剖析大型语言模型的训练、微调和推理的运行时性能
††感谢:*同等贡献。
††感谢:†通讯作者。
摘要
大语言模型在学术界和工业界都取得了巨大的进步,其受欢迎程度导致了许多开源框架和技术的出现,用于加速大语言模型的预训练、微调和推理。 训练和部署大语言模型的成本很高,因为它需要大量的计算资源和内存,因此人们开发了许多有效的方法来改进系统管道和操作员。 然而,不同硬件和软件堆栈的运行时性能可能存在很大差异,这使得选择最佳配置变得困难。 在这项工作中,我们的目标是从宏观和微观角度对性能进行基准测试。 首先,我们在三个 8 上对不同规模的大语言模型(即 7、13 和 700 亿个参数(7B、13B 和 70B))的预训练、微调和服务的端到端性能进行基准测试。 -具有或不具有单独优化技术的 GPU 平台,包括 ZeRO、量化、重新计算、FlashAttention。 然后,我们更深入地提供子模块的详细运行时分析,包括大语言模型中的计算和通信运算符。 对于最终用户来说,我们的基准测试和研究结果有助于更好地理解不同的优化技术、训练和推理框架,以及选择部署大语言模型配置的硬件平台。 对于研究人员来说,我们深入的模块分析发现了未来进一步优化大语言模型运行时性能的潜在机会。
索引术语:
大型语言模型、性能评估、基准测试我简介
近年来,大语言模型(大语言模型)在人工智能应用中变得非常流行[1, 2]。 随着规模的增加,大语言模型在各种任务中表现出更好的泛化能力[3,4,5]。 然而,在最近的工作中,模型规模变得巨大,例如,GPT-3 [6] 有 1750 亿个参数,PaLM [7] 有 5400 亿个参数。 因此,大语言模型的训练和部署既复杂又昂贵。
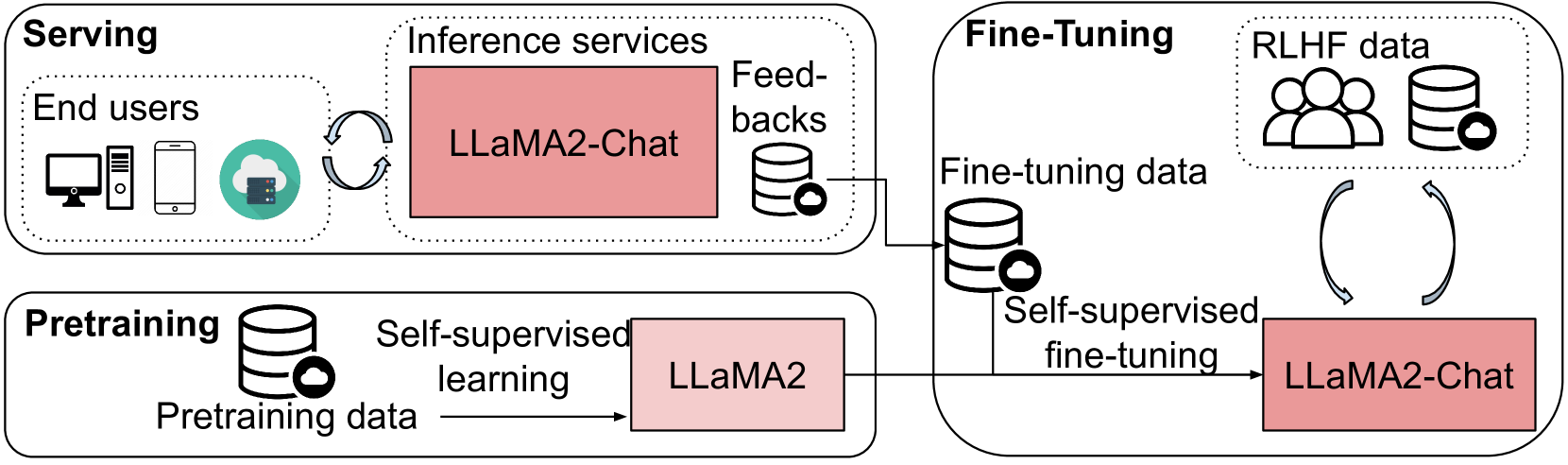
具体来说,大语言模型的流程(如图1所示)具有三个主要阶段:预训练、微调和服务,用于为实际应用部署大语言模型[8]。 首先,模型(例如Llama2)在应用于下游任务之前使用自监督学习进行预训练,这是大语言模型流程中最耗时的阶段。 例如,预训练 PaLM 模型需要大约 次浮点运算 (FLOP),在 6,144 个 Google TPUv4 芯片上执行时需要 64 天[7]。 其次,预训练模型在下游任务或指令数据集上进一步微调111在本文中,利用人类反馈进行指令调优也被视为微调,因为其范式与下游任务数据集的微调几乎相同。 以提高其在实际应用中的性能[1],例如,Llama2-Chat 使用微调和 RLHF 数据与 Llama2 进行微调。 第三,模型经过微调(例如 Llama2-Chat)后,它被部署为 Web(或 API)服务,为给定的输入查询提供推理结果。
为了降低大语言模型流程中的计算成本,人们提出了专用框架来进行高效的预训练(例如 DeepSpeed [10] 和 Megatron-LM [11])、微调(例如 PEFT [12])和推理(例如 vLLM [13]、LightLLM [14]和 TGI [15])。 在每个框架内,都应用了优化技术来提高内存和计算效率。 具体来说,在预训练中,内存高效方法(ZeRO [16]、激活重新计算 [17, 18, 19] 和量化 [20])通常用于使内存有限的 GPU 能够训练大型模型。 在微调方面,LoRA [21, 22]等参数高效微调(PEFT)方法已被用于通过调整适配器的参数而不是适配器的全部参数来调整大语言模型。模型,以便内存有限的 GPU 能够构建大语言模型。 在大语言模型服务中,为了最大限度地利用部署中的GPU资源,对训练好的模型进行量化[20]和内核级优化[23]。
然而,由于各种大语言模型框架和相关优化技术运行在不同类型的硬件上(例如Nvidia A800等高端GPU和Nvidia Geforce RTX4090和RTX3090等消费级GPU),有两个尚未开发的领域对于最终用户和研究人员来说至关重要的问题。 第一的, 针对特定应用进行预训练、微调和部署大语言模型需要哪些配置来平衡效率和成本? 例如,8x A800 训练 80GB GPU 是否足以预训练 7B 模型,需要多长时间,以及应该启用什么样的优化技术来加速? 第二, 现有的具有高度优化技术的最先进系统是否充分利用了 GPU 资源?性能瓶颈在哪里? 特别是,在不同配置下现代 GPU 服务器上计算和带宽资源的峰值利用率是多少?
为了解决这些问题,我们在各种类型的 GPU 服务器上对大语言模型管道中现有系统的运行时和内存性能进行了基准测试。 具体来说,我们提供以下详细的基准测试来了解不同软件和硬件系统的时间和内存效率。 (1) 在框架层面,我们选择 DeepSpeed 和 Megatron-LM 来研究 Llama2 [9] 三种尺度(7B、13B 和 70B)在三种类型硬件上的训练性能( A800、RTX4090 和 RTX3090 服务器)。 (2)我们研究了集成ZeRO、量化、激活重新计算和FlashAttention对内存和计算效率的影响。 (3) 我们评估了流行的 PEFT 框架,包括 LoRA 和 QLoRA,以了解它们的微调效率。 (4) 我们使用高度优化的推理库(包括 vLLM、LightLLM 和 TGI)研究端到端推理性能。 (5) 为了深入了解性能,我们对最耗时的关键内核进行了微基准测试。
通过全面的基准测试和分析,我们得出以下重要发现。 (1) DeepSpeed 在所有配置中均实现了比 Megatron-LM 更高的吞吐量。 (2)ZeRO在不牺牲训练效率的情况下节省了大量内存,否则当GPU数量低于4时可能会出现OOM。 (3) 卸载进一步减少了内存使用,但显着减慢了训练过程。 (4) 激活重新计算只有与其他优化技术结合才能很好地发挥作用,否则无法减少太多内存消耗。 (5) 与其他方法相比,量化提高了训练速度,在所有硬件平台上实现了最大吞吐量。 然而,这可能会导致收敛失败。 (6) FlashAttentionn加速了各种硬件平台上的训练过程,峰值内存消耗稍高,可以与其他内存高效方法进行迁移。 (7) PEFT方法使各种设备能够训练大语言模型。 (8)在A800平台上,LightLLM表现出优越的吞吐量。 相反,在 24G GPU 平台上,TGI 表现出增强的吞吐量,而 vLLM 和 LightLLM 显示的吞吐量水平相当。
II 背景与基础知识
II-A 基于纯解码器Transformer的大语言模型
传统的 Transformer [24] 由编码器和解码器架构组成,解码器已广泛用于现代文本生成大语言模型(例如 GPT-3 [25]、Llama [26]、Llama2 [9]、BLOOM [27] 等)。 解码器的结构如图2所示。 输入数据首先通过嵌入层进行编码,其输出被馈送到多个注意力块中。 每个注意力块由多头注意力和具有多个线性层的前馈网络组成。 然后,多个块的输出被连接起来作为下一个线性层(称为生成或分类头)的输入,然后是一个 softmax 层来计算下一个词符的概率。

II-B 预训练框架
深速。 DeepSpeed [10] 是一款尖端的深度学习 (DL) 优化软件套件,专为大规模训练和推理而开发。 它采用了ZeRO [16,28,29]、卸载和DeepSpeed-Inference [30]等技术。 该软件封装在开源库中,可以无缝集成到训练和推理中。 它已在 DL 社区中得到广泛采用,并且是 Microsoft 大规模 AI 计划的基石。
威震天-LM。 Megatron-LM [31, 11] 解决了高效训练昂贵的 Transformer 模型的挑战。 Megatron-LM 针对支持 3D 并行性和激活重新计算进行了很好的优化[17]。 它还引入了序列并行性与张量并行性相结合,因此大大减少了激活重新计算的需要。 由于Megatron-LM具有高度可扩展性,因此它一直是常用的大语言模型训练系统。
II-C 微调框架
对下游任务进行大语言模型微调的一种直接方法是调整所有参数(即 Full-FT),但这种方法非常消耗内存且耗时。 在实际应用中,参数高效微调 (PEFT) [12] 方法更受欢迎,因为与 Full-FT 相比,它们需要更少的内存资源来调节模型。 在 PEFT 中,LoRA [21](或 QLoRA [22],LoRA 的量化版本)和 Prompt Tuning [32] 是两个广泛使用的采用的方法。
LoRA。 低秩适应(LoRA)方法[21]基于过参数化模型通常在低内在维度内运行的观察。 对于预训练的权重矩阵,其更新使用低秩分解来约束:,其中, ,以及排名。 在训练过程中,保持静态,没有梯度更新,而和是可训练的。 修改后的前向传播表示为。 因此,LoRA 通过将 LoRA 等级 设置为预训练的权重矩阵来训练低等级矩阵来近似 Full-FT,并且在推理过程中几乎不会产生额外开销。
QLoRA。 QLoRA [22] 是 LoRA 的量化版本。 它将预训练模型转换为特定的 4 位数据类型(NormalFloat 或 NF4),从而大幅减少内存使用量并提高计算效率,同时在量化期间保持数据完整性。
及时调整。 提示调优[32]是一种专为使冻结语言模型适应特定下游任务而定制的新技术。 具体来说,提示调整强调通过反向传播学习“软提示”,从而允许使用来自标记示例的信号对它们进行微调。
