OpenAnnotate3D: 用于多模态 3D 数据的开放词汇自动标注系统
摘要
在大数据和大型模型时代,多模态数据的自动标注功能对于自动驾驶和具身人工智能等现实世界人工智能驱动的应用具有重要意义。 与传统的封闭集标注不同,开放词汇标注对于实现人类水平的认知能力至关重要。 然而,针对多模态 3D 数据的开放词汇自动标注系统很少。 在本文中,我们介绍了 OpenAnnotate3D,这是一个开源的开放词汇自动标注系统,可以自动为视觉和点云数据生成 2D 掩码、3D 掩码和 3D 边界框标注。 我们的系统集成了大型语言模型 (LLM) 的思维链能力和视觉语言模型 (VLM) 的跨模态能力。 据我们所知,OpenAnnotate3D 是开放词汇多模态 3D 自动标注的先驱作品之一。 我们对公共数据集和内部真实世界数据集进行了全面评估,结果表明,与手动标注相比,该系统显著提高了标注效率,同时提供了准确的开放词汇自动标注结果。
I 介绍
机器学习领域一直以一种范式为主导,即对封闭集数据集进行手动标注,以便随后对学习模型进行训练和评估。 良好标注的基准可以显著提高相应任务的性能,无论是在研究中还是在实际应用中,例如 ImageNet [1]、COCO [2]、KITTI [3] 和 SemanticKITTI [4] 等知名数据集。
数据和标注无疑是机器学习和深度学习任务的基石。 特别是,随着大型语言模型 (LLM) [5, 6, 7] 的出现,大量数据已被证明可以显著提高模型能力,如 LLM [8] 的出现所证明。 与用于训练 LLM 的互联网上容易获得的文本语料库相比,获取良好标注的多模态 (2D & 3D) 数据仍然是一个待解决的挑战。
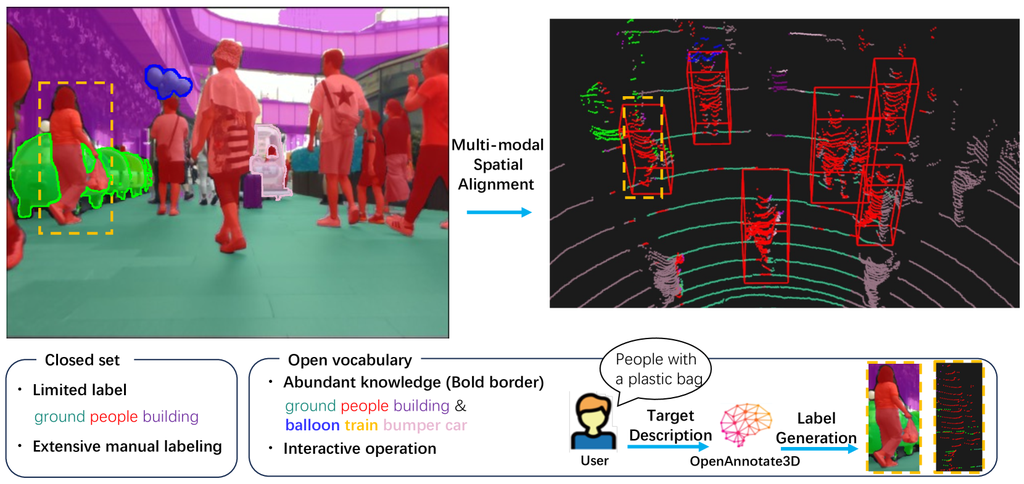
近年来,视觉和语言基础模型的出现突显了开发高效标注流程以生成多样化且庞大的多模态 3D 数据集的紧迫性。 尤其是对于像具身人工智能和自动驾驶这样的应用,需要大量的标注(2D 和 3D 分割、3D 边界框)。 此外,与传统的封闭集数据标注不同,开放词汇场景理解[9] 是实现人类水平推理能力的普遍趋势。 手动生成标注非常耗时,无法满足标注开放词汇多模态 3D 数据的需求。 因此,迫切需要一种开放词汇的自动标注工具,可以根据各种用户提示自动为多模态数据生成准确的 3D 标注。
关于多模态 3D 数据的自动标注方法,学术界和工业界都没有进行广泛的研究。 目前,最先进且最有效的方法之一是特斯拉 AI 日 2022 年展示的自动标注机[10],它基于具有封闭集分类法(预定义类别,如车辆、行人、车道拓扑结构等)的预训练模型。 但是,这些预训练模型难以在开放词汇环境中有效地执行自动标注,并且无法适应灵活的标注需求。
近年来,LLM 在一系列自然语言任务中展现出非凡的少样本、零样本和文本推理能力,其中最显著的应用是 ChatGPT[11]。 受此启发,我们提出了一种名为 OpenAnnotate3D 的新型数据标注系统,它包含一个基于 LLM 的解释器模块、一个可提示的视觉模块和一个时空 3D 自动标注过程。 我们的标注系统在接收到多模态 3D 数据(视觉和点云)和高级标注请求后,例如“标注路边的气球”和“标注最右侧带有奇怪负载的骑车人”。 该系统使用 LLM 解释器明确地推理请求,自动将文本信息与语义 3D 世界中的特定对象匹配,并生成 2D 掩码、3D 掩码和 3D 边界框标注,如图1 所示。 该系统有两个亮点。 首先,基于LLM的解释器模块以闭环迭代的方式结合了LLM和可提示视觉模型(VLM),以更精确地解释高级用户命令。 其次,加入了时空融合和校正模块,以克服VLM单帧结果的不完美性。
