EffOCR:用于高效数字化世界知识的可扩展开源包
摘要
数十亿公共领域文档仍然被困在硬拷贝中或缺乏准确的数字化。 现代自然语言处理方法无法用于索引、检索和总结其文本;进行计算文本分析;或提取信息进行统计分析,这些文本训练无法纳入语言模型。 鉴于公共领域文本的多样性和数量庞大,大规模释放它们需要准确的光学字符识别 (OCR)、部署成本极低,并且样本效率高,可以根据新颖的集合、语言和字符集进行定制。 现有的 OCR 引擎主要是为高资源语言的小规模商业应用程序而设计的,通常无法满足这些要求。 EffOCR (EfficientOCR) 是一种新颖的开源 OCR 软件包,通过以下方式满足大规模解放文本的计算和样本效率要求:放弃通常用于 OCR 的序列到序列架构,该架构将学习的视觉模型的表示作为学习的语言模型的输入。 相反,EffOCR 将 OCR 建模为字符或单词级图像检索问题。 EffOCR 对于训练来说成本低且样本效率高,因为模型只需要学习字符的视觉外观,而不需要学习它们如何按顺序使用来形成语言。 EffOCR 模型库中的模型只需几行代码即可现成部署,其中包括专为移动电话设计的轻量级模型,部署成本极低。 重要的是,EffOCR 训练 还允许通过简单的模型界面进行简单、示例高效的定制,并且由于其示例效率而将标签要求降至最低。 我们通过廉价而准确地数字化 2000 万份美国历史报纸扫描件、评估从美国国家档案馆随机选择的文档的零样本性能,以及准确地数字化日本文档集来说明 EffOCR 的实用性。 OCR 解决方案失败。
1简介
大量文档集仍然被困在硬拷贝中或缺乏准确的数字化文本。 例如,美国国家档案馆拥有大约 132.8 亿页的文本记录,其中大部分属于公共领域。111对于在美国发布的文件,公有领域包括美国政府官员/雇员在执行公务过程中发布的任何内容,所有发布时间超过95年前,以及1989年之前发布的一些内容,要么没有发布通知,要么没有更新版权。 例如,在当地报纸 Ockerbloom (2019) 等出版物中,这种情况很常见。 详情请参阅补充材料。 这些文件之所以被保存下来,是因为它们对美国政府的运作至关重要,具有长期研究价值,或者为公众提供有价值的信息,但处理其中大多数文件成本高昂且耗时。 美国国家档案馆并不是独一无二的:许多其他国家都拥有国家档案馆,其公共领域馆藏的藏书量达数十亿页,更不用说州和地方档案馆和图书馆了。 如果没有准确的机器可读数据,现代自然语言处理(NLP)工具就无法用于索引、检索和总结材料;进行计算文本分析;或提取信息进行统计调查。 公共领域文本如果准确数字化,还可以为训练大型语言模型提供大规模信息,并且不存在侵犯版权的风险。
使用光学字符识别 (OCR) 大规模数字化公共领域馆藏会带来一些挑战。
成本:首先,考虑到文档集合的大小达到数百万甚至数十亿页,OCR 解决方案的部署成本必须低廉。 商业引擎以及大型开源 OCR 模型都远远达不到这一要求。 使用它们对大规模藏品进行数字化需要天文数字的预算。
准确性:其次,数字化文本需要足够准确,以满足高度多样化的最终用户的目标。 准确性对于定量应用尤其重要,小错误可能会产生重大的统计异常值。 较低资源语言的模型(如果存在)往往比英语等高资源设置的模型表现得更差。
示例高效、简单的训练: 文档在字体或笔迹、语言、脚本、背景以及扫描和老化的伪像方面存在高度异构性。 现有的 OCR 解决方案无法对多种文档进行零样本处理,尤其是在资源匮乏的语言中。 然而想要将这些文档数字化的利益相关者很少熟悉深度学习框架。 将高质量 OCR 引入低资源环境需要一个简单的 API 进行训练和一个示例高效架构,以及可访问的计算和标注负担。
各种预训练和可调整的模型: 用户有不同的精度需求、扩展要求和预算。 全面的 OCR 解决方案可以轻松比较不同规模模型的准确性和部署成本,以便用户可以选择最适合其特定应用需求的解决方案。
为了实现这些目标,我们开发了 EffOCR,这是一个开源 OCR 软件包,专为寻求计算和样本高效 OCR 解决方案以数字化不同文档集合的研究人员、图书馆和档案馆而设计。 EffOCR 有两个关键要素:1) 新颖的 OCR 架构;2) 精心设计的界面,以促进现成的 OCR 使用、必要时通过模型训练进行定制以及轻松共享 OCR 模型。
Carlson 等人 (2023) 详细介绍了新颖的 EffOCR 模型架构,我们将准确性、样本效率和部署成本与一系列流行的 OCR 引擎进行了比较。 简而言之,OCR 主要将文本识别建模为序列到序列 (seq2seq) 问题,其中从视觉模型中学习到的表示被视为学习到的语言模型的输入。 学习如何按顺序使用视觉嵌入来形成语言需要大量数据。 例如,主要的 Transformer 序列到序列 OCR 包 Li 等人 (2021b) 使用 32 个 32GB V100 GPU 卡对 6.84 亿个文本行进行训练。 最先进的 seq2seq OCR 的样本调整效率低下,并且用户无法扩展到低资源语言,这些语言甚至可能没有可用于初始化模型的 Transformer 大语言模型(大语言模型),因为语言建模的进步集中在不到两打语言Joshi 等人 (2020)。 使用低资源文档的典型利益相关者的训练预算极低,深度学习框架的经验也有限,这凸显了对具有易于使用的 API 的样本效率更高的框架的需求。
此外,seq2seq OCR 需要自回归解码,这使得推理速度比并行解码(其他条件相同)慢。
EffOCR 放弃了文献中占主导地位的 seq2seq OCR 模型,而是将 OCR 建模为单词或字符级图像检索问题。 EffOCR 首先使用高精度、可扩展的对象检测方法来本地化单词Ultalytics (2023);陈等人 (2019);吴等人(2019)。 然后将识别建模为对比训练的图像检索问题,其中相同字符或单词的图像嵌入具有相似的表示,无论其风格如何。 EffOCR 主要针对数字字体进行训练,并结合现实文档中的少量字符和文字裁剪。 在推理时,通过计算使用数字字体创建的示例嵌入的离线字典中的最近邻来识别字符/单词。 Carlson 等人 (2023) 使用英语、日语和 Polytonic Greek 基准表明,EffOCR 架构准确、样本效率高、训练成本低且速度极快使用专为移动电话设计的主干网时进行部署。
为了应对大规模和低资源文档集合数字化的挑战,EffOCR 软件包包含以下组件:
-
1.
