LoRAMoE:通过 MoE 风格的插件减轻大型
语言模型中的世界知识遗忘
摘要
监督微调(SFT)是大型语言模型(大语言模型)的关键一步,使它们能够与人类指令保持一致并增强其在下游任务中的能力。 大幅增加指令数据是使模型与更广泛的下游任务保持一致或显着提高其在特定任务上的性能的直接解决方案。 然而,我们发现指令数据的大规模增加会损害先前存储在大语言模型中的世界知识。 为了应对这一挑战,我们提出了 LoRAMoE,这是一种新颖的框架,它引入了多个低级适配器(LoRA),并通过使用路由器网络来集成它们,例如混合专家(MoE)的插件版本。 它冻结了骨干模型,迫使一部分 LoRA 专注于利用世界知识来解决下游任务,以减轻世界知识的遗忘。 实验结果表明,随着指令数据的增加,LoRAMoE可以显着提高处理下游任务的能力,同时保持大语言模型中存储的世界知识111 https://github.com/Ablustrund/LoRAMoE。
LoRAMoE:通过 MoE 风格的插件减轻大型
语言模型中的世界知识遗忘
Shihan Dou, Enyu Zhou, Yan Liu, Songyang Gao, Jun Zhao, Wei Shen, Yuhao Zhou, Zhiheng Xi, Xiao Wang, Xiaoran Fan, Shiliang Pu, Jiang Zhu, Rui Zheng, Tao Gui††thanks: Corresponding author. , Qi Zhang, Xuanjing Huang NLP Group, Fudan University Hikvision Inc shdou21@m.fudan.edu.cn, eyzhou23@m.fudan.edu.cn {rzheng20, tgui, qz}@fudan.edu.cn
1简介
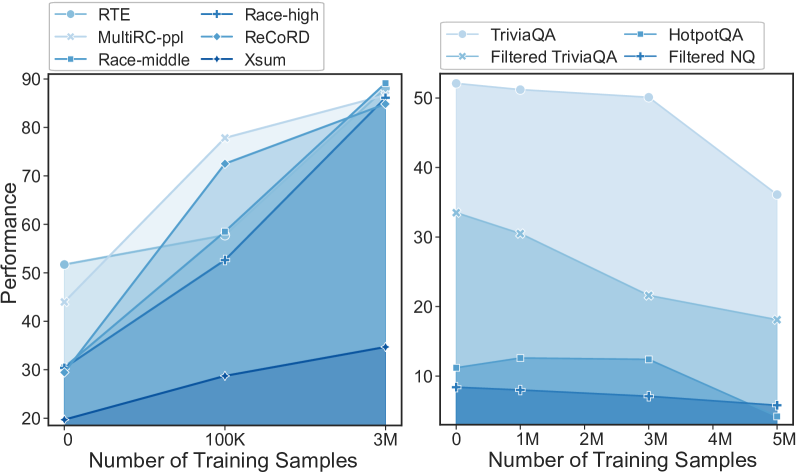
有监督微调(SFT)提供了一种关键技术,可以使大语言模型遵循人类指令并提高其下游任务的性能(Chung等人,2022;Ouyang等人,2022)。 虽然一些研究(周等人,2023;曹等人,2023)表明,在少量数据上训练的大语言模型可以很好地遵循指令,但增加数据量是增强其性能的直接方法。能够执行多个下游任务或提高其在特定任务上的性能,如图1左侧所示。
然而,指令数据的大规模增加会破坏大语言模型中存储的世界知识,如图1右侧所示。 具体来说,随着指令数据量的增加,我们观察到闭卷问答(CBQA)数据集的性能显着下降,该数据集用于衡量大语言模型Touvron等人(2023)中的世界知识; Neeman 等人 (2022)。 在监督微调的范式中,维护大语言模型内部的世界知识与通过扩大指令数据来提高下游任务的性能之间的冲突尚未得到彻底的检验。
在本文中,我们提出了 LoRAMoE,一种 SFT 的新颖框架,以增强模型解决下游任务的能力,同时减轻训练阶段的世界知识遗忘。 LoRAMoE 是一个 Mixture-of-Experts 风格(MoE 风格)的插件,它引入了多个低等级适配器(LoRA Hu 等人 (2021))作为专家,并通过使用路由器网络将它们集成。 路由器网络自动为专家分配权重,这可以提高大语言模型在多个下游任务上的性能。
为了证明我们提出的方法的有效性,我们在一系列下游任务中进行了广泛的实验。 实验结果表明,LoRAMoE 通过在大量指令数据上对模型进行微调,可以显着提高大语言模型处理各种下游任务的能力,同时保持模型中存储的世界知识。 此外,我们通过可视化任务的专家权重来进一步评估我们的方法。 结果表明,LoRAMoE 充分缓解了世界知识遗忘,并通过促进专家之间的协作实现了模型的改进。 我们论文的主要贡献如下:
-
1.
我们发现,在SFT阶段显着增加指令数据量会损害大语言模型内的世界知识。 通过扩大指令数据来改进下游任务的需要与维护模型内部的世界知识相冲突。
-
2.
我们介绍 LoRAMoE,这是 SFT 的一种新颖框架,它引入 LoRA 作为专家并通过路由器将它们集成。 LoRAMoE 可以增强模型处理下游任务的能力,同时减轻世界知识遗忘。
-
3.
