大型语言模型满足开放世界意图发现和识别:ChatGPT 的评估
摘要
域外(OOD)意图发现和广义意图发现(GID)的任务旨在将封闭意图分类器扩展到开放世界意图集,这对于面向任务的对话(TOD)系统至关重要。 以前的方法通过微调判别模型来解决这些问题。 近年来,虽然有一些研究在探索以ChatGPT为代表的大语言模型在各种下游任务中的应用,但ChatGPT是否能够发现并逐步扩展OOD意图仍不清楚。 在本文中,我们综合评估了 ChatGPT 在 OOD 意图发现和 GID 方面的表现,然后概述了 ChatGPT 的优缺点。 总体而言,ChatGPT 在零样本设置下表现出一致的优势,但与微调模型相比仍处于劣势。 更深入地说,通过一系列的分析实验,我们总结和讨论了大语言模型面临的挑战,包括聚类、特定领域理解和跨领域上下文学习场景。 最后,我们为应对这些挑战的未来方向提供实证指导。111We release our code at https://github.com/songxiaoshuai/OOD-Evaluation
1简介
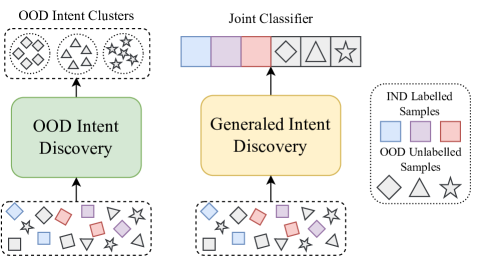
传统的任务导向对话(TOD)系统基于闭集假设Chen 等人(2019);杨等人 (2021); Zeng 等人 (2022) 并且只能处理有限范围内的域内 (IND) 意图的查询。 然而,用户可能在真实的开放世界中输入具有域外(OOD)意图的查询,这给TOD系统带来了新的挑战。 最近,一系列针对 OOD 查询的任务得到了广泛的研究。 OOD 意图发现 Lin 等人 (2020);张等人 (2021); Mou 等人 (2022a) 旨在根据 OOD 查询的意图将其分组到不同的集群中,这有助于识别潜在的方向并开发新技能。 通用意图发现(GID)任务Mou等人(2022b)进一步考虑了OOD意图的增量,旨在自动发现和增量意图分类器,从而扩展现有IND意图集的识别范围到开放世界,如图1所示。
之前的工作通过微调判别性预训练模型 BERT Devlin 等人 (2018) 来研究上述 OOD 任务。 近年来,一系列强大的生成大语言模型相继提出,如GPT-3 Brown 等人 (2020)、PaLM Chowdhery 等人 (2022)和 LLaMA Touvron 等人 (2023)。 大语言模型的出现给自然语言处理(NLP)领域带来了革命性的变化。 由于其优越的情境学习能力,提示大语言模型已成为自然语言处理研究和应用广泛采用的范式董等人(2022b)。 由于这些大语言模型是在大量通用文本语料上训练的,具有出色的泛化能力,这引发了人们的思考:大语言模型在应用于开放场景意图发现时能带来什么好处,又会面临哪些挑战和认可?
作为大语言模型的代表之一,OpenAI开发的ChatGPT在短时间内引起了研究者和实践者的极大关注。 而NLP界一直在研究大语言模型应用于各种下游任务的能力,例如翻译Jiao等人(2023)、数学Frieder等人(2023) t1>、教育Malinka等人(2023)、情感识别Lei等人(2023),其在OOD方面的能力还没有完全发挥出来。 与Wang等人(2023)从对抗性和分布外的角度评估ChatGPT的鲁棒性不同,OOD意图发现和GID侧重于利用IND知识转移来帮助通过OOD改进TOD系统数据。 本文一方面关注OOD意图发现和GID这两个开放场景意图任务,探讨提示ChatGPT是否能够在发现和增量识别OOD意图方面取得良好的性能;另一方面,我们的目标是深入了解大语言模型在处理开放域任务时面临的挑战以及潜在的改进方向。

据我们所知,我们是第一个全面评估 ChatGPT 在 OOD 意图发现和 GID 方面的性能的人。 具体来说,我们首先根据不同的 IND 设计三种基于提示的方法,然后引导 ChatGPT 以端到端的方式执行 OOD 发现。 对于GID,我们创新性地提出了一个在生成大语言模型下执行GID任务的管道框架(第3节)。 然后我们在三个数据集分区下对 ChatGPT 和代表性基线进行详细的比较实验(第 4 节)。 为了进一步探究实验背后的根本原因,我们进行了一系列分析实验,包括跨域演示下的上下文学习、召回分析以及影响 ChatGPT 在 OOD 发现和 GID 上性能的因素。 最后,我们比较了不同大语言模型在这些 OOD 任务上的性能(第 5 节)。
我们的发现。 该研究的主要发现包括:
ChatGPT 擅长什么:
-
•
由于其强大的语义理解能力,ChatGPT 在没有任何 IND 事先的 OOD 任务上可以比非微调的 BERT 表现得更好。
-
•
对于 OOD 意图发现,当用于聚类的样本很少时,ChatGPT 的性能可以与微调基线相媲美。
-
•
ChatGPT 可以同时进行文本聚类并诱导每个聚类的意图,这是判别模型所不具备的。
ChatGPT 做得不好的地方:
-
•
对于OOD意图发现,ChatGPT在多样本或多类别场景下的表现远不如微调基线,并且受聚类和样本数量的影响严重,鲁棒性较差。
-
•
对于 GID,ChatGPT 的整体性能不如微调基线。 主要原因是缺乏领域知识,次要原因是伪意图集的质量。
-
•
OOD发现和GID都存在明显的召回错误。 在OOD发现中,这主要归功于ChatGPT的生成架构。 在GID中,召回错误主要是由于ChatGPT缺乏领域知识和对意图集边界理解不清晰而造成的。
-
•
ChatGPT 很难从 IND 演示中学习有助于 OOD 任务的知识,并且可能将 IND 演示视为噪音,这给 OOD 任务带来负面影响。
除上述发现外,我们还在第 6 节中进一步总结和讨论了大语言模型所面临的挑战性场景,包括 大规模聚类、特定领域的语义理解和跨领域上下文学习,并为未来的发展方向提供了指导。
2相关工作
2.1 大型语言模型
最近,人们越来越关注利用大型语言模型(大语言模型)来执行各种 NLP 任务,特别是在评估 ChatGPT 的各个方面。 例如,Frieder 等人 (2023) 通过在公开可用的数据集以及手工制作的数据集上进行测试来研究 ChatGPT 的数学功能。 Tan 等人 (2023) 探讨 ChatGPT 在基于知识的问答(KBQA)方面的性能。 Wang 等人 (2023) 从分布外(OOD)角度评估 ChatGPT 的鲁棒性。 刘等人系列作品(2023);郭等人 (2023);董等人(2022a, 2023)探讨输入扰动问题对从小模型到大语言模型的模型性能的影响。 在本文中,我们旨在研究ChatGPT发现和增加OOD意图的能力,并进一步探讨大语言模型面临的挑战和潜在的改进方向。
2.2 OOD意图发现
与简单的文本聚类任务不同,OOD 意图发现考虑如何使用 IND 意图的先验知识来促进未知 OOD 意图的发现。 Lin 等人 (2020) 使用 OOD 表示来计算弱监督信号的相似性。 Zhang 等人 (2021) 提出了一种迭代方法 DeepAligned,迭代地执行表示学习和聚类分配,而 Mou 等人 (2022c) 执行对比聚类来联合学习表示和聚类聚类作业。 在本文中,我们评估了基于 ChatGPT 的 OOD 发现方法的性能,并提供了详细的定性分析。
