统一物体接地和检测的开放综合管道
摘要
Grounding-DINO 是一种最先进的开放集检测模型,可处理多种视觉任务,包括开放词汇检测 (OVD)、短语接地 (PG) 和引用表达理解 (REC)。 其有效性使其被广泛采用作为各种下游应用程序的主流架构。 然而,尽管具有重要意义,原始的 Grounding-DINO 模型由于无法获得训练代码,因此缺乏全面的公开技术细节。 为了弥补这一差距,我们推出了MM-Grounding-DINO,这是一个开源、全面且用户友好的管道,它是使用 MMDetection 工具箱构建的。 它采用丰富的视觉数据集进行预训练,并采用各种检测和接地数据集进行微调。 我们对每个报告的结果进行全面分析,并进行详细的再现设置。 对上述基准进行的广泛实验表明,我们的 MM-Grounding-DINO-Tiny 优于 Grounding-DINO-Tiny 基线。 我们向研究界发布了所有模型。 代码和训练模型发布于 https://github.com/open-mmlab/mmdetection/tree/main/configs/mm_grounding_dino。
![[Uncaptioned image]](show.png)
1简介
对象检测的任务通常涉及将图像输入到模型中以获得建议,然后通过多模态对齐将其与文本进行匹配,使其成为大多数最先进的多模态理解架构的关键组成部分。 目前,根据输入文本的类型,对象检测可以细分为三个子任务:开放词汇检测(OVD)、短语基础(PG)和指代表达理解(REC)。
按照零样本设置,OVD 模型在基本类别上进行训练,但需要在大规模语言词汇表 [29] 中预测基本类别和新类别。 短语基础任务不仅需要一个类别,而且需要一个短语,将所有候选类别描述为输入和输出对应的框[25]。 REC 任务的主要目标是准确识别给定文本描述指定的目标,然后利用边界框 [9] 划分其位置。
近年来,人们探索了许多视觉基础和检测模型来解决上述任务。 其中,Grounding-DINO[20]已成为性能优越的主流架构。 基于闭集探测器 DINO [34],Grounding-DINO-Large 在 COCO [17] 上实现了最先进的零样本性能(mAP 52.5 )没有任何 COCO 训练数据。 Grounding-DINO在各个阶段执行视觉和语言模态的集成,包括特征增强器、查询选择模块和解码器。 这种深刻的融合方法显着增强了开放集上下文中对象的检测,并且基于 DETR 的结构使其成为一个端到端网络,无需任何精心设计的模块。
鉴于 Grounding-DINO 在上述三个下游任务中表现出了卓越的精度,但并非完全开源(仅提供测试和演示代码),我们利用 MMDetection 工具箱重建 Grounding-DINO 模型[4] 在OpenMMLab项目中,遵循Grounding-DINO官方测试代码。 除了初始化期间的修改之外,模型的结构几乎保持不变。 基于Grounding-DINO框架,我们建议应用更多的数据集进行预训练,包括COCO、Objects365 [27]、GRIT [23]、V3Det [ 28]、RefCOCO [13]、RefCOCO+ [33]、RefCOCOg [22]、GQA [11] / Flickr30k 实体 [24](组合也称为 Golden-G 数据集 [12]),产生更强大的基于 Grounding-DINO 的模型,我们将其呼叫 MM-接地-DINO。 由于 Grounding-DINO 使用的 Cap4M 数据集 [25] 不是开源的,因此我们在研究中选择了 GRIT 和 V3Det 数据集作为替代数据集。
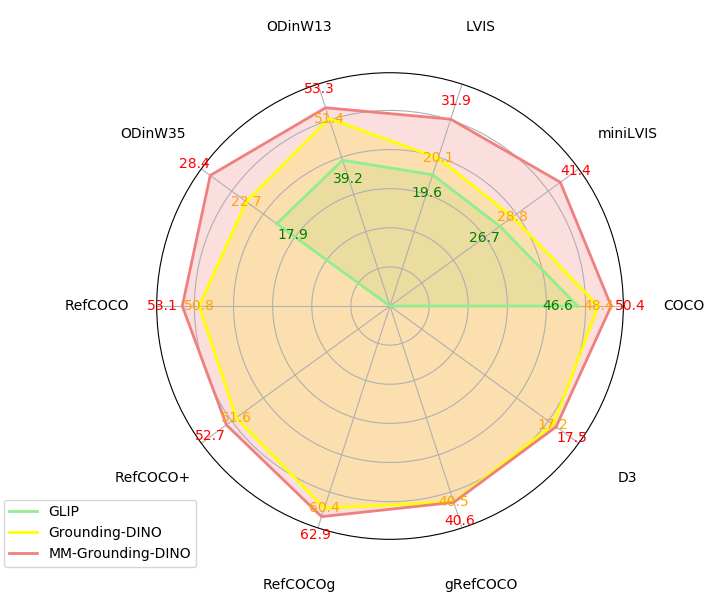
我们进一步扩展了 OVD、PG 和 REC 评估的所有可用基准,包括 COCO、LVIS [8]、RefCOCO/+/g、Flickr30k Entities、ODinW13/35 [15]、gRefCOCO [19] 和描述检测数据集() [30]。 据我们所知,我们是第一个实施框架来促进对如此广泛的数据集进行系统评估的框架。 所有评估指标均可在 MMDetection 中轻松获得。 经过大量数据预训练,MM-Grounding-DINO-Tiny在COCO上实现零样本50.6 mAP,在LVIS mini上达到41.4 mAP,在REC任务中全面超越Grounding-DINO-Tiny,详细结果见3。 我们希望我们的管道能够成为 OVD、PG 和 REC 任务进一步研究的宝贵资源。
我们论文的贡献如下:
-
1.
我们提出了 MM-Grounding-DINO,这是一个基于 Grounding-DINO 的综合开源接地管道,并使用丰富的视觉数据集进行了预训练,可全面解决 OVD、PG 和 REC 任务。
-
2.
我们率先扩展了 OVD、PG 和 REC 评估的所有可用基准,包括 COCO、LVIS、RefCOCO/+/g、Flickr30K Entities、ODinW13/35、gRefCOCO 和 。 所有评估指标均可在 MMDetection 中轻松获得。
-
3.
