Unified-IO 2:使用视觉、语言、音频和动作扩展自回归多模态模型
摘要
我们推出了Unified-IO 2,这是第一个能够理解和生成图像、文本、音频和动作的自回归多模态模型。 为了统一不同的模式,我们将输入和输出(图像、文本、音频、动作、边界框等.)标记化到共享语义空间中,然后使用单个编码器-解码器 Transformer 模型。 由于采用如此多样化的模式进行训练具有挑战性,因此我们提出了各种架构改进来稳定模型训练。 我们在来自不同来源的大型多模态预训练语料库上从头开始训练我们的模型,并采用多模态混合降噪器目标。 为了学习一系列广泛的技能,例如遵循多模式指令,我们在包含提示和增强的 120 个数据集上构建和微调。 凭借单一统一模型,Unified-IO 2 在 GRIT 基准测试中实现了最先进的性能,并在超过 35 个基准测试中取得了优异的成绩,包括图像生成和理解、自然语言理解、视频以及音频理解和机器人操作。 我们向研究界发布了所有模型。
![[Uncaptioned image]](x1.png)
1简介
作为人工智能研究人员,我们寻求构建能够感知环境、与他人交流、在世界中行动并推理其交互的智能代理。 世界是多模式的,因此我们的智能体必须通过视觉、语言、声音、动作等参与本质上多模式的丰富交互。 心理学家认为,我们的感觉系统的冗余可以作为监督机制来相互改进[144,48,167]。 这提供了创建具有相似学习能力的模型的自然动机,支持许多不同的模式,可以在训练过程中相互监督。
构建可以解析和生成多种模式的模型是一项复杂的任务。 训练具有数十亿参数的大型语言模型(大语言模型),尽管只支持单一模态,但在许多方面都极具挑战性——从采购和处理海量数据集、确保数据质量和管理偏差、设计有效的模型架构、维护稳定的训练流程和指令调整,以增强模型遵循和理解用户指令的能力。 随着每种新模式的增加,这些挑战被极大地放大。
鉴于这些困难,最近一系列构建多模态系统的工作利用了预训练的大语言模型,其中一些用新的模态编码器进行了增强[5,46,119],一些添加了特定于模态的解码器[96, 14]和其他利用大语言模型的功能来构建模块化框架[64, 166, 173]。 从头开始训练多模态模型的另一系列工作重点是生成文本输出 [81, 143],最近的一些工作支持理解和生成两种模态 - 文本和图像 [125 ,123]。 构建具有更广泛模式覆盖的生成模型,尤其是从头开始训练时,仍然是一个开放的挑战。
在这项工作中,我们提出了Unified-IO 2,这是一种大型多模态模型 (LMM),可以对文本、图像、音频、视频和交错序列进行编码,并生成文本、动作、音频、图像和稀疏或密集的标签。 它可以输出自由形式的多模式响应,并通过遵循指令处理训练期间看不见的任务。 Unified-IO 2 包含 70 亿个参数,并针对各种多模态数据从头开始进行预训练 - 10 亿个图像文本对、1 万亿个文本标记、1.8 亿个视频剪辑、1.3 亿个交错视频图片和文本、300 万条 3D 资产和 100 万条代理轨迹。 我们通过组合涵盖视觉、语言、音频和动作领域 220 个任务的 120 多个数据集,利用庞大的多模态语料库进一步对模型进行指令调整。
我们的预训练和指令调优数据总计超过 600 TB,由于其多样性和数量,给我们带来了巨大的挑战。 为了有效地促进跨多种模式的自我监督学习信号,我们开发了一种新颖的多模式混合降噪器目标,它将跨模式的去噪和生成结合起来。 我们还开发了动态打包——一种有效的实现方式,可将训练吞吐量提高 4 倍,以处理高度可变的序列。 为了克服训练中的稳定性和可扩展性问题,我们建议应用关键的架构更改,包括 2D 旋转嵌入、QK 归一化和感知器重采样器上的缩放余弦注意机制。 对于指令调整,我们确保每个任务都有明确的提示,无论是使用现有的提示还是创建新的提示。 我们还包括开放式任务,并为不太常见的模式创建综合任务,以增强任务和教学的多样性。
我们在超过 35 个数据集及其支持的各种模式上评估了 Unified-IO 2。 我们的单一模型在 GRIT [66] 基准上树立了新的技术水平,其中包括关键点估计和表面法线估计等各种任务。 在视觉和语言任务上,它的性能匹配或优于许多最近提出的利用预训练大语言模型的 VLM。 在图像生成方面,它优于利用预先训练的稳定扩散模型[154]的最接近的竞争对手[174],特别是在按照中定义的指标的忠实度方面。 [76]。 它还显示了视频、自然语言、音频和具体人工智能任务的有效性,尽管其功能范围广泛,但仍展现出多功能性。 此外,Unified-IO 2 可以遵循自由格式的指令,包括新颖的指令。 图 1 展示了它如何处理各种任务。 更多示例以及代码和模型可以在我们的项目网站上访问。
2相关工作
受到语言模型作为通用文本处理系统[122,177,20]的成功的启发,最近出现了一波多模态系统试图通过附加模态实现类似的通用功能。 一种常见的方法是使用视觉编码器构建输入图像的特征,然后使用适配器将这些特征映射到嵌入中,嵌入可以用作输入的一部分一个大语言模型。 然后对网络进行配对图像/语言数据的训练,以使大语言模型适应视觉特征。 这些模型已经可以执行一些任务零样本或上下文示例[178,109,132],但通常会使用指令、视觉输入和目标文本三元组进行视觉指令调整的第二阶段增加零样本功能[119,118,218,34,205,225,25]。
在此设计的基础上,许多研究人员扩展了这些模型可以支持的任务的广度。 这包括创建可以执行 OCR [220, 12]、视觉基础 [26, 189, 219, 143, 207, 12, 212]、图像文本的模型检索[97]、其他语言[112]、具体人工智能任务[17,140,135,152]或利用其他专家系统[52]。 其他努力增加了新的输入方式。 这包括视频输入 [110, 126]、音频 [80] 或两者 [216]。 PandaGPT [170] 和 ImageBind-LLM [69] 使用通用编码器 ImageBind [56] 对多种输入模态进行编码,而 ChatBridge [222]使用类似的基于语言的通用编码器。 虽然这些努力对于理解任务是有效的,但它们不允许复杂的多模态生成,并且通常排除长期被认为是计算机视觉核心的模态(例如。,ImageBind 无法支持稀疏标注图片)。
很少有作品考虑多模式生成。 Unified-IO [123]、LaVIT [88]、OFA [186]、Emu [ 172] 和 CM3Leon [210] 训练模型生成 VQ-GAN [49, 179] 可以解码的 Token 转化为图像,而 GILL [96]、Kosmos-G [141] 和 SEED [53]0> 生成扩散模型可以使用的特征,而 JAM [4]1> 融合了预先训练的语言和图像生成模型。 Unified-IO 2 也使用 VQ-GAN,但支持文本、图像和音频生成。
总体而言,这显示了扩大支持的任务和模式数量的强劲趋势。 Unified-IO 2 将这一趋势推向了极限,包括这些先前作品的功能(几乎没有例外)以及以更多模式生成输出的能力。 最近,CoDi [174] 还通过使用多个独立训练的扩散模型并对齐其嵌入空间,实现了类似的任意生成功能。 Unified-IO 2具有更强的语言能力,可以在更多任务上表现出色。
Unified-IO 2的一个显着特点是模型是从头开始训练的,而不是使用预先训练的大语言模型进行初始化。 遵循这种方法的先前作品[186,188,192,114]通常不是为了产生复杂的生成(例如自由格式的文本响应、图像或声音)或遵循文本指令而设计的。 与最近的通用多模态模型[81,143,210]相比,Unified-IO 2具有更广泛的任务和输出范围。 从头开始训练意味着该方法可以在没有语言模型预训练的昂贵的基础知识阶段的情况下进行复制,并且更自然地适合人类如何通过共现来同时学习模态,而不是一次一个。
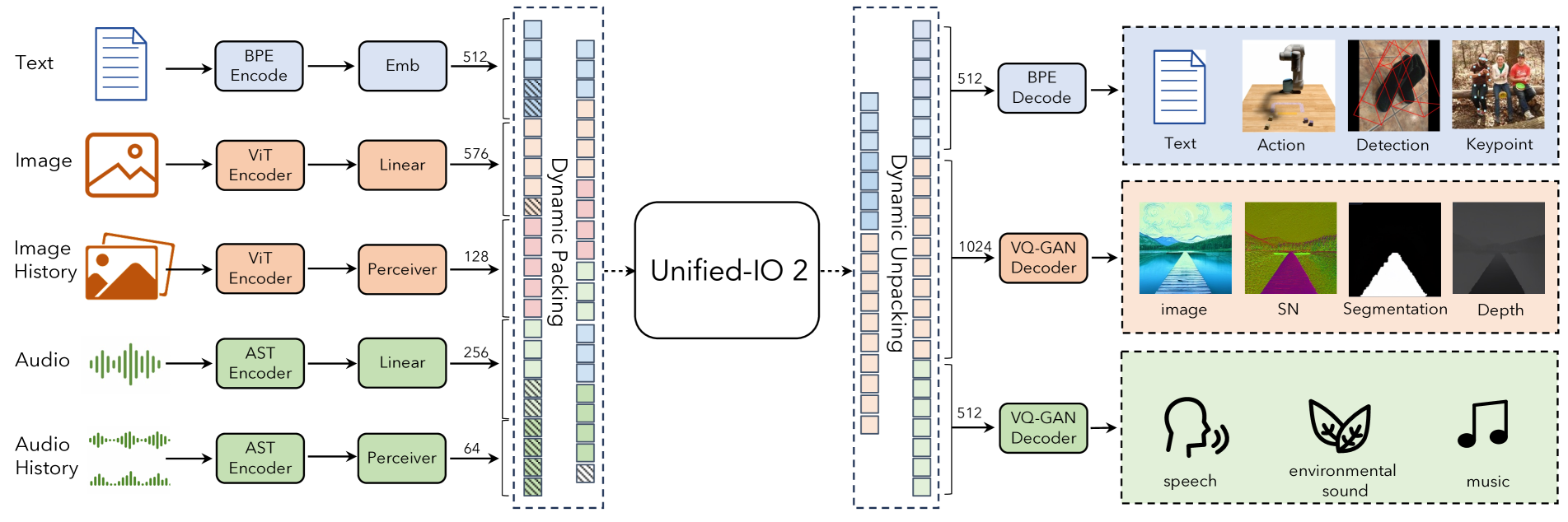
3方法
3.1 统一任务表示
Unified-IO 2 使用单个统一的编码器-解码器 Transformer [181] 处理所有模态。 这是通过将各种输入和输出(图像、文本、音频、动作、框等.)编码为共享表示空间中的标记序列来实现的。 我们的编码过程遵循Unified-IO[123]的设计,进行了一些修改以提高性能以及新的编码器和解码器以实现附加模式。 图2显示了该模型的概述。 下面给出了有关如何编码模式的详细信息。
文本、稀疏结构和动作。 文本输入和输出使用 LLaMA [177] 中的字节对编码 [161] 进行标记化,我们选择它是因为它支持 Unicode 符号并保留空格。 边界框、关键点和相机姿势等稀疏结构被离散化,然后使用添加到词汇表 [27, 123] 中的 1000 个特殊标记进行编码。 点使用两个此类标记的序列进行编码(一个用于 ,一个用于 ),框使用四个标记的序列进行编码(左上角和右下角), 3D 长方体用 12 个标记表示,这些标记对投影中心、虚拟深度、对数归一化框尺寸和连续异心旋转 [16] 进行编码。 对于具体任务,离散机器人动作[17]生成为文本命令(例如。,“向前移动”以命令机器人移动导航中向前)。 特殊标记用于对机器人的状态进行编码,例如其位置和旋转。 详情参见附录B.1。
图像和致密结构。 图像使用预先训练的 Vision Transformer (ViT) [84] 进行编码。 我们将 ViT 的第二层和倒数第二层的补丁特征连接起来,以捕获低级和高级视觉信息。 这些特征通过线性层来获得嵌入,这些嵌入可以用作 Transformer 输入序列的一部分。 为了生成图像,我们使用 VQ-GAN [49] 将图像转换为离散标记。 这些标记被添加到词汇表中,然后用作目标输出序列以生成图像。 为了获得更好的图像质量,我们使用具有 补丁大小的密集预训练 VQ-GAN 模型,将 图像编码为 1024 个标记,码本大小为 16512。
在[123]之后,我们将每像素标签(包括深度、表面法线和二进制分割掩模)表示为可以使用我们的图像生成和编码能力生成或编码的RGB图像。 对于分段,Unified-IO 2 经过训练以预测给定类和边界框的二进制掩码。 可以通过首先进行检测,然后向模型查询每个检测到的边界框和类别的分割掩模来分割整个图像。 详情请参见附录B.1。
音频。 Unified-IO 2 将长达 4.08 秒的音频编码为频谱图(请参阅附录 B.1 和表 8)。 然后使用预先训练的音频频谱图变换器 (AST) [57] 对频谱图进行编码,并通过连接 AST 中的第二层和倒数第二层特征并应用来构建输入嵌入与图像 ViT 一样的线性层。 为了生成音频,我们使用 ViT-VQGAN [208] 将音频转换为离散 Token 。 由于没有公共代码库,我们实现并训练了我们自己的 ViT-VQGAN,其补丁大小为 ,将 频谱图编码为 512 个标记,代码本大小为 8196。
图像和音频历史。 我们允许最多四个附加图像和音频片段作为输入,我们将其称为图像或音频历史记录。 这些元素也使用 ViT 或 AST 进行编码,但我们随后使用感知器重采样器 [5],请参阅表 8 了解超参数,以进一步将特征压缩为更小的尺寸。 Token 数量(图像 32 个,音频 16 个)。 这种方法大大减少了序列长度,并允许模型在使用历史记录中的元素作为上下文的同时,以高水平的细节检查图像或音频片段。 此历史记录用于对先前的视频帧、先前的音频片段或参考图像进行编码,以执行多视图图像重建或图像条件图像编辑等任务。 文本词汇表中添加了八个特殊标记,用于在文本输入或输出中引用这些历史记录中的各个元素。

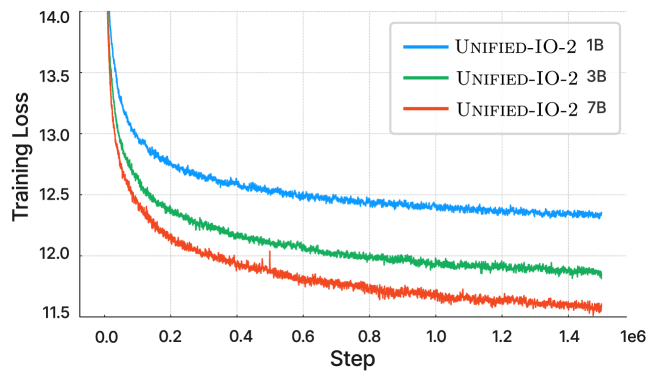
3.2架构
Unified-IO 2 使用 Transformer 编码器-解码器架构。 然而,我们观察到,当我们集成其他模式时,使用遵循 Unified-IO 的标准实现会导致越来越不稳定。 如图3(a)和(b)所示,仅在图像生成(绿色曲线)上进行训练会导致稳定的损失和梯度范数收敛。 与单一模态相比,引入图像和文本任务的组合(橙色曲线)稍微增加了梯度范数,但保持稳定。 然而,随后包含的视频模态(蓝色曲线)导致梯度范数不受限制的升级。 当该模型的 XXL 版本在所有模态上进行训练时,如图 3 (c) 和 (d) 所示,损失在 350k 步后爆炸,并且下一个词符预测准确度在 400k 步时显着下降。 为了解决这个问题,我们进行了各种架构更改,以显着稳定多模式训练。
二维旋转嵌入。 我们在每个 Transformer 层应用旋转位置嵌入 (RoPE) [169],而不是相对位置嵌入 [147]。 对于非文本模态,我们将 RoPE 扩展到二维位置:对于任何 2D 索引 ,我们将 Transformer 注意力头的每个查询和键嵌入分成两半,并应用由两半的坐标分别参见附录B.2。
QK 归一化。 当包含图像和音频模态时,我们观察到多头注意力逻辑值非常大,这导致注意力权重变为 0 或 1,并导致训练不稳定。 为了解决这个问题,在[38]之后,我们在点积注意力计算之前将 LayerNorm [10] 应用于查询和键。
缩放余弦注意力。 我们使用感知器重采样器[86]将每个图像帧和音频片段压缩为固定数量的 Token 。 我们发现,即使使用 QK 归一化,感知者的注意力逻辑也会增长到极值。 因此,我们通过使用缩放余弦注意力[121]在感知器中应用更严格的归一化,这显着稳定了训练。
为了避免数值不稳定,我们还启用 float32 注意力逻辑。 联合更新预训练的 ViT 和 AST 也会导致不稳定。 因此,我们在预训练期间冻结 ViT 和 AST,并在指令调优结束时对它们进行微调。 图4显示,尽管输入和输出模态存在异质性,但我们模型的预训练损失是稳定的。
3.3培训目标
强大的多模态模型必须在预训练期间解决不同的问题。 UL2 [175]提出了混合降噪器(MoD),这是训练大语言模型的统一视角,它结合了跨度损坏[147]和因果语言建模[19] 目标。 受此启发,我们提出了多模态预训练的通用且统一的视角。
降噪器的多模式混合。 MoD 使用三种范例:[R] – 标准跨度损坏、[S] – 因果语言建模和 [X] – 极端跨度损坏。 对于文本目标,我们遵循 UL2 范例。 对于图像和音频目标,我们定义了两个类似的范例:[R] - 掩蔽去噪,其中我们随机掩蔽输入图像或音频块特征的 %,并任务模型重新构建它和 [S] – 我们要求模型生成仅以其他输入模态为条件的目标模态。 在训练过程中,我们为输入文本添加模态词符([Text]、[Image] 或 [Audio])和范例词符([R]、[S] 或 [X])来指示任务。
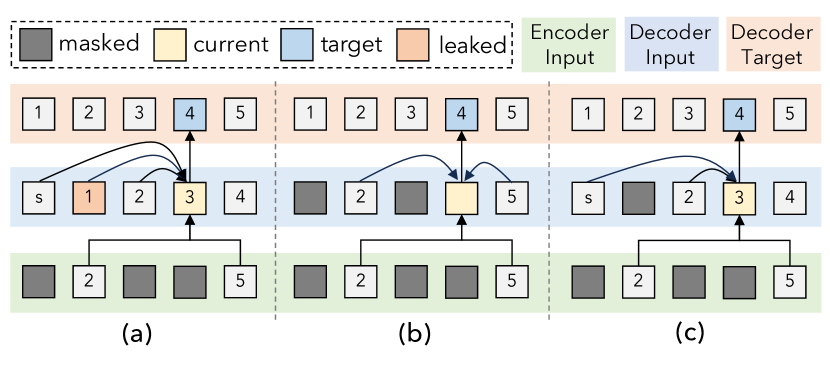
具有动态掩蔽的自回归。 以自回归方式进行图像和音频掩蔽去噪的一个问题是解码器侧的信息泄漏。参见图5(a)。 当前解码器的输入词符(3)以编码器的信息(2,5)和所有先前的标记(s 2)来预测目标(4)。 因此,预测的词符将以 1 为条件,即使它在编码器中被屏蔽,因为它出现在解码器中,这将简化任务并损害表示学习。 简单地屏蔽解码器中的词符,如图5(b)所示,可以避免这种信息泄漏,但会导致生成任务和去噪任务相互干扰。 例如,我们发现联合训练与生成(50% MAE 和 50% 因果建模)显着降低了图像生成性能。 我们的解决方案是在解码器中屏蔽词符,除非在预测该词符时,如图5(c)所示,这不会干扰因果预测,同时基本上消除了数据泄漏。 对于图像和音频生成,我们还在解码器中使用行、列和卷积形状的屏蔽稀疏注意力[148]。
3.4高效实施
对大量多模态数据进行训练会导致 Transformer 输入和输出的序列长度高度可变,这既是因为单个示例通常缺少模态,也因为用于编码特定模态的标记数量可能会有所不同,从几个标记(对于一个句子)到 1024 个标记(对于输出图像)。 为了有效地处理这个问题,我们使用打包,将多个示例的标记打包到单个序列中,并屏蔽注意力以防止 Transformer 在示例之间交叉参与。
通常,打包是在预处理期间完成的,但这在我们的设置中具有挑战性,因为我们的编码器和解码器并不总是支持它。 相反,我们在 Transformer 编码器-解码器阶段之前和之后进行打包,这允许模态编码器/解码器在解包数据上运行。 在训练过程中,我们使用启发式算法重新排列传输到模型的数据,以便长示例与可以打包的短示例相匹配。 [100] 中也探讨了打包优化,但没有在流设置中进行探讨。 动态打包使训练吞吐量增加了近 4 倍(详情参见附录 B.3)。
| Model | model dims | mlp dims | encoder lyr | decoder lyr | heads | Params |
|---|---|---|---|---|---|---|
| UIO-2 | 1024 | 2816 | 24 | 24 | 16 | 1.1B |
| UIO-2 | 2048 | 5120 | 24 | 24 | 16 | 3.2B |
| UIO-2 | 3072 | 8192 | 24 | 24 | 24 | 6.8B |
3.5优化器
4 多模式数据

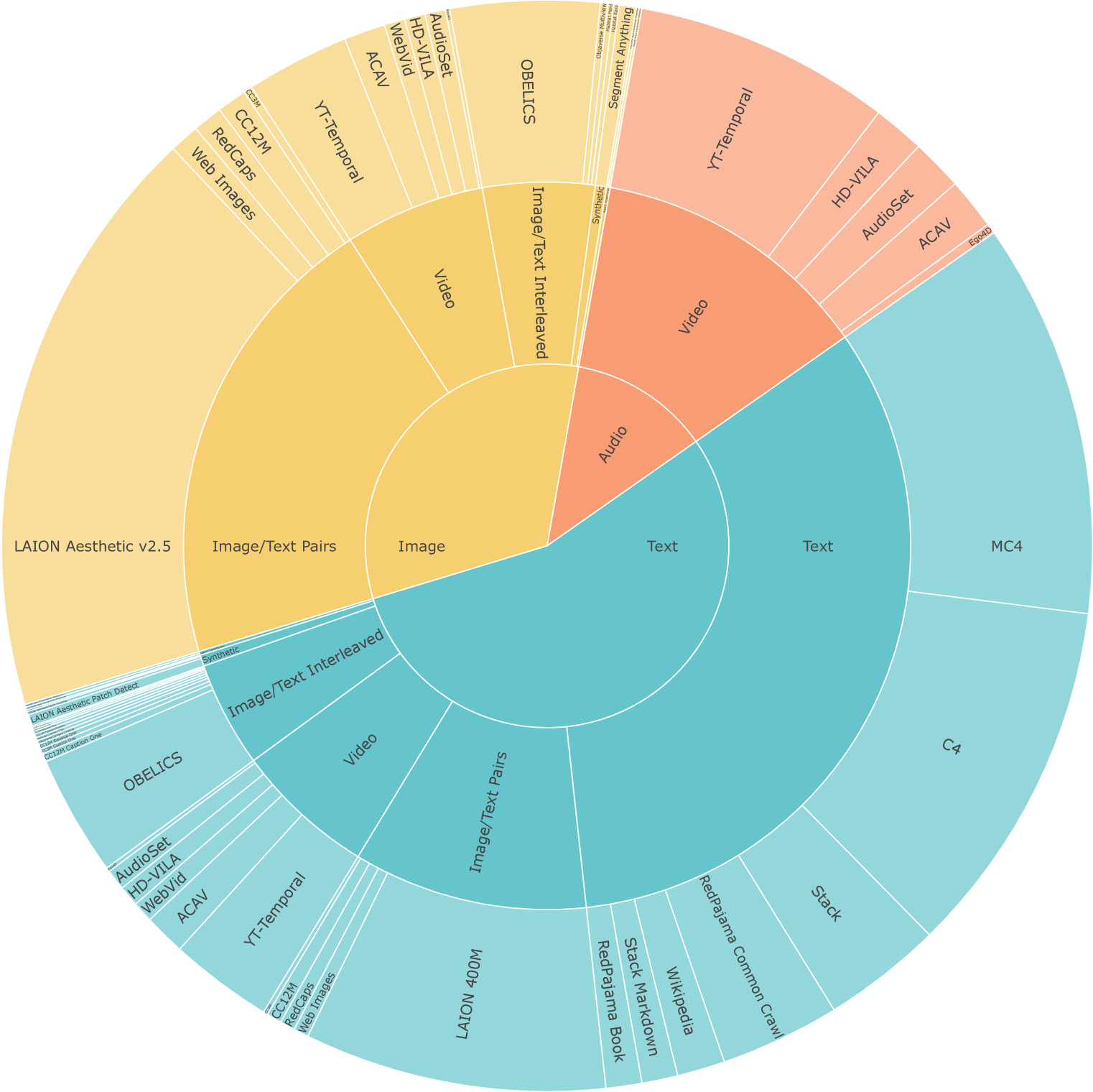
4.1预训练数据
我们的预训练数据来自各种来源,涵盖多种模式。 我们在附录C中提供了高级概述和详细信息。
自然语言处理[33%]。 我们使用用于训练 MPT-7B [176] 的公开数据集。 该数据集强调英语自然语言文本,但也包含代码和 Markdown。 它包括来自 RedPajama 数据集 [32]、C4 [68]、Wikipedia 和堆栈溢出的文本。 我们遵循[176]建议的比例,删除多语言和科学数据。
图像和文本 [40%]。 文本和图像配对数据来自 LAION-400M [159]、CC3M [163]、CC12M [23] 和 RedCaps [42]。 为了帮助训练图像历史模态,我们还使用 OBELICS [104] 中的交错图像/文本数据。 我们使用最后一张图像作为图像输入,其余图像作为图像历史。 特殊标记用于标记这些图像在文本中出现的位置。
视频和音频 [25%]。 视频提供了强大的自我监控信号,音频和视频通道之间具有高度相关性。 我们从各种公共数据集中采样音频和视频数据,包括 YT-Temporal-1B [215]、ACAV100M [105]、AudioSet [54] 、WebVid-10M [13]、HD-VILA-10M [200] 和 Ego4D [60]。
3D 和体现 [1%]。 对于自监督 3D 和实例预训练,我们使用 CroCo [194] 进行跨视图生成和去噪; Objaverse [40] 用于视图合成; ProcTHOR [39] 和 Habitat [157] 中的随机轨迹用于下一个动作和帧预测。
增强[1%]。 虽然网络上有大量图像、文本、视频和音频的无监督数据,但密集和稀疏注释的选项却更加有限。 我们建议通过大规模数据增强来解决这个问题。 我们考虑两种类型的数据增强:1. 从 SAM [94] 自动生成分割数据,以训练模型在给定点或边界框的情况下分割对象。 2. 合成补丁检测数据,要求模型列出图像中合成添加的形状的边界框。 我们还训练模型输出图像中的补丁总数,以预训练其计数能力。
训练样本构建。 在预训练期间,我们的大多数数据包含各种没有监督目标的模式。 在这些情况下,我们随机选择其中一种模式作为目标输出。 然后,我们要么从示例中删除该模式,要么用损坏的版本替换它。 示例中可能存在的其他模态被随机保留或屏蔽,以强制模型使用剩下的任何信息进行预测。 图 7 显示了使用包含图像帧序列、相应音频和文本记录的视频的示例。 预训练样本的构建过程如下: 1. 选择目标模态; 2. 选择保留哪些其他输入方式; 3. 选择目标; 4. 根据去噪或生成任务生成随机输入掩码; 5.添加表示任务的前缀词符。

4.2 配置参数数据
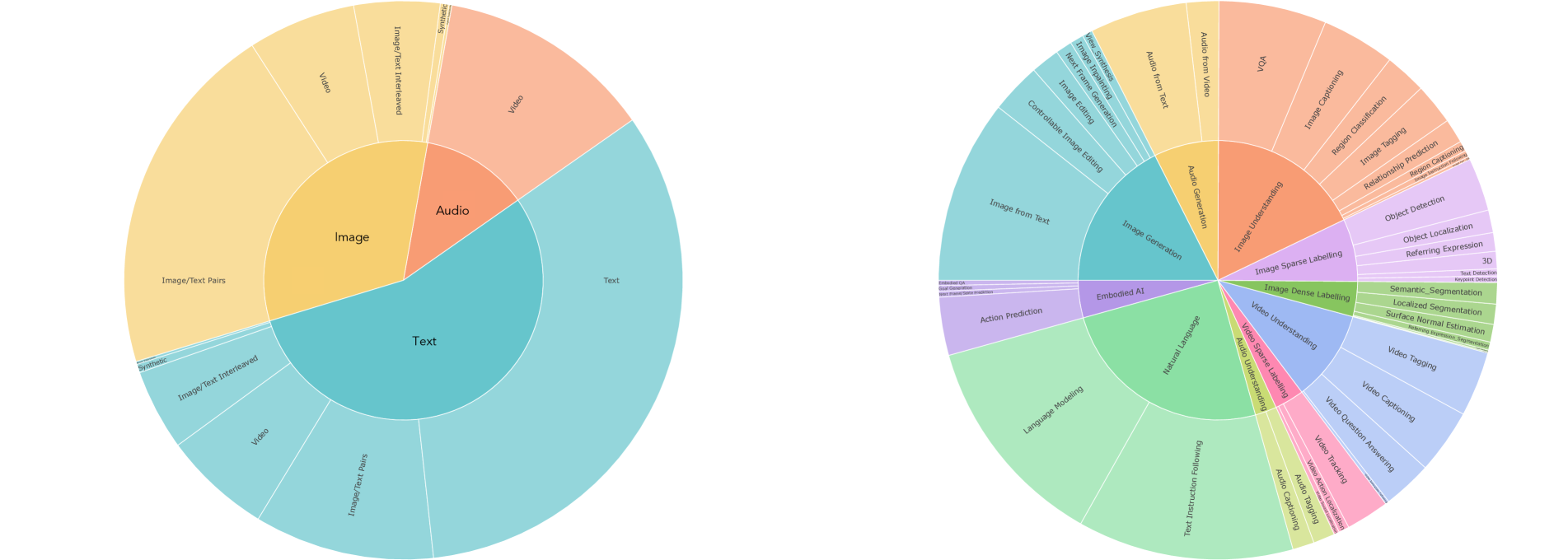
多模态指令调优是为模型配备跨各种模态的多种技能和能力,甚至适应新的独特指令的关键过程。 我们通过结合广泛的监督数据集和任务来构建多模式指令调整数据集。 我们确保每项任务都有明确的提示,无论是使用现有的提示还是编写新的提示。 我们还包括开放式任务,并为不太常见的模式创建综合任务,以增强任务和教学的多样性。 我们的混合物包括从 120 多个外部数据集中提取的 220 个任务。 我们在此提供高级概述和示例,并在附录 D 中提供详细信息。
自然语言[25.0%]。 对于自然语言,我们使用 FlanV2 [122] 和数据集 [33, 142] 后面的各种其他指令的混合。 此外,我们继续对无监督 NLP 混合物进行预训练,以帮助防止模型忘记在广泛的指令调整阶段从预训练中学到的信息。
图像生成 [17.6%]。 对于文本到图像的生成,我们使用预训练期间使用的相同图像和文本对。 我们还包含来自 [103, 115, 102] 的数据,这些数据可提供更好的字幕质量。 我们还训练模型通过视图合成[194, 40]、图像编辑[18, 217]、基于分割的图像生成[123]来生成图像 并修复[123]。
音频生成 [7.5%]。 这包括文本到音频数据集,其中包含野外音频 [93, 47, 131]、音乐 [2] 和人类语音 [85]. 我们还添加了预训练数据,以预测视频中的下一个音频剪辑。 更具体地说,我们将音频划分为多个片段,然后在给定文本和之前的片段作为输入的情况下生成其中一个片段。
图像理解[17.8%]。 我们包括来自视觉问答[6]、图像标记[41]、区域分类[102]的各种数据源以及开放的数据集-结束类似聊天的响应[119, 220]。 我们还包括多模式指令调整数据集 MIT [112] 和 MIMIC-IT [107]。
视频理解[10.6%]。 我们包含来自视频字幕 [190, 199]、视频标记 [168, 111, 35] 和视频问答 [198, 196]< 的数据源/t2>. 我们还使用 MIT [112] 和 MIMIC-IT [107] 中的示例进行视频说明。
音频理解 [10.6%]。 我们包括来自音频标记 [54, 24] 和音频字幕 [93, 47] 的数据源。 我们还在数据集中包含来自视频动作分类 [7] 的数据和音频。
图像稀疏标签[7.25%]。 这些任务需要根据输入图像输出稀疏坐标。 我们主要考虑对象检测[115]、引用表达[91]、3D检测[16]、相机姿态预测[40 ]、文本检测[183]和人体关键点[115]。
图像密集标签[4.06%]。 我们做了几个图像标记任务,包括表面法线估计 [78, 204]、深度估计 [138] 和光流 [44, 21]。 我们还在各种分割任务上训练我们的模型,包括语义分割、本地化分割和引用表达分割。
视频稀疏标签[3.42%]。 我们进行视频检测[151]、单个对象跟踪[50, 79]和视频动作定位[61]。
体现人工智能[4.33%]。 对于VIMA-Bench [87],我们使用图像输入作为环境的初始观察以及提示中图像或视频的图像历史记录。 我们添加了大规模操作数据集[127,184,63],并在模拟和现实环境中进行连续控制。 我们还对 Habitat Gibson 场景中的 PointNav 任务进行了训练。
指令调整数据的分布如图6。 总体而言,我们的指令调优混合物由 60% 的提示数据组成,这意味着监督数据集与提示相结合。 为了避免灾难性遗忘,30% 的数据是从预训练中遗留下来的。 此外,6% 是我们通过使用现有数据源构建新任务来构建的任务增强数据,这增强了现有任务并增加了任务多样性。 剩下的 4% 由自由格式的文本组成,以实现类似聊天的响应。
5实验
