ChartGPT:利用大语言模型从抽象自然语言生成
图表
摘要
由于自然语言交互的直观性,使用自然语言界面(NLI)创建图表变得越来越流行。 这种方法的一个关键挑战是准确捕获用户意图并将其转换为正确的图表规范。 这阻碍了 NLI 在图表生成中的广泛使用,因为用户的自然语言输入通常是摘要(即模糊或不明确),没有明确的视觉编码规范。 最近,预训练的大语言模型(大语言模型)在理解和生成自然语言方面表现出了优异的性能,展示了下游任务的巨大潜力。 受这一主要趋势的启发,我们提出了 ChartGPT,从 Abstract 自然语言输入生成图表。 然而,大语言模型正在努力解决复杂的逻辑问题。 为了使模型能够准确地指定复杂的参数并执行图表生成中的操作,我们将生成过程分解为一步一步的推理管道,以便模型在每次运行时只需要推理单个特定的子任务。 此外,大语言模型是在通用数据集上进行预训练的,这对于图表生成任务可能会有偏差。 为了提供足够的可视化知识,我们创建了一个由摘要话语和图表组成的数据集,并通过微调提高模型性能。 我们进一步为ChartGPT设计了一个交互界面,允许用户检查和修改每个步骤的中间输出。 通过定量评估和用户研究来评估所提出系统的有效性。
索引术语:
自然语言界面、大语言模型、数据可视化1 简介
自然语言界面(NLI)允许用户通过自然语言传达他们的意图,然后由机器将其翻译成可执行脚本以实现期望的结果。 这种易用性引发了大量研究,例如 NL4DV [1] 和 ncNet [2],探索使用 NLI 进行可视化生成以提高数据效率分析。 例如,用户只需说“创建显示 IMDB 评分分布的直方图”即可轻松创建显示电影数据集的 IMDB 评分分布的直方图。与传统方法相比,NLI 为不精通可视化编程(例如 d3 或 Vega-Lite)的分析人员提供了创建可视化的捷径。 即使对于高级可视化用户,NLI 也可以将他们从繁琐的编程问题或可视化工具包(例如 Tableau [3])上的交互式编辑中解放出来。
这种新方法的关键是精确捕获用户意图并生成适当的可视化,尽管自然语言存在模糊性和不规范性。 虽然可视化分析专家可能能够在一篇文章中指定可视化生成所需的所有必要信息,包括属性、数据转换、图表类型和可视化编码,但可视化编程的初学者可能很难提供所有必要的信息。 现有的研究[1, 2]为显式和完整的请求提供了一系列有效的解决方案,但这些解决方案在面对模糊或不完整的表达时可能会失败。 例如,“什么类型的电影最赚钱?”这样的表述。与“毛利润”领域隐含相关。此外,术语“类型”还可以指不同上下文中的不同字段(例如,流派、评级等)。 这种含蓄且模棱两可的表达方式使得很难将话语映射到具体操作。 这就提出了从摘要表达式生成有效可视化的问题,摘要表达式是不完整或隐式表达用户视觉分析意图的自然语言话语。
研究人员采用基于规则和基于约束的方法来解决这个问题。 其中一个示例是 NL4DV [1],它有助于根据对数据值或定义别名的引用进行属性推断。 此外,它还可以从选定的属性推断适当的任务和图表类型。 另一个例子是 Arklang [4],它定义了一组语法和语义约束,以允许各种类型的推理,包括对“昂贵”和“流行”等模糊表达式的解释。 这是通过在语义模型中使用元数据来实现的。 这两种方法都采用精心设计的规则或约束,提供用户的话语和数据集之外的额外人类知识,即使在用户的陈述不充分的情况下也可以进行推理。 然而,规则和约束可能很难维护、修改和扩展[5]。
最近出现了大型语言模型,例如 Bert[6]、GPT-3 [7] 和 ChatGPT [8] ,在自然语言理解方面表现出了出色的表现。 这些模型在大量文本语料库上进行了预训练,获得了大量知识,可用于各种下游任务,包括语言翻译、文本分类和数据解析[9]。 研究人员还在探索使用大语言模型来完成代码生成[10]、故事生成[11]和网页设计[12]<等任务/t2>. 这些大语言模型应用程序的巨大成功激励我们研究它们在可视化生成方面的潜力。 然而,使用大语言模型从摘要表达式生成可视化存在两个主要挑战。
控制图表生成中的参数和操作。 可视化生成的过程涉及一组复杂的参数和操作。 用户必须仔细指定标记、字段、编码和聚合等参数,然后由可视化系统(例如Vega-Lite和Tableau)执行这些参数来转换原始数据表并生成图表。 然而,虽然语言模型(大语言模型)可以对人类问题生成流畅且信息丰富的答案,但它们可能并不总是准确的,这就是众所周知的“幻觉问题”[13]。 这使得在可视化生成中直接使用大语言模型变得具有挑战性,因为单个不正确的参数可能会对后续操作产生负面影响,并可能危及整个过程。 为了应对这一挑战,我们采用系统方法,将图表生成过程分解为一系列相互关联的子任务,遵循从最少到最多想法的原则[14]。 这种分解使我们能够利用大语言模型的优势,为图表创建中涉及的复杂参数和操作生成定义明确且可管理的输出。
缺乏注入可视化知识的方法。 大语言模型的设计和训练是为了处理一般的语言相关任务,例如文本生成、识别和摘要。 为了使大语言模型更加具有领域针对性,通常使用两种方法:提示和微调。 提示是指向模型提供包含领域任务上下文和预期输出的文本。 然而,虽然有效,但这种方法并不总是实用,特别是当模型需要在一个提示中提供大量知识(例如,我们场景中的 Draco 规则)时。 使用适当的数据集对大语言模型进行微调可以提供更多的示例和知识。 虽然 NL2VIS [15, 16] 中有完善的数据集,但它们主要由明确的自然语言描述组成,不适合我们的场景。 为了应对这一挑战,我们构建了一个带有相应图表的摘要话语数据集。 该数据集使大语言模型能够在可视化数据分析中学习用户意图,并生成所需格式的图表配置。
在本研究中,我们引入了 ChartGPT,从 Abstract 话语生成图表。 我们利用流行的大语言模型卓越的语言理解能力来解决从摘要话语生成图表的挑战。 为了使大语言模型能够学习可视化知识并适应图表生成任务,我们构建了摘要话语数据集并对模型进行了建模。 基于微调的大语言模型,开发了一个交互式界面,将模型的中间步骤可视化,并允许用户探索和编辑结果。 我们使用最先进的 NL 图表模型、定量实验和比较用户研究来评估我们提出的方法。 实验结果表明,我们的方法在一致性和相似性方面可以获得更好的结果。 对比用户研究表明,该系统可以生成满足用户需求的令人满意的图表。 我们总结了对于改进基于 LLM 的图表生成系统具有洞察力的用户反馈。 这项研究有三个主要贡献。
-
我们提出了一个框架,使用微调的大语言模型从摘要话语生成图表。
-
我们构建了一个用于大语言模型微调的摘要话语和图表数据集。 该数据集可以促进未来这一方向的机器学习研究。
-
我们进行了定量实验和比较用户研究来证明所提出方法的有用性。 这些反馈可以为大语言模型在可视化方面的未来应用提供启示。
2 相关工作
2.1 可视化推荐
最近,人们对探索可视化推荐技术越来越感兴趣,这些技术可以帮助数据工作者解决创建可视化的艰巨任务[17]。 这些技术主要分为两类:基于规则的和基于机器学习(ML)的[18, 5]。 基于规则的方法根据可视化知识将数据映射到视觉编码,例如从实证研究中得出的结论。 大量推荐系统,如APT [19]、Show Me [20]、CompassQL [21]、Voyager [22, 23],是根据可视化规则编译的。 为了提高可视化规则的可用性,Moritz等人[24]将规则转化为答案集编程,并制定了知识库。 基于规则的方法虽然有效,但灵活性可能有限,因为规则是由领域专家手动指定的,并且难以更新、修改和维护。 依赖一组固定的预定义规则限制了它们适应不同类型数据或不断变化的数据条件的能力。
相比之下,基于机器学习的方法的优点是能够从数据中学习并适应不断变化的条件,从而使其更加灵活和稳健。 例如,DeepEye [25] 和 Draco-learn [24] 使用机器学习算法根据可视化设计规则对推荐的可视化进行排名。 其他研究,例如 Data2Vis [26] 和 Table2Charts [27] 利用序列到序列模型将数据集映射到视觉表示。 KG4Vis [28] 使用知识图来支持推荐的可解释性。 为了生成多视图可视化,MultiVision [29] 和 Dashbot [30] 采用深度学习方法对数据表进行建模。
这些研究的主要焦点是从数据表创建视觉表示。 然而,我们的论文采用了更具挑战性的方法,通过探索自然语言意图的理解并生成准确反映表格中数据的可视化。
2.2 数据可视化的自然语言接口
事实证明,自然语言界面在指定数据可视化方面非常有效[31,32,33]。 许多研究利用语义或词汇解析技术来推断用户意图并以适当的可视化进行响应。 Articulate [34] 使用图形推理算法提取视觉任务和属性并选择可视化。 DataTone [35]提出了交互式歧义小部件来帮助用户解决自然语言中的歧义。 FlowSense [36] 利用语义解析器来协助数据流图构建。 用户可以通过自然语言扩展和调整数据流图。 Eviza [37] 采用基于概率语法的方法,并允许使用现有可视化进行交互式查询对话框。 Evizeon [38]进一步应用语言语用学原理来支持视觉分析对话。 NL4DV [1] 还结合了基于词法和依存解析的技术,从用户话语和生成的视觉规范中推断属性和任务。 NL4DV 是一个与接口无关的工具包,允许开发人员通过包含 Python 包轻松集成它。 随着自然语言处理的最新进展,人们尝试利用基于深度学习的语言模型来产生可视化。 例如,ncNet [2] 采用基于 Transformer 的序列到序列模型将自然语言查询转换为可视化。
