解开混乱背景的思路
摘要
大型语言模型(大语言模型)开创了自然语言处理领域的变革时代,在文本理解和生成相关的任务中表现出色。 然而,当面对混乱的环境(例如,干扰因素而不是长期不相关的环境)时,他们会遇到困难,导致在混乱的环境中无意中遗漏了某些细节。 为了应对这些挑战,我们引入了“思维线索”(ThoT)策略,该策略从人类认知过程中汲取灵感。 ThoT 系统地分割和分析扩展的上下文,同时熟练地选择相关信息。 该策略作为一个多功能的“即插即用”模块,与各种大语言模型和提示技术无缝集成。 在实验中,我们利用 PopQA 和 EntityQ 数据集以及我们收集的多轮对话响应数据集(MTCR)来说明,与其他提示技术相比,ThoT 显着提高了推理性能。
解开混乱背景的思路
Yucheng Zhou1††thanks: Work is done during internship at Microsoft. , Xiubo Geng2, Tao Shen3, Chongyang Tao2, Guodong Long3, Jian-Guang Lou2†, Jianbing Shen1††thanks: Corresponding author. 1 SKL-IOTSC, CIS, University of Macau, 2Microsoft Corporation, 3AAII, FEIT, University of Technology Sydney yucheng.zhou@connect.um.edu.mo, {xigeng,chongyang.tao,jlou}@microsoft.com {tao.shen, guodong.long}@uts.edu.au, jianbingshen@um.edu.mo
1简介
大型语言模型(大语言模型)代表了人工智能领域的重大进步。 他们在自然语言理解和生成方面取得了显着的成就 Brown 等人 (2020);魏等人(2022)。 大语言模型的发展产生了深远的影响,引起了学术界的高度重视。 这些模型展示了对各种自然语言处理任务的熟练程度,包括情感分析 Zhang 等人 (2023)、机器翻译 Moslem 等人 (2023) 和摘要 Tam 等人 (2023). 此外,他们在各行业产生了深远的影响,为复杂的问题提供了有前途的解决方案,例如协助法律咨询岳等人(2023)和协助医疗诊断王等人(2023a) )。
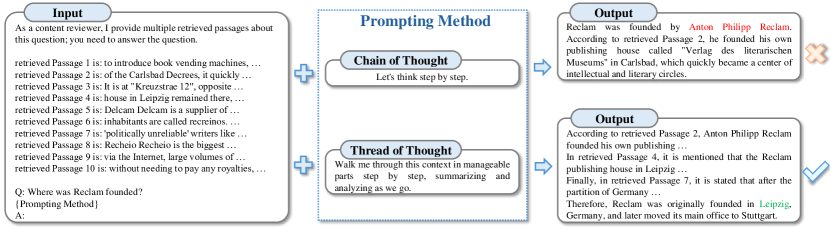
随着任务的复杂性和多样性日益增加,需要广泛的信息处理和推理,特别是在检索增强一代(RAG)Lewis 等人(2020)和会话Xu 等人(2022)的背景下) 场景中,输入文本通常包含来自各种来源的大量信息,包括用户查询、对话历史记录、外部知识库等。 这些信息可能是相互关联的,也可能是完全不相关的。 此外,这些信息的重要性可能会根据上下文而变化,某些部分对于解决特定问题至关重要,而其他部分则无关紧要。 这种情况可以恰当地描述为“混乱的环境”。 与“长语境”类似但又不同,“混乱语境”强调信息的复杂性和数量,而不仅仅是语境的长度。 此外,Liu等人(2023)发现,现有的大语言模型在从通过检索增强的上下文中有效识别相关信息时常常遇到困难,特别是当它位于中间位置时。
近期研究Xu 等人 (2023); Jiang等人(2023)根据输入容量优化的直觉,提出了各种解决方案来增强大语言模型在长上下文场景中的性能。 Xu 等人 (2023) 提出了一种在各种长文本任务上比较和组合大型语言模型(大语言模型)的检索增强和长上下文扩展的方法。 然而,这种方法需要使用位置插值重新训练大语言模型。 此外,Jiang 等人(2023)引入了LongLLMLingua,一种通过剔除不相关或冗余信息来简化输入提示的方法。 尽管如此,该方法要求对辅助模型(例如 LLaMA-7B Touvron 等人 (2023a))进行微调以实现快速压缩。 这些辅助模型的效用可能不足以解决未知或复杂的内容,并且它对可以有效处理的文本长度施加了限制。 此外,其非端到端框架可能会导致错误传播。 相比之下,思想链(CoT)提示Wei等人(2022)可以增强模型的推理能力,而不需要对大语言模型进行任何重新训练或微调。 然而,由于混沌上下文中包含大量信息,CoT 在推理中仍然会遇到信息缺失的情况,如图1所示。
为了应对这些挑战,我们引入了“思路”(ThoT)策略。 ThoT 从人类认知过程中汲取灵感,使大型语言模型(大语言模型)能够系统地分割和分析扩展上下文。 这种分段增强了响应查询的相关内容的提取。 ThoT 代表了个人在筛选大量信息时所保持的思想的不间断连续性,允许有选择地提取相关细节并排除无关细节。 文档各部分之间的注意力平衡对于准确解释和响应所提供的信息至关重要。 此外,对分段信息的逐步分析和总结提高了对多个段落的理解,并保护大语言模型免受误导但看似相关的数据的影响。
与现有的需要复杂多阶段提示 Zhou 等人 (2023) 或多路径采样 Wang 等人 (2023b) 的方法相比,ThoT 是一种更简单、更高效的方法。通用且高效的解决方案。 它作为“即插即用”模块与各种预先训练的语言模型和提示策略无缝集成,避免了复杂的程序。 ThoT不仅提高了大语言模型在混沌环境中的表现,还增强了他们的推理能力。
