用于 3D CT 图像的整个放射学报告的视觉定位
摘要
建立大规模训练数据集是医疗图像识别系统开发中的一个基本问题。 视觉定位技术能够自动将图像中的物体与相应的描述关联起来,可以促进大量图像的标注。 然而,CT 图像放射学报告的视觉定位仍然具有挑战性,因为通过 CT 成像可以检测到许多类型的异常,并且由此产生的报告描述很长且很复杂。 在本文中,我们提出了第一个专门针对涵盖各种身体部位和不同异常类型的 CT 图像和报告对的视觉定位框架。 我们的框架结合了两个组成部分:1) 图像的解剖分割,和 2) 报告结构化。 解剖分割提供了给定 CT 图像的多个器官掩模,并帮助定位模型识别详细的解剖结构。 报告结构化有助于准确地提取有关相应报告中描述的每个异常的存在、位置和类型的信息。 鉴于这两个额外的图像/报告特征,定位模型可以实现更好的定位。 在验证过程中,我们构建了一个大型数据集,其中包含 7,321 名患者的 10,410 项研究的区域描述对应标注。 我们使用定位精度(正确定位异常的百分比)作为指标评估了我们的框架,并证明了解剖分割和报告结构的结合,显著提高了性能,与基线模型相比有较大提升(66.0% 对 77.8%)。 与现有技术的比较也表明,我们的方法具有更高的性能。
关键词:
深度学习 视觉语言 视觉定位 计算机断层扫描1 简介
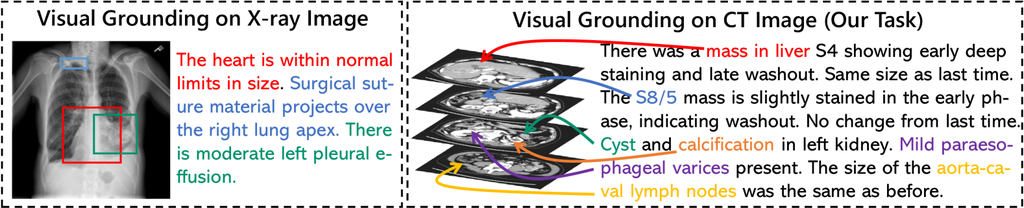
近年来,已开发出许多医学图像识别系统 [6],以减轻放射科医生日益增长的负担 [2, 22, 21]。 在此类系统开发中,手动标记图像的任务是一个重大瓶颈。 自动标注,即使用机器学习算法自动为图像分配标签的过程,已成为解决此问题的一种有前景的解决方案。 在图像和标题对数量众多的情况下,自动标注的一种潜在方法是视觉定位 [12],它利用自然语言描述来识别和定位图像中的物体。
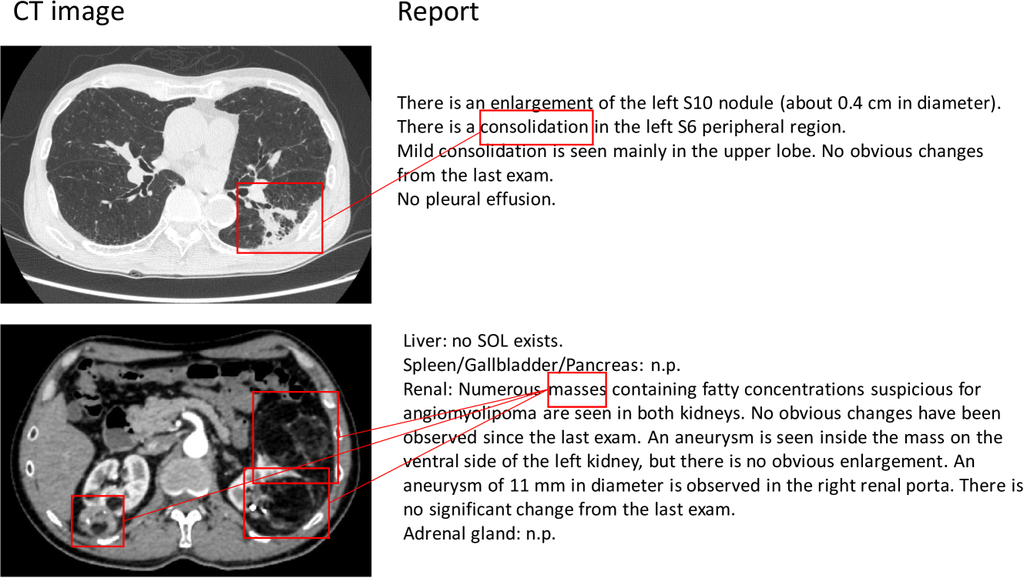
随着基于深度学习的跨模态技术的最新进展,已经提出了许多用于视觉定位的框架 [11, 7]。 在医学领域,有几个带有放射学报告的大规模数据集可用(例如 OpenI [3],MIMIC-CXR [9]),并且这些数据集产生了关于医学图像视觉定位的研究 [25, 1]。 然而,据我们所知,以前的研究侧重于二维 X 射线图像 [28] 或视频 [15],目前还没有研究将视觉定位应用于三维计算机断层扫描 (CT) 图像。 CT 图像上的视觉定位具有以下困难: 1) 需要检测大量异常类型: 现有利用 X 射线图像进行视觉定位的研究仅处理胸部 X 射线图像。 需要检测的异常类型最多只有十几种(例如,13种发现[8])。 相比之下,我们的研究处理的是包括人体各个部位的CT图像。 因此,要检测的异常类型数量超过一百种。 2) 长而复杂的句子: X射线图像的放射学报告通常很简单,只记录异常的有无。 另一方面,在CT检查中,通常会对每个异常进行定性诊断。 在某些情况下,多个异常会在同一个句子中同时描述。 因此,描述往往很长很复杂,包含多个句子(图1)。 CT图像的视觉定位需要从这些复杂的句子中提取有关每个异常的位置和类型的的信息。
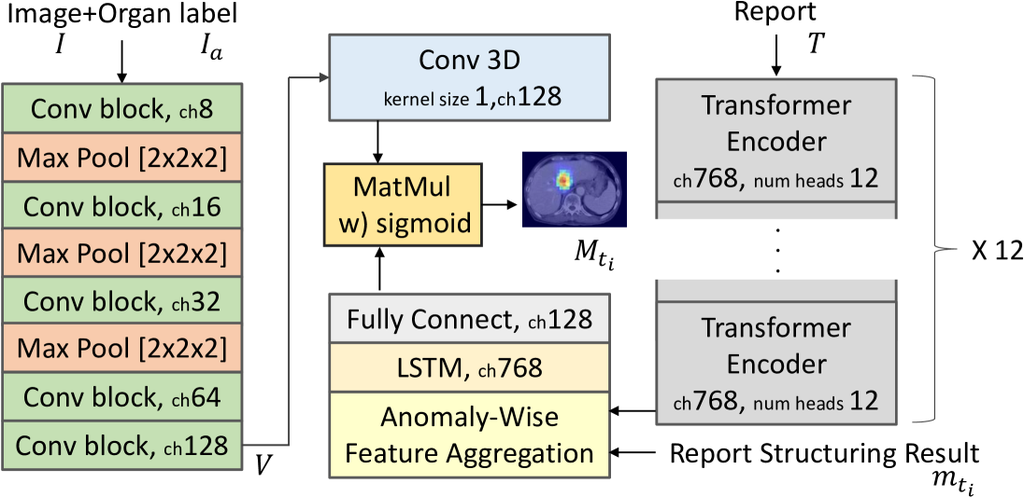
在这项工作中,我们提出了一种针对3D CT图像和放射学报告的新型视觉定位框架。 主要思想是将任务分成三个部分:1) 图像的解剖分割,2) 报告结构化,以及3) 描述的异常的定位。 在解剖分割中,使用基于深度学习的分割模型提取多个器官和组织,并作为地标提供。 还引入了基于BERT[5]的报告结构化模型,用于从复杂的报告中提取每个异常的信息。 这两种特征都输入到定位模型(3)中,以推断医学领域知识,从而实现准确的视觉定位。
我们的贡献如下:
-
•
我们展示了3D CT图像的第一个视觉定位结果,涵盖了各种身体部位和异常。
-
•
我们引入了一种新颖的定位架构,可以利用对描述的异常的存在/类型/位置的报告结构化结果。
-
•
我们使用一个具有区域-描述对应标注的大规模数据集验证了该框架的有效性。
2 相关工作
视觉接地
