通过基础模型迈向通用机器人:
调查和荟萃分析
摘要
构建能够在任何环境、任何物体上无缝操作的通用机器人,并利用各种技能完成不同的任务一直是人工智能领域的长期目标。 然而不幸的是,大多数现有的机器人系统都受到限制——它们是为特定任务而设计、在特定数据集上进行训练并在特定环境中部署的。 这些系统通常需要广泛标记的数据,依赖于特定于任务的模型,在现实场景中部署时存在许多泛化问题,并且很难对分布变化保持鲁棒性。 受到自然语言处理 (NLP) 和计算机等研究领域中网络规模、大容量预训练模型(即基础模型)令人印象深刻的开放集性能和内容生成能力的推动Vision (CV),我们致力于本次调查探索 (i) 如何将 NLP 和 CV 的现有基础模型应用于机器人领域,并探索 (ii) 机器人特定的基础模型是什么样子。 我们首先概述传统机器人系统的构成以及使其普遍适用的基本障碍。 接下来,我们建立一个分类法来讨论当前的工作,探索如何利用现有的机器人基础模型并开发适合机器人的模型。 最后,我们讨论了使用基础模型来实现通用机器人系统的主要挑战和有希望的未来方向。 我们鼓励读者查看我们的实时 GitHub 存储库555本文当前版本为v1.1-2023.12(格式为‘[major].[次要]-YYYY.MM’)。 资源,包括本次调查中审查的论文以及用于开发机器人基础模型的相关项目和存储库:https://robotics-fm-survey.github.io/。
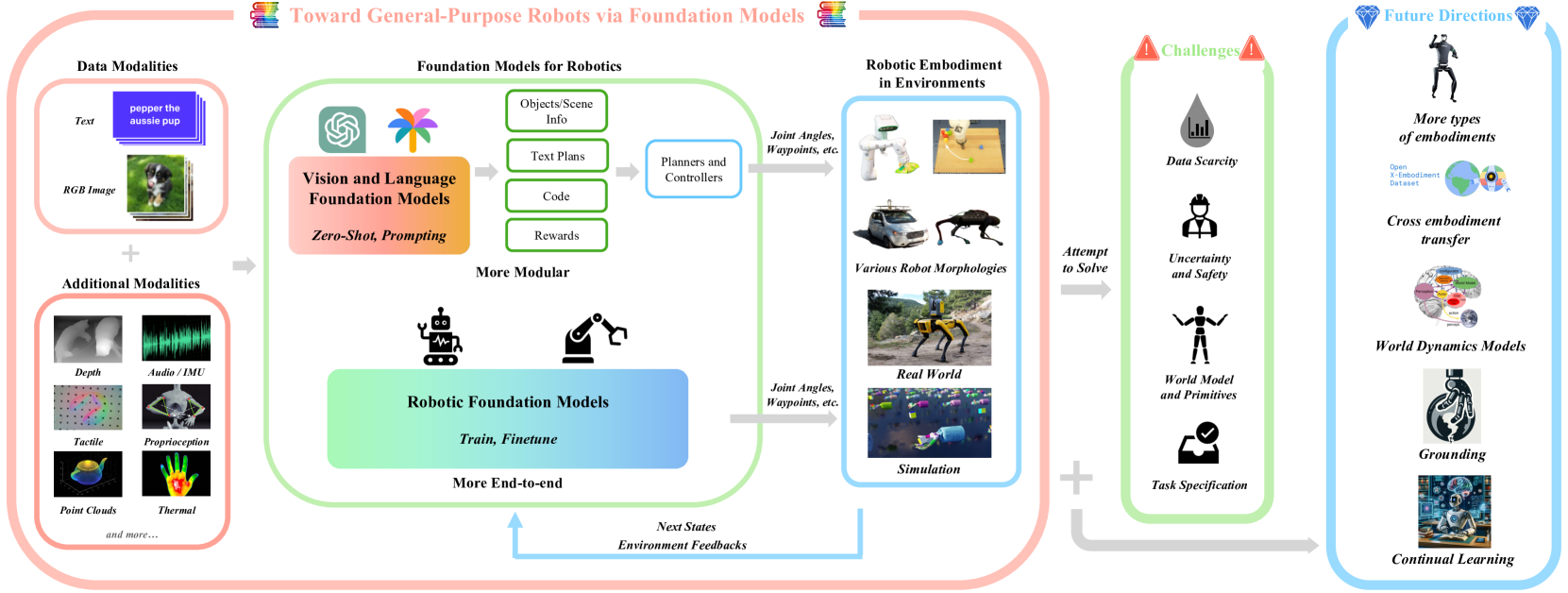
1 概述
1.1简介
在开发能够在不同环境中运行和适应不同环境的自主机器人系统方面,我们仍然面临许多挑战。 以往利用传统深度学习方法的机器人感知系统通常需要大量标记数据来训练监督学习模型[1,2,3];与此同时,用于构建这些大型数据集的众包标记流程仍然相当昂贵。 此外,由于经典监督学习方法的泛化能力有限,训练后的模型通常需要精心设计的领域适应技术来将这些模型部署到特定的场景或任务[4, 5],这通常需要进一步的数据收集和标记步骤。 同样,经典的机器人规划和控制方法通常需要仔细建模世界、自我代理的动态和/或其他代理的行为[6,7,8]。 这些模型是为每个单独的环境或任务构建的,并且通常需要在发生变化时重新构建,从而暴露了它们有限的可移植性[8];事实上,在许多情况下,建立有效的模型要么成本太高,要么很棘手。 尽管基于深度(强化)学习的运动规划[9, 10]和控制方法[11,12,13,14]可以帮助缓解这些问题,但它们仍然遭受分布变化和普遍性降低的影响[15, 16]。
在构建通用机器人系统面临的挑战的同时,我们注意到自然语言处理(NLP)和计算机视觉(CV)领域的显着进步——随着大语言模型(大语言模型)的引入[17] 对于NLP,引入扩散模型的高保真图像生成[18, 19],以及大容量视觉模型和Vision的CV任务的零样本/少样本泛化语言模型 (VLM)[20,21,22]。 这些大容量的视觉和语言模型被称为“基础模型”[23],或者简称为大型预训练模型(LPTMS),也已应用于机器人领域[24, 25, 26],具有赋予机器人系统开放世界感知、任务规划甚至运动控制能力的潜力。 除了在机器人技术中应用现有的视觉和/或语言基础模型之外,我们还看到开发更多机器人技术特定模型的巨大潜力,例如用于操纵 [27, 28] 或运动的动作模型导航规划模型[29]。 这些机器人基础模型在不同的任务甚至实施例中表现出强大的泛化能力。 视觉/语言基础模型也已直接应用于机器人任务[30, 31],显示了将不同机器人模块融合到单个统一模型中的可能性。
尽管我们看到视觉和语言基础模型在机器人任务中的应用前景广阔,并且开发了新颖的机器人基础模型,但机器人技术中的许多挑战仍然遥不可及。 从实际部署的角度来看,模型通常不可重复,缺乏多实施例泛化,或者无法准确捕获环境中可行(或可接受)的内容。 此外,大多数出版物都利用基于 Transformer 的架构,并专注于对象和场景的语义感知、任务级规划或控制[28];机器人系统的其他组件可以从跨域泛化能力中受益,但尚未得到充分探索,例如世界动力学的基础模型或可以执行符号推理的基础模型。 最后,我们想强调需要更大规模的现实世界数据以及具有不同机器人任务的高保真模拟器。
在本文中,我们研究了基础模型在机器人技术中的应用,旨在了解基础模型如何帮助缓解核心机器人挑战。 我们使用术语“机器人基础模型”来包含两个不同的方面:(1)将现有(主要)视觉和语言模型应用于机器人,主要通过零样本和情境学习; (2) 通过使用机器人生成的数据,开发和利用专门用于机器人任务的机器人基础模型。 我们总结了机器人论文基础模型的方法,并对我们调查的论文的实验结果进行了荟萃分析。 图 4 总结了本文的主要组成部分。
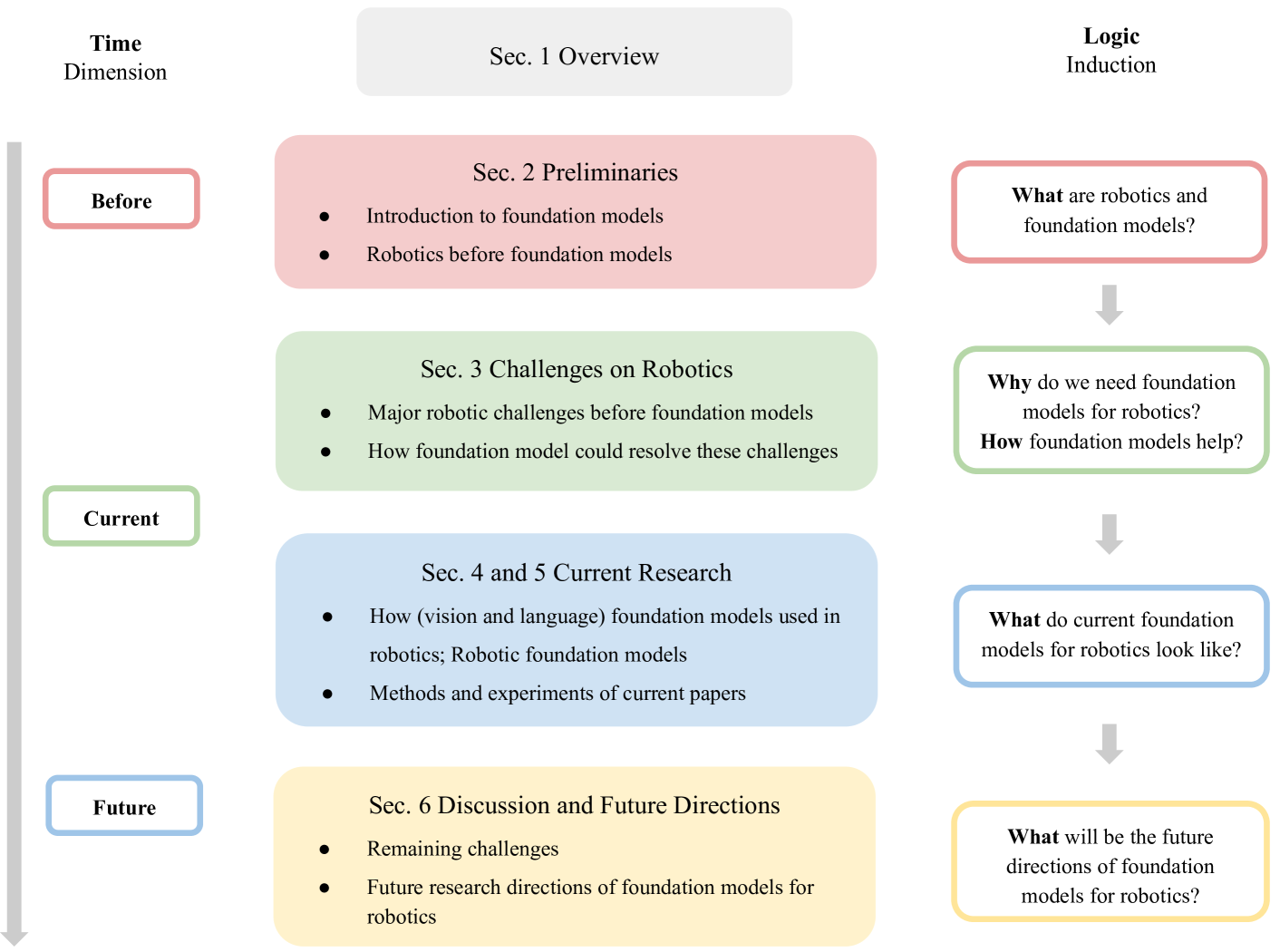
本文总体结构如图2所示。 在第2节中,我们简要介绍了基础模型时代之前的机器人研究,并讨论了基础模型的基础知识。 在第3节中,我们列举了机器人研究中的挑战,并讨论了基础模型如何缓解这些挑战。 在4节中,我们总结了机器人基础模型的研究现状。 最后,在第 6 节中,我们提供了可能对该研究交叉产生重大影响的潜在研究方向。
1.2相关调查论文
最近,随着基础模型的流行,出现了各种关于视觉和语言基础模型的调查论文,值得一提[32,33,34,35]。 这些调查论文涵盖基础模型,包括视觉基础模型(VFM)[36, 37]、大语言模型(大语言模型)[34]、视觉语言模型(VLM) [38, 39] 和视觉内容生成模型 (VGM) [32]。 由于机器人技术的基础模型仍然是相对新兴的领域,因此结合基础模型和机器人技术的现有调查论文并不多,也许最相关的调查论文是[35,40,41,42,43]然而,这些论文与我们的论文仍然存在显着差异,例如:Yang et al. [35] 和 Wang et al. [40] 关注广义定义的自主代理,而不是物理机器人; Lin 等人 [41]专注于导航大语言模型;基础模型和机器人技术之间的联系仅限于[42]。 与[43]相比,我们提出了对当前研究方法的更多细分,提供了对实验的详细分析,并重点关注基础模型如何解决典型的机器人挑战。 同时,Firoozi 等。 al. [44] 进行了一项有关机器人基础模型的调查。 他们和我们的工作都揭示了在机器人技术中使用基础模型的机遇和挑战,并确定了进一步扩展它们的关键陷阱。 他们的工作重点是基础模型如何有助于提高机器人能力以及未来的挑战。 相比之下,我们的调查试图对机器人能力以及基础模型进行分类,以提高这些能力。 我们还提出了机器人(第一)基础模型和机器人技术中使用的其他基础模型之间的二分法,并对我们调查的论文进行了全面的元分析。
在本文中,我们提供了一项调查,其中包括应用于机器人技术的现有单模态和多模态基础模型,以及我们所知的各种机器人任务中所有形式的机器人基础模型。 我们还将调查的论文范围缩小到仅那些在高保真模拟环境中进行真实物理机器人实验或使用真实机器人数据集的论文。 我们相信,通过这样做,它可以帮助我们了解基础模型在现实世界机器人应用中的力量。
2 预赛
在本节中,我们将介绍一些预备知识,以帮助读者更好地理解本文的内容。 由于我们专注于以机器人技术为中心的基础模型,因此我们将首先介绍机器人技术的基础知识和当前的技术水平。 这些基础知识将重点关注基础模型应用于机器人之前的方法。 为了便于组织,我们根据机器人的功能引入机器人模块,例如感知2.1.1、规划2.1.2和控制2.1.3 我们注意到,虽然我们分别介绍这些模块,但这些模块之间的界限通常是模糊的[45, 12]:这些模块通常协同连接,促进端到端的可微性——允许梯度跨不同模块的流动,特别是在基于学习的方法中。 本节的第二个重点是介绍基础模型,主要集中在 NLP 和 CV 领域;这些模型包括:大语言模型、VLM、视觉基础模型以及文本条件图像生成模型。
2.1 机器人系统的组成部分
2.1.1 机器人感知
机器人需要感知机制,以便从原始传感器观察中提取语义知识,建立状态表示,并在其操作环境中进行推理。 与典型的计算机视觉系统不同,机器人感知强调实时能力、多模态(RGB、深度、LiDAR、IMU、触觉等)的使用、与其他机器人系统模块(决策、规划、控制)的耦合,并与实施例和环境接地[46, 47]。
被动感知
机器人感知系统中典型计算机视觉算法最常见的用例是场景理解。 这里的目标是通过处理视觉信号(例如,2D 图像数据、雷达信息、LiDAR/RGB-D 点云)来提取有关环境的语义和几何属性的见解,也许是为了执行目标检测和跟踪等特定任务、语义分割、姿势估计、新颖的视图合成或场景重建[48,49,50,51,52]。 然而,主流的基于学习的方法的问题在于,它们主要依赖于大量的标记数据进行训练,而获取大规模标签尤其具有挑战性。 此外,这些方法在分布外场景中往往会崩溃,使得它们对于广泛部署而言过于脆弱。 正如部分2.2.1中所讨论的,这个问题已经通过视觉基础模型令人印象深刻的开放集能力得到了很大程度的缓解[ 53、22]。
状态估计
状态估计是基于传感器测量估计机器人的姿态或速度的具有挑战性的问题。 同步定位与建图(SLAM)任务将姿态估计和建图问题无缝地集成在一起。 状态估计和 SLAM 可以使用各种传感器模式来解决,基于视觉的方法[54,55,56,57,58,59]和基于 LiDAR 的技术的集合证明了这一点[60, 61, 62],利用惯性测量单元 (IMU) [63, 64] 的方法,以及涉及多个传感器的传感器融合方法[65, 66, 67, 68、69]。 虽然传统方法通常依赖于严格的基于几何的解决方案,但最近人们对基于学习的方法越来越感兴趣,这种方法利用监督[70, 71]和自我监督[72 、73、74、75]方法。 这些基于学习的方法已经证明了它们能够提供准确的姿势跟踪结果,并且在某些情况下,即使不使用深度传感器也能实现密集重建。
主动感知
先前介绍的方法使机器人只能以被动方式感知环境,其中信息获取或决策在感知系统的暂时演化中不起作用。 由于机器人会移动并经常与环境交互,因此机器人还应该能够主动感知环境。 先前解决主动感知问题的方法主要着眼于与环境交互的镜头[76]或通过改变观看方向来获取更多视觉信息[77,78,79].
2.1.2机器人决策与规划
经典规划
机器人规划是在给定自身和世界模型的情况下组织机器人应执行的一组动作的过程,以达到期望的状态并最大限度地减少执行这些动作时的累积成本。 运动规划旨在找到一条无碰撞路径来达到所需状态。 基于搜索的规划[80,81,82,83,84]利用启发式方法和图表,基于问题的离散表示来计算机器人的轨迹。 另一个主要领域,基于采样的规划[85,86,87,88,89,90],寻求配置空间中的随机采样点,通过连接附近的点或增量生成来找到到达所需状态的路径next 状态,非常适合高维规划和连续空间。
任务规划[91]处理具有大状态空间的易处理和紧凑表示的离散域,通常利用域的结构属性和对象级抽象。 紧凑表示的方法包括将状态表示分解为一组较小的状态变量,使用一组指定机器人可以执行动作的状态的前提条件,以及用于符号推理的面向对象抽象[92].