一个现成的工具包,只需几行代码即可应用 OCR 模型
-
2.
预训练 OCR 模型的存储库,是现成使用的基础
-
3.
ONNX 运行时支持快速部署
-
4.
用于高效模型调整的综合工具
-
5.
支持流行后端的模型 Chen 等人 (2019);用于初始化本地化的 Ultalytics (2023) 以及用于初始化识别的任何 timm 支持的模型
-
6.
轻松共享模型,促进可重用性、再现性和可扩展性
EffOCR 已经过广泛测试。 例如,我们使用它以低廉的成本将 2000 万页极其异构的历史公共领域美国报纸扫描件数字化,并将大规模输出发布到 Hugging Face。222https://huggingface.co/datasets/dell-research-harvard/AmericanStories 创建此数据集如果没有 EffOCR,在我们有限的预算范围内满足准确性要求是不可能的。 我们还检查了现有 OCR 解决方案无法提供可用输出的情况下的性能,并在随机选择的美国国家档案馆文档上测试了零样本性能,模型在训练期间没有看到任何类似内容。 教程可在 https://effocr.github.io/ 获取。
EffOCR 拥有 GNU 通用公共许可证。 它正在得到积极维护,并且正在进行注释众包,以将预训练的模型动物园扩展到其他语言和设置(包括手写)。
2 与其他 OCR 引擎的比较
关于 OCR 的文献有大量。 这里主要关注的是广泛使用的 OCR 软件,它们是 EffOCR 最合理的替代品。
EffOCR - 顾名思义 - 专为需要计算或样本效率的应用程序而定制。 Carlson 等人 (2023) 进行了详细的实验,将 EffOCR 架构与其他广泛使用的解决方案进行比较,考虑准确性、样本效率和计算效率。 我们建议感兴趣的读者阅读该论文以了解详细信息,总结此处出现的两个关键主题。
定制是高度相关的: 正如大多数研究人员仍在使用数据输入公司所表明的那样,有时现有的 OCR 解决方案无法提供可接受的准确性。 对于 20 世纪中叶的日文打字文档,这些文档与研究日本在 20 世纪的卓越增长表现具有相当大的相关性,Carlson 等人 (2023) 表明,性能最佳的引擎(百度、领先的商业搜索引擎)亚洲语言的 OCR 错误)超过一半的字符错误。 大量 OCR 后纠错文献也证明了 OCR 普遍未能提供可接受的结果(例如, 吕等人 (2021); Nguyen 等人 (2021);范·斯特里恩. 等人。 (2020))。
EffOCR 的样本效率明显高于领先的开源 OCR 引擎:EasyOCR JaidedAI (2021)、TrOCR Li 等人 (2021b) 和PaddleOCR Du 等人 (2022),如补充材料所示。333EasyOCR使用seq2seq卷积循环神经网络(CRNN)框架Shi等人(2016),TrOCR使用seq2seq编码器-解码器Transformer Li 等人 (2021b),而 PaddleOCR 使用单视觉文本识别 (SVTR),它与 EffOCR 一样放弃了 seq2seq,将文本图像划分为小的(非字符)补丁,使用混合块感知字符间和字符内模式,并通过线性预测识别文本Du 等人 (2022)。 学习识别单个字符的视觉特征是一个非常简约的问题,使得 EffOCR 调整或从头开始训练的成本很低。 由于 EffOCR 不需要理解语言,因此可以直接扩展到新的语言和脚本,包括那些缺乏 Transformer 大语言模型来初始化最先进的 seq2seq 的语言和脚本。 EffOCR 模型库中的卷积模型可以在 Google Colab 帐户上进行训练,而在 6.84 亿文本行上训练 TrOCR 需要 32 个 32GB V100 卡。
EffOCR 的中心目标是使对资源匮乏的语言和环境的 OCR 访问民主化,因为现有的解决方案不适合这些用例,因此难以研究。 虽然我们没有用于训练所有这些设置的 OCR 模型的资源,但我们用于训练模型的简单 API 并将其上传到 EffOCR 模型中心可以鼓励这项工作的众包。
在高资源环境中(例如,英语),最精确的 OCR 引擎在大规模部署时成本高昂: TrOCR (Base) 是一种高度准确的最先进的英文 OCR。 它拥有 3.34 亿个参数,其部署速度比我们预训练的轻量级 EffOCR 英语单词识别模型慢了近 50 倍,同时在 Carlson 等人的评估任务上只提供了相对有限的收益( 2023)。444TrOCR 有一个小模型(62M 参数),但 Carlson 等人 (2023) 发现它的性能优于 334M 参数基础模型历史文献中的差距很大。 对于英语,Google Cloud Vision (GCV)(一种专有的商业产品)主导了所有开源解决方案(包括 EffOCR),但部署成本要高出几个数量级。 根据我们的经验,对于大型项目来说,它经常超出学术预算。
