人类记忆和大型语言模型的各个方面
摘要
大型语言模型(大语言模型)是巨大的人工神经网络,主要用于生成文本,但也提供非常复杂的语言使用概率模型。 由于生成语义一致的文本需要一种有效的记忆形式,因此我们研究了大语言模型的记忆特性,并发现与人类记忆的关键特征惊人的相似之处。 我们认为,大语言模型的类人记忆特性并不是从大语言模型架构中自动遵循的,而是从训练文本数据的统计中学习的。 这些结果强烈表明,人类记忆的生物学特征在我们构建文本叙述的方式上留下了印记。
1简介
语言的使用是智人的标志,并且可以被视为我们物种在过去数千年中取得巨大进步的关键驱动力。 这里的语言是在最一般的层面上理解的,不仅包括语法规则,还包括语义和叙述的整体结构,所有这些都是它执行复杂的交流手段的功能所必需的。
当然,理解人类认知能力与上述一般意义上概念化的语言属性之间的相互关系是一个非常有趣的问题。 我们认为,大型语言模型[1, 2](大语言模型)可以作为朝这个方向进行研究的非常有用的工具。 正如我们在下一节中解释的那样,大语言模型为我们提供了一个非常复杂的语言使用概率模型,该模型是从巨大的文本语料库中提取的。
我们关注的也许是进行连贯叙述的最简单的认知先决条件——记忆。 事实上,在撰写或生成文本时,人们必须跟踪已经呈现的事实,以免与文本后面的事实相矛盾。 从上述角度来看,记忆的研究特别有趣,因为记忆的具体特征对于保持生成文本的连贯性似乎并不重要。 然而众所周知,尽管人类记忆看似简单,但它却表现出一些相当特殊的特性,认知心理学家已经研究了一个多世纪。 人类记忆表现出所谓的首要效应和新近效应[3, 4],即分别从列表的开头和结尾更好地回忆要记忆的项目,以及由于添加阐述而增强回忆[6, 7]。 人类的遗忘主要是通过干扰而不是记忆痕迹的衰退[8]-[11]发生的。 延迟一段时间后重复效果最佳[12]。 所有这些属性都可以被认为与人类记忆的特定生物实现相关,并且在很大程度上独立于语言使用的本质。 因此,在完全人工的语言系统(大型语言模型)中研究这些现象非常具有启发性。
将本文与针对 ChatGPT(和其他聊天机器人)或 GPT-3/4 进行的决策、因果推理或创造力等高级认知特性的非常有趣的研究进行对比非常重要(参见[13]-[16]),其中主要兴趣完全集中在人工智能方面。 在这里,我们关注的是非常低水平的人类认知能力——(短期)记忆及其在人类中观察到的特定特征,这对于记忆在语言背景下的整体功能作用似乎并不重要。 在这项研究的过程中,我们最终有效地得出了人类作为生物实体和语言的一些意想不到的相互关系,大语言模型主要用作探索语言使用的重要统计特性的复杂工具,如下所述。
本文的关键结果是大型语言模型表现出记忆特性111请注意,在本文中,我们研究了与某些大语言模型 [17] 的训练数据段落记忆截然不同的现象。 在质量上与人类的特征相似(例如,参见图 1 的首要性和新近度效应的示例)。 在本文中,大语言模型的记忆被功能性理解,并根据其语言使用的概率模型来定义,而不是作为大语言模型的物理子系统语言模型。 事实上,GPT 类模型的 Transformer 架构[2]没有任何专用的内存子系统。 因此,记忆在这些大语言模型中表现为一种突现现象。
人类生物记忆特征与大语言模型记忆的相似性可以通过两种方式先验来解释:
-
1.
这可能是因为大语言模型的架构特征在某种程度上类似于人类记忆的运作方式。
-
2.
