用于抗噪声合成语音检测的双分支知识蒸馏
摘要
合成语音检测 (SSD) 方面的大多数研究都集中于提高标准无噪声数据集的性能。 然而,在实际情况中,通常存在噪声干扰,导致SSD系统的性能显着下降。 为了提高噪声鲁棒性,本文提出了一种双分支知识蒸馏合成语音检测(DKDSSD)方法。 具体来说,设计了干净教师分支和噪声学生分支的并行数据流,并提出了交互式融合模块和基于响应的师生范式,从数据分布和决策角度指导噪声数据的训练。 在噪声较大的学生分支中,首先引入语音增强进行去噪,旨在减少强噪声的干扰。 所提出的交互式融合结合了去噪特征和噪声特征,以减轻语音失真的影响并确保与干净分支的数据分布的一致性。 师生范式将学生的决策空间映射到教师的决策空间,使嘈杂的语音表现得与干净的语音类似。 此外,采用联合训练方法来优化两个分支以实现全局最优。 基于多个数据集的实验结果表明,所提出的方法在噪声环境中有效执行,并在跨数据集实验中保持其性能。 源代码可在 https://github.com/fchest/DKDSSD 获取。
索引术语:
合成语音检测、抗噪声、知识蒸馏、交互式融合。我简介
语音合成技术近年来发展迅速。 高质量的文本到语音合成[1]应用先进的深度学习框架,能够生成与真实语音几乎没有区别的合成语音。 这种合成语音不仅对生物识别验证系统[2]构成严重的安全威胁,而且还可能干扰互联网信息的传播。 因此,提高合成语音的检测能力对于保证网络安全至关重要。
许多研究侧重于提高清洁条件下的模型性能。 ASVspoof 系列挑战[3,4,5]贡献了高质量的无噪声数据集。 一些工作探索判别子带[6,7,8,9,10]来提高特征的表示能力。 此外,还有更多的工作[11,12,13]倾向于利用原始波形进行端到端检测,从而避免与手工制作的特征相关的信息损失。 最近的分类网络[14, 15]主要基于卷积神经网络,并表现出强大的特征建模能力。 尽管上述模型在标准数据集上表现出出色的性能,但它们通常不能推广到嘈杂的环境。
在早期的研究中,已经表明加性噪声[16]会显着降低在纯语音上训练的检测器的性能,因此有必要提高噪声鲁棒性。 最近,也有相关的比赛。 ADD 2022 [17]竞赛提出了低质量的假音频检测赛道,ASVspoof 2021 [18]逻辑访问(LA)赛道也引入了信道噪声干扰。 在处理噪声数据时,数据增强[19,20,21,22]是一种广泛采用的方法,可以有效提高模型的特征表示能力。 多条件训练[23]基于数据增强原理,利用噪声数据进行训练,提高模型对噪声的感知能力(如图1( A))。 此外,大规模语音预训练模型[24]已针对[25]中的SSD任务进行了微调。 对抗训练 [21] 通过在分类器中添加梯度反转层来寻求噪声不变特征。 然而,数据增强和预训练模型在泛化未知噪声类型方面表现出局限性,并且对抗性策略的使用可能会增加训练的不稳定性。
另一种方法是引入语音增强来学习噪声掩模[26, 27],从而增强声学条件。 如图1(b)所示,语音增强作为前端,与SSD模型[28]级联,或者两个模块联合训练[29, 30]。 然而,级联方法在实现全局优化方面面临挑战,联合方法中的语音增强可能会导致不可避免的语音失真问题。
为了提高噪声场景中的性能,本文提出了一种用于噪声鲁棒合成语音检测(DKDSSD)的双分支知识蒸馏方法。 我们提出了交互式融合和基于响应的师生范式,为噪声数据和干净数据设计并行流,并利用干净的教师模型来指导噪声数据的训练。 前端采用语音增强进行去噪,但由于估计误差,不可避免地会引入语音失真。 因此,增强功能必须仅保留对下游有用的信息。 所提出的交互式融合模块可以自适应地结合原始噪声特征和去噪特征的有益信息,以生成抗噪声特征。 知识蒸馏促进学生学习廉洁教师的分类能力。 它涉及将学生模型的决策空间映射到教师的决策空间。 此外,通过联合训练来优化整个结构,使师生网络达到全局最优。 这项工作的主要贡献总结如下:
-
提出了从干净场景到噪声场景的知识蒸馏,利用基于响应的知识蒸馏损失来约束噪声分支以学习干净教师的最终预测。
-
交互式融合被提出来实现去噪和噪声特征的通道交互,并在空间水平上融合它们,自适应地减少噪声干扰并平衡失真问题。
-
在多个模拟噪声数据集和官方数据集上进行了大量的实验,结果表明我们提出的方法优于级联系统或联合训练方法,同时保持了干净场景的性能。 在跨数据集实验中,所提出的方法表现出最好的泛化能力。
本文的其余部分结构如下。 第二部分介绍了相关工作,第三部分描述了所提出的 DKDSSD 方法,第四部分给出了实验设置的详细信息,第五部分讨论了实验结果并提供了可视化分析。 最后在第六节进行总结。
II 相关作品
II-A 抗噪性
在额外的噪声和混响条件下[16],在干净语音上训练的SSD存在泛化不足的问题。 在[31]中,应用了不同的前端特征和传统的语音增强技术,但并没有显着提高准确性。 语音增强[32, 33]旨在从噪声语音中恢复干净的频谱,可以用作前端[34,35,36]来预处理语音和减少强噪音的干扰。 然而,在之前的工作[37,38,39]中,我们发现语音增强会产生不可避免的估计误差,并且未知伪影[40]可能比噪声更有害。 为了缓解这种现象,研究[41]提出根据信噪比(SNR)的高低在增强信号和原始信号之间切换输入,以平衡噪声和失真。 一些工作[42,43,44,45,46]提出融合语音的两种状态以降低识别错误率。 在 SSD 任务中,原始语音包含合成方法产生的伪影。 因此,我们提出与原始语音的交互式融合,它可以在去噪的同时保留伪影,从而生成抗噪声的嵌入。
II-B 知识蒸馏
知识蒸馏[47]是压缩模型的流行方法。 它可以有效地从较大的教师模型 [9] 训练较小的学生模型,从而加快推理速度。 即使不需要压缩,知识蒸馏也可以通过从教师模型转移知识[48]来提高学生模型的性能。 应用知识蒸馏进行持续学习[49, 50]可以增强领域泛化能力,而不会影响源领域知识的保留。 此外,[51]提出了一种基于积分知识融合的方法来实现广义的合成语音检测。 最近的研究[52]将知识蒸馏应用于噪声环境中的反欺骗检测,将特征知识从干净的教师转移到噪声的学生。 在涉及音乐和白噪声的实验设置中,该模型在高信噪比场景下实现了显着的性能改进。 然而,实验结果表明,特征蒸馏在低信噪比场景下会失败,凸显了强制对齐特征空间的风险。 我们认为,当两个特征空间差异比较大时,选择基于响应的蒸馏更为合理。 所提出的交互式融合方法可以自适应地组合有用信息。 这保证了学生模型的输入数据的分布空间与教师模型的输入数据的分布空间保持一致。
III提出的方法
如图2所示,我们提出的方法包括师生模型的双分支。 教师分支使用干净的语音进行训练,而学生分支使用嘈杂的语音进行训练。 在学生分支前端,语音增强后与噪声语音进行自适应交互融合,旨在减轻噪声干扰,解决语音失真问题,便于噪声语音学习干净语音的初始数据分布。 在分类过程中,通过蒸馏损失将学生的输出logit映射到教师的logit,从而使学生获得教师模型的决策能力。 使用联合训练同时优化整个结构,使交互式融合模块能够生成更有利于SSD任务的特征。
III-A 语音增强
语音增强的目的是从噪声语音中去除噪声并估计目标干净语音,只能使用并行的干净和噪声数据进行训练。 我们选择一些数据集作为干净数据集,并向它们添加噪声以形成相应的模拟噪声数据集,详细信息可以在第四节中找到。 嘈杂的语音可以表示为:
| (1) |
其中、和分别表示源噪声、干净和噪声时域语音。 我们对源噪声语音进行短时傅立叶变换(STFT)以获得幅度谱作为输入特征,表示频率-时间仓的索引。 并以干净语音对应的幅度谱作为训练目标:
| (2) | |||
| (3) | |||
| (4) |
其中表示语音增强网络,表示输出增强幅度特征。 SE后,与带噪语音的相位谱相乘,并应用短时傅里叶逆变换(iSTFT)生成增强语音 在时域中。 使用均方误差(MSE)作为损失函数,定义如下:
| (5) |
去噪后,不受大部分噪声干扰。 然而,由于MSE损失往往强调幅度误差的最小化而忽略了语音信号的细节,因此通常会导致语音失真问题。 因此,我们提出了一个交互式融合模块来在去噪和保留信息之间进行权衡。
III-B 互动融合
语音增强的目的是恢复干净的幅度谱。 然而,由于训练目标不一致,避免失真问题通常具有挑战性。 直接对从降噪语音中提取的特征进行分类可能会对下游任务产生不利影响。 我们认为这是因为扭曲的语音缺乏精细的结构,这可能会破坏原始的伪影或引入新的未知伪影。 一些研究观察到工件[40]对下游任务具有特别负面的影响,而噪声的影响相对有限。 为了引导噪声分支学习与教师分支类似的数据分布,我们提出了交互式融合模块,它将原始噪声频谱与去噪频谱融合。 它是一个可训练的嵌入式模块,在训练过程中与分类器一起优化。
考虑到SSD更注重频率细节,通常需要高频分辨率的特征,我们使用较长的窗长从生成的时域特征中重新提取对数幅度谱特征由SE模块。 根据低频频段更鲁棒的特性,直接对对数幅度谱(LMS)特征的频域进行切片并取前半部分,得到低频特征:
