GPTuner:通过 GPT 引导贝叶斯优化的手动读取数据库调优系统
摘要。
现代数据库管理系统 (DBMS) 公开了数百个可配置旋钮来控制系统行为。 确定这些旋钮的适当值以提高 DBMS 性能是数据库社区中长期存在的问题。 由于需要调整的旋钮数量不断增加,并且每个旋钮都可能是连续值或分类值,因此手动调整变得不切实际。 最近,使用机器学习方法的自动调优系统显示出了巨大的潜力。 然而,现有的方法仍然会产生大量的调整成本,或者只能产生次优的性能。 这是因为他们要么忽略了广泛的可用领域知识(例如 DBMS 手册和论坛讨论),而仅依赖基准评估的运行时反馈来指导优化,要么以有限的方式利用领域知识。 因此,我们提出了GPTuner,这是一种手动读取数据库调优系统,它广泛且自动地利用领域知识来优化搜索空间并增强基于运行时反馈的优化过程。 首先,我们开发了一个基于大语言模型(大语言模型)的管道来收集和提炼异构知识,并提出了一种即时集成算法来统一提炼知识的结构化视图。 其次,利用结构化知识,我们(1)设计一种工作负载感知且免训练的旋钮选择策略,(2)考虑每个旋钮的值范围开发搜索空间优化技术,(3)提出一种粗略到-精细贝叶斯优化框架,探索优化空间。 最后,我们在不同的基准(TPC-C 和 TPC-H)、指标(吞吐量和延迟)以及 DBMS(PostgreSQL 和 MySQL)下评估 GPTuner。 与最先进的方法相比,GPTuner平均在16x的时间内识别出更好的配置。 此外,与性能最佳替代方案相比,GPTuner的性能提升高达30%(更高的吞吐量或更低的延迟)。
PVLDB 工件可用性:
源代码、数据和/或其他工件已在 %leave␣empty␣if␣no␣availability␣url␣should␣be␣sethttps://github.com 提供/SolidLao/GPTuner。
1. 介绍
现代数据库管理系统 (DBMS) 公开数百个可配置参数(即旋钮)来控制其运行时行为(pavlo2017self)。 为这些旋钮选择适当的值对于提高 DBMS 性能至关重要,这构成了数据库社区(10.14778/3450980.3450992)中长期存在的挑战。 考虑到配置空间的高维性(例如,PostgreSQL v14.7 有 351 个旋钮)以及这些旋钮固有的异构性(由于它们的连续域和分类域),数据库管理员 (DBA) 在识别有希望的定制配置时遇到了很大的困难特定的查询工作负载。 这一挑战的严重性在云环境中变得更加明显,其中不同 DBMS 实例之间的底层物理配置可能存在显着差异(10.14778/3476311.3476411)。
为了减少 DBA 的手动调整工作,最先进的方法通过机器学习 (ML) 技术实现旋钮调整自动化,包括贝叶斯优化 (10.14778/1687627.1687767; 10.1145/3035918.3064029; 10.1145/3448016.3457291; 10.1477 8/ 3457390.3457404;10.1145/3514221.3526176;10.1145/3318464.3380591)和强化学习(10.1145/3299869.3300085;10.14778/335206 3.3352129;10.1145/3514221.3517882;10.1145/3514221.3517843)。 这些基于机器学习的调整系统遵循“试错”的主要概念,迭代地探索配置空间,在探索未见区域和利用已知空间之间取得平衡。
虽然这些调谐系统确实具有最终达到性能良好的旋钮配置的潜力,但它们仍然会产生大量的调谐成本(10.14778/3551793.3551844;10.1145/3318464.3380591)。 例如,之前的研究(10.1145/3514221.3517882; 10.1145/3448016.3457291; 10.14778/3538598.3538604)表明,最先进的系统仍然需要数百到数千次迭代才能达到理想配置,每个迭代迭代需要几分钟或更长时间才能执行目标工作负载。 如此高的调整成本源于它们在处理两个困难时效率低下:(1)需要调整的旋钮数量众多和(2)每个旋钮可能值的广泛搜索空间 t1>. 