然而,这些研究主要针对显性请求,难以处理不完整或隐含的表达。 现有研究包括 Ask Data [4],它根据句法和语义约束解析部分话语,并生成可由 VizQL [39] 执行以生成可视化的中间语言。 这些方法的性能很大程度上受到语言解析器能力的限制。 在本文中,我们的目标是利用迄今为止最强大的语言模型(预训练的大语言模型)的语言理解能力来解决摘要自然语言的问题。
2.3 用于数据分析的大型语言模型
最近,大型语言模型(大语言模型)取得了重大进展,例如在线模型 Codex [10]、GPT-3 [7] 和 GPT-4 [40],以及开源模型 flan-T5 [41] 和 LLaMa [42, 43]。 这些模型经过数十TB文本数据的预训练,在自然语言的理解和生成方面表现出了卓越的性能。 大语言模型已应用于多个领域,包括代码生成[10]、故事生成[11]和网页设计[12] 。
具体来说,最近的研究探索了利用大语言模型进行数据分析。 一些研究采用大语言模型直接生成可视化代码,例如Python和Vega-Lite。 例如,CHAT2VIS [44] 通过用表模式、列类型和自然语言查询提示大语言模型,生成 Python 可视化代码。 类似地,LIDA [45] 将可视化生成定义为四阶段生成问题,并利用 GPT-3.5 生成可视化代码。 其他研究探索了大语言模型在数据分析中更广泛的应用。 GPT4-Analyst [46] 提出了一个框架,利用提示来指导 GPT-4 执行数据收集、可视化和分析。 Data-Copilot[47]无需编写代码,即可生成请求、选择所需接口并顺序或并行调用相应的接口工具。 所有这些工作都基于即时工程,依赖于 Codex、GPT-3、GPT-4 等在线模型,这些模型并不完全可控和稳定[13, 40]。 这些模型存在 ChatGPT 固有的幻觉问题,有时会提供不稳定的输出和错误的答案,导致无法遵循设计的流程。
与上述使用通用大语言模型的方法不同,我们选择训练一个可视化专用的大语言模型来解决图表推荐问题。 具体来说,我们采用思想链[48, 14]思想来分解任务,然后依次解决。 与之前依赖在线大语言模型即时工程的研究不同,我们在我们专门构建的数据集上使用 Abstract 自然语言对开源大语言模型进行了微调。 此外,我们还开发了模型输入和输出的模板,增强了各种可视化表示的解析和适用性,以 Vega-lite 为例。
3 问题表述
本节描述我们如何将图表生成问题表述为逐步推理子任务。
3.1 LM 中的推理策略
在语言模型 (LM) 领域,推理被定义为将复杂任务分解为 LM 可以轻松解决的更简单的子任务的过程。 具体来说,在从最少到最多的推理策略中,首先将原始任务划分为一系列子任务,从最简单的开始,逐渐复杂。 通过推理过程,LM 能够借助先前解决的子任务来解决更复杂的子任务。
为了解决图表生成问题,我们还采用了分解方法,将其分解为一系列明确定义的子任务。 因此,我们将任务制定为固定的子任务序列,每个子任务都由一个语言模型(大语言模型)处理,该模型根据问题上下文和先前子任务的输出生成答案。 最后,将所有子任务的答案合并以生成完整的图表。
3.2 问题表述
我们基于信息可视化数据状态参考模型[49, 50]来制定我们的问题,该模型将可视化管道概述为一系列数据阶段,并解释数据如何经历从一个阶段到另一个阶段的各种转换。下一个。
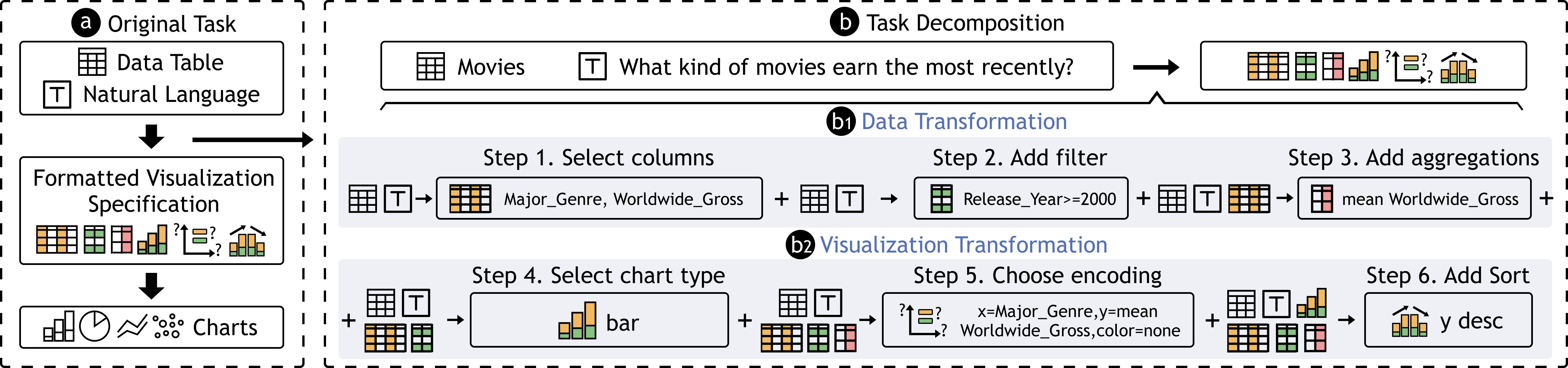
如 Figure 1a 所示,我们将问题划分为三个数据阶段:表格数据、格式化可视化规范和可视化图表。 具体来说,格式化的可视化规范是满足特定可视化语法的文本序列,可以被解析、编译并呈现为可视化图表。 示例包括 Vega-Lite [51]、Vega-Zero [2] 以及 Table2Charts [27] 中定义的图表模板。 我们还提出了一个与我们的方法和管道兼容的格式化模板。
我们的关键挑战是阶段性的转变,即如何根据用户话语从表数据生成可视化规范。 为此,我们将流程分解为一系列子任务,并将每个子任务表述为格式化的序列到序列问题,如 Figure 1b 所示。
3.2.1 问题分解
受图形语法[52,53,54]的启发,我们将数据到格式化可视化规范的过程分为两个连续的转换:数据转换和可视化转换(Figure 1 b1 和Figure 1b2)。 两者都包含三个子任务,从而产生六个子任务的序列,这些子任务是逐步执行的。
数据转换。 数据转换包含处理表数据的操作。 完成此转换后,转换后的数据就可以直接编码到视觉通道中。 我们的数据转换过程包括三个子任务:选择列、过滤所需的行以及添加聚合。 首先根据表格数据和用户话语选择相关列,通常涉及1-3列。 其次,根据用户话语按需过滤表格行。 第三,我们需要聚合数据并获得新的必要数据属性(例如,使用计数、平均值、总和等函数)。
可视化转型。 获得变换后的数据后,可视化变换确定视觉通道的适当编码。 此过程也包含三个子任务:选择图表类型、确定视觉编码以及添加可选操作。 首先,模型需要根据用户话语推断哪种图表类型适合所选数据和聚合。 其次,选择图表类型后,模型需要将数据字段映射到可视化通道。 请注意,在该子任务中,字段是数据转换后的字段。 例如,如果对特定字段“a”执行分箱和计数,则要编码的字段应为“count(binned(a))”。 第三,结果图表可能有可选操作,例如颜色、排序顺序和 bin 宽度等。 在本研究中,为了简单起见,我们主要考虑按轴排序。
经过这六步连续的转换过程,获得足够的信息来制定可视化规范。 事实上,图表生成远远超出了上述步骤。 其他设计方案包括颜色、尺寸、带宽和方向等因素。 图表生成中涉及的转换不仅限于简单的过滤条件和多种聚合函数。 这些替代方案可以通过工程扩展来实现,即引入额外的步骤或选项以及扩展相关数据集。 在本研究中,作为概念验证系统,我们仅考虑六个子任务和几个主要设计选择,以简化问题并鼓励在未来的工作中探索更多的设计方案。
3.2.2 子任务答案模板
我们将问题分解为六个子任务。 下一步是将每个子任务建模为序列到序列问题,以便可以通过 LM 来解决。
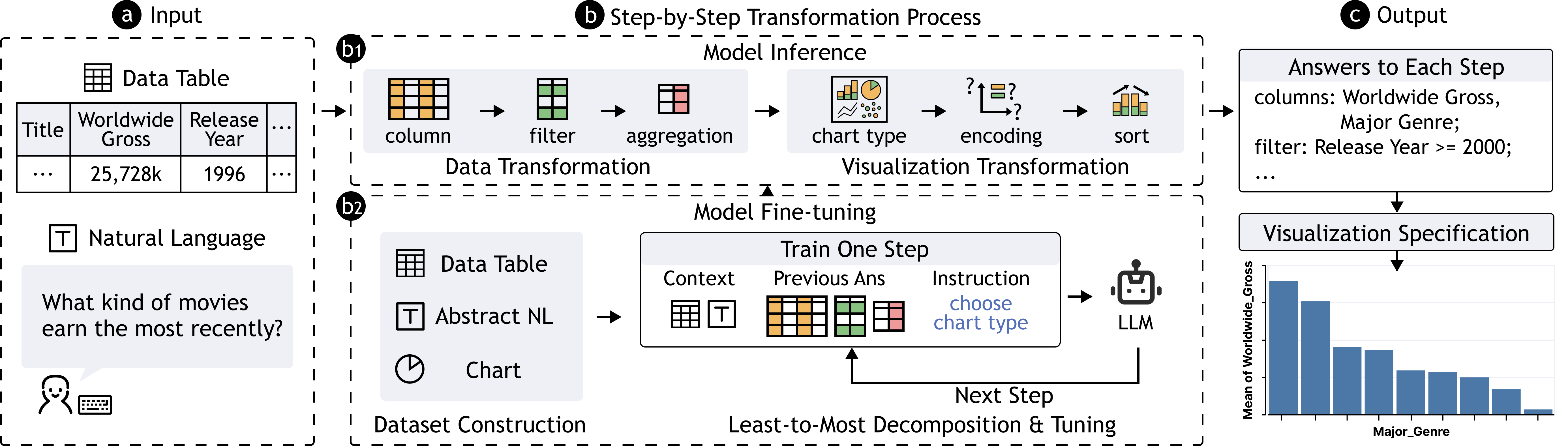
如 Figure 2 所示,对于每个子任务,模型都会获得一个文本序列作为输入,其中包含表格数据、用户话语和之前子任务的答案,以便更好地帮助模型进行推理。 然后,该模型将输出一个文本序列作为子任务的答案,该序列预计满足三个标准:(1) 涵盖所有强制性信息,(2) 格式良好,以实现准确的解析和有效的规范构建,以及(3) 以线性结构表示,因为分层或代码结构(例如 Vega-Lite 和 D3)不适合一般 LM 提出。 为此,我们为每个子任务定义了相应的模板序列,如 Figure 3 所示。 与 Vega-Zero [2] 类似,我们将图表创建的工作流程分解为多个子任务。
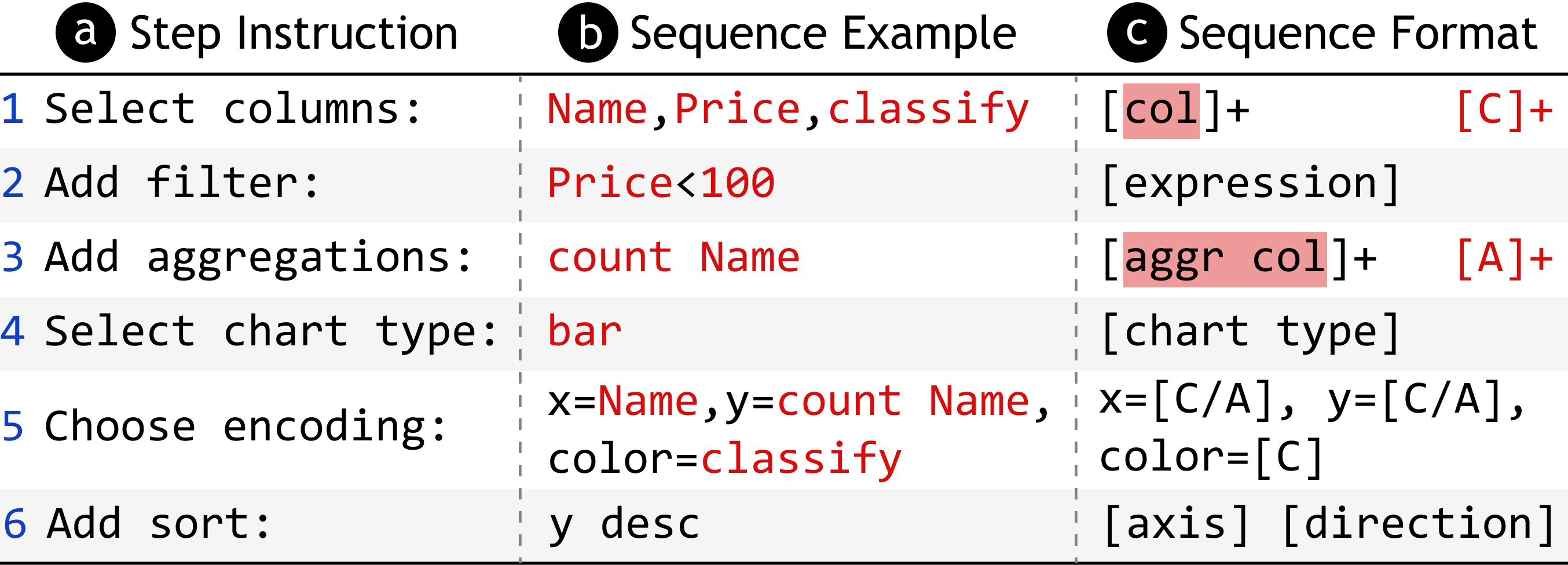
具体来说,选定的列由用逗号分隔的标题名称(用“col”表示)表示。 Filter 是由条件组成的表达式字符串,每个条件涉及特定列并使用等于、大于、小于等谓词。 这些条件通过“与”/“或”进行逻辑连接。 聚合函数(用“aggr”表示)可以应用于某些选定的列,用“aggr col”表示。 函数包括计数、平均值、总和、最大值和最小值。 Mark指定图表类型,包括条形图、饼图、折线图和散点图。 编码将轴与选定的列 (C) 和聚合 (A) 进行映射。 Sort 指示要排序的轴 (x/y) 以及排序顺序 (desc/asc)。
模型输出每个子任务的答案,然后构造过滤、标记、编码和排序的答案,以生成合适的 Vega-Lite 规范。 一些子任务,包括过滤、聚合、颜色编码和排序,可能并不总是必要的,在这些情况下模型将输出“None”。
我们的系统涵盖了数据分析中常见的七种图表[55, 56]:条形图、堆积条形图、折线图、分组折线图、散点图、分组散点图和饼图。 模板中不考虑更复杂的图表类型,例如雷达图和热图。 此外,过滤器和聚合任务还包含不支持的其他设计选项。 在我们的工作中,我们只关注每个子任务的常见和基本设计方案,以初步验证大语言模型推理可视化设计的潜力。
4 图表GPT
本节描述用于指导大语言模型推理以回答每个子任务的方法。 我们派生了一个 NL2VIS 数据集来构建一个大型语言模型,并通过该模型生成答案。 数据集是通过提示GPT-3[7]构建的。 https://github.com/bebinca/ChartGPT-materials 上提供了提示、数据集和模型输入设置的详细信息。
