FOSS:查询优化器的自学医生
摘要
各种工作都利用深度强化学习(DRL)来解决数据库系统中的查询优化问题。 他们要么学习以自下而上的方式从头开始构建计划,要么使用提示指导传统优化器的计划生成行为。 虽然这些方法取得了一些成功,但它们面临着训练效率低或计划搜索空间有限的挑战。 为了应对这些挑战,我们引入了 FOSS,这是一种基于 DRL 的新型查询优化框架。 FOSS 从传统优化器生成的原始计划开始优化,并通过一系列操作逐步完善计划的次优节点。 此外,我们设计了一个不对称优势模型来评估两个计划之间的优势。 我们将其与传统优化器集成以形成模拟环境。 利用这种模拟环境,自由开源软件可以自我引导,快速生成大量高质量的模拟体验。 然后,自由开源软件从这些模拟经验中学习并提高其优化能力。 我们评估了 FOSS 在 Join Order Benchmark、TPC-DS 和 Stack Overflow 上的性能。 实验结果表明,FOSS 在延迟性能和优化时间方面优于最先进的方法。 与 PostgreSQL 相比,FOSS 在不同基准测试中的总延迟节省了 15% 到 83%。
索引术语:
查询优化、深度强化学习、DBMS我简介
查询优化器在数据库管理系统(DBMS)中起着至关重要的作用。 它采用从解析器导出的关系代数表达式作为输入,并输出优化的物理执行计划。 大多数查询优化器遵循 Selinger 的设计,由基数估计器、成本估计器和查询计划生成器 [1] 组成。 这些组件共同探索计划空间并找到潜在的最佳查询计划。
然而,对于传统的查询优化器来说,在巨大的计划空间中找到最优计划是一个NP难题[2]。 即使在连接顺序中只考虑左深树,计划空间仍然呈指数增长到,其中表示查询涉及的表的数量。 当考虑其他因素(例如灌木丛、连接方法和访问路径)时,计划搜索空间进一步扩展。 同时,传统基数和成本估算器中的错误通常会导致性能不佳的计划[2]。 此外,传统的查询优化器无法从过去的经验中学习,经常为相同的查询重复生成类似的性能较差的计划[3]。
I-A 用于查询优化的机器学习
为了解决传统查询优化器的问题,许多研究集中于在端到端查询优化中使用机器学习。 我们将当前的方法大致分为两类:计划构造器和计划引导器。
计划构造函数。 这是一种专业知识省略方法,丢弃或未充分利用传统优化器的专业知识,并专注于从头开始构建计划[4,5,6,7,8,9] 。 它将查询计划生成过程建模为马尔可夫决策过程 (MDP),并使用深度强化学习 (DRL) 来解决它。 它的框架涉及几个组件。 代理(即学习模型)从查询中涉及的一组单独表开始,在每个步骤中,它连接表、连接子计划或指定运算符。 每个步骤都会产生一个新状态,其中包含部分计划和尚未连接的其他表。 该过程将持续进行,直到查询涉及的所有表都被连接起来,从而形成一个完整的计划。 在此过程中,DBMS 充当环境并提供奖励反馈,这些反馈通常与最终计划的执行成本或真实执行延迟相关。 虽然计划构造函数经过一定时间的训练后可以逐渐超越传统查询优化器的性能,但它有以下缺点:
-
•
(C1) 从头开始学习。 代理人需要付出相当大的努力来学习如何从头开始制定具有成本效益的计划。 这通常需要大量的试错学习,逐渐使代理达到与传统查询优化器类似的熟练水平。
-
•
(C2) 体验采样不佳。 培养一名熟练的特工需要大量的高质量经验。 先前的方法[4,5,6,7,9,8]通常采用成本估算或执行延迟作为塑造体验的奖励。 然而,传统成本模型引起的成本估算错误经常导致次优结果。 虽然使用执行延迟更有可能生成更好的计划,但获取执行延迟的效率较低,会带来巨大的开销。 这种低效率导致了探索不足的问题,从而需要大量的时间来进行模型收敛。
-
•
(C3) 奖励稀疏。 代理完成计划构建所需的步骤数取决于查询中涉及的表的数量。 在连接顺序基准 (JOB) [2] 中,查询具有 3 到 16 个连接,每个查询平均有 8 个连接。 然而,诸如[8,7,6,10]之类的现有方法在获得完整计划之前在为子计划提供具体评估方面遇到了挑战。 在他们的场景中,中间状态的奖励通常被分配为 0 值,导致代理的奖励稀疏并限制获得足够的指导[11]。
计划引导者。 这是一种黑盒专家方法,利用传统查询优化器[12,13,14]中嵌入的专家知识。 在各种提示的引导下,它通过传统的查询优化器生成多个计划。 例如,在 Bao [12] 中,使用粗粒度提示(例如禁用整个查询的嵌套循环连接)来指导传统查询优化器。 然后,它利用学习价值网络来评估这些候选计划并预测成本。 最终,它选择执行成本可能最低的计划。 然而,它存在以下问题:
-
•
(S1) 需要提示设计的专业知识。 虽然计划引导器利用传统查询优化器通过提示指导生成更好的计划,但提示的设计仍然需要专业知识,如 Bao [12] 中提示集分组的情况所示。
-
•
(S2) 有限的搜索空间。 虽然某些提示可以引导传统优化器选择更好的计划,但提示的粗粒度性质可能会限制计划引导器接受次优计划。
-
•
(S3) 难以平衡。 添加更多候选提示会增加候选计划的数量,从而提高生成更好计划的概率。 然而,这种扩展也导致优化时间的增加。
I-B 查询优化的新颖框架
在本文中,为了缓解上述问题,我们引入了一种新颖的框架FOSS,该框架修改fyo原始计划s步步s步。 FOSS 可以归类为plan-doctor,这是一种白盒专家方法。 与引导或限制传统优化器行为的黑盒专业知识方法不同,自由开源软件通过优化传统查询优化器生成的计划,更明确地利用专家优化知识。
FOSS 背后的见解是,尽管传统的查询优化器经常由于基数估计和成本估计中的错误而产生次优计划,但可以通过对这些次优计划进行有限数量的修改来检索更好的计划。 例如,JOB 中的查询 1b 使用 来执行,计划由 PostgreSQL 的优化器生成。 由于成本估计不准确,优化器在表和表之间选择了哈希连接运算符,这会减慢计划的执行速度。 在这个例子中,FOSS将首先重写两个表之间的连接方法以使用嵌套循环连接,然后将和的位置交换为正确的顺序。 使用 FOSS,总执行延迟可减少至 。 在类似的情况下,自由开源软件就像医生一样,识别出给定计划中导致性能问题的次优方面。 然后,它采取行动,例如更改连接节点的物理实现或为两个表呈现正确的顺序,以逐步的方式对其进行优化。
