这些作者同等贡献这项工作。 这些作者同等贡献这项工作。 这些作者同等贡献这项工作。 [1]高志敏
1]中国郑州大学计算机与人工智能学院 2]美国 Amazon Prime Video
基于人体姿势的深度学习估计、跟踪和动作识别:一项调查
摘要
人体姿势分析由于其用途不断扩大,包括游戏、视频监控、运动表现分析和人机交互等,在研究界和实际应用中都引起了极大的关注。 深度学习的出现显着提高了姿势捕捉的准确性,使得基于姿势的应用变得越来越实用。 本文对利用深度学习的基于姿势的应用进行了全面的调查,包括姿势估计、姿势跟踪和动作识别。姿势估计涉及从图像或图像序列确定人体关节位置。 姿势跟踪是一个新兴的研究方向,旨在随着时间的推移生成一致的人体姿势轨迹。 另一方面,动作识别的目标是使用姿势估计或跟踪数据来识别动作类型。 这三项任务错综复杂地相互关联,后者往往依赖于前者。 在本次调查中,我们全面回顾了相关工作,从单人姿势估计到多人姿势估计,从2D姿势估计到3D姿势估计,从单图像到视频,从逐渐挖掘时间上下文到姿势跟踪,最后从跟踪到基于姿势的动作识别。 作为一项以深度学习在姿势分析中的应用为中心的调查,我们明确讨论了现有技术的优点和局限性。 值得注意的是,我们强调将这三个任务集成到视频序列中的统一框架中的方法。 此外,我们探讨了所涉及的挑战并概述了未来研究的潜在方向。
关键词:
姿势估计、姿势跟踪、动作识别、深度学习、调查1简介
人体姿势估计、跟踪和基于姿势的动作识别代表了计算机视觉领域的三个基本研究方向。 这些领域有着广泛的应用,从视频监控、人机交互、游戏、运动分析、智能驾驶到新零售商店的新兴景观。 关节式人体姿势估计涉及估计给定图像或视频中人体配置的任务。 人体姿态跟踪的目标是随着时间的推移生成一致的姿态轨迹,通常用于分析人体的运动特性。 基于人体姿势或基于骨架的动作识别是基于姿势估计或跟踪数据来识别动作类型。 尽管这三个任务属于人体运动分析领域,但在现有文献中它们通常被视为不同的实体。
人体运动分析是一个长期存在的研究课题,关于此任务有大量的工作和多项调查[1,2,3,4,5,6,7,8,9] 。 在这些调查中,人体检测、跟踪、姿势估计和运动识别通常会一起进行审查。 多篇调查论文总结了人体姿态估计[10, 11]、跟踪[12,13,14,15,16]和动作识别的研究[17,18,19,20]。 随着深度学习的发展,这三个任务相比手工制作特征时代[21, 22]都取得了显着的改进。 之前的调查要么回顾了整个基于视觉的人体运动领域[1,2,3,4,5,6,7,8],要么专注于特定任务[10, 11、22、23、24、25、26、27]。 然而,还没有这样的综述论文同时回顾姿态估计、姿态跟踪和姿态识别。 受拉格朗日运动分析观点[28]的启发,姿态信息和跟踪有利于动作识别。 因此,这三项任务是密切相关的。 它对于回顾将三个任务联系在一起的方法非常有用,并为每个任务的单独解决方案提供深刻的理解,并为联合任务的统一解决方案提供更多探索。
在本文中,我们将分别对之前使用深度学习方法在这三个任务上的工作进行全面回顾,并讨论之前研究论文的优点和缺点。 此外,我们阐明了将这三个任务结合在一起的内在联系,同时倡导采用基于深度学习的框架来无缝集成它们。 具体来说,我们将回顾以前的深度学习工作,从 2D 姿势估计到 3D 姿势估计,从单个图像到视频,从逐渐挖掘时间上下文到姿势跟踪,最后从跟踪到基于姿势的动作识别。 根据姿态估计的人数,2D/3D姿态估计可以分为单人姿态估计和多人姿态估计。 根据网络的输入,每个类别可以进一步分为基于图像和视频的单人/多人姿势估计。 为了跨帧链接姿势,姿势跟踪可以分为单人姿势跟踪的后处理和集成方法、多人姿势跟踪的自上而下和自下而上的方法。 获得视频中姿势的轨迹后,可以自然地进行基于姿势的动作识别,可以分为估计姿势和基于骨架的动作识别。 前者以RGB视频作为输入,联合进行姿态估计、跟踪和动作识别。 后者提取由运动捕捉、飞行时间和结构光相机等传感器捕获的骨架序列以进行动作识别。 对于基于骨架的动作识别,确定了四个类别,包括卷积神经网络(CNN)、循环神经网络(RNN)、图神经网络(GCN)和基于 Transformer 的方法。 图1说明了本次调查的分类。
这项调查的主要新颖之处在于,重点关注了使用深度学习方法的三个密切相关的任务,这在之前的调查中从未做过。 在回顾各种方法时,考虑到了三个任务之间的联系,因此,本次调查倾向于从组装它们以获得更多实际应用的角度来讨论所审查方法的优点和局限性。 这是深度学习时代第一个将他们放在一起分析其内在联系的调查。 此外,本次调查与其他调查的不同之处在于:
-
•
全面、全面地涵盖了 2014 年以来开发的最先进的基于深度学习的方法。 这种广泛的报道使读者能够全面了解最新的研究方法及其结果。
-
•
对这三个任务的方法进行了深入的分类和分析,并突出了优缺点,促进了更好解决方案的潜在探索。
-
•
对这三个任务最常用的基准数据集以及基准数据集的最新结果进行了广泛的审查。
-
•
通过对现有方法的局限性分析,认真讨论了三项任务的挑战和潜在的研究方向。
本次调查的后续部分组织如下。 2 到 4 部分分别深入研究了姿态估计、姿态跟踪和动作识别的方法。 5 节介绍了常用的基准数据集和三个任务的性能比较。 6 节介绍了这三项任务的挑战以及未来方向的指示。 该调查在第 7 节中提供了结论性意见。
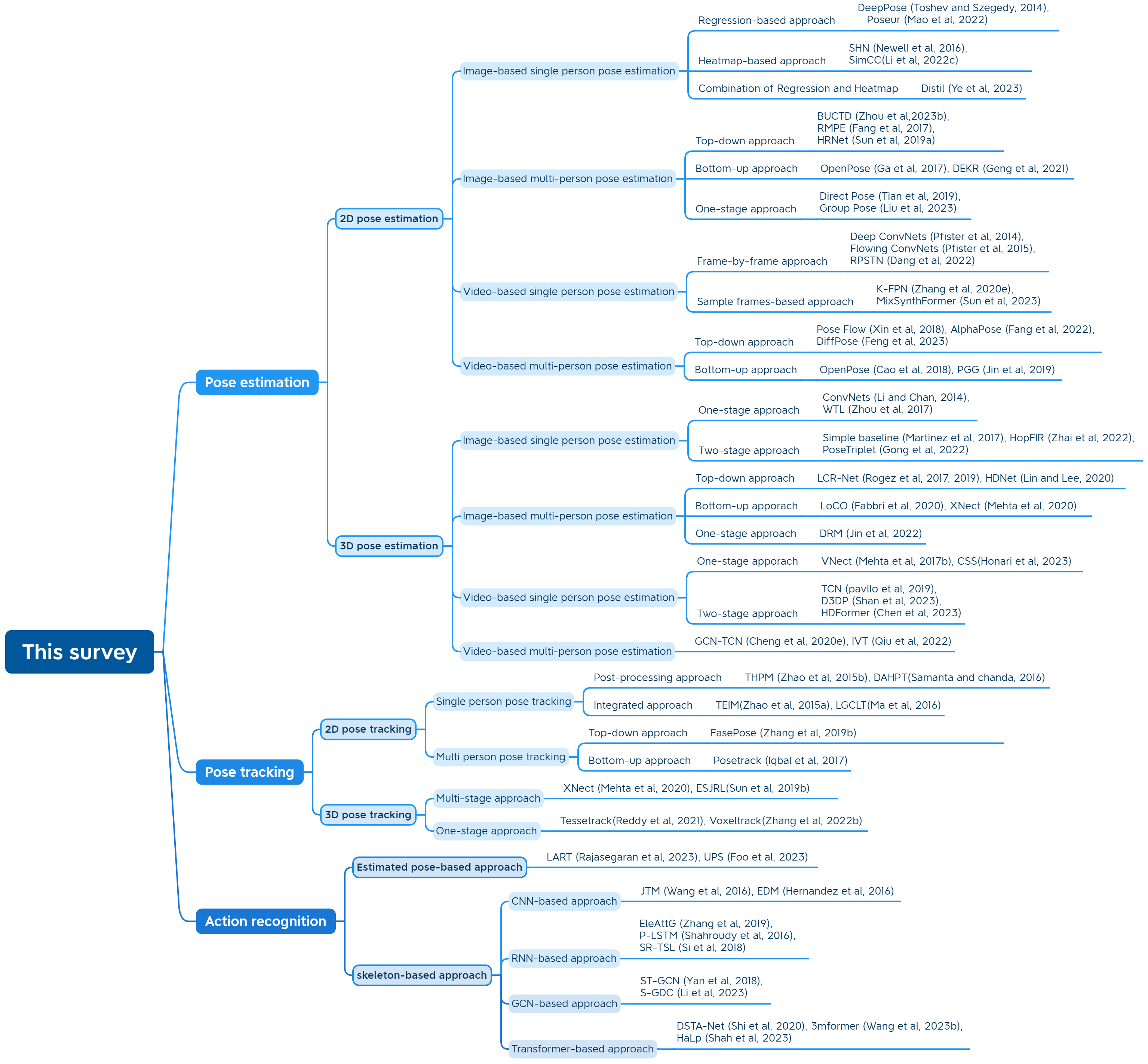
2 姿势估计
人类表征可以通过三种不同的模型来实现:运动学模型、平面模型和体积模型。 运动学模型采用关节位置和肢体方向的组合来忠实地描绘人体结构。 相比之下,平面模型利用矩形来表示身体形状和外观,而体积模型则利用网格数据来捕捉人体形状的复杂性。 必须强调的是,本文专门关注基于运动学模型的人体表示。
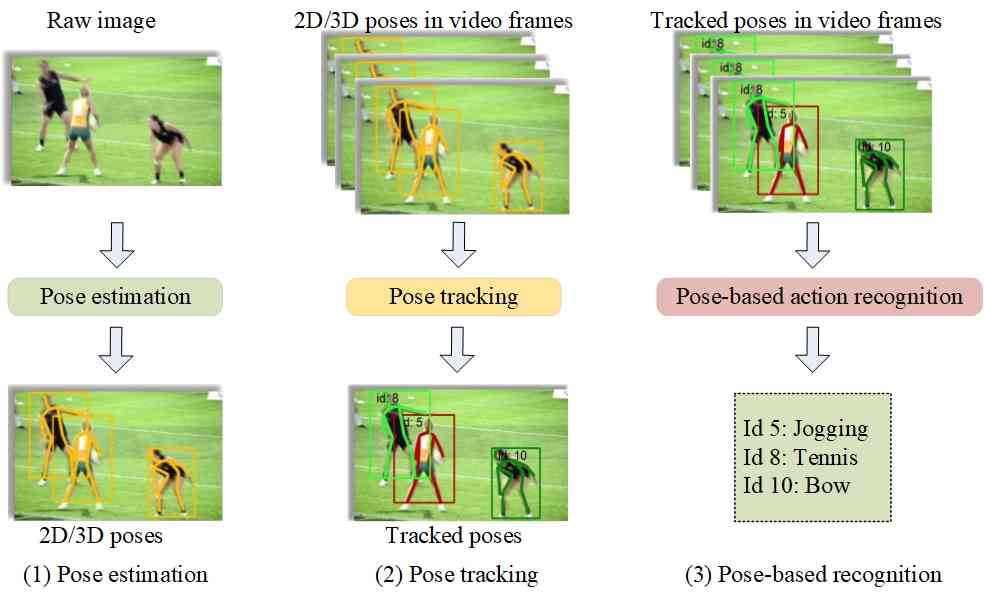
姿势估计、姿势跟踪和动作识别是三个密切相关的任务。 图2展示了三个任务之间的关系。 姿态估计旨在从图像或视频中估计关节坐标。 姿势跟踪是视频环境中姿势估计的扩展,它将每个估计的姿势随着时间的推移与其相应的身份相关联。 有趣的是,最近的一项工作[29]倾向于在跟踪人体体积后估计姿势,这意味着姿势估计和跟踪的双向关系。 基于姿势的动作识别旨在为具有身份的跟踪姿势提供相应的动作标签。
对于姿态估计,我们通常将所审查的方法分为两类:2D 姿态估计和 3D 姿态估计。 2D 位姿估计是从 RGB 图像或视频中估计每个关节的 2D 位姿 坐标,而 3D 位姿估计是估计 3D 位姿 坐标。
2.12D姿态估计
对于 2D 姿态估计,确定了两个细分:单人姿态估计和多人姿态估计。 根据网络的输入,单(多人)姿态估计可以进一步分为基于图像的单(多人)姿态估计和基于视频的单(多人)姿态估计。
2.1.1 基于图像的单人姿态估计
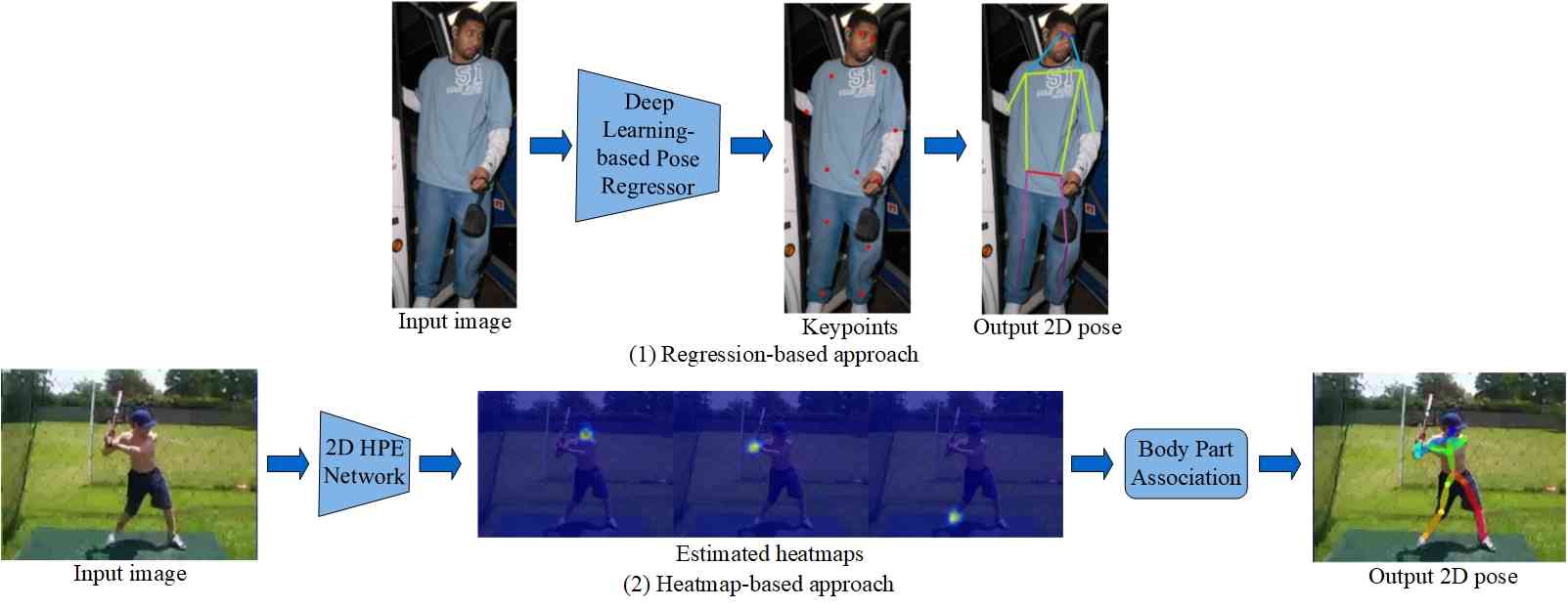
对于基于图像的单人姿势估计 (SPPE),任务涉及提供人或其边界框的位置和粗略比例,作为估计过程的前兆。 早期作品采用图像结构框架,通过以可变形配置排列的部分的集合来表示对象,集合中的部分是与图像匹配的外观模板。 与早期的工作不同,基于深度学习的方法的目标是定位人体部位的关键点。 两种典型的框架,即直接回归和基于热图的方法,可用于基于图像的单人姿势估计。 在基于直接回归的方法中,直接从图像特征预测关键点,而基于热图的方法首先生成热图,然后根据这些热图推断关键点位置。 图 3 提供了基于图像的 2D SPPE 总体框架的说明性概述,展示了两种主要方法。
(1)基于回归的方法
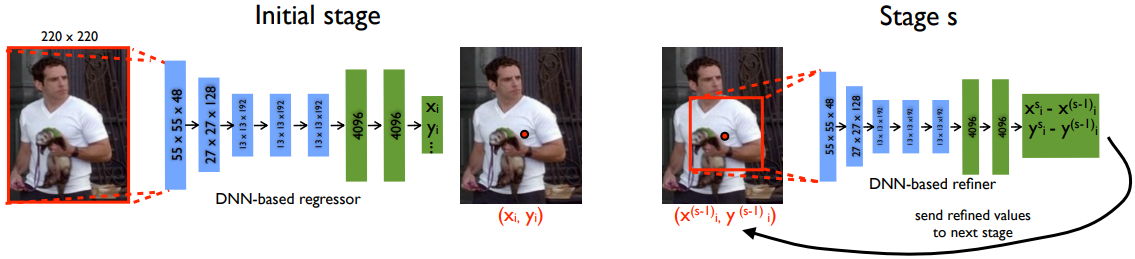
先驱工作[30] DeepPose 将姿势估计制定为基于卷积神经网络(CNN)的身体关节回归任务。 采用级联回归器来细化姿态估计,如图4所示。 这项工作可以在遮挡情况下以整体方式推理姿势。 Carreira等人[31]引入了迭代误差反馈方法,其中预测误差被递归地反馈到输入空间,从而逐步改进估计。 Sun 等人[32]提出了一种使用骨骼而不是关节的重新参数化姿势表示。 该方法定义了一个组合损失函数,该函数通过利用关节连接结构来捕获姿势内的长程交互。 在最近的发展中,[33] 引入了一种新颖的方法,该方法采用 softmax 函数以完全可微分的方式将热图转换为坐标。 这种创新技术与基于关键点误差距离的损失函数和基于上下文的结构相结合。
随后,研究人员[34,35,36,37]开始探索基于 Transformer 架构的姿态估计方法。 Transformer 中的注意力模块提供了捕获远程依赖性和全局证据的能力,这对于准确的姿态估计至关重要。 例如,TFPose [34] 首先以基于回归的方式将 Transformer 引入姿态估计框架。 PRTR [35] 引入了一个两阶段、端到端的基于回归的框架,该框架采用级联 Transformer,在基于回归的方法中实现了最先进的性能。 Mao 等人[36]将姿势估计定义为序列预测任务,他们用 Poseur 模型来解决这个问题。
然而,值得注意的是,这些直接回归方法有时在高精度场景中会遇到困难。 这种限制可能源于 RGB 图像到 位置的复杂映射,给学习过程增加了不必要的复杂性并阻碍了泛化。 例如,在处理多模态输出时,直接回归可能会遇到挑战,其中有效关节出现在两个不同的空间位置。 为给定的回归输入生成单个输出的约束可能会限制网络表示小错误的能力,可能导致过度训练。
(2) 基于热图的方法
热图由于能够提供全面的空间信息而受到广泛关注,这对于训练卷积神经网络 (CNN) 来说非常有价值。 这激起了人们对开发用于姿态估计的 CNN 架构的兴趣。 Jain 等人[38]开创了一种方法,其中多个 CNN 被训练用于独立的二元身体部位分类,每个网络专用于一个特定的特征。 该策略有效地将网络的输出限制为小得多的有效配置类别,从而提高了整体性能。 认识到结构域约束的重要性,例如身体关节位置之间的几何关系,Tompson 等人[39]追求联合训练方法,同时训练 CNN 和用于人体姿势估计的图形模型。 同样,Chen 和 Yuille [40] 采用卷积网络来学习图像块中零件存在及其空间关系的条件概率。 为了解决[39]中池化技术在提高空间局部性精度方面的局限性,Tompson等人[41]提出了一种位置细化模型(即多分辨率Convents) ),经过训练以预测图像局部区域内的关节偏移位置。 [39]、[40]和[41]的作品试图将图形模型固有的表示灵活性与效率和统计性相结合CNN 提供的能力。 为了避免使用图模型,Wei等人[42]引入了卷积姿势机来学习远程空间关系,而无需明确采用图模型。 Hu 和 Ramanan [43] 提出了一种可用于多个预测阶段的架构,并将权重与计算的自下而上和自上而下部分以及跨迭代联系起来。 类似地,Newell等人[44]提出了用于单人姿态估计的堆叠沙漏网络(SHN)。 SHN 利用一系列连续的池化和上采样步骤来生成最终的一组预测,展示了其功效。 在解决以严重部分遮挡为特征的挑战性场景时,Bulat 和 Tzimiropoulos [45] 提出了一种检测后回归的 CNN 级联。 即使存在明显的遮挡,这种强大的方法也能熟练地推断姿势。 Lifshitz 等人[46]引入了一种新颖的投票方案,该方案利用整个图像的信息,允许聚合大量投票以产生高度准确的关键点检测。 Chu 等人[47]将 CNN 纳入他们的方法中,通过用于姿态估计的多上下文注意机制来增强该方法。 这种动态机制自主学习和推断上下文表示,将模型的焦点引导到感兴趣的区域。 此外,Yang等人[48]设计了金字塔残差模块(PRM)来增强CNN的尺度不变性。 PRM 可以有效地学习特征金字塔,这在精确的姿态估计中发挥了重要作用。
随着生成对抗网络(GAN)[49]的发展,Chen等人[50]设计了判别器来区分真实姿势和假姿势,以结合有关先验的信息人体结构。 Ning 等人[51]提出探索外部知识,以使用施加适当先验的学习投影来指导网络过程。 孙等人[52]提出了一种两阶段归一化方案,人体归一化和肢体归一化,使相对关节位置的分布更加紧凑,从而使卷积空间模型更容易学习并且更准确姿态估计。 Marras 等人[53]在粗略模型和细化模型之间引入了基于马尔可夫随机场(MRF)的空间模型网络,该网络引入了对身体关节相对位置的几何约束。 为了处理注释姿势问题,Liu 和 Ferrari[54] 提出了一种用于姿势估计的主动学习框架。 Ke等人[55]提出了一种用于人体姿态估计的多尺度结构感知网络。 Peng 等人[56]提出了对抗性数据增强来联合优化数据增强和网络训练。 主要思想是设计一个增强网络(生成器),通过在线生成“硬”增强操作来与目标网络(鉴别器)竞争。 Tang 等人[57]提出了一种利用深度神经网络学习人体成分来进行姿势估计的深度学习成分模型。 Nie等人[58]提出了解析诱导学习器,包括解析编码器和姿态模型参数适配器,它通过联合学习估计姿态模型中的动态参数,以提取互补的有用特征以实现更准确的姿态估计。 Nie等人[59]提出通过整合来自同行的信息,在一个框架中联合进行人体解析和姿态估计,从而给出更稳健和准确的结果。 Tang 和 Wu [60] 提出了一种基于组相关部件共享信息量的数据驱动方法,然后引入基于部件的分支网络(PBN)来学习特定于组的表示每个零件组。 为了加速姿态估计,Zhang等人[61]提出了一种快速姿态蒸馏(FPD)模型,该模型通过有效地传递姿态来训练能够以低计算成本快速执行的轻量级姿态神经网络架构构建强大的教师网络的知识。
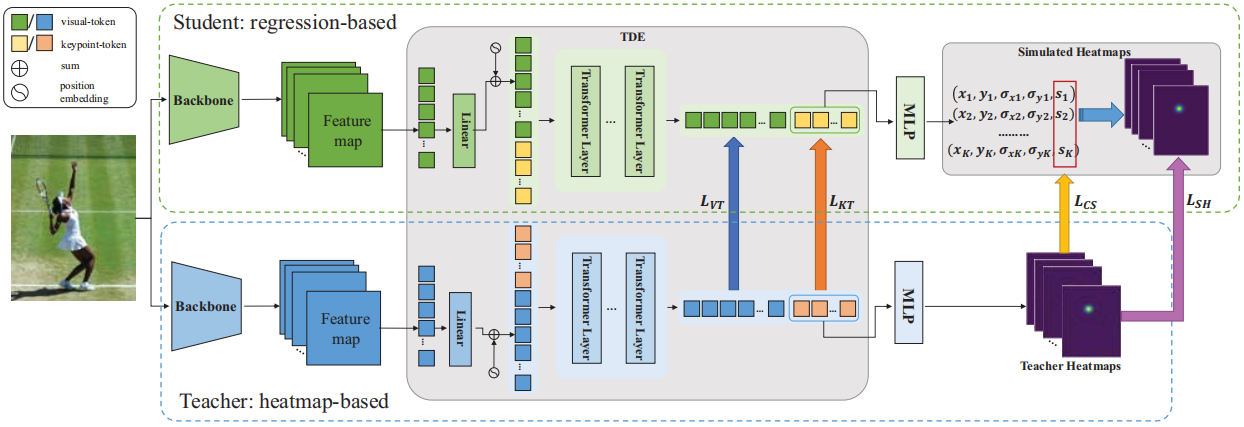
综上所述,基于回归的方法在位姿估计任务中具有速度优势,但在准确性方面存在劣势。 基于热图的方法可以通过估计热图可能性来显式学习空间信息,从而获得较高的准确度。 然而,基于热图的方法长期面临着严重的挑战,称为量化误差问题,这是由于将连续坐标值映射到离散的缩小热图而引起的。 为了解决这个问题,Li等人[62]提出了一种简单坐标分类(SimCC)方法,该方法将姿态估计制定为水平和垂直坐标的两个分类任务。 尽管量化误差有所改善,但热图的估计需要极高的计算成本,导致预处理操作缓慢。 因此,如何利用基于热图和基于回归的方法仍然是一个具有挑战性的问题。 一些工作[63, 64]倾向于通过将知识从基于热图的模型转移到基于回归的模型来解决上述问题。 然而,由于回归模型和热图模型的输出空间不同,直接在热图和向量之间传递知识可能会导致信息损失。 最后,提出了 DistilPose [64](如图 5 所示),通过以下方式将基于热图的知识从教师模型转移到基于回归的学生模型:令牌蒸馏编码器和模拟热图。
2.1.2基于图像的多人姿态估计
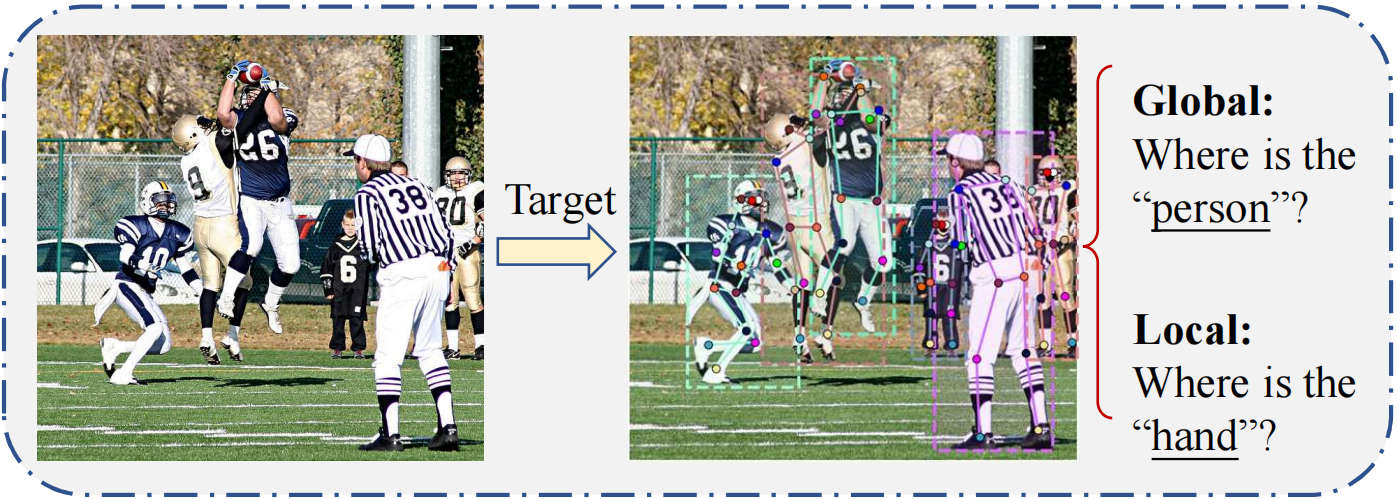
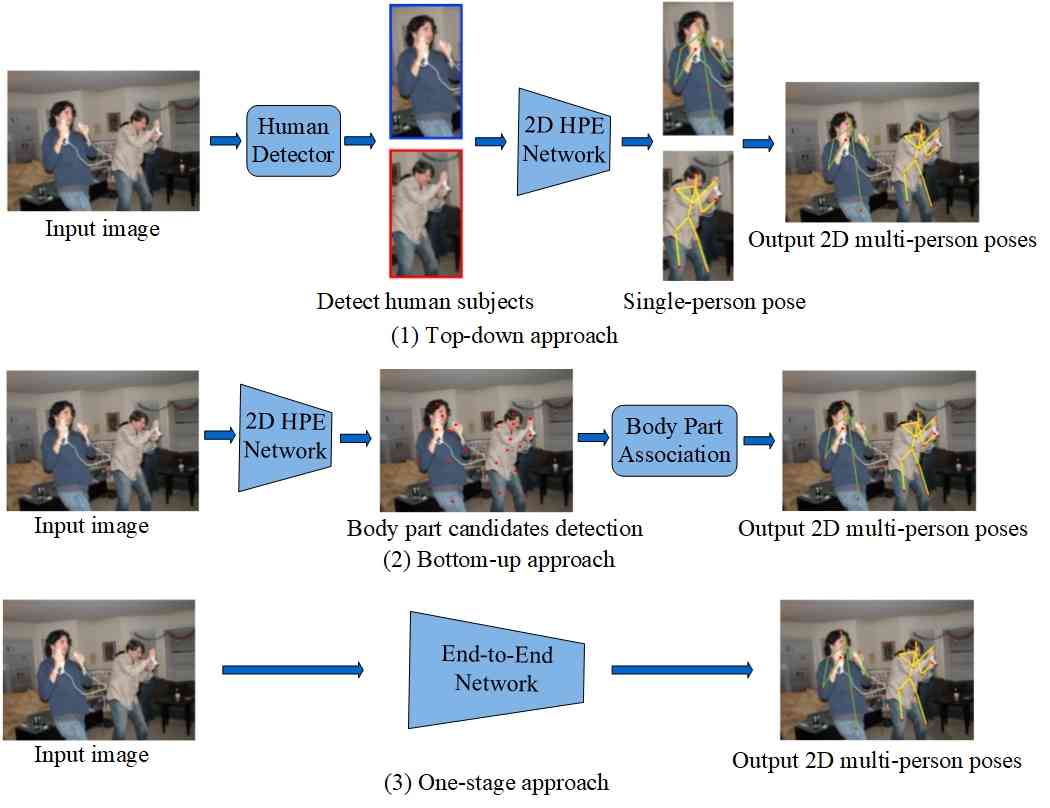
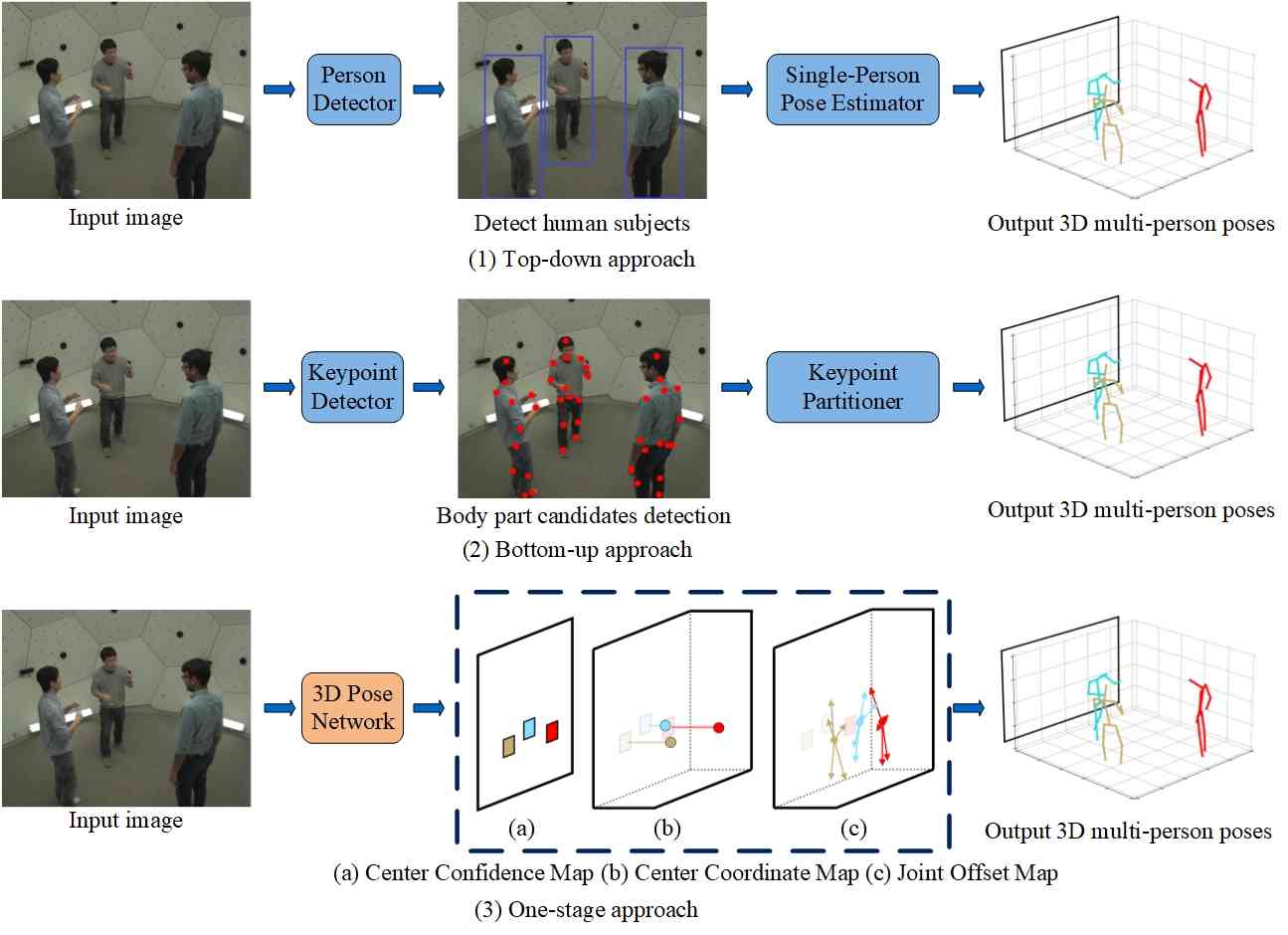
与单人姿态估计(SPPE)相比,多人姿态估计(MPPE)更加困难。 首先,人的数量或位置没有给出,姿势可以出现在任何位置或尺度;其次,人与人之间的互动由于接触、咬合和肢体关节等原因而产生复杂的空间干扰,使得部件的关联变得困难;第三,运行时复杂性往往随着图像中人数的增加而增加,这使得实时性能成为一个挑战。 MPPE 必须解决全局(人类级别)和局部(关键点级别)依赖性(如图 6 所示),这涉及不同级别的语义粒度。 主流解决方案通常是两阶段方法,将问题分为两个独立的子问题,包括全局人体检测和局部关键点回归。 通常,提出了两个主要框架来解决这些子问题,称为自上而下和自下而上的方法。 受到端到端目标检测成功的启发,另一种可行的解决方案是单阶段方法。 这种方法旨在开发一种完全端到端的可训练方法,能够统一两个分解的子问题。
(1)自上而下的方法
多人姿势估计中的自上而下方法首先检测给定图像内的所有个体,如图 7 所示,然后在每个检测到的边界框中采用单人姿势估计技术。
一组方法[67,68,69,70,71,72,73,74,75,76,77,78]旨在设计和改进姿态估计网络中的模块。 Papandreou 等人[67]采用Faster RCNN [79]进行人体检测和边界框内的关键点估计。 他们引入了聚合过程来获得高度本地化的关键点预测,以及基于关键点的非极大值抑制(NMS)来防止重复的姿势检测。 Sun等人[71]提出了一种新颖的高分辨率网络(HRNet)来学习这种表示。 为了解决标准数据转换和编码解码结构中降低自上而下管道性能的系统错误,黄等人[73]提出了纠正人体姿态估计中常见偏差数据处理的解决方案。
由于肢体重叠影响的遮挡,人体检测器可能会在自上而下管道的第一步中失败。 另一组作品[80,81,82,83,84]旨在解决这个问题。 Fang等人[81]提出了一种新颖的区域多人姿势估计(RMPE),即使存在不准确的人体边界框,也能促进姿势估计。 Chen等人[82]设计了一个级联金字塔网络(CPN),其中包含GlobalNet和RefineNet,分别用于定位具有遮挡的简单和硬关键点。 Su 等人[83]提出了两个新颖的模块来增强遮挡场景下多人姿态估计的信息,即通道洗牌模块(CSM)和空间、通道方向注意残留瓶颈(SCARB),其中 CSM 促进金字塔特征图之间的跨通道信息通信,SCARB 突出空间和通道上下文中特征图的信息。 提出了一种遮挡姿态估计和校正模块[84]来解决人群姿态估计中的遮挡问题。
与单人姿势估计非常相似,多人姿势估计也经历了快速发展,从 CNN 过渡到视觉 Transformer 网络。 最近的一些作品倾向于将 Transformer 视为更好的解码器。 TransPose [85] 处理 CNN 提取的特征来建模全局关系。 Zhou等人[86]提出了一种自下而上条件自上而下姿态估计(BUCTD)方法,该方法修改TransPose以接受条件作为CTD生成的辅助信息。 与其他自上而下的方法不同,BUCTD 采用自下而上的模型作为人体检测器。 TokenPose [87] 提出了一种基于标记的表示来估计被遮挡关键点的位置并对不同关键点之间的关系进行建模。 HRFormer [88] 提出通过 Transformer 模块融合多分辨率特征。 上述工作要么需要 CNN 进行特征提取,要么需要仔细设计 Transformer 结构。 相比之下,基于普通视觉变换器提出了一种简单而有效的基线模型 ViTPose [89]。
(2)自下而上的方法
与自上而下的方法相反,自下而上的方法首先检测所有单独的身体部位或关键点,然后使用部位关联策略将它们与相应的主题相关联。 Pishchulin 等人[90]的开创性工作提出了一种自下而上的方法,联合标记部分检测候选者并将其与个人相关联。 然而,解决全连接图上的整数线性规划问题是一个 NP 难题,平均处理时间约为小时。 Insafutdinov 等人[91]的工作中,提出了一种更鲁棒的零件检测器和创新的图像条件成对项来提高运行时效率。 然而,这项工作在精确回归成对表示方面遇到了挑战,并且需要单独的逻辑回归。 Iqbal 和 Gall [80] 将多人姿势估计视为联合与人关联问题。 他们从图像中检测到的一组候选关节构建完全连接的图,并使用整数线性规划解决关节与人的关联和异常值检测。 OpenPose [92, 93] 通过部分关联场 (PAF) 提出第一个自下而上的关联分数表示,PAF 是一组 2D 矢量场,用于编码图像域上肢体的位置和方向。 Kreiss等人[94]提出使用部位强度场(PIF)进行身体部位定位,使用PAF进行身体部位相互关联以形成完整的人体姿势。 为了处理漏掉的小规模人员,程等人[95]提出了多尺度训练和双解剖慢跑来增强网络。 上述方法主要应用基于整体L2损失的热图预测来定位关键点。 然而,最小化 L2 损失并不总是能找到所有关键点,因为每个热图通常包括多个身体关节。 为了解决这个问题,Qu等人[96]提出基于最小化预测热图和真实热图特征函数之间的距离来优化热图预测。
与上述两阶段自下而上方法不同,一些工作侧重于联合检测和分组,属于单阶段自下而上方法。 Newell等人[97]同时生成分数图和逐像素嵌入,以对不同人之间的候选关键点进行分组,以获得最终的多人姿势估计。 Kocabas 等人[kocabas2018multiposenet]设计了一个MultiPoseNet,通过实现姿势残差网络(PRN)来联合处理人物检测、人物分割和姿势估计问题,该网络接收关键点和人物检测,并产生准确的姿势通过将关键点分配给人员实例。 为了应对拥挤的场景,Li等人[Li_2019_CVPR]构建了一个名为CrowdPose的新基准,并针对拥挤的姿势提出了两个组件,即关节候选单人姿势估计和全局最大关节关联估计。 Jin等人[jin2020 Differentiable]提出了一种新的可微分层次图分组方法来学习人体部位分组。 Cheng等人[heng2020higherhrnet]扩展了HRNet,并通过对HRNet生成的高分辨率hetamap进行反卷积提出了更高分辨率的网络(HigherHRNet)来解决变化挑战。 除了上述自下而上的方法之外,一些方法直接从图像像素回归一组候选姿势,并且每个候选中的关键点可能来自同一个人。 需要后处理步骤来生成空间更准确的最终姿势。 例如,单阶段多人姿势机(SPM)方法[nie2019single]应用分层结构的2D/3D姿势表示来辅助远程回归。 关键点是根据与人无关的热图来预测的,因此需要进行分组后处理才能将关键点组装到全身姿势。 解缠结关键点回归 (DEKR) [geng2021bottom] 通过学习关注关键点区域的表示来回归候选姿势。 对候选姿势进行评分和排名,以根据关键点和中心热图估计损失生成最终姿势。 PolarPose [10034548] 旨在通过在极坐标中执行来将 2D 回归简化为分类任务。
