理解人类偏好学习的一般理论范式
Mohammad Gheshlaghi Azar Mark Rowland Bilal Piot
Daniel Guo Daniele Calandriello Michal Valko Rémi Munos
Google DeepMind
摘要
通过强化学习 (RLHF) 从人类偏好中学习的普遍部署依赖于两个重要的近似:第一个假设可以用逐点奖励代替成对偏好。 第二个假设基于这些逐点奖励训练的奖励模型可以从收集的数据推广到策略采样的分布外数据。 最近,直接偏好优化(DPO)被提出作为一种绕过第二次近似并直接从收集的数据中学习策略的方法,而无需奖励建模阶段。 然而,该方法仍然严重依赖第一近似。
在本文中,我们试图对这些实用算法有更深入的理论理解。 特别是,我们推导出一个名为 PO 的新通用目标,用于从人类偏好中学习,该偏好以成对偏好表示,因此绕过了两种近似。 这个新的总体目标使我们能够对 RLHF 和 DPO (作为 PO的特殊情况)的行为进行深入分析并确定其潜在的陷阱。 然后,我们通过将 简单地设置为 Identity 来考虑 PO 的另一个特殊情况,为此我们可以导出有效的优化过程,证明性能保证并通过一些示例证明其相对于DPO的实证优越性。
1简介
从人类偏好(Christiano 等人,2017 年)中学习是自然语言处理文献中采用的一种范式,目的是使预训练(Radford 等人,2018 年;Ramachandran 等人,2016 年)和指令微调(Wei 等人,2022 年)生成语言模型更好地与人类需求相一致。 它包括首先收集大量数据,其中每个数据由上下文、成对的上下文延续(也称为 generations)以及指示哪一个 generation 最好的成对人类偏好组成。 然后,从收集的数据中学习在给定背景下生成好 的 generations 的策略。 我们将从人类偏好中学习的问题描述为离线上下文 bandit 问题(Lu等人,2010)。 这个 bandit 问题的目标是,在给定一个上下文的情况下选择一个动作(扮演生成者的角色),该动作在确保赌徒策略接近某个已知参考策略的约束下,最受人类评分者青睐。 接近已知参考策略的约束可以通过使用 KL 正则化 (Geist 等人, 2019) 来满足,其作用是避免模型漂移 (Lazaridou 等人, 2020 ; 卢等人, 2020).
解决从人类偏好中学习问题的一个突出方法是通过强化学习从人类反馈中学习(RLHF,Ouyang等,2022年; Stiennon等,2020年),首先训练一个奖励模型,以分类器的形式对喜欢和不喜欢的动作进行训练。 然后通过强化学习训练 bandit 策略,以最大化学习到的奖励模型,同时最小化与参考策略的距离。 最近,RLHF已成功用于解决生成语言模型与人类偏好匹配的问题(Ouyang等人,2022)。 此外,最近的工作,例如直接偏好优化(DPO,Rafailov等人,2023)和(SLiC-HF,Zhao等人,2023)已经表明,可以直接根据人类偏好优化 bandit 策略,无需学习奖励模型。 他们还表明,在选择的标准语言任务上,它们与最先进的 RLHF 具有竞争力,同时它们更易于实现并且需要更少的资源。
尽管取得了实际的成功,但人们对这些实用方法的理论基础知之甚少。 值得注意的特殊例外情况是(Wang 等人,2023;Chen 等人,2022)和之前的关于偏好的工作(Busa-Fekete 等人,2014,2013) ) 以及与 bandits 和 RL 的对抗(Novoseller 等人, 2020; Pacchiano 等人, 2023)。 然而,这些理论工作侧重于为标准 bandit 设置中的 regret 界限提供理论保证,而没有涉及RLHF、DPO和SLiC-HF。
在这项工作中,我们的重点是通过介绍用于学习人类偏好的实用算法的简单而通用的理论表示来弥合理论与实践之间的差距。 特别是,我们表明可以将 RLHF 和 DPO 的目标函数描述为专门用成对偏好表示的更一般目标的特殊情况。 我们将此目标称为 -偏好优化目标 (PO) ,其中 是任意非递减映射。 然后,我们在 RLHF 和 DPO 的特殊情况下分析这个目标函数,并研究其潜在的缺陷。 我们对 RLHF 和 DPO 的理论研究表明,原则上它们都容易受到过度拟合的影响。 这是因为这些方法依赖于这样一个强有力的假设:成对偏好可以通过 Bradley-Terry (BT) 模型化用 ELo-score(逐点奖励)替代(Bradley 和 Terry,1952)。 