对于第一个困难,大多数方法要么选择固定的旋钮子集 (10.1145/3514221.3517882; 10.14778/3551793.3551844; 10.14778/3457390.3457404; 10.14778/1687627.1687767; 10.1145/3299869.3300085;10.1145/3127479.3128605),牺牲灵活性选择与工作负载相关的旋钮,或多次执行工作负载来识别重要旋钮(10.14778/3538598.3538604; 10.1145/3035918.3064029; 10.5555/3488733.3488749),这是资源密集型的。 关于第二个困难,大多数方法使用DBMS供应商提供的默认值范围(10.14778/1687627.1687767; 10.1145/3035918.3064029; 10.1145/3448016.3457291; 10.14778/3457390.3457404; 10.1145/3514221.3526176;10.1145/3318464.3380591;10.1145/3299869.3300085; 3352063.3352129;10.1145/3514221.3517882)。 然而,由于默认值范围对于灵活性来说过于宽泛,这使得优化过程变得复杂并引入系统崩溃的风险(10.14778/3476311.3476411; 10.14778/3450980.3450992)。
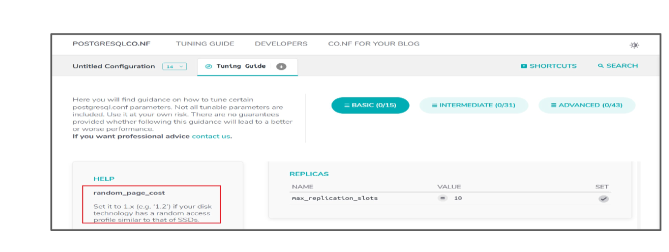
与仅根据性能统计数据调整 DBMS 的基于 ML 的调优方法相比,人类 DBA 通常依赖领域知识进行调优(例如 DBMS 手册和 DBMS 论坛的讨论)。 与性能统计不同,外部领域知识直接揭示调优提示,包括重要的旋钮和每个旋钮的典型值范围。 首先,讨论哪些旋钮会显着影响 DBMS 性能。 例如,在像 Hacker News 这样的网络论坛中,人们经常提到并行旋钮(例如“max_parallel_workers_per_gather”)对于 OLAP 工作负载至关重要,而与 I/O 相关的工作负载则非常重要。旋钮(例如“max_wal_size”)对于 OLTP 工作负载(黑客新闻)非常重要。 其次,总结了旋钮的典型值范围。 表1提供了从自然语言调优指导中提取改进值范围的两个示例。 对于旋钮“shared_buffers”,不使用默认值范围[0.125 MB,8192 GB],改进的值范围可以是[4 GB,6.4 GB],因为指南建议将值设置在25之间RAM 的 % 和 40%(在具有 16 GB RAM 的计算机上)。 对于旋钮“random_page_cost”,如果机器使用SSD作为磁盘,我们可以尝试取值范围[1.0, 2.0]而不是[0, 1.79769 ]。 我们可以观察到,这些提示对于减少基于 ML 的方法的搜索空间非常有价值,从而加快收敛并实现更好的性能。
| 2 Knob | shared_buffers | random_page_cost |
|---|---|---|
| Default Range | ||
| Guidance | “shared_buffers” can be 25% of the RAM but no more than 40% …(PostgreSQL2023) | “random_page_cost” can be 1.x if disk has a speed similar to SSDs …(PostgreSQLCONF) |
| DBA | The machine has a 16 GB RAM. Thus we can set “shared_buffers” from 16 GB 25% = 4 GB to 16 GB 40% = 6.4 GB. | The machine uses SSDs as disks. Thus we can set “random_page_cost” to a value from 1.0 to 2.0. |
| Improved Range | [4 GB, 6.4 GB] | [1.0, 2.0] |
| 2 |