我们的贡献可以概括如下:
-
•
一个开创性的开源开放词汇自动标注系统,用于多模态3D数据。
-
•
一个基于LLM的解释器,它以闭环迭代的方式与可提示的视觉模块交互,从而能够有效地推理高级命令。
-
•
一种时空融合和校正方法,克服了单帧自动标注的不完美性。
-
•
广泛的实验验证了所提议系统的优越效率和开放词汇场景理解能力。
II 相关工作
II-A 2D标注
为了标注2D RGB数据,人们开发了许多工具,如LabelMe [12],Vatic [13],Label Studio [14],VIA [15],DEXTR [16],PolygonRNN++ [17],和CVAT [18]。 这些标注工具涵盖了从基本的图像分类到视频标注的大多数基于RGB的视觉任务。 由于手动标注非常耗时,大多数工具都支持模型辅助的自动标注功能。 例如,DEXTR [16]和PolygonRNN++ [17]可用于通过手动提供的粗略信息(如边界框和极值点)获得精确的密集标注。 一些开源标注工具,如CVAT,以及商业工具(Roboflow [19],Labelbox [20])都支持SAM [21],以提高标注效率。 但是,大多数这些标注工具仍然停留在 2D 领域,无法处理多模态 3D 数据。
II-B 3D 标注
与标注直观的 2D RGB 数据相比,标注 3D 点云由于 3D 数据的稀疏性和不规则性而固有地更加复杂。 在上述开源标注工具中,只有 CVAT 支持对点云上的 3D 边界框进行手动标注。 在 [22] 中,提出了一种基于最小割的方法来从 3D 点云中的背景中分割单个物体。 为了扩展到多物体分割,[23] 开发了一种基于最短路径树的交互式方法,要求用户在 3D 场景中选择稀疏的控制点。 在 [24] 中,引入了深度网络用于 3D 实例分割,该网络可以很好地推广到以前未知的物体,只需很少的人工标注工作。 如果输入数据包含 2D RGB 和 3D 点云,LATTE [25] 和 LiLaNet [26] 支持由 2D 掩码引导的 3D 点云分割。 PALF [27] 使用预先训练的 3D 物体检测模型生成 3D 边界框,并使用 2D 边界框对其进行校准。
以上提到的 3D 点云标注工具通常要求用户直接在点云数据空间内进行标注,或者具有复杂且错综复杂的运行逻辑。 所有这些条件都显著提高了 3D 点云标注的门槛和工作量。 此外,这些标注工具中很少有支持开放词汇标注。 相比之下,OpenAnnotate3D 为多模态 3D 数据提供了开放词汇自动标注的系统解决方案。
III 系统架构
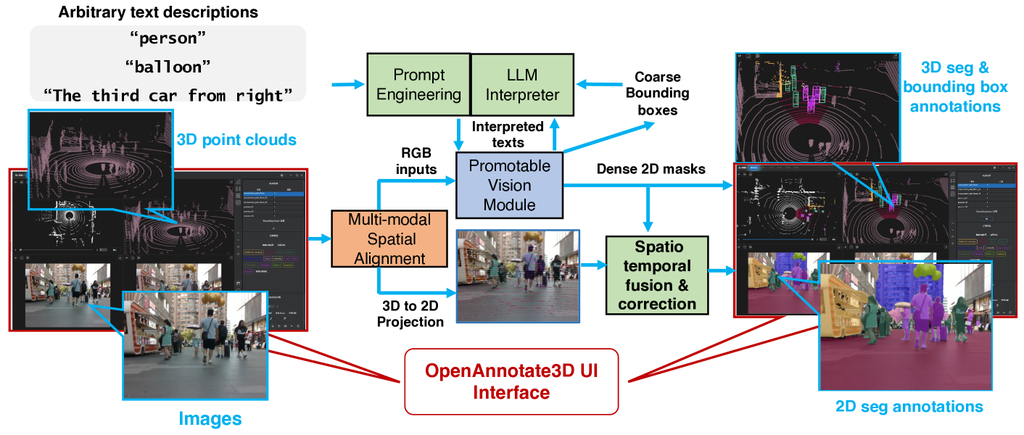
本节将详细介绍 OpenAnnotate3D 的工作流程及其实现的组件。 图 2 说明了我们系统的整个自动标注过程,该过程以文本描述 、RGB 图像 和 3D 点云 作为输入。 为了进一步减少用户物理交互的频率,我们的系统还支持语音输入。 这些语音信号使用语音识别模型 Whisper [28] 自动转录为文本。 我们的系统基于用户提供的任何描述性文本,实现了精确的 2D 掩码、3D 掩码和 3D 边界框标注的生成。
III-A 基于 LLM 的解释器模块
我们的系统旨在根据灵活的用户提供的文本描述来标注一个或多个开放词汇实例。 标注请求可以是高级的和抽象的,例如“标注路上的气球”。 为此,采用一个 LLM 作为语义解释器,将用户提供的提示转换为可被 VLM 理解的纯文本输出。 原因是,即使是最近最先进的可提示视觉模块 (VLM) 也比 LLM 具有有限的文本推理能力,如果我们将原始用户文本命令直接馈送到可提示视觉模块,则可能会导致视觉识别结果很差。 鉴于基于 LLM 的解释器,用户只需要提供一个用于标注命令的高级文本短语,而无需在标注过程之前精心设计分割算法。