2.3 一般意图发现
由于OOD意图发现忽略了IND和OOD意图的融合,因此无法进一步扩大现有TOD系统的识别范围。 受上述问题的启发,Mou 等人 (2022b) 提出了通用意图发现(GID)任务,该任务要求系统从未标记的 OOD 数据中发现语义概念,然后自动对 IND 和 OOD 意图进行联合分类。 此外,Mou等人(2022b)提出了两种在判别模型下执行GID任务的框架:基于管道的框架和端到端框架。 在本文中,我们在生成大语言模型下提出了一种新的 GID 管道,并探讨了 ChatGPT 在不同场景下的性能。
3方法论
3.1问题表述
OOD 意图发现 给定一组标记的 IND 数据集 和未标记的 OOD 数据集 ,其中来自 的所有查询都属于一个包含 意图的预定义意图集 ,来自 的所有查询都属于包含 的未知集 > 意图222估计超出了本文的范围。 在下面的实验中,我们假设是真实的,并在5.5节中提供分析。 需要注意的是,中意图的具体语义是未知的。. OOD 意图发现旨在将来自 的 OOD 组聚集到来自 的 IND 传输之前。
通用意图发现 GID 旨在训练一个网络,该网络可以同时对一组包含 意图的标记 IND 意图类 进行分类并发现新的意图意图集 包含来自未标记的 OOD 集 的 意图。 与获取个OOD组的OOD发现聚类不同,GID的最终目标是将网络意图查询的分类能力扩展到包含的总标签集 > 意图。
3.2 用于 OOD 发现的 ChatGPT
我们通过设计包括任务指令、测试样本和 IND 先验的提示来评估 ChatGPT 在 OOD 意图发现方面的性能。 基于不同的 IND 先验,我们启发性地提出了以下三种方法:
直接聚类(DC): 由于 OOD 意图发现本质上是一个聚类任务,因此一种简单的方法是直接聚类,而不使用任何 IND 先验。 提示符格式为:<簇指令><簇数><响应格式><>。
零射击发现(ZSD): 该方法提供提示中设置的 IND 意图作为先验知识,但不提供任何 IND 样本。 可用于需要保护用户隐私的场景。 The prompt is in the following format: <Prior: ><Cluster Instruction><Number of Clusters><Response Format><>.
少炮发现(FSD): FSD 在提示中为每个 IND 意图提供了多个标记样本,希望 ChatGPT 能够从 IND 演示中挖掘领域知识并将其转移到辅助 OOD 意图聚类。 The prompt is in the following format: <Prior: & ><Cluster Instruction><Number of Clusters><Response Format><>.
According to the input, ChatGPT outputs the index of OOD samples contained in each cluster, in the form of <Cluster Index><OOD Sample Index>. 我们在图2中展示了这些方法的提示。
3.3GID 的 ChatGPT
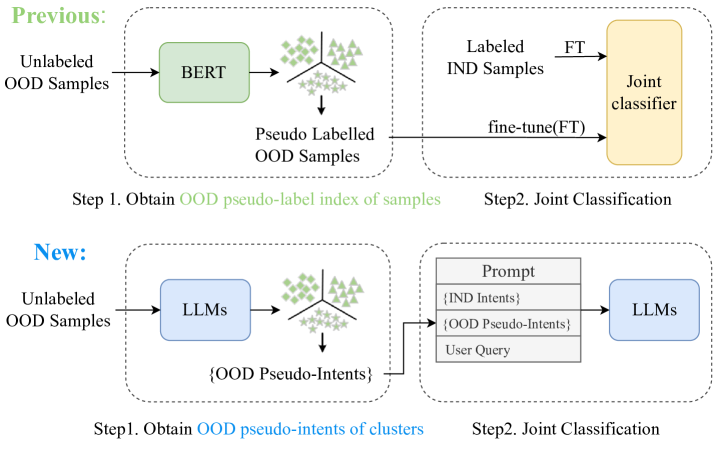
以前的判别式 GID 框架首先通过聚类为每个 OOD 样本分配一个伪标签索引,然后将分类器与标记的 IND 数据联合起来。 然而,生成大语言模型对查询的分类取决于特定的意图语义,而不是摘要伪标签索引符号。 在此基础上,我们创新性地提出了一种适合生成式大语言模型的新框架,该框架依靠大语言模型生成具有特定语义的意图描述作为每个簇的伪意图,如图3。
In the first stage, on the basis of OOD intent discovery prompts, we add an additional instruction for generating intent descriptions, which are formally <OOD Discovery Prompt><Intent Describe Instruction>, input to ChatGPT, and obtain the intent description of each cluster. 通过聚合这些意图描述,我们得到OOD伪意图集合。 然后,我们逐步将伪意图集添加到现有的 IND 意图集中,即 。
4实验
| Prior | Method | IND/OOD=3:1 | IND/OOD=3:2 | IND/OOD=1:1 | ||||||
| ACC | NMI | ARI | ACC | NMI | ARI | ACC | NMI | ARI | ||
| W/O IND Prior | BERT | 52.00 | 41.58 | 15.36 | 36.00 | 42.33 | 5.616 | 29.33 | 45.26 | 2.499 |
| ChatGPT(DC) | 88.00 | 84.62 | 73.36 | 78.00 | 78.20 | 55.32 | 58.22 | 65.30 | 28.21 | |
| With IND Prior | DeepAligned | 100.0 | 100.0 | 100.0 | 78.67 | 82.18 | 61.01 | 74.67 | 80.83 | 55.35 |
| DKT | 93.33 | 91.71 | 84.82 | 80.67 | 82.59 | 64.53 | 76.45 | 83.23 | 60.92 | |
| ChatGPT(ZSD) | 92.00 | 87.25 | 80.16 | 67.33 | 68.72 | 39.32 | 50.67 | 60.73 | 21.25 | |
| ChatGPT(FSD) | 74.67 | 64.77 | 45.92 | 56.67 | 63.56 | 31.47 | 49.78 | 60.98 | 20.72 | |
| Method | IND/OOD=3:1 | IND/OOD=3:2 | IND/OOD=1:1 | |||||||||||||||
| IND | OOD | ALL | IND | OOD | ALL | IND | OOD | ALL | ||||||||||
| F1 | ACC | F1 | ACC | F1 | ACC | F1 | ACC | F1 | ACC | F1 | ACC | F1 | ACC | F1 | ACC | F1 | ACC | |
