图与大型语言模型的综述:进展和未来方向
摘要
图在表示和分析现实应用程序(例如引文网络、社交网络和生物数据)中的复杂关系方面发挥着重要作用。 最近,在各个领域取得巨大成功的大型语言模型(大语言模型)也被用于图相关任务,以超越传统的基于图神经网络(GNN)的方法并产生最先进的性能。 在本次调查中,我们首先对现有的大语言模型与图相结合的方法进行了全面的回顾和分析。 首先,我们提出了一种新的分类法,根据大语言模型在图相关任务中所扮演的角色(即增强器、预测器和对齐组件)将现有方法分为三类。 然后我们系统地调查了分类法三个类别的代表性方法。 最后,我们讨论了现有研究的剩余局限性,并强调了未来研究的有希望的途径。 相关论文进行了总结,并将持续更新:https://github.com/yhLeeee/Awesome-LLMs-in-Graph-tasks。
1简介
图或图论是现代世界众多领域的基础组成部分,特别是在技术、科学和物流领域(Ji 等人,2021)。 图数据表示节点之间的结构特征,从而阐明图组件内的关系。 许多现实世界的数据集,例如引文网络(Sen等人,2008),社交网络(Hamilton等人,2017)和分子(Wu等)人,2018),本质上是用图表来表示的。 为了解决与图相关的任务,图神经网络(GNN)(Kipf 和 Welling,2016;Velickovic 等人,2018) 已成为处理和分析图数据的最流行的选择之一。 GNN 的主要目标是通过节点之间的递归消息传递和聚合机制,获取不同类型下游任务的节点、边缘或图级别的表达表示。
近年来,Transformers (Vaswani 等人,2017)、BERT (Kenton and Toutanova,2019)等大型语言模型取得了重大进展。 、GPT (Brown 等人, 2020) 及其变体。 这些大语言模型可以轻松应用于各种下游任务,几乎不需要任何调整,在情感分析、机器翻译和文本分类等各种自然语言处理任务中表现出出色的性能(Zhao等人,2023d)。 虽然他们的主要关注点是文本序列,但人们越来越有兴趣增强大语言模型的多模态功能,使其能够处理包括图形在内的多种数据类型(Chai 等人,2023)、图片(Zhang 等人, 2023b)、视频(Zhang 等人, 2023a)。
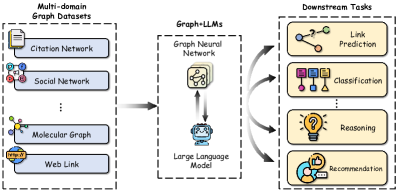
大语言模型帮助图形相关的任务。 在大语言模型的帮助下,我们与图形交互的方式发生了显着的转变,特别是那些包含与文本属性相关的节点的图形。 如图1所示,图和大语言模型的集成展示了跨无数图域的各种下游任务的成功。 将大语言模型与传统 GNN 集成可以互惠互利并增强图学习。 虽然 GNN 擅长捕获结构信息,但它们主要依赖语义约束的嵌入作为节点特征,限制了它们表达节点全部复杂性的能力。 结合大语言模型,GNN 可以通过更强大的节点特征来增强,从而有效地捕获结构和上下文方面。 另一方面,大语言模型擅长对文本进行编码,但常常难以捕获图形数据中存在的结构信息。 将 GNN 与大语言模型相结合,可以利用大语言模型强大的文本理解能力,同时利用 GNN 捕获结构关系的能力,从而实现更全面、更强大的图学习。 例如,TAPE (He 等人, 2023) 利用与大语言模型生成的节点(即论文)相关的语义知识来提高 GNN 中初始节点嵌入的质量。 此外,InstructGLM (Ye 等人, 2023) 用大语言模型取代了 GNN 中的预测器,通过扁平化图形和设计指令提示等技术来利用自然语言的表达能力。 MoleculeSTM (Liu 等人, 2022) 将 GNN 和大语言模型对齐到同一向量空间,将文本知识引入图(即分子)中,从而提高推理能力。
0-1=
Graph Meets Large Language Model
很明显,从不同角度来看,大语言模型对图相关任务都有显着影响。 为了获得更好的系统概述,如图2所示,我们按照Chen 等人(2023a)来组织我们的第一级分类法,根据角色进行分类(即、增强器、预测器和对齐组件)由大语言模型在整个模型流程中发挥作用。 我们进一步完善我们的分类法,并为初始类别引入更多粒度。
动机。 尽管大语言模型越来越多地应用于图相关任务,但这个快速扩展的领域仍然缺乏系统的综述。 Zhang 等人 (2023d) 进行了一项前瞻性调查,提出了一篇透视论文,讨论了图与大语言模型集成相关的挑战和机遇。 Liu 等人 (2023b) 提供了另一项相关调查,总结了现有的图基础模型,并概述了预训练和适应策略。 然而,它们在全面覆盖方面都有局限性,并且缺乏专门关注大语言模型如何增强图形的分类法。 相比之下,我们专注于图和文本模态共存的场景,并提出更细粒度的分类法来系统地回顾和总结图相关任务的大语言模型技术的现状。
贡献。 这项工作的贡献可以概括为以下三个方面。 (1) 结构化分类法。 通过结构化分类法对该领域进行了广泛的概述,该分类法将现有作品分为四类(图2)。 (2) 全面审查。 基于所提出的分类法,系统地描述了图相关任务的大语言模型的当前研究进展。 (3) 一些未来的方向。 我们讨论现有工作的剩余局限性并指出未来可能的方向。
2 初步
在本节中,我们首先介绍与本次调查相关的两个关键领域的基本概念,即 GNN 和大语言模型。 接下来,我们对新提出的分类法进行简要介绍。
2.1图神经网络
定义。 大多数现有的 GNN 遵循包含消息聚合和特征更新的消息传递范式,例如 GCN (Kipf 和 Welling,2016) 和 GAT (Velickovic 等人,2018) 。 它们通过迭代聚合邻居信息并使用非线性函数更新它们来生成节点表示。 前向过程可以定义为:
其中是第层节点的特征向量,是节点的邻居节点集合。 表示聚合邻居信息的消息传递函数,表示以中心节点特征和邻居节点特征为输入的更新函数。 通过堆叠多个层,GNN 可以聚合来自高阶邻居的消息。
图预训练和提示。 虽然 GNN 在图机器学习方面取得了一些成功,但它们需要昂贵的注释,并且几乎无法泛化到看不见的数据。 为了弥补这些缺陷,图预训练的目的是为图模型提取一些通用知识,以便在没有显着成本的情况下轻松处理不同的任务。 目前主流的图相关方法可以分为对比方法和生成方法。 例如,GraphCL (You 等人, 2020) 和 GCA (Zhu 等人, 2021) 遵循对比学习框架并最大化两个增强视图之间的一致性。 Sun 等人 (2023b) 将对比思想扩展到超图。 GraphMAE (Hou 等人, 2022)、S2GAE (Tan 等人, 2023a) 和 WGDN (Cheng 等人, 2023) 掩盖了图的组成部分并尝试重建原始数据。 “预训练和微调”的典型学习方案是基于预训练任务和下游任务共享一些共同的内在任务空间的假设。 相反,在 NLP 领域,研究人员逐渐关注“预训练、提示和微调”的新范式,其目的是重新表述输入数据以适应借口。 这个想法也自然地应用到了图学习领域。 GPPT (Sun 等人, 2022) 首先通过掩模边缘预测来预训练图模型,然后将独立节点修改为词符对,并将下游分类重新表述为边缘预测任务。 此外,All in One(Sun等人,2023a)提出了一种多任务提示框架,统一了图形提示和语言提示的格式。
2.2 大型语言模型
定义。 虽然目前大语言模型(Shayegani 等人, 2023)还没有明确的定义,但这里我们对本次调查中提到的大语言模型给出具体的定义。 关于大语言模型的两项有影响力的调查(Zhao 等人, 2023d; Yang 等人, 2023)从模型大小和训练方法的角度区分了大语言模型和预训练语言模型(PLM) 。 具体来说,大语言模型是指那些经过大量数据预训练的巨大语言模型(即十亿级),而PLM是指早期预训练的参数大小适中(即百万级)的模型。 level),可以轻松地对特定于任务的数据进行进一步微调,以获得下游任务更好的结果。 由于GNN的参数量相对较小,将GNN和大语言模型结合起来通常不需要大参数的大语言模型。 因此,我们按照Liu 等人(2023b)的思路,将本次调查中大语言模型的定义扩展为涵盖之前调查中定义的大语言模型和PLM。
