tcb@breakable kattributesattributestyleattributestyleld
Chain-of-Table:
推理链中的演化表以实现表理解
摘要
基于表格的大型语言模型推理(大语言模型)是解决许多表格理解任务的一个有前途的方向,例如基于表格的问答和事实验证。 与通用推理相比,基于表格的推理需要从自由形式的问题和半结构化表格数据中提取底层语义。 思想链及其类似方法以文本上下文的形式整合了推理链,但如何在推理链中有效利用表格数据仍然是一个悬而未决的问题。 我们建议 表链 框架,其中表格数据在推理链中明确使用作为中间思想的代理。 具体来说,我们指导大语言模型使用上下文学习来迭代生成操作并更新表格以表示表格推理链。 因此大语言模型可以 动态计划 根据前面操作的结果进行下一步操作。 表格的这种不断演变形成了一条链,显示了给定表格问题的推理过程。 该链承载中间结果的结构化信息,从而实现更准确、更可靠的预测。 表链 在 WikiTQ、FeTaQA 和 TabFact 基准测试中跨多个大语言模型选择实现了新的最先进性能。
1 介绍
表格是一种流行的数据格式,在日常生活中广泛使用(Cafarella 等人,2008)。 使用语言模型理解表格数据可以使各种下游任务受益,例如基于表格的事实验证(陈等人,2019)和基于表格的问答(金等人,2022) 。 与纯文本不同,表格通过表格结构中行与列之间的交互来传递丰富的信息,这增强了数据容量,但也增加了语言模型理解它们的难度。 因此,表格数据的推理是自然语言处理的一个重要方向,并越来越受到学术界和工业界的关注。
近年来,人们提出了几种通过训练来解决表格理解问题的方法训练 语言模型。 一个常见的方向是在语言模型中添加专门的嵌入层或注意力机制,并通过恢复表格单元格或片段来预训练模型(Herzig 等人,2020;Wang 等人,2021;Gu 等人,2022;Andrejczuk等人,2022)。 通过这种方式,预训练的模型就可以了解表格结构。 另一个方向是合成 SQL 查询-响应对并预训练编码器-解码器模型作为神经 SQL 执行器(Eisenschlos 等人,2020;Liu 等人,2021;Jiang 等人,2022) 。
最近,大型语言模型(大语言模型)仅通过提示提示即可在各种任务中取得出色的性能,得益于大规模的预训练(Brown等人,2020;Kojima等人,2022)。 随着一系列提示技术的工作通过设计推理链进一步提高了大语言模型的可靠性,如Chain-of-Thought (Wei 等人, 2022)、Least-to-Most (周等人,2022)、思想纲领(陈等人,2022)和思想树(姚等人,2023) t3>. 不同的工作还探索了使用大语言模型解决基于表格的问题的可能性(Chen,2023;Cheng等人,2022;Ye等人,2023)。 然而,这些方法(Hsieh等人,2023)通常表示自由格式文本或代码中的推理步骤,不太适合解决涉及复杂表格的场景,如图所示 1(a)和图1(b)。

另一方面,表推理通常涉及一系列中间推理步骤,每个步骤都与特定的表格操作相关。 我们提出Chain-of-Table,我们将逐步推理作为逐步的表格运算来形成链条 的桌子。 链中的表是经过表格运算转换后的表,代表中间推理结果。 此过程类似于 想法 思想链推理(Wei 等人,2022)。 具体来说,我们定义了一组表操作,例如添加列、选择行、分组等,这些操作在 SQL 和 DataFrame 开发中常用(Pönighaus, 1995; Shi 等人, 2020; Katsogiannis-Meimarakis &Koutrika,2023)。 然后我们提示大语言模型进行逐步推理。 在每个步骤中,大语言模型都会动态生成一个操作作为下一步及其所需的参数,然后我们以编程方式在表上执行该操作。 此操作可以通过添加详细的中间结果来丰富表格,也可以通过删除不相关的信息来压缩表格。 直观地说,可视化中间结果对于实现正确的预测至关重要。 我们将转换后的表反馈给下一步。 这个迭代过程一直持续到达到结束状态。 我们认为,在推理步骤中获得的表格比自由格式的文本更能结构化地表示中间思想。 最后, 表链 推理结果形成表格,大语言模型更容易从中得出问题的最终答案。
我们验证表链 使用三个表格基准来评估基于表格的推理:WikiTQ (Pasupat & Liang, 2015)、TabFact (Chen 等人, 2019) 和 FeTaQA (Nan等人,2022)。 我们使用专有的 PaLM 2 (Anil 等人, 2023) 和 GPT-3.5 (Brown 等人, 2020; OpenAI, 2023) 以及开源 LLaMA 进行实验2 (Touvron 等人, 2023),证明我们提出的方法 表链 能够推广到各种大语言模型选项。 我们的贡献总结如下:
-
•
我们将思想链的概念扩展到表格设置,其中我们转换输入表以存储中间结果。 这种带有表格演化的多步骤表格推理方法可以带来更准确的表格理解。
-
•
基于表的事实验证和问答的大量实验表明Chain-of-Table 在 WikiTQ、TabFact 和 FeTaQA 数据集中存档最先进的性能。
2 相关工作
微调语言模型以实现表理解