因此,为了减轻基于 ML 的技术的高调整成本,需要设计一个利用领域知识来增强优化过程的旋钮调整系统。 然而,对于以下挑战而言,这并非易事。 C1。 在平衡成本和质量之间的权衡的同时,统一异构领域知识的结构化视图是具有挑战性的。 领域知识通常以 DBMS 手册和网络论坛讨论的形式出现。 为了在基于机器学习的技术中利用这些知识,我们需要将其转换为统一的机器可读格式(即结构化数据)。 然而,准备这样的结构化视图涉及复杂而漫长的工作流程:数据摄取、数据清理、数据集成和数据提取(nargesian2019data),现有方法无法满足我们在成本和质量之间的权衡。 他们要么需要特定于领域的训练 (shin2015incremental),这在我们的场景中更加复杂,因为它需要专业知识来注释 DBMS 调优知识,或者他们依赖于缺乏灵活性的强假设(例如,专注于具体文档格式)(deng2022dom;lockard2019openceres;lockard2020zeroshotceres)。 C2。 即使有了准备好的结构化知识,我们也缺乏将这些知识整合到优化过程中的方法。 贝叶斯优化(snoek2012practical)和强化学习(henderson2018deep)等优化算法的固有设计不支持直接集成外部领域知识,需要对其标准工作流程进行大量修改。 对于从领域知识中手动总结静态规则的方法,生成的规则无法捕获所有工作负载的细微差别,并且环境的更新可能会使它们过时(10.5555/1287369.1287454;Kwan2002AutomaticCF)。 为了解决上述挑战,我们提出了 GPTuner,这是一种手动读取数据库调优系统,可自动、广泛地利用领域知识来增强优化过程。
面对C1的挑战,我们开发了一个基于大语言模型(大语言模型)的管道来收集和提炼异构知识,并提出了一种即时集成算法来统一提炼知识的结构化视图。 首先,我们从各种资源(数据摄取)中准备异构调优知识。 其次,我们过滤掉噪音知识(数据清理)。 第三,我们通过优先处理可能的冲突(数据集成)来总结多源知识。 第四,我们确保汇总结果与源内容事实一致(数据修正)。 最后,我们开发了一种即时集成算法来构建知识的结构化视图(数据提取)。
关于挑战 C2,我们使用结构化知识来(1)设计一种工作负载感知且免训练的旋钮选择策略,(2)考虑每个旋钮的值范围开发搜索空间优化技术,以及(3)提出一个新颖的基于知识的优化框架来探索优化空间。 在调整过程之前,我们根据数据维度和每个维度的值优化搜索空间。 对于数据维度,我们利用大语言模型的文本分析能力来模拟DBA的旋钮选择过程,考虑DBMS的特点、工作负载、特定查询和旋钮依赖关系。 对于每个维度的值,我们丢弃无意义的区域,突出有希望的空间并考虑特殊情况。 接下来,我们开发了一种新颖的从粗到细的贝叶斯优化框架。 首先,由于减少搜索空间的大小,同时仍然保留最佳结果的潜力(feurer2019hyperparameter)是很重要的,因此我们寻求领域知识的帮助来仔细设计两个不同粒度的搜索空间。 接下来,BO 使用引导技术作为桥接机制,从粗粒度到细粒度顺序探索这两个空间。 该框架平衡了粗粒度搜索的效率和细粒度搜索的彻底性。
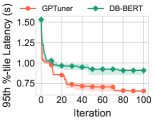
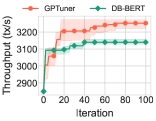
我们只知道 DB-BERT (10.1145/3514221.3517843) 的一项工作,它利用预先训练的语言模型来阅读手册,并使用挖掘的提示来指导强化学习算法。 它表现出快速收敛,因为它受益于通过文本分析获得的信息。 然而,它只能产生次优的性能,因为它利用的领域知识很窄,并且受到搜索空间探索不充分的影响。 GPTuner解决了这些限制,从而实现更快的收敛和更好的性能改进。 如图1所示,GPTuner在具有不同优化目标(延迟和吞吐量)的两个代表性基准测试(TPC-H 和 TPC-C)上显着优于 DB-BERT。 值得注意的是,与 DB-BERT 相比,GPTuner 是一种独特的方法,其功效并非源于简单地替换语言模型。 我们通过用 GPT-4 替换 DB-BERT 中的 BERT 模型来验证这一点,并再次与 GPTuner 进行比较。 2.3 节提供了更多详细信息。