我们通过大量外部特殊数据集微调我们的模型,广泛评估我们模型的迁移能力。
2方法
在本节中,我们详细介绍模型和数据集。 除非另有说明,MM-G 表示 MM-Grounding-DINO。 G-DINO指接地-DINO。 在以下章节中,O365 表示 Objects365 V1,GoldG 表示 GQA 和 Flickr30k 实体的组合。
2.1模型
| Model | Training Datasets | Image Consumption |
|---|---|---|
| MDETR | COCO, RefC, VG, GoldG | 52M (40 Ep 1.3M Img) |
| GLIP | O365, OpenImages, VG, INB, COCO, RefC, GoldG, Cap24M | 64M (64 Bs 1M Iter) |
| GLIPv2 (stage II) | COCO, LVIS, PhraseCut, Cap16M | 5.36M (24 Ep 0.2M Img + 8 Ep 0.07M Img) |
| G-DINO-Tiny(a) | O365 | 18.3M (30 Ep 128 Bs 4755 Iter) |
| G-DINO-Tiny(b) | O365, GoldG | 41.3M (30 Ep 128 Bs 10763 Iter) |
| G-DINO-Tiny(c) | O365, GoldG, Cap4M | - |
| MM-G-Tiny(a) | O365 | 18.3M (30 Ep 128 Bs 4755 Iter) |
| MM-G-Tiny(b) | O365, GoldG | 41.3M (30 Ep 128 Bs 10763 Iter) |
| MM-G-Tiny(c1) | O365, GoldG, GRIT | 56.3M (30 Ep 128 Bs 14669 Iter) |
| MM-G-Tiny(c2) | O365, GoldG, V3Det | 46.8M (30 Ep 128 Bs 12196 Iter) |
| MM-G-Tiny(c3) | O365, GoldG, GRIT, V3Det | 61.8M (30 Ep 128Bs 16102 Iter) |
| MM-G-Large | COCO, RefC, O365V2, GoldG, GRIT, Open-Images, V3Det | - |
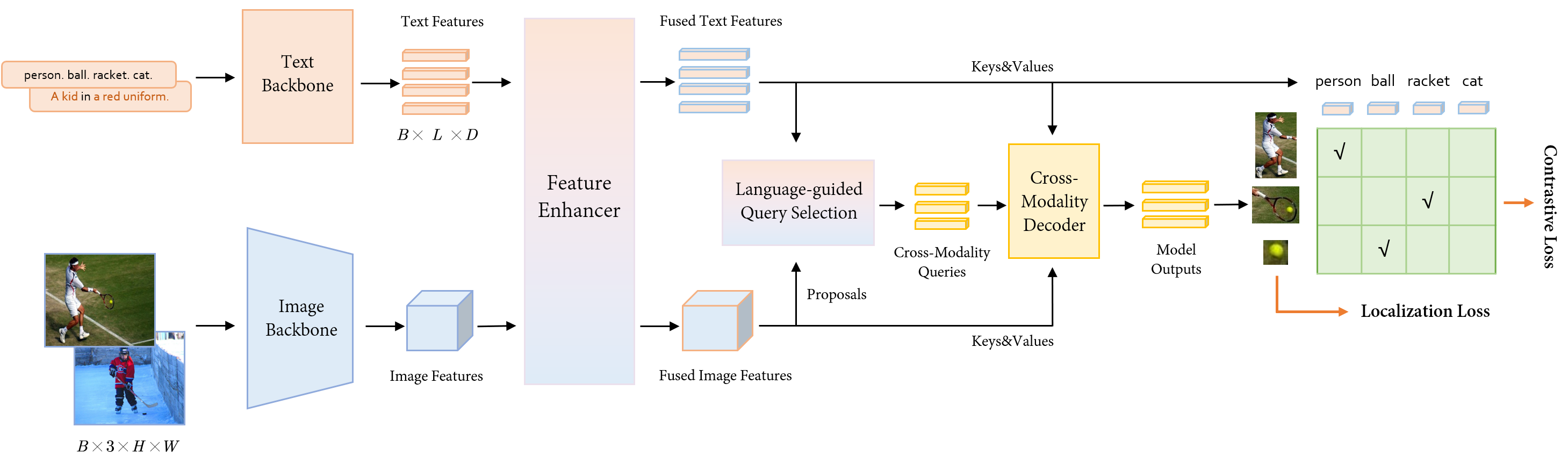
正如我们在An Open and Comprehensive Pipeline for Unified Object Grounding and Detection中提到的,我们的模型基于Grounding-DINO [20]和几乎保持不变。 我们的框架如图3所示。 给定具有形状 的图像和文本描述,我们的模型可以将描述与相应生成的边界框对齐。 我们模型的组件包含用于提取文本特征的文本主干、用于提取图像特征的图像主干、用于深度融合图像和文本特征的特征增强器、用于查询初始化的语言引导查询选择模块以及跨模态解码器用于框细化。 该结构的更多细节在[20]中绘制。
特征提取和融合。 给定图像-文本对,我们使用图像主干来提取多个尺度的图像特征,同时使用文本主干来提取文本特征。 然后我们将这两个特征输入特征增强器模块以进行跨模态融合。 在特征增强器模块中,文本特征和图像特征首先通过包含文本到图像交叉注意层和图像到文本交叉注意层的双注意块融合。 然后,分别使用普通自注意力层和可变形自注意力层以及后面的 FFN 层进一步增强融合的文本特征和图像特征,如算法 1 中所示。
语言引导的查询选择。 为了优化利用文本来指导对象检测,Grounding-DINO 设计了一个语言引导的查询选择模块。 语言引导查询选择模块根据与输入文本特征的余弦相似度选择建议作为解码器查询。 参数 表示输入解码器的查询数量,在我们的实现中,它已配置为值 900,遵循 DINO [34]。 解码器的输入查询由两部分组成:内容部分和位置部分。 位置部分表示动态锚框,并根据语言引导查询选择模块的输出进行初始化,而内容部分则初始化为全零可学习查询。
跨模态解码器。 Grounding-DINO 中的跨模态解码器层旨在进一步合并文本和图像特征以进行跨模态学习。 在自注意力之后,该架构合并了一个图像交叉注意力层,随后是一个文本交叉注意力层,最后是一个 FFN 层。 与 DINO 解码器层相比,每个解码器层都拥有一个额外的文本交叉注意力层。 由于需要将文本信息注入查询,因此需要进行此增强,从而提高模型的性能。
训练损失。 L1 损失和 GIOU [26] 损失是针对框回归分支实现的。 遵循 GLIP [16],我们利用焦点损失 [18] 作为预测框和语言标记之间的对比损失进行分类。 每个预测框将与所有语言标记相乘,以计算它们之间的相似度。 盒回归和分类损失联合用于计算二分匹配损失[3]。 与 Grounding-DINO 一致,我们为每个解码器层以及编码器输出纳入了辅助损失。”
差异。 MM-G 和 G-DINO 之间的主要区别在于对比嵌入模块。 受 CLIP [25] 的启发,我们在初始化对比嵌入模块时添加了偏差。 这可以显着降低初始损失值并加速我们模型的收敛。
实现代码如算法2所示。
2.2数据集准备
我们的数据格式受 Open Grounding-DINO [35] 中的格式启发,并根据 MMDetection 中的格式进行修改。 由于 MM-Grounding-DINO 旨在解决具有不同类型注释的数据集的三项任务,因此我们将使用的 15 个数据集分别分为三组。 数据集的综合详细信息如表2所示。 值得注意的是,GRIT 中超过 1300 万的全部数据在训练过程中并没有在每个 epoch 中得到充分利用。 相反,它被分为每个时期 500,000 个段。
OVD 数据集。 我们用于训练的数据集包括 COCO [17]、Objects365V1 [27]、Objects365V2 [27]、V3Det [28]、Open-Images,评估数据集包含COCO,LVIS0>[8]1>,ODinW12/352>[15]3>。
PG 数据集。 训练数据集包含 GQA [11]、GRIT [23]、Flickr30K 实体 [24],同时 Flickr30K Entities数据集也用于评估。
REC 数据集 训练数据集包括 RefCOCO [13]、RefCOCO+ [33] ,RefCOCOg[22]。 为了进行评估,我们利用了更广泛的数据集,其中包含 RefCOCO、RefCOCO+、RefCOCOg、gRefCOCO [19] 和描述检测数据集() [30]。
| Dataset | Task | Images | Instances | categories |
| COCO111Both utilized for training and evaluation [17] | OVD | 123K | 896K | 80 |
| Objects365-V1 [27] | OVD | 638K | 10M | 365 |
| Objects365-V2 [27] | OVD | 1.7M | 25M | 365 |
| OpenImages-V6 | OVD | 1.5M | 14M | 600 |
| V3Det [28] | OVD | 245K | 1753K | 13029 |
| Flickr30k Entities111 [24] | PG | 31K | 275K | - |
| GQA [11] | PG | 113K | - | - |
| GRIT [23] | PG | 9M | 137M | - |
| RefCOCO111 [13] | REC | 19K | 50K | - |
| RefCOCO+111 [33] | REC | 19K | 49K | - |
| RefCOCOg111 [22] | REC | 26K | 54K | - |
| LVIS [8] | OVD Benchmark | 164K | 2M | 1000 |
| ODinW [15] | OVD Benchmark | 20K | 135K | 314 |
| gRefCOCO [19] | REC Benchmark | 19K | 60K | - |
| [30] | REC Benchmark | 10K | 18K | - |
