexion | GPT-4 | 91.0 |
| LATS (ReAct) | GPT-4 | 92.7 |
为了证明外部观察对于复杂推理任务的重要性,我们使用 HumanEval 评估编程的基线和 LATS (Chen 等人, 2021)111一些基线使用 HumanEval 中的 161 个问题。 我们使用 LATS 的所有 164 个问题,发现性能差异最小,因此我们报告两种设置的基线。 和 MBPP (Austin 等人,2022)。 这两个数据集都根据自然语言文档字符串衡量 Python 中合成程序的正确性。 我们使用单独的解决方案作为操作空间,使用测试套件和编译器反馈作为外部观察。 我们遵循 Chen 等人 (2023a) 并使用 LM 为每个问题生成语法上有效的“assert”语句的综合测试套件。 对于每个步骤,都会在此测试套件上评估解决方案,并将结果(包括成功和失败的测试以及编译器输出)添加到上下文中作为观察。
对于此任务,推理和行动基线共享一个行动空间,但行动方法能够将观察结果合并为附加上下文。 对于LATS,由于每个动作对应一个完整的解决方案,因此我们跳过LATS的模拟步骤,直接使用通过测试的百分比作为反向传播的奖励。 我们使用 迭代,在 设置生成测试的数量,并在扩展期间采样 解决方案。 搜索完成后,我们选择具有最高值的解决方案,并在真实测试套件上对其进行评估,以进行 pass@1 精度评估。 更多详细信息请参见附录二。 D。
结果。 标签。 4 和选项卡。 5 表明搜索和语义反馈对于提高性能至关重要。 尽管不使用观察,ToT 和 RAP 仍可与 Reflexion 竞争。 LATS 在两个数据集上都具有最高的性能。 RAP 使用类似于 LATS 的搜索算法,揭示了外部反馈对于编程等困难推理任务的重要性。 借助 GPT-4,使用 LATS 为 HumanEval 设置了最先进的技术,验证了 LATS 可以与更先进的 LM 一起使用以获得更高的性能。
| Prompt Method | Pass@1 |
|---|---|
| CoT (Wei et al., 2022) | 54.9 |
| ReAct (Wei et al., 2022) | 67.0 |
| Reflexion (Shinn et al., 2023) | 70.0 |
| ToT (Yao et al., 2023a) | 65.8 |
| RAP (Hao et al., 2023) | 71.4 |
| LATS (ReAct) | 81.1 |
5.3网上商店
对于具有实际应用的复杂决策环境,我们考虑WebShop(Yao等人,2022),这是一个由具有118万个真实世界产品和12k条人工指令的网站组成的在线购物环境。 代理必须通过各种命令浏览网站才能购买符合用户规格的商品。 我们使用搜索和点击命令的预先构建的动作空间以及浏览器反馈和反射来进行观察。 使用两个指标来衡量性能:平均分数,反映所选产品满足用户指定属性的百分比;成功率,表明所选产品满足所有给定条件的频率。 我们与基于行为的提示方法和基于强化学习的方法进行比较。 我们评估 50 条指令,展开 LATS 的 子级,并为 LATS、ReAct( 中的最佳值)和反射设置 。 更多详细信息和提示请参见附录二。 D 和秒。 G。
结果。 我们在选项卡中找到。 6 表明带有 ReAct 的 GPT-3.5 与模仿学习 (IL) 相比具有竞争力,并且可以通过更强的提示策略超越强化学习技术。 使用 ReAct 和 Reflexion 对 轨迹进行采样会产生类似的性能,这表明语义反馈在 WebShop 等复杂环境中没有那么有用。 与 Shinn 等人 (2023) 类似,我们发现生成的反射通常是通用的,并且不提供有用的反馈,导致智能体倾向于陷入局部最小值。 然而,使用 LATS 确实带来了显着的改进,这表明对于相同次数的迭代来说,探索更有效。
| Method | Score | SR |
|---|---|---|
| ReAct (Yao et al., 2023b) | 53.8 | 28.0 |
| ReAct (best of k) | 59.1 | 32.0 |
| Reflexion (Shinn et al., 2023) | 64.2 | 35.0 |
| LATS (ReAct) | 75.9 | 38.0 |
| IL (Yao et al., 2022) | 59.9 | 29.1 |
| IL+RL (Yao et al., 2022) | 62.4 | 28.7 |
| Fine-tuning (Furuta et al., 2024) | 67.5 | 45.0 |
| Expert | 82.1 | 59.6 |
| Prompt Method | Game of 24 (Success Rate) |
|---|---|
| CoT (Wei et al., 2022) | 0.08 |
| Reflexion (Shinn et al., 2023) | 0.12 |
| ToT (Yao et al., 2023a) | 0.20 |
| RAP (Hao et al., 2023) | 0.40 |
| LATS (CoT) | 0.44 |
5.4消融研究和附加分析
我们进一步在 Game of 24 上测试 LATS 的推理能力,并在 HotPotQA 上进行额外的实验,以证明 LATS 各个组件的效果(结果如表 1 所示)。 8)。 HotPotQA 上词符消耗的更多消融见表 1。 附录二中的9。 C。
24 人游戏的推理。 为了展示 LATS 如何应用于纯粹的内部推理任务,我们还对 24 游戏 (Yao 等人,2023a) 进行了评估,这是一项数学推理任务,其中代理必须从一组数字和基本运算。 我们使用 CoT 作为基础提示设计,并采用与其他设置相同的操作。 我们在选项卡中找到。 7 LATS 优于之前专门为推理而提出的方法。 这是由于我们提出的价值函数,它将自我一致性作为额外的启发式。
| Prompt Method | HotPotQA (EM) |
|---|---|
| ToT (ReAct) | 0.39 |
| RAP (ReAct) | 0.54 |
| LATS (No LM Heuristic) | 0.37 |
| LATS (DFS) | 0.42 |
| LATS (No Reflection) | 0.58 |
| LATS (ReAct) | 0.63 |
自我反思。 LATS 使用自我反射为代理提供额外的语义信号。 在选项卡中。 8(第 5、6 行),当从 LATS 中删除自反射时,我们观察到 性能下降,验证了其有用性。 该增益比 Reflexion 相对于 ReAct 的 增益要小,如表 1 所示。 3,表明问题之间存在重叠,可以通过自我反思和搜索来改进答案。 该变体的性能优于 RAP (ReAct),反映了我们对 MCTS 的改进。
| Method | Performance | Sample complexity | Token Consumption |
|---|---|---|---|
| ReAct (Best ) | - | ||
| CoT-SC () | - | ||
| LATS () | - | ||
| ToT (ReAct, ) | |||
| RAP (ReAct, ) | |||
| LATS () |
| Method | HotPotQA | # of Nodes | |
|---|---|---|---|
| ToT | 10 | 0.34 | 33.97 |
| RAP | 10 | 0.44 | 31.53 |
| LATS | 10 | 0.44 | 28.42 |
| ToT | 30 | 0.39 | 47.54 |
| RAP | 30 | 0.50 | 37.71 |
| LATS | 30 | 0.52 | 34.12 |
| ToT | 50 | 0.49 | 84.05 |
| RAP | 50 | 0.54 | 70.60 |
| LATS | 50 | 0.61 | 66.65 |
搜索算法。 MCTS 是一种比 A* (庄等人,2023) 或 DFS 等变体更具原则性的搜索算法,是观察到的性能提升的基础。 我们观察使用 DFS 的效果,并结合 ToT 中使用的基于 LM 的启发式算法,其中低值分支被修剪。 这样就去掉了选择和反向传播操作,我们观察到表中的性能下降了。 8(第 4 行)在采样相同数量的节点时但优于 ToT (ReAct)。 尽管 LATS 也受益于真实反馈,但它比 ToT 和 RAP 更好地使用它,并且可以超越这些方法。 我们还在选项卡中找到。 8(第 3 行)LM 评分是我们价值函数的主要组成部分,对于利用外部反馈和强劲绩效至关重要。
样本复杂度和词符消耗。 LATS 的一个可能的担忧是树结构搜索可能比现有方法消耗更多的标记。 为了进一步研究 LATS 与现有方法相比的计算成本,我们检查了本文考虑的所有方法的样本复杂性(即渐近词符成本),并计算了我们的方法和其他树结构方法扩展的平均节点数(ToT 和 RAP)在 HotPotQA 上成功搜索后。 我们在选项卡中呈现结果。 9 和选项卡。 10,这表明我们的方法具有与其他基于树的搜索方法相同的样本复杂性,并且需要更少的总体标记和状态。 当考虑到失败的轨迹时,词符成本差距会更大,因为我们的方法具有更高的成功率并且很少达到计算预算限制。 当采样较少数量的轨迹时也是如此;平均而言,LATS 比 RAP 需要的节点少 3.55 个,比 ToT 需要的节点少 12.12 个。 这些发现强调了我们对 MCTS 的改进和对 LM 代理的适应,从而产生了更有原则性和更高效的搜索机制。
6结论
这项工作引入了语言代理树搜索 (LATS),这是第一个统一推理、行动和规划以增强 LM 问题解决能力的框架。 LATS 通过使用搜索算法有意构建轨迹、结合外部反馈以及使代理能够从经验中学习,解决了先前提示技术的关键局限性。 我们的评估证明了 LATS 能够利用 LM 能力来完成各种决策任务,同时保持其推理能力无需额外训练。 所提出的搜索、交互和反射之间的协同作用为自主决策提供了一种通用的方法,凸显了 LM 作为通才代理的潜力。
局限性和未来方向。 LATS 有两个主要限制,在应用之前应考虑这些限制。 首先,与 ReAct 或 Reflexion 等更简单的提示方法相比,它的计算成本更高,这可能会限制其在某些情况下的实用性。 其次,LATS 假设能够在决策环境中恢复到早期状态,这可能并不普遍适用于所有可能的环境。 尽管存在这些限制,但值得注意的是,与类似方法相比,LATS 仍然实现了更好的性能和效率,并且每一步扩展的节点数量提供了性能和效率之间的权衡。 此外,我们预计推理时间计算成本会随着时间的推移而降低,从而提高 LATS 和其他“System-2”LM 方法的实用性。 最后,回归属性在许多实际应用中都是可行的,为 LM 决策社区开辟了新的机会。 未来的方向包括将 LATS 扩展到更复杂的环境或多代理框架,以及提高效率以降低成本。 关于 LATS 局限性的更详细讨论可以在附录 Sec 中找到。 B。