然而,要获得优秀的计划医生,两个关键能力是必不可少的:i)能够识别原始计划中的次优方面并生成适当的候选行动序列以进行优化。 请注意,应用于原始计划的不同操作顺序将产生不同的新计划。 ii) 从候选者中选择能够为原始计划产生最佳结果的序列的能力。 为了实现这些目标,对于 i),FOSS 学习一个规划器,该规划器将次优方面的识别和动作序列的生成建模为 MDP,并采用 DRL 来解决它;对于 ii),FOSS 学习一个不对称优势模型 (AAM)作为最优动作序列选择器。 AAM 通过评估候选行动序列生成的候选计划对之间的优势值来确定最佳序列。 此外,受基于模型的强化学习(MBRL)的启发,FOSS将AAM与传统优化器集成,形成模拟环境,其中AAM作为奖励指标,传统优化器作为状态转换器。
我们总结FOSS的特点如下:
-
•
训练效率高。 FOSS从最初的计划开始,专注于优化次优方面,消除了从头开始学习的需要(解决C1)。 在每个步骤中,自由和开源软件都可以生成一个新的完整执行计划,从而可以根据新计划的绩效直接评估奖励。 此外,VI中的实验结果表明,FOSS通常只需要1-3步即可实现更好的性能计划(解决C3)。 借助模拟环境,自由开源软件可以有效地引导自身,产生丰富的高质量模拟体验,以增强其优化能力(解决C2)。
-
•
智能候选人计划生成。 自由和开放源码软件可以通过学习规划器来自动生成候选计划,这与计划引导器依赖预先注入的专家知识进行提示设计(解决S1和S3)不同。
-
•
足够的计划搜索空间。 与计划引导器的粗略提示相比,自由和开放源码软件采用更细粒度的优化。 在类似的场景下,FOSS 与 plan-constructor 共享相同的计划搜索空间,这表明它有可能发现全局最优计划(针对 S2)。
单独的计划构建者和计划引导者都无法涵盖所有上述功能。 因此,FOSS 在这两种方法之间取得了很好的平衡。
I-C 贡献
我们的贡献总结如下:
-
•
我们引入了一种称为 plan-doctor 的白盒专业知识方法,它由规划器和选择器组成。 它通过逐步优化原始计划来生成性能更好的计划。
-
•
我们构建一个模拟环境并使用模拟经验来加速自由开源软件的学习。
-
•
我们设计了一个不对称优势模型,作为模拟环境中的奖励指标,并作为选择最佳计划的选择器。
-
•
实验结果表明,FOSS 在延迟性能和优化时间方面优于最先进的 (SOTA) 方法,同时与 PostgreSQL 相比,总延迟降低了 15% 至 83%。
II 系统概述
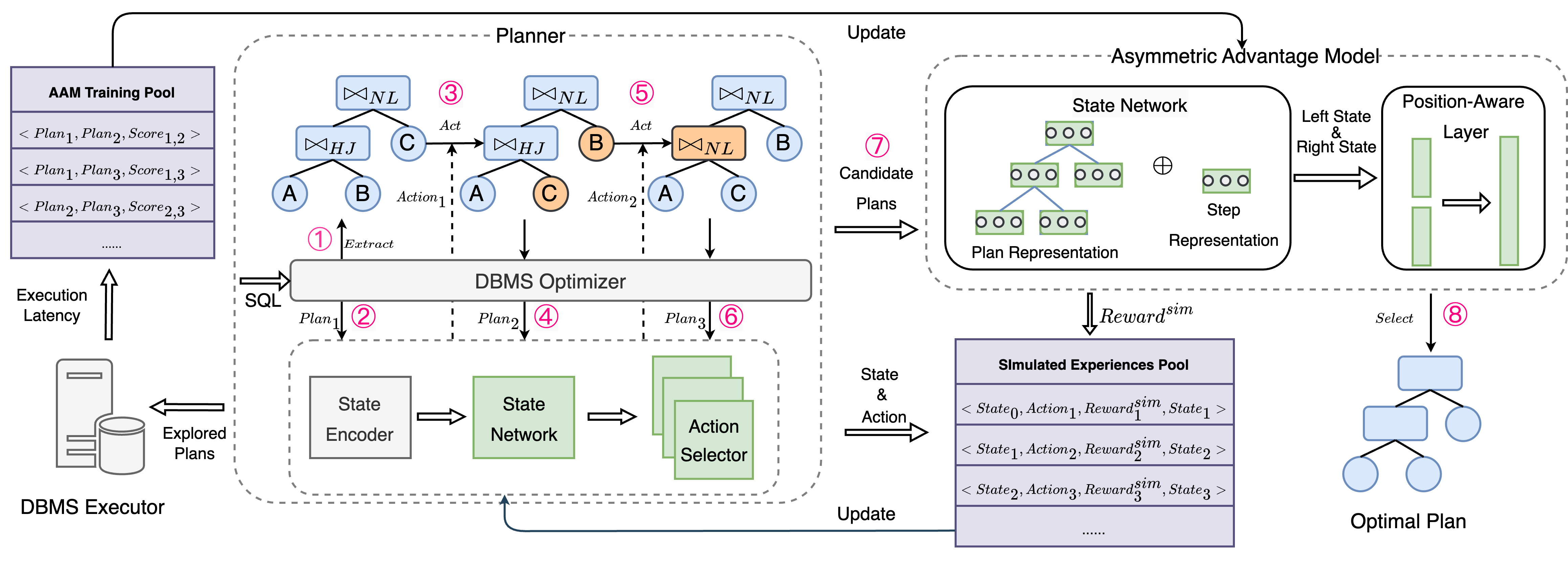
FOSS的整体架构如图1所示。 对于给定的查询,FOSS 按照粉红色数字指示的顺序输出性能更好的计划。 首先,规划器利用过去的经验迭代修改原始计划,产生一组有潜力的计划。 然后,按照时间顺序(即生成候选计划的顺序),非对称优势模型(AAM)充当选择器,评估特定的候选计划对并选择估计的最佳计划。 为了加快规划者的学习速度,自由开源软件构建了一个模拟学习者来生成充足的高质量体验。 我们将框架分为以下三个关键模块。
计划者。 我们使用DRL框架部署规划器的整个流程。 从原始计划开始,规划器首先对计划特征进行编码。 考虑到规划器生成的计划的时间性质,我们合并了步骤状态。 这些特征作为初始状态连接起来,然后传递给代理。 代理首先使用状态网络来表示状态。 然后,状态表示随后被转发到操作选择器以生成操作,这可能涉及交换表位置或覆盖连接方法等操作。 执行动作后,会生成新的计划并转发给奖励功能模块以获得奖励。 同时,新的计划被用来生成新的状态。 此迭代过程持续进行,直到达到最大步数限制。 将收集 格式的经验来更新代理。 通过大量的训练,规划者可以生成比原计划更优化的计划。
不对称优势模型。 它既充当模拟环境中的最优计划选择器又充当奖励指标。 它由状态网络和位置感知输出层组成。 首先,我们定义状态网络,这也有助于规划者的代理理解状态。 其主要架构基于Transformer[15],可以有效捕获计划的结构和节点信息。 它涉及分别嵌入计划特征和步骤状态,将它们传递到多头注意力网络,最终输出状态表示。 对于位置感知输出层,输入包括两个状态表示和,而输出表示超过。 我们将输出映射到不同的分数。 根据这些分数来确定最优计划的选择和奖励的评估。
模拟学习者。 在DBMS中,使用传统优化器生成计划的成本较低。 FOSS利用传统的优化器和AAM来形成模拟环境。 因此,自由开源软件由三个关键组件组成:代理、真实环境和模拟环境。 规划器的代理与真实环境交互,在实际系统中执行探索的规划以收集 AAM 训练池。 然后,这些数据用于通过监督学习过程更新 AAM。 然后,智能体将与模拟环境交互以获得模拟经验,这些经验将用于更新智能体。 经过几次模拟学习迭代后,我们使用更新后的代理继续与真实环境交互,重复上述过程。 此外,我们还采用了动态超时机制,以确保在与真实环境交互过程中高效地收集数据。 我们还集成了验证机制。 在模拟学习迭代期间,我们选择具有高估计性能的计划,执行这些计划以测量其执行延迟,然后将它们合并到 AAM 训练池中。
III 计划者
在本节中,我们将提供规划器的详细描述。 请注意,在当前框架中,我们只考虑左深度计划,这是现有 DBMS(例如 PostgreSQL 和 MySQL)中经常使用的结构。 尽管我们可以探索茂密的计划,并对行动空间中的计划结构进行修改,但这会显着增加行动空间的大小,但不一定会产生相应的好处。 因此,目前我们只关注左侧的深入计划,而将考虑复杂的计划留到未来的工作中。
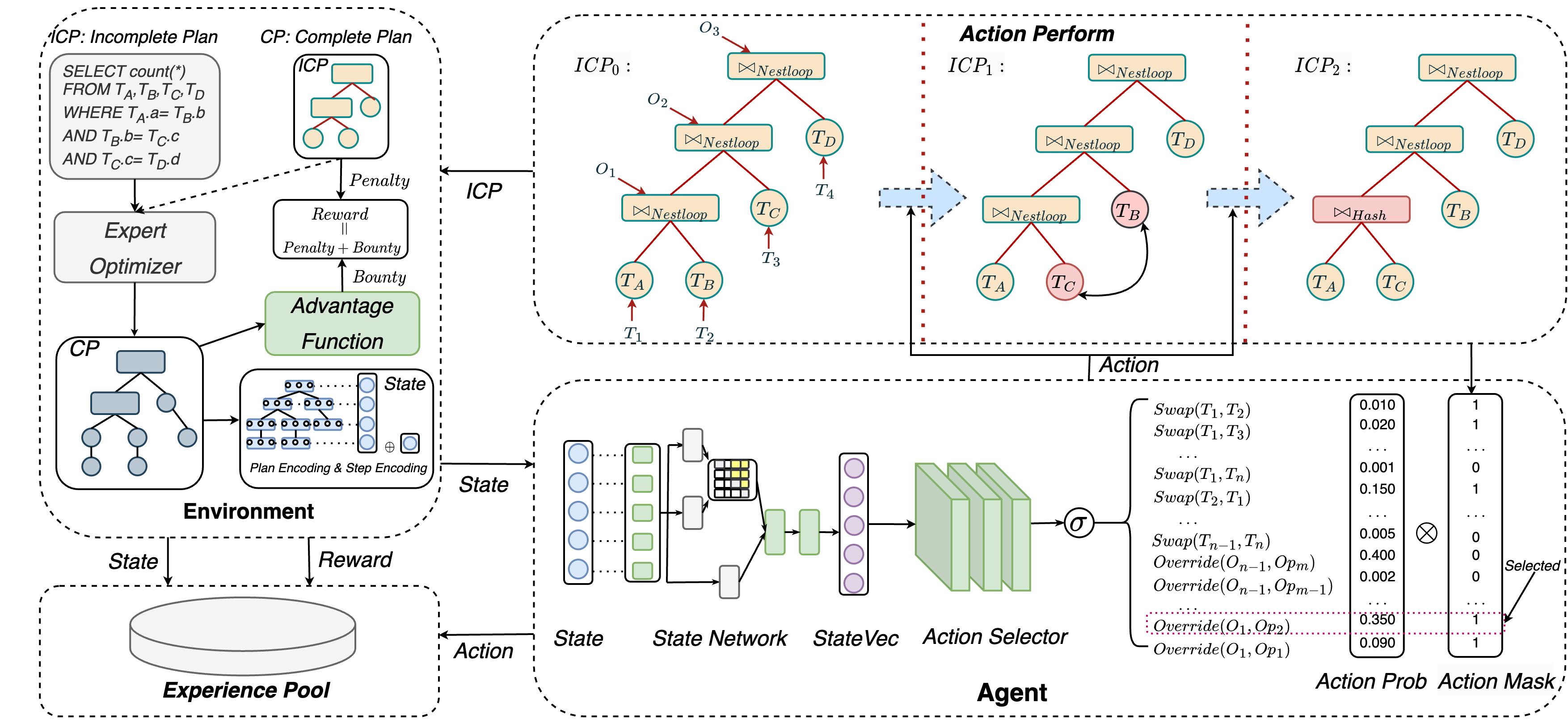
给定一个带有表的模式,当收到查询时,我们从传统的输出中获得完整的计划(即执行计划)优化器。 我们从 中提取对计划性能非常重要的关键信息。 这会产生一个不完整的计划,如图2所示。 表示 的子集,包括连接顺序和连接方法。 规划器的主要流程是逐步迭代修改。 在 上执行一步后,在新的 的引导下,我们可以使用 DBMS 钩子派生新的 ,例如 pg_hint_plan 在 PostgreSQL 中。 当达到每集的最大步骤数时,计划修改过程将停止。 Planner采用DRL的框架,由agent、环境、状态、动作、奖励等关键组件组成。 接下来,我们将对每个组件进行详细说明。
状态。 它是环境的输出和代理的输入。 它主要由组成,通常采用树状结构的形式。 为了促进代理处理,有必要从计划中提取关键信息并对其进行编码。 我们将在IV-A中提供计划编码的具体细节。 现在,我们用来表示的编码。 此外,为了结合状态的时间特征,我们还在状态中包含 。 通过连接这两种类型的特征,我们获得了时间步的状态特征。
| (1) |
行动。 首先,我们以自下而上的方式为 的节点分配顺序标签。 我们使用两种类型的标签: 表示叶节点(即表), 表示非叶节点(即连接方法)。 如图2所示,我们从最深层的两个叶子节点开始,其中左节点标记为,右节点标记为. 它们之上级别的叶节点标记为 ,依此类推。 类似地,我们将最深的非叶节点标记为,其父节点标记为,依此类推,遵循自下而上的顺序。
