用于多域假新闻检测的双师去偏蒸馏框架
††感谢:李嘉阳和冯轩对这项工作做出了同等的贡献。
††感谢:顾天龙为通讯作者。
††感谢:该工作得到了国家自然科学基金项目(批准号:2017)的资助。 U22A2099)。
摘要
多领域假新闻检测旨在识别来自不同领域的各种新闻是真是假,已经变得紧迫和重要。 然而,现有方法致力于提高假新闻检测的整体性能,忽略了数据不平衡导致不同领域的区别对待的事实,即领域偏差问题。 为了解决这个问题,我们提出了双师去偏差蒸馏框架(DTDBD)来减轻不同领域之间的偏差。 遵循知识蒸馏的方法,DTBDD采用师生结构,由经过培训的大教师指导学生模型。 特别是,DTBDD 由一名公正的教师和一名干净的教师组成,共同指导学生模型减轻领域偏见并保持性能。 对于无偏见的教师,我们引入对抗性去偏见蒸馏损失来指导学生模型学习无偏见的领域知识。 对于干净的老师,我们设计了领域知识蒸馏损失,这有效地激励学生模型在保持性能的同时专注于表示领域特征。 此外,我们提出了一种基于动量的动态调整算法来权衡两名教师的影响。 对中文和英文数据集的大量实验表明,所提出的方法在偏差指标方面大大优于最先进的基线方法,同时保证了竞争性能111Our codes are available at https://github.com/ningljy/DTDBD 获取。
索引术语:
多领域假新闻检测、知识蒸馏、领域对抗我简介
随着社交媒体平台的普及,多领域假新闻检测变得紧迫而重要。 该任务旨在识别来自不同领域的各种新闻是真是假[1, 2]。 尽管现有方法在平均性能方面取得了非凡的成就,但它们缺乏对每个领域[3]的公正考虑。 不同领域对假新闻的区别对待可能会导致严重后果[4,5,6,7]。 例如,将真实的灾难新闻错误分类为假新闻可能会导致用户对危险的紧急响应延迟。 因此,减少偏差是在现实场景中部署多域假新闻检测模型的最关键的方面之一。
| Domain | Science | Military | Education | Disaster | Politics |
|---|---|---|---|---|---|
| %Fake | 39.4 | 64.7 | 50.5 | 76.1 | 64.0 |
| %News | 2.6 | 3.8 | 5.3 | 8.5 | 9.3 |
| Domain | Health | Finance | Ent. | Society | Average |
| %Fake | 51.5 | 27.4 | 30.5 | 55.1 | 51.0 |
| %News | 11.0 | 14.5 | 15.8 | 29.2 | 11.1 |
| Method | Single-domain | Multi-domain | Debiasing | Bias Type | Dataset |
|---|---|---|---|---|---|
| BiGRU[8] | Twitter, Weibo | ||||
| StyleLSTM[9] | StyleLSTM | ||||
| DualEmo[10] | RumourEval-19, Weibo-16, Weibo-20 | ||||
| EANN [11] | Twitter, Weibo | ||||
| Diachronic Bias Mitigation [12] | Diachronic | MultiFC, Horne17, Celebrity, Constraint | |||
| EDDFN[13] | PolitiFact, Gossipcop, CoAID | ||||
| MDFEND[1] | Weibo21 | ||||
| ENDEF[7] | Entity | Weibo, GossipCop | |||
| M3FEND[14] | Weibo21, Politifact, Gossipcop, COVID | ||||
| Our | Domain | Weibo21, Politifact, Gossipcop, COVID |
受实时事件、社会趋势、公共信息需求等因素影响,不同领域的新闻量存在较大差异[15, 16]。 由于这一特性,现有数据集也受到以下限制(以Weibo21 [1]为例,其统计数据如表I所示)): 1)不同领域的假新闻数量不平衡(例如,社交新闻占假新闻总数的 29.2%,而科学仅占 2.6%); 2)各个领域的假新闻报道率实际上是不平等的(例如,只有 27.4% 的财经新闻和 30.5% 的娱乐新闻是假的。 然而,这一比例在灾难新闻和政治新闻中高达 76.1% 和 64.0%); 3)在不平衡数据集上训练的模型在预测来自不同领域的新闻时可能会出现差异。 此外,不平衡的数据集可能导致模型学习新闻标签和领域标签之间的虚假相关性,这可能会影响泛化并引发严重的领域偏差问题。 因此,在监督环境下解决多域假新闻检测所暴露的域偏差问题需要更多的关注。
现有的单域假新闻检测方法[17,8,18]致力于提高检测性能,但忽略了新闻的领域特征。 这导致他们在学习中很容易受到攻击,甚至会放大基于不平衡数据集的领域偏见。 反过来,大多数多领域假新闻检测工作[1, 14]结合了领域知识来指导更全面特征的表示。 然而,缺乏公正设计的模型可能会无意中在领域和新闻真实性之间建立虚假的相关性。 事实上,一条新闻可能与多个领域相关,但与其他领域的相关性有限。 因此,迫使模型学习所有领域的不变特征将进一步恶化领域偏差。 然而,虽然直接应用现有的去偏差方法[11, 13]可以在一定程度上减轻偏差,但会导致严重的性能下降。 因此,多领域假新闻检测任务中去偏差有效性和预测性能之间的权衡是一个亟待解决的问题。
在这方面,我们提出了双师去偏差蒸馏框架(DTDBD),该框架可以减轻由于现实世界数据集中域和类别分布不平衡而产生的域偏差。 遵循知识蒸馏的方法,DTBDD采用师生结构,由经过培训的大教师指导学生模型。 特别是,DTBDD由公正的老师和干净的老师组成,共同指导学生模型。 对于无偏教师,受特征蒸馏[19]的启发,我们设计了一种称为对抗性去偏蒸馏的新型优化目标,它将无偏分布转换为知识。 通过将无偏分布视为软标签,我们可以防止学生模型单独负责从无偏教师模型中学习无偏分布的复杂性。 对于干净的老师,我们引入了领域知识蒸馏损失,以鼓励学生模型灵活地关注每个领域的多个相关领域。 此外,我们提出了一种基于动量的动态调整算法,该算法动态调整无偏和干净教师的权重。 无偏见表述和新闻表述之间的权衡使得 DTDBD 能够在保持竞争性表现的同时减少偏见。
总而言之,贡献可概括为以下几点:
-
•
我们提出了一种新颖的双师去偏差蒸馏框架(DTDBD)来减轻多域假新闻检测中的域偏差。 由一位公正的老师和一位专业分明的清廉老师组成,共同指导学生模式。
-
•
为了减少学生模型的领域偏差,我们为无偏见的教师设计了一种对抗性去偏差蒸馏。 这种蒸馏方法捕获中间层中样本的相关性,并将其用作去偏蒸馏的知识。
-
•
考虑到两位老师的影响之间的权衡,我们引入了一种基于动量的动态调整算法,该算法由学生模型的性能和偏差指标的变化决定。
-
•
大量的实验结果证明了我们的方法在同时提高模型性能和减轻域偏差方面的有效性。 此外,我们的方法在中文数据集上实现了最先进的性能,凸显了其在多领域假新闻检测方面的优越性。
II 相关工作
II-A 多域假新闻检测