III-A1 提示工程
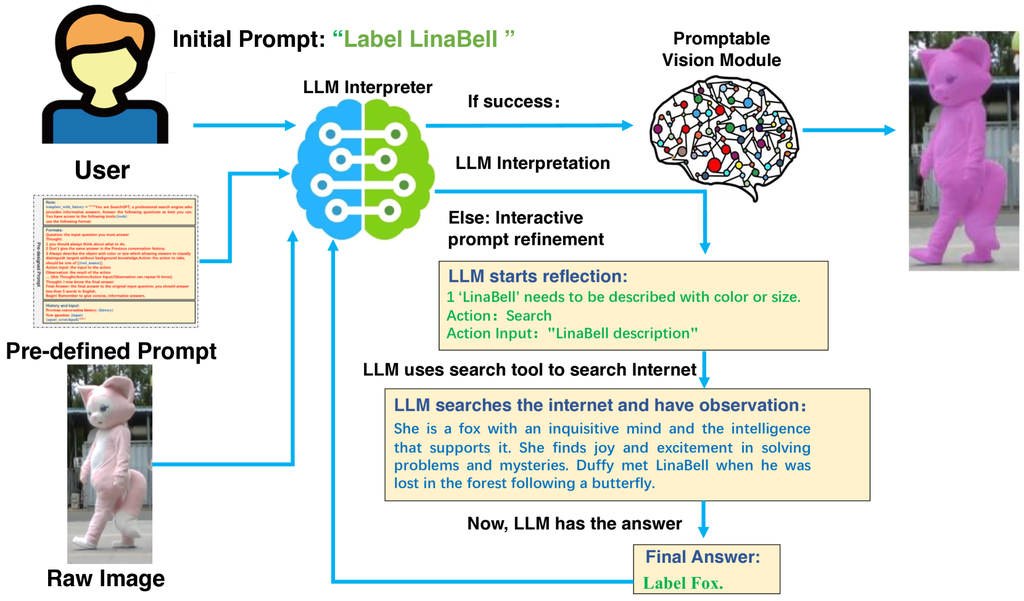
对于诸如“带有垃圾的垃圾桶”之类的直接提示,我们使用预定义的提示来增强文本,如 图 3 所示。 提示模板主要包括三个组成部分:1)LLM 解释器的基本作用及其基本任务描述;2)关于解释器输出格式的几个重要规则;3)用户最近 5 个文本输入的对话历史。 这种提示工程使 LLM 能够更好地解释用户提供的文本,最大限度地减少任何先验知识,从而使后续的视觉模块能够实现更高的命中率。
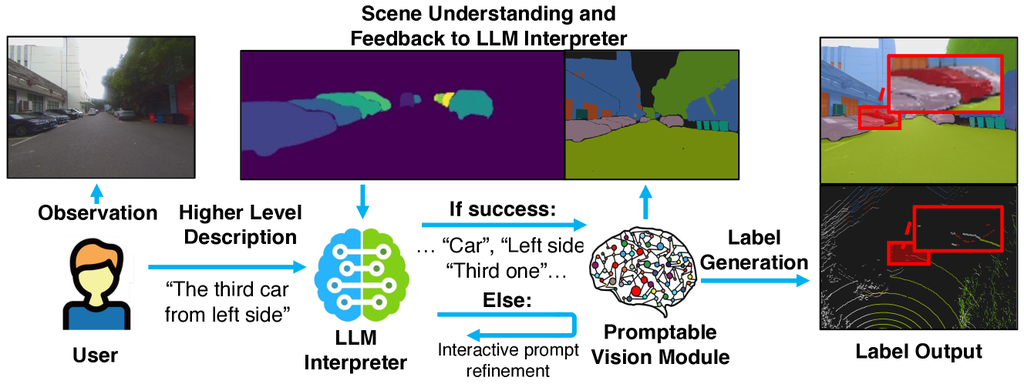
对于诸如“为从左侧数的第三辆车生成 3D 边界框”之类的 高级提示,我们首先使用 LLM 解析用户输入,提取所有相关信息(即使来自互联网)。 随后,我们使用可提示视觉模块进行粗略查询,获取二维分割数据并将分割质量反馈给 LLM。 基于对场景的理解,LLM 能够准确地识别用户的意图和目标,稍微调整输出的解释文本,并再次提示视觉模块。 图 4 展示了一个玩具示例。 这一过程可以迭代进行,具体说明如下。
III-A2 迭代文本解释
我们设计了一种迭代文本解释策略,如 Algo 中所述。 1,旨在更好地将开放词汇用户提示连接到下游可提示视觉模块。 如果视觉模块无法在文本描述和图像之间建立匹配,它会向 LLM 解释器提供反馈。 提示历史会被记忆并进一步整合到下一个提示中。 然后,LLM 解释器利用嵌入在 LLM 中的语言理解和推理能力调整其输出,直到可提示视觉模块能够很好地理解其指令。 然后,LLM 解释器利用 LLM 中嵌入的语言理解和推理能力来调整其输出,直到可提示的视觉模块能够很好地理解其指令。
假设视觉模块在 次迭代后仍然无法生成有效的输出,我们的注释系统会中断并向用户提供反馈,要求他们改进文本输入以描述所需的对象。 如果他们对结果不满意,此反馈也会传递给解释器,使系统能够继续迭代以获得更好的标注。 如果他们对结果不满意,该反馈也会传达给解释器,使系统能够继续迭代以获得更好的注释。
III-B 可提示的视觉模块和 3D 自动标注
遵循基于 LLM 的解释器,我们构建了一个自动标注 3D 多模态数据的标注过程。 当前现成的跨模态视觉语言模型基于 2D 图像,例如 CLIP [29] 和 SAM [21]。 在本节中,我们将详细说明如何基于现成的 VLM 对 3D 多模态数据进行标注。
III-B1 多模态空间对齐
如前所述,我们的 OpenAnnotate3D 旨在对 RGB 和 3D 点云数据执行对象级标注。 很少有开放词汇模型直接对多模态 3D 数据进行操作。 为此,我们进行多模态空间对齐,以便更好地利用 2D VLM 的推理能力。
当 RGB 和 3D 点云在空间上对齐时,精确的 2D 掩码可以被直接投影到 3D 空间中,作为 3D 分割标注。 现在,从视觉模块产生了 2D 掩码标注,为了获得 3D 标注,我们需要将 RGB 相机图像与 3D LiDAR 点云在空间上对齐。
我们使用外在和内在参数直接将世界坐标系中的 3D 点云转换为 2D 图像坐标,如下所示:
| (1) |
其中 和 分别是 2D 齐次图像坐标和 3D 齐次世界坐标。 代表投影矩阵,其中 是内在矩阵, 是外在矩阵,包含旋转矩阵 和平移向量 。 是一个缩放因子。