表格可以有效地组织、存储和分析信息。 人们已经在语言模型(LM)上做出了努力来解决表理解任务。 继 BERT (Devlin 等人, 2019) 中成功提出掩码语言建模(MLM)之后,TaPas (Herzig 等人, 2020) 采用了这种方法,并要求模型在预训练期间重建表中的某些单元格。 Pasta (Gu 等人, 2022) 和 TUTA (Wang 等人, 2021) 进一步提出屏蔽表中的整个列或段。 另一方面,TAPEX (Liu 等人, 2021) 使用大型合成 SQL 数据集预训练编码器-解码器模型,以便它可以作为 SQL 执行器执行,以更好地理解表格结构。 Eisenschlos 等人 (2020) 和 Jiang 等人 (2022) 还利用合成 SQL,通过使用以下命令预训练模型,额外考虑 SQL 和自然语言问题之间的一致性:自然数据和合成数据。
表理解的提示语言模型
大语言模型可以通过上下文学习从少量样本作为提示进行学习。 该策略被广泛用于为模型提供额外的指令,以更好地解决下游任务。 Chain-of-Thought (CoT) (Wei 等人, 2022) 提出在回答之前生成推理步骤,而不是直接生成端到端答案。 继 CoT 之后,Least-to-Most (Zhou 等人, 2022) 和 DecomP (Khot 等人, 2022) 提出将问题分解为推理链中的子问题。 在推理过程中,后面的步骤知道前面的步骤。 这种具有任务分解的迭代链通过利用解决子问题的中间结果进一步改善复杂问题的结果。 Jin & Lu (2023) 通过表格填充过程增强 CoT,主要关注输入和输出均为文本格式的基于文本的任务。 然而,CoT 之后的工作系列并不是专门为表格数据设计的。 正如 Chen (2023) 所报道的,使用这些通用推理方法的大型语言模型可以取得不错的结果,但这些方法与专门针对表格场景的方法之间仍然存在差距(Cheng 等人, 2022;叶等人,2023)。 我们建议 表链 通过直接合并表格操作中的中间表作为中间思想的代理来填补空白。
为了更好地使用大语言模型解决基于表格的任务,研究人员超越了一般文本,并诉诸于使用外部工具。 Chen 等人 (2022);高等人(2023)提出通过生成Python程序来解决推理任务,然后使用Python解释器执行这些程序。 这种方法极大地提高了算术推理的性能。 在表理解的场景中,大语言模型的 Text-to-SQL (Rajkumar 等人, 2022) 就是这个思想的直接应用。 为了进一步突破程序的极限,Binder(程等人,2022)生成SQL或Python程序,并通过在程序中调用大语言模型作为API来扩展其功能。 LEVER (Ni 等人, 2023) 还建议用程序解决基于表的任务,但需要额外的步骤来验证生成的程序及其执行结果。 然而,这些程序辅助方法中的辅助程序在解决涉及复杂表格的困难情况方面仍然存在不足。 这些限制主要是由于 单程 生成过程中,大语言模型缺乏针对特定问题修改表的能力,需要它们对静态表进行推理。 相反,我们的方法是 多重步骤 逐步进行表格推理的推理框架。 它转换针对给定问题定制的表格。
据我们所知,Dater (Ye 等人, 2023) 是唯一在解决基于表格的任务时修改表格上下文的模型。 然而,Dater 中的表分解的动机是表太大,大语言模型无法进行推理。 因此,它更类似于 LLM 辅助的数据预处理,而不是推理链的一部分,因为表格操作仅限于列和行选择,并且对于所有表格和问题都是固定的。 相比之下,我们的 Chain-of-Table概括了一组更大的通用表操作,并且动态地 利用大语言模型的规划能力(Valmeekam等人,2022;Hao等人,2023),根据输入自适应地生成推理链。
3 表链推理
问题表述。
在基于表格的推理中,每个条目可以表示为一个三元组,其中代表表,表示与表相关的问题或陈述, 是预期的答案。 特别是在基于表格的问答任务中, 和是自然语言形式的问题和预期答案;在基于表格的事实验证任务中,是关于表格内容的陈述, 是一个布尔值,指示语句的正确性。 目标是根据问题和表格来预测答案。为了在通用推理所采用的同一范例中促进基于表格的推理,我们将包括表格在内的所有数据值转换为文本表示(参见附录D 用于表格格式编码方法)。
3.1 概述
Chain-of-Table使大语言模型能够动态规划表上的一系列操作回答给定问题. 它利用基于原子工具的操作来构建表链。 这些操作包括添加列、选择行或列、分组和排序,这些操作在 SQL 和 DataFrame 开发中很常见(请参阅附录 A 更多细节)。
此前,Dater (Ye 等人, 2023) 采用专用但固定的过程来分解表格和问题,这限制了其与新操作的兼容性。 此外,Binder (Cheng 等人,2022) 虽然可能与新操作兼容,但仅限于与 SQL 或 Python 等代码解释器一起使用的操作。 相比之下,我们的框架是可扩展的,并且由于具有灵活的上下文学习能力来采样和执行有效操作,因此可以合并来自各种工具的操作。
如算法1所示,在每次迭代时,我们提示大语言模型对预定义的原子操作之一进行采样,表示为f使用相应的问题,最新的表状态,以及操作链链0> (第 4 行)。 然后,我们查询大语言模型来生成所需的参数 args for f(第5行)并执行它来转换表格 (第 6 号线)。 我们跟踪操作情况 f对操作链中的表执行chain (7 号线)。 当结束标签结束时,该过程结束 [E] 生成(第 8 行)。 最后,我们将最新的表格输入到大语言模型中来预测答案(第9行)。 这一系列的操作作为推理步骤,引导大语言模型理解输入表并更好地生成最终答案。
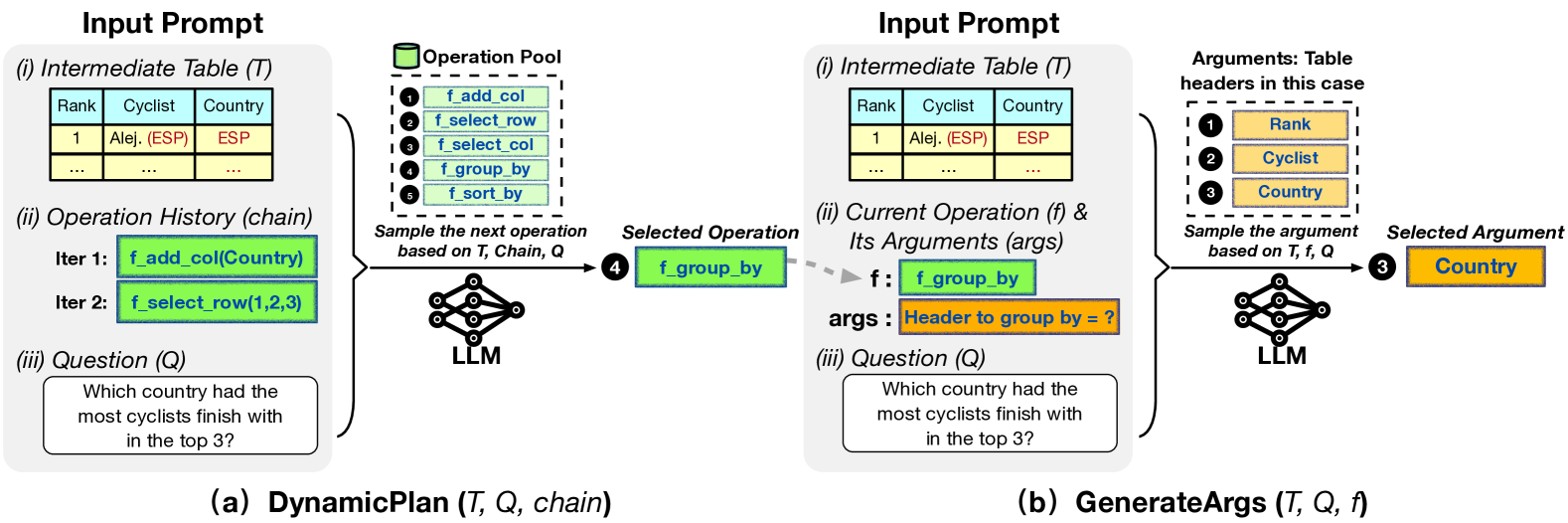
3.2 动态规划
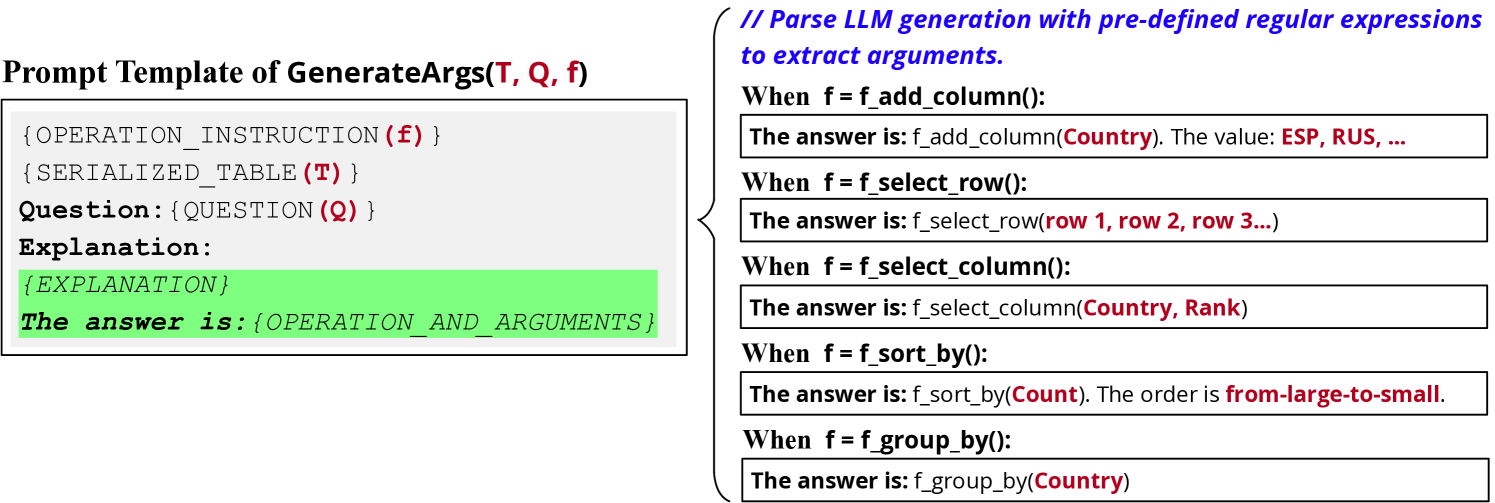
3.3 参数生成
3.4 最终查询
4 实验