虚假新闻检测旨在识别新闻片段的真假[20]。 传统方法[17,8,18]专注于假新闻检测的单一领域。 这些方法可以大致分为基于内容的假新闻检测和基于社交情境的假新闻检测。 基于内容的信息包括新闻文本[21, 22]、图像[23, 24]、样式[25, 9]和情感[26,10,27]。 基于社交情境的信息取决于用户个人资料 [28, 29]、传播网络 [30, 31, 32] 和人群反馈 [33, 34] 。
在现实场景中,假新闻通常源自多个不同的域,因此多域假新闻检测受到了关注。 王等人[11]首先认识到新闻事件多样性对假新闻检测的影响。 他们引入了事件对抗神经网络(EANN),可以学习事件不变特征。 Silva等人[13]提出了一种具有特定领域和跨领域知识的框架来检测来自不同领域的新闻的真实性。 Nan 等人[1]从新浪微博收集了中国多领域假新闻检测数据集Weibo21,其中包括科学、军事、教育、灾难、政治、健康、金融、娱乐和新闻九个领域。社会。 他们开发了一个可学习的域门来聚合多个专家提取的特征。 Zhu等人[14]进一步设计了一个域内存库来发现新闻的潜在域标签,以指导域适配器的聚合特征。 然而,上述努力仅仅关注于性能改进,而忽略了域之间存在的偏差问题。 只有少数研究关注假新闻检测中的偏见问题。 朱等人[7]在推理过程中采用因果图来消除实体与新闻之间的实体偏差。 为了减轻历时偏差,Murayama T 等人[12]用维基数据代替专有名称,涵盖个人和地理位置。 假新闻检测相关工作的功能比较如表II所示。
| Model | Disaster | Politics | Finance | Ent. | ||||
|---|---|---|---|---|---|---|---|---|
| FNR | FPR | FNR | FPR | FNR | FPR | FNR | FPR | |
| EANN [11] | 0.0738 | 0.1756 | 0.0420 | 0.2115 | 0.1644 | 0.0938 | 0.1310 | 0.0735 |
| EDDFN [13] | 0.0656 | 0.2674 | 0.1261 | 0.1923 | 0.1918 | 0.0729 | 0.1429 | 0.0735 |
| MDFEND [1] | 0.0574 | 0.1471 | 0.0588 | 0.1713 | 0.1370 | 0.0573 | 0.1429 | 0.0441 |
| M3FEND[14] | 0.0410 | 0.2059 | 0.0420 | 0.2308 | 0.1370 | 0.0573 | 0.1429 | 0.0245 |
II-B 领域对抗训练
域对抗训练[35]旨在将具有不同分布的源域和目标域的数据映射到相同的特征空间。 同时,该方法期望不同分布的数据在该空间中的距离尽可能接近。 Ganin 等人[36]引入了领域对抗神经网络(DANN),该网络已成功应用于利用领域对抗来减轻偏差。 Kashyap 等人[37]定制了一种领域对抗方法来减轻机器学习模型中的纹理偏差。 Liu等人[38]采用领域对抗性学习来解决神经对话生成中的性别偏见。 Chowdhury 等人[39]引入了“对抗性洗涤器”,这是一种对抗性学习框架,旨在消除上下文表征并减轻人口相关性造成的偏见。 Choi等人[40]将领域对抗模块集成到动作识别框架中,以减轻动作场景共现引起的场景偏差。
II-C 公平知识蒸馏
知识蒸馏[41]是一种模型压缩方法,通过将知识从复杂模型(教师模型)转移到简单模型(学生模型)来实现模型轻量化和性能提升。 之前的工作主要集中在如何迁移知识[41, 19, 42]以及迁移什么样的知识[43, 44]以提高性能学生模型。
最近,一些研究发现模型压缩会影响公平性,并且知识蒸馏在偏差缓解任务中的作用越来越受到关注[45, 6]。 Chai等人[46]采用知识蒸馏来减轻群体偏见,而不依赖于人口统计信息。 Liu等人[47]提出了一种新颖的通用知识蒸馏框架来解决推荐系统中的偏差。 此外,知识蒸馏已被用来处理信息检索[48]和人脸识别[49, 50]中的偏差。 因此,知识蒸馏是减轻领域偏差的一种有前途的方法。
III 初步
在本节中,我们首先介绍本文中使用的基本符号和基本知识概念。 随后,我们继续将领域偏差问题形式化。
III-A 符号和定义
定义 1(假新闻检测[15])。 给定一个新闻数据集,其中是一组新闻文本,是一组新闻标签。 每个新闻项都与二进制标签相关联,其中表示新闻是真实的,表示新闻是假的。 假新闻检测旨在通过训练模型找到新闻文本 和标签 之间的关联来检测新闻的真实性。
定义2(多域假新闻检测[1])。 我们将多域新闻数据集表示为,其中表示新闻文本,表示新闻标签,是新闻领域。 每个新闻被分配一个域标签和一个新闻标签。多领域假新闻检测的特点是利用领域标签捕捉同一领域内的新闻特征来检测假新闻。
定义 3(领域差异性虐待[51])。 领域不同的虐待是领域偏见的衡量标准。 给定假新闻检测模型 和示例 ,其中 是新闻文本, 是新闻域,并且 是新闻标签。 如果该分类器在任意两个不同域 、 上的真阳性率或假阳性率相等,则称为无偏,即
| (1) |
| (2) |
定义 4(知识蒸馏[41])。 知识蒸馏的目的是通过最小化逻辑之间的差异,使学生模型能够向教师模型学习。 在这种情况下,教师模型通常是复杂且高性能的模型,而学生模型是轻量级模型。 给定一个预训练的教师模型和一个未经训练的学生模型,我们表示来自教师模型和学生模型的新闻数据的logits分别为 (软标签)和 。 必须强调的是,logits 是基于响应的知识。 此外,在我们的方法中,我们利用基于特征的蒸馏[19],其中模型的中间层输出充当要转移的知识。
III-B 问题陈述
给定一个多领域新闻数据集,我们的目标是训练一个假新闻检测模型,该模型公正地对待来自不同领域的新闻。 在我们的问题设置中,我们采用领域不同的虐待来测量模型的假阴性率(FNR)和假阳性率(FPR)。 给定两个不同域 、 上预训练模型的 FNR 和 FPR。 域偏差约束可以表示为:
| (3) |
| (4) |
IV 域偏差分析
IV-A 现有方法中的域偏差
使用四种先进的假新闻检测模型对四个不平衡领域进行了彻底的分析,揭示了对领域偏见问题的值得注意的担忧。 表III表明,与平均值相比,灾难和政治领域的 FPR 显着升高。 这意味着这些模型已经形成了一种倾向,将假新闻普遍存在的领域的新闻标记为假新闻。 相反,真实新闻比例较大的金融和娱乐领域表现出较高的 FNR。 这表明模型更倾向于将这些领域的新闻分类为真实新闻。
IV-B 挑战
为了解决领域偏差问题,我们强调以下两个关键点:
IV-B1 领域知识整合
将领域知识纳入学习过程对于减轻领域漂移和提高学习绩效至关重要。 在这种情况下,领域漂移是指来自不同领域的假新闻在词汇、情绪基调和写作风格上表现出显着差异[14]。 然而,在使用领域知识作为分类因素时必须谨慎,因为它可能会无意中学习领域偏好,从而可能影响泛化并带来领域偏差问题。
IV-B2 模糊标签的考虑
现实世界新闻涵盖的主题多种多样,一条新闻通常可以同时与多个领域相关[14]。 因此,新闻的领域标签应该是模糊的;换句话说,领域标签应该反映新闻与每个领域的相似程度。 结合模糊标签有助于识别超出单个域范围的潜在相关新闻。 然而,过度强调相关性较低的数据可能会阻碍跨领域知识的获取。