(3) 一阶段法
单阶段方法旨在学习 MPPE 的端到端网络,无需人员检测和分组后处理。 Tian等人[tian2019directpose]首先提出了一种基于DirectPose的单阶段方法,从图像中直接预测所有人的实例感知关键点。 为了提高准确性和速度,Mao 等人[mao2021fcpose]随后提出了一种全卷积姿势(FCPose)估计框架,用于在紧凑的关键点头中构建动态滤波器。 同时,石等人[shi2021inspose]设计了InsPose,它自适应地调整每个实例的网络参数。 为了减少假阳性姿势对回归损失的影响,通过采用三种阳性姿势识别策略来进行初始和最终姿势回归,提出了单阶段多人姿势回归(SMPR)网络[MIAO2023109743] ,以及非极大值抑制(NMS)步骤。 这些方法可以避免自下而上方法中的启发式分组或自上而下方法中的边界框检测和感兴趣区域(RoI)裁剪的需要。 然而,它们仍然需要手工操作(例如 NMS)来在后处理阶段删除重复项。 为了进一步去除 NMS,带有 TRansformers (PETR) 的多人姿势估计框架[shi2022end]将姿势估计视为集合预测,这是第一个完全端到端的框架,无需任何后处理。 上述一阶段方法采用带有随机初始化姿势查询的姿势解码器,使得人与人之间的关键点匹配不明确且收敛缓慢。 为此,Yang等人[65]提出了一种用于姿势估计(ED-pose)的显式框检测过程,通过使用解码器实现每个框检测并将它们级联以形成端到端框架,使得模型收敛速度快、精确且可扩展。
尽管上述端到端方法取得了可喜的性能,但它们依赖于复杂的解码器。 例如,ED-pose 包括人体检测解码器和人体到关键点检测解码器,以显式检测人体和关键点框。PETR 包括姿势解码器和联合解码器。 相比之下,Group Pose [liu2023group] 仅使用简单的 Transformer 解码器来追求效率。
总之,自上而下的方法直接利用现有技术进行单人姿势估计,但会受到早期承诺的影响:如果人体检测器发生故障(当人们靠近时很容易发生这种情况),则无法进行恢复。 此外,这些自上而下方法的运行时间与人数成正比。 对于每次检测,都会运行一个单人姿态估计器,因此,人越多,计算成本就越大。 相比之下,自下而上的方法之所以有吸引力,是因为它们对早期承诺具有鲁棒性,并且有可能将运行时复杂性与图像中的人数脱钩。 然而,自下而上的方法并不直接利用来自其他身体部位和个体的全局上下文线索。 一阶段方法消除了分组、ROI、边界框检测、NMS 等中间操作,并绕过了自上而下和自下而上方法的主要缺点。
2.1.3 基于视频的单人姿态估计
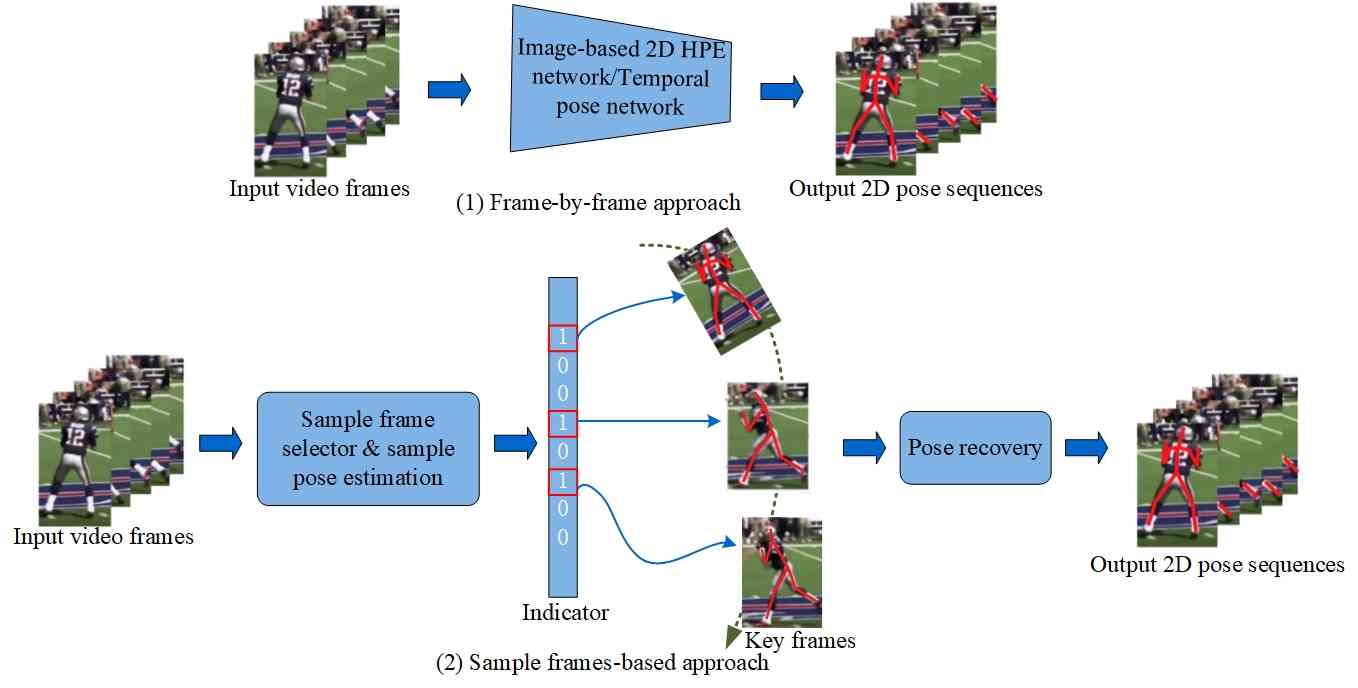
基于视频的姿势估计旨在估计每个视频帧中的单个或多个姿势。 与基于图像的姿势估计相比,由于人体姿势和前景外观(例如服装和自遮挡)的高度变化,它更具挑战性。 对于基于视频的姿态估计,视频中不考虑人体跟踪。 与基于图像的 SPPE 类似,直接回归和基于热图的方法也可用于基于视频的 SPPE。 然而,不同的是,基于视频的姿态估计具有时间信息的优势,这可以提高姿态估计的准确性,但也可能由于时间冗余而引入额外的计算开销。 因此,实现精度和效率之间的平衡对于基于视频的姿态估计至关重要。 根据处理效率,基于视频的SPPE方法分为逐帧方法和基于样本帧的方法。 图8说明了基于视频的SPPE的两种方法的总体框架。
(1)逐帧方法
如图 8 所示,逐帧方法侧重于单独估计视频序列中每一帧的姿势。 随着基于图像的姿态估计的成功,此类方法主要通过结合时间信息来在每个视频帧上应用基于图像的姿态估计方法以保持帧之间的几何一致性。 时间信息通常是通过融合连接的连续帧、应用 3D 时间卷积、使用密集光流和姿态传播来捕获的。
在该方法的早期阶段,Pfister 等人[pfister2014deep]提出使用深度ConvNets来估计视频中的人体姿势。 他们设计了一个回归层来预测上半身关节的位置,同时通过直接处理沿通道轴连接的连续帧来考虑时间信息。 Grinciunaite 等人[grinciunaite2016 human]将2D卷积扩展到3D卷积,并且可以在3D卷积的第三维中有效地表示时间信息,用于基于视频的人体姿势估计。
有些作品倾向于使用光流来产生平滑的运动。 Pfister 等人[pfister2015flowing]使用密集光流来预测所有相邻帧的关节位置,并设计空间融合层来学习人体部位位置之间的依赖关系。 Song 等人[song2017thin]还利用光流扭曲来捕获高时间一致性,并提出时空消息传递层将特定领域的知识纳入深度网络。 Jain 等人[jain2014modeep]使用局部对比度归一化和局部运动归一化分别处理RGB图像和光流特征,然后将它们组合起来输入零件检测器网络。 这些方法由于密集的流动计算而具有很高的复杂性,使得它们不适用于实时应用。
随后,一些作品[gkioxari2016chained, charles2016personalizing, luo2018lstm, nie2019dynamic, li2019temporal, liwen2019temporal, xu2021vipnas, dang2022relation, jin2023kinematic]应用姿势传播,以在线方式将特征从先前帧转移到当前帧。 例如,Charles等人[charles2016personalizing]提出了一种个性化ConvNet来估计人体姿势,包括四个阶段:初始标注、空间匹配、时间传播和自我评估。 在初始阶段,通过使用流动的Convnets获得高精度位姿估计。 然后,通过空间匹配过程,将来自新帧的没有注释的图像块与具有注释的帧中的身体关节的图像块进行匹配。 密集光流用于时间传播。 最后,自动评估时空传播注释的质量以优化模型。 Luo 等人[luo2018lstm]通过结合卷积姿势机(CPM)[42]和学习姿势之间的时间依赖性的LSTM网络,提出了长短期记忆(LSTM)姿势机视频帧有效捕捉关节在空间和时间上的几何关系。 Nie等人[nie2019dynamic]设计了动态核蒸馏(DKD)模型。 DKD模型引入了位姿核蒸馏器并及时传输位姿知识。 Xu等人[xu2021vipnas]提出了一种新颖的神经架构搜索来选择最有效的时间特征融合,以优化视频帧的准确性和速度。 Dang等人[dang2022relation]提出了一种基于关系的姿势语义传输网络(RPSTN),通过设计联合关系引导的姿势语义传播器来学习姿势的时间语义连续性。 尽管采用了各种策略来降低计算成本,但由于逐帧估计,此类方法仍然导致效率提高不理想。
(2) 基于样本帧的方法
此类方法旨在根据所选帧的估计姿势恢复所有姿势。 如图8所示,总体工作流程包括样本姿态估计和所有姿态恢复。 一系列工作通过选择关键帧并估计关键帧的姿势来生成样本姿势。 例如,Zhang等人[zhang2020key]引入了关键帧提议网络(K-FPN)来选择信息帧和人体姿势插值模块,以根据人体关键帧中的姿势生成所有姿势姿势动力学。 当要插值的姿势序列变得复杂时,基于动态的姿势字典公式可能会变得具有挑战性。 因此,为了有效利用动态信息,REinforced MOtion Transformation nEtwork (REMOTE) [ma2022remote] 包含一个运动 Transformer 来进行跨帧重建。 上述工作虽然由于关键帧的存在而提高了计算效率,但仍然需要在关键帧选择上付出代价,难以进一步降低复杂度。 为了解决这个问题,Zeng等人[zeng2022deciwatch]提出了一种新颖的Sample-Denoise-Recover pipeline(即DeciWatch)来均匀采样少于10%的视频帧进行估计。 基于样本帧的估计姿势通过 Transformer 架构进行去噪,其余姿势也通过另一个 Transformer 网络恢复。 DeciWatch 可用于视频的 2D/3D 姿态估计,它可以保持甚至提高之前方法的姿态估计精度,且计算成本较小。 尽管均匀采样降低了选择关键帧的成本,但添加了细化模块来清除噪声姿势。 相比之下,MixSynthFormer [sunmixsynthformer] 通过将 Transformer 编码器与基于 MLP 的混合合成注意力相结合来删除细化模块,从而追求高效的基于 2D/3D 视频的姿态估计。
总体而言,逐帧方法可以受益于基于图像的姿态估计,但会受到计算复杂性的影响。 基于样本帧的方法提供了一种提高效率的解决方案,但提出了如何获取样本帧和恢复姿势的问题。 本文采用均匀抽样;然而,考虑到不同动作下关节运动的显着变化,自适应采样策略可能更适合进一步提高效率。 此外,还应探索动态恢复方法的设计,以有效处理非均匀采样。
2.1.4基于视频的多人姿态估计
鉴于刚刚推出的基于视频的 SPPE,很自然地将它们扩展到处理多个个体。 按照基于视频的 SPPE 分类,大多数基于视频的 MPPE 方法都属于逐帧类别。 它们可以通过逐帧采用基于图像的 MPPE 来实现。 因此,基于视频的MPPE方法可以分为自上而下和自下而上的方法。
(1)自上而下的方法
自上而下的方法主要通过首先检测所有帧的所有人,然后逐帧进行基于图像的单人姿势估计来估计姿势。 肖等人[69]提出了一个基于ResNet的简单基线来估计每帧中的姿势,然后基于光流跟踪估计的姿势。 Xiu 等人[xiu2018pose]基于RMPE方法估计每帧的多个姿势,该方法可以被其他基于图像的MPPE自上而下的方法替代。 根据每帧中的估计姿势,提出了姿势流生成器(PF-Builder),通过最大化沿时间序列的整体置信度来构建跨帧姿势的关联(如图9所示) ),姿势流非极大值抑制(PF-NMS)旨在稳健地减少冗余姿势流并重新链接时间不相交的姿势流。 Girdhar 等人[girdhar2018detect]基于Mask R-CNN估计每一帧的姿势,然后通过轻量级跟踪生成链接到视频的关键点预测。 Wang等人[wang2020combining]提出了一种剪辑跟踪网络,可以同时执行姿态估计和跟踪。 为了构建剪辑跟踪网络,提出了 3D HRNet 来估计姿势,并将时间维度合并到原始 HRNet 中。 AlphaPose [fang2022alphapose] 也被提出用于联合姿态估计和跟踪。 特别是,首先使用 YoloV3 或 EfficientDet 等现成的物体检测器检测每帧的所有人员。 为了解决量化误差,提出了对称积分关键点回归方法来准确定位不同尺度的关键点。 将姿势引导对齐模块应用于预测的人体重新识别特征,基于NMS去除冗余姿势后获得姿势对齐的人体重新识别特征。 最后,提出了姿势感知身份嵌入来生成跟踪身份。 逐帧估计姿势会忽略运动动力学,这对于从视频中准确估计姿势至关重要。 最近的一种方法[feng2023mutual]提出了基于互信息(TDMI)的时间差异学习来进行姿态估计。 设计了多级时间差分编码器来学习信息丰富的运动表示,并引入表示解缠模块来提取与任务相关的运动特征,以增强姿势估计的帧表示。 通过测量数据关联的运动相似性,可以将时间差异特征应用于姿势跟踪。 Gai等人[gai2023spatiotemporal]提出了一种用于基于视频的姿势估计(SLT-Pose)的Sptiotemporal Learning Transformer来捕获浅层特征信息。 随着计算机视觉任务中引入扩散模型(例如 图像分割[amit2021segdiff],目标检测[chen2022diffusiondet]),DiffPose [feng2023diffpose]是第一个扩散模型,并制定基于视频的姿态估计作为条件热图生成问题。
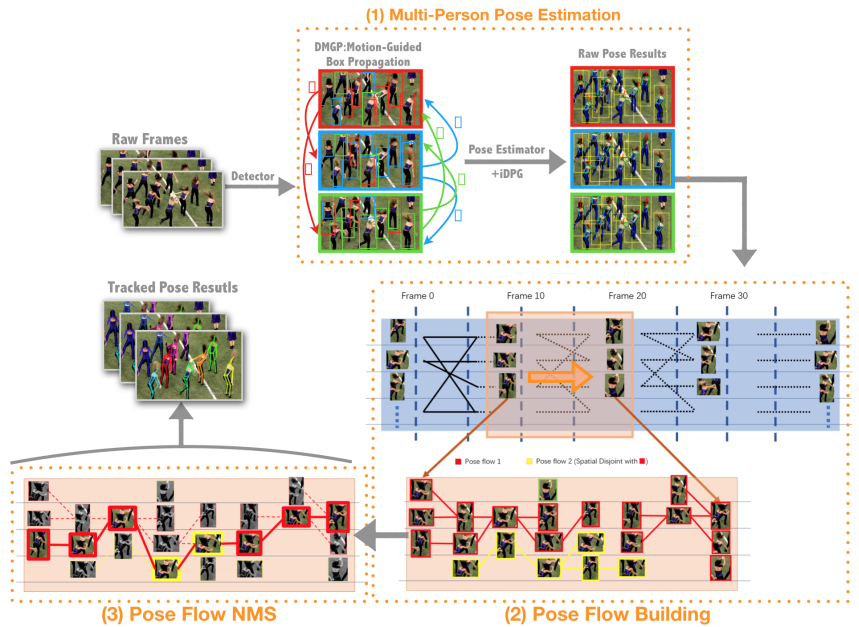
(2)自下而上的方法
自下而上的方法通过应用身体部位检测和逐帧分组来估计姿势。 例如,一种常用的基于图像的 MPPE 方法 OpenPose[93] 也可以通过直接逐帧估计姿势来应用于视频的 MPPE。 Jin等人[jin2019multi]提出了一种用于联合姿态估计和跟踪的姿态引导分组(PGG)网络。 PGG 由 SpatialNet 和 TemporalNet 两个组件组成。 SpatialNet 通过身体部位检测和每帧的部位级空间分组来处理多人姿势估计。 TemporalNet 扩展了 SpatialNet 以处理在线人类级别的时间分组。
总体而言,随着深度学习技术的发展,2D HPE 得到了显着提高。 对于基于图像的 SPPE,基于热图的方法在准确性方面通常优于基于回归的方法,但在量化误差问题上可能存在挑战。 将SPPE扩展到MPPE时,自上而下和自下而上的方法各有优缺点。 此外,这两种方法都面临着在严重遮挡下可靠检测个体的挑战。 自上而下方法中的人体检测器可能无法识别重叠人体的边界。 在自下而上的方法中,遮挡场景的身体部位关联可能会失败。 一阶段方法绕过了自上而下和自下而上方法的缺点,但仍然较少使用。 随着基于图像的姿态估计的进步,通过直接逐帧应用现成的基于图像的姿态估计方法或结合时间网络,很自然地将其扩展到视频。 基于样本帧的方法是视频姿态估计的首选方法,因为它们可以在很大程度上提高效率,而无需查看所有帧,但在基于视频的 MPPE 中使用较少。 考虑到基于图像的 MPPE 的一阶段方法的优势,需要付出更多努力来探索基于视频的 MPPE 的一阶段方法。
2.23D姿态估计
一般来说,由于 3D 姿态空间更大且模糊性更多,恢复 3D 姿态被认为比 2D 姿态估计更困难。 算法必须对某些因素保持不变,包括背景场景、照明、服装形状和纹理、肤色和图像缺陷等。
2.2.1 基于图像的单人姿态估计
基于图像的单人 3D 人体姿态估计 (HPE) 可以分为基于骨架和基于网格的方法。 前者将 3D 人体关节估计为最终输出,后者需要重建 3D 人体网格表示。 由于本文仅关注基于运动学模型的人体表示,因此我们只回顾基于骨架的方法,这些方法可以进一步分类为一步姿势估计和两步姿势估计(从 2D 姿势恢复 3D 姿势)。 图10显示了两种基于图像的3D SPPE方法的总体框架。
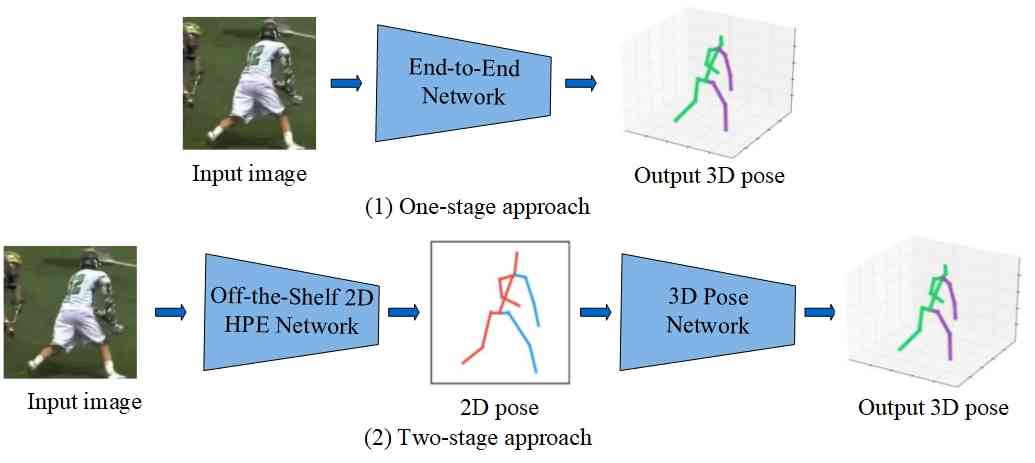
(1) 一阶段法
此类方法直接从图像推断 3D 姿势,而不估计 2D 姿势表示。 Li 和 Chan [li20143d] 首先提出使用 ConvNet 从单眼图像估计 3D 姿态。 该框架由两类任务组成:关节点回归和关节点检测。 这两个任务都将包含人类主体的边界框图像作为输入。 回归任务旨在估计关节点相对于根关节位置的位置,而每个检测任务对局部窗口中是否存在一个特定关节进行分类。
多任务学习框架首次表明深度神经网络可以应用于单图像的 3D 人体姿势估计。 然而,这些基于回归的方法的一个缺点是它们在预测给定图像的仅一种姿势方面存在局限性,这可能会导致图像中的困难,其中姿势由于部分自遮挡而不明确,因此多个姿势可能是有效的。 相比之下,Li等人[li2015maximum]提出了一种利用深度神经网络进行最大边缘结构化学习的统一框架,用于3D人体姿态估计,该统一框架可以联合学习图像和姿态特征表示和得分函数。 Tekin 等人[tekin2016structed]引入了一种依赖于过完备自动编码器来学习关节依赖性的高维潜在姿态表示的架构。 Zhou等人[zhou2016deep]提出了一种新颖的方法,将运动学对象模型直接嵌入到深度神经网络学习中,其中运动学函数是在适当参数化的对象运动变量上定义的。 Mehta 等人[mehta2017mon eyes]探索了迁移学习,以结合现有带注释的3D姿势数据集利用2D姿势数据集中高度相关的中高级特征。 同样,周等人[zhou2017towards]介绍了一种弱监督迁移学习(WTL)方法,该方法在统一的深度神经网络中采用混合2D和3D标签,该方法是端到端的并充分利用2D 姿态和深度估计子任务之间的相关性。 由于直接从图像空间回归,基于一步的方法通常需要很高的计算成本。
(2) 两阶段法
此类方法从中间估计的 2D 姿态推断 3D 姿态。 它们通常分两个步骤进行:1)基于基于图像的单人 2D 姿态估计方法估计 2D 姿态。 2)通过简单的回归器将 2D 姿势提升为 3D 姿势。 例如,Martinez 等人[martinez2017simple]提出了一个基于全连接残差网络的简单基线,用于从 2D 姿势回归 3D 姿势。 这种基线方法当时取得了良好的效果,但是,由于过度依赖 2D 位姿检测器的重建模糊性,它可能会失败。 为了克服这个问题,应用了多种技术,例如用热图替换 2D 姿势来估计 3D 姿势[tekin2017learning, zhou2019hemlets],从 2D 姿势和深度信息回归 3D 姿势[wang2018drpose3d, CARBONERALUVIZON2023109714] ,使用排名网络从 3D 姿势假设中选择最佳 3D 姿势[jahangiri2017generating、sharma2019mon eyes、li2019generating]。
随着基于图卷积网络(GCN)的人体关节表示的引入,一些方法[ci2019optimizing, zhao2019semantic, choi2020pose2mesh, zeng2020srnet, liu2020compressive, zou2021modulated, xu2021graph, 2023Learning, 10179252]将GCN应用于提升二维到 3D 姿势。 为了克服 GCN 中共享权重的限制,提出了一种本地连接网络(LCN)[ci2019optimizing],它利用全连接网络和 GCN 来编码关节之间的关系。 同样,Zhao等人[zhao2019semantic]提出了一种语义GCN来学习边缘的通道权重。 提出了基于 GCN 的 Pose2Mesh [choi2020pose2mesh],以细化其 PoseNet 的中间 3D 姿势。 Xu和Takano[xu2021graph]提出了一种图堆叠沙漏(GraphSH)网络,该网络由重复的编码器-解码器组成,用于表示三种不同尺度的人体骨骼。 为了克服当前 GCN 方法中联合交互的损失,Zhai 等人[zhai2023hopfir]提出了具有组内联合细化(HopFIR)的 Hop-wise GraphFormer 来提升 3D 位姿。
受到自然语言领域最近成功的启发,人们越来越有兴趣探索将 Transformer 架构用于视觉任务。 Lin等人[lin2021end]首先应用Transformer进行3D姿态估计。 提出了一种渐进降维的多层 Transformer 来回归关节的 3D 坐标。 这里,标准 Transformer 忽略了邻接节点的交互。 为了克服这个问题,Zhao等人[zhao2022graformer]提出了一种面向图的Transformer,它通过自注意力扩大感受野,并通过GCN对图结构进行建模,以提高3D姿态估计的性能。
对于野外数据,很难获得准确的 3D 位姿注释。 为了处理缺乏3D姿势的标注问题,一些弱监督、自监督或无监督方法[zhou2017towards, yang20183d, habibie2019wild, chen2019unsupervised, wandt2019repnet, iqbal2020weakly, kundu2020self, schmidtke2021unsupervised, yu2 021向,gong2022posetriplet,chai2023global] 被提议用于从没有 3D 姿势注释的野外图像中估计 3D 姿势。 提出了一种弱监督迁移学习方法[zhou2017towards],将室内图像的3D注释知识迁移到野外图像。 3D 骨长度约束引起的损失应用于弱监督学习。 Habibie 等人[habibie2019wild]应用投影损失来细化 3D 姿势,且没有标注。 提出了一种提升网络[chen2019unsupervised],通过引入基于闭包和不变性提升特性的几何一致性损失,以自监督模式恢复3D姿态。 以前的自监督方法很大程度上依赖于一致性损失等弱监督来指导学习,这不可避免地导致在具有未见姿势的现实场景中得到较差的结果。 相比之下,Gong等人[gong2022posetriplet]提出了一种PoseTriplet方法,该方法允许通过自我增强的双环学习框架显式生成2D-3D姿势对以增强监督。 受益于可靠的 2D 姿态检测,基于两步的方法通常优于基于一步的方法。
2.2.2 基于图像的多人姿态估计
与2D多人姿态估计类似,图像的3D多人姿态估计也可以分为:自上而下的方法、自下而上的方法和单阶段方法。 自上而下和自下而上的方法涉及姿态估计的两个阶段。 图11说明了基于图像的3D MPPE 的两种方法的总体框架。
(1)自上而下的方法
