FedDiv:带有噪声标签的联邦学习的协作噪声过滤
摘要
带有噪声标签的联合学习(F-LNL)旨在通过聚合使用本地噪声或干净样本训练的多个客户端模型,通过协作分布式学习来寻求最佳服务器模型。 在联邦学习框架的基础上,最近的进展主要采用标签噪声过滤来将每个客户端上的干净样本与噪声样本分离,从而减轻标签噪声的负面影响。 然而,这些现有方法并没有通过利用所有客户端的知识来学习噪声滤波器,导致噪声过滤性能次优且较差,从而损害训练稳定性。 在本文中,我们提出了 FedDiv 来应对 F-LNL 的挑战。 具体来说,我们提出了一种称为联合噪声滤波器的全局噪声滤波器,用于有效识别每个客户端上带有噪声标签的样本,从而提高本地训练会话期间的稳定性。 在不牺牲数据隐私的情况下,这是通过对所有客户端的标签噪声的全局分布进行建模来实现的。 然后,为了使全局模型达到更高的性能,我们引入了基于预测一致性的采样器来为局部模型训练识别更可信的局部数据,从而防止噪声记忆并进一步提高训练稳定性。 在 CIFAR-10、CIFAR-100 和 Clothing1M 上进行的大量实验表明,在 IID 和非 IID 的不同标签噪声设置下,FedDiv 的性能优于最先进的 F-LNL 方法数据分区。 源代码可在 https://github.com/lijichang/FLNL-FedDiv 上公开获取。
介绍
与传统的集中学习(Li 等人 2019b, 2021, a; Wu 等人 2019b, a; Huang 等人 2023)相比,联邦学习(FL)是一种促进跨多个客户端协作学习的新颖范式无需集中式本地数据(McMahan 等人 2017)。 最近,FL 在医疗保健 (Nguyen 等人 2022)、推荐系统 (Yang 等人 2020) 和智慧城市 等领域取得了巨大的现实成功(郑等人2022)。 然而,这些 FL 方法假定所有客户的私人数据都有清洁标签,但由于数据复杂性和标签质量不受控制,现实情况往往并非如此(Tanno 等人 2019;Kuznetsova 等人 2020)。 尤其是在隐私保护的加持下,不可能保证绝对的标签准确性。 因此,这项工作的重点是带有噪声标签的联邦学习(F-LNL)。 在 F-LNL 中,全局神经网络模型通过跨多个具有噪声样本的本地客户端的分布式学习进行微调。 与(Xu 等人 2022) 一样,我们在这里也假设一些本地客户端具有嘈杂标签(即嘈杂客户端),而其他本地客户端仅具有干净标签(即干净客户端)。
除了本地客户的私有数据外,F-LNL 还面临两个主要挑战:数据异质性和噪声异质性(Kim 等人 2022; Yang 等人 2022b)。 数据异质性是指不同客户端之间统计上异质的数据分布,而噪声异质性表示客户端之间不同的噪声分布。 (Xu 等人 2022; Kim 等人 2022) 已经证明,F-LNL 中的这两个挑战可能会导致本地训练过程中的不稳定。 F-LNL 先前的研究(Xu 等人 2022; Kim 等人 2022) 已经证明了许多 FL 方法,例如 (McMahan 等人 2017; Li 等人 2020),现在用于充分解决第一个挑战。 这些方法主要侧重于通过协调本地更新和全局聚合的优化目标来实现具有收敛保证的训练稳定性。 然而,他们并没有解决个别客户的标签噪音问题。 因此,为了解决噪声异质性,此类 F-LNL 算法建议将噪声数据分离为干净样本和噪声样本,偶尔通过重新标记噪声样本来补充。 这样做的目的是减轻噪声标签的负面影响,并防止局部模型过度拟合此类标签噪声,从而避免局部训练过程的严重不稳定。
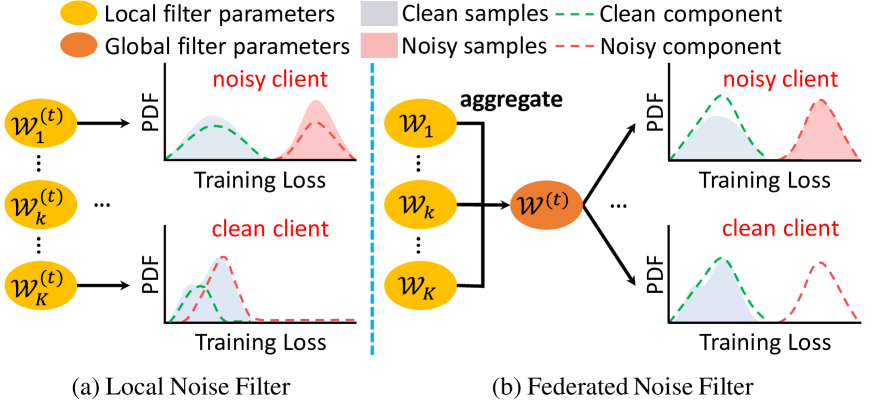
因此,一些 F-LNL 方法(Kim 等人 2022; Xu 等人 2022) 强调提出局部噪声过滤,其中每个客户端开发自己的噪声过滤器来识别噪声标签。 然而,这些噪音过滤策略忽略了从其他客户那里学习丰富知识以增强其能力的潜力。 相反,他们严重依赖每个客户自己的私人数据进行训练,从而导致次优和较差的性能。 例如,如图1(a)所示,每个客户端上可用的训练样本有限,阻碍了对其局部噪声分布的准确建模,从而严重限制了噪声过滤能力。 此外,如果噪声过滤和重新标记处理不当,不可避免地会发生噪声标签的过度拟合,导致噪声记忆,从而降低模型聚合时的全局性能。 制定防止噪声记忆的策略(Yang 等人 2022a),同时增强训练稳定性至关重要,但现有的 F-LNL 算法尚未成功实现这一目标。
在本文中,我们提出了一个新颖的框架 FedDiv 来应对 F-LNL 的挑战。 为了对每个客户端执行标签噪声过滤,FedDiv 由一个称为联合噪声滤波器 (FNF) 的全局噪声滤波器组成,它是通过对所有客户端上噪声样本的全局分布进行建模而构建的。 具体来说,通过拟合私有数据的损失函数值,可以在每个客户端上迭代学习局部高斯混合模型(GMM)的参数,以对其局部噪声分布进行建模。 然后,这些参数在服务器上聚合以构建全局 GMM 模型,该模型充当全局噪声滤波器,有效地将每个本地客户端上的样本分类为干净或噪声。 如图 1(b) 所示,通过利用所有客户端协作学习的知识,FedDiv 展示了适应各个干净或嘈杂客户端内的本地标签噪声分布的强大能力。 此功能增强了每个客户端的噪声过滤性能,从而减少了本地会话期间训练的不稳定性,同时保护了数据隐私。
在标签噪声过滤之后,我们从每个客户端上识别的噪声样本中删除噪声标签,并使用全局模型预测的伪标签重新标记那些表现出高预测置信度的样本。 为了进一步防止本地模型记住标签噪声并提高训练稳定性,我们引入了基于预测一致性的采样器(PCS),用于识别本地模型训练的可信本地数据。 具体来说,我们强制全局和局部模型预测的类标签的一致性,并应用反事实推理(Holland 1986;Wang等人2022)为局部样本生成更可靠的预测。
综上所述,本文的贡献如下。
-
•
我们提出了一种新颖的单阶段框架 FedDiv,用于解决带有噪声标签的联邦学习 (F-LNL) 的任务。 为了实现稳定的训练,FedDiv 通过提取所有客户端的补充知识来学习全局噪声滤波器,同时在每个客户端上本地执行标签噪声过滤。
-
•
我们引入了基于预测一致性的采样器来对每个客户端执行标记样本重新选择,从而防止本地模型记住标签噪声并进一步提高训练稳定性。
-
•
通过对 CIFAR-10 (Krizhevsky 2009)、CIFAR-100 (Krizhevsky 2009) 和 Clothing1M (Xiao 等人 2015) 进行大量实验数据集上,我们证明了 FedDiv 在 IID 和非 IID 数据分区的各种标签噪声设置下显着优于最先进的 F-LNL 方法。
