探索联合社区检测的框架
摘要
联合学习是在客户端网络环境中进行机器学习,同时保持数据驻留和/或隐私限制。 社区检测是图结构数据中节点集群的无监督发现。 这两个领域的交叉揭示了很多机遇,但也带来了挑战。 例如,由于私有图之间缺少连接信息,它增加了复杂性。 在这项工作中,我们通过在一系列现有数据集上进行初步实验来探索联合社区检测的潜力,这些数据集展示了分布式数据带来的性能差距。 我们证明,孤立的模型将受益于建立一个调查该领域挑战的框架的合作。 我们讨论了这些研究前沿的复杂性,并提出了这些问题的解决方案。
介绍
数据所有权可以分布在机构或个人之间,这些机构或个人可能因技术或法律原因而无法共享数据,以实现集中式机器学习的使用(Liu and Yu 2022;Tan 等人 2022)。 由于这种结构的分区创建的场景多种多样(Zhang 等人 2021),图联邦学习非常复杂。 GNN 在之前的文献中广泛用于学习网络表示(Chen 等人 2020;Hamilton, Ying, and Leskovec 2017;Scarselli 等人 2008;Kipf 和 Welling 2016),并且有许多研究无监督的作品使用这些方法(Tsitsulin 等人 2020; Wang 等人 2019)。 基于数据集中的潜在模式而不是“真实情况”来识别集群对于缺少或禁止信息访问的应用程序非常有用。 这使得社区检测成为研究图联邦学习的强大工具。 关于联邦学习方法 (Ma 等人 2022; Yang 等人 2019) 和图联邦学习 (Yang 等人 2019; Liu and Yu 2022) 有大量调查,但没有关于联邦学习方法的调查联合社区检测。
联合图学习涵盖了多种场景,每种场景都有重要的应用。 对于想要合作实施反欺诈措施但无法共享客户信息的银行(Suzumura 等人 2019),研究每个客户拥有全局图的子部分的设置很有用。 社交媒体网络遭受网络之间传播虚假新闻的困扰(Han、Karunasekera 和 Leckie 2020;Liu 等人 2022),但数据在客户端之间分割异构,因为一个平台上的评论与其他平台上的评论并不相同一条转发。 制药公司拥有分子版权,并且不想共享(Manu 等人 2021),这意味着他们知道空间图结构,但不想共享收集成本高昂的重要特征空间信息。 医院无法共享敏感信息,但合作可以改善患者护理,因此研究节点之间缺少连接的分区在这里很有帮助。 这种联合范例也适用于学习个性化模型,其中每个客户端都是同一平台的用户。 我们希望学习针对每个用户的特定模型,同时分享与数据隐私法规(例如通用数据保护法规 (GDPR))(Truong 等人 2021) 等数据隐私法规相关的全球信息见解。 因此,该范例还可以扩展到学习客户端的拓扑,以促进客户端网络之间更好的通信。
我们探索了无监督联合图聚类的初始场景和方法,它使用基于模块化的聚类目标(Tsitsulin 等人 2020) 来平均客户端的权重(McMahan 等人 2017) 。 我们针对不在三个数据集上进行协作的客户端测试了该方法,并证明联合会带来比孤立情况更好的性能,但与集中式替代方案相比仍然存在不足。 这项工作创建了一个基准和框架,可以在其上使用其他图聚类目标和联合方法。 已经提出了使用 GNN 进行有监督联合图学习的解决方案,解决可适用于问题的无监督版本的各种子问题,例如:个性化 (Xie 等人 2021)、非相同分布图(Caldarola 等人 2021),多任务和多领域联邦学习(Zhuang 等人 2021)。 一些已应用于图像的无监督联合技术包括非 IID 数据(Zhang 等人 2020) 和不平衡数据(Servetnyk、Fung 和 Han 2020)。
我们将讨论与图联邦学习直接相关的开放挑战,如果没有明确的标签(例如恶意攻击漏洞和分布式通信协议)以及缓解这些挑战的解决方案,这些挑战将变得越来越困难。