在本节中,我们将在需要解析和生成所有模式(图像、视频、音频、文本和动作)的广泛任务上评估我们的预训练和指令调整模型。 我们不会在任何实验中执行特定于任务的微调。 有关实验设置、其他结果详细信息、自然语言任务结果以及 Unified-IO 2 指令功能的其他研究的详细信息,请参阅附录 E。
5.1训练前评估
我们通过评估 Unified-IO 2 在常识性自然语言推理(HellaSwag [214])、文本到图像生成(TIFA [76])和文本到音频生成(AudioCaps [93])方面的表现,证明了预训练的有效性。 我们还评估了 SEED-Bench [106] 上的空间和时间理解,这是综合评估图像和视频模态感知和推理的基准。 表 2 显示,与特定任务专家 [154] 相比,Unified-IO 2 在生成和理解任务上实现了相当甚至更好的性能> 或通用多模式模型[9]。
尽管需要进行大量的多任务处理,HellaSwag 上的结果表明 Unified-IO 2 具有介于典型 3B 和 7B 语言模型之间的语言建模功能。 这可能是因为与基于语言的大语言模型相比,该模型看到的标记要少得多——总共大约 2500 亿个标记。 预训练的定性结果见附录E.1。
| Method | HellaSwag | TIFA | SEED-S | SEED-T | AudioCaps |
|---|---|---|---|---|---|
| LLaMA-7B [177] | 76.1 | - | - | - | - |
| OpenLLaMa-3Bv2 [55] | 52.1 | - | - | - | - |
| SD v1.5 [154] | - | 78.4 | - | - | - |
| OpenFlamingo-7B [9] | - | - | 34.5 | 33.1 | - |
| UIO-2 | 38.3 | 70.2 | 37.2 | 32.2 | 3.08 |
| UIO-2 | 47.6 | 77.2 | 40.9 | 34.0 | 3.10 |
| UIO-2 | 54.3 | 78.7 | 40.7 | 35.0 | 3.02 |
| Method | Cat. | Loc. | Vqa | Ref. | Seg. | KP | Norm. | All | |
|---|---|---|---|---|---|---|---|---|---|
| Ablation | UIO-2 | 70.1 | 66.1 | 67.6 | 66.6 | 53.8 | 56.8 | 44.5 | 60.8 |
| UIO-2 | 74.2 | 69.1 | 69.0 | 71.9 | 57.3 | 68.2 | 46.7 | 65.2 | |
| UIO-2 | 74.9 | 70.3 | 71.3 | 75.5 | 58.2 | 72.8 | 45.2 | 66.9 | |
| Test | GPV-2 [89] | 55.1 | 53.6 | 63.2 | 52.1 | - | - | - | - |
| UIO [123] | 60.8 | 67.1 | 74.5 | 78.9 | 56.5 | 67.7 | 44.3 | 64.3 | |
| UIO-2 | 75.2 | 70.2 | 71.1 | 75.5 | 58.8 | 73.2 | 44.7 | 67.0 |
5.2GRIT 结果
我们对通用鲁棒图像任务(GRIT)基准[66]进行评估,其中包括七个任务:分类、定位、VQA、引用表达、实例分割、关键点和表面法线估计。 完成所有 7 项任务需要理解图像、文本和稀疏输入并生成文本、稀疏和密集输出。 尽管这是 Unified-IO 2 支持的模式的子集,但我们还是对 GRIT 进行评估,因为它为这组功能提供了标准化且全面的基准。 有关 GRIT 的其他推理详细信息,请参阅附录 E.3。
结果如表3所示。 总体而言,Unified-IO 2 是 GRIT 上最先进的模型,比之前的最佳模型 Unified-IO 提高了 2.7 个百分点。 在各个任务上,我们可以观察到定位(3 分)、分类(14 分)、分割(2 分)和关键点(5 分)方面的进步。 在 VQA 上,我们的 GRIT 评估显示 Unified-IO 2 在同源问题上表现更好(84.6 vs. 81.2),表明差距为由于从视觉基因组构建的新源问题的性能下降;有关更多讨论,请参阅附录 E.3。 尽管稍微落后于 Unified-IO,Unified-IO 2 仍然获得了强大的引用表达分数,与之前在通用多模态模型上的研究相比毫不逊色,参见表 5. 超越Unified-IO,同时还支持更高质量的图像和文本生成,以及更多的任务和模式,说明了我们模型令人印象深刻的多任务处理能力。 Unified-IO 2 甚至在大小大致相等的 30 亿参数模型中保持了更好的整体性能(65.2 vs. 64.5)到统一IO。 消融结果显示平均性能,并且所有单独任务都随着模型大小而改进,这表明 Unified-IO 2 从规模中受益。
5.3生成结果
| Method | Image | Audio | Action | |||
|---|---|---|---|---|---|---|
| FID | TIFA | FAD | IS | KL | Succ. | |
| minDALL-E [37] | - | 79.4 | - | - | - | - |
| SD-1.5 [154] | - | 78.4 | - | - | - | - |
| AudioLDM-L [117] | - | - | 1.96 | 8.13 | 1.59 | - |
| AudioGen [101] | - | - | 3.13 | - | 2.09 | - |
| DiffSound [203] | - | - | 7.75 | 4.01 | 2.52 | - |
| VIMA [87] | - | - | - | - | - | 72.6 |
| VIMA-IMG [87] | - | - | - | - | - | 42.5 |
| CoDi [174] | 11.26 | 71.6 | 1.80 | 8.77 | 1.40 | - |
| Emu [172] | 11.66 | 65.5 | - | - | - | - |
| UIO-2 | 16.68 | 74.3 | 2.82 | 5.37 | 1.93 | 50.2 |
| UIO-2 | 14.11 | 80.0 | 2.59 | 5.11 | 1.74 | 54.2 |
| UIO-2 | 13.39 | 81.3 | 2.64 | 5.89 | 1.80 | 56.3 |
| Method | VQA | OKVQA | SQA | SQA | Tally-QA | RefCOCO | RefCOCO+ | RefCOCO-g | COCO-Cap. | POPE | SEED | MMB |
| InstructBLIP (8.2B) | - | - | - | 79.5 | 68.2 | - | - | - | 102.2 | - | 53.4 | 36 |
| Shikra (7.2B) | 77.4 | 47.2 | - | - | - | 87.0 | 81.6 | 82.3 | 117.5 | 84.7 | - | 58.8 |
| Ferret (7.2B) | - | - | - | - | - | 87.5 | 80.8 | 83.9 | - | 85.8 | - | - |
| Qwen-VL (9.6B) | 78.8 | 58.6 | - | 67.1 | - | 89.4 | 83.1 | 85.6 | 131.9 | - | 38.2 | |
| mPLUG-Owl2 (8.2B) | 79.4 | 57.7 | - | 68.7 | - | - | - | - | 137.3 | 86.2 | 57.8 | 64.5 |
| LLaVa-1.5 (7.2B) | 78.5 | - | - | 66.8 | - | - | - | - | - | 85.9 | 58.6 | 64.3 |
| LLaVa-1.5 (13B) | 80.0 | - | - | 71.6 | 72.4 | - | - | - | - | 85.9 | 61.6 | 67.7 |
| Single Task SoTA | 86.0 [29] | 66.8 [77] | 90.9 [119] | 90.7 [34] | 82.4 [77] | 92.64 [202] | 88.77 [187] | 89.22 [187] | 149.1 [29] | - | - | - |
| UIO-2 (1.1B) | 75.3 | 50.2 | 81.6 | 78.6 | 69.1 | 84.1 | 71.7 | 79.0 | 128.2 | 77.8 | 51.1 | 62.1 |
| UIO-2 (3.2B) | 78.1 | 53.7 | 88.8 | 87.4 | 72.2 | 88.2 | 79.8 | 84.0 | 130.3 | 87.2 | 60.2 | 68.1 |
| UIO-2 (6.8B) | 79.4 | 55.5 | 88.7 | 86.2 | 75.9 | 90.7 | 83.1 | 86.6 | 125.4 | 87.7 | 61.8 | 71.5 |
表4显示了需要生成图像、音频和动作输出的任务的结果。 我们使用 TIFA [76] 进行评估,TIFA 使用 VQA 模型衡量对提示的忠实度,并已被证明与人类判断良好相关,并使用 MS COCO 上的 FID [73] 进行评估[115]。 在 TIFA 上,我们发现 Unified-IO 2 得分接近 minDALL-E [37],比其他通用模型(例如 CoDi )领先约 10 分[ 174] 和鸸鹋[172]。 我们将这种强大的图像生成能力归功于广泛的预训练和细粒度 VQ-GAN 的使用。 我们在附录 E.5 中提供了 TIFA 基准生成结果的示例。 Unified-IO 2 的 FID 分数略高于比较模型,尽管我们注意到生成的图像在质量上仍然非常平滑和详细。
对于文本到音频的生成,我们在 AudioCaps [93] 测试集上进行评估。 AudioCaps 由 10 秒的音频片段组成,而我们的模型一次可以生成 4.08 秒的音频,因此我们无法对此基准进行直接评估。 相反,我们根据文本描述和之前的音频片段作为附加输入生成音频片段;更多详情请参见附录E.6。 虽然这不是与相关工作直接可比的设置,但它仍然可以合理地定量测量我们的音频生成能力。 Unified-IO 2 的得分高于除最近的潜在扩散模型 [117] 之外的专业模型,这显示了其具有竞争力的音频生成能力。
对于行动,我们使用 VIMA-Bench [87] 进行评估,这是一个机器人操作基准,包含 17 个带有文本图像交错提示的任务。 由于 VIMA 的动作空间是动作原语,因此 Unified-IO 2 在给定初始观察和多模式提示的情况下直接预测所有动作。 我们报告了 4 级评估协议[87]的平均成功率,并与以对象为中心输入的原始随意 VIMA 策略以及 VIMA-IMG(Gato [152)进行比较] 类似的政策,具有像我们这样的图像输入。
5.4视觉语言结果
我们评估视觉语言性能,并将其与其他视觉/语言通才模型进行比较,即即。,这些模型也被设计为执行许多任务并且可以遵循指令。 表 5 显示了 12 个视觉/语言基准集合的结果。 显示专业模型的 SoTA 结果以供参考。
Unified-IO 2 在 VQA 上取得了出色的结果,仅在 VQA v2 [59] 上超过了更大的 13B LLaVa 模型 [118],并领先于 ScienceQA [124] 和 TallyQA [1] 上的所有其他通才模型。 OK-VQA [130] 是例外。 我们假设,因为它需要外部知识,所以广泛的语言预训练对于这项任务很重要,因此我们的性能下降是因为 Unified-IO 2 没有像专用的那样对文本进行广泛的预训练。 Qwen-VL [12] 和 mPLUG-Owl2 [206] 使用的语言模型。
| Video | Audio | |||||||||
| Method |
Kinetics-400 [90] |
VATEXCaption [190] |
MSR-VTT [199] |
MSRVTT-QA [198] |
MSVD-QA [198] |
STAR [196] |
SEED-T [106] |
VGG-Sound [24] |
AudioCaps [93] |
Kinetics-Sounds [7] |
| MBT [137] | - | - | - | - | - | - | - | 52.3 | - | 85.0 |
| CoDi [174] | - | - | 74.4 | - | - | - | - | - | 78.9 | - |
| ImageBind [69] | 50.0 | - | - | - | - | - | - | 27.8 | - | - |
| BLIP-2 [109] | - | - | - | 9.2 | 18.3 | - | 36.7 | - | - | - |
| InstructBLIP [34] | - | - | - | 22.1 | 41.8 | - | 38.3 | - | - | - |
| Emu [172] | - | - | - | 24.1 | 39.8 | - | - | - | - | - |
| Flamingo-9B [5] | - | 57.4 | - | 29.4 | 47.2 | 41.2 | - | - | ||
| Flamingo-80B [5] | - | 84.2 | - | 47.4 | - | - | - | - | - | - |
| UIO-2 | 68.5 | 37.1 | 44.0 | 39.6 | 48.2 | 51.0 | 37.5 | 37.8 | 45.7 | 86.1 |
| UIO-2 | 71.4 | 41.6 | 47.1 | 39.3 | 50.4 | 52.0 | 45.6 | 44.2 | 45.7 | 88.0 |
| UIO-2 | 73.8 | 45.6 | 48.8 | 41.5 | 52.1 | 52.2 | 46.8 | 47.7 | 48.9 | 89.3 |
在指代表达方面,Unified-IO 2 领先于 Shikra [26] 和 Ferret [207],并且与 Qwen-VL 取得的分数相当。 在字幕方面,Unified-IO 2 也取得了很高的 CIDEr 分数 [182] 130.3,领先于 Shikra 和 InstructBLIP [34],但落后于Qwen-VL 和 mPLUG-Owl2。
最后,我们使用三个最近提出的仅评估基准进行评估。 MMB (MMBench [120]) 通过多项选择题测试视觉语言理解的多个方面,而 SEED-Bench 还测试视频理解。 我们在附录 E.4 中显示了分数的详细分类。 就总体得分而言,Unified-IO 2 在 SEED-Bench 排行榜上的所有 7B 模型中得分最高111as of 11/17/23,在 MMB 上得分最高 3.8 分。 值得注意的是,它在两项基准测试中均优于 LLaVa-1.5 13B 模型。 Unified-IO 2 在 POPE 物体幻觉基准 [113] 上也达到了 87.7,表明它不太容易出现物体幻觉。
总体而言,尽管包含更多模式并支持高质量图像和音频生成,Unified-IO 2 在这些基准测试中可以匹配或超越其他视觉和语言通用模型。 这表明其广泛的功能并不以牺牲视觉/语言性能为代价。
5.5视频、音频和其他结果
| AP3D | AP3D@15 | AP3D@25 | AP3D@50 | |
|---|---|---|---|---|
| Cube-RCNN [16] | 50.8 | 65.7 | 54.0 | 22.5 |
| UIO-2 | 42.9 | 54.4 | 45.7 | 21.7 |
| UIO-2 | 43.3 | 54.4 | 46.8 | 21.8 |
| UIO-2 | 42.4 | 54.0 | 45.6 | 20.9 |
Unified-IO 2在音视频分类和字幕以及视频问答方面表现出合理的性能,如表6所示。 值得注意的是,Unified-IO 2 在 Seed-Bench Temporal [106] 上优于 BLIP-2 [109] 和 InstructBLIP [34] 8.5 分。 Unified-IO 2 在 Kinetics-Sounds [7] 上也取得了比仅在该数据集上训练的 MBT [137] 更好的性能。
我们在表7中展示了单目标3D检测结果。 我们的模型在 Objectron 基准 [3] 上显示了不错的结果,类似于 Cube-RCNN [16]。 然而,它的性能在多目标 3D 检测任务中显着下降,例如 nuScenes [22] 和 Hypersim [153] 上的任务。 这可能是因为我们的训练数据中只有 1.0% 专注于 3D 检测。 一个潜在的解决方案可能是结合 2D 和 3D 检测技术。
在 COCO 目标检测中,排除“东西”类别,我们的模型达到了 47.2 的平均精度 (AP),其中 AP50 为 57.7,AP75 为 50.0。 然而,它在处理包含许多对象的图像时遇到困难。 之前的研究,如 Pix2Seq [27],表明自回归模型面临类似的挑战,可以通过广泛的数据增强来改进。 我们的模型在对象检测方面的数据增强相对更有限。
我们的模型在深度估计方面表现较差,NYUv2 深度数据集 [138] 上的 RMSE 为 0.623。 然而,专门针对此任务进行的微调将 RMSE 提高到了 0.423。 在我们的实验中,我们简单地使用每个数据集中的最大深度值对深度图进行归一化。 由于不同数据集[150]之间的密集地面实况深度不兼容,我们的模型无法捕获当前提示中的准确比例,这可以通过使用更好的归一化和度量评估来解决。
附录 E 显示其他任务的定性可视化,例如单个对象跟踪、机器人操作的未来状态预测以及基于图像的 3D 视图合成等等。 缺失
6 限制
-
•
由于内存限制,我们在整个项目中使用 ViT 和 AST 模型的基本版本来处理图像和音频功能。 使用这些图像和音频编码器的更大版本可以显着提高性能。
-
•
虽然我们的图像生成比基于 SD 的方法更忠实,但其质量与稳定扩散模型的质量不符。 此外,我们的音频生成时间上限约为 4 秒,这限制了音频输出的实际应用。
-
•
有限的计算资源限制了我们对模型超参数的探索。 使用更大的批量大小可能会提高模型的性能。
-
•
我们的模型对于深度、视频等模式或需要 3D 对象检测等更多利基功能时的可靠性要差得多。等。 这可能是由于我们在这些领域的任务种类有限。
-
•
提高数据质量可以提高模型的性能。 然而,尽管付出了巨大的努力,我们的人工编写的提示仍然缺乏多样性。 我们注意到,与训练的任务相比,模型在处理新的指令任务时的性能显着下降。
7结论
我们推出了Unified-IO 2,这是第一个能够理解和生成图像、文本、音频和动作的自回归多模态模型。 该模型是在广泛的多模态数据上从头开始训练的,并通过在大规模多模态语料库上进行指令调整来进一步完善。 我们开发了各种架构更改来稳定多模态训练,并提出了降噪器目标的多模态混合以有效利用多模态信号。 我们的模型在广泛的任务中取得了有希望的结果。 我们证明,从大语言模型到 LMM 可以带来新的功能和机会。 将来,我们希望将 Unified-IO 2 从编码器-解码器模型扩展到仅解码器模型。 此外,我们计划扩大模型的规模,提高数据质量,并完善整体模型设计。
致谢 我们感谢 Klemen Kotar 帮助收集 Embodied AI 预训练数据,感谢 MosaicML 的 Jonathan Frankle 建议混合使用 NLP 预训练数据,感谢 Jack Hessel 提供交错图像和文本数据集,感谢 Micheal Schmitz 帮助支持计算基础设施。 我们还感谢 Tanmay Gupta 的有益讨论,以及 Hamish Ivison 和 Ananya Harsh Jha 对于模型设计的富有洞察力的讨论。 我们还感谢 Oscar Michel、Yushi Hu 和 Yanbei Chen 帮助编辑本文,以及 Matt Deitke 帮助设置网页。 Savya Khosla 和 Derek Hoiem 得到了 ONR 奖项 N00014-23-1-2383 的部分支持。 这项研究是通过 Google 的 TPU 研究云 (TRC) 的云 TPU 实现的。
参考
- Acharya et al. [2019] Manoj Acharya, Kushal Kafle, and Christopher Kanan. TallyQA: Answering Complex Counting Questions. In AAAI, 2019.
- Agostinelli et al. [2023] Andrea Agostinelli, Timo I Denk, Zalán Borsos, Jesse Engel, Mauro Verzetti, Antoine Caillon, Qingqing Huang, Aren Jansen, Adam Roberts, Marco Tagliasacchi, et al. MusicLM: Generating Music From Text. arXiv preprint arXiv:2301.11325, 2023.
- Ahmadyan et al. [2021] Adel Ahmadyan, Liangkai Zhang, Artsiom Ablavatski, Jianing Wei, and Matthias Grundmann. Objectron: A Large Scale Dataset of Object-Centric Videos in the Wild with Pose Annotations. In CVPR, 2021.
- Aiello et al. [2023] Emanuele Aiello, Lili Yu, Yixin Nie, Armen Aghajanyan, and Barlas Oguz. Jointly Training Large Autoregressive Multimodal Models. arXiv preprint arXiv:2309.15564, 2023.
- Alayrac et al. [2022] Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a Visual Language Model for Few-Shot Learning. In NeurIPS, 2022.
- Antol et al. [2015] Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C Lawrence Zitnick, and Devi Parikh. VQA: Visual Question Answering. In ICCV, 2015.
- Arandjelovic and Zisserman [2017] Relja Arandjelovic and Andrew Zisserman. Look, Listen and Learn. In ICCV, 2017.
- Austin et al. [2021] Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and Charles Sutton. Program Synthesis with Large Language Models. arXiv preprint arXiv:2108.07732, 2021.
