TableLlama:迈向表的通用大型语言模型
摘要
半结构化表无处不在。 有多种旨在自动解释、扩充和查询表的任务。 当前的方法通常需要对表进行预训练或特殊的模型架构设计,仅限于特定的表类型,或者对表和任务进行简化的假设。 本文朝着开发开源大型语言模型(大语言模型)作为各种基于表格的任务的通才迈出了第一步。 为此,我们构建了TableInstruct,一个包含各种现实表格和任务的新数据集,用于指令调优和评估大语言模型。 我们通过使用 LongLoRA 微调 Llama 2 (7B) 来进一步开发第一个开源通用表模型 TableLlama,以解决长上下文挑战。 我们在域内设置和域外设置下进行实验。 在 8 个域内任务中的 7 个中,TableLlama 在每个任务中都实现了与 SOTA 相当或更好的性能,尽管后者通常具有特定于任务的[Huan:我们可以说“任务-具体'因为它会更好]设计。 在 6 个域外数据集上,与基础模型相比,它获得了 5-44 的绝对分数增益,表明 TableInstruct 上的训练增强了模型的泛化性。 我们开源我们的数据集和训练模型,以促进未来开发开放通用表模型的工作。111代码、模型和数据可在以下位置获取:https://osu-nlp-group.github.io/TableLlama/。
1简介
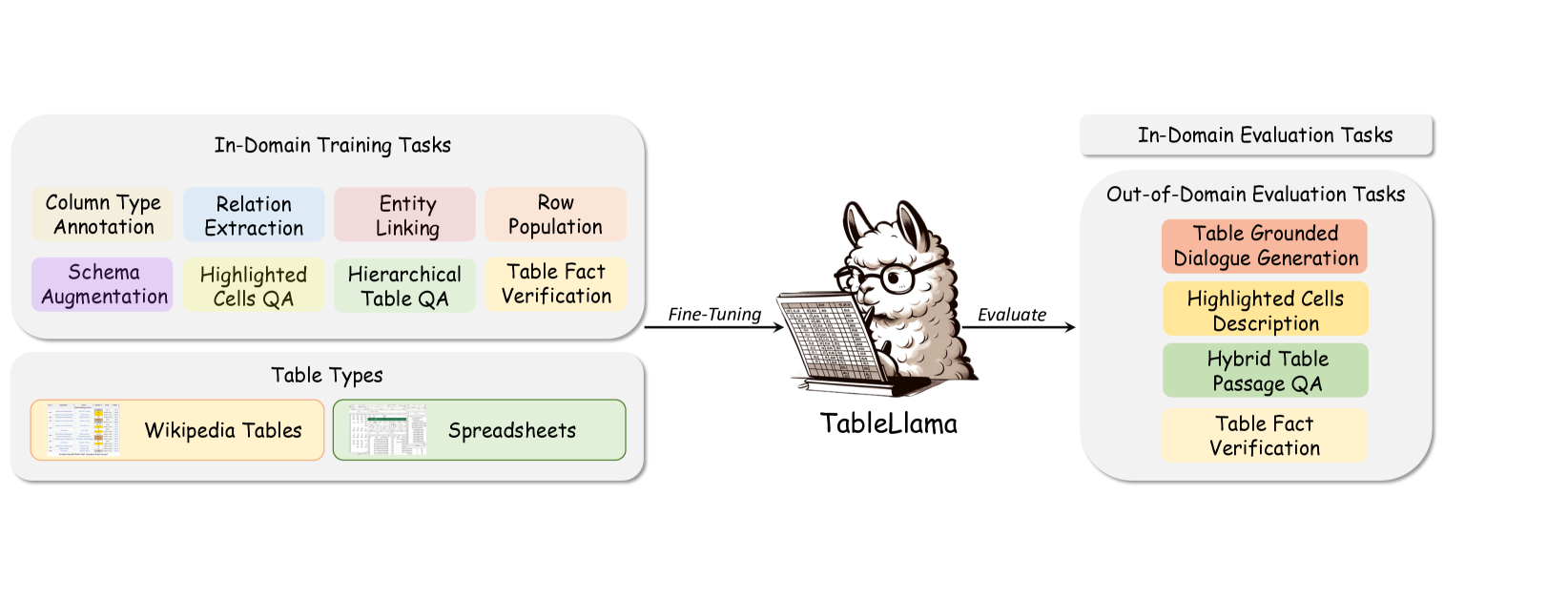
半结构化表是流行的数据结构,用于存储和呈现几乎每个领域的信息,从科学研究、业务报告、医疗记录到财务报表。[欢:虽然提到这些领域很好,但有一个问题:这些领域中的表通常有很多数字,但在我们的数据集中,我们并没有专门处理数字,对吧? 或者有些任务实际上有很多数字?]我觉得还可以。我们有一个包含大量数字的分层质量保证任务。 人们提出了各种基于表的任务,例如实体链接(ritze2015matching),列类型标注(hulsebos2019sherlock),模式增强(zhang2017entables) t2> 和基于表格的问答(heng-etal-2022-hitab; Nan2021FeTaQAFT; chen2020hybridqa),这激发了人们极大的研究兴趣(deng2020turl; yin-etal-2020-tabert; wang2021tuta;iida-etal-2021-tabbie) 近年来。
构建表格模型并不是什么新鲜事。 然而,它们都不满足上面列出的通才模型的所有要求。 大多数基于表格的任务的现有方法至少具有以下限制之一:(1)需要表格预训练(liu2022tapex; yin-etal-2020-tabert; deng2020turl; iida-etal-2021-tabbie)和/或表的特殊模型架构设计(deng2020turl; wang2021tuta; iida-etal-2021-tabbie),(2)仅支持有限的、特定类型的表和任务(Chen2020TabFact :; Nan2021FeTaQAFT), (3) 关于表和任务(li2023tablegpt)做出强有力的简化假设(参见第2.1节的“域内”部分) 。
另一方面,像 T5 (raffel2020exploring) 这样的语言模型已被证明在将语言打造成结构化知识 (xie2022unifiedskg) 方面表现出色。 此外,指令调优(chung2022scaling; wang-etal-2022-super; mishra-etal-2022-cross)作为一项重要技术出现,可以引导大语言模型遵循指令完成各种任务任务。
[欢:现在直接抛出这个问题还为时过早。除了上述评论之外,您还应该提到最近的趋势,表明通过指令调优使用大语言模型来执行多个任务的前景。 因此,您探索以下问题。 目前你的第一句话和这一句之间差距太大了。] 在此背景下,我们试图回答以下问题: 我们能否使用大语言模型和指令调优建立一个通用模型来处理各种基于表格的任务? 一些示例任务如图1所示。表的通用模型可以吗? 使表格更容易操作和注释,因此可以作为用户友好的工具,大大减少体力劳动()。[Huan:您是否试图用最后一句话来激励为什么要构建通用模型而不是为每个任务微调特定模型? 如果是这样,那就根本没有说服力了。 为什么它在“……更容易操作和注释”和“作为一种用户友好的工具,大大减少体力劳动”方面比后者更好?] 这种通才模型应满足以下要求:首先, 它不仅应该在各种基于表格的任务上表现良好,而且还应该推广到看不见的任务。 由于新的表数据和任务可以随着新信息的到来而动态构建,因此很难收集涵盖所有任务和所有表的训练数据,这需要模型本质上可推广到任务【欢:在我们的OOD设置中,它有两个子设置,对吧? 一种是测试新任务,另一种是测试旧任务但新数据集] 以及以前从未见过的数据集。 第二, 它应该适用于现实世界的表格和实际任务,这些任务可能很大、复杂且不完整。 该模型不应做出强有力的假设来仅处理简化的合成表和任务,而必须接受实际挑战,例如处理大型分层电子表格上的复杂数字推理以及大量候选分类和排名任务。