| DeepAligned-GID | 95.36 | 94.50 | 97.00 | 97.00 | 95.77 | 95.12 | 94.49 | 92.67 | 85.99 | 86.00 | 91.09 | 90.00 | 94.16 | 91.50 | 76.38 | 77.33 | 85.27 | 84.42 |
| E2E | 96.13 | 95.50 | 97.00 | 97.00 | 96.35 | 95.88 | 95.21 | 93.33 | 78.69 | 80.5 | 88.602 | 88.2 | 94.22 | 92.17 | 71.92 | 74.00 | 83.07 | 83.08 |
| ChatGPT(GID-DC) | 67.41 | 68.44 | 70.26 | 75.33 | 67.96 | 70.17 | 62.15 | 64.67 | 57.53 | 61.33 | 60.30 | 63.33 | 63.06 | 66.44 | 59.72 | 62.00 | 61.39 | 64.22 |
| ChatGPT(GID-ZSD) | 64.47 | 65.11 | 61.50 | 70.00 | 63.73 | 66.33 | 55.14 | 58.22 | 46.83 | 50.33 | 51.81 | 55.07 | 53.94 | 57.78 | 52.20 | 57.57 | 53.07 | 57.67 |
| ChatGPT(GID-FSD) | 72.77 | 79.11 | 20.27 | 17.33 | 59.65 | 63.67 | 68.74 | 74.89 | 50.75 | 52.00 | 61.54 | 65.73 | 68.29 | 74.89 | 52.57 | 51.78 | 60.43 | 63.33 |
4.1 数据集
我们在广泛使用的意图数据集 Banking Casanueva 等人 (2020) 上进行了实验。 银行业包含 13,083 个用户查询,其中涉及银行领域的 77 个意图。 由于 ChatGPT 对话的长度限制,我们从银行业随机抽取 15 个类别作为 IND 意图,并考虑了三个 OOD 类别数量设置。 具体地,OOD类别数量分别为5(IND/OOD=3:1)、10(IND/OOD=3:2)和15(IND/OOD=1:1)。 对于 OOD 意图发现,我们从每个 OOD 类的测试集中随机抽取 5 个查询,其中 OOD 类的真实数量作为先验给出。 对于GID,我们从测试集中随机抽取10个查询进行测试。 此外,仅当使用 FSD 或 GID-FSD 方法时,我们从训练集中为每个 IND 类随机抽取 3 个查询进行演示。 我们在附录A中提供了数据集的详细统计数据。
4.2基线
对于 OOD 意图发现,我们选择直接使用 BERT 进行 k 均值聚类 MacQueen (1965) 和两种代表性的微调方法:
-
•
DeepAligned Zhang 等人 (2021) 是 DeepClusterCaron 等人 (2018) 的改进版本。 它设计了一种伪标签对齐策略来生成对齐的聚类分配,以实现更好的表示学习。
-
•
DKT Mou 等人 (2022c) 设计了一个统一的多头对比学习框架来匹配 IND 预训练目标和 OOD 聚类目标。 在IND预训练阶段,联合优化CE和SCL目标函数,在OOD聚类阶段,使用实例级CL和簇级CL目标来联合学习表示和簇分配。
对于 GID,基线如下:
-
•
DeepAligned-GID是Mou等人(2022b)基于DeepAligned构建的一种具有代表性的流水线方法,首先使用聚类算法DeepAligned对OOD数据进行聚类,获得伪OOD标签,然后与 IND 数据一起训练新的分类器。
-
•
E2E Mou 等人 (2022b) 在训练过程中混合 IND 和 OOD 数据,同时学习伪 OOD 簇作为符号,并通过自标记对所有类别进行分类。 给定一个输入查询,E2E通过两个独立的投影层IND head和OOD head连接编码器输出作为最终的logit,并通过统一分类损失优化模型,其中OOD伪标签是通过交换预测获得的Caron等人(2020)。
我们仅使用银行训练集中属于 IND 和 OOD 意图的样本来训练所有微调方法。
4.3评估指标
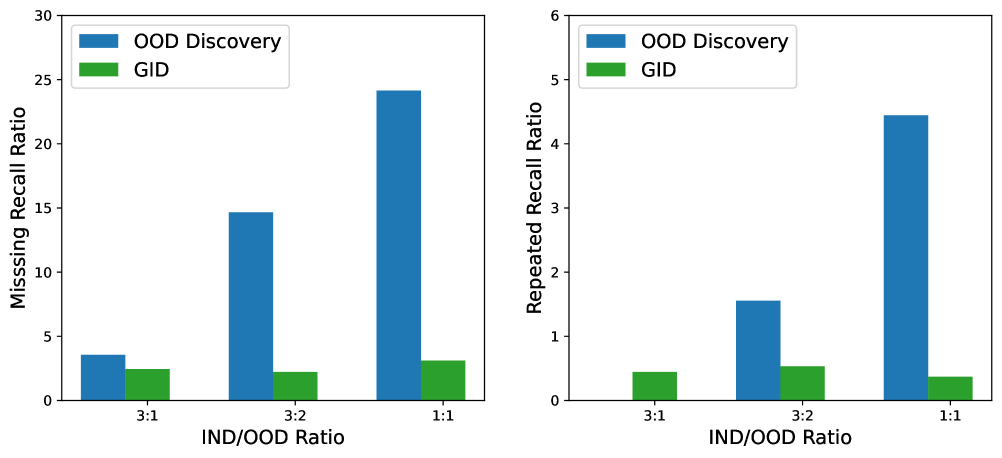
对于 OOD 意图发现,我们采用三个广泛使用的指标来评估聚类结果: 准确性 (ACC)333我们使用匈牙利算法Kuhn (1955)来获得预测和真实类别之间的映射。、标准化互信息 (NMI) 和调整兰德指数 (ARI)。 对于GID,我们采用两个指标:准确度(ACC)和F1分数(F1)来评估联合分类结果的性能。 此外,我们观察到所有 ChatGPT 方法都存在这样的现象:某些样本没有分配任何聚类或意图(缺失召回),而有些样本则分配了多个聚类或意图(重复召回)。 对于缺失召回的样本,我们随机分配一个聚类或意图;对于那些重复回忆的人,我们只保留第一个分配的集群或意图。 我们在5.3节中提供了详细的召回分析。
4.4 主要结果
(1)没有 IND 先验的比较方法 从表1可以看出,在没有任何 IND 先验知识,即直接聚类的情况下,ChatGPT 的性能在三个条件下明显优于 BERT数据集分区,表明 ChatGPT 在不使用任何私有特定数据的情况下在自然语言理解方面的优势。 例如,在 IND/OOD=3:1 下,ChatGPT(DC) 的性能优于 BERT 36.00% (ACC)。 随着 OOD 类数量的增加,ChatGPT(DC) 和 BERT 的聚类指标迅速下降,但 ChatGPT(DC) 仍然取得了比 BERT 更好的性能,在 IND/OOD=1:1 下超过 BERT 28.89% (ACC)。
(2) 比较 ChatGPT 与 Finetuned BERT 对于 OOD 发现,当 OOD 比率较低时,最优 ChatGPT 方法略逊于 Finetuned 基线。 然而,随着 OOD 比率的增加,ChatGPT 明显低于微调模型。 我们认为这是因为随着OOD比率的增加,聚类样本的数量增加,更多的数据给生成大语言模型带来了更困难的语义理解挑战。 然而,判别性微调方法对样本进行一一编码,因此受 OOD 比率的影响较小。
对于 GID,ChatGPT 在 IND 和 OOD 指标上都明显弱于微调模型。 根据表2,在三种场景下,平均而言,最优ChatGPT方法比最优微调方法弱17.37%(IND ACC)、20.56%(OOD ACC)和23.40%(所有 ACC),分别。 我们认为这是因为 ChatGPT 是在大规模通用训练数据上进行预训练的,这使得它很难在特定领域数据上比微调模型表现得更好。
