少样本图像中 3D 高斯分布的深度正则化优化
摘要
在本文中,我们提出了一种用有限数量的图像优化高斯分布的方法,同时避免过度拟合。 通过组合大量高斯图来表示 3D 场景,产生了出色的视觉质量。 然而,当只有少量图像可用时,它往往会过度拟合训练视图。 为了解决这个问题,我们引入了密集深度图作为几何指南来减轻过度拟合。 我们使用预训练的单目深度估计模型获得深度图,并使用稀疏 COLMAP 特征点对齐比例和偏移。 调整后的深度有助于基于颜色的 3D 高斯泼溅优化、减轻浮动伪影并确保遵守几何约束。 我们在 NeRF-LLFF 数据集上用不同数量的少量图像验证了所提出的方法。 与仅依赖图像的原始方法相比,我们的方法展示了稳健的几何结构。
1简介
从图像重建三维空间一直是计算机视觉领域的一个挑战。 最近的进展表明了真实感新颖视图合成的可行性[3, 31],引发了从图像重建完整 3D 空间的研究。 在计算机图形技术进步和行业需求的推动下,特别是在虚拟现实[14]和移动[11]等领域,实现高质量和高质量的研究极速实时渲染一直在持续进行。 在最近的显着发展中,3D 高斯溅射 (3DGS) [23] 凭借其高质量、快速重建速度和对实时渲染的支持的结合而脱颖而出。 3DGS 采用高斯衰减球谐函数 [38, 12] 和不透明度作为基元来表示场景的每个部分。 它通过对 splats 施加约束来引导 splats 构造一致的几何形状,以同时满足多个图像。
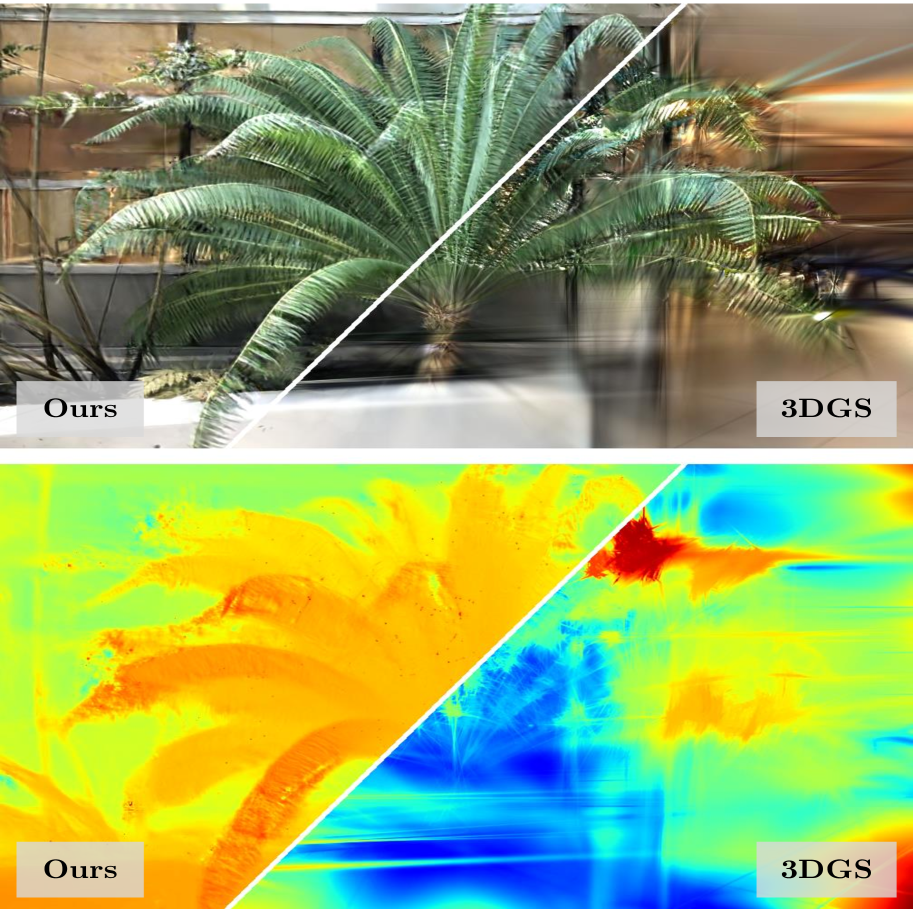
为场景聚合小块的方法提供了表达复杂细节的能力,但由于其局部性质,它很容易过度拟合。 3DGS [24] 根据多视图颜色监督优化独立图块,无需全局结构。 因此,在缺乏足够数量的图像来提供全局几何线索的情况下,不存在防止过度拟合的预防措施。 当用于优化 3D 场景的图像数量较少时,这个问题变得更加明显。 来自少量图像的有限几何信息会导致错误地收敛到局部最优,从而导致优化失败或浮动伪影,如图 1 所示。 然而,用有限数量的图像重建 3D 场景的能力对于实际应用至关重要,这促使我们解决少样本优化问题。
一种直观的解决方案是补充额外的几何线索,例如深度。 在众多 3D 重建环境中[6],深度通过提供直接的几何信息对于重建 3D 场景具有巨大的价值。 为了获得如此强大的几何线索,采用了与 RGB 相机对齐的深度传感器。 尽管这些设备提供了误差最小的密集深度图,但此类设备的必要性也给实际应用带来了障碍。
因此,我们通过使用来自著名的运动结构 (SfM) 的稀疏深度图来调整深度估计网络的输出,从而获得密集的深度图,该算法同时计算相机参数和 3D 特征点。 3DGS 还使用 SfM,特别是 COLMAP [41] 来获取此类信息。 然而,当图像数量较少时,SfM 也会遇到可用 3D 特征点显着缺乏的问题。 点云的稀疏性质也使得对所有高斯图进行正则化是不切实际的。 因此,一种推断密集深度图的方法至关重要。 从图像中提取密集深度的方法之一是利用单目深度估计模型。 虽然这些模型能够根据从数据中获得的先验从各个图像推断出密集的深度图,但由于尺度模糊,它们仅产生相对深度。 由于尺度模糊会导致多视图图像中的关键几何冲突,因此我们需要调整尺度以防止独立推断的深度之间的冲突。 我们证明这可以通过拟合稀疏深度来完成,稀疏深度是从 COLMAP [41] 到估计的密集深度图的自由输出。
在本文中,我们提出了一种使用少量 RGB 图像表示 3D 场景的方法,利用来自预训练单目深度估计模型 [5] 的先验信息和平滑度约束。 我们将估计深度的比例和偏移调整为稀疏 COLMAP 点,解决了比例模糊问题。 我们使用调整后的深度作为几何指南来协助基于颜色的优化,减少浮动伪影并满足几何条件。 我们观察到,即使是修改后的深度也有助于引导场景达到几何最佳解决方案,尽管它很粗糙。 我们通过采用早期停止策略来防止过度拟合问题,当深度引导损失开始上升时,优化过程就会停止。 此外,为了实现更高的稳定性,我们应用平滑度约束,确保相邻 3D 点具有相似的深度。 我们采用 3DGS 作为基线,并比较我们的方法在 NeRF-LLFF [30] 数据集中的性能。 我们确认,我们的策略不仅在 RGB 新视图合成方面而且在 3D 几何重建方面都能产生合理的结果。 通过进一步的实验,我们证明了深度和初始点等几何线索对高斯泼溅的影响。 它们显着影响高斯泼溅的稳定优化。
总之,我们的贡献如下:
-
我们提出了深度引导的高斯泼溅优化策略,该策略可以使用少量图像来优化场景,从而减轻过度拟合问题。 我们证明,即使是使用稀疏点云调整的估计深度(SfM 管道的结果)也可以在几何正则化中发挥至关重要的作用。
-
我们提出了一种新颖的早期停止策略:当深度引导损失下降时,停止训练过程。 我们通过彻底的消融研究来说明每种策略的影响。
-
我们证明,对深度图采用平滑项可以指导模型找到正确的几何形状。 综合实验表明,由于包含平滑项,性能得到了提高。