我们评估提议的Chain-of-Table 基于三个公共表理解基准:WikiTQ (Pasupat & Liang,2015)、FeTaQA (Nan 等人,2022) 和 TabFact (Chen 等人,2019) )。 WikiTQ 和 FeTaQA 是专注于基于表格的问答的数据集。 他们需要对所提供的表格进行复杂的表格推理来回答问题。 WikiTQ 通常需要简短的文本范围答案,而 FeTaQA 则需要更长的、自由格式的响应。 另一方面,TabFact 是一个基于表的二进制事实验证基准。 任务是根据表格确定给定陈述的真实性。 对于 WikiTQ 评估,我们使用官方表示精度(Pasupat & Liang,2015),对于 TabFact,我们使用二元分类精度。 鉴于 FeTaQA 的性质,涉及将预测与较长的目标文本进行比较,我们利用 BLEU (Papineni 等人, 2002)、ROUGE-1、ROUGE-2 和 ROUGE-L (Lin ,2004)进行评估。 在我们的实验中,我们使用PaLM 2-S111https://cloud.google.com/vertex-ai/docs/generative-ai/learn/generative-ai-studio,GPT 3.5(turbo-16k-0613)2 22http://openai.com/api/和LLaMA 2(Llama-2-17B-聊天)5>37>33https://ai.meta.com/llama/ 作为大语言模型的骨干。 我们将训练集中的少样本演示样本合并到提示中以执行上下文学习。 这些提示的示例可以在附录中找到 E。有关大语言模型推理参数和所使用的演示样本数量的详细信息,请参阅附录C。
4.1 基线
基线方法分为两类:(a) 通用推理,包括端到端 QA、少样本 QA、思想链(Wei 等人, 2022); (b) 程序辅助推理,包括 Text-to-SQL (Rajkumar 等人, 2022)、Binder (Cheng 等人, 2022)、Dater (叶等人,2023))。 下面提供了这些基线方法的详细描述。
| Prompting | PaLM 2 | GPT 3.5 | LLaMA 2 | |||
|---|---|---|---|---|---|---|
| TabFact | WikiTQ | TabFact | WikiTQ | TabFact | WikiTQ | |
| Generic Reasoning | ||||||
| End-to-End QA | 77.92 | 60.59 | 70.45 | 51.84 | 44.86 | 23.90 |
| Few-Shot QA | 78.06 | 60.33 | 71.54 | 52.56 | 62.01 | 35.52 |
| Chain-of-Thought (Wei et al., 2022) | 79.05 | 60.43 | 65.37 | 53.48 | 60.52 | 36.05 |
| Program-aided Reasoning | ||||||
| Text-to-SQL (Rajkumar et al., 2022) | 68.37 | 52.42 | 64.71 | 52.90 | 64.03 | 36.14 |
| Binder (Cheng et al., 2022) | 76.98 | 54.88 | 79.17 | 56.74 | 62.76 | 30.92 |
| Dater (Ye et al., 2023) | 84.63 | 61.48 | 78.01 | 52.81 | 65.12 | 41.44 |
| Chain-of-Table (ours) | 86.61 (+1.98) | 67.31 (+5.83) | 80.20 (+1.03) | 59.94 (+3.20) | 67.24 (+2.12) | 42.61 (+1.17) |
通用推理
端到端QA指导大语言模型在提供表格和问题作为输入提示时直接给出答案。 少样本 QA 操作类似,但它在提示中包含(表、问题、答案)三元组的少样本示例,详见 Brown 等人 (2020)。 我们从训练集中选择这些示例,模型也直接输出答案。 思想链(Wei等人,2022)提示大语言模型在提出问题之前以文本格式阐明其推理过程。 参见附录 F 对于基线的提示。
程序辅助推理
Text-to-SQL (Rajkumar 等人, 2022) 利用上下文样本来指导大语言模型生成 SQL 查询来回答问题。 这种方法遵循 Chen 等人 (2022) 引入的概念;高等人(2023)。 Binder (Cheng 等人, 2022) 将语言模型 API 与 SQL 或 Python 等编程语言集成。 这种集成促使大语言模型生成可执行程序,对给定的表格和问题执行表格推理任务。 Dater (叶等人,2023)采用少样本样本来高效解构表格上下文和问题,通过分解的子表和子问题增强端到端表格推理。
4.2 结果
我们比较Chain-of-Table 在三个数据集上使用通用推理方法和程序辅助推理方法:WikiTQ、TabFact 和 FeTaQA。 WikiTQ 和 TabFact 上的结果如表所示 1。我们在附录 B 中提供了有关 FeTaQA 的其他结果。我们遵循之前的工作并使用官方评估管道报告性能444日期者 Ye 等人 (2023) 使用 OpenAI Codex 大语言模型在 WikiTQ 和 TabFact 上分别实现了 65.9% 和 85.6% 的准确率。 在 FeTaQA 上,它的 BLEU 得分为 27.96,ROUGE-1 得分为 0.62,ROUGE-2 得分为 0.40,ROUGE-L 得分为 0.52。 但是,由于 Codex 不再公开,因此我们不会将 Chain-of-Table 与 Dater 与 Codex 进行比较。.
