提示有邪恶的双胞胎
摘要
我们发现,许多自然语言提示可以用相应的提示来代替,这些提示对人类来说是不可理解的,但可以证明在语言模型中会引发类似的行为。 我们将这些提示称为“邪恶的双胞胎”,因为它们是混淆的且无法解释的(邪恶),但同时模仿了原始自然语言提示的功能(双胞胎)。 值得注意的是,邪恶的双胞胎在模型之间转移。 我们通过解决一个最大似然问题来找到这些提示,这个问题有独立的兴趣应用。111Our code and data is available at https://github.com/rimon15/evil_twins.
提示有邪恶的双胞胎
Rimon Melamed GWU rmelamed@gwu.edu Lucas H. McCabe GWU and LMI lucasmccabe@gwu.edu Tanay Wakhare MIT twakhare@mit.edu
Yejin Kim GWU yejinjenny@gwu.edu H. Howie Huang GWU howie@gwu.edu Enric Boix-Adsera MIT eboix@mit.edu
1 引言
大型语言模型 (LLM) 在广泛的任务中迅速改进 (OpenAI, 2023; Touvron 等人, 2023a, b; Jiang 等人, 2023; Bubeck 等人, 2023)。 LLM 通常经过指令调优 (Ouyang 等人, 2022) 以接受用户查询作为提示,这些提示已成为与这些模型交互的主要接口。 然而,关于模型如何解析提示的许多基本问题仍然很大程度上悬而未决。 在本文中,我们考察了以下问题:
为了引发期望的行为,语言模型提示是否必须为人所理解?
这个问题具有深远的意义,既体现在为了最大限度地提高性能而设计提示,也体现在安全性方面(例如,无法解释的提示可以用来绕过安全过滤器并在语言模型中诱发恶意行为);参见第 2 节的讨论。
1.1 我们的贡献
本文的主要贡献是构建反对上述问题的负面证据。 我们发现,自然语言提示词通常可以被人类无法理解的提示词所取代,但这些提示词会导致模型的行为 在功能上 与原始自然语言提示词类似。 更详细地说:

提示词之间的功能相似性
首先,我们提出了一种定量衡量两个提示词 和 之间功能相似性的方法,即通过将它们视为在输入语言模型时在输出上诱导分布 和 。 如果这两个分布相似,那么这两个提示词在功能上是相似的,我们通过 Kullback-Leibler 散度 (KL) 来衡量:
| (1) |
KL 散度是衡量两个分布之间距离的信息论度量,当且仅当两个分布相同 (Cover 等人,1991) 时,它才为零。
寻找具有相似功能的提示词
给定一个真实提示词 ,我们希望找到一个在功能上类似的提示词 。 为此,我们从模型中抽取一组输出,,并求解最大似然问题,其中目标是在给定提示词 下,这些示例输出最有可能被抽取。
| (2) |
此问题对应于优化提示 和 之间 KL 散度的经验近似值,并在第 4 节中推导。
对优化后的提示进行调查
我们探索了这些优化后的提示的几个有趣特性。
-
•
邪恶双胞胎。 在许多情况下,我们找到的优化后的提示在功能上与原始提示(双胞胎)类似,但对人类来说是混乱且难以理解的(邪恶)。 因此,我们将它们称为 邪恶双胞胎。 请参见图 1 中的一些示例。
-
•
可迁移性。 值得注意的是,这些“邪恶双胞胎”提示可以迁移到各种开源和专有语言模型之间;请参见第 6 节。
-
•
鲁棒性。 我们研究了邪恶双胞胎提示对符元顺序更改和符元替换的鲁棒性。 我们发现,邪恶双胞胎对随机排列其符元是否具有鲁棒性取决于 LLM 家族。 另一方面,在所有 LLM 家族中,与真实提示相比,邪恶双胞胎更容易受到随机替换其符元的影响。 这表明,即使是优化提示中不常见的非英语标记,在驱动模型输出方面也发挥着重要作用;请参阅第 7 节。
- •
2 相关工作
本文属于一个快速发展的文献,研究了语言模型如何解析提示。 此外,本文中使用的技术建立在关于提示优化的研究成果之上。 我们将在下面概述相关工作。
模型如何解析提示
越来越多的证据表明,大型语言模型以非直观的方式解释自然语言提示。 例如,模型难以处理被否定的提示,例如要求“给出错误的示例”而不是“给出正确的示例”的提示(Jang 等人,2023)。 此外,在少样本设置中,提示中的自然语言指令通常可以用无关的文本串替换,而性能不会下降(Webson 和 Pavlick,2022)。 此外,在少样本设置中,上下文示例的标签可以用随机标签替换,而性能几乎不会下降(Min 等人,2022)。 这些实验表明,大型语言模型遵循提示中的指令的方式与人类不同,这与我们发现的邪恶孪生提示的发现一致。