4.1 模型输入
对于特定的子任务,由于其答案基于整个任务上下文和之前子任务的答案,因此模型输入应包含三部分信息:(1)表格数据,(2)用户话语,以及( 3)先前子任务的答案。 然而,对于表数据,由于大语言模型可以处理的标记大小有限,将整个表数据输入到模型中是不可行的。 因此,我们仅将列名称和前两个数据行合并到模型输入中。 此外,为了补偿仅包含部分数据可能导致的模型认知偏差,我们将每个数据列的类型添加到输入中以提供整体数据概述。
4.2 推理提示和摘要话语
将大语言模型用于特定下游任务的一个有效方法是设计精心设计的提示来指导模型理解任务目标。 提示可以包括说明和示例。 例如,当任务是对推文的情绪进行分类时,提示可能包括一条指令,指出“确定推文的情绪是积极的、中性的还是消极的”,以及一些示例,例如“我喜欢新蝙蝠侠”电影! =>积极”。 然后,该模型应该能够对“我讨厌巧克力”生成“否定”响应。这种在提示中包含示例的技术称为少样本提示[7]。 少样本提示可以促进模型理解上下文和任务,这促使我们考虑该技术是否可以应用于从自然语言生成可视化。
然而,由于自然语言的灵活性,用户的话语可以针对不同的信息和不同的层次进行摘要。 例如,在信息抽象方面,用户可能会在文章中省略图表类型,或者以模糊的术语引用数据列,例如使用“流行”来表示“评级”或“总的”。 对于级别抽象,用户可以具体表达自己的可视化需求,例如“一个饼图,显示每个级别的教职人员数量”,它直接指定所选的列(级别)、聚合(计数) )和图表类型(饼图)。 另一方面,他们也可能使用更多的摘要查询,例如简单地说“显示排名”。这种规范的省略可能会导致特定子任务的多种解释和推理路径。 例如,图表类型的选择可以由所选列(例如,两个定量属性的散点图)或用户的分析意图(例如,“分布”等短语的直方图)来确定。
解释和推理路径的复杂性使得在单个提示中为每个子任务提供足够的示例变得特别具有挑战性。 为了帮助模型更全面地理解子任务的解释,我们构建了一个训练数据集并相应地调整了模型。
4.3 微调数据集
4.3.1 数据集要求
我们模型的数据集应该由(数据、文章、图表)三元组组成。 为了确保数据集能够为模型提供足够的知识,它应该涵盖尽可能完整的解释路径和推理方式。 因此,数据集应满足几个要求:
各种领域和类型的数据和图表。 表数据应涵盖各个域,以避免对单个域的过度拟合。 如果数据集的领域过于集中,例如,如果大多数表格与电影和电视相关,则模型可能会过度拟合该数据集上下文,从而难以面对其他领域的数据。 另外,涉及的数据类型、图表类型也应该全面、多样。
用于数据分析的不同级别的信息。 对于不同的信息和不同的层次,自然语言应该是摘要,如subsection 4.2中提到的。 它还应该涵盖各种表达方式,例如描述所选列的方式(例如显式或隐式)和措辞(例如命令、问题或查询)。
之前有关 NL2VIS 数据集的工作包括 Quda [57]、NLV Corpus [15] 和 nvBench [16]。 具体来说,Quda 由 14,035 个用户单词查询组成,涵盖各种分析任务。 但是,没有提供相关图表。 NLV语料库收集了涉及10种图表的893条话语,并进一步分析了收集的话语跨越不同表达和抽象的特征。 但NLV语料库仅基于三个数据表,过于集中。 nvBench 的数据集最接近满足我们的要求,其中包含来自 105 个表数据域的 25,750 个(数据、文章、图表)三元组。 然而,nvBench 中的大多数话语都非常明确[46]。 因此,我们基于 nvBench 构建数据集,该数据集由不同抽象和表达的话语组成。
4.3.2 数据集构建
要构建基于 nvBench 的数据集,主要任务是维护多样化的数据集和视觉配置,并从原始三元组生成 Abstract 话语。 为了维护多样化的数据集,我们随机选择覆盖所有领域和图表类型等的原始三元组的一部分。对于摘要话语,我们使用 GPT-3 (text-davinci-003) 生成它们,并让四位共同作者进行检查他们的正确性。 我们通过以下过程生成数据集:
图表选择。 我们选择了nvBench中的部分图表,使其符合我们的要求。 首先,由于nvBench在生成过程中包含一些涉及多个表(使用“join”操作)的图表,因此我们删除了这部分数据。 其次,nvBench 由来自不同领域和图表类型的(数据、文章、图表)三元组组成。 此外,nvBench 将这些三元组分为四个硬度级别,即简单、中等、困难和超硬。 这些硬度级别反映了图表生成的复杂性。 例如,对三列进行编码并需要筛选、聚合和排序操作的图表可能会被归类为超难图表。 我们随机选择图表,并确保所选数据仍然涵盖所有领域、硬度级别和图表类型。 我们没有尽可能保留nvBench训练的数据,而是只选择了一部分图表,以减少后续手动操作的成本,考虑到微调大语言模型所需的数据比完全一个新模型要少。
摘要话语生成。 选择图表后,我们使用 GPT-3 从其相应的(数据、文章、图表)三元组自动为每个图表生成摘要话语。 对于每个三元组,我们手动设计一个提示来指导 GPT-3 执行此操作:首先,我们提供 CSV 表数据的前几行,并描述一个场景,在该场景中,我们开发一个工具来根据用户话语自动生成图表,表数据。 然后,我们给出一个来自三联体的原始单词作为一个明确的单词示例。 我们告诉GPT-3模型,我们需要摘要话语来测试工具的性能,并要求模型根据明确的原始话语和表数据生成摘要话语。 我们还指导模型生成的话语应该更加自然、模糊和不完整,并且可以采用各种措辞。
此外,在生成过程中,我们动态检查了单词生成结果的多样性。 例如,起初,我们观察到结果倾向于使用许多礼貌和口头表达,例如“Can you show me”(例如,“Can you show me the amount of matches for every racing on a graph?”)或“我想看看”(例如,“我想看看不同地点的电影院数量的可视化。”)。 这可能归因于 GPT-3 对“自然”的解释为包含更多礼貌和口头表达。 虽然这些短语很常用,但 NLV 语料库表明用户的话语通常是简短的查询或命令。 NLV 语料库的示例包括“创意类型直方图”和“根据烂番茄评分绘制 IMDB 评分”。由于 NLV 语料库将大多数话语分为查询、问题和命令,我们修改了提示以适应一系列短语,并获得了没有过度礼貌和口头表达的话语,例如“预算创建趋势”和“按开年划分的情节容量” 。 我们保留了之前生成的话语,并将它们与新添加的内容一起包含在最终数据集中。
摘要论文修正。 生成的话语应与 nvBench 中的(数据、话语、图表)三元组中的原始图表保持一致。 换句话说,图表应该是对文章的合理回答。 由于大多数生成的摘要话语删除或模糊了原始话语中的某些信息,因此某些生成的结果与原始图表不一致。 具体来说,对于过滤器而言,相比于图表类型等设置在文章中删除后仍可能与原始图表保持一致,删除过滤器信息的话语不再与原始图表一致。 一般来说,不一致的数据是通过三位共同作者手动过滤的,然后由另一位共同作者审查。 数据修正中的任何分歧均通过讨论解决。
逐步生成答案。 由于我们的模型输出包含中间子任务的答案,因此我们需要解析图表配置并提取每个子任务的答案。 然后,我们结合答案和格式化模板来构建模型的预期输出。
4.3.3 数据集统计
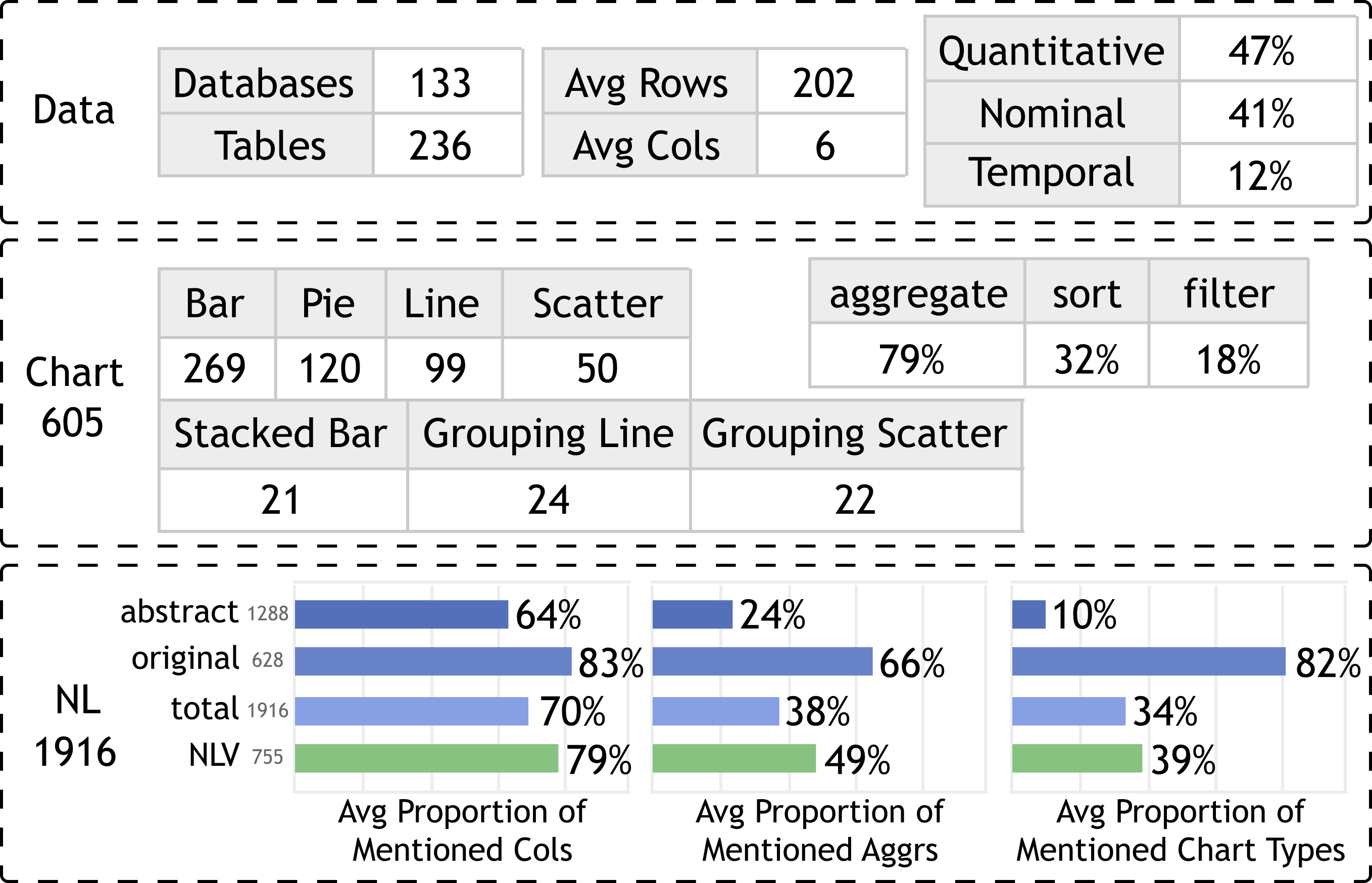
我们构建的数据集包含 1,916 个(数据、图表、话语)三元组,其中包括 236 个数据表、605 个图表和 1,916 个话语。 Figure 4 说明了我们数据集的统计数据。
对于数据表,我们的数据集包含来自 133 个数据库的 236 个表。 数据表平均有5列202行,其中定量列占47%,名义列占41%,时间列占12%。 对于图表,我们的数据集涵盖七种图表类型。 具体来说,所有图表中,79%涉及聚合,32%涉及排序,18%涉及过滤操作。
对于话语,我们保留了 nvBench 中的原始话语。 最终数据集总共包含 1916 个话语,其中包括 1288 个新生成的摘要话语和 628 个原始话语。 此外,我们还比较了我们的数据集和手动创建的数据集 NLV Corpus [15] 之间的统计数据。 我们量化了与话语中提到的选定列、聚合和图表类型相关的显式信息的频率。 对于选定的列,我们计算了明确提及的列名称的比例。 例如,如果一个图表涉及三栏,但相应的文章只涉及其中两栏,则比例为2/3。 对于图表类型和聚合,我们检查了是否存在显式表达式,例如图表类型的“bar”、“scatterplot”以及聚合的“number of”、“count”。
结果表明,在 NLV 语料库话语中,选定的列被更频繁地明确提及 (79%),而图表类型 (49%) 和聚合 (39%) 经常被省略或模糊表达。 nvBench 的话语中显式信息的出现率较高,特别是对于聚合 (66%) 和图表类型 (82%)。 然而,在与 GPT-3 生成的摘要话语融合后,生成的数据集显示显式信息显着减少,特别是在聚合和图表类型方面,这与 NLV 语料库非常相似。 结果,我们创建了一个看起来自然的数据集,并且在某种程度上与手动创建的数据集相似。