2.3训练设置
文本输入规则。 对于 OVD 训练,我们将检测数据集中的所有类别连接为一个长字符串,例如“People”。球。球拍。猫。”。 对于 PG 和 REC 任务,遵循 M-DETR [12],在预训练阶段,我们注释文本中引用的每个对象,这会导致模型应用程序略有修改为了这个任务。 例如,在预训练期间,给出标题“穿着蓝色连衣裙的女人站在玫瑰丛旁边。”,MM-Grounding-DINO 将被训练来预测所有引用对象(例如 女人)的边界框、蓝色连衣裙和玫瑰丛。
型号变体。 与 Grounding-DINO 类似,我们选择一个经过良好预训练的基于 BERT 的 uncased [6] 模型作为我们的语言编码器,并选择 Swin Transformer [21] 作为图像主干。 我们比较了 MM-G-tiny 和 G-DINO-Tiny 中数据集的不同组合。 训练数据集的选择取决于图像主干的规模,如表1所示。
数据增强。 除了随机调整大小、随机剪辑和随机翻转之外,我们还在数据增强中引入随机负样本。 我们将从其他图像中随机采样的类别或文本描述作为反例,将真实描述作为正例连接起来。 这可以有效抑制模型产生的幻觉现象,从而模型不会预测图像中不存在的物体。
计算资源。 我们在 32 个 NVIDIA 3090 GPU 上训练了 MM-G-Tiny,总批量大小为 128,持续 30 个周期。 由于MM-G-Large的计算成本极高,MM-G-Large模型仍处于训练阶段。
3 主要结果
3.1 零样本传输
在零样本设置中,MM-G 模型最初在基础数据集上进行训练,随后在新数据集上进行评估。 此外,我们还提供了一组微调结果,以便于将我们的模型与 Grounding-DINO 进行全面比较。 这种方法可确保对模型的性能及其在该领域的相对地位进行稳健的评估。
| Model | Backbone | Lr schd | COCO mAP |
|---|---|---|---|
| GLIP | Swin-T | zero-shot | 46.6 |
| G-DINO-T(a) | Swin-T | zero-shot | 46.7 |
| G-DINO-T(b) | Swin-T | zero-shot | 48.1 |
| G-DINO-T(c) | Swin-T | zero-shot | 48.4 |
| MM-G-T(a) | Swin-T | zero-shot | 48.5(+1.8) |
| MM-G-T(b) | Swin-T | zero-shot | 50.4(+2.3) |
| MM-G-T(c1) | Swin-T | zero-shot | 50.5(+2.1) |
| MM-G-T(c2) | Swin-T | zero-shot | 50.6(+2.2) |
| MM-G-T(c3) | Swin-T | zero-shot | 50.4(+2.0) |
| Model | Backbone | Lr schd |
|
|
|
|
|
|
|
|
||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| GLIP | Swin-T | zero-shot | 18.1 | 21.2 | 33.1 | 26.7 | 10.8 | 14.7 | 29.0 | 19.6 | ||||||||||||||||
| G-DINO-T(c) | Swin-T | zero-shot | 18.8 | 24.2 | 34.7 | 28.8 | 10.1 | 15.3 | 29.9 | 20.1 | ||||||||||||||||
| MM-G-T(b) | Swin-T | zero-shot | 28.1 | 30.2 | 42.0 | 35.7 | 17.1 | 22.4 | 36.5 | 27.0 | ||||||||||||||||
| MM-G-T(c1) | Swin-T | zero-shot | 26.6 | 32.4 | 41.8 | 36.5(+7.7) | 17.3 | 22.6 | 36.4 | 27.1(+7.0) | ||||||||||||||||
| MM-G-T(c2) | Swin-T | zero-shot | 33.0 | 35.6 | 45.9 | 40.5(+11.7) | 17.3 | 22.6 | 36.4 | 27.1(+7.0) | ||||||||||||||||
| MM-G-T(c3) | Swin-T | zero-shot | 34.2 | 37.4 | 46.2 | 41.4(+12.6) | 23.6 | 27.6 | 40.5 | 31.9(+11.8) |
COCO 基准。 我们对 O365 数据集和其他 PG/REC 数据集上预训练的 MM-Grounding-DINO 进行评估。 继Grounding-DINO之后,COCO数据集用于建立零样本学习基线。 我们在表 3 中比较了 MM-Grounding-DINO-Tiny 和 Grounding-DINO-Tiny。 结果表明,即使仅使用 O365 训练的 MM-G(a)(mAP 48.5)也可以优于使用 O365、Gold-G 和 Cap4M 训练的 G-DINO(c)(mAP 48.4),这证明了我们的效率模型。 使用objects365、Gold-G 和GRIT 进行训练后,MM-G-T(c) 表现出 50.5 mAP 的性能,在 COCO 基准上比 G-DINO(c) 提高了 2.1 AP。 这是在模型在训练期间不暴露于任何 COCO 图像的情况下实现的,并且我们使用的 GRIT 数据()甚至比 Cap4M(4M)还要少。 对此有两种可能的解释:
-
•
我们的训练策略,特别是初始化期间的额外偏差,有助于模型的收敛。
-
•
O365数据集包含COCO数据集的类别。 因此,我们的模型已经在 O365 数据集上进行了广泛的训练,并且自然地在 COCO 数据集上表现出了更高的准确性。 在其他数据集上评估模型时观察到的相对较低的性能间接验证了这一断言。
还观察到,V3Det 数据集的纳入对 COCO 零样本评估没有积极贡献,甚至可能产生有害影响。
LVIS 基准。 LVIS 数据集构成了一个长尾检测数据集,包含 1000 多个不同的评估类别。 继 Grounding-DINO 之后,LVIS 还用于零样本 OVD 评估。 我们在表 4 中比较了 MM-Grounding-DINO-Tiny 和 Grounding-DINO-Tiny。 我们观察到,尽管 MM-G(a) 在没有 Cap4M 的情况下接受了 O365 和 GoldG 的训练,但它仍然在 LVIS MiniVal 和 Val 上超过了 G-DINO(c) +6.9AP。 MM-G(c1) 在 MiniVal 上超过 G-DINO(c) +7.7AP,在 Val 上超过 +7.0AP,在添加 V3Det 后,MM-G(c3) 大幅提高了近 5 AP,达到 上的 mAP 为 >41.4,Val 上的 mAP 为 31.9,在 MiniVal 和 + 上显着超过 G-DINO(c) +12.6 AP Val 11.8 AP! 潜在的原因可以分为两个方面:
-
•
模型展示了更全面的 LVIS 类别词汇训练。
-
•
V3Det包含超过13k个类别,可能涵盖了LVIS的很大一部分类别,[31]中也得出了类似的结论。
| Method | Backbone | Setting | RefCOCO | RefCOCO+ | RefCOCOg | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| val | testA | testB | val | testA | testB | val | test | |||
| G-DINO-T(c) | Swin-T | zero-shot | 50.8 | 57.4 | 45.0 | 51.6 | 57.3 | 46.4 | 60.4 | 59.7 |
| MM-G-T(b) | Swin-T | zero-shot | 53.1 | 59.7 | 46.4 | 53.1 | 58.9 | 47.9 | 61.2 | 61.1 |
| MM-G-T(c1) | Swin-T | zero-shot | 53.4 | 58.8 | 46.8 | 53.5 | 59.0 | 47.9 | 62.7 | 62.6 |