2相关工作
新颖的视图合成
运动结构 (SfM) [46] 和多视图立体 (MVS) [45] 是使用多个图像重建 3D 结构的技术,这些技术已被研究了很多年。长期从事计算机视觉领域。 在不断的发展中,COLMAP[41]是广泛使用的代表性工具。 COLMAP 执行相机姿态校准,并使用多视图图像的极线约束 [22] 查找稀疏 3D 关键点。 为了更密集和更真实的重建,主要研究了基于深度学习的3D重建技术。 [21, 51, 31] 其中,神经辐射场(NeRF)[31]是一种代表性的方法,它使用神经网络作为表示方法。 NeRF 使用 MLP 网络作为 3D 空间表达和体积渲染来创建逼真的 3D 场景,产生了许多关于 3D 重建研究的后续论文。 [44, 18, 3, 54, 47, 4] 特别是,为了克服 NeRF 速度慢的问题,许多人继续努力利用稀疏体素等显式表达来实现实时渲染 [27, 56, 43, 16],特征点云[52],张量[10],多边形[11]。 这些表示具有独立操作的本地元素,因此它们显示出快速的渲染和优化速度。 基于这个思想,出现了多级层次结构[32, 33]、无穷小网络[19, 39]、三平面[9]等各种表示形式t2> 已尝试过。 其中,3D高斯溅射[23]提出了一种通过alpha混合光栅化而不是耗时的体渲染的快速高效的方法。 它使用数百万高斯衰减球谐函数以不透明度作为基元来优化 3D 场景,从而显示出简单快速的高质量 3D 重建。
3D 重建样本少
由于图像仅包含3D场景的部分信息,因此3D重建需要大量的多视图图像。 COLMAP将多个图像之间匹配的特征点上传到3D空间,因此使用的图像越多,可以获得越可靠的3D点和相机位姿。[41, 17] NeRF还根据大量图像的像素颜色来优化3D场景的颜色和几何形状,以获得高质量的场景。 [48, 57] 然而,对大量图像的需求阻碍了实际应用,引发了仅使用少量图像的 3D 重建研究。 许多少样本 3D 重建研究利用深度为创建 3D 场景提供有价值的几何线索。 深度通过引入表面平滑度约束 [25, 35],监督从 COLMAP [13, 49] 获得的稀疏深度,有助于减少通过多个图像中的颜色一致性推断几何的工作量t1>,使用从附加传感器[2,7,15]获得的密集深度,或利用来自预训练网络的估计密集深度。 [37,40,34]这些研究基于神经网络的全局性对几何进行正则化,因此很难将它们应用于具有大局部性的表示,例如稀疏体素[16] 或特征点[52]。 相反,他们尝试通过总变差 (TV) 损失 [59, 16, 53] 在 3D 空间中的局部元素之间建立连接,但这需要对总变差进行详尽的超参数调整,而总变差随场景和地点。 由于其较强的局部性,3D 高斯分布 [23] 会生成带有少量图像的浮动伪影。 从Gaussian splat子过程中得到的稀疏COLMAP特征点是一种自由深度引导,无需附加信息即可得到[40],但是从少量图像中得到的稀疏点数量太小以至于无法引导所有具有强局域性的高斯splats。 我们使用粗几何指南通过预训练的深度估计模型[5,58,29]进行优化。 即使它们没有精确的详细深度,它们也可以提供对splats位置的粗略指导,这极大地有助于少样本情况下的优化稳定性,并有助于消除随机位置中出现的浮动伪影。
3方法
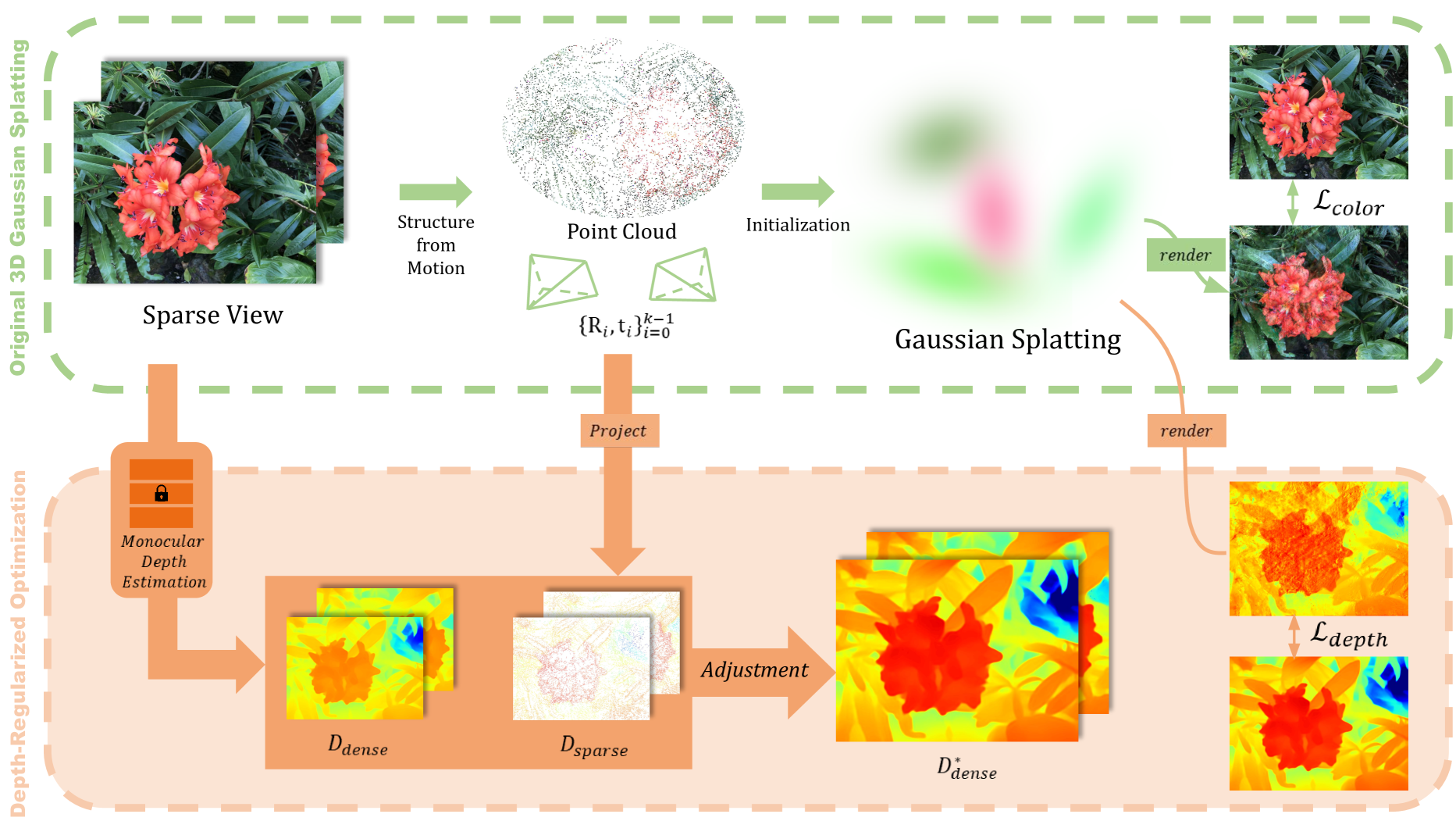
我们的方法有助于从一小组图像 进行优化。 作为预处理,我们运行 SfM(例如 COLMAP[41])管道并获取相机位姿 、内在参数 和点云。 有了这些信息,我们可以通过将所有可见点投影到像素空间来轻松获得每个图像的稀疏深度图:
| (1) | |||
| (2) |
我们的方法建立在 3DGS [23] 之上。 他们基于具有颜色损失 和 D-SSIM 损失 的渲染图像来优化高斯图。 在 3DGS 优化之前,我们使用深度估计网络估计每个图像的深度图并拟合稀疏深度图(第 3.1 节)。 我们利用颜色光栅化过程从一组高斯泼溅中渲染深度,并使用密集深度先验添加深度约束(第 3.2 节)。 我们为相邻像素的深度之间的平滑度添加了额外的约束(第3.3节),并细化了少样本设置的优化选项(第3.4节)。
3.1 准备密集深度先验
为了将图块引导成合理的几何形状,由于高斯图块的局部性,我们需要提供全局几何信息。 密度深度是最有前途的几何学之一,但构建它存在挑战。 SfM 点的密度取决于图像的数量,因此有效点的数量太少,无法在少样本设置中直接估计密集深度。 (例如,根据 19 个图像进行 SfM 重建可创建平均有效像素为 0.04% 的稀疏深度图。 [40])即使是最新的深度补全模型也由于巨大的信息差距而无法完成密集深度。
在事先设计深度时,需要注意的是,即使是粗略的深度也能显着帮助引导板片并消除因板片陷入不正确的几何形状而产生的伪影。 因此,我们采用最先进的单目深度估计模型和尺度匹配来为优化提供粗密深度指南。 从训练图像 中,单目深度估计模型 输出密集深度 ,