在上面的分析中,我们重点评估所选列、聚合和图表类型的分布,因为这些属性可以更明确地确定,同时量化是否明确提到的编码、过滤器和排序涉及不同人的主观意见。 为了进一步衡量我们生成的话语的质量并确定它是否接近人类创造的话语,我们进行了图灵测试。
4.3.4图灵测试
我们招募了 14 名受试者(7 名男性和 7 名女性,他们都拥有数据分析经验)来进行图灵测试,评估我们生成的话语的质量。 我们从 NLV 语料库中的 3 个表中随机选择了 30 个话语,并从我们生成的摘要话语中随机选择了 30 个话语,涉及 8 个顺序打乱的表。 在测试过程中,每次向每个受试者提供一篇文章以及相应的表格。 向受试者展示的场景如下:“想象一个可以根据表格和用户话语自动生成图表的工具。 下面哪些话语可能是由真实用户创建的?”我们明确告知受试者,显示的一些话语是人类创造的,而另一些则不是。 他们的任务是根据两个角度区分这两个类别:(1)措辞的自然性和(2)上下文的意义。 我们假设生成的被判断为人类创建的摘要话语的比率将与 NLV 语料库处于同一水平。 实验结束后,我们给每位受试者补偿 5 美元。
总体结果。 结果显示平均错误率为 56%(Figure 5a),最低错误率为 33%,这表明受试者很难区分 GPT 生成的话语和人类的话语-创建的。 此外,我们还计算了每篇文章被判断为人类创作的平均比率 ()。 所有 60 个样本的总体平均值 为 0.73,表明受试者将大多数样本标记为人造。
生成的话语与人类创建的话语之间的比较。 比较这两组,我们生成的摘要话语和 NLV 语料库的平均 值分别为 0.79 和 0.67(Figure 5b)。 相应的标准偏差(SD)值为0.17和0.23。
为了评估差异,我们进行了 Mann-Whitney U 检验,结果表明存在显着差异 (p = 0.03 <0.05)。 这一结果表明,生成的话语比 NLV 语料库的话语更有可能被视为人类创造的。 为了理解这种差异,我们检查了 值相对较低的 NLV 语料库样本。 有一篇文章以明显较低的 0.14 脱颖而出:“Sum(Sales) by Order Date split by Category render line asc”。 这篇文章在格式上类似于字幕,被大多数科目认为不太自然。 NLV Corpus 本身也承认,他们收集的话语中包含此类措辞相对不常见的样本。
4.4 模型微调
我们首先将数据集划分为一个由 1,538 个三元组组成的训练集,用于微调,以及一个包含 378 个三元组(模型不可见)的测试集,用于评估(4:1 分割)。 然后,我们在训练集上使用 AdamW 优化器 [58] 对开源 FLAN-T5-XL 模型 [41] 进行微调。
我们选择Flan-T5进行微调,是因为它经过了各种任务的预训练,包括涉及推理的任务,具有很强的推理能力。 在此过程中,我们采用的学习率为 1e-4,全局批量大小为 16,并训练了 5 个 epoch。 一般来说,训练后的模型获得的评估损失为0.05。 这些参数是根据模型文档111https://huggingface.co/docs/transformers/model_doc/t5,试验和错误,以及我们的计算资源的容量。 我们在section 6中展示了评估结果。
5 接口
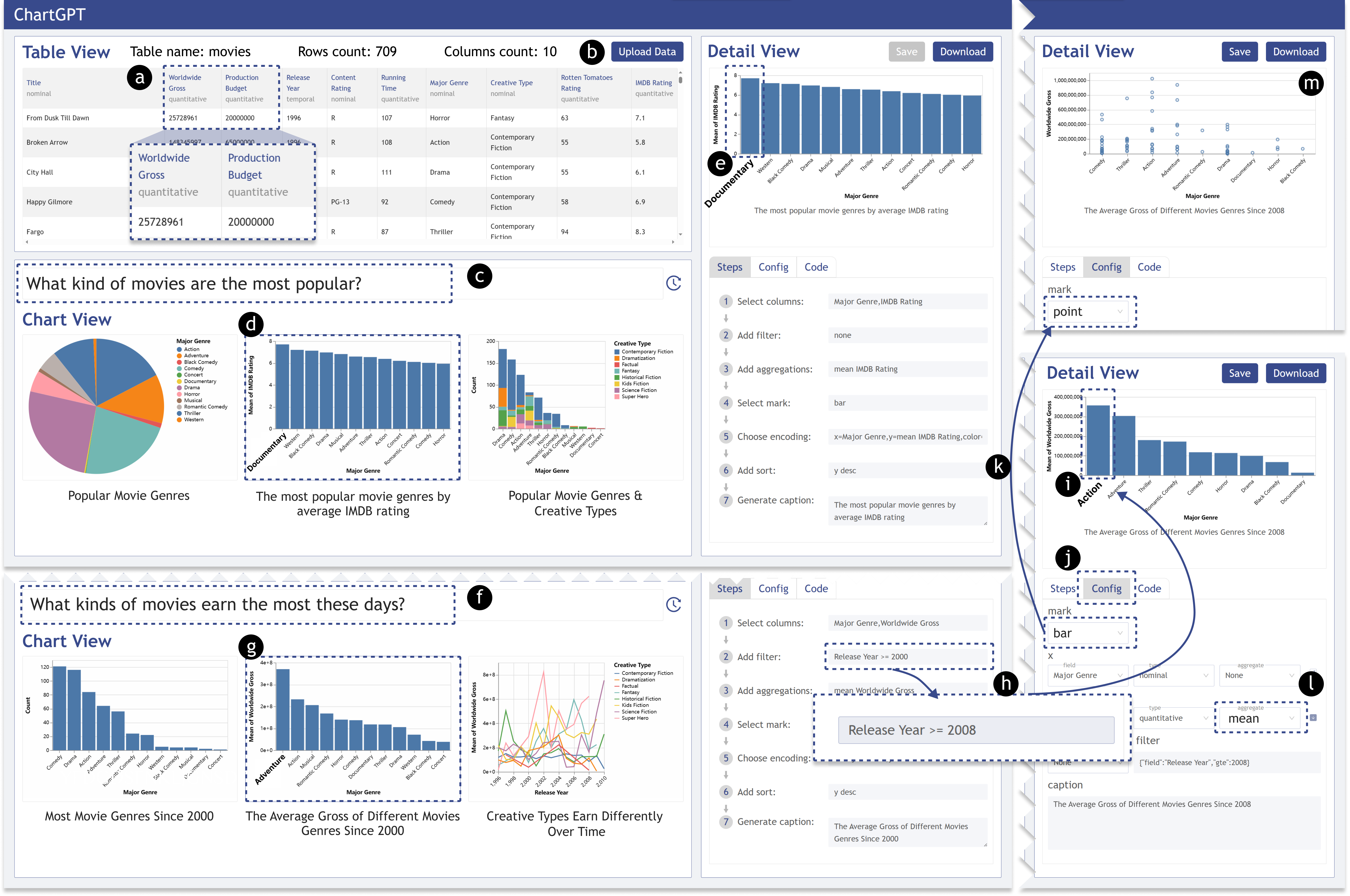
我们开发了一个具有三个视图的界面:表格视图、图表视图和详细视图。 在本节中,我们通过基于电影数据集的使用场景来展示我们的界面的功能。
首先,用户上传 CSV 文件(Figure 6b)。 表格数据将随每列的类型一起显示,包括标称、定量或时间。 然后,用户可以快速浏览表标题及其类型和相关数据。 她/他注意到电影数据表包含 10 列和 709 行,每行提供有关特定电影的详细信息。
用户想知道“什么类型的电影最受欢迎?”并将该问题输入搜索框(Figure 6c)。 然后 ChartGPT 根据输入返回前三个图表。 用户观察到,第一张图表和第三张图表分别按流派和创意类型显示了电影数量,第二张图表显示了每种流派的平均 IMDB 评分。 用户对第二个(Figure 6d)感兴趣,并了解 IMDB 平均评分最高的电影类型是纪录片。
6 评估
本节介绍 ChartGPT 与 NL4DV 和 ncNet 的对比评估以及 ChartGPT 界面的可用性研究。
6.1 评估设置
我们使用subsection 4.4中导出的测试集来评估 ChartGPT、NL4DV 和 ncNet 的性能。 由于我们的系统和 NL4DV 都可以返回多个结果,因此我们报告了这两种方法的 top-1 和 top-3 结果,并报告了 ncNet 的 top-1 结果。 但请注意,三种方法的设计空间也略有不同。 例如,NL4DV 支持箱线图和刻度图,但不支持饼图。 为了公平起见,我们只比较所有方法可以产生的结果。 对于NL4DV不支持的设计空间配置的测试数据,我们也没有将其引入结果统计中。
6.2 评估指标
我们测量了两个指标:一致性和相似性。 一致性用于计算系统产生的结果与真实情况完全相同的数量。 此外,由于我们的输入是抽象的,可能会导致歧义,因此我们进一步考虑了结果与真实情况的相似程度。 我们假设,即使输入是不明确的并且可以对应多个正确答案,这些答案在某种程度上也与真实值相似。 因此,我们利用相似度来进一步衡量系统处理 Abstract 自然语言的能力。
一致性指标。 如果结果与基本事实相同,我们将结果定义为“一致”。 此外,在我们的场景中,“相同”意味着所有支持的设计方案都是相同的,即标记、编码、聚合、排序和过滤器都是相同的。 此外,我们认为 x 和 y 反转的两个散点图也是一致的,因为它们仍然指向相同的结果[15]。
相似性度量。 我们将结果的“相似性”定义为在综合设计方案方面与基本事实的相似程度。 我们将groundtruth和不同方法的结果转换为等长的单词序列,然后比较序列的相似度。 特别地,我们将序列的格式定义为8个字的序列,即[标记] [x字段] [x聚合] [y字段] [y聚合] [颜色字段] [过滤器] [排序],并且每个部分是一个单词。 然后,我们测量了结果和真实值之间的 ROUGH-L [59] 和 BLEU [60] 指标。 ROUGH-L根据最长公共子序列(LCS)的长度计算两个序列之间的相似度。 该值受单词的值和顺序的影响。 在这个指标下,如果地面实况和模型结果中所选的字段和聚合相同但在不同的轴上编码,则分数将会降低。 我们假设与具有不适当编码的图表相比,具有相同选定字段和聚合但映射到与地面实况不同的轴的图表仍然是可以接受的。 因此,作为 ROUGE-L 的补充,我们使用 BLEU 分数测试模型,该分数允许模型切换某些编码字段的顺序。
具体来说,在转换为序列之前,我们首先验证结果是否与输入数据表相关,并且可以正确解析为Vega-Lite代码格式。 例如,如果结果包含表中不存在的列名,则结果无效。 将结果解析到Vega-Lite并显示后,会报错或者显示为undefined,因为找不到对应的数据。 我们将这些结果的相似性和一致性标记为零。
6.3评估结果
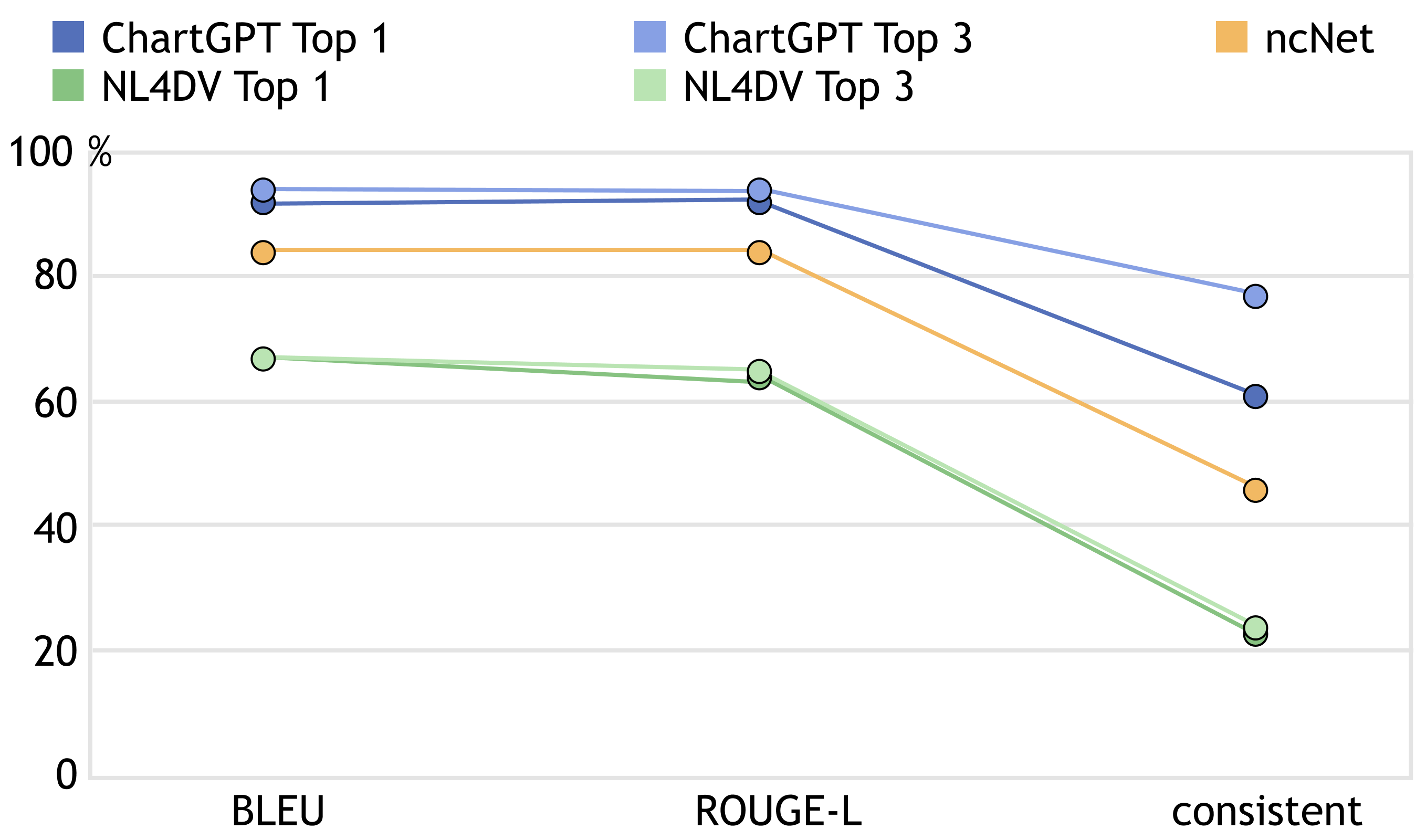
我们的评估结果见 Figure 7,其中展示了 ChartGPT、ncNet 和 NL4DV 的前 1 名和前 3 名评论。 结果表明,ChartGPT 在一致性指标和相似性指标方面均优于其他两个模型,其 top-1 和 top-3 评论得分高于 ncNet 和 NL4DV。
与基线的比较。 纵观测试用例,有两个关键因素导致了这些方法之间的差异:一是语义理解。 ChartGPT 对表头和话语的语义信息有更好的解析。 示例包括从“男性和女性”推断“性别”列,从“多大”推断“年龄”列,以及从“何时创建最多部门”推断时间列和计数聚合。 另一种是省略信息。 摘要话语经常省略聚合和图表类型等信息,这需要推理可视化规范的能力。 ChartGPT基于Flan-T5,Flan-T5之前在思想链(CoT)推理任务上进行了微调,我们在可视化数据集上以CoT的方式进一步微调,使其具有更好的推理能力的遗漏信息。
度量差异分析。 与其他两个指标相比,一致性指标要低得多,这可能是由于两个因素造成的。 首先,摘要话语中的歧义通常会导致多个合理的答案。 例如,考虑摘要文章“每个位置有多少文档? ” 摘自原文“在饼图中显示每个位置代码的文档数量”。 这种抽象删除了图表类型的信息,使条形图也是一种合理的响应。 其次,当模型错过一些微妙但对图表表达力至关重要的信息时,就会出现部分正确的推论。 例如,模型可能正确提取所需的列,但给出错误的聚合,或者错过过滤和排序条件。
7 用户研究
我们进行了比较研究和可用性研究来进一步评估 ChartGPT。 通过用户研究,我们希望(1)从用户的角度比较 ChartGPT 与两种基线方法的结果,以及(2)评估 ChartGPT 的可用性。