进化。 大语言模型可以根据非自回归和自回归语言模型分为两类。 非自回归大语言模型通常专注于自然语言理解,并采用“掩码语言建模”预训练任务,而自回归大语言模型更关注自然语言生成,经常利用“下一个词符预测”目标作为其基础任务。 经典的仅编码器模型,例如 BERT (Kenton 和 Toutanova,2019)、SciBERT (Beltagy 等人,2019) 和 RoBERTa (Liu 等人,2019) )属于非自回归大语言模型范畴。 近年来,自回归大语言模型不断发展。 示例包括基于编码器-解码器结构以及 GPT 构建的 Flan-T5 (Chung 等人, 2022) 和 ChatGLM (Zeng 等人, 2022) -3 (Brown 等人, 2020)、PaLM (Chowdhery 等人, 2022)、卡拉狄加 (Taylor 等人, 2022), 以及LLaMA (Touvron 等人, 2023),基于仅解码器架构。 值得注意的是,大语言模型架构和训练方法的进步催生了新兴能力(Wei等人,2022a),即通过一些方法处理少样本或零样本场景中的复杂任务的能力情境学习(Radford等人,2021;Dong等人,2022)和思维链(Wei等人,2022b)等技术。
2.3 建议的分类法
我们提出了一种分类法(如图 2 所示),将涉及图形和文本模态的代表性技术组织为三个主要类别:(1) 大语言模型作为增强器,其中大语言模型用于增强 GNN 的分类性能。 (2) 大语言模型作为预测器,其中大语言模型利用输入的图结构信息进行预测。 (3) GNN-LLM Alignment,其中大语言模型通过对齐技术在语义上增强 GNN。 我们注意到,在某些模型中,由于大语言模型的参与很少,因此很难将它们分为这三个主要类别。 因此,我们将它们单独组织到“其他”类别中,并在图2中给出了它们的具体角色。 例如,LLM-GNN (Chen 等人, 2023b) 主动选择 ChatGPT 的节点进行注释,从而利用大语言模型作为注释器来增强 GNN 训练。 GPT4GNAS (Wang 等人, 2023a) 将大语言模型视为图神经架构搜索任务中经验丰富的控制器。 它利用 GPT-4 (OpenAI,2023) 来探索搜索空间并生成新颖的 GNN 架构。 此外,ENG (Yu 训练等人, 2023) 使大语言模型能够作为样本生成器生成带有标签的额外样本,为 GNN 提供足够的监督信号。
在以下部分中,我们分别针对将大语言模型纳入图相关任务的分类法的三个主要类别进行了全面的调查。
3 LLM 作为增强者
GNN 已成为分析图结构数据的强大工具。 然而,最主流的基准数据集(例如 Cora (Yang 等人, 2016) 和 Ogbn-Arxiv (Hu 等人, 2020))采用朴素的方法来编码文本使用浅嵌入的标签中的信息,例如词袋、skip-gram (Mikolov 等人, 2013) 或 TF-IDF (Salton and Buckley, 1988)。 这不可避免地限制了 GNN 在 TAG 上的性能。 LLM作为增强器方法对应于在强大的大语言模型的帮助下增强节点嵌入的质量。 派生的嵌入附加到图结构以供任何 GNN 使用或直接输入到下游分类器中以执行各种任务。 我们自然地将这些方法分为两个分支:基于解释的和基于嵌入的,具体取决于它们是否使用大语言模型来产生额外的文本信息。
3.1 基于解释的增强
为了丰富文本属性,基于解释的增强方法侧重于利用大语言模型强大的零样本能力来捕获更高层次的信息。 如图3(a)所示,它们通常促使大语言模型生成语义丰富的附加信息,例如解释、知识实体和伪标签。 典型的管道如下:
其中为原始文本属性,为设计的文本提示,为大语言模型附加文本输出, 和 表示节点 的增强初始节点嵌入,维度为 和嵌入矩阵,以及邻接矩阵 通过 GNN 获取节点表示 ,其中 是表示的维度。 例如,TAPE (He 等人, 2023) 是基于解释的增强的开创性工作,它促使大语言模型生成解释和伪标签来增强文本属性。 之后,相对较小的语言模型在原始文本数据和解释上进行微调,以将文本语义信息编码为初始节点嵌入。 Chen 等人 (2023a) 探索大语言模型在图学习方面的潜在能力。 他们首先将嵌入可见大语言模型与浅嵌入方法进行比较,然后提出 KEA 来丰富文本属性。 KEA 提示大语言模型生成知识实体列表以及文本描述,并通过微调的 PLM 和深度句子嵌入模型对其进行编码。 LLM4Mol (Qian 等人, 2023)尝试利用大语言模型辅助分子性质预测。 具体来说,它使用大语言模型为原始 SMILES 生成语义丰富的解释,然后微调小规模语言模型来执行下游任务。 LLMRec (Wei 等人, 2023)旨在利用大语言模型来解决图推荐系统中的数据稀疏性和数据质量问题。 它强化了用户-项目交互边缘并通过大语言模型生成用户/项目边信息。 最后,它采用轻量级 GNN (He 等人,2020) 对增强推荐网络进行编码。
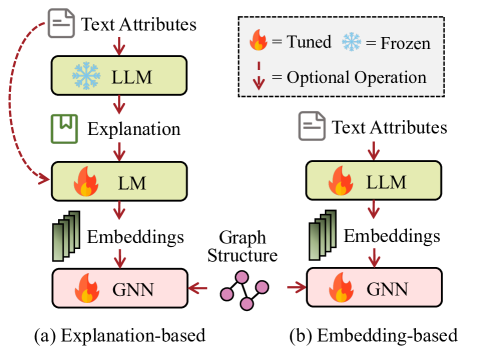
3.2 基于嵌入的增强
参见图3(b),基于嵌入的增强方法直接利用大语言模型输出文本嵌入作为GNN训练的初始节点嵌入:
这种方法需要使用嵌入可见或开源的大语言模型,因为它需要直接访问文本嵌入和带有结构信息的较大语言模型。 当前许多先进的大语言模型(例如GPT4 (OpenAI,2023)和PaLM (Chowdhery等人,2022))都是闭源的,仅提供在线服务。 严格的限制阻止研究人员访问其参数和输出嵌入。 此类方法大多采用级联形式,利用结构信息辅助语言模型进行预训练或微调。 通常,GALM (Xie 等人,2023) 在给定的大型图语料库上预训练 PLM 和 GNN 聚合器,以捕获可以最大限度地提高大规模应用程序效用的信息然后针对特定的下游应用程序对框架进行微调,以进一步提高性能。
有几项工作旨在通过将结构信息纳入大语言模型的微调阶段来生成节点嵌入。 具有代表性的是,GIANT (Chien 等人, 2021) 通过一种新颖的自监督学习框架对语言模型进行了微调,该框架采用 XR-Transformers 来解决链接预测上的极端多标签分类问题。 SimTeG (Duan 等人, 2023) 和 TouchUp-G (Zhu 等人, 2023) 遵循类似的方式,它们都通过类似链接预测的方法来构建 PLM帮助他们感知结构信息。 它们之间的细微区别在于,TouchUp-G 在链路预测期间使用负采样,而 SimTeG 采用参数高效的微调来加速微调过程。 G-Prompt (Huang 等人, 2023b) 在 PLM 末端引入了图形适配器,以帮助提取图形感知节点特征。 一旦经过训练,特定于任务的提示就会被合并起来,为各种下游任务生成可解释的节点表示。 WalkLM (Tan 等人, 2023b) 是一种无监督的通用图表示学习方法。 第一步是在图上生成归因随机游走,并通过自动文本化程序组成大致有意义的文本序列。 第二步是使用文本序列构建大语言模型并从大语言模型中提取表示。 METERN (Jin 等人, 2023b) 引入关系先验标记来捕获特定于关系的信号,并使用一种语言编码器来对跨关系的共享知识进行建模。 LEADING (Xue 等人, 2023) 有效地微调大语言模型,并将大语言模型中的风险知识转移到下游 GNN 模型,计算成本和内存开销较小。
最近的一项工作 OFA (Liu 等人, 2023a) 尝试提出一种通用的图学习框架,可以利用单个图模型进行自适应下游预测。 它使用人类可读的文本描述所有节点和边,并通过大语言模型将它们从不同的域编码到同一空间中。 随后,该框架通过将特定于任务的提示子结构插入到输入图中来自适应地执行不同的任务。
3.3讨论