在追求这一目标的过程中,我们意识到缺乏可以支持通才模型的开发和评估的全面的现实表格和任务集合。 因此,我们通过从广泛使用的数据集中精心选择代表性的基于表格的任务,统一所有任务的格式并手动注释指令来构建TableInstruct。 表1中所示的TableInstruct提供了以下独特功能:(1)表和任务的多样化覆盖。 TableInstruct 拥有 14 个数据集,总共 11 个任务,具有域内和域外评估设置。 我们的训练数据包括 8 个任务,这些任务是从包含 260 万个实例的 124 万个表中挑选出来的,这些实例涵盖表解释、表扩充【欢:你能在表1中标记出表解释和表扩充的任务是什么吗? 我认为人们对这两个不是很熟悉。]、基于表格的 QA 和基于表格的事实验证。 我们为这 8 个任务选择 8 个数据集进行域内评估,并将其他 6 个数据集留给 4 个任务进行域外评估。 域内训练任务可以使模型学习更基础的表格理解能力,例如表格解释和表格增强,而我们选择需要更高层次推理能力的任务,例如表格QA和单元格描述来测试模型的泛化能力。 广泛的表格和多样化的任务不仅为表格建模提供了宝贵的资源,而且还促进了对通才模型的更全面的评估。 【欢:我们应该多谈谈 InD 和 OOD 的设定吗? InD 和 OOD 有多少/什么? 选择一些作为 InD 而另一些作为 OOD 是否有任何理由?] (2) 使用真实世界的表格和现实任务。 与现有工作(li2023tablegpt)相比,TableInstruct使用真实的真实世界数据,而不是过度简化的合成任务数据。 我们整合了大量来自统计科学报告的维基百科表格和电子表格,并收集【欢:我还有之前的问题:我们“收集”了吗? 如果不是,则将其重新表述为“以及不同长度的表格......”] 内容长度各异的表格,来自 Freebase (freebase) 的真实且复杂的语义类型,用于列类型标注和关系提取,以及来自 Wikidata (vrandevcic2014wikidata)< 的具有丰富元数据的大型指称实体语料库 用于实体链接。 此外,我们还包括具有层次表结构的复杂数字推理任务和现有的手动注释[Huan:你的意思是他们“手动注释”还是你这样做?]表QA和事实验证任务。 通过这样做,我们的目标是使模型具备处理现实和复杂的基于表格的任务的能力。
TableInstruct要求模型能够容纳长输入[Huan:你能在表1中显示上下文长度的最小/最大/中位数吗?] (表1)。 我们采用基于 Llama 2 (7B) (touvron2023llama) 的 LongLoRA (longlora) 作为我们的骨干模型,该模型已被证明可以高效且有效地处理长上下文。 我们在 TableInstruct 上调用它,并将我们的模型命名为 TableLlama。 我们进行了大量的实验和分析[欢:没有分析吧?] 在域内和域外设置下。 我们的实验表明,TableLlama 在各种域内表理解和增强任务方面具有强大的能力,并且在泛化到未见过的任务和数据集方面也取得了良好的性能。

总之,我们的主要贡献是:
-
我们构建了TableInstruct,这是一个大规模指令调优数据集,具有基于真实世界表格的多样化、现实任务。 我们统一其格式并手动注释说明以保证质量。
-
我们开发了TableLlama,这是一个基于开源LLM的通才模型,在TableInstruct上进行了微调。 实验表明,与每个任务上通常对表进行特殊预训练或模型架构设计的 SOTA 相比,TableLlama 可以在几乎所有域内任务上获得类似甚至更好的性能[欢:这里很混乱。 你这是什么意思:当对表使用相同的训练数据时]. 对于域外任务,与基础模型相比,TableLlama可以在6个数据集上实现5-44个绝对点增益,与GPT-4相比,TableLlama有在 6 个数据集中的 4 个上,差距更小,甚至更好的零样本性能,这表明 TableInstruct 可以显着增强模型的通用性。 【欢:我觉得后半部分不太有说服力,为什么要与预训练模型进行比较? 我想你可以承认OOD与SoTA还有一些差距,这是可以理解的,然后强调相对于预训练/未微调模型的改进]
[Huan:在这一段中,你应该谈谈你在统一任务格式和准备指令方面所做的努力(简要),然后是你训练了什么模型来进行指令调优,以及你是如何解决长上下文问题的。 ] [Huan:总结一下本段的结果,或许也谈谈对未来工作的见解。]