7.1 比较研究
在这项研究中,我们招募了 12 名受试者(6 名男性和 6 名女性,他们都拥有生成数据可视化的经验)进行比较研究,评估不同方法(ChartGPT、ncNet 和 NL4DV)生成的图表的质量。 他们都没有使用上述方法的经验。
任务和数据。 我们从测试数据集中采样了 15 个话语,对应于 NL4DV (top-1)、ncNet 和 ChartGPT (top-1) 生成的 13 个数据表和 42 个图表。 以随机顺序向受试者提供表格、话语和生成的图表,然后要求他们对图表的质量进行比较和排名,根据他们的偏好决定哪些图表对于表格和话语的输出更合理。 如果他们认为某个图表没有意义,则不会将其包含在排名中。 抽样基于两个步骤。 首先,我们选择了接近常识的表格,以确保受试者能够理解表格上下文。 其次,我们从选定的表中选择摘要话语,并确保(1)话语采用各种抽象和措辞,(2)图表类型都包含在内。
过程。 整个实验持续约10-25分钟。 首先,向受试者介绍用于生成数据可视化的自然语言界面的背景,时间为 3 分钟。 然后,他们开始根据提供的数据表和话语对生成的图表的质量进行比较和排名。 受试者在执行操作之前必须确保他们理解数据表和话语的内容。 他们可以询问数据表、文章或图表中特定图例的含义,但必须完全根据自己的想法和喜好对图表进行排名。 实验结束后,我们给每位受试者补偿 5 美元。
结果。 我们统计了各科目的排名结果。 具体来说,对于用户对某一篇文章对应的图表的排名,我们将排名归一化为0到3的分数,其中第一个排名为3,未出现在排名中的图表为0。 此外,我们还计算了每种方法排名第一的比例。 我们使用弗里德曼检验来检查这些方法是否存在显着差异,并使用事后威尔科克森检验来比较配对组。
结果显示,排名分数(=8.00,p 0.05)和第一排名比例(=17.64,p =17.64, p 0.001)。 总体而言,ChartGPT 的表现最好(即平均排名分数和第一排名比例较高,p 0.05)。 结果见 Figure 8。

7.2 可用性研究

7.2.1 实验设置
参与者。 我们从不同院系招收了12个科目(中一至中二,6男6女),包括计算机科学(3)、体育科学(2)、数字媒体设计(2)、城市信息学(1)、工业设计(1) 、地理信息科学(1)、农业工程(1)和公司金融(1)。 大多数受试者熟悉数据可视化图表,在 5 点李克特量表中,自我报告的平均得分为 3.4。 所有受试者都有使用工具创作数据图表的经验,包括 Microsoft Excel、Vega-Lite、D3.js、G2、ECharts 和 Matplotlib。 此外,他们都有使用自然语言界面(包括ChatGPT)和科技英语写作的经验。
任务和数据。 向受试者提供两张数据表(电影和汽车),并要求他们选择他们更熟悉或更感兴趣的一张。 他们需要使用 ChartGPT 探索选定的数据,并根据自然语言输入创建至少四个所需的图表。 在创建过程中,如果默认生成的图表不符合他们的愿望,受试者可以重新措辞他们的输入单词,修改步骤答案并重新生成结果,或者直接修改图表配置以获得所需的图表。 然而,如果受试者无论采取什么行动都无法获得所需的图表,或者如果他们想要的图表不受 ChartGPT 支持,他们可以放弃意图并尝试生成另一个新的所需图表。 总的来说,创建的图表应包含至少两种图表类型,涉及至少三个不同的数据列。 电影和汽车数据均来自 NLV 语料库[15],超过 9 列和 300 行,涉及所有三种类型的值(时间、名义和定量)。 我们选择这两个数据表是因为它们的上下文接近常识且易于理解。
过程。 整个实验持续约20-35分钟。 首先要求受试者从电影和汽车数据集中选择他们更感兴趣和熟悉的数据表。 我们确保受试者在下一步之前能够理解数据集。 然后向受试者介绍了 ChartGPT 系统的功能和交互。 在介绍过程中,我们没有向受试者提供任何具体的输入示例,以避免影响他们组织语言的方式。 相反,我们鼓励这个阶段的用户将任何东西视为自己的输入,并在此过程中引入界面和交互。 介绍完毕后,受试者开始用他们选择的数据创建他们想要的图表。 记录受试者采取的所有输入和行动。 最后,完成任务后,我们采访了受试者,收集他们对 ChartGPT 的反馈。 实验结束后,我们给每个受试者补偿10美元。
7.2.2定量结果
可用性研究的结果见 Figure 9,相应的统计数据见 Figure 9b。 总共从受试者那里收集了 53 条历史日志,其中 49 条成功生成了图表。 另外4个失败的日志表明受试者无法获得满意的图表,从而放弃输入并开始生成不同的图表。 根据受试者为获得图表而执行的操作,这些成功生成的图表被进一步分为三类:(i)在第一次尝试时获得,(ii)在调整步骤或配置设置后获得,以及(iii)在重新表述后获得输入单词。
近一半的排行榜(49 个排行榜中的 23 个,占 47%)是第一次尝试就获得的。 在 13 个案例中,受试者对步骤或配置设置进行了调整,其中 13 个案例重新表述了他们的输入语句。 然而,这种调整并不一定意味着系统生成的结果与他们的输入不匹配。 事实上,对于所有调整步骤和配置案例以及大多数改写案例,输入和系统生成的图表都是一致的。 尽管如此,一些参与者在查看最初的图表后,希望根据自己的想法进行进一步的调整。 因此,我们进一步统计了改写案例中系统生成的图表和用户输入匹配的案例数量(13 例中有 10 例)。 在剩下的三个案例中,参与者尝试分别改写一次、两次和三次他们的输入语句,直到获得与他们的输入相匹配的令人满意的结果。
在四个失败的输入中,其中三个涉及系统不支持的数据转换或视觉编码,例如将总额除以预算或在单个结果中并排显示两个条形图。 剩余的输入无法生成有效的图表,因为提供的编码是自相矛盾的(尝试对 x 轴上的两个数据字段进行编码)。
7.2.3 定性反馈
该系统能够响应不完整的意图,从而简化了思维过程,使用户能够从浅到深地探索数据。 大多数用户在使用系统时都参与了一些不完全意图的输入。 这些输入往往只涉及他们感兴趣的数据列,而不是表明他们想要查看趋势、分布或关系,例如 S7 中的“显示一些关于主要流派的图表”(Figure 9 S7 指出,“当我第一次开始查看数据表时,我最初只对某些数据列(例如主要流派)感兴趣。”这使得他们能够在有了初步想法后就给出输入并观察系统的响应。 S6进一步提到,“在查看相关结果之前,我只需要进行一小步思考,而在使用其他工具时,我往往必须先仔细定义自己的意图,从模糊到明确。 此外,一些受试者使用不完整输入的结果来理解数据、建立联系并开发进一步的输入。 例如,如 Figure 9a2 所示,在输入 "显示马力 "并查看结果后,S12 对 "每加仑英里数 "产生了兴趣,并输入了 "描述马力和加仑数"。 另外,她想关注日本车,输入“显示有关加仑和马力的日本车型信息”,终于得到了想要的结果。 因此,系统能够回答未阐明完整意图的摘要请求,从而缩短了每轮交互所需的思维过程,使用户能够从浅到深地探索数据。
ChartGPT 支持视觉意图的语义理解,允许用户灵活、自然地表达自己。 我们的一些主题涉及的输入无法直接匹配相应的数据列。 例如,当 S6 输入“哪种类型的电影收入最高”时,系统能够理解关键字“类型”和“收入”并推断出“主要类型”和“全球总收入”列(Figure 9) >a1). 具体来说,我们的系统为每个主要类型返回了全球最高的票房收入。 而且,这种语义推理并不局限于逐字逐句,或者直接对关键词进行映射,而是一种概括性的理解。 例如,在 S8 输入“一段时间内的电影数量”时,系统能够确定“发行年份”列可能是比“运行时间”更合适的选择。 对此,大约一半的受试者评价该系统“聪明”,因为它具有一定的语义推理能力,并且对自然语言灵活性有很好的支持。 具体来说,S2 称赞其“灵活的语义关联”,这减轻了他完善语言以使系统更加精确的负担。 一般来说,我们的系统中对自然语言的语义理解有助于提供更加用户友好的体验,因为它减少了用户在输入文本时精确措辞和组织的需要。
通过交互修改中间步骤的结果可以缩短系统生成的结果与用户期望的结果之间的距离。 尽管大多数受试者认识到 ChartGPT 能够理解语义自然语言并产生准确的结果,但由于用户偏好和用户自然语言的模糊性,生成的结果有时会遵循他们的表达方式,但在某些部分并没有产生他们想要的结果。 例如,S3最初输入“显示全球总评分和烂番茄评分之间的关系”,并获得了上述两列之间的散点图。 然而,她认为这个图表的点太多,并且想专注于喜剧电影,因此她在过滤步骤中添加了条件“主要流派 = '喜剧”'并重新生成结果(Figure 9 S3 评论道:“当我有明确的目标针对特定步骤时,我可以从中间重新生成结果,而无需重新制定原始输入。 ” 总体而言,我们 12 名受试者中有 10 名根据自己的喜好对步骤或配置进行了修改。 S2进一步指出,在看到系统生成的初步结果后,很容易确定其细节是否符合他的喜好,从而获得“明确的修改方向”。
8 讨论
本节包括我们系统的影响、经验教训、局限性和未来的工作。
