训练稳健且可推广的量子模型
摘要
对抗性鲁棒性和泛化性都是可靠机器学习模型的关键属性。 在本文中,我们在基于 Lipschitz 界限的量子机器学习背景下研究这些属性。 我们为具有可训练编码的量子模型推导了定制的、参数相关的 Lipschitz 界限,表明数据编码的范数对输入数据扰动的鲁棒性具有至关重要的影响。 此外,我们得出了泛化误差的界限,该界限明确取决于数据编码的参数。 我们的理论研究结果提出了一种实用策略,通过规范成本中的 Lipschitz 界限来训练稳健且可推广的量子模型。 此外,我们表明,对于量子机器学习中经常使用的固定和不可训练的编码,Lipschitz 界限不能通过调整参数来影响。 因此,可训练的编码对于在训练过程中系统地调整训练的鲁棒性和泛化性至关重要。 通过数值结果,我们证明,利普希茨约束正则化确实会带来更加稳健和可推广的量子模型。
机器学习 (ML) 模型的稳健性是一个越来越重要的属性,尤其是在处理受扰动的现实世界数据时。 在实践中,存在各种可能的扰动来源,例如噪声数据采集或对抗性攻击。 后者是微小但精心选择的数据操作,它们可能会导致神经网络[1, 2]中出现严重的错误分类。 因此,许多研究致力于更好地理解和提高对抗鲁棒性[3,4,5]。 众所周知,鲁棒性与泛化[1,2,6,7,8]密切相关,即模型推断训练数据之外的能力。 直观上,如果模型是稳健的,那么小的输入变化只会导致小的输出变化,从而抵消了过度拟合的风险。
模型 的 Lipschitz 约束是满足以下条件的任意
| (1) |
对于所有。 根据定义,Lipschitz 界限量化了数据扰动可能引起的最坏情况输出变化,因此,它们提供了对抗鲁棒性的有用度量。 因此,它们是表征机器学习模型的鲁棒性和泛化属性的成熟工具[2,6,9,10,11,12,13,14,15]。 Lipschitz 界限不仅可以用于更好地理解这两个属性,还可以通过在训练 [2, 6, 16, 17, 18] 期间规范 Lipschitz 界限来改进它们。
在本文中,我们研究了量子机器学习(QML)中鲁棒性和泛化性的相互作用。 变分量子电路是一类经过充分研究的量子模型[19,20,21],它们在可训练性、表达性和泛化性能等各个方面都优于经典机器学习[22, 23]。 数据重新上传电路通过将数据编码和参数化量子电路不仅连接一次而且重复连接,从而在数据相关门和参数相关门[24]之间进行迭代,从而概括了经典变分电路。 这种交替极大地提高了表达能力,即使在单量子位情况下也能实现通用量子分类器[24, 25]。
正如在经典情况下一样,鲁棒性对于量子模型至关重要。 首先,如果 QML 要提供优于经典 ML 的优势,则有必要实现稳健的 QML 电路。 在嘈杂的中尺度量子(NISQ)时代,由于硬件不完善而发生量子错误[26]。 量子模型针对此类硬件错误的鲁棒性问题已经被研究,例如,在[27, 28]中。 Lipschitz 界限可用于研究量子算法针对某些类型的硬件错误(例如相干控制错误[29])的鲁棒性。
然而,针对硬件错误的鲁棒性完全不同于并且独立于量子模型针对数据扰动的鲁棒性,这将是本文的主题。 后一种鲁棒性已在量子对抗机器学习的背景下进行了研究[30, 31]。 毫不奇怪,就像经典模型一样,量子模型也容易受到对抗性攻击,无论是基于经典数据 [32, 33] 还是量子数据 [34, 32, 35, 36、37、38、39]。 为了减轻这些攻击,需要设计训练方案来鼓励所得量子模型的对抗鲁棒性。 这个方向的现有方法包括在训练[32]期间解决(对抗性)最小-最大优化问题或向训练数据集[40]添加对抗性示例。 我们的研究结果通过利普希茨界限研究量子模型的鲁棒性,为量子对抗机器学习做出了贡献,从而形成了基于利普希茨界限正则化的鲁棒量子模型的训练方案。 我们用数值结果证明了所提出的正则化的鲁棒性优势。
除了鲁棒性之外,任何量子模型的另一个重要方面是其泛化到未见数据的能力[42, 43]。 特别是,各种工作已经显示了泛化界限[22,44,45,46,47],即模型预期风险的界限取决于其在训练数据上的表现。 虽然这些界限为构建泛化良好的量子模型的可能性提供了见解,但由于其统一性质,它们也面临着固有的局限性[48]。
在本文中,我们推导了一种新颖的泛化界限,它明确依赖于量子模型的参数,突出了数据编码对于泛化性的作用。 我们用数值结果表明,正则化 Lipschitz 界限确实会导致泛化性能的显着提高。 最后,考虑到导出的 Lipschitz 界限主要取决于数据编码的范数,我们的结果显示了可训练编码相对于具有先验固定编码的量子电路的重要性和优势,如变分 QML [49, 19, 20、21、22、25]。
