]Meta 的 FAIR †]加州大学圣巴巴拉分校 [代码]https://github.com/facebookresearch/seamless_communication。
高效的单调多头注意力
摘要
我们引入了高效单调多头注意力(EMMA),这是一种最先进的同步翻译模型,具有数值稳定且无偏的单调对齐估计。 此外,我们提出了改进的训练和推理策略,包括离线翻译模型的同步微调和单调对齐方差的减少。 实验结果表明,所提出的模型在西班牙语和英语翻译任务上的同步语音到文本翻译中达到了最先进的性能。
1简介
同声翻译是一项专注于减少机器翻译系统延迟的任务。 在这种方法中,同声翻译模型甚至在说话者完成句子之前就启动翻译过程。 这种模型在各种低延迟场景中发挥着关键作用,例如个人旅行和国际会议,人们渴望无缝、实时的翻译体验。 与处理整个输入句子并在单个步骤中生成翻译输出的离线模型相反,同步翻译模型对部分输入序列进行操作。 同步模型结合了策略机制来确定模型何时应生成翻译输出。 该策略有两个操作:读取和写入。 虽然write操作指示模型应该生成部分翻译,但read操作在生成过程中引入了暂停,允许模型获取额外的输入信息。 同步策略可以是基于规则的,也可以是通过训练过程学习的。
近年来,在学习策略领域内,出现了一种称为单调注意策略的特定类别(Raffel 等人,2017;Chiu & Raffel,2018;Arivazhagan 等人,2019),特别是 Transformer基于单调多头注意力(MMA)(Ma等人,2019b)在同步文本到文本翻译任务中展示了最先进的性能。 单调注意力提供了一个无监督的策略学习框架,该框架基于训练期间单调对齐的估计。 尽管MMA在文本到文本翻译方面取得了令人瞩目的成就,但其对语音输入的适应仍面临一定的挑战。 Ma 等人 (2020b) 揭示了 MMA 模型在应用于语音输入时未能在简单的 wait-k 基线上产生显着的改进。 Ma 等人 (2020b) 将 MMA 在语音输入上的次优性能归因于语音编码器状态的粒度和连续性特征。
在本文中,我们进一步研究了单调注意力对语音翻译的适应。 我们展示了导致次优性能的两个主要因素。 首先是单调对齐估计过程中的数值不稳定性和偏差的引入,这来自于Raffel等人(2017)引入的技术。 第二个是单调对齐估计的显着差异,特别是在句子的后半部分,由于编码器状态的连续性。 为了应对这些挑战,我们提出了高效单调多头注意力(EMMA)。 具体来说,这项工作的主要贡献包括:
-
•
一种新颖的数值稳定、无偏单调对齐估计,在同步文本到文本和语音到文本翻译方面产生最先进的性能。
-
•
一种新的单调对齐整形策略,包括新的延迟正则化和单调对齐方差减少
-
•
增强的训练方案,涉及基于预训练的离线模型对同步模型进行微调。
2 背景
2.1 符号
给定矩阵 和 ,我们注释后面章节中使用的操作,以及它们在 Table 1 中 PyTorch 工具包中的实现。
| Notation | Definition | PyTorch |
|---|---|---|
| Index -th row and -th column in matrix | A[i, j] | |
| Index -th row of as a vector | A[[i], :] | |
| Index -th column of as a vector | A[:, [j]] | |
| Element-wise product (Hadamard roduct) | A * B | |
| Matrix multiplication | torch.bmm(A, B) | |