视觉接地任务涉及从给定的区域-描述对训练集中学习文本和图像区域之间的对应关系 [12]。 主要有两种方法:单阶段方法和两阶段方法。 大多数研究遵循两阶段方法 [14, 17]。 但是,这种方法通常采用预训练的目标检测器,这会导致限制接地中类别和属性的能力。 因此,最近的研究正转向采用单阶段方法,其中视觉接地通过端到端训练来执行 [27, 4, 10]。
医学图像上的视觉-语言任务
存在带有配对图像和报告的公共数据集 [3, 9, 26] 加快了医学领域跨模态任务的研究 [25, 16]。 受视觉接地成功的启发,也报道了一些针对医学图像和放射学报告的视觉接地研究 [28, 1, 23]。 这些研究利用了大规模数据集和基于注意力的语言解释模型,如 BERT [5],来接地报告中的描述。 然而,这些研究集中在 X 射线图像上,据我们所知,还没有关于 CT 图像的研究,CT 图像覆盖了整个身体,并且具有复杂的报告。
3 方法
我们首先对问题进行公式化。 接下来,我们解释了框架中解剖分割、报告结构化和异常定位的三个关键组成部分。 在我们的框架中,作为解剖分割输出获得的多个器官标签鼓励接地模型学习详细的解剖结构,并且报告结构化允许接地模型从复杂的句子中准确地提取目标异常的特征。
3.1 问题公式
我们的研究假设,提供了具有区域-描述对应注释的图像-报告对数据集用于训练。 我们在图 2 中展示了整体框架。 我们分别将图像和配对报告表示为 I 和 T。 令 是一个标签图像,其中从 中提取多个器官。 每个报告 包含对多个(图像)异常的描述。 我们将每个异常表示为 。 给定图像 I 和相应的器官标签图像 ,编码为 以及关于异常 的描述,编码为 ,我们的框架的目标是生成一个分割图 ,该图表示异常 的位置。

3.2 解剖分割
解剖分割的任务是提取相关的解剖结构,这些结构可以作为视觉接地的线索。 我们使用 3D 图像分析软件的商业版本(Synapse 3D V6.8,富士胶片公司,日本)来提取 32 个器官和组织(见附录表 A1)。 在该软件中,解剖结构是使用基于 U-Net 的架构提取的 [13, 18]。 提取的解剖标签图像为 。
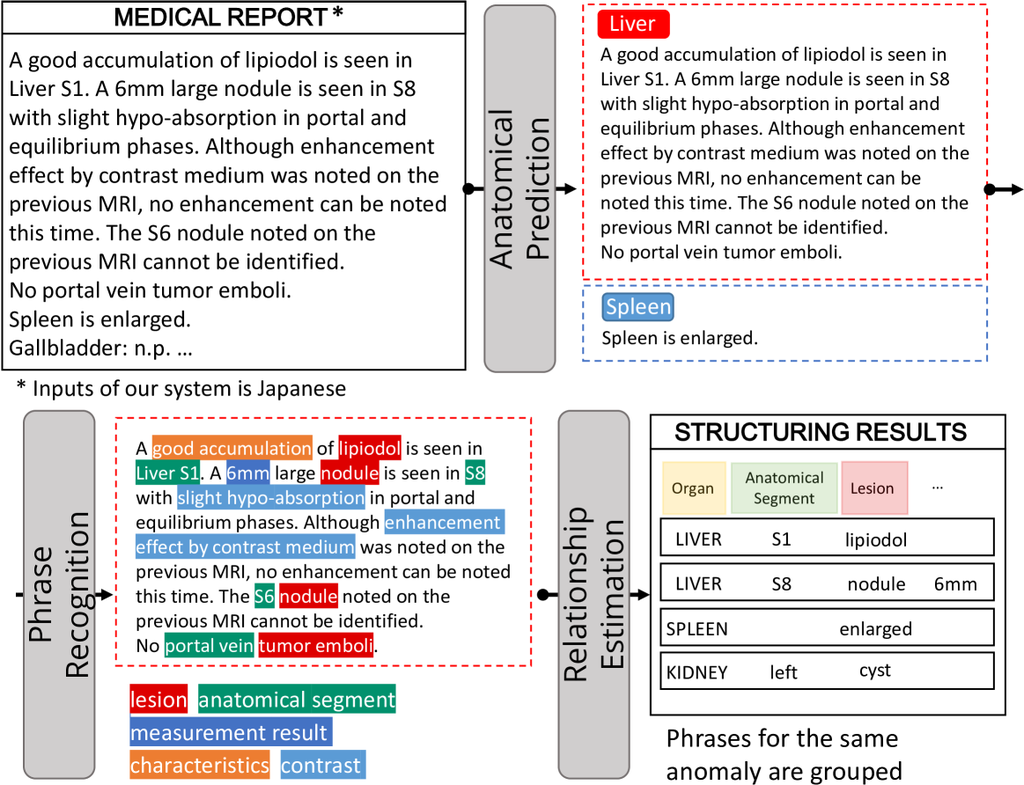
3.3 报告结构化
报告结构化的任务如下:1)解剖预测,2)短语识别,以及 3)短语之间的关系估计(见附录图 A1)。 解剖预测是对每个句子进行逐句预测,以确定每个句子中提到了哪个器官或身体部位。 待识别的器官和身体部位列在附录表 A2 中。 将属于同一类的句子连接起来,然后对每个类进行短语识别和关系估计。
短语识别模块提取短语,并将每个短语分类为 9 类(见附录表 A2)。 随后,关系估计模块确定异常短语(例如“结节”、“骨折”)与其他短语(例如“6mm”、“肝 S6”)之间是否存在关系,从而将与同一异常相关的短语分组。 如果多个解剖短语在同一组中,则根据规则将它们拆分为单独的组(例如,[“右 S1”、“左 S6”、“结节”] -> [“右 S1”、“结节”],[“左 S6”、“结节”])。 关于实现和训练方法的更多详细信息,请参见 Nakano 等人 [20] 和 Tagawa 等人 [24]。
3.4 异常定位
异常定位的任务是输出输入报告中提到的异常的定位图 。 CT 图像 和器官标签图像 在通道维度上连接起来,并通过卷积主干编码以生成视觉嵌入 。 报告中的句子 通过 BERT [5] 编码,以生成每个字符的嵌入。 令 为字符嵌入集,其中 为字符数量。 我们的框架接下来采用异常感知特征聚合器 (AFA)。 对于每个异常 ,AFA 通过聚合基于报告结构化结果的相关短语的嵌入来生成一个代表性嵌入 。 最终的接地结果 通过以下源目标注意力获得。
| (1) |
其中 、 是可训练变量。
本模块的整体架构如图 A2 所示(见附录)。
3.4.1 异常特征聚合器
报告结构的结果定义如下:
| (2) |
| (3) |
其中 是短语识别模块标记的类别索引(令 为类别数)。 在此模块中,基于以下公式聚合字符级的嵌入。
| (4) |
| (5) |
