潜在空间中基于分数的扩散的混合类型表格数据合成
摘要
表格数据生成的最新进展极大地提高了综合数据质量。 然而,由于表格数据的分布错综复杂且数据类型混合,将扩散模型扩展到表格数据具有挑战性。 本文介绍了 TabSyn,这是一种通过利用变分自动编码器 (VAE) 制作的潜在空间中的扩散模型来合成表格数据的方法。 所提出的 TabSyn 的主要优点包括 (1) 通用性:通过将各种数据类型转换为单个统一空间并显式捕获数据类型来处理广泛的数据类型的能力。列关系,(2) 质量:优化潜在嵌入的分布,以增强扩散模型的后续训练,有助于生成高质量的合成数据,(3) 速度 :与现有的基于扩散的方法相比,反向步骤数量少得多,合成速度更快。 对具有五个指标的六个数据集进行的广泛实验表明,TabSyn 优于现有方法。 具体来说,与最具竞争力的基线相比,它将列分布和成对列相关估计的错误率降低了 86% 和 67%。 代码已在 https://github.com/amazon-science/tabsyn 上提供。
1简介
表格数据合成具有广泛的应用,例如增强训练数据(Fonseca&Bacao,2023),保护私有数据实例(Assefa等人,2021;Hernandez等人,2022) ,并估算缺失值(Zheng & Charoenphakdee,2022)。 表格数据生成的最新进展显着提高了合成数据的质量(Xu 等人, 2019; Borisov 等人, 2023; Liu 等人, 2023b),但合成数据与实际数据仍有很大差距。真实的。 为了进一步提高生成质量,研究人员探索将在图像合成任务中表现出色的扩散模型(Ho等人,2020年;Rombach等人,2022年)用于表格数据生成(Kim等人,2022年;Kotelnikov等人,2023年;Kim等人,2023年;Lee等人,2023年)。 尽管这些方法取得了进展,但为表格数据定制扩散模型仍面临一些挑战。 与由具有局部空间相关性的纯连续像素值组成的图像数据不同,表格数据特征具有复杂且变化的分布(徐等人,2019),使得学习多列的联合概率变得困难。 此外,典型的表格数据通常包含混合数据类型,即连续(例如数字特征)和离散(例如分类特征)变量。 标准扩散过程假设具有高斯噪声扰动的连续输入空间,这导致了分类特征的额外挑战。 现有的解决方案要么使用 one-hot 编码 (Kim 等人,2023;Liu 等人,2023b) 和模拟位编码 (Zheng & Charoenphakdee,2022)等技术将分类特征转换为数值特征。 或对数值和分类特征采用两个独立的扩散过程(Kotelnikov 等人,2023;Lee 等人,2023)。 然而,事实证明,简单的编码方法会导致性能不佳(Lee等人,2023),并且针对不同数据类型学习单独的模型使得模型捕获共现模式变得具有挑战性不同类型的数据。 因此,我们寻求在数值和分类特征的联合空间中开发一种扩散模型,以保留列间相关性。
本文提出了TabSyn,这是一种表格数据合成的原理方法。 TabSyn 首先将原始表格数据转换为连续嵌入空间,在该空间中,具有高斯噪声的完善扩散模型变得可行。 随后,我们在嵌入空间中学习基于分数的扩散模型,以捕获潜在嵌入的分布。 为了学习信息丰富、平滑的潜在空间,同时保持解码器的重建能力,我们专门为表格结构数据设计了变分自动编码器(VAE (Kingma & Welling,2013))模型。 我们提出的 VAE 模型包括 1)Transformer 架构编码器和解码器,用于对列间关系进行建模并获取 Token 级表示,从而促进 Token 级任务。 2)自适应损失权重,动态调整重建损失权重和KL散度权重,使模型在保持正则化嵌入空间的同时逐渐提高重建性能。 3)最后,当在潜在空间中应用扩散模型时,我们采用简化的前向扩散过程,添加相对于时间的线性标准偏差的高斯噪声。 我们通过理论分析和实证证明,这种方法可以减少逆向过程中的误差,从而提高采样速度。 TabSyn的优点有三个:(1)通用性:混合类型特征处理 - TabSyn转换将不同的输入特征(包括数字、分类等)放入统一的嵌入空间中。 (2) 质量:高生成质量 - 通过VAE模型的定制设计,表格数据被映射到良好形状的正则化潜在空间,例如标准正态分布。 这将大大简化后续扩散模型(Vahdat等人,2021)的训练,使TabSyn更具表现力,并使其能够生成高质量的合成数据。 (3) 速度:利用所提出的线性噪声调度,我们的TabSyn可以用少于个反向步骤生成高质量的合成数据,即明显少于现有方法。
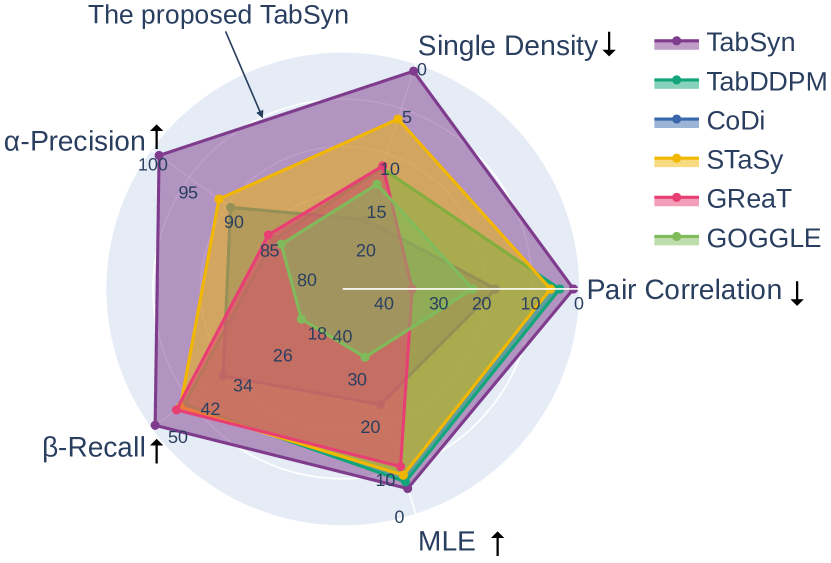
认识到表格数据合成方法缺乏统一和全面的评估,我们进行了广泛的实验,其中涉及使用超过五个在六个混合类型表格数据集上将 TabSyn 与七种最先进的方法进行比较不同的评估指标。 实验结果表明 TabSyn 始终优于以前的方法(见图1)。 具体来说,TabSyn 将列分布形状估计(即单密度)和成对列相关估计(即成对相关)任务中的平均误差降低了 和 比最具竞争力的基线。 此外,我们还证明 TabSyn 在两个下游表格数据任务、机器学习效率和缺失值插补方面实现了具有竞争力的性能。 具体来说,经过充分学习的无条件 TabSyn 能够应用于缺失值插补,而无需重新训练。 此外,彻底的消融研究和可视化案例研究证实了我们开发的方法的基本原理和有效性。
2相关作品
用于表格数据生成的深度生成模型。
表格数据的生成模型变得越来越重要并具有广泛的应用Assefa 等人 (2021);郑和 Charoenphakdee (2022);埃尔南德斯等人 (2022)。 为了处理不平衡的分类特征,Xu 等人 (2019) 在流行的生成对抗网络 (Goodfellow 等人, 2014) 和 VAE (Kingma & Welling,2013),分别。 去年,人们提出了多种用于合成表格数据生成的先进方法。 具体来说,GOGGLE (Liu 等人, 2023b) 成为第一个对列之间的依赖关系进行显式建模的人,提出了一种基于 VAE 的模型,使用图神经网络作为编码器和解码器模型。 受到大型语言模型在自然语言分布建模方面取得的成功的启发,GReaT 将表中的每一行转换为自然句子,并使用自回归 GPT2 学习句子级分布。 近年来,物理扩散过程激发了深度学习领域的许多高级研究。 例如,DIFFormer (Wu 等人, 2023) 通过约束扩散过程开发了一种可扩展的几何数据 Transformer 模型,而 Denoising Diffusion 模型在图像生成方面取得了巨大成功(Ho 等人,2020)。 STaSy (Kim 等人, 2023)、TabDDPM (Kotelnikov 等人, 2023) 和 CoDi (Lee 等人, 2023) 同时适用用于合成表格数据生成的流行的基于扩散的生成模型。
潜在空间中的生成建模。
虽然数据空间中的生成模型取得了巨大的成功,但潜在生成模型已经展示了多种优势,包括更紧凑和解缠结的表示、对噪声的鲁棒性以及控制生成样式的更大灵活性(van den Oord等人,2017; Razavi 等人,2019;Esser 等人,2021)。 例如,最近的 GAN 文献(Li 等人,2022)通过潜在空间中的对抗性学习证明了卓越的可控性。 最近,潜在扩散模型(LDM)(Rombach 等人,2022;Vahdat 等人,2021) 在图像生成方面取得了巨大成功,因为它们比普通扩散模型表现出更好的缩放特性和表现力。数据空间(Ho 等人, 2020; Song 等人, 2021b; Karras 等人, 2022)。 LDM 在图像生成方面的成功也启发了它们在视频(Blattmann 等人,2023)和音频数据(Liu 等人,2023a)中的应用。 据我们所知,所提出的工作是第一个探索潜在扩散模型在一般表格数据生成任务中的应用的工作。