广泛的实验证明了我们提出的方法在多任务方面的有效性,并减少了模型内世界知识的遗忘。 可视化实验表明,LoRAMoE 可以通过促进专家之间的协作来实现改进。
2动机
在本节中,我们验证大规模SFT可以对大语言模型内的世界知识造成不可逆转的损害,同时提高大语言模型在各种下游任务中的性能。
2.1 分化趋势
我们构建了一个包含七类任务、总共 500 万个训练样本的数据集,并用它在 Llama-2-7B 模型上进行 SFT。 实施细节在附录A中描述。 在微调数据的扩展过程中,我们观察到两类任务的性能呈现出不同的趋势,如图2所示:
在摘要、自然语言推理 (NLI)、机器翻译等下游任务中,微调模型的性能最初显示出巨大的增长,并最终稳定在有希望的水平。 然而,当涉及到用作世界知识基准的闭卷质量保证(CBQA)任务(Touvron等人,2023;Neeman等人,2022)时,模型的性能在基线下灾难性地下降值得注意的是,随着训练数据的扩大,可以看到持续的下降。 此外,如果测试集被过滤,这种下降会更早发生。 附录 B 具有更大数据集(包括更多任务)的案例显示,世界知识基准的下降幅度更大,尽管性能相对于其他基准仍然具有竞争力。
2.2 不可逆的知识遗忘
在本节中,我们将剖析这些世界知识基准在微调数据扩张过程中下降的原因。 我们发现这是由于大语言模型内部发生了不可逆的知识遗忘造成的。
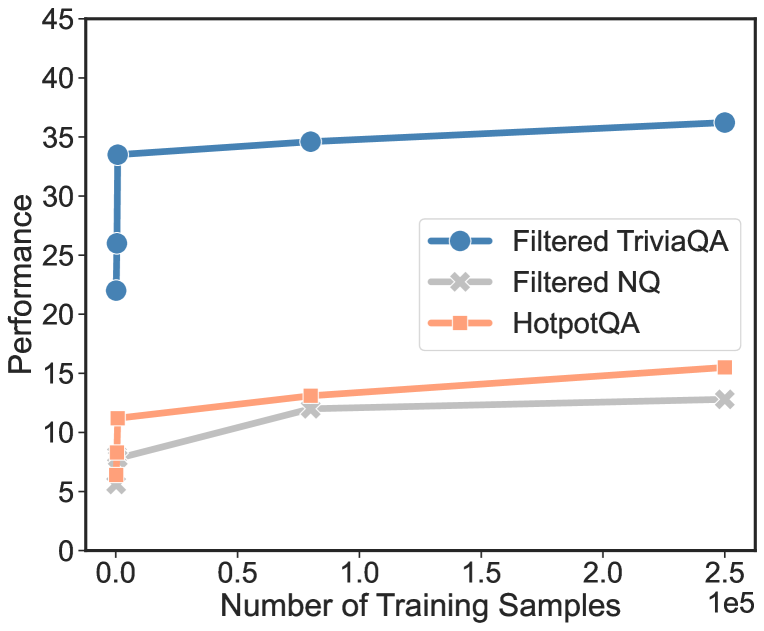
世界知识基准的表现高度依赖于预训练阶段学到的知识和技能。 为了研究世界知识基准的表现与预训练模型中嵌入的知识之间的关系(Petroni等人,2019;Roberts等人,2020;AlKhamassi等人,2022),我们进行了精细- 仅在具有 25 万个样本的 CBQA 数据集上进行调整,并对测试集进行评估,而无需训练-测试重叠。 图 3 中的结果显示,初始训练显着提高了性能,尤其是前 1%(大约 1k 个样本),此后的增益有限。 这是因为早期微调使现有知识与新指令保持一致,从而改善 CBQA 结果。 然而,由于训练-测试数据重叠极少,添加更多样本并不能进一步提高性能。 因此,模型的基准成功取决于从预训练中获得的世界知识。
鉴于此,我们很自然地认为知识基准性能下降是由于大规模指令调优导致大语言模型中存储的知识遭到破坏。 为了验证假设,我们使用两个数据集依次微调模型,首先排除 CBQA 数据,然后使用 CBQA 数据。 表1中的结果显示,与原始大语言模型相比,知识能力大幅下降。 这表明模型中的世界知识在大规模微调的第一阶段受到损害,导致模型无法在后续微调阶段中仅通过CBQA。
综上所述,通过扩展训练数据来提高下游任务的性能与普通 SFT 模型中世界知识的保存相冲突。
| Task Name | Baseline |
|
|
||||
| TriviaQA | 33.5 | 36.22 | 13.7 | ||||
| NQ | 7.8 | 12.8 | 3.6 | ||||
| HotpotQA | 11.2 | 16.1 | 7.1 |
3LoRAMoE
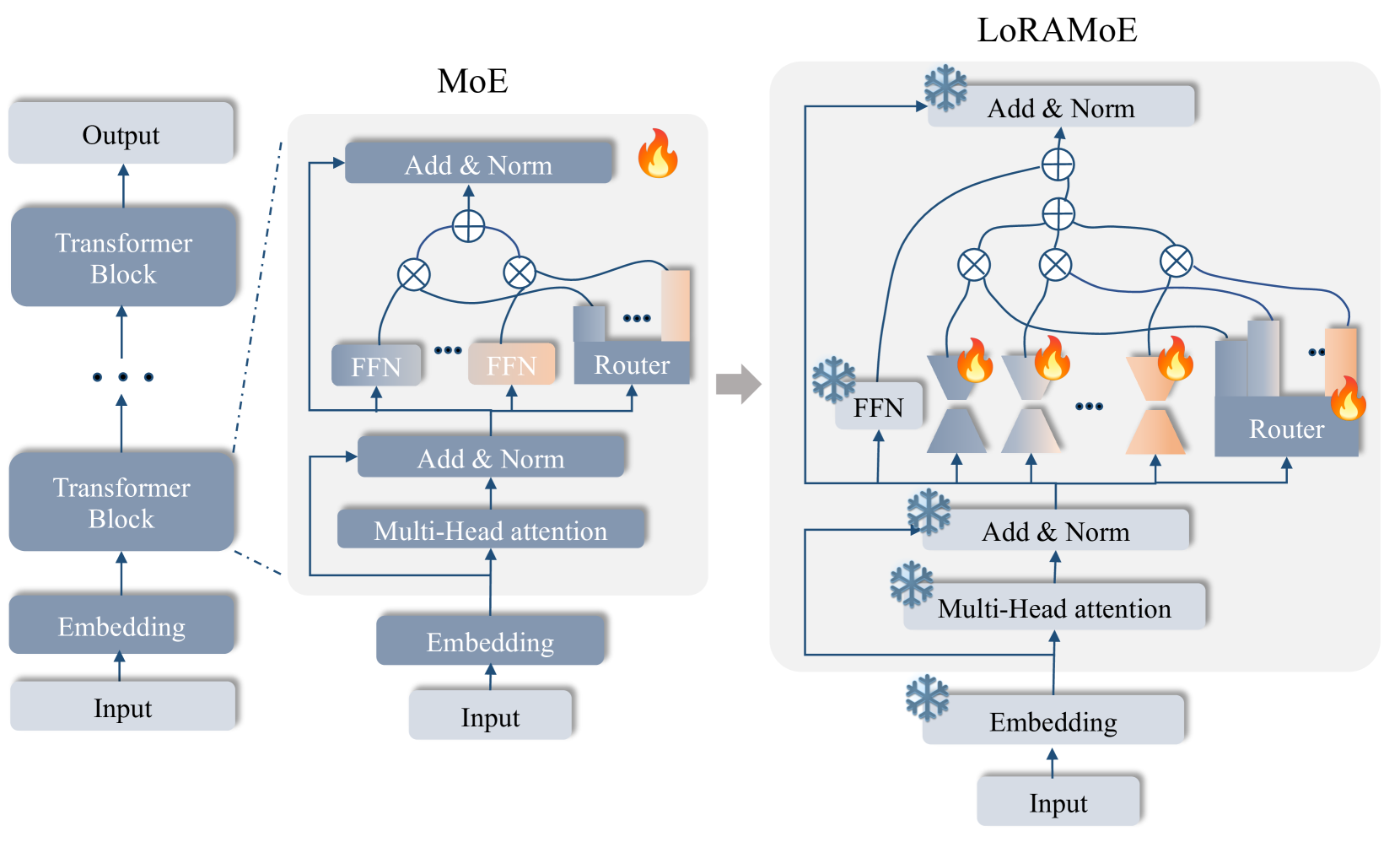
在本节中,我们将详细介绍 LoRAMoE 的方法细节,LoRAMoE 是一个 MoE 风格的插件,并在训练阶段引入了局部平衡约束来减轻世界知识,如图 4 所示。
3.1架构
图4左侧展示了标准MoE架构的前向流程(Shazeer等人,2016;Fedus等人,2021;Lepikhin等人,2020)。 在MoE中,路由器根据数据给专家分配权重,让他们分工完成转发过程(Jacobs等人,1991)。 LoRAMoE 的关键在于我们冻结骨干模型来维护世界知识,并引入专家利用这些知识来解决任务,同时提高多个下游任务的性能。 此外,我们利用 LoRA Hu 等人 (2021) 作为 Expert 的架构来提高训练和推理效率。
形式上,对于传统的 Transformer 架构,前馈神经(FFN)网络块的前向传播过程可以简化如下:
| (1) |
该前向传播中线性层的矩阵运算可以表示为:
| (2) |
其中表示骨干模型的参数矩阵,表示训练阶段更新的参数。 对于 LoRAMoE,我们用 MoE 风格的插件替换了 FFN 块中的线性层,这使得专家能够协作解决任务。 在训练阶段,我们冻结骨干网以维护世界知识并仅更新。 考虑包含个专家的LoRAMoE层,记为,该层的前向过程可以用数学表达如下:
| (3) |
其中和分别表示LoRAMoE层中的第个专家和路由器。 是路线网络的可训练参数矩阵。 这样,专家与外部协同工作,使专家能够发挥多种能力,高效地处理多种类型的任务。