在我们的实验中,我们将 GPTuner 与 DB-BERT 以及其他不使用文本作为输入的最先进方法进行比较。 我们考虑不同的基准(TPC-C 和 TPC-H)、指标(吞吐量和延迟)和 DBMS(PostgreSQL 和 MySQL)。 与最先进的方法相比,GPTuner平均在16x的时间内识别出更好的配置。 此外,与性能最佳替代方案相比,GPTuner的性能提升高达30%(更高的吞吐量或更低的延迟)。 总之,我们做出以下贡献:
-
•
我们提出GPTuner,一种新颖的手动读取数据库调整系统,它自动且广泛地利用领域知识来增强旋钮调整过程。
-
•
我们开发了一个基于 LLM 的管道来收集和提炼领域知识,并提出了一种即时集成算法来统一提炼知识的结构化视图。
-
•
我们设计了一种工作负载感知且免训练的旋钮选择策略,开发了每个旋钮的值范围的优化方法,并提出了从粗到细的贝叶斯优化框架来探索优化空间。
-
•
我们开源 PostgreSQL 和 MySQL 构建的结构化领域知识,以便更广泛的数据库社区进行进一步研究。
-
•
我们考虑不同的基准、指标和 DBMS 进行了大量实验,以证明 GPTuner 的有效性。 与最先进的方法相比,GPTuner找到了性能最佳的旋钮配置,并且调谐次数显着减少。
2. 背景及相关工作
2.1. 数据库旋钮调整
DBMS 公开了数十到数百个可配置旋钮来控制其运行时行为(10.14778/3450980.3450992)。 DBMS旋钮调优问题是为每个旋钮选择合适的值,以优化特定工作负载(例如,工作负载是一组SQL语句)上的DBMS性能(例如,吞吐量或延迟)。 形式上,给定一组可配置旋钮 及其域 ,配置空间定义为 。 我们希望找到一个配置来最大化DBMS性能:
| (1) |
找到这个问题的最佳解决方案具有挑战性,主要原因有两个。 首先,由于有数百个可调节旋钮,每个旋钮都可能影响性能,因此复杂性非常大。 其次,旋钮本身差异很大——有些具有连续数值,而另一些则具有分类值,这使得问题变得更加复杂,因为很难对异构空间进行建模。 为了应对这些挑战,提出了三种方法:基于启发式、基于贝叶斯优化(BO)的(snoek2012practical)和基于强化学习(RL)的(henderson2018deep)。
• 基于启发式。 基于启发式的方法可以分为基于规则的和基于搜索的。 基于规则的方法依靠手动创建的静态规则以预定义的方式探索空间(10.5555/1287369.1287454;Kwan2002AutomaticCF)。 基于搜索的方法根据多种启发式探索空间(例如,避免重新访问已探索区域并探索附近区域以改进当前最优值)(10.1145/3127479.3128605; 10.1145/2628071.2628092)。
• 基于 BO。 基于BO的方法(10.14778/1687627.1687767;10.1145/3035918.3064029;10.1145/3448016.3457291;10.14778/3457390.3457404;10.1145/3514 221.3526176; 10.1145/3318464.3380591)遵循通用BO框架来搜索最优配置:(1 ) 拟合概率代理模型来映射旋钮配置和 DBMS 性能之间的关系,(2) 选择最大化获取函数的下一个配置。
• 基于强化学习。 基于强化学习的方法通过试错策略探索配置空间。 其本质是在探索未探索的空间和利用已知区域之间取得平衡,这是通过代理(例如神经网络)和目标环境(例如DBMS)之间的交互来实现的 (10.1145/3299869.3300085; 10.14778/3352063.3352129; 10.1145/3514221.3517882)。
性能比较。 我们进行了实验评估来比较这些方法(10.14778/3538598.3538604)。 基于 BO 的方法,基于序列模型的算法配置 (SMAC)(lindauer-jmlr22a) 产生最佳性能,因为它使用随机森林 (RF) 作为替代方法来利用其在建模高效率方面的效率。 - 维度和异构配置空间。 由于 SMAC 被评估为性能最佳的优化器, 我们认为它是当前最先进的技术,不以文本作为输入,并旨在进一步改进它。
2.2. 语言模型
