DriveMLM: Aligning Multi-Modal Large Language Models with
Behavioral Planning States for Autonomous Driving
摘要
大型语言模型(LLM)为智能体开辟了新的可能性,赋予它们类似人类的思维和认知能力。 在这项工作中,我们深入研究了大型语言模型 (LLM) 在自动驾驶 (AD) 中的潜力。 我们介绍 DriveMLM,这是一个基于 LLM 的 AD 框架,可以在现实模拟器中执行闭环自动驾驶。 为此,(1)我们根据现成的运动规划模块标准化决策状态,从而弥合语言决策和车辆控制命令之间的差距。 (2)我们采用多模态大语言模型(MLLM)对模块 AD 系统的行为规划模块进行建模,该模块使用驾驶规则、用户命令和来自各种传感器的输入(例如。 、摄像头、激光雷达)作为输入并做出驾驶决策并提供解释;该模型可以在Apollo等现有自动驾驶系统中即插即用,实现闭环驾驶。 (3)我们设计了一个有效的数据引擎来收集包含决策状态和相应解释的数据集,用于模型训练和评估。 我们进行了大量的实验,结果表明我们的模型在 CARLA Town05 Long 上获得了 76.1 的驾驶分数,并且在相同设置下超出了 Apollo 基线 4.7 分,这证明了我们模型的有效性。 我们希望这项工作能够成为法学硕士自动驾驶的基线。
1简介

edu.cn)
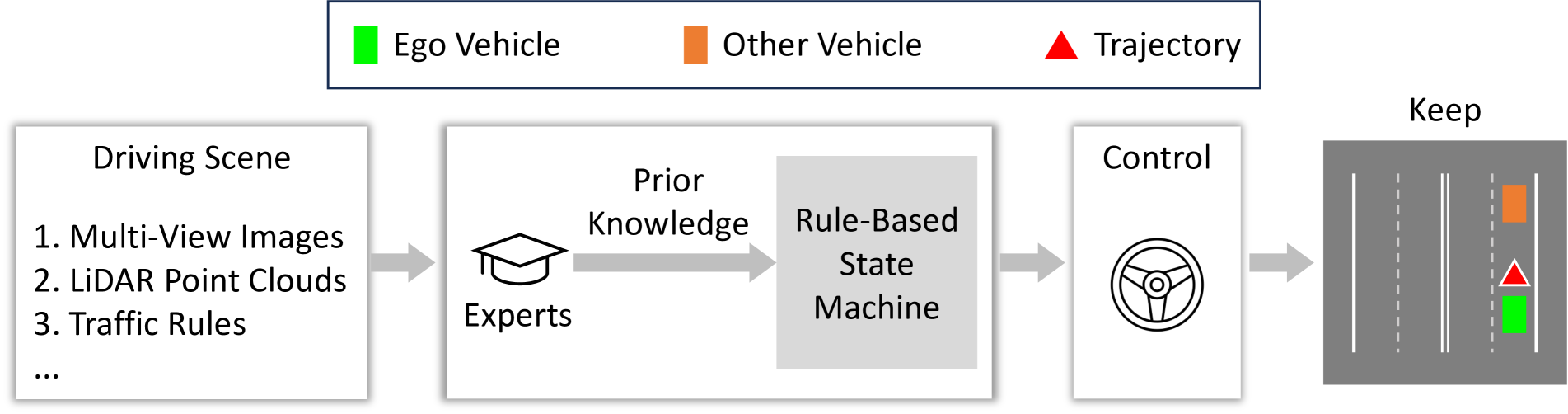
自动驾驶 (AD) 近年来取得了显着进步,从传统的基于规则的系统发展而来,传统的系统依赖于先验知识告知的一组预定义规则(见图 0(a)),数据驱动的端到端系统,如图0(b)所示。 尽管取得了进步,但由于专家知识的限制或训练数据的多样性,这些系统仍遇到了局限性。 这使得它们处理极端情况变得具有挑战性,尽管人类驾驶员可能会发现它们可以直观地处理。 与这些传统的基于规则或数据驱动的 AD 规划器相比,使用网络规模文本语料库训练的大型语言模型 (LLM) 配备了广泛的世界知识、强大的逻辑推理和先进的认知能力。 这些功能使它们成为自动驾驶系统中的潜在规划者,为自动驾驶提供类似人类的方法。
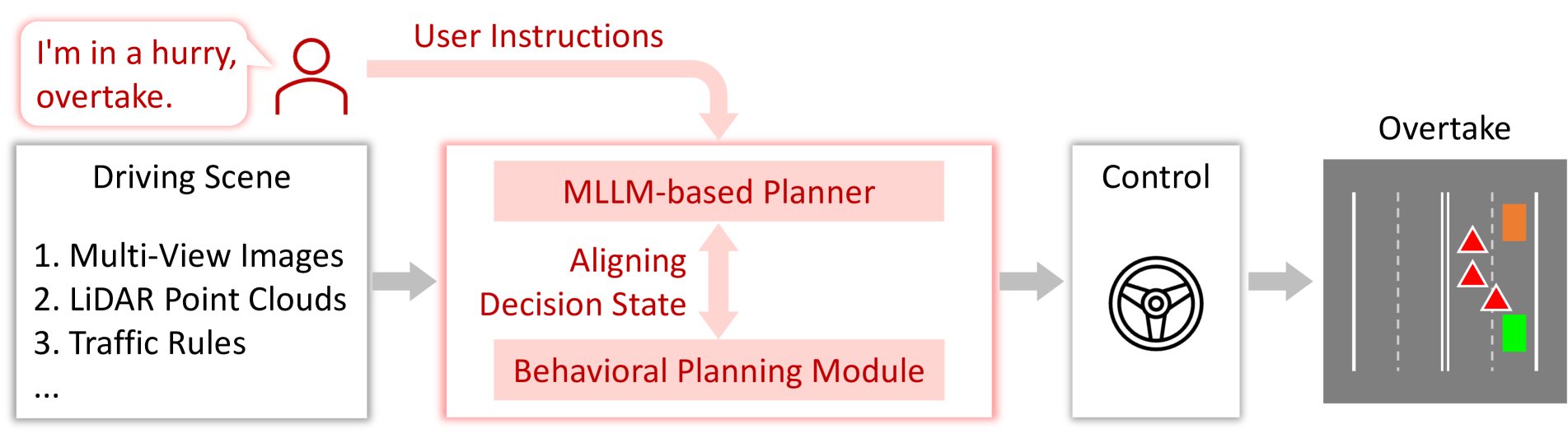
最近的一些研究[16, 72, 68, 39, 24, 13, 56]已经将 LLM 集成到自动驾驶系统中,重点是根据驾驶场景生成基于语言的决策。 然而,这些方法在现实环境或现实模拟器中执行闭环驾驶时存在局限性。 这是因为法学硕士的输出主要是语言学和概念性的,不能用于车辆控制。 在传统的模块化AD系统[3、22、21]中,高层战略目标与目标之间的差距低层操作动作由行为规划模块连接,其决策状态可以通过后续运动规划和控制轻松转换为车辆控制信号。 这促使我们将大语言模型与行为规划模块的决策状态进行对齐,并进一步设计基于大语言模型的闭环 AD 系统,通过将对齐后的大语言模型用于行为规划,该系统可在真实环境或现实模拟器上运行。
基于这一点,我们提出了DriveMLM,这是第一个基于LLM的AD框架,可以在现实模拟器中执行闭环自动驾驶。 为了实现这一目标,我们进行了三个关键设计:(1)我们研究了成熟的 Apollo 系统[3]的行为规划模块的决策状态,并将其转换为将它们转换成法学硕士可以轻松处理的形式。 (2)我们开发了一个多模态大语言模型(MLLM)规划器,可以接受当前的多模态输入,包括多视图图像、LiDAR点云、交通规则、系统消息和用户指令,并预测决策状态; (3)为了获得足够的训练数据用于行为规划状态对齐,我们在CARLA上手动收集280小时的驾驶数据,并通过高效的数据引擎将其转换为决策状态和相应的解释注释。 通过这些设计,我们可以获得一个能够根据驾驶场景和用户需求做出决策的MLLM规划器,并且其决策可以很容易地转换为闭环驾驶的车辆控制信号。
我们的工作具有以下优点:(1)受益于一致的决策状态,我们的MLLM规划器可以轻松地与现有的模块化AD系统(例如Apollo)集成,以实现闭环驱动,而不需要任何重大改变或修改。 (2) 通过将语言指令作为输入,我们的模型可以处理用户需求(例如.,超车)和高级系统消息(例如.,定义基本驱动逻辑)。 这使得我们的模型更加灵活,能够适应不同的驾驶情况和极端情况。 (3)它可以提供可解释性并解释不同的决策。 这增强了我们模型的透明度和可信度,因为它可以向用户解释其行为和选择。
总的来说,这项工作的贡献有三个方面:
(1)我们提出了一种基于法学硕士的AD框架,通过将法学硕士的输出与行为规划模块的决策状态保持一致,弥合了大语言模型和闭环驱动之间的差距。
(2)为了实现这个框架,我们定制了一组LLM可以轻松处理的形式的决策状态,设计用于决策预测的MLLM规划器,并开发一个可以有效生成决策状态和模型相应解释的数据引擎训练和评估。
(3)为了验证我们方法的有效性,我们不仅在闭环驾驶指标上评估我们的方法,包括驾驶分数(DS)和每次干预里程(MPI),而且还使用理解指标,包括准确性、F1测量决策状态、BLEU-4、CIDEr 和 METEOR 用于决策解释,以评估我们模型的驾驶理解能力。 值得注意的是,我们的方法在 CARLA Town05 Long 上取得了 76.1 DS、0.955 MPI 的结果,比 Apollo 提高了 4.7 分,提高了 1.25 倍。 此外,我们可以通过用语言指令描述特殊要求(例如让救护车或交通规则)来改变 MLLM 规划者的决策,如图2所示。