(3) 比较不同的ChatGPT方法 对于OOD发现,DC一般实现最好的性能,而ZSD稍差,FSD表现最差。 虽然DC在IND/OOD=3:1场景下稍逊于ZSD,但在其他两种场景下明显优于其他ChatGPT方法。 FSD 几乎是三种方法中表现最差的。 ZSD 提供 IND 类别的额外先验知识,而 FSD 提供标记的 IND 样本作为上下文。 然而,更多的 IND 先验实际上会导致 ChatGPT 的性能变差。
5定性分析
5.1 从 IND 到 OOD 的情境学习
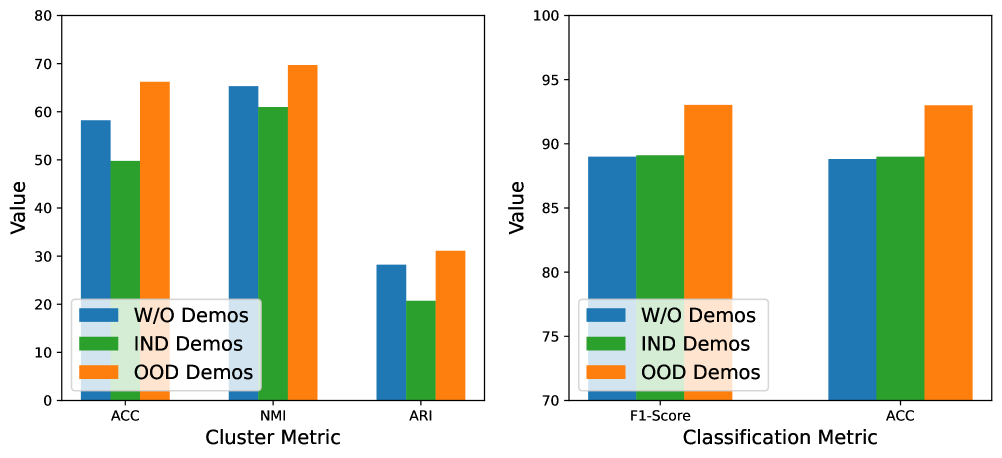
在4.4节中,我们发现IND先验并没有给OOD任务带来积极的影响。 为了进一步探讨不同类型演示的影响,我们比较了三种演示策略下 OOD 任务的性能:W/O 演示、IND 演示和 OOD 演示。 具体来说,对于 OOD 发现,我们执行 15 个 OOD 类聚类;对于分类,我们在 10 个类别下测试 OOD 分类,其中 OOD 意图使用真实意图集以避免伪意图集的影响。
结果如图4所示。 与W/O Demos相比,OOD Demos在聚类和分类任务上都实现了显着的性能提升。 相比之下,IND 演示导致聚类性能下降,分类性能几乎没有改善。 对于OOD Demos,可以认为演示和测试具有相同的分布,因此ChatGPT可以通过上下文学习来提高任务性能。 对于IND Demos来说,演示和测试之间的不同分布导致ChatGPT不仅无法通过上下文学习带来性能提升,而且还将演示视为干扰任务性能的上下文噪声。 这说明演示文本的分布对情境学习的效果影响很大,Min等人(2022)中也提到了这一点。 值得注意的是,由于 IND 和 OOD 类都来自银行领域,因此微调模型可以通过 IND 样本的知识迁移来提高 OOD 任务性能。 然而,这在ChatGPT上却失败了,这表明目前大语言模型的上下文学习缺乏深度挖掘和迁移演示知识(即从IND到OOD)的能力。
5.2 限制GID性能的原因
由于ChatGPT以管道方式执行GID,因此我们分别分析ChatGPT在生成伪意图集和执行联合分类方面的性能。 我们在表3中展示了一组伪意图集。 可以看出,这三组伪意图在语义上与真实意图大致相似,但在粒度上表现出一定的随机性。 以ID 5的Intent为例,run-1将支付方式解释为“google pay或apple pay”,与真实标签的粒度一致; run-2将其扩展为“不同方法”,run-3进一步将其扩展为“与支付相关”,粒度更粗。
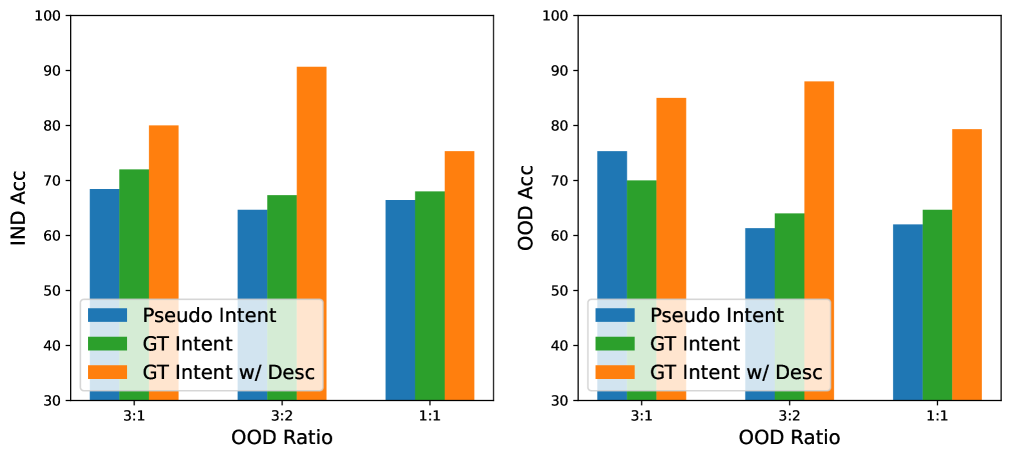
接下来,我们使用OOD真实意图集来替换OOD伪意图集,并进一步为每个IND&OOD意图添加人工描述,如图5所示。 与使用伪意图集相比,使用groundtruth意图集只能带来轻微的性能提升,而添加意图描述可以显着提高分类性能。 这表明限制ChatGPT在GID任务上进一步改进的主要原因是领域知识的缺乏,其次是伪意图的质量。
5.3召回分析
正如4.3节提到的,ChatGPT存在缺失和重复回忆的问题,这是生成式大语言模型特有的问题。444我们在附录E中提供了相关案例。 图6展示了ChatGPT错误召回的统计。 对于OOD发现来说,随着OOD比率(聚类数)的增加,缺失召回和重复召回的比例都显着增加。 例如,在IND/OOD=1:1下,漏回忆和重复回忆的概率分别达到24.15%和4.44%,严重损害了任务性能。 由于聚类任务需要将所有样本同时输入ChatGPT,因此更多的样本给ChatGPT带来了更困难的任务理解和处理,导致更高的错误召回率。 对于 GID,错误召回的比例几乎不受 OOD 比率的影响,因为 GID 是在逐个样本的基础上执行的。 此外,我们发现 GID 的错误召回主要是由于缺乏领域知识造成的。 这导致 ChatGPT 无法清楚地识别意图集边界,并可能主动将查询分配给多个意图或拒绝将查询分配给预定义的意图集。
| ID | Ground Truth Intent | Pseudo Intent 1 (run-1) | Pseudo Intent 2 (run-2) | Pseudo Intent 3 (run-3) |
| 1 | card_delivery_estimate | Inquires about delivery time or schedule | Delivery and shipment related questions. | Delivery related inquiries |
|---|---|---|---|---|
| 2 | cancel_transfer | Requests for cancellation, urgent card needs, and transaction reversion | Transaction cancellation or reversion related questions. | Account/card related inquiries |
| 3 | verify_my_identity | Inquires about identity verification process | Identity verification related questions | Identity verification inquiries |
| 4 | cash_withdrawal_charge | Questions related to fees charged for transactions or withdrawals | Fee related questions, especially related to cash withdrawals. | Fee related inquiries |
| 5 | apple_pay_or_google_pay | Issues related to topping up accounts with mobile payment services such as Google Pay or Apple Pay. | Various questions related to top-ups and adding money to an account using different methods. | Payment related inquiries |
5.4聚类样本数的影响
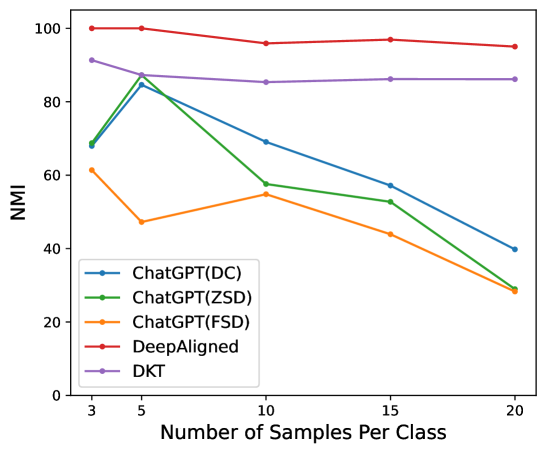
我们通过改变每个 OOD 意图的真实数量来探索聚类样本数量对 ChatGPT 的影响。 如图7所示,ChatGPT对样本数量的鲁棒性较差。 聚类性能首先在每类 5 到 10 个样本之间达到最佳效果,然后迅速下降。 相比之下,判别性微调方法表现出良好的鲁棒性。 我们认为这是因为当样本太少时,ChatGPT 很难发现聚类模式。 并且当样本过多时,ChatGPT需要同时处理过多的样本,导致聚类更加困难。
5.5估计簇K的数量
| Method | IND/OOD=3:1 | IND/OOD=3:2 | IND/OOD=1:1 | |||
