自然域基础模型对医学图像分类有用吗?
摘要
深度学习领域正在趋向于使用可以轻松适应不同任务的通用基础模型。 虽然这种范式转变已成为自然语言处理领域的常见做法,但计算机视觉领域的进展却较慢。 在本文中,我们试图通过研究各种最先进的基础模型到医学图像分类任务的可迁移性来解决这个问题。 具体来说,我们评估了五个基础模型的性能,即 Sam、Seem、Dinov2、BLIP 和OpenCLIP 跨越四个成熟的医学成像数据集。 我们探索不同的训练设置,以充分利用这些模型的潜力。 我们的研究结果好坏参半。 Dinov2 始终优于 ImageNet 预训练的标准做法。 然而,其他基础模型未能始终如一地超越这一既定基线,这表明它们在医学图像分类任务中的可迁移性存在局限性。
1简介
最近,人们对使用在计算机视觉领域内的大规模数据集上训练的基础模型产生了浓厚的兴趣。 这导致了一种日益增长的趋势,即以最小的努力使这些模型适应各种下游应用。
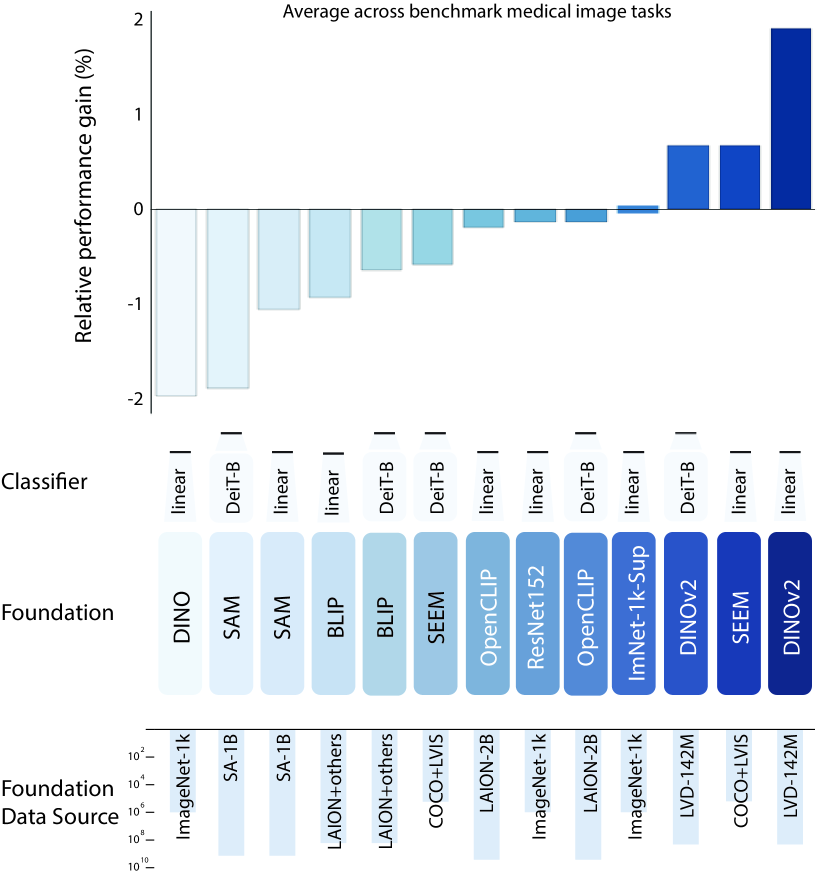
基础模型以其庞大的规模和在不同数据集上进行自我监督训练为特点,具有跨多个领域生成有意义的表示的卓越能力[1]。 这些模型作为各种下游任务的参数初始化策略具有显着的优势。 虽然大规模预训练的概念起源于自然语言处理(NLP)领域的 BERT [9],但后续的进展如 BART [18]、RoBERTa [21]、GPT [31,32,2]进一步推动了任务无关模型的利用。 这种范式转变不仅推动了对适应方法的研究,而且还激发了人们对理解基础模型内部工作原理的兴趣日益增长[44, 1]。
可以说,计算机视觉领域目前正在经历类似的转变。 直到最近,计算机视觉很大程度上依赖于使用监督学习在 ImageNet [7] 上预训练的模型。 然而,最近的进步导致出现了使用更大数据集和自我监督的替代计算机视觉基础模型,这与作为预训练数据主要来源的 ImageNet 有所不同。 这些模型大致可以分为两类:在借口任务上训练的特征编码模型,例如 Dino [28, 3]、CLIP [30] 和 BLIP [19],以及专门为解决特定任务而设计的模型,例如 Sam 的情况下的分割t6> [16] 和 似乎 [46]。 值得注意的是,每个模型都报告了卓越的零样本能力和跨广泛任务的强大泛化能力。
由于隐私和伦理方面的限制,医学成像任务面临数据短缺的问题。 因此,这是一个可以从迁移学习中受益匪浅的领域[26, 25]。 因此,采用医疗任务的基础模型预计也会带来显着的优势。 然而,基础模型预训练的数据和目标医疗任务之间的领域转换带来了相当大的挑战。 因此,需要专门在该领域测试这些模型的有效性。 尽管已经做出了一些尝试使基础模型适应医学领域(例如。采用Sam进行医学分割)[29, 23, 39, 8, 35, 38, 41] 据我们所知,目前缺乏对医学图像分类前沿基础模型的全面评估。
在这项工作中,我们的目标是通过在医学图像分类的背景下对最先进的基础模型进行彻底的评估和分析来弥补这一差距,揭示它们在医学领域的适用性和性能。
我们的研究结果如下:
-
•
并非所有基金会都能很好地转移到医学领域。 有些无法超越 ImageNet-1k 基线。 Dinov2 显示性能提升,Seem 匹配,而 Sam、BLIP 和 OpenCLIP 滞后在后面。
-
•
基础模型需要适应下游任务。 其中低级特征展示了对医疗任务的可转移性,而后面的层在解冻基础模型时进行特定于任务的适应。
-
•
将 DeiT 分类器附加到基础模型会带来边际性能提升。 获得的边际增益表明高级特征可能无法有效地充当分类器的输入。
重现我们实验的代码可以在 https://github.com/joanaapa/Foundation-Medical 找到。
2相关工作
基金会模型在社区中引起了极大的兴奋。 在分割任务领域,两个基础模型最近引起了人们的关注。 第一个模型 Sam [16] 结合了基于 ViT 的编码器和基于 Transformer 的轻量级解码器,展示了卓越的零样本分割功能。 Sam 尽管是一个相对较新的出版物,但在医学领域已经获得了相当大的关注。 多项研究对 Sam 在医学成像任务中的表现进行了评估开箱即用 [4,8,35,27,45,12] 。 此外,研究人员还探索了对 Sam 模型进行轻微修改,以专门针对医学成像应用[39, 29]进行定制,或针对特定数据集对其进行微调[ 23]。
Seem [46],另一个用于分割的基础模型在众多基准测试中表现出了出色的性能。 然而,目前探索Sem在医学领域应用的文献还很少。 尽管进行了详尽的搜索,但我们没有发现有关其在医学领域内使用的相关参考文献,这使其成为我们研究的一个令人信服的候选者。
Dinov2 由 Oquab 等人 [28] 引入,是一个基于 ViT 的模型,利用稳健的无监督预训练方法。 以 Dino [3] 为基础,Dinov2 受益于在大规模精选数据集上的训练,从而产生了捕获语义的表示图像非常好。 这使得 Dinov2 能够在各种任务中展示有效的性能,包括像素级和图像级分类。
CLIP 系列模型是在图像文本对 [30] 上进行预训练的。 语言和视觉在其表示中的结合为CLIP配备了多功能的多模态分析功能,事实证明这些功能在各个领域都很强大。 Wang等人[38]证明了CLIP在医学领域的适应性。 他们的研究展示了 CLIP 的卓越适应性,超越了特定于放射学的最先进模型。 Tiu 等人 [36]、Zhang 等人 [43] 和 Huang [13] 的值得注意的研究探索了与 类似的方法CLIP,展示了其出色的零样本能力。 与使用 ImageNet 权重初始化的同行相比,CLIP 始终优于强大的基线,具有出色的数据效率。 BLIP [19] 通过采用单模态编码器、基于图像的文本编码器和基于图像的文本解码器来统一视觉语言理解和生成,迎合各种图像-文本任务。 预训练涉及优化图像文本对比、图像文本匹配和语言建模目标。 大多数讨论的研究都利用基于 CNN 的视觉主干网,并使用 ImageNet 中的预训练权重进行初始化。 有些还在 ImageNet 初始化之上合并了域内预训练。
3方法
| Classifier | Foundation | APTOS2019, | DDSM, AUC | ISIC2019, Rec. | CheXpert, AUC | |