随着大型语言模型(大语言模型)的出现,自然语言处理(NLP)领域发生了重大转变。 从注意力机制和 Transformer 架构(wolf-etal-2020-transformers)的引入开始,众多语言模型(LM)被开发出来,导致语言处理能力的大幅增强。 值得注意的是,BERT 引入了仅编码器的 Transformer 架构,通过改进嵌入(devlin-etal-2019-bert)彻底改变了下游学习任务。 GPT 系列的最新成员,例如 ChatGPT (luo2023chatgpt) 和 GPT-4 (openai2023gpt4),在广泛的任务中表现出了更强大的能力。
而且,这些大语言模型的影响超出了NLP的范围。 数据库社区经历了大语言模型的采用激增,以增强 DBMS 的各个方面,包括数据分析 (zhang2023schema; trummer2021can; narayan2022foundation)、代码生成 (trummer2023demonstrating; yu2019spider; heng2023binding ; scholak2021picard) 和基于表格的问答(ye2023large; zhang2023reactable; jian2022omnitab)。 在实际使用大语言模型时,有三种典型的设计选择:(1)从头开始训练语言模型,(2)对现有语言模型进行微调,(3)使用预训练的语言模型而不修改参数。 前两种方案需要消耗较多的资源,包括硬件资源和训练数据。 鉴于 GPT-4 所展示的令人印象深刻的上下文学习能力,我们选择了第三个选项,并在整篇论文中使用 GPT-4 作为我们的默认语言模型,除非另有说明。
| Criterion | DB-BERT | GPTuner |
|---|---|---|
| Language Model | BERT | GPT-4 |
| Workload-Aware Knob Selection | no | yes |
| Fine-Tuning | yes | no |
| Filter Noise | no | yes |
| Space Type | Discrete | Heterogeneous |
| Optimization Algorithm | Reinforcement Learning | Coarse-to-Fine Bayesian |
| Considered Knowledge | Suggested Value | Suggested Value Bound Constraint Special Cases |
2.3. 使用 LM 增强 DBMS 旋钮调优
借助互联网上或 DBMS 供应商提供的大量调优指南,可以利用语言模型来“阅读手册”并提供结构化调优提示,以增强旋钮调优方法。 作为最先进的 LM 增强调优方法,DB-BERT (10.1145/3514221.3517843) 将调优过程建模为一系列“多项选择题回答问题”,并使用强化学习建立一个预训练的 BERT 模型来回答这些问题。 虽然 DB-BERT 由于受益于文本分析而收敛得很快,但它只能产生次优的性能。
我们在表2中总结了GPTuner和DB-BERT之间的主要区别。 首先,DB-BERT 的旋钮选择不具有工作负载感知能力,因为它只调整输入文档中提到的旋钮。 GPTuner考虑调优上下文(例如,DBMS 的特征、工作负载、特定查询和旋钮依赖性)来选择哪些旋钮值得调优。 其次,DB-BERT需要在离线和在线调优阶段对训练BERT模型进行微调,这需要大量的资源。 GPTuner采用大语言模型的上下文学习能力,无需修改模型参数。 第三,DB-BERT 依赖于输入文档,而不过滤掉噪声内容,而 GPTuner 通过将内容与 DBMS 的系统视图进行比较来解决这个问题(例如,来自 PostgreSQL 的 pg_settings )。 第四,DB-BERT仅依赖于文档中的建议值来构建离散空间并仅探索该空间。 然而,对领域知识的有限利用和对搜索空间的探索不充分是导致性能不佳的决定性因素。 另一方面,GPTuner 利用领域知识中的更多信息(例如,建议值、边界约束和特殊情况),并通过新颖的基于知识的优化框架探索搜索空间。 最后,我们在LABEL:subsec:_performance-compare节中进行实验来评估两种方法的性能。 此外,我们在LABEL:subsec:_differ-llm节中研究了语言模型的影响。 无论是使用相同的高级模型(均为 GPT-4)还是不太复杂的模型(即带有 GPT-4 的 DB-BERT 和带有 GPT-3.5 的 GPTuner ),GPTuner 在这两种情况下都始终优于 DB-BERT。