| K(Pred) | Error | K(Pred) | Error | K(Pred) | Error | |
| DeepAligned(=2) | 4 | 1 | 11 | 1 | 11 | 4 |
| DeepAligned(=3) | 8 | 3 | 16 | 6 | 16 | 1 |
| ChatGPT(DC) | 5 | 0 | 14 | 4 | 23 | 8 |
在上面的实验中,OOD 类的数量被假设为真实值。 然而,在实际应用中,OOD 集群的数量通常需要自动估计。 我们使用与 Zhang 等人 (2021) 相同的估计算法 DeepAligned 作为基线;牟等人(2022a)。 对于 ChatGPT,我们从提示中删除真实的簇数,并根据结果计算估计的簇数。 结果报告于表4中。 当集群数量较少时,ChatGPT 可以获得更准确的估计。 然而,随着集群数量的增加,ChatGPT 的表现比基线更差,并且容易高估。 对于基线来说,合适的超参数可以取得很好的效果,但超参数的鲁棒性较差。 所以, ChatGPT更适合估计少量的簇。
5.6 不同大语言模型比较
| Model | OOD Discovery | GID | ||||
| ACC | NMI | ARI | IND ACC | OOD ACC | ALL ACC | |
|---|---|---|---|---|---|---|
| text-davinci-002 | 38.00 | 39.11 | 9.577 | 31.56 | 28.67 | 30.40 |
| text-davinci-003 | 71.33 | 72.12 | 49.84 | 59.56 | 63.33 | 61.07 |
| Claude | 70.00 | 84.27 | 62.24 | 56.67 | 70.00 | 62.00 |
| ChatGPT | 78.00 | 78.20 | 55.32 | 68.44 | 75.33 | 70.17 |
在本节中,我们评估其他主流大语言模型的性能,并与ChatGPT进行比较。 Text-davinci-002和text-davinci-003属于InstructGPT,text-davinci-003是text-davinci-002的改进版本。555https://platform.openai.com/docs/models 与 GPT-3 相比,InstructGPT 最大的区别在于它进行了微调供人类指示。 除了GPT家族模型之外,我们还评估了Anthropic开发的新大语言模型Claude666https://www.anthropic.com/product。 如表5所示,ChatGPT的性能优于text-davinci-002和text-davinci-003,因为ChatGPT在text-davinci-003的基础上进一步优化。 Claude 在 OOD 发现方面与 ChatGPT 表现出竞争性的性能,但在 GID 方面较弱。 此外,我们尝试评估GPT-3(达芬奇),发现GPT-3无法执行任务,这说明了指令调优的重要性。
5.7不同提示的效果
| Prompt/Baseline | OOD Discovery | GID | ||||
| ACC | NMI | ARI | IND ACC | OOD ACC | ALL ACC | |
|---|---|---|---|---|---|---|
| Original | 58.22 | 65.30 | 28.21 | 66.44 | 62.00 | 64.22 |
| Paraphrase | 58.67 | 66.80 | 30.10 | 69.33 | 62.00 | 65.67 |
| verbosity | 60.89 | 68.74 | 34.85 | 68.67 | 60.67 | 64.67 |
| Simplification | 53.78 | 64.20 | 25.26 | 65.33 | 58.67 | 62.00 |
| Average | 57.89 | 66.26 | 29.60 | 67.44 | 60.83 | 64.14 |
| Deepaligned(-GID) | 74.67 | 80.83 | 55.35 | 91.50 | 77.33 | 84.42 |
6 挑战和未来的工作
基于以上实验和分析,我们总结了大语言模型面临的三个挑战场景,并为未来提供指导。
6.1 大规模集群
实验表明 大语言模型在执行大规模聚类任务方面受到限制主要有以下三个原因: (1)输入token的最大长度限制了簇的数量。 (2)当簇数量增加时,大语言模型会出现严重的召回错误。 (3)大语言模型对聚类样本数量的鲁棒性较差。
已经有一些工作尝试解决基于 Transformer 的模型的序列长度约束,例如 Bertsch 等人 (2023)。 另一种可行的方法是在聚类之前将样本归纳为主题词。 对于召回问题,一种事后修复方法是首先在聚类后筛选出召回错误的样本索引,然后通过多轮对话提示大语言模型完成或删除样本分配。 为了鲁棒性,一种可能的方法是首先估计最佳簇数,从原始样本集中选择一小部分种子样本进行聚类,然后将剩余样本分类到种子簇中。
6.2 特定领域的语义理解
6.3跨领域情境学习
在一些实际场景中,例如需要执行新任务或扩展业务范围时,往往缺乏与新任务直接相关的演示示例。 我们希望通过利用之前的领域演示来提高新任务的性能。 然而,之前的实验表明,跨领域的上下文学习在当前的大语言模型中已经失败。 一个有意义但具有挑战性的问题是通过 IND 演示进行的情境学习如何在 OOD 任务中表现良好? 一个初步的知识想法是使用手动思维链提供从 IND 演示样本到标签的推理路径,从而产生更细粒度的特定领域知识。 这些细粒度的中间知识可能有助于推广到 OOD 任务。
7结论
本文对 ChatGPT 在 OOD 意图发现和 GID 方面进行了综合评估,总结了 ChatGPT 在这两个任务中的优缺点。 尽管 ChatGPT 在零样本或少样本性能方面取得了显着改进,但我们的实验表明 ChatGPT 仍然落后于微调模型。 此外,我们还进行了大量的分析实验,深入探讨了大语言模型面临的三个具有挑战性的场景:大规模聚类、特定领域理解、跨领域上下文学习,并为未来的方向提供指导。
局限性
在本文中,我们通过评估 ChatGPT 在域外(OOD)意图发现和广义意图发现(GID)方面的性能,研究大型语言模型(大语言模型)在开放域意图发现和识别方面的优点、缺点和挑战任务。 尽管我们进行了大量的实验,但仍有几个方向需要改进:(1)考虑到论文的重点是像 ChatGPT 这样的大规模语言模型,值得注意的是,ChatGPT 只能用于输出,这使得彻底研究和分析具有挑战性。分析其内部运作。 (2)虽然我们对每个任务执行了三种不同的数据分割,但它们都来自相同的源数据集,这使得它们的意图粒度一致。 对于不同意图粒度的分析本文不再进一步探讨。 (3)虽然我们保证本文中所有关于ChatGPT的实验都基于同一版本,但ChatGPT的进一步更新可能会导致本文结果的变化。