- Awadalla et al. [2023] Anas Awadalla, Irena Gao, Josh Gardner, Jack Hessel, Yusuf Hanafy, Wanrong Zhu, Kalyani Marathe, Yonatan Bitton, Samir Gadre, Shiori Sagawa, et al. OpenFlamingo: An Open-Source Framework for Training Large Autoregressive Vision-Language Models. arXiv preprint arXiv:2308.01390, 2023.
- Ba et al. [2016] Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer Normalization. In NeurIPS Deep Learning Symposium, 2016.
- Bae et al. [2021] Gwangbin Bae, Ignas Budvytis, and Roberto Cipolla. Estimating and Exploiting the Aleatoric Uncertainty in Surface Normal Estimation. In ICCV, 2021.
- Bai et al. [2023] Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond. arXiv preprint arXiv:2308.12966, 2023.
- Bain et al. [2021] Max Bain, Arsha Nagrani, Gül Varol, and Andrew Zisserman. Frozen in Time: A Joint Video and Image Encoder for End-to-End Retrieval. In ICCV, 2021.
- Borsos et al. [2023] Zalán Borsos, Raphaël Marinier, Damien Vincent, Eugene Kharitonov, Olivier Pietquin, Matt Sharifi, Dominik Roblek, Olivier Teboul, David Grangier, Marco Tagliasacchi, et al. AudioLM: A Language Modeling Approach to Audio Generation. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 31:2523–2533, 2023.
- Bradbury et al. [2018] James Bradbury, Roy Frostig, Peter Hawkins, Matthew James Johnson, Chris Leary, Dougal Maclaurin, George Necula, Adam Paszke, Jake VanderPlas, Skye Wanderman-Milne, and Qiao Zhang. Jax: composable transformations of python+numpy programs, 2018.
- Brazil et al. [2023] Garrick Brazil, Abhinav Kumar, Julian Straub, Nikhila Ravi, Justin Johnson, and Georgia Gkioxari. Omni3D: A Large Benchmark and Model for 3D Object Detection in the Wild. In CVPR, 2023.
- Brohan et al. [2023] Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Xi Chen, Krzysztof Choromanski, Tianli Ding, Danny Driess, Avinava Dubey, Chelsea Finn, et al. RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control. In CoRL, 2023.
- Brooks et al. [2023] Tim Brooks, Aleksander Holynski, and Alexei A Efros. InstructPix2Pix: Learning to Follow Image Editing Instructions. In CVPR, 2023.
- Brown et al. [2020] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language Models are Few-Shot Learners. In NeurIPS, 2020.
- Bubeck et al. [2023] Sébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, Yin Tat Lee, Yuanzhi Li, Scott Lundberg, et al. Sparks of Artificial General Intelligence: Early experiments with GPT-4. arXiv preprint arXiv:2303.12712, 2023.
- Butler et al. [2012] Daniel J Butler, Jonas Wulff, Garrett B Stanley, and Michael J Black. A Naturalistic Open Source Movie for Optical Flow Evaluation. In ECCV, 2012.
- Caesar et al. [2020] Holger Caesar, Varun Bankiti, Alex H. Lang, Sourabh Vora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuScenes: A multimodal dataset for autonomous driving. In CVPR, 2020.
- Changpinyo et al. [2021] Soravit Changpinyo, Piyush Sharma, Nan Ding, and Radu Soricut. Conceptual 12M: Pushing Web-Scale Image-Text Pre-Training To Recognize Long-Tail Visual Concepts. In CVPR, 2021.
- Chen et al. [2020] Honglie Chen, Weidi Xie, Andrea Vedaldi, and Andrew Zisserman. VGGSound: A Large-Scale Audio-Visual Dataset. In ICASSP, 2020.
- Chen et al. [2023a] Jun Chen, Deyao Zhu, Xiaoqian Shen, Xiang Li, Zechun Liu, Pengchuan Zhang, Raghuraman Krishnamoorthi, Vikas Chandra, Yunyang Xiong, and Mohamed Elhoseiny. MiniGPT-v2: Large Language Model As a Unified Interface for Vision-Language Multi-task Learning. arXiv preprint arXiv:2310.09478, 2023a.
- Chen et al. [2023b] Keqin Chen, Zhao Zhang, Weili Zeng, Richong Zhang, Feng Zhu, and Rui Zhao. Shikra: Unleashing Multimodal LLM’s Referential Dialogue Magic. arXiv preprint arXiv:2306.15195, 2023b.
- Chen et al. [2022] Ting Chen, Saurabh Saxena, Lala Li, David J Fleet, and Geoffrey Hinton. Pix2seq: A Language Modeling Framework for Object Detection. In ICLR, 2022.
- Chen et al. [2015] Xinlei Chen, Hao Fang, Tsung-Yi Lin, Ramakrishna Vedantam, Saurabh Gupta, Piotr Dollár, and C. Lawrence Zitnick. Microsoft COCO Captions: Data Collection and Evaluation Server. arXiv preprint arXiv:1504.00325, 2015.
- Chen et al. [2023c] Xi Chen, Josip Djolonga, Piotr Padlewski, Basil Mustafa, Soravit Changpinyo, Jialin Wu, Carlos Riquelme Ruiz, Sebastian Goodman, Xiao Wang, Yi Tay, et al. PaLI-X: On Scaling up a Multilingual Vision and Language Model. arXiv preprint arXiv:2305.18565, 2023c.
- Clark et al. [2019] Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions. In NAACL-HLT, 2019.
- Clark et al. [2018] Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge. arXiv preprint arXiv:1803.05457, 2018.
- Computer [2023] Together Computer. RedPajama: an Open Dataset for Training Large Language Models. https://github.com/togethercomputer/RedPajama-Data, 2023.
- Conover et al. [2023] Mike Conover, Matt Hayes, Ankit Mathur, Jianwei Xie, Jun Wan, Sam Shah, Ali Ghodsi, Patrick Wendell, Matei Zaharia, and Reynold Xin. Free Dolly: Introducing the World’s First Truly Open Instruction-Tuned LLM. https://www.databricks.com/blog/2023/04/12/dolly-first-open-commercially-viable-instruction-tuned-llm, 2023.
- Dai et al. [2023] Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, and Steven Hoi. InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning. In NeurIPS, 2023.
- Damen et al. [2022] Dima Damen, Hazel Doughty, Giovanni Maria Farinella, Antonino Furnari, Jian Ma, Evangelos Kazakos, Davide Moltisanti, Jonathan Munro, Toby Perrett, Will Price, and Michael Wray. Rescaling Egocentric Vision: Collection, Pipeline and Challenges for EPIC-KITCHENS-100. International Journal of Computer Vision, 130:33–55, 2022.
- Das et al. [2017] Abhishek Das, Satwik Kottur, Khushi Gupta, Avi Singh, Deshraj Yadav, José MF Moura, Devi Parikh, and Dhruv Batra. Visual Dialog. In CVPR, 2017.
- Dayma et al. [2021] Boris Dayma, Suraj Patil, Pedro Cuenca, Khalid Saifullah, Tanishq Abraham, Phúc Lê Khac, Luke Melas, and Ritobrata Ghosh. DALL·E Mini, 2021.
- Dehghani et al. [2023] Mostafa Dehghani, Josip Djolonga, Basil Mustafa, Piotr Padlewski, Jonathan Heek, Justin Gilmer, Andreas Peter Steiner, Mathilde Caron, Robert Geirhos, Ibrahim Alabdulmohsin, et al. Scaling Vision Transformers to 22 Billion Parameters. In ICML, 2023.
- Deitke et al. [2022] Matt Deitke, Eli VanderBilt, Alvaro Herrasti, Luca Weihs, Kiana Ehsani, Jordi Salvador, Winson Han, Eric Kolve, Aniruddha Kembhavi, and Roozbeh Mottaghi. ProcTHOR: Large-Scale Embodied AI Using Procedural Generation. In NeurIPS, 2022.
- Deitke et al. [2023] Matt Deitke, Dustin Schwenk, Jordi Salvador, Luca Weihs, Oscar Michel, Eli VanderBilt, Ludwig Schmidt, Kiana Ehsani, Aniruddha Kembhavi, and Ali Farhadi. Objaverse: A Universe of Annotated 3D Objects. In CVPR, 2023.
- Deng et al. [2009] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. ImageNet: A Large-Scale Hierarchical Image Database. In CVPR, 2009.
- Desai et al. [2021] Karan Desai, Gaurav Kaul, Zubin Aysola, and Justin Johnson. RedCaps: Web-curated image-text data created by the people, for the people. In NeurIPS Datasets and Benchmarks Track, 2021.
- Ding et al. [2021] Ming Ding, Zhuoyi Yang, Wenyi Hong, Wendi Zheng, Chang Zhou, Da Yin, Junyang Lin, Xu Zou, Zhou Shao, Hongxia Yang, et al. CogView: Mastering Text-to-Image Generation via Transformers. In NeurIPS, 2021.
- Dosovitskiy et al. [2015] Alexey Dosovitskiy, Philipp Fischer, Eddy Ilg, Philip Hausser, Caner Hazirbas, Vladimir Golkov, Patrick Van Der Smagt, Daniel Cremers, and Thomas Brox. FlowNet: Learning Optical Flow with Convolutional Networks. In ICCV, 2015.
- Dosovitskiy et al. [2021] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In ICLR, 2021.
- Driess et al. [2023] Danny Driess, Fei Xia, Mehdi SM Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, et al. PaLM-E: An Embodied Multimodal Language Model. In ICML, 2023.
- Drossos et al. [2020] Konstantinos Drossos, Samuel Lipping, and Tuomas Virtanen. Clotho: An Audio Captioning Dataset. In ICASSP, 2020.
- Edelman [1993] Gerald M Edelman. Neural Darwinism: Selection and reentrant signaling in higher brain function. Neuron, 10(2):115–125, 1993.
- Esser et al. [2021] Patrick Esser, Robin Rombach, and Bjorn Ommer. Taming Transformers for High-Resolution Image Synthesis. In CVPR, 2021.
- Fan et al. [2021] Heng Fan, Hexin Bai, Liting Lin, Fan Yang, Peng Chu, Ge Deng, Sijia Yu, Harshit, Mingzhen Huang, Juehuan Liu, et al. LaSOT: A High-quality Large-scale Single Object Tracking Benchmark. International Journal of Computer Vision, 129:439–461, 2021.
- Gao et al. [2021] Leo Gao, Jonathan Tow, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Kyle McDonell, Niklas Muennighoff, Jason Phang, Laria Reynolds, Eric Tang, Anish Thite, Ben Wang, Kevin Wang, and Andy Zou. A framework for few-shot language model evaluation, 2021.
- Gao et al. [2023] Peng Gao, Jiaming Han, Renrui Zhang, Ziyi Lin, Shijie Geng, Aojun Zhou, Wei Zhang, Pan Lu, Conghui He, Xiangyu Yue, et al. LLaMA-Adapter V2: Parameter-Efficient Visual Instruction Model. arXiv preprint arXiv:2304.15010, 2023.
- Ge et al. [2023] Yuying Ge, Yixiao Ge, Ziyun Zeng, Xintao Wang, and Ying Shan. Planting a SEED of Vision in Large Language Model. arXiv preprint arXiv:2307.08041, 2023.
- Gemmeke et al. [2017] Jort F. Gemmeke, Daniel P. W. Ellis, Dylan Freedman, Aren Jansen, Wade Lawrence, R. Channing Moore, Manoj Plakal, and Marvin Ritter. Audio Set: An Ontology and Human-Labeled Dataset for Audio Events. In ICASSP, 2017.
- Geng and Liu [2023] Xinyang Geng and Hao Liu. OpenLLaMA: An Open Reproduction of LLaMA. https://github.com/openlm-research/open_llama, 2023.
- Girdhar et al. [2023] Rohit Girdhar, Alaaeldin El-Nouby, Zhuang Liu, Mannat Singh, Kalyan Vasudev Alwala, Armand Joulin, and Ishan Misra. ImageBind: One Embedding Space To Bind Them All. In CVPR, 2023.
- Gong et al. [2021] Yuan Gong, Yu-An Chung, and James Glass. AST: Audio Spectrogram Transformer. In Interspeech, 2021.
- Goyal et al. [2017a] Raghav Goyal, Samira Ebrahimi Kahou, Vincent Michalski, Joanna Materzynska, Susanne Westphal, Heuna Kim, Valentin Haenel, Ingo Fruend, Peter Yianilos, Moritz Mueller-Freitag, et al. The” something something” video database for learning and evaluating visual common sense. In ICCV, 2017a.