表1显示表链 在 PaLM 2、GPT 3.5 和 LLaMA 2 上,TabFact 和 WikiTQ 上的所有通用推理方法和程序辅助推理方法都显着优于所有通用推理方法和程序辅助推理方法。 这归因于动态采样操作和信息丰富的中间表 表链。 表链 迭代生成充当表格推理步骤代理的操作。 这些操作生成并向大语言模型呈现定制的中间表,传达基本的中间思想(参见图1中的示例) 4)。在Chain-of-Table的支持下,大语言模型能够可靠地得出正确答案。
从结果中,我们观察到,当使用 PaLM 2 将普通思想链引入端到端 QA 时,由于表格结构的复杂性,WikiTQ 的性能有所下降。 相比之下,我们提出的 表链 使用 PaLM 2 将 TabFact 上的端到端 QA 性能持续提高 8.69%,将 WikiTQ 上的端到端 QA 性能提高 6.72%。
我们还观察到我们提出的Chain-of-Table 在所有实验的骨干模型中都是有效的,而其他竞争方法,例如 Binder,在较大的大语言模型上表现更好,但其性能随着较小的 LLaMA 2 (Llama-2-17B-chat) 而下降。 我们将这种下降归因于 Binder 单程 生成过程。 虽然 Binder 确实在其框架中合并了 API 调用,但它缺乏修改和观察转换后的表的功能。 因此,Binder 只能在静态表上进行表格推理,这使得用较小的大语言模型解决复杂的情况变得具有挑战性。
| Dataset | Length of operation chain | ||||
|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | |
| WikiTQ | 95 | 1308 | 1481 | 1084 | 341 |
| TabFact | 4 | 547 | 732 | 517 | 223 |
4.3 不同操作链长度下的性能分析
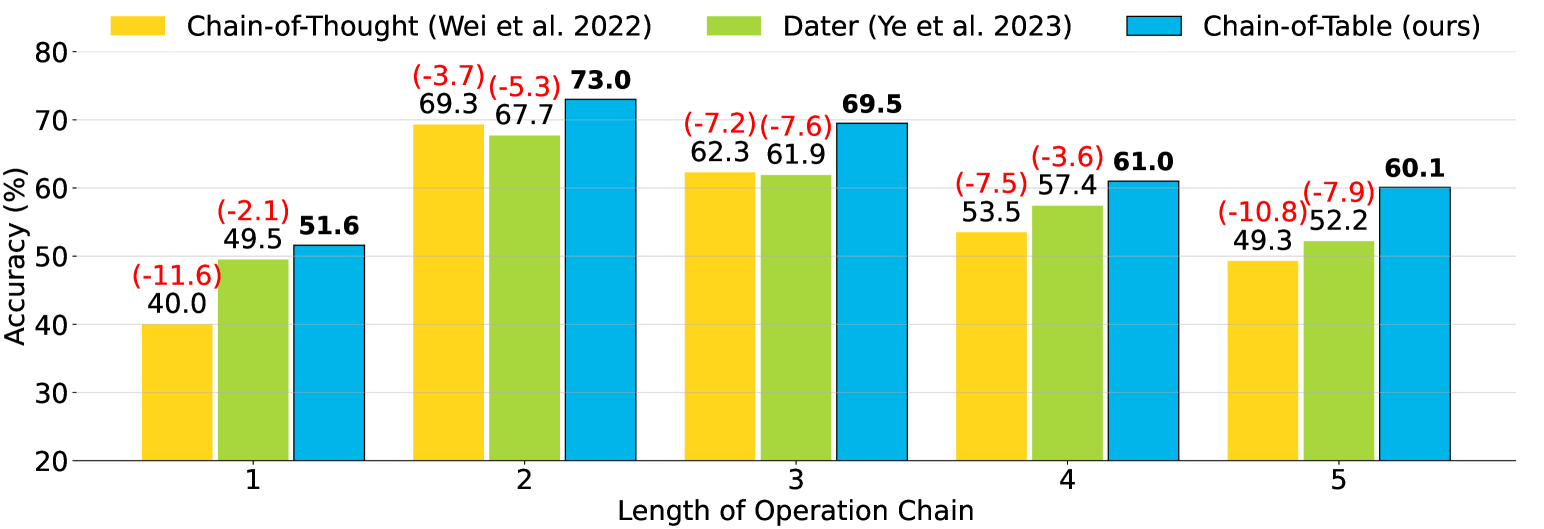
在表链中,每个操作的选择是根据问题的难度和复杂度及其对应的表格动态确定的。 因此,我们通过将测试样本根据操作长度进行分类,对不同操作次数下的性能进行详细研究。 我们报告样本数量与样本数量的分布。 表中所需操作链长度 2. 本次分析重点关注推理过程中需要运算的样本。 我们使用 PaLM 2 的结果作为示例。 我们的观察表明,大多数样本需要 2 到 4 次操作才能生成最终输出。
对于每个链长度,我们进一步比较Chain-of-Table 以 Chain-of-Thought 和 Dater 分别作为代表性的通用推理方法和程序辅助推理方法。 我们使用 WikiTQ 上 PaLM 2 的结果来说明这一点。 我们在图中使用条形图绘制了所有方法的准确性 3,突出了比较方法和我们的方法之间的差距。 尤其, 表链 在所有操作链长度上始终超过两种基线方法,与 Chain-of-Thought 相比显着提高了 11.6%,与 Dater 相比显着提高了 7.9%。
一般来说,由于问题和表格的难度和复杂性较高,这些方法的性能随着表格推理链中所需的表格运算数量的增加而下降。 尽管如此,我们提出的 表链 与其他基线方法相比,下降幅度较小。 例如, 表链 当操作数从四增加到五时,性能仅表现出最小的下降。
| Prompting | Table Size | ||
|---|---|---|---|
| Small (2k) | Medium (2k4k) | Large (4k) | |
| Binder (Cheng et al., 2022) | 56.54 | 26.13 | 6.41 |
| Dater (Ye et al., 2023) | 62.50 | 42.34 | 34.62 |
| Chain-of-Table (ours) | 68.13 (+5.63) | 52.25 (+9.91) | 44.87 (+10.25) |
4.4 不同表大小下的性能分析
大型表格对大语言模型提出了重大挑战,因为大语言模型常常难以解释和整合长输入提示中的上下文(Liu 等人,2023a;Ye 等人,2023)。 为了评估不同大小的表的性能,我们根据词符数量将 WikiTQ 的输入表分为 3 组:小(2000 个 Token )、中型(2000 到 4000 个 Token )和大型(4000 个 Token )。 然后我们比较 表链 以 Dater (Ye 等人, 2023) 和 Binder (Cheng 等人, 2022) 这两个最新且最强的基线作为代表性方法。 详细结果见表 3.