2相关工作
2.1 多模态大语言模型
The swift evolution of Large Language Models (LLMs) [53, 54, 7, 47, 46] has recently given rise to the emergence of multi-modal LLMs (MLLMs) [1, 26, 38, 37, 83, 17, 78, 12, 67, 51, 30, 2, 23, 33, 79, 71, 29, 80], which augment language models with the capacity to analyze and comprehend information from diverse modalities. 这些进步的突出例子包括 GPT-4 [46], Flamingo [1], KOSMOS-1 [26]、LLaVA系列[38, 37]和MiniGPT-4 [83],以及InstructBLIP [17]。 这些模型集成了视觉指令调整方法,以增强 MLLM 遵守规定指令的能力。 此外,mPLUG-DocOwl [78] 通过合并数字文档数据集,拓宽了 MLLM 的文档理解能力。 同时,Shikra [12]、VisionLLM [67]、KOSMOS-2 [51]、LISA [30 和 Qwen-VL [2 VideoChat [33] 和 VideoLLaMA [79] 的推出,迎来了视频处理能力的集成法学硕士。 此外,NExT-GPT [71]引入了一种用于多模态提示调整的模态切换指令调整技术,方便处理任意文本组合的输入和输出、图像、视频和音频。 ASM [29] 和 GPT4RoI [80] 将区域级识别和理解能力引入 LLM。 这些努力证明了 LLM 的有效性和通用性,为开放世界任务奠定了基础。
2.2 具有大型语言模型的智能代理
法学硕士的一个新兴应用是它们在促进智能代理(例如机器人、虚拟助理或游戏角色)和各种实体(包括人类、环境,甚至智能代理本身)之间的交互和通信方面发挥的作用。 Several API-based methods, including Visual ChatGPT [69], MM-REACT [77], HuggingGPT [59], InternGPT [40], ViperGPT [62], ControlLLM [41], and GPT4Tool [76] have attempted to integrate diverse modal APIs with LLMs to accomplish complex tasks in the open world, such as image editing, video processing, and audio synthesis. 这些方法允许语言模型通过遵循自然语言指令来执行复杂的现实世界任务。 与此同时,替代研究计划,例如 Camel [31]、AutoGPT [75]、MetaGPT [24] 和 Smallville [50,研究法学硕士在角色扮演对话或交流中的效用游戏。 此外,在体现人工智能领域,PaLM-E [19]、EmbodiedGPT [45] 等作品>,以及 RT 系列 [5, 6, 48 利用 LLM 生成自然语言动作,从而控制能够在真实或 3D 环境中熟练执行导航、操作和交互任务的实体代理。 这些工作展示了法学硕士在智能代理控制领域取得的显着进步。
2.3自动驾驶模型
近年来,自动驾驶(AD)模型的发展迅速加速,催生了许多颠覆性、突破性的技术。 值得注意的是,Apollo [3] 和 Autoware [22] 等开源框架已经发挥了作用通过提供强大的工具和资源,发挥关键作用,从而促进自动驾驶技术的发展并为其广泛采用和发展做出贡献。 在自动驾驶感知方面,BEV(鸟瞰图)[34, 73, 36, 61] 和 Occupancy Network(占用网络)[63, 60, 35] 已成为自动驾驶车辆的重要组成部分,帮助它们更好地了解周围环境并做出相应决策。 传统自动驾驶系统的决策过程通常依赖于有限状态机[14]。 这些系统通常需要手动创建大量规则来确定它们之间转换的状态和条件。 然而,考虑到世界不断变化的性质,设计规则来覆盖现实世界的所有场景通常很费力。 近年来,端到端自动驾驶模型也取得了令人瞩目的进展,例如UniAD[25]采用了新颖的端到端方法,直接将感知、预测、规划融为一体,避免了传统模块化设计方法中的信息损失和效率问题。 最近,开源模拟器 [18, 66, 82] 被提出来弥合模型之间的差距预测和闭环控制。 Among them, CARLA [18], featuring comprehensive sensor simulations and realistic environments, is the most widely used benchmark for evaluating closed-loop performance by many state-of-the-art methods [27, 58, 57, 28, 15, 10, 11, 9].