其中 和 分别是每个器官和每个类别标签的可训练嵌入。 代表连接操作。 通过这种方式,与异常 相关的字符嵌入被聚合和连接起来。 随后,异常的代表性嵌入由一个 LSTM 层生成。 在专注于 3D CT 图像的视觉接地任务中,可创建的数据集大小相对较小。 考虑到这一限制,我们使用一个具有强归纳偏差的 LSTM 层来实现高泛化性能。
4 数据集和实现细节
4.1 临床数据
我们回顾性地收集了来自日本一家大学医院的 10,410 份 CT 研究(11,163 卷/7,321 名独特患者)和 671,691 份放射学报告。 我们为报告中描述的每个异常分配了一个边界框,如图 A3 所示(见附录)。 将解剖区域和异常类型相结合,总类别数约为 130(详细信息见图 4)。对于每个异常,都与报告中的异常短语进行了对应标注。 标注区域的总数为 17,536 个(头部:713 个区域,颈部:285 个区域,胸部:8,598 个区域,腹部:7,940 个区域)。 我们将数据分成 9,163/1,000/1,000 卷作为训练/验证/测试拆分。
4.2 实施细节
我们使用一个类似 VGG 的网络作为图像编码器,它具有 15 个 3D 卷积层和 3 个最大池化层。 为了训练,所有三个维度的体素间距都归一化为 1.0 毫米。 CT 值被线性归一化,以获得 [0-1] 的值。 解剖标签图像(其中每个体素仅分配一个标签)也被归一化为 [0-1] 的值,并且 CT 图像和标签图像沿通道维度连接起来。 作为我们的文本编码器,我们使用一个 BERT,它具有 12 个 Transformer 编码层,每个层具有 768 的隐藏维度和多头注意力中的 12 个头。 首先,我们使用从报告中提取的 670 万个句子在掩码语言模型任务中预训练 BERT。 然后我们使用 dice 损失 [19] 联合训练整个架构,并将 BERT 的前 8 个 Transformer 编码层冻结。 关于实现的更多信息在附录表中显示。 A3。
5 实验
我们进行了两种类型的实验以进行比较和消融研究。 比较研究是对 TransVG [4] 和 MDETR [10] 进行的,它们是一阶段视觉接地方法,并在照片和标题上取得了最先进的性能。 为了使 TransVG 和 MDETR 适应 3D 模态,主干被更改为具有 3D 卷积层的类似 VGG 的网络,与所提出的方法相同。 我们将其中一种不使用解剖学分割和报告结构的方法作为基线模型。
5.1 评估指标
我们使用 Dice 得分、平均交并比 (mIoU) 和接地准确率报告分割性能。 输出掩码被阈值化以计算 mIoU 和接地准确率得分。 mIoU 被定义为在阈值 [0.1, 0.2, 0.3, 0.4, 0.5] 上的平均 IoU。 接地准确率被定义为 IoU 超过 0.1(在阈值 0.1 下)的异常百分比。
5.2 结果
两项研究的实验结果如表 1 所示。 MDETR 和 TransVG 都未能在此任务中实现稳定的接地。 这些模型和我们基线模型之间的主要区别在于使用源-目标注意力层而不是 Transformer。 众所周知,基于 Transformer 的算法具有许多参数,且没有强烈的归纳偏差,很难在如此有限的训练数据下进行泛化。 出于这个原因,基线模型比对比方法实现了更高的准确率。
| Method | Anatomical | Report | Dice | mIoU | Accuracy |
|---|---|---|---|---|---|
| Seg. | Struct. | ||||
| MDETR [10] |
- |
- |
N/A |
- |
- |
| TransVG [4] |
- |
- |
N/A |
8.5 |
21.8 |
| Baseline |
✗ |
✗ |
27.4 |
15.6 |
66.0 |
| Proposed |
✓ |
✗ |
28.1 |
16.6 |
67.9 |
|
✗ |
✓ |
33.0 |
20.3 |
75.9 |
|
|
✓ |
✓ |
34.5 | 21.5 | 77.8 |
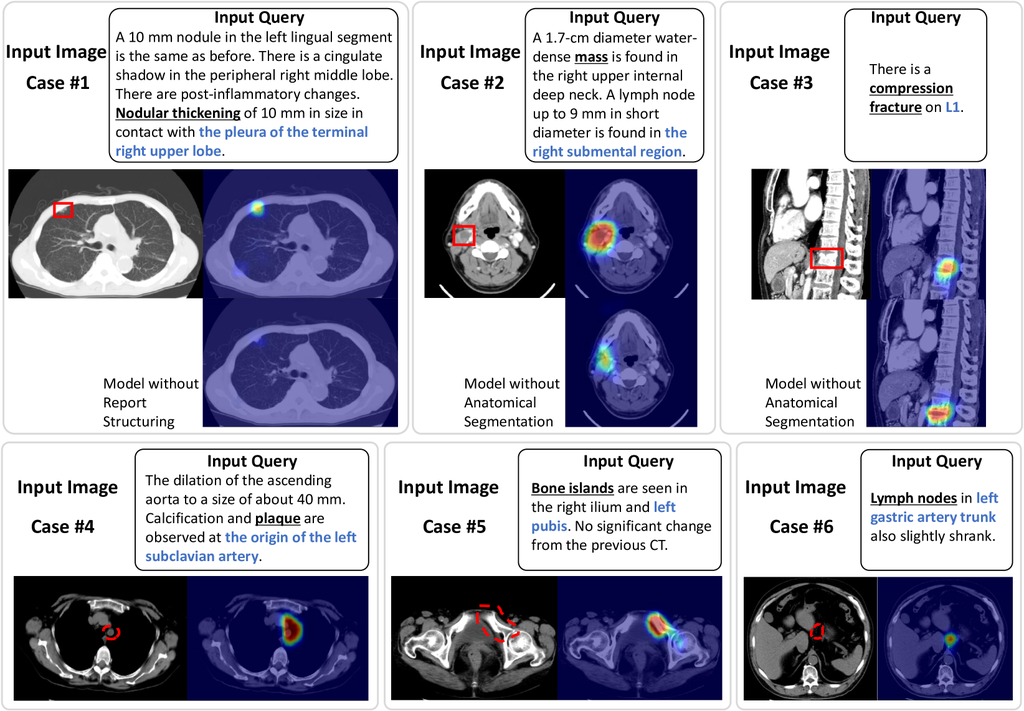