LLM 作为增强器的方法在 TAG 上表现出了卓越的性能,能够有效地捕获文本和结构信息。 此外,它们还表现出很强的灵活性,因为 GNN 和大语言模型是即插即用的,使它们能够利用最新的技术来解决遇到的问题。 此类方法(特别是基于解释的增强)的另一个优点是,它们为使用闭源大语言模型辅助图形相关任务铺平了道路。 然而,尽管一些论文声称具有强大的可扩展性,但实际上,LLM 作为增强器的方法在处理大规模数据集时会带来巨大的开销。 以基于解释的方法为例,对于具有 个节点的图,他们需要查询大语言模型的 API 次,这确实是一个巨大的成本。
4 LLM 作为预测器
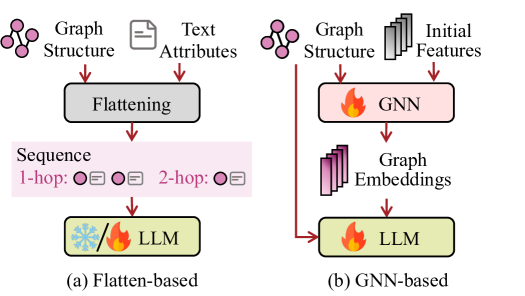
该类别背后的核心思想是利用大语言模型在统一的生成范式中对各种与图相关的任务(例如分类和推理)进行预测。 然而,将大语言模型应用于图模态面临着独特的挑战,主要是因为图数据通常缺乏到顺序文本的直接转换,因为不同的图以不同的方式定义结构和特征。 在本节中,我们将模型大致分为基于 flatten 和基于 GNN 的预测,具体取决于它们是否使用 GNN 来提取大语言模型的结构特征。
4.1 基于扁平化的预测
大多数现有的利用大语言模型作为预测器的尝试都采用将图扁平化为文本描述的策略,这有利于大语言模型通过文本序列直接处理图数据。 如图4(a)所示,基于展平的预测通常涉及两个步骤:(1)利用展平函数来变换图将结构转换为节点或标记序列,然后应用解析函数从(2)生成的输出中检索预测标签大语言模型,如下图:
其中 、、 和 表示节点、边、节点文本属性和边文本属性的集合,分别。 表示当前图形任务的指令提示,是预测标签。
模型的解析策略通常是标准化的。 例如,鉴于大语言模型的输出经常涉及其推理和逻辑过程,特别是在思想链(CoT)场景中,一些作品(Fatemi等人,2023;Zhao等人,2023c; Chen 等人,2023a;Guo 等人,2023;Liu 等人,2023b) 利用正则表达式从输出中提取预测标签。 部分模型(Chen 等人, 2023a; Fatemi 等人, 2023; Wang 等人, 2023b; Chai 等人, 2023; Huang 等人, 2023a)进一步设定了大语言模型的解码温度,以减少大语言模型预测的方差,获得更可靠的结果。 另一个方向是将图任务制定为多选问答问题(Robinson and Wingate,2022),其中指示大语言模型在提供的选项中选择正确的答案。 例如,有些作品(黄等人, 2023a; 胡等人, 2023; 施等人, 2023)通过在零样本设置中的提示中给出选择和附加指令来约束大语言模型的输出格式,例如“不要为你的答案给出任何推理或逻辑”。 此外,还有一些方法,如GIMLET (Zhao 等人, 2023a) 和 InstructGLM (Ye 等人, 2023)、分布式大语言模型等直接输出预测标签,使他们能够提供准确的预测,而无需额外的解析步骤。
与解析策略相比,展平策略可能表现出显着的变化。 下面我们根据大语言模型参数是否更新来整理扁平化的方法。
4.1.1 LLM 冻结
GPT4Graph (Guo 等人, 2023) 使用 GML (Himsolt, 1997) 和 GraphML (Brandes 等人, 2013) 等图描述语言来表示图形。 这些语言提供标准化语法和语义来表示图中的节点和边。 受语言语法树(Chiswell and Hodges,2007)的启发,GraphText (Zhao等人,2023c)利用图语法树将图结构转换为节点序列,然后将其输入大语言模型进行免训练图推理。 此外,ReLM (Shi 等人,2023)使用简化的分子输入行输入系统(SMILES)字符串来提供分子图结构的一维线性化。 图数据还可以通过邻接矩阵和邻接表等方法来表示。 几种方法(Wang等人,2023b;Fatemi等人,2023;Liu和Wu,2023;Zhang等人,2023c)直接采用数字组织的节点和边列表来以纯文本形式描述图数据。 GraphTMI (Das 等人, 2023)进一步探索了主题和图像等不同模态,将图数据与大语言模型集成。
相反,使用自然叙述来表达图形结构也在稳步取得进展。 Chen 等人 (2023a) 和 Hu 等人 (2023) 都将引文网络的结构信息整合到提示中,这是通过通过单词“cite”并使用论文索引或标题表示节点。 另一方面,Huang 等人(2023a)没有使用“cite”一词来表示边,而是通过枚举随机选择的跳邻居来描述关系当前节点。 此外,GPT4Graph (Guo 等人, 2023) 和 Chen 等人 (2023a) 模仿 GNN 的聚合行为,将当前邻居的属性总结为附加输入,旨在提供更多的结构信息。 值得注意的是,Fatemi 等人 (2023) 研究了各种表示节点和边的方法,总共检查了 11 种策略。 例如,它们使用索引或字母来表示节点,并应用箭头或括号来表示边缘。
4.1.2 LLM 调整
GIMLET (Zhao 等人, 2023a) 采用基于距离的位置嵌入来扩展大语言模型感知图结构的能力。 在对图进行位置编码时,GIMLET将两个节点的相对位置定义为图中两个节点之间的最短距离,这在图变换器的文献中得到了广泛的应用(Ying等人,2021)。 与黄等人(2023a)类似,InstructGLM (叶等人, 2023)根据最大跳数设计了一系列可扩展的提示。 这些提示允许中央纸节点通过利用以自然语言表达的所描述的连接关系,与其邻居建立直接关联,直至任何所需的跳跃级别。

4.2 基于GNN的预测
GNN 在通过节点之间的递归信息交换和聚合来理解图结构方面表现出了令人印象深刻的能力。 如图4(b)所示,与基于扁平化的预测(将图数据转换为文本描述作为大语言模型的输入)相比,基于GNN的预测利用了GNN的优势,将固有的大语言模型的图数据中存在结构特征和依赖关系,使大语言模型具有结构感知能力,如下所示:
其中 表示节点嵌入矩阵, 是邻接矩阵, 表示与图关联的结构感知嵌入。 基于 GNN 的预测还依赖于解析器从大语言模型中提取输出。 然而,将 GNN 表示集成到大语言模型中通常需要调整,通过在训练期间提供所需的输出,可以更轻松地标准化大语言模型的预测格式。
人们提出了各种策略来融合 GNN 学习的结构模式和大语言模型捕获的上下文信息。 例如,GIT-Mol (Liu 等人, 2023c) 和 MolCA (Liu 等人, 2023d) 都实现了 BLIP-2 的 Q-Former (Li 等人, 2023a) 作为跨模式投影仪,将图形编码器的输出映射到大语言模型的输入文本空间。 采用具有不同注意屏蔽策略的多个目标来实现有效的图文交互。 GraphLLM (Chai 等人, 2023) 通过在前缀调整期间对图表示应用线性投影来导出图增强前缀,从而使大语言模型能够与图 Transformer 协同合并关键的结构信息进行图形推理。 此外,GraphGPT (Tang 等人, 2023) 和 InstructMol (Cao 等人, 2023) 都采用简单的线性层作为轻量级对齐投影仪来映射编码的图形表示一些图形标记,而大语言模型擅长将这些标记与不同的文本信息对齐。 DGTL (Qin 等人, 2023) 将解纠缠的图嵌入直接注入到大语言模型的每一层中,突出显示图的拓扑和语义的不同方面。
4.3讨论
直接利用大语言模型作为预测器在处理图的文本属性方面显示出优越性,特别是与传统的 GNN 相比,实现了显着的零样本性能。 最终目标是开发和完善将图结构信息编码为大语言模型可以有效理解和操作的格式的方法。 基于 Flatten 的预测可能在有效性方面具有优势,而基于 GNN 的预测往往更有效。 在基于扁平化的预测中,大语言模型的输入长度限制限制了每个节点只能在几跳内访问其邻居,这使得捕获远程依赖关系变得具有挑战性。 此外,如果没有 GNN 的参与,GNN 的固有问题(例如异质性)就无法解决。 另一方面,对于基于 GNN 的预测,训练一个额外的 GNN 模块并将其插入到大语言模型中进行联合训练是具有挑战性的,因为深度 Transformer 的早期层存在梯度消失的问题(Zhao等人, 2023a; 秦等人, 2023).