| MM-G-T(c2) | Swin-T | zero-shot | 52.1 | 58.4 | 45.4 | 52.5 | 58.2 | 46.9 | 61.7 | 61.0 |
| MM-G-T(c3) | Swin-T | zero-shot | 53.1 | 59.1 | 46.8 | 52.7 | 58.7 | 48.4 | 62.9 | 62.9 |
| G-DINO-T(c) | Swin-T | - | 89.2 | 91.9 | 86.0 | 81.1 | 87.4 | 74.7 | 84.2 | 84.9 |
| MM-G-T(c3) | Swin-T | 5e | 89.5 | 91.4 | 86.6 | 82.1 | 87.5 | 74.0 | 85.5 | 85.8 |
ODinW 基准。 ODinW(野外对象检测)基准代表了一个更严格的基准,旨在评估现实环境中的模型性能。 它由 35 个对象检测数据集组成,每个数据集都通过外部知识进行了增强。 我们利用 ODinW13/35 来评估我们模型的可迁移性,总结结果如表6所示。 我们的 MM-G-T(c3) 表现出优于 G-DINO-T(c) 的性能,并在 ODinW13 和 ODinW35 上分别获得 53.3 mAP 和 28.4 mAP 的分数,这证明我们的模型具有强大的可移植性。 显然,广泛的词汇表对于 ODinW 数据集具有重要意义。 集成V3Det后,模型的性能得到了大幅提升。 这一改进的主要原因是 V3Det 在 ODinW 中包含了更广泛的类别。 各子数据集的详细结果见附录A.3。
| Model | Backbone | ODinW13 | ODinW35 |
|---|---|---|---|
| G-DINO-T(c) | Swin-T | 51.4 | 22.7 |
| MM-G-T(b) | Swin-T | 45.3 | 20.2 |
| MM-G-T(c1) | Swin-T | 51.1 | 22.8 |
| MM-G-T(c2) | Swin-T | 51.1 | 22.8 |
| MM-G-T(c3) | Swin-T | 53.3(+1.9) | 28.4(+5.7) |
| Method | Backbone | gRefCOCO | ||
|---|---|---|---|---|
| Pr(F1=1, IoU0.5) / N-acc | ||||
| val | testA | testB | ||
| G-DINO-T(c) | Swin-T | 40.5/83.8 | 29.3/82.9 | 30.0/86.1 |
| MM-G-T(c3) | Swin-T | 40.6/83.1 | 29.2/84.3 | 31.6/96.7 |
RefCOCO/+/g 和 gRefCOCO 基准。 我们还评估了 MM-G 在 REC 任务上的零样本能力。 建立RefCOCO、RefCOCO+、RefCOCOg进行REC评估,结果如表5所示。 与 RefCOCO 相比,gRefCOCO 扩大了其范围以涵盖多目标表达式,这需要通过单个表达式指定多个目标对象。 此外,gRefCOCO 还可以容纳不引用图像中任何对象的无目标表达式。 这种增强显着提高了输入表达式的多功能性,从而增强了 REC 在实际应用中的实用性和鲁棒性。 我们还对 gRefCOCO 基准进行了评估,以评估 REC 的零样本能力,结果如表7所示。 我们的模型能够超越 RefCOCO 上所有零样本评估指标的基线,并且可以超过或近似等于 gRefCOCO 上的 G-DINO。 从结果可以看出,V3Det 数据集无法为 REC 任务提供任何好处。
描述检测数据集()基准。 的特点是语言表达灵活,从简洁的类别名称到广泛的描述,保证了所有图像中所描述的所有对象的全面标注,无遗漏。 中的句子比普通单词稍长,因此不需要模型具有很高的理解能力。 事实上,它更倾向于OVD任务。 此外,中有24,282个正对象文本对和7,788,626个负对象文本对,这对模型区分负对象的能力提出了严格的要求。 我们在表 8 中报告了我们的结果。 从结果中,我们观察到使用 GRIT 训练的 MM-G-T(c1) 和使用 Cap4M 训练的 G-DINO-T(c) 表现出了相当的性能。 特别是,MM-G-T(c1) 在长句子中表现出进步,而 G-DINO-T(c) 在处理短句子时表现出进步。 这将在3.2节中详细阐述。 加入包含大量精确标注的V3Det后,MM-G-T(c3)在短句上的性能超过了G-DINO-T(c),而在长句上的性能则变差。 这主要是因为 V3Det 中的大多数文本注释都是短句。
| Method | mode | G-DINO-T(c) | MM-G-T(b) | MM-G-T(c1) | MM-G-T(c2) | MM-G-T(c3) |
|---|---|---|---|---|---|---|
| FULL/s/m/l/vl | concat | 17.2/18.0/18.7/14.8/16.3 | 15.6/17.3/16.7/14.3/13.1 | 17.0/17.7/18.0/15.7/15.7 | 16.2/17.4/16.8/14.9/15.4 | 17.5/23.4/18.3/14.7/13.8 |
| parallel | 22.3/28.2/24.8/19.1/13.9 | 21.7/24.7/24.0/20.2/13.7 | 22.5/25.6/25.1/20.5/14.9 | 22.3/25.6/24.5/20.6/14.7 | 22.9/28.1/25.4/20.4/14.4 | |
| PRES/s/m/l/vl | concat | 17.8/18.3/19.2/15.2/17.3 | 16.4/18.4/17.3/14.5/14.2 | 17.9/19.0/18.3/16.5/17.5 | 16.6/18.8/17.1/15.1/15.0 | 18.0/23.7/18.6/15.4/13.3 |
| parallel | 21.0/27.0/22.8/17.5/12.5 | 21.3/25.5/22.8/19.2/12.9 | 21.5/25.2/23.0/19.0/15.0 | 21.6/25.7/23.0/19.5/14.8 | 21.9/27.4/23.2/19.1/14.2 | |
| ABS/s/m/l/vl | concat | 15.4/17.1/16.4/13.6/14.9 | 13.4/13.4/14.5/13.5/11.9 | 14.5/13.1/16.7/13.6/13.3 | 14.8/12.5/15.6/14.3/15.8 | 15.9/22.2/17.1/12.5/14.4 |
| parallel | 26.0/32.0/33.0/23.6/15.5 | 22.8/22.2/28.7/22.9/14.7 | 25.6/26.8/33.9/24.5/14.7 | 24.1/24.9/30.7/23.8/14.7 | 26.0/30.3/34.1/23.9/14.6 |
| Model | Backbone | Setting |
|
|
|
|
|
|
|
|
||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MM-G-T(c3) | Swin-T | zero-shot | 34.2 | 37.4 | 46.2 | 41.4 | 23.6 | 27.6 | 40.5 | 31.9 | ||||||||||||||||
| MM-G-T(c3) | Swin-T | open-set 1x | 50.7(+16.5) | 58.8(+21.4) | 60.1(+13.9) | 58.7(+17.3) | 45.2(+21.6) | 50.2(+12.6) | 56.1(+15.6) | 51.7(+19.8) | ||||||||||||||||
| MM-G-T(c3) | Swin-T | open vocabulary 1x | 43.2(+9.0) | 57.4(+20.0) | 59.3(+13.1) | 57.1(+15.7) | - | - | - | - |
| Model | Backbone | Setting | mAP |
|---|---|---|---|
| GLIP | Swin-T | zero-shot | 46.6 |