轻量级 EffOCR 模型也比 Tesseract 和 PaddleOCR 更快 - 与 EasyOCR 的比较取决于部署所用的硬件。 尽管参数比 Tesseract 多大约 8 倍,比 EasyOCR 多大约 4 倍(参数数量与 PaddleOCR 类似)。 这是通过并行而不是顺序解码和 ONNX 集成来实现的。 EffOCR 在执行数字化 2000 万份美国历史报纸扫描等任务时也明显更加准确。
对于那些既不关心计算效率又不关心样本效率的用户 - 因为他们在资源丰富的环境中工作,并且不会面临问题规模的成本限制 - 不是我们的目标受众,并且很可能会找到像这样的现有 OCR 引擎Google Cloud Vision 更好地满足了他们的需求。 在实践中,文献收藏的学术或大规模档案数字化通常涉及资源匮乏的语言或环境、紧张的预算限制,或两者兼而有之。
3 EffOCR 库
3.1 现成的使用
EffOCR 的核心是一个现成的工具包。 EffOCR 是一个模块化框架,它首先使用对象检测来本地化线条、字符和(对于某些模型)单词,然后通过嵌入它们的裁剪并从离线索引中检索它们最近的邻居来识别字符和单词从数字字体创建的示例嵌入。
本地化: EffOCR 支持两种广泛使用的本地化推理后端:MMDetection Chen 等人 (2019),其中包括最先进的对象检测模型,以及 Yolo Ultalytics (2023),其中包括快速、高效的对象检测模型。 用户可以从预训练的模型库中部署线条、单词和字符模型,这些模型使用 Yolo v8 Ultalytics (2023)(针对效率进行了优化)、Yolo v5 Jocher (2020)(更少的依赖性)或 Cascade R-CNN Cai 和 Vasconcelos (2018)(针对准确性进行了优化)。 预训练的本地化模型可用于字母英语/拉丁语、多音希腊语和 CJK 字符(它们的长宽比和分组差异很大)。
识别: EffOCR 使用对比训练的图像检索模型来识别单词和字符裁剪。 EffOCR模型动物园目前包含30个预训练模型,涵盖英语、多音希腊语以及横写和竖写的日语。 我们选择这些语言是为了检查 EffOCR 在高资源环境、现有解决方案失败的环境以及中间情况下的实用性。
EffOCR 预训练模型使用各种主干:两个轻量级卷积主干,部署起来非常高效 Howard 等人 (2019); Maaz 等人 (2022)、最先进的 CNN 编码器 Liu 等人 (2022) 和三个视觉转换器 Ali 等人 (2021);李等人 (2022);刘等人(2021)。 对于英语,有一个单词级模型,当单词低于默认(可调)余弦相似度阈值时,默认进行字符识别,还有一个仅字符模型。
该文档提供了有关模型选择的更多指导。 训练数据集的描述与经过训练的模型一起提供,以便用户可以快速识别最适合其任务的模型。
EffOCR 可以直接使用,只需几行代码:
ONNX ONNX (2021) 集成是一个重要组件,因为它可以实现高效的 CPU 部署和深度学习框架之间的互操作性。 所有 EffOCR 阶段都可以选择采用 ONNX 格式模型和 ONNX 运行时推理,并且模型可以在包内转换为 ONNX 格式。 ONNX 运行时将 EffOCR 中使用的 YOLO 模型的 CPU 吞吐量提高了四倍 Jocher (2020),从而可以实现经济高效的云部署来处理大型文档集。 ONNX 兼容性允许通过图形优化、量化和修剪来额外加速模型。
3.2 定制模型训练
现有 OCR 引擎无法很好地服务许多资源匮乏的环境,EffOCR 的中心目标是通过为自定义模型训练提供简单的界面来实现这些环境的 OCR 民主化,可供研究人员和深度学习经验有限的其他人使用构架。 可以使用用于定位的 Yolo 对象检测模型和用于识别的任何 timm 图像编码器模型来初始化自定义训练。 在不久的将来,将添加对使用 MMDetection 的训练本地化模型的支持。 随着新模型的开发,这可以保证 EffOCR 的未来发展。
EffOCR 支持记录权重和偏差 Biewald (2020) 上的训练运行。 它采用行业标准 coco json 标签作为输入,因此与一系列开源和专有标签软件的输出兼容。 它还以相同的格式导出输出,以便用户可以轻松地纠正模型预测(如果需要加快标记速度)。
使用EffOCR进行模型训练非常高效,例如可以在Google Colab上训练卷积主干。 我们在单个 Nvidia RTX 3090 或 A6000 卡上训练所有模型。
3.3 可视化、存储和导出
EffOCR 附带了一个工具,可以与原始图像并排显示 OCR 可视化,以及可视化行、单词和字符预测。 这些极大地方便了输出的质量检查和潜在问题的排除。
EffOCR为用户提供不同的数据导出选项。 EffOCR 的默认输出包括行坐标、单词坐标、字符坐标以及与每个注释关联的文本。 完整图像的文本也按正确的顺序组装。 用户可以选择仅导出组合文本、仅导出与给定级别的边界框(行、单词或字符)关联的文本注释,或以上全部。
3.4 用户贡献