8.1 影响
在技术方面,我们提出的框架采用大语言模型,使用涉及有限大小数据集的“分解和调节”方法从摘要话语生成图表。 我们通过定量评估和用户研究证明了其有效性。 在评估方面,我们贡献了使用大语言模型生成的摘要话语数据集和相应的图表。 该数据集可以作为未来研究的基准和机器学习研究的训练数据。 此外,我们从大语言模型构建数据集并将其用于大语言模型的方法也很重要。 在适用性方面,我们的框架的适用性超出了NL2VIS一代,因为它可以用来解决大语言模型无法直接处理的复杂下游任务。 例如,长篇小说的写作也可以分解为几个子模块,从人物、大纲的规划到续篇的起草和编辑[61]。 这些实验的反馈为大语言模型在生成可视化方面的潜在应用提供了宝贵的见解,启发了该领域的进一步研究。
8.2 经验教训
修改对于适应不同的喜好很重要。 用户对图表设计选择有不同的偏好,并且可能并不总是遵循一致的设计规则。 在我们的数据收集过程中,我们整理的大多数数据都倾向于遵循常见的设计原则,例如使用两个定量数据列的散点图和用于显示随时间变化的趋势的折线图。 然而,我们的用户研究表明,用户的偏好并不总是一致的。 例如,当话语中没有明确指定聚合时,一些受试者更喜欢平均数据,而另一些受试者则更喜欢查看最大值。 此外,在自由探索任务期间,一些受试者从显示两个定量数据列的散点图转换为折线图,或从显示随时间变化的趋势的折线图转换为条形图。 这强调了为用户提供交互以修改或调整创作工具中的结果以促进人机交互的重要性,因为生成的结果不能保证始终符合每个人的偏好。
8.3 局限性和未来的工作
支持更大范围。 目前,ChartGPT 仅支持一些关键的图表组件和图表生成的设计选择,目的是展示我们框架的实用性。 首先,可以考虑额外的转换和可视化参数。 诸如密度、扩展和枢轴等变换支持可以通过扩展我们的分解步骤来覆盖。 可以通过扩大我们的数据集来扩展标记类型和视觉通道等参数。 其次,支持后续话语来修改生成的图表也是人类与 LLM 交互的直观方式。 为了实现这一目标,我们可以使用现有规范和修改命令作为输入来训练大语言模型,并生成更新的规范。 它需要构建数据集,这也可以借助 ChatGPT 来实现。 第三,作为特定领域的大语言模型,需要识别域外查询并发出警告。 为此,我们可以添加一个额外的布尔词符,表示词是否与输入数据和视觉分析相关。 可以生成负例并将其与我们提出的数据集混合。
大型数据集的可扩展性。 我们通过表头、列类型、两个数据行和用户话语构建模型输入,因此表中的列数会影响提示长度。 对于我们的数据集,我们使用最大提示长度 582 个输入标记来训练模型。 为了容纳超过此大小的数据集,有两个潜在的改进:(a)重新配置模型输入以减少词符数量。 例如,有选择地包含与用户的文章最相关的列或值。 我们可以改进数据选择策略,以获得更有效的数据集视图,包括数据集洞察挖掘和自然语言理解。 (b) 扩展我们的训练数据集并分配额外的计算资源以适应更长的提示。
灵感与灵感 准确性。 ChartGPT 旨在从用户的 Abstract 自然语言中准确捕捉意图并做出合理的推断。 因此,我们的系统倾向于优先考虑结果的准确性,首先呈现最相关的信息,然后提供可选的图表。 我们的数据集也反映了这种趋势。 当一篇文章只涉及某个数据列而缺乏其他分析意图时,我们的groundtruth往往是展示与文章信息最密切相关的列的分布。
尽管强调准确性,但用户反馈表明这并不总是主要问题。 例如,在比较和排名任务中,对于“显示有关起源的内容”这句话,我们的一些受试者更喜欢显示起源和其他数据字段的图表。 同样,在自由探索阶段,三个受试者表示他们希望看到能够激发他们超出言语范围的内容。 其中两人特别强调,这种需求并不是始终如一的。 针对这一反馈,我们计划提出一个选项,让用户在未来的查询中指定他们想要的灵感水平(例如,“高灵感”与“仅准确性”)。 这使得系统能够更好地匹配用户的需求并增强他们的体验。
灵活性与灵活性 肯定。 我们的系统能够适应广泛的用户意图,但是当用户表达的意图超出系统当前功能时就会出现限制。 在我们的研究过程中,我们观察到两名受试者试图使用系统不支持的意图来探索数据。 其中一个受试者表达了无法绘制为图表的意图,而另一个受试者则希望进行数据转换,其中计算表中的两列,例如,总额除以预算。 在这种情况下,我们的系统仍然产生结果,不幸的是这与他们的意图不符。 然而,受试者花了相当长的时间来评估,并在多次调整输入后最终意识到系统并不支持他们的意图。 虽然我们的设计空间可以扩展以适应更多的需求,但自然语言的灵活性和系统有限的设计空间意味着系统的能力有限,无法支持全方位的自然语言表达,导致用户对哪些输入感到困惑将导致成功的图表结果。 未来的工作可以探索增强系统更智能、更直观地识别超出其支持范围的输入的能力。
9 结论
本文介绍了 ChartGPT,利用大语言模型从摘要话语生成图表。 我们将图表生成问题表述为顺序推理任务,并构建一个语义数据集来构建用于解决每个任务的语言模型。 此外,我们为 ChartGPT 设计了一个交互式界面,使用户能够检查和修改中间输出。 通过比较研究和可用性研究来评估所提出系统的有效性。
参考
- [1] A. Narechania, A. Srinivasan, and J. Stasko, “Nl4dv: A toolkit for generating analytic specifications for data visualization from natural language queries,” IEEE Transactions on Visualization and Computer Graphics, vol. 27, no. 2, pp. 369–379, 2020.
- [2] Y. Luo, N. Tang, G. Li, J. Tang, C. Chai, and X. Qin, “Natural language to visualization by neural machine translation,” IEEE Transactions on Visualization and Computer Graphics, vol. 28, no. 1, pp. 217–226, 2021.
- [3] Tableau Software, “Tableau,” https://www.tableau.com/, 2003.
- [4] V. Setlur, M. Tory, and A. Djalali, “Inferencing underspecified natural language utterances in visual analysis,” in Proceedings of the 24th International Conference on Intelligent User Interfaces, 2019, pp. 40–51.
- [5] A. Wu, Y. Wang, X. Shu, D. Moritz, W. Cui, H. Zhang, D. Zhang, and H. Qu, “Ai4vis: Survey on artificial intelligence approaches for data visualization,” IEEE Transactions on Visualization and Computer Graphics, 2021.
- [6] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” arXiv preprint arXiv:1810.04805, 2018.
- [7] T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell et al., “Language models are few-shot learners,” Advances in neural information processing systems, vol. 33, pp. 1877–1901, 2020.
- [8] OpenAI, “Introducing chatgpt,” https://openai.com/blog/chatgpt, November 2022.
- [9] J. Wei, Y. Tay, R. Bommasani, C. Raffel, B. Zoph, S. Borgeaud, D. Yogatama, M. Bosma, D. Zhou, D. Metzler et al., “Emergent abilities of large language models,” arXiv preprint arXiv:2206.07682, 2022.
