具有动态潜在图的神经时间点过程的变分自动编码器
摘要
连续观察的事件发生通常表现出自激励和互激励效应,可以使用时间点过程很好地对其进行建模。 除此之外,这些事件动态也可能随着时间的推移而变化,并具有某些周期性趋势。 我们提出了一种新颖的变分自动编码器来捕获这种时间动态的混合。 更具体地,输入序列的整个时间间隔被划分为一组子间隔。 假设事件动态在每个子区间内是固定的,但可能在这些子区间内发生变化。 特别是,我们使用顺序潜变量模型来学习每个子区间的观察维度之间的依赖图。 该模型通过使用学习到的依赖图来消除过去事件的无贡献影响,从而预测未来的事件时间。 通过这样做,与现有的最先进的神经点过程相比,所提出的模型在预测几个现实世界事件序列的事件间时间和事件类型方面表现出更高的准确性。
介绍
人们对建模和理解事件发生的时间动态越来越感兴趣。 例如,对客户行为和交互进行建模对于推荐系统和在线社交媒体至关重要,可以改善资源分配和客户体验(Farajtabar 等人 2014, 2016)。 这些事件的发生通常表现出异质动态。 一方面,个体在彼此的互动中通常会互惠互利(互惠性)。 例如,如果 Alice 向 Bob 发送电子邮件,则 Bob 更有可能向 Alice 发送电子邮件不久之后。 另一方面,长事件序列通常表现出一定量的周期性趋势。 例如,在工作时间,个人更有可能在与同事的电子邮件互动中进行回报,但这种相互刺激的效果在非工作时间会减弱,如图1所示。
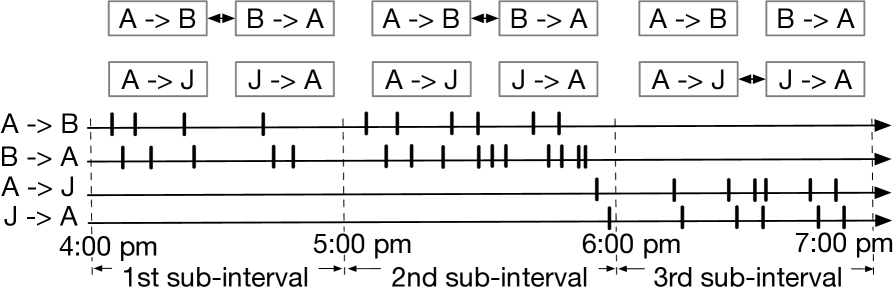
时间点过程 (TPP),例如霍克斯过程 (HP)(Hawkes 1971),特别适合捕获倒数和聚类 事件动态的影响。 尽管如此,传统的 HP 无法充分捕捉潜在的状态转换动态。 最近,神经时间点过程(神经 TPP)展示了使用神经网络捕获事件序列中的远程依赖性的强大能力(Du 等人 2016;Xiao 等人 2017、2019;Omi、Ueda 和 Aihara 2019) 、注意力机制(Zhang 等人 2020;Zuo 等人 2020) 和神经密度估计(Shchur、Bilos 和 Günnemann 2019)。 这些神经 TPP 通常使用所有过去的事件来预测未来事件的发生时间,因此无法消除无贡献事件的干扰。 为了减轻这一缺陷,最近的一些工作(Zhang,Lipani和Yilmaz 2021;Lin等人2021)通过学习静态图来明确捕获来制定神经时间点过程事件类型之间的依赖关系。 因此,他们可以通过学习的图表消除过去事件的无贡献影响,从而提高预测未来事件时间的准确性。 尽管如此,事件类型之间的依赖性也可能随着时间而改变。 使用静态图,神经TPP将检索随时间平均的依赖图。 为了填补这一空白,本文做出了一些主要贡献:(i)我们建议从新颖的变分自动编码器(VAE)角度学习输入序列的事件类型之间的动态图(Kingma和Welling 2014;Rezende、Mohamed 和 Wierstra 2014)。 更具体地说,我们使用规则间隔的间隔来捕获不同的状态,并假设每个子间隔内的平稳动态。 特别是,两种事件类型之间的依赖关系是使用潜在变量捕获的,该变量允许在子区间内演变。 我们通过从观察到的序列编码事件类型之间的潜在动态图来制定变分自动编码器框架。 使用对数正态混合分布来解码事件间等待时间。 通过学习的图,可以有效地消除过去事件的无贡献影响。 (ii)最终实验表明,与现有的密切相关的方法相比,所提出的方法在预测事件时间和类型方面的准确性有所提高。 通过纽约机动车辆碰撞数据证明了所提出的方法估计的动态图的可解释性。
背景
多元点过程。 时间点过程(TPP)涉及连续时域中的随机事件序列建模。 让表示事件序列,是时间戳,是第事件的类型。 此外,表示截至时间发生的历史事件的顺序。多元霍克斯过程 (MHP) 使用由下式指定的条件强度函数捕获事件类型之间的互激励