| (3) |
为了解决估计密集深度中的尺度模糊性,我们将估计深度的尺度和偏移量调整为稀疏SfM深度:
| (5) |
其中 是标准化权重,表示每个特征点的可靠性,计算为 SfM 重投影误差的倒数。 最后,我们使用调整后的密集深度来正则化高斯泼溅的优化损失。
3.2 通过光栅化进行深度渲染
3D 高斯splatting 利用光栅化管道[1] 来渲染利用GPU 并行架构的断开连接和非结构化splats。 基于可微分的基于点的渲染技术[50,55,26],它们通过混合光栅化splats来渲染图像。 基于点的方法利用与 NeRF 风格体积渲染类似的方程,用覆盖该像素的有序点对像素颜色进行光栅化,
| (6) | |||
是像素颜色, 是图块的颜色, 这里是学习的不透明度乘以 2D 高斯的协方差。 此公式优先考虑靠近相机的不透明斑点的颜色,显着影响最终结果。受到 NeRF 中深度实现的启发,我们利用光栅化管道来渲染高斯图的深度图,
| (7) |
其中 是渲染深度, 是来自相机的每个 splat 的深度。 方程。 (7) 可以直接利用方程式中计算的 和 。 (6),以最小的计算负载促进快速深度渲染。 最后,我们使用 L1 距离将渲染深度引导至估计的密集深度,
| (9) |
| PSNR | SSIM | LPIPS | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2-view | 3-view | 4-view | 5-view | 2-view | 3-view | 4-view | 5-view | 2-view | 3-view | 4-view | 5-view | |||
| NeRF-LLFF[31] | Fern | 3DGS | 13.03 | 14.29 | 16.73 | 18.59 | 0.336 | 0.408 | 0.517 | 0.603 | 0.476 | 0.389 | 0.296 | 0.217 |
| Ours | 17.59 | 19.13 | 19.91 | 20.55 | 0.516 | 0.588 | 0.616 | 0.642 | 0.286 | 0.232 | 0.203 | 0.167 | ||
| Oracle | 18.18 | 20.30 | 20.78 | 21.81 | 0.524 | 0.636 | 0.654 | 0.701 | 0.278 | 0.201 | 0.185 | 0.157 | ||
| Flower | 3DGS | 14.90 | 17.75 | 19.71 | 21.39 | 0.351 | 0.508 | 0.605 | 0.671 | 0.406 | 0.257 | 0.190 | 0.146 | |
| Ours | 15.92 | 17.80 | 19.15 | 20.45 | 0.395 | 0.445 | 0.538 | 0.576 | 0.414 | 0.376 | 0.323 | 0.293 | ||
| Oracle | 19.71 | 22.16 | 23.26 | 24.65 | 0.570 | 0.673 | 0.714 | 0.760 | 0.250 | 0.163 | 0.128 | 0.097 | ||
| Fortress | 3DGS | 13.87 | 15.98 | 19.26 | 19.98 | 0.363 | 0.492 | 0.609 | 0.631 | 0.389 | 0.283 | 0.201 | 0.191 | |
| Ours | 19.80 | 21.85 | 23.07 | 23.72 | 0.567 | 0.655 | 0.724 | 0.740 | 0.232 | 0.191 | 0.162 | 0.144 | ||
| Oracle | 23.07 | 24.51 | 26.39 | 26.73 | 0.654 | 0.728 | 0.787 | 0.797 | 0.159 | 0.130 | 0.100 | 0.093 | ||
| Horns | 3DGS | 11.43 | 12.48 | 13.76 | 14.75 | 0.264 | 0.339 | 0.433 | 0.498 | 0.531 | 0.464 | 0.395 | 0.350 | |
| Ours | 15.91 | 16.22 | 18.09 | 18.39 | 0.420 | 0.466 | 0.527 | 0.565 | 0.362 | 0.349 | 0.306 | 0.296 | ||
| Oracle | 18.56 | 20.08 | 20.88 | 22.52 | 0.568 | 0.644 | 0.668 | 0.725 | 0.259 | 0.212 | 0.199 | 0.168 | ||