正如预期的那样,性能随着输入表的增大而降低,因为模型需要通过更长的上下文进行处理和推理。 尽管如此,拟议的绩效 表链 优雅地减少,在处理大型表时比第二最佳竞争方法实现了 10+% 的显着改进。 这证明了推理链在处理长表格输入方面的有效性。
| Prompting | Total # of | # of generated samples |
| generated samples | in each steps | |
| Binder (Cheng et al., 2022) | 50 | Generate Neural-SQL: 50 |
| Dater (Ye et al., 2023) | 100 | Decompose Table: 40; Generate Cloze: 20; |
| Generate SQL: 20; Query: 20 | ||
| Chain-of-Table (ours) | 25 | DynamicPlan: 5; GenerateArgs: 19; |
| Query: 1 |
4.5 Chain-of-Table效率分析
我们分析Chain-of-Table的效率 通过评估所需生成样本的数量。 我们比较 表链 其中Binder (Cheng 等人, 2022) 和 Dater (Ye 等人, 2023) 是两种最新且最具竞争力的基线方法。 WikiTQ 上的分析结果如表所示 4. Binder 生成 Neural-SQL 查询,需要 50 个样本才能获得自洽的结果。 Dater 涉及多个微妙但固定的步骤,例如分解表格和生成问题的完形填空查询。 在每个步骤中,Dater 还采用自我一致性来提高大语言模型输出的准确性,从而生成大量所需的样本。 有关这些框架的详细描述,请参阅相应论文 Ye 等人 (2023) 和 Cheng 等人 (2022)。
与之前的方法不同,我们提出的Chain-of-Table 在表格推理过程中采用贪婪搜索策略,而不是依靠自洽采样来提高性能。 尽管这种方法减少了我们方法的查询计数 表链 采用迭代推理过程。 更具体地说,我们观察到所需的查询数量 表链 是最新基线中最低的 – 比 Binder 低 50%,比 Dater 低 75%。 我们将我们方法的查询效率归因于通过表格推理提出的动态操作执行。 该模型能够找到有效的推理过程,更快、更可靠地达到最终输出。

4.6 案例分析
在图4中,我们通过Chain-of-Table来说明表格推理过程. 该问题基于复杂的表格,需要多个推理步骤来 1) 识别相关列,2) 进行聚合,3) 对聚合的中间信息重新排序。 我们提出的 表链 涉及动态规划操作链并将中间结果准确存储在转换后的表中。 这些中间表格作为表格思维过程,可以指导大语言模型更可靠地得出正确答案。
5 结论
我们提出的表链 利用表格结构表达表格推理的中间思想,增强大语言模型的推理能力。 它指示大语言模型根据输入表及其相关问题动态规划操作链。 这种不断发展的表格设计为促进大语言模型对表格的理解提供了新的思路。
6 再现性声明
We include the prompt examples of DynamicPlan(,,chain) in Appendix E.1, the demo examples of GenerateArgs(,,f) in Appendix E.2, the prompt examples of Query(,) in Appendix E.3. We run the generic reasoning methods (End-to-End QA, FewShot QA, Chain-of-Thought) using the prompts reported in Appendix F. We run Text-to-SQL and Binder using the official open-sourced code and prompts in https://github.com/HKUNLP/Binder. We run Dater using the official open-sourced code and prompts in https://github.com/AlibabaResearch/DAMO-ConvAI. We revise the code to use publicly available GPT 3.5, PaLM 2, and LLaMA 2 (Section 4)作为大语言模型的骨干,而不是 OpenAI Codex,因为它的不可访问性。
参考
- Andrejczuk et al. (2022) Ewa Andrejczuk, Julian Eisenschlos, Francesco Piccinno, Syrine Krichene, and Yasemin Altun. Table-to-text generation and pre-training with TabT5. In Findings of the Association for Computational Linguistics: EMNLP 2022, pp. 6758–6766, Abu Dhabi, United Arab Emirates, December 2022. Association for Computational Linguistics. doi: 10.18653/v1/2022.findings-emnlp.503.
- Anil et al. (2023) Rohan Anil, Andrew M Dai, Orhan Firat, Melvin Johnson, Dmitry Lepikhin, Alexandre Passos, Siamak Shakeri, Emanuel Taropa, Paige Bailey, Zhifeng Chen, et al. Palm 2 technical report. arXiv preprint arXiv:2305.10403, 2023.
- Brown et al. (2020) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- Cafarella et al. (2008) Michael J. Cafarella, Alon Halevy, Daisy Zhe Wang, Eugene Wu, and Yang Zhang. Webtables: Exploring the power of tables on the web. Proc. VLDB Endow., 1(1):538–549, aug 2008. ISSN 2150-8097. doi: 10.14778/1453856.1453916.
- Chen (2023) Wenhu Chen. Large language models are few(1)-shot table reasoners. In Findings of the Association for Computational Linguistics: EACL 2023, pp. 1120–1130, Dubrovnik, Croatia, May 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.findings-eacl.83.
- Chen et al. (2019) Wenhu Chen, Hongmin Wang, Jianshu Chen, Yunkai Zhang, Hong Wang, Shiyang Li, Xiyou Zhou, and William Yang Wang. Tabfact: A large-scale dataset for table-based fact verification. In International Conference on Learning Representations, 2019.
- Chen et al. (2022) Wenhu Chen, Xueguang Ma, Xinyi Wang, and William W Cohen. Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks. arXiv preprint arXiv:2211.12588, 2022.
- Cheng et al. (2022) Zhoujun Cheng, Tianbao Xie, Peng Shi, Chengzu Li, Rahul Nadkarni, Yushi Hu, Caiming Xiong, Dragomir Radev, Mari Ostendorf, Luke Zettlemoyer, et al. Binding language models in symbolic languages. In International Conference on Learning Representations, 2022.
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 4171–4186, 2019.
- Dhingra et al. (2019) Bhuwan Dhingra, Manaal Faruqui, Ankur Parikh, Ming-Wei Chang, Dipanjan Das, and William Cohen. Handling divergent reference texts when evaluating table-to-text generation. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pp. 4884–4895, 2019.