给定对齐良好的 RGB 图像和 3D 点云,我们可以建立准确的点到像素对应关系。 在第 III-B 节中,我们通过可提示的视觉模块获得 2D 掩码,该模块使用 SAM 等 VLM 实现。 感兴趣的读者可以参考第 IV 节以了解实现细节。 基于在 2D 图像坐标中标注的语义对象,我们可以将同一区域内的对应点标记为相同的语义对象。 当这些点云被投影回 3D 世界坐标时,我们可以直接获得不同对象的 3D 掩码标注。 此外,我们的系统还支持通过将 3D 边界框拟合到分割和聚类的 3D 点云来标记 3D 边界框。
III-B2 空时融合与校正
在处理多帧视频数据时,我们提供了两种可选解决方案,支持连续帧标注。 在第一种方法中,用户可以明确指定视频片段内的起始帧和结束帧。 系统自动标记两帧后,采用插值算法对该视频中剩余帧进行标注。 这种方法效率很高,但不能保证中间帧标注的准确性。
因此,我们的系统还支持视频的逐帧自动标注。 然而,问题在于 VLM 可能会偶尔对特定帧的某些对象进行错误标记或遗漏,这可能会导致较差的 3D 标注质量,尤其是在遮挡等困难情况下。
为此,我们提出了一种基于以下观察的融合和校正方法:跨帧利用空间和时间信息至关重要。 如果我们将时间视为一个额外的轴,一个移动的物体将随着时间推移生成一个三维体积。 此体积的横截面表示物体在时间上的瞬时姿态。 鉴于物理世界中的大多数物体都遵循运动学定律,保持几何和空间一致性,我们可以评估和校正物体的轨迹。 图 5 展示了时空融合和校正如何修复错误标注的结果。

IV 实验
为了评估我们的 OpenAnnotate3D 系统,我们在公共基准数据集和内部多模式数据集上进行了实验。
IV-A 实现细节
对于我们系统中的 LLM 解释器模块,我们使用了来自 OpenAI 的 API [30] 和来自 Langchain 的 Langchain API [31]。 在可提示的视觉模块中,我们集成了两个现成的预训练模型,Grounding DINO [32] 和 SAM [21],无需任何训练或微调。 这两个模型都是强大的基础模型,支持视觉-语言输入。 给定用户提供的文本和二维图像,我们使用 Grounding DINO 根据文本特征匹配为图像生成二维建议边界框。 随后,这些边界框被馈送到 SAM 的提示编码器,用作分割提示。 SAM根据这些边界框生成最终的二维掩码。 值得注意的是,Grounding DINO和SAM是即插即用的组件,可以被具有类似功能的其他模型替换。 所有实验都在一台配备GTX-4090的机器上进行。
| Annotation Methods | road | car | person | vegetation | building | pole | motorcycle |
|---|---|---|---|---|---|---|---|
| Junior User IOU(%) | 88.6 | 63.1 | 35.4 | 67.2 | 59.1 | 18.1 | 59.8 |
| Senior User IOU(%) | 91.5 | 95.3 | 67.8 | 69.9 | 88.1 | 45.3 | 84.7 |
| OpenAnnotate3D IOU(%) | 94.2 | 92.3 | 75.3 | 81.4 | 85.7 | 58.2 | 93.8 |
| OpenAnnotate3D w.o. spatio-temporal fusion(%) | 94.2 | 87.4 (-4.9) | 72.3 (-3.0) | 81.4 | 85.7 | 58.2 | 88.5 (-5.3) |
