启发式的演变:使用大型语言模型进行高效的自动算法设计
摘要
启发式方法广泛用于处理复杂的搜索和优化问题。 然而,启发式的手动设计通常非常费力,并且需要丰富的工作经验和知识。 本文提出启发式进化(EoH),这是一种新颖的进化范式,利用大语言模型(大语言模型)和进化计算(EC)方法进行自动启发式设计(AHD)。 EoH 代表自然语言中的启发式思想,称为思想。 然后它们被大语言模型翻译成可执行的代码。 进化搜索框架中思想和代码的进化使其能够非常有效且高效地生成高性能启发式算法。 对三个广泛研究的组合优化基准问题的实验表明,EoH 优于常用的手工启发式方法和其他最近的 AHD 方法(包括 FunSearch)。 特别是,EoH 产生的启发式算法具有较低的计算预算(就大语言模型的查询数量而言),其性能显着优于广泛使用的人类手工制作的在线装箱问题基线算法。
1简介
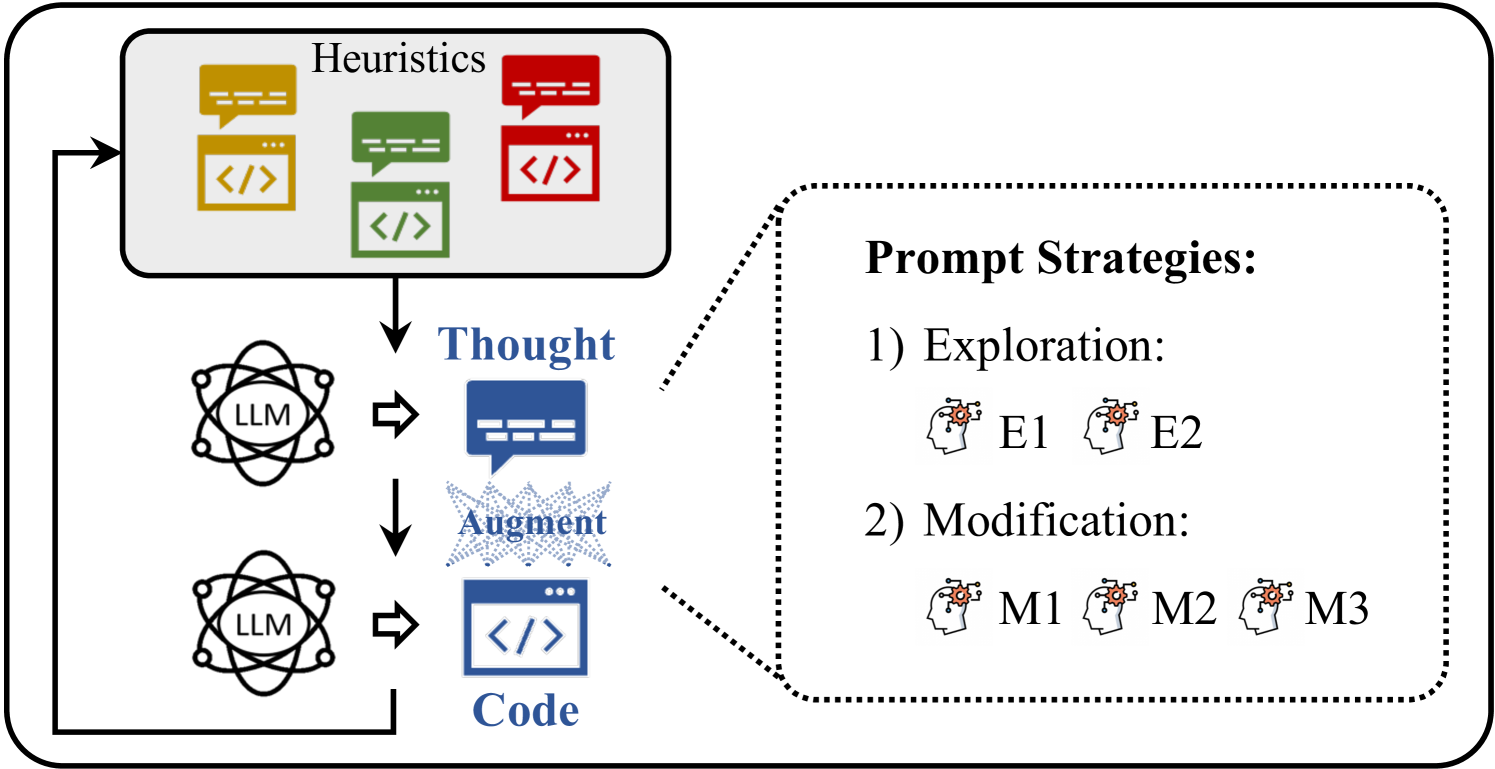
启发式方法通常用于解决复杂的搜索和优化问题。 在过去的几十年里,人们在设计有效的启发式方法上投入了大量的精力,导致了模拟退火(Van Laarhoven等人,1987),禁忌搜索(Glover&Laguna,1998),迭代本地搜索(Lourenço等人,2003),以及许多其他方法(Mart等人,2018)。 这些手工方法已成功应用于广泛的现实应用中。 然而,不同的应用可能需要不同的算法和/或算法配置。 针对给定问题手动设计、修改和配置启发式方法可能非常耗费人力,并且需要丰富的专家经验。 这是许多应用领域的瓶颈。 为了解决这个问题,自动启发式设计(AHD)被提出并成为一个活跃的研究领域(Burke等人,2013;Stützle&López-Ibáñez,2019)。 AHD 自动为给定的问题类别选择、调整或构建有效的启发式方法。 遗传编程(GP)已用于 AHD (Langdon & Poli, 2013;Zhang 等人, 2023)。 GP 需要一组允许的原语或变异操作来定义和生成启发式方法。 在实践中构建一个合适的集合可能非常困难(O’Neill 等人,2010)。
人们相信,大语言模型(Large Language Models)(Chen 等人,2021;Austin 等人,2021;Li 等人,2023b)可以成为产生新想法和启发式的强大工具。 然而,具有即时工程的独立大语言模型可能不足以产生超出现有知识的新颖且有用的想法(Mahowald 等人,2023)。 人们尝试将大语言模型与进化计算(EC)方法相结合,以自动方式产生启发式(Yang等人,2023;Meyerson等人,2023;Chen等人,2023) 。 一个代表作品是 FunSearch (Romera-Paredes 等人, 2024)。 它将 AHD 建模为函数空间中的搜索问题,其中每个函数都是由程序表示的启发式算法,并在进化框架中使用大语言模型来迭代提高生成函数的质量。 FunSearch 已应用于多个问题并取得了巨大成功。 然而,它的机制不是很有效,并且需要大量的计算资源来生成质量启发式。
在本文中,我们提出了一种新的进化范式,称为启发式进化(EoH) 111我们的工作及其物品知识版本(Liu 等人,2023b)是独立于Romera-Paredes 等人( 2024)。,利用大语言模型和 EC 进行 AHD。 具体来说,我们利用称为思想的语言描述来表示启发式的高级思想(即关键逻辑)。 然后,通过大语言模型生成相应的代码表示,即启发式的可执行实现。 我们提出了一个进化框架,以合作的方式同时进化启发式的思想和代码。 我们证明,在 LLM 的帮助下,思想和代码的进化以及精心策划的提示可以带来最先进的 AHD 性能。 我们期望 EoH 能够成为实现高效、自动算法设计的一步。
总之,我们的贡献如下:
-
•
我们提出了 EoH,一种新颖的范式,它使用大语言模型来进化思想和代码,以最少的手工设计和无领域模型训练的方式自动设计启发式方法。
-
•
我们开发了几种简单而有效的提示策略来指导大语言模型产生更加多样化和有效的启发式。 这些提示策略普遍适用于其他LLM辅助检索方法。
-
•
我们在三个广泛研究的组合优化基准问题上综合评估 EoH。 我们证明 EoH 优于许多现有的 AHD 方法。 特别是,EoH 识别的启发式方法比 FunSearch 设计的启发式方法具有更好的性能。 在在线装箱问题上,EoH 使用的大语言模型查询量比 FunSearch 少得多。
2 背景及相关作品
2.1 自动启发式设计
自动启发式算法设计通常被称为超启发式(Burke等人,2013,2019;Stützle&López-Ibáñez,2019)。 通过各种有效的方法(Blot 等人,2016;López-Ibáñez 等人,2016;Akiba 等人,2019)和框架(Burke 等人,2019),一可以自动调整启发式或组合不同的算法组件。 在自动算法设计中使用机器学习技术已经做出了很多努力(Bengio等人,2021;Chen等人,2022;He等人,2021;Li等人,2023a)。 其中,遗传编程(Mei等人,2022;Jia等人,2022)为算法设计提供了一种可解释的方法。 然而,它需要手工制作的算法组件和领域知识。
2.2 启发式设计 LLM
过去几年,大型语言模型的能力显着增强(Naveed 等人,2023)。 最近,人们在使用大语言模型作为基本算法组件来提高算法性能方面做出了一些努力(杨等人,2023;郭等人,2023a)。 这些作品大多采用大语言模型作为优化器(Yang等人,2023)通过上下文学习直接生成新的试验解决方案。 这种方法在应用于具有大搜索空间的复杂问题时面临挑战(Yang 等人,2023;Nasir 等人,2023;Zhao 等人,2023;Liu 等人,2023a)。 还有人集成大语言模型辅助算法设计,提取深层算法特征用于启发式选择(Wu等人,2023),为启发式选择提供指导(Shah等人,2023),并设计一个算法组件(Xiao & Wang,2023)。 然而,对于具有快速工程能力的独立大语言模型来说,设计竞争性启发式仍然是一个挑战。
2.3 LLM + EC
进化计算是受自然进化启发的通用优化原理(Bäck等人,1997;Eiben & Smith,2015)。 将 EC 集成到大语言模型的即时工程中对于提高各个领域的性能非常有前景(Guo 等人,2023b;Lehman 等人,2023;Wu 等人,2024)。 代码生成(Liventsev 等人,2023;Ma 等人,2023;Lehman 等人,2024;Hemberg 等人,2024)和文本生成(Guo 等)均采用进化方法。人,2023b;费尔南多等人,2023;徐等人,2023a)。 与我们的工作最相关的工作是 FunSearch (Romera-Paredes 等人, 2024),一个带有大语言模型的自动搜索功能的进化框架。 FunSearch 生成的算法在某些优化问题上优于精心设计的算法。 然而,FunSearch 的计算成本很高,通常需要生成数百万个程序(即对大语言模型的查询)来识别有效的启发式函数,这对于许多用户来说不太实用。
3 启发式算法 (EoH) 的演变
3.1 主要思想
EoH 旨在发展思想和代码,以模仿人类专家进行的启发式开发,以实现高效的自动启发式设计。 为了实现这一目标,EoH
-
•
为每个启发式维护自然语言描述及其相应的代码实现。 在每次试验中,大语言模型首先生成自然语言的启发式,然后生成相应的代码。 自然语言描述总结了主要思想并提供了高层理解,而代码则提供了补充高层思想的实现细节和设置。
-
•
采用多种提示策略来引导大语言模型对已有的思想和代码进行推理。 这些策略旨在从以前的经验中学习并有效地探索启发式空间。 它们可以被视为细粒度的上下文学习方法,结合了启发式搜索的思想和代码。
-
•
发展出一批候选启发法。 它在遗传算子中使用大语言模型,例如交叉和变异来产生新的启发式。 选择还用于指导搜索。 每个启发式的质量是根据一组问题实例进行评估的。
与大多数进化算法不同,其中个体是优化问题的候选解决方案,EoH 中的个体是为解决给定问题而设计的启发式算法。 我们认为“思想”的演化应该是一个重要的研究方向。
EoH 将大语言模型集成到进化框架中。 它自动生成并完善启发式。 与一些经典的自动启发式设计方法(Burke等人,2013)不同,EoH不需要任何手工制作的启发式组件或训练新模型。
EoH 不断发展思想和代码。 自然语言的思维和设计的提示策略使 EoH 能够产生更加多样化和有效的启发法。 相比之下,FunSearch 只进行代码的进化,并没有明确使用提示策略。
