作弊深度:通过深度模拟增强 3D 表面异常检测
摘要
基于 RGB 的表面异常检测方法取得了显着进步。 然而,某些表面异常现象仅在 RGB 中实际上仍然不可见,因此需要结合 3D 信息。 采用点云主干的现有方法由于处理速度慢而导致表示不理想并且适用性降低。 由于足够大的数据集的可用性有限,在工业深度数据集上重新训练 RGB 主干网(旨在实现更快的密集输入处理)受到阻碍。 我们为应对这些挑战做出了多项贡献。 (i) 我们提出了一种新颖的深度感知离散自动编码器 (DADA) 架构,该架构能够学习通用离散潜在空间,对 RGB 和 3D 数据进行联合建模以进行 3D 表面异常检测。 (ii)我们通过引入在深度编码器中学习信息深度特征的模拟过程来解决缺乏多样化工业深度数据集的问题。 (iii) 我们提出了一种新的表面异常检测方法 3DSR,该方法在具有挑战性的 MVTec3D 异常检测基准上,在准确性和处理速度方面均优于所有现有的最先进技术。 实验结果验证了我们方法的有效性和效率,凸显了利用深度信息改进表面异常检测的潜力。 代码位于:https://github.com/VitjanZ/3DSR
1简介
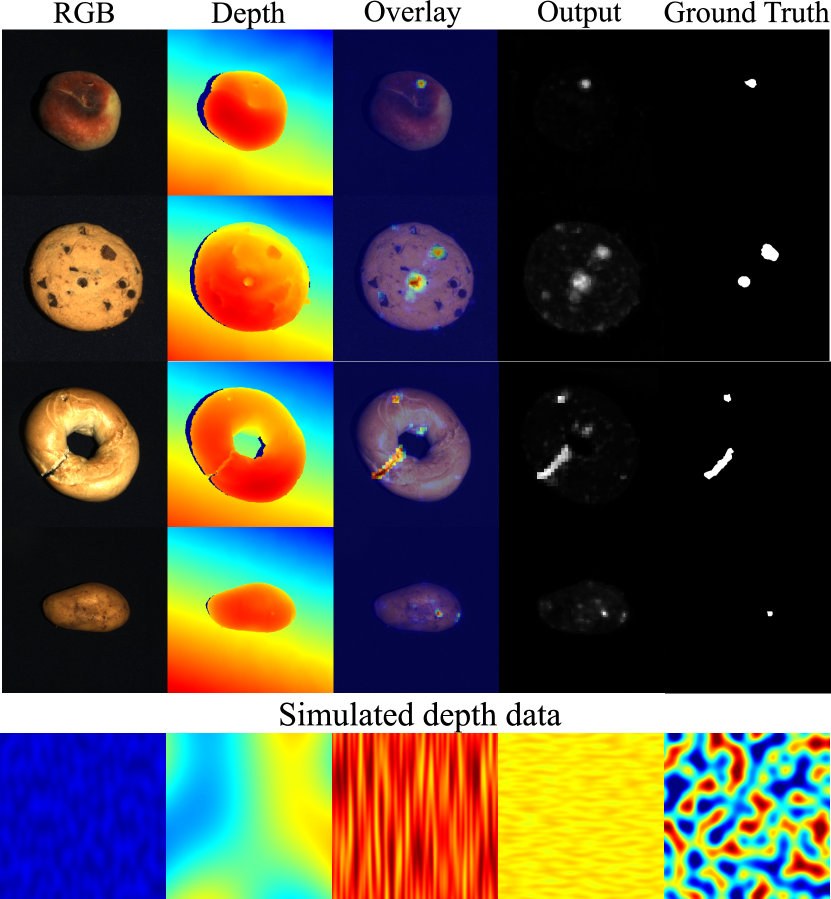
表面异常检测解决偏离正常物体外观的图像区域的定位。 大多数工作都考虑了基于 RGB 的检测问题,近年来该技术取得了显着的进展,多种方法在广泛采用的 MVTec 异常检测数据集[1]上接近完美。 然而,由于实际应用中的某些表面异常在RGB中无法检测到(图1),最近的工作[2,17,3,9]考虑了一个新的研究问题RGB+3D异常检测。
最先进的方法通常依赖于通用骨干网络[14,15,17,20]提取的特征,并在大型数据集上进行预训练。 目前最先进的 3D 异常检测方法 M3DM [19] 应用两个主干网,一个在 RGB 上进行预训练,另一个在点云数据集上进行预训练。 然而,一般的点云数据集不能很好地表示工业设置的深度外观分布,导致表示不理想。 此外,点云主干网大大减慢了处理速度,降低了该方法的实用性。 通过将深度图像视为灰度图像并用 RGB 预训练的主干替换点云主干可以加快推理速度,但有证据表明 [9] RGB 预训练的主干不足以代表深度与异常检测相关的属性。
或者,可以在工业深度数据集上重新训练 RGB 主干网,但当前的工业深度数据集太小,无法有效地训练大型主干网。 最近的工作 DSR [22] 提出利用矢量量化自动编码器 (VQVAE) [13],它仅学习固定数量的离散潜在表示向量,因此有可能能够从较小的数据集。 然而,我们的经验表明,在可用的工业深度数据集 MVTec3D [2] 上训练 DSR 会导致次优结果,表明即使对于表示高效的 VQVAE 而言,现有数据也太小。 因此,RGB+3D 表面异常检测的进展因缺乏足够大的数据集而受到阻碍,这些数据集无法预训练一般深度主干,并允许足够快地开发适合实际应用的方法。
我们通过认识到可以总结工业表面异常检查深度数据典型的空间和强度内容的统计特性来解决上述问题,这允许为此类数据创建参数化生成模型。 我们假设这样的模型可以用来生成一个大型训练集,用于预训练特定深度的主干(图1,底部)。 此外,我们注意到处理时间限制需要有效的架构设计来编码 RGB 和深度数据,以联合利用这两种模式来检测复杂的异常。
这项工作的主要贡献有三个方面:(i)提出了一种新颖的深度感知离散自动编码器(DADA)架构,该架构能够学习联合建模 RGB 和深度数据的通用离散潜在空间用于 3D 表面异常检测。 (ii) 我们通过提出工业深度数据模拟过程来直接解决缺乏多样化工业深度数据集的问题,该过程有利于 DADA 模块学习信息丰富的深度特征。 (iii) 我们通过提出 3DSR 来证明学习特征空间的有效性,这是一种新颖的判别性 3D 表面异常检测方法,在最具挑战性的 MVTec3D 异常上显着优于所有竞争的最先进方法检测基准[2]。 由于其高效的设计,3DSR 在速度上也优于当前最先进的[19]一个数量级。
2相关工作
MVTec 异常检测数据集[1]已广泛应用于无监督表面异常检测研究。 训练数据集仅包含正常情况,而测试数据集包含正常情况和异常情况。 大多数表现最佳的异常检测方法[14,15,5,17,20]依赖强大的预训练主干来提取信息特征。 在获得训练集中每个无异常图像的良好表示后,通常会构建一个简单的统计模型,该模型紧密绑定无异常特征空间[14, 5]。 这使得能够基于选定的距离函数到无异常表示模型来检测异常。 利用预训练特征提取器训练流模型的基于流的方法也取得了最先进的结果[16,15,17,21]。 某些判别方法[23,10,22]不需要强大的预训练主干,而是依赖于使用分布外数据集的模拟异常来构建强大的分类器,该分类器可以很好地推广到真实异常测试时间。 事实证明,性能最佳的 RGB 异常检测方法不能很好地推广到 3D 表面异常检测[2,17,9]。