自上而下的方法首先根据人体检测网络检测每个人,然后根据单人估计方法生成 3D 姿势。 定位分类回归网络(LCR-Net)[rogez2017lcr, rogez2019lcr]提出了一个姿势提议网络来生成人体边界框和一系列人体姿势假设。 基于用于生成 3D 姿势的裁剪 ROI 特征来细化姿势假设。 Moon等人[moon2019camera]提出了一种相机距离感知方法,用于估计以相机为中心的人体姿势,该方法包括人体检测、绝对3D人体根定位和根相对3D单人姿势估计模块。 这里,根相对姿势忽略每个姿势的绝对位置。 相比之下,Lin 和 Lee [lin2020hdnet] 提出了人体深度估计网络(HDNet),用于相机坐标空间中的绝对根关节定位。 HDNet 可以基于人体姿势和身体关节的典型尺寸的先验知识,以相当高的性能估计人体深度。 自上而下的方法大多基于每个边界框来估计姿势,这导致人们怀疑自上而下的模型无法理解多人关系并处理复杂的场景。 为了解决这个限制,Wang等人[wang2020hmor]提出了一种分层多人序数关系(HMOR)来利用多人之间的关系进行姿势估计。 HMOR 可以将交互信息编码为顺序关系,监督网络以正确的顺序输出 3D 姿势。 Cha 等人[cha2022multi]设计了一种基于变压器的关系感知细化来捕获人内和人际关系。 尽管自上而下的方法实现了高精度,但随着人数的增加,它们的计算成本也很高。 同时,这些方法可能会忽略场景中的全局信息(人际关系),因为姿势是单独估计的。
(2)自下而上的方法
自下而上的方法首先生成所有身体关节位置,然后根据根深度和部位相对深度将关节与每个人关联起来。 Zanfir 等人[zanfir2018deep]提出MubyNet,根据基于集成2D和3D信息的身体部位得分对人体关节进行分组。 一组自下而上的方法旨在对属于每个人的身体关节进行分组。 学习压缩输出 (LoCO) 方法[fabbri2020compressed] 首先应用体积热图通过编码器-解码器网络生成关节位置以进行特征压缩,然后应用基于距离的启发式方法检索 3D 姿态每个人。 基于距离的启发式方法被应用于连接关节。 之前的方法都是以完全监督的方式进行训练,需要 3D 姿态注释,而 Kundu 等人[kundu2020unsupervised]提出了一种用于 3D 姿态估计的无监督方法。 在没有配对 2D 图像和 3D 姿态注释的情况下,应用冻结网络来基于跨模态对齐来利用两种不同模态之间的共享潜在空间。
另一组自下而上的方法侧重于遮挡。 Mehta 等人[mehta2018single] 结合关节位置图和遮挡鲁棒姿势图来推断 3D 姿势。 应用关节位置冗余来推断被遮挡的关节。 XNect [mehta2020xnect] 对运动树中关节的直接局部上下文进行编码以解决遮挡问题。 Chen 等人[zhen2020smap]通过推理人与人之间的遮挡,开发了用于深度感知零件关联的 3D 零件亲和力场,并利用细化网络在给定预测的 2D 和 3D 关节坐标的情况下细化 3D 姿势。 所有这些方法都是从单人的角度处理遮挡,并且需要初始将关节分组为个体,这导致多人场景中的估计容易出错。 Liu等人[liu2022explicit]提出了一种基于深度监督编码器蒸馏网络的遮挡关键点推理模块,用于从可见信息中推理出不可见信息。 Chen 等人[chen2023multi]提出了咬合情况下与渐进方案相关的关键点的清晰度感知知识探索(AKE)。 与自上而下的方法相比,自下而上的方法具有不需要重复的单人姿势估计的优点,并且它们喜欢线性计算。 然而,自下而上的方法需要第二个关联阶段来进行联合分组。 此外,由于所有人都以相同的尺度进行处理,这些方法不可避免地对人体尺度的变化敏感,这限制了它们在野外视频中的适用性。
(3) 一阶段法
一阶段方法将姿态估计视为并行的人体中心定位和中心到关节回归问题。 这些方法不是在两阶段方法中分离关节定位和分组,而是预测每个关节相对于检测到的中心点的偏移量,这些中心点通常被设置为人类的根关节。 由于关节偏移与估计的中心点直接相关,因此该策略避免了手动设计的分组后处理,并且是端到端可训练的。 Zhou等人[zhou2019objects]将物体建模为单点,并根据人体中心的图像特征对关节进行回归。 Wei 等人[wei2020point]提出从点集锚点回归关节,作为基本人体姿势的先验。 Wang 等人[wang2022distribution]根据2.5D人体中心和3D中心相对关节偏移重建关节。 Jin等人[jin2022single]通过求解2D姿态回归和深度回归提出了解耦回归模型(DRM)。 最近,Qiu 等人[qiu2023weakly]通过在 3D 姿势数据集上微调弱监督预训练(WSP)网络来直接估计 3D 姿势。
2.2.3 基于视频的单人姿态估计
视频可以提供时间信息,而不是根据图像估计 3D 姿势,以提高姿势估计的准确性和鲁棒性。 与基于图像的3D HPE类似,基于视频的3D HPE也可以分为一阶段和两阶段方法。
(1) 一阶段法
属于此类方法的研究很少。 Tekin等人[tekin2016direct]提出了一种回归函数,可以从以序列为中心的时空体积直接预测序列给定帧中的3D姿态。 该体积包括在中心帧之前和之后的连续帧中围绕人的边界框。 Mehta等人[mehta2017vnect]提出了VNect,它能够通过Convents回归和运动学骨骼拟合从单目RGB相机获得时间一致的、完整的3D人体骨骼姿势。 VNect 可以同时回归 2D 和 3D 关节位置。 Dabral等人[dabral2018learning]提出了两种结构感知损失函数:非法角度损失和左右对称损失,以直接从视频序列中预测3D身体姿势。 非法角度损失是为了区分3D关节的内部和外部角度,对称性损失被定义为左/右骨对的长度差异。 Qiu [qiu2022ivt]提出了一种基于实例引导视频变换器(IVT)的端到端框架,可以直接从视频中预测 3D 单个和多个姿势。 提出了一种基于对比自监督(CSS)学习的无监督特征提取方法[9921314],以捕获丰富的时间特征以进行姿态估计。 使用 CSS 通过重建输入视频帧来学习时变和时不变的潜在特征,然后将时变特征应用于预测 3D 姿势。
(2) 两阶段法
与从图像估计的两步 3D 姿态类似,两步 3D HPE 涉及两个阶段:估计 2D 姿态和从 2D 姿态提升 3D 姿态。 然而,不同之处在于,在基于视频的 3D HPE 中,应用 2D 姿势序列来提升 3D 姿势序列。 基于不同的提升方法,这类方法可以概括为Seq2frame和基于Seq2seq的方法。
基于 Seq2frame 的方法注重预测输入视频的中心帧,以产生稳健的预测并且对噪声的敏感性较低。 Pavllo 等人[pavllo20193d]提出了一种基于2D关键点轨迹的时域卷积网络(TCN),采用半监督训练方法。 在网络中,一维卷积用于以较少的参数捕获时间信息。 在半监督训练中,3D 姿态估计器用作编码器,解码器将预测的姿态映射回 2D 空间。 以下一些工作通过解决遮挡问题[heng2019occlusion]、利用注意力[liu2020gast]或将姿态估计任务分解为骨骼长度和骨骼方向来提高TCN的性能预测[chen2021anatomy]。 除了 TCN 之外,Cai 等人[cai2019exploiting]采用 GCN 来对时间信息进行建模,其中从短序列的 2D 联合检测中学习用于 3D 人体估计的多尺度特征。 在不涉及卷积架构的情况下,Zheng等人[zheng20213d]提出了一种基于时空Transformer的PoseFormer,用于估计中心帧的3D姿态。 为了克服 PoseFormer 在增加帧数以获得更好性能时的巨大计算成本,PoseFormerV2 [zhao2023poseformerv2] 应用 2D 姿态序列的频域表示来提升 3D 姿态。 类似地,Li等人[li2022exploiting]提出了一种stridden Transformer编码器,通过减少序列冗余和计算成本来重建中心帧的3D姿态。 Li等人[li2022mhformer]进一步设计了一个多假设变换器(MHFormer)来利用多个姿势假设的时空表示。 在MHFormer的基础上,提出了MHFormer++[li2023multi],通过结合图Transformer编码器进一步对关节的局部信息进行建模,并通过添加融合块有效聚合多假设特征。 与姿势假设 [li2022mhformer, li2023multi]、DiffPose [holmquist2022diffpose] 和 Diffusion-based 3D Pose (D3DP) [shan2023diffusionbased] 类似的想法目标是应用扩散模型来预测给定 2D 姿势的多个可调整假设,因为它具有高场样本的能力。 上述基于Transformer的方法[zheng20213d, zhao2023poseformerv2, li2022exploiting, li2023multi]主要通过网络的不同阶段顺序对空间和时间信息进行建模,从而导致对运动模式的学习不足。 因此,Tang等人[tang20233d]提出了时空纵横变换器(STCFormer),通过堆叠多个STC注意力块来与双路径网络并行地建模空间和时间信息。
基于 Seq2seq 的方法一次重建输入序列的所有帧,以提高 3D 姿态估计的一致性和效率。 早期的方法应用循环神经网络(RNN)或长短期记忆(LSTM)作为Seq2Seq网络。 Lin 等人[lin2017recurrent]设计了一个循环3D姿势序列机(RPSM),用于从图像序列中估计3D人体姿势。 RPSM由三个模块组成:2D位姿模块; 3D 姿态循环模块和特征自适应模块,用于将姿态表示从 2D 域转换为 3D 域。 Hossain 等人[rayat2018exploiting]通过使用LSTM单元和解码器端的残差连接提出了一个序列到序列网络。 2D 关节位置序列作为序列到序列网络的输入,以预测时间相干的 3D 姿势序列。 Lee等人[lee2018propagating]提出传播长短期记忆网络(p-LSTM),通过学习内在的关节相互依赖性来估计二维关节位置的深度信息。 Katircioglu 等人[katircioglu2018learning]提出了一种深度学习回归架构,通过使用自动编码器来学习高维潜在姿势表示,并提出了长短期记忆网络来强制 3D 姿势预测的时间一致性。 Raymond 等人[yeh2019chirality]提出了手性网络。 在手性网络中,全连接层、卷积层、批量归一化和 LSTM/GRU 单元可以是手性的。 根据这种对称性,它自然地利用人体的左/右镜像来估计 3D 姿势。 后来有一些方法[wang2020motion, yu2023gla, zhang2022mixste, ijcai2023p65, 9815549, zhu2022motionbert]应用GCN或Transformer进行Seq2seq学习。 Wang等人[wang2020motion]利用基于GCN的方法结合相应的损失来对短时间间隔和长时间范围内的运动进行建模。 张等人[zhang2022mixste]提出了一种混合时空编码器(MixSTE),其中包括一个用于对每个关节的时间运动进行建模的时间 Transformer 和一个用于学习关节间空间相关性的空间 Transformer。 MixSTE 直接重建整个帧以提高输入和输出序列之间的一致性。 Chen等人[ijcai2023p65]提出高阶定向变换器(HDFormer),通过将自注意力和高阶注意力结合到模型关节-关节、骨-关节中,从2D姿势序列重建3D姿势序列,以及超骨关节相互作用。
2.2.4基于视频的多人姿态估计
与基于图像的多人姿势估计不同,基于视频的多人姿势估计经常面临快速运动、外观和服装变化大以及人与人之间遮挡等问题。 在这种情况下,成功的方法必须能够准确识别每个视频帧中存在的个体数量,以及确定每个人的精确关节位置,并随着时间的推移有效地关联这些关节。
随着基于视频的单人3D HPE的改进,基于视频的多基3D HPE的一种方法是基于两步的方法,首先基于人体检测网络检测每个人,然后基于视频生成3D姿势。基于单人 3D HPE 方法。 Cheng等人[heng2021graph]提出了一种集成图卷积网络(GCN)和时间卷积网络(TCN)来估计多人3D姿势的新颖框架。 特别地,首先检测用于表示人类的边界框,然后基于边界框估计二维姿势。 通过将 2D 姿势输入关节和骨骼 GCN 来估计每帧的 3D 姿势。 3D 姿势序列最终被输入到时间 TCN 中以强制执行时间和人体动态约束。 此类方法应用自上而下的技术来估计 3D 姿势,这依赖于独立检测每个人。 因此,很可能会遭受人际遮挡和近距离互动的困扰。 为了克服这个问题,同一作者[heng2021moneye]后来提出了一种多人姿势估计集成(MPEI)网络,通过添加一个自下而上的分支来捕获同一自上而下的全局意识姿势分支为论文[heng2021graph]。 最终的 3D 姿势是根据匹配自下而上和自上而下分支的估计 3D 姿势来估计的。 应用交互感知鉴别器来强制两个人的自然交互。 为了克服遮挡问题,Park等人[park2023robust]提出了POTR-3D,通过直接处理2D姿势序列而不是一次处理单帧来提升3D姿势序列,并设计了一种数据增强策略使用设计视图生成遮挡感知数据。 捕获长距离时间信息通常需要计算更多帧,这导致计算成本很高。 为了解决这个问题,最近的一项工作,TEMporal POse 估计方法(TEMPO)[29],通过循环架构学习时空表示,以加快推理时间,同时保持估计精度。 具体来说,首先检测人物并用特征体表示。 然后通过循环组合当前和先前时间步的特征来学习时空姿势表示。 它最终被解码为当前姿态和未来时间戳的姿态的估计。 请注意,姿势是根据特征量的跟踪结果估计的,这暗示姿势估计性能可以通过姿势跟踪来提高。 此外,TEMPO还提供了动作预测的解决方案。
在上述基于两步的方法中,后一步的结果取决于前一步的结果。 因此,最近提出了基于端到端网络的一步姿态估计。 IVT [qiu2022ivt] 还可用于直接从视频预测多个姿势。 实例引导标记包括深度特征和实例 2D 偏移(从身体中心到关键点),这些偏移被发送到视频 Transformer 中,以捕获空间和时间维度上多人关节之间的上下文深度信息。 引入跨尺度实例引导注意机制来处理多人之间的变化尺度。
总之,3D HPE 近年来取得了重大进步。 由于2D HPE的进展,大量基于3D图像/视频的单人HPE方法应用2D到3D提升策略。 在基于 3D 图像/视频的 HPE 中将单人扩展到多人时,始终采用两步法(自上而下和自下而上)和一步法。 尽管自上而下的方法可以通过最先进的人员检测和单人方法取得有希望的结果,但随着人员数量的增加和缺乏人际关系测量,它们会遭受高计算成本的困扰。 自下而上的方法可以享受线性计算,但是它们对人体尺度的变化很敏感。 因此,基于一步的方法更适合基于 3D 图像/视频的多人 HPE。 将基于图像的 3D 单人/多人 HPE 扩展到基于视频的 HPE 时,会测量时间信息以学习跨帧的关节关联。 与图像方法类似,由于 2D 到 3D 提升策略的成功,通常使用基于两步的方法。 其中,基于 Seq2seq 的方法是优选的,因为它们有助于增强 3D 位姿估计的一致性和效率。 为了捕获时间信息,TCN(时间卷积网络)、RNN(循环神经网络)相关架构和 Transformer 是常用的网络。
3 姿势跟踪
姿势跟踪旨在从视频中估计人体姿势,并将跨帧的姿势链接起来以获得多个跟踪器。 它与基于视频的姿态估计相关,但它需要捕获跨帧的估计姿态的关联,这与基于视频的姿态估计不同。 根据第 2 节中回顾的姿态估计方法,姿态跟踪的主要任务变成了姿态链接。 姿势链接的基本问题是测量相邻帧中姿势对之间的相似性。 姿势相似度通常是基于时间信息(例如,时间信息)来测量的。 光流、时间平滑先验)和图像的外观信息。 根据两种估计姿态的分类,我们将姿态跟踪方法分为两类:2D 姿态跟踪和 3D 姿态跟踪。
3.12D姿态跟踪
根据跟踪人数,2D姿态跟踪可分为单人姿态跟踪和多人姿态跟踪。 很少有方法可以解决单人姿势跟踪问题,因为它们实际上旨在更新估计姿势以获得具有时间一致性的更准确姿势。 因此,姿态跟踪主要解决多人的跟踪问题。 尽管如此,我们将回顾两类方法,包括单人和多人姿势跟踪。
3.1.1 单人姿态跟踪
基于通过跟踪更新估计姿态的核心思想,此类方法通常可以分为两种类型:后处理方法和集成方法。 后处理方法单独估计每个帧的姿态,然后对不同帧之间的估计姿态进行相关分析,以减少不一致并生成平滑的结果。 集成方法将姿态估计和视觉跟踪结合在一个框架内。 视觉跟踪确保姿势的时间一致性,而姿势估计则提高了跟踪身体部位的准确性。 通过结合视觉跟踪和姿态估计的优势,集成方法在姿态跟踪方面取得了改进的结果。 图12说明了两种单人姿态跟踪方法的总体框架。
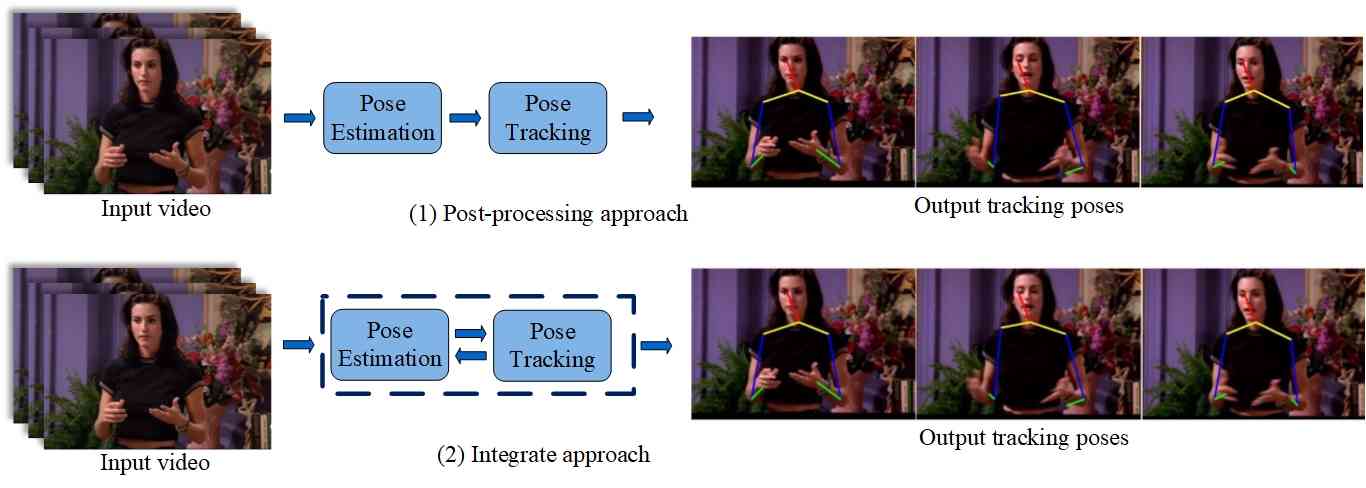
(1)后处理方式
赵等人[zhao2015tracking]提出采用最大边缘马尔可夫模型来跟踪人体姿态。 他们提出了一个时空模型,由分别用于空间解析和时间解析的两个子模型组成。 空间解析用于估计帧中的候选人体姿势,而时间解析则确定随着时间的推移最可能的姿势部分位置。 对子模型进行推理迭代,得到最终结果。 Samanta等人[samanta2016data]提出了一种数据驱动的视频数据中人体姿态跟踪方法。 他们最初估计了视频第一帧中的姿势,并采用局部对象跟踪来维持不同帧之间身体部位之间的空间关系。
(2)综合方法
赵等人[zhao2015learning]提出了一种两步迭代方法,将姿态估计和视觉跟踪结合到一个统一的框架中以相互补偿,姿态估计提高了视觉跟踪的准确性,结果视觉跟踪有助于姿态估计。 迭代执行这两个步骤以获得最终的姿势。 此外,他们还设计了一种重新初始化机制来防止姿态跟踪失败。 以前的方法需要未来的帧或整个序列来细化当前的姿势,并且很难在线跟踪。 马等人[ma2016local]解决了动态环境下关节运动人体姿态在线跟踪问题。 他们提出了一个耦合层框架,由用于姿态跟踪的全局层和用于姿态估计的局部层组成。 其核心思想是将任意特定帧中的全局姿态候选分解为多个局部候选,然后重新组合选定的局部部分以获得该帧的准确姿态。
后处理方法首先从视频中获得一组合理的姿势假设,然后随着时间的推移将兼容的检测拼接在一起以形成姿势跟踪。 然而,由于使用全局信息的乘法成本,此类模型通常只能包含局部时空轨迹(证据)。 这些局部时空轨迹可能是模糊的,从而导致客观模型的缺点。 此外,后处理方法很难在线跟踪,但集成方法可以随着时间的推移更稳健、更准确地表示姿势,确保被跟踪的身体在整个跟踪过程中重新训练其适当的配置。
3.1.2 多人姿态跟踪
与单人姿势跟踪不同,多人姿势跟踪涉及测量人类交互,这可能会给跟踪过程带来挑战。 跟踪人数未知,人机交互可能造成遮挡和重叠。 与多人姿态估计类似,现有方法可以分为两类:自上而下和自下而上的方法。
(1) 自上而下的方法
自上而下的方法[wang2020combining,fang2022alphapose]首先检测帧中人体的整体位置和边界框,然后估计每个人的关键点。 最后,根据不同帧中姿势之间的相似性将估计的人体姿势关联起来。 Girdhar等人[girdhar2018detect]提出了一种两阶段方法,用于估计和跟踪复杂多人视频中的人体关键点。 该方法利用 Mask R-CNN 执行帧级姿态估计,检测人管并估计预测管中的关键点,然后通过使用轻量级优化来随时间连接估计的关键点来执行人级跟踪模块。 然而,该方法没有考虑运动和姿势信息,这导致跟踪偶尔被截断的人体变得困难。 针对这一问题,Xiu等人[xiu2018pose]以位姿流为单元,提出了一种新的位姿流生成器,由位姿流生成器和位姿流NMS组成。 他们最初通过采用改进的 RMPE 来估计多人姿势,然后最大化构建姿势流的整体置信度。 最后,通过应用 Plough Flow NMS 纯化位姿流,以获得合理的多位姿轨迹。 为了减轻方法的复杂性,Xiao等人[69]提出了一种简单但有效的姿态估计和跟踪方法。 他们采用基于光流的姿态传播和相似度测量来改进姿态跟踪的贪婪匹配方法。 张等人[zhang2019fastpose]解决了关节式多人姿态估计和实时速度跟踪。 端到端多任务网络 (MTN) 旨在同时执行人体检测、姿势估计和人员重新识别 (Re-ID) 任务。 考虑到 MTN 提供的检测框、关键点和 Re-ID 功能,采用遮挡感知策略进行姿态跟踪。 Ning等人[ning2020lighttrack]提出了一种自上而下的方法,将单人姿态跟踪(SPT)和视觉对象跟踪(VOT)结合成一个统一的在线功能实体,可以通过可替换的轻松实现单人姿势估计器。 他们分别处理每个人类候选者,并通过姿势匹配将丢失的跟踪候选者与前一帧中的目标相关联。 通过应用Siamese图卷积网络作为Re-ID模块可以实现人体姿态匹配。 Umer等人[umer2020self]提出了一种依靠关键点的对应关系来关联视频中人物的方法。 它在大型图像数据集上进行训练,以使用自我监控来估计身体姿势。 与自上而下的人体姿势估计框架相结合,关键点对应用于基于时间上下文恢复丢失的姿势检测,并将检测到的姿势和恢复的姿势关联起来以进行姿势跟踪。