II-D 推理框架
TGI。 文本生成推理(TGI)[15]是专门为大语言模型的部署和服务而设计的工具包。 迎合一系列知名开源大语言模型,包括Llama系列[26, 9]、BLOOM [27]。 它采用张量并行性(或模型并行性[33])来加速跨多个GPU的推理,并通过服务器发送事件(SSE)[34]使用词符流。 值得注意的是,TGI 的连续批处理优化了传入请求的处理,从而最大限度地提高了吞吐量。 该工具包利用 FlashAttention [23] 和 PagedAttention [13] 等先进技术,通过优化的 Transformer 代码进一步完善推理。
vLLM。 PagedAttention算法[13]受到操作系统虚拟内存和分页机制的启发,将动态变化的键值缓存(KV缓存)内存分割成更小的块,这些块可以放置在不连续的位置地区。 这种方法解决了碎片等问题,为优化内存利用率铺平了道路。 vLLM 以 PagedAttention 为基础构建而成222https://github.com/vllm-project/vllm是一个高吞吐量的大语言模型服务引擎。
LightLLM。 LightLLM [14] 是一种基于 Python 的前沿大语言模型推理和服务框架,以其轻量级架构、可扩展性和快速性能而著称。 LightLLM 采用三进程异步协作,允许标记化、模型推理和去标记化同时发生,从而最大限度地提高 GPU 利用率。 此外,它还引入了“Nopad”功能来巧妙地管理不同长度的请求,并引入动态批量调度机制来简化请求处理。 LightLLM 独特的 token-wise KV 缓存管理,称为“词符注意力”,可显着减少推理过程中的内存使用。 另一个功能是 Int8KV 缓存,它可以有效地将词符容量翻倍。
II-E 优化技术
零。 ZeRO 串行技术(即 ZoRO-1/2/3 [16]、ZeRO-Offload [28] 和 ZeRO-Infinity [29]) 优化训练大语言模型的记忆效率。 ZeRO-1 在 GPU 之间划分模型的优化器状态,从而减少这些状态使用的内存。 ZeRO-2 通过添加跨 GPU 的梯度分区来扩展 ZeRO-1,进一步减少梯度所需的内存。 然而,ZeRO-2 在后向过程中引入了额外的Reduce 集体通信原语。 在ZeRO-1和ZeRO-2的基础上,ZeRO-3进一步增加了激活的模型参数分区和模型并行性,最大限度地节省了内存,并允许在减少通信开销的情况下训练更大的模型,但它需要额外的Reduce-Scatter进行分区模型参数。 通过 ZeRO-Offload,作者的目标是使数十亿规模的模型训练变得更容易,弥合计算需求和可用资源之间的差距。
激活卸载。 激活卸载[28]是一种旨在有效管理训练和部署大语言模型中固有的大量计算和GPU内存需求的技术。 通过在神经网络的前向传递期间选择性地将激活(中间神经元输出)从 GPU 内存传输到 CPU 内存或磁盘存储,并随后在梯度计算的反向传递期间重新加载它们,激活卸载有助于内存和计算资源优化。 此外,可以采用优化器卸载和模型参数卸载这两种主要方法来显着减轻 GPU 内存的压力。 然而,它引入了额外的数据传输开销。
激活重新计算。 它涉及在训练的向后传递期间重新计算中间激活,而不是从向前传递中保留它们以优化内存使用。 通过避免模型每一层的激活存储,它可以显着减少内存消耗。 然而,这种方法引入了额外的计算开销。 虽然内存优势很大,但重新计算过程需要对传统的反向传播算法进行更改,从而为训练范例增加了一层复杂性。
量化。量化是一种重要的技术,使用低位格式表示权重或激活,以减少内存大小和计算时间。 ZeroQuant [20] 是流行的系统之一,它引入了一种新颖的训练后量化方法,并为权重和激活开发了一种硬件友好的量化方案,这是一种独特的逐层知识蒸馏算法和高度优化的量化系统后端。 它已证明能够将 BERT 和 GPT-3 等模型的权重和激活精度降低至 INT8,同时将精度下降降至最低。
闪光注意。 FlashAttention [23] 旨在解决 Transformer 在处理大量序列时所带来的固有挑战。 该算法具有 IO 感知能力,可优化 GPU 内存级别之间的相互作用。 它利用平铺来减少 GPU 高带宽内存 (HBM) 和片上静态随机存取存储器 (SRAM) 之间的内存读/写,以提高注意力效率。
III 方法论
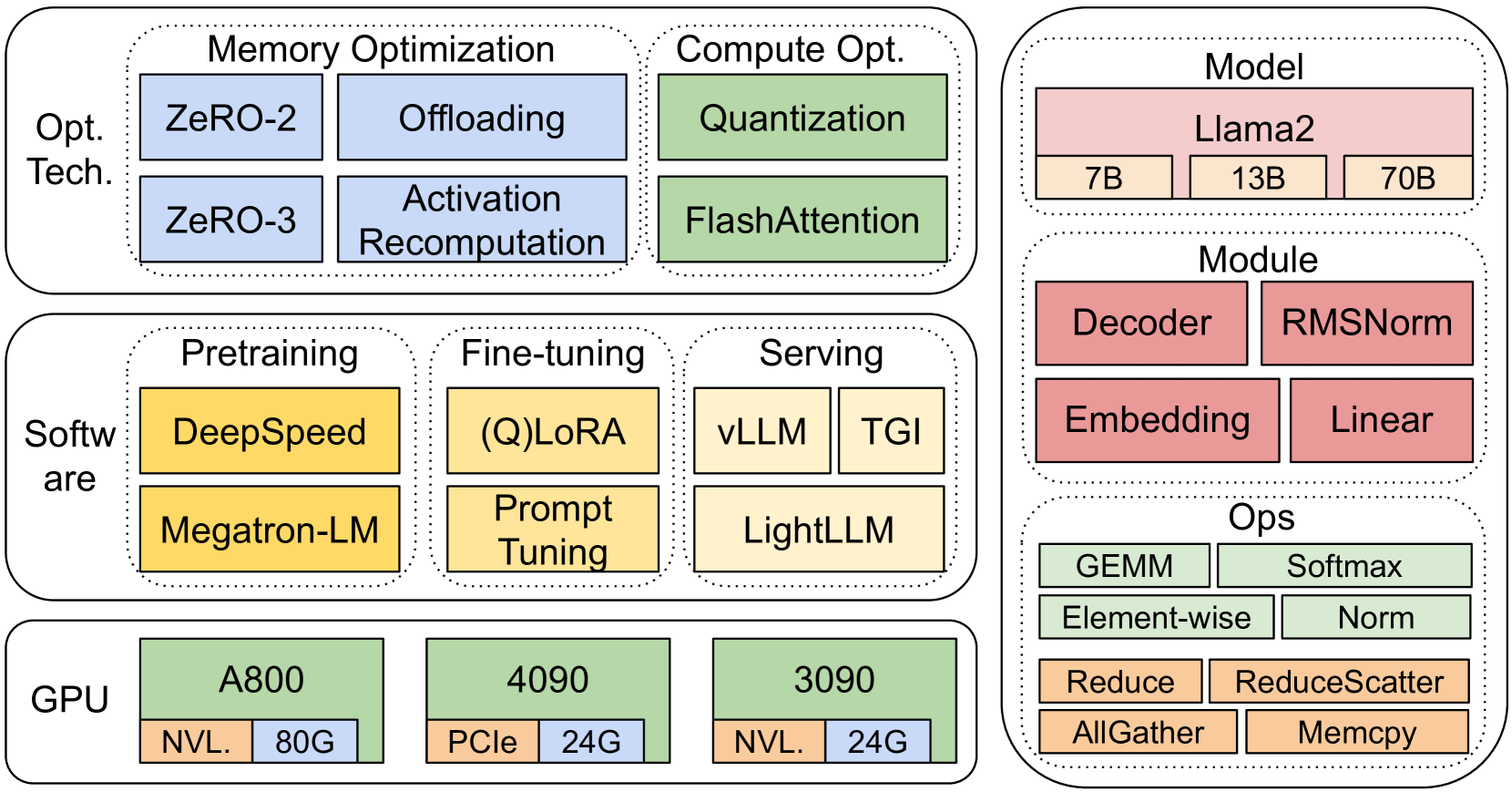
我们的基准测试使用自上而下的方法,涵盖 Llama2 [9] 在三个 8-GPU 硬件平台上的端到端步骤时间性能、模块级时间性能和运算符时间性能,如下所示如图3所示。
| Platform | A800 | RTX4090 | RTX3090 |
| GPU | A800-80G | RTX4090-24G | RTX3090-24G |
| @ 1.155GHz | @ 2.235GHz | @ 1.395GHz | |
| CPU | 2x AMD | 2x Intel(R) | 2x AMD |
| 7402 | Xeon(R) Gold 6230 | 7302 | |
| @ 2.80GHz | @ 2.10GHz | @ 3.00GHz | |
| Memory | 512GiB DDR4 | 512GB DDR4 | 128GB |
| Network | NVLink | PCIe4.0x16 | NVLink |
硬件。 在硬件评估方面,我们涵盖了三个8-GPU平台,其配置如表I所示。 在这些平台中,我们使用不同的软件(例如 DeepSpeed 和 Megatron-LM)测量大语言模型的预训练、微调和服务的时间性能。
软件。 在软件评估方面,我们比较了 DeepSpeed 和 Megatron-LM 在预训练和微调方面的端到端步骤时间。 为了评估优化技术,我们使用 DeepSpeed 逐一启用这些优化(即 ZeRO-2、ZeRO-3、卸载、激活重新计算、量化和 FlashAttention),以衡量性能改进以及时间和内存消耗方面的下降。 在大语言模型服务上,有vLLM [13]、LightLLM [14]、TGI [15]三个高度优化的系统。 我们在三个测试平台上比较了它们的性能(延迟和吞吐量)。 为了深入了解端到端性能,我们提供了模型模块和运算符性能的微基准测试,这些模型模块和运算符是预训练、微调和推理服务管道的基本组成部分。
数据集。 为了保证结果的准确性和可重复性,我们计算了大语言模型常用数据集alpaca的指令、输入和输出的平均长度,即每个样本350个token,并随机生成字符串以达到序列长度350,在预训练、微调和模块分析方面。 在推理服务中,为了综合利用计算资源并评估框架的鲁棒性和效率,所有请求都以突发模式调度。 实验数据集由 1000 个合成句子组成,每个句子包含 512 个输入标记,确保评估环境的一致性。 我们在同一 GPU 平台上的所有实验中始终保持“最大生成 Token 长度”参数,以保证结果的一致性和可比性。
III-A 衡量端到端性能
我们通过在预训练、微调和服务三种尺寸的 Llama2 模型(Llama2-7B、Llama2-13B 和 Llama2-)中使用步骤时间、吞吐量和内存消耗等指标来测量端到端性能。 70B)在三个测试平台上。
预训练 (§IV)。 我们首先比较 DeepSpeed 和 Magetron-LM 之间的性能(吞吐量、时间和内存)差异。 然后,我们使用 DeepSpeed 来评估优化技术 ZeRO-2、ZeRO-3、卸载、激活重新计算、量化和 FlashAttention 对我们测试台上的时间和内存效率的影响。 为了了解导致测量性能的根本原因,我们进一步测量模块和操作员的性能。
微调 (§V)。 我们将两种流行的微调技术 LoRA 和 QLoRA 与三个测试平台上的基线(全参数调整或 Full-FT)进行比较,并采用吞吐量和内存消耗指标。
推理服务 (§VI)。 我们使用三个测试平台评估了三个广泛认可的推理服务系统:vLLM [13]、LightLLM [14] 和 TGI [15] ,重点关注延迟、吞吐量和内存消耗等指标。 最初,我们为每个框架部署了 API 服务器。 随后,使用基准测试脚本,利用 asyncio 将 HTTP 请求分派到模型服务器。 作为已确认的错误333RTX 40x0 NCCL Issue Comment 适用于 RTX40X0 GPU 系列,为了纠正此问题并确保推理框架在 RTX4090 上正常运行,应用了配置 NCCL_P2P_DISABLE=1。 然而,这种配置可能会影响最终的性能,使 RTX4090 与其他平台相比处于劣势。
III-B 测量模块性能