3.2演化框架
EoH 在每一代都维护一个 启发式种群,表示为 。 每个启发式 都会在一组问题实例上进行评估,并分配一个适应度值 。
设计了五种提示策略来产生新的启发法。 在每一代,每个策略都会被调用 次以生成 启发式。 每个新生成的启发式算法都将根据问题实例进行评估,并在可行的情况下添加到当前群体中。 每代最多个新启发法将添加到当前群体中。 然后,从当前群体中选择个最佳个体解决方案来形成下一代群体。
EoH总结如下:
步骤0初始化: 通过初始化提示提示大语言模型来初始化启发式的种群,具体参见3.4节。
Step 1 Heuristics生成:如果不满足停止条件,则同时使用5种进化提示策略(详见3.4节)生成新的启发法。 对于五种提示策略中的每一种,重复以下过程 次:
-
•
步骤 1.1:从当前群体中选择父启发式以构建策略提示。
-
•
步骤1.2:请求大语言模型生成新的启发式及其相应的代码实现。
-
•
步骤1.3:在一组评估实例上评估新的启发式以确定其适应度值。
-
•
步骤1.4:如果启发式和代码可行,则将新的启发式添加到当前群体中。
步骤 2 人口管理: 从当前群体中选择最佳个体启发法来形成下一代群体。 转到步骤 1。
3.3启发式表示
每个启发式由三部分组成:1) 自然语言描述,2) 预定义格式的代码块,3) 适应度值。
启发式描述包括一些自然语言的句子。 它由大语言模型创建,呈现了高层次的思想。
代码块是启发式的实现。 它应该遵循预定义的格式,以便可以识别并无缝集成到 EoH 框架中。 在实验中,我们选择将其实现为Python函数。 应明确给出三个基本组成部分来格式化代码块:1) 函数名称,2) 输入变量,3) 输出变量。
EoH 中的启发式评估涉及在相关问题的实例集上运行生成的算法。 此评估过程不同于传统的进化算法,传统的进化算法通常在单个实例中评估目标函数。 它类似于一些 AHD 方法(López-Ibáñez 等人,2016;Hutter 等人,2011),并且通常成本高昂。
3.4提示策略
初始化提示
在我们的实验中,我们使用大语言模型来创建所有初始启发式,从而消除了对专业知识的需求。 我们将启发式设计任务告知大语言模型,并通过首先呈现启发式的描述然后将其实现为Python代码块来指示它设计新的启发式。 每个问题的提示详情列于附录的相应小节中。 我们重复 次以生成 初始启发式。
进化提示
提出了五种即时策略,用于在进化过程中创建新的启发式方法,以模仿人类的启发式发展。 它们分为两组:E探索(E1、E2)和M修改(M1 、M2、M3)。 探索策略更侧重于通过对父启发式进行类似交叉的算子来探索启发式空间。 修改策略通过修改、调整参数和删除冗余部分来细化父启发式。 这些进化提示的详细内容如下:
E1:生成与父启发式尽可能不同的新启发式。 首先,从当前群体中选择启发法。 然后,提示大语言模型尽可能设计与这些选定的启发式不同的新启发式,以探索新的想法。
E2:探索与所选父启发法具有相同想法的新启发法。 首先,从当前群体中选择启发法。 然后,指示大语言模型识别这些启发式背后的共同想法。 然后,设计一个新的启发式,该启发式基于共同的想法,但通过引入新的部分尽可能与所选的父级不同。
M1:修改一个启发式以获得更好的性能。 首先,从总体中选择一个启发式。 然后,提示大语言模型对其进行修改以产生新的启发式。
M2:修改一个选定启发式的参数。 首先,从当前群体中选择一个启发式。 然后,提示大语言模型在当前启发式中尝试不同的参数,而不是设计新的参数。
M3:通过删除冗余组件来简化启发式。 首先,从当前群体中选择一个启发式。 然后,提示大语言模型分析识别所选启发式中的主要成分,并分析是否存在冗余成分。 最后,在分析的基础上,提出大语言模型简化启发式代码的实现。
在上述所有提示中,要求大语言模型首先描述启发式,然后以预定义格式提供代码实现。
EoH 中可以使用任何选择方法。 在我们的实验研究中,当前群体中的所有启发式算法都根据其适应度进行排名。 当前群体中的启发式以概率随机选择,其中是其排名,是群体规模。
4实验
4.1实验设置
基准和数据集。
我们考虑三个经过充分研究的组合优化基准问题:
-
•
在线装箱问题。 目标是将不同大小的项目集合分配到尽可能少的具有固定容量的容器中。我们关注在线场景(Seiden,2002),其中物品在到达时就被包装,这与所有物品事先已知的离线场景形成鲜明对比。 启发式进化过程中用于评估的实例是 5 个大小为 5k、容量为 100 的 Weibull 实例(Romera-Paredes 等人,2024)。 适应度值设置为五个实例的平均值 ,其中 表示按照 Martello & Toth (1990) 计算的最佳 bin 数量的下限 和 是用于通过评估的启发式打包所有项目的箱数。
比较的方法包括
-
–
人类手工启发式算法:首次拟合和最佳拟合启发式(Romera-Paredes 等人,2024)。 第一个适合启发式将传入项目分配到第一个具有足够可用空间的容器,而最佳适合启发式则选择仍可容纳该项目的可用空间最少的容器。
-
–
自动生成的启发式算法:FunSearch (Romera-Paredes 等人, 2024) 因其出色的性能而被考虑。 我们直接使用 FunSearch (Romera-Paredes 等人, 2024) 生成的启发式进行比较。
-
–
-
•
旅行商问题(TSP)(Matai 等人,2010)。 就是找到一次访问所有给定地点并返回起始地点的最短路线。 它是研究最广泛的组合优化问题之一,也是启发式算法常用的测试平台。 启发式进化过程在一组 64 个 TSP100 实例上进行。 这些实例中的位置是从 (Kool 等人, 2018) 中随机采样的。 与最优解的平均差距(由 Concorde (Applegate 等人, 2006) 生成)用作适应度值。
比较的方法包括
-
–
手工启发式:最近插入(Rosenkrantz 等人,1977)和最远插入(Rosenkrantz 等人,1977),两种常用的构造启发式进行比较。 还使用了最流行的求解器之一 Google Or-Tools (Perron & Furnon,)。 我们使用 Or-Tools 的默认设置和 OR-Tools 中建议的本地搜索选项来提高解决方案质量。 每个实例的停止标准为 60 秒。
-
–
AI方法自动设计的启发式:注意力模型(AM)(Kool等人,2018)、POMO(Kwon等人,2020)和LEHD (罗等人,2023)。 AM (Kool 等人, 2018) 是一种使用神经网络学习启发式组合优化的开创性且众所周知的方法。 POMO (Kwon 等人, 2020)采用AM思想并取得了state-of-the-art的结果。 LEHD (Luo 等人, 2023) 是 AM 的新版本,具有不同的重型解码器结构,并使用监督学习进行训练。
-
–
-
•
流水车间调度问题 (FSSP)(Emmons 和 Vairaktarakis,2012)。 它是在 机器上调度 作业,其中每个作业包含必须在相应机器上按预定顺序执行的 操作。 目标是最小化总进度长度(称为完工时间)。 在扰动流水车间调度问题中,每个步骤的处理顺序保持一致,并且没有机器可以同时执行多个操作。 在启发式进化过程中,我们对 64 个随机生成的实例进行进化。 每个实例由 50 个作业和 2 到 20 台机器组成。 作业的处理时间是从 0 到 1 范围内的均匀分布随机生成的(Pan 等人,2021)。 平均完工时间作为适应值。
比较的方法包括
-
–
手工启发式:它们是 GUPTA (Gupta, 1971)、CDS (Campbell 等人, 1970) NEH (Nawaz 等人, 1983) 和 NEHFF (Fernandez-Viagas 和 Framinan,2014 年)。 GUPTA (Gupta,1971)和CDS (Campbell等人,1970)是流水车间调度的两种经典方法。 NEH (Nawaz 等人, 1983) 和 NEHFF (Fernandez-Viagas & Framinan, 2014) 是该问题广泛认可的有效启发式方法。
-
–
自动设计的启发式:使用 PFSPNet 和 PFSPNet_NEH (Pan 等人, 2021)。 它们是最近提出的两个用于流水车间调度的端到端深度学习求解器。
-
–
实施细节。
-
•
