EfficientSAM:利用屏蔽图像预训练实现高效分段
摘要
任意分段模型(SAM)已成为众多视觉应用的强大工具。 推动零样本传输和高通用性取得骄人成绩的一个关键因素是在大量高质量 SA-1B 数据集上训练的超大型 Transformer 模型。 SAM 模型虽然有益,但其巨大的计算成本限制了它在现实世界中的广泛应用。 为了解决这一局限性,我们提出了 EfficientSAMs 模型,它是一种轻量级的 SAM 模型,在大幅降低复杂性的同时还能表现出良好的性能。 我们的想法是基于利用遮蔽图像预训练,即 SAMI,它能学会从 SAM 图像编码器中重建特征,从而实现有效的视觉表征学习。 此外,我们还采用 SAMI 预训练的轻量级图像编码器和掩码解码器来构建 EfficientSAM,并在 SA-1B 上对模型进行微调,以完成任何分段任务。 我们对图像分类、物体检测、实例分割和语义物体检测等多项视觉任务进行了评估,发现我们提出的预训练方法 SAMI 始终优于其他遮蔽图像预训练方法。 在诸如零样本分割等任何分割任务中,我们的 EfficientSAM 与经过 SAMI 预训练的轻量级图像编码器表现出色,与其他快速 SAM 模型相比有显著提升(例如,COCO/LVIS 上的 4 AP)。
1导言
Segment Anything Model(SAM)[31]在视觉领域取得了巨大成功,在各种图像分割任务中实现了最先进的性能,例如零样本边缘检测[1, 31]、零样本对象建议生成[54, 31]和零样本实例分割[31]、以及许多其他实际应用[41, 51, 24, 50, 52, 37]。 SAM 的主要特点是基于提示的视觉变换器(ViT)[19]模型,该模型是在一个大规模视觉数据集 SA-1B[31] 上训练的,该数据集包含来自 1100 万张图像的 1B 多个掩码,可以分割给定图像上的任何对象。 Segment Anything 的这种能力使 SAM 成为视觉领域的基础模型,并使其应用甚至超越了视觉领域。
尽管有上述优点,但由于 SAM 的结构,特别是图像编码器(如 ViT-H)非常昂贵,因此 SAM 的模型成为实际部署的主要效率瓶颈。 请注意,SAM 中的 ViT-H 图像编码器有 632M 个参数,而基于提示的解码器只需要 387M 个参数。 因此,在实际使用 SAM 执行任何细分任务时,计算和内存成本都会很高,这对实时应用来说具有挑战性。
为了应对这一挑战,最近有几项研究提出了一些策略,以避免在基于提示的实例分割中应用 SAM 时产生巨大的成本。 例如,[68] 建议将默认 ViT-H 图像编码器中的知识提炼为一个微小的 ViT 图像编码器。 在[71]中,使用基于实时 CNN 的架构可以降低"任意分段"任务的计算成本。
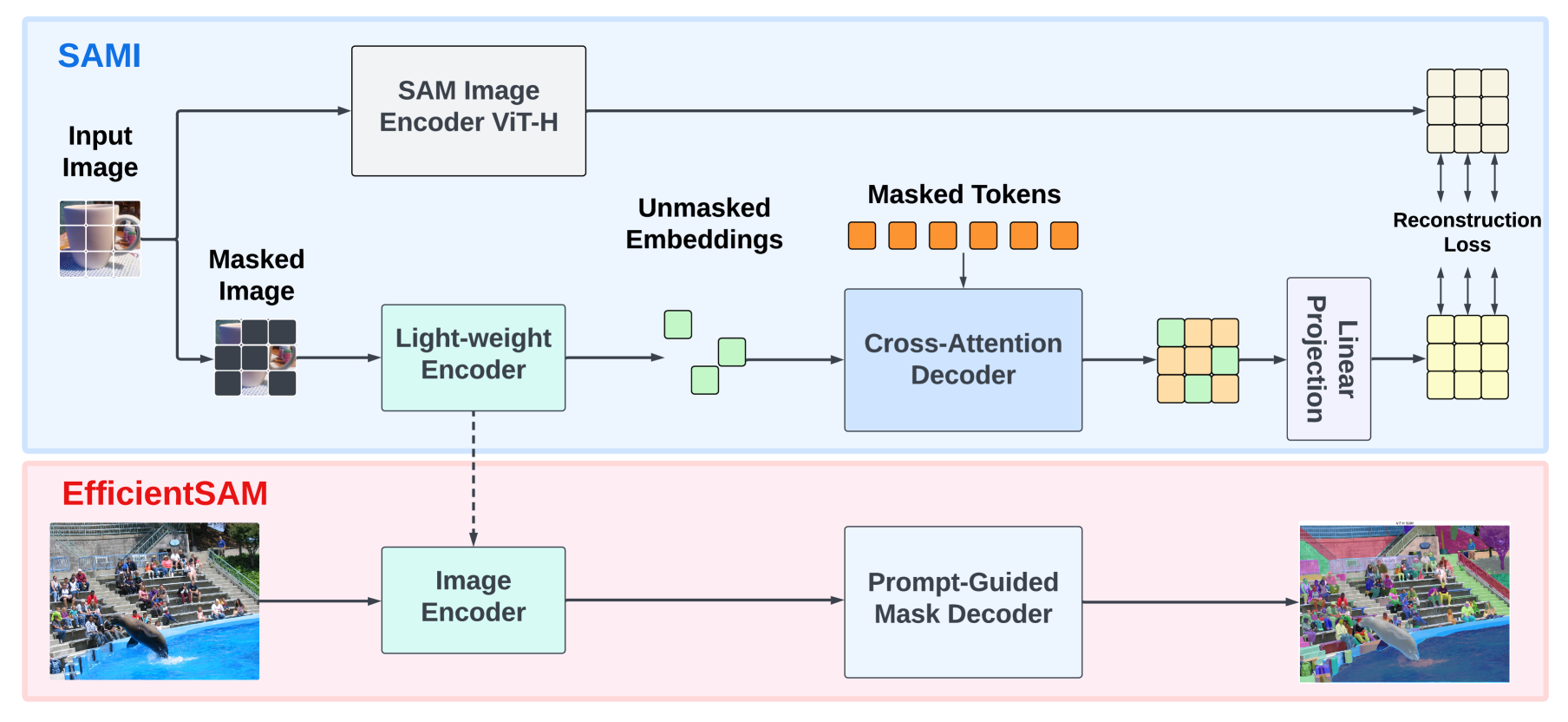
在本文中,我们建议使用经过良好预训练的轻量级 ViT 图像编码器(例如 ViT-Tiny/-Small[53])来降低 SAM 的复杂性,同时保持不错的性能。 我们的方法--SAM-veraged masked image pertraining (SAMI)--可为任何分段任务生成所需的预训练轻量级 ViT 骨架。 这是通过利用著名的 MAE[26]预训练方法和 SAM 模型来获得高质量的预训练 ViT 编码器来实现的。 具体来说,我们的 SAMI 利用 SAM 编码器 ViT-H 生成特征嵌入,并用轻量级编码器训练遮蔽图像模型,从而从 SAM 的 ViT-H 代替图像补丁重建特征。 这就产生了通用的 ViT 主干网,可用于下游任务,如图像分类、对象检测和分段。 然后,我们利用 SAM 解码器对预训练的轻量级编码器进行微调,以处理任何分段任务[31]。
为了评估我们的方法,我们考虑了屏蔽图像预训练的迁移学习设置,即首先在图像分辨率为 的 ImageNet 上使用重构损失对模型进行预训练,然后使用监督数据在目标任务上对模型进行微调。 我们的 SAMI 学习轻量级编码器,并能很好地进行泛化。 通过 SAMI 预训练,我们可以在 ImageNet-1K 上训练 ViT-Tiny/-Small/-Base 等模型,并提高泛化性能。 对于 ViT-Small 模型,我们在 ImageNet-1K 上进行 100 次微调后,达到了 82.7% 的 top-1 准确率,超过了其他最先进的图像预训练基线。 我们还对物体检测、实例分割和语义分割方面的预训练模型进行了微调。 在所有这些任务中,我们的预训练方法都取得了比其他预训练基线更好的结果,更重要的是,我们观察到了小模型的显著收益。 此外,我们还在 "分段 "任务中对我们的模型进行了评估。 在零样本分割方面,与包括 FastSAM 在内的最新轻量级 SAM 方法相比,我们的模型表现出色,在 COCO/LVIS 上的差距为 4.1AP/5.2 AP。
我们的主要贡献可以概括如下:
-
•
我们提出了一种名为SAMI的 SAM 杠杆遮蔽图像预训练框架,它可以训练模型从 SAM ViT-H 图像编码器中重建特征。 我们的研究表明,这可以大幅提高图像屏蔽预训练方法的性能。
-
•
我们证明,经过 SAMI 预训练的骨干能够很好地推广到许多任务中,包括图像分类、物体检测和语义分割。
-
•
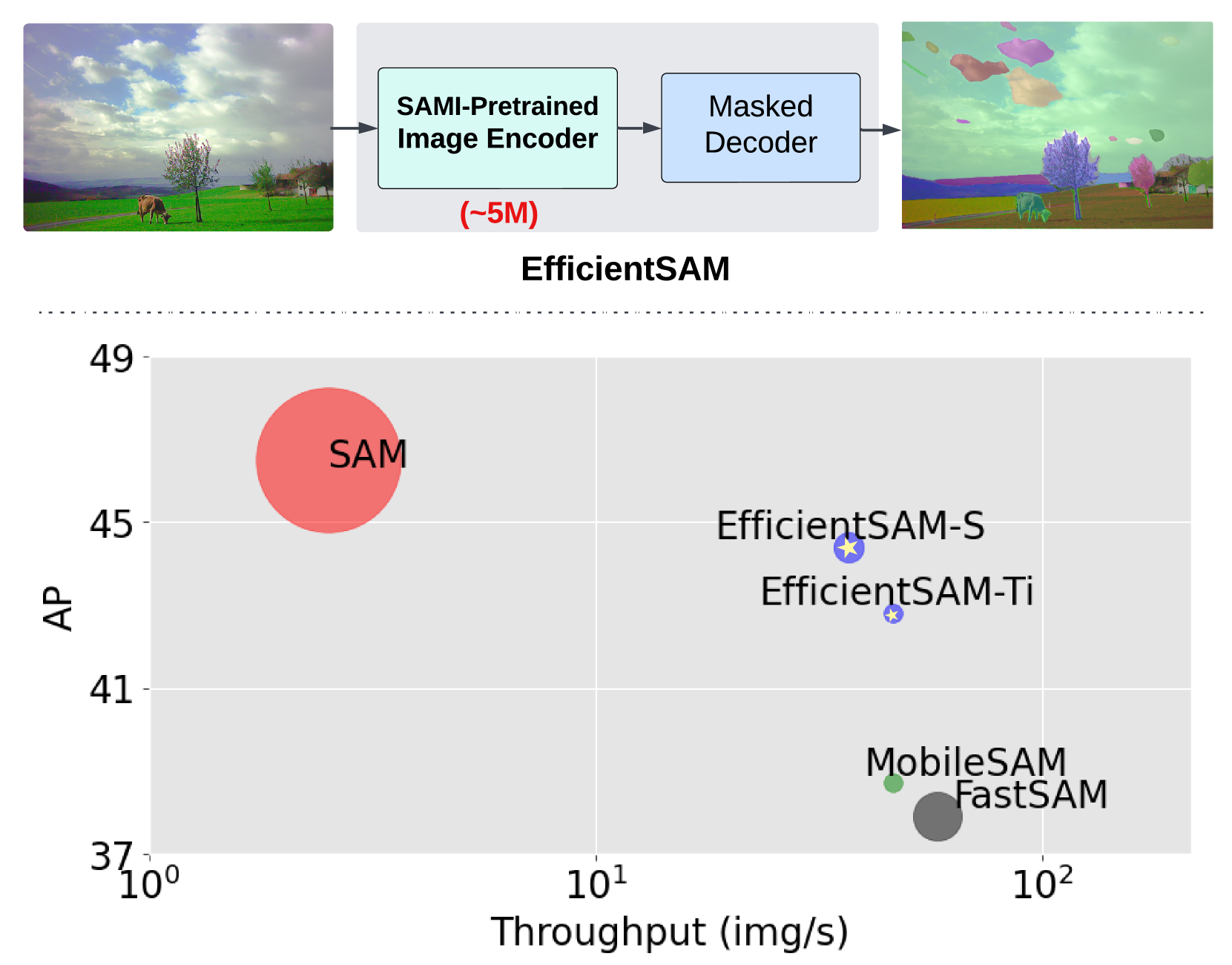
我们提供的 EfficientSAMs 是轻量级的 SAM 模型,具有最先进的质量-效率权衡 (图 1),在实际部署中与 SAM 相辅相成。 代码和模型的发布将使更多的高效 SAM 应用受益。
2相关工作
我们简要回顾了分段任何模型、视觉 Transformer、知识提炼和遮蔽图像预训练方面的相关工作。
2.1分段模式
SAM[31] 被认为是一个里程碑式的视觉基础模型,它可以根据交互提示分割图像中的任何对象。 SAM 在许多视觉任务中表现出了卓越的零样本传输性能和高度通用性,包括各种分割应用[8, 7, 17, 10], 画中画[67]、图像修复[29]、图像编辑[21]、图像阴影去除[69]、对象跟踪[14, 65]和 3D 对象重建[49]。 还有许多其他作品试图将 SAM 推广到现实世界的场景中,包括医学图像分割[41]、伪装物体检测[51]、透明物体检测[24]、基于概念的解释[50]、语义交流[52]以及帮助视觉障碍人士[37]。 由于 SAM 在现实世界中的广泛应用,其实际部署也越来越受到关注。 包括 [68、71] 在内的一些最新研究提出了降低 SAM 计算成本的策略。 FastSAM[68] 开发了一种基于 CNN 的架构 YOLOv8-seg[30] 来分割图像中的所有对象,以提高效率。 MobileSAM[71]提出了一种解耦蒸馏法,用于获得 SAM 的轻量级图像编码器。 我们的工作重点是解决这一效率问题,以便实际部署 SAM。
