生成式人工智能驱动的语义通信网络:架构、技术及应用
摘要
生成式人工智能 (GAI) 已经成为一个快速发展的领域,在智能化和自动化地创建各种内容方面展现出巨大的潜力。 为了支持此类人工智能生成的内容 (AIGC) 服务,未来的通信系统应该在有限而宝贵的频谱资源下满足更严格的要求(包括数据速率、吞吐量、延迟等)。 为了应对这一挑战,语义通信 (SemCom) 通过提取和传输语义来大幅减少资源消耗,被认为是一种革命性的通信方案。 先进的 GAI 算法为 SemCom 提供了强大的智能,用于模型训练、知识库构建和信道自适应。 此外,GAI 算法在 SemCom 网络的管理中也发挥着重要作用。 在这篇综述中,我们首先概述了 GAI 和 SemCom 的基础知识,以及这两种技术的协同作用。 特别地,我们介绍了 GAI 驱动的 SemCom 框架,其中分别讨论了用于信息创建、SemCom 驱动的信息传输和信息有效性的许多 GAI 模型。 然后,我们深入研究了 GAI 驱动的 SemCom 网络管理,包括新颖的管理层、知识管理和资源分配。 最后,我们展望了几个有希望的用例,即自动驾驶、智慧城市和元宇宙,以进行更全面的探索。
索引词:
语义通信、AIGC、生成式人工智能、智能无线网络、知识管理。I 引言
生成式人工智能 (GAI) 被认为是人工智能 (AI) 领域最重大的进步之一,近年来在自然语言处理 (NLP) 和多媒体内容合成等许多领域取得了显著进展 [1]。 本质上,GAI 从外部知识中学习,对数据进行分类,分析示例,并理解模式,以在数字内容创作中生成类似人类的成果。 GAI 带来的革命正在重塑行业,并开创新的经济市场。 据麦肯锡估计,GAI 每年可以增加相当于 2.6 万亿美元到 4.4 万亿美元的价值,显著提升所有 AI 的影响力 [2]。
I-A 背景
在 GAI 领域,人工智能生成内容 (AIGC),即由机器学习 (ML) 算法自动生成的数字内容,包括文本、图像、音频和视频,是信息技术领域一个值得注意的应用。 近年来,许多高效率、知识丰富的 AIGC 产品满足了人们对数据获取的巨大需求,吸引了广泛关注。 最重要的原因之一是,由于先进的计算能力,AIGC 服务能够在短时间内处理大规模数据库。 例如,Anthropic 公司的生成式 AI 推出的 Claude,到 2023 年 5 月,能够在一分钟内处理 100,000 个文本符元(相当于约 75,000 个单词) [3]。 特别是,一些先进的 AIGC 服务是由复杂的跨模态 GAI 模型实现的,这些模型可以处理多种数据格式。 一个著名的例子是 ChatGPT-4 [4],它允许用户共享图像并进行语音对话。 与 ChatGPT-3.5 主要基于文本的交互相比,它极大地丰富了用户体验,提供了一种更动态、更交互式的沟通方式。
除了享受 GAI 带来的益处之外,预计无线通信网络领域将出现新的挑战 [5]。 为了适应 GAI 和 AIGC 服务带来的新型通信场景,流量需求的激增以及更严格的延迟和可靠性要求是不可避免的。 而目前的无线通信系统仍在传统香农理论的框架下运行,即无论内容格式(文本、图像和视频)如何,所有内容都通过预定义的码本编码成二进制比特进行传输 [6]。 它们只关注比特,而忽略了消息的含义,从而导致带宽利用率低。 此外,这些传统系统专注于从数据速率、延迟、吞吐量、可靠性等方面提高网络性能,这些性能与比特的数量密切相关,而不是内容的含义。 这种僵化的方案无法利用上下文信息,无法根据通信对的知识定制内容并做出明智的决定,因此无法适应知识驱动的 AIGC 服务 [7]。
幸运的是,语义通信 (SemCom) 被认为是具有开创性的范式转变。 与传统通信系统相比,SemCom 专注于交换信息的含义,而不是重现源数据。 通常,SemCom 中的发射器首先从源数据中提取隐藏的语义,然后根据无线信道条件调整编码比特 [8, 9]。 然后信息通过无线信道传输,接收机努力恢复源数据的含义,旨在最大程度地减少语义歧义。 在此过程中,SemCom 只传递必要的语义,并过滤掉无关信息,从而显着节省无线资源消耗。 此外,语义编码器可以根据个人的背景知识个性化内容创建。 此外,在发射机和接收机之间的相互知识的帮助下,语法错误通过基于上下文的推理得到纠正,同时在接收机处恢复接收到的语义。 因此,即使在恶劣的信道条件下,SemCom 也可以保持良好的性能。
I-B 动机
考虑到 SemCom 的优越性,预计它将成为 AIGC 传输的有前景的范式。 可以观察到,AIGC 的结构和逻辑与 GAI 模型内在地联系在一起,使根据当前上下文进行含义推断成为可能。 这与 SemCom 的框架高度兼容。 同时,SemCom 系统能够以可持续的资源消耗处理海量数据和各种内容类型,满足复杂 AIGC 服务的需求,同时缓解互联网压力。 通过利用从用户历史记录和传感数据中收集的知识,SemCom 系统允许提供更智能的个性化服务。
另一方面,GAI 为 SemCom 设计带来了诸多好处。 SemCom 的编码器和解码器核心由 GAI 增强。 通过生成上下文敏感、适应性和语义密集型内容,GAI 极大地增强了 SemCom 有效传输内容的能力。 此外,GAI 可用于持续改进知识库 (KB) 和学习模型,确保 SemCom 系统能够观察网络环境并适应不断变化的动态网络条件。
然而,在智能无线通信网络中合成 SemCom 和 GAI 不可避免地会遇到许多挑战,包括:
-
•
挑战 1:如何构建融合 GAI 以处理任何数据格式的 SemCom 系统? 相关语义由 GAI 通过 SemCom 中的语义编码器/解码器生成和解释。 但是,基本数据处理无法满足数据密集型 AIGC 服务的需求,因此需要使用多模态算法来处理各种数据类型。 此外,还必须考虑训练所需的计算时间和能力。 在传输过程中,信道编码器和解码器应根据不同的信道条件自适应地压缩语义信息。
-
•
挑战 2:如何衡量 GAI 在基于 SemCom 的网络中生成的信息的有效性? 由于 SemCom 强调传递的信息的含义而不是传输的比特,因此从香农框架得出的传统性能指标不适合评估 SemCom 网络 [10]。 为了提供增强的服务,信息有效性度量与特定目标和时间的实现相关联。 此外,交互现在包含人机和机机交互,超越了仅仅的人机通信。 因此,考虑到不同的目标和场景确定适当的指标构成了另一个挑战。
-
•
挑战 3:如何利用 GAI 技术管理基于 SemCom 的网络? 由于所有网络节点中 GAI/ML 工具的普遍使用,需要协调管理计算、通信和控制资源。 重要的是,SemCom 严重依赖背景知识进行语义表示和解释。 通信方之间过时或不匹配的知识会降低语义恢复的准确性。 因此,有效的知识管理策略在基于 SemCom 的网络中变得至关重要,这带来了第三个挑战。
| References | Contributions |
|
|
|
|
|
|||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| [11] |
|
||||||||||||||||||
| [12] |
|
||||||||||||||||||
| [13] |
|
||||||||||||||||||
| [14] |
|
||||||||||||||||||
| [15] |
|
||||||||||||||||||
| [16] |
|
||||||||||||||||||
| [17] |
|
||||||||||||||||||
| [18] |
|
||||||||||||||||||
| This paper |
|
I-C 相关调查、贡献和组织
最近完成了一些杰出的工作,如表 I 所示。 在 SemCom 方面,[12] 对智能无线网络中 SemCom 的最新技术趋势进行了详细的调查。 [11] 对 6G 中 SemCom 的实现进行了调查,并讨论了 6G 在 SemCom 支持的网络架构中的潜在应用。 至于 GAI 和 AIGC,[13] 回顾了 GAI 领域的最新挑战和成果,并将其应用于移动电信网络。 [14, 15] 提供了对 AIGC 技术、应用和挑战的调查,作为对 GAI 的探索。 此外,[16] 通过结合移动边缘云通信、计算和存储基础设施的努力,对移动边缘网络中 AIGC 的定义、生命周期、模型和评估指标进行了全面的调查。 它还在讨论 AIGC 传输时将 GAI 技术与 SemCom 联系起来。 考虑到 GAI 与 SemCom 之间的协作,[17] 中的作者提出了一个 GAI 辅助 SemCom 网络框架,该框架将全局和局部 GAI 与语义编码模型集成到协作的云边缘移动设计中。 此外,[18] 中的作者提出了一种 GAI 辅助的 SemCom 框架,该框架无需与传统 SemCom 方法进行联合训练,与传统 SemCom 方法相比,计算复杂度和能源成本都降低了。 这两项工作深入探讨了由 GAI 辅助的 SemCom 网络的详细框架,但没有广泛讨论无线网络中的信息有效性和知识管理。 在本调查中,与表 I 中的相关工作相比,我们对无线通信网络中 GAI 与 SemCom 之间的相互作用进行了全面调查,并特别关注了 GAI 辅助的信息创建、SemCom 启用信息传输、信息有效性、资源分配和知识管理。
本文组织和主要贡献可以概括如下:
-
•
第二部分 - 我们主要介绍了一个用于 AIGC 传输的 GAI 驱动的 SemCom 框架。 这是第一篇深入探讨 SemCom 系统与 GAI 算法综合的框架体系结构、组件、KPI 和网络管理方法的论文。
-
•
第三部分 - 我们从单模态和多模态的角度对 GAI 模型进行了广泛的回顾,然后将它们分类为文本到文本、视觉到视觉、音频到音频、文本到 X (Text2X)、X 到文本 (X2Text) 和语音机器人。
-
•
第四部分 - 我们对 SemCom 可以为 AIGC 传输提供的益处进行了全面探索,介绍了 SemCom 的数学理论和收发器设计。
-
•
第五部分 - 我们对 AIGC 的信息有效性进行了三个方面的调查:面向任务的系统、信息时效 (AoI)、信息价值 (VoI) 和因果控制。
-
•
第六部分 - 我们介绍了优化通信和计算资源分配以及知识管理的新架构和相关算法,包括知识构建、更新和共享,以运行和维护 GAI 驱动的 SemCom 网络。
-
•
第七部分 - 我们讨论了几个用例,并进一步总结了所设想系统在某些场景中的优势。
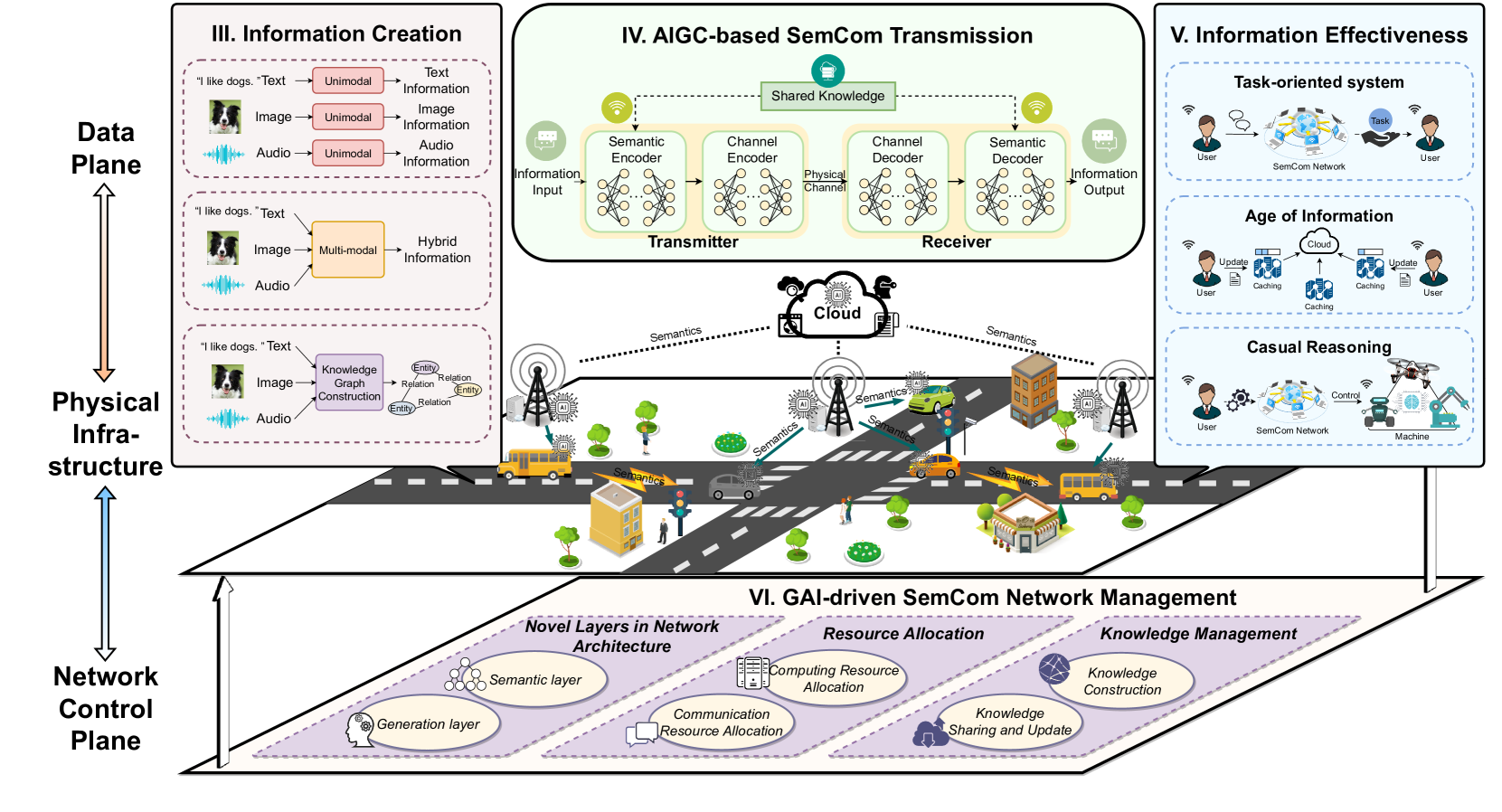
II 生成式 AI 驱动的语义通信网络
在本节中,我们首先介绍 GAI 和 SemCom 的基础知识。 在这种情况下,我们从数据平面、物理基础设施和网络控制平面的角度来展望 GAI 驱动的 SemCom 网络。
II-A GAI 和 AIGC 的基础知识
GAI 是人工智能的一个分支,旨在理解、学习和应用跨越广泛任务和领域的知识 [19]。 与针对特定任务(如图像识别或自然语言处理)量身定制的专用或狭义 AI 不同,GAI 旨在展示类似于人类智力的认知能力。 这包括逻辑推理、解决问题、感知、语言理解,甚至可能是情商的能力。
AIGC 代表了一种尖端的通过 GAI 算法创建、操作和修改各种形式的内容的方法。 GAI 从先前的内容中学习,包括专业生成内容 (PGC) 和用户生成内容 (UGC),以创建 AIGC [20, 21, 15]。 一般来说,AIGC 的优势可以从五个角度来划分:低延迟、创造力、效率、可扩展性和个性化 [16]。 AIGC 能够以接近实时速度处理和生成内容,这在需要立即响应的环境中(如实时聊天交互、实时游戏或即时内容推荐)显着提高了运营效率 [21]。 此外,AIGC 正在重新定义创造力的界限,合成完全不受传统人类认知限制的新内容。 这种创造能力在从数字艺术和音乐创作到广告和产品设计的各个领域都有重要的应用 [14]。 至关重要的是,AIGC 快速高效地生成大量内容的能力在海量数据的时代优势明显,简化了新闻报道、社交媒体内容生成和学术研究等领域的运营。 AIGC 最具变革性的方面之一是其个性化能力。 通过生成针对个人喜好、过去互动和特定情境的定制内容,AIGC 正在提升众多领域的的用户体验,包括电子商务、教育、娱乐和客户服务 [15]。
II-B 语义通信基础