通过使 OCR 样本高效且易于训练,EffOCR 旨在提高 OCR 管道的可重用性和可重复性。 这对于资源匮乏的环境和语言尤其重要,因为产品开发几乎没有商业动机,而且众包模式的替代方案也很少。 EffOCR 用户可以将自己训练的模型上传到 EffOCR Hugging Face 中心。 每当保存模型时,都会自动生成一张模型卡,该模型卡遵循 Hugging Face 模型卡指南中列出的最佳实践。555https://huggingface.co/docs/hub/model-card-guidebook此外,自动生成的卡片包含有关如何在 上下文中使用模型的说明EffOCR 和特定于模型的架构和训练细节,以提高可重复性。
3.5 与布局解析器集成
OCR 引擎通常检测线条,而不是检测和分类文档中的不同布局对象。 许多文档都有复杂的布局--例如,报纸的标题、文章、标题、广告和页眉都是以复杂的多栏布局排列的,而表格同样也有不同类型的信息,这些信息通常都是以复杂的布局排列的。 这些结构需要应用对象检测模型进行文档布局分析,这些模型已经过训练来检测每个布局对象的坐标并对其类型进行分类(例如标题、文章等)。
为了便于将 EffOCR 与基于深度学习的文档布局模型相结合,包装器将集成到流行的开源布局检测包 Layout Parser Shen 等人 (2020) 中,这将允许布局解析器用户调用任何 EffOCR 模型。 布局解析器还具有调用 GCV 和 Tesseract 的包装器,这将允许用户轻松地将 EffOCR 输出与这些其他包进行比较,以决定什么最能满足其准确性和成本目标。 Layout Parser 和 EffOCR 由同一实验室设计,有利于软件包之间的长期协调。
4应用

可扩展性:我们已经通过各种实际应用程序测试了EffOCR的实用性。 在第一个应用程序中,我们以廉价且准确的方式对美国国会图书馆《美国编年史》馆藏国会图书馆(2022 年) 中的 2000 万份报纸页面扫描进行了数字化处理。 生成的数据集 American Stories 可在 Hugging Face 上下载。666https://huggingface.co/datasets/dell-research-harvard/AmericanStories。 图 1 说明了为什么这是一项具有挑战性的任务:报纸的字体和图像质量极其参差不齐。 Dell 等人 (2023) 对生成的文本数据集的质量进行了详细分析。
我们首先使用合成数据以及在几个小时内创建的包含 291 个报纸行的标记集 Carlson 等人 (2023) 来训练字符 EffOCR。 然后,我们通过使用字符级 EffOCR 模型创建单词级注释来引导单词级注释,过滤掉非单词率较高的行。
借助 EffOCR,结合使用 Layout Parser 进行布局分析,我们可以使用 6 万美元的云计算预算(加上管道开发成本)对数据集进行数字化。 当送入完整的报纸扫描时,GCV 会出现严重的布局错误,而当送入单独的行时,GCV 会实现最佳性能。 按照目前的价格,由于 GCV 按每张图像收费,在生产线级别对馆藏进行数字化将花费超过 2300 万美元。 TrOCR Base 是最准确的开源 OCR,它会超出我们的预算近 50 倍。
零样本性能: 其次,我们证明我们的英语轻量级单词级模型在从美国国家档案馆随机选择的文档集合上具有很强的零样本性能。 该模型在训练中只看到报纸,以测试真正的零样本性能。 我们从来自不同国家档案馆记录组的 300 个随机文档中,每一个都选择了一个文本行。 EffOCR 在不同的集合上实现了 11.2% 的 CER,而 Tesseract(最佳)的 CER 为 11.8%,EasyOCR 的 CER 为 12.1%,TrOCR(小)的 CER 为 51%,后者似乎与模糊和部分模糊作斗争。文本。 我们怀疑,通过在训练中包含国家档案馆文档的随机样本,以扩大模型所接触的现实世界文档集,可以显着改善结果。
所有开源模型的表现都明显比 GCV (1.2% CER) 差,但正如前面所讨论的,成本问题目前阻碍了其大规模使用。 尽管 EffOCR 是针对资源匮乏、零样本环境而设计的,但在资源丰富、零样本情况下仍然具有竞争力。
低资源设置: 最后,我们使用 EffOCR 对垂直书写的日语文档 Teikoku Koshinjo (1957) 的历史日本公司级别记录进行数字化,其中最佳可用解决方案(来自百度 OCR)的预测错误超过一半的字符。 我们使用Carlson等人(2023)中的评估集,它由随机选择的双标记片段组成。
使用包含 898 个标记表格单元格的训练集,我们实现了 0.7% 的 CER,比现有最佳解决方案准确 80 倍。 因此,我们能够研究有关日本卓越增长表现的各种问题,如果没有 EffOCR,这些问题是不可能研究的。
为了进一步检查样本效率的限制,我们计算了当(字符)模型仅看到训练集中出现的每个字符(包括 77 个字符)的一个(或最多 5 个)标记字符时的字符分类错误测试集中字符的百分比。 这导致字符分类错误分别为 13.4% 和 2.0%。 虽然该模型确实受益于看到频繁出现的多种字符,但这说明了可行的少样本性能。