- Goyal et al. [2017b] Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Making the V in VQA Matter: Elevating the Role of Image Understanding in Visual Question Answering. In CVPR, 2017b.
- Grauman et al. [2022] Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Rohit Girdhar, Jackson Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, et al. Ego4D: Around the World in 3,000 Hours of Egocentric Video. In CVPR, 2022.
- Gu et al. [2018] Chunhui Gu, Chen Sun, David A Ross, Carl Vondrick, Caroline Pantofaru, Yeqing Li, Sudheendra Vijayanarasimhan, George Toderici, Susanna Ricco, Rahul Sukthankar, et al. AVA: A Video Dataset of Spatio-temporally Localized Atomic Visual Actions. In CVPR, 2018.
- Gupta et al. [2019a] Agrim Gupta, Piotr Dollar, and Ross Girshick. LVIS: A Dataset for Large Vocabulary Instance Segmentation. In CVPR, 2019a.
- Gupta et al. [2019b] Abhishek Gupta, Vikash Kumar, Corey Lynch, Sergey Levine, and Karol Hausman. Relay Policy Learning: Solving Long-Horizon Tasks via Imitation and Reinforcement Learning. In CoRL, 2019b.
- Gupta and Kembhavi [2023] Tanmay Gupta and Aniruddha Kembhavi. Visual Programming: Compositional visual reasoning without training. In CVPR, 2023.
- Gupta et al. [2022a] Tanmay Gupta, Amita Kamath, Aniruddha Kembhavi, and Derek Hoiem. Towards General Purpose Vision Systems: An End-to-End Task-Agnostic Vision-Language Architecture. In CVPR, 2022a.
- Gupta et al. [2022b] Tanmay Gupta, Ryan Marten, Aniruddha Kembhavi, and Derek Hoiem. GRIT: General Robust Image Task Benchmark. arXiv preprint arXiv:2204.13653, 2022b.
- Gurari et al. [2018] Danna Gurari, Qing Li, Abigale J Stangl, Anhong Guo, Chi Lin, Kristen Grauman, Jiebo Luo, and Jeffrey P Bigham. VizWiz Grand Challenge: Answering Visual Questions from Blind People. In CVPR, 2018.
- Habernal et al. [2016] Ivan Habernal, Omnia Zayed, and Iryna Gurevych. C4Corpus: Multilingual Web-size Corpus with Free License. In LREC, 2016.
- Han et al. [2023] Jiaming Han, Renrui Zhang, Wenqi Shao, Peng Gao, Peng Xu, Han Xiao, Kaipeng Zhang, Chris Liu, Song Wen, Ziyu Guo, et al. ImageBind-LLM: Multi-modality Instruction Tuning. arXiv preprint arXiv:2309.03905, 2023.
- He et al. [2017] Kaiming He, Georgia Gkioxari, Piotr Dollár, and Ross Girshick. Mask R-CNN. In ICCV, 2017.
- He et al. [2022] Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked Autoencoders Are Scalable Vision Learners. In CVPR, 2022.
- Hendrycks et al. [2021] Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring Massive Multitask Language Understanding. In ICLR, 2021.
- Heusel et al. [2017] Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium. In NeurIPS, 2017.
- Ho and Salimans [2021] Jonathan Ho and Tim Salimans. Classifier-Free Diffusion Guidance. In NeurIPS Workshop on Deep Generative Models and Downstream Applications, 2021.
- Holtzman et al. [2020] Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. The Curious Case of Neural Text Degeneration. In ICLR, 2020.
- Hu et al. [2023a] Yushi Hu, Benlin Liu, Jungo Kasai, Yizhong Wang, Mari Ostendorf, Ranjay Krishna, and Noah A. Smith. TIFA: Accurate and Interpretable Text-to-Image Faithfulness Evaluation with Question Answering. In ICCV, 2023a.
- Hu et al. [2023b] Yushi Hu, Otilia Stretcu, Chun-Ta Lu, Krishnamurthy Viswanathan, Kenji Hata, Enming Luo, Ranjay Krishna, and Ariel Fuxman. Visual Program Distillation: Distilling Tools and Programmatic Reasoning into Vision-Language Models. arXiv preprint arXiv:2312.03052, 2023b.
- Huang et al. [2019a] Jingwei Huang, Yichao Zhou, Thomas Funkhouser, and Leonidas J Guibas. FrameNet: Learning Local Canonical Frames of 3D Surfaces from a Single RGB Image. In ICCV, 2019a.
- Huang et al. [2019b] Lianghua Huang, Xin Zhao, and Kaiqi Huang. GOT-10k: A Large High-Diversity Benchmark for Generic Object Tracking in the Wild. IEEE Transactions on Pattern Analysis and Machine Intelligence, 43(5):1562–1577, 2019b.
- Huang et al. [2023a] Rongjie Huang, Mingze Li, Dongchao Yang, Jiatong Shi, Xuankai Chang, Zhenhui Ye, Yuning Wu, Zhiqing Hong, Jiawei Huang, Jinglin Liu, et al. AudioGPT: Understanding and Generating Speech, Music, Sound, and Talking Head. arXiv preprint arXiv:2304.12995, 2023a.
- Huang et al. [2023b] Shaohan Huang, Li Dong, Wenhui Wang, Yaru Hao, Saksham Singhal, Shuming Ma, Tengchao Lv, Lei Cui, Owais Khan Mohammed, Qiang Liu, et al. Language Is Not All You Need: Aligning Perception with Language Models. In NeurIPS, 2023b.
- Huang et al. [2016] Ting-Hao Huang, Francis Ferraro, Nasrin Mostafazadeh, Ishan Misra, Aishwarya Agrawal, Jacob Devlin, Ross Girshick, Xiaodong He, Pushmeet Kohli, Dhruv Batra, et al. Visual Storytelling. In NAACL-HLT, 2016.
- Hudson and Manning [2019] Drew A Hudson and Christopher D Manning. GQA: A New Dataset for Real-World Visual Reasoning and Compositional Question Answering. In CVPR, 2019.
- Ilharco et al. [2021] Gabriel Ilharco, Mitchell Wortsman, Ross Wightman, Cade Gordon, Nicholas Carlini, Rohan Taori, Achal Dave, Vaishaal Shankar, Hongseok Namkoong, John Miller, Hannaneh Hajishirzi, Ali Farhadi, and Ludwig Schmidt. OpenCLIP, 2021.
- Ito and Johnson [2017] Keith Ito and Linda Johnson. The LJ Speech Dataset. https://keithito.com/LJ-Speech-Dataset/, 2017.
- Jaegle et al. [2022] Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, et al. Perceiver IO: A General Architecture for Structured Inputs & Outputs. In ICLR, 2022.
- Jiang et al. [2023] Yunfan Jiang, Agrim Gupta, Zichen Zhang, Guanzhi Wang, Yongqiang Dou, Yanjun Chen, Li Fei-Fei, Anima Anandkumar, Yuke Zhu, and Linxi Fan. VIMA: General Robot Manipulation with Multimodal Prompts. In ICML, 2023.
- Jin et al. [2023] Yang Jin, Kun Xu, Liwei Chen, Chao Liao, Jianchao Tan, Bin Chen, Chenyi Lei, An Liu, Chengru Song, Xiaoqiang Lei, et al. Unified Language-Vision Pretraining in LLM with Dynamic Discrete Visual Tokenization. arXiv preprint arXiv:2309.04669, 2023.
- Kamath et al. [2022] Amita Kamath, Christopher Clark, Tanmay Gupta, Eric Kolve, Derek Hoiem, and Aniruddha Kembhavi. Webly Supervised Concept Expansion for General Purpose Vision Models. In ECCV, 2022.
- Kay et al. [2017] Will Kay, Joao Carreira, Karen Simonyan, Brian Zhang, Chloe Hillier, Sudheendra Vijayanarasimhan, Fabio Viola, Tim Green, Trevor Back, Paul Natsev, et al. The Kinetics Human Action Video Dataset. arXiv preprint arXiv:1705.06950, 2017.
- Kazemzadeh et al. [2014] Sahar Kazemzadeh, Vicente Ordonez, Mark Matten, and Tamara Berg. ReferItGame: Referring to Objects in Photographs of Natural Scenes. In EMNLP, 2014.
- Kilgour et al. [2019] Kevin Kilgour, Mauricio Zuluaga, Dominik Roblek, and Matthew Sharifi. Fréchet Audio Distance: A Reference-Free Metric for Evaluating Music Enhancement Algorithms. In Interspeech, 2019.
- Kim et al. [2019] Chris Dongjoo Kim, Byeongchang Kim, Hyunmin Lee, and Gunhee Kim. AudioCaps: Generating Captions for Audios in The Wild. In NAACL-HLT, 2019.
- Kirillov et al. [2023] Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollar, and Ross Girshick. Segment Anything. In ICCV, 2023.
- Kocetkov et al. [2023] Denis Kocetkov, Raymond Li, Loubna Ben Allal, Jia Li, Chenghao Mou, Carlos Muñoz Ferrandis, Yacine Jernite, Margaret Mitchell, Sean Hughes, Thomas Wolf, Dzmitry Bahdanau, Leandro von Werra, and Harm de Vries. The Stack: 3 TB of permissively licensed source code. Transactions on Machine Learning Research, 2023.
- Koh et al. [2023a] Jing Yu Koh, Daniel Fried, and Ruslan Salakhutdinov. Generating Images with Multimodal Language Models. In NeurIPS, 2023a.
- Koh et al. [2023b] Jing Yu Koh, Ruslan Salakhutdinov, and Daniel Fried. Grounding Language Models to Images for Multimodal Inputs and Outputs. In ICML, 2023b.
- Kong et al. [2020] Jungil Kong, Jaehyeon Kim, and Jaekyoung Bae. HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis. In NeurIPS, 2020.
- Köpf et al. [2023] Andreas Köpf, Yannic Kilcher, Dimitri von Rütte, Sotiris Anagnostidis, Zhi-Rui Tam, Keith Stevens, Abdullah Barhoum, Nguyen Minh Duc, Oliver Stanley, Richárd Nagyfi, et al. OpenAssistant Conversations – Democratizing Large Language Model Alignment. In NeurIPS Datasets and Benchmarks Track, 2023.
- Krell et al. [2021] Mario Michael Krell, Matej Kosec, Sergio P Perez, and Andrew Fitzgibbon. Efficient Sequence Packing without Cross-contamination: Accelerating Large Language Models without Impacting Performance. arXiv preprint arXiv:2107.02027, 2021.
- Kreuk et al. [2023] Felix Kreuk, Gabriel Synnaeve, Adam Polyak, Uriel Singer, Alexandre Défossez, Jade Copet, Devi Parikh, Yaniv Taigman, and Yossi Adi. AudioGen: Textually Guided Audio Generation. In ICLR, 2023.
- Krishna et al. [2017] Ranjay Krishna, Yuke Zhu, Oliver Groth, Justin Johnson, Kenji Hata, Joshua Kravitz, Stephanie Chen, Yannis Kalantidis, Li-Jia Li, David A. Shamma, Michael S. Bernstein, and Fei-Fei Li. Visual Genome: Connecting Language and Vision Using Crowdsourced Dense Image Annotations. International Journal of Computer Vision, 2017.
- Kuznetsova et al. [2020] Alina Kuznetsova, Hassan Rom, Neil Alldrin, Jasper Uijlings, Ivan Krasin, Jordi Pont-Tuset, Shahab Kamali, Stefan Popov, Matteo Malloci, Alexander Kolesnikov, Tom Duerig, and Vittorio Ferrari. The Open Images Dataset V4: Unified image classification, object detection, and visual relationship detection at scale. International Journal of Computer Vision, 128(7):1956–1981, 2020.
- Laurençon et al. [2023] Hugo Laurençon, Lucile Saulnier, Léo Tronchon, Stas Bekman, Amanpreet Singh, Anton Lozhkov, Thomas Wang, Siddharth Karamcheti, Alexander M Rush, Douwe Kiela, et al. OBELICS: An Open Web-Scale Filtered Dataset of Interleaved Image-Text Documents. In NeurIPS Datasets and Benchmarks Track, 2023.
- Lee et al. [2021] Sangho Lee, Jiwan Chung, Youngjae Yu, Gunhee Kim, Thomas Breuel, Gal Chechik, and Yale Song. ACAV100M: Automatic Curation of Large-Scale Datasets for Audio-Visual Video Representation Learning. In ICCV, 2021.
- Li et al. [2023a] Bohao Li, Rui Wang, Guangzhi Wang, Yuying Ge, Yixiao Ge, and Ying Shan. SEED-Bench: Benchmarking Multimodal LLMs with Generative Comprehension. arXiv preprint arXiv:2307.16125, 2023a.
- Li et al. [2023b] Bo Li, Yuanhan Zhang, Liangyu Chen, Jinghao Wang, Fanyi Pu, Jingkang Yang, Chunyuan Li, and Ziwei Liu. MIMIC-IT: Multi-Modal In-Context Instruction Tuning. arXiv preprint arXiv:2306.05425, 2023b.
- Li et al. [2023c] Bo Li, Yuanhan Zhang, Liangyu Chen, Jinghao Wang, Jingkang Yang, and Ziwei Liu. Otter: A Multi-Modal Model with In-Context Instruction Tuning. arXiv preprint arXiv:2305.03726, 2023c.
- Li et al. [2023d] Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models. In ICML, 2023d.
- Li et al. [2023e] Kunchang Li, Yinan He, Yi Wang, Yizhuo Li, Wen Wang, Ping Luo, Yali Wang, Limin Wang, and Yu Qiao. VideoChat: Chat-Centric Video Understanding. arXiv preprint arXiv:2305.06355, 2023e.
- Li et al. [2023f] Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Limin Wang, and Yu Qiao. UniFormerV2: Unlocking the Potential of Image ViTs for Video Understanding. In ICCV, 2023f.
- Li et al. [2023g] Lei Li, Yuwei Yin, Shicheng Li, Liang Chen, Peiyi Wang, Shuhuai Ren, Mukai Li, Yazheng Yang, Jingjing Xu, Xu Sun, et al. MIT: A Large-Scale Dataset towards Multi-Modal Multilingual Instruction Tuning. arXiv preprint arXiv:2306.04387, 2023g.
- Li et al. [2023h] Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji rong Wen. Evaluating Object Hallucination in Large Vision-Language Models. In EMNLP, 2023h.
- Liang et al. [2023] Paul Pu Liang, Yiwei Lyu, Xiang Fan, Jeffrey Tsaw, Yudong Liu, Shentong Mo, Dani Yogatama, Louis-Philippe Morency, and Russ Salakhutdinov. High-Modality Multimodal Transformer: Quantifying Modality & Interaction Heterogeneity for High-Modality Representation Learning. TMLR, 2023.
- Lin et al. [2014] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft COCO: Common Objects in Context. In ECCV, 2014.
- Liu et al. [2023a] Fangyu Liu, Guy Emerson, and Nigel Collier. Visual Spatial Reasoning. Transactions of the Association for Computational Linguistics, 11:635–651, 2023a.
- Liu et al. [2023b] Haohe Liu, Zehua Chen, Yi Yuan, Xinhao Mei, Xubo Liu, Danilo Mandic, Wenwu Wang, and Mark D Plumbley. AudioLDM: Text-to-Audio Generation with Latent Diffusion Models. In ICML, 2023b.
- Liu et al. [2023c] Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved Baselines with Visual Instruction Tuning. arXiv preprint arXiv:2310.03744, 2023c.
- Liu et al. [2023d] Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual Instruction Tuning. In NeurIPS, 2023d.
- Liu et al. [2023e] Yuanzhan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, Kai Chen, and Dahua Lin. MMBench: Is Your Multi-modal Model an All-around Player? arXiv preprint arXiv:2307.06281, 2023e.
- Liu et al. [2022] Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, et al. Swin Transformer V2: Scaling Up Capacity and Resolution. In CVPR, 2022.
- Longpre et al. [2023] Shayne Longpre, Le Hou, Tu Vu, Albert Webson, Hyung Won Chung, Yi Tay, Denny Zhou, Quoc V Le, Barret Zoph, Jason Wei, and Adam Roberts. The Flan Collection: Designing Data and Methods for Effective Instruction Tuning. In ICML, 2023.
- Lu et al. [2023a] Jiasen Lu, Christopher Clark, Rowan Zellers, Roozbeh Mottaghi, and Aniruddha Kembhavi. Unified-IO: A Unified Model for Vision, Language, and Multi-Modal Tasks. In ICLR, 2023a.
- Lu et al. [2022] Pan Lu, Swaroop Mishra, Tony Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. Learn to Explain: Multimodal Reasoning via Thought Chains for Science Question Answering. In NeurIPS, 2022.
- Lu et al. [2023b] Pan Lu, Baolin Peng, Hao Cheng, Michel Galley, Kai-Wei Chang, Ying Nian Wu, Song-Chun Zhu, and Jianfeng Gao. Chameleon: Plug-and-Play Compositional Reasoning with Large Language Models. In NeurIPS, 2023b.
- Luo et al. [2023] Ruipu Luo, Ziwang Zhao, Min Yang, Junwei Dong, Ming-Hui Qiu, Pengcheng Lu, Tao Wang, and Zhongyu Wei. Valley: Video Assistant with Large Language model Enhanced abilitY. arXiv preprint arXiv:2306.07207, 2023.
- Lynch et al. [2023] Corey Lynch, Ayzaan Wahid, Jonathan Tompson, Tianli Ding, James Betker, Robert Baruch, Travis Armstrong, and Pete Florence. Interactive Language: Talking to Robots in Real Time. IEEE Robotics and Automation Letters, 2023.
- Maaz et al. [2023] Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fahad Shahbaz Khan. Video-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models. arXiv preprint arXiv:2306.05424, 2023.
- Mao et al. [2016] Junhua Mao, Jonathan Huang, Alexander Toshev, Oana Camburu, Alan Yuille, and Kevin Murphy. Generation and Comprehension of Unambiguous Object Descriptions. In CVPR, 2016.
- Marino et al. [2019] Kenneth Marino, Mohammad Rastegari, Ali Farhadi, and Roozbeh Mottaghi. OK-VQA: A Visual Question Answering Benchmark Requiring External Knowledge. In CVPR, 2019.
- Martin Morato and Mesaros [2021] Irene Martin Morato and Annamaria Mesaros. Diversity and Bias in Audio Captioning Datasets. In DCASE, 2021.
- Merullo et al. [2023] Jack Merullo, Louis Castricato, Carsten Eickhoff, and Ellie Pavlick. Linearly Mapping from Image to Text Space. In ICLR, 2023.
- Mishra et al. [2019] Anand Mishra, Shashank Shekhar, Ajeet Kumar Singh, and Anirban Chakraborty. OCR-VQA: Visual Question Answering by Reading Text in Images. In ICDAR, 2019.
- Mishra et al. [2023] Utkarsh Mishra, Shangjie Xue, Yongxin Chen, and Danfei Xu. Generative Skill Chaining: Long-Horizon Skill Planning with Diffusion Models. In CoRL, 2023.
- Mu et al. [2023] Yao Mu, Qinglong Zhang, Mengkang Hu, Wenhai Wang, Mingyu Ding, Jun Jin, Bin Wang, Jifeng Dai, Yu Qiao, and Ping Luo. EmbodiedGPT: Vision-Language Pre-Training via Embodied Chain of Thought. In NeurIPS, 2023.
- Nagaraja et al. [2016] Varun K Nagaraja, Vlad I Morariu, and Larry S Davis. Modeling Context Between Objects for Referring Expression Understanding. In ECCV, 2016.
- Nagrani et al. [2021] Arsha Nagrani, Shan Yang, Anurag Arnab, Aren Jansen, Cordelia Schmid, and Chen Sun. Attention Bottlenecks for Multimodal Fusion. In NeurIPS, 2021.
- Nathan Silberman and Fergus [2012] Pushmeet Kohli Nathan Silberman, Derek Hoiem and Rob Fergus. Indoor Segmentation and Support Inference from RGBD Images. In ECCV, 2012.
- Oquab et al. [2023] Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. DINOv2: Learning Robust Visual Features without Supervision. arXiv preprint arXiv:2304.07193, 2023.
- Padalkar et al. [2023] Abhishek Padalkar, Acorn Pooley, Ajinkya Jain, Alex Bewley, Alex Herzog, Alex Irpan, Alexander Khazatsky, Anant Rai, Anikait Singh, Anthony Brohan, et al. Open X-Embodiment: Robotic Learning Datasets and RT-X Models. In CoRL Workshop TGR, 2023.
- Pan et al. [2023] Xichen Pan, Li Dong, Shaohan Huang, Zhiliang Peng, Wenhu Chen, and Furu Wei. Kosmos-G: Generating Images in Context with Multimodal Large Language Models. arXiv preprint arXiv:2310.02992, 2023.
- Peng et al. [2023a] Baolin Peng, Chunyuan Li, Pengcheng He, Michel Galley, and Jianfeng Gao. Instruction Tuning with GPT-4. arXiv preprint arXiv:2304.03277, 2023a.
- Peng et al. [2023b] Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, and Furu Wei. Kosmos-2: Grounding Multimodal Large Language Models to the World. arXiv preprint arXiv:2306.14824, 2023b.
- Piaget et al. [1952] Jean Piaget, Margaret Cook, et al. The Origins of Intelligence in Children. International Universities Press New York, 1952.
- Qin et al. [2023] Can Qin, Shu Zhang, Ning Yu, Yihao Feng, Xinyi Yang, Yingbo Zhou, Huan Wang, Juan Carlos Niebles, Caiming Xiong, Silvio Savarese, et al. UniControl: A Unified Diffusion Model for Controllable Visual Generation In the Wild. In NeurIPS, 2023.
- Radford et al. [2021] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning Transferable Visual Models From Natural Language Supervision. In ICML, 2021.
- Raffel et al. [2020] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. JMLR, 21(140):1–67, 2020.
- Ramesh et al. [2021] Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Radford, Mark Chen, and Ilya Sutskever. Zero-Shot Text-to-Image Generation. In ICML, 2021.
- Ramrakhya et al. [2022] Ram Ramrakhya, Eric Undersander, Dhruv Batra, and Abhishek Das. Habitat-Web: Learning Embodied Object-Search Strategies from Human Demonstrations at Scale. In CVPR, 2022.