这可能是因为我们以符合生物记忆特征的方式构建叙事。 经过这些文本训练的大语言模型将这些微妙的统计印记融入到语言使用的概率模型中。
这两种可能性中的任何一种都会非常有趣。 事实上,它们并不相互排斥,而且它们之间可能存在一些重叠。 然而,在本文的后面,我们提供了支持后一种选择的论据。
2 大型语言模型
大型语言模型的出现,即生成人工神经网络作为人工智能聊天机器人的底层模型,例如 ChatGPT [18],为我们的语言建模能力带来了突破并生成人类水平的文本输出。 这些模型已经在巨大的文本语料库上进行了训练,有效地建立了非常复杂且精确的语言使用概率模型。 由于聊天机器人还通过人类反馈的所谓强化学习对对话进行了专门微调[19, 20],因此这里我们专注于纯粹以传统方式训练的大语言模型在文本语料库上预测下一个单词/标记222标记和单词之间的关系取决于标记生成器。 对于本文研究的GPT-J,最常见的单词和标点符号是单个标记。 根据前面的文字。 训练好的大语言模型为我们提供了条件概率
| (1) |
它描述了统计属性333由于大语言模型的内部架构,这个函数显然也存在一些归纳偏差。 我们将在本文后面详细讨论这一点。 用于训练的文本语料库 – 对于本文考虑的大语言模型,这是 825Gb 开源 Pile 数据集 [21]。
值得注意的是,语言的概率模型 (1) 包含的现象比思考语言学时通常考虑的要丰富得多。 条件概率不仅包括对语法正确性的约束,还包含训练数据中存在的大量事实知识(可以客观正确或不正确)。 所有这些信息都编码在神经网络层的权重中444这可以理解为人类长期记忆的类比。 这是对大量文本进行训练的结果。
更重要的是,将 (1) 视为语言使用的非常普遍的形式化,它还必须包含更具全球性的现象,超出语法正确性或原子事实的范围。 事实上,为了使语言模型能够生成连贯的叙述,概率模型 (1) 还必须捕获文本内的远程语义相关性。 特别是,生成有意义的文本的先决条件是拥有某种形式的有效记忆,它功能上被理解为跟踪已经说过的内容。 尽管如此,我们注意到,尚不清楚先验是否需要对前文提供的原子事实进行具体记忆,还是只需记住一般要点就足够了。
这个问题特别有趣,因为这里考虑的大语言模型神经网络架构没有任何特殊的内存子系统。 因此,如果存在记忆,则必须以一种涌现方式从大语言模型的 Transformer 子单元中的语言处理本质中产生。 更重要的是,需要强调的是,大语言模型在计算时可以同时访问整个前面的文本(1)。 如果记忆可以在其中被识别,那么它只能以功能性的方式来理解,例如如下节所述。 本文的目标是识别和探索大型语言模型的记忆特征,并将其与人类记忆的某些方面进行比较。
3 探测大型语言模型中的内存
认知心理学中的标准串行记忆测试范例包括按顺序向受试者提供单词列表,然后测试回忆准确性作为列表中位置的函数。
如何为大型语言模型构建此类人类记忆实验的模拟并不完全明显,因为人们不应该依赖于向神经网络提供记忆任务的指令——这些指令当然是给予人类参与者的。 尽管人们可以设想对聊天机器人这样做,但结果的解释会不太清楚,因为它还会因测试聊天机器人对指令的理解而变得混乱。 就聊天机器人而言,人们还必须了解与人类教练一起训练聊天机器人的更复杂(且很大程度上未公开)方法的影响。 因此,我们将自己限制在传统的大语言模型上,并通过专门构建前面的文本来利用条件概率模型(1)来探测特定的记忆现象。
网络不是记住单词列表,而是呈现一系列基本事实,这些事实涉及一组通过名字识别的任意人。 我们主要考虑具有 has-a 关系的事实:
保罗有一把吉他。 安有一辆自行车……
此外,我们还研究了一个is-a关系:
保罗是一位物理学家。 安是一名程序员...
以及居住类型的事实:
保罗住在都柏林。 安住在马德里……
在进一步插入文本之后555除非另有说明,否则我们使用中间文本 现在,在您收到所有这些信息后,尝试集中注意力,喝一杯咖啡,去散步。 那么请完成下面的句子。 ,我们附加一个查询,例如
保罗住在X
在选择基本事实的具体例子时,我们必须确保正确答案是由单个词符代表的单词,并且在has-a或is-a<的情况下/t1> 关系,我们确保它以辅音开头,因为将冠词从 a 更改为 an 会为正确答案提供不必要的提示。