5 限制
如果文档的大部分内容难以辨认,仅视觉 OCR 将不适合,并且语言理解可能有助于推断内容。 对于英语等高资源语言,当不考虑成本时,用户可以从 GCV 等领先的商业产品中获得最佳效果。
目前,EffOCR 模型库拥有支持打字英语、日语和多音希腊语的预训练模型。 在接下来的几个月中,我们将从软件包用户和同事那里众包注释(包括手写)。 我们将使用它们和数字字体来预训练其他模型。 此外,鼓励用户贡献他们的模型。
EffOCR 目前不支持手写。 我们从打字文档开始,因为有数十亿的公共领域字体文档对研究人员和公众非常感兴趣。 我们计划扩展模型动物园以包括手写内容,并且用户已经提出提供注释。 合成手写生成器,例如 Bhunia 等人 (2021),可以为它们支持的脚本的预训练提供大量数据,类似于在字体文档中使用数字字体。 我们将提供合成手写数据集,以便训练包用户也可以将它们用于自己的自定义模型。
补充材料
S-1 模型架构和模型动物园
S-2样本效率
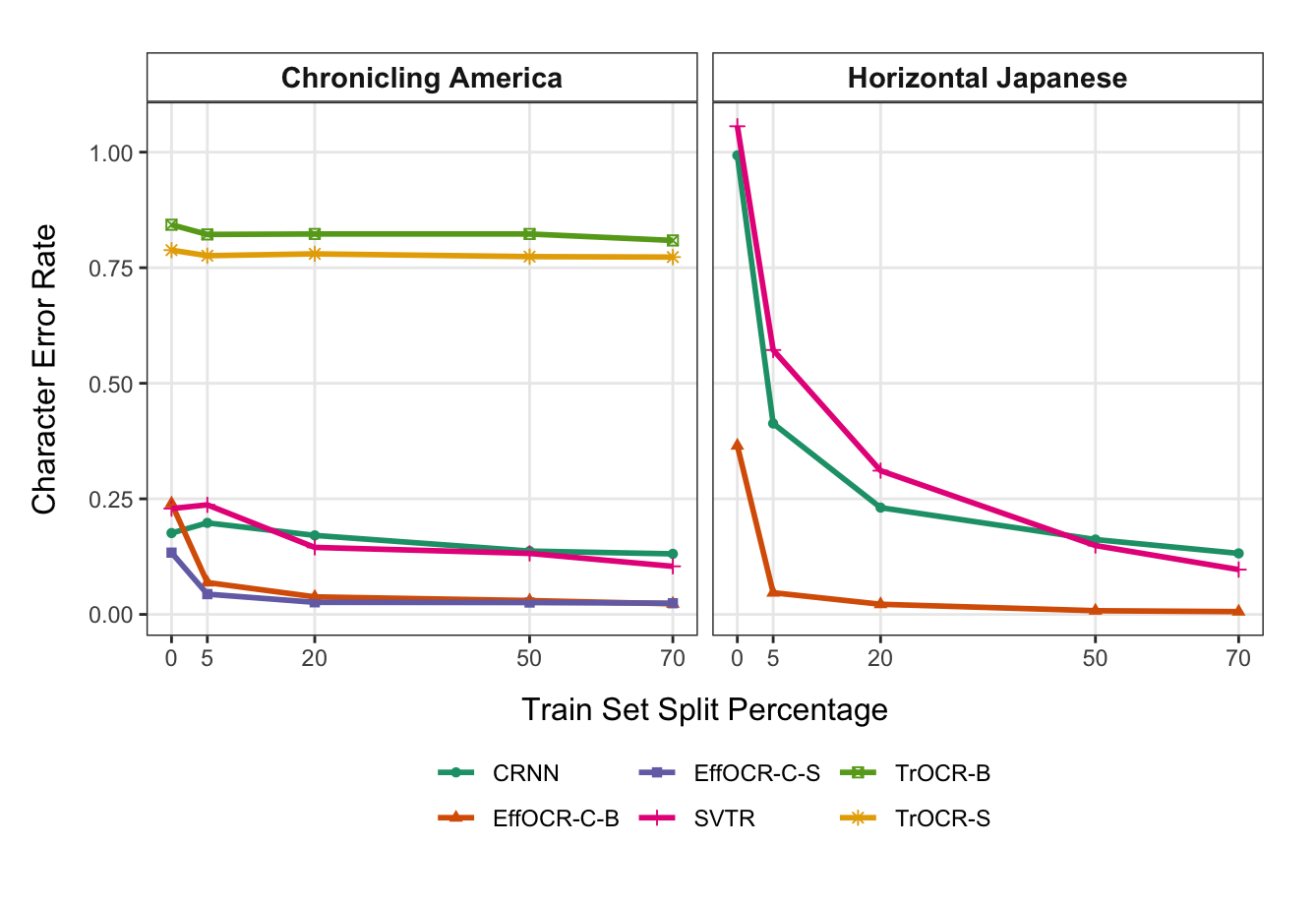
为了检查 EffOCR 与领先的开源架构相比的学习效率,我们使用不同数量的注释数据从头开始训练不同的 OCR 模型。 EffOCR-C(基础)与 SVTR(通过 PaddleOCR 实现)Du 等人 (2022)、CRNN(通过 EasyOCR 实现)Shi 等人 (2016) 进行比较,以及TrOCR Li 等人 (2021b)。 所有架构均从头开始在 8,000 个合成文本行上进行预训练,从框架支持时未针对 OCR 定制的预训练检查点开始。 然后根据研究的基准数据集进行微调,并采用不同的训练-测试-验证划分:70%-15%-15%、50%-25%-25%、20%-40%-40%、5% -47.5%-47.5%和0%-50%-50%(即零样本)。 这些练习是针对英语报纸字符级别模型和水平日语进行的,因为比较架构不支持垂直日语。
图S-2在x轴上绘制了训练中使用的基准数据集的百分比,在y轴上绘制了CER。 在仅 99 个日语标记的表格单元格和 LoCCA 21 个标记行(5% 训练分割)上,EffOCR 的 CER 仅 5%(日语)和 7%(英语),显示了可行的少样本性能。 其他架构仍然无法使用。 使用 20% 或训练数据时,EffOCR 的表现几乎与使用 70% 时一样好,并且继续优于所有其他替代方案。 这说明其简约的架构能够高效学习。
S-3 训练配置详细信息
EffOCR 包向用户公开了各种训练选项和超参数。 这里描述了一些关键元素,想要了解更多详细信息的读者请参阅包文档。
识别器训练选项:
-
•
timm_model_name 来自 timm Wightman (2019) 包的模型名称,用作识别器的基本编码器。
-
•
render_dict 用于在本地存储作物渲染和黄金训练数据的文件夹。
-
•
font_dir_path 从中绘制 tff(字体)文件的本地路径,该文件用于创建字符/单词渲染。
-
•
hns_txt_path 用于提取硬负样本的本地文件路径。 默认情况下,在识别器训练结束时创建硬负文本文件。 大多数识别器训练应用程序使用两个阶段:初始运行和硬负采样运行。
-
•
latin_suggested_args 使用字母书写系统(例如拉丁语、希腊语和西里尔语)的默认参数。
除了这些选项之外,还公开了各种标准模型训练参数,包括学习率、优化器选项、权重衰减、批量大小、设备选择和训练纪元数。
定位器训练选项:
-
•
vertical 模型是否应期望字符水平对齐(如英语和许多拉丁脚本中)或垂直对齐(如许多基于字符的脚本中)。
-
•
no_words 仅检测字符,不检测单词。 推荐用于没有单词分组的语言。
-
•
iou_thresh 用于字符/单词检测的训练和验证 IOU 阈值。
-
•
conf_thresh 用于字符/单词检测的训练和验证置信度阈值。
与识别器一样,其他标准训练参数也被公开。 特别是,调整图像输入形状对于特别长或短的线可能很有价值。
Carlson 等人 (2023) 中列出了用于生成 Model Zoo 中列出的模型(表 S-1)的超参数和训练过程。
S-4可视化
图S-3展示了EffOCR可视化界面。
S-5 美国故事
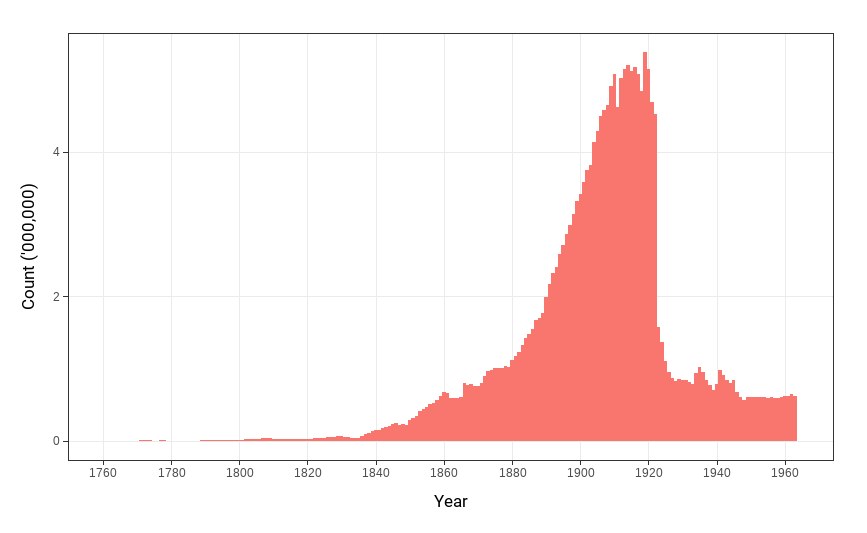
图 S-4 绘制了使用 EffOCR 创建的 American Stories 数据集中随时间变化的文章数量。
S-6 公共领域
表S-2提供了有关在美国发布的信息进入公共领域的要求的详细信息,以便让读者更好地了解这些馆藏。
S-7 推理速度
EffOCR 实现了两项旨在提高计算效率的功能。 首先,定位和识别推理都以多线程方式运行,确保计算资源得到充分利用。 其次,EffOCR 提供对 ONNX 运行时和 ONNX 格式模型的支持,与本机 PyTorch 运行时 ONNX (2021) 相比,CPU 速度提升高达 3 倍。 对于大规模数字化来说,GPU 的成本通常过高。