| (6) |
为了捕获更多的光谱信息和局部特征,并与教师分支的特征保持一致,交互式融合分为两个部分:通道交互和空间融合。 我们对从源语音和中提取的LMS特征进行卷积和池化,生成多通道频率-时间特征和。 这两个功能都扩展到16通道功能,最初需要跨所有通道的信息交互。 它们在通道维度中串联:。 根据生成融合特征和融合权重,公式如下:
| (7) | |||
| (8) |
其中 和 表示不同的 卷积层, 表示 sigmoid 激活函数。 因此,基础知识交互后的增强特征和噪声特征表示为:
| (9) | |||
| (10) |
鉴于我们的目标是在去噪过程中保留尽可能多的有用信息,在这一步中,我们需要关注包含所有信息的交互特征。 矩阵用于对增强特征和噪声特征进行加权。
获得交互特征后,需要进行空间信息融合。 在语音特征的背景下,空间信息是指频域-时域特征。 与上一步中的交互不同,此融合步骤更侧重于确定频率-时间空间中每个点的重要性。 噪声特征包含更多的信息,因此,空间掩模矩阵是基于噪声特征计算的。 为了聚合空间信息,通常采用平均池化。 该技术平滑整个特征图以导出整体特征。 相反,最大池化保留了特征图中最重要的特征,捕获显着特征。 因此,我们利用这两种池化操作。 分别对进行最大池化和平均池化,然后在通道维度上连接得到的特征图。 接下来,在应用卷积和 sigmoid 激活后获得掩码矩阵 。 最后根据这个mask融合和,得到最终的交互特征:
| (11) |
交互融合模块分别通过通道交互和空间信息融合自适应地组合特征,满足去噪和失真抑制的要求。 我们假设增强的特征用于为原本沉默的语音片段提供信息,而噪声特征用于减轻人声片段中的语音失真。 实验部分的特征可视化(图5)和掩模矩阵的统计分析(图6)进一步支持了这一论断。
III-C 知识蒸馏
知识蒸馏从神经反应的角度指导学生分支学习。 如图3所示,教师和学生都进行在线蒸馏,参数同时更新。 教师模型最后输出层的神经响应被软化,然后根据教师和学生的软目标计算蒸馏损失。 教师模型和学生模型的输入数据不同,特征层面的蒸馏可能会导致收敛困难。 Soft logit 代表类别概率分布,因此基于响应的蒸馏使学生能够直接模仿老师的最终预测。 由于不需要减少模型参数的数量,并且教师和学生的网络结构相同,因此我们使用 SeNet34 [7] 作为主干。 该模型在 ASVspoof 2019 LA 评估集上表现出了优异的性能。 在训练过程中,教师模型使用干净的语音,而学生模型使用融合特征作为输入。
损失惨重。 硬损失是指模型预测和标签之间计算的损失。 令和分别表示教师模型和学生模型最后一个输出层的logit。 使用 A-softmax [53] 计算真实标签 之间的损失。 学生模型和教师模型的硬损失可以表示为:
| (12) | |||
| (13) |
软损失。 软损失是指教师和学生的软化逻辑之间计算的蒸馏损失。 超参数代表蒸馏温度,它调节教师网络输出的logits中的软化程度。 越大,软化程度越高,类别之间的过渡越平滑。 较高的温度会导致更平滑的概率分布,促进更多知识的传递,但也可能会降低学生模型的准确性。 学生的软化 logit 旨在通过 Kullback-Leibler 散度 (KL) 匹配教师模型的软输出 :
| (14) |
基于反应的知识使学生能够像老师一样进行预测。 整个合成语音检测网络的损失由软损失和硬损失组成,其中用于控制学生损失和KD损失之间的权衡:
| (15) |
在知识提炼过程中,能力的显着差异可能需要助教[54]的干预,以促进学生的有效学习。 因此,我们采用在线蒸馏方法,教师和学生同时学习并同时更新参数。 在线蒸馏的优点在于最小化教师和学生预测结果之间的差距,有利于学生模型更好地模仿教师模型的行为。 如果教师使用预训练,可能会给学生模型准确模仿教师对能力差距较大的数据(例如低信噪比)的预测带来挑战。
III-D 联合训练
语音增强作为学生分支的前端模块,其训练目标是重构干净的频谱。 如果该模块是预先训练或独立优化的,则它可能会无意中消除原始工件或引入难以察觉的噪声,因为其目标与最终分类任务不同。 为了使 SE 能够估计对 SSD 有利的目标语音,我们将 SE 和 SSD 联合训练。 联合训练的损失函数表述为:
| (16) |
在反向传播过程中,语音增强模块受到合成语音检测网络的影响,联合训练有利于模型之间的相互反馈,从而实现全局优化。
IV 实验
| Subset | SNRs | Noise corpus | |||
|---|---|---|---|---|---|
| Training |
|
100 Nonspeech Sounds | |||
| Development |
|
100 Nonspeech Sounds | |||
| Test | seen | {0, 5, 10, 15, 20}dB | 100 Nonspeech Sounds | ||
| unseen | {0, 5, 10, 15, 20}dB | NOISEX-92 | |||
IV-A 数据集
IV-A1 干净的数据集
ASVspoof 2019 挑战赛提供了一个包含两个子集的大型数据集:LA 和 PA。 两个子集都由没有噪音的纯人声组成。 在本研究中,我们选择 LA 子集作为主要实验数据集。 ASVspoof 2019 数据集仍然是一个重要的资源,促使我们基于它进行实验。 在 ASVspoof 2019 中观察到的沉默问题[55]在 ASVspoof 2021 中也持续存在,这是我们尚未解决的一个方面。 我们的实验重点是提高嘈杂环境中的性能。 在未来的调查中,我们计划探索删除静默段后的性能改进。 为了研究泛化性,选择 ASVspoof2015 进行跨数据集实验。 因此,ASVspoof 2015和ASVspoof 2019 LA的原始数据集被认为是干净的数据集。
IV-A2 嘈杂的数据集
在本文中,实验场景通过人为地将噪声引入 ASVspoof 2019 LA 数据集来模拟噪声条件。 对于训练集和开发集,我们在训练期间添加随机噪声,SNR 区间范围为 0 到 20 dB。 噪声源自 100 个非语音 [56] 数据集 111http://web.cse.ohio-state.edu/pnl/corpus/HuNonspeech/HuCorpus.html。 对于测试集,我们从 NOISEX-92 语料库 [57] 中随机选择噪声,并将噪声添加到评估集中。 SNR 是从集合 {0, 5, 10, 15, 20}dB 中随机选择的。 生成的新噪声评估数据集被命名为unseen。 然后,我们从 100 个非语音数据集中随机选择噪声并将其添加到评估集中,命名为 seen,如表 I 所示。 它是一个广泛使用的数据集[56]。 数据集的具体内容如下: N1-N17:人群噪声; N18-N29:机器噪音; N30-N43:警报和警笛; N44-N46:交通和汽车噪音; N47-N55:动物的声音; N56-N69:水声; N70-N78:风; N79-N82:铃; N83-N85:咳嗽; N86:拍手; N87:打鼾; N88:点击; N88-N90:笑; N91-N92:打哈欠; N93:哭; N94:淋浴; N95:刷牙; N96-N97:脚步声; N98:门动; N99-N100:电话拨号。 在跨数据集实验中,我们对 ASVspoof 2015 数据集应用相同的过程。 ASVspoof 2021 LA 的测试集已经包含通道噪声。 因此,ASVspoof 2015 和 ASVspoof 2019 LA 产生了两个噪声测试集:看不见的和看见的。 此外,ASVspoof 2021 LA 数据集的测试集本身就是一个噪声数据集。 表III说明了所有系统(无噪声除外)使用的噪声数据集的组成。
IV-A3 实验数据集
在实验中,我们首先评估了 ASVspoof 2019 LA clean 数据集、unseen 噪声数据集和 seen 噪声数据集。 随后,我们对 ASVspoof 2019 LA 的 unseen 和 clean 集进行离线语音增强,并在上述数据集。 接下来,我们在ASVspoof 2015的原始clean测试集、unseen噪声数据集和seen噪声数据集上进行跨数据集实验,分别。 此外,还在 ASVspoof 2021 LA 测试集上进行了跨数据集实验。 对于消融实验,我们选择 ASVspoof 2019 LA 的unseen数据集作为集合。
IV-B 实验装置
IV-B1 基线