也有一些证据表明,大型语言模型能够解析一些非自然语言提示。 Daras 和 Dimakis,2022 发现 DALLE-2 图像中出现的乱码文本可以被重新用作图像生成模型的提示,并产生自然图像。 Millière,2022 建议这可能是模型字节对编码的产物,指出示例提示“Apoploe vesrreaitais”,它生成鸟类图像,让人想起真正的拉丁语鸟类家族 Apodidae 和 Ploceidae。 此外,越狱模型有时包含不可解释的后缀的对抗性示例提示(例如,(Cherepanova 和 Zou,2024;Zou 等人,2023;Liu 等人,2023))。 本文的结果表明,语言模型解析非自然语言提示的现象比以前已知的更为普遍,因为许多自然语言提示都有非自然语言的类似物。 为了完全了解模型如何解析提示,需要处理邪恶双胞胎提示的存在。
提示优化
本文中的技术借鉴了提示优化文献。 这篇文献主要包括针对 硬提示(文本字符串,即符元序列)和 软提示(即不受限于对应文本字符串的嵌入向量序列)的优化方法。 硬提示更可取,因为它们更容易被人为检查,并且可以在不同模型中输入。
软提示优化的基础工作包括前缀调优 (Li 和 Liang,2021;Lester 等人,2021),它使用梯度下降训练软提示。 然后将此软提示置于硬提示之前,以改进一系列任务的条件生成。 我们在附录 D 中包含了关于软提示的实验,但本文的重点是硬提示。
硬提示优化在模型的离散符元空间中运行,这意味着优化不是直接可微的。 硬提示优化最常在对抗攻击或查找生成恶意输出或导致模型错误分类的“越狱”(提示)的背景下进行描述。 已经开发出几种方法,如 HotFlip (Ebrahimi 等人,2018)、AutoPrompt (Shin 等人,2020)、贪婪坐标梯度 (GCG) (Zou 等人,2023) 和 AutoDAN (Liu 等人,2023) 来优化硬提示。 这些方法通过从一个任意的提示开始,并迭代地修改符元,以获得对抗攻击行为为目标。 在我们的工作中,我们将 GCG(加上额外的热启动、剪枝和流畅性惩罚)应用于我们的优化框架,证明它可以用于对抗攻击之外的场景。
与我们工作最接近的是 PEZ (Wen et al., 2023),它提出了一种方法,该方法接收输入图像并在 CLIP 嵌入空间中找到匹配的提示。 这与 (2) 中的最大似然问题类似,但我们的设置与 PEZ 大不相同,因为我们的优化问题不依赖于具有共享嵌入空间的多模态模型——我们唯一需要的是计算给定提示的文档的对数似然的能力。 特别是,我们对提示优化的公式意味着我们的方法即使在模型输出的文档与提示含义不同时(即,双重提示不必在某个嵌入空间中接近文档)也适用。 这就是所有对话语言模型的设置,其中模型的响应不是提示的释义。
3 预备知识
3.1 自回归语言模型
在我们的工作中,我们重点关注具有仅解码器架构的 Transformer (Vaswani et al., 2017),因为大多数最近的语言模型都采用了这种架构。 我们定义了一个 Transformer 语言模型 ,其词汇量为 个符元,其中每个符元映射到一个 维嵌入。 模型的输入是一个长度为 的序列,表示为一个矩阵 ,通过将符元的独热编码 堆叠起来。
给定一个序列 ,模型输出 个符元概率 的 logits。
3.2 文档的概率
给定输入序列 ,模型在输入上诱导一个概率分布 :
其中 是 的第 行,对于任何向量 ,softmax 是 中的一个向量,由 给出。
现在,给定一个以提示和文档形式连接的输入序列
其中 和 分别是提示和文档,则给定提示的文档的条件概率为
| (3) |
4 优化问题
4.1 提示之间的KL散度
给定两个提示,,我们使用KL散度 (1) 来衡量提示所诱导的文档分布差异。 由于分布 之间的KL散度定义为
因此,提示之间的距离可以等效地表示为
由于我们可以访问模型的输出对数概率,我们可以通过绘制一些数量 的文档 并计算来估计距离
| (4) |
当我们增加 时,估计器 集中在其期望值 周围,我们获得了高质量的近似值。 我们选择KL散度作为提示优化的统计距离,因为 (i) 它是通过Pinsker不等式 (Pinsker, 1964) 对总变异距离的界限,而且正如我们现在将看到的,(ii) 最小化它自然对应于最大似然估计,以及 (iii) 它允许有效优化。
4.2 优化问题