为了评估 ThoT 在处理混沌上下文信息方面的有效性,我们使用了长尾问答数据集,特别是 PopQA Mallen 等人 (2023) 和 EntityQ Sciavolino 等人 (2021)。 这些数据集包含大型模型通常不熟悉的知识,从而减少了其固有知识保留对我们结果的影响。 此外,我们根据日常对话构建了多轮对话响应(MTCR)数据集,以进一步评估我们的方法。 与其他提示技术的比较分析表明,ThoT 显着提高了推理能力,证明了其有效性。 我们还探索了各种提示以确定最佳提示策略。
2相关工作
2.1 长上下文大语言模型
大型语言模型(大语言模型)的最新进展在管理扩展上下文方面取得了重大进展,超越了传统预定义上下文窗口的限制。 Ratner 等人 (2023) 介绍了并行上下文窗口(PCW)方法,该方法采用独立的注意力机制,将广泛的上下文分割为多个窗口。 在此概念的基础上,Chen 等人 (2023) 通过将位置索引与预训练阶段的最大位置索引对齐,以最小的微调来实现更长的上下文窗口。 此外,另一种方法 LongNet 利用扩张注意力,使注意力领域随着距离 Ding 等人 (2023) 呈指数级扩展。 此外,Xiao等人(2023)强调了注意力收敛现象,即维持初始标记的键值(KV)状态可以显着增强窗口注意力性能。 最后,Press 等人 (2022) 引入了线性偏差注意力(ALiBi),这是一种根据距离对查询关键注意力分数进行偏差的方法,实现了与在较长序列上训练的模型相当的困惑度。 然而,这些方法主要集中在长上下文上。 相比之下,混乱的上下文的特点是信息超载,通常混杂着许多相似和不相关的元素。
2.2 大型语言模型推理
大语言模型(大语言模型)的进步对人工智能产生了重大影响,特别是在复杂的推理任务中。 大语言模型推理能力的增强以Wei等人(2022)为例,其中引入了思想链(CoT)提示。 该方法通过生成中间步骤来提高算术、常识和符号推理。 在此基础上,思想图(GoT)框架将大语言模型输出概念化为图,从而显着提高任务性能和效率Besta等人(2023)。 姚等人(2023a)扩展了CoT概念,提出了思想树(ToT)框架,该框架在24点游戏等复杂问题解决任务中取得了显着的成功。 此外,周等人(2023)引入了从最少到最多的提示策略,将复杂的问题分解为更简单的子问题,并在需要高级符号操作的任务中显示出有效性。 最后,Yao 等人 (2023b) 通过 GoT 推理探索非线性思维过程,在数学和金融问题数据集中优于线性 CoT 方法。 然而,这些方法虽然有效,但却忽略了混乱的上下文场景。
2.3 长上下文中的知识追踪
大语言模型可以处理大量的输入上下文,但在提取隐藏在这些上下文中的相关信息时,其性能显着下降,这对它们管理长上下文的效率提出了挑战Liu等人(2023)。 为了解决在流应用中部署大语言模型的问题,Xiao 等人 (2023) 引入了 StreamingLLM 框架,使具有有限注意力窗口的大语言模型能够处理无限长的序列,而无需额外的微调。 一些研究发现,检索增强使 4K 上下文窗口大语言模型的性能与在长上下文任务中通过位置插值进行微调的 16K 上下文窗口大语言模型的性能相当,强调了检索方法在增强大语言模型能力方面的潜力徐等人 (2023)。 此外,LongLLMLingua引入即时压缩来改善大语言模型的关键信息感知,显着提升性能Jiang等人(2023)。
3方法论

我们提出了一种基于模板的提示的创新方法,该方法专门用于增强思路(ThoT)推理。 这种新颖的策略与Wei等人(2022)的传统思维链截然不同,它擅长在信息可能交织或不同的无序环境中导航。 ThoT提示可以与各种现有的语言模型和提示技术无缝集成,提供模块化的“即插即用”改进,无需复杂的提示策略或采样方法。 我们的方法的基本原则既简单又高效,如图2所示:在提示中插入“逐步引导我通过可管理的部分完成此上下文,边走边总结和分析”有助于 ThoT 推理。
如图2所示,与思维链(CoT)提示难以应对复杂而混乱的情境相比,ThoT提示巧妙地保持了推理的逻辑进程,而不会被淹没。 虽然提示压缩器和类似策略试图解决这些复杂性,但它们通常在处理不熟悉或特别复杂的材料时表现不佳,并且通常需要对大型语言模型(大语言模型)进行重大修改,例如使用附加数据集徐等人 (2023);江等人(2023)。 然而,ThoT 不仅可以有效管理混乱的环境,而且还简化了提示过程,与 CoT 相比,只需要两次提示工作。
3.1 第一步:启动推理
最初的提示旨在引导大语言模型对上下文进行分析剖析,使用指令“逐步引导我通过可管理的部分完成此上下文,边走边总结和分析”。 具体来说,我们采用一个模板,将混沌上下文 和查询 合并到提示 中,作为“[] Q: [] [] A:”,其中表示启动推理过程的触发句。 例如,利用“一步一步地在可管理的部分中引导我完成此上下文,边总结边分析”作为触发器,提示符 变为“[] Q: [] 引导我逐步通过可管理的部分完成此上下文,并在进行过程中进行总结和分析。 A:”。 然后将该提示文本输入到大语言模型中,该模型生成后续句子。 这一过程模仿了人类在面对复杂信息时所采用的认知策略,将其分解为可消化的部分,提炼关键点,并持续专注地浏览材料。 这种增量方法促进了更加结构化和连贯的推理,在混乱的环境中证明特别有利。
3.2第二步:完善结论