结果
量子模型及其利普希茨界限。 我们考虑以下形式的参数化酉算子
| (2) |
具有输入数据、可训练参数、和埃尔米特生成器。
根据 的选择,运算符 作用于一个或多个量子位。 运算符 产生参数化量子电路
| (3) |
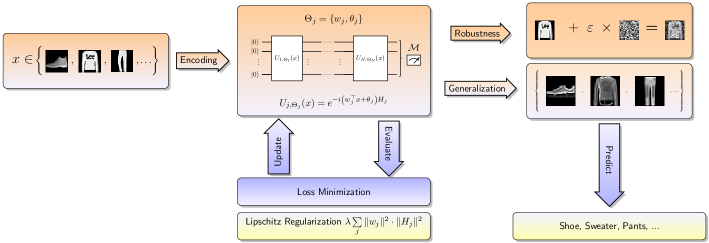
其中 包含可训练参数集。 本文考虑的量子模型由应用于 的 和随后的测量 w.r.t 组成。 可观察的 ,即
| (4) |
比较图1。 请注意,每个酉运算符都涉及完整的数据向量,即数据被重复加载到电路中,这种策略通常称为数据重新上传[24]。 将数据编码到每个中是通过仿射函数实现的,其中和 是可训练参数。 因此,我们将 (4) 称为具有可训练编码的量子模型。 这种可训练编码是常见量子模型 [49, 19, 20, 21, 22, 25] 的泛化,其中 是固定的(通常是单位向量)并且只有 被训练。 特别是,我们的分析结果同样适用于这些固定编码量子模型。 在本文的后面,我们通过理论和数值结果证明,与固定(即不可训练)编码相比,可训练编码可以产生显着的鲁棒性和泛化性改进。
我们的结果利用 (1) 中定义的 Lipschitz 边界。 Lipschitz 界限量化了输入变化可能引起的 的最大扰动。 对于量子模型 ,我们可以陈述以下 Lipschitz 界
| (5) |
正式推导可以在补充部分1-B中找到。
对于给定的一组参数 ,(5) 允许计算相应量子模型的 Lipschitz 界限。 请注意, 仅取决于 ,但独立于 。 这一事实对于可训练编码的潜在优势起着重要作用,因为参数 在固定编码电路的训练过程中并未优化。
量子模型的稳健性。 假设我们想在处评估量子模型,即我们对值感兴趣,但我们只能访问 在一些扰动输入与未知的。 这种设置可能由于各种原因而出现,例如 可能是某些物理过程的输出,只能通过嘈杂的传感器访问。 扰动 也可能是对抗性攻击的结果,即,旨在通过选择 来导致错误分类的扰动,使得
| (6) |
被最大化。 无论哪种情况,为了在存在扰动的情况下正确分类 ,我们要求 接近 ,这意味着 (6 ) 是小。 根据 (1), 的 Lipschitz 界限 精确地量化了此差异,这意味着 的最大可能偏差从 的边界为
| (7) |
这表明较小的 Lipschitz 界限 意味着模型针对数据扰动的鲁棒性更好(最坏情况)。 因此,利用 (5),量子模型 的鲁棒性主要受数据编码参数 、 和可观测参数 的影响。 特别是, 和 的值越小,模型就越稳健。
现在,我们将这种理论见解应用到使用 Lipschitz 边界正则化来训练稳健的量子模型。 更准确地说,我们考虑一个具有损失 和大小为 的训练数据集 的监督学习设置。因此,以下优化问题可用于训练量子模型
| (8) |
为了确保不仅训练损失小,而且具有鲁棒性和泛化性好,我们添加了正则化项,从而得到正则化优化问题
| (9) |
规范化参数 鼓励数据编码的小规范,从而鼓励 Lipschitz 边界 的小值。 超参数允许在训练损失小和成本函数的鲁棒性/泛化这两个目标之间进行权衡。 请注意,正则化不涉及 ,因为它们不影响 Lipschitz 界限 (5),我们将在本文后面更详细地讨论这个问题。 此外,我们没有引入正则化对 的显式依赖,因为我们在本文中没有对可观察值进行优化。 我们注意到,与所提出的正则化类似的惩罚项可用于通过量子近似优化算法[50, 51]处理二元优化中的硬约束。 事实上,上述正则化可以解释为相应约束训练问题的基于惩罚的松弛,即训练 Lipschitz 限制在特定值以下的量子模型。
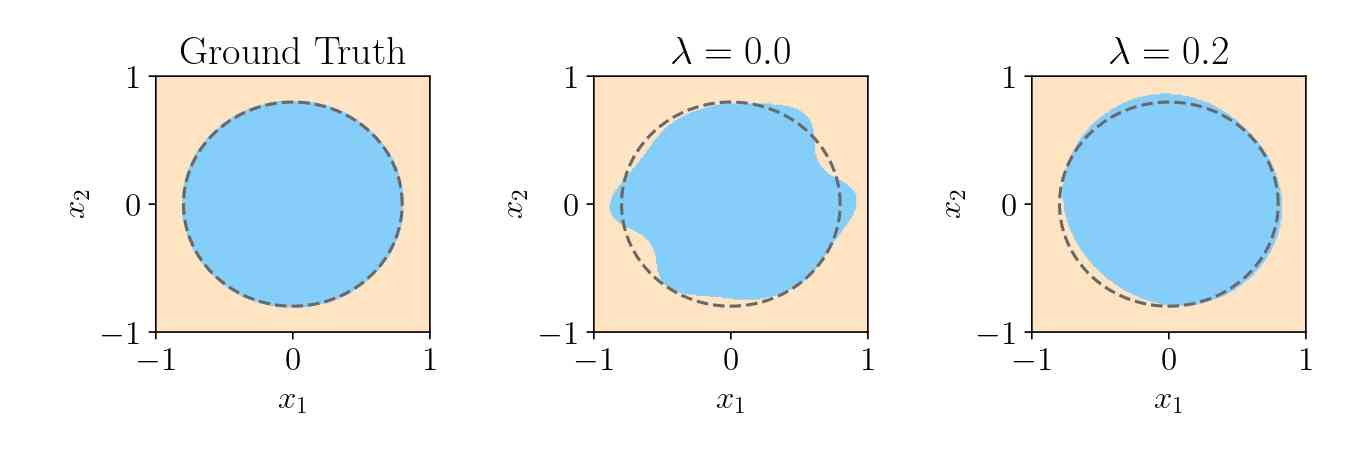
我们现在基于 2D 分类问题评估我们的理论结果,我们将其称为圆分类问题 [52]:在 域内,画一个半径为的圆,圆内所有数据点用标记,圆外点用标记,见图6 在补充部分 3 中。 对于具有可训练编码的量子模型,我们使用通用 SU(2) 算子并将 编码为前两个旋转角度。 我们对每个考虑的 量子位重复此编码,然后是基于 CNOT 的最近邻纠缠门。 然后将这样的层重复次。 可以看出,我们使用 。 由此产生的电路如图4所示。
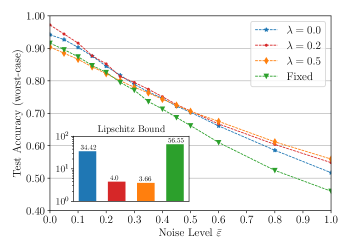