特别是,当(采样的)偏好是确定性或接近确定性时,这种假设可能会出现问题,因为它会导致过度拟合偏好数据集,而代价是忽略 KL 正则化项(参见第 4.2。 然后,我们提出了一个简单的解决方案来避免过度拟合的问题,即通过将 设置为 PO 中的同一性。 这种方法称为 Identity-PO (IPO),并且通过构造绕过偏好的 BT 模型化假设(参见第 5 节)。 最后,我们提出了一个实用的解决方案,通过采样损失函数(参见第5.2节),根据经验优化这个简化版本的PO并且,我们在简单的 bandit 示例上将其性能与 DPO 进行了比较,为我们的理论发现提供了实证支持(参见第 5.3 节和第 5.4 节) )。
2 符号
剩下的部分,我们以 DPO (Rafailov 等人, 2023) 的符号为基础。 给定一个上下文 ,其中 是上下文的有限空间,我们假设一个有限的动作空间。 策略将每个上下文关联起来 离散概率分布 ,其中 是 上的离散分布集合。 我们表示 行为策略。 从给定的上下文 中,设 是由参考策略独立生成的两个操作。 然后将这些结果呈现给表达对某一代的偏好的人类评估者,表示为 ,其中 和 表示 分别。 然后,我们写出真正的人类偏好在知道上下文 的情况下,优于 的概率。 概率来自于我们询问他们的偏好的人的选择的随机性。 所以,其中,期望值是对人类 的期望值。我们还引入了一代人对已知的分布的预期偏好、noted , via the following equation:
对于任意两个政策 和上下文分布 ,我们将政策 对 的总偏好表示为
在实践中,我们不会直接观察 ,而是观察样本 来自伯努利分布,其均值为(i.e., is with probability和 、其中 是数据集大小。 此外,对于一般有限集 、离散概率分布 和实函数 、我们注意到 在 下的期望为. 对于有限数据集 、其中每个 都有 实函数 、我们将 在 下的 经验期望表示为.
3背景
3.1 根据人类反馈进行强化学习 (RLHF)
标准RLHF范式(Christiano等人,2017;Stiennon等人,2020)由两个主要阶段组成:(i)学习奖励模型; (ii) 使用学习到的奖励进行策略优化。 在这里,我们回顾一下这些阶段。
3.1.1 学习奖励模型
学习奖励模型包括训练一个二元分类器,以使用逻辑回归损失来区分首选和不首选的操作。 对于分类器,一个流行的选择是 Bradley-Terry 模型:对于给定的上下文 和动作 ,我们表示逐点奖励,也可以解释为 Elo 分数, 由 给定 。 Bradley-Terry 模型表示偏好函数 (分类器)作为奖励差异的 sigmoid:
| (1) |
其中表示sigmoid函数,起到归一化的作用。 给定数据集 可以通过优化以下函数来学习奖励函数逻辑回归损失
| (2) |
假定 符合布拉德利-特里模型、我们可以证明,随着数据集 的增大、 becomes a more and more accurate对真实并在极限收敛于.
3.1.2 利用学习奖励进行策略优化
利用奖励(Elo 分数),RLHF 目标就是通过以下 KL 规则化目标函数,优化出使预期奖励最大化的策略 ,同时使 与某个参考策略 之间的距离最小:
| (3) |
其中上下文 来自 ,动作 来自 。 散度定义如下:
其中:
方程 (3) 中的目标本质上是通过 PPO (Schulman 等人, 2017) 或类似方法进行优化。
RLHF+PPO的组合在实践中取得了巨大成功(例如,InsturctGPT和GPT-4 Ouyang等人,2022;OpenAI,2023)。
3.2直接偏好优化
上述 RL 范式的另一种方法是直接偏好优化(DPO; Rafailov 等人,2023),它完全避免了奖励模型。 给定经验数据集 ,DPO 优化的损失作为 的函数,由下式给出
| (4) |
就其人口形式而言,损失表现为
| (5) |
Rafailov et al. (2023) show that when (i) the Bradley-Terry model in Equation (1) perfectly fits the preference data and (ii) the optimal reward function is obtained from the loss in Equation (2), then the global optimisers of the RLHF objective in Equation (3) and the DPO objective in Equation (3.2) perfectly coincide. 事实上,这种对应关系更普遍。请参阅附录B中的命题4。