| (A) | Cumulative product on the -th dimension | torch.cumprod(A, dim=l) |
| (A) | Cumulative summation on the -th dimension | torch.cumsum(A, dim=l) |
| (A) | Upper triangle of with a offset of | torch.triu(A, diagonal=b) |
| A matrix with size of by , filled with 1 | torch.ones(N, M) | |
| Shift matrix by elements, on last dimension | A.roll(k, dims=[-1]) |
2.2同声翻译
表示翻译系统的输入和输出序列的和。 是用于文本输入的文本词符和用于语音输入的语音编码器状态。 我们引入延迟序列的概念,表示为,其中每个元素是用于生成相应输出元素的输入长度。 需要注意的是 形成严格单调的非递减序列。
在同声翻译系统中,存在使得。 同时,离线翻译意味着所有的。 的测量值随输入和输出媒体的不同而变化。 在本文中,以文本输入的标记数量和语音输入的秒数来衡量。
评价同步语音翻译系统有两个方面:质量和延迟。 虽然质量评估与离线系统相同,但对于延迟评估,我们使用最常用的指标平均滞后(AL)Ma等人(2019a),定义为
| (1) |
其中 是当策略首次到达源句子末尾时第一个目标翻译的索引。 是理想的策略,定义为
| (2) |
其中 是参考翻译。 正如 Ma 等人 (2020b) 所建议的, 以文本输入的源单词数量和语音输入的源语音秒数来衡量。
2.3 单调注意力
单调注意力模型(Raffel 等人, 2017; Chiu & Raffel, 2018; Arivazhagan 等人, 2019; Ma 等人, 2019b) 具有基于训练期间单调对齐估计的可学习策略。 在给定时间,当第 个目标翻译已被预测并且第 个源输入已被处理时,逐步概率(表示为 )描述模型将写入第个预测而不是读取下一个输入的可能性。 具体来说,它被定义为
| (3) |
其中 是策略网络, 是 个解码器状态, 是 个编码器状态。
Raffel 等人 (2017) 提出了训练期间来自 的源和目标 之间对齐的封闭形式估计:
| (4) |
Raffel 等人 (2017) 处理源和目标之间的硬对齐,Chiu & Raffel (2018) 引入单调分块注意力 (MoChA),它可以在块跟随移动的注意力头。 Arivazhagan 等人 (2019) 进一步提出了单调无限回溯注意力(MILk),其中在所有先前的历史上计算软注意力。 给定第 个解码器状态和第 个编码器状态的能量 ,预期的软注意力由Equation 5:
| (5) |
其中,在训练中使用 而不是 。 Arivazhagan 等人训练 (2019) 还引入了延迟增强来控制延迟。 Ma 等人 (2019b) 进一步将 Transformer 模型的单调注意力扩展到多头注意力(MMA)。 MMA的设计是让每个注意力头都成为单独的单调注意力。
3 高效的单调多头注意力
在本节中,我们将讨论高效单调多头注意力(EMMA)的三个关键因素:数值稳定估计、对齐整形和流式微调。 值得注意的是,本节讨论的单调对齐估计(表示为)是基于单个注意力头的。 遵循与 Ma 等人 (2019b) 相同的设计,对 的相同估计应用于集成到 Transformer 中的 MMA 中的每个注意力头(Vaswani 等人) ,2017)模型。 值得注意的是,仅应用了单调注意力的无限回顾(Arivazhagan 等人, 2019) 变体。