接下来,我们将解释两种类型的动作的表示。 第一种是交换两个表的位置,表示为。 桌子位置交换有种不同的操作。 第二种是用中的第个join方法覆盖节点的join方法,表示为,其中 是 DBMS 中所有可用连接方法的集合。 重写 join 方法有 种不同的操作。 操作被编码为 范围内的整数 。 我们定义一个动作映射函数,它将整数映射到上相应的动作行为。 我们可以将其表示如下:
| (2) |
,其中 中的整数表示表位置交换操作, 中的整数表示 join 方法重写操作。 如果满足,则调用,其中和满足以下条件:
. 如果满足,则调用,其中和满足以下条件:
. 但是,每个查询可能有不同的操作空间限制,具体取决于查询图中的表数量。 例如,在图2所示的查询中,被认为是非法动作。 为了解决这个问题,我们在代理选择操作之前对操作空间进行有效性检查。 我们使用来禁止非法行为。 为了进一步修剪动作空间,我们采用启发式规则。 执行后,后续动作只能选择如何重写与上一步交换的两个表相关的join方法。 这也可以使用来实现。
奖励。 在规划器的训练过程中,我们维护每个查询的已知最佳计划和FOSS感知的最佳计划。 并且在一个episode的每一步,都会生成一个新的不完整计划和一个新的完整计划。 我们根据这些计划确定奖励。 每一步的奖励是赏金和惩罚的总和。 而每一集的奖励是每一步获得的奖励之和。
赏金。 首先,我们定义初始优势函数来计算两个计划之间的初始优势值,表示与相比好多少。
,其中 与 的性能相关。 然而,细粒度的值不适合动态变化的系统工作负载。 我们将初始优势值离散成几个区间。 我们采用 元素有限有序点集 并用它来将区间 划分为 子区间,从而得到一组有序子区间。 我们使用来表示中的第个元素(即子区间)并设置。 我们定义最终的优势函数,它以一对计划作为输入并输出一个分数。
| (3) |
在每一集中,我们都维持当前的最佳计划。 在每一步中,我们都会计算 并提供步骤赏金 :
. 此外,如果当前步骤是,我们将附加剧集赏金。 我们首先定义 和 来表示 FOSS 的剧集赏金和已知的最佳剧集赏金。
,其中 表示最大剧集赏金。 然后我们计算优势值、和。 剧集赏金可以表示如下:
. 最后我们得到如下:
处罚。 为了鼓励智能体以尽可能少的步骤到达每个不同的状态,我们实施了惩罚措施。 在规划器中,从初始状态到达某个状态可能涉及多个不同长度的动作序列,其中动作序列是指和运算符的组合。 为了获得更多奖励,智能体可能会选择不适当的动作序列。 例如,假设位置 处的散列连接运算符的执行延迟为 ,合并连接的执行延迟为 ,以及 用于嵌套循环连接。 假设,原计划选择使用hash join。 为了获得更多的赏金,代理可能会选择最初将 处的方法重写为合并连接,然后在后续步骤中将其重写为嵌套循环连接。 为了解决这个问题,我们计算从原始不完整计划到当前不完整计划所需的最少步骤数,表示为。 此外,我们引入了惩罚系数。 我们根据以下公式设置惩罚值:
| (4) |
. 如果当前步数已经是最小值,则惩罚值为 0。 否则会对奖励产生负面影响。 它确保智能体能够更有效地学习有用的知识。
在 FOSS 中, 设置为 0.5, 设置为 12, 设置为 2。
代理。 在规划器中,代理主要由两个模型组成:状态网络和动作选择器。 前者是一个基于 Transformer 的网络,用于处理状态。 它将状态作为输入并输出状态表示向量。 关于状态网络的更多细节将在IV-A中解释。 我们使用多层全连接神经网络作为动作选择器。 它将 和 作为输入,并输出编码 的操作,以最大化累积预期奖励。
环境。 其主要功能包括: i)根据智能体采取的行动提供新的状态; ii) 评估代理人提供奖励的行动。 对于 i),我们使用 DBMS 优化器 来提供新状态。 我们可以用下面的公式来表达:
. 在初始步骤的情况下,它将查询作为输入并输出完整的计划。 在非初始步骤中,它会将不完整计划 和查询 作为输入,生成由 引导的完整计划 。 然后我们可以使用 (1) 对 进行编码以获得新状态。 对于ii),在获得后,我们提供如奖励部分所述的奖励。 关键的区别在于,在真实环境中,我们使用DBMS执行器来执行计划,然后使用执行延迟来表示计划的性能。 随后,我们计算优势和最终奖励。 在模拟环境中,在不执行计划的情况下,通过非对称优势模型评估优势值。 具体细节将在IV-B中讨论。
算法1展示了规划器的整体训练过程。 当输入工作负载的查询时,DBMS优化器生成原始计划(第2行)。 规划器从 中提取由连接顺序和连接方法组成的不完整计划 (第 3 行)。 规划器初始化历史计划集和估计的最佳计划(第4-5行)。 对于每一步,规划器都会根据 (第 7 行)计算禁止的操作。 如果前一个操作是运算符,则当前操作将仅限于更改相邻的连接方法(第8-10行)。 接下来,规划器根据 和步骤状态表示先前的状态(第 11-12 行),并根据状态表示 和 评估操作>(第 13 行)。 然后它将此操作应用于 并生成一个新的不完整计划 (第 14 行)。 将由 DBMS 完成,从而产生完整的计划 (第 15 行)。 规划器计算惩罚值并用它来初始化奖励值(第 16 行)。 如果当前不完整的计划没有出现在本集中,我们将赏金添加到奖励中,并将添加到(第17-20行)。 如果当前计划优于最优计划,则规划器更新估计的最优计划(第21行)。 收集经验是为了更新代理(第 22 行)。 最后,在结束当前工作负载的探索后,使用 更新代理(第 25 行)。
IV 非对称优势模型
在本节中,我们将详细描述非对称优势模型。 我们首先介绍状态表示,然后介绍优势模型。 最后,我们将讨论损失函数的设计。
IV-A 国家代表
如(1)中所述,状态由计划编码和步骤编码组成。 我们引入了步进编码。 接下来,我们将详细解释如何编码完整的计划。 最后,我们将介绍将状态转换为状态表示的状态网络。
计划编码。 我们的工作是基于 QueryFormer [16] 构建的,它是一个用于表示查询计划的树 Transformer 模型。 根据他们的工作,我们首先提取节点特征,包括运算符、谓词、连接和表。 但出于计算效率的考虑,我们放弃使用直方图数据和采样信息。 为了捕获查询计划的节点结构特征,我们对节点的高度进行编码,该高度被定义为计划树中从该节点到叶节点的最长向下路径的长度。 此外,与[16]不同的是,我们对每个节点的结构类型进行编码。 我们将节点分为四种类型:左节点、右节点、无兄弟节点和根节点。 我们用标签0、1、2、3来表示这四类节点,得到节点结构特征。 为了捕获计划的树结构特征,我们利用带有注意掩模的注意网络。 由于原始的注意力网络将关注计划树中的所有节点,这并不完全合理,因此我们的目标是将注意力网络集中在有意义的结构信息上。 为了实现这一点,我们屏蔽了查询计划树中不可达节点之间的相互影响,将两个不可达节点之间的注意力分数设置为 0,将两个可达节点之间的注意力分数设置为 1。 它与他们的工作不同,他们的工作使用有偏权重来调整不同级别节点之间的注意力分数。 我们认为,对于不同查询计划或同一查询计划中的不同节点,假设相同程度的差异同样会影响注意力分数是不合理的。 这种限制阻碍了模型的力量。