我们使用每个类别(物体、地名和职业)的 20 个名称和 20 个单词的列表。 我们通过修改要记忆的事实列表的长度、类别和中间文本来构造各种实验,以探究各种记忆现象。 我们通过随机排列名称和目标词并保留适当数量的事实来构建给定长度的列表,从而获得每个实验的 30 次重复。 这样做是为了大语言模型中任何更多“难忘”的单词都不会导致结果出现偏差。 当报告列表中给定位置的召回准确性时,我们使用 5 个随机种子重复上述实验,以增加统计数据,总共给出 次重复。 我们在补充信息中提供了实验的完整详细信息。 在整篇论文中,我们主要研究具有约 60 亿个参数的开源 GPT-J 模型[5]。 在一组实验中,为了研究模型大小的依赖性,我们从Pythia家族[22]中选择了大语言模型。 所有实验的代码均在 github.com/rmldj/memory-llm-paper 中提供。
4结果
在本节中,我们回顾了我们的实验结果,探讨了人类记忆特性的大语言模型类似物:首要效应和近因效应、详细阐述对记忆回忆的影响、记忆衰退或干扰引起的遗忘;我们还研究重复的影响。 此外,我们还讨论了 LLM 特有的特征——“记忆形成时间”——这对于解释整体结果非常重要。
首因效应和近因效应
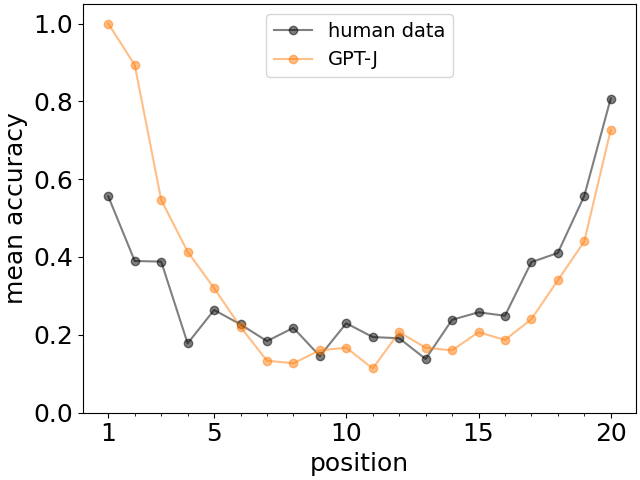
在记忆单词列表时,人类记忆的一个非常典型的特征是,列表开头和结尾的单词更容易被记住,这种现象称为首要性和新近效应 [4](参见图1中的示例人类数据)。 为了研究大型语言模型的类似属性,我们将召回的准确性计算为给定事实在事实列表中的位置的函数。
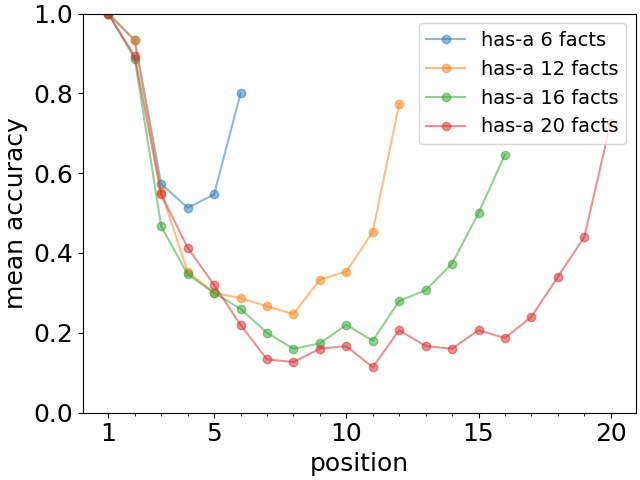
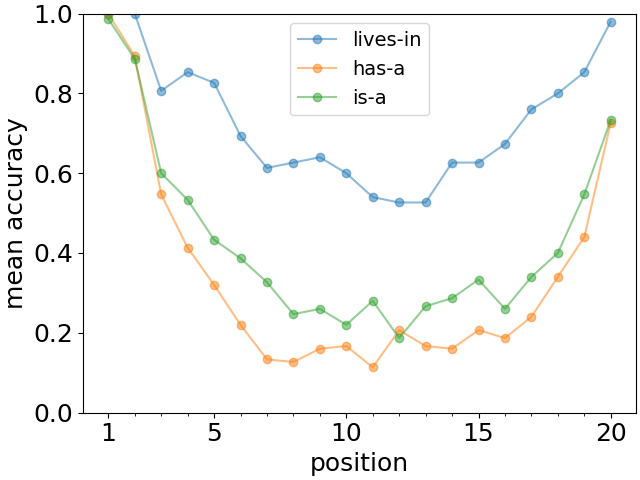
不同长度的列表的结果如图 3(顶部)所示。 我们观察到首要性和新近效应的非常清晰的模式特征。 此外,前两个或三个事实的召回准确率随着列表的长度而基本保持不变。 同样,最后一两个事实的回忆也相当稳定。 在图3(底部)中,我们显示对于长度为 20 的列表,所有三种关系都出现整体定性 U 形召回模式。 请注意,尽管对于大语言模型来说,lives-in 的情况似乎更容易记住,但首因效应和近因效应仍然明显存在。
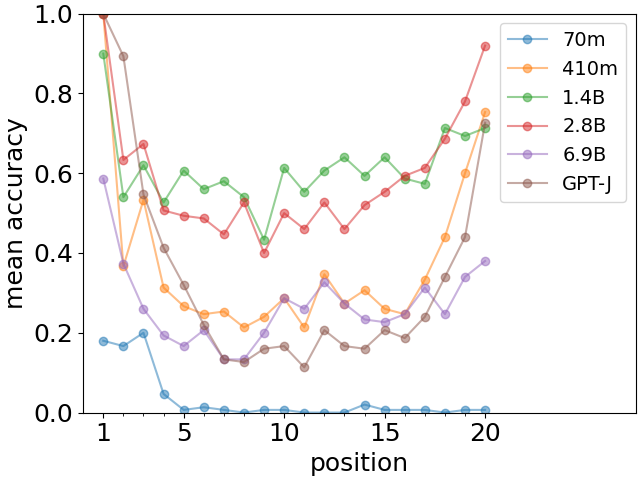
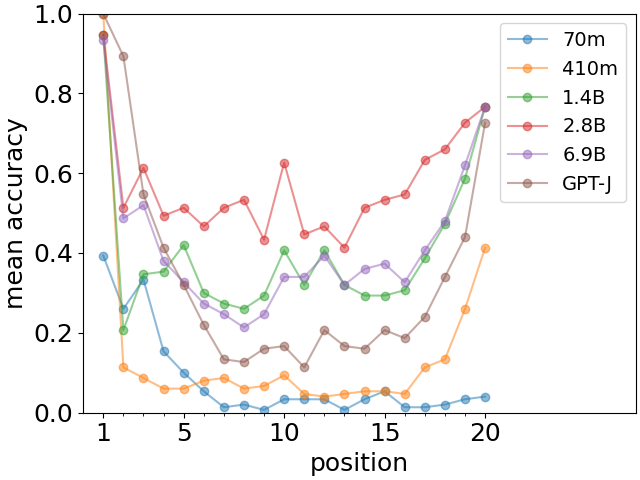
为了检验U型召回曲线的稳健性,我们也进行了相同的实验666但是,Pythia 分词器有所不同,并且对于这些实验来说不太方便。 有关更多详细信息,请参阅补充信息。 Pythia家族[22]的一系列大语言模型在模型大小上差异很大。 截至 2023 年 4 月 3 日更新模型的结果如图4所示。 我们观察到,首因效应在所有模型中都清晰可见,而新近效应则在子集中出现。 特别值得注意的是,最小模型(Pythia-70m)完全不存在新近效应,其参数数量约为 GPT-J)。 在补充信息图S1中,我们显示了Pythia模型之前版本的类似图,其中训练方案取决于模型大小。 在这种情况下,新近效应显得更加系统(但也除了最小模型),并且 U 形召回曲线清晰可见。
总而言之,我们观察到首因效应和新近效应是大型语言模型的一个非常普遍的特征,然而,模型需要足够大才能充分发展。 首因效应似乎非常稳定,而近因效应可能更脆弱,并且对 的特性更敏感,从 Pythia 模型的两个版本的比较中可以看出。 当这两种效应都存在时,对于本文研究的GPT-J模型来说,无论事实类型或列表长度如何,它们都会系统地出现,如图3所示。
阐述和回忆
在人类记忆测试中观察到的另一个显着特征是,提供有关给定概念的附加信息可以提高其回忆的机会,即使查询不涉及任何附加提供的信息[6, 7]。 为了测试大型语言模型是否也会发生类似的现象,我们考虑来自 has-a 关系的长度为 19 的事实的基线列表。 然后在列表中的第 5、10 和 15 位,我们添加了对这些事实的阐述。 例如。
保罗有一把吉他。
基线列表中的内容替换为
保罗有一把吉他,一把电吉他,他在当地的车库乐队中演奏。