基于学习的规划
规划方面存在较新的工作,它们使用强化学习[93, 94]并将运动规划制定为端到端问题[9, 10]。 在导航中,ReViND [95]和FastRLAP [94]使用离线强化学习来学习规划策略视觉导航。 通过优化静态数据集的价值函数,机器人可以在短时间内学习驾驶行为[94]。 此外,利用奖励重新标记的优点是可以让机器人根据用户指定的奖励[95]获得不同的导航行为。 任务规划学习包括最近将强化学习与任务规划相结合的工作[96, 97]以提高动态环境中的适应性并生成计划,以及学习任务规划的符号抽象模型和表示[98, 99]。
2.1.3 机器人动作生成
经典控制
通过直接驱动或电机控制实现的低级动作控制是大多数机器人堆栈的最后一步。 堆栈的这一部分通常取决于确切的平台,并且通常包含动力学和执行器约束,从而通过将机器人保持在其操作范围内来确保生成的动作的可行性。 虽然控制输入通常位于连续空间中,但运动原语通常用于提供一组离散的动作,以便于与更高级别的决策循环连接。 可以说,PID 控制回路是机器人系统中使用最广泛的底层控制结构。 当成本函数可用时,基于优化的方法,又名: 最优控制,例如模型预测控制 (MPC) 及其变体 [100, 101, 102, 103] 通常用于在后退视野设置中生成动作序列。 模型预测路径积分 (MPPI) 控制器[104]是 MPC 的一种变体,广泛应用于学习成本图的采样公式中。
基于学习的控制
在机器人控制中应用模仿学习[105]或强化学习[106]已经研究了数十年。 随着深度学习[107]和深度强化学习[108, 109]的成功,我们看到这一领域的研究近年来获得了大量成功案例[110,12,111,112,13,113]。
模仿学习旨在通过模仿某些专家的演示来学习控制策略,这可能隐含在轨迹数据集中。 它可以是监督学习的形式,直接从专家演示中学习动作[114],逆向强化学习[115, 116],学习奖励函数,以及对抗性模仿通过生成对抗网络学习策略[117, 118]。 模仿学习广泛应用于各种机器人控制应用,包括:城市驾驶[101]、高速赛车[119]、自主无人机杂技[110 ],通过模仿动物学习运动技能[11],通过对抗性模仿学习学习四足敏捷技能[120]。
强化学习 (RL) [121] 通常在马尔可夫决策过程的背景下使用,以便通过累积奖励来学习和优化控制策略。 与基于最优控制的方法不同,强化学习方法可能不需要动力学模型。 机器人强化学习中的许多现有工作都遵循无模型学习范式,其中策略学习直接映射传感器观察结果(例如,图像 [12, 111, 122]、本体感觉 [13、 113、123] 或两者 [124])来生成操作。 无模型方法通常具有样本效率低下的缺点。 基于模型的强化学习方法[125]通过学习世界动力学模型然后规划或学习控制策略来提供可行的解决方案。 这些世界动力学模型可以是视觉观察[126, 127]的形式,也可以是基于本体感觉的动力学模型[14]。 然而,上述在线强化学习方法在现实世界中可能会引起安全问题[95]。 离线强化学习方法[95,128,129]试图解决这个问题,因为学习仅基于离线数据集。 我们已经看到了一些在机器人技术中应用离线强化学习的作品,例如视觉导航[93]、高速地面车辆驾驶[94]和操纵[130, 131]。
2.2基础模型简介
根据[23]中的定义,基础模型是在广泛数据(通常使用大规模自我监督)上进行训练的任何模型,可以转移或调整(例如微调)以广泛的下游任务。 现有成功的基础模型主要来自CV和NLP领域,例如(从单模态到多模态排序):视觉基础模型(VFM;第 2.2.1 节)、大型语言模型(大语言模型;第 2.2.3 节)、视觉语言模型(VLM;2.2.4 节)和大型多模态模型(LMM;2.2.5 节)。 最近,我们还看到专门为机器人任务设计并在机器人数据上进行训练的基础模型(“机器人基础模型”)的兴起:这个特定主题将在稍后的 4.2 节中介绍。
2.2.1 视觉基础模型(VFM)
随着大语言模型和 VLM 的出现,人们提出了几种基于视觉的基础模型(VFM)[132,21,20,22]。 由于其在像素和对象级别上令人印象深刻的领域不变性和语义特性[133,134,135,136,137],这些视觉基础模型已被广泛应用于下游被动感知任务。 此外,这些重大进步是通过自我监督[133]和/或大规模数据管理[22, 21]实现的。
自监督 VFM 系列可大致分为以下三个子类:(1) 联合嵌入预测架构(JEPA;[138]),(2) 基于对比学习的方法[53, 139]、(3) 和屏蔽自动编码器 (MAE; [132]) JEPA 采用 Bootstrap Your Own Latent (BYOL; [140])自我监督技术的风格,其中主要监督信号是预测图像不同增强中的相似嵌入。 在 JEPA 方法中,最值得注意的是 DINO [20]、DINOv2 [22]、I-JEPA [141] 和 MC-JEPA [142]。 最近的探索表明,这些基于联合嵌入的方法可以捕获更长期的全局模式和面向形状的特征[133, 134]。 另一方面,基于对比学习的方法利用多模态数据的弱监督来学习不同模态的共同潜在空间。 值得注意的方法包括 CLIP [53],它使用大规模图像标题对。 除了这两类之外,MAE [132] 还构成了另一类模型,经过训练以重建屏蔽输入作为借口任务。 探索表明,这些模型捕获本地标记级语义上下文,从而使其在语义分割等密集预测问题中广泛流行[133, 134]。
通过仔细管理大型数据集而启用的两个著名的 VFM 是分段任意模型 (SAM [21]) 和 DINOv2 [22]。 SAM 利用基于迭代模型预测的管理流程获得了 10 亿个用于监督学习的语义分割掩码。 事实证明,在大规模精选数据上训练的 SAM 模型在广泛的领域中表现出了令人印象深刻的实例分割性能。 同样,DINOv2 [22] 是一个自监督模型,使用基于模型预测的精选数据(包含 1.42 亿张图像)进行训练。 事实证明,这种对精选数据的大规模自我监督使 DINOv2 能够比针对特定任务训练的模型和对比零样本模型(例如 CLIP)表现得更好,同时展示了令人印象深刻的语义一致性。
2.2.2 视觉内容生成模型(VGM)
由于扩散模型的进展[143],文本条件图像生成模型最近因其直接从语言提示生成新颖的高保真图像的惊人能力而受到极大关注。 GLIDE [144] 是一种文本条件扩散模型,具有 CLIP 指导和无分类器指导。 DALLE-2 [18] 提出了一种两阶段扩散模型,该模型由先验组成,该先验在给定文本标题的情况下生成 CLIP 图像嵌入和生成以编码图像嵌入为条件的图像的解码器。 IMAGEN [19] 是另一种具有无分类器指导的文本条件扩散模型。 与之前的方法不同,它提出了动态阈值训练来生成更真实的图像,并提出了 U-Net 结构来提高效率。 为了方便起见,我们在本文中将这种类型的基础模型命名为视觉内容生成模型(VGM)。
2.2.3 大型语言模型(大语言模型)
大型语言模型(大语言模型)是一种语言模型,以其能够用最少的特定任务训练数据处理各种语言任务而闻名,这使其有别于传统的人工智能模型[145]。 术语大指的是模型大小和数据集大小。 此外,语言表示模型是在互联网规模上使用单一模式(即文本)进行训练的。 大语言模型的关键发展是引入了Transformer架构,由于Transformer的高度并行特性,使得大规模数据的高效训练成为可能,使得扩展文本序列的处理更加高效。 基于 Transformer 架构构建的两条工作线:生成式预训练 Transformer (GPT) 系列 [146, 17] 和 Transformer 双向编码器表示 (BERT) 系列 [147]. GPT 被训练为解码器,其任务是预测序列中的下一个单词,而 BERT 被训练为编码器,专注于理解句子之间的上下文关系。 然而,根据Yang等人[148]的说法,自2021年以来,BERT家族并没有看到显着的进步,目前所有最先进的大语言模型建立在 GPT 结构之上。 另一种对 GPT-3.5 模型 (ChatGPT) 等模型的成就做出贡献的技术是人类反馈强化学习 (RLHF) 范式[149]。 该技术将 Transformer 的输出与通过逆强化学习学到的人类偏好保持一致,使模型能够生成更接近人类、更流畅的句子。
然而,大语言模型的局限性仍然很大,特别是它们倾向于产生可信的输出。 此外,由于仅接受单一文本模态训练的限制,大语言模型缺乏对现实世界对象的引用,因此无法准确回答诸如“我可以把这个西瓜放进搅拌机里吗?”。 这种缺乏空间基础的问题对于大语言模型在机器人领域的应用尤为重要。 因此,最近的研究开始将其他信息源(例如视觉)集成到 Transformer 架构中。
2.2.4 视觉语言模型 (VLM)
视觉语言模型(VLM)代表了生成模型的另一个重大进步。 这些模型在需要理解视觉内容和语言的任务中表现出色,例如开放集图像分类[53]、对象检测[150]和分割 [151]、视觉问答(VQA)[152]等。 这些模型利用大规模数据集和复杂的神经网络架构(通常是 Transformer 的变体)来学习图像与其文本描述或查询之间的相关性。 这种方法使他们能够执行一系列任务,而无需进行特定任务的训练,展现出令人印象深刻的泛化能力。 根据预训练方法,它们可以大致分为两大类:对比学习模型和生成预训练模型。
基于对比学习的模型,例如CLIP [53]和ALIGN [153] ,通过使匹配图像-文本对的表示在嵌入空间中更接近,同时将非匹配对分开,来训练理解图像和文本之间的对应关系。 例如,CLIP 能够理解细致入微的文本描述及其相应的图像,因此在各种视觉分类任务中表现出色。 同样,ALIGN 专注于对齐大规模图像文本对,显着提高图像字幕和视觉问答等任务的性能。 生成预训练模型,例如ViLBERT [152]和VL-BEiT [154]采用与大语言模型2.2.3类似的训练方法。
结合这两种方法的优点,Flamingo[155]结合了一个大的冻结语言模型,保留了预训练固有的上下文少样本学习能力语言模型。 相反,GIT [156] 采用大型对比预训练图像编码器,并伴有相对较小的文本解码器。 Flamingo 和 GIT 都首先通过对比学习预训练图像编码器,然后进行生成预训练。
最近,BLIP [157] 和 BLIP-2 [158] 已成为 VLM 中的变革模型,引入了一种课程学习策略,从更简单的任务引导到更复杂的任务,显着提高图像字幕和视觉问答等任务的表现。 最新的 GPT 迭代 GPT-4 [159] 引入了处理文本和视觉输入的功能。 然而,截至上次更新,这些新的多式联运功能的技术细节和范围尚未发布。 总的来说,这些模型体现了 VLM 的快速进步,每个模型都有助于多模态系统在理解和基于视觉数据生成类人响应方面的鲁棒性和适应性。
2.2.5 大型多模式模型 (LMM)
视觉和语言模式的结合揭示了自我监督学习的巨大潜力。 因此,很自然地超越视觉和语言,开发具有更多模式的新型基础模型。 这些模型被称为大型多模式模型 (LMM)。 附加模式丰富多样,例如结合图像、文本、深度、热和音频的模型,例如 ImageBind [139];结合文本、图像、视频和音频的模型,例如 NExT-GPT [160] 和 Audio-GPT [161];结合语言文本和音频的模型,例如 SpeechGPT [162];以及将点云与视觉和语言相结合的模型,例如ULIP[163]。 这些 LMM 使用不同的训练方法,例如对比预训练 [139] 或通过学习输入/输出投影 [160] 来微调大语言模型。 这些 LMM 中显示的对比学习方法与大语言模型非常相似,因为不同模态的嵌入是相互对齐的。 这些基于多模态对比学习的方法可以实现跨模态检索,并带来更有趣的应用,例如音频到图像生成等。
3 机器人技术的挑战
在本节中,我们总结了典型机器人系统中的各个模块面临的五个核心挑战,每个挑战将在以下小节中详细介绍。 尽管之前的文献(1.2节)中已经讨论了类似的挑战,但本节主要关注根据当前研究结果的证据,通过适当利用基础模型可能解决的挑战。 我们还在图 3 中描述了本节中的分类,以便于查看。
3.1 泛化
机器人系统常常难以准确感知和理解其环境。 计算机视觉、物体识别和语义理解的局限性使得机器人很难与周围环境进行有效的交互。 传统的机器人系统通常依赖于手工分析算法,这使得适应新的或未见过的情况变得具有挑战性。 他们还缺乏将训练从一项任务推广到另一项任务的能力,这进一步限制了它们在现实世界应用中的实用性。 这种泛化能力还体现在不同任务、环境和机器人形态下规划和控制的泛化上。 例如,需要针对特定环境调整经典运动规划器和控制器等的特定超参数[164,102,103];基于强化学习的控制器很难在不同的任务和环境之间迁移[47, 165]。 此外,由于机器人硬件的差异,跨不同机器人形态的模型迁移也具有挑战性[166, 167]。 通过在机器人技术中应用基础模型,泛化问题得到了部分解决,这将在下一节4中讨论。 进一步的挑战,例如不同机器人形态的泛化,仍然艰巨。
3.2数据稀缺
数据一直是基于学习的机器人方法的基石。 对大规模、高质量数据的需求对于开发可靠的机器人模型至关重要。 人们已经尝试收集现实世界中的大规模数据集,包括自动驾驶[1,2,168]、机器人操纵轨迹[112,111,169] 等 从人类演示中收集机器人数据的成本很高[27]。 使用机器人的任务和环境多种多样,甚至使在现实世界中收集足够和广泛数据的过程变得复杂。 此外,出于安全考虑,在现实环境中收集数据可能会出现问题[164]。 为了克服这些挑战,许多工作[170,171,172,173,174,175]尝试在模拟环境中生成合成数据。 这些模拟提供了真实的虚拟世界,机器人可以在其中学习并将其技能应用于现实生活场景。 模拟还允许域随机化,以及更新模拟器参数以更好地匹配现实世界物理[164]的潜力,帮助机器人开发多功能策略。 然而,这些模拟环境仍然有其局限性,特别是在对象的多样性方面,使得很难将学到的技能直接应用于现实世界的情况。 收集规模与用于训练基础模型的互联网规模图像/文本数据相当的真实世界机器人数据尤其具有挑战性。 一种有前途的方法是跨不同实验室和机器人类型进行协作数据收集[176],如图3(a)所示。 然而,对 Open-X 实施例数据集的深入分析揭示了有关数据类型可用性的某些限制。 首先,用于数据收集的机器人形态是有限的;在前 35 个数据集中,有 30 个专门用于单臂操作任务。 只有一个数据集涉及四足动物的运动,并且一个数据集解决双手任务。 其次,这些操作任务的主要场景类型是桌面设置,通常使用玩具厨房物品。 此类物体具有固有的假设,包括刚性和可忽略不计的重量,这可能无法准确地代表更广泛的现实世界场景。 第三,我们对数据收集方法的检查表明人类专家的参与占主导地位,主要通过虚拟现实(VR)或触觉设备。 这种对人类专业知识的依赖凸显了获取高质量数据的挑战,并表明需要大量的人类监督。 例如,RT-1 机器人动作数据集需要 17 个月的收集期,这凸显了在人类参与的情况下积累数据所需的大量努力和时间投入。

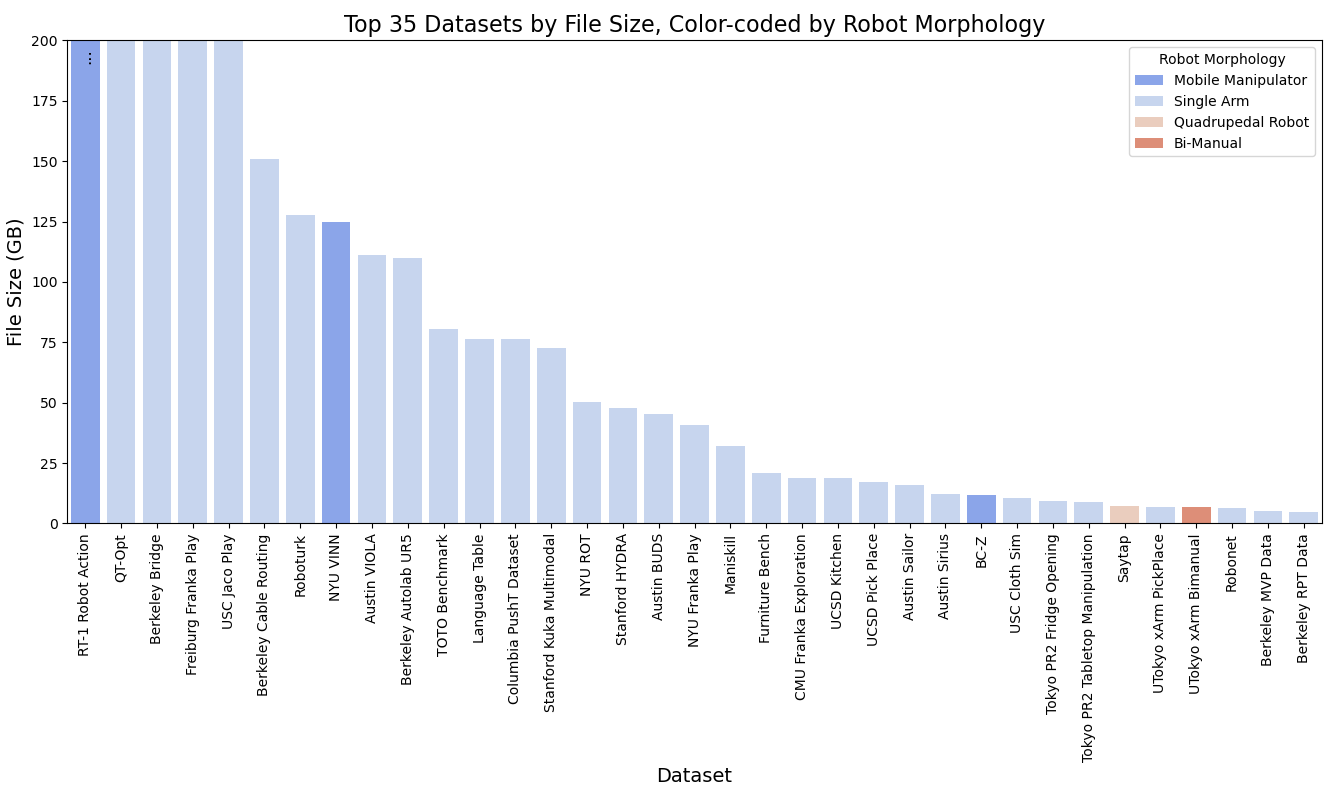

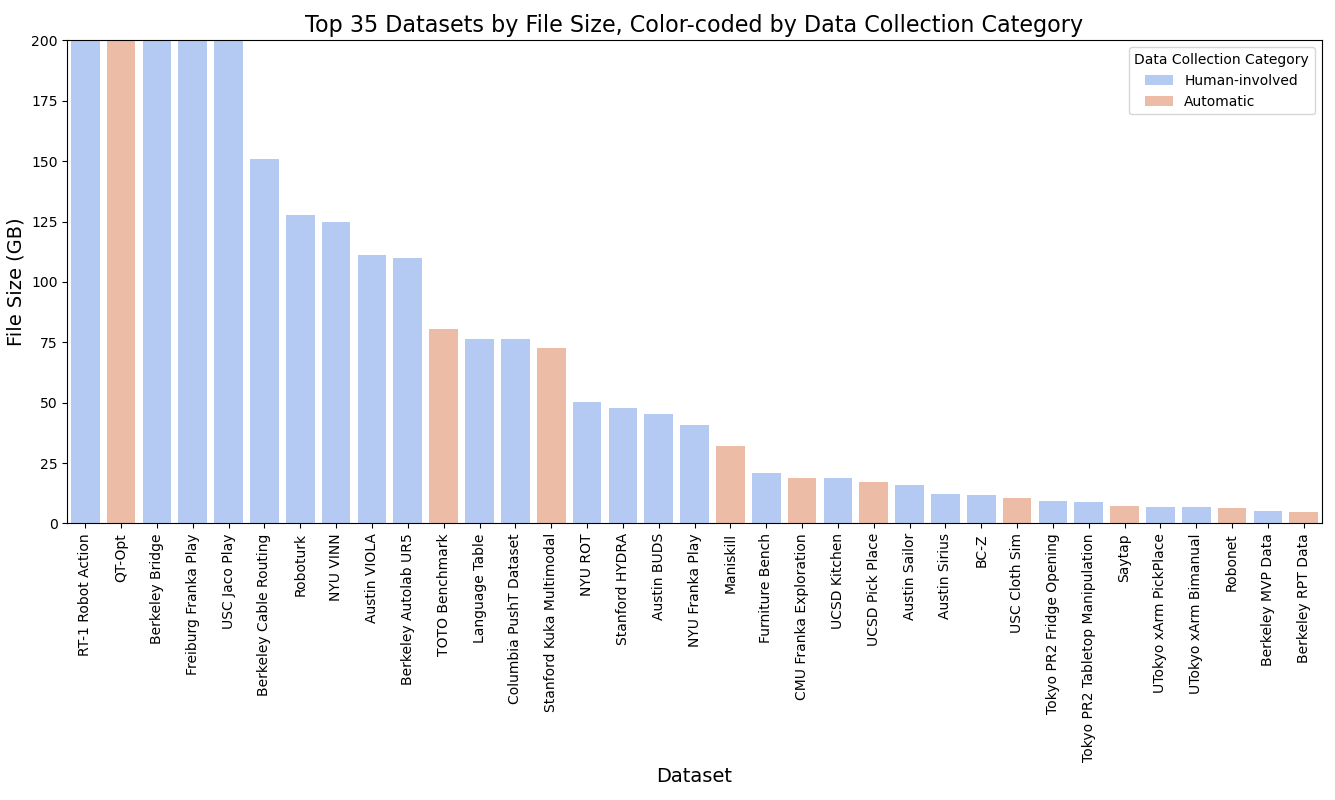
3.3 模型和原语的要求
经典的规划和控制方法通常需要精心设计的环境和机器人模型。 最优控制方法需要良好的动力学模型(即世界转移模型)[8, 177];运动规划需要环境地图[178]、机器人与[179]交互的对象的状态或一组预定义的运动基元 [180];任务规划需要预先计算的对象类和预定义的规则[92]等。 以前基于学习的方法(例如模仿和强化学习)以端到端的方式训练策略,直接从感官输入获取控制输出[112],避免构建和使用模型。 这些方法部分解决了依赖显式模型的问题,但它们通常很难在不同的环境和任务中进行泛化。 这就提出了两个问题:(1)我们如何学习能够很好泛化的与模型无关的策略? 或者,(2)我们如何学习好的世界模型,以便我们可以应用基于模型的经典方法? 我们看到一些最近的工作旨在使用基础模型(特别是以无模型的方式)解决这些问题,这些工作将在第 4 节中进行系统讨论。 然而,对机器人世界模型的需求仍然是一个有趣的前沿领域,这将在第 6 节中讨论。
3.4任务规范
理解任务规范并将其扎根于机器人当前对世界的理解是获得通才智能体的关键挑战。 通常,这些任务规范是由对机器人认知和身体能力的限制了解有限的用户提供的。 这不仅引发了关于提供这些任务规范的最佳实践是什么的问题,而且还引发了关于制定这些规范的自然性和易用性的问题。 以机器人对其自身能力的理解为条件,理解和解决任务规范中的模糊性也具有挑战性。 基础模型再次是应对这一挑战的一个有前途的解决方案:任务规范可以表述为语言提示[27,28,24]、目标图像[181]、奖励用于政策学习[26, 182]等
3.5不确定性和安全性
在现实世界中部署机器人的关键挑战之一来自于处理环境和任务规范固有的不确定性。 根据其来源,不确定性可以分为认知性(由于缺乏知识而导致的不确定性)或随意性(环境中固有的噪音)。 当机器人在测试分布中遇到不熟悉的情况时,认知不确定性通常表现为分布外错误。 虽然在高风险安全关键领域采用基于学习的决策技术促进了不确定性量化(UQ)和缓解[183]、分布外检测、可解释性等方面的努力、可解释性和对抗性攻击的脆弱性仍然是开放的挑战。 不确定性量化的成本可能过高,并且可能导致下游任务性能次优[184]。 考虑到基础模型的大规模过度参数化性质,提供在不牺牲这些模型的通用性的情况下实现可扩展性的关键是提供在对底层架构进行最小更改的情况下保留训练配方的 UQ 方法。 设计能够对其行为提供可靠置信度估计并反过来智能地请求澄清反馈的机器人仍然是一个未解决的挑战[185]。 共形预测[186]提供了一种为任何黑盒模型生成统计上严格的不确定性集的无分布方法,并已在机器人[187]的 VLN 任务中得到证明。
在传统背景下,机器人技术中的可证明安全性[188, 189]是指为机器人安全界限提供理论保证的一组控制技术。 控制屏障函数[190]、可达性分析[191, 122]和通过逻辑规范进行运行时监控[192]是众所周知的技术。确保机器人在有限干扰下的安全。 最近的工作探索了使用这些技术来确保机器人的安全[193]。 虽然这些贡献提高了安全性,但解决方案通常会导致行为不佳并阻碍机器人在野外学习[194]。 因此,尽管最近取得了进展,但赋予机器人从经验中学习的能力以调整其策略,同时在新环境中保持安全仍然是一个悬而未决的问题。
4当前研究方法回顾
在本节中,我们总结了当前机器人学基础模型的研究方法。 在4.1节中,我们主要讨论两类基础模型如何在机器人技术中使用:机器人技术中使用的基础模型和机器人技术基础模型(RFM) )。 对于机器人技术中使用的基础模型,我们主要强调以零样本方式使用视觉和语言基础模型的应用,这意味着不进行额外的微调或训练。 然而,在4.2节中,我们主要关注机器人基础模型,其中这些方法可以通过视觉语言预训练初始化来热启动模型和/或直接在机器人数据集上训练模型。 图5显示了本节的详细分类。
正如2(预备知识)中介绍的,典型的机器人系统由感知、规划和控制模块组成。 在本节中,我们将按照这种分类方法回顾这些论文中提出的方法。 在这里,我们将运动规划和控制结合成一个整体——动作生成,并将运动规划模块视为较高级别,将控制视为较低级别的动作生成。 值得注意的是,尽管大多数工作在机器人系统的不同功能模块中使用基础模型,但我们将根据论文贡献最大的模块对这些论文进行分类。 然而,视觉和语言基础模型的某些应用贯穿这些机器人模块,例如,这些模型在机器人技术中的基础,以及从大语言模型和 VLM 生成数据。 鉴于当前大语言模型的自回归性质,他们经常努力应对扩展视野的任务。 因此,我们还深入研究了文献中提出的高级提示方法,以改善这种限制并增强计划能力。 我们在4.1.4、4.1.5和4.1.6部分列出了这些应用程序,作为分析这些作品的不同视角。
我们发现第4.1节中的工作通常遵循模块化策略,应用视觉和语言基础模型来服务于单个机器人功能,例如,将VLM应用为开放集机器人感知模块,然后将其“插入” in” 与下游的运动规划器和控制器 [25] 一起工作。 由于此类基础模型以零样本的方式应用,因此在应用基础模型的模块与机器人系统中的其他模块之间不存在梯度流动。 相反,4.2节中的工作大多遵循端到端的可微性范式,这模糊了方法中典型机器人模块的边界(在4.1节中描述;例如,感知和控制[27, 195]),一些机器人基础模型甚至提供统一的模型来执行不同的机器人功能[30, 31]。
4.1 机器人技术中使用的基础模型
在本节中,我们重点关注视觉和语言基础模型在机器人技术中的零样本应用。 这主要包括用于机器人感知的VLM的零样本部署、用于任务级和运动级规划以及动作生成的大语言模型的上下文学习。 我们在图5(c)中展示了一些代表性作品。
4.1.1 机器人感知中的 VFM 和 VLM
最近,以几何和以对象为中心的世界表示为基础的视觉和语言基础模型使得上下文理解取得了巨大进步,这是机器人与现实世界交互的重要要求。 我们将从不同角度深入研究 VFM 和 VLM 在机器人感知中的应用。