2 TableInstruct 基准
| Task Category | Task Name | Dataset | In- domain | #Train | #Test | Input Token Length | ||||||
| (Table/Sample) | (Table/Sample) | min | max | median | ||||||||
| Table Interpretation | Col Type Annot. | TURL (deng2020turl) | Yes | 397K/628K | 1K/2K | 106 | 8192 | 2613 | ||||
| Relation Extract. | Yes | 53K/63K | 1K/2K | 2602 | 8192 | 3219 | ||||||
| Entity Linking | Yes | 193K/1264K | 1K/2K | 299 | 8192 | 4667 | ||||||
| Table Augmentation | Schema Aug. | TURL (deng2020turl) | Yes | 288K/288K | 4K/4K | 160 | 1188 | 215 | ||||
| Row Pop. | Yes | 286K/286K | 0.3K/0.3K | 264 | 8192 | 1508 | ||||||
| Question Answering | Hierarchical Table QA | HiTab (cheng-etal-2022-hitab) | Yes | 3K/7K | 1K/1K | 206 | 5616 | 978 | ||||
| Highlighted Cells QA | FeTaQA (Nan2021FeTaQAFT) | Yes | 7K/7K | 2K/2K | 261 | 5923 | 740 | |||||
| Hybrid Table QA | HybridQA (chen2020hybridqa) | No | – | 3K/3K | 248 | 2497 | 675 | |||||
| Table QA | WikiSQL (wikisql) | No | – | 5K/16K | 198 | 2091 | 575 | |||||
| Table QA | WikiTQ (wikitq) | No | – | 0.4K/4K | 263 | 2688 | 709 | |||||
| Fact Verification | Fact Verification | TabFact (Chen2020TabFact:) | Yes | 16K/92K | 2K/12K | 253 | 4975 | 630 | ||||
| FEVEROUS (feverous) | No | – | 4K/7K | 247 | 8192 | 648 | ||||||
|
|
KVRET (kvret) | No | – | 0.3K/0.8K | 187 | 1103 | 527 | ||||
| Data-to-Text |
|
ToTTo (parikh-etal-2020-totto) | No | – | 7K/8K | 152 | 8192 | 246 | ||||
与主要为特定于训练任务的表模型设计的现有数据集不同,我们的目标是弥合多个复杂的特定于任务的模型和一个简单的通用模型之间的差距,该模型可以处理所有基于表的任务,而无需额外的模型设计工作。 为了实现这一目标,我们构造 TableInstruct 的方法遵循以下原则。 首先,我们尝试使任务和表类型多样化,而不是从高度同质的任务中收集多个数据集。 我们选择需要不同模型能力的代表性基于表格的任务,例如表格解释、表格扩充、表格 QA 以及来自维基百科表格和统计科学报告中电子表格的表格事实验证。 其次,我们选择现实的任务并以统一的方式构建高质量的指令数据,而无需简化假设(参见2.1的“域内”部分)我认为“简化假设”这个术语出现了很多次,所以远的。 我们应该第一时间明确这个概念。 TableInstruct 将支持强大的建模和现实的评估方法,确保为研究提供有价值且实用的数据集。
2.1数据收集
TableInstruct 包含来自 11 个独特任务的 14 个基于表格的数据集的样本(表 1)。 我们将它们分开并选择 8 个任务的 8 个数据集进行训练和域内评估。 我们将 4 个任务的其他 6 个数据集保留为未见过的数据集,用于域外评估。