在线装箱。 我们采用 Romera-Paredes 等人 (2024) 中的设置来设计启发式,以确定传入项目的合适箱分配(Angelopoulos 等人, 2023)。 具体来说,EoH 的任务是设计用于分配项目的评分函数。 输入是物品的尺寸和箱子的剩余容量。 输出是各个箱的分数。 该项目将被分配到得分最高的垃圾箱中。
-
•
旅行推销员。 我们使用 EoH 来设计引导本地搜索(GLS)启发式(Alsheddy 等人,2018)。 GLS 是一种帮助局部搜索逃避局部最优解的策略。 GLS启发式的一个关键问题是如何更新目标函数(即景观)以引导局部搜索移动到更有前景的区域。 注意到景观主要由距离矩阵决定,EoH 的目标是产生一种更新距离矩阵的方法。 在(Alsheddy 等人, 2018; Arnold & Sörensen, 2019)之后,输入是距离矩阵、当前路线和边数。 输出是更新的距离矩阵。 GLS 在更新的景观上迭代运行本地搜索运算符。 我们实验中使用的两个本地搜索运算符是 relocate 和 2-opt 运算符。 附录中详细介绍了 GLS 启发法。
-
•
流水车间调度。 我们使用 EoH 来生成启发式方法来更新 GLS 中针对此问题的客观情况。 启发式中的输入是时间矩阵、当前调度以及机器和作业的数量。 输出是更新的时间矩阵和计算的作业扰动优先级。 使用的本地搜索运算符是重定位和交换运算符。
在我们的实验中,所有问题的 EoH 代数均设置为 20。 在线装箱的总体规模为 20,TSP 和 FSSP 的总体规模为 10。 E1和E2中使用的父启发式的数量是。 使用GPT-3.5-turbo预训练的大语言模型。 对于TSP和FSSP,本地搜索的最大迭代次数设置为1000次,每个实例的最大运行时间为60秒。 整个框架和EoH在三个问题上的实现都是用Python实现的,并在单CPU i7-9700上执行。
4.2结果
在线装箱。
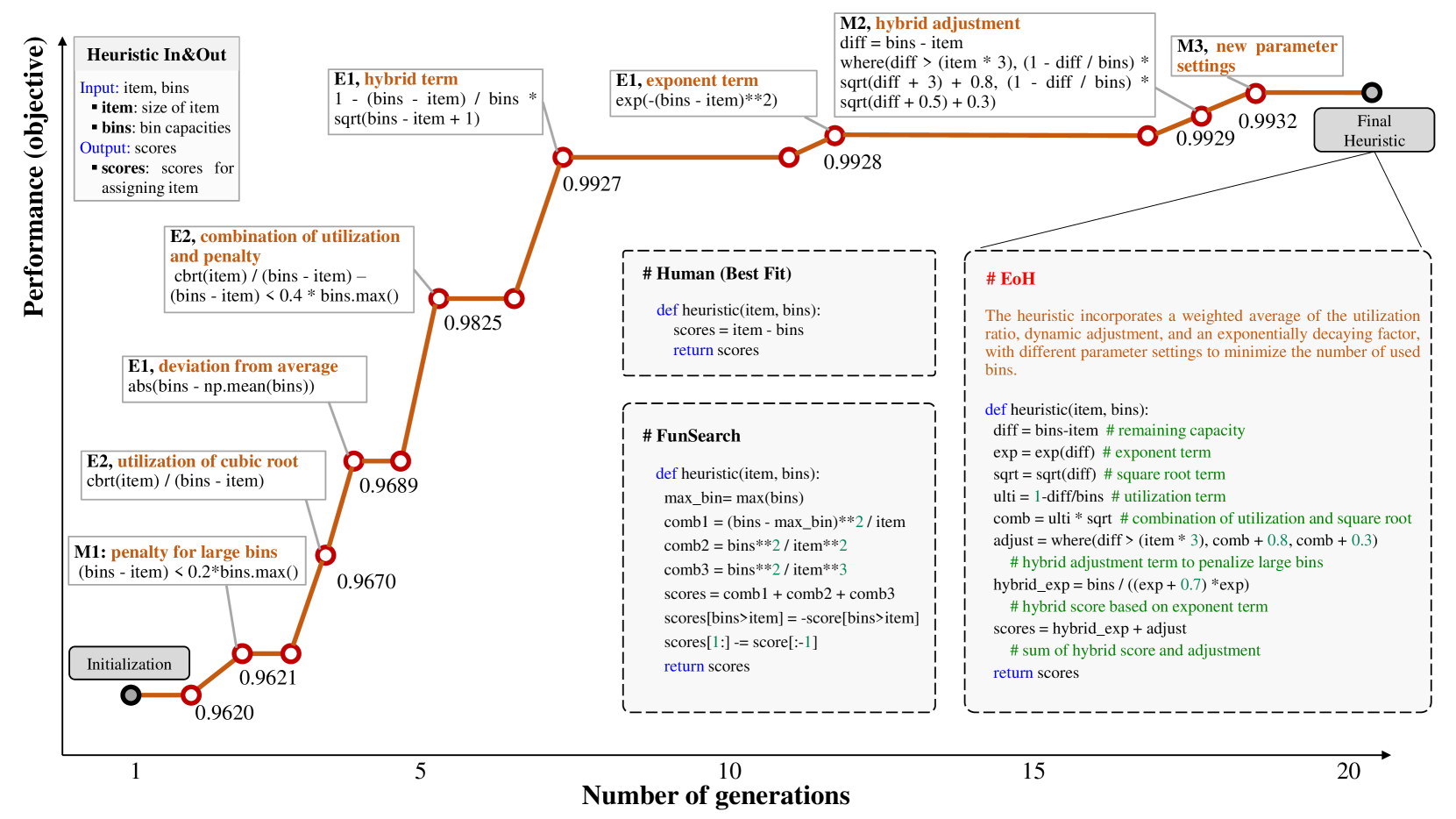
我们在图 2 中可视化在线装箱问题的 EoH 演变。 我们概述了进化过程中某些世代发现的最佳启发式的关键思想和相应代码。 我们还列出了生成想法和代码的提示策略。 适应度值(目标)在20代内从0.962增加到0.993,涉及2000个大语言模型查询。 如图2所示,与最佳拟合启发式相比,FunSearch 和 EoH 设计的启发式都比较复杂。 EoH 发现的最佳启发式方法是具有多个组件的混合函数。 它由剩余容量、剩余容量指数项、剩余容量平方根项及其组合组成。 这是进化的结果。 附录B.2中详细介绍了使用E2提示策略的启发式设计示例。
我们在不同大小和容量的实例上测试 EoH 生成的最佳启发式,并将其与两种手工制作的启发式(即第一拟合和最佳拟合)以及 FunSearch 生成的最佳启发式进行比较。 问题规模从1k到10k,容量为100和500。 每组包含 5 个随机生成的实例。 表 1 显示了与下限的平均差距,其中最佳结果以粗体突出显示。 除了 10k_C100 集(问题大小为 10k、容量为 100 的实例)上的结果外,我们的方法是最好的。 EoH 只进行了几千个大语言模型查询,这比 FunSearch 快得多(Romera-Paredes 等人 (2024) 中报告了大约 100 万个查询)。 此外,我们的方法在训练分布中实现了相同的最佳差距,并对分布外实例展示了出色的泛化性能。 例如,在包含 1k 个项目和容量为 500 的实例集上,FunSearch 的表现比两种手工设计的启发式方法更差,而我们的方法实现了 2.13% 的最佳差距。 更多结果在附录B.4中提供
| 1k_C100 | 5k_C100 | 10k_C100 | 1k_C500 | 5k_C500 | 10k_C500 | |
| First Fit | 5.32% | 4.40% | 4.44% | 4.97% | 4.27% | 4.28% |
| Best Fit | 4.87% | 4.08% | 4.09% | 4.50% | 3.91% | 3.95% |
| FunSearch | 3.78% | 0.80% | 0.33% | 6.75% | 1.47% | 0.74% |
| EoH (ours) | 2.24% | 0.80% | 0.61% | 2.13% | 0.78% | 0.61% |
| rd100 | pr124 | bier127 | kroA150 | u159 | kroB200 | |
| NI | 19.91 | 15.50 | 23.21 | 18.17 | 23.59 | 24.10 |
| FI | 9.38 | 4.43 | 8.04 | 8.54 | 11.15 | 7.54 |
| Or-Tools | 0.01 | 0.55 | 0.66 | 0.02 | 1.75 | 2.57 |
| AM | 3.41 | 3.68 | 5.91 | 3.78 | 7.55 | 7.11 |
| POMO | 0.01 | 0.60 | 13.72 | 0.70 | 0.95 | 1.58 |
| LEHD | 0.01 | 1.11 | 4.76 | 1.40 | 1.13 | 0.64 |
| EoH(Ours) | 0.01 | 0.00 | 0.42 | 0.00 | 0.00 | 0.20 |
| n20m10 | n20m20 | n50m10 | n50m20 | n100m10 | n100m20 | |
| GUPTA | 23.42 | 21.79 | 20.11 | 22.78 | 15.03 | 21.00 |
| CDS | 12.87 | 10.35 | 12.72 | 15.03 | 9.36 | 13.55 |
| NEH | 4.05 | 3.06 | 3.47 | 5.48 | 2.07 | 3.58 |
| NEHFF | 4.15 | 2.72 | 3.62 | 5.10 | 1.88 | 3.73 |
| PFSPNet | 14.78 | 14.69 | 11.95 | 16.95 | 8.21 | 16.47 |
| PFSPNet_NEH | 4.04 | 2.96 | 3.48 | 5.05 | 1.72 | 3.56 |
| EoH (ours) | 0.30 | 0.10 | 0.19 | 0.60 | 0.14 | 0.41 |
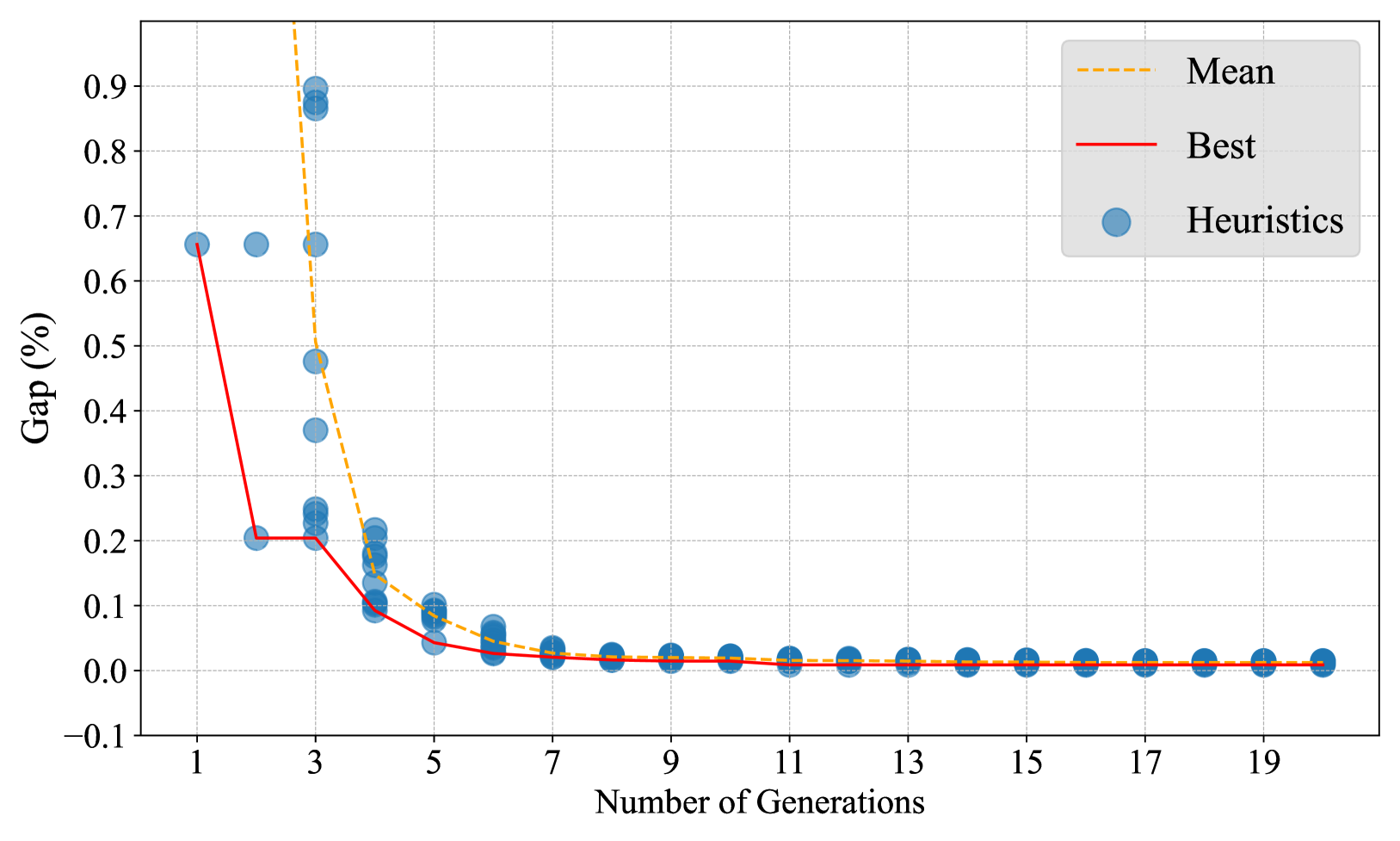
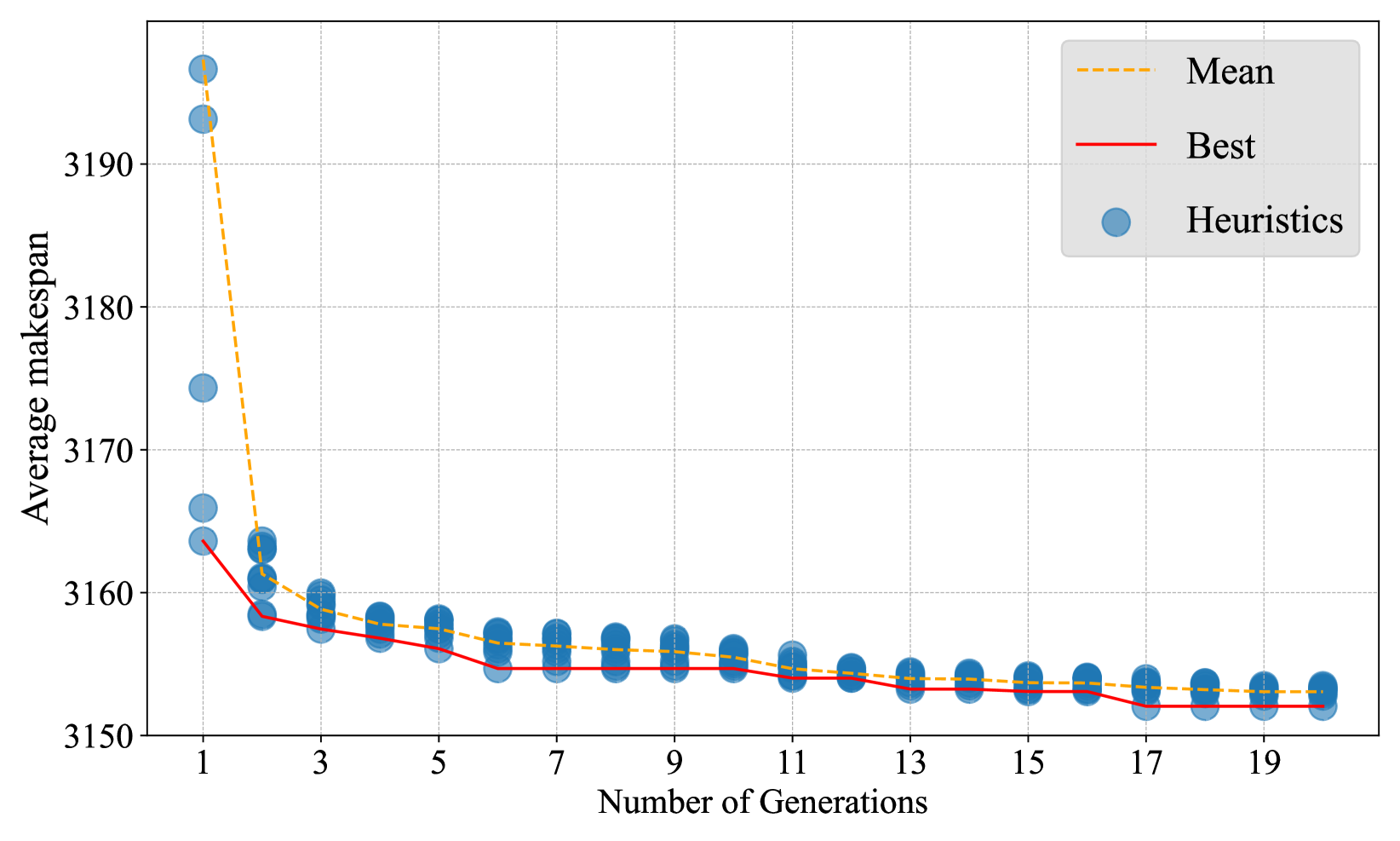
旅行推销员。
图3(a)说明了EoH中针对TSP的启发式演化过程。 y 轴表示与最优解的差距 (%),x 轴表示代数。 每个蓝色数据点代表 EoH 生成的 GLS 启发式。 每个总体由 10 个启发式组成。 红色曲线显示了每一代中发现的最佳启发式的性能如何得到改进。 橙色曲线显示了每一代群体的平均表现。 很明显,EoH 在大约 20 代后收敛。 我们在表 2 中列出了 TSPLib (Reinelt,1991) 中六个实例与最著名解决方案的差距 (%)。 附录C.4中提供了对其他 TSP 实例的综合评估以及与一些其他启发式方法(包括手工制作的 GLS 算法)的比较。
应该指出的是,EoH 产生的启发式方法在所有测试实例上始终优于其他启发式方法。 值得注意的是,对于 pr124、kroA150 和 u159,EoH 启发式找到了最著名的解决方案(即,gap= 0%)。 平均而言,OR-Tools 运行良好。 然而,它在大型实例上的性能可能会由于运行时间有限而变得更差。 神经求解器在均匀分布的实例上进行训练,这与 EoH 中用于适应度评估的神经求解器相同。 这些求解器可以在同一分布的实例上生成高质量的解决方案。 但是,它们在分发外实例(例如 TSPLib 实例)上会恶化。 相比之下,EoH 设计的启发式方法在这些分布外实例上效果很好。
流水车间调度。
4.3消融研究
进行消融研究是为了更好地了解 EoH 中主要成分的贡献。 我们考虑 EoH 的以下变体:
-
•
EoH-e1:不使用三种修改提示策略和E2,即 它仅使用E1。
-
•
EoH-e2:不使用三种修改提示策略,即 它仅使用E1和E2。
-
•
EoC:它是 EoH 的纯代码变体。 它不包括思想部分(即自然语言中启发式的描述)。 EoC仅使用E1(没有语言描述)来生成新代码。 父级 的数量。
表 4 总结了各种比较变体中使用的组件。
| Thoughts | Codes | Prompt Strategies | |
| EoC | ✗ | ✓ | E1 |