3.1 数值稳定估计
与Raffel 等人(2017)类似,单调估计的目标是通过逐步写入行动概率来计算预期排列。 然而,数值不稳定是由方程4中的分母引起的,特别是在处理几个小概率的乘法时。 为了解决这个问题,我们引入了一种创新的数值稳定方法来估计单调注意力。
3.2 对齐整形
当训练单调注意力的无限回溯变体时,有必要添加延迟正则化,以防止模型学习琐碎的策略。 如果没有延迟正则化,最小化交叉熵损失的最佳策略是在开始翻译之前读取整个序列。 因此,我们应用延迟和方差正则化来控制学习的同声翻译策略的翻译质量和延迟之间的权衡。
对齐的延迟描述了模型需要多少部分输入信息来生成部分翻译。 延迟的减少通常是通过引入从估计对齐中导出的正则化项来实现的。 与之前的工作一致,例如 Arivazhagan 等人 (2019); Ma 等人 (2019b),预期延迟是根据训练期间的预期对齐估计的。 目标词符的预期延迟,表示为,计算如下
| (11) |
给定延迟度量 ,损失项计算如下
| (12) |
对齐的方差表征了估计的确定性。 值得注意的是,对齐估计可以是低延迟但高方差的。 例如,产生线性延迟的单调对齐的随机游走策略在估计上存在巨大差异。 Arivazhagan等人(2019)提出了一种通过在逐步概率网络的输入中引入高斯噪声来降低不确定性的方法。 然而,实证结果表明该方法效率不高,尤其是应用于语音翻译模型时。 因此,我们提出了一种基于正则化的替代策略。
将 表示为单调对齐的预期方差。 目标词符的期望方差记为,可表示为
| (13) |
然后我们引入对齐方差损失如下:
| (14) |
为了进一步减少对齐方差,我们提出了一种增强的逐步概率网络:
| (15) |
和作为能量投影,使用多层前馈网络构建,与先前单调工作采用的线性投影相比,提高了逐步概率网络的表达能力。 是一个可学习的偏差,由负值初始化。 其目的是从离线策略中安排更容易的策略优化过程。 是温度因子,以鼓励逐步概率网络的极化输出。
最后,我们以以下目标优化模型
| (16) |
其中 和 是损失权重。
3.3同时微调
在大多数先前的同声翻译工作中,模型通常是从头开始训练的。 然而,在处理广泛或多语言场景时,这种方法通常需要大量资源。 例如,使用最近的大规模多语言模型(例如 Whisper 或 SeamlessM4T)的配置重新训练同步模型可能是一项重大挑战。 为了利用大型基础翻译模型的最新进展并增强同步翻译模型的适应性,我们引入了一种同步微调方法。
将任意离线编码器-解码器翻译模型表示为,其中表示编码器参数,表示解码器参数。 同步模型表示为,其中表示策略网络。 同时微调涉及使用 初始化 和使用 初始化 。 训练过程中,编码器参数保持固定,仅对和进行优化。 这种设计的动机是假设模型的生成组件(即 和 )应该与离线模型的生成组件非常相似。 在同时设置中,它们适应部分上下文信息。
3.3.1 流式推理
我们使用 SimulEval (Ma 等人, 2020a) 来构建推理管道。 整体推理算法如算法1所示。 对于流式语音输入,每次模型收到新的语音块时,我们都会更新整个编码器。 然后,我们运行解码器以根据策略生成部分文本翻译。
4实验设置
我们评估了语音到文本翻译任务所提出的模型。 使用 SimulEval (Ma 等人, 2020a) 工具包对模型进行评估。 模型的评估侧重于两个因素:质量和延迟。 质量是使用 SacreBLEU (Post,2018) 工具包通过去标记化 BLEU 来衡量的。 延迟评估通过平均滞后(AL)来衡量(Ma等人,2019a)我们遵循部分中介绍的同步微调策略3.3。 同步模型是从离线翻译模型初始化的。 有关本研究中使用的任务、评估数据集以及离线模型性能的详细信息,请参阅表 2