在这项工作中,为了研究所提出方法的有效性,我们选择 SENet-34 [7] 作为所有基线模型的骨干 SSD 网络。 语音增强模块使用卷积递归神经(CRN)模型[58]。 本工作中用于比较的不同基线的详细信息可以在表II中找到。 前三个模型为传统结构,与图1(a)一致。 “Cascade”和“Joint”的结构与图1(b)一致。 “Cascade”系统简单地将语音增强模型和合成语音检测模型连接起来。 在训练过程中,语音增强部分的损失是独立反向传播的,导致前端和后端之间的相关性较小。 相反,“联合”系统联合训练语音增强模型和合成语音检测模型。 在实际训练中,这两个任务都需要完成,并且反向传播是同时进行的。 这种方法影响共享参数的学习,有利于优化语音增强部分以实现最终目标。 与“联合”系统相比,“DKDSSD”结构的不同之处在于它采用了双分支知识蒸馏结构和交互融合模块。
| Systems name | Details |
|---|---|
| Noise-Free [7] | System trained with only clean data. |
| MCT1 [23] | System trained with half noisy speech and half clean. |
| MCT2 [23] | System trained with completely noisy speech. |
| Cascade [29] | Cascaded system of SSD and SE, trained with noisy speech. The system is optimized using SSD training objective only. |
| Joint [28] | Multitask-based joint training system of SSD and SE, trained with noisy speech. |
| DKDSSD | Proposed dual-branch system, trained with pairs of clean and noisy speech. |
IV-B2 实施细节
对于SE,我们使用161维幅度谱作为输入特征,时间帧设置为600。 对于SSD,为了提取对数幅度谱图特征,我们将STFT的布莱克曼窗长度和跳长度分别设置为1728和130。 语音被截断或拼接,使得所有输入特征的帧数保持为 600 帧。 由于[7, 59]中的研究,我们的工作中使用了低子带对数幅度谱图特征,因此合成语音检测的所有输入特征都保持433×600的相同形状。 此外,Adam是SE和SSD的优化器,超参数设置为0.05,温度设置为3。 这些超参数是经过多次实验确定的。 我们对每个系统进行 32 个 epoch 的训练,并选择开发集上损失最低的模型作为最终模型进行评估。 对于DKDSSD模型,训练时教师模型和学生模型并行训练,仅使用学生模型进行推理。 我们使用等错误率(EER)来评估所有系统的性能,该指标反映了检测合成语音的能力。 此外,最小串联检测成本函数(t-DCF)被用作 ASVspoof 2021 的评估指标,官方认为该指标是该数据集上更重要的指标。
| Systems | seen | unseen | clean | ||||||||||
| 0dB | 5dB | 10dB | 15dB | 20dB | AVG. | 0dB | 5dB | 10dB | 15dB | 20dB | AVG. | AVG. | |
| Noise-Free [7] | 44.91 | 39.70 | 26.30 | 19.90 | 18.46 | 27.98 | 55.53 | 53.40 | 34.12 | 21.81 | 19.36 | 36.04 | 2.21 |
| MCT1 [23] | 7.91 | 5.16 | 4.14 | 3.83 | 2.99 | 5.01 | 14.04 | 11.02 | 7.46 | 5.69 | 3.76 | 8.59 | 2.43 |
| MCT2 [23] | 6.72 | 4.39 | 3.52 | 3.42 | 2.86 | 4.27 | 12.03 | 9.10 | 5.57 | 4.37 | 3.08 | 7.16 | 3.37 |
| Cascade [29] | 7.53 | 6.13 | 5.04 | 4.45 | 4.57 | 5.74 | 12.10 | 8.49 | 6.22 | 5.27 | 4.10 | 7.60 | 4.01 |
| Joint [28] | 6.80 | 4.89 | 3.73 | 3.89 | 3.52 | 4.74 | 10.33 | 7.94 | 5.50 | 4.51 | 3.41 | 6.92 | 3.29 |
| DKDSSD | 5.26 | 3.82 | 2.83 | 2.93 | 2.39 | 3.55 | 8.52 | 6.53 | 4.58 | 3.41 | 2.95 | 5.40 | 3.28 |
| Systems | unseen | clean | |||||
|---|---|---|---|---|---|---|---|
| 0dB | 5dB | 10dB | 15dB | 20dB | AVG. | AVG. | |
| Noise-Free [7] | 37.11 | 30.27 | 19.83 | 18.68 | 18.19 | 23.48 | 15.66 |
| MCT1 [23] | 21.23 | 18.03 | 15.71 | 13.67 | 11.92 | 16.14 | 9.00 |
| MCT2 [23] | 29.83 | 25.73 | 20.56 | 15.34 | 11.01 | 20.92 | 8.67 |
| Noise | SNR | Noise-Free | MCT1 | MCT2 | Cascade | Joint | DKDSSD | Noise | SNR | Noise-Free | MCT1 | MCT2 | Cascade | Joint | DKDSSD |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| white | 0 | 67.42 | 9.10 | 6.42 | 8.32 | 7.40 | 6.37 | m109 | 0 | 68.96 | 9.23 | 10.80 | 10.28 | 9.39 | 6.88 |
| 5 | 66.79 | 7.61 | 5.93 | 6.08 | 6.94 | 4.91 | 5 | 32.64 | 8.91 | 6.75 | 7.12 | 7.94 | 6.11 | ||
| 10 | 53.04 | 4.35 | 2.62 | 5.24 | 3.46 | 2.62 | 10 | 20.00 | 5.74 | 5.04 | 5.74 | 4.33 | 4.18 | ||
| 15 | 21.48 | 2.79 | 2.94 | 5.42 | 3.72 | 2.79 | 15 | 18.47 | 5.05 | 3.38 | 5.05 | 3.43 | 2.50 | ||
| 20 | 19.73 | 3.56 | 3.76 | 4.53 | 3.76 | 2.03 | 20 | 18.67 | 2.83 | 1.85 | 2.83 | 3.75 | 2.83 | ||
| AVG. | 21.48 | 5.74 | 4.47 | 5.81 | 4.88 | 3.61 | AVG. | 30.58 | 6.49 | 5.64 | 6.71 | 5.64 | 4.79 | ||
| f16 | 0 | 72.95 | 11.64 | 8.81 | 10.36 | 9.07 | 7.93 | hfchannel | 0 | 67.76 | 6.59 | 5.66 | 7.53 | 6.70 | 4.78 |
| 5 | 69.21 | 9.56 | 9.51 | 7.46 | 6.20 | 6.36 | 5 | 66.11 | 4.18 | 3.29 | 4.13 | 5.75 | 2.46 | ||
| 10 | 32.50 | 5.94 | 3.62 | 5.99 | 4.30 | 3.48 | 10 | 37.36 | 1.76 | 1.76 | 3.56 | 2.59 | 1.66 | ||
| 15 | 17.69 | 6.34 | 3.34 | 3.56 | 3.62 | 3.34 | 15 | 17.20 | 3.65 | 4.57 | 5.48 | 5.48 | 2.89 | ||
| 20 | 19.04 | 4.15 | 3.02 | 3.94 | 4.04 | 3.07 | 20 | 15.64 | 2.63 | 1.75 | 2.63 | 2.68 | 1.75 | ||
| AVG. | 41.08 | 8.23 | 6.29 | 6.46 | 5.88 | 5.13 | AVG. | 40.67 | 3.58 | 3.19 | 4.76 | 4.60 | 3.01 | ||
| machinegun | 0 | 19.80 | 8.72 | 7.92 | 13.89 | 9.93 | 7.02 | buccaneer1 | 0 | 71.48 | 15.22 | 12.41 | 13.35 | 11.21 | 9.44 |
