用于车辆网络语义通信的可扩展人工智能生成内容
摘要
感知驾驶员盲点中的车辆对于安全驾驶至关重要。 对这些盲点中潜在危险车辆的检测可以受益于车联网语义通信技术。 然而,有效的语义通信涉及准确性和延迟之间的权衡,特别是在带宽有限的情况下。 本文推出了一种可扩展的人工智能生成内容(AIGC)系统,该系统利用编码器-解码器架构。 该系统将图像转换为文本表示,并将其重建为质量可接受的图像,优化车辆网络语义通信的传输。 此外,在带宽允许的情况下,还可以集成辅助信息。 编码器-解码器的目标是在各种任务中保持与原始图像的语义等效性。 然后,所提出的方法采用强化学习来增强生成内容的可靠性。 实验结果表明,该方法在盲点感知车辆方面超越了基线,并有效压缩了通信数据。 虽然这种方法是专门为驾驶场景而设计的,但这种编码器-解码器架构也具有在各种语义通信场景中广泛使用的潜力。
索引术语—车载网络语义通信、可扩展的人工智能生成内容、编码器-解码器、强化学习
1简介
人工智能生成内容 (AIGC) [1,2,3,4] 利用先进的机器学习和深度学习技术,使计算机能够从最少的内容生成大量文本、图形、听觉和视频内容信息。 然而,AIGC 应用中仍然存在挑战,包括生成特定于任务的、上下文相关的内容以及输出质量的评估。
AIGC 的一项实际应用是车载网络语义通信。 在高速公路上高速行驶时,驾驶员通常会将视线集中在前方,从而导致侧面盲点。 帮助驾驶员检测这些盲点的运动,尤其是快速接近的车辆,对于安全至关重要。 车联网语义通信技术可以检测这些盲点中潜在危险的车辆。 它通过捕获、编码和传输这些车辆的实时图像,然后解码这些信息并将其以图像形式呈现给驾驶员来实现这一目标。 然而,车载网络语义通信常常面临带宽限制,使得有效的图像传输成为挑战。
为了克服这一挑战,在本文中,我们提出了一种可扩展的 AIGC 编码器-解码器架构,该架构提取特定于任务的图像语义并通过车联网以文本形式传输它们[5]。 在此过程中,强化学习技术[6, 7]增强了语义信息的文本表示。 如果带宽允许,还可以传达具有重要语义的图像区域。 最终目标是改进和评估重建图像的质量,直到满足验收标准。 本文的主要贡献包括:
-
1.
我们引入了一种可扩展的 AIGC 编码器-解码器架构,主要将图像转换为语义文本信息。 根据带宽可用性,它还可以包括相关的语义图像数据。 我们的方法提供了双重好处:当带宽受限时,它优先传输语义文本信息,而当带宽充足时,它会合并具有重要语义的本地图像区域。
-
2.
我们利用强化学习技术来优化编码和解码过程。 通过将编码和解码视为顺序决策,我们确保生成的文本数据保留充足的语义信息,旨在最大限度地提高重建图像的质量。
-
3.