本节讨论的方法通常从检测人体边界开始,这可能使它们容易受到遮挡和截断等挑战。 此外,大多数方法首先估计每帧中的姿势,然后实现数据关联和细化。 这种策略本质上严重依赖于遮挡情况下不存在的视觉证据,因此检测不可避免地很容易被错过。 为此,Yang等人[yang2021learning]通过GNN导出动态预测,明确考虑时空和视觉信息。 它利用历史姿势轨迹作为输入,并预测每个轨迹的后续帧中的相应姿势。 然后,预测的姿势将与检测到的姿势聚合,以恢复估计器可能错过的遮挡关节,从而显着提高方法的鲁棒性。
上述方法主要强调基于姿势的相似性进行匹配,通常很难重新识别长时间被遮挡或显着姿势变形的轨迹。 有鉴于此,Doering等人[doering2023lated]提出了一种新颖的门控注意力方法,该方法利用重复感知关联,并根据与每个相似性度量相关的注意概率。
(2)自下而上的方法
相比之下,自下而上的方法首先检测人体的关键点,然后将关键点分组为个体。 然后将分组的关键点跨帧连接和关联以生成完整的姿势。 Iqbal 等人[iqbal2017posetrack]提出了一种新颖的方法,在单个公式中联合建模多人姿态估计和跟踪。 他们用时空图表示视频中检测到的身体关节,通过求解整数线性程序,该时空图可以分为与每个人体姿势的可能轨迹相对应的子图。 Raaj 等人[raaj2019efficient]提出了跨视频序列的时空亲和力场(STAF),用于在线姿势跟踪。 每帧中关键点之间的连接由部分关联字段 (PAF) 表示,跨帧关键点之间的连接由时间关联字段表示。 Jin 等人[jin2019multi]将姿势跟踪视为分层检测和分组问题。 他们提出了一个由 SpatialNet 和 TemporalNet 组成的统一框架。 SpatialNet 实现单帧身体部位检测和部位级数据关联,TemporalNet 将连续帧中的人体实例分组为轨迹。 分组过程由可微分姿势引导分组(PGG)模块建模,使整个零件检测和分组管道完全端到端可训练。
自下而上的方法在空间和时间上关联关节,而不检测边界框。 因此,这些方法的计算成本几乎不受人类候选者数量变化的影响。 然而,它们需要大量的计算资源,并且经常会在没有全局姿态视图的情况下遭受不明确的关键点分配。 自上而下的方法通过合并时间上下文信息来关联不同帧之间的估计姿势,从而增强单帧姿势估计。 它简化了复杂的任务并提高了关键点分配的准确性,尽管在大量人类候选者的情况下可能会增加计算成本。 综上所述,自上而下的方法在准确性和跟踪速度上都优于自下而上的方法,因此大多数最先进的方法都遵循自上而下的方法。
3.23D姿态跟踪
随着 3D 姿态估计的进步,姿态跟踪可以自然地扩展到 3D 空间。 鉴于当前的方法主要关注多人场景,我们将它们分为两组,而不指定单人或多人跟踪:多阶段和单阶段方法。
(1) 多阶段方法
多阶段方法通常跟踪姿态,涉及多个步骤,例如 2D/3D 姿态估计、2D 到 3D 姿态提升和 3D 姿态链接。 这些任务作为独立的子任务。 例如,Bridgeman等人[bridgeman2019multi]通过快速贪婪算法执行每帧独立的2D姿态检测以及不同相机视图之间的关联2D姿态检测。 然后使用关联的姿势来生成和跟踪 3D 姿势。 Zanfir等人[zanfir2018mon eyes]首先进行单人前馈-反馈模型来计算2D和3D姿势,然后在约束下进行联合多人优化以重建和跟踪多人3D姿势。 Metha等人[mehta2020xnect]估计了2D和3D姿势特征,并使用全连接神经网络将特征解码为完整的3D姿势,然后进行时空骨骼模型拟合。
上述工作首先估计姿势,然后跨帧链接姿势,其中跟踪的概念是使用每个帧中独立定位的关节,随着时间的推移将同一个人的关节关联在一起。 相比之下,Sun 等人[sun2019explicit]根据其他帧的信息改进了联合定位。 他们建议首先学习时空关节关系,然后将姿势跟踪表述为简单的线性优化问题。
(2) 一阶段法
单阶段方法[reddy2021tessetrack, zhang2022voxeltrack, 29, zou2023snipper]旨在训练一个用于联合估计和链接3D姿势的单一端到端框架,该框架可以传播子任务的误差多阶段方法返回视频的输入图像像素。 例如,Reddy 等人[reddy2021tessetrack]引入了Tessetrack,在单个端到端可学习框架中联合推断3D姿势重建以及空间和时间关联。 Tessetrack 由三个关键组件组成:人物检测、姿势跟踪和姿势估计。 对于检测到的人,通过解决基于二分图匹配的分配问题来学习时空人特定表示,用于测量链接姿势的相似性。 然后将所有匹配的表示合并为单个表示,该表示被解卷积为 3D 姿势并作为估计姿势。 为了处理遮挡,VoxelTrack [zhang2022voxeltrack] 引入了一种用于链接姿势的遮挡感知多视图特征融合策略。 具体来说,它根据由多视图图像构建的基于 3D 体素的表示来联合估计和跟踪 3D 姿势。 通过基于来自不同视图的融合表示的二分图匹配,姿势随着时间的推移而链接,而没有遮挡。 PHALP [rajasegaran2022tracking] 随着时间的推移累积 3D 表示,以实现更好的跟踪。 它依赖于一个主干来估计每个人体检测的 3D 表示,随着时间的推移聚合表示并预测未来状态,并最终使用概率框架中的预测表示将轨迹与检测相关联。 Snipper [zou2023snipper] 采用可变形注意机制来聚合时空信息,以便在单次拍摄中同时进行多人 3D 姿态估计、跟踪和运动预测。 与 Snipper 类似,TEMPO [29] 采用循环架构将空间和时间信息融合到单个表示中,从而在不牺牲效率的情况下根据多视图信息进行姿态估计、跟踪和预测。
虽然这两种方法在 3D 多人姿态跟踪上都取得了良好的性能,但对于第一种方法,独立解决每个子问题会导致性能下降。 1)2D姿态估计很容易受到噪声的影响,尤其是在存在遮挡的情况下。 2) 3D 估计的准确性取决于所有视图的 2D 估计和关联。 3)遮挡引起的不可靠的外观特征影响3D姿态跟踪的准确性。 因此,第二种方法近年来在 3D 多人姿势跟踪中得到了重视。
4动作识别
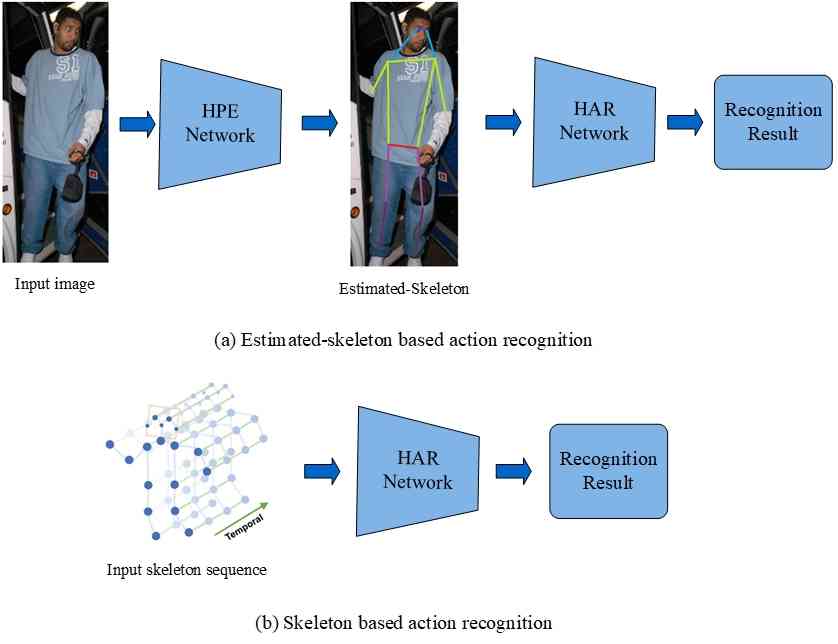
动作识别旨在识别输入图像或视频中人类动作的类别标签。 对于与姿态估计和跟踪的联系,本文仅回顾基于姿态的动作识别方法。 基于姿势的动作识别可以分为两种方法:基于估计姿势和基于骨架。 基于估计姿势的动作识别方法应用 RGB 视频作为输入,并使用从 RGB 视频估计的姿势对动作进行分类。 另一方面,基于骨架的动作识别方法利用骨架作为输入,该输入可以通过各种传感器获得,包括运动捕捉设备、飞行时间相机和结构光相机。 图13说明了这两类基于姿势的动作识别方法的主流框架。
4.1 基于姿势的估计动作识别
姿势特征已被证明比低/中特征表现得更好,并且可以作为动作识别的判别线索[jhuang2013towards]。 随着姿势估计的成功,一些方法遵循两阶段策略,首先应用现有的姿势估计方法从视频生成姿势,然后使用姿势特征进行动作识别。 Cheron 等人[cheron2015p]提出P-CNN,根据估计的人体姿势提取外观和流量特征,以进行动作识别。 Mohammadreza 等人[zolfaghari2017chained]设计了一个身体部位分割网络来生成姿势,然后将其应用于多流3D-CNN,以整合姿势、光流和RGB视觉信息进行动作识别。 通过姿势估计器生成关节热图后,Choutas 等人[choutas2018potion]通过暂时聚合热图以进行动作识别,提出了姿势运动(PoTion)表示。 为了避免依赖姿势估计图中不准确的姿势,Liu 等人[liu2018recognizing]聚合姿势估计图以形成姿势和热图,然后将其演化用于动作识别。 Moon等人[moon2021integralaction]提出了一种姿势驱动方法的算法,用于整合外观和预先估计的姿势信息以进行动作识别。 Shah 等人[shah2022pose]设计了一个联合运动推理网络(JMRN),用于更好地捕获生成的姿势的关节间依赖性,然后在每个视频帧上运行姿势检测器。 这一系列方法将姿势估计和动作识别视为两个独立的任务,因此动作识别性能可能会受到不准确的姿势估计的影响。 Duan等人[duan2022revisiting]提出PoseConv3D通过现有姿势估计器估计2D姿势并沿时间维度堆叠2D热图来形成3D热图体积,并通过3D CNN在体积之上对动作进行分类。 Sato等人[Sato_2023_CVPR]提出了一种基于目标域独立关节特征的用户提示引导的零样本学习方法,并通过现有的多人姿态估计技术预先提取关节。 Rajasegaran等人[28]提出了一种拉格朗日动作识别与跟踪(LART)方法,将跟踪结果应用于预测动作。 首先通过 PHALP 跟踪算法[rajasegaran2022tracking]获得姿态和外观特征,然后融合作为 Transformer 网络的输入来预测动作。 Hachiuma等人[Hachiuma_2023_CVPR]提出了一种基于结构化关键点池的统一框架,用于增强基于骨架的动作识别的适应性和可扩展性。 通过多人姿态估计和物体检测初步获得人体关键点和物体轮廓点。 然后应用结构化关键点池来聚合关键点特征,以克服骨架检测和跟踪错误。 此外,非人类对象关键点被切断作为附加输入,以消除目标动作的各种限制。 最后,提出了一种弱监督时空动作定位的池化开关技巧,以实现每帧中每个人的动作识别。
另一种方法联合解决姿势估计和动作识别任务。 Luvizon等人[luvizon20182d]提出了一种多任务CNN,用于基于外观和姿势特征的静止图像的联合姿势估计和视频序列的动作识别。 由于姿势估计和动作识别任务的输出格式不同,Foo等人[foo2023unified]设计了统一姿势序列(UPS)多任务模型,该模型构建基于文本的动作标签和基于坐标的姿势转换为异构输出格式,用于同时处理两个任务。
4.2 基于骨架的动作识别
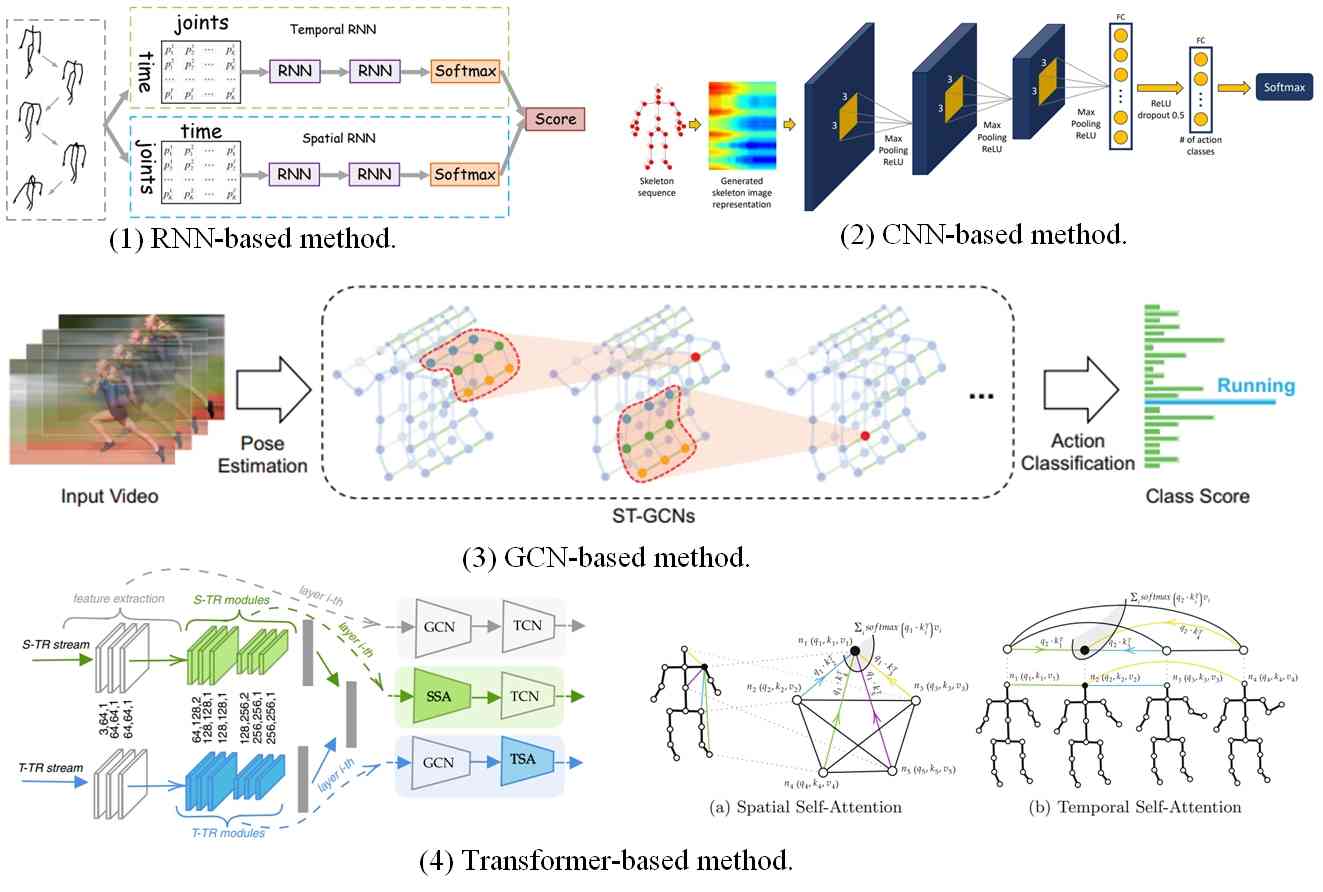
骨架数据是常用于动作识别的 3D 数据的一种形式。 它由一系列骨骼组成,代表人体躯干、头部和四肢位置的示意性模型。 与另外两种常用的数据(包括 RGB 和深度)相比,骨架数据对光照变化具有鲁棒性,并且对相机位置和主体外观具有不变性。 随着深度学习技术的发展,基于骨架的动作识别已经从手工制作的特征转变为基于深度学习的特征。 本综述主要回顾了最近基于不同深度学习网络的方法,可分为基于CNN、基于RNN、基于GCN和基于Transformer的方法,如图14所示。
4.2.1 基于CNN的方法
卷积神经网络(CNN)广泛应用于计算机视觉领域,由于其卓越的局部感知和权重共享能力,在图像特征提取方面具有天然的优势。 由于CNN在图像处理方面的成功,CNN可以更好地捕捉骨架序列中的空间信息。 基于 CNN 的骨架动作识别方法可以分为 2D 和 3D CNN 方法,具体取决于所使用的神经网络的类型。
大多数基于 2D CNN 的方法[du2015骨骼、wang2016action、hou2016骨骼、li2017joint、liu2017enhanced、ke2017骨骼net、caetano2019骨骼、li2019learning]首先将骨骼序列转换为伪图像,其中时空信息骨架序列的特征嵌入在颜色和纹理中。 Du等人[du2015骨骼]将关节的笛卡尔坐标映射到RGB坐标,然后将骨骼序列量化为图像以进行特征提取和动作识别。 为了减少由于透视变换引起的关节间遮挡,一些工作[wang2016action,hou2016骨骼]提出将骨架序列的时空信息编码为三个正交的彩色纹理图像。 单个或多个骨架序列上关节之间的成对距离由关节距离图 (JDM) [li2017joint] 表示,它被编码为纹理图像中的颜色变化。 为了探索更好的空间特征表示,丁等人[ding2017investigation]将关节的距离、方向和角度作为空间特征编码到纹理彩色图像中。 Ke等人[ke2017new]提出使用基于CNN的多任务学习网络通过图像和分类动作来表示骨架序列片段。 类似地,Liang等人[liang2019 Three]应用基于三流CNN的多任务学习来编码骨骼片段特征、位置和运动信息。
当通过 2D CNN 将骨架序列压缩为图像时,不可避免地会丢失一些时间信息。 相比之下,基于 3D CNN 的方法[liu2017two,hernandez20173d]在学习时空特征方面更加出色。 Hernandez 等人 [hernandez20173d] 将骨架序列编码为在关节上计算的堆叠欧几里得距离矩阵 (EDM),然后沿时间维度执行卷积以学习数据的时空动态。
4.2.2 基于RNN的方法
RNN 相关网络通常用于处理时间序列数据,以有效捕获骨架序列内的时间信息。 除了时间信息之外,空间信息是动作识别的另一个重要线索,但可能会被 RNN 相关网络忽略。 一些方法侧重于通过人体的空间划分来解决这个问题。 例如,杜等人[du2015hierarchical, du2016representation]提出了一种分层RNN,用于处理五个身体部位的骨架序列以进行动作识别。 Shahroudy等人[shahroudy2016ntu]提出了一种部分感知LSTM(P-LSTM),用于分别建模身体部位的骨架序列和基于记忆细胞串联的分类动作。
为了更好地关注骨架数据中的关键空间信息,一些方法倾向于结合注意力机制。 Song等人[song2017end]提出了一种使用LSTM的时空注意力模型,其中包括用于自适应地选择每帧中的关键关节的空间注意力模块,以及用于选择骨架序列中的关键帧的时间注意力模块。 类似地,Liu等人[liu2017global]提出了一种循环注意力机制,迭代增强关注关键关节的注意力性能。 Song 等人[song2018spatio]随后的改进工作使用时空正则化来鼓励探索所有节点之间的关系,而不是过分强调某些节点,并避免了时间注意力的无限制增加。 张等人[zhang2019eleatt]提出了一种简单、有效、泛化的元素注意力门(EleAttG)来增强RNN神经元的注意力能力。 Si等人[si2019attention]提出了一种注意力增强图卷积LSTM(AGC-LSTM)来增强关键节点的特征表示。
为了同时利用骨架序列的时间和空间特征,一些方法旨在设计空间和/或时间网络。 Wang等人[wang2017modeling]提出了一种双流RNN,用于同时学习骨架序列的空间和时间关系,并通过3D变换的骨架数据增强技术增强模型的泛化能力。 Liu等人[liu2016spatio]提出了一种时空LSTM网络,将传统的基于LSTM的学习扩展到时空域。 考虑到骨架数据中非相邻关节之间关系的重要性,Zhang等人[zhang2017geometric]设计了八个几何关系特征来对空间信息进行建模,并在三层LSTM网络中对其进行评估。 Si等人[si2018sculpture]提出了一种基于空间的推理和时间堆栈学习(SR-TSL)新颖的模型来捕获每个帧内的高级空间结构信息,并通过组合来对详细的动态信息进行建模多个跳跃段 LSTM。
4.2.3 基于GCN的方法
由于人体骨骼是一种自然的图结构,GCN 是最近流行的基于骨骼的动作识别网络。 与基于 CNN 和 RNN 的方法相比,基于 GCN 的方法可以更好地捕获骨架序列中关节之间的关系。 根据推理时是否动态调整拓扑(即顶点连接关系),基于GCN的方法可以分为静态方法[yan2018spatial, huang2020spatio, liu2020disentangling, zhang2020context]和动态方法[ li2019actional, shi2019two, Cheng2020骨骼, korban2020ddgcn, chen2021channel, chi2022infogcn, duan2022dg, wang2022骨骼, 9763364, lin2023actionlet, li2022smam, DAI2023109540, 9997556, shu20 22multi,WU2023109231]。
对于静态方法,GCN 的拓扑在推理过程中保持固定。 例如,提出了图卷积的早期应用,时空 GCN (ST-GCN)[yan2018spatial],它应用基于人体结构的预定义和固定拓扑。 Liu等人[liu2020disentangling]提出了一种GCN的多尺度图拓扑,用于建模多范围关节关系。
对于动态方法,GCN 的拓扑是在推理过程中动态推断的。 动作结构图卷积网络 (AS-GCN) [li2019actional] 应用 A-link 推理模块来捕获特定于动作的相关性。 双流自适应 GCN (2s-AGCN) [shi2019two] 和语义引导网络 (SGN) [zhang2020semantics] 通过自注意力机制增强拓扑学习,用于建模之间的相关性两个关节。 尽管拓扑动态建模有利于推断关节的内在关系,但由于捕获的拓扑独立于姿势,因此可能难以对动作的上下文进行编码。 因此,一些方法侧重于上下文相关的内在拓扑建模。 在Dynamic GCN [ye2020dynamic]中,结合了所有关节的上下文特征来学习关节的关系。 通道拓扑细化 GCN (CTR-GCN) [chen2021channel] 专注于在不同通道中嵌入联合拓扑,而 InfoGCN [chi2022infogcn] 引入基于注意力的图卷积来捕获上下文基于信息瓶颈学习的潜在表示的依赖拓扑。 多级时空激发图网络(ML-STGNet)[9997556]引入了基于Transformer的空间数据驱动的激发模块,以数据依赖的方式学习不同样本的联合关系。 多视图交互图网络(MV-IGNet)[9234715]设计了一个全局上下文适应模块,用于在多级空间骨架上下文上自适应学习拓扑结构。 空间图扩散卷积(S-GDC)网络[10023982]旨在通过图扩散来学习新图,以捕获同一物体和两个相互作用物体上远处关节的连接。 在上述动态方法中,拓扑建模仅基于关节信息。 相比之下,语言模型知识辅助 GCN (LA-GCN) [xu2023language] 应用大规模语言模型来合并与动作相关的先验信息,以学习动作识别的拓扑。
无论是静态还是动态方法,他们的目标都是构建不同的 GCN 来建模动作的空间和时间特征。 相比之下,一些论文研究了辅助不同 GCN 能力的策略。 例如,Wang等人[Wang_2023_CVPR]提出了神经Koopman池化来取代时间平均/最大池化来聚合时空特征。 库普曼池学习类动态以实现更好的分类。 Zhou等人[Zhou_2023_CVPR]提出了一种基于对比学习的特征细化头(FR Head),以提高模糊动作的判别力。 有了 FR Head,一些现有方法的性能(例如 2s-AGCN [shi2019two]、CTR-GCN [chen2021channel])可提升1%左右。
综上所述,基于 GCN 的方法可以有效地利用和处理拓扑网络的联合关系,但通常仅限于局部时空邻域。 与静态方法相比,动态方法由于动态拓扑而具有更强的泛化能力。
4.2.4 基于变压器的方法
Transformer 最初是为自然语言处理中的机器翻译任务而设计的。 Vision Transformer (ViT)[dosovitskiy2020image]是第一个在计算机视觉中使用 Transformer 编码器提取图像特征的工作。 将Transformer引入基于骨架的动作识别时,核心是如何设计更好的编码器来对骨架序列的空间和时间信息进行建模。 与GCN方法相比,基于Transformer的方法可以快速获取全局拓扑信息并增强非物理关节的相关性。 主要有三类方法:纯 Transformer、混合 Transformer 和无监督 Transformer。
第一类方法应用标准 Transformer 来学习空间和时间特征。 空间 Transformer 和时间 Transformer 通常基于单流[shi2020de Coupled, wang2021iip, ijaz2022multimodal]或双流[zhang2021stst, shi2021star, gedamu2023relation]网络交替或一起应用。 Shi等人[shi2020de Coupled]提出将数据解耦为空间和时间维度,其中空间和时间流分别包含运动无关和运动相关特征。 提出了一种解耦时空注意力网络(DSTA-Net),基于注意力模块对两个流进行顺序编码。 它允许对关节之间的时空依赖性进行建模,而无需有关其位置或相互连接的信息。 Ijaz等人[ijaz2022multimodal]提出了一种基于Transformer的多模态护理活动识别网络,融合了时空骨架模型和加速模型的编码结果。 时空骨架模型由顺序处理中的时空 Transformer 编码器组成,它计算关节的时空特征。 加速模型有一个 Transformer 块,用于计算给定动作样本的加速数据点之间的相关性。 张等人[zhang2021stst]提出了一种时空特殊变换器(STST)来分别捕获时间和空间维度的骨架序列。 STST 是一个双流结构,包括空间 Transformer 块和方向时间 Transformer 块。 关系挖掘自注意力网络(RSA-Net)[gedamu2023relation]在空间和时间域中应用七个RSA块来学习帧内和帧间动作特征。 这样的双流结构导致了特征维度的扩展,使得网络捕获更丰富的信息,但同时也增加了计算成本。 为了降低计算成本,石等人[shi2021star]提出了一种基于稀疏变换器的动作识别(ST-AR)模型。 ST-AR 由一个稀疏自注意力模块组成,该模块在稀疏矩阵乘法上执行以捕获空间相关性,以及一个分段线性自注意力模块,在可变长度的序列上进行处理以捕获时间相关性,以进一步减少计算和内存成本。