| EoH-e1 | ✓ | ✓ | E1 |
| EoH-e2 | ✓ | ✓ | E1, E2 |
| EoH | ✓ | ✓ | E1, E2, M1, M2, M3 |
针对在线装箱问题进行了实验。 人口规模为20人。 使用GPT-3.5-turbo预训练的大语言模型。 E1和E2中使用的父启发式的数量是。 为了进行公平比较,所有变体都使用相同的初始群体。 考虑一下 EoH 使用五种提示策略,而其他人则使用很少的策略。 我们相应地增加每个变体中的代数,以便评估启发式的总数相同。 表5比较了不同变体产生的最终最佳启发法。 我们可以做出以下观察:
-
•
平均而言,EoH 表现最好,EoH-e2 表现第二好。 这意味着和确实对EoH的性能做出了积极的贡献。
-
•
EoC 在这些测试实例上表现最差或第二差。 这意味着EoH中的思想部分也是非常有益的。
| 1k_100 | 5k_100 | 10k_100 | 1k_500 | 5k_500 | 10k_500 | |
| EoC | 148.63% | 3.23% | 24.55% | 150.89% | 12.53% | 32.02% |
| EoH-e1 | 4.13% | 0.99% | 0.60% | 58.17% | 55.48% | 54.79% |
| EoH-e2 | 4.28% | 0.97% | 0.56% | 5.86% | 1.36% | 0.73% |
| EoH | 2.24% | 0.80% | 0.61% | 2.13% | 0.78% | 0.61% |
5 讨论和未来的工作
5.1讨论
思想和代码之间的交互
我们进行了以下实验来证明在 EoH 中使用思想和代码的好处。 其思想和代码可以看作是启发式的多重观点。 我们将展示多视图思想和代码表示对 EoH 的贡献。 我们将 EoH 与以下三个变体进行比较:
-
•
C2C:它仅使用代码来表示启发式。 没有自然语言(思想)表示。
-
•
T2T2C:它仅使用思想进行启发式表示。 进化提示(即 E1-2、M1-3)仅使用思维表征来生成新的启发式。 然而,我们仍然需要查询大语言模型来为每个启发式的性能评估生成代码实现。
-
•
T&C2T2C:它在进化提示中使用输入启发式的思想和代码表示。 我们使用这些提示(即 E1-2、M1-3)查询大语言模型,以仅给出所产生的启发式的自然语言表示。 与T2T2C一样,我们需要要求大语言模型为每个生成的启发式生成代码实现以进行性能评估。
表6列出了EoH与上述三种变体在在线装箱威布尔测试实例上的比较结果(与磅的平均差距(%))。 所有实验均在相同的实验设置下针对在线装箱问题进行了三次。
显然,在进化提示中仅使用代码(C2C)或思想(T2T2C)比EoH差得多。 因此,我们可以断言,代码和思想的演变确实对 EoH 做出了重大贡献。 EoH 也比 T&C2T2C 更好。 这意味着让这些提示输出代码和想法有助于提高启发式的质量。
| Setting | Run 1 | Run 2 | Run 3 | Average |
| C2C | 2.92 | 1.25 | 3.53 | 2.57 |
| T2T2C | 3.72 | 1.66 | 1.00 | 2.13 |
| T&C2T2C | 0.79 | 0.76 | 1.00 | 0.85 |
| EoH | 0.68 | 0.67 | 0.62 | 0.66 |
不一样的大语言模型
我们比较了四种常用的大语言模型:GPT3.5、Gemini Pro、CodeLlama、Deepseek。 所有实验均在相同的实验设置下针对在线装箱问题进行了三次。 一般来说,EoH 可以使用这些不同的大语言模型生成性能良好的启发式算法。 EoH 使用不同的大语言模型对大语言模型进行 2,000 次查询,其性能优于随机查询 GPT3.5 10,000 次。 尽管如此,我们的实验结果也显示了使用更强大的大语言模型的好处,例如GPT3.5和Gemini Pro优于其他大语言模型。
| Method | LLM | Run 1 | Run 2 | Run 3 | Average |
| Sampling | GPT3.5 | 2.76 | 1.92 | 2.65 | 2.44 |
| EoH | CodeLlama | 0.93 | 0.62 | 1.66 | 1.07 |
| EoH | Deepseek | 1.01 | 1.47 | 1.75 | 1.41 |
| EoH | Gemini Pro | 0.92 | 0.61 | 0.61 | 0.71 |
| EoH | GPT3.5 | 0.68 | 0.67 | 0.62 | 0.66 |
使用专家启发法
我们研究了在 EoH 中使用现有启发法(专家启发法)的影响。 以装箱问题为例,我们采用FunSearch论文(Romera-Paredes等人,2024)中提供的启发式作为现有的专家启发式,并将其放入EoH的初始种群中。 其余的初始启发法是随机生成的。 结果如表8所示。 我们将 EoH 称为初始种群 EoH 专家中的专家,并将其与原始 EoH 和 FunSearch 进行比较。 结果表明,在人群中采用精英专家启发式方法有利于我们测试用例的最终结果。 EoH 专家显然超越了 FunSearch 和 EoH。 专家启发法的知识可以在进化过程中继承和发展,以产生更好的启发法。
| Method | Run 1 | Run 2 | Run 3 | Average |
| FunSearch | 0.94 | 0.82 | 1.15 | 0.97 |
| EoH | 0.68 | 0.67 | 0.62 | 0.66 |
| EoH expert | 0.57 | 0.55 | 0.52 | 0.55 |
5.2未来的作品
应该指出的是,利用大语言模型进行启发式进化的发展仍处于起步阶段。 这篇论文和其他研究(Romera-Paredes等人,2024)表明它对于自动算法设计非常有前景。 应付出很大努力来推进这一领域。
预训练领域大语言模型
与其使用通用的预训练的具有语言和代码生成能力的大语言训练模型,不如研究如何专门用于自动算法设计的大语言模型。 领域知识可以用于此目的。
启发式搜索空间的理解
EoH 直接在启发式空间上进行搜索。 它与经典优化算法不同,经典优化算法在明确定义的数学空间(例如 )中进行搜索。 研究和理解启发式搜索空间对于进一步建立算法自动设计的理论和基本原理应该是非常重要的。
与人类专家互动
EoH中的大语言模型可以看作是一个智能体。 在EoH的过程中,在某个阶段可以直接让人类专家代替大语言模型来生成、修改和评估启发式。 研究如何在 EoH 中与人类专家实现高效、有效的交互应该是很有趣的。 集体智慧的想法和技术(Malone & Bernstein,2022)应用于此目的。
6结论
本文提出启发式进化(EoH),结合大语言模型(大语言模型)和进化计算(EC)方法以自动方式设计启发式。 通过引入思想和代码的演变,并使用五种提示策略,EoH 模仿了人类专家的启发式设计过程。 我们在三个经过充分研究的优化问题上测试了 EoH,即在线装箱问题、旅行推销员问题和流水店调度问题。 实验表明,在某些问题实例中,EoH 的性能优于人类手工设计的启发式方法。 EoH 仅需要几千个大语言模型请求,同时在大多数测试实例上实现更好的性能。 EoH 提供了一种自动算法设计的原则性方法。 源代码可以在https://github.com/FeiLiu36/EoH中找到。
致谢
本文所述的工作得到了中国香港特别行政区研究资助局的支持(GRF项目编号:2017)。 CityU11215622),国家自然科学基金(批准号: 62106096),广东省自然科学基金(批准号: 2024A1515011759),深圳市国家自然科学基金(批准号: JCYJ20220530113013031)。
影响报告
本文介绍的工作旨在推动机器学习领域的发展。 我们的工作有许多潜在的社会后果,我们认为没有必要在此特别强调。
参考
- Akiba et al. (2019) Akiba, T., Sano, S., Yanase, T., Ohta, T., and Koyama, M. Optuna: A next-generation hyperparameter optimization framework. In Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining, pp. 2623–2631, 2019.