大语言模型通常由一系列模块(或层)组成。 以Llama2模型为例。 顶级类 LlamaForCausalLM 由一个 LlamaModel 模块组成,该模块具有用于下游任务的线性层。 每个模块都有自己的子模块,这些子模块可能具有独特的计算和通信特性。 具体来说,一个LlamaModel由一个嵌入层和多个解码层(LlamaDecoderLayer)[24]组成,并且LlamaDecoderLayer的数量是可配置的。 LlamaAttention 是自注意力层 [24],由四个线性层组成,用于计算 、、 和 投影和一个嵌入层 (LlamaRotaryEmbedding)。 LlamaMLP 由三个大小可配置的线性层和一个 SiLU 激活 [35] 层 (SiLUActivation) 组成。 LlamaRMSNorm 是 RMS 归一化 [36] 层。 综上所述,构成 Llama2 模型的关键模块是 Embedding(naive Embedding 和 LlamaRotaryEmbedding)、LlamaDecoderLayer、Linear、SiLUActivation 和 LlamaRMSNorm。
在微调中,不同的方法引入了额外的模块来更新模型参数或适配器参数。 特别是,LoRA 需要额外的线性层,即低阶适配器。 QLoRA 具有与 LoRA 类似的训练范例,但其计算使用低位表示,这会导致低精度线性层,例如 8 位或 4 位线性层。
IV 预训练结果
在本节中,我们首先分析三个测试平台(§IV-A)上不同模型大小(7B、13B、70B)的预训练性能(迭代时间或吞吐量和内存消耗),然后通过模块级和操作级微基准(§VII)。 除非另有说明,否则每个任务的每个指标(迭代时间或吞吐量和内存消耗)都会测量三次,并报告平均值。
IV-A 端到端性能
| Framework | BS | Throughput (Tokens/s) | Memory (GB) |
|---|---|---|---|
| Megatron | 1 | 10936 | 49.1 |
| 32 | 13977 | 55.6 | |
| DeepSpeed | 1 | 7488 | 66.76 |
| 4 | 19348 | 72.64 |
IV-A1 Megatron-LM 与 DeepSpeed
我们首先进行了一个实验来比较 Megatron-LM 和 DeepSpeed 之间的性能,两者在 A800-80GB 服务器上预训练 Llama2-7B 时都没有使用任何内存优化技术,例如 ZeRO。 我们对 Megatron-LM 和 DeepSpeed 使用 350 的序列长度和两组批量大小 (BS),从 1 到最大批量大小。 我们报告训练吞吐量(每秒 Token 数或 Token /秒)和消耗的 GPU 内存(以 GB 为单位)作为基准。 结果如表II所示。 结果表明,当批量大小等于 1 时,Megatron-LM 的执行速度略快于 DeepSpeed,但是 当达到最大批量大小时,DeepSpeed 在训练速度方面领先。 与基于张量并行的 Megatron-LM 相比,在相同的批量大小下,DeepSpeed 消耗更多的 GPU 内存。 即使批量大小很小,这两个系统也会占用大量 GPU 内存,这会导致 RTX4090 或 RTX3090 GPU 服务器出现内存不足 (OOM)。
IV-A2 GPU 扩展效率
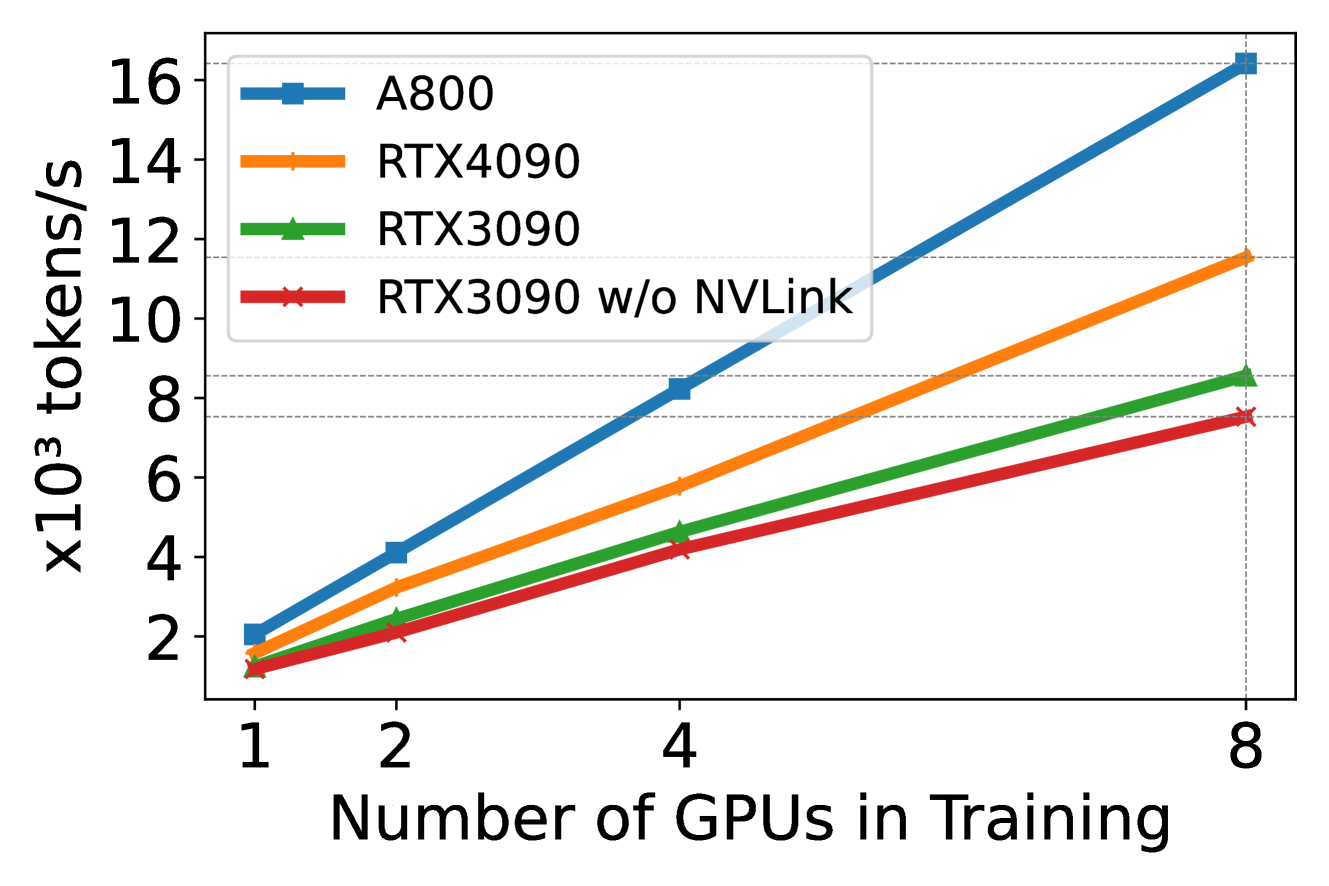
我们使用 DeepSpeed 进行量化来研究训练 Llama2-7B(序列长度为 350,批量大小为 2)中不同硬件平台上的扩展效率(从 1 个 GPU 到 8 个 GPU)。 结果如图4所示,其中斜率表示缩放效率。 从图中可以看出,A800几乎具有线性缩放,而RTX4090和RTX3090的缩放效率稍低(分别为90.8%和85.9%)。 RTX4090 的缩放效率比 RTX3090 高 4.9%。 在 RTX3090 平台中,与不使用 NVLink 的情况相比,NVLink 连接有助于将扩展效率提高 10%。
IV-A3 硬件和优化技术
我们使用 DeepSpeed 来评估不同内存和计算效率方法下的训练性能。 我们在所有评估中使用序列长度为 350、批量大小为 1 进行公平比较,并在所有实验中默认将模型权重加载到 bf16 中。 对于具有卸载功能的 ZeRO-2 和 ZeRO-3,我们分别将优化器状态和优化器状态 + 模型权重卸载到 CPU RAM。 对于量化,我们使用 4 位双量化配置,如先前研究[22]中所建议。 我们还报告了禁用 NVLink 时(即所有数据均通过 PCIe 总线传输)时 RTX3090 的性能。 结果如表III所示。
| Model | Method | Hardware platform | |||||||
|---|---|---|---|---|---|---|---|---|---|
| A800 | RTX4090 | RTX3090 w/ NVLink | RTX3090 w/o NVLink | ||||||
| Tokens/s | M (GB) | Tokens/s | M (GB) | Tokens/s | M (GB) | Tokens/s | M (GB) | ||
| 7B | Naive | 66.7 | - | - | - | ||||
| Z2 | 37.8 | - | - | - | |||||
| Z2+O | 32.8 | 19.1 | 19 | 19 | |||||
| Z3 | 30.5 | 22.6 | 22.6 | 22.6 | |||||
| Z3+O | 10.4 | 10.4 | 10.4 | 10.4 | |||||
| Q | 9.8 | 10.1 | 9.8 | 9.8 | |||||
| R | 65.9 | - | - | - | |||||
| F | 66.7 | - | - | - | |||||
| R+Z2 | 38.1 | - | - | - | |||||
| R+Z2+O | 29.6 | 19 | 19 | 19 | |||||
| R+Z3 | 28.8 | 22.6 | 22.6 | 22.6 | |||||
| R+Z3+O | 6.4 | 6.4 | 6.4 | 6.4 | |||||
| R+Q | 6 | 6 | 6 | 6.0 | |||||
| R+F | 66.1 | - | - | - | |||||
| F+Z2 | 38.2 | - | - | - | |||||
| F+Z2+O | 32 | 18.1 | 18 | 18 | |||||
| F+Z3 | 29.2 | 21.6 | 21.4 | 21.4 | |||||
| F+Z3+O | 8.8 | 8.8 | 8.8 | 8.8 | |||||
| F+R+Z2 | 38.1 | - | - | - | |||||
| F+R+Z2+O | 29.6 | 17.7 | 17.7 | 17.7 | |||||
| F+R+Z3 | 27.4 | 21 | 21 | 21 | |||||
| F+R+Z3+O | 6.7 | 6.7 | 6.5 | 6.5 | |||||
| 13B | Z2 | 71.4 | - | - | - | ||||
| Z2+O | 57.9 | - | - | - | |||||
| Z3 | 48.9 | - | - | - | |||||
| Z3+O | 12.7 | 12.7 | 12.2 | 12.2 | |||||
| R+Z2 | 71.8 | - | - | - | |||||
| R+Z2+O | 53.1 | - | - | - | |||||
| R+Z3 | 48.9 | - | - | - | |||||
| R+Z3+O | 7.8 | 7.8 | 7.8 | 7.8 | |||||
| F+Z2 | 72.2 | - | - | - | |||||
| F+Z2+O | 56.8 | - | - | - | |||||
| F+Z3 | 52.2 | - | - | ||||||
| F+Z3+O | 11.5 | 11.5 | 11.3 | 11.3 | |||||
| F+R+Z2 | 71.7 | - | - | - | |||||
| F+R+Z2+O | 52.9 | - | - | - | |||||
| F+R+Z3 | 53.7 | - | - | - | |||||
| F+R+Z3+O | 7.9 | 7.9 | 7.9 | 7.9 | |||||
硬件影响。 (1) 在除量化之外的所有评估案例中,A800 的吞吐量超过 RTX4090 和 RTX3090 GPU 的 50 倍。 在使用量化的情况下,RTX GPU可以实现A800性能的一半。 (2) RTX4090 比 RTX3090 性能提升 50%,RTX3090 中的 NVLink 有助于性能提升 10% 左右。 (3) 由于 A800 具有 80GB 内存,而 RTX4090 和 RTX3090 只有 24GB,因此某些情况(例如 Naive 和 ZeRO-2)无法在 RTX4090 和 RTX3090 GPU 上运行。 (4) 通过 ZeRO(和卸载训练),8x 80GB (8x 24GB) GPU 服务器最多可以容纳 30B 模型的混合半精度。