在3D表面异常检测的问题设置中,MVTec-3D异常检测数据集[2]是包含RGB和3D信息的最全面的数据集。 在[2]中,基于重建的异常检测方法已作为初始基线应用于3D异常检测问题。 在[3]中,提出了一种专注于点云几何描述符的3D学生-教师网络。 [9]中提出了一种类似于[14]的基于内存的方法,该方法利用RGB和FPFH的预训练主干特征[18] 3D 表示的特征。 在[17]中,提出了一种基于师生流的模型,该模型对 RGB 数据使用预训练的主干特征,但使用原始深度像素值进行 3D 表示。 在 [19] 中,3D 特征由点 Transformer [24] 提取,该点 Transformer 在不适合工业 3D 数据的通用点云数据集上进行预训练。 工业领域 3D 数据的缺乏以及强大的特定领域特征提取器的缺乏提出了重大挑战,因为需要更好的 3D 表示来提高 3D 表面异常检测方法的准确性。
3我们的方法:3DSR
我们提出了一种基于双子空间重投影(3DSR)的新型 3D 表面异常检测方法。 输入图像被编码到离散特征空间中,然后由两个解码器重新投影到图像空间中。 特定对象解码器和通用对象解码器分别重建无异常外观和异常外观。 然后,异常检测模块根据两个重新投影之间的差异来分割潜在的异常。 3DSR 分两个阶段进行训练。 首先,在 RGB 和深度图像对上训练新型深度感知离散自动编码器 (DADA),以学习 RGB+3D 深度数据的通用联合离散表示。
第二阶段,将 DADA 集成到 DSR [22] 表面异常检测框架中,生成 3DSR,然后在 3D 异常检测数据集 [2, 4] 上进行训练。 在3.1节中描述了所提出的深度感知离散自动编码器(DADA)模块的架构。 然后在3.2节中描述了工业深度数据模拟过程。 最终的 3DSR 表面异常检测流程在第 3.3 节中进行了描述。
3.1 深度感知离散自动编码器
要学习 RGB 和深度数据的表示,一种简单的方法可能是训练具有 4 个输入通道的矢量量化自动编码器 [13] 来表示 RGB 和深度。 由于 RGB 和深度图像的特性,这种方法有一些缺点。 图2显示了电缆密封套的示例。 感兴趣的区域在 和 中用绿色矩形标记,并以 RGB () 和深度 ()。 由于阴影而表现出显着的局部变化,但在 中几乎看不到任何变化。 在深度图像中,即使是轻微的深度变化也可以为缺陷检测提供信息,因此表示 中的变化至关重要。 离散自动编码器通常使用 损失进行训练,它对 中的变化类型不太敏感,其中值变化最小,但对 中的变化敏感,其中局部梯度较高。 因此, 中的细微变化对最终损失影响很小,从而导致训练期间更加重视 RGB 数据的重建。

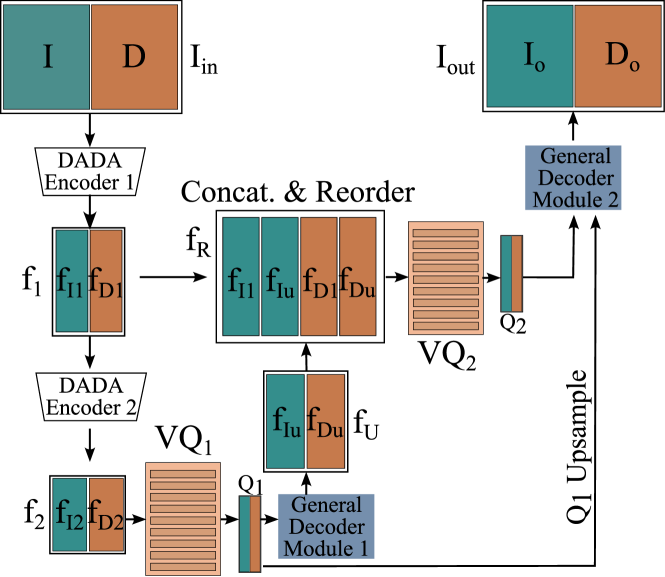
为了确保 RGB 和深度的良好表示,需要一种新的深度感知离散自动编码器 (DADA) 架构,如图 3 所示。 离散自动编码器的输入 是一个 4 通道张量,是 RGB 图像 和深度图像 的串联。编码器是一个卷积网络,其中 RGB 和深度信息由分组卷积层 [8] 分开,确保 RGB 和深度特征不会相互作用。 这种通道方式的分离对于防止单一模态对损失函数的压倒性影响是必要的。
为了最大限度地减少低空间分辨率离散化带来的信息损失,使用了两级离散化架构[13]。 首先,DADA 编码器 1 对输入进行编码,并通过 生成特征 对空间分辨率进行下采样,其中 和 代表分别是 RGB 和深度特征。 第二个编码器阶段,DADA 编码器 2,进一步将特征下采样为总 下采样,生成 。 特征根据 L2 距离量化为码本 的最近邻居。 然后,量化的特征被输入到解码器模块,该解码器模块将空间分辨率上采样到。 然后将特征 和 连接并按通道重新排序,以对图像特征 和 以及深度特征 和。 的这种重新排序对于保持解码器分组卷积中 RGB 和深度特征的分离是必要的。 然后将所得特征 量化为 中的最近邻码本向量,生成 。 然后对 进行上采样以适应 的空间分辨率,之后将 和 输入到第二个解码器模块,该模块输出RGB 和深度 的重建连接为 。 我们使用 VQ-VAE [13] 损失函数(经过修改以解决添加的深度信息)来训练 DADA:
| (1) |
其中 是欧氏距离, 是停止梯度运算符。 和是损失权重因子,除非另有说明,在所有实验中均设置为。 控制与对应的码本向量的不愿意改变,并在[13]之后的所有实验中固定为。
3.2深度数据生成模型
由于缺乏工业深度数据集,训练 DADA 需要模拟数据。 有效的模拟过程需要考虑工业深度数据的关键属性。 首先,物体深度可以从距传感器最近到最远连续变化。 其次,小凹痕和凹凸可能会导致 RGB 强度发生显着变化,或者完全不可见,具体取决于照明情况。 在深度上,这种微小的变化总是可以通过最小的局部深度值改变来检测到。 最后,深度图像的平均值可能会有很大差异。 模拟数据必须捕获工业图像中的局部变化和可变平均对象深度。 因此,模拟深度图像生成过程被设计为明确地解决这些属性。 模拟图像的核心生成器是 Perlin 噪声生成器[12],它产生各种局部平滑的纹理,很好地模拟深度的渐变,解决了第一个属性。 然后通过使用随机仿射变换调整 Perlin 噪声图像来模拟细微的局部变化和变化的平均物距。
