Uni3D:探索大规模统一 3D 表示
摘要
过去几年中,对图像或文本表示的扩展研究一直在深入进行,并引发了视觉和语言学习领域的革命。 但是,对于 3D 对象和场景的可扩展表示研究相对较少。 在这项工作中,我们提出了 Uni3D,这是一种 3D 基础模型,旨在探索大规模的统一 3D 表示。 Uni3D 使用一个 2D 初始化的 ViT,进行端到端的预训练,以使 3D 点云特征与图像-文本对齐特征保持一致。 通过简单的架构和预训练任务,Uni3D 可以利用丰富的 2D 预训练模型作为初始化,并使用图像-文本对齐模型作为目标,释放了 2D 模型的巨大潜力,并将扩展策略应用于 3D 世界。 我们有效地将 Uni3D 扩展到十亿个参数,并在各种 3D 任务中创下了新的记录,例如零样本分类、少样本分类、开放世界理解和部分分割。 我们展示了强大的 Uni3D 表示还可以支持应用程序,例如 3D 绘画和野外检索。 我们相信 Uni3D 为探索 3D 领域表示的扩展性和效率提供了新的方向。
1 引言
3D 表示学习是 3D 计算机视觉中最基本的问题之一,特别是在 3D 传感器(例如,LiDAR)快速发展以及现实世界应用(例如,自动驾驶、增强/虚拟现实和机器人技术)需求日益增长的背景下。 现有的方法在 3D 模型架构方面取得了重大进展 (Qi 等人,2017a; b; Yu 等人,2021; Wang 等人,2019),学习目标 (Yu 等人,2022; Wang 等人,2021),面向任务的建模 (Zhou 等人,2020; Yin 等人,2021; Zhao 等人,2021) 等。 但是,大多数工作是在相对较小的规模上进行的,参数、数据和任务场景有限。 学习可扩展的 3D 表示,使其能够在野外进行迁移,目前研究较少,仍然是一个具有挑战性的问题。
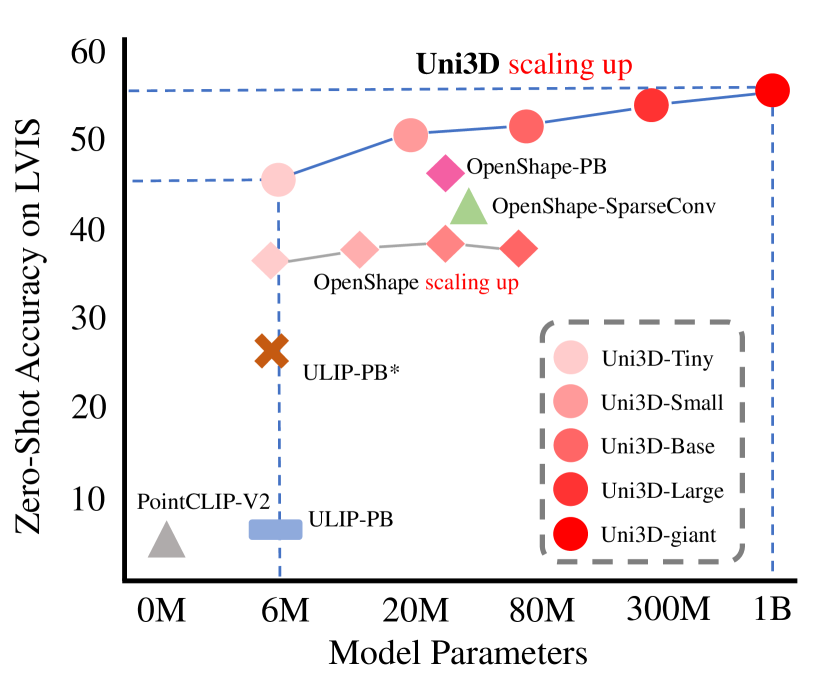
在过去几年中,扩展预训练语言模型 (Brown 等人,2020; Liu 等人,2019; Raffel 等人,2020) 极大地改变了自然语言处理。 一些最近的工作 (Radford 等人,2021;Dosovitskiy 等人,2020;Bao 等人,2021;He 等人,2022;Fang 等人,2022) 通过模型和数据扩展将语言的进展转化为二维视觉。 受到它们成功的启发,我们也可以将这种成功从二维提升到三维,即学习一个可扩展的三维表示模型,该模型可以在三维世界中进行迁移。 最近,随着大型三维数据集 Objaverse (Deitke 等人,2023b) 的发布,一些工作尝试探索三维的可扩展预训练,但要么仍然局限于小型三维骨干网络 (Xue 等人,2023a;b),要么难以扩展到相对较大的规模 (Liu 等人,2023),例如图 2 中的 72M。
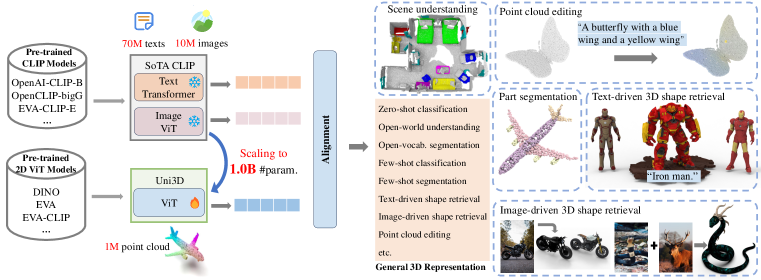
在这项工作中,我们提出了 Uni3D,一个用于大规模三维表示学习的统一且可扩展的三维预训练框架,并探索了它在十亿参数规模、一百万个三维形状和一千个万张图像(与七千万个文本配对)上的极限。 Uni3D 使用二维 ViT 作为三维编码器,并使用最佳二维先验进行初始化,然后进行端到端预训练,以将三维点云特征与图像文本对齐的特征对齐。 通过简单的架构和预训练任务,Uni3D 可以利用丰富的二维预训练模型作为初始化 (Fang 等人,2022;Caron 等人,2021),并将图像文本对齐的模型作为目标 (Radford 等人,2021;Sun 等人,2023;Cherti 等人,2023),释放了二维模型和扩展策略在三维世界中的巨大潜力。
此外,我们系统地研究了 Uni3D 在以下方面的可扩展性和灵活性:1)模型扩展,从 6M 参数扩展到 1B 参数;2)二维初始化,从视觉自监督扩展到文本监督;3)文本图像对齐的目标模型,从 150M 参数扩展到 5B 参数。 我们观察到,在灵活且统一的框架下,每个组件的扩展都带来了持续的性能提升。 可共享的二维先验和扩展策略也极大地有利于大规模三维表示学习。
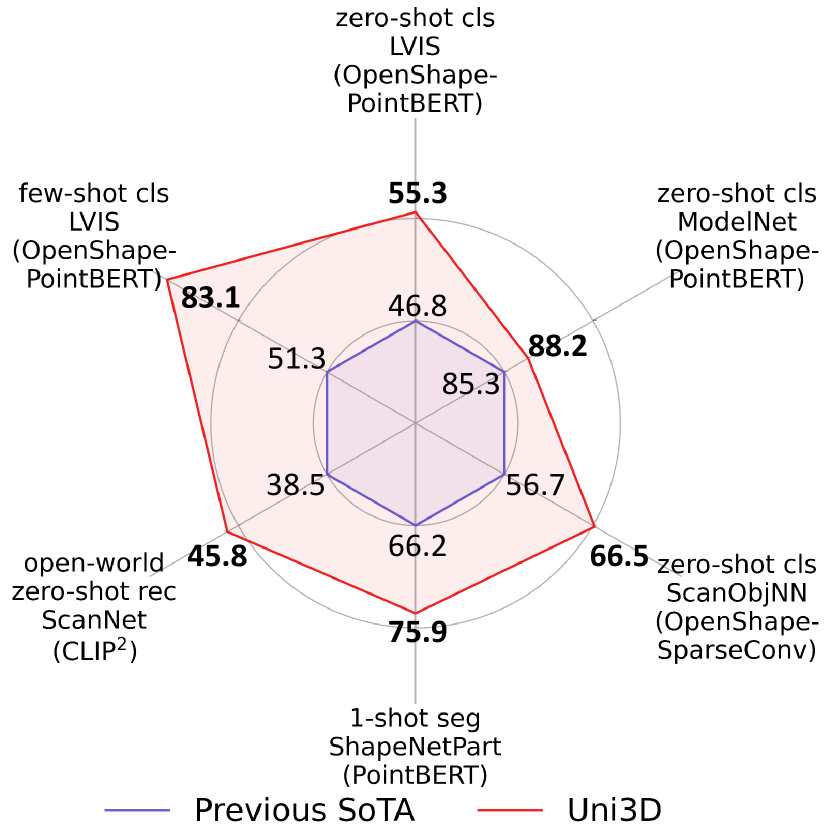
我们首次展示了一个十亿规模的三维表示模型,该模型能够很好地迁移到各种下游任务和场景中。 如图 2 所示,Uni3D 在各种零样本和少样本三维任务中相较于现有技术取得了提升。 具体来说,Uni3D 在 ModelNet 上实现了 88.2% 的零样本分类准确率,令人惊讶的是,它的表现与一些监督方法不相上下。 Uni3D 还获得了其他具有代表性的三维任务的最新性能,例如开放世界理解、部件分割等。 此外,我们还展示了 Uni3D 学习到的强大三维表示的一些有趣的应用,例如点云绘画和基于文本/图像的三维形状检索。
通过将三维基础模型扩展到一个简单且统一的预训练中,以学习跨任务的强大三维表示,我们希望 Uni3D 能够弥合二维和三维视觉之间的差距,并促进不同模态之间的大融合。 为了促进未来的研究,我们将发布所有代码和三维基础模型。
2 相关工作
3D 表示学习。 近年来,从点云中学习表示以进行 3D 理解 (Qi 等人,2017a;b;Wang 等人,2019;Yu 等人,2021) 已得到充分探索。 一些工作进一步研究了点云的自监督预训练,方法是使用特定于 3D 的预文本任务,如自我重建 (Wang 等人,2021)、掩码点建模 (Yu 等人,2022) 和对比学习 (Qi 等人,2023)。 这些工作仅仅在有限的 3D 数据(例如 ShapeNet (Chang 等人,2015))下进行探索,并没有研究从 2D/NLP 到 3D 的多模态表示。
随着最近在使用对比学习(如 CLIP (Radford 等人,2021;Jia 等人,2021;Li 等人,2022;Ramesh 等人,2022;Gregoromichelaki 等人,2022))从原始文本中学习视觉概念方面的成功, 最近的工作 (Liu 等人,2023;Qi 等人,2023;Xue 等人,2023a;Hegde 等人,2023;Lei 等人,2023) 试图通过以类似的对比学习方式对齐文本、图像和点云特征来学习 3D 表示。 最近,随着大型 3D 数据集 Objaverse (Deitke 等人,2023b)、OpenShape (Liu 等人,2023) 和 ULIP2 (Xue 等人,2023b) 的发布,一些工作尝试探索 3D 中的可扩展预训练,但要么仍然局限于小型 3D 主干 (Xue 等人,2023b),要么难以扩展到相对较大的规模 (Liu 等人,2023)。 在这项工作中,我们旨在探索一个统一且可扩展的 3D 预训练框架,即 Uni3D,用于大规模 3D 表示学习,并探索其在数十亿规模模型尺寸上的极限。