- Eisenschlos et al. (2020) Julian Eisenschlos, Syrine Krichene, and Thomas Müller. Understanding tables with intermediate pre-training. In Findings of the Association for Computational Linguistics: EMNLP 2020, pp. 281–296, Online, November 2020. Association for Computational Linguistics. doi: 10.18653/v1/2020.findings-emnlp.27.
- Gao et al. (2023) Luyu Gao, Aman Madaan, Shuyan Zhou, Uri Alon, Pengfei Liu, Yiming Yang, Jamie Callan, and Graham Neubig. PAL: Program-aided language models. In International Conference on Machine Learning, pp. 10764–10799. PMLR, 2023.
- Gu et al. (2022) Zihui Gu, Ju Fan, Nan Tang, Preslav Nakov, Xiaoman Zhao, and Xiaoyong Du. PASTA: Table-operations aware fact verification via sentence-table cloze pre-training. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pp. 4971–4983, Abu Dhabi, United Arab Emirates, December 2022. Association for Computational Linguistics. doi: 10.18653/v1/2022.emnlp-main.331.
- Hao et al. (2023) Shibo Hao, Yi Gu, Haodi Ma, Joshua Jiahua Hong, Zhen Wang, Daisy Zhe Wang, and Zhiting Hu. Reasoning with language model is planning with world model. arXiv preprint arXiv:2305.14992, 2023.
- Herzig et al. (2020) Jonathan Herzig, Pawel Krzysztof Nowak, Thomas Müller, Francesco Piccinno, and Julian Eisenschlos. TaPas: Weakly supervised table parsing via pre-training. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pp. 4320–4333, Online, July 2020. Association for Computational Linguistics. doi: 10.18653/v1/2020.acl-main.398.
- Hsieh et al. (2023) Cheng-Yu Hsieh, Chun-Liang Li, Chih-kuan Yeh, Hootan Nakhost, Yasuhisa Fujii, Alex Ratner, Ranjay Krishna, Chen-Yu Lee, and Tomas Pfister. Distilling step-by-step! outperforming larger language models with less training data and smaller model sizes. In Findings of the Association for Computational Linguistics: ACL 2023. Association for Computational Linguistics, 2023.
- Imani et al. (2023) Shima Imani, Liang Du, and Harsh Shrivastava. MathPrompter: Mathematical reasoning using large language models. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 5: Industry Track), pp. 37–42, Toronto, Canada, July 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.acl-industry.4.
- Jiang et al. (2022) Zhengbao Jiang, Yi Mao, Pengcheng He, Graham Neubig, and Weizhu Chen. OmniTab: Pretraining with natural and synthetic data for few-shot table-based question answering. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 932–942, Seattle, United States, July 2022. Association for Computational Linguistics. doi: 10.18653/v1/2022.naacl-main.68.
- Jin et al. (2022) Nengzheng Jin, Joanna Siebert, Dongfang Li, and Qingcai Chen. A survey on table question answering: recent advances. In China Conference on Knowledge Graph and Semantic Computing, pp. 174–186. Springer, 2022.
- Jin & Lu (2023) Ziqi Jin and Wei Lu. Tab-cot: Zero-shot tabular chain of thought. arXiv preprint arXiv:2305.17812, 2023.
- Katsogiannis-Meimarakis & Koutrika (2023) George Katsogiannis-Meimarakis and Georgia Koutrika. A survey on deep learning approaches for text-to-sql. The VLDB Journal, pp. 1–32, 2023.
- Khot et al. (2022) Tushar Khot, Harsh Trivedi, Matthew Finlayson, Yao Fu, Kyle Richardson, Peter Clark, and Ashish Sabharwal. Decomposed prompting: A modular approach for solving complex tasks. In International Conference on Learning Representations, 2022.
- Kojima et al. (2022) Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners. In Advances in Neural Information Processing Systems, 2022.
- Lin (2004) Chin-Yew Lin. ROUGE: A package for automatic evaluation of summaries. In Text Summarization Branches Out, pp. 74–81, Barcelona, Spain, July 2004. Association for Computational Linguistics.
- Liu et al. (2023a) Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts. arXiv preprint arXiv:2307.03172, 2023a.
- Liu et al. (2021) Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, and Jian-Guang Lou. TAPEX: Table pre-training via learning a neural sql executor. In International Conference on Learning Representations, 2021.
- Liu et al. (2023b) Qian Liu, Fan Zhou, Zhengbao Jiang, Longxu Dou, and Min Lin. From zero to hero: Examining the power of symbolic tasks in instruction tuning. arXiv preprint arXiv:2304.07995, 2023b.
- Maynez et al. (2023) Joshua Maynez, Priyanka Agrawal, and Sebastian Gehrmann. Benchmarking large language model capabilities for conditional generation. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 9194–9213, 2023.
- Nan et al. (2022) Linyong Nan, Chiachun Hsieh, Ziming Mao, Xi Victoria Lin, Neha Verma, Rui Zhang, Wojciech Kryściński, Hailey Schoelkopf, Riley Kong, Xiangru Tang, Mutethia Mutuma, Ben Rosand, Isabel Trindade, Renusree Bandaru, Jacob Cunningham, Caiming Xiong, Dragomir Radev, and Dragomir Radev. FeTaQA: Free-form table question answering. Transactions of the Association for Computational Linguistics, 10:35–49, 2022. doi: 10.1162/tacl_a_00446.
- Ni et al. (2023) Ansong Ni, Srini Iyer, Dragomir Radev, Veselin Stoyanov, Wen-tau Yih, Sida Wang, and Xi Victoria Lin. Lever: Learning to verify language-to-code generation with execution. In International Conference on Machine Learning, pp. 26106–26128. PMLR, 2023.
- OpenAI (2023) OpenAI. Gpt-4 technical report. ArXiv, abs/2303.08774, 2023.
- Papineni et al. (2002) Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, pp. 311–318, Philadelphia, Pennsylvania, USA, July 2002. Association for Computational Linguistics. doi: 10.3115/1073083.1073135.
- Pasupat & Liang (2015) Panupong Pasupat and Percy Liang. Compositional semantic parsing on semi-structured tables. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pp. 1470–1480, Beijing, China, July 2015. Association for Computational Linguistics. doi: 10.3115/v1/P15-1142.
- Pönighaus (1995) Richard Pönighaus. ’favourite’sql-statements—an empirical analysis of sql-usage in commercial applications. In International Conference on Information Systems and Management of Data, pp. 75–91. Springer, 1995.
- Rajkumar et al. (2022) Nitarshan Rajkumar, Raymond Li, and Dzmitry Bahdanau. Evaluating the text-to-sql capabilities of large language models. arXiv preprint arXiv:2204.00498, 2022.
- Shi et al. (2020) Tianze Shi, Chen Zhao, Jordan Boyd-Graber, Hal Daumé III, and Lillian Lee. On the potential of lexico-logical alignments for semantic parsing to sql queries. Findings of the Association for Computational Linguistics: EMNLP 2020, 2020.