语义通信不同于传统的香农通信,它将类似人类的“理解”和“推理”融入数据编码和解码过程,而不是追求精确的比特复制 [22]。 它通常优先考虑在受限的信道带宽下将从发射机提取的最重要和最相关的信息传输给接收机,而不是专注于最大化比特吞吐量 [23]。 具体而言,在语义编码中,原始消息首先被表示为语义信息 (SI),其中包含背景知识和与上下文相关的信息 [24]。 语义编码器的 KB 需要在传输之前与语义解码器中的 KB 共享,以确保接收器能够理解接收到的消息。 在等效的背景知识下,语义解码作为编码的反向操作来解释接收到的 SI。
最近有几项开创性的工作完成。 [25] 中的作者首次提出了一种模型,该模型集成了深度学习技术来解释和传输通信系统中信息的语义本质。 在 [26] 中,作者介绍了对未来语义和目标导向的通信网络的新视角,并概述了架构、底层数学理论和相关的 ML 策略。 [27] 中的作者确定了 SemCom 的两种架构:之前提出的跨层设计框架和被称为 SplitNet 的层耦合方法。 此外,[12] 中的作者介绍了 SemCom 的三种类别及其相应的系统设计,并详细探讨了 SI 提取、SI 传输和 SI 指标领域的尖端方法。 然而,[28] 中的作者认为,先前的工作不太关注语义表示、语言、推理、KPI 和 SemCom 可扩展性的基本概念和原则,然后清楚地将 SemCom 的概念与其他框架和概念区分开来,这些框架和概念对应于提到的接受。 值得注意的是,他们观察到,在 6G 语义网络中,实际上需要知识驱动和推理驱动的 AI 原生网络,而不是数据驱动和信息驱动的 AI 增强的网络。
II-C GAI驱动的SemCom网络架构
鉴于GAI和SemCom的基础知识和特点,接下来,我们展示GAI算法和SemCom网络之间的协同互动。 因此,在本节中,我们介绍GAI驱动的SemCom网络架构的愿景,如图1所示。 我们从物理基础设施、数据平面和网络控制平面的角度来说明这种架构。
II-C1 物理基础设施
与传统通信网络类似,GAI驱动的SemCom网络的物理基础设施由多个无线终端设备(TDs)、接入点(APs)、基站(BSs)、边缘服务器和中央云服务器组成[29]。 除了执行通信系统中的传统功能外,这些实体还配备了额外的智能技术来支持新型AIGC服务。 具体来说,TDs,如智能手机、平板电脑和笔记本电脑,配备了KBs和经过良好训练的GAI模型,包括SemCom系统中的编码器和解码器模块。 在传输之前,TDs通过APs和BSs上传感知数据,以及下载知识和经过良好训练的模型,从而整合知识并更新KBs。
在GAI驱动的SemCom网络中,边缘节点,包括移动边缘计算(MEC)服务器和BSs,能够使用来自自身、连接的TDs和中央云服务器的知识来预训练和微调GAI模型。 然后,边缘节点将经过良好训练的模型卸载到与它们的特定任务和环境相对应的TDs上。 此外,边缘服务器还负责管理知识共享和更新,并优化资源消耗(能源、带宽等)。
由于中央云服务器具有庞大的存储和计算资源,因此可以采用和预训练大规模的GAI模型。 实际上,大多数全球AIGC服务(例如,ChatGPT)都是利用来自许多数据供应商的数据在云中训练的。 同时,集中式模型将被更新,吸收新知识以刷新模型并调整资源分配策略。
II-C2 数据平面
AIGC 数据在这个网络的数据平面上生成、传输和评估。 首先,AIGC 信息是通过 GAI 模型创建的,包括单模态和多模态模型,这些将在第三部分中讨论。
然后,AIGC 数据通过 SemCom 的方法通过无线通道传输。 具体来说,源消息被输入到发射机上的语义编码器和信道编码器中,以提取和压缩它们的 SI。 随后,压缩后的 SI 通过无线信道。 在另一端,扭曲的数据通过信道解码器和语义解码器根据之前共享的知识进行恢复。 通过这种方法,SemCom 可以通过仅传输 AIGC 数据的基本 SI 来提高 AIGC 传输和资源利用的效率。
数据平面实现的另一个功能是从任务完成、数据新鲜度和相关性以及因果推理的角度衡量 AIGC 信息的有效性。 首先,针对面向任务的系统,一些用于评估任务执行的性能指标已提供 [30]。 接下来,AoI [31] 被认为是衡量信息新鲜度的重要指标,这对实时监督系统和更新系统至关重要。 如果信息已过期,可能会降低系统决策的准确性和可靠性。 此外,关注信息传输重要性和相关性的 VoI 也是 SemCom 中信息有效性衡量的一个实用指标 [32]。 最后,由于无线环境的动态性,考虑到 SemCom 网络的状态,正在设想与因果推理相关的新测量方法。
II-C3 网络控制平面
与传统的通信网络不同,在 GAI 驱动的 SemCom 网络中,网络管理应该更加智能、知识丰富,并且能够适应 GAI。 因此,网络控制平面涵盖网络架构、知识管理和资源分配。 首先,讨论了所提议网络中的新层,包括语义层和生成层。
接下来,知识管理的特点是利用 KB,KB 在训练 GAI 和 SemCom 模型(包含公共和私有知识,特别是针对个性化功能)的过程中必不可少。 在这个网络中,关键程序包括 KB 的构建、共享和更新。 为了创建 KB,收集、分类和编码原始数据,例如用户的历史记录和信道状态。 反过来,GAI 自动持续监控 KB,根据新知识和用户的反馈更新 KB,确保知识随着时间的推移保持动态和可靠。 此外,收发器中的 KB 需要保持一致,因为不一致的 KB 会导致内容误解。
此外,由于有限的资源限制了 AIGC 服务在海量数据上的实现,因此迫切需要为 GAI 驱动的 SemCom 网络开发新的资源分配方法。 除了传统上使用的通信资源,如能量和带宽,还探索了 SemCom 网络的一些前所未有的问题,例如物理信道和 KB 的匹配程度。 此外,GAI 作为附加模块来提升网络性能。 资源分配策略由 GAI 自动决定,并且可以根据新的网络状态动态调整。
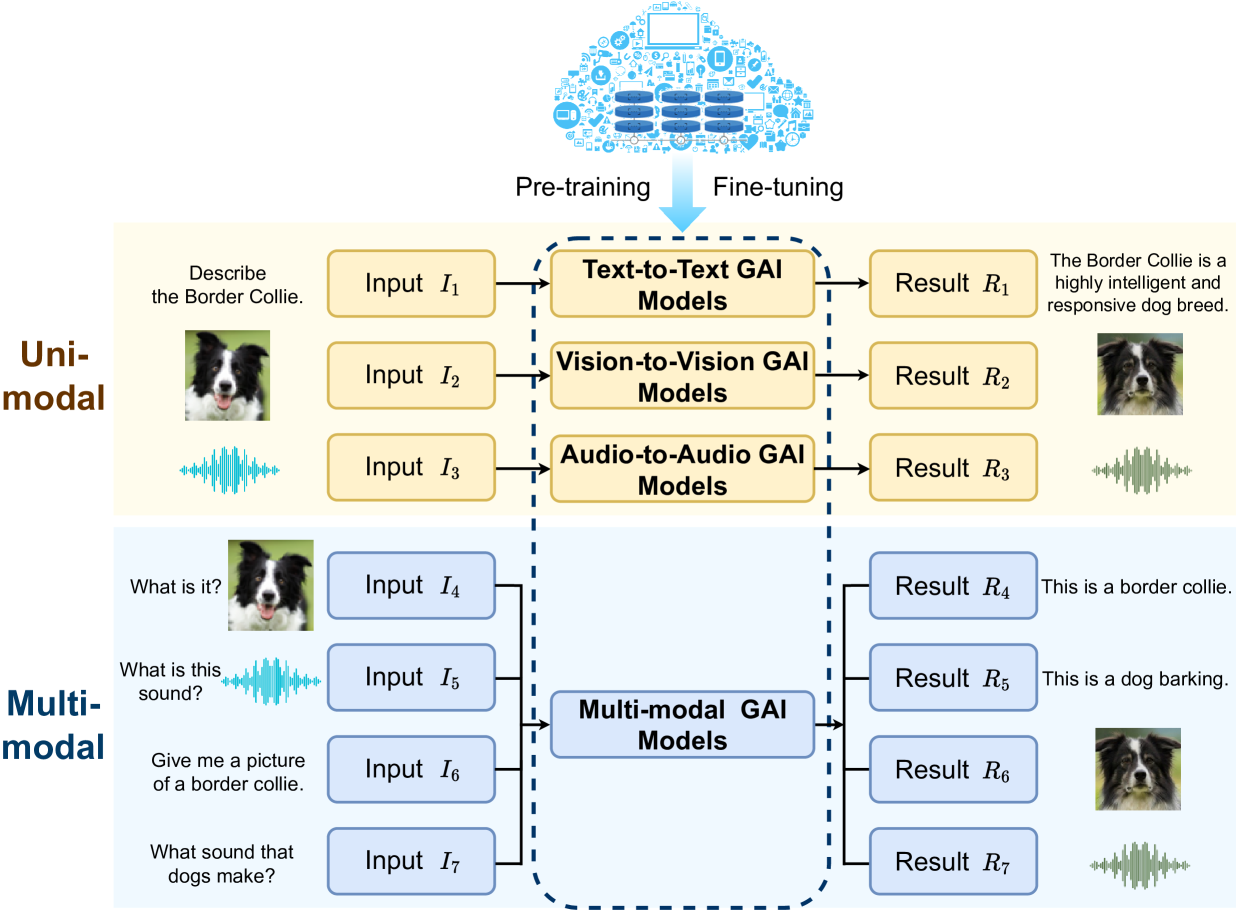
III 通过生成式 AI 创建信息
本节介绍了 AIGC 中用于信息创建的 GAI 模型概述,分为单模态和多模态两类,如图 2 所示。
III-A 单模态模型
我们探索基于单一类型输入数据(文本、视觉和音频)的单模态模型,以了解它们如何利用来自单一来源的信息来生成连贯的输出,如表 II 所示。
III-A1 文本到文本
文本到文本 GAI 模型在文本生成、机器翻译、摘要和问答等任务中特别有效。 这些模型可以分为四类:序列到序列 (Seq2Seq) 模型、基于变分自动编码器 (VAE) 的模型、基于生成对抗网络 (GAN) 的模型以及基于 Transformer 的模型。 Seq2Seq 模型 [33, 34, 35, 36] 旨在使用长短期记忆 (LSTM) [37]、循环神经网络 (RNN) [38] 和门控循环单元 (GRU) [39] 等架构来处理可变长度的输入和输出序列。 基于 VAE 的模型通过将输入序列编码为固定维度的表示,然后对其进行解码来发挥作用。 一些相关的例子在 [40, 41, 42, 43] 中给出。 基于 GAN 的模型 [44, 45, 46, 47, 48] 以 GAN 为特色,GAN 是一种生成模型,由两个神经网络组成,一个生成器和一个鉴别器,它们在训练过程中相互竞争。 基于 Transformer 的模型源于 Transformer [49],已成为许多最先进的 GAI 模型(例如 GPT [50]、BERT [51] 和 T5 [52])的支柱,它们的自注意力机制擅长处理文本中的长距离依赖关系。 值得注意的是,一些工作,如 VGAN [46] 和 TranGAN [48] 整合了各种技术,包括 GAN、VAEs、Transformer 和强化学习 (RL),以提高性能。
| Model Type | AIGC Applications | AI Models |
|
|||||||||||||||
| Text-to-Text |
|
|
|
|||||||||||||||
|
Vision-to-Vision |
|
|
|
||||||||||||||
| Audio-to-Audio |
|
|
|
|||||||||||||||
| Text-to-Image |
|
|
|
|||||||||||||||
| Text2X | Text-to-Video |
|
CogVideo [84], Phenaki [85] |
|
||||||||||||||
| Text-to-Audio |
|
WaveNet [88], AudioLM [89] |
|
|||||||||||||||
|
Image-to-Text | Transkribus [90] |
|
|
||||||||||||||
| X2Text | Video-to-Text |
|
|
|
||||||||||||||
| Audio-to-Text | Speak AI [97] |
|
|
|||||||||||||||
|
|
|
|
|
||||||||||||||
III-A2 视觉到视觉
视觉到视觉的 GAI 模型包括基于图像和基于视频的 GAI 模型。 基于图像的 GAI 模型可以广泛分为五类:基于卷积神经网络 (CNN) 的模型、基于 VAE 的模型、基于 GAN 的模型、基于流的模型和基于扩散的模型。 基于 CNN 的模型 [105, 106, 107, 108, 109] 基于 CNN,CNN 由多个卷积层、池化层和全连接层组成,能够从图像中学习特征的空间层次结构。 基于 VAE 的模型,例如条件 VAE [110] 和 IntroVAEs [111] 可以有效地修改图像,同时保留结构保真度,这对更改面部表情或昼夜转换等任务很有用。 此外,基于 GAN 的模型中的生成器可以创建合成图像,而鉴别器则试图区分真实图像和生成图像。 一些著名的模型,例如 DCGAN [112]、CycleGAN [113] 和 StyleGAN [60] 被用于各种图像合成任务,例如图像到图像的转换、超分辨率和风格迁移。 基于流的模型 [62] 通过学习数据分布和已知分布(例如高斯分布)之间的可逆变换来生成图像。 基于扩散的模型主要模拟随机扩散过程来生成图像。 最近和最突出的扩散模型示例之一是 [114] 中提出的去噪扩散概率模型 (DDPM)。 以扩散为特色,DALL-E 2 从 DALL-E [115] 推出,具有更好的处理能力,由 [116] 创建。
基于视频的 GAI 模型,包括图像到视频和视频到视频模型,在图像处理对比中考虑了时间维度。 图像到视频模型基于单个图像或图像序列合成新的视频内容,例如 [117, 118] 中的作品。 视频到视频模型是专注于增强视频质量的视频处理模型,例如视频超分辨率、视频修复或视频降噪。 这些模型采用深度学习技术,例如 CNN、GAN、VAE、Transformer 和扩散模型,其中值得注意的例子包括视频扩散模型 [63] 和 EDVR [119]。
III-A3 音频到音频
音频到音频 GAI 模型可以根据输入音频生成新的声音,包括四类:基于 GAN 的模型、基于 VAE 的模型、自回归模型和基于 Transformer 的模型。 基于 GAN 的模型,例如 WaveGAN [67] 和 SpecGAN [68],用于创建逼真的高保真音频。 基于 VAE 的模型,例如 VAE-VC [70],对于需要对连续潜在空间进行建模的任务特别有效。 自回归模型,包括 WaveNet [88] 和 WaveRNN [69],采用深度学习技术,例如 CNN 和 RNN,以顺序方式生成高度真实的语音和音乐音频。 同时,基于 Transformer 的模型,以 OpenAI 的 Jukebox [72] 为例,利用注意力机制来有效地处理音乐作品中的长距离序列。
III-B 多模态模型
目前大多数流行的 AIGC 服务,如 DALL-E 2,都由多模态 GAI 模型驱动。 与单模态 GAI 模型相比,多模态 GAI 模型更复杂,更灵活,可以处理多种类型的输入和输出。 我们根据多模态 GAI 模型的输入和输出类型对其进行分类:文本输入(text2X)、文本输出(X2text)和语音对话(语音机器人),如表 II 所示。
III-B1 文本到 X
文本到X GAI 模型将文本输入转换为各种形式的输出,包括图像、视频和音频。 首先,在文本到图像模型方面,DALL-E [76] 是最著名的产品之一,它根据文本描述生成图像。 它建立在 GPT-3 架构之上,并已证明从各种文本输入中创建连贯且与上下文相关的图像的出色能力。 CLIP [77] 也是由 OpenAI 开发的,可以从文本-图像对中学习并执行各种任务,例如零样本图像分类、图像字幕,甚至使用 Transformer 架构和 CNN 进行文本到图像生成。 在 [78] 中提出了将 CLIP 和 VQGAN 集成的 VQGAN-CLIP,它利用多模态编码器从提示创建高质量的图像,无需任何训练。 在 [79] 中提供的扩散模型集合称为 eDiff-I,它在保持推理的计算成本恒定并保持卓越的视觉质量的同时,增强了文本同步。 [80] 中的作者将两个著名的预训练模型的能力合并,一个基于文本的模型(GPT-3)和一个图像生成模型(Stable Diffusion [120]),以从人类指令中编辑图像。