| 5 | 19.78 | 7.14 | 3.70 | 8.94 | 5.29 | 3.40 | 5 | 75.24 | 10.63 | 7.14 | 7.87 | 8.01 | 6.02 | ||
| 10 | 18.46 | 5.16 | 4.30 | 6.01 | 5.06 | 3.34 | 10 | 58.00 | 7.43 | 5.77 | 6.86 | 5.77 | 4.31 | ||
| 15 | 19.03 | 5.78 | 3.31 | 6.82 | 5.82 | 3.27 | 15 | 23.97 | 5.34 | 4.48 | 2.82 | 3.58 | 2.57 | ||
| 20 | 16.94 | 4.30 | 2.59 | 3.47 | 3.42 | 3.27 | 20 | 16.68 | 2.52 | 3.37 | 3.47 | 3.37 | 3.31 | ||
| AVG. | 19.48 | 6.19 | 4.24 | 9.48 | 6.66 | 3.86 | AVG. | 44.90 | 9.16 | 7.41 | 8.09 | 7.04 | 5.07 | ||
| factory2 | 0 | 68.95 | 13.01 | 8.04 | 9.02 | 9.02 | 6.86 | factory1 | 0 | 68.78 | 13.54 | 9.67 | 11.38 | 10.52 | 9.72 |
| 5 | 45.47 | 11.09 | 7.29 | 7.90 | 7.95 | 6.18 | 5 | 71.31 | 11.06 | 7.92 | 8.73 | 8.89 | 7.70 | ||
| 10 | 20.09 | 7.89 | 5.27 | 7.03 | 6.13 | 4.37 | 10 | 43.26 | 7.14 | 4.29 | 5.39 | 4.49 | 3.59 | ||
| 15 | 20.70 | 5.06 | 5.96 | 5.96 | 5.16 | 3.97 | 15 | 21.26 | 5.29 | 3.49 | 3.54 | 3.49 | 2.51 | ||
| 20 | 21.18 | 3.81 | 3.45 | 3.86 | 3.45 | 3.61 | 20 | 20.81 | 4.11 | 3.28 | 4.79 | 3.28 | 3.23 | ||
| AVG. | 34.41 | 5.93 | 8.62 | 7.03 | 6.51 | 5.35 | AVG. | 43.36 | 8.37 | 5.95 | 7.21 | 6.64 | 5.60 | ||
| destroyerops | 0 | 76.19 | 14.18 | 11.69 | 10.93 | 9.69 | 8.64 | pink | 0 | 70.80 | 15.11 | 10.62 | 12.28 | 11.48 | 10.57 |
| 5 | 65.44 | 10.94 | 10.84 | 9.20 | 8.60 | 7.01 | 5 | 75.65 | 12.58 | 8.80 | 7.09 | 8.30 | 8.00 | ||
| 10 | 27.38 | 7.36 | 6.33 | 5.30 | 6.43 | 5.25 | 10 | 55.45 | 7.28 | 6.19 | 5.58 | 6.35 | 5.37 | ||
| 15 | 17.25 | 4.38 | 3.60 | 4.22 | 3.60 | 2.11 | 15 | 21.81 | 5.21 | 5.21 | 5.21 | 4.22 | 5.21 | ||
| 20 | 19.97 | 4.33 | 1.92 | 3.49 | 3.44 | 3.44 | 20 | 19.84 | 4.87 | 2.51 | 4.15 | 3.18 | 2.31 | ||
| AVG. | 46.40 | 8.64 | 8.45 | 7.68 | 7.01 | 5.60 | AVG. | 44.55 | 9.07 | 6.76 | 7.10 | 6.91 | 6.32 | ||
| babble | 0 | 77.86 | 16.89 | 16.28 | 15.38 | 14.63 | 12.08 | leopard | 0 | 18.31 | 15.59 | 13.78 | 12.78 | 9.16 | 9.11 |
| 5 | 59.40 | 13.30 | 12.40 | 11.55 | 11.05 | 8.55 | 5 | 17.91 | 13.03 | 11.18 | 7.95 | 8.11 | 6.62 | ||
| 10 | 26.95 | 10.71 | 6.25 | 5.38 | 6.04 | 5.38 | 10 | 19.96 | 12.60 | 8.20 | 8.00 | 8.65 | 7.02 | ||
| 15 | 18.20 | 7.72 | 6.55 | 6.86 | 6.76 | 5.54 | 15 | 18.51 | 7.70 | 3.90 | 6.04 | 5.85 | 4.87 | ||
| 20 | 17.77 | 3.94 | 3.00 | 3.73 | 3.83 | 2.80 | 20 | 20.83 | 4.97 | 4.97 | 6.42 | 3.47 | 4.97 | ||
| AVG. | 44.29 | 11.15 | 11.52 | 10.25 | 9.75 | 6.97 | AVG. | 19.13 | 11.66 | 9.12 | 8.28 | 7.55 | 6.54 |
V实验结果
V-A ASVspoof 2019 LA 结果
V-A1 SE 的有效性和局限性
我们首先分析SE的有效性和局限性。 从表IV中,我们观察到SE过程显着提高了“Noise-Free”在噪声条件下的性能,而“MCT1”和“MCT2”的性能下降。 对于仅接受干净语音训练的“无噪音”者来说,噪音是最大的干扰,而去噪可以提高表现。 然而,对于 MCT 系统来说,失真比噪声更具破坏性。 在干净的环境中,去噪会显着降低“MCT1”、“MCT2”和“Noise-Free”的性能。 这是因为对于干净的数据,SE 是不必要的。 虽然 SE 有利于从噪声条件下重建语音,但处理失真通常会引入看不见的伪影。 因此,在降噪的同时解决失真问题变得至关重要。
V-A2 与其他基线的比较
表III显示了所有SSD系统的结果。 我们可以观察到,仅在清洁条件下训练的模型缺乏噪声鲁棒性,特别是在低信噪比的情况下。 因此,有必要提高SSD系统的通用性,以应对更复杂的现实情况。 “MCT1”模型的整体性能比“Noise-Free”模型要好得多,并且在噪声较强时更稳定,因为它是用干净的语音和噪声语音一起训练的。 多条件训练允许神经网络建模更具辨别力的特征表示,从而提高噪声条件下的检测能力。 然而,由于噪声的过度拟合,在干净的数据集上进行多条件训练的性能下降,并且仅使用噪声数据训练的“MCT2”的退化更为明显。
“Cascade”采用语音增强作为前端,相比没有SE的系统有显着的性能提升,但不如“MCT2”的性能。 这是因为级联方法只优化了合成语音检测,并没有优化语音增强。 当联合训练用于多任务学习时,“联合”系统在级联系统的基础上进一步完善,这表明联合训练有利于促进整体结构的全局优化。 在干净的条件下,它也表现良好。 原因是模型可以共享信息并相互影响。
所有系统在看不见的噪声数据集上都会显着退化,这表明看不见的噪声仍然是一个难以处理的问题。 我们提出的“DKDSSD”系统在可见和不可见的数据集上分别实现了最低的EER 3.55%和5.40%,并且在所有SNR情况下都表现最好,这表明我们提出的方法可以有效提高噪声场景中的检测能力,并且具有更好的性能。在看不见的嘈杂情况下进行泛化。
V-A3 所有看不见的噪音条件的结果
表V显示了五个模型在所有噪声场景下的EER。 可以看出,当SNR低于20dB时,DKDSSD在几乎所有类型的噪声中表现最好,表明“DKDSSD”具有很强的噪声鲁棒性。 当信噪比为20dB时,“MCT2”的性能仅次于“DKDSSD”,因为“MCT2”在训练过程中也对噪声进行了建模,对不可见的噪声保持了一定的感知能力。 然而,当信噪比较低时,性能不如带有语音增强模块的模型。 其中,胡言乱语是最难检测的噪声,因为胡言乱语中含有模糊的人声。 它与说话人的基频处于同一频段,会污染原始频谱,语音增强方法很难重构语音。 “DKDSSD”整体性能比较均衡,但在babble、leopard等周期性较差的非平稳噪声下表现较差,而白噪声等频谱相对均匀的噪声则更容易去除。
V-B 跨数据集结果
