3D 全身人体运动的表达预测
摘要
人体运动预测的目标是估计未来一段时间内人类的行为,是许多现实应用中的一项基本任务。 然而,现有的工作通常集中于预测人体的主要关节,而没有考虑人手的微妙运动。 在实际应用中,手势在人类与现实世界的交流中发挥着重要作用,表达了人类的首要意图。 在这项工作中,我们首次制定了全身人体姿势预测任务,共同预测未来的身体和手部活动。 相应地,我们提出了一种新颖的编码对齐交互(EAI)框架,旨在协同预测粗粒度(身体关节)和细粒度(手势)活动,从而实现 3D 全身人体运动的表达和交叉促进预测。 具体来说,我们的模型涉及两个关键组成部分:跨上下文对齐(XCA)和跨上下文交互(XCI)。 考虑到全身内的异构信息,XCA旨在对齐各个人体成分的潜在特征,而XCI则侧重于有效捕获人体成分之间的上下文交互。 我们在新推出的大规模基准上进行了广泛的实验,并实现了最先进的性能。 该代码在 https://github.com/Dingpx/EAI 上公开用于研究目的。
介绍
预测人类行为/活动在物理世界中随时间的演变是机器智能的一个重要方面(Tarvainen 和 Valpola 2017;Ruiz、Gall 和 Moreno-Noguer 2018;Yuan 和 Kitani 2020)。 例如,为了实现无缝的人机交互(HRI),机器人应该对人们在不久的将来将如何移动或行动有一些概念,以一系列历史观察到的姿势(Gui等人2018;Cui 等人 2021;Zhang、Black 和 Tang 2021;Cai 等人 2021;Dang 等人 2021)。
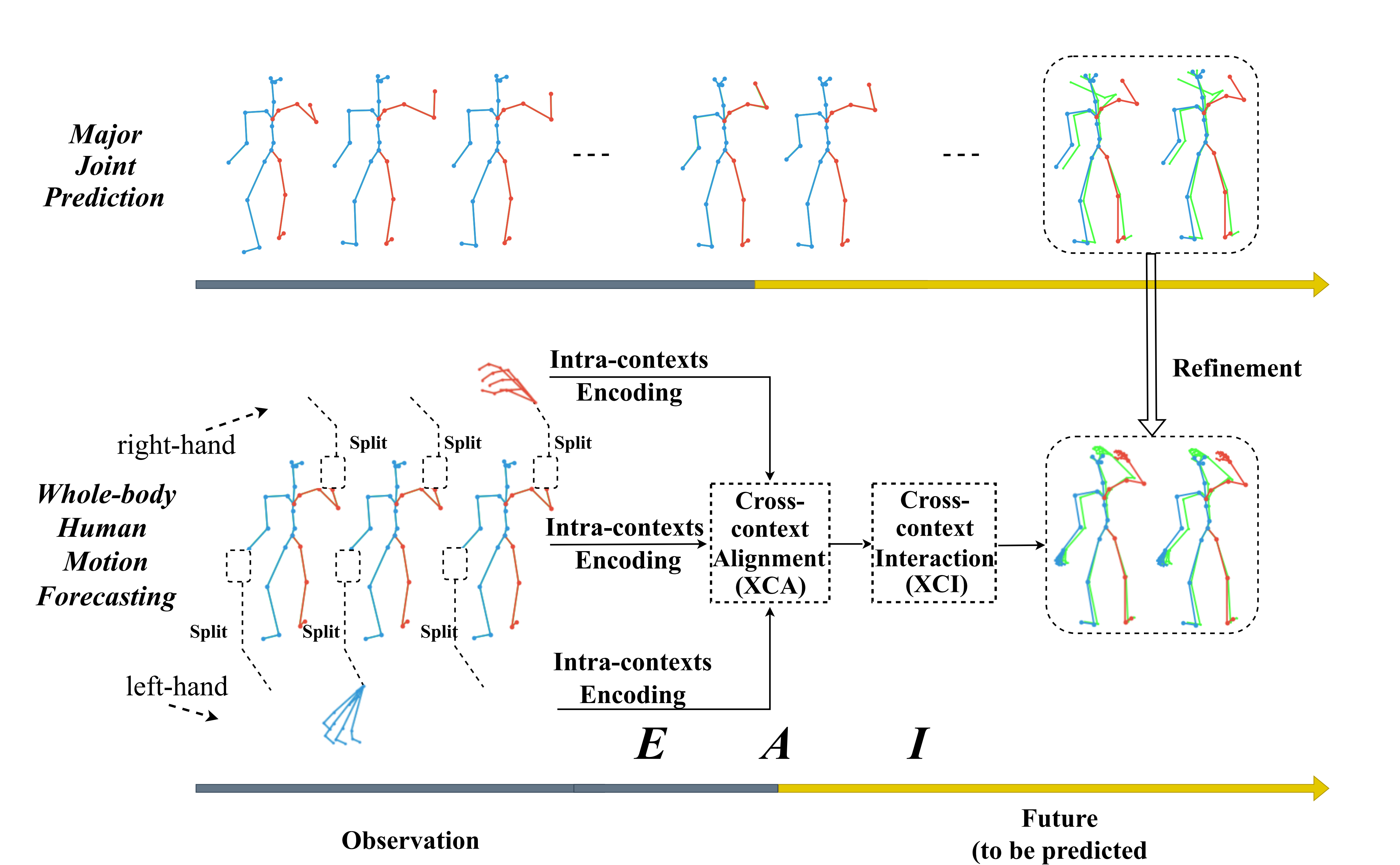
在过去的几年里,这个有吸引力的话题受到了相当多的关注,出现了大量的方法,深度学习技术被证明是很受欢迎的(Cai 等人 2021; Feng 等人 2021; Li 等人 2022; Petrovich、Black 和 Varol 2021;Ruiz、Gall 和 Moreno-Noguer 2018;Vaswani 等人 2017)。 此外,我们注意到现有的工作属于粗粒度范围,即,预测人体的主要关节运动(Adeli 等人 2021; Cui and Sun 2021; Butepage 等人 2017 ;Ruiz、Gall 和 Moreno-Noguer 2018;Zhong 等人 2022;。 然而,就实际应用而言,它仍然是一个重大限制:没有考虑微妙的活动(即,手势)。 人手是与世界互动的重要桥梁,同时,对于 HRI 应用,它通常包括对机器人的详细命令,以主体 体现人类行为(Zhang、Black 和 Tang 2021; Diller、Funkhouser 和 Dai 2022;Hidalgo 等人 2019;Taheri 等人 2020)。 因此,从人体姿势预测的实际应用来看,我们认为仅考虑主要关节而忽略微妙的手势是不够的。
为了充分研究这个问题,我们提出了一种新的范式:全身人体运动预测,即联合预测身体和手内所有关节的未来活动,如图1。 与传统任务相比,它在以下方面提出了重大挑战:1)主要身体和手势有不同的运动模式(运动幅度、骨骼自由度),因此平等对待它们并不是最理想的; 2)人类活动通常涉及全身不同部分的协作/交互;例如,拍手体现了双手的互动;对于饮酒来说,则由手和嘴的语义关联主导。 3)由于尺度和特征的异构性,无法像现有的多人交互预测方法那样直接对这种跨粒度交互进行建模(Guo等人2022)。
在这项工作中,我们提出了一种新颖的编码-对齐-交互(EAI)框架来解决这些具有挑战性的问题。 具体来说,为了避免负面的相互干扰,我们首先从身体和手势的异构运动属性中提取它们各自的内部时空相关性。 我们观察到,全身内各种元素的相互作用/协作对于执行特定活动至关重要。 然而,这种交互与现有的多人交互(Guo等人2022)不兼容,因为人与人之间的信息是尺度统一的,而体内上下文是异构的,例如,从粗粒度到细粒度(身体到手势),反之亦然。 因此,我们建议利用跨上下文对齐(XCA)来有效地对齐和平滑不同部分的潜在特征,从而消除它们的异质性。 最后,通过对齐的特征,我们进一步引入跨上下文交互(XCI),这是交叉注意力的一种变体(Hao等人2017),它能够捕获不同人体部分之间的成对交互性全身之内。 我们注意到,所提出的 EAI 是一个通用框架,能够同时考虑全身内不同部分的交互性以及异构属性,从而产生更高质量的全身预测。
我们的贡献如下:(1)据我们所知,这项工作是第一个同时预测主要关节和人类手势的未来动作的工作。 (2)我们提出了一种配备XCA和XCI的编码-对齐-交互(EAI)方法,能够提取全身内的异构交互。 (3) 大量实验表明,与竞争对手相比,我们的模型在短期和长期预测方面均取得了优异的性能。
相关工作
人体运动预测。 RNN 是广泛用于时间序列数据建模和人体姿势预测的架构(Butepage 等人 2017;Bütepage、Kjellström 和 Kragic 2018;Honda、Kawakami 和 Naemura 2020;Corona 等人 2020)。 尽管取得了令人鼓舞的进展,但它们通常会遭受错误积累,并且往往会收敛到静态姿势。 前馈网络,例如卷积神经网络 (CNN) (Liu 等人 2020; Ding and Yin 2022) 和图神经网络 (GNN)(Mao 等人 2019; Mao, Liu 、Salzmann 2020;Li 等人 2021, 2022),被提出作为替代解决方案来减轻循环模型的缺点。 (Mao 等人 2019) 提出了可学习的相邻矩阵来模拟人体关节之间的空间依赖性。 这种方法后来通过对整条历史信息(Mao、Liu和Salzmann 2020)或其中的一部分(Li等人2021)的自注意力进行扩展。 尽管性能很好,但现有的方法都属于预测人体主要关节运动的范围,没有共同分析手势(Pavlakos 等人 2019;Cui 和 Sun 2021)。 从实际应用中,我们注意到微妙的手部动作对于表达人类行为和意图是不可或缺的。 我们的工作首先注意到了这一具有挑战性的问题,即如何预测富有表现力的全身人体运动(统一手势和人体主要关节),并致力于解决这一问题。