| (1) |
其中 是第 事件类型的基本速率, 捕获由于事件 ' 导致的强度瞬时提升' s 到达, 确定该事件随时间的影响衰减。 MHP 的静止条件需要 。
与 MHP 不同,互回归点过程 (MRPP)(Apostolopoulou 等人 2019) 旨在捕获事件之间的兴奋和抑制效应类型。 这些参数点过程通过相应地设计条件强度函数来捕获对历史事件的某种形式的依赖性。
尽管简单有用,这些参数点过程要么在实践中遭受模型错误指定导致的某些近似误差,要么缺乏捕获远程依赖关系的能力。为了解决这些限制,最近的一些进展(Du等人2016;Omi、Ueda 和 Aihara 2019;Shchur、Bilos 和 Günnemann 2020;Zuo 等人 2020) 将时间点过程和深度学习方法结合起来,对事件序列背后的复杂依赖结构进行建模。 在高层次上,这些神经时间点过程将每个事件视为一个特征,并使用各种深度学习方法(包括循环神经网络(RNN)、门控循环单元(GRU)或长链)将事件序列编码到历史嵌入中。短期记忆(LSTM)网络。
Du 等人 (2016) 使用循环神经网络从观察到的过去事件中提取历史嵌入,然后使用历史嵌入来参数化其条件强度函数。 该强度的指数形式允许闭式积分,因此导致易于处理的对数似然。
Mei 和 Eisner (2017) 研究了更复杂的条件强度函数,同时计算对数似然涉及使用蒙特卡罗方法逼近积分 。 Omi、Ueda 和 Aihara (2019) 提出使用神经网络对累积条件强度函数进行建模,从而可以准确有效地计算对数似然。 然而,使用这种方法进行采样的成本很高,并且导出的概率密度函数不能积分为 1。 为了解决这些问题,Shchur、Bilos 和 Günnemann(2019) 建议使用归一化流直接对事件间时间进行建模。 神经密度估计方法(Shchur、Bilos 和 Günnemann 2019) 不仅允许以分析方式执行采样和似然计算,而且与其他神经 TPP 相比,在各种应用中也显示出有竞争力的性能。
变分自动编码器。
我们简要介绍了变分自动编码器(VAE)的定义,并请读者参考(Kingma and Welling 2014;Rezende、Mohamed 和 Wierstra 2014)了解更多属性。
VAE 是最成功的生成模型之一,它允许直接从数据分布 中进行采样。 它对于高维数据分布建模特别有用,因为使用马尔可夫链蒙特卡罗进行采样的速度非常慢。 更具体地说,我们的目标是在 指定的生成过程下最大化数据对数似然 ,其中 是潜在变量,表示先验分布,观察分量由参数化。
在VAE框架下,后验分布可以定义为,其中指正态分布,均值和协方差 由具有参数 的神经网络参数化。
为了学习模型参数,我们最大化由
给出的证据下界 (ELBO),其中 表示 Kullback-Leibler (KL) 散度。 第一项是进行近似后验以产生可以尽可能重建数据的潜在变量。
第二项是将潜在变量的近似后验与潜在变量的先验分布相匹配。
使用重新参数化技巧(Kingma and Welling 2014),我们通过使用自动微分辅助的随机梯度下降最大化 ELBO 来学习 和 。
模型
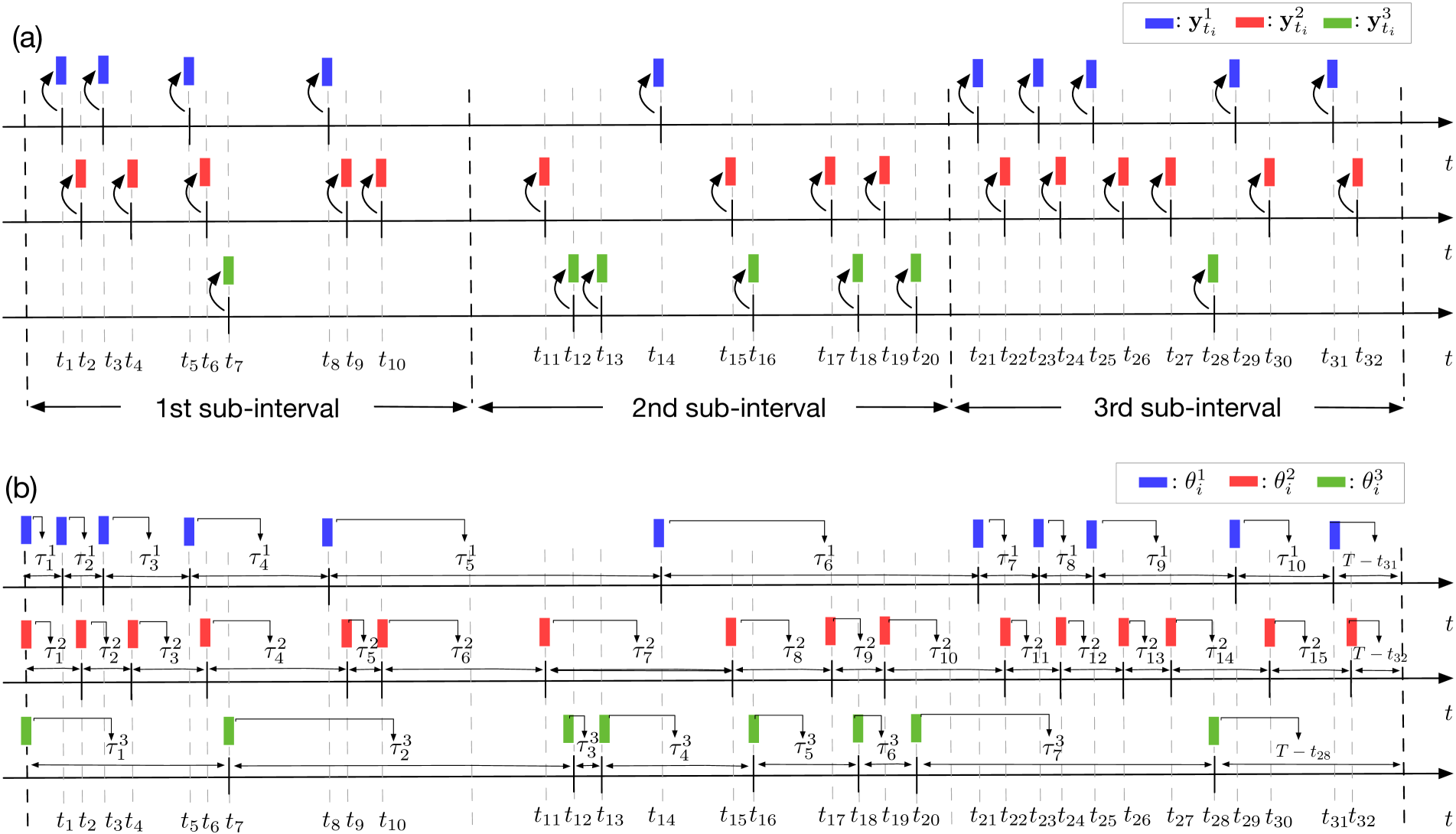
给定一系列事件,我们的目标是使用动态图结构神经点过程来捕获事件类型之间的复杂依赖关系。
序列的整个时间间隔被划分为规则间隔的子间隔,指定了先验,以近似表示不同的状态。
我们假设事件类型之间的潜在图正在改变状态,但在每个子区间内静止,如图2(a)所示。 具体来说,让代表第个子区间,以为起点,为终点。 让潜在变量捕获子内第事件类型对第事件类型的依赖性间隔。 为了便于说明,我们用
表示第个子间隔内发生的事件集。 请注意,我们使用对数正态混合对每种事件类型的事件间时间进行建模。 因此,我们用 表示第 类型的事件序列,其中 是序列中观察到的第 事件第个事件类型,表示对应的事件间时间,表示事件总数。