消融研究表明,解剖学分割和报告结构可以提高性能。 图 3(上排)展示了几个案例,有助于直观地理解每种效应。 较长的报告通常会提到不止一个异常,这使得识别基础目标变得困难,并导致定位错误。 所提出的方法可以明确地指示短语,例如目标异常的位置和大小,从而降低失败的风险。 图 3(下排)显示了当输入与图像无关的查询时的基础结果示例。 在这种情况下,基础结果与解剖学短语的一致性较低。 结果表明,该模型在丰富的解剖学知识背景下,以解剖学信息为重点进行基础定位。
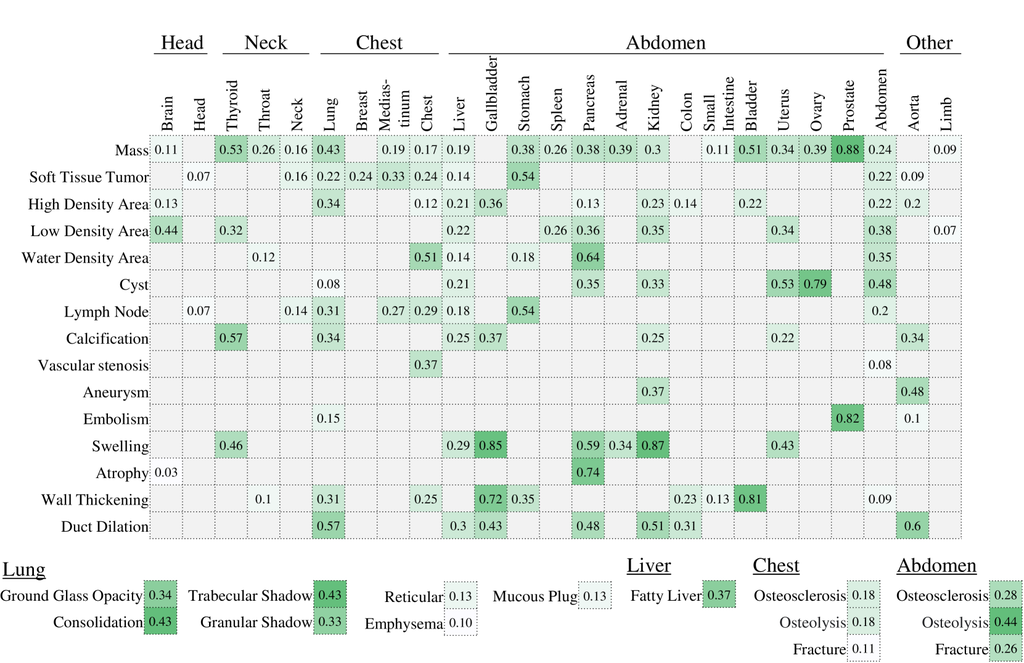
图 4 显示了器官和异常类型每种组合的基础定位性能。 对于器官形状异常(例如肿胀、导管扩张)和小型器官中的高频异常(例如甲状腺/前列腺肿块),性能相对较高。 对于这些异常类型,我们的模型被认为可用于自动训练数据生成。 另一方面,对于罕见异常(例如小肠肿块)和大型身体部位的异常(例如肢体),性能往往较低。 提高这些目标的基础定位性能将是未来的一项重要工作。
6 结论
在本文中,我们提出了第一个针对 3D CT 图像和报告的视觉定位框架。 为了处理贯穿整个身体的各种类型的异常和复杂的报告,我们引入了一种新方法,使用解剖识别结果和报告结构化结果。 实验表明了我们方法的有效性,与以前的技术相比取得了更高的性能。 然而,在临床实践中,放射科医生通过比较多个图像(如时间序列图像或多相扫描)来撰写报告。 通过视觉定位模型实现如此复杂的诊断过程将是未来的研究方向。
参考文献
- [1] Bhalodia, R., Hatamizadeh, A., Tam, L., Xu, Z., Wang, X., Turkbey, E., Xu, D.: Improving Pneumonia Localization via Cross-Attention on Medical Images and Reports. In: Proceedings of Medical Image Computing and Computer Assisted Intervention. pp. 571–581. Springer (2021)
- [2] Dall, T.: The Complexities of Physician Supply and Demand: Projections from 2016 to 2030. IHS Markit Limited (2018)
- [3] Demner-Fushman, D., Kohli, M.D., Rosenman, M.B., Shooshan, S.E., Rodriguez, L., Antani, S., Thoma, G.R., McDonald, C.J.: Preparing a collection of radiology examinations for distribution and retrieval. Journal of the American Medical Informatics Association 23(2), 304–310 (2016)
- [4] Deng, J., Yang, Z., Chen, T., Zhou, W., Li, H.: TransVG: End-to-End Visual Grounding with Transformers. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 1769–1779 (2021)
- [5] Devlin, J., Chang, M.W., Lee, K., Toutanova, K.: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In: Proceedings of NAACL-HLT. pp. 4171–4186 (2019)