| Annotation Methods | road | car | person | vegetation | building | pole | motorcycle |
|---|---|---|---|---|---|---|---|
| Junior User (Sec) | 168 | 110 | 95 | 226 | 183 | 75 | 134 |
| Senior User (Sec) | 152 | 98 | 87 | 200 | 162 | 65 | 120 |
| OpenAnnotate3D (Sec) | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
我们主要对两种类型的数据进行实验:
-
•
公共数据集 为了评估标注的准确性,我们使用我们的OpenAnnotate3D系统在SemanticKITTI [4]上生成标注,并将自动标注结果与SemanticKITTI提供的真实标注进行比较。 SemanticKITTI是使用3D激光雷达和双摄像头收集的,从左右两个角度捕获了3D点云和RGB图像。 由于我们的标注系统依赖于二维图像来标注三维数据,因此在SemanticKITTI上评估它时,我们选择左视图图像,并过滤掉3D场景中未被左视图图像覆盖的点云。 此外,SemanticKITTI由22个序列组成,每个序列包含数千帧。 为了便于比较,我们只选择了08 val序列作为评估子集。
-
•
内部数据集 公共数据集只包含封闭场景的封闭集标注,这些场景是单调的。 为了全面评估开放词汇推理,我们使用两台设备记录了一系列复杂开放场景数据。 第一个设备是手持式3D现实扫描仪,称为Metacam,它配备了32线激光雷达和三个鱼眼摄像头。 LiDAR 的视野范围为 45° × 360°,而摄像机输出 40323040 像素的全彩图像。 此外,我们还使用了一辆带有 32 线 LiDAR 和 640480 摄像头的自动地面车辆。 这两种设备如图 7 所示。
IV-B 指标
为了评估 OpenAnnotate3D 在 SemanticKITTI 数据集的 3D 语义分割任务上的标注性能,我们使用每个类的 IoU(交并比)作为评估指标,即:
| (2) |
其中 、 和 分别对应于类 的真阳性、假阳性和假阴性点预测的数量。
请注意,使用 IOU 指标评估封闭集数据集上的标注结果是因为封闭集标注具有真实值。 但是,除了标注这些封闭集对象之外,OpenAnnotate3D 还能够标记各种开放集对象,由于缺乏真实值,这在定量实验中没有体现出来。
IV-C 准确性和效率的定量分析
除了标注准确性之外,我们还评估了标注效率。 为此,我们招募了两名人工标注员(一名初级和一名高级),他们都接受过标注过程的培训。 在基线比较实验中,我们分别手动和自动标注了 SemanticKITTI 中 30 帧的 10 个对象。
OpenAnnotate3D 支持供用户使用的手动微调界面。 在实践中,我们发现,通过基于 OpenAnnotate3D 进行轻微的手动校正,由于 LLM 解释器中的迭代过程以及时空融合和校正,整个系统甚至更加强大。 然而,在本实验部分,我们仅测试了 OpenAnnotate3D 的自动标注组件,以代表纯粹的自动标注准确性。