相关工作
带噪声标签的集中学习(C-LNL)。 与集中学习的传统范式不同,例如(Li, Li, and Yu 2023a, b) 仅对具有干净标签的训练样本进行操作,多项研究已经证明了解决 C-LNL 的方法在减少模型对噪声标签的过度拟合方面的效果。 例如,JointOpt (Tanaka 等人 2018a) 提出了一种联合优化框架,通过交替更新模型参数和标签来纠正训练期间噪声样本的标签。 此外,DivideMix (Li、Socher 和 Hoi 2019) 将带有标签噪声的训练示例动态分离为干净和噪声子集,并结合辅助半监督学习算法以进行进一步模型训练。 处理 C-LNL 任务的其他策略包括估计噪声转移矩阵(Cheng 等人 2022)、重新权衡训练数据(Ren 等人 2018)、设计稳健的损失函数(Englesson 和 Azizpour 2021),集成现有技术(Li 等人 2022),等等。
考虑到去中心化应用程序中的隐私限制,服务器无法直接访问所有客户端的本地样本来构建集中式噪声过滤算法。 此外,本地客户端上有限数量的私有数据也可能限制噪声过滤能力。 因此,尽管现有的 C-LNL 算法取得了成功,但它们在联邦设置中可能不再可行(Xu 等人 2022)。
带有噪音标签的联邦学习。 许多方法可以解决带有标签噪声的联合场景中的挑战。 例如,FedRN (Kim 等人 2022) 使用集成高斯混合模型 (GMM) 检测本地客户端中的干净样本,该模型经过训练以拟合由多个评估的本地数据的损失函数值可靠的邻近客户模型。 RoFL (Yang 等人 2022b) 在本地训练期间直接使用客户端的小损失实例进行优化,以减轻标签噪声影响。 同时,FedCorr(Xu 等人 2022) 首先引入了基于维度的噪声滤波器,利用局部固有维度将客户端分为干净组和噪声组(Ma 等人2018),并训练本地噪声滤波器,根据每个样本的训练损失将干净的示例与已识别的噪声客户端分开。
然而,现有的 F-LNL 算法专注于本地噪声过滤,利用每个客户端的私有数据,但未能利用跨客户端的集体知识。 此限制可能会损害噪声过滤效果,导致标签噪声去除不完整并影响本地训练会话的稳定性。 相反,FedDiv训练提出从所有客户端中提取知识以进行联合噪声过滤,增强每个客户端样本中的标签噪声识别并改进标签噪声中的FL模型。
方法
在本节中,我们介绍了提出的名为 FedDiv 的单阶段框架,用于带有噪声标签的联邦学习。 具体来说,我们首先采用经典的 FL 范式,即 FedAvg (McMahan 等人 2017) 来训练神经网络模型。 在此 FL 框架的基础上,我们提出了一种称为联邦噪声滤波器(FNF)的全局滤波器模型,用于在每个客户端上执行标签噪声过滤和噪声样本重新标记。 然后,为了提高本地训练的稳定性,提出了基于预测一致性的采样器(PCS)来进行标记样本重选,防止客户端模型记住标签噪声。
让我们考虑一个 FL 场景,其中包含一台服务器和 个本地客户端(用 表示)。 每个客户都有自己的私有数据,包括样本-label pairs ,其中,是训练样本,是类的标签索引。 在这里,我们将本地客户端分为两组:干净客户端(噪声级别 其中 ),只有样本带有干净的标签和嘈杂的客户端(带有 此外,在这项工作中,还考虑了 IID 和非 IID 异构数据分区。
| Method | Best Test Accuracy Standard Deviation | |||||
|---|---|---|---|---|---|---|
| =0.4 | =0.6 | =0.8 | ||||
| =0.0 | =0.5 | =0.0 | =0.5 | =0.0 | =0.5 | |
| FedAvg | 89.460.39 | 88.310.80 | 86.090.50 | 81.221.72 | 82.911.35 | 72.002.76 |
| RoFL | 88.250.33 | 87.200.26 | 87.770.83 | 83.401.20 | 87.080.65 | 74.133.90 |
| ARFL | 85.871.85 | 83.143.45 | 76.771.90 | 64.313.73 | 73.221.48 | 53.231.67 |
| JointOpt | 84.420.70 | 83.010.88 | 80.821.19 | 74.091.43 | 76.131.15 | 66.161.71 |
| DivideMix | 77.350.20 | 74.402.69 | 72.673.39 | 72.830.30 | 68.660.51 | 68.041.38 |
| FedCorr | 94.010.22 | 94.150.18 | 92.930.25 | 92.500.28 | 91.520.50 | 90.590.70 |
| FedDiv (Ours) | 94.420.29 | 94.300.19 | 93.670.22 | 93.410.21 | 92.980.60 | 91.440.25 |
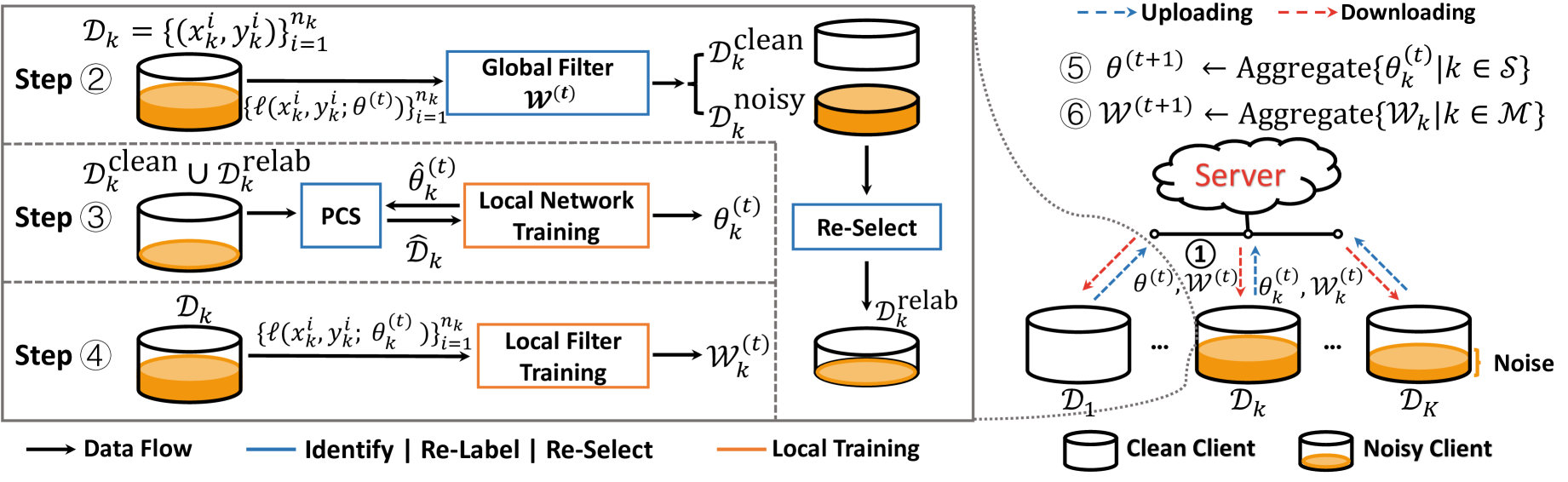
如图2所示,第轮通信的训练过程执行以下步骤:
步 : The server broadcasts the parameters of the global neural network model and the federated noise filtering model to every client , where is a subset of clients randomly selected with a fixed fraction in this round.
步 :在每个 上、 用于将 分离为噪声样本和干净样本、并将预测置信度高的噪声样本分配给由 预测的伪标签。
步 (本地模型训练):每个客户端使用干净的子集训练其本地神经网络并使用PCS重新标记噪声样本以获得其更新的局部参数。 在这里,我们使用 表示本次训练期间优化的本地模型的参数。
步 (本地滤波器训练):每个客户端使用更新的参数 通过拟合其私有数据 Such loss function values are evaluated using the logits of training samples in predicted by .