2.2视觉变形金刚
ViTs [19]在视觉应用[5, 20, 39, 34, 44, 26]中取得了令人瞩目的性能。 ViT 展示了与 CNN 同类产品相比的优势和通用性[26]。 此外,还有一些关于高效 ViT 部署的研究。 [53]中引入了 ViT-Small/Deit-Small、ViT-Tiny/DeiT-Tiny 等较小的 ViT,以补充 [19]中的 ViT-Huge、ViT-Large 和 ViT-Base。 受卷积捕捉局部信息的能力的启发,MobileViT[42]探索将 ViT 与卷积相结合,其性能优于轻量级 CNN 模型(如 MobileNet-v2/v3[48, 32]),具有更好的任务级泛化特性,并减少了内存大小和计算成本。 这一技巧已被用于许多后续工作,包括 LeViT[22]、EfficientFormer[35]、Next-ViT[33], Tiny-ViT[61], Castling-ViT[66], EfficientViT[38]. 设计高效 ViT 的这一进展与我们为建立高效 SAM 而开展的 EfficientSAM 工作是相辅相成的。
2.3知识提炼
知识蒸馏(KD)是一种在不改变深度学习模型架构的情况下提高其性能的技术。 [27]是一项开创性的工作,它将暗知识从较大的教师模型提炼为较小的学生模型。 学生模型的学习受到教师模型的硬标签和软标签的监督。 在这一做法之后,又有多部作品旨在更好地利用软标签来传递更多知识。 在[64]中,蒸馏法将表示学习和分类分离开来。 解耦知识提炼[70]将经典的KD损失分离为目标类知识提炼和非目标类知识提炼两部分,提高了知识转移的有效性和灵活性。 另一项工作是从中间特征转移知识。 FitNet [47]是一项开创性的工作,它直接从教师模型的中间特征中提炼语义信息。 在[60]中,引入了自我监督助教(SSTA),以指导基于 ViT 的学生模型与受监督教师共同学习。 [2]通过调整较大的 MAE 教师模型和较小的 MAE 学生模型之间的中间特征,研究从训练前 MAE 模型中提炼知识的潜力。
2.4蒙版图像预训练
自我监督预训练方法[6]在计算机视觉领域引起了极大的关注。 其中一种方法是对比学习法[9, 11, 62, 57],这种方法通过给定图像的不同增强视图之间的高相似性来学习增强内方差。 虽然学习到的表征显示出良好的特性,如高度线性可分性,但对比学习方法依赖于强增强和负采样。 另一项有趣的工作是遮蔽图像建模(MIM),它通过重建遮蔽的图像片段来帮助模型学习有意义的表征。 MIM 的开创性工作侧重于使用去噪自编码器[56]和上下文编码器[43]来训练具有掩码预测目标的视觉 Transformer。 在利用 MIM 进行自我监督图像预训练方面,有各种前景广阔的工作。 BEiT[3] 是第一个采用 MIM 进行 ViT 预训练来预测视觉词符的方法。 在 BEiTv2[44]中,利用了语义丰富的图像词符转换器来实现更好的重建目标。 在 MaskFeat[59]中,重构由 HOG 描述子生成的局部梯度特征可实现有效的视觉预训练。 在 SimMIM[63] 和 MAE[26] 中,直接重建屏蔽图像片段的像素值可实现有效的视觉表征学习。 有基于 MAE 的后续工作,使用大型教师模型指导 MAE 预训练[60, 28, 2]。 我们的工作建立在 MAE 的基础上,发现利用 MAE 重构 SAM 图像编码器的特征能够使预训练非常有效。
3方法
3.1初稿
屏蔽自动编码器 屏蔽自动编码器(MAE)模型由编码器和解码器两部分组成。 编码器和解码器都建立在 Transformer 层[55]上。 MAE 将图像词符(即输入图像中的非重叠斑块)作为输入。 这些输入词符被分组为未屏蔽词符和屏蔽词符,屏蔽率给定。 未屏蔽词符将保留给编码器用于提取特征,而屏蔽词符将被设置为 MAE 解码器的学习目标,需要在自超级学习(MIM)过程中进行重构。 MAE[26]采用了较高的掩蔽率(如 75%),从而防止了预训练阶段的信息泄露(如简单地根据邻域推断出被掩蔽的像素)。
3.2SAM-杠杆屏蔽图像预训练
现在,我们调整 MAE 框架,以获得适用于任何细分模型的高效图像编码器。 受 SAM [31] 高通用性的激励,我们探索将 SAM 图像编码器中的潜在特征作为重建目标,以充分利用 MAE。 我们的方法强调传递蕴含在 SAM 中的知识。 图 2 (上图)展示了所提出的 SAM 杠杆遮蔽图像预训练(SAMI)的概况。 编码器将未掩码词符转换为潜在特征表示,解码器在编码器输出特征嵌入的帮助下重建掩码词符的表示。 重构的表征学习以 SAM 的潜在特征为指导。
交叉注意力解码器 在 SAM 特征的监督下,我们发现只需通过解码器重建屏蔽词符,而编码器的输出可在重建过程中作为锚点。 在交叉注意力解码器中,查询来自屏蔽词符,键和值来自编码器的未屏蔽特征和屏蔽特征。 我们将交叉注意解码器输出的屏蔽词符特征和编码器输出的未屏蔽词符特征合并,进行 MAE 输出嵌入。 然后,将这些组合特征重新排序到输入图像词符的原始位置,以获得最终的 MAE 输出结果。
线性投影头。 我们通过编码器和交叉注意解码器获得图像输出。 然后,我们将这些特征输入一个小型项目头,用于对齐来自 SAM 图像编码器的特征。 为简单起见,我们只使用线性投影头来解决 SAM 图像编码器和 MAE 输出之间的特征维度不匹配问题。
重建损失。 在每次训练迭代中,SAMI 由 SAM 图像编码器的前馈特征提取以及 MAE 的前馈和反向传播过程组成。 比较 SAM 图像编码器和 MAE 线性投影头的输出,计算重建损失。
我们将 SAM 图像编码器记为 、并将 MAE 的编码器和解码器分别记为权重为 的 和权重为 的 、线性投影头为,权重分别为。 假设输入的词符用 表示,其中 是词符数。 输入词符被随机分组为未屏蔽词符 、具有给定屏蔽比率的屏蔽词符 。 假设特征重排序算子为 ,合并算子为 。
来自 SAM 图像编码器的目标特征可写成,MAE 编码器的输出为,解码器输出为. 线性投影头的输出为. 因此,我们的目标重建损失可以表述为
| (1) |
其中, 是输入词符的数量, 表示规范。 我们在实验中使用 准则来计算重建损失。 通过最小化重构损失,,我们的编码器经过优化,可作为 SAM 图像编码器提取特征的图像骨干。 我们对编码器、解码器和线性投影头进行了优化,以便从 SAM 图像编码器中学习上下文建模能力。 优化所有词符的重构损失,转移 SAM 中蕴含的知识。
4实验
4.1实验设置