此外,LoRA已被证明对于大语言模型的SFT阶段既有效又高效(王等人,2023a;刘等人,2022;潘等人,2022)。 为了提高微调过程的效率和资源节约,我们用低秩格式替换了专家的参数矩阵。 具体来说,LoRAMoE层中专家的矩阵可以写成如下:
| (4) |
其中 、 和排名 。 LoRA 有助于显着减少可训练参数,从而在微调过程中提高效率并节省成本。
总体而言,LoRAMoE层取代传统FFN层的前向过程可以表示为:
| (5) |
其中表示第个专家的权重,是常量超参数,大约相当于学习率。
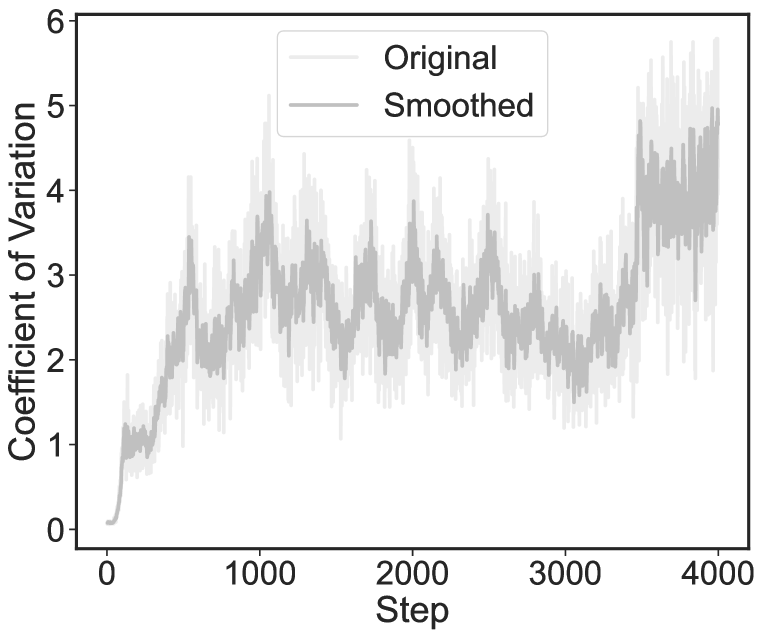
3.2 局部平衡约束
专家利用率的不平衡是MoE的一个典型问题(Shazeer等人,2016;Fedus等人,2021),在我们提出的方法中也观察到了这一问题,如图5。 传统的解决方案是平衡专家利用率(Shazeer等人,2016),其中涉及将专家重要性的变异系数作为损失函数。 然而,该方法假设所有训练样本都处于相同的分布下,忽略了样本可能来自不同分布的事实,例如问答任务和其他下游任务,更详细的分析和概念证明参见附录C。
考虑到数据分布的混合特征很重要,在训练阶段,我们引入了局部平衡约束,这是一种新颖的平衡专家利用方法,使一部分专家更加专注于利用世界知识来解决任务。 如图6所示,在微调阶段,我们软约束专家专注于两个方面,其中一个侧重于通过学习相关数据集来利用世界知识,而另一个侧重于其他方面下游任务。 另外,同一方面的所有专家都是平衡的,比如平衡专家利用率。
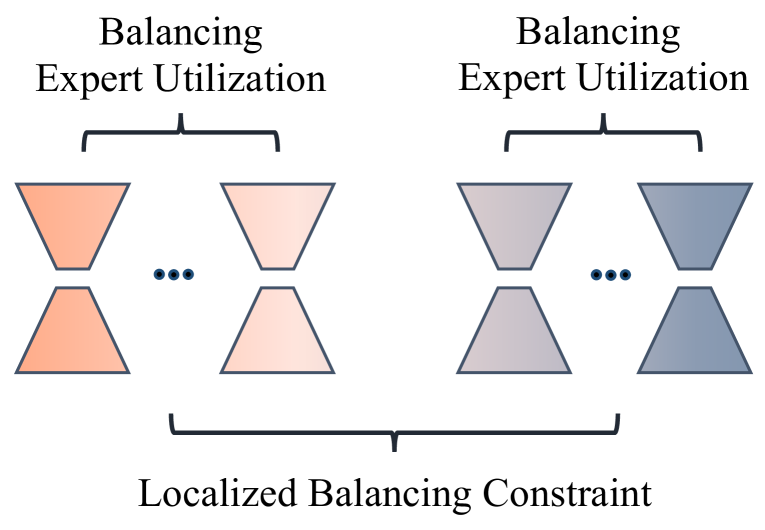
形式上,我们定义了 LoRAMoE 层的重要性矩阵 , 表示 专家对批次中 第 3 个训练样本的路由器值总和,可表示如下:
| (6) |
其中 和 分别表示第 个训练样本的专家数量和标记数量。 是第 个词符的隐藏输入。 然后我们定义与大小相同的系数矩阵,对应于重要性矩阵。 表示的重要性系数,可以写成:
| (7) |
其中 控制专家类型之间的不平衡程度。 和是第个专家的预定义目标类型和第个训练样本的任务类型分别批次。
我们将指令数据分为两种不同的类型:与世界知识相关的任务(例如 TriviaQA)和其他下游任务(例如 Flores)。 然后,我们让一部分专家学习与世界知识相关的任务,使人类指令与世界知识保持一致,同时让其他专家更加专注于提高下游任务的性能。 形式上,假设 和 表示第 和 专家对于 个样本。 如果专家在同一组中,则它们在系数矩阵中相应位置的值相同,即。 这表明这些专家具有相同的重要性,因为他们被分配专注于学习相同类型的任务。 相反,来自不同群体的专家在其系数矩阵上的值是不同的,即。
定义局部平衡约束损失来衡量加权重要性矩阵的离散度,数学上可以表示为:
| (8) |
其中 和 分别表示 的方差和均值。 具体来说,如果特定样本来自世界知识相关数据集,则专注于解决此类问题的专家在系数矩阵中将具有较大的值。优化损失的减少可以使相应的专家从该样本中学到更多的知识,并被路由器分配更大的权重。 同时,解决同一类型任务的专家是平衡的,例如Shazeer等人(2016)。 此外,约束是软性的,以鼓励专家之间的合作以保持泛化能力。
总体而言,局部平衡约束实现了两类专家之间的局部平衡:一类专家专门通过在与世界知识相关的数据集上进行更多训练来利用世界知识,而另一类专家则专注于各种下游任务。 LoRAMoE的损失可以表示为:
| (9) |
其中是大语言模型的下一个token预测损失,控制局部平衡约束的强度。 在训练阶段,我们冻结主干模型,可训练参数仅是 LoRAMoE 层内的专家和路由器的参数。 在推理过程中,路由器自动为所有专家分配权重,从而避免了预先指定数据类型的需要。
| Task Name | Baseline |
|
SFT | LoRA | LoRAMoE |
|
||||
| WSC | 65.4 | - | 76.0 | 65.4 | 71.2 | 70.2 | ||||
| winogrande | 61.7 | - | 71.2 | 64.3 | 66.3 | 69.6 | ||||
| Flores | 0.1 | - | 24.3 | 26.6 | 26.4 | 25.9 | ||||
| Xsum | 19.7 | - | 34.7 | 34.5 | 34.8 | 33.2 | ||||
| Race-middle | 30.5 | - | 89.1 | 78.8 | 84.5 | 90.0 | ||||
| Race-high | 30.4 | - | 86.1 | 75.3 | 80.6 | 86.5 | ||||
| RTE | 52.7 | - | 88.1 | 77.3 | 80.9 | 87.4 | ||||