VLM used for: Object and Scene Representation VFM and VLM used for: Policy learning, State estimation and Interactive perception
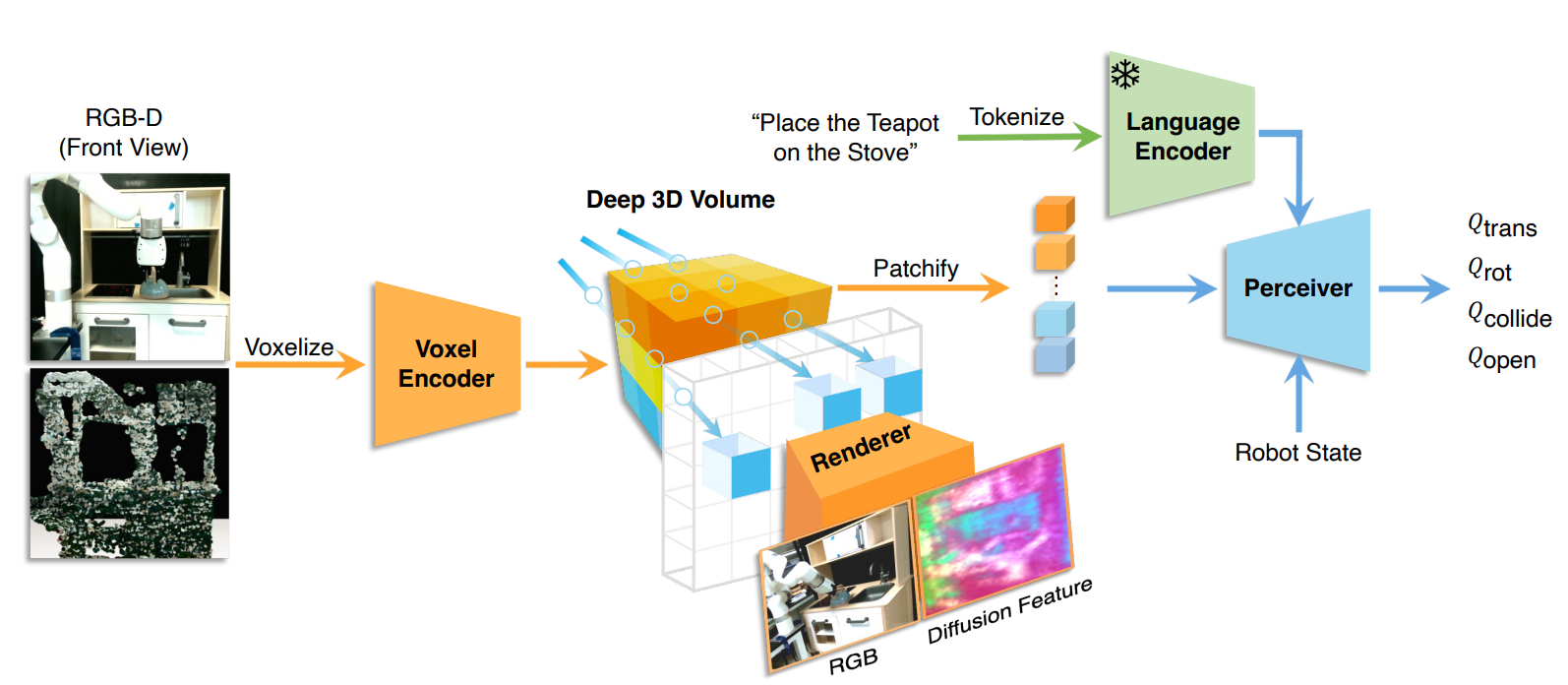

用于对象和场景表示的 VFM、VLM
VLM 在机器人领域最直接的应用是利用其在面向机器人的下游任务中执行开放集对象识别和场景理解的能力,包括语义映射和导航[25,201,202,203,204]、操作[196,197,198,205]等 这些作品提出的方法有一个共同的属性:它们试图从物体和物体中提取语义信息(来自VLM)和空间信息(来自其他模块或传感器模态)。机器人与之互动的场景。 然后,该信息被用作场景语义图中的表示或对象的表示。
对于语义映射和/或导航,NLMap [25] 是对周围场景中的大语言模型的地面任务计划的开放集和可查询的场景表示。 机器人首先使用基于边界的探索来探索环境,同时构建地图并提取与类别无关的感兴趣区域,然后由 VLM 进行编码并聚合到地图中。 然后由大语言模型解析自然语言指令,以搜索这些对象在场景表示图中的可用性和位置。 ConceptFusion [203] 根据 RGB-D 输入和基础模型的特征构建开放集多模态 3D 地图,允许从不同模态(例如图像、音频、文本和点击互动。 结果表明,ConceptFusion 可应用于现实世界的机器人任务,例如新物体的桌面操作和自动驾驶车辆的语义导航。 类似地,CLIP-Fields [202] 将场景的 RGB-D 图像编码为可语言查询的潜在表示,作为内存结构中的元素,机器人策略可以灵活检索。 VLMap [201] 使用 LSeg [151] 提取每像素表示,然后与深度信息融合,以创建 3D 地图。 然后,对该语义 3D 地图进行下投影,以获得具有每像素嵌入的 2D 地图;然后可以将这些嵌入与来自 LSeg 的语言嵌入进行匹配,以获得 2D 地图的每像素语义掩码。 至于将VLM应用于拓扑图中进行视觉导航,LM-Nav [204]是一个很好的例子:它使用大语言模型从自然中提取用于导航的地标语言说明。 然后,这些地标描述以及图像观察结果将通过 VLM 建立在预先构建的图表中。 然后,规划模块用于将机器人导航到指定的地标。
上面讨论的大多数先前作品仅利用对象和环境的 2D 表示。 为了丰富 3D 空间中基础模型的表示,F3RM [197] 和 GNFactor [198] 提取 2D通过结合 NeRF 和泛化 NeRF,将基础模型特征引入 3D 空间。 此外,GNFactor [198]还将这些提炼出来的特征应用于策略学习中。 Act3D [206] 采用类似的方法,但通过感测深度构建 3D 特征场。
用于状态估计和定位的 VLM
除了上下文理解之外,还有一些方法探索使用 VLM 的开放词汇特性进行状态估计[207, 199, 199, 208, 209]。 两种这样的方法,LEXIS [207] 和 FM-Loc [199],探索了 CLIP [53] 功能用于执行室内定位和地图绘制。 特别是,FM-Loc [199] 利用了 CLIP 和 GPT-3 提供的视觉语言基础检测查询图像的对象和房间标签,然后使用该语义信息将其与参考图像进行匹配。 同样,LEXIS[207]构建了一个实时拓扑SLAM图,其中CLIP特征与图节点关联,从而实现房间级场景识别。 尽管这些方法显示了视觉语言特征在室内地点识别中的潜力,但它们没有探索基础模型特征的广泛适用性。 在此背景下,AnyLoc[208]探索了密集基础模型特征的属性,并将其与无监督特征聚合技术相结合,以实现最先进的地点识别,无论何时何地,在任何视图下,都大幅展示了 SLAM 自监督基础模型功能的广泛适用性。
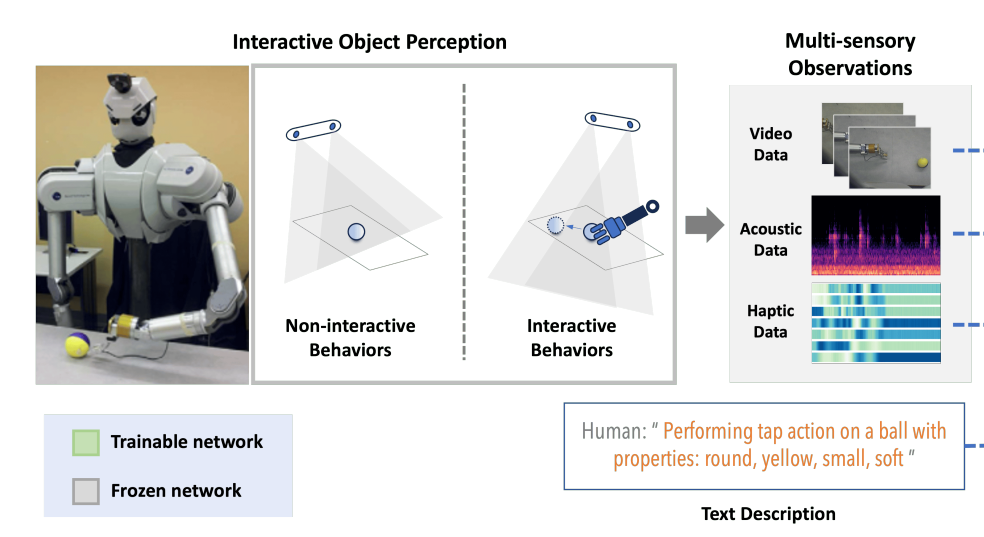
用于交互式感知的 VLM
一些工作考虑了使机器人能够利用交互式感知过程的概念,以推断有关对象属性的隐式知识,以便获得下游交互式机器人学习任务的性能改进[210,211,212,213,214,215 、167、166、200]。 这种交互感知的过程通常模仿人类婴儿最初了解物理世界的方式,即通过交互,并通过从感觉信息(触觉、听觉、听觉等)学习物体概念的表征,例如重量和硬度。视觉)是由对具有不同属性的物体的物理探索动作(例如,抓、举、落、推)产生的。 特别是,MOSAIC [200]利用LMM来加速获取统一的多感官对象属性表示;作者展示了他们的框架在类别识别和模糊目标对象获取任务中的竞争性能,尽管存在干扰对象,但在零样本传输条件下。
4.1.2 任务规划中的LLM和VLM

grounding of visual states, SayCan [24]

LLM: Code as policy [216]
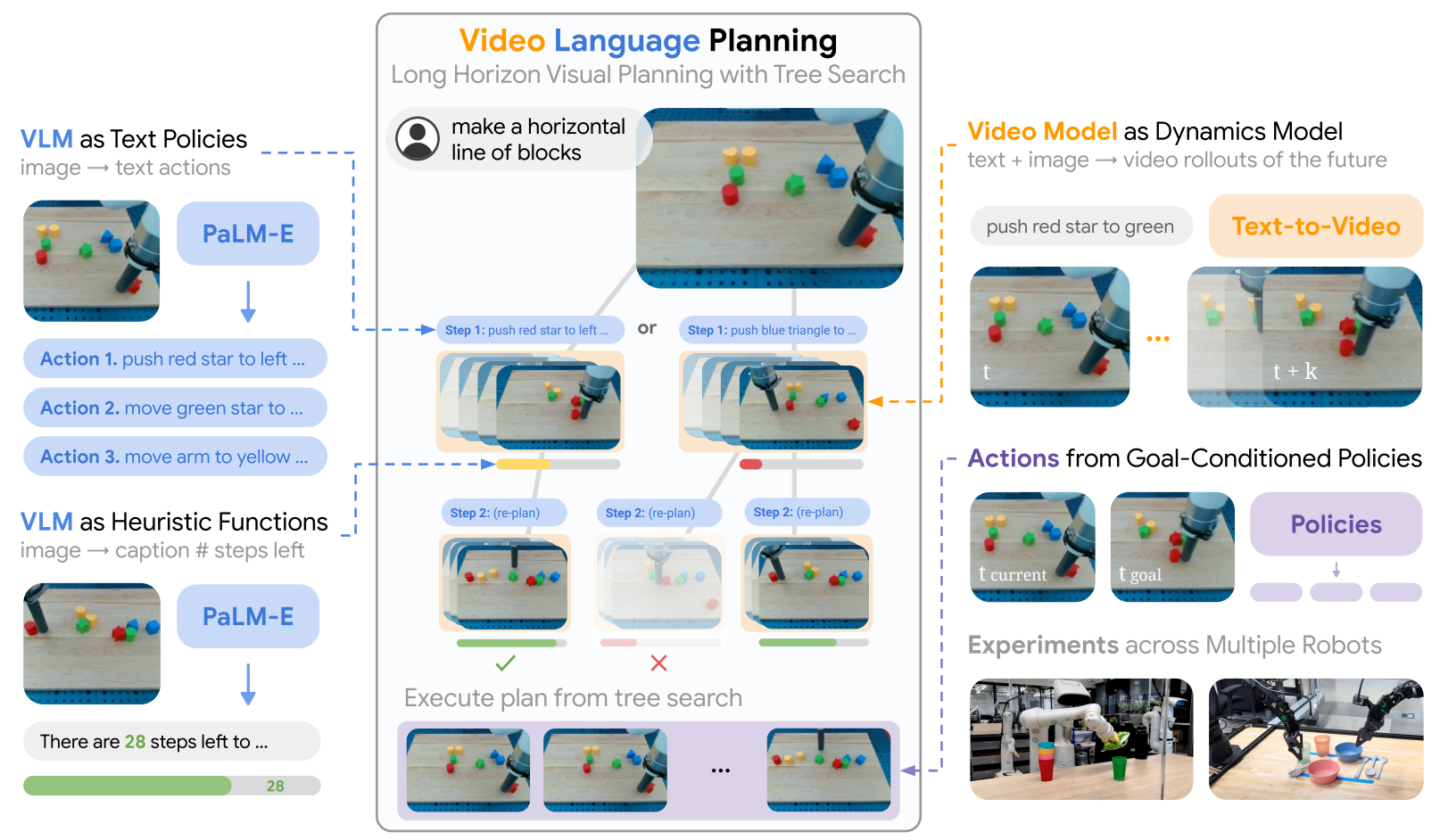
plus a video dynamics model: VLP [217]
机器人学的规划界一直渴望有一个模型能够在不同的任务和环境中泛化,并且对机器人任务的演示最少。 鉴于视觉和语言基础模型在复杂推理和上下文泛化方面所展现出的强大能力,机器人社区考虑将基础模型应用于机器人规划问题是一个自然的进展。 本节根据规划的粒度组织工作,划分任务级和运动级规划。 我们将在这一部分中主要介绍任务级规划,并将运动规划和动作生成一起留给下一部分(第4.1.3节)。
任务级规划是将复杂的任务划分为可操作的小步骤。 在这种情况下,我们主要讨论代理自行规划,而不是使用大语言模型作为解析器,例如视觉语言导航[218]。 代理需要采取智能子步骤,通过与环境交互来达到目标。 SayCan [24]是任务级规划的一个典型例子:它使用大语言模型来规划一个高级任务,例如“我把饮料洒了,你能帮我吗?”。 然后它给出了具体的任务计划,比如去柜台、找海绵等等。 同样,VLP [217]旨在通过额外的文本到视频动态模型来改进长期规划方法。 这些任务级规划方法不必担心环境中这些子任务的精确执行,因为它们可以利用一组预定义/预训练的技能,然后使用大语言模型来简单地执行任务。找到正确的方法来组合技能以实现预期目标。 此类别还有更多论文,例如:LM-ZSP [219]将这种任务级粒度引入为可操作的步骤; Text2Motion [220] 使用类似的想法并提高了基于语言的操作任务的成功率。 以前的方法通常以文本形式生成任务计划。 有些作品如 ProgPrompt [221]、Code as Policy [216]、GenSim [222]等利用大语言模型以代码生成的形式获取任务计划。 使用代码作为高级计划的好处是可以表达处理感知输出和参数化控制原语 API 的函数或反馈循环。 此外,它还可以准确地描述物体的空间位置。 这种改进的组合性节省了收集更多原始技能的时间。 它还根据上下文为“更快”和“向左”等模糊描述规定了精确的值(例如速度)。 因此,由于这些好处,代码似乎是比自然语言更高效、更有效的任务级规划语言。 其他形式的规划技术,例如用规划领域定义语言 (PDDL)[223] 表达高层规划,也显示出大语言模型在长期任务上规划能力的显着提升,更多内容将在将在4.1.6节中讨论。
除了使用大语言模型直接生成方案外,还用于利用场景图等外部存储结构进行搜索和评估。 SayPlan [224] 采用 3D 场景图 (3DSG) 表示来管理广阔环境的复杂性。 通过利用分层 3DSG,大语言模型可以在多层家庭环境中语义搜索相关子图,缩小规划范围并集成经典路径规划以迭代地完善初始计划。 Reasoned Explorer [225]采用大语言模型作为评估器对二维无向图中的每个节点进行评分。 它使用该图作为地图来存储访问点和边界的大语言模型评估。 这些外部记忆和增量地图构建方法打破了使用大语言模型生成长计划的上下文长度限制,从而将基于 LLM 的导航代理扩展到大型环境。 需要注意的一件事是,尽管任务级规划与物理体现无关,但它确实需要扎根于特定机器人的物理形态(或“形态”)和部署时的环境; 4.1.4 节将介绍接地技术。
4.1.3 LLM 和 VLM 在行动生成中

L2R [226]
matching with LLM: SayTap [26]

planning: VoxPoser [227]
如果不首先使用动作数据对这些模型进行微调,仅通过提示现成的大语言模型/VLM 来直接控制机器人可能具有挑战性,甚至可能无法实现。 与高级机器人任务规划不同,大语言模型用于组合和组合不同技能来完成任务,个体动作,无论是像路径点这样的高级动作,还是像关节角度这样的低级动作,通常在语义上都不是。有意义的或有成分的。 社区正在尝试寻找合适的接口来解决这个问题。 对于导航任务中的运动规划,ReasonedExplorer [225] 和 Not_Train_Dragon [228] 提出了这样一个接口:使用大语言模型作为扩展边界的评估器,被定义为潜在的探索路径点(通常在二维空间中);在这里,大语言模型的任务是根据给定观察结果与预期目标之间的相似性对边界进行评分。 类似地,VoxPoser[227]应用VLM来获得运动规划中使用的可供性函数(在原始论文中称为3D值图)。
一些论文研究了使用大语言模型直接输出较低级别的动作。 Prompt2Walk [229]使用大语言模型通过从物理环境收集的少量样本提示直接输出关节角度。 它研究大语言模型是否可以通过在环境反馈数据(观察-动作对)的上下文中学习来充当低级控制器。 Saytap [26],引入了利用脚部接触模式作为动作表示的新颖概念。 在该模型中,语言模型输出“0”表示没有接触,输出“1”表示与地板接触,从而使大语言模型能够为四足运动任务(例如跳跃和跳跃)生成零样本可操作命令。跑步。 然而,这些方法对不同机器人形态的通用性仍然存在疑问,因为它们仅在四足平台上进行了测试。 相反,在机器人[226, 182]中奖励[230, 231, 232]的语言是比通过大语言模型直接生成动作更通用的方法;这些方法涉及使用大语言模型作为生成器来合成基于强化学习的策略的奖励函数,因此通常不受机器人实施例的限制[182]。 大语言模型的奖励合成方法可以产生人类难以设计的奖励,例如Eureka[182]表明它可以使机器人学习灵巧的转笔使用人类奖励设计被认为非常困难的任务。
4.1.4 机器人技术基础
除了上述维度之外,同样重要的一个方面是“接地气”的概念。 接地是指将上下文含义与信号或符号相关联的能力,例如将单词与其在世界中的表现联系起来的能力。 人类通过音频(单词、语气)和视觉信号(手势、行为、肢体语言)来理解语义概念。 在本次调查的范围内,接地指的是将基础模型所拥有的抽象知识与机器人技术的有形的、现实世界的细节相结合的过程——确保语言驱动的决策与物理行为和环境背景有意义地对应。 例如,如果我们要求一个大语言模型生成一个计划,在没有任何环境信息的情况下在特定房子里找到一支笔,那么这个任务就类似于盲人推理如何在房屋中导航。未知的空间,使得任务几乎不可能完成。 类似地,虽然大语言模型可以通过建议“用左手抓住左把手,用右手抓住右把手,然后抬起”来轻松生成举起椅子的计划,但如果现实世界的情况如此,则该计划将变得不切实际该模型的体现是一个典型的仅配备一只手臂的机器人。 由于接地本身就是一个很大的领域,因此我们并不试图涵盖所有内容;相反,我们将讨论如图 9 所示的四个概念: (1) 将语言与环境结合起来; (2) 将潜在概念扎根于环境; (3) 实施例的基础语言; (4)将潜在概念扎根于实施例。
语言与环境的基础
正如前面几节,特别是 4.1.2 和 4.1.3 节所讨论的,为了将大语言模型或 VLM 直接成功集成到机器人中,建立语言输出与技能或低级动作之间的联系。 SayCan [24] 学习了一个价值函数,用于对任务级计划和通过强化学习或行为克隆获得的技能之间的联合可能性进行评分。 ZSP [219] 利用语言指令和技能名称之间的语义相似性来表示地面机器人技能,而 ProgPrompt [221] 和代码作为策略通过程序代码合成来掌握机器人技能。 然而,这些技能是专门针对测试环境进行培训的。 因此,我们将所有将语言与技能相关联的方法归类为环境基础。 一些研究工作,例如接地解码 [233],试图通过将基础模型与在单一环境中训练的技能结合起来,使用在以下环境中训练的小型语言条件模型来解决这个问题:各种环境作为概率过滤器。 尽管如此,这种方法仍然是有限的,因为它预设了适合其所体现的环境的基础模型的可用性。 除了技能基础之外,像Voxposer[227]这样的工作也尝试使用大语言模型来生成构建环境价值图的代码,然后可以对其进行规划使用现有的规划器。 与基于技能库相比,这代表了一种集成环境上下文信息的更通用的方法。
将概念扎根于环境
术语“概念”指的是统一的潜在表示,源自具有不同输入数据的训练。 CLIP-Fields [202]、VLMap [201] 和 NLMaps 等方法t4> [25] 致力于将 CLIP 视觉表示和语义标签表示直接投影到 3D 点云上。 除了构建显式 3D 地图之外,GLAM [234] 还提出通过与环境交互,使用强化学习对带有内部地图的地面语言模型进行强化学习。 这种方法证明了大语言模型可以在文本环境中有效地充当强化学习(RL)代理。 然而,当前文献中仍然没有解决通过将概念扎根于点云或通过隐式映射将这些方法推广到不同环境和任务的挑战。
实施例的基础语言
我们将语言基础归类为需要特定条件:它必须与不同的环境无关。 这类似于拥有一个将语言转化为动作的通用界面。 Prompt2Walk [235] 和 Saytap [26] 等举措已经尝试直接使用大语言模型生成联合用于运动控制的语言空间中的角度或脚部模式。
将概念接地到实施例
实施例的基础概念涉及直接锚定基础模型以输出关节扭矩,绕过诸如文本之类的中间界面。 一个著名的例子是 Gato [30],它展示了玩 Atari、为图像添加字幕、对话以及使用机械臂操纵物体等任务的多功能性。 Gato 根据当前任务的上下文动态决定其输出格式 - 文本、关节扭矩、按钮按下或其他标记。 另一个相关的开发是RT-2[28],尽管以文本形式指定了末端执行器空间,但它能够直接生成用于机器人操纵器操作的可执行命令。
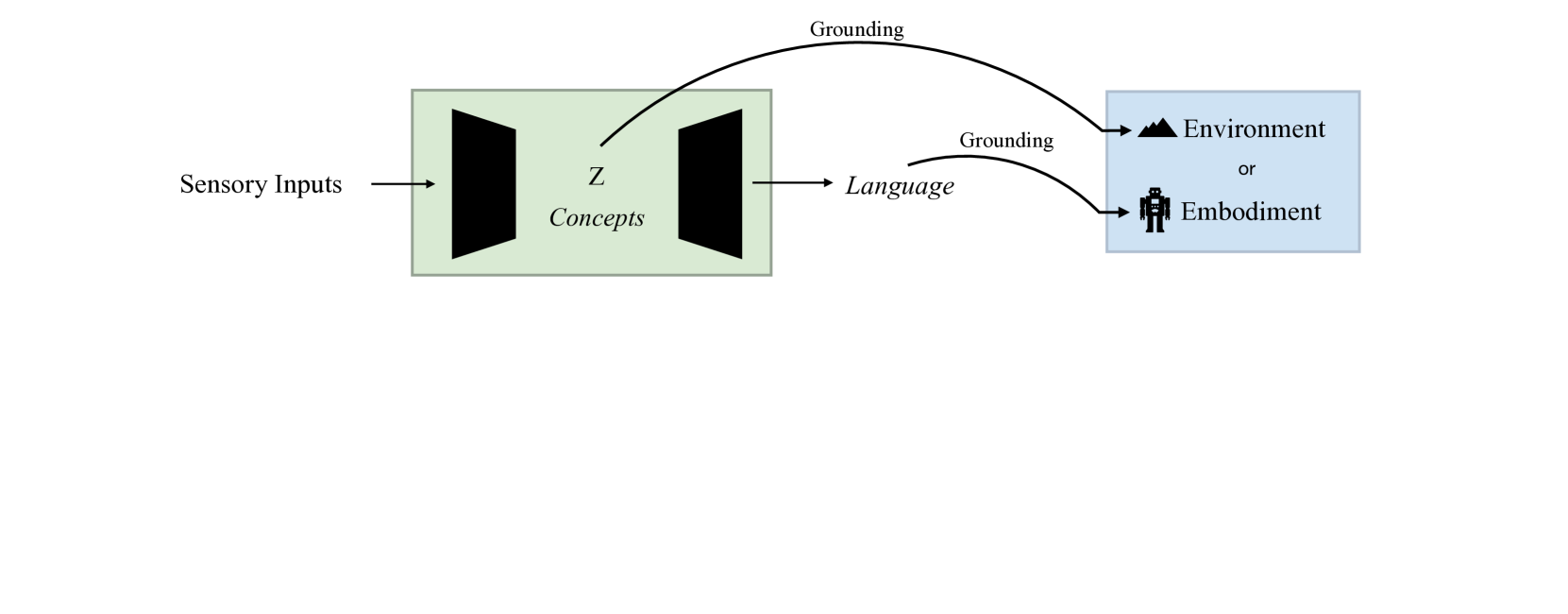
总之,将语言与环境和实施例结合的主要优点是易于实施零样本学习,而无需额外的训练。 然而,存在重大缺陷。 对于无法用语言描述的概念,例如手指运动的细微差别,实施例的基础可能会失败。 此外,对一组固定技能库的依赖限制了对不同环境的适应性。 因此,直接基于潜在概念空间似乎是一个更可行的解决方案。 利用交互数据[234]或专家数据[28]的方法在应对这些挑战方面都显示出了有希望的结果。
4.1.5 使用大语言模型和VGM生成数据
最近,我们见证了大语言模型和VGM的内容生成能力的强大。 利用这种能力,研究人员已经开始尝试通过使用基础模型生成数据来解决数据稀缺问题。 Ha 等人 [236]提出了一个框架,“扩展和蒸馏”,在给定自然语言指令的情况下,可以自动生成标有成功条件和语言的不同机器人轨迹。 Wang 等人的 RoboGen [237] 通过将自动动作轨迹建议纳入物理真实模拟环境 Genesis 中,进一步增强了这种方法,能够生成潜在无限的数据。 然而,这些方法仍然面临局限性:生成的数据受到资产和机器人形态多样性低的影响,这些问题可以通过先进的模拟或硬件得到改善。 Wang 等人的GenSim [222]提出利用给定语言指令的大语言模型生成新颖的长视野任务,从而产生超过100个用于训练语言条件多任务机器人策略的模拟任务。 该框架展示了模拟和现实世界中的任务级泛化,并阐明了如何通过模拟程序将基础模型提炼为机器人策略。 Yu 等人的ROSIE [238]使用文本引导图像生成器来修改机器人的视觉观察,以在训练机器人时执行数据增强调控政策。 修改命令来自用户的语言指令,然后由开放词汇分割模型定位增强区域。 RT-Trajectory [239] 生成策略网络所依赖的轨迹。 轨迹生成还有助于机器人学习任务中的任务规范。 Black 等人 [240]使用基于扩散的模型为目标条件强化学习策略生成子目标以进行操作[241]。
4.1.6通过提示增强计划和控制力
Wei等人[242]引入的思想链技术迫使大语言模型在最终输出的同时产生中间步骤。 这种方法利用更广泛的上下文窗口来明确列出规划步骤,从而增强了大语言模型的规划能力。 其有效性的根本原因是 GPT 系列作为自回归解码器的本质。 指令到步骤和步骤到目标之间的语义相似性比指令到直接输出之间的相似性更为明显。 尽管如此,思想链的顺序性质意味着单个不正确的步骤可能会导致与正确的最终答案[243]的指数分歧。
替代方法尝试通过显式列出图 [244] 或树结构 [245] 中的步骤来解决此问题,这已证明了性能的提高。 此外,还探索了基于搜索的方法来增强规划,例如蒙特卡洛树搜索 (MCTS) [246] 和快速探索随机树 (RRT) [225]能力。
此外,将目标规范从自然语言转换为外部规划语言(例如规划领域定义语言 (PDDL))也被证明可以提高规划准确性[247]。 最后,与开环提示风格相反,结合环境反馈的迭代提示方法可以为长期规划能力提供更扎实、更精确的增强[248, 31]。
4.2 机器人基础模型 (RFM)

Robotic Foundation Models for: manipulation Robotics Foundation Models for: motion planning for navigation and multipurpose task

随着包含来自真实机器人的状态-动作对的机器人数据集数量的不断增加,机器人基础模型 (RFM) 类同样变得越来越可行[28,176,29]。 这些模型的特点是使用机器人数据来训练它们,以解决机器人任务。 在本小节中,我们总结并讨论了不同类型的 RFM。 我们将首先介绍可以在第 2.1 节中的一个机器人模块中执行一组任务的 RFM,该模块被定义为单一用途机器人基础模型。 例如,可以生成低级动作来控制机器人的 RFM,或者可以生成高级运动计划的模型。 我们稍后介绍可以在多个机器人模块中执行任务的 RFM,因此是可以执行感知、控制甚至非机器人任务的通用模型[30, 31]。
4.2.1 机器人动作生成基础模型
机器人动作基础模型可以采用原始感官观察(例如图像或视频),并学习直接应用于机器人末端执行器的控制输出。 此类别的型号包括RT系列[27,28,176]、RoboCat[195]、MOO [249] 等 根据论文的结果,这些模型在机器人控制任务(例如操纵)中表现出泛化能力。
模仿学习
语言输入还用于为机器人技术的端到端直接下游控制提供任务规范,形成语言条件模仿策略学习。 Li 等人 [250]使用预先训练的语言模型来初始化预测下一步行动的策略网络。 通过行为克隆和主动学习来微调控制策略,以提高任务完成率。 还提出了直接使用语言输入生成机器人动作以改善人机协作:语言通知潜在动作(LILA)框架[251]学习使用语言来调制低级控制器,有效地使用语言将 7-DoF 机械臂输出映射到 2-DoF 输入。 此外,Hu 等人 [252]使用多智能体强化学习来配置大语言模型策略,使人类能够指定他们期望从人工智能中获得什么样的策略伙伴。 以通过语言指导机器人为主题,Lynch 等人 [253]在包含数十万个语言注释轨迹的数据集上使用行为克隆来改善视觉 -现实世界中的语言运动技能。 尽管之前的工作大多采用语言条件方法,但 RoboCat [195] 仅使用机器人数据来训练模仿学习策略。
大规模强化学习
正如 2.1.3 节(预备知识)中所讨论的,离线强化学习有潜力在不与环境交互的情况下学习好的策略。 随着大规模机器人数据集的出现,离线强化学习开始在开发有效的 RFM 方面发挥重要作用。 早期的大规模离线强化学习模型,例如QT-OPT[112]以离线方式使用基于Q学习的方法从收集的机器人数据中学习策略由机器人农场。 QT-OPT的后继者通过结合多任务课程或预测信息将其扩展到多任务学习[254, 255]。 最近,随着Transformer模型的成功,基于Transformer的Q-learning(Q-Transformer)也显示出了其潜力[256]。 PTR [257] 是另一项有前途的工作,它采用保守 Q-Learning (CQL) [258]多任务学习设置。 我们期待看到更多基于强化学习的机器人基础模型。
视觉和语言预训练
动作基础模型的另一个方向涉及视觉或语言预训练[259,260,261,262,263,264,28]。 例如,受到基于自监督视觉的预训练的强大泛化能力的启发,Radosavovic 等人的MVP [261]通过掩码自动编码器训练来自互联网和以自我为中心的视频数据集的真实世界图像和视频的视觉表示,并展示扩展机器人学习视觉预训练的有效性。 在这项工作之后,RPT [262]提出了使用真实机器人轨迹数据进行掩模预训练。 VC-1 [264]实际上对基于视觉的预训练对政策学习的有效性做了全面的研究。 我们还建议读者从该论文中了解有关此问题的更多信息。 尽管这些视觉预训练方法很有效,Hansen 等人 [263]重新检查了其中一些方法,发现了显着的领域差距,并提出了一种从头开始学习的方法,该方法仍然存在竞争的。 这为我们思考机器人视觉预训练提供了一个新的视角。