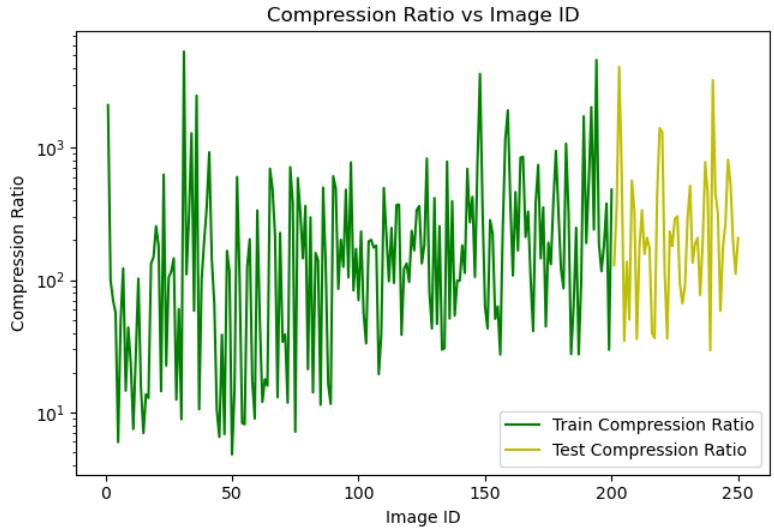
我们使用车辆图像数据集进行实验来验证我们提出的 AIGC 方法的有效性。 结果表明,我们提出的方法在图像质量和压缩率方面都超过了基线,这表明它对于现实场景(例如不同带宽条件下的车辆通信)具有潜在的有用性。
2相关工作
2.1图像压缩与传输
JPEG [8] 和 PNG [9] 等传统图像压缩方法被广泛用于减小图像大小,同时保持可接受的质量。 最近的进展利用深度学习架构,例如循环神经网络 (RNN) [10] 和自动编码器 [11],在不影响图像保真度的情况下获得卓越的压缩率。
2.2 视觉数据的文本描述
将图像转换为文本描述或提示已在研究中获得关注,特别是自深度学习兴起以来。 最初的努力集中在模板驱动技术[12]上,而最近的方法利用 RNN [13] 和 Transformers [14] 来生成更多自然且描述性的图像标题。
2.3 文本到图像的合成
将文本描述转换回图像的反向挑战也引起了相当大的兴趣。 生成对抗网络 (GAN) [1] 一直处于这项研究的前沿,DALL·E [2] 等模型展示了生成高质量图像的能力根据文字提示。 我们已经探索了整合补充线索或上下文来指导合成过程,从而提高所生成图像的准确性和相关性[15]。
2.4图像处理中的强化学习
强化学习在图像处理任务(例如优化和增强)中的应用是一个相对较新的途径。 像[16]这样的工作已经表明,与传统技术相比,基于强化学习的方法在取得更好结果方面具有潜力,特别是在目标未明确定义的情况下。
3方法论
所提出的可扩展 AIGC 系统代表了我们如何处理数据传输和语义通信的范式转变,特别是在带宽受限的环境中。 可扩展的 AIGC 系统可动态适应带宽可用性,优先传输重要信息。 这种适应性源于复杂的编码和强化学习优化,使可扩展的 AIGC 系统能够决定传输内容和方式。
可扩展 AIGC 系统的动机是传输高分辨率图像并不总是实用或必要的。 通常,捕捉图像本质的简洁文本表示就足够了。 通过将图像转换为通信数据,可扩展的 AIGC 系统确保高效传输,同时保留数据的语义价值。
所提出的可扩展 AIGC 系统的核心是将图像数据转换为特定于任务且更紧凑的通信数据格式。 传输后,该数据会在解码为图像之前使用强化学习进行优化。 强化学习方法可以迫使通信数据与特定任务更加相关。 我们提出的方法分为三个主要阶段:
-
•
信息编码。 初始阶段涉及将图像编码为文本表示。 这个过程,我们称之为“信息编码”,利用编码器将图像的基本特征提炼成适合传输的简洁文本格式。
-
•