| Task | Evaluation Set | Language | BLEU |
|---|---|---|---|
| Bilingual | mTedX | spa-eng | 37.1 |
| Must-C | eng-spa | 38.1 | |
| Multilingual | Fleurs | 100-eng | 28.8 111Average on 100 language directions |
对于语音到文本(S2T)翻译任务,我们建立了两种实验配置:双语和多语。
双语设置旨在展示模型在提供大量训练数据的情况下的潜力。 我们为spa-engt0>和eng-spa每个方向训练了一个模型。 多语言任务展示了该模型从现有的大规模多语言翻译模型 SeamlessM4T (Seamless Communication 等人,2023) 离线到同步转换的快速适应能力。
在双语设置中,我们遵循Inaguma等人(2023)的数据设置。 在多语言环境中,我们使用Seamless Communication 等人 (2023) 中标记数据和伪标记数据中的语音到文本数据
在双语 S2T 设置中,我们使用预训练的 wav2vec 2.0 编码器 (Baevski 等人, 2020) 和 mBART 解码器 (Liu 等人, 2020) 初始化离线模型。 随后,我们基于这个预训练的离线模型初始化同步模型。 双语模型是在半无监督数据的监督下进行训练的。 在多语言设置中,我们使用离线 SeamlessM4T 模型的 S2T 部分初始化同步模型,使用相同的标记和伪标记数据进行训练,并在 100-engt0> 方向上评估模型。
5相关工作
最近的研究集中在神经端到端方法上,预计更简单的系统可以减少子系统之间的错误并提高直接翻译的整体效率。 这种方法最初应用于文本翻译,后来扩展到语音到文本的任务,显示出与级联方法相比的竞争力。 Duong 等人 (2016) 使用基于循环神经网络 (RNN) 的编码器-解码器架构,引入了一种用于语音到文本的基于注意力的序列到序列结构。 尽管新颖,但与级联方法相比,质量显着下降。 后续研究Berard 等人 (2016); Weiss 等人 (2017); Bansal 等人 (2018); Bérard等人(2018)添加了卷积层,显着提高了端到端模型性能。 利用 Transformer 在文本翻译方面的成功Vaswani 等人 (2017)、Di Gangi 等人 (2019) 和 Inaguma 等人 (2020) 将其应用于语音翻译,实现质量和训练速度的进一步提升。
同声翻译策略分为三组。 第一类由预定义的上下文无关的基于规则的策略组成。 Cho & Esipova (2016)提出了离线同步解码的 Wait-If-* 策略,后来被 Dalvi 等人 (2018) 修改用于连续预测。 另一种变体,Wait- 策略,由 Ma 等人 (2019a) 引入,其中模型在读取 输入和执行 read- 之间交替。写操作。 第二类涉及具有代理的可学习的灵活策略,应用强化学习。 例子包括 Grissom II 等人 (2014),他使用基于马尔可夫链的代理进行基于短语的机器翻译,以及 Gu 等人 (2017),他引入了通过与预先训练的神经机器翻译模型的交互来学习翻译决策的代理。 第三类特征模型使用单调注意力,取代 Softmax 注意力并利用封闭形式的预期注意力。 著名作品包括Raffel 等人 (2017)、Chiu & Raffel (2018)、Arivazhagan 等人 (2019) 和 Ma等人 (2019b),展示了在线线性时间解码和翻译质量改进方面的进步。