3 使用 TabSyn 生成综合表格数据
图2给出了TabSyn的概述。 在3.1节中,我们首先正式定义表格数据生成任务。 然后,我们在3.2和3.3节中介绍了TabSyn的自动编码和扩散过程的设计细节。 我们在附录A中总结了训练和采样算法。

3.1 表格数据生成的问题定义
令 和 分别为数字列和分类列的数量。 每行都表示为数字特征和分类特征 的向量,其中 和 。 具体来说,第 个分类属性具有 个有限候选值,因此我们有 。 本文重点关注无条件生成任务。 通过表格数据集,我们的目标是学习参数化生成模型,通过该模型可以生成真实且多样化的合成表格数据。
3.2 表格数据的自动编码
表格数据是由混合类型的列特征组成的高度结构化的数据,不同的列具有不同的含义并且彼此高度依赖。 这些特征使得设计近似编码器来建模并有效利用列之间的丰富关系变得具有挑战性。 受 Transformers 在表格数据分类/回归方面取得的成功(Gorishniy 等人,2021) 的启发,我们首先为每一列学习一个独特的分词器,然后词符(列)方面的表示为输入到 Transformer 中以捕获列之间复杂的关系。
特征标记器。 特征分词器将每一列(数值列和分类列)转换为 维向量。 首先,我们使用 one-hot 编码来预处理分类特征,即 。 每条记录表示为。 然后,我们对数值列应用线性变换,并为分类列创建嵌入查找表,其中每个类别都分配有一个可学习的 维向量,即
| (1) |
其中 、 是标记器 的可学习参数。 现在,每条记录都表示为所有列嵌入的堆栈
| (2) |
Transformer 编码和解码。 与典型的 VAE 一样,我们使用编码器来获取潜在变量的均值和对数方差。 然后,我们通过重新参数化技巧获得潜在嵌入。 然后将潜在嵌入通过解码器以获得重建的词符矩阵。 详细架构参见附录D。
解标记器。 最后,我们将去标记器应用于每列恢复的词符表示以重建列值。 去标记器的设计与标记器的设计是对称的:
| (3) |
其中,是detokenizer的参数。
使用自适应权重系数进行训练。
VAE模型通常使用经典的ELBO损失函数来学习,但这里我们使用-VAE (Higgins等人, 2016),其中系数 平衡重建损失和KL散度损失的重要性
| (4) |
是输入数据和重建数据之间的重建损失,是对潜在空间的均值和方差进行正则化的KL散度损失。 在普通 VAE 模型中, 设置为 ,因为这两个损失项对于从高斯噪声生成高质量合成数据同样重要。 然而,在我们的模型中, 预计会更小,因为我们不需要嵌入的分布精确遵循标准高斯分布,因为我们有一个额外的扩散模型。 因此,我们建议在训练过程中自适应地安排 的尺度,鼓励模型在保持适当的嵌入形状的同时实现较低的重建误差。
使用初始(最大值),我们监控历元重建损失。 当在预定义的epoch数内未能减少时(这表明KL散度主导了整体损失),权重由安排。 此过程一直持续到 接近预定义的最小值。 这种策略简单但非常有效,我们在4节中凭经验证明了设计的有效性。
3.3潜在空间中基于分数的生成建模
通过去噪进行训练和采样。
充分学习 VAE 模型后,我们通过编码器提取潜在嵌入,并将编码器的输出展平为 ,使得记录的嵌入是向量而不是矩阵。 为了了解嵌入的底层分布,我们考虑以下前向扩散过程和反向采样过程(Song等人,2021b;Karras等人,2022):
| (5) | |||||
| (6) |
其中 是编码器的初始嵌入, 是时间 时的扩散嵌入, 是噪声级别。 在逆过程中,是的得分函数,是标准维纳过程。 扩散模型的训练是通过去噪分数匹配(Karras等人,2022)来实现的:
| (7) |
其中是一个神经网络(称为去噪函数),使用扰动数据和时间来近似高斯噪声。然后。 模型训练完成后,可以通过式(1)的逆过程获得合成数据。 6。 TabSyn的详细算法描述在附录A中提供。 详细推导见附录B。
噪声级的时间表。
噪声水平定义了在不同时间步扰动数据的噪声规模,并显着影响最终的微分方程解轨迹(Song等人,2021b;Karras等人,2022). 根据 Karras 等人 (2022) 中的建议,我们设置与线性关系的噪声级别 。 时间。 我们在命题 1 中表明,线性噪声水平计划在逆过程中导致最小的近似误差:
Proposition 1。
考虑方程(6)中从到的反向扩散过程,数值解具有最小的近似误差当时。
4对综合表格数据生成算法进行基准测试
4.1 实验设置
基线。 我们将所提出的 TabSyn 与七种现有的合成表格数据生成方法进行比较。 前两个是经典的 GAN 和 VAE 模型:CTGAN (Xu 等人, 2019) 和 TVAE (Xu 等人, 2019)。 此外,我们评估了最近推出的五种 SOTA 方法:GOGGLE (Liu 等人, 2023b),一种基于 VAE 的方法; GREAT (Borisov 等人, 2023),一种语言模型变体;以及三种基于扩散的方法:STaSy (Kim 等人, 2023)、TabDDPM (Kotelnikov 等人, 2023) 和 CoDi (Lee 等人, 2023 )。 值得注意的是,这些方法几乎是同时引入的,限制了广泛比较的机会。 作为参考,我们还与代表性的基于插值的方法 SMOTE (Chawla 等人,2002)进行了比较。 我们的论文通过在标准化环境中首次对他们的表现进行全面评估来填补这一空白。
评估方法。 我们从三个方面评估合成数据的质量:1)低阶统计 - 列密度估计和成对列相关性,估计每个单列的密度以及每个列对之间的相关性(第4.2节)。 我们还通过测试是否可以通过机器学习模型从真实数据中检测到合成数据来评估密度估计性能(附录F.3)。 2) 高阶指标 – -精确度和-召回分数(Alaa 等人, 2022) 衡量合成数据的整体保真度和多样性(结果推迟到附录F.2),以及 3) 下游性能任务 – 机器学习效率 (MLE) 和缺失值插补0>。 MLE 是在综合生成的表格数据集上进行训练时,比较真实数据的测试准确性。 隐私保护的性能是通过先前文献中广泛采用的MLE任务来衡量的(第4.3.1节)。 我们还为缺失值插补任务扩展了 TabSyn,其目的是在给定部分列值的情况下填充缺失的特征/标签(附录 F.4)。
实施细节。 报告的结果是对随机采样的合成数据进行平均。 实施细节见附录E。
4.2估计数据密度的低阶统计量
指标。 我们对数值列采用柯尔莫哥洛夫-西尔诺夫检验 (KST),对分类列采用总变异距离 (TVD) 来量化按列密度估计。 对于成对列相关性,我们对数值列使用皮尔逊相关性,对分类列使用列联相似性。 性能是通过根据实际数据和合成数据计算出的相关性之间的差异来衡量的。 对于数值列和分类列之间的相关性,我们首先通过分桶将数值分组为分类列,然后计算相应的列联相似度。 有关这些指标的更多详细信息,请参见附录 E.3。
| Method | Adult | Default | Shoppers | Magic | Beijing | News | Average | |
| SMOTE | ||||||||
| CTGAN | ||||||||
| TVAE | ||||||||
| GOGGLE1 | ||||||||
| GReaT2 | OOM | |||||||
| STaSy | ||||||||
| CoDi | ||||||||
| TabDDPM3 | ||||||||
| TabSyn | ||||||||
| Improv. |
-
1
GOGGLE fixes the random seed during sampling in the official codes, and we follow it for consistency.