基础模型。 最近,设计用于统一和扩展不同模态(例如 NLP、2D 视觉)下的表示的基础模型引起了广泛关注。 从 NLP 开始,最近在扩展预训练语言模型规模方面的研究 (Brown 等人,2020;Liu 等人,2019;Raffel 等人,2020) 已经彻底改变了自然语言处理。 2D 视觉领域的一些研究 (Radford 等人,2021;Dosovitskiy 等人,2020;Bao 等人,2021;He 等人,2022;Fang 等人,2022) 通过模型和数据扩展将语言的进展转化为 2D 视觉。 然而,由于 3D 数据有限以及统一和扩展 3D 主干的困难,这种现象在 3D 领域尚未得到很好地建立和探索。 Meta-Transformer (Zhang 等人,2023) 和 FrozeCLIP (Huang 等人,2022b) 为开发具有模态共享编码器的统一框架指明了光明的前景。 但是,它们需要重新训练特定于任务的头部,并对不同的下游任务进行人工标注,这导致缺乏域外零样本能力。 在这项工作中,我们设计了第一个具有统一 3D 表示的十亿级 3D 基础模型。 统一的 ViT 架构使我们能够简单地利用经过充分研究的统一 2D/NLP 扩展策略来扩展 Uni3D。 我们预计 Uni3D 将充当 2D 和 3D 视觉之间的桥梁,促进各种模态的显著融合。
3 方法
我们介绍了 Uni3D,一个统一且可扩展的 3D 预训练框架,用于通过将 3D 点云特征与图像-文本对齐特征对齐来进行大规模 3D 表示学习。 Uni3D 的概述如图 3 所示。 我们首先介绍如何在 Uni3D 中设计、扩展和初始化统一的 3D 表示,如第 3.1 节所示。 然后,我们在第 3.2 节中介绍用于将图像和语言与点云对齐的多模态对比学习。 更多训练细节见附录的第 A 节。
3.1 统一 3D 表示
Uni3D 利用一个统一的 vanilla transformer,其结构与 2D Vision Transformer (ViT) (Dosovitskiy 等人,2020) 等效,作为其主干。 唯一的区别是,我们用一个特定的点词元化器替换了 ViT 中的 patch embedding 层,以实现 3D embedding。 该点词元化器与 PointBERT (Yu 等人,2022) 相同,首先使用 FPS(最远点采样)和 kNN(k 近邻)将点分组到局部 patch 中,然后使用一个微小的 PointNet (Qi 等人,2017a) 为每个 patch 提取词元 embedding。 然后将 vanilla transformer 应用于 3D 词元以提取 3D 表示。
扩展 Uni3D。 之前关于点云表示学习的工作仅专注于设计针对不同应用追求更好性能的特定模型架构,并且局限于一定的小规模数据集(例如 ShapeNet (Chang 等人,2015),ModelNet (Wu 等人,2015))。 随着最近在大规模 3D 数据(例如 Objaverse (Deitke 等人,2023b;a))方面的成功,最近的一些工作 (Xue 等人,2023a;Liu 等人,2023;Xue 等人,2023b) 尝试探索 3D 中的可扩展预训练,但要么仍然局限于小规模 3D 主干 (Xue 等人,2023a),要么难以扩展到相对较大的规模 (Liu 等人,2023)。 困难在于 3D 领域中不统一的主干和预训练,其中每个主干都需要一个特定的扩展策略,而这很少被探索。 此外,一些主干(例如 PointMLP (Ma 等人,2021),DGCNN (Wang 等人,2019))需要对密集点完全建模局部模式,这在扩展时会带来巨大的计算成本。
我们论证了 Uni3D,其结构上等同于 ViT 的普通 Transformer,可以通过简单地使用经过充分研究的统一 2D/NLP 扩展策略来扩展模型规模,从而自然地解决这些困难。 具体来说,我们利用 ViT 的策略,逐步将 Transformer 从 Tiny(6 M)、Small(23M)、Base(88 M)、Large(307 M)扩展到巨大(1B),并将 Uni3D 的 Transformer 替换为不同大小的 ViT,作为 Uni3D 在不同模型规模下的扩展版本。 我们在 2D 视觉领域对 ViT 的扩展进行了全面的探索,充分证明了我们的扩展策略的有效性和效率。 如图 2 和表 5 所示,我们观察到在灵活统一的框架下,随着模型规模的扩展,性能持续改善。
在统一的扩展策略下,我们在一个包含近百万个 3D 形状的大规模数据集上,以及成对的 1000 万张图像和 7000 万段文本,使用多模态对齐学习目标训练了拥有十亿个参数的最大 3D 表征模型。 我们首次展示了一个十亿规模的 3D 表征模型,该模型可以很好地迁移到各种下游任务和场景中。
初始化 Uni3D。 另一个阻碍先前工作扩展 3D 主干网络的挑战是,更大的模型规模会导致过拟合,并难以收敛。 一个简单的解决方案是使用特定的 3D 预训练任务(例如 PointBERT (Yu et al., 2022)、OcCo (Wang et al., 2021))对每个 3D 主干网络进行预训练,并将预训练参数作为初始化。 然而,这会导致昂贵的训练成本,而用于预训练的 3D 数据规模相对有限,这使得为稳定跨模态对比学习建立一个鲁棒的初始化具有挑战性。
在 Uni3D 中,我们直接利用结构上等同于 ViT 的普通 Transformer 作为 3D 主干网络,这为引入预训练先验提供了一个新的视角。 具体来说,我们可以自然地采用其他模态中已预训练的大型模型来初始化 Uni3D,这些模型与我们的模型共享相同的普通 Transformer,例如 2D 预训练模型 DINO (Caron et al., 2021)、EVA (Fang et al., 2022)、EVA-02 (Fang et al., 2023) 和跨模态模型 CLIP (Radford et al., 2021)、EVA-CLIP (Sun et al., 2023) 等。 这些预训练模型是在包含数十亿张图像和文本的数据集上训练的,它们已经学习了 Transformer 的丰富的潜在表征能力,并且有可能增强和稳定大规模 3D 表征的学习。 Uni3D 不限于使用特定的预训练模型进行初始化,我们可以灵活地利用任何现成的基于 Transformer 的预训练模型,无论其模态如何,以提升性能并探索跨模态预训练(有关详细分析,请参考第 7 节)。
3.2 多模态对齐
我们训练 Uni3D 来学习语言、图像和点云之间的多模态对齐,遵循与 ULIP (Xue et al., 2023a) 和 OpenShape (Liu et al., 2023) 相似的范式。
数据集. 为了保持实验设置与其他方法一致,以便进行公平比较,我们采用 OpenShape 提供的集成 3D 数据集进行训练,该数据集包含四个 3D 数据集,即 Objaverse (Deitke 等人,2023b)、ShapeNet (Chang 等人,2015)、3D-FUTURE (Fu 等人,2021) 和 ABO (Collins 等人,2022)。 我们从网格表面采样 10,000 个点,并带有颜色,从不同视角渲染 10 个彩色图像,均匀覆盖整个形状。 点云-文本-图像三元组的生成方式与 OpenShape 相同。