国家网. 我们分别将提取的四种类型的节点特征通过特定的嵌入层,以获得每个特征的向量表示。 随后,我们连接四个向量以获得第 个节点的节点表示,表示为 。 我们使用专用的嵌入层来表示高度和节点结构特征,获得每个节点的和。 最后,我们连接 、、 并将它们与注意力分数一起输入到多头注意力网络中。 这个过程最终产生查询计划的表示。 随后,它与步骤编码连接并通过线性层以生成最终状态表示向量。
IV-B 优势模型
如(3)中所述,我们需要计算两个计划之间的优势。 在真实环境中,通过使用DBMS执行器执行计划可以获得精确的优势值。 在模拟环境中,我们使用优势模型来估计优势值,该模型以计划对 作为输入。 它最初分别对两个输入计划进行编码,并使用状态网络将它们转换为 。 接下来,它合并每个的位置信息以获得。 最后,该对被传递到最终输出层,在那里它被映射到分数(即 的输出)。 非对称优势模型可以描述如下:
,其中 表示全连接网络。 在模拟环境中,作为优势函数,格式的训练数据将用于更新 。
考虑到系统工作负载的动态变化可能会导致执行延迟相似的计划对的标签不断变化,从而选择明显更优的计划,我们取点集来划分区间,为 的输出产生三个分数(即 )。
IV-C 不对称损失
由于从传统优化器获得的计划通常具有合理的性能,因此从作为基线的计划开始并进行修改通常会产生更差的计划。 因此, 的训练样本偏向于得分为 0 的样本数量较多和得分为 2 的样本数量较少。 不同标签上的样本分布不均匀将对 的训练产生不利影响。 受不对称损失[17]的启发,自由和开源软件通过增加难以分类样本的权重来解决这个问题。 此外,为了防止训练过程中的过度拟合,FOSS 还采用了标签平滑。
对于给定的训练样本集,其中表示训练样本的数量,我们采用one-hot编码来表示真实标签:
. 我们使用将的输出转换为分数概率分布。 表示第个样本中第个标签的概率,表示样本的分类难度。 值越小表示难度越高,反之亦然。
| (5) |
为了使更加关注难以分类的样本,FOSS引入了衰减因子,其中表示衰减系数。 为了强调正样本的贡献,我们为正样本和负样本分配不同的衰减系数。 我们将正样本的衰减系数表示为,将负样本的衰减系数表示为,并设置。 这由以下公式表示:
. 我们将概率分布修改如下:
,其中 是超参数, 表示分数数。 在 FOSS 中, 设置为 3, 设置为 0.1。 最终的损失函数可以表示为:
V 模拟学习者
在本节中,我们将首先介绍模拟环境。 接下来,我们将解释 FOSS 如何探索真实环境并使用模拟环境训练代理。
V-A 模拟环境
如算法1中所述,收集形式的数据来更新代理。 然而,在许多环境中,由于成本高昂或安全问题,获取真实状态和奖励具有挑战性。 为了克服这一挑战,研究人员提出使用神经网络模拟环境来加速智能体的学习。 模拟环境始终包括状态转换动力学模型和奖励函数模型[18]。 他们将让代理与真实环境进行交互,然后使用真实经验来执行模拟环境的监督训练[19]。 然后,代理有效地与模拟环境交互以生成模拟体验,然后用于相应地更新代理。
在规划器的上下文中,状态由完整的计划和步骤状态组成,而步骤状态是确定的,并且可以从DBMS优化器以低成本获得,特别是在指导范围内。 因此,我们可以使用 DBMS 优化器 来分配 。 然而,获得真正的奖励需要执行完整的计划,这可能非常耗时。 我们只需要知道如何模拟来及时提供奖励反馈即可。 使用我们建立的不对称优势模型来分配奖励是一个自然的想法。 因此,我们使用DBMS优化器和构建模拟环境。
V-B 训练循环
在本小节中,我们将讨论如何使用模拟环境和真实环境有效地训练规划器的代理,以及如何收集训练数据以更新。 它可以分为三个阶段:探索阶段、训练阶段和验证阶段。
探索阶段。 对于一批训练工作负载查询,代理与真实环境交互以执行计划探索并将执行延迟收集到执行缓冲区中。 然而,在探索的初始阶段,智能体有可能生成比原始计划明显糟糕的灾难性计划,甚至可能导致超时,从而显着减慢探索阶段的速度。 为了解决这个问题,我们引入动态超时来终止执行性能不佳的计划。 超时设置为原始计划执行延迟的 倍。 如果新生成的计划的执行延迟超过此阈值,则会终止该计划并标记为超时。 然后,如IV-B训练中所述,我们利用执行缓冲区中的数据来形成的数据并更新它。 我们将过滤掉涉及两者超时的计划对。 虽然超时策略会导致训练样本的损失,但它显着提高了数据收集率。
训练阶段。 FOSS 从历史查询中随机采样,并通过与模拟环境 交互来获取模拟体验,遵循算法 1 中概述的过程。 同时,FOSS也会根据的成果收集优秀的方案。
验证阶段。 FOSS执行训练阶段收集的计划,将其执行延迟记录到执行缓冲区中,并相应地更新。 这个过程可以及时纠正中的错误,防止由于奖励估计不准确而导致DRL训练中的错误累积。
全球流程。 自由开源软件启动探索阶段,随后进行多轮训练阶段,并在每次训练迭代后进行验证阶段。 这个循环过程重复几次,直到 FOSS 收敛。 这三个阶段可以交互进行,也可以同时进行。
六实验
在本节中,我们概述了我们的实验配置并分析了 FOSS 的性能,同时还与 SOTA 方法进行了比较。 最后,我们分析了 FOSS 各个组件的影响,并展示了 FOSS 的附加功能。
VI-A 实验设置
实验支持。 我们在 Ubuntu 20.04 系统上部署 FOSS 和 SOTA 方法,其硬件配置包括 2.40GHz Intel Xeon E5-2640 CPU、256GB 内存和 NVIDIA Tesla P40 GPU。 我们使用 PyTorch 实现 FOSS,并利用 Ray [20] 作为 RL 组件。 我们利用 PPO [21] 作为基本 RL 算法,因为它可以有效地通过 KL 散度缓解智能体更新前后动作分布的显着差异。 进一步保证了模拟环境中提供的预估奖励的准确性。
工作负载。 我们在三个不同的基准上评估所有优化器的性能:Join Order Benchmark (JOB) [2]、TPC-DS[22] 和 Stack [ 12]。