情境互动。 情境交互已被证明在人与人之间的交互中是有效的(Guo 等人 2022;Wang 等人 2021;Rong、Shiratori 和 Joo 2021)。 具体来说,(Wang 等人 2021) 通过多范围 Transformers 结构对个人运动和社交互动的背景进行建模。 (Guo 等人 2022) 通过设计的交叉交互模块探索多人上下文交互。 然而,全身内各个组件的交互/协作与上述方法不兼容,因为人与人之间的信息是尺度统一的,而体内环境是异构的。 因此,在我们提出的 EAI 中,我们引入了跨人体成分的异构特征的对齐,以更有效地提取随后的全身内部交互性。
提议的方法
问题设置。 以前的工作通常考虑对主要人体关节的预测。 给定历史人类姿势,非正式地,其目标可以定义为学习映射 估计未来姿势Y,其中X是观察到的主要关节,是帧上相应的未来姿势。 这项工作将上述标准设置扩展到统一的全身人体运动预测,包括主体、左手和右手,分别表示为、、为简单起见,使用变量。 类似地,我们将新任务定义为学习统一的映射:
|
|
(1) |
其中 () 是主体过去(未来)的骨骼序列。 是单帧中3D关节坐标的数量,是主要身体关节的数量。 另外,和是左(右)手过去和未来的动作。
上下文内编码
由于主要身体和手势的运动模式不同,我们应该单独考虑不同的身体部位。 值得注意的是,我们在特征空间中提取了由左手、头部和右手位置组成的 3D 骨骼序列的内部上下文,表示为 。 这是因为特征空间中的时空相关性比原始运动空间中的相关性更具表现力。 接下来我们以主体为例来说明编码过程的细节。
在时域中,利用离散余弦变换(DCT)通过将观察到的序列变换到轨迹空间来捕获时间平滑度。 给定过去的运动 ,我们将此序列 的 DCT 系数计算为:
|
|
(2) |
其中 是 的变体,通过在 (Mao 等人 2019) 之后复制最后观察到的姿势 次; 是预定义的DCT矩阵,C的每一行是轨迹的DCT系数。
在空间域中,我们利用 GCN (Mao 等人 2019; Cui and Sun 2021) 将骨架表示为全连接图,描述为邻接矩阵 。 形式上,我们将 定义为 GCN 中第 层的输入特征,将 定义为权重矩阵。 然后输出特征导出为:
|
|
(3) |
其中 是输入特征, 在第一层;隐藏层数设置为; 是一个激活函数。 最后一层的最终输出特征是,w.r.t 。
按照上述形式,我们还获得了左(右)手的内部上下文,形成全身内部上下文。 我们注意到,虽然在标准解剖学中手腕被认为来自主体,但由于与手的物理联系,我们也将其包含在手特征提取中。 因此,手的特征尺寸稍微改变为和。
鉴于特定部分表示的异质性和交互性,我们因此提出跨上下文对齐(XCA)和跨上下文交互(XCI),以在以下部分中有效地捕捉全身内的合作。
跨上下文对齐(XCA)
与人人交互(Guo 等人 2022) 任务相反,由于独特的运动模式,不同身体部位的体内环境在尺度上不一致。 体内环境是异构的、从粗到细(身体到手势)的,反之亦然,这与当前的多人交互形成鲜明对比,其中人与人之间的信息是尺度统一的。 换句话说,需要减轻运动模式的这些差异,因为它们可能会极大地干扰整体运动感知。
直观上,全身内的异质上下文主要源于不同部位的运动幅度、尺度和骨骼自由度,典型地反映了特征分布的差异(Li等人2018)。 为了解决这个问题,我们在身体组件之间引入交叉中和,并结合差异约束,以有效地对齐不同部分的潜在特征。 具体来说,我们通过可根据 MMD 约束自动调整的可学习因子来消除不同特征之间的分布差异。 这将原始特征重新组织为分布更紧密的新特征。 这样的策略能够缓解不同身体组件的不兼容性,同时更有利于提取相互作用。 我们以主体与左手的对齐过程为例。
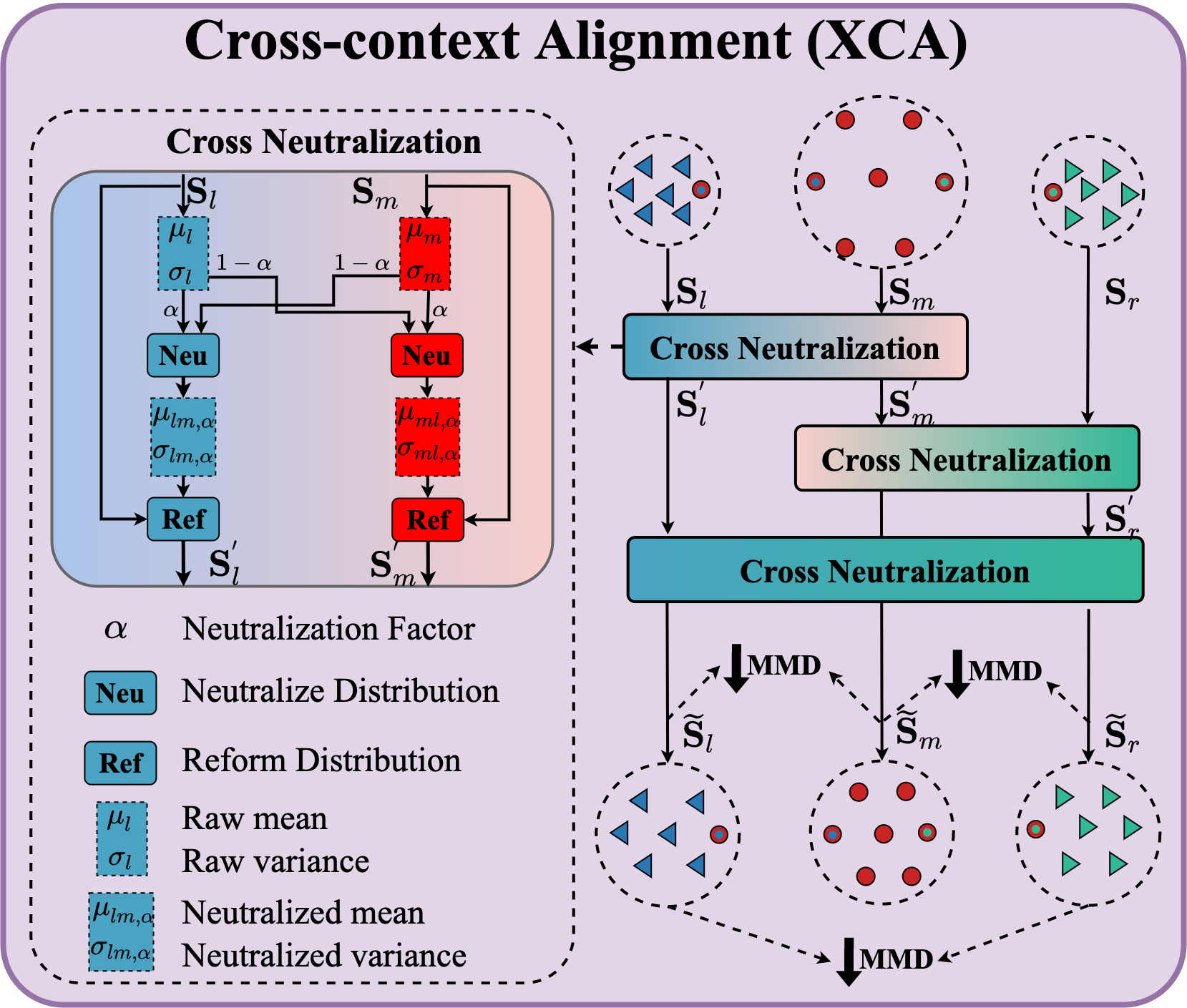
交叉中和(CN)。 给定上下文内,,我们引入一个可学习因子来构成融合分布,以抵消之间的分布差异> 和。 正式地, 定义为:
| (4) | ||||
其中 和 是上下文内特征 的均值和方差; 和 可以类似得到; 和 是沿联合维计算均值和方差的操作; ;()是融合特征分布的均值和方差向量; (), () 是上下文内特征 () 和融合特征 () 的行向量;是避免数值问题的系数。 为了进一步实现部件与部件之间的对齐,我们将 扩展为圆形版本:
| (5) | ||||
其中 、 和 是圆形 的中间(输出)特征; 和是与类似的因子,在训练阶段更新。
差异约束。 我们应用最大平均差异(MMD)来减轻部件与部件之间的差异。
| (6) |
其中是沿空间维度的平均操作,/。 类似地可以得到和。
通过交叉中和和差异约束,减少了上下文内特征的分布差异,我们提出的跨上下文对齐(XCA)可以减轻不同上下文内的异质性。 接下来,我们提出跨情境交互(XCI)来探索整个身体内的交互,为感知未来人类意图提供重要线索。