| Leaves | 3DGS | 12.33 | 12.36 | 12.49 | 12.26 | 0.260 | 0.275 | 0.298 | 0.297 | 0.412 | 0.397 | 0.397 | 0.401 | |
| Ours | 13.04 | 13.63 | 13.97 | 14.13 | 0.235 | 0.270 | 0.283 | 0.297 | 0.460 | 0.445 | 0.440 | 0.438 | ||
| Oracle | 13.52 | 14.23 | 14.78 | 14.85 | 0.287 | 0.353 | 0.377 | 0.397 | 0.380 | 0.348 | 0.341 | 0.356 | ||
| Orchids | 3DGS | 11.78 | 13.94 | 15.41 | 16.08 | 0.182 | 0.320 | 0.416 | 0.460 | 0.426 | 0.310 | 0.245 | 0.219 | |
| Ours | 12.88 | 14.71 | 15.40 | 16.13 | 0.216 | 0.297 | 0.343 | 0.391 | 0.462 | 0.383 | 0.366 | 0.352 | ||
| Oracle | 14.89 | 16.45 | 17.42 | 18.45 | 0.365 | 0.471 | 0.525 | 0.576 | 0.303 | 0.237 | 0.200 | 0.174 | ||
| Room | 3DGS | 10.18 | 11.51 | 11.59 | 12.21 | 0.404 | 0.494 | 0.510 | 0.552 | 0.606 | 0.559 | 0.556 | 0.515 | |
| Ours | 17.21 | 18.11 | 18.87 | 19.63 | 0.668 | 0.719 | 0.732 | 0.757 | 0.352 | 0.360 | 0.326 | 0.295 | ||
| Oracle | 20.66 | 22.31 | 23.80 | 24.59 | 0.758 | 0.801 | 0.839 | 0.864 | 0.217 | 0.188 | 0.160 | 0.156 | ||
| Trex | 3DGS | 10.72 | 11.72 | 13.11 | 14.14 | 0.322 | 0.417 | 0.492 | 0.548 | 0.520 | 0.446 | 0.394 | 0.351 | |
| Ours | 14.90 | 15.90 | 16.75 | 17.37 | 0.480 | 0.537 | 0.567 | 0.625 | 0.358 | 0.362 | 0.348 | 0.305 | ||
| Oracle | 17.76 | 19.58 | 20.84 | 22.83 | 0.591 | 0.669 | 0.714 | 0.786 | 0.284 | 0.226 | 0.192 | 0.134 | ||
| Mean | 3DGS | 12.25 | 13.75 | 15.26 | 16.17 | 0.306 | 0.407 | 0.485 | 0.533 | 0.471 | 0.388 | 0.334 | 0.299 | |
| Ours | 15.94 | 17.17 | 18.15 | 18.74 | 0.439 | 0.497 | 0.541 | 0.571 | 0.365 | 0.337 | 0.309 | 0.288 | ||
| Oracle | 18.29 | 19.95 | 21.02 | 22.05 | 0.539 | 0.622 | 0.660 | 0.701 | 0.266 | 0.213 | 0.188 | 0.167 | ||
3.3 无监督平滑约束
尽管每个独立估计的深度都适合 COLMAP 点,但经常会出现冲突。 受 [20] 启发,我们引入了几何平滑度的无监督约束来规范冲突。 此约束意味着相似 3D 位置的点在图像平面上具有相似的深度。 我们利用 Canny 边缘检测器 [8] 作为掩模,以确保它不会规范沿边界深度具有显着差异的区域。 对于深度 及其相邻深度 ,我们对它们之间的差异进行正则化:
| (11) |
其中是指示函数,表示两个深度是否不在边缘。
3.4少样本学习的修改