影响报告
LATS 是一个通过与环境交互来增强 LM 性能的框架。 自主决策的这种改进可能会促进LM的有害使用。 另一方面,LATS 增强了可解释性和更大一致性的潜力,因为它涉及通过多轮决策和反思进行高级语言推理和行动,而不是依赖于自回归生成。 最后,增强 LM 代理的功能可能会增加安全风险,例如执行恶意软件。 我们鼓励进一步研究,以充分了解和减轻 LM 的风险。
致谢
我们感谢 Daniel Campos 对本文早期版本的有用反馈。 这项工作得到了 NSF 拨款 2106825、NIFA 奖 2020-67021-32799、伊利诺伊州医疗保健工程系统中心和 OSF 基金会的 Jump ARCHES 捐赠以及 IBM-伊利诺伊州发现加速器研究所的部分支持。 这项工作通过 ACCESS 计划分配的 CIS220014、CIS230012 和 CIS230218 使用了 NCSA Delta 的 NVIDIA GPU。
参考
- Ahn et al. (2022) Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Chebotar, Omar Cortes, Byron David, Chelsea Finn, Chuyuan Fu, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Daniel Ho, Jasmine Hsu, Julian Ibarz, Brian Ichter, Alex Irpan, Eric Jang, Rosario Jauregui Ruano, Kyle Jeffrey, Sally Jesmonth, Nikhil J Joshi, Ryan Julian, Dmitry Kalashnikov, Yuheng Kuang, Kuang-Huei Lee, Sergey Levine, Yao Lu, Linda Luu, Carolina Parada, Peter Pastor, Jornell Quiambao, Kanishka Rao, Jarek Rettinghouse, Diego Reyes, Pierre Sermanet, Nicolas Sievers, Clayton Tan, Alexander Toshev, Vincent Vanhoucke, Fei Xia, Ted Xiao, Peng Xu, Sichun Xu, Mengyuan Yan, and Andy Zeng. Do as I can, not as I say: Grounding language in robotic affordances. In CoRL, 2022.
- Austin et al. (2022) Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and Charles Sutton. Program synthesis with large language models. In NeurIPS, 2022.
- Baker et al. (2022) Bowen Baker, Ilge Akkaya, Peter Zhokhov, Joost Huizinga, Jie Tang, Adrien Ecoffet, Brandon Houghton, Raul Sampedro, and Jeff Clune. Video pretraining (VPT): Learning to act by watching unlabeled online videos. In NeurIPS, 2022.
- Besta et al. (2023) Maciej Besta, Nils Blach, Ales Kubicek, Robert Gerstenberger, Lukas Gianinazzi, Joanna Gajda, Tomasz Lehmann, Michal Podstawski, Hubert Niewiadomski, Piotr Nyczyk, and Torsten Hoefler. Graph of thoughts: Solving elaborate problems with large language models. arXiv:2308.09687, 2023.
- Bowman et al. (2015) Samuel R Bowman, Gabor Angeli, Christopher Potts, and Christopher D Manning. A large annotated corpus for learning natural language inference. In EMNLP, 2015.
- Brown et al. (2020) Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. Language models are few-shot learners. In NeurIPS, 2020.
- Campbell et al. (2002) Murray Campbell, A Joseph Hoane Jr, and Feng-hsiung Hsu. Deep blue. Artificial intelligence, 2002.
- Chen et al. (2023a) Bei Chen, Fengji Zhang, Anh Nguyen, Daoguang Zan, Zeqi Lin, Jian-Guang Lou, and Weizhu Chen. CodeT: Code generation with generated tests. In ICLR, 2023a.
- Chen et al. (2021) Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde, Jared Kaplan, Harrison Edwards, Yura Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian, Clemens Winter, Philippe Tillet, Felipe Petroski Such, David W. Cummings, Matthias Plappert, Fotios Chantzis, Elizabeth Barnes, Ariel Herbert-Voss, William H. Guss, Alex Nichol, Igor Babuschkin, Suchir Balaji, Shantanu Jain, Andrew Carr, Jan Leike, Joshua Achiam, Vedant Misra, Evan Morikawa, Alec Radford, Matthew M. Knight, Miles Brundage, Mira Murati, Katie Mayer, Peter Welinder, Bob McGrew, Dario Amodei, Sam McCandlish, Ilya Sutskever, and Wojciech Zaremba. Evaluating large language models trained on code. arXiv:2107.03374, 2021.
- Chen et al. (2023b) Wenhu Chen, Xueguang Ma, Xinyi Wang, and William W. Cohen. Program of thoughts prompting: disentangling computation from reasoning for numerical reasoning tasks. TMLR, 2023b. ISSN 2835-8856.
- Chowdhery et al. (2023) Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, Parker Schuh, Kensen Shi, Sasha Tsvyashchenko, Joshua Maynez, Abhishek Rao, Parker Barnes, Yi Tay, Noam Shazeer, Vinodkumar Prabhakaran, Emily Reif, Nan Du, Ben Hutchinson, Reiner Pope, James Bradbury, Jacob Austin, Michael Isard, Guy Gur-Ari, Pengcheng Yin, Toju Duke, Anselm Levskaya, Sanjay Ghemawat, Sunipa Dev, Henryk Michalewski, Xavier Garcia, Vedant Misra, Kevin Robinson, Liam Fedus, Denny Zhou, Daphne Ippolito, David Luan, Hyeontaek Lim, Barret Zoph, Alexander Spiridonov, Ryan Sepassi, David Dohan, Shivani Agrawal, Mark Omernick, Andrew M. Dai, Thanumalayan Sankaranarayana Pillai, Marie Pellat, Aitor Lewkowycz, Erica Moreira, Rewon Child, Oleksandr Polozov, Katherine Lee, Zongwei Zhou, Xuezhi Wang, Brennan Saeta, Mark Diaz, Orhan Firat, Michele Catasta, Jason Wei, Kathy Meier-Hellstern, Douglas Eck, Jeff Dean, Slav Petrov, and Noah Fiedel. PaLM: Scaling language modeling with pathways. JMLR, 24(240):1–113, 2023.