鲁棒性模拟的数值结果如图2所示,其中我们比较了具有不同正则化参数的三个训练模型的最坏情况测试精度和Lipschitz界限。 此外,该图还显示了针对相同数量的量子位和层采用固定编码的量子模型的准确性(有关详细信息,请参阅 (16) 和补充部分 3)。 所有模型的最坏情况测试精度是通过从 中采样不同的噪声样本 获得的,从而近似由 。 正如预期的那样,所有四个模型都会随着噪声水平的增加而恶化。 对于零噪声水平,具有最大正则化参数(因此具有最小Lipschitz界限)的模型的测试精度低于具有 的非正则化模型。 这可以通过额外的成本正则化导致训练准确性下降来解释。 然而,对于增加的噪声水平,增强的鲁棒性超过了训练性能的损失,因此,具有 的模型优于具有 的模型。 对于小噪声,固定编码模型的性能与具有 的可训练编码模型相当,而对于高噪声,固定编码模型的性能是所有模型中最差的。 这些观察结果可以通过固定编码模型的表达性降低但 Lipschitz 界限较高来解释。 最后,具有 的模型几乎始终优于具有 的模型,特别是,它对于小噪声水平产生了更高的测试精度。 这可以通过正则化提高泛化性能来解释,我们将在下面更详细地讨论这种效果。
量子模型的推广。 Lipschitz 界 (5) 不仅影响鲁棒性,而且对量子模型 的泛化特性也有至关重要的影响。 直观上,较小的 Lipschitz 界限意味着 的变异性较小,因此降低了过度拟合的风险。 这种直觉通过以下泛化界限变得正式。

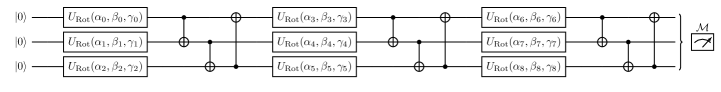
Theorem 1。
(非正式版本) 考虑一个监督学习设置,其中包含根据概率分布 绘制的结果 和大小为 的数据集 。对于来自 (4) 的量子模型 ,定义预期风险
| (10) |
和经验风险
| (11) |
的泛化误差有界为
| (12) |
对于某些。
定理1的详细版本和证明在补充部分2中提供。 (12) 中的泛化界限量化了 泛化到可用数据之外的能力。 界限 (12) 直接取决于通过 的数据编码和通过 的可观察值。 特别是,如果 的 Lipschitz 边界 较小并且数据集的大小 较大,则 会实现较小的泛化误差。 但请注意以下基本权衡:太小的 Lipschitz 边界 可能会限制 的表达性,因此导致较高的经验风险 ,在这种情况下泛化界限(12)是没有意义的。 总之,如果 大, 小,且 的经验风险 小,则定理 1 意味着预期风险 小。 与现有泛化边界 [22, 44, 45, 46, 47] 相比,边界 (12) 明确涉及 Lipschitz 边界 (5),即数据编码的范数。
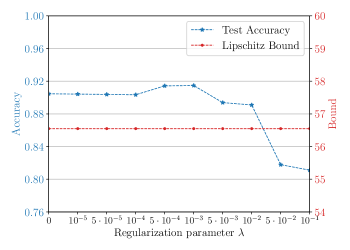
我们再次评估可训练编码在圆分类问题上的泛化性能。 训练设置与鲁棒性模拟相同,数值结果如图 3 所示,其中我们根据正则化参数 绘制了测试精度和 Lipschitz 界限。 增加正则化参数 会降低训练模型的 Lipschitz 边界 。 根据泛化界限 (12), 的减少提高了泛化性能,并在 处实现了最大测试精度。 超过该值,正则化会导致 Lipschitz 界限太小,限制表达性,从而降低训练准确性。 结果,测试精度也会降低。 这说明了 作为超参数的作用:正则化并不总能提高性能,但 有一个最佳点,在该点上,比非正则化设置(即,更优越的泛化性和鲁棒性) , ) 可以得到。 在实践中,超参数 可以通过交叉验证等方式进行调整。
可训练编码的好处。 一类流行的量子模型是通过构建在数据相关门和参数相关门之间交替的电路来获得的,即将 (3) 中的 替换为
| (13) |
比较[49,19,20,21,22,25]。 酉运算符 由下式给出
| (14) | ||||
| (15) |
对于可训练参数 和生成器 、。 图5描绘了相应量子模型的电路表示
| (16) |
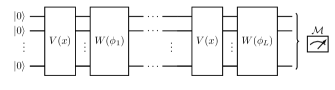
不难证明(3)中的参数化量子电路概括了(13)中的量子电路。 事实上, (2) 中的 减少为
| (17) |
用于选择合适的 、 和 。 请注意,量子模型 的数据编码是通过选择 预先固定的,特别是,它在训练期间不会受到影响。 因此,我们将称为具有固定编码的量子模型,而不是(4)中的,其中包含可训练参数,因此是可训练的编码。
可训练编码对量子模型表达能力的好处已在 [53, 54, 55] 中以数值方式得到证明,在 [24, 25] 中从理论上得到证明。 下面,我们讨论可训练编码对于鲁棒性和泛化性的重要性。 回想一下,我们证明了 Lipschitz 界限 (5) 是量子模型鲁棒性和泛化的关键量词,它仅取决于可观察的 和数据编码 、,但与参数无关。 因此,在具有固定编码的量子模型 中,Lipschitz 边界 (5) 在训练期间不会受到影响,而是通过选择 Hermitian 生成器先验固定。 因此,训练对固定编码量子模型的鲁棒性和泛化特性的影响有限。