为了证明我们提出的模型的泛化性,我们对两个数据集进行了跨数据集测试:ASVspoof 2021 LA 测试集和 ASVspoof 2015 测试集。 这意味着训练和开发数据集都是 ASVspoof 2019 LA,并且仅在两个域外数据集上进行了测试。 其中,ASVspoof 2021 LA 是官方数据集,由于该数据集本身已经用一些电话信道噪声进行了压缩和编码,因此我们没有做任何更改。 我们对ASVspoof 2015测试的数据进行了噪声模拟。 实验结果分为三类:看见的、看不见的、干净的。 可见和不可见噪声的类型以及信噪比与表I中的ASVspoof 2019测试数据集一致。 干净意味着测试数据集没有经过任何处理。
V-B1 ASVspoof 2015 的结果
表VI显示了ASVspoof 2015测试数据集的结果。 “Noise-Free”模型在所有三种条件下都表现不佳,这表明2015年数据集的分布与2019年有很大不同。 即使在无噪音的清洁条件下,“Noise-Free”也只能达到33.96%的能效比。 然而,“DKDSSD”模型仍然表现出最好的泛化能力,并在三种三类场景中实现了最低的EER。 我们可以看到,所有模型在所见数据集上都表现更好,因为所见数据集的加性噪声在训练时是已知的。 当面对看不见的噪声时,模型的性能会下降。 这是因为语音增强模型难以处理看不见的噪声,从而引入看不见的伪像,从而影响 SSD 任务。
V-B2 ASVspoof 2021 LA 结果
表VII显示了ASVspoof 2021 LA测试数据集的结果。 除了5个基线之外,还列出了两个官方最佳基线(B03、B04)和两个新模型。 其中,“AASIST”是ASVspoof2019上的SOTA单一模型。 我们使用“AASIST”的开源代码在ASVspoof 2021 LA测试集上进行跨数据集实验。 “无噪声”的概括性最差,因为该测试集考虑了电话编码和传输,而这在训练过程中是完全看不到的。 “MCT1”和“MCT2”表现更好,因为这两个模型在训练过程中添加了噪声,相当于做了数据增强,使它们对电话噪声有感知。 从结果可以看出,带有语音增强的基线具有更好的泛化能力,“DKDSSD”实现了最低的EER,为4.35%。 结果表明,所提出的模型不仅可以应对一般的加性噪声,而且可以保持对电话传输信道噪声的泛化。
| Systems | seen | unseen | clean | ||||||||||
| 0dB | 5dB | 10dB | 15dB | 20dB | AVG. | 0dB | 5dB | 10dB | 15dB | 20dB | AVG. | AVG. | |
| Noise-Free [7] | 46.19 | 45.94 | 44.92 | 44.61 | 41.30 | 45.32 | 46.55 | 49.14 | 48.94 | 47.01 | 41.40 | 46.74 | 33.96 |
| MCT1 [23] | 18.39 | 15.05 | 12.42 | 11.58 | 10.97 | 14.45 | 25.07 | 19.98 | 15.31 | 13.43 | 11.81 | 17.64 | 9.33 |
| MCT2 [23] | 16.68 | 13.43 | 11.17 | 9.59 | 9.16 | 12.64 | 24.31 | 17.07 | 13.09 | 11.14 | 10.20 | 16.04 | 7.85 |
| Cascade [29] | 15.82 | 11.15 | 9.70 | 8.81 | 8.94 | 11.40 | 21.32 | 14.75 | 11.76 | 10.22 | 9.73 | 14.34 | 8.50 |
| Joint [28] | 15.51 | 11.71 | 10.03 | 9.20 | 9.43 | 11.81 | 20.08 | 15.14 | 12.40 | 10.77 | 9.34 | 14.59 | 8.92 |
| DKDSSD | 14.10 | 10.57 | 8.88 | 8.03 | 7.71 | 10.53 | 19.92 | 14.30 | 11.34 | 9.82 | 8.27 | 13.61 | 7.76 |
| Systems | EER | min t-DCF |
|---|---|---|
| AASIST [15] | 10.51 | 0.4884 |
| LFCC-LCNN (B03) [18] | 9.26 | 0.3445 |
| RawNet2 (B04) [18] | 9.50 | 0.4257 |
| BTS-E [60] | 8.75 | 0.3893 |
| SE-Rawformer [61] | 4.53 | 0.3088 |
| Noise-Free [7] | 15.33 | 0.3655 |
| MCT1 [23] | 5.93 | 0.3157 |
| MCT2 [23] | 5.8 | 0.3304 |
| Cascade [29] | 5.28 | 0.3072 |
| Joint [28] | 4.82 | 0.2969 |
| DKDSSD | 4.35 | 0.2839 |
| Systems | Unseen | ||||||
|---|---|---|---|---|---|---|---|
| 0dB | 5dB | 10dB | 15dB | 20dB | AVG. | params | |
| DKDSSD | 8.52 | 6.53 | 4.58 | 3.41 | 2.95 | 5.40 | 21.06 M |
| w/o joint training | 11.48 | 8.70 | 5.82 | 4.44 | 3.56 | 7.18 | 21.06 M |
| w/o IF | 10.52 | 7.48 | 5.36 | 4.51 | 3.56 | 6.87 | 20.26M |
| w/o KD | 12.04 | 8.85 | 5.63 | 4.23 | 3.33 | 7.57 | 19.72M |
V-C 消融研究
V-C1 模型本身的消融研究结果
表VIII展示了消融实验的结果。 我们主要分析看不见的数据集的结果,因为看不见的噪声更具挑战性。 当不使用联合训练时,语音增强和合成语音检测成为独立的任务,这极大地影响了两个任务的优化,并可能导致陷入局部最优,从而导致EER从5.40%增加到7.18%。 联合训练有利于系统中所有模型的共同优化。 当有多个模块需要优化时,联合训练是一种有效的策略。
教师模型可以引导学生分支学习类似于干净数据的分布,并且当教师分支丢失(无KD)时,剩余的噪声分支由于缺乏干净的教师监督而无法生成噪声鲁棒特征。 交互式融合模块无法在没有蒸馏损失约束的情况下自适应地融合噪声语音,并且可能会引入看不见的伪影。 这导致表VIII中的EER性能最差(7.57%)。
交互式融合模块的作用是自适应地融合去噪频谱和带噪频谱,可以吸收带噪频谱的有益信息,减轻语音失真。 当没有交互融合时,系统直接将增强后的谱输入后端分类器进行识别。 对分类任务最大的干扰是由失真引起的看不见的伪影,它影响了数据的数据分布。
V-C2 更换模块消融研究结果
表IX为ASVspoof 2019 unseen set更换DKDSSD模块后的消融实验结果。 为了方便展示各模块的性能,“DKDSSD”记为“CRN+IF+KD+SeNet”,其中CRN代表前端语音增强模型,IF为交互融合模块,KD为知识蒸馏框架,SeNet是后端欺骗检测分类器。 观察添加(OA)[40]是一种被证实简单有效的融合方法,通过按比例叠加原始带噪语音来减少失真的影响。 TSSD [13] 是一个在 ASVspoof2019 上对时域特征建模表现良好的网络。 它使用原始波形作为特征以避免信息丢失。 Diffusion[62]是一种基于扩散的生成模型,使用Diffusion的预训练模型进行测试,看看成熟的预训练模型是否对下游任务更有优势。
| Systems | Unseen | ||||||
|---|---|---|---|---|---|---|---|
| 0dB | 5dB | 10dB | 15dB | 20dB | AVG. | params | |
| CRN+IF+KD+SeNet | 8.52 | 6.53 | 4.58 | 3.41 | 2.95 | 5.40 | 21.06 M |
| CRN+IF+PKD+SeNet | 10.03 | 7.07 | 4.83 | 3.75 | 3.15 | 5.95 | 21.06 M |
| CRN+OA[40]+KD+SeNet | 10.11 | 7.14 | 4.84 | 3.94 | 2.86 | 6.37 | 20.26M |
| CRN+KD+TSSD[13] | 11.33 | 6.19 | 5.36 | 5.06 | 4.43 | 6.53 | 18.28M |
| CRN+TSSD[13] | 16.84 | 10.46 | 6.55 | 5.41 | 5.25 | 10.12 | 17.93M |