基于强化学习的优化。 在解码之前,通信数据通过强化学习模块。 该模块识别并调整文本信息,确保解码的图像与预期的上下文和要求保持一致。 具体来说,使用演员评论家方法,该模型可以识别有害的文本细节并识别可以增强最终图像表示的短语。
-
•
信息解码。 然后,优化后的通信数据被输入解码器,将文本信息转换回视觉形式,从而生成既节省带宽又与上下文相关的图像。
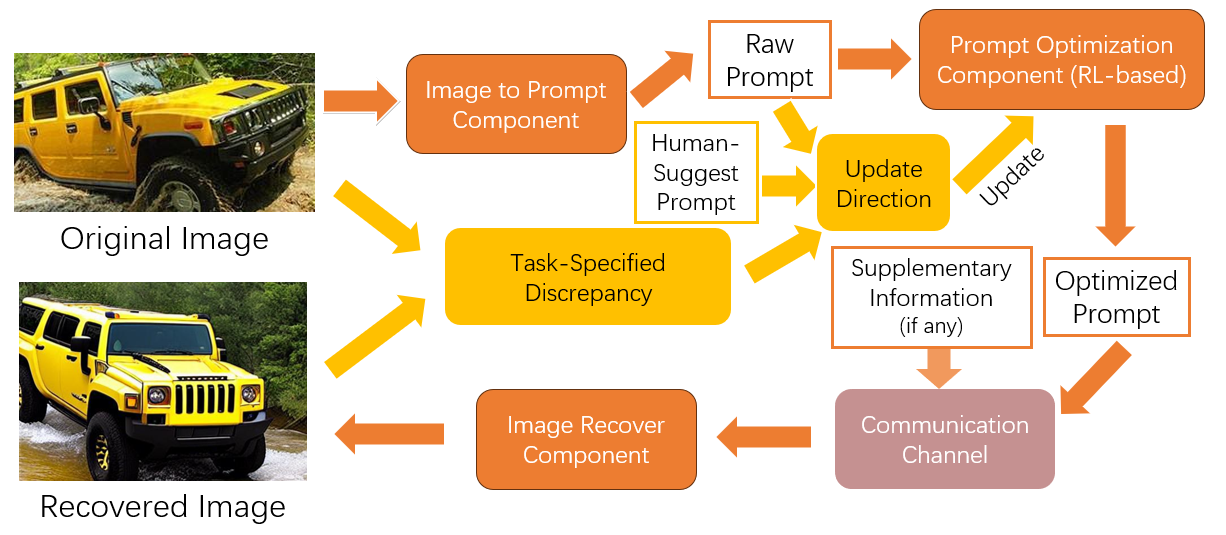
如图1所示,可扩展的AIGC系统包含三个不同的组件:图像提示组件、提示优化组件和图像恢复组件。 这些组件分别对应于前面描述的三个阶段。 在后续章节中,我们将分别深入讨论这些组件。
3.1 信息编码与解码
3.1.1 信息编码
我们系统中的信息编码过程利用了大型语言模型的功能。 给定图像,此阶段的主要目标是生成简洁且描述性的文本提示,其中包含图像的基本特征和细节。 这是通过将图像输入编码器来实现的,该编码器已经在大量图像文本对数据集上进行了训练。 基本原则是利用最先进的语言模型的力量将图像的丰富视觉信息提炼成紧凑的文本表示。 这种表示形式被称为“提示”,充当视觉域和文本域之间的桥梁,确保以带宽有效的方式保留图像的核心语义。
3.1.2信息解码
解码阶段的任务是将生成的文本提示转换回视觉表示。 这不是一个简单的翻译,因为挑战在于重新生成与上下文相关且与原始图像非常相似的图像。 我们的解码器采用先进的文本到图像合成技术来实现这一点。
此外,为了提高重新生成图像的准确性和保真度,我们的系统允许集成图像提示。 这些提示为解码器提供了额外的上下文和指导,确保输出图像与原始上下文很好地对齐。 例如,如果原始图像是山脉上的日落,则提示可能会强调山脉的调色板或轮廓。 通过合并这些提示,我们的解码器可以生成不仅在语义上与文本提示一致而且在视觉上与原始图像一致的图像。
从本质上讲,我们的编码和解码方法确保了视觉域和文本域之间的无缝过渡,为带宽受限场景中高效且语义丰富的通信铺平了道路。
3.2基于强化学习的优化
将图像的丰富细节压缩为文本表示的过程(称为“信息编码”)可能并不总能捕获对特定任务和应用场景至关重要的细微差别。 例如,在对周围车辆的细节进行编码时,用户主要关心特定方面,例如车辆接近的方向、车辆前端的方向以及车辆的类型(无论是大型卡车、轿车还是轿车)。小型三轮电动车)。
为了弥合模型生成的内容和以用户为中心的需求之间的差距,我们提出了一种基于强化学习的方法来增强编码文本信息的表达能力。 目标是将与驾驶环境高度相关的细节无缝集成到生成的文本中,从而提高模型的性能。
在我们的环境中采用强化学习方法的主要目标有两个:
-
1.
有害信息的识别。 识别并查明编码通信数据中可能适得其反或与总体任务无关的文本元素。
-
2.