由于Transformer在从局部特征和短期时间信息中提取判别性信息方面较弱,所以第二类方法[plizzari2021spatial, zhou2022hypergraph, qiu2022spatio, kong2022mtt, zhang2022zoom, gao2022focal, liu2022graph, pang2022igformer, Wang_2023_CVPR, du an2023skeletr] 将Transformer与GCN、CNN结合起来,可以更好的进行特征提取,有利于发挥不同网络的优势。 Plizzari等人[plizzari2021spatial]通过将空间和时间Transformers与时间卷积网络和GCN相结合,提出了一种双流空间时间变换网络(ST-TR)。 Qiu等人[qiu2022spatio]提出了一种时空元组变换器(STTFormer),其中包括用于捕获连续帧中的关节关系的时空元组自注意力模块和帧间特征聚合( IFFA)模块,用于增强区分相似动作的能力。 与ST-TR类似,IFFA模块应用TCN来聚合子动作的特征。 Yang等人[zhang2022zoom]展示了Zoom-Former,将单人动作识别扩展到多人团体活动。 Zoom-Former通过设计关系感知注意力机制改进了传统的GCN,该机制综合利用身体结构的先验知识和人体运动的全局特征来开发多层次特征。 通过这一改进,Zoom-Former 可以分层提取单个人的低级运动信息和多人的高级交互信息。 为了有效捕捉时空维度上关键局部关节与全局上下文信息之间的关系,高等人[gao2022focal]提出了一种端到端的焦点和全局时空变换器(FG- STForm)通过将时间卷积集成到全局自注意力机制中。 Liu等人[liu2022graph]提出了一种内核注意力自适应图变换网络(Kernel Attention Adaptive Graph Transformer Network),使用图变换算子来建模关节之间的高阶空间依赖关系。 Wang等人[Wang_2023_CVPR]提出了一种多阶多模式变压器(3Mformer),通过应用高阶变压器来处理骨骼数据的超图,以更好地捕获身体关节之间的高阶运动模式。 SkeleTR [duan2023skeletr] 最初使用 GCN 来捕获人内动态信息,然后应用堆叠式 Transformer 编码器来对人的交互进行建模。 它可以处理不同的任务,包括视频级动作识别、实例级动作检测和群体活动识别。
为了提高特征的泛化能力,第三类方法[kim2022global, dong2023hierarchical, shah2023halp, heng2021motion, 10222534, ijcai2023p95]专注于基于Transformer的无监督或自监督动作识别,并表现出了优异的性能捕捉全球背景和当地联合动态。 这些方法通常应用对比学习或编码器-解码器架构来学习更好的动作表示。 Kim等人[kim2022global]提出了GL-Transformer,设计了全局和局部注意力机制来学习骨架序列的局部关节运动变化和全局上下文信息。 通过运动序列表示,动作根据时间轴上的平均池化进行分类。 Anshul等人[shah2023halp]通过生成幻觉潜在正样本来设计HaLP模块,用于基于对比学习的自监督学习。 该模块可以探索人体姿势在适当方向上的潜在空间来生成新的正样本,并通过新的近似函数优化求解效率。
综上所述,基于骨架的动作识别研究近年来取得了很大进展。 基于CNN的方法主要将骨架序列转换为图像,擅长捕获动作的空间信息,但可能会丢失时间信息。 借助RNN来表示时间信息,基于RNN的方法侧重于基于人体的空间划分并结合注意力机制来表示空间信息。 与基于CNN和RNN的方法相比,基于GCN和Transformer的方法具有更大的优势,成为主流方法。 基于 GCN 的方法有利于通过拓扑网络来表示关节关系,其中基于动态拓扑的方法比静态方法具有更强的泛化能力。 然而,它们大多局限于局部时空邻域。 基于Transformer的方法可以快速获取全局拓扑信息并增强非物理关节的相关性。 将 Transformer 与 CNN 和 GCN 相结合是一种很有前途的提取局部和全局特征、增强动作识别性能的方法。
5 基准数据集
本节回顾了这三个任务的常用数据集,并比较了不同方法在一些流行数据集上的性能。
| Dataset | Year | Citation | #Poses | #Joints | Train | Val | Test | SP/MP | Actions | Metrics | ||
| IB | LSP [johnson2010clustered] | 2010 | 971 | 2,000 | 14 | 1k | - | 1k | SP | PCP/PCK | ||
|
2011 | 509 | 10,000 | 14 | 10k | - | - | SP | PCP | |||
|
2013 | 537 | 5,003 | 10 | 4k | - | 1k | SP | PCK/PCP | |||
|
2014 | 2583 | 26,429 | 16 | 29k | - | 12k | SP | ✓ | PCPm/PCKh | ||
|
2014 | 2583 | 14,993 | 16 | 3.8k | - | 1.7k | MP | ✓ | mAP | ||
|
2014 | 37862 | 105,698 | 17 | 45k | 22k | 80k | MP | AP | |||
|
2014 | 37862 | - | 17 | 64k | 2.7k | 40k | MP | AP | |||
|
2017 | 482 | 50462 | 16 | 30k | 10k | 10k | SP | PCK | |||
|
2019 | 423 | 80000 | 14 | 10k | 2k | 8k | MP | mAP | |||
| VB |
|
2013 | 849 | 31,838 | 15 | 2.4k | - | 0.8k | SP | ✓ | PCK | |
|
2013 | 367 | 159,633 | 13 | 1k | - | 1k | SP | ✓ | PCK | ||
|
2017 | 420 | 153,615 | 15 | 292 | 50 | 208 | MP | ✓ | mAP | ||
|
2018 | 420 | - | 15 | 593 | 170 | 375 | MP | ✓ | mAP | ||
|
2022 | 15 | - | 15 | 593 | 170 | - | MP | ✓ | mAP |
| Dataset | Year | Citation | #Joints | #Frames | SP/MP | Actions | Metrics | ||
|---|---|---|---|---|---|---|---|---|---|
| VB |
|
2010 | 1678 | 15 | 37.6k | SP | ✓ | MPJPE/PA-MPJPE | |
|
2014 | 2677 | 17 | 3.6M | SP | ✓ | MPJPE | ||
|
2017 | 851 | 15 | 1.3M | SP | ✓ | 3DPCK | ||
|
2017 | 680 | 15 | 1.5M | MP | ✓ | 3DPCK/MPJPE | ||
|
2018 | 674 | 18 | 51k | MP | MPJPE/MPJAE/PA-MPJPE | |||
|
2018 | 346 | 15 | 8k | MP | 3DPCK | |||
|
2018 | 346 | - | - | MP | 3DPCK |
5.1 姿态估计
5.1.1 二维姿态估计数据集
对于基于图像的 2D 姿态估计,Microsoft Common Objects in Context (COCO) [lin2014microsoft] 和 Max Planck Institute for Informatics (MPII) [andriluka20142d] 是流行的数据集。 联合注释的 HMDB (J-HMDB) 数据集 [jhuang2013towards] 和 Penn Action [zhang2013actemes] 数据集通常用于基于 2D 视频的单人姿态估计(SPPE) ),而 PoseTrack [andriluka2018posetrack] 通常用于基于视频的多人姿势估计(MPPE)。
COCO 数据集 [lin2014microsoft] 是姿势估计中使用最广泛的大型数据集。 它是通过提取具有常见对象的日常场景图像并使用每个实例分割来标记对象来创建的。 该数据集由超过 330,000 张图像和 200,000 个标记人物组成,每个人标记有 17 个关键点。 它有两个版本的姿态估计,包括 COCO2016 和 COCO2017。 两个版本的训练、测试和验证图像数量不同,如表1所示。 除了姿态估计之外,该数据集还适用于对象检测、图像分割和字幕。
MPII 数据集 [andriluka20142d] 由马克斯普朗克信息研究所从 3,913 个 YouTube 视频中收集。 它由 24,920 张图像组成,其中包括超过 40,000 个人以及 16 个带注释的身体关节。 这些图像是通过两级分层方法收集的,以捕捉人类的日常活动。 该数据集涉及 21 个类别 491 个活动样本,所有图像均已标记。 除了关节之外,Amazon Mechanical Turk 上还标注了丰富的注释,包括身体遮挡、3D 躯干和头部方向。 MPII 数据集是 2D 单人和多人姿势估计的宝贵资源。
J-HMDB数据集 [jhuang2013towards]是通过注释HMDB51动作数据集的人体关节而创建的。 从 HMDB51 中提取了 928 个视频,其中包括一个人的 21 个动作,并使用 2D 铰接人体木偶模型对每个视频的人体关节进行了注释。 每个视频由 15-40 帧组成。 总共有 31,838 个带注释的帧。 该数据集可以作为人体检测、姿势估计、姿势跟踪和动作识别的基准。 它还为基于视频的姿势估计或跟踪带来了新的挑战,因为它包括相机运动、运动模糊以及局部或全身可见性的更多变化。 Sub-J-HMDB数据集 [jhuang2013towards]是J-HMDB数据集的子集,包含316个视频,总共11,200帧。
Penn Action 数据集 [zhang2013actemes] 也是宾夕法尼亚大学收集的带注释的体育动作数据集。 它由 2,326 个视频组成,每个视频有 15 个动作,每个帧都注释有每个人的 13 个关键点。 该数据集可用于姿态估计、动作检测和识别任务。
PoseTrack 数据集 [andriluka2018posetrack] 是从 MPII 姿势数据集的原始视频中收集的。 对于 MPII 中的每一帧,选择 41-298 个具有拥挤场景和多个个体的相邻帧作为 PoseTrack 数据集。 所选视频带有人物位置、身份、身体姿势和忽略区域的注释。 根据视频数量的不同,该数据集目前存在三个版本:PoseTrack2017、PoseTrack2018、PoseTrack2021。 PoseTrack2017 总共包含 292 个训练视频、50 个验证视频和 208 个测试视频。 其中,23,000 帧被标记了数量非常多(即 153,615)的带注释姿势。 PoseTrack2018增加了视频数量,包含593个训练视频、170个验证视频和315个测试视频,由46,933个标记帧组成。 PoseTrack2021 是 PoseTrack2018 的扩展,具有更多注释(例如 小人物的边界框,关节遮挡)。 凭借人员身份,该数据集已被广泛用作评估多人姿势估计和跟踪算法的基准。
| Category | Year | Method | COCO | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Backbone | Inputsize | AP | AP.5 | AP.75 | APM | APL | ||||
| SP | Regression-based | 2021 | TFPose [34] | ResNet-50 | 384×288 | 72.2 | 90.9 | 80.1 | 69.1 | 78.8 |
| 2021 | PRTR [35] | HRNet-W32 | 512×384 | 72.1 | 90.4 | 79.6 | 68.1 | 79.4 | ||
| 2022 | Panteleris et al. [37] | - | 384×288 | 72.6 | - | - | - | - | ||
| Heatmap-based | 2021 | Li et al. [63] | HRNet-W48 | - | 75.7 | 92.3 | 82.9 | 72.3 | 81.3 | |
| 2022 | Li et al. [62] | HRNet-W48 | 384×288 | 76.0 | 92.4 | 83.5 | 72.5 | 81.9 | ||
| 2023 | DistilPose [64] | HRNet-W48-stage3 | 256×192 | 73.7 | 91.6 | 81.1 | 70.2 | 79.6 | ||
| MP | Top-down | 2017 | Papandreou et al. [67] | ResNet-101 | 353×257 | 68.5 | 87.1 | 75.5 | 65.8 | 73.3 |
| 2017 | RMPE [81] | Hourglass | - | 61.8 | 83.7 | 69.8 | 58.6 | 67.6 | ||
| 2018 | Xiao et al. [69] | ResNet-152 | 384×288 | 73.7 | 91.9 | 81.1 | 70.3 | 80.0 | ||
| 2018 | CPN [82] | ResNet | 384×288 | 73.0 | 91.7 | 80.9 | 69.5 | 78.1 | ||
| 2019 | Posefix [70] | ResNet-152 | 384×288 | 73.6 | 90.8 | 81.0 | 70.3 | 79.8 | ||
| 2019 | Sun et al. [71] | HRNet-W48 | 384×288 | 77 | 92.7 | 84.5 | 73.4 | 83.1 | ||
| 2019 | Su et al. [83] | ResNet-152 | 384×288 | 74.6 | 91.8 | 82.1 | 70.9 | 80.6 | ||
| 2020 | Cai et al. [72] | 4×RSN-50 | 384×288 | 78.6 | 94.3 | 86.6 | 75.5 | 83.3 | ||
| 2020 | Huang et al. [73] | HRNet | 384×288 | 77.5 | 92.7 | 84.0 | 73.0 | 82.4 | ||
| 2020 | Zhang et al. [74] | HRNet-W48 | 384×288 | 77.4 | 92.6 | 84.6 | 73.6 | 83.7 | ||
| 2020 | Graphpcnn [75] | HR48 | 384×288 | 76.8 | 92.6 | 84.3 | 73.3 | 82.7 | ||
| 2020 | Qiu et al. [84] | - | 384×288 | 74.1 | 91.9 | 82.2 | - | - | ||
| 2021 | TransPose [85] | HRNet-W48 | 256×192 | 75.0 | 92.2 | 82.3 | 71.3 | 81.1 | ||
| 2021 | TokenPose [87] | - | 384×288 | 75.9 | 92.3 | 83.4 | 72.2 | 82.1 | ||
| 2021 | HRFormer [88] | - | 384×288 | 76.2 | 92.7 | 83.8 | 72.5 | 82.3 | ||
| 2022 | ViTPose [89] | ViTAE-G | 576×432 | 81.1 | 95.0 | 88.2 | 77.8 | 86.0 | ||
| 2022 | Xu et al. [76] | HR48 | 384×288 | 76.6 | 92.4 | 84.3 | 73.2 | 82.5 | ||
| 2023 | PGA-Net [77] | HRNet-W48 | 384x288 | 76.0 | 92.5 | 83.5 | 72.4 | 82.1 | ||
| 2023 | BCIR [78] | HRNet-W48 | 384x288 | 76.1 | - | - | - | - | ||
| Bottom-up | 2017 | Associative embedding [97] | Hourglass | 512×512 | 65.5 | 86.8 | 72.3 | 60.6 | 72.6 | |
| 2018 | Multiposenet [kocabas2018multiposenet] | ResNet50 | 480×480 | 69.6 | 86.3 | 76.6 | 65.0 | 76.3 | ||
| 2018 | OpenPose [93] | - | - | 61.8 | 84.9 | 67.5 | 57.1 | 68.2 | ||
| 2019 | Pifpaf [94] | ResNet50 | - | 55.0 | 76.0 | 57.9 | 39.4 | 76.4 | ||
| 2020 | Jin et al. [jin2020differentiable] | Hourglass | 512×512 | 67.6 | 85.1 | 73.7 | 62.7 | 74.6 | ||
| 2020 | Higherhrnet [cheng2020higherhrnet] | HrHRNet-W48 | 640×640 | 72.3 | 91.5 | 79.8 | 67.9 | 78.2 | ||
| 2021 | DEKR [geng2021bottom] | HRNet-W48 | 640x640 | 71.0 | 89.2 | 78.0 | 67.1 | 76.9 | ||
| 2023 | HOP [96] | HRNet-W48 | 640×640 | 70.5 | 89.3 | 77.2 | 66.6 | 75.8 | ||
| 2023 | Cheng et al. [95] | HRNet-W48 | 640×640 | 71.5 | 89.1 | 78.5 | 67.2 | 78.1 | ||
| 2023 | PolarPose [10034548] | HRNet-W48 | 640x640 | 70.2 | 89.5 | 77.5 | 66.1 | 76.4 | ||
| One-stage | 2019 | Directpose [tian2019directpose] | ResNet-101 | 800×800 | 64.8 | 87.8 | 71.1 | 60.4 | 71.5 | |
| 2021 | FCPose [mao2021fcpose] | DLA-60 | 736 × 512 | 65.9 | 89.1 | 72.6 | 60.9 | 74.1 | ||
| 2021 | InsPose [shi2021inspose] | HRNet-w32 | - | 71.0 | 91.3 | 78.0 | 67.5 | 76.5 | ||
| 2022 | PETR [shi2022end] | Swin-L | - | 71.2 | 91.4 | 79.6 | 66.9 | 78.0 | ||
| 2023 | ED-pose [65] | Swin-L | - | 72.7 | 92.3 | 80.9 | 67.6 | 80.0 | ||
| 2023 | GroupPose [liu2023group] | Swin-L | - | 72.8 | 92.5 | 81.0 | 67.7 | 80.3 | ||
| 2023 | SMPR [MIAO2023109743] | HRNet-w32 | 800x800 | 70.2 | 89.7 | 77.5 | 65.9 | 77.2 | ||
| Category | Year | Method | Penn | JHMDB |
|---|---|---|---|---|
| PCK | PCK | |||
| FF | 2016 | Gkioxari et al. [gkioxari2016chained] | 91.8 | - |