- Cobbe et al. (2021) Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems. arXiv:2110.14168, 2021.
- Deng et al. (2023) Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Samuel Stevens, Boshi Wang, Huan Sun, and Yu Su. Mind2Web: Towards a generalist agent for the web. In NeurIPS Datasets and Benchmarks Track, 2023.
- Driess et al. (2023) Danny Driess, Fei Xia, Mehdi S. M. Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, Wenlong Huang, Yevgen Chebotar, Pierre Sermanet, Daniel Duckworth, Sergey Levine, Vincent Vanhoucke, Karol Hausman, Marc Toussaint, Klaus Greff, Andy Zeng, Igor Mordatch, and Pete Florence. PaLM-E: An embodied multimodal language model. In ICML, 2023.
- Du et al. (2023) Yilun Du, Mengjiao Yang, Bo Dai, Hanjun Dai, Ofir Nachum, Joshua B. Tenenbaum, Dale Schuurmans, and Pieter Abbeel. Learning universal policies via text-guided video generation. In NeurIPS, 2023.
- Evans (2010) Jonathan St BT Evans. Intuition and reasoning: A dual-process perspective. Psychological Inquiry, pages 313 – 326, 2010.
- Fan et al. (2022) Linxi Fan, Guanzhi Wang, Yunfan Jiang, Ajay Mandlekar, Yuncong Yang, Haoyi Zhu, Andrew Tang, De-An Huang, Yuke Zhu, and Anima Anandkumar. MineDojo: Building open-ended embodied agents with internet-scale knowledge. In NeurIPS Datasets and Benchmarks Track, 2022.
- Furuta et al. (2024) Hiroki Furuta, Ofir Nachum, Kuang-Huei Lee, Yutaka Matsuo, Shixiang Shane Gu, and Izzeddin Gur. Multimodal web navigation with instruction-finetuned foundation models. In ICLR, 2024.
- Gao et al. (2023) Luyu Gao, Aman Madaan, Shuyan Zhou, Uri Alon, Pengfei Liu, Yiming Yang, Jamie Callan, and Graham Neubig. PAL: Program-aided language models. In ICML, 2023.
- Guo et al. (2018) Jiaxian Guo, Sidi Lu, Han Cai, Weinan Zhang, Yong Yu, and Jun Wang. Long text generation via adversarial training with leaked information. In AAAI, 2018.
- Guss et al. (2019) William H. Guss, Brandon Houghton, Nicholay Topin, Phillip Wang, Cayden Codel, Manuela Veloso, and Ruslan Salakhutdinov. MineRL: A large-scale dataset of Minecraft demonstrations. In IJCAI, 2019.
- Hafner et al. (2019) Danijar Hafner, Timothy Lillicrap, Ian Fischer, Ruben Villegas, David Ha, Honglak Lee, and James Davidson. Learning latent dynamics for planning from pixels. In ICML, 2019.
- Hafner et al. (2023) Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse domains through world models. arXiv:2301.04104, 2023.
- Hao et al. (2023) Shibo Hao, Yi Gu, Haodi Ma, Joshua Jiahua Hong, Zhen Wang, Daisy Zhe Wang, and Zhiting Hu. Reasoning with language model is planning with world model. In EMNLP, 2023.
- Huang et al. (2024) Jie Huang, Xinyun Chen, Swaroop Mishra, Huaixiu Steven Zheng, Adams Wei Yu, Xinying Song, and Denny Zhou. Large language models cannot self-correct reasoning yet. In ICLR, 2024.
- Huang et al. (2022) Wenlong Huang, F. Xia, Ted Xiao, Harris Chan, Jacky Liang, Peter R. Florence, Andy Zeng, Jonathan Tompson, Igor Mordatch, Yevgen Chebotar, Pierre Sermanet, Noah Brown, Tomas Jackson, Linda Luu, Sergey Levine, Karol Hausman, and Brian Ichter. Inner monologue: Embodied reasoning through planning with language models. In CoRL, 2022.
- Kocsis and Szepesvári (2006) Levente Kocsis and Csaba Szepesvári. Bandit based monte-carlo planning. In ECML, 2006.
- Kojima et al. (2022) Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners. In NeurIPS, 2022.
- LaValle (1998) Steven M. LaValle. Rapidly-exploring random trees : A new tool for path planning. The Annual Research Report, 1998.
- Liu et al. (2018) Evan Zheran Liu, Kelvin Guu, Panupong Pasupat, Tianlin Shi, and Percy Liang. Reinforcement learning on web interfaces using workflow-guided exploration. In ICLR, 2018.
- Liu et al. (2024) Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Aohan Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tianjun Zhang, Yu Su, Huan Sun, Minlie Huang, Yuxiao Dong, and Jie Tang. AgentBench: Evaluating LLMs as agents. In ICLR, 2024.
- Liu et al. (2023) Zhihan Liu, Hao Hu, Shenao Zhang, Hongyi Guo, Shuqi Ke, Boyi Liu, and Zhaoran Wang. Reason for future, act for now: A principled framework for autonomous LLM agents with provable sample efficiency. arXiv:2309.17382, 2023.
- Madaan et al. (2023) Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. Self-refine: Iterative refinement with self-feedback. In NeurIPS, 2023.
- Nallapati et al. (2016) Ramesh Nallapati, Bowen Zhou, Cicero dos Santos, Caglar Gulcehre, and Bing Xiang. Abstractive text summarization using sequence-to-sequence RNNs and beyond. In Special Interest Group on Natural Language Learning, 2016.
- OpenAI (2023) OpenAI. GPT-4 technical report. arXiv:2303.08774, 2023.
- Qin et al. (2024) Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, Sihan Zhao, Runchu Tian, Ruobing Xie, Jie Zhou, Mark Gerstein, Dahai Li, Zhiyuan Liu, and Maosong Sun. ToolLLM: Facilitating large language models to master 16000+ real-world APIs. In ICLR, 2024.
- Saparov and He (2023) Abulhair Saparov and He He. Language models are greedy reasoners: A systematic formal analysis of chain-of-thought. In ICLR, 2023.
- Schick et al. (2023) Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. In NeurIPS, 2023.
- Shen et al. (2023) Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, and Yueting Zhuang. HuggingGPT: Solving AI tasks with ChatGPT and its friends in Hugging Face. In NeurIPS, 2023.
- Shinn et al. (2023) Noah Shinn, Federico Cassano, Beck Labash, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning. In NeurIPS, 2023.
- Shridhar et al. (2020) Mohit Shridhar, Xingdi Yuan, Marc-Alexandre Côté, Yonatan Bisk, Adam Trischler, and Matthew Hausknecht. ALFWorld: Aligning text and embodied environments for interactive learning. In ICLR, 2020.
- Silver et al. (2016) David Silver, Aja Huang, Chris J. Maddison, Arthur Guez, L. Sifre, George van den Driessche, Julian Schrittwieser, Ioannis Antonoglou, Vedavyas Panneershelvam, Marc Lanctot, Sander Dieleman, Dominik Grewe, John Nham, Nal Kalchbrenner, Ilya Sutskever, Timothy P. Lillicrap, Madeleine Leach, Koray Kavukcuoglu, Thore Graepel, and Demis Hassabis. Mastering the game of Go with deep neural networks and tree search. Nature, 529:484–489, 2016.