为了生成单个模拟深度图像,首先生成 Perlin 噪声图像 ,并在 和 之间进行归一化。 然后将 乘以均匀采样的 以生成 。 在 值较低时, 的最大值和最小值仅略有不同。 为了对平均物距的变化进行建模, 使用均匀采样的 进行平移。 因此,最终的模拟深度图像为。
图4显示了具有各种和参数的模拟深度图像的示例。 控制的最小值和最大值之间的差值,模拟深度的局部变化,控制的最小值。

然后 DADA 在 RGB 和深度图像对上进行训练。 RGB 图像是从 ImageNet[6] 采样的,深度图像是模拟的(图 4),与输入 RGB 数据无关。
3.3 3D异常检测管道
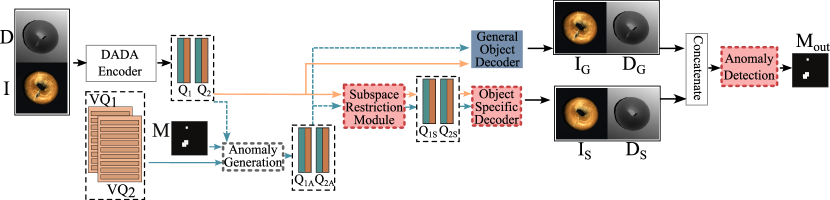
在第二阶段,DSR[22]被用作判别性异常检测框架。 DSR 用于 RGB 表面异常检测的 VQ-VAE-2 [13] 网络已替换为 DADA,经过预训练以从 3D 和 RGB 数据中提取信息表示。 此外,DADA 的矢量量化特征空间可实现高效的模拟异常采样。 3DSR的架构如图5所示。
DADA编码器模块提取并量化特征和。 然后,异常生成过程会修改 和 ,以生成包含模拟特征级异常的 和 。 然后将 和 输入到子空间限制模块中,该模块尝试将提取的特征恢复为无异常表示 、 。 请注意,异常生成过程仅在训练期间执行,因此在推理时 和 直接输入到子空间限制模块中,因为它们在测试期间可能已经包含异常。
对象特定解码器经过训练,可以根据重建的特征 和 重建无异常外观。 预训练的一般外观解码器在训练或 时根据 和 重建异常外观 和 和 进行推理。 然后,将、、和连接起来并输入到异常检测模块中。 异常检测模块经过训练,可以定位训练期间的模拟异常和测试时的真实异常。 它直接输出异常分割掩码,并使用焦点损失[11]进行训练。 在[22, 23]之后,首先使用高斯滤波器平滑,然后取平滑掩模的最大值来估计图像级异常分数。
在训练期间,通过如下修改量化特征图和来生成异常。 首先,按照之前的工作[22, 23],通过对 Perlin 噪声图进行阈值化和二值化来生成异常图 。 然后调整 的大小以适合 和 的空间维度。 与 的正值相对应的区域内 和 的特征向量分别被从代码集 和 中随机取样的特征向量所替换,从而生成包含模拟异常的修改后特征图 和 。
4实验
数据集。 3DSR 在最近的两个 3D 异常检测基准(MVTec3D 数据集 [2] 和 Eyecandies 数据集 [4])上进行评估,每个基准包含 10 个不同的对象类。 MVTec3D [2] 异常检测基准包含由高分辨率工业 3D 传感器获得的 4147 次扫描,该传感器还采集 RGB 数据。 在 扫描中, 是异常的,包含在 RGB 或 3D 数据中可见的各种缺陷。 3DSR 还在 Eyecandies 数据集 [4] 上进行了评估,这是一个具有 RGB 和 3D 异常的困难渲染数据集。 它包含 无异常训练示例和 用于测试 异常的示例。
评估问题设置。 评估分为不同的问题设置,其中仅使用深度(3D设置)、RGB图像(RGB设置)或同时使用深度和RGB图像(3D+RGB)。 由于 3DSR 是一种 3D 和 RGB+3D 方法,因此我们在 RGB 设置中提供 DSR [22] 结果。
评估指标。 评估每种方法的异常定位和图像级异常检测能力。 对于图像级检测,使用标准图像级 AUROC 指标。 对于异常定位,使用 PRO 指标 [1]。 此外,平均像素级 AUROC 用于定位评估。
4.1实现细节
在训练的第一阶段,使用 3D 模拟深度数据和用于 RGB 监督的 ImageNet 数据集 [6] 来训练 DADA 模块。 DADA 使用 的批量大小进行训练,并使用 的学习率进行 次迭代。 矢量量化码本包含维度 的 嵌入。 在第二阶段,在 MVTec3D 数据集 [2] 或 Eyecandies 数据集 [4] 上训练 3DSR。 在这两个数据集中,3D 数据均以排序点云的形式给出。 通过首先将深度图标准化为 和 之间的值来预处理数据。 然后,将每个深度图像中的缺失值替换为 邻域中所有有效像素的平均值。 如果周围没有有效像素,则该值设置为 0。 前景掩模是通过根据点到背景平面的距离将点分类为前景或背景来获得的。 背景平面方程是从排序点云边缘的有效点获得的。 在训练期间,仅在前景对象上生成异常。 3DSR 在每个数据集的单个对象类上进行训练,这是表面异常检测方法的标准[23,22,14,17]。 它以 的批量大小进行 次迭代的训练,学习率为 。
4.2结果
| Method | Bagel | Cable Gland | Carrot | Cookie | Dowel | Foam | Peach | Potato | Rope | Tire | Mean | |