预训练数据集。 我们的遮蔽图像预训练方法 SAMI 是在有 120 万张图像的 ImageNet-1K 训练集上进行的。 在屏蔽图像预训练 [26] 之后,我们不使用标签信息。 在预训练我们的 ViT 模型 ViT-Tiny、ViT-Small 和 ViT-Base 时,我们使用 [31] 中的 SAM ViT-H 图像编码器生成重建特征。
预训练实施细节。 我们的 ViT 模型采用均方误差(MSE)损失进行重建预训练。 我们使用的批量大小为 4096,AdamW 优化器 [40],学习率为 2.4e-3,,,权重衰减为 0.05。95,权重衰减为 0.05,线性学习率在第一个 epochs 中预热,余弦学习率衰减以更新我们的模型。 我们只采用了随机调整裁剪至 224x224 分辨率、随机水平翻转和归一化等方法进行数据扩增。 掩码比率设置为 ,解码器包含 8 个尺寸为 512 的 Transformer 块,如 [26]。 我们在 V100 机器上使用 PyTorch 框架对 SAMI 进行了 400 个历元的预训练。 作为参考,MAE[26]需要 1600 个波段的预训练。
下游任务/数据集/模型。 任务和数据集。 我们首先考虑了三个基准数据集和几个具有代表性的视觉任务,以证明所提出的 SAMI 的优越性,其中包括 ImageNet 数据集 [16] 上的图像分类,其中包含 1.2 百万幅训练图像和 50K 幅验证图像;COCO 数据集 [36] 上的物体检测和实例分割,训练图像为 118K 幅,验证图像为 5K 幅;ADE20K 数据集 [72] 上的语义分割,训练、验证和测试图像分别为 20K/2K/3K 幅。 然后,我们将考虑任何分段任务,以进一步展示我们所提出的 SAMI 的优势。 我们在SA-1B数据集[31]上微调了针对SAM的预训练轻量级图像编码器,该数据集包含来自1100万张高分辨率图像的1B多个掩码,我们还在COCO和LVIS数据集[23]上测试了EfficientSAM的交互式实例分割和零样本实例分割能力。 型号 我们舍弃了 SAMI 的解码器,而保留了编码器作为骨干,以提取 MAE[26] 中不同任务的特征。 我们将训练有素的 ViT 骨干用于不同的任务,包括用于分类的 ViTs、用于检测和实例分割的 ViTDet [34] 、用于语义分割任务的 Mask2former [13] 以及用于任何分割的 SAM。
微调设置。 对于分类任务,我们使用 AdamW 优化器,其中 , ,权重衰减 ,使用 32 个 V100 GPU(每个 GPU 的批量大小为 32)对 100 个历元的 ViT 进行微调。 初始学习率为 1e-3,最初 个历元用于线性预热,然后通过余弦学习率调度器降至零。 我们将 ViT-Small 和 ViT-Base 的分层学习率衰减因子设为 0.75。 我们不对 ViT-Tiny 采用分层学习率衰减。 在数据增强方面,我们采用 RandAugment [15],并将标签平滑化设置为 0.1,mixup 设置为 0.8。 对于检测和实例分割任务,我们遵循 ViTDet [34]框架,将 ViT 骨架调整为简单的特征金字塔,用于对象检测和实例分割。 我们采用动量、和权重衰减的 AdamW 优化器在 COCO 上训练模型。 所有模型均在 64 个 V100 GPU 上进行 100 次训练,每个 GPU 有 1 个批次,图像分辨率为 。 初始学习率为,在最初的个历元中线性升温,并通过余弦学习率计划衰减为 0。 模型训练 100 个历元。 对于分割任务,我们预训练的 ViT 模型是 Mask2former [13]的骨干,它与 ADE20K 上的分割层一起进行微调。 我们采用 AdamW 优化器,其中 , ,迷你批次大小为 16,权重衰减为 0.05,初始学习率为 2e-4。 通过多学习率计划,学习率会衰减为 0。 主干网的学习率乘数设为 0.1。 输入图像的分辨率为 。 使用 8 个 V100 GPU 对模型进行了 160K 次迭代训练。 对于任何分割任务,按照[31],我们将预训练的轻量级 ViT 模型(ViT-Tiny 和 ViT-Small)作为 SAM 框架的图像编码器,并在 SA-1B 数据集上对 EfficientSAM 的编码器和解码器进行 5 次微调。 我们使用 AdamW 优化器,其动量为 (, ),小批量大小为 128,初始学习率为 。 学习率通过线性学习率计划衰减为 0。 我们将权重衰减设置为 0.1。 我们不进行数据扩增。 输入图像的分辨率为 。 我们的 EfficientSAM 在 64 个 A100 GPU 上训练,GPU 内存为 40GB。
基线和评估指标。 基线。 对于分类任务,我们比较了不同预训练/蒸馏方法的 ViT 主干网的性能,包括 MAE[26]、SSTA[60]、DMAE[2], BEiT[3], CAE[12], DINO[6], iBOT[73], DeiT[53], etc.在检测和实例语义任务以及语义分割任务中,我们还将 ViTDet[34] 和 Mask2former[13] 与几种预训练的 ViT 骨干进行了比较。 在分段一切任务方面,我们与 SAM[31]、FastSAM[71] 和 MobileSAM[68] 进行了比较。 评估指标。 我们从准确性的角度对我们的方法和所有基线进行了评估。 具体来说,准确度指标指的是分类任务的 top-1 准确度;AP、AP,用于检测和实例分割任务(AP:平均精度);mIoU,用于语义分割任务(mIoU:mean intersection over union);mIoU、AP、AP、AP、AP,用于任何分割任务。 在效率指标方面,我们比较模型参数数量或推理吞吐量。
4.2主要成果
| Method | Backbone | Training Data | Acc.(%) |
| DeiT-Ti[53] | ViT-Tiny | IN1K | 74.5 |
| SSTA-Ti[60] | ViT-Tiny | IN1K | 75.2 |
| DMAE-Ti[2] | ViT-Tiny | IN1K | 70.0 |
| MAE-Ti[26] | ViT-Tiny | IN1K | 75.2 |
| SAMI-Ti (ours) | ViT-Tiny | SA1B (11M) + IN1K | 76.8 |
| DeiT-S[53] | ViT-Small | IN1K | 81.2 |
| SSTA-S[60] | ViT-Small | IN1K | 81.4 |
| DMAE-S[2] | ViT-Small | IN1K | 79.3 |
| MAE-S[26] | ViT-Small | IN1K | 81.5 |
| BEiT-S[3] | ViT-Small | D250M+IN22K+IN1K | 81.7 |