Recent works [16, 72, 43, 68, 39, 13, 56] changes our perception by introducing LLM for driving planning, opening up a new direction for the autonomous driving field. 作为早期探索,一些 [68, 56] 使用 ChatGPT 和 GPT-4 来预测驾驶决策。 以下工作大语言模型模型来预测驾驶信号[13]、轨迹[43]或设计决策空格 [39],仅以语言作为输入为条件。 DriveGPT4 [72] 微调多模态大语言模型来预测控制信号。 然而,DriveGPT4 受到单目相机输入的限制,限制了其构建全面场景信息的能力。 上述所有基于LLM的工作都没有在闭环驾驶的真实模拟器上进行评估,因为要么LLM的语言决策很难转化为实际可靠的控制信号,要么大语言模型对控制信号的直接预测仍然存在很大差距。实时闭环驾驶。
3 建议的方法
3.1系统概述
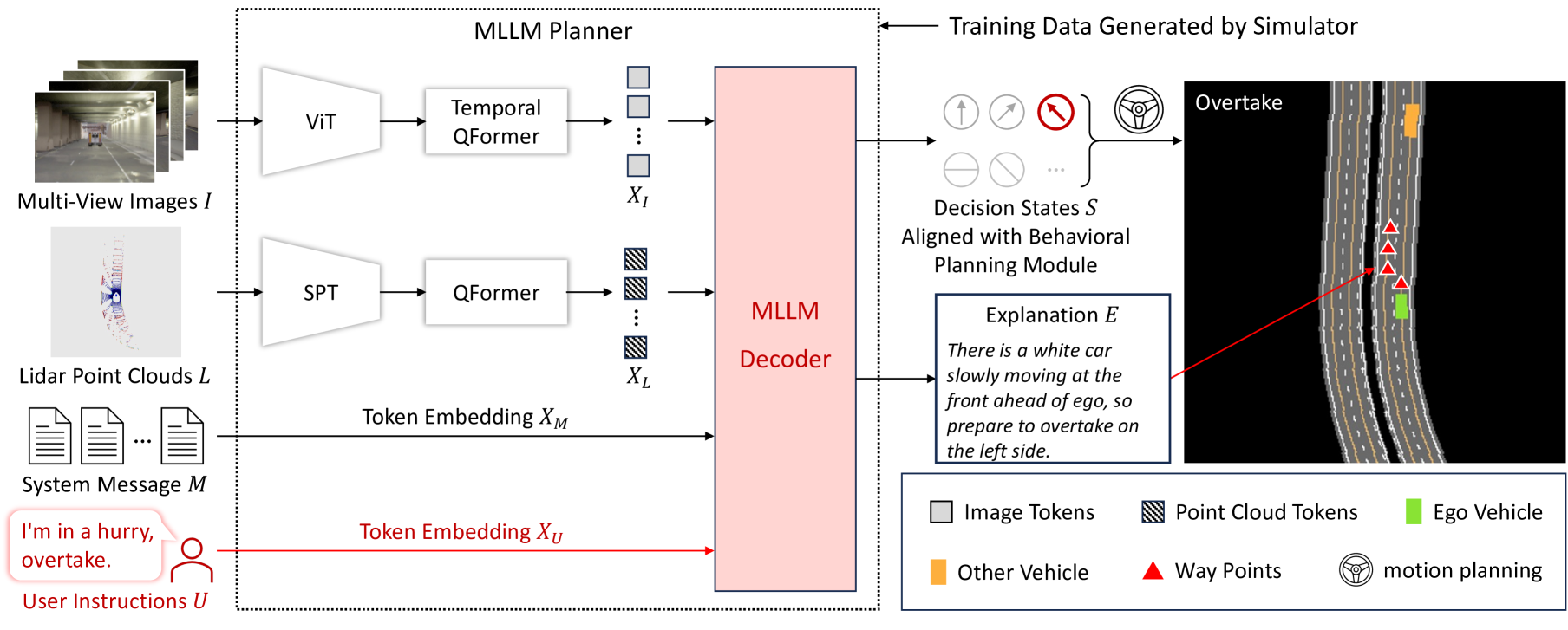
DriveMLM框架将大语言模型(LLM)的世界知识和推理能力集成到自动驾驶(AD)系统中,实现现实模拟器中的闭环驾驶。 如图3所示,该框架有三个关键设计:(1) 行为规划表明一致性。 这部分将大语言模型的语言决策输出与成熟的模块化AD系统(如Apollo [3])的行为规划模块结合起来。 这样,大语言模型的输出就可以方便地转化为车辆控制信号。 (2) MLLM 规划师。 它是多模态分词器和多模态大语言模型(MLLM)解码器的组合。 多模态标记器将多视图图像、LiDAR、交通规则和用户需求等不同输入转换为统一标记,MLLM 解码器根据统一标记做出决策。 (3) 高效的数据收集策略。 它为基于LLM的自动驾驶引入了定制的数据收集方法,确保了包含决策状态、决策解释和用户命令的全面数据集。
在推理过程中,DriveMLM 框架利用多模态数据来做出驾驶决策。 These data include: multi-view images , where denotes the time length, indicates the number of views, and and denotes the height and width of images. 点云 来自 LiDAR 点云,其中 系统消息,其中 系统消息是任务定义、交通规则和决策状态定义的集合。 使用说明 ,其中 These inputs undergo tokenization through a multi-modal tokenizer, resulting in: , , , , which represent the tokens embedding of multi-view images, LiDAR point clouds, traffic rules, and user instructions, respectively. 其中表示输出词符个数,由QFormer的查询次数决定[32],每个词符嵌入都是维度。 接下来,这些标记被输入到 MLLM 解码器,解码器生成决策状态词符 以及相应的解释 。最后,决策状态被输入到运动规划和控制模块。 该模块计算车辆控制的最终轨迹。
3.2 行为规划状态调整
将大语言模型 (LLM) 的语言选择转换为可操作的控制信号对于车辆控制至关重要。 为了实现这一目标,我们将大语言模型的输出与流行的 Apollo 系统中行为规划模块的决策阶段相结合。 按照惯例[3],我们将决策过程分为两类:速度决策和路径决策。 具体地,速度决策状态包括[KEEP、ACCELERATE、DECELERATE、STOP],而路径决策状态包括[FOLLOW、LEFT_CHANGE、RIGHT_CHANGE、LEFT_BORROW、RIGHT_BORROW]。
为了使语言模型能够在这些状态之间做出精确的预测,我们在语言描述和决策状态之间建立了全面的链接,如表1的系统按摩所示。 这种相关性用作系统消息的一部分,并集成到 MLLM 规划器中。 因此,一旦大语言模型描述了某些情况,预测就会在决策空间内收敛为明确的决策。 每次,都会相互推断一速度决策和一路径决策,并将其发送到运动规划框架。 决策状态的更详细定义可以在补充材料中找到。
3.3 MLLM 规划器
DriveMLM 的 MLLM 规划器由两个组件组成:多模态分词器和 MLLM 解码器。 这两个组件密切协作,处理各种输入以准确确定驾驶决策并为这些决策提供解释。
多模态分词器。 该分词器旨在有效处理各种形式的输入:
(1) 对于时间多视图图像:我们使用时间 QFormer 来处理从时间戳 到 0(当前时间戳)。 First, it takes each view at timestamp and feeds it to ViT-g and QFormer with random initialized queries of dimension. 这会生成图像词符嵌入 。 然后,使用图像词符嵌入 作为 QFormer 的查询,我们得到下一个时间戳的图像词符嵌入 我们重复这两个步骤,直到得到当前时间戳的图像词符嵌入 ,收集来自 这种方法避免了处理时间序列数据所需的资源随着时间长度的增加而线性增加。
(2)对于LiDAR数据,我们首先发送点云作为稀疏金字塔变换器(SPT)主干[74]的输入以提取LiDAR特征。 然后我们使用Qformer和维度的随机初始化查询来获得点云词符嵌入。 我们将其与图像词符嵌入连接起来。
(3) 对于系统消息和用户指令,我们简单地将其视为普通文本数据,并使用大语言模型的词符嵌入层来提取其嵌入,,
MLLM 解码器。 解码器是将标记化输入转换为决策状态和决策解释的核心。 为此,我们设计了一个基于LLM的AD的系统消息模板,如表1所示。 我们看到系统消息包含 AD 任务的描述、交通规则、决策状态的定义以及指示每种模态信息合并位置的占位符。 这种方法确保来自各种模式和来源的输入能够无缝集成。
3.4高效的数据引擎
我们提出了一个数据生成管道,可以根据 CARLA 模拟器中的各种场景创建决策状态和解释注释。 该管道可以解决现有驾驶数据的局限性,这些数据缺乏基于 LLM 的 AD 系统训练的决策状态和详细解释。 我们的管道由两个主要部分组成:数据收集和数据标注。
数据收集旨在提高决策多样性,同时保持现实。 首先,在模拟器中构建各种具有挑战性的场景。 需要复杂的驾驶行为才能安全行驶。 然后,专家(无论是经验丰富的人类驾驶员还是代理人)被要求安全地驾驶通过在其许多可通行地点之一触发的这些场景。 值得注意的是,当专家随机提出驾驶需求并相应驾驶时,就会生成交互数据。 一旦专家安全驾驶到达目的地,数据就会被记录下来。
数据标注主要侧重于决策和解释。 首先,通过使用手工制定的规则,根据专家的驾驶轨迹自动注释速度和路径决策状态。 其次,解释注释首先根据场景生成,由附近的当前元素动态定义。 第三,生成的解释注释由人类注释者细化,并且 GPT-3.5 扩展了它们的多样性。 此外,交互内容也由人工注释者进行细化,包括执行或拒绝人工请求的情况。 这样,我们就避免了成本高昂的逐帧决策状态标注,以及从头开始人工编写解释标注的昂贵成本,大大加快了我们的数据标注流程。
4实验
4.1数据分析
我们收集了 小时的驾驶数据。 这些数据包括 50,000 条路线,在 CARLA 的 8 张地图(Town01、Town02、Town03、Town04、Town06、Town07、Town10HD、Town12)中的 30 个不同天气和照明条件的驾驶场景中收集。 平均而言,每个场景在每张地图上大约有200个触发点可供随机触发。 每种情况都是驾驶中常见或罕见的安全关键情况。 这些场景的详细信息在补充中。 对于每一帧,我们收集来自前、后、左、右 4 个摄像头的图像,以及来自添加在自我车辆中心的 LiDAR 传感器的点云。 我们收集的所有数据都有相应的解释和准确的决策,可以成功地推动场景的发展。
表 2 展示了与之前为促进自然语言理解而设计的数据集的比较。 我们的数据有两个独特的特征。 首先是行为规划状态的协调。 这使我们能够将 MLLM 规划器的输出转换为控制信号,以便我们的框架可以控制闭环驾驶中的车辆。 二是人际互动的标注。 它的特点是人类给出的自然语言指令以及响应决策和解释。 目标是提高理解人类指令并做出相应反应的能力。
4.2实现细节
我们的 MLLM 模型是根据 LLaMA [23] 构建的。 具体来说,我们使用 EVA-CLIP [20] 中的 ViT-g/14 作为视觉编码器,并使用 LLaMA-7B [64 ]作为大语言模型。 具有 查询的查询 Transformer 用于从 ViT 中提取图像标记,其中我们设置 。 对于 LiDAR 编码器,我们使用在 ONCE [42] 上微调的 GD-MAE [74] 模型。 基于预训练的 husky 模型,我们使用指令跟踪数据来训练 MLLM。 我们采用 AdamW 优化器,其中 ,,余弦学习率随学习率 训练epoch为2,batch size为256。 我们训练QFormer和大语言模型来保证大语言模型的指令跟随能力,从而获得预定义的路径决策和速度决策格式。 输入MLLM的图像分辨率设置为。