| 3D | Voxel AE [2] | 69.3 | 42.5 | 51.5 | 79.0 | 49.4 | 55.8 | 53.7 | 48.4 | 63.9 | 58.3 | 57.1 |
| Depth GAN [2] | 53.0 | 37.6 | 60.7 | 60.3 | 49.7 | 48.4 | 59.5 | 48.9 | 53.6 | 52.1 | 52.3 | |
| Depth AE [2] | 46.8 | 73.1 | 49.7 | 67.3 | 53.4 | 41.7 | 48.5 | 54.9 | 56.4 | 54.6 | 54.6 | |
| FPFH [9] | 82.5 | 55.1 | 95.2 | 79.7 | 88.3 | 58.2 | 75.8 | 88.9 | 92.9 | 65.3 | 78.2 | |
| 3D-ST [3] | 86.2 | 48.4 | 83.2 | 89.4 | 84.8 | 66.3 | 76.3 | 68.7 | 95.8 | 48.6 | 74.8 | |
| AST3D [17] | 88.1 | 57.6 | 96.5 | 95.7 | 67.9 | 79.7 | 99.0 | 91.5 | 95.6 | 61.1 | 83.3 | |
| M3DM3D [19] | 94.1 | 65.1 | 96.5 | 96.9 | 90.5 | 76.0 | 88.0 | 97.4 | 92.6 | 76.5 | 87.4 | |
| 3DSR3D | 94.5 | 83.5 | 96.9 | 85.7 | 95.5 | 88.0 | 96.3 | 93.4 | 99.8 | 88.8 | 92.2 | |
| RGB | PatchCore [14] | 87.6 | 88.0 | 79.1 | 68.2 | 91.2 | 70.1 | 69.5 | 61.8 | 84.1 | 70.2 | 77.0 |
| DifferNet [15] | 85.9 | 70.3 | 64.3 | 43.5 | 79.7 | 79.0 | 78.7 | 64.3 | 71.5 | 59.0 | 69.6 | |
| PADiM [5] | 97.5 | 77.5 | 69.8 | 58.2 | 95.9 | 66.3 | 85.8 | 53.5 | 83.2 | 76.0 | 76.4 | |
| CS-Flow [16] | 94.1 | 93.0 | 82.7 | 79.5 | 99.0 | 88.6 | 73.1 | 47.1 | 98.6 | 74.5 | 83.0 | |
| ASTRGB [17] | 94.7 | 92.8 | 85.1 | 82.5 | 98.1 | 95.1 | 89.5 | 61.3 | 99.2 | 82.1 | 88.0 | |
| M3DMRGB [19] | 94.4 | 91.8 | 89.6 | 74.9 | 95.9 | 76.7 | 91.9 | 64.8 | 93.8 | 76.7 | 85.0 | |
| DSRRGB [22] | 84.4 | 93.0 | 96.4 | 79.4 | 99.8 | 90.4 | 93.8 | 73.0 | 97.8 | 90.0 | 89.8 | |
| 3D+RGB | Voxel AE [2] | 51.0 | 54.0 | 38.4 | 69.3 | 44.6 | 63.2 | 55.0 | 49.4 | 72.1 | 41.3 | 53.8 |
| Depth GAN [2] | 53.8 | 37.2 | 58.0 | 60.3 | 43.0 | 53.4 | 64.2 | 60.1 | 44.3 | 57.7 | 53.2 | |
| Depth AE [2] | 64.8 | 50.2 | 65.0 | 48.8 | 80.5 | 52.2 | 71.2 | 52.9 | 54.0 | 55.2 | 59.5 | |
| PatchCore+FPFH [9] | 91.8 | 74.8 | 96.7 | 88.3 | 93.2 | 58.2 | 89.6 | 91.2 | 92.1 | 88.6 | 86.5 | |
| AST [17] | 98.3 | 87.3 | 97.6 | 97.1 | 93.2 | 88.5 | 97.4 | 98.1 | 100 | 79.7 | 93.7 | |
| M3DM [19] | 99.4 | 90.9 | 97.2 | 97.6 | 96.0 | 94.2 | 97.3 | 89.9 | 97.2 | 85.0 | 94.5 | |
| 3DSR | 98.1 | 86.7 | 99.6 | 98.1 | 100 | 99.4 | 98.6 | 97.8 | 100 | 99.5 | 97.8 |