| ReCoRD | 29.4 | - | 84.8 | 83.2 | 84.3 | 85.9 | ||||
| AX-g | 52.0 | - | 84.8 | 76.1 | 81.7 | 87.1 | ||||
| multiRC | 44.0 | - | 86.7 | 81.4 | 87.3 | 87.9 | ||||
| TriviaQA | 52.2 | 57.8 | 51.1 | 47.8 | 55.3 | 58.1 | ||||
| NQ | 18.5 | 28.6 | 24.5 | 16.2 | 23.8 | 28.0 | ||||
| Filtered TriviaQA | 33.5 | 36.2 | 21.6 | 33.4 | 38.5 | 35.4 | ||||
| Filtered NQ | 7.8 | 12.8 | 7.3 | 11.6 | 13.4 | 12.0 | ||||
| HotpotQA | 11.2 | 16.1 | 13.4 | 10.7 | 14.4 | 16.1 |
4实验
4.1 实验设置
在本节中,我们介绍 LoRAMoE 的训练实现。 我们仅将大语言模型前馈神经网络中的线性层替换为LoRAMoE层,每层初始化有六名专家,其中三名专家致力于解决下游任务,另外三名负责利用世界知识通过学习其相关任务来在基本模型中。 控制约束强度和不平衡程度的超参数均设置为。 对于 LoRA 设置, 和 分别设置为 和 4 作为主要结果。 dropout为,学习率为。 训练数据集为300万组,与附录A中描述的数据集相同,评估设置也是如此。 我们冻结基本模型的参数,仅渲染 LoRAMoE 中的专家和路由器可训练。 每个节点的批量大小设置为。
4.2 主要结果
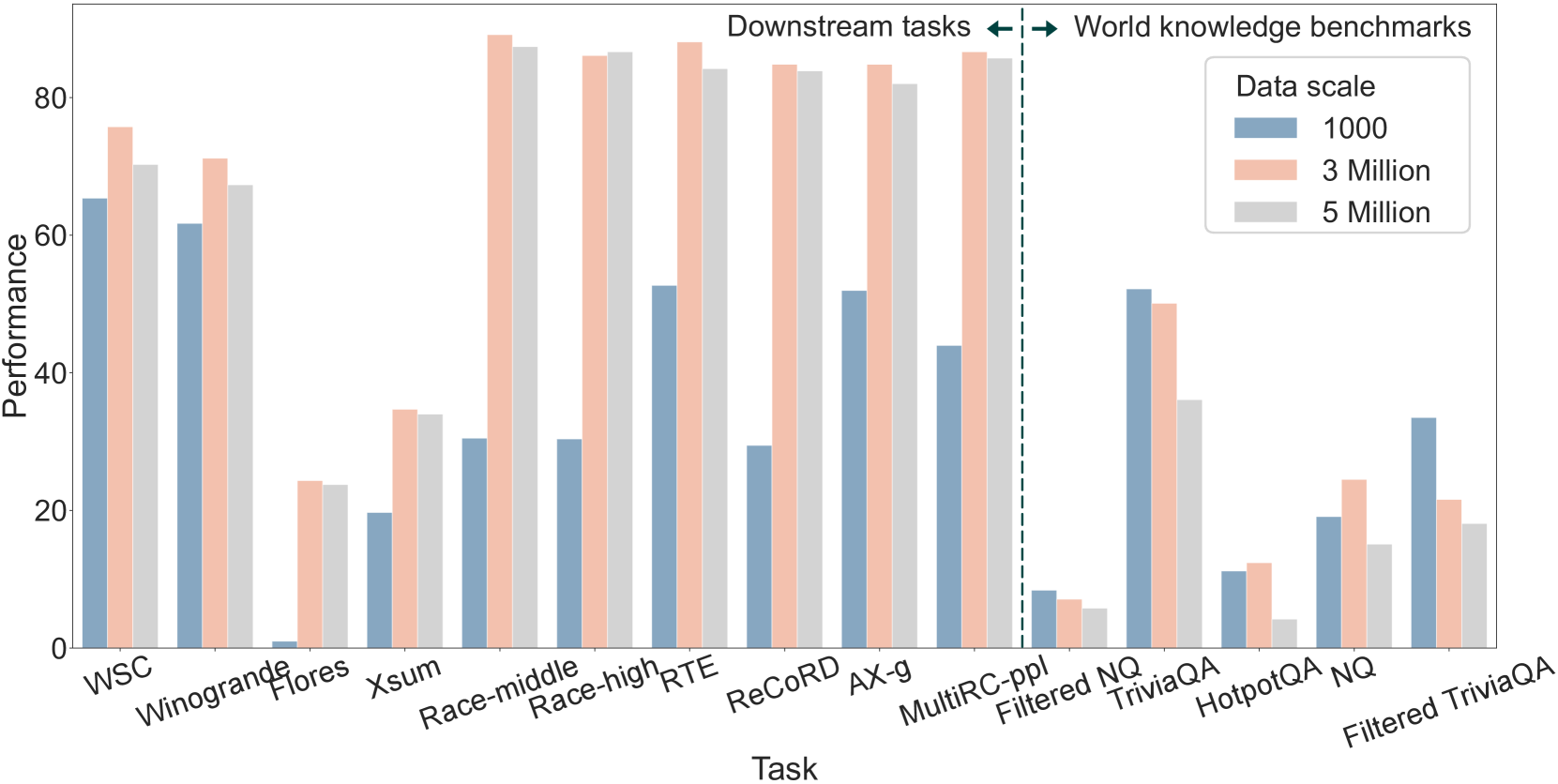
表2显示了LoRAMoE的性能,并将该结果与直接将SFT应用于模型或利用LoRA调整的结果进行比较。 结果表明,采用 LoRAMoE 的语言模型在世界知识基准测试和其他测试中均取得了良好的性能,表明其在避免知识遗忘和提高多任务能力方面的有效性。
对于世界知识基准,与第2节中看到的灾难性崩溃相反,LoRAMoE不仅避免了这个问题,而且超越了仅使用CBQA数据集微调的模型。 LoRAMoE 在世界知识基准上表现出比普通 SFT 显着的性能提升,提升高达 63.9%,平均增长 35.3%。
对于其他下游任务,LoRAMoE 能够实现接近甚至超过直接 SFT 的性能。 例如,在所有阅读理解任务(即 Race、ReCoRD、multiRC)中,LoRAMoE 都取得了优异的性能。
我们还将我们的方法与单个 LoRA 的 PEFT 进行比较。 知识遗忘也发生在单次 LoRA 调优过程中,因为它本质上与普通 SFT (Hu 等人, 2021) 相同。 与单个 LoRA 相比,LoRAMoE 中的多个协作 LoRA 增强了世界知识保留和多任务处理性能。 它们在世界知识基准中平均提升了 30.9%,在其他下游任务中平均提升了 8.4%。
此外, 改善了 LoRAMoE 在绝大多数任务中的结果,包括世界知识基准和其他任务。 值得注意的是,对于阅读理解、NLI 和原始 CBQA 数据集,该方法的收益相当可观,高达 17.6%。 这表明专家组中的能力划分有利于多任务学习的性能。
| # Experts |
|
|
|
||||||
| 6 | 4 | 0.57% | 58.21 | ||||||
| 4 | 4 | 0.38% | 55.84 | ||||||
| 8 | 4 | 0.76% | 56.58 | ||||||
| 6 | 8 | 1.07% | 58.11 | ||||||
| 6 | 16 | 2.08% | 58.86 |
4.3敏感性分析
在本节中,我们分析 LoRAMoE 的参数敏感性。 保持其他设置不变,我们改变专家的数量和 LoRA 的等级。 表 3 显示了所有测试集(包括世界知识基准和所有其他下游任务)上不同参数设置的平均性能。 附录D中有详细的结果。
随着可训练参数数量的增加,性能总体上是稳定的。 6 名专家是最有利的选择,因为更多专家并不会带来更高的性能。 虽然 LoRA 等级的增加在一定程度上提高了模型的能力,但它带来了可训练参数的指数级增长。
4.4 可视化专家利用率
为了确认 LoRAMoE 在专门处理两种类型的专家方面的有效性,我们分别可视化了路由器在遇到来自下游任务和知识基准的数据时分配的权重,如图 7 所示。
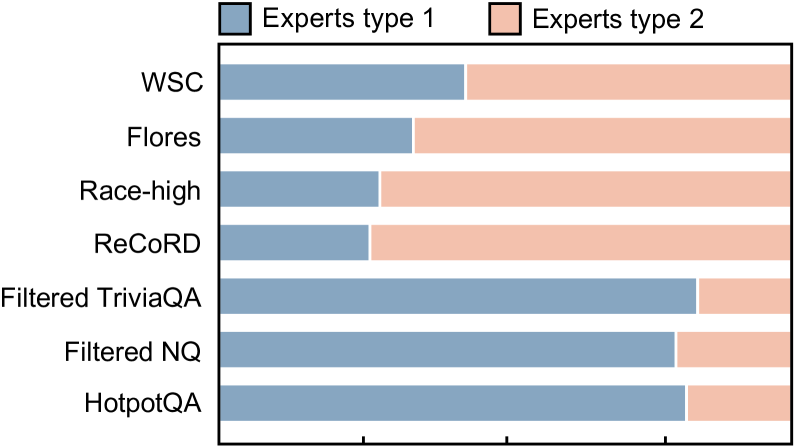