| Method | Type | Acc. | Path F1 | Speed F1 | BLEU-4 | CIDEr | METEOR | |||||
| follow | change | borrow | keep | accelerate | decelerate | stop | ||||||
| LLaVA 1.5 [37] | LLM | 22.92 | 0.73 | 0.00 | 0.00 | 0.75 | 0.00 | 0.02 | 0.00 | 10.00 | 18.03 | 23.00 |
| InstructBLIP [17] | LLM | 17.92 | 0.00 | 0.30 | 0.08 | 0.23 | 0.00 | 0.28 | 0.00 | 9.81 | 18.61 | 22.95 |
| Apollo [3] | FSM | 18.53 | 0.76 | 0.40 | 0.04 | 0.54 | 0.05 | 0.19 | 0.37 | - | - | - |
| DriveMLM | LLM | 75.23 | 0.90 | 0.52 | 0.89 | 0.91 | 0.61 | 0.66 | 0.89 | 40.46 | 124.91 | 56.54 |
为了评估闭环驾驶性能,我们使用广泛使用的 Town05Long 基准,该基准遵循之前的工作[15,57]。 值得注意的是,Town05 并不在我们的训练数据中。 我们使用驾驶分数 (DS)、路线完成度 (RC) 和违规分数 (IS) [18] 作为指标。 RC 计算代理完成的路线的平均百分比。 IS测量之间的违规处罚,包括碰撞和违反交通规则。 请注意,IS 仅针对路线的已完成部分进行计算。 DS是三者中的核心指标,是RC和IS的乘积。 我们还使用每次干预里程 (MPI) 来评估驾驶性能,这是行业中广泛使用的指标。 它是根据人类接管总时间的总行驶距离来计算的。 如果自动驾驶汽车违反交通规则或发生碰撞,它将被接管并在安全位置继续自动驾驶,直到到达目的地。 与 DS 在某些条件下终止路线不同,MPI 需要 ego-car 来完成整个路线。
4.3闭环驱动评估
| Method | Type | DS | RC | IS | MPI |
| Roach [81] | DD | 43.6 | 80.4 | 0.54 | - |
| Interfuser [57] | DD | 68.3 | 95.0 | 0.72 | 0.70 |
| ThinkTwice [27] | DD | 70.9 | 95.5 | 0.75 | 0.40 |
| Apollo [3] | FSM | 71.4 | 92.2 | 0.80 | 0.76 |
| DriveMLM | LLM | 76.1 | 98.1 | 0.78 | 0.96 |
我们在 CARLA 中评估闭环驾驶,CARLA 是使用最广泛、最真实的公开模拟基准。 最先进的方法 [81, 57, 27] 能够执行闭环CARLA 中的循环驱动也包含在内以进行性能比较。 开源 Apollo [3] 也在 CARLA 中作为基线进行评估。 除了我们的方法之外,没有其他基于法学硕士的方法可以部署和评估。 所有方法均在 Town05 长基准 [15] 上进行评估。
表4显示驾驶分数、路线完成度和违规分数。 请注意,尽管 Apollo 是一种基于规则的方法,但其性能几乎与最近的端到端方法相当。 DriveMLM 在驾驶分数方面大幅超越所有其他方法。 这表明 DriveMLM 更适合处理状态转换,以安全地通过困难情况。 表4中的最后一列展示了MPI评估的结果。 该指标显示了更全面的驾驶性能,因为客服人员需要完成所有路线。 换句话说,所有路线上的所有情况都会被测试代理遇到。 由于频繁越过停止线,Thinktwice 比 Interfuser 实现了更好的 DS,但 MPI 更低。 然而,CARLA 对这种行为的处罚是最低限度的。 相比之下,MPI 将每次违反交通规则的行为视为一次接管。 DriveMLM 还实现了所有其他方法中最高的 MPI,这表明它能够避免更多情况,从而获得更安全的驾驶体验。
4.4驾驶知识评价
我们采用开环评估来评估驾驶知识,包括决策预测和解释预测任务。 表 3 列出了预测决策对的准确性、决策预测的每种决策的 F1 分数以及 BLEU-4 [49]、CIDEr [65] 和 METEOR [4] 用于预测解释。 对于 Apollo,手动收集的 Town05 场景将作为表 3 中模型的输入重放。 每个重播时间戳的相应模型状态和输出被保存为用于度量计算的预测。 对于其他方法,我们给他们相应的图像作为输入和适当的提示。 通过将模型预测与我们手动收集的地面实况进行比较,准确性揭示了决策的正确性以及与人类行为的相似性,而 F1 分数则展示了每种路径类型和速度决策的决策能力。 DriveMLM 总体精度最高,以 40.97% 的精度超越 LLaVA。 与 Apollo 基线相比,DriveMLM 较高的 F1 分数表明它在超越基于规则的状态机来解决各种道路情况方面要有效得多。 LLaVA [37]、InstructBLIP [17] 和我们提出的 DriveMLM 可以以以下形式输出决策解释的问答。 就BLEU-4、CIDEr和METEOR而言,DriveMLM可以达到最高的性能,这表明DriveMLM可以给出最合理的决策解释。
4.5消融研究
传感器形态
表 5 显示了输入传感器模式对 DriveMLM 的不同影响的结果。 多视图 (MV) 图像在路径和速度 F1 分数方面带来了显着的性能改进,同时精度提高了 18.19%。 与直接连接时间标记相比,时间 QFormer 带来了 7.4% 的较大提升,同时保证了多模态决策能力,这导致速度决策的平均 F1 分数提高了 0.05。 点云并没有表现出增强性能的能力。
| MV | CT | TQ | PC | Acc. | 路径 (F1 平均值) | 速度 (F1 平均值) |
| - | - | - | - | 47.83 | 0.55 | 0.61 |
| ✓ | - | - | - | 64.54 | 0.78 | 0.70 |
| ✓ | ✓ | - | - | 67.22 | 0.70 | 0.68 |
| ✓ | - | ✓ | - | 75.23 | 0.78 | 0.75 |
| ✓ | - | ✓ | ✓ | 74.99 | 0.77 | 0.75 |
时间模块设计
我们提出时间 QFormer 模块来处理时间多视图图像。 一个简单而幼稚的设计是直接连接临时查询标记以生成 作为大语言模型输入的标记。 但 随着 ,导致大量的计算成本。 相反,我们提出时间 QFormer 模块来分别处理每个视图的时间图像,生成 大语言模型输入标记。 时间模块的比较如表5所示,表明我们的时间模块设计在使用更少的图像标记时具有更好的性能。 我们在实验中默认设置 。


4.6 案例研究与可视化
人际交往
图4提供了如何通过人类指令实现车辆控制的示例。 控制过程包括分析路况、做出决策选择并提供解释性陈述。 当给出相同的“超车”指令时,DriveMLM 根据对当前交通状况的分析表现出不同的响应。 在右车道被占用且左车道可用的情况下,系统选择从左侧超车。 然而,在给定的指令可能造成危险的情况下,例如当所有车道都被占用时,DriveMLM 选择不执行超车动作并做出适当的响应。 在这种情况下,DriveMLM 充当人车交互的接口,它根据交通动态评估指令的合理性,并在最终选择行动方案之前确保其符合预定义的规则。
真实场景表现
5结论
在这项工作中,我们提出了 DriveMLM,这是一种利用大型语言模型 (LLM) 进行自动驾驶 (AD) 的新颖框架。 DriveMLM可以通过使用多模态大语言模型(MLLM)对模块化AD系统的行为规划模块进行建模,在现实模拟器中执行闭环AD。 DriveMLM还可以为其驾驶决策生成自然语言解释,这可以增强AD系统的透明度和可信度。 我们已经证明,DriveMLM 在 CARLA Town05 Long 基准测试中的性能优于 Apollo 基准。 我们相信我们的工作可以激发更多关于法学硕士和 AD 整合的研究。
补充材料
附录A提示详细信息
如表A,我们提供完整的系统消息,其中包括路径决策状态和速度决策状态的详细定义。 具体来说,我们的路径决策状态包括5个状态,分别是{FOLLOW_LANE、LEFT_LANE_CHANGE、RIGHT_LANE_CHANGE、LEFT_LANE_BORROW、RIGHT_LANE_BORROW},我们的速度决策状态包括4个状态:{KEEP、ACCELERATE、DECELERATE、STOP}。
表中B,我们详细介绍了用于描述周围环境的提示。 表中 C,提示用于根据导航命令得出驾驶决策。 表中列出的提示 D 用于从模型中得出有关其决策的解释。 最后在表中 E,我们提出了用于指导模型决策过程的人类指令。