其次,对于文本到视频模型,Cogvideo 在 [84] 中被提出,它利用 9B 参数 Transformer 生成视频。 [85] 中的作者介绍了 Phenaki,它能够根据一系列文本提示(例如时间敏感文本或开放域中的叙述)生成无限长度的视频。
第三,在音频领域,WaveNet 在 [88] 中被提出,通过 CNN 预测序列中给定先前样本的下一个样本。 [121] 中提供的另一个示例是 AudioLM,它可以通过多阶段基于 Transformer 的语言模型生成语法和语义上连贯的语音扩展,同时保留看不见的说话者的说话者身份和韵律。
III-B2 X 到文本
与文本到X 模型不同,X 到文本 GAI 模型将各种形式的输入转换为文本输出。 在图像到文本领域,GAI 模型能够准确地解释图像中的视觉元素并生成描述性的文本内容。 CLIP 是前面提到的一个例子,它用于根据文本到图像的对齐生成文本。 此外,[91] 中提出的神经图像字幕(NIC)用于生成描述图像的自然句子,该句子依赖于视觉 CNN 后跟语言生成 RNN。 [92] 中的作者介绍了 VisualGPT,它利用了一种新颖的自我复活编码器-解码器注意机制,旨在使用有限的特定领域图像-文本数据快速微调大型预训练语言模型 (PLM)。 [93] 中的 Vision Transformer (ViT) 是一种直接的 Transformer 模型,应用于一系列图像片段,在图像分类任务中表现出色。
视频到文本模型能够从一系列帧中提取上下文并生成连贯的文本内容。 [94] 中的 VideoCLIP 通过将时间相关的正视频-文本组合与通过最近邻搜索识别的具有挑战性的负视频-文本组合进行对比,为视频和文本训练了一个 Transformer。 此外,[96] 中的作者提出了一种统一的视频和语言预训练模型 (UniVL),其管道包含两个单模编码器、一个交叉编码器和一个具有 Transformer 主干的解码器。 此外,[95] 中的作者扩展了 BERT 框架,以学习对包括动作分类和视频字幕在内的任务的视觉和语言标记序列的双向联合分布。
最后,音频到文本转换是 GAI 中一个成熟的领域,其中口语被转录成书面文本。 DeepSpeech [98] 是一种基于 RNN 的语音识别系统,使用大量的简单端到端深度学习。 此外,[99] 中的 wav2vec 2.0 在潜在空间中屏蔽语音输入,并仅从语音音频中学习强大的表示,然后基于 Transformer 架构微调转录的语音。
III-B3 语音机器人
语音机器人,也称为基于语音的聊天机器人或语音助手,使人机交互中能够进行语音对话 [122]。 许多产品已被广泛使用,例如亚马逊的 Alexa [103]、苹果的 Siri [100] 和 Google 助理 [102]。 基本上,语音机器人通过自动语音识别 (ASR) 算法解释用户的语音输入,并将音频转换为文本。 然后使用自然语言理解 (NLU) 技术处理此文本,以理解用户查询背后的意图和上下文。 一旦理解,机器人就会生成一个响应,通过自然语言生成 (NLG) 算法将文本转换回类似人类的语音 [104]。
IV 用于 AIGC 传输的语义通信
为了实现 AIGC 传输的 SemCom,我们首先对用于 SemCom 的高级信息论进行了文献综述。 随后,根据四个类别(文本、图像、音频和视频传输)讨论了有关 SemCom 收发器设计的相关工作。 最后,我们探讨了 GAI 和 SemCom 交互的复杂性以及潜在的影响。
IV-A 用于 SemCom 的信息论
信息论在理解和建模通信系统方面起着至关重要的作用。 它提供了一个数学框架来量化交换的信息量,评估通信信道的容量,并确定最佳编码方案以最大程度地减少错误并最大限度地提高效率。 由于 SemCom 中的传输内容发生了变化,SIT 是一种范式转变,它关注如何测量与上下文和外部知识相关的 SI。
语义信息论 (SIT) 源于香农的经典信息论 (CIT),融合了语言学和认知科学的见解 [25, 12]。 语义的概念可以追溯到 [123],作者介绍了三元组:句法、语义和语用学,作为符号理论的基础元素。 后来,[124] 中的作者提出了一个三层通信框架,更深入地探讨了句法、语义和语用方面的区别。 在 [125] 中,作者使用命题逻辑并结合信息的语义概率度量,发展了一种以 SI 为中心的理论。 [126] 中的作者通过整合情境逻辑,将 SIT 推进一步。 此外,[127] 研究了两个没有共同知识的智能实体之间的通用 SemCom 情况。 关于一般“沟通目标”的更多条件在 [128] 中进行了更深入的探讨。 [129] 中的作者们解决了准确测量矛盾的挑战,而 [130] 中的作者们则利用了似真性的概念来衡量语义信息,以适应更广泛的应用场景。
最近,语义信息理论在提供关于语义信息核心本质的更广泛的视角方面不断发展。 [131] 中的作者们提出了关于语义信息的独特理论,强调了它在信息三元组中的独特地位。 从物理学的角度来看,[132] 的工作将语义信息描述为系统与其周围环境之间的句法数据,这在因果上有助于系统的持续运行。 [132] 的工作后来提供了跨越各种通信系统层次的语义信息的层次化解释,并采用 [133] 中使用的语义熵对其进行评估。
IV-B 语义通信中的收发器设计
语义通信系统中的收发器可以通过通用人工智能模型在优化信息理解、传输和管理方面得到显著增强。 从本质上讲,语义收发器的目的是在发送端提取语义,并在接收端以最小的语义错误率恢复语义,即使在不同的信道条件下也是如此。 从知识库中学习到的语义特征首先由语义编码器提取,然后由信道编码器压缩。 这些失真后的语义特征经过物理信道后,由信道解码器和语义解码器进行恢复。 最近,这种流行的架构通过众多针对不同任务的开创性工作得到了增强和改进。 在本部分中,语义通信的收发器设计根据源数据的类型进行分类,包括文本、图像、语音和视频。
IV-B1 文本传递
在大多数情况下,消息中的每个词都被转换为符元,它们作为语义表示的基本单元。 Transformer结构被广泛使用。 在这方面,每个符元的位置和注意力权重可以被纳入语义编码。 在[25]中,提出了一种基于Transformer的端到端SemCom系统,名为DeepSC,用于文本传输,这在基于深度学习的SemCom收发器设计中树立了一个重要的里程碑。 受DeepSC启发,出现了许多变体。 [134]中的作者将语义编码与里德-所罗门编码和混合自动重传请求(称为SC-RS-HARQ)相结合,以提高文本语义传输的可靠性,并提出了一种语义错误相似度检测网络。 [135]中的作者还提出了一种基于Transformer的SemCom系统,该系统采用了一种新的损失函数来量化语义失真的影响,从而可以在语义压缩损失和语义精度之间实现动态平衡。 为了使训练后的模型适应能力有限的物联网(IoT)设备,[136]中的作者通过对完全训练的DeepSC模型进行剪枝和量化,提出了DeepSC的精简版本,实现了高达40倍的压缩率,而性能没有下降。
此外,与上述研究中仅仅作为未经处理文本语料库的KB不同,由结构化和相互关联的实体及其关系组成的KG增强了推理能力,并改善了SemCom的个性化。 基于KG的SemCom系统能够根据KG描述的关系来预测词语,而不是仅仅依靠上下文,从而提高了预测的准确性。 例如,[137]引入了一个由KG驱动的SemCom系统,并在语义编码器和语义解码器中使用Text2KG和KG2Text网络。 此外,[138]提供了一个更可靠的SemCom系统,它将提取的语义和KG相结合。 特别是,它在KG提取和语义恢复中聚合上下文,这在信道质量差的情况下表现出极强的鲁棒性。
IV-B2 音频传输
利用最先进的自然语言处理技术,可以有效地将口语转换为文本,然后将其传输到SemCom中。 然而,与纯粹由字符组成的文本相比,语音信号的复杂性使其更难处理。 这种复杂性不仅源于语音的保真度和音量,还包括其频率和音调等因素。 [139] 中的作者介绍了 DeepSC 的语音专用变体,称为 DeepSC-S。 均方误差 (MSE) 用作损失函数,以最小化原始语音信号和恢复语音信号之间的差异。 此外,信噪比 (SDR) 和语音质量感知评价 (PESQ) 被用作性能指标,以评估重建语音信号的质量。 [140] 中的作者将此框架扩展到适应多个用户,使用联邦学习在各种本地设备和中央服务器上协同训练基于 CNN 的编码器和解码器。 虽然 MSE 可以用作这种情况下的性能指标,但它不能充分捕获接收端的语义内容。 为应对智能任务不断增长的需求,DeepSC-ST [141] 利用 RNN 从发送端的语音信号中提取文本语义内容,并在接收端重建文本序列以进行语音合成。 这种方法显著减少了传输所需的资源。 连接时序分类 (CTC) [142] 用作损失函数,以字符错误率 (CER) 和词错误率 (WER) 作为性能指标来评估转录文本的准确性。
IV-B3 图像传输
在用于图像传输的SemCom系统中,通常会计算相邻像素之间的相关性,以使用语义标签对图像进行分类和分割。 在这种情况下,最小的语义表示单元是像素。 Transformer、CNN、GAN通常用于图像传输的收发器设计。 例如,[143]中的作者开发了一个用于图像传输的端到端SemCom系统,其中接收器处的预训练GAN从语义分割的图像输入重建逼真的图像。 [144]中的作者提出了一种使用GAN和更好的便携式图形(BPG)残差编码的从粗到细的图像压缩框架。 在[145]中,提出了一种基于RL的自适应语义编码(RL-ASC)方法用于图像SemCom,该方法使用卷积语义编码器和基于注意力的生成语义解码器。
此外,人们正在探索针对特定视觉相关任务定制的任务导向型SemCom系统的专门解决方案。 在[146]中,设计了一个统一的传输分类系统用于图像传输,其中接收器直接生成图像分类结果。 [147]中的作者开发了一个面向任务的SemCom系统,用于无人机场景中场景的同步传输和分类,利用深度强化学习(DRL)算法精确识别必要的语义特征。 此外,在[148]中,作者提出了一个基于SemCom的无人机节能框架,该框架包含一个个性化的语义编码器,可以选择性地传输与用户特定兴趣相一致的图像。
IV-B4 视频传输
与图像传输相比,视频传输需要在连续帧之间保持时间一致性,以考虑时间维度。 同时,可以通过理解视频内容来根据动作/轨迹逻辑和行为模式推断帧。 具体来说,[149]中的作者设计了一种联合信源信道编码(JSCC)策略,以优化空中视频传输的传输速率和失真之间的权衡。 [150]中的作者介绍了一种用于视频会议的独特方法,该方法使用语义错误检测器,并使用说话者的静止照片作为先验信息来帮助重建说话者的面部表情,从而显着减少对无线资源的需求。 [151] 中的作者提出了一种新颖的框架,该框架将视频中的每个帧分割为环境部分和动作部分,然后分别提取语义并传输它们,以减少重复环境图像和不必要的动作图像的冗余。 [152] 中的作者开发了一个移动视频传输框架,以确保高体验质量 (QoE),并创建了一个庞大的数据集来了解主观 QoE 分数与神经网络参数之间的相关性。 此外,[153] 中的作者介绍了一种通过文本修改来编辑说话头视频的方法,而 [154] 中的作者则提出仅传输文本而不是视频,以大幅减轻网络流量。
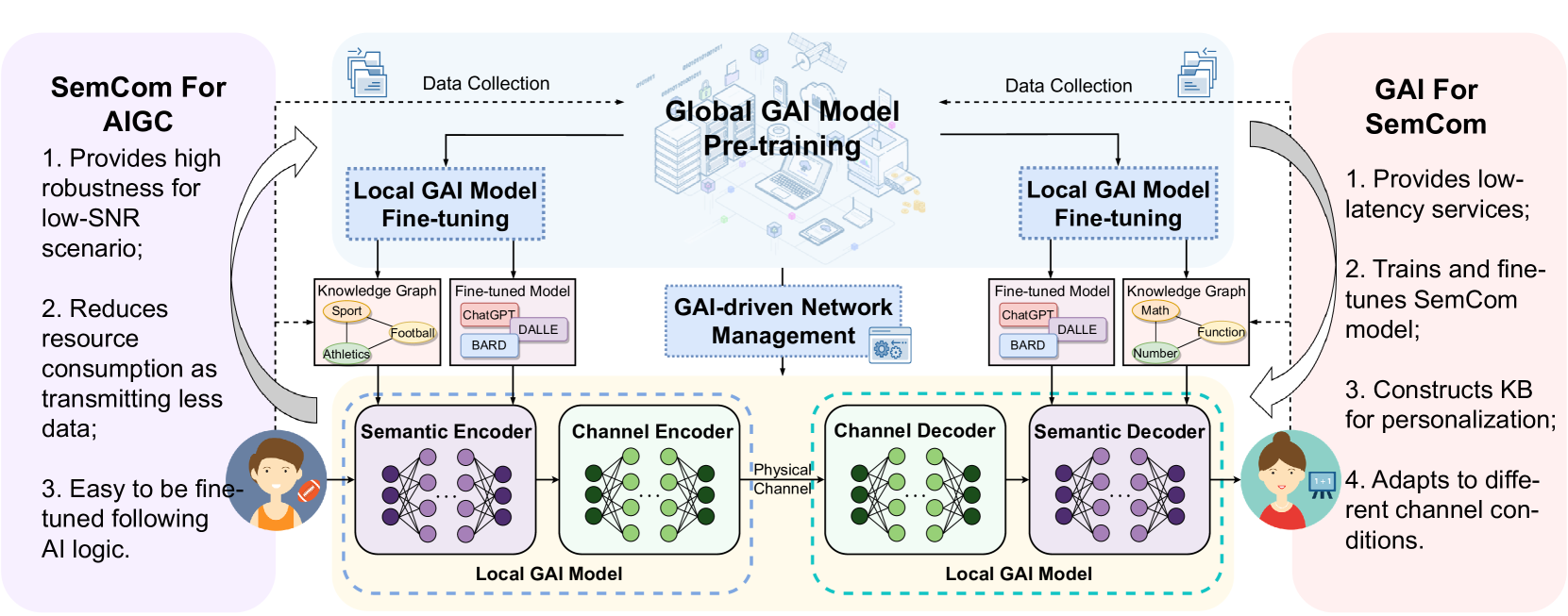
IV-C GAI 在 SemCom 中的作用
通过上述回顾,我们观察到 GAI 技术可以显着增强 SemCom 系统,如 Fig. 3 所示。 这些好处可以在以下方面总结:
-
•
模型训练和微调: GAI 在高效生成海量内容方面的熟练程度为 SemCom 系统提供了一种可扩展的解决方案,使它们能够处理大型数据集。 此功能在生成 ML 模型的训练数据、用上下文相关的有意义内容增强数据库以及促进大规模语义分析方面非常有用 [15]。 此外,GAI 的速度和效率使其非常适合语义分析的低延迟要求,这是需要实时语言翻译或立即响应生成的应用程序中的一个关键属性 [14]。 此外,GAI 可以创建与个人偏好和上下文相一致的个性化内容,以进行微调 [16]。 此功能可以显着提高语义分析的精度和个人相关性,从而带来更个性化的用户体验和服务,这些服务基于对用户需求和兴趣的语义理解。