我们修改了原始论文中的两项优化技术,以创建具有有限图像的 3D 场景。 3DGS 中采用的技术是在利用大量图像的假设下设计的,这可能会阻碍少样本设置中的收敛。 通过迭代实验,我们确认了这一点并修改了技术以适应少样本设置。 首先,我们将球谐函数(SH)的最大阶数设置为1。 这可以防止由于信息不足而导致高频的球谐系数过度拟合。 二是根据深度损失实行早停政策。 我们配置方程式。 (12) 主要由颜色损失驱动,同时采用深度损失和平滑度损失作为指导因素。 因此,由于颜色损失的主要影响,过拟合逐渐出现。 当图块开始偏离深度指南时,我们使用移动平均深度损失来停止优化。 最后,我们删除定期重置过程。 我们观察到,重置所有图块的不透明度 会导致不可逆转的有害后果。 由于有限图像中缺乏信息,无法恢复图块的不透明度导致所有图块都被删除或陷入局部最优,从而导致意外结果和优化失败。 由于上述技术,我们在少样本学习中实现了稳定的优化。
4实验
4.1 实验设置
数据集。
我们在 NeRF-LLFF [30] 数据集上评估我们的方法。 NeRF-LLFF 包括 8 个带有前置摄像头的场景,我们将每个场景的图像分为训练集和测试集。 由于相机分布为前向,我们使用相机组的图像外边缘作为基于凸包算法[36]的训练集。 对于每个实验,我们使用从训练集中随机选择的 k-shot (k=2,3,4,5) 图像来优化场景,并在同一测试集上进行评估。 我们使用十个随机选择的种子并报告十次实验的平均值。
|
(iv) Horns |
(iii) Fortress |
(ii) Room |
(i) Fern |
|
5-view |
2-view |
5-view |
2-view |
5-view |
2-view |
5-view |
2-view |
 ()
()
 ()
()
 ()
()
 ()
()
 ()
()
 ()
()
 ()
()
 ()
()
 ()
()
 ()
()
 ()
()
 ()
()
 ()
()
 ()
()
 ()
()
 ()
()
 ()
()
 ()
()
 ()
()
 ()
()
 ()
()
 ()
()
 ()
()
 ()
()
 ()
()
 ()
()
 ()
()
 ()
()
 ()
()
 ()
()
 ()
()
 ()
()
 ()
()
 ()
()
 ()
()
 ()
()
 ()
()
 ()
()
 ()
()
 ()
()




实施细节。
为了公平地比较不同选项,有必要在每个场景中使用统一的坐标并标准化评估值。 我们通过 COLMAP 处理场景的整个图像以获得一致的相机姿势和特征点,并选择与每个 k-shot 实验相关的那些来实现这一点。 我们从训练集中选择 摄像机,并提取在至少三个 摄像机中可见的特征点。 我们使用这些特征点作为等式中的深度指导。 (5) 和高斯分布优化的初始点。 在基线 (3DGS) 中,我们使用相同的 相机姿势和相同的过滤初始点,报告 30k 迭代时的评估值,就像原始设置一样。 对于oracle,我们旨在说明精确深度的有效性。 我们通过优化训练和测试的整个图像来创建伪 GT 深度。 我们用伪 GT 深度替换我们方法中的估计深度,并将结果报告为预言机。 最后,我们实现了等式中概述的可微深度光栅化器。 (7) 基于 CUDA。
| Method | 2-views | 5-views | ||||
|---|---|---|---|---|---|---|
| PSNR | SSIM | LPIPS | PSNR | SSIM | LPIPS | |
| w/o Adjustment | 7.86 | 0.319 | 0.740 | 10.01 | 0.346 | 0.761 |
| (Section 3.1) | ||||||
| w/o | 11.49 | 0.344 | 0.533 | 12.97 | 0.506 | 0.418 |
| (Section 3.2) | ||||||
| w/o | 14.75 | 0.415 | 0.391 | 17.79 | 0.561 | 0.297 |
| (Section 3.3) | ||||||
| w/o early stop | 13.99 | 0.345 | 0.433 | 17.28 | 0.494 | 0.333 |
| (Section 3.4) | ||||||
| Ours | 15.91 | 0.420 | 0.362 | 18.39 | 0.565 | 0.296 |
| Initialization | 2-views | 5-views | ||||
|---|---|---|---|---|---|---|
| points | PSNR | SSIM | LPIPS | PSNR | SSIM | LPIPS |
| COLMAP from | 19.80 | 0.567 | 0.232 | 23.72 | 0.740 | 0.144 |
| sparse-view (Ours) | ||||||
| Unprojected | 16.39 | 0.457 | 0.281 | 19.15 | 0.569 | 0.222 |
| from | ||||||
| COLMAP | 21.18 | 0.681 | 0.200 | 24.09 | 0.778 | 0.127 |