优化技术。 在预训练 Llama2-7B 时,ZeRO-2 的 GPU 内存消耗约为 Naive 的 57%,并且没有牺牲模型性能和训练效率。 同时,ZeRO-3 的性能比 ZeRO-2 稍慢,内存消耗也更少。 然而,在预训练 Llama2-13B 时,ZeRO-3 的表现优于 ZeRO-2。 这种差异是因为对完整模型状态训练进行分片有助于进一步减少通信,尤其是在模型较大时。 卸载会显着减慢训练过程,因为它将一些分片和计算卸载到 RAM 和 CPU,并减少 GPU 内存消耗。 量化在所有硬件平台上实现了最高吞吐量,但可能会影响收敛。 FlashAttention 还可以加速训练,并且可以与内存高效方法(例如 ZeRO)一起使用。 激活重新计算进一步减少 GPU 内存使用,但会降低吞吐量。 请注意,当批大小 = 1 时,激活内存较小,并且批大小较大时,激活重新计算可以节省更多内存。 在表III中,使用ZeRO或卸载时,相同方法的内存消耗在不同平台上有所不同。 具体来说,A800 上比其他平台需要更多内存。 这种差异是因为内存在分片和卸载中固定在 CPU 上,并且句柄根据可用物理内存动态加载到 GPU 内存中,而 A800 上的可用物理内存比其他平台更大。 此表还表明,训练 Llama2-13B 的吞吐量是 Llama2-7B 的一半。 鉴于 Llama2-7B 和 Llama2-13B 之间的模型性能,训练具有 13B 参数的模型可能是比 7B 模型更好的选择。 我们进一步利用不同 GPU 服务器的计算能力,通过最大化每种方法的批量大小来获得最大吞吐量。 结果如表IV所示。
在此表中,我们发现当批量大小为 16 时,与使用 ZeRO3 的 FlashAttention 相比,使用 ZeRO-3 和卸载的 FlashAttention 消耗的 GPU 内存更多(77.5GB 与 73GB)。 在进行此实验时,具有卸载功能的 ZeRO-3 通常会产生不平衡的设备映射,即它在 GPU 0 上占用的内存多于其他 GPU。 我们将在未来的研究中解决这个问题。 总体而言,表IV表明,扩大批量大小可以轻松提高训练过程,这也与通信和GPU计算重叠。 因此,高带宽、大显存的GPU服务器比消费级GPU服务器更适合全参数混合精度预训练。
| Model | Method | Hardware platform | |||||||||||
| A800 | RTX4090 | RTX3090 w/ NVLink | RTX3090 w/o NVLink | ||||||||||
| Tokens/s | M (GB) | BS | Tokens/s | M (GB) | BS | Tokens/s | M (GB) | BS | Tokens/s | M (GB) | BS | ||
| 7B | Naive | 72.6 | 4 | - | - | - | |||||||
| Z2 | 58.0 | 8 | - | - | - | ||||||||
| Z2+O | 77.7 | 16 | 22.5 | 2 | 22.5 | 2 | 22.5 | 2 | |||||
| Z3 | 77.2 | 16 | 22.6 | 2 | 22.68 | 2 | 22.6 | 2 | |||||
| Z3+O | 74.9 | 16 | 20.5 | 4 | 20.5 | 4 | 20.5 | 4 | |||||
| Q | 49.8 | 8 | 22.7 | 4 | 22.7 | 4 | 22.7 | 4 | |||||
| R | 75.1 | 64 | - | - | - | ||||||||
| F | 76.4 | 8 | - | - | - | ||||||||
| R+Z2 | 45.9 | 64 | - | - | - | ||||||||
| R+Z2+O | 58.5 | 64 | 19.8 | 16 | 19.8 | 16 | 19.8 | 16 | |||||
| R+Z3 | 59.2 | 64 | 22.8 | 16 | 22.8 | 16 | 22.8 | 16 | |||||
| R+Z3+O | 52.8 | 64 | 22.5 | 64 | 17.5 | 32 | 17.5 | 32 | |||||
| R+Q | 56.8 | 64 | 20 | 32 | 18.9 | 16 | 18.9 | 16 | |||||
| R+F | 73.1 | 64 | - | - | - | ||||||||
| F+Z2 | 76.5 | 16 | - | - | - | ||||||||
| F+Z2+O | 70.3 | 16 | 18.1 | 1 | 18 | 1 | 18 | 1 | |||||
| F+Z3 | 73 | 16 | 21.6 | 1 | 21.4 | 1 | 21.4 | 1 | |||||
| F+Z3+O | 77.5 | 16 | 19.4 | 16 | 19.4 | 16 | 19.4 | 16 | |||||
| F+R+Z2 | 45.4 | 64 | - | - | - | ||||||||
| F+R+Z2+O | 61 | 64 | 17.7 | 1 | 17.7 | 1 | 17.7 | 1 | |||||
| F+R+Z3 | 56.7 | 64 | 21 | 1 | 21 | 1 | 21 | 1 | |||||
| F+R+Z3+O | 49.8 | 64 | 17.2 | 32 | 17.2 | 32 | 17.2 | 32 | |||||
| 13B | Z2 | 71.8 | 4 | - | - | - | |||||||
| Z2+O | 78.9 | 8 | - | - | - | ||||||||
| Z3 | 78.5 | 8 | - | - | - | ||||||||
| Z3+O | 66.7 | 8 | 18.8 | 2 | 18.8 | 2 | 18.8 | 2 | |||||
| R+Z2 | 75.7 | 64 | - | - | - | ||||||||
| R+Z2+O | 77.7 | 64 | - | - | - | ||||||||
| R+Z3 | 77.8 | 64 | - | - | - | ||||||||
| R+Z3+O | 63.6 | 64 | 22 | 16 | 22 | 16 | 22 | 16 | |||||
| F+Z2 | 75.7 | 4 | - | - | - | ||||||||
| F+Z2+O | 27.5 | 8 | - | - | - | ||||||||
| F+Z3 | 74.4 | 8 | - | - | - | ||||||||
| F+Z3+O | 74.9 | 16 | 22.6 | 4 | 22.6 | 4 | 22.6 | 4 | |||||
| F+R+Z2 | 71.8 | 64 | - | - | - | ||||||||
| F+R+Z2+O | 57.9 | 64 | - | - | - | ||||||||
| F+R+Z3 | 77.1 | 64 | - | - | - | ||||||||
| F+R+Z3+O | 34.9 | 64 | 23 | 32 | 23 | 32 | 23 | 32 | |||||
IV-B 模块分析
为了深入了解预训练性能,我们对预训练过程进行了详细的模块分析。 具体来说,我们在A800平台上选择了Llama2-7B模型,以确保所有案例都能运行进行性能分析。 跟踪是使用“torch.profiler”生成的,本节中提供的所有性能数据都是十个步骤的平均值。 实验设置与 IV-A 节中描述的一致。
| Forward | Backward | Optimizer | ||
|---|---|---|---|---|
| Overall (ms) | 75.0 | 250.0 | 193.9 | |
| Breakdown in one step(%) | 14.3 | 47.5 | 36.9 | |
|
68.8 | 200.9 | 181.4 |
考虑到 A800 的内存容量,我们将批量大小设置为 2。 表V详细说明了一个预训练步骤中前向、后向和优化器阶段所消耗的时间。值得注意的是,大约 37% 的时间专用于优化器,这与预期不同,因为优化器仅进行逐元素操作。 我们在IV-C节中分析了这种现象,重点关注重新计算的影响。
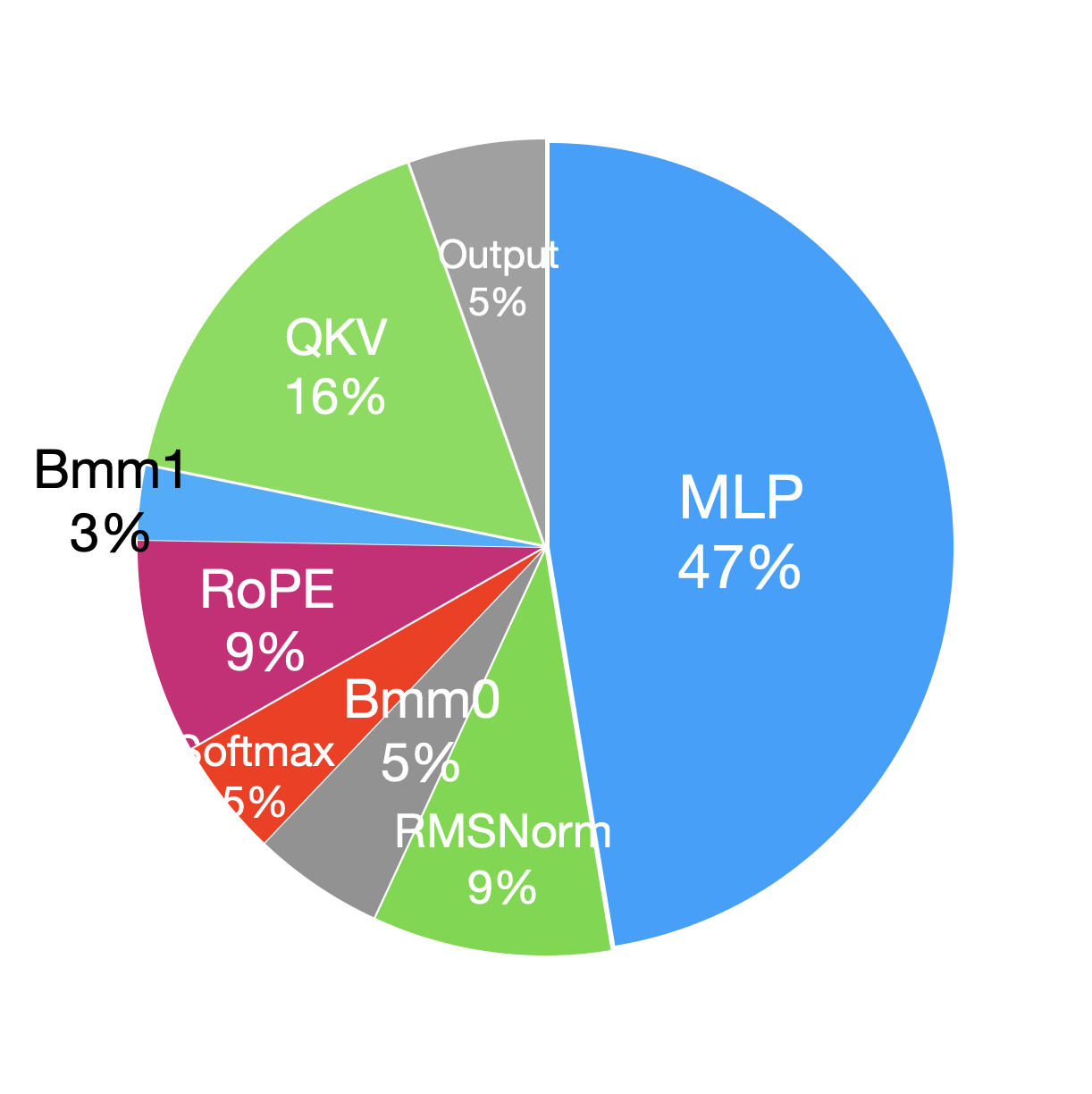
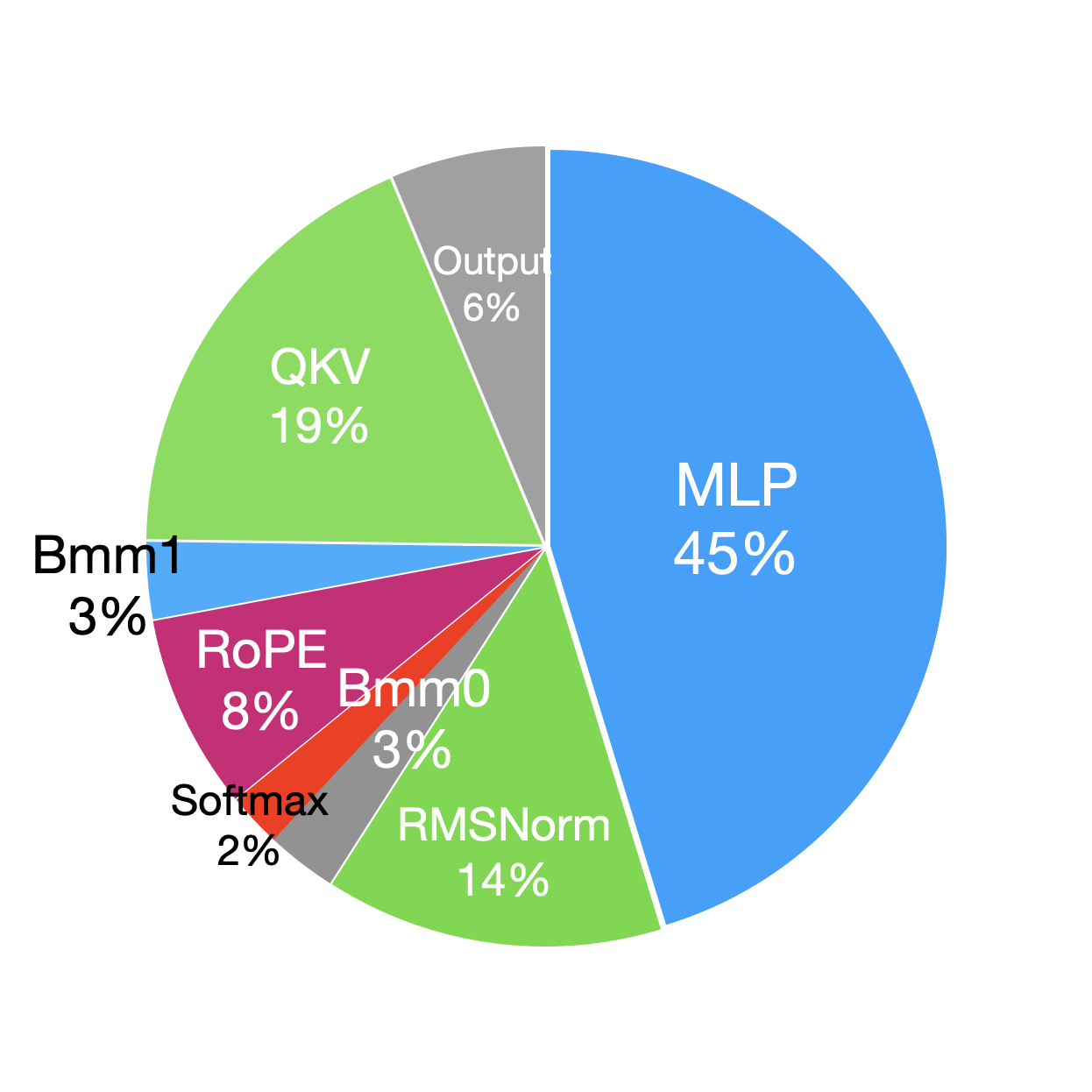
我们对前向和后向阶段进行了按模块的时间分析,结果如表V所示。
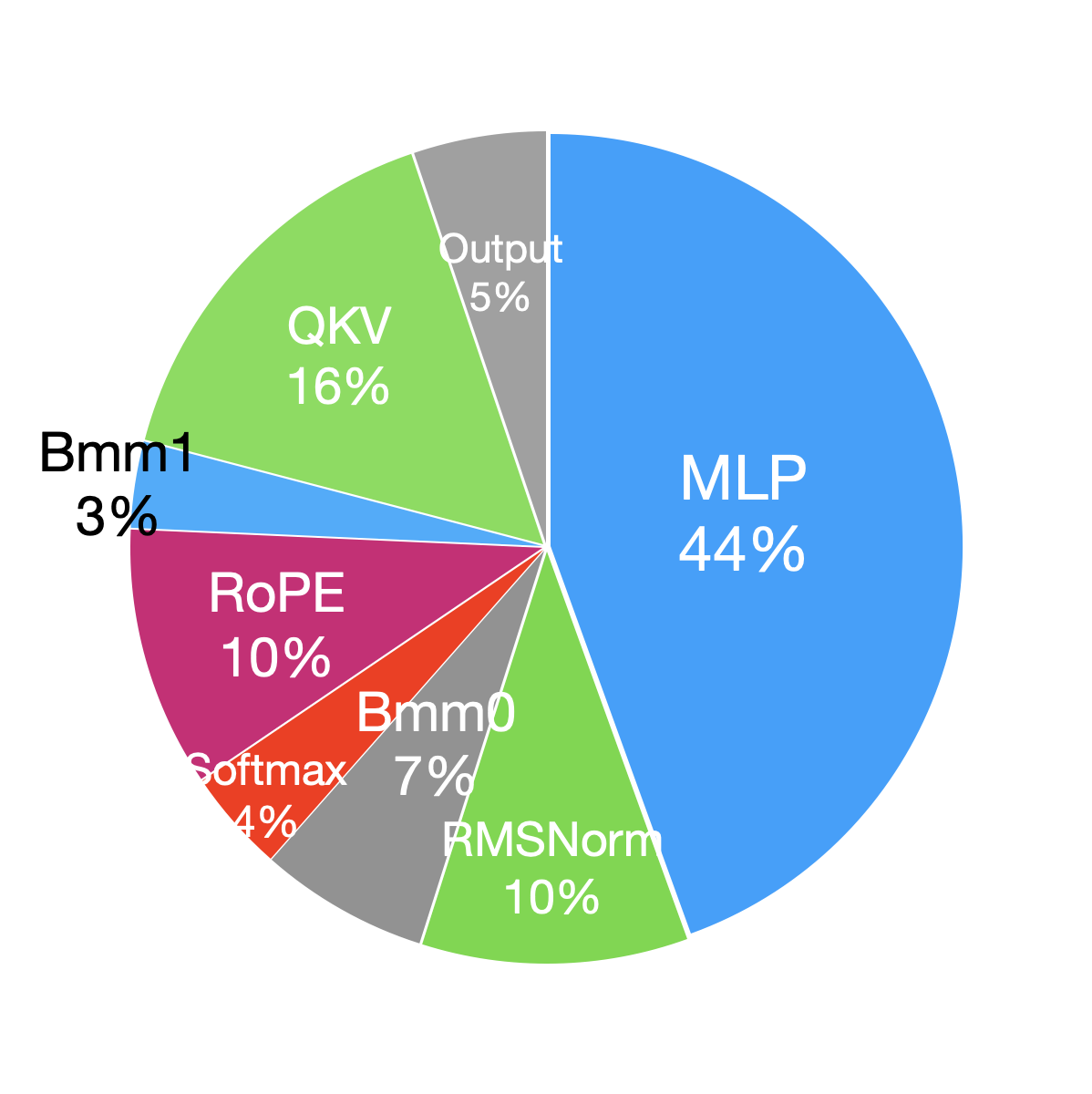
在 Llama2 中,基于 Transformer-decoder 架构构建的解码器层占据了大部分计算时间。 具体来说,依赖于通用矩阵乘法 (GEMM) 运算的多层感知器 (MLP) 和查询、键和值 (QKV) 投影是最耗时的组件。 此外,由于大量的逐元素操作,RMSNorm 和 RoPE 模块需要花费大量时间。 与前向阶段相比,后向阶段会因 GPU 之间的梯度同步而产生额外的通信开销。