-
•
KB 建设: GAI 通过自动识别和构建来自不同数据源的信息来简化 KB 建设。 GAI 通过不断学习以更好地识别和集成各种数据类型来提高 KB 的准确性和深度。 这些进步带来了动态的、自我更新的知识库,这些知识库增强了语义分析和决策能力,使它们不仅更加全面,而且在上下文中更加智能。
-
•
频道适应: GAI 可以通过根据内容、上下文和用户行为进行动态调整,显著增强通信频道的适应性。 GAI 模型分析实时数据流以优化频道性能,调整带宽和信号调制等参数,以便在不同条件下保持高质量的传输。 它们可以预测并主动缓解潜在的干扰,确保通信无缝进行。 此外,GAI 的预测能力允许预先分配资源,从而减少延迟并增强整体用户体验。 这种智能驱动的适应性在具有不稳定无线频道的动态网络中尤为重要,确保数据交换的可靠性和效率。
V AIGC 的信息有效性
显然,传统的网络性能指标,如吞吐量、延迟/延迟、数据包丢失率和误码率 (BER),不再适用于全新的 GAI 驱动的 SemCom 网络,这些网络以内容为导向,对数据新鲜度敏感。 因此,如何评估此类网络的信息有效性至关重要。 在本节中,我们将阐明新的观点,考虑到三种 AIGC 模式(即面向任务的系统、AoI、VoI 和因果控制系统)的通信目标、数据新鲜度和因果推理。
V-1 面向任务的系统
面向任务的 SemCom 系统旨在不仅关注数据传输,还确保传输的数据有效地用于完成特定任务或目标。 这种方法超越了仅仅传递信息,而是保证传输的信息对实现接收方的目标具有最大效用。 例如,在制造环境中,面向任务的 SemCom 系统可能用于传输机器传感数据。 相比于仅仅发送原始传感器读数,该系统可以被设计成仅在读数指示潜在问题时传输 - 例如温度或振动突然飙升 - 这可能预示着需要干预的问题。
一些相关工作提出了用于在面向任务的 SemCom 系统中测量信息有效性的各种方法。 [155] 中探索了专注于传输单模态和多模态数据的面向任务的多用户 SemCom,其输入为图像和文本源。 选择了三个智能任务作为代表性案例研究:图像检索和机器翻译用于单模态数据传输,以及更复杂的多模态数据传输视觉问答 (VQA) 任务。 此外,[148] 中的作者提出了一种基于 SemCom 的能量效率框架,用于无人机,该框架包含一个个性化的语义编码器,以选择性地传输与用户特定兴趣一致的图像。 该任务涉及优化目标以增强所提出的多用户资源分配方案中的资源利用率,该方案以博弈论为基础。
V-2 信息时效 (AoI) 和信息价值 (VoI)
AoI 是通信系统中的一个概念,它量化了在 [31] 中提出的目的地接收到的信息的时效性或及时性。 AoI 可用于一些应用,这些应用迫切需要接收者接收最新的状态更新,以确保采取的行动的正确性,例如物联网网络 [156]、无线传感器网络 (WSN) [157]、云游戏 [158] 等。
因此,考虑到 AoI 对时间敏感性的强调,它被认为是 SemCom 系统优化的有用标准 [12, 159]。 [160] 中的作者将 AoI 视为从数据重要性角度来看,用于年龄感知 SemCom 系统的语义度量。 此外,[161] 中提出了一种新的与年龄相关的指标,称为错误信息时效 (AoII)。 与 AoI 相比,AoII 通过结合信息惩罚方面和时间相关函数来实现进步,从而增强了 SemCom 系统。
此外,VoI 指的是在 [32] 中提出的正在传输的信息的重要性以及相关性,而不是仅仅关注数据量。 它强调确保共享的信息对预期目的或接收者有意义且有用,这是 SemCom 的合适指标 [162]。 VoI 也可以被视为在给定时间 上,由 表示的值和新鲜度之间的非线性关系,其中 代表 AoI 惩罚函数,描述了 VoI 随着 AoI 的增长如何演变 [163]。 例如,在 [164] 中,作者利用 VoI 来制定网络控制系统中事件触发器和控制器之间的速率调节权衡,即包速率和调节成本之间的权衡。
V-3 因果推理
因果推理技术通过提供一个结构化框架来理解因果机制以进行推理和推断,从而获得了普及。 该方法的核心是因果推断,也称为反事实推断,其目的是解决诸如“如果我采取了不同的行动会怎样?”之类的问题。 虽然因果关系因其可解释性和外推数据的能力而脱颖而出,但传统的因果模型难以处理高维、非结构化数据,这使得因果结构的识别成为一项复杂且计算量大的任务。 幸运的是,GAI 模型可以相对轻松地近似复杂和高维数据,因此弥补了因果模型的优势。 此外,SemCom 系统确保所进行的因果分析不仅是数据驱动的,而且是意义驱动的,并且具有低延迟,从而导致更准确和实时的推断。 此外,SemCom 网络中的知识更新和共享可以通过因果推理进行动态监控。
在这方面,无线网络状态和动态是需要在 SemCom 网络的信息有效性测量中考虑的新视角。 [165] 中的作者提出了一种新兴 SemCom (ESC) 框架,该框架由一个用于新兴语言设计的信号博弈和一个用于因果推理的神经符号 (NeSy) AI 方法组成。 他们还介绍了 ESC 中因果影响的指标,这些指标捕获了语义有效性(SI 测量优于经典的互信息指标)。 在 [166] 的工作中,在因果语义通信 (CSC) 框架中,针对模仿者学习的结构因果模型 (SCM) 引入了新的信息度量。 此外,它还基于动态网络状态,提出了一个新的语义状态抽象概念,该概念利用了来自集成信息理论的内在信息概念。 此外,还讨论了所提框架中“网络状态模型”的 GAI 架构和组件。
VI 生成式 AI驱动的语义通信网络管理
本节深入探讨了 GAI驱动的 SemCom 网络的管理。 我们首先从架构的角度说明了在网络中引入的新层,以管理资源。 然后,我们讨论了知识管理,包括知识构建、知识共享和更新。 最后,我们研究了计算和通信资源分配策略。
VI-A GAI驱动的 SemCom 架构中的新层
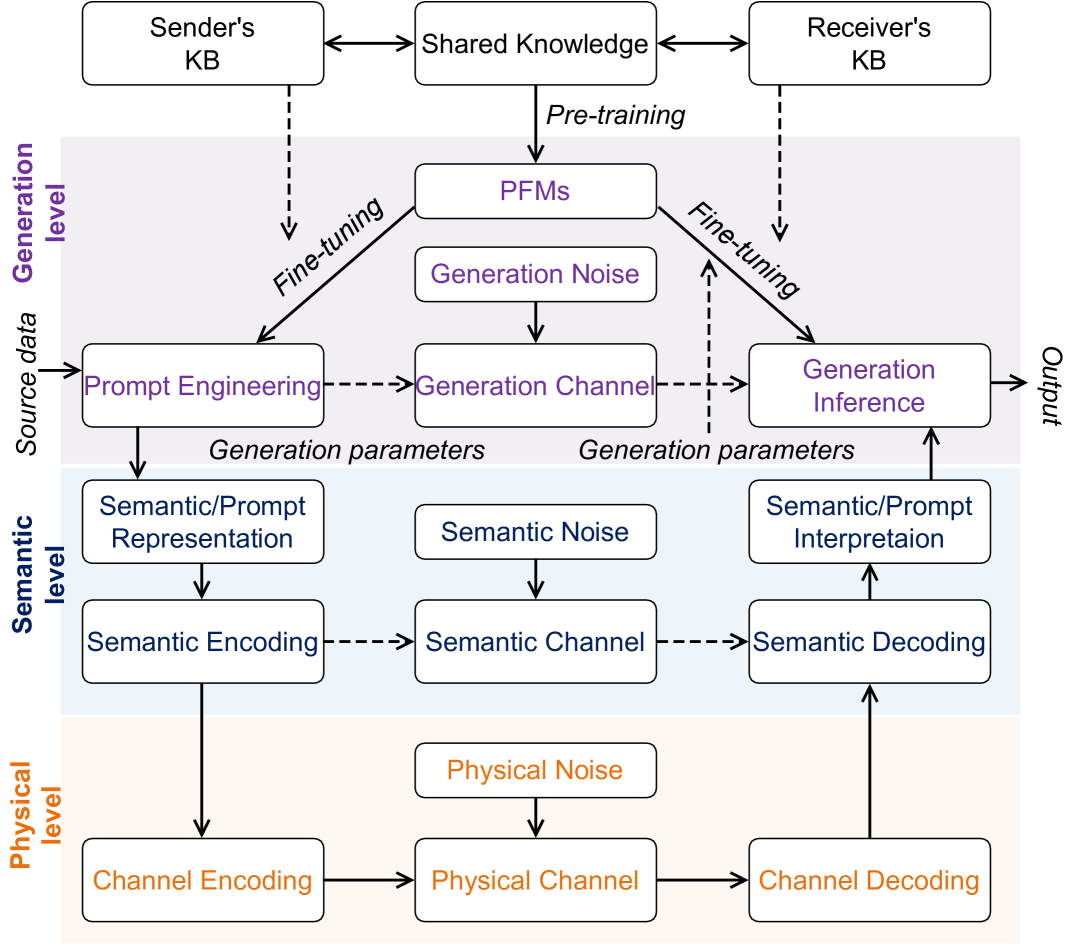
为了管理 GAI驱动的 SemCom 网络,一些研究工作提出了专门用于处理语义消息的新层。 [17] 中提出了一种新颖的 GAI辅助 SemCom 网络框架,它采用了云-边缘-移动设计,支持多模态语义内容供应、语义级联合源信道编码和 AIGC 获取。 [12] 中的作者提出了一个两层架构,主要包括语义感知网络管理和通信领域中的物理层和语义层。
受先前研究的启发,所提出的网络架构(如图 4 所示)包含三个不同的层:物理层、语义层 和新引入的 生成层。 物理层 处理实际数据传输,包括信号的编码和解码。 语义层 关注传输信息的含义或上下文。 创新的 生成层 利用 SI 和算法参数来引导 GAI 模型,生成与特定通信目标一致的内容。 至关重要的是,知识在发送者和接收者之间事先共享,以预训练 GAI 基础模型。 发送者根据发送者的知识库,运用提示工程,从源数据中创建生成参数。 一旦通过信道传输,这些信号在接收端被处理成生成推断,并由接收者的知识库引导,然后被解释成最终的输出。 该架构代表了物理传输、语义理解和内容生成的紧密集成,旨在增强 AIGC 服务的通信效率。
此外,预训练的基础模型 (PFMs) 可以针对特定任务进行微调,例如特征提取和参数优化,以提供个性化服务并满足各种应用的独特需求 [167]。 引入的新层还限制了敏感信息的暴露,因为只有语义指令和提示被传输。 因此,GAI 与 SemCom 模型的集成有望开启一个前所未有的个性化、适应性和安全性时代。
VI-B GAI 驱动的 SemCom 网络中的知识管理
如图 4 所示,知识被视为 GAI 的基础,包含以下两类:
-
•
背景知识: 发送端的任务特定参数和接收端模型微调所需的专业知识构成该层的组成部分。
-
•
常识: 共享数据库使发送方和接收方能够提取相关数据,从而促进使用 PFMs 进行进一步的细化。
从这个意义上说,知识管理在所提出的网络中至关重要,因为 GAI 依赖于累积的知识进行学习,而网络则依赖于持续的知识共享和更新以实现无缝运行 [168, 169]。 具体而言,知识首先从原始数据中构建,然后在每个通信实体之间共享和更新。
VI-B1 知识构建
知识库 (KB) 包含各种数据,例如模型参数、传感数据、知识图谱 (KG) 以及全面的文本、图像、音频和视频语料库。 尤其是,KG 通过编织实体和关系三元组,使数据框架更加复杂,从而增强了存储信息的结构。 KG 的突出例子,例如 Freebase [170]、DBpedia [171]、Wikidata [172] 和 Google 的知识图谱 [173],增强了 GAI 的演绎能力,需要高度个性化,如推荐引擎和问答 (QA) 系统 [174, 175, 176]。
在 GAI 驱动的 SemCom 网络中的知识构建方面,KB 是从公开和专有数据源的融合中汇集而来的,并通过 GAI 算法进行处理。 这些来源多种多样,从众包内容到数据市场,从物联网传感器的输入到被动收集,以及包含用户历史记录和记录 [177]。 这种广泛的数据同化对于所提议网络的有效运行至关重要。
此外,KG 的创建更为复杂,它包含三个基本过程:知识提取 (KE)、知识表示学习 (KRL) 和知识图谱补全 (KGC) [176]。 知识管理过程的初始阶段涉及利用算法进行命名实体识别 (NER) 和关系抽取,从非结构化数据中提取有价值的实体及其连接,形成一个三元组网络。 这些三元组由头部实体、关系和尾部实体组成,表示为 并由资源描述框架 (RDF) [178] 组织。 然后,GAI 算法使用 KRL 将这些三元组转换为紧凑的低维向量,将复杂的知识转换为机器可解释的格式。 最后,KGC 算法负责通过基于三元组和关系的推理推断和插入这些三元组中的缺失部分,以确保数据完整性和完整性 [179]。
VI-B2 知识共享和更新
在各种通信节点收集知识后,知识共享和更新对于维护 SemCom 系统中知识的高度准确性和相关性至关重要。 知识共享和更新流程确保了GAI的决策来自于最新数据,从而促进效率和创新。 定期更新知识库对于快速适应新的市场趋势、技术和用户需求至关重要。 尤其是在以客户为中心的领域,它可以增强个性化体验和专享的用户体验。
-
•
知识共享: 边缘节点之间的共享可以实现集体学习和协作知识创建,通常通过联邦学习等方法实现[180, 181, 182]。 此外,边缘GAI平台提供了一种在工业物联网(IIoT)环境中进行知识共享的具体应用[180]。
-
•
知识更新: 为了维护知识库社区的准确性和相关性,定期进行审核,以识别和剔除过时或不正确的数据,同时整合新的研究成果和见解[183, 184, 185]。 建议定期跟踪知识库版本,以简化这些更新的管理。 这样的系统允许将重大更新存档为单独的版本,为用户提供比较更改和在需要时恢复到先前版本的灵活性[180]。
通过这些多方面的策略,知识库社区保持了高完整性、适应性和效用,从而成为GAI驱动网络中的一个强大资产。
VI-C GAI驱动的资源分配
在GAI驱动的SemCom网络中,资源分配策略优先考虑与知识相关的指标,专注于带宽、频谱和能量的智能使用,而不是仅仅优化传统的与比特相关的指标,如数据吞吐量和带宽效率。 本节重点介绍了计算和通信资源分配的复杂性,强调了一种更智能、更具战略性的网络资源管理方法。
VI-C1 计算资源分配
计算资源,包括处理能力、存储和内存,是 GAI 驱动的 SemCom 网络运行的基础。 直观地,GAI 可以根据实时网络需求动态分配计算资源,有效地响应网络流量和负载变化 [18]。 具体而言, [186, 187] 中的研究表明,GAI 可以从历史网络行为中学习,预测未来的资源消耗模式,并因此为资源分配生成明智的决策。 在支持各种应用程序的多样化无线网络环境中,GAI 算法可以持续监控网络状态和特定于应用程序的资源需求。 例如,高清视频流可能需要强大的处理能力和内存,而物联网传感器数据传输可能需要较少的计算量,但需要更大的存储容量。 GAI 可以使用实时和历史数据来预测这些不同的需求,并自适应地重新分配计算资源 [188]。 在 [12] 中,作者指出,GAI 驱动的 SemCom 可以通过这种动态策略来减少资源浪费,并提高整体网络性能和用户满意度。