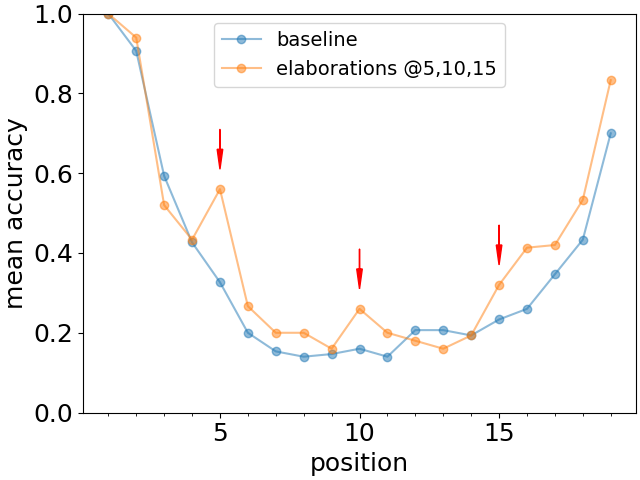
然后,我们再次查询 has-a 关系,因此不会调用详细说明中包含的任何其他知识。 图 5 显示了基线列表和在选定位置添加了详细说明的列表的召回准确率随位置变化的比较。 我们观察到,阐述确实明显提高了回忆的准确性,有效地提高了给定事实的感知显着性。 补充信息中列出了详细说明的完整列表。
干扰与遗忘
遗忘或记忆的丧失可能与两种截然不同的机制先验相关。 一种可能是记忆的痕迹会消失,因此主要机制是记忆衰退。 或者,新的记忆会覆盖旧的记忆,遗忘的主要机制是通过记忆干扰。 尽管这两种机制确实都会在遗忘中发挥作用,但许多心理学研究[8]-[11]发现记忆干扰作为主导因素。
为了在大语言模型方面构建对类似现象的研究,我们现在将以适当的方式更改中间文本(见图2)来对每个模型进行建模这些机制。
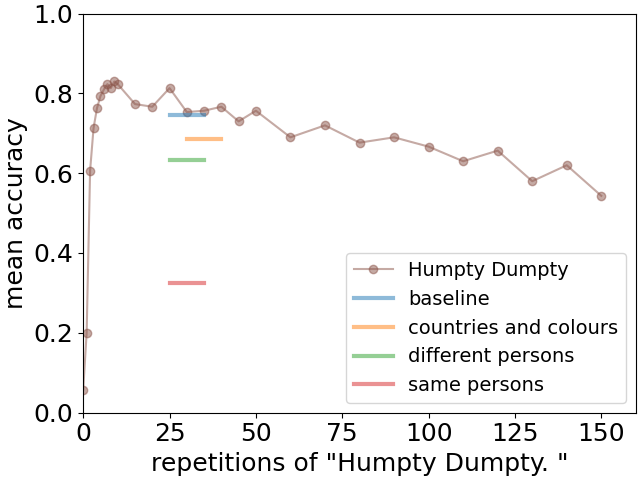
为了研究记忆衰退,我们使用基本上不携带任何长度的任何语义内容的中间文本。 具体来说,我们采用 “Humpty Dumpty.” 的 次重复,对此我们使用速记符号
平均召回率作为函数的结果如图6中带点的实线所示。 我们观察到性能随着增加而缓慢下降777这里我们重点关注中度到较大的的依赖性。我们将在内存形成时间小节中讨论的初始上升。 ,表明可以在大语言模型上下文中识别出记忆衰退的类似物。 然而,至关重要的是,将其与干扰造成的下降进行比较。
为了对干扰进行建模,我们将中间文本设为
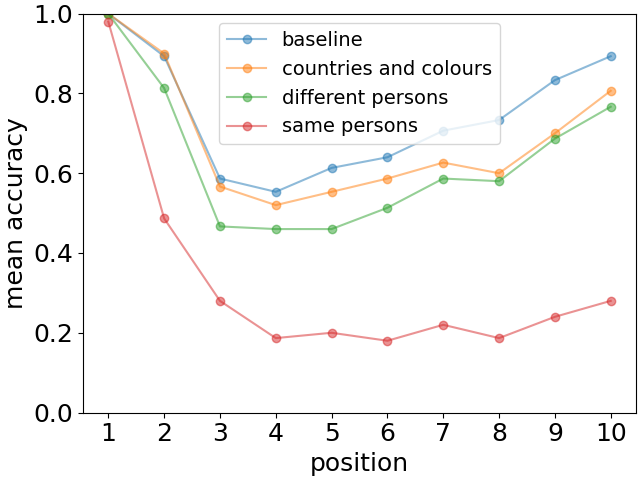
其中干扰项是 10 个各种干扰事实的列表:i) 地图上国家的颜色,ii) 10 个人的职业与给出的职业不同原始事实清单,以及 iii) 原始清单中提到的相同 10 个人的职业。 请注意,这些分散注意力的事实与原始事实并不矛盾。 它们要么完全独立(如情况 i) 和 ii)),要么提供补充信息(情况 iii)),例如除了保罗有一把吉他之外,保罗还是一位物理学家。 召回性能在图6中用水平条表示。 基线是当干扰物仅被 10 次重复替换时 矮胖子。.
我们观察到,干扰对回忆准确性的降低程度远强于衰减,其降低程度取决于干扰信息的类型。 对于涉及与原始列表中同一组人员的分散注意力的事实来说,这一点尤其明显。 在这种情况下,我们还观察到新近效应消失(见图7)。
重复次数
重复给定的材料显然可以增加其记忆。 我们预计大语言模型在这方面也应该有类似的表现。 就人类记忆而言,自艾宾浩斯时代以来,人们已经充分认识到,如果与要学习的材料的初始呈现相隔一定的时间间隔,重复效果最好[12] 。 似乎没有任何明显的理由可以证明这一点也适用于大语言模型,因为这一特性应该与生物记忆巩固的特征联系在一起。
为了研究大语言模型在重复情况下的记忆回忆表现,我们在 3 部分的标准插入文本之前添加以下任一内容:
| (3) |
或者
| (4) |
其中repetition是要记住的事实的重复列表。 我们还可以选择排列重复列表中事实的顺序。 作为基线,我们在标准插入文本之前插入适当数量的 Humpty Dumpty 以匹配重复的长度:
| (5) |
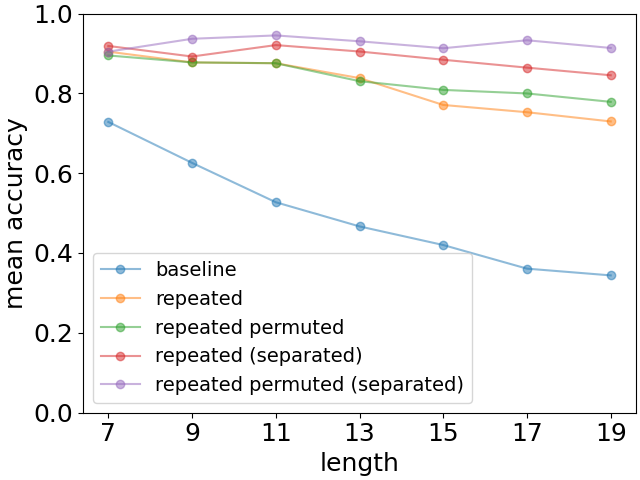
结果如图8所示。 正如预期的那样,重复显着提高了回忆的准确性。 基线。 此外,我们观察到,当重复与原始事实列表分离(如(4)所示)时,性能明显提高,这与人类发生的情况一致[12]。 在后一种情况下,我们还看到排列后的情况具有稍微更好的准确性888差异非常小,但对于所有列表长度大于 7 的情况,差异仍然存在。 如果这只是统计波动的影响,我们预计差异对于不同的列表长度会有不同的符号。. 我们不知道后一种现象是否已针对人类受试者进行过研究。
记忆形成时间