实验方法
基线问题陈述
我们考虑联邦图学习的最简单版本,该问题是通过拥有多个客户端来定义的,每个客户端都拥有全局图的子图。 每个图由一组节点和一组边表示,这取决于分配的节点集对于每个客户端,它也规定了总 边的数量,但都拥有相同的一组 特征。 这允许我们将每个客户端图表示为 ,其中 是节点特征矩阵,邻接矩阵由 表示。 节点 具有度 ,它是连接到 的节点数。 因此,度向量由给出。 我们寻求为每个客户端学习一个函数,以查找数据中存在的集群的集群分配。 实际上,每个客户端都会找到自己的集群分配,因此矩阵的大小将取决于每个客户端 拥有的节点数,用 表示。
数据集
在这些实验中,模型在三个不同的数据集上进行了测试:Cora (McCallum 等人 2000)、Citeseer (Giles, Bollacker, and Lawrence 1998) 和 PubMed ( Sen 等人 2008) 通过节点进行分割,为每个客户端创建数据集分区。 这可以与典型的 GNN 聚类算法进行直接比较,这些算法通常用于测试模仿集中式替代方案。 每张图都是一个出版物引用网络,其中包含从论文中的单词中提取的特征。 我们根据潜在的图拓扑将这些图置于上下文中,因为与原始图相比,分区方案可能会导致非同构图。 平均聚类系数是为每个节点计算的所有局部聚类系数的平均值,它是节点邻域中存在的所有连接占该邻域中可能存在的所有链接的比例。 紧密中心性定义为距图中所有其他节点的平均最短路径距离的倒数,因此该平均值是平均节点与其他节点的接近程度的度量。
| Datasets | Cora | CiteSeer | PubMed |
|---|---|---|---|
| N Nodes | 2708 | 3327 | 19717 |
| N Features | 1433 | 3703 | 500 |
| N Edges | 10556 | 9104 | 88648 |
| Mean Closeness | |||
| Centrality | 0.137 | 0.047 | 0.160 |
| Average Clustering | |||
| Coefficient | 0.241 | 0.144 | 0.060 |
无监督 GNN 聚类架构
这里描述了每个客户端优化的每个 GNN 的聚类目标和前向传递,为了简单起见,我们省略了客户端上标。 在这些实验中,每个客户端都使用相同的模型,因为算法的联合部分平均权重。 如果联邦聚合使用嵌入式空间最小化(Makhija 等人 2022),则有可能使用不同的 GNN 模型。
图神经网络 (GNN) 在每个节点的邻域 上计算函数 。 对层 的特征进行计算可以得出下一层的特征,而我们使用的排列不变聚合运算符是 。 使用的 GNN 架构的第一步是通过添加自循环来转换邻接矩阵 ,然后通过度矩阵 so 进行归一化。 节点 的邻域作为其连接到的节点。 节点的邻域特征矩阵是所有邻域特征的多重集合,其中包括节点的特征。 我们使用单层 GNN,因此单个节点 的隐藏表示由 给出,其中 ; 是节点的偏差,选择的激活函数 是 SELU (Klambauer 等人 2017)。
前向传递由 给出,其中 是神经网络, 是 Softmax 激活函数,选择该函数来查找集群分配 。 该算法优化由方程 (1) 给出的模块性,其中如果节点 和 属于同一集群,则函数 否则。 模块化度量的是在给定度数 和 的随机图中,以概率 连接节点 和 的簇内边与预期边之间的偏差。
| (1) |