跨上下文交互(XCI)
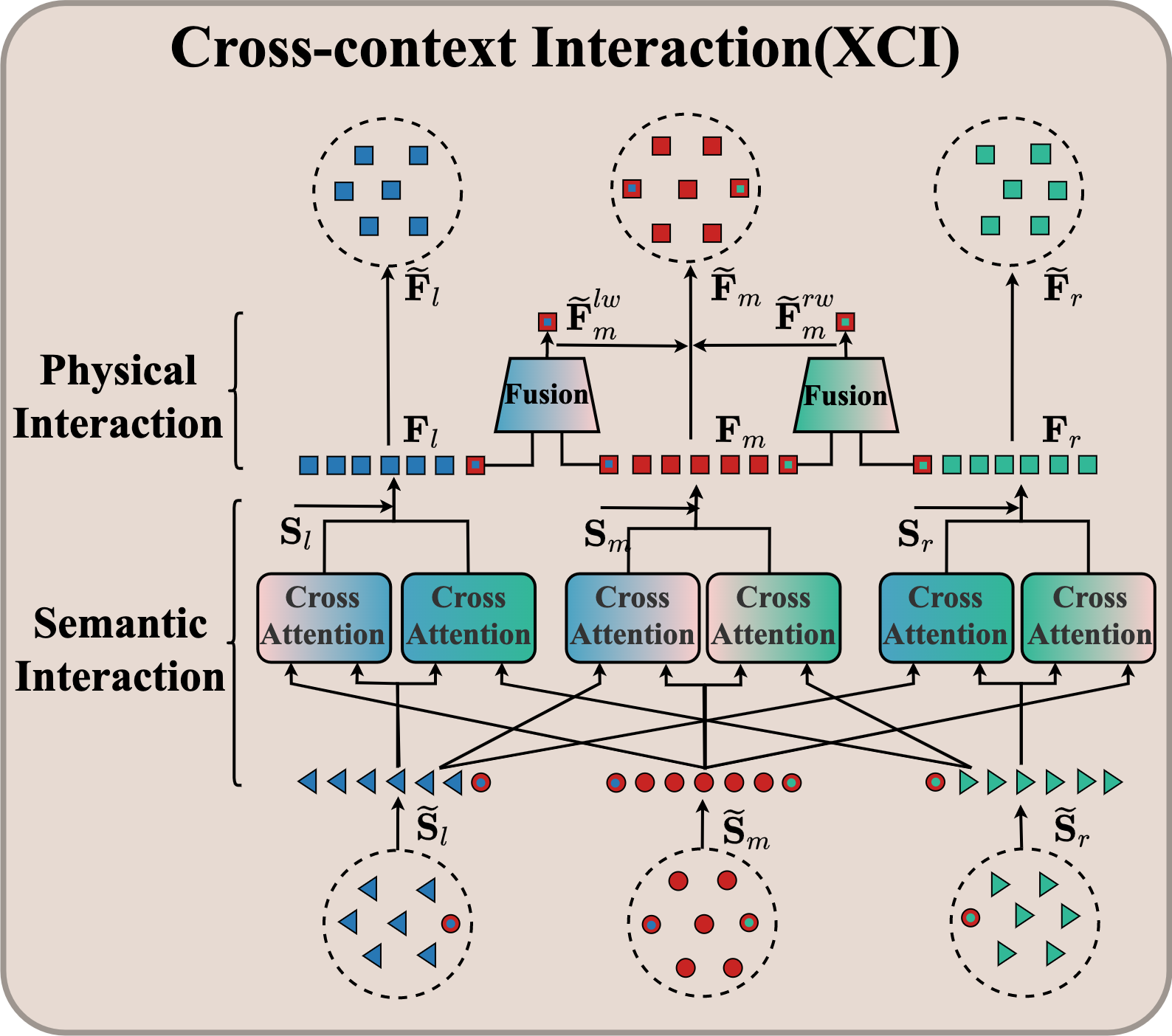
与人人外部交互(郭等人2022)相比,身体手/手手涉及整个身体内不同部分之间的内部相互作用。 准确地说,它既包括语义交互(由不同部分协作驱动以执行特定动作),也包括物理交互(通过身体手腕内在的链环)。 因此,我们提出了交叉注意力的变体(Hao等人2017)来捕获人类各个部分的语义和物理交互性。
语义交互。 三个身体部位的相关性主要来源于整体动作内的相互语义交互。 例如,对于吃饭的动作,手指和头关节有很强的相关性。 因此,我们的目标是通过交叉注意力机制(Hao等人2017)来建模组件之间的语义依赖关系。 我们以主体和左手之间的跨上下文语义交互为例。 整个过程描述为:
| (7) | ||||
其中,()为输入(输出)特征;第一层的输入特征为 ,最后一层的输出特征为 ;、和是投影矩阵,大小为;、和分别是查询特征、关键特征和值特征;是由计算出的注意力图谱。 由多层感知器(MLP)组成。
对于主体来说,可以利用与左手的语义相关性来逐步将语义交互上下文融合到自身中。 类似地,我们还可以获得主体右手的跨上下文语义交互。 将上述语义相关特征与自我特征相结合,我们可以得到表达特征:
| (8) |
其中 是沿特征维度的连接操作。 我们还获得了左手和右手的特征、。
身体互动。 作为身体和手之间的桥梁,手腕在这两个组成部分之间提供了直接的链相关性。 因此,我们采用“分而治之”的策略。 也就是说,我们首先复制腕关节将其纳入其中,如Intra-context Encoding部分所示,然后进行动态特征融合以形成最终的手腕特征。 通过这种方式,可以更好地对身体部位之间的物理连接进行建模。 具体来说,我们将主要身体的手腕特征、左手识别为互补对。 它被输入 MLP 来测量相互置信度,并用作融合配对特征的权重,以实现更明智的推理:
| (9) | |||
| (10) |
其中 (或 )是左手(或主体)手腕的特征; 是重要性权重。 是融合的手腕特征。 是可学习的温度系数,与所有网络参数联合训练。 类似地,我们获得主要身体、右手的融合手腕特征。
| Body Parts | Major body | Left Hands | Right Hands | Left Hands (AW) | Right Hands (AW) | Whole Body | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Time (sec) | 0.2 | 0.4 | 1.0 | 0.2 | 0.4 | 1.0 | 0.2 | 0.4 | 1.0 | 0.2 | 0.4 | 1.0 | 0.2 | 0.4 | 1.0 | 0.2 | 0.4 | 1.0 | |
| LTD (D) | 8.7 | 18.9 | 48.7 | 19.7 | 57.0 | 181.5 | 33.3 | 77.5 | 195.6 | 9.1 | 18.3 | 41.4 | 17.2 | 28.3 | 53.1 | 18.3 | 45.6 | 126.1 | |
| DMGNN (D) | 11.2 | 23.1 | 53.5 | 24.8 | 62.0 | 190.1 | 38.1 | 83.0 | 205.7 | 10.0 | 21.7 | 44.4 | 21.6 | 32.6 | 60.5 | 23.0 | 55.7 | 131.4 | |
| PGBIG (D) | 10.4 | 21.7 | 52.8 | 22.8 | 61.5 | 186.7 | 37.6 | 82.4 | 203.9 | 10.5 | 22.2 | 43.5 | 21.5 | 31.1 | 58.7 | 22.6 | 53.6 | 129.6 | |
| Divided | SPGSN (D) | 9.3 | 21.0 | 52.6 | 25.3 | 61.1 | 164.2 | 37.2 | 81.5 | 202.8 | 9.3 | 18.5 | 41.6 | 16.1 | 28.8 | 56.9 | 21.2 | 48.4 | 124.0 |
| LTD (U) | 9.1 | 19.9 | 50.2 | 19.9 | 50.5 | 162.5 | 32.3 | 74.6 | 195.5 | 8.9 | 17.1 | 42.5 | 16.7 | 29.3 | 58.3 | 18.4 | 43.1 | 120.4 | |
| DMGNN (U) | 13.7 | 26.4 | 56.9 | 22.4 | 57.3 | 172.0 | 36.3 | 78.9 | 203.7 | 9.7 | 20.3 | 46.4 | 19.0 | 33.2 | 64.1 | 22.7 | 50.0 | 128.2 | |
| PGBIG (U) | 13.2 | 24.9 | 54.2 | 23.0 | 56.4 | 165.7 | 35.0 | 77.2 | 199.4 | 10.2 | 19.5 | 45.7 | 19.1 | 32.5 | 62.0 | 22.2 | 48.1 | 125.8 | |
| SPGSN (U) | 12.7 | 24.5 | 53.4 | 21.6 | 55.5 | 161.6 | 34.3 | 75.5 | 190.8 | 9.6 | 18.2 | 42.3 | 18.5 | 31.0 | 58.2 | 21.0 | 46.9 | 120.3 | |