我们以一种似乎是大语言模型特有的现象来结束对所获得结果的介绍,并且预计这种现象不会发生在人类受试者中。 在图 6 中,我们观察到性能最初从非常低的水平开始强劲增长,在 Humpty Dumpty 重复 10 次左右的插入文本时达到最大值。 因此,似乎需要一些有效的“记忆形成时间”才能使先前的信息可供稍后在文本中使用。 这种行为是相当违反直觉的,因为人们会期望在给出事实后直接回忆事实应该是最容易的。 这显然也与之前对大语言模型描述的近因效应的清晰且非常有力的观察相悖。 这些观察结果对于讨论本文所获得结果的可能解释非常重要。
5讨论
在本文中,我们证明了大型语言模型 - GPT-J - 展现了人类记忆的许多关键定性特征:i)首要性和新近度效应,ii)由于额外的阐述而提高了召回率,iii)遗忘主要是通过干扰而不是记忆衰退,以及iv)间隔一定时间重复的好处。 这里,大语言模型的记忆是通过对输入到网络的先前文本进行适当的构造,根据条件概率(1)来定义的。 这相当于内存的功能性定义,大语言模型的行为就好像它要参与串行内存测试。
人类和大语言模型记忆的特征如此密切的相似性实际上是非常令人惊讶和需要解释的。 这个问题特别有趣,因为本文所考虑的大语言模型类型没有任何专用的内存子系统,因此它们的“内存”以涌现的方式出现。
条件概率(1)是大语言模型记忆定义的根源,完全取决于两个因素:i)大语言模型的特定神经网络架构[ 1, 2, 5] 和 ii) 训练文本语料库 – 这里是 925Gb Pile 数据集 [21]。 根据这两个因素的相对重要性,我们可能会得出本文开头总结的两种可能的解释。
如果大语言模型架构的特定特征会使概率模型(1)产生偏差,从而导致所有这些类似人类的记忆特征,我们可以怀疑 Transformer 模型的内部工作原理以某种方式捕捉(功能上)人类记忆运作的某些方面999当然,理论上仍然存在存在两个完全独立的归纳偏差(人类和大语言模型)导致相同属性的可能性。.
另一方面,如果大型语言模型的深度神经网络架构真正发挥通用函数逼近器的作用,具有足够的能力来对人类文本语料库中非常复杂的统计相互关系进行建模,那么架构偏差将不重要。 因此,我们将类人记忆特性归因于文本训练数据中真正的统计相关性,而大语言模型是检测它们的足够精确的工具。 这意味着我们人类以与我们的生物记忆特性兼容的方式构建我们的文本。
区分这两种可能性是先验相当困难的,特别是因为当然,架构归纳偏差和训练数据的真实属性之间可能存在一些重叠。 理想情况下,如果我们拥有一个性能相似的语言模型,但内部架构完全不同,就可以做出区分。 不幸的是,目前所有具有可比性能的大语言模型都是基于 Transformer 的,所以我们只能局限于间接论证。
基于 Transformer 的大语言模型的内部工作原理与人类在处理文本时的一个关键区别在于,大语言模型中不存在时间流逝的因素。 事实上,在计算条件概率 (1) 时,大语言模型可以同时处理整个前面的文本。 因此,不存在像人类真实的短期记忆那样及时保存或丢失信息的问题。 在内部,Transformer 计算前面文本中任何位置处的标记(及其在网络中更深层的表示)之间的(加权)相似性 - 因此也直接计算查询中的词符与查询中的标记之间的相似性。给出的事实清单。 因此,大语言模型的记忆特性相当于它们分析前面的文本并提取相关信息的能力。 因此,整体机制显然是完全不同的。
现在让我们讨论大语言模型架构对于类人记忆特征可能存在的归纳偏差。 大语言模型中单词/标记的位置是通过添加所谓的(旋转)位置嵌入 [23] 进行编码的,这实际上是时间的唯一代理。 因此,神经网络知道哪些标记距离较远,哪些标记相邻。 此外,嵌入向量的重叠随着 Token 间距离的增加而减少。 从这个角度来看,人们可能会认为这为新近度效应提供了非常明显的架构偏差。 然而,我们可以提出两个论点,事实并非如此。
首先,具有相同位置嵌入的最小Pythia-70m模型根本不表现出新近效应(见图4)。 这种效果仅在较大的模型中出现,并且相对于训练方案也更脆弱,这表明它是学习的,而不仅仅是由架构偏差引起的。
其次,“记忆形成时间”的影响最初表现出随着查询与列表的距离增加而提高的准确性(参见图6上的连续曲线)。 这再次违背了新近度的架构偏见假设,这意味着相反的效果。
很可能直接受到大语言模型架构影响的记忆的唯一特征是通过干扰遗忘。 由于 Transformer 的主要机制本质上是(加权)相似性匹配,因此与同一个人相关的干扰事实很可能会严重降低召回率(见图 6),因为它们可能会干扰相似性。 事实上,与同一个人相关的两个事实可以在匹配过程中同时选择,因此在“回答”查询的过程中可能会相互干扰。