任务类别: TableInstruct 中的任务可以分为几组:表格解释、表格扩充、问答、事实验证、对话生成和数据到文本。 表解释的目的是揭示关系表中包含的数据的语义属性,并将这些信息转化为机器可理解的知识。 表扩充是用额外的数据扩展部分表。 问答的目的是通过表格和可选的突出显示单元格或段落作为证据来获得答案。 事实验证是为了区分表格是否可以支持或反驳主张。 对话生成是根据表格和对话历史生成响应。 数据到文本是根据突出显示的单元格生成描述。我们选择表格解释、表格扩充、一些代表性的问答任务和一个事实验证数据集作为训练模型的域内数据集。 我们将其余的数据集(从问答、事实验证、对话生成到数据到文本)作为域外数据集提供。 通过选择需要模型学习更基本的表格理解能力的任务,例如训练中的表格解释和表格增强,我们希望模型能够在域外数据集上展示泛化能力,例如高级表格 QA 和表格单元格描述任务。 [Huan:也许在这里你可以简单介绍一下任务类别,就像一般表解释的作用一样,然后介绍一下你的理由,为什么有些用于域内评估,有些用于ood。]
域内:训练通才表模型的任务包括列类型标注、关系提取、实体链接、行填充、模式扩充、分层表 QA、突出显示单元格 QA 和表事实验证。训练通才表模型的任务包括列类型标注(deng2020turl)、关系提取(deng2020turl)、实体链接(deng2020turl)、行填充(deng2020turl),模式增强 (deng2020turl),分层表 QA ( Cheng-etal-2022-hitab),突出显示单元格 QA (Nan2021FeTaQAFT),以及表事实验证(Chen2020TabFact:)。 这些任务要求模型理解表格列的语义、表格列对之间的关系、表格单元格的语义,并要求模型获得推理能力来回答与表格相关的问题并验证事实。 对于每个任务的数据集,我们有意挑选那些享受现实任务复杂性而不简化假设的数据集。 例如,对于列类型标注和关系抽取,这两个任务本质上是多选分类任务。 我们使用 Freebase (freebase) 中的真实列语义类型和关系类型,其中包含数百个复杂的选择,例如图 LABEL 中所示的“government.politician.partygovernment.political_party_tenure.party”附录LABEL:sec:prompt_format中的:fig:rel_extraction。 对于实体链接,参考实体来自现实世界的维基数据 (vrandevcic2014wikidata),其中包含数百个复杂的元数据,例如“¡2011-12 墨尔本胜利赛季 [DESCRIPTION] Association Football Club 2011/12墨尔本胜利 [TYPE] SoccerClubSeason 赛季”,如附录 LABEL:sec:prompt_format 中的图 LABEL:fig:ent_link 所示。 对于模式增强和行填充,大语言模型需要对大量候选对象进行排序。 对于分层表 QA,所有表都具有复杂的结构,具有多级列名和行名。 此外,它是密集的数值推理,需要大语言模型理解表格结构、识别相关单元格并进行计算。 通过这样做,我们希望使大语言模型成为真正强大的通用模型,可以处理复杂的表格任务,并且与专门设计的表格模型相比,TableInstruct可以成为评估大语言模型能力的现实基准。
域外:强大的通用表模型不仅能够在域内任务上表现出强大的性能,而且能够很好地泛化到未见过的任务或相同任务的未见过的数据集。 模型学习到的底层表理解能力应该能够转移到看不见的任务或数据集。 我们选择诸如表 QA 和单元格描述等需要模型高级表理解和推理能力的任务作为域外数据集。 我们涉及 HybridQA (chen2020hybridqa)、KVRET (kvret)、FEVEROUS (发烧)、ToTTo (parikh-etal-2020-totto )、WikiSQL (wikisql) 和 WikiTQ (wikitq) 作为 6 个域外数据集来测试我们模型的泛化能力。 HybridQA 是一项基于表格和段落的问答任务。 KVRET 是一项基于表格和对话历史的响应生成任务。 ToTTo是根据突出显示的表格单元格生成文本描述。 FEVEROUS 是一项表事实验证任务。 WikiSQL 和 WikiTQ 是两个表 QA 任务[欢:你在上一段中没有对每个任务进行这样的描述。 也许正如表1标题中所说的那样,在附录中留下这样的简短描述。]. 通过在这些数据集上评估我们的模型,我们希望展示我们模型的泛化能力。 [Huan:解释为什么有些是域内的,而另一些是 OOD 的。 润色你在 Teams 中所说的语言]
2.2任务制定和挑战
[欢:我觉得你应该先讲3.2节(这些任务是什么),然后讲3.1节(如何将它们制定成统一的格式)。 请向读者指出一些示例,无论是在主要内容中还是在附录中。 不然读起来很无趣。]