| (Unfrozen) | (Frozen) | 3,662 | 10,239 | 25,333 | 224,316 | |
| Dinov1 | 0.878 0.004 | 0.912 0.002 | 0.588 0.015 | 0.738 0.001 | ||
| ImNet-1k-Sup | 0.864 0.007 | 0.908 0.001 | 0.513 0.015 | 0.719 0.001 | ||
| ResNet152 | 0.824 0.003 | 0.883 0.001 | 0.461 0.027 | 0.712 0.000 | ||
| Linear | Sam | 0.873 0.010 | 0.916 0.004 | 0.402 0.014 | 0.724 0.001 | |
| Seem | 0.852 0.003 | 0.891 0.001 | 0.527 0.007 | 0.731 0.001 | ||
| OpenCLIP | 0.857 0.003 | 0.897 0.002 | 0.489 0.010 | 0.702 0.001 | ||
| Dinov2 | 0.881 0.002 | 0.905 0.001 | 0.569 0.012 | 0.722 0.000 | ||
| BLIP | 0.818 0.014 | 0.845 0.005 | 0.416 0.021 | 0.647 0.000 | ||
| DeiT-B | Sam | 0.890 0.005 | 0.940 0.007 | 0.740 0.015 | 0.788 0.003 | |
| Seem | 0.887 0.002 | 0.925 0.006 | 0.747 0.028 | 0.777 0.001 | ||
| OpenCLIP | 0.903 0.006 | 0.948 0.004 | 0.748 0.010 | 0.790 0.001 | ||
| Dinov2 | 0.901 0.005 | 0.945 0.008 | 0.790 0.010 | 0.798 0.001 | ||
| BLIP | 0.895 0.009 | 0.945 0.004 | 0.763 0.011 | 0.785 0.000 |
本研究的主要目的是评估视觉基础模型在医学图像分类背景下的功效。 具体来说,我们的目标是评估这些模型生成的特征到医学领域的可转移性,并确定最佳利用策略。 我们考虑的基础模型是使用不同的数据和不同的目标进行训练的,因此有理由认为,某些模型比其他模型更适合传输医疗任务的特征。 我们采用两种不同的方法进行了一系列实验:使用基础模型作为独立模型(带有线性预测头)并将其与称为“分类器模型”的模型堆叠。 为了保持一致性,使用 Transformer 家族的成员 DeiT [37] 作为分类器。
3.1数据集
为了确保对医学领域的特征可转移性进行全面评估,我们仔细选择了四个公开可用且完善的数据集。 这些涵盖了广泛的成像模式、色阶和数据集大小,提供了评估场景的多样性。 对于每个数据集,我们采用了适合分类任务性质的特定评估指标,从而能够对模型性能进行详细分析。
-
•
APTOS 2019 [15] - 该数据集包含 3,662 张与糖尿病视网膜病变相关的高分辨率图像,分为五个严重级别。 该数据集上模型性能的评估是使用二次 Cohen kappa 度量来衡量的。
-
•
CBIS-DDSM [17] - 本研究中使用的数据集包含 10,239 个用于检测异常肿块的乳房 X 线摄影图像。 使用 ROC-AUC 指标对该数据集进行模型评估。
-
•
ISIC 2019 [5] - 该数据集包含一组 25,331 个皮肤镜图像。 这些图像用于将皮肤病变分为 9 个不同的诊断类别。 使用召回指标来评估该数据集上的模型性能。
-
•
CHEXPERT [14] - 该数据集包含一系列 224,316 张胸部 X 光片,其中包含 14 种不同的诊断观察结果,涵盖一系列病症和异常。 使用 ROC-AUC 指标评估模型性能。
| Classifier | Foundation | APTOS2019, | DDSM, AUC | ISIC2019, Rec. | CheXpert, AUC | |
| (Unfrozen) | (Unfrozen) | 3,662 | 10,239 | 25,333 | 224,316 | |
| Dinov1 | 0.886 0.004 | 0.958 0.004 | 0.775 0.007 | 0.794 0.001 | ||
| ImNet-1k-Sup | 0.904 0.006 | 0.960 0.003 | 0.823 0.008 | 0.797 0.002 | ||
| ResNet152 | 0.899 0.002 | 0.960 0.003 | 0.817 0.007 | 0.807 0.000 | ||
| Linear | Sam | 0.894 0.007 | 0.950 0.006 | 0.798 0.010 | 0.801 0.001 | |
| Seem | 0.902 0.003 | 0.958 0.003 | 0.835 0.009 | 0.808 0.001 | ||
| OpenCLIP | 0.903 0.013 | 0.945 0.012 | 0.818 0.008 | 0.806 0.001 | ||
| Dinov2 | 0.909 0.009 | 0.966 0.003 | 0.859 0.007 | 0.812 0.001 | ||
| BLIP | 0.891 0.006 | 0.961 0.003 | 0.798 0.016 | 0.797 0.000 | ||
| DeiT-B | Sam | 0.890 0.005 | 0.951 0.004 | 0.778 0.013 | 0.796 0.002 | |
| Seem | 0.901 0.007 | 0.946 0.002 | 0.808 0.022 | 0.802 0.001 | ||
| OpenCLIP | 0.907 0.011 | 0.955 0.010 | 0.809 0.013 | 0.805 0.001 | ||