除了仅使用视觉信息之外,RT-2 [28] 和 Moo [249] 使用视觉和语言预- 作为控制策略支柱的训练模型。 PaLM-E [31] 和 PALI-X [265] 用于将知识从网络传输到机器人动作。 与之前的方法略有不同,VRB [266]从大规模视频中学习可供性函数(而不是策略本身),为我们研究如何RFM 可以推广到现实世界的任务中。
机器人运动规划基础模型
最近,我们看到 RFM 的兴起,特别用于视觉导航任务中的运动规划目的[267,29,268]。 这些基础模型利用大规模异构数据,并在预测高级运动规划动作方面表现出泛化能力。 这些方法依赖于仅由图像观察组成的粗糙拓扑图[267, 29],而不是传统运动规划方法中的精确度量图和精确定位(如3.3 与应用于运动规划的视觉和语言基础模型不同,机器人运动规划基础模型仍处于早期阶段。
4.2.2 通用机器人基础模型
开发通用机器人系统始终是机器人和人工智能领域的圣杯。 一些现有的作品[30, 31]朝着这一目标迈出了一步。 Gato [30] 提出了一种多模式、多任务、多实施例的通才基础模型,可以与真实的机器人一起玩 Atari 游戏、字幕图像、聊天、堆叠积木手臂等,均具有相同的型号重量。 与Gato类似,PaLM-E[31]也是用于机器人推理和规划、视觉语言任务的通用多模态基础模型,以及仅限语言的任务。 虽然没有被证明可以解决我们在第 2 节中介绍的所有机器人任务,但 Gato 和 PaLM-E 显示了融合感知和规划的可能性整合为一个模型。 此外,Gato和PaLM-E显示了使用同一模型解决各种看似不相关的任务的有希望的结果,凸显了通用人工智能系统的可行性。 PACT [269] 专为机器人任务而设计,提出了一种基于 Transformer 的基础模型,具有常见的预训练表示,可用于各种下游机器人任务,例如本地化、地图和导航。 尽管我们还没有看到许多统一的机器人基础模型,但我们期望在这个特定问题上有更多的努力。
4.3 基础模型如何帮助解决机器人挑战
在第3节中,我们列出了机器人技术的五个主要挑战。 在本节中,我们总结了基础模型(视觉和语言模型或机器人基础模型)如何以更有组织的方式帮助解决这些挑战。
所有与视觉信息相关的基础模型,例如VFM、VLM和VGM,都用于机器人的感知模块中。 另一方面,大语言模型更加通用,可以应用于规划和控制。 我们还在这里列出了 RFM,这些机器人基础模型通常用于规划和行动生成模块。 我们在表 1 中总结了基础模型如何解决上述机器人挑战。 从该表中我们注意到,所有基础模型都擅长泛化各种机器人模块的任务。 此外,大语言模型特别擅长任务规范。 另一方面,RFM 擅长应对动力学模型的挑战,因为大多数 RFM 都是无模型方法。 对于机器人感知来说,泛化能力和模型的挑战是耦合的,因为如果感知模型已经具有很好的泛化能力,就不需要获取更多的数据来进行领域适应或额外的微调。 此外,解决安全挑战的呼吁很大程度上缺失,我们将在第 6 节中讨论特定问题。
| Modules | Foundation Models | Generalization 3.1 | Data 3.2 | Model 3.3 | Task Specification 3.4 | Uncertainty 3.5 | |||||||
| Perception 2.1.1 | VFM 2.2.1 | Conceptgraphs [270] | Conceptgraphs [270] | - | - | - | |||||||
| VGM 2.2.2 | - |
|
- | - | |||||||||
| VLM 2.2.4 | NLMap [25] |
|
- | RT-Traj. [239] | - | ||||||||
| Task Planning and Action Generation 2.1.2 and 2.1.3 | LLM 2.2.3 | SayCan [24] |
|
RAP [271] |
|
KNOWNO [187] | |||||||
| RFM 4.2 |
|
RT-X [176] |
|
|
- |
泛化基础模型
零样本泛化是当前基础模型最显着的特征之一。 机器人学几乎在所有方面和模块都受益于基础模型的泛化能力。 对于第一个,感知的泛化,VLM 和 VFM 是默认机器人感知模型的绝佳选择。 第二个方面是任务级规划的泛化能力,具体任务计划由大语言模型[24]生成。 第三个是利用 RFM 的力量来推广运动规划和控制。
数据稀缺的基础模型
基础模型对于解决机器人数据稀缺问题至关重要。 它们为使用最少的特定数据学习和适应新任务提供了坚实的基础。 例如,最近的方法利用基础模型生成数据来帮助训练机器人,例如机器人轨迹[236]和模拟[237]。 这些模型擅长从一小部分示例中学习,使机器人能够使用有限的数据快速适应新任务。 从这个角度来看,解决数据稀缺就相当于解决机器人领域的泛化能力问题。 除此之外,基础模型——尤其是大语言训练模型和VGM——可以为感知模块[238]中使用的机器人生成数据集(参见上面的4.1.5节) ),以及任务规范[239]。
减轻模型需求的基础模型如3.3节中所述,构建或学习模型——环境地图、世界模型或环境动力学模型——对于解决机器人问题至关重要,特别是在运动规划和控制方面。 然而,基础模型所呈现的强大的少样本/零样本泛化能力可能会打破这一要求。 这包括使用大语言模型生成任务计划[24]、使用RFM学习无模型的端到端控制策略[27, 256]等。
任务规范的基础模型 作为语言提示的任务规范[27, 28, 24]、目标图像[181, 272]、视频演示任务 [273, 274] 的人员、奖励 [26, 182]、粗略的轨迹 [239]、政策草图 [275] 和手绘图像 [276] 允许以更自然、更人性化的格式指定目标。 多模式基础模型不仅允许用户指定目标,还可以通过对话帮助解决歧义。 最近在理解人机交互领域中的信任和意图识别方面的工作为我们理解人类如何使用显式和隐式提示来传达任务规范开辟了新的范式。 虽然已经取得了重大进展,但最近在大语言模型的即时工程方面的工作表明,即使使用单一模态,生成相关输出也具有挑战性。 视觉语言模型被证明特别擅长任务规范,显示出解决机器人技术中这一问题的潜力。 Cui 等人 [181]扩展了基于视觉语言的任务规范的思想,探索了使用更自然的输入(例如获得的图像)来实现多模式任务规范的方法来自网络。 Brohan 等人 [27]通过提供一种新颖的模型类来进一步探索从与任务无关的数据进行零样本传输的想法,该模型表现出有前途的可扩展模型属性。 该模型将高维输入和输出(包括相机图像、指令和电机命令)编码为紧凑的词符表示,以实现移动操纵器的实时控制。
不确定性和安全性的基础模型 尽管不确定性和安全性是机器人技术中的一个关键问题,但使用机器人基础模型的不确定性和安全性仍然尚未得到充分探索。 KNOWNO [187] 等现有作品提出了一个用于测量和调整基于 LLM 的任务规划器的不确定性的框架。 大语言模型中思想链提示[277]、开放词汇学习[278]和幻觉识别的最新进展[279] 可能会开辟新的途径来应对这些挑战。
5当前实验和评估回顾
在本节中,我们总结了当前研究工作的数据集、基准和实验。
5.1 数据集和基准
仅仅依靠从语言和视觉数据集中学到的知识是有限制的。 正如高 等人 [280] 和 Tatiya 等人所建议的,一些概念,如摩擦力或重量,仅通过这些模式是不容易学习的。 /t2> [200] 在他们关于物理接地 VLM 的工作中。 因此,为了使机器人代理能够更好地理解世界,研究人员不仅要调整语言和视觉领域的基础模型,还要调整语言和视觉领域的基础模型。他们还在推进大型、多样化和多模式机器人数据集的开发,用于训练或微调这些基础模型。 这项工作现在分为两个方向:从现实世界收集数据,与从模拟收集数据然后将其传输到现实世界。 每个方向都有其优点和缺点。 我们将在下面的段落中介绍这些数据集和模拟,并讨论它们各自的优点和缺点。
5.1.1 现实世界机器人数据集
现实世界的机器人数据集由于其多样化的对象类别和多模式输入而非常有吸引力,为机器人系统提供了丰富的资源,而无需复杂且通常不准确的物理模拟。 然而,创建这些大规模数据集提出了重大挑战,主要是由于缺乏实质性的“数据飞轮”效应。 这种效应通过数百万互联网用户的贡献使 CV 和 NLP 等领域受益匪浅,但在机器人技术中却不太明显。 个人上传大量感官输入和相应动作序列的激励有限,这构成了数据采集的主要障碍。 尽管存在这些挑战,当前的努力重点是解决这些差距。 RoboNet [281] 是在这个方向上的一项值得注意的努力,它为多机器人学习提供了跨不同机器人平台的大规模、多样化的数据集。 Bridge 数据集 V1 [282] 收集了 7200 小时的真实家庭厨房操作任务演示,其后续 Bridge-V2 [283] 包含在 24 个环境中收集的 60,096 个轨迹低成本机器人。 Language-Table [253] 收集了 600,000 个语言标记的轨迹,比之前可用的数据集大一个数量级。 RT-1 [27] 包含 13 万集,涵盖 700 多项任务,是使用 13 个 Google 移动操纵机器人在 17 个月内收集的。 虽然上述数据集比之前的实验室规模数据集有了显着进步,提供了相对大量的数据,但它们仅限于单一模式或特定的机器人任务。
为了克服这些限制,最近的一些举措取得了显着进展。 例如,GNM [267]利用基于航点的统一导航界面,成功集成了六个不同的大规模导航数据集。 此外,最近各个实验室之间的一项名为 RT-X [176] 的合作旨在通过使用 7 自由度末端执行器的姿势作为通用参考来标准化不同数据集的数据跨越不同的实施例。 这种方法促进了不同数据集的联合使用,并在跨形态迁移学习中表现出了积极的性能。
在这些进步的基础上,现实世界的机器人数据集的规模开始增长,尽管仍然落后于大量的互联网规模的语言和视觉语料库。 先进硬件(例如 Hello Stretch Robot、Unitree Quadrupeds 和开源灵巧操纵器[284])的普及预计将促进这一增长。 随着这些技术变得越来越广泛,它们可能会在机器人领域引发所需的“数据飞轮”效应。
5.1.2 机器人模拟器
当我们等待机器人硬件的广泛部署来收集大量机器人数据时,另一种方法是开发密切模仿现实世界图形和物理的模拟器。 使用模拟的优点是能够在模拟世界中部署数以万计的机器人实例,从而实现同步数据收集。
模拟器专注于不同的方面,例如照片真实感、物理真实感和人机交互。 对于导航任务,逼真的模拟器至关重要。 AI Habitat 通过利用 Matterport3D [285] 和 Gibson [286] 数据集的真实扫描 3D 场景来解决这个问题。 此外,Habitat [287] 是一个模拟器,允许 AI 代理在各种真实的 3D 空间中导航并执行任务,包括对象操作。 它具有多个传感器并处理通用 3D 数据集。 Habitat 2.0 [174] 在原始版本的基础上引入了动态场景建模、刚体物理和更高的速度。 Habitat 3.0 [175] 进一步集成了可编程人形机器人以增强模拟体验。 此外,AI2THOR 模拟器 [288] 是另一个有前景的逼真视觉基础模型研究框架,如 [201, 289] 所示。 其他模拟器,如 Mujoco [170],专注于为高级操作和运动任务创建物理真实环境。
此外,像 AirSim [290] 和 Arrival Autonomous Racing Simulator [102] 这样的模拟器都基于虚幻引擎构建,提供了合理的物理和真实感之间的平衡。 最终,虽然上述模拟器在各个领域都表现出色,但它们面临着并行性等共同挑战。 Issac Gym [171] 和 Mujoco 3.0 [291] 等模拟器尝试通过使用 GPU 加速来加快数据收集过程来克服这些挑战。
尽管模拟器中有大量可用数据,但其使用仍存在固有的挑战。 首先,模拟与现实世界之间的领域差距使得从模拟到真实的转换成为问题——早期工作已经在寻求解决的问题[164]。 其次,环境和基础对象的多样性还不够。 因此,为了在未来有效地利用模拟,这两个领域的持续改进至关重要。
| Title | Datasets & Simulation | Real Robot |
|
Base Model | SR | SR Descriptions | Frequency | |||||||||||||||
| RT-X |
|
Google robot | 160266 | RT-2(PaLI) |
|
|
3-10Hz | |||||||||||||||
| RT-2 |
|
Google robot | 480+ | PaLI, PaLM-E |
|
|
1-5Hz | |||||||||||||||
| RT-1[27] | RL Bench (RT-1) [27] | Google robot | 744 | RT-1 |
|
|
3 Hz | |||||||||||||||
| GNFactor [198] | RL Bench (RT-1) [27] | XArm7 | 166 |
|
|
|
Unspec. | |||||||||||||||
| MOO [249] |
|
Google robot | 106 |
|
|
|
Unspec. | |||||||||||||||
| PhysObjects [280] | PhysObjects [280] | Franka Panda | 51 |
|
|
|
open loop | |||||||||||||||
| Matcha [297] | CoppeliaSim [298] | NiCOL | 50 |
|
|
|
open loop | |||||||||||||||
| Scalingup [236] | Scalingup benchmark [236] | UR5 arm | 18 | GPT-3 | 79% | Mean Success | 35 Hz | |||||||||||||||
| F3RM [197] |
|
Franka Panda | 18 | CLIP |
|
|
Unspec. | |||||||||||||||
| VIMA [272] | VIMABench [272] | None | 17 |
|
|
|
Unspec. | |||||||||||||||
| Instruct2Act [300] | VIMABench [272] | None | 17 |
|
84% | Mean Success | open loop | |||||||||||||||
| VoxPoser [227] |
|
Franka Emika | 13 |
|
|
|
5HZ | |||||||||||||||
| Text2Motion [220] | TableEnv [220] | Franka Panda | 6 | text-davinci-003 | 82% | Mean Success | open loop | |||||||||||||||
| GenSim [222] |
|
XArm7 | 100+ | GPT-4 |
|
|
Unspec. |
| Title | Datasets & Simulation | Real Robot |
|
Base Model | SR | SR Descriptions | Frequency | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
RoboCat [195] |
|
|
253 | RoboCat |
|
|
|
| Title | Datasets & Simulation | Real Robot |
|
Base Model | SR | SR Descriptions | Frequency | ||||||||||||||||
| LLaRP [304] |
|
None | 1000 | LLaMA-7B |
|
|
open loop | ||||||||||||||||
| Code-As-Policies [216] |
|
|
214 |
|
|
|
open loop | ||||||||||||||||
| InnerMonlogue [248] | Ravens [306]; |
|
130 |
|
|
|
Unspec. | ||||||||||||||||
| LIV [307] |
|
Franka panda | 114 | LIV |
|
|
15hz | ||||||||||||||||
| SayCan [24] |
|
Google robot | 101 |
|
74% | Mean Success | open loop | ||||||||||||||||
| PaLM-E [31] | Lang-table [253] |
|
100 | PaLM-E |
|
|
1-5Hz | ||||||||||||||||
| TidyBot [309] | TidyBot [309] |
|
96 |
|
|
|
open loop | ||||||||||||||||
| LLM-Grop [310] | Gazebo [311] |
|
8 | GPT-3 | 4.08 |
|
open loop | ||||||||||||||||
| LLM+P [247] |
|
None | 7 | GPT-4 |
|
|
open loop | ||||||||||||||||
| HomeRobot [205] | Habitat [312] |
|
8 | - | 20% |
|
closed loop |
| Title | Datasets & Simulation | Real Robot |
|
Base Model | SR | SR Descriptions |
Frequency |
||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
LM-Nav [204] |
Self-created datasets |
|
20 |
GPT-3 |
80% |
Mean Success |
open loop |
||||||
|
CLIP-Fields [202] |
|
|
14 |
|
79% |
Mean Success |
open loop |
||||||
|
GNM [267] |
GNM datasets [267] |
|
3 |
GNM |
96% |
Mean Success |
Unspec. |
| Title | Datasets & Simulation | Real Robot |
|
Base Model | SR | SR Descriptions |
Frequency |
||
|---|---|---|---|---|---|---|---|---|---|
|
SayTap [26] |
IsaacGym [171] |
Unitree A1 |
30 |
GPT-4 |
97% |
Mean Success |
openloop |
||
|
Prompt2Walk [229] |
Mujoco [170] |
None |
1 |
GPT-4 |
80% |
Mean Success |
10 Hz |
| Title | Datasets & Simulation | Real Robot |
|
Base Model | SR | SR Descriptions | Frequency | |||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Gato [30] |
|
Sawyer arm | 604 | GPT-4 |
|
|
20 Hz | |||||||||||||||||||||
|
|
None | 124 |
|
|
|
open loop | |||||||||||||||||||||
| Eureka [182] |
|
None | 29 | GPT-4 |
|
|
open loop | |||||||||||||||||||||
| Lang2Reward [226] | MuJoCo MPC [321] | Google robot | 17 | GPT-4 |
|
|
open loop | |||||||||||||||||||||
| VC-1 [264] | CortexBench [264] | None | 17 | VC-1 |
|
|
open loop |
5.2现行方法评估分析
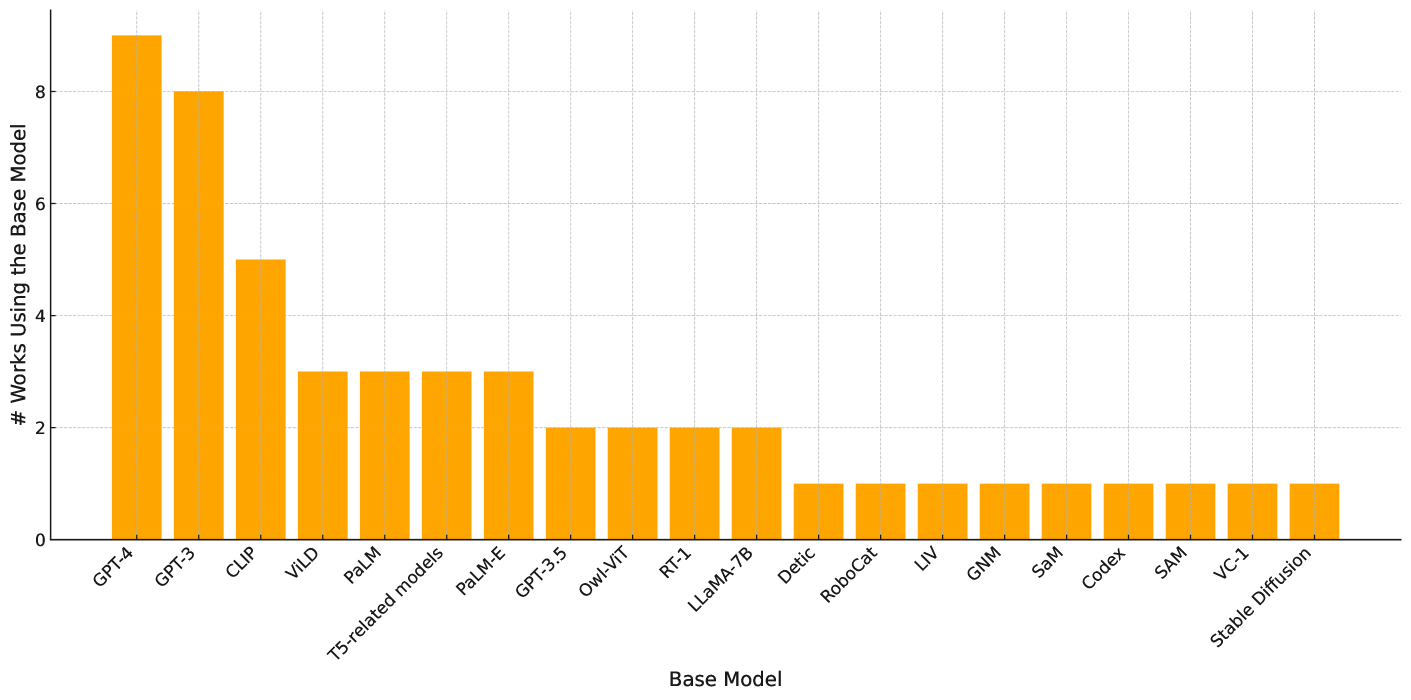
我们对表2至7和图11中列出的论文的实验进行了荟萃分析,鼓励读者考虑以下问题
-
1.
正在解决哪些任务?
-
2.
他们在哪些数据集或模拟器上接受过培训? 使用哪些机器人平台进行测试?
-
3.
正在使用哪些基础模型? 任务解决的效率如何?
-
4.
这些方法中更常使用哪些基础模型?