我们寻求一个提示 ,该提示可以最小化 和 之间在 (4) 中给出的KL散度的经验估计。 然而,(4) 包含取决于 的加性项,除非我们知道 ,否则我们无法计算这些项。 幸运的是,这些项不依赖于 ,因此在优化中我们可以丢弃这些项并定义损失函数
解决方案集保持不变
| (5) |
这里 是硬提示集,其中 的每一行都是一个符元的独热指示向量。
备注. 正如引言中所讨论的那样,我们解决的优化问题对应于寻找最大似然估计器 (MLE)
是使文档 被抽取的概率最大化的提示。
5 优化方法的比较
我们考虑了各种方法来优化 (5)。
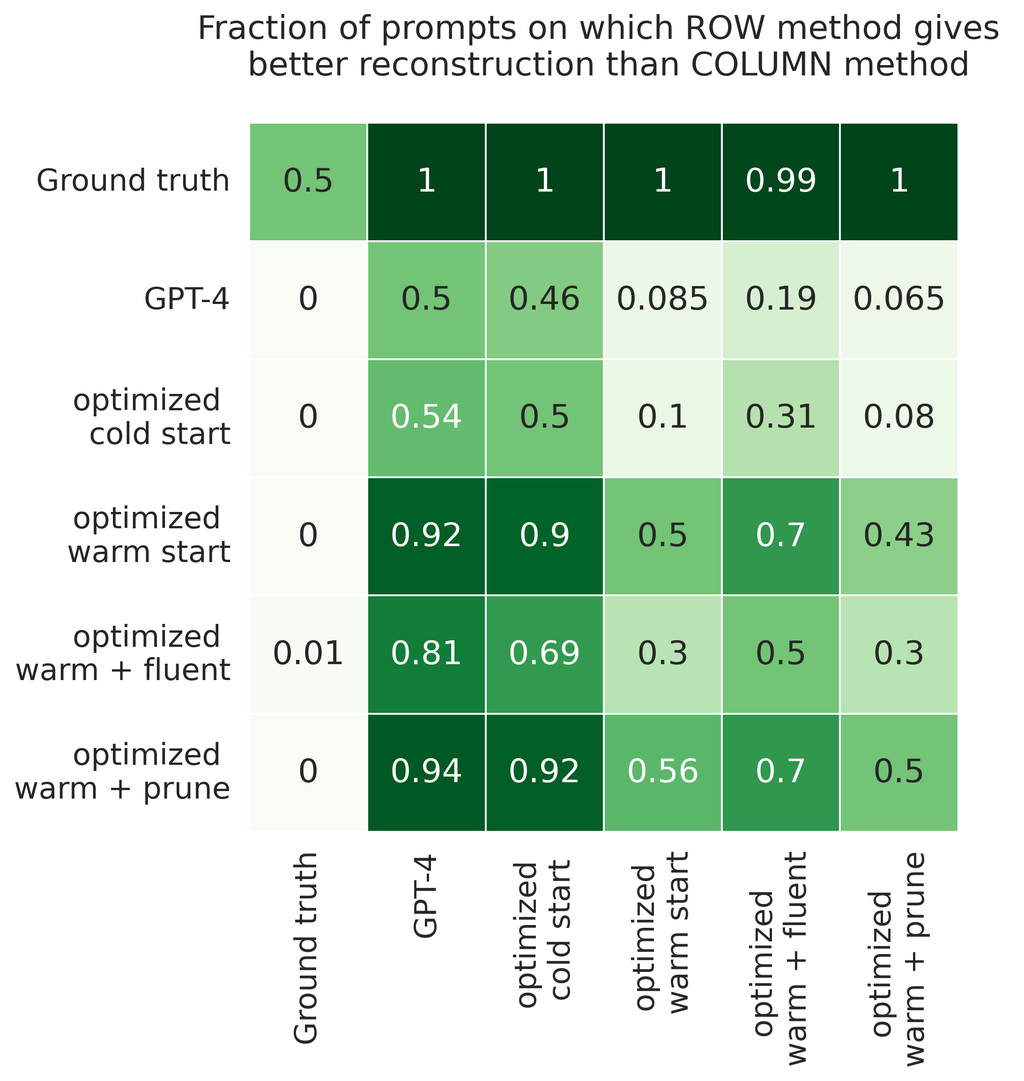
我们在来自 Alpaca 指令调优数据集 (Taori 等人,2023) 的 100 个随机采样提示上比较这些方法,其中 Vicuna-7b-v1.5 是经过指令调优的模型。 附录 C 中介绍了对各种模型系列和数据集的额外实验。对于每种方法和提示,我们计算优化后的提示相对于原始提示的 KL 散度。 我们根据哪种方法找到更接近地面实况的提示来比较方法对,见图 2。 GPT-4 的建议与冷启动 GCG 的建议大致相当。 另一方面,使用热启动的 GCG 比冷启动 GCG 和 GPT-4 提示建议都有很大改进。 通过添加流畅度惩罚或修剪词汇表来强制解释性不会改进优化后的提示(见第 8 节)。 所有结果都在图 10 中报告。
6 邪恶双胞胎提示在模型之间转移
我们测试在一个模型上优化的提示是否适用于来自不同系列且大小不同的其他模型。
6.1 向开源和专有模型的可转移性
尽管优化后的“邪恶双胞胎”提示通常对人类来说是不可理解的,但我们惊讶地发现它们可以转移到多个开源和闭源工业 LLM。 我们使用 100 个来自 Vicuna 的经过优化的(从 GPT-4 热启动开始)提示,并将它们通过各种开源和闭源模型运行。 我们使用 GPT-4 作为评判,以判断从优化后的提示中引发的响应在 1 到 3 的范围内是否忠实于原始提示。
| Model | Score = 1 | Score = 2 | Score = 3 (best) |
| Gemini Pro | 17 | 8 | 75 |
| GPT-3.5-turbo | 31 | 6 | 63 |
| GPT-4 | 31 | 7 | 62 |
| Claude 3 Haiku | 59 | 5 | 36 |
| Claude 3 Sonnet | 38 | 8 | 54 |
| mistral-medium | 16 | 30 | 54 |
| mistral-small | 21 | 12 | 67 |
| mistral-tiny | 24 | 22 | 53 |
| OpenHermes-2.5 | 5 | 24 | 71 |
| OpenHermes-13B | 28 | 19 | 53 |
| Llama2-7b-chat | 7 | 28 | 64 |
| Llama2-13b-chat | 8 | 27 | 64 |
| Vicuna-7B | 7 | 22 | 71 |
| Vicuna-13B | 8 | 27 | 64 |
具体来说,我们用于 GPT-4 的提示是:
请判断以下响应是否回答了提示。 使用 3 级评分,其中:1 表示响应根本没有回答提示,并且完全错误;2 表示响应理解了提示的总体思路,并在一定程度上回答了提示;3 表示响应忠实地回答了提示。
6.2 模型大小之间的可迁移性
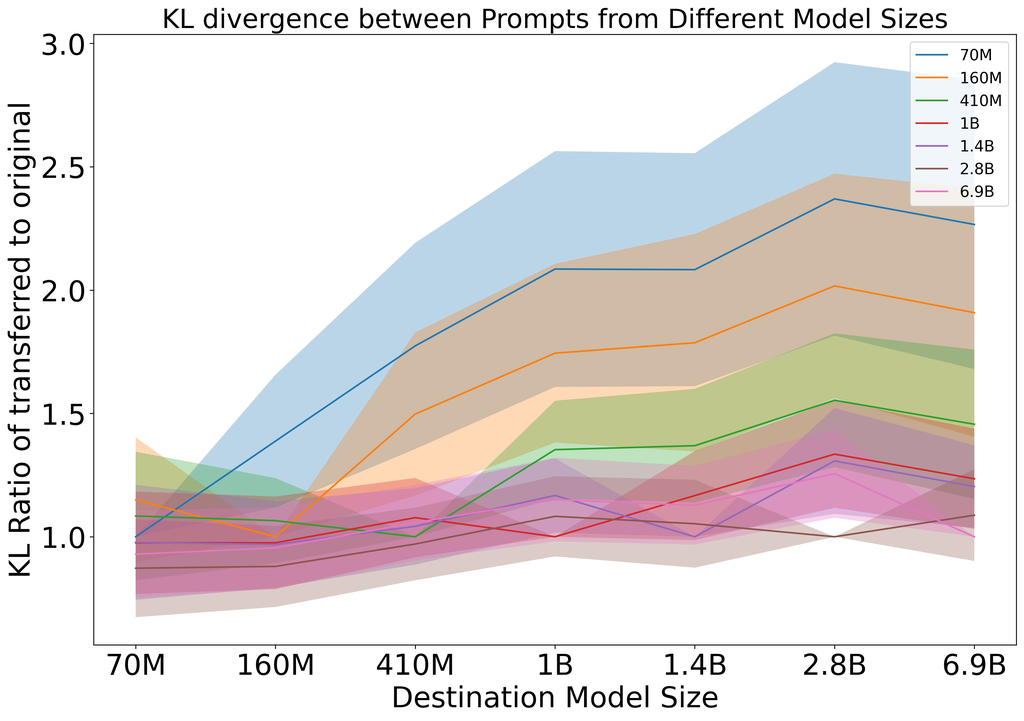
接下来,我们研究在同一模型族中不同模型之间,同时改变模型大小,优化提示的可转移性。 Pythia (Biderman et al., 2023) 套件包含从 70M 到 12B 个参数的模型。 除了参数数量外,每个模型都相同,这使其成为研究提示之间的距离如何随模型大小而变化的理想选择。 此外,每个模型都使用相同顺序的相同数据进行训练。 我们的结果如图 3 所示。 我们发现,在较小模型上优化的提示对较大的模型的可转移性较差。 但是,在较大模型上优化的提示可以很好地转移到较小的模型上。
7 优化提示的鲁棒性
7.1 令牌顺序敏感性
自然语言对令牌顺序很敏感,因为序列的含义可能会因其组成令牌的重新排列而受到影响。 Ishibashi et al., 2023 发现 AutoPrompt 学习的提示比手动编写的提示对令牌重新排列更敏感,如通过自然语言推理任务的性能衡量所示。 我们检查了我们的优化提示是否也如此,调用了基于 KL 的评估:
Definition 1.
