用大型语言模型重新思考表格数据理解
摘要
大型语言模型(LLM)已证明能够执行各种任务,但它们在解释和推理表格数据的能力仍然是一个尚未充分探索的领域。 在这种背景下,本研究从三个核心角度进行了调查:LLM 对表格中结构扰动的鲁棒性,文本和符号推理在表格上的比较分析,以及通过聚合多个推理路径来提升模型性能的潜力。 我们发现,呈现相同内容的表格的结构差异会导致明显的性能下降,尤其是在符号推理任务中。 这促使我们提出了一种表格结构规范化方法。 此外,文本推理略微优于符号推理,详细的错误分析表明,每种推理方式在特定任务上表现出不同的优势。 值得注意的是,文本和符号推理路径的聚合,再加上混合自一致性机制,实现了最先进的性能,在WikiTableQuestions上准确率达到 73.6%,这比以往的 LLM 表格处理范式有了实质性进展。
用大型语言模型重新思考表格数据理解
Tianyang Liu UC San Diego til040@ucsd.edu Fei Wang USC fwang598@usc.edu Muhao Chen UC Davis muhchen@ucdavis.edu
1 引言
大型语言模型(LLM; Brown 等人 (2020); Chowdhery 等人 (2022); Zhang 等人 (2022); OpenAI (2022, 2023a, 2023c); Touvron 等人 (2023a, b))彻底改变了自然语言处理领域,展现出理解和推理丰富文本数据的非凡能力Wei 等人 (2023); Wang 等人 (2023); Zhou 等人 (2023); Kojima 等人 (2023); Li 等人 (2023b)。 在 LLM 的现有自然语言处理能力之上,进一步加强它们从外部知识来源获取信息的决策能力,是一个令人振奋的研究前沿Nakano 等人 (2022); Mialon 等人 (2023); Hao 等人 (2023); Jiang 等人 (2023b)。 在这些知识来源中,表格数据由于其对关系、属性和统计数据的表达能力以及人类管理员易于构建的特点,成为一种无处不在的知识来源。