目标. 多模态对齐的示意图如图 3 所示。 我们使用预训练的 2D ViT 模型初始化 Uni3D 点编码器 ,并从 CLIP 模型中获得文本编码器 和图像编码器 。 我们训练 以学习 3D 表示,方法是将它们与 CLIP 模型的学习良好的 2D/语言表示进行对齐,并提取跨模态知识。 和 都被冻结,因为它们经过了良好优化,并且只有 在训练期间可学习。 给定一批 三元组 ,其中 、 、 代表从同一 3D 形状获得的点云及其相应的图像和文本。 我们首先获得采样三元组的归一化特征,如 所示。 然后,对比损失被表述为:
| (1) |
其中 是一个可学习的温度。 训练目标是最小化三元组对比损失。
图像-文本对齐目标。 我们进一步证明 Uni3D 不限于特定的 CLIP 教师,我们可以灵活地将其切换到具有不同模型规模的现成的 SoTA CLIP 模型,以实现更好的性能。 例如,我们可以简单地将 CLIP 源从 OpenAI-CLIP (Radford 等人,2021)、OpenCLIP (Cherti 等人,2023) 更改为最佳的 EVA-CLIP (Sun 等人,2023),并可能在将来更改为更好的 CLIP。 我们也可以直接将 CLIP 教师从 EVA-CLIP-B (1.5 亿) 扩展到 EVA-CLIP-E (50 亿)。 这证明了 Uni3D 的灵活性和可扩展性,并展示了 Uni3D 随着 CLIP 模型进步而进步的潜力。
| Method | training shape | Objaverse-LVIS | ModelNet40 | ScanObjectNN | ||||||
| source | Top1 | Top3 | Top5 | Top1 | Top3 | Top5 | Top1 | Top3 | Top5 | |
| ULIP-PointBERT | Ensembled | 21.4 | 38.1 | 46.0 | 71.4 | 84.4 | 89.2 | 46.0 | 66.1 | 76.4 |
| OpenShape-SparseConv | (no LVIS) | 37.0 | 58.4 | 66.9 | 82.6 | 95.0 | 97.5 | 54.9 | 76.8 | 87.0 |
| OpenShape-PointBERT | 39.1 | 60.8 | 68.9 | 85.3 | 96.2 | 97.4 | 47.2 | 72.4 | 84.7 | |
| Uni3D | 47.2 | 68.8 | 76.1 | 86.8 | 97.3 | 98.4 | 66.5 | 83.5 | 90.1 | |
| ULIP-PointBERT | Ensembled | 26.8 | 44.8 | 52.6 | 75.1 | 88.1 | 93.2 | 51.6 | 72.5 | 82.3 |
| OpenShape-SparseConv | 43.4 | 64.8 | 72.4 | 83.4 | 95.6 | 97.8 | 56.7 | 78.9 | 88.6 | |
| OpenShape-PointBERT | 46.8 | 69.1 | 77.0 | 84.4 | 96.5 | 98.0 | 52.2 | 79.7 | 88.7 | |
| Uni3D | 53.5 | 75.5 | 82.0 | 87.3 | 98.1 | 99.2 | 63.9 | 84.9 | 91.7 | |
| Uni3D | 55.3 | 76.7 | 82.9 | 88.2 | 98.4 | 99.3 | 65.3 | 85.5 | 92.7 | |
4 实验
4.1 零样本形状分类
我们首先在零样本形状分类任务下评估 Uni3D。 我们在三个基准上进行了实验:ModelNet (Wu 等人,2015)、ScanObjNN (Uy 等人,2019) 和 Objaverse-LVIS (Deitke 等人,2023b)。 ModelNet 和 ScanObjNN 是广泛使用的数据集,分别包含 15 个和 40 个常见类别。 Objaverse-LVIS 基准是 Objaverse 的一个已标注和清理的子集,包含 1,156 个 LVIS 类别的 46,832 个形状。 我们遵循 OpenShape (Liu 等人,2023) 的设置进行评估。 对于 Objaverse-LVIS,我们使用 10,000 个采样的彩色点作为输入。 对于 ModelNet40,我们使用 10,000 个不带颜色的采样点作为输入。 对于 ScanObjNN,输入是来自 OBJ_ONLY 版本的 2,048 个不带颜色的采样点。 我们将 Uni3D 与之前零样本形状分类任务中的最先进方法进行比较,例如 PointCLIP (Zhang 等人,2022)、PointCLIP V2 (Zhu 等人,2022)、ULIP (Xue 等人,2023a) 和 OpenShape (Liu 等人,2023)。 注意,PointCLIP 和 PointCLIP V2 将点云直接投影到图像中,并利用 2D CLIP 进行分类,而其他方法采用类似的方案来训练一个本地的 3D 主干,用于将 3D 表示与预训练 CLIP 生成的图像和文本表示对齐。 我们遵循 OpenShape (Liu 等人,2023) 报告两种不同训练设置下的性能。 “Ensembled” 表示主干在所有四个数据集上进行训练,与 OpenShape 相同,“Ensembled (no LVIS)” 进一步排除了 Objaverse-LVIS 子集中的形状。 我们证明,即使 LVIS 形状包含在训练形状中,即“Ensembled”数据集,它们的测试时类别标签可能也不包含在训练文本中。 定量比较如 Tab. 1 所示,其中 Uni3D 在不同设置下显著优于之前最先进的方法。
4.2 少样本线性探测
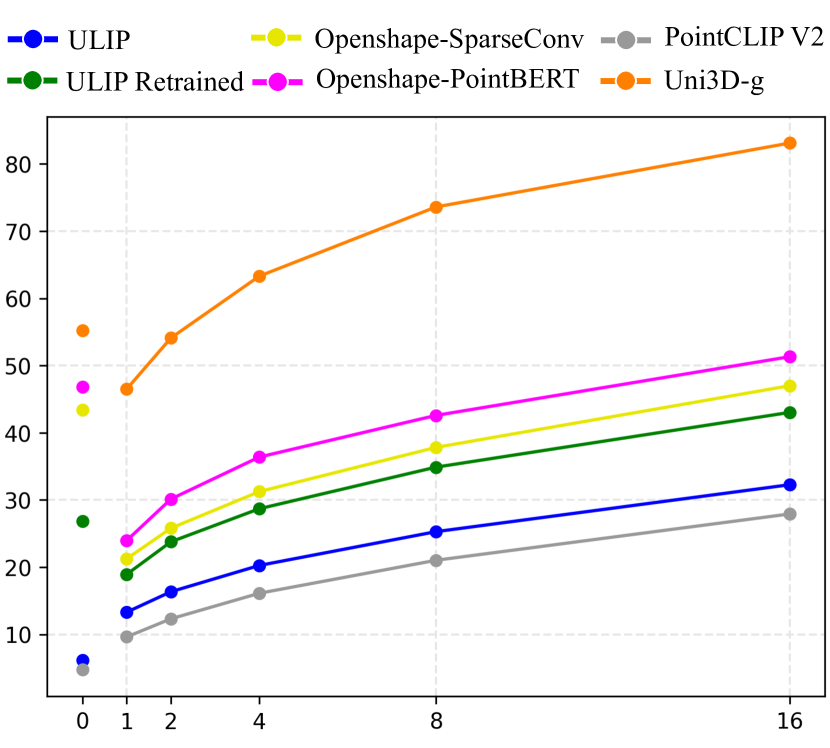
线性探测是一种广泛用于评估模型学习表示的常用方法。 为了评估 Uni3D 的线性探测能力,我们遵循 OpenShape (Liu 等人,2023) 的常用设置,冻结 Uni3D 的参数,并在少样本类别标签上仅训练一个线性分类器。 我们在困难的 Objaverse-LVIS 数据集上进行少样本线性探测,每个类别的标记训练样本数量从 1、2、4、8 到 16 不等。 图 4 总结了 Uni3D 的性能,与 OpenShape (Liu 等人,2023)(PointBERT 主干和 SparseConv 主干)、ULIP (Xue 等人,2023a)(官方发布和在大型集成数据集上重新训练的版本)和 PointCLIP V2 (Zhu 等人,2022) 进行比较。 在所有少样本设置下,Uni3D 的性能显著优于所有其他方法,优势明显。
4.3 开放世界理解