- Alsheddy et al. (2018) Alsheddy, A., Voudouris, C., Tsang, E. P., and Alhindi, A. Guided local search., 2018.
- Angelopoulos et al. (2023) Angelopoulos, S., Kamali, S., and Shadkami, K. Online bin packing with predictions. Journal of Artificial Intelligence Research, 78:1111–1141, 2023.
- Applegate et al. (2006) Applegate, D., Bixby, R., Chvatal, V., and Cook, W. Concorde tsp solver, 2006.
- Arnold & Sörensen (2019) Arnold, F. and Sörensen, K. Knowledge-guided local search for the vehicle routing problem. Computers & Operations Research, 105:32–46, 2019.
- Austin et al. (2021) Austin, J., Odena, A., Nye, M., Bosma, M., Michalewski, H., Dohan, D., Jiang, E., Cai, C., Terry, M., Le, Q., et al. Program synthesis with large language models. arXiv preprint arXiv:2108.07732, 2021.
- Bäck et al. (1997) Bäck, T., Fogel, D. B., and Michalewicz, Z. Handbook of evolutionary computation. Release, 97(1):B1, 1997.
- Bello et al. (2016) Bello, I., Pham, H., Le, Q. V., Norouzi, M., and Bengio, S. Neural combinatorial optimization with reinforcement learning. arXiv preprint arXiv:1611.09940, 2016.
- Bengio et al. (2021) Bengio, Y., Lodi, A., and Prouvost, A. Machine learning for combinatorial optimization: a methodological tour d’horizon. European Journal of Operational Research, 290(2):405–421, 2021.
- Blot et al. (2016) Blot, A., Hoos, H. H., Jourdan, L., Kessaci-Marmion, M.-É., and Trautmann, H. Mo-paramils: A multi-objective automatic algorithm configuration framework. In Learning and Intelligent Optimization: 10th International Conference, LION 10, Ischia, Italy, May 29–June 1, 2016, Revised Selected Papers 10, pp. 32–47. Springer, 2016.
- Burke et al. (2013) Burke, E. K., Gendreau, M., Hyde, M., Kendall, G., Ochoa, G., Özcan, E., and Qu, R. Hyper-heuristics: A survey of the state of the art. Journal of the Operational Research Society, 64:1695–1724, 2013.
- Burke et al. (2019) Burke, E. K., Hyde, M. R., Kendall, G., Ochoa, G., Özcan, E., and Woodward, J. R. A classification of hyper-heuristic approaches: revisited. Handbook of metaheuristics, pp. 453–477, 2019.
- Campbell et al. (1970) Campbell, H. G., Dudek, R. A., and Smith, M. L. A heuristic algorithm for the n job, m machine sequencing problem. Management science, 16(10):B–630, 1970.
- Chen et al. (2023) Chen, A., Dohan, D., and So, D. Evoprompting: Language models for code-level neural architecture search. In Advances in Neural Information Processing Systems, 2023.
- Chen et al. (2021) Chen, M., Tworek, J., Jun, H., Yuan, Q., Pinto, H. P. d. O., Kaplan, J., Edwards, H., Burda, Y., Joseph, N., Brockman, G., et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021.
- Chen et al. (2022) Chen, T., Chen, X., Chen, W., Wang, Z., Heaton, H., Liu, J., and Yin, W. Learning to optimize: A primer and a benchmark. The Journal of Machine Learning Research, 23(1):8562–8620, 2022.
- Chu et al. (2023) Chu, Z., Chen, J., Chen, Q., Yu, W., He, T., Wang, H., Peng, W., Liu, M., Qin, B., and Liu, T. A survey of chain of thought reasoning: Advances, frontiers and future. arXiv preprint arXiv:2309.15402, 2023.
- Deudon et al. (2018) Deudon, M., Cournut, P., Lacoste, A., Adulyasak, Y., and Rousseau, L.-M. Learning heuristics for the tsp by policy gradient. In International conference on the integration of constraint programming, artificial intelligence, and operations research, pp. 170–181. Springer, 2018.
- Drakulic et al. (2023) Drakulic, D., Michel, S., Mai, F., Sors, A., and Andreoli, J.-M. Bq-nco: Bisimulation quotienting for generalizable neural combinatorial optimization. arXiv preprint arXiv:2301.03313, 2023.
- Eiben & Smith (2015) Eiben, A. E. and Smith, J. From evolutionary computation to the evolution of things. Nature, 521(7553):476–482, 2015.
- Emmons & Vairaktarakis (2012) Emmons, H. and Vairaktarakis, G. Flow shop scheduling: theoretical results, algorithms, and applications, volume 182. Springer Science & Business Media, 2012.
- Fernandez-Viagas & Framinan (2014) Fernandez-Viagas, V. and Framinan, J. M. On insertion tie-breaking rules in heuristics for the permutation flowshop scheduling problem. Computers & Operations Research, 45:60–67, 2014.
- Fernando et al. (2023) Fernando, C., Banarse, D., Michalewski, H., Osindero, S., and Rocktäschel, T. Promptbreeder: Self-referential self-improvement via prompt evolution. arXiv preprint arXiv:2309.16797, 2023.
- Fu et al. (2021) Fu, Z.-H., Qiu, K.-B., and Zha, H. Generalize a small pre-trained model to arbitrarily large tsp instances. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, pp. 7474–7482, 2021.
- Glover & Laguna (1998) Glover, F. and Laguna, M. Tabu search. Springer, 1998.
- Guo et al. (2023a) Guo, P.-F., Chen, Y.-H., Tsai, Y.-D., and Lin, S.-D. Towards optimizing with large language models. arXiv preprint arXiv:2310.05204, 2023a.
- Guo et al. (2023b) Guo, Q., Wang, R., Guo, J., Li, B., Song, K., Tan, X., Liu, G., Bian, J., and Yang, Y. Connecting large language models with evolutionary algorithms yields powerful prompt optimizers. arXiv preprint arXiv:2309.08532, 2023b.
- Gupta (1971) Gupta, J. N. A functional heuristic algorithm for the flowshop scheduling problem. Journal of the Operational Research Society, 22:39–47, 1971.
- He et al. (2021) He, X., Zhao, K., and Chu, X. Automl: A survey of the state-of-the-art. Knowledge-Based Systems, 212:106622, 2021.
- Helsgaun (2017) Helsgaun, K. An extension of the lin-kernighan-helsgaun tsp solver for constrained traveling salesman and vehicle routing problems. Roskilde: Roskilde University, 12, 2017.
- Hemberg et al. (2024) Hemberg, E., Moskal, S., and O’Reilly, U.-M. Evolving code with a large language model. arXiv preprint arXiv:2401.07102, 2024.
- Hudson et al. (2021) Hudson, B., Li, Q., Malencia, M., and Prorok, A. Graph neural network guided local search for the traveling salesperson problem. arXiv preprint arXiv:2110.05291, 2021.
- Hutter et al. (2011) Hutter, F., Hoos, H. H., and Leyton-Brown, K. Sequential model-based optimization for general algorithm configuration. In Learning and Intelligent Optimization: 5th International Conference, LION 5, Rome, Italy, January 17-21, 2011. Selected Papers 5, pp. 507–523. Springer, 2011.
- Jia et al. (2022) Jia, Y.-H., Mei, Y., and Zhang, M. Learning heuristics with different representations for stochastic routing. IEEE Transactions on Cybernetics, 2022.
- Joshi et al. (2019) Joshi, C. K., Laurent, T., and Bresson, X. An efficient graph convolutional network technique for the travelling salesman problem. arXiv preprint arXiv:1906.01227, 2019.
- Kojima et al. (2022) Kojima, T., Gu, S. S., Reid, M., Matsuo, Y., and Iwasawa, Y. Large language models are zero-shot reasoners. Advances in neural information processing systems, 35:22199–22213, 2022.
- Kool et al. (2018) Kool, W., Van Hoof, H., and Welling, M. Attention, learn to solve routing problems! arXiv preprint arXiv:1803.08475, 2018.
- Kool et al. (2022) Kool, W., van Hoof, H., Gromicho, J., and Welling, M. Deep policy dynamic programming for vehicle routing problems. In Integration of Constraint Programming, Artificial Intelligence, and Operations Research: 19th International Conference, CPAIOR 2022, Los Angeles, CA, USA, June 20-23, 2022, Proceedings, pp. 190–213. Springer, 2022.
- Kwon et al. (2020) Kwon, Y.-D., Choo, J., Kim, B., Yoon, I., Gwon, Y., and Min, S. Pomo: Policy optimization with multiple optima for reinforcement learning. Advances in Neural Information Processing Systems, 33:21188–21198, 2020.
- Kwon et al. (2021) Kwon, Y.-D., Choo, J., Yoon, I., Park, M., Park, D., and Gwon, Y. Matrix encoding networks for neural combinatorial optimization. In Advances in Neural Information Processing Systems, 2021.
- Langdon & Poli (2013) Langdon, W. B. and Poli, R. Foundations of genetic programming. Springer Science & Business Media, 2013.
- Lehman et al. (2023) Lehman, J., Gordon, J., Jain, S., Ndousse, K., Yeh, C., and Stanley, K. O. Evolution through large models. In Handbook of Evolutionary Machine Learning, pp. 331–366. Springer, 2023.
- Lehman et al. (2024) Lehman, J., Gordon, J., Jain, S., Ndousse, K., Yeh, C., and Stanley, K. O. Evolution Through Large Models, pp. 331–366. Springer Nature Singapore, Singapore, 2024.
- Li et al. (2023a) Li, N., Ma, L., Yu, G., Xue, B., Zhang, M., and Jin, Y. Survey on evolutionary deep learning: Principles, algorithms, applications, and open issues. ACM Computing Surveys, 56(2):1–34, 2023a.
- Li et al. (2023b) Li, R., Allal, L. B., Zi, Y., Muennighoff, N., Kocetkov, D., Mou, C., Marone, M., Akiki, C., Li, J., Chim, J., et al. Starcoder: may the source be with you! arXiv preprint arXiv:2305.06161, 2023b.
- Liu et al. (2023a) Liu, F., Lin, X., Wang, Z., Yao, S., Tong, X., Yuan, M., and Zhang, Q. Large language model for multi-objective evolutionary optimization. arXiv preprint arXiv:2310.12541, 2023a.
- Liu et al. (2023b) Liu, F., Tong, X., Yuan, M., and Zhang, Q. Algorithm evolution using large language model. arXiv preprint arXiv:2311.15249, 2023b.
- Liventsev et al. (2023) Liventsev, V., Grishina, A., Härmä, A., and Moonen, L. Fully autonomous programming with large language models. arXiv preprint arXiv:2304.10423, 2023.
- Long (2023) Long, J. Large language model guided tree-of-thought. arXiv preprint arXiv:2305.08291, 2023.
- López-Ibáñez et al. (2016) López-Ibáñez, M., Dubois-Lacoste, J., Cáceres, L. P., Birattari, M., and Stützle, T. The irace package: Iterated racing for automatic algorithm configuration. Operations Research Perspectives, 3:43–58, 2016.