-
2
GReaT cannot be applied on News because of the maximum length limit.
-
3
TabDDPM fails to generate meaningful content on the News dataset.
| Method | Adult | Default | Shoppers | Magic | Beijing | News | Average | |
| SMOTE | ||||||||
| CTGAN | ||||||||
| TVAE | ||||||||
| GOGGLE | ||||||||
| GReaT | OOM | |||||||
| STaSy | ||||||||
| CoDi | ||||||||
| TabDDPM | ||||||||
| TabSyn | ||||||||
| Improve. |
列式分布密度估计。
在表 1 中,我们注意到 TabSyn 在按列分布密度估计任务中始终优于基线方法。 平均而言,TabSyn 比最具竞争力的基线超出 。 虽然 STaSy 和 TabDDPM 表现良好,但 STaSy 并不是最优的,因为它将分类列的 one-hot 嵌入视为连续特征。 此外,TabDDPM 在整个数据集上表现出不稳定的性能,尽管有标准的训练过程,但无法在新闻数据集上生成有意义的内容。
成对列相关性。
表2显示成对列相关的结果。 TabSyn 的平均性能优于最佳基线 。 值得注意的是,GReaT 在该任务中的性能明显比在按列任务中差。 这表明自回归语言模型在密度估计方面的局限性,特别是在捕获列之间的联合概率分布方面。
4.3 下游任务的性能
4.3.1 机器学习效率
然后,我们通过评估合成数据在机器学习效率任务中的表现来评估合成数据的质量。 按照既定的设置(Kotelnikov等人,2023;Kim等人,2023;Lee等人,2023),我们首先将真实表分成真实训练集和真实测试集。 生成模型是在真实训练集上学习的,并从中采样了等效大小的合成集。 然后,使用这些合成数据来训练分类/回归模型(XGBoost 分类器和 XGBoost 回归器(Chen & Guestrin,2016)),该模型将使用真实测试集进行评估。 MLE 的性能通过分类任务的 AUC 分数和回归任务的 RMSE 来衡量。 MLE评估的详细设置参见附录E.4。
在表 3 中,我们证明 TabSyn 始终优于所有基线方法。 与按列密度和成对列相关性估计任务相比,方法之间的性能差距更小(表1和2)。 这表明某些列可能不会显着影响分类/回归任务,从而允许在先前任务中性能较低的方法在 MLE 中显示有竞争力的结果(例如,默认数据集上的 GReaT)。 这强调了对 MLE 指标之外的综合评估方法的需求。 如上所示,我们合并了低阶和高阶统计数据以进行更稳健的评估。
| Methods | Adult | Default | Shoppers | Magic | Beijing | News1 | Average Gap |
| AUC | AUC | AUC | AUC | RMSE | RMSE | ||
| Real | |||||||
| SMOTE | |||||||
| CTGAN | |||||||
| TVAE | |||||||
| GOGGLE | |||||||
| GReaT | OOM | ||||||
| STaSy | |||||||
| CoDi | |||||||
| TabDDPM2 | |||||||
| TabSyn |
-
1
Following CoDi (Lee et al., 2023), the continuous targets are standardized to prevent large values.
-
2
TabDDPM collapses on News, leading to an extremely high error on this dataset. We exclude this dataset
when computing the average gap of TabDDPM.
4.3.2 缺失值估算和隐私保护
4.4消融研究
自适应-VAE的效果。
我们评估了 VAE 模型中调度权重系数 的有效性。 图3展示了预定值和恒定值(来自)的重建损失和KL散度损失的趋势> 到 )跨越 4,000 个时期的训练。 值得注意的是,较大的值会导致重建效果不佳,而较小的值会导致嵌入分布与标准高斯分布之间存在较大差异,从而难以实现平衡。 相反,通过在训练期间动态调度(),我们不仅可以防止过度的KL发散,还可以提高质量。 表 4 通过合成数据质量(单列密度和成对列相关性估计任务)进一步评估从 VAE 模型的各种 值学习到的嵌入。 这证明了我们提出的 VAE 模型预定 训练方法的卓越性能。

| Single | Pair | |
| Scheduled |
线性噪声水平的影响。
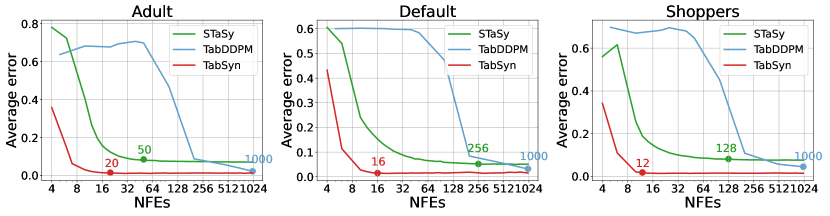
我们评估在扩散过程中使用线性噪声水平 的有效性。 正如 3.3 节所述,线性噪声会导致线性轨迹和更快的采样速度。 因此,我们根据相对于函数评估 (NFE) 数量的单列密度和成对列相关估计误差,对 TabSyn 和其他两种扩散模型(STaSy 和 TabDDPM)进行比较,即,去噪步骤生成真实数据。 作为连续时间扩散模型,所提出的 TabSyn 和 STaSy 在选择 NFE 方面非常灵活。 对于TabDDPM,我们使用DDIM采样器(Song等人,2021a)来调整NFE。 图 4 显示 TabSyn 不仅显着提高了采样速度,而且始终能产生更好的性能(使用少于 20 个 NFE 即可获得最佳结果)。 相比之下,STaSy 需要 50-200 个 NFE(因数据集而异),并且实现了次优性能。 TabDDPM 在 1,000 个 NFE 的情况下实现了具有竞争力的性能,但在减少 NFE 时性能显着下降。
| Variants | Single | Pair |
| TabDDPM | ||
| TabSyn-OneHot | ||
| TabSyn-DDPM | ||
| TabSyn |
比较不同的编码/扩散方法。
我们通过创建两个 TabSyn 变体来评估在 VAE 学习的潜在空间中学习扩散模型的有效性:1)TabSyn-OneHot:用 one-hot 编码替换 VAE分类变量和 2) TabSyn-DDPM:用 TabDDPM 中使用的 DDPM 代替方程 (5) 中的扩散过程。 表5中的结果表明:1)分类变量的One-hot编码加上连续扩散模型导致性能最差,表明将分类列简单地视为连续特征是不合适的; 2) TabSyn-潜在空间中的 DDPM 优于数据空间中的 TabDDPM,凸显了学习高质量潜在嵌入对于改进扩散建模的好处; 3)TabSyn超越TabSyn-DDPM,表明在连续潜在空间中采用定制扩散模型以实现更好的数据分布学习的优势。
4.5可视化
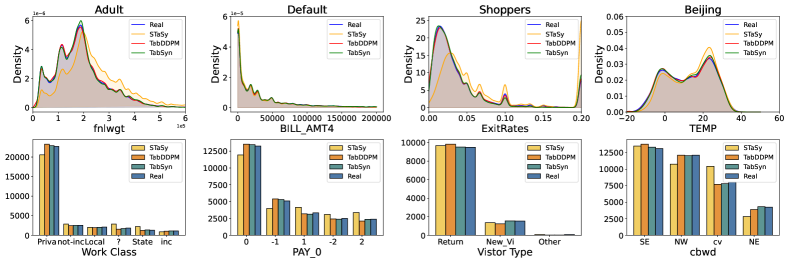
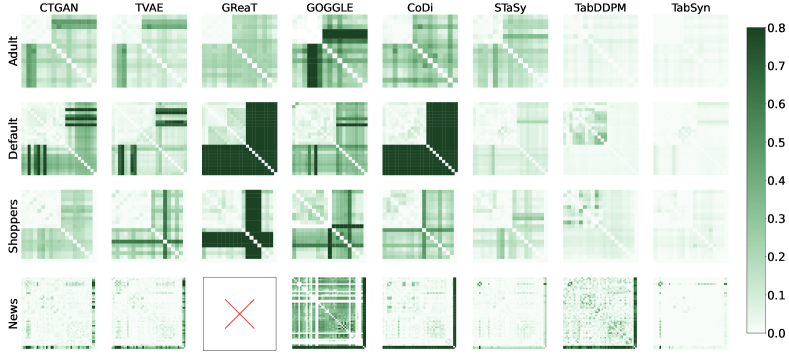
在图5中,我们比较了四个数据集(每个数据集一个数字和一个分类)的八列的列密度。 TabDDPM 在数字列上与 TabSyn 的准确性相匹配,但在分类列上则较差。 图6显示了估计的成对列相关性与实际相关性之间的散度热图。 TabSyn 给出最准确的相关性估计,而其他方法则表现出次优的性能。 这些结果证明,在潜在空间中采用生成建模可以增强对分类特征和联合列分布的学习。
5结论
在本文中,我们提出了用于合成表格数据生成的TabSyn。 TabSyn 框架利用 VAE 将表格数据映射到潜在空间,然后利用基于扩散的生成模型来学习潜在分布。 这种方法具有在统一潜在空间中容纳数值和分类特征的双重优势,从而有助于更全面地理解它们的相互关系,并能够在连续嵌入空间中利用先进的生成模型。 为了解决潜在的挑战,TabSyn提出了模型设计和训练方法,从而形成了高度稳定的生成模型。 此外,TabSyn通过采用多种评估指标将所提出的方法与现有方法进行全面比较,纠正了先前研究的不足,展示了生成的样本在捕获原始数据方面的卓越质量和保真度分配。
参考
- Alaa et al. (2022) Ahmed Alaa, Boris Van Breugel, Evgeny S Saveliev, and Mihaela van der Schaar. How faithful is your synthetic data? sample-level metrics for evaluating and auditing generative models. In International Conference on Machine Learning, pp. 290–306. PMLR, 2022.