| Diffuision[62]+SeNet | 20.84 | 19.87 | 20.88 | 20.83 | 21.45 | 21.75 | 66.93M |
| Diffuision[62]+IF+SeNet | 13.21 | 10.68 | 7.99 | 6.87 | 4.86 | 8.62 | 67.73M |
知识蒸馏方法的影响。 我们采用的知识蒸馏(KD)方法涉及将教师模型和学生模型一起训练,称为在线蒸馏。 PKD表示首先对教师训练模型进行预训练,称为离线蒸馏,涉及两阶段过程。 实验上,单独预训练教师模型(“CRN+IF+PKD+SeNet”)后,结果不如我们提出的“DKDSSD”(“CRN+IF+KD+SeNet”)。 我们推测这是因为预训练的教师模型和学生模型之间的预测存在显着差异(由于训练数据不同),阻碍了学生的学习过程。 同时训练教师和学生模型有助于缩小这种差距。 线下蒸馏通常需要大规模的教师模型来指导学生,而大教师和小学生之间总是存在能力差距,学生往往对教师有严重依赖。 我们的师生网络具有相同的结构和较少的参数数量,使其更适合在线蒸馏。 在线蒸馏中,师生共同学习,训练能力差距始终较小。
交互融合的影响。 为了证明融合噪声语音的必要性,我们用 OA 方法[40]代替交互式融合方法。 OA是一种经过验证的简单有效的融合方法,通过将增强语音和原始噪声语音按比例线性叠加来减少失真的影响。 具体来说,我们以 0.7:0.3 的比例线性组合增强语音和原始噪声语音。 该超参数设置基于[40]中报告的最佳实验结果。 可以看出,尽管与使用交互式融合的方法相比,性能略有下降,但OA仍然取得了良好的性能,表明原始噪声语音包含有利于检测的信息。 我们提出的交互式融合方法可以通过多个训练时期自适应地学习最佳融合掩模矩阵,从而表现更好。
分类器的影响。 表IX中的实验“CRN+KD+TSSD”和“CRN+TSSD”是针对端到端模型进行的。 TSSD是一种端到端模型,在ASVspoof2019上对时域特征进行建模时表现良好。 它使用原始波形作为特征以避免信息丢失。 从实验结果来看,TSSD的性能不如我们提出的“DKDSSD”(“CRN+IF+KD+SeNet”)。 手动提取特征的缺点在于相位信息的丢失,因为原始波形同时包含相位谱和幅度谱信息。 尽管DKDSSD采用手动提取的特征会丢失相位信息,但交互融合模块(IF)有效地补偿了这种损失。 在我们之前的工作中,我们探索了如何充分利用相位特征,发现基于复杂谱的子带融合方法表现出色。 然而,我们还没有研究抗噪方面的复杂光谱特征,这将是我们未来的工作。 此外,带有知识蒸馏(KD)的TSSD表现出相对更好的性能,表明知识蒸馏的框架是有用的。





预训练 SE 模型的影响。 Diffusion 是在 WSJ0 [63]、CHiME3 [64] 和 VoiceBank-DEMAND [65] 上训练的基于扩散的生成模型。 它在包含真实噪声的数据集上表现最佳。 我们使用Diffusion的预训练模型进行语音增强,来测试成熟的预训练模型是否对下游任务更有优势。 从表IX可以看出,“Diffusion+SeNet”在所有SNR条件下表现始终较差,结果徘徊在20%左右。 试听扩散模型去噪后的语音,我们发现其语音增强效果非常优越,可以有效滤除几乎所有噪声。 然而,由于预训练模型与下游检测任务之间缺乏交互,存在过度去噪的问题。 语音失真使真实和虚假特征之间的区分变得复杂,可能导致性能不佳。 结合交互式融合模块(“Diffusion+IF+SeNet”)带来了显着的性能提升,将平均 EER 从 21.75% 降低到 8.62%。 我们选择训练语音增强模型,而不是使用现有的预训练模型。 因为对于下游任务来说,需要的是保留工件的有效特征,而不仅仅是减少噪声。 尽管预训练的语音增强前端表现出强大的性能,但它们需要与下游任务联合优化才能有效检测欺骗。 其他研究,例如[66],也表明预先训练的前端可能并不总是最佳解决方案。 从参数角度来看,预训练模型通常会导致模型尺寸较大,这会显着降低推理速度并对部署带来挑战。
V-D 视觉分析
首先,我们使用 t 分布随机邻域嵌入(t-SNE)来降低所有 6 个模型最后一层特征的维度,并可视化 ASVspoof2019 unseen 数据集和 ASVspoof2021 数据集上的特征分布。 其次,为了分析交互式融合模块的作用,我们可视化了融合前后的频谱特征,以及交互式融合模块学习到的融合权重矩阵。 最后对融合权重矩阵进行统计分析。
V-D1 特征嵌入的可视化
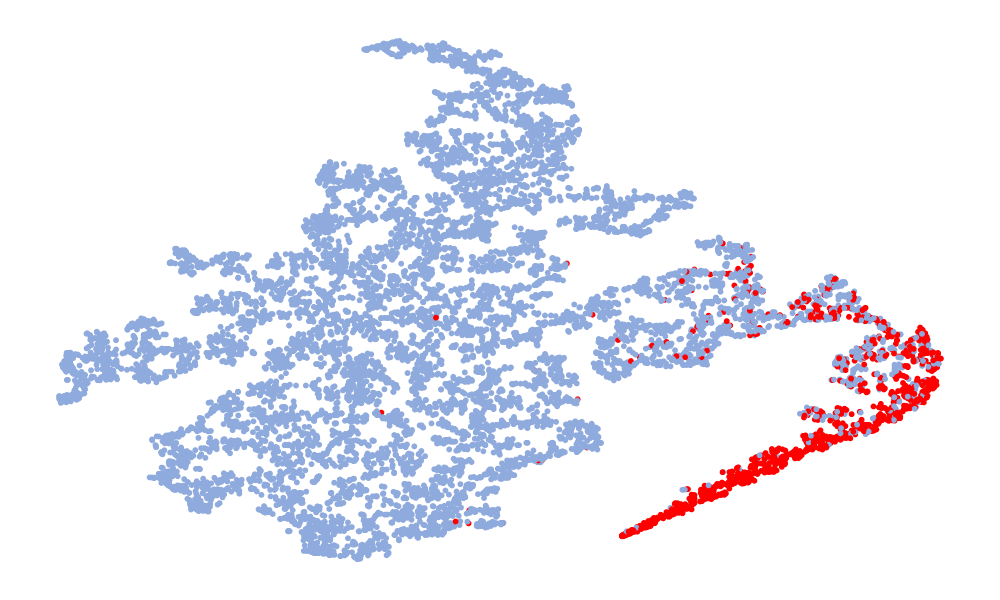
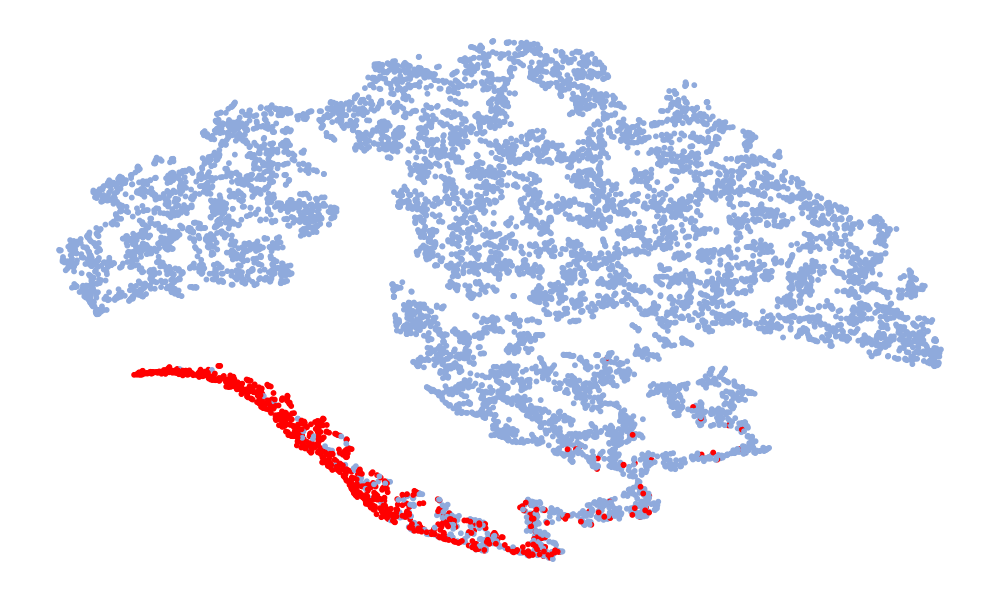
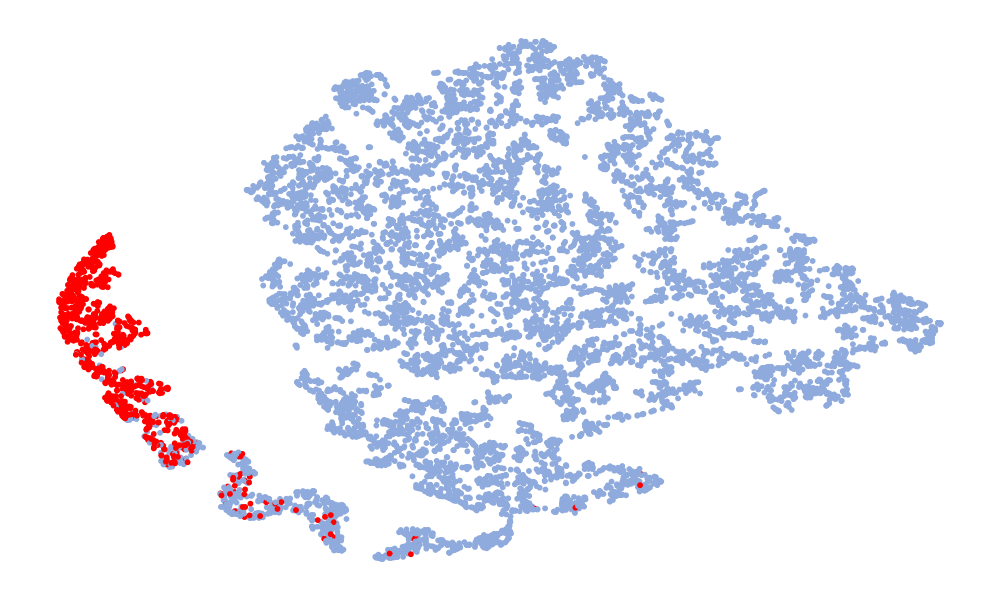
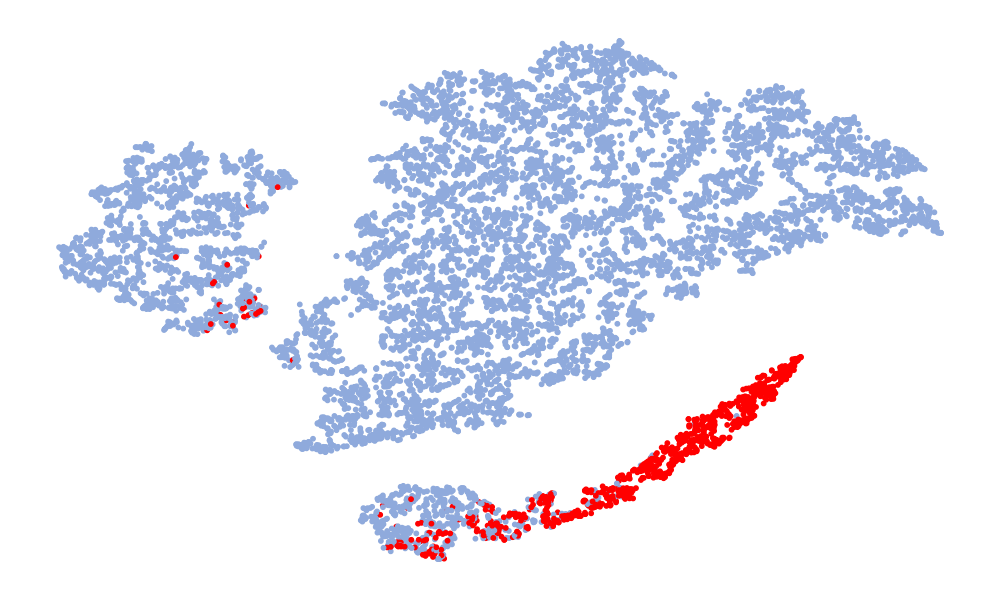
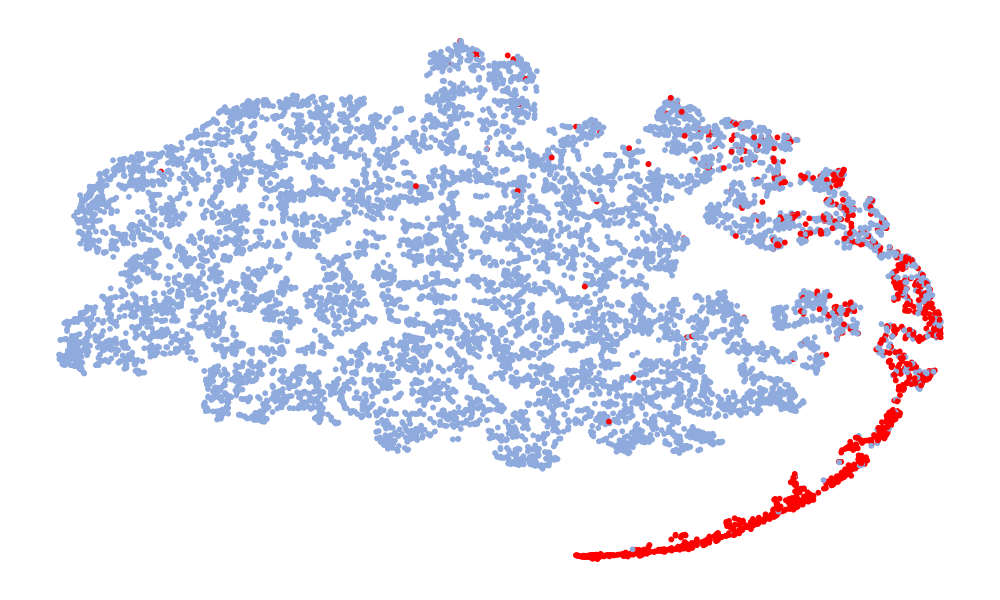
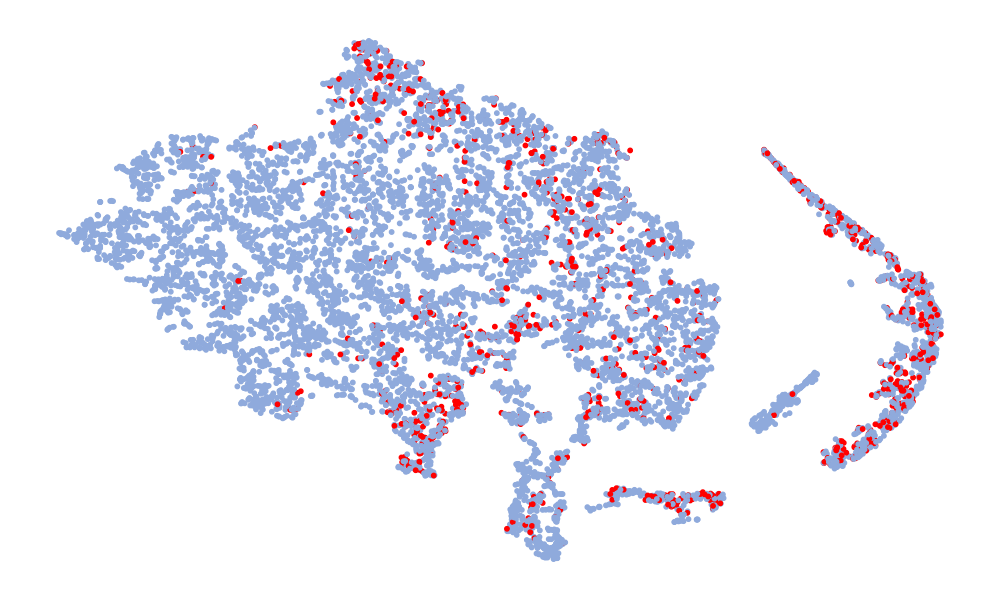
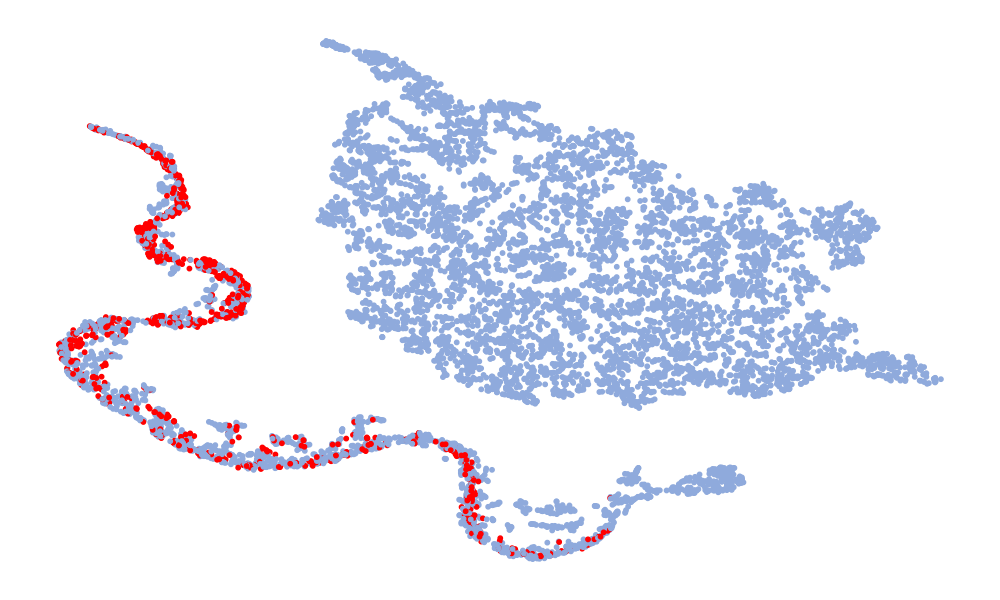
图4是特征的可视化,取的特征是分类前的128维特征。 图中红色代表真实语音,蓝色代表假语音。 左列是6个模型在ASVspoof 2019 unseen数据集上的t-SNE,右列是模型在ASVspoof 2021上的t-SNE。 考虑Noise-Free模型(图4(f),(l)),可以看出真实语音和假语音的特征空间重叠,噪声严重干扰数据的分布。 总体而言,在t-SNE可视化中,真实数据的分布显得相对集中,而假数据由于各种类型的攻击,分布显得更加分散。 尽管真实语音的不同模型的特征嵌入分布相似,但假语音的分布差异很大。 这种差异可能归因于噪声干扰,噪声干扰可能会掩盖伪影并改变特征分布。 与其他模型相比,“DKDSSD”模型的 t-SNE 可视化显示红色和蓝色簇之间的分离更清晰,表明真假分类能力更强。
V-D2 交互式融合的特征和权重可视化
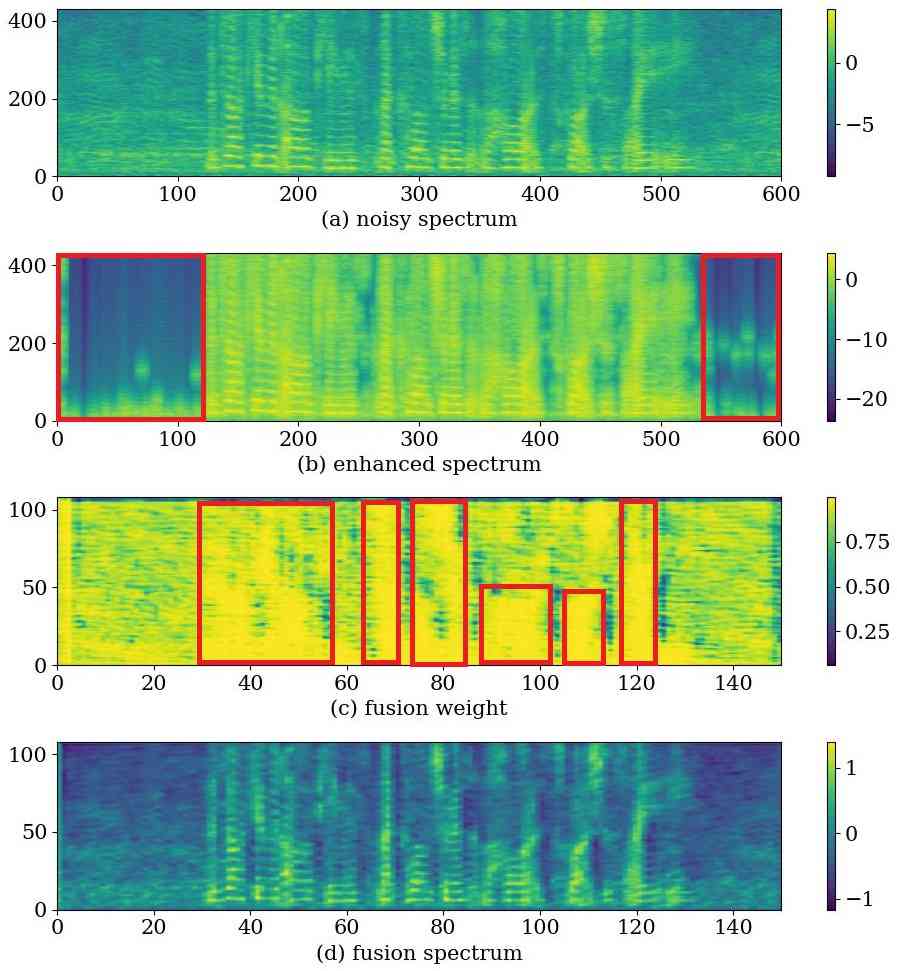
图5是单个语音的特征可视化(LA_E_2178426_snr15_babble.wav)。 该语音是由 ASVspoof 2019 中的 LA_E_2178426.wav 通过叠加信噪比为 15dB 的驱逐舰噪声生成的。 交互融合后的特征通道数为16,对通道维度进行平均后得到图中第四行。 可以观察到,在有人声的区域(图5(c)中红框部分),噪声频谱占据较大的权重,而在没有人声的区域,增强频谱占据了较大的权重。较大的重量。 这表明交互式融合模块倾向于吸收噪声语音中的声音片段并在其他区域保留更多增强的特征。 增强后的特征中,静默段几乎没有噪声(图5(b)中的红框)。 交互式融合后,语音特征(图5(d))呈现出比噪声频谱更清晰的结构,受噪声影响较小,减少了语音失真。 这些结果表明,交互式融合模块可以自适应地吸收人类语音片段,同时保留增强特征的噪声污染较少的状态。
V-D3 交互式融合的融合权重统计可视化
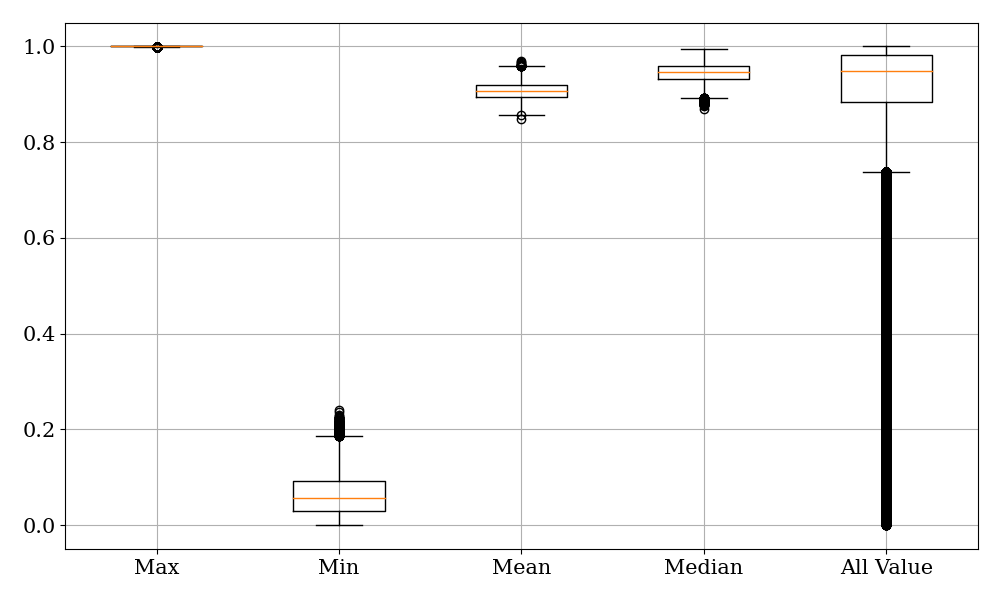
图6从左到右显示了最大值、最小值、平均值、中位数和所有掩码值的箱线图。 可以看出,大多数掩码值分布在 0.8 和 1 之间。 这些掩模值表示融合过程中原始噪声特征所占据的权重。 这意味着在融合过程中,模型倾向于吸收更多的原始噪声频谱。 我们推测这是因为原始语音包含更多信息并且不存在失真问题。 增强频谱的主要作用是提供有关非语音区域的信息。 而在一段演讲中,人声通常占据主要部分。 它证实了交互式融合模块倾向于从噪声语音中吸收人声片段,并在非语音区域保留更多增强的特征。
六结论
针对噪声场景下鲁棒性不足的问题,提出一种基于知识蒸馏的双分支合成语音检测方法。 提出了交互式融合和知识蒸馏来指导噪声数据的训练,促使其表现得像干净的语音。 交互式融合利用通道交互和空间信息融合,自适应地将噪声数据与增强数据结合起来,促使学生分支生成不受噪声干扰的特征。 知识蒸馏可以通过师生范式约束学生模型的决策,将嘈杂的学生分支的决策空间映射到干净的教师分支的决策空间,让学生像老师一样做出最终的预测。 实验结果表明,我们提出的 DKDSSD 优于其他基线模型,尤其是在低 SNR 场景下,并且在跨数据集实验中也显示出很强的泛化性。 在可视化融合权重矩阵后,我们观察到噪声语音起着主要作用,而增强的特征则提供了原本是无声片段的信息。 未来,我们将更加关注无声片段在检测合成语音中的作用。
参考
- [1] X. Tan, T. Qin, F. Soong, and T.-Y. Liu, “A survey on neural speech synthesis,” arXiv preprint arXiv:2106.15561, 2021.