| CAE-S[12] | ViT-Small | D250M+IN1K | 82.0 |
| DINO-S[6] | ViT-Small | IN1K | 82.0 |
| iBOT-S[73] | ViT-Small | IN22K+1N1K | 82.3 |
| SAMI-S (ours) | ViT-Small | SA1B (11M) + IN1K | 82.7 |
| DeiT-B[53] | ViT-Base | IN1K | 83.8 |
| DMAE-B[2] | ViT-Base | IN1K | 84.0 |
| BootMAE[18] | ViT-Base | IN1K | 84.2 |
| MAE-B[26] | ViT-Base | IN1K | 83.6 |
| BEiT-B[3] | ViT-Base | D250M+IN22K+IN1K | 83.7 |
| CAE-B[12] | ViT-Base | D250M+IN1K | 83.9 |
| DINO-B[6] | ViT-Base | IN1K | 82.8 |
| iBOT-B[73] | ViT-Base | IN22K+1N1K | 84.4 |
| SAMI-B (ours) | ViT-Base | SA1B (11M) + IN1K | 84.8 |
图像分类。 为了评估我们提出的技术在图像分类任务中的有效性,我们将提出的 SAMI 理念应用于 ViT 模型,并比较了它们在 ImageNet-1K 上与基线相比的性能。 如图所示 Tab. 1我们将 SAMI 与 MAE、iBOT、CAE 和 BEiT 等预训练方法以及 DeiT 和 SSTA 等蒸馏方法进行了比较。 SAMI-B 的最高准确率达到 84.8%,分别比预训练基线、MAE、DMAE、iBOT、CAE 和 BEiT 高出 1.2%、0.8%、1.1%、0.9% 和 0.4%。 与 DeiT 和 SSTA 等蒸馏法相比,SAMI 也有很大改进。 对于 ViT-Tiny 和 ViT-Small 等轻量级模型,与 DeiT、SSTA、DMAE 和 MAE 相比,SAMI 报告了显著的增益。
| Method | Backbone | AP | AP |
| MAE-Ti[26] | ViT-Tiny | 37.9 | 34.9 |
| SAMI-Ti(ours) | ViT-Tiny | 44.7 | 40.0 |
| MAE-S[26] | ViT-Small | 45.3 | 40.8 |
| DeiT-S[53] | ViT-Small | 47.2 | 41.9 |
| DINO-S[6] | ViT-Small | 49.1 | 43.3 |
| iBOT-S[73] | ViT-Small | 49.7 | 44.0 |
| SAMI-S (ours) | ViT-Small | 49.8 | 44.2 |
| MAE-B[26] | ViT-Base | 51.6 | 45.9 |
| SAMI-B (ours) | ViT-Base | 52.5 | 46.5 |
对象检测和实例分割 我们还将经过 SAMI 预训练的 ViT 骨干扩展到下游的对象检测和实例分割任务中,并在 COCO 数据集上与之前的预训练基线进行比较,以评估其效果。 具体来说,我们采用预训练的 ViT 骨架,并将其调整为掩码 R-CNN 框架中的简单特征金字塔[25],以构建检测器 ViTDet[34]。 Tab. 2 显示了我们的 SAMI 与其他基线的总体比较。 我们可以看到,我们的 SAMI 性能始终优于其他基线。 与 MAE-B 相比,SAMI-B 获得了 0.9 AP 和 0.6 增益。 在轻质骨干网方面,SAMI-S 和 SAMI-Ti 与 MAE-Ti 和 MAE-S 相比有显著提高。 此外,SAMI-S 明显优于 DeiT-S 2.6 个 AP 和 2.3 个 AP。 在其他预训练基线方面,我们的 SAMI 仍然优于 DINO 和 iBOT。 这组实验验证了所提出的 SAMI 在物体检测和实例分割任务中提供预训练检测器骨干的有效性。
4.3用于任何任务分段的高效 SAM
Segment Anything 任务是一个可提示的分割过程,可根据任何形式的提示(包括点集、粗略方框或掩码、自由格式文本)生成分割掩码。 我们遵循 SAM [31],重点关注 COCO/LVIS 上基于点和基于盒的提示分割。 现在,我们将在包括零样本单点有效掩码评估和零样本实例分割在内的任何任务中测试模型的泛化能力。 我们将 SAMI 预训练的轻量级骨干作为 SAM 的图像编码器,用于构建高效 SAM,即 EfficientSAM。 然后,我们在 SA-1B 数据集上对 EfficientSAM 进行了微调,并报告了零样本单点有效掩码评估和零样本实例分割的性能。
| Method | COCO | LVIS | ||||
| box | 1 click | 3 click | box | 1 click | 3 click | |
| SAM[31] | 78.4 | 55.6 | 74.1 | 78.9 | 59.8 | 75.2 |
| MobileSAM[68] | 74.2 | 43.7 | 59.7 | 73.8 | 51.0 | 54.4 |
| SAM-MAE-Ti[31] | 74.7 | 43.3 | 65.8 | 73.8 | 50.6 | 65.3 |
| EfficientSAM-Ti (ours) | 75.7 | 45.5 | 67.2 | 74.3 | 52.7 | 66.8 |
| EfficientSAM-S (ours) | 76.9 | 50.0 | 69.8 | 75.4 | 56.2 | 68.7 |
零样本单点有效屏蔽评估。 类似于 SAM[31],我们评估的是从单个前景点分割对象。 对于一般的交互式分割,我们还考虑从单个方框和 [31] 中介绍的多个点进行对象分割。 为此,我们在点击的地面实况掩码范围内均匀随机采样点,并计算与地面实况掩码对应的最窄边界框。 由于我们的模型能够预测多个掩码,因此我们只对最有把握的掩码进行评估,即 SAM [31] 。
结果 在 Tab. 4将 EfficientSAM 与 SAM、MobileSAM 和 SAM-MAE-Ti 进行了比较。 在 COCO 上,我们的 EfficientSAM-Ti 在 1 次点击上比 MobileSAM 高出 1.9 mIoU,在复杂度相当的 1 个盒子上比 MobileSAM 高出 1.5 mIoU。 采用 SAMI 预训练权重的 EfficientSAM-Ti 在 COCO/LVIS 交互式分割上的表现也优于 MAE 预训练权重。 我们注意到,我们的 EfficientSAM-S 在 COCO 盒子上的性能仅比 SAM 低 1.5 mIoU,在 LVIS 盒子上的性能仅比 SAM 低 3.5 mIoU,而参数却减少了 20 倍。 我们发现,与 MobileSAM 和 SAM-MAE-Ti 相比,我们的 EfficientSAM 在多次点击方面也表现出良好的性能。