接下来,我们将在以下小节中解释变分自动编码器的每个组件。
先验。 我们假设事件类型之间的依赖关系图在子区间内演变。 因此,我们使用自回归模型来捕获潜在变量的先验概率。 更具体地说, 的先验分布取决于其先前的状态 以及截至时间 的事件序列(第一个 子区间):
先验组件指定如下:对于每个 类型 的事件,其中 表示辅助事件标记(如果可用),我们嵌入 和 转化为固定维度向量 。 然后,我们将事件嵌入 通过全连接图神经网络 (GNN),得到事件类型 和 之间的关系嵌入 :
其中 表示 GNN 每层的多层感知器(MLP), 和 表示 GNN 的节点级和边缘级隐藏状态分别为第中间层。 GNN 的最终输出对时间 的关系进行建模。 GNN 架构如图3(a)所示。
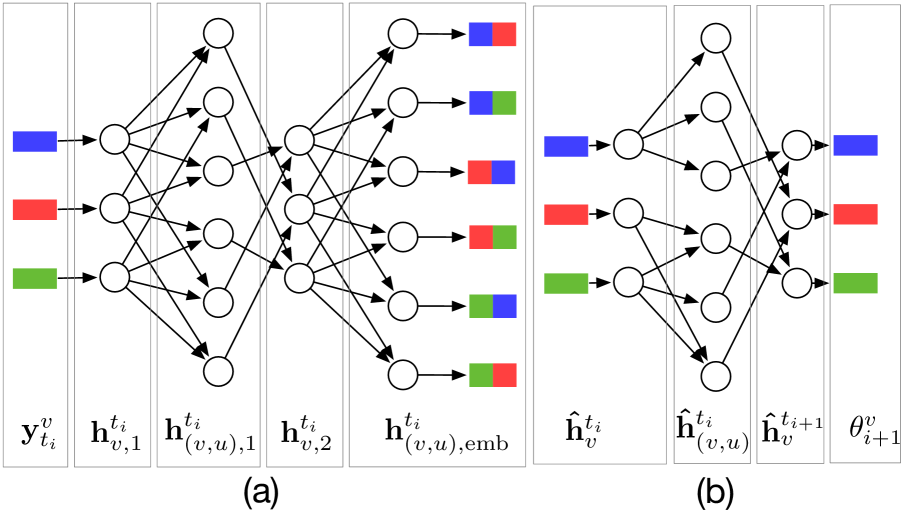
我们需要使用 MLP 连接所有关系变量 ,并将它们转换为第 个子区间的关系状态 :
前向递归神经网络 (RNN) 用于捕获关系状态 对其当前嵌入 及其先前状态 的依赖性:
最后,我们使用 MLP 将 编码为 先验分布的 logits:
图4显示了基于前向RNN的先验分布。
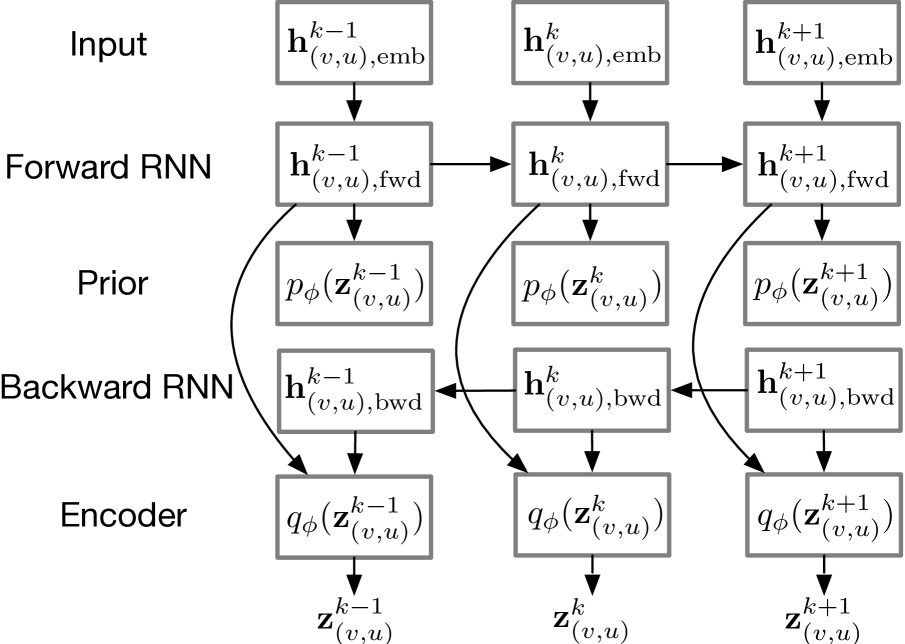
编码器。 潜在变量 的后验分布取决于过去和未来的事件:
因此,编码器被设计为使用整个事件序列来近似关系变量的分布。 为此,使用后向 GNN 反向传播隐藏状态 :
最后,我们连接前向状态 和后向状态 ,并使用 MLP 将它们转换为近似后验的 logits:
请注意,先验和编码器共享参数,因此这两个组件的参数用表示。
解码器。 解码器的作用是预测每个事件类型的事件间时间。 特别是,我们使用由下式指定的图递归神经网络(GRNN)捕获这些事件间时间背后的潜在动态
其中 确定第 事件类型 如何影响第 事件类型 通过时间 的关系 。 潜在嵌入 本身使用门控循环单元 (GRU) 随着时间的推移而演变。
给定动态嵌入 ,我们使用对数正态混合模型 对事件间时间 进行建模(Shchur、Bilos 和 Günnemann 2019),
其中分别表示第个混合物成分的混合物权重、平均值和标准差。 特别地,每个事件间时间 的分布参数构造为
其中指的是可学习的参数。 我们使用 softmax 和 exp 变换对分布参数相应地施加和对一和正约束。 图3(b)展示了用于构造解码器部分中对数正态混合的参数的GNN架构。 给定模型参数,我们假设事件间时间 有条件地独立于过去的事件。 因此,解码器下事件间时间的分布可分解为
VAE框架的解码器部分如图2(b)所示。 因此,我们自然可以使用以下方法来预测下一个事件时间
训练。 接下来我们解释如何学习动态图结构神经点过程的 VAE 框架的参数。 事件序列 通过编码器中的 GNN,得到所有时间戳 和每对两个事件类型 的关系嵌入 。 然后,我们连接所有关系嵌入,并将它们转换为每个子区间 的关系状态 。关系状态被馈送到前向和后向RNN中以计算先验分布和后验分布。 然后,我们从后验分布的具体可重新参数化近似中采样 。 隐藏状态通过GRNN演化,其中消息只能通过暗示的非零边缘。 这些隐藏状态 用于参数化事件间时间的对数正态混合分布。 为了学习模型参数,我们将证据下界 (ELBO) 计算为
| (2) | |||
当我们使用可重新参数化的近似值绘制样本 时,我们可以使用反向传播计算梯度并优化 ELBO。 此后,我们将所提出的模型表示为变分自动编码器时间点过程(VAETPP)。
相关工作