- [2] Z. Wu, N. Evans, T. Kinnunen, J. Yamagishi, F. Alegre, and H. Li, “Spoofing and countermeasures for speaker verification: A survey,” speech communication, vol. 66, pp. 130–153, 2015.
- [3] Z. Wu, T. Kinnunen, N. Evans, J. Yamagishi, C. Hanilçi, M. Sahidullah, and A. Sizov, “Asvspoof 2015: the first automatic speaker verification spoofing and countermeasures challenge,” in Sixteenth annual conference of the international speech communication association, 2015.
- [4] T. Kinnunen, M. Sahidullah, H. Delgado, M. Todisco, N. Evans, J. Yamagishi, and K. A. Lee, “The ASVspoof 2017 Challenge: Assessing the Limits of Replay Spoofing Attack Detection,” in Proc. Interspeech 2017, 2017, pp. 2–6.
- [5] M. Todisco, X. Wang, V. Vestman, M. Sahidullah, H. Delgado, A. Nautsch, J. Yamagishi, N. Evans, T. H. Kinnunen, and K. A. Lee, “ASVspoof 2019: Future Horizons in Spoofed and Fake Audio Detection,” in Proc. Interspeech 2019, 2019, pp. 1008–1012.
- [6] J. Yang, R. K. Das, and H. Li, “Significance of subband features for synthetic speech detection,” IEEE Transactions on Information Forensics and Security, vol. 15, pp. 2160–2170, 2019.
- [7] Y. Zhang, W. Wang, and P. Zhang, “The Effect of Silence and Dual-Band Fusion in Anti-Spoofing System,” in Proc. Interspeech 2021, 2021, pp. 4279–4283.
- [8] Y. Wang, X. Wang, H. Nishizaki, and M. Li, “Low pass filtering and bandwidth extension for robust anti-spoofing countermeasure against codec variabilities,” in 2022 13th International Symposium on Chinese Spoken Language Processing (ISCSLP). IEEE, 2022, pp. 438–442.
- [9] J. Xue, C. Fan, J. Yi, C. Wang, Z. Wen, D. Zhang, and Z. Lv, “Learning from yourself: A self-distillation method for fake speech detection,” in ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023, pp. 1–5.
- [10] H. Ling, L. Huang, J. Huang, B. Zhang, and P. Li, “Attention-based convolutional neural network for asv spoofing detection,” Proc. Interspeech 2021, pp. 4289–4293, 2021.
- [11] H. Tak, J. Patino, M. Todisco, A. Nautsch, N. Evans, and A. Larcher, “End-to-end anti-spoofing with rawnet2,” in ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021, pp. 6369–6373.
- [12] H. Tak, J.-W. Jung, J. Patino, M. Kamble, M. Todisco, and N. Evans, “End-to-end spectro-temporal graph attention networks for speaker verification anti-spoofing and speech deepfake detection,” in ASVSPOOF 2021, Automatic Speaker Verification and Spoofing Countermeasures Challenge. ISCA, 2021, pp. 1–8.
- [13] G. Hua, A. B. J. Teoh, and H. Zhang, “Towards end-to-end synthetic speech detection,” IEEE Signal Processing Letters, vol. 28, pp. 1265–1269, 2021.
- [14] X. Li, N. Li, C. Weng, X. Liu, D. Su, D. Yu, and H. Meng, “Replay and synthetic speech detection with res2net architecture,” in ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021, pp. 6354–6358.
- [15] J.-w. Jung, H.-S. Heo, H. Tak, H.-j. Shim, J. S. Chung, B.-J. Lee, H.-J. Yu, and N. Evans, “Aasist: Audio anti-spoofing using integrated spectro-temporal graph attention networks,” in ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 6367–6371.
- [16] X. Tian, Z. Wu, X. Xiao, E. S. Chng, and H. Li, “An investigation of spoofing speech detection under additive noise and reverberant conditions.” in Proc. Interspeech 2016, 2016, pp. 1715–1719.
- [17] J. Yi, R. Fu, J. Tao, S. Nie, H. Ma, C. Wang, T. Wang, Z. Tian, Y. Bai, C. Fan et al., “Add 2022: the first audio deep synthesis detection challenge,” in ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 9216–9220.
- [18] J. Yamagishi, X. Wang, M. Todisco, M. Sahidullah, J. Patino, A. Nautsch, X. Liu, K. A. Lee, T. Kinnunen, N. Evans, and H. Delgado, “ASVspoof 2021: accelerating progress in spoofed and deepfake speech detection,” in Proc. 2021 ASVspoof Workshop, 2021, pp. 47–54.
- [19] A. Cohen, I. Rimon, E. Aflalo, and H. H. Permuter, “A study on data augmentation in voice anti-spoofing,” Speech Communication, vol. 141, pp. 56–67, 2022.
- [20] T. Chen, A. Kumar, P. Nagarsheth, G. Sivaraman, and E. Khoury, “Generalization of audio deepfake detection,” in Proc. Odyssey 2020 The Speaker and Language Recognition Workshop, 2020, pp. 132–137.
- [21] Y. Zhang, G. Zhu, F. Jiang, and Z. Duan, “An Empirical Study on Channel Effects for Synthetic Voice Spoofing Countermeasure Systems,” in Proc. Interspeech 2021, 2021, pp. 4309–4313.
- [22] R. Yan, C. Wen, S. Zhou, T. Guo, W. Zou, and X. Li, “Audio deepfake detection system with neural stitching for add 2022,” in ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 9226–9230.
- [23] Y. Qian, N. Chen, H. Dinkel, and Z. Wu, “Deep feature engineering for noise robust spoofing detection,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 25, no. 10, pp. 1942–1955, 2017.
- [24] A. Babu, C. Wang, A. Tjandra, K. Lakhotia, Q. Xu, N. Goyal, K. Singh, P. von Platen, Y. Saraf, J. Pino et al., “Xls-r: Self-supervised cross-lingual speech representation learning at scale,” arXiv preprint arXiv:2111.09296, 2021.
- [25] X. Wang and J. Yamagishi, “Investigating self-supervised front ends for speech spoofing countermeasures,” arXiv preprint arXiv:2111.07725, 2021.
- [26] A. Gomez-Alanis, A. M. Peinado, J. A. Gonzalez, and A. M. Gomez, “A gated recurrent convolutional neural network for robust spoofing detection,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 27, no. 12, pp. 1985–1999, 2019.
- [27] G. Dişken, “Differential convolutional network for noise mask estimation,” Applied Acoustics, vol. 211, p. 109568, 2023.
- [28] D. Ma, N. Hou, H. Xu, E. S. Chng et al., “Multitask-based joint learning approach to robust asr for radio communication speech,” in 2021 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC). IEEE, 2021, pp. 497–502.
- [29] A. S. Subramanian, X. Wang, M. K. Baskar, S. Watanabe, T. Taniguchi, D. Tran, and Y. Fujita, “Speech enhancement using end-to-end speech recognition objectives,” in WASPAA 2019. IEEE, 2019, pp. 234–238.
- [30] X. Wang, B. Zeng, S. Hongbin, Y. Wan, and M. Li, “Robust Audio Anti-spoofing Countermeasure with Joint Training of Front-end and Back-end Models,” 2023, pp. 4004–4008.
- [31] C. Hanilci, T. Kinnunen, M. Sahidullah, and A. Sizov, “Spoofing detection goes noisy: An analysis of synthetic speech detection in the presence of additive noise,” Speech Communication, vol. 85, pp. 83–97, 2016.
- [32] Q. Zhang, X. Qian, Z. Ni, A. Nicolson, E. Ambikairajah, and H. Li, “A time-frequency attention module for neural speech enhancement,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 31, pp. 462–475, 2022.
- [33] C. Zheng, H. Zhang, W. Liu, X. Luo, A. Li, X. Li, and B. C. Moore, “Sixty years of frequency-domain monaural speech enhancement: From traditional to deep learning methods,” Trends in Hearing, vol. 27, p. 23312165231209913, 2023.
- [34] D. Cai, W. Cai, and M. Li, “Within-sample variability-invariant loss for robust speaker recognition under noisy environments,” in ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020, pp. 6469–6473.
- [35] S. Shon, H. Tang, and J. Glass, “Voiceid loss: Speech enhancement for speaker verification,” Proc. Interspeech 2019, pp. 2888–2892, 2019.