当将量子模型表示为傅里叶级数[25]时,可训练数据编码和固定数据编码之间的区别变得更加明显。 在这种情况下,固定编码量子模型在训练之前选择傅立叶基函数的频率,并且仅对其系数进行优化。 相反,可训练编码量子模型同时优化频率和系数,根据 Lipschitz 界限 (5),这是影响鲁棒性和泛化特性的关键。
这些见解证实了[56,57,58]的观察结果,即固定编码量子模型既对数据扰动也不敏感,也不对过度拟合敏感。 一方面,对这两种现象的恢复能力是一种理想的特性。 然而,上述讨论也意味着 Lipschitz 界限正则化是影响鲁棒性和泛化性的系统且有效的工具[2,6,16,17,18],不能用于固定编码量子模型以提高鲁棒性和泛化性。 图 2 中的鲁棒性模拟说明了这一事实的不利影响。 在这里,固定编码模型的 Lipschitz 界限比所有考虑的可训练编码模型都要高得多。 这意味着鲁棒性明显较差。 数据扰动,因此导致较大噪声水平的测试精度迅速下降。 此外,按照建议(例如,通过[59])对参数进行正则化不会影响Lipschitz界限,因此不能用于提高鲁棒性。 在补充部分3中,我们研究了正则化对泛化的影响。 我们发现正则化 对测试精度的影响是有限的,并且可能取决于生成数据的特定真实分布和所选电路 ansatz。
总而言之,我们的结果表明,在量子模型中训练编码不仅提高了表达能力,而且还带来了卓越的鲁棒性和泛化特性。
讨论
在本文中,我们研究了基于 Lipschitz 界限的量子模型的鲁棒性和泛化特性。 Lipschitz 界限是经典机器学习文献中一个成熟的工具,它不仅可以量化对抗鲁棒性,而且还与泛化性能密切相关。 我们根据数据编码的大小得出 Lipschitz 界限,然后用它来研究鲁棒性和泛化属性。 鉴于我们的泛化界限明确涉及数据编码的参数,它不是统一界限。 因此,它可以克服统一 QML 泛化边界的一些限制[48]。 此外,我们的理论结果强调了可训练编码与正则化技术相结合对于获得稳健且可概括的量子模型的作用。 数值结果证实了我们的理论发现,表明正则化参数存在最佳点,与非正则化训练方案相比,我们的训练方案提高了鲁棒性和泛化性。 需要强调的是,这些具有特定旋转和纠缠门选择的数值结果主要用于说明,但我们的理论框架适用于所有可以写成 (4) 的量子模型,并且,因此,还允许不同的旋转门、纠缠层,甚至参数化的多量子位门。
虽然我们的结果表明在 QML 中使用 Lipschitz 界限的潜力,但未来的研究还有各种有前途的方向。 首先也是最重要的,将经典 ML 中 Lipschitz 边界的现有研究转移到 QML 设置中,为处理鲁棒性和泛化性提供了一个系统框架,超出了本文提出的第一个结果。 特别是,虽然我们专注于变分量子模型,但我们结果的基本原理可以转移到不同的量子模型,包括量子核方法[20, 21]或线性量子模型[23] 。 此外,虽然我们强调了可训练编码的重要性,但所考虑的量子模型仅采用特定的仿射编码。 将我们的结果扩展到更一般的、可能是非线性的编码,为设计强大的量子模型提供了一条有前途的途径。 鉴于经典机器学习对其 Lipschitz 属性的广泛研究[2,6,9,10,11,12,13,14,15],经典神经网络是实现非线性编码的理想候选者。 最后,我们计划在更复杂的分类任务和真实的量子硬件上验证我们的理论发现。
代码可用性
数值案例研究的源代码以及数据生成和分析脚本可通过 https://github.com/daniel-fink-de/training-robust-and-generalized-quantum 在 GitHub 上公开访问-模型。
致谢
这项工作由 Deutsche Forschungsgemeinschaft(DFG,德国研究基金会)根据德国卓越战略 - EXC 2075 - 390740016 资助。 我们感谢斯图加特模拟科学中心 (SimTech) 的支持。 这项工作还得到了德国联邦经济事务和气候行动部通过 AutoQML 项目(拨款号:2017)的支持。 01MQ22002A)。
参考
- [1] I. J. Goodfellow, J. Shlens, and C. Szegedy, “Explaining and harnessing adversarial examples,” arXiv:1412.6572, 2014.