- Ranftl et al. [2020] René Ranftl, Katrin Lasinger, David Hafner, Konrad Schindler, and Vladlen Koltun. Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-Shot Cross-Dataset Transfer. IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(3):1623–1637, 2020.
- Real et al. [2017] Esteban Real, Jonathon Shlens, Stefano Mazzocchi, Xin Pan, and Vincent Vanhoucke. YouTube-BoundingBoxes: A Large High-Precision Human-Annotated Data Set for Object Detection in Video. In CVPR, 2017.
- Reed et al. [2022] Scott Reed, Konrad Zolna, Emilio Parisotto, Sergio Gomez Colmenarejo, Alexander Novikov, Gabriel Barth-Maron, Mai Gimenez, Yury Sulsky, Jackie Kay, Jost Tobias Springenberg, et al. A Generalist Agent. Transactions on Machine Learning Research, 2022.
- Roberts et al. [2021] Mike Roberts, Jason Ramapuram, Anurag Ranjan, Atulit Kumar, Miguel Angel Bautista, Nathan Paczan, Russ Webb, and Joshua M. Susskind. Hypersim: A Photorealistic Synthetic Dataset for Holistic Indoor Scene Understanding. In ICCV, 2021.
- Rombach et al. [2022] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-Resolution Image Synthesis With Latent Diffusion Models. In CVPR, 2022.
- Salimans et al. [2016] Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. Improved Techniques for Training GANs. In NeurIPS, 2016.
- Sanh et al. [2022] Victor Sanh, Albert Webson, Colin Raffel, Stephen H Bach, Lintang Sutawika, Zaid Alyafeai, Antoine Chaffin, Arnaud Stiegler, Teven Le Scao, Arun Raja, et al. Multitask Prompted Training Enables Zero-Shot Task Generalization. In ICLR, 2022.
- Savva et al. [2019] Manolis Savva, Abhishek Kadian, Oleksandr Maksymets, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub, Jia Liu, Vladlen Koltun, Jitendra Malik, et al. Habitat: A Platform for Embodied AI Research. In ICCV, 2019.
- Schuhmann [2022] Christoph Schuhmann. LAION-AESTHETICS. https://laion.ai/blog/laion-aesthetics/, 2022.
- Schuhmann et al. [2021] Christoph Schuhmann, Richard Vencu, Romain Beaumont, Robert Kaczmarczyk, Clayton Mullis, Aarush Katta, Theo Coombes, Jenia Jitsev, and Aran Komatsuzaki. LAION-400M: Open Dataset of CLIP-Filtered 400 Million Image-Text Pairs. In NeurIPS Data-Centric AI Workshop, 2021.
- Schwenk et al. [2022] Dustin Schwenk, Apoorv Khandelwal, Christopher Clark, Kenneth Marino, and Roozbeh Mottaghi. A-OKVQA: A Benchmark for Visual Question Answering using World Knowledge. In ECCV, 2022.
- Sennrich et al. [2016] Rico Sennrich, Barry Haddow, and Alexandra Birch. Neural Machine Translation of Rare Words with Subword Units. In ACL, 2016.
- Sermanet et al. [2023] Pierre Sermanet, Tianli Ding, Jeffrey Zhao, Fei Xia, Debidatta Dwibedi, Keerthana Gopalakrishnan, Christine Chan, Gabriel Dulac-Arnold, Sharath Maddineni, Nikhil J Joshi, et al. RoboVQA: Multimodal Long-Horizon Reasoning for Robotics. arXiv preprint arXiv:2311.00899, 2023.
- Sharma et al. [2018] Piyush Sharma, Nan Ding, Sebastian Goodman, and Radu Soricut. Conceptual Captions: A Cleaned, Hypernymed, Image Alt-text Dataset For Automatic Image Captioning. In ACL, 2018.
- Shazeer and Stern [2018] Noam Shazeer and Mitchell Stern. Adafactor: Adaptive Learning Rates with Sublinear Memory Cost. In ICML, 2018.
- Singh et al. [2019] Amanpreet Singh, Vivek Natarjan, Meet Shah, Yu Jiang, Xinlei Chen, Devi Parikh, and Marcus Rohrbach. Towards VQA Models That Can Read. In CVPR, 2019.
- Singh et al. [2023] Ishika Singh, Valts Blukis, Arsalan Mousavian, Ankit Goyal, Danfei Xu, Jonathan Tremblay, Dieter Fox, Jesse Thomason, and Animesh Garg. ProgPrompt: Generating Situated Robot Task Plans using Large Language Models. ICRA, 2023.
- Smith and Gasser [2005] Linda Smith and Michael Gasser. The Development of Embodied Cognition: Six Lessons from Babies. Artificial life, 11(1-2):13–29, 2005.
- Soomro et al. [2012] Khurram Soomro, Amir Roshan Zamir, and Mubarak Shah. UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild. arXiv preprint arXiv:1212.0402, 2012.
- Su et al. [2023a] Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, and Yunfeng Liu. RoFormer: Enhanced Transformer with Rotary Position Embedding. Neurocomputing, 2023a.
- Su et al. [2023b] Yixuan Su, Tian Lan, Huayang Li, Jialu Xu, Yan Wang, and Deng Cai. PandaGPT: One Model To Instruction-Follow Them All. arXiv preprint arXiv:2305.16355, 2023b.
- Suhr et al. [2019] Alane Suhr, Stephanie Zhou, Ally Zhang, Iris Zhang, Huajun Bai, and Yoav Artzi. A Corpus for Reasoning About Natural Language Grounded in Photographs. In ACL, 2019.
- Sun et al. [2023] Quan Sun, Qiying Yu, Yufeng Cui, Fan Zhang, Xiaosong Zhang, Yueze Wang, Hongcheng Gao, Jingjing Liu, Tiejun Huang, and Xinlong Wang. Generative Pretraining in Multimodality. arXiv preprint arXiv:2307.05222, 2023.
- Surís et al. [2023] Dídac Surís, Sachit Menon, and Carl Vondrick. ViperGPT: Visual Inference via Python Execution for Reasoning. In ICCV, 2023.
- Tang et al. [2023] Zineng Tang, Ziyi Yang, Chenguang Zhu, Michael Zeng, and Mohit Bansal. Any-to-Any Generation via Composable Diffusion. In NeurIPS, 2023.
- Tay et al. [2023] Yi Tay, Mostafa Dehghani, Vinh Q Tran, Xavier Garcia, Jason Wei, Xuezhi Wang, Hyung Won Chung, Dara Bahri, Tal Schuster, Steven Zheng, et al. UL2: Unifying Language Learning Paradigms. In ICLR, 2023.
- Team [2023] MosaicML NLP Team. Introducing MPT-7B: A New Standard for Open-Source, Commercially Usable LLMs, 2023. Accessed: 2023-05-05.
- Touvron et al. [2023] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. LLaMA: Open and Efficient Foundation Language Models. arXiv preprint arXiv:2302.13971, 2023.
- Tsimpoukelli et al. [2021] Maria Tsimpoukelli, Jacob Menick, Serkan Cabi, S. M. Ali Eslami, Oriol Vinyals, Felix Hill, and Zacharias Janssen. Multimodal Few-Shot Learning with Frozen Language Models. In NeurIPS, 2021.
- Van Den Oord et al. [2017] Aaron Van Den Oord, Oriol Vinyals, and Koray Kavukcuoglu. Neural Discrete Representation Learning. In NeurIPS, 2017.
- Van Horn et al. [2018] Grant Van Horn, Oisin Mac Aodha, Yang Song, Yin Cui, Chen Sun, Alex Shepard, Hartwig Adam, Pietro Perona, and Serge Belongie. The iNaturalist Species Classification and Detection Dataset. In CVPR, 2018.
- Vaswani et al. [2017] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention Is All You Need. In NeurIPS, 2017.
- Vedantam et al. [2015] Ramakrishna Vedantam, C Lawrence Zitnick, and Devi Parikh. CIDEr: Consensus-based Image Description Evaluation. In CVPR, 2015.
- Veit et al. [2016] Andreas Veit, Tomas Matera, Lukas Neumann, Jiri Matas, and Serge Belongie. COCO-Text: Dataset and Benchmark for Text Detection and Recognition in Natural Images. arXiv preprint arXiv:1601.07140, 2016.
- Walke et al. [2023] Homer Walke, Kevin Black, Abraham Lee, Moo Jin Kim, Max Du, Chongyi Zheng, Tony Zhao, Philippe Hansen-Estruch, Quan Vuong, Andre He, et al. BridgeData V2: A Dataset for Robot Learning at Scale. In CoRL, 2023.
- Wang et al. [2019a] Limin Wang, Yuanjun Xiong, Zhe Wang, Yu Qiao, Dahua Lin, Xiaoou Tang, and Luc Van Gool. Temporal Segment Networks for Action Recognition in Videos. IEEE Transactions on Pattern Analysis and Machine Intelligence, 41(11):2740–2755, 2019a.
- Wang et al. [2022a] Peng Wang, An Yang, Rui Men, Junyang Lin, Shuai Bai, Zhikang Li, Jianxin Ma, Chang Zhou, Jingren Zhou, and Hongxia Yang. OFA: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework. In ICML, 2022a.
- Wang et al. [2023a] Peng Wang, Shijie Wang, Junyang Lin, Shuai Bai, Xiaohuan Zhou, Jingren Zhou, Xinggang Wang, and Chang Zhou. ONE-PEACE: Exploring One General Representation Model Toward Unlimited Modalities. arXiv preprint arXiv:2305.11172, 2023a.
- Wang et al. [2023b] Wenhui Wang, Hangbo Bao, Li Dong, Johan Bjorck, Zhiliang Peng, Qiang Liu, Kriti Aggarwal, Owais Khan Mohammed, Saksham Singhal, Subhojit Som, and Furu Wei. Image as a Foreign Language: BEiT Pretraining for Vision and Vision-Language Tasks. In CVPR, 2023b.
- Wang et al. [2023c] Wenhai Wang, Zhe Chen, Xiaokang Chen, Jiannan Wu, Xizhou Zhu, Gang Zeng, Ping Luo, Tong Lu, Jie Zhou, Yu Qiao, et al. VisionLLM: Large Language Model is also an Open-Ended Decoder for Vision-Centric Tasks. In NeurIPS, 2023c.
- Wang et al. [2019b] Xin Wang, Jiawei Wu, Junkun Chen, Lei Li, Yuan-Fang Wang, and William Yang Wang. VATEX: A Large-Scale, High-Quality Multilingual Dataset for Video-and-Language Research. In ICCV, 2019b.
- Wang et al. [2022b] Yizhong Wang, Swaroop Mishra, Pegah Alipoormolabashi, Yeganeh Kordi, Amirreza Mirzaei, Anjana Arunkumar, Arjun Ashok, Arut Selvan Dhanasekaran, Atharva Naik, David Stap, et al. Super-NaturalInstructions: Generalization via Declarative Instructions on 1600+ NLP Tasks. In EMNLP, 2022b.
- Wang et al. [2022c] Zirui Wang, Jiahui Yu, Adams Wei Yu, Zihang Dai, Yulia Tsvetkov, and Yuan Cao. SimVLM: Simple Visual Language Model Pretraining with Weak Supervision. In ICLR, 2022c.
- Wei et al. [2022] Jason Wei, Maarten Bosma, Vincent Y Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M Dai, and Quoc V Le. Finetuned Language Models are Zero-Shot Learners. In ICLR, 2022.
- Weinzaepfel et al. [2022] Philippe Weinzaepfel, Vincent Leroy, Thomas Lucas, Romain Brégier, Yohann Cabon, Vaibhav Arora, Leonid Antsfeld, Boris Chidlovskii, Gabriela Csurka, and Jérôme Revaud. CroCo: Self-Supervised Pre-training for 3D Vision Tasks by Cross-View Completion. In NeurIPS, 2022.
- Welinder et al. [2010] Peter Welinder, Steve Branson, Takeshi Mita, Catherine Wah, Florian Schroff, Serge Belongie, and Pietro Perona. Caltech-UCSD Birds 200. Technical Report CNS-TR-2010-001, California Institute of Technology, 2010.
- Wu et al. [2021] Bo Wu, Shoubin Yu, Zhenfang Chen, Joshua B Tenenbaum, and Chuang Gan. STAR: A Benchmark for Situated Reasoning in Real-World Videos. In NeurIPS Datasets and Benchmarks Track, 2021.
- Xiao et al. [2010] Jianxiong Xiao, James Hays, Krista A Ehinger, Aude Oliva, and Antonio Torralba. SUN Database: Large-scale Scene Recognition from Abbey to Zoo. In CVPR, 2010.
- Xu et al. [2017] Dejing Xu, Zhou Zhao, Jun Xiao, Fei Wu, Hanwang Zhang, Xiangnan He, and Yueting Zhuang. Video Question Answering via Gradually Refined Attention over Appearance and Motion. In ACM MM, 2017.
- Xu et al. [2016] Jun Xu, Tao Mei, Ting Yao, and Yong Rui. MSR-VTT: A Large Video Description Dataset for Bridging Video and Language. In CVPR, 2016.
- Xue et al. [2022] Hongwei Xue, Tiankai Hang, Yanhong Zeng, Yuchong Sun, Bei Liu, Huan Yang, Jianlong Fu, and Baining Guo. Advancing High-Resolution Video-Language Representation with Large-Scale Video Transcriptions. In CVPR, 2022.
- Xue et al. [2021] Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, and Colin Raffel. mT5: A Massively Multilingual Pre-trained Text-to-Text Transformer. In NAACL-HLT, 2021.
- Yan et al. [2023] Bin Yan, Yi Jiang, Jiannan Wu, Dong Wang, Zehuan Yuan, Ping Luo, and Huchuan Lu. Universal Instance Perception as Object Discovery and Retrieval. In CVPR, 2023.
- Yang et al. [2023] Dongchao Yang, Jianwei Yu, Helin Wang, Wen Wang, Chao Weng, Yuexian Zou, and Dong Yu. Diffsound: Discrete Diffusion Model for Text-to-sound Generation. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 31:1720–1733, 2023.
- Yao et al. [2020] Yao Yao, Zixin Luo, Shiwei Li, Jingyang Zhang, Yufan Ren, Lei Zhou, Tian Fang, and Long Quan. BlendedMVS: A Large-scale Dataset for Generalized Multi-view Stereo Networks. In CVPR, 2020.
- Ye et al. [2023a] Qinghao Ye, Haiyang Xu, Guohai Xu, Jiabo Ye, Ming Yan, Yiyang Zhou, Junyang Wang, Anwen Hu, Pengcheng Shi, Yaya Shi, et al. mPLUG-Owl: Modularization Empowers Large Language Models with Multimodality. arXiv preprint arXiv:2304.14178, 2023a.
- Ye et al. [2023b] Qinghao Ye, Haiyang Xu, Jiabo Ye, Ming Yan, Haowei Liu, Qi Qian, Ji Zhang, Fei Huang, and Jingren Zhou. mPLUG-Owl2: Revolutionizing Multi-modal Large Language Model with Modality Collaboration. arXiv preprint arXiv:2311.04257, 2023b.
- You et al. [2023] Haoxuan You, Haotian Zhang, Zhe Gan, Xianzhi Du, Bowen Zhang, Zirui Wang, Liangliang Cao, Shih-Fu Chang, and Yinfei Yang. Ferret: Refer and Ground Anything Anywhere at Any Granularity. arXiv preprint arXiv:2310.07704, 2023.
- Yu et al. [2022] Jiahui Yu, Xin Li, Jing Yu Koh, Han Zhang, Ruoming Pang, James Qin, Alexander Ku, Yuanzhong Xu, Jason Baldridge, and Yonghui Wu. Vector-quantized Image Modeling with Improved VQGAN. In ICLR, 2022.
- Yu et al. [2016] Licheng Yu, Patrick Poirson, Shan Yang, Alexander C Berg, and Tamara L Berg. Modeling Context in Referring Expressions. In ECCV, 2016.
- Yu et al. [2023] Lili Yu, Bowen Shi, Ramakanth Pasunuru, Benjamin Muller, Olga Golovneva, Tianlu Wang, Arun Babu, Binh Tang, Brian Karrer, Shelly Sheynin, et al. Scaling Autoregressive Multi-Modal Models: Pretraining and Instruction Tuning. arXiv preprint arXiv:2309.02591, 2023.
- Zamir et al. [2018] Amir R Zamir, Alexander Sax, William Shen, Leonidas J Guibas, Jitendra Malik, and Silvio Savarese. Taskonomy: Disentangling Task Transfer Learning. In CVPR, 2018.
- Zang et al. [2023] Yuhang Zang, Wei Li, Jun Han, Kaiyang Zhou, and Chen Change Loy. Contextual Object Detection with Multimodal Large Language Models. arXiv preprint arXiv:2305.18279, 2023.
- Zellers et al. [2019a] Rowan Zellers, Yonatan Bisk, Ali Farhadi, and Yejin Choi. From Recognition to Cognition: Visual Commonsense Reasoning. In CVPR, 2019a.
- Zellers et al. [2019b] Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. HellaSwag: Can a Machine Really Finish Your Sentence? In ACL, 2019b.
- Zellers et al. [2022] Rowan Zellers, Jiasen Lu, Ximing Lu, Youngjae Yu, Yanpeng Zhao, Mohammadreza Salehi, Aditya Kusupati, Jack Hessel, Ali Farhadi, and Yejin Choi. MERLOT Reserve: Neural Script Knowledge through Vision and Language and Sound. In CVPR, 2022.
- Zhang et al. [2023a] Hang Zhang, Xin Li, and Lidong Bing. Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding. arXiv preprint arXiv:2306.02858, 2023a.
- Zhang et al. [2023b] Kai Zhang, Lingbo Mo, Wenhu Chen, Huan Sun, and Yu Su. MagicBrush: A Manually Annotated Dataset for Instruction-Guided Image Editing. In NeurIPS Datasets and Benchmarks Track, 2023b.
- Zhang et al. [2023c] Renrui Zhang, Jiaming Han, Aojun Zhou, Xiangfei Hu, Shilin Yan, Pan Lu, Hongsheng Li, Peng Gao, and Yu Qiao. LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention. arXiv preprint arXiv:2303.16199, 2023c.
- Zhang et al. [2023d] Shilong Zhang, Peize Sun, Shoufa Chen, Min Xiao, Wenqi Shao, Wenwei Zhang, Kai Chen, and Ping Luo. GPT4RoI: Instruction Tuning Large Language Model on Region-of-Interest. arXiv preprint arXiv:2307.03601, 2023d.
- Zhang et al. [2023e] Yanzhe Zhang, Ruiyi Zhang, Jiuxiang Gu, Yufan Zhou, Nedim Lipka, Diyi Yang, and Tong Sun. LLaVAR: Enhanced Visual Instruction Tuning for Text-Rich Image Understanding. arXiv preprint arXiv:2306.17107, 2023e.
- Zhao et al. [2022] Minyi Zhao, Bingjia Li, Jie Wang, Wanqing Li, Wenjing Zhou, Lan Zhang, Shijie Xuyang, Zhihang Yu, Xinkun Yu, Guangze Li, et al. Towards Video Text Visual Question Answering: Benchmark and Baseline. In NeurIPS Datasets and Benchmarks Track, 2022.
- Zhao et al. [2023] Zijia Zhao, Longteng Guo, Tongtian Yue, Sihan Chen, Shuai Shao, Xinxin Zhu, Zehuan Yuan, and Jing Liu. ChatBridge: Bridging Modalities with Large Language Model as a Language Catalyst. arXiv preprint arXiv:2305.16103, 2023.
- Zheng et al. [2022] Chuanxia Zheng, Tung-Long Vuong, Jianfei Cai, and Dinh Phung. MoVQ: Modulating Quantized Vectors for High-Fidelity Image Generation. In NeurIPS, 2022.
- Zhou et al. [2017] Bolei Zhou, Agata Lapedriza, Aditya Khosla, Aude Oliva, and Antonio Torralba. Places: A 10 Million Image Database for Scene Recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 40(6):1452–1464, 2017.
- Zhu et al. [2023] Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models. arXiv preprint arXiv:2304.10592, 2023.
- Zhu et al. [2019] Minfeng Zhu, Pingbo Pan, Wei Chen, and Yi Yang. DM-GAN: Dynamic Memory Generative Adversarial Networks for Text-to-Image Synthesis. In CVPR, 2019.