| United | EAI (Ours) | 8.3 | 18.7 | 46.8 | 17.7 | 49.2 | 136.4 | 29.8 | 69.0 | 169.0 | 8.6 | 17.3 | 38.8 | 16.2 | 27.8 | 51.6 | 16.7 | 40.7 | 104.6 |
然后,对最终的表现特征作如下进一步重组:(1) 从 / 中删除左(右)腕特征 /,最终左/右手特征变为 ();(2) 至于身体,物理手腕细化后,特征的尺寸不变,但 / 通过 / 更新,生成最终特征 ;(3) 得到的特征 然后由 MLP 和 IDCT 组成的预测器将最终特征回归到预测序列 ,其中 、 和 。
训练损失: 预测损失被定义为衡量预测3D坐标的准确性,我们计算每个关节位置误差的平均值:
|
|
(11) |
其中 表示帧 中预测的第 关节位置, 表示相应的地面实况(GT)。 左手骨骼中的关节数量。 同样,我们也可以实现右手和身体的和,形成全身的预测损失。
此外,为了进一步考虑手部语义,我们对手势进行预处理,使其与手腕对齐:
|
|
(12) |
其中表示预测的与左手腕对齐的第关节位置,是相应的GT。 然后,我们就可以得到两只手的细粒度预测损失。
由于人体骨骼的骨长度是固定的,因此我们引入骨长度损失:
|
|
(13) |
其中表示第骨骼的长度,表示GT。 全身骨长度损失。
为了减轻不同身体部位的特征异质性,我们利用Cross-context Alignment (XCA)部分提出的最小分布差异误差作为对齐损失
| (14) |
最终损失,是上述损失的加权和:
| (15) |
其中 、、 是权衡参数。
实验
| Action | A1 pass | A2 eat | A3 drink | A4 lift | A5 on | A6 squeeze | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Time (sec) | 0.2 | 0.4 | 1.0 | 0.2 | 0.4 | 1.0 | 0.2 | 0.4 | 1.0 | 0.2 | 0.4 | 1.0 | 0.2 | 0.4 | 1.0 | 0.2 | 0.4 | 1.0 | |
| LTD (U) | 10.2 | 20.8 | 42.4 | 12.1 | 28.0 | 71.7 | 12.2 | 23.4 | 40.1 | 7.9 | 20.3 | 54.9 | 9.8 | 17.8 | 36.4 | 5.6 | 12.7 | 26.6 | |
| DMGNN (U) | 11.7 | 26.4 | 40.7 | 17.9 | 37.6 | 88.4 | 14.5 | 32.1 | 58.0 | 12.1 | 26.3 | 61.5 | 12.2 | 22.0 | 42.5 | 23.1 | 48.1 | 75.4 | |
| PGBIG (U) | 12.0 | 26.9 | 38.9 | 17.5 | 36.5 | 83.2 | 15.7 | 30.2 | 53.2 | 11.4 | 24.3 | 62.4 | 13.0 | 20.7 | 41.2 | 21.5 | 46.2 | 72.4 | |
| SPGSN (U) | 13.1 | 25.8 | 35.1 | 18.4 | 34.8 | 82.0 | 15.6 | 28.9 | 48.6 | 10.6 | 22.6 | 51.6 | 12.4 | 21.7 | 39.3 | 7.9 | 13.8 | 27.9 | |
| Major body | EAI (Ours) | 9.0 | 19.7 | 31.6 | 10.5 | 26.4 | 72.5 | 10.2 | 19.1 | 30.8 | 6.5 | 16.4 | 44.4 | 7.9 | 15.6 | 31.3 | 5.4 | 12.2 | 24.4 |
| LTD (U) | 24.4 | 52.2 | 211.2 | 21.7 | 52.5 | 187.5 | 51.8 | 123.4 | 185.8 | 21.0 | 66.3 | 163.8 | 12.1 | 34.1 | 50.1 | 18.1 | 35.6 | 54.6 | |
| DMGNN (U) | 36.7 | 68.9 | 196.6 | 38.6 | 87.5 | 234.4 | 56.2 | 128.8 | 265.4 | 22.2 | 68.7 | 181.2 | 15.3 | 44.3 | 54.2 | 24.1 | 49.3 | 73.1 | |
| PGBIG(U) | 33.5 | 66.3 | 186.2 | 36.9 | 88.2 | 225.6 | 56.7 | 126.4 | 264.6 | 23.1 | 66.9 | 178.4 | 15.0 | 43.2 | 50.1 | 23.0 | 45.6 | 72.4 | |
| SPGSN (U) | 30.9 | 71.1 | 165.1 | 36.5 | 94.6 | 263.6 | 51.4 | 119.8 | 242.7 | 20.3 | 65.2 | 175.5 | 14.9 | 41.1 | 53.7 | 22.9 | 47.3 | 70.3 | |
| Left hands | EAI (Ours) | 25.4 | 52.6 | 145.1 | 17.8 | 49.0 | 148.7 | 42.5 | 107.7 | 144.4 | 14.3 | 48.4 | 129.7 | 9.6 | 28.5 | 45.8 | 10.8 | 32.9 | 42.2 |