5 GNN-LLM 对齐
对齐 GNN 和大语言模型的嵌入空间是将图模态与文本模态集成的有效方法。 GNN-LLM 对齐可确保保留每个编码器的独特功能,同时在特定阶段协调其嵌入空间。 在本节中,我们总结了 GNN 和大语言模型的对齐技术,可以将其分为对称或不对称,具体取决于 GNN 和大语言模型是否同等重视,或者一种模式是否优先于另一种模式。
5.1对称
对称对齐是指在对齐过程中平等对待图形和文本模态。 这些方法确保两种模式的编码器在各自的应用中实现可比较的性能。
典型的对称对齐架构如图5(a)所示,采用双塔风格,采用单独的编码器对图形和文本进行单独编码。 请注意,在对齐过程中,两种模式仅交互一次。 一些方法,例如 SAFER (Chandra 等人,2020),在这些单独的嵌入上使用简单的串联。 然而,这种方法无法实现结构信息和文本信息的无缝融合,从而导致两种模式的松散耦合集成。 因此,大多数两塔式模型利用对比学习技术来促进对齐,类似于 CLIP (Radford 等人,2021) 用于对齐视觉和语言模态。 一般来说,这些方法包括两个步骤。 第一步是特征提取,获得图形表示和文本表示。 第二步涉及使用对比学习过程和修改后的 InfoNCE 损失 (Oord 等人, 2018),用以下等式描述:
其中表示特定图形的表示,而表示图形相应文本的表示。 表示评分函数,为正对分配高值,为负对分配低值。 是温度参数, 表示训练数据集中的图表数量。 两个编码器的参数都根据对比损失通过反向传播进行更新。
| Model | GNN | LLM | Predictor | Fine-tuning | Prompting | Domain | Task | Code | |
| LLM as Enhancer | GIANT (Chien et al., 2021) | SAGE, RevGAT, etc. | BERT | GNN | ✗ | ✗ | Citation, Co-purchase | Node | Link |
| GALM (Xie et al., 2023) | RGCN, RGAT | BERT | GNN | ✓ | ✗ | E-Commerce, Recommendation | Node, Link | - | |
| TAPE (He et al., 2023) | RevGAT | ChatGPT | GNN | ✗ | ✓ | Citation | Node | Link | |
| Chen et al. (Chen et al., 2023a) | GCN, GAT | ChatGPT | GNN | ✗ | ✓ | Citation, Co-purchase | Node | - | |
| LLM4Mol (Qian et al., 2023) | - | ChatGPT | LM | ✗ | ✗ | Molecular | Graph | Link | |
| SimTeG (Duan et al., 2023) | SAGE, RevGAT, SEAL | allMiniLM-L6-v2, etc. | GNN | ✓♡ | ✗ | Citation, Co-purchase | Node, Link | Link | |
| G-Prompt (Huang et al., 2023b) | SAGE, RevGAT | RoBERTa-Large | GNN | ✓ | ✓ | Citation, Social | Node | - | |
| TouchUp-G (Zhu et al., 2023) | SAGE, MB-GCN, etc. | BERT | GNN | ✓ | ✗ | Citation, Co-purchase, Recommendation | Node, Link | - | |
| OFA (Liu et al., 2023a) | R-GCN | Sentence-BERT | GNN | ✗ | ✓ | Citation, Web link, Knowledge, Molecular | Node, Link, Graph | Link | |
| LLMRec (Wei et al., 2023) | LightGCN | ChatGPT | GNN | ✗ | ✓ | Recommendation | Recommendation | Link | |
| WalkLM (Tan et al., 2023b) | - | DistilRoBERTa | MLP | ✓ | ✗ | Knowledge | Node, Link | Link | |
| METERN (Jin et al., 2023b) | - | BERT | LM | ✓ | ✗ | Citation, E-Commerce | Node | - | |
| LEADING (Xue et al., 2023) | GCN, GAT | BERT | GNN | ✓ | ✗ | Citation | Node | - | |
| LLM as Predictor | NLGraph (Wang et al., 2023b) | - | Text-davinci-003 | LLM | ✗ | ✓ | - | Reasoning | Link |
| GPT4Graph (Guo et al., 2023) | - | Text-davinci-003 | LLM | ✗ | ✓ | - | Reasoning, Node, Graph | Link | |
| GIMLET (Zhao et al., 2023a) | - | T5 | LLM | ✓/✗ | ✓ | Molecular | Graph | Link | |
| Chen et al. (Chen et al., 2023a) | - | ChatGPT | LLM | ✗ | ✓ | Citation | Node | Link | |
| GIT-Mol (Liu et al., 2023c) | GIN | MolT5 | LLM | ✓♡ | ✓ | Molecular | Graph, Captioning | - | |
| InstructGLM (Ye et al., 2023) | - | FLAN-T5/LLaMA-v1 | LLM | ✓♡ | ✓ | Citation | Node | Link | |
| Liu et al. (Liu and Wu, 2023) | - | GPT-4, etc. | LLM | ✗ | ✓ | - | Reasoning | Link | |
| Huang et al. (Huang et al., 2023a) | - | ChatGPT | LLM | ✗ | ✓ | Citation, Co-purchase | Node | Link | |
| GraphText (Zhao et al., 2023c) | - | ChatGPT/GPT-4 | LLM | ✗ | ✓ | Citation, Web link | Node | - | |
| Fatemi et al. (Fatemi et al., 2023) | - | PaLM/PaLM 2 | LLM | ✗ | ✓ | - | Reasoning | - | |
| GraphLLM (Chai et al., 2023) | Graph Transformer | LLaMA-v2 | LLM | ✓♡ | ✓ | - | Reasoning | Link | |
| Hu et al. (Hu et al., 2023) | - | ChatGPT/GPT-4 | LLM | ✗ | ✓ | Citation, Knowledge, Social | Node, Link, Graph | - | |
| MolCA (Liu et al., 2023d) | GINE | Galactica/MolT5 | LLM | ✓♡ | ✓ | Molecular | Graph, Retrieval, Captioning | Link | |
| GraphGPT (Tang et al., 2023) | Graph Transformer | Vicuna | LLM | ✓♡ | ✓ | Citation | Node | Link | |
| ReLM (Shi et al., 2023) | TAG, GCN | Vicuna/ChatGPT | LLM | ✗ | ✓ | Molecular | Reaction Prediction | Link | |
| LLM4DyG (Zhang et al., 2023c) | - | Vicuna/LLaMA-v2/ChatGPT | LLM | ✗ | ✓ | - | Reasoning | - | |
| DGTL (Qin et al., 2023) | Disentangled GNN | LLaMA-v2 | LLM | ✓ | ✓ | Citation, E-Commerce | Node | - | |
| GraphTMI (Das et al., 2023) | - | GPT-4/GPT-4V | LLM | ✗ | ✓ | Citation | Node | - | |
| InstructMol (Cao et al., 2023) | GIN | Vicuna | LLM | ✓♡ | ✓ | Molecular | Graph, Captioning | Link | |
| GNN-LLM Alignment | SAFER(Chandra et al., 2020) | GCN, GAT, etc. | RoBERTa | Linear | ✓ | ✗ | News | Node | Link |
| GraphFormers (Yang et al., 2021) | Graph Transformer | UniLM | LLM | ✓ | ✗ | Citation, E-Commerce, Knowledge | Link | Link | |
| Text2Mol(Edwards et al., 2021) | GCN | SciBERT | GNN/LLM | ✓ | ✗ | Molecular | Retrieval | Link | |
| MoMu (Su et al., 2022) | GIN | BERT | GNN/LLM | ✓ | ✗ | Molecular | Graph, Retrieval | Link | |
| MoleculeSTM (Liu et al., 2022) | GIN | BERT | GNN/LLM | ✓ | ✗ | Molecular | Graph, Retrieval | Link | |
| GLEM (Zhao et al., 2022) | SAGE, RevGAT, etc. | DeBERTa | GNN/LLM | ✓ | ✗ | Citation, Co-purchase | Node | Link | |
| GRAD (Mavromatis et al., 2023) | SAGE | SciBERT/DistilBERT | LLM | ✓ | ✗ | Citation, Co-purchase | Node | Link | |
| G2P2 (Wen and Fang, 2023) | GCN | Transformer | GNN/LLM | ✓ | ✓ | Citation, Recommendation | Node | Link | |
| Patton (Jin et al., 2023a) | Graph Transformer | BERT/SciBERT | Linear/LLM | ✓ | ✗ | Citation, E-Commerce | Node, Link, Retrieval, Reranking | Link | |
| ConGraT (Brannon et al., 2023) | GAT | all-mpnet-base-v2/DistilGPT2 | GNN/LLM | ✓ | ✗ | Citation, Knowledge, Social | Node, Link | Link | |
| THLM (Zou et al., 2023) | R-HGNN | BERT | LLM | ✓ | ✗ | Academic, Recommendation, Patent | Node, Link | Link | |