最初,我们的目标是消除领域和新闻准确性之间的虚假相关性。 然而,我们发现来自不同领域的新闻可以表现出高度的相关性。 消除这种相关性会削弱新闻文本与其准确性之间的联系。 因此,我们采用双师知识蒸馏框架。 该框架不仅消除了领域与新闻真实性之间的虚假相关性,而且还保留了新闻内容与其真实性之间的相关性。 通过采用知识蒸馏,我们确保学到的关联更加准确,并且与新闻的实际真实性保持一致。
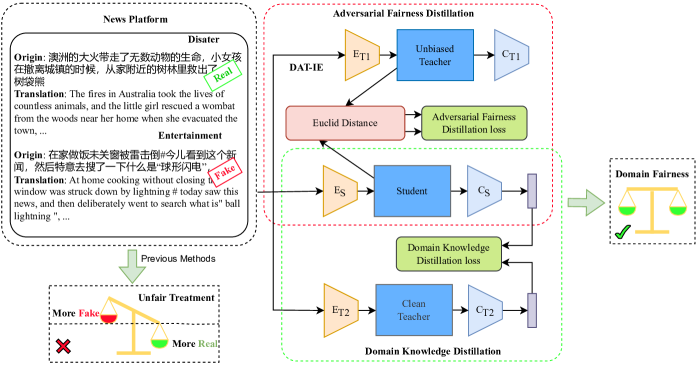
V 框架
在本节中,我们将详细解释所提出的 DTDBD 框架,该框架由对抗性去偏差蒸馏和领域知识蒸馏组成。 此外,我们引入了一种基于动量的动态调整算法,用于自适应调整这两种蒸馏方法的权重。 DTDBD的总体框架如图1所示。
V-A DTDBD 框架
为了减少域偏差,同时减轻多域假新闻检测中的性能下降,我们提出了一种新颖的去偏差框架,称为双教师去偏差蒸馏(DTDBD)。 与之前的多教师蒸馏方法[52, 53]不同,我们的方法同时关注两个不同的指标:偏差和性能。
虽然一些先前的工作已经利用对抗性知识蒸馏[54, 55]通过引入对抗性示例来从教师模型转移知识来增强学生模型的稳健性,但稳健性主要仍然是异常情况下的性能指标。 相比之下,DTBDD 集成了两种关键的蒸馏方法:对抗性去偏见蒸馏和领域知识蒸馏,分别利用公正的教师和干净的教师来指导学生模型。 值得注意的是,无偏和干净教师的权重在蒸馏过程中被冻结。
对抗性去偏差蒸馏旨在通过使用无偏差教师将与无偏差分布相关的知识转移到学生模型来减轻领域偏差。 另一方面,领域知识蒸馏利用干净的教师将特定领域的知识转移到学生模型中,使其能够有效地处理不同领域的细微差别和特征。
通过结合这两种蒸馏方法,DTBDD 提供了一个全面的框架,在保证性能的同时解决多域假新闻检测中的域偏差,从而形成一个更加平衡和有效的框架。 首先,我们选择一个经过微调的多领域训练假新闻检测模型,其中包含领域知识学习模块作为干净的教师和无偏的教师模型。 其次,分别在无偏教师和干净教师的指导下计算学生模型的对抗性去偏蒸馏损失和领域知识蒸馏损失。 最后,基于动量的动态调整算法为这两个损失分配权重,并随后更新学生模型。
V-B 对抗性去偏蒸馏
虽然强制模型学习不变特征可以在一定程度上减轻偏差,但它可能会对性能产生严重影响。 因此,我们设计了对抗性去偏差蒸馏,通过将无偏差分布作为知识转移到学生模型来减少域偏差。 考虑到偏差体现在样本之间的相对关系上,我们将中间特征之间的相关性作为无偏分布知识,并采用欧氏距离来衡量两个样本的相关性。 给定一组由特征提取器获得的中间特征,相关矩阵M可以表示为:
| (5) |
然后我们在中间层进行对抗性去偏见蒸馏,这使得学生模型能够学习无偏见教师掌握的样本之间的相关性。 对抗性去偏差蒸馏可以表述为:
| (6) |
其中KL是Kullback-Leibler散度损失,是知识蒸馏中使用的温度超参数。 和来自无偏教师和学生,代表参数为的学生网络和参数为的无偏教师网络。
对于无偏教师的设计,由于不同模型的编码器之间存在较大差距,并且学习到的无偏分布知识难以相互迁移,因此我们将无偏教师的结构设置为与学生模型。 应用领域对抗训练来获得公正的老师。 具体来说,编码器、域分类器和标签分类器可以描述为以下优化过程:
| (7) |
| (8) |
| (9) |
然而,我们发现,在多领域假新闻检测任务上,这种方法导致模型学习捷径,即仅学习与其自身领域最相关的领域的共同特征,而忽略其他相关领域。
为了解决这个问题,我们提出了领域对抗训练-信息熵(DAT-IE)损失,它通过在领域对抗训练中添加信息熵损失来鼓励模型关注更相关的领域。 信息熵可以表达向量的不确定程度,这与我们在领域对抗中的目标相同。 尽管这可能导致模型无法区分域而不是错误分类,但信息熵损失可以定义为:
| (10) |
此时,DAT-IE损失可表示为:
| (11) |
其中表示交叉熵的损失。 在本文中,我们设置来扩展对不变特征的关注范围。
V-C 领域知识蒸馏
先前在多域假新闻检测方面的工作[14, 56]已经证明,模糊域标签有助于提高假新闻检测的准确性。 此外,我们发现来自不同领域的一些新闻可能比同一领域的新闻表现出更多的相似性。
因此,我们设计了领域知识蒸馏来鼓励模型学习可转移的无偏见领域知识,从而保证偏差缓解的性能。 在领域知识蒸馏中,我们使用最先进的微调多领域假新闻检测模型 M3FEND [14] 作为教师。部分原因是它通过构建领域知识学习模块来有效地学习共享领域知识。 领域知识蒸馏过程的损失可以表示为:
| (12) |
其中和分别表示干净教师和学生的分类器。 和 分别是干净教师和学生的中间特征。
V-D 基于动量的动态调整算法
为了权衡公正教师和干净教师对学生模型的影响并防止单个教师过度发挥其作用,我们引入了基于动量的动态调整算法。 DTDBD采用对抗性去偏蒸馏损失、领域知识蒸馏损失和分类损失的权重作为整体损失,可以表示为:
| (13) |
其中、、分别表示对抗性去偏蒸馏损失、领域知识蒸馏损失和学生分类损失的权重。 我们计算自第二个纪元以来性能 和偏差指标 的变化。 和的更新过程可以表述为:
| (14) |
| (15) |
其中是动量系数。
我们在算法1中详细介绍了 DTDBD 框架。
| Domain | Science | Military | Education | Disaster | Politics |
|---|---|---|---|---|---|
| Fake | 93 | 222 | 248 | 591 | 546 |
| Real | 143 | 121 | 243 | 185 | 306 |
| Total | 236 | 343 | 491 | 776 | 852 |
| Domain | Health | Finance | Ent. | Society | All |
| Fake | 515 | 362 | 440 | 1,471 | 4,488 |
| Real | 485 | 959 | 1,000 | 1,198 | 4,640 |
| Total | 1,000 | 1,321 | 1,440 | 2,669 | 9,128 |
| Domain | Gossipcop | Politifact | COVID | All |
|---|---|---|---|---|
| Fake | 5,067 | 379 | 1,317 | 6,763 |
| Real | 16,804 | 447 | 4,750 | 22,001 |
| Total | 21,871 | 826 | 6,067 | 28,764 |
六实验
VI-A 实验设置
VI-A1 数据集
-
•
中文数据集。 Weibo21[1]是一个中国多领域假新闻检测数据集,旨在评估跨领域假新闻检测模型的平均性能。 它由从新浪微博收集的新闻组成,分为科普、军事、教育、灾害、政治、健康、财经、娱乐、社会九个领域。
-
•
英语数据集。 继[14, 3]之后,我们使用的英文数据集是FakeNewsNet [57]和COVID [58]的合并,包括三个域:八卦警察、政治和新冠病毒。
VI-A2 基线模型
在我们的研究中,我们采用了最先进的多域假新闻检测方法[14],并采用了与该工作中使用的相同的基线。 我们的基线模型包含以下 11 种方法:
| Methods | Science | Military | Education | Disaster | Politics | Health | Finance | Ent. | Society | Overall | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| F1 | FNED | FPED | Total | ||||||||||