| Dinov2 | 0.904 0.007 | 0.966 0.004 | 0.822 0.011 | 0.812 0.001 | ||
| BLIP | 0.897 0.001 | 0.955 0.002 | 0.806 0.016 | 0.799 0.000 |
3.2基础模型
本研究选择的基础模型均基于 Transformer 架构。 为了保持比较的公平性,我们专门选择了尺寸尽可能接近的模型版本。 这种方法确保观察到的任何性能差异都可以归因于特定的架构差异,而不是模型大小或复杂性的显着差异。 我们在本研究中考虑的基础模型是:
-
•
Sam(88.8M 参数)[16] - Sam 是专为提示分割任务而设计的编码器-解码器架构。 它已在由 1100 万张高分辨率图像以及 十亿个相关蒙版组成的数据集上进行了训练。 我们使用Sam的图像编码器作为基础模型。 微调 Sam 时,我们使用与原始训练分辨率不同的分辨率
-
•
Seem(29.9M 参数)[46] - Seem 采用通用编码器-解码器架构,由单独的视觉和文本编码器组成,然后是用于掩码生成的解码器,适用于视觉和文本的联合嵌入空间。 训练使用了COCO2017[20]和Ref-COCO数据集[42]的组合。 我们的特征提取器是 Focal Transformer [40] 视觉主干。
-
•
Dinov2(86.5M 参数)[28] - 此通用 ViT 模型使用判别式进行预训练自我监督方法。 预训练数据集( 万张图像)是用于分类、检索和分割任务的 公开可用的自然图像数据集的集合。 我们使用 ViT-B 模型,它是 ViT-H 架构的精炼版本。
-
•
OpenCLIP(86.2M 参数)[30] - 多功能 ViT 模型,在 laion-5B 数据集[34]。 子集 laion-2B-EN 包含通过网络抓取获得的 十亿个图像标题(英文)对。 在我们的实验中,我们使用该模型的基本版本。
-
•
BLIP(85.7M 参数)[19] - 利用视觉转换器和基于 BERT 的编码器,BLIP 通过交叉注意力和专用标记集成视觉和文本信息。 对从 laion-400M 到 COCO2017 数据集精选的 万张图像进行训练。 我们的特征提取器是 ViT-B 视觉主干。
APTOS2019 DDSM 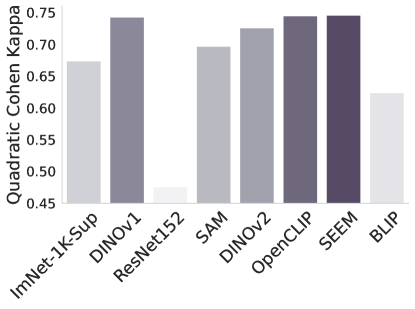
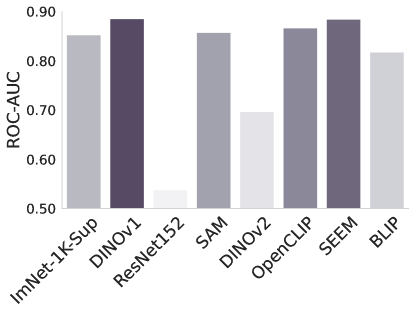
CheXpert ISIC 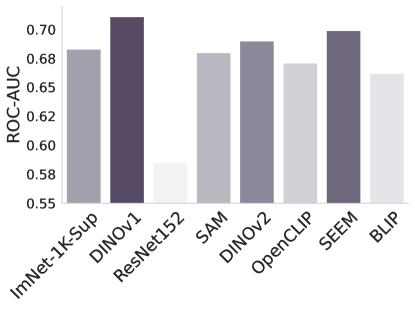
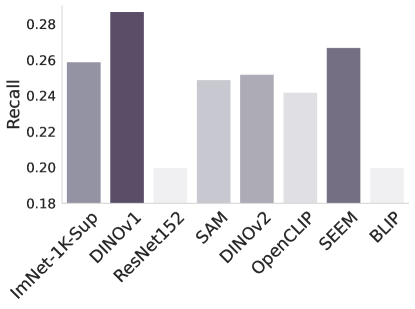
图2: -NN评估不同基础模型和基线模型的性能。
除了这些基础模型之外,我们还考虑在 ImageNet-1k (ILSVRC-2012) [33] 上训练的基线模型
-
•
ImNet-1k-Sup(86.6M 参数) - 将学习迁移到医学分类任务的标准做法是使用 ImageNet-1k 预训练网络[26] 用于初始化。 在这项工作中,我们使用在 ImageNet-1k 上以监督方式预训练的 DeiT-B [37] 作为基线。
-
•
Dinov1(86.6M 参数)[3] - 我们还在比较中包含了这个通用的 ViT模型,与 Dinov2 相比,它使用较旧的自监督方法进行预训练,但在 ImageNet-1k [33] 上进行。 在这项工作中,我们使用基于 DeiT-B 架构的基本模型。
-
•
ResNet(6040 万参数)[11] - 我们还包含了这个通用 CNN 主干网,它在 ImageNet< 上进行了预训练/t3>-1k。 我们使用 ResNet152 来匹配其他基线的复杂性。
3.3实现细节
在训练之前,所有图像都被下采样到分辨率 ,然后进行中心裁剪以获得最终尺寸 。 一组标准增强被应用于训练图像。 这些增强功能包括标准化、垂直和水平翻转、颜色抖动(调整亮度、对比度、饱和度和色调)以及随机调整裁剪大小。 每个训练集分为训练(80%)、验证(10%)和测试(10%)。 对于较小尺寸的 APTOS,分割比例分别调整为 70%、15% 和 15%。 一些基础模型(例如 Sam)使用不同的分辨率进行训练。 为了解决这个问题,我们使用双三次插值将位置嵌入与图像比例对齐并确保兼容性[10]。
| Train time - Unfrozen Train time - Frozen Inference time |
 |
除了训练分辨率之外,基础模型的架构也表现出显着的差异,需要针对当前的医疗任务进行调整。 具体来说,在考虑视觉 Transformer 架构的 Seem 和 Sam 改编时,缺少 [cls] 词符要求我们采用全球平均水平- 汇集从最后一层获得的补丁表示,以便附加线性头或执行 -NN 评估。 对于OpenCLIP、BLIP和Dinov2,我们可以利用原来的[cls]词符无需修改。 在所有情况下,在基础模型之上集成分类器模型都涉及从基础模型中提取块表示,添加投影层,绕过堆叠分类器的块嵌入层,并将块表示传输到分类器以进行精细分类。调整过程。 附加的分类器的[cls]词符用于分类任务。
使用 AdamW 优化器 [22] 对每个医学数据集进行监督学习,并采用线性学习率预热策略,对模型进行微调。 为了确定最佳基础学习率,对从 到 的四个值进行了搜索。 当达到饱和点时,学习率下降了 10 倍。 应用了 的权重衰减,并将整个过程重复五次以解决性能差异。 模型的评估基于选择性能最佳的检查点,通过对验证集的分析来确定。
| APTOS2019 | DDSM |
 |
 |
| CheXpert | ISIC |
 |
 |
3.4评估协议
我们采用两步方法来评估基础模型的性能。 最初,我们保持基础模型冻结,并通过微调顶部的线性分类器头来执行迁移学习。 这使我们能够与基线 (ImNet-1k-Sup) 相比评估适应模型的性能。 我们对多个医疗数据集进行了评估,以衡量模型的功效。 随后,我们在冻结的基础上附加了一个 Transformer 分类器 (DeiT-B)。 我们针对医疗任务对这种组合架构进行了微调,并评估了其性能。 为了获得进一步的见解,我们重复上述过程,同时解冻基础模型的权重。 这使得基础模型能够在微调期间适应其特征,无论是使用线性头还是分类器。 总而言之,我们考虑了四种场景:
-
1.