- Assefa et al. (2021) Samuel A. Assefa, Danial Dervovic, Mahmoud Mahfouz, Robert E. Tillman, Prashant Reddy, and Manuela Veloso. Generating synthetic data in finance: Opportunities, challenges and pitfalls. In Proceedings of the First ACM International Conference on AI in Finance, ICAIF ’20. Association for Computing Machinery, 2021. ISBN 9781450375849.
- Ba et al. (2016) Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer normalization. arXiv preprint arXiv:1607.06450, 2016.
- Blattmann et al. (2023) Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dockhorn, Seung Wook Kim, Sanja Fidler, and Karsten Kreis. Align your latents: High-resolution video synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 22563–22575, 2023.
- Borisov et al. (2023) Vadim Borisov, Kathrin Sessler, Tobias Leemann, Martin Pawelczyk, and Gjergji Kasneci. Language models are realistic tabular data generators. In The Eleventh International Conference on Learning Representations, 2023.
- Chawla et al. (2002) Nitesh V Chawla, Kevin W Bowyer, Lawrence O Hall, and W Philip Kegelmeyer. Smote: synthetic minority over-sampling technique. Journal of artificial intelligence research, 16:321–357, 2002.
- Chen & Guestrin (2016) Tianqi Chen and Carlos Guestrin. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pp. 785–794, 2016.
- Esser et al. (2021) Patrick Esser, Robin Rombach, and Bjorn Ommer. Taming transformers for high-resolution image synthesis. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 12873–12883, 2021.
- Fonseca & Bacao (2023) Joao Fonseca and Fernando Bacao. Tabular and latent space synthetic data generation: a literature review. Journal of Big Data, 10(1):115, 2023.
- Goodfellow et al. (2014) Ian J Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. In Proceedings of the 27th International Conference on Neural Information Processing Systems, pp. 2672–2680, 2014.
- Gorishniy et al. (2021) Yury Gorishniy, Ivan Rubachev, Valentin Khrulkov, and Artem Babenko. Revisiting deep learning models for tabular data. In Proceedings of the 35th International Conference on Neural Information Processing Systems, pp. 18932–18943, 2021.
- Hernandez et al. (2022) Mikel Hernandez, Gorka Epelde, Ane Alberdi, Rodrigo Cilla, and Debbie Rankin. Synthetic data generation for tabular health records: A systematic review. Neurocomputing, 493:28–45, 2022.
- Higgins et al. (2016) Irina Higgins, Loic Matthey, Arka Pal, Christopher Burgess, Xavier Glorot, Matthew Botvinick, Shakir Mohamed, and Alexander Lerchner. beta-vae: Learning basic visual concepts with a constrained variational framework. In The Forth International Conference on Learning Representations, 2016.
- Ho et al. (2020) Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In Proceedings of the 34th International Conference on Neural Information Processing Systems, pp. 6840–6851, 2020.
- Hoogeboom et al. (2021) Emiel Hoogeboom, Didrik Nielsen, Priyank Jaini, Patrick Forré, and Max Welling. Argmax flows and multinomial diffusion: Learning categorical distributions. In Proceedings of the 35th International Conference on Neural Information Processing Systems, pp. 12454–12465, 2021.
- Karras et al. (2022) Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models. In Proceedings of the 36th International Conference on Neural Information Processing Systems, pp. 26565–26577, 2022.
- Kim et al. (2022) Jayoung Kim, Chaejeong Lee, Yehjin Shin, Sewon Park, Minjung Kim, Noseong Park, and Jihoon Cho. Sos: Score-based oversampling for tabular data. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pp. 762–772, 2022.
- Kim et al. (2023) Jayoung Kim, Chaejeong Lee, and Noseong Park. Stasy: Score-based tabular data synthesis. In The Eleventh International Conference on Learning Representations, 2023.
- Kingma & Ba (2015) Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In International Conference on Learning Representations, 2015.
- Kingma & Welling (2013) Diederik P Kingma and Max Welling. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114, 2013.
- Kotelnikov et al. (2023) Akim Kotelnikov, Dmitry Baranchuk, Ivan Rubachev, and Artem Babenko. Tabddpm: Modelling tabular data with diffusion models. In International Conference on Machine Learning, pp. 17564–17579. PMLR, 2023.
- Lee et al. (2023) Chaejeong Lee, Jayoung Kim, and Noseong Park. Codi: Co-evolving contrastive diffusion models for mixed-type tabular synthesis. In International Conference on Machine Learning, pp. 18940–18956. PMLR, 2023.
- Li et al. (2022) Yang Li, Yichuan Mo, Liangliang Shi, and Junchi Yan. Improving generative adversarial networks via adversarial learning in latent space. Advances in Neural Information Processing Systems, 35:8868–8881, 2022.
- Liu et al. (2023a) Haohe Liu, Zehua Chen, Yi Yuan, Xinhao Mei, Xubo Liu, Danilo Mandic, Wenwu Wang, and Mark D Plumbley. Audioldm: Text-to-audio generation with latent diffusion models. arXiv preprint arXiv:2301.12503, 2023a.
- Liu et al. (2023b) Tennison Liu, Zhaozhi Qian, Jeroen Berrevoets, and Mihaela van der Schaar. Goggle: Generative modelling for tabular data by learning relational structure. In The Eleventh International Conference on Learning Representations, 2023b.
- Lugmayr et al. (2022) Andreas Lugmayr, Martin Danelljan, Andres Romero, Fisher Yu, Radu Timofte, and Luc Van Gool. Repaint: Inpainting using denoising diffusion probabilistic models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 11461–11471, 2022.
- Razavi et al. (2019) Ali Razavi, Aäron van den Oord, and Oriol Vinyals. Generating diverse high-fidelity images with vq-vae-2. In Proceedings of the 33rd International Conference on Neural Information Processing Systems, pp. 14866–14876, 2019.
- Rombach et al. (2022) Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 10684–10695, 2022.
- Song et al. (2021a) Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. In The Ninth International Conference on Learning Representations, 2021a.
- Song et al. (2021b) Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. In The Ninth International Conference on Learning Representations, 2021b.
- Vahdat et al. (2021) Arash Vahdat, Karsten Kreis, and Jan Kautz. Score-based generative modeling in latent space. In Proceedings of the 35th International Conference on Neural Information Processing Systems, pp. 11287–11302, 2021.
- van den Oord et al. (2017) Aaron van den Oord, Oriol Vinyals, and Koray Kavukcuoglu. Neural discrete representation learning. In Proceedings of the 31st International Conference on Neural Information Processing Systems, pp. 6309–6318, 2017.
- Wu et al. (2023) Qitian Wu, Chenxiao Yang, Wentao Zhao, Yixuan He, David Wipf, and Junchi Yan. Difformer: Scalable (graph) transformers induced by energy constrained diffusion. In The Eleventh International Conference on Learning Representations, 2023.