附录 A贡献
Jiasen Lu、Christopher Clark、Sangho Lee 和 Zichen Zhu 共同为数据集构建、快速开发做出了贡献,并为该项目进行了大量探索性实验。
Jiasen Lu主导并设计了该项目的主要思想和范围。 开发了模型管道的大部分——图像和音频分词器、主要架构、模型稳定性和训练目标。 领导并设计了预训练和指令调整数据管道。 使用各种模型和数据超参数进行实验,监督模型训练过程,并撰写论文。 与整个团队协调。
Christopher Clark 共同领导并设计了基础设施、指令调整和评估。 开发了动态打包系统、模态处理管道以及用于图像和音频推理的无分类器指导。 添加了 NLP 和许多 V&L 数据集,添加了许多综合任务,并构建了指令调整任务的提示。 在§5.1(NLP)、5.2和6(检测、深度)中进行评估并撰写论文。
Sangho Lee 对预训练数据管道的核心贡献。 添加了所有大规模多模态预训练数据集以及视频和音频指令调优数据集。 开发了用于预训练的示例构建管道。 帮助模型实现——位置编码、感知器重采样器和模型稳定。 在§5.1(音频)、5.3(音频和图像 FID)、6(视频和音频理解)中进行评估,并编写了部分内容纸。
Zichen Zhang 对指令调优数据管道的核心贡献。 添加了许多 V&L、实施例、视频、音频、数据增强和所有指令调整数据集。 内置指令调整提示。 研究了模型架构和训练管道并稳定了训练。 在§ 5.1(图像 TIFA,SeedBench)、5.3(图像 TIFA、动作)、5.4 中进行实验,撰写了论文的部分内容,开发了模型演示和项目页面。
Savya Khosla 添加了 3D 物体检测、光流和多点跟踪数据集,运行了 3D 检测的评估,并启动了演示。
Ryan Marten 添加了部分视频和跟踪数据集。
Derek Hoiem 就研究方向提供了建议。
Aniruddha Kembhavi 为研究方向和评估提供建议,帮助管理计算资源并撰写论文。
附录 B模型实现细节
在本节中,我们将介绍模型的实现细节。
B.1 统一任务表示详解
首先,我们提供有关如何在模型中表示不同模式的详细信息。
文本表示。 字节对编码 (BPE) 词汇大小为 32000。 与[147]类似,我们在去噪时向指示的屏蔽跨度添加了200个额外的特殊标记。 我们进一步添加了 10 个特殊标记,可用于引用文本中的图像、音频和历史输入。 两个特殊标记用于指示 和 ,8 个特殊标记表示图像和音频历史输入中的各个元素,两者都最多有 4 帧。 我们最多使用 512 个输入和输出标记。
稀疏结构表示。 我们使用额外的 1000 个特殊标记来表示所有连续值,例如点、框、相机变换和 3D 长方体。 点用 坐标表示,框用 坐标表示,其值由图像大小标准化。 相机变换表示为极角 、方位角 和距离 。 1000 个特殊标记,表示从 到 的离散角度。 继[16]之后,3D长方体由12个参数表示,包括投影中心、虚拟深度、对数归一化框尺寸,以及连续的异心旋转。
-
•
表示相对于 2D RoI 在图像平面上投影的 3D 中心
-
•
是对象的中心深度(以米为单位)。
-
•
是对数归一化的物理盒子尺寸(以米为单位)。
-
•
是连续的 6D 异心旋转。
对于3D长方体检测,我们使用提示来指示目标格式,例如“使用投影的 3D 中心、虚拟深度、对数归一化框大小和图像中的旋转来定位 3D 中的所有对象。”
动作表示。 对于具体的导航任务,离散动作空间直接表示为文本,例如.“前进”,“向左” >”、“右转”、“停止”。 对于对象操纵任务,根据机器人的不同,动作的表示方式也不同。 总体而言,位置变化(例如. )、旋转变化(例如. ),并且夹具打开或关闭使用相同的 1000 个特殊标记进行离散化,并且我们使用文本提示来指示输入和目标格式。 对于需要多步骤规划的任务(例如。 VIMA [87]),操作将表示为人类可读的文本,并带有指示步骤、使用的技能(例如。拾取、放置或推动)以及离散的位置和旋转参数。 图D.10提供了机器人任务的详细说明。
| Audio Input |
Sample rate |
16000 Hz |
|
FFT hop length |
256 samples | |
|
FFT window size |
1024 | |
|
Mel bins |
128 | |
|
Subsegment length |
256 hops, (4.08 sec) | |
|
Mel Spectrogram size |
128 mels 256 hops | |
|
fmin |
0 | |
|
fmax |
8000 | |
|
AST patch size |
16 | |
|
token size |
8 16 | |
|
Pretrain sub-sample |
64 | |
|
Final size |
64 or 128 tokens | |
| Image Input |
ViT patch size |
16 |
|
Pretraining size |
384 384 | |
|
Token size |
24 24 | |
|
Pretrain sub-sample |
288 | |
|
Final size |
288 or 576 tokens | |
| Text |
Seq length |
512 |
|
Final size |
512 tokens | |
| Image History |
ViT patch size |
16 |
|
Pretraining size |
256 256 | |
|
Token size |
16 16 | |
|
Pretrain sub-sample |
128 | |
|
Max num segments |
4 | |
|
Latent size |
32 | |
|
Final size |
32, 64, 96, 128 tokens | |
| Audio History |
AST patch size |
16 |
|
Pretraining size |
128 256 | |
|
Token size |
8 16 | |
|
Pretrain sub-sample |
64 | |
|
Max num segments |
4 | |
|
Latent size |
16 | |
|
Final size |
16, 32, 48, 64 tokens |
图像表示。 图像使用预先训练的 ViT [45] 进行编码。 我们使用在 LAION 2B 数据集上训练的 ViT-B 检查点222https://github.com/mlfoundations/open_clip。 对于图像输入,我们使用最大长度为 576 个标记(即。 来自 图像的补丁编码)。 我们连接 ViT 的第二层和倒数第二层的特征来捕获低级和高级视觉信息。 为了生成图像,我们将这些图像编码为离散标记[49]。 与Unified-IO [123]不同,它使用在ImageNet [41]上训练的VQ-GAN来转换 将图像分辨率转换为 标记,我们使用在 Open Images 数据集 [103] 上训练的 VQ-GAN,压缩比为 8,词汇量为 16384 333https://github.com/CompVis/taming-transformers。 这会将 分辨率图像转换为 标记。 我们还将 VQ-GAN 分词器与 ViT-VQGAN [208] 和 MoVQ [223] 进行比较。 我们凭经验发现 VQ-GAN 可以带来最佳的生成结果。
密集结构表示。 为了处理这种模式,我们将每像素标签转换为 RGB 图像。 对于深度,我们通过标准化深度图来构建灰度图像。 对于表面法线估计,我们将 方向转换为 值。 对于分割,我们训练 Unified-IO 2 来预测由类和边界框指定的特定对象的单个黑白掩模。 然后可以通过首先对目标类执行定位,然后对每个检测到的框执行分割来执行实例分割(如 GRIT [66] 中所做的那样)。 Unified-IO 相反,训练模型为每个实例生成具有随机选择颜色的图像。 我们发现这使得后处理变得困难,因为输出图像有时不完全遵循配色方案,并且模型可能会难以处理具有许多不同实例的图像。
音频表示。 此模式对 4.08 秒的音频片段进行编码。 我们采用以 16000 Hz 采样的波形并将其转换为对数梅尔标度的频谱图。 我们同时计算整个音频段(4.08 秒)的频谱图。 每个窗口涉及 1024 个样本和窗口之间的 256 个样本“跳跃”。 生成的频谱图大小为 128 个梅尔箱,有 256 个窗口。 我们选择这些超参数主要是围绕效率。 然后,我们使用预训练的 AST [57] 对其进行编码,补丁大小为 ,因此总共有 128 个标记。
为了生成音频,我们使用 ViT-VQGAN [208] 将频谱图转换为离散标记。 由于[208]的作者没有发布源代码或任何预训练模型,因此我们使用补丁大小实现并训练我们自己的ViT-VQGAN版本,该版本编码将 频谱图分解为 512 个标记,代码本大小为 8196。 该模型使用 AudioSet [54]、ACAV100M [105] 和 YT-Temporal-1B [215] 数据集上的音频进行训练。 获得对梅尔尺度的频谱图后,我们使用 HiFi-GAN444https://github.com/jik876/hifi-gan [98] 声码器将频谱图解码回波形。 我们使用表 8 中所示的相同参数来训练 HiFi-GAN。 我们在 AudioSet 和 LJSpeech [85] 的混合上训练模型,以涵盖自然声音和人声。
历史表征。 该历史记录中的图像和音频输入首先以与图像和音频输入相同的方式进行编码。 然后,我们使用感知器重采样器[5]进一步压缩图像和音频特征,并产生固定数量的视觉输出(32)和音频输出(16),以减少模型的总序列长度。 如表8所示,我们最多考虑4个图像和音频片段。 在我们的实验中,我们使用感知器实现的两种不同变体进行测试:1)一小组潜在嵌入分别查询每个帧/片段[5, 9],2)一大组潜在嵌入查询所有历史同时发生。 虽然第二种实现可以精细地表示参考图像和音频,但第一种实现可以保留更好的时间信息。 因此,我们的最终实现使用第一个。
B.2 二维旋转嵌入
我们使用旋转位置编码来模拟输入序列[169]的相对位置。 我们选择这个主要是因为我们不想使用绝对(附加)位置嵌入,这必须添加到每个编码器的输入中,并且还希望与 LLaMA [177] 保持一致位置编码。
旋转编码不使用参数,而是使用内核技巧来允许模型恢复 Transformer 注意力头中键和查询元素之间的相对距离。 对于文本,我们在网络的每一层应用旋转编码。 对于其他模态,我们通过将 Transformer 注意力头的每个查询和键嵌入分成两半并将 RoPE 扩展到二维情况,并将由两个坐标中的每一个坐标构造的单独旋转嵌入应用到两半。
我们将每个词符(图像、音频、图像历史记录和音频历史记录)视为具有一个二维位置,对应于 1) 图像或音频频谱图中的 坐标;2) 其中 和 分别代表图像或音频历史记录中的帧和感知器潜向量的索引。 与使用 4 维位置表示所有输入的 [215] 不同,我们使用可学习分段(模态)嵌入和旋转编码的组合。
|
L |
XL |
XXL |
||
| Transformer |
Params |
1.1B |
3.2B |
6.8B |
|
Vocab size |
33280 | |||
|
Image vocab size |
16512 | |||
|
Audio vocab size |
8320 | |||
|
Model dims |
1024 |
2048 |
3072 |
|
|
MLP dims |
2816 |
5120 |
8192 |
|
|
encoder layer |
24 | |||
|
decoder layer |
24 | |||
|
Heads |
16 |
16 |
24 |
|
|
MLP activations |
silu, linear | |||
|
Logits_via_embedding |
True | |||
|
Dropout |
0 | |||
| Image Resampler |
Latents size |
32 | ||
|
Model dims |
768 |
1024 |
1024 |
|
|
Heads |
12 |
16 |
16 |
|
|
Head Dims |
64 | |||
|
Number layer |
2 | |||
|
MLP Dims |
2048 |
4096 |
4096 |
|
|
MLP activations |
gelu | |||
| Audio Resampler |
Latents size |
16 | ||
|
Model dims |
768 |
1024 |
1024 |
|
|
Heads |
12 |
16 |
16 |
|
|
Head Dims |
64 | |||
|
Number layer |
2 | |||
|
MLP Dims |
2048 |
4096 |
4096 |
|
|
MLP activations |
gelu | |||
| ViT |
Patch size |
16 | ||
|
Model dims |
768 | |||
|
Heads |
12 | |||
|
Head Dims |
64 | |||
|
Number layer |
11 | |||
|
MLP Dims |
3072 | |||
|
MLP activations |
gelu | |||
| AST |
Patch size |
16 | ||
|
Model dims |
768 | |||
|
Heads |
12 | |||
|
Head Dims |
64 | |||
|
Number layer |
11 | |||
|
MLP Dims |
2048 | |||
|
MLP activations |
gelu | |||
B.3 动态保压
在这里,我们更详细地描述动态打包算法。 按照标准做法,当将输入批处理在一起时,我们将输入张量填充到最大长度,并使用注意力屏蔽来防止 Transformer 关注填充元素。 然而,这在我们的多模式设置中效率非常低,因为大多数示例中并不存在许多模式,这会导致大量的填充。 例如,如果批次中的一个示例具有图像输出,则每个其他示例都必须用 1024 个目标图像标记进行填充,即使它们的输出采用不同的模态。
一种解决方案是安排批次,以便每个批次包含每种模态中具有相似数量标记的示例。 然而,这在实践中实现起来很复杂,因为 (1) 我们的数据不适合 RAM,因此我们无法轻松地以这种方式对数据进行排序和分组,特别是如果需要跨五个输入和三个输出模式匹配标记,并且 (2)我们的编码框架 JAX [15] 在构造执行图时不支持可变长度张量,这使得处理批次之间的可变长度变得极其困难。
相反,我们使用打包,将多个示例的标记打包到单个序列中的过程,并且屏蔽注意力以防止 Transformer 在示例之间交叉参与。 打包通常作为处理文本时的预处理步骤完成,但这在我们的设置中不起作用,因为我们网络的某些部分无法对打包数据进行操作(例如。 、VAE 或图像 ViT)。 相反,我们从一批解压的示例开始,首先运行这些组件,然后在运行 Transformer 之前以背景兼容的方式动态打包生成的 Token 。 为了在 TPU 上高效运行,我们使用矩阵乘法和精心构造的 one-hot 矩阵来打包示例。
为了考虑所有模态,我们的 Transformer 需要作为输入的最大序列长度是 1152,最大目标长度是 2048。 打包时,我们通常可以将两个示例打包为 864 的输入序列和 1280 的目标序列,由于减少了序列长度并且能够同时处理两个示例,因此速度提高了大约 4 倍。 流式传输数据时,无法可靠地进行打包。 例如,如果两个连续的示例具有图像输出,则它们无法打包,因为它们总共将超过 1280 个输出标记。 为了解决这个问题,我们使用启发式算法在数据传输时重新排列数据。 该算法在内存中保留一小部分示例。 给定一个新示例,它将其与池中可容纳的最大示例配对,并将两者作为一对输出。 如果不存在这样的示例,则会将该示例添加到池中。 如果池达到最大大小 10,则发出并处理最大的示例,而不与其他示例一起打包。 我们发现训练期间这种情况发生的概率不到 0.1%。
B.4完整模型详细信息
在表 9 中,我们展示了模型的完整超参数。 在预训练期间,我们训练了 UIO-2、UIO-2 和 UIO- 2 由于内存限制,批处理大小为 512。 我们对 50% 的图像、音频和历史输入补丁进行子采样。 编码器的总打包长度为 864,解码器的总打包长度为 1280。 在指令调优期间,由于计算限制,我们使用批量大小 256 来训练所有模型。 我们对 87.5% 的图像、音频和历史输入补丁进行了子采样。 预训练的总打包长度为 1024,指令调优的总打包长度为 1280。 使用8路层内并行和64路数据并行来扩展到7B模型训练。
我们训练 150 万步,有效批量大小为 512。 这导致训练大约 1 万亿个 Token 。 在预训练期间,我们在图像历史记录或图像编码器中保留最多 50% 的图像块,这是 MAE 预训练 [71] 的常见做法。 我们在图像/音频历史记录中使用最多四个图像/片段。
附录C预训练详细信息
| Size | Rate | Text | Sparse | Dense | Image | Audio | ImageH | AudioH | Text | Sparse | Dense | Image | Audio | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Text | 6.6b | 33.0 | ✓ | - | - | - | - | - | - | ✓ | - | - | - | - |
| MC4 [201] | 5.0b | 11.7 | ✓ | - | - | - | - | - | - | ✓ | - | - | - | - |
| C4 [68] | 266m | 10.6 | ✓ | - | - | - | - | - | - | ✓ | - | - | - | - |
| Stack [95] | 147m | 3.55 | ✓ | - | - | - | - | - | - | ✓ | - | - | - | - |
| RedPajama CC [32] | 1.2b | 3.55 | ✓ | - | - | - | - | - | - | ✓ | - | - | - | - |
| Wikipedia | 6.8m | 1.42 | ✓ | - | - | - | - | - | - | ✓ | - | - | - | - |
| RedPajama Book [32] | 13m | 1.06 | ✓ | - | - | - | - | - | - | ✓ | - | - | - | - |
| Stack-Markdown [95] | 34m | 1.06 | ✓ | - | - | - | - | - | - | ✓ | - | - | - | - |
| Image/Text | 970m | 31.3 | ✓ | - | - | ✓ | - | - | - | ✓ | - | - | ✓ | - |
| LAION Aesthetics v2.5 [158] | 491m | 17.7 | ✓ | - | - | ✓ | - | - | - | - | - | - | ✓ | - |
| LAION-400M [159] | 346m | 8.95 | ✓ | - | - | ✓ | - | - | - | ✓ | - | - | - | - |
| CC12M [23] | 11m | 1.48 | ✓ | - | - | ✓ | - | - | - | ✓ | - | - | ✓ | - |
| RedCaps [42] | 12m | 1.39 | ✓ | - | - | ✓ | - | - | - | ✓ | - | - | ✓ | - |
| Web Images | 107m | 1.33 | ✓ | - | - | ✓ | - | - | - | ✓ | - | - | ✓ | - |
| CC3M [163] | 3.0m | 0.49 | ✓ | - | - | ✓ | - | - | - | ✓ | - | - | ✓ | - |
| Video | 181m | 25.0 | ✓ | - | - | ✓ | ✓ | ✓ | ✓ | ✓ | - | - | ✓ | ✓ |
| YT-Temporal [215] | 146m | 13.7 | ✓ | - | - | ✓ | ✓ | ✓ | ✓ | ✓ | - | - | ✓ | ✓ |
| ACAV [105] | 17m | 3.98 | ✓ | - | - | ✓ | - | ✓ | - | ✓ | - | - | ✓ | ✓ |
| HD-VILA [200] | 7.1m | 2.75 | ✓ | - | - | ✓ | ✓ | ✓ | ✓ | ✓ | - | - | ✓ | ✓ |
| AudioSet [54] | 1.7m | 2.75 | ✓ | - | - | ✓ | ✓ | ✓ | ✓ | ✓ | - | - | ✓ | ✓ |
| WebVid [13] | 9.2m | 1.23 | ✓ | - | - | ✓ | ✓ | ✓ | ✓ | ✓ | - | - | ✓ | - |
| Ego4D [60] | 0.7m | 0.55 | ✓ | - | - | ✓ | ✓ | ✓ | ✓ | ✓ | - | - | ✓ | ✓ |
| Interleaved Image/Text | 157m | 8.70 | ✓ | - | - | ✓ | - | ✓ | - | ✓ | - | - | ✓ | - |
| OBELICS [104] | 131m | 8.00 | ✓ | - | - | ✓ | - | ✓ | - | ✓ | - | - | ✓ | - |
| CC12M Interleaved | 11m | 0.35 | ✓ | - | - | ✓ | - | ✓ | - | ✓ | - | - | - | - |
| CC3M Interleaved | 3.0m | 0.21 | ✓ | - | - | ✓ | - | ✓ | - | ✓ | - | - | - | - |
| RedCaps Interleaved | 12m | 0.14 | ✓ | - | - | ✓ | - | ✓ | - | ✓ | - | - | - | - |
| Multi-View | 3.4m | 0.67 | ✓ | - | - | ✓ | - | ✓ | - | - | ✓ | - | ✓ | - |
| CroCo Habitat [194, 157] | 2.6m | 0.33 | ✓ | - | - | ✓ | - | ✓ | - | - | - | - | ✓ | - |
| Objaverse [40] | 0.8m | 0.33 | ✓ | - | - | ✓ | - | ✓ | - | - | ✓ | - | ✓ | - |
| Agent Trajectories | 1.3m | 0.33 | ✓ | - | - | ✓ | - | ✓ | - | ✓ | - | - | ✓ | - |
| ProcTHOR [39] | 0.7m | 0.17 | ✓ | - | - | ✓ | - | ✓ | - | ✓ | - | - | ✓ | - |
| Habitat [157] | 0.6m | 0.17 | ✓ | - | - | ✓ | - | ✓ | - | ✓ | - | - | ✓ | - |
| Synthetic | 504m | 1.00 | ✓ | ✓ | - | ✓ | - | - | - | - | ✓ | ✓ | - | - |
| Segment Anything [94] | 1.1m | 0.50 | ✓ | ✓ | - | ✓ | - | - | - | - | - | ✓ | - | - |
| Laion Aesthetics Patches | 491m | 0.45 | ✓ | - | - | ✓ | - | - | - | - | ✓ | - | - | - |
| RedCaps Patches | 12m | 0.05 | ✓ | - | - | ✓ | - | - | - | - | ✓ | - | - | - |
| All | 8.5b | 100 | ✓ | ✓ | - | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
在本节中,我们提供有关 Unified-IO 2 预训练数据的更多详细信息。 我们用于预训练的数据集列于表10中。 除非另有说明,我们使用第 3.3 节中描述的预训练目标,其中随机选择一种现有模式作为目标。 我们对数据进行采样,以确保所有输出模式都能得到很好的体现,并根据各种语料库的大小来平衡其使用频率。 分布如图9所示。
C.1 数据源
文本。 我们的数据遵循 MPT-7B [176] 使用的混合物。
图像和文本。 图文配对数据来自各种无监督语料库,如表10所示。 对于 LAION 数据,我们仅从 LAION 美学中的图像/文本对生成图像,其中包含更高质量的图像,而我们从 LAION 400M 中为图像/文本对生成文本。 如果 LAION 元数据中的图像被标记为不太可能是 NSFW,我们也只会保留来自 LAION 的图像。 网络图像是我们下载的图像数据集,重点关注图标和风格化图像。
视频。 我们从各种来源收集了总共 1.8 亿条短视频。 在训练过程中,我们从视频中随机选择最多五帧的序列。 前四帧将使用图像/音频历史编码器进行编码,而第五帧将使用图像/音频编码器进行编码。 与这些帧匹配的文本使用文本编码器以及标记标记进行编码,以显示每个帧发生的位置,如 B.1 中所述,或者,如果数据集仅包含与单个帧,而是对整个标题进行编码。 可以选择文本、音频或图像模态作为目标模态。 与往常一样,其他模态被随机屏蔽,目标模态被随机屏蔽或在输入中注入噪声。 请注意,我们对许多此类语料库的数据进行了二次采样,以保持数据集大小更易于管理,有时是由于视频链接损坏。
交错的图像和文本。 我们主要使用 OBELICS [104],其中包含交错在一起的段落和图像。 对于每个文档,我们随机选择一个图像或一个段落作为目标,并使用最多之前的四个(如果目标是图像)或五个(如果目标是段落)图像作为上下文。 最后一个图像使用图像编码器进行编码,其余图像在图像历史记录中进行编码。 与这些图像匹配的文本被连接并插入标记标记,以指示图像历史或图像输入中的图像出现的位置。 我们要么进行去噪,其中目标的噪声版本包含在输入中,要么进行生成,其中目标不是输入的一部分,尽管我们总是包括文本和图像输入模式。