用线性头冷冻。 向医疗任务的迁移学习是在保持基础模型冻结的情况下完成的,只有线性头针对任务进行微调。
-
2.
冻结并附加分类器。 向医疗任务的迁移学习是在保持基础模型冻结的情况下完成的,并附加一个 DeiT-B 分类器并针对该任务进行微调。
-
3.
用线性头解冻。 基础模型和线性头都针对任务进行了微调。
-
4.
使用附加分类器解冻。 基础模型和附加的 DeiT-B 分类器都针对该任务进行了微调。
| APTOS2019- Unfrozen foundation | DDSM- Unfrozen foundation |
 |
 |
| APTOS2019- Frozen foundation | DDSM- Frozen foundation |
 |
 |
在上述设置中,我们评估了微调模型在医疗任务上的最终性能。 我们还考虑了特征的泛化能力和对类可分离性的鲁棒性,这可以使用对基础模型提取的特征进行k-最近邻评估来评估。
-
5.
-NN评估。 我们使用 -最近邻来检查基础模型特征对于医疗任务的适用性。
此外,我们评估模型复杂性和分辨率对性能以及训练和推理时间的影响
-
6.
型号尺寸。 我们选择表现最好的模型和评估协议,然后检查不同大小的各种可用模型。
-
7.
图像分辨率。 我们将训练分辨率提高到 并使用最佳识别场景进行评估。
-
8.
训练和推理时间。 我们将训练时间定义为验证指标达到最大性能(跨数据集标准化)之前的迭代次数。 推理时间计算为对单个实例进行分类的平均时间。 两者都是相对于基线 ImNet-1k-Sup 进行报告的。
最后,为了研究基础模型中的内部表示如何适应医疗任务,我们采用中心核对齐(CKA)来比较微调前后的模型。
-
9.
居中内核对齐(CKA)。 我们采用中心核对齐(CKA)[6]来分析基础模型中内部表示对医疗任务的适应性。 CKA 是衡量不同神经网络层之间相似性的指标。 这使我们能够深入了解微调过程中发生变化的特定层。 为了可视化和量化这些变化,我们计算了 CKA 热图,比较了基础模型微调前和微调后的版本。
4实验
| APTOS2019 | DDSM | ISIC |
 |
 |
 |
4.1 医疗任务的基本特征
冻结和未冻结的地基。 我们还通过在微调期间解冻其权重来衡量基础模型适应医疗任务的能力,同时使用线性头 (3) 和附加分类器 (4),如 3.4 节中所述。 表2提供了该实验的结果。 从这里可以看出,Dinov2 在转移到医疗任务时始终提供显着的性能提升。 表 2 中线性分类器的结果表明,Dinov2 在所有数据集上均优于基线,性能提升高达 3.2%。 APTOS2019 和 ISIC 上取得的性能凸显了即使在处理小型数据集时也有显着改进的潜力。 事实上,Dinov2 似乎甚至优于在域内预训练的自监督 ResNet,如附录 B 中所示。
| Foundation | APTOS2019, | DDSM, AUC | ISIC2019, Rec. | CheXpert, AUC |
| (UnFrozen) | 3,662 | 10,239 | 25,333 | 224,316 |
| Sam | 0.908 (1.4) | 0.984 (3.4) | 0.804 (0.6) | 0.820 (1.9) |
| Seem | 0.911 (0.9) | 0.967 (0.2) | 0.868 (3.3) | 0.821 (1.3) |
| OpenCLIP | 0.904 (0.1) | 0.980 (3.5) | 0.852 (3.4) | 0.813 (0.7) |
| Dinov2 | 0.917 (0.8) | 0.983 (1.7) | 0.895 (3.6) | 0.825 (1.3) |
| BLIP | 0.909 (1.2) | 0.984 (2.9) | 0.839 (3.3) | 0.813 (1.4) |
-NN评估。 在图2中,我们使用-最近邻来检查基础模型中特征的适应性。 在没有任何微调或监督的情况下,这测试了基础模型在手头任务中区分类的能力。 结果与表1和2的结果基本一致,但令人惊讶的是Dinov1总体表现最好,尽管它在以下情况下表现不佳针对任务进行了微调。 另一个令人惊讶的观察结果是 ImNet-1k-Sup 和 ResNet 的性能始终不佳。 它们的原始特征在 -NN 测量中表现不佳,但它们比 Sam 和 OpenCLIP 更容易通过微调来适应任务。
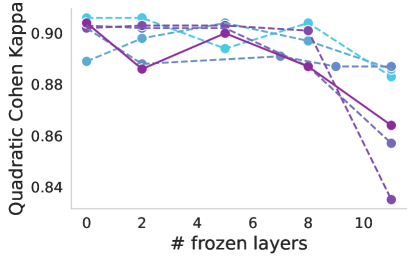
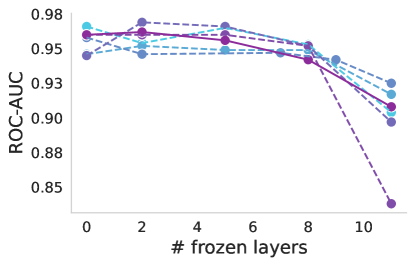
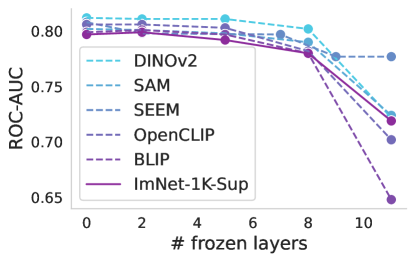
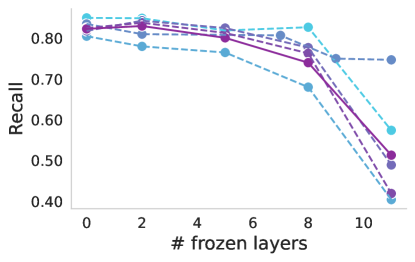
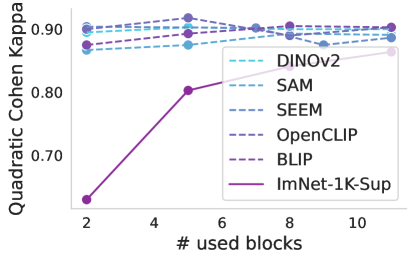
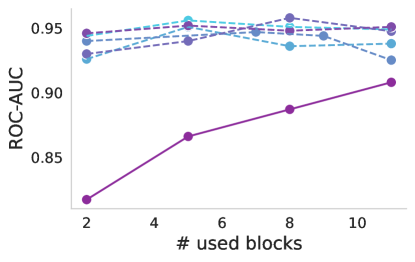
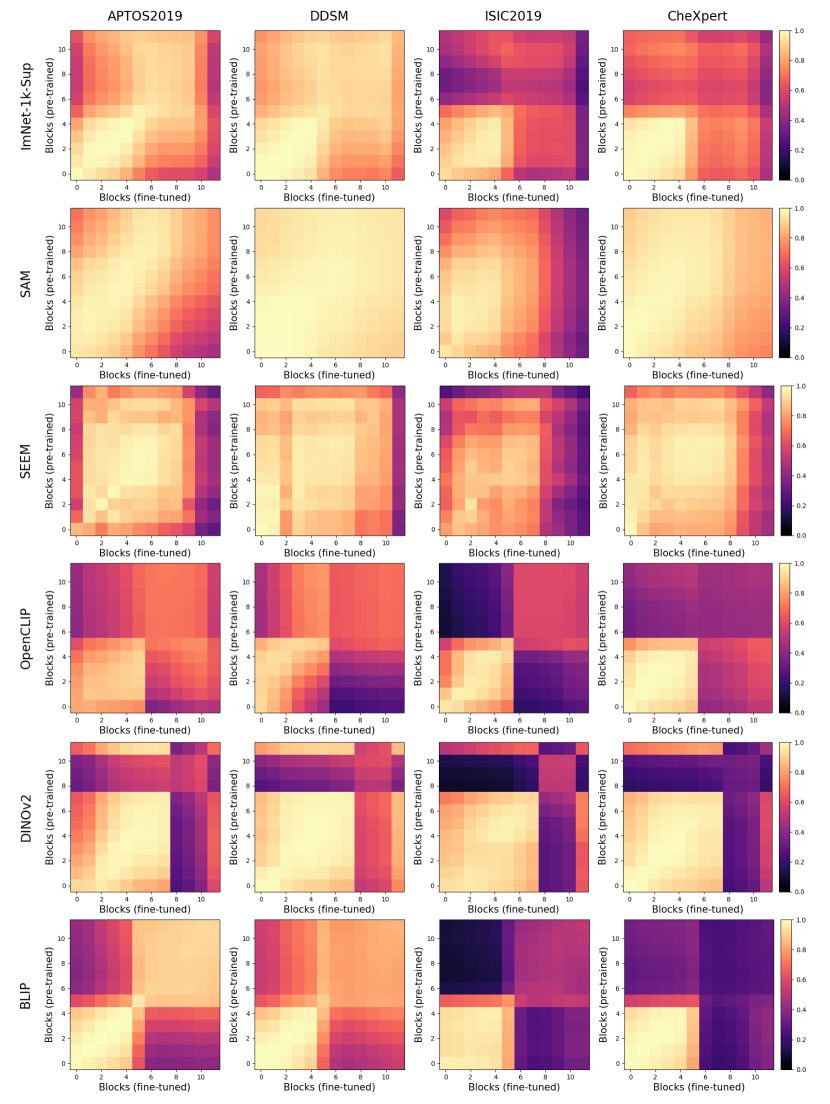