根据上述考虑,我们得出的结论是,将人类和大语言模型记忆的特征的大部分相似性归因于用于训练大语言模型的文本数据的真实属性,从而归因于人类文本的可能性更大。输出。 这表明人类记忆训练定性特征的语义相关性特征以某种方式存在于文本中。 因此,我们得出的结论是,我们的生物记忆的特性对我们如何在全球范围内构建文本叙事留下了印记。 这种令人着迷的可能性表明,语言和生物学之间的联系比人们天真的想象的更加紧密。 我们希望上述观点能够引发沿着这些方向的进一步研究。
致谢。 我要感谢 Tadeusz Marek、Magdalena Fafrowicz、Igor Podolak、Natasha Klein-Atlas 对手稿的讨论和评论,以及 Michael Olesik 在本项目初始阶段的合作。 这项工作得到了研究项目仿生人工神经网络(批准号:2017)的支持。 POIR.04.04.00-00-14DE/18-00)属于波兰科学基金会的 Team-Net 计划,由欧洲区域发展基金下的欧盟共同资助,并由优先研究领域 DigiWorld 的资助雅盖隆大学卓越战略计划倡议。
参考
- [1] Brown, T., et al., Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 33, 1877–1901 (2020).
- [2] Vaswani A. et al., Attention is all you need. Adv. Neural Inf. Process. Syst. 30, 5998–6008 (2017).
- [3] Robinson, E.S., Brown, M.A., Effect of Serial Position upon Memorization, The American Journal of Psychology 37, 538-552, 1926.
- [4] Glanzer, M., Cunitz, A.R., Two storage mechanisms in free recall, Journal of Verbal Learning and Verbal Behavior, 5, 1966, 351-360.
- [5] Wang, B., Komatsuzaki A. 2021. GPT-J model available at https://huggingface.co/EleutherAI/gpt-j-6b
- [6] Bower, G. H., and Clark, M. C. (1969). Narrative stories as mediators for serial learning. Psychonomic Science, 14, 181–182.
- [7] Stein, B. S., and Bransford, J. D. (1979). Constraints on effective elaboration: effects of precision and subject generation. Journal of Verbal Learning and Verbal Behavior, 18, 769–777.
- [8] Jenkins, J. G., and Dallenbach, K. M. (1924). Oblivescence during sleeping and waking. American Journal of Psychology, 35, 605–612.
- [9] Baddeley, A. D., and Hitch, G. J. (1974). Working memory. In G. H. Bower (ed.), The psychology of learning and motivation (vol. 8, pp. 47–89). New York: Academic Press. (1977).