| Module | Time(ms) | Percentage(%) | Module | Time(ms) | Percentage(%) | ||
| Forward | Embedding | 0.032 | 0.04 | Backward | Embedding | 0.252 | 0.1 |
| QKV | 9.92 | 13.2 | QKV | 36.26 | 14.5 | ||
| RoPE | 6.66 | 8.9 | RoPE | 15.58 | 6.2 | ||
| Bmm0 | 4.32 | 5.8 | Bmm0 | 5.63 | 2.3 | ||
| Softmax | 2.62 | 3.5 | Softmax | 4.29 | 1.7 | ||
| Bmm1 | 2.21 | 2.9 | Bmm1 | 6.14 | 2.5 | ||
| Output | 3.39 | 4.5 | Output | 12.32 | 4.9 | ||
| MLP | 29.06 | 38.7 | MLP | 88.70 | 35.5 | ||
| RMSNorm | 6.91 | 9.2 | RMSNorm | 27.40 | 11.0 | ||
| Linear | 1.08 | 1.4 | Linear | 2.898 | 1.2 | ||
| - | - | - |
|
38.76 | 15.5 |
IV-C 重新计算和 FlashAttention 的影响
加速预训练的技术大致可以分为两类:节省内存以增加批量大小和加速计算内核。 如表 5 所示,GPU 在前向、后向和优化器阶段有 5-10% 的时间处于空闲状态。 我们认为这种空闲时间是由于批量较小造成的。 我们测试了所有可用技术可使用的最大批量大小,发现重新计算可以将批量大小从 2 增加到最大 32。 因此,我们选择重新计算来增加批量大小,并选择 flashattention 来加速计算内核分析。
重新计算。 随着批量大小的增加,前向和后向阶段的时间显着增加,GPU 空闲时间很少(表VII)。 优化器根据优化器状态更新模型参数,因此这个过程将有大量的逐元素操作,尽管批量大小增加,但时间消耗将保持不变。 相比之下,前向和后向阶段有很多批量操作,这会随着批量大小的增加而增加时间消耗。 因此,当batch size比较小时,优化器占用的时间百分比会比较大;当使用重新计算技术以大批量进行预训练时,优化器所花费的时间百分比将非常小。
为了进一步探讨较大批量大小对预训练性能的影响,我们比较了使用和不使用重新计算(即批处理之间的比较)解码器层模块在前向和后向(删除后向重新计算部分)阶段所花费的时间百分比大小 = 32,批量大小 = 2)。 由于后向阶段的重新计算部分本质上是重新运行前向阶段,因此我们在分析过程中分别分析前向和后向阶段。 图5显示,当batch size从2增加到32时,模块在前向和后向阶段的时间分解都没有太大变化。 这是因为,逐元素操作是受内存限制的,并且它们的运行时间大致与批量大小成线性比例。 相比之下,解码器层中的 GEMM 操作受计算限制,更改批量大小通常仅影响 M、N 或 K 之一,因此运行时间也随着批量大小线性增长。
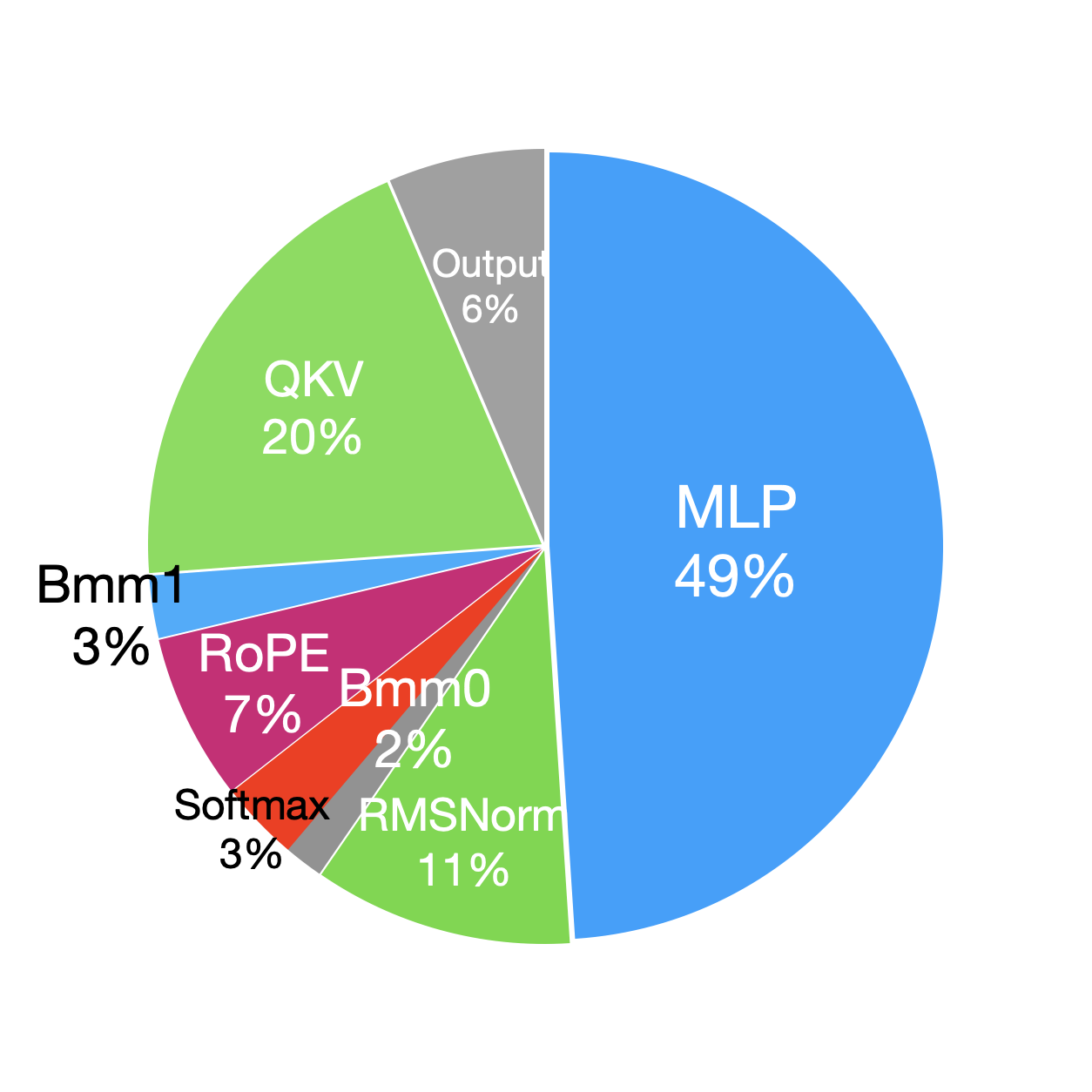
| Forward | Backward# | Optimizer | ||
|---|---|---|---|---|
| Overall (ms) | 900.8 | 2651.8 | 187.7 | |
| Percentage(%) | 24.0 | 70.8 | 5.1 | |
|
895.0 | 2614.4 | 180.0 |
FlashAttention 将 、softmax、PV(P=softmax()) 的操作和一些逐元素操作融合到一个内核中,使用更多减少对低延迟高带宽GPU SRAM的访问,减少对高延迟低带宽GPU DRAM的访问。 表VIII显示该技术可以将注意力模块分别加速34.9%和24.7%。
| Forward | backward | |
|---|---|---|
| Naive(ms) | 1.06 | 2.75 |
| FlashAttention(ms) | 0.69 | 2.07 |
| Improvement(%) | 34.9 | 24.7 |
V 微调结果
在微调中,我们的主要关注点是参数高效的微调方法(PEFT 方法),因为全参数训练已经在第 IV-A 节中讨论过。 我们报告了 LoRA 和 QLoRA 在各种模型大小和硬件设置上的微调性能。 我们使用序列长度为 350、批量大小为 1、LoRA 等级为 64,默认将模型权重加载到 bf16 中。 对于 QLoRA,我们采用双量化的 4 位配置[22]。 我们还将 LoRA 和 QLoRA 与其他技术结合起来,保持与第 IV-A 节中相同的配置。 Llama2-7B 的微调结果如表IX所示。
表IX显示,使用LoRA和QLoRA微调Llama2-13B的性能趋势与Llama2-7B一致。 具体来说,在所有评估中,LoRA 的吞吐量大约比 QLoRA 高 ,这主要是由于与量化和反量化操作相关的开销。 然而,QLoRA 的内存消耗是 LoRA 的一半。 FlashAttention 和 ZeRO-2 与 LoRA 结合进行微调时,在所有硬件平台上分别比单独使用 LoRA 提高 20% 和 10% 的吞吐量。 相比之下,ZeRO-3 或卸载在 LoRA 微调中表现出较差的性能,因为 LoRA 只更新一小部分参数,即低阶适配器。 由于优化器状态仅限于处理 LoRA 参数更新,而这些更新不受计算限制,因此与计算时间相比,卸载或分片如此小的一部分状态会带来更多的通信开销,并且不会显着减少内存使用量。
与 Llama2-7B 相比,微调 Llama2-13B 的吞吐量下降了约 30%。 然而,当所有优化技术结合起来时,即使是 RTX4090 和 RTX3090 也可以对 Llama2-70B 进行调节,实现每秒约 200 个 Token 的总吞吐量。
| Model | Method | Hardware platform | |||||||
|---|---|---|---|---|---|---|---|---|---|
| A800 | RTX4090 | RTX3090 w/ NVLink | RTX3090 w/o NVLink | ||||||
| Tokens/s | M (GB) | Tokens/s | M (GB) | Tokens/s | M (GB) | Tokens/s | M (GB) | ||
| 7B | L | 22.7 | 20.5 | 20.5 | 20.5 | ||||
| QL | 13.7 | 14 | 14 | 14 | |||||
| L+R | 21.9 | 20.1 | 20.1 | 20.1 | |||||
| QL+R | 11 | 11.9 | 11.9 | 11.9 | |||||
| L+F | 20.5 | 18.9 | 18.9 | 18.9 | |||||
| QL+F | 9.5 | 10.5 | 10.5 | 10.5 | |||||
| L+Z2 | 19.1 | 19 | 19 | 19 | |||||
| L+Z2+O | 18.8 | 18.7 | 18.7 | 18.7 | |||||
| L+Z3 | 13.3 | 13.3 | 13.3 | 13.3 | |||||
| L+Z3+O | 11.2 | 11.4 | 11.4 | 11.4 | |||||
| QL+Z2 | 10.6 | 10.5 | 10.5 | 10.5 | |||||
| QL+Z2+O | 10.3 | 10.3 | 10.3 | 10.3 | |||||
| L+F+R | 22.2 | 18.9 | 18.9 | 18.9 | |||||
| QL+F+R | 8.5 | 10.1 | 10.1 | 10.1 | |||||
| L+F+R+Z2 | 15.6 | 15.5 | 15.5 | 15.5 | |||||
| L+F+R+Z2+O | 15.3 | 15.2 | 15.2 | 15.2 | |||||
| L+F+R+Z3 | 8.5 | 9.3 | 9.3 | 9.3 | |||||
| L+F+R+Z3+O | 7 | 7.7 | 7.7 | 7.7 | |||||
| 13B | L | 40.3 | - | - | - | ||||
| QL | 21.7 | 21.7 | 21.7 | 21.7 | |||||
| L+R | 36.5 | - | - | - | |||||
| QL+R | 15.5 | 18.5 | 18.5 | 18.5 | |||||
| L+F | 41.4 | - | - | - | |||||
| QL+F | 15.7 | 16.8 | 16.8 | 16.8 | |||||