- [6] Ebrahimian, S., Kalra, M.K., Agarwal, S., Bizzo, B.C., Elkholy, M., Wald, C., Allen, B., Dreyer, K.J.: FDA-regulated AI algorithms: Trends, Strengths, and Gaps of Validation Studies. Academic Radiology 29(4), 559–566 (2022)
- [7] Hu, R., Rohrbach, M., Darrell, T.: Segmentation from Natural Language Expressions. In: Proceedings of the European Conference on Computer Vision. pp. 108–124. Springer (2016)
- [8] Irvin, J., Rajpurkar, P., Ko, M., Yu, Y., Ciurea-Ilcus, S., Chute, C., Marklund, H., Haghgoo, B., Ball, R., Shpanskaya, K., et al.: CheXpert: A Large Chest Radiograph Dataset with Uncertainty Labels and Expert Comparison. In: Proceedings of the AAAI conference on artificial intelligence. vol. 33, pp. 590–597 (2019)
- [9] Johnson, A.E., Pollard, T.J., Berkowitz, S.J., Greenbaum, N.R., Lungren, M.P., Deng, C.y., Mark, R.G., Horng, S.: MIMIC-CXR, a de-identified publicly available database of chest radiographs with free-text reports. Scientific data 6(1), 317 (2019)
- [10] Kamath, A., Singh, M., LeCun, Y., Synnaeve, G., Misra, I., Carion, N.: MDETR-Modulated Detection for End-to-End Multi-Modal Understanding. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 1780–1790 (2021)
- [11] Karpathy, A., Fei-Fei, L.: Deep Visual-Semantic Alignments for Generating Image Descriptions. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 3128–3137 (2015)
- [12] Karpathy, A., Joulin, A., Fei-Fei, L.F.: Deep Fragment Embeddings for Bidirectional Image Sentence Mapping. In: Proceedings of Advances in Neural Information Processing System. pp. 1889–1897 (2014)
- [13] Keshwani, D., Kitamura, Y., Li, Y.: Computation of Total Kidney Volume from CT Images in Autosomal Dominant Polycystic Kidney Disease Using Multi-task 3D Convolutional Neural Networks. In: Proceedings of Medical Image Computing and Computer Assisted Intervention. pp. 380–388. Springer (2018)