| from all-view | ||||||
4.2实验结果
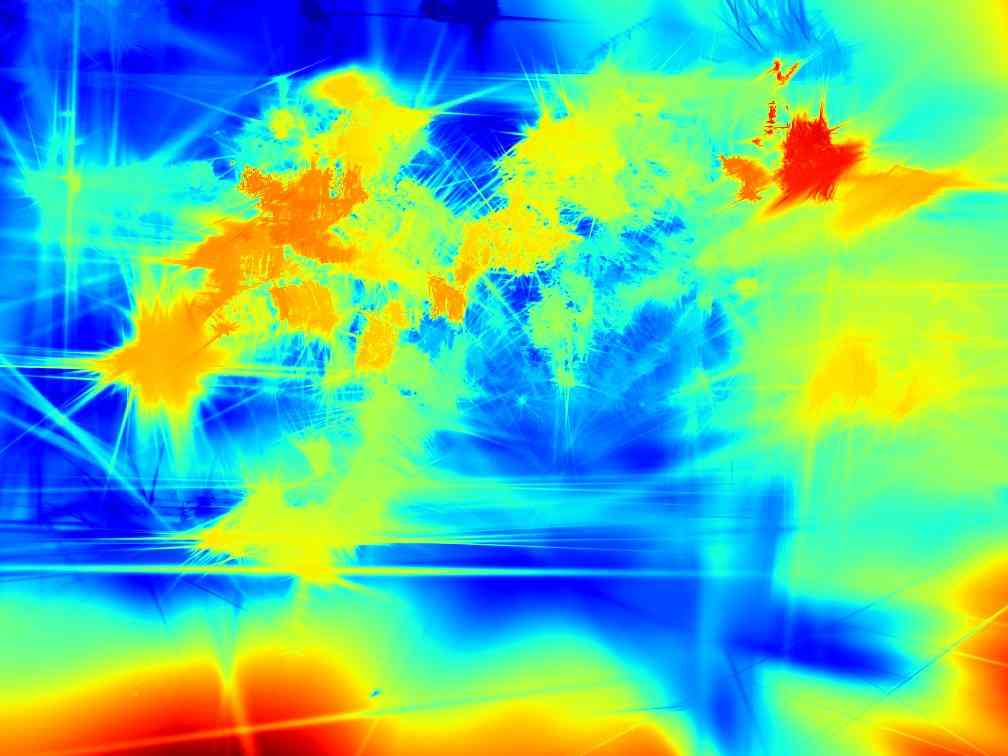
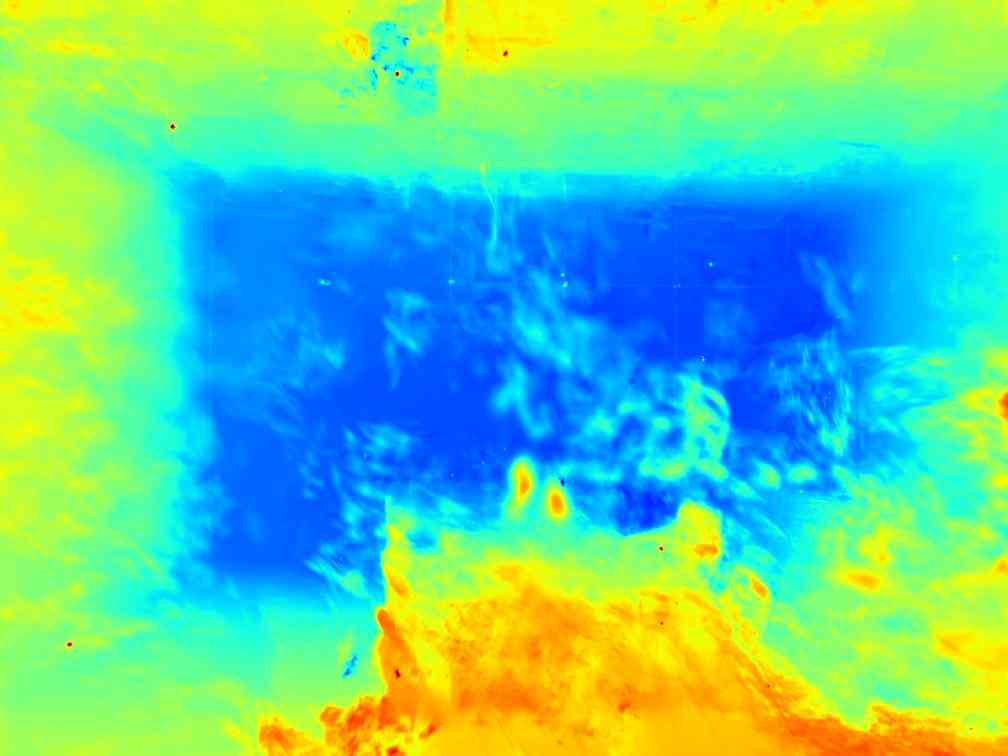
我们在表 1 中展示了 NeRF-LLFF 场景的 3DGS、我们的方法和预言机的比较结果。 在所有方法和场景中,使用图像数量的减少始终会导致视觉质量下降。 与 3DGS 相比,我们的方法通常表现出更好的结果,特别是当图像数量有限时。 图 3 可视化 3DGS 和我们的方法之间的差异。 深度图突出显示了 3DGS 在样本较少的情况下的几何故障。 例如,在 Fern 的 2 视图中,与 RGB 中的相似性相比,它显示完全错误的几何形状。 在 2 视图场景等恶劣条件下,3DGS 通常无法形成适当的几何形状。 相比之下,我们的方法形成合理的几何形状,同时生成有吸引力的图像。 我们在图 4 中提供了更多示例。 裁剪后的补丁表明我们的方法通过深度引导取得了更好的结果。 因此,我们确认深度提供的几何线索对于高斯分布的重建非常有益,特别是当图像数量有限时。 预言机的卓越性能再次证实了这一事实,该预言机采用了精确的几何结构。 预言机的示例图像展示了精确深度的有效性,如图5所示。 即使使用有限数量的图像,伪 GT 深度提供的丰富信息也能创建详细且可靠的结果。

需要注意的一个重要观察是我们的方法很大程度上依赖于预先训练的单目深度估计模型。 我们利用在室内数据集 NYU Depth v2 [42] 和城市数据集 KITTI [28] 上训练的 ZoeDepth [5] 预训练模型>。 因此,我们的模型在室内场景(堡垒、房间、蕨类植物)中表现相对较高,而在自然场景(兰花、花卉)中表现相对较差。 请注意,Leaves 给 COLMAP 带来了挑战,导致高斯泼溅训练通常不成功。
4.3 消融
我们在表2中展示了我们提出的方法的每个组成部分的消融研究。 第一行和第二行证明了绝对深度引导的必要性。 如果没有3.1节中的调整过程,密集的Depth 的单目深度估计模型的比例不正确。 深度与训练 COLMAP 中的相机内在参数不一致,导致完全失败。 我们还观察到仅使用无监督平滑约束而没有 3.2 节中介绍的深度监督时优化失败。 与基线相比,在没有绝对几何监督的情况下应用平滑度约束会产生更差的结果。 表2的第三行和第四行展示了附加技术的性能增强程度。 通过深度监督,第3.3节中的平滑度约束通过提供额外的几何线索有助于性能改进。 值得注意的是,3.4 节中引入的提前停止机制在防止我们的方法性能下降方面发挥着关键作用。 通过利用深度损失,它可以仔细检查板片与规定几何形状指南的差异,从而有效地阻止潜在的过度拟合情况。
在表3中,我们比较了不同高斯分布初始化之间的性能。 第二行说明了利用未投影密集深度 生成的点云作为初始化点时的结果。 通过非投影生成的大量初始点没有被有效地合并或修剪,导致与稀疏 COLMAP 初始化相比性能较低。 相反,第三行中描述的结果假设使用了所有 COLMAP 点。 采用 k 图像无法实现的大量有利初始点有助于通过密集深度调整和初始化来增强结果。
5 限制和未来的工作
我们的方法证明了通过深度引导在少样本设置中进行高斯泼溅优化的可行性,但它也有局限性。 首先,它严重依赖于单目深度估计模型的估计性能。 此外,该模型的深度估计性能可能会根据学习的数据域而变化,从而影响高斯泼溅优化的性能。 此外,依赖于将估计深度拟合到 COLMAP 点意味着依赖于 COLMAP 的性能,使其无法处理无纹理的平原或具有挑战性的表面,而 COLMAP 可能会失败。 我们将通过相互依赖的估计深度而不是 COLMAP 点来优化 3D 场景作为未来的工作。 此外,探索在各种数据集上规范几何形状的方法,包括深度估计(例如天空)可能具有挑战性的区域,是未来工作的另一个途径。
6结论
在这项工作中,我们引入了 Depth-Regularized Optimization for 3D Gaussian Splatting in 少样本图像,这是一种用少量图像学习 3D Gaussian splatting 的模型。 我们的模型使用深度来规范碎片,证明了这种几何引导的有效性。 为了获得密集的深度引导,我们利用单目深度估计模型并根据 SfM 点调整深度尺度。 我们在 NeRF-LLFF 数据集中检查了我们提出的深度损失、无监督平滑约束和早期停止技术的有效性。 我们的方法在样本量较少的情况下优于 3D 高斯溅射,可创建合理的几何形状。 最后,我们通过额外的实验证明,改进的深度和初始化点可以显着提高基于高斯分布的 3D 重建的性能。
参考
- Akenine-Möller et al. [2019] Tomas Akenine-Möller, Eric Haines, and Naty Hoffman. Real-time rendering. Crc Press, 2019.