| GRENADE (Li et al., 2023b) | SAGE, RevGAT-KD, etc. | BERT | GNN/MLP | ✓ | ✗ | Citation, Co-purchase | Node, Link | Link | |
| RLMRec (Ren et al., 2023) | GCCF, LightGCN, etc. | ChatGPT, text-embedding-ada-002 | GNN/LLM | ✓ | ✗ | Recommendation | Node | Link | |
| Others | LLM-GNN (Chen et al., 2023b) | GCN, SAGE | ChatGPT | GNN | ✗ | ✓ | Citation, Co-purchase | Node | Link |
| GPT4GNAS (Wang et al., 2023a) | GCN, GIN, etc. | GPT-4 | GNN | ✗ | ✓ | Citation | Node | - | |
| ENG (Yu et al., 2023) | GCN, GAT | ChatGPT | GNN | ✗ | ✓ | Citation | Node | - |
Text2Mol (Edwards 等人, 2021) 提出了一种跨模态注意力机制来实现图和文本嵌入的早期融合。 Text2Mol 通过 Transformer 解码器实现,使用大语言模型的输出作为源序列,使用 GNN 的输出作为目标序列。 这种设置允许注意力机制学习多模态关联规则。 然后,解码器的输出用于对比学习,并与 GNN 处理后的输出配对。
MoMu (Su 等人, 2022)、MoleculeSTM (Liu 等人, 2022)、ConGraT (Brannon 等人, 2023) 和 RLMRec (Ren 等人, 2023) 具有类似的框架,采用配对图嵌入和文本嵌入来实现对比学习,但在细节上仍然存在差异。 MoMu 和 MoleculeSTM 都从 PubChem (Wang 等人,2009)收集分子。 前者从已发表的科学论文中检索相关文本,而后者则利用分子的相应描述。 ConGraT 将这种架构扩展到分子领域之外。 它在社交、知识和引文网络上验证了这种图文配对对比学习方法。 RLMRec 提出通过对比建模将大语言模型的语义空间与推荐系统中协作关系信号(指示用户-项目交互)的表示空间对齐。
G2P2 (Wen and Fang, 2023) 和 GRENADE (Li 等人, 2023b) 等多项研究进一步推进了对比法的使用学习。 具体来说,G2P2增强了对比学习的粒度,并在微调阶段引入了提示。 它在预训练阶段采用三个级别的对比学习:节点-文本、文本-文本摘要和节点-节点摘要,从而加强文本和图形表示之间的对齐。 在下游任务中使用提示,在少样本和零样本文本分类和节点分类任务中表现出强大的性能。 另一方面,GRENADE通过将以图为中心的对比学习与以图为中心的双层知识对齐相结合进行优化,其中包括节点级对齐和邻域级对齐。
与之前的方法相反,如图5(b)所示的迭代对齐方法平等地对待两种模态,但在训练过程中通过允许模态之间的迭代交互来区分自己。 例如,GLEM (Zhao 等人, 2022) 采用期望最大化 (EM) 框架,其中一个编码器迭代地为另一个编码器生成伪标签,使它们能够对齐其表示空间。
5.2不对称
对称对齐旨在对两种模式给予同等重视,而不对称对齐则侧重于允许一种模式辅助或增强另一种模式。 在当前的研究中,主要方法是利用 GNN 处理结构信息的能力来强化大语言模型。 这些研究可以分为两种类型:图嵌套 Transformer 和图感知蒸馏。
图5(c)中的Graphformer (Yang 等人, 2021) 所示的图嵌套 Transformer 通过将 GNN 集成到每个 Transformer 层来演示非对称对齐。 在大语言模型的每一层中,节点嵌入是从第一个 Token 级嵌入获得的,它对应于[CLS]词符。 该过程涉及从所有相关节点收集嵌入并将其应用到图 Transformer。 然后将输出与输入嵌入连接起来并传递到大语言模型的下一层。 Patton (Jin 等人, 2023a) 通过提出两种预训练策略来扩展 GraphFormer,即网络上下文化屏蔽语言建模和屏蔽节点预测,专门针对文本丰富的图。 其强大的性能表现在各种下游任务中,包括分类、检索、重排序和链接预测。
此外,GRAD (Mavromatis 等人,2023) 采用图感知蒸馏来对齐两种模态,如图 5(d) 所示。 它利用 GNN 作为教师模型,为大语言模型生成软标签,促进聚合信息的传输。 此外,由于大语言模型共享参数,GNN 可以在大语言模型参数更新后受益于改进的文本编码。 通过迭代更新,开发了图感知大语言模型,由于没有 GNN,因此增强了推理的可扩展性。 与 GRAD 类似,THLM (Zou 等人, 2023) 采用异构 GNN 来增强大语言模型的多阶拓扑学习能力。 它涉及通过两种不同的策略预训练大语言模型和辅助 GNN。 第一个策略侧重于预测节点是否是目标节点的上下文图的一部分。 第二种策略利用掩码语言建模任务,有助于通过大语言模型开发强大的语言理解能力。 预训练过程结束后,辅助 GNN 被丢弃,大语言模型针对下游任务进行微调。
5.3讨论
为了对齐 GNN 和大语言模型,对称对齐平等对待每种模态,目的是同时增强 GNN 和大语言模型。 这使得编码器可以有效地处理涉及两种模态的任务,利用它们各自的编码优势来改进特定模态的表示。 此外,非对称方法通过将图编码器插入到 Transformer 中或直接使用 GNN 作为教师来增强大语言模型。 然而,在处理数据稀缺问题时,对齐技术面临着挑战。 特别是,只有少数图数据集(即分子数据集)包含原生图文本对,限制了这些方法的适用性。
6 未来方向
表1总结了根据建议的分类法利用大语言模型来协助图形相关任务的模型。 基于以上回顾和分析,我们认为该领域还有很大的进一步提升空间。 在本节中,我们讨论利用大语言模型理解图数据的能力的剩余局限性,并列出后续研究中进一步探索的一些方向。
处理非TAG。 利用大语言模型辅助文本属性图的学习已经表现出了优异的性能。 然而,图结构数据在现实场景中普遍存在,并且大量缺乏丰富的文本信息。 例如,在交通网络中(例如,PeMS03 (Song 等人, 2020)),每个节点代表一个运行传感器,而在超像素图中(例如,PascalVOC-SP (Dwivedi等人, 2022)),每个节点代表一个超像素。 这些数据集的每个节点上没有附加文本属性,并且使用人类可理解的语言描述每个节点的语义也具有挑战性。 尽管OFA (Liu 等人, 2023a)提出使用人类可理解的文本来描述所有节点和边,并通过大语言模型将文本嵌入到同一空间中,但它可能不适用于所有领域(例如,超像素图),并且其性能在某些领域和数据集中可能不是最佳的。 探索如何利用大语言模型强大的泛化能力来帮助构建图基础模型是一个很有价值的研究方向。
处理数据泄露。 大语言模型中的数据泄露已成为讨论的焦点(Aiyaappa等人,2023)。 鉴于大语言模型在广泛的文本语料库上进行了预训练,大语言模型可能已经看到并记住了至少部分常见基准数据集的测试数据,尤其是引文网络。 这破坏了依赖早期基准数据集的当前研究的可靠性。 此外,陈等人(2023a)证明,特定的提示可能会增强大语言模型相应记忆的“激活”,从而影响评估。 Huang 等人 (2023a) 和 He 等人 (2023) 都试图通过收集新的引文数据集来避免数据泄露问题,确保试卷是抽样的从 ChatGPT 数据截止后的时间段开始。 然而,它们仍然局限于引用领域,并且数据集中图结构的影响并不显着。 因此,重新考虑用于准确评估大语言模型在图相关任务上的性能的方法至关重要。 还需要一个公平、系统、全面的基准。
提高可转移性。 可迁移性一直是图领域的一个具有挑战性的问题(Jiang等人,2022)。 由于各个图的独特特征和结构,所学知识从一个数据集到另一个数据集或从一个领域到另一个领域的可迁移性并不简单。 图在大小、连通性、节点类型、边类型和整体拓扑方面可能存在很大差异,因此很难在它们之间直接传输知识。 虽然大语言模型由于对大量语料库进行了广泛的预训练,在语言任务中表现出了有前途的零/少样本能力,但利用大语言模型中嵌入的知识来增强图相关任务的可迁移性的探索已经取得了进展。受到了相对的限制。 OFA (Liu 等人, 2023a) 尝试一种统一的方法来在图上执行跨域,将所有节点和边描述为人类可读的文本,并将来自不同域的文本嵌入到相同的嵌入空间中单个大语言模型。 提高可迁移性的话题仍然值得研究。
提高可解释性。 可解释性,也称为可解释性,表示以人类可理解的术语解释或呈现模型行为的能力(Zhao等人,2023b)。 在处理图相关任务时,与 GNN 相比,大语言模型表现出更好的可解释性,这主要是由于大语言模型的推理和解释能力为图推理提供了用户友好的解释,包括生成附加解释作为 3 并提供推理过程作为第 4 节中讨论的预测器。 多项研究探讨了提示范式中的解释技巧,例如情境学习(Radford等人,2021)和思维链(Wei等人,2022b),其中涉及向大语言模型提供一系列演示和提示,以引导其生成到特定方向并让它解释其推理。 应该进行进一步的探索以增强可解释性。
提高效率。 虽然大语言模型已经证明了它们在图学习方面的有效性,但它们可能在时间和空间方面面临效率低下的问题,特别是与专用图学习模型(例如本质上处理图结构的 GNN)相比。 当大语言模型依赖于顺序图描述来进行4节中讨论的预测时,这一点尤其明显。 例如,通过API(即ChatGPT和GPT-4)访问大语言模型时,计费模型在处理大规模图形时会产生高昂的成本。 此外,本地部署的开源大语言模型的训练和推理都需要大量的时间消耗和大量的硬件资源。 现有研究(段等人,2023;刘等人,2023c;叶等人,2023;柴等人,2023;刘等人,2023d;唐等人,2023)试图启用大语言模型通过采用参数高效的微调策略来实现高效自适应,例如 LoRA (Hu 等人, 2021) 和前缀调整 (Li and Liang, 2021) 。 我们相信,更有效的方法可以释放大语言模型在计算资源有限的图相关任务上应用的更多能力。
表达能力的分析与提高。 尽管大语言模型最近在图相关任务中取得了成就,但其理论表达能力在很大程度上仍未得到探索。 人们普遍认为,标准消息传递神经网络的表达能力与 1-Weisfeiler-Lehman (WL) 测试一样,这意味着它们无法区分 1 跳聚合下的非同构图 (Xu 等人,2018 )。 因此,出现了两个基本问题:大语言模型如何有效地理解图结构? 他们的表达能力能否超越 GNN 或 WL 测试? 此外,排列等方差是典型 GNN 的一个有趣的性质,这在几何图学习中具有重要意义(Han 等人,2022)。 探索如何赋予大语言模型这种属性也是一个有趣的方向。
大语言模型作为代理。 在当前图与大语言模型的集成中,大语言模型常常扮演增强器、预测器和对齐组件的角色。 然而,在更复杂的场景中,此类应用可能无法完全释放大语言模型的潜力。 最近的研究探索了大语言模型作为代理的新角色,例如生成代理(Park等人,2023)和特定领域代理(Bran等人,2023) 。 在 LLM 支持的智能体系统中,大语言模型充当智能体的大脑,并由规划、记忆和使用(Weng,2023)的工具等基本组件支持。 在复杂的图相关场景中,例如推荐系统和知识发现,将大语言模型视为代理,首先将任务分解为多个子任务,然后为每个子任务识别最合适的工具(例如,GNN)可能会提高性能。 此外,采用大语言模型作为代理有望为图相关任务构建强大且高度通用的求解器。
7结论
近年来,大语言模型在图相关任务中的应用已成为一个突出的研究领域。 在本次调查中,我们的目的是深入概述使大语言模型适应图的现有策略。 首先,我们引入了一种新的分类法,根据大语言模型所扮演的不同角色,将涉及图和文本模态的技术分为三类,即增强器、预测器和对齐组件。 其次,我们根据分类系统地回顾了代表性研究。 最后,我们讨论了一些局限性并强调了几个未来的研究方向。 通过这次全面的回顾,我们希望通过大语言模型揭示图学习领域的进展和挑战,从而鼓励该领域的进一步增强。
参考
- Aiyappa et al. [2023] Rachith Aiyappa, Jisun An, Haewoon Kwak, and Yong-Yeol Ahn. Can we trust the evaluation on chatgpt? arXiv preprint arXiv:2303.12767, 2023.