表S-3提供了EffOCR和其他常用OCR框架的python实现之间的比较。 值得注意的是,这些数字(跨软件)可能会根据可用的硬件资源而有很大差异。 所有比较都是在四个 2200 MHz CPU 内核上进行的,选择这些内核是为了代表合理且相对实惠的研究计算设置。 EffOCR 性能与其他广泛使用的框架相比具有竞争力,其中 EffOCR (Small) 具有最快的性能。 Tesseract Ooms (2023) 测试使用具有默认设置的 pytesseract 包。 EasyOCR JaidedAI (2021) 测试使用具有默认英语设置的 easyocr 包。 PaddleOCR PaddlePaddle (2022) 测试使用带有 use_angle_cls 选项和默认英语设置的 paddleocr 包。 TrOCR Li 等人 (2021a) 测试使用 transformers 包实现,以及 trocr-base-printed 和 trocr-small-printed分别用于基本测试和小型测试的模型。 EffOCR 测试使用来自模型动物园的预训练 ONNX 英文报纸模型的默认设置。

| Training Set | Line Detection | Localizer | Word Recognition | Character Recognition | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| YOLO | YOLO | MaskRCNN | MobileNetV3 | EdgeNeXt | MobileNetV3 | EdgeNeXt | ViT | ConvNeXt | XCiT | |
| English Newspapers | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| English Mixed Archival | ✓ | - | ✓ | ✓ | - | ✓ | - | - | - | - |
| Japanese Vertical | ✓ | ✓ | ✓ | N/A | N/A | ✓ | ✓ | ✓ | ✓ | ✓ |
| Japanese Horizontal | ✓ | ✓ | ✓ | N/A | N/A | ✓ | ✓ | ✓ | ✓ | ✓ |
| Polytonic Greek | ✓ | ✓ | - | N/A | N/A | ✓ | - | - | ✓ | - |
| Date of Publication | Conditions | Copyright Term |
|---|---|---|
| Public Domain | ||
| Anytime | Works prepared by an officer/employee of the | None |
| U.S. Government as part of their official duties | ||
| Before 1928 | None | None. Copyright expired. |
| 1928 through 1977 | Published without a copyright notice | None. Failure to comply with required formalities |
| 1978 to 1 March 1989 | Published without notice and | None. Failure to comply with required formalities |
| without subsequent registration within 5 years | ||
| 1928 through 1963 | Published with notice | None. Copyright expired |
| but copyright was not renewed | ||
| Copyrighted | ||
| 1978 to 1 March 1989 | Published without notice, but with | 70 (95) years after the death of author (corporate author) |
| subsequent registration within 5 years | ||
| 1928 through 1963 | Published with notice | 95 years after publication |
| and the copyright was renewed | ||
| 1964 through 1977 | Published with notice | 95 years after publication |