JOB 基于现实世界的 IMDb 数据集,该数据集由 21 个关系组成,总数据大小为 3.6GB。 在 JOB 工作负载中,有 33 个查询模板,包含 113 个单独的查询。 我们遵循 Balsa 的 [8] 随机分区,将查询分为 94 个用于训练,19 个用于测试。
TPC-DS 是一个标准基准。 我们利用其数据生成工具创建了一个 10GB 大小的数据集。 它包括 99 个查询模板。 然而,这些模板中的大多数不满足某些 SOTA 方法的要求(例如需要选择项目加入查询)和 FOSS 的左深度约束。 我们最终选择了 19 个查询模板111TPC-DS 选择的模板编号为 3, 7, 12, 18, 20, 26, 27, 37, 42, 43, 50, 52, 55 、62、82、91、96、98 和 99。. 从每个模板中,我们生成 6 个单独的查询,并从中随机选择 5 个查询用于训练工作负载,其余 1 个查询用于测试工作负载。
Stack 包含十多年来从 StackExchange 网站(例如 StackOverflow.com)收集的 1800 万个问题和答案。 由[12]生成,占用总空间100GB。 在工作负载中,有 16 个查询模板。 与TPC-DS类似,我们过滤掉不符合要求的模板,然后从剩余的12个模板中随机选择10个查询222为 STACK 1、4、5、6、7、8、11、12、13、14、15、16 选择的模板编号。. 对于每个模板,为训练工作负载分配 8 个查询,为测试分配 2 个查询。
比较。 我们使用 PostgreSQL 作为基线,并将 FOSS 与 SOTA 方法进行比较,包括 Bao [12]、Balsa [8] 和 HybridQO [14] 。
PostgreSQL 是一个带有传统优化器的开源 DBMS。 我们将其作为传统优化器的代表。
Bao 遵循计划引导框架。 它通过使用价值模型来选择不同的分支(即提示集)来引导传统优化器选择更好的查询计划。 默认配置下,它有 5 个可用臂。 我们根据他们的文档[23]中提供的说明进行配置。
Balsa 是一种端到端查询优化器,它独立于传统优化器运行,遵循计划构造函数框架。 我们按照其源代码[24]中概述的说明进行部署。
HybridQO 将基于学习的优化器与传统优化器相结合。 它还遵循计划指导框架。 它采用蒙特卡洛树搜索来发现有希望的领先连接顺序,并使用这些作为提示来指导传统优化器生成更好的查询计划。 我们按照[25]中的描述复制他们的实验设置。
专家引擎。 为了公平比较,我们使用 PostgreSQL 12.1 进行所有实验。 我们为 PostgreSQL 设置了 32GB 共享缓冲区,并由于使用了 pg_hint_plan 而禁用了 GEQO。 我们在实验中将其用作专家引擎。
指标。 我们在训练工作负载上部署所有学习的查询优化器,并使用两个指标评估它们在测试工作负载上的性能:i)工作负载相关延迟(WRL):它主要反映整个工作负载的总体延迟水平,如该方法中先前使用的那样[13,8,9]。 其计算涉及基于学习的优化器执行的整个工作负载的总延迟与专家优化器中观察到的总延迟的比率。 ii) 几何平均相关延迟(GMRL):在[6]中介绍,演示了查询级别的优化有效性。 它可以使用公式来表达,其中和分别表示基于学习的优化器和专家优化器的执行延迟。 对于这两个指标,值越小表示性能越好。 大于 1 的值意味着与专家优化器相比较差,而小于 1 的值则表示相反。
VI-B 自由开源软件性能和比较
除非另有说明,我们将 设置为 3,在探索阶段的每轮中探索 10 个查询,并在训练阶段为代理的每次更新使用 900 个情节(即 900 个查询)。 我们在每个基准测试上部署所有方法,使用不同的随机种子运行它们五次。
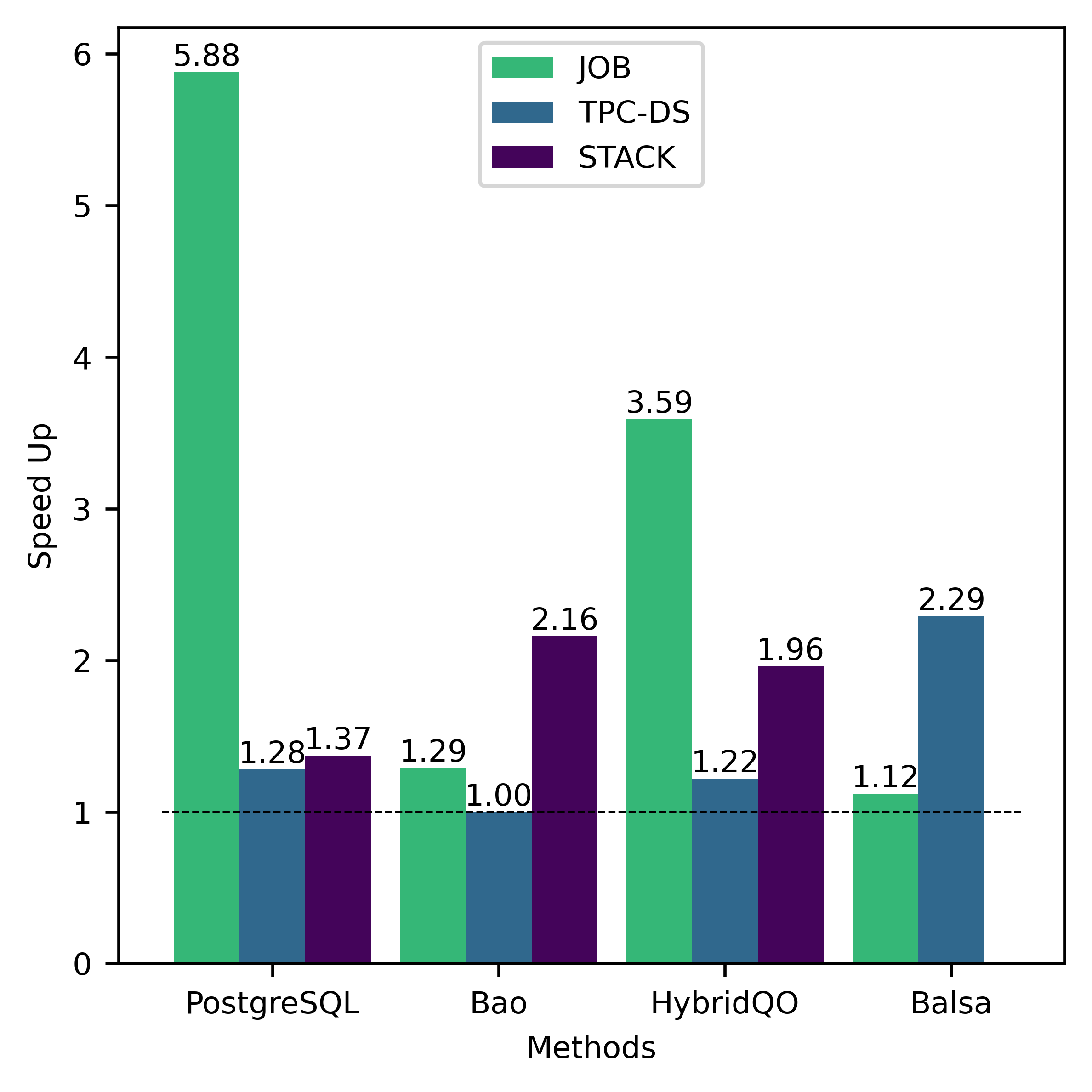
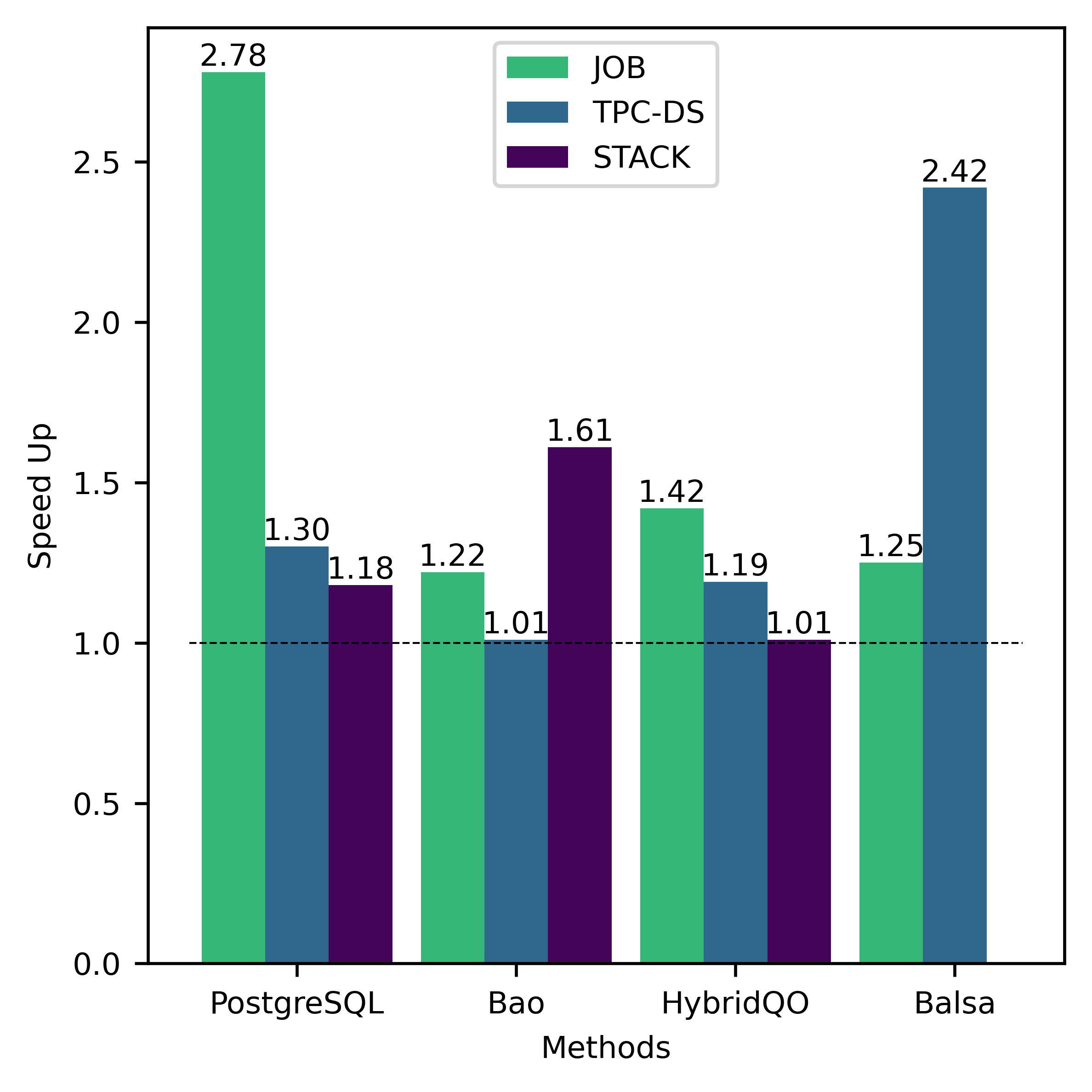
VI-B1 自由和开源软件性能概述
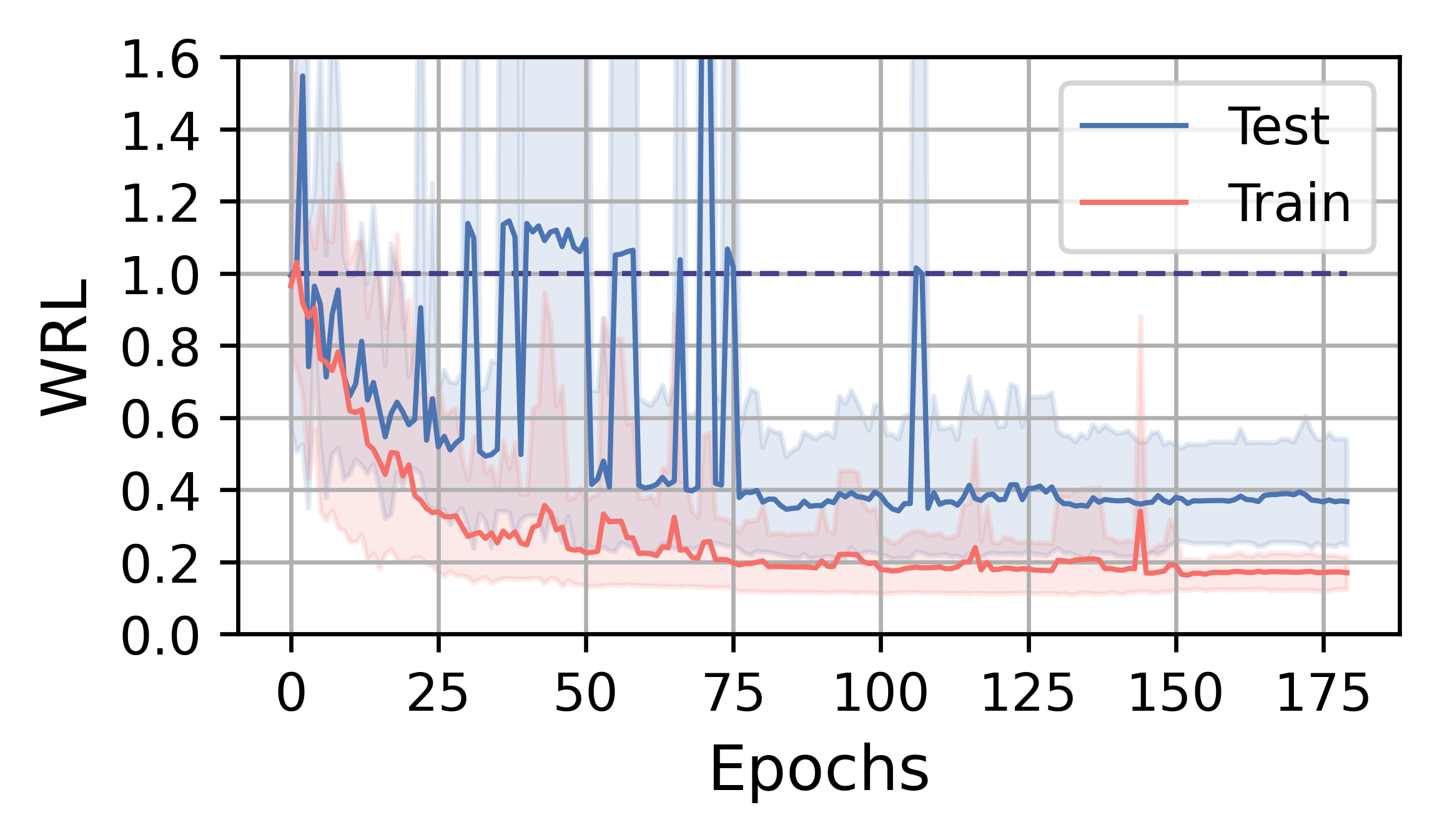
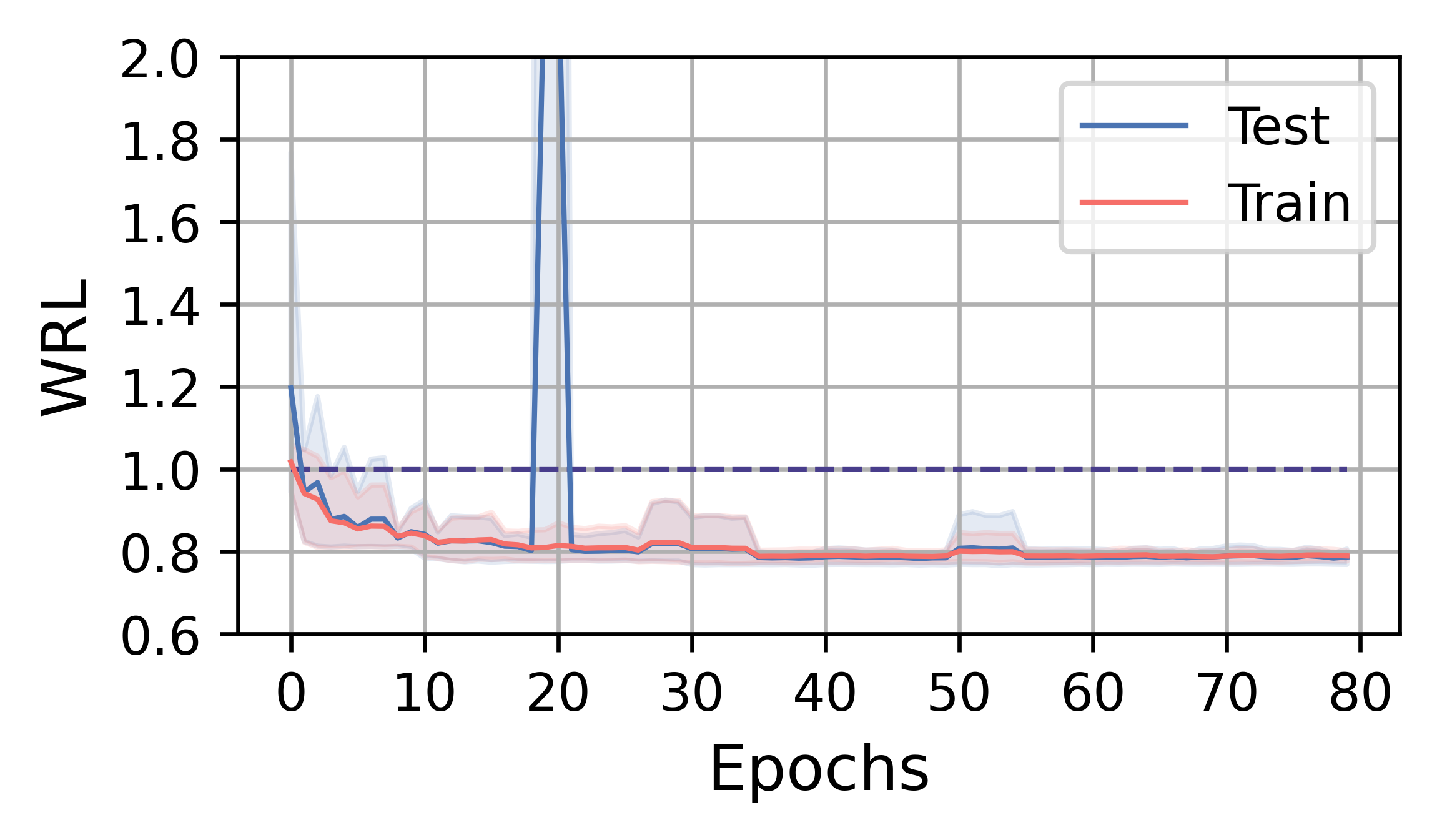
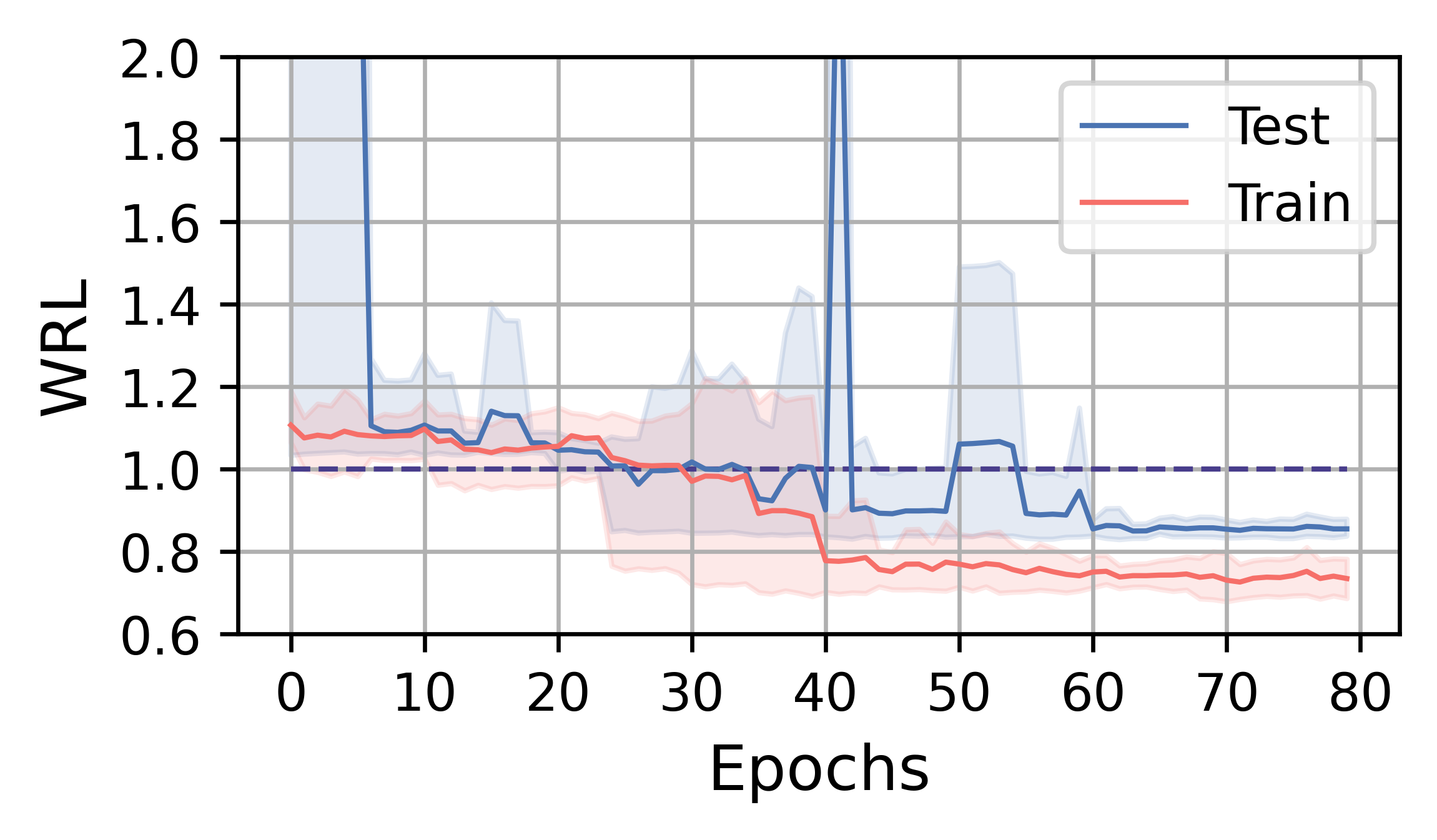
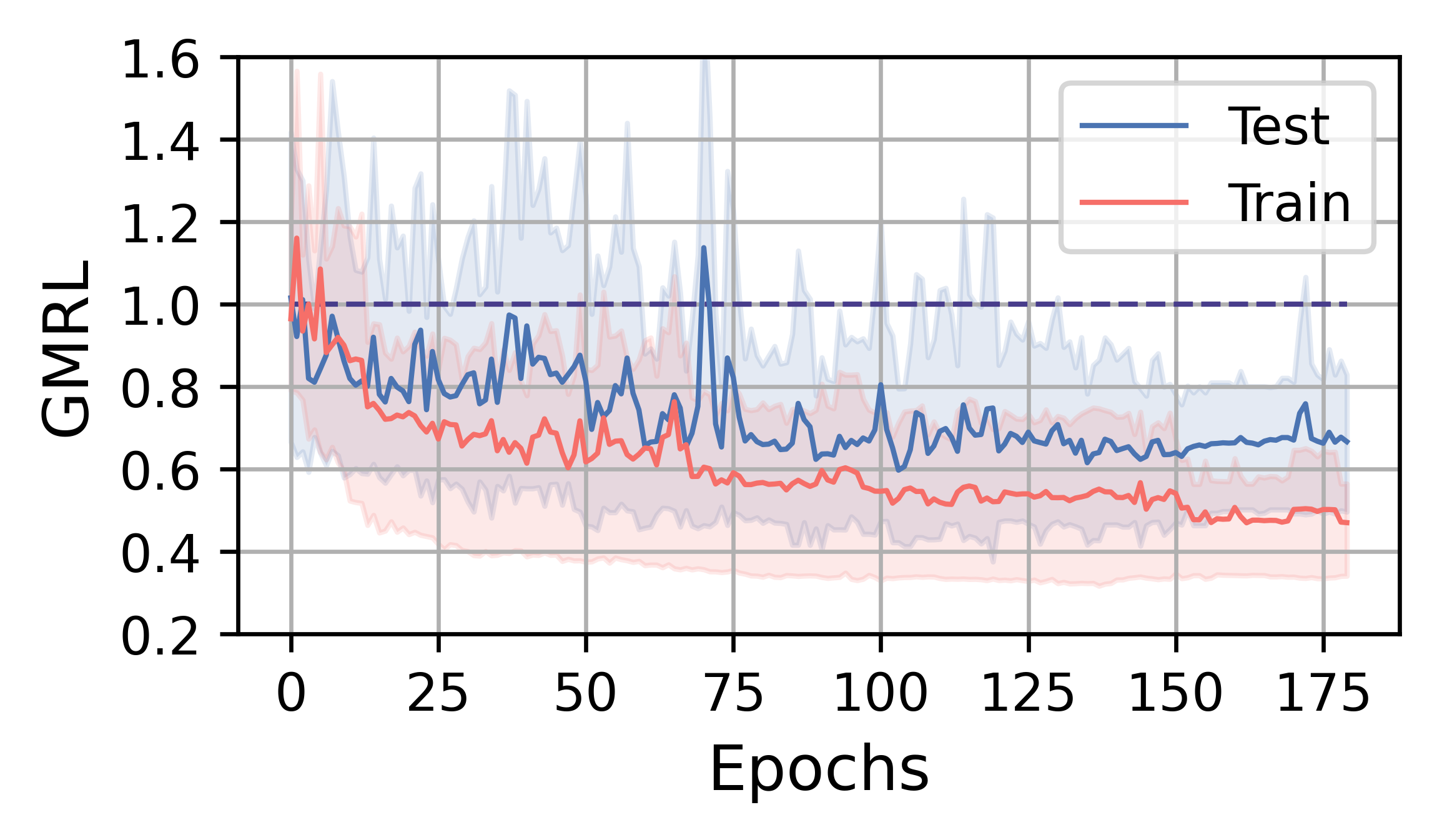
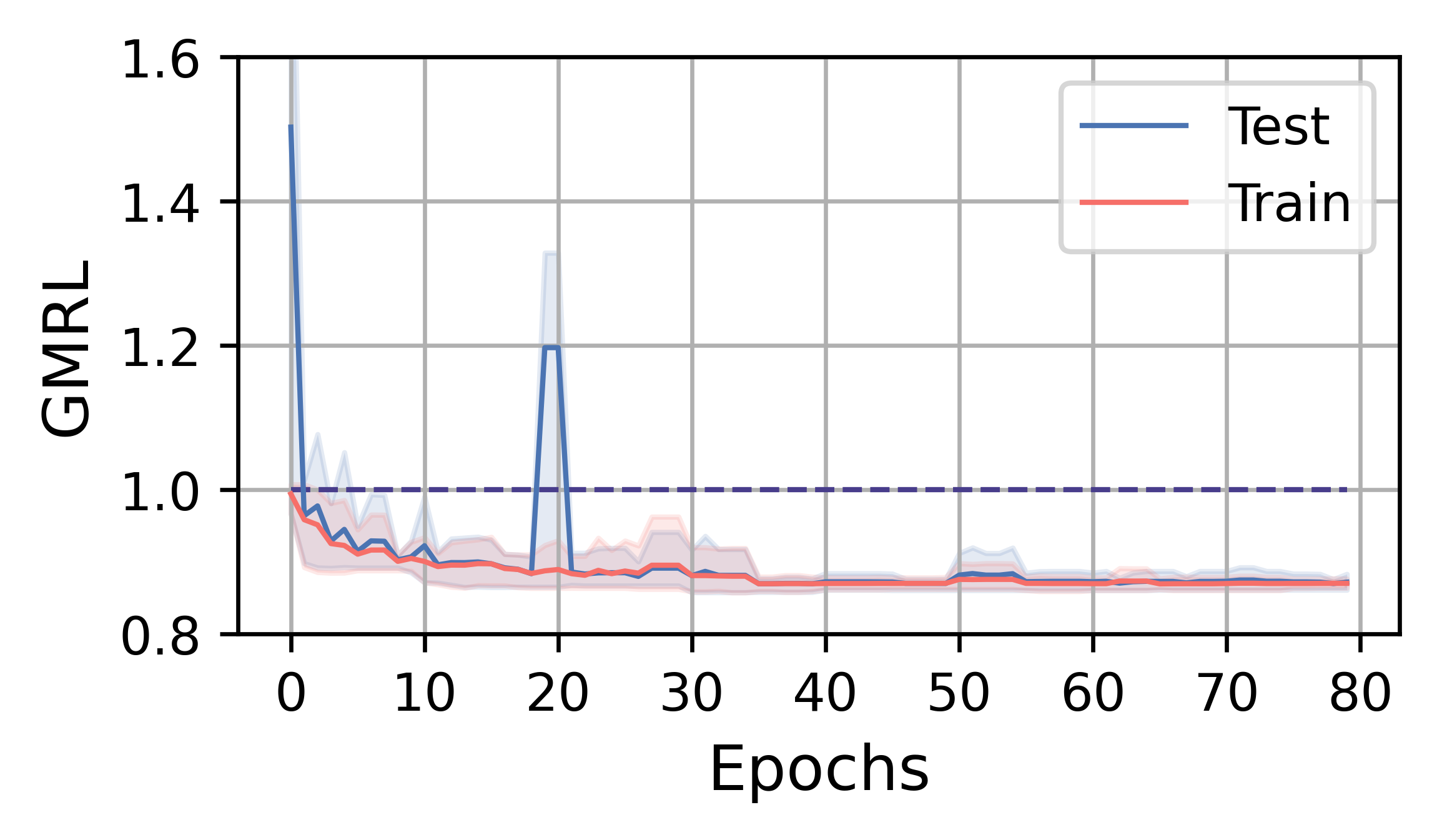
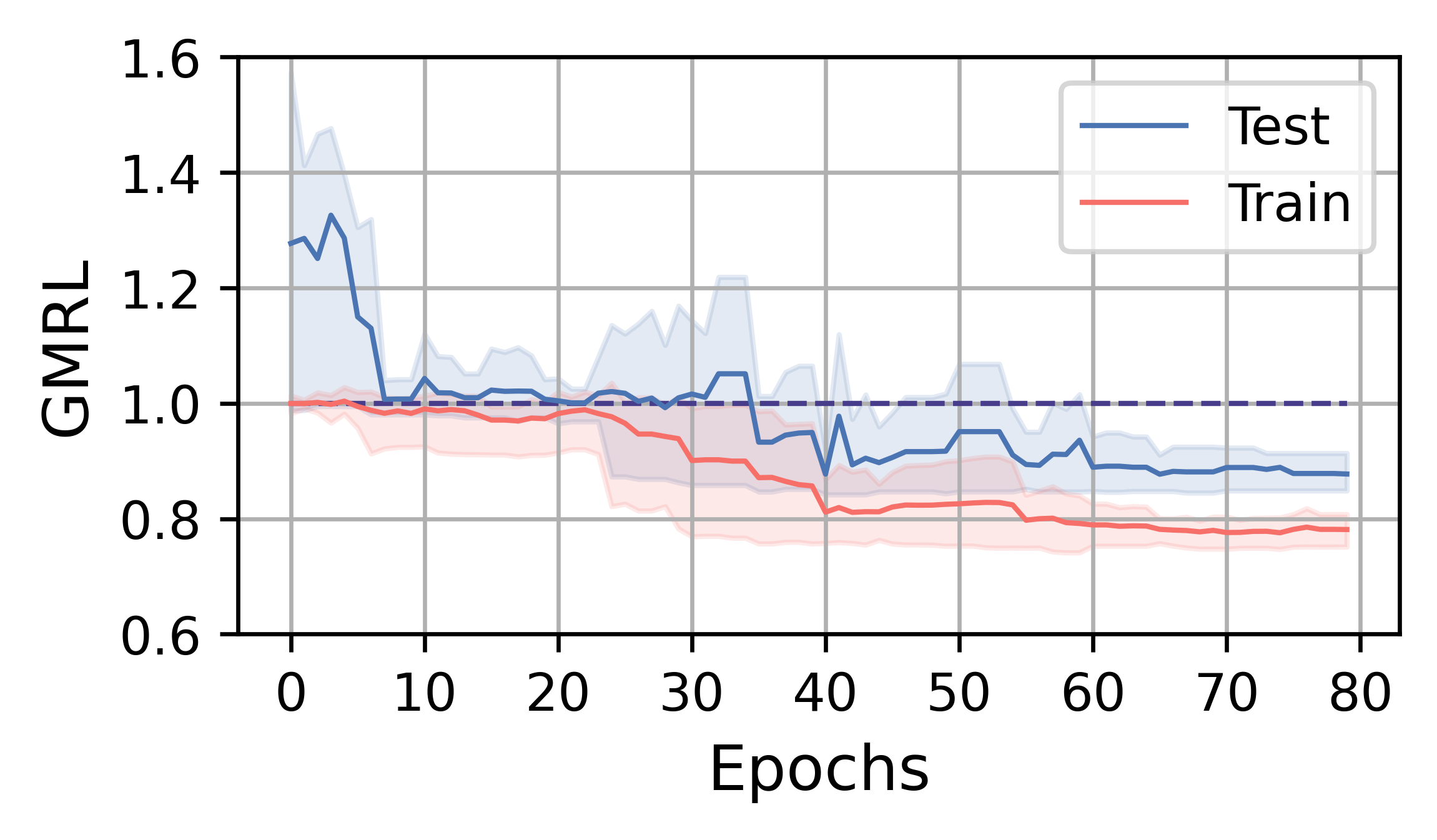
在本小节中,我们分析 FOSS 的训练效率和性能。 总体而言,FOSS 优于专家优化器(即 PostgreSQL 优化器),训练工作负载(JOB、TPC-DS、STACK)的总延迟加速为 5.88×、1.28× 和 1.37×,以及 2.78×、1.30× 和 1.18 × 分别表示测试工作量(图3)。
图4展示了FOSS在JOB、TPC-DS和STACK上的训练曲线。 红实线表示训练工作负载五次运行中指标的平均变化,而蓝线表示测试工作负载指标的平均变化。 阴影区域表示最小值和最大值之间的范围。 1.0 处的线表示专家优化器的性能。 受益于原计划提供的保证,FOSS可以迅速展现其优化效果,并超越专家优化器的性能。
在JOB工作负载上,查询和数据分布的复杂性让FOSS有更大的优化空间。 经过大约 8 小时的训练,FOSS 实现了收敛,最终相对于专家优化器节省了测试工作负载的 延迟。 GMRL 曲线稳步下降,直到测试工作负载收敛到 ,这表明 FOSS 能够优化大多数原始计划并实现高性能。 在训练工作量上,FOSS表现出类似的收敛趋势,表明其具有良好的泛化性。
在TPC-DS和STACK工作负载上,FOSS在训练过程中偶尔会遇到灾难性的计划,导致WRL和GMRL突然增加。 但随着训练的进行,它可以避开这些计划,最终收敛并取得相对较好的结果。 由于工作量更简单,他们的训练过程在 1-3 小时内收敛,并且尾部方差较低。
VI-B2 性能比较
| Methods | WRL, train | GMRL, train | WRL, test | GMRL, test | Training time (hours) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| JOB | TPC-DS | STACK | JOB | TPC-DS | STACK | JOB | TPC-DS | STACK | JOB | TPC-DS | STACK | JOB | TPC-DS | STACK | |