| BiGRU[8] | 0.7479 | 0.9129 | 0.8182 | 0.8574 | 0.8694 | 0.8850 | 0.8582 | 0.8671 | 0.8602 | 0.8754 | 0.6361 | 0.3538 | 0.9899 |
| TextCNN[59] | 0.7890 | 0.9270 | 0.9091 | 0.8765 | 0.8680 | 0.9250 | 0.8935 | 0.8404 | 0.8801 | 0.8934 | 0.5730 | 0.4535 | 1.0265 |
| BERT | 0.7566 | 0.9129 | 0.8887 | 0.8895 | 0.8728 | 0.9200 | 0.8823 | 0.9076 | 0.8901 | 0.9032 | 0.6241 | 0.4160 | 1.0401 |
| RoBERTa[60] | 0.7166 | 0.9417 | 0.8382 | 0.8684 | 0.8806 | 0.9100 | 0.8000 | 0.8750 | 0.8754 | 0.8884 | 0.8287 | 0.4108 | 1.2395 |
| StyleLSTM[9] | 0.8196 | 0.9273 | 0.8582 | 0.8790 | 0.8697 | 0.9250 | 0.8932 | 0.9121 | 0.8881 | 0.9049 | 0.5616 | 0.5464 | 1.1080 |
| DualEmo[10] | 0.8271 | 0.9419 | 0.8384 | 0.8821 | 0.8665 | 0.9050 | 0.8889 | 0.9133 | 0.8992 | 0.9027 | 0.5429 | 0.4261 | 0.9690 |
| EANN[11] | 0.8487 | 0.9419 | 0.8485 | 0.8760 | 0.8525 | 0.9300 | 0.8833 | 0.8967 | 0.8963 | 0.9021 | 0.4438 | 0.3410 | 0.7848 |
| EANN_NoDAT | 0.8196 | 0.9417 | 0.9089 | 0.8684 | 0.8934 | 0.9350 | 0.9012 | 0.9069 | 0.9033 | 0.9132 | 0.5696 | 0.3964 | 0.9660 |
| MMoE[61] | 0.8594 | 0.9275 | 0.8888 | 0.8496 | 0.8618 | 0.9299 | 0.8417 | 0.8840 | 0.8739 | 0.8911 | 0.4728 | 0.3982 | 0.8710 |
| MoSE | 0.8125 | 0.8384 | 0.8586 | 0.8014 | 0.8240 | 0.9050 | 0.8573 | 0.9108 | 0.8676 | 0.8825 | 0.5093 | 0.8786 | 1.3879 |
| EDDFN[13] | 0.8271 | 0.9273 | 0.8574 | 0.8765 | 0.8244 | 0.9374 | 0.8573 | 0.8802 | 0.8749 | 0.8912 | 0.5790 | 0.5597 | 1.1387 |
| EDDFN_NoDAT | 0.8021 | 0.9270 | 0.9088 | 0.8694 | 0.8525 | 0.9247 | 0.8414 | 0.8810 | 0.8624 | 0.8916 | 0.5507 | 0.4530 | 1.0037 |
| MDFEND[1] | 0.8487 | 0.9417 | 0.8917 | 0.8872 | 0.8597 | 0.9400 | 0.9020 | 0.9121 | 0.8903 | 0.9120 | 0.5795 | 0.5250 | 1.1045 |
| M3FEND[14] | 0.8196 | 0.9417 | 0.8787 | 0.8684 | 0.8856 | 0.9450 | 0.9016 | 0.9318 | 0.9131 | 0.9207 | 0.5867 | 0.5099 | 1.0966 |
| Our(MD) | 0.9030 | 0.9419 | 0.8987 | 0.9060 | 0.9152 | 0.9450 | 0.8893 | 0.9023 | 0.9131 | 0.9213 | 0.4345 | 0.3155 | 0.7500 |
| Our(M3) | 0.9259 | 0.9546 | 0.9292 | 0.8955 | 0.9087 | 0.9500 | 0.9074 | 0.9293 | 0.9234 | 0.9290 | 0.3446 | 0.4038 | 0.7484 |
-
•
罗伯塔[60]。 这是一个采用动态掩码语言建模技术的预训练模型。 我们将其用作具有冻结参数的编码器来保留学习的表示。 该模型采用多层感知器 (MLP) 进行分类。
-
•
BiGRU [8]。 它是基于常见循环神经网络 (RNN) 架构的文本编码器。 在我们的实现中,我们使用了隐藏层大小为 300 的单层 BiGRU。
-
•
TextCNN [59]。 TextCNN 专为处理和分析文本数据而设计,采用卷积神经网络架构。 我们使用了 5 个卷积核,其核步长分别为 1、2、3、5 和 10,每个核有 64 个通道。
-
•
StyleLSTM [9]。 该模型利用双向 LSTM 作为编码器。 然后将编码后的特征与风格特征一起输入 MLP 以获得预测结果。
-
•
DualEmo [10]。 它采用 BiGRU 作为编码器,情感特征与文本特征一起输入到 MLP。 编码器设置与 BiGRU 方法类似。
-
•
MMoE [61]。 该模型采用 MLP 作为专家网络,并使用门控机制结合多个专家的表示。
-
•
摩西。 与 MMoE 类似,MoSE 用 LSTM 代替 MLP 作为专家网络。
-
•
EANN [11]。 它由特征提取器、假新闻分类器和事件鉴别器组成。 其目标是识别并删除事件特定的特征,同时保留不同事件之间的共享特征。 我们使用了[14]中描述的设置。
-
•
EDDFN [13]。 该框架旨在保留新闻数据中特定领域和跨领域的知识,以检测不同领域的假新闻。 我们遵循[1]中描述的设置。
-
•
MDFEND [1]。 它是一种多域检测模型,采用可学习的域门来聚合专家网络。 TextCNN 充当专家网络,每个专家网络的设置与基线 TextCNN 方法类似。
-
•
M3FEND[14]。 它是一种最先进的多域假新闻检测模型,使用域适配器聚合语义、情感和风格以获得全面的新闻表示,同时使用域内存库为样本生成潜在域标签。
| Method | Gossipcop | Politics | COVID | Overall | |||
|---|---|---|---|---|---|---|---|
| F1 | FNED | FPED | Total | ||||
| BiGRU[8] | 0.7774 | 0.7726 | 0.9016 | 0.8048 | 0.2125 | 0.1317 | 0.3442 |