渐进式冷冻。 众所周知,不同的层捕获不同的图像特征,从第一层的低级特征开始到最后一层的高级特征。 上面,我们只考虑了两种场景,即使用基础提供的开箱即用的功能或在训练过程中完全适应基础。 在这里,我们研究每层基础模型产生的特征的适用性。 图4说明了使用线性分类器通过逐步冻结块进行训练时基础模型的性能。 几乎所有案例(包括基线)都可以观察到一致的趋势。 冻结到第八个块会导致性能略有下降,但超过该点,就会出现显着下降,这对于 ISIC 来说尤其明显。 这可能表明高级基础功能对于预训练任务变得过于专业,并且不适合医疗任务。 唯一的例外是似乎没有表现出如此显着的性能下降。
| APTOS2019 DDSM |
 |
| CheXpert ISIC |
 |
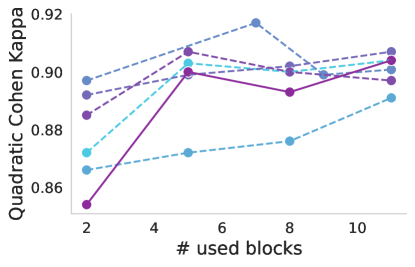
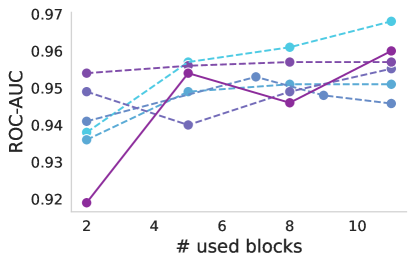
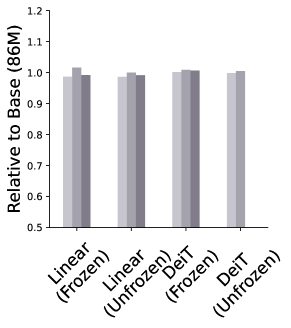
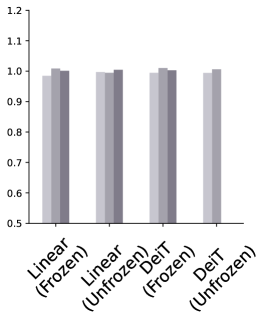
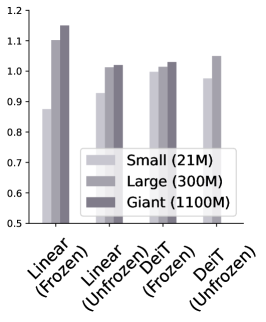
斩首基础。 扩展更深层次倾向于捕获可能与迁移学习不太相关的高级特征的概念,我们探索了如果我们仅使用基础的一部分作为特征提取器并将 Token 传播到 DeiT 会发生什么 分类器。 我们砍掉基础模型并附加一个 DeiT-B 分类器,然后再添加一个。 我们考虑两种情况:基础要么保持冻结,要么与分类器一起进行微调。 当基础与分类器一起进行微调时,可以观察到更好的性能。 在这种情况下,观察到一个明显的趋势,表明合并更多层可以提高性能(图5顶部)。 另一方面,当基础模型仅用作特征提取器而不进行调整时(图5底部),依赖早期层的特征似乎会带来好处,因为它们往往会捕获更多特征。低级(和更一般的)图像信息。 最佳点根据数据集和模型的不同而变化,其中块 5 对于 DDSM 表现良好,而对于 APTOS2019 则根据模型表现不同的最佳点。
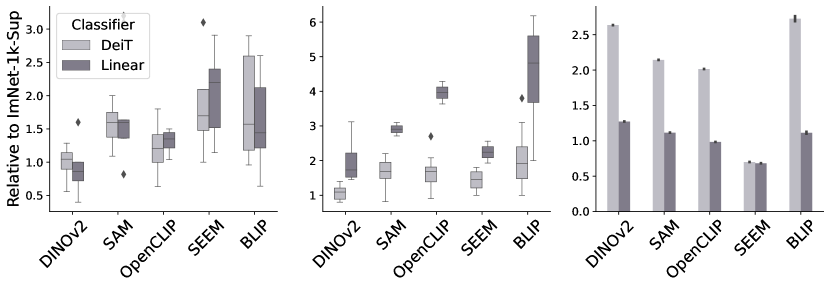
训练和推理时间。 我们还评估了不同模型的训练和推理时间,如图3所示。 与其他配置相比,在冰冻基础上训练线性分类器需要更长的时间。 在不同的基础模型中,Dinov2 的训练时间与基线 ImNet-1k-Sup 相似,而其他模型的训练时间有所增加,Seem 和 BLIP 解冻时速度最慢。 至于推理时间,在基础上添加完整的 DeiT 分类器会导致推理时间显着增加。 然而,正如预期的那样,Seem 是推理速度最快的模型,因为它逐渐减少了整个网络中的空间标记数量。
4.2 内部表示适配
考虑了 4.1 节中的结果后,出现了一个有趣的问题: 为什么与线性头相比,在基础之上堆叠一个完整的基于 Transformer 的分类器只能产生微小的改进? 为了解决这个问题,我们研究了学习到的表示在从基础模型传播到分类器网络时如何共享和适应,特别是考虑到数据集大小和域的变化。 为此,我们使用 3.4 节中所述的 CKA 相似性度量 (9)。 这种相似性分析是在两种不同的场景下进行的:
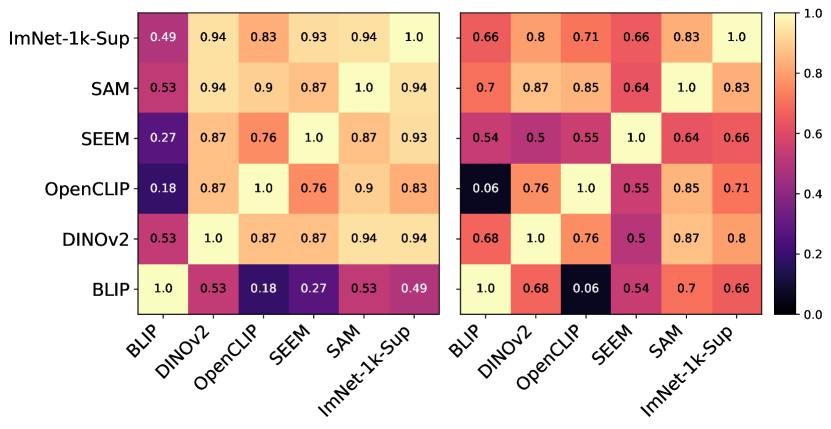
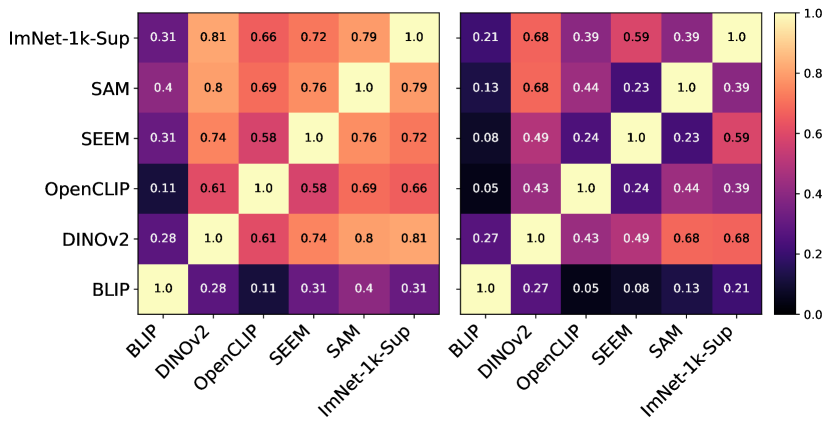
在图7中,我们观察到基础模型的适应趋势与ImNet-1k-Sup类似。 具体来说,在微调模型的相当多的上层中观察到了显着的转变。 此转换是特定于数据集的,ISIC 数据集需要更高程度的适应。 有趣的是,在早期层中观察到的低程度变化表明基础模型具有异常丰富的表示,需要最少的适应。 类似的分析(附录图A)表明,在这种未冻结的地基设置中,堆叠分类器需要高度适应。
在图8中,我们可以观察不同数据集的基础模型之间最后一层中可用的特征有何不同。 总体而言,ISIC 导致模型之间的差异最大,这与我们之前的观察结果一致。 有趣的是,BLIP 仍然是唯一一个能够学习与其他模型非常不同的特征的模型。 此外,针对类似任务训练的BLIP和OpenCLIP没有表现出任何特征相似性。
5讨论
考虑了通用基础模型和分段基础模型后,我们的调查表明 Dinov2 可以作为将学习迁移到医疗任务的坚实基础,只需要标准微调即可获得最佳性能。 其他模型未能始终优于基线——冻结基础模型的策略显然失败了。 有趣的是,紧凑的 Seem 模型可以与较大的模型有效竞争。
我们推测为什么基础模型在自然域图像中表现出色,但在我们的测试中表现不佳。 Sam 和 Seem 之间的架构差异(两者都是针对分割进行预训练的)可能会导致不同的特征层次结构。 虽然 OpenCLIP 和 BLIP 都使用文本引导的预训练,但它们的目标不同,可能会影响仅图像输入的表示质量。 值得注意的是,Dinov2 在没有额外解码器或文本条件的情况下表现出色。 这表明预训练方法和架构显着影响迁移学习的成功。
当对基础进行微调时,我们获得了最佳性能,并且表明与使用附加分类器相比,使用线性头通常会产生相同或更高的性能。 当基础冻结时,堆叠一个分类器是获得最佳性能所必需的,但它往往不如当前标准做法的ImageNet预训练(ImNet-1k-Sup) >)。 尽管 -NN 性能较差,但预训练的 CNN 与监督环境中的对应模型相匹配。
在基础模型中,我们的分析表明,早期层具有很大程度的特征重用,而较深层对目标任务的适应至关重要——如果后面的层不适应任务,它们可能会影响性能。
此外,我们还注意到以下主要发现:
-
•