| PostgreSQL | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | / | / | / |
| Bao | 0.22 | 0.78 | 1.58 | 0.54 | 0.96 | 1.18 | 0.44 | 0.78 | 1.37 | 0.84 | 0.95 | 1.78 | 3.35 | 1.32 | 3.03 |
| Balsa | 0.19 | 1.79 | NA | 0.62 | 1.98 | NA | 0.45 | 1.86 | NA | 1.25 | 2.08 | NA | 12.18 | 10.58 | TLE |
| HybridQO | 0.61 | 0.95 | 1.43 | 0.71 | 1.07 | 1.40 | 0.51 | 0.92 | 0.86 | 0.75 | 1.04 | 1.01 | 3.51 | 0.52 | 1.58 |
| FOSS | 0.17 | 0.78 | 0.73 | 0.48 | 0.87 | 0.78 | 0.36 | 0.77 | 0.85 | 0.64 | 0.87 | 0.87 | 8.09 | 1.55 | 2.31 |
在本小节中,我们将 FOSS 与 SOTA 方法的性能进行比较。 我们确保所有方法在收敛后进行评估。 值得注意的是,Balsa 在 STACK 上的训练受到初始阶段制定的灾难性计划的阻碍,使其无法在合理的时间内完成。
如图3所示,尽管存在左深度限制,FOSS 在训练和测试工作负载方面始终优于或匹配其他三种方法。 FOSS 的性能优于 Bao、HybridQO 和 Balsa,在训练工作负载上的平均加速分别为 1.48×、2.26× 和 1.71×,在测试工作负载上的平均加速分别为 1.28×、1.21× 和 1.84×。
如表I所示,FOSS 不仅在工作负载总延迟方面优于其他方法,而且在 GMRL 指标中也表现出卓越的性能。 值得一提的是 JOB 工作负载上的性能,在 WRL 中,Bao 和 Balsa 与 FOSS 相比表现出相对较小的差异,但在 GMRL 中出现了更显着的差距。 这种差异是由于 FOSS 与模拟环境有效交互而产生的,与 Balsa 相比,允许进行更多探索。 与 Bao 相比,FOSS 采用了更细粒度的优化,从而更有可能生成更好的计划。 这些因素使得FOSS能够在更广泛的查询范围内超越专家优化器,表明其具有更强的优化能力。 这将在VI-B4中得到进一步确认。 然而,这些优势伴随着相关成本,导致与 HybridQO 和 Bao 相比,JOB 的训练时间相对较长。 然而,与另一种基于 MDP 的方法 Balsa 相比,FOSS 显着减少了训练时间。 而在 STACK 和 TPC-DS 上,FOSS、Bao 和 HybridQO 之间的训练时间差异并不明显,并且远小于 Balsa,FOSS 超越了所有其他方法,这证明了我们方法的优越性。
VI-B3 优化时间比较
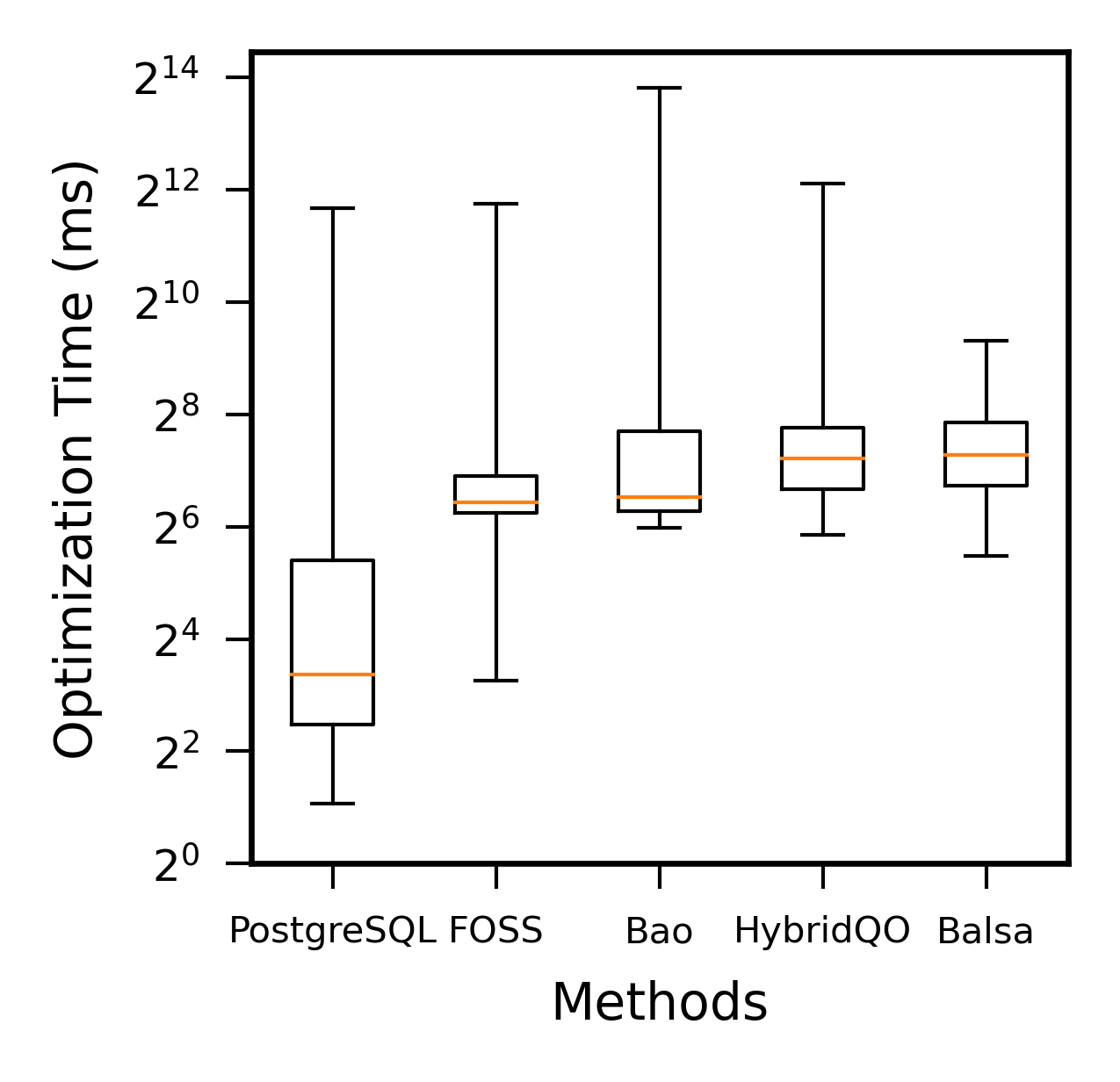
我们在整个JOB基准上比较了各种优化器的优化时间,即从SQL输入到执行计划生成的时间。 如图6所示,我们使用箱线图表示比较结果。 与 PostgreSQL 相比,基于学习的优化器由于模型推理和计划编码等操作通常需要更长的优化时间。 然而,与执行中节省的时间相比,开销可以忽略不计。 在这些基于学习的优化器中,FOSS 的优化时间第 25 个百分位、第 50 个百分位和第 75 个百分位最小,且分布相对集中。 它的大部分优化时间都花在获取原始计划和计划编码上。 过度依赖专家优化器会导致Bao和HybridQO的优化时间较长。 此外,Balsa 的特点是平均决策序列较长,计划探索策略范围广泛,在优化时间方面也表现不佳。
VI-B4 已知最佳计划比较
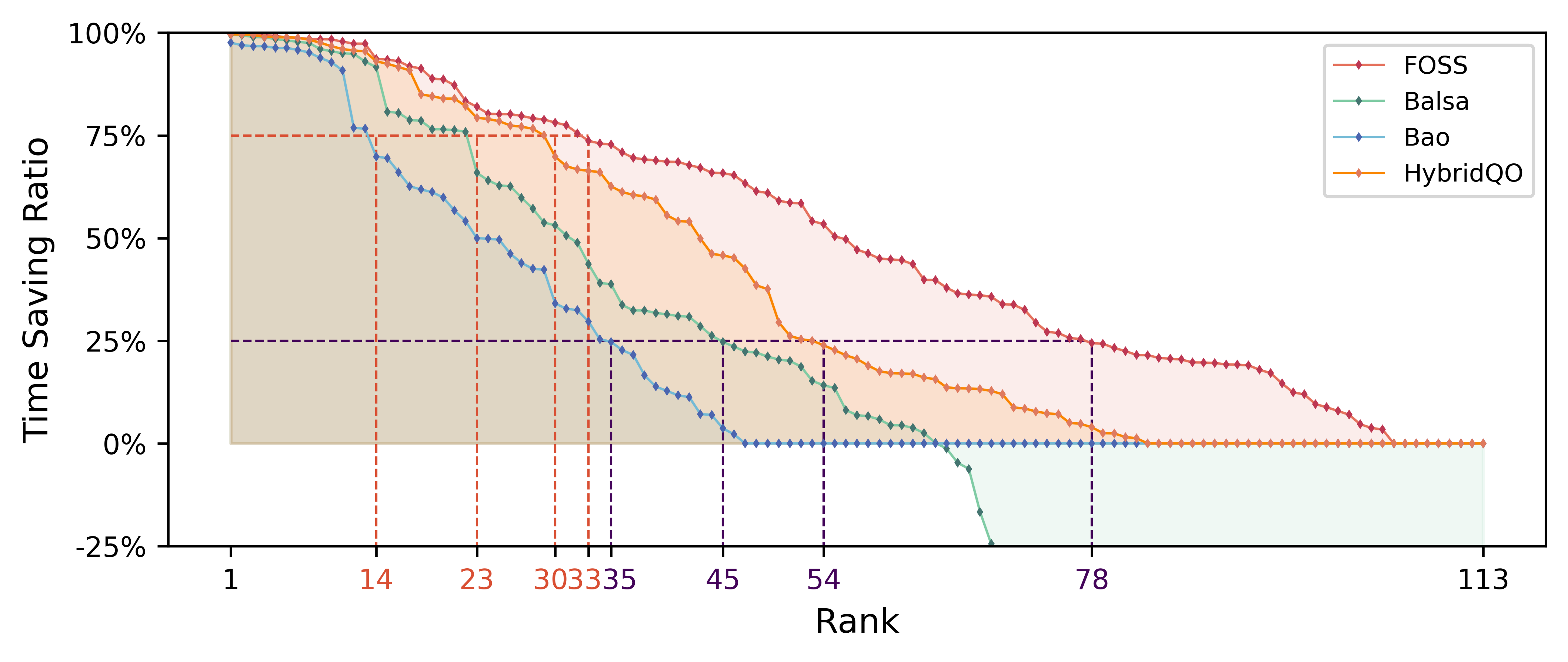
在本小节中,我们分析每个基于学习的查询优化器的优化上限。 我们对整个 JOB 工作负载的每种方法进行五次运行。 从所有结果中,我们获取每种方法的每个查询的已知最佳计划(即执行延迟最低的计划)。 对比结果如图7所示。
它说明了基于学习的方法相对于专家优化器在已知最佳计划方面的时间节省比率。 总体而言,FOSS 全面优于其他三种方法,在每个百分点上都在更广泛的查询上超越了专家优化器。 特别是,FOSS、HybridQO、Balsa 和 Bao 分别在 78、54、45 和 35 个查询上至少节省了 时间。 它们分别在 33、30、23 和 14 个查询上至少节省 的时间。 此外,由于 Bao 的计划搜索空间有限,它在最小范围的查询中生成比专家优化器更好的性能计划。 Balsa 由于缺乏原始计划的保证,在许多查询上生成的计划的性能比专家优化器要差。
VI-C 设计选择分析
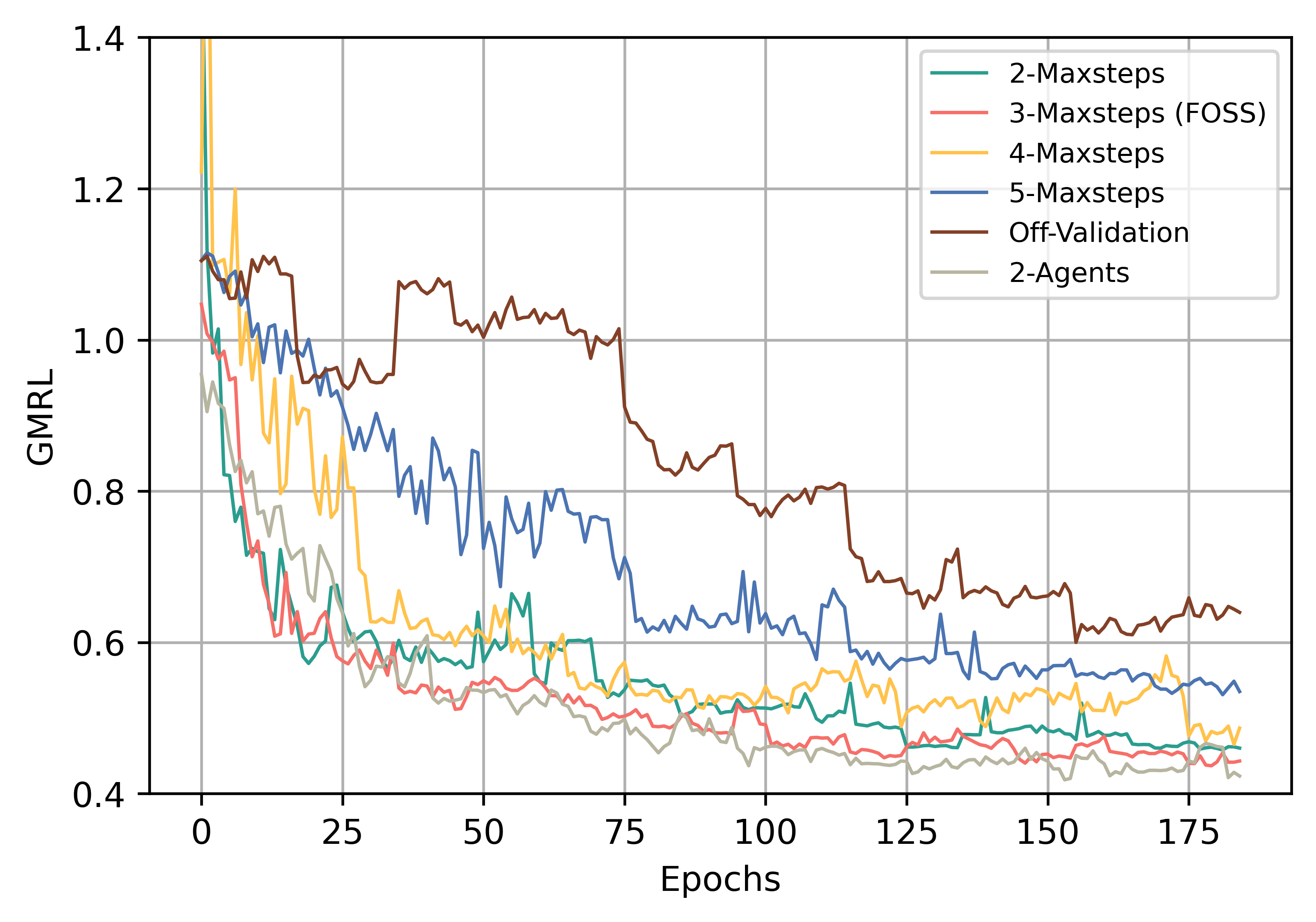
在本小节中,我们通过用替代方案单独替换每个组件来分析 FOSS 中的设计选择。 我们使用 GMRL 作为评估指标来测试他们在整个 JOB 工作负载上的表现,并考虑训练时间和平均计划优化时间以获得实际见解。 表II展示了我们的比较结果,图8说明了训练过程中GMRL的变化。
| Experiments | Training time | Optimization Time | GMRL |
|---|---|---|---|
| (hours) | (milliseconds) | ||
| 2-Maxsteps | 8.52 | 152.95 | 0.46 |
| 3-Maxsteps (FOSS) | 9.23 | 170.57 | 0.44 |
| 4-Maxsteps | 11.24 | 178.18 | 0.48 |
| 5-Maxsteps | 15.21 | 190.43 | 0.53 |
| Off-Simulated | 48.01 | 171.12 | 0.65 |
| Off-Validation | 7.90 | 173.82 | 0.62 |
| 2-Agents | 14.21 | 202.25 | 0.42 |
VI-C1 最大步数的确定
较大的意味着FOSS可以通过对原始计划修改更长的序列来探索更多样化的计划。 然而,这也使得FOSS的训练变得更具挑战性。 我们将分别设置为2、3、4和5,并比较它们的性能。 如表II所述,随着的增加,由于考虑更多的计划,优化时间也随之增加。 同时,随着计划搜索空间的扩大,训练时间逐渐增加,执行的计划数量也随之增加。 如图8所示,当设置为3时,FOSS以最小的GMRL实现最佳性能。