| G-DINO-T(c) | Swin-T | zero-shot | 48.4 |
| MM-G-T(c1) | Swin-T | zero-shot | 50.5(+2.1) |
| MM-G-T(c2) | Swin-T | zero-shot | 50.6(+2.2) |
| MM-G-T(c3) | Swin-T | zero-shot | 50.4(+2.0) |
| Faster R-CNN | R-50 | close-set 1x | 37.4 |
| Cascade R-CNN | R-50 | close-set 1x | 40.3 |
| ATSS | R-50 | close-set 1x | 39.4 |
| TOOD | R-50 | close-set 1x | 42.4 |
| DINO | R-50 | close-set 1x | 50.1 |
| GLIP | Swin-T | close-set 1x | 55.4 |
| G-DINO-T(c) | Swin-T | close-set 1x | 58.1 |
| MM-G-T(c3) | Swin-T | close-set 1x | 58.2(+7.8) |
| MM-G-T(c3) | Swin-T | open-set 1x | 54.7(+4.3) |
3.2GRIT 分析
GRIT[23] 是一个大型数据集,用作我们在 GLIP [16] 中创建的 Cap4M 的替代品,因为后者不是开源的。 然而,从上面的结果可以看出,GRIT 的性能并没有达到我们的预期。 对于 OVD 任务,带有 GRIT 的 MM-G-T(c1) 仅比 MM 在表 3 中的 COCO 上提高了 +0.1 AP,在表 4 中的 LVIS 上仅提高了 +0.1 AP(Val) -G-T(b) 没有勇气。 对于REC任务,GRIT带来的增益在表5和7中的RefCOCO和gRefCOCO上相对较低。 根据我们对 GRIT 中图像和注释的观察,主要原因可以列举如下:
-
•
GRIT 的文字标注来自 spaCy[10] 从 COYO-700M 和 LAION-2B 的字幕中提取的短语或句子,包括大量的人名、事件、设施等摘要短语。地缘政治实体,这可能会导致模型的误导。
-
•
在 GRIT 数据集中,大多数图像都伴有单一的标注。 单个标注包含一个长句子(实际上是图像的整个标题)和一个大约跨越图像整个范围的噪声框。
但值得注意的是,GRIT 的大规模数据仍然有其用途。 带有 GRIT 的 MM-G-T(c1) 在表 6 中的 ODinW13/35 上超过 MM-G-T(b) 5.8/2.6 AP,与用 GRIT 预训练的 G-DINO-T(c) 相当Cap4M。 因此,我们从表 8 中观察到,带有 GRIT 的 MM-G-T(c1) 和带有 Cap4M 的 G-DINO-T(c) 在 上表现出了相当的性能。 幸运的是,GRIT 的单个长文本标注有助于增强 MM-G-T(c1) 在长句子上的表现。
| Method | Backbone | Fine-tune | RTTS11footnotemark: 1 | RUOD11footnotemark: 1 | Brain Tumor22footnotemark: 2 | Cityscapes22footnotemark: 2 | People in Painting22footnotemark: 2 |
|---|---|---|---|---|---|---|---|
| Faster R-CNN | R-50 | ✓ | 48.1 | 52.4 | 43.5 | 30.1 | 17.0 |
| Cascade R-CNN | R-50 | ✓ | 50.8 | 55.3 | 46.2 | 31.8 | 18.0 |
| ATSS | R-50 | ✓ | 48.2 | 55.7 | - | - | - |
| TOOD | R-50 | ✓ | 50.8 | 57.4 | - | - | - |
| DINO | R-50 | ✓ | - | - | 46.4 | 34.5 | 12.0 |
| Cascade-DINO | R-50 | ✓ | - | - | 48.6 | 34.8 | 13.4 |
| MM-GDINO | Swin-T | ✗ | 49.8 | 29.8 | 0.4 | 34.2 | 23.1 |
| MM-GDINO | Swin-T | ✓ | 69.1 | 65.5 | 47.5 | 51.5 | 38.9 |
3.3 通过微调进行验证
本报告中默认的微调是基于MM-G-T(c3)预训练模型。
3.3.1 COCO/LVIS 微调
对COCO来说。 我们使用 MM-Grounding-DINO 实现了三种主流的微调方法来全面评估其能力:封闭集微调、开放集持续预训练微调和开放词汇微调。 后两种微调方法旨在保持模型的泛化性,同时增强 COCO 数据集上的性能。
-
•
在闭集微调中,我们使用闭集算法微调我们的模型,专门针对 COCO 数据集进行优化。 微调后,文本输入仅限于 COCO 类别。
-
•
在开放集持续预训练微调中,我们基于预训练阶段相同的训练策略得出了两种不同的方法。 第一个涉及降低学习率并冻结某些模块,然后继续在 COCO 数据集上训练。 第二种方法将COCO数据集与MM-G-T(c3)的其他预训练数据集结合起来继续训练。
-
•
对于开放词汇微调,我们将数据集分为基础类别和新颖类别。 在微调期间,仅使用基本类别。 随后,我们评估了模型在基础类别和新类别中的表现。
如表10所示,MM-G-T通过闭集微调和开集持续预训练微调,显着提高了COCO数据集上的性能。 值得注意的是,MM-G-T 经过 12 个 epoch 的近集微调后,mAP 提高了 7.8,达到 58.2 mAP。 有关开放词汇微调的更多结果,请参阅附录A.4中的表15。
LVIS 上的压力。 LVIS 数据集具有长尾分布的特点,包含 1203 个类别。 鉴于这种广泛的分类,我们专门对该数据集采用了开放集继续预训练微调和开放词汇微调。
如表9所示,开放集持续预训练微调显着提高了MM-G-T的性能。 值得注意的是,MM-G-T 在 Mini LVIS 的 4 月份指标中实现了 9.0 mAP 的大幅增长。
3.3.2 REC微调
3.3.3 下游任务微调
为了全面展示 MM-Grounding-DINO 的通用性,我们将其评估扩展到各种下游任务。 在微调设置中,模型最初在广泛的数据集上进行训练,然后使用来自相应下游任务的训练集进行专门训练。
雾霾中的物体检测。 我们的研究利用了真实世界任务驱动测试集 (RTTS),其中包含 4,322 张真实世界模糊图像,主要包含交通和驾驶场景[14]。 RTTS 数据集包含雾霾条件下的各种常见类别,提供了一个合适的平台来访问我们的模型在不同环境中的有效性和通用性。 我们采用了基准测试中提出的相同的去雾和检测联合流程。 令人印象深刻的是,经过 12 个 epoch 的微调后,MM-Grounding-DINO 达到了 69.1 AP,大幅超越了之前的标准,如表11所示。
水下物体检测。 在本研究中,我们评估了 MM-Grounding-DINO 在真实水下物体检测数据集 (RUOD)[7] 上的性能。 该数据集包含 14,000 张高分辨率图像和 74,903 个标记实例。 该数据集以其多样化的类别、对象尺度、图像尺度、对象密度和类别密度为特征,还引入了一系列水下挑战。 这些包括雾状效果、色偏、光干扰和复杂的海洋物体。 此评估利用 RUOD 数据集来确定我们的模型在不同图像域中的功能,同时处理常见对象的子集。
表11显示,在零样本设置中,MM-Grounding-DINO 的 mAP 为 29.8,这主要是由于主要由陆地图像组成的训练数据集与 RUOD 之间的分布不匹配。 然而,经过 12 个 epoch 的微调,模型显示出 35.7 mAP 的改进,从而树立了新的基准。 该性能比之前的最先进水平高出 8.1 mAP。
脑肿瘤的物体检测。 我们利用脑肿瘤数据集[2]进一步将我们的评估扩展到医学领域。 值得注意的是,该数据集的标记方法是独一无二的,因为它仅使用数字标识符,而不提供描述性标签信息。 如表11所示,MM-Grounding-DINO 的性能低于 Cascade-DINO[32]。 我们假设我们的模型的相对次优结果可能归因于数据集对纯数字标签的依赖所带来的挑战,特别是在文本上下文完全未知的情况下。