步 :服务器聚合 ,然后更新全局模型,如下所示,
| (1) |
步 (联邦过滤器聚合):服务器收集 更新现有服务器cached local filter parameters ,然后汇总所有本地过滤器 以获得更新的联合噪声过滤模型 。
重复此训练过程,直到全局模型稳定收敛或达到预定义的通信轮数。 每轮沟通都涉及本地培训课程(步骤 - )在几个随机选择的客户端和模型聚合阶段(步骤 - )在服务器上。 步骤的详细内容 , 步 ,和步骤 在“联邦噪声滤波器”中提供了,而步骤的详细描述 在“基于预测一致性的采样器”和“局部模型训练的目标”中给出。
联合噪声滤波器
为了识别 F-LNL 任务的标签噪声,我们提出了一种联合噪声滤波器(FNF),它对所有客户端中干净和噪声样本的全局分布进行建模。 受(Zhu 等人 2022) 的启发,这个 FNF 模型可以通过联邦 EM 算法构建。 具体来说,我们首先进行局部过滤训练以获得局部估计的GMM参数。 这个目标是通过对每个客户端迭代执行标准 EM 算法(Dempster、Laird 和 Rubin 1977) 以适应其局部噪声分布来实现的。 然后,我们执行联合滤波器聚合来聚合从所有客户端接收到的本地 GMM 参数,以构建联合噪声滤波器。
本地过滤训练。 一般来说,带有标签噪声的样本在模型训练过程中往往具有较高的损失函数值,因此可以使用混合模型使用训练样本的每个样本损失值将噪声样本与干净样本分开(Arazo 等人 2019a ;Li、Socher 和 Hoi 2019)。 因此,对于第轮通信中的第个客户端,可以构建局部GMM,通过拟合每个样本来对干净样本和噪声样本的局部分布进行建模。 -样本损失分布,
| (2) |
其中 是样本-标签对 当本地模型 被用于预测时。 Then, we denote the two-component GMM model by , where and are vectors with entries and denoting the mean and variance of the -th Gaussian component, respectively. 这里,我们设置 来表示“干净”的高斯分量,即具有较小的平均值(较小的损失),而 表示“嘈杂”的平均值。
我们进一步定义一个离散变量来表示样本是干净的还是有噪声的。 表示 的先验分布,即,where should satisfyand for 。 因此, 被建模为高斯分布 。 然后,后验 ,表示给定损失值的样本 是干净样本()还是噪声样本()的概率,计算公式为
| (3) |
Afterwards, for each client , leveraging its private data , updated local parameters , and the federated filter parameters received from the server, its optimal local filter parameters at current round are derived through the training of the local GMM models utilizing a standard EM algorithm (Dempster, Laird, and Rubin 1977). 注意到,起源这里来自服务器用于初始化 加速收敛。
在第轮通信中,一旦我们在中的客户端上执行了本地过滤器训练,我们就上传本地过滤器参数 到服务器。 然后,服务器更新其缓存的与中每个客户端对应的本地过滤器参数,如下所示:
| (4) |
其中 是第 客户端上本地噪声滤波器的服务器缓存版本。 请注意,FedDiv 只发送三个数字矩阵(即、、和)从每个客户端发送到服务器,它们只是反映了每个客户端的本地噪声分布,而不是原始输入数据,从而避免了任何数据隐私泄露的风险。
| Method | Best Test Accuracy Standard Deviation | ||
|---|---|---|---|
| FedAvg | 78.882.34 | 75.982.92 | 67.754.38 |
| RoFL | 79.561.39 | 72.752.21 | 60.723.23 |
| ARFL | 60.193.33 | 55.863.30 | 45.782.84 |
| JointOpt | 72.191.59 | 66.921.89 | 58.082.18 |
| DivideMix | 65.700.35 | 61.680.56 | 56.671.73 |
| FedCorr | 90.520.89 | 88.031.08 | 81.573.68 |
| FedDiv (Ours) | 93.180.42 | 91.950.26 | 85.312.28 |
联合过滤器聚合。 参数上传后,聚合所有客户端对应的本地过滤器参数即可构建联邦过滤器模型 如下,
| (5) |
其中 将用于在
标签噪声过滤。 在第 轮通信中、一旦 -th 客户端从服务器接收到全局模型 和联合筛选模型 的参数、来自 的样本 是干净的概率可以通过其 "干净 "部分的后验概率估算如下
| (6) |
Afterwards, we can divide the samples of into a clean subset and a noisy subset by thresholding their probabilities of being clean with the threshold as follows,
| (7) |
嘈杂的样本重新标记。 我们将第 个客户端的噪声级别计算为 ,而如果 对于识别出的噪声客户端,我们只需丢弃来自 的噪声样本的给定标签,以防止通过在进一步的本地训练中记忆标签噪声来建立模型。 为了利用这些未标记(有噪声)的样本,我们通过从全局模型分配预测标签来重新标记具有高预测置信度的样本(通过设置置信度阈值),如下所示,
| (8) |
其中 is the pseudo-是全局模型 预测的样本 的伪标签。
| Method | Best Test Accuracy Standard Deviation | ||
|---|---|---|---|
| =0.4 | =0.6 | =0.8 | |
| =0.5 | =0.5 | =0.5 | |
| FedAvg | 64.411.79 | 53.512.85 | 44.452.86 |
| RoFL | 59.422.69 | 46.243.59 | 36.653.36 |
| ARFL | 51.534.38 | 33.031.81 | 27.471.08 |
| JointOpt | 58.431.88 | 44.542.87 | 35.253.02 |
| DivideMix | 43.251.01 | 40.721.41 | 38.911.25 |
| FedCorr | 74.430.72 | 66.784.65 | 59.105.12 |
| FedDiv (Ours) | 74.860.91 | 72.371.12 | 65.492.20 |
基于预测一致性的采样器
在客户机 的 第三轮中、在获得干净子集 和重新标注子集 后、我们将它们整合到跨 局部纪元的有监督局部模型训练中。 然而,在噪声过滤和重新标记过程中完全消除客户端之间的标签噪声是无法实现的。 另一方面,重新标记不可避免地引入新的标签训练噪声,导致局部模型不稳定,从而进一步对聚合过程中全局模型的性能产生负面影响。 为了解决这个问题,我们提出了一个基于预测一致性训练的采样器(PCS)来重新选择本地标记样本。 具体来说,我们观察到强制全局和局部模型分别预测的类标签的一致性是实现这一目标的一个很好的策略。 随着训练的进行,模型针对标签噪声的鲁棒性将显着提高(见下文)。),从而轻松提高具有新标签噪声的样本的预测可靠性。
此外,由于联合设置中的数据异构性,特别是对于非 IID 数据分区,各个客户端拥有的本地训练样本通常属于较小的主导类集合。 因此,具有新引入的标签噪声的主导类样本在局部模型训练期间会更好地进行自我校正,逐渐导致与全局模型的预测不一致。 然而,这种类不平衡的局部数据也会导致局部模型偏向于主导类(Wei等人2021),这使得局部模型更难产生正确的伪数据-属于少数类别的样本的标签。 所提出的 PCS 策略减轻了模型偏差,以提高本地模型生成的类标签的可靠性。 在这里,我们可以通过反事实推理改善因果关系来消除模型预测的偏差(Holland 1986; Pearl 2009; Wang 等人 2022),因此,样本 来自 或
| (9) |
其中 是稍后用于生成去偏伪标签的去偏 logit,即 ,而。 是样本的原始对数。、目前正在优化。 表示本地模型相对于所有类的总体偏差,之前根据方程式更新过。 (12) 并在最后一次本地训练会话期间缓存在第 个客户端上。
| Dataset | CIFAR-100 | Clothing1M |
|---|---|---|
| Noise level (, ) | (0.4, 0.0) | - |
| Method\(, ) | (0.7, 10) | - |
| FedAvg | 64.751.75 | 70.49 |
| RoFL | 59.314.14 | 70.39 |
| ARFL | 48.034.39 | 70.91 |
| JointOpt | 59.841.99 | 71.78 |
| DivideMix | 39.761.18 | 68.83 |
| FedCorr | 72.731.02 | 72.55 |
| FedDiv (Ours) | 74.470.34 | 72.960.43 |
之后,使用PCS重新选择质量更高、更可靠的标记训练样本进行本地训练,如下:
| (10) |
与(Xu 等训练2022)类似,我们更新数据集以进一步优化本地模型,如下所示,
| (11) |
一旦获得优化的 来自本地训练会话,我们用它来更新 动量如下,
| (12) |
其中 是动量系数。 We save on the -th client to update existing client-cached .
本地模型训练的目标
为了增强模型对标签噪声的鲁棒性,我们在这里使用 MixUp 正则化 (Zhang 等人 2018) 进行本地模型训练,进一步削弱训练的不稳定性。 Specifically, two sample-label pairs and from are augmented using linear interpolation, and , where is a mixup ratio, is a scalar to control its distribution, and is a function to generate a one-hot vector for a given label. 因此,在第 轮通信中的第 客户端上,本地模型 通过应用于一个小批量中的
| (13) |
由于非独立同分布数据分区的高度异质性,每个客户端上可能只有有限数量的类别,大量实验表明,这种数据分区迫使本地模型预测相同的类标签,以最大限度地减少训练损失。 如(Tanaka 等人 2018b; Arazo 等人 2019b) 所示,使用均匀先验分布对每个小批量的局部模型的平均预测进行正则化是克服上述问题的可行解决方案,即,
| (14) |
where denotes the prior probability of a class . is the -th element of the vector q, which refers to the predicted probability of the class averaged over augmented training samples in a mini-batch.