我们记录了标注与真实情况相比的精确度,以及不同标注者完成任务所花费的时间。 标注结果如表 I 所示,其中我们展示了每个类别的 IoU。 尤其是对于形状复杂的物体,例如“person”、“vegetation”,或相对较小的物体,例如“pole”,即使是资深的人类标注员也只能分别达到 67.8%、69.9% 和 45.3% 的 IoU。 相反,我们的 OpenAnnotate 在没有任何手动微调的情况下,分别达到了 75.3%、81.4% 和 58.2% 的 IoU。 对于人类眼睛难以精确识别物体,我们的自动系统表现出更明显的优势。 时间成本如表 II 所示。 正如我们所见,我们的 OpenAnnotate3D 与手动标注相比,显着降低了时间消耗,特别是对于形状不规则、面积较大的物体,例如“vegetation” 和“motorcycle”。 此外,我们的 OpenAnnotate3D 具有稳定的程序执行速度(主要取决于 GPU 性能),可以用时间进行量化。 相反,手动标注不仅效率低下,而且不同用户在专业水平上也存在差异。
IV-D 开放词汇推理的定性分析
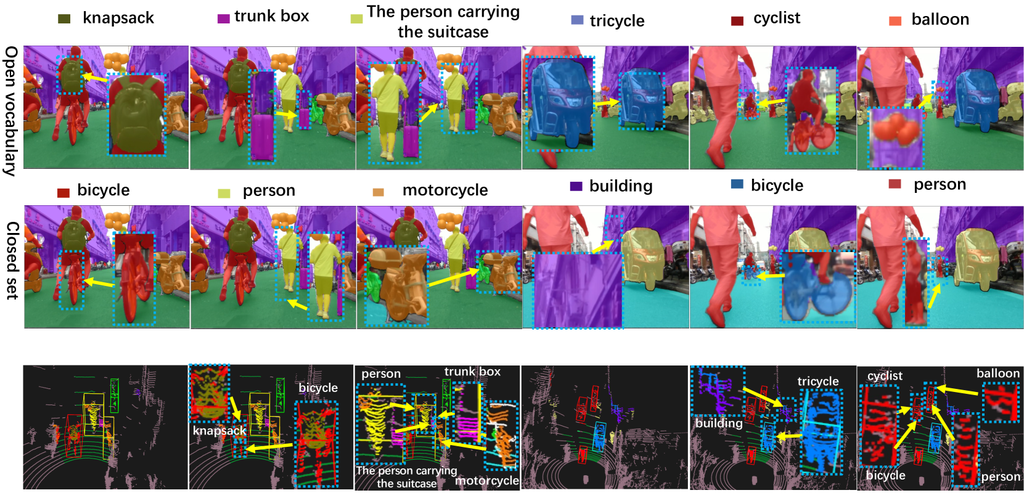
此外,如图 6 所示,我们进一步展示了 OpenAnnotate3D 在现实世界场景数据上的标注能力。 我们的标注系统不仅始终如一地自动标注了几个常见的封闭集物体,例如“bicycle”、“person”、“building” 和“motorcycle”,而且还准确地识别了许多以前在封闭集数据集中未标注过的开放词汇物体。 这些开放词汇物体包括“balloon”、“knapsack”、“trunk box,以及诸如“the person carrying the suitcase” 之类的长描述。 这些示例突出了我们的标注系统强大的开放词汇标注功能。
IV-E 消融研究
我们还进行了一项消融研究,以评估我们的 OpenAnnotate3D 的自动校正功能,即时空混淆和校正模块。 使用与之前实验相同的设置,我们首先允许 OpenAnnotate3D 执行自动校正。 然后,我们进行了另一轮标注,禁用自动校正。 结果如 Tab 中的第 3 行和第 4 行所示。 I。 可以观察到,在经过时空混淆模块的自动校正后,标注系统的精度进一步提高,特别是对于“摩托车”和“汽车”等移动物体。
IV-F 限制
我们的 OpenAnnotate3D 工具仍然在一定程度上依赖于用户输入。 对于模棱两可或过于抽象的提示,例如“其他车辆”,该工具的标注功能可能受到一定限制。 此外,OpenAnnotate3D 的性能受硬件特定参数的影响,包括相机分辨率、帧速率和激光扫描仪分辨率。 在相机分辨率不理想的情况下,对远处或模糊物体的标注结果可能无法达到预期标准。
V 结论
在本文中,我们提出了 OpenAnnotate3D,一个用于多模态 3D 数据的开源开放词汇自动标注系统,其中包括一个基于 LLM 的解释器模块、一个可提示的视觉模块和一个时空 3D 自动标注过程。 OpenAnnotate3D 集成了大型语言模型 (LLM) 的思维链能力和视觉语言模型的跨模态能力。 据我们所知,OpenAnnotate3D 是开放词汇多模态 3D 自动标注的先驱作品之一。
参考文献
- [1] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in 2009 IEEE conference on computer vision and pattern recognition. Ieee, 2009, pp. 248–255.
- [2] T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, and C. L. Zitnick, “Microsoft coco: Common objects in context,” in Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13. Springer, 2014, pp. 740–755.