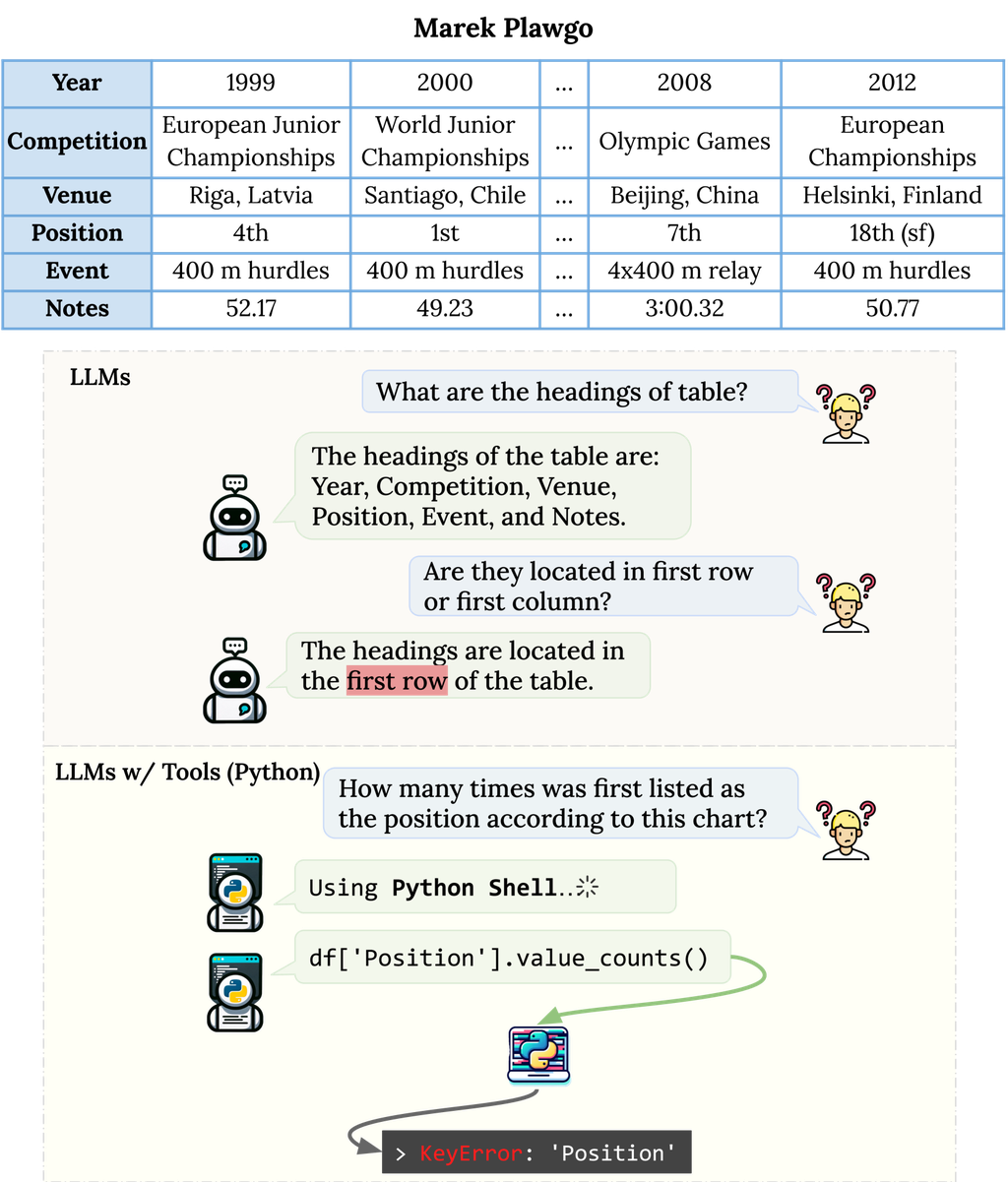
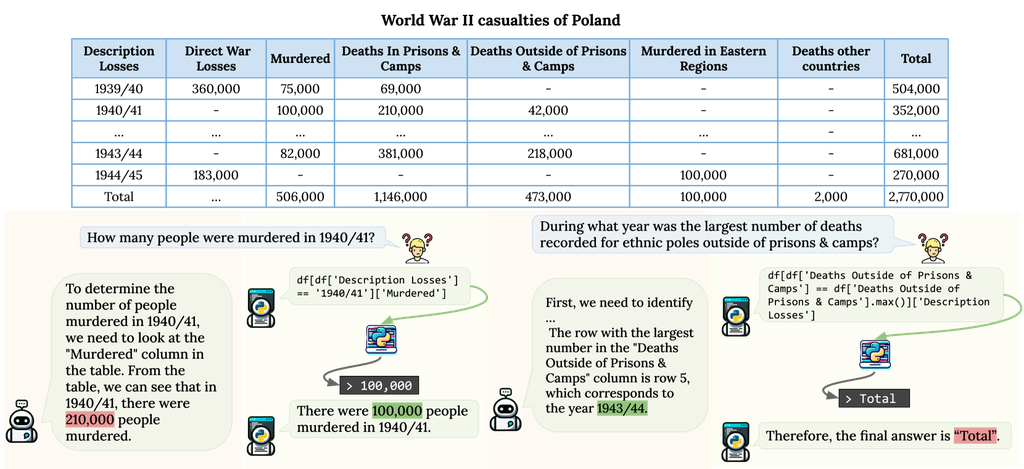
与人类一样,LLM 也能从阅读文本附带的表格数据中获益。 然而,正如 图 1 所示,表格的结构特性对这些模型提出了独特的挑战。 LLM 固有地设计用于解析和处理大量的非结构化文本内容,在面对表格数据时,它们面临着范式转变。 将表格线性化以适应 LLM 范式可能会掩盖固有的结构和关系信息,从而使精确定位和复杂统计分析等任务变得困难。 此外,表格的设计变体,无论是第一行有标题的“列表格”还是第一列有标题的“行表格”,都会进一步复杂化解释过程。 除了结构方面的考虑外,表格数据的数值推理和聚合还带来了另一层复杂性。 虽然 LLM 在文本理解方面表现出色,但当遇到需要在表格中进行精确数值计算的任务时,它们偶尔会遇到困难。 此外,表格通常呈现文本或数值数据的密集融合。 这种信息的巨大体量和复杂性可能会掩盖关键细节,从而阻碍 LLM 的决策能力 Shi 等人 (2023)。
随着指令微调技术 Wei 等人 (2022); Chung 等人 (2022) 的出现以及人类反馈强化学习 (RLHF) Stiennon 等人 (2022); Gao 等人 (2022); Christiano 等人 (2017) 的应用,LLM 在其对齐能力方面取得了显著提升,为从少样本学习设置向零样本学习设置过渡铺平了道路 Kojima 等人 (2023)。 鉴于这些进展,本文深入探讨了 LLM 对表格理解和推理的挑战和复杂性,并在 图 2 中进行了举例说明。 我们围绕三个 关键研究问题 组织我们的探索: (1) LLM 对表格结构的感知能力如何,我们如何确保对结构变化的鲁棒性? (2) 比较 LLM 中用于表格数据的文本推理和符号推理,哪种推理在有效性方面占主导地位,每种策略的优势和挑战分别是什么? (3) 多种推理路径的聚合是否会提高 LLM 对表格数据解释的准确性和可靠性?