6结果
6.1 质量与延迟的权衡
我们提出了双语环境下的质量与延迟的权衡。 图 1显示了不同延迟设置下的BLEU得分。 我们可以看到,EMMA 模型在两个方向的所有延迟区域上都显着优于 Wait-k 模型。
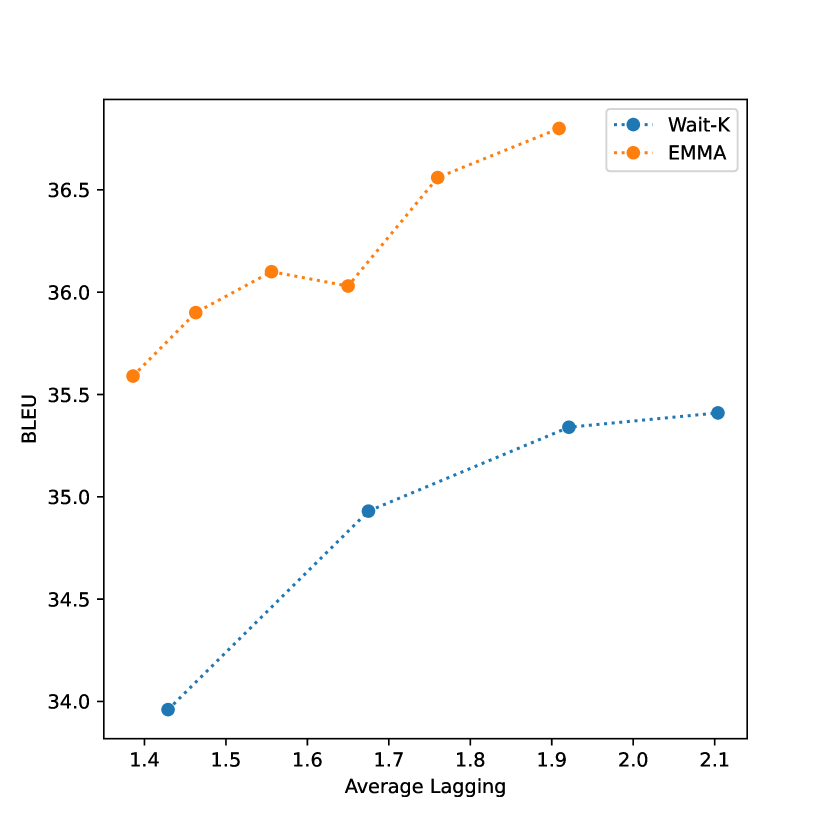
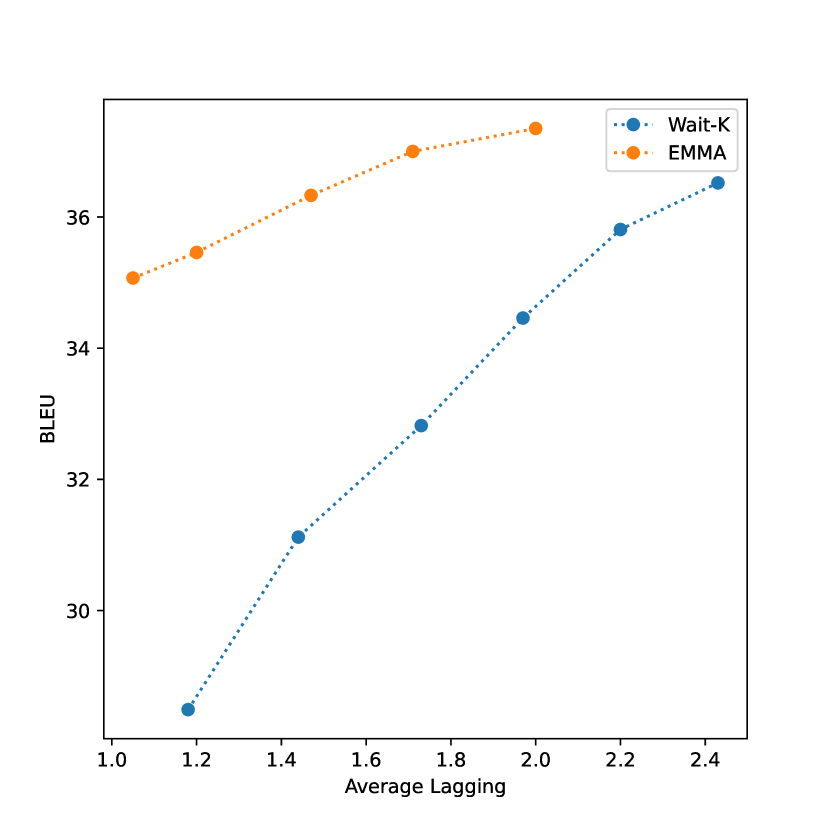
我们在表3中展示了多语言设置下的质量与延迟权衡。 与从头开始训练相比,SeamlessM4T-EMMA 可以在更短的训练时间内实现良好的翻译质量。
| BLEU | AL | ||
|---|---|---|---|
| SeamlessM4T | 28.8 | - | |
| SeamlessM4T-EMMA | 0.5 | 26.0 | 1.75 |
| 0.7 | 26.4 | 1.88 | |
| 0.4 | 25.9 | 1.68 | |
| 0.6 | 26.2 | 1.81 |
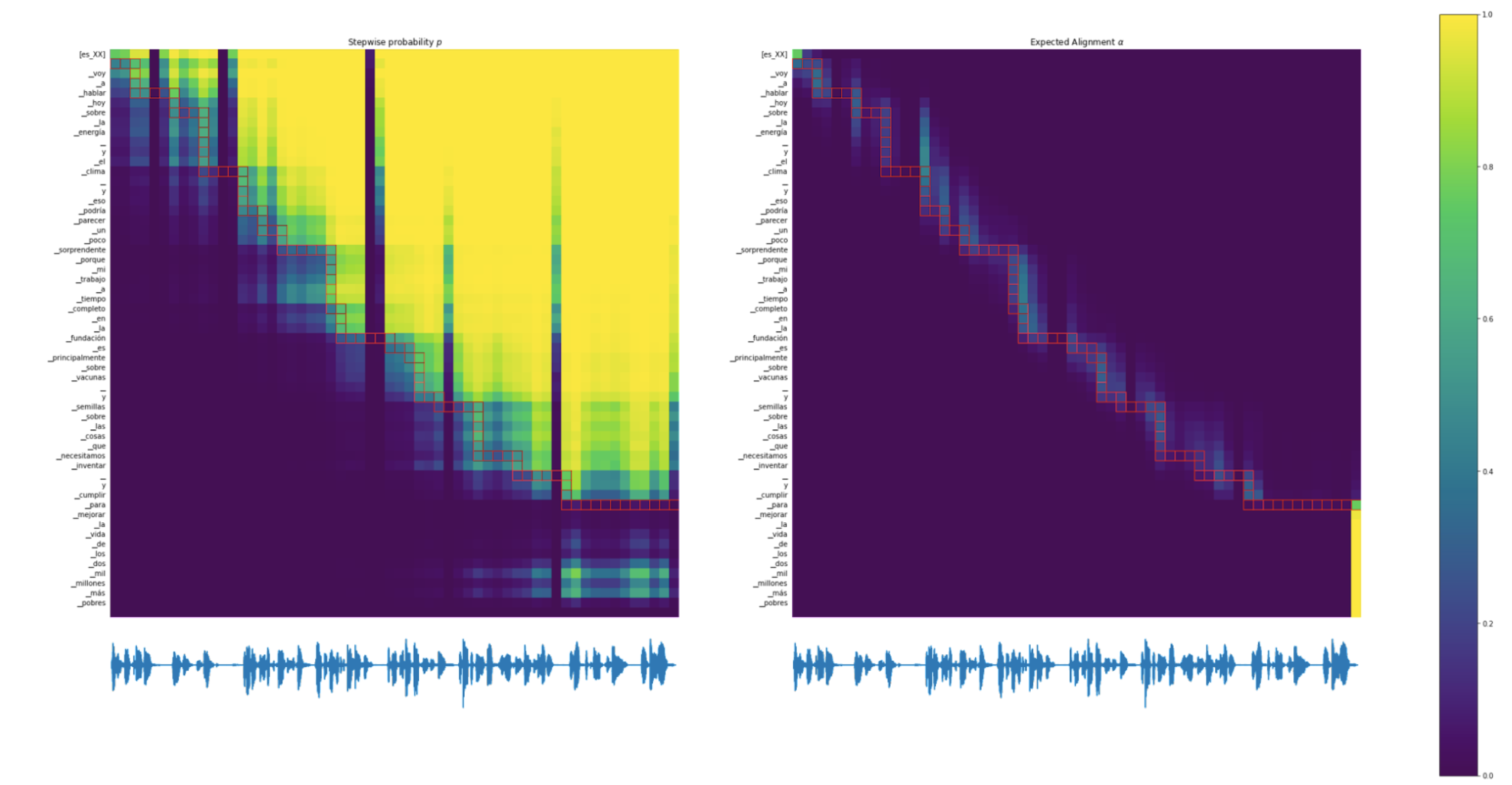
6.2可视化
我们还将从 EMMA 学到的策略可视化为图2。 我们可以看到,在延迟和方差正则化的指导下,模型可以学习对齐输入语音和输出文本的单调策略。
7结论
我们提出了高效单调多头注意力(EMMA),以及一种新颖的数值稳定对齐估计。 我们从离线模型初始化我们的模型,以加快训练速度并提高性能。 我们在双语和多语言环境中评估我们的模型,并观察到两者相对于基线的改进。
大寮
- Arivazhagan et al. (2019) Naveen Arivazhagan, Colin Cherry, Wolfgang Macherey, Chung-Cheng Chiu, Semih Yavuz, Ruoming Pang, Wei Li, and Colin Raffel. Monotonic Infinite Lookback Attention for Simultaneous Machine Translation. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pp. 1313–1323, Florence, Italy, July 2019. Association for Computational Linguistics. 10.18653/v1/P19-1126. URL https://www.aclweb.org/anthology/P19-1126.
- Baevski et al. (2020) Alexei Baevski, Yuhao Zhou, Abdelrahman Mohamed, and Michael Auli. wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations. In Advances in Neural Information Processing Systems, volume 33, pp. 12449–12460. Curran Associates, Inc., 2020. URL https://proceedings.neurips.cc/paper/2020/hash/92d1e1eb1cd6f9fba3227870bb6d7f07-Abstract.html.