3. 动机
基于机器学习的方法仍然会产生大量的调整成本。 最先进的基于 ML 的调整方法需要数百到数千次迭代才能收敛到良好的 DBMS 旋钮配置。 如此高的调优费用源于基于运行时反馈的优化算法的低效率。 具体来说,反馈信息是有限的(即,一些基准测试运行无法提供所有条件下 DBMS 性能的完整情况)并且不稳定(即,不能保证 DBMS 性能在旋钮调整的每一步后都会提高)。 鉴于反馈如此微弱,机器学习模型需要大量观察才能对预测有足够的信心,尤其是在空间复杂的情况下。
广泛的领域知识有所帮助,但没有得到很好的利用。 自 2000 年代初以来,当调音系统考虑旋钮设置时,大量的调音知识以自然语言的形式不断积累,这些知识确实有助于优化搜索空间。 如图2(左部分)所示,通过分析调节知识,我们可以识别哪些旋钮值得调节,并深入了解旋钮的典型值设置(例如,建议尝试值、范围)约束和特殊值)。 然而,这种智慧似乎是 DBA 独有的,并且不能用来减轻基于 ML 的方法的昂贵的调整成本。 有一些方法利用 DBA 总结的静态规则来完成旋钮调整。 不幸的是,这些规则无法捕捉所有工作负载的细微差别,并且环境的更新可能会使这些静态规则过时。 因此,我们呼吁采用更先进的方法来利用这些知识。
大语言模型是一个显着的进步,但还不够。 尽管人们普遍认为领域知识是有用的,但由于自然语言理解的障碍,这种智慧被认为是机器无法获得的。 最近,大语言模型(大语言模型)的出现使得利用这些知识成为可能,因为我们可以利用大语言模型将知识转换为统一的机器可读格式(例如,JSON和关系表等结构化数据)。 然而,由于两个主要原因,这个过程仍然具有挑战性。 首先,由于领域知识通常以 DBMS 文档和 DBMS 论坛讨论的形式出现,因此处理此类异构且嘈杂的知识需要复杂而漫长的工作流程:数据摄取、数据清理、数据集成和数据提取。 其次,大语言模型的脆弱性(即对提示的微小修改可能会导致模型输出的较大变化)和大语言模型的幻觉问题(即大语言模型生成看似正确但实际上是错误的答案)使得这一挑战更加明显。 例如,如图2(中部分)所示,大语言模型可能会生成有缺陷甚至错误的内容。 因此,一种可靠、有效的方法来利用大语言模型的力量是非常重要的,也是必要的。
即使开发了结构化知识,其与优化过程的集成也是有缺陷的。 据我们所知,没有任何 DBMS 调优框架能够解释结构化知识。 现有的优化算法(例如 BO 和 RL)不支持直接集成外部知识,需要对其标准工作流程进行大量修改。 在不进行修改的情况下,唯一可以使用的信息是手册推荐的范围约束(即下限和上限)。 然而,还有更多有用的信息可用(例如,建议值和特殊值)。 我们在图2(右部分)中提出了一些利用这些值的简单想法。 不幸的是,可以预见的是,这种幼稚的想法不能作为有效的解决方案,特别是在 DBMS 旋钮调整的背景下,该问题被证明是 NP 难的(10.1145/1005686.1005739)。 因此,当前的情况需要一种创新的优化框架,该框架本质上支持结构化领域知识的有效利用。
4. GPTuner 概述
工作流程。 GPTuner是一个手动读取数据库调谐系统,可建议令人满意的旋钮配置并降低调谐成本。 图3展示了涉及七个步骤的调整工作流程。 ❶ 用户提供要调优的 DBMS(例如 PostgreSQL 或 MySQL)、目标工作负载和优化目标(例如延迟或吞吐量)。 ❷ GPTuner收集并提炼来自不同来源(例如 GPT-4、DBMS 手册和网络论坛)的异构知识,构建 DBMS 调优知识集合Tuning Lake。 ❸ GPTuner将来自Tuning Lake的精炼调优知识统一为机器可访问的结构化视图(例如 JSON)。 ❹ GPTuner通过选择重要的旋钮来调整来减少搜索空间维度(即,更少的旋钮来调整意味着更少的维度)。 ❺ GPTuner基于结构化知识,根据每个旋钮的值范围优化搜索空间。 ❻GPTuner通过新颖的从粗到细贝叶斯优化框架探索优化空间,最后❼在资源限制(例如,用户指定的最大优化时间或迭代次数)内确定令人满意的旋钮配置。