| TextCNN[59] | 0.7953 | 0.7145 | 0.8851 | 0.8114 | 0.1619 | 0.1173 | 0.2792 |
| RoBERTa[60] | 0.7998 | 0.8033 | 0.9131 | 0.8258 | 0.2918 | 0.2315 | 0.5233 |
| StyleLSTM[9] | 0.7983 | 0.8123 | 0.9264 | 0.8268 | 0.2031 | 0.0767 | 0.2798 |
| DualEmo[10] | 0.7941 | 0.8204 | 0.9007 | 0.8194 | 0.2480 | 0.1282 | 0.3762 |
| EANN[11] | 0.7934 | 0.7731 | 0.8749 | 0.8019 | 0.1196 | 0.1475 | 0.2671 |
| EANN_NoDAT | 0.7857 | 0.7386 | 0.8734 | 0.8062 | 0.3381 | 0.1304 | 0.4685 |
| MMoE[61] | 0.8047 | 0.8486 | 0.9453 | 0.8380 | 0.3079 | 0.0750 | 0.3829 |
| MoSE | 0.7982 | 0.8553 | 0.9380 | 0.8324 | 0.3723 | 0.1156 | 0.4879 |
| EDDFN[13] | 0.7862 | 0.8605 | 0.9307 | 0.8217 | 0.3495 | 0.0754 | 0.4249 |
| EDDFN_NoDAT | 0.7986 | 0.8451 | 0.9423 | 0.8343 | 0.4156 | 0.0859 | 0.5015 |
| MDFEND[1] | 0.8080 | 0.8473 | 0.9331 | 0.8433 | 0.4376 | 0.1076 | 0.5452 |
| M3FEND [14] | 0.8237 | 0.8478 | 0.9392 | 0.8454 | 0.4397 | 0.1472 | 0.5869 |
| Our(MD) | 0.8025 | 0.8005 | 0.9259 | 0.8294 | 0.1779 | 0.0830 | 0.2609 |
| Our(M3) | 0.8073 | 0.8291 | 0.9332 | 0.8359 | 0.2021 | 0.0677 | 0.2698 |
此外,我们还评估了不包含域对抗模块的EANN和EDDFN版本,分别表示为EANN_NoDAT和EDDFN_NoDAT。
需要强调的是,在这些基线模型中,只有 EANN、EDDFN、MDFEND 和 M3FEND 将域标签作为其输入的一部分。
VI-A3 评估指标
与之前的许多研究[62,63,64,65]一致,我们利用假阳性等式差异(FPED)和假阴性等式差异(FNED)[66]测量偏差以及 F1 分数来评估绩效。 FPED 量化每个域的总体 FNR 和 FPR 之间的绝对差异,而 FNED 对漏报执行类似的计算,如 (16) 和 (17) 所示。 我们用 Total 来表示 FNED 和 FPED 之和。
| (16) |
| (17) |
VI-A4 教师和学生网络
对于对抗性去偏差蒸馏,我们采用与域对抗训练的学生模型具有相同架构的网络。 这使我们能够获得一个无偏教师模型,有利于无偏分布知识的迁移。 在领域知识蒸馏阶段,我们选择了两种最先进的多领域假新闻检测方法,即MDFEND [1]和M3FEND [14],由于其在捕获领域知识方面的有效性而被视为干净的教师模型。 值得注意的是,MDFEND 和 M3FEND 分别有 8.14M 和 11.36M 可训练参数。 为了确保可比性,我们设计了一个名为 TextCNN-S 的学生网络,它利用常用的网络结构并具有 771 万个可训练参数。 TextCNN-S 将 BERT 与第 11 层的激活结合起来,并采用 5 个具有 64 个通道的卷积核,每个卷积核具有不同的核步长 1、2、3 和 5 作为编码器。 MLP 用于分类目的。
VI-A5 训练设置
VI-B 性能比较
在本节中,我们评估 DTDBD 在中文和英文多域假新闻检测数据集上的有效性。 评估结果如表VI和VII所示,其中显示了每个域的F1分数以及包括F1、FPED和FNED在内的总体指标。 表现最好的结果以粗体突出显示,而第二好的结果则用下划线突出显示。
| Model | TextCNN-S | BiGRU-S | ||||||
|---|---|---|---|---|---|---|---|---|
| F1 | FNED | FPED | Total | F1 | FNED | FPED | Total | |
| Student | 0.9136 | 0.7161 | 0.4059 | 1.1220 | 0.8999 | 0.6503 | 0.4577 | 1.1080 |
| Student+DAT-IE | 0.8967 | 0.3409 | 0.3347 | 0.6756 | 0.8743 | 0.4735 | 0.3229 | 0.7964 |
| Teacher(M3) | 0.9207 | 0.5867 | 0.5099 | 1.0996 | 0.9207 | 0.5867 | 0.5099 | 1.0996 |
| Student+DND | 0.9185 | 0.6721 | 0.4271 | 1.0992 | 0.9127 | 0.5272 | 0.4418 | 0.9690 |
| Student+ADD | 0.9109 | 0.4741 | 0.3053 | 0.7794 | 0.8980 | 0.5294 | 0.3391 | 0.8685 |
| w/o DAA | 0.9213 | 0.4908 | 0.4597 | 0.9505 | 0.9131 | 0.4361 | 0.4253 | 0.8614 |
| Our(M3) | 0.9290 | 0.3446 | 0.4038 | 0.7484 | 0.9142 | 0.4138 | 0.3491 | 0.7629 |
VI-B1 领域不公平测量
通过分析基线方法的结果,我们观察到大多数单域和多域假新闻检测方法都表现出较高的 FPED 和 FNED 值。 这表明这些方法倾向于从不平衡的数据集中学习领域偏差。 我们还发现 EANN 在基线模型中取得了最好的去偏差结果,这表明强制模型学习跨域特征有利于减轻域偏差。 然而,EANN的性能明显低于EANN_NODAT,这验证了域对抗训练的有效性。 这种差异背后的原因是对抗性结构忽略了新闻项可能与具有不同相关程度的多个领域相关的场景。 值得注意的是,与 EDDFN 相比,EDDFN_NODAT 在英语数据集上表现出显着的性能改进,但在中文数据集上这种变化不太明显。 这可能归因于EDDFN结合了域内知识学习模块,减少了域对抗模块在学习跨域特征时的影响。 此外,由于英语数据集仅由三个领域组成,它们之间的内容差距很大,因此领域内知识学习模块不会产生明显的影响。
| Model | TextCNN-S | BiGRU-S | ||||||
|---|---|---|---|---|---|---|---|---|
| F1 | FNED | FPED | Total | F1 | FNED | FPED | Total | |