| Scenario ID | Scenario Name |
| 1 | YieldBehindEmergencyVehicles |
| 2 | OvertakingFromLeft |
| 3 | OvertakingFromRight |
| 4 | LeftBorrowPassObstacle |
| 5 | LeftBorrowPassAccident |
| 6 | LeftInvasionBorrowPassObstacle |
| 7 | LeftInvasionBorrowPassAccident |
| 8 | RightBorrowPassObstacle |
| 9 | RightBorrowPassAccident |
| 10 | RightInvasionBorrowPassObstacle |
| 11 | RightInvasionBorrowPassAccident |
| 12 | JunctionRightChange |
| 13 | JunctionLeftChange |
| 14 | JunctionStraight |
| 15 | JunctionYieldPedestrian |
| 16 | JunctionYieldPedestrianAfterTurn |
| 17 | YieldJunctionSpecialisedVehicles |
| 18 | LeftChangeInRoute |
| 19 | RightChangeInRoute |
| 20 | UnprotectedJunctionLeftTurn |
| 21 | UnprotectedJunctionStraight |
| 22 | UnprotectedJunctionRightTurn |
| 23 | SignedJunctionLeftTurn |
| 24 | SignedJunctionStraight |
| 25 | SignedJunctionRightTurn |
| 26 | PedestrianBlindSpotA |
| 27 | PedestrianBlindSpotB |
| 28 | VehicleBlindSpotA |
| 29 | VehicleBlindSpotB |
| 30 | FollowerChange |
附录 B场景详细信息
我们的训练数据包含 30 种常见或罕见的安全关键场景,表F 列出所有场景的名称并描述场景的来源。 非自定义场景(标记为 和 )通常通过加载预设触发点来设置,这使得在其他地图中设置它们变得困难。 因此,我们对场景进行了动态化,以在任何地图上自动找到合适的触发点,为场景设置做好准备。 值得注意的是,表中所有场景 F 已被动态化。
定制场景描述如下:
(1) YieldBehindEmergencyVehicles:紧急车辆(警车、救护车、消防车)从后面高速驶来,由于其后方左右侧车道都有车辆行驶,本车需要向左变道/给紧急车辆让路的权利。
(2)从左侧超车:因前方车辆缓慢行驶而从左侧超车。
(3)从右侧超车:因前方车辆缓慢行驶而从右侧超车。
(4) JunctionLeftChange:在前方路口左转,但本车当前不在最左边的左转车道,因此本车向左变道,然后通过路口左转。
(5) JunctionRightChange:在前方路口右转,但本车当前不在最右侧右转车道,因此本车向右变道,然后右转通过路口。
(6)路口直行:在路口直行,遵守交通规则,避免与其他车辆碰撞。
(7) JunctionYieldPedestrian:行人正在前方路口过人行横道,因此本车给行人让路。
(8) LeftChangeInRoute:本车前方车辆缓慢行驶,向左变道取消跟随。
(9)RightchangeInRoute:本车前方车辆缓慢行驶,向右变道取消跟随。

附录C多种方法的比较分析
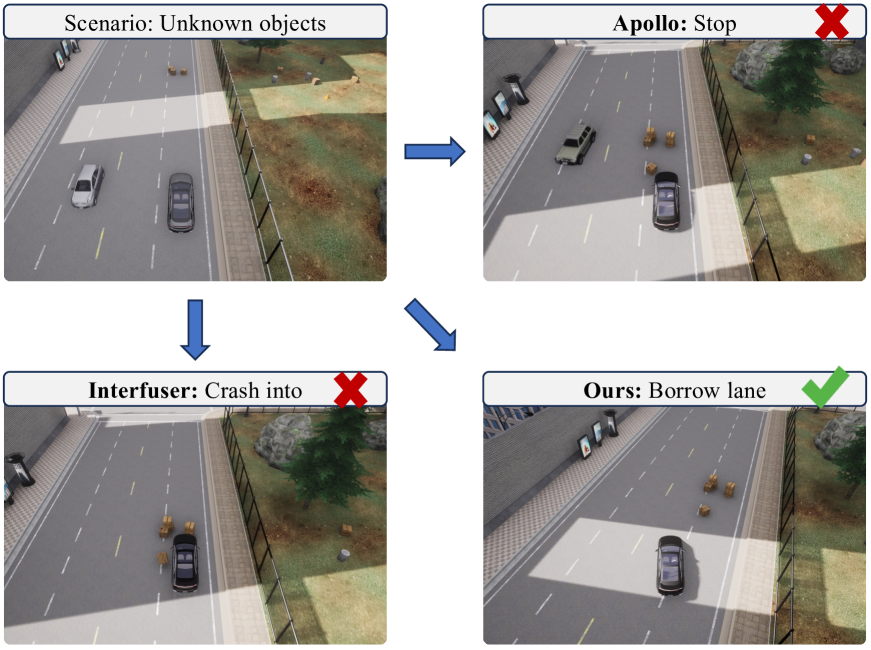
与 Interfuser 等方法相比 [57] 或 Apollo [3]1>,我们的方法在具有未知障碍或需要常识的场景中表现出卓越的性能。 如图所示 A (a),当面对道路上的未知障碍物时,以前的方法通常要么忽略它们,要么停止车辆,这两种策略都偏离了最佳驾驶实践。 相比之下,我们的方法采用了更符合逻辑的“借道”决策,有效防止了事故的发生。 此外,先前的方法在体现现实世界常识或理解交通规则方面存在缺陷,限制了它们管理复杂驾驶场景中遇到的各种特殊场景的能力。 举例来说,如图 A (b),当紧急车辆从后面接近时,传统方法无法让路,而我们的方法会主动为消防车清理道路。
我们认为,由于驾驶中的极端情况实际上是无限的,因此思想链的整合,加上预定义的交通知识,对于驾驶场景中的决策尤为重要。 鉴于大型语言模型 (LLM) 的固有特征,我们的 DriveMLM 展示了适应不同环境以及适应不同环境中不同驾驶风格的巨大潜力。



附录 D 与 DriveMLM 的人机交互
如图B,我们通过更多示例证明人类可以使用自然语言与 DriveMLM 进行交互。 人类可以向 DriveMLM 提供驾驶指令或请求 DriveMLM 解释其驾驶决策。 利用大型语言模型的优势,我们的方法提供了增强的可解释性,有助于开发更安全的自动驾驶系统。
附录E与其他多模态大语言模型的比较
As shown in Figure C, in the context of autonomous driving scenarios, LLaVA 1.5 [38] and InstructBLIP [17] 无法充分理解驾驶环境,经常发出错误的指令和幻觉的解释。

附录F与GPT-4V比较
附录 GnuScenes 上的零样本结果

我们在 nuScenes 上提供了我们模型的零样本结果的更多可视化结果。 如图 E尽管我们的模型仅在模拟器图像上进行训练,但它仍然在现实世界数据上表现出值得称赞的泛化能力。 我们的模型强大的通用性显着增强了其应用潜力。
附录 H闭环消融研究
| MV | TQ | PC | DS | RC | 是 |
| - | - | - | 36.7 | 70.6 | 0.52 |
| ✓ | - | - | 65.2 | 90.5 | 0.72 |
| ✓ | ✓ | - | 76.1 | 98.1 | 0.78 |
| ✓ | ✓ | ✓ | 72.2 | 96.3 | 0.75 |
| LLM | Acc. | BLEU-4 | CIDEr | METEOR |
| LLaMA-7B | 47.83 | 22.03 | 38.85 | 40.10 |
| LLaMA-13B | 48.92 | 25.54 | 75.68 | 42.50 |
| Data Size | 35h | 70h | 140h | 280h |
| Acc. | 41.83 | 45.16 | 46.12 | 47.83 |
为了探索模型中各种设计的影响,我们在闭环评估框架内进行了全面的消融研究。 如表所示 G,与仅使用前视图像相比,多视图输入图像的结合显着提高了驾驶性能。 我们提出的 Temporal QFormer 可以进一步大幅提高驾驶性能。 在我们的方法中,点云的整合并没有带来进一步的收益,可能是由于调整更多样化的模式面临更大的挑战。
附录一模型和数据规模的消融实验
大型语言模型规模。 我们通过前视图模型研究大型语言模型 (LLM) 的参数规模如何影响我们方法的结果。 桌子 H 显示我们的方法在更大的模型上取得了更好的性能。 然而LLaMA-13B的改进 [64] 由于其运行效率和内存消耗较低,因此我们选择LLaMA-7B进行其他实验。
训练设置规模。 我们还研究了训练数据大小如何影响我们的前视图模型的方法的结果。 桌子 I 显示通过增加训练集大小仍然可以提高性能,这表明我们的方法可以从缩放法则中受益。 因此,我们未来将扩大训练数据的收集。
参考
- Alayrac et al. [2022] Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning. Advances in Neural Information Processing Systems, 35:23716–23736, 2022.
- Bai et al. [2023] Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond. arXiv preprint arXiv:2308.12966, 1(2):3, 2023.
- Baidu [2019] Baidu. Apollo auto. https://github.com/ApolloAuto/apollo, 2019.