【欢:这一段还可以好好打磨一下。 关于提示格式,可以参考本段开头的图LABEL:fig:examplars b-d。 然后强调我们任务制定中的挑战,例如候选人数量和上下文长度。] TableInstruct 的主要目标是为所有基于表格的任务设计一个通用模型。 如图 2 (a)-(c) 所示,数据集中的每个实例都将三个组件映射到输出:“指令、表输入、问题”。 该指令是手动设计的,用于指出任务并给出详细的任务描述。 我们将表元数据(例如维基百科页面标题、章节标题和表标题)与序列化表连接起来作为表输入。 在问题中,我们放入模型完成任务所需的所有信息,并提示模型生成答案。 例如,对于列类型标注任务,如图2(a)所示,名为“Player”的列需要标注其语义类型。 在格式中,“指令”给出了任务的描述。 “输入”包含与表相关的信息。 然后我们在“问题”中提供整个候选池,并要求模型为此列选择一种或多种正确的语义类型。
挑战。 由于我们选择实际的任务和表,因此表的长度可以从几行到数千行不等。 此外,对于一些本质上是多选分类或排名的任务,整个候选池可能非常大,多达数千个。 此外,由于候选者来自现实世界的 Freebase(freebase) 和 Wikidata(vrandevcic2014wikidata),因此每个候选者都很长,例如“¡2011-12 墨尔本胜利赛季 [描述] 墨尔本胜利足球俱乐部 2011/12 赛季 [类型] SoccerClubSeason¿”是实体链接的候选之一。 这些特征不仅使模型难以学习,而且还带来了处理长上下文的挑战。
【欢:也许可以专门找一段话来谈谈我们任务制定中的挑战。 例如,将上一段中的一些内容以及第 3 节中“模型选择”段落中的前几句移至此处。]
3实验
[Huan:我们还想把早期实验的模型结果放在你使用处理长上下文的技巧中吗? 如果是这样,你应该考虑如何在主要内容中描述它们,而不需要深入太多细节。 我认为你可能只是将 Llama 2 的结果包含在那里,即,有 llama 2(使用你的技巧进行短修剪候选)与 Llama 2(使用 LongLoRa 进行长上下文)。]
我们在五个大语言模型上演示了完成表格任务的能力:Alpaca、Llama-2、Llama-2-Chat、Vicuna-1.5 和 Tulu。 Alpaca 是源自 Llama-1 的指令调整模型。 Llama2 是一个更强大的预训练模型,它表现出了比 Llama-1 更好的性能。 Llama-2-Chat 是 Llama-2 的微调版本,针对对话用例进行了优化。 它通过指令调整和 RLHF 等对齐技术进行训练。 Vicuna-1.5 是根据从 ShareGPT 收集的用户共享对话对 Llama 2 进行微调的最新版本。 Tulu 是一个 Llama 模型,在 FLAN V2、CoT、Dolly、Open Assistant 1、GPT4-Alpaca、Code-Alpaca 和 ShareGPT 等指令数据集的混合上进行了微调。 这些是仅具有解码器架构的 LLaMA 系列。 由于计算资源限制,我们只评估LLaMA家族7B模型的性能,并将更大尺寸的模型性能留给未来的工作。 我们还大幅减少了训练样例,每个任务训练样例分别为100个和1000个,以展示大语言模型的能力。
评估指标。 我们遵循现有的工作来使用他们的指标。 对于多标签分类任务(列类型标注和关系提取),我们使用精度、召回率和 F1。 对于只有一个基本事实和事实验证的实体链接,我们使用准确性。 对于排名任务(行填充和模式增强),我们使用 MAP(平均精度)。 对于自由形式的 QA,我们使用scareBLEU、Rough-1、Rough-2、Rough-L 和 METEOR。 对于分层表 QA,我们使用执行准确性。
训练和推理细节。 对于动态表分段,自由格式QA的保留指令长度为50;实体链接为 500;其他数据集为 100。 所有任务的偏移量为 200。 所有任务的保留表元数据长度为20。 当使用整个 968k 训练数据时,我们训练 LLaMA 系列模型 1 epoch。 当使用 100 和 1000 个训练示例时,我们训练了 3 个 epoch。 列类型标注、关系提取和实体链接指令中的候选大小为 10,行填充的子集大小为 20。 行填充的最大世代长度为 512;自由形式 QA 和模式增强为 128;对于其他人来说是 64。
4结果和分析。
| Alpaca | Llama-2 | Vicuna-1.5 | Tulu | Llama-2-Chat | SOTA | ||||
| 100 | 1000 | full | full | ||||||