| 2017 | Song et al. [song2017thin] | 96.4 | 92.1 | |
| 2018 | LSTM [luo2018lstm] | 97.7 | 93.6 | |
| 2019 | DKD [nie2019dynamic] | 97.8 | 94 | |
| 2019 | Li et al. [li2019temporal] | - | 94.8 | |
| 2022 | RPSTN [dang2022relation] | 98.7 | 97.7 | |
| 2023 | HANet [jin2023kinematic] | - | 99.6 | |
| SF | 2020 | K-FPN [zhang2020key] | 98 | 94.7 |
| 2022 | REMOTE [ma2022remote] | 98.6 | 95.9 | |
| 2022 | DeciWatch [zeng2022deciwatch] | - | 98.9 | |
| 2023 | MixSynthFormer [sunmixsynthformer] | - | 99.3 |
| Category | Year | Method | Val | Test |
|---|---|---|---|---|
| mAP | mAP | |||
| Top-down | 2018 | Xiao et al. [69] | 76.7 | 73.9 |
| 2018 | Pose Flow [xiu2018pose] | 66.5 | 63.0 | |
| 2018 | Detect-Track [girdhar2018detect] | - | 64.1 | |
| 2020 | Wang et al. [wang2020combining] | 81.5 | 73.5 | |
| 2022 | AlphaPose [fang2022alphapose] | 74.7 | - | |
| 2023 | SLT-Pose [gai2023spatiotemporal] | 81.5 | - | |
| 2023 | DiffPose [feng2023diffpose] | 83.0 | - | |
| 2023 | TDMI [feng2023mutual] | 83.6 | - | |
| Bottom-up | 2019 | PGG [jin2019multi] | 77.0 | - |
5.1.2 3D姿态估计数据集
与 2D 数据集相比,获取 3D 姿势的高质量标注更具挑战性,并且需要运动字幕系统(例如 Mocap、可穿戴 IMU)。 因此,3D 姿态数据集通常是在受限环境中构建的。 目前,Human3.6M和MPI-INF-3DHP广泛用于SPPE任务,MuPoTs-3D常用于MPPE任务。
Human3.6M 数据集 [ionescu2013 human3] 是用于 3D 单人姿态估计的最大且最具代表性的室内数据集。 它是通过记录 11 名人类受试者从 4 个摄像机视图进行 17 项活动的视频,并通过基于标记的动捕系统捕获姿势来收集的。 该数据集总共包含 360 万个姿势,其中一帧中有一个姿势。 该数据集适用于图像或视频的 HPE 任务。 对于基于视频的 HPE,合适感受野中的帧序列被视为输入。 协议1是最常见的协议,它应用5个科目(S1、S5、S6、S7、S8)的帧进行训练,并使用2个科目(S9、S11)的帧进行测试。
MPI-INF-3DHP 数据集 [mehta2017moneye] 是室内和室外环境中的大型 3D 单人姿势数据集。 它是由多摄像机工作室中的无创动捕捉系统捕获的。 有 8 个主体从 14 个摄像机视图中执行 8 项活动。 该数据集提供了 130 万帧,但比 Human3.6M 的运动更加多样化。 与 Human3.6M 相同,该数据集也适用于图像或视频的 HPE 任务。 测试集包括6个不同场景的主体的帧。
MuPoTs-3D 数据集 [mehta2018single] 是室内和室外环境中的多人 3D 姿势数据集。 与 MPI-INF-3DHP 相同,它也是由多视图无标记 MoCap 系统捕获的。 8 位受试者在 20 个视频中收集了 8,000 多个帧。 在一些户外场景中,存在一些具有挑战性的帧,其中包括遮挡、剧烈的照明变化和镜头眩光。
| Category | Year | Method |
|
|
|||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| IB | One-stage | 2015 | Li et al. [li2015maximum] | 122.0 | - | - | - | ||||
| 2016 | Zhou et al. [zhou2016deep] | 107.3 | - | - | - | ||||||
| 2017 | Mehta et al. [mehta2017monocular] | 74.1 | - | 57.3 | 28.0 | ||||||
| 2017 | WTL [zhou2017towards] | 64.9 | - | 69.2 | 32.5 | ||||||
| Two-stage | 2017 | Martinez et al. [martinez2017simple] | 62.9 | 47.7 | - | - | |||||
| 2017 | Tekin et al. [tekin2017learning] | 69.7 | - | - | - | ||||||
| 2017 | Jahangiri et al. [jahangiri2017generating] | - | 68.0 | - | - | ||||||
| 2018 | Drpose3d [wang2018drpose3d] | 57.8 | 42.9 | - | - | ||||||
| 2018 | Yang et al. [yang20183d] | 58.6 | 37.7 | 80.1 | 45.8 | ||||||
| 2019 | Habibie et al. [habibie2019wild] | 49.2 | - | 82.9 | 45.4 | ||||||
| 2019 | Chen et al. [chen2019unsupervised] | - | 68.0 | 71.1 | 36.3 | ||||||
| 2019 | RepNet [wandt2019repnet] | 80.9 | 65.1 | 82.5 | 58.5 | ||||||
| 2019 | Hemlets pose [zhou2019hemlets] | - | - | 75.3 | 38.0 | ||||||
| 2019 | Sharma et al. [sharma2019monocular] | 58.0 | 40.9 | - | - | ||||||
| 2019 | Li and Lee [li2019generating] | 52.7 | 42.6 | 67.9 | - | ||||||
| 2019 | LCN [ci2019optimizing] | 52.7 | 42.2 | 74.0 | 36.7 | ||||||
| 2019 | semantic-GCN [zhao2019semantic] | - | 57.6 | - | - | ||||||
| 2020 | Iqbal et al. [iqbal2020weakly] | 67.4 | 54.5 | 79.5 | - | ||||||
| 2020 | Pose2mesh [choi2020pose2mesh] | 64.9 | 48.0 | - | - | ||||||
| 2020 | Srnet [zeng2020srnet] | 44.8 | - | 77.6 | 43.8 | ||||||
| 2020 | Liu et al. [liu2020comprehensive] | 52.4 | 41.2 | - | - | ||||||
| 2021 | Zou et al. [zou2021modulated] | 49.4 | 39.1 | 86.1 | 53.7 | ||||||
| 2021 | GraphSH [xu2021graph] | 51.9 | - | 80.1 | 45.8 | ||||||
| 2021 | Lin et al. [lin2021end] | 54.0 | 36.7 | - | - | ||||||
| 2021 | Yu et al. [yu2021towards] | 92.4 | 52.3 | 86.2 | 51.7 | ||||||
| 2022 | Graformer [zhao2022graformer] | 51.8 | - | - | - | ||||||
| 2022 | PoseTriplet [gong2022posetriplet] | 78 | 51.8 | 89.1 | 53.1 | ||||||
| 2023 | HopFIR [zhai2023hopfir] | 48.5 | - | 87.2 | 57.0 | ||||||
| 2023 | SSP-Net [CARBONERALUVIZON2023109714] | 51.6 | - | 83.2 | 44.3 | ||||||
| 2023 | PHGANet [2023Learning] | 49.1 | - | 86.9 | 55.0 | ||||||
| 2023 | RS-Net [10179252] | 47.0 | 38.6 | 85.6 | 53.2 | ||||||
| VB | One-stage | 2016 | Tekin et al. [tekin2016direct] | 125.0 | - | - | - | ||||
| 2017 | Vnect [mehta2017vnect] | 80.5 | - | 79.4 | 41.6 | ||||||
| 2018 | Dabral et al. [dabral2018learning] | 52.1 | 36.3 | 76.7 | 39.1 | ||||||
| 2022 | IVT [qiu2022ivt] | 40.2 | 28.5 | - | - | ||||||
| 2023 | CSS [9921314] | 60.1 | 46.0 | - | - | ||||||
| Two-stage | 2017 | RPSM [lin2017recurrent] | 73.1 | - | - | - | |||||
| 2018 | Rayat et al. [rayat2018exploiting] | 51.9 | 42.0 | - | - | ||||||
| 2018 | p-LSTMs [lee2018propagating] | 55.8 | 46.2 | - | - | ||||||
| 2018 | Katircioglu et al. [katircioglu2018learning] | 67.3 | - | - | - | ||||||
| 2019 | Cheng et al. [cheng2019occlusion] | 42.9 | 32.8 | - | - | ||||||
| 2019 | Cai et al. [cai2019exploiting] | 48.8 | 39.0 | - | - | ||||||
| 2019 | TCN [pavllo20193d] | 46.8 | 36.5 | - | - | ||||||
| 2019 | Chirality Nets [yeh2019chirality] | 46.7 | - | - | - | ||||||
| 2020 | UGCN [wang2020motion] | 42.6 | 32.7 | 86.9 | 62.1 | ||||||
| 2020 | GAST-Net [liu2020gast] | 44.9 | 35.2 | - | - | ||||||
| 2021 | Chen et al. [chen2021anatomy] | 44.1 | 35.0 | 87.9 | 54.0 | ||||||
| 2021 | PoseFormer [zheng20213d] | 44.3 | 34.6 | 88.6 | 56.4 | ||||||
| 2022 | Strided [li2022exploiting] | 43.7 | 35.2 | - | - | ||||||
| 2022 | Mhformer [li2022mhformer] | 43.0 | - | 93.8 | 63.3 | ||||||
| 2022 | MixSTE [zhang2022mixste] | 39.8 | 30.6 | 94.4 | 66.5 | ||||||
| 2022 | UPS [foo2023unified] | 40.8 | 32.5 | - | - | ||||||
| 2023 | DSTFormer [zhu2022motionbert] | 37.5 | - | - | - | ||||||
| 2023 | GLA-GCN [yu2023gla] | 44.4 | 34.8 | 98.5 | 79.1 | ||||||
| 2023 | D3DP [shan2023diffusionbased] | 35.4 | - | 98.0 | 79.1 | ||||||
| 2023 | DiffPose [holmquist2022diffpose] | 43.3 | 32.0 | 84.9 | - | ||||||
| 2023 | STCFormer [tang20233d] | 40.5 | 31.8 | 98.7 | 83.9 | ||||||
| 2023 | PoseFormerV2 [zhao2023poseformerv2] | 45.2 | 35.6 | 97.9 | 78.8 | ||||||
| 2023 | MTF-Transformer [9815549] | 26.2 | - | - | - | ||||||
| MuPoTS-3D | ||||||||
| Category | Year | Method | All people | Matched people | ||||
| PCKrel | PCKabs | PCKrel | PCKabs | PCKroot | AUCrel | |||
| Top-down | 2019 | LCR-Net [rogez2019lcr] | 70.6 | - | 74.0 | - | - | - |
| 2019 | Moon et al. [moon2019camera] | 81.8 | 31.5 | 82.5 | 31.8 | 31.0 | 40.9 | |
| 2020 | HDNet [lin2020hdnet] | - | - | 83.7 | 35.2 | - | - | |
| 2020 | HMOR [wang2020hmor] | - | - | 82.0 | 43.8 | - | - | |
| 2022 | Cha et al. [cha2022multi] | 89.9 | - | 91.7 | - | - | - | |
| Bottom-up | 2018 | Mehta et al. [mehta2018single] | 65.0 | - | 69.8 | - | - | - |
| 2020 | Kundu et al. [kundu2020unsupervised] | 74.0 | 28.1 | 75.8 | - | - | - | |
| 2020 | XNect [mehta2020xnect] | 70.4 | - | 75.8 | - | - | - | |
| 2020 | Smap [zhen2020smap] | 73.5 | 35.4 | 80.5 | 38.7 | 45.5 | 42.7 | |
| 2022 | Liu et al. [liu2022explicit] | 79.4 | 36.5 | 86.5 | 39.3 | - | - | |
| 2023 | AKE [chen2023multi] | 74.7 | 37.2 | 81.1 | 40.1 | - | - | |
| One-stage | 2022 | Wang et al. [wang2022distribution] | 82.7 | 39.2 | - | - | - | - |
| 2022 | DRM [jin2022single] | 80.9 | 39.3 | 85.1 | 41.0 | 45.6 | 45.4 | |
| 2023 | WSP [qiu2023weakly] | 82.4 | - | 83.2 | - | - | - | |
5.1.3性能比较
在表3中,我们对 COCO 数据集上基于 2D 图像的 SPPE 和 MPPE 的不同方法进行了比较。 对于 SPPE 任务,基于热图的方法的性能通常优于基于回归的方法。 这种优势可以归因于热图提供的更丰富的空间信息,其中每个像素的概率预测提高了关键点定位的准确性。 然而,基于热图的方法[64]严重受到量化误差问题和使用高分辨率热图的高计算成本的影响。 对于 MPPE 任务,由于现有 SPPE 技术在检测个体后的成功,自上而下的方法总体优于自下而上的方法。 然而,它们受到早期承诺的影响,并且比自下而上的方法具有更大的计算成本。 一阶段方法通过消除自上而下和自下而上方法引入的中间操作(例如分组、ROI、NMS)来加快进程,但其性能[liu2023group]仍然较低(在最好的情况下大约是 AP 分数的 9%)比自上而下的方法[89]。 此外,还观察到主干和输入图像大小是结果的两个因素。 常用的backbone包括ResNet、HRNet和Hourglass。 最近基于Transformer的网络(例如ViTAE-G、Swin-L)也可以用作骨干网,并且基于ViTAE-G网络的方法[89]实现了最佳性能。 当对同一类别的方法使用相同的主干[74, 85]时,图像尺寸越大,性能越好。
表4和表5比较了基于2D视频的SPPE和MPPE的不同方法。 总体而言,基于视频的 SPPE 的两类方法在两个数据集上取得了可比较的结果。 然而,通过忽略查看所有帧,基于帧的示例方法[zeng2022deciwatch]通常比逐帧方法更快。 与基于图像的 MPPE 类似,对于基于视频的 MPPE,自上而下的方法比自下而上的方法获得更好的性能。
对于3D姿态估计,以Human3.6M、MPI-INF-3DHP和MuPoTS-3D数据集为例,表6和表7分别显示了SPPE和MPPE的比较来自图像或视频。 由于现有方法较少,因此未对基于视频的 MPPE 进行比较。 对于 SPPE 任务,两阶段方法通常从估计的 2D 姿势中提升 3D 姿势,由于 2D 姿势估计技术的成功,它们通常优于一阶段方法。 还值得注意的是,最近基于 Transformer 网络的单阶段方法[qiu2022ivt]也取得了相当不错的结果。 与图像和视频之间的同类方法相比,基于视频的性能优于基于图像的方法。 它表明视频的时间信息有利于估计更准确的姿势。 从表7可以看出,近年来MPPE任务取得了良好的进展。 具体来说,一阶段方法通常比大多数自上而下和自下而上的方法表现更好,这进一步意味着端到端训练可以减少中间错误,例如人类检测和联合分组。
| Dataset | Year | Citation | #Joints | Size | 2D/3D | Metrics | ||
|---|---|---|---|---|---|---|---|---|
|
2011 | 198 | - | 44 videos | 2D |
|
||
|
2017 | 238 | 14 | 16 subjects, 60 videos | 2D | MOTA | ||
|
2018 | 420 | 15 | 40 subjects, 550 videos | 2D | MOTA | ||
|
2018 | 420 | 15 | 1138 videos | 2D | MOTA | ||
|
2018 | 250 | 14 | 60 videos | 2D | MOTA | ||
|
2011 | 1253 | - | 3 subjects, 3 views, 6k frames | 3D | PCP | ||
|
2013 | 61 | 14 | 4 subjects, 828 frames | 3D | PCP/KLE | ||
|
2017 | 680 | 15 | 8 subjects, 480 views, 65 videos | 3D | MOTA |
| Method | Category | Year | AP |
|---|---|---|---|
| Zhao et al. | |||
| [zhao2015tracking] | Post-processing | 2015 | 85.0 |
| Samanta et al. | |||