- [10] M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. d. O. Pinto, J. Kaplan, H. Edwards, Y. Burda, N. Joseph, G. Brockman et al., “Evaluating large language models trained on code,” arXiv preprint arXiv:2107.03374, 2021.
- [11] J. J. Y. Chung, W. Kim, K. M. Yoo, H. Lee, E. Adar, and M. Chang, “Talebrush: sketching stories with generative pretrained language models,” in Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems, 2022, pp. 1–19.
- [12] T. S. Kim, D. Choi, Y. Choi, and J. Kim, “Stylette: Styling the web with natural language,” in Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems, 2022, pp. 1–17.
- [13] S. Welleck, I. Kulikov, S. Roller, E. Dinan, K. Cho, and J. Weston, “Neural text generation with unlikelihood training,” arXiv preprint arXiv:1908.04319, 2019.
- [14] D. Zhou, N. Schärli, L. Hou, J. Wei, N. Scales, X. Wang, D. Schuurmans, O. Bousquet, Q. Le, and E. Chi, “Least-to-most prompting enables complex reasoning in large language models,” arXiv preprint arXiv:2205.10625, 2022.
- [15] A. Srinivasan, N. Nyapathy, B. Lee, S. M. Drucker, and J. Stasko, “Collecting and characterizing natural language utterances for specifying data visualizations,” in Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, 2021, pp. 1–10.
- [16] Y. Luo, N. Tang, G. Li, C. Chai, W. Li, and X. Qin, “Synthesizing natural language to visualization (nl2vis) benchmarks from nl2sql benchmarks,” in Proceedings of the 2021 International Conference on Management of Data, 2021, pp. 1235–1247.
- [17] X. Qin, Y. Luo, N. Tang, and G. Li, “Making data visualization more efficient and effective: a survey,” The VLDB Journal, vol. 29, pp. 93–117, 2020.
- [18] B. Saket, D. Moritz, H. Lin, V. Dibia, C. Demiralp, and J. Heer, “Beyond heuristics: Learning visualization design,” arXiv preprint arXiv:1807.06641, 2018.
- [19] J. Mackinlay, “Automating the design of graphical presentations of relational information,” Acm Transactions On Graphics (Tog), vol. 5, no. 2, pp. 110–141, 1986.
- [20] J. Mackinlay, P. Hanrahan, and C. Stolte, “Show me: Automatic presentation for visual analysis,” IEEE transactions on visualization and computer graphics, vol. 13, no. 6, pp. 1137–1144, 2007.
- [21] K. Wongsuphasawat, D. Moritz, A. Anand, J. Mackinlay, B. Howe, and J. Heer, “Towards a general-purpose query language for visualization recommendation,” in Proceedings of the Workshop on Human-In-the-Loop Data Analytics, 2016, pp. 1–6.
- [22] Wongsuphasawat, Kanit and Moritz, Dominik and Anand, Anushka and Mackinlay, Jock and Howe, Bill and Heer, Jeffrey, “Voyager: Exploratory analysis via faceted browsing of visualization recommendations,” IEEE transactions on visualization and computer graphics, vol. 22, no. 1, pp. 649–658, 2015.
- [23] K. Wongsuphasawat, Z. Qu, D. Moritz, R. Chang, F. Ouk, A. Anand, J. Mackinlay, B. Howe, and J. Heer, “Voyager 2: Augmenting visual analysis with partial view specifications,” in Proceedings of the 2017 chi conference on human factors in computing systems, 2017, pp. 2648–2659.
- [24] D. Moritz, C. Wang, G. L. Nelson, H. Lin, A. M. Smith, B. Howe, and J. Heer, “Formalizing visualization design knowledge as constraints: Actionable and extensible models in draco,” IEEE transactions on visualization and computer graphics, vol. 25, no. 1, pp. 438–448, 2018.
- [25] Y. Luo, X. Qin, N. Tang, and G. Li, “Deepeye: Towards automatic data visualization,” in 2018 IEEE 34th international conference on data engineering (ICDE). IEEE, 2018, pp. 101–112.
- [26] V. Dibia and Ç. Demiralp, “Data2vis: Automatic generation of data visualizations using sequence-to-sequence recurrent neural networks,” IEEE computer graphics and applications, vol. 39, no. 5, pp. 33–46, 2019.
- [27] M. Zhou, Q. Li, X. He, Y. Li, Y. Liu, W. Ji, S. Han, Y. Chen, D. Jiang, and D. Zhang, “Table2charts: recommending charts by learning shared table representations,” in Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, 2021, pp. 2389–2399.