4 偏好优化的总体目标
本文的核心概念贡献是基于最大化偏好的非线性函数,提出 RLHF 的总体目标。 为此,我们考虑一个一般的非递减函数 ,一个参考策略 ,和一个实正则化参数 ,并将 -偏好优化目标 (PO) 定义为
| (6) |
该目标平衡了偏好概率的潜在非线性函数与 KL 正则化项的最大化,从而鼓励策略接近参考 。 这是由方程 (3) 的形式推动的,我们将在下一小节中看到它严格概括了 RLHF 和 DPO,当BT模型成立时。
4.1 深入分析DPO和RLHF
在剩下的部分中,为了便于表示,我们省略了对 的依赖。 这不失一般性,并且以下所有结果对于所有 。
我们首先将DPO和RLHF与方程(6)中的-偏好目标连接起来,在特殊选择下。 更准确地说,以下命题建立了这种联系。
Proposition 1。
证明。
4.2 弱正则化和过拟合
值得退后一步并反问上述目标引导我们发现什么样的策略。 这种高度非线性的偏好概率转换意味着,对于已经接近1的偏好概率的微小增加和对处于 左右的偏好概率的较大增加一样受到激励,这可能是不太理想的。 即使在传递性设置中,logit 偏好(博弈论术语中的 Elo 分数)的最大化也可能产生反直觉的效果(Bertrand 等人,2023)。
请看这样一个简单的例子:我们有两个动作 和 ,使得,即 总是优于 。 那么 Bradley-Terry 模型将需要 满足 (1 如果我们将其插入最优政策(7)中,就会得到(即 ),与 KL-正则化所使用的常数 无关。 因此,偏好的确定性越大,KL 正则化的强度就越弱。
KL 正则化的弱点在有限数据体系中变得更加明显,我们只能访问偏好 。 即使真正的偏好是,例如、根据经验,当我们只有几个数据点进行估计时,这是很有可能的,在这种情况下,经验最优政策将使,适用于任何。 这意味着过度拟合可能是一个重大的经验问题,尤其是当上下文和动作空间非常大(就像大型语言模型一样)时。
为什么标准RLHF在实践中对这个问题更加稳健? 虽然 DPO 据称的优点是它避免了拟合奖励函数的需要,但我们观察到,在实践中,当经验偏好概率位于集合 ,奖励函数最终欠拟合 。 存在 偏好概率训练是无限的,但这些值是可以避免的,实际上奖励函数的正则化已被观察到是实践中 RLHF 的一个重要方面(Christiano 等人, 2017)。 因此,奖励函数的欠拟合对于获得针对参考策略 和 充分正则化的最终策略至关重要。 DPO在避免奖励函数的训练时,失去了欠拟合的奖励函数所提供的策略的正则化。
虽然提前停止等标准经验实践仍然可以用作正则化的附加形式来减少这种过度拟合,但在下一节中,我们将介绍 PO 的修改 目标,即使偏好是确定性的,最优经验策略也可以接近 。
5 IPO:具有恒等映射的PO
我们在上一节中观察到,DPO容易出现过度拟合,这是由于的无界性以及没有训练明确的奖励函数的组合。 不直接训练奖励函数是DPO的明显优势,但我们也希望避免过度拟合的问题。
对 DPO 的分析激发了对有界 的选择,确保方程 6 中的 KL 正则化即使在 - 值偏好,如使用经验数据集时经常出现这种情况。 通过将 视为方程 (6) 中的恒等映射,给出了要考虑的特别自然的目标形式,从而导致总偏好的直接正则化优化:
| (8) |
优化方程 (8) 目标函数的标准方法是通过 RLHF 并选择奖励 。 然而,都使用强化学习并估计奖励模型可能成本高昂。 受到DPO的启发,人们希望为方程(8)的优化问题设计一种经验解决方案,它可以直接从偏好数据集中学习。 因此,它将能够完全避免强化学习和奖励建模。
5.1 推导和计算高效的算法
与DPO一样,将方程(8)重新表达为离线学习目标将是有益的。 为了推导这样的表达式,我们首先遵循Rafailov等人(2023)的推导,将最优策略的分析表达式操纵成一个寻根问题系统。 与上一节一样,我们从符号中删除了对上下文 的依赖,因为所有参数都可以在每个上下文的基础上应用。
IPO 的损失。 现在,我们从 Rafailov 等人 (2023) 所采用的分析方法出发,在 作为同一函数的特定情况下,对公式 (6) 进行离线计算。 在这种情况下,方程 (12) 简化为
我们首先将这些寻根问题重新表示为单个优化问题 :
| (13) |
我们可以很容易地证明,对于 的选择,我们有 。 因此 是 。 以下定理证明了该解的唯一性。
Theorem 2 (全局/局部最优的唯一性).