在处理世界知识基准和其他下游任务时,两类专家的利用存在明显的对比。 这表明路由器可以在推理阶段自动将特定任务分配给具有相应能力的专家。 具体来说,被要求利用世界知识的专家在世界知识基准(例如 TriviaQA、Natural Questions 和 HotpotQA)中得到了大量运用,强调了他们在防止世界知识遗忘方面的重要作用。 这与我们在第 2 节中所述的事实相对应,即监督微调通过将模型中预先存储的世界知识与人类指令相关联来增强模型在这些任务中的能力。 另一方面,被分配专注于提高下游任务绩效的专家在遇到这些任务时会更加突出。 通过这个可视化结果,我们发现一些下游任务仍然需要其他类型的专家。 这是合理的。 例如,在阅读理解任务中,模型在预训练时学到的知识可以更好地辅助做出事实判断。 这种现象在基于语言的任务中更为明显。 在WSC任务(Levesque等人,2012)中,路由器平均将大约45%的注意力分配给负责世界知识的专家。
5相关工作
参数高效的微调。 随着语言模型规模越来越大,参数高效的微调(PEFT (He 等人, 2021))对于节省资源变得至关重要。 研究人员提出了多种方法,例如 LoRA (Hu 等人, 2021)、适配器 (Houlsby 等人, 2019) 和即时学习 (Lester 等人, 2021),提高微调效率。 基于低秩适配器的 PEFT (Hu 等人, 2021) 很流行并被广泛使用,它在每个全连接层中引入两个可训练的低秩矩阵,在不增加训练资源的情况下实现显着节省训练资源额外的推理计算成本。 我们将低秩技术应用于专家结构以节省资源消耗。
专家组合。 混合专家(MoE)用稀疏激活的专家取代了前馈神经网络层,这在不显着增加计算成本的情况下显着扩大了模型(Jacobs等人,1991)。 目前, Token 级 MoE 架构广泛应用于预训练语言模型和视觉模型(Shazeer 等人, 2016; Lepikhin 等人, 2020; Du 等人, 2022; Riquelme 等人, 2021). 此外,研究人员(Zhou等人,2022;Chi等人,2022)旨在研究MoE中的路由器选择问题。 与这些扩大模型规模和解决选择问题的努力不同,我们提出了一种 MoE 风格的框架,用于多任务学习和维护大语言模型中存储的世界知识。
多LoRA架构。 研究人员还利用多个 LoRA 来增强模型性能。 Huang等人(2023)提出LoraHub选择不同的LoRA组合进行任务泛化。 MOELoRA (Liu 等人,2023) 利用 LoRA 和 MoE 进行特定于任务的调整和多任务处理,特别是在医疗保健领域。 然而,这些方法在推理阶段需要数据类型作为输入,这限制了模型在其他任务中的应用。 Chen 等人 (2023a) 首先介绍了多个 LoRA 服务系统,Sheng 等人 (2023) 提出了 S-LoRA,这是一个可以从单个 LoRA 适配器提供服务的系统机器。 Chen 等人(2023b)引入多位专家来增强模型的多模态学习能力。 与这些方法不同的是,LoRAMoE 引入了 MoE 风格的插件和 Localize Balancing Constraint 来解决大语言模型中的世界知识遗忘问题,同时增强模型的多任务学习能力。
6结论
在本文中,我们首先深入研究了通过在 SFT 阶段扩展数据来提高大语言模型在下游任务上的性能与阻止世界知识遗忘之间的冲突。 为了解决这个冲突,我们随后引入了LoRAMoE,这是一种新颖的SFT框架,它引入了LoRA作为专家并通过路由器将它们集成。 大量的实验结果表明,LoRAMoE 可以促进专家之间的协作,以提高模型下游任务的性能,同时保留其中的世界知识。
7 限制
在本节中,我们讨论我们提出的方法 LoRAMoE 的潜在局限性。 首先,虽然我们已经证明了LoRAMoE在减轻世界知识遗忘方面的有效性,同时通过SFT增强大语言模型的下游能力,但由于资源和时间限制,我们将模型大小限制为7B。 进一步的工作将在更大的大语言模型上进行,以了解大规模SFT对这些大语言模型的影响并提高它们的多任务处理能力。 其次,局部平衡约束可以软约束专家类型,平衡专家利用率。 然而,我们还没有研究针对更细粒度的任务类别有更多专家类型的情况。 未来的工作将更加细致地了解 SFT 的影响和 LoRAMoE 的利用。
参考
- AlKhamissi et al. (2022) Badr AlKhamissi, Millicent Li, Asli Celikyilmaz, Mona Diab, and Marjan Ghazvininejad. 2022. A review on language models as knowledge bases. arXiv preprint arXiv:2204.06031.