| [samanta2016data] | Post-processing | 2016 | 89.9 |
| Zhao et al. | |||
| [zhao2015learning] | Integrated | 2015 | 80.0 |
| Ma et al. | |||
| [ma2016local] | Integrated | 2016 | 95.0 |
| Method | Category | Year |
|
|
|
|
||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Detect-and-Track | ||||||||||||||
| [girdhar2018detect] | Top-down | 2018 | 51.8 | 55.2 | - | - | ||||||||
| Pose Flow | ||||||||||||||
| [xiu2018pose] | Top-down | 2018 | 51.0 | 58.3 | - | - | ||||||||
| Flow Track | ||||||||||||||
| [69] | Top-down | 2018 | 57.8 | 65.4 | - | - | ||||||||
| Fastpose | ||||||||||||||
| [zhang2019fastpose] | Top-down | 2019 | 57.4 | 63.2 | - | - | ||||||||
| LightTrack | ||||||||||||||
| [ning2020lighttrack] | Top-down | 2020 | 58.0 | - | - | 64.6 | ||||||||
| Umer et al. | ||||||||||||||
| [umer2020self] | Top-down | 2020 | 60.0 | 68.3 | 60.7 | 69.1 | ||||||||
| Clip Tracking | ||||||||||||||
| [wang2020combining] | Top-down | 2020 | 64.1 | 71.6 | 64.3 | 68.7 | ||||||||
| Yang et al. | ||||||||||||||
| [yang2021learning] | Top-down | 2021 | - | 73.4 | - | 69.2 | ||||||||
| AlphaPose | ||||||||||||||
| [fang2022alphapose] | Top-down | 2022 | - | 65.7 | - | 64.7 | ||||||||
| GatedTrack | ||||||||||||||
| [doering2023gated] | Top-down | 2023 | - | - | - | 64.5 | ||||||||
| Posetrack | ||||||||||||||
| [iqbal2017posetrack] | Bottom-up | 2017 | 48.4 | - | - | - | ||||||||
| Raaj et al. | ||||||||||||||
| [raaj2019efficient] | Bottom-up | 2019 | 53.8 | 62.7 | - | 60.9 | ||||||||
| Jin et al. | ||||||||||||||
| [jin2019multi] | Bottom-up | 2019 | - | 71.8 | - | - |
| Method | Category | Year |
|
|
||||
|---|---|---|---|---|---|---|---|---|
| Bridgeman et al. | ||||||||
| [bridgeman2019multi] | Multi-stage | 2019 | - | 92.6 | ||||
| Tessetrack | ||||||||
| [reddy2021tessetrack] | One-stage | 2021 | 94.1 | 97.4 | ||||
| Voxeltrack | ||||||||
| [zhang2022voxeltrack] | One-stage | 2022 | 98.5 | 96.7 | ||||
| Snipper | ||||||||
| [zou2023snipper] | One-stage | 2023 | 93.4 | - | ||||
| TEMPO | ||||||||
| [29] | One-stage | 2023 | 98.4 | - |
5.2姿势跟踪
本节回顾了姿势跟踪的数据集,并比较了某些数据集上的不同方法。
5.2.1 数据集
表8总结了数据集,重点关注 Campus、CMP Panoptic 和 PoseTrack 数据集,这些数据集被广泛引用并经常用于评估多人姿势跟踪。 这些数据集是首选,因为多人姿势更能代表现实世界的场景。 早期,VideoPose2.0多应用于单人姿态跟踪。 PoseTrack 数据集已在 5.1.1 节中讨论。 下面我们只回顾其他三个数据集。
VideoPose2.0数据集 [sapp2011parsing]是用于跟踪上臂和下臂姿势的视频数据集。 这些视频是从电视节目《老友记》和《迷失》中收集的,通常由单一演员和多种动作组成。 该数据集包含 44 个视频,每个视频持续 2-3 秒,总共 1,286 帧。 每个框架都带有关节位置的手工注释。 该数据集是 VideoPose 数据集 [weiss2010sidestepping] 的扩展,但更具挑战性,因为大约 30% 的下臂被显着缩短。
CMU Panoptic 数据集 [joo2017panoptic] 是通过使用具有 480 个视图的摄像系统捕捉参与社交互动的对象而创建的。 受试者参与不同的游戏:最后通牒(有 3 个受试者)、囚徒困境(有 8 个受试者)、黑手党(有 8 个受试者)、讨价还价(有 3 个受试者)和 007 爆炸游戏(有 5 个受试者)。 每场比赛的科目数量从三到八不等。 该数据集总共包含 65 个视频和使用 Kinect 估计的 150 万个 3D 姿势。 它通常用于评估多人 3D 姿态估计和姿态跟踪方法。
校园数据集 [belagiannis20143d]是通过使用 3 个摄像头捕捉室外环境中三个人之间的交互来收集的。 它包含 6,000 个帧,其中包括 3 个视图,每个视图提供 2,000 个帧。 它广泛用于 3D 多人姿态估计和跟踪。 由于相机数量较少和基线视图较宽,姿势跟踪具有挑战性。
5.2.2性能比较
表9和表10分别显示了2D姿态跟踪方法的比较。 对于 2D 单人姿态跟踪,集成方法在统一框架内联合优化姿态估计和姿态跟踪,利用各自的优点来获得更好的结果。 从表9可以看出,其中一种集成方法[ma2016local]表现出了最先进的性能。 对于 2D 多人姿势跟踪,大多数方法都遵循自上而下的策略,通过单人估计技术来很好地估计姿势。 毫无疑问,这些方法在 Posetrack2017 和 2018 数据集上的 MOTA 分数上优于自下而上的方法约 2-15%。 关于3D多人姿态跟踪,目前现有的工作较少。 其中,单阶段方法的性能优于表11所示的多阶段方法,并且Voxeltrack [zhang2022voxeltrack]取得了最好的结果。 这是因为一阶段方法联合估计和链接 3D 姿态,这可以将多阶段方法中子任务的误差传播回视频的输入图像像素。
5.3 动作识别
本节回顾了更常用于基于姿势的动作识别的数据集,并比较了不同类别的方法。
| Dataset | Year | Citation | Modality | Sensors | #Actions | #Subjects | #Samples | Protocol | ||
|---|---|---|---|---|---|---|---|---|---|---|
|
2007 | 503 | C,D,S | RRM | 130 | 5 | 2317 | 10-fold CV | ||
|
2010 | 1736 | D,S | Kinect | 20 | 10 | 557 | CS(1/3 tr; 2/3 tr; half tr, half te) | ||
|
2012 | 494 | S | Kinect | 12 | 30 | 6244 | LOSubO | ||
|
2012 | 262 | C,D,S | Kinect | 20 | 10 | 659 | CS(4 tr, 1 va, 5 te) | ||
|
2012 | 575 | C,D,S | Kinect | 8 | 7 | 300 | 5-fold CV | ||
|
2012 | 1716 | C,D,S | Kinect | 10 | 10 | 200 | LOSubO | ||
|
2014 | 497 | C,D,S | Kinect | 10 | 10 | 1494 | LOSubO; cross view(2 tr, 1 te) | ||
|
2015 | 706 | C,D,S,I | Kinect | 27 | 8 | 861 | CS(odd tr, even te) | ||
|
2015 | 594 | C,D,S | Kinect | 12 | 40 | 480 | CS(half tr, half te) | ||
|
2016 | 2452 | C,D,S,I | Kinect | 60 | 40 | 56880 | CS(half tr, half te); cross view(half tr, half te) | ||
|
2017 | 195 | C,D,S,I | Kinect | 51 | 66 | 1076 | CS(57 tr, 9 te); cross view(2 tr, 1 te) | ||
|
2017 | 3402 | C,S | YouTube | 400 | - | 306245 | CV(250-1000 tr, 50 va, 100 te per action) | ||
|
2019 | 907 | C,D,S,I | Kinect | 120 | 106 | 114480 | CS(half tr, half te); cross view(half tr, half te) |
5.3.1 数据集
在第4节中,我们回顾了基于姿势的动作识别方法,可分为基于估计姿势的动作识别和基于骨架的动作识别。 前者应用RGB数据,后者直接使用骨架数据作为输入。 表12总结了基于深度学习的动作识别中普遍存在的大规模数据集。
NTU RGB+D 数据集 [shahroudy2016ntu] 由新加坡南洋理工大学构建。 使用 Mincrosoft Kinect v2 传感器收集四种模式,包括 RGB、深度图、骨骼和红外帧。 该数据集由 40 名受试者执行的 60 个动作组成。 这些动作可分为三组,包括:40个日常动作、9个与健康相关的动作和11个人与人互动的动作。 受试者的年龄范围为10至35岁,每个受试者执行一个动作多次。 总共有 56880 个样本,是在 80 个不同的摄像机视图中捕获的。 主体和观点的大量变化使得动作识别方法有可能进行更多的跨主体和跨观点评估。
NTU RGB+D 120 数据集 [liu2019ntu] 是 NTU RGB+D 数据集[shahroudy2016ntu]的扩展。 另外 66 名受试者执行的另外 60 个动作类别(包括 57,600 个样本)已添加到 NTU RGB+D 数据集中。 该数据集还提供四种模式,包括 RGB、深度图、骨架和红外帧。 更多的动作、主题和样本使其在动作识别方面比 NTU RGB+D 数据集更具挑战性。
| Dataset | Method | Highlights | Accuracy |
|---|---|---|---|
| JHMDB | PoTion | estimated poses | 58.51.5 |
| GT poses | 62.11.1 | ||
| [choutas2018potion] | GT poses + crop | 67.92.4 | |
| AVA | LART | -poses-tracking | 40.2 |
| -poses | 41.4 | ||
| [28] | full model | 42.3 | |
| NTU60 | UPS | separate training | 89.6 |
| [foo2023unified] | joint training | 92.6 |
PKU-MMD数据集 [liu2017pku]是一个用于动作检测和识别任务的大规模多模态数据集。 Mincrosoft Kinect v2 传感器捕获四种模式,包括 RGB、深度图、骨骼和红外帧。 该数据集由 1,076 个视频组成,由 66 名受试者在 3 个视图中执行 51 个动作。 动作类涵盖41个日常动作和10个人际互动动作。 每个视频包含二十多个动作样本。 该数据集总共包含 3,000 分钟和 5,400,000 帧。 一段未经修剪的视频中存在大量动作,这使得动作检测方法具有鲁棒性。
Kinetics-Skeleton 数据集 [kay2017kinetics] 是通过从 YouTube 搜索 RGB 视频并通过 OpenPose 生成骨骼捕获的超大规模动作数据集。 它有 400 个动作,每个动作有 400-1150 个剪辑,每个剪辑都来自一个独特的 YouTube 视频。 每个剪辑持续约 10 秒。 视频样本总数为306,245。 动作类包括:人动作、人-人动作和人-物体动作。 由于YouTube来源的原因,视频不如实验背景录制的那么专业。 因此,该数据集具有相当大的相机运动、照明变化、阴影、背景杂乱和各种各样的主题。
| Method | Category | Sub-category | Year |
|
|
||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Zolfaghari et al. [zolfaghari2017chained] | Estimated Pose-based | two-stage strategy | 2017 | 80.8 | - | - | - | ||||
| Liu et al. [liu2018recognizing] | Estimated Pose-based | two-stage strategy | 2018 | 91.7 | 95.3 | - | - | ||||
| IntegralAction [moon2021integralaction] | Estimated Pose-based | two-stage strategy | 2021 | 91.7 | - | - | - | ||||
| PoseConv3D [duan2022revisiting] | Estimated Pose-based | two-stage strategy | 2021 | 94.1 | 97.1 | 86.9 | 90.3 | ||||
| Luvizonet al. [luvizon20182d] | Estimated Pose-based | one-stage strategy | 2018 | 85.5 | - | - | - | ||||
| UPS [foo2023unified] | Estimated Pose-based | one-stage strategy | 2023 | 92.6 | 97.0 | 89.3 | 91.1 | ||||
| 2 Layere P-LSTM [shahroudy2016ntu] | RNN-based | spatial division of human body | 2016 | 62.9 | 70.3 | - | - | ||||
| Trust Gate ST-LSTM [liu2016spatio] | RNN-based | spatial and/or temporal networks | 2016 | 69.2 | 77.7 | - | - | ||||
| Two-stream RNN [wang2017modeling] | RNN-based | spatial and/or temporal networks | 2017 | 71.3 | 79.5 | - | - | ||||
| Zhang et al. [zhang2017geometric] | RNN-based | spatial and/or temporal networks | 2017 | 70.3 | 82.4 | - | - | ||||
| SR-TSL [si2018skeleton] | RNN-based | spatial and/or temporal networks | 2018 | 84.8 | 92.4 | - | - | ||||
| GCA-LSTM [liu2017global] | RNN-based | attention mechanism | 2017 | 74.4 | 82.8 | 58.3 | 59.2 | ||||
| STA-LSTM [song2018spatio] | RNN-based | attention mechanism | 2018 | 73.4 | 81.2 | - | - | ||||
| EleAtt-GRU [zhang2019eleatt] | RNN-based | attention mechanism | 2019 | 80.7 | 88.4 | - | - | ||||
| 2s AGC-LSTM [si2019attention] | RNN-based | attention mechanism | 2019 | 89.2 | 95.0 | - | - | ||||
| JTM [wang2016action] | CNN-based | 2D CNN | 2017 | 73.4 | 75.2 | - | - | ||||
| JDM [li2017joint] | CNN-based | 2D CNN | 2017 | 76.2 | 82.3 | - | - | ||||
| Liu et al. [liu2017enhanced] | CNN-based | 2D CNN | 2017 | 80.0 | 87.2 | 60.3 | 63.2 | ||||
| SkeletonNet [ke2017skeletonnet] | CNN-based | 2D CNN | 2017 | 75.9 | 81.2 | - | - | ||||
| Ke et al. [ke2017new] | CNN-based | 2D CNN | 2017 | 79.6 | 86.8 | - | - | ||||
| Li et al. [li2017skeleton] | CNN-based | 2D CNN | 2017 | 85.0 | 92.3 | - | - | ||||
| Ding et al. [ding2017investigation] | CNN-based | 2D CNN | 2017 | - | 82.3 | - | - | ||||
| Li et al. [li2019learning] | CNN-based | 2D CNN | 2017 | 82.8 | 90.1 | - | - | ||||
| TSRJI [caetano2019skeleton] | CNN-based | 2D CNN | 2019 | 73.3 | 80.3 | 65.5 | 59.7 | ||||
| SkeletonMotion [caetano2019skeleton] | CNN-based | 2D CNN | 2019 | 76.5 | 84.7 | 67.7 | 66.9 | ||||
| 3SCNN [liang2019three] | CNN-based | 2D CNN | 2019 | 88.6 | 93.7 | - | - | ||||
| DM-3DCNN [hernandez20173d] | CNN-based | 3D CNN | 2017 | 82.0 | 89.5 | - | - | ||||
| ST-GCN [yan2018spatial] | GCN-based | static method | 2018 | 81.5 | 88.3 | - | - | ||||
| STIGCN [huang2020spatio] | GCN-based | static method | 2020 | 90.1 | 96.1 | - | - | ||||
| MS-G3D [liu2020disentangling] | GCN-based | static method | 2020 | 91.5 | 96.2 | 86.9 | 88.4 | ||||
| CA-GCN [zhang2020context] | GCN-based | static method | 2020 | 83.5 | 91.4 | - | - | ||||