我们总结了当前文献中观察到的有关实验的几个主要趋势:
操作任务之间的焦点不平衡:
重点强调一般拾取任务,特别是桌面和移动操作。 这可能是由于基于桌面夹具的操作技能的训练很容易,并且它们有形成与基础模型交互的技能库的潜力。 然而,缺乏对低级动作输出的广泛探索,例如灵巧的操作和运动。
需要改进泛化性和鲁棒性:
端到端基础机器人模型的泛化性和鲁棒性还有改进的空间。 在桌面操作中,使用基础模型会导致在看不见的任务中性能下降 21% [227, 27] 到 31% [28]。 此外,这些模型仍然需要提高对干扰的鲁棒性,对于类似的任务,性能下降了 14% [27] 到 18% [227]。
低级操作的有限探索:
在探索直接的低水平行动产出方面仍然存在差距。 大多数研究侧重于任务级规划,并利用带有预先训练或预先编程的技能库的基础模型。 然而,现有的探讨低级动作输出的论文[28,176,30]主要集中在桌面操作上,其中动作空间仅限于末端执行器的7个自由度(DoF) 。 直接输出关节角度以完成灵巧操作和运动等任务的模型仍然需要更彻底的研究周期。
控制频率太慢而无法部署在真实的机器人上:
目前大多数机器人控制方法都是开环的,即使是闭环的方法也面临推理速度的限制。 这些速度通常为 1 至 10 Hz,对于大多数机器人任务来说,该速度被认为较低。 特别是对于像人形运动这样的任务,需要约 500 Hz 的高频控制来稳定机器人的身体[322]。
缺乏统一的测试基准:
机器人技术中模拟、实施例和任务的多样性导致了不同的基准,使结果的比较变得复杂。 此外,虽然成功率通常被用作主要指标,但它可能无法充分评估涉及大型基础模型的现实世界任务的性能,因为延迟并不能单独通过成功率来捕获。 考虑推理时间的更细致的评估指标,例如计算感知成功率 (CASR) [225]。
6 讨论和未来方向
6.1 剩余的挑战和公开讨论
机器人实施例的接地
尽管已经探索了多种策略来解决接地问题(如第 9 节中所述),但该领域仍存在许多开放挑战。 首先,接地需要一个有效的媒介或界面来连接概念和机器人动作。 现有的接口,例如使用自然语言 [24, 31] 和代码 [216, 221] 的接口是有限的。 虽然概念可以通过语言和代码来表达,但它们并不普遍适用于灵巧的身体动作等细微差别。 此外,这些接口通常依赖于预定义的技能库,这些库不仅开发起来耗时,而且缺乏对新环境的泛化。 使用奖励作为接口[226,232,182]可以通过动态获取技能来缓解模拟中的一些泛化问题。 然而,现实世界中训练强化学习算法的耗时和潜在不安全性引发了人们对该方法可行性的质疑,其有效性的现实验证尚未得到证实。
其次,我们需要从单模态的基础概念(例如将单词映射到含义)转向更全面的多种感官模式的基础。 仅依赖视觉数据[280]的方法可以捕获某些物理属性,例如材料、透明度和可变形性。 然而,它们在掌握摩擦等概念方面存在不足,摩擦需要具有本体感觉反馈的交互式数据,或者物体的气味,如果没有嗅觉等额外的方式就无法获得这些概念。
最后,我们应该从实施例的角度考虑接地。 根据机器人的具体情况,相同的任务可能需要不同的动作;例如,与四足机器人相比,打开一扇门需要人形机器人截然不同的动作。 当前关于接地的研究通常强调环境适应,而很少考虑具体化如何塑造交互策略。
安全性和不确定性
当我们寻求部署真正的机器人在工厂与人类一起工作、提供老年人护理或在家庭和办公室提供协助时,这些自主系统(以及为其提供动力的基础模型)将需要更有效的安全措施。 虽然正式的硬件和软件安全检查仍然适用,但使用基础模型来支持可证明的安全分析将成为越来越必要的方向。 以将机器人部署到安全关键场景为目标,先前的工作考虑利用李亚普诺夫式安全指数函数[323,324,122],试图为复杂的非线性系统提供硬安全保证动态和外部干扰(另见第 3.5 节)。 传统上,可证明安全文献所考虑的系统维度较低,通常需要仔细规范世界/动力学模型,需要指定初始安全集和/或集边界距离函数,需要一些启发式方法和训练“技巧”获得有用的安全值函数,平衡保守性与性能,不自然支持多代理设置,并在安全更新安全值函数和在线增长安全集方面提出挑战。 Herbert 等人 [324] 将多种技术综合到一个框架中,从而简化了计算,与现有技术相比,将安全集的更新简化了一个或多个数量级,并将 Hamilton-Jacobi 可达性分析扩展到控制四轴飞行器控制的 10 维系统。 Chen 等人 [122]将RL与HJ可达性分析相结合,从高维输入(RGB图像,加上车辆状态)学习安全价值函数,以进行权衡在联合优化的双重行动者-批评家框架内,针对模拟自动驾驶赛车,制定了以性能为导向的政策和以安全为导向的政策。 Tian 等人 [325] 通过将问题表述为一般和 Stackelberg 博弈,将 HJ 可达性分析集成到城市自动驾驶多智能体交互的背景下。
然而,在所有这些工作中,关于将社会可接受的安全约束和系统与机器人基础模型的正式保证相结合仍然存在悬而未决的问题。 其中一个方向是将安全制定为可供性[326]。 安全的定义根据机器人的能力和社会背景而变化。 安全的另一个重点是确保机器人推断的任务规范与人类用户的交流意图保持一致。 基础模型提供了一种对巨大的世界知识进行编码的方法,它可以作为常识先验来解码潜在的意图。 最近的工作通过保形预测[187]和显式约束检查[327]改进了大语言模型在机器人领域的使用。 尽管取得了这些进步,但基础模型目前缺乏推理与其输出相关的不确定性的能力。 如果经过适当校准,基础模型中的不确定性量化可用于触发后备安全措施,例如提前终止、预定义的安全操作或人机交互干预。
端到端方法和模块化方法之间是否存在二分法?
人脑是学习和泛化功能性方法的一个例子。 虽然神经科学家已经确定了大脑的特定区域,例如视觉皮层、体感皮层和运动皮层,但大脑表现出显着的可塑性和重组其功能以适应变化或大脑损伤的能力。 这种灵活性表明,由于统一训练,大脑可能已经进化为模块化,结合特定功能,同时保持一般学习能力[328, 329]。 同样,在“Bertology”中,NLP 研究人员展示了受过训练的网络的局部部分如何能够比其他领域更专注于一个领域。 这表明大型模型的某些模块可能会针对特定功能变得高度专业化,可以适应下游任务而无需重新训练整个网络。 这种迁移学习方法可以更有效地利用计算资源并更快地适应新任务。
在机器人技术的背景下,过早地采取模块化或端到端策略架构可能会限制机器人基础模型的潜力。 模块化解决方案可以提供特定的偏差并实现有效的特定任务性能,但它们可能无法充分利用一般学习和可迁移性的潜力。 另一方面,端到端解决方案在 CV 和 NLP 的某些任务上一直表现良好,但它们可能无法提供适应新情况所需的灵活性。 正如[45]指出的那样,对于模块化与端到端二分法似乎存在误解。 这是因为前者与架构有关,而后者与优化有关——它们并不相互排斥。
关于机器人技术中使用的基础模型的架构和优化设计,我们可以专注于功能方法,而不是将其归类为模块化或端到端可微分。 机器人基础模型的目标之一是允许灵活的模块化组件,每个组件负责特定的功能,并具有利用共享表示和通用学习功能的统一学习。
对具体身体变化的适应性
从用笔打开电灯开关,到用石膏包裹着断腿走下楼梯,人类大脑展示了多才多艺、适应性强的推理能力。 它是控制感知理解、运动控制和对话功能的单个单元。 对于运动控制,它适应实施例中由于工具使用或受伤而发生的变化。 这种适应性延伸到更深刻的转变,例如个人学习用脚绘画或用专门的假肢掌握乐器。 我们希望在机器人技术中构建这种交互式和适应性强的智能。
在之前的讨论中,我们看到现有的工作成功地为各种机器人平台部署了导航基础模型[29],例如不同的轮式机器人和四足机器人。 我们还见证了不同机械臂[28, 330]中使用的操纵基础模型,该模型可以在不同的机器人平台上使用,从桌面机械臂到移动机械臂。
关键的开放研究问题之一是机器人基础模型如何实现跨不同物理实施例的运动控制。 部署在家庭和办公室的机器人策略必须能够应对机械运动故障,例如传感器故障或执行器故障,确保在充满挑战的环境中持续发挥功能。 此外,机器人系统的设计必须能够适应各种工具和外围设备,反映人类与不同仪器交互以完成特定任务和物理工具用途的能力。 虽然一些作品[331,332,333]已经探索了不同工具使用的学习表示,但这些方法尚未通过基础模型进行扩展。
世界模型,还是模型不可知论?
在经典机器人技术中,特别是在规划和控制问题中,通常尝试尽可能多地对机器人任务所需的世界进行建模。 这通常是通过利用任务的结构先验,或者依靠启发式或简化假设来实现的。 当然,如果可以完美地模拟世界,那么解决机器人问题就会变得简单得多。 不幸的是,由于现实世界的复杂性,机器人领域的世界建模仍然极其困难,有时甚至棘手。 因此,获得跨任务和环境通用的策略仍然是一个核心问题。
本文调查的基础模型大多采用与模型无关(无模型)的方法,利用广泛的数据集和大规模深度学习架构的优势。 一些例外尝试通过直接使用大语言模型作为动态模型来模拟基于模型的方法。 然而,这些尝试仍然受到纯文本描述的固有局限性的限制,并且容易遇到幻觉问题,如[271, 225]中所述。 许多研究人员认为[138]这些基础模型的数据规模学习范式与人类和动物的学习方式仍然有很大不同,人类和动物的学习方式是一种极端的数据和能源效率方式。 实现接近人类学习能力的联合表现和效率仍然令人着迷。 在[138]中,LeCun 认为解决该难题的一个可能答案可能在于学习世界模型,该模型可以预测世界状态将如何发展因采取的行动而发生变化。 如果我们要开发能够通过严格的数学和物理建模来模拟世界表示精度的世界模型,那么这将使我们更接近于解决和概括机器人技术中的复杂问题。 这些复杂且可靠的世界模型将使已建立的基于模型的方法的应用成为可能,包括基于搜索和基于样本的规划以及轨迹优化技术。 这种方法不仅有助于解决机器人技术中的规划和控制挑战,而且还增强了这些过程的可解释性。 人们认为,追求以卓越的泛化能力和零样本学习能力为特征的“基础世界模型”,有可能成为该领域范式转变的发展。
新型机器人平台和多感官信息
如图3(c)和表2-7中的元分析所示,现有用于部署基础模型的真实机器人平台是主要限于基于夹具的单臂机器人操纵器。 从这些硬件系统执行的任务中可学习的概念范围受到限制,主要是因为夹具的简单打开和关闭动作很容易用语言描述。 为了使机器人达到与动物和人类相当的灵活性和运动技能水平,或者执行复杂的家务任务,基础模型必须对物理和家庭概念有更深入的理解。 这种学习需要更广泛的信息源,例如不同的传感器(包括气味、触觉和热传感器),以及更复杂的数据,例如来自高自由度机器人平台的本体感觉数据。
目前的灵巧操纵器,例如 Shadow Hand [334],价格昂贵且容易频繁出现故障,因此它们主要在模拟中进行实验。 此外,触觉传感器的应用仍然受到限制,通常局限于指尖,如[335],或者仅提供低分辨率,如机器人毛衣[336]. 此外,由于大部分数据收集仍然通过人工演示进行,因此需要更准确、更高效的数据获取平台,例如 ALOHA [337] 和 Leap Hands [284],越来越受欢迎。 因此,我们认为尚未做出重大贡献——不仅在软件创新方面,而且在硬件方面。 这些进步对于提供更丰富的数据收集至关重要,从而扩展机器人基础模型的概念空间。
持续学习
持续学习广义上是指学习和适应动态和变化环境的能力。 具体来说,它是指随着时间的推移,可以学习并适应底层训练数据分布和不断变化的学习目标的学习算法。
持续学习具有挑战性,因为神经网络模型经常遭受灾难性遗忘,导致先前任务的整体模型性能显着下降。 缓解灾难性遗忘导致的性能下降的一种简单解决方案是使用收集的整个数据集定期重新训练模型,这通常允许模型避免遗忘问题,因为该过程包含旧数据和新数据。 然而,这种方法需要大量的计算和内存资源。 相比之下,仅对新任务或当前数据进行训练或微调,而不重新访问以前的数据,资源密集程度较低,但由于模型倾向于覆盖以前学习的信息,因此会导致灾难性遗忘。 这种遗忘可归因于新旧数据之间的任务干扰、数据分布随时间演变而产生的概念漂移以及基于模型大小的模型表达力的限制。
此外,随着模型容量的增加,在不断扩大的数据语料库上不断地重新训练它们变得不太可行。 最近在视觉和语言持续学习方面的工作[338,339,340,341]提出了各种解决方案,但实现可应用于机器人技术的有效持续学习仍然是一个具有挑战性的目标。 对于持续学习,大型预训练基础模型目前面临上述挑战以及更多挑战,主要是因为它们的庞大规模使得再训练变得更加困难。 特别是在机器人应用中,持续学习对于机器人学习策略在不同环境中的可部署性至关重要,但这仍然是一个很大程度上未经探索的领域。 而最近的一些作品研究了持续学习的各种子主题[342],例如增量学习[343]、快速运动适应[344]、人机循环学习[345, 346]——这些解决方案通常是为单个任务/平台设计的,尚未考虑基础模型。
我们需要在设计时考虑到机器学习基础知识和实际实时系统的持续学习算法。 一些开放的研究问题和可行的方法是:(1)在对最新数据进行微调时混合不同比例的先验数据分布,以减轻灾难性遗忘[347],(2)根据先验数据开发有效的原型学习新任务的分布或课程[348]以进行任务推理,(3)提高在线学习算法的训练稳定性和样本效率[349, 350],以及( 4)确定将大容量模型无缝整合到控制框架中的原则性方法(可能采用分层学习[351,352,353]/慢速控制[354])用于实时推理。
标准化和可重复性
机器人社区需要鼓励标准化和可重复的研究实践,以确保已发表的研究结果可以被其他人验证和比较。 为了实现大规模的可重复性,我们需要弥合模拟环境和现实世界硬件之间的差距,并提高机器学习模型的可迁移性。 Homerobot [205] 是朝着支持开放词汇拾放任务的模拟和硬件平台迈出的充满希望的一步。 我们需要建立标准化的任务定义和功能可供性来处理不同的机器人形态,从而实现更高效的模型开发。
6.2总结
在这篇调查论文中,我们根据两个主要类别分析了当前机器人基础模型的研究工作:(1)将基础模型应用于机器人任务的工作,以及(2)尝试使用机器人技术开发用于机器人任务的机器人基础模型的工作数据。 我们回顾了这些论文的方法和实验,并根据这些研究工作提供了分析和见解。 此外,我们还特别介绍了这些基础模型如何帮助解决机器人技术中的常见挑战。 最后,我们讨论了基础模型尚未解决的机器人技术的剩余挑战,以及其他有前途的研究方向。
免责声明
由于该领域快速变化的性质,我们于 2023 年 12 月 13 日检查了此版本的文献综述,可能错过了一些相关工作。 此外,由于文献丰富且调查范围广泛,本文可能存在不准确或错误。 我们欢迎读者向我们的 GitHub 存储库(在 https://robotics-fm-survey.github.io/ 内)发送拉取请求,以便我们可以继续更新我们的参考资料,纠正错误和不准确之处,以及更新论文中元研究的条目。 请参阅 GitHub 存储库中的贡献指南。
致谢
我们要感谢 Vincent Vanhoucke 对本调查文件草稿的反馈。 此外,我们还要感谢 Kedi Xu 对论文列表的富有洞察力的讨论。
参考
- [1] Andreas Geiger, Philip Lenz, Christoph Stiller, and Raquel Urtasun. Vision meets robotics: The kitti dataset. International Journal of Robotics Research (IJRR), 2013.
- [2] Daniel Maturana, Po-Wei Chou, Masashi Uenoyama, and Sebastian Scherer. Real-time semantic mapping for autonomous off-road navigation. In Field and Service Robotics, pages 335–350. Springer, 2018.
- [3] Berk Calli, Arjun Singh, James Bruce, Aaron Walsman, Kurt Konolige, Siddhartha Srinivasa, Pieter Abbeel, and Aaron M Dollar. Yale-cmu-berkeley dataset for robotic manipulation research. In International Journal of Robotics Research, page 261 – 268, 2017.
- [4] Jeff Donahue, Yangqing Jia, Oriol Vinyals, Judy Hoffman, Ning Zhang, Eric Tzeng, and Trevor Darrell. Decaf: A deep convolutional activation feature for generic visual recognition. In ICML, 2014.
- [5] Eric Tzeng, Judy Hoffman, Kate Saenko, and Trevor Darrell. Adversarial discriminative domain adaptation. In CVPR, 2017.
- [6] William Shen, Felipe Trevizan, and Sylvie Thiébaux. Learning domain-independent planning heuristics with hypergraph networks. In Proceedings of the International Conference on Automated Planning and Scheduling, volume 30, pages 574–584, 2020.
- [7] Beomjoon Kim and Luke Shimanuki. Learning value functions with relational state representations for guiding task-and-motion planning. In Conference on Robot Learning, pages 955–968. PMLR, 2020.
- [8] Grady Williams, Paul Drews, Brian Goldfain, James M. Rehg, and Evangelos A. Theodorou. Aggressive driving with model predictive path integral control. In ICRA, 2016.
- [9] Ahmed H Qureshi, Yinglong Miao, Anthony Simeonov, and Michael C Yip. Motion planning networks: Bridging the gap between learning-based and classical motion planners. IEEE Transactions on Robotics, pages 1–9, 2020.
- [10] Adam Fishman, Adithyavairavan Murali, Clemens Eppner, Bryan Peele, Byron Boots, and Dieter Fox. Motion policy networks. In Proceedings of the 6th Conference on Robot Learning (CoRL), 2022.
- [11] Xue Bin Peng, Erwin Coumans, Tingnan Zhang, Tsang-Wei Lee, Jie Tan, and Sergey Levine. Learning agile robotic locomotion skills by imitating animals. In RSS, 2020.
- [12] Sergey Levine, Chelsea Finn, Trevor Darrell, and Pieter Abbeel. End-to-end training of deep visuomotor policies. In Journal of Machine Learning Research, 2016.
- [13] Jemin Hwangbo, Joonho Lee, Alexey Dosovitskiy, Dario Bellicoso, Vassilios Tsounis, Vladlen Koltun, and Marco Hutter. Learning agile and dynamic motor skills for legged robots. In Science Robotics, 30 Jan 2019.
- [14] Anusha Nagabandi, Kurt Konoglie, Sergey Levine, and Vikash Kumar. Deep dynamics models for learning dexterous manipulation. In CoRL, 2019.
- [15] Dmitry Kalashnkov and Jake Varley and Yevgen Chebotar and Ben Swanson and Rico Jonschkowski and Chelsea Finn and Sergey Levine and Karol Hausman. Mt-opt: Continuous multi-task robotic reinforcement learning at scale. arXiv:2104.08212, 2021.
- [16] Eric Jang, Alex Irpan, Mohi Khansari, Daniel Kappler, Frederik Ebert, Corey Lynch, Sergey Levine, and Chelsea Finn. BC-Z: Zero-Shot Task Generalization with Robotic Imitation Learning. In 5th Annual Conference on Robot Learning, 2021.
- [17] Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. Language models are few-shot learners, 2020.
- [18] Aditya Ramesh, Prafulla Dhariwal Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125, 2022.
- [19] Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily Denton, Seyed Kamyar, Seyed Ghasemipour, Burcu Karagol Ayan, S. Sara Mahdavi, Rapha Gontijo Lopes, Tim Salimans, Jonathan Ho, David J Fleet, and Mohammad Norouzi. Photorealistic text-to-image diffusion models with deep language understanding. arXiv preprint arXiv:2205.11487, 2022.
- [20] Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. In Proceedings of the International Conference on Computer Vision (ICCV), 2021.
- [21] Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollár, and Ross Girshick. Segment anything. arXiv:2304.02643, 2023.
- [22] Maxime Oquab, Timothée Darcet, Theo Moutakanni, Huy V. Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Russell Howes, Po-Yao Huang, Hu Xu, Vasu Sharma, Shang-Wen Li, Wojciech Galuba, Mike Rabbat, Mido Assran, Nicolas Ballas, Gabriel Synnaeve, Ishan Misra, Herve Jegou, Julien Mairal, Patrick Labatut, Armand Joulin, and Piotr Bojanowski. Dinov2: Learning robust visual features without supervision, 2023.
- [23] Rishi Bommasani et. al. from the Center for Research on Foundation Models (CRFM) at the Stanford Institute for Human-Centered Artificial Intelligence (HAI). On the opportunities and risks of foundation models. In arXiv:2108.07258, 2021.
- [24] Ahn et. al. Do as i can, not as i say: Grounding language in robotic affordances. In CoRL, 2022.
- [25] Boyuan Chen, Fei Xia, Brian Ichter, Kanishka Rao, Keerthana Gopalakrishnan, Michael S. Ryoo, Austin Stone, and Daniel Kappler. Open-vocabulary queryable scene representations for real world planning. In arXiv:2209.09874, 2022.
- [26] Yujin Tang, Wenhao Yu, Jie Tan, Heiga Zen, Aleksandra Faust, and Tatsuya Harada. Saytap: Language to quadrupedal locomotion, 2023.
- [27] Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, et al. Rt-1: Robotics transformer for real-world control at scale. arXiv preprint arXiv:2212.06817, 2022.
- [28] Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Xi Chen, Krzysztof Choromanski, Tianli Ding, Danny Driess, Avinava Dubey, Chelsea Finn, Pete Florence, Chuyuan Fu, Montse Gonzalez Arenas, Keerthana Gopalakrishnan, Kehang Han, Karol Hausman, Alex Herzog, Jasmine Hsu, Brian Ichter, Alex Irpan, Nikhil Joshi, Ryan Julian, Dmitry Kalashnikov, Yuheng Kuang, Isabel Leal, Lisa Lee, Tsang-Wei Edward Lee, Sergey Levine, Yao Lu, Henryk Michalewski, Igor Mordatch, Karl Pertsch, Kanishka Rao, Krista Reymann, Michael Ryoo, Grecia Salazar, Pannag Sanketi, Pierre Sermanet, Jaspiar Singh, Anikait Singh, Radu Soricut, Huong Tran, Vincent Vanhoucke, Quan Vuong, Ayzaan Wahid, Stefan Welker, Paul Wohlhart, Jialin Wu, Fei Xia, Ted Xiao, Peng Xu, Sichun Xu, Tianhe Yu, and Brianna Zitkovich. Rt-2: Vision-language-action models transfer web knowledge to robotic control. In arXiv preprint arXiv:2307.15818, 2023.
- [29] Dhruv Shah, Ajay Sridhar, Nitish Dashora, Kyle Stachowicz, Kevin Black, Noriaki Hirose, and Sergey Levine. Vint: A foundation model for visual navigation. In arxiv preprint arXiv:2306.14846, 2023.
- [30] Scott Reed, Konrad Zolna, Emilio Parisotto, Sergio Gomez Colmenarejo, Alexander Novikov, Gabriel Barth-Maron, Mai Gimenez, Yury Sulsky, Jackie Kay, Jost Tobias Springenberg, Tom Eccles, Jake Bruce, Ali Razavi, Ashley Edwards, Nicolas Heess, Yutian Chen, Raia Hadsell, Oriol Vinyals, Mahyar Bordbar, and Nando de Freitas. A generalist agent. In Transactions on Machine Learning Research (TMLR), November 10, 2022.
- [31] Danny Driess, F. Xia, Mehdi S. M. Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Ho Vuong, Tianhe Yu, Wenlong Huang, Yevgen Chebotar, Pierre Sermanet, Daniel Duckworth, Sergey Levine, Vincent Vanhoucke, Karol Hausman, Marc Toussaint, Klaus Greff, Andy Zeng, Igor Mordatch, and Peter R. Florence. PaLM-E: An embodied multimodal language model. ArXiv, abs/2303.03378, 2023.
- [32] Jean Kaddour, Joshua Harris, Maximilian Mozes, Herbie Bradley, Roberta Raileanu, and Robert McHardy. Challenges and applications of large language models. arXiv:2307.10169, 2023.
- [33] Chenshuang Zhang, Chaoning Zhang, Mengchun Zhang, and In So Kweon. Text-to-image diffusion models in generative ai: A survey. arXiv:2303.07909, 2023.
- [34] Jingfeng Yang, Hongye Jin, Ruixiang Tang, Xiaotian Han, Qizhang Feng, Haoming Jiang, Bing Yin, and Xia Hu. Harnessing the power of llms in practice: A survey on chatgpt and beyond. arXiv:2304.13712, 2023.
- [35] Sherry Yang, Ofir Nachum, Yilun Du, Jason Wei, Pieter Abbeel, and Dale Schuurmans. Foundation models for decision making: Problems, methods, and opportunities. arXiv:2303.04129, 2023.
- [36] Chaoning Zhang, Fachrina Dewi Puspitasari, Sheng Zheng, Chenghao Li, Yu Qiao, Taegoo Kang, Xinru Shan, Chenshuang Zhang, Caiyan Qin, Francois Rameau, Lik-Hang Lee, Sung-Ho Bae, and Choong Seon Hong. A survey on segment anything model (sam): Vision foundation model meets prompt engineering, 2023.
- [37] Muhammad Awais, Muzammal Naseer, Salman Khan, Rao Muhammad Anwer, Hisham Cholakkal, Mubarak Shah, Ming-Hsuan Yang, and Fahad Shahbaz Khan. Foundational models defining a new era in vision: A survey and outlook, 2023.
- [38] Yifan Du, Zikang Liu, Junyi Li, and Wayne Xin Zhao. A survey of vision-language pre-trained models. IJCAI-2022 survey track, 2022.
- [39] Jindong Gu, Zhen Han, Shuo Chen, Ahmad Beirami, Bailan He, Ruotong Liao Gengyuan Zhang, Yao Qin, Volker Tresp, and Philip Torr. A systematic survey of prompt engineering on vision-language foundation models. arXiv:2307.12980, 2023.
- [40] Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, Wayne Xin Zhao, Zhewei Wei, and Ji-Rong Wen. A survey on large language model based autonomous agents. arXiv:2308.11432, 2023.
- [41] Jinzhou Lin, Han Gao, Rongtao Xu, Changwei Wang, Man Zhang, Li Guo, and Shibiao Xu. The development of llms for embodied navigation. In IEEE/ASME TRANSACTIONS ON MECHATRONICS, volume 1, Sept. 2023.
- [42] Anirudha Majumdar. Robotics: An idiosyncratic snapshot in the age of llms, 8 2023.
- [43] Xuan Xiao, Jiahang Liu, Zhipeng Wang, Yanmin Zhou, Yong Qi, Qian Cheng, Bin He, and Shuo Jiang. Robot learning in the era of foundation models: A survey, 2023.
- [44] Roya Firoozi, Johnathan Tucker, Stephen Tian, Anirudha Majumdar, Jiankai Sun, Weiyu Liu, Yuke Zhu, Shuran Song, Ashish Kapoor, Karol Hausman, Brian Ichter, Danny Driess, Jiajun Wu, Cewu Lu, and Mac Schwager. Foundation models in robotics: Applications, challenges, and the future, 2023.
- [45] Vincent Vanhoucke. The end-to-end false dichotomy: Roboticists arguing lego vs. playmo. Medium, October 28 2018.
- [46] Yuke Zhu. Cs391r: Robot learning, 2021.
- [47] Jonathan Francis, Nariaki Kitamura, Felix Labelle, Xiaopeng Lu, Ingrid Navarro, and Jean Oh. Core challenges in embodied vision-language planning. Journal of Artificial Intelligence Research, 74:459–515, 2022.
- [48] Shaoqing Ren, Kaiming He, Ross Girshick, , and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. In NIPS, 2015.
- [49] Joseph Redmon and Ali Farhadi. Yolov3: An incremental improvement. arXiv preprint arXiv:1804.02767, 2018.