| Method | COCO | LVIS | ||||||
| AP | AP | AP | AP | AP | AP | AP | AP | |
| ViTDet-H[34] | 51.0 | 32.0 | 54.3 | 68.9 | 46.6 | 35.0 | 58.0 | 66.3 |
| SAM[31] | 46.5 | 30.8 | 51.0 | 61.7 | 44.7 | 32.5 | 57.6 | 65.5 |
| MobileSAM[68] | 38.7 | 23.7 | 42.2 | 54.3 | 34.4 | 23.8 | 44.9 | 53.7 |
| FastSAM[71] | 37.9 | 23.9 | 43.4 | 50.0 | 34.5 | 24.6 | 46.2 | 50.8 |
| EfficientSAM-Ti (ours) | 42.3 | 26.7 | 46.2 | 57.4 | 39.9 | 28.9 | 51.0 | 59.9 |
| EfficientSAM-S (ours) | 44.4 | 28.4 | 48.3 | 60.1 | 42.3 | 30.8 | 54.0 | 62.3 |
结果 在 Tab. 5, 我们报告了零样本分割的 AP、AP、AP、AP。 我们将 EfficientSAM 与 MobileSAM 和 FastSAM 进行了比较。 我们可以看到,与 FastSAM 相比,EfficientSAM-S 在 COCO 上获得了超过 6.5 个 AP,在 LVIS 上获得了超过 7.8 个 AP。 就 EffidientSAM-Ti 而言,它仍然远远优于 FastSAM,在 COCO 上为 4.1 个 AP,在 LVIS 上为 5.3 个 AP,而在 MobileSAM 上,在 COCO 上为 3.6 个 AP,在 LVIS 上为 5.5 个 AP。 请注意,我们的 EfficientSAM 比 FastSAM 轻得多,例如,efficientSAM-Ti 的参数为 980 万,而 FastSAM 的参数为 6800 万。 EfficientSAM-S 还大大缩小了与 0.6G 参数的 SAM 之间的差距,仅减少了 2 个 AP。 这些结果证明了 EfficientSAMs 在零样本分割方面的非凡优势,也验证了我们的 SAMI 预训练方法的优势。
定性评估。 现在,我们将提供定性结果,以补充对 EfficientSAMs 实例分割能力的理解。 以下是一些例子 图 3, 图 4和 图 5. 具体来说,我们报告了 MobileSAM [68]中两种提示类型(点和框)的预测掩码,以及所有结果的分段。 更多定性结果见补编。 这些结果表明,与 SAM 相比,我们的 EfficientSAM 具有竞争能力。 请注意,我们的 EfficientSAM 比 SAM 要轻便得多,而且我们的模型可以有效地提供不错的分割结果。 这表明,在许多实际任务中,我们的模型可以作为 SAM 的补充版本。
突出实例分割 突出对象分割 [4] 的目的是从图像中分割出最具视觉吸引力的对象。 我们将交互式实例分割扩展到突出实例分割,而无需手动创建点/框。 具体来说,我们采用最先进的突出物体检测模型 U-net[45]来预测突出图,并在突出图中均匀采样 3 个随机点(3 次点击),利用 EfficientSAM 进行实例分割。 在 图 6由此可见,我们的 EfficientSAM 能够很好地完成突出实例分割。 这一初步探索为帮助有手部障碍的人分割图像中感兴趣的物体提供了可能。
4.4消融研究
现在,我们通过一系列使用 ViT 骨架的消融研究来分析 SAMI 和 EfficientSAM。
| Method | Loss | Top-1 Acc.(%) |
| SAMI-Ti | 1 - Cosine | 76.1 |
| SAMI-Ti | MSE | 76.8 |
| SAMI-S | 1 - Cosine | 82.3 |
| SAMI-S | MSE | 82.7 |
重建损失。 我们在 ImageNet-1K 上研究了重建损失对 SAMI 性能的影响。 我们将均方误差(MSE)重建损失与余弦相似性损失进行了比较。 我们发现 MSE 重建损失的表现更好,如图所示 Tab. 6. 这建议直接重建 SAM 特征,而不是角度相似度高的目标。
交叉注意力解码器 为了重构 SAM 特征,我们直接使用编码器输出的词符,只采取解码器对屏蔽词符进行交叉注意变换。 我们以 MAE[26] 来研究通过解码器的所有词符的性能变化情况。 当在解码器中查询屏蔽词符时,我们发现 SAMI-Ti 在 ImageNet-1K 上的表现比将所有词符输入解码器进行目标重构的 MAE[26] 要好 3%。 与 AnchorDETR 中的锚点[58]类似,编码器的输出词符已经通过直接对齐 SAM 特征很好地学习了,这些词符可以作为锚点,通过交叉注意解码器帮助屏蔽词符对齐。
| Mask Ratio | 50% | 75% | 85% |
| Top-1 Acc.(%) | 84.6 | 84.8 | 84.7 |
遮罩率。 在 MAE[26]中,建议使用 75% 的高掩码比。 我们探讨了 SAMI 中不同掩码比的性能变化情况。 如图所示 Tab. 7我们可以看到,观测结果与 MAE [26]一致,即高掩码比往往会产生好的结果。
重建目标。 我们研究了重建目标的影响。 我们采用与 CLIP [46] 不同的编码器来生成特征,作为 SAMI 的重建目标。 对于 ImageNet-1K 上的 ViT-Tiny 模型,CLIP 编码器的对齐特征也比 MAE 高出 0.8%。 这表明,遮蔽图像预训练得益于强大的引导重建功能。
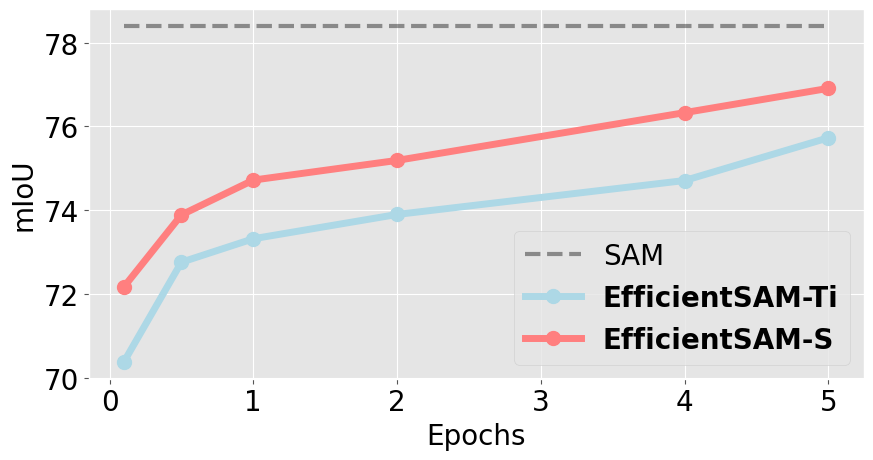
微调步骤对 EfficientSAMs 的影响。 我们探讨了微调步骤对 EfficientSAM 的影响。 如图所示 图 7而 EfficientSAM-Ti 和 EfficientSAM-S 甚至在 个时间点时也能实现不错的性能。 在 1 个历时周期内,性能增益大于 2.5 mIoU。 EfficientSAM-S 的最终性能达到 76.9 mIoU,仅比 SAM 低 1.5 mIoU。 这些结果证明了 SAMI 预训练图像编码器和我们的 EfficientSAMs 的优势。