城市景观的物体检测。 Cityscapes[5] 是一个广泛的城市街道场景集合,包含 3k 图像和 500 个验证图像。 它具有在 50 个不同城市的街道上捕获的广泛且多样化的立体视频序列,并附有高质量的像素级注释。 该数据集评估了我们的模型在识别日常生活中遇到的常见物体方面的表现。 值得注意的是,在表 11 中,我们可以观察到我们的预训练 MM-Grounding-DINO 已经与微调模型相媲美,而无需任何特定于数据集的训练。 经过 50 个 epoch 的微调,它的 mAP 提高了 17.3,达到了新的 state-of-the-art。
绘画中人物的对象检测。 People in Paintings [1] 最初由 Raya AI 创建,作为 RF100 的一部分,RF100 是一项旨在为模型泛化性建立新的对象检测基准的计划。 该数据集中的注释仅与绘画中描绘的人物有关。 如表 11 所示,我们的 MM-Grounding-DINO 模型在零样本设置中的性能已经超过了微调模型的性能。 经过 50 个 epoch 的微调后,它表现出了显着的改进,实现了 +15.8AP 的增长,设定了 38.9 mAP 的新基准。
4结论
在本文中,我们提出了MM-Grounding-DINO,这是一种基于Grounding-DINO的综合开源接地基线,并使用丰富的视觉数据集进行了预训练,全面解决OVD、PG和REC任务。 我们扩展了 OVD、PG 和 REC 评估的所有可用基准,并且所有评估指标都可以在 MMDetection 中轻松获得。 对上述基准进行的广泛实验表明,我们的 MM-Grounding-DINO 优于(或相当于)Grounding-DINO 基线。 我们希望我们的管道能够成为进一步研究接地和检测任务的宝贵资源。
参考
- 100 [2023] Roboflow 100. people in paintings dataset. https://universe.roboflow.com/roboflow-100/people-in-paintings, 2023. visited on 2023-12-21.
- AABBCCEEFFGG [2022] AABBCCEEFFGG. Brain tumor detection dataset. https://universe.roboflow.com/aabbcceeffgg/brain-tumor-detection-69d9s, 2022. visited on 2023-12-21.
- Carion et al. [2020] Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers, 2020.
- Chen et al. [2019] Kai Chen, Jiaqi Wang, Jiangmiao Pang, Yuhang Cao, Yu Xiong, Xiaoxiao Li, Shuyang Sun, Wansen Feng, Ziwei Liu, Jiarui Xu, Zheng Zhang, Dazhi Cheng, Chenchen Zhu, Tianheng Cheng, Qijie Zhao, Buyu Li, Xin Lu, Rui Zhu, Yue Wu, Jifeng Dai, Jingdong Wang, Jianping Shi, Wanli Ouyang, Chen Change Loy, and Dahua Lin. MMDetection: Open mmlab detection toolbox and benchmark. arXiv preprint arXiv:1906.07155, 2019.
- Cordts et al. [2016] Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, and Bernt Schiele. The cityscapes dataset for semantic urban scene understanding, 2016.
- Devlin et al. [2019] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding, 2019.
- Fu et al. [2023] Chenping Fu, Risheng Liu, Xin Fan, Puyang Chen, Hao Fu, Wanqi Yuan, Ming Zhu, and Zhongxuan Luo. Rethinking general underwater object detection: Datasets, challenges, and solutions. Neurocomputing, 517:243–256, 2023.
- Gupta et al. [2019] Agrim Gupta, Piotr Dollár, and Ross Girshick. Lvis: A dataset for large vocabulary instance segmentation, 2019.
- He et al. [2023] Shuting He, Henghui Ding, Chang Liu, and Xudong Jiang. Grec: Generalized referring expression comprehension, 2023.
- Honnibal et al. [2020] Matthew Honnibal, Ines Montani, Sofie Van Landeghem, and Adriane Boyd. spaCy: Industrial-strength Natural Language Processing in Python. 2020.
- Hudson and Manning [2019] Drew A Hudson and Christopher D Manning. Gqa: A new dataset for real-world visual reasoning and compositional question answering. Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
- Kamath et al. [2021] Aishwarya Kamath, Mannat Singh, Yann LeCun, Gabriel Synnaeve, Ishan Misra, and Nicolas Carion. Mdetr – modulated detection for end-to-end multi-modal understanding, 2021.
- Kazemzadeh et al. [2014] Sahar Kazemzadeh, Vicente Ordonez, Mark Matten, and Tamara Berg. ReferItGame: Referring to objects in photographs of natural scenes. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 787–798, Doha, Qatar, 2014. Association for Computational Linguistics.
- Li et al. [2019] Boyi Li, Wenqi Ren, Dengpan Fu, Dacheng Tao, Dan Feng, Wenjun Zeng, and Zhangyang Wang. Benchmarking single image dehazing and beyond, 2019.
- Li et al. [2022a] Chunyuan Li, Haotian Liu, Liunian Harold Li, Pengchuan Zhang, Jyoti Aneja, Jianwei Yang, Ping Jin, Houdong Hu, Zicheng Liu, Yong Jae Lee, and Jianfeng Gao. Elevater: A benchmark and toolkit for evaluating language-augmented visual models, 2022a.