- Lourenço et al. (2003) Lourenço, H. R., Martin, O. C., and Stützle, T. Iterated local search. In Handbook of metaheuristics, pp. 320–353. Springer, 2003.
- Luo et al. (2023) Luo, F., Lin, X., Liu, F., Zhang, Q., and Wang, Z. Neural combinatorial optimization with heavy decoder: Toward large scale generalization. arXiv preprint arXiv:2310.07985, 2023.
- Ma et al. (2023) Ma, Y. J., Liang, W., Wang, G., Huang, D.-A., Bastani, O., Jayaraman, D., Zhu, Y., Fan, L., and Anandkumar, A. Eureka: Human-level reward design via coding large language models. arXiv preprint arXiv:2310.12931, 2023.
- Mahowald et al. (2023) Mahowald, K., Ivanova, A. A., Blank, I. A., Kanwisher, N., Tenenbaum, J. B., and Fedorenko, E. Dissociating language and thought in large language models: a cognitive perspective. arXiv preprint arXiv:2301.06627, 2023.
- Malone & Bernstein (2022) Malone, T. W. and Bernstein, M. S. Handbook of collective intelligence. MIT press, 2022.
- Mart et al. (2018) Mart, R., Pardalos, P. M., and Resende, M. G. Handbook of heuristics. Springer Publishing Company, Incorporated, 2018.
- Martello & Toth (1990) Martello, S. and Toth, P. Lower bounds and reduction procedures for the bin packing problem. Discrete applied mathematics, 28(1):59–70, 1990.
- Matai et al. (2010) Matai, R., Singh, S. P., and Mittal, M. L. Traveling salesman problem: an overview of applications, formulations, and solution approaches. Traveling salesman problem, theory and applications, 1(1):1–25, 2010.
- Mei et al. (2022) Mei, Y., Chen, Q., Lensen, A., Xue, B., and Zhang, M. Explainable artificial intelligence by genetic programming: A survey. IEEE Transactions on Evolutionary Computation, 2022.
- Meyerson et al. (2023) Meyerson, E., Nelson, M. J., Bradley, H., Moradi, A., Hoover, A. K., and Lehman, J. Language model crossover: Variation through few-shot prompting. arXiv preprint arXiv:2302.12170, 2023.
- Nasir et al. (2023) Nasir, M. U., Earle, S., Togelius, J., James, S., and Cleghorn, C. Llmatic: Neural architecture search via large language models and quality-diversity optimization. arXiv preprint arXiv:2306.01102, 2023.
- Naveed et al. (2023) Naveed, H., Khan, A. U., Qiu, S., Saqib, M., Anwar, S., Usman, M., Barnes, N., and Mian, A. A comprehensive overview of large language models. arXiv preprint arXiv:2307.06435, 2023.
- Nawaz et al. (1983) Nawaz, M., Enscore Jr, E. E., and Ham, I. A heuristic algorithm for the m-machine, n-job flow-shop sequencing problem. Omega, 11(1):91–95, 1983.
- O’Neill et al. (2010) O’Neill, M., Vanneschi, L., Gustafson, S., and Banzhaf, W. Open issues in genetic programming. Genetic Programming and Evolvable Machines, 11:339–363, 2010.
- Pan et al. (2021) Pan, Z., Wang, L., Wang, J., and Lu, J. Deep reinforcement learning based optimization algorithm for permutation flow-shop scheduling. IEEE Transactions on Emerging Topics in Computational Intelligence, 2021.
- (66) Perron, L. and Furnon, V. Or-tools. URL https://developers.google.com/optimization/.
- Qiu et al. (2022) Qiu, R., Sun, Z., and Yang, Y. Dimes: A differentiable meta solver for combinatorial optimization problems. arXiv preprint arXiv:2210.04123, 2022.
- Reinelt (1991) Reinelt, G. Tsplib—a traveling salesman problem library. ORSA journal on computing, 3(4):376–384, 1991.
- Romera-Paredes et al. (2024) Romera-Paredes, B., Barekatain, M., Novikov, A., Balog, M., Kumar, M. P., Dupont, E., Ruiz, F. J., Ellenberg, J. S., Wang, P., Fawzi, O., et al. Mathematical discoveries from program search with large language models. Nature, 625(7995):468–475, 2024.
- Rosenkrantz et al. (1977) Rosenkrantz, D. J., Stearns, R. E., and Lewis, II, P. M. An analysis of several heuristics for the traveling salesman problem. SIAM journal on computing, 6(3):563–581, 1977.
- Seiden (2002) Seiden, S. S. On the online bin packing problem. Journal of the ACM (JACM), 49(5):640–671, 2002.
- Sel et al. (2023) Sel, B., Al-Tawaha, A., Khattar, V., Wang, L., Jia, R., and Jin, M. Algorithm of thoughts: Enhancing exploration of ideas in large language models. arXiv preprint arXiv:2308.10379, 2023.
- Shah et al. (2023) Shah, D., Equi, M. R., Osiński, B., Xia, F., Ichter, B., and Levine, S. Navigation with large language models: Semantic guesswork as a heuristic for planning. In Conference on Robot Learning, pp. 2683–2699. PMLR, 2023.
- Shi et al. (2018) Shi, J., Zhang, Q., and Tsang, E. Eb-gls: an improved guided local search based on the big valley structure. Memetic computing, 10:333–350, 2018.
- Stützle (1998) Stützle, T. Applying iterated local search to the permutation flow shop problem. Technical report, Technical Report AIDA-98-04, FG Intellektik, TU Darmstadt, 1998.
- Stützle & López-Ibáñez (2019) Stützle, T. and López-Ibáñez, M. Automated design of metaheuristic algorithms. Handbook of metaheuristics, pp. 541–579, 2019.
- Sui et al. (2023) Sui, J., Ding, S., Xia, B., Liu, R., and Bu, D. Neuralgls: learning to guide local search with graph convolutional network for the traveling salesman problem. Neural Computing and Applications, pp. 1–20, 2023.
- Taillard (1993) Taillard, E. Benchmarks for basic scheduling problems. european journal of operational research, 64(2):278–285, 1993.
- Van Laarhoven et al. (1987) Van Laarhoven, P. J., Aarts, E. H., van Laarhoven, P. J., and Aarts, E. H. Simulated annealing. Springer, 1987.
- Vinyals et al. (2015) Vinyals, O., Fortunato, M., and Jaitly, N. Pointer networks. Advances in neural information processing systems, 28, 2015.
- Voudouris & Tsang (1999) Voudouris, C. and Tsang, E. Guided local search and its application to the traveling salesman problem. European journal of operational research, 113(2):469–499, 1999.
- Wei et al. (2022) Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., Le, Q. V., Zhou, D., et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35:24824–24837, 2022.
- Wu et al. (2023) Wu, X., Zhong, Y., Wu, J., and Tan, K. C. As-llm: When algorithm selection meets large language model. arXiv preprint arXiv:2311.13184, 2023.
- Wu et al. (2024) Wu, X., Wu, S.-h., Wu, J., Feng, L., and Tan, K. C. Evolutionary computation in the era of large language model: Survey and roadmap. arXiv preprint arXiv:2401.10034, 2024.
- Xiao & Wang (2023) Xiao, H. and Wang, P. Llm a*: Human in the loop large language models enabled a* search for robotics. arXiv preprint arXiv:2312.01797, 2023.
- Xin et al. (2020) Xin, L., Song, W., Cao, Z., and Zhang, J. Step-wise deep learning models for solving routing problems. IEEE Transactions on Industrial Informatics, 17(7):4861–4871, 2020.
- Xu et al. (2023a) Xu, C., Sun, Q., Zheng, K., Geng, X., Zhao, P., Feng, J., Tao, C., and Jiang, D. Wizardlm: Empowering large language models to follow complex instructions. arXiv preprint arXiv:2304.12244, 2023a.
- Xu et al. (2023b) Xu, W., Banburski-Fahey, A., and Jojic, N. Reprompting: Automated chain-of-thought prompt inference through gibbs sampling. arXiv preprint arXiv:2305.09993, 2023b.
- Yang et al. (2023) Yang, C., Wang, X., Lu, Y., Liu, H., Le, Q. V., Zhou, D., and Chen, X. Large language models as optimizers. arXiv preprint arXiv:2309.03409, 2023.
- Yao et al. (2023) Yao, Y., Li, Z., and Zhao, H. Beyond chain-of-thought, effective graph-of-thought reasoning in large language models. arXiv preprint arXiv:2305.16582, 2023.
- Zhang et al. (2023) Zhang, F., Mei, Y., Nguyen, S., and Zhang, M. Survey on genetic programming and machine learning techniques for heuristic design in job shop scheduling. IEEE Transactions on Evolutionary Computation, 2023.
- Zhao et al. (2023) Zhao, Z., Lee, W. S., and Hsu, D. Large language models as commonsense knowledge for large-scale task planning. arXiv preprint arXiv:2305.14078, 2023.