| Column Type Annotation | Precision | 24.30 | 67.75 (0.08%x) (71%) | 88.74 | 89.26 | 88.84 | 89.48 (5%x)(94%) | 95.15 | |
| Recall | 30.16 | 64.94 (0.08%x)(69%) | 87.40 (5%x) (92%) | 86.75 | 87.13 | 86.60 | 94.54 | ||
| F1 | 26.91 | 66.31(0.08%x)(71%) | 88.07 (5%x) (94%) | 87.99 | 87.98 | 88.02 | 93.94 | ||
| Relation Extraction | Precision | 32.28 | 59.39 (0.2%x)(63%) | 91.53 | 93.07 (40%x)(98%) | 92.43 | 92.45 | 94.57 | |
| Recall | 5.54 | 43.08 (0.2%x)(45%) | 73.19 (40%x) (77%) | 73.00 | 72.14 | 72.28 | 95.25 | ||
| F1 | 9.46 | 49.94 (0.2%x)(53%) | 81.34 | 81.83 (40%x) (86%) | 81.03 | 81.13 | 94.91 | ||
| Entity Linking | EM | 16.69 | 62.57 | 71.91 | 69.57 | 71.41 | 67.91 | – | |
| Relax EM? | 23.34 | 69.73 | 81.77 | 82.2 | 80.41 | 79.94 | – | ||
| Schema Augmentation | MAP | 42.06 | 48.84 (0.3%x)(63%) | 68.10 (10%x)(88%) | 67.74 | 67.39 | 67.89 | 77.55 | |
| Row Population | MAP | 18.55 | 24.79 | 25.99 | 29.09 | 53.78 | 45.32 | – | |
| Hierarchical Table QA | Exec Acc | 30.43 (68%) | 36.74 (14%x)(81%) | 34.47 | 39.58 (100%x)(88%) | 37.63 | 34.91 | 45.1 | |
| Free-form QA | sacreBLEU | 30.90 (92%) | 35.77 (14%x)(107%) | 36.62 | 36.79 | 36.66 | 36.93 (100%x) (110%) | 33.44 | |
| Rough-1 | 64.51 (99%) | 69.10 (14%x)(106%) | 71.11 | 71.13 | 71.32 (100%x)(109%) | 71.27 | 65.21 | ||
| Rough-2 | 41.51 (96%) | 45.87 (14%x)(106%) | 48.43 | 48.56 | 48.73 (100%x)(113%) | 48.61 | 43.09 | ||
| Rough-L | 53.22 (96%) | 57.16 (14%x)(103%) | 59.82 | 59.71 | 59.97 | 60.20 (100%x)(109%) | 55.31 | ||
| METEOR | 58.64 (114%) | 63.06 (14%x)(123%) | 63.55 | 63.77 | 63.84 (100%x)(125%) | 63.79 | 51.23 | ||
| Fact Verification | Accuracy | 50.00 | 51.58 (1%x)(61%) | 66.93 | 64.40 | 64.51 | 68.35 (20%x)(81%) | 84.2 | |
4.1整体表现。
表2显示了五个指令跟踪大语言模型在我们的基准测试中的性能。 比较五个大语言模型的完整训练规模表现,我们发现: (1) 不存在适用于所有任务的最佳模型。 (2) 对于大多数任务,除了行填充之外,不同 LM 的性能非常相似。 由于这些大语言模型要么没有指令调整,要么在不同的数据集上调整指令,我们假设这些不同的数据集帮助模型获得与我们不同任务相关的不同能力,因此在我们的例子中,不同的模型更有利于不同的任务。 然而,相似的表现表明这些学习能力对于大多数任务来说并不重要,因为 Llama-2 仅经过预训练,没有任何指令调整,但其他大语言模型的表现并不明显优于 Llama-2。 (3)仅用不超过1.4%的训练数据,大语言模型就可以在大多数任务上实现超过60%的SOTA性能;在5%-40%的训练数据下,大语言模型可以达到80%以上的SOTA性能,有的甚至优于SOTA。