- [3] A. Geiger, P. Lenz, C. Stiller, and R. Urtasun, “Vision meets robotics: The kitti dataset,” The International Journal of Robotics Research, vol. 32, no. 11, pp. 1231–1237, 2013.
- [4] J. Behley, M. Garbade, A. Milioto, J. Quenzel, S. Behnke, C. Stachniss, and J. Gall, “Semantickitti: A dataset for semantic scene understanding of lidar sequences,” in Proceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 9297–9307.
- [5] T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, et al., “Language models are few-shot learners,” Advances in neural information processing systems, vol. 33, pp. 1877–1901, 2020.
- [6] OpenAI, “Gpt-4 technical report,” 2023.
- [7] A. Chowdhery, S. Narang, J. Devlin, M. Bosma, G. Mishra, A. Roberts, P. Barham, H. W. Chung, C. Sutton, S. Gehrmann, et al., “Palm: Scaling language modeling with pathways,” arXiv preprint arXiv:2204.02311, 2022.
- [8] J. Wei, Y. Tay, R. Bommasani, C. Raffel, B. Zoph, S. Borgeaud, D. Yogatama, M. Bosma, D. Zhou, D. Metzler, et al., “Emergent abilities of large language models,” arXiv preprint arXiv:2206.07682, 2022.
- [9] S. Peng, K. Genova, C. Jiang, A. Tagliasacchi, M. Pollefeys, T. Funkhouser, et al., “Openscene: 3d scene understanding with open vocabularies,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 815–824.
- [10] Tesla, “Tesla ai day 2022,” 2000. [Online]. Available: https://www.youtube.com/watch?v=ODSJsviD˙SU&ab˙channel=Tesla
- [11] OpenAI, “Chatgpt (september 17 version),” https://chat.openai.com/chat, 2023.