- [14] Lee, K.H., Chen, X., Hua, G., Hu, H., He, X.: Stacked Cross Attention for Image-Text Matching. In: Proceedings of the European Conference on Computer Vision. pp. 201–216 (2018)
- [15] Li, B., Weng, Y., Sun, B., Li, S.: Towards Visual-Prompt Temporal Answering Grounding in Medical Instructional Video. arXiv preprint arXiv:2203.06667 (2022)
- [16] Li, Y., Wang, H., Luo, Y.: A Comparison of Pre-Trained Vision-and-Language Models for Multimodal Representation Learning across Medical Images and Reports. In: Proceedings of the IEEE international conference on bioinformatics and biomedicine. pp. 1999–2004. IEEE (2020)
- [17] Lu, J., Batra, D., Parikh, D., Lee, S.: ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks. Advances in neural information processing systems 32, 13–23 (2019)
- [18] Masuzawa, N., Kitamura, Y., Nakamura, K., Iizuka, S., Simo-Serra, E.: Automatic Segmentation, Localization, and Identification of Vertebrae in 3D CT Images Using Cascaded Convolutional Neural Networks. In: Proceedings of Medical Image Computing and Computer Assisted Intervention. pp. 681–690. Springer (2020)
- [19] Milletari, F., Navab, N., Ahmadi, S.A.: V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation. In: Proceedings of the international conference on 3D vision. pp. 565–571. IEEE (2016)
- [20] Nakano, N., Tagawa, Y., Ozaki, R., Taniguchi, T., Ohkuma, T., Suzuki, Y., Kido, S., Tomiyama, N.: Pre-training methods for creating a language model with embedded knowledge of radiology reports. In: Proceedings of the annual meeting of the Association for Natural Language Processing (2022)