- Bansal et al. (2018) Sameer Bansal, Herman Kamper, Karen Livescu, Adam Lopez, and Sharon Goldwater. Low-Resource Speech-to-Text Translation. In Interspeech 2018, pp. 1298–1302. ISCA, September 2018. 10.21437/Interspeech.2018-1326. URL http://www.isca-speech.org/archive/Interspeech_2018/abstracts/1326.html.
- Berard et al. (2016) Alexandre Berard, Olivier Pietquin, Christophe Servan, and Laurent Besacier. Listen and Translate: A Proof of Concept for End-to-End Speech-to-Text Translation. NIPS Workshop on End- to-end Learning for Speech and Audio Processing, December 2016. URL http://arxiv.org/abs/1612.01744. arXiv: 1612.01744.
- Bérard et al. (2018) A. Bérard, L. Besacier, A. C. Kocabiyikoglu, and O. Pietquin. End-to-End Automatic Speech Translation of Audiobooks. In 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 6224–6228, April 2018. 10.1109/ICASSP.2018.8461690. ISSN: 2379-190X.
- Chiu & Raffel (2018) Chung-Cheng Chiu and Colin Raffel. Monotonic Chunkwise Attention. February 2018. URL https://openreview.net/forum?id=Hko85plCW.
- Cho & Esipova (2016) Kyunghyun Cho and Masha Esipova. Can neural machine translation do simultaneous translation? arXiv:1606.02012 [cs], June 2016. URL http://arxiv.org/abs/1606.02012. arXiv: 1606.02012.
- Dalvi et al. (2018) Fahim Dalvi, Nadir Durrani, Hassan Sajjad, and Stephan Vogel. Incremental Decoding and Training Methods for Simultaneous Translation in Neural Machine Translation. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), pp. 493–499, New Orleans, Louisiana, June 2018. Association for Computational Linguistics. 10.18653/v1/N18-2079. URL https://www.aclweb.org/anthology/N18-2079.