5结论
我们提出了一种屏蔽图像预训练方法--SAMI,在 SAM 基础模型的指导下挖掘 ViTs 的潜力。 SAMI 通过重建 SAM 图像编码器的潜在特征,将视觉基础模型的知识转移到 ViTs 上,从而改进了遮蔽图像预训练。 在图像分类、对象检测和实例分割、语义分割以及任何分割任务方面进行的大量实验不断验证了 SAMI 的优势。 我们还证明,通过预训练轻量级编码器,SAMI 可以帮助构建高效的 SAM。 我们的初步工作表明,SAMI 具有潜在的应用价值,而不仅仅是高效的分段任务。
参考资料
- Arbelaez et al. [2010] Pablo Arbelaez, Michael Maire, Charless Fowlkes, and Jitendra Malik. Contour detection and hierarchical image segmentation. IEEE transactions on pattern analysis and machine intelligence, 33(5):898–916, 2010.
- Bai et al. [2023] Yutong Bai, Zeyu Wang, Junfei Xiao, Chen Wei, Huiyu Wang, Alan L Yuille, Yuyin Zhou, and Cihang Xie. Masked autoencoders enable efficient knowledge distillers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24256–24265, 2023.
- Bao et al. [2021] Hangbo Bao, Li Dong, Songhao Piao, and Furu Wei. Beit: Bert pre-training of image transformers. arXiv preprint arXiv:2106.08254, 2021.
- Borji et al. [2019] Ali Borji, Ming-Ming Cheng, Qibin Hou, Huaizu Jiang, and Jia Li. Salient object detection: A survey. Computational visual media, 5:117–150, 2019.
- Carion et al. [2020] Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. In European conference on computer vision, pages 213–229. Springer, 2020.
- Caron et al. [2021] Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. In Proceedings of the IEEE/CVF international conference on computer vision, pages 9650–9660, 2021.
- Cen et al. [2023] Jun Cen, Yizheng Wu, Kewei Wang, Xingyi Li, Jingkang Yang, Yixuan Pei, Lingdong Kong, Ziwei Liu, and Qifeng Chen. Sad: Segment any rgbd. arXiv preprint arXiv:2305.14207, 2023.
- Chen et al. [2023a] Jiaqi Chen, Zeyu Yang, and Li Zhang. Semantic segment anything. https://github.com/fudan-zvg/Semantic-Segment-Anything, 2023a.
- Chen et al. [2020] Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. In International conference on machine learning, pages 1597–1607. PMLR, 2020.
- Chen et al. [2023b] Tianrun Chen, Lanyun Zhu, Chaotao Deng, Runlong Cao, Yan Wang, Shangzhan Zhang, Zejian Li, Lingyun Sun, Ying Zang, and Papa Mao. Sam-adapter: Adapting segment anything in underperformed scenes. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 3367–3375, 2023b.
- Chen and He [2021] Xinlei Chen and Kaiming He. Exploring simple siamese representation learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15750–15758, 2021.
- Chen et al. [2023c] Xiaokang Chen, Mingyu Ding, Xiaodi Wang, Ying Xin, Shentong Mo, Yunhao Wang, Shumin Han, Ping Luo, Gang Zeng, and Jingdong Wang. Context autoencoder for self-supervised representation learning. International Journal of Computer Vision, pages 1–16, 2023c.
- Cheng et al. [2022] Bowen Cheng, Ishan Misra, Alexander G Schwing, Alexander Kirillov, and Rohit Girdhar. Masked-attention mask transformer for universal image segmentation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1290–1299, 2022.