参考
- Bertsch et al. (2023) Amanda Bertsch, Uri Alon, Graham Neubig, and Matthew R Gormley. 2023. Unlimiformer: Long-range transformers with unlimited length input. arXiv preprint arXiv:2305.01625.
- Brown et al. (2020) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901.
- Caron et al. (2018) Mathilde Caron, Piotr Bojanowski, Armand Joulin, and Matthijs Douze. 2018. Deep clustering for unsupervised learning of visual features. In Proceedings of the European conference on computer vision (ECCV), pages 132–149.
- Caron et al. (2020) Mathilde Caron, Ishan Misra, Julien Mairal, Priya Goyal, Piotr Bojanowski, and Armand Joulin. 2020. Unsupervised learning of visual features by contrasting cluster assignments. Advances in neural information processing systems, 33:9912–9924.
- Casanueva et al. (2020) Iñigo Casanueva, Tadas Temčinas, Daniela Gerz, Matthew Henderson, and Ivan Vulić. 2020. Efficient intent detection with dual sentence encoders. arXiv preprint arXiv:2003.04807.
- Chen et al. (2019) Qian Chen, Zhu Zhuo, and Wen Wang. 2019. Bert for joint intent classification and slot filling. arXiv preprint arXiv:1902.10909.
- Chowdhery et al. (2022) Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. 2022. Palm: Scaling language modeling with pathways. arXiv preprint arXiv:2204.02311.
- Devlin et al. (2018) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
- Dong et al. (2022a) Guanting Dong, Daichi Guo, Liwen Wang, Xuefeng Li, Zechen Wang, Chen Zeng, Keqing He, Jinzheng Zhao, Hao Lei, Xinyue Cui, Yi Huang, Junlan Feng, and Weiran Xu. 2022a. Pssat: A perturbed semantic structure awareness transferring method for perturbation-robust slot filling.
- Dong et al. (2023) Guanting Dong, Jinxu Zhao, Tingfeng Hui, Daichi Guo, Wenlong Wang, Boqi Feng, Yueyan Qiu, Zhuoma Gongque, Keqing He, Zechen Wang, and Weiran Xu. 2023. Revisit input perturbation problems for llms: A unified robustness evaluation framework for noisy slot filling task. In Natural Language Processing and Chinese Computing, pages 682–694, Cham. Springer Nature Switzerland.
- Dong et al. (2022b) Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Zhiyong Wu, Baobao Chang, Xu Sun, Jingjing Xu, and Zhifang Sui. 2022b. A survey for in-context learning. arXiv preprint arXiv:2301.00234.
- Frieder et al. (2023) Simon Frieder, Luca Pinchetti, Ryan-Rhys Griffiths, Tommaso Salvatori, Thomas Lukasiewicz, Philipp Christian Petersen, Alexis Chevalier, and Julius Berner. 2023. Mathematical capabilities of chatgpt. arXiv preprint arXiv:2301.13867.
- Guo et al. (2023) Daichi Guo, Guanting Dong, Dayuan Fu, Yuxiang Wu, Chen Zeng, Tingfeng Hui, Liwen Wang, Xuefeng Li, Zechen Wang, Keqing He, Xinyue Cui, and Weiran Xu. 2023. Revisit out-of-vocabulary problem for slot filling: A unified contrastive framework with multi-level data augmentations. In ICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5.