| Student | 0.9136 | 0.7161 | 0.4059 | 1.1220 | 0.8999 | 0.6503 | 0.4577 | 1.1080 |
| Student+DAT | 0.8856 | 0.3719 | 0.3807 | 0.7526 | 0.8599 | 0.4836 | 0.3290 | 0.8126 |
| Student+DAT-IE | 0.8967 | 0.3409 | 0.3347 | 0.6756 | 0.8743 | 0.4735 | 0.3229 | 0.7964 |
VI-B2 DTBD 的结果
关于我们提出的方法,使用 DTDBD 训练的 TextCNN-U 实现了最先进的去偏结果,同时在中文数据集上也获得了最先进的性能。 这表明 DTDBD 是一种有效的方法,不仅可以减少域偏差,还可以缓解性能下降问题。 这一成功背后的主要原因在于DTDBD采用的双师蒸馏结构,它将无偏分布的知识和领域知识转移到学生模型中。 然而,在英语数据集上,我们的方法的性能略低于 MDFEND 和 M3FEND,但在减轻领域偏差方面有显着的改进。 这种差异可以归因于英语数据集仅包含三个领域,新闻内容差异很大,使得学习重要的跨领域知识具有挑战性。
此外,我们发现与 MDFEND 相比,M3FEND 在传授领域知识方面更有效。 虽然这两种方法都采用软共享机制来学习跨领域知识,但 M3FEND 为每个领域构建了一个记忆矩阵,通过计算新闻样本与新闻样本的相似度来更丰富地表示领域信息。记忆矩阵以获得域标签分布。
VI-C 消融研究
VI-C1 不同组件的重要性
为了更深入地了解两位老师在 DTDBD 中的教学特点、信息熵损失的作用以及基于动量的动态调整算法的效果,我们进行了一系列的消融研究。 我们采用 TextCNN-U 模型作为学生模型。 Student+DND 和 Student+ADD 分别表示使用领域知识蒸馏和对抗性去偏差蒸馏来训练学生模型。 Student+DTDBD代表我们的DTDBD方法。 DAA表示基于动量的动态调整算法。 此外,我们引入了 BiGRU-S 模型来演示每个蒸馏模块的有效性,该模型利用冻结的 BERT 和隐藏大小为 300 的单层 BiGRU 进行特征提取,然后使用 MLP 进行分类。
VI-C2 对抗性去偏蒸馏的有效性
如表VIII所示,对抗性去偏差蒸馏显着减轻了模型的域偏差,表明使用无偏差分布作为知识的有效性。 此外,我们发现与领域对抗训练相比,对抗性去偏差蒸馏减轻了性能下降的问题,同时改善了偏差缓解。 这符合我们的目标,即不要过度强迫模型专注于学习不变特征,而是尽可能在具有高度相关性的领域中学习它们。
VI-C3 领域知识蒸馏的有效性
如表VIII所示,我们发现领域知识蒸馏可以提高学生模型的性能。 原因是干净的老师将有效的领域知识传递给学生,这是学生模型所不具备的。 我们还看到领域知识蒸馏稍微降低了模型的领域偏差,这表明知识蒸馏方法本身可以限制冗余知识的学习。

VI-C4 基于动量的动态调整算法的有效性
如表VIII所示,我们观察到即使没有基于动量的动态调整算法,性能和公平性也能得到增强,这凸显了解决公平性蒸馏和领域知识蒸馏的重要性。 然而,值得注意的是,公平性的改善往往相对较小,而实现进一步的性能提升则提出了更大的挑战。 这可以归因于学生模型和干净教师模型中都缺乏对抗性模块。 因此,学生模型往往主要从干净的老师那里获取知识,在某种程度上忽视了公正的老师的贡献。 这导致学习过程中公平相关知识的获取不足,最终限制了进一步提高绩效的潜力。
VI-C5 信息熵损失的有效性
我们评估信息熵损失对两个学生模型的影响。 Student+DAT 表示使用传统的领域对抗训练,而 Student+DAT-IE 指的是我们修改后的包含信息熵损失的领域对抗训练。 如表IX所示,我们观察到与 DAT 方法相比,DAT-IE 有助于进一步减轻域偏差并提高性能。 这是因为 DAT 方法允许模型通过仅关注最相关的领域来学习捷径,而忽略从其他领域提取共享知识。 相反,信息熵损失鼓励模型优先考虑所有领域中共同的特征,突出了共享特征在减少领域偏差方面的重要性。
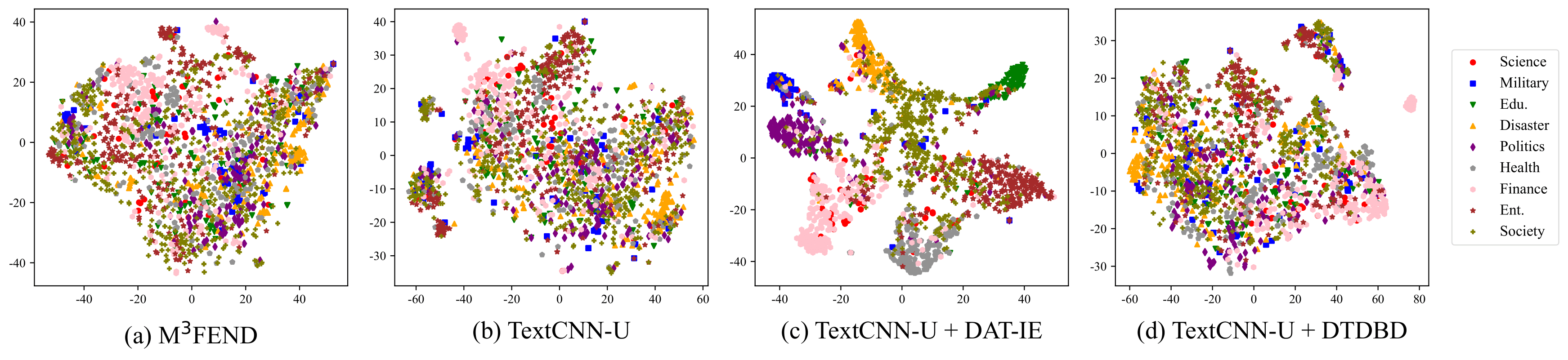
VI-D DTDBD 的可视化
为了直观地说明我们的方法在学习跨域特征方面的有效性,我们使用 t-SNE 进行降维,将测试数据的中间特征投影到二维空间中,如图 2 所示>。 考虑到来自不同领域的新闻之间的相关性,对样本分布保持细致入微的视角非常重要。
我们观察到,在 M3FEND 和 TextCNN-U 模型中,有多个区域仅包含来自一个或几个域的样本。 这表明这些模型可能会学习冗余的特定领域知识或主要关注有限数量领域的共享特征。
在TextCNN-U+DAT-IE模型中,上述情况更为明显。 这可以归因于在新闻分类训练中纳入了 DAT-IE 损失,这迫使模型专注于最相关的领域。 因此,该模型在特征空间中的域之间表现出更高程度的分离。
相比之下,使用我们的 DTDBD 方法训练的 TextCNN-U 模型在领域表示中表现出更多样化的模式。 在 2(d) 中,大多数区域包含来自多个域的样本,这表明 DTDBD 有效减轻了域虚假相关的现象。 重要的是,DTDBD 不仅避免了对每个领域的同等关注,而且还表现出了精确对具有高相关性的领域进行优先级排序的能力。 这些视觉表示让我们深入了解我们的方法如何使模型能够学习跨领域的共享特征,同时准确捕获各个领域的相关性。
VI-E 案例分析
这三则新闻的案例研究如图3所示。 从案例1可以看出,当传统的假新闻检测器遇到假新闻占主导地位的领域(例如娱乐和金融)时,他们更有可能将该新闻错误地分类为假新闻。 相反,在真实内容丰富的领域,例如灾难和政治,以前的方法会遭受相同的领域偏差(如案例 2 所示)。 相比之下,我们的 DTDBD 框架通过利用领域知识蒸馏和对抗性去偏差蒸馏,有效减轻了领域信息对模型决策的影响。
此外,从案例1、案例2和案例3可以看出,双教师框架DTDBD可以更准确地预测新闻标签,并且具有更高的预测置信度。 这体现了廉洁老师在模范表现中的作用。 另一方面,也表明了基于动量的动态调整算法在去偏和检测性能之间权衡的有效性。
七结论
在本文中,我们提出了双师去偏差蒸馏框架(DTDBD),该框架可以减轻由于现实世界数据集分布不平衡而产生的领域偏差。 DTDBD 由一名公正的教师和一名干净的教师组成,共同指导学生模型减少领域偏差并缓解性能下降问题。 对于无偏见的教师,我们设计了一种对抗性去偏见蒸馏损失,将无偏见分布作为一种知识形式。 对于干净的老师,我们引入了领域知识蒸馏损失,以激励学生模型专注于学习跨相关领域的知识。 此外,我们提出了一种基于动量的动态调整算法来平衡两名教师对学生模型的影响。 我们对英文和中文多域假新闻数据集进行了广泛的实验,以评估 DTDBD 的有效性。 结果表明,DTDBD 有效地减轻了领域偏差,提高了性能,并在中文数据集上实现了最先进的性能。
参考
- [1] Q. Nan, J. Cao, Y. Zhu, Y. Wang, and J. Li, “Mdfend: Multi-domain fake news detection,” in Proceedings of the 30th ACM International Conference on Information & Knowledge Management, 2021, pp. 3343–3347.