- Cao et al. (2023) Yihan Cao, Yanbin Kang, and Lichao Sun. 2023. Instruction mining: High-quality instruction data selection for large language models. arXiv preprint arXiv:2307.06290.
- Chen et al. (2023a) Lequn Chen, Zihao Ye, Yongji Wu, Danyang Zhuo, Luis Ceze, and Arvind Krishnamurthy. 2023a. Punica: Multi-tenant lora serving. arXiv preprint arXiv:2310.18547.
- Chen et al. (2023b) Zeren Chen, Ziqin Wang, Zhen Wang, Huayang Liu, Zhenfei Yin, Si Liu, Lu Sheng, Wanli Ouyang, Yu Qiao, and Jing Shao. 2023b. Octavius: Mitigating task interference in mllms via moe. arXiv preprint arXiv:2311.02684.
- Chi et al. (2022) Zewen Chi, Li Dong, Shaohan Huang, Damai Dai, Shuming Ma, Barun Patra, Saksham Singhal, Payal Bajaj, Xia Song, Xian-Ling Mao, et al. 2022. On the representation collapse of sparse mixture of experts. Advances in Neural Information Processing Systems, 35:34600–34613.
- Chung et al. (2022) Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, et al. 2022. Scaling instruction-finetuned language models. arXiv preprint arXiv:2210.11416.
- Du et al. (2022) Nan Du, Yanping Huang, Andrew M Dai, Simon Tong, Dmitry Lepikhin, Yuanzhong Xu, Maxim Krikun, Yanqi Zhou, Adams Wei Yu, Orhan Firat, et al. 2022. Glam: Efficient scaling of language models with mixture-of-experts. In International Conference on Machine Learning, pages 5547–5569. PMLR.
- Fedus et al. (2021) William Fedus, Barret Zoph, and Noam Shazeer. 2021. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. arXiv: Learning,arXiv: Learning.
- Guzmán et al. (2019) Francisco Guzmán, Peng-Jen Chen, Myle Ott, Juan Pino, Guillaume Lample, Philipp Koehn, Vishrav Chaudhary, and Marc’Aurelio Ranzato. 2019. The flores evaluation datasets for low-resource machine translation: Nepali-english and sinhala-english. arXiv preprint arXiv:1902.01382.
- Han et al. (2019) Moonsu Han, Minki Kang, Hyunwoo Jung, and Sung Ju Hwang. 2019. Episodic memory reader: Learning what to remember for question answering from streaming data. arXiv preprint arXiv:1903.06164.
- He et al. (2021) Junxian He, Chunting Zhou, Xuezhe Ma, Taylor Berg-Kirkpatrick, and Graham Neubig. 2021. Towards a unified view of parameter-efficient transfer learning. Cornell University - arXiv,Cornell University - arXiv.
- Houlsby et al. (2019) Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. 2019. Parameter-efficient transfer learning for nlp. In International Conference on Machine Learning, pages 2790–2799. PMLR.
- Hu et al. (2021) Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685.
- Huang et al. (2023) Chengsong Huang, Qian Liu, Bill Yuchen Lin, Tianyu Pang, Chao Du, and Min Lin. 2023. Lorahub: Efficient cross-task generalization via dynamic lora composition. arXiv preprint arXiv:2307.13269.
- Jacobs et al. (1991) Robert A Jacobs, Michael I Jordan, Steven J Nowlan, and Geoffrey E Hinton. 1991. Adaptive mixtures of local experts. Neural computation, 3(1):79–87.
- Khashabi et al. (2018) Daniel Khashabi, Snigdha Chaturvedi, Michael Roth, Shyam Upadhyay, and Dan Roth. 2018. Looking beyond the surface: A challenge set for reading comprehension over multiple sentences. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages 252–262.
- Kwiatkowski et al. (2019) Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, et al. 2019. Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics, 7:453–466.
- Lai et al. (2017) Guokun Lai, Qizhe Xie, Hanxiao Liu, Yiming Yang, and Eduard Hovy. 2017. Race: Large-scale reading comprehension dataset from examinations. arXiv preprint arXiv:1704.04683.
- Lepikhin et al. (2020) Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. 2020. Gshard: Scaling giant models with conditional computation and automatic sharding. In International Conference on Learning Representations.
- Lester et al. (2021) Brian Lester, Rami Al-Rfou, and Noah Constant. 2021. The power of scale for parameter-efficient prompt tuning. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 3045–3059.
- Levesque et al. (2012) Hector Levesque, Ernest Davis, and Leora Morgenstern. 2012. The winograd schema challenge. In Thirteenth international conference on the principles of knowledge representation and reasoning.
- Lewis et al. (2020) Patrick Lewis, Pontus Stenetorp, and Sebastian Riedel. 2020. Question and answer test-train overlap in open-domain question answering datasets. arXiv preprint arXiv:2008.02637.
- Liu et al. (2022) Haokun Liu, Derek Tam, Mohammed Muqeeth, Jay Mohta, Tenghao Huang, Mohit Bansal, and Colin A Raffel. 2022. Few-shot parameter-efficient fine-tuning is better and cheaper than in-context learning. Advances in Neural Information Processing Systems, 35:1950–1965.
- Liu et al. (2023) Qidong Liu, Xian Wu, Xiangyu Zhao, Yuanshao Zhu, Derong Xu, Feng Tian, and Yefeng Zheng. 2023. Moelora: An moe-based parameter efficient fine-tuning method for multi-task medical applications. arXiv preprint arXiv:2310.18339.
- Liu et al. (2020) Xiaodong Liu, Yu Wang, Jianshu Ji, Hao Cheng, Xueyun Zhu, Emmanuel Awa, Pengcheng He, Weizhu Chen, Hoifung Poon, Guihong Cao, et al. 2020. The microsoft toolkit of multi-task deep neural networks for natural language understanding. arXiv preprint arXiv:2002.07972.
- Narayan et al. (2018) Shashi Narayan, Shay B Cohen, and Mirella Lapata. 2018. Don’t give me the details, just the summary! topic-aware convolutional neural networks for extreme summarization. arXiv preprint arXiv:1808.08745.