- Silver et al. (2017) David Silver, Aja Huang, Chris J. Maddison, Arthur Guez, L. Sifre, George van den Driessche, Julian Schrittwieser, Ioannis Antonoglou, Vedavyas Panneershelvam, Marc Lanctot, Sander Dieleman, Dominik Grewe, John Nham, Nal Kalchbrenner, Ilya Sutskever, Timothy P. Lillicrap, Madeleine Leach, Koray Kavukcuoglu, Thore Graepel, and Demis Hassabis. Mastering chess and Shogi by self-play with a general reinforcement learning algorithm. arXiv:1712.01815, 2017.
- Sloman (1996) Steven A. Sloman. The empirical case for two systems of reasoning. Psychological Bulletin, 119:3–22, 1996.
- Sun et al. (2023) Haotian Sun, Yuchen Zhuang, Lingkai Kong, Bo Dai, and Chao Zhang. AdaPlanner: Adaptive planning from feedback with language models. In NeurIPS, 2023.
- Surís et al. (2023) Dídac Surís, Sachit Menon, and Carl Vondrick. ViperGPT: Visual inference via Python execution for reasoning. In ICCV, 2023.
- Swiechowski et al. (2021) Maciej Swiechowski, Konrad Godlewski, Bartosz Sawicki, and Jacek Ma’ndziuk. Monte Carlo tree search: A review of recent modifications and applications. Artificial Intelligence Review, 56:2497–2562, 2021.
- Touvron et al. (2023) Hugo Touvron, Louis Martin, Kevin R. Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Daniel M. Bikel, Lukas Blecher, Cristian Cantón Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony S. Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez, Madian Khabsa, Isabel M. Kloumann, A. V. Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushkar Mishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, R. Subramanian, Xia Tan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zhengxu Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, and Thomas Scialom. Llama 2: Open foundation and fine-tuned chat models. arXiv:2307.09288, 2023.
- Vodopivec et al. (2017) Tom Vodopivec, Spyridon Samothrakis, and Branko Ster. On Monte Carlo tree search and reinforcement learning. Journal of Artificial Intelligence Research, 60:881–936, 2017.
- Wang et al. (2023) Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. Voyager: An open-ended embodied agent with large language models. arXiv:2305.16291, 2023.
- Wang et al. (2022) Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. In ICLR, 2022.
- Wei et al. (2022) Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Ed Chi, Quoc Le, and Denny Zhou. Chain of thought prompting elicits reasoning in large language models. In NeurIPS, 2022.
- Wooldridge and Jennings (1995) Michael Wooldridge and Nicholas R Jennings. Intelligent agents: Theory and practice. The Knowledge Engineering Review, 10:115 – 152, 1995.
- Wu et al. (2023) Philipp Wu, Alejandro Escontrela, Danijar Hafner, Pieter Abbeel, and Ken Goldberg. Daydreamer: World models for physical robot learning. In CoRL, 2023.
- Xie et al. (2023) Yuxi Xie, Kenji Kawaguchi, Yiran Zhao, Xu Zhao, Min-Yen Kan, Junxian He, and Qizhe Xie. Decomposition enhances reasoning via self-evaluation guided decoding. arXiv:2305.00633, 2023.
- Yang et al. (2018) Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W Cohen, Ruslan Salakhutdinov, and Christopher D Manning. HotpotQA: A dataset for diverse, explainable multi-hop question answering. In EMNLP, 2018.