遵循这个思路, [18] 中的作者引入了 AI 生成的最佳决策 (AGOD) 算法,该算法利用基于扩散模型的 GAI 技术。 该算法作为 AIGC 即服务 (AaaS) 架构中的一个基本组成部分,部署在无线边缘网络上,以实现对 AIGC 功能的无处不在访问,特别是针对元宇宙用户定制的。 具体而言,用户的请求会不断到达并被分配给不同的 AIGC 服务提供商 (ASP) 进行处理。 随后,AIGC 的结果将交付给用户。
VI-C2 通信资源分配
通过关注数据的语义或含义,GAI 驱动的 SemCom 网络需要更加智能、上下文感知和以用户为中心的通信资源分配 [189]。 采用合理的资源管理方案可以优先传输重要和相关的语义,确保信息及时可靠地传递。 这可以通过 GAI 算法来实现,根据数据的语义价值来理解、解释和优先排序数据。
现有研究展示了一系列针对 GAI 驱动的 SemCom 网络定制的通信资源分配策略。 [187, 18, 190] 中的工作利用基于扩散模型的联合资源分配策略。 具体来说,在 [187] 中,作者提出了两种资源分配方案:基于置信度的方案和人工智能生成的方案,两者都旨在提高传输重要语义信息的质量。 [18] 中的作者引入了多模态(视觉和文本)提示来解决 SemCom 或基于生成式解码器的 GAI 驱动的 SemCom 系统在消息恢复中的不稳定性。 视觉提示旨在恢复图像的结构保真度,而文本提示则封装了其语义上下文。 他们还评估了基于生成扩散模型 (GDM) 的资源分配方案的有效性,以实现高结构相似性指标度量 (SSIM),同时保持安全的隐蔽通信 [191]。 [190] 中的研究探讨了 GAI 驱动的 SemCom 中 AIGC 服务的资源分配。 边缘设备收集原始数据并提取 SI,AIGC 提供商使用这些数据通过 GAI 模型创建有意义的内容。 然后,此内容将帮助多媒体服务提供商制作定制的数字内容。 效率是通过这些过程使用的资源与整个系统需求之间的平衡来衡量的。
此外,由于 SemCom 中不同的知识匹配程度会导致移动用户观察到的语义性能差异,因此一些最近的相关工作已从知识匹配的角度关注资源分配问题。 在 [10] 中,作者首次基于收发机之间的特定知识匹配程度开发了比特到消息的转换函数,以优化支持 SemCom 的蜂窝网络中的资源管理。 此外,[177] 中的作者为支持 SemCom 的车联网中的知识匹配问题提出了一种高效且低延迟的语义服务供应解决方案。
VII 案例研究
在本节中,我们将为 GAI 驱动的 SemCom 网络构思重要的案例,包括自动驾驶、智慧城市和元宇宙。
VII-A 自动驾驶
在自动驾驶领域,自动驾驶汽车 (AV) 需要积极收集传感数据并快速分析数据,以形成对其周围环境的感知。 然而,自动驾驶汽车的数据收集和传输过程通常很繁琐且昂贵 [16]。 此外,值得注意的是,目前自动驾驶汽车中的感知模型提供了一种相当初级的理解,为自动驾驶汽车的控制决策提供参考。 在 GAI 驱动的 SemCom 网络中,通过先进的 GAI 算法可以降低数据传输成本。 累积的历史和传感数据提供了有价值的语义细节,增强了 GAI 驱动的 SemCom 网络中自动驾驶汽车的上下文推理能力。 它们促进了对复杂交通情况和环境线索的更准确的解释,从而在实时驾驶场景中做出更明智的决策。
针对自动驾驶的 SemCom 系统,已经进行了多项突出的研究。 在 [192] 中,作者提出了一种语义模型来捕获自动驾驶系统中的相关 SI,以通过增强信息交换和集成以及丰富背景知识来改进自动驾驶。 [193] 中的作者为高空平台 (HAP) 支持的自动驾驶网络开发了一个 SemCom 框架,其中交通基础设施可以将其 SI 传输到 BS,无论何时观察到连接的自动驾驶汽车。 在 [194] 中,提出了一种多模态语义感知框架,以基于文本和图像为接收车辆生成增强的引导,并采用基于 DRL 的资源分配策略。
VII-B 智能城市
智能城市代表着由各种相互关联的组件组成的复杂社会技术网络,例如物联网设备、手机、其他便携式设备、物理基础设施、服务、应用程序以及这些元素之间共享的数据 [195]。 智能城市网络的高度复杂性来自于处理大量数据、多样化的内容类型、空间和动态网络结构、分布式控制系统以及跨越物理、数字、组织和社会领域的各种城市子系统之间错综复杂的相互关联 [196]。 在这方面,由 GAI 驱动的 SemCom 网络预计将从各种传感数据类型中提取语义,提高数据交换效率,并准确地做出决策以在各种情况下实现异构目标。 由 GAI 驱动的 SemCom 网络中的软件和算法能够增强城市在交通效率和节能方面的表现,协助城市规划,例如分区,并通过控制方法和风险管理策略增强城市韧性。
一些相关工作涵盖了智能城市中的 GAI 技术和语义模型。 [197] 中的作者提出了一些初步的想法,用于创建语义描述模型来描述和帮助发现、索引和查询智能城市数据。 在 [198] 中,介绍了一种智能城市数字孪生架构,该架构促进语义知识的表示和推理,并与 ML 方法紧密协作。 [199] 中的作者详细概述了智能城市应用中使用的语义互操作性技术,用于全面集成物联网语义数据。 此外,[200] 中的作者专注于语义技术的应用,旨在增强智能城市中万物互联组件之间的互操作性。
VII-C 元宇宙
元宇宙是一个集体的虚拟共享空间,它源于我们物理世界增强型虚拟描述与持久数字领域的融合。 GAI 技术的进步导致元宇宙应用显著增加,特别是在增强现实 (AR)、虚拟现实 (VR) 和扩展现实 (XR) 领域 [201, 202, 203, 204]。 学界和业界都在探索元宇宙,以创建身临其境、动态的虚拟景观,这些景观可以实时适应,反映用户交互和倾向。 但是,要真实地反映这些虚拟领域中的物理世界,需要大量的数据,包括文本、图像和视频。 传统的通信基础设施受到数据压缩和传输能力的限制,无法支持这种数据密集型服务。 在这种情况下,由 GAI 驱动的 SemCom 网络通过提取有意义的语义数据并消除与用户偏好和辅助 KB 不一致的冗余信息而脱颖而出。 这种新颖的网络范式有可能减轻元宇宙应用对互联网的数据需求,从而提高整体资源效率。
近期研究开始探索通过 SemCom 网络实现元宇宙应用的潜在解决方案,以确保满意的服务体验。 [205] 中的作者提出了一种框架,将元宇宙划分为特定于代理的语义多元宇宙 (SM),基于分布式学习和多智能体强化学习。 [206] 中的框架促进了感知信息从物理世界到元宇宙的传输,整合了语义基础和基于竞赛的策略,以激励数据上传。 在 [188] 中,作者探索了 SemCom 中的内容竞争理论,以优化元宇宙服务提供商的资源分配。 在 [190] 中,提出了一种集成框架,该框架应用扩散模型来分配语义提取和内容生成中的资源。 此外,鉴于传统 SemCom 网络指标的局限性,[207] 中的作者采用 AoI 作为指标来衡量虚拟服务提供商创建物理世界的数字孪生时的數據及时性。 由依赖于来自多个服务提供商和个人用户的共享知识的 GAI 技术不断推动,元宇宙服务中数据隐私和安全的重要性变得至关重要。 为了解决这些问题,[208] 中的作者设计了一个可信的 SemCom 系统用于元宇宙,利用联邦学习架构的分布式决策和隐私保护能力。
VIII 结论
在本综述中,我们研究了 GAI 与 SemCom 的集成,从而产生了 GAI驱动的 SemCom 网络。 我们详细介绍了 GAI 和 SemCom 的基础知识,强调了它们的协同作用及其对 AIGC 服务的影响。 我们还深入研究了网络管理,涵盖了新层、知识管理和资源分配等方面。 本文中的综合探索不仅突出了 GAI 驱动的 SemCom 网络在各个领域的革命性潜力,而且还突出了无线通信领域的新兴趋势和未来方向。 从本综述中获得的见解可以为增强网络效率和用户体验的创新解决方案铺平道路。 我们进一步探索了在自动驾驶、智慧城市和元宇宙等领域的实际应用,展示了这些技术在 GAI 驱动的 SemCom 网络中的现实世界潜力。
参考文献
- [1] M. Jovanovic and M. Campbell, “Generative Artificial Intelligence: Trends and Prospects,” Computer, vol. 55, no. 10, pp. 107–112, 2022.
- [2] M. Chui, E. Hazan, R. Roberts, A. Singla, K. Smaje, A. Sukharevsky, L. Yee, and R. Zemmel, “The Economic Potential of Generative AI: The Next Productivity Frontier,” June 2023. [Online]. Available: https://www.mckinsey.com/capabilities/mckinsey-digital/our-insights/the-economic-potential-of-generative-AI-the-next-productivity-frontier#key-insights
- [3] Anthropic PBC. Video AI. Accessed: Jul. 19, 2023. [Online]. Available: https://www.promptengineering.org/claudes-100k-context-window-how-this-will-transform-business-education-and-research/
- [4] OpenAI. ChatGPT Can Now See, Hear, and Speak. Accessed: Dec. 9, 2023. [Online]. Available: https://openai.com/blog/chatgpt-can-now-see-hear-and-speak
- [5] H. Du, Z. Li, D. Niyato, J. Kang, Z. Xiong, D. I. Kim et al., “Enabling AI-generated Content (AIGC) Services in Wireless Edge Networks,” arXiv preprint arXiv:2301.03220, 2023.
- [6] D. Gündüz, Z. Qin, I. E. Aguerri, H. S. Dhillon, Z. Yang, A. Yener, K. K. Wong, and C.-B. Chae, “Beyond Transmitting Bits: Context, Semantics, and Task-Oriented Communications,” IEEE Journal on Selected Areas in Communications, vol. 41, no. 1, pp. 5–41, 2023.
- [7] R. Cheng, Y. Sun, D. Niyato, L. Zhang, L. Zhang, and M. A. Imran, “A Wireless AI-Generated Content (AIGC) Provisioning Framework Empowered by Semantic Communication,” arXiv preprint arXiv:2310.17705, 2023.
- [8] X. Luo, H.-H. Chen, and Q. Guo, “Semantic Communications: Overview, Open Issues, and Future Research Directions,” IEEE Wireless Communications, vol. 29, no. 1, pp. 210–219, 2022.
- [9] Z. Qin, X. Tao, J. Lu, W. Tong, and G. Y. Li, “Semantic Communications: Principles and Challenges,” arXiv preprint arXiv:2201.01389, 2021.
- [10] L. Xia, Y. Sun, D. Niyato, X. Li, and M. A. Imran, “Joint User Association and Bandwidth Allocation in Semantic Communication Networks,” IEEE Transactions on Vehicular Technology, 2023.