| LTD (U) | 37.0 | 82.1 | 136.1 | 35.3 | 79.3 | 204.3 | 22.9 | 82.2 | 167.2 | 25.5 | 81.5 | 229.1 | 45.1 | 97.0 | 187.2 | 25.1 | 47.8 | 93.7 | |
| DMGNN (U) | 39.2 | 80.5 | 129.5 | 37.5 | 78.3 | 215.0 | 23.5 | 85.8 | 221.4 | 27.3 | 83.4 | 231.0 | 47.3 | 105.6 | 230.2 | 26.4 | 54.2 | 103.7 | |
| PGBIG (U) | 36.8 | 78.3 | 124.6 | 34.2 | 76.4 | 212.5 | 24.0 | 87.6 | 210.5 | 26.1 | 82.5 | 233.7 | 47.2 | 103.4 | 221.9 | 25.7 | 54.0 | 102.5 | |
| SPGSN (U) | 33.7 | 73.0 | 108.7 | 31.8 | 59.5 | 207.6 | 22.5 | 92.0 | 249.4 | 21.3 | 76.4 | 215.6 | 42.4 | 101.4 | 173.5 | 24.7 | 52.6 | 98.7 | |
| Right hands | EAI (Ours) | 21.7 | 50.3 | 69.6 | 31.8 | 70.2 | 180.3 | 15.2 | 60.8 | 111.0 | 17.6 | 51.0 | 136.9 | 35.1 | 79.5 | 146.2 | 23.1 | 46.1 | 86.6 |
数据集:据我们所知,以前广泛使用的数据集,例如, H3.6M (Ionescu 等人 2013)、3DPW ( von Marcard 等人 2018),只记录主要的身体动作(没有人手)。 为了与我们提出的新任务兼容,这里我们选择 GRAB (Taheri 等人 2020)。 这是一个最近发布的数据集,包含 10 个不同演员的超过 160 万帧,总共执行 29 个动作。
它是使用高精度动作捕捉技术捕捉的。 GRAB 提供了 SMPL-X (Pavlakos 等人 2019) 参数,从中我们提取 25 个关节(3D 位置)定义为身体(),每只手表示为 15 - 关节 ()。
基线:我们注意到,对于 3D 全身人体运动预测,没有直接的比较方法。 因此,为了全面研究所提出的 EAI,我们选择了 4 种标准主关节预测的 SOTA 方法作为基线,包括 LTD (Mao 等人 2019)、DMGNN (Li 等人 2020) 、PGBIG (马等人 2022)、SPGSN (李等人 2022)。 值得注意的是,所有基线都基于 GCN 来考虑 关节人体骨骼( 或 )。 为了公平比较,我们在以下训练设置下重新训练基线。
我们应用两种训练策略来研究这项新任务。 (1) 对于分割的(D)训练,我们分别训练每个人体成分的基线。 这种独立的策略缺乏组件之间的交互,因此可以用来说明XCI的有效性。 (2) 对于 united (D) 训练,我们将 GCN 的节点数扩展到 55 (, ),就像我们的实验设置一样。 该策略隐含地包含通过全身图的跨上下文交互,但没有考虑不同身体部位的异质性。 因此,用它来证明XCA的有效性。
训练详情: 我们采用 AdamW (Loshchilov 和 Hutter 2017) 优化器,初始学习率为 0.001,批量大小为 64 来训练我们的模型(50 epoch)。 每两个 epoch 学习率衰减 0.96。 权衡参数设置为。 更多详细信息请参阅补充材料。
指标:对于全身运动,我们使用平均每个关节位置误差(MPJPE)(Mao 等人 2019; Mao, Liu, and Salzmann 2020; Li 等人 2020; Ma等人2022)测量整体运动的3D预测精度。 此外,由于手部预测没有基线,我们扩展了主要身体运动预测的基线(Mao 等人 2019; Mao, Liu, and Salzmann 2020; Li 等人 2020; Ma 等人 2022) 进行手动预测,并利用 MPJPE 来衡量预测准确性。 然而,手部的MPJPE受到手腕运动的严重影响,无法显示微妙的手部活动和语义信息。 因此,我们还报告了与手腕对齐(Martinez等人2017)后的MPJPE-AW。
与 SOTA 方法的比较
基线 (U) 与 基线 (D)。 表 1 显示了我们的方法与上述四个基线之间所有操作的平均预测误差。 基线采用两种策略进行训练:分开和联合,如2部分所示。 值得注意的是,由于手部的 MPJPE 受到手腕运动的严重影响,我们还展示了 MPJPE-AW 对精细手部运动的预测。 与分散策略相比,统一训练对身体的预测效果较差。 牌局结果在两个指标上显示出相反的趋势。 上述结果表明: (1) 交互作用对于提高预测精度确实有意义(手牌的 MPJPE 较低)。 (2) 然而,由于主要身体和手势具有异构的运动模式,全身图中交互的隐式建模可能会带来负面的相互干扰(身体的 MPJPE 和手部的 MPJPE-AW 较高) 。