沃瑟曼(1980); Huisman 和 Snijders (2003) 提出使用连续时间马尔可夫链来捕获非平稳网络动态。 图结构时间点过程。 Bhattacharjya、Subramanian和Gao(2018)提出了一种近端图形事件模型来推断事件类型之间的关系,从而假设事件的发生仅取决于其父事件不久前的发生。 Shang 和 Sun (2019) 开发了一种几何霍克斯过程,使用图卷积神经网络捕获多点过程之间的相关性,尽管推断的图是无向的。 Zuo等人(2020)开发了多点过程之间的图结构Transformer Hawkes过程。 它假设每个点过程与静态图的一个顶点相关联,并通过将该图合并到注意模块设计中来对这些点过程之间的依赖关系进行建模。 Zhang、Lipani 和 Yilmaz (2021) 通过使用生成器对潜在图进行采样,制定了图结构神经时间点过程 (NTPP)。 图结构 NTPP 及其相关图的模型参数可以使用高效的双层编程同时优化。 Lin 等人 (2021) 最近还通过使用类型内历史嵌入生成潜在图,开发了一种用于图结构神经点过程的变分框架。 然后,使用潜在图来控制类型内嵌入之间传递的消息,以解码类型条件强度函数。 Zhang 和 Yan (2021) 提出通过结合先验知识来学习事件类型之间的静态条件图。 此外,Linderman 和 Adams(2014)提出通过概率模型来学习事件之间的潜在图结构。 Wu 等人 (2020) 尝试使用基于图的时间点过程来建模事件传播,并使用社交媒体上个人之间的以下关系指定的图。 Pan 等人 (2020) 研究了一种用于建模事件序列的变分自动编码器框架,但尚未考虑捕获维度之间的潜在图。 时间序列背后的动态潜在图。 Kipf 等人 (2018) 开发了一种变分自动编码器,用于学习物理动态系统中交互的实体之间的潜在静态图。 继这一成功之后,Graber 和 Schwing (2020) 使用顺序潜变量模型从离散时间观察中推断出实体之间的动态潜图。 虽然 Graber 和 Schwing (2020) 和所提出的方法都旨在学习多元顺序观察背后的动态图,但主要区别在于我们的输入是异步事件序列,对于我们需要确定规则间隔的子区间,并同时学习每个子区间的动态图。 一个有趣但具有挑战性的方向是自动推断规则间隔的时间间隔和动态图结构,我们将其留给未来的研究。
实验
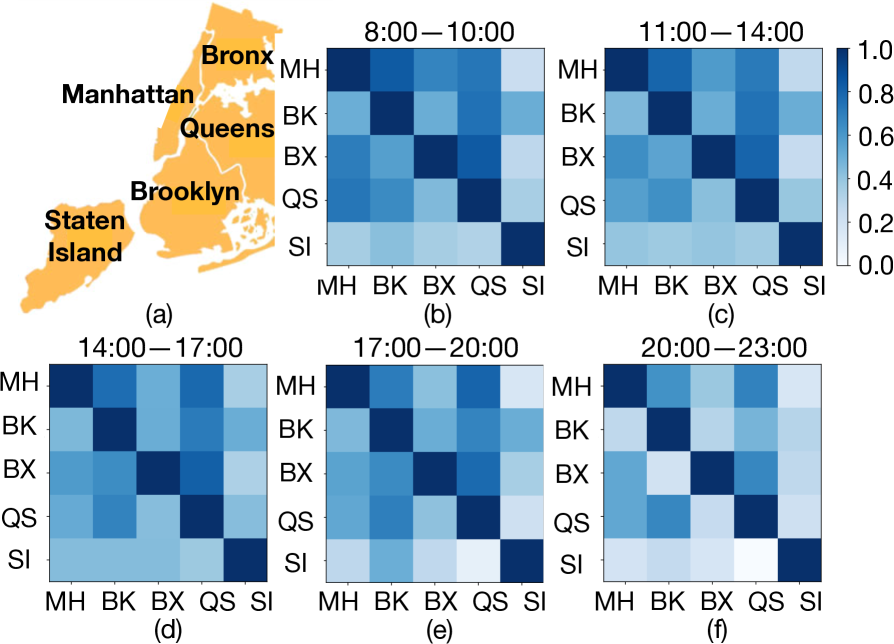
所提出的变分自动编码器时间点过程在事件时间和类型预测的任务上进行评估。 我们使用四个真实世界的数据来演示所提出的方法,并与现有的相关方法进行比较。 纽约机动车碰撞事故(NYMVC): 该数据包含自 2014 年 4 月以来纽约市发生的车辆碰撞事件的集合。 每个碰撞事件记录在区、时间发生的机动车碰撞。 具体而言,在高峰时段,一次车辆碰撞可能会在短时间内引发同一地区或附近地区的一系列碰撞事故。 因此,它非常适合使用多元点过程来建模和预测这些事件的发生。 此外,由于上述触发效应在夜间比白天更弱,因此各地区之间的影响关系可能会随着时间而变化。 我们使用 8:00 至 23:00 之间的机动车碰撞记录创建每个事件序列,并将每三个小时视为一个子间隔。 我们考虑了五个地区:曼哈顿、布鲁克林、布朗克斯、皇后区和斯塔顿岛 作为事件类型。
| Methods | MathOF | AskUbuntu | SuperUser | NYMVC |
|---|---|---|---|---|
| Exponential | ||||
| RMTPP | ||||
| FullyNN | ||||
| LogNormMix | ||||
| THP | ||||
| VAETPP (static) | ||||
| VAETPP |
| Datasets | sequences | events | types |
|---|---|---|---|
| MathOF | |||
| AskUbuntu | |||
| SuperUser | |||
| NYMVC |