为了回答上述研究问题,我们对 GPT-3.5 等 SOTA LLM 进行了实验 OpenAI (2023a)。 我们在 部分 4 中的发现强调,尽管 LLM 在语义上解释表格方面很擅长,但它们抵御结构差异 (部分 4.1) 和理解表格结构 (部分 4.2) 的能力不足。 受到这些发现的启发,我们提出了一种表格结构规范化方法,以增强 LLM 对表格结构变化的抵抗能力 部分 4.3。 有趣的是,部分 5.1 表明,文本推理在表格内容有限的情况下优于符号推理,这与符号推理在其他领域占主导地位的传统观念相矛盾 Mialon 等人 (2023)。 文本推理和符号推理策略都包含不同的优势和挑战,这将在 部分 5.2 中详细介绍。 为了利用每种策略的独特优势,我们实施了混合自一致性机制 (部分 6),该机制在表格问答方面取得了 SOTA 性能,体现了两种推理策略聚合时的协同潜力。
2 相关工作
用于表格数据处理的 PLM。 表格推理由于将自由形式的自然语言问题与结构化或半结构化表格数据融合而呈现独特的挑战,为此,在过去几年中开发了在表格和文本上联合训练的 PLM,包括 TaBERT Yin 等人 (2020)、TaPas Herzig 等人 (2020)、TAPEX Liu 等人 (2022)、ReasTAP Zhao 等人 (2022) 和 PASTA Gu 等人 (2022)。 尽管取得了这些进展,但最近的研究发现,在表格扰动下存在泛化问题 Zhao et al. (2023); Chang et al. (2023),这引发了人们对 PLM 鲁棒性的担忧。 LETA Zhao et al. (2023) 和 LATTICE Wang et al. (2022) 等具体工作已经研究并缓解了与表格数据的结构性扰动相关的漏洞,例如行/列洗牌和表格转置,方法是使用各种技术,包括数据增强和顺序不变图注意力。 但是,这些方法需要对模型进行白盒访问,这限制了它们对仅具有黑盒访问权限的 SOTA LLM 的适用性,本工作直接解决了这一局限性。
使用 LLM 处理表格数据。 LLM 的最新进展,特别是在少样本学习中,已经证明了它们在表格推理方面的潜力。 Chen (2023) 利用思想链 (CoT) 技术 Wei et al. (2023) 说明了 LLM 在该领域中的有效性。 在 CoT 的基础上,Cheng et al. (2023a) 和 Ye et al. (2023) 引入了包含符号推理的框架,以提高理解能力,并 Ye et al. 强调了它们能够熟练地分解证据和问题的能力。 对齐模型的出现,例如 ChatGPT,已经使零样本表格推理成为可能。 但是,这些模型通常缺乏对表格结构的敏感性,难以处理结构性扰动。 StructGPT Jiang et al. (2023a) 虽然为 LLM 有效地处理结构化数据提供了一个有希望的框架,但其有效性受到没有集成符号推理的限制,而符号推理是增强 LLM 在表格推理方面的全部能力的关键方面,这也是本研究的重点。 此外,虽然基于编程的方法可以缓解一些挑战,但它们在处理自由形式的查询方面能力有限,这在当前格局中形成了一种差距。 AutoGPT Significant Gravitas (2023) 等创新试图解决这个问题,催生了 LangChain Chase (2022)、SheetCopilot Li et al. (2023a) 和 DataCopilot Zhang et al. (2023) 等表格代理的发展。 这些代理提供了传统编程无法实现的解决方案,但仍需要在各种场景中进行严格的评估。 在我们的研究中,我们深入研究了如何解决这些挑战,以增强 LLM 在结构性扰动中的推理能力,从而在当前背景下提供促进提高准确性的见解。
3 预备知识
3.1 问题定义
基于表格数据的问答 (QA),通常被称为 TableQA 任务,是 NLP 中一项重要的挑战。 在本研究中,我们以 TableQA 为目标,探索并增强 LLM 在表格数据推理方面的熟练程度。 此外,我们通过向表格引入结构扰动,来探究这些模型的鲁棒性和适应性。
令 表示包含 行和 列的表格, 表示其标题/说明。 中的每个单元格用 表示,其中 和 。 是标题。 给定一个关于表格的问题 ,我们的任务是识别一个答案 。 这个答案通常是一组值,表示为 ,其中 。
此外,为了更深入地研究 LLM 的结构理解,我们引入了结构扰动,包括: 1 11由于典型列数有限,且列置换对准确率影响极小,因此未采用列置换 赵等人 (2023)。
-
1.