- Yao et al. (2022) Shunyu Yao, Howard Chen, John Yang, and Karthik R Narasimhan. WebShop: Towards scalable real-world web interaction with grounded language agents. In NeurIPS, 2022.
- Yao et al. (2023a) Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: deliberate problem solving with large language models. In NeurIPS, 2023a.
- Yao et al. (2023b) Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models. In ICLR, 2023b.
- Ye et al. (2021) Weirui Ye, Shaohuai Liu, Thanard Kurutach, Pieter Abbeel, and Yang Gao. Mastering Atari games with limited data. In NeurIPS, 2021.
- Zhou et al. (2022) Denny Zhou, Nathanael Schärli, Le Hou, Jason Wei, Nathan Scales, Xuezhi Wang, Dale Schuurmans, Olivier Bousquet, Quoc Le, and Ed Chi. Least-to-most prompting enables complex reasoning in large language models. In ICLR, 2022.
- Zhuang et al. (2023) Yuchen Zhuang, Xiang Chen, Tong Yu, Saayan Mitra, Victor Bursztyn, Ryan A. Rossi, Somdeb Sarkhel, and Chao Zhang. ToolChain*: Efficient action space navigation in large language models with A* search. In ICLR, 2023.
LATS 附录
附录 A LATS 伪代码
藻类。 1 显示了我们的算法 LATS 的伪代码。 节点显式存储在内存中。 除非另有说明,在所有实验中,我们将采样节点数设置为,探索权重设置为。 对于 HotPotQA 和 Game,我们使用自一致性权重 24,对于编程和 WebShop 使用自一致性权重 。
附录 B有关限制的更多讨论
如第 2 节所述。 6,LATS 有两个主要限制:
计算成本。 尽管 LATS 可以改进推理和决策,但相对于 ReAct 或 Reflexion 等更简单的提示方法,这会带来更高的计算成本。 然而,以下事实可以缓解这个问题:
- •
-
•
每一步扩展的节点数量提供了性能和效率之间的自然权衡。 事实上,设置 使得该方法与多次试验的 ReAct [Yao 等人,2023b] 或 CoT-SC [Wang 等人,2022]< 一样高效。 /t2>.
一般来说,我们建议使用 LATS 来完成编程等困难任务,或者实践中性能优先于效率的情况。 我们希望 LM 的持续进步能够降低成本并提高 LATS 的适用性。
此外,查询环境会产生很小的成本,我们发现这对于我们研究的环境来说是微不足道的。 大多数基于 LM 的环境都涉及基于 API 的工具,这些工具价格低廉且使用速度快。 还值得注意的是,这比使用 LM 作为世界模型相关的推理成本要便宜,如之前的搜索方法[Hao 等人, 2023, Liu 等人, 2023]。
决策中环境回归的假设。 由于我们的方法基于蒙特卡罗树搜索并且是无模型的,因此 LATS 对决策任务的限制之一是它要求代理能够恢复到环境中的早期状态。 然而,这种回归属性在许多现实环境和应用中是可行的(尽管并不普遍适用于所有可能的环境),包括编程(HumanEval [Chen 等人,2021])、网络搜索( WebShop [Yao 等人, 2022])、基于文本的操作任务 (Alfworld [Shridhar 等人, 2020]) 和使用工具的 LM (ToolBench [秦等人, 2024])。 因此,我们认为利用回归属性并不是一个缺点,而是LM决策社区尚未明确通知的一个功能——它为新兴的LM代理社区开辟了新的机会。
此外,与现实世界交互环境的复杂性相比,我们在本文中使用的基准相对简单,并且侧重于决策。 此外,某些环境可能不容易支持回滚到以前的状态。 然而,LATS 的设计是灵活的,可以根据各种资源限制进行调整。 在 Minecraft [Fan 等人,2022] 等环境中使用基于计划的提示方法(例如 LATS)和更多推理基准将是未来工作的有趣途径。
附录 C其他消融
| Prompt Method | HotpotQA (EM) |
|---|---|
| LATS () | 0.55 |
| LATS () | 0.63 |
| LATS () | 0.58 |
| LATS (CoT) | 0.62 |
| LATS (No LM Heuristic) | 0.37 |
| LATS (, ) | 0.63 |
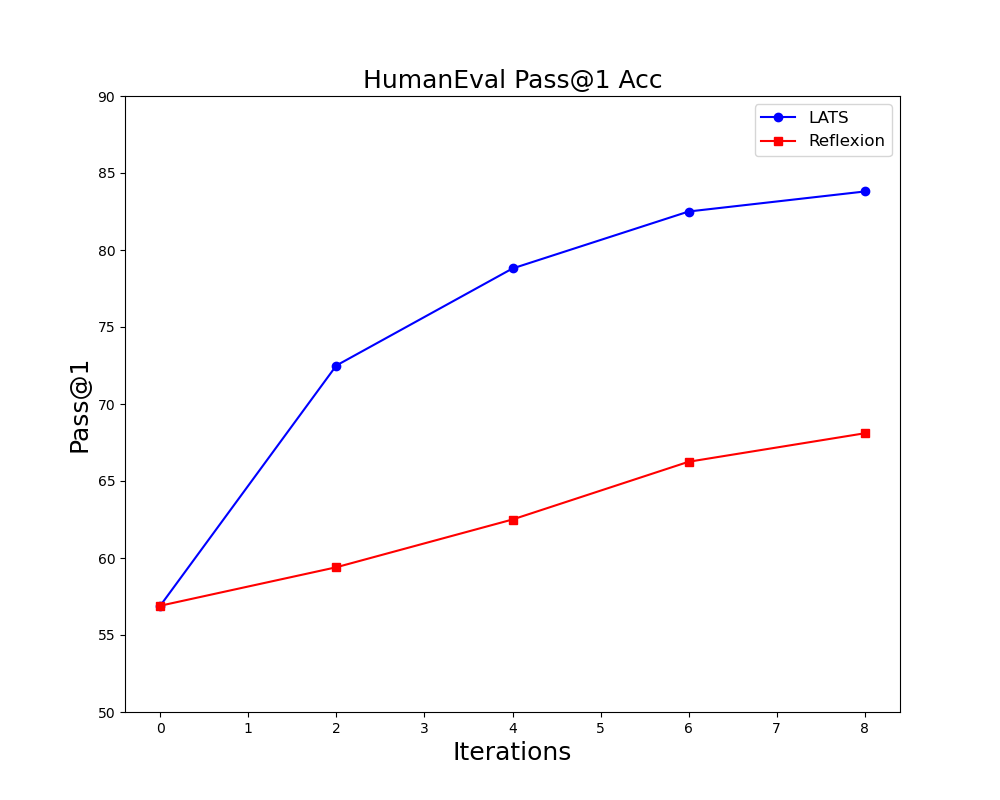
在本节中,我们将消除 LATS 的各种设计。 实验在 HotPotQA 上进行,最多有 条轨迹,采样大小为 ;在 HumanEval 上进行最多 条轨迹,采样大小为 . HotPotQA 的结果如表 1 所示。 图8和HumanEval如图3。
探索权重。 我们发现,当选择公式中的探索权重 减小到 时,HotPotQA 的性能较低,这表明这降低了搜索的有效性。 将 增加到 不会导致性能提高,但我们倾向于观察到更快的收敛。 最佳设置取决于特定环境和状态空间的复杂性。
深度。 在我们的主要实验中,我们遵循之前的工作[Yao等人,2023b],在HotPotQA上对所有方法使用最大深度。 我们将 LATS 的影响降低到 后消除。 这只会导致性能略有下降。 我们发现大多数问题可以在四个步骤内得到回答,而使用更多的步骤往往会迫使智能体陷入局部最小值,并且很少能提高成功率。
LM值函数。 LM 价值函数根据预期的未来奖励对状态进行评分。 如果没有这种启发式方法,指导搜索的唯一信号将来自于已完成轨迹的环境奖励,这些轨迹是稀缺的且通常是二元的。 当我们删除评估操作时,我们观察到性能急剧下降。
随着时间的推移表现。 为了查看增加采样轨迹数量的效果,我们将 更改为不同的值。 我们在 HumanEval 上进行了这个实验,由于采样的轨迹较少,因此具有更明显的差异。 结果如图3所示,其中LATS比Reflexion具有更好的扩展性和更多的迭代次数。
附录 D环境详细信息
D.1 HotPotQA
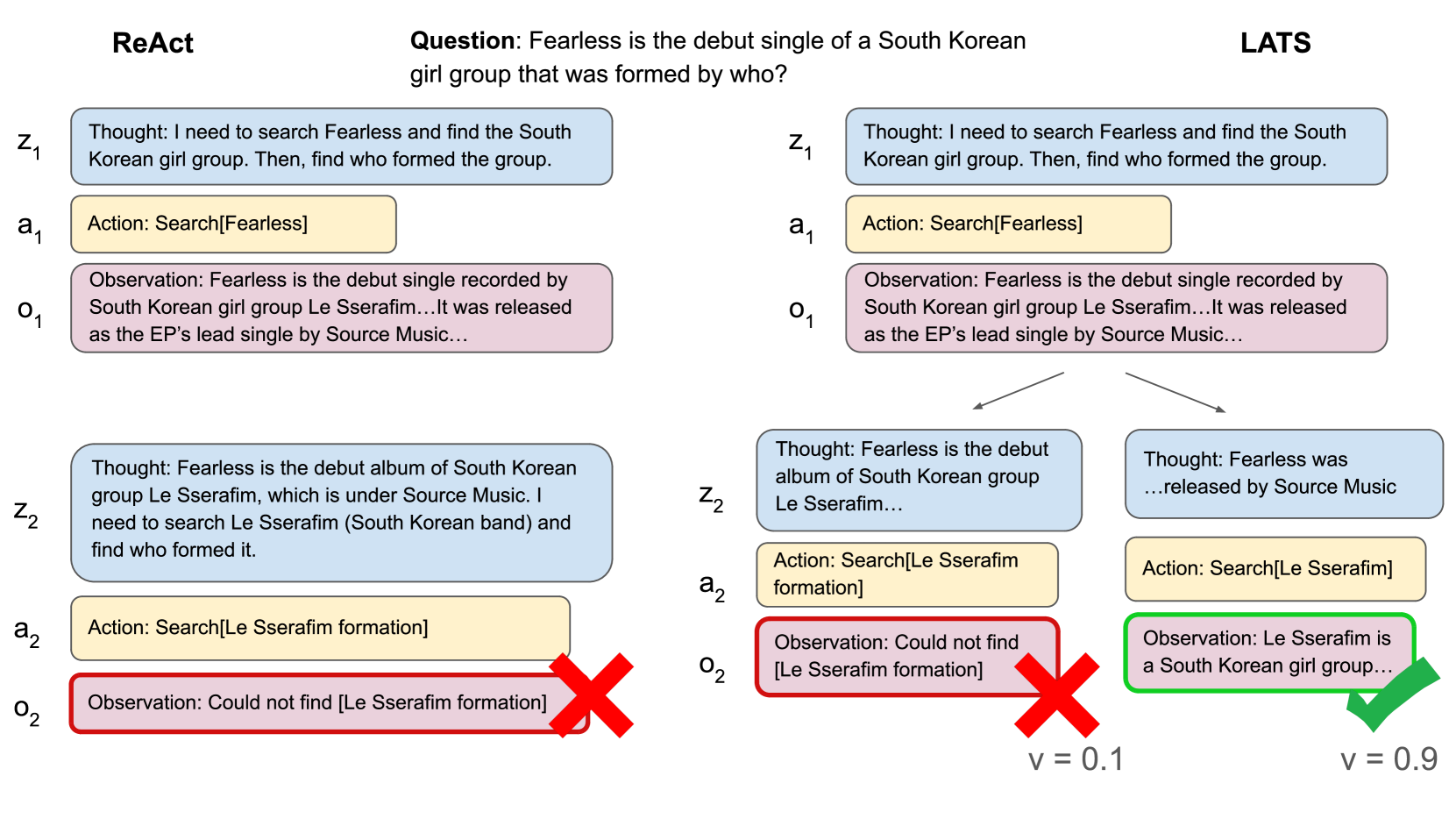
HotPotQA [Yang 等人, 2018] 是一个问答数据集,需要对多个支持文档进行推理才能回答问题。 它包含由众包工作者制作的 113k 个基于维基百科的问答对,这些问答对是多样化的、多跳的且可解释的。 问题涵盖一系列类型,例如实体、位置、日期以及两个实体之间共享属性的比较。 Crowdworks 还提供文件中的支持事实来证明答案的合理性。 我们使用 HotPotQA 基准设置和所有维基百科段落来测试检索。 我们使用随机选择的 100 个问题子集进行实验,最大深度限制为 6。 图4说明了ReAct和LATS如何在HotPotQA的示例任务上工作,并给出了LATS如何在该任务上优于ReAct的定性示例。 对于价值函数超参数,我们使用 作为 LM 分数和自洽分数。