- Xu et al. (2019) Lei Xu, Maria Skoularidou, Alfredo Cuesta-Infante, and Kalyan Veeramachaneni. Modeling tabular data using conditional gan. In Proceedings of the 33rd International Conference on Neural Information Processing Systems, pp. 7335–7345, 2019.
- Zheng & Charoenphakdee (2022) Shuhan Zheng and Nontawat Charoenphakdee. Diffusion models for missing value imputation in tabular data. arXiv preprint arXiv:2210.17128, 2022.
附录A算法
附录 B扩散模型基础知识
扩散模型通常表示为一对两个过程。
-
•
模型的训练由固定的前向过程控制,该过程将尺度递增的高斯噪声添加到原始数据中。
-
•
相应的后向过程涉及迭代地利用经过训练的模型从完全噪声的先验分布开始对样本进行去噪。
B.1 转发过程
虽然扩散模型有不同的数学公式(离散或连续),但宋等人(2021b)通过随机微分方程(SDE)提供了统一的公式,并将扩散的前向过程定义为(请注意,在本文中,自变量表示为)
| (8) |
其中 和 是漂移和扩散系数,并且针对不同的扩散过程进行不同的选择,例如方差保持 (VP) 和方差爆炸 (VE) 公式。 是标准维纳过程。 通常, 的形式为。 因此,SDE 可以等效地写为
| (9) |
假设 是时间 的函数,即 ,那么给定 的 的条件分布(称为 SDE 的扰动核)可以表述为
| (10) |
在哪里
| (11) |
因此,前向扩散过程可以通过定义扰动核(通过定义适当的和)来等效地表述。
方差保持(VP)实现了扰动核方程。 10 通过设置 和 ()。 去噪扩散概率模型(DDPM,Ho等人(2020))属于VP-SDE,使用离散有限时间步长并给出的具体函数定义。
B.2 逆向过程
B.3训练
附录C证明
C.1 命题证明1
我们首先引入引理1(来自(Karras等人, 2022)),它引入了一系列具有不同转发过程的共享相同解决方案轨迹的SDE:
Lemma 1.
令 为 的自由参数函数,以下(正向)SDE 系列具有与噪声水平 相同的解轨迹边际分布对于 的任何选择:
| (19) |
由于我们的转发扩散过程(等式5)让(参见附录B中的推导),它的解决轨迹可以通过让 在等式中20:
| (21) |
等式。 21 通常被称为概率流 ODE,因为它描述了没有噪声项的确定性逆过程。 根据引理1,我们可以研究式(1)的解。 6 使用等式。 21。
从开始,就有。
的的解可以使用一阶欧拉法得到:
| (23) |
| (24) |
具体来说,如果,则有
| (25) |
类似地,设置 (如 VE-SDE Song 等人 (2021b))会导致
| (26) |
因此,证明完成。
附录D网络架构
D.1 VAE的架构
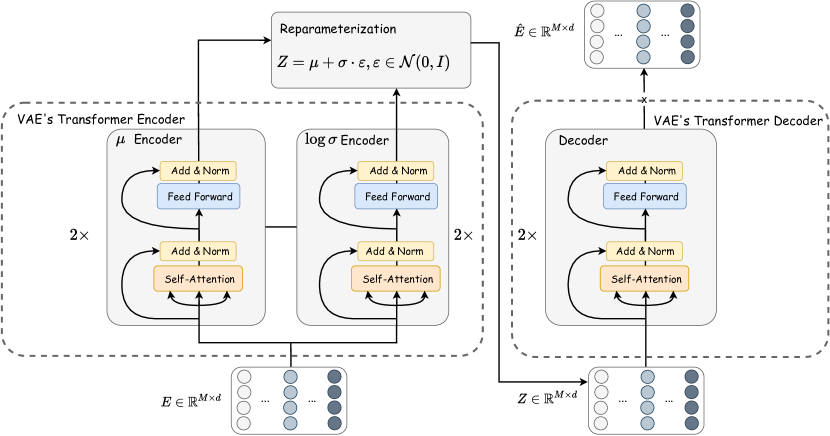
VAE 的编码器将分词器的输出 作为输入。 由于我们使用的是变分自动编码器,编码器模块由相同架构的 编码器和 编码器组成。 每个编码器都实现为一个两层 Transformer,每个都有一个自注意力(无多头)模块和一个前馈神经网络(FFNN)。 TabSyn 中使用的 FFNN 是一个带有 ReLU 激活的简单两层 MLP(FFNN 的输入用 表示):
| (27) |
其中FC表示全连接层,是FFNN的隐藏维度。 在本文中,我们为所有数据集设置和。 图7中的“Add & Norm”分别表示残差连接和Layer Normalization(Ba等人, 2016)。
VAE编码器输出两个矩阵:均值矩阵和对数标准差矩阵。 然后,通过参数化技巧获得潜在变量:
| (28) |
VAE的解码器是另一个与编码器架构相同的两层Transformer,它以作为输入。 解码器预计会为去标记器输出 。
D.2 去噪MLP的架构
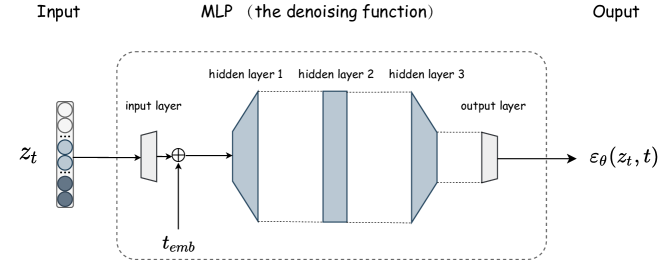
去噪MLP以当前时间步和相应的潜在向量作为输入。 首先,被输入线性投影层,将向量维度转换为:
| (29) |
其中 是变换后的向量, 是输入层的输出维度。
然后,按照TabDDPM (Kotelnikov 等人, 2023)中的做法,将正弦时间步嵌入与相加,得到输入向量:
| (30) |
隐藏层是大小为 的三个全连接层,具有 SiLU 激活函数(与 TabDDPM (Kotelnikov 等人, 2023) 一致):
| (31) |
估计分数是通过最后一个线性层获得的:
| (32) |
最后,将 应用于等式。 7 用于模型训练。
附录 E实验设置详细信息
我们使用 PyTorch 实现 TabSyn 和所有基线方法。 所有方法均使用 Adam (Kingma & Ba, 2015) 优化器进行优化。 所有实验均在具有 24G 内存的 Nvidia RTX 4090 GPU 上进行。
E.1 数据集
我们使用来自 UCI 机器学习存储库的 表格数据集111https://archive.ics.uci.edu/datasets:Adult、Default、Shoppers、Magic、Beijing 和 News,其中每个表格数据集都与一个机器学习任务相关联。 分类:成人、默认、魔法和购物者。 回归:北京和新闻。 数据集的统计数据如表6所示。
| Dataset | # Rows | # Num | # Cat | # Train | # Validation | # Test | Task |
| Adult | Classification | ||||||
| Default | Classification | ||||||
| Shoppers | Classification | ||||||
| Magic | Classification | ||||||
| Beijing | Regression | ||||||
| News | Regression |
表6中,#Rows表示表中的行(记录)数。 # Num 和 # Cat 分别表示数值特征和分类特征的数量。 请注意,目标列被计为数字或分类特征,具体取决于任务类型。 具体来说,如果任务是分类,则目标列属于分类列;否则,它是一个数字列。 每个数据集都分为机器学习效率实验的训练集、验证集和测试集。 由于Adult有其官方的测试集,我们直接使用它作为测试集。 Adult 的原始训练集进一步分为训练和验证,比例为 。 剩余的数据集被分成训练/验证/测试集,其比例为 并具有固定种子。
下面对各个数据集进行详细介绍:
-
•
成人222https://archive.ics.uci.edu/dataset/2/adult:“Adult人口普查收入”数据集包含人口统计和就业相关特征。 任务是预测一个人的收入是否超过。
-
•
默认333https://archive.ics.uci.edu/dataset/350/default+of+credit+card+clients:“信用卡客户数据集Default”数据集包含有关违约的信息2005年4月至2005年9月台湾信用卡客户的付款、人口因素、信用数据、付款历史和账单。 任务是预测客户下个月是否会拖欠付款。
-
•
购物者444https://archive.ics.uci.edu/dataset/468/online+shoppers+purchasing+intention+dataset:“在线Shoppers购买意向数据集”包含用户访问的网页信息会议。 任务是预测用户的会话是否以购物行为结束。
-
•
魔法555https://archive.ics.uci.edu/dataset/159/magic+gamma+telescope:“Magic伽马望远镜”数据集是模拟高能伽马粒子在使用成像技术的地面大气切伦科夫伽马望远镜。 任务是对大气中的高能伽马粒子进行分类。
-
•