- [12] B. C. Russell, A. Torralba, K. P. Murphy, and W. T. Freeman, “Labelme: a database and web-based tool for image annotation,” International journal of computer vision, vol. 77, pp. 157–173, 2008.
- [13] C. Vondrick, D. Patterson, and D. Ramanan, “Efficiently scaling up crowdsourced video annotation: A set of best practices for high quality, economical video labeling,” International journal of computer vision, vol. 101, pp. 184–204, 2013.
- [14] M. Tkachenko, M. Malyuk, A. Holmanyuk, and N. Liubimov, “Label Studio: Data labeling software,” 2020-2022, open source software available from https://github.com/heartexlabs/label-studio. [Online]. Available: https://github.com/heartexlabs/label-studio
- [15] A. Dutta and A. Zisserman, “The VIA annotation software for images, audio and video,” in Proceedings of the 27th ACM International Conference on Multimedia, ser. MM ’19. New York, NY, USA: ACM, 2019. [Online]. Available: https://doi.org/10.1145/3343031.3350535
- [16] K.-K. Maninis, S. Caelles, J. Pont-Tuset, and L. Van Gool, “Deep extreme cut: From extreme points to object segmentation,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 616–625.
- [17] D. Acuna, H. Ling, A. Kar, and S. Fidler, “Efficient interactive annotation of segmentation datasets with polygon-rnn++,” in Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, 2018, pp. 859–868.
- [18] B. Sekachev, M. Nikita, and Z. Andrey, “Computer vision annotation tool: A universal approach to data annotation. 2019,” URL https://github.com/opencv/cvat, 2019.
- [19] B. Dwyer, J. Nelson, J. Solawetz, and et al., “Roboflow (version 1.0),” Available from https://roboflow.com, 2022, computer Vision.
- [20] Labelbox. (2023) Labelbox. [Online]. [Online]. Available: https://labelbox.com
- [21] A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y. Lo, et al., “Segment anything,” arXiv preprint arXiv:2304.02643, 2023.
- [22] A. Golovinskiy and T. Funkhouser, “Min-cut based segmentation of point clouds,” in 2009 IEEE 12th International Conference on Computer Vision Workshops, ICCV Workshops. IEEE, 2009, pp. 39–46.
- [23] R. Monica, J. Aleotti, M. Zillich, and M. Vincze, “Multi-label point cloud annotation by selection of sparse control points,” in 2017 International Conference on 3D Vision (3DV). IEEE, 2017, pp. 301–308.
- [24] T. Kontogianni, E. Celikkan, S. Tang, and K. Schindler, “Interactive object segmentation in 3d point clouds,” in 2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2023, pp. 2891–2897.
- [25] B. Wang, V. Wu, B. Wu, and K. Keutzer, “Latte: accelerating lidar point cloud annotation via sensor fusion, one-click annotation, and tracking,” in 2019 IEEE Intelligent Transportation Systems Conference (ITSC). IEEE, 2019, pp. 265–272.
- [26] F. Piewak, P. Pinggera, M. Schafer, D. Peter, B. Schwarz, N. Schneider, M. Enzweiler, D. Pfeiffer, and M. Zollner, “Boosting lidar-based semantic labeling by cross-modal training data generation,” in Proceedings of the European Conference on Computer Vision (ECCV) Workshops, 2018, pp. 0–0.
- [27] Y. Zhang, M. Fukuda, Y. Ishii, K. Ohshima, and T. Yamashita, “Palf: Pre-annotation and camera-lidar late fusion for the easy annotation of point clouds,” arXiv preprint arXiv:2304.08591, 2023.
- [28] A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervision,” in International Conference on Machine Learning. PMLR, 2023, pp. 28 492–28 518.
- [29] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al., “Learning transferable visual models from natural language supervision,” in International conference on machine learning. PMLR, 2021, pp. 8748–8763.
- [30] OpenAI. (2023) OpenAI. [Online]. Available: https://www.openai.com
- [31] H. Chase, “Langchain,” Available at https://github.com/hwchase17/langchain, 2022, cff-version: 1.2.0.
- [32] S. Liu, Z. Zeng, T. Ren, F. Li, H. Zhang, J. Yang, C. Li, J. Yang, H. Su, J. Zhu, et al., “Grounding dino: Marrying dino with grounded pre-training for open-set object detection,” arXiv preprint arXiv:2303.05499, 2023.