组件。 GPTuner由三个组件组成:知识处理程序、基于知识的搜索空间优化器和基于知识的配置推荐器它们的工作原理如下:
知识处理程序。 知识处理程序使用DBMS调优面向知识的数据管道来统一异构领域知识的结构化视图。 首先,我们在5.1节中提出了一个基于LLM的管道来平衡成本和质量。 接下来,我们提出了一种基于LLM的Prompt Ensemble算法,将精炼的知识转换为结构化格式,以便它可以被LABEL:subsec:_knowledge-transform节中的机器使用>。
基于知识的搜索空间优化器。 优化器从两个方面优化搜索空间。 首先,它在维数方面减少了搜索空间的大小。 具体来说,我们在LABEL:subsec:_knob-select节中提出了一种工作负载感知和免训练的方法来选择重要旋钮。 其次,我们通过关注每个旋钮的值范围来优化搜索空间。 我们提出了区域丢弃、微小可行空间和虚拟旋钮扩展方法,分别丢弃无意义的区域、突出有前途的空间和处理特殊情况(第1节) 标签:亚秒:_空间缩减)。
基于知识的配置推荐器。 推荐器使用新颖的从粗到细的 BO 框架来计算最佳配置。 在第一阶段,BO仅探索整个异构空间的离散子空间。 这个子空间尺寸很小,但有希望包含良好的配置,因为我们是根据可靠的领域知识生成它的。 在下一阶段,为了避免粗粒度搜索的忽视问题(即,任何空间缩减技术都不可避免地会丢失一些有用的配置),BO通过LABEL节中的优化来彻底探索异构空间:sec:_space-explorer。 经过两个阶段后,推荐器会输出在用户指定的预算限制内找到的性能最佳的旋钮配置。
5. 知识处理者
5.1. 知识准备
在本节中,我们将讨论知识处理程序如何完成知识准备任务。 正如算法 1 中所述,此任务是从各种资源中收集调优知识(数据摄取,第 1-3 行),过滤掉噪声内容(数据清理,第 4 行),总结合法部分(数据集成,第 5-6 行)并确保摘要与源内容真实一致(数据更正,第 7-10 行)。 输出是一个Tuning Lake,定义如下:
定义 1(调整湖)。
Tuning Lake 是一组 文本,其中 是可配置旋钮的数量, 是第 个旋钮的自然语言调优知识。 例如,“set shared_buffers to 25% of the RAM”(记为)就是旋钮“shared_buffers”(-第一个旋钮)。
步骤1:从大语言模型中提取知识。 除了常见的调优知识源(例如手册和网页内容)外,我们建议也使用大语言模型作为知识源。 由于GPT是在与数据库(ameryahia2023large)相关的庞大语料库上进行训练的,因此GPT本身就是一本信息手册,可以让我们通过提示来检索知识。 在实践中,我们惊奇地发现GPT可以给出手册中没有的合理建议。 这些建议来自 DBA 总结的网页内容,并用作 GPT 的训练数据。 由于不可能向任何系统提供所有网络内容,而 GPT 已经了解其中的大部分内容,因此使用 GPT 作为知识的补充来源是合理的。 如果GPT给出了无意义的建议,下一步我们将利用大语言模型来处理这种异常情况。

示例 0。
图4描述了从GPT中提取旋钮“ effective_io_concurrency”的知识的过程。 虽然手册没有提供有用的建议,但 GPT 建议 SSD 的值为 200,HDD 的值为 2,该值可从博客 (metis) 中获取。
步骤2:过滤噪音知识。 调音知识的来源多种多样,其质量无法保证。 因此,我们通过将这个过程建模为“二元分类问题”来过滤掉噪声知识,并利用大语言模型来解决它。 我们为大语言模型提供了某个旋钮的候选调优知识以及该旋钮的官方系统视图(例如来自 PostgreSQL 的 pg_settings 和来自 MySQL 的 information_schema)。 此外,我们在提示中给出了一些利用大语言模型(dai-etal-2023-gpt)情境学习能力的例子。 大语言模型评估调优知识是否与系统视图冲突,我们丢弃任何冲突的知识。