- Cheng et al. [2023] Yangming Cheng, Liulei Li, Yuanyou Xu, Xiaodi Li, Zongxin Yang, Wenguan Wang, and Yi Yang. Segment and track anything. arXiv preprint arXiv:2305.06558, 2023.
- Cubuk et al. [2020] Ekin D Cubuk, Barret Zoph, Jonathon Shlens, and Quoc V Le. Randaugment: Practical automated data augmentation with a reduced search space. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, pages 702–703, 2020.
- Deng et al. [2009] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009.
- Deng et al. [2023] Ruining Deng, Can Cui, Quan Liu, Tianyuan Yao, Lucas W Remedios, Shunxing Bao, Bennett A Landman, Lee E Wheless, Lori A Coburn, Keith T Wilson, et al. Segment anything model (sam) for digital pathology: Assess zero-shot segmentation on whole slide imaging. arXiv preprint arXiv:2304.04155, 2023.
- Dong et al. [2022] Xiaoyi Dong, Jianmin Bao, Ting Zhang, Dongdong Chen, Weiming Zhang, Lu Yuan, Dong Chen, Fang Wen, and Nenghai Yu. Bootstrapped masked autoencoders for vision bert pretraining. In European Conference on Computer Vision, pages 247–264. Springer, 2022.
- Dosovitskiy et al. [2020] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020.
- Fan et al. [2021] Haoqi Fan, Bo Xiong, Karttikeya Mangalam, Yanghao Li, Zhicheng Yan, Jitendra Malik, and Christoph Feichtenhofer. Multiscale vision transformers. In Proceedings of the IEEE/CVF international conference on computer vision, pages 6824–6835, 2021.
- Gao et al. [2023] Shanghua Gao, Zhijie Lin, Xingyu Xie, Pan Zhou, Ming-Ming Cheng, and Shuicheng Yan. Editanything: Empowering unparalleled flexibility in image editing and generation. In Proceedings of the 31st ACM International Conference on Multimedia, pages 9414–9416, 2023.
- Graham et al. [2021] Benjamin Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, and Matthijs Douze. Levit: a vision transformer in convnet’s clothing for faster inference. In Proceedings of the IEEE/CVF international conference on computer vision, pages 12259–12269, 2021.
- Gupta et al. [2019] Agrim Gupta, Piotr Dollár, and Ross Girshick. Lvis: A dataset for large vocabulary instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019.
- Han et al. [2023] Dongsheng Han, Chaoning Zhang, Yu Qiao, Maryam Qamar, Yuna Jung, SeungKyu Lee, Sung-Ho Bae, and Choong Seon Hong. Segment anything model (sam) meets glass: Mirror and transparent objects cannot be easily detected. arXiv preprint arXiv:2305.00278, 2023.
- He et al. [2017] Kaiming He, Georgia Gkioxari, Piotr Dollár, and Ross Girshick. Mask r-cnn. In Proceedings of the IEEE international conference on computer vision, pages 2961–2969, 2017.
- He et al. [2022] Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16000–16009, 2022.
- Hinton et al. [2015] Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015.
- Hou et al. [2022] Zejiang Hou, Fei Sun, Yen-Kuang Chen, Yuan Xie, and Sun-Yuan Kung. Milan: Masked image pretraining on language assisted representation. arXiv preprint arXiv:2208.06049, 2022.
- Jiang and Holz [2023] Jiaxi Jiang and Christian Holz. Restore anything pipeline: Segment anything meets image restoration. arXiv preprint arXiv:2305.13093, 2023.
- Jocher et al. [2023] Glenn Jocher, Ayush Chaurasia, and Jing Qiu. Yolo by ultralytics. https://github.com/ultralytics/ultralytics, 2023.
- Kirillov et al. [2023] Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. Segment anything. arXiv preprint arXiv:2304.02643, 2023.
- Koonce and Koonce [2021] Brett Koonce and Brett Koonce. Mobilenetv3. Convolutional Neural Networks with Swift for Tensorflow: Image Recognition and Dataset Categorization, pages 125–144, 2021.
- Li et al. [2022a] Jiashi Li, Xin Xia, Wei Li, Huixia Li, Xing Wang, Xuefeng Xiao, Rui Wang, Min Zheng, and Xin Pan. Next-vit: Next generation vision transformer for efficient deployment in realistic industrial scenarios. arXiv preprint arXiv:2207.05501, 2022a.
- Li et al. [2022b] Yanghao Li, Hanzi Mao, Ross Girshick, and Kaiming He. Exploring plain vision transformer backbones for object detection. In European Conference on Computer Vision, pages 280–296. Springer, 2022b.
- Li et al. [2022c] Yanyu Li, Geng Yuan, Yang Wen, Ju Hu, Georgios Evangelidis, Sergey Tulyakov, Yanzhi Wang, and Jian Ren. Efficientformer: Vision transformers at mobilenet speed. Advances in Neural Information Processing Systems, 35:12934–12949, 2022c.
- Lin et al. [2014] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In European conference on computer vision, pages 740–755. Springer, 2014.
- Liu et al. [2023a] Ruiping Liu, Jiaming Zhang, Kunyu Peng, Junwei Zheng, Ke Cao, Yufan Chen, Kailun Yang, and Rainer Stiefelhagen. Open scene understanding: Grounded situation recognition meets segment anything for helping people with visual impairments. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 1857–1867, 2023a.
- Liu et al. [2023b] Xinyu Liu, Houwen Peng, Ningxin Zheng, Yuqing Yang, Han Hu, and Yixuan Yuan. Efficientvit: Memory efficient vision transformer with cascaded group attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14420–14430, 2023b.
- Liu et al. [2021] Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF international conference on computer vision, pages 10012–10022, 2021.
- Loshchilov and Hutter [2018] Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. In International Conference on Learning Representations, 2018.
- Ma and Wang [2023] Jun Ma and Bo Wang. Segment anything in medical images. arXiv preprint arXiv:2304.12306, 2023.
- Mehta and Rastegari [2021] Sachin Mehta and Mohammad Rastegari. Mobilevit: Light-weight, general-purpose, and mobile-friendly vision transformer. In International Conference on Learning Representations, 2021.
- Pathak et al. [2016] Deepak Pathak, Philipp Krahenbuhl, Jeff Donahue, Trevor Darrell, and Alexei A Efros. Context encoders: Feature learning by inpainting. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2536–2544, 2016.
- Peng et al. [2022] Zhiliang Peng, Li Dong, Hangbo Bao, Qixiang Ye, and Furu Wei. Beit v2: Masked image modeling with vector-quantized visual tokenizers. arXiv preprint arXiv:2208.06366, 2022.
- Qin et al. [2020] Xuebin Qin, Zichen Zhang, Chenyang Huang, Masood Dehghan, Osmar Zaiane, and Martin Jagersand. U2-net: Going deeper with nested u-structure for salient object detection. page 107404, 2020.
- Ramesh et al. [2021] Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Radford, Mark Chen, and Ilya Sutskever. Zero-shot text-to-image generation. In International Conference on Machine Learning, pages 8821–8831. PMLR, 2021.
- Romero et al. [2014] Adriana Romero, Nicolas Ballas, Samira Ebrahimi Kahou, Antoine Chassang, Carlo Gatta, and Yoshua Bengio. Fitnets: Hints for thin deep nets. arXiv preprint arXiv:1412.6550, 2014.
- Sandler et al. [2018] Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, and Liang-Chieh Chen. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4510–4520, 2018.