- Neeman et al. (2022) Ella Neeman, Roee Aharoni, Or Honovich, Leshem Choshen, Idan Szpektor, and Omri Abend. 2022. Disentqa: Disentangling parametric and contextual knowledge with counterfactual question answering. arXiv preprint arXiv:2211.05655.
- Ouyang et al. (2022) Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730–27744.
- Pan et al. (2022) Junting Pan, Ziyi Lin, Xiatian Zhu, Jing Shao, and Hongsheng Li. 2022. St-adapter: Parameter-efficient image-to-video transfer learning. Advances in Neural Information Processing Systems, 35:26462–26477.
- Petroni et al. (2019) Fabio Petroni, Tim Rocktäschel, Patrick Lewis, Anton Bakhtin, Yuxiang Wu, Alexander H Miller, and Sebastian Riedel. 2019. Language models as knowledge bases? arXiv preprint arXiv:1909.01066.
- Qi et al. (2019) Peng Qi, Xiaowen Lin, Leo Mehr, Zijian Wang, and Christopher D Manning. 2019. Answering complex open-domain questions through iterative query generation. arXiv preprint arXiv:1910.07000.
- Riquelme et al. (2021) Carlos Riquelme, Joan Puigcerver, Basil Mustafa, Maxim Neumann, Rodolphe Jenatton, André Susano Pinto, Daniel Keysers, and Neil Houlsby. 2021. Scaling vision with sparse mixture of experts. Advances in Neural Information Processing Systems, 34:8583–8595.
- Roberts et al. (2020) Adam Roberts, Colin Raffel, and Noam Shazeer. 2020. How much knowledge can you pack into the parameters of a language model? arXiv preprint arXiv:2002.08910.
- Saha et al. (2018) Amrita Saha, Rahul Aralikatte, Mitesh M Khapra, and Karthik Sankaranarayanan. 2018. Duorc: Towards complex language understanding with paraphrased reading comprehension. arXiv preprint arXiv:1804.07927.
- Sakaguchi et al. (2021) Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. 2021. Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM, 64(9):99–106.
- Shazeer et al. (2016) Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. 2016. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. In International Conference on Learning Representations.
- Sheng et al. (2023) Ying Sheng, Shiyi Cao, Dacheng Li, Coleman Hooper, Nicholas Lee, Shuo Yang, Christopher Chou, Banghua Zhu, Lianmin Zheng, Kurt Keutzer, et al. 2023. S-lora: Serving thousands of concurrent lora adapters. arXiv preprint arXiv:2311.03285.
- Touvron et al. (2023) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. 2023. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
- Wang et al. (2023a) Xiao Wang, Tianze Chen, Qiming Ge, Han Xia, Rong Bao, Rui Zheng, Qi Zhang, Tao Gui, and Xuanjing Huang. 2023a. Orthogonal subspace learning for language model continual learning. arXiv preprint arXiv:2310.14152.
- Wang et al. (2023b) Xiao Wang, Weikang Zhou, Can Zu, Han Xia, Tianze Chen, Yuansen Zhang, Rui Zheng, Junjie Ye, Qi Zhang, Tao Gui, et al. 2023b. Instructuie: Multi-task instruction tuning for unified information extraction. arXiv preprint arXiv:2304.08085.
- Wang et al. (2022) Yizhong Wang, Swaroop Mishra, Pegah Alipoormolabashi, Yeganeh Kordi, Amirreza Mirzaei, Anjana Arunkumar, Arjun Ashok, Arut Selvan Dhanasekaran, Atharva Naik, David Stap, et al. 2022. Super-naturalinstructions: Generalization via declarative instructions on 1600+ nlp tasks. arXiv preprint arXiv:2204.07705.
- Wang et al. (2017) Zhiguo Wang, Wael Hamza, and Radu Florian. 2017. Bilateral multi-perspective matching for natural language sentences. arXiv preprint arXiv:1702.03814.
- Zhang et al. (2018) Sheng Zhang, Xiaodong Liu, Jingjing Liu, Jianfeng Gao, Kevin Duh, and Benjamin Van Durme. 2018. Record: Bridging the gap between human and machine commonsense reading comprehension. arXiv preprint arXiv:1810.12885.
- Zhang et al. (2015) Xiang Zhang, Junbo Zhao, and Yann LeCun. 2015. Character-level convolutional networks for text classification. Advances in neural information processing systems, 28.
- Zhou et al. (2023) Chunting Zhou, Pengfei Liu, Puxin Xu, Srini Iyer, Jiao Sun, Yuning Mao, Xuezhe Ma, Avia Efrat, Ping Yu, Lili Yu, et al. 2023. Lima: Less is more for alignment. arXiv preprint arXiv:2305.11206.
- Zhou et al. (2022) Yanqi Zhou, Tao Lei, Hanxiao Liu, Nan Du, Yanping Huang, Vincent Zhao, Andrew M Dai, Quoc V Le, James Laudon, et al. 2022. Mixture-of-experts with expert choice routing. Advances in Neural Information Processing Systems, 35:7103–7114.
附录A实验实施细节
| Task Name | # Train | # Test | Task Type |
| TriviaQA (Han et al., 2019) | 78785 | 254 | closed-book QA |
| NQ (Kwiatkowski et al., 2019) | 104071 | 357 | closed-book QA |
| HotpotQA (Qi et al., 2019) | 72798 | 5622 | closed-book QA |
| WSC (Levesque et al., 2012) | 554 | 146 | coreference resolution |
| WinoGrande (Sakaguchi et al., 2021) | 40398 | 1767 | coreference resolution |