假设并将 定义为是政策 的集合,使得. 那么在中有一个唯一的局部/全局最小值,即。
证明。
假设,根据定义为 此外,根据公式 (11),可以立即得出 、因此我们推导出 是 的全局最优值。现在我们证明,在 中, 没有其他局部/全局最小值。
我们写。 我们通过对数向量 对集合 进行参数化、设置for ,and otherwise. 让我们写成 目标作为 logits
| (14) | ||||
目标是 logits 的二次函数。此外,通过展开上面的二次方,我们看到损失可以表示为平方和
| (15) |
加上线性项和常数项。 因此,这是一个正半定二次方程,因此是凸的。 因此我们推断出损失的所有局部最小化 也是全局最小化器 (Boyd 和 Vandenberghe,2004 年,第 1 章) 4). 我们现在注意到,由于 是一个从 到 的连续射影,因此从局部最小值的定义中可以很容易地证明, 的每个局部最小值 都对应于 的局部最小值 的集合。 因此, 的所有局部最小值也是全局最小值。
最后,方程 (15) 中的二次方不远离 0 增加的唯一方向 是当所有括号内的项保持为 0 时;也就是说,在方向 。 因此, 是严格凸的,除了方向 。 (Boyd 和 Vandenberghe,2004 年,第 1 章) 3). 但是,沿 不会修改所得到的策略 ,因为对于 、
严格的凸性与 是全局最小值这一事实相结合,证明 是 (Boyd 和 Vandenberghe,2004 年,第 1 章) 4). ∎
5.2 IPO的抽样损失
为了获得 IPO 的采样损失,我们需要证明我们可以对方程右侧 (13) 建立无偏估计。 为此,我们考虑Population IPO损失:
| (16) |
其中 取自伯努利分布,其均值为,i.e.,为,如果优于(发生这种情况的概率为probability ),和偏好数据集中的 ,并参考记录的偏好,从 中获取样本。 下面的命题通过证明方程 (13) 到方程 (16) 的相等性来证明它们的转换是正确的。
证明。
我们现在讨论如何使用经验数据集来近似方程 (16) 中的损失。 正如我们之前的讨论一样,经验数据集 的形式为 。 请注意,每个数据点 为公式 (16) 的经验近似值贡献了两个项,其中 ,and also . 这种对称性对于利用很重要,并且可以减少损失的方差。 因此,总体经验损失由下式给出
| , |
直到一个常数等于:
| (17) |
这种损失的简化形式为 IPO 优化政策 的方式提供了一些有价值的见解:(i) IPO 只需增加对数似然比即可从偏好数据集中学习 通过常数 因此,正则化越弱, 与 。 (ii) IPO 与 DPO 不同,始终将其解决方案规范化为 通过控制对数似然比之间的距离 和
5.3说明性示例
为了说明我们的算法和 DPO 之间的质的差异,我们将考虑一些简单的案例。 为了简单起见,我们假设没有上下文,即我们处于 bandit 设置中。
5.3.1 渐近设置
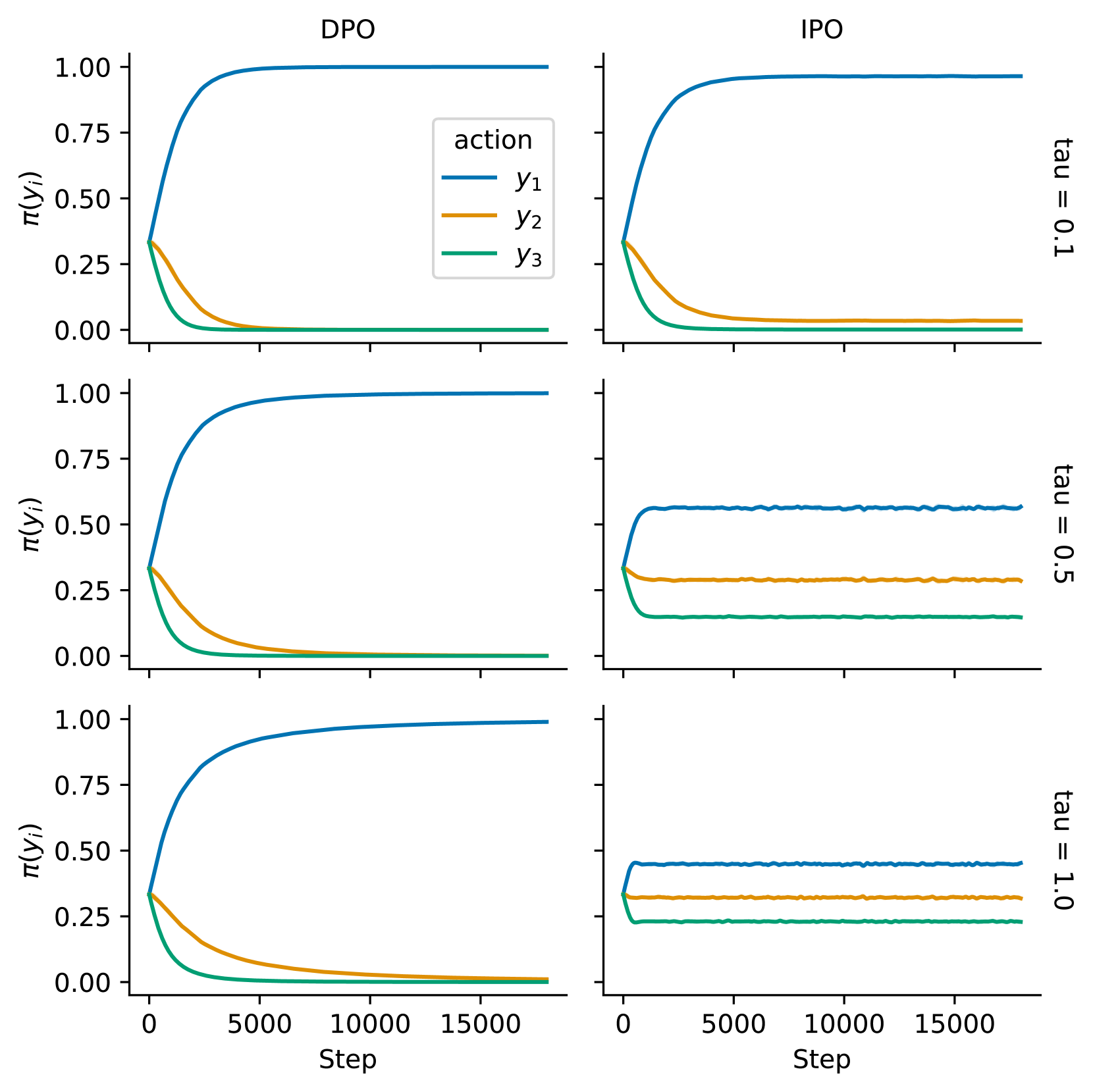
我们首先考虑只有 2 个动作的简单情况, 和 ,以及它们之间的确定性偏好:。 假设我们从统一的 和 开始。 我们从第 4.2 中知道,DPO 将收敛于确定性策略 、,而无论 的值是什么。 因此,即使正则化系数非常大,这也与均匀的有很大不同。
现在,让我们推导出IPO的最优政策。 我们有 和 。 将其与 一起代入 (9) 公式,可以得出 以及 ,其中 是 sigmoid 函数。 因此,我们可以看到,如果我们采用 这样的大正则化,则 收敛到统一策略 ;反之 ,那么 且 ,这就是确定性最优策略。 正则化参数 现在实际上可以用来控制我们与 的接近程度。