附录 A其他相关工作
A.1 神经求解器
最近,人们在开发端到端神经求解器方面做出了很多努力,特别是组合优化(Bengio等人,2021)。 Vinyals 等人 (2015) 中提出了将指针网络作为神经求解器来自回归构造解。 这项工作做了一些改进,包括使用高效的强化学习框架来替代原来的监督学习(Bello等人,2016)以及采用注意力模型来替代指针网络(Kool等人,2018;Deudon 等人,2018)。 在这些变体(Xin等人,2020;Kwon等人,2020,2021)中,(Kwon等人,2020)中提出的多重最优政策存档了国家-在小型或中等规模的各种问题上具有最先进的性能。 最近的进展,利用重型编码器和轻型解码器,增强了其标量化(Drakulic等人,2023;Luo等人,2023)。
人们还做出了一些努力来混合神经求解器和经典启发式算法,包括基于热图的方法(Joshi等人,2019;Fu等人,2021;Qiu等人,2022),热图引导束搜索 (Joshi 等人, 2019)、蒙特卡洛树搜索 (MCTS) (Fu 等人, 2021)、动态规划 (Kool 等人, 2022) ),并引导本地搜索(Hudson等人,2021;Sui等人,2023)。 混合通常需要付出巨大的努力来设计和训练领域神经模型。
A.2及时工程
简单推广的大语言模型在解决复杂推理任务时面临挑战(Chu等人,2023)。 为了应对这一挑战,思想链(CoT)(Wei等人,2022)被提出,通过逐步推理过程进行上下文学习,以增强大的推理能力没有人类标注的语言模型。
因此,CoT 出现了许多扩展和修改,例如多重采样、思维树(Long,2023)、思维图(Yao 等人,2023) 、思想算法(Sel等人,2023)和自动CoT构建(Kojima等人,2022;Xu等人,2023b)。 EoH 中使用的提示策略可以被视为 CoT 的变体,用于设计启发式,其中父启发式和指令作为上下文信息。
附录B在线装箱问题
B.1 及时工程
下面介绍在线装箱问题的详细提示工程。 每个进化过程的提示工程由五个主要部分组成:1)任务描述,2)特定于策略的提示,3)预期输出,4)注释,以及5)父启发式。 图4给出了两个提示示例:初始化提示和E2提示。 其他运营商(E1、M1、M2 和 S1)的提示工程与这两个示例具有相同的结构,为简洁起见,未列出。 五个不同颜色的部分介绍如下:
-
•
任务描述:告知大语言模型问题描述。 不同的提示策略通常共享相同的任务描述。
-
•
策略特定提示:指示大语言模型对上下文信息进行推理并生成新的启发式以及相应的代码实现。 不同的提示策略有不同的策略特定提示。 例如,在初始化过程中,我们指示大语言模型创建一个全新的启发式。 在进化过程中,我们要求大语言模型对父启发式执行不同类型的推理,以探索启发式搜索空间。
-
•
预期输出:要求大语言模型提供设计启发式的描述,然后生成启发式的代码实现。 本文的代码实现是Python中的一个函数。 我们明确定义了代码的名称、输入和输出,以便于 EoH 框架识别。
-
•
注意:为大语言模型提供了额外的指令,以提高效率和鲁棒性。 例如,我们可能会建议特定类型的输入和输出,并阻止额外的解释以防止长时间的响应。
-
•
父启发式:它包括父启发式,以实现对语言启发式描述和代码实现的上下文学习。 初始化提示不包含这部分内容。
B.2 启发式进化
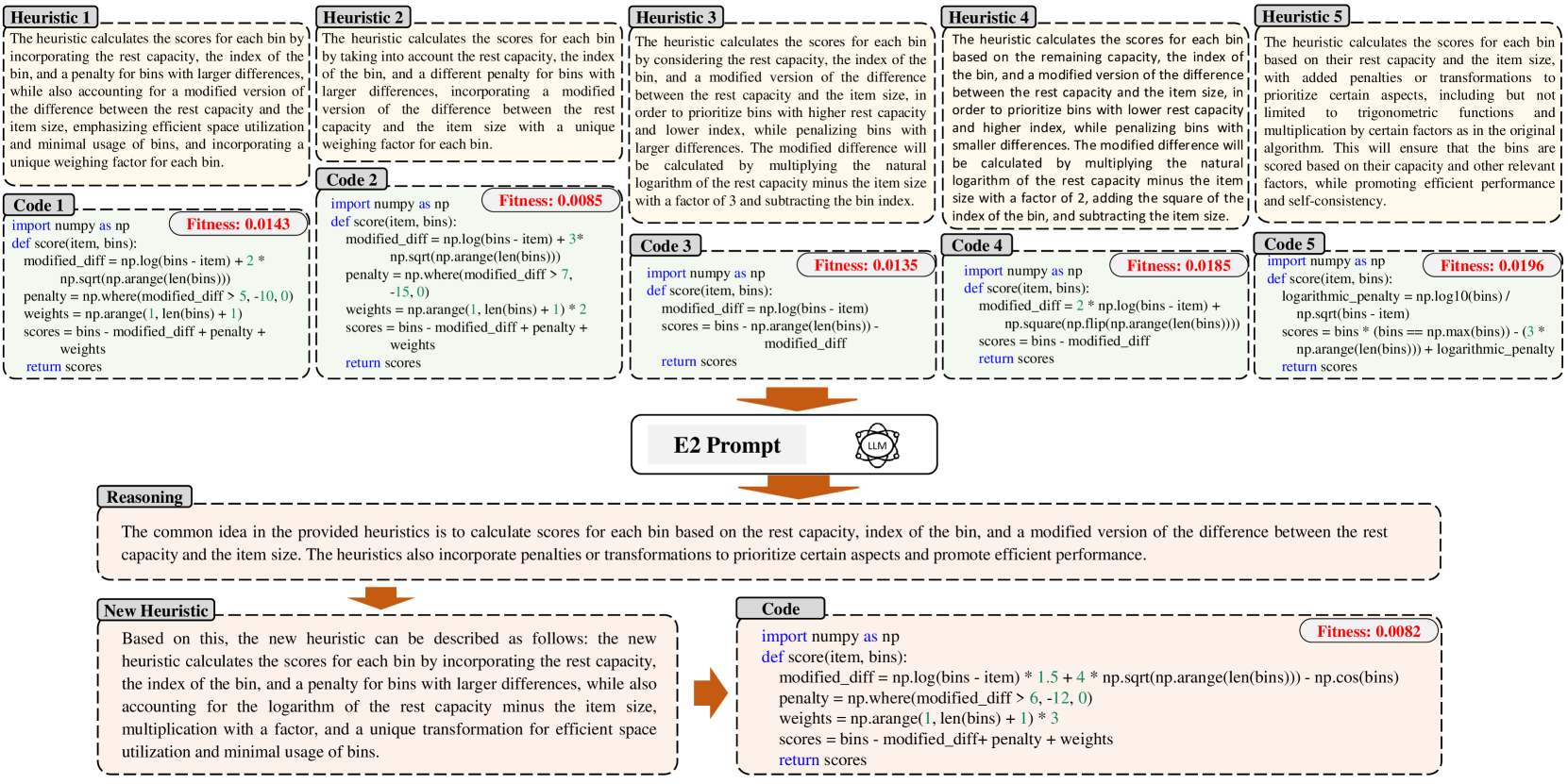
主体部分已经讨论了进化的趋同过程。 图 6 展示了一代 E2 的详细说明。 从总体中选择了五种启发式方法,每种方法都包含高级描述和详细的 Python 实现。 然后,这些启发式方法将用作 E2 中提示工程的输入,这已在上一节中介绍过。 大语言模型被赋予三个指令:首先,根据所提供的启发式的描述和代码来识别共享概念;其次,基于此分析设计新的启发式;第三,使用给定的名称、输入和输出在 Python 中实现启发式。 改进的启发式遵循已确定的共同想法并集成了新组件。
B.3 设计启发式
图 6 展示了人类设计的启发式方法、EoC、FunSearch 和我们提出的 EoH 的比较。 我们将它们呈现为具有相同输入和输出的 Python 函数。 输入“item”和“bins”代表当前项目的大小以及Romera-Paredes等人(2024)之后的箱的剩余容量。 输出是分配给箱的分数。 在每一步中,该项目都会被分配到得分最高的垃圾箱中。 值得注意的是,两种最常用的手工启发式方法可以在一行代码中实现。 另一方面,EoC、FunSearch 和我们的方法 EoH 设计的启发式方法更加复杂,使得人类设计师难以实现。
B.4 更多结果
表9总结了首次拟合、最佳拟合以及FunSearch、EoC和EoH在不同容量和大小的Weibull实例上产生的算法的结果。 针对不同的启发法报告了五个实例与下限的平均差距。 最佳结果以粗体表示,代表与下限平均差距最小的启发法。 我们观察到,EoC 设计的启发式算法在分布 (100, 5k) 上过度拟合,该分布用于评估进化过程中生成的启发式算法的适应性。 在所有启发式方法中,EoH 始终取得最佳性能,与下限的平均差距为 1.18%。 重要的是,EoH 仅利用几千个查询,这比 FunSearch 所需的计算预算要少得多(Romera-Paredes 等人 (2024) 中报告的大约 100 万个查询)。 EoH 在训练分布中实现了相同的最佳差距,同时展示了卓越的泛化性能,特别是对于不同的容量。
| Capacity | Size | First Fit | Best Fit | FunSearch | EoC | EoH |
| 100 | 1k | 5.32% | 4.87% | 3.78% | 148.63% | 2.24% |
| 5k | 4.40% | 4.08% | 0.80% | 3.23% | 0.80% | |
| 10k | 4.44% | 4.09% | 0.33% | 24.55% | 0.61% | |
| 200 | 1k | 4.86% | 4.42% | 4.20% | 134.59% | 2.10% |
| 5k | 4.14% | 3.80% | 0.93% | 5.26% | 0.76% | |
| 10k | 4.16% | 3.83% | 0.36% | 23.96% | 0.58% | |
| 300 | 1k | 4.93% | 4.48% | 4.93% | 141.48% | 2.18% |
| 5k | 4.18% | 3.83% | 1.07% | 8.31% | 0.77% | |
| 10k | 4.20% | 3.87% | 0.49% | 27.62% | 0.59% | |
| 400 | 1k | 4.97% | 4.50% | 5.38% | 150.06% | 2.16% |
| 5k | 4.24% | 3.88% | 1.57% | 10.52% | 0.79% | |
| 10k | 4.25% | 3.91% | 0.69% | 30.45% | 0.61% | |
| 500 | 1k | 4.97% | 4.50% | 6.75% | 150.89% | 2.13% |
| 5k | 4.27% | 3.91% | 1.47% | 12.53% | 0.78% | |
| 10k | 4.28% | 3.95% | 0.74% | 32.02% | 0.61% | |
| Average | 4.51% | 4.13% | 2.23% | 60.27% | 1.18% | |
附录C旅行商问题
C.1 引导式本地搜索
EoH 设计的启发式方法与 TSP 和 FSSP 的引导本地搜索框架中的本地搜索运算符一起工作。 与 SOTA 求解器中复杂的局部搜索(Helsgaun,2017)相比,我们只采用了两个基本的局部搜索算子。 我们证明,即使使用这两个简单的算子,EoH 也可以设计出非常有竞争力的算法。
引导局部搜索(GLS)是一种广泛使用的策略,用于引导局部搜索逃离局部最优解,以解决组合优化问题(Alsheddy等人,2018;Vouudouris&Tsang,1999)。 在典型的局部搜索(Alsheddy等人,2018)中,当局部搜索陷入局部最优解时,GLS会修改目标函数来引导局部搜索移动到其他有希望的搜索区域(Alsheddy 等人,2018)。
GLS 算法交替两个阶段:局部搜索和扰动(Arnold & Sörensen,2019)。 在本地搜索阶段,我们使用本地搜索运算符进行搜索。 当搜索陷入局部最优时,将调用扰动阶段,以使用启发式策略更新目标函数(即景观)。
EoH 用于设计更新目标函数的策略。 通过一些预先选择的本地搜索运算符,该策略可以定义 GLS 启发式。 在我们的实验中,对于 EoH 中生成的每个更新策略,都会在一组问题实例上评估其相应 GLS 启发式的性能,并将平均性能作为其适应度值。
C.2 及时工程
下面,我们详细介绍用于 TSP 的即时工程。 我们使用提示工程部分中概述的相同五个组件进行装箱。 在图7中,我们提供了初始化和E2提示的两个说明性示例,每个组件以不同的颜色表示。 为了简洁起见,我们省略了其他提示策略的提示工程细节。
C.3 设计的启发式策略
图8说明了EoH设计的用于更新TSP距离矩阵的启发式策略。 该矩阵是通过修改原始距离矩阵并添加一些随机因素得到的,其中涉及几个中间变量,包括距离的平均值、使用的边缘的平均值以及对当前局部最优路线的惩罚。
C.4 更多实验结果
我们还将 EoH 生成的启发式与以下方法进行比较:
-
•
TSP 的图卷积网络(GCN)方法(Joshi 等人,2019)。
-
•
注意力模型(AM)(Kool等人,2018)。 它使用神经网络来学习组合优化的启发式方法。
-
•
POMO (Kwon 等人,2020)。 它采用增材制造理念并取得了最先进的成果。
-
•
LEHD (罗等人,2023)。 它是 AM 的新变体,具有不同的重型解码器结构,并使用监督学习进行训练。
-
•
GLS (Vouudouris 和 Tsang,1999)。 它是 TSP 的 GLS 的普通版本。
-
•
EBGLS (石等人,2018)。 考虑到TSP的大山谷特征,它扩展了GLS。
-
•
KGLS (Arnold 和 Sörensen,2019)。 它使用从先前的路由问题知识中提取的多个特征。
-
•
GNNGLS (Hudson 等人, 2021) 和 NeuralGLS (Sui 等人, 2023)。 他们在 GLS 中使用深度学习模型。
我们将每个测试实例上每个 GLS 算法的 LS 最大调用次数设置为 1,000。 我们使用 POMO (Kwon 等人, 2020) 、 BQ (Drakulic 等人, 2023) 和 LEHD (Luo 等人, 2023) 的源代码 在我们的实验中。 GNNGLS Hudson 等人 (2021)、NeuralGLS Sui 等人 (2023)、AM Hudson 等人 (2021) 和 GCN 的实验结果Sui 等人 (2023) 直接摘自他们各自的论文。 Concorde (Applegate 等人, 2006) 得到的解作为计算性能差距的基线。
我们考虑三种不同数量的位置:20、50 和 100。 对于每个位置,我们从 中随机生成 1,000 个位置,从而获得 1,000 个测试实例。 表 10 显示了启发式方法在这些随机实例上的平均性能。 该表提供了与基线求解器 Concorde 相比的平均差距,以及每个实例的平均运行时间。 需要指出的是,POMO、BQ、LEHD在GPU上以并行方式运行,因此不提供单实例运行时间。 从表10可以清楚地看出,EoH 生成的启发式性能最好。
| Method | TSP20 | TSP50 | TSP100 | |||
| Gap (%) | Time (s) | Gap (%) | Time (s) | Gap (%) | Time (s) | |
| Concorde | 0.000 | 0.010 | 0.000 | 0.051 | 0.000 | 0.224 |
| LKH3 | 0.000 | 0.020 | 0.000 | 0.069 | 0.011 | 0.118 |
| NN | 17.448 | 0.000 | 23.230 | 0.002 | 25.104 | 0.010 |