我们使用由 Tsitsulin 等人 (2020) 制定的优化过程,该过程首先将簇分配矩阵放松为单热分配矩阵,使其变为 。 最大化 的最佳 是模块化矩阵 的前 k 个特征向量。 模块化矩阵可以重新表示为 ,这允许我们将计算 分解为稀疏矩阵-矩阵乘法和秩一阶归一化的总和,从而降低了时间复杂度,因此计算变为。 使用崩溃正则化项,其中 是 Frobenius 范数。 因此,模型的损失函数由方程 (2) 给出,其中 和 分别定义为节点数和边数在图表中。
| (2) | |||
联邦学习
McMahan 等人 (2017) 的权重平均算法用于创建算法的联合部分,该部分对服务器上的所有客户端参数进行平均,然后将结果分发回每个客户端以进行本地训练。 如果联邦在异构图上进行操作,那么这将是不合适的,因为权重将对应于不同的特征,因此激活不会对齐。 在这些实验中,由于分区是按节点进行的,因此每个客户端对平均值的贡献由本地数据样本的数量进行加权。 该周期被定义为在预设数量的局部历元之后等式(3)中的全局聚合,其中参数在每轮使用更新,其中 是学习率。 这并不适合所讨论的所有场景,因为客户端可能会经历不同的数据流,这将影响每轮通信之间的参数更新量。 在这种情况下,需要开发技术来调节每个客户的贡献和重新分配。 然而,这里在全局聚合之后对所有客户端进行重新分配。 参数 从 Xavier 均匀分布初始化,此术语用于指代前向传播中的所有权重,包括 GNN 和线性层 包含所有偏差项。
| (3) |
实验详情
在所有实验中,联邦、集中模型和不协作的孤立模型的算法变体均受到以下约束。 与放宽这一约束相比,实验的设计使得在一个实验中只有一个客户端可以访问每个节点。 每组模型的每轮通信训练相当于 5 个本地 epoch,总共训练 250 轮。 实验中簇大小正则化参数设置为常数,客户端数量在2到15之间变化。
所有模型均使用 Adam 优化器 (Kingma 和 Ba 2014) 进行优化,学习率为 ,无权重衰减。 支持每个模型的 GNN 函数将特征的维度减少到 。 训练/验证/测试分割是通过将邻接矩阵划分为比例 来创建的。 所有考虑的图都是无向的,并在分割中维护。 Macro-F1用于评估性能,以确保评估不会因标签分布而产生偏差。 训练中的最佳权重参数是在 F1 验证得分最高时获取的,性能由测试集决定。 所有实验均针对三个种子进行评估,并报告平均性能。 所有实验均在具有 96GB RAM 的单个 2080 Ti GPU (12GB) 和 16 核 Xeon CPU 上执行。 随机系数用于评估结果的可靠性,其中较低的值表示实验中随机种子的一致性较高(Leeney 和 McConville 2023)。
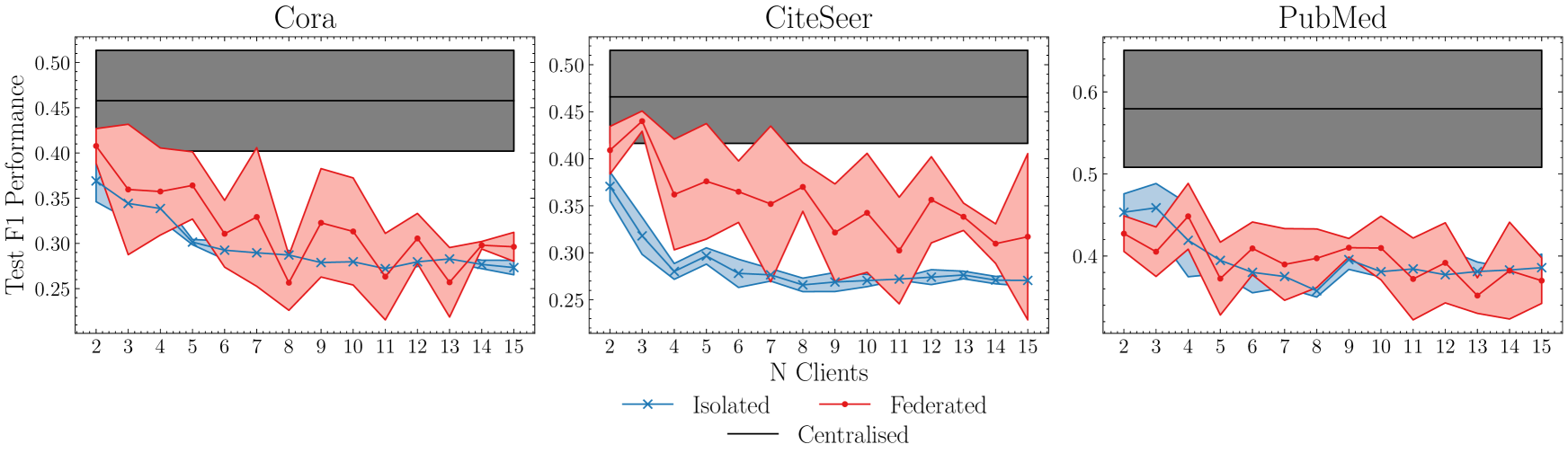
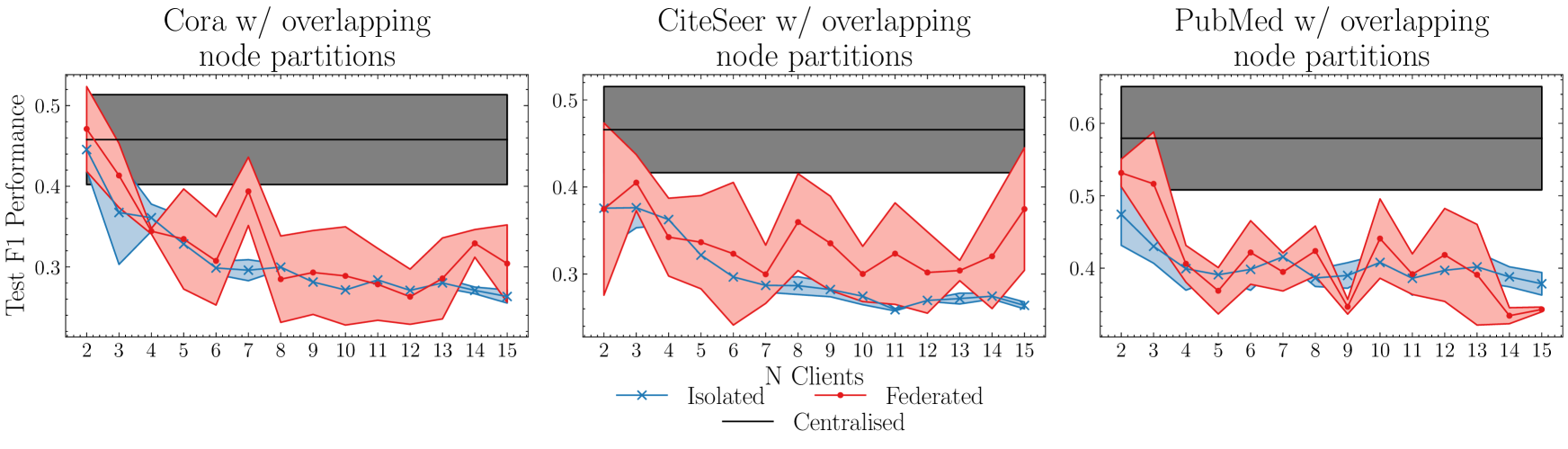
讨论
实验
开放挑战
型号多样
图 1 突出显示,集中式模型的性能优于军团和不协作的客户端。 这建立了联邦社区检测的框架,但是,只考虑了一种联邦 GNN 模型。 全面的研究应该考虑各种不同的 GNN 模型。 数据集分区意味着由于连接丢失,本地 GNN 无法从高阶邻居中提取信息,因此与集中式模型相比性能下降。 此外,共享模型的详细信息并因此通过权重聚合进行共享可能不切实际。 使用类似于 Makhija 等人 (2022) 的损失函数来最小化嵌入空间中的距离可能是解决此问题的方法。
非独立同分布数据
孤立模型的性能与数据集分区方案中丢失的边缘和客户端数量的增加成正比。 与集中式模型(Ma等人2022)相比,数据的偏向分区(其中每个客户端拥有一个集群中的大多数节点)会增加性能下降。 这项工作的扩展可能适合这种情况,即根据簇大小分布与相似性函数成比例地缩放权重平均。 或者,共享聚类中心并通过计算客户端聚类中心之间的平均距离来调整权重平均可能是相关的。
异构分区