- [10] Waugh, N. C., and Norman, D. A. (1965). Primary memory. Psychological Review, 72, 89–104.
- [11] Oberauer, K., and Lewandowsky, S. (2008). Forgetting in immediate serial recall: decay, temporal distinctiveness, or interference? Psychological Review, 115, 544–576.
- [12] Dempster, F. N. (1996). Distributing and managing the conditions of encoding and practice. In E. L. Bjork and R. A. Bjork (eds.), Memory (pp. 317–344). San Diego, CA: Academic Press.
- [13] Bubeck, S., et.al. Sparks of Artificial General Intelligence: Early experiments with GPT-4, arXiv:2303.12712.
- [14] Binz M., Schulz, E., Using cognitive psychology to understand GPT-3, Proc. Natl. Acad. Sci. U.S.A. 120, e2218523120 (2023).
- [15] Shaki, J., Kraus, S., and Woolridge, M., Cognitive Effects in Large Language Models, arXiv:2308.14337, to appear in ECAI 2023.
- [16] Chakrabarty, T., et.al. Art or Artifice? Large Language Models and the False Promise of Creativity, In Hawaii’24: ACM (Association of Computing Machinery) CHI conference on Human Factors in Computing Systems. [arXiv:2309.14556].
- [17] Biderman, S., et.al. Emergent and Predictable Memorization in Large Language Models, arXiv:2304.11158.
- [18] OpenAI 2022, https://openai.com/blog/chatgpt
- [19] Christiano, P., et.al. Deep reinforcement learning from human preferences, arXiv:1706.03741
- [20] Ouyang, L., et.al. Training language models to follow instructions with human feedback, arXiv:2203.02155.
- [21] Gao, L., et.al. The Pile: An 800GB Dataset of Diverse Text for Language Modeling, arXiv:2101.00027.
- [22] Biderman, S., et.al. Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling, arXiv:2304.01373.
- [23] Su, J., et.al. RoFormer: Enhanced Transformer with Rotary Position Embedding, arXiv:2104.09864.