- Touvron et al. (2023) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.
- Valmeekam et al. (2022) Karthik Valmeekam, Alberto Olmo, Sarath Sreedharan, and Subbarao Kambhampati. Large language models still can’t plan (a benchmark for llms on planning and reasoning about change). In NeurIPS 2022 Foundation Models for Decision Making Workshop, 2022.
- Wang et al. (2021) Zhiruo Wang, Haoyu Dong, Ran Jia, Jia Li, Zhiyi Fu, Shi Han, and Dongmei Zhang. TUTA: Tree-based transformers for generally structured table pre-training. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, pp. 1780–1790, 2021.
- Wei et al. (2022) Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35:24824–24837, 2022.
- Yao et al. (2023) Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. arXiv preprint arXiv:2305.10601, 2023.
- Ye et al. (2023) Yunhu Ye, Binyuan Hui, Min Yang, Binhua Li, Fei Huang, and Yongbin Li. Large language models are versatile decomposers: Decompose evidence and questions for table-based reasoning. arXiv preprint arXiv:2301.13808, 2023.
- Zhou et al. (2022) Denny Zhou, Nathanael Schärli, Le Hou, Jason Wei, Nathan Scales, Xuezhi Wang, Dale Schuurmans, Claire Cui, Olivier Bousquet, Quoc V Le, et al. Least-to-most prompting enables complex reasoning in large language models. In International Conference on Learning Representations, 2022.
附录
附录A Chain-of-Table 中的原子操作
A.1 介绍
在本研究中,我们采用 SQL 和 DataFrame 开发中常用的一组五个表操作作为示例。 我们注意到,我们的框架可以轻松容纳额外的操作,我们将其留到未来的工作中。
-
•
f_add_column() 向表中添加新列以存储中间推理或计算结果。
-
•
f_select_row() 选择与问题相关的行子集。 表格可能包含与给定问题(Ye等人,2023)无关的信息。 此操作有助于找到必要的上下文。
-
•
f_select_column() 选择列的子集。 一列通常对应于表中的一个属性。 此操作允许模型找到回答问题所需的属性。
-
•
f_group_by() 按特定列的内容对行进行分组,并提供该列中每个枚举值的计数。 许多基于表格的问题或陈述都涉及计数,但大语言模型并不精通这项任务(Imani 等人,2023)。
-
•
f_sort_by() 根据特定列的内容对行进行排序。 当处理涉及比较或极值的问题或陈述时,大语言模型可以利用此操作来重新排列行。 从排序行的顺序可以很容易地推断出这种关系。
A.2 消融研究
为了证明我们提出的原子操作的有效性,我们通过创建我们方法的五个留一变体来执行消融研究,每个变体都会从预定义操作池中删除一个预定义操作。 例如, w/o f_add_column() 表示 f_add_column() 从操作池中删除。 结果,大语言模型只能从剩下的四个操作中进行规划(f_select_column、f_select_row、f_group_by和f_sort_by)构建运营链。 我们在表中报告了消融研究的结果 5.
| Prompting | TabFact | WikiTQ |
|---|---|---|
| Accuracy | Accuracy | |
| Chain-of-Table | 86.61 | 67.31 |
| w/o f_add_column() | 85.23 (-1.38) | 65.88 (-1.43) |
| w/o f_select_column() | 82.61 (-4.00) | 65.68 (-1.63) |
| w/o f_select_row() | 82.21 (-4.40) | 65.06 (-2.25) |
| w/o f_group_by() | 84.78 (-1.83) | 61.88 (-5.43) |
| w/o f_sort_by() | 86.21 (-0.40) | 65.85 (-1.46) |
如表5所示,所有五个操作都有助于实现Chain-of-的最终最先进性能表,因为删除任何操作都会导致性能下降。 特别是,我们观察到 f_select_row() 和 f_select_column() 在 TabFact 上贡献最大,而 f_group_by() 在 WikiTQ 上贡献最多。 这表明不同的任务需要不同的操作来帮助大语言模型确定正确的答案。 因此,利用大语言模型通过动态规划来设计定制操作链自然适合不同的任务,从而使我们的方法具有卓越的性能。
附录B Chain-of-Table在FeTaQA上的实验
表6显示表链 还提高了 FeTaQA 上自由格式问答在所有指标上的性能,而 Dater (Ye 等人, 2023) 与端到端 QA 相比,未能提高 ROUGE 分数。 我们还观察到边际改善 表链 与基线方法相比。 我们将此归因于 ROUGE-1/2/L (Lin,2004) 的 n-gram 文本相似性度量的性质。 正如Maynez 等人 (2023) 中所讨论的; Dhingra 等人 (2019),众所周知,这些指标在使用上下文学习时对捕获改进不敏感,因为模型无法仅从指令或几个示例中学习长文本的预期风格。 我们从 FeTaQA 中抽取了几个案例,如图所示 5 其中 ROUGE 指标得分较低;然而,经过审查,我们发现生成的答案是正确的。