这项工作使用所有客户端在同一图上学习的约束来证明无监督联合图学习的潜力,但是有许多应用程序处理复杂的图。 MuMin (Nielsen 和 McConville 2022) 是一个多模态图数据集,用于研究和开发错误信息检测,由于现实世界假新闻背后的来源未知,错误信息检测传统上是无监督任务。 通过类似于 Zhuang 等人 (2021) 的特征对齐来了解哪些特征信息在全球范围内相关的联合可能对于聚合这些不同的模态很有用。
恶意攻击漏洞
在这些实验中,假设所有各方都诚实行事,并且不会使用不良数据来故意恶化联邦的平均值。 如果无法验证所有客户端的完整性,那么在开发解决方案时必须意识到这一点。 解决方案可能是生成随机图发送给每个参与者,对每个客户端的聚类能力进行排名,然后根据 W 随机系数给出的可信度分数按比例缩放权重平均。
高效沟通
在实践中应用联邦学习算法时,通信和内存消耗可能是一个关键瓶颈(Liu 和 Yu 2022)。 这种聚合客户端权重的方案意味着整个网络需要与服务器通信,这会带来大量的内存开销。 现实世界的实现需要高效的通信协议,这可以通过学习稀疏掩码来最小化开销来实现,类似于 Baek 等人 (2022) 提出的想法。 另一种方法可能是使用 GNN 来学习客户端的拓扑,这将允许客户端通过未完全连接的网络进行共享。
最后的评论
在这项工作中,我们提出了一个框架,将联合图学习与社区检测相结合,并验证其可行性,同时证明与私人持有数据的连接丢失是很严重的。 该框架扩展到由不同图分区包含的各种联邦,每个联邦都与实际应用程序相关。 该范式中的许多开放挑战是通过本文中进行的初始实验组揭示的,我们讨论了这些问题的潜在解决方案。
参考
- Baek et al. (2022) Baek, J.; Jeong, W.; Jin, J.; Yoon, J.; and Hwang, S. J. 2022. Personalized Subgraph Federated Learning. arXiv preprint arXiv:2206.10206.
- Caldarola et al. (2021) Caldarola, D.; Mancini, M.; Galasso, F.; Ciccone, M.; Rodolà, E.; and Caputo, B. 2021. Cluster-driven graph federated learning over multiple domains. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2749–2758.
- Chen et al. (2020) Chen, F.; Wang, Y.-C.; Wang, B.; and Kuo, C.-C. J. 2020. Graph representation learning: a survey. APSIPA Transactions on Signal and Information Processing, 9: e15.
- Giles, Bollacker, and Lawrence (1998) Giles, C. L.; Bollacker, K. D.; and Lawrence, S. 1998. CiteSeer: An automatic citation indexing system. In Proceedings of the third ACM conference on Digital libraries, 89–98.
- Hamilton, Ying, and Leskovec (2017) Hamilton, W. L.; Ying, R.; and Leskovec, J. 2017. Representation learning on graphs: Methods and applications. arXiv preprint arXiv:1709.05584.