- Beltagy et al. [2019] Iz Beltagy, Kyle Lo, and Arman Cohan. Scibert: A pretrained language model for scientific text. arXiv preprint arXiv:1903.10676, 2019.
- Bran et al. [2023] Andres M Bran, Sam Cox, Andrew D White, and Philippe Schwaller. Chemcrow: Augmenting large-language models with chemistry tools. arXiv preprint arXiv:2304.05376, 2023.
- Brandes et al. [2013] Ulrik Brandes, Markus Eiglsperger, Jürgen Lerner, and Christian Pich. Graph markup language (graphml). 2013.
- Brannon et al. [2023] William Brannon, Suyash Fulay, Hang Jiang, Wonjune Kang, Brandon Roy, Jad Kabbara, and Deb Roy. Congrat: Self-supervised contrastive pretraining for joint graph and text embeddings. arXiv preprint arXiv:2305.14321, 2023.
- Brown et al. [2020] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. NeurIPS, 33:1877–1901, 2020.
- Cao et al. [2023] He Cao, Zijing Liu, Xingyu Lu, Yuan Yao, and Yu Li. Instructmol: Multi-modal integration for building a versatile and reliable molecular assistant in drug discovery. arXiv preprint arXiv:2311.16208, 2023.
- Chai et al. [2023] Ziwei Chai, Tianjie Zhang, Liang Wu, Kaiqiao Han, Xiaohai Hu, Xuanwen Huang, and Yang Yang. Graphllm: Boosting graph reasoning ability of large language model. arXiv preprint arXiv:2310.05845, 2023.
- Chandra et al. [2020] Shantanu Chandra, Pushkar Mishra, Helen Yannakoudakis, Madhav Nimishakavi, Marzieh Saeidi, and Ekaterina Shutova. Graph-based modeling of online communities for fake news detection. arXiv preprint arXiv:2008.06274, 2020.
- Chen et al. [2023a] Zhikai Chen, Haitao Mao, Hang Li, Wei Jin, Hongzhi Wen, Xiaochi Wei, Shuaiqiang Wang, Dawei Yin, Wenqi Fan, Hui Liu, et al. Exploring the potential of large language models (llms) in learning on graphs. arXiv preprint arXiv:2307.03393, 2023.
- Chen et al. [2023b] Zhikai Chen, Haitao Mao, Hongzhi Wen, Haoyu Han, Wei Jin, Haiyang Zhang, Hui Liu, and Jiliang Tang. Label-free node classification on graphs with large language models (llms). arXiv preprint arXiv:2310.04668, 2023.
- Cheng et al. [2023] Jiashun Cheng, Man Li, Jia Li, and Fugee Tsung. Wiener graph deconvolutional network improves graph self-supervised learning. In AAAI, pages 7131–7139, 2023.
- Chien et al. [2021] Eli Chien, Wei-Cheng Chang, Cho-Jui Hsieh, Hsiang-Fu Yu, Jiong Zhang, Olgica Milenkovic, and Inderjit S Dhillon. Node feature extraction by self-supervised multi-scale neighborhood prediction. arXiv preprint arXiv:2111.00064, 2021.
- Chiswell and Hodges [2007] Ian Chiswell and Wilfrid Hodges. Mathematical logic. OUP Oxford, 2007.
- Chowdhery et al. [2022] Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. Palm: Scaling language modeling with pathways. arXiv preprint arXiv:2204.02311, 2022.
- Chung et al. [2022] Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, et al. Scaling instruction-finetuned language models. arXiv preprint arXiv:2210.11416, 2022.
- Das et al. [2023] Debarati Das, Ishaan Gupta, Jaideep Srivastava, and Dongyeop Kang. Which modality should i use–text, motif, or image?: Understanding graphs with large language models. arXiv preprint arXiv:2311.09862, 2023.
- Dong et al. [2022] Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Zhiyong Wu, Baobao Chang, Xu Sun, Jingjing Xu, and Zhifang Sui. A survey for in-context learning. arXiv preprint arXiv:2301.00234, 2022.
- Duan et al. [2023] Keyu Duan, Qian Liu, Tat-Seng Chua, Shuicheng Yan, Wei Tsang Ooi, Qizhe Xie, and Junxian He. Simteg: A frustratingly simple approach improves textual graph learning. arXiv preprint arXiv:2308.02565, 2023.
- Dwivedi et al. [2022] Vijay Prakash Dwivedi, Ladislav Rampášek, Michael Galkin, Ali Parviz, Guy Wolf, Anh Tuan Luu, and Dominique Beaini. Long range graph benchmark. NeurIPS, 35:22326–22340, 2022.
- Edwards et al. [2021] Carl Edwards, ChengXiang Zhai, and Heng Ji. Text2mol: Cross-modal molecule retrieval with natural language queries. In EMNLP, pages 595–607, 2021.
- Fatemi et al. [2023] Bahare Fatemi, Jonathan Halcrow, and Bryan Perozzi. Talk like a graph: Encoding graphs for large language models. arXiv preprint arXiv:2310.04560, 2023.
- Guo et al. [2023] Jiayan Guo, Lun Du, and Hengyu Liu. Gpt4graph: Can large language models understand graph structured data? an empirical evaluation and benchmarking. arXiv preprint arXiv:2305.15066, 2023.
- Hamilton et al. [2017] Will Hamilton, Zhitao Ying, and Jure Leskovec. Inductive representation learning on large graphs. NeurIPS, 30, 2017.
- Han et al. [2022] Jiaqi Han, Yu Rong, Tingyang Xu, and Wenbing Huang. Geometrically equivariant graph neural networks: A survey. arXiv preprint arXiv:2202.07230, 2022.
- He et al. [2020] Xiangnan He, Kuan Deng, Xiang Wang, Yan Li, Yongdong Zhang, and Meng Wang. Lightgcn: Simplifying and powering graph convolution network for recommendation. In SIGIR, pages 639–648, 2020.
- He et al. [2023] Xiaoxin He, Xavier Bresson, Thomas Laurent, and Bryan Hooi. Explanations as features: Llm-based features for text-attributed graphs. arXiv preprint arXiv:2305.19523, 2023.
- Himsolt [1997] Michael Himsolt. Gml: Graph modelling language. University of Passau, 1997.
- Hou et al. [2022] Zhenyu Hou, Xiao Liu, Yukuo Cen, Yuxiao Dong, Hongxia Yang, Chunjie Wang, and Jie Tang. Graphmae: Self-supervised masked graph autoencoders. In SIGKDD, pages 594–604, 2022.
- Hu et al. [2020] Weihua Hu, Matthias Fey, Marinka Zitnik, Yuxiao Dong, Hongyu Ren, Bowen Liu, Michele Catasta, and Jure Leskovec. Open graph benchmark: Datasets for machine learning on graphs. NeurIPS, 33:22118–22133, 2020.