EAI 对比 基线 (UD)。 我们提出的 EAI 解决了现有方法的上述两个局限性。 (1) 对于统一策略,EAI 大幅优于所有基线。 它验证了跨上下文对齐(XCA)的有效性,该对齐考虑了不同身体部位的运动异质性。 (2) 与使用划分策略的基线结果相比,我们的方法更好,这表明跨身体组件的跨上下文交互(XCI)至关重要。 粗糙(主要关节)和精细(手势)属性相互促进,通过 EAI 框架实现更高保真度的预测。
兼容性。 表 2 显示了使用评估指标 MPJPE 进行常见操作的更详细结果。 在大多数情况下,我们的方法获得的误差比其他方法要小。 具有细粒度(喝 吃)和粗粒度(举 通过)运动模式的活动比基线方法实现了更多的改进,这证明了我们提出的兼容性环境影响评估。 此外,所有身体部位的性能增强也验证了考虑不同身体部位的异质性和交互性的必要性。 其他操作的结果可以在补充材料中找到。
可视化。 在图5中,我们通过骨骼形式展示了“玩耍”动作的全身定性结果。 正如紫色虚线椭圆突出显示的那样,上肢和手的绝对预测更接近地面实况(由绿色实线表示)。 它表明,从 EAI 中提取的表达上下文信息可以导致粗细运动的整体细化。 此外,另外两个虚线椭圆通过将手序列与手腕对齐来显示细粒度的手势。 我们观察到 EAI 在相对结果中仍然优于其他基线,这说明可以更好地考虑手势的微妙语义信息。 细粒度和粗粒度运动的结果得到了增强,验证了共同分析不同身体部位对于新颖的全身姿势预测任务的重要性。
消融研究
我们对模型架构进行消融研究以进行更深入的分析。 更多讨论请参见补充材料。 我们在分别去除XCA和XCI以及以下子模块的情况下进行实验:(a)交叉中和(CN),(b)XCA中的差异约束(DC); XCI 中的 (c) 语义交互 (SI),(d) 物理交互 (PI)。
表3报告了详细结果。 完整模型同时包含XCA和XCI,平均预测误差为61.9mm。 (1) 在没有 CN 和 DC 的情况下,预测误差为 66.6mm,这是一个明显的性能下降,表明有必要减轻分布差异。 去掉CN/DC,平均误差增加2.5/1.4mm。 说明CN在XCA中更为关键; (2) 排除整个XCI,预测误差从61.9mm急剧增加到68.7mm。 这个差距比没有整个XCA的情况要大,这表明交互提取相对于异质性减少更为重要。 值得注意的是,XCI (w/o SI) / XCI (w/o PI) 的预测误差增加了 5.6/2.6mm。 它揭示了身体成分的语义相关性对于感知运动属性更有价值。
| CN | DC | PI | SI | 0.2s | 0.4s | 1.0s | Avg. | |
| ✓ | ✓ | ✓ | 16.7 | 40.7 | 90.4 | 64.4 | ||
| ✓ | ✓ | ✓ | 17.0 | 41.3 | 87.9 | 63.3 | ||
| XCA | ✓ | ✓ | 17.0 | 42.8 | 93.7 | 66.6 | ||
| ✓ | ✓ | ✓ | 16.7 | 41.1 | 89.8 | 64.5 | ||
| ✓ | ✓ | ✓ | 17.0 | 42.5 | 94.2 | 67.5 | ||
| XCI | ✓ | ✓ | 17.8 | 43.2 | 95.0 | 68.7 | ||
| Full model | ✓ | ✓ | ✓ | ✓ | 16.7 | 40.7 | 85.8 | 61.9 |
结论
在这项工作中,我们引入了一项新任务:3D 全身人体运动的表达预测。 为了应对这一挑战,我们提出了一种新颖的编码-对齐-交互(EAI)框架,该框架考虑了整个身体内的异构信息以及各个人体成分之间的协作。 我们的方法共同考虑全身内的异构信息以及人体各个组成部分之间的相互作用/协作。 与传统的预测算法相比,EAI 可以交叉促进粗粒度(身体)和细粒度(手势)属性。 大量的实验表明,所提出的方法实现了卓越的性能,并大幅超越了最先进的方法。 考虑到全身预测的下游应用,我们得出结论,所提出的模型具有实际意义;然而,未来仍有一些领域需要进一步探索。 例如,结合与物体的交互可以提供重要的线索,以提高运动预期的准确性。
致谢
该工作得到国家科技创新2030重大专项(批准号: 2022ZD0208800)和国家自然科学基金面上项目(批准号: 62176215)。 该工作得到国家自然科学基金项目(62306141)、江苏省优秀博士后人才资助计划(2022ZB269)、江苏省自然科学基金项目(BK20220939)的资助中国博士后科学基金(2022M721629)资助。
参考
- Adeli et al. (2021) Adeli, V.; Ehsanpour, M.; Reid, I.; Niebles, J. C.; Savarese, S.; Adeli, E.; and Rezatofighi, H. 2021. TRiPOD: Human Trajectory and Pose Dynamics Forecasting in the Wild. In IEEE/CVF International Conference on Computer Vision, 13390–13400.
- Butepage et al. (2017) Butepage, J.; Black, M. J.; Kragic, D.; and Kjellstrom, H. 2017. Deep representation learning for human motion prediction and classification. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, 6158–6166.