堆栈交换数据: 实验中包含来自不同来源的三个堆栈交换数据:MathOF、AskUbuntu 和SuperUser。 堆栈交换数据由参与者之间的各种交互组成。 每个事件意味着在时间戳,用户可以发布对的问题或评论的回答或评论。 用户之间的这些交互事件通常表现出一定的聚类效应和周期性趋势。 例如,有关流行技术的一些问题可能很快会引起具有相似兴趣的其他人的大量答案或评论。 此外,这些触发效应表现出周期性趋势:用户更倾向于在工作日而不是周末/节假日响应技术主题。 我们将向对方做出操作的用户视为事件类型。 因此,我们从一周内发生的事件中得出每个序列,并将每一天视为一个子间隔。 这些数据集详见表2。
| Methods | MathOF | AskUbuntu | SuperUser | NYMVC |
|---|---|---|---|---|
| RMTPP | ||||
| LogNormMix | ||||
| THP | ||||
| VAETPP(static) | ||||
| VAETPP |
| Methods | MathOF | AskUbuntu | SuperUser | NYMVC |
|---|---|---|---|---|
| RMTPP | ||||
| LogNormMix | ||||
| THP | ||||
| VAETPP(static) | ||||
| VAETPP |
实验装置。 对于每种事件类型 ,我们比较了模型使用历史事件 预测事件间时间 的能力,如图 1 所示。 2(b)。 每个现实世界的数据被分成多个事件序列。 对于每个真实世界的数据,我们选择序列的 用于训练, 用于验证, 用于测试。 对于训练,我们最大化方程式中的 ELBO。 2 表示所提出的模型,以及其他模型的预期对数似然。 通过学习到的参数,我们使用验证集上获得的负对数似然(NLL)来衡量每个模型的预测性能。 因此,可以使用验证集来选择实现最佳预测性能的模型配置。 最后,测试集上的 NLL 损失用于比较模型预测事件间时间的能力。 我们报告十次随机训练/验证/测试分组的平均结果。 对于开发的 VAETPP,输入嵌入 的维度为 。 对于编码器的全连接 GNN, 和 是两层 MLP,每层有 64 个单元和指数线性单元 (ELU) 激活。 我们使用 将每个子区间内的串联隐藏状态转换为一个隐藏状态,从而使用具有 64 个隐藏单元和 ReLU 激活的单层 MLP 参数化 。 前向 RNN 和后向 RNN 都有 64 个隐藏单元。 我们通过具有 64 个隐藏单元和修正线性单元 (ReLU) 激活的单层 MLP 参数化 和 。 我们将事件类型中的动态图的边类型的数量设置为两个,并指定第一个边类型以指示不依赖。 对于解码器部分,我们针对两种边缘类型中的每一种,使用具有 64 个隐藏/输出单元的单独两层 MLP 来参数化 。 GRU 有 64 个隐藏单元。 我们使用验证数据选择了 VAETPP 对数正态混合分布中使用的混合组件的数量。 在实验中,我们在实验中使用了混合组件。 我们还考虑用静态潜在图来限制 VAETPP,并将其表示为 VAETPP(静态),以验证学习动态图在捕获事件序列中的周期趋势方面的重要性。 我们将所提出的方法与以下基线进行了比较:指数。 恒定强度模型(Upadhyay, De, and Gomez-Rodrizuez 2018)的条件强度函数定义为,其中表示事件RNN 学习的历史嵌入, 和 指的是模型参数。 恒定强度模型的概率密度函数 (PDF) 是指数分布,如 所示,其中 。 循环标记时间点过程(RMTPP) (杜等人 2016)。 该方法使用 RNN 将过去的事件编码为历史嵌入,并对指数分布的条件强度进行建模。 完全神经网络 (FullyNN) (Omi、Ueda 和 Aihara 2019)。 它使用神经网络捕获事件间时间的累积分布。 对数正态混合 (LogNormMix) (Shchur、Bilos 和 Günnemann 2019)。 该方法使用 RNN 将事件历史编码为嵌入向量,并使用对数正态混合分布解码等待时间。 Transformer 霍克斯过程(THP) (Zuo 等人 2020)。 它利用自注意力机制来捕获观察到的事件序列中的长期依赖性。