给定提示 和 ,定义 为通过均匀洗牌其符元形成的随机提示。 我们说提示 比 更 token-order-sensitive,如果
我们希望将优化后的提示的符元顺序敏感性与自然语言基本事实提示的符元顺序敏感性进行比较。 我们使用算法 1 来评估这一点,该算法计算 和 之间的符元顺序敏感性“胜率” ,比较提示在随机符元重新排序下的变化程度。
| Model | ||
| pythia-70m | (, ) | (, ) |
| pythia-160m | (, ) | (, ) |
| pythia-410m | (, ) | (, ) |
| pythia-1b | (, ) | (, ) |
| pythia-1.4b | (, ) | (, ) |
| pythia-2.8b | (, ) | (, ) |
| pythia-6.9b | (, ) | (, ) |
| vicuna-7b (cold) | (, ) | (, ) |
| vicuna-7b (warm) | (, ) | (, ) |
| gemma-2b-it (cold) | (, ) | (, ) |
| gemma-2b-it (warm) | (, ) | (, ) |
| mistral-7b-ins (warm) | (, ) | (, ) |
| phi-2 (warm) | (, ) | (, ) |
我们发现,符元顺序敏感性似乎取决于模型族;见表 2。 对于 Pythia、Phi-2 和 Gemma,优化提示明显比地面真实提示的顺序敏感性更低。 对于 Mistral,优化提示的顺序敏感性略高。 对于 Vicuna,优化提示和地面真实提示之间没有显著差异。
7.2 符元替换敏感性
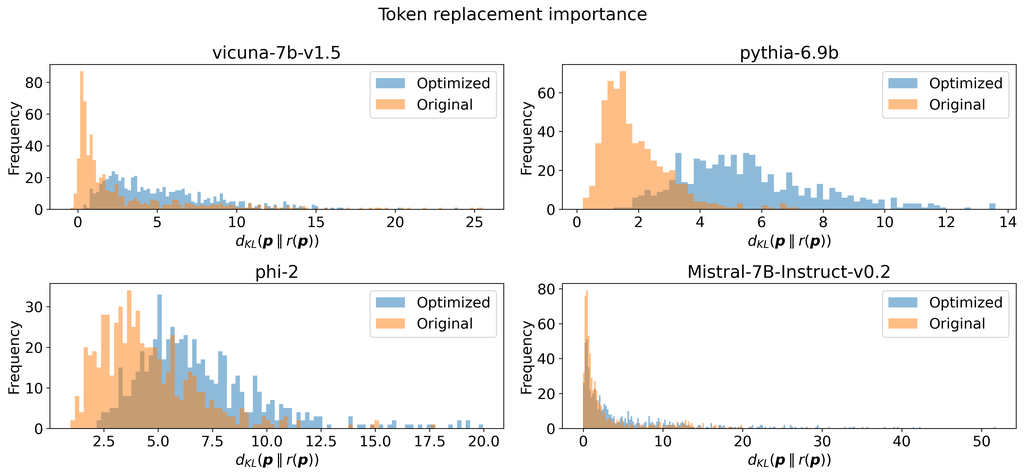
我们定量地检验了这一假设,检查优化后的提示中是否存在一些符元对提示的功能有巨大的影响。 我们计算每个优化后的提示 的 ,其中 是一个函数,它用 [UNK] 替换序列的 符元。 我们对基本事实提示 做同样的事情。 图 4 绘制了所有提示和符元位置 上这些 KL 散度的直方图。
令人惊讶的是,这个实验与假设相矛盾。 图 4 显示,用“未知”符元 [UNK] 替换优化后的提示中的符元,其影响通常 大于 用 [UNK] 替换基本事实提示中的符元的影响。 因此,优化后的提示更依赖于所有符元的出现,而自然提示则不然,即使其中许多符元可能看起来很乱而且无法解释。 这种影响在 Pythia、Vicuna 和 Phi-2 模型中尤为显著,因为优化后的提示中只有很少的符元在被 [UNK] 替换时产生零 KL 散度变化。
8 优化更易理解的提示
我们优化生成的提示通常是难以理解的,而且可能需要恢复一个更容易被人理解的提示。 在本节中,我们探索了对优化过程的两种调整,旨在提高可理解性:(1) 流畅度惩罚,以及 (2) 将优化后的提示的词汇量限制为常见的英语符元。 我们发现这些变体没有提高优化后的提示与原始提示的 KL 散度。
8.1 流畅度惩罚
受先前工作 (Guo et al., 2021; Mehrabi et al., 2022; Shi et al., 2022; Wen et al., 2023) 的启发,这些工作将诸如困惑度、BERTscore (Zhang* et al., 2020) 和流畅度惩罚等附加项添加到损失中,以提高下游性能,我们遵循 (Shi et al., 2022),并将一个项添加到硬提示损失函数中,以惩罚提示的对数似然 (流畅度惩罚)。 我们的硬提示损失函数随后变为
其中 是一个控制恢复自然提示重要性的参数。 更大的 会使优化偏向于更自然的提示,这些提示可能并不一定适合文档。 我们发现添加流畅性惩罚会降低优化后的提示和真实提示之间的相似度;参见图 2。 然而,使用流畅性惩罚生成的提示包含更少的奇怪符元,并且具有更高的流畅度;参见图 10 以获取完整结果。 附录 B 提供了关于调整流畅性超参数 的分析。
8.2 词汇修剪
我们探索限制为 GCG 选择的符元,以提高重构和流畅度。 由于我们所有的测试都在英语提示和文档上进行,因此我们只关注分词器中的英语子词。 为了实现这一点,我们对从 spaCy (Honnibal 和 Montani, 2017) 获得的英语语料库运行 Llama 分词器,并屏蔽掉语料库中未出现的全部符元。 Llama 分词器包含 32,000 个符元,我们的修剪过程导致大约 15,000 个符元被移除。
9 讨论和未来工作
我们的工作从一个新的角度 探讨了提示优化,通过询问我们是否可以优化提示使其在功能上等效于某个真实提示。 功能相似性通过真实提示分布和优化提示分布之间的 KL 散度来量化。 这产生了最大似然问题 (2),其解揭示了“邪恶双胞胎”提示。 除了我们对模型之间可转移性和对邪恶孪生提示扰动的鲁棒性的探索之外,还有几个开放的方向可供未来研究。 这些方向包括对最大似然问题 (2) 的应用,这些应用本身就很有意义。
-
•
提示压缩。 通过在 (2) 中添加长度惩罚到优化提示,我们的框架可以用于生成更短的提示,这些提示模仿原始的、更长的提示,然后可以用于按符元付费的 API 服务,以减少推理时间、上下文长度使用和总成本。
-
•
条件生成。 最大似然问题 (2) 可以扩展到允许条件生成的提示。 这可能是有用的一个例子是风格/内容转换:给定一组用户电子邮件,形式为 (主题,电子邮件),用户可以优化提示,以便连接的输入字符串 [提示; 主题] 更有可能生成相应的电子邮件,并且可以以用户在用户先前电子邮件语料库中定义的风格在新的主题上撰写新的电子邮件。
-
•
语料库压缩。 可以将我们的框架 (2) 应用于帮助压缩文档语料库。 给定从分布中抽取的文档 ,将找到一个优化的提示,该提示将配置模型,使其更擅长预测来自该分布的文档。 如果模型作为压缩算法通过算术编码使用,如 (Delétang 等人,2023) 中所述,这将产生改进的性能。
局限性
我们发现的邪恶孪生是使用 GCG 算法 (Zou 等人,2023) 以及额外的预热启动、符元修剪和流畅性惩罚来发现的。 但是,GCG 并非在所有情况下都能产生稳定的优化。 这可以在附录 E 中看到,在某些示例中,优化未能找到与原始提示具有低 KL 散度的提示。 因此,将来有必要探索替代优化算法,例如可能不仅一次编辑一个符元,而且可能进行多个符元的插入和删除,以及在优化过程中改变符元数量的算法。 此外,还需要进行额外的未来工作以将我们的框架适应独立感兴趣的应用,因为 GCG 可能需要多次迭代才能收敛,这可能会引入显著的运行时开销。
我们寻找邪恶双胞胎的方法依赖于完全访问模型梯度,而对于许多闭源模型(如 GPT-4)来说,情况并非如此。 然而,邪恶双胞胎在模型之间的可迁移性使我们能够在开源模型上找到它们并将它们应用于闭源模型。
潜在风险
恶意用户可以使用我们的框架构造一个提示,该提示会生成一个有毒或有害文档语料库,而不会在表面层面上显得恶意。 然而,有许多方法可以减轻这些风险,例如困惑度过滤器和提示改述 (Jain et al., 2023)。
致谢
本研究部分由 NSF 在 2127207 号拨款下提供资金支持。 EB 由 NSF 拨款 1745302 提供资金。
参考文献
- Bailey et al. (2023) Luke Bailey, Gustaf Ahdritz, Anat Kleiman, Siddharth Swaroop, Finale Doshi-Velez, and Weiwei Pan. 2023. Soft prompting might be a bug, not a feature. In ICML 2023 Workshop on Deployment Challenges for Generative AI.