- Bütepage, Kjellström, and Kragic (2018) Bütepage, J.; Kjellström, H.; and Kragic, D. 2018. Anticipating many futures: Online human motion prediction and generation for human-robot interaction. In 2018 IEEE/CVF International Conference on Robotics and Automation (ICRA), 4563–4570.
- Cai et al. (2020) Cai, Y.; Huang, L.; Wang, Y.; Cham, T.-J.; Cai, J.; Yuan, J.; Liu, J.; Yang, X.; Zhu, Y.; Shen, X.; et al. 2020. Learning progressive joint propagation for human motion prediction. In European Conference on Computer Vision, 226–242.
- Cai et al. (2021) Cai, Y.; Wang, Y.; Zhu, Y.; Cham, T.-J.; Cai, J.; Yuan, J.; Liu, J.; Zheng, C.; Yan, S.; Ding, H.; et al. 2021. A Unified 3D Human Motion Synthesis Model via Conditional Variational Auto-Encoder. In IEEE/CVF International Conference on Computer Vision, 11645–11655.
- Corona et al. (2020) Corona, E.; Pumarola, A.; Alenya, G.; and Moreno-Noguer, F. 2020. Context-aware human motion prediction. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, 6992–7001.
- Cui and Sun (2021) Cui, Q.; and Sun, H. 2021. Towards Accurate 3D Human Motion Prediction From Incomplete Observations. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, 4801–4810.
- Dang et al. (2021) Dang, L.; Nie, Y.; Long, C.; Zhang, Q.; and Li, G. 2021. MSR-GCN: Multi-Scale Residual Graph Convolution Networks for Human Motion Prediction. In IEEE/CVF International Conference on Computer Vision, 11467–11476.
- Diller, Funkhouser, and Dai (2022) Diller, C.; Funkhouser, T.; and Dai, A. 2022. Forecasting characteristic 3D poses of human actions. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, 15914–15923.
- Ding and Yin (2021) Ding, P.; and Yin, J. 2021. Uncertainty-aware Human Motion Prediction. arXiv preprint arXiv:2107.03575.
- Ding and Yin (2022) Ding, P.; and Yin, J. 2022. Towards more realistic human motion prediction with attention to motion coordination. IEEE Transactions on Circuits and Systems for Video Technology, 32(9): 5846–5858.
- Feng et al. (2021) Feng, Y.; Choutas, V.; Bolkart, T.; Tzionas, D.; and Black, M. J. 2021. Collaborative regression of expressive bodies using moderation. In 2021 International Conference on 3D Vision (3DV), 792–804.
- Gui et al. (2018) Gui, L.-Y.; Wang, Y.-X.; Liang, X.; and Moura, J. M. 2018. Adversarial geometry-aware human motion prediction. In European Conference on Computer Vision, 786–803.