5.4 采样首选项
到目前为止,我们依赖于方程(1)中的封闭形式最优策略(9) 来研究 DPO 和 IPO 的稳定性,但该方程不适用于更复杂的设置,比如我们只能访问采样的偏好而不是 。 不过,我们仍然可以通过选择一个参数 来找到最优策略的精确近似值,并通过数据集上的经验损失和基于梯度的迭代更新来优化 。 我们将使用这种方法来展示两个非渐进的例子,在这两个例子中,DPO过度拟合了偏好数据集,忽略了:当一个行动 赢得所有其他行动 DPO 时, 推至 1,与 无关、反之,当一个行动 从未赢得其他行动 DPO 时, 将再次推至 0,而与 无关。 在相同的场景中,IPO不会收敛到这些退化的解决方案,而是仍然接近于,基于正则化的强度。
对于这两种情况,我们考虑一个离散空间 with 3 actions,并选择一个数据对 . 给定,我们利用等式中的经验损失。 3.2 和等式。 13找到DPO和IPO的最优政策。 我们使用向量 将策略编码为 ,并使用 Adam 针对 步骤优化它们(Kingma 和 Ba,2014)学习率 和小批量大小 。 小批量是使用统一采样和 替换来构建的。 策略和损失均使用flax python框架(Bradbury等人,2018;Heek等人,2023)实现,Adam实现来自optax (Babuschkin 等人,2020)。 对于每组超参数,我们使用不同的种子重复实验 10 次,并报告平均值和 95% 置信区间。 所有实验均在具有 4 核和 32GB RAM 的现代云虚拟机上执行。
IPO 避免贪婪策略
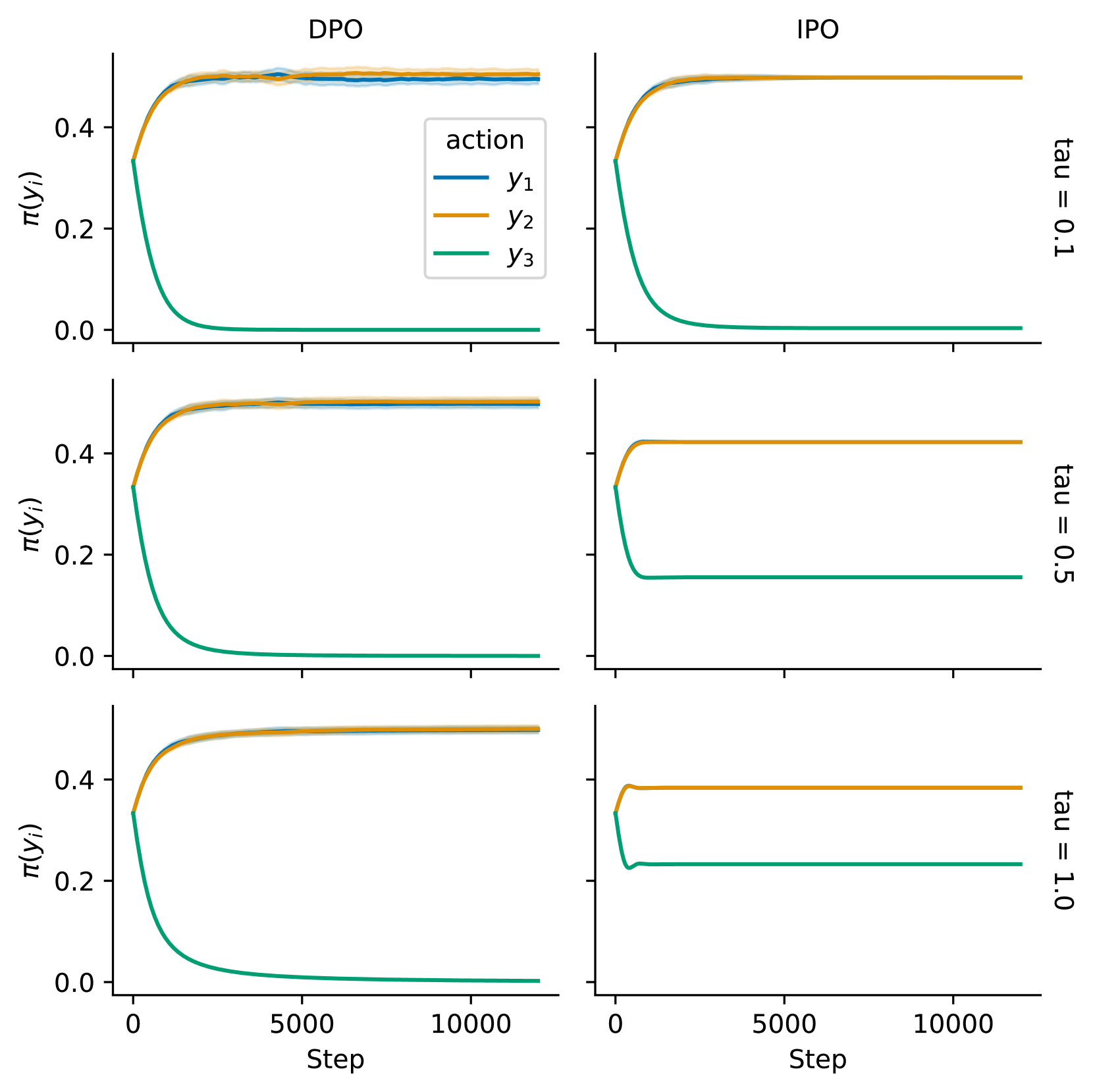
对于第一个示例,我们对每个唯一的操作对进行一次采样,以收集包含 3 个观察到的偏好的数据集 。 由于成对偏好的对称性,仅对 3 个偏好进行采样只能产生两种结果(取决于操作的排列):
我们关注 ,它代表总排序,而不是 ,代表一个循环。 实验结果如图 1 所示,其中,我们报告了不同 值的学习曲线。 我们观察到,对于所有 值,DPO 始终收敛于确定性策略。 换句话说,无论正则化项有多强,DPO 都完全忽略参考策略,并收敛到数据集中首选的操作。 另一方面,IPO防止政策在正则化较强时变得贪婪。
IPO 不排除动作
在第一个示例中,DPO 收敛于确定性策略,因为一个操作严格支配所有其他操作,并且损失继续推高其可能性直至饱和。 相反的效果发生在逻辑相反的条件下,即,当一个动作在数据集中没有至少取得胜利时,DPO 会将其概率设置为 0,而不管 。 虽然这比第一个例子的破坏性要小(单个概率受到干扰,而之前整个政策因过度实现的行动而扭曲),但它在现实世界的数据中也更为常见。 特别是,当动作空间很大但数据集很小时,某些动作必然会很少或仅被采样一次,从而可能永远不会观察到胜利。 特别是因为我们没有关于其性能的数据,为了安全起见,应该接近,但是DPO 的目标并不提倡这一点。
在最后一个示例中,数据集由两个观察到的偏好组成 并保留对 我们再次使用 Adam 计算解决方案,并在图 2 中报告不同 值的结果。 我们在这里再次观察到,无论我们对目标的正则化有多强,DPO 都会完全忽略先前的 ,而 IPO 逐渐降低 未观察到行动的概率。
6 结论和未来工作