- [11] S. Iyer, R. Khanai, D. Torse, R. J. Pandya, K. M. Rabie, K. Pai, W. U. Khan, and Z. Fadlullah, “A Survey on Semantic Communications for Intelligent Wireless Networks,” Wireless Personal Communications, vol. 129, no. 1, pp. 569–611, 2023.
- [12] W. Yang, H. Du, Z. Q. Liew, W. Y. B. Lim, Z. Xiong, D. Niyato, X. Chi, X. S. Shen, and C. Miao, “Semantic Communications for Future Internet: Fundamentals, Applications, and Challenges,” IEEE Communications Surveys & Tutorials, 2022.
- [13] A. Karapantelakis, P. Alizadeh, A. Alabassi, K. Dey, and A. Nikou, “Generative AI in Mobile Networks: A Survey,” Annals of Telecommunications, pp. 1–19, 2023.
- [14] Y. Cao, S. Li, Y. Liu, Z. Yan, Y. Dai, P. S. Yu, and L. Sun, “A Comprehensive Survey of AI-Generated Content (AIGC): A History of Generative AI from GAN to ChatGPT,” arXiv preprint arXiv:2303.04226, 2023.
- [15] J. Wu, W. Gan, Z. Chen, S. Wan, and H. Lin, “AI-Generated Content (AIGC): A Survey,” arXiv preprint arXiv:2304.06632, 2023.
- [16] M. Xu, H. Du, D. Niyato, J. Kang, Z. Xiong, S. Mao, Z. Han, A. Jamalipour, D. I. Kim, V. Leung et al., “Unleashing the Power of Edge-Cloud Generative AI in Mobile Networks: A Survey of AIGC Services,” arXiv preprint arXiv:2303.16129, 2023.
- [17] L. Xia, Y. Sun, C. Liang, L. Zhang, M. A. Imran, and D. Niyato, “Generative AI for Semantic Communication: Architecture, Challenges, and Outlook,” arXiv preprint arXiv:2308.15483, 2023.
- [18] H. Du, G. Liu, D. Niyato, J. Zhang, J. Kang, Z. Xiong, B. Ai, and D. I. Kim, “Generative AI-aided Joint Training-free Secure Semantic Communications via Multi-modal Prompts,” arXiv preprint arXiv:2309.02616, 2023.
- [19] R. Gozalo-Brizuela and E. C. Garrido-Merchán, “A Survey of Generative AI Applications,” arXiv preprint arXiv:2306.02781, 2023.
- [20] A. Z. Bahtar and M. Muda, “The Impact of User–Generated Content (UGC) on Product Reviews towards Online Purchasing–A Conceptual Framework,” Procedia Economics and Finance, vol. 37, pp. 337–342, 2016.
- [21] Y. Li, L. Feng, J. Xu, T. Zhang, Y. Liao, and J. Li, “Full-Reference and No-Reference Quality Assessment For Compressed User-Generated Content Videos,” in 2021 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), 2021, pp. 1–6.
- [22] W. Yang, Z. Q. Liew, W. Y. B. Lim, Z. Xiong, D. Niyato, X. Chi, X. Cao, and K. B. Letaief, “Semantic Communication Meets Edge Intelligence,” IEEE Wireless Communications, vol. 29, no. 5, pp. 28–35, 2022.
- [23] P. Basu, J. Bao, M. Dean, and J. Hendler, “Preserving quality of information by using semantic relationships,” in 2012 IEEE International Conference on Pervasive Computing and Communications Workshops, 2012, pp. 58–63.
- [24] F. Zhao, Y. Sun, R. Cheng, and M. A. Imran, “Background Knowledge Aware Semantic Coding Model Selection,” in 2022 IEEE 22nd International Conference on Communication Technology (ICCT), 2022, pp. 84–89.
- [25] H. Xie, Z. Qin, G. Y. Li, and B.-H. Juang, “Deep Learning Enabled Semantic Communication Systems,” IEEE Transactions on Signal Processing, vol. 69, pp. 2663–2675, 2021.
- [26] E. C. Strinati and S. Barbarossa, “6G Networks: Beyond Shannon Towards Semantic and Goal-Oriented Communications,” Computer Networks, vol. 190, p. 107930, 2021.
- [27] Q. Lan, D. Wen, Z. Zhang, Q. Zeng, X. Chen, P. Popovski, and K. Huang, “What is Semantic Communication? A View on Conveying Meaning in the Era of Machine Intelligence,” Journal of Communications and Information Networks, vol. 6, no. 4, pp. 336–371, 2021.
- [28] C. Chaccour, W. Saad, M. Debbah, Z. Han, and H. V. Poor, “Less Data, More Knowledge: Building Next Generation Semantic Communication Networks,” arXiv preprint arXiv:2211.14343, 2022.
- [29] K. B. Letaief, W. Chen, Y. Shi, J. Zhang, and Y.-J. A. Zhang, “The Roadmap to 6G: AI Empowered Wireless Networks,” IEEE Communications Magazine, vol. 57, no. 8, pp. 84–90, 2019.
- [30] C. Cai, X. Yuan, and Y.-J. A. Zhang, “Multi-Device Task-Oriented Communication via Maximal Coding Rate Reduction,” arXiv preprint arXiv:2309.02888, 2023.
- [31] S. Kaul, R. Yates, and M. Gruteser, “Real-time Status: How Often Should One Update?” in 2012 Proceedings IEEE INFOCOM, 2012, pp. 2731–2735.
- [32] R. A. Howard, “Information Value Theory,” IEEE Transactions on Systems Science and Cybernetics, vol. 2, no. 1, pp. 22–26, 1966.
- [33] D. Bahdanau, K. Cho, and Y. Bengio, “Neural Machine Translation by Jointly Learning to Align and Translate,” arXiv preprint arXiv:1409.0473, 2014.
- [34] A. See, P. J. Liu, and C. D. Manning, “Get to the Point: Summarization with Pointer-Generator Networks,” arXiv preprint arXiv:1704.04368, 2017.
- [35] I. Sutskever, O. Vinyals, and Q. V. Le, “Sequence to Sequence Learning with Neural Networks,” Advances in Neural Information Processing Systems, vol. 27, 2014.
- [36] O. Vinyals and Q. Le, “A Neural Conversational Model,” arXiv preprint arXiv:1506.05869, 2015.
- [37] S. Hochreiter and J. Schmidhuber, “Long Short-Term Memory,” Neural Computation, vol. 9, no. 8, pp. 1735–1780, 1997.
- [38] T. Mikolov, M. Karafiát, L. Burget, J. Cernockỳ, and S. Khudanpur, “Recurrent Neural Network Based Language Model.” in Interspeech, vol. 2, no. 3. Makuhari, 2010, pp. 1045–1048.
- [39] R. Dey and F. M. Salem, “Gate-variants of Gated Recurrent Unit (GRU) neural networks,” in 2017 IEEE 60th International Midwest Symposium on Circuits and Systems (MWSCAS), 2017, pp. 1597–1600.
- [40] S. R. Bowman, L. Vilnis, O. Vinyals, A. M. Dai, R. Jozefowicz, and S. Bengio, “Generating Sentences from a Continuous Space,” arXiv preprint arXiv:1511.06349, 2015.
- [41] W. Wang, Z. Gan, H. Xu, R. Zhang, G. Wang, D. Shen, C. Chen, and L. Carin, “Topic-guided Variational Autoencoders for Text Generation,” arXiv preprint arXiv:1903.07137, 2019.
- [42] S. Semeniuta, A. Severyn, and E. Barth, “A Hybrid Convolutional Variational Autoencoder for Text Generation,” arXiv preprint arXiv:1702.02390, 2017.
- [43] W. Xu, H. Sun, C. Deng, and Y. Tan, “Variational Autoencoder for Semi-Supervised Text Classification,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 31, no. 1, 2017.
- [44] L. Yu, W. Zhang, J. Wang, and Y. Yu, “SeqGAN: Sequence Generative Adversarial Nets with Policy Gradient,” in Proceedings of the AAAI conference on artificial intelligence, vol. 31, no. 1, 2017.
- [45] Y. Zhang, Z. Gan, K. Fan, Z. Chen, R. Henao, D. Shen, and L. Carin, “Adversarial Feature Matching for Text Generation,” in International conference on machine learning. PMLR, 2017, pp. 4006–4015.
- [46] H. Wang, Z. Qin, and T. Wan, “Text Generation Based on Generative Adversarial Nets with Latent Variable,” in Advances in Knowledge Discovery and Data Mining: 22nd Pacific-Asia Conference, PAKDD 2018, Melbourne, VIC, Australia, June 3-6, 2018, Proceedings, Part II 22. Springer, 2018, pp. 92–103.
- [47] J. Guo, S. Lu, H. Cai, W. Zhang, Y. Yu, and J. Wang, “Long Text Generation via Adversarial Training with Leaked Information,” in Proceedings of the AAAI conference on artificial intelligence, vol. 32, no. 1, 2018.
- [48] C. Zhang, C. Xiong, and L. Wang, “A research on generative adversarial networks applied to text generation,” in 2019 14th International Conference on Computer Science & Education (ICCSE), 2019, pp. 913–917.
- [49] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is All You Need,” Advances In Neural Information Processing Systems, vol. 30, 2017.
- [50] A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, I. Sutskever et al., “Language Models are Unsupervised Multitask Learners,” OpenAI Blog, vol. 1, no. 8, p. 9, 2019.
- [51] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,” arXiv preprint arXiv:1810.04805, 2018.
- [52] C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y. Zhou, W. Li, and P. J. Liu, “Exploring the Limits of Transfer Learning with A Unified Text-To-Text Transformer,” The Journal of Machine Learning Research, vol. 21, no. 1, pp. 5485–5551, 2020.
- [53] OpenAI. ChatGPT: Optimizing Language Models for Dialogue. Accessed: Jul. 13, 2023. [Online]. Available: https://openai.com/blog/chatgpt/
- [54] M. Corporation. Reinventing Search with A New AI-powered Microsoft Bing and Edge, your Copilot for the Web. Accessed: Jul. 13, 2023. [Online]. Available: https://blogs.microsoft.com/blog/2023/02/07/reinventing-search-with-a-new-ai-powered-microsoft-bing-and-edge-your-copilot-for-the-web/
- [55] S. Smith, M. Patwary, B. Norick, P. LeGresley, S. Rajbhandari, J. Casper, Z. Liu, S. Prabhumoye, G. Zerveas, V. Korthikanti et al., “Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model,” arXiv preprint arXiv:2201.11990, 2022.
- [56] T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell et al., “Language Models are Few-shot Learners,” Advances in Neural Information Processing Systems, vol. 33, pp. 1877–1901, 2020.
- [57] PaintMe. PaintMe AI: Home. Accessed: Jul. 19, 2023. [Online]. Available: https://www.paintme.ai/index.php
- [58] Vizcom. The Next Generation of Product Visualization. Accessed: Jul. 19, 2023. [Online]. Available: https://www.vizcom.ai/
- [59] Steve.AI. Convert Photos to Videos Instantly Using Steve.AI. Accessed: Jul. 19, 2023. [Online]. Available: https://www.steve.ai/photo-video-maker
- [60] T. Karras, S. Laine, and T. Aila, “A Style-Based Generator Architecture for Generative Adversarial Networks,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 4401–4410.
- [61] A. Van Den Oord, O. Vinyals et al., “Neural Discrete Representation Learning,” Advances in Neural Information Processing Systems, vol. 30, 2017.
- [62] D. Rezende and S. Mohamed, “Variational Inference with Normalizing Flows,” in International conference on machine learning. PMLR, 2015, pp. 1530–1538.
- [63] J. Ho, T. Salimans, A. Gritsenko, W. Chan, M. Norouzi, and D. J. Fleet, “Video Diffusion Models,” arXiv:2204.03458, 2022.
- [64] Murf.AI. Transform Your Voiceover from A Home Recording to A Professional AI Voice. Accessed: Jul. 19, 2023. [Online]. Available: https://murf.ai/voice-changer
- [65] Resemble.AI. Real-time Speech-to-Speech Voice Conversion. Accessed: Jul. 19, 2023. [Online]. Available: https://www.resemble.ai/speech-to-speech/
- [66] MetaVoice. Accessed: Jul. 19, 2023. [Online]. Available: https://themetavoice.xyz/
- [67] C. Donahue, J. McAuley, and M. Puckette, “Adversarial Audio Synthesis,” arXiv preprint arXiv:1802.04208, 2018.
- [68] Y. Meng, W. Li, S. Lei, Z. Zou, and Z. Shi, “Large-Factor Super-Resolution of Remote Sensing Images With Spectra-Guided Generative Adversarial Networks,” IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–11, 2022.
- [69] N. Kalchbrenner, E. Elsen, K. Simonyan, S. Noury, N. Casagrande, E. Lockhart, F. Stimberg, A. Oord, S. Dieleman, and K. Kavukcuoglu, “Efficient Neural Audio Synthesis,” in International Conference on Machine Learning. PMLR, 2018, pp. 2410–2419.
- [70] K. Akuzawa, K. Onishi, K. Takiguchi, K. Mametani, and K. Mori, “Conditional Deep Hierarchical Variational Autoencoder for Voice Conversion,” in 2021 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC). IEEE, 2021, pp. 808–813.
- [71] K. Zhou, B. Sisman, and H. Li, “VAW-GAN for Disentanglement and Recomposition of Emotional Elements in Speech,” in 2021 IEEE Spoken Language Technology Workshop (SLT). IEEE, 2021, pp. 415–422.
- [72] P. Dhariwal, H. Jun, C. Payne, J. W. Kim, A. Radford, and I. Sutskever, “Jukebox: A Generative Model for Music,” arXiv preprint arXiv:2005.00341, 2020.
- [73] OpenAI. DALL·E 2: Exploring the Limits of Data-Driven Image Generation with Transformers. Accessed: Jul. 19, 2023. [Online]. Available: https://openai.com/dall-e-2
- [74] NightCafe Studio. NightCafe Studio - AI Art Generator. Accessed: Jul. 19, 2023. [Online]. Available: https://creator.nightcafe.studio/
- [75] DreamStudio. DreamStudio - Image Generator. Accessed: Jul. 19, 2023. [Online]. Available: https://dreamstudio.ai/generate
- [76] A. Ramesh, M. Pavlov, G. Goh, S. Gray, C. Voss, A. Radford, M. Chen, and I. Sutskever, “Zero-Shot Text-to-Image Generation,” in International Conference on Machine Learning. PMLR, 2021, pp. 8821–8831.
- [77] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark et al., “Learning Transferable Visual Models From Natural Language Supervision,” arXiv preprint arXiv:2103.00020, 2021.
- [78] K. Crowson, S. Biderman, D. Kornis, D. Stander, E. Hallahan, L. Castricato, and E. Raff, “VQGAN-CLIP: Open Domain Image Generation and Editing with Natural Language Guidance,” in European Conference on Computer Vision. Springer, 2022, pp. 88–105.
- [79] Y. Balaji, S. Nah, X. Huang, A. Vahdat, J. Song, K. Kreis, M. Aittala, T. Aila, S. Laine, B. Catanzaro et al., “eDiff-I: Text-to-Image Diffusion Models with an Ensemble of Expert Denoisers,” arXiv preprint arXiv:2211.01324, 2022.