此外,我们通过交错多个图像/文本对语料库中的多个图像和标题来构造交错数据。 这些图像被编码为图像输入和/或图像历史记录,并且通过使用特殊标记来指定这些图像中的一幅或全部图像的标题来构造匹配文本,以标记每个标题所指的图像。 对于此任务,我们仅以文本模态为目标,并训练模型以 (1) 对单个图像的标题进行去噪,(2) 为使用标记在输入提示中指定的单个图像生成标题词符或 (3) 生成描述每个输入图像的一系列标记标记和标题。 此任务旨在确保模型学习历史图像的语义并理解标记标记。
多视图。 我们对 CroCo [194] 的跨视图完成任务进行训练,其中模型必须使用同一场景的图像(但角度略有不同)作为上下文来完成一张噪声很大的图像。 带噪声的输入被编码为图像,并且第二图像通过图像历史编码器被编码。 此外,我们通过捕获 3D 对象的多个视图,使用 Objaverse [40] 对象生成数据,并指定输入文本中的相机坐标和模型以生成与新图像匹配的新图像相机坐标,或训练模型来预测相机如何在不同图像之间移动。 我们通过提供上下文示例进一步增强视图合成任务。 例如,通过给出图像历史记录中的视图和变换的一个或多个示例,模型根据提示指定的新相机变换来预测新视图。 这两项任务都旨在提高模型在预训练期间的 3D 理解。
代理轨迹。 我们在 ProcTHOR [39] 中使用脚本化的最短路径轨迹,并在 Habitat [149, 157] 中使用人类收集的演示。 虽然原始数据集用于具有相对较长情节长度的对象导航,但我们仅对图像历史和图像输入的最后几帧进行二次采样,以便大部分目标对象位于观察范围内。 该任务是从 1)生成下一个视觉观察帧作为目标图像,2)预测下一个位置观察坐标作为文本目标,以及 3)预测下一个动作作为文本目标中随机选择的。 1)需要从图像和图像历史输入以及文本输入中指定的最后一个动作进行推断,2)进一步需要位置信息,3)基于目标对象名称和视觉观察来预测下一个动作。
合成。 我们添加两个综合任务。 首先,我们使用来自 Segment Anything [94] 的自动注释数据。 我们为模型提供一组点或一个边界框作为输入,并对其进行训练以生成分割掩码作为输出。 其次,我们向来自其他无监督数据集的图像添加各种形状和颜色的人工补丁,并训练模型输出它们的位置,以便训练模型生成稀疏坐标作为输出。 我们还训练模型输出图像上的补丁总数,以预训练其计数能力。
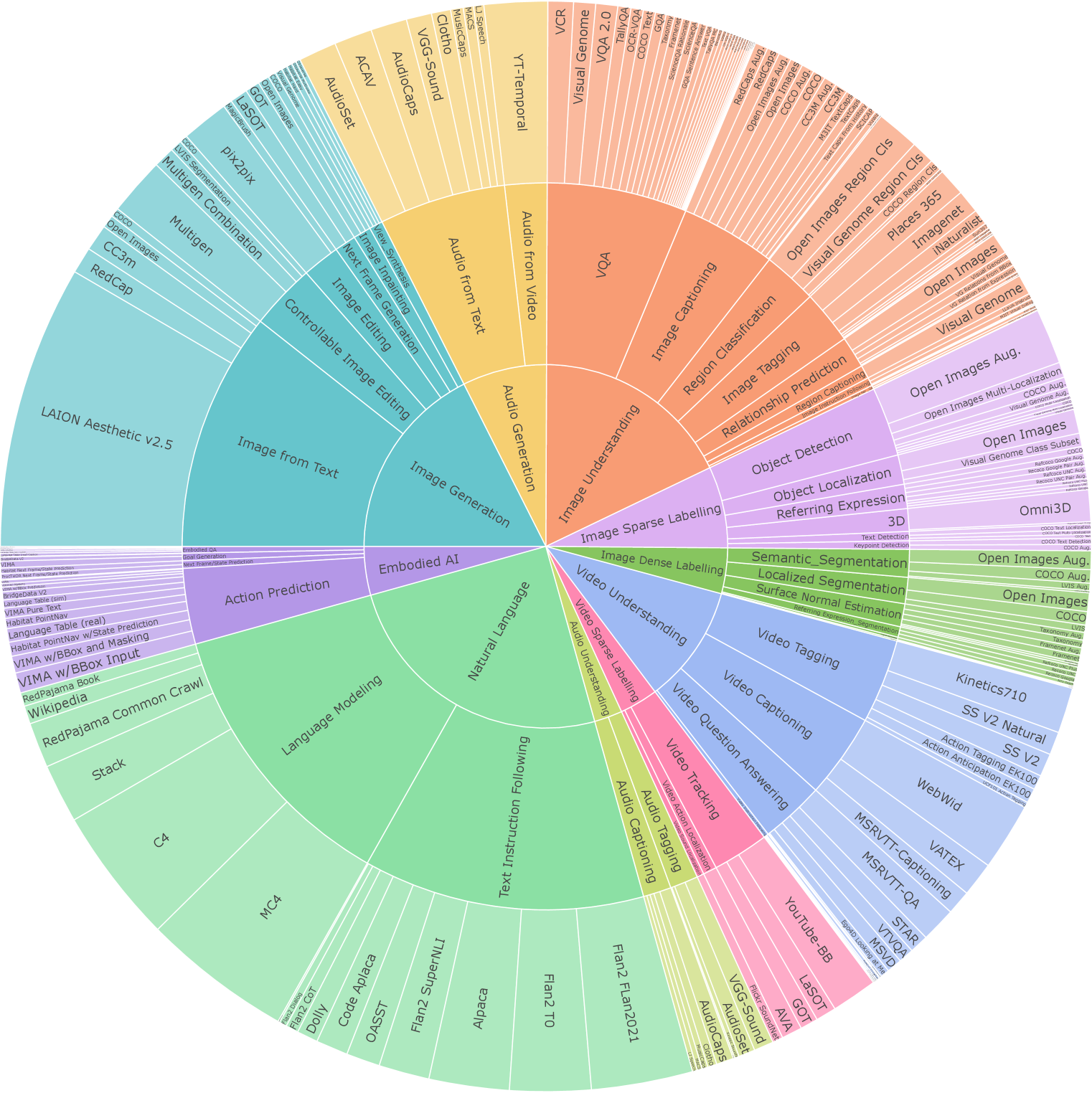
附录 D 指令调节详细信息
| Size | Rate | Datasets | Text | Sparse | Dense | Image | Audio | ImageH | AudioH | Text | Sparse | Dense | Image | Audio | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Image Generation | 506m | 17.6 | 21 | ✓ | ✓ | ✓ | ✓ | - | ✓ | ✓ | ✓ | - | - | ✓ | - |
| Image from Text | 497m | 10.6 | 5 | ✓ | - | - | - | - | - | - | - | - | - | ✓ | - |
| Controllable Image Editing | 3.0m | 2.92 | 4 | ✓ | - | ✓ | ✓ | - | ✓ | - | - | - | - | ✓ | - |
| Image Editing | 1.1m | 1.66 | 3 | ✓ | - | - | ✓ | - | - | - | - | - | - | ✓ | - |
| Next Frame Generation | 24k | 0.96 | 2 | ✓ | ✓ | - | - | - | ✓ | ✓ | - | - | - | ✓ | - |
| Image Inpainting | 1.0m | 0.79 | 3 | ✓ | ✓ | - | ✓ | - | - | - | - | - | - | ✓ | - |
| View Synthesis | 4.2m | 0.60 | 4 | ✓ | - | - | ✓ | - | ✓ | - | ✓ | - | - | ✓ | - |
| Audio Generation | 164m | 7.50 | 9 | ✓ | - | - | ✓ | ✓ | ✓ | ✓ | - | - | - | - | ✓ |
| Audio from Text | 19m | 5.62 | 8 | ✓ | - | - | - | - | - | ✓ | - | - | - | - | ✓ |
| Audio from Video | 145m | 1.88 | 1 | ✓ | - | - | ✓ | ✓ | ✓ | ✓ | - | - | - | - | ✓ |
| Image Understanding | 53m | 17.8 | 73 | ✓ | ✓ | - | ✓ | - | ✓ | - | ✓ | - | - | - | - |
| VQA | 5.8m | 6.23 | 31 | ✓ | - | - | ✓ | - | - | - | ✓ | - | - | - | - |
| Image Captioning | 32m | 4.25 | 14 | ✓ | - | - | ✓ | - | - | - | ✓ | - | - | - | - |
| Region Classification | 6.1m | 2.41 | 4 | ✓ | ✓ | - | ✓ | - | - | - | ✓ | - | - | - | - |
| Image Tagging | 3.8m | 2.38 | 8 | ✓ | - | - | ✓ | - | - | - | ✓ | - | - | - | - |
| Relationship Prediction | 0.8m | 1.41 | 6 | ✓ | ✓ | - | ✓ | - | - | - | ✓ | - | - | - | - |
| Region Captioning | 3.5m | 0.60 | 1 | ✓ | ✓ | - | ✓ | - | - | - | ✓ | - | - | - | - |
| Image Instruction Following | 0.4m | 0.37 | 6 | ✓ | - | - | ✓ | - | - | - | ✓ | - | - | - | - |
| Image Pair QA | 0.1m | 0.17 | 3 | ✓ | - | - | ✓ | - | ✓ | - | ✓ | - | - | - | - |
| Image Sparse Labelling | 13m | 7.25 | 26 | ✓ | ✓ | - | ✓ | - | ✓ | - | - | ✓ | - | ✓ | - |
| Object Detection | 5.3m | 3.08 | 9 | ✓ | - | - | ✓ | - | - | - | - | ✓ | - | - | - |
| Object Localization | 6.0m | 1.31 | 3 | ✓ | - | - | ✓ | - | - | - | - | ✓ | - | - | - |
| Referring Expression | 0.2m | 1.08 | 7 | ✓ | - | - | ✓ | - | - | - | - | ✓ | - | - | - |
| 3D | 1.0m | 1.00 | 2 | ✓ | - | - | ✓ | - | ✓ | - | - | ✓ | - | ✓ | - |
| Text Detection | 37k | 0.41 | 3 | ✓ | - | - | ✓ | - | - | - | - | ✓ | - | - | - |
| Keypoint Detection | 0.3m | 0.38 | 2 | ✓ | ✓ | - | ✓ | - | - | - | - | ✓ | - | - | - |
| Image Dense Labelling | 6.9m | 4.06 | 19 | ✓ | ✓ | - | ✓ | - | ✓ | - | - | - | ✓ | - | - |
| Semantic Segmentation | 2.4m | 1.23 | 4 | ✓ | - | - | ✓ | - | - | - | - | - | ✓ | - | - |
| Localized Segmentation | 3.2m | 1.17 | 3 | ✓ | ✓ | - | ✓ | - | - | - | - | - | ✓ | - | - |
| Surface Normal Estimation | 1.1m | 1.03 | 6 | ✓ | - | - | ✓ | - | - | - | - | - | ✓ | - | - |
| Referring Expression Segmentation | 0.1m | 0.47 | 3 | ✓ | - | - | ✓ | - | - | - | - | - | ✓ | - | - |
| Depth Estimation | 47k | 0.11 | 1 | ✓ | - | - | ✓ | - | - | - | - | - | ✓ | - | - |
| Optical Flow | 24k | 0.06 | 2 | ✓ | - | - | ✓ | - | ✓ | - | - | - | ✓ | - | - |
| Video Understanding | 13m | 10.6 | 24 | ✓ | - | - | ✓ | ✓ | ✓ | ✓ | ✓ | - | - | - | - |
| Video Captioning | 9.1m | 3.75 | 3 | ✓ | - | - | ✓ | - | ✓ | ✓ | ✓ | - | - | - | - |
| Video Tagging | 1.1m | 3.75 | 6 | ✓ | - | - | ✓ | - | ✓ | ✓ | ✓ | - | - | - | - |
| Video Question Answering | 2.5m | 2.84 | 9 | ✓ | - | - | ✓ | ✓ | ✓ | ✓ | ✓ | - | - | - | - |
| Video Instruction Following | 0.2m | 0.21 | 6 | ✓ | - | - | ✓ | - | ✓ | ✓ | ✓ | - | - | - | - |
| Video Sparse Labelling | 0.4m | 3.42 | 5 | ✓ | ✓ | - | ✓ | - | ✓ | ✓ | - | ✓ | - | - | - |
| Video Tracking | 0.2m | 2.50 | 3 | ✓ | ✓ | - | ✓ | - | ✓ | ✓ | - | ✓ | - | - | - |
| Video Action Localization | 0.2m | 0.61 | 1 | ✓ | - | - | ✓ | - | ✓ | ✓ | - | ✓ | - | - | - |
| Video Sound Localization | 2.5k | 0.31 | 1 | ✓ | - | - | ✓ | - | ✓ | ✓ | - | ✓ | - | - | - |
| Audio Understanding | 2.2m | 2.50 | 10 | ✓ | - | - | ✓ | ✓ | ✓ | - | ✓ | - | - | - | - |
| Audio Tagging | 2.1m | 1.25 | 5 | ✓ | - | - | ✓ | ✓ | ✓ | - | ✓ | - | - | - | - |
| Audio Captioning | 75k | 1.25 | 5 | ✓ | - | - | - | ✓ | - | - | ✓ | - | - | - | - |
| Natural Language | 11m | 25.0 | 17 | ✓ | - | - | - | - | - | - | ✓ | - | - | - | - |
| Text Instruction Following | 11m | 12.5 | 10 | ✓ | - | - | - | - | - | - | ✓ | - | - | - | - |
| Language Modeling | - | 12.5 | 7 | ✓ | - | - | - | - | - | - | ✓ | - | - | - | - |
| Embodied AI | 7.2m | 4.33 | 23 | ✓ | - | - | ✓ | - | ✓ | - | ✓ | ✓ | - | ✓ | - |
| Action Prediction | 4.3m | 3.37 | 12 | ✓ | - | - | ✓ | - | ✓ | - | ✓ | - | - | - | - |
| Next Frame/State Prediction | 1.3m | 0.33 | 2 | ✓ | - | - | ✓ | - | ✓ | - | ✓ | - | - | ✓ | - |
| Goal Generation | 0.7m | 0.33 | 3 | ✓ | - | - | ✓ | - | ✓ | - | - | - | - | ✓ | - |
| Embodied QA | 1.0m | 0.30 | 6 | ✓ | - | - | ✓ | - | ✓ | - | ✓ | ✓ | - | - | - |
| All Tasks | 775m | 100 | 227 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
在本节中,我们提供有关指令调整数据和 Unified-IO 2 支持的各个任务的更多详细信息。 指令调整数据概览如表11所示。 我们在图 10 中展示了包含各个数据集的可视化。 我们均匀地对大类任务进行采样,然后通常按其大小的平方根的比例对各个数据集进行采样,尽管进行了一些小的手工调整以降低噪声数据集的权重或提高非常罕见的任务的权重。
D.1 自然语言
对于自然语言数据,我们使用 FlanV2 [122] 的混合,其中又包括 Muffin [193]、T0-SF [156] 的数据t2>、NIV2 [191] 和 CoT 注释,以及来自 Alpaca [142]、Dolly [33]、Open Assistant 的数据 [99] 和 MDPP [8]。 此外,我们继续在微调阶段对无监督 NLP 混合物进行预训练,以确保模型不会忘记在广泛的指令调整阶段从无监督数据中学到的信息。
D.2 图像生成
对于文本到图像的生成,我们使用在预训练期间使用的相同图像/文本对,以及 Open Images [103] 中的本地化叙述和 COCO [115 中的标题] 和视觉基因组 (VG) [102]。 我们对这些任务的提示指定图像对于无监督语料库可能有噪声或近似(例如。“生成大致匹配此文本的图像:{caption}”)并且给出有关监督语料库风格的提示(例如。“你在这张图片中看到了什么? 简单地描述你观察到的单个元素。”用于本地化叙述)以帮助消除数据集之间的风格差异。 我们使用简单的提示(例如。“为该图像添加标题。”)作为 COCO 标题。
我们还训练模型通过视图合成 [194, 40] 生成图像,就像预训练期间所做的那样。 我们还集成了图像编辑数据[18, 217]和基于各种密集控制信号(例如深度图、边缘、分割等)的图像编辑。 遵循[145],以及使用来自 COCO 和 LVIS [62] 的数据从 Unified-IO 生成基于分割的图像。 最后,我们通过掩盖输入图像中包含对象的区域来训练修复,并训练模型在给定对象名称和位置的情况下生成完整图像。 我们从 COCO、Open Images 和 VG 中的对象标注数据中获取此任务的数据。
在推理过程中,我们使用top-p采样,也称为核采样[75],来生成具有温度和的图像。 我们还通过将提示替换为非信息性提示“随机图片的图像”来启用无分类器指导[74]。训练期间10%的时间。 然后,在推理过程中,将该提示用作无分类器提示,指导比例为 。
D.3音频生成
用于从文本生成音频的数据集包括 AudioCaps [93]、Clotho [47]、MACS [131]、MusicCaps [2] 和LJSpeech [85]。 在训练过程中,我们将音频分为 4 秒长的片段,然后生成目标音频的一个片段,并将文本和任何先前的片段作为输入。 我们还对下一帧预测任务进行训练,该任务旨在为 YT-Temporal-1B [215] 视频中的下一帧生成音频。
我们对这些任务的提示指定了目标音频的特征; 例如.,“根据描述生成声音/音乐:{caption}”分别用于自然声音和音乐,“Speak: {passage}”用于语音。 我们使用与图像生成相同的采样方法,即温度 和 的 top-p 采样。 我们不使用无分类器指导,因为它可能导致性能不佳。 当在推理过程中生成超过 4.08 秒的音频时,我们生成一个长度为 4.08 秒的初始片段,然后通过使用先前的音频片段作为音频历史输入生成附加片段来扩展它。
D.4 图像理解
这些任务需要生成文本以响应有关图像或图像对的查询。 我们使用来自 MIT [112] 和 MIMIC-IT [108, 107] 以及各种其他附加来源的数据。 对于 VQA,我们添加 GQA [83]、TallyQA [1]、OK-VQA [130]、A-OKVQA [ 160]、基于 OCR 的 VQA 数据集 [133, 165]、视觉基因组、ScienceQA [124]、VCR [213] 和 VizWiz [67]。 对于图像标记,我们添加 Caltech Birds [195]、iNaturalist [180]、Sun397 [197] 和 Places365 [224] 。 对于区域分类,我们添加了源自 Open Images、VG 和 COCO 对象标注的示例。 我们将具有开放式响应的数据集分类,例如 LLaVa [119]、Visual Storytelling [82] 和 Visual Dialog [36] 作为视觉遵循指令,我们将 NLVR [171] 和 MIMIC-IT 中的“找出差异”任务分类为图像对 QA。 对于图像对 QA 任务,我们对图像历史模态中的第二张图像进行编码。
我们还使用来自 Visual Genome 和 VSR [116] 的数据添加了基础关系预测任务,并使用我们用于图像生成的相同监督源添加了图像字幕。
我们再次在这些任务的提示中添加风格提示。 例如,在 VQA 和字幕数据集中,我们指定返回一个简短的答案(例如。“非常简洁地回答这个问题:{question}”),我们发现这是当用户提出问题时,让模型能够产生更长、更自然的响应至关重要。 同样,我们粗略地指定要输出图像标记的类的类型,例如。,“”这种动物的学名是什么?对于 iNaturist 数据集。
D.5 图像稀疏标签
这些任务需要根据输入图像输出稀疏坐标。 我们使用 Open Images、Visual Genome 和 COCO 进行对象检测和定位,这需要检测属于特定类的所有对象以及三个 COCO 引用表达式数据集 [91, 209, 136] 用于引用表达式。
此外,我们通过生成投影 3D 中心、虚拟深度、对数归一化框大小和每个 3D 框的旋转,在 OmniLabel [16] 3D 检测数据集上进行训练,再次对这些值进行归一化0 和 1,然后使用位置标记对它们进行编码。 我们还使用预训练期间使用的 Objaverse 对象添加了相机姿势预测任务。
我们包含来自 COCO-Text [183] 的 3 个文本检测数据集,包括查找多个文本字符串的输入文本字符串的边界框或查找并列出图像中的所有文本及其边界框。
最后,我们使用 COCO 姿态数据进行关键点检测。 对于关键点检测,我们输入图像中人物周围的边界框,并训练模型以返回该人的关键点列表。 在推理过程中,我们首先定位图像中的所有人物,然后使用每个返回的边界框作为关键点查询来查找该人的关键点。 在训练期间,模型针对不可见的关键点预测“MISSING”(例如.“右肘:MISSING”)。 在推理过程中,我们在模型的 logit 上使用掩蔽函数来强制它猜测每个关键点的有效点,因为关键点度量不会因正确识别不可见的关键点而奖励分数。
D.6 图像密集标签
我们做了几个图像标记任务,包括 FramNet [78]、BlendedMVS [204] 和 Taskonomy [211] 上的表面法线估计、深度纽约大学深度[138],以及飞椅[44]和MPI Sintel[21]上的光流。
我们还训练了几个分割任务:语义分割(分割特定类)、本地化分割(分割输入边界框中的对象)和引用表达式分割(分割与引用表达式匹配的对象)。 数据来自 Open Images、COCO、LVIS,以及来自 COCO refexp 数据集 [91, 209, 136] 的引用表达式。 为了根据 GRIT 的需要进行实例分割,我们首先对目标类进行本地化,然后对每个返回的边界框执行本地化分割。
在推理过程中,我们像以前一样以 0.95 的 top-p 进行温度采样,但没有无分类器指导。 对于分割,我们发现将 p 值增加到 0.97 是有益的。
D.7 视频理解
这些任务需要生成文本来响应有关视频的查询。 对于视频字幕,我们添加 VATEX [190] 和 MSR-VTT [199]。 对于动作分类(视频标记),我们添加 UCF101 [168]、Kinetics-710 [111]、Something-Something v2 [58]和 EPIC-KITCHENS-100 [35]。 我们还使用 EPIC-KITCHENS-100 中的示例来预测操作。 对于视频问答,我们添加了 MSRVTT-QA [198]、MSVD-QA [198]、STAR [196] 和 M4-ViteVQA [221]。 最后,我们使用 MIT 和 MIMIC-IT 中的示例来进行以下视频说明。
为了用少量帧(5)覆盖整个视频的视觉内容,我们使用以下基于分段的采样[185];我们首先将视频分为五个长度相等的片段,然后在训练期间从每个片段中随机采样一帧,并在推理时从中间帧中随机采样。 我们使用前四帧作为图像历史输入,最后一帧作为动作分类和视频字幕的图像输入。 我们凭经验发现,使用第三帧作为图像输入,同时使用其他帧作为图像历史输入对于视频问答来说效果更好。
我们使用与图像理解任务类似的提示,例如。,“为该视频写一个简短的描述。”,“问题 {question} 可以使用视频。 一个简短的答案是“和”他们在这段视频中做什么? 简短回答:分别在视频字幕、视频问答和视频标记中,以确保简短回答。
D.8 视频稀疏标签
我们对视频数据进行单对象跟踪和时空动作定位。 我们通过输入目标对象周围的边界框在 YouTube-BB [151]、LaSOT [50] 和 GOT-10k [79] 上进行训练并让模型返回下一个位置作为边界框(“从所有先前图像中预测对象的下一个位置以及对象在这些帧中的位置:{locations}。”)。 我们还在 AVA [61] 上训练模型,输入由五个帧组成的视频片段,并要求模型检测出现在视频片段中间(第三)帧的人类的所有动作(“给定视频中的时间上下文,检测图像中执行动作的所有人类。”)。 请注意,我们提供视频片段,而不是单个视频帧,因为某些操作需要时间上下文才能正确回答(例如。,站立和坐下)。 我们使用视频中五个连续帧的最后/中间帧作为图像输入,其他帧作为图像历史输入,分别用于单个对象跟踪和动作定位。
D.9音频理解
我们对音频标记和音频字幕任务的模型进行训练。 对于音频标记,我们添加了 AudioSet [54]、VGG-Sound [24] 和 MACS。 对于音频字幕,我们使用与文本到音频生成相同的数据集,即 AudioCaps、Clotho、MACS、MusicCaps 和 LJSpeech。 对于视听动作分类,我们在 Kinetics-Sounds [7] 和 VGG-Sound 上进行训练。
我们再次在这些任务的提示中使用风格提示。 例如,我们指定目标音频的特征(例如.,“描述音乐。”和“将音频转录为文本。”分别用于 MusicCaps 和 LJSpeech) ,强制执行简短的回答(例如。,“音频中的这是什么? 简短回答:”和“给出此音频的简短描述。”),并指定要输出音频标记的类类型,例如。,“此音频描述了MACS 的“a”场景。 我们使用与视频标记相同的提示来进行视听动作分类。
我们使用与视频理解相同的采样策略;我们从整个音频中以均匀的间隔采样五个音频片段,并使用中间/最后的音频片段作为音频输入,同时使用其他片段分别作为音频分类和音频字幕的音频历史输入。
D.10 体现人工智能

虽然许多机器人操作任务可以通过交错语言和图像或视频帧的多模式提示来制定,但我们使用 VIMA-Bench [87] 来评估机器人操作技能。 我们使用图像输入作为对环境的初始观察以及提示中图像或视频的图像历史记录。 文本输入或语言指令还包括特殊标记以明确表达交错的多模式提示。 动作空间由使用吸盘作为末端执行器的任务的“拾取和放置”或使用抹刀的任务的“推动”的原始动作组成。 两个基元动作都包含两个姿势和一个旋转,指定末端执行器的起始状态和目标状态。
通过B.1中描述的动作表示,我们无缝添加大规模操作数据集语言表[127],BridgeData V2 [184]和 FrankaKitchen [63] 在模拟和现实环境中进行连续控制。 该模型基于当前观察作为图像输入、先前帧作为图像历史、以及语言指令和先前动作作为文本输入,直接预测下一个动作作为文本目标。
由于模型的非因果性和图像历史的序列长度有限,我们只添加了 Habitat [157] Gibson 场景中的 PointNav 任务进行导航。 该模型需要根据点目标(位置)、视觉观察以及先前的动作和状态(如果有)来预测下一个动作,并通过随机增强来预测下一个位置和旋转状态。
D.11 任务增强
除了这些来源之外,我们还得出了几个附加任务,这些任务使用与其他任务相同的监督注释,但需要执行略有不同的功能。 我们称之为任务增强。 新任务包括指定所需输出的提示。 这些任务有助于增加我们的指令跟踪数据的多样性。 我们回顾一下我们在下面构建的任务增强。
细分。 我们构建了分割任务的几个增强,包括(1)分割属于一组 2-4 个类别之一的像素,可能包括图像中不存在的类别,(2)分割属于一个类并且在输入边界框,(3) 构建不属于 1-4 组集合的像素图。 Prompts are designed for these that state the requirement, e.g., “Show pixels that are part of chair, paper and in <extra_id_289> <extra_id_871> <extra_id_781> <extra_id_1156>”.