正如 -NN 评估协议所证明的那样,基础模型具有丰富的特征,可以重复使用或适应医学图像分类任务。 这可能是受到基础模型训练所用的大量自然图像的影响。
-
•
冻结基础模型通常会导致性能下降,这表明基础模型生成的高级特征不太适合医疗任务。 特征相似性分析支持了这一观察结果,表明在微调过程中未冻结基础模型的最后几层中出现了新的高级特征。
-
•
与其他基础模型相比,微调 Dinov2 表现出明显更快的收敛速度,可实现高水平的性能。 这种现象似乎可以归因于需要适应的层数较少,这可以从特征相似性图中观察到。
-
•
基础模型的训练数据与其迁移能力之间的相关性尚不清楚。 然而,趋势表明使用更大的微调数据集(例如 Chexpert)可以提高性能。
-
•
[cls]词符的作用尚不清楚。 虽然 Dinov2 的整体表现确实最好,但缺少 [cls] 词符并没有阻止 Seem 的表现几乎同样好。
-
•
高分辨率微调可以提高高分辨率和低分辨率预训练模型的性能。 此外,基础模型往往会在性能和模型复杂性之间取得最佳平衡。
6 结论
总之,这项研究的主要发现是,现代基础模型,特别是 Dinov2,可以作为将学习迁移到医疗任务的坚实基础,并且只需进行最少的微调。 具体的预训练方案和架构是影响性能的关键因素,但今天我们已经有了基础模型,可以取代 ImageNet 预训练医学分类任务。 展望未来,随着更新、规模更大的基础模型的不断出现,以及人工智能在医疗应用中的需求不断增加,需要进一步的研究和探索,以增强基础模型在医疗领域的适应性和有效性。 这些进步有可能显着改善医学图像分析并有助于改善医疗保健结果。
致谢。
这项工作得到了 Wallenberg 人工智能、自治系统和软件程序 (WASP) 的支持。 我们感谢使用国家超级计算机中心的克努特和爱丽丝·瓦伦堡基金会提供的 Berzelius 计算资源。
参考
- [1] Rishi Bommasani, Drew A Hudson, Ehsan Adeli, Russ Altman, Simran Arora, Sydney von Arx, Michael S Bernstein, Jeannette Bohg, Antoine Bosselut, Emma Brunskill, et al. On the opportunities and risks of foundation models. arXiv preprint arXiv:2108.07258, 2021.
- [2] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- [3] Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. In Proceedings of the IEEE/CVF international conference on computer vision, pages 9650–9660, 2021.
- [4] Dongjie Cheng, Ziyuan Qin, Zekun Jiang, Shaoting Zhang, Qicheng Lao, and Kang Li. Sam on medical images: A comprehensive study on three prompt modes. arXiv preprint arXiv:2305.00035, 2023.
- [5] Noel CF Codella, David Gutman, M Emre Celebi, Brian Helba, Michael A Marchetti, Stephen W Dusza, Aadi Kalloo, Konstantinos Liopyris, Nabin Mishra, Harald Kittler, et al. Skin lesion analysis toward melanoma detection: A challenge at the 2017 international symposium on biomedical imaging (isbi), hosted by the international skin imaging collaboration (isic). In 2018 IEEE 15th international symposium on biomedical imaging (ISBI 2018), pages 168–172. IEEE, 2018.
- [6] Corinna Cortes, Mehryar Mohri, and Afshin Rostamizadeh. Algorithms for learning kernels based on centered alignment, 2014.
- [7] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009.