行动空间。 我们采用Yao等人[2023b]中提出的Wikipedia Web API,通过三种类型的操作来支持交互式信息检索:
(1) search[entity],返回相应 entity wiki 页面的前 5 个句子(如果存在),否则建议置顶-来自维基百科搜索引擎的 5 个类似实体,
(2) lookup[string],返回页面中包含string的下一个句子,
(3) finish[answer],以answer结束当前任务。
这些 API 调用和自由形式的想法构成了该环境的操作空间。
D.2编程
HumanEval 数据集[Chen 等人, 2021] 是 164 个手写编程问题的集合,旨在评估从自然语言描述合成程序的模型的功能正确性。 每个问题都包含函数签名、文档字符串描述、参考实现和多个单元测试,每个问题平均有 7.7 次测试。 编程任务评估对自然语言、推理、算法和基础数学的理解,其难度水平与简单的软件面试问题相当。 通过率使用 pass@k 指标进行评估,其中每个问题生成 k 个样本,如果任何样本通过所有测试,则认为问题已解决。 我们在实验中使用了全部 164 个问题,最大深度限制为 8。 对于没有示例测试用例的三个问题,我们自己编写。 对于价值函数超参数,我们使用 作为 LM 分数和自洽分数。 对于 GPT-3.5,我们使用六个内部测试,而对于 GPT-4,我们使用四个内部测试。
大多数基本编程问题 (MBPP) [Austin 等人, 2022] 基准测试包含 974 个简短的 Python 函数,旨在评估程序综合技术。 该数据集是由具有基本 Python 知识的工作人员通过众包构建的。 每个数据点都包含编程任务的自然语言描述、参考解决方案实现以及三个功能正确性测试用例。 自然语言提示通常是简短的一句话描述。 解决方案涵盖常见的编程结构,包括数学运算、列表处理、字符串操作和 Python 标准库的使用。 平均而言,解决方案有 6.8 行代码。 该数据集还补充了另外一组 426 个问题,这些问题经过手动验证,具有明确的规范、标准函数签名和准确的测试用例。 我们使用随机选择的 397 个问题子集进行实验。 对于价值函数超参数,我们使用 作为 LM 分数和自洽分数。
D.3 网上商店
WebShop [Yao 等人, 2022] 是一个基于网络的交互式环境,旨在评估代理的基础语言理解和决策。 它通过向代理商提供从亚马逊抓取的超过 100 万种真实产品(涵盖 5 个类别和 113 个子类别)来模拟电子商务购物任务。 这些产品包含丰富的语言信息,平均文本长度为262个单词,词汇量为224k。 此外,还有超过 80 万种独特的产品选项可供定制。 该环境以两种模式呈现网页:HTML 模式提供具有交互元素的像素级观察,而简单模式将原始 HTML 转换为更适合训练代理的结构化文本观察。 操作空间由查询搜索和按钮单击组成,它们在 4 页面类型之间转换:搜索、结果、项目和项目详细信息。 说明是众包自然语言,指定产品属性和选项,总共收集了 12k。 自动奖励是通过使用词汇匹配和语义相似性指标将代理购买的产品与指令中指定的属性和选项进行比较来计算的。
| Type | Argument | State Next State |
|---|---|---|
| search | [Query] | Search Results |
| choose | Back to search | Search |
| choose | Prev/Next page | Results Results |
| choose | [Product title] | Results Item |
| choose | [Option] | Item Item |
| choose | Desc/Overview | Item Item-Detail |
| choose | Previous | Item-Detail Item |
| choose | Buy | Item Episode End |
WebShop 使用两种评估指标: (1) Task Score 定义为 ,它捕获跨情节获得的平均奖励; (2)成功率(SR)定义为所在的指令部分。 奖励是根据所选项目满足的属性数量来计算的。 我们使用 50 个环境进行实验,最大深度限制为 15。 对于价值函数超参数,我们使用 作为 LM 分数和自洽分数。
D.4 24 人游戏
24 游戏是一项数学推理挑战,目标是使用基本算术运算从 4 个数字中构造出 24 个。 我们遵循 Yao 等人 [2023a] 的设置,如果智能体产生等于 24 的正确方程并且每个输入数字仅使用一次,我们就衡量成功。 我们报告了超过 50 场比赛的成功率。 我们使用 迭代,最大深度限制为 5。 对于价值函数超参数,我们使用 作为 LM 分数和自洽分数。 标签。 13显示了和之间的性能比较,这验证了我们的自洽项的设计。
| Prompt Method | Game of 24 (Success Rate) |
|---|---|
| LATS (CoT, ) | 0.40 |
| LATS (CoT) | 0.44 |
附录 EHotPotQA 提示
E.1 基本动作提示
通过交叉思考、行动、观察步骤来解决问题回答任务。 思想可以推理当前的情况,而行动可以分为三种:
(1) Search[entity],在维基百科上搜索确切的实体并返回第一段(如果存在)。 如果没有,它将返回一些相似的实体进行搜索。
(2) Lookup[keyword],返回当前段落中包含关键字的下一个句子。
(3) Finish[answer],返回答案并完成任务。
每次观察后,提供下一个想法和下一个行动。
这里有些例子:
问题:哪一本杂志最先创办,是《亚瑟杂志》还是《First for Women》?
想法 1:我需要搜索《Arthur’s Magazine》和《First for Women》,找到哪个先开始的。
行动一:搜索[亚瑟杂志]
观察一:《亚瑟杂志》是 19 世纪在费城出版的美国文学期刊。 该书由蒂莫西·谢伊·阿瑟 (Timothy Shay Arthur) 编辑,收录了埃德加·坡 (Edgar A. Poe)、J.H. 英格拉汉姆、莎拉·约瑟夫·黑尔、托马斯·G·斯皮尔等。[1][2] 1846 年 5 月,它被并入戈迪的《女士之书》。[3]
想法 2:《亚瑟杂志》创刊于 1844 年。 接下来我需要搜索“First for Women”。
行动2:搜索[女性优先]
观察2:《First for Women》是美国鲍尔传媒集团出版的一本女性杂志。[1] 该杂志创刊于1989年。 它的总部位于新泽西州恩格尔伍德悬崖。[2] 2011年该杂志发行量为1,310,696份。[3]
想法 3:First for Women 始于 1989 年。 1844年(《亚瑟杂志》)1989年(《第一本女性杂志》),所以《亚瑟杂志》首先创刊。
行动 3:完成[亚瑟杂志]
(例子)
您之前曾尝试回答以下问题但失败了。 以下思考给出了一个计划,以避免无法像之前那样回答问题。 使用它们来改进正确回答给定问题的策略。
(轨迹)
(输入)
E.2 基本推理提示
通过思考来解决问题回答任务,然后完成你的答案。 思想可以推理当前的情况。 Finish[answer] 返回答案并完成任务。 您将获得上下文来帮助您回答问题。 从行动或索引思想开始你的回应
这里有些例子:
问题:科罗拉多造山带东段延伸的区域的海拔范围是多少?