最后,在第轮通信中的第个客户端上,优化局部模型的整体损失函数定义如下:
| (15) |
其中是平衡 和 实验中,当数据分区为非独立同分布时,我们设置;否则,。
实验
实验设置
公平地说,我们在这里采用与 FedCorr (Xu 等人 2022) 一致的实验设置来评估我们提出的方法 FedDiv 的有效性。 补充文件(缩写)中提供了更多详细信息,例如数据分区以及其他实现和分析。 补充111https://github.com/lijichang/FLNL-FedDiv/blob/main/supp.pdf)。
数据集和数据分区。 我们在三个经典基准数据集上验证了 FedDiv 的优越性,其中包括两个合成数据集,即 CIFAR-10 (Krizhevsky 2009) 和 CIFAR-100 (Krizhevsky 2009),以及一个真实世界的噪声数据集,即 Clothing1M (Xiao 等人 2015)。 与(Xu 等人 2022) 一样,我们在 CIFAR-10 和 CIFAR-100 上同时考虑 IID 和非 IID 数据分区,但在 Clothing1M 上仅考虑非 IID 数据分区。 在 IID 数据分区下,每个客户端都被随机分配到每个类别的相同数量的样本。 对于非独立同分布数据分区,它是使用具有两个预定义参数的狄利克雷分布(Lin等人2020)构建的,即固定概率和浓度参数。
标签噪声设置。 与(Xu 等人 2022)类似,第个客户端的噪声级别可以定义如下:
| (16) |
这里,表示客户端有噪音的概率。 对于 的嘈杂客户端>,噪声水平最初从均匀分布中随机采样 , 随后, 的本地示例被随机选择为噪声样本,其真实标签被所有可能的类标签替换。
基线。 我们将 FedDiv 与现有最先进 (SOTA) F-LNL 方法进行比较,包括 FedAvg (McMahan 等人 2017), RoFL (杨等人 2022b), ARFL (杨等人 2022b), JointOpt (Tanaka 等人 2018a)、DivideMix (Li、Socher 和 Hoi 2019)0> 和 FedCorr1> (徐等人2022)2>。 他们在本文中报道的实验结果借鉴于(Xu等人2022)。
实现。 我们将 CIFAR-10、CIFAR-100 和 Clothing1M 上的 和 分别设置为 950、900 和 100,以及 0.1、0.1 和 0.02,同时我们还设置用于在所有数据集上重新标记的置信度阈值 。 请注意,为了实现更快的收敛,我们为 次迭代(不是训练轮次;参见 (Xu 等人 2022)),使用 MixUp 正则化 (Zhang 等人 2018). 此外,公平地说,对于所有联合设置下的每个数据集,我们涉及本地训练和模型聚合的大多数实现细节都与 FedCorr (Xu 等人 2022) 一致,并且所有标签噪声设置。
型号变体。 我们构建 FedDiv 的变体来评估所提出的噪声滤波器的效果,如下所示。
-
•
FedDiv(Degraded):继(Zhu等人2022)之后,我们在这里通过仅使用在本轮而不是所有客户的轮次。
-
•
FedDiv(本地过滤器):使用自己的私有数据为每个客户端训练本地噪声过滤器,以识别各个客户端内的噪声标签。
与最先进技术的比较
表 1-4 总结了 FedDiv 相对于 CIFAR-10 上最先进的 (SOTA) F-LNL 方法的分类性能, CIFAR-100 和 Clothing1M 涵盖 IID 和非 IID 数据分区的各种噪声设置。 基于五次试验的平均准确度和标准差的比较结果证明了 FedDiv 相对于现有 F-LNL 算法的显着优势,尤其是在具有挑战性的情况下。 例如,在 IID 数据分区中,表 3 说明 FedDiv 在 CIFAR-100 上的表现优于 FedCorr 6.39%,在最严格的噪声设置中使用 。 Similarly, for non-IID partitions in Table 2, FedDiv consistently surpasses FedCorr by 3.74% in the most challenging setting on CIFAR-10. 此外,在表 4 中,FedDiv 在 Clothing1M 上比 FedCorr 提高了 0.41%,表明其在现实世界标签噪声分布中的功效。
| Dataset | CIFAR-10 | CIFAR-100 |
|---|---|---|
| Noise level (, ) | (0.6, 0.5) | (0.4,0.0) |
| Method\(, ) | (0.3, 10) | (0.7, 10) |
| FedDiv (Ours) | 85.312.28 | 74.470.34 |
| FedDiv (Degraded) | 83.222.61 | 73.060.93 |
| FedDiv (Local filter) | 81.343.65 | 71.370.76 |
| FedDiv w/o Relab. & w/o PCS | 82.173.06 | 73.091.89 |
| FedDiv w/o PCS | 82.832.59 | 73.660.96 |
| FedDiv w/o | 83.603.65 | 72.431.29 |
消融分析
为了强调 FedDiv 的功效,我们进行了一项消融研究来证明每个组件的效果。
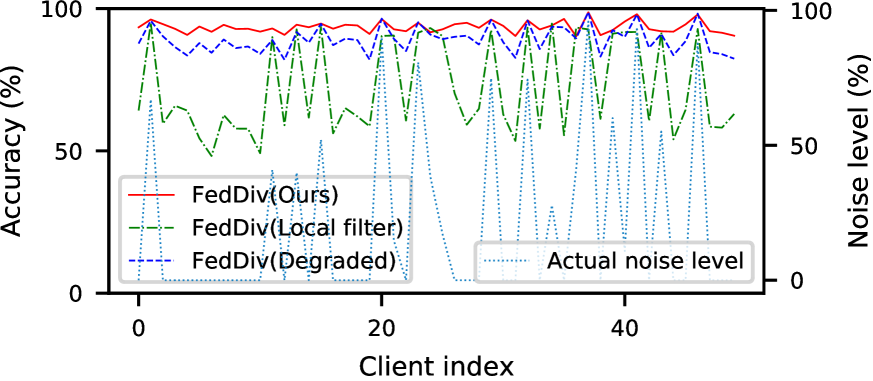
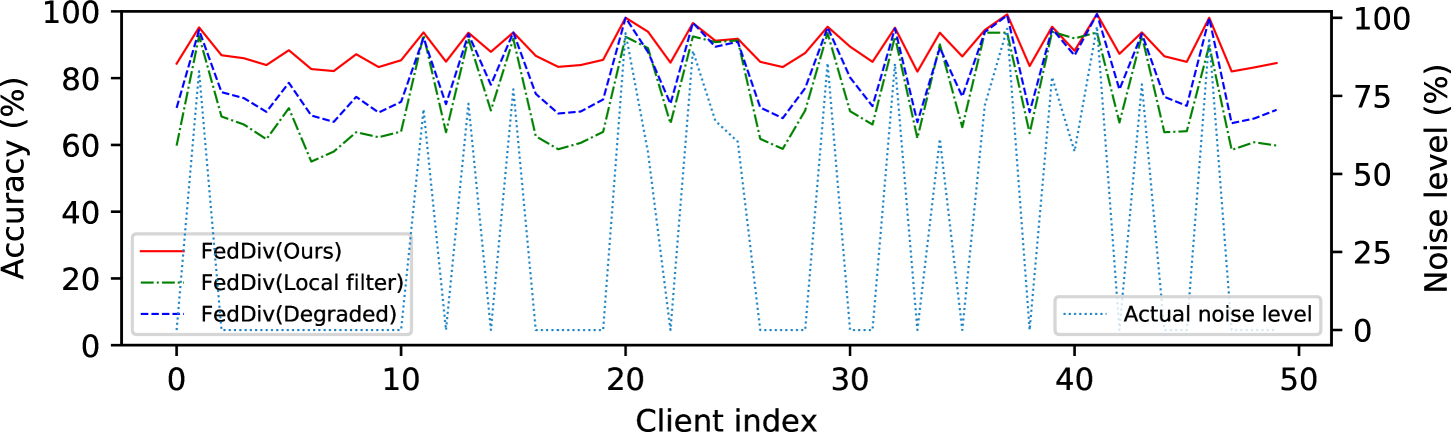
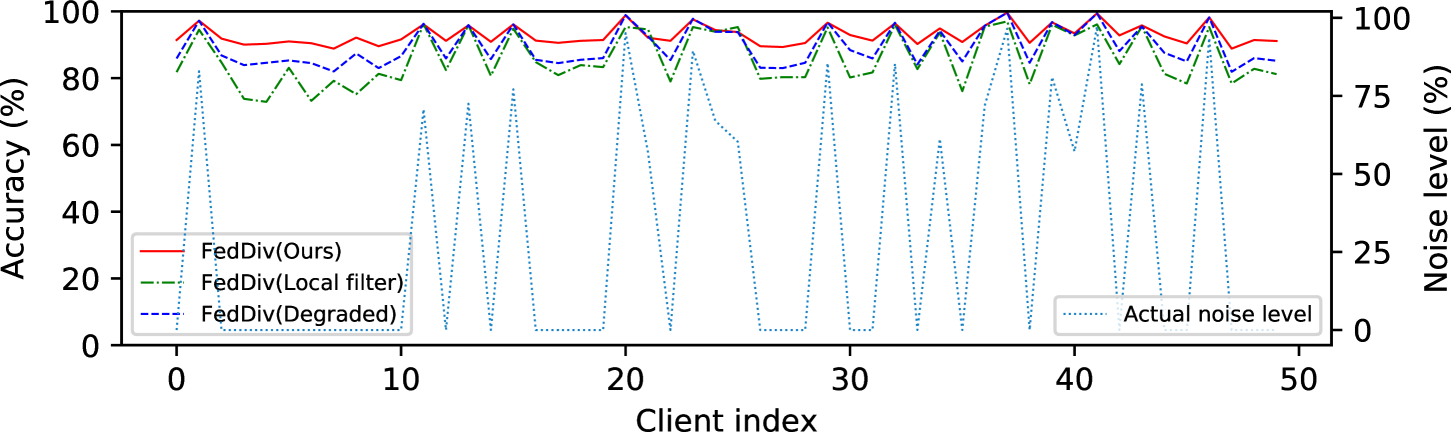
联合噪声过滤的评估。 为了确认所提出的标签噪声过滤方案的优越性,我们首先将 FedDiv 与我们的模型变体 FedDiv(Local filter) 和 FedDiv(Degraded) 进行比较t2>。 根据图3和表5,所提出的噪声滤波器在干净和有噪声的客户端上都表现出识别标签噪声的卓越能力,与它的两个变体。
评估重新标记和重新选择。 为了评估所提出的噪声样本重新标记和标记样本重新选择策略的有效性,我们系统地从 FedDiv 框架中删除它们各自的组件。 表 5 中描述的结果表明,两种类型的数据分区的各种噪声设置的准确度均大幅下降。 这表明了每个单独组件的重要性。
结论
在本文中,我们提出了 FedDiv 来处理带有噪声标签的联邦学习(F-LNL)的任务。 它可以有效应对F-LNL任务中涉及数据异构性和噪声异构性的挑战,同时考虑隐私问题。 在FL框架的基础上,我们首先提出联合噪声过滤,将每个客户端上的干净样本与噪声样本分开,从而减少训练过程中的不稳定性。 然后,我们执行重新标记,以将伪标签分配给具有高预测置信度的噪声样本。 此外,我们引入了基于预测一致性的采样器来识别本地模型训练的可信本地数据,从而避免标签噪声记忆并进一步提高训练稳定性。 实验和综合消融分析揭示了 FedDiv 在处理 F-LNL 任务方面的优越性。
致谢
该工作得到了国家自然科学基金项目(No. 62322608),部分由深圳市科技计划(NO.62322608)资助。 JCYJ20220530141211024),部分成果由辽宁省人工智能感知与理解重点实验室开放课题(AIPU,No. 20230003),部分由香港研究资助局合作研究基金资助(项目编号:20230003) 香港大学 C7004-22G)。
参考
- Arazo et al. (2019a) Arazo, E.; Ortego, D.; Albert, P.; O’Connor, N.; and McGuinness, K. 2019a. Unsupervised label noise modeling and loss correction. In International conference on machine learning, 312–321. PMLR.