我们提出了一个统一的目标,称为PO,用于从偏好中学习。 它统一了RLHF和DPO方法。 此外,我们还介绍了 PO 的特殊情况,称为 IPO,它允许直接从偏好中学习,无需奖励建模阶段,也无需依赖于 Bradley-Terry 模型假设,该假设假设成对偏好可以用逐点奖励替代。 这很重要,因为它可以避免过度拟合问题。 仅当可以导出经验采样损失函数时,这种理论贡献才在实践中有用。 这就是我们在第5节中所做的,我们证明IPO可以被表述为一个寻根问题,从中可以导出经验采样损失函数。 IPO损失函数简单、易于实现且理论上合理。 最后,在 5.3 节 和 5.4 节,我们提供了说明性示例,其中我们强调了当偏好完全已知以及对偏好进行采样时 DPO 的不稳定性。 这些最小的实验足以证明 IPO 比 DPO 更适合从抽样偏好中学习。 未来的工作应该将这些实验扩展到更复杂的设置,例如基于人类偏好数据的训练语言模型。
参考
- Babuschkin et al. (2020) Igor Babuschkin, Kate Baumli, Alison Bell, Surya Bhupatiraju, Jake Bruce, Peter Buchlovsky, David Budden, Trevor Cai, Aidan Clark, Ivo Danihelka, et al. The DeepMind JAX ecosystem, 2020, 2020. URL http://github.com/deepmind.
- Bertrand et al. (2023) Quentin Bertrand, Wojciech Marian Czarnecki, and Gauthier Gidel. On the limitations of the Elo: Real-world games are transitive, not additive. In Proceedings of the International Conference on Artificial Intelligence and Statistics, 2023.
- Boyd and Vandenberghe (2004) Stephen P. Boyd and Lieven Vandenberghe. Convex optimization. Cambridge University Press, 2004.
- Bradbury et al. (2018) James Bradbury, Roy Frostig, Peter Hawkins, Matthew James Johnson, Chris Leary, Dougal Maclaurin, George Necula, Adam Paszke, Jake VanderPlas, Skye Wanderman-Milne, and Qiao Zhang. JAX: composable transformations of Python+NumPy programs, 2018. URL http://github.com/google/jax.
- Bradley and Terry (1952) Ralph Allan Bradley and Milton E Terry. Rank analysis of incomplete block designs: I. The method of paired comparisons. Biometrika, 39(3/4):324–345, 1952.
- Busa-Fekete et al. (2014) Róbert Busa-Fekete, Balázs Szörényi, Paul Weng, Weiwei Cheng, and Eyke Hüllermeier. Preference-based reinforcement learning: Evolutionary direct policy search using a preference-based racing algorithm. Machine Learning, (3):327–351, 2014.