- Li et al. [2022b] Liunian Harold Li, Pengchuan Zhang, Haotian Zhang, Jianwei Yang, Chunyuan Li, Yiwu Zhong, Lijuan Wang, Lu Yuan, Lei Zhang, Jenq-Neng Hwang, Kai-Wei Chang, and Jianfeng Gao. Grounded language-image pre-training, 2022b.
- Lin et al. [2015] Tsung-Yi Lin, Michael Maire, Serge Belongie, Lubomir Bourdev, Ross Girshick, James Hays, Pietro Perona, Deva Ramanan, C. Lawrence Zitnick, and Piotr Dollár. Microsoft coco: Common objects in context, 2015.
- Lin et al. [2018] Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollár. Focal loss for dense object detection, 2018.
- Liu et al. [2023a] Chang Liu, Henghui Ding, and Xudong Jiang. Gres: Generalized referring expression segmentation, 2023a.
- Liu et al. [2023b] Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, and Lei Zhang. Grounding dino: Marrying dino with grounded pre-training for open-set object detection, 2023b.
- Liu et al. [2021] Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows, 2021.
- Mao et al. [2016] Junhua Mao, Jonathan Huang, Alexander Toshev, Oana Camburu, Alan Yuille, and Kevin Murphy. Generation and comprehension of unambiguous object descriptions, 2016.
- Peng et al. [2023] Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, and Furu Wei. Kosmos-2: Grounding multimodal large language models to the world, 2023.
- Plummer et al. [2017] Bryan A. Plummer, Liwei Wang, Christopher M. Cervantes, Juan C. Caicedo, Julia Hockenmaier, and Svetlana Lazebnik. Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models. IJCV, 123(1):74–93, 2017.
- Radford et al. [2021] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision, 2021.
- Rezatofighi et al. [2019] Hamid Rezatofighi, Nathan Tsoi, JunYoung Gwak, Amir Sadeghian, Ian Reid, and Silvio Savarese. Generalized intersection over union: A metric and a loss for bounding box regression, 2019.
- Shao et al. [2019] Shuai Shao, Zeming Li, Tianyuan Zhang, Chao Peng, Gang Yu, Xiangyu Zhang, Jing Li, and Jian Sun. Objects365: A large-scale, high-quality dataset for object detection. In 2019 IEEE/CVF International Conference on Computer Vision (ICCV), pages 8429–8438, 2019.
- Wang et al. [2023] Jiaqi Wang, Pan Zhang, Tao Chu, Yuhang Cao, Yujie Zhou, Tong Wu, Bin Wang, Conghui He, and Dahua Lin. V3det: Vast vocabulary visual detection dataset, 2023.
- [29] Jianzong Wu, Xiangtai Li, Shilin Xu, Haobo Yuan, Henghui Ding, Yibo Yang, Jiangning Zhang, Yunhai Tong, Xudong Jiang, Bernard Ghanem, and Dacheng Tao. Towards open vocabulary learning: A survey.
- Xie et al. [2023] Chi Xie, Zhao Zhang, Yixuan Wu, Feng Zhu, Rui Zhao, and Shuang Liang. Described object detection: Liberating object detection with flexible expressions, 2023.
- Yang et al. [2023] Haosen Yang, Chuofan Ma, Bin Wen, Yi Jiang, Zehuan Yuan, and Xiatian Zhu. Recognize any regions, 2023.
- Ye et al. [2023] Mingqiao Ye, Lei Ke, Siyuan Li, Yu-Wing Tai, Chi-Keung Tang, Martin Danelljan, and Fisher Yu. Cascade-detr: Delving into high-quality universal object detection, 2023.
- Yu et al. [2016] Licheng Yu, Patrick Poirson, Shan Yang, Alexander C. Berg, and Tamara L. Berg. Modeling context in referring expressions, 2016.
- Zhang et al. [2022] Hao Zhang, Feng Li, Shilong Liu, Lei Zhang, Hang Su, Jun Zhu, Lionel M. Ni, and Heung-Yeung Shum. Dino: Detr with improved denoising anchor boxes for end-to-end object detection, 2022.
- Zuwei Long [2023] Wei Li Zuwei Long. Open grounding dino:the third party implementation of the paper grounding dino. https://github.com/longzw1997/Open-GroundingDino, 2023.
补充材料
附录 A更多结果
A.1 gRefCOCO 上的详细结果
在我们的实验中,我们最初将默认阈值设置为 0.7,遵循 [19]。 然后我们使用不同的阈值进行了一系列广泛的测试。 这些不同阈值对我们结果的影响详见表12. 我们观察到阈值调整对输出的明显影响。 具体来说,阈值 0.8 产生验证集的最高 F1 分数。 相比之下,对于测试集 A 和 B,较低的阈值 0.5 被证明更有效。 这导致人们期望为此数据集开发更强大的评估指标。 值得注意的是,经过微调过程(阈值设置为 0.7)后,gRefCOCO 的所有子集都表现出了显着的改进。
A.2 Flickr30K 实体的详细结果
如表13,与 Flickr30K 实体上的 G-DINO-T 相比,MM-G-T(c) 表现出较低的性能。 鉴于 GoldG 数据集包含来自 Flickr30K 实体的图像,需要注意的是,这些结果并不代表零样本场景。 观察到的表现差异可能归因于训练策略和设置的变化。
A.3 ODinW 数据集的详细结果
我们在表中提供了我们使用的 35 个数据集的详细信息14. 考虑到 ODinW13/35 数据集中类别的稀有性,GRIT 和 V3Det 数据集带来的附加概念被证明是有益的。
A.4 COCO 上的开放词汇微调
| Method | Threshold | Setting | gRefCOCO | ||
|---|---|---|---|---|---|
| Pr(F1=1, IoU0.5) | |||||
| val | testA | testB | |||
| G-DINO-T(c) | 0.5 | zero-shot | 39.3 | 31.9 | 30.0 |
| G-DINO-T(c) | 0.6 | zero-shot | 40.5 | 29.3 | 30.0 |
| G-DINO-T(c) | 0.7 | zero-shot | 41.3 | 27.2 | 29.7 |
| G-DINO-T(c) | 0.8 | zero-shot | 41.5 | 25.1 | 29.1 |
| MM-G-T(c3) | 0.5 | zero-shot | 39.4 | 33.1 | 33.0 |