第二个提示建立在之前建立的结构化推理的基础上,使用另一个提示将分析提炼成明确的答案。 通过利用第一个提示引发的有组织的思维序列,这一步旨在简洁地捕捉结论的本质。 具体来说,我们使用一个简单的模板来组合初始提示文本 、响应 和结论标记 ,如“[] [] ”,其中表示旨在提取答案的触发语句,例如“因此,答案:” 。 这种提取提示延续了思维过程,促使模型筛选分析并分离出主要结论作为最终答案。 提示的设计是一种刻意的策略,旨在突出模型的焦点,促进响应的精确性和明确性。
这种两层提示系统有效地解决了现有方法的局限性,同时消除了对密集模型重新训练或复杂修改的需要。 我们的方法不仅增强了模型在混乱环境中导航的能力,而且还使其推理过程与人类认知模式更加紧密地结合起来。
4实验
4.1实验设置
数据集。

我们在两个混乱的上下文场景中评估了我们的方法:检索增强生成和多轮对话响应。 我们的评估使用了三个数据集:PopQA 数据集 Mallen 等人 (2023)、EntityQ 数据集 Sciavolino 等人 (2021) 以及我们自己的多轮对话响应 (MTCR) )数据集。 具体来说,选择旨在包含长尾知识的 PopQA 和 EntityQ 数据集是为了最大限度地减少大型模型的广泛内部知识的干扰,从而促进不同方法的更有效比较。 与原始 PopQA 和 EntityQ 数据集不同,我们随机选择了 1,000 个样本的测试集进行分析。 为了评估 PopQA 和 EntityQ 数据集,我们遵循原始数据集的指标,即精确匹配 (EM)。 此外,用于评估多轮对话响应的MTCR数据集是基于多会话聊天(MSC)数据集Xu等人(2022)开发的。 数据集构建涉及顺序使用两个提示,如图3所示。 提示的输入是MSC数据集的对话和Speaker2的角色,以生成Speaker1的响应。 在推理阶段,模型需要考虑前面提到的多轮对话上下文细节,以生成发言者 2 的响应,以应对为发言者 1 创建的响应。 此后,进行了手动筛选过程,以消除不符合某些标准的样本,例如角色内容泄漏以及与上下文或角色无关的内容,最终精炼出 304 个样本。 对于 MTCR 数据集的评估,我们将角色作为已知条件与提示中的扬声器 2 的模型生成响应合并,如图 4 所示,然后将它们传递到 GPT-4 OpenAI (2023),获得评分。

迅速的。
在实验比较中,我们考虑了检索增强生成的四种不同提示。 (1) “Vanilla”需要使用指令和问题作为提示,而不提供任何检索结果,即“{指令} {问题}”。 (2)“检索”在提示中包含检索结果,格式为“{指令}{检索结果}{问题}”。 (3)“CoT”(思想链)合并检索结果,并在指令和问题后面附加短语“Let's think step by step”,从而得到“{指令} {检索结果} {问题}让我们一步一步思考” .”。 (4)“ThoT”(Thought-by-Thought)也整合了检索结果,并遵循更详细的提示结构:“{指令} {检索结果} {问题}逐步引导我在可管理的部分中浏览此上下文,总结和我们边走边分析”。 对于 MTCR 数据集,我们仅使用“Vanilla”、“CoT”和“ThoT”提示。 它们的格式分别是:“{指令} {对话}”,“{指令}让我们一步一步思考。 {对话}”和“{说明} 逐步引导我通过可管理的部分完成此上下文,并在进行过程中进行总结和分析。 {对话}”。
语言模型。
我们评估了四种大规模语言模型:GPT-3.5-turbo Schulman 等人 (2022)、GPT-4 OpenAI (2023)、LLaMA 2 Chat Touvron等人 (2023b) 和 Vicuna Chiang 等人 (2023)。 由于GPT-3.5-turbo和GPT-4未开源,其模型参数的详细信息尚未公开。 对于 LLaMA 2 Chat 模型,我们在实验中使用了具有 7B、13B 和 70B 参数的变体。 类似地,采用了 Vicuna 模型的 7B、13B 和 33B 参数版本。 使用贪婪解码策略对这些模型进行采样。
| Method | GPT-3.5-turbo | LLaMA 2 Chat (70B) |
|---|---|---|
| Vanilla | 0.398 | 0.330 |
| Retrieval | 0.475 | 0.510 |
| CoT | 0.482 | 0.525 |
| ThoT | 0.574 | 0.561 |
| Method | GPT-3.5-turbo | LLaMA 2 Chat (70B) |
|---|---|---|
| Vanilla | 0.497 | 0.430 |
| Retrieval | 0.512 | 0.522 |
| CoT | 0.517 | 0.547 |
| ThoT | 0.565 | 0.559 |
| Method | GPT-3.5-turbo | LLaMA 2 Chat (70B) | ||||||
|---|---|---|---|---|---|---|---|---|
| Relevance | Accuracy | Persona | Average | Relevance | Accuracy | Persona | Average | |
| Vanilla | 3.211 | 3.135 | 3.345 | 3.230 | 2.819 | 2.901 | 2.914 | 2.878 |
| CoT | 3.352 | 3.220 | 3.349 | 3.307 | 2.783 | 2.806 | 2.882 | 2.823 |