北京666https://archive.ics.uci.edu/dataset/381/beijing+pm2+5+data:“北京PM2.5数据”数据集包含每小时的PM2.5数据美国驻北京大使馆的气象数据和北京首都国际机场的气象数据。 任务是预测PM2.5值。
-
•
新闻777https://archive.ics.uci.edu/dataset/332/online+news+popularity:“在线新闻流行度”数据集包含一组关于 Mashable 发布的文章的异构特征两年内。 目标是预测社交网络中的分享数量(受欢迎程度)。
E.2 基线
在本节中,我们介绍并比较本文使用的基线方法的属性。
-
•
CTGAN和TVAE是一篇论文(Xu等人,2019)中提出的两种合成表格数据生成方法,使用相同的技术,但是基于不同的基本生成模型 - CTGAN 为 GAN,TVAE 为 VAE。 这两种方法包含两个重要的设计:1)特定于模式的归一化,用于处理具有复杂分布的数值列。 2)基于分类列有条件生成数值列,以处理类别不平衡问题。
-
•
GOGGLE (Liu 等人, 2023b)是最近提出的一种基于VAE的合成表格数据生成模型。 GOGGLE 的主要动机是以前的文献很难利用不同列之间的复杂关系。 因此,它提出学习图邻接矩阵来建模不同列之间的依赖关系。 VAE模型的编码器和解码器均实现为图神经网络(GNN),并且图邻接矩阵与GNN参数联合优化。
-
•
GREaT (Borisov 等人, 2023) 将一行表格数据视为一个句子,并应用自回归 GPT 模型来学习句子级行分布。 GreaT 涉及一个精心设计的序列化过程,将行转换为特定格式的自然语言句子,以及相应的反序列化过程,将句子转换回表格式。 为了保证表格数据的排列不变性,GReaT 在序列化之前对每一行进行多次洗牌。
-
•
STaSy (Kim 等人, 2023) 是一种最新的基于扩散的合成表格数据生成模型。 STaSy 将分类列的独热编码视为连续特征,然后与数值列一起处理。 STaSy 采用 Song 等人 (2021b) 中的 VP/VE SDE 作为扩散过程来学习表格数据的分布。 STaSy 进一步提出了几种训练策略,包括自定进度学习和微调,以稳定过程,提高采样质量和多样性。
-
•
CoDi (Lee 等人, 2023) 提出分别对数值列和分类列使用两种扩散模型。 对于数值列,它使用带有高斯噪声的 DDPM (Ho 等人, 2020) 模型。 对于分类列,它使用带有分类噪声的多项扩散模型(Hoogeboom等人,2021)。 这两个扩散过程相互制约,以模拟数值列和分类列的联合分布。 此外,CoDi采用对比学习方法进一步绑定两种扩散方法。
-
•
TabDDPM (Kotelnikov 等人,2023)。 与 CoDi 一样,TabDDPM 引入了两种扩散过程:针对数值列的具有高斯噪声的 DDPM 和针对分类列的带有分类噪声的多项式扩散。 与 CoDi 不同,CoDi 引入了许多附加技术,例如通过互条件学习和对比学习进行协同进化学习,TabDDPM 将数字和分类特征连接起来作为去噪函数(MLP)的输入和输出。 尽管它很简单,但我们的实验表明 TabDDPM 的性能甚至比 CoDi 更好。
我们在表 7 中进一步比较了这些基线方法和建议的 TabSyn 的属性。 比较的属性包括: 1) 兼容性:该方法是否可以处理混合类型的数据列,例如数字和分类。 2) 鲁棒性:该方法在不同数据集上是否具有稳定的性能(通过分数的标准差(或不)来衡量)在不同数据集上(来自表1 和表2)。 3) 质量:合成数据是否能够通过列卡方检验()。 4)效率:每种方法都可以在不到步内生成满足质量的合成表格数据。
| Method | Base Model | Compatibility | Robustness | Quality | Efficiency | |
| CTGAN | GAN | ✓ | ✗ | ✗ | ✓ | |
| TVAE | VAE | ✓ | ✓ | ✗ | ✓ | |
| GOGGLE | VAE | ✗ | ✗ | ✗ | ✓ | |
| GReaT | AR | ✓ | ✗ | ✗ | ✗ | |
| STaSy | Diffusion | ✗ | ✓ | ✓ | ✗ | |
| CoDi | Diffusion | ✓ | ✗ | ✗ | ✗ | |
| TabDDPM | Diffusion | ✓ | ✗ | ✓ | ✗ | |
| TabSyn | Diffusion | ✓ | ✓ | ✓ | ✓ |
E.3 低阶统计量的度量
在本节中,我们详细介绍了 Sec. 中使用的指标。 4.2。
E.3.1 逐列密度估计
Kolmogorov-Sirnov 检验 (KST):给定两个(连续)分布 和 ( 表示实数, 表示合成),KST 使用两个相应的累积分布函数 (CDF) 之间的差异上限来量化两个分布之间的距离:
| (33) |
其中 和 分别是 和 的 CDF:
| (34) |
总变异距离(TVD):TVD计算每个类别值的频率并将其表示为概率。 那么,TVD 分数是类别概率之间的平均差:
| (35) |
其中 描述了 列中所有可能的类别。 和 表示这些类别的真实频率和合成频率。
E.3.2 成对列相关性
皮尔逊相关系数:皮尔逊相关系数衡量两个连续分布是否线性相关,计算公式为:
| (36) |
其中 和 是两个连续的列。 Cov 是协方差, 是标准差。
然后,相关性估计的性能通过真实数据的相关性和合成数据的校正之间的平均差异来衡量:
| (37) |
其中和分别表示真实数据和合成数据的列和列之间的皮尔逊相关系数。 如,将平均分数除以,以确保其落在范围内,则分数越小,估计越好。
列联相似性:对于一对分类列 和 ,列联相似性得分使用总变异距离计算列联表之间的差异。 该过程总结为以下公式:
| (38) |
其中 和 分别描述 列和 列中所有可能的类别。 和分别是和在真实数据和合成数据中的联合频率。
E.4 机器学习效率实验的详细信息
MLE 任务上的合成数据的性能是根据使用真实和合成训练数据的测试分数的差异来评估的。 因此,我们首先在真实训练集上训练机器学习模型,并按 比例分为训练集和验证集。 分类器/回归器在训练集上进行训练,并根据验证集上的性能选择最佳超参数设置。 获得最佳超参数设置后,在训练集上重新训练相应的分类器/回归器,并在真实测试集上进行评估。 我们为训练集和验证集创建 20 个随机分割,表 3 中报告的性能是 随机轨迹的 AUC/RMSE 分数的平均值和标准差。 以同样的方式获得合成数据的性能。
下面是 MLE 任务中使用的 XGBoost 分类器/回归器的超参数搜索空间,我们通过网格搜索选择最佳超参数。
-
•
估计器数量:[10, 50, 100]
-
•
儿童最低体重:[5,10,20]。
-
•
最大树深度:[1,10]。
-
•
伽玛:[0.0,1.0]。
我们使用 SDMetric888https://docs.sdv.dev/sdmetrics。
附录F附加实验结果
在本节中,我们以 Adult 数据集为例,比较不同方法的训练和采样时间。
F.1 训练/采样时间
| Method | Training | Sampling |
| CTGAN | 1029.8s | 0.8621s |
| TVAE | 352.6s | 0.5118s |
| GOGGLE | 1h 34min | 5.342s |
| GReaT | 2h 27min | 2min 19s |
| STaSy | 2283s | 8.941s |
| CoDi | 2h 56min | 4.616s |
| TabDDPM | 1031s | 28.92s |
| TabSyn | 1758s + 664s | 1.784s |
如图8所示,虽然有一个额外的VAE训练过程,但所提出的TabSyn与大多数基线方法具有相似的训练时间。 在采样时间上,TabSyn只需要s即可生成与Adult训练数据大小相同的合成数据,接近一步采样方法CTGAN和电视AE。 其他基于扩散的方法需要更长的采样时间。 例如,最具竞争力的方法 TabDDPM (Kotelnikov 等人, 2023) 需要 s 进行采样。 所提出的 TabSyn 将采样时间减少了 ,并实现了更好的合成质量。