- Busa-Fekete et al. (2013) Róbert Busa-Fekete, Balázs Szörenyi, Paul Weng, Weiwei Cheng, and Eyke Hüllermeier. Preference-based evolutionary direct policy search. In Autonomous Learning Workshop @ ICRA, 2013.
- Chen et al. (2022) Xiaoyu Chen, Han Zhong, Zhuoran Yang, Zhaoran Wang, and Liwei Wang. Human-in-the-loop: Provably efficient preference-based reinforcement learning with general function approximation. In Proceedings of the International Conference on Machine Learning, 2022.
- Christiano et al. (2017) Paul F. Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences. In Advances in Neural Information Processing Systems, 2017.
- Geist et al. (2019) Matthieu Geist, Bruno Scherrer, and Olivier Pietquin. A theory of regularized Markov decision processes. In Proceedings of the International Conference on Machine Learning, 2019.
- Heek et al. (2023) Jonathan Heek, Anselm Levskaya, Avital Oliver, Marvin Ritter, Bertrand Rondepierre, Andreas Steiner, and Marc van Zee. Flax: A neural network library and ecosystem for JAX, 2023. URL http://github.com/google/flax.
- Kingma and Ba (2014) Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations, 2014.
- Lazaridou et al. (2020) Angeliki Lazaridou, Anna Potapenko, and Olivier Tieleman. Multi-agent communication meets natural language: Synergies between functional and structural language learning. In Proceedings of the Annual Meeting of Association for Computational Linguistics, 2020.