- Biderman et al. (2023) Stella Biderman, Hailey Schoelkopf, Quentin Gregory Anthony, Herbie Bradley, Kyle O’Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, et al. 2023. Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling. In International Conference on Machine Learning, pages 2397–2430. PMLR.
- Bubeck et al. (2023) Sébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, Yin Tat Lee, Yuanzhi Li, Scott Lundberg, et al. 2023. Sparks of Artificial General Intelligence: Early experiments with GPT-4. arXiv preprint arXiv:2303.12712.
- Cherepanova and Zou (2024) Valeriia Cherepanova and James Zou. 2024. Talking nonsense: Probing large language models’ understanding of adversarial gibberish inputs. In ICML 2024 Next Generation of AI Safety Workshop.
- Clopper and Pearson (1934) Charles J Clopper and Egon S Pearson. 1934. The Use of Confidence or Fiducial Limits Illustrated in the Case of the Binomial. Biometrika, 26(4):404–413.
- Cover et al. (1991) Thomas M Cover, Joy A Thomas, et al. 1991. Entropy, relative entropy and mutual information. Elements of information theory, 2(1):12–13.
- Daras and Dimakis (2022) Giannis Daras and Alex Dimakis. 2022. Discovering the Hidden Vocabulary of DALLE-2. In NeurIPS 2022 Workshop on Score-Based Methods.
- Delétang et al. (2023) Grégoire Delétang, Anian Ruoss, Paul-Ambroise Duquenne, Elliot Catt, Tim Genewein, Christopher Mattern, Jordi Grau-Moya, Li Kevin Wenliang, Matthew Aitchison, Laurent Orseau, et al. 2023. Language Modeling Is Compression. arXiv preprint arXiv:2309.10668.
- Ebrahimi et al. (2018) Javid Ebrahimi, Anyi Rao, Daniel Lowd, and Dejing Dou. 2018. HotFlip: White-box adversarial examples for text classification. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 31–36, Melbourne, Australia. Association for Computational Linguistics.
- Google (2024) Google. 2024. Gemma: Open models based on gemini research and technology.
- Guo et al. (2021) Chuan Guo, Alexandre Sablayrolles, Hervé Jégou, and Douwe Kiela. 2021. Gradient-based adversarial attacks against text transformers. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 5747–5757, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
- Honnibal and Montani (2017) Matthew Honnibal and Ines Montani. 2017. spaCy 2: Natural language understanding with Bloom embeddings, convolutional neural networks and incremental parsing. To appear.
- Ishibashi et al. (2023) Yoichi Ishibashi, Danushka Bollegala, Katsuhito Sudoh, and Satoshi Nakamura. 2023. Evaluating the robustness of discrete prompts. In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, pages 2373–2384, Dubrovnik, Croatia. Association for Computational Linguistics.
- Jain et al. (2023) Neel Jain, Avi Schwarzschild, Yuxin Wen, Gowthami Somepalli, John Kirchenbauer, Ping-yeh Chiang, Micah Goldblum, Aniruddha Saha, Jonas Geiping, and Tom Goldstein. 2023. Baseline defenses for adversarial attacks against aligned language models. arXiv preprint arXiv:2309.00614.
- Jang et al. (2023) Joel Jang, Seonghyeon Ye, and Minjoon Seo. 2023. Can large language models truly understand prompts? a case study with negated prompts. In Transfer Learning for Natural Language Processing Workshop, pages 52–62. PMLR.
- Jiang et al. (2023) Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. 2023. Mistral 7b.
- Lester et al. (2021) Brian Lester, Rami Al-Rfou, and Noah Constant. 2021. The Power of Scale for Parameter-Efficient Prompt Tuning. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 3045–3059, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
- Li and Liang (2021) Xiang Lisa Li and Percy Liang. 2021. Prefix-tuning: Optimizing continuous prompts for generation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 4582–4597, Online. Association for Computational Linguistics.
- Liu et al. (2023) Xiaogeng Liu, Nan Xu, Muhao Chen, and Chaowei Xiao. 2023. AutoDAN: Generating Stealthy Jailbreak Prompts on Aligned Large Language Models.
- Mehrabi et al. (2022) Ninareh Mehrabi, Ahmad Beirami, Fred Morstatter, and Aram Galstyan. 2022. Robust conversational agents against imperceptible toxicity triggers. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 2831–2847, Seattle, United States. Association for Computational Linguistics.
- Millière (2022) Raphaël Millière. 2022. Adversarial attacks on image generation with made-up words. arXiv preprint arXiv:2208.04135.
- Min et al. (2022) Sewon Min, Xinxi Lyu, Ari Holtzman, Mikel Artetxe, Mike Lewis, Hannaneh Hajishirzi, and Luke Zettlemoyer. 2022. Rethinking the role of demonstrations: What makes in-context learning work? arXiv preprint arXiv:2202.12837.
- OpenAI (2023) OpenAI. 2023. GPT-4 technical report. arXiv, pages 2303–08774.
- Ouyang et al. (2022) Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. 2022. Training language models to follow instructions with human feedback.
- Pinsker (1964) Mark S. Pinsker. 1964. Information and Information Stability of Random Variables and Processes. Holden-Day, San Francisco.
- Shi et al. (2022) Weijia Shi, Xiaochuang Han, Hila Gonen, Ari Holtzman, Yulia Tsvetkov, and Luke Zettlemoyer. 2022. Toward Human Readable Prompt Tuning: Kubrick’s The Shining is a good movie, and a good prompt too? arXiv preprint arXiv:2212.10539.
- Shin et al. (2020) Taylor Shin, Yasaman Razeghi, Robert L. Logan IV, Eric Wallace, and Sameer Singh. 2020. AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 4222–4235, Online. Association for Computational Linguistics.
- Taori et al. (2023) Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. 2023. Stanford Alpaca: An Instruction-following LLaMA model. https://github.com/tatsu-lab/stanford_alpaca.
- Touvron et al. (2023a) Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. 2023a. LLaMA: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971.
- Touvron et al. (2023b) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. 2023b. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. 2017. Attention is All You Need. In Advances in Neural Information Processing Systems.
- Webson and Pavlick (2022) Albert Webson and Ellie Pavlick. 2022. Do prompt-based models really understand the meaning of their prompts? In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 2300–2344, Seattle, United States. Association for Computational Linguistics.
- Wen et al. (2023) Yuxin Wen, Neel Jain, John Kirchenbauer, Micah Goldblum, Jonas Geiping, and Tom Goldstein. 2023. Hard Prompts Made Easy: Gradient-Based Discrete Optimization for Prompt Tuning and Discovery. In Thirty-seventh Conference on Neural Information Processing Systems.
- Zellers et al. (2019) Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. 2019. HellaSwag: Can a machine really finish your sentence? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4791–4800, Florence, Italy. Association for Computational Linguistics.
- Zhang* et al. (2020) Tianyi Zhang*, Varsha Kishore*, Felix Wu*, Kilian Q. Weinberger, and Yoav Artzi. 2020. BERTScore: Evaluating Text Generation with BERT. In International Conference on Learning Representations.