| AS-GCN [li2019actional] | GCN-based | dynamic method | 2018 | 86.8 | 94.2 | - | - | ||||
| 2s-AGCN [shi2019two] | GCN-based | dynamic method | 2020 | 88.5 | 95.1 | - | - | ||||
| SGN [zhang2020semantics] | GCN-based | dynamic method | 2020 | 89.0 | 94.5 | 79.2 | 81.5 | ||||
| 4s Shift-GCN [cheng2020skeleton] | GCN-based | dynamic method | 2020 | 90.7 | 96.5 | 85.9 | 87.6 | ||||
| DC-GCN+ADC [cheng2020decoupling] | GCN-based | dynamic method | 2020 | 90.8 | 96.6 | 86.5 | 88.1 | ||||
| DDGCN [korban2020ddgcn] | GCN-based | dynamic method | 2020 | 91.1 | 97.1 | - | - | ||||
| Dynamic GCN [ye2020dynamic] | GCN-based | dynamic method | 2020 | 91.5 | 96.0 | 87.3 | 88.6 | ||||
| CTR-GCN [chen2021channel] | GCN-based | dynamic method | 2021 | 92.4 | 96.8 | 88.9 | 90.6 | ||||
| InfoGCN [chi2022infogcn] | GCN-based | dynamic method | 2021 | 93.0 | 97.1 | 89.8 | 91.2 | ||||
| DG-STGCN [duan2022dg] | GCN-based | dynamic method | 2022 | 93.2 | 97.5 | 89.6 | 91.3 | ||||
| TCA-GCN [wang2022skeleton] | GCN-based | dynamic method | 2022 | 92.8 | 97.0 | 89.4 | 90.8 | ||||
| ML-STGNet [9997556] | GCN-based | dynamic method | 2023 | 91.9 | 96.2 | 88.6 | 90.0 | ||||
| MV-IGNet [9234715] | GCN-based | dynamic method | 2023 | 89.2 | 96.3 | 83.9 | 85.6 | ||||
| S-GDC [10023982] | GCN-based | dynamic method | 2023 | 88.6 | 94.9 | 85.2 | 86.1 | ||||
| Motif-GCN+TBs [9763364] | GCN-based | dynamic method | 2023 | 90.5 | 96.1 | 87.1 | 87.7 | ||||
| 3s-ActCLR [lin2023actionlet] | GCN-based | dynamic method | 2023 | 84.3 | 88.8 | 74.3 | 75.7 | ||||
| GSTLN [DAI2023109540] | GCN-based | dynamic method | 2023 | 91.9 | 96.6 | 88.1 | 89.3 | ||||
| 4s STF-Net [WU2023109231] | GCN-based | dynamic method | 2023 | 91.1 | 96.5 | 86.5 | 88.2 | ||||
| LA-GCN [xu2023language] | GCN-based | dynamic method | 2023 | 93.5 | 97.2 | 90.7 | 91.8 | ||||
| DSTA-Net [shi2020decoupled] | Transformer-based | pure Transformer | 2020 | 91.5 | 96.4 | 86.6 | 89.0 | ||||
| STAR [shi2021star] | Transformer-based | pure Transformer | 2021 | 83.4 | 89.0 | 78.3 | 80.2 | ||||
| STST [zhang2021stst] | Transformer-based | pure Transformer | 2021 | 91.9 | 96.8 | - | - | ||||
| IIP-Former [wang2021iip] | Transformer-based | pure Transformer | 2022 | 92.3 | 96.4 | 88.4 | 89.7 | ||||
| RSA-Net [gedamu2023relation] | Transformer-based | pure Transformer | 2023 | 91.8 | 96.8 | 88.4 | 89.7 | ||||
| ST-TR [plizzari2021spatial] | Transformer-based | hybrid Transformer | 2021 | 89.9 | 96.1 | 81.9 | 84.1 | ||||
| Zoom Transformer [zhang2022zoom] | Transformer-based | hybrid Transformer | 2022 | 90.1 | 95.3 | 84.8 | 86.5 | ||||
| KA-AGTN [liu2022graph] | Transformer-based | hybrid Transformer | 2022 | 90.4 | 96.1 | 86.1 | 88.0 | ||||
| STTFormer [qiu2022spatio] | Transformer-based | hybrid Transformer | 2022 | 92.3 | 96.5 | 88.3 | 89.2 | ||||
| FG-STFormer [gao2022focal] | Transformer-based | hybrid Transformer | 2022 | 92.6 | 96.7 | 89.0 | 90.6 | ||||
| GSTN [jiang2022graph] | Transformer-based | hybrid Transformer | 2022 | 91.3 | 96.6 | 86.4 | 88.7 | ||||
| IGFormer [pang2022igformer] | Transformer-based | hybrid Transformer | 2022 | 93.6 | 96.5 | 85.4 | 86.5 | ||||
| 3Mformer [Wang_2023_CVPR] | Transformer-based | hybrid Transformer | 2023 | 94.8 | 98.7 | 92.0 | 93.8 | ||||
| SkeleTR [duan2023skeletr] | Transformer-based | hybrid Transformer | 2023 | 94.8 | 97.7 | 87.8 | 88.3 | ||||
| GL-Transformer [kim2022global] | Transformer-based | unsupervised Transformer | 2022 | 76.3 | 83.8 | 66.0 | 68.7 | ||||
| HiCo-LSTM [dong2023hierarchical] | Transformer-based | unsupervised Transformer | 2023 | 81.4 | 88.8 | 73.7 | 74.5 | ||||
| HaLP+CMD [shah2023halp] | Transformer-based | self-supervised Transformer | 2023 | 82.1 | 88.6 | 72.6 | 73.1 | ||||
| SkeAttnCLR [ijcai2023p95] | Transformer-based | self-supervised Transformer | 2023 | 82.0 | 86.5 | 77.1 | 80.0 | ||||
| SkeletonMAE [10222534] | Transformer-based | self-supervised Transformer | 2023 | 86.6 | 92.9 | 76.8 | 79.1 | ||||
5.3.2性能比较
在表14中,我们比较了不同动作识别方法在两个重要数据集上的结果。 基于姿势估计的方法应用 RGB 数据作为输入,并且最佳性能 [duan2022revisiting, foo2023unified] 低于使用骨骼作为两个数据集的输入的 [Wang_2023_CVPR]数据集(尤其是较大的数据集)。 这是合理的,因为有些事实(例如。 使用 RGB 时,照明、背景)可能会影响性能。 特别是,基于一阶段策略的方法联合解决了姿态估计和动作识别,从而减少了中间步骤的错误,并且通常比基于两阶段策略的方法获得更好的结果。 此外,表13说明了姿势估计(PE)和跟踪对动作识别(AR)的影响。 不难看出,姿态估计和跟踪结果可以提高动作识别的性能,这进一步强调了这三个任务的关系。
对于基于骨架的方法,最近的方法主要应用 GCN 和 Transformer,始终优于基于 CNN 和 RNN 的方法。 这一改进证明了基于 GCN 和 Transformer 的局部和全局特征学习对于动作识别的好处。 具体来说,由于泛化能力更强,基于动态 GCN 的方法通常比基于静态 GCN 的方法表现更好。 基于混合 Transformer 的方法在大型数据集上优于纯基于 Transformer 的方法,因为将 Transformer 与 GCN 或 CNN 集成可以更好地学习局部和全局特征。 具体来说,在超图上应用 Transformer 编码器的方法[Wang_2023_CVPR]在两个数据集上取得了最佳性能,这为使用超图表示动作进行分类提供了提示。 还值得注意的是,基于自然语言指导的方法[xu2023language]分别在两个数据集上取得了相当好的性能,这意味着结合语言上下文进行动作识别的优势。
6 挑战和未来方向
本文回顾了最近基于深度学习的姿态估计、跟踪和动作识别方法。 它还包括对常用数据集的讨论和各种方法的比较分析。 尽管在这些领域取得了显着的成功,但仍然存在一些挑战和相应的研究方向来推动这三个任务的进展。
6.1 姿态估计
位姿估计任务面临以下五个主要挑战。
(1) 遮挡
尽管当前的方法在公共数据集上取得了出色的性能,但仍然存在遮挡问题。 遮挡会导致人体检测不可靠并导致姿势估计性能下降。 自上而下方法中的人体检测器可能无法识别重叠人体的边界,而自下而上方法中遮挡场景的身体部位关联可能会失败。 人群场景中的相互遮挡导致当前 3D HPE 方法的性能大幅下降。
为了克服这个问题,人们提出了一些基于多视图学习的方法[dong2019fast,tu2020voxelpose,zhang2021direct]。 这是因为一个视图中被遮挡的部分可能在其他视图中变得可见。 然而,这些方法通常需要大量的内存和昂贵的计算成本,特别是对于多视图下的3D MPPE。 此外,一些基于多模态学习的方法也被证明具有对遮挡的鲁棒性,可以从不同的传感模式中提取丰富的特征,例如深度[shah2019robustness]和可穿戴惯性测量单元[ zhang2020fusing]。 当应用不同模态的姿态估计时,可能会面临另一个问题,即不同模态的可用数据集很少。 随着视觉语言模型的发展,文本可以为姿态估计提供语义,并且可以很容易地由 GPT 生成,从而为另一种模态提供了更好的方向。 基于姿势语义,可以推断被遮挡的部分。 在语义方面,人景关系还可以提供一些语义线索,例如一个人不能同时出现在场景中其他物体的位置上。
(2) 分辨率低
在实际应用中,由于广角摄像头、远距离拍摄采集设备等原因,常常会采集到低分辨率的图像或视频。 由于环境阴影,也存在被遮挡的人。 当前的方法通常是在高分辨率输入上进行训练的,当将它们应用于低分辨率输入时可能会导致精度较低。 从低分辨率输入估计姿势的一种解决方案是通过应用超分辨率方法作为图像预处理来恢复图像分辨率。 然而,超分辨率的优化对高水平的人体姿态分析没有贡献。 Wang等人[wang2022low]观察到低分辨率会夸大量化误差的程度,因此偏移建模可能有助于低分辨率输入的姿态估计。
(3)计算复杂度
正如2节中所回顾的,已经提出了许多方法来解决计算复杂性。 例如,提出了基于图像的 MPPE 的一阶段方法,以节省中间步骤造成的时间消耗增加。 提出了用于基于视频的姿态估计的基于样本帧的方法,以降低处理每帧的复杂性。 然而,这种单阶段方法在提高效率时可能会牺牲准确性(例如 最近的 ED-pose 网络 [65] 花费的时间最短,并且在 CoCO val2017 数据集上会牺牲大约 %4 AP)。 因此,需要在 MPPE 的一阶段方法上付出更多努力,以实现计算高效的姿态估计,同时保持高精度。 基于帧的示例方法[zeng2022deciwatch]基于三个步骤估计姿势,这仍然会导致更多的时间消耗。 因此,端到端网络优选与基于样本帧的方法结合以进行基于视频的姿态估计。
用于基于视频的 3D 姿态估计的基于 Transformer 的架构不可避免地会产生高昂的计算成本。 这是因为他们通常将每个视频帧视为一个姿势词符,并应用极长的视频帧来实现高级性能。 例如,Strided [li2022exploiting] 和 Mhformer [li2022mhformer] 需要 351 帧,MixSTE [li2022mhformer] 和 DSTformer [zhu2022motionbert] 需要243帧。 自注意力复杂度随着 token 数量的增加呈二次方增加。 虽然直接减少帧数可以降低成本,但由于时间感受野较小,可能会导致性能较低。 因此,最好设计一个有效的架构,同时保持大的时间感受野以进行准确的估计。 考虑到深度 Transformer 块[wang2022vtc]中可能存在类似的标记,一种潜在的解决方案是修剪姿势标记以提高效率。
(4) 不常见姿势的数据有限
当前的公共数据集对于不常见姿势(例如, 下降),这会导致模型偏差和此类姿势的精度进一步降低。 针对不常见姿势的数据增强[jian2022posetrans, 10050391]是生成更具多样性的新样本的常用方法。 基于优化的方法[jian2023back]可以通过逐案估计姿势而不是学习来减轻领域差距的影响。 因此,基于深度学习的方法结合优化技术可能有助于罕见的姿态估计。 此外,开放词汇学习还可以应用于通过这些姿势与其他常见姿势之间的语义关系来估计不常见姿势。
(5) 3D位姿不确定性高
需要根据 2D 姿势预测 3D 姿势,以处理由于深度模糊和潜在遮挡而导致的不确定性和不确定性。 然而,大多数现有方法[shan2023diffusionbased]属于确定性方法,旨在从图像构建单一且确定的3D姿势。 因此,如何处理姿势的不确定性和不确定性仍然是一个悬而未决的问题。 受扩散模型生成具有高不确定性的样本的强大能力的启发,应用扩散模型是姿态估计的一个有前途的方向。 最近提出了一些方法[gong2022diffpose、holmquist2022diffpose、feng2023diffpose],将 3D 位姿估计公式化为反向扩散过程。
6.2姿势跟踪
大多数姿态跟踪方法遵循姿态估计和链接策略,姿态跟踪性能高度依赖于姿态估计的结果。 因此,姿态跟踪中也存在姿态估计的一些挑战,例如遮挡。 多视图特征融合[zhang2022voxeltrack]是一种通过遮挡消除不可靠外观以改善姿势链接结果的方法。 链接每个检测框而不仅仅是高分检测框[zhang2022bytetrack]是通过遮挡构成不可忽略的真实姿势的另一种方法。 接下来,我们将提出姿势跟踪的更多挑战。
(1) 多摄像机下多人姿态跟踪
主要的挑战是如何融合不同视图的场景。 虽然Voxteltrack [zhang2022voxeltrack]倾向于融合多视图特征融合,但仍需要更多研究。 如果来自非重叠摄像机的场景被融合并投影在虚拟世界中,则可以在长区域中连续跟踪姿势。
(2) 外观相似,运动多样
为了跨帧链接姿势,一般的解决方案是根据外观和运动来测量相邻帧中每对姿势之间的相似性。 人们有时会同时具有统一的外观和多样化的动作,例如团体舞者和体育运动员。 他们的外表非常相似,穿着统一的衣服,动作和互动模式也很复杂,几乎没有区别。 在这种情况下,测量相似度具有挑战性。 然而,这些具有相似外观的姿势可以通过文本语义轻松区分。 一种可能的解决方案是结合一些多模态预训练模型,例如对比语言图像预训练 (CLIP)[radford2021learning],用于根据语义表示来测量相似性。
(3) 相机快速移动
现有方法主要通过假设相机缓慢运动来解决姿态跟踪问题。 然而,在实际应用中,使用自我相机捕捉进行快速相机运动是很常见的。 如何通过快速相机运动来解决以自我为中心的姿势跟踪是一个具有挑战性的问题。 Khirodkar 等人[khirodkar2023ego humans]提出了一种新的以自我为中心的姿态估计和跟踪基准(EgoHumans),并设计了一个多流Transformer来跟踪多人。 实验表明,由于相机同步和校准的原因,静态和动态捕捉系统的性能之间仍然存在差距。 可以做出更多努力来弥合差距。
6.3 动作识别
随着深度学习技术的快速进步,在大规模动作数据集上已经取得了可喜的结果。 仍有一些悬而未决的问题如下。
(1)计算复杂度
根据不同方法的性能比较(表14),Transformer与GCNs集成的方法达到了最好的精度。 然而,正如之前提到的,Transformer 所需的计算和所需的内存量随着标记 [ulhaq2022vision] 数量的二次方增加。 因此,如何从视频帧或骨架中选择重要的标记是基于变压器的高效动作识别的一个悬而未决的问题。 与基于 Transformer 的姿态估计类似,修剪标记或丢弃输入匹配 [qing2023mar] 往往会降低成本。 此外,集成轻量级 GCN [kang2023efficient] 可以进一步提高效率。
(2)零样本骨骼学习
注释和标记大量数据的成本很高,而零样本学习在实际应用中是可取的。 现有的零样本动作识别方法主要采用RGB数据作为输入。 然而,由于骨架数据对外观和背景变化的鲁棒性,它已成为 RGB 数据的有前途的替代品。 因此,基于零样本骨架的动作识别更为理想。 很少有方法[gupta2021syntically, zhou2023zero]被提出来学习类标签的骨架和词嵌入之间的映射。 类标签可能比文本描述具有更少的语义,文本描述是用于描述如何执行动作的自然语言。 未来,可以寻求基于文本描述的新方法,以进行基于零样本骨架的动作识别。
(3)多模态融合
基于估计姿势的方法以 RGB 数据作为输入,并根据 RGB 和估计的骨架识别动作。 此外,文本数据可以指导提高视觉相似动作和零样本学习的性能,这是动作识别的另一种模式。 由于不同模式的异质性,如何充分利用它们值得研究者进一步探索。 尽管一些方法[duan2022revisiting]倾向于提出融合不同模态的特定模型,但这种模型缺乏泛化性。 未来,无论型号如何通用的熔断方式是更好的选择。
6.4统一模型
7结论
这项调查系统地概述了有关基于人体姿势的深度学习估计、跟踪和动作识别的最新研究成果。 我们回顾了从 2D 到 3D、从单人到多人、从图像到视频的姿势估计方法。 在估计姿势之后,我们总结了跨帧链接姿势以跟踪姿势的方法。 还回顾了基于姿势的动作识别方法,将其视为姿势估计和跟踪的应用。 对于每项任务,我们回顾了不同类别的方法并讨论了它们的优点和缺点。 同时,在基于估计姿势的动作识别类别中,强调了联合进行姿势估计、跟踪和动作识别的端到端方法。 我们回顾了常用的数据集,并对不同方法的性能进行了比较,以进一步证明某些方法的优点。
根据现有工作的优点和缺点,我们指出了一些有前途的未来方向。 对于姿势估计,可以在遮挡、低分辨率、不常见姿势的有限数据以及平衡性能与计算复杂度的姿势估计上做出更多努力。 多人姿态跟踪可以在多个摄像机、相似的外观、不同的运动和快速摄像机运动的情况下得到进一步解决。 骨骼零样本学习和多模态融合也可以进一步探索用于动作识别。
致谢本工作得到国家自然科学基金项目(批准号:2017)的资助。 62006211、61502491)和中国博士后科学基金(批准号: 2019TQ0286、2020M682349)。