为了评估 Uni3D 在真实世界形状和场景的三维理解方面的能力,我们遵循 CLIP2 (Zeng et al., 2023) 在 ScanNet (Dai et al., 2017) 上进行实验,以探索 Uni3D 在真实世界场景下的零样本识别性能。 注意,所有方法都提供了地面实况实例分割,目标是以零样本的方式识别场景中每个实例的类别。 ScanNet (Dai et al., 2017) 是一个流行的真实扫描三维数据集,包含 1.5K 个真实世界场景的重建网格。 我们采用与 CLIP2 相同的设置来划分类别并在 ScanNet 的测试集上评估结果。
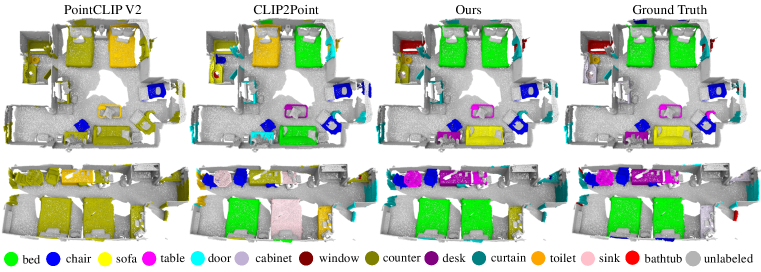
我们将我们提出的 Uni3D 与最先进的方法 PointCLIP (Zhang et al., 2022)、PointCLIP V2 (Zhu et al., 2022)、CLIP2Point (Huang et al., 2022a) 和 CLIP2 (Zeng et al., 2023) 进行比较。 定量比较如 Tab. 2 所示。 “PointCLIP w/TP” 和 “CLIP2Point w/TP” 表示使用 CLIP2 提供的真实世界数据训练 PointCLIP 和 CLIP2Point。 注意,“PointCLIP w/TP”、"CLIP2Point w/TP" 和 CLIP2 是在 1.6M 组真实世界点云-图像-文本样本上训练的,而 Uni3D 仅在可用的合成数据上训练。 尽管如此,Uni3D 在所有先前方法中取得了最佳性能。 结果表明 Uni3D 能够在没有真实世界数据训练的情况下执行真实世界识别和理解。 原因是 Uni3D 从 CLIP 模型中提取了一些对真实世界的感知,而 CLIP 模型是在大规模的真实世界图像和文本上训练的。 此外,通过扩展模型尺寸,Uni3D 获得了更大的表示带宽,从而在困难的真实世界场景下取得了优异的性能。 定性比较如 Fig. 5 所示,其中 Uni3D 比 PointCLIP V2 和 CLIP2Point 生成了更准确的零样本识别结果。 我们没有与 CLIP2 进行视觉比较,因为它的代码和模型尚未公开。
| Method | Avg. | Bed | Cab | Chair | Sofa | Tabl | Door | Wind | Bksf | Pic | Cntr | Desk | Curt | Fridg | Bath | Showr | Toil | Sink |
| PointCLIP | 6.3 | 0.0 | 0.0 | 0.0 | 0.0 | 0.7 | 0.0 | 0.0 | 91.8 | 0.0 | 0.0 | 0.0 | 15.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| PointCLIP V2 | 11.0 | 0.0 | 0.0 | 23.8 | 0.0 | 0.0 | 0.0 | 0.0 | 7.8 | 0.0 | 90.7 | 0.0 | 0.0 | 0.0 | 0.0 | 64.4 | 0.0 | 0.0 |
| CLIP2Point | 24.9 | 20.8 | 0.0 | 85.1 | 43.3 | 26.5 | 69.9 | 0.0 | 20.9 | 1.7 | 31.7 | 27.0 | 0.0 | 1.6 | 46.5 | 0.0 | 22.4 | 25.6 |
| PointCLIP w/ TP. | 26.1 | 0.0 | 55.7 | 72.8 | 5.0 | 5.1 | 1.7 | 0.0 | 77.2 | 0.0 | 0.0 | 51.7 | 0.3 | 0.0 | 0.0 | 40.3 | 85.3 | 49.2 |
| CLIP2Point w/ TP. | 35.2 | 11.8 | 3.0 | 45.1 | 27.6 | 10.5 | 61.5 | 2.6 | 71.9 | 0.3 | 33.6 | 29.9 | 4.7 | 11.5 | 72.2 | 92.4 | 86.1 | 34.0 |
| CLIP2 | 38.5 | 32.6 | 67.2 | 69.3 | 42.3 | 18.3 | 19.1 | 4.0 | 62.6 | 1.4 | 12.7 | 52.8 | 40.1 | 9.1 | 59.7 | 41.0 | 71.0 | 45.5 |
| Uni3D | 45.8 | 58.5 | 3.7 | 78.8 | 83.7 | 54.9 | 31.3 | 39.4 | 70.1 | 35.1 | 1.9 | 27.3 | 94.2 | 13.8 | 38.7 | 10.7 | 88.1 | 47.6 |
4.4 开放词汇表 / 少样本部件分割
一些先前的研究 (Rao 等人,2022;Yang 等人,2022) 表明,将从图像文本对比学习中获得的知识(即 CLIP)迁移到二维密集预测任务(例如分割和检测)中,可以显着提高性能。 然而,将这种知识迁移到三维密集预测任务中却鲜有研究。 我们提出了一种利用 Uni3D 进行三维密集预测的新方法,并通过部件分割实验验证了其有效性。 有关该方法的更多详细信息,请参阅附录的第 B 节。
| Method | Data | mIoUC | Data | mIoUC |
| PointNet | 10% train set | 72.7 | 20% train set | 73.5 |
|---|---|---|---|---|
| PointNet++ | 74.8 | 76.8 | ||
| PointCNN | 60.4 | 64.1 | ||
| SSCN | 60.2 | 65.2 | ||
| PointBERT | 76.4 | 79.6 | ||
| PointBERT | 1-shot | 66.2 | 2-shot | 71.9 |
| Uni3D | 75.9 | 78.2 |
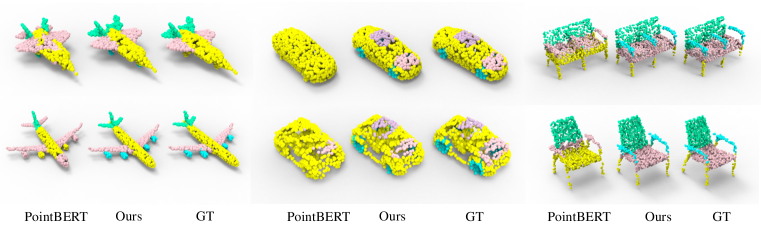
我们在 ShapeNetPart 数据集 (Yi 等人,2016) 上进行了部件分割实验。 表 3 中的结果表明,当仅用每个类别 1 或 2 个样本进行监督时,Uni3D 的性能比 PointBERT 高出 +13.3%/+9.8%。 此外,我们大幅增加了用于比较方法的训练样本数量,达到训练集的 10% 或 20%。 这些设置比 Uni3D 的单样本或双样本设置中的训练样本数量高出两个数量级。 即使在训练样本数量存在如此大的差异的情况下,Uni3D 在总体 mIoU 方面仍然取得了相当的性能。 附录B节提供了与 PointBERT 的视觉比较。
| Method | Seen Categories | Unseen Categories | |||||||||||||||||
| mIoUC | Car | Knife | Lamp | Moto | Pistol | Rocket | Guitar | Skate | Chair | Cap | Plane | Bag | Earph | Laptop | Mug | Table | mIoUC | mIoUC-ALL | |