- [50] Nikhil Varma Keetha, Chen Wang, Yuheng Qiu, Kuan Xu, and Sebastian Scherer. Airobject: A temporally evolving graph embedding for object identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8407–8416, 2022.
- [51] Charles Ruizhongtai Qi, Li Yi, Hao Su, and Leonidas J. Guibas. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In NIPS, 2017.
- [52] Antoni Rosinol, John J Leonard, and Luca Carlone. Nerf-slam: Real-time dense monocular slam with neural radiance fields. arXiv preprint arXiv:2210.13641, 2022.
- [53] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. In ICML, 2021.
- [54] Raul Mur-Artal, Jose Maria Martinez Montiel, and Juan D Tardos. Orb-slam: a versatile and accurate monocular slam system. IEEE transactions on robotics, 31(5):1147–1163, 2015.
- [55] Jakob Engel, Vladlen Koltun, and Daniel Cremers. Direct sparse odometry. IEEE transactions on pattern analysis and machine intelligence, 40(3):611–625, 2017.
- [56] Xiang Gao, Rui Wang, Nikolaus Demmel, and Daniel Cremers. Ldso: Direct sparse odometry with loop closure. In 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 2198–2204. IEEE, 2018.
- [57] Jakob Engel, Thomas Schöps, and Daniel Cremers. Lsd-slam: Large-scale direct monocular slam. In European conference on computer vision, pages 834–849. Springer, 2014.
- [58] Jon Zubizarreta, Iker Aguinaga, and J. M. M. Montiel. Direct sparse mapping. IEEE Transactions on Robotics, 2020.
- [59] Shibo Zhao, Peng Wang, Hengrui Zhang, Zheng Fang, and Sebastian Scherer. Tp-tio: A robust thermal-inertial odometry with deep thermalpoint. In 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 4505–4512. IEEE, 2020.
- [60] Wolfgang Hess, Damon Kohler, Holger Rapp, and Daniel Andor. Real-time loop closure in 2d lidar slam. In 2016 IEEE international conference on robotics and automation (ICRA), pages 1271–1278. IEEE, 2016.
- [61] S. Kohlbrecher, J. Meyer, O. von Stryk, and U. Klingauf. A flexible and scalable slam system with full 3d motion estimation. In Proc. IEEE International Symposium on Safety, Security and Rescue Robotics (SSRR). IEEE, November 2011.
- [62] Ji Zhang and Sanjiv Singh. Loam: Lidar odometry and mapping in real-time. In Robotics: Science and systems, volume 2, pages 1–9. Berkeley, CA, 2014.
- [63] Shuo Yang, Zixin Zhang, Zhengyu Fu, and Zachary Manchester. Cerberus: Low-drift visual-inertial-leg odometry for agile locomotion. ICRA, 2023.
- [64] Christian Forster, Luca Carlone, Frank Dellaert, and Davide Scaramuzza. Imu preintegration on manifold for efficient visual-inertial maximum-a-posteriori estimation. Technical report, EPFL, 2015.
- [65] Ji Zhang and Sanjiv Singh. Visual-lidar odometry and mapping: Low-drift, robust, and fast. In ICRA, 2015.
- [66] Johannes Graeter, Alexander Wilczynski, and Martin Lauer. Limo: Lidar-monocular visual odometry. In 2018 IEEE/RSJ international conference on intelligent robots and systems (IROS), pages 7872–7879. IEEE, 2018.
- [67] Thien-Minh Nguyen, Shenghai Yuan, Muqing Cao, Thien Hoang Nguyen, and Lihua Xie. Viral slam: Tightly coupled camera-imu-uwb-lidar slam. arXiv preprint arXiv:2105.03296, 2021.
- [68] Tixiao Shan, Brendan Englot, Drew Meyers, Wei Wang, Carlo Ratti, and Daniela Rus. Lio-sam: Tightly-coupled lidar inertial odometry via smoothing and mapping. In 2020 IEEE/RSJ international conference on intelligent robots and systems (IROS), pages 5135–5142. IEEE, 2020.
- [69] Shibo Zhao, Hengrui Zhang, Peng Wang, Lucas Nogueira, and Sebastian Scherer. Super odometry: Imu-centric lidar-visual-inertial estimator for challenging environments. In 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 8729–8736. IEEE, 2021.
- [70] Sen Wang, Ronald Clark, Hongkai Wen, and Niki Trigoni. Deepvo: Towards end-to-end visual odometry with deep recurrent convolutional neural networks. In 2017 IEEE international conference on robotics and automation (ICRA), pages 2043–2050. IEEE, 2017.
- [71] Wenshan Wang, Yaoyu Hu, and Sebastian Scherer. Tartanvo: A generalizable learning-based vo. In CoRL, 2020.
- [72] T. Zhou, M. Brown, N. Snavely, and D. G. Lowe. Unsupervised learning of depth and ego-motion from video. In CVPR, 2017.
- [73] Zachary Teed and Jia Deng. Droid-slam: Deep visual slam for monocular, stereo, and rgb-d cameras. In NeurIPS, 2021.
- [74] Zihan Zhu, Songyou Peng, Viktor Larsson, Zhaopeng Cui, Martin R Oswald, Andreas Geiger, and Marc Pollefeys. Nicer-slam: Neural implicit scene encoding for rgb slam. arXiv preprint arXiv:2302.03594, 2023.
- [75] Nikhil Keetha, Jay Karhade, Krishna Murthy Jatavallabhula, Gengshan Yang, Sebastian Scherer, Deva Ramanan, and Jonathon Luiten. Splatam: Splat, track & map 3d gaussians for dense rgb-d slam. arXiv preprint arXiv:2312.02126, 2023.
- [76] Lerrel Pinto, Dhiraj Gandhi, Yuanfeng Han, Yong-Lae Park, and Abhinav Gupta. The curious robot: Learning visual representations via physical interactions. In ECCV, 2016.
- [77] Dinesh Jayaraman and Kristen Grauman. Learning to look around: Intelligently exploring unseen environments for unknown tasks. In CVPR, 2018.
- [78] Liren Jin, Xieyuanli Chen, Julius Rückin, and Marija Popović. Neu-nbv: Next best view planning using uncertainty estimation in image-based neural rendering. arXiv preprint arXiv:2303.01284, 2023.
- [79] Yafei Hu, Junyi Geng, Chen Wang, John Keller, and Sebastian Scherer. Off-Policy Evaluation with Online Adaptation for Robot Exploration in Challenging Environments. In IEEE Robotics and Automation Letters (RA-L), 2023.
- [80] Peter E. Hart, Nils J. Nilsson, and Bertram Raphael. A formal basis for the heuristic determination of minimum cost paths. IEEE Transactions on Systems Science and Cybernetics, 4(2):100–107, 1968.
- [81] Venkatraman Narayanan, Mike Phillips, and Maxim Likhachev. Anytime safe interval path planning for dynamic environments. In 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 4708–4715, 2012.
- [82] Sandip Aine, Siddharth Swaminathan, Venkatraman Narayanan, Victor Hwang, and Maxim Likhachev. Multi-heuristic A. In Dieter Fox, Lydia E. Kavraki, and Hanna Kurniawati, editors, Robotics: Science and Systems X, University of California, Berkeley, USA, July 12-16, 2014, 2014.
- [83] Brian MacAllister, Jonathan Butzke, Alex Kushleyev, Harsh Pandey, and Maxim Likhachev. Path planning for non-circular micro aerial vehicles in constrained environments. In 2013 IEEE International Conference on Robotics and Automation, pages 3933–3940, 2013.
- [84] Benjamin J. Cohen, Sachin Chitta, and Maxim Likhachev. Single- and dual-arm motion planning with heuristic search. Int. J. Robotics Res., 33(2):305–320, 2014.
- [85] Steven M LaValle et al. Rapidly-exploring random trees: A new tool for path planning. Technical report, Iowa State University, 1998.
- [86] J.J. Kuffner and S.M. LaValle. Rrt-connect: An efficient approach to single-query path planning. In Proceedings 2000 ICRA. Millennium Conference. IEEE International Conference on Robotics and Automation. Symposia Proceedings (Cat. No.00CH37065), volume 2, pages 995–1001 vol.2, 2000.
- [87] L.E. Kavraki, P. Svestka, J.-C. Latombe, and M.H. Overmars. Probabilistic roadmaps for path planning in high-dimensional configuration spaces. IEEE Transactions on Robotics and Automation, 12(4):566–580, 1996.
- [88] Sertac Karaman and Emilio Frazzoli. Sampling-based algorithms for optimal motion planning. The international journal of robotics research, 30(7):846–894, 2011.
- [89] Jonathan D Gammell, Siddhartha S Srinivasa, and Timothy D Barfoot. Batch informed trees (bit): Sampling-based optimal planning via the heuristically guided search of implicit random geometric graphs. In 2015 IEEE international conference on robotics and automation (ICRA), pages 3067–3074. IEEE, 2015.
- [90] Sanjiban Choudhury, Jonathan D Gammell, Timothy D Barfoot, Siddhartha S Srinivasa, and Sebastian Scherer. Regionally accelerated batch informed trees (rabit): A framework to integrate local information into optimal path planning. In 2016 IEEE International Conference on Robotics and Automation (ICRA), pages 4207–4214. IEEE, 2016.
- [91] Malik Ghallab, Dana Nau, and Paolo Traverso. Automated Planning and Acting. Cambridge University Press, 2016.
- [92] Caelan Reed Garrett, Rohan Chitnis, Rachel Holladay, Beomjoon Kim, Tom Silver, Leslie Pack Kaelbling, and Tomas Lozano-P´erez. Integrated Task and Motion Planning. In arXiv:2010.01083, 2010.
- [93] Dhruv Shah, Arjun Bhorkar, Hrish Leen, Ilya Kostrikov, Nick Rhinehart, and Sergey Levine. Offline reinforcement learning for visual navigation. In CoRL, 2022.
- [94] Kyle Stachowicz, Arjun Bhorkar, Dhruv Shah, Ilya Kostrikov, and Sergey Levine. Fastrlap: A system for learning high-speed driving via deep rl and autonomous practicing. arXiv pre-print, 2023.
- [95] Sergey Levine, Aviral Kumar, George Tucker, and Justin Fu. Offline reinforcement learning: Tutorial, review, and perspectives on open problems. In NeurIPS 2020 Tutorial, 2020.
- [96] Fangkai Yang, Daoming Lyu, Bo Liu, and Steven Gustafson. Peorl: Integrating symbolic planning and hierarchical reinforcement learning for robust decision-making. arXiv preprint arXiv:1804.07779, 2018.
- [97] Yuqian Jiang, Fangkai Yang, Shiqi Zhang, and Peter Stone. Task-motion planning with reinforcement learning for adaptable mobile service robots. In 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 7529–7534. IEEE, 2019.
- [98] Garrett Andersen and George Konidaris. Active exploration for learning symbolic representations. Advances in Neural Information Processing Systems, 30, 2017.
- [99] George Konidaris, Leslie Pack Kaelbling, and Tomas Lozano-Perez. From skills to symbols: Learning symbolic representations for abstract high-level planning. Journal of Artificial Intelligence Research, 61:215–289, 2018.
- [100] Brian Paden, Michal Čáp, Sze Zheng Yong, Dmitry Yershov, and Emilio Frazzoli. A survey of motion planning and control techniques for self-driving urban vehicles. IEEE Transactions on intelligent vehicles, 1(1):33–55, 2016.
- [101] Jonathan Francis, Bingqing Chen, Weiran Yao, Eric Nyberg, and Jean Oh. Distribution-aware goal prediction and conformant model-based planning for safe autonomous driving. ICML Workshop on Safe Learning for Autonomous Driving, 2022.
- [102] James Herman, Jonathan Francis, Siddha Ganju, Bingqing Chen, Anirudh Koul, Abhinav Gupta, Alexey Skabelkin, Ivan Zhukov, Max Kumskoy, and Eric Nyberg. Learn-to-race: A multimodal control environment for autonomous racing. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 9793–9802, 2021.
- [103] Jonathan Francis, Bingqing Chen, Siddha Ganju, Sidharth Kathpal, Jyotish Poonganam, Ayush Shivani, Vrushank Vyas, Sahika Genc, Ivan Zhukov, Max Kumskoy, et al. Learn-to-race challenge 2022: Benchmarking safe learning and cross-domain generalisation in autonomous racing. ICML Workshop on Safe Learning for Autonomous Driving, 2022.
- [104] Grady Williams, Andrew Aldrich, and Evangelos A Theodorou. Model predictive path integral control: From theory to parallel computation. Journal of Guidance, Control, and Dynamics, 40(2):344–357, 2017.
- [105] Christopher G Atkeson and Stefan Schaal. Robot learning from demonstration. In ICML, 1997.
- [106] Jens Kober, J. Andrew Bagnell, and Jan Peters. Reinforcement learning in robotics: A survey. The International Journal of Robotics Research, 2013.
- [107] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton. Imagenet classification with deep convolutional neural networks. In NIPS, 2012.
- [108] Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, and Martin Riedmiller. Playing atari with deep reinforcement learning. In NIPS Deep Learning Workshop, 2013.
- [109] David Silver, Aja Huang, Chris J. Maddison, Arthur Guez, Laurent Sifre, George van den Driessche, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, Sander Dieleman, Dominik Grewe, John Nham, Nal Kalchbrenner, Ilya Sutskever, Timothy Lillicrap, Madeleine Leach, Koray Kavukcuoglu, Thore Graepel, and Demis Hassabis. Mastering the game of go with deep neural networks and tree search. In Nature, 2016.
- [110] Elia Kaufmann, Antonio Loquercio, René Ranftl, Matthias Müller, Vladlen Koltun, and Davide Scaramuzza. Deep drone acrobatics. In Proceedings of Robotics: Science and Systems, Corvalis, Oregon, USA, July 2020.
- [111] Sergey Levine, Peter Pastor, Alex Krizhevsky, and Deirdre Quillen. Learning hand-eye coordination for robotic grasping with deep learning and large-scale data collection. In arXiv:1603.02199, 2016.
- [112] Dmitry Kalashnikov, Alex Irpan, Peter Pastor, Julian Ibarz, Alexander Herzog, Eric Jang, Deirdre Quillen, Ethan Holly, Mrinal Kalakrishnan, Vincent Vanhoucke, and Sergey Levine. Qt-opt: Scalable deep reinforcement learning for vision-based robotic manipulation. In CoRL, 2018.
- [113] Joonho Lee, Jemin Hwangbo, Lorenz Wellhausen, Vladlen Koltun, and Marco Hutter. Learning quadrupedal locomotion over challenging terrain. In Science Robotics, 21 Oct 2020.
- [114] Stephane Ross, Geoffrey J. Gordon, and J. Andrew Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. In AISTATS, 2011.
- [115] Pieter Abbeel and Andrew Y. Ng. Apprenticeship learning via inverse reinforcement learning. In ICML, 2004.
- [116] Brian D. Ziebart, Andrew Maas, J.Andrew Bagnell, and Anind K. Dey. Maximum entropy inverse reinforcement learning. In AAAI, 2008.
- [117] Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial networks. In NIPS, 2014.
- [118] Jonathan Ho and Stefano Ermon. Generative adversarial imitation learning. In NIPS, 2016.
- [119] Yunpeng Pan, Ching-An Cheng, Kamil Saigol, Keuntaek Lee, Xinyan Yan, Evangelos Theodorou, and Byron Boots. Agile autonomous driving using end-to-end deep imitation learning. In RSS, 2018.
- [120] Chenhao Li, Marin Vlastelica, Sebastian Blaes, Jonas Frey, Felix Grimminger, and Georg Martius. Learning agile skills via adversarial imitation of rough partial demonstrations. In CoRL, 2022.
- [121] Richard S. Sutton and Andrew G. Barto. Reinforcement Learning: An Introduction , second edition. The MIT Press, 2018.
- [122] Bingqing Chen, Jonathan Francis, Jean Oh, Eric Nyberg, and Sylvia L Herbert. Safe autonomous racing via approximate reachability on ego-vision. arXiv preprint arXiv:2110.07699, 2021.
- [123] Deepak Pathak Zipeng Fu, Xuxin Cheng. Deep whole-body control: Learning a unified policy for manipulation and locomotion. In CoRL, 2022.
- [124] Xuxin Cheng, Kexin Shi, Ananye Agarwal, and Deepak Pathak. Extreme parkour with legged robots. In arXiv:2309.14341, 2023.
- [125] Kurtland Chua, Roberto Calandra, Rowan McAllister, and Sergey Levine. Deep reinforcement learning in a handful of trials using probabilistic dynamics models. In Neural Information Processing Systems, 2018.
- [126] Chelsea Finn, Ian Goodfellow, and Sergey Levine. Unsupervised learning for physical interaction through video prediction. In NIPS, 2016.
- [127] Chelsea Finn and Sergey Levine. Deep visual foresight for planning robot motion. In ICRA, 2017.
- [128] S. Levine I. Kostrikov, A. Nair. Offline reinforcement learning with implicit q-learning. In ICLR, 2022.
- [129] Tianhe Yu, Garrett Thomas, Lantao Yu, Stefano Ermon, James Y. Zou, Sergey Levine, Chelsea Finn, and Tengyu Ma. Mopo: Model-based offline policy optimization. In NeurIPS, 2020.
- [130] Wenxuan Zhou, Sujay Bajracharya, and David Held. Plas: Latent action space for offline reinforcement learning. In Conference on Robot Learning (CoRL), 2020.
- [131] Rafael Rafailov, Tianhe Yu, Aravind Rajeswaran, and Chelsea Finn. Offline reinforcement learning from images with latent space models. In Proceedings of Machine Learning Research, volume 144:1–15, 2021.
- [132] Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollar, and Ross Girshick. Masked autoencoders are scalable vision learners. In CVPR, 2022.
- [133] Namuk Park, Wonjae Kim, Byeongho Heo, Taekyung Kim, and Sangdoo Yun. What do self-supervised vision transformers learn? In ICLR, 2023.
- [134] Shashank Shekhar, Florian Bordes, Pascal Vincent, and Ari Morcos. Objectives matter: Understanding the impact of self-supervised objectives on vision transformer representations. arXiv:2304.13089, 2023.
- [135] Krishna Murthy Jatavallabhula, Alihusein Kuwajerwala, Qiao Gu, et al. Conceptfusion: Open-set multimodal 3d mapping. RSS, 2023.
- [136] Shir Amir, Yossi Gandelsman, Shai Bagon, and Tali Dekel. Deep vit features as dense visual descriptors. arXiv:2112.05814, 2021.
- [137] Jiarui Xu, Sifei Liu, Arash Vahdat, Wonmin Byeon, Xiaolong Wang, and Shalini De Mello. Open-vocabulary panoptic segmentation with text-to-image diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2955–2966, 2023.
- [138] Yann LeCun. A path towards autonomous machine intelligence version 0.9. 2, 2022-06-27. Open Review, 62, 2022.
- [139] Rohit Girdhar, Alaaeldin El-Nouby, Zhuang Liu, Mannat Singh, Kalyan Vasudev Alwala, Armand Joulin, and Ishan Misra. Imagebind: One embedding space to bind them all. arXiv preprint arXiv:2211.05778, 2022.
- [140] Jean-Bastien Grill, Florian Strub, Florent Altché, Corentin Tallec, Pierre H. Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Daniel Guo, Mohammad Gheshlaghi Azar, Bilal Piot, Koray Kavukcuoglu, Rémi Munos, and Michal Valko. Bootstrap your own latent: A new approach to self-supervised learning. In NeurIPS, 2020.
- [141] Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Yann LeCun, and Nicolas Ballas. Self-supervised learning from images with a joint-embedding predictive architecture. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15619–15629, 2023.
- [142] Adrien Bardes, Jean Ponce, and Yann LeCun. Mc-jepa: A joint-embedding predictive architecture for self-supervised learning of motion and content features. arXiv preprint arXiv:2307.12698, 2023.
- [143] Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. arXiv preprint arXiv:2006.11239, 2006.
- [144] Alex Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob McGrew Ilya Sutskever, and Mark Chen. Glide: Towards photorealistic image generation and editing with text-guided diffusion models. arXiv preprint arXiv:2112.10741, 2021.
- [145] Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. Improving language understanding by generative pre-training. Technical report, OpenAI, 2018.
- [146] Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. Technical report, OpenAI, 2019.
- [147] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding, 2019.
- [148] Jingfeng Yang, Hongye Jin, Ruixiang Tang, Xiaotian Han, Qizhang Feng, Haoming Jiang, Bing Yin, and Xia Hu. Harnessing the power of llms in practice: A survey on chatgpt and beyond, 2023.
- [149] Paul F Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences. Advances in neural information processing systems, 30, 2017.
- [150] Xiuye Gu, Tsung-Yi Lin, Weicheng Kuo, and Yin Cui. Open-vocabulary object detection via vision and language knowledge distillation. In ICLR, 2022.
- [151] Boyi Li, Kilian Q. Weinberger, Serge Belongie, Vladlen Koltun, and René Ranftl. Language-driven semantic segmentation. In ICLR, 2022.
- [152] Jiasen Lu, Dhruv Batra, Devi Parikh, and Stefan Lee. Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. In arXiv:1908.02265, 2019.
- [153] Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc V. Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representation learning with noisy text supervision. In International Conference on Machine Learning, 2021.
- [154] Hangbo Bao, Wenhui Wang, Li Dong, and Furu Wei. Vl-beit: Generative vision-language pretraining, 2022.
- [155] Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katie Millican, Malcolm Reynolds, Roman Ring, Eliza Rutherford, Serkan Cabi, Tengda Han, Zhitao Gong, Sina Samangooei, Marianne Monteiro, Jacob Menick, Sebastian Borgeaud, Andy Brock, Aida Nematzadeh, Sahand Sharifzadeh, Mikolaj Binkowski, Ricardo Barreira, Oriol Vinyals, Andrew Zisserman, and Karen Simonyan. Flamingo: a visual language model for few-shot learning. ArXiv, abs/2204.14198, 2022.
- [156] Jianfeng Wang, Zhengyuan Yang, Xiaowei Hu, Linjie Li, Kevin Lin, Zhe Gan, Zicheng Liu, Ce Liu, and Lijuan Wang. GIT: A generative image-to-text transformer for vision and language. Transactions on Machine Learning Research, 2022.
- [157] Junnan Li, Dongxu Li, Caiming Xiong, and Steven C. H. Hoi. BLIP: bootstrapping language-image pre-training for unified vision-language understanding and generation. In International Conference on Machine Learning, ICML 2022, 17-23 July 2022, Baltimore, Maryland, USA, 2022.
- [158] Junnan Li, Dongxu Li, Silvio Savarese, and Steven C. H. Hoi. BLIP-2: bootstrapping language-image pre-training with frozen image encoders and large language models. CoRR, abs/2301.12597, 2023.
- [159] OpenAI. Gpt-4 technical report. ArXiv, abs/2303.08774, 2023.
- [160] Shengqiong Wu, Hao Fei, Leigang Qu, Wei Ji, and Tat-Seng Chua. Next-gpt: Any-to-any multimodal llm, 2023.
- [161] Rongjie Huang, Mingze Li, Dongchao Yang, Jiatong Shi, Xuankai Chang, Zhenhui Ye, Yuning Wu, Zhiqing Hong, Jiawei Huang, Jinglin Liu, Yi Ren, Zhou Zhao, and Shinji Watanabe. Audiogpt: Understanding and generating speech, music, sound, and talking head, 2023.
- [162] Dong Zhang, Shimin Li, Xin Zhang, Jun Zhan, Pengyu Wang, Yaqian Zhou, and Xipeng Qiu. Speechgpt: Empowering large language models with intrinsic cross-modal conversational abilities, 2023.
- [163] Le Xue, Mingfei Gao, Chen Xing, Roberto Martín-Martín, Jiajun Wu, Caiming Xiong, Ran Xu, Juan Carlos Niebles, and Silvio Savarese. Ulip: Learning a unified representation of language, images, and point clouds for 3d understanding, 2023.
- [164] Peide Huang, Xilun Zhang, Ziang Cao, Shiqi Liu, Mengdi Xu, Wenhao Ding, Jonathan Francis, Bingqing Chen, and Ding Zhao. What went wrong? closing the sim-to-real gap via differentiable causal discovery. In 7th Annual Conference on Robot Learning, 2023.
- [165] Jonathan Francis. Knowledge-enhanced Representation Learning for Multiview Context Understanding. PhD thesis, Carnegie Mellon University, 2022.
- [166] Gyan Tatiya, Jonathan Francis, and Jivko Sinapov. Transferring implicit knowledge of non-visual object properties across heterogeneous robot morphologies. In 2023 IEEE International Conference on Robotics and Automation (ICRA), pages 11315–11321. IEEE, 2023.
- [167] Gyan Tatiya, Jonathan Francis, and Jivko Sinapov. Cross-tool and cross-behavior perceptual knowledge transfer for grounded object recognition. arXiv preprint arXiv:2303.04023, 2023.
- [168] Pei Sun, Henrik Kretzschmar, Xerxes Dotiwalla, Aurelien Chouard, Vijaysai Patnaik, Paul Tsui, James Guo, Yin Zhou, Yuning Chai, Benjamin Caine, Vijay Vasudevan, Wei Han, Jiquan Ngiam, Hang Zhao, Aleksei Timofeev, Scott Ettinger, Maxim Krivokon, Amy Gao, Aditya Joshi, Yu Zhang, Jonathon Shlens, Zhifeng Chen, and Dragomir Anguelov. Scalability in perception for autonomous driving: Waymo open dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2020.