- Zheng et al. (2023) Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. 2023. Judging LLM-as-a-judge with MT-Bench and Chatbot Arena. arXiv preprint arXiv:2306.05685.
- Zou et al. (2023) Andy Zou, Zifan Wang, J Zico Kolter, and Matt Fredrikson. 2023. Universal and transferable adversarial attacks on aligned language models. arXiv preprint arXiv:2307.15043.
附录 A 贪婪坐标梯度算法
我们的论文基于 (Zou 等人,2023) 中提出的贪婪坐标梯度 (GCG) 算法(如算法 2 所示),用于提示优化,通过整合热启动并实验词汇修剪来实现。 GCG 属于一系列离散优化算法,这些算法使用符元翻转迭代构建提示,并结合各种启发式方法来确定要翻转的符元以及翻转顺序。
早期的工作,例如 HotFlip (Ebrahimi 等人,2018),会选择一个符元,并近似于词汇表中翻转时损失减少最多的前 1 个符元。 这会导致情感分析的错误分类。
在此基础上,AutoPrompt 在原始提示中添加少量随机初始化的“触发器”符元。 随后,这些“触发器”中的符元会被屏蔽并通过掩码语言建模进行优化,目标是通过为每个触发器选择一些具有最高梯度的前 个符元来最小化输入序列的损失 (Shin 等人,2020)。
GCG 使用与 AutoPrompt 类似的方法;对于任务提示的后缀符元,它们会通过计算后缀中每个位置具有最大负梯度的前 个符元来优化该后缀,然后均匀地采样单个符元作为后缀中每个位置的候选替换。 最后,对于每个候选后缀,他们通过运行前向传递来计算损失,并选择损失最小的候选后缀作为最终的新后缀。 使用他们优化的后缀,他们能够生成提示,这些提示会从开源 LLM(如 Llama)以及 ChatGPT 和 GPT-4 等大型商业模型中诱导出恶意输出。 GCG 的完整算法细节如算法 2 所示。
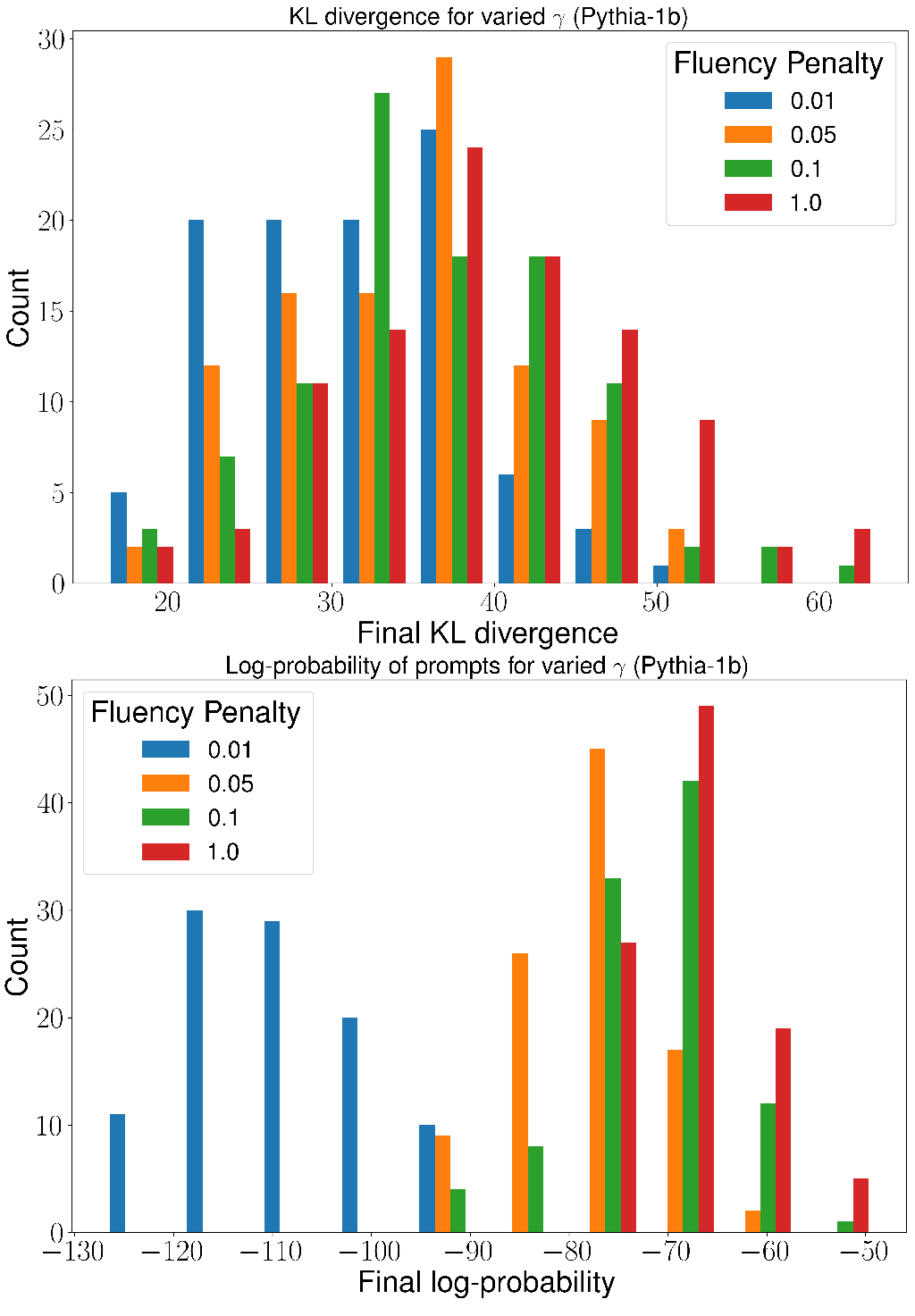
附录 B 流畅度超参数分析
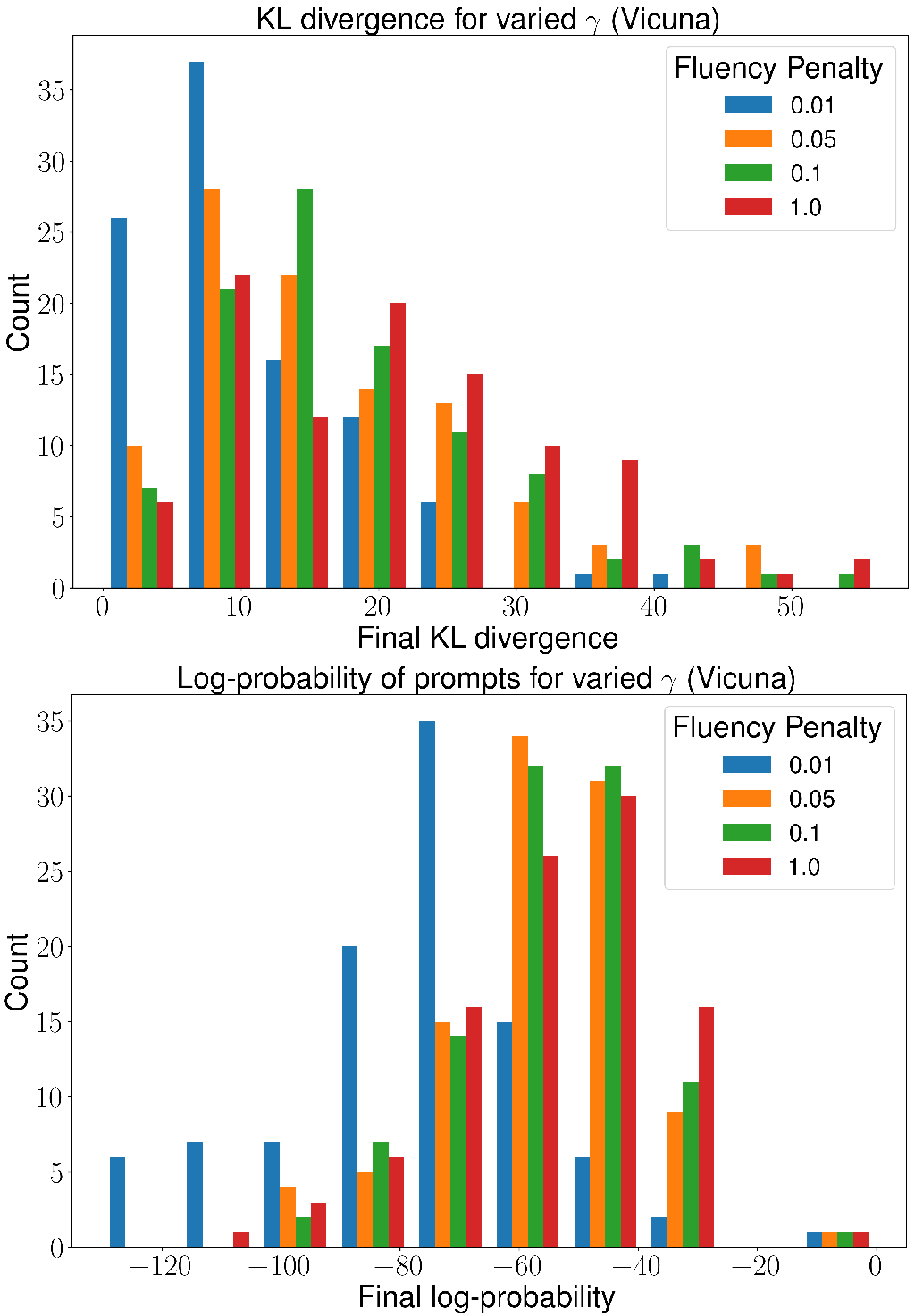