注入有益的短语。 检测并建议可以显着增强模型输出的上下文相关性和准确性的短语或细节。
通过实现这些目标,该模型旨在消除有害的文本细节并纳入有益的信息,确保解码的视觉表示既上下文丰富又符合用户偏好。
我们使用演员评论家框架。 state 被定义为当前的文本表示。 初始状态是从输入图像生成的通信数据。 可能的动作是添加、删除和修改之一。 这三种动作可以分别向通信数据中引入新的短语或细节、从通信数据中移除特定短语或细节、以及改变通信数据内的现有短语或细节。 奖励是根据其被解码为上下文相关图像的能力来衡量调整后的通信数据的质量。 质量可以是各种因素的函数,例如上下文相关性、清晰度以及与用户偏好的一致性。
框架中有一个演员和一个评论家。 参与者定义了一个策略,它给出了在状态下采取行动的概率。其表示为:
批评者评估在特定状态下采取行动的预期回报或价值。 它由下式给出:
优势函数衡量在该状态下采取特定行动相对于平均行动的相对价值:
其中 是折扣系数。
Actor 使用策略梯度方法进行更新:
批评家根据其预测值和实际回报之间的均方误差进行更新:
4实验
在实验中,我们利用斯坦福汽车数据集进行实验。 该数据集包含 196 类汽车,总共 16,185 张图像。 分类通常基于汽车的品牌、型号和年份。 每个图像的尺寸为 360×240。
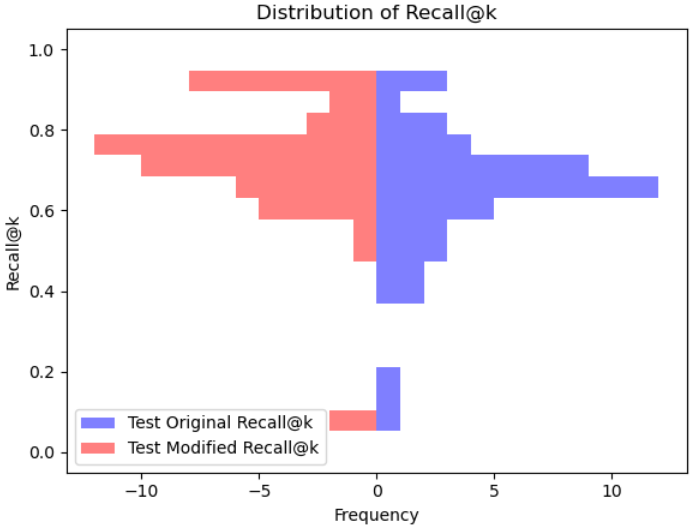
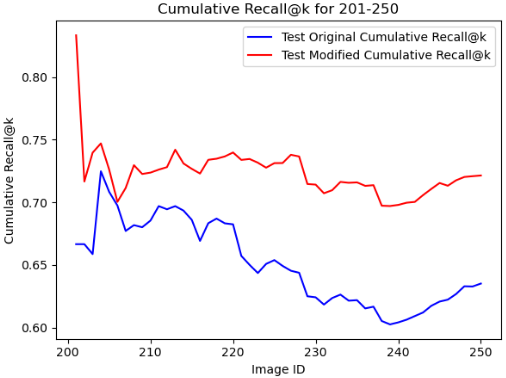
我们考虑一种立即将图像转换为文本,然后返回图像作为基线的方法。 我们将可扩展 AIGC 系统的性能与此基线进行比较。 实验使用 i9-10920X CPU 和 GeForce RTX 2080 Ti 进行。 评估基于重建图像的 Recall@k 指标。 该指标评估测试集上分类任务的 top-k 预测的准确性,使其适合评估图像重建的性能。
我们使用斯坦福汽车数据集训练的子集报告结果:200 张图像用于测试,50 张图像用于测试。

5结论
在本文中,我们提出了一种可扩展的人工智能生成内容系统——一种在带宽有限的环境中进行高效语义通信的方法。 利用编码器-解码器架构和强化学习,我们的方法将图像编码为更精简的方式,以便在解码器端进行传输和重建。 对车辆图像数据集的实验测试证实,我们的框架将原始图像压缩为特定于任务的文本表示。 然后,它根据这些文本提示生成高质量的图像,如累积 Recall@k 指标所证明的那样。 这些结果说明了我们可扩展系统的功效和前景,我们相信该系统具有在各个领域应用的多功能性。
参考
- [1] I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. C. Courville, and Y. Bengio, “Generative adversarial nets,” in Advances in Neural Information Processing Systems 27: Annual Conference on Neural Information Processing Systems, Montreal, Quebec, Canada, December 2014, pp. 2672–2680.