- [2] C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow, and R. Fergus, “Intriguing properties of neural networks,” arXiv:1312.6199, 2014.
- [3] E. Wong and Z. Kolter, “Provable defenses against adversarial examples via the convex outer adversarial polytope,” in Proc. International Conference on Machine Learning, 2018, pp. 5283–5292.
- [4] Y. Tsuzuku, I. Sato, and M. Sugiyama, “Lipschitz-margin training: Scalable certification of perturbation invariance for deep neural networks,” in Proc. Advances in Neural Information Processing Systems, 2018, pp. 6541–6550.
- [5] A. Madry, A. Makelov, L. Schmidt, D. Tsipras, and A. Vladu, “Towards deep learning models resistant to adversarial attacks,” arXiv:1706.06083, 2019.
- [6] A. Krogh and J. Hertz, “A simple weight decay can improve generalization,” in Advances in Neural Information Processing Systems, vol. 4, 1991. [Online]. Available: https://proceedings.neurips.cc/paper/1991/file/8eefcfdf5990e441f0fb6f3fad709e21-Paper.pdf
- [7] H. Xu and S. Mannor, “Robustness and generalization,” Mach. Learn., vol. 86, no. 3, pp. 391–423, 2012.
- [8] N. Papernot, P. McDaniel, X. Wu, S. Jha, and A. Swami, “Distillation as a defense to adversarial perturbations against deep neural networks,” in Proc. IEEE Symposium on Security and Privacy (SP), 2016, pp. 582–597.
- [9] U. von Luxburg and O. Bousquet, “Distance-based classification with Lipschitz functions,” Journal of Machine Learning Research, vol. 5, pp. 669–695, 2004.
- [10] P. Bartlett, D. J. Foster, and M. Telgarsky, “Spectrally-normalized margin bounds for neural networks,” in Advances in Neural Information Processing Systems, vol. 30, 2017, pp. 6240–6249.
- [11] B. Neyshabur, S. Bhojanapalli, D. McAllester, and N. Srebro, “Exploring generalization in deep learning,” in Advances in Neural Information Processing Systems, 2017, pp. 5947–5956.
- [12] J. Sokolić, R. Giryes, G. Sapiro, and M. R. D. Rodrigues, “Robust large margin deep neural networks,” IEEE Trans. Signal Processing, vol. 65, no. 16, pp. 4265–4280, 2017.
- [13] T.-W. Weng, H. Zhang, P.-Y. Chen, J. Yi, D. Su, Y. Gao, C.-J. Hsieh, and L. Daniel, “Evaluating the robustness of neural networks: an extreme value theory approach,” in Proc. 6th Int. Conf. Learning Representations (ICLR), 2018.
- [14] W. Ruan, X. Huang, and M. Kwiatkowska, “Reachability analysis of deep neural networks with provable guarantees,” in Proc. 27th Int. joint Conf. Artificial Intelligence (IJCAI), 2018, pp. 2651–2659.
- [15] C. Wei and T. Ma, “Data-dependent sample complexity of deep neural networks via Lipschitz augmentation,” in Advances in Neural Information Processing Systems, 2019, pp. 9725–9736.
- [16] M. Hein and M. Andriushchenko, “Formal guarantees on the robustness of a classifier against adversarial manipulation,” in Proc. Advances in Neural Information Processing Systems, 2017, pp. 2266–2276.
- [17] H. Gouk, E. Frank, B. Pfahringer, and M. Cree, “Regularisation of neural networks by enforcing Lipschitz continuity,” Machine Learning, vol. 110, pp. 393–416, 2021.
- [18] P. Pauli, A. Koch, J. Berberich, P. Kohler, and F. Allgöwer, “Training robust neural networks using Lipschitz bounds,” IEEE Control Systems Lett., vol. 6, pp. 121–126, 2022.
- [19] M. Benedetti, E. Lloyd, S. Sack, and M. Fiorentini, “Parameterized quantum circuits as machine learning models,” Quantum Sci. Technol., vol. 4, p. 043001, 2019.
- [20] V. Havlíček, A. D. Córcoles, K. Temme, A. W. Harrow, A. Kandala, J. M. Chow, and J. M. Gambetta, “Supervised learning with quantum-enhanced feature spaces,” Nature, vol. 567, pp. 209–212, 2019.
- [21] M. Schuld and N. Killoran, “Quantum machine learning in feature Hilbert spaces,” Physical Review Letters, vol. 122, p. 040504, 2019.
- [22] A. Abbas, D. Sutter, C. Zoufal, A. Lucchi, A. Figalli, and S. Woerner, “The power of quantum neural networks,” Nature Computational Science, vol. 1, pp. 403–409, 2021.
- [23] S. Jerbi, L. J. Fiderer, H. P. Nautrup, J. M. Kübler, H. J. Briegel, and V. Dunjko, “Quantum machine learning beyond kernel methods,” Nature Communications, vol. 14, p. 517, 2023.
- [24] A. Pérez-Salinas, A. Cervera-Lierta, E. Gil-Fuster, and J. I. Latorre, “Data re-uploading for a universal quantum classifier,” Quantum, vol. 4, p. 226, 2020.
- [25] M. Schuld, R. Sweke, and J. J. Meyer, “Effect of data encoding on the expressive power of variational quantum-machine-learning models,” Physical Review A, vol. 103, p. 032430, 2021.
- [26] J. Preskill, “Quantum computing in the NISQ era and beyond,” Quantum, vol. 2, p. 79, 2018.
- [27] R. LaRose and B. Coyle, “Robust data encodings for quantum classifiers,” Physical Review A, vol. 102, p. 032420, 2020.