- Arazo et al. (2019b) Arazo, E.; Ortego, D.; Albert, P.; O’Connor, N.; and McGuinness, K. 2019b. Unsupervised label noise modeling and loss correction. In International conference on machine learning, 312–321. PMLR.
- Cheng et al. (2022) Cheng, D.; Liu, T.; Ning, Y.; Wang, N.; Han, B.; Niu, G.; Gao, X.; and Sugiyama, M. 2022. Instance-Dependent Label-Noise Learning with Manifold-Regularized Transition Matrix Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 16630–16639.
- Dempster, Laird, and Rubin (1977) Dempster, A. P.; Laird, N. M.; and Rubin, D. B. 1977. Maximum likelihood from incomplete data via the EM algorithm. Journal of the Royal Statistical Society: Series B (Methodological), 39(1): 1–22.
- Englesson and Azizpour (2021) Englesson, E.; and Azizpour, H. 2021. Generalized jensen-shannon divergence loss for learning with noisy labels. Advances in Neural Information Processing Systems, 34: 30284–30297.
- He et al. (2016) He, K.; Zhang, X.; Ren, S.; and Sun, J. 2016. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, 770–778.
- Holland (1986) Holland, P. W. 1986. Statistics and causal inference. Journal of the American statistical Association, 81(396): 945–960.
- Huang et al. (2023) Huang, D.; Li, J.; Chen, W.; Huang, J.; Chai, Z.; and Li, G. 2023. Divide and Adapt: Active Domain Adaptation via Customized Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 7651–7660.
- Kim et al. (2022) Kim, S.; Shin, W.; Jang, S.; Song, H.; and Yun, S.-Y. 2022. FedRN: Exploiting k-Reliable Neighbors Towards Robust Federated Learning. arXiv preprint arXiv:2205.01310.
- Krizhevsky (2009) Krizhevsky, A. 2009. Learning Multiple Layers of Features from Tiny Images. Master’s thesis, University of Tront.
- Kuznetsova et al. (2020) Kuznetsova, A.; Rom, H.; Alldrin, N.; Uijlings, J.; Krasin, I.; Pont-Tuset, J.; Kamali, S.; Popov, S.; Malloci, M.; Kolesnikov, A.; et al. 2020. The open images dataset v4. International Journal of Computer Vision, 128(7): 1956–1981.
- Li et al. (2022) Li, J.; Li, G.; Liu, F.; and Yu, Y. 2022. Neighborhood Collective Estimation for Noisy Label Identification and Correction. In European Conference on Computer Vision. Springer.
- Li et al. (2021) Li, J.; Li, G.; Shi, Y.; and Yu, Y. 2021. Cross-Domain Adaptive Clustering for Semi-Supervised Domain Adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2505–2514.
- Li, Li, and Yu (2023a) Li, J.; Li, G.; and Yu, Y. 2023a. Adaptive Betweenness Clustering for Semi-Supervised Domain Adaptation. IEEE Transactions on Image Processing.
- Li, Li, and Yu (2023b) Li, J.; Li, G.; and Yu, Y. 2023b. Inter-Domain Mixup for Semi-Supervised Domain Adaptation. Pattern Recognition.
- Li, Socher, and Hoi (2019) Li, J.; Socher, R.; and Hoi, S. C. 2019. DivideMix: Learning with Noisy Labels as Semi-supervised Learning. In International Conference on Learning Representations.
- Li et al. (2019a) Li, J.; Wu, S.; Liu, C.; Yu, Z.; and Wong, H.-S. 2019a. Semi-supervised deep coupled ensemble learning with classification landmark exploration. IEEE Transactions on Image Processing, 29: 538–550.
- Li et al. (2019b) Li, L.; Wang, J.; Li, J.; Ma, Q.; and Wei, J. 2019b. Relation classification via keyword-attentive sentence mechanism and synthetic stimulation loss. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 27(9): 1392–1404.
- Li et al. (2020) Li, T.; Sahu, A. K.; Zaheer, M.; Sanjabi, M.; Talwalkar, A.; and Smith, V. 2020. Federated optimization in heterogeneous networks. Proceedings of Machine Learning and Systems, 2: 429–450.
- Lin et al. (2020) Lin, T.; Kong, L.; Stich, S. U.; and Jaggi, M. 2020. Ensemble distillation for robust model fusion in federated learning. Advances in Neural Information Processing Systems, 33: 2351–2363.
- Ma et al. (2018) Ma, X.; Wang, Y.; Houle, M. E.; Zhou, S.; Erfani, S.; Xia, S.; Wijewickrema, S.; and Bailey, J. 2018. Dimensionality-driven learning with noisy labels. In International Conference on Machine Learning, 3355–3364. PMLR.
- McMahan et al. (2017) McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; and y Arcas, B. A. 2017. Communication-efficient learning of deep networks from decentralized data. In Artificial intelligence and statistics, 1273–1282. PMLR.
- Nguyen et al. (2022) Nguyen, D. C.; Pham, Q.-V.; Pathirana, P. N.; Ding, M.; Seneviratne, A.; Lin, Z.; Dobre, O.; and Hwang, W.-J. 2022. Federated learning for smart healthcare: A survey. ACM Computing Surveys (CSUR), 55(3): 1–37.
- Pearl (2009) Pearl, J. 2009. Causal inference in statistics: An overview. Statistics surveys, 3: 96–146.
- Ren et al. (2018) Ren, M.; Zeng, W.; Yang, B.; and Urtasun, R. 2018. Learning to reweight examples for robust deep learning. In International conference on machine learning, 4334–4343. PMLR.
- Tanaka et al. (2018a) Tanaka, D.; Ikami, D.; Yamasaki, T.; and Aizawa, K. 2018a. Joint optimization framework for learning with noisy labels. In Proceedings of the IEEE conference on computer vision and pattern recognition, 5552–5560.
- Tanaka et al. (2018b) Tanaka, D.; Ikami, D.; Yamasaki, T.; and Aizawa, K. 2018b. Joint optimization framework for learning with noisy labels. In Proceedings of the IEEE conference on computer vision and pattern recognition, 5552–5560.
- Tanno et al. (2019) Tanno, R.; Saeedi, A.; Sankaranarayanan, S.; Alexander, D. C.; and Silberman, N. 2019. Learning from noisy labels by regularized estimation of annotator confusion. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 11244–11253.
- Wang et al. (2022) Wang, X.; Wu, Z.; Lian, L.; and Yu, S. X. 2022. Debiased Learning from Naturally Imbalanced Pseudo-Labels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 14647–14657.
- Wei et al. (2021) Wei, C.; Sohn, K.; Mellina, C.; Yuille, A.; and Yang, F. 2021. Crest: A class-rebalancing self-training framework for imbalanced semi-supervised learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 10857–10866.
- Wu et al. (2019a) Wu, S.; Deng, G.; Li, J.; Li, R.; Yu, Z.; and Wong, H.-S. 2019a. Enhancing TripleGAN for semi-supervised conditional instance synthesis and classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 10091–10100.
- Wu et al. (2019b) Wu, S.; Li, J.; Liu, C.; Yu, Z.; and Wong, H.-S. 2019b. Mutual learning of complementary networks via residual correction for improving semi-supervised classification. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 6500–6509.
- Xiao et al. (2015) Xiao, T.; Xia, T.; Yang, Y.; Huang, C.; and Wang, X. 2015. Learning from massive noisy labeled data for image classification. In 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2691–2699.
- Xu et al. (2022) Xu, J.; Chen, Z.; Quek, T. Q.; and Chong, K. F. E. 2022. FedCorr: Multi-Stage Federated Learning for Label Noise Correction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 10184–10193.
- Yang et al. (2022a) Yang, E.; Yao, D.; Liu, T.; and Deng, C. 2022a. Mutual Quantization for Cross-Modal Search With Noisy Labels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 7551–7560.
- Yang et al. (2020) Yang, L.; Tan, B.; Zheng, V. W.; Chen, K.; and Yang, Q. 2020. Federated recommendation systems. In Federated Learning, 225–239. Springer.
- Yang et al. (2022b) Yang, S.; Park, H.; Byun, J.; and Kim, C. 2022b. Robust federated learning with noisy labels. IEEE Intelligent Systems, 37(2): 35–43.