- Azinović et al. [2022] Dejan Azinović, Ricardo Martin-Brualla, Dan B Goldman, Matthias Nießner, and Justus Thies. Neural rgb-d surface reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022.
- Barron et al. [2021] Jonathan T Barron, Ben Mildenhall, Matthew Tancik, Peter Hedman, Ricardo Martin-Brualla, and Pratul P Srinivasan. Mip-nerf: A multiscale representation for anti-aliasing neural radiance fields. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021.
- Barron et al. [2022] Jonathan T Barron, Ben Mildenhall, Dor Verbin, Pratul P Srinivasan, and Peter Hedman. Mip-nerf 360: Unbounded anti-aliased neural radiance fields. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022.
- Bhat et al. [2023] Shariq Farooq Bhat, Reiner Birkl, Diana Wofk, Peter Wonka, and Matthias Müller. Zoedepth: Zero-shot transfer by combining relative and metric depth. arXiv preprint arXiv:2302.12288, 2023.
- Bian et al. [2023] Wenjing Bian, Zirui Wang, Kejie Li, Jiawang Bian, and Victor Adrian Prisacariu. Nope-nerf: Optimising neural radiance field with no pose prior. 2023.
- Cai et al. [2022] Hongrui Cai, Wanquan Feng, Xuetao Feng, Yan Wang, and Juyong Zhang. Neural surface reconstruction of dynamic scenes with monocular rgb-d camera. Advances in Neural Information Processing Systems, 2022.
- Canny [1986] John Canny. A computational approach to edge detection. IEEE Transactions on pattern analysis and machine intelligence, 1986.
- Chan et al. [2022] Eric R Chan, Connor Z Lin, Matthew A Chan, Koki Nagano, Boxiao Pan, Shalini De Mello, Orazio Gallo, Leonidas J Guibas, Jonathan Tremblay, Sameh Khamis, et al. Efficient geometry-aware 3d generative adversarial networks. In CVPR, 2022.
- Chen et al. [2022] Anpei Chen, Zexiang Xu, Andreas Geiger, Jingyi Yu, and Hao Su. Tensorf: Tensorial radiance fields. In ECCV, 2022.
- Chen et al. [2023] Zhiqin Chen, Thomas Funkhouser, Peter Hedman, and Andrea Tagliasacchi. Mobilenerf: Exploiting the polygon rasterization pipeline for efficient neural field rendering on mobile architectures. In CVPR, 2023.
- Crawfis and Max [1993] Roger A Crawfis and Nelson Max. Texture splats for 3d scalar and vector field visualization. In Proceedings Visualization’93, 1993.
- Deng et al. [2022a] Kangle Deng, Andrew Liu, Jun-Yan Zhu, and Deva Ramanan. Depth-supervised nerf: Fewer views and faster training for free. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022a.
- Deng et al. [2022b] Nianchen Deng, Zhenyi He, Jiannan Ye, Budmonde Duinkharjav, Praneeth Chakravarthula, Xubo Yang, and Qi Sun. Fov-nerf: Foveated neural radiance fields for virtual reality. IEEE Transactions on Visualization and Computer Graphics, 2022b.
- Dey et al. [2022] Arnab Dey, Yassine Ahmine, and Andrew I Comport. Mip-nerf rgb-d: Depth assisted fast neural radiance fields. arXiv preprint arXiv:2205.09351, 2022.
- Fridovich-Keil et al. [2022] Sara Fridovich-Keil, Alex Yu, Matthew Tancik, Qinhong Chen, Benjamin Recht, and Angjoo Kanazawa. Plenoxels: Radiance fields without neural networks. In CVPR, 2022.
- Furukawa et al. [2015] Yasutaka Furukawa, Carlos Hernández, et al. Multi-view stereo: A tutorial. Foundations and Trends® in Computer Graphics and Vision, 2015.
- Gao et al. [2022] Kyle Gao, Yina Gao, Hongjie He, Dening Lu, Linlin Xu, and Jonathan Li. Nerf: Neural radiance field in 3d vision, a comprehensive review. arXiv preprint arXiv:2210.00379, 2022.
- Garbin et al. [2021] Stephan J Garbin, Marek Kowalski, Matthew Johnson, Jamie Shotton, and Julien Valentin. Fastnerf: High-fidelity neural rendering at 200fps. In ICCV, 2021.
- Godard et al. [2017] Clément Godard, Oisin Mac Aodha, and Gabriel J Brostow. Unsupervised monocular depth estimation with left-right consistency. In Proceedings of the IEEE conference on computer vision and pattern recognition, 2017.
- Han et al. [2019] Xian-Feng Han, Hamid Laga, and Mohammed Bennamoun. Image-based 3d object reconstruction: State-of-the-art and trends in the deep learning era. PAMI, 2019.
- Hartley and Zisserman [2003] Richard Hartley and Andrew Zisserman. Multiple view geometry in computer vision. Cambridge university press, 2003.
- Kerbl et al. [2023a] Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering. TOG, 2023a.
- Kerbl et al. [2023b] Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering. ACM Transactions on Graphics, 2023b.
- Kim et al. [2022] Mijeong Kim, Seonguk Seo, and Bohyung Han. Infonerf: Ray entropy minimization for few-shot neural volume rendering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022.
- Kopanas et al. [2021] Georgios Kopanas, Julien Philip, Thomas Leimkühler, and George Drettakis. Point-based neural rendering with per-view optimization. In Computer Graphics Forum, 2021.
- Liu et al. [2020] Lingjie Liu, Jiatao Gu, Kyaw Zaw Lin, Tat-Seng Chua, and Christian Theobalt. Neural sparse voxel fields. NIPS, 2020.
- Menze and Geiger [2015] Moritz Menze and Andreas Geiger. Object scene flow for autonomous vehicles. In Proceedings of the IEEE conference on computer vision and pattern recognition, 2015.
- Mertan et al. [2022] Alican Mertan, Damien Jade Duff, and Gozde Unal. Single image depth estimation: An overview. Digital Signal Processing, 2022.
- Mildenhall et al. [2019] Ben Mildenhall, Pratul P. Srinivasan, Rodrigo Ortiz-Cayon, Nima Khademi Kalantari, Ravi Ramamoorthi, Ren Ng, and Abhishek Kar. Local light field fusion: Practical view synthesis with prescriptive sampling guidelines. ACM Transactions on Graphics (TOG), 2019.
- Mildenhall et al. [2021] Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. Communications of the ACM, 2021.