- [28] L. Cincio, K. Rudinger, M. Sarovar, and P. J. Coles, “Machine learning of noise-resilient quantum circuits,” PRX Quantum, vol. 2, p. 010324, 2021.
- [29] J. Berberich, D. Fink, and C. Holm, “Robustness of quantum algorithms against coherent control errors,” arXiv:2303.00618, 2023.
- [30] D. Edwards and D. B. Rawat, “Quantum adversarial machine learning: status, challenges and perspectives,” in Proc. 2nd IEEE Int. Conf. Trust, Privacy and Security in Intelligent Systems and Applications (TPS-ISA), 2020, pp. 128–133.
- [31] M. T. West, S.-L. Tsang, J. S. Low, C. D. Hill, C. Leckie, L. C. L. Hollenberg, S. M. Erfani, and M. Usman, “Towards quantum enhanced adversarial robustness in machine learning,” arXiv:2306.12688, 2023.
- [32] S. Lu, L.-M. Duan, and D.-L. Deng, “Quantum adversarial machine learning,” Physical Review Research, vol. 2, p. 033212, 2020.
- [33] M. T. West, S. M. Erfani, C. Leckie, M. Sevior, L. C. L. Hollenberg, and M. Usman, “Benchmarking adversarially robust quantum machine learning at scale,” arXiv:2211.12681, 2022.
- [34] N. Liu and P. Wittek, “Vulnerability of quantum classification to adversarial perturbations,” Physical Review A, vol. 101, p. 062331, 2020.
- [35] H. Liao, I. Convy, W. J. Huggins, and K. B. Whaley, “Robust in practice: adversarial attacks on quantum machine learning,” Physical Review A, vol. 103, p. 042427, 2021.
- [36] Y. Du, M.-H. Hsieh, T. Liu, D. Tao, and N. Liu, “Quantum noise protects quantum classifiers against adversaries,” Physical Review Research, vol. 3, p. 023153, 2021.
- [37] J. Guan, W. Fang, and M. Ying, “Robustness verification of quantum classifiers,” in Proc. Int. Conf. Computer Aided Verification, 2021, pp. 151–174.
- [38] M. Weber, N. Liu, B. Li, C. Zhang, and Z. Zhao, “Optimal provable robustness of quantum classification via quantum hypothesis testing,” Quantum Information, vol. 7, p. 76, 2021.
- [39] W. Gong and D.-L.-. Deng, “Universal adversarial examples and perturbations for quantum classifiers,” National Science Review, vol. 9, no. 6, p. nwab130, 2022.
- [40] W. Ren, W. Li, S. Xu, K. Wang, W. Jiang, F. Jin, X. Zhu, J. Chen, Z. Song, P. Zhang, H. Dong, X. Zhang, J. Deng, Y. Gao, C. Zhang, Y. Wu, B. Zhang, Q. Guo, H. Li, Z. Wang, J. Biamonte, C. Song, D.-L. Deng, and H. Wang, “Experimental quantum adversarial learning with programmable superconducting qubits,” arXiv:2204.01738, 2022.
- [41] H. Xiao, K. Rasul, and R. Vollgraf, “Fashion-MNIST: a novel image dataset for benchmarking machine learning algorithms,” arXiv:1708.07747, 2017.
- [42] M. Cerezo, G. Verdon, H.-Y. Huang, L. Cincio, and P. J. Coles, “Challenges and opportunities in quantum machine learning,” Nature Computational Science, vol. 2, pp. 567–576, 2022.
- [43] E. Peters and M. Schuld, “Generalization despite overfitting in quantum machine learning models,” arXiv:2209.05523, 2022.
- [44] H.-Y. Huang, M. Bourghton, M. Mohseni, R. Babbush, S. Boixo, H. Neven, and J. R. McClean, “Power of data in quantum machine learning,” Nature communications, vol. 12, no. 1, pp. 1–9, 2021.
- [45] L. Banchi, J. Pereira, and S. Pirandola, “Generalization in quantum machine learning: a quantum information standpoint,” PRX Quantum, vol. 2, p. 040321, 2021.
- [46] M. C. Caro, E. Gil-Fuster, J. J. Meyer, J. Eisert, and R. Sweke, “Encoding-dependent generalization bounds for parametrized quantum circuits,” arXiv:2106.03880, 2021.
- [47] S. Jerbi, C. Gyurik, S. C. Marshall, R. Molteni, and V. Dunjko, “Shadows of quantum machine learning,” arXiv:2306.00061, 2023.
- [48] E. Gil-Fuster, J. Eisert, and C. Bravo-Prieto, “Understanding quantum machine learning also requires rethinking generalization,” arXiv:2306.13461, 2023.
- [49] M. Schuld and F. Petruccione, Machine learning with quantum computers. Springer, 2021.
- [50] E. Farhi, J. Goldstone, and S. Gutmann, “A quantum approximate optimization algorithm,” arXiv:1411.4028, 2014.
- [51] S. Hadfield, Z. Wang, E. G. Rieffel, B. O’Gorman, D. Venturelli, and R. Biswas, “Quantum approximate optimization with hard and soft constraints,” in Proc. 2nd Int. Workshop on Post Moores Era Supercomputing, 2017, pp. 15–21.
- [52] S. Ahmed, “Tutorial: Data reuploading circuits,” https://pennylane.ai/qml/demos/tutorial˙data˙reuploading˙classifier/, 2021.
- [53] F. J. Gil Vidal and D. O. Theis, “Input redundancy for parameterized quantum circuits,” Frontiers in Physics, vol. 8, p. 297, 2020.