| 1978 to 1 March 1989 | Created after 1977 and published with notice | 70 (95) years after the death of author (corporate author) |
| or 120 years after creation, if earlier | ||
| 1978 to 1 March 1989 | Created before 1978 and first published | The greater of the term specified in the previous entry |
| with notice in the specified period | or 31 December 2047 | |
| From 1 March 1989 through 2002 | Created after 1977 | 70 (95) years after the death of author (corporate author) |
| or 120 years after creation, if earlier | ||
| From 1 March 1989 through 2002 | Created before 1978 and | The greater of the term specified in the previous entry |
| first published in this period | or 31 December 2047 | |
| After 2002 | None | 70 (95) years after the death of author (corporate author) |
| or 120 years after creation, if earlier |
| Model | Textline/s | Article/s |
|---|---|---|
| EffOCR Base | 0.46 | 0.02 |
| EffOCR Small | 21.07 | 1.08 |
| Tesseract | 4.47 | 0.21 |
| EasyOCR | 19.80 | 1.03 |
| PaddleOCR | 13.56 | 0.61 |
| TrOCR (Base) | 0.43 | 0.02 |
| TrOCR (Small) | 0.97 | 0.05 |
参考
- Ali et al. (2021) Alaaeldin Ali, Hugo Touvron, Mathilde Caron, Piotr Bojanowski, Matthijs Douze, Armand Joulin, Ivan Laptev, Natalia Neverova, Gabriel Synnaeve, Jakob Verbeek, et al. 2021. Xcit: Cross-covariance image transformers. Advances in neural information processing systems, 34.
- Bhunia et al. (2021) Ankan Kumar Bhunia, Salman Khan, Hisham Cholakkal, Rao Muhammad Anwer, Fahad Shahbaz Khan, and Mubarak Shah. 2021. Handwriting transformers. Proceedings of the IEEE/CVF international conference on computer vision, pages 1086–1094.
- Biewald (2020) Lukas Biewald. 2020. Experiment tracking with weights and biases. Software available from wandb.com.
- Cai and Vasconcelos (2018) Zhaowei Cai and Nuno Vasconcelos. 2018. Cascade r-cnn: Delving into high quality object detection. Proceedings of the IEEE conference on computer vision and pattern recognition, pages 6154–6162.
- Carlson et al. (2023) Jacob Carlson, Tom Bryan, and Melissa Dell. 2023. Efficient ocr for building a diverse digital history. arXiv preprint arXiv:2304.02737.