| Uni3D | 76.0 | 74.1 | 86.3 | 85.7 | 62.7 | 77.8 | 41.7 | 89.3 | 71.0 | 89.9 | 81.8 | 23.4 | 57.1 | 57.1 | 26.2 | 50.0 | 54.4 | 44.7 | 64.3 |
“开放词汇部分分割” 量化了 Uni3D 在多模态对比预训练期间学习局部点云细粒度语义信息的能力。 我们将 ShapeNetPart 数据集划分为两个子集:“已见类别” 和 “未见类别”。 在 “已见类别” 子集中,地面真实部分标签的文本作为 Uni3D 学习部分语义的训练样本,而在 “未见类别” 子集中,地面真实部分标签的文本在训练期间是看不见的,仅用于测试。 Tab.4 中 Uni3D 的优异性能证明了它识别细粒度 3D 模式的能力,即使对于在 “已见类别” 中未遇到的部分级语义概念也是如此。 这些结果有力地证实了 Uni3D 将学习的模式从一组封闭的 3D 部件转移到开放词汇部件的能力,利用从预训练 CLIP 模型中提取的丰富的开放世界知识。 我们相信 Uni3D 为实现开放词汇 3D 概念的细粒度跨类别分割开辟了道路,方法是利用数量有限的类别无关分割示例。
4.5 点云绘画

我们建议通过探索 Uni3D 中学习的 3D 语义模式,利用训练好的 Uni3D 来绘制点云。 具体来说,给定一个初始点云和一个输入提示,我们通过最大化 Uni3D 提取的点云特征与使用 CLIP 文本编码器提取的提示特征之间的余弦相似度来优化点云的外观,即点云的 RGB 通道。 点云的绘制可以在单个 V100 GPU 上在一分钟内完成。 我们在图 6 中展示了绘画,其中 Uni3D 通过从提示中揭示复杂的语义成功地优化了点云。 结果表明,Uni3D 通过对比式预训练学习了大量和多样的 3D 模式。
4.6 跨模态检索
利用 Uni3D 学习的多模态表示,我们可以自然地从图像或文本中检索 3D 形状。 具体来说,我们通过计算查询图像或查询文本提示的嵌入与 3D 形状的嵌入之间的余弦相似度,从大型 3D 数据集 (Deitke et al., 2023b) 中检索 3D 形状。 然后我们执行 kNN 以获得与查询最相似的 3D 形状。 在图 7 中,我们展示了 Uni3D 成功地从真实世界图像中检索 3D 形状。 请注意,用于训练的图像只是渲染图,并且训练图像和真实世界图像之间存在很大差距。 我们还将两张图像作为输入,并通过计算两张图像的嵌入平均值与 3D 形状的嵌入之间的余弦相似度,检索与两张图像都相似的形状。 这些有趣的结果表明,Uni3D 学习了一个多样的 3D 表示,能够感知多个 2D 信号。 我们进一步展示了利用 Uni3D 从图 7 中的输入文本中检索 3D 形状的结果。 更多可视化结果在附录的第 C 节中提供。

4.7 消融研究
然后,我们进行了消融研究,以证明 Uni3D 中每个设计的有效性。 默认设置是使用 ViT-Base 作为主干,并使用 EVA (Fang 等人,2022) 初始化,默认 CLIP 教师是 EVA-CLIP-E (Sun 等人,2023)。 默认数据设置是“Ensembled(无 LVIS)”。 在消融研究期间,我们保留了默认实验设置,除了下面每个消融实验中描述的修改部分。
扩大模型尺寸。 我们首先在 Tab. 5 中探讨了扩大 Uni3D 模型尺寸的有效性。 由于我们利用结构上等效于 ViT 的统一 vanilla transformer 作为基础的 3D 表示模型,因此我们可以简单地使用经过充分研究的统一 2D/NLP 扩展策略来扩大 Uni3D 的规模。 具体来说,我们遵循普通 ViT (Dosovitskiy 等人,2020) 的扩展原则,将参数从 6 M(Tiny)、23 M(Small)、88 M(Base)、307 M(Large)增加到 1 B(Giant)。 模型架构上的超参数在 Tab. 5 中详细介绍。 在不同模型规模下的性能表明,扩大 Uni3D 的模型尺寸可以显著提高 3D 表示。
| Model | Depth | Width | Heads | #Params | MNet40⋄ | O-LVIS⋄ | MNet40† | O-LVIS† |
| Uni3D-Ti | 12 | 192 | 3 | 6.2M | 85.8 | 43.5 | 85.9 | 46.5 |
| Uni3D-S | 12 | 384 | 6 | 22.6M | 86.0 | 44.8 | 86.0 | 50.6 |
| Uni3D-B | 12 | 768 | 12 | 88.4M | 86.2 | 45.8 | 86.5 | 51.6 |
| Uni3D-L | 24 | 1024 | 16 | 306.7M | 86.6 | 46.2 | 86.6 | 53.2 |
| Uni3D-g | 40 | 1408 | 16 | 1016.5M | 86.8 | 47.2 | 88.2 | 55.3 |
切换/扩大 CLIP 教师。 我们证明 Uni3D 是一个灵活的框架,我们可以在其中将现成的 SoTA CLIP 模型作为教师进行切换。 为此,我们研究了 Uni3D 在不同规模下使用不同 CLIP 教师时的性能。 具体来说,我们评估了各种 CLIP 模型(例如 OpenAI-CLIP (Radford 等人,2021)、OpenCLIP (Cherti 等人,2023) 和 EVA-CLIP (Sun 等人,2023)),并探索了大型 CLIP 模型(例如 OpenCLIP-bigG、EVA-CLIP-E)。 定量比较如 Tab. 7 所示,其中最大的 CLIP 模型 EVA-CLIP-E 实现了最佳性能。 结果表明,CLIP 教师的能力和模型规模是 Uni3D 提高性能的关键因素。 此外,它表明 Uni3D 能够随着 CLIP 模型的进步而进步,方法是切换最新的 CLIP 教师。
| CLIP variant | Pretrain data | #Params | O-LVIS |
| EVA-CLIP-B/16 | Merged-2B | 150M | 42.3 |
| OpenAI-CLIP-B/16 | WIT-400M | 150M | 42.7 |
| OpenCLIP-B/16 | LAION-2B | 150M | 43.4 |
| OpenCLIP-bigG/14 | LAION-2B | 2.5B | 44.5 |
| EVA-CLIP-E/14+ | LAION-2B | 5.0B | 45.8 |
| Init variant | O-LVIS |
| None | 44.8 |
| DINO | 45.0 |
| EVA-CLIP | 45.2 |
| EVA | 45.8 |
| EVA + Freeze ViT | 15.7 |