- Jiao et al. (2023) WX Jiao, WX Wang, JT Huang, Xing Wang, and ZP Tu. 2023. Is chatgpt a good translator? yes with gpt-4 as the engine. arXiv preprint arXiv:2301.08745.
- Kuhn (1955) Harold W Kuhn. 1955. The hungarian method for the assignment problem. Naval research logistics quarterly, 2(1-2):83–97.
- Larson et al. (2019) Stefan Larson, Anish Mahendran, Joseph J. Peper, Christopher Clarke, Andrew Lee, Parker Hill, Jonathan K. Kummerfeld, Kevin Leach, Michael A. Laurenzano, Lingjia Tang, and Jason Mars. 2019. An evaluation dataset for intent classification and out-of-scope prediction. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 1311–1316, Hong Kong, China. Association for Computational Linguistics.
- Lei et al. (2023) Shanglin Lei, Guanting Dong, Xiaoping Wang, Keheng Wang, and Sirui Wang. 2023. Instructerc: Reforming emotion recognition in conversation with a retrieval multi-task llms framework. arXiv preprint arXiv:2309.11911.
- Lin et al. (2020) Ting-En Lin, Hua Xu, and Hanlei Zhang. 2020. Discovering new intents via constrained deep adaptive clustering with cluster refinement. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 8360–8367.
- Liu et al. (2023) Jiachi Liu, Liwen Wang, Guanting Dong, Xiaoshuai Song, Zechen Wang, Zhengyang Wang, Shanglin Lei, Jinzheng Zhao, Keqing He, Bo Xiao, and Weiran Xu. 2023. Towards robust and generalizable training: An empirical study of noisy slot filling for input perturbations.
- MacQueen (1965) J MacQueen. 1965. Some methods for classification and analysis of multivariate observations. In Proc. 5th Berkeley Symposium on Math., Stat., and Prob, page 281.
- Malinka et al. (2023) Kamil Malinka, Martin Perešíni, Anton Firc, Ondřej Hujňák, and Filip Januš. 2023. On the educational impact of chatgpt: Is artificial intelligence ready to obtain a university degree? arXiv preprint arXiv:2303.11146.
- Min et al. (2022) Sewon Min, Xinxi Lyu, Ari Holtzman, Mikel Artetxe, Mike Lewis, Hannaneh Hajishirzi, and Luke Zettlemoyer. 2022. Rethinking the role of demonstrations: What makes in-context learning work? In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 11048–11064, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
- Mou et al. (2022a) Yutao Mou, Keqing He, Pei Wang, Yanan Wu, Jingang Wang, Wei Wu, and Weiran Xu. 2022a. Watch the neighbors: A unified k-nearest neighbor contrastive learning framework for OOD intent discovery. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 1517–1529, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
- Mou et al. (2022b) Yutao Mou, Keqing He, Yanan Wu, Pei Wang, Jingang Wang, Wei Wu, Yi Huang, Junlan Feng, and Weiran Xu. 2022b. Generalized intent discovery: Learning from open world dialogue system. In Proceedings of the 29th International Conference on Computational Linguistics, pages 707–720, Gyeongju, Republic of Korea. International Committee on Computational Linguistics.
- Mou et al. (2022c) Yutao Mou, Keqing He, Yanan Wu, Zhiyuan Zeng, Hong Xu, Huixing Jiang, Wei Wu, and Weiran Xu. 2022c. Disentangled knowledge transfer for OOD intent discovery with unified contrastive learning. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 46–53, Dublin, Ireland. Association for Computational Linguistics.
- Tan et al. (2023) Yiming Tan, Dehai Min, Yu Li, Wenbo Li, Nan Hu, Yongrui Chen, and Guilin Qi. 2023. Evaluation of chatgpt as a question answering system for answering complex questions. arXiv preprint arXiv:2303.07992.
- Touvron et al. (2023) Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. 2023. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971.
- Wang et al. (2023) Jindong Wang, Xixu Hu, Wenxin Hou, Hao Chen, Runkai Zheng, Yidong Wang, Linyi Yang, Haojun Huang, Wei Ye, Xiubo Geng, et al. 2023. On the robustness of chatgpt: An adversarial and out-of-distribution perspective. arXiv preprint arXiv:2302.12095.
- Yang et al. (2021) Jingkang Yang, Kaiyang Zhou, Yixuan Li, and Ziwei Liu. 2021. Generalized out-of-distribution detection: A survey. arXiv preprint arXiv:2110.11334.
- Zeng et al. (2022) Weihao Zeng, Keqing He, Zechen Wang, Dayuan Fu, Guanting Dong, Ruotong Geng, Pei Wang, Jingang Wang, Chaobo Sun, Wei Wu, and Weiran Xu. 2022. Semi-supervised knowledge-grounded pre-training for task-oriented dialog systems. In Proceedings of the Towards Semi-Supervised and Reinforced Task-Oriented Dialog Systems (SereTOD), pages 39–47, Abu Dhabi, Beijing (Hybrid). Association for Computational Linguistics.
- Zhang et al. (2021) Hanlei Zhang, Hua Xu, Ting-En Lin, and Rui Lyu. 2021. Discovering new intents with deep aligned clustering. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 14365–14373.