F.2 合成数据的样本质量得分(-Precison 和 -Recall)
秒中的实验。 4 使用低阶统计量评估了不同模型生成的合成数据的性能,包括列式密度估计(表1)和成对列相关性估计(表2)。 然而,这些结果不足以评估合成数据的整体密度估计性能,因为生成模型可能只是简单地学习单独估计每个单列的密度,而不是所有列的联合概率。 此外,MLE 任务也无法反映整体密度估计性能,因为一些不重要的列可能会被忽略。 因此,在本节中,我们采用高阶度量,更关注整个数据分布,即所有列的联合分布。
继Liu 等人(2023b)和Alaa 等人(2022)之后,我们采用-精度和-回想一下 Alaa 等人 (2022) 中提出的两个样本级指标,用于量化合成数据的可信度。 一般来说,-Precision评估合成数据的保真度——每个合成示例是否来自真实数据分布,-Recall评估合成数据的覆盖范围,例如,合成数据是否能够覆盖真实数据的整个分布(即真实数据样本是否接近合成数据)。 Liu等人(2023b)还采用了第三个指标,真实性——合成样本是随机生成的还是简单地从真实数据中复制而来。 然而,我们发现真实性得分和 β 召回率表现出显着的负相关性——它们的总和几乎恒定,并且 β 召回率的提高通常伴随着真实性得分的下降(我们认为这就是真实性得分相对较小的原因)。 GOGGLE 中各个模型的质量得分差异(Liu 等人, 2023b))。 因此,我们认为 beta-recall 和真实性不适合同时使用。
在表9和表10中,我们分别报告了-精确度和-召回率的分数。 TabSyn 在所有数据集上获得了最好的-精度分数,证明了 TabSyn 在生成接近真实数据的合成数据方面的卓越能力。 在表 10 中,我们观察到 TabSyn 在六个数据集上始终获得较高的 -召回分数。 尽管一些基线方法在特定数据集上获得了较高的回忆分数,但很难得出这些方法生成的合成数据质量更好的结论,因为1)它们的合成数据的-精度分数(例如,Adult 上的 GREaT,Magic 上的 STaSy),表明合成数据与真实数据的流形相差甚远; 2)他们未能在其他数据集上表现出稳定的竞争性能(例如,GREaT 在 Adult 上具有较高的 -Recall 分数,但在 Magic 上的分数较差)。 我们认为,评估生成的质量,首先考虑的是生成的数据是否足够真实(-精度),其次是生成的数据是否能够覆盖真实数据集的所有模式(-回忆)。 根据这个标准,TabSyn 生成的数据质量是最高的。 它不仅拥有最高的保真度得分,而且在每个数据集上始终表现出极高的覆盖率。
| Methods | Adult | Default | Shoppers | Magic | Beijing | News | Average | Ranking |
| CTGAN | ||||||||
| TVAE | ||||||||
| GOGGLE | 8 | |||||||
| GReaT | - | |||||||
| STaSy | ||||||||
| CoDi | ||||||||
| TabDDPM | ||||||||
| TabSyn |
| Methods | Adult | Default | Shoppers | Magic | Beijing | News | Average | Ranking |
| CTGAN | ||||||||
| TVAE | ||||||||
| GOGGLE | ||||||||
| GReaT | - | |||||||
| STaSy | ||||||||
| CoDi | ||||||||
| TabDDPM | ||||||||
| TabSyn |
F.3检测:分类器两个样本测试(C2ST)
我们进一步研究区分真实数据和合成数据的难度,从而评估合成数据是否可以恢复真实数据分布。 为此,我们采用 sdmetrics 999https://docs.sdv.dev/sdmetrics/metrics/metrics-in-beta/detection-single-table。 在表11中,我们展示了使用逻辑回归作为检测方法获得的结果。
| Method | Adult | Default | Shoppers | Magic | Beijing | News |
| SMOTE | ||||||
| CTGAN | ||||||
| TVAE | ||||||
| GOGGLE | ||||||
| GReaT | - | |||||
| STaSy | ||||||
| CoDi | ||||||
| TabDDPM | ||||||
| TabSyn |
如表中所示,与其他指标(例如单列密度估计、成对列形状估计和 MLE)相比,检测分数表现出卓越的判别能力。 检测分数显示合成数据生成的不同模型之间存在显着差异。 如表中所示,与其他指标(例如单列密度估计、成对列形状估计和 MLE)相比,检测分数表现出卓越的判别能力。 检测分数显示合成数据生成的不同模型之间存在显着差异。 所提出的 TabSyn 在所有数据集上始终获得显着的高分(SMOTE (Chawla 等人, 2002) 直接在训练集中进行插值,因此它获得高分也就不足为奇了检测指标中的分数。)。
F.4 缺失值插补
调整 TabSyn 以进行缺失值插补
扩散模型的一个重要优点是无条件模型可以直接用于缺失数据插补任务(例如图像修复 (Song 等人, 2021b; Lugmayr 等人, 2022) 和缺失值插补) )无需再培训。 遵循Lugmayr等人(2022)中提出的修复方法,我们在缺失值插补任务中应用了建议的TabSyn。
对于一行表格数据、、。 假设屏蔽数字列的索引集是,屏蔽分类列的索引集是,我们首先对屏蔽列进行如下预处理:
-
•
屏蔽数字列的值设置为该列的平均值,即。
-
•
屏蔽的分类列设置为 。
更新后的(我们省略了剩余部分中的下标)被馈送到TabSyn的冻结VAE编码器以获得嵌入。 由于 TabSyn 的 VAE 采用 Transformer 架构,因此数据空间 和 中的屏蔽索引到数据空间中的屏蔽索引存在确定性映射。潜在空间。 例如,数值列的第一个维度映射到中的维度到。 因此,我们可以创建一个掩蔽向量来指示每个维度是否被掩蔽。 那么的已知部分和未知部分可以分别表示为和。
继Lugmayr等人(2022)之后,反向步骤被修改为已知部分的转发和未知部分的去噪的混合:
| (39) |
从时间到的反向插补还涉及重采样,以减少每个步骤带来的误差(Lugmayr等人,2022)。 重采样表明方程。 39 将重复从 到 的 个步骤。 完成相反的步骤后,我们获得了估算的潜在向量,可以将其放入TabSyn的VAE解码器中以恢复原始输入数据。
缺失值插补的算法在算法4中给出。
分类/回归作为缺失值插补。
通过算法 4,我们可以使用 TabSyn 对任何缺失的列进行插补。 在本节中,我们考虑一个更有趣的应用——直接将分类/回归视为缺失值插补任务。 如 E.1 节所示,每个数据集都分配有一个机器学习任务,即数据集中目标列的分类或回归。 因此,我们可以对目标列的值进行屏蔽,然后应用TabSyn对屏蔽值进行插补,完成分类或回归任务。
在表12中,我们展示了TabSyn在每个数据集的目标列上缺失值插补任务中的性能。 将性能与直接训练分类器/回归器、使用剩余列来预测目标列(机器学习效率任务中的“真实”行,表 3)进行比较。 令人惊讶的是,使用 TabSyn 进行插补在所有数据集上都显示出极具竞争力的结果。 在六个数据集中的四个上,TabSyn 的表现优于在真实数据上训练判别 ML 分类器/回归器。 我们怀疑造成这种现象的原因可能是训练判别性机器学习模型更容易在集合上过度拟合。 相比之下,通过学习整个数据的平滑分布,生成模型显着降低了过度拟合的风险。 缺失值插补任务的出色结果进一步凸显了我们提出的 TabSyn 对于实际应用的重要性。
我们的 TabSyn 没有在其他列上针对缺失值插补任务进行条件训练,并且可以通过专门针对该任务训练单独的条件模型来进一步提高性能。 我们把它留到以后的工作中。
| Methods | Adult | Default | Shoppers | Magic | Beijing | News |