- Zhang et al. (2018) Zhang, H.; Cisse, M.; Dauphin, Y. N.; and Lopez-Paz, D. 2018. mixup: Beyond Empirical Risk Minimization. In International Conference on Learning Representations.
- Zheng et al. (2022) Zheng, Z.; Zhou, Y.; Sun, Y.; Wang, Z.; Liu, B.; and Li, K. 2022. Applications of federated learning in smart cities: recent advances, taxonomy, and open challenges. Connection Science, 34(1): 1–28.
- Zhu et al. (2022) Zhu, C.; Xu, Z.; Chen, M.; Konečný, J.; Hard, A.; and Goldstein, T. 2022. Diurnal or Nocturnal? Federated Learning of Multi-branch Networks from Periodically Shifting Distributions. In International Conference on Learning Representations.
补充材料(缩写。 补充)
在本补充材料中,我们详细介绍了其他实验设置,包括数据分区、实施细节和基线 F-LNL 方法。 此外,我们还对我们提出的方法 FedDiv 进行了进一步分析。 为了全面理解,我们在表6中总结了F-LNL和FedDiv的关键符号。 此外,训练FedDiv的详细训练过程和本地过滤器的细节分别在算法1和算法2中概述。 为了进一步提高清晰度,我们在表 7 中提供了每个数据集的超参数摘要。 每个数据集上 IID 和非 IID 数据分区的不同标签噪声设置保持超参数设置的一致性。 值得注意的是,所有实验均在广泛使用的 PyTorch 平台上进行222https://pytorch.org/ 并在具有 12GB 内存的 NVIDIA GeForce GTX 2080Ti GPU 上执行。
| Symbol | Definition |
|---|---|
|
Current communication round |
|
|
Collection of all clients |
|
|
Collection of clients randomly selected at current round |
|
|
Current index for the client selected from or |
|
|
Given local samples for client |
|
|
Clean samples separated from |
|
|
Noisy samples separated from |
|
|
Relabeled samples produced from |
|
|
More reliable labeled samples re-selected by PCS |
|
|
Training data for further optimization of the local model |
|
|
Actual noise level for client |
|
|
Estimated noise level for client |
|
|
Global network model at round |
|
|
Local network model being optimized during local training for client at round |
|
|
Local network model for client at round |
|
|
Global filter parameters for client at round |
|
|
Server-cached local filter parameters for client |
|
|
Local filter parameters for client obtained at round |
|
|
Overall bias of the local model for client w.r.t all classes |
| Hyper-parameter | CIFAR-10 | CIFAR-100 | Clothing1M |
|---|---|---|---|
| # of clients () | 100 | 50 | 500 |
| # of classes () | 10 | 100 | 14 |
| # of samples | 50,000 | 50,000 | 1,000,000 |