| L+Z2 | 33.8 | - | - | - | |||||
| L+Z2+O | 33.5 | - | - | - | |||||
| L+Z3 | 18.1 | 17.9 | 17.9 | 17.9 | |||||
| L+Z3+O | 14.1 | 14.2 | 14.2 | 14.2 | |||||
| QL+Z2 | 16.7 | 16.8 | 16.8 | 16.8 | |||||
| QL+Z2+O | 16.3 | 16.4 | 16.4 | 16.4 | |||||
| L+F+R | 40.3 | - | - | - | |||||
| QL+F+R | 13.9 | 16.8 | 16.8 | 16.8 | |||||
| L+F+R+Z2 | 28.1 | - | - | - | |||||
| L+F+R+Z2+O | 27.8 | - | - | - | |||||
| L+F+R+Z3 | 10.8 | 11.9 | 11.9 | 11.9 | |||||
| L+F+R+Z3+O | 8.7 | 8.8 | 8.8 | 8.8 | |||||
| 70B | QL+F+R | 59.8 | - | - | - | ||||
| L+F+R+Z3 | 29.4 | - | - | - | |||||
| L+F+R+Z3+O | 13.2 | 13.2 | 13.2 | 13.2 | |||||
| QL+R | 63.6 | - | - | - | |||||
| QL+F | 61.2 | - | - | - | |||||
VI 推理结果
VI-A 端到端性能
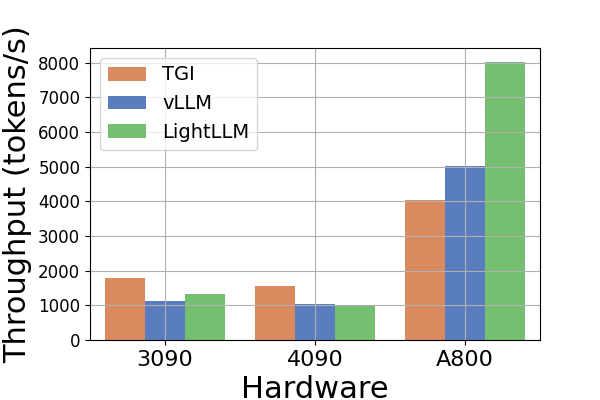
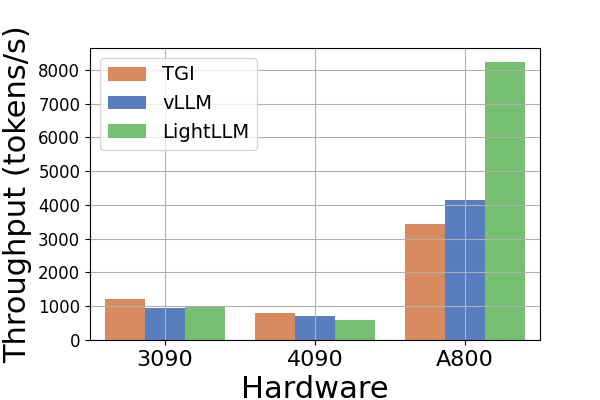
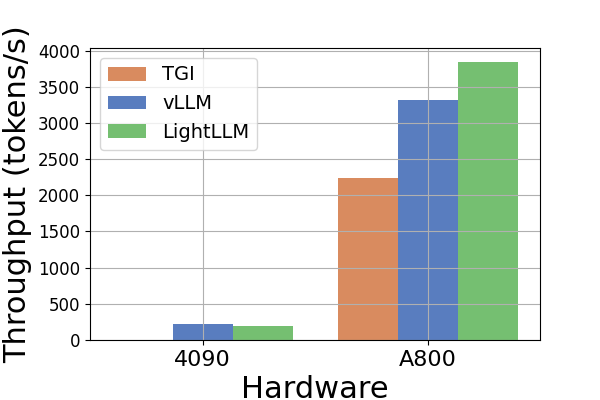
吞吐量。 图6展示了各种硬件平台和推理框架的吞吐量比较分析。 由于Llama2-70B模型在RTX3090和RTX4090上的TGI框架会导致OOM错误,因此图6中省略了Llama2-70B的相关数据推断。 TGI 框架展示了卓越的吞吐量,特别是在具有 24GB 内存的 GPU 上,例如 RTX3090 和 RTX4090。 相比之下,LightLLM 在 A800 GPU 平台上的性能显着优于 TGI 和 vLLM,吞吐量几乎翻倍。 这些实验表明,TGI 推理框架在 24GB GPU 平台上具有卓越的性能,而 LightLLM 推理框架在 A800 80GB GPU 平台上表现出最高的吞吐量。 这一发现表明 LightLLM 专门针对 A800/A100 系列等高性能 GPU 进行了优化。
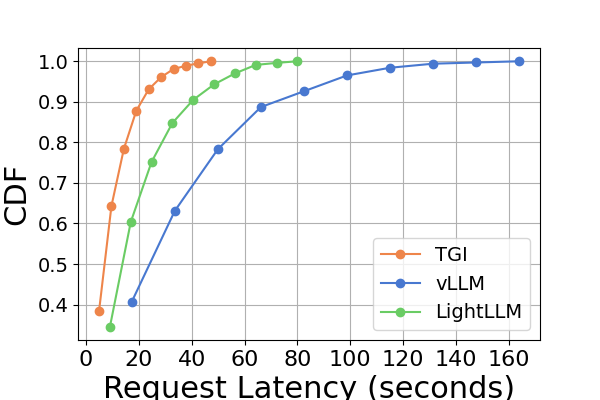
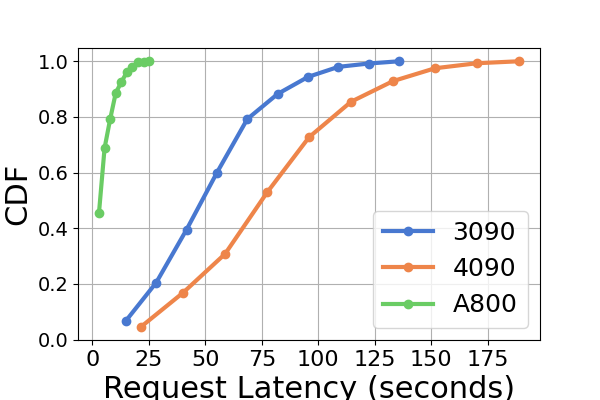
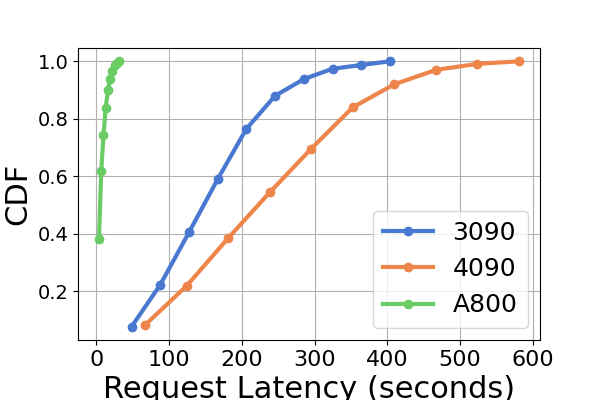
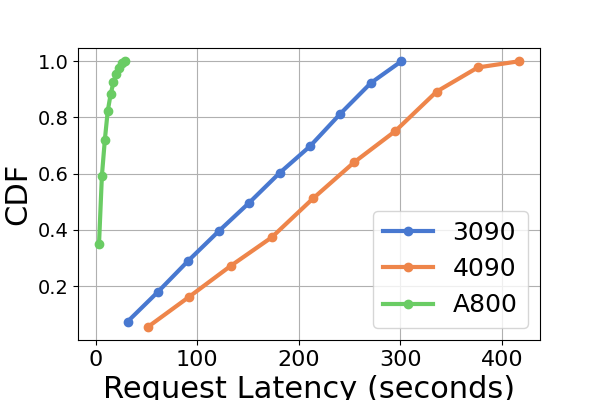
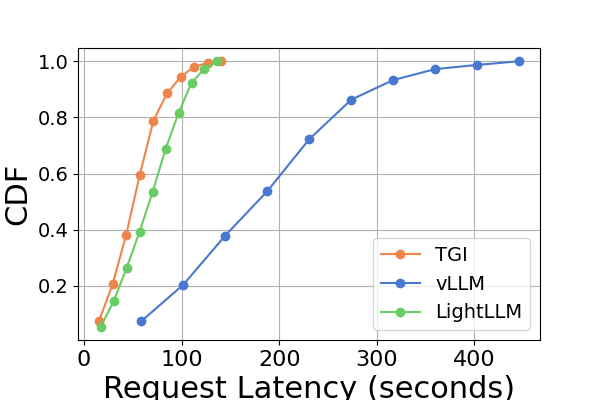
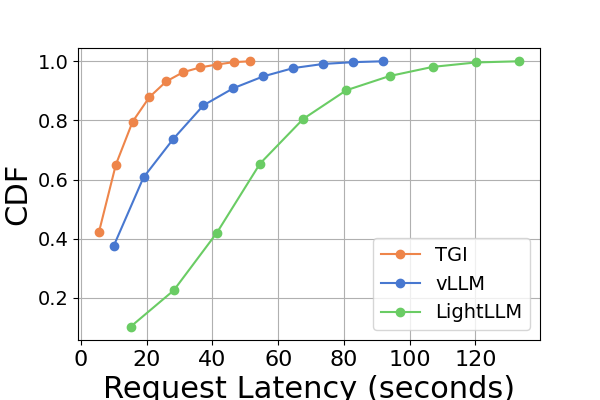
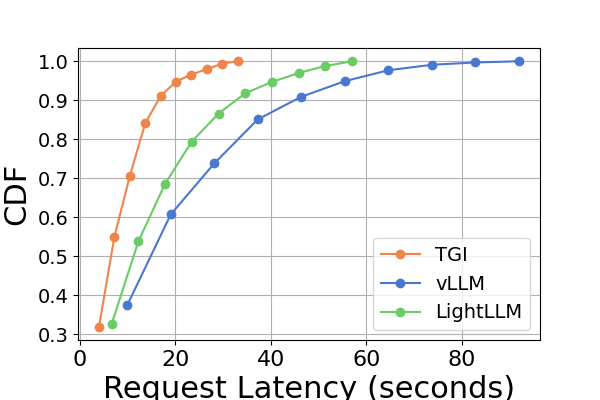
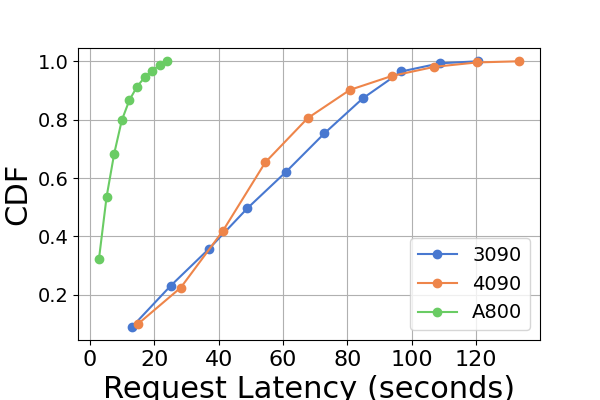
延迟。 图 7 和图 8 以及图 9 和图 10。 我们使用累积分布函数(CDF)来绘制不同推理框架的延迟。 CDF 表示变量的值小于或等于样本空间中特定点的概率。 例如,图7说明LightLLM大约需要20秒来响应60%的请求,并且需要大约80秒来响应100%的请求。
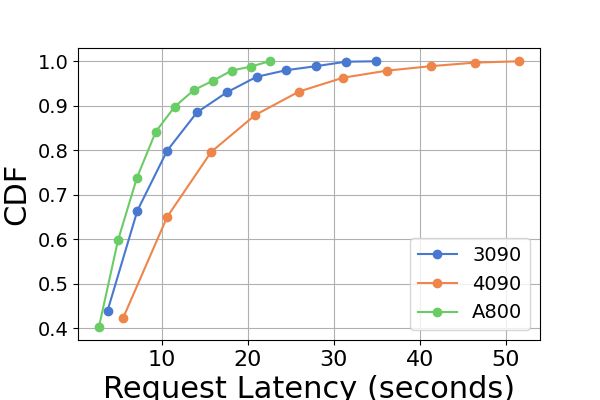
在图7中,我们专门比较了同一 GPU 平台上三个推理框架的延迟。 RTX3090 和 A800 平台上的性能表现出相似的趋势,TGI 的延迟最低,其次是 LightLLM,vLLM 的延迟最高。 其他实验如图9所示。
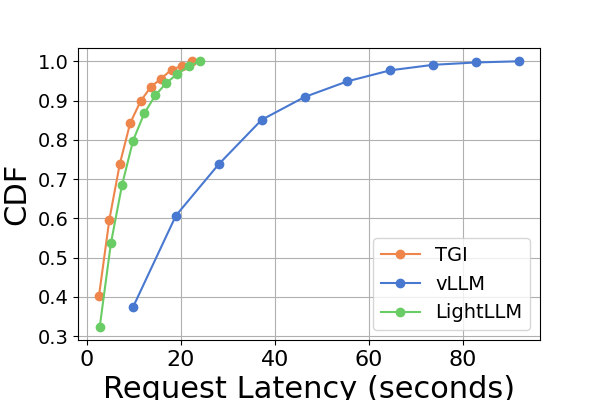
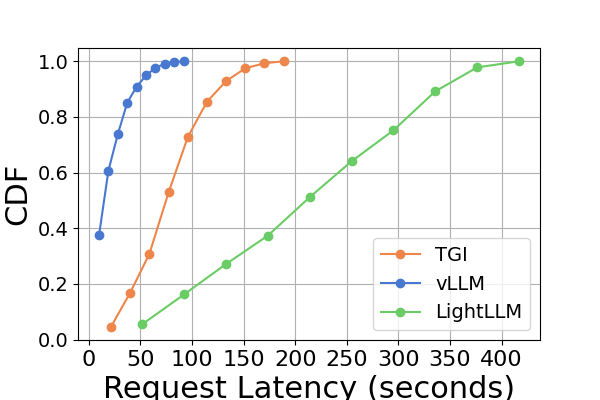
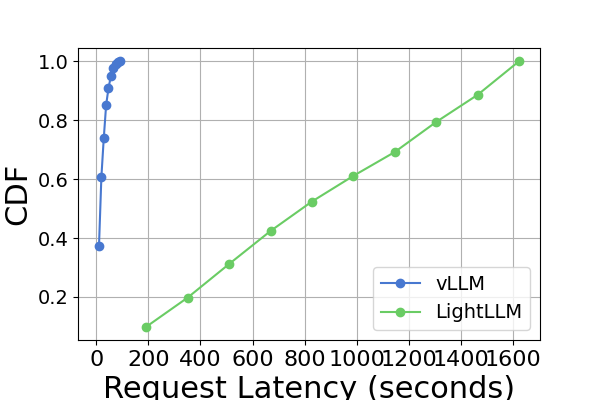
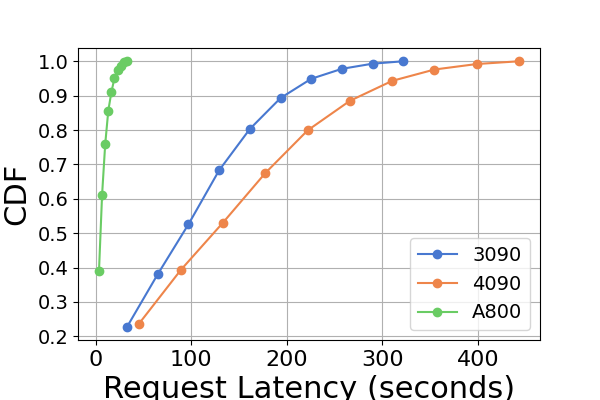
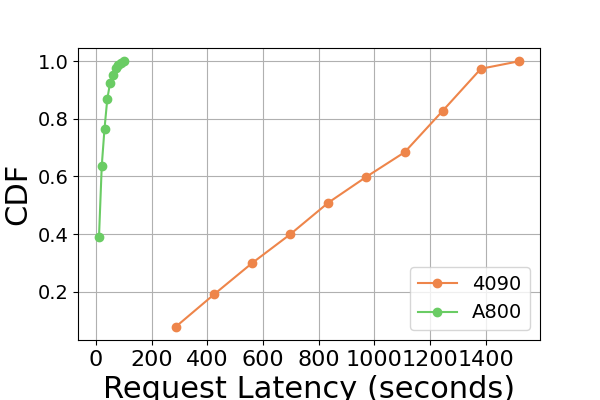
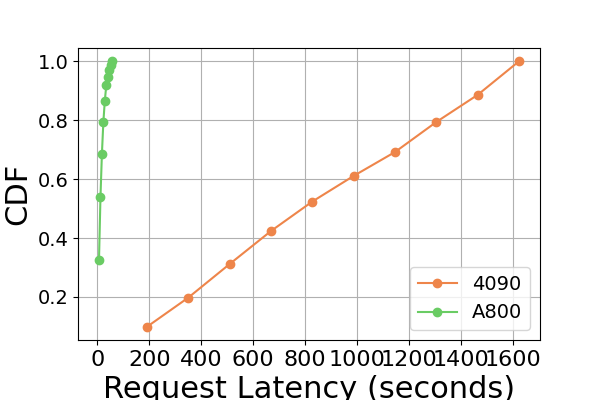
图 9 是图 7 的扩展,包含在同一 GPU 平台上进行推理基准测试的额外延迟实验。 RTX4090平台上的性能结果与其他两个平台不同。 此差异可能是由于 NCCL_P2P_DISABLE=1 设置造成的。 在 RTX4090 平台上,LightLLM 显示了最高的延迟,而 TGI 对于 Llama2-7B 模型的延迟最低。 延迟实验的另一个明显发现是,在消费级 GPU 平台上,总推理时间随着模型参数大小的增加而增加。 具体在RTX4090平台上,Llama2-7B和Llama2-70B的推理时间差可达13倍,从120秒到1600秒。 然而,这种现象在 A800 GPU 平台上没有观察到,较大模型的推理时间仍然在一个狭窄的范围内。 这表明,对于目前流行的大语言模型大小,A800平台可以在没有任何延迟影响的情况下处理推理,并且70B模型尚未达到A800平台推理的性能极限。
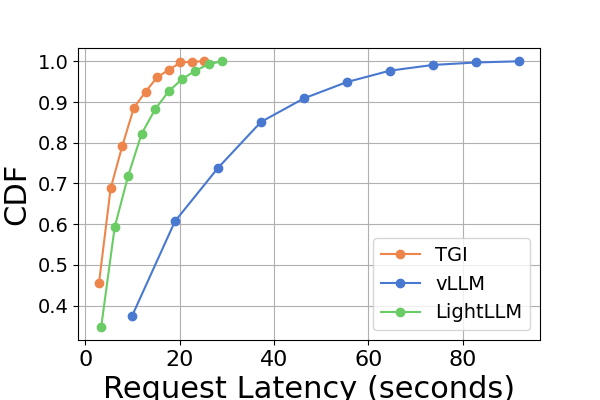
在图8中,我们比较了不同 GPU 平台上每个推理框架的延迟。 A800 在几乎所有实验中始终表现出最低的延迟。 此外,在大多数实验中,RTX3090 GPU 平台表现出比 RTX4090 更低的延迟,这种情况也可能是由 NCCL_P2P_DISABLE=1 设置造成的。 这些实验表明,如果目标是提供最低延迟的推理服务,A800 GPU 平台是最佳选择,它可以在各种模型和推理框架组合中提供显着的性能优势。 其他实验如图10所示。
综上所述,A800 平台在吞吐量和延迟方面均显着优于其他两个消费级平台。 两款消费级平台中,RTX3090相比RTX4090略有优势。 当在消费者级平台上运行时,这三个推理框架在吞吐量方面没有表现出实质性差异。 相比之下,TGI 框架在延迟方面始终优于其他框架。 在A800 GPU平台上,LightLLM在吞吐量方面表现最好,其延迟也非常接近TGI框架。
| (a) TGI |
| (b) vLLM |
| (c) LightLLM |
| (a) Llama2-7B with |
| TGI |
| (b) Llama2-7B with |
| vLLM |
| (c) Llama2-70B with |
| vLLM |
| (d) Llama2-7B with |
| LightLLM |
| (e) Llama2-70B with |
| LightLLM |
VI-B 模块分析
在本小节中,我们以 LightLLM 为例讨论模块方面的时间成本。 为了模拟大量用户访问服务的场景,我们在A800 GPU服务器上将批量大小设置为1024,输出长度设置为64,提示长度设置为512。 结果列于表X和表XI中。 我们观察到 GPU 遇到了瓶颈,这在表 X 的“其他”行中很明显,占总时间的 7.55%。 这表明融合 GPU 内核可能会减少该瓶颈的总体持续时间。
| Task | Time(ms) | Percentage(%) | ||||
| Forward | Comp. | Element-Wise | 36 | 1.69 | 70.44 | 3.3 |
| RoPE | 0.19 | 0.37 | ||||
| Triton | 23.05 | 45.1 | ||||
| GeMM | 9.4 | 18.4 | ||||
| RMSNorm | 1.18 | 2.31 | ||||
| Other | 0.49 | 0.96 | ||||
| Comm. | AllReduce | 11.3 | 10.74 | 22.11 | 21.01 | |
| AllGather | 0.46 | 0.9 | ||||
| Other | 0.1 | 0.2 | ||||
| Other | 3.81 | 7.55 | ||||
| Timeline | Time(ms) | Percentage(%) | |||
| Before Transformer | 1.66 | 3.25 | |||
| Transformer | 32 x Attention | 47.60 | 35.13 | 93.13 | 68.73 |
| 32 x FFN | 12.47 | 24.4 | |||
| After Transformer | 1.85 | 3.62 | |||
VII 微基准