转置表格 (): 通过将行转换为列,反之亦然,保留行和列顺序得到的表格:
-
2.
行混洗表 (): 通过随机排列函数 随机混洗行(不包括标题),同时保持列顺序不变得到的表:
-
3.
行混洗和转置表 (): 通过首先随机混洗行(不包括标题),然后应用转置得到的表:
更正式地定义我们的研究问题:我们的主要目标是研究函数 ,该函数可以使用提供的表格适当地回答所提出的问题。 具体来说,此函数将采用三个参数:表格变体 ,其标题 以及问题 。 它将输出一个答案 。 整个问题可以正式表述为:
3.2 实验设置
本节详细介绍了我们研究中采用的实验设置,包括使用的数据集、模型选择、评估指标、推理方法和其他细节。
数据集。 我们在实验中使用了 WikiTableQuestions (WTQ;Pasupat 和 Liang 2015) 数据集。 测试集包含 421 个表格。 每个表格提供最多两个问答对;如果一个表格少于两个,则只选择一个,总共 837 个唯一数据点。 随着我们的四种表格配置(原始和三种扰动),总体评估数据点达到 。
模型。 我们在研究中采用了 GPT-3.5 OpenAI (2023a) 系列。 鉴于表格通常包含大量数据, 根据提示长度,我们动态使用 gpt-3.5-turbo-0613 和 gpt-3.5-turbo-16k-0613,主要目标是在查询 API 时优化成本。
评估指标。 遵循先前的工作 Jiang 等人 (2022); Ni 等人 (2023); Cheng 等人 (2023b); Ye 等人 (2023),我们采用 精确匹配准确率 作为评估指标,以验证预测与基本事实的匹配情况,将指令嵌入提示中以获得一致且可解析的输出。
推理方法。 我们的评估依赖于两种截然不同的零样本推理方法:
其他细节。 根据情况,我们会调整温度设置。 在不使用自一致性的情况下,我们将温度设置为 0。 对于涉及自一致性的场景,温度设置为 0.8。 为获得更细致的粒度,附录 A 提供了我们实验中实施的所有提示的完整列表。 重要的是要注意,所有提示都以零样本的方式部署,没有任何演示或示例。
4 LLM 对结构扰动的鲁棒性
本节探讨了 LLM 如何根据我们的第一个研究问题 (部分 1) 解释不同的表格结构。 我们探究了三种表格扰动对 LLM 性能的影响 (部分 4.1),揭示了 LLM 在直接表格转置和识别转置表格方面的挑战和局限性 (部分 4.2),并介绍了一种结构规范化策略 (Norm) 来缓解这些问题 (部分 4.3)。
4.1 表格扰动对 LLM 的影响
| Perturbation | DP | PyAgent |
| Original | 59.50 | 55.91 |
| +Shuffle | 52.21 -12.25% | 47.91 -14.31% |
| +Transpose | 51.14 -14.05% | 12.45 -77.73% |
| +Transpose&Shuffle | 37.51 -36.96% | 8.96 -83.97% |
在 部分 3.1 中,我们介绍了三种结构性表格扰动类型:转置 ()、行混排 () 以及它们的组合 ()。 如 表格 1 所示,两种推理方法 DP 和 PyAgent 都表现出显著的性能下降,在应用转置时下降更为明显。 DP 在很大程度上始终优于 PyAgent,这表明文本推理往往对这些结构变化更具弹性。 这种弹性可以归因于 LLM 能够理解语义连接和含义,而与结构变化无关。 相反,以 PyAgent 为代表的符号推理严重依赖于表格结构,使其更易受攻击,尤其是对转置的攻击。
| LLMs As | Task Description | Accuracy |
| Transposer | 53.68 | |
| 51.07 | ||
| Detector | 93.35 | |
| 32.54 | ||
| Determinator | 97.39 | |
| 94.77 |
4.2 LLM 表格转置的局限性
为了更好地理解大型语言模型 (LLM) 在表格结构方面的能力,我们研究了它们在检测需要转置的表格和执行表格转置方面的能力。
大型语言模型作为转置检测器。 给定一个表格 ,目标是检测是否应该将表格转置以便大型语言模型更好地理解。 这被表述为一个二元分类任务:
其中 0 表示“不需要转置”,1 表示“需要转置”。 表格 2 显示了使用 第 A.4 节中的提示的结果。 GPT-3.5 正确地将 93.35% 的原始表格 分类为不需要转置。 然而,它在转置后的表格 上的准确率急剧下降至 32.54%。 我们的观察结果表明,大型语言模型在表格方向解释方面存在结构性偏差,主要导致反对转置的建议。
大型语言模型作为表格转置器。 目标是在原始表格格式和转置后的表格格式之间切换。 具体来说,目标是直接生成 ,给定 ,反之亦然。 形式上,任务是:
我们观察到,GPT-3.5 在这项任务中的熟练程度有限,转置行表格的准确率为 53.68%,逆向操作的准确率为 51.07%,这表明大型语言模型无法精确地转置表格。 有关详细的错误案例研究和进一步分析,请参阅 附录 B。
4.3 表格结构规范化
在解决表格中的结构变化方面,我们的目标是确保在各种表格结构中的一致解释和效用。 为了在后续任务之前将各种表格结构规范化为有序的行表格,我们引入了Norm,这是一种两阶段规范化策略:第一阶段检测列表格并将它们转置为行表格,而第二阶段对行表格进行排序,以增强可理解性。 通过这种方法,Norm 适应了结构扰动,而不会损害对标准化行表格的理解。
内容感知转置确定 在第 4.2节中提到的简单方法中,LLM 会受到表格结构信息丢失的影响。 我们的方法旨在通过引入内容感知确定过程来减少这种结构依赖性,该过程利用 LLM 的语义推理能力,而不是感知表格的结构。 具体来说,我们分析给定表格 () 的第一行 () 和第一列 () 中的内在内容,以确定哪个更适合作为表格的标题。 这种内容感知方法可以用数学模型表示为:
在这里,选择第一行表明当前的表格结构是首选,而选择第一列则表明需要转置。 在第 A.5节中提供了详细说明此方法的提示。 表 2中的结果突出了 GPT-3.5 在语义上识别表格标题的能力,原始表格和转置表格的准确率分别为 97.39% 和 94.77%。
| Method | ||||
| DP | 59.50 | 52.21 | 51.14 | 37.51 |
| +Norm | 58.66 | 58.66 | 58.30 | 57.71 |
| -1.41% | +12.35% | +14.00% | +53.85% | |
| PyAgent | 55.91 | 47.91 | 12.43 | 8.96 |
| +Norm | 56.87 | 57.11 | 55.44 | 55.08 |
| +1.72% | +19.20% | +346.02% | +514.73% |
行重新排序。 转置后,我们的下一个目标是通过重新排序行来确保表格数据的逻辑一致性。 我们指示 LLM 使用第 A.6节中详细说明的提示来建议改进的重新排序策略。 由于识别表格数据最合适顺序所涉及的主观性,以及鉴于没有广泛认可的标准来执行此过程,因此所提出的排序策略的有效性将根据其对表格 QA 任务结果的下游影响进行评估。 我们注意到,当整个有序表格被展示时,GPT-3.5 有时会建议使用替代排序策略,从而导致不必要的复杂性。 为了抵消这种趋势并确保更好的排序建议,我们策略性地只向模型展示表格的前三行和后三行。 这种选择性展示通常可以让模型辨别逻辑排序模式,而不受现有表格配置的影响。
表 3 强调了 Norm 在应用于两种推理方法(DP 和 PyAgent)之前时的有效性。 显然,Norm 有效地减轻了结构扰动,优化了表格的可理解性,使 LLM 能够更好地理解表格。 结果表明,应用 Norm 不会对原始结果产生负面影响 (),而且它有效地细化了扰动数据,使结果与原始结果紧密一致,在某些情况下甚至表现出略微的改进。 这表明 Norm 作为准备表格数据的预处理步骤,可以增强 LLM 的稳健分析能力。
在解决我们最初的研究问题时,分析表明 LLM 的性能对表格结构变化很敏感,在转置和洗牌的情况下,观察到 LLM 在准确解释相同表格内容方面存在重大困难。 虽然 文本推理对结构变化表现出一定的抵抗力,但 符号推理受到很大影响,特别是对于转置表格。 Norm 策略通过消除对表格结构的依赖,在不损害原始内容的完整性或含义的情况下提供跨不同表格结构的一致解释,有效地应对这些挑战。
5 比较文本推理和符号推理
在本节中,我们深入探讨了 LLM 中用于表格数据理解的文本推理和符号推理方法的比较 (节 5.1),并进行了详细的错误分析 (节 5.2) 以解决第二个研究问题 (节 1)。 我们使用 GPT-3.5 评估每种推理策略的性能,揭示了它们的优势和挑战。 在 节 4.3 中,我们探索了 Norm 以减轻结构扰动,增强 LLM 的泛化性能,并成功地将扰动表格恢复到与其原始状态类似的准确率水平。 因此,后续分析将专门考虑原始表格 ()。