负对数似然比较。 表1比较了事件间时间建模中所有方法的负对数似然损失。 正如预期的那样,与使用单峰分布(Gompertz/RMTPP、指数)的简单模型相比,LogNormMix 具有更大的灵活性,因此表现出大幅提高的性能。 Transformer Hawkes process(THP)可以有效地学习事件之间的远程依赖关系,从而实现较低的 NLL 损失。 所提出的 VAETPP 不仅可以使用对数正态混合解码器捕获复杂的事件间时间分布。 它还可以通过动态依赖图有效地消除不相关的过去事件的无贡献影响,进一步改进事件间时间预测。 因此,所提出的 VAETPP 在所有数据集上一致地实现了最佳 NLL 损失值。
事件预测比较。 我们还在实验中考虑了事件时间和类型预测的任务。 特别是,在(Zuo等人2020)之后,我们使用线性预测器进行下一个事件时间预测,如,其中是更新的历史嵌入由 VAETPP 在观察到第 类型的第 个事件后计算, 表示事件时间预测器的参数。 下一个事件类型预测是
其中 表示事件类型预测器的参数, 指 的第 条目。 事件时间和类型预测的损失函数定义为
分别,其中 是第 事件类型的 one-hot 编码。
为了了解事件时间和类型预测器的参数,我们考虑将复合损失函数最小化为
,其中 是等式2。
我们使用训练数据来学习模型参数,并根据验证集上的预测性能选择最佳配置。 最后,我们评估了测试集上的模型性能。 具体来说,我们根据历史记录预测了每个保留事件。 我们通过准确性评估事件类型预测,通过均方根误差 (RMSE) 评估事件时间预测。 标签。 3 和 4 分别显示事件时间和类型预测的结果。 我们的 VAETPP 在预测所有数据的事件时间和类型方面优于基线。
结论
我们提出了一种新颖的变分自动编码器,用于对异步事件序列进行建模。 为了捕捉长序列背后的周期性趋势,我们使用规则间隔来捕捉序列背后的不同状态,并假设每个子区间内的平稳动态。 事件类型之间的依赖结构是使用潜在变量捕获的,该变量允许随着时间的推移而演变,以捕获随时间变化的图表。 因此,与其他神经点过程相比,所提出的模型可以有效地消除不相关的过去事件类型的影响,并在预测事件间时间和类型方面取得更好的准确性。 我们计划在未来的研究中推广捕获非平稳网络动态的工作(Yang and Koeppl 2018b, a, 2020;Yang and Zha 2023)。
致谢
该工作得到深圳市科技计划项目(JCYJ20210324120011032)和深圳市人工智能与社会机器人研究院的部分资助。
参考
- Apostolopoulou et al. (2019) Apostolopoulou, I.; Linderman, S.; Miller, K.; and Dubrawski, A. 2019. Mutually Regressive Point Processes. In Advances in Neural Information Processing Systems (NeurIPS), 1–12.
- Bhattacharjya, Subramanian, and Gao (2018) Bhattacharjya, D.; Subramanian, D.; and Gao, T. 2018. Proximal Graphical Event Models. In Advances in Neural Information Processing Systems (NeurIPS), 1–10.