4.2不同任务的分析。
柱型标注。 我们研究了影响大语言模型在大类别分类任务上表现的不同因素。 我们研究正负比、指令顺序和添加其他任务如何影响标注任务列。 我们对四种设置进行实验:(1) Pos:Neg = 1:3,第一个指令然后表输入 (2) Pos:Neg = 1:10,第一个表输入然后指令 (3) Pos:Neg = 1:3,先指令后表输入 (4) Pos:Neg = 1:3,统一模型,先指令后表输入。
| Precision | Recall | F1 | |
|---|---|---|---|
| (1) | 81.60 | 85.08 | 83.30 |
| (2) | 88.49 | 87.55 | 88.02 |
| (3) | 81.17 | 92.58 | 86.50 |
| (4) | 81.36 | 92.14 | 86.41 |
比较(1)和(2),我们可以看到正类和负类的比例很重要:通过增加负类训练样例,准确率和召回率都有很大提高。 比较(1)和(3),我们可以看到指令和表格的顺序很重要:在保持精度的同时,精度大大提高。 由于(liu2023lost)发现当相关信息出现在输入上下文的开头或结尾时,大语言模型的性能总是最高,我们的观察可能是因为候选者位于输入上下文的末尾指令和模型会更加关注候选者,从而帮助模型轻松选择更正确的候选者。 比较(1)和(4),我们可以看到合并其他表任务事项,这可以大大提高列类型标注任务的召回率。
实体链接。 我们观察到大多数错误来自于模型选择了非常相似的实体名称而描述不正确。 由于描述通常与维基百科页面标题高度相关,因此我们假设模型没有对标题给予足够的关注,因此选择了错误的实体。 这表明对于指令设计来说,给出一些特殊的提示来明确突出维基百科标题可能有助于模型做出正确的选择。
表 QA 和事实验证。 在我们的实验中(图4,我们发现统一后
| Train | Hitab | Unified | ||
|---|---|---|---|---|
| Eval | Hitab | Exec Acc | 58.71 | 34.47 |
| FeTaQA | sacreBLEU | 23.47 | 36.62 | |
| Rough-1 | 19.70 | 71.11 | ||
| Rough-1 | 9.23 | 48.43 | ||
| Rough-L | 18.14 | 59.82 | ||
| METEOR | 8.84 | 63.55 | ||
| TabFact | Accuracy | 15.42 | 66.93 | |
不同的任务得到一个统一的模型,与仅指令调整单个任务相比,分层表 QA (Hitab) 任务的性能显着下降。 由于(Gudibande 等人,2023)提出指令调优主要改进其训练数据集中大力支持的任务,我们假设与其他任务相比,性能下降是由于分层表 QA 任务的训练大小非常小当训练统一模型时。 此外,我们还展示了 Hitab、FeTaQA 和 TabFact 之间的任务转移性能。 可以看到,如果模型仅在 Hitab 上进行指令调优,那么 FeTaQA 和 TabFact 的模型性能与统一模型相比会有很大差距,这也说明了从不同任务构建特定表数据并训练通才的必要性桌子的模型。
行人口。 图3显示了行填充任务的案例研究。 左图显示了等待排名的初始候选列表。 橙色候选人是目标候选人,但目前他们分散在整个候选人名单的不同位置。 整个候选人规模约为200人。 右子图显示了应用我们的树排名算法后的排名列表。 我们可以看到目标候选者在列表中排名靠前,这证明了我们设计的算法的有效性。

5相关工作
表表示学习。 鉴于表中存储的大量知识,人们提出了各种基于表的任务pujara2021tables,例如列类型标注(hulsebos2019sherlock)、行填充(zhang2017entables ),表 QA sun2016table;维基百科; Cheng-etal-2022-hitab; Nan2021FeTaQAFT等 为了处理半结构化表,现有工作致力于设计特殊的模型架构,[欢:对于你要提到的工作,如果他们有模型名称,请提及它,因为它可以使人们很容易记住该作品。] 例如具有结构感知注意力的 TURL (deng2020turl)、具有基于树的注意力的 TUTA (wang2021tuta) 和具有垂直自注意力机制的 TaBERT (yin-etal -2020-tabert);或者设计特殊的编码如单元格文本编码(yin-etal-2020-tabert; eisenschlos2021mate; wang2021tuta)、表格位置编码(herzig-etal-2020-tapas; wang2021tuta),以及数字编码(wang2021tuta),以更好地编码表结构并向神经架构注入更多信息。 此外,一些工作侧重于表预训练(liu2022tapex; yin-etal-2020-tabert; deng2020turl; iida-etal-2021-tabbie),以在大规模表中编码知识。 然而,尽管现有的这些工作已经显示出可喜的进展,但它们仍然是数据特定的和下游任务特定的,这需要针对表和基于表的任务进行特殊设计。