- [54] E. Ovalle-Magallanes, D. E. Alvarado-Carrillo, J. G. Avina-Cervantes, I. Cruz-Aceves, and J. Ruiz-Pinales, “Quantum angle encoding with learnable rotation applied to quantum-classical convolutional neural networks,” Applied Soft Computing, vol. 141, p. 110307, 2023.
- [55] B. Jaderberg, A. A. Gentile, Y. A. Berrada, E. Shishenina, and V. E. Elfving, “Let quantum neural networks choose their own frequencies,” arXiv:2309.03279, 2023.
- [56] K. Mitarai, M. Negoro, M. Kitagawa, and K. Fujii, “Quantum circuit learning,” Physical Review A, vol. 98, p. 032309, 2018.
- [57] M. Schuld, A. Bocharov, K. Svore, and N. Wiebe, “Circuit-centric quantum classifiers,” Physical Review A, vol. 101, p. 032308, 2020.
- [58] C.-C. Chen, M. Watabe, K. Shiba, M. Sogabe, K. Sakamoto, and T. Sogabe, “On the expressibility and overfitting of quantum circuit learning,” ACM Transactions on Quantum Computing, vol. 2, no. 2, p. 8, 2021.
- [59] Y. Du, M.-H. Hsieh, T. Liu, S. You, and D. Tao, “Learnability of quantum neural networks,” PRX Quantum, vol. 2, p. 040337, 2021.
- [60] T. M. Apostol, Mathematical Analysis. Pearson Education, 1974, 2nd edition.
- [61] M. Mohri, A. Rostamizadeh, and A. Talwalkar, Foundations of machine learning, 2nd ed., Adaptive Computation and Machine Learning. MIT Press, Cambridge, MA, 2018.
- [62] V. Bergholm, J. Izaac, M. Schuld, C. Gogolin, S. Ahmed, V. Ajith, M. S. Alam, G. Alonso-Linaje, B. AkashNarayanan, A. Asadi, J. M. Arrazola, U. Azad, S. Banning, C. Blank, T. R. Bromley, B. A. Cordier, J. Ceroni, A. Delgado, O. D. Matteo, A. Dusko, T. Garg, D. Guala, A. Hayes, R. Hill, A. Ijaz, T. Isacsson, D. Ittah, S. Jahangiri, P. Jain, E. Jiang, A. Khandelwal, K. Kottmann, R. A. Lang, C. Lee, T. Loke, A. Lowe, K. McKiernan, J. J. Meyer, J. A. Montañez-Barrera, R. Moyard, Z. Niu, L. J. O’Riordan, S. Oud, A. Panigrahi, C.-Y. Park, D. Polatajko, N. Quesada, C. Roberts, N. Sá, I. Schoch, B. Shi, S. Shu, S. Sim, A. Singh, I. Strandberg, J. Soni, A. Száva, S. Thabet, R. A. Vargas-Hernández, T. Vincent, N. Vitucci, M. Weber, D. Wierichs, R. Wiersema, M. Willmann, V. Wong, S. Zhang, and N. Killoran, “Pennylane: Automatic differentiation of hybrid quantum-classical computations,” arXiv:1811.04968, 2018.
- [63] D. P. Kingma and J. Ba, “Adam: a method for stochastic optimization,” arXiv:1412.6980, 2014.
- [64] Dask Development Team, “Dask: Library for dynamic task scheduling,” https://dask.org, 2016.
补充材料
1 量子模型的 Lipschitz 界限
在本节中,我们研究量子模型的 Lipschitz 界限,如 (4) 所示。 我们首先导出一个 Lipschitz 界限,它不如 (5) 紧,但可以使用简单的串联参数来显示(第 1-A 节)。 接下来,在1-B节中,我们证明(5)确实是Lipschitz约束。
1-A 基于串联的简单 Lipschitz 绑定
在陈述结果之前,我们先介绍一下符号
| (18) |
Theorem 2.
以下是 的 Lipschitz 界限:
| (19) |
证明。
我们的证明依赖于这样一个事实:可以根据各个 Lipschitz 界限的乘积获得级联函数的 Lipschitz 界限。 准确地说,假设可以写成,其中表示串联,每个承认一个Lipschitz边界,。 然后,对于的任意输入参数,我们得到
| (20) |
现在,我们通过将 表示为三个函数的串联来证明 (19) 是 Lipschitz 约束
| (21) | ||||
| (22) | ||||
| (23) |
更准确地说,它认为
| (24) |
因此,任何一组 Lipschitz 边界 、、 对于三个函数 、、 产生 的 Lipschitz 界作为它们的乘积:
| (25) |
因此,在下文中,我们将导出各个 Lipschitz 边界 、 和 。
的利普希茨界限:
注意
| (26) |
使用,我们推断
| (27) |
因此, 是 的 Lipschitz 界。
的利普希茨界限:
从 [29,定理 2.2] 可以得出, 是 的 Lipschitz 界。
的利普希茨界限:
给定的线性形式,我们直接得到是Lipschitz界限。
∎
1-B 证明 (5) 是 Lipschitz 界限
我们首先导出参数化酉 上的 Lipschitz 界。 为此,我们计算其微分
| (28) | ||||
请注意,每个术语 都可以写为由以下定义的两个映射 和 的串联
| (29) | ||||
| (30) |
准确的说,是。 两个映射 和 的差异由下式给出
| (31) | ||||
其中 表示 在 处应用于 的微分,对于 也类似。 因此,我们有
| (32) | ||||
将其插入 (28),我们得到
| (33) |
因此,我们证明了映射 的雅可比行列式 由下式给出
| (34) |
利用 有单位范数, 是酉的,以及三角不等式, 的范数有界为
| (35) |
因此, 是 [60,p.1] 的 Lipschitz 界限。 356]。
2 完整版本和定理证明1
我们首先陈述一般监督学习设置的主要结果,然后将其应用于本文考虑的量子模型。 考虑一个监督学习设置,其中数据样本 根据某种概率分布 从 独立且相同地分布。我们定义 的 覆盖数如下。
Definition 2.1。
(adapted from [7, Definition 1]) We say that is an -cover of , if, for all , there exists such that . 的覆盖数为
| (36) |
对于通用模型 、损失函数 和训练数据 ,我们定义预期损失和经验损失:
| (37) |
和
| (38) |
分别。 以下结果说明了 的泛化界限。
Lemma 2.1.