- Di Gangi et al. (2019) Mattia Antonino Di Gangi, Matteo Negri, Roldano Cattoni, Roberto Dessi, and Marco Turchi. Enhancing Transformer for End-to-end Speech-to-Text Translation. In Proceedings of Machine Translation Summit XVII Volume 1: Research Track, pp. 21–31, Dublin, Ireland, August 2019. European Association for Machine Translation. URL https://www.aclweb.org/anthology/W19-6603.
- Duong et al. (2016) Long Duong, Antonios Anastasopoulos, David Chiang, Steven Bird, and Trevor Cohn. An Attentional Model for Speech Translation Without Transcription. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 949–959, San Diego, California, June 2016. Association for Computational Linguistics. 10.18653/v1/N16-1109. URL https://www.aclweb.org/anthology/N16-1109.
- Grissom II et al. (2014) Alvin Grissom II, He He, Jordan Boyd-Graber, John Morgan, and Hal Daumé III. Don’t Until the Final Verb Wait: Reinforcement Learning for Simultaneous Machine Translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 1342–1352, Doha, Qatar, October 2014. Association for Computational Linguistics. 10.3115/v1/D14-1140. URL https://www.aclweb.org/anthology/D14-1140.
- Gu et al. (2017) Jiatao Gu, Graham Neubig, Kyunghyun Cho, and Victor O.K. Li. Learning to Translate in Real-time with Neural Machine Translation. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 1, Long Papers, pp. 1053–1062, Valencia, Spain, April 2017. Association for Computational Linguistics. URL https://www.aclweb.org/anthology/E17-1099.
- Inaguma et al. (2020) Hirofumi Inaguma, Shun Kiyono, Kevin Duh, Shigeki Karita, Nelson Yalta, Tomoki Hayashi, and Shinji Watanabe. ESPnet-ST: All-in-One Speech Translation Toolkit. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations, pp. 302–311, Online, July 2020. Association for Computational Linguistics. 10.18653/v1/2020.acl-demos.34. URL https://www.aclweb.org/anthology/2020.acl-demos.34.
- Inaguma et al. (2023) Hirofumi Inaguma, Sravya Popuri, Ilia Kulikov, Peng-Jen Chen, Changhan Wang, Yu-An Chung, Yun Tang, Ann Lee, Shinji Watanabe, and Juan Pino. UnitY: Two-pass direct speech-to-speech translation with discrete units. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki (eds.), Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 15655–15680, Toronto, Canada, July 2023. Association for Computational Linguistics. 10.18653/v1/2023.acl-long.872. URL https://aclanthology.org/2023.acl-long.872.
- Liu et al. (2020) Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, and Luke Zettlemoyer. Multilingual Denoising Pre-training for Neural Machine Translation. Transactions of the Association for Computational Linguistics, 8:726–742, 2020. 10.1162/tacl_a_00343. URL https://aclanthology.org/2020.tacl-1.47. Place: Cambridge, MA Publisher: MIT Press.
- Ma et al. (2019a) Mingbo Ma, Liang Huang, Hao Xiong, Renjie Zheng, Kaibo Liu, Baigong Zheng, Chuanqiang Zhang, Zhongjun He, Hairong Liu, Xing Li, Hua Wu, and Haifeng Wang. STACL: Simultaneous Translation with Implicit Anticipation and Controllable Latency using Prefix-to-Prefix Framework. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pp. 3025–3036, Florence, Italy, July 2019a. Association for Computational Linguistics. 10.18653/v1/P19-1289. URL https://www.aclweb.org/anthology/P19-1289.
- Ma et al. (2019b) Xutai Ma, Juan Miguel Pino, James Cross, Liezl Puzon, and Jiatao Gu. Monotonic Multihead Attention. September 2019b. URL https://openreview.net/forum?id=Hyg96gBKPS.
- Ma et al. (2020a) Xutai Ma, Mohammad Javad Dousti, Changhan Wang, Jiatao Gu, and Juan Pino. SIMULEVAL: An Evaluation Toolkit for Simultaneous Translation. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pp. 144–150, Online, October 2020a. Association for Computational Linguistics. 10.18653/v1/2020.emnlp-demos.19. URL https://www.aclweb.org/anthology/2020.emnlp-demos.19.
- Ma et al. (2020b) Xutai Ma, Juan Pino, and Philipp Koehn. SimulMT to SimulST: Adapting Simultaneous Text Translation to End-to-End Simultaneous Speech Translation. In Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing, pp. 582–587, Suzhou, China, December 2020b. Association for Computational Linguistics. URL https://aclanthology.org/2020.aacl-main.58.