- Hu et al. [2021] Edward J Hu, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models. In ICLR, 2021.
- Hu et al. [2023] Yuntong Hu, Zheng Zhang, and Liang Zhao. Beyond text: A deep dive into large language models’ ability on understanding graph data. arXiv preprint arXiv:2310.04944, 2023.
- Huang et al. [2023a] Jin Huang, Xingjian Zhang, Qiaozhu Mei, and Jiaqi Ma. Can llms effectively leverage graph structural information: when and why. arXiv preprint arXiv:2309.16595, 2023.
- Huang et al. [2023b] Xuanwen Huang, Kaiqiao Han, Dezheng Bao, Quanjin Tao, Zhisheng Zhang, Yang Yang, and Qi Zhu. Prompt-based node feature extractor for few-shot learning on text-attributed graphs. arXiv preprint arXiv:2309.02848, 2023.
- Ji et al. [2021] Shaoxiong Ji, Shirui Pan, Erik Cambria, Pekka Marttinen, and S Yu Philip. A survey on knowledge graphs: Representation, acquisition, and applications. TNNLS, 33(2):494–514, 2021.
- Jiang et al. [2022] Junguang Jiang, Yang Shu, Jianmin Wang, and Mingsheng Long. Transferability in deep learning: A survey. arXiv preprint arXiv:2201.05867, 2022.
- Jin et al. [2023a] Bowen Jin, Wentao Zhang, Yu Zhang, Yu Meng, Xinyang Zhang, Qi Zhu, and Jiawei Han. Patton: Language model pretraining on text-rich networks. arXiv preprint arXiv:2305.12268, 2023.
- Jin et al. [2023b] Bowen Jin, Wentao Zhang, Yu Zhang, Yu Meng, Han Zhao, and Jiawei Han. Learning multiplex embeddings on text-rich networks with one text encoder. arXiv preprint arXiv:2310.06684, 2023.
- Kenton and Toutanova [2019] Jacob Devlin Ming-Wei Chang Kenton and Lee Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of NAACL-HLT, pages 4171–4186, 2019.
- Kipf and Welling [2016] Thomas N Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. In ICLR, 2016.
- Li and Liang [2021] Xiang Lisa Li and Percy Liang. Prefix-tuning: Optimizing continuous prompts for generation. In ACL, pages 4582–4597, 2021.
- Li et al. [2023a] Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. arXiv preprint arXiv:2301.12597, 2023.
- Li et al. [2023b] Yichuan Li, Kaize Ding, and Kyumin Lee. Grenade: Graph-centric language model for self-supervised representation learning on text-attributed graphs. arXiv preprint arXiv:2310.15109, 2023.
- Liu and Wu [2023] Chang Liu and Bo Wu. Evaluating large language models on graphs: Performance insights and comparative analysis. arXiv preprint arXiv:2308.11224, 2023.
- Liu et al. [2019] Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692, 2019.
- Liu et al. [2022] Shengchao Liu, Weili Nie, Chengpeng Wang, Jiarui Lu, Zhuoran Qiao, Ling Liu, Jian Tang, Chaowei Xiao, and Anima Anandkumar. Multi-modal molecule structure-text model for text-based retrieval and editing. arXiv preprint arXiv:2212.10789, 2022.
- Liu et al. [2023a] Hao Liu, Jiarui Feng, Lecheng Kong, Ningyue Liang, Dacheng Tao, Yixin Chen, and Muhan Zhang. One for all: Towards training one graph model for all classification tasks. arXiv preprint arXiv:2310.00149, 2023.
- Liu et al. [2023b] Jiawei Liu, Cheng Yang, Zhiyuan Lu, Junze Chen, Yibo Li, Mengmei Zhang, Ting Bai, Yuan Fang, Lichao Sun, Philip S Yu, et al. Towards graph foundation models: A survey and beyond. arXiv preprint arXiv:2310.11829, 2023.
- Liu et al. [2023c] Pengfei Liu, Yiming Ren, and Zhixiang Ren. Git-mol: A multi-modal large language model for molecular science with graph, image, and text. arXiv preprint arXiv:2308.06911, 2023.
- Liu et al. [2023d] Zhiyuan Liu, Sihang Li, Yanchen Luo, Hao Fei, Yixin Cao, Kenji Kawaguchi, Xiang Wang, and Tat-Seng Chua. Molca: Molecular graph-language modeling with cross-modal projector and uni-modal adapter. arXiv preprint arXiv:2310.12798, 2023.
- Mavromatis et al. [2023] Costas Mavromatis, Vassilis N Ioannidis, Shen Wang, Da Zheng, Soji Adeshina, Jun Ma, Han Zhao, Christos Faloutsos, and George Karypis. Train your own gnn teacher: Graph-aware distillation on textual graphs. arXiv preprint arXiv:2304.10668, 2023.
- Mikolov et al. [2013] Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, and Jeff Dean. Distributed representations of words and phrases and their compositionality. NeurIPS, 26, 2013.
- Oord et al. [2018] Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748, 2018.
- OpenAI [2023] OpenAI. Gpt-4 technical report, 2023.
- Park et al. [2023] Joon Sung Park, Joseph C O’Brien, Carrie J Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. Generative agents: Interactive simulacra of human behavior. arXiv preprint arXiv:2304.03442, 2023.
- Qian et al. [2023] Chen Qian, Huayi Tang, Zhirui Yang, Hong Liang, and Yong Liu. Can large language models empower molecular property prediction? arXiv preprint arXiv:2307.07443, 2023.
- Qin et al. [2023] Yijian Qin, Xin Wang, Ziwei Zhang, and Wenwu Zhu. Disentangled representation learning with large language models for text-attributed graphs. arXiv preprint arXiv:2310.18152, 2023.
- Radford et al. [2021] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In ICLR, pages 8748–8763, 2021.
- Ren et al. [2023] Xubin Ren, Wei Wei, Lianghao Xia, Lixin Su, Suqi Cheng, Junfeng Wang, Dawei Yin, and Chao Huang. Representation learning with large language models for recommendation. arXiv preprint arXiv:2310.15950, 2023.
- Robinson and Wingate [2022] Joshua Robinson and David Wingate. Leveraging large language models for multiple choice question answering. In ICLR, 2022.
- Salton and Buckley [1988] Gerard Salton and Christopher Buckley. Term-weighting approaches in automatic text retrieval. IPM, 24(5):513–523, 1988.
- Sen et al. [2008] Prithviraj Sen, Galileo Namata, Mustafa Bilgic, Lise Getoor, Brian Galligher, and Tina Eliassi-Rad. Collective classification in network data. AI magazine, 29(3):93–93, 2008.
- Shayegani et al. [2023] Erfan Shayegani, Md Abdullah Al Mamun, Yu Fu, Pedram Zaree, Yue Dong, and Nael Abu-Ghazaleh. Survey of vulnerabilities in large language models revealed by adversarial attacks. arXiv preprint arXiv:2310.10844, 2023.
- Shi et al. [2023] Yaorui Shi, An Zhang, Enzhi Zhang, Zhiyuan Liu, and Xiang Wang. Relm: Leveraging language models for enhanced chemical reaction prediction. arXiv preprint arXiv:2310.13590, 2023.
- Song et al. [2020] Chao Song, Youfang Lin, Shengnan Guo, and Huaiyu Wan. Spatial-temporal synchronous graph convolutional networks: A new framework for spatial-temporal network data forecasting. In AAAI, pages 914–921, 2020.
- Su et al. [2022] Bing Su, Dazhao Du, Zhao Yang, Yujie Zhou, Jiangmeng Li, Anyi Rao, Hao Sun, Zhiwu Lu, and Ji-Rong Wen. A molecular multimodal foundation model associating molecule graphs with natural language. arXiv preprint arXiv:2209.05481, 2022.
- Sun et al. [2022] Mingchen Sun, Kaixiong Zhou, Xin He, Ying Wang, and Xin Wang. Gppt: Graph pre-training and prompt tuning to generalize graph neural networks. In SIGKDD, pages 1717–1727, 2022.
- Sun et al. [2023a] Xiangguo Sun, Hong Cheng, Jia Li, Bo Liu, and Jihong Guan. All in one: Multi-task prompting for graph neural networks. In SIGKDD, page 2120–2131, 2023.
- Sun et al. [2023b] Xiangguo Sun, Hong Cheng, Bo Liu, Jia Li, Hongyang Chen, Guandong Xu, and Hongzhi Yin. Self-supervised hypergraph representation learning for sociological analysis. TKDE, 2023.
- Tan et al. [2023a] Qiaoyu Tan, Ninghao Liu, Xiao Huang, Soo-Hyun Choi, Li Li, Rui Chen, and Xia Hu. S2gae: Self-supervised graph autoencoders are generalizable learners with graph masking. In WSDM, pages 787–795, 2023.