- [2] J. Zhang, B. Dong, and S. Y. Philip, “Fakedetector: Effective fake news detection with deep diffusive neural network,” in 2020 IEEE 36th International Conference on Data Engineering (ICDE). IEEE, 2020, pp. 1826–1829.
- [3] Q. Nan, D. Wang, Y. Zhu, Q. Sheng, Y. Shi, J. Cao, and J. Li, “Improving fake news detection of influential domain via domain-and instance-level transfer,” in Proceedings of the 29th International Conference on Computational Linguistics, 2022, pp. 2834–2848.
- [4] Y. Wang, F. Fabbri, and M. Mathioudakis, “Streaming algorithms for diversity maximization with fairness constraints,” in 2022 IEEE 38th International Conference on Data Engineering (ICDE). IEEE, 2022, pp. 41–53.
- [5] T.-D. Truong, N. Le, B. Raj, J. Cothren, and K. Luu, “Fredom: Fairness domain adaptation approach to semantic scene understanding,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 19 988–19 997.
- [6] G. Xu and Q. Hu, “Can model compression improve nlp fairness,” arXiv preprint arXiv:2201.08542, 2022.
- [7] Y. Zhu, Q. Sheng, J. Cao, S. Li, D. Wang, and F. Zhuang, “Generalizing to the future: Mitigating entity bias in fake news detection,” in Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, 2022, pp. 2120–2125.
- [8] J. MA, W. GAO, P. MITRA, S. KWON, B. J. JANSEN, K.-F. WONG, and M. CHA, “Detecting rumors from microblogs with recurrent neural networks.(2016),” in Proceedings of the 25th International Joint Conference on Artificial Intelligence (IJCAI 2016), pp. 3818–3824.
- [9] P. Przybyla, “Capturing the style of fake news,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 01, 2020, pp. 490–497.
- [10] X. Zhang, J. Cao, X. Li, Q. Sheng, L. Zhong, and K. Shu, “Mining dual emotion for fake news detection,” in Proceedings of the Web Conference 2021, 2021, pp. 3465–3476.
- [11] Y. Wang, F. Ma, Z. Jin, Y. Yuan, G. Xun, K. Jha, L. Su, and J. Gao, “Eann: Event adversarial neural networks for multi-modal fake news detection,” in Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 2018, pp. 849–857.
- [12] T. Murayama, S. Wakamiya, and E. Aramaki, “Mitigation of diachronic bias in fake news detection dataset,” in Proceedings of the Seventh Workshop on Noisy User-generated Text (W-NUT 2021), 2021, pp. 182–188.
- [13] A. Silva, L. Luo, S. Karunasekera, and C. Leckie, “Embracing domain differences in fake news: Cross-domain fake news detection using multi-modal data,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 35, no. 1, 2021, pp. 557–565.
- [14] Y. Zhu, Q. Sheng, J. Cao, Q. Nan, K. Shu, M. Wu, J. Wang, and F. Zhuang, “Memory-guided multi-view multi-domain fake news detection,” IEEE Transactions on Knowledge and Data Engineering, pp. 7178–7191, 2022.
- [15] K. Shu, A. Sliva, S. Wang, J. Tang, and H. Liu, “Fake news detection on social media: A data mining perspective,” ACM SIGKDD Explorations Newsletter, vol. 19, no. 1, pp. 22–36, 2017.
- [16] S. Shetiya, I. P. Swift, A. Asudeh, and G. Das, “Fairness-aware range queries for selecting unbiased data,” in 2022 IEEE 38th International Conference on Data Engineering (ICDE). IEEE, 2022, pp. 1423–1436.
- [17] N. Ruchansky, S. Seo, and Y. Liu, “Csi: A hybrid deep model for fake news detection,” in Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, 2017, pp. 797–806.
- [18] S. Kwon, M. Cha, K. Jung, W. Chen, and Y. Wang, “Prominent features of rumor propagation in online social media,” in 2013 IEEE 13th International Conference on Data Mining. IEEE, 2013, pp. 1103–1108.
- [19] A. Romero, N. Ballas, S. E. Kahou, A. Chassang, C. Gatta, and Y. Bengio, “Fitnets: Hints for thin deep nets,” arXiv preprint arXiv:1412.6550, 2014.
- [20] X. Zhou, R. Zafarani, K. Shu, and H. Liu, “Fake news: Fundamental theories, detection strategies and challenges,” in Proceedings of the twelfth ACM International Conference on Web Search and Data Mining, 2019, pp. 836–837.
- [21] Q. Sheng, J. Cao, X. Zhang, R. Li, D. Wang, and Y. Zhu, “Zoom out and observe: News environment perception for fake news detection,” in Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2022, pp. 4543–4556.
- [22] J. Ma, W. Gao, and K.-F. Wong, “Detect rumors on twitter by promoting information campaigns with generative adversarial learning,” in The World Wide Web Conference, 2019, pp. 3049–3055.
- [23] Y. Wang, F. Ma, H. Wang, K. Jha, and J. Gao, “Multimodal emergent fake news detection via meta neural process networks,” in Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, 2021, pp. 3708–3716.
- [24] D. Khattar, J. S. Goud, M. Gupta, and V. Varma, “Mvae: Multimodal variational autoencoder for fake news detection,” in The World Wide Web Conference, 2019, pp. 2915–2921.
- [25] C. Castillo, M. Mendoza, and B. Poblete, “Information credibility on twitter,” in Proceedings of the 20th International Conference on World Wide Web, 2011, pp. 675–684.
- [26] A. Giachanou, P. Rosso, and F. Crestani, “Leveraging emotional signals for credibility detection,” in Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, 2019, pp. 877–880.
- [27] A. Choudhry, I. Khatri, A. Chakraborty, D. Vishwakarma, and M. Prasad, “Emotion-guided cross-domain fake news detection using adversarial domain adaptation,” in Proceedings of the 19th International Conference on Natural Language Processing (ICON), 2022, pp. 75–79.
- [28] Y. Dou, K. Shu, C. Xia, P. S. Yu, and L. Sun, “User preference-aware fake news detection,” in Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, 2021, pp. 2051–2055.
- [29] K. Shu, S. Wang, and H. Liu, “Understanding user profiles on social media for fake news detection,” in 2018 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR). IEEE, 2018, pp. 430–435.
- [30] Y. Liu and Y.-F. Wu, “Early detection of fake news on social media through propagation path classification with recurrent and convolutional networks,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 32, no. 1, 2018, pp. 354–361.
- [31] V.-H. Nguyen, K. Sugiyama, P. Nakov, and M.-Y. Kan, “Fang: Leveraging social context for fake news detection using graph representation,” in Proceedings of the 29th ACM International Conference on Information & Knowledge Management, 2020, pp. 1165–1174.