- [169] Alexander Herzog*, Kanishka Rao*, Karol Hausman*, Yao Lu*, Paul Wohlhart*, Mengyuan Yan, Jessica Lin, Montserrat Gonzalez Arenas, Ted Xiao, Daniel Kappler, Daniel Ho, Jarek Rettinghouse, Yevgen Chebotar, Kuang-Huei Lee, Keerthana Gopalakrishnan, Ryan Julian, Adrian Li, Chuyuan Kelly Fu, Bob Wei, Sangeetha Ramesh, Khem Holden, Kim Kleiven, David Rendleman, Sean Kirmani, Jeff Bingham, Jon Weisz, Ying Xu, Wenlong Lu, Matthew Bennice, Cody Fong, David Do, Jessica Lam, Yunfei Bai, Benjie Holson, Michael Quinlan, Noah Brown, Mrinal Kalakrishnan, Julian Ibarz, Peter Pastor, and Sergey Levine. Deep rl at scale: Sorting waste in office buildings with a fleet of mobile manipulators. In Robotics: Science and Systems (RSS), 2023.
- [170] Emanuel Todorov, Tom Erez, and Yuval Tassa. Mujoco: A physics engine for model-based control. In 2012 IEEE/RSJ international conference on intelligent robots and systems, pages 5026–5033. IEEE, 2012.
- [171] Viktor Makoviychuk, Lukasz Wawrzyniak, Yunrong Guo, Michelle Lu, Kier Storey, Miles Macklin, David Hoeller, Nikita Rudin, Arthur Allshire, Ankur Handa, and Gavriel State. Isaac gym: High performance gpu-based physics simulation for robot learning, 2021.
- [172] Mayank Mittal, Calvin Yu, Qinxi Yu, Jingzhou Liu, Nikita Rudin, David Hoeller, Jia Lin Yuan, Pooria Poorsarvi Tehrani, Ritvik Singh, Yunrong Guo, Hammad Mazhar, Ajay Mandlekar, Buck Babich, Gavriel State, Marco Hutter, and Animesh Garg. Orbit: A unified simulation framework for interactive robot learning environments, 2023.
- [173] Manolis Savva, Abhishek Kadian, Oleksandr Maksymets, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub, Jia Liu, Vladlen Koltun, Jitendra Malik, et al. Habitat: A platform for embodied ai research. In Proceedings of the IEEE/CVF international conference on computer vision, pages 9339–9347, 2019.
- [174] Andrew Szot, Alex Clegg, Eric Undersander, Erik Wijmans, Yili Zhao, John Turner, Noah Maestre, Mustafa Mukadam, Devendra Chaplot, Oleksandr Maksymets, Aaron Gokaslan, Vladimir Vondrus, Sameer Dharur, Franziska Meier, Wojciech Galuba, Angel Chang, Zsolt Kira, Vladlen Koltun, Jitendra Malik, Manolis Savva, and Dhruv Batra. Habitat 2.0: Training home assistants to rearrange their habitat, 2022.
- [175] Xavier Puig, Eric Undersander, Andrew Szot, Mikael Dallaire Cote, Tsung-Yen Yang, Ruslan Partsey, Ruta Desai, Alexander William Clegg, Michal Hlavac, So Yeon Min, Vladimír Vondruš, Theophile Gervet, Vincent-Pierre Berges, John M. Turner, Oleksandr Maksymets, Zsolt Kira, Mrinal Kalakrishnan, Jitendra Malik, Devendra Singh Chaplot, Unnat Jain, Dhruv Batra, Akshara Rai, and Roozbeh Mottaghi. Habitat 3.0: A co-habitat for humans, avatars and robots, 2023.
- [176] Embodiment Collaboration. Open x-embodiment: Robotic learning datasets and rt-x models, 2023.
- [177] Elena Arcari, Maria Vittoria Minniti, Anna Scampicchio, Andrea Carron, Farbod Farshidian, Marco Hutter, and Melanie N. Zeilinger. Bayesian multi-task learning mpc for robotic mobile manipulation, 2023.
- [178] Chao Cao, Hongbiao Zhu, Howie Choset, and Ji Zhang. TARE: A Hierarchical Framework for Efficiently Exploring Complex 3D Environments. In ICRA, 2023.
- [179] Fahad Islam, Oren Salzman, Aditya Agarwal, and Maxim Likhachev. Provably constant-time planning and replanning for real-time grasping objects off a conveyor belt. In RSS, 2020.
- [180] Dhruv Mauria Saxena, Muhammad Suhail Saleem, and Maxim Likhachev. Manipulation planning among movable obstacles using physics-based adaptive motion primitives. In 2021 IEEE International Conference on Robotics and Automation (ICRA). IEEE, May 2021.
- [181] Yuchen Cui, Scott Niekum, Abhinav Gupta, Vikash Kumar, and Aravind Rajeswaran. Can foundation models perform zero-shot task specification for robot manipulation? In Learning for Dynamics and Control Conference, pages 893–905. PMLR, 2022.
- [182] Yecheng Jason Ma, William Liang, Guanzhi Wang, De-An Huang, Osbert Bastani, Dinesh Jayaraman, Yuke Zhu, Linxi Fan, and Anima Anandkumar. Eureka: Human-level reward design via coding large language models. In 2nd Workshop on Language and Robot Learning: Language as Grounding, 2023.
- [183] Jakob Gawlikowski, Cedrique Rovile Njieutcheu Tassi, Mohsin Ali, Jongseok Lee, Matthias Humt, Jianxiang Feng, Anna Kruspe, Rudolph Triebel, Peter Jung, Ribana Roscher, et al. A survey of uncertainty in deep neural networks. Artificial Intelligence Review, 56(Suppl 1):1513–1589, 2023.
- [184] Xuhong Li, Haoyi Xiong, Xingjian Li, Xuanyu Wu, Xiao Zhang, Ji Liu, Jiang Bian, and Dejing Dou. Interpretable deep learning: Interpretation, interpretability, trustworthiness, and beyond. Knowledge and Information Systems, 64(12):3197–3234, 2022.
- [185] Ta-Chung Chi, Minmin Shen, Mihail Eric, Seokhwan Kim, and Dilek Hakkani-tur. Just ask: An interactive learning framework for vision and language navigation. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 2459–2466, 2020.
- [186] Anastasios N Angelopoulos and Stephen Bates. A gentle introduction to conformal prediction and distribution-free uncertainty quantification. arXiv preprint arXiv:2107.07511, 2021.
- [187] Allen Z. Ren, Anushri Dixit, Alexandra Bodrova, Sumeet Singh, Stephen Tu, Noah Brown, Peng Xu, Leila Takayama, Fei Xia, Jake Varley, Zhenjia Xu, Dorsa Sadigh, Andy Zeng, and Anirudha Majumdar. Robots that ask for help: Uncertainty alignment for large language model planners. In 7th Annual Conference on Robot Learning, 2023.
- [188] Kim P Wabersich, Andrew J Taylor, Jason J Choi, Koushil Sreenath, Claire J Tomlin, Aaron D Ames, and Melanie N Zeilinger. Data-driven safety filters: Hamilton-jacobi reachability, control barrier functions, and predictive methods for uncertain systems. IEEE Control Systems Magazine, 43(5):137–177, 2023.
- [189] Kai-Chieh Hsu, Haimin Hu, and Jaime Fernández Fisac. The safety filter: A unified view of safety-critical control in autonomous systems. arXiv preprint arXiv:2309.05837, 2023.
- [190] Aaron D Ames, Samuel Coogan, Magnus Egerstedt, Gennaro Notomista, Koushil Sreenath, and Paulo Tabuada. Control barrier functions: Theory and applications. In 2019 18th European control conference (ECC), pages 3420–3431. IEEE, 2019.
- [191] Somil Bansal, Mo Chen, Sylvia Herbert, and Claire J Tomlin. Hamilton-jacobi reachability: A brief overview and recent advances. In 2017 IEEE 56th Annual Conference on Decision and Control (CDC), pages 2242–2253. IEEE, 2017.
- [192] Karen Leung, Nikos Aréchiga, and Marco Pavone. Backpropagation through signal temporal logic specifications: Infusing logical structure into gradient-based methods. The International Journal of Robotics Research, 42(6):356–370, 2023.
- [193] Shangding Gu, Long Yang, Yali Du, Guang Chen, Florian Walter, Jun Wang, Yaodong Yang, and Alois Knoll. A review of safe reinforcement learning: Methods, theory and applications. arXiv preprint arXiv:2205.10330, 2022.
- [194] Charles Dawson, Sicun Gao, and Chuchu Fan. Safe control with learned certificates: A survey of neural lyapunov, barrier, and contraction methods for robotics and control. IEEE Transactions on Robotics, 2023.
- [195] Konstantinos Bousmalis, Giulia Vezzani, Dushyant Rao, Coline Devin, Alex X. Lee, Maria Bauza, Todor Davchev, Yuxiang Zhou, Agrim Gupta, Akhil Raju, Antoine Laurens, Claudio Fantacci, Valentin Dalibard, Martina Zambelli, Murilo Martins, Rugile Pevceviciute, Michiel Blokzijl, Misha Denil, Nathan Batchelor, Thomas Lampe, Emilio Parisotto, Konrad Żołna, Scott Reed, Sergio Gómez Colmenarejo, Jon Scholz, Abbas Abdolmaleki, Oliver Groth, Jean-Baptiste Regli, Oleg Sushkov, Tom Rothörl, José Enrique Chen, Yusuf Aytar, Dave Barker, Joy Ortiz, Martin Riedmiller, Jost Tobias Springenberg, Raia Hadsell, Francesco Nori, and Nicolas Heess. Robocat: A self-improving foundation agent for robotic manipulation, 2023.
- [196] Mohit Shridhar, Lucas Manuelli, and Dieter Fox. Cliport: What and where pathways for robotic manipulation. In CoRL, 2021.
- [197] William Shen, Ge Yang, Alan Yu, Jansen Wong, Leslie Pack Kaelbling, and Phillip Isola. Distilled feature fields enable few-shot language-guided manipulation. CoRL, 2023.
- [198] Yanjie Ze, Ge Yan, Yueh-Hua Wu, Annabella Macaluso, Yuying Ge, Jianglong Ye, Nicklas Hansen, Li Erran Li, and Xiaolong Wang. Multi-task real robot learning with generalizable neural feature fields. CoRL, 2023.
- [199] Reihaneh Mirjalili, Michael Krawez, and Wolfram Burgard. Fm-loc: Using foundation models for improved vision-based localization. arXiv:2304.07058, 2023.
- [200] Gyan Tatiya, Jonathan Francis, Ho-Hsiang Wu, Yonatan Bisk, and Jivko Sinapov. Mosaic: Learning unified multi-sensory object property representations for robot perception. arXiv preprint arXiv:2309.08508, 2023.
- [201] Chenguang Huang, Oier Mees, Andy Zeng, and Wolfram Burgard. Visual language maps for robot navigation. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), London, UK, 2023.
- [202] Nur Muhammad (Mahi) Shafiullah, Chris Paxton, Lerrel Pinto1 Soumith Chintala, and Arthur Szlam. Clip-fields: Weakly supervised semantic fields for robotic memory. In RSS, 2023.
- [203] Krishna Murthy Jatavallabhula, Alihusein Kuwajerwala, Qiao Gu, Mohd Omama, Tao Chen, Shuang Li, Ganesh Iyer, Soroush Saryazd, Nikhil Keetha, Ayush Tewari, Joshua B. Tenenbaum, Celso Miguel de Melo, Madhava Krishna, Liam Paull, Florian Shkurti, and Antonio Torralba. Conceptfusion: Open-set multimodal 3d mapping. In arXiv:2302.07241, 2023.
- [204] Dhruv Shah, Blazej Osinski, Brian Ichter, and Sergey Levine. Lm-nav: Robotic navigation with large pre-trained models of language, vision, and action. In CoRL, 2022.
- [205] Sriram Yenamandra, Arun Ramachandran, Mukul Khanna, Karmesh Yadav, Devendra Singh Chaplot, Gunjan Chhablani, Alexander Clegg, Theophile Gervet, Vidhi Jain, Ruslan Partsey, Ram Ramrakhya, Andrew Szot, Tsung-Yen Yang, Aaron Edsinger, Charlie Kemp, Binit Shah, Zsolt Kira, Dhruv Batra, Roozbeh Mottaghi, Yonatan Bisk, and Chris Paxton. The homerobot open vocab mobile manipulation challenge. In Thirty-seventh Conference on Neural Information Processing Systems: Competition Track, 2023.
- [206] Theophile Gervet, Zhou Xian, Nikolaos Gkanatsios, and Katerina Fragkiadaki. Act3d: 3d feature field transformers for multi-task robotic manipulation, 2023.
- [207] Christina Kassab, Matias Mattamala, Lintong Zhang, and Maurice Fallon. Language-extended indoor slam (lexis): A versatile system for real-time visual scene understanding. arXiv preprint arXiv:2309.15065, 2023.
- [208] Nikhil Keetha, Avneesh Mishra, Jay Karhade, Krishna Murthy Jatavallabhula, Sebastian Scherer, Madhava Krishna, and Sourav Garg. Anyloc: Towards universal visual place recognition. RA-L, 2023.
- [209] Yao He, Ivan Cisneros, Nikhil Keetha, Jay Patrikar, Zelin Ye, Ian Higgins, Yaoyu Hu, Parv Kapoor, and Sebastian Scherer. Foundloc: Vision-based onboard aerial localization in the wild, 2023.
- [210] Jivko Sinapov, Connor Schenck, Kerrick Staley, Vladimir Sukhoy, and Alexander Stoytchev. Grounding semantic categories in behavioral interactions: Experiments with 100 objects. Robotics and Autonomous Systems, 62(5):632–645, may 2014.
- [211] Jivko Sinapov, Connor Schenck, and Alexander Stoytchev. Learning relational object categories using behavioral exploration and multimodal perception. In International Conference on Robotics and Automation (ICRA), pages 5691–5698, Hong Kong, China, may 2014. IEEE.
- [212] Mevlana C. Gemici and Ashutosh Saxena. Learning haptic representation for manipulating deformable food objects. In Intelligent Robots and Systems (IROS), pages 638–645, Chicago, IL, USA, Sep 2014. IEEE.
- [213] Gyan Tatiya, Ramtin Hosseini, Michael C. Hughes, and Jivko Sinapov. Sensorimotor cross-behavior knowledge transfer for grounded category recognition. In International Conference on Development and Learning and Epigenetic Robotics (ICDL-EpiRob). IEEE, 2019.
- [214] Gyan Tatiya, Ramtin Hosseini, Michael Hughes, and Jivko Sinapov. A framework for sensorimotor cross-perception and cross-behavior knowledge transfer for object categorization. Frontiers in Robotics and AI, 7:137, 2020.
- [215] Gyan Tatiya, Yash Shukla, Michael Edegware, and Jivko Sinapov. Haptic knowledge transfer between heterogeneous robots using kernel manifold alignment. In IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2020.
- [216] Jacky Liang, Wenlong Huang, Fei Xia, Peng Xu, Karol Hausman, Brian Ichter, Pete Florence, and Andy Zeng. Code as policies: Language model programs for embodied control. ArXiv, abs/2209.07753, 2023.
- [217] Yilun Du, Mengjiao Yang, Pete Florence, Fei Xia, Ayzaan Wahid, Brian Ichter, Pierre Sermanet, Tianhe Yu, Pieter Abbeel, Joshua B Tenenbaum, et al. Video language planning. arXiv preprint arXiv:2310.10625, 2023.
- [218] Peter Anderson, Qi Wu, Damien Teney, Jake Bruce, Mark Johnson, Niko Sünderhauf, Ian Reid, Stephen Gould, and Anton Van Den Hengel. Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3674–3683, 2018.
- [219] Wenlong Huang, Pieter Abbeel, Deepak Pathak, and Igor Mordatch. Language models as zero-shot planners: Extracting actionable knowledge for embodied agents, 2022.
- [220] Kevin Lin, Christopher Agia, Toki Migimatsu, Marco Pavone, and Jeannette Bohg. Text2motion: From natural language instructions to feasible plans. arXiv preprint arXiv:2303.12153, 2023.
- [221] Ishika Singh, Valts Blukis, Arsalan Mousavian, Ankit Goyal, Danfei Xu, Jonathan Tremblay, Dieter Fox, Jesse Thomason, and Animesh Garg. ProgPrompt: Generating situated robot task plans using large language models, 2022.
- [222] Lirui Wang, Yiyang Ling, Zhecheng Yuan, Mohit Shridhar, Chen Bao, Yuzhe Qin, Bailin Wang, Huazhe Xu, and Xiaolong Wang. Gensim: Generating robotic simulation tasks via large language models. In CoRL, 2023.
- [223] J. Seipp, Á. Torralba, and J. Hoffmann. Pddl generators, 2022.
- [224] Krishan Rana, Jesse Haviland, Sourav Garg, Jad Abou-Chakra, Ian Reid, and Niko Suenderhauf. Sayplan: Grounding large language models using 3d scene graphs for scalable task planning. In 7th Annual Conference on Robot Learning, 2023.
- [225] Quanting Xie, Tianyi Zhang, Kedi Xu, Matthew Johnson-Roberson, and Yonatan Bisk. Reasoning about the unseen for efficient outdoor object navigation, 2023.
- [226] Wenhao Yu, Nimrod Gileadi, Chuyuan Fu, Sean Kirmani, Kuang-Huei Lee, Montse Gonzalez Arenas, Hao-Tien Lewis Chiang, Tom Erez, Leonard Hasenclever, Jan Humplik, Brian Ichter, Ted Xiao, Peng Xu, Andy Zeng, Tingnan Zhang, Nicolas Heess, Dorsa Sadigh, Jie Tan, Yuval Tassa, and Fei Xia. Language to rewards for robotic skill synthesis. Arxiv preprint arXiv:2306.08647, 2023.
- [227] Wenlong Huang, Chen Wang, Ruohan Zhang, Yunzhu Li, Jiajun Wu, and Li Fei-Fei. Voxposer: Composable 3d value maps for robotic manipulation with language models. arXiv preprint arXiv:2307.05973, 2023.
- [228] Junting Chen, Guohao Li, Suryansh Kumar, Bernard Ghanem, and Fisher Yu. How to not train your dragon: Training-free embodied object goal navigation with semantic frontiers. arXiv preprint arXiv:2305.16925, 2023.
- [229] Yen-Jen Wang, Bike Zhang, Jianyu Chen, and Koushil Sreenath. Prompt a robot to walk with large language models, 2023.
- [230] Yuqing Du, Olivia Watkins, Zihan Wang, Cédric Colas, Trevor Darrell, Pieter Abbeel, Abhishek Gupta, and Jacob Andreas. Guiding pretraining in reinforcement learning with large language models, 2023.
- [231] Minae Kwon, Sang Michael Xie, Kalesha Bullard, and Dorsa Sadigh. Reward design with language models, 2023.
- [232] Tianbao Xie, Siheng Zhao, Chen Henry Wu, Yitao Liu, Qian Luo, Victor Zhong, Yanchao Yang, and Tao Yu. Text2reward: Automated dense reward function generation for reinforcement learning, 2023.
- [233] Wenlong Huang, Fei Xia, Dhruv Shah, Danny Driess, Andy Zeng, Yao Lu, Pete Florence, Igor Mordatch, Sergey Levine, Karol Hausman, and Brian Ichter. Grounded decoding: Guiding text generation with grounded models for robot control, 2023.
- [234] Thomas Carta, Clément Romac, Thomas Wolf, Sylvain Lamprier, Olivier Sigaud, and Pierre-Yves Oudeyer. Grounding large language models in interactive environments with online reinforcement learning, 2023.
- [235] Yen-Jen Wang, Bike Zhang, Jianyu Chen, and Koushil Sreenath. Prompt a robot to walk with large language models, 2023.
- [236] Huy Ha, Pete Florence, and Shuran Song. Scaling up and distilling down: Language-guided robot skill acquisition. In Proceedings of the 2023 Conference on Robot Learning, 2023.
- [237] Yufei Wang, Zhou Xian, Feng Chen, Tsun-Hsuan Wang, Yian Wang, Katerina Fragkiadaki, Zackory Erickson, David Held, and Chuang Gan. Robogen: Towards unleashing infinite data for automated robot learning via generative simulation, 2023.
- [238] Tianhe Yu, Ted Xiao, Austin Stone, Jonathan Tompson, Anthony Brohan, Su Wang, Jaspiar Singh, Clayton Tan, Jodilyn Peralta Dee M, Brian Ichter, Karol Hausman, and Fei Xia. Scaling robot learning with semantically imagined experience. In arXiv:2302.11550, 2023.
- [239] Jiayuan Gu, Sean Kirmani, Paul Wohlhart, Yao Lu, Montserrat Gonzalez Arenas, Kanishka Rao, Wenhao Yu, Chuyuan Fu, Keerthana Gopalakrishnan, Zhuo Xu, Priya Sundaresan, Peng Xu, Hao Su, Karol Hausman, Chelsea Finn, Quan Vuong, and Ted Xiao. Rt-trajectory: Robotic task generalization via hindsight trajectory sketches, 2023.
- [240] Kevin Black, Mitsuhiko Nakamoto, Pranav Atreya, Homer Walke, Chelsea Finn, Aviral Kumar, and Sergey Levine. Zero-shot robotic manipulation with pretrained image-editing diffusion models, 2023.
- [241] Yilun Du, Mengjiao Yang, Bo Dai, Hanjun Dai, Ofir Nachum, Joshua B. Tenenbaum, Dale Schuurmans, and Pieter Abbeel. Learning universal policies via text-guided video generation. In NeurIPS, 2023.
- [242] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models, 2023.
- [243] Nouha Dziri, Ximing Lu, Melanie Sclar, Xiang Lorraine Li, Liwei Jiang, Bill Yuchen Lin, Peter West, Chandra Bhagavatula, Ronan Le Bras, Jena D. Hwang, Soumya Sanyal, Sean Welleck, Xiang Ren, Allyson Ettinger, Zaid Harchaoui, and Yejin Choi. Faith and fate: Limits of transformers on compositionality, 2023.
- [244] Maciej Besta, Nils Blach, Ales Kubicek, Robert Gerstenberger, Lukas Gianinazzi, Joanna Gajda, Tomasz Lehmann, Michal Podstawski, Hubert Niewiadomski, Piotr Nyczyk, and Torsten Hoefler. Graph of thoughts: Solving elaborate problems with large language models, 2023.
- [245] Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models, 2023.
- [246] Shun Zhang, Zhenfang Chen, Yikang Shen, Mingyu Ding, Joshua B. Tenenbaum, and Chuang Gan. Planning with large language models for code generation. In The Eleventh International Conference on Learning Representations, 2023.
- [247] Bo Liu, Yuqian Jiang, Xiaohan Zhang, Qiang Liu, Shiqi Zhang, Joydeep Biswas, and Peter Stone. Llm+p: Empowering large language models with optimal planning proficiency, 2023.
- [248] Wenlong Huang, Fei Xia, Ted Xiao, Harris Chan, Jacky Liang, Pete Florence, Andy Zeng, Jonathan Tompson, Igor Mordatch, Yevgen Chebotar, Pierre Sermanet, Noah Brown, Tomas Jackson, Linda Luu, Sergey Levine, Karol Hausman, and Brian Ichter. Inner monologue: Embodied reasoning through planning with language models, 2022.
- [249] Austin Stone, Ted Xiao, Yao Lu, Keerthana Gopalakrishnan, Kuang-Huei Lee, Quan Vuong, Paul Wohlhart, Brianna Zitkovich, Fei Xia, Chelsea Finn, et al. Open-world object manipulation using pre-trained vision-language models. arXiv preprint arXiv:2303.00905, 2023.
- [250] Shuang Li, Xavier Puig, Chris Paxton, Yilun Du, Clinton Wang, Linxi Fan, Tao Chen, De-An Huang, Ekin Akyürek, Anima Anandkumar, et al. Pre-trained language models for interactive decision-making. Advances in Neural Information Processing Systems, 35:31199–31212, 2022.
- [251] Siddharth Karamcheti, Megha Srivastava, Percy Liang, and Dorsa Sadigh. Lila: Language-informed latent actions. In Conference on Robot Learning, pages 1379–1390. PMLR, 2022.
- [252] Hengyuan Hu and Dorsa Sadigh. Language instructed reinforcement learning for human-ai coordination. arXiv preprint arXiv:2304.07297, 2023.
- [253] Corey Lynch, Ayzaan Wahid, Jonathan Tompson, Tianli Ding, James Betker, Robert Baruch, Travis Armstrong, and Pete Florence. Interactive language: Talking to robots in real time. arXiv preprint arXiv:2210.06407, 2022.
- [254] Kuang-Huei Lee, Ted Xiao, Adrian Li, Paul Wohlhart, Ian Fischer, and Yao Lu. Pi-qt-opt: Predictive information improves multi-task robotic reinforcement learning at scale. CoRL, 2022.
- [255] Alexander Herzog, Kanishka Rao, Karol Hausman, Yao Lu, Paul Wohlhart, Mengyuan Yan, Jessica Lin, Montserrat Gonzalez Arenas, Ted Xiao, Daniel Kappler, Daniel Ho, Jarek Rettinghouse, Yevgen Chebotar, Kuang-Huei Lee, Keerthana Gopalakrishnan, Ryan Julian, Adrian Li, Chuyuan Kelly Fu, Bob Wei, Sangeetha Ramesh, Khem Holden, Kim Kleiven, David Rendleman, Sean Kirmani, Jeff Bingham, Jon Weisz, Ying Xu, Wenlong Lu, Matthew Bennice, Cody Fong, David Do, Jessica Lam, Yunfei Bai, Benjie Holson, Michael Quinlan, Noah Brown, Mrinal Kalakrishnan, Julian Ibarz, Peter Pastor, and Sergey Levine. Deep rl at scale: Sorting waste in office buildings with a fleet of mobile manipulators. In RSS, 2023.