- Chen et al. (2019) Kai Chen, Jiaqi Wang, Jiangmiao Pang, Yuhang Cao, Yu Xiong, Xiaoxiao Li, Shuyang Sun, Wansen Feng, Ziwei Liu, Jiarui Xu, et al. 2019. Mmdetection: Open mmlab detection toolbox and benchmark. arXiv preprint arXiv:1906.07155.
- Dell et al. (2023) Melissa Dell, Jacob Carlson, Tom Bryan, Emily Silcock, Abhishek Arora, Zejiang Shen, Luca D’Amico-Wong, Quan Le, Pablo Querubin, and Leander Heldring. 2023. American stories: A large-scale structured text dataset of historical u.s. newspapers.
- Du et al. (2022) Yongkun Du, Zhineng Chen, Caiyan Jia, Xiaoting Yin, Tianlun Zheng, Chenxia Li, Yuning Du, and Yu-Gang Jiang. 2022. Svtr: Scene text recognition with a single visual model. arXiv preprint arXiv:2205.00159.
- Howard et al. (2019) Andrew Howard, Mark Sandler, Grace Chu, Liang-Chieh Chen, Bo Chen, Mingxing Tan, Weijun Wang, Yukun Zhu, Ruoming Pang, Vijay Vasudevan, et al. 2019. Searching for mobilenetv3. Proceedings of the IEEE/CVF international conference on computer vision, pages 1314–1324.
- JaidedAI (2021) JaidedAI. 2021. Easyocr. https://github.com/JaidedAI/EasyOCR.
- Jocher (2020) Glenn Jocher. 2020. YOLOv5 by Ultralytics.
- Joshi et al. (2020) Pratik Joshi, Sebastin Santy, Amar Budhiraja, Kalika Bali, and Monojit Choudhury. 2020. The state and fate of linguistic diversity and inclusion in the nlp world. arXiv preprint arXiv:2004.09095.
- Li et al. (2021a) Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, and Furu Wei. 2021a. Trocr github repository. https://github.com/microsoft/unilm/tree/master/trocr.
- Li et al. (2021b) Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, and Furu Wei. 2021b. Trocr: Transformer-based optical character recognition with pre-trained models. arXiv preprint arXiv:2109.10282.
- Li et al. (2022) Yanghao Li, Hanzi Mao, Ross Girshick, and Kaiming He. 2022. Exploring plain vision transformer backbones for object detection. arXiv preprint arXiv:2203.16527.
- Library of Congress (2022) Library of Congress. 2022. Chronicling America: Historic American Newspapers.
- Liu et al. (2021) Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. 2021. Swin transformer: Hierarchical vision transformer using shifted windows. arXiv preprint arXiv:2103.14030.
- Liu et al. (2022) Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, and Saining Xie. 2022. A convnet for the 2020s. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11976–11986.
- Lyu et al. (2021) Lijun Lyu, Maria Koutraki, Martin Krickl, and Besnik Fetahu. 2021. Neural ocr post-hoc correction of historical corpora. Transactions of the Association for Computational Linguistics, 9:479–483.
- Maaz et al. (2022) Muhammad Maaz, Abdelrahman Shaker, Hisham Cholakkal, Salman Khan, Syed Waqas Zamir, Rao Muhammad Anwer, and Fahad Shahbaz Khan. 2022. Edgenext: efficiently amalgamated cnn-transformer architecture for mobile vision applications. In European Conference on Computer Vision, pages 3–20. Springer.
- Nguyen et al. (2021) Thi Tuyet Hai Nguyen, Adam Jatowt, Mickael Coustaty, and Antoine Doucet. 2021. Survey of post-ocr processing approaches. ACM Comput. Surv., 54(6).
- Ockerbloom (2019) John Mark Ockerbloom. 2019. Newspaper copyrights, notices, and renewals.
- ONNX (2021) ONNX. 2021. Onnx runtime. https://www.onnxruntime.ai. Version: x.y.z.
- Ooms (2023) J Ooms. 2023. Tesseract: Open source ocr engine.
- PaddlePaddle (2022) PaddlePaddle. 2022. PaddleOCR.
- Shen et al. (2020) Zejiang Shen, Kaixuan Zhang, and Melissa Dell. 2020. A large dataset of historical japanese documents with complex layouts. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pages 548–549.
- Shi et al. (2016) Baoguang Shi, Xiang Bai, and Cong Yao. 2016. An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE transactions on pattern analysis and machine intelligence, 39(11):2298–2304.
- Teikoku Koshinjo (1957) Teikoku Koshinjo. 1957. Teikoku Ginko Kaisha Yoroku. Teikoku Koshinjo.
- Ultalytics (2023) Ultalytics. 2023. Yolo v8 github repository. https://github.com/ultralytics/ultralytics.
- van Strien. et al. (2020) Daniel van Strien., Kaspar Beelen., Mariona Coll Ardanuy., Kasra Hosseini., Barbara McGillivray., and Giovanni Colavizza. 2020. Assessing the impact of ocr quality on downstream nlp tasks. In Proceedings of the 12th International Conference on Agents and Artificial Intelligence - Volume 1: ARTIDIGH,, pages 484–496. INSTICC, SciTePress.
- Wightman (2019) Ross Wightman. 2019. Pytorch image models. https://github.com/rwightman/pytorch-image-models.
- Wu et al. (2019) Yuxin Wu, Alexander Kirillov, Francisco Massa, Wan-Yen Lo, and Ross Girshick. 2019. Detectron2. https://github.com/facebookresearch/detectron2.