我们通过选择 并对来自 GPT-4 热启动的 Vicuna-7b 进行 50 个 epoch 的硬提示优化来探索改变流畅度惩罚强度的影响;参见图 5。 我们还对 Pythia-1b 从冷启动进行 50 个 epoch 的硬提示优化;参见图 6。
这些图表明,提示的可读性(以最终的对数概率衡量)与它重建原始提示的程度之间存在着令人惊讶的权衡。 对于我们在图 2 中的优化,我们选择 ,并且这个值确实在 KL 散度到真实值的方面降低了优化性能。
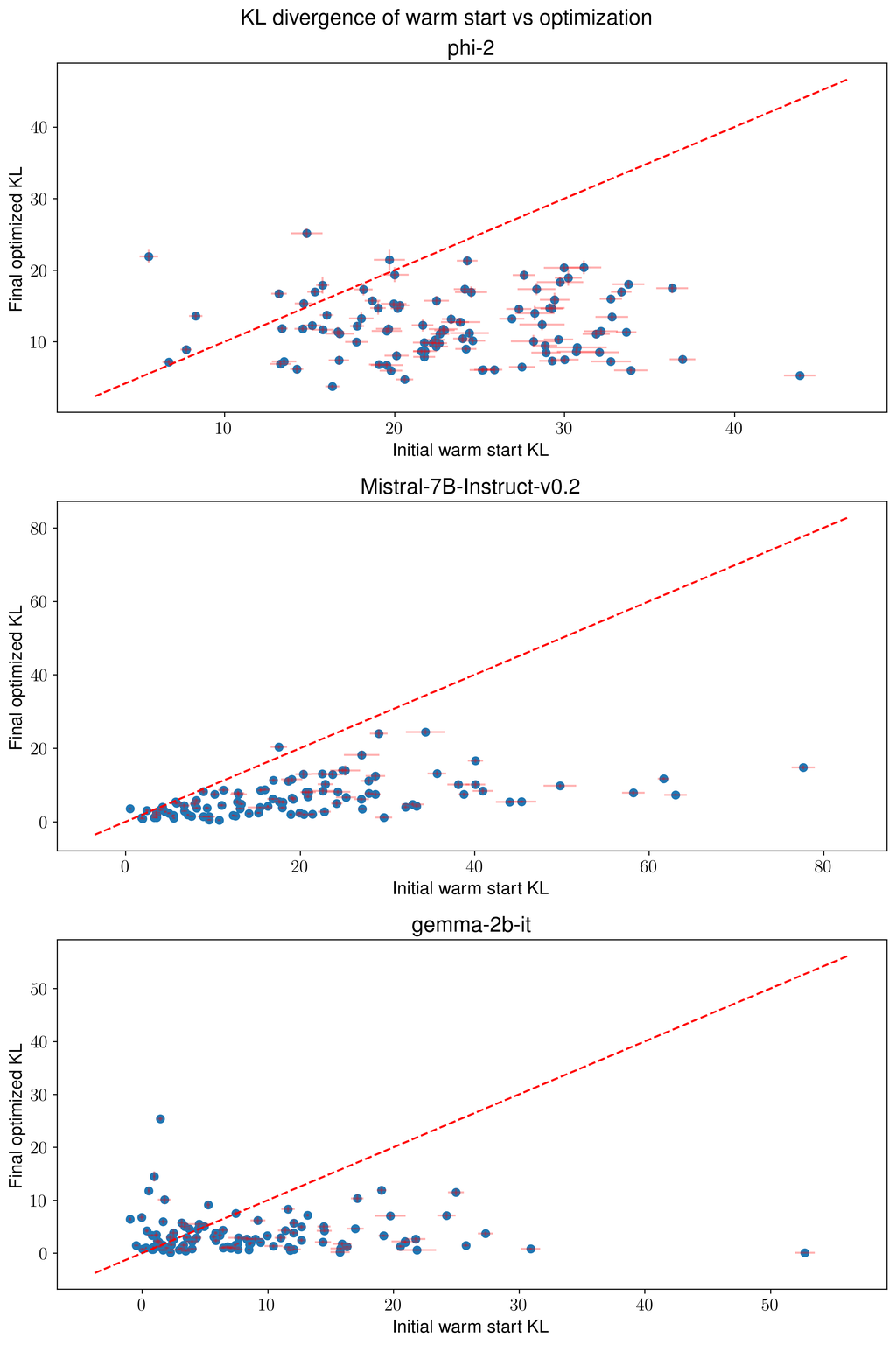
附录 C 使用不同模型族和数据集的额外实验
我们对微软的 Phi-2(27 亿个参数)、Mistral 的 Mistral-7B-Instruct-v0.2(70 亿个参数)和谷歌的 Gemma(20 亿个参数)(Google, 2024) 进行了额外实验。 我们使用了流行的提示数据集 OpenHermes-2.5,它包含各种各样的提示,用于各种任务,例如编码、问答等等。 我们过滤了一部分与编写代码相关的提示。
对于所有模型,我们从 GPT-4 的热启动开始,对 100 个时期进行硬提示优化。 我们发现,我们获得了与其他模型族类似的结果;见图 7。
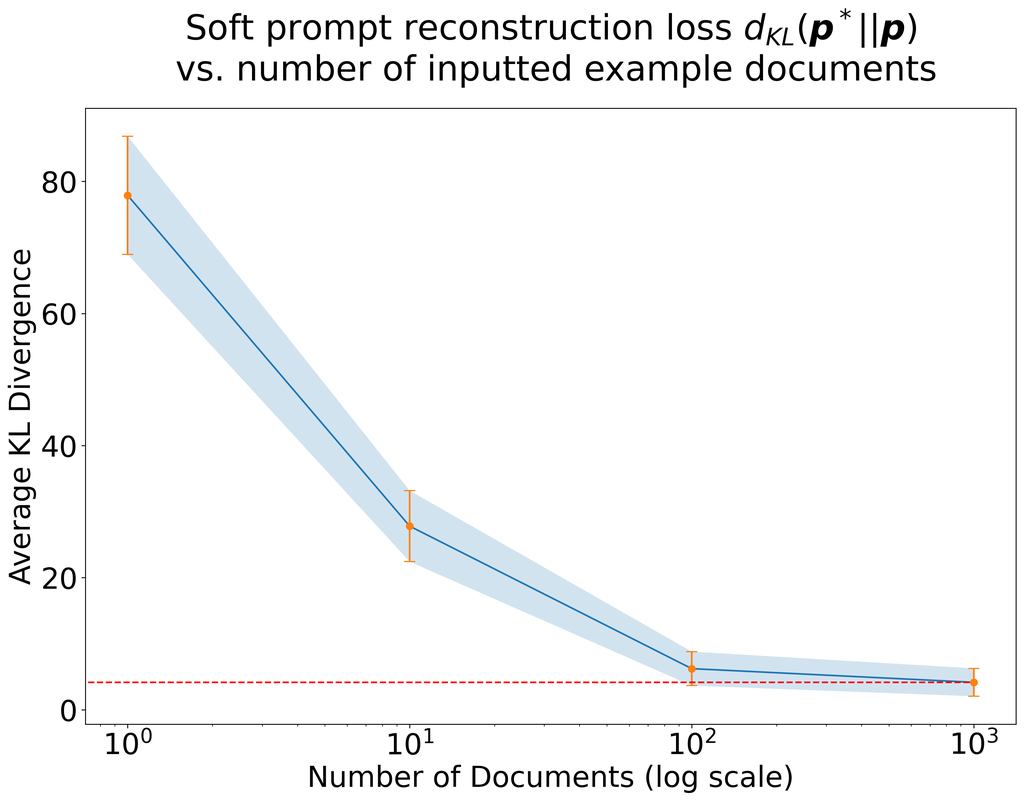
附录 D 软提示结果
词汇表 中的每个标记都映射到 维度嵌入。 我们用 表示嵌入层,这意味着模型的形式为 ,其中 是除嵌入层之外的 Transformer 模型的其余部分。
回想一下,软提示 是位于 中的向量序列,其中 是嵌入空间的维数,而不是词元序列。 具体来说,我们可以将软提示表示为一个矩阵 ,它被馈送到 LLM 中,而不是提示的嵌入,并且类似于 (3) 诱导了文档 上的分布。 在略微滥用符号的情况下:
因此,我们可以使用在 (5) 中定义的 MLE 公式,其中损失函数为
软提示中的向量不必对应于符元的嵌入,这使得优化问题 (5) 成为连续的。 这意味着我们可以通过运行梯度下降 (GD) 来优化提示 ,其中我们将 初始化为每一行上的随机嵌入向量, 是步长
| (GD on prompt embeddings) |
在图 8 中,我们绘制了使用不同数量的文档进行软提示重建的结果。 随着文档数量的增加,恢复的软提示在 KL 散度上收敛到地面真实值。
 |
与我们的硬提示结果类似,Bailey et al., 2023 研究了软提示的行为,发现它们与词汇符元嵌入相比是分布外的。
附录 E 完整提示优化结果