- [8] Ruining Deng, Can Cui, Quan Liu, Tianyuan Yao, Lucas W Remedios, Shunxing Bao, Bennett A Landman, Lee E Wheless, Lori A Coburn, Keith T Wilson, et al. Segment anything model (sam) for digital pathology: Assess zero-shot segmentation on whole slide imaging. arXiv preprint arXiv:2304.04155, 2023.
- [9] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
- [10] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale, 2021.
- [11] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition, 2015.
- [12] Sheng He, Rina Bao, Jingpeng Li, Jeffrey Stout, Atle Bjornerud, P. Ellen Grant, and Yangming Ou. Computer-vision benchmark segment-anything model (sam) in medical images: Accuracy in 12 datasets, 2023.
- [13] Shih-Cheng Huang, Liyue Shen, Matthew P. Lungren, and Serena Yeung. Gloria: A multimodal global-local representation learning framework for label-efficient medical image recognition. 2021 IEEE/CVF International Conference on Computer Vision (ICCV), pages 3922–3931, 2021.
- [14] Jeremy Irvin, Pranav Rajpurkar, Michael Ko, Yifan Yu, Silviana Ciurea-Ilcus, Chris Chute, Henrik Marklund, Behzad Haghgoo, Robyn Ball, Katie Shpanskaya, et al. Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison. In Proceedings of the AAAI conference on artificial intelligence, volume 33, pages 590–597, 2019.
- [15] Sohier Dane Karthik, Maggie. Aptos 2019 blindness detection, 2019.
- [16] Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollár, and Ross Girshick. Segment anything. arXiv:2304.02643, 2023.
- [17] Rebecca Sawyer Lee, Francisco Gimenez, Assaf Hoogi, Kanae Kawai Miyake, Mia Gorovoy, and Daniel L Rubin. A curated mammography data set for use in computer-aided detection and diagnosis research. Scientific data, 4(1):1–9, 2017.
- [18] Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov, and Luke Zettlemoyer. Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. ArXiv, 2019.
- [19] Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation, 2022.
- [20] Tsung-Yi Lin, Michael Maire, Serge Belongie, Lubomir Bourdev, Ross Girshick, James Hays, Pietro Perona, Deva Ramanan, C. Lawrence Zitnick, and Piotr Dollár. Microsoft coco: Common objects in context, 2015.
- [21] Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692, 2019.
- [22] Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization, 2019.
- [23] Jun Ma and Bo Wang. Segment anything in medical images. arXiv preprint arXiv:2304.12306, 2023.