- [28] H. Li, Y. Wang, S. Zhang, Y. Song, and H. Qu, “Kg4vis: A knowledge graph-based approach for visualization recommendation,” IEEE Transactions on Visualization and Computer Graphics, vol. 28, no. 1, pp. 195–205, 2021.
- [29] A. Wu, Y. Wang, M. Zhou, X. He, H. Zhang, H. Qu, and D. Zhang, “MultiVision: Designing analytical dashboards with deep learning based recommendation,” IEEE Transaction on Visualization and Computer Graphics, vol. 28, no. 1, pp. 162–172, 2022.
- [30] D. Deng, A. Wu, H. Qu, and Y. Wu, “DashBot: Insight-driven dashboard generation based on deep reinforcement learning,” IEEE Transaction on Visualization and Computer Graphics, vol. 29, no. 1, pp. 690–700, 2023.
- [31] L. Shen, E. Shen, Y. Luo, X. Yang, X. Hu, X. Zhang, Z. Tai, and J. Wang, “Towards natural language interfaces for data visualization: A survey,” CoRR, vol. abs/2109.03506, 2021.
- [32] H. Voigt, Ö. Alaçam, M. Meuschke, K. Lawonn, and S. Zarrieß, “The why and the how: A survey on natural language interaction in visualization,” in Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, M. Carpuat, M. de Marneffe, and I. V. M. Ruíz, Eds., 2022, pp. 348–374.
- [33] R. Chen, X. Shu, J. Chen, D. Weng, J. Tang, S. Fu, and Y. Wu, “Nebula: A coordinating grammar of graphics,” IEEE Transactions on Visualization and Computer Graphics, vol. 28, no. 12, pp. 4127–4140, 2021.
- [34] Y. Sun, J. Leigh, A. Johnson, and S. Lee, “Articulate: A semi-automated model for translating natural language queries into meaningful visualizations,” in Smart Graphics: 10th International Symposium on Smart Graphics, Banff, Canada, June 24-26, 2010 Proceedings 10. Springer, 2010, pp. 184–195.
- [35] T. Gao, M. Dontcheva, E. Adar, Z. Liu, and K. G. Karahalios, “Datatone: Managing ambiguity in natural language interfaces for data visualization,” in Proceedings of the 28th annual acm symposium on user interface software & technology, 2015, pp. 489–500.
- [36] B. Yu and C. T. Silva, “Flowsense: A natural language interface for visual data exploration within a dataflow system,” IEEE transactions on visualization and computer graphics, vol. 26, no. 1, pp. 1–11, 2019.
- [37] V. Setlur, S. E. Battersby, M. Tory, R. Gossweiler, and A. X. Chang, “Eviza: A natural language interface for visual analysis,” in Proceedings of the 29th annual symposium on user interface software and technology, 2016, pp. 365–377.
- [38] E. Hoque, V. Setlur, M. Tory, and I. Dykeman, “Applying pragmatics principles for interaction with visual analytics,” IEEE transactions on visualization and computer graphics, vol. 24, no. 1, pp. 309–318, 2017.
- [39] P. Hanrahan, “Vizql: a language for query, analysis and visualization,” in Proceedings of the 2006 ACM SIGMOD international conference on Management of data, 2006, pp. 721–721.
- [40] OpenAI, “Gpt-4 technical report,” 2023.
- [41] H. W. Chung, L. Hou, S. Longpre, B. Zoph, Y. Tay, W. Fedus, E. Li, X. Wang, M. Dehghani, S. Brahma, A. Webson, S. S. Gu, Z. Dai, M. Suzgun, X. Chen, A. Chowdhery, S. Narang, G. Mishra, A. Yu, V. Zhao, Y. Huang, A. Dai, H. Yu, S. Petrov, E. H. Chi, J. Dean, J. Devlin, A. Roberts, D. Zhou, Q. V. Le, and J. Wei, “Scaling instruction-finetuned language models,” 2022.
- [42] H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozière, N. Goyal, E. Hambro, F. Azhar, A. Rodriguez, A. Joulin, E. Grave, and G. Lample, “LLaMA: Open and efficient foundation language models,” 2023.
- [43] H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y. Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosale, D. Bikel, L. Blecher, C. C. Ferrer, M. Chen, G. Cucurull, D. Esiobu, J. Fernandes, J. Fu, W. Fu, B. Fuller, C. Gao, V. Goswami, N. Goyal, A. Hartshorn, S. Hosseini, R. Hou, H. Inan, M. Kardas, V. Kerkez, M. Khabsa, I. Kloumann, A. Korenev, P. S. Koura, M.-A. Lachaux, T. Lavril, J. Lee, D. Liskovich, Y. Lu, Y. Mao, X. Martinet, T. Mihaylov, P. Mishra, I. Molybog, Y. Nie, A. Poulton, J. Reizenstein, R. Rungta, K. Saladi, A. Schelten, R. Silva, E. M. Smith, R. Subramanian, X. E. Tan, B. Tang, R. Taylor, A. Williams, J. X. Kuan, P. Xu, Z. Yan, I. Zarov, Y. Zhang, A. Fan, M. Kambadur, S. Narang, A. Rodriguez, R. Stojnic, S. Edunov, and T. Scialom, “Llama 2: Open foundation and fine-tuned chat models,” 2023.
- [44] P. Maddigan and T. Susnjak, “Chat2vis: Generating data visualisations via natural language using chatgpt, codex and gpt-3 large language models,” IEEE Access, 2023.
- [45] V. Dibia, “Lida: A tool for automatic generation of grammar-agnostic visualizations and infographics using large language models,” March 2023.
- [46] L. Cheng, X. Li, and L. Bing, “Is gpt-4 a good data analyst?” arXiv preprint arXiv:2305.15038, 2023.
- [47] W. Zhang, Y. Shen, W. Lu, and Y. Zhuang, “Data-copilot: Bridging billions of data and humans with autonomous workflow,” 2023.
- [48] J. Wei, X. Wang, D. Schuurmans, M. Bosma, E. Chi, Q. Le, and D. Zhou, “Chain of thought prompting elicits reasoning in large language models,” arXiv preprint arXiv:2201.11903, 2022.
- [49] E. H.-h. Chi, “A taxonomy of visualization techniques using the data state reference model,” in IEEE Symposium on Information Visualization 2000. INFOVIS 2000. Proceedings. IEEE, 2000, pp. 69–75.
- [50] M. Card, Readings in information visualization: using vision to think. Morgan Kaufmann, 1999.
- [51] A. Satyanarayan, D. Moritz, K. Wongsuphasawat, and J. Heer, “Vega-lite: A grammar of interactive graphics,” IEEE Trans. Visualization & Comp. Graphics (Proc. InfoVis), 2017. [Online]. Available: http://idl.cs.washington.edu/papers/vega-lite
- [52] L. Wilkinson, “The grammar of graphics: The ggplot2 package,” in Handbook of computational statistics. Springer, 2012, pp. 375–414.
- [53] R. L. Harris, Information Graphics: A Comprehensive Illustrated Reference. Oxford University Press, USA, 1999.
- [54] J. Mackinlay, “Automating the design of graphical presentations of relational information,” ACM Transactions on Graphics, vol. 5, no. 2, pp. 110–141, 1986.
- [55] L. Battle, P. Duan, Z. Miranda, D. Mukusheva, R. Chang, and M. Stonebraker, “Beagle: Automated extraction and interpretation of visualizations from the web,” in Proceedings of the 2018 CHI conference on human factors in computing systems, 2018, pp. 1–8.
- [56] M. Vartak, S. Rahman, S. Madden, A. Parameswaran, and N. Polyzotis, “Seedb: Efficient data-driven visualization recommendations to support visual analytics,” in Proceedings of the VLDB Endowment International Conference on Very Large Data Bases, vol. 8, no. 13. NIH Public Access, 2015, p. 2182.
- [57] S. Fu, K. Xiong, X. Ge, S. Tang, W. Chen, and Y. Wu, “Quda: natural language queries for visual data analytics,” arXiv preprint arXiv:2005.03257, 2020.
- [58] I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” 2019.
- [59] C.-Y. Lin, “Rouge: A package for automatic evaluation of summaries,” in Text summarization branches out, 2004, pp. 74–81.
- [60] K. Papineni, S. Roukos, T. Ward, and W.-J. Zhu, “Bleu: a method for automatic evaluation of machine translation,” in Proceedings of the 40th annual meeting of the Association for Computational Linguistics, 2002, pp. 311–318.
- [61] K. Yang, Y. Tian, N. Peng, and D. Klein, “Re3: Generating longer stories with recursive reprompting and revision,” 2022.
![[Uncaptioned image]](ytian.png) |
Yuan Tian received her B.S. degree in computer science from Zhejiang University in 2022. She is currently a Ph.D. student in the State Key Lab of CAD&CG, Zhejiang University. Her research interests include machine learning for visualization and visual analytics. |
![[Uncaptioned image]](x1.png) |
Weiwei Cui received the BS degree in computer science and technology from Tsinghua University, China, and the PhD degree in computer science and engineering from the Hong Kong University of Science and Technology, Hong Kong. He is a principal researcher at Microsoft. His primary research interest is visualization, with the focuses on democratizing visualization and AI-assisted design. For more information, please visit https://www.microsoft.com/en-us/research/people/weiweicu/. |
![[Uncaptioned image]](dazhen.jpg) |
Dazhen Deng is currently a tenure-track assistant professor at the School of Software Technology, Zhejiang University. He received Ph.D. in Computer Science from Zhejiang University in 2023. His research interests mainly lie in machine learning for visual analytics. For more information, please visit https://dengdazhen.github.io/. |
![[Uncaptioned image]](xinjingyi.jpg) |
Xinjing Yi received her B.S degree in computer science from Wuhan University in 2022. She is currently a graduate student in Software Engineering, Zhejiang University. Her research interests mainly include visualization and visual analytics. |
![[Uncaptioned image]](yurunyang.jpg) |
Yurun Yang received his B.S. degree in Software Engineering from University of Electronic Science and Technology of China in 2022. He is currently a graduate student in School of Software Technology, Zhejiang University. His research interests mainly include visualization and visual analytics. |
![[Uncaptioned image]](hzhang.jpg) |
Haidong Zhang received the PhD degree in Computer Science from Peking University, China. He is a Principal Architect at Microsoft. His research interests include visualization and human-computer interaction. |
![[Uncaptioned image]](ywu.jpeg) |
Yingcai Wu is a Professor at the State Key Lab of CAD&CG, Zhejiang University. His main research interests are in information visualization and visual analytics, with focuses on urban computing, sports science, immersive visualization, and narrative visualization. He received his Ph.D. degree in Computer Science from the Hong Kong University of Science and Technology. Prior to his current position, Dr. Wu was a postdoctoral researcher in the University of California, Davis from 2010 to 2012, a researcher in Microsoft Research Asia from 2012 to 2015, and a ZJU100 Young Professor at Zhejiang University from 2015 to 2020. For more information, please visit http://www.ycwu.org. |