- [21] Nishie, A., Kakihara, D., Nojo, T., Nakamura, K., Kuribayashi, S., Kadoya, M., Ohtomo, K., Sugimura, K., Honda, H.: Current radiologist workload and the shortages in japan: how many full-time radiologists are required? Japanese journal of radiology 33, 266–272 (2015)
- [22] Rimmer, A.: Radiologist shortage leaves patient care at risk, warns royal college. BMJ: British Medical Journal (Online) 359 (2017)
- [23] Seibold, C., Reiß, S., Sarfraz, S., Fink, M.A., Mayer, V., Sellner, J., Kim, M.S., Maier-Hein, K.H., Kleesiek, J., Stiefelhagen, R.: Detailed Annotations of Chest X-Rays via CT Projection for Report Understanding. arXiv preprint arXiv:2210.03416 (2022)
- [24] Tagawa, Y., Nakano, N., Ozaki, R., Taniguchi, T., Ohkuma, T., Suzuki, Y., Kido, S., Tomiyama, N.: Performance improvement of named entity recognition on noisy data using teacher-student training. In: Proceedings of the annual meeting of the Association for Natural Language Processing (2022)
- [25] Wang, X., Peng, Y., Lu, L., Lu, Z., Summers, R.M.: TieNet: Text-Image Embedding Network for Common Thorax Disease Classification and Reporting in Chest X-rays. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 9049–9058 (2018)
- [26] Yan, K., Wang, X., Lu, L., Summers, R.M.: DeepLesion: automated mining of large-scale lesion annotations and universal lesion detection with deep learning. Journal of medical imaging 5(3), 036501–036501 (2018)
- [27] Yang, Z., Gong, B., Wang, L., Huang, W., Yu, D., Luo, J.: A Fast and Accurate One-Stage Approach to Visual Grounding. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 4683–4693 (2019)
- [28] You, D., Liu, F., Ge, S., Xie, X., Zhang, J., Wu, X.: AlignTransformer: Hierarchical Alignment of Visual Regions and Disease Tags for Medical Report Generation. In: Proceedings of Medical Image Computing and Computer Assisted Intervention. pp. 72–82. Springer (2021)