- [80] T. Brooks, A. Holynski, and A. A. Efros, “InstructPix2Pix: Learning to Follow Image Editing Instructions,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 18 392–18 402.
- [81] Synthesia. Create Professional Videos without Mics, Cameras, or Actors. Accessed: Jul. 19, 2023. [Online]. Available: https://www.synthesia.io/
- [82] Pictory. Script To Video Creation In Minutes. Accessed: Jul. 19, 2023. [Online]. Available: https://pictory.ai/pictory-features/script-to-video
- [83] Meta AI. Accessed: Jul. 19, 2023. [Online]. Available: https://makeavideo.studio/
- [84] W. Hong, M. Ding, W. Zheng, X. Liu, and J. Tang, “CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers,” arXiv preprint arXiv:2205.15868, 2022.
- [85] R. Villegas, M. Babaeizadeh, P.-J. Kindermans, H. Moraldo, H. Zhang, M. T. Saffar, S. Castro, J. Kunze, and D. Erhan, “Phenaki: Variable Length Video Generation From Open Domain Textual Description,” arXiv preprint arXiv:2210.02399, 2022.
- [86] Murf.AI. Go from Text to Speech with A Versatile AI Voice Generator. Accessed: Jul. 19, 2023. [Online]. Available: https://murf.ai/
- [87] PlayHT. AI Powered Text to Voice Generator. Accessed: Jul. 19, 2023. [Online]. Available: https://play.ht/blog/ai-text-to-speech-voice-cloning-technology-overview/
- [88] A. v. d. Oord, S. Dieleman, H. Zen, K. Simonyan, O. Vinyals, A. Graves, N. Kalchbrenner, A. Senior, and K. Kavukcuoglu, “WaveNet: A Generative Model for Raw Audio,” arXiv preprint arXiv:1609.03499, 2016.
- [89] Z. Borsos, R. Marinier, D. Vincent, E. Kharitonov, O. Pietquin, M. Sharifi, D. Roblek, O. Teboul, D. Grangier, M. Tagliasacchi et al., “AudioLM: A Language Modeling Approach to Audio Generation,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2023.
- [90] READ-COOP. Unlock Historical Documents with AI. Accessed: Jul. 19, 2023. [Online]. Available: https://readcoop.eu/transkribus/
- [91] O. Vinyals, A. Toshev, S. Bengio, and D. Erhan, “Show and Tell: A Neural Image Caption Generator,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2015.
- [92] J. Chen, H. Guo, K. Yi, B. Li, and M. Elhoseiny, “VisualGPT: Data-efficient Adaptation of Pretrained Language Models for Image Captioning,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 18 030–18 040.
- [93] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly et al., “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale,” arXiv preprint arXiv:2010.11929, 2020.
- [94] H. Xu, G. Ghosh, P.-Y. Huang, D. Okhonko, A. Aghajanyan, F. Metze, L. Zettlemoyer, and C. Feichtenhofer, “VideoCLIP: Contrastive Pre-training for Zero-shot Video-Text Understanding,” arXiv preprint arXiv:2109.14084, 2021.
- [95] C. Sun, A. Myers, C. Vondrick, K. Murphy, and C. Schmid, “VideoBERT: A Joint Model for Video and Language Representation Learning,” in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), October 2019.
- [96] H. Luo, L. Ji, B. Shi, H. Huang, N. Duan, T. Li, J. Li, T. Bharti, and M. Zhou, “UniVL: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation,” arXiv preprint arXiv:2002.06353, 2020.
- [97] SpeakAI. Turn Your Language Data into Insights, Fast and with No Code. Accessed: Jul. 19, 2023. [Online]. Available: https://speakai.co/
- [98] A. Hannun, C. Case, J. Casper, B. Catanzaro, G. Diamos, E. Elsen, R. Prenger, S. Satheesh, S. Sengupta, A. Coates et al., “Deep Speech: Scaling Up End-to-End Speech Recognition,” arXiv preprint arXiv:1412.5567, 2014.
- [99] A. Baevski, Y. Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations,” Advances in neural information processing systems, vol. 33, pp. 12 449–12 460, 2020.
- [100] Apple: Siri. Accessed: Jul. 19, 2023. [Online]. Available: http://www.apple.com/ios/siri/
- [101] XiaoIce. Accessed: Jul. 19, 2023. [Online]. Available: https://www.xiaoice.com/
- [102] Google: Google Assistant. Accessed: Jul. 19, 2023. [Online]. Available: https://assistant.google.com/
- [103] Amazon Inc.: Alexa. Accessed: Jul. 19, 2023. [Online]. Available: https://developer.amazon.com/public/solutions/alexa/
- [104] L. Zhou, J. Gao, D. Li, and H.-Y. Shum, “The Design and Implementation of XiaoIce, an Empathetic Social Chatbot,” Computational Linguistics, vol. 46, no. 1, pp. 53–93, 2020.
- [105] Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner, “Gradient-Based Learning Applied to Document Recognition,” Proceedings of the IEEE, vol. 86, no. 11, pp. 2278–2324, 1998.
- [106] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “ImageNet Classification with Deep Convolutional Neural Networks,” Communications of the ACM, vol. 60, no. 6, pp. 84–90, 2017.
- [107] K. Simonyan and A. Zisserman, “Very Deep Convolutional Networks for Large-Scale Image Recognition,” arXiv preprint arXiv:1409.1556, 2014.
- [108] K. He, X. Zhang, S. Ren, and J. Sun, “Deep Residual Learning for Image Recognition,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 770–778.
- [109] G. Huang, Z. Liu, L. Van Der Maaten, and K. Q. Weinberger, “Densely Connected Convolutional Networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 4700–4708.
- [110] K. Sohn, H. Lee, and X. Yan, “Advances in Neural Information Processing Systems,” Advances in neural information processing systems, vol. 28, 2015.
- [111] H. Huang, R. He, Z. Sun, T. Tan et al., “Advances in Neural Information Processing Systems,” Advances in neural information processing systems, vol. 31, 2018.
- [112] A. Radford, L. Metz, and S. Chintala, “Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks,” arXiv preprint arXiv:1511.06434, 2015.
- [113] J.-Y. Zhu, T. Park, P. Isola, and A. A. Efros, “Unpaired Image-To-Image Translation Using Cycle-Consistent Adversarial Networks,” in Proceedings of the IEEE International Conference on Computer Vision, 2017, pp. 2223–2232.
- [114] J. Song, C. Meng, and S. Ermon, “Denoising Diffusion Implicit Models,” arXiv preprint arXiv:2010.02502, 2020.
- [115] M. D. M. Reddy, M. S. M. Basha, M. M. C. Hari, and M. N. Penchalaiah, “DALL-E: Creating Images from Text,” UGC Care Group I Journal, vol. 8, no. 14, pp. 71–75, 2021.
- [116] A. Ramesh, P. Dhariwal, A. Nichol, C. Chu, and M. Chen, “Hierarchical Text-Conditional Image Generation with CLIP Latents,” arXiv preprint arXiv:2204.06125, 2022.
- [117] M. Dorkenwald, T. Milbich, A. Blattmann, R. Rombach, K. G. Derpanis, and B. Ommer, “Stochastic Image-to-Video Synthesis using cINNs,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 3742–3753.
- [118] L. Zhao, X. Peng, Y. Tian, M. Kapadia, and D. Metaxas, “Learning to Forecast and Refine Residual Motion for Image-to-Video Generation,” in Proceedings of the European Conference on Computer Vision (ECCV), September 2018.
- [119] X. Wang, K. C. Chan, K. Yu, C. Dong, and C. Change Loy, “EDVR: Video Restoration with Enhanced Deformable Convolutional Networks,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 2019, pp. 0–0.
- [120] R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High-Resolution Image Synthesis with Latent Diffusion Models,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 10 684–10 695.
- [121] J. Finnie-Ansley, P. Denny, B. A. Becker, A. Luxton-Reilly, and J. Prather, “The Robots are Coming: Exploring the Implications of OpenAI Codex on Introductory Programming,” in Australasian Computing Education Conference, 2022, pp. 10–19.
- [122] R. Batish, Voicebot and Chatbot Design: Flexible Conversational Interfaces with Amazon Alexa, Google Home, and Facebook Messenger. Packt Publishing Ltd, 2018.
- [123] C. W. Morris, “Foundations of the Theory of Signs,” in International Encyclopedia of Unified Science. Chicago University Press, 1938, pp. 1–59.
- [124] C. E. Shannon and W. Weaver, The Mathematical Theory of Communication. University of Illinois Press, 1949.
- [125] R. Carnap and Y. Bar-Hillel, “An Outline of a Theory of Semantic Information,” Journal of Symbolic Logic, vol. 19, no. 3, pp. 230–232, 1954.
- [126] J. Barwise and J. Perry, Situations and Attitudes, J. Perry, Ed. Cambridge, Mass.: MIT Press, 1983.
- [127] B. Juba and M. Sudan, “Universal Semantic Communication I,” in Proceedings of the fortieth annual ACM symposium on theory of computing, 2008, pp. 123–132.
- [128] Juba, Brendan and Sudan, Madhu, “Universal Semantic Communication II: A Theory of Goal-oriented Communication,” in Electronic Colloquium on Computational Complexity (ECCC), vol. 15, no. 095, 2008.
- [129] L. Floridi, “Outline of A Theory of Strongly Semantic Information,” Minds and Machines, vol. 14, pp. 197–221, 2004.
- [130] S. D’Alfonso, “On Quantifying Semantic Information,” Information, vol. 2, no. 1, pp. 61–101, 2011.
- [131] Y. Zhong, “A Theory of Semantic Information,” China Communications, vol. 14, no. 1, pp. 1–17, 2017.
- [132] A. Kolchinsky and D. H. Wolpert, “Semantic Information, Autonomous Agency and Non-equilibrium Statistical Physics,” Interface Focus, vol. 8, no. 6, p. 20180041, 2018.
- [133] A. Rényi, “On Measures of Entropy and Information,” in Proceedings of the Fourth Berkeley Symposium on Mathematical Statistics and Probability, Volume 1: Contributions to the Theory of Statistics, vol. 4. University of California Press, 1961, pp. 547–562.
- [134] P. Jiang, C.-K. Wen, S. Jin, and G. Y. Li, “Deep Source-Channel Coding for Sentence Semantic Transmission With HARQ,” IEEE Transactions on Communications, vol. 70, no. 8, pp. 5225–5240, 2022.
- [135] M. Sana and E. C. Strinati, “Learning Semantics: An Opportunity for Effective 6G Communications,” in 2022 IEEE 19th Annual Consumer Communications & Networking Conference (CCNC), 2022, pp. 631–636.
- [136] H. Xie and Z. Qin, “A Lite Distributed Semantic Communication System for Internet of Things,” IEEE Journal on Selected Areas in Communications, vol. 39, no. 1, pp. 142–153, 2021.
- [137] F. Zhou, Y. Li, X. Zhang, Q. Wu, X. Lei, and R. Q. Hu, “Cognitive Semantic Communication Systems Driven by Knowledge Graph,” in ICC 2022-IEEE International Conference on Communications. IEEE, 2022, pp. 4860–4865.
- [138] S. Jiang, Y. Liu, Y. Zhang, P. Luo, K. Cao, J. Xiong, H. Zhao, and J. Wei, “Reliable Semantic Communication System Enabled by Knowledge Graph,” Entropy, vol. 24, no. 6, p. 846, 2022.
- [139] Z. Weng and Z. Qin, “Semantic Communication Systems for Speech Transmission,” IEEE Journal on Selected Areas in Communications, vol. 39, no. 8, pp. 2434–2444, 2021.
- [140] H. Tong, Z. Yang, S. Wang, Y. Hu, O. Semiari, W. Saad, and C. Yin, “Federated Learning for Audio Semantic Communication,” Frontiers in communications and networks, vol. 2, p. 734402, 2021.
- [141] Z. Weng, Z. Qin, X. Tao, C. Pan, G. Liu, and G. Y. Li, “Deep Learning Enabled Semantic Communications with Speech Recognition and Synthesis,” IEEE Transactions on Wireless Communications, pp. 1–1, 2023.
- [142] A. Graves, S. Fernández, F. Gomez, and J. Schmidhuber, “Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks,” in Proceedings of the 23rd International Conference on Machine Learning, 2006, pp. 369–376.
- [143] M. U. Lokumarambage, V. S. S. Gowrisetty, H. Rezaei, T. Sivalingam, N. Rajatheva, and A. Fernando, “Wireless End-to-End Image Transmission System using Semantic Communications,” IEEE Access, 2023.
- [144] D. Huang, X. Tao, F. Gao, and J. Lu, “Deep Learning-Based Image Semantic Coding for Semantic Communications,” in 2021 IEEE Global Communications Conference (GLOBECOM), 2021, pp. 1–6.
- [145] D. Huang, F. Gao, X. Tao, Q. Du, and J. Lu, “Toward Semantic Communications: Deep Learning-Based Image Semantic Coding,” IEEE Journal on Selected Areas in Communications, vol. 41, no. 1, pp. 55–71, 2023.
- [146] C.-H. Lee, J.-W. Lin, P.-H. Chen, and Y.-C. Chang, “Deep Learning-Constructed Joint Transmission-Recognition for Internet of Things,” IEEE Access, vol. 7, pp. 76 547–76 561, 2019.
- [147] X. Kang, B. Song, J. Guo, Z. Qin, and F. R. Yu, “Task-Oriented Image Transmission for Scene Classification in Unmanned Aerial Systems,” IEEE Transactions on Communications, vol. 70, no. 8, pp. 5181–5192, 2022.
- [148] J. Kang, H. Du, Z. Li, Z. Xiong, S. Ma, D. Niyato, and Y. Li, “Personalized Saliency in Task-Oriented Semantic Communications: Image Transmission and Performance Analysis,” IEEE Journal on Selected Areas in Communications, vol. 41, no. 1, pp. 186–201, 2023.
- [149] S. Wang, J. Dai, Z. Liang, K. Niu, Z. Si, C. Dong, X. Qin, and P. Zhang, “Wireless Deep Video Semantic Transmission,” IEEE Journal on Selected Areas in Communications, vol. 41, no. 1, pp. 214–229, 2023.
- [150] P. Jiang, C.-K. Wen, S. Jin, and G. Y. Li, “Wireless Semantic Communications for Video Conferencing,” IEEE Journal on Selected Areas in Communications, vol. 41, no. 1, pp. 230–244, 2023.
- [151] C. Liang, X. Deng, Y. Sun, R. Cheng, L. Xia, D. Niyato, and M. A. Imran, “VISTA: Video Transmission over A Semantic Communication Approach,” in 2023 IEEE International Conference on Communications Workshops (ICC Workshops), 2023, pp. 1777–1782.
- [152] X. Tao, Y. Duan, M. Xu, Z. Meng, and J. Lu, “Learning QoE of Mobile Video Transmission With Deep Neural Network: A Data-Driven Approach,” IEEE Journal on Selected Areas in Communications, vol. 37, no. 6, pp. 1337–1348, 2019.