| Prompting | FeTaQA | |||
|---|---|---|---|---|
| BLEU | ROUGE-1 | ROUGE-2 | ROUGE-L | |
| End-to-End QA | 28.37 | 0.63 | 0.41 | 0.53 |
| Dater (Ye et al., 2023) | 29.47 | 0.63 | 0.41 | 0.53 |
| Chain-of-Table (ours) | 32.61 (+3.14) | 0.66 (+0.03) | 0.44 (+0.03) | 0.56 (+0.03) |
附录C Chain-of-Table推理参数及演示样本数量
我们在表7中报告Chain-of-Table中使用的参数和演示样本编号、 8 和 9. 总的来说,我们注释了 29 个样本并在不同的数据集中使用它们。 不同功能的使用之间存在很大的重叠。 例如我们使用相同的demo示例来介绍如何使用 函数中的f_add_columnDynamicPlan 跨不同的数据集。 我们保证所有演示样本均来自训练集,因此在测试过程中看不到它们。 我们认为,这进一步表明我们的框架不依赖于一组特定的演示,并且可以很好地推广到具有相同提示的新数据集。
| Function | WikiTQ | ||||
|---|---|---|---|---|---|
| temperature | top_p | decode_steps | n_samples | n_demos | |
| DynamicPlan() | 0.0 | 1.0 | 200 | - | 4 |
| f_add_column() | 0.0 | 1.0 | 200 | - | 6 |
| f_select_row() | 1.0 | 1.0 | 200 | 8 | 3 |
| f_select_column() | 1.0 | 1.0 | 200 | 8 | 8 |
| f_group_by() | 0.0 | 1.0 | 200 | - | 2 |
| f_sort_by() | 0.0 | 1.0 | 200 | - | 2 |
| query() | 0.0 | 1.0 | 200 | - | 1 |
| Function | TabFact | ||||
|---|---|---|---|---|---|
| temperature | top_p | decode_steps | n_samples | n_demos | |
| DynamicPlan() | 0.0 | 1.0 | 200 | - | 4 |
| f_add_column() | 0.0 | 1.0 | 200 | - | 7 |
| f_select_row() | 0.5 | 1.0 | 200 | 8 | 4 |
| f_select_column() | 0.5 | 1.0 | 200 | 8 | 8 |
| f_group_by() | 0.0 | 1.0 | 200 | - | 2 |
| f_sort_by() | 0.0 | 1.0 | 200 | - | 2 |
| query() | 0.0 | 1.0 | 200 | - | 4 |
| Function | FeTaQA | ||||
|---|---|---|---|---|---|
| temperature | top_p | decode_steps | n_samples | n_demos | |
| DynamicPlan() | 0.0 | 1.0 | 200 | - | 3 |
| f_add_column() | 0.0 | 1.0 | 200 | - | 6 |
| f_select_row() | 1.0 | 1.0 | 200 | 8 | 3 |
| f_select_column() | 1.0 | 1.0 | 200 | 8 | 8 |
| f_group_by() | 0.0 | 1.0 | 200 | - | 2 |
| f_sort_by() | 0.0 | 1.0 | 200 | - | 2 |
| query() | 0.0 | 1.0 | 200 | - | 8 |
附录D 表格格式编码比较
与之前的研究一致Liu 等人 (2023b; 2021); Jiang 等人 (2022) 和基线方法 Cheng 等人 (2022); Ye等人(2023),我们采用PIPE编码 Chain-of-Table(如附录E)。 这将所提出的具有原子操作的表格 CoT 的性能增益与各种表格式选择的影响分离开来。
为了进一步了解不同编码方法对表格理解性能的影响,我们使用 3 种额外的表格表示形式进行了额外的实验:HTML、TSV 和 Markdown。 对于这些实验,我们使用 WikiTQ 上的端到端 QA 并以 PaLM 2 作为运行示例。 结果见表 10. 这些发现表明,不同的表格格式编码方法会导致不同的结果。 值得注意的是,我们研究中采用的 PIPE 格式在测试的四种编码方法中具有最高的性能。
| Prompting | Tabular Format Encoding | |||
|---|---|---|---|---|
| PIPE | HTML | TSV | Markdown | |
| End-to-End QA | 60.6 | 56.1 | 58.1 | 58.0 |
附录E Chain-of-Table 中的提示
E.1 动态计划
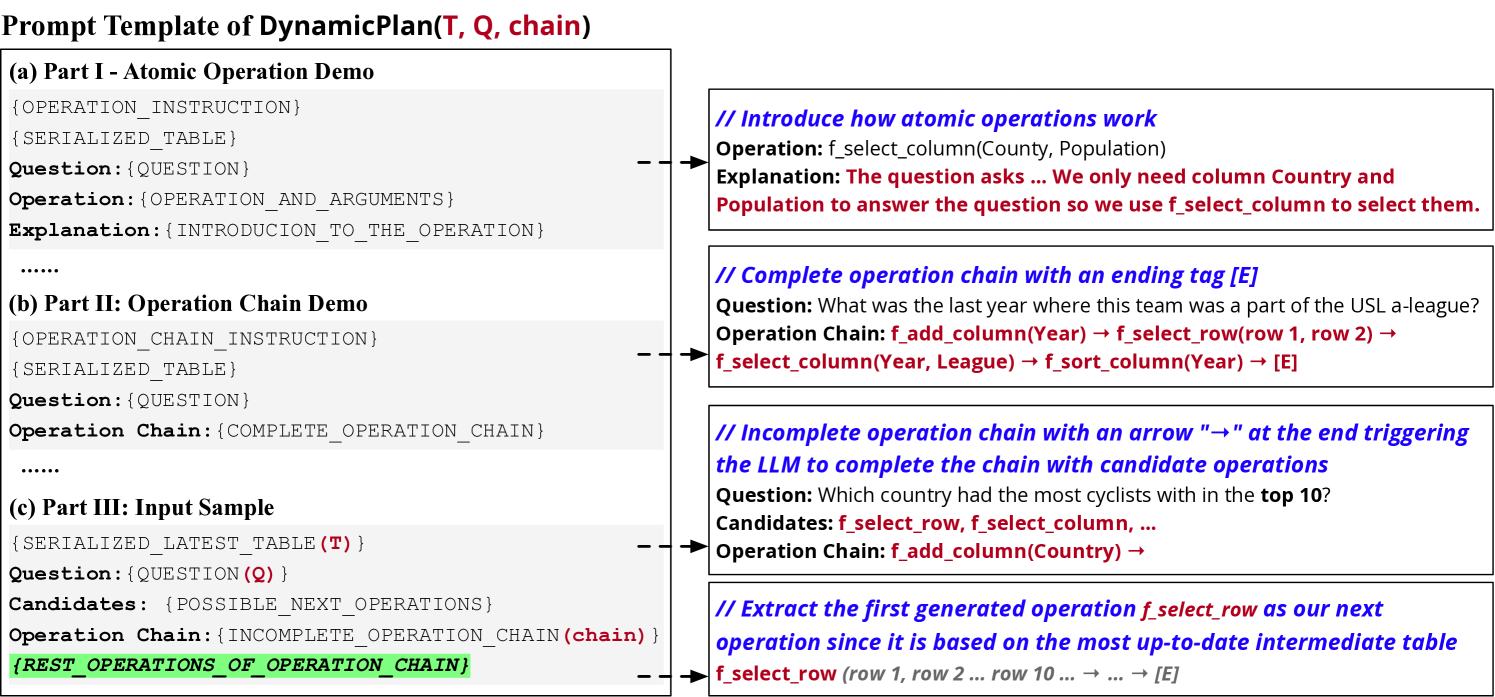
我们在图6中说明了DynamicPlan(T,Q,chain)使用的提示方法,其中是最新的中间表,是其对应的问题; 链条0> 是对表执行的操作的列表。
E.2 生成参数
E.3 询问
附录F 基线方法的实施细节
我们使用官方开源代码和提示运行Text-to-SQL和Binderhttps://github.com/HKUNLP/Binder。我们使用官方开源代码运行 Dater,并在https://github.com/AlibabaResearch/DAMO-ConvAI中进行提示。我们修改代码以使用公开可用的 GPT 3.5、PaLM 2 和 LLaMA 2(第 4 节))作为大语言模型的骨干,而不是 OpenAI Codex,因为它的不可访问性。 我们报告其他基线方法中使用的详细提示如下。
-
•
端到端质量检查:见图16。
-
•
少样本QA:见图17。
-
•
Chain-of-Thought:WikiTQ 和 TabFact 的 Chain-of-Thought 演示示例来自 Chen (2023) ( https://github.com/wenhuchen/TableCoT)。见图18。