附录A数据集
原始数据集 Banking 包含 77 个类别,且类别不平衡。 其训练集有9003个样本,验证集有1000个样本,测试集有3080个样本。 样本平均词符长度为11.91,最长为79。 我们展示了从表 7 中的 77 个类别中抽取的 15 个 IND 类别和 15 个 OOD 类别。
| IND Class | OOD Class |
| pin_blocked | card_delivery_estimate |
| balance_not_updated_after_bank_transfer | cancel_transfer |
| pending_card_payment | verify_my_identity |
| verify_source_of_funds | cash_withdrawal_charge |
| disposable_card_limits | apple_pay_or_google_pay |
| card_about_to_expire | pending_top_up |
| direct_debit_payment_not_recognised | request_refund |
| top_up_failed | card_linking |
| card_payment_fee_charged | transfer_not_received_by_recipient |
| card_arrival | declined_card_payment |
| card_payment_not_recognised | get_disposable_virtual_card |
| activate_my_card | card_acceptance |
| transfer_timing | get_physical_card |
| getting_spare_card | exchange_rate |
| contactless_not_working | compromised_card |
| OOD Discovery | GID | ||||||
| Method | ACC | NMI | ARI | Method | IND ACC | OOD ACC | ALL ACC |
|---|---|---|---|---|---|---|---|
| DeepAligned | 94.22 | 95.27 | 90.21 | DeepAligned-GID | 98.67 | 94.22 | 96.44 |
| DKT | 97.78 | 96.97 | 95.16 | E2E | 99.11 | 97.78 | 98.44 |
| ChatGPT(DC) | 80.89 | 84.02 | 62.70 | ChatGPT(GID-DC) | 86.00 | 82.67 | 84.33 |
| ChatGPT(ZSD) | 65.33 | 71.11 | 39.15 | ChatGPT(GID-ZSD) | 88.00 | 72.00 | 80.00 |
| ChatGPT(FSD) | 56.00 | 64.15 | 26.32 | ChatGPT(GID-FSD) | 90.00 | 56.67 | 73.33 |
| Method | Stage | Prompt |
| GID-DC | 1 | Next, I will first give you a set of sentences, which will be recorded as Set 1. First, please classify the sentences in Set 1 into 5 (Number of Clusters) categories according to their intentions. You only need to output the category number and the corresponding sentence number in the following format: Category 1: 1,2,3,4,5 …… Then, you need to summarize the intent of each class from Category 1 to Category 5. Set 1(): 1. can I choose a date for delivery? …… |
|---|---|---|
| 2 | Below is a predefined set of intent categories, recorded as Set 1:1. pin_blocked;…… Please classify the following sentence into Set 1 according to its intention, just response the corresponding category number:<test sample> | |
| GID-ZSD | 1 | Next, I will first give you a set of intent categories, which will be recorded as Set 1. Then I will give you another set of sentences without intention labels, recorded as Set 2. You first need to learn the knowledge in Set 1, and then use the learned knowledge to classify the sentences in Set 2 into 5 (Number of Clusters) categories according to their intentions. You only need to output the category number and the corresponding sentence number in the following format: Category 1: 1,2,3,4,5 …… It should be noted that the intention in set 1 and the intention in set 2 do not overlap. Then, you need to summarize the intent of each class from Category 1 to Category 5. Set 1(): pin_blocked; …… Set 2(): 1. can I choose a date for delivery? …… |
| 2 | Below is a predefined set of intent categories, recorded as Set 1:1. pin_blocked;…… Please classify the following sentence into Set 1 according to its intention, just response the corresponding category number:<test sample> | |
| GID-FSD | 1 | Next, I will first give you a set of sentences with intention labels, which will be recorded as Set 1.Then I will give you another set of sentences without intention labels, recorded as Set 2. You first need to learn the knowledge in Set 1, and then use the learned knowledge to classify the sentences in Set 2 into 5 (Number of Clusters) categories according to their intentions. You only need to output the category number and the corresponding sentence number in the following format: Category 1: 1,2,3,4,5 …… It should be noted that the intention in set 1 and the intention in set 2 do not overlap. Then, you need to summarize the intent of each class from Category 1 to Category 5. Set 1 (): How do I unblock my card? intention:pin_blocked; …… Set 2 (): 1. can I choose a date for delivery? …… |
| 2 | Next, I will first give you a predefined set of intent categories, which will be recorded as Set 1. Then I will give you another set of sentences with intention labels, recorded as Set 2. Set 1:1. pin_blocked;…… Set 2:sentence: How do I unblock my card? intention:pin_blocked;…… You first need to learn the knowledge in Set 2, and then use the learned knowledge to classify the following sentence into Set 1 according to its intention , just response the corresponding category : <test sample> |
| Type | Prompt |
| Original | Next, I will first give you a set of sentences , which will be recorded as Set 1. First,Please classify the sentences in Set 1 into 5 categories according to their intentions. You only need to output the category number and the corresponding sentence number in the following format: Category 1: 1,2,3,4,5 …… |
|---|---|
| Paraphrase | I will provide you with a collection of sentences, noted as Set 1. Your task is to categorize the sentences in Set 1 into 5 distinct groups based on their underlying intentions. Your output should include the category number along with the corresponding sentence number, formatted as follows: Category 1: 1, 2, 3, 4, 5, and so on… |
| Verbosity | Next, I will be presenting you with a compilation of sentences, collectively labeled as "Set 1". Your task is to categorize these sentences into 5 distinct groups according to their underlying intentions. Upon completing the task, your response is anticipated to take the form of a structured enumeration. Your response should consist of the assigned category number along with the respective sentence numbers following this format: Category 1: 1, 2, 3, 4, 5… |
| Simplification | Next, I’ll provide sentences in Set 1. Please categorize them into 5 groups based on intentions. Output the category number and sentence number in this format: Category 1: 1, 2, 3, 4, 5… |
附录B实施细节
对于所有基线,我们使用预训练的 BERT 模型 (bert-base-uncased888https://huggingface.com/bert-base-uncased,以12层Transformer为骨干,并冻结除最后一个Transformer层之外的所有参数,以实现更好的性能并加快训练过程: Zhang 等人 (2021) 中建议。 此外,我们保持所有基线的超参数与官方开源代码中的一致。 对于基于ChatGPT的方法,我们通过调用OpenAI的官方API进行实验,我们使用的ChatGPT版本是gpt-3.5-turbo-0301。 对于 API 中的温度等超参数,我们保持 OpenAI 的默认值不变。为了减少随机性,我们对 ChatGPT 和基线的所有方法的 3 次随机运行的结果进行平均。
附录 CCLINC 数据集的结果
此外,我们利用广泛使用的替代数据集 CLINC Larson 等人 (2019) 进行实验结果的探索,IND/OOD 比例为 1:1,如表 8。 尽管 CLINC 和银行数据集之间的标签粒度和领域不同,但 CLINC 的实验结果与我们从银行数据集得出的结论一致并增强了其普遍性。
附录 D提示详细信息
附录E错误召回案例
| Input | Response | Missing Recall | Repeated Recall |
|---|---|---|---|
| Please classify the sentences in Set 2 into 10 categories according to their intentions. | Category 1: 2, 10, 30, 31, 50 | 20,26,29, 35,40,41, 42,46,48 | 2,27 |
| Category 2: 4, 25, 27, 34, 44 | |||
| Category 3: 5, 6, 15, 16, 36 | |||
| Category 4: 1, 2, 3 | |||
| Category 5: 7, 17, 27 | |||
| Category 6: 8, 18, 28, 38 | |||
| Category 7: 9, 22, 32, 39, 49 | |||
| Category 8: 11, 12, 21 | |||
| Category 9: 13, 23, 33, 43 | |||
| Category 10: 14, 19, 24, 37, 45, 47 |
| Type | Input | Response | Ground-Truth Intent |
| Missing Recall | How many days until the money will be in my account? | It does not fit in any category in Set 1. | transfer_timing (IND) |
|---|---|---|---|
| I would like to cancel a payment. I purchased something several days ago and i still have not received it. | The sentence does not match any intents in as it is not related to issues with payment or card management. It could potentially fall under a "purchase delivery inquiry" category. | request_refund (OOD) | |
| Repeated Recall | I don’t know where this transaction came from? | 8. top_up_failed. ( Note: The sentence could also fit under 3. pending_card_payment or 11. card_payment_not_recognised, depending on the context of the conversation.) | card_payment_not_ recognised (IND) |
| My credit card was declined. | 12. activate_my_card; 24. Issues related to card payme | declined_card_payment (OOD) |