初始化 Transformer。 我们进一步进行了消融研究,以探索使用 2D 预训练或多模态大型模型初始化 Uni3D 的有效性。 在 Tab. 7 中,我们报告了从头开始训练 Uni3D(无)以及使用现成的 2D 预训练模型 DINO (Caron 等人,2021) / EVA (Fang 等人,2022) 和 SoTA CLIP 模型 EVA-CLIP (Sun 等人,2023) 初始化 Uni3D 的性能。 使用 SoTA 2D 预训练模型 EVA (Fang 等人,2022) 初始化 Uni3D 实现了最佳性能。 我们还证明,利用来自 2D 预训练 ViT 模型的冻结参数可能无法提供强大的 3D 理解,而无需微调,如 Tab. 7 的“EVA + Freeze ViT”所示。 有关初始化 Uni3D 的更多分析,请参阅附录的 Sec. D。
5 结论
我们提出了Uni3D,一个将3D表示模型扩展到十亿参数的统一框架。 我们直接利用与ViT结构上等效的统一vanilla transformer作为模型,这使我们能够利用经过充分研究的统一2D/NLP扩展策略简单地扩展Uni3D。 此外,Uni3D可以利用丰富的2D预训练模型作为初始化,以及图像文本对齐模型作为目标,释放2D模型和策略在3D世界的巨大潜力。 我们在包含约一百万个3D点云、一千万张图像和七千万文本的大型数据集上训练Uni3D,通过将3D点云特征与图像文本对齐特征对齐来探索强大的3D表示。 Uni3D在各种3D理解任务中取得了最先进的性能,包括零样本和少样本分类、开放世界理解、部分分割等。我们相信Uni3D可以作为一个3D基础模型,为3D社区的许多应用提供支持。
参考文献
- Bao et al. (2021) Hangbo Bao, Li Dong, Songhao Piao, and Furu Wei. Beit: Bert pre-training of image transformers. In International Conference on Learning Representations, 2021.
- Brown et al. (2020) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- Caron et al. (2021) Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. In Proceedings of the IEEE/CVF international conference on computer vision, pp. 9650–9660, 2021.
- Chang et al. (2015) Angel X Chang, Thomas Funkhouser, Leonidas Guibas, Pat Hanrahan, Qixing Huang, Zimo Li, Silvio Savarese, Manolis Savva, Shuran Song, Hao Su, et al. Shapenet: An information-rich 3d model repository. arXiv preprint arXiv:1512.03012, 2015.
- Cherti et al. (2023) Mehdi Cherti, Romain Beaumont, Ross Wightman, Mitchell Wortsman, Gabriel Ilharco, Cade Gordon, Christoph Schuhmann, Ludwig Schmidt, and Jenia Jitsev. Reproducible scaling laws for contrastive language-image learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 2818–2829, 2023.
- Collins et al. (2022) Jasmine Collins, Shubham Goel, Kenan Deng, Achleshwar Luthra, Leon Xu, Erhan Gundogdu, Xi Zhang, Tomas F Yago Vicente, Thomas Dideriksen, Himanshu Arora, et al. Abo: Dataset and benchmarks for real-world 3d object understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 21126–21136, 2022.
- Dai et al. (2017) Angela Dai, Angel X Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 5828–5839, 2017.
- Deitke et al. (2023a) Matt Deitke, Ruoshi Liu, Matthew Wallingford, Huong Ngo, Oscar Michel, Aditya Kusupati, Alan Fan, Christian Laforte, Vikram Voleti, Samir Yitzhak Gadre, et al. Objaverse-xl: A universe of 10m+ 3d objects. arXiv preprint arXiv:2307.05663, 2023a.
- Deitke et al. (2023b) Matt Deitke, Dustin Schwenk, Jordi Salvador, Luca Weihs, Oscar Michel, Eli VanderBilt, Ludwig Schmidt, Kiana Ehsani, Aniruddha Kembhavi, and Ali Farhadi. Objaverse: A universe of annotated 3d objects. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 13142–13153, 2023b.
- Dosovitskiy et al. (2020) Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020.
- Fang et al. (2022) Yuxin Fang, Wen Wang, Binhui Xie, Quan Sun, Ledell Wu, Xinggang Wang, Tiejun Huang, Xinlong Wang, and Yue Cao. Eva: Exploring the limits of masked visual representation learning at scale. arXiv preprint arXiv:2211.07636, 2022.