补充资料
实验任务详情
在本文进行的实验中,我们考虑了 20 个通过以下名字识别的人:
保罗、海伦、安、玛丽、大卫、马克、迈克尔、苏珊、罗伯特、彼得、克里斯汀、莎拉、伊万、夏洛特、皮埃尔、凯瑟琳、奥黛丽、约翰、阿曼达、凯文
对于本文主要研究的 has-a 关系,事实的形式为 N has a X,其中 是名称之一 是其中之一
自行车、猫、狗、吉他、钢琴、相机、笔记本电脑、摩托车、房子、姐妹、兄弟、喇叭、键盘、小提琴、丰田、保时捷、福特、梅赛德斯、马、船
对于 is-a 关系,事实的形式为 N is a X,其中 是以下之一
生物学家、司机、农民、数学家、物理学家、程序员、记者、律师、医生、外科医生、心理学家、政治家、护士、老师、作家、士兵、飞行员、面包师、画家、音乐家
对于 lives-in 关系,事实的形式为 N lives in X,其中 是以下之一
都柏林、哥本哈根、布达佩斯、华沙、马德里、斯德哥尔摩、东京、悉尼、德里、西雅图、哈瓦那、开罗、墨尔本、芝加哥、里斯本、檀香山、首尔、罗马、雅典、马尼拉
用于 has-a 关系的特定对象的详细说明如下:
N 有一辆自行车,他/她每天骑着它去上班。
N有一只猫,它非常喜欢玩球。
N 有一只狗,名叫 Fido,它非常喜欢抓住他的绳子玩具。
N 有一把吉他,一把电吉他,他/她在当地的车库乐队中演奏。
N有一架钢琴,不幸的是有点跑调。
N有一台相机,一台相当重的全画幅数码单反相机,带有几个镜头。
N有一台笔记本电脑,上面贴满了各种贴纸。
N有一辆摩托车,不是哈雷戴维森,而是一种很容易融入的朴素模型。
N有一所房子,坐落在镇上一个安静的地方的大花园里。
N有一个妹妹,比她小很多,所以他们在高中的时候没有重叠。
N有一个哥哥,比他早一年上学,所以学校是一个熟悉的地方。
N 有一把小号,他/她每个周末都会在当地的爵士俱乐部定期演奏小号。
N有一个键盘,他/她尝试在上面练习阅读笔记和演奏标准。
N 有一把小提琴,他/她每天早上都尝试用它练习,这让邻居们感到沮丧。
N有一辆丰田车,是在二手店以相当便宜的价格买来的旧车型。
N有一辆保时捷,漆成红色,几乎符合刻板印象。
N有一辆福特,一辆坚固的皮卡车,对园艺生意非常有用。
N有一辆梅赛德斯,到目前为止一直非常可靠,但现在一些小问题开始浮出水面。
N有一匹马,饲养在距离城市以北几英里的一个农场里。
N有一艘船,实际上是一艘小艇,用来在湖上钓鱼。
其中 he/she 代表给定名称 的适当代词。
事实列表与查询通过中间文本分隔开。 除非另有说明,我们将其视为
现在,在您收到所有这些信息后,尝试集中注意力,喝一杯咖啡,去散步。 那么请完成下面的句子。
图6和7中称为国家和颜色的干扰事实如下:
法国在地图上的颜色是蓝色
芬兰在地图上的颜色是白色
西班牙在地图上的颜色是黄色
日本在地图上的颜色是紫色
意大利在地图上的颜色是绿色
印度在地图上的颜色是棕色
希腊在地图上的颜色是紫色
巴西在地图上的颜色是橙色的
地图上丹麦的颜色是灰色
地图上墨西哥的颜色是红色。
技术细节
为了确保没有任何名称或对象使结果产生偏差,名称和对象被独立排列 30 次,并选择适当数量的事实。 在所有情况下,所有名称和物体/职业/地点都是不同的。 在测量作为列表上位置的函数的准确度的情况下,使用 5 个不同的随机种子重复这些实验 5 次,总共提供 150 次重复。 因此,对于列表中的每个位置,我们得到 150 个二元答案(正确/错误回忆)。 该数据的全部特征是指定列表中该位置的平均精度。 对于这样的二进制数据,准确性本身就已经是足够的统计数据。 绝大多数实验采用的神经网络是 GPT-J,在 NVIDIA V100 GPU 上进行评估。
Pythia大语言模型实验
正文图 4 中总结的涉及 Pythia 网络系列的实验需要小心谨慎。 由于分词器不同,许多由 GPT-J 的单个词符组成的单词变成了复合词(trump-et 和 P- 发生了这种情况) orsche 中与 has-a 关系相关的单词)。 在这种情况下,仅测试了第一个词符。 此外,在这种情况下,我们没有将自己限制为名词标记,因为单词和标记之间的对应关系似乎比 GPT-J 宽松得多。
代码库
本文中执行实验所使用的所有代码均可在 github.com/rmldj/memory-llm-paper 上获取。