| ThoT | 3.849 | 3.921 | 3.645 | 3.805 | 3.158 | 3.295 | 3.268 | 3.240 |
| Method | PopQA | EntityQ | ||||
|---|---|---|---|---|---|---|
| GPT-4 | GPT-3.5-turbo | LLaMA 2 Chat (70B) | GPT-4 | GPT-3.5-turbo | LLaMA 2 Chat (70B) | |
| Vanilla | 0.430 | 0.391 | 0.314 | 0.405 | 0.405 | 0.369 |
| Retrieval | 0.360 | 0.477 | 0.430 | 0.571 | 0.560 | 0.643 |
| CoT | 0.442 | 0.465 | 0.558 | 0.560 | 0.583 | 0.667 |
| ThoT | 0.651 | 0.674 | 0.663 | 0.643 | 0.667 | 0.702 |
4.2结果
表1和表2显示了检索增强生成的性能。 在 PopQA 和 EntityQ 数据集中,我们注意到一个一致的模式,即逐个思考 (ThoT) 提示配置优于其他方法。 CoT 的引入也展示了积极的效果,表明促使模型遵循有条理的问题解决方法可以提高性能指标。 特别值得注意的是,ThoT 在结果上比 CoT 配置有了显着的改进,凸显了逐步上下文处理在提高生成响应的质量方面的功效。 在表3中,出现了类似的趋势。 ThoT 保持领先地位,这表明其详细的提示结构鼓励以结构化方式总结和分析信息,在复杂的对话环境中特别有效。 它强调了有条不紊地分解背景对于生成相关、准确和人物角色一致的响应的重要性。 ThoT 提示的结构化方法通过详细的逐步分析来指导模型,在混乱的环境中始终如一地产生最佳性能。
| No. | Template | EM |
|---|---|---|
| 1 | Let’s read through the document section by section, analyzing each part carefully as we go. | 0.43 |
| 2 | Take me through this long document step-by-step, making sure not to miss any important details. | 0.47 |
| 3 | Divide the document into manageable parts and guide me through each one, providing insights as we move | 0.51 |
| along. | ||
| 4 | Analyze this extensive document in sections, summarizing each one and noting any key points. | 0.47 |
| 5 | Let’s go through this document piece by piece, paying close attention to each section. | 0.50 |
| 6 | Examine the document in chunks, evaluating each part critically before moving to the next. | 0.49 |
| 7 | Walk me through this lengthy document segment by segment, focusing on each part’s significance. | 0.52 |
| 8 | Let’s dissect this document bit by bit, making sure to understand the nuances of each section. | 0.45 |
| 9 | Systematically work through this document, summarizing and analyzing each portion as we go. | 0.45 |
| 10 | Navigate through this long document by breaking it into smaller parts and summarizing each, so we don’t | 0.48 |
| miss anything. | ||
| 11 | Let’s explore the context step-by-step, carefully examining each segment. | 0.44 |
| 12 | Take me through the context bit by bit, making sure we capture all important aspects. | 0.49 |
| 13 | Let’s navigate through the context section by section, identifying key elements in each part. | 0.47 |
| 14 | Systematically go through the context, focusing on each part individually. | 0.46 |