| FI | 2.242 | 0.005 | 7.263 | 0.065 | 12.456 | 0.444 |
| AM | 0.069 | 0.038 | 0.494 | 0.124 | 2.368 | 0.356 |
| GCN | 0.035 | 0.974 | 0.884 | 3.080 | 1.880 | 6.127 |
| POMO | 0.120 | / | 0.640 | / | 1.070 | / |
| POMO aug8 | 0.000 | / | 0.030 | / | 0.140 | / |
| BQ | 0.379 | / | 0.245 | / | 0.579 | / |
| LEHD | 0.950 | / | 0.485 | / | 0.577 | / |
| LS | 1.814 | 0.006 | 3.461 | 0.006 | 4.004 | 0.008 |
| GLS | 0.004 | 0.088 | 0.045 | 0.248 | 0.659 | 0.683 |
| EBGLS | 0.002 | 0.091 | 0.003 | 0.276 | 0.155 | 0.779 |
| KGLS | 0.000 | 1.112 | 0.000 | 3.215 | 0.035 | 7.468 |
| GNNGLS | 0.000 | 10.010 | 0.009 | 10.037 | 0.698 | 10.108 |
| NeuralGLS | 0.000 | 10.005 | 0.003 | 10.011 | 0.470 | 10.024 |
| EoH | 0.000 | 0.498 | 0.000 | 1.494 | 0.025 | 4.510 |
我们还在 29 个 TSPLib 实例上进行了实验。 如表11所示,EoH 设计的 GLS 算法在 29 个实例的平均差距方面优于所有其他启发式算法,包括手工设计的启发式算法。
| Instance | Other Algorithms | GLS Algorithms | EoH | |||||||
| AM | POMO | LEHD | GNNGLS | NeuralGLS | LS | GLS | EBGLS | KGLS | ||
| eil51 | 1.63 | 0.83 | 1.64 | 0.00 | 0.00 | 2.85 | 0.67 | 0.67 | 0.67 | 0.67 |
| berlin52 | 4.17 | 0.04 | 0.03 | 0.14 | 0.00 | 3.89 | 0.03 | 0.03 | 0.03 | 0.03 |
| st70 | 1.74 | 0.31 | 0.33 | 0.76 | 0.00 | 2.64 | 0.31 | 0.31 | 0.31 | 0.31 |
| eil76 | 1.99 | 1.18 | 2.54 | 0.16 | 0.00 | 3.93 | 1.37 | 1.18 | 1.18 | 1.48 |
| pr76 | 0.82 | 0.00 | 0.22 | 0.04 | 0.82 | 6.71 | 0.00 | 0.00 | 0.00 | 0.00 |
| rat99 | 2.65 | 2.39 | 1.10 | 0.55 | 0.72 | 6.58 | 1.55 | 0.74 | 0.68 | 0.68 |
| kroA100 | 4.02 | 0.41 | 0.12 | 0.73 | 0.03 | 3.00 | 0.02 | 0.02 | 0.06 | 0.02 |
| kroB100 | 5.14 | 0.32 | 0.26 | 0.15 | 0.88 | 0.58 | 0.23 | 0.00 | 0.25 | 0.00 |
| kroC100 | 0.97 | 0.18 | 0.32 | 1.57 | 1.77 | 4.70 | 0.50 | 0.01 | 0.01 | 0.01 |
| kroD100 | 2.72 | 0.84 | 0.38 | 0.57 | 0.00 | 5.67 | 0.00 | 0.20 | 0.00 | 0.00 |
| kroE100 | 1.47 | 0.45 | 0.43 | 1.22 | 1.05 | 4.64 | 0.49 | 0.00 | 0.07 | 0.14 |
| rd100 | 3.41 | 0.01 | 0.01 | 0.46 | 0.00 | 1.27 | 0.01 | 0.01 | 0.02 | 0.01 |
| eil101 | 2.99 | 1.84 | 2.31 | 0.20 | 0.36 | 8.82 | 3.28 | 1.91 | 2.07 | 2.27 |
| lin105 | 1.74 | 0.52 | 0.34 | 0.61 | 0.65 | 1.87 | 0.03 | 0.03 | 0.03 | 0.03 |
| pr107 | 3.93 | 0.52 | 11.24 | 0.44 | 0.81 | 0.72 | 0.40 | 0.00 | 0.00 | 0.00 |
| pr124 | 3.68 | 0.60 | 1.11 | 0.76 | 0.08 | 2.44 | 0.60 | 0.60 | 0.08 | 0.00 |
| bier127 | 5.91 | 13.72 | 4.76 | 1.95 | 2.73 | 1.79 | 0.59 | 0.29 | 0.42 | 0.42 |
| ch130 | 3.18 | 0.16 | 0.55 | 3.52 | 1.19 | 7.61 | 1.09 | 0.46 | 0.01 | 0.01 |
| pr136 | 5.06 | 0.93 | 0.45 | 3.39 | 2.32 | 6.30 | 2.01 | 0.28 | 0.24 | 0.00 |
| pr144 | 7.64 | 0.53 | 0.19 | 3.58 | 0.74 | 4.19 | 0.09 | 0.00 | 0.00 | 0.00 |
| ch150 | 4.58 | 0.53 | 0.52 | 2.11 | 2.49 | 1.35 | 0.68 | 0.37 | 0.04 | 0.24 |
| kroA150 | 3.78 | 0.70 | 1.40 | 2.98 | 0.77 | 5.05 | 1.75 | 0.26 | 0.17 | 0.00 |
| kroB150 | 2.44 | 1.17 | 0.76 | 3.26 | 3.11 | 5.55 | 1.01 | 0.00 | 0.08 | 0.00 |
| pr152 | 7.49 | 1.05 | 12.14 | 3.12 | 0.00 | 2.75 | 0.19 | 0.19 | 0.19 | 0.19 |
| u159 | 7.55 | 0.95 | 1.13 | 1.02 | 0.90 | 5.63 | 0.74 | 0.78 | 0.96 | 0.00 |
| rat195 | 6.89 | 8.15 | 1.42 | 1.67 | 0.48 | 2.14 | 0.61 | 0.61 | 0.97 | 0.82 |
| d198 | 373.02 | 17.29 | 9.23 | 4.77 | 1.28 | 7.96 | 2.08 | 1.87 | 0.31 | 0.59 |
| kroA200 | 7.11 | 1.58 | 0.64 | 2.03 | 0.86 | 0.91 | 0.75 | 0.18 | 0.71 | 0.15 |
| kroB200 | 8.54 | 1.44 | 0.16 | 2.59 | 3.74 | 4.71 | 1.43 | 1.27 | 0.89 | 0.20 |
| Average | 16.77 | 2.02 | 1.92 | 1.53 | 0.96 | 4.01 | 0.78 | 0.42 | 0.36 | 0.28 |
附录D流水车间调度问题
D.1 及时工程
本小节将介绍用于 FSSP 的提示工程的详细信息。 我们使用相同的组件进行装箱。 图9提供了初始化和E2提示的两个说明性示例,每个组件以不同的颜色表示。
D.2 设计的启发式策略
我们采用相同的 GLS 框架,并选择两个本地搜索运算符:交换和重新定位。 EoH 用于设计启发式策略来更新执行时间矩阵并确定受到干扰的作业。 图10说明了EoH为FSSP设计的启发式方法。 更新原始矩阵中的一些选定元素。
D.3 更多结果
我们还将 EoH 产生的启发式与以下方法进行比较。
-
•
古普塔(古普塔,1971)。 它是 FSSP 的经典启发式算法。
-
•
CDS (Campbell 等人,1970)。 它是 FSSP 的经典启发式算法。
-
•
NEH (Nawaz 等人, 1983)。 它被广泛认为是 FSSP 的有效启发式方法。
-
•
NEHFF (费尔南德斯-维亚加斯和弗拉米南,2014)。 它是 NEH 的修订版。
-
•
PFSPNet 和 PFSPNet_NEH (潘等人,2021)。 它们是最近开发的用于流水车间调度的深度学习求解器。
-
•
本地搜索(LS)。 它是基本的本地搜索,具有与 EoH 中使用的相同运算符。
-
•
ILS1 (Stützle,1998):它是为 FSSP 开发的迭代本地搜索。
-
•
ILS2:它使用与我们相同的框架,但采用手工设计的启发式策略。
我们在广泛使用的 Taillard 实例上评估算法。 我们测试了 11 个不同的测试集。 这些实例中的作业数量从 20 到 200 个不等,机器数量从 5 到 20 台不等。
表12展示了在Taillard实例上通过不同算法获得的结果。 该表给出了与 Taillard (1993) 中提供的上限的平均差距。 平均值是根据每个测试集的 10 个实例计算的。 最佳结果以粗体突出显示。 EoH 在大多数测试集上都是最好的,获得了 0.23% 的最佳平均差距。 EoH 的性能优于这些常用的启发式算法以及最近的深度学习神经求解器。 值得注意的是,EoH 的性能优于 ILS2,后者共享相同的框架和局部搜索算子,但使用人工设计的启发式扰动策略。
| Test Set | GUPTA | CDS | NEH | NEHFF | PFSPNet | LS | ILS1 | ILS2 | EoH |
| 20_5 | 12.89 | 9.03 | 3.24 | 2.30 | 2.30 | 1.91 | 0.42 | 0.18 | 0.09 |
| 20_10 | 23.42 | 12.87 | 4.05 | 4.15 | 4.04 | 2.77 | 0.33 | 0.25 | 0.30 |
| 20_20 | 21.79 | 10.35 | 3.06 | 2.72 | 2.96 | 2.60 | 0.29 | 0.25 | 0.10 |
| 50_5 | 12.23 | 6.98 | 0.57 | 0.40 | 0.51 | 0.32 | 0.15 | 0.32 | 0.02 |
| 50_10 | 20.11 | 12.72 | 3.47 | 3.62 | 3.48 | 3.33 | 1.47 | 0.29 | 0.19 |
| 50_20 | 22.78 | 15.03 | 5.48 | 5.10 | 5.05 | 4.67 | 2.13 | 0.34 | 0.60 |
| 100_5 | 5.98 | 5.10 | 0.39 | 0.31 | 0.31 | 0.28 | 0.20 | 0.38 | -0.04 |
| 100_10 | 15.03 | 9.36 | 2.07 | 1.88 | 1.72 | 1.38 | 0.77 | 0.34 | 0.14 |
| 100_20 | 21.00 | 13.55 | 3.58 | 3.73 | 3.56 | 3.51 | 2.27 | 0.43 | 0.41 |
| 200_10 | 11.59 | 7.22 | 0.98 | 0.70 | 0.82 | 0.87 | 0.74 | 0.54 | 0.12 |
| 200_20 | 18.09 | 11.89 | 2.90 | 2.52 | 2.49 | 2.53 | 2.26 | 0.59 | 0.61 |
| Average | 16.81 | 10.37 | 2.71 | 2.49 | 2.48 | 2.20 | 1.00 | 0.36 | 0.23 |