- Han, Karunasekera, and Leckie (2020) Han, Y.; Karunasekera, S.; and Leckie, C. 2020. Graph neural networks with continual learning for fake news detection from social media. arXiv preprint arXiv:2007.03316.
- Kingma and Ba (2014) Kingma, D. P.; and Ba, J. 2014. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980.
- Kipf and Welling (2016) Kipf, T. N.; and Welling, M. 2016. Semi-supervised classification with graph convolutional networks. arXiv preprint arXiv:1609.02907.
- Klambauer et al. (2017) Klambauer, G.; Unterthiner, T.; Mayr, A.; and Hochreiter, S. 2017. Self-normalizing neural networks. Advances in neural information processing systems, 30.
- Leeney and McConville (2023) Leeney, W.; and McConville, R. 2023. Uncertainty in GNN Learning Evaluations: The Importance of a Consistent Benchmark for Community Detection. Forthcoming.
- Liu and Yu (2022) Liu, R.; and Yu, H. 2022. Federated Graph Neural Networks: Overview, Techniques and Challenges. arXiv preprint arXiv:2202.07256.
- Liu et al. (2022) Liu, Z.; Yang, L.; Fan, Z.; Peng, H.; and Yu, P. S. 2022. Federated social recommendation with graph neural network. ACM Transactions on Intelligent Systems and Technology (TIST), 13(4): 1–24.
- Ma et al. (2022) Ma, X.; Zhu, J.; Lin, Z.; Chen, S.; and Qin, Y. 2022. A state-of-the-art survey on solving non-IID data in Federated Learning. Future Generation Computer Systems, 135: 244–258.
- Makhija et al. (2022) Makhija, D.; Han, X.; Ho, N.; and Ghosh, J. 2022. Architecture agnostic federated learning for neural networks. In International Conference on Machine Learning, 14860–14870. PMLR.