| Method | Bagel | Cable Gland | Carrot | Cookie | Dowel | Foam | Peach | Potato | Rope | Tire | Mean | |
| 3D | Depth AE [2] | 14.7 | 6.9 | 29.3 | 21.7 | 20.7 | 18.1 | 16.4 | 6.6 | 54.5 | 14.2 | 20.3 |
| Depth GAN [2] | 11.1 | 7.2 | 21.2 | 17.4 | 16.0 | 12.8 | 0.3 | 4.2 | 44.6 | 7.5 | 14.3 | |
| Voxel AE [2] | 26.0 | 34.1 | 58.1 | 35.1 | 50.2 | 23.4 | 35.1 | 65.8 | 1.5 | 18.5 | 34.8 | |
| FPFH [9] | 97.3 | 87.9 | 98.2 | 90.6 | 89.2 | 73.5 | 97.7 | 98.2 | 95.6 | 96.1 | 92.4 | |
| M3DM [19] | 94.3 | 81.8 | 97.7 | 88.2 | 88.1 | 74.3 | 95.8 | 97.4 | 95.0 | 92.9 | 90.6 | |
| 3DSR | 92.2 | 87.2 | 98.4 | 85.9 | 94.0 | 71.4 | 97.0 | 97.8 | 97.7 | 85.8 | 90.7 | |
| RGB | CFlow [7] | 85.5 | 91.9 | 95.8 | 86.7 | 96.9 | 50.0 | 88.9 | 93.5 | 90.4 | 91.9 | 87.1 |
| PatchCore [14] | 90.1 | 94.9 | 92.8 | 87.7 | 89.2 | 56.3 | 90.4 | 93.2 | 90.8 | 90.6 | 87.6 | |
| PADiM [2] | 98.0 | 94.4 | 94.5 | 92.5 | 96.1 | 79.2 | 96.6 | 94.0 | 93.7 | 91.2 | 93.0 | |
| M3DM [19] | 95.2 | 97.2 | 97.3 | 89.1 | 93.2 | 84.3 | 97.0 | 95.6 | 96.8 | 96.6 | 94.2 | |
| DSR [22] | 92.3 | 97.0 | 97.9 | 85.9 | 97.9 | 89.4 | 94.3 | 95.1 | 96.4 | 98.0 | 94.4 | |
| 3D+RGB | Depth AE [2] | 43.2 | 15.8 | 80.8 | 49.1 | 84.1 | 40.6 | 26.2 | 21.6 | 71.6 | 47.8 | 48.1 |
| Depth VM [2] | 38.8 | 32.1 | 19.4 | 57.0 | 40.8 | 28.2 | 24.4 | 34.9 | 26.8 | 33.1 | 33.5 | |
| Voxel AE [2] | 46.7 | 75.0 | 80.8 | 55.0 | 76.5 | 47.3 | 72.1 | 91.8 | 1.9 | 17.0 | 56.4 | |
| 3D-ST [3] | 95.0 | 48.3 | 98.6 | 92.1 | 90.5 | 63.2 | 94.5 | 98.8 | 97.6 | 54.2 | 83.3 | |
| PatchCore + FPFH [9] | 97.6 | 96.9 | 97.9 | 97.3 | 93.3 | 88.8 | 97.5 | 98.1 | 95.0 | 97.1 | 95.9 | |
| M3DM [19] | 97.0 | 97.1 | 97.9 | 95.0 | 94.1 | 93.2 | 97.7 | 97.1 | 97.1 | 97.5 | 96.4 | |
| 3DSR | 96.4 | 96.6 | 98.1 | 94.2 | 98.0 | 97.3 | 98.1 | 97.7 | 97.9 | 97.9 | 97.2 |
图像级AUROC的异常检测结果如表1所示。 3DSR 在 3D 设置中显着优于仅使用深度信息的竞争方法。 3D图像级AUROC提升约个百分点。 这展示了 DADA 学到的信息丰富的深度表示并验证了 3DSR 管道。
在深度信息对于异常检测至关重要的类别(例如轮胎和泡沫)中,3D 设置的改进甚至更大。 此外,3DSR 在 3D+RGB 设置中的性能优于竞争方法 个百分点,证明了 DSR 有效利用深度和 RGB 模态信息的能力,再次强调了 3D 和 RGB 学习的强大联合表示。 DADA 使用所提出的数据模拟过程。 在表1中,为每个对象类标记了第一、第二和第三最佳执行方法。 请注意,3DSR 在 3D 设置的 类中的 上获得第一名,在 3D+ 的 类中,3DSR 在 类上获得第一名RGB 设置,同时在每个对象类别中保持前 3 名。