| Architecture | ResNet-18 | ResNet-34 | Pre-trained ResNet-50 |
| Mini-batch size | 10 | 10 | 16 |
| Learning rate | 0.03 | 0.01 | 0.001 |
| 5 | 10 | 2 | |
| 500 | 450 | 50 | |
| 450 | 450 | 50 | |
| 950 | 900 | 100 | |
| 5 | 5 | 5 | |
| 0.1 | 0.1 | 0.02 |
Input: ; ; ; ; ; Initialized ; Initialized ; Initialized ; Initialized
Output: Global network model
Input: ; ;
Output: Optimal local filter parameters
额外的实验设置
非 IID 数据分区。 我们采用狄利克雷分布 (Lin 等人 2020),固定概率 和浓度参数 构造非独立同分布数据分区。 Specifically, we begin by introducing an indicator matrix , and each entry determines whether the -th client has samples from the -th class. For every entry, we assign a 1 or 0 sampled from the Bernoulli distribution with a fixed probability . For the row of the matrix that corresponds to the -th class, we sample a probability vector from the Dirichlet distribution with a concentration parameter , where . Then, we assign the -th client a proportion of the samples that belong to the -th category, where denotes the client index with , and .
其他实施细节。 与FedCorr (Xu 等人 2022)类似,我们选择ResNet-18 (He 等人 2016),ResNet-34 ( He 等人 2016) 和预训练的 ResNet-50 (He 等人 2016) 分别作为 CIFAR-10、CIFAR-100 和 Clothing1M 的网络主干。 在本地模型训练会话期间,我们在每次通信中训练每个本地客户端模型超过 个本地训练周期对于 CIFAR-10、CIFAR-100 和 Clothing1M,分别使用动量为 0.5 和小批量大小为 10、10 和 16 的 SGD 优化器。 对于每个优化器,我们在 CIFAR-10、CIFAR-100 和 Clothing1M 上分别将学习率设置为 0.03、0.01 和 0.001。 此外,在数据预处理过程中,训练样本首先被归一化,然后通过随机水平翻转和随机裁剪(填充为 4)进行增强。 For most thresholds conducted on the experiments, we set them to default as in FedCorr (Xu et al. 2022), e.g. in Eq. (11), the probability of a sample being clean/noisy in Eq. (7), in Eq. (9), etc. Additionally, we determine in Eq. (8) using a small validation set, where meets the peak of validation accuracies.
如何设置、和。 在这项工作中,我们将 FedCorr (Xu 等人 2022) 中提出的多阶段 F-LNL 流程简化为单阶段流程,避免了执行多个流程的复杂性。跨不同阶段的复杂步骤,如 FedCorr 中。 然而,为了公平比较,我们保持了与 FedCorr 中相同数量的通信轮次。 总计 ,包含来自 FedCorr 的训练迭代和 的联合预处理,涵盖联合微调和涉及 FedCorr2> 的常规训练阶段。 值得注意的是,在 中,我们仅利用 MixUp 正则化(Zhang 等人 2018) 来预热局部神经网络模型以实现更快的收敛。
下面,我们首先介绍FedCorr提出的多阶段F-LNL流程,然后分析分数调度和FedDiv的训练轮次构建。
-
•