让我们一步步思考。
想法1:科罗拉多造山运动的东段延伸至高原。
想法 2:高原海拔从 1,800 英尺左右上升到 7,000 英尺
想法 3:答案是 1,800 到 7,000 英尺。
动作:完成[1,800 至 7,000 英尺]
(例子)
先前的试验:(轨迹)
(输入)
E.3 值函数提示
分析问答任务的解决方案的轨迹。 轨迹由对情况的环境观察、可以推理当前情况的想法以及可以分为三种类型的行动来标记:
(1) Search[entity],在维基百科上搜索确切的实体并返回第一段(如果存在)。 如果没有,它将返回一些相似的实体进行搜索。
(2) Lookup[keyword],返回当前段落中包含关键字的下一个句子。
(3) Finish[answer],返回答案并完成任务。
给定一个问题和一个轨迹,评估其正确性并提供详细的推理和分析。 关注最新的想法、行动和观察。 如果到目前为止的想法和行动是正确的,那么即使尚未找到答案,不完整的轨迹也可能是正确的。 不要产生额外的想法或行动。 然后在最后一行得出结论“因此正确性得分为 s”,其中 s 是 1 到 10 之间的整数。
问题:哪一本杂志最先创办,是《亚瑟杂志》还是《First for Women》?
想法 1:我需要搜索《Arthur’s Magazine》和《First for Women》,找到哪个先开始的。
行动一:搜索[亚瑟杂志]
观察一:《亚瑟杂志》是 19 世纪在费城出版的美国文学期刊。 该书由蒂莫西·谢伊·阿瑟 (Timothy Shay Arthur) 编辑,收录了埃德加·坡 (Edgar A. Poe)、J.H. 英格拉汉姆、莎拉·约瑟夫·黑尔、托马斯·G·斯皮尔等。[1][2] 1846 年 5 月,它被并入戈迪的《女士之书》。[3]
该轨迹是正确的,因为搜索问题中提供的第一本杂志是合理的。 最好进行与单个实体相对应的简单搜索,这使其成为最佳操作。
因此正确性得分为 10
(其他例子)
(失败的轨迹)
(语境)
E.4 反思提示
分析问答任务的解决方案的轨迹。 轨迹由对情况的环境观察、可以推理当前情况的想法以及可以分为三种类型的行动来标记:
(1) Search[entity],在维基百科上搜索确切的实体并返回第一段(如果存在)。 如果没有,它将返回一些相似的实体进行搜索。
(2) Lookup[keyword],返回当前段落中包含关键字的下一个句子。
(3) Finish[answer],返回答案并完成任务。
给定一个问题和一个轨迹,评估其正确性并提供详细的推理和分析。 关注最新的想法、行动和观察。 如果到目前为止的想法和行动是正确的,那么即使尚未找到答案,不完整的轨迹也可能是正确的。 不要产生额外的想法或行动。 然后在最后一行得出结论“因此正确性得分为 s”,其中 s 是 1 到 10 之间的整数。
问题:哪一本杂志最先创办,是《亚瑟杂志》还是《First for Women》?
想法 1:我需要搜索《Arthur’s Magazine》和《First for Women》,找到哪个先开始的。
行动一:搜索[亚瑟杂志]
观察一:《亚瑟杂志》是 19 世纪在费城出版的美国文学期刊。 该书由蒂莫西·谢伊·阿瑟 (Timothy Shay Arthur) 编辑,收录了埃德加·坡 (Edgar A. Poe)、J.H. 英格拉汉姆、莎拉·约瑟夫·黑尔、托马斯·G·斯皮尔等。[1][2] 1846 年 5 月,它被并入戈迪的《女士之书》。[3]
该轨迹是正确的,因为搜索问题中提供的第一本杂志是合理的。 最好进行与单个实体相对应的简单搜索,这使其成为最佳操作。
因此正确性得分为 10
(其他例子)
(失败的轨迹)
(语境)
附录F编程提示
F.1HumanEval函数实现示例
函数签名示例:
函数体实现示例:
F.2 基本动作/推理提示
你是一个AI Python助手。 您将获得以前的功能实现、一系列单元测试结果以及您对以前的实现的自我反思。 编写完整的实现(重述函数签名)。
示例1:
[先前的实现]:
[之前 impl 的单元测试结果]:
测试通过:
测试失败:
断言 add(1, 2) == 3 # 输出:-1
断言 add(1, 2) == 4 # 输出:-1
[对先前实现的反思]:
该实现未能通过输入整数为 1 和 2 的测试用例。 出现此问题的原因是代码不会将两个整数相加,而是从第一个整数中减去第二个整数。 要解决这个问题,我们应该将 return 语句中的运算符从“-”更改为“+”。 这将确保函数针对给定输入返回正确的输出。
[改进的实现]:
F.3反思提示
你是一名Python编程助理。 您将获得一个函数实现和一系列单元测试结果。 您的目标是写几句话来解释为什么您的实现是错误的,如测试所示。 当您稍后重试时,您将需要此作为指导。 仅提供答案中的几句话描述,而不提供实现。 用户将为您提供一些示例。
示例1:
[先前的实现]:
[之前 impl 的单元测试结果]:
测试通过:
测试失败:
断言 add(1, 2) == 3 # 输出:-1
断言 add(1, 2) == 4 # 输出:-1
[对先前实现的反思]:
该实现未能通过输入整数为 1 和 2 的测试用例。 出现此问题的原因是代码不会将两个整数相加,而是从第一个整数中减去第二个整数。 要解决这个问题,我们应该将 return 语句中的运算符从“-”更改为“+”。 这将确保函数针对给定输入返回正确的输出。
F.4测试用例生成提示
您是一名人工智能编码助手,可以为给定签名和文档字符串的函数编写独特、多样化且直观的单元测试。
(输入)
附录 G网上商店提示
G.1 动作提示
网上商店
操作说明:
我想要一瓶 3 盎司的适合敏感皮肤的明亮柑橘除臭剂,价格低于 50.00 美元
[搜索]
行动:搜索[3盎司明亮柑橘除臭剂敏感肌肤]
观察:
[返回搜索]
第 1 页(总结果:50)
[下一页] [B078GWRC1J]
Earth Mama 的明亮柑橘除臭剂 — 天然、安全,适合敏感肌肤、孕妇和哺乳期,含有有机金盏花 3 盎司
10.99 美元
[B078GTKVXY]
Earth Mama 生姜清新除臭剂 — 天然、安全,适合敏感肌肤、孕妇和哺乳期,含有有机金盏花 3 盎司
10.99 美元
[B08KBVJ4XN]
Barrel and Oak - 无铝除臭剂,男士除臭剂,精油香味,24 小时异味防护,雪松和广藿香混合,温和呵护敏感肌肤(山鼠尾草,2.7 盎司,2 件装)
15.95 美元
行动:认为[B078GWRC1J和B078GTKVXY是明亮的柑橘除臭剂,不到50美元。 我可以先查一下B078GWRC1J。]
观察:好的。
操作:单击[B078GWRC1J]
观察:
[返回搜索]
[上一页]
香味 [什锦香味][明亮的柑橘][平静的薰衣草][生姜新鲜][完全无香味] 尺寸 [旅行套装(4 件装)][3 盎司(1 件装)][3 盎司(2 件装) )] Earth Mama 出品的明亮柑橘除臭剂 — 天然、安全,适合敏感肌肤、孕妇和哺乳期,含有有机金盏花 3 盎司
价格:10.99 美元
评级:不适用
[描述]
[特征]
[评论]
[立即购买]
行动:想想[针对敏感皮肤的 3 盎司瓶装明亮柑橘除臭剂,该产品有“明亮柑橘”和“3 盎司(1 包)”选项,似乎很值得购买。]
观察:好的。
操作:点击【明亮柑橘】
观察:您点击了明亮的柑橘。
操作:点击[3 盎司(1 包)]
观察:您已点击 3 盎司(1 包)。
操作:点击【立即购买】