- Banerjee and Lavie [2005] Satanjeev Banerjee and Alon Lavie. Meteor: An automatic metric for mt evaluation with improved correlation with human judgments. In Proceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization, pages 65–72, 2005.
- Brohan et al. [2022] Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, et al. Rt-1: Robotics transformer for real-world control at scale. arXiv preprint arXiv:2212.06817, 2022.
- Brohan et al. [2023] Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Xi Chen, Krzysztof Choromanski, Tianli Ding, Danny Driess, Avinava Dubey, Chelsea Finn, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. arXiv preprint arXiv:2307.15818, 2023.
- Brown et al. [2020] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- Caesar et al. [2020] Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh Vora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuscenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11621–11631, 2020.
- Chen and Krähenbühl [2022] Dian Chen and Philipp Krähenbühl. Learning from all vehicles. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17222–17231, 2022.
- Chen et al. [2020] Dian Chen, Brady Zhou, Vladlen Koltun, and Philipp Krähenbühl. Learning by cheating. In Conference on Robot Learning, pages 66–75. PMLR, 2020.
- Chen et al. [2021] Dian Chen, Vladlen Koltun, and Philipp Krähenbühl. Learning to drive from a world on rails. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 15590–15599, 2021.
- Chen et al. [2023a] Keqin Chen, Zhao Zhang, Weili Zeng, Richong Zhang, Feng Zhu, and Rui Zhao. Shikra: Unleashing multimodal llm’s referential dialogue magic. arXiv preprint arXiv:2306.15195, 2023a.
- Chen et al. [2023b] Long Chen, Oleg Sinavski, Jan Hünermann, Alice Karnsund, Andrew James Willmott, Danny Birch, Daniel Maund, and Jamie Shotton. Driving with llms: Fusing object-level vector modality for explainable autonomous driving. arXiv preprint arXiv:2310.01957, 2023b.
- Chen et al. [2019] Shitao Chen, Zhiqiang Jian, Yuhao Huang, Yu Chen, Zhuoli Zhou, and Nanning Zheng. Autonomous driving: cognitive construction and situation understanding. Science China Information Sciences, 62:1–27, 2019.
- Chitta et al. [2022] Kashyap Chitta, Aditya Prakash, Bernhard Jaeger, Zehao Yu, Katrin Renz, and Andreas Geiger. Transfuser: Imitation with transformer-based sensor fusion for autonomous driving. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022.
- Contributors [2023] DriveLM Contributors. Drivelm: Drive on language. https://github.com/OpenDriveLab/DriveLM, 2023.
- Dai et al. [2023] Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, and Steven Hoi. Instructblip: Towards general-purpose vision-language models with instruction tuning. arXiv preprint arXiv:2305.06500, 2023.
- Dosovitskiy et al. [2017] Alexey Dosovitskiy, German Ros, Felipe Codevilla, Antonio Lopez, and Vladlen Koltun. Carla: An open urban driving simulator. In Conference on robot learning, pages 1–16. PMLR, 2017.
- Driess et al. [2023] Danny Driess, Fei Xia, Mehdi SM Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, et al. Palm-e: An embodied multimodal language model. arXiv preprint arXiv:2303.03378, 2023.
- Fang et al. [2023] Yuxin Fang, Wen Wang, Binhui Xie, Quan Sun, Ledell Wu, Xinggang Wang, Tiejun Huang, Xinlong Wang, and Yue Cao. Eva: Exploring the limits of masked visual representation learning at scale. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19358–19369, 2023.
- FONTANA [2021] FRANCESCO FONTANA. Self-driving cars and openpilot: a complete overview of the framework, 2021.
- Foundation [2018] The Autoware Foundation. Autoware: Open-source software for urban autonomous driving. https://github.com/CPFL/Autoware, 2018.
- Gao et al. [2023] Peng Gao, Jiaming Han, Renrui Zhang, Ziyi Lin, Shijie Geng, Aojun Zhou, Wei Zhang, Pan Lu, Conghui He, Xiangyu Yue, et al. Llama-adapter v2: Parameter-efficient visual instruction model. arXiv preprint arXiv:2304.15010, 2023.