- [36] K. Kinoshita, T. Ochiai, M. Delcroix, and T. Nakatani, “Improving noise robust automatic speech recognition with single-channel time-domain enhancement network,” in ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020, pp. 7009–7013.
- [37] C. Fan, H. Zhang, J. Yi, Z. Lv, J. Tao, T. Li, G. Pei, X. Wu, and S. Li, “Specmnet: Spectrum mend network for monaural speech enhancement,” Applied Acoustics, vol. 194, p. 108792, 2022.
- [38] C. Fan, J. Yi, J. Tao, Z. Tian, B. Liu, and Z. Wen, “Gated recurrent fusion with joint training framework for robust end-to-end speech recognition,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 29, pp. 198–209, 2020.
- [39] C. Fan, M. Ding, J. Yi, J. Li, and Z. Lv, “Two-stage deep spectrum fusion for noise-robust end-to-end speech recognition,” Applied Acoustics, vol. 212, p. 109547, 2023.
- [40] K. Iwamoto, T. Ochiai, M. Delcroix, R. Ikeshita, H. Sato, S. Araki, and S. Katagiri, “How bad are artifacts?: Analyzing the impact of speech enhancement errors on ASR,” in Proc. Interspeech 2022, 2022, pp. 5418–5422.
- [41] H. Sato, T. Ochiai, M. Delcroix, K. Kinoshita, N. Kamo, and T. Moriya, “Learning to enhance or not: Neural network-based switching of enhanced and observed signals for overlapping speech recognition,” in ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 6287–6291.
- [42] A. Pandey, C. Liu, Y. Wang, and Y. Saraf, “Dual application of speech enhancement for automatic speech recognition,” in 2021 IEEE Spoken Language Technology Workshop (SLT). IEEE, 2021, pp. 223–228.
- [43] Y. Wang, J. Li, H. Wang, Y. Qian, C. Wang, and Y. Wu, “Wav2vec-switch: Contrastive learning from original-noisy speech pairs for robust speech recognition,” in ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 7097–7101.
- [44] Q.-S. Zhu, J. Zhang, Z.-Q. Zhang, M.-H. Wu, X. Fang, and L.-R. Dai, “A noise-robust self-supervised pre-training model based speech representation learning for automatic speech recognition,” in ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 3174–3178.
- [45] C. Zorilă and R. Doddipatla, “Speaker reinforcement using target source extraction for robust automatic speech recognition,” in ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 6297–6301.
- [46] Y. Hu, N. Hou, C. Chen, and E. S. Chng, “Interactive feature fusion for end-to-end noise-robust speech recognition,” in ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 6292–6296.
- [47] J. Gou, B. Yu, S. J. Maybank, and D. Tao, “Knowledge distillation: A survey,” International Journal of Computer Vision, vol. 129, pp. 1789–1819, 2021.
- [48] M. Zhu, K. Han, C. Zhang, J. Lin, and Y. Wang, “Low-resolution visual recognition via deep feature distillation,” in ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2019, pp. 3762–3766.
- [49] Z. Li and D. Hoiem, “Learning without forgetting,” IEEE transactions on pattern analysis and machine intelligence, vol. 40, no. 12, pp. 2935–2947, 2017.
- [50] M. Kim, S. Tariq, and S. S. Woo, “Fretal: Generalizing deepfake detection using knowledge distillation and representation learning,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. IEEE, 2021, pp. 1001–1012.
- [51] Y. Ren, H. Peng, L. Li, X. Xue, Y. Lan, and Y. Yang, “Generalized voice spoofing detection via integral knowledge amalgamation,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 31, pp. 2461–2475, 2023.
- [52] P. Liu, Z. Zhang, and Y. Yang, “End-to-end spoofing speech detection and knowledge distillation under noisy conditions,” in 2021 International Joint Conference on Neural Networks (IJCNN). IEEE, 2021, pp. 1–7.
- [53] W. Liu, Y. Wen, Z. Yu, M. Li, B. Raj, and L. Song, “Sphereface: Deep hypersphere embedding for face recognition,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. IEEE, 2017, pp. 6738–6746.
- [54] S. I. Mirzadeh, M. Farajtabar, A. Li, N. Levine, A. Matsukawa, and H. Ghasemzadeh, “Improved knowledge distillation via teacher assistant,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 04, 2020, pp. 5191–5198.
- [55] N. Müller, F. Dieckmann, P. Czempin, R. Canals, K. Böttinger, and J. Williams, “Speech is Silver, Silence is Golden: What do ASVspoof-trained Models Really Learn?” in Proc. 2021 Edition of the Automatic Speaker Verification and Spoofing Countermeasures Challenge, 2021, pp. 55–60.
- [56] G. Hu and D. Wang, “A tandem algorithm for pitch estimation and voiced speech segregation,” IEEE Transactions on Audio, Speech, and Language Processing, vol. 18, no. 8, pp. 2067–2079, 2010.
- [57] A. Varga and H. J. Steeneken, “Assessment for automatic speech recognition: Ii. noisex-92: A database and an experiment to study the effect of additive noise on speech recognition systems,” Speech communication, vol. 12, no. 3, pp. 247–251, 1993.
- [58] K. Tan and D. Wang, “A convolutional recurrent neural network for real-time speech enhancement.” vol. 2018, 2018, pp. 3229–3233.
- [59] J. Xue, C. Fan, Z. Lv, J. Tao, J. Yi, C. Zheng, Z. Wen, M. Yuan, and S. Shao, “Audio deepfake detection based on a combination of f0 information and real plus imaginary spectrogram features,” in DDAM 2022, 2022, pp. 19–26.
- [60] T.-P. Doan, L. Nguyen-Vu, S. Jung, and K. Hong, “Bts-e: Audio deepfake detection using breathing-talking-silence encoder,” in ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023, pp. 1–5.
- [61] X. Liu, M. Liu, L. Wang, K. A. Lee, H. Zhang, and J. Dang, “Leveraging positional-related local-global dependency for synthetic speech detection,” in ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023, pp. 1–5.
- [62] J. Richter, S. Welker, J.-M. Lemercier, B. Lay, and T. Gerkmann, “Speech enhancement and dereverberation with diffusion-based generative models,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 31, pp. 2351–2364, 2023.
- [63] J. Garofalo, D. Graff, D. Paul, and D. Pallett, “Csr-i (wsj0) complete,” Linguistic Data Consortium, Philadelphia, 2007.
- [64] J. Barker, R. Marxer, E. Vincent, and S. Watanabe, “The third ‘chime’speech separation and recognition challenge: Dataset, task and baselines,” in 2015 IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU). IEEE, 2015, pp. 504–511.
- [65] C. Valentini-Botinhao, X. Wang, S. Takaki, and J. Yamagishi, “Investigating rnn-based speech enhancement methods for noise-robust text-to-speech.” in SSW, 2016, pp. 146–152.
- [66] X. Wang, B. Zeng, H. Suo, Y. Wan, and M. Li, “Robust audio anti-spoofing countermeasure with joint training of front-end and back-end models,” in Proc. Interspeech 2023, vol. 2023, 2023, pp. 4004–4008.
| Cunhang Fan (Member, IEEE) received the Ph.D degree with the National Laboratory of Pattern Recognition (NLPR), Institute of Automation, Chinese Academy of Sciences (CASIA), Beijing, China, in 2021, and the B.S. degree from the Beijing University of Chemical Technology (BUCT), Beijing, China, in 2016. He is currently an associate professor with the School of Computer Science and Technology, Anhui University, Heifei, China. His current research interests include speech enhancement, fake speech detection, speech recognition and speech processing. |
![[Uncaptioned image]](mm.jpg) |
Mingming Ding received a B.S. degree in civil engineering from Anhui Jianzhu University in 2018. She is currently currently studying for a M.S. degree in computer science and technology from Anhui University. Her main interests include speech enhancement, speech anti-spoofing and deep learning. |
| Jianhua Tao (Senior Member, IEEE) received the M.S. degree from Nanjing University, Nanjing, China, in 1996, and the Ph.D. degree from Tsinghua University, Beijing, China, in 2001. He is currently a Professor with Department of Automation, Tsinghua University, Beijing, China. He has authored or coauthored more than 300 papers on major journals and proceedings including the IEEE TASLP, IEEE TAFFC, IEEE TIP, IEEE TSMCB, Information Fusion, etc. His current research interests include speech recognition and synthesis, affective computing, and pattern recognition. He is the Board Member of ISCA, the chairperson of ISCA SIG-CSLP, the Chair or Program Committee Member for several major conferences, including Interspeech, ICPR, ACII, ICMI, ISCSLP, etc. He was the subject editor for the Speech Communication, and is an Associate Editor for Journal on Multimodal User Interface and International Journal on Synthetic Emotions. He was the recipient of several awards from important conferences, including Interspeech, NCMMSC, etc. |
![[Uncaptioned image]](furuibo.jpg) |
Ruibo Fu (Member, IEEE) is an assistant professor in the National Laboratory of Pattern Recognition, Institute of Automation, Chinese Academy of Sciences, Beijing. He obtained B.E. from Beijing University of Aeronautics and Astronautics in 2015 and Ph.D. from the Institute of Automation, Chinese Academy of Sciences in 2020. His research interest is speech synthesis and transfer learning. He has published more than 20 papers in international conferences and journals such as ICASSP and INTERSPEECH and has won the best paper award twice in NCMMSC 2017 and 2019. He won the first prize in the personalized speech synthesis competition held by the Ministry of Industry and Information Technology twice in 2019 and 2020. He also won the first prize in the ICASSP2021 Multi-Speaker Multi-Style Voice Cloning Challenge (M2VoC) Challenge. |
| Jiangyan Yi (Member, IEEE) received the Ph.D. degree from the University of Chinese Academy of Sciences, Beijing, China, in 2018, and the M.A. degree from the Graduate School of Chinese Academy of Social Sciences, Beijing, in 2010. During 2011 to 2014, she was a Senior R&D Engineer with Alibaba Group. She is currently an Associate Professor with the State Key Laboratory of Multimodal Artificial Intelligence Systems, Institute of Automation, Chinese Academy of Sciences. Her research interests include speech signal processing, speech recognition and synthesis, fake audio detection, audio forensics, and transfer learning. |
| Zhengqi Wen (Member, IEEE) received the B.S.degree from the University of Science and Technology of China, Hefei, China, in 2008, and the Ph.D. degree from the Chinese Academy of Sciences, Beijing, China, in 2013, both in pattern recognition and intelligent system. He is currently an Associate Professor with the National Laboratory of Pattern Recognition Institute of Automation, Chinese Academy of Sciences. His current research interests include speech processing, speech recognition, and speech synthesis. |
| Zhao Lv (Member, IEEE) received his Ph.D. degree in Computer Application Technology from Anhui University, Hefei, China, in 2011. He was a visiting scholar with the University of Utah, Salt Lake City, USA, from 2017 to 2018. He is currently a professor in the School of Computer Science and Technology at Anhui University, Hefei, China. His research interests include intelligent information processing and pattern recognition regarding biomedical signals (EEG, EOG, etc.) as well as speech signal processing. |