为了更深入地了解实验结果,我们进行了涵盖计算和通信的微基准分析。
VII-A GEMM分析
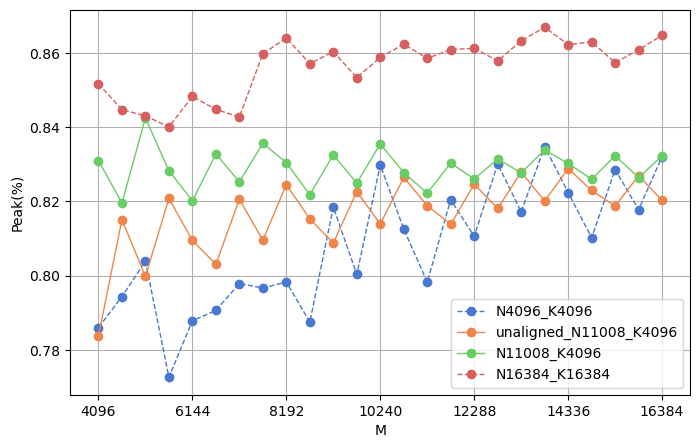
在第IV-B节中,我们观察到包含GEMM操作的模块的时间消耗相对较高。 我们使用朴素方法和重新计算来计算 GEMM 操作在前向和后向阶段的时间分解。 表XIII显示GEMM内核在两个阶段中均占据了60%以上的时间,凸显了GEMM性能对于大语言模型的关键性。 为了更好地理解 GEMM 性能,我们分析了 MLP 模块中的第一个 GEMM(表XII)。 我们选择这个 GEMM 操作是因为 MLP 是最耗时的模块,包含三个大小相似的 GEMM。 与重新计算相比,朴素方法峰值较低的主要原因是矩阵尺寸较小,无法充分利用硬件。 使用重新计算将大小增加32倍后,峰值性能仍然低于90%的理想值。 我们在实验平台(A800)上测试了不同的矩阵大小,结果如图11所示。 在这些 GEMM 操作中,批量大小会影响 。由于我们在 和 值恒定的情况下逐渐增加 ,因此有两种选择 的场景。对于 N4096_K4096、N11008_K4096(由 Llama2-7B 模型确定的形状)和 N16384_K16384, 以 512 为步长从 4096 增加到 16384,确保大小是 TensorCore 计算规模的倍数。 这三个曲线表明,盲目增加批量大小并不总能提高峰值性能。 一旦批量大小足够大,可以通过增加 和 来进一步提高 GEMM 峰值。对于 unaligned_N11008_K4096 情况,我们的 从 4096+13 开始(幻数 13 是一个奇数,选择它不会显着影响 的大小),并增加到 16384+13步骤512。 我们分析了 作为 TensorCore 计算规模的整数倍和非整数倍之间的性能差异。 结果清楚地表明,当 是 TensorCore 计算规模的整数倍时,峰值性能高于非整数倍。
| Naive | Recomputation | |
|---|---|---|
| Shape(,,) | 666,11008,4096 | 10624,11008,4096 |
| Time(ms) | 0.289 | 3.870 |
| Peak(%) | 66.6 | 79.4 |
| Forward | Backward | |
|---|---|---|
| Naive | 66.4% | 62.5% |
| Recomputation | 66.1% | 69.0% |
VII-B 内存复制
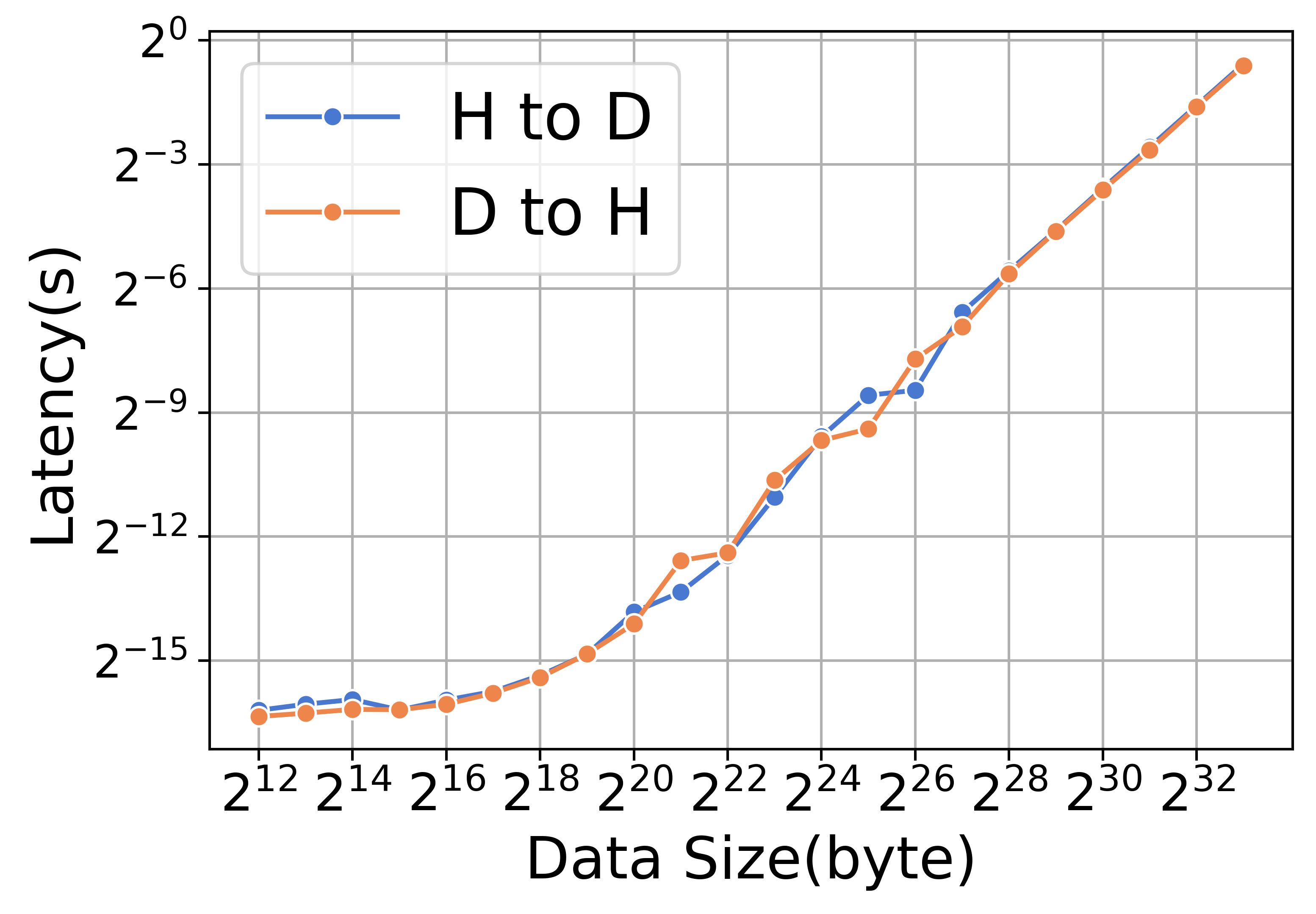
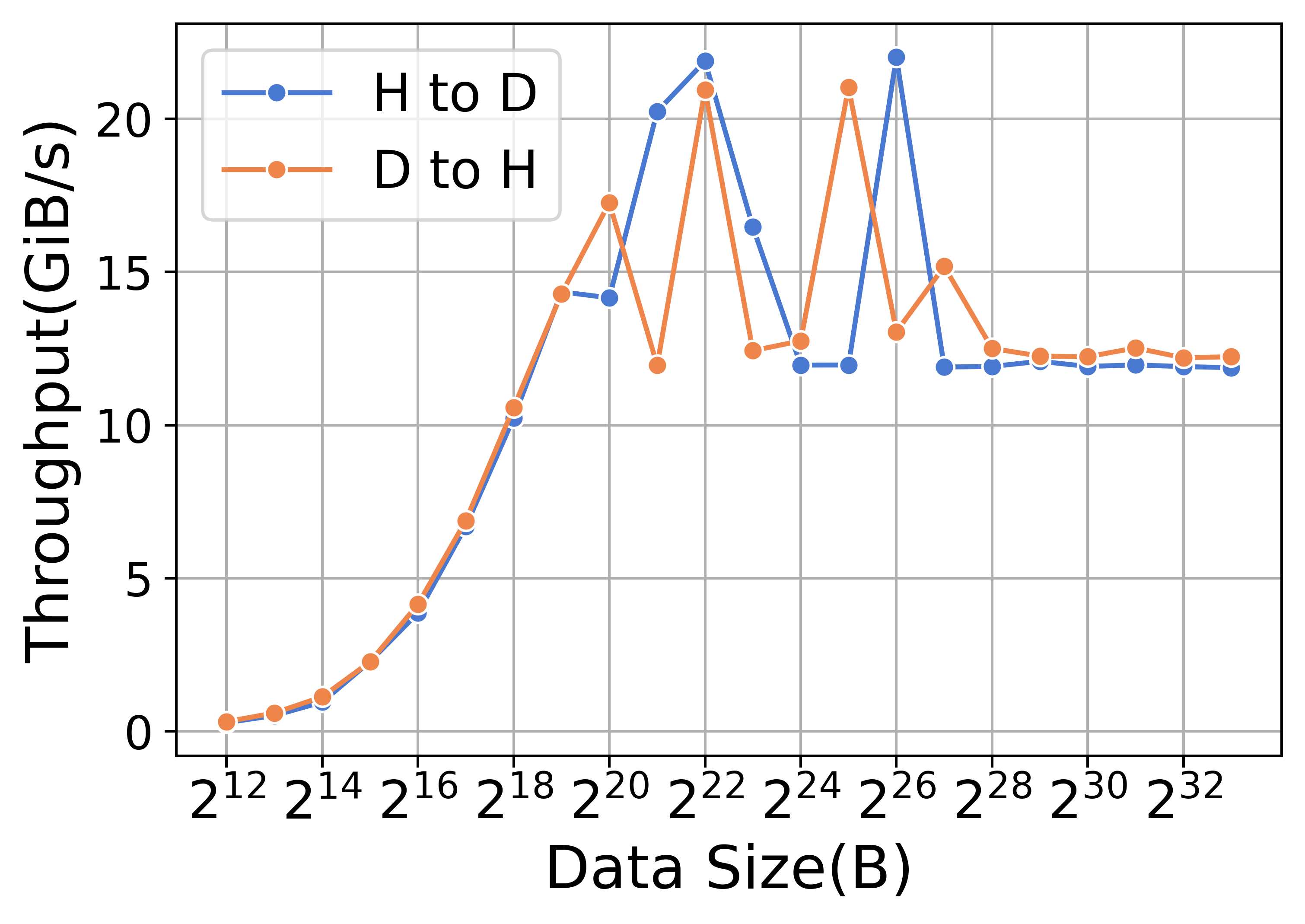
卸载和上传操作是使用内存复制内核实现的。 表XIV总结了A800平台上每次迭代的绝对时间成本和内存复制的百分比。 如表XIV所示,与ZeRO-2相比,ZeRO-3的上传和卸载时间更长。 然而,内存复制在这种情况下的影响相对较小。 图12展示了上传操作(用H到D表示)和卸载操作(用D到H表示)在内核方面的性能。 该图显示上传和卸载操作的吞吐量和延迟相似。 对于较小的数据量,启动时间往往占主导地位,而对于较大的数据量,带宽变得越来越重要。
| Method | Model | Time(s/iteration) | Percentage(%) |
|---|---|---|---|
| ZeRO-2 | Llama2-7B | 0.596 | 4.9% |
| Llama2-13B | 1.160 | 7.3% | |
| ZeRO-3 | Llama2-7B | 0.638 | 4.0% |
| Llama2-13B | 1.560 | 6.7% |
VII-C 集体交流
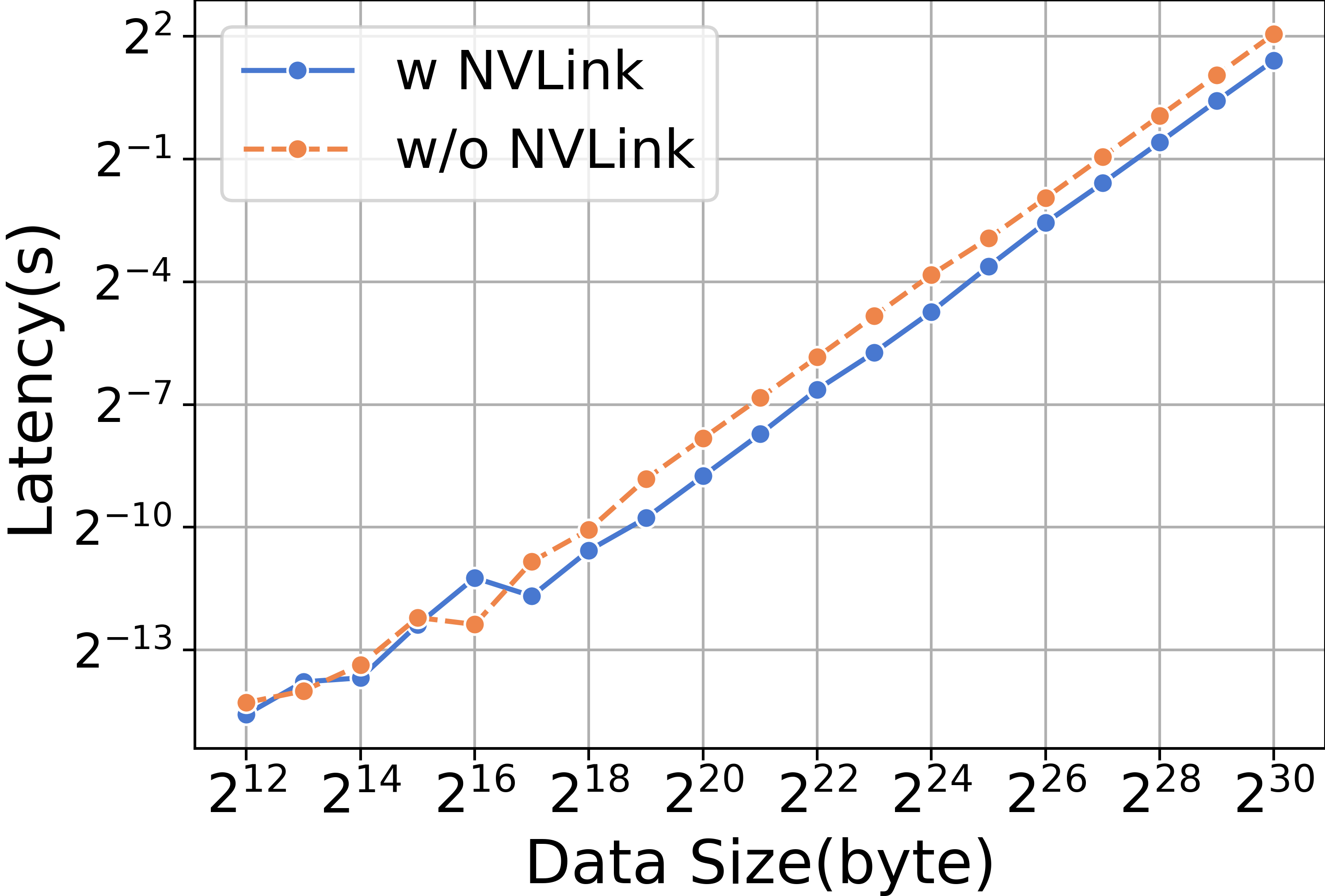
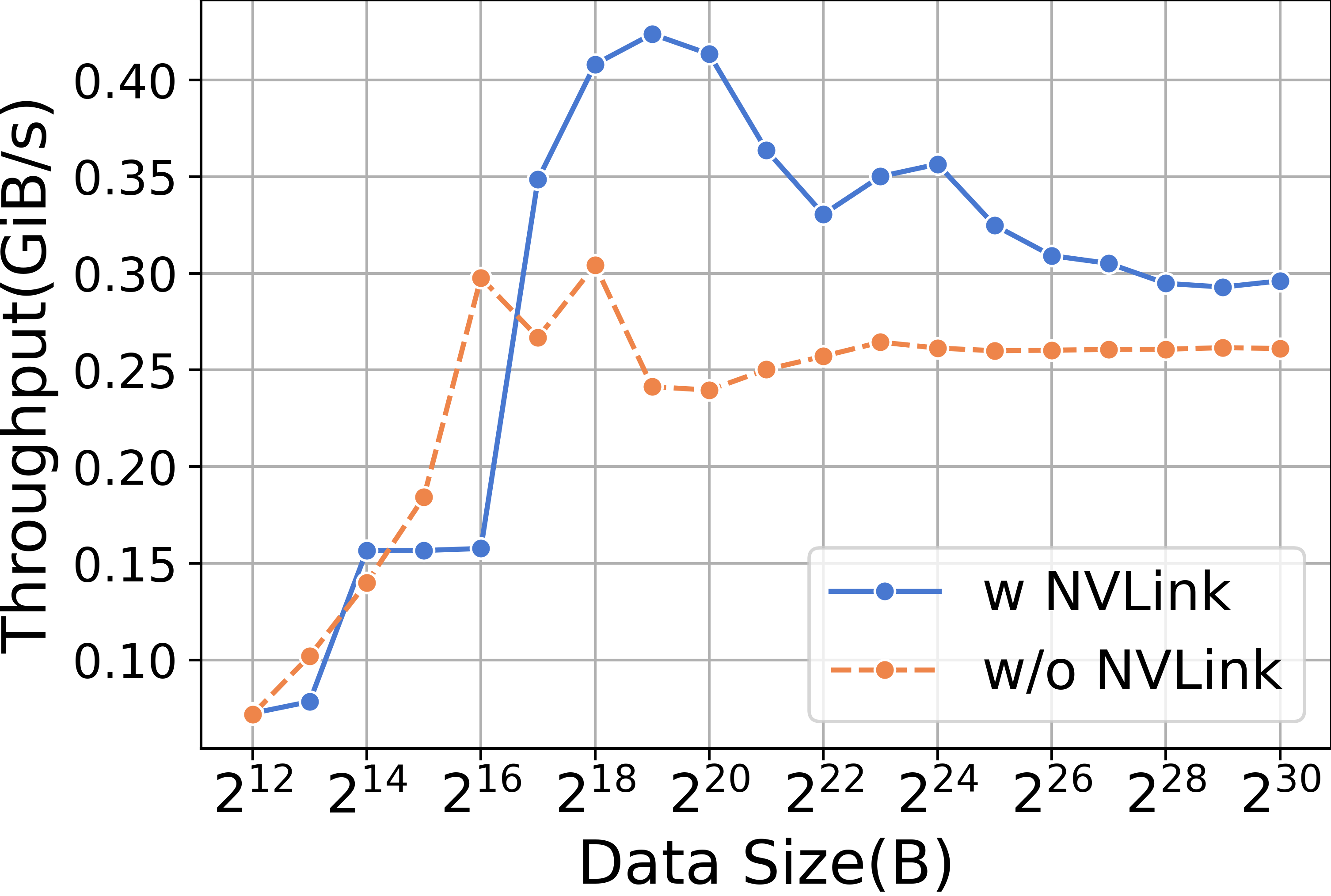
我们首先强调NVLink提供的高通信速度。 在各种数据规模下进行 AllGather 操作时,我们发现配备 NVLink 的 RTX3090 的性能明显优于未配备 NVLink 的 RTX3090,如图13所示。
不同的训练范式涉及不同的集体通信操作。 在数据并行范例中,AllReduce 在后向阶段用于同步权重,如表XV所示。
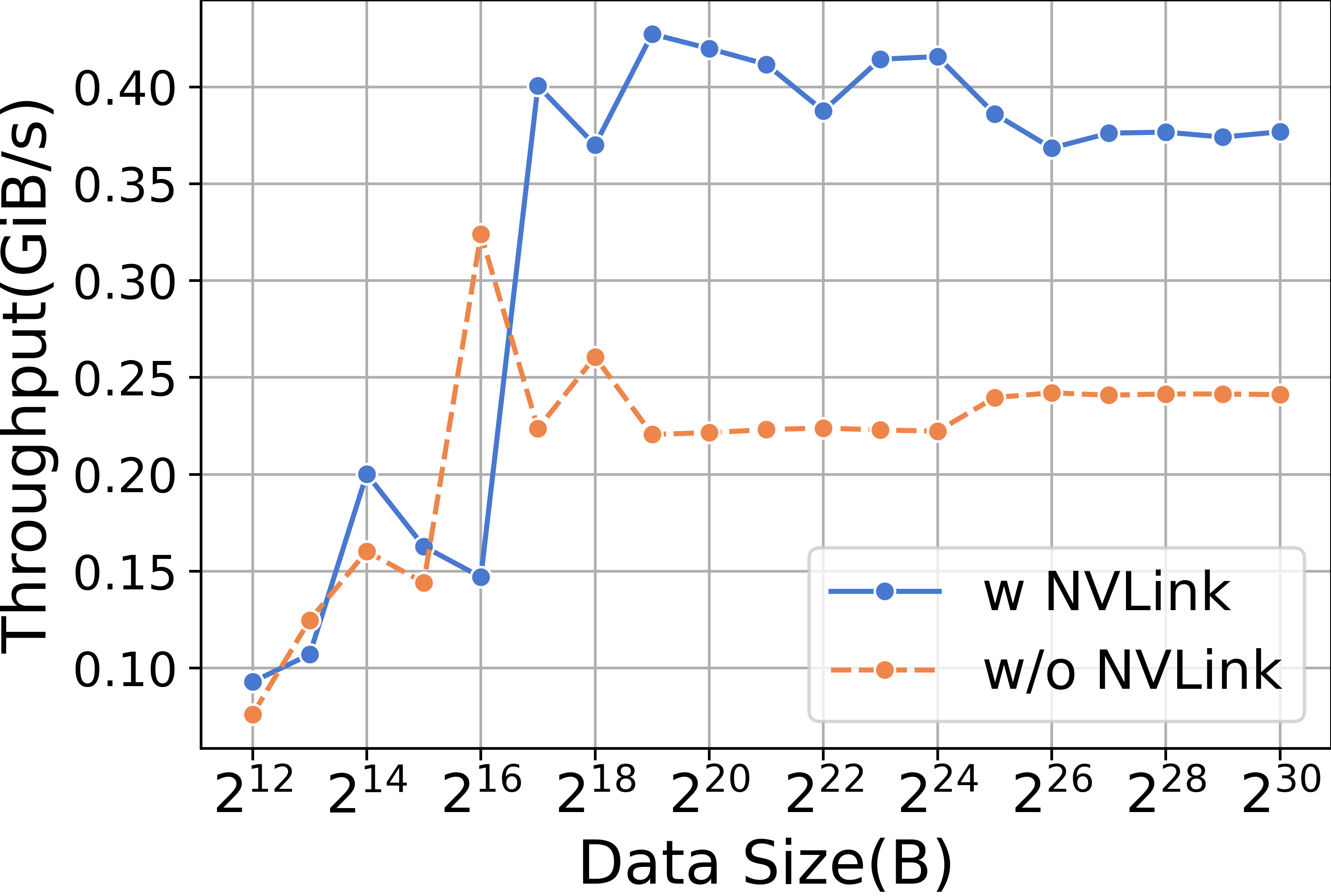
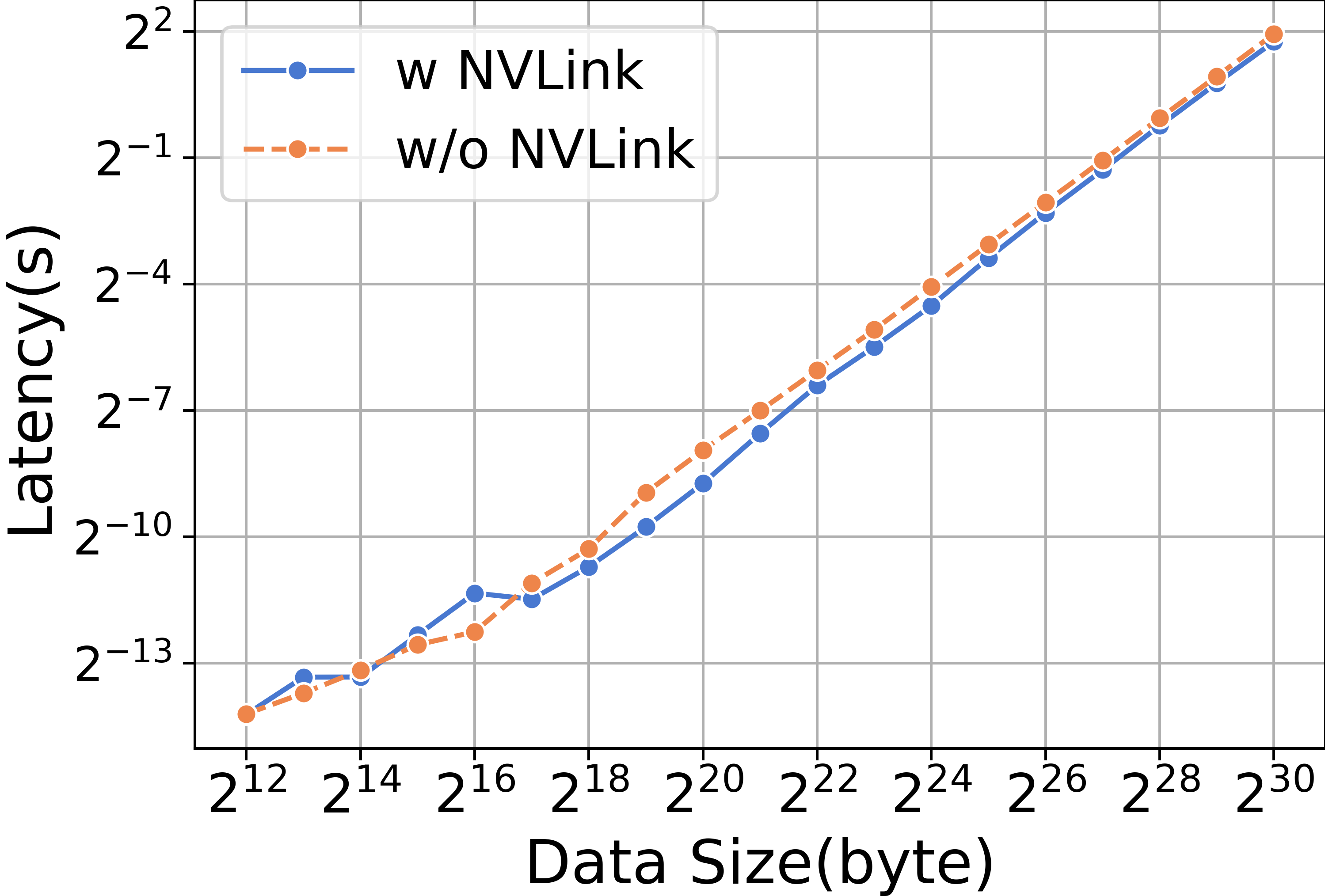
当使用ReduceScatter和不同的数据大小进行实验时,我们发现带有NVLink的RTX3090的性能明显优于不带NVLink的RTX3090,如图14所示。
| Llama2-7B | Time(s/iteration) | Percentage(%) |
|---|---|---|
| Naive | 0.24 | 45.00 |
| F | 0.23 | 44.97 |
| R | 0.86 | 25.31 |
| R+F | 0.69 | 20.41 |
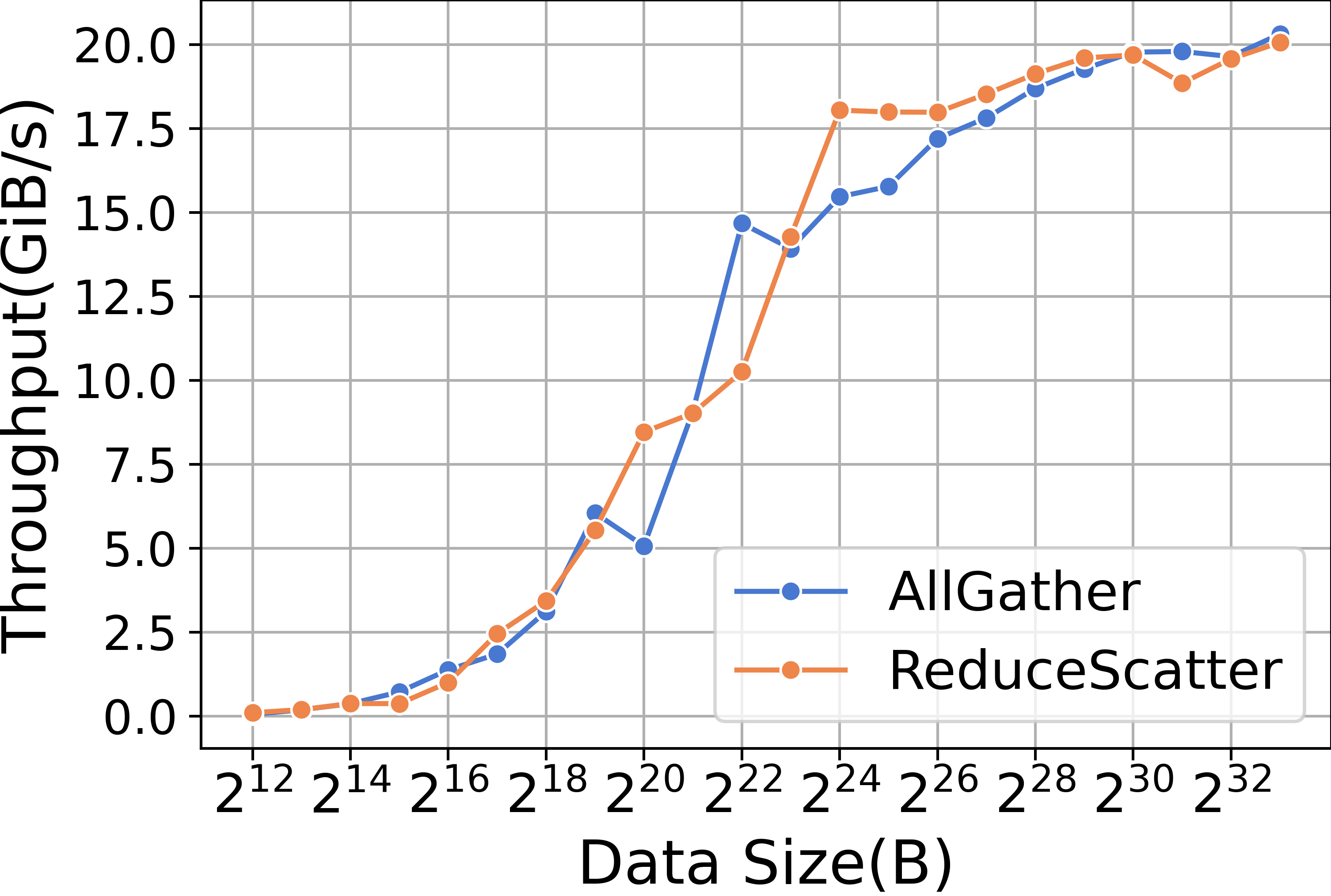
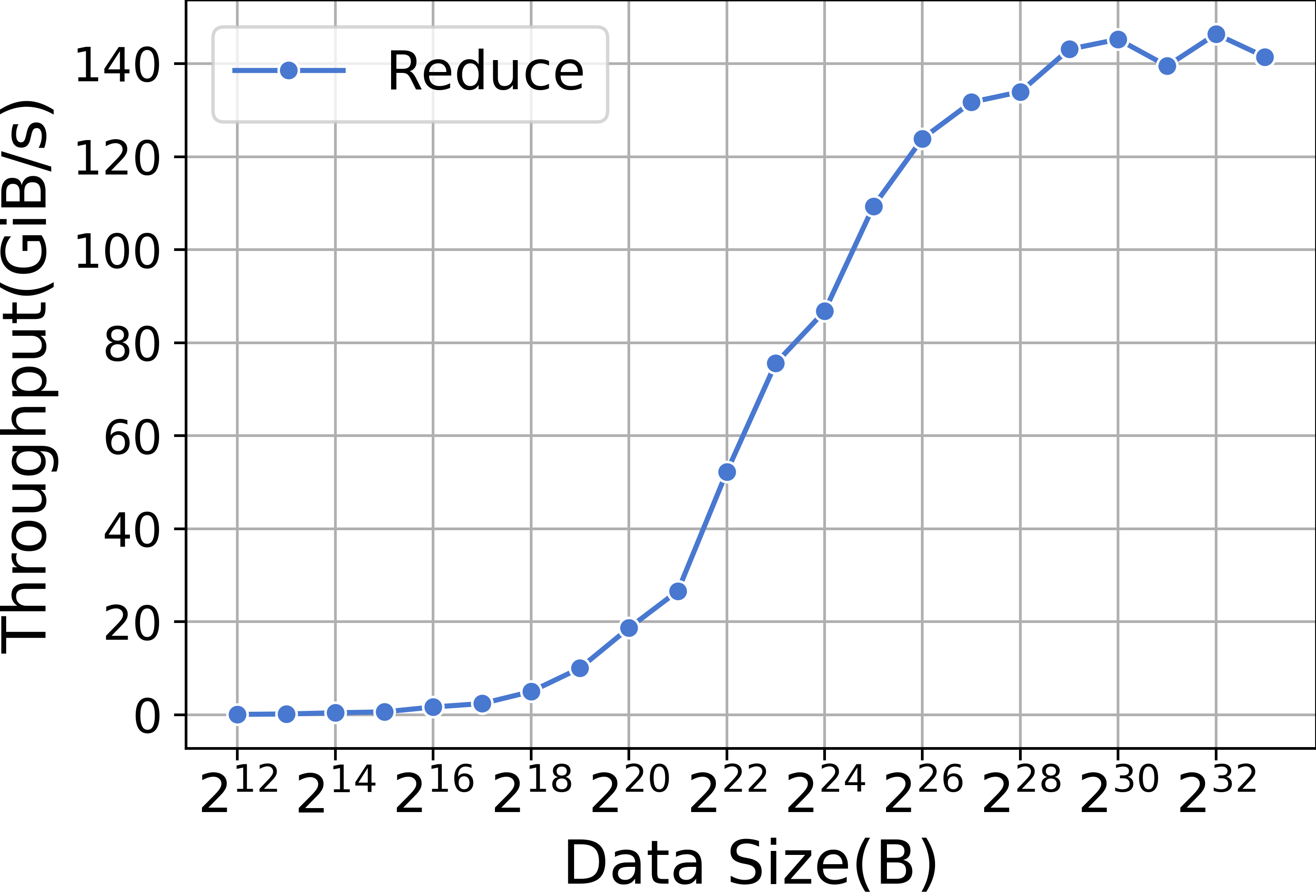
ZeRO-2 要求在后向阶段使用Reduce 集体通信原语。 图15显示了Reduce内核的性能。 与内存复制类似,Reduce 内核的小数据量会导致启动时间占主导地位,而大数据量的性能则依赖于带宽。 相比之下,ZeRO-3 使用ReduceScatter 而不是Reduce 进行后向阶段的集体通信。 图15说明了ReduceScatter 内核的性能。 ZeRO-2和ZeRO-3都利用AllGather来更新参数,图15也展示了AllGather内核的性能。
| Method | Model | Time(s/iteration) | Percentage(%) |
|---|---|---|---|
| ZeRO-2 | Llama2-7B | 4.254 | 41.8% |
| Llama2-13B | 3.779 | 27.4% | |
| ZeRO-3 | Llama2-7B | 4.576 | 28.1% |
| Llama2-13B | 2.791 | 11.9% |
八相关作品
大量研究在下游任务的泛化能力和准确性方面对模型性能进行了基准测试[37,8,38,39,2]。 然而,很少有研究侧重于评估和分析研究硬件[40, 41]和软件[42, 43]效率的时间,在训练中解决这些方面的研究就更少了,微调,服务大语言模型。 AIPerf[44]以高度并行且灵活的方式实现算法,并评估其在各种系统上的性能。 MLPerf[45] 是另一个前沿基准测试,用于比较深度学习(包括大语言模型)在训练和推理中的时间性能,不受硬件平台限制。 在 LLM 之前的时代,人们提出了基准来比较各种模型的软件和硬件性能,包括 CNN、LSTM 和 Transformer [46,47,48,49,50,51,52]。 Xu等人[53]提供了一项比较模型压缩技术的调查,这些技术在模型微调和推理方面特别有用。 曹等人[54]还概述了高效大语言模型,重点关注算法方面,如ELECTRA [55]、Prompt Tuning等。 [56]提出了HELM,一种综合性能评估,用于比较模型泛化能力和时间效率。 然而,他们的时间效率结果侧重于使用特定硬件平台和给定软件进行推理。 具体来说,在推理方面,LLMPerf[57]对各种大语言模型的吞吐量性能进行了基准测试。
据我们所知,这是第一项分析大语言模型在各种硬件平台上的所有三个关键阶段(预训练、微调和服务)运行时性能的研究。
九结论
在这项工作中,我们在三个 8-GPU 硬件平台:Nvidia A800-80G、RTX4090 和 RTX3090 上对预训练、微调和服务大语言模型的运行时性能进行了基准测试。 根据基准测试结果,我们分析了对总体时间贡献最大的关键模块和运算符。 实验结果和分析为最终用户在预训练、微调和服务大语言模型的硬件、软件和优化技术方面选择配置提供了更多信息。 此外,对性能的深入了解为系统优化提供了进一步的机会。
致谢
我们要感谢赵永科先生的宝贵反馈。 该工作得到了国家自然科学基金委的部分资助,批准号为: 62272122,香港 RIF 资助,资助编号:62272122 R6021-20 和香港 CRF 拨款,拨款号: C2004-21GF 和 C7004-22GF。 我们也感谢香港科技大学(广州)HPC-AI集成智能计算中心为本项目提供了部分硬件平台。
修订记录
参考
- [1] L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray et al., “Training language models to follow instructions with human feedback,” Advances in Neural Information Processing Systems, vol. 35, pp. 27 730–27 744, 2022.