- Manu et al. (2021) Manu, D.; Sheng, Y.; Yang, J.; Deng, J.; Geng, T.; Li, A.; Ding, C.; Jiang, W.; and Yang, L. 2021. FL-DISCO: Federated Generative Adversarial Network for Graph-based Molecule Drug Discovery: Special Session Paper. In 2021 IEEE/ACM International Conference On Computer Aided Design (ICCAD), 1–7. IEEE.
- McCallum et al. (2000) McCallum, A. K.; Nigam, K.; Rennie, J.; and Seymore, K. 2000. Automating the construction of internet portals with machine learning. Information Retrieval, 3(2): 127–163.
- McMahan et al. (2017) McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; and y Arcas, B. A. 2017. Communication-efficient learning of deep networks from decentralized data. In Artificial intelligence and statistics, 1273–1282. PMLR.
- Nielsen and McConville (2022) Nielsen, D. S.; and McConville, R. 2022. Mumin: A large-scale multilingual multimodal fact-checked misinformation social network dataset. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, 3141–3153.
- Scarselli et al. (2008) Scarselli, F.; Gori, M.; Tsoi, A. C.; Hagenbuchner, M.; and Monfardini, G. 2008. The graph neural network model. IEEE transactions on neural networks, 20(1): 61–80.
- Sen et al. (2008) Sen, P.; Namata, G.; Bilgic, M.; Getoor, L.; Galligher, B.; and Eliassi-Rad, T. 2008. Collective classification in network data. AI magazine, 29(3): 93–93.
- Servetnyk, Fung, and Han (2020) Servetnyk, M.; Fung, C. C.; and Han, Z. 2020. Unsupervised federated learning for unbalanced data. In GLOBECOM 2020-2020 IEEE Global Communications Conference, 1–6. IEEE.
- Suzumura et al. (2019) Suzumura, T.; Zhou, Y.; Baracaldo, N.; Ye, G.; Houck, K.; Kawahara, R.; Anwar, A.; Stavarache, L. L.; Watanabe, Y.; Loyola, P.; et al. 2019. Towards federated graph learning for collaborative financial crimes detection. arXiv preprint arXiv:1909.12946.
- Tan et al. (2022) Tan, A. Z.; Yu, H.; Cui, L.; and Yang, Q. 2022. Towards personalized federated learning. IEEE Transactions on Neural Networks and Learning Systems.
- Truong et al. (2021) Truong, N.; Sun, K.; Wang, S.; Guitton, F.; and Guo, Y. 2021. Privacy preservation in federated learning: An insightful survey from the GDPR perspective. Computers & Security, 110: 102402.
- Tsitsulin et al. (2020) Tsitsulin, A.; Palowitch, J.; Perozzi, B.; and Müller, E. 2020. Graph clustering with graph neural networks. arXiv preprint arXiv:2006.16904.
- Wang et al. (2019) Wang, C.; Pan, S.; Hu, R.; Long, G.; Jiang, J.; and Zhang, C. 2019. Attributed graph clustering: A deep attentional embedding approach. arXiv preprint arXiv:1906.06532.
- Xie et al. (2021) Xie, H.; Ma, J.; Xiong, L.; and Yang, C. 2021. Federated graph classification over non-iid graphs. Advances in Neural Information Processing Systems, 34: 18839–18852.
- Yang et al. (2019) Yang, Q.; Liu, Y.; Chen, T.; and Tong, Y. 2019. Federated machine learning: Concept and applications. ACM Transactions on Intelligent Systems and Technology (TIST), 10(2): 1–19.
- Zhang et al. (2020) Zhang, F.; Kuang, K.; You, Z.; Shen, T.; Xiao, J.; Zhang, Y.; Wu, C.; Zhuang, Y.; and Li, X. 2020. Federated unsupervised representation learning. arXiv preprint arXiv:2010.08982.
- Zhang et al. (2021) Zhang, H.; Shen, T.; Wu, F.; Yin, M.; Yang, H.; and Wu, C. 2021. Federated Graph Learning–A Position Paper. arXiv preprint arXiv:2105.11099.
- Zhuang et al. (2021) Zhuang, W.; Gan, X.; Wen, Y.; Zhang, X.; Zhang, S.; and Yi, S. 2021. Towards unsupervised domain adaptation for deep face recognition under privacy constraints via federated learning. arXiv preprint arXiv:2105.07606.