| Prompt | Model Response |
|---|---|
| A video of a man (woman) saying Unified-IO 2 is a model that works with vision, language, audio, and action. | () |
A video of a man playing guitar.
![[Uncaptioned image]](x12.png)
|

检测和参考表达。 对于检测、定位和引用表达式,我们还训练模型输出输出边界框的各种属性,而不是输出边界框本身。 属性包括宽度、高度、面积、左/右/上/下半部分、中心坐标、距图像左/右/上/下边缘的距离或边界框不同角的坐标。 我们还更改输出边界框的格式(例如.、而不是格式),并更改是否模型是否使用对象类别来标记框。
对于检测,我们训练模型来检测属于一组 1-4 个类的任何对象。 对于引用表达式,我们训练模型以从单个查询中定位多个引用表达式。 在这种情况下,我们有时会训练模型来预测两个引用框的属性,而不是直接输出,例如哪个框最小,哪个框最大,相交面积,包含两个框的框等。
关系预测。 我们训练模型列出图像中特定对象与任何其他对象之间的所有关系。 边界框和类别指定目标对象。 同样,我们训练模型来预测特定类对象的任何实例与图像中任何其他对象之间的所有关系。
字幕。 对于字幕,我们训练模型生成比给定字符或单词长度更长或更短的字幕,或者包含特定单词或单词集。 我们还随机要求标题以特定前缀开头。 同样,这些要求在提示中指定,例如,“为此图像生成超过五个单词的标题。 以文本“我的标题是:”开始输出。
表面法线估计。 对于表面法线估计,我们训练模型生成以不同方式编码像素方向的 RGB 图像。 这包括更改与 x、y 和 z 方向相对应的 RGB 通道,并且仅包括这些方向的子集。 我们还包括需要使用位置标记在提示中指定的特定点指定 x、y 和 z 方向的任务。 最后,我们包括需要对具有特定方向的像素进行分割掩模的任务,例如。,“在具有向上方向的表面上构建二进制掩模”。

体现人工智能。 我们通过视频 QA 和目标图像生成任务进一步增强实施例数据集。 QA 增强旨在增强机器人的规划和可供性。 例如,给定机器人视频轨迹,模型应该预测计划(标题),或者根据语言指令预测给定的动作是否合理。 在体现空间中应用图像编辑,我们进一步让模型根据图像输入中的初始视觉观察和文本输入中的语言提示生成目标或子目标图像。 虽然最近的工作表明,使用 VLM [46, 162] 的实施例 QA 和使用扩散模型 [134] 的(子)目标生成在决策下游任务中是有效的,我们的模型结合了两种增强策略。
附录E实验细节
| Categorization | Localization | VQA | Refexp | Segmentation | Keypoint | Normal | All | ||||||||||
| ablation | test | ablation | test | ablation | test | ablation | test | ablation | test | ablation | test | ablation | test | ablation | test | ||
| 0 | NLL-AngMF [11] | - | - | - | - | - | - | - | - | - | - | - | - | 49.6 | 50.5 | 7.2 | 7.1 |
| 1 | Mask R-CNN [70] | - | - | 44.7 | 45.1 | - | - | - | - | 26.2 | 26.2 | 70.8 | 70.6 | - | - | 20.2 | 20.3 |
| 2 | GPV-1 [65] | 33.2 | 33.2 | 42.8 | 42.7 | 50.6 | 49.8 | 25.8 | 26.8 | - | - | - | - | - | - | 21.8 | 21.8 |
| 3 | CLIP [146] | 48.1 | - | - | - | - | - | - | - | - | - | - | - | - | - | 6.9 | - |
| 4 | OFA [186] | 22.6 | - | - | - | 72.4 | - | 61.7 | - | - | - | - | - | - | - | 22.4 | - |
| 5 | GPV-2 [89] | 54.7 | 55.1 | 53.6 | 53.6 | 63.5 | 63.2 | 51.5 | 52.1 | - | - | - | - | - | - | 31.9 | 32.0 |
| 5 | DINO + SAM [94, 139] | - | - | 66.0 | 66.0 | - | - | - | - | 60.2 | 60.1 | - | - | - | - | 18.0 | 18.0 |
| 6 | Unified-IO | 42.6 | - | 50.4 | - | 52.9 | - | 51.1 | - | 40.7 | - | 46.5 | - | 33.5 | - | 45.4 | - |
| 7 | Unified-IO | 53.1 | - | 59.7 | - | 63.0 | - | 68.3 | - | 49.3 | - | 60.2 | - | 37.5 | - | 55.9 | - |
| 8 | Unified-IO | 57.0 | - | 64.2 | - | 67.4 | - | 74.1 | - | 54.0 | - | 67.6 | - | 40.2 | - | 60.7 | - |
| 9 | Unified-IO | 61.7 | 60.8 | 67.0 | 67.1 | 74.5 | 74.5 | 78.6 | 78.9 | 56.3 | 56.5 | 68.1 | 67.7 | 45.0 | 44.3 | 64.5 | 64.3 |
| 9 | UIO-2 | 70.1 | - | 66.1 | - | 67.6 | - | 66.6 | - | 53.8 | - | 56.8 | - | 44.5 | - | 60.8 | - |
| 10 | UIO-2 | 74.2 | - | 69.1 | - | 69.0 | - | 71.9 | - | 57.3 | - | 68.2 | - | 46.7 | - | 65.2 | - |
| 11 | UIO-2 | 74.9 | 75.2 | 70.3 | 70.2 | 71.3 | 71.1 | 75.5 | 75.5 | 58.2 | 58.8 | 72.8 | 73.2 | 45.2 | 44.7 | 66.9 | 67.0 |
E.1 预训练可视化
E.2 NLP 结果
| HellaSwag | MMLU | Arc Easy | Arc Cha. | BoolQ | |
|---|---|---|---|---|---|
| UIO-2 | 39.4 | 28.4 | 41.8 | 26.2 | 66.6 |
| UIO-2 | 49.9 | 29.7 | 49.5 | 31.3 | 72.8 |
| UIO-2 | 52.7 | 30.4 | 55.3 | 33.5 | 77.3 |
| Open LLaMA 3B | 52.0 | 23.9 | 69.3 | 33.8 | 67.0 |
| LLaMA 7B | 57.1 | 42.6 | 76.4 | 43.5 | 77.7 |
| LLaMA 7B Chat | 57.7 | 47.6 | 74.4 | 44.0 | 80.7 |
我们展示了一组 NLP 任务的结果,以评估模型的语言理解能力。 我们使用 EleutherAI LM-Eval 工具 [51] 进行评估,使用默认提示对任务进行零样本评估,除了添加 [Text] [S] 前缀之外,无需进行任何调整用于所有文本生成任务。 我们对 HellaSwag [214] 以及一系列其他问答基准进行评估:MMLU [72]、ARC [31] 和 BoolQ [30]。 结果如表14所示。 在相同的设置中评估基线,即。,零样本,使用默认提示,并使用 LM-Eval。 Unified-IO 2 通常领先于 Open LLaMA 3B,但落后于 LLaMA。
E.3GRIT 详细信息
我们在表 13 中更详细地展示了 GRIT 结果。 值得注意的是,Unified-IO 2 是第一个通过 Masked R-CNN 本地化基线的统一模型,并且在缩小 SAM 与统一模型在分割方面的差距方面大有帮助。
对于 GRIT VQA,查看 GRIT 在不同 VQA 子集上的得分,我们发现 Unified-IO 2 在同一源子集上表现更好(84.6 与 58.5),但在新源子集上表现较差(57.7 比 67.2)。 同源问题来自 VQA 2.0,新源问题来自 VG,因此差异可以归因于所提出问题的类型。 定性地讲,很难理解为什么这些子集的分数不同,因为 GRIT 消融问题缺乏基本事实注释。 然而,我们注意到,当面对模棱两可的问题时,模型经常会产生不同的答案(例如。“马的黑色是什么颜色”,“头发”代表统一-IO vs. Unified-IO 2 的“鬃毛”),因此一种可能性是 Unified-IO 2 与 VG 答案风格以及 Unified-IO 不匹配,这可能是由于模型训练所用的 VQA 训练数据类型存在差异。
对于 GRIT 定位,我们发现该模型可能会难以处理具有许多目标类实例的图像,特别是在使用波束搜索时。 我们假设这是因为概率质量可以在许多相似的位置 Token 之间分配,导致 EOS 成为最可能的词符,即使它的概率很低。 作为解决方案,在推理过程中,我们仅在 EOS 词符本身的概率超过 0.5 时输出 EOS,我们发现这显着提高了拥挤图像的性能。 在极少数情况下,我们观察到这会导致模型多次为同一实例生成边界框。 作为解决方案,我们应用更高阈值 0.8 的非极大值抑制来删除这些重复项。 我们将这种推理技巧应用于定位以及为关键点和分割任务执行初始定位步骤。
E.4 多模式基准详细信息
| Splits | Metrics | UIO-2 | UIO-2 | UIO-2 | [206] | [207] | [26] |
|---|---|---|---|---|---|---|---|
| Random | Accuracy () | 90.90 | 88.27 | 84.03 | 88.28 | 90.24 | 86.90 |
| Precision () | 94.30 | 97.44 | 77.73 | 94.34 | 97.72 | 94.40 | |
| Recall () | 87.07 | 78.60 | 95.40 | 82.20 | 83.00 | 79.27 | |
| F1-Score () | 90.54 | 87.01 | 85.66 | 87.85 | 89.76 | 86.19 | |
| % Yes | 46.17 | 40.33 | 61.37 | 44.91 | 43.78 | 43.26 | |
| Popular | Accuracy () | 88.17 | 87.47 | 77.27 | 86.20 | 84.90 | 83.97 |
| Precision () | 89.13 | 95.69 | 70.03 | 89.46 | 88.24 | 87.55 | |
| Recall () | 86.93 | 78.47 | 95.33 | 82.06 | 80.53 | 79.20 | |
| F1-Score () | 88.02 | 86.23 | 80.75 | 85.60 | 84.21 | 83.16 | |
| % Yes | 48.77 | 41.00 | 68.07 | 45.86 | 45.63 | 45.23 | |
| Adversarial | Accuracy () | 84.17 | 85.77 | 72.00 | 84.12 | 82.36 | 83.10 |
| Precision () | 82.17 | 92.01 | 65.00 | 85.54 | 83.60 | 85.60 | |
| Recall () | 87.27 | 78.33 | 95.33 | 82.13 | 80.53 | 79.60 | |
| F1-Score () | 84.64 | 84.62 | 77.30 | 83.80 | 82.00 | 82.49 | |
| % Yes | 53.10 | 42.57 | 73.30 | 48.00 | 48.18 | 46.50 |
| Img | Video | All | |
| InstructBLIP [34] | 58.8 | 38.1 | 53.4 |
| VideoChat-7B [110] | 39.0 | 33.9 | 37.6 |
| Otter-7B [108] | 42.9 | 30.6 | 39.7 |
| Qwen-VL-7B [12] | 62.3 | 39.1 | 56.3 |
| Qwen-VL-chat-7B [12] | 65.4 | 37.8 | 58.2 |
| mPLUG-Owl2-7B [206] | 64.1 | 39.8 | 57.8 |
| LLaVA-1.5-7B [118] | - | - | 58.6 |
| LLaVA-1.5-13B [118] | 68.2 | 42.7 | 61.6 |
| Unified-IO 2 | 56.0 | 37.5 | 51.1 |
| Unified-IO 2 | 64.1 | 45.6 | 60.2 |
| Unified-IO 2 | 65.7 | 46.8 | 61.8 |
我们现在提供仅评估多模式基准、POPE [113] 和 SEED-Bench [106] 的细分结果。 POPE 是物体幻觉基准,需要回答“是”或“否”。 如表15所示,我们最大的模型在所有 3 个维度上都获得了最高的 F1 分数。 有趣的是,较小的模型倾向于“否”响应,这可能是由于指令调整阶段遇到的负面示例的偏差。 SEED-Bench 提供 19k 个带有人工注释的多项选择题,用于评估 12 个维度的多模态模型,包括空间(图像)和时间(视频)理解。 如表16所示,我们的XXL模型优于所有其他7B视觉/视频语言模型,甚至比LLaVA-1.5 13B模型稍好。 值得注意的是,我们的 XL (3B) 模型在时间理解分割方面已经优于所有其他模型。 虽然最近的视频语言模型[128,110,108]在视频标记和字幕等传统视频任务中表现出了熟练程度,但它们在 SEED-Bench 时间理解上的表现甚至比视觉语言模型更差,这可能归因于它们遵循指令的能力有限。
E.5 图像生成详细信息


图 15 显示了使用多个基线以及 UIO-2 为 TIFA 基准字幕 [76] 生成的图像。 我们使用官方实现代码(Emu [172] 和 CoDi [174])或 TIFA 官方 GitHub 存储库中共享的图像555https://github.com/Yushi-Hu/tifa/tree/main/human_annotations(稳定扩散 v1.5 [154] 和 miniDALL-E [37]0>)用于基线。 除 miniDALL-E 之外的所有基线均使用在大规模、高质量图像数据集上训练的稳定扩散解码器,生成高保真度图像。 然而,它们经常生成不完全遵循输入说明的图像,而 Unified-IO 2 生成忠实的图像。
对于 MS COCO [115] 上的文本到图像生成,我们遵循标准约定 [226];我们对从验证集中采样的 30K 字幕子集进行评估。666We use the evaluation code at https://github.com/MinfengZhu/DM-GAN 继[43]之后,我们为每个标题生成 8 张图像,并选择最好的一个使用 CLIP 文本-图像相似性 [146]0>。 尽管无分类器指导 [74] 生成的图像质量更高,但计算出的 FID 分数 [73] 与不使用分类器时所获得的结果相比要差得多它(33.77 比 13.39);参见图14。
E.6音频生成详细信息
![[Uncaptioned image]](x17.png)
![[Uncaptioned image]](x18.png)
![[Uncaptioned image]](x19.png)
![[Uncaptioned image]](x20.png)
![[Uncaptioned image]](x21.png)
![[Uncaptioned image]](x22.png)
![[Uncaptioned image]](x23.png)
![[Uncaptioned image]](x24.png)
![[Uncaptioned image]](x25.png)
![[Uncaptioned image]](x26.png)
![[Uncaptioned image]](x27.png)
![[Uncaptioned image]](x28.png)
对于文本到音频的生成,我们在 AudioCaps [93] 测试集上进行评估。 请注意,我们无法与其他方法进行同类比较,因为 AudioCaps 由 10 秒的音频剪辑组成,而我们的模型一次可以生成 4.08 秒的音频。 相反,我们在以下设置中评估数据集:我们首先对四个 2 秒音频片段进行采样,将它们转换为具有零填充的 log-mel-声谱图,并生成以下音频,并提示“根据什么生成以下声音”你听到的和描述:{caption}”。 我们使用预训练的 HiFi-GAN 将模型输出(即对数梅尔缩放的频谱图)转换为波形,并使用包括 Fréchet Audio Distance [92] 在内的计算指标来比较地面实况音频和生成的音频、初始分数 [155] 和 Kullback-Leibler 散度。 我们使用与 AudioLDM 相同的评估代码777https://github.com/haoheliu/audioldm_eval [117]。 我们在表 17 中显示音频生成示例,在表 18 中显示视听定性示例。
E.7视频和音频理解细节


我们将分类和问答任务视为开放式答案生成,并使用精确匹配(EM)来衡量性能。 我们还尝试将分类任务制定为多项选择回答,并通过计算每个数据集标签的 Logit 并选择 Logit 最高的标签来生成答案,但性能提升相当有限。 请注意,我们不会直接在 Kinetics-400 [90] 上训练模型;相反,我们在 Kinetics-710 上进行训练,它是属于 Kinetics 系列的三个不同数据集的混合体,即 Kinetics-400、600 和 700。 当按照 [111] 在 Kinetics-400 上进一步微调 5 个周期时,我们的模型达到了 top-1 精度 79.1(vs。仅指令调整:73.8)。 对于动力学声音,同时利用音频和视觉输入可以极大地提高性能(音频-视觉:89.3 vs。 仅视频:87.4 vs。 纯音频:38.2)。 对于字幕任务,我们使用 CIDEr [182] 作为评估指标。 图17显示了视频理解任务的定性示例。
E.8实施例细节

| L1 | L2 | L3 | L4 | Avg. | |
| VIMA [87] | 81.5 | 81.5 | 78.7 | 48.6 | 72.6 |
| VIMA-Gato [152] | 57.0 | 53.9 | 45.6 | 13.5 | 42.5 |
| VIMA-Flamingo [5] | 47.4 | 46.0 | 40.7 | 12.1 | 36.6 |
| VIMA-GPT [19] | 46.9 | 46.9 | 42.2 | 12.1 | 37.0 |
| Unified-IO 2 | 66.9 | 63.8 | 57.5 | 12.6 | 50.2 |
| Unified-IO 2 | 70.3 | 69.8 | 64.5 | 13.1 | 54.2 |
| Unified-IO 2 | 71.3 | 70.4 | 68.0 | 15.5 | 56.3 |
在VIMA-Bench[87]中,有4个级别的评估协议:L1对象放置、L2新颖组合、L3新颖对象和L4新颖任务。 结果和比较如表19所示。 自回归 Transformer 模型 VIMA [87] 的输入是由裁剪图像和边界框组成的对象标记; ViT 为 VIMA-Gato 编码的图像补丁标记 [152];由 ViT 编码的图像补丁标记,由 VIMA-Flamingo [5] 的感知器模块进一步下采样;以及 ViT 为 VIMA-GPT 编码的单张图像词符[19]。 这些基线的输出都是下一步行动的预测。 由于我们的模型必须仅通过初始观察立即预测所有动作,因此任务设置比临时策略学习基线更具挑战性。 尽管如此,我们的模型仍然优于输入所有 4 个级别的图像或图像块的模型,并且仅落后于以对象为中心的方法[87]。 在图18中,我们展示了机器人操作任务的未来状态预测示例。 给定输入状态图像和自然语言提示,我们的模型可以成功合成目标图像状态。
E.9 其他任务