- [24] Christos Matsoukas, Johan Fredin Haslum, Magnus Söderberg, and Kevin Smith. Is it time to replace cnns with transformers for medical images? arXiv preprint arXiv:2108.09038, 2021.
- [25] Christos Matsoukas, Johan Fredin Haslum, Magnus Söderberg, and Kevin Smith. Pretrained vits yield versatile representations for medical images. arXiv preprint arXiv:2303.07034, 2023.
- [26] Christos Matsoukas, Johan Fredin Haslum, Moein Sorkhei, Magnus Söderberg, and Kevin Smith. What makes transfer learning work for medical images: feature reuse & other factors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9225–9234, 2022.
- [27] Sovesh Mohapatra, Advait Gosai, and Gottfried Schlaug. Brain extraction comparing segment anything model (sam) and fsl brain extraction tool. arXiv preprint arXiv:2304.04738, 2023.
- [28] Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023.
- [29] Zhongxi Qiu, Yan Hu, Heng Li, and Jiang Liu. Learnable ophthalmology sam. arXiv preprint arXiv:2304.13425, 2023.
- [30] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR, 2021.
- [31] Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever, et al. Improving language understanding by generative pre-training. ArXiv, 2018.
- [32] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9, 2019.
- [33] Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, et al. Imagenet large scale visual recognition challenge. International journal of computer vision, 115:211–252, 2015.
- [34] Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, Patrick Schramowski, Srivatsa Kundurthy, Katherine Crowson, Ludwig Schmidt, Robert Kaczmarczyk, and Jenia Jitsev. Laion-5b: An open large-scale dataset for training next generation image-text models, 2022.
- [35] Peilun Shi, Jianing Qiu, Sai Mu Dalike Abaxi, Hao Wei, Frank P-W Lo, and Wu Yuan. Generalist vision foundation models for medical imaging: A case study of segment anything model on zero-shot medical segmentation. Diagnostics, 13(11):1947, 2023.
- [36] Ekin Tiu, Ellie Talius, Pujan Patel, Curtis P Langlotz, Andrew Y Ng, and Pranav Rajpurkar. Expert-level detection of pathologies from unannotated chest x-ray images via self-supervised learning. Nature Biomedical Engineering, pages 1–8, 2022.
- [37] Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Hervé Jégou. Training data-efficient image transformers & distillation through attention. In International conference on machine learning, pages 10347–10357. PMLR, 2021.
- [38] Zifeng Wang, Zhenbang Wu, Dinesh Agarwal, and Jimeng Sun. Medclip: Contrastive learning from unpaired medical images and text. arXiv preprint arXiv:2210.10163, 2022.
- [39] Junde Wu, Rao Fu, Huihui Fang, Yuanpei Liu, Zhaowei Wang, Yanwu Xu, Yueming Jin, and Tal Arbel. Medical sam adapter: Adapting segment anything model for medical image segmentation. arXiv preprint arXiv:2304.12620, 2023.
- [40] Jianwei Yang, Chunyuan Li, Xiyang Dai, and Jianfeng Gao. Focal modulation networks. Advances in Neural Information Processing Systems, 35:4203–4217, 2022.
- [41] Huahui Yi, Ziyuan Qin, Qicheng Lao, Wei Xu, Zekun Jiang, Dequan Wang, Shaoting Zhang, and Kang Li. Towards general purpose medical ai: Continual learning medical foundation model. arXiv preprint arXiv:2303.06580, 2023.
- [42] Licheng Yu, Patrick Poirson, Shan Yang, Alexander C. Berg, and Tamara L. Berg. Modeling context in referring expressions, 2016.
- [43] Yuhao Zhang, Hang Jiang, Yasuhide Miura, Christopher D. Manning, and Curtis P. Langlotz. Contrastive learning of medical visual representations from paired images and text, 2022.
- [44] Ce Zhou, Qian Li, Chen Li, Jun Yu, Yixin Liu, Guangjing Wang, Kai Zhang, Cheng Ji, Qiben Yan, Lifang He, et al. A comprehensive survey on pretrained foundation models: A history from bert to chatgpt. arXiv preprint arXiv:2302.09419, 2023.
- [45] Tao Zhou, Yizhe Zhang, Yi Zhou, Ye Wu, and Chen Gong. Can sam segment polyps?, 2023.
- [46] Xueyan Zou, Jianwei Yang, Hao Zhang, Feng Li, Linjie Li, Jianfeng Gao, and Yong Jae Lee. Segment everything everywhere all at once. arXiv preprint arXiv:2304.06718, 2023.
补充材料自然域基础模型对医学图像分类有用吗?
附录 A 附加 CKA 分析
| Frozen foundation | Unfrozen foundation |
![[Uncaptioned image]](x21.png) |
![[Uncaptioned image]](x22.png) |
附录B域内预训练
我们研究了域内自我监督预训练的影响。 具体来说,我们在下游数据集上使用 Dinov1 [3] 和预训练 ResNet152 模型。 我们遵循[24]中描述的训练配方,然后按照3节中的监督微调。 我们在表B和表B中报告了结果。 为了进行比较,我们还展示了在 ImageNet-1k 上预训练的 ResNet152 基线的结果,以及在此方面表现最好的 Dinov2工作。 当基础模型保持冻结时,域内自我监督显着优于其他两种预训练策略。 鉴于该模型已在下游数据集上调整了其功能,这是一个相当预期的结果。 令人惊讶的是,我们发现,当对完整模型进行微调时(正如实践中通常遵循的那样),Dinov2 甚至优于其自我监督的 ResNet152 对应模型。
| Foundation | APTOS2019, | DDSM, AUC | ISIC2019, Rec. | CheXpert, AUC | |
| (Frozen) | 3,662 | 10,239 | 25,333 | 224,316 | |
| ResNet152– pretrained on ImageNet-1k | 0.824 0.003 | 0.883 0.001 | 0.461 0.027 | 0.712 0.000 | |
| ResNet152– self-supervised with Dinov1 | 0.855 0.004 | 0.920 0.001 | 0.610 0.020 | 0.708 0.000 | |
| Dinov2 | 0.881 0.002 | 0.905 0.001 | 0.569 0.012 | 0.722 0.000 |
| Foundation | APTOS2019, | DDSM, AUC | ISIC2019, Rec. | CheXpert, AUC | |
| (Unfrozen) | 3,662 | 10,239 | 25,333 | 224,316 | |
| ResNet152– pretrained on ImageNet-1k | 0.899 0.002 | 0.960 0.003 | 0.817 0.007 | 0.807 0.000 | |
| ResNet152– self-supervised with Dinov1 | 0.898 0.006 | 0.954 0.004 | 0.818 0.002 | 0.810 0.000 | |
| Dinov2 | 0.909 0.009 | 0.966 0.003 | 0.859 0.007 | 0.812 0.001 |