| 15 | Let’s dissect the context into smaller pieces, reviewing each one for its importance and relevance. | 0.47 |
| 16 | Analyze the context by breaking it down into sections, summarizing each as we move forward. | 0.49 |
| 17 | Guide me through the context part by part, providing insights along the way. | 0.52 |
| 18 | Examine each segment of the context meticulously, and let’s discuss the findings. | 0.44 |
| 19 | Approach the context incrementally, taking the time to understand each portion fully. | 0.42 |
| 20 | Carefully analyze the context piece by piece, highlighting relevant points for each question. | 0.47 |
| 21 | In a step-by-step manner, go through the context, surfacing important information that could be useful. | 0.53 |
| 22 | Methodically examine the context, focusing on key segments that may answer the query. | 0.45 |
| 23 | Progressively sift through the context, ensuring we capture all pertinent details. | 0.46 |
| 24 | Navigate through the context incrementally, identifying and summarizing relevant portions. | 0.48 |
| 25 | Let’s scrutinize the context in chunks, keeping an eye out for information that answers our queries. | 0.42 |
| 26 | Take a modular approach to the context, summarizing each part before drawing any conclusions. | 0.47 |
| 27 | Read the context in sections, concentrating on gathering insights that answer the question at hand. | 0.48 |
| 28 | Proceed through the context systematically, zeroing in on areas that could provide the answers we’re | 0.49 |
| seeking. | ||
| 29 | Let’s take a segmented approach to the context, carefully evaluating each part for its relevance to the | 0.39 |
| questions posed. | ||
| 30 | Walk me through this context in manageable parts step by step, summarizing and analyzing as we go. | 0.55 |
4.3迷失在中间
如表4所示,我们深入研究了“迷失在中间”的现象Liu等人(2023),重点是检查各种模型在两个不同的问答数据集,PopQA 和 EntityQ。 所呈现的结果对四种方法进行了比较:普通方法、检索方法、思维链 (CoT) 和思维理论 (ThoT),并应用于三种高级语言模型:GPT-4、GPT-3.5-turbo 和 LLaMA 2聊天(70B)。
PopQA 上的表现
:结果表明 ThoT 在所有三个模型中均显着优于其他方法。 GPT-4 以 0.651 的分数领先,紧随其后的是 GPT-3.5-turbo 和 LLaMA 2 Chat (70B),分别为 0.674 和 0.663。 这表明 ThoT 的先进技术可能包含对上下文和推理的更细致的理解,在处理 PopQA 的复杂性方面具有明确的优势。 Vanilla 方法在 GPT-4 上产生了中等的性能,超过了其他两个模型的分数,暗示了最新模型迭代的卓越推理能力。
EntityQ 上的性能