5.1 结果
| Method | Accuracy (%) |
| Few-shot Prompting Methods | |
| Binder Cheng et al. (2023b) | 63.61 |
| Binder Cheng et al. (2023b) | 55.07 |
| DATER w/o SC Ye et al. (2023) | 61.75 |
| DATER w/ SC Ye et al. (2023) | 68.99 |
| Zero-shot Prompting Methods | |
| StructGPT Jiang et al. (2023a) | 51.77 |
| Norm+DP | 58.66 |
| Norm+PyAgent | 56.87 |
| Norm+PyAgent-Omitted | 52.45 |
| Norm+DP&PyAgent w/ Eval | 64.22 |
| DP w/ SC | 66.39 |
| +Norm | 64.10 |
| +Norm w/o Resort | 66.99 |
| PyAgent w/ SC | 61.39 |
| +Norm | 63.77 |
| +Norm w/o Resort | 62.84 |
| DP&PyAgent w/ Mix-SC | 73.06 |
| +Norm | 72.40 |
| +Norm w/o Resort | 73.65 |
| Error Types | DP | PyAgent | Description | Case Study |
| Table Misinterpretation | 42% | - |
LLMs incorrectly interpret the content in tables. |
|
| Coding Errors | - | 38% |
LLMs produce inaccurate code, typically due to issues with minor details. |
|
| Misalignment Issue | 24% | 28% |
Outputs are conceptually correct but the answers do not align with the instructions. |
|
| Logical Inconsistency | 20% | 10% |
LLMs exhibit failures in reasoning, leading to contradictions or inconsistencies. |
|
| Execution Issue | - | 12% |
Issues emerge related to the execution of Python code. |
|
| Resorting Issue | 10% | 8% |
The resorting stage in Norm changes the answers of some sequence-dependent questions. |
脚注 3 展示了 GPT-3.5 在用于直接文本推理(使用 DP)和交互式符号推理(使用 PyAgent)时的性能。 通过使用 CoT Wei 等人 (2023) 推理策略来指导模型 逐步思考,然后给出最终答案,如 部分 A.1 中所述,我们可以达到 58.66% 的准确率。 这超越了 StructGPT 的迭代式阅读推理方法,该方法通过持续收集相关证据来集中推理任务。 对于符元有限的表格,通过 PyAgent 进行符号推理的准确率为 56.87%,略低于 DP 单次尝试的准确率。 符号推理的一个明显优势是它能够仅在提示中呈现表格的部分内容。 正如我们的实验所揭示的,在排除中间行并仅展示最初和最后的 3 行后,我们设法保持了 52.45% 的准确率,与完整表格 PyAgent 结果相比下降了 4.42%。 这使得使用上下文窗口有限的大语言模型来处理包含大量行的较大表格成为可能。 在接下来的部分中,我们将对这些方法中观察到的差异和错误进行全面分析。