我们的工作提出TableInstruct来统一不同的基于表格的任务,并开发一个通用的大语言模型TableLlama来减少建模过程中的额外工作,并评估其表格理解以及域内和域外设置下的泛化能力。 这种高级洞察类似于 UnifiedSKG (xie2022unifiedskg),它将一组不同的结构化知识基础任务统一为文本到文本的格式。 并通过多任务微调增强T5模型的性能。 然而,UnifiedSKG 处理不同的知识源,如数据库、知识图和网络表格,并没有探索指令调优,而我们通过指令调优专注于基于现实世界表格的广泛现实任务。 此外,并行工作(li2023tablegpt)综合了各种与表格相关的任务,并通过指令调优对GPT-3.5等闭源大语言模型进行了微调。 【欢:改写? 你是什么意思? 在ChatGPT等闭源大语言模型上统一各种基于表的任务,] 与他们相比,我们从 Freebase 和 Wikidata 中收集了更现实和复杂的任务数据,例如 HiTab 以及分类和排名任务,并为基于表格的任务开发了开源大语言模型。 我们相信我们构建的高质量表指令调整数据集和经过训练的模型都可以成为促进这一研究领域的宝贵资源。
指令执行。 以监督方式使用指令、输出对训练大语言模型的指令调优是增强大语言模型能力和可控性的关键技术(chung2022scaling; wang-etal-2022-super;mishra-etal-2022-cross)。 这些指令用于约束模型的输出,使其与所需的响应特征或领域知识保持一致,并可以帮助大语言模型快速适应特定领域,而无需进行大量的再训练或架构设计(zhang2023指令)。 因此,人们提出了不同的指令调优数据集来指导大语言模型的行为(wang-etal-2022-super; honovich2022unnatural; longpre2023flan; xu2023wizardlm; yue2024mammoth)。 这些数据集是通过模板 (longpre2023flan) 格式化现有自然语言处理任务或提示 ChatGPT (xu2023wizardlm) 和 GPT-4 (gpt4llm) 来收集的> 生成指令。 不同的指令调优模型,如 InstructGPT (instructgpt)、Vicuna (vicuna) 和 Claude222https://www.anthropic.com/index/introducing-claude【欢:你能用另一种方式引用克劳德吗? 第一个脚注位于论文末尾,这很奇怪。 如果你找不到论文,只需为此网址创建一个 bibtex。] 与预先训练的模型相比,出现并表现出更高的性能。 此外,指令调优已应用于图像、视频和音频等不同模式(li2023blip2),并已显示出可喜的结果。 这表明指令调整可能是一种有前途的技术,可以使大型预训练模型能够处理各种任务。 然而,如何利用指令调优来指导大语言模型完成基于表格的任务仍处于探索之中。 我们的工作通过构建高质量的表指令调优数据集来填补这一空白:TableInstruct,它涵盖了大规模多样化且真实的表和任务,以实现建模和评估。 我们还发布了 TableLlama,这是一个基于开源 LLM 的通才模型,在 TableInstruct 上进行了微调,以促进这一研究途径。
6结论
本文朝着开发用于各种基于表格的任务的开源大型通用模型迈出了第一步。 为此,我们构建了TableInstruct并开发了第一个开源的表格通用模型TableLlama,这是一个用于指导调整和评估表格的大语言模型的综合数据集。通过使用 LongLoRA 微调 Llama 2 (7B) 来解决上下文长度挑战,开发第一个开源通用表模型 TableLlama。 我们对域内和域外设置进行了评估,实验表明TableLlama获得了很强的表格理解能力和泛化能力。 在 8 个域内任务中的 7 个中,我们的通才模型 TableLlama 在每个任务中都实现了与现有 SOTA 方法相当或更好的性能,尽管后者通常具有特定于表的模型设计或预训练。 在 6 个域外数据集上,与基本模型相比,它实现了 6-48 的绝对点增益,这表明我们的 TableInstruct 上的训练增强了泛化性。