FedCorr。 FedCorr 包含三个 FL 阶段:联合预处理、联合微调和联合常规训练。 在预处理阶段,FL 模型最初在所有客户端上进行预训练 迭代(不是训练回合)以保证模型训练的初始收敛。 同时,FedCorr 评估每个客户数据集的质量,并识别和重新标记噪声样本。 在此阶段之后,提出了基于维度的过滤器(Ma等人2018)将客户端分类为干净的和嘈杂的客户端。 在联邦微调阶段,FedCorr仅在相对干净的客户端上对 轮。 在此阶段结束时,FedCorr 重新评估并重新标记剩余的嘈杂客户端。 最后,在联邦常规训练阶段,全局模型在 在所有客户端上使用 FedAvg (McMahan 等人 2017) 进行轮次,合并在前两个训练阶段纠正的标签。
-
•
FedDiv 的分数调度和通信轮次。 FL训练时,每轮开始时都会随机抽取固定比例的客户参加本地模型训练。 这里,我们设置一个分数参数来控制分数调度,这与FedCorr中的微调和通常的训练阶段相同。 然而,在 FedCorr 的预处理阶段,每个客户端必须在每次迭代中参与本地训练一次。 因此,可以从所有客户端中随机抽取任何一个客户端,概率为 参加本地模特训练,无需更换。 As three stages of FedCorr have been merged into one in FedDiv, to ensure fairness in training, we convert the training iterations of the pre-processing stage into the training rounds we used, which gives us the corresponding training rounds . 因此,在我们的工作中,整个训练过程中的通信轮次总数为 ,其中
附加分析
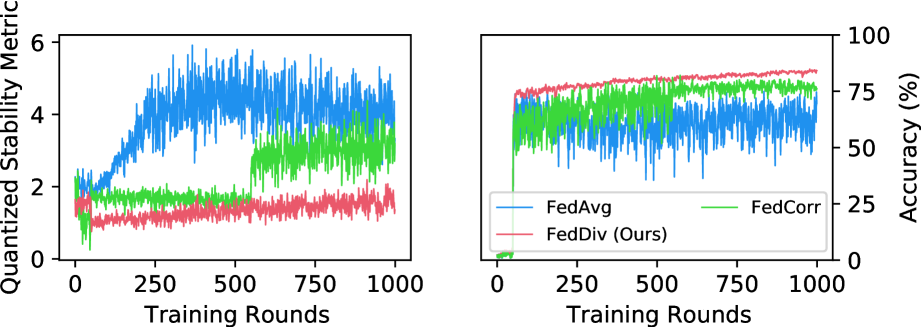
量化训练稳定性。 为了更好地理解这种方法背后的动机,我们建议使用“量化训练稳定性”来量化数据异质性和噪声异质性(Kim 等人 2022; Yang 等人 2022b) 对训练不稳定性的影响在当地训练期间。 Technically, quantized training stability can be measured by the average proximal regularization metric between local and global model weights, denoted as and respectively, at round . This is calculated by . 如图4所示,这种不稳定性会导致局部模型和全局模型之间的权重差异存在显着差异,如果不加以解决,可能会阻碍聚合模型性能的提高。 此外,考虑到不同噪声过滤策略的功效,我们提出的联合噪声过滤在每个客户端的标签噪声识别方面表现出了卓越的性能,从而减少了本地训练会话期间的训练不稳定性,从而实现了聚合模型的更高分类性能。
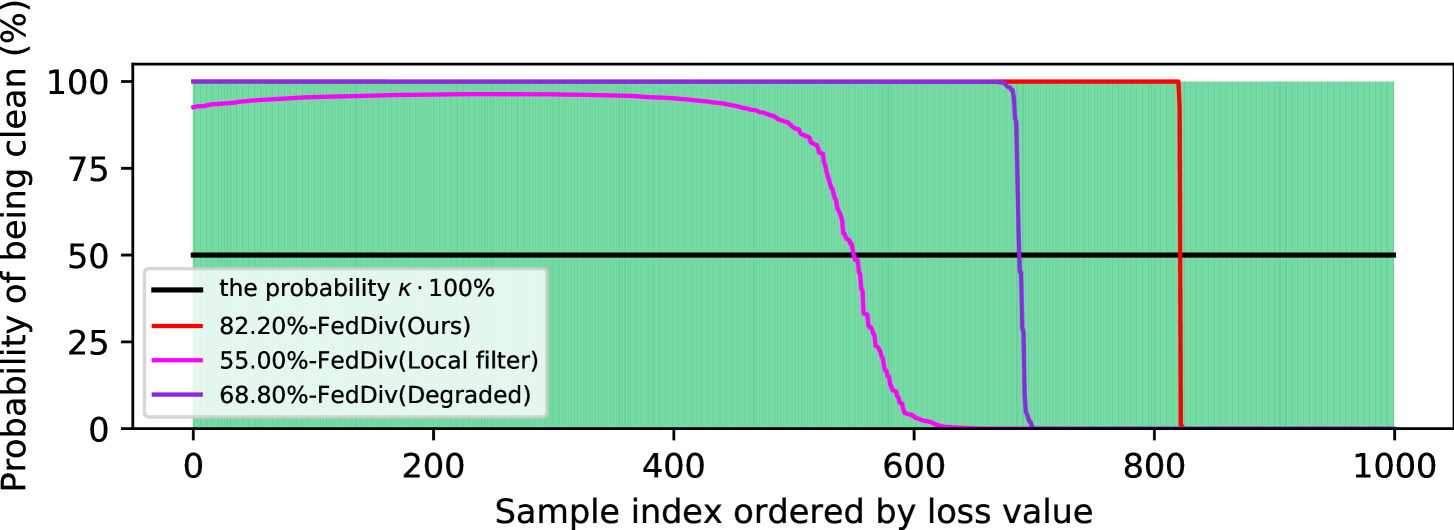
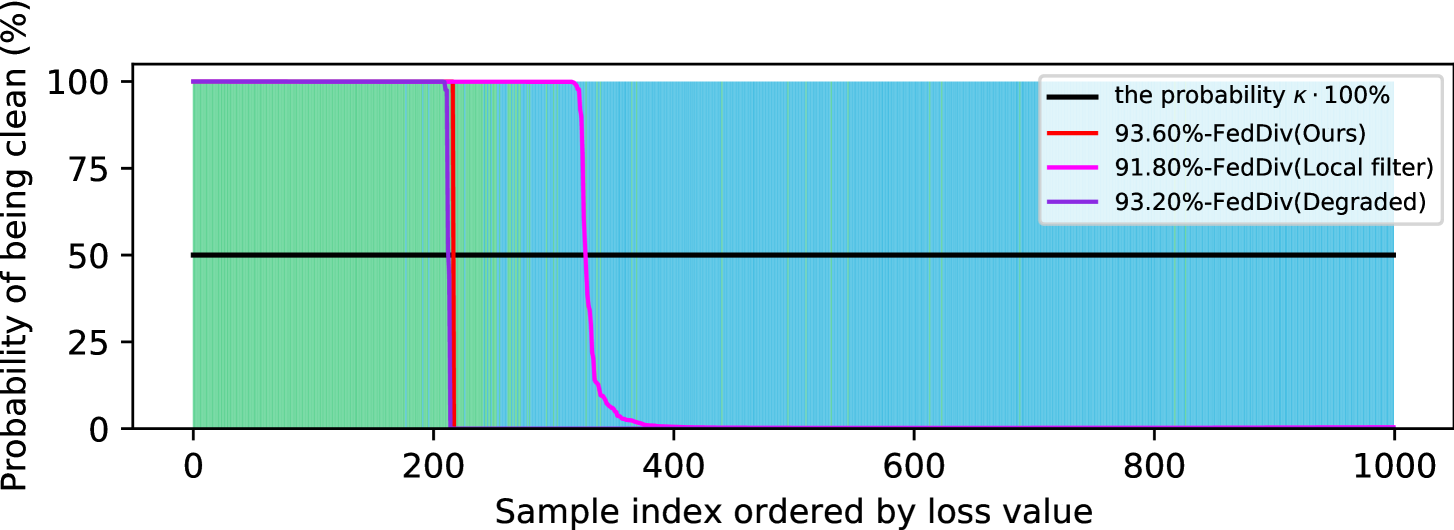
联合噪声过滤的进一步评估。 为了进一步验证我们提出的标签噪声过滤策略的能力,我们再次将 FedDiv 与 FedDiv(Local filter) 和 FedDiv(Degraded) 进行比较图5和图6。 两个实验均在 CIFAR-100 上进行,噪声设置为 用于 IID 数据分区。 具体来说,图5显示了所有50个客户端在不同通信轮次上的标签噪声过滤的准确性,而图6提供了两个示例来说明不同噪声滤波器的噪声过滤性能干净和吵闹的客户。
如图5和图6所示,与替代解决方案相比,所提出的策略在绝大多数客户端上始终能够产生更强的标签噪声过滤能力。 此外,图5还显示,随着模型训练的进行,所有这三种噪声过滤方案都显着提高了标签噪声识别性能,尤其是在干净的客户端上 - 可能是因为网络模型提供了更好的分类性能 - 但我们的继续表现最好。 这些结果再次凸显了我们提出的噪声过滤策略的可行性。
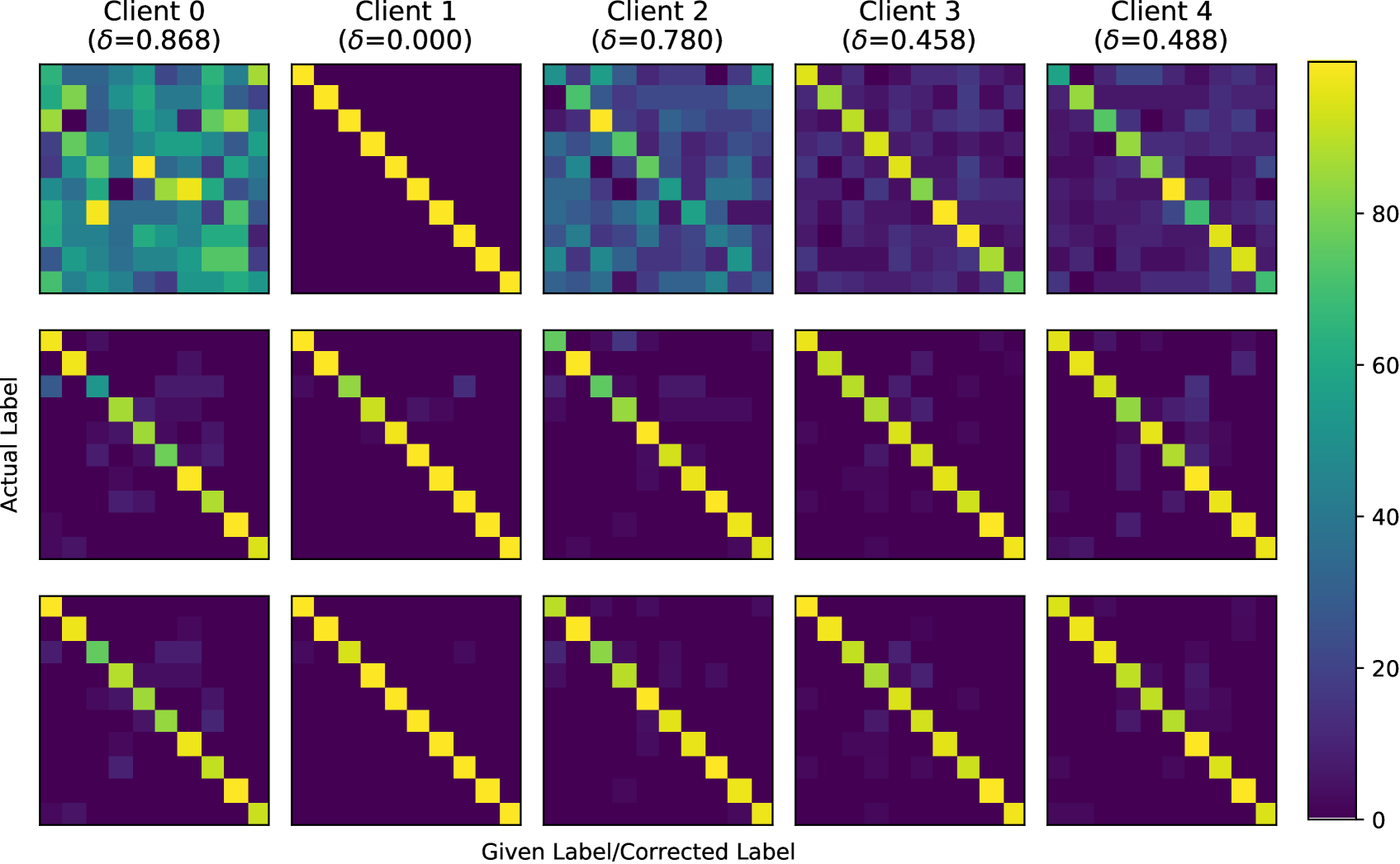
进一步评估过滤、重新标记和重新选择。 为了强调每个 FedDiv 线程在标签噪声过滤、噪声样本重新标记和标记样本重新选择方面的有效性,我们在处理之前、标签噪声过滤和噪声样本重新标记之后(线程 1)比较混淆矩阵,以及图7中标记样本重新选择(线程2)后。 图7显示了五个代表性客户端上这三个混淆矩阵的热图。 在具有不同噪声级别的干净或嘈杂的客户端上,每个线程逐渐消除标签噪声,从而确认每个 FedDiv 组件的性能。
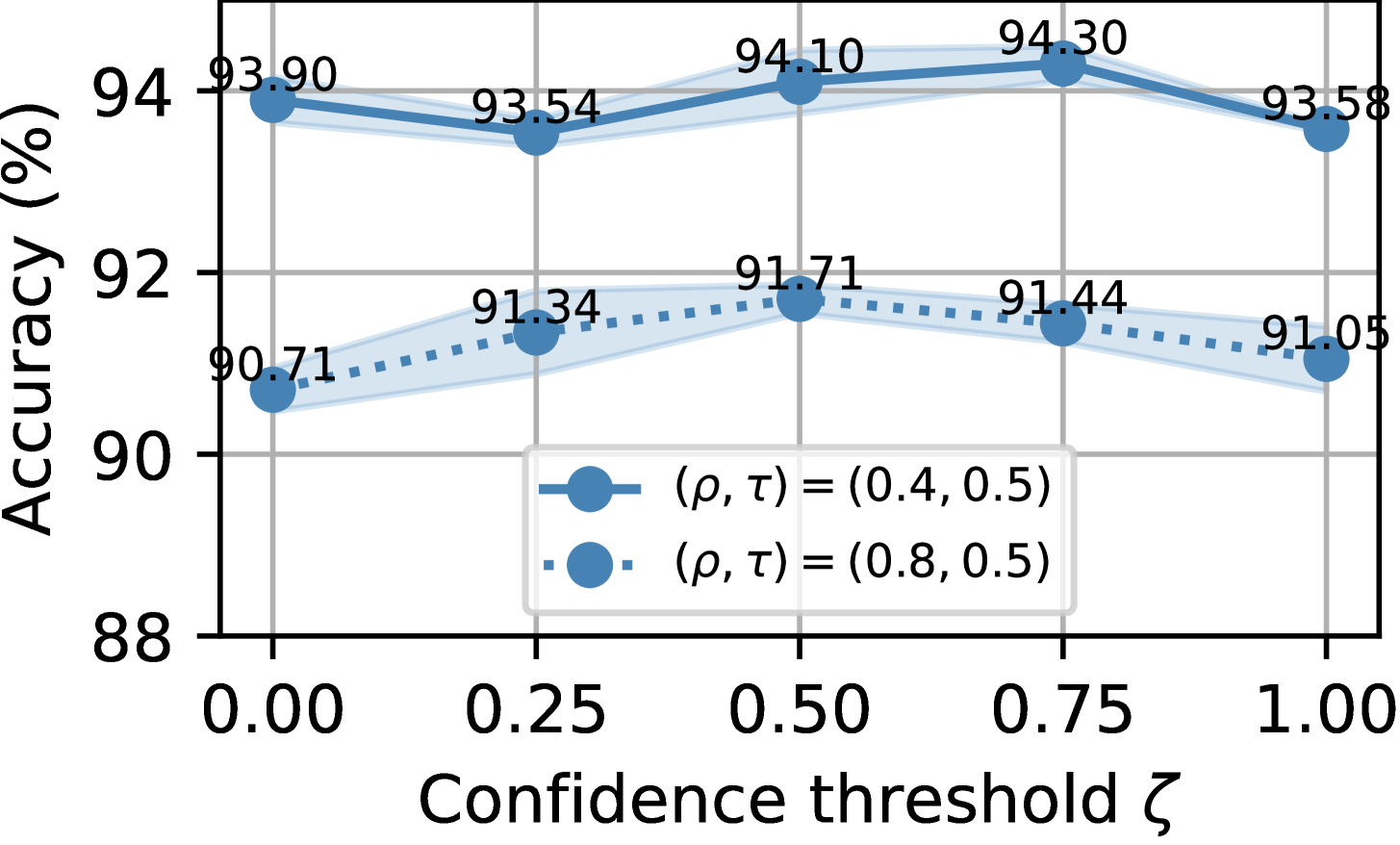
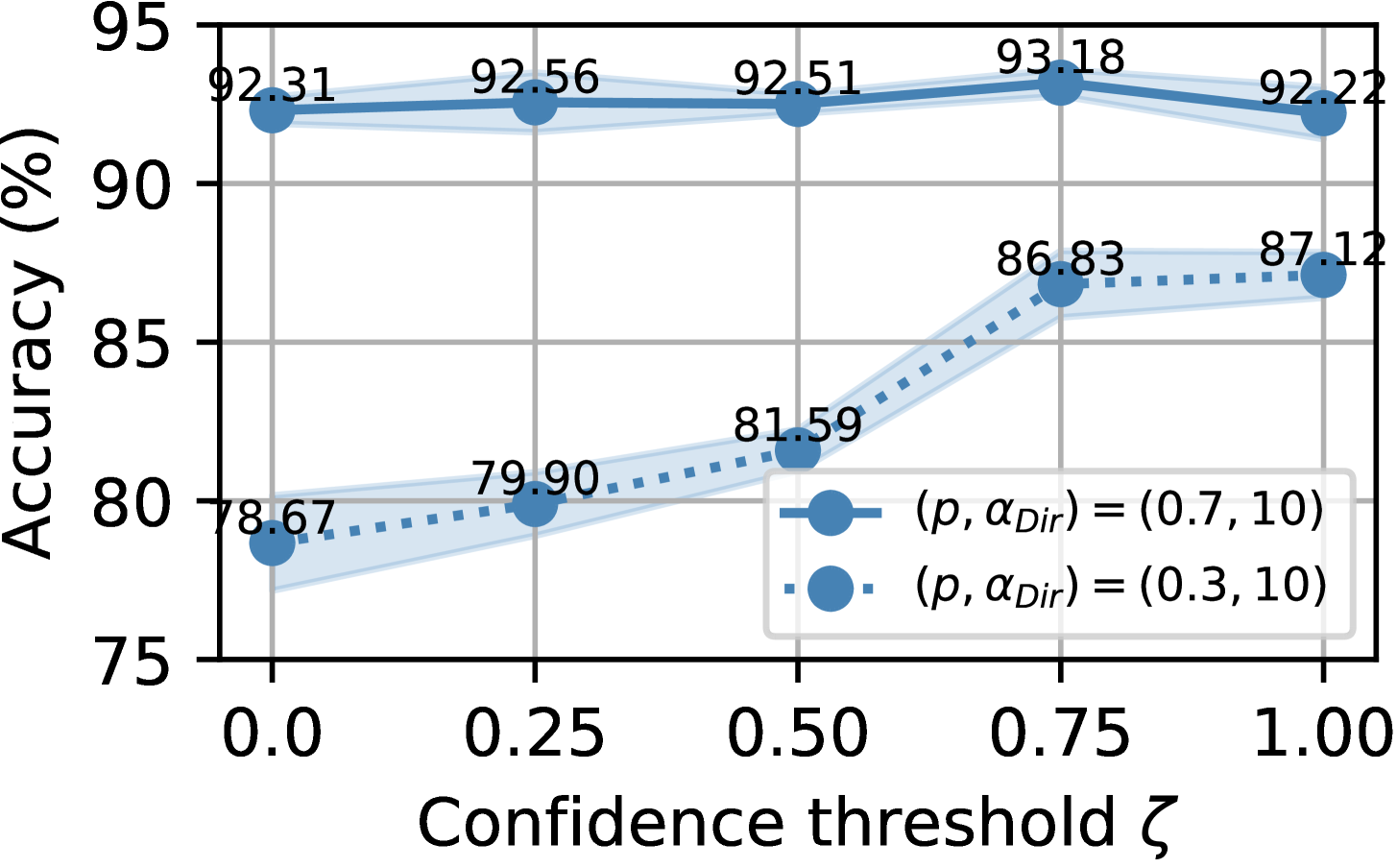
超参数敏感性。 我们分析超参数对置信度阈值的敏感性。 如图8所示,当设置为0.75时,所提出的方法始终获得更高的分类性能。 因此, 是训练 FL 时设置噪声样本重新标记的置信度阈值的绝佳选择IID 和非 IID 数据分区在不同标签噪声设置下的 CIFAR-10 和 CIFAR-100 上的模型。
| Given |
 |
| Thread 1 | |
| Thread 2 |