- Fang et al. (2023) Yuxin Fang, Quan Sun, Xinggang Wang, Tiejun Huang, Xinlong Wang, and Yue Cao. Eva-02: A visual representation for neon genesis. arXiv preprint arXiv:2303.11331, 2023.
- Fu et al. (2021) Huan Fu, Rongfei Jia, Lin Gao, Mingming Gong, Binqiang Zhao, Steve Maybank, and Dacheng Tao. 3d-future: 3d furniture shape with texture. International Journal of Computer Vision, 129:3313–3337, 2021.
- Gregoromichelaki et al. (2022) Eleni Gregoromichelaki, Arash Eshghi, Christine Howes, Gregory J Mills, Ruth Kempson, Julian Hough, Patrick GT Healey, Matthew Purver, et al. Language and cognition as distributed process interactions. In Proceedings of the 26th Workshop on the Semantics and Pragmatics of Dialogue, pp. 160–171, 2022.
- He et al. (2022) Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 16000–16009, 2022.
- Hegde et al. (2023) Deepti Hegde, Jeya Maria Jose Valanarasu, and Vishal M Patel. Clip goes 3d: Leveraging prompt tuning for language grounded 3d recognition. arXiv preprint arXiv:2303.11313, 2023.
- Huang et al. (2016) Gao Huang, Yu Sun, Zhuang Liu, Daniel Sedra, and Kilian Q Weinberger. Deep networks with stochastic depth. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part IV 14, pp. 646–661. Springer, 2016.
- Huang et al. (2022a) Tianyu Huang, Bowen Dong, Yunhan Yang, Xiaoshui Huang, Rynson WH Lau, Wanli Ouyang, and Wangmeng Zuo. Clip2point: Transfer clip to point cloud classification with image-depth pre-training. arXiv preprint arXiv:2210.01055, 2022a.
- Huang et al. (2022b) Xiaoshui Huang, Sheng Li, Wentao Qu, Tong He, Yifan Zuo, and Wanli Ouyang. Frozen clip model is efficient point cloud backbone. arXiv preprint arXiv:2212.04098, 2022b.
- Jia et al. (2021) Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representation learning with noisy text supervision. In International conference on machine learning, pp. 4904–4916. PMLR, 2021.
- Kingma & Ba (2014) Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- Lei et al. (2023) Weixian Lei, Yixiao Ge, Jianfeng Zhang, Dylan Sun, Kun Yi, Ying Shan, and Mike Zheng Shou. Vit-lens: Towards omni-modal representations. arXiv preprint arXiv:2308.10185, 2023.
- Li et al. (2022) Liunian Harold Li, Pengchuan Zhang, Haotian Zhang, Jianwei Yang, Chunyuan Li, Yiwu Zhong, Lijuan Wang, Lu Yuan, Lei Zhang, Jenq-Neng Hwang, et al. Grounded language-image pre-training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10965–10975, 2022.
- Li et al. (2023) Yanghao Li, Haoqi Fan, Ronghang Hu, Christoph Feichtenhofer, and Kaiming He. Scaling language-image pre-training via masking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 23390–23400, 2023.
- Liu et al. (2023) Minghua Liu, Ruoxi Shi, Kaiming Kuang, Yinhao Zhu, Xuanlin Li, Shizhong Han, Hong Cai, Fatih Porikli, and Hao Su. Openshape: Scaling up 3d shape representation towards open-world understanding. arXiv preprint arXiv:2305.10764, 2023.
- Liu et al. (2019) Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692, 2019.
- Ma et al. (2021) Xu Ma, Can Qin, Haoxuan You, Haoxi Ran, and Yun Fu. Rethinking network design and local geometry in point cloud: A simple residual mlp framework. In International Conference on Learning Representations, 2021.
- Qi et al. (2017a) Charles R Qi, Hao Su, Kaichun Mo, and Leonidas J Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 652–660, 2017a.
- Qi et al. (2017b) Charles Ruizhongtai Qi, Li Yi, Hao Su, and Leonidas J Guibas. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. Advances in neural information processing systems, 30, 2017b.
- Qi et al. (2023) Zekun Qi, Runpei Dong, Guofan Fan, Zheng Ge, Xiangyu Zhang, Kaisheng Ma, and Li Yi. Contrast with reconstruct: Contrastive 3d representation learning guided by generative pretraining. arXiv preprint arXiv:2302.02318, 2023.
- Radford et al. (2021) Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pp. 8748–8763. PMLR, 2021.
- Raffel et al. (2020) Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. The Journal of Machine Learning Research, 21(1):5485–5551, 2020.
- Rajbhandari et al. (2020) Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. Zero: Memory optimizations toward training trillion parameter models. In SC20: International Conference for High Performance Computing, Networking, Storage and Analysis, pp. 1–16. IEEE, 2020.
- Ramesh et al. (2022) Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125, 1(2):3, 2022.
- Rao et al. (2022) Yongming Rao, Wenliang Zhao, Guangyi Chen, Yansong Tang, Zheng Zhu, Guan Huang, Jie Zhou, and Jiwen Lu. Denseclip: Language-guided dense prediction with context-aware prompting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 18082–18091, 2022.
- Rasley et al. (2020) Jeff Rasley, Samyam Rajbhandari, Olatunji Ruwase, and Yuxiong He. Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pp. 3505–3506, 2020.
- Sun et al. (2023) Quan Sun, Yuxin Fang, Ledell Wu, Xinlong Wang, and Yue Cao. Eva-clip: Improved training techniques for clip at scale. arXiv preprint arXiv:2303.15389, 2023.
- Uy et al. (2019) Mikaela Angelina Uy, Quang-Hieu Pham, Binh-Son Hua, Thanh Nguyen, and Sai-Kit Yeung. Revisiting point cloud classification: A new benchmark dataset and classification model on real-world data. In Proceedings of the IEEE/CVF international conference on computer vision, pp. 1588–1597, 2019.
- Wang et al. (2021) Hanchen Wang, Qi Liu, Xiangyu Yue, Joan Lasenby, and Matt J Kusner. Unsupervised point cloud pre-training via occlusion completion. In Proceedings of the IEEE/CVF international conference on computer vision, pp. 9782–9792, 2021.
- Wang et al. (2019) Yue Wang, Yongbin Sun, Ziwei Liu, Sanjay E Sarma, Michael M Bronstein, and Justin M Solomon. Dynamic graph cnn for learning on point clouds. ACM Transactions on Graphics (tog), 38(5):1–12, 2019.
- Wu et al. (2015) Zhirong Wu, Shuran Song, Aditya Khosla, Fisher Yu, Linguang Zhang, Xiaoou Tang, and Jianxiong Xiao. 3d shapenets: A deep representation for volumetric shapes. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 1912–1920, 2015.
- Xue et al. (2023a) Le Xue, Mingfei Gao, Chen Xing, Roberto Martín-Martín, Jiajun Wu, Caiming Xiong, Ran Xu, Juan Carlos Niebles, and Silvio Savarese. Ulip: Learning a unified representation of language, images, and point clouds for 3d understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023a.
- Xue et al. (2023b) Le Xue, Ning Yu, Shu Zhang, Junnan Li, Roberto Martín-Martín, Jiajun Wu, Caiming Xiong, Ran Xu, Juan Carlos Niebles, and Silvio Savarese. Ulip-2: Towards scalable multimodal pre-training for 3d understanding. arXiv preprint arXiv:2305.08275, 2023b.
- Yang et al. (2022) Zhao Yang, Jiaqi Wang, Yansong Tang, Kai Chen, Hengshuang Zhao, and Philip HS Torr. Lavt: Language-aware vision transformer for referring image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 18155–18165, 2022.