我们现在报告了使用 Vicuna-7b-v1.5 作为 LLM (Zheng et al., 2023),从 Alpaca 指令调优数据集 (Taori et al., 2023) 中优化 100 个随机采样的提示的完整实验结果。
在图 10 中,我们报告了一个完整的表格,其中包含 100 个地面真实提示中的每一个,由不同方法找到的每个优化提示,以及每个优化提示的近似 KL 散度(越低越好)。 这些方法是:
-
•
优化的冷启动 是从随机初始化开始优化的结果。
-
•
优化后的热启动 是基于 GPT-4 的热初始化优化结果。 我们从 GPT-4 提供的 5 个建议提示中均匀地采样一个热启动。
-
•
GPT-4 热启动 是用于初始化优化后的热启动的 GPT-4 建议提示。
-
•
优化后的热启动 + 流畅度 是使用热启动和流畅度惩罚进行优化后的结果。 请注意,它通常包含较少的特殊字符,并且比没有这种惩罚的方法略微更流畅。
-
•
GPT-4 热启动 + 流畅度 是用于初始化优化后的热启动 + 流畅度的 GPT-4 建议提示。
-
•
优化后的热启动 + 剪枝 是使用热启动和词汇剪枝(仅限于英语文本中最常见的符元)进行优化后的结果。 请注意,这些优化的提示不包含特殊 unicode 字符。
-
•
GPT-4 热启动 + 剪枝 是用于初始化优化后的热启动 + 剪枝的 GPT-4 建议提示。
注意:在我们的示例中,我们省略了指令模型的提示模板,但实际上在优化时它存在(尽管没有被优化)。
我们用于提示 GPT-4 的模板是: 请生成 5 个不同的提示,这些提示可以创建以下文档,并确保仅以 JSON 格式生成响应,并使提示简短:
{文档在此处}
以下是一个关于牛排烹饪的文档集示例:
{
"提示":
[
"牛排的最佳烹饪方法是什么?",
"给我一份牛排晚餐食谱。",
"告诉我如何烹饪牛排",
"制作牛排的好方法是什么?",
"制作快手牛排的最佳食谱是什么?",
]
}
只需以以下格式提供 JSON。 不要提供任何偏离示例中指定格式的额外文本。
| Average KL | |||||||
| Size | 70M | 160M | 410M | 1B | 1.4B | 2.8B | 6.9B |
| 70M | |||||||
| 160M | |||||||
| 410M | |||||||
| 1B | |||||||
| 1.4B | |||||||
| 2.8B | |||||||
| 6.9B | |||||||
见 img/table.pdf 的第 1-13 页