- Du et al. (2016) Du, N.; Dai, H.; Trivedi, R. S.; Upadhyay, U.; Gomez-Rodriguez, M.; and Song, L. 2016. Recurrent Marked Temporal Point Processes: Embedding Event History to Vector. In SIGKDD, 1555–1564. New York, NY, USA.
- Farajtabar et al. (2014) Farajtabar, M.; Du, N.; Gomez-Rodriguez, M.; Valera, I.; Zha, H.; and Song, L. 2014. Shaping Social Activity by Incentivizing Users. In Advances in Neural Information Processing Systems (NeurIPS), 2474–2482.
- Farajtabar et al. (2016) Farajtabar, M.; Ye, X.; Harati, S.; Song, L.; and Zha, H. 2016. Multistage Campaigning in Social Networks. In Advances in Neural Information Processing Systems (NeurIPS), 2–9.
- Graber and Schwing (2020) Graber, C.; and Schwing, A. G. 2020. Dynamic Neural Relational Inference. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 8513–8522.
- Hawkes (1971) Hawkes, A. G. 1971. Spectra of some self-exciting and mutually exciting point processes. Biometrika, 58(1): 83–90.
- Huisman and Snijders (2003) Huisman, M.; and Snijders, T. 2003. Statistical analysis of longitudinal network data with changing composition. Sociological Methods & Research, 32(2): 253–287.
- Kingma and Welling (2014) Kingma, D. P.; and Welling, M. 2014. Auto-Encoding Variational Bayes. In Proceedings of the International Conference on Learning Representations (ICLR), 1–14.
- Kipf et al. (2018) Kipf, T.; Fetaya, E.; Wang, K.-C.; Welling, M.; and Zemel, R. 2018. Neural Relational Inference for Interacting Systems. In Proceedings of the International Conference on Machine Learning (ICML), 2688–2697.
- Lin et al. (2021) Lin, H.; Tan, C.; Wu, L.; Gao, Z.; and Li, S. Z. 2021. An Empirical Study: Extensive Deep Temporal Point Process. CoRR.