- Hong et al. [2023] Sirui Hong, Xiawu Zheng, Jonathan Chen, Yuheng Cheng, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, et al. Metagpt: Meta programming for multi-agent collaborative framework. arXiv preprint arXiv:2308.00352, 2023.
- Hu et al. [2023] Yihan Hu, Jiazhi Yang, Li Chen, Keyu Li, Chonghao Sima, Xizhou Zhu, Siqi Chai, Senyao Du, Tianwei Lin, Wenhai Wang, et al. Planning-oriented autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17853–17862, 2023.
- Huang et al. [2023] Shaohan Huang, Li Dong, Wenhui Wang, Yaru Hao, Saksham Singhal, Shuming Ma, Tengchao Lv, Lei Cui, Owais Khan Mohammed, Qiang Liu, et al. Language is not all you need: Aligning perception with language models. arXiv preprint arXiv:2302.14045, 2023.
- Jia et al. [2023] Xiaosong Jia, Penghao Wu, Li Chen, Jiangwei Xie, Conghui He, Junchi Yan, and Hongyang Li. Think twice before driving: Towards scalable decoders for end-to-end autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21983–21994, 2023.
- Jiang et al. [2023] Bo Jiang, Shaoyu Chen, Qing Xu, Bencheng Liao, Jiajie Chen, Helong Zhou, Qian Zhang, Wenyu Liu, Chang Huang, and Xinggang Wang. Vad: Vectorized scene representation for efficient autonomous driving. arXiv preprint arXiv:2303.12077, 2023.
- Junqing et al. [2023] He Junqing, Pan Kunhao, Dong Xiaoqun, Song Zhuoyang, Liu Yibo, Liang Yuxin, Wang Hao, Sun Qianguo, Zhang Songxin, Xie Zejian, et al. Never lost in the middle: Improving large language models via attention strengthening question answering. arXiv preprint arXiv:2311.09198, 2023.
- Lai et al. [2023] Xin Lai, Zhuotao Tian, Yukang Chen, Yanwei Li, Yuhui Yuan, Shu Liu, and Jiaya Jia. Lisa: Reasoning segmentation via large language model. arXiv preprint arXiv:2308.00692, 2023.
- Li et al. [2023a] Guohao Li, Hasan Abed Al Kader Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. Camel: Communicative agents for” mind” exploration of large language model society. In Thirty-seventh Conference on Neural Information Processing Systems, 2023a.
- Li et al. [2023b] Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. arXiv preprint arXiv:2301.12597, 2023b.
- Li et al. [2023c] KunChang Li, Yinan He, Yi Wang, Yizhuo Li, Wenhai Wang, Ping Luo, Yali Wang, Limin Wang, and Yu Qiao. Videochat: Chat-centric video understanding. arXiv preprint arXiv:2305.06355, 2023c.
- Li et al. [2022] Zhiqi Li, Wenhai Wang, Hongyang Li, Enze Xie, Chonghao Sima, Tong Lu, Yu Qiao, and Jifeng Dai. Bevformer: Learning bird’s-eye-view representation from multi-camera images via spatiotemporal transformers. In European conference on computer vision, pages 1–18. Springer, 2022.
- Li et al. [2023d] Zhiqi Li, Zhiding Yu, David Austin, Mingsheng Fang, Shiyi Lan, Jan Kautz, and Jose M Alvarez. Fb-occ: 3d occupancy prediction based on forward-backward view transformation. arXiv preprint arXiv:2307.01492, 2023d.
- Liang et al. [2022] Tingting Liang, Hongwei Xie, Kaicheng Yu, Zhongyu Xia, Zhiwei Lin, Yongtao Wang, Tao Tang, Bing Wang, and Zhi Tang. Bevfusion: A simple and robust lidar-camera fusion framework. Advances in Neural Information Processing Systems, 35:10421–10434, 2022.
- Liu et al. [2023a] Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. arXiv preprint arXiv:2310.03744, 2023a.
- Liu et al. [2023b] Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. arXiv preprint arXiv:2304.08485, 2023b.
- Liu et al. [2023c] Jiaqi Liu, Peng Hang, Jianqiang Wang, Jian Sun, et al. Mtd-gpt: A multi-task decision-making gpt model for autonomous driving at unsignalized intersections. arXiv preprint arXiv:2307.16118, 2023c.
- Liu et al. [2023d] Zhaoyang Liu, Yinan He, Wenhai Wang, Weiyun Wang, Yi Wang, Shoufa Chen, Qinglong Zhang, Yang Yang, Qingyun Li, Jiashuo Yu, et al. Internchat: Solving vision-centric tasks by interacting with chatbots beyond language. arXiv preprint arXiv:2305.05662, 2023d.
- Liu et al. [2023e] Zhaoyang Liu, Zeqiang Lai, Zhangwei Gao, Erfei Cui, Xizhou Zhu, Lewei Lu, Qifeng Chen, Yu Qiao, Jifeng Dai, and Wenhai Wang. Controlllm: Augment language models with tools by searching on graphs. arXiv preprint arXiv:2310.17796, 2023e.
- Mao et al. [2021] Jiageng Mao, Minzhe Niu, Chenhan Jiang, Hanxue Liang, Jingheng Chen, Xiaodan Liang, Yamin Li, Chaoqiang Ye, Wei Zhang, Zhenguo Li, et al. One million scenes for autonomous driving: Once dataset. arXiv preprint arXiv:2106.11037, 2021.
- Mao et al. [2023] Jiageng Mao, Yuxi Qian, Hang Zhao, and Yue Wang. Gpt-driver: Learning to drive with gpt. arXiv preprint arXiv:2310.01415, 2023.
- Movva et al. [2023] Rajiv Movva, Sidhika Balachandar, Kenny Peng, Gabriel Agostini, Nikhil Garg, and Emma Pierson. Large language models shape and are shaped by society: A survey of arxiv publication patterns. arXiv preprint arXiv:2307.10700, 2023.
- Mu et al. [2023] Yao Mu, Qinglong Zhang, Mengkang Hu, Wenhai Wang, Mingyu Ding, Jun Jin, Bin Wang, Jifeng Dai, Yu Qiao, and Ping Luo. Embodiedgpt: Vision-language pre-training via embodied chain of thought. arXiv preprint arXiv:2305.15021, 2023.
- OpenAI [2023] OpenAI. GPT-4 Technical Report, 2023. https://cdn.openai.com/papers/gpt-4.pdf.
- Ouyang et al. [2022] Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730–27744, 2022.
- Padalkar et al. [2023] Abhishek Padalkar, Acorn Pooley, Ajinkya Jain, Alex Bewley, Alex Herzog, Alex Irpan, Alexander Khazatsky, Anant Rai, Anikait Singh, Anthony Brohan, et al. Open x-embodiment: Robotic learning datasets and rt-x models. arXiv preprint arXiv:2310.08864, 2023.
- Papineni et al. [2002] Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, pages 311–318, 2002.
- Park et al. [2023] Joon Sung Park, Joseph C O’Brien, Carrie J Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. Generative agents: Interactive simulacra of human behavior. arXiv preprint arXiv:2304.03442, 2023.
- Peng et al. [2023] Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, and Furu Wei. Kosmos-2: Grounding multimodal large language models to the world. arXiv preprint arXiv:2306.14824, 2023.
- Qian et al. [2023] Tianwen Qian, Jingjing Chen, Linhai Zhuo, Yang Jiao, and Yu-Gang Jiang. Nuscenes-qa: A multi-modal visual question answering benchmark for autonomous driving scenario. arXiv preprint arXiv:2305.14836, 2023.
- Radford et al. [2018] Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever, et al. Improving language understanding by generative pre-training. OpenAI, 2018.
- Radford et al. [2019] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9, 2019.