| AUC | AUC | AUC | AUC | RMSE | RMSE | |
| Real with XGBoost | ||||||
| Impute with TabSyn |
F.5 VAE质量的影响
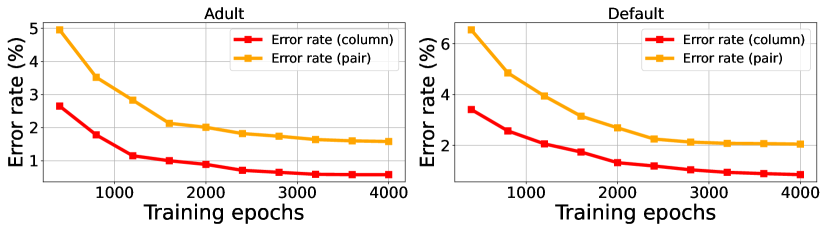
直观上,TabSyn 的性能似乎高度依赖于预训练 VAE 模型的质量。 因此,我们进行了进一步的研究,以调查训练较少的 VAE 模型将如何影响 TabSyn 生成的合成数据的质量。 为此,我们使用在不同时期获得的 VAE 的嵌入作为潜在空间来研究 TabSyn 生成的合成数据的质量。 图9绘制了Adult和Default数据集上的单列密度估计和成对列相关性估计的结果,间隔设置为400个epoch。 我们可以观察到,增加 VAE 的训练周期确实提高了 TabSyn 生成数据的质量。 此外,即使 VAE 训练不是最优的(例如 2000 年左右的 epoch),TabSyn 的性能也已经非常接近最优性能。 此外,即使 VAE 训练次数相对较少(例如 800-1200),TabSyn 的性能也接近甚至超过了最具竞争力的基线 TabDDPM。 基于这一观察,我们建议彻底训练 VAE,以在资源丰富时实现卓越的数据生成质量。 然而,当资源有限时,减少 VAE 训练持续时间仍然可以获得不错的性能。
F.6隐私保护:最近记录距离(DCR)
为了研究合成数据是否会导致隐私信息泄露问题,我们计算了合成数据的 DCR。 具体来说,我们遵循“合成与保留”设置 101010https://www.clearbox.ai/blog/2022-06-07-synthetic-data-for-privacy-
preservation-part-2。 我们最初将数据集分为两个相等的部分:第一部分作为生成模型的训练集,而第二部分被指定为保留集,不用于 。 完成模型训练后,我们对与训练集(和保留集)大小相同的合成集进行采样。
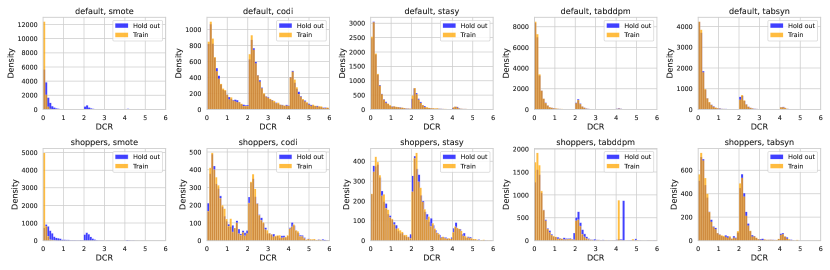
然后,我们计算合成集中每个样本的 DCR 分数,涉及训练集和保留集。 我们可以创建直方图来可视化合成集与训练集和保留集相比的 DCR 分数分布。 直观上,如果存在隐私问题(例如,如果直接从训练集中复制合成集),则训练集的 DCR 分数应该比测试集的 DCR 分数更接近 0。 相反,如果不存在隐私问题,训练集和保留集的 DCR 分数的分布应该大部分重叠。 在图10中,我们绘制了关于默认集和购物者集和保留集的合成集 DCR 的分布。 我们可以观察到,CoDi、STaSy、TabDDPM 和 TabSyn 等深度生成模型不会遇到隐私问题,而基于插值的方法 SMOTE 可能无法保护隐私信息。
此外,我们还计算合成样本更接近训练集(而不是保留集)的概率。 当该概率接近 50%(即 0.5)时,表明合成实例和训练实例之间的距离分布与合成实例和保留实例之间的距离分布非常相似(或者至少不是系统地小于),即隐私风险方面的积极指标。 表13显示了不同模型在默认数据集和购物者数据集上获得的结果。
| Method | Default | Shoppers |
| SMOTE | % | % |
| STaSy | % | % |
| CoDi | % | % |
| TabDDPM | % | % |
| TabSyn | % | % |
附录 G复制详细信息
在本节中,我们将介绍 TabSyn 的详细信息,例如数据预处理、训练和超参数详细信息。 我们还介绍了基线方法的再现细节。
G.1 实施TabSyn的详细信息
数据预处理。
现实世界的表格数据通常包含缺失值,并且每列的数据可能具有不同的比例。 因此,我们需要对数据进行预处理。 按照 TabDDPM (Kotelnikov 等人, 2023),缺失的单元格将用数字列的平均值填充。 对于分类列,缺失的单元格被视为一种附加类别。 然后,使用 QuantileTransformer111111https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.QuantileTransformer.html/OneHotEncoder121212https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.OneHotEncoder.html分别来自 scikit-learn。
超参数设置。
标签同步 对不同的数据集使用相同的参数集。 (购物者的 除外)。 TabSyn 的 VAE 和 Diffusion 模型的详细架构分别在附录 D.1 和附录 D.2 中介绍。 下面是详细的超参数设置。
VAE的超参数:
-
•
词符维度,
-
•
VAE编码器/解码器层数:,
-
•
Transformer FFN 的隐藏维度:,
-
•
( 对于购物者),
-
•
,
-
•
。
扩散的超参数:
-
•
MLP的隐藏维度。
与当前一些方法中繁琐的超参数搜索过程(Kotelnikov等人,2023;Kim等人,2023;Lee等人,2023)不同,TabSyn持续生成高质量数据,无需细致的超参数调整。
G.2 实施基线的详细信息
由于不同的方法采用了不同的神经网络架构,因此使用相同的网络来比较不同方法的性能是不合适的。 为了公平比较,我们调整了不同方法的隐藏维度,确保可训练参数的数量接近(大约百万)。 请注意,扩大模型大小确实会提高基线方法的性能。 在这些条件下,我们根据官方代码重现了基线方法,并且我们重现的代码在补充中提供了。 以下是基线的详细实现。
CTGAN 和 TVAE (Xu 等人, 2019):对于 CTGAN,我们按照官方代码中的实现131313https://github.com/sdv-dev/CTGAN,其中超参数很好-给定。 由于默认的判别器/生成器 MLP 很小,为了公平比较,我们将它们放大到与 TabSyn 相同的大小。 没有提供 TVAE 的接口,因此我们只需使用 TVAE 模块中定义的默认超参数。 TVAE的编码器/解码器的尺寸也扩大了。
GOGGLE (Liu 等人, 2023b):我们遵循官方实现141414https://github.com/vanderschaarlab/GOGGLE。 在GOGGLE的官方实现中,每个节点就是一列,节点特征就是该列的维数值。 然而GOGGLE没有说明,也没有解释如何处理分类列151515https://github.com/tennisonliu/GOGGLE/issues/2。 为了将 GOGGLE 扩展到混合类型的表格数据,我们首先将每个分类列转换为其 维单热编码。 然后, 二进制值的每个单一维度就成为图节点。 因此,对于 数值列和 分类列以及 的第 分类列的混合类型表格数据类别,GOGGLE 的图表有 节点。
GREaT:我们遵循官方实现161616https://github.com/kathrinse/be_great/tree/main。 在我们的复现过程中,我们发现GReaT的训练非常消耗内存和时间(因为它是在对大型语言模型进行微调)。 通常,成人数据集上的批量大小限制为 ,并且 epoch 的训练需要超过 小时。 此外,由于 GReaT 是基于文本的,因此不能保证生成的内容遵循给定表格的格式。 因此,必须进行额外的后处理。
STaSy (Kim 等人, 2023):在 STaSy 中,分类列采用 one-hot 编码,然后与数值列一起放入连续扩散模型。 我们遵循官方代码给出的默认超参数171717https://github.com/JayoungKim408/STaSy/tree/main 除了去噪函数的大小之外,为了公平比较而将其放大。
CoDi (Lee 等人, 2023):我们遵循官方代码给出的默认超参数181818https://github.com/ChaejeongLee/CoDi/tree/main。 类似地,CoDi使用的去噪U-Net也被放大,以确保模型参数相似。
TabDDPM (Kotelnikov 等人, 2023):TabDDPM 官方代码191919https://github.com/yandex-research/tab-ddpm 用于条件生成任务,其中非目标列以目标列为条件生成。 我们稍微修改一下代码以应用于无条件生成。