- Linderman and Adams (2014) Linderman, S. W.; and Adams, R. P. 2014. Discovering Latent Network Structure in Point Process Data. In Proceedings of the International Conference on Machine Learning (ICML), 1413–1421. Bejing, China.
- Mei and Eisner (2017) Mei, H.; and Eisner, J. 2017. The Neural Hawkes Process: A Neurally Self-Modulating Multivariate Point Process. In Advances in Neural Information Processing Systems (NeurIPS), 6757–6767.
- Omi, Ueda, and Aihara (2019) Omi, T.; Ueda, N.; and Aihara, K. 2019. Fully Neural Network based Model for General Temporal Point Processes. In Advances in Neural Information Processing Systems (NeurIPS), 1–11.
- Pan et al. (2020) Pan, Z.; Huang, Z.; Lian, D.; and Chen, E. 2020. A Variational Point Process Model for Social Event Sequences. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 173–180.
- Rezende, Mohamed, and Wierstra (2014) Rezende, D. J.; Mohamed, S.; and Wierstra, D. 2014. Stochastic Backpropagation and Approximate Inference in Deep Generative Models. In Proceedings of the International Conference on Machine Learning (ICML), 1278–1286. Bejing, China.
- Shang and Sun (2019) Shang, J.; and Sun, M. 2019. Geometric Hawkes Processes with Graph Convolutional Recurrent Neural Networks. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 4878–4885.
- Shchur, Bilos, and Günnemann (2019) Shchur, O.; Bilos, M.; and Günnemann, S. 2019. Intensity-Free Learning of Temporal Point Processes. In Proceedings of the International Conference on Learning Representations (ICLR), 1–21.
- Upadhyay, De, and Gomez-Rodrizuez (2018) Upadhyay, U.; De, A.; and Gomez-Rodrizuez, M. 2018. Deep Reinforcement Learning of Marked Temporal Point Processes. In Advances in Neural Information Processing Systems (NeurIPS), 3172–3182.
- Wasserman (1980) Wasserman, S. 1980. Analyzing Social Networks as Stochastic Processes. Journal of the American Statistical Association, 75(370): 280–294.
- Wu et al. (2020) Wu, W.; Liu, H.; Zhang, X.; Liu, Y.; and Zha, H. 2020. Modeling Event Propagation via Graph Biased Temporal Point Process. IEEE Transactions on Neural Networks and Learning Systems, 1–11.
- Xiao et al. (2017) Xiao, S.; Farajtabar, M.; Ye, X.; Yan, J.; Yang, X.; Song, L.; and Zha, H. 2017. Wasserstein Learning of Deep Generative Point Process Models. In Advances in Neural Information Processing Systems (NeurIPS).
- Xiao et al. (2019) Xiao, S.; Yan, J.; Farajtabar, M.; Song, L.; Yang, X.; and Zha, H. 2019. Learning Time Series Associated Event Sequences With Recurrent Point Process Networks. IEEE Transactions on Neural Networks and Learning Systems, 30(10): 3124–3136.
- Yang and Koeppl (2018a) Yang, S.; and Koeppl, H. 2018a. Dependent Relational Gamma Process Models for Longitudinal Networks. In Proceedings of the International Conference on Machine Learning (ICML), 5551–5560.
- Yang and Koeppl (2018b) Yang, S.; and Koeppl, H. 2018b. A Poisson Gamma Probabilistic Model for Latent Node-Group Memberships in Dynamic Networks. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 4366–4373.
- Yang and Koeppl (2020) Yang, S.; and Koeppl, H. 2020. The Hawkes Edge Partition Model for Continuous-time Event-based Temporal Networks. In Proceedings of the 36th Conference on Uncertainty in Artificial Intelligence (UAI), 460–469.
- Yang and Zha (2023) Yang, S.; and Zha, H. 2023. Estimating Latent Population Flows from Aggregated Data via Inversing Multi-Marginal Optimal Transport. In Proceedings of the 2023 SIAM International Conference on Data Mining (SDM), 181–189.
- Zhang et al. (2020) Zhang, Q.; Lipani, A.; Kirnap, O.; and Yilmaz, E. 2020. Self-Attentive Hawkes Process. In Proceedings of the International Conference on Machine Learning (ICML), 11183–11193.
- Zhang, Lipani, and Yilmaz (2021) Zhang, Q.; Lipani, A.; and Yilmaz, E. 2021. Learning Neural Point Processes with Latent Graphs. In Proceedings of the international conference on World Wide Web (WWW), 1495–1505. New York, NY, USA.
- Zhang and Yan (2021) Zhang, Y.; and Yan, J. 2021. Neural Relation Inference for Multi-dimensional Temporal Point Processes via Message Passing Graph. In Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI), 3406–3412.
- Zuo et al. (2020) Zuo, S.; Jiang, H.; Li, Z.; Zhao, T.; and Zha, H. 2020. Transformer Hawkes Process. In Proceedings of the International Conference on Machine Learning (ICML), 11692–11702.