:与 PopQA 类似,ThoT 方法再次名列前茅,表明其在不同数据集上的稳健性。 GPT-4 的性能虽然仍然是 Vanilla 方法中最高的,但在应用 ThoT 时显着跃升至 0.643,这表明 GPT-4 的功能和 ThoT 的高级推理框架之间具有更好的协同作用。 值得注意的是,对于所有模型,检索方法都比 Vanilla 有了明显的改进,其中 LLaMA 2 Chat (70B) 获得了 0.643 的最高分。
4.4模型规模的影响
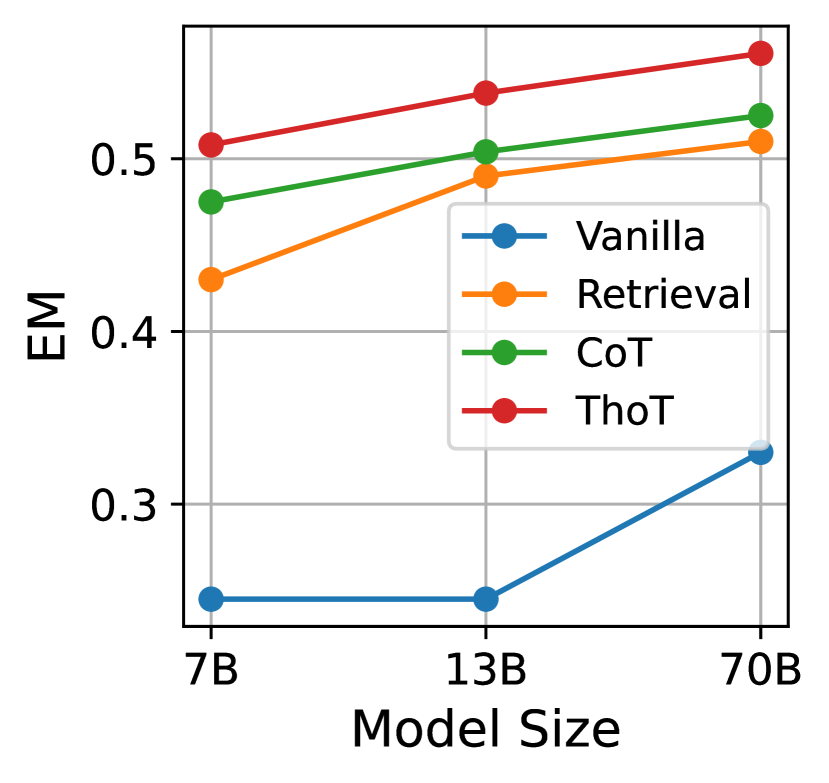
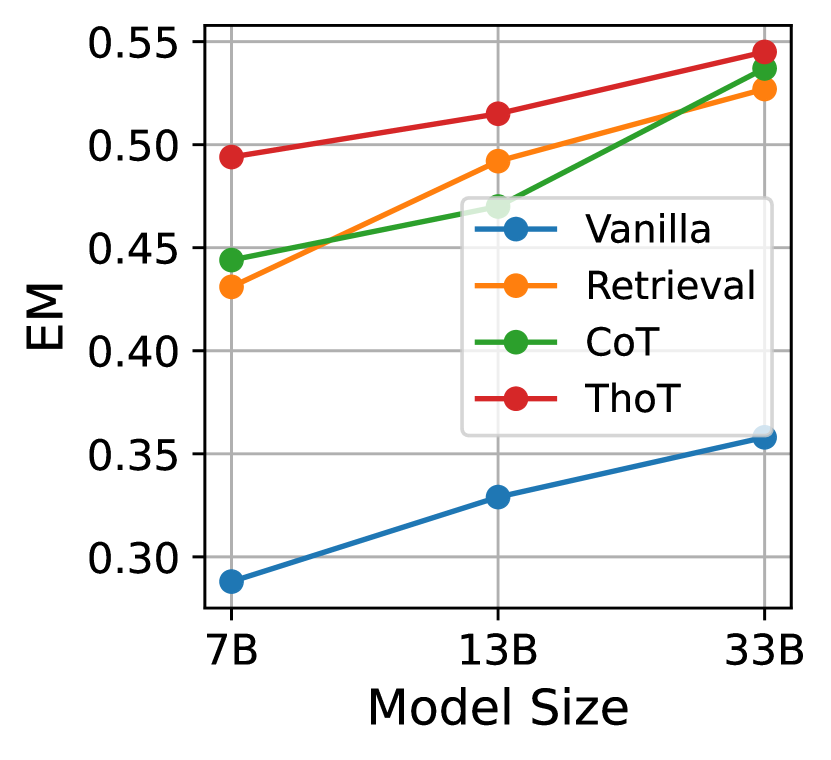
如图5所示,结果表明模型的规模与其在不同提示策略下的性能之间存在明显的相关性。 当我们在 LLama2 中从 70 亿个参数扩展到 700 亿个参数时,所有提示配置的 EM 分数都有显着增加。 Vicuna 模型也观察到相同的趋势。 这种增加证实了这样的假设:较大的模型具有更大的理解和生成准确响应的能力。 逐个思考 (ThoT) 配置在所有模型大小上都保持性能领先,这表明无论模型大小如何,ThoT 提示似乎都能更有效地利用模型的功能。 此外,实验数据表明,模型规模对检索增强生成方法的性能有积极影响,其中 CoT 和 ThoT 等提示显示出最显着的好处。 这一趋势强调了即时设计在充分发挥大型语言模型潜力方面的重要性。
4.5提示选择


如表 5 所示,提示分析揭示了对语言模型性能有直接影响的措辞策略变化,如精确匹配 (EM) 分数所示。 提示旨在引导模型逐步系统地分析文档或上下文。 较成功的提示(尤其是 EM 分数高于 0.50 的提示)的一个共同主题是,明确指示模型不仅要分析文档的每个部分,还要在进展过程中总结和记录关键见解。 例如,指示模型总结每个部分并且不错过重要细节的提示(例如提示 2 和提示 4)会导致更高的 EM 分数。 鼓励采用更精细的方法、指导模型关注各个部分及其重要性或相关性的提示也表现良好。 提示 14 就证明了这一点,它获得了相对较高的 EM 分数。 模型剖析和分析上下文的指令越详细,模型的性能就越好。 相反,指导性较差或结构性较差的提示(例如提示 29)往往会导致 EM 分数较低。 这表明模型受益于清晰、具体和以行动为导向的指令,这些指令在分析过程中几乎没有模糊的空间。 得分最高的提示,数字 30,结合了成功提示的几个要素。 它要求模型通过将其分解为多个部分来管理复杂性,这意味着进行彻底的分析,并进行总结和分析,表明对材料的积极参与,而不仅仅是阅读或被动理解。 总之,结果表明,旨在执行详细分析过程、鼓励逐步剖析、总结和批判性评估的提示可以带来更好的模型性能。
4.6案例研究
图6中的案例研究显示了PopQA中CoT和ThoT之间的比较分析。 CoT仅表示这些段落包含有关各个乐队的信息,但没有具体说明“The Red Hearts”的流派。 这说明了 CoT 方法的潜在局限性:当答案未明确说明而是需要从给定数据推断时,它可能无法有效地综合来自多个来源的信息。 相反,ThoT 方法成功识别出“红心乐队演奏车库朋克音乐”。 这一结果展示了 ThoT 方法的优势。 ThoT 擅长综合和关联多段文本中的信息。 它拼凑了第 6 段和第 8 段的相关细节,并指出“红心乐队”被描述为“车库朋克乐队”。
4.7错误分析
从图7来看,ThoT方法无法得出这种情况的答案。 这段文字指出,“安迪·艾根曼是他与女演员贾克琳·何塞的女儿”,这是正确推断马克·吉尔与贾克琳·何塞结婚的关键。 ThoT 方法未能做出这一推论,这表明虽然该模型擅长提取显式信息,但它难以进行需要理解细微关系的隐式推理。 这种疏忽可能归因于模型的推理能力,特别是关系推理——这是大型模型中的一个已知缺陷,先前的研究 Berglund 等人 (2023) 也发现了这一点。 该案例研究强调模型不仅需要解析和总结信息,还需要进行类似于人类认知的演绎推理。 因此,增强模型对实体关系的推断和推理能力非常重要。
5结论
本文提出了“思想线索”(ThoT)策略,这是一种旨在增强大型语言模型(大语言模型)处理混沌上下文信息的性能的新方法。 ThoT受人类认知过程的启发,显着提高了大语言模型分割和分析扩展上下文的能力。 我们将 ThoT 与现有方法进行了比较,现有方法通常需要复杂的再训练、微调,或者处理大量复杂信息的能力有限。 相比之下,ThoT 提供了一种更直接、更高效的解决方案。 它充当“即插即用”模块,与各种预先训练的语言模型无缝集成并提示策略,而无需复杂的程序。 ThoT 的有效性使用 PopQA 和 EntityQ 等长尾问答数据集以及基于日常对话的多轮对话响应数据集进行了严格测试。 这些评估的结果很明确:ThoT 不仅在处理混沌上下文方面表现出色,而且还增强了大语言模型的推理能力。
参考
- Berglund et al. (2023) Lukas Berglund, Meg Tong, Max Kaufmann, Mikita Balesni, Asa Cooper Stickland, Tomasz Korbak, and Owain Evans. 2023. The reversal curse: Llms trained on "a is b" fail to learn "b is a". CoRR, abs/2309.12288.