- Müller et al. [2021] Thomas Müller, Fabrice Rousselle, Jan Novák, and Alexander Keller. Real-time neural radiance caching for path tracing. arXiv preprint arXiv:2106.12372, 2021.
- Müller et al. [2022] Thomas Müller, Alex Evans, Christoph Schied, and Alexander Keller. Instant neural graphics primitives with a multiresolution hash encoding. TOG, 2022.
- Neff et al. [2021] Thomas Neff, Pascal Stadlbauer, Mathias Parger, Andreas Kurz, Joerg H Mueller, Chakravarty R Alla Chaitanya, Anton Kaplanyan, and Markus Steinberger. Donerf: Towards real-time rendering of compact neural radiance fields using depth oracle networks. In Computer Graphics Forum, 2021.
- Niemeyer et al. [2022] Michael Niemeyer, Jonathan T Barron, Ben Mildenhall, Mehdi SM Sajjadi, Andreas Geiger, and Noha Radwan. Regnerf: Regularizing neural radiance fields for view synthesis from sparse inputs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022.
- Preparata and Shamos [2012] Franco P Preparata and Michael I Shamos. Computational geometry: an introduction. Springer Science & Business Media, 2012.
- Prinzler et al. [2023] Malte Prinzler, Otmar Hilliges, and Justus Thies. Diner: Depth-aware image-based neural radiance fields. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023.
- Reed [2012] Michael Reed. Methods of modern mathematical physics: Functional analysis. Elsevier, 2012.
- Reiser et al. [2021] Christian Reiser, Songyou Peng, Yiyi Liao, and Andreas Geiger. Kilonerf: Speeding up neural radiance fields with thousands of tiny mlps. In ICCV, 2021.
- Roessle et al. [2022] Barbara Roessle, Jonathan T Barron, Ben Mildenhall, Pratul P Srinivasan, and Matthias Nießner. Dense depth priors for neural radiance fields from sparse input views. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022.
- Schonberger and Frahm [2016] Johannes L Schonberger and Jan-Michael Frahm. Structure-from-motion revisited. In CVPR, 2016.
- Silberman et al. [2012] Nathan Silberman, Derek Hoiem, Pushmeet Kohli, and Rob Fergus. Indoor segmentation and support inference from rgbd images. In Computer Vision–ECCV 2012: 12th European Conference on Computer Vision, Florence, Italy, October 7-13, 2012, Proceedings, Part V 12, 2012.
- Sun et al. [2022] Cheng Sun, Min Sun, and Hwann-Tzong Chen. Direct voxel grid optimization: Super-fast convergence for radiance fields reconstruction. In CVPR, 2022.
- Tewari et al. [2022] Ayush Tewari, Justus Thies, Ben Mildenhall, Pratul Srinivasan, Edgar Tretschk, Wang Yifan, Christoph Lassner, Vincent Sitzmann, Ricardo Martin-Brualla, Stephen Lombardi, et al. Advances in neural rendering. In Computer Graphics Forum, 2022.
- Tomasi and Kanade [1992] Carlo Tomasi and Takeo Kanade. Shape and motion from image streams under orthography: a factorization method. International journal of computer vision, 1992.
- Ullman [1979] Shimon Ullman. The interpretation of structure from motion. Proceedings of the Royal Society of London. Series B. Biological Sciences, 1979.
- Wang et al. [2021a] Peng Wang, Lingjie Liu, Yuan Liu, Christian Theobalt, Taku Komura, and Wenping Wang. Neus: Learning neural implicit surfaces by volume rendering for multi-view reconstruction. arXiv preprint arXiv:2106.10689, 2021a.
- Wang et al. [2021b] Zirui Wang, Shangzhe Wu, Weidi Xie, Min Chen, and Victor Adrian Prisacariu. Nerf–: Neural radiance fields without known camera parameters. arXiv preprint arXiv:2102.07064, 2021b.
- Wei et al. [2021] Yi Wei, Shaohui Liu, Yongming Rao, Wang Zhao, Jiwen Lu, and Jie Zhou. Nerfingmvs: Guided optimization of neural radiance fields for indoor multi-view stereo. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021.
- Wiles et al. [2020] Olivia Wiles, Georgia Gkioxari, Richard Szeliski, and Justin Johnson. Synsin: End-to-end view synthesis from a single image. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020.
- Xie et al. [2022] Yiheng Xie, Towaki Takikawa, Shunsuke Saito, Or Litany, Shiqin Yan, Numair Khan, Federico Tombari, James Tompkin, Vincent Sitzmann, and Srinath Sridhar. Neural fields in visual computing and beyond. In Computer Graphics Forum, 2022.
- Xu et al. [2022] Qiangeng Xu, Zexiang Xu, Julien Philip, Sai Bi, Zhixin Shu, Kalyan Sunkavalli, and Ulrich Neumann. Point-nerf: Point-based neural radiance fields. In CVPR, 2022.
- Yang et al. [2023] Chen Yang, Peihao Li, Zanwei Zhou, Shanxin Yuan, Bingbing Liu, Xiaokang Yang, Weichao Qiu, and Wei Shen. Nerfvs: Neural radiance fields for free view synthesis via geometry scaffolds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023.
- Yariv et al. [2021] Lior Yariv, Jiatao Gu, Yoni Kasten, and Yaron Lipman. Volume rendering of neural implicit surfaces. Advances in Neural Information Processing Systems, 2021.
- Yifan et al. [2019] Wang Yifan, Felice Serena, Shihao Wu, Cengiz Öztireli, and Olga Sorkine-Hornung. Differentiable surface splatting for point-based geometry processing. ACM Transactions on Graphics (TOG), 2019.
- Yu et al. [2021] Alex Yu, Ruilong Li, Matthew Tancik, Hao Li, Ren Ng, and Angjoo Kanazawa. Plenoctrees for real-time rendering of neural radiance fields. In ICCV, 2021.
- Zhang et al. [2020] Kai Zhang, Gernot Riegler, Noah Snavely, and Vladlen Koltun. Nerf++: Analyzing and improving neural radiance fields. arXiv preprint arXiv:2010.07492, 2020.
- Zhao et al. [2023] Wenliang Zhao, Yongming Rao, Zuyan Liu, Benlin Liu, Jie Zhou, and Jiwen Lu. Unleashing text-to-image diffusion models for visual perception. arXiv preprint arXiv:2303.02153, 2023.
- Zhou et al. [2017] Chao Zhou, Hong Zhang, Xiaoyong Shen, and Jiaya Jia. Unsupervised learning of stereo matching. In Proceedings of the IEEE International Conference on Computer Vision, 2017.