根据AUPRO指标[1],异常定位结果如表2所示。 3DSR 在分割结果中获得第二名。 它在 3D 问题设置中实现了与 M3DM 相当的结果,同时在 RGB+3D 设置中表现优于 M3DM。 表 3 显示了 3DSR 和最先进方法在 RGB+3D 设置的平均像素级和图像级 AUROC 方面的比较,其中 3DSR 在图像级和像素级 AUROC 方面均优于 AST [17] 和 M3DM [19] 。
| Method | I-AUROC | P-AUROC |
|---|---|---|
| PatchCore + FPFH [9] | 86.5 | 99.2 |
| AST [17] | 93.7 | 97.6 |
| M3DM [19] | 94.5 | 99.2 |
| 3DSR | 97.8 | 99.5 |
| Method | Candy | Chocolate | Chocolate | Confetto | Gummy | Hazelnut | Licorice | Lollipop | Marshmallow | Peppermint | Mean |
|---|---|---|---|---|---|---|---|---|---|---|---|
| cane | cookie | praline | Bear | truffle | sandwich | candy | |||||
| 3DSR3D | 60.0 | 76.8 | 74.2 | 77.0 | 76.1 | 74.9 | 81.1 | 83.1 | 81.1 | 91.7 | 77.6 |
| M3DM3D | 48.2 | 58.9 | 80.5 | 84.5 | 78.0 | 53.8 | 76.6 | 82.7 | 80.0 | 82.2 | 72.5 |
| DSRRGB [22] | 70.6 | 96.5 | 95.0 | 96.6 | 87.0 | 79.0 | 88.5 | 85.7 | 99.8 | 99.2 | 89.8 |
| M3DMRGB | 64.8 | 94.9 | 94.1 | 100 | 87.8 | 63.2 | 93.3 | 81.1 | 998 | 100 | 87.9 |
| 3DSR3D+RGB | 65.1 | 99.8 | 90.4 | 97.8 | 87.5 | 86.1 | 96.5 | 89.9 | 99.0 | 97.1 | 90.9 |
| M3DM3D+RGB | 62.4 | 95.8 | 95.8 | 100 | 88.6 | 75.8 | 94.9 | 83.6 | 100 | 100 | 89.7 |
表 4 显示了 3DSR 与先前表现最佳的方法 M3DM [19] 在 Eyecandies [4] 数据集上的图像比较3D 和 3D+RGB 问题设置的 AUROC 级。 3DSR 在 3D 异常检测设置上优于 M3DM [19],并且图像级 AUROC 得分比 M3DM [19]< 高 个百分点/t2>. 在 3D+RGB 异常检测设置上,3DSR 实现了最先进的性能,在平均 AUROC 分数方面略优于 M3DM [19],同时实现了较低的跨类别分数方差。 结果表明,在 Eyecandies 数据集 [4] 中,大多数在 3D 中可感知的异常在 RGB 中也可见,因为在 RGB 和 3D+RGB 问题设置中实现了类似的结果。
图 6 显示了 MVTec3D [2] 和 Eyecandies [4] 数据集的定性示例。 前两行分别包含 RGB 和深度图像。 第三行显示覆盖在 RGB 图像上的 3DSR 输出蒙版。 地面实况异常掩码如第 4 行所示。 在 Cookie(第 4 列)、Peach(第 7 列)和 Potato(第 8 列)等类中,异常现象在 RGB 图像中很细微,但在深度图像中可见,并且可以通过 3DSR 检测到。 在第 6 列中,泡沫上的异常仅在 RGB 空间中可见,并且也可以通过 3DSR 检测到。 在其他列中,异常现象在 RGB 和深度图像中都可见。 最后两列显示了 Eyecandies 数据集 [4] 中的示例。 第 11 列包含 3D 异常,第 12 列包含仅在 RGB 图像中可见的异常。 3DSR 准确地分割了所有这些示例。

5消融研究
消融研究的结果如表5所示。 首先,在实验中评估了在 MVTec3D [2] 训练集中所有类别的 RGB+深度图像对上训练 DSR [22] 的 VQVAE 的简单方法。 这导致异常检测性能较差,表明需要通过所提出的贡献实现更好的 RGB+3D 表示。