- [153] O. Fried, A. Tewari, M. Zollhöfer, A. Finkelstein, E. Shechtman, D. B. Goldman, K. Genova, Z. Jin, C. Theobalt, and M. Agrawala, “Text-based Editing of Talking-Head Video,” ACM Transactions on Graphics (TOG), vol. 38, no. 4, pp. 1–14, 2019.
- [154] P. Tandon, S. Chandak, P. Pataranutaporn, Y. Liu, A. M. Mapuranga, P. Maes, T. Weissman, and M. Sra, “Txt2Vid: Ultra-Low Bitrate Compression of Talking-Head Videos via Text,” IEEE Journal on Selected Areas in Communications, vol. 41, no. 1, pp. 107–118, 2023.
- [155] H. Xie, Z. Qin, X. Tao, and K. B. Letaief, “Task-Oriented Multi-User Semantic Communications,” IEEE Journal on Selected Areas in Communications, vol. 40, no. 9, pp. 2584–2597, 2022.
- [156] J. Hribar, M. Costa, N. Kaminski, and L. A. DaSilva, “Updating Strategies in the Internet of Things by Taking Advantage of Correlated Sources,” in GLOBECOM 2017 - 2017 IEEE Global Communications Conference, 2017, pp. 1–6.
- [157] Q. Abbas, S. A. Hassan, H. K. Qureshi, K. Dev, and H. Jung, “A Comprehensive Survey on Age of Information in Massive IoT Networks,” Computer Communications, vol. 197, pp. 199–213, 2023.
- [158] R. D. Yates, M. Tavan, Y. Hu, and D. Raychaudhuri, “Timely Cloud Gaming,” in IEEE INFOCOM 2017 - IEEE Conference on Computer Communications, 2017, pp. 1–9.
- [159] R. D. Yates, Y. Sun, D. R. Brown, S. K. Kaul, E. Modiano, and S. Ulukus, “Age of Information: An Introduction and Survey,” IEEE Journal on Selected Areas in Communications, vol. 39, no. 5, pp. 1183–1210, 2021.
- [160] E. Uysal, O. Kaya, A. Ephremides, J. Gross, M. Codreanu, P. Popovski, M. Assaad, G. Liva, A. Munari, T. Soleymani et al., “Semantic Communications in Networked Systems: A Data Significance Perspective,” arXiv preprint arXiv:2103.05391, 2021.
- [161] A. Maatouk, M. Assaad, and A. Ephremides, “The Age of Incorrect Information: An Enabler of Semantics-Empowered Communication,” IEEE Transactions on Wireless Communications, 2022.
- [162] E. Uysal, O. Kaya, A. Ephremides, J. Gross, M. Codreanu, P. Popovski, M. Assaad, G. Liva, A. Munari, B. Soret et al., “Semantic Communications in Networked Systems: A Data Significance Perspective,” IEEE Network, vol. 36, no. 4, pp. 233–240, 2022.
- [163] A. Li, S. Wu, S. Meng, and Q. Zhang, “Towards Goal-Oriented Semantic Communications: New Metrics, Open Challenges, and Future Research Directions,” arXiv preprint arXiv:2304.00848, 2023.
- [164] T. Soleymani, J. S. Baras, and S. Hirche, “Value of Information in Feedback Control: Quantification,” IEEE Transactions on Automatic Control, vol. 67, no. 7, pp. 3730–3737, 2021.
- [165] C. K. Thomas and W. Saad, “Neuro-Symbolic Causal Reasoning Meets Signaling Game for Emergent Semantic Communications,” IEEE Transactions on Wireless Communications, pp. 1–1, 2023.
- [166] C. K. Thomas, W. Saad, and Y. Xiao, “Causal Semantic Communication for Digital Twins: A Generalizable Imitation Learning Approach,” arXiv preprint arXiv:2304.12502, 2023.
- [167] G. Liu, H. Du, D. Niyato, J. Kang, Z. Xiong, D. I. Kim et al., “Semantic Communications for Artificial Intelligence Generated Content (AIGC) Toward Effective Content Creation,” arXiv preprint arXiv:2308.04942, 2023.
- [168] Q. Hu, G. Zhang, Z. Qin, Y. Cai, G. Yu, and G. Y. Li, “Robust Semantic Communications with Masked VQ-VAE Enabled Codebook,” IEEE Transactions on Wireless Communications, pp. 1–1, 2023.
- [169] G. Shi, Y. Xiao, Y. Li, and X. Xie, “From Semantic Communication to Semantic-Aware Networking: Model, Architecture, and Open Problems,” IEEE Communications Magazine, vol. 59, no. 8, pp. 44–50, 2021.
- [170] K. Bollacker, C. Evans, P. Paritosh, T. Sturge, and J. Taylor, “Freebase: A Collaboratively Created Graph Database for Structuring Human Knowledge,” in Proceedings of the 2008 ACM SIGMOD international conference on Management of data, 2008, pp. 1247–1250.
- [171] S. Auer, C. Bizer, G. Kobilarov, J. Lehmann, R. Cyganiak, and Z. Ives, “DBpedia: A Nucleus for A Web of Open Data,” in Proceedings of the 6th International The Semantic Web and 2nd Asian Conference on Asian Semantic Web Conference, ser. ISWC’07/ASWC’07. Berlin, Heidelberg: Springer-Verlag, 2007, p. 722–735.
- [172] D. Vrandečić and M. Krötzsch, “Wikidata: A Free Collaborative Knowledgebase,” Communications of the ACM, vol. 57, no. 10, pp. 78–85, 2014.
- [173] Google. Introducing the Knowledge Graph: Things, not Strings. Accessed: Jul. 19, 2023. [Online]. Available: https://blog.google/products/search/introducing-knowledge-graph-things-not/
- [174] X. Wang, D. Wang, C. Xu, X. He, Y. Cao, and T.-S. Chua, “Explainable Reasoning over Knowledge Graphs for Recommendation,” in Proceedings of the AAAI conference on artificial intelligence, vol. 33, no. 01, 2019, pp. 5329–5336.
- [175] W. Zheng, L. Yin, X. Chen, Z. Ma, S. Liu, and B. Yang, “Knowledge Base Graph Embedding Module Design for Visual Question Answering Model,” Pattern recognition, vol. 120, p. 108153, 2021.
- [176] X. Chen, S. Jia, and Y. Xiang, “A Review: Knowledge Reasoning over Knowledge Graph,” Expert Systems with Applications, vol. 141, p. 112948, 2020.
- [177] L. Xia, Y. Sun, D. Niyato, D. Feng, L. Feng, and M. A. Imran, “xURLLC-Aware Service Provisioning in Vehicular Networks: A Semantic Communication Perspective,” arXiv preprint arXiv:2302.11993, 2023.
- [178] S. Ji, S. Pan, E. Cambria, P. Marttinen, and S. Y. Philip, “A Survey on Knowledge Graphs: Representation, Acquisition, and Applications,” IEEE transactions on neural networks and learning systems, vol. 33, no. 2, pp. 494–514, 2021.
- [179] T. Vu, T. D. Nguyen, D. Q. Nguyen, D. Phung et al., “A Capsule Network-based Embedding Model for Knowledge Graph Completion and Search Personalization,” in Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 2019, pp. 2180–2189.
- [180] Y. Lin, X. Wang, H. Ma, L. Wang, F. Hao, and Z. Cai, “An Efficient Approach to Sharing Edge Knowledge in 5G-Enabled Industrial Internet of Things,” IEEE Transactions on Industrial Informatics, vol. 19, no. 1, pp. 930–939, 2023.
- [181] H. Chai, S. Leng, Y. Chen, and K. Zhang, “A Hierarchical Blockchain-Enabled Federated Learning Algorithm for Knowledge Sharing in Internet of Vehicles,” IEEE Transactions on Intelligent Transportation Systems, vol. 22, no. 7, pp. 3975–3986, 2021.
- [182] Z. Cai and X. Zheng, “A Private and Efficient Mechanism for Data Uploading in Smart Cyber-Physical Systems,” IEEE Transactions on Network Science and Engineering, vol. 7, no. 2, pp. 766–775, 2020.
- [183] R. Mullins and M. T. Barros, “Cognitive Network Management for 5G,” 5GPPP Working Group on Network Management and QoS, Tech. Rep., 2017.
- [184] T. Maksymyuk, S. Dumych, M. Brych, D. Satria, and M. Jo, “An IoT Based Monitoring Framework for Software Defined 5G Mobile Networks,” in Proceedings of the 11th international conference on ubiquitous information management and communication, 2017, pp. 1–4.
- [185] H. Du, J. Wang, D. Niyato, J. Kang, Z. Xiong, and D. I. Kim, “AI-generated Incentive Mechanism and Full-duplex Semantic Communications for Information Sharing,” arXiv preprint arXiv:2303.01896, 2023.
- [186] H. Du, R. Zhang, Y. Liu, J. Wang, Y. Lin, Z. Li, D. Niyato, J. Kang, Z. Xiong, S. Cui et al., “Beyond Deep Reinforcement Learning: A Tutorial on Generative Diffusion Models in Network Optimization,” arXiv preprint arXiv:2308.05384, 2023.
- [187] B. Du, H. Du, H. Liu, D. Niyato, P. Xin, J. Yu, M. Qi, and Y. Tang, “YOLO-based Semantic Communication with Generative AI-aided Resource Allocation for Digital Twins Construction,” arXiv preprint arXiv:2306.14138, 2023.
- [188] G. Liu, H. Du, D. Niyato, J. Kang, Z. Xiong, and B. H. Soong, “Vision-based Semantic Communications for Metaverse Services: A Contest Theoretic Approach,” arXiv preprint arXiv:2308.07618, 2023.
- [189] Y. Xu, G. Gui, H. Gacanin, and F. Adachi, “A Survey on Resource Allocation for 5G Heterogeneous Networks: Current Research, Future Trends, and Challenges,” IEEE Communications Surveys & Tutorials, vol. 23, no. 2, pp. 668–695, 2021.
- [190] Y. Lin, Z. Gao, H. Du, D. Niyato, J. Kang, A. Jamalipour, and X. S. Shen, “A Unified Framework for Integrating Semantic Communication and AI-Generated Content in Metaverse,” arXiv preprint arXiv:2305.11911, 2023.
- [191] H. Du, J. Wang, D. Niyato, J. Kang, Z. Xiong, M. Guizani, and D. I. Kim, “Rethinking Wireless Communication Security in Semantic Internet of Things,” IEEE Wireless Communications, vol. 30, no. 3, pp. 36–43, 2023.
- [192] S. Zhang, I.-L. Yen, F. Bastani, H. Moeini, and D. Moore, “A Semantic Model for Information Sharing in Autonomous Vehicle Systems,” in 2017 IEEE 11th International Conference on Semantic Computing (ICSC), 2017, pp. 32–39.
- [193] A. Deb Raha, M. Shirajum Munir, A. Adhikary, Y. Qiao, S.-B. Park, and C. Seon Hong, “An Artificial Intelligent-Driven Semantic Communication Framework for Connected Autonomous Vehicular Network,” in 2023 International Conference on Information Networking (ICOIN), 2023, pp. 352–357.
- [194] R. Zhang, K. Xiong, H. Du, D. Niyato, J. Kang, X. Shen, and H. V. Poor, “Generative AI-enabled Vehicular Networks: Fundamentals, Framework, and Case Study,” arXiv preprint arXiv:2304.11098, 2023.
- [195] L. Carvalho, “Smart Cities from Scratch? A Socio-technical Perspective,” Cambridge Journal of Regions, Economy and Society, vol. 8, no. 1, pp. 43–60, 2015.
- [196] S. Rinaldi, J. Peerenboom, and T. Kelly, “Identifying, Understanding, and Analyzing Critical Infrastructure Interdependencies,” IEEE Control Systems Magazine, vol. 21, no. 6, pp. 11–25, 2001.
- [197] S. Bischof, A. Karapantelakis, C.-S. Nechifor, A. P. Sheth, A. Mileo, and P. Barnaghi, “Semantic Modelling of Smart City Data,” in W3C Workshop on the Web of Things, 2014.
- [198] M. Austin, P. Delgoshaei, M. Coelho, and M. Heidarinejad, “Architecting Smart City Digital Twins: Combined Semantic Model and Machine Learning Approach,” Journal of Management in Engineering, vol. 36, no. 4, p. 04020026, 2020.
- [199] S. Balakrishna, V. K. Solanki, V. K. Gunjan, and M. Thirumaran, “A Survey on Semantic Approaches for IoT Data Integration in Smart Cities,” in ICICCT 2019–System Reliability, Quality Control, Safety, Maintenance and Management: Applications to Electrical, Electronics and Computer Science and Engineering. Springer, 2020, pp. 827–835.
- [200] P. Antonios, K. Konstantinos, and G. Christos, “A Systematic Review on Semantic Interoperability in the IoE-enabled Smart cities,” Internet of Things, p. 100754, 2023.
- [201] L. Xia, Y. Sun, C. Liang, D. Feng, R. Cheng, Y. Yang, and M. A. Imran, “WiserVR: Semantic Communication Enabled Wireless Virtual Reality Delivery,” IEEE Wireless Communications, vol. 30, no. 2, pp. 32–39, 2023.
- [202] C. Wang, Y. Li, F. Gao, D. Deng, J. Xu, Y. Liu, and W. Wang, “Adaptive Semantic-Bit Communication for Extended Reality Interactions,” IEEE Journal of Selected Topics in Signal Processing, pp. 1–13, 2023.
- [203] B. Zhang, Z. Qin, Y. Guo, and G. Y. Li, “Semantic Sensing and Communications for Ultimate Extended Reality,” arXiv preprint arXiv:2212.08533, 2022.
- [204] B. Zhang, Z. Qin, and G. Y. Li, “Semantic Communications with Variable-Length Coding for Extended Reality,” arXiv preprint arXiv:2302.08645, 2023.
- [205] J. Park, J. Choi, S.-L. Kim, and M. Bennis, “Enabling the Wireless Metaverse via Semantic Multiverse Communication,” in 2023 20th Annual IEEE International Conference on Sensing, Communication, and Networking (SECON). IEEE, 2023, pp. 85–90.
- [206] J. Wang, H. Du, Z. Tian, D. Niyato, J. Kang, and X. Shen, “Semantic-Aware Sensing Information Transmission for Metaverse: A Contest Theoretic Approach,” IEEE Transactions on Wireless Communications, 2023.
- [207] Z. Q. Liew, H. Du, W. Y. B. Lim, Z. Xiong, D. Niyato, C. Miao, and D. I. Kim, “Economics of Semantic Communication System: An Auction Approach,” IEEE Transactions on Vehicular Technology, 2023.
- [208] J. Chen, J. Wang, C. Jiang, Y. Ren, and L. Hanzo, “Trust-Worthy Semantic Communications for the Metaverse Relying on Federated Learning,” arXiv preprint arXiv:2305.09255, 2023.