- [256] Yevgen Chebotar, Quan Vuong, Alex Irpan, Karol Hausman, Fei Xia, Yao Lu, Aviral Kumar, Tianhe Yu, Alexander Herzog, Karl Pertsch, Keerthana Gopalakrishnan, Julian Ibarz, Ofir Nachum, Sumedh Sontakke, Grecia Salazar, Huong T Tran, Jodilyn Peralta, Clayton Tan, Deeksha Manjunath, Jaspiar Singht, Brianna Zitkovich, Tomas Jackson, Kanishka Rao, Chelsea Finn, and Sergey Levine. Q-transformer: Scalable offline reinforcement learning via autoregressive q-functions. In CoRL, 2023.
- [257] Aviral Kumar, Anikait Singh, Frederik Ebert, Mitsuhiko Nakamoto, Yanlai Yang, Chelsea Finn, and Sergey Levine. Pre-training for robots: Offline rl enables learning new tasks from a handful of trials. In RSS, 2023.
- [258] Aviral Kumar, Aurick Zhou, George Tucker, and Sergey Levine. Conservative q-learning for offline reinforcement learning. In NeurIPS, 2020.
- [259] Simone Parisi, Aravind Rajeswaran, Senthil Purushwalkam, and Abhinav Gupta. The unsurprising effectiveness of pre-trained vision models for control, 2022.
- [260] Suraj Nair, Aravind Rajeswaran, Vikash Kumar, Chelsea Finn, and Abhinav Gupta. R3m: A universal visual representation for robot manipulation, 2022.
- [261] Ilija Radosavovic, Tete Xiao, Stephen James, Pieter Abbeel, Jitendra Malik, and Trevor Darrell. Real-world robot learning with masked visual pre-training. In Conference on Robot Learning, pages 416–426. PMLR, 2023.
- [262] Ilija Radosavovic, Baifeng Shi, Letian Fu, Ken Goldberg, Trevor Darrell, and Jitendra Malik. Robot learning with sensorimotor pre-training, 2023.
- [263] Nicklas Hansen, Zhecheng Yuan, Yanjie Ze, Tongzhou Mu, Aravind Rajeswaran, Hao Su, Huazhe Xu, and Xiaolong Wang. On pre-training for visuo-motor control: Revisiting a learning-from-scratch baseline. In ICML, 2023.
- [264] Arjun Majumdar, Karmesh Yadav, Sergio Arnaud, Yecheng Jason Ma, Claire Chen, Sneha Silwal, Aryan Jain, Vincent-Pierre Berges, Pieter Abbeel, Jitendra Malik, Dhruv Batra, Yixin Lin, Oleksandr Maksymets, Aravind Rajeswaran, and Franziska Meier. Where are we in the search for an artificial visual cortex for embodied intelligence?, 2023.
- [265] Xi Chen, Josip Djolonga, Piotr Padlewski, Basil Mustafa, Soravit Changpinyo, Jialin Wu, Carlos Riquelme Ruiz, Sebastian Goodman, Xiao Wang, Yi Tay, Siamak Shakeri, Mostafa Dehghani, Daniel Salz, Mario Lucic, Michael Tschannen, Arsha Nagrani, Hexiang Hu, Mandar Joshi, Bo Pang, Ceslee Montgomery, Paulina Pietrzyk, Marvin Ritter, AJ Piergiovanni, Matthias Minderer, Filip Pavetic, Austin Waters, Gang Li, Ibrahim Alabdulmohsin, Lucas Beyer, Julien Amelot, Kenton Lee, Andreas Peter Steiner, Yang Li, Daniel Keysers, Anurag Arnab, Yuanzhong Xu, Keran Rong, Alexander Kolesnikov, Mojtaba Seyedhosseini, Anelia Angelova, Xiaohua Zhai, Neil Houlsby, and Radu Soricut. Pali-x: On scaling up a multilingual vision and language model, 2023.
- [266] Shikhar Bahl, Russell Mendonca, Lili Chen, Unnat Jain, and Deepak Pathak. Affordances from human videos as a versatile representation for robotics. CVPR, 2023.
- [267] Dhruv Shah, Ajay Sridhar, Arjun Bhorkar, Noriaki Hirose, and Sergey Levine. Gnm: A general navigation model to drive any robot. In ICRA, 2023.
- [268] Joanne Truong, April Zitkovich, Sonia Chernova, Dhruv Batra, Tingnan Zhang, Jie Tan, and Wenhao Yu. Indoorsim-to-outdoorreal: Learning to navigate outdoors without any outdoor experience. In arXiv:2305.01098, 2023.
- [269] Rogerio Bonatti, Sai Vemprala, Shuang Ma, Felipe Frujeri, Shuhang Chen, and Ashish Kapoor. Pact: Perception-action causal transformer for autoregressive robotics pre-training. In arXiv:2209.11133, 2022.
- [270] Qiao Gu, Alihusein Kuwajerwala, Sacha Morin, Krishna Murthy Jatavallabhula, Bipasha Sen, Aditya Agarwal, Corban Rivera, William Paul, Kirsty Ellis, Rama Chellappa, et al. Conceptgraphs: Open-vocabulary 3d scene graphs for perception and planning. arXiv preprint arXiv:2309.16650, 2023.
- [271] Shibo Hao, Yi Gu, Haodi Ma, Joshua Jiahua Hong, Zhen Wang, Daisy Zhe Wang, and Zhiting Hu. Reasoning with language model is planning with world model. arXiv preprint arXiv:2305.14992, 2023.
- [272] Yunfan Jiang, Agrim Gupta, Zichen Zhang, Guanzhi Wang, Yongqiang Dou, Yanjun Chen, Li Fei-Fei, Anima Anandkumar, Yuke Zhu, and Linxi Fan. VIMA: general robot manipulation with multimodal prompts. ArXiv, abs/2210.03094, 2022.
- [273] Shikhar Bahl, Abhinav Gupta, and Deepak Pathak. Human-to-robot imitation in the wild. In RSS, 2022.
- [274] Vidhi Jain, Yixin Lin, Eric Undersander, Yonatan Bisk, and Akshara Rai. Transformers are adaptable task planners. In 6th Annual Conference on Robot Learning, 2022.
- [275] Jacob Andreas, Dan Klein, and Sergey Levine. Modular multitask reinforcement learning with policy sketches. In International conference on machine learning, pages 166–175. PMLR, 2017.
- [276] Marjorie Skubic, Derek Anderson, Samuel Blisard, Dennis Perzanowski, and Alan Schultz. Using a hand-drawn sketch to control a team of robots. Autonomous Robots, 22:399–410, 2007.
- [277] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35:24824–24837, 2022.
- [278] Jianzong Wu, Xiangtai Li, Shilin Xu Haobo Yuan, Henghui Ding, Yibo Yang, Xia Li, Jiangning Zhang, Yunhai Tong, Xudong Jiang, Bernard Ghanem, et al. Towards open vocabulary learning: A survey. arXiv preprint arXiv:2306.15880, 2023.
- [279] Chenhang Cui, Yiyang Zhou, Xinyu Yang, Shirley Wu, Linjun Zhang, James Zou, and Huaxiu Yao. Holistic analysis of hallucination in gpt-4v (ision): Bias and interference challenges. arXiv preprint arXiv:2311.03287, 2023.
- [280] Jensen Gao, Bidipta Sarkar, Fei Xia, Ted Xiao, Jiajun Wu, Brian Ichter, Anirudha Majumdar, and Dorsa Sadigh. Physically grounded vision-language models for robotic manipulation. In arxiv, 2023.
- [281] Sudeep Dasari, Frederik Ebert, Stephen Tian, Suraj Nair, Bernadette Bucher, Karl Schmeckpeper, Siddharth Singh, Sergey Levine, and Chelsea Finn. Robonet: Large-scale multi-robot learning, 2020.
- [282] Frederik Ebert, Yanlai Yang, Karl Schmeckpeper, Bernadette Bucher, Georgios Georgakis, Kostas Daniilidis, Chelsea Finn, and Sergey Levine. Bridge data: Boosting generalization of robotic skills with cross-domain datasets, 2021.
- [283] Homer Walke, Kevin Black, Abraham Lee, Moo Jin Kim, Max Du, Chongyi Zheng, Tony Zhao, Philippe Hansen-Estruch, Quan Vuong, Andre He, et al. Bridgedata v2: A dataset for robot learning at scale. arXiv preprint arXiv:2308.12952, 2023.
- [284] Kenneth Shaw, Ananye Agarwal, and Deepak Pathak. Leap hand: Low-cost, efficient, and anthropomorphic hand for robot learning. arXiv preprint arXiv:2309.06440, 2023.
- [285] Angel Chang, Angela Dai, Thomas Funkhouser, Maciej Halber, Matthias Niessner, Manolis Savva, Shuran Song, Andy Zeng, and Yinda Zhang. Matterport3d: Learning from rgb-d data in indoor environments. arXiv preprint arXiv:1709.06158, 2017.
- [286] Fei Xia, Amir R Zamir, Zhiyang He, Alexander Sax, Jitendra Malik, and Silvio Savarese. Gibson env: Real-world perception for embodied agents. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 9068–9079, 2018.
- [287] Manolis Savva*, Abhishek Kadian*, Oleksandr Maksymets*, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub, Jia Liu, Vladlen Koltun, Jitendra Malik, Devi Parikh, and Dhruv Batra. Habitat: A Platform for Embodied AI Research. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019.
- [288] Eric Kolve, Roozbeh Mottaghi, Winson Han, Eli VanderBilt, Luca Weihs, Alvaro Herrasti, Matt Deitke, Kiana Ehsani, Daniel Gordon, Yuke Zhu, et al. Ai2-thor: An interactive 3d environment for visual ai. arXiv preprint arXiv:1712.05474, 2017.
- [289] So Yeon Min, Devendra Singh Chaplot, Pradeep Ravikumar, Yonatan Bisk, and Ruslan Salakhutdinov. Film: Following instructions in language with modular methods, 2022.
- [290] Shital Shah, Debadeepta Dey, Chris Lovett, and Ashish Kapoor. Airsim: High-fidelity visual and physical simulation for autonomous vehicles, 2017.
- [291] Google DeepMind. Mujoco 3.0. https://github.com/google-deepmind/mujoco/releases/tag/3.0.0, 2023. Accessed: [Insert date of access].
- [292] S. Dass, J. Yapeter, J. Zhang, J. Zhang, K. Pertsch, S. Nikolaidis, and J. J. Lim. Clvr jaco play dataset. https://github.com/clvrai/clvr-jaco-play-dataset, 2023.
- [293] Jianlan Luo, Charles Xu, Xinyang Geng, Gilbert Feng, Kuan Fang, Liam Tan, Stefan Schaal, and Sergey Levine. Multi-stage cable routing through hierarchical imitation learning, 2023.
- [294] Jyothish Pari, Nur Muhammad Shafiullah, Sridhar Pandian Arunachalam, and Lerrel Pinto. The surprising effectiveness of representation learning for visual imitation. arXiv preprint arXiv:2112.01511, 2021.
- [295] L. Y. Chen, S. Adebola, and K. Goldberg. Berkeley ur5 demonstration dataset. https://sites.google.com/view/berkeley-ur5/home. Accessed: [Insert Date Here].
- [296] Erick Rosete-Beas, Oier Mees, Gabriel Kalweit, Joschka Boedecker, and Wolfram Burgard. Latent plans for task agnostic offline reinforcement learning. In Proceedings of the 6th Conference on Robot Learning (CoRL), 2022.
- [297] Xufeng Zhao, Mengdi Li, Cornelius Weber, Muhammad Burhan Hafez, and Stefan Wermter. Chat with the environment: Interactive multimodal perception using large language models, 2023.
- [298] Coppelia Robotics. Coppeliasim. https://www.coppeliarobotics.com/. Accessed: [Insert Date Here].
- [299] E. Coumans and Y. Bai. Pybullet, a python module for physics simulation for games, robotics and machine learning.
- [300] Siyuan Huang, Zhengkai Jiang, Hao Dong, Yu Qiao, Peng Gao, and Hongsheng Li. Instruct2act: Mapping multi-modality instructions to robotic actions with large language model, 2023.
- [301] Fanbo Xiang, Yuzhe Qin, Kaichun Mo, Yikuan Xia, Hao Zhu, Fangchen Liu, Minghua Liu, Hanxiao Jiang, Yifu Yuan, He Wang, et al. Sapien: A simulated part-based interactive environment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11097–11107, 2020.
- [302] Kaichun Mo, Leonidas Guibas, Mustafa Mukadam, Abhinav Gupta, and Shubham Tulsiani. Where2act: From pixels to actions for articulated 3d objects, 2021.
- [303] Alex X. Lee, Coline Devin, Yuxiang Zhou, Thomas Lampe, Konstantinos Bousmalis, Jost Tobias Springenberg, Arunkumar Byravan, Abbas Abdolmaleki, Nimrod Gileadi, David Khosid, Claudio Fantacci, Jose Enrique Chen, Akhil Raju, Rae Jeong, Michael Neunert, Antoine Laurens, Stefano Saliceti, Federico Casarini, Martin Riedmiller, Raia Hadsell, and Francesco Nori. Beyond pick-and-place: Tackling robotic stacking of diverse shapes, 2021.
- [304] Andrew Szot, Max Schwarzer, Harsh Agrawal, Bogdan Mazoure, Walter Talbott, Katherine Metcalf, Natalie Mackraz, Devon Hjelm, and Alexander Toshev. Large language models as generalizable policies for embodied tasks, 2023.
- [305] Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021.
- [306] Andy Zeng, Pete Florence, Jonathan Tompson, Stefan Welker, Jonathan Chien, Maria Attarian, Travis Armstrong, Ivan Krasin, Dan Duong, Vikas Sindhwani, and Johnny Lee. Transporter networks: Rearranging the visual world for robotic manipulation. Conference on Robot Learning (CoRL), 2020.
- [307] Yecheng Jason Ma, William Liang, Vaidehi Som, Vikash Kumar, Amy Zhang, Osbert Bastani, and Dinesh Jayaraman. Liv: Language-image representations and rewards for robotic control, 2023.
- [308] Tianhe Yu, Deirdre Quillen, Zhanpeng He, Ryan Julian, Avnish Narayan, Hayden Shively, Adithya Bellathur, Karol Hausman, Chelsea Finn, and Sergey Levine. Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning, 2021.
- [309] Jimmy Wu, Rika Antonova, Adam Kan, Marion Lepert, Andy Zeng, Shuran Song, Jeannette Bohg, Szymon Rusinkiewicz, and Thomas Funkhouser. Tidybot: Personalized robot assistance with large language models. arXiv preprint arXiv:2305.05658, 2023.
- [310] Yan Ding, Xiaohan Zhang, Chris Paxton, and Shiqi Zhang. Task and motion planning with large language models for object rearrangement. arXiv preprint arXiv:2303.06247, 2023.
- [311] N. Koenig and A. Howard. Design and use paradigms for gazebo, an open-source multi-robot simulator. In 2004 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (IEEE Cat. No.04CH37566), volume 3, pages 2149–2154 vol.3, 2004.
- [312] Karmesh Yadav, Ram Ramrakhya, Santhosh Kumar Ramakrishnan, Theo Gervet, John Turner, Aaron Gokaslan, Noah Maestre, Angel Xuan Chang, Dhruv Batra, Manolis Savva, Alexander William Clegg, and Devendra Singh Chaplot. Habitat-matterport 3d semantics dataset, 2023.
- [313] Théophane Weber, Sébastien Racaniere, David P Reichert, Lars Buesing, Arthur Guez, Danilo Jimenez Rezende, Adria Puigdomenech Badia, Oriol Vinyals, Nicolas Heess, Yujia Li, et al. Imagination-augmented agents for deep reinforcement learning. arXiv preprint arXiv:1707.06203, 2017.
- [314] Maxime Chevalier-Boisvert, Dzmitry Bahdanau, Salem Lahlou, Lucas Willems, Chitwan Saharia, Thien Huu Nguyen, and Yoshua Bengio. Babyai: A platform to study the sample efficiency of grounded language learning. arXiv preprint arXiv:1810.08272, 2018.
- [315] Karl Cobbe, Chris Hesse, Jacob Hilton, and John Schulman. Leveraging procedural generation to benchmark reinforcement learning. In International conference on machine learning, pages 2048–2056. PMLR, 2020.
- [316] Marc G Bellemare, Yavar Naddaf, Joel Veness, and Michael Bowling. The arcade learning environment: An evaluation platform for general agents. Journal of Artificial Intelligence Research, 47:253–279, 2013.
- [317] Yuval Tassa, Yotam Doron, Alistair Muldal, Tom Erez, Yazhe Li, Diego de Las Casas, David Budden, Abbas Abdolmaleki, Josh Merel, Andrew Lefrancq, et al. Deepmind control suite. arXiv preprint arXiv:1801.00690, 2018.
- [318] Wenlong Huang, Fei Xia, Dhruv Shah, Danny Driess, Andy Zeng, Yao Lu, Pete Florence, Igor Mordatch, Sergey Levine, Karol Hausman, and Brian Ichter. Grounded decoding: Guiding text generation with grounded models for robot control. ArXiv, abs/2303.00855, 2023.
- [319] M. Chevalier-Boisvert, L. Willems, and S. Pal. Minimalistic gridworld environment for gymnasium. https://github.com/pierg/environments-rl, 2018.
- [320] Yuanpei Chen, Tianhao Wu, Shengjie Wang, Xidong Feng, Jiechuan Jiang, Zongqing Lu, Stephen McAleer, Hao Dong, Song-Chun Zhu, and Yaodong Yang. Towards human-level bimanual dexterous manipulation with reinforcement learning. Advances in Neural Information Processing Systems, 35:5150–5163, 2022.
- [321] Taylor Howell, Nimrod Gileadi, Saran Tunyasuvunakool, Kevin Zakka, Tom Erez, and Yuval Tassa. Predictive sampling: Real-time behaviour synthesis with mujoco, 2022.
- [322] Matthew Chignoli, Donghyun Kim, Elijah Stanger-Jones, and Sangbae Kim. The mit humanoid robot: Design, motion planning, and control for acrobatic behaviors. In 2020 IEEE-RAS 20th International Conference on Humanoid Robots (Humanoids), pages 1–8. IEEE, 2021.
- [323] Weiye Zhao, Tairan He, and Changliu Liu. Model-free safe control for zero-violation reinforcement learning. In 5th Annual Conference on Robot Learning, 2021.
- [324] Sylvia Herbert, Jason J. Choi, Suvansh Sanjeev, Marsalis Gibson, Koushil Sreenath, and Claire J. Tomlin. Scalable learning of safety guarantees for autonomous systems using hamilton-jacobi reachability, 2021.
- [325] Ran Tian, Liting Sun, Andrea Bajcsy, Masayoshi Tomizuka, and Anca D Dragan. Safety assurances for human-robot interaction via confidence-aware game-theoretic human models. In 2022 International Conference on Robotics and Automation (ICRA), pages 11229–11235. IEEE, 2022.
- [326] S.H. Cheong, J.H. Lee, and C.H. Kim. A new concept of safety affordance map for robots object manipulation. In 2018 27th IEEE International Symposium on Robot and Human Interactive Communication (RO-MAN), pages 565–570, 2018.
- [327] Ziyi Yang, Shreyas Sundara Raman, Ankit Shah, and Stefanie Tellex. Plug in the safety chip: Enforcing constraints for LLM-driven robot agents. In 2nd Workshop on Language and Robot Learning: Language as Grounding, 2023.
- [328] Olaf Sporns and Richard F Betzel. Modular brain networks. Annual review of psychology, 67:613–640, 2016.
- [329] David Meunier, Renaud Lambiotte, and Edward T Bullmore. Modular and hierarchically modular organization of brain networks. Frontiers in neuroscience, 4:200, 2010.
- [330] Montserrat Gonzalez Arenas, Ted Xiao, Sumeet Singh, Vidhi Jain, Allen Z. Ren, Quan Vuong, Jake Varley, Alexander Herzog, Isabel Leal, Sean Kirmani, Dorsa Sadigh, Vikas Sindhwani, Kanishka Rao, Jacky Liang, and Andy Zeng. How to prompt your robot: A promptbook for manipulation skills with code as policies. In 2nd Workshop on Language and Robot Learning: Language as Grounding, 2023.
- [331] Zengyi Qin, Kuan Fang, Yuke Zhu, Li Fei-Fei, and Silvio Savarese. Keto: Learning keypoint representations for tool manipulation, 2019.
- [332] Dylan Turpin, Liquang Wang, Stavros Tsogkas, Sven J. Dickinson, and Animesh Garg. Gift: Generalizable interaction-aware functional tool affordances without labels. ArXiv, abs/2106.14973, 2021.
- [333] Carl Qi, Sarthak Shetty, Xingyu Lin, and David Held. Learning generalizable tool-use skills through trajectory generation. ArXiv, abs/2310.00156, 2023.
- [334] Shadow Robot Company. Dexterous hand series. https://www.shadowrobot.com/dexterous-hand-series/, 2023. Accessed: 2023-12-10.
- [335] Siyuan Dong, Wenzhen Yuan, and Edward H. Adelson. Improved gelsight tactile sensor for measuring geometry and slip. In 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, September 2017.
- [336] Zilin Si, Tianhong Catherine Yu, Katrene Morozov, James McCann, and Wenzhen Yuan. Robotsweater: Scalable, generalizable, and customizable machine-knitted tactile skins for robots. arXiv preprint arXiv:2303.02858, 2023.
- [337] Tony Z. Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. Learning fine-grained bimanual manipulation with low-cost hardware, 2023.
- [338] Jungo Kasai, Keisuke Sakaguchi, Yoichi Takahashi, Ronan Le Bras, Akari Asai, Xinyan Yu, Dragomir Radev, Noah A. Smith, Yejin Choi, and Kentaro Inui. Realtime qa: What’s the answer right now?, 2022.
- [339] Sanket Vaibhav Mehta, Jai Gupta, Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Jinfeng Rao, Marc Najork, Emma Strubell, and Donald Metzler. Dsi++: Updating transformer memory with new documents. ArXiv, abs/2212.09744, 2022.
- [340] Sanket Vaibhav Mehta, Darshan Patil, Sarath Chandar, and Emma Strubell. An empirical investigation of the role of pre-training in lifelong learning. Journal of Machine Learning Research, 24(214):1–50, 2023.
- [341] James Seale Smith, Paola Cascante-Bonilla, Assaf Arbelle, Donghyun Kim, Rameswar Panda, David Cox, Diyi Yang, Zsolt Kira, Rogerio Feris, and Leonid Karlinsky. Construct-vl: Data-free continual structured vl concepts learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14994–15004, 2023.
- [342] Timothée Lesort, Vincenzo Lomonaco, Andrei Stoian, Davide Maltoni, David Filliat, and Natalia Díaz-Rodríguez. Continual learning for robotics: Definition, framework, learning strategies, opportunities and challenges. Information Fusion, 58:52–68, June 2020.
- [343] Guilherme Maeda, Marco Ewerton, Takayuki Osa, Baptiste Busch, and Jan Peters. Active incremental learning of robot movement primitives. In Sergey Levine, Vincent Vanhoucke, and Ken Goldberg, editors, Proceedings of the 1st Annual Conference on Robot Learning, volume 78 of Proceedings of Machine Learning Research, pages 37–46. PMLR, 13–15 Nov 2017.
- [344] Ashish Kumar, Zipeng Fu, Deepak Pathak, and Jitendra Malik. Rma: Rapid motor adaptation for legged robots. In Robotics: Science and Systems, 2021.
- [345] Joey Hejna and Dorsa Sadigh. Inverse preference learning: Preference-based rl without a reward function, 2023.
- [346] Zihao Li, Zhuoran Yang, and Mengdi Wang. Reinforcement learning with human feedback: Learning dynamic choices via pessimism, 2023.
- [347] Ananya Kumar, Aditi Raghunathan, Robbie Matthew Jones, Tengyu Ma, and Percy Liang. Fine-tuning can distort pretrained features and underperform out-of-distribution. In International Conference on Learning Representations, 2022.
- [348] OpenAI, Ilge Akkaya, Marcin Andrychowicz, Maciek Chociej, Mateusz Litwin, Bob McGrew, Arthur Petron, Alex Paino, Matthias Plappert, Glenn Powell, Raphael Ribas, Jonas Schneider, Nikolas Tezak, Jerry Tworek, Peter Welinder, Lilian Weng, Qiming Yuan, Wojciech Zaremba, and Lei Zhang. Solving rubik’s cube with a robot hand, 2019.
- [349] Viraj Mehta, Vikramjeet Das, Ojash Neopane, Yijia Dai, Ilija Bogunovic, Jeff Schneider, and Willie Neiswanger. Sample efficient reinforcement learning from human feedback via active exploration, 2023.
- [350] Gaon An, Junhyeok Lee, Xingdong Zuo, Norio Kosaka, Kyung-Min Kim, and Hyun Oh Song. Direct preference-based policy optimization without reward modeling, 2023.
- [351] Anurag Ajay, Seungwook Han, Yilun Du, Shuang Li, Abhi Gupta, Tommi Jaakkola, Josh Tenenbaum, Leslie Kaelbling, Akash Srivastava, and Pulkit Agrawal. Compositional foundation models for hierarchical planning, 2023.
- [352] Kevin Frans, Jonathan Ho, Xi Chen, Pieter Abbeel, and John Schulman. Meta learning shared hierarchies, 2017.
- [353] Suraj Nair and Chelsea Finn. Hierarchical foresight: Self-supervised learning of long-horizon tasks via visual subgoal generation. In International Conference on Learning Representations, 2020.
- [354] Christoph Feichtenhofer, Haoqi Fan, Jitendra Malik, and Kaiming He. Slowfast networks for video recognition, 2019.