- Lu et al. (2010) Tyler Lu, Dávid Pál, and Martin Pál. Contextual multi-armed bandits. In Proceedings of the International Conference on Artificial Intelligence and Statistics, 2010.
- Lu et al. (2020) Yuchen Lu, Soumye Singhal, Florian Strub, Aaron Courville, and Olivier Pietquin. Countering language drift with seeded iterated learning. In Proceedings of the International Conference on Machine Learning, 2020.
- Novoseller et al. (2020) Ellen Novoseller, Yibing Wei, Yanan Sui, Yisong Yue, and Joel Burdick. Dueling posterior sampling for preference-based reinforcement learning. In Proceedings of the Conference on Uncertainty in Artificial Intelligence, 2020.
- OpenAI (2023) OpenAI. Gpt-4 technical report, 2023.
- Ouyang et al. (2022) Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller amd Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedback. In Advances in Neural Information Processing Systems, 2022.
- Pacchiano et al. (2023) Aldo Pacchiano, Aadirupa Saha, and Jonathan Lee. Dueling RL: Reinforcement learning with trajectory preferences. arXiv, 2023.
- Radford et al. (2018) Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. Improving language understanding by generative pre-training. 2018.
- Rafailov et al. (2023) Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. arXiv, 2023.
- Ramachandran et al. (2016) Prajit Ramachandran, Peter J. Liu, and Quoc V. Le. Unsupervised pretraining for sequence to sequence learning. In Proceedings of the Conference on Empirical Methods in Natural Language Processings, 2016.
- Schulman et al. (2017) John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv, 2017.
- Stiennon et al. (2020) Nisan Stiennon, Long Ouyang, Jeffrey Wu, Daniel Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, and Paul F. Christiano. Learning to summarize with human feedback. Advances in Neural Information Processing Systems, 2020.
- Wang et al. (2023) Yuanhao Wang, Qinghua Liu, and Chi Jin. Is RLHF more difficult than standard RL? arXiv, 2023.
- Wei et al. (2022) Jason Wei, Maarten Bosma, Vincent Y. Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M. Dai, and Quoc V. Le. Finetuned language models are zero-shot learners. In Proceedings of the International Conference on Learning Representations, 2022.
- Zhao et al. (2023) Yao Zhao, Rishabh Joshi, Tianqi Liu, Misha Khalman, Mohammad Saleh, and Peter J Liu. SLiC-HF: Sequence likelihood calibration with human feedback. arXiv, 2023.
附录
附录A证明
A.1 正则化argmaximum的存在唯一性
为了完整起见,我们简要回顾一下以下正则化准则的 argmaximum 的存在性和唯一性证明,该证明也可以在 Rafailov 等人 (2023) 的工作中找到:
其中 是有限集, 是将 中的元素映射为实数的函数、一个严格的正实数、 and 是 上的离散概率分布。 特别是,我们记得离散概率分布 可以识别为正实函数 验证:
现在,如果我们定义 softmax 概率 为:
那么,根据前面的定义,我们得到以下结果:
证明。
根据 KL 的定义,我们现在 如下:
其中是一个常数(不依赖于 ),是一个正乘法项、then 和 具有相同的 argmaximum。 证明到此结束。 ∎
A.2非唯一性,当:
请注意,如果我们搜索 的支持严格大于 的支持的解决方案,则可能有多个解决方案。 让我们用一个简单的例子来说明这个案例。 只有一个状态和3个动作 参考策略 在 ,而策略 分配的概率为, 和 和 。
因此损失为 。 我们推导出任何政策 such that是 的全局最小值。
特别是,有无数种与最优解 不同的解。 问题来自于这样一个事实:当 的支持没有覆盖整个动作空间时,没有足够的约束来唯一地表征 。 假设 和 的支持重合使我们能够恢复解的唯一性,如定理2。
附录 B其他结果
在本节中,我们将展示 DPO 和 RLHF 的等价性,无论偏好模型是否 对应于Bradley-Terry模型。 请注意,存在最小化器的假设是为了排除通过将某些操作的奖励设为 。
Proposition 4。
证明。
现在,假设 对于 Bradley-Terry 奖励目标而言是最佳的,这意味着 对于 RLHF 目标而言是最佳的。 如果 对于 DPO 目标不是最优的,则存在另一种策略 为 DPO2> 损失获得严格较低的值。 但是存在一个奖励函数 ,使得 、such as ,因此, 得到的布拉德利-特里损失比 低,这是一个矛盾。
同样,如果 对于 DPO 目标是最优的,则相应的奖励函数 必须是 Bradley 的最佳选择 -特里奖励损失。 因此,RLHF 目标的相应优化器为,根据要求。 ∎