- Shen et al. [2023] Qiuhong Shen, Xingyi Yang, and Xinchao Wang. Anything-3d: Towards single-view anything reconstruction in the wild. arXiv preprint arXiv:2304.10261, 2023.
- Sun et al. [2023] Ao Sun, Pingchuan Ma, Yuanyuan Yuan, and Shuai Wang. Explain any concept: Segment anything meets concept-based explanation. arXiv preprint arXiv:2305.10289, 2023.
- Tang et al. [2023] Lv Tang, Haoke Xiao, and Bo Li. Can sam segment anything? when sam meets camouflaged object detection. arXiv preprint arXiv:2304.04709, 2023.
- Tariq et al. [2023] Shehbaz Tariq, Brian Estadimas Arfeto, Chaoning Zhang, and Hyundong Shin. Segment anything meets semantic communication. arXiv preprint arXiv:2306.02094, 2023.
- Touvron et al. [2021] Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Hervé Jégou. Training data-efficient image transformers & distillation through attention. In International conference on machine learning, pages 10347–10357. PMLR, 2021.
- Van de Sande et al. [2011] Koen EA Van de Sande, Jasper RR Uijlings, Theo Gevers, and Arnold WM Smeulders. Segmentation as selective search for object recognition. In 2011 international conference on computer vision, pages 1879–1886. IEEE, 2011.
- Vaswani et al. [2017] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
- Vincent et al. [2010] Pascal Vincent, Hugo Larochelle, Isabelle Lajoie, Yoshua Bengio, Pierre-Antoine Manzagol, and Léon Bottou. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. Journal of machine learning research, 11(12), 2010.
- Wang et al. [2021] Xinlong Wang, Rufeng Zhang, Chunhua Shen, Tao Kong, and Lei Li. Dense contrastive learning for self-supervised visual pre-training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3024–3033, 2021.
- Wang et al. [2022] Yingming Wang, Xiangyu Zhang, Tong Yang, and Jian Sun. Anchor detr: Query design for transformer-based detector. In Proceedings of the AAAI conference on artificial intelligence, pages 2567–2575, 2022.
- Wei et al. [2022] Chen Wei, Haoqi Fan, Saining Xie, Chao-Yuan Wu, Alan Yuille, and Christoph Feichtenhofer. Masked feature prediction for self-supervised visual pre-training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14668–14678, 2022.
- Wu et al. [2022a] Haiyan Wu, Yuting Gao, Yinqi Zhang, Shaohui Lin, Yuan Xie, Xing Sun, and Ke Li. Self-supervised models are good teaching assistants for vision transformers. In Proceedings of the 39th International Conference on Machine Learning, pages 24031–24042. PMLR, 2022a.
- Wu et al. [2022b] Kan Wu, Jinnian Zhang, Houwen Peng, Mengchen Liu, Bin Xiao, Jianlong Fu, and Lu Yuan. Tinyvit: Fast pretraining distillation for small vision transformers. In European Conference on Computer Vision, pages 68–85. Springer, 2022b.
- Xie et al. [2021] Zhenda Xie, Yutong Lin, Zheng Zhang, Yue Cao, Stephen Lin, and Han Hu. Propagate yourself: Exploring pixel-level consistency for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16684–16693, 2021.
- Xie et al. [2022] Zhenda Xie, Zheng Zhang, Yue Cao, Yutong Lin, Jianmin Bao, Zhuliang Yao, Qi Dai, and Han Hu. Simmim: A simple framework for masked image modeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9653–9663, 2022.
- Yang et al. [2021] Jing Yang, Brais Martinez, Adrian Bulat, and Georgios Tzimiropoulos. Knowledge distillation via softmax regression representation learning. In International Conference on Learning Representations, 2021.
- Yang et al. [2023] Jinyu Yang, Mingqi Gao, Zhe Li, Shang Gao, Fangjing Wang, and Feng Zheng. Track anything: Segment anything meets videos. arXiv preprint arXiv:2304.11968, 2023.
- You et al. [2023] Haoran You, Yunyang Xiong, Xiaoliang Dai, Bichen Wu, Peizhao Zhang, Haoqi Fan, Peter Vajda, and Yingyan Celine Lin. Castling-vit: Compressing self-attention via switching towards linear-angular attention at vision transformer inference. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14431–14442, 2023.
- Yu et al. [2023] Tao Yu, Runseng Feng, Ruoyu Feng, Jinming Liu, Xin Jin, Wenjun Zeng, and Zhibo Chen. Inpaint anything: Segment anything meets image inpainting. arXiv preprint arXiv:2304.06790, 2023.
- Zhang et al. [2023a] Chaoning Zhang, Dongshen Han, Yu Qiao, Jung Uk Kim, Sung-Ho Bae, Seungkyu Lee, and Choong Seon Hong. Faster segment anything: Towards lightweight sam for mobile applications. arXiv preprint arXiv:2306.14289, 2023a.
- Zhang et al. [2023b] Xiao Feng Zhang, Tian Yi Song, and Jia Wei Yao. Deshadow-anything: When segment anything model meets zero-shot shadow removal. arXiv preprint arXiv:2309.11715, 2023b.
- Zhao et al. [2022] Borui Zhao, Quan Cui, Renjie Song, Yiyu Qiu, and Jiajun Liang. Decoupled knowledge distillation. In Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition, pages 11953–11962, 2022.
- Zhao et al. [2023] Xu Zhao, Wenchao Ding, Yongqi An, Yinglong Du, Tao Yu, Min Li, Ming Tang, and Jinqiao Wang. Fast segment anything. arXiv preprint arXiv:2306.12156, 2023.
- Zhou et al. [2017] Bolei Zhou, Hang Zhao, Xavier Puig, Sanja Fidler, Adela Barriuso, and Antonio Torralba. Scene parsing through ade20k dataset. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 633–641, 2017.
- Zhou et al. [2021] Jinghao Zhou, Chen Wei, Huiyu Wang, Wei Shen, Cihang Xie, Alan Yuille, and Tao Kong. ibot: Image bert pre-training with online tokenizer. arXiv preprint arXiv:2111.07832, 2021.
补充材料
在本补充材料中,我们提供了更多结果,以展示我们高效 SAM 模型的实例分割能力。
6效率评估
| Method |
|
|
||||
| SAM[31] | 636 | 2 | ||||
| EfficientSAM-Ti (ours) | 10 | 54 | ||||
| EfficientSAM-S (ours) | 25 | 47 |
我们模型的吞吐量和参数数量记录在Tab. 8. 我们在一台 NVIDIA A100 上测量吞吐量(每秒图像),只需一个提示框。 输入图像的分辨率为 .
7定性评价
为了研究我们的模型能否根据提示生成分割掩码,我们使用我们的模型进行了基于提示的实例分割,包括基于点和基于框的提示分割。 我们还利用我们的模型来执行一切分割和突出实例分割,而无需手动创建点和框提示。
针对每项任务,我们分享了 4 个示例,以展示我们模型的实例分割能力。 这些结果直接证明了我们的 EfficientSAM 在不同提示下的竞争实例分割能力。 例如,在点提示实例分割的情况下,我们的模型能够给出合理的实例分割结果(见 图 8). 在方框提示实例分割的情况下,我们的模型还能生成预期的对象分割(见 图 9). 就一切细分而言,我们的模型具有不错的细分性能(见 图 10). 在突出实例分割方面,我们的模型具有生成掩码的能力,无需手动创建点或框,即可自动进行实例分割(见图 1)。 图 11). 但我们仍然需要注意,我们的模型有时可能会产生噪声分割,如图所示 图 12.