模拟训练数据的贡献在和实验中进行评估。 在 实验中,省略了 DADA 的 Perlin 噪声图的使用,并将深度训练数据替换为转换为灰度的 ImageNet 图像。 灰度图像无法充分模拟深度图像的属性,图像级 AUROC 分数显着下降约 个百分点。 在 中,只使用了从 缩放至 的培林噪声图,而没有使用 和 的额外缩放,详见第 3.2 节。 这会导致图像级 AUROC 下降大约 个百分点。 实验和证明了使用Perlin噪声作为工业深度模拟源的有效性以及使用模拟数据的仿射变换来对数据特征进行建模的好处。
DADA 模块的贡献在实验 、 中进行评估。 在这些实验中,使用来自[22]的VQVAE来学习联合RGB和深度表示,其中RGB和深度表示没有通过分组卷积来分离。 在 中,建议的 DADA 模块被替换为 VQVAE [13] 模型,这导致图像级 AUROC 大约下降 个百分点。 该实验展示了在 DADA 架构中分离 RGB 和深度数据的好处,并表明这种分离可以改进下游异常检测。 实验 还使用来自 [22] 的矢量量化自动编码器,但方程中损失的 和 值 (1)被设置为性能最佳的值和,增加了深度图像重建的损失贡献。 这导致图像级 AUROC 下降 个百分点,表明用 VQ-VAE 替换 DADA 和简单的损失重新权衡是不够的。 、的变化也解释了和之间的差异,显示了,。
| Method | I-AUROC | P-AUROC | PRO |
|---|---|---|---|
| DSRnaive | 87.6 | 96.5 | 92.3 |
| 3DSRno_perlin | 90.0 | 98.3 | 93.3 |
| 3DSRno_affine | 94.8 | 99.2 | 95.9 |
| 3DSRVQVAE | 95.8 | 99.3 | 96.3 |
| 3DSRweighted | 96.5 | 99.4 | 96.7 |
| 3DSR | 97.8 | 99.5 | 97.2 |
推理效率。 在 NVIDIA RTX A4500 GPU 上评估每秒帧数 (FPS) 的性能,如表 6 所示。 与其他最近的方法(例如 M3DM [19])相比,3DSR 速度非常快,并且由于 DADA 和异常分割模块的效率,可以在 GPU 上实时运行。 之前使用点云数据的最佳方法 M3DM [19] 需要大量预处理和两个大型 Transformer 网络。 3DSR 比 M3DM 快一个数量级,并且就 FPS 而言几乎是 AST [17] 的两倍。
| Method | AST [17] | M3DM [19] | 3DSR |
|---|---|---|---|
| FPS | 18 | 0.6 | 33 |
限制。 图 7 显示了对于 3DSR 来说特别困难的 Eyecandies 数据集 [4] 示例。 在第一行中,异常现象是物体边缘的小凹痕。 它在 RGB 图像中不可见,也无法与深度图中的自然边缘区分开来,因此难以检测。 在第 2 行和第 3 行中,异常是基于深度的,并导致对象表面发生微小变化。 它们在 RGB 图像中几乎不可见。 尽管如此,3DSR 能够以较低的置信度对它们进行分割。 在第 4 行中,异常是 RGB 图像中可见的变形,但由于对象的透明度,此类异常很难检测到。 请注意,Eyecandies 数据集 [4] 包含具有挑战性的异常,这些异常与物体的正常外观非常相似,因此即使对于人类来说也难以检测到它们。

6结论
我们提出了一种3D异常检测方法3DSR,它能够检测工业深度数据中的3D异常,甚至可以利用深度和RGB数据进一步提高异常检测性能。 我们的第一个贡献是新颖的深度感知离散自动编码器 (DADA),它在训练期间单独编码 3D 和 RGB 数据,从而学习更好的个体模态表示。 第二个贡献是用于学习工业 3D 数据的稳健表示的模拟深度生成过程。 新方法 3DSR(第三个贡献)在 MVTec3D [2] 和 Eyecandies [4] 数据集上取得了最先进的结果。 在 MVTec3D 异常检测数据集 [2] 上,3DSR 在 3D 和 3D+RGB 异常检测设置中显着超越了竞争方法,展示了强大的 3D 异常检测能力,验证了所提出的贡献。 3DSR 比竞争方法更快,并且比之前使用基于点云的 3D 信息提取的最佳方法 M3DM [19] 快一个数量级。 所提出的深度模拟还可以通过在具有自我监督的模拟数据上进行训练来改进主干网络提取的表示,从而有助于将 RGB 异常检测方法的最新进展转移到 3D 领域。
致谢 这项工作得到了斯洛文尼亚研究机构计划 J2-3169、J2-2506、P2-0214 和 23-20MR.R588 的支持
参考
- [1] Paul Bergmann, Michael Fauser, David Sattlegger, and Carsten Steger. MVTec AD – A Comprehensive Real-World Dataset for Unsupervised Anomaly Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 9592–9600, 2019.