- Yi et al. (2016) Li Yi, Vladimir G Kim, Duygu Ceylan, I-Chao Shen, Mengyan Yan, Hao Su, Cewu Lu, Qixing Huang, Alla Sheffer, and Leonidas Guibas. A scalable active framework for region annotation in 3d shape collections. ACM Transactions on Graphics (ToG), 35(6):1–12, 2016.
- Yin et al. (2021) Tianwei Yin, Xingyi Zhou, and Philipp Krahenbuhl. Center-based 3d object detection and tracking. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 11784–11793, 2021.
- Yu et al. (2021) Xumin Yu, Yongming Rao, Ziyi Wang, Zuyan Liu, Jiwen Lu, and Jie Zhou. Pointr: Diverse point cloud completion with geometry-aware transformers. In Proceedings of the IEEE/CVF international conference on computer vision, pp. 12498–12507, 2021.
- Yu et al. (2022) Xumin Yu, Lulu Tang, Yongming Rao, Tiejun Huang, Jie Zhou, and Jiwen Lu. Point-bert: Pre-training 3d point cloud transformers with masked point modeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 19313–19322, 2022.
- Zeng et al. (2023) Yihan Zeng, Chenhan Jiang, Jiageng Mao, Jianhua Han, Chaoqiang Ye, Qingqiu Huang, Dit-Yan Yeung, Zhen Yang, Xiaodan Liang, and Hang Xu. Clip2: Contrastive language-image-point pretraining from real-world point cloud data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 15244–15253, 2023.
- Zhang et al. (2022) Renrui Zhang, Ziyu Guo, Wei Zhang, Kunchang Li, Xupeng Miao, Bin Cui, Yu Qiao, Peng Gao, and Hongsheng Li. Pointclip: Point cloud understanding by clip. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8552–8562, 2022.
- Zhang et al. (2023) Yiyuan Zhang, Kaixiong Gong, Kaipeng Zhang, Hongsheng Li, Yu Qiao, Wanli Ouyang, and Xiangyu Yue. Meta-transformer: A unified framework for multimodal learning. arXiv preprint arXiv:2307.10802, 2023.
- Zhao et al. (2021) Hengshuang Zhao, Li Jiang, Jiaya Jia, Philip HS Torr, and Vladlen Koltun. Point transformer. In Proceedings of the IEEE/CVF international conference on computer vision, pp. 16259–16268, 2021.
- Zhou et al. (2020) Hui Zhou, Xinge Zhu, Xiao Song, Yuexin Ma, Zhe Wang, Hongsheng Li, and Dahua Lin. Cylinder3d: An effective 3d framework for driving-scene lidar semantic segmentation. arXiv preprint arXiv:2008.01550, 2020.
- Zhu et al. (2022) Xiangyang Zhu, Renrui Zhang, Bowei He, Ziyao Zeng, Shanghang Zhang, and Peng Gao. Pointclip v2: Adapting clip for powerful 3d open-world learning. arXiv preprint arXiv:2211.11682, 2022.
附录 A 训练细节
在利用跨模态对比损失训练3D编码器时,我们冻结了CLIP文本和图像编码器。 我们采用Adam (Kingma & Ba, 2014) 优化器,峰值学习率为1e-3,根据余弦学习率调度逐步降低。 为了提高训练稳定性,我们采用了随机深度 (Huang et al., 2016) 正则化。 我们还利用FLIP (Li et al., 2023) 技术,在训练期间随机屏蔽50%的点符元,将时间复杂度降低一半。 我们预缓存所有形状的文本和图像CLIP嵌入,使我们能够将总批次大小增加到1152,并大大加快训练速度。 为了进一步改进训练过程,我们采用DeepSpeed (Rasley et al., 2020),使用ZeRO stage-1优化器和fp16精度,并采用动态损失缩放 (Rajbhandari et al., 2020)。 利用上述策略,我们最大的模型,即具有十亿参数的Uni3D-g,在约20小时内收敛,使用24个 NVIDIA-A100-SXM4-40GB GPU。
附录 B 部分分割细节
一些先前方法 (Rao 等人,2022 年;杨等人,2022 年) 已经证明,将从图像-文本对比学习(即 CLIP)中获得的知识转移到二维密集预测任务(例如分割和检测)中,可以显著提高性能。 但是,将这种知识转移到 3D 密集预测任务中,却鲜有研究。 我们试图找到一种方法,将 Uni3D 学习到的全局点云-文本对齐转换为局部点-文本对齐。 我们的目标是证明 Uni3D 中的对象级预训练足以学习详细的局部 3D 视觉概念。 具体来说,我们从 、 和 Uni3D 中 ViT 的最后一层中选择特征,分别表示为 、 和 。 借鉴 PointNet++ (Qi 等人,2017b),我们使用特征传播将组特征 、 和 上采样到点特征。 在训练过程中,我们冻结 Uni3D 主干网络,只优化特征传播层中的参数,并通过监督来对齐点特征和地面真值部件标签的文本特征,这些特征是由 CLIP 文本编码器提取的。 通过冻结学习到的 Uni3D 的参数,我们专注于有效地探索预训练的细粒度知识。
图 8 中的视觉比较表明,我们的方法可以在单样本部件分割设置中生成更准确的分割结果。
附录 C 跨模态检索的更多可视化


附录 D 关于初始化 Uni3D 的更多分析
如表 7所示,通过使用 SoTA 2D 预训练模型 EVA (Fang 等人,2022) 初始化 Uni3D,获得了最佳性能。 原因是 EVA 模型学习了强大且通用的表示,可以作为跨模态对比学习(例如, CLIP)的精细初始化,如 EVA (Fang 等人,2022)、EVA-02 (Fang 等人,2023) 和 EVA-CLIP (Sun 等人,2023) 中所证明的。
| Init variant | O-LVIS |
| None Init + only text | 20.7 |
| None Init + only image | 12.4 |
| EVA + only text | 40.1 |
| EVA + only image | 26.3 |
我们证明 Uni3D 也学习了一种类似于 CLIP 的跨模态表示,其中 EVA 学习到的通用模式在改进和稳定 Uni3D 训练中发挥着关键作用。 表 8 中所示的双模态对比学习结果进一步支持了这一分析。 具体来说,我们进行了实验,分别使用仅对比损失与 CLIP 图像特征 (+仅图像) 或 CLIP 文本特征 (+仅文本) 训练 Uni3D。 结果表明,在仅图像可用 (20.7 对 40.1) 或仅文本可用 (12.4 对 26.3) 的困难情况下,如果没有 EVA 初始化,优化将会崩溃。
附录 E 少样本结果
我们在困难的 Objaverse-LVIS 数据集上进行了少样本线性探测,每个类别的标记训练样本从 1、2、4、8 到 16 不等。 比较结果如图 4 所示。 我们还在表 9 中提供了详细的定量结果。
| Objaverse-LVIS | 1-shot | 2-shot | 4-shot | 8-shot | 16-shot |
| PointCLIP V2 | 9.6 | 12.3 | 16.1 | 21.0 | 27.9 |
| ULIP | 13.3 | 16.3 | 20.3 | 25.3 | 32.3 |
| ULIP Retrained | 18.9 | 23.8 | 28.7 | 34.9 | 43.0 |
| OpenShape-PointBERT | 24.0 | 30.1 | 36.4 | 42.6 | 51.3 |
| OpenShape-SparseConv | 21.2 | 25.8 | 31.2 | 37.8 | 47.0 |
| Uni3D | 46.5 | 54.1 | 63.3 | 73.6 | 83.1 |