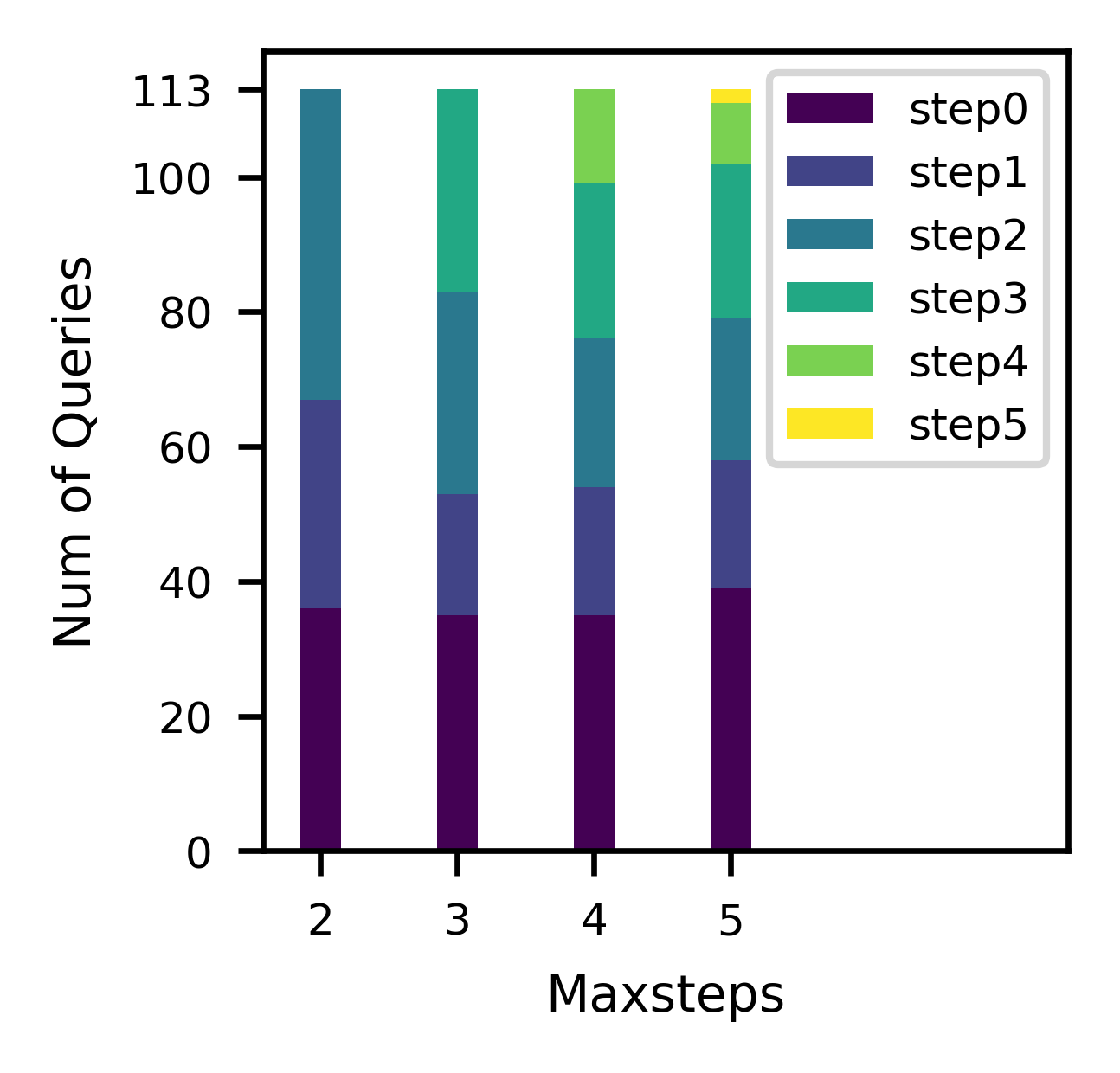
为了进行更深入的比较,如图6所示,我们分析了已知最佳计划的步骤状态分布,其中step0计划指的是原始计划, stepN计划是指从原始计划采取步骤的计划。 在 栏中,有大量的 step2 计划。 这表明 可能不够。 在的条形图中,step4和step5计划的比例相对较小。 尽管花费的训练时间几乎是 的两倍,但 产生的 GMRL 最低。 这是因为随着 的增加,较长的动作序列会使智能体的探索变得复杂,并使 从候选计划中选择一个好的计划变得更具挑战性。 正如其他两个结果所证明的那样,FOSS 总是在 1-3 个步骤内产生有效的计划。 综合考虑训练复杂度和实验效果,我们将设置为3。
VI-C2 模拟环境的影响
为了说明模拟环境的效果,我们在 FOSS 中禁用它。 它允许代理仅与真实环境交互。 由于在真实环境中执行大量查询,因此显着延长了训练时间。 为了使训练更加可行,我们必须将每次代理更新的查询数量减少到 200。 经过48小时的训练,尽管受益于更可靠的奖励反馈,但其表现仍然不尽如人意。 其最终的 GMRL 为 0.63,明显比 FOSS 差。 不足之处在于探索不够。 它表明了模拟环境的有效性。
VI-C3 验证阶段的影响
VI-C4 使用多代理进行训练
为了增强 FOSS 的稳健性,我们还集成了多代理开关。 FOSS 可以用不同的策略(例如不同的折扣因子)初始化 代理。 在训练模式下,它们单独与真实环境交互,生成执行延迟数据池。 然后这些数据被集成到新的执行缓冲区中并用于训练。 随后,它们与模拟环境交互以生成模拟体验并同时更新自身。 在推理模式下,对于给定的查询,代理独立生成候选计划,利用选择最佳计划,并从中选择最终最佳计划t2> 使用 制定最佳计划。
七相关工作
学习了查询优化器。 近年来,人们提出了各种学习查询优化器。 一些工作[4,5,7,6,10,8,9]将计划生成过程建模为MDP。 他们的主要目标是训练一个学习价值网络,以指导自下而上生成更具延迟效率的计划。 然而,该方法由于计划搜索效率低,训练成本较高,限制了其实用性。 其他工作[12,26,13,27]旨在使用提示集引导传统优化器中的计划生成。 该方法比较实用,但其粗粒度提示优化方法无法对连接顺序和物理运算符进行细粒度优化,限制了计划搜索空间。 自由和开源软件在这两种方法之间取得了平衡,提供实用性,同时仍然探索大部分优化可能性。
最近的作品[28, 29]建立在Bao[12]的基础上,采用了与Bao类似的提示集。 他们专注于使候选提示集的选择更加智能,而不是仅仅依赖专家知识。 他们的工作对计划指导员的进步做出了积极贡献。
强化学习。 强化学习可以分为无模型强化学习和基于模型强化学习。 前者在过去几年中经历了快速发展,许多经典算法[30,31,21,32,33]被提出,并在各个领域展示了优异的性能[34, 35 、 36、 37]。 然而,样本复杂度高的无模型强化学习很难直接应用于现实世界的任务,其中试错的成本可能很高[18]。 因此,一些学者致力于构建模拟环境模型,以更有效地与智能体交互。 FOSS遵循Dyna风格的[38]方法,使用学习到的环境模型为代理生成更多模拟经验数据。 除了上述方法之外,在许多基于模型的强化学习场景中,模拟环境模型是可微分的。 这使得能够通过差异化规划和价值梯度方法进行政策学习[18]。
从人类反馈中强化学习。 根据人类反馈进行强化学习 (RLHF) 是一种用于训练人工智能系统以与人类目标保持一致的技术。 RLHF 已成为微调 SOTA 大型语言模型的主要方法[39]。 目前使用的 RLHF 标准方法是 [40] 在 2017 年引入的。 它的框架与 FOSS 类似,需要两个样本的外部训练比较反馈给奖励模型。 然后将该奖励模型用于训练传统的强化学习,即策略优化。 主要区别在于,RLHF 接收来自人类的反馈,由于人类的主观性,使得样本标记更具挑战性,而 FOSS 则从 DBMS 的实际执行中获取反馈。
八结论
我们介绍 FOSS,一种新颖的基于 DRL 的查询优化系统。 自由开源软件的规划器从传统优化器生成的原始计划开始,通过逐步修改对这些计划进行优化实验,从而产生候选计划。 我们设计了一个不对称优势模型作为选择器,从候选计划中选择最优计划。 此外,为了提高训练效率,我们采用非对称优势模型作为奖励指标,并将其与传统优化器集成以构建模拟环境。 借助模拟环境,自由开源软件可以通过自引导来增强其优化能力。
据我们所知,FOSS 是开创性的基于学习的查询优化器,它通过对原始计划进行细粒度修改来实现更好的性能计划,并采用学习模型来加速 DRL 的训练过程。 我们相信FOSS为查询优化开辟了一条新的道路,值得进一步探索。
参考
- [1] P. G. Selinger, M. M. Astrahan, D. D. Chamberlin, R. A. Lorie, and T. G. Price, “Access path selection in a relational database management system,” in Proceedings of the 1979 ACM SIGMOD International Conference on Management of Data, ser. SIGMOD ’79. New York, NY, USA: Association for Computing Machinery, 1979, p. 23–34. [Online]. Available: https://doi.org/10.1145/582095.582099
- [2] V. Leis, A. Gubichev, A. Mirchev, P. Boncz, A. Kemper, and T. Neumann, “How good are query optimizers, really?” Proc. VLDB Endow., vol. 9, no. 3, p. 204–215, nov 2015. [Online]. Available: https://doi.org/10.14778/2850583.2850594
- [3] X. Zhou, C. Chai, G. Li, and J. Sun, “Database meets artificial intelligence: A survey,” IEEE Transactions on Knowledge and Data Engineering, vol. 34, no. 3, pp. 1096–1116, 2022.