- [2] Y. Chang, X. Wang, J. Wang, Y. Wu, K. Zhu, H. Chen, L. Yang, X. Yi, C. Wang, Y. Wang et al., “A survey on evaluation of large language models,” arXiv preprint arXiv:2307.03109, 2023.
- [3] J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, and D. Amodei, “Scaling laws for neural language models,” arXiv preprint arXiv:2001.08361, 2020.
- [4] J. Hoffmann, S. Borgeaud, A. Mensch, E. Buchatskaya, T. Cai, E. Rutherford, D. d. L. Casas, L. A. Hendricks, J. Welbl, A. Clark et al., “Training compute-optimal large language models,” arXiv preprint arXiv:2203.15556, 2022.
- [5] OpenAI, “GPT-4 technical report,” 2023.
- [6] T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell et al., “Language models are few-shot learners,” Advances in Neural Information Processing Systems, vol. 33, pp. 1877–1901, 2020.
- [7] A. Chowdhery, S. Narang, J. Devlin, M. Bosma, G. Mishra, A. Roberts, P. Barham, H. W. Chung, C. Sutton, S. Gehrmann et al., “PaLM: Scaling language modeling with pathways,” in Proceedings of Machine Learning and Systems 2022, 2022.
- [8] J. Kaddour, J. Harris, M. Mozes, H. Bradley, R. Raileanu, and R. McHardy, “Challenges and applications of large language models,” arXiv preprint arXiv:2307.10169, 2023.
- [9] H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y. Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosale et al., “Llama 2: Open foundation and fine-tuned chat models,” arXiv preprint arXiv:2307.09288, 2023.
- [10] J. Rasley, S. Rajbhandari, O. Ruwase, and Y. He, “DeepSpeed: System optimizations enable training deep learning models with over 100 billion parameters,” in Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 2020, pp. 3505–3506.
- [11] D. Narayanan, M. Shoeybi, J. Casper, P. LeGresley, M. Patwary, V. Korthikanti, D. Vainbrand, P. Kashinkunti, J. Bernauer, B. Catanzaro et al., “Efficient large-scale language model training on gpu clusters using megatron-lm,” in Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, 2021, pp. 1–15.
- [12] S. Mangrulkar, S. Gugger, L. Debut, Y. Belkada, S. Paul, and B. Bossan, “PEFT: State-of-the-art parameter-efficient fine-tuning methods,” https://github.com/huggingface/peft, 2022.
- [13] W. Kwon, Z. Li, S. Zhuang, Y. Sheng, L. Zheng, C. H. Yu, J. E. Gonzalez, H. Zhang, and I. Stoica, “Efficient memory management for large language model serving with pagedattention,” in Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023.
- [14] GitHub, “LightLLM: A python-based large language model inference and serving framework,” https://github.com/ModelTC/lightllm, 2023.
- [15] HuggingFace, “Text generation inference,” https://github.com/huggingface/text-generation-inference, 2023.
- [16] S. Rajbhandari, J. Rasley, O. Ruwase, and Y. He, “ZeRO: Memory optimizations toward training trillion parameter models,” in SC20: International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 2020, pp. 1–16.
- [17] V. A. Korthikanti, J. Casper, S. Lym, L. McAfee, M. Andersch, M. Shoeybi, and B. Catanzaro, “Reducing activation recomputation in large transformer models,” Proceedings of Machine Learning and Systems, vol. 5, 2023.
- [18] P. Jain, A. Jain, A. Nrusimha, A. Gholami, P. Abbeel, K. Keutzer, I. Stoica, and J. E. Gonzalez, “Checkmate: Breaking the memory wall with optimal tensor rematerialization,” arXiv preprint arXiv:1910.02653, 2020.
- [19] S. Smith, M. Patwary, B. Norick, P. LeGresley, S. Rajbhandari, J. Casper, Z. Liu, S. Prabhumoye, G. Zerveas, V. Korthikanti, E. Zhang, R. Child, R. Y. Aminabadi, J. Bernauer, X. Song, M. Shoeybi, Y. He, M. Houston, S. Tiwary, and B. Catanzaro, “Using DeepSpeed and Megatron to train Megatron-turing NLG 530B, a large-scale generative language model,” arXiv preprint arXiv:2201.11990, 2022.
- [20] Z. Yao, R. Yazdani Aminabadi, M. Zhang, X. Wu, C. Li, and Y. He, “Zeroquant: Efficient and affordable post-training quantization for large-scale transformers,” Advances in Neural Information Processing Systems, vol. 35, pp. 27 168–27 183, 2022.
- [21] E. J. Hu, yelong shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, and W. Chen, “LoRA: Low-rank adaptation of large language models,” in International Conference on Learning Representations, 2022. [Online]. Available: https://openreview.net/forum?id=nZeVKeeFYf9
- [22] T. Dettmers, A. Pagnoni, A. Holtzman, and L. Zettlemoyer, “QLoRA: Efficient finetuning of quantized LLMs,” arXiv preprint arXiv:2305.14314, 2023.
- [23] T. Dao, D. Fu, S. Ermon, A. Rudra, and C. Ré, “Flashattention: Fast and memory-efficient exact attention with io-awareness,” Advances in Neural Information Processing Systems, vol. 35, pp. 16 344–16 359, 2022.
- [24] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” Advances in Neural Information Processing Systems, vol. 30, 2017.
- [25] T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-Voss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Amodei, “Language models are Few-Shot learners,” in Advances in Neural Information Processing Systems, H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, Eds., vol. 33. Curran Associates, Inc., 2020, pp. 1877–1901. [Online]. Available: https://proceedings.neurips.cc/paper_files/paper/2020/file/1457c0d6bfcb4967418bfb8ac142f64a-Paper.pdf
- [26] H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozière, N. Goyal, E. Hambro, F. Azhar, A. Rodriguez, A. Joulin, E. Grave, and G. Lample, “LLaMA: Open and efficient foundation language models,” arXiv preprint arXiv:2302.13971, 2023.
- [27] T. L. Scao, A. Fan, C. Akiki, E. Pavlick, S. Ilić, D. Hesslow, R. Castagné, A. S. Luccioni, F. Yvon, M. Gallé et al., “Bloom: A 176b-parameter open-access multilingual language model,” arXiv preprint arXiv:2211.05100, 2022.
- [28] J. Ren, S. Rajbhandari, R. Y. Aminabadi, O. Ruwase, S. Yang, M. Zhang, D. Li, and Y. He, “ZeRO-Offload: Democratizing Billion-Scale model training,” in 2021 USENIX Annual Technical Conference (USENIX ATC 21), 2021, pp. 551–564.
- [29] S. Rajbhandari, O. Ruwase, J. Rasley, S. Smith, and Y. He, “Zero-infinity: Breaking the gpu memory wall for extreme scale deep learning,” in Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, 2021, pp. 1–14.
- [30] R. Y. Aminabadi, S. Rajbhandari, A. A. Awan, C. Li, D. Li, E. Zheng, O. Ruwase, S. Smith, M. Zhang, J. Rasley et al., “DeepSpeed-inference: enabling efficient inference of transformer models at unprecedented scale,” in SC22: International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 2022, pp. 1–15.
- [31] M. Shoeybi, M. Patwary, R. Puri, P. LeGresley, J. Casper, and B. Catanzaro, “Megatron-LM: Training multi-billion parameter language models using model parallelism,” arXiv preprint arXiv:1909.08053, 2019.
- [32] B. Lester, R. Al-Rfou, and N. Constant, “The power of scale for parameter-efficient prompt tuning,” in Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, 2021, pp. 3045–3059.
- [33] J. Dean, G. Corrado, R. Monga, K. Chen, M. Devin, M. Mao, M. Ranzato, A. Senior, P. Tucker, K. Yang et al., “Large scale distributed deep networks,” Advances in Neural Information Processing Systems, vol. 25, 2012.
- [34] S. Vinoski, “Server-sent events with yaws,” IEEE internet computing, vol. 16, no. 5, pp. 98–102, 2012.
- [35] S. Elfwing, E. Uchibe, and K. Doya, “Sigmoid-weighted linear units for neural network function approximation in reinforcement learning,” Neural Networks, vol. 107, pp. 3–11, 2018.
- [36] B. Zhang and R. Sennrich, “Root mean square layer normalization,” Advances in Neural Information Processing Systems, vol. 32, 2019.
- [37] W. X. Zhao, K. Zhou, J. Li, T. Tang, X. Wang, Y. Hou, Y. Min, B. Zhang, J. Zhang, Z. Dong et al., “A survey of large language models,” arXiv preprint arXiv:2303.18223, 2023.
- [38] C. Fu, P. Chen, Y. Shen, Y. Qin, M. Zhang, X. Lin, Z. Qiu, W. Lin, J. Yang, X. Zheng et al., “MME: A comprehensive evaluation benchmark for multimodal large language models,” arXiv preprint arXiv:2306.13394, 2023.
- [39] K. Valmeekam, S. Sreedharan, M. Marquez, A. Olmo, and S. Kambhampati, “On the planning abilities of large language models (a critical investigation with a proposed benchmark),” arXiv preprint arXiv:2302.06706, 2023.
- [40] Y. Wang, Q. Wang, S. Shi, X. He, Z. Tang, K. Zhao, and X. Chu, “Benchmarking the performance and energy efficiency of AI accelerators for AI training,” in 2020 20th IEEE/ACM International Symposium on Cluster, Cloud and Internet Computing (CCGRID), 2020, pp. 744–751.
- [41] D. Yan, W. Wang, and X. Chu, “Demystifying tensor cores to optimize half-precision matrix multiply,” in 2020 IEEE International Parallel and Distributed Processing Symposium (IPDPS), 2020, pp. 634–643.
- [42] P. Xu, S. Shi, and X. Chu, “Performance evaluation of deep learning tools in docker containers,” in 2017 3rd International Conference on Big Data Computing and Communications (BIGCOM). IEEE, 2017, pp. 395–403.
- [43] S. Shi, Z. Tang, X. Chu, C. Liu, W. Wang, and B. Li, “A Quantitative Survey of Communication Optimizations in Distributed Deep Learning,” IEEE Network, vol. 35, no. 3, pp. 230–237, 2021.
- [44] Z. Ren, Y. Liu, T. Shi, L. Xie, Y. Zhou, J. Zhai, Y. Zhang, Y. Zhang, and W. Chen, “AIPerf: Automated machine learning as an AI-HPC benchmark,” 2021.
- [45] V. J. Reddi, C. Cheng, D. Kanter, P. Mattson, G. Schmuelling, C.-J. Wu, B. Anderson, M. Breughe, M. Charlebois, W. Chou, R. Chukka, C. Coleman, S. Davis, P. Deng, G. Diamos, J. Duke, D. Fick, J. S. Gardner, I. Hubara, S. Idgunji, T. B. Jablin, J. Jiao, T. S. John, P. Kanwar, D. Lee, J. Liao, A. Lokhmotov, F. Massa, P. Meng, P. Micikevicius, C. Osborne, G. Pekhimenko, A. T. R. Rajan, D. Sequeira, A. Sirasao, F. Sun, H. Tang, M. Thomson, F. Wei, E. Wu, L. Xu, K. Yamada, B. Yu, G. Yuan, A. Zhong, P. Zhang, and Y. Zhou, “MLPerf Inference Benchmark,” 2019.
- [46] S. Shi, Q. Wang, P. Xu, and X. Chu, “Benchmarking state-of-the-art deep learning software tools,” in 2016 7th International Conference on Cloud Computing and Big Data (CCBD). IEEE, 2016, pp. 99–104.
- [47] S. Shi, Q. Wang, and X. Chu, “Performance modeling and evaluation of distributed deep learning frameworks on GPUs,” in 2018 IEEE 16th Intl Conf on Dependable, Autonomic and Secure Computing, 16th Intl Conf on Pervasive Intelligence and Computing, 4th Intl Conf on Big Data Intelligence and Computing and Cyber Science and Technology Congress (DASC/PiCom/DataCom/CyberSciTech). IEEE, 2018, pp. 949–957.
- [48] S. Li, R. J. Walls, and T. Guo, “Characterizing and modeling distributed training with transient cloud GPU servers,” in 2020 IEEE 40th International Conference on Distributed Computing Systems (ICDCS). IEEE, 2020, pp. 943–953.
- [49] Z. Tang, S. Shi, X. Chu, W. Wang, and B. Li, “Communication-efficient distributed deep learning: A comprehensive survey,” arXiv preprint arXiv:2003.06307, 2020.
- [50] M. Jansen, V. Codreanu, and A.-L. Varbanescu, “DDLBench: towards a scalable benchmarking infrastructure for distributed deep learning,” in 2020 IEEE/ACM Fourth Workshop on Deep Learning on Supercomputers (DLS). IEEE, 2020, pp. 31–39.
- [51] G. Liang and I. Alsmadi, “Benchmark assessment for deepspeed optimization library,” arXiv preprint arXiv:2202.12831, 2022.
- [52] Z. Lu, C. Du, Y. Jiang, X. Xie, T. Li, and F. Yang, “Quantitative evaluation of deep learning frameworks in heterogeneous computing environment,” CCF Transactions on High Performance Computing, pp. 1–18, 2023.
- [53] C. Xu and J. McAuley, “A survey on model compression and acceleration for pretrained language models,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 37, no. 9, 2023, pp. 10 566–10 575.
- [54] Y. Cao, S. Li, Y. Liu, Z. Yan, Y. Dai, P. S. Yu, and L. Sun, “A comprehensive survey of AI-generated content (AIGC): A history of generative AI from GAN to ChatGPT,” arXiv preprint arXiv:2303.04226, 2023.
- [55] K. Clark, M.-T. Luong, Q. V. Le, and C. D. Manning, “ELECTRA: Pre-training text encoders as discriminators rather than generators,” in International Conference on Learning Representations, 2020. [Online]. Available: https://openreview.net/forum?id=r1xMH1BtvB
- [56] P. Liang, R. Bommasani, T. Lee, D. Tsipras, D. Soylu, M. Yasunaga, Y. Zhang, D. Narayanan, Y. Wu, A. Kumar, B. Newman, B. Yuan, B. Yan, C. Zhang, C. A. Cosgrove, C. D. Manning, C. Re, D. Acosta-Navas, D. A. Hudson, E. Zelikman, E. Durmus, F. Ladhak, F. Rong, H. Ren, H. Yao, J. WANG, K. Santhanam, L. Orr, L. Zheng, M. Yuksekgonul, M. Suzgun, N. Kim, N. Guha, N. S. Chatterji, O. Khattab, P. Henderson, Q. Huang, R. A. Chi, S. M. Xie, S. Santurkar, S. Ganguli, T. Hashimoto, T. Icard, T. Zhang, V. Chaudhary, W. Wang, X. Li, Y. Mai, Y. Zhang, and Y. Koreeda, “Holistic evaluation of language models,” Transactions on Machine Learning Research, 2023, featured Certification, Expert Certification. [Online]. Available: https://openreview.net/forum?id=iO4LZibEqW
- [57] ray project, “llmperf,” 2023, https://github.com/ray-project/llmperf.