- Besta et al. (2023) Maciej Besta, Nils Blach, Ales Kubicek, Robert Gerstenberger, Lukas Gianinazzi, Joanna Gajda, Tomasz Lehmann, Michal Podstawski, Hubert Niewiadomski, Piotr Nyczyk, and Torsten Hoefler. 2023. Graph of thoughts: Solving elaborate problems with large language models. CoRR, abs/2308.09687.
- Brown et al. (2020) Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language models are few-shot learners. In Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual.
- Chen et al. (2023) Shouyuan Chen, Sherman Wong, Liangjian Chen, and Yuandong Tian. 2023. Extending context window of large language models via positional interpolation. CoRR, abs/2306.15595.
- Chiang et al. (2023) Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E. Gonzalez, Ion Stoica, and Eric P. Xing. 2023. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality.
- Ding et al. (2023) Jiayu Ding, Shuming Ma, Li Dong, Xingxing Zhang, Shaohan Huang, Wenhui Wang, Nanning Zheng, and Furu Wei. 2023. Longnet: Scaling transformers to 1, 000, 000, 000 tokens. CoRR, abs/2307.02486.
- Jiang et al. (2023) Huiqiang Jiang, Qianhui Wu, , Xufang Luo, Dongsheng Li, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. 2023. Longllmlingua: Accelerating and enhancing llms in long context scenarios via prompt compression. ArXiv preprint, abs/2310.06839.
- Lewis et al. (2020) Patrick S. H. Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-augmented generation for knowledge-intensive NLP tasks. In Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual.
- Liu et al. (2023) Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2023. Lost in the middle: How language models use long contexts. CoRR, abs/2307.03172.
- Mallen et al. (2023) Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, and Hannaneh Hajishirzi. 2023. When not to trust language models: Investigating effectiveness of parametric and non-parametric memories. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, Canada, July 9-14, 2023, pages 9802–9822. Association for Computational Linguistics.
- Moslem et al. (2023) Yasmin Moslem, Rejwanul Haque, John D. Kelleher, and Andy Way. 2023. Adaptive machine translation with large language models. In Proceedings of the 24th Annual Conference of the European Association for Machine Translation, EAMT 2023, Tampere, Finland, 12-15 June 2023, pages 227–237. European Association for Machine Translation.