| Brain | Lung | Liver | Aorta |
| - Cerebraspinal Fluid | - Left Upper Lobe | Gallbladder | Bone |
| - Left Lateral Ventricle | - Left Lower Lobe | Stomach | - Cervical Vertebra |
| - Right Lateral Ventricle | - Right Upper Lobe | Duodenum | - Thoracic Vertebra |
| - Third Ventricle | - Right Middle Lobe | Spleen | - Lumber Vertebra |
| - Fourth Ventricle | - Right Lower Lobe | Pancreas | - Left Rib |
| - Brainstem | Heart | Kidney | - Right Rib |
| - Left Cerebellum | - Left Kidney | ||
| - Right Cerebellum | - Right Kidney | ||
| - Left Cerebrum | Prostate | ||
| - Right Cerebrum | Bladder |
| Anatomical Prediction |
Phrase Classification |
||
|---|---|---|---|
|
Head |
Breast |
Small Intestine |
Anatomical Segment |
|
Brain |
Pleural Cavity |
Colon |
Lesion |
|
Ear |
Chest |
Prostate |
Shape Abnormality |
|
Nose |
Liver |
Uterus |
Diagnosis |
|
Neck |
Stomach |
Bladder |
Characteristics |
|
Oropharynx |
Gallbladder |
Ovary |
Contrast Information |
|
Thyroid |
Adrenal |
Abdomen |
Quantity |
|
Lung |
Spleen |
Abdominal Cavity |
Measurement Result |
|
Heart |
Pancreas |
Limb |
Temporal Change |
|
Mediastinum |
Kidney |
Aorta |
|
| Value | |
|---|---|
| Optimizer |
Adam |
| Initial Learning Rate | |
| Learning Rate Schedule |
Linearly increased to within the first 5,000 steps, and then multiplied by 0.1 every 30,000 steps |
| Batch Size |
10 |
| Normalization Method |
Batch Renormalization |
| Data Augmentation for Image |
Random Crop, Random Rotation, Random Scaling, Sharpness change, Smoothing, and Gaussian noise addition |
| Data Augmentation for Text |
Random deletion, Random insertion, and Random crop |
| Machine Learning Library |
Tensorflow 2.3 |
| GPU |
NVIDIA Tesla V100 2 |