- [2] A. Ramesh, M. Pavlov, G. Goh, S. Gray, C. Voss, A. Radford, M. Chen, and I. Sutskever, “Zero-shot text-to-image generation,” in Proceedings of the 38th International Conference on Machine Learning (ICML), Virtual Event, vol. 139, July 2021, pp. 8821–8831.
- [3] M. Xu, H. Du, D. Niyato, J. Kang, Z. Xiong, X. Shen, Z. Han, and H. V. Poor, “Unleashing the power of edge-cloud generative AI in mobile networks: A survey of AIGC services,” to appear IEEE Communications Surveys & Tutorials.
- [4] M. Xu, D. Niyato, J. Chen, H. Zhang, J. Kang, Z. Xiong, S. Mao, and Z. Han, “Generative AI-empowered simulation for autonomous driving in vehicular mixed reality metaverses,” to appear IEEE Journal on Selected Topics on Signal Processing.
- [5] B. Ji, X. Zhang, S. Mumtaz, C. Han, C. Li, H. Wen, and D. Wang, “Survey on the internet of vehicles: Network architectures and applications,” IEEE Communications Standards Magazine, vol. 4, no. 1, pp. 34–41, March 2020.
- [6] H. van Hasselt, “Double q-learning,” in Advances in Neural Information Processing Systems 23: 24th Annual Conference on Neural Information Processing Systems, Vancouver, British Columbia, Canada, December 2010, pp. 2613–2621.
- [7] H. van Hasselt, A. Guez, and D. Silver, “Deep reinforcement learning with double q-learning,” in Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, Arizona, February 2016, pp. 2094–2100.
- [8] G. K. Wallace, “The JPEG still picture compression standard,” Commun. ACM, vol. 34, no. 4, pp. 30–44, April 1991.
- [9] T. Boutell, “PNG (portable network graphics) specification version 1.0,” RFC, vol. 2083, no. 1, pp. 1–102, March 1997.
- [10] G. Toderici, S. M. O’Malley, S. J. Hwang, D. Vincent, D. Minnen, S. Baluja, M. Covell, and R. Sukthankar, “Variable rate image compression with recurrent neural networks,” in 4th International Conference on Learning Representations (ICLR), San Juan, Puerto Rico, May 2016.
- [11] L. Theis, W. Shi, A. Cunningham, and F. Huszár, “Lossy image compression with compressive autoencoders,” in 5th International Conference on Learning Representations (ICLR), Toulon, France, April 2017.
- [12] A. Farhadi, S. M. M. Hejrati, M. A. Sadeghi, P. Young, C. Rashtchian, J. Hockenmaier, and D. A. Forsyth, “Every picture tells a story: Generating sentences from images,” in 11th European Conference on Computer Vision (ECCV), Heraklion, Crete, Greece, vol. 6314, September 2010, pp. 15–29.
- [13] O. Vinyals, A. Toshev, S. Bengio, and D. Erhan, “Show and tell: A neural image caption generator,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, June 2015, pp. 3156–3164.
- [14] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” in Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems, Long Beach, CA, December 2017, pp. 5998–6008.
- [15] H. Zhang, T. Xu, and H. Li, “Stackgan: Text to photo-realistic image synthesis with stacked generative adversarial networks,” in IEEE International Conference on Computer Vision (ICCV), Venice, Italy, October 2017, pp. 5908–5916.
- [16] V. Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. A. Riedmiller, A. Fidjeland, G. Ostrovski, S. Petersen, C. Beattie, A. Sadik, I. Antonoglou, H. King, D. Kumaran, D. Wierstra, S. Legg, and D. Hassabis, “Human-level control through deep reinforcement learning,” Nat., vol. 518, no. 7540, pp. 529–533, February 2015.