- Tan et al. [2023b] Yanchao Tan, Zihao Zhou, Hang Lv, Weiming Liu, and Carl Yang. Walklm: A uniform language model fine-tuning framework for attributed graph embedding. In NeurIPS, 2023.
- Tang et al. [2023] Jiabin Tang, Yuhao Yang, Wei Wei, Lei Shi, Lixin Su, Suqi Cheng, Dawei Yin, and Chao Huang. Graphgpt: Graph instruction tuning for large language models. arXiv preprint arXiv:2310.13023, 2023.
- Taylor et al. [2022] Ross Taylor, Marcin Kardas, Guillem Cucurull, Thomas Scialom, Anthony Hartshorn, Elvis Saravia, Andrew Poulton, Viktor Kerkez, and Robert Stojnic. Galactica: A large language model for science. arXiv preprint arXiv:2211.09085, 2022.
- Touvron et al. [2023] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
- Vaswani et al. [2017] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. NeurIPS, 30, 2017.
- Velickovic et al. [2018] Petar Velickovic, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lio, and Yoshua Bengio. Graph attention networks. stat, 1050:4, 2018.
- Wang et al. [2009] Yanli Wang, Jewen Xiao, Tugba O Suzek, Jian Zhang, Jiyao Wang, and Stephen H Bryant. Pubchem: a public information system for analyzing bioactivities of small molecules. Nucleic acids research, 37(suppl_2):W623–W633, 2009.
- Wang et al. [2023a] Haishuai Wang, Yang Gao, Xin Zheng, Peng Zhang, Hongyang Chen, and Jiajun Bu. Graph neural architecture search with gpt-4. arXiv preprint arXiv:2310.01436, 2023.
- Wang et al. [2023b] Heng Wang, Shangbin Feng, Tianxing He, Zhaoxuan Tan, Xiaochuang Han, and Yulia Tsvetkov. Can language models solve graph problems in natural language? arXiv preprint arXiv:2305.10037, 2023.
- Wei et al. [2022a] Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, et al. Emergent abilities of large language models. TMLR, 2022.
- Wei et al. [2022b] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. NeurIPS, 35:24824–24837, 2022.
- Wei et al. [2023] Wei Wei, Xubin Ren, Jiabin Tang, Qinyong Wang, Lixin Su, Suqi Cheng, Junfeng Wang, Dawei Yin, and Chao Huang. Llmrec: Large language models with graph augmentation for recommendation. arXiv preprint arXiv:2311.00423, 2023.
- Wen and Fang [2023] Zhihao Wen and Yuan Fang. Prompt tuning on graph-augmented low-resource text classification. arXiv preprint arXiv:2307.10230, 2023.
- Weng [2023] Lilian Weng. Llm-powered autonomous agents. lilianweng.github.io, Jun 2023.
- Wu et al. [2018] Zhenqin Wu, Bharath Ramsundar, Evan N Feinberg, Joseph Gomes, Caleb Geniesse, Aneesh S Pappu, Karl Leswing, and Vijay Pande. Moleculenet: a benchmark for molecular machine learning. Chemical science, 9(2):513–530, 2018.
- Xie et al. [2023] Han Xie, Da Zheng, Jun Ma, Houyu Zhang, Vassilis N Ioannidis, Xiang Song, Qing Ping, Sheng Wang, Carl Yang, Yi Xu, et al. Graph-aware language model pre-training on a large graph corpus can help multiple graph applications. arXiv preprint arXiv:2306.02592, 2023.
- Xu et al. [2018] Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. How powerful are graph neural networks? arXiv preprint arXiv:1810.00826, 2018.
- Xue et al. [2023] Rui Xue, Xipeng Shen, Ruozhou Yu, and Xiaorui Liu. Efficient large language models fine-tuning on graphs. arXiv preprint arXiv:2312.04737, 2023.
- Yang et al. [2016] Zhilin Yang, William Cohen, and Ruslan Salakhudinov. Revisiting semi-supervised learning with graph embeddings. In ICLR, pages 40–48, 2016.
- Yang et al. [2021] Junhan Yang, Zheng Liu, Shitao Xiao, Chaozhuo Li, Defu Lian, Sanjay Agrawal, Amit Singh, Guangzhong Sun, and Xing Xie. Graphformers: Gnn-nested transformers for representation learning on textual graph. NeurIPS, 34:28798–28810, 2021.
- Yang et al. [2023] Jingfeng Yang, Hongye Jin, Ruixiang Tang, Xiaotian Han, Qizhang Feng, Haoming Jiang, Bing Yin, and Xia Hu. Harnessing the power of llms in practice: A survey on chatgpt and beyond. arXiv preprint arXiv:2304.13712, 2023.
- Ye et al. [2023] Ruosong Ye, Caiqi Zhang, Runhui Wang, Shuyuan Xu, and Yongfeng Zhang. Natural language is all a graph needs. arXiv preprint arXiv:2308.07134, 2023.
- Ying et al. [2021] Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen, and Tie-Yan Liu. Do transformers really perform badly for graph representation? NeurIPS, pages 28877–28888, 2021.
- You et al. [2020] Yuning You, Tianlong Chen, Yongduo Sui, Ting Chen, Zhangyang Wang, and Yang Shen. Graph contrastive learning with augmentations. NeurIPS, pages 5812–5823, 2020.
- Yu et al. [2023] Jianxiang Yu, Yuxiang Ren, Chenghua Gong, Jiaqi Tan, Xiang Li, and Xuecang Zhang. Empower text-attributed graphs learning with large language models (llms). arXiv preprint arXiv:2310.09872, 2023.
- Zeng et al. [2022] Aohan Zeng, Xiao Liu, Zhengxiao Du, Zihan Wang, Hanyu Lai, Ming Ding, Zhuoyi Yang, Yifan Xu, Wendi Zheng, Xiao Xia, et al. Glm-130b: An open bilingual pre-trained model. arXiv preprint arXiv:2210.02414, 2022.
- Zhang et al. [2023a] Hang Zhang, Xin Li, and Lidong Bing. Video-llama: An instruction-tuned audio-visual language model for video understanding. arXiv preprint arXiv:2306.02858, 2023.
- Zhang et al. [2023b] Renrui Zhang, Jiaming Han, Aojun Zhou, Xiangfei Hu, Shilin Yan, Pan Lu, Hongsheng Li, Peng Gao, and Yu Qiao. Llama-adapter: Efficient fine-tuning of language models with zero-init attention. arXiv preprint arXiv:2303.16199, 2023.
- Zhang et al. [2023c] Zeyang Zhang, Xin Wang, Ziwei Zhang, Haoyang Li, Yijian Qin, Simin Wu, and Wenwu Zhu. Llm4dyg: Can large language models solve problems on dynamic graphs? arXiv preprint arXiv:2310.17110, 2023.
- Zhang et al. [2023d] Ziwei Zhang, Haoyang Li, Zeyang Zhang, Yijian Qin, Xin Wang, and Wenwu Zhu. Large graph models: A perspective. arXiv preprint arXiv:2308.14522, 2023.
- Zhao et al. [2022] Jianan Zhao, Meng Qu, Chaozhuo Li, Hao Yan, Qian Liu, Rui Li, Xing Xie, and Jian Tang. Learning on large-scale text-attributed graphs via variational inference. arXiv preprint arXiv:2210.14709, 2022.
- Zhao et al. [2023a] Haiteng Zhao, Shengchao Liu, Chang Ma, Hannan Xu, Jie Fu, Zhi-Hong Deng, Lingpeng Kong, and Qi Liu. Gimlet: A unified graph-text model for instruction-based molecule zero-shot learning. arXiv preprint arXiv:2306.13089, 2023.
- Zhao et al. [2023b] Haiyan Zhao, Hanjie Chen, Fan Yang, Ninghao Liu, Huiqi Deng, Hengyi Cai, Shuaiqiang Wang, Dawei Yin, and Mengnan Du. Explainability for large language models: A survey. arXiv preprint arXiv:2309.01029, 2023.
- Zhao et al. [2023c] Jianan Zhao, Le Zhuo, Yikang Shen, Meng Qu, Kai Liu, Michael Bronstein, Zhaocheng Zhu, and Jian Tang. Graphtext: Graph reasoning in text space. arXiv preprint arXiv:2310.01089, 2023.
- Zhao et al. [2023d] Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, et al. A survey of large language models. arXiv preprint arXiv:2303.18223, 2023.
- Zhu et al. [2021] Yanqiao Zhu, Yichen Xu, Feng Yu, Qiang Liu, Shu Wu, and Liang Wang. Graph contrastive learning with adaptive augmentation. In WWW, pages 2069–2080, 2021.
- Zhu et al. [2023] Jing Zhu, Xiang Song, Vassilis N Ioannidis, Danai Koutra, and Christos Faloutsos. Touchup-g: Improving feature representation through graph-centric finetuning. arXiv preprint arXiv:2309.13885, 2023.
- Zou et al. [2023] Tao Zou, Le Yu, Yifei Huang, Leilei Sun, and Bowen Du. Pretraining language models with text-attributed heterogeneous graphs. arXiv preprint arXiv:2310.12580, 2023.