- OpenAI (2023) OpenAI. 2023. GPT-4 technical report. CoRR, abs/2303.08774.
- Press et al. (2022) Ofir Press, Noah A. Smith, and Mike Lewis. 2022. Train short, test long: Attention with linear biases enables input length extrapolation. In The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net.
- Ratner et al. (2023) Nir Ratner, Yoav Levine, Yonatan Belinkov, Ori Ram, Inbal Magar, Omri Abend, Ehud Karpas, Amnon Shashua, Kevin Leyton-Brown, and Yoav Shoham. 2023. Parallel context windows for large language models. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, Canada, July 9-14, 2023, pages 6383–6402. Association for Computational Linguistics.
- Schulman et al. (2022) John Schulman, Barret Zoph, Christina Kim, Jacob Hilton, Jacob Menick, Jiayi Weng, Juan Felipe Ceron Uribe, Liam Fedus, Luke Metz, Michael Pokorny, et al. 2022. Chatgpt: Optimizing language models for dialogue. OpenAI blog.
- Sciavolino et al. (2021) Christopher Sciavolino, Zexuan Zhong, Jinhyuk Lee, and Danqi Chen. 2021. Simple entity-centric questions challenge dense retrievers. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, EMNLP 2021, Virtual Event / Punta Cana, Dominican Republic, 7-11 November, 2021, pages 6138–6148. Association for Computational Linguistics.
- Tam et al. (2023) Derek Tam, Anisha Mascarenhas, Shiyue Zhang, Sarah Kwan, Mohit Bansal, and Colin Raffel. 2023. Evaluating the factual consistency of large language models through news summarization. In Findings of the Association for Computational Linguistics: ACL 2023, Toronto, Canada, July 9-14, 2023, pages 5220–5255. Association for Computational Linguistics.
- Touvron et al. (2023a) Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurélien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. 2023a. Llama: Open and efficient foundation language models. CoRR, abs/2302.13971.
- Touvron et al. (2023b) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton-Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez, Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushkar Mishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing Ellen Tan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurélien Rodriguez, Robert Stojnic, Sergey Edunov, and Thomas Scialom. 2023b. Llama 2: Open foundation and fine-tuned chat models. CoRR, abs/2307.09288.
- Wang et al. (2023a) Sheng Wang, Zihao Zhao, Xi Ouyang, Qian Wang, and Dinggang Shen. 2023a. Chatcad: Interactive computer-aided diagnosis on medical image using large language models. CoRR, abs/2302.07257.
- Wang et al. (2023b) Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V. Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2023b. Self-consistency improves chain of thought reasoning in language models. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net.
- Wei et al. (2022) Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. 2022. Chain-of-thought prompting elicits reasoning in large language models. In NeurIPS.
- Xiao et al. (2023) Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. 2023. Efficient streaming language models with attention sinks. CoRR, abs/2309.17453.
- Xu et al. (2022) Jing Xu, Arthur Szlam, and Jason Weston. 2022. Beyond goldfish memory: Long-term open-domain conversation. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2022, Dublin, Ireland, May 22-27, 2022, pages 5180–5197. Association for Computational Linguistics.
- Xu et al. (2023) Peng Xu, Wei Ping, Xianchao Wu, Lawrence McAfee, Chen Zhu, Zihan Liu, Sandeep Subramanian, Evelina Bakhturina, Mohammad Shoeybi, and Bryan Catanzaro. 2023. Retrieval meets long context large language models. CoRR, abs/2310.03025.
- Yao et al. (2023a) Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. 2023a. Tree of thoughts: Deliberate problem solving with large language models. CoRR, abs/2305.10601.
- Yao et al. (2023b) Yao Yao, Zuchao Li, and Hai Zhao. 2023b. Beyond chain-of-thought, effective graph-of-thought reasoning in large language models. CoRR, abs/2305.16582.
- Yue et al. (2023) Shengbin Yue, Wei Chen, Siyuan Wang, Bingxuan Li, Chenchen Shen, Shujun Liu, Yuxuan Zhou, Yao Xiao, Song Yun, Xuanjing Huang, and Zhongyu Wei. 2023. Disc-lawllm: Fine-tuning large language models for intelligent legal services. CoRR, abs/2309.11325.
- Zhang et al. (2023) Wenxuan Zhang, Yue Deng, Bing Liu, Sinno Jialin Pan, and Lidong Bing. 2023. Sentiment analysis in the era of large language models: A reality check. CoRR, abs/2305.15005.
- Zhou et al. (2023) Denny Zhou, Nathanael Schärli, Le Hou, Jason Wei, Nathan Scales, Xuezhi Wang, Dale Schuurmans, Claire Cui, Olivier Bousquet, Quoc V. Le, and Ed H. Chi. 2023. Least-to-most prompting enables complex reasoning in large language models. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net.