- [4] R. Marcus and O. Papaemmanouil, “Deep reinforcement learning for join order enumeration,” in Proceedings of the First International Workshop on Exploiting Artificial Intelligence Techniques for Data Management, ser. aiDM’18. New York, NY, USA: Association for Computing Machinery, 2018. [Online]. Available: https://doi.org/10.1145/3211954.3211957
- [5] S. Krishnan, Z. Yang, K. Goldberg, J. M. Hellerstein, and I. Stoica, “Learning to optimize join queries with deep reinforcement learning,” ArXiv, vol. abs/1808.03196, 2018.
- [6] X. Yu, G. Li, C. Chai, and N. Tang, “Reinforcement learning with tree-lstm for join order selection,” in 2020 IEEE 36th International Conference on Data Engineering (ICDE), 2020, pp. 1297–1308.
- [7] R. Marcus, P. Negi, H. Mao, C. Zhang, M. Alizadeh, T. Kraska, O. Papaemmanouil, and N. Tatbul, “Neo: A learned query optimizer,” Proc. VLDB Endow., vol. 12, no. 11, p. 1705–1718, jul 2019. [Online]. Available: https://doi.org/10.14778/3342263.3342644
- [8] Z. Yang, W.-L. Chiang, S. Luan, G. Mittal, M. Luo, and I. Stoica, “Balsa: Learning a query optimizer without expert demonstrations,” in Proceedings of the 2022 International Conference on Management of Data, ser. SIGMOD/PODS ’22. New York, NY, USA: Association for Computing Machinery, 2022, pp. 931–944. [Online]. Available: https://doi.org/10.1145/3514221.3517885
- [9] T. Chen, J. Gao, H. Chen, and Y. Tu, “Loger: A learned optimizer towards generating efficient and robust query execution plans,” Proc. VLDB Endow., vol. 16, pp. 1777–1789, 2023.
- [10] J. Chen, G. Ye, Y. Zhao, S. Liu, L. Deng, X. Chen, R. Zhou, and K. Zheng, “Efficient join order selection learning with graph-based representation,” in Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, ser. KDD ’22. New York, NY, USA: Association for Computing Machinery, 2022, p. 97–107. [Online]. Available: https://doi.org/10.1145/3534678.3539303
- [11] M. A. Riedmiller, R. Hafner, T. Lampe, M. Neunert, J. Degrave, T. V. de Wiele, V. Mnih, N. M. O. Heess, and J. T. Springenberg, “Learning by playing - solving sparse reward tasks from scratch,” ArXiv, vol. abs/1802.10567, 2018. [Online]. Available: https://api.semanticscholar.org/CorpusID:3562704
- [12] R. Marcus, P. Negi, H. Mao, N. Tatbul, M. Alizadeh, and T. Kraska, “Bao: Making learned query optimization practical,” in Proceedings of the 2021 International Conference on Management of Data, ser. SIGMOD ’21. New York, NY, USA: Association for Computing Machinery, 2021, p. 1275–1288. [Online]. Available: https://doi.org/10.1145/3448016.3452838
- [13] R. Zhu, W. Chen, B. Ding, X. Chen, A. Pfadler, Z. Wu, and J. Zhou, “Lero: A learning-to-rank query optimizer,” Proc. VLDB Endow., vol. 16, no. 6, p. 1466–1479, apr 2023. [Online]. Available: https://doi.org/10.14778/3583140.3583160
- [14] X. Yu, C. Chai, G. Li, and J. Liu, “Cost-based or learning-based? a hybrid query optimizer for query plan selection,” Proc. VLDB Endow., vol. 15, no. 13, p. 3924–3936, sep 2022. [Online]. Available: https://doi.org/10.14778/3565838.3565846
- [15] A. Vaswani, N. M. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” in Neural Information Processing Systems, 2017. [Online]. Available: https://api.semanticscholar.org/CorpusID:13756489
- [16] Y. Zhao, G. Cong, J. Shi, and C. Miao, “Queryformer: A tree transformer model for query plan representation,” Proc. VLDB Endow., vol. 15, no. 8, p. 1658–1670, apr 2022. [Online]. Available: https://doi.org/10.14778/3529337.3529349
- [17] E. B. Baruch, T. Ridnik, N. Zamir, A. Noy, I. Friedman, M. Protter, and L. Zelnik-Manor, “Asymmetric loss for multi-label classification,” 2021 IEEE/CVF International Conference on Computer Vision (ICCV), pp. 82–91, 2020. [Online]. Available: https://api.semanticscholar.org/CorpusID:221995872
- [18] F. Luo, T. Xu, H. Lai, X.-H. Chen, W. Zhang, and Y. Yu, “A survey on model-based reinforcement learning,” ArXiv, vol. abs/2206.09328, 2022.
- [19] T. M. Moerland, J. Broekens, and C. M. Jonker, “Model-based reinforcement learning: A survey,” Found. Trends Mach. Learn., vol. 16, pp. 1–118, 2020.
- [20] “Ray,” https://www.ray.io, 2023.
- [21] J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,” ArXiv, vol. abs/1707.06347, 2017.
- [22] M. Poess, B. Smith, L. Kollar, and P. Larson, “Tpc-ds, taking decision support benchmarking to the next level,” in Proceedings of the 2002 ACM SIGMOD International Conference on Management of Data, ser. SIGMOD ’02. New York, NY, USA: Association for Computing Machinery, 2002, p. 582–587. [Online]. Available: https://doi.org/10.1145/564691.564759
- [23] “Bao project,” https://rmarcus.info/bao_docs/, 2021.
- [24] “Balsa project,” https://github.com/balsa-project/balsa, 2022.
- [25] “Hybridqo project,” https://github.com/yxfish13/HyperQO, 2022.
- [26] L. Sun, T. Ji, C. Li, and H. Chen, “Deepo: A learned query optimizer,” Proceedings of the 2022 International Conference on Management of Data, 2022. [Online]. Available: https://api.semanticscholar.org/CorpusID:249579130
- [27] X. Chen, H. Chen, Z. Liang, S. Liu, J. Wang, K. Zeng, H. Su, and K. Zheng, “Leon: A new framework for ml-aided query optimization,” Proc. VLDB Endow., vol. 16, pp. 2261–2273, 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:259246460
- [28] C. Anneser, N. Tatbul, D. Cohen, Z. Xu, N. P. Laptev, R. Marcus, P. Pandian, and R. M. AutoSteer, “Autosteer: Learned query optimization for any sql database,” Proceedings of the VLDB Endowment, 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:261259493
- [29] L. Woltmann, J. Thiessat, C. Hartmann, D. Habich, and W. Lehner, “Fastgres: Making learned query optimizer hinting effective,” Proceedings of the VLDB Endowment, 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:261199199
- [30] V. Mnih, K. Kavukcuoglu, D. Silver, A. Graves, I. Antonoglou, D. Wierstra, and M. A. Riedmiller, “Playing atari with deep reinforcement learning,” ArXiv, vol. abs/1312.5602, 2013.
- [31] H. Van Hasselt, A. Guez, and D. Silver, “Deep reinforcement learning with double q-learning,” in Proceedings of the AAAI conference on artificial intelligence, vol. 30, no. 1, 2016.
- [32] V. Mnih, A. P. Badia, M. Mirza, A. Graves, T. Harley, T. P. Lillicrap, D. Silver, and K. Kavukcuoglu, “Asynchronous methods for deep reinforcement learning,” in Proceedings of the 33rd International Conference on International Conference on Machine Learning - Volume 48, ser. ICML’16. JMLR.org, 2016, p. 1928–1937.
- [33] T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine, “Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor,” International Conference on Machine Learning (ICML), 2018.
- [34] V. Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. A. Riedmiller, A. K. Fidjeland, G. Ostrovski, S. Petersen, C. Beattie, A. Sadik, I. Antonoglou, H. King, D. Kumaran, D. Wierstra, S. Legg, and D. Hassabis, “Human-level control through deep reinforcement learning,” Nature, vol. 518, pp. 529–533, 2015.
- [35] D. Silver, A. Huang, C. J. Maddison, A. Guez, L. Sifre, G. van den Driessche, J. Schrittwieser, I. Antonoglou, V. Panneershelvam, M. Lanctot, S. Dieleman, D. Grewe, J. Nham, N. Kalchbrenner, I. Sutskever, T. P. Lillicrap, M. Leach, K. Kavukcuoglu, T. Graepel, and D. Hassabis, “Mastering the game of go with deep neural networks and tree search,” Nature, vol. 529, pp. 484–489, 2016.
- [36] D. Silver, J. Schrittwieser, K. Simonyan, I. Antonoglou, A. Huang, A. Guez, T. Hubert, L. baker, M. Lai, A. Bolton, Y. Chen, T. P. Lillicrap, F. Hui, L. Sifre, G. van den Driessche, T. Graepel, and D. Hassabis, “Mastering the game of go without human knowledge,” Nature, vol. 550, pp. 354–359, 2017.
- [37] S. Levine, C. Finn, T. Darrell, and P. Abbeel, “End-to-end training of deep visuomotor policies,” J. Mach. Learn. Res., vol. 17, pp. 39:1–39:40, 2015.
- [38] R. S. Sutton, “Dyna, an integrated architecture for learning, planning, and reacting,” SIGART Bull., vol. 2, no. 4, p. 160–163, jul 1991. [Online]. Available: https://doi.org/10.1145/122344.122377
- [39] S. Casper, X. Davies, C. Shi, T. K. Gilbert, J. Scheurer, J. Rando, R. Freedman, T. Korbak, D. Lindner, P. Freire, T. Wang, S. Marks, C.-R. Ségerie, M. Carroll, A. Peng, P. J. Christoffersen, M. Damani, S. Slocum, U. Anwar, A. Siththaranjan, M. Nadeau, E. J. Michaud, J. Pfau, D. Krasheninnikov, X. Chen, L. L. di Langosco, P. Hase, E. Biyik, A. D. Dragan, D. Krueger, D. Sadigh, and D. Hadfield-Menell, “Open problems and fundamental limitations of reinforcement learning from human feedback,” ArXiv, vol. abs/2307.15217, 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:260316010
- [40] P. F. Christiano, J. Leike, T. B. Brown, M. Martic, S. Legg, and D. Amodei, “Deep reinforcement learning from human preferences,” ArXiv, vol. abs/1706.03741, 2017. [Online]. Available: https://api.semanticscholar.org/CorpusID:4787508