| MM-G-T(c3) | 0.6 | zero-shot | 40.6 | 29.2 | 31.6 |
| MM-G-T(c3) | 0.7 | zero-shot | 41.0 | 26.1 | 30.4 |
| MM-G-T(c3) | 0.8 | zero-shot | 41.1 | 23.8 | 29.5 |
| MM-G-T(c3) | 0.7 | fine-tune | 45.1(+4.1) | 42.5(+16.4) | 40.3(+9.9) |

附录 B可视化
B.1 预训练数据集的可视化
如图4,我们展示了预训练数据集的可视化。 我们对这些数据集的分析揭示了一些可能会破坏训练有效性的噪声元素。 例如,某些标题包含虚词,但没有实质性内容,例如左上图像中的“谁”和专有名词,例如左下图像中的人名。 此外,GRIT 数据集利用 GLIP 生成伪标签,注释可能不准确。 这在右下图像中很明显,其中框注释似乎分配不正确。 GQA数据集中也有类似的情况。 在右上角的图像中,标题中的同一短语“女人”被分配到不同的框,这与短语基础设置相矛盾。
| Model | Pre-Train Data | Val R@1 | Val R@5 | Val R@10 | Test R@1 | Test R@5 | Test R@10 |
|---|---|---|---|---|---|---|---|
| GLIP-T | O365,GoldG | 84.9 | 94.9 | 96.3 | 85.6 | 95.4 | 96.7 |
| GLIP-T | O365,GoldG,CC3M,SBU | 85.3 | 95.5 | 96.9 | 86.0 | 95.9 | 97.2 |
| G-DINO-T(c) | O365,GoldG,Cap4M | 87.8 | 96.6 | 98.0 | 88.1 | 96.9 | 98.2 |
| MM-G-T(b) | O365,GoldG | 85.5 | 95.6 | 97.2 | 86.2 | 95.7 | 97.4 |
| MM-G-T(c1) | O365,GoldG,GRIT | 86.7 | 95.8 | 97.6 | 87.0 | 96.2 | 97.7 |
| MM-G-T(c2) | O365,GoldG,GRIT | 86.7 | 95.8 | 97.6 | 87.0 | 96.2 | 97.7 |
| MM-G-T(c3) | O365,GoldG,GRIT,V3Det | 86.7 | 96.0 | 97.6 | 87.2 | 96.2 | 97.7 |
| Method | OdinW13 | ODinW35 | G-DINO-T(c) | MM-G-T(b) | MM-G-T(c1) | MM-G-T(c2) | MM-G-T(c3) |
|---|---|---|---|---|---|---|---|
| AerialMaritimeDrone_large | ✓ | ✓ | 0.173 | 0.133 | 0.155 | 0.177 | 0.151 |
| AerialMaritimeDrone_tiled | ✓ | 0.206 | 0.170 | 0.225 | 0.184 | 0.206 | |
| AmericanSignLanguageLetters | ✓ | 0.002 | 0.016 | 0.020 | 0.011 | 0.007 | |
| Aquarium | ✓ | ✓ | 0.195 | 0.252 | 0.261 | 0.266 | 0.283 |
| BCCD | ✓ | 0.161 | 0.069 | 0.118 | 0.083 | 0.077 | |
| boggleBoards | ✓ | 0.000 | 0.002 | 0.001 | 0.001 | 0.002 | |
| brackishUnderwater | ✓ | 0.021 | 0.033 | 0.021 | 0.025 | 0.025 | |
| ChessPieces | ✓ | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| CottontailRabbits | ✓ | ✓ | 0.806 | 0.771 | 0.810 | 0.778 | 0.786 |
| dice | ✓ | 0.004 | 0.002 | 0.005 | 0.001 | 0.001 | |
| DroneControl | ✓ | 0.042 | 0.047 | 0.097 | 0.088 | 0.074 | |
| EgoHands_generic | ✓ | 0.608 | 0.527 | 0.537 | 0.506 | 0.519 | |
| EgoHands_specific | ✓ | 0.002 | 0.001 | 0.005 | 0.007 | 0.003 | |
| EgoHands | ✓ | 0.608 | 0.499 | 0.537 | 0.506 | 0.519 | |
| HardHatWorkers | ✓ | 0.046 | 0.048 | 0.070 | 0.070 | 0.108 | |
| MaskWearing | ✓ | 0.004 | 0.009 | 0.004 | 0.011 | 0.009 | |
| MountainDewCommercial | ✓ | 0.430 | 0.453 | 0.465 | 0.194 | 0.430 | |
| NorthAmericaMushrooms | ✓ | ✓ | 0.471 | 0.331 | 0.462 | 0.669 | 0.767 |
| openPoetryVision | ✓ | 0.000 | 0.001 | 0.000 | 0.000 | 0.000 | |
| OxfordPets_by_breed | ✓ | 0.003 | 0.002 | 0.004 | 0.006 | 0.004 | |
| OxfordPets_by_species | ✓ | 0.011 | 0.019 | 0.016 | 0.020 | 0.015 | |
| PKLot | ✓ | 0.001 | 0.004 | 0.002 | 0.008 | 0.007 | |
| Packages | ✓ | ✓ | 0.695 | 0.707 | 0.687 | 0.710 | 0.706 |
| PascalVOC | ✓ | ✓ | 0.563 | 0.565 | 0.580 | 0.566 | 0.566 |
| pistols | ✓ | ✓ | 0.726 | 0.585 | 0.709 | 0.671 | 0.729 |
| plantdoc | ✓ | 0.005 | 0.005 | 0.007 | 0.008 | 0.011 | |
| pothole | ✓ | ✓ | 0.215 | 0.136 | 0.219 | 0.077 | 0.168 |
| Raccoons | ✓ | ✓ | 0.549 | 0.469 | 0.511 | 0.553 | 0.535 |
| selfdrivingCar | ✓ | 0.089 | 0.091 | 0.076 | 0.094 | 0.083 | |
| ShellfishOpenImages | ✓ | ✓ | 0.393 | 0.321 | 0.437 | 0.519 | 0.488 |
| ThermalCheetah | ✓ | 0.087 | 0.063 | 0.081 | 0.030 | 0.045 | |
| thermalDogsAndPeople | ✓ | ✓ | 0.657 | 0.556 | 0.603 | 0.493 | 0.543 |
| UnoCards | ✓ | 0.006 | 0.012 | 0.010 | 0.009 | 0.005 | |
| VehiclesOpenImages | ✓ | ✓ | 0.613 | 0.566 | 0.603 | 0.614 | 0.615 |
| WildfireSmoke | ✓ | 0.134 | 0.106 | 0.154 | 0.042 | 0.127 | |
| websiteScreenshots | ✓ | 0.012 | 0.02 | 0.016 | 0.016 | 0.016 | |
| ODinW13 Average | 0.514 | 0.453 | 0.511 | 0.516 | 0.533 | ||
| ODinW35 Average | 0.227 | 0.202 | 0.228 | 0.214 | 0.284 |
| Model | Backbone | Setting | mAP | AP@50 | ||||
|---|---|---|---|---|---|---|---|---|
| box | Base | Novel | box | Base | Novel | |||
| MM-G-T(c3) | Swin-T | zero-shot | 51.1 | 48.4 | 58.9 | 66.7 | 64.0 | 74.2 |
| MM-G-T(c3) | Swin-T | open vocabulary 1x | 57.2(+8.8) | 56.1(+7.7) | 60.4(+1.5) | 73.6(+6.9) | 73.0(+9.0) | 75.3(+1.1) |

B.2 模型预测的可视化
评估的局限性。 我们对评估过程进行基于可视化的分析揭示了评估数据集的真实注释中的不准确性。 这在图中很明显 5,关于“女孩”对象,我们的模型的预测似乎比现有的注释更精确。
模型的局限性。 在预训练阶段,虽然模型可以访问整个标题,但它倾向于优先考虑名词,这对于短语基础设置至关重要。 例如,如图所示的标题“不戴头盔的骑士” 5(a),该模型主要关注“骑士”和“头盔”,但忽略了关键的关系术语“没有”。 这导致无法区分“头盔”和“不戴头盔”。 此外,该模型很难解释某些详细描述,如图所示 5(b),模型错误地检测到“马越过栏杆”。 就标题中的位置描述而言,模型仅实现了次优性能,如图所示 5(c),这将左侧的对象与右侧的对象混淆了。 图中 5,由于短语接地设置,我们的模型还预测了“飞盘”,这导致评估性能较低。