- [2] Paul Bergmann., Xin Jin., David Sattlegger., and Carsten Steger. The mvtec 3d-ad dataset for unsupervised 3d anomaly detection and localization. In Proceedings of the 17th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2022) - Volume 5: VISAPP, pages 202–213. INSTICC, SciTePress, 2022.
- [3] Paul Bergmann and David Sattlegger. Anomaly detection in 3d point clouds using deep geometric descriptors. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 2613–2623, 2023.
- [4] Luca Bonfiglioli, Marco Toschi, Davide Silvestri, Nicola Fioraio, and Daniele De Gregorio. The eyecandies dataset for unsupervised multimodal anomaly detection and localization. In Proceedings of the Asian Conference on Computer Vision, pages 3586–3602, 2022.
- [5] Thomas Defard, Aleksandr Setkov, Angelique Loesch, and Romaric Audigier. Padim: A patch distribution modeling framework for anomaly detection and localization. In International Conference on Pattern Recognition, pages 475–489. Springer, 2021.
- [6] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009.
- [7] Denis Gudovskiy, Shun Ishizaka, and Kazuki Kozuka. Cflow-ad: Real-time unsupervised anomaly detection with localization via conditional normalizing flows. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 98–107, 2022.
- [8] Geoffrey E Hinton, Alex Krizhevsky, and Ilya Sutskever. Imagenet classification with deep convolutional neural networks. Advances in neural information processing systems, 25(1106-1114):1, 2012.
- [9] Eliahu Horwitz and Yedid Hoshen. An empirical investigation of 3d anomaly detection and segmentation. arXiv preprint arXiv:2203.05550, 2022.
- [10] Chun-Liang Li, Kihyuk Sohn, Jinsung Yoon, and Tomas Pfister. Cutpaste: Self-supervised learning for anomaly detection and localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9664–9674, 2021.
- [11] Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollár. Focal loss for dense object detection. In Proceedings of the IEEE international conference on computer vision, pages 2980–2988, 2017.
- [12] Ken Perlin. An image synthesizer. ACM Siggraph Computer Graphics, 19(3):287–296, 1985.
- [13] Ali Razavi, Aaron van den Oord, and Oriol Vinyals. Generating diverse high-fidelity images with vq-vae-2. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché-Buc, E. Fox, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 32, pages 14866–14876. Curran Associates, Inc., 2019.
- [14] Karsten Roth, Latha Pemula, Joaquin Zepeda, Bernhard Schölkopf, Thomas Brox, and Peter Gehler. Towards total recall in industrial anomaly detection. arXiv preprint arXiv:2106.08265, 2021.
- [15] Marco Rudolph, Bastian Wandt, and Bodo Rosenhahn. Same same but differnet: Semi-supervised defect detection with normalizing flows. In Proceedings of the IEEE/CVF winter conference on applications of computer vision, pages 1907–1916, 2021.
- [16] Marco Rudolph, Tom Wehrbein, Bodo Rosenhahn, and Bastian Wandt. Fully convolutional cross-scale-flows for image-based defect detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 1088–1097, 2022.
- [17] Marco Rudolph, Tom Wehrbein, Bodo Rosenhahn, and Bastian Wandt. Asymmetric student-teacher networks for industrial anomaly detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 2592–2602, 2023.
- [18] Radu Bogdan Rusu, Nico Blodow, and Michael Beetz. Fast point feature histograms (fpfh) for 3d registration. In 2009 IEEE international conference on robotics and automation, pages 3212–3217. IEEE, 2009.
- [19] Yue Wang, Jinlong Peng, Jiangning Zhang, Ran Yi, Yabiao Wang, and Chengjie Wang. Multimodal industrial anomaly detection via hybrid fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8032–8041, 2023.
- [20] Minghui Yang, Peng Wu, and Hui Feng. Memseg: A semi-supervised method for image surface defect detection using differences and commonalities. Engineering Applications of Artificial Intelligence, 119:105835, 2023.
- [21] Jiawei Yu, Ye Zheng, Xiang Wang, Wei Li, Yushuang Wu, Rui Zhao, and Liwei Wu. Fastflow: Unsupervised anomaly detection and localization via 2d normalizing flows. arXiv preprint arXiv:2111.07677, 2021.
- [22] Vitjan Zavrtanik, Matej Kristan, and Danijel Skočaj. Dsr–a dual subspace re-projection network for surface anomaly detection. In Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXXI, pages 539–554. Springer, 2022.
- [23] Vitjan Zavrtanik, Matej Kristan, and Danijel Skočaj. Draem - a discriminatively trained reconstruction embedding for surface anomaly detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 8330–8339, October 2021.
- [24] Hengshuang Zhao, Li Jiang, Jiaya Jia, Philip HS Torr, and Vladlen Koltun. Point transformer. In Proceedings of the IEEE/CVF international conference on computer vision, pages 16259–16268, 2021.