- Sachdeva et al. [2023] Enna Sachdeva, Nakul Agarwal, Suhas Chundi, Sean Roelofs, Jiachen Li, Behzad Dariush, Chiho Choi, and Mykel Kochenderfer. Rank2tell: A multimodal driving dataset for joint importance ranking and reasoning. arXiv preprint arXiv:2309.06597, 2023.
- Sha et al. [2023] Hao Sha, Yao Mu, Yuxuan Jiang, Li Chen, Chenfeng Xu, Ping Luo, Shengbo Eben Li, Masayoshi Tomizuka, Wei Zhan, and Mingyu Ding. Languagempc: Large language models as decision makers for autonomous driving. arXiv preprint arXiv:2310.03026, 2023.
- Shao et al. [2023a] Hao Shao, Letian Wang, Ruobing Chen, Hongsheng Li, and Yu Liu. Safety-enhanced autonomous driving using interpretable sensor fusion transformer. In Conference on Robot Learning, pages 726–737. PMLR, 2023a.
- Shao et al. [2023b] Hao Shao, Letian Wang, Ruobing Chen, Steven L Waslander, Hongsheng Li, and Yu Liu. Reasonnet: End-to-end driving with temporal and global reasoning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13723–13733, 2023b.
- Shen et al. [2023] Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, and Yueting Zhuang. Hugginggpt: Solving ai tasks with chatgpt and its friends in huggingface. arXiv preprint arXiv:2303.17580, 2023.
- Shi et al. [2023] Yining Shi, Kun Jiang, Jiusi Li, Junze Wen, Zelin Qian, Mengmeng Yang, Ke Wang, and Diange Yang. Grid-centric traffic scenario perception for autonomous driving: A comprehensive review. arXiv preprint arXiv:2303.01212, 2023.
- Singh and Bankiti [2023] Apoorv Singh and Varun Bankiti. Surround-view vision-based 3d detection for autonomous driving: A survey. arXiv preprint arXiv:2302.06650, 2023.
- Surís et al. [2023] Dídac Surís, Sachit Menon, and Carl Vondrick. Vipergpt: Visual inference via python execution for reasoning. arXiv preprint arXiv:2303.08128, 2023.
- Tong et al. [2023] Wenwen Tong, Chonghao Sima, Tai Wang, Li Chen, Silei Wu, Hanming Deng, Yi Gu, Lewei Lu, Ping Luo, Dahua Lin, et al. Scene as occupancy. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 8406–8415, 2023.
- Touvron et al. [2023] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
- Vedantam et al. [2015] Ramakrishna Vedantam, C Lawrence Zitnick, and Devi Parikh. Cider: Consensus-based image description evaluation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4566–4575, 2015.
- Vinitsky et al. [2022] Eugene Vinitsky, Nathan Lichtlé, Xiaomeng Yang, Brandon Amos, and Jakob Foerster. Nocturne: a scalable driving benchmark for bringing multi-agent learning one step closer to the real world. Advances in Neural Information Processing Systems, 35:3962–3974, 2022.
- Wang et al. [2023] Wenhai Wang, Zhe Chen, Xiaokang Chen, Jiannan Wu, Xizhou Zhu, Gang Zeng, Ping Luo, Tong Lu, Jie Zhou, Yu Qiao, et al. Visionllm: Large language model is also an open-ended decoder for vision-centric tasks. arXiv preprint arXiv:2305.11175, 2023.
- Wen et al. [2023] Licheng Wen, Daocheng Fu, Xin Li, Xinyu Cai, Tao Ma, Pinlong Cai, Min Dou, Botian Shi, Liang He, and Yu Qiao. Dilu: A knowledge-driven approach to autonomous driving with large language models. arXiv preprint arXiv:2309.16292, 2023.
- Wu et al. [2023a] Chenfei Wu, Shengming Yin, Weizhen Qi, Xiaodong Wang, Zecheng Tang, and Nan Duan. Visual chatgpt: Talking, drawing and editing with visual foundation models. arXiv preprint arXiv:2303.04671, 2023a.
- Wu et al. [2023b] Dongming Wu, Wencheng Han, Tiancai Wang, Yingfei Liu, Xiangyu Zhang, and Jianbing Shen. Language prompt for autonomous driving. arXiv preprint arXiv:2309.04379, 2023b.
- Wu et al. [2023c] Shengqiong Wu, Hao Fei, Leigang Qu, Wei Ji, and Tat-Seng Chua. Next-gpt: Any-to-any multimodal llm. arXiv preprint arXiv:2309.05519, 2023c.
- Xu et al. [2023] Zhenhua Xu, Yujia Zhang, Enze Xie, Zhen Zhao, Yong Guo, Kenneth KY Wong, Zhenguo Li, and Hengshuang Zhao. Drivegpt4: Interpretable end-to-end autonomous driving via large language model. arXiv preprint arXiv:2310.01412, 2023.
- Yang et al. [2023a] Chenyu Yang, Yuntao Chen, Hao Tian, Chenxin Tao, Xizhou Zhu, Zhaoxiang Zhang, Gao Huang, Hongyang Li, Yu Qiao, Lewei Lu, et al. Bevformer v2: Adapting modern image backbones to bird’s-eye-view recognition via perspective supervision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17830–17839, 2023a.
- Yang et al. [2023b] Honghui Yang, Tong He, Jiaheng Liu, Hua Chen, Boxi Wu, Binbin Lin, Xiaofei He, and Wanli Ouyang. Gd-mae: generative decoder for mae pre-training on lidar point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9403–9414, 2023b.
- Yang et al. [2023c] Hui Yang, Sifu Yue, and Yunzhong He. Auto-gpt for online decision making: Benchmarks and additional opinions. arXiv preprint arXiv:2306.02224, 2023c.
- Yang et al. [2023d] Rui Yang, Lin Song, Yanwei Li, Sijie Zhao, Yixiao Ge, Xiu Li, and Ying Shan. Gpt4tools: Teaching large language model to use tools via self-instruction. arXiv preprint arXiv:2305.18752, 2023d.
- Yang et al. [2023e] Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Ehsan Azarnasab, Faisal Ahmed, Zicheng Liu, Ce Liu, Michael Zeng, and Lijuan Wang. Mm-react: Prompting chatgpt for multimodal reasoning and action. arXiv preprint arXiv:2303.11381, 2023e.
- Ye et al. [2023] Qinghao Ye, Haiyang Xu, Guohai Xu, Jiabo Ye, Ming Yan, Yiyang Zhou, Junyang Wang, Anwen Hu, Pengcheng Shi, Yaya Shi, et al. mplug-owl: Modularization empowers large language models with multimodality. arXiv preprint arXiv:2304.14178, 2023.
- Zhang et al. [2023a] Hang Zhang, Xin Li, and Lidong Bing. Video-llama: An instruction-tuned audio-visual language model for video understanding. arXiv preprint arXiv:2306.02858, 2023a.
- Zhang et al. [2023b] Shilong Zhang, Peize Sun, Shoufa Chen, Min Xiao, Wenqi Shao, Wenwei Zhang, Kai Chen, and Ping Luo. Gpt4roi: Instruction tuning large language model on region-of-interest. arXiv preprint arXiv:2307.03601, 2023b.
- Zhang et al. [2021] Zhejun Zhang, Alexander Liniger, Dengxin Dai, Fisher Yu, and Luc Van Gool. End-to-end urban driving by imitating a reinforcement learning coach. In Proceedings of the IEEE/CVF international conference on computer vision, pages 15222–15232, 2021.
- Zhou et al. [2020] Ming Zhou, Jun Luo, Julian Villella, Yaodong Yang, David Rusu, Jiayu Miao, Weinan Zhang, Montgomery Alban, Iman Fadakar, Zheng Chen, et al. Smarts: Scalable multi-agent reinforcement learning training school for autonomous driving. arXiv preprint arXiv:2010.09776, 2020.
- Zhu et al. [2023] Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. Minigpt-4: Enhancing vision-language understanding with advanced large language models. arXiv preprint arXiv:2304.10592, 2023.