- Guo et al. (2022) Guo, W.; Bie, X.; Alameda-Pineda, X.; and Moreno-Noguer, F. 2022. Multi-Person Extreme Motion Prediction. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, 13053–13064.
- Hao et al. (2017) Hao, Y.; Zhang, Y.; Liu, K.; He, S.; Liu, Z.; Wu, H.; and Zhao, J. 2017. An end-to-end model for question answering over knowledge base with cross-attention combining global knowledge. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 221–231.
- Hidalgo et al. (2019) Hidalgo, G.; Raaj, Y.; Idrees, H.; Xiang, D.; Joo, H.; Simon, T.; and Sheikh, Y. 2019. Single-network whole-body pose estimation. In IEEE/CVF International Conference on Computer Vision, 6982–6991.
- Honda, Kawakami, and Naemura (2020) Honda, Y.; Kawakami, R.; and Naemura, T. 2020. RNN-based Motion Prediction in Competitive Fencing Considering Interaction between Players. In BMVC.
- Ionescu et al. (2013) Ionescu, C.; Papava, D.; Olaru, V.; and Sminchisescu, C. 2013. Human3. 6m: Large scale datasets and predictive methods for 3d human sensing in natural environments. IEEE transactions on pattern analysis and machine intelligence, 36(7): 1325–1339.
- Jin et al. (2020) Jin, S.; Xu, L.; Xu, J.; Wang, C.; Liu, W.; Qian, C.; Ouyang, W.; and Luo, P. 2020. Whole-body human pose estimation in the wild. In European Conference on Computer Vision, 196–214.
- Li et al. (2021) Li, J.; Yang, F.; Ma, H.; Malla, S.; Tomizuka, M.; and Choi, C. 2021. RAIN: Reinforced Hybrid Attention Inference Network for Motion Forecasting. In IEEE/CVF International Conference on Computer Vision.
- Li et al. (2022) Li, M.; Chen, S.; Zhang, Z.; Xie, L.; Tian, Q.; and Zhang, Y. 2022. Skeleton-Parted Graph Scattering Networks for 3D Human Motion Prediction. In European Conference on Computer Vision.
- Li et al. (2020) Li, M.; Chen, S.; Zhao, Y.; Zhang, Y.; Wang, Y.; and Tian, Q. 2020. Dynamic multiscale graph neural networks for 3d skeleton based human motion prediction. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, 214–223.
- Li et al. (2018) Li, R.; Wang, S.; Zhu, F.; and Huang, J. 2018. Adaptive graph convolutional neural networks. In AAAI Conference on Artificial Intelligence, 1.
- Liu et al. (2020) Liu, X.; Yin, J.; Liu, J.; Ding, P.; Liu, J.; and Liu, H. 2020. Trajectorycnn: a new spatio-temporal feature learning network for human motion prediction. IEEE Transactions on Circuits and Systems for Video Technology, 31(6): 2133–2146.
- Loshchilov and Hutter (2017) Loshchilov, I.; and Hutter, F. 2017. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101.
- Ma et al. (2022) Ma, T.; Nie, Y.; Long, C.; Zhang, Q.; and Li, G. 2022. Progressively Generating Better Initial Guesses Towards Next Stages for High-Quality Human Motion Prediction. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, 6437–6446.
- Mao, Liu, and Salzmann (2020) Mao, W.; Liu, M.; and Salzmann, M. 2020. History repeats itself: Human motion prediction via motion attention. In European Conference on Computer Vision, 474–489.
- Mao et al. (2019) Mao, W.; Liu, M.; Salzmann, M.; and Li, H. 2019. Learning trajectory dependencies for human motion prediction. In International Conference on Computer Vision, 9489–9497.
- Martinez et al. (2017) Martinez, J.; Hossain, R.; Romero, J.; and Little, J. J. 2017. A simple yet effective baseline for 3d human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2640–2649.
- Pavlakos et al. (2019) Pavlakos, G.; Choutas, V.; Ghorbani, N.; Bolkart, T.; Osman, A. A.; Tzionas, D.; and Black, M. J. 2019. Expressive body capture: 3d hands, face, and body from a single image. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, 10975–10985.
- Petrovich, Black, and Varol (2021) Petrovich, M.; Black, M. J.; and Varol, G. 2021. Action-Conditioned 3D Human Motion Synthesis With Transformer VAE. In IEEE/CVF International Conference on Computer Vision, 10985–10995.
- Rong, Shiratori, and Joo (2021) Rong, Y.; Shiratori, T.; and Joo, H. 2021. Frankmocap: A monocular 3d whole-body pose estimation system via regression and integration. In IEEE/CVF International Conference on Computer Vision, 1749–1759.
- Ruiz, Gall, and Moreno-Noguer (2018) Ruiz, A. H.; Gall, J.; and Moreno-Noguer, F. 2018. Human Motion Prediction via Spatio-Temporal Inpainting. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, 7134–7143.
- Taheri et al. (2020) Taheri, O.; Ghorbani, N.; Black, M. J.; and Tzionas, D. 2020. GRAB: A dataset of whole-body human grasping of objects. In European Conference on Computer Vision, 581–600.
- Tarvainen and Valpola (2017) Tarvainen, A.; and Valpola, H. 2017. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. Advances in Neural Information Processing Systems, 30.
- Vaswani et al. (2017) Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A. N.; Kaiser, L.; and Polosukhin, I. 2017. Attention is All you Need. In Advances in Neural Information Processing Systems.
- von Marcard et al. (2018) von Marcard, T.; Henschel, R.; Black, M.; Rosenhahn, B.; and Pons-Moll, G. 2018. Recovering Accurate 3D Human Pose in The Wild Using IMUs and a Moving Camera. In European Conference on Computer Vision.
- Wang et al. (2021) Wang, J.; Xu, H.; Narasimhan, M.; and Wang, X. 2021. Multi-Person 3D Motion Prediction with Multi-Range Transformers. Advances in Neural Information Processing Systems, 34: 6036–6049.
- Yuan and Kitani (2020) Yuan, Y.; and Kitani, K. 2020. Dlow: Diversifying Latent Flows for Diverse Human Motion Prediction. In European Conference on Computer Vision, 346–364.
- Zhang, Black, and Tang (2021) Zhang, Y.; Black, M. J.; and Tang, S. 2021. We Are More Than Our Joints: Predicting How 3D Bodies Move. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, 3372–3382.
- Zhong et al. (2022) Zhong, C.; Hu, L.; Zhang, Z.; Ye, Y.; and Xia, S. 2022. Spatio-Temporal Gating-Adjacency GCN for Human Motion Prediction. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, 6447–6456.