- [32] A. Silva, Y. Han, L. Luo, S. Karunasekera, and C. Leckie, “Propagation2vec: Embedding partial propagation networks for explainable fake news early detection,” Information Processing & Management, vol. 58, no. 5, p. 102618, 2021.
- [33] K. Shu, L. Cui, S. Wang, D. Lee, and H. Liu, “defend: Explainable fake news detection,” in Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 2019, pp. 395–405.
- [34] J. Ma, W. Gao, and K.-F. Wong, “Detect rumor and stance jointly by neural multi-task learning,” in Companion Proceedings of the Web Conference 2018, 2018, pp. 585–593.
- [35] C. Rong, J. Feng, and J. Ding, “Goddag: Generating origin-destination flow for new cities via domain adversarial training,” IEEE Transactions on Knowledge and Data Engineering, pp. 10 048–10 057, 2023.
- [36] Y. Ganin and V. Lempitsky, “Unsupervised domain adaptation by backpropagation,” in International Conference on Machine Learning. PMLR, 2015, pp. 1180–1189.
- [37] D. Kashyap, S. K. Aithal, C. Rakshith, and N. Subramanyam, “Towards domain adversarial methods to mitigate texture bias,” in ICML 2022: Workshop on Spurious Correlations, Invariance and Stability, 2022, pp. 1–8.
- [38] H. Liu, W. Wang, Y. Wang, H. Liu, Z. Liu, and J. Tang, “Mitigating gender bias for neural dialogue generation with adversarial learning,” in Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2020, pp. 893–903.
- [39] S. B. R. Chowdhury, S. Ghosh, Y. Li, J. Oliva, S. Srivastava, and S. Chaturvedi, “Adversarial scrubbing of demographic information for text classification,” in Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, 2021, pp. 550–562.
- [40] J. Choi, C. Gao, J. C. Messou, and J.-B. Huang, “Why can’t i dance in the mall? learning to mitigate scene bias in action recognition,” Advances in Neural Information Processing Systems, vol. 32, pp. 1–13, 2019.
- [41] G. Hinton, O. Vinyals, and J. Dean, “Distilling the knowledge in a neural network,” arXiv preprint arXiv:1503.02531, 2015.
- [42] W. Park, D. Kim, Y. Lu, and M. Cho, “Relational knowledge distillation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 3967–3976.
- [43] M. Ji, B. Heo, and S. Park, “Show, attend and distill: Knowledge distillation via attention-based feature matching,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 35, no. 9, 2021, pp. 7945–7952.
- [44] S. Du, S. You, X. Li, J. Wu, F. Wang, C. Qian, and C. Zhang, “Agree to disagree: Adaptive ensemble knowledge distillation in gradient space,” Advances in Neural Information Processing Systems, vol. 33, pp. 12 345–12 355, 2020.
- [45] J. Ahn, H. Lee, J. Kim, and A. Oh, “Why knowledge distillation amplifies gender bias and how to mitigate from the perspective of distilbert,” in Proceedings of the 4th Workshop on Gender Bias in Natural Language Processing (GeBNLP), 2022, pp. 266–272.
- [46] J. Chai, T. Jang, and X. Wang, “Fairness without demographics through knowledge distillation,” Advances in Neural Information Processing Systems, vol. 35, pp. 19 152–19 164, 2022.
- [47] D. Liu, P. Cheng, Z. Lin, J. Luo, Z. Dong, X. He, W. Pan, and Z. Ming, “Kdcrec: Knowledge distillation for counterfactual recommendation via uniform data,” IEEE Transactions on Knowledge and Data Engineering, pp. 8143–8156, 2022.
- [48] Z. Zhu, S. Si, J. Wang, Y. Yang, and J. Xiao, “Debias the black-box: A fair ranking framework via knowledge distillation,” in International Conference on Web Information Systems Engineering. Springer, 2022, pp. 395–405.
- [49] P. Dhar, J. Gleason, A. Roy, C. D. Castillo, P. J. Phillips, and R. Chellappa, “Distill and de-bias: Mitigating bias in face verification using knowledge distillation,” arXiv preprint arXiv:2112.09786, 2021.
- [50] S. Jung, D. Lee, T. Park, and T. Moon, “Fair feature distillation for visual recognition,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 12 115–12 124.
- [51] E. Purificato, L. Boratto, and E. W. De Luca, “Do graph neural networks build fair user models? assessing disparate impact and mistreatment in behavioural user profiling,” in Proceedings of the 31st ACM International Conference on Information & Knowledge Management, 2022, pp. 4399–4403.
- [52] T. Furlanello, Z. Lipton, M. Tschannen, L. Itti, and A. Anandkumar, “Born again neural networks,” in International Conference on Machine Learning. PMLR, 2018, pp. 1607–1616.
- [53] F. Yuan, L. Shou, J. Pei, W. Lin, M. Gong, Y. Fu, and D. Jiang, “Reinforced multi-teacher selection for knowledge distillation,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 35, no. 16, 2021, pp. 14 284–14 291.
- [54] S. Zhao, J. Yu, Z. Sun, B. Zhang, and X. Wei, “Enhanced accuracy and robustness via multi-teacher adversarial distillation,” in European Conference on Computer Vision. Springer, 2022, pp. 585–602.
- [55] P. Micaelli and A. J. Storkey, “Zero-shot knowledge transfer via adversarial belief matching,” Advances in Neural Information Processing Systems, vol. 32, pp. 9551–9561, 2019.
- [56] C. Liang, Y. Zhang, X. Li, J. Zhang, and Y. Yu, “Fudfend: fuzzy-domain for multi-domain fake news detection,” in CCF International Conference on Natural Language Processing and Chinese Computing. Springer, 2022, pp. 45–57.
- [57] K. Shu, D. Mahudeswaran, S. Wang, D. Lee, and H. Liu, “Fakenewsnet: A data repository with news content, social context, and spatiotemporal information for studying fake news on social media,” Big Data, vol. 8, no. 3, pp. 171–188, 2020.
- [58] Y. Li, B. Jiang, K. Shu, and H. Liu, “Mm-covid: A multilingual and multimodal data repository for combating covid-19 disinformation,” arXiv preprint arXiv:2011.04088, 2020.
- [59] Y. Kim, “Convolutional neural networks for sentence classification,” in Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2014, pp. 1746–1751.
- [60] Y. Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, and V. Stoyanov, “Roberta: A robustly optimized bert pretraining approach,” arXiv preprint arXiv:1907.11692, 2019.
- [61] J. Ma, Z. Zhao, X. Yi, J. Chen, L. Hong, and E. H. Chi, “Modeling task relationships in multi-task learning with multi-gate mixture-of-experts,” in Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 2018, pp. 1930–1939.
- [62] H. Liu, W. Jin, H. Karimi, Z. Liu, and J. Tang, “The authors matter: Understanding and mitigating implicit bias in deep text classification,” in Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, 2021, pp. 74–85.
- [63] J. H. Park, J. Shin, and P. Fung, “Reducing gender bias in abusive language detection,” in Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, 2018, pp. 2799–2804.
- [64] P. Lertvittayakumjorn, L. Specia, and F. Toni, “Find: Human-in-the-loop debugging deep text classifiers,” in Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2020, pp. 332–348.
- [65] F. Liu and B. Avci, “Incorporating priors with feature attribution on text classification,” in Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019, pp. 6274–6283.
- [66] L. Dixon, J. Li, J. Sorensen, N. Thain, and L. Vasserman, “Measuring and mitigating unintended bias in text classification,” in Proceedings of the 2018 AAAI/ACM Conference on AI, Ethics, and Society, 2018, pp. 67–73.