- Post (2018) Matt Post. A Call for Clarity in Reporting BLEU Scores. In Proceedings of the Third Conference on Machine Translation: Research Papers, pp. 186–191, Brussels, Belgium, October 2018. Association for Computational Linguistics. 10.18653/v1/W18-6319. URL https://aclanthology.org/W18-6319.
- Raffel et al. (2017) Colin Raffel, Minh-Thang Luong, Peter J. Liu, Ron J. Weiss, and Douglas Eck. Online and linear-time attention by enforcing monotonic alignments. In Proceedings of the 34th International Conference on Machine Learning - Volume 70, ICML’17, pp. 2837–2846, Sydney, NSW, Australia, August 2017. JMLR.org.
- Seamless Communication et al. (2023) Seamless Communication, Loïc Barrault, Yu-An Chung, Mariano Cora Meglioli, David Dale, Ning Dong, Paul-Ambroise Duquenne, Hady Elsahar, Hongyu Gong, Kevin Heffernan, John Hoffman, Christopher Klaiber, Pengwei Li, Daniel Licht, Jean Maillard, Alice Rakotoarison, Kaushik Ram Sadagopan, Guillaume Wenzek, Ethan Ye, Bapi Akula, Peng-Jen Chen, Naji El Hachem, Brian Ellis, Gabriel Mejia Gonzalez, Justin Haaheim, Prangthip Hansanti, Russ Howes, Bernie Huang, Min-Jae Hwang, Hirofumi Inaguma, Somya Jain, Elahe Kalbassi, Amanda Kallet, Ilia Kulikov, Janice Lam, Daniel Li, Xutai Ma, Ruslan Mavlyutov, Benjamin Peloquin, Mohamed Ramadan, Abinesh Ramakrishnan, Anna Sun, Kevin Tran, Tuan Tran, Igor Tufanov, Vish Vogeti, Carleigh Wood, Yilin Yang, Bokai Yu, Pierre Andrews, Can Balioglu, Marta R. Costa-jussà, Onur Celebi, Maha Elbayad, Cynthia Gao, Francisco Guzmán, Justine Kao, Ann Lee, Alexandre Mourachko, Juan Pino, Sravya Popuri, Christophe Ropers, Safiyyah Saleem, Holger Schwenk, Paden Tomasello, Changhan Wang, Jeff Wang, and Skyler Wang. Seamlessm4t—massively multilingual & multimodal machine translation. ArXiv, 2023.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is All you Need. In Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017. URL https://proceedings.neurips.cc/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html.
- Weiss et al. (2017) Ron J. Weiss, Jan Chorowski, Navdeep Jaitly, Yonghui Wu, and Zhifeng Chen. Sequence-to-Sequence Models Can Directly Translate Foreign Speech. In Interspeech 2017, pp. 2625–2629. ISCA, August 2017. 10.21437/Interspeech.2017-503. URL http://www.isca-speech.org/archive/Interspeech_2017/abstracts/0503.html.
附录
Phụ lục A 数值稳定估计
直观上, 可以通过动态规划来估计:
| (17) |
虽然 Equation 4 给出了对齐的封闭形式和并行估计,但方程中的分母可能会导致训练中的不稳定和对齐消失。 我们将方程 17重写为
| (18) |
其中 转换矩阵及其每个元素定义为:
| (19) |
是读取从到的概率,其中没有写入. 表示 我们可以看到,如果我们设法得到,那么可以通过矩阵乘法简单地计算出。
通过编写一个新词符定义从跳转到的概率:
那么我们可以将 扩展为
| (20) |
可以进一步表示为
| (21) | ||||
| (22) |
其中 是提取矩阵上三角形的函数,偏移量为 222See torch.triu,表示沿着第二维进行计算。 另外,扩展概率矩阵定义为
| (23) | ||||
| (24) | ||||
| (25) |
其中是一个全1矩阵,其大小为乘以1, 333可以通过torch.expand函数实现。 是将矩阵移动 个元素的函数 444See torch.roll。
综上所述,我们可以将 Equation 17 重写为
| (26) |
PyTorch中实现EMMA的代码片段如下所示:
def monotonic_alignment(p):
bsz, tgt_len, src_len = p.size()
# Extension probablity matrix
p_ext = p.roll(1, [-1]).unsqueeze(-2).expand(-1, -1, src_len, -1).triu(1)
# Transition matrix
T = (1 - p_ext).comprod(-1).triu()
alpha = [p[:, [0]] * T[:, [0]]
for i in range(1, tgt_len):
alpha.append(p[:, [i]] * torch.bmm(alpha[i - 1], T[:, i]))
return torch.cat(alpha[1:], dim=1)