G.2 值函数提示
给定要购买的商品和旨在购买完全符合规格的商品的轨迹(对应于理想分数 1.0),分析以下轨迹,然后在最后一行得出结论:“因此正确性分数为 s”,其中 s 是 1 到 10 之间的整数。
这里有些例子
网上商店
操作说明:
我正在寻找不含乳制品和苹果品种的薯片,价格低于 30.00 美元
[搜索]
行动:搜索[不含乳制品和苹果品种的薯片]
观察:
[返回搜索]
第 1 页(总结果:50)
[下一个]
[B07HRFJWP8]
Enjoy Life Foods 软烤椭圆形早餐棒,无坚果棒,不含大豆,不含乳制品,非转基因,无麸质,纯素食,多种装,4 盒(共 20 块)
100.0 美元
[B01KMHY5PG]
Enjoy Life 软烤耐嚼棒,多种装,不含坚果棒,不含大豆,不含乳制品,不含麸质,6 盒(共 30 根)
21.49 美元
[B008D2X8C4]
Enjoy Life 扁豆片多种包装,不含乳制品,不含大豆,不含坚果,非转基因,纯素食,不含麸质,24 袋(0.8 盎司)
100.0 美元
行动:思考[前两项不是我想要的。 第三件是我想要的不含乳制品和苹果的薯条包。]
观察:好的。
操作:单击[B008D2X8C4]
观察:
[返回搜索]
[上一页]
口味名称 [莳萝和酸奶油][大蒜和帕尔马干酪][淡海盐][玛格丽特披萨][泰国辣椒酸橙][多种装] 尺寸 [0.8 盎司(24 件装)][4 盎司(12 件装)]
价格:$100.0
评级:不适用
[描述]
[特征]
[评论]
[立即购买]
行动:思考[该商品有“多种包装”和“0.8 盎司(24 件装)”选项,似乎很值得购买。]
观察:好的。
操作:点击【多种包】
观察:您点击了品种包。
操作:点击[0.8 盎司(24 件装)]
观察:您点击了 0.8 盎司(24 件装)。
操作:点击【立即购买】
反思:这次尝试,我没有成功。 我不小心买了一个 100 美元的产品,超出了我 30 美元的预算。 不管怎样,最初的搜索结果并不好。 下次,我会搜索[“各种薯片包装”;],然后检查结果是否满足不含乳制品和 30 美元的预算限制。 我将继续完善我的搜索,以便找到更多产品。
因此正确性得分为 5
(输入)
G.3反思提示
你是一个高级推理代理,可以通过自我反思来提高。 您将接受先前的推理试验,其中您被允许访问购物网站并购买特定类型的商品。 您可以访问相关上下文并购买商品。 您未能成功购买正确的商品,因为您没有找到符合所有要求规格的商品,或者因为您没有选择正确的商品。 理想的分数是 1.0,低于 1.0 的分数都是不正确的。 用几句话,诊断失败的可能原因,并设计一个新的、简洁的、高级的计划,旨在减轻同样的失败。 使用完整的句子。 这里有些例子:
以前的试用说明:我正在寻找不含奶制品和苹果品种的薯片,价格低于 30.00 美元 [搜索]
操作:搜索[不含乳制品和苹果的各种薯片包] 观察:[返回搜索] 第 1 页(总结果:50)[下一个 ] [B07HRFJWP8] Enjoy Life Foods 软烤椭圆形、早餐棒,无坚果棒,不含大豆,不含乳制品,非转基因,不含麸质,纯素食,品种装,4 盒(共 20 条)100.0 美元 [B01KMHY5PG] Enjoy Life 软烤耐嚼棒,品种装,不含坚果棒,不含大豆,不含乳制品,不含麸质,6 盒(共 30 条)21.49 美元 [B008D2X8C4] Enjoy Life 扁豆片多种包装,不含乳制品薯片,不含大豆,不含坚果,非转基因,纯素食,不含麸质,24 袋(0.8 盎司)100.0 美元
行动:思考[前两项不是我想要的。 第三件是我想要的不含乳制品和苹果的薯条包。] 观察:好的。
操作:点击 [B008D2X8C4] 观察:[返回搜索] [ 上一页] 风味名称 [莳萝和酸奶油][大蒜和帕尔马干酪][淡海盐][玛格丽塔披萨][泰国辣椒酸橙] [多种装] 尺寸 [0.8 盎司(每包 24 个)][4 盎司(每包 12 个)] 价格:$100.0 评级:N.A. [描述] [功能] [评论] [立即购买]
行动:思考[该商品有“多种包装”和“0.8 盎司(24 件装)”选项,似乎很值得购买。] 观察:好的。
操作:单击[综艺包] 观察:您已单击综艺包。
操作:单击[0.8 盎司(每包 24 个)] 观察:您已单击 0.8 盎司(每包 24 个)。
操作:点击【立即购买】
状态:失败
反思:这次尝试,我没有成功。 我不小心买了一个 100 美元的产品,超出了我 30 美元的预算。 不管怎样,最初的搜索结果并不好。 下次,我会搜索[“各种薯片包”],然后检查结果是否符合不含乳制品和 30 美元的预算限制。 我将继续完善我的搜索,以便找到更多产品。
之前的试用说明:我需要无麸质素食烟熏胡椒培根 - 4 盎司(2 包),价格低于 40.00 美元 [搜索]
操作:搜索[无麸质素食烟熏胡椒培根 4 盎司,每包 2 个] 观察:[返回搜索] 第 1 页(总结果:50)[下一个 ] [B06Y96MXJV] 烟熏培根海盐 3-包装:烟熏培根墨西哥辣椒、烟熏培根和洋葱、烟熏胡椒培根 - 全天然海盐在赤杨木上缓慢熏制 - 无麸质、无味精、非转基因(共 12 盎司) 29.99 美元 [B06Y96N1KG] 辣辣椒海盐 3 件装:鬼椒、墨西哥辣椒、哈瓦那 - 全天然、美味的辣椒和海盐混合物 - 无麸质、犹太洁食、无味精、非转基因(共 12 盎司) 29.99 美元 [B07GJTKYJQ] 路易斯维尔纯素肉干 - 5 种口味多种装,非转基因大豆蛋白,无麸质(黑胡椒、水牛莳萝、意大利辣香肠、枫树培根和卡罗莱纳烧烤,3 盎司)42.99 美元
行动:思考[前两项不是我想要的。 第三项不是我想要的,但它是最接近的。] 观察:好的。
操作:点击[B07GJTKYJQ] 观察:[返回搜索] [ 上一页] Louisville Vegan Jerky - 5 种口味多种装,非转基因大豆蛋白,无麸质(黑胡椒、水牛莳萝、意大利辣香肠、枫培根和卡罗莱纳烧烤,3 盎司) 价格:42.99 美元 评级:N.A. [描述] [功能] [评论] [立即购买]
行动:思考【价格太高,不是我想要的。】 观察:好的。
操作:点击[上一页]观察:[返回搜索]第1页(总结果:50)[下一页] [B06Y96MXJV]烟熏培根海盐3件装:烟熏培根墨西哥辣椒、烟熏培根和洋葱、烟熏胡椒培根 - 全天然海盐在赤杨木上缓慢熏制 - 无麸质、无味精、非转基因(共 12 盎司) 29.99 [B06Y96N1KG] 辣辣椒海盐 3 件装:鬼椒、墨西哥辣椒、哈瓦那 - 全天然、美味的辣椒和海盐混合物 - 无麸质、犹太洁食、无味精、非转基因(共 12 盎司) 29.99 [B07GJTKYJQ] 路易斯维尔纯素肉干 - 5 种口味多种装,非转基因大豆蛋白,无麸质(黑胡椒、水牛莳萝、意大利辣香肠、枫树培根和卡罗莱纳烧烤,3 盎司)42.99
行动:思考[前两项不是我想要的。] 观察:好的。
操作:单击[下一步 ] 观察:无效操作!
行动:思考[我需要改进我的搜索。] 观察:好的。
操作:单击[ 返回搜索] 观察:无效操作!
操作:点击[返回搜索]
状态:失败
反思:这次尝试,我没有成功。 最初的搜索结果不是我正在寻找的产品。 下次,我将搜索[“素食培根”]以进行更广泛的搜索。 我将检查新结果是否满足无麸质和 2 件装 4 盎司的限制。 我将继续完善我的搜索,以便找到更多产品。
先前的试验:轨迹反射:”'