| Flores (Guzmán et al., 2019) | 0 | 1600 | machine translation |
| WMT 222https://huggingface.co/datasets/wmt14, https://huggingface.co/datasets/wmt16 | 500000 | - | machine translation |
| RTE 333https://aclweb.org/aclwiki/Recognizing_Textual_Entailment | 2490 | 3000 | NLI |
| ReCoRD (Zhang et al., 2018) | 100730 | 10000 | reading comprehension |
| AX-g 444https://super.gluebenchmark.com | 0 | 356 | NLI |
| multiRC (Khashabi et al., 2018) | 27243 | 9693 | reading comprehension |
| anli r1/r2/r3 (Liu et al., 2020) | 162874 | - | NLI |
| qqp (Wang et al., 2017) | 363846 | - | NLI |
| Xsum (Narayan et al., 2018) | 204045 | 11334 | single-document summarization |
| Race (Lai et al., 2017) | 87866 | 4934 | reading comprehension |
| duorc-selfRC (Saha et al., 2018) | 60721 | - | reading comprehension |
| AG-news (Zhang et al., 2015) | 120000 | - | topic classification |
| yelp review (Zhang et al., 2015) | 650000 | - | sentiment classification |
| openai tldr 555https://github.com/openai/summarize-from-feedback | 232188 | - | summarization |
数据集。 这七个任务分别是闭卷问答(CBQA)、共指消解、自然语言推理(NLI)、摘要摘要、多语言翻译、阅读理解和文本分类。 表4显示了300万样本数据集的组成。 我们使用的 500 万个微调数据包括数据增强策略的 300 万个版本及其变体。 100 万样本版本是原始 300 万样本数据集的子集。
评估。 我们使用 opencompass666https://opencompass.org.cn/ 框架来运行上述任务的评估过程。 值得注意的是,考虑到之前的工作已经注意到 CBQA 数据集中的训练-测试重叠(Lewis 等人,2020),我们精心选择了 CBQA 数据集中没有训练-测试重叠的部分作为我们的测试集,即 Filtered NQ 和 Filtered TriviaQA,更好地分析模型的世界知识。
附录B大语言模型的世界知识在更多数据训练后进一步下降
随着任务类型的增加,SFT训练数据量的增加是必然的趋势。 为了进一步验证大规模SFT训练过程是否会导致大语言模型的知识遗忘,如第2节所述,我们构建了一个包含一千万个样本的更大的数据集。 除了上一节的数据集之外,我们还添加了以下任务:
-
•
命名实体识别:采样自Wang 等人(2023b)。 包含 17 个不同的 NER 任务。
-
•
程序执行:采样自Wang 等人 (2022)。 包含 90 个不同的任务,需要大语言模型理解程序的指令并执行它。
-
•
问题生成:从现有的huggingface数据集777https://huggingface.co/datasets/qa_zre。 给定上下文,大语言模型需要根据答案生成适当的问题。
-
•
Text2sql:从两个现有的huggingface数据集采样888https://huggingface.co/datasets/Clinton/Text-to-sql-v1, https://huggingface.co/datasets/cfq。 给定自然语言描述,大语言模型需要生成适当的 SQL 序列。
-
•
有毒分类:从现有的huggingface数据集中采样999https://huggingface.co/datasets/google/civil_comments。
在这个 1000 万样本数据集上使用与附录 A 相同的实验设置训练 LLaMa-2-7b 后,我们发现大语言模型表现出更强的知识遗忘能力,但在其他方面也表现出了有希望的表现除了知识基准之外的任务。
| Task Name | Baseline | Result |
| NER | 42.1 | 82.2 |
| Program Execution | 18.7 | 78.5 |
| Toxic Classification | 96 | 97.4 |
| Question Generation | 46.2 | 61.1 |
| Text2sql | 56 | 96.2 |
| WSC | 65.4 | 70.2 |
| winogrande | 61.7 | 66.1 |
| Flores | 0.1 | 26.0 |
| Xsum | 19.7 | 33.2 |
| Race-middle | 30.5 | 87.0 |
| Race-high | 30.4 | 83.3 |
| RTE | 52.7 | 87.4 |
| ReCoRD | 29.5 | 56.6 |
| AX-g | 52.0 | 87.9 |
| multiRC | 44.0 | 86.0 |
| TriviaQA | 52.2 | 30.9 |
| NQ | 18.5 | 14.2 |
| Filtered TriviaQA | 33.5 | 15.7 |
| Filtered NQ | 7.8 | 5.0 |
| HotpotQA | 11.2 | 7.6 |
附录 C 专家平衡的混合分配困境
当在没有任何约束的情况下微调 MoE 时,路由器机制通常会收敛到一种状态,即少数专家通过路由器接收到不成比例的大量偏好,如图5所示。 专家之间的这种不平衡提出了纠正的挑战,因为在训练的早期阶段接收更大路由权重的专家会经历更快速的优化,从而从路由器获得更多的偏好。 Shazeer 等人 (2016) 和 Fedus 等人 (2021) 中提出的工作中也记录了类似的现象。
平衡专家利用率的传统解决方案是采用专家重要性的变异系数作为损失函数,旨在均衡每个专家的重要性(Shazeer等人,2016)。 该解决方案假设用于优化 MoE 的训练样本的分布是单一分布,这本质上消除了考虑数据分布的不同来源的必要性。 具体来说,这种传统方法通过假设数据源的同质性来简化建模过程,而这些数据源通常与包含事实知识 QA 和其他下游任务的微调数据不一致。 因此,这种简化可能会导致显着的偏差,特别是在遇到具有不同分布特征的数据集时。
传统的平衡约束旨在在所有专家之间分配均匀分布的训练样本,可能会导致参数估计不准确。 这是因为此类约束没有考虑到不同类别的数据表示和重要性的内在差异。 认识到数据分布的不同性质,LoRAMoE 有策略地将数据分配给专家,不是统一分配,而是基于观察到的不平衡情况。 这种分配由一组权重控制,这些权重经过校准以反映整个数据集中不同数据类别的不同重要性和表示形式。
这种专门的分配方法对于解决数据分布不均匀带来的挑战至关重要。 通过根据数据的固有差异为每位专家定制训练样本的分布,LoRAMoE 有助于更准确和更具代表性的参数估计。 这种细致入微的数据分布方法可以使模型更有效地适应不同的数据子集,从而显着增强模型的预测准确性和泛化能力。 该策略在数据不平衡可能导致学习偏差和泛化错误的情况下特别有效,可确保每个数据类别在整个系统中得到适当的表示和建模。
为了用简化模型来说明这个概念,我们假设我们的训练数据是从两个高斯分布的混合中采样的。 这些分布的均值 和方差 是隐式的。 每个分布的训练数据比例表示为,其中,不失一般性,我们假设。 当 MoE 模型用平衡权重 拟合建议的分布时,给定数据的模型的似然可以表示为:
| (10) |
| Task Name |
|
|
|
|
||||||||
| WSC | 71.2 | 76.0 | 70.2 | 76.9 | ||||||||
| winogrande | 69.8 | 56.0 | 69.5 | 70.9 | ||||||||
| Flores | 25.0 | 25.8 | 26.1 | 26.3 | ||||||||
| Xsum | 32.8 | 33.3 | 33.7 | 34.0 | ||||||||
| Race-middle | 90.3 | 84.2 | 90.3 | 90.5 | ||||||||
| Race-high | 87.1 | 80.7 | 87.3 | 87.2 | ||||||||
| RTE | 84.5 | 80.1 | 88.1 | 85.2 | ||||||||
| ReCoRD | 85.6 | 85.5 | 86.0 | 86.1 | ||||||||
| AX-g | 88.8 | 77.5 | 88.2 | 85.7 | ||||||||
| multiRC | 77.2 | 87.6 | 81.1 | 87.3 | ||||||||
| TriviaQA | 54.4 | 57.8 | 58.2 | 58.9 | ||||||||
| NQ | 25.6 | 27.9 | 27.8 | 28.2 | ||||||||
| Filtered TriviaQA | 30.7 | 35.8 | 36.7 | 34.3 | ||||||||
| Filtered NQ | 11.5 | 13.4 | 12.0 | 15.4 | ||||||||
| HotpotQA | 14.5 | 16.0 | 16.4 | 16.5 |
其中。 使用 和 表示 和 ,
的最佳平均值满足以下条件,当拟合分布与抽样分布属于同一族混合分布 时,其值为 0:
| (11) |
在方程 10 中,我们可以用输入 x 均值的经验估计来替换部分求和。 对于理想的路由网络,必须存在一个分布,使得分配到该分布的数据与采样分布中的峰值之一独立同分布。 我们假设这个分布是。 在这种情况下,如果,则分布的拟合结果将是。 根据微分求导的链式法则,我们最终得到:
| (12) |
类似地可以得到逆结果。 因此,只有先验分布的混合系数与实际采样分布权重一致时,训练误差才能达到最佳。