认为
-
1.
损失是非负的并且承认Lipschitz界限,
-
2.
是紧凑的,使得 是有限的,并且
-
3.
是 的 Lipschitz 界限。
那么,对于任何 , 的泛化误差至少有 的概率,其界限为
| (39) | ||||
证明。
在下面的证明中,我们引用了 -robustness 的概念(改编自 [7, 定义 2]):分类器 对于 和 是 -robust 的,如果 可以划分为 不相邻的集合(用 表示),且以下条件成立:对于所有 、、,如果 ,则
| (40) |
此属性在以下意义上量化了 的鲁棒性:集合 可以划分为多个子集,这样,如果新抽取的样本 位于与测试样本 位于同一子集中,则它们的相关损失值很接近。 现在让我们继续注意,对于任何 、 和 ,它认为
| (41) | ||||
其中我们分别使用 的 Lipschitz 界 、三角不等式以及 的 Lipschitz 界 。 使用[7,定理6],我们推断对于所有都是鲁棒的。 现在从[7,定理1]得出,对于任何,概率至少为不等式(39 ) 成立。 ∎
Theorem 2.1.
认为
-
1.
损失是非负的并且承认Lipschitz界限和
-
2.
是紧凑的,使得 是有限的。
那么,对于任何 , 的泛化误差至少有 的概率,其界限为
| (42) |
3 数字:设置和进一步结果
3-A 数值设定
这项工作中的所有数值模拟都是使用 Python QML 库 PennyLane [62] 执行的。 作为设备,我们使用无噪声模拟器“lightning.qubit”以及伴随微分方法,以实现快速且内存高效的梯度计算。 为了解决 (9) 中的优化问题,我们使用学习率 和所有其他超参数的建议值 [63] 应用 ADAM 优化器。 此外,我们始终运行 epoch,并根据不同的初始参数训练 模型,以适应不同的正则化参数 。 添加正则化不会引入显着的计算开销,因为成本的评估仅涉及项的加权和。 作为最终模型,我们采用所有运行和历元中成本最小的模型参数集。 此外,使用 Dask [64] 并行化训练以及鲁棒性和泛化分析。
对于可训练的编码模型,经典数据被编码到具有由 3 个欧拉角 参数化的通用 单位的量子电路中,
| (45) | ||||
| (46) | ||||
| (47) |
PennyLane中的是通过以下分解实现的
| (48) | ||||
| (49) |
在我们的数值案例研究中,我们为所有 设置 ,因为这 1) 仍然允许到达布洛赫球上的任意点,2) 可以更轻松地与固定编码量子模型进行比较。 为了以硬件高效的方式引入纠缠,我们使用 CNOT 环。 图 4 所示的电路涉及三层旋转和纠缠,我们观察到这是表达性和泛化性之间的良好权衡。 更准确地说,在我们的模拟中,较少的层不足以准确地解决分类任务,而更多的层会导致更高程度的过度拟合。 对于 (16) 中的固定编码量子模型,我们使用类似的 层 ansatz,将 2D 数据点的两个条目编码为第一和第二角度旋转门的 、,然后是具有三个自由参数的参数化 旋转。 我们还执行经典的数据预处理,将输入域从 缩放到 ,以便可以利用旋转角度的全部可能范围。
在图6中,我们绘制了与和对应的两个量子模型的基本事实和决策边界。 正如预期的那样,正则化训练产生的决策边界比非正则化训练产生的决策边界明显更平滑,这解释了前者具有卓越的鲁棒性和泛化性。
3-B 具有固定编码的量子模型的正则化
在正文中,我们看到(16)中具有固定编码的量子模型的Lipschitz界限不能通过改变参数来适应>。 因此,不可能使用 Lipschitz 界限正则化来提高鲁棒性和泛化性。 接下来,我们研究是否可以使用 的正则化来提高泛化性能。 更准确地说,我们考虑与图 3 中所示的可训练编码的泛化结果相同的数值设置。 主要区别在于我们考虑固定编码量子模型 ,它通过以下正则化训练问题进行训练
| (50) |
使用超参数进行正则化旨在保持角度的范数较小。 图7描述了不同正则化参数的结果量子模型的测试精度和Lipschitz界限。 首先,请注意,由于固定编码,对于 的所有选择,Lipschitz 界限确实是恒定的。 比较图 3 和 7,我们发现可训练编码与固定编码相比具有显着更高的测试精度。 此外,固定编码的正则化参数对测试精度的影响远不如可训练编码那么明显,这证实了我们之前关于可训练编码优点的讨论。 测试精度并不完全独立于 ,因为 1) 参数 的正则化会影响优化并可以改善或恶化收敛性,2) 使 偏向如果通过具有小值 的量子模型更好地近似底层真实分布,那么零可能是有益的。 然而,2) 是